ainews-every-7-months-the-moores-law-for-agent
每 7 个月:智能体自主性的摩尔定律
METR 发布了一篇衡量 AI 智能体自主性进展的论文,研究显示自 2019 年(GPT-2)以来,AI 的自主能力每 7 个月就会翻一倍。他们引入了一个新指标——“50% 任务完成时间跨度” (50%-task-completion time horizon),目前 Claude 3.7 Sonnet 等模型在大约 50 分钟的时间跨度内能达到 50% 的成功率。据预测,AI 将在 2028 年实现 1 天的自主性,并在 2029 年底实现 1 个月的自主性。
与此同时,英伟达 (Nvidia) 发布了用于条件式世界生成的 Cosmos-Transfer1,以及拥有 20 亿参数的类人机器人推理开源基础模型 GR00T-N1-2B。Canopy Labs 推出了 Orpheus 3B,这是一款具备零样本语音克隆和低延迟特性的高质量文本转语音 (TTS) 模型。据报道,Meta 因性能问题推迟了 Llama-4 的发布。微软 (Microsoft) 则推出了 Phi-4-multimodal 多模态模型。
视角即一切。
2025年3月18日至3月19日的 AI 新闻。我们为您检查了 7 个 Reddit 子版块、433 个 Twitter 账号 和 29 个 Discord 服务器(227 个频道和 4117 条消息)。预计节省阅读时间(以每分钟 200 字计):426 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
除了 Llama 4 传闻 和 600 美元的 o1 pro API 之外,我们很少能将一篇论文作为 AINews 的头条故事,所以当它发生时我们非常高兴。METR 长期以来以对 AI 进展进行高质量分析而闻名,在《衡量 AI 完成长任务的能力》(Measuring AI Ability to Complete Long Tasks)中,他们回答了一个迄今为止极难回答的有价值问题:Agent 自主性正在增加,但速度有多快?
自 2019 年 (GPT2) 以来,它每 7 个月翻一番。
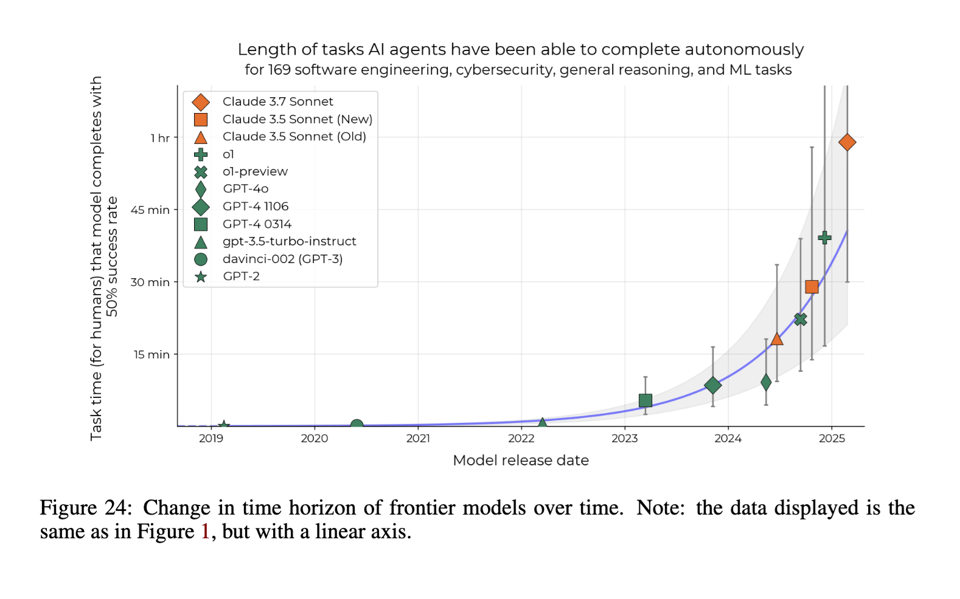
显然,Agent 完成任务所需的时间各不相同,这使得这个问题难以回答,因此其方法论也非常值得关注:
“为了根据人类能力量化 AI 系统的能力,我们提出了一个新的指标:50% 任务完成时间跨度(50%-task-completion time horizon)。这是人类通常完成 AI 模型能以 50% 成功率完成的任务所需的时间。 我们首先对具有相关领域专业知识的人员在 RE-Bench、HCAST 和 66 个新型短任务的组合上进行了计时。在这些任务上,当前的前沿 AI 模型(如 Claude 3.7 Sonnet)的 50% 时间跨度约为 50 分钟。”

作者发现在 1 分钟跨度处存在显著的不连续性:
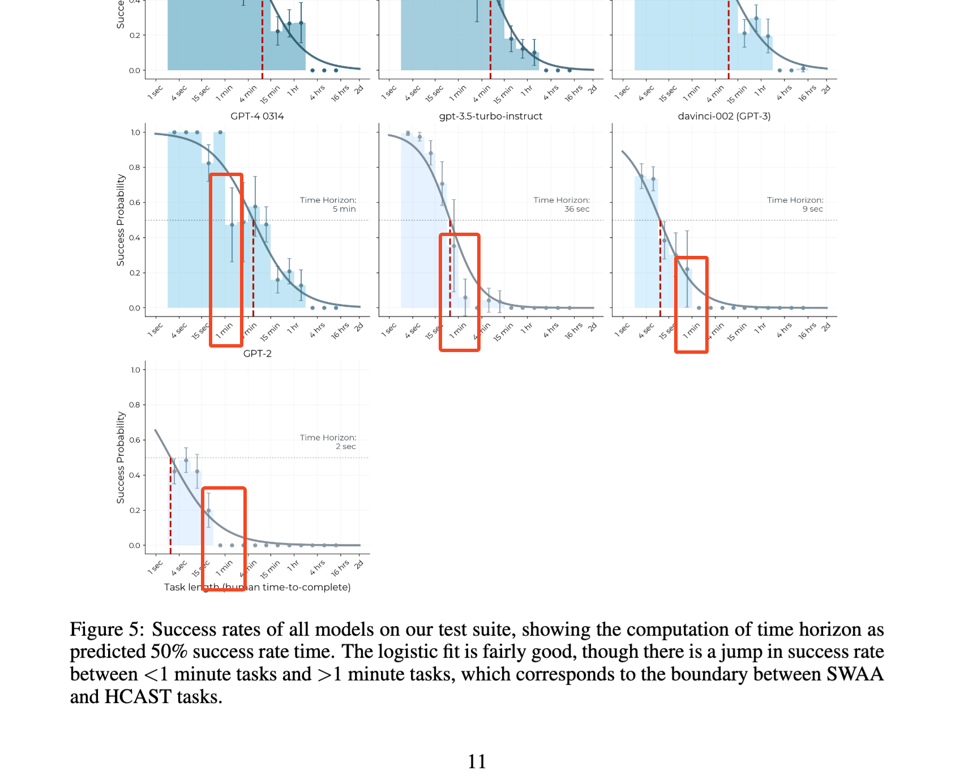
以及在 80% 的截止点,但 Scaling Laws 依然稳健。
按照目前的速度,我们将拥有:
- 1 天的自主性:(5 个指数级增长 * 7 个月) = 3 年 (2028 年)
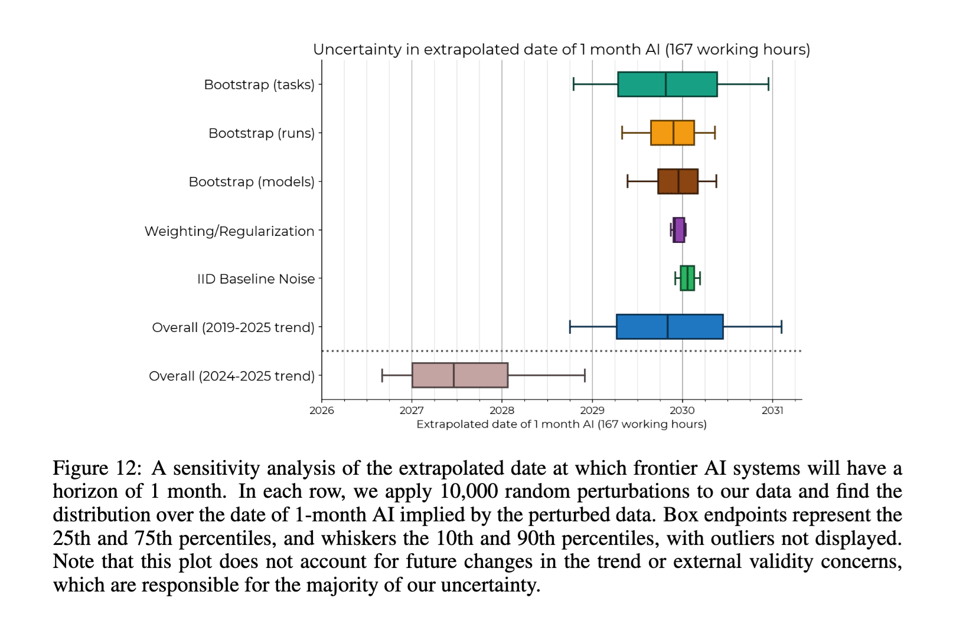
- 1 个月的自主性:在 “2029 年底” (+/- 2 年,仅计算人类工作时间)
AI Twitter 回顾
AI 进展与模型发布
- Nvidia 在 Hugging Face 上发布了 Cosmos-Transfer1,用于具有自适应多模态控制的条件式世界生成:@_akhaliq 分享了 Nvidia’s Cosmos-Transfer1 在 Hugging Face 上的发布,该模型支持具有自适应多模态控制的条件式世界生成。
- Nvidia 在 Hugging Face 上发布了 GR00T-N1-2B:@_akhaliq 宣布 Nvidia 在 Hugging Face 上发布了 GR00T-N1-2B,这是一个用于通用人形机器人推理和技能的开源基础模型,@reach_vb 也提到了这一点。@DrJimFan 提供了关于 GR00T N1 的细节,强调其作为全球首个仅有 2B 参数的人形机器人开源基础模型的地位。该模型从多样化的物理动作数据集中学习,并部署在各种机器人和仿真基准测试中。包含了白皮书、代码库和数据集的链接 (@DrJimFan, @DrJimFan, @DrJimFan, @DrJimFan, @DrJimFan)。
- @reach_vb 宣布了 Orpheus 3B,这是一个来自 Canopy Labs 的高质量、富有情感的 Text to Speech 模型,采用 Apache 2.0 许可证。主要特性包括 zero-shot 语音克隆、自然语音、可控语调、在 100K 小时音频上进行训练、输入/输出流式传输、100ms 延迟以及易于 fine-tuning。
- Meta 压着 Llama-4 不发是因为它表现太差:@scaling01 评论说 Meta 因为性能不佳而未发布 Llama-4。
- Microsoft 推出了 Phi-4-multimodal:@DeepLearningAI 报道称 Microsoft 推出了 Phi-4-multimodal,这是一个拥有 56 亿参数的高性能开源权重模型,能够同时处理文本、图像和语音。
- 腾讯的 Hunyuan3D 2.0 加速了模型生成速度:@_akhaliq 宣布 腾讯 在整个 Hunyuan3D 2.0 系列中实现了 30 倍加速 的模型生成速度,将处理时间从 30 秒缩短至仅 1 秒,已在 Hugging Face 上提供。
- Together AI 推出 Instant GPU Clusters:@togethercompute 宣布了 Together Instant GPU Clusters,配备 8–64 个 @nvidia Blackwell GPUs,完全自助服务并在几分钟内就绪,非常适合大型 AI 工作负载或短期爆发式需求。
研究与评估
- METR 关于 AI 任务完成情况的研究:@METR_Evals 强调了他们的新研究,指出 AI 能完成的任务长度大约每 7 个月翻一番。他们定义了一个名为 “50%-task-completion time horizon” 的指标来跟踪模型自主性的进展,目前像 Claude 3.7 Sonnet 这样的模型跨度约为 50 分钟 (@iScienceLuvr)。研究还表明,AI 系统可能在 5 年内能够自动化处理许多目前人类需要一个月才能完成的软件任务。该论文可在 arXiv 上查阅 (@METR_Evals)。
- NVIDIA 推理模型:@ArtificialAnlys 报道称 NVIDIA 宣布了他们的首批推理模型,这是一个新的开源权重 Llama Nemotron 模型 系列:Nano (8B), Super (49B) 和 Ultra (249B)。
Agent 开发与工具
- LangGraph Studio 更新:@hwchase17 宣布 Prompt Engineering 现已集成在 LangGraph Studio 中。@LangChainAI
- LangGraph 与 LinkedIn 的 SQL Bot:@LangChainAI 重点介绍了由 LangGraph 和 LangChain 驱动的 LinkedIn Text-to-SQL Bot,该工具能将自然语言问题转化为 SQL,使数据更易于访问。
- Hugging Face 关于在 LlamaIndex 中构建 Agent 的课程:@llama_index 分享了 @huggingface 编写的一门关于在 LlamaIndex 中构建 Agent 的课程,涵盖了组件、RAG、Tools、Agents 和 Workflows,该课程免费提供。
- Canvas UX:@hwchase17 指出 Canvas UX 正在成为在文档上与 LLM 交互的标准。
框架与库
- Gemma 软件包:@osanseviero 介绍了 Gemma package,这是一个用于使用和微调 Gemma 的极简库,包含关于 Fine-tuning、Sharding、LoRA、PEFT、Multimodality 和 Tokenization 的文档。
- AutoQuant:@maximelabonne 宣布了 AutoQuant 的更新,以优化 Gemma 3 的 GGUF 版本,实现了 imatrix 并将模型拆分为多个文件。
- 字节跳动 OSS 发布 DAPO:@_philschmid 重点介绍了 ByteDanceOSS 发布的新开源 RL 方法 DAPO,其性能优于 GRPO,并在 AIME 2024 benchmark 上获得了 50 分。
行业合作与活动
- Perplexity 与 NVIDIA 合作:@AravSrinivas 宣布 Perplexity 正与 NVIDIA 合作,利用其新的 Dynamo 库增强在 Blackwell 上的 Inference;@perplexity_ai 表示他们正在实施 NVIDIA Dynamo 以提升推理能力。
- Google 与 NVIDIA 合作:@Google 宣布他们正在整个 Alphabet 范围内扩大与 NVIDIA 的合作。
- vLLM 与 Ollama 推理之夜:@vllm_project 和 @ollama 正在旧金山的 Y Combinator 举办推理之夜,讨论 Inference 相关话题。
幽默与杂项
- @willdepue 分享了 “在 YC W25 学到的 10 件事”,这是对受说唱歌词启发的商业规则的幽默解读。
- 广告拦截器:@nearcyan 表示,广告拦截器(Adblockers)甚至还无法在普通大众中普及,你居然认为我们会给每个人开放任意代码执行(Arbitrary Code Execution)权限?
- 关于 AI Waifus 的题外话:@scaling01 在 TPOT 的背景下开玩笑说要拒绝现实女性,拥抱 AI waifus。
- 职业生涯:@cto_junior 调侃道:该死,结婚完全毁掉了我的发帖量(换取了无条件的爱和终身的幸福)。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. Llama4 传闻:下月发布,多模态,1M Context
- Llama4 可能下个月发布,支持多模态和长上下文 (Score: 295, Comments: 114): Llama4 预计将于下个月发布,其特点是具备 多模态能力 和约 100 万 token 的 长上下文窗口。该公告与 Meta 博客 讨论即将举行的 2025 年 Llamacon 活动有关。
- 针对 上下文大小 的讨论集中在对 100 万 token 上下文窗口 实用性的怀疑上,用户指出模型在达到此类限制之前通常会出现明显的性能下降。Qwen 2.5 因使用 Exact Attention 微调 和 Dual Chunk Attention 来有效管理长上下文而受到关注,详见 基准测试论文。
- Llama4 的 多模态能力 引发了辩论,一些用户对其效用表示怀疑,而另一些人则强调了潜在的好处,例如增强的图像和音频处理能力。DeepSeek 以及 Mistral 和 Google Gemini 等其他模型被提及作为竞争基准,用户对 Llama4 的创新架构寄予厚望。
- 针对 Llama 模型中的 审查(censorship) 问题也被提出,希望 Llama4 相比 Llama3 能减少审查。对话还涉及了 llama.cpp 等项目中 零日支持(zero-day support) 的重要性,暗示与 Meta 的合作可能会大有裨益。
- 只有老玩家才记得 (Score: 300, Comments: 58): Tom Jobbins (TheBloke) 在 Hugging Face 上的贡献受到关注,特别是他关于“使用 AutoGPTQ 和 transformers 让 LLM 更轻量”的文章。他的个人资料展示了最近的模型及其创建和更新日期,表明了他对 AI 和 ML 的积极参与和兴趣。
- Tom Jobbins 的影响与消失: 许多用户对 Tom Jobbins 为 开源 AI 社区 做出的重大贡献表示感谢,特别是他在提高 AI 可访问性方面的工作。讨论推测了他突然消失的原因,有人认为是职业倦怠,或者是跳槽到了私人公司,可能担任 CTO。
- 职业转型与推测: Jobbins 转向一家初创公司的职业变动受到关注,一些用户提到之前资助他工作的拨款已用完。关于他目前的活动存在幽默且乐观的推测,包括他可能在严格的 NDA(保密协议)下获得了一份丰厚的录用通知。
- 社区情感与遗产: 用户深情地怀念 Jobbins 在 模型量化 方面的开创性工作,以及他在为社区简化复杂流程方面发挥的作用。他的遗产继续受到赞赏,一些用户将他的 Hugging Face 个人资料加入书签以示致敬。
- 梦想还是要有的 (Score: 617, Comments: 79): 该帖子通过一张表情逐渐震惊的梗图,幽默地对比了 AI 模型 “DEESEEK-R1”、”QWQ-32B”、”LLAMA-4” 和 “DEESEEK-R2”,突显了围绕这些模型(尤其是 LLAMA-4)能力的期待和兴奋。
- 评论者表达了对擅长编程的 小模型 的渴望,因为目前的模型更多地关注语言和通用知识,而 Sonnet 3.7 的 API 使用成本被认为过高。
- 针对 AI 模型快速发布周期的推测和幽默不断,有人提到 R1 发布还不到 60 天,并对未来模型(如 LLAMA-4 和 DEESEEK-R2)可能达到 1T 和 2T 参数 规模开起了玩笑。
- 讨论还包括对 QwQ 和 QwQ-Max 等模型名称的幽默解读,以及对 Pro ProMax Ultra Extreme 等命名惯例的调侃,并提及了 Dell 和 Nvidia 等品牌。
{kind=link}
{kind=link}
主题 2. 微软的 KBLaM 及其替代 RAG 的潜力
- 微软的 KBLaM,这看起来很有趣 (Score: 104, Comments: 23): 微软的 KBLaM 引入了一种将外部知识集成到语言模型中的方法,可能作为 RAG (Retrieval-Augmented Generation) 的替代方案。该帖子质疑 KBLaM 是否能取代 RAG,并认为解决与 RAG 相关的挑战可能是 AI 领域的重大进步。
- KBLaM 的集成方法 通过使用“矩形注意力 (rectangular attention)”机制将知识直接编码到模型的注意力层中,绕过了 RAG 等传统方法的低效。这使得模型能随知识库大小线性扩展,从而在单个 GPU 上高效处理超过 10,000 个知识三元组 (knowledge triples),提高了可靠性并减少了幻觉 (hallucinations)。
- 讨论了 模型优化的潜力,通过将知识与智能分离,可以减小模型尺寸,允许根据需要注入知识。然而,关于智能是否能与知识完全分离存在争议,因为一些人认为它们是相互关联的。
- 社区参与 包括对 KBLaM 效率提升和可解释性的兴奋,用户正在评估 KBLaM 仓库。该方法无需重新训练即可保持动态更新的能力,被视为优于 RAG 的重大进步,因为 RAG 存在分块 (chunking) 等效率低下的问题。
- 如果《模型即产品》这篇文章属实,许多 AI 公司将面临危机 (Score: 180, Comments: 94): 该帖子讨论了一篇博客文章,暗示 AI 的未来可能会看到像 OpenAI 和 Anthropic 这样的大型实验室使用 Reinforcement Learning (RL) 为 Agent 用途训练模型,这可能会削弱应用层 AI 公司的作用。文中提到了 DataBricks AI 副总裁的一个预测,即闭源模型实验室可能会在未来 2-3 年内关闭其 API,这可能导致这些实验室与当前的 AI 公司之间竞争加剧。点击此处阅读更多。
- 讨论集中在 数据比模型更重要,多位评论者强调,持久的价值在于数据和领域专业知识,而非模型本身。这通过 Google 2006 年算法 成功的类比得到了强调,突出了数据和 UI 是关键要素。
- 对于 OpenAI 和 Anthropic 等主要 AI 实验室将关闭其 API 的预测存在怀疑。评论者认为 API 是这些公司商业模式的核心,关闭它们会适得其反,特别是考虑到 Meta 和 DeepSeek 等公司开源模型的兴起。
- 对话还涉及了 在第三方平台上建立业务的风险,将其比作移动应用生态系统,平台所有者可以吸收成功的创意。共识是,虽然大型 AI 公司将主导通用用例,但利基、特定领域的解决方案仍有空间。
主题 3. Gemma 3 无审查模型发布
- 无审查版 Gemma 3 (Score: 147, Comments: 27): 作者发布了 Gemma 3 的微调模型,可在 Hugging Face 上获取,声称该模型不会拒绝任何任务。他们还在努力训练 4B 和 27B 版本,旨在尽快测试并发布。
- 用户测试了 Gemma 3 以查看它是否会拒绝任务,并指出尽管有相关声明,它有时仍会拒绝。Xamanthas 和 StrangeCharmVote 报告了褒贬不一的结果,Xamanthas 指出它仍然拒绝了一些任务,而 StrangeCharmVote 发现原始的 27B 模型出人意料地没有审查 (uncensored)。
- 人们对 Gemma 3 与默认版本相比的性能指标很感兴趣,mixedTape3123 质疑其智能水平,而 Reader3123 承认可能存在差异,但缺乏详细指标。
- Reader3123 分享了各贡献者的量化工作,提供了 Hugging Face 上的模型链接以供进一步探索:soob3123、bartowski 和 mradermacher。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. Gemini 插件和 AI Studio 的使用
- 天哪,我太爱 gemini photoshop 了 (评分: 124, 评论: 29): 该帖子表达了对 Gemini Photoshop 的热忱,表明用户对该工具有良好的体验。然而,文中未提供该工具的具体细节或功能。
- 关于 Gemini 的困惑:用户对 Gemini Photoshop 的提法感到困惑,质疑是否存在 Photoshop 的 Gemini 插件,或者是否将其与占星术符号等其他事物混淆了。
- Google AI Studio:一些用户提到使用 Google AI Studio Flash 2.0 作为创建图像的工具,一名用户澄清它是免费的,只需在 Google 上搜索 “AI studio” 即可访问。
- 用户体验褒贬不一:虽然一些人对该工具表示热衷,但也有人表示不满,称其在遵循基本指令方面表现不佳,这表明用户体验存在差异。
主题 2. MailSnitch 利用邮件标记识别垃圾邮件
- 多亏了 ChatGPT,我知道谁在卖我的电子邮箱了。 (评分: 2119, 评论: 204): 该帖子概述了 MailSnitch 的开发过程,这是一个受 email tagging 启发而开发的工具,通过使用独特的标记邮箱地址来追踪谁卖掉了你的邮箱。作者在 ChatGPT 的帮助下,计划发布一个具有自动填充、唯一邮件标记和历史记录功能的 Chrome Extension,并考虑免费发布,未来可能进行商业化。
- 许多评论者强调了在邮箱地址中使用 “+” 号来追踪泄露源是无效的,因为垃圾邮件发送者和数据经纪人可以轻易地绕过或删除它。为了更好的隐私和控制,建议使用 email alias services(如 Firefox Relay、ProtonPass 和 Apple 的 “hide my email” 功能)。
- 几位用户强调了在使用代码之前理解代码的重要性,尤其是由 ChatGPT 生成的代码,因为存在潜在的安全和责任问题。讨论涉及运行未经验证代码的风险,以及在严肃应用中进行代码审查的必要性。
- 评论者还讨论了替代方案,例如使用带有 catchall 地址的自定义域名,这可以实现更强大的邮件管理和追踪。一些用户分享了使用 Gmail 的点号(dot)功能的经验,并提到了它在不同平台上的局限性。
主题 3. 逆向工程 ChatGPT:获得更好回答的策略
- 我逆向工程了 ChatGPT 的思考方式。以下是获得更好答案的方法。 (评分: 2064, 评论: 234): 该帖子解释说 ChatGPT 本质上并不“思考”,而是预测下一个最可能的词,这导致它对宽泛的问题给出平庸的回答。作者建议通过指示 ChatGPT 首先分析关键因素、自我批判其答案并考虑多个视角来增强回复,从而显著提高在 AI/ML、商业策略和调试等主题上的深度和准确性。
- ChatGPT 仅仅是一个“下一个词预测器”的概念已被广泛认可,几位评论者指出该帖子的见解并不新颖,有人认为这些想法只是基础的 prompting 技术而非突破。LickTempo 和 Plus_Platform9029 强调,虽然 ChatGPT 预测下一个 token,但如果提示得当,它仍能表现出结构化的推理,他们推荐参考 Andrej Karpathy 的视频等资源以进行深入了解。
- Chain-of-thought prompting 和 Monte Carlo Tree Search 被强调为改进 ChatGPT 回复的方法,djyoshmo 建议在 arxiv.org 或 Medium 上进一步阅读以掌握这些技术。EverySockYouOwn 分享了一个实际案例,即使用结构化的 20 个问题方法来分解复杂询问,从而增强 AI 回复的深度和相关性。
- 讨论中还涉及了自我批判和非回声筒(non-echo chamber)提示词的有效性,VideirHealth 和 legitimate_sauce_614 等用户分享了鼓励 ChatGPT 挑战假设并提供更具逻辑性、多样化视角的策略。然而,SmackEh 等人提醒说,ChatGPT 的默认行为是顺从并避免冒犯,因此需要刻意引导才能进行更具批判性的互动。
主题 4. 成功在本地运行 Wan2.1
- 终于让 Wan2.1 在本地运行了 (Score: 108, Comments: 25): Wan2.1 已成功在本地实现,用于 video processing。
- 用户讨论了使用 Wan2.1 进行视频处理的时间,并比较了不同的硬件配置。Aplakka 分享说他们的 720p 生成耗时超过 60 分钟,而 Kizumaru31 报告使用 RTX 4070 生成 480p 需要 6-9 分钟,这表明使用像 RTX 4090 这样更强大的显卡速度会更快。
- Aplakka 提供了一个 工作流链接 并详细说明了他们的设置,包括在 Windows Subsystem for Linux 中使用 ComfyUI 以及 Sageattention。他们提到了在 RTX 4090 上将 720p 视频放入 VRAM 的挑战,并建议重启或调整设置可能会解决该问题。
- 重点在于提高视频质量和对输出的控制,BlackPointPL 指出使用 gguf 会降低质量,而 vizualbyte73 表示希望对花瓣运动等视觉元素有更多控制。
AI Discord 摘要
由 Gemini 2.0 Flash Thinking 提供的摘要之摘要的总结
主题 1. NVIDIA 的 Blackwell 闪电战:新 GPU 与营销炒作
- Blackwell Ultra 与 Ruben 发布,Feynman 紧随其后: NVIDIA 发布了 Blackwell Ultra 和 Ruben GPU,下一代命名为 Feynman。Ruben 结合了 silicon photonics 以提高能效,并配备了新的 ARM CPU,以及带宽达到 1.6 Tbps 的 Spectrum X 交换机。尽管有性能宣称和新产品发布,一些用户仍对 NVIDIA 的营销炒作和性能夸大持怀疑态度,特别是关于 H200 和 B200 的加速效果。
- DGX Spark & Station:个人 AI 超级计算机问世: NVIDIA 推出了 DGX Spark 和 DGX Station,这是基于 Grace Blackwell platform 的紧凑型 AI 超级计算机。DGX Spark(前身为 Project DIGITS,售价 $3,000)旨在为开发者、研究人员和学生提供桌面级的 AI 原型设计和微调能力,尽管有些人认为其规格与 Mac Mini M4 Pro 或 Ryzen 395+ 等替代方案相比并无优势。
- DeepSeek-R1 推理声称在 Blackwell 上全球最快: NVIDIA 断言 Blackwell GPUs 实现了 全球最快的 DeepSeek-R1 推理,在 NVL8 配置下的单台八卡 Blackwell GPUs 系统在全量 DeepSeek-R1 671B parameter model 上可提供 253 TPS/user 和 30K TPS 系统吞吐量。尽管有这些性能宣称,一些用户仍对 NVIDIA 的营销策略持批评态度,称其“不严肃”且可能误导投资者。
主题 2. 开源 AI 生态系统:工具、数据集与社区
- 哈佛研究发现开源投资产生巨额回报: 哈佛大学的研究表明,对开源的 41.5 亿美元投资为公司创造了 8.8 万亿美元的价值,强调了 每投入 1 美元就有 2,000 美元的回报。这凸显了 AI 领域开源贡献所驱动的巨大经济影响和价值创造。
- Nvidia 为 Llama Nemotron 开源大规模编程数据集: NVIDIA 发布了一个大型 开源 instruct coding dataset,以增强 Llama instruct models 在数学、代码、推理和指令遵循方面的能力。该数据集包含来自 DeepSeek-R1 和 Qwen-2.5 的数据,引发了社区对专门训练进行过滤和微调的兴趣。
- PearAI 作为 Cursor 的开源 IDE 替代方案出现: PearAI 是一款集成了 Roo Code/Cline、Continue、Perplexity、Mem0 和 Supermaven 等工具的新型开源 AI 代码编辑器,正在 Cursor 社区中获得关注。用户认为 PearAI 是 Cursor 的一个更便宜且可行的替代方案,尽管其上下文窗口较小,这凸显了开源工具领域的不断发展。
主题 3. 模型性能与局限性:Gemini、Claude 及开源替代方案
- [Gemini Deep Research 为用户节省 10 倍时间,但基准测试成本隐忧浮现]:用户发现 Gemini Deep Research 显著加快了研究任务,潜在地节省了 10 倍的时间,一位用户提到它在科学医学研究中的价值,生成了包含 90 个文献来源的列表。然而,其成本对于在 LMArena 等平台上进行广泛的基准测试来说可能过于昂贵,引发了对其在大范围评估中可访问性的质疑。
- [Perplexity AI 面临“比 Claude 笨”的质疑,O1 热度消退]:一些用户发现 Perplexity AI 不如 Claude 3.5 智能,理由是上下文保留(context retention)和摘要生成方面存在问题,一位用户表示“Perplexity 感觉比 Claude 3.5 更笨”。此外,由于引入了付费墙,社区最初对 Perplexity O1 模型的热情正在减退,削弱了其吸引力。
- [Anthropic 的 Claude 3.7 Sonnet 经历宕机后恢复]:Anthropic 模型,特别是 Claude 3.7 Sonnet,经历了服务中断和宕机。虽然据报道服务正在趋于稳定,但这一事件凸显了与基于云的 AI 模型访问相关的潜在不稳定性和可靠性担忧。
Theme 4. AI Agents 与工具:Agents 课程、MCP 以及工作流创新
- Hugging Face 推出免费 LlamaIndex Agents 课程:Hugging Face 发布了关于在 LlamaIndex 中构建 Agent 的免费课程,涵盖了核心组件、RAG、工具和工作流。该课程为使用 LlamaIndex 开发 AI 驱动的应用提供了全面指南,扩展了 Agentic AI 领域的教育资源。
- Model Context Protocol (MCP) 凭借 Python REPLs 和新工具势头强劲:Model Context Protocol (MCP) 正受到关注,出现了如 hdresearch/mcp-python 和 Alec2435/python_mcp 等新的 Python REPL 实现,以及一个用户为 Windows 上的 Cursor 构建的 DuckDuckGo MCP (GitHub),展示了其日益增长的生态系统和在工具集成方面的实用性。
- Aider 代码编辑器新增网页和 PDF 读取功能,增强多模态能力:Aider 代码编辑器现在支持读取网页和 PDF 文件,使 GPT-4o 和 Claude 3.7 Sonnet 等具备视觉能力的模型能够直接在编码环境中处理多样化的信息源。这一增强功能通过
/add <filename>等命令访问,扩展了 Aider 在处理复杂、信息密集型编码任务中的用途。
Theme 5. 硬件与软件挑战:性能、兼容性与成本
- [LM Studio 中报告多 GPU 性能下降]:用户在 LM Studio 中使用多个 RTX 3060s 配合 CUDA llama.cpp 时遇到了性能和稳定性问题,并指出单 GPU 的性能更优。这些问题归因于模型在 GPU 间的拆分以及潜在的 PCI-e 3.0 x4 带宽限制,表明多 GPU 配置在实现最佳性能方面并不总是即插即用的。
- [Gemma 3 Vision 微调遭遇 Transformers 库故障]:用户在为视觉任务微调 Gemma 3 时遇到问题,这表明当前 Transformers 库版本的视觉支持中可能存在 Bug,特别是在进行
qlora期间。该问题表现为RuntimeError,需要进一步调查兼容性和库依赖关系。 - [M1 Mac 在模型训练中表现吃力,即使是小批量任务]:用户报告称 M1 Mac Airs 在模型训练方面动力不足,即使是小批量任务,在 Kaggle 和 Hugging Face Spaces 等平台上也会遇到与 clang 相关的问题。这凸显了消费级 Apple silicon 在处理高需求 AI 训练任务时的局限性,促使用户寻求替代硬件或基于云的解决方案。
PART 1: Discord 高层级摘要
Cursor Community Discord
- Sonnet MAX 作为 Agent 表现出色:Sonnet MAX 模型在 Agent 工作流中的后处理(post-processing)能力受到赞赏,详见此 X 帖子。
- 用户强调,由于库的限制,Cursor 必须从代码库和自身的错误中学习。
- Cursor 的 Claude Max 定价引发争议:社区成员对 Cursor 上 Claude Max 的定价表示质疑,指出订阅中的快速请求(fast requests)配额未被充分利用。
- 一些人表示不满,建议如果 Cursor 优化了 Max 的快速请求消耗,他们可能会寻找替代方案,并指出 “Cursor 团队在不允许 Max 消耗更多快速请求方面做得非常糟糕”。
- 终端问题困扰用户:用户对 Agent 生成多个终端并重新运行项目感到沮丧,引发了关于实施预防性规则和配置的讨论。
- 提议了一项增强型终端管理规则,用于终止打开的终端,将测试输出定向到新终端,并防止在测试运行期间创建重复终端。
- PearAI 开源 IDE 出现:社区正在关注 PearAI (https://trypear.ai/),这是一个集成了 Roo Code/Cline、Continue、Perplexity、Mem0 和 Supermaven 等工具的开源 AI 代码编辑器。
- 成员们认为,与 Cursor 相比,Pear 目前的表现非常出色,因为尽管它的上下文窗口较小,但它是 Cursor 的廉价替代方案。
Unsloth AI (Daniel Han) Discord
- Gemma 3 Vision 遇到 Transformers 故障:用户报告了在视觉任务中微调 Gemma 3 的问题,表明当前的 Transformers 版本在视觉支持方面可能存在问题,可能发生在
qlora期间。- 一名用户在尝试对
gemma-3-12b-pt-bnb-4bit进行qlora以进行图像标注时遇到了 RuntimeError: Unsloth: Failed to make input require gradients!,建议需要进一步调查。
- 一名用户在尝试对
- Unsloth 即将支持多节点多 GPU:Unsloth 计划在未来几周内支持多节点和多 GPU 微调,尽管具体发布日期尚未确定,可订阅 Unsloth 时事通讯。
- 一名成员确认多节点支持将仅限企业版。
- Unsloth 在旧金山加入 vLLM 和 Ollama 活动:Unsloth 将于下周四(3 月 27 日)在旧金山加入 vLLM 和 Ollama 的活动,承诺在 Y Combinator 的旧金山办公室进行社交和演示。
- 更多详情请见 vLLM & Ollama 推理之夜,现场将提供食物和饮料。
- 文件系统问题导致文档保存失败:一名用户在尝试本地保存合并模型时遇到了
HFValidationError和FileNotFoundError,原因是调用save_pretrained_merged时仓库 ID 无效。- 建议更新
unsloth-zoo,因为该问题在最新版本中应该已经修复。
- 建议更新
- ZO2 微调 175B LLM:ZO2 框架 仅需 18GB GPU 显存即可实现 175B LLM 的全参数微调,特别适用于 GPU 显存有限的设置。
- 一名成员指出 ZO2 采用了零阶优化(zeroth order optimization),这与 SGD 等更常见的阶优化方法形成对比。
LM Studio Discord
- OpenVoice 克隆你的声音:成员们重点介绍了 OpenVoice,这是一种多功能的即时语音克隆方法,仅需一段短音频即可复制声音并生成多种语言的语音,并附带了其 GitHub 仓库。
- 它让你能够对语音风格进行细粒度控制,包括情感、口音、节奏、停顿和语调,并能复制参考说话者的音色。
- Oblix 在云端编排模型:一位成员分享了 Oblix Project,这是一个用于本地和云端模型之间无缝编排的平台,并在演示视频中进行了展示。
- Oblix 根据复杂性、延迟需求和成本将 AI 任务路由到云端或边缘,从而智能地根据复杂性、延迟要求和成本考虑来引导 AI 任务。
- PCIE 带宽影响不大:成员们发现,在设置双 4090时,PCIE 带宽对推理速度的影响微乎其微,与 PCI-e 4.0 x8 相比,最多只多出 2 个 tps。
- 共识是,从 PCIE 4.0 升级到 PCIE 5.0 对推理任务的提升非常有限。
- RTX PRO 6000 Blackwell 发布:NVIDIA 发布了其 RTX PRO 6000 “Blackwell” GPU,该显卡采用 GB202 GPU,拥有 24K 核心、96 GB VRAM,功耗需求为 600W TDP。
- 由于配备了 HBM,这款显卡的性能被认为远好于 5090。
- 多 GPU 性能受损:一位用户分享到,在 LM Studio 中使用 CUDA llama.cpp 运行多个 RTX 3060(3 个在 PCI-e x1 上,1 个在 x16 上)时,观察到性能下降和不稳定性,因为单 GPU 性能(x16)更优。
- 有人建议,性能问题源于模型在多个 GPU 之间的拆分方式,且 Pci-e 3.0 x4 会使推理速度降低高达 10%。
HuggingFace Discord
- 矿卡拯救 AI 家庭服务器:用户正在考虑将旧的 Radeon RX 580 GPU 用于本地 AI 服务器,但被引导去购买阿里巴巴上的 P104-100 或 P102-100,它们拥有 8-10 GB VRAM。
- Nvidia 在 BIOS 中限制了 VRAM,但中国卖家通过刷入固件来解锁所有可用显存。
- 开源投资价值倍增:哈佛大学的研究显示,投入开源的 41.5 亿美元为公司创造了 8.8 万亿美元的价值,正如这篇 X 帖子中所讨论的,这意味着 1 美元的投入 = 2,000 美元的价值创造。
- 这突显了开源贡献带来的显著经济回报。
- Oblix 编排本地与云端模型:Oblix Project 提供了一个用于本地和云端模型之间无缝编排的平台,如演示视频所示。
- Oblix 中的自主 Agent 监控系统资源,并动态决定是在本地还是在云端执行 AI 任务。
- Gradio Sketch AI 代码生成上线!:Gradio Sketch 发布了一项更新,其中包括针对事件函数的 AI 驱动代码生成,可以通过输入
gradio sketch或访问托管版本来使用。- 这使得无需编写代码即可在几分钟内完成工作,而以前则需要数小时。
- LangGraph 资料已在 GitHub 发布:由于同步问题,LangGraph 单元 2.3 的资料已在 GitHub 仓库上线。
- 这让急切的用户可以在网站更新前获取内容,确保他们能继续课程学习。
OpenAI Discord
- Gemini 与 ChatGPT 争夺霸主地位:成员们讨论了 Gemini Advanced 与 ChatGPT Plus 的优劣,对 Gemini 2.0 Flash Thinking 和 ChatGPT 的安全对齐(safety alignment)及实现方式意见不一。
- 一位成员称赞 Gemini 提供免费且无限的访问权限,而另一位成员则批评其缺乏基础安全功能以及整体实现水平。
- o1 和 o3-mini-high 依然稳坐头把交椅:尽管 Gemini 备受关注,一些用户坚持认为 OpenAI 的 o1 和 o3-mini-high 模型在编程、规划和数学等推理任务中表现卓越。
- 这些用户认为 Google 模型在这些领域表现最差,只有 Grok 3 和 Claude 3.7 Thinking 可能与 o1 和 o3-mini-high 竞争。
- GPT-4.5 的创意写作表现平平:一位成员发现 GPT-4.5 的创意写作表现不一致,指出其存在逻辑错误、重复,且偶尔与 GPT-4 Turbo 相似。
- 虽然在随后的运行中性能有所提高,但该用户对该模型极低的消息限制表示遗憾。
- DeepSeek 被大学校园禁用:一位成员报告称其大学禁用了 DeepSeek,可能是因为其缺乏准则或过滤器,在避开非法话题时性能会大幅下降。
- 禁令似乎只针对 DeepSeek,而不针对其他 LLM。
- ChatGPT 沙盒探索“有用性”的边界:成员们正在通过探索模型对不同提示词和系统消息的反应来实验 ChatGPT 的个性,并展示了“不友好的助手”角色扮演的示例。
- 一位成员发现,在不更改系统消息的情况下,很难让 GPT-4o sandbox 中的模型脱离“不友好”的状态。
OpenRouter (Alex Atallah) Discord
- Anthropic 的 Claude 3.7 Sonnet 出现停机:Anthropic 模型,特别是 Claude 3.7 Sonnet,经历了停机,目前正在恢复中。
- 用户报告称 Anthropic 的服务在停机后似乎正在趋于稳定。
- Cline 兼容性看板为模型排名:一位社区成员创建了一个 Cline Compatibility Board,用于根据模型在 Cline 中的表现进行排名。
- 该看板提供了关于 API providers、plan mode、act mode、输入/输出成本以及 Claude 3.5 Sonnet 和 Gemini 2.0 Pro EXP 02-05 等模型最大输出的详细信息。
- Gemini 2.0 Pro EXP-02-05 存在故障:OpenRouter 上的 Gemini-2.0-pro-exp-02-05 模型确认可用,但会遇到随机故障和频率限制(rate limiting)。
- 根据兼容性看板,该模型目前以 0 成本提供,输出限制为 8192。
- Gemini 模型在 RP 场景中表现狂躁?:一些用户发现 Gemini 模型(如 gemini-2.0-flash-lite-preview-02-05 和 gemini-2.0-flash-001)在角色扮演(RP)场景中表现不稳定,呈现出狂躁行为,即使在 Temperature 设置为 1.0 时也是如此。
- 然而,其他用户报告 gemini-2.0-flash-001 完全没有问题,认为它在 Temperature 为 1.0 时非常连贯且稳定。
- OpenRouterGo SDK v0.1.0 发布:OpenRouterGo v0.1.0 已发布,这是一个用于访问 OpenRouter API 的 Go SDK,具有简洁流畅的接口。
- 该 SDK 包含自动模型回退(fallbacks)、函数调用(function calling)和 JSON 响应验证功能。
aider (Paul Gauthier) Discord
- NVIDIA 发布 Nemotron 开源权重 LLMs:NVIDIA 推出了 Llama Nemotron 系列开源权重模型,包括 Nano (8B)、Super (49B) 和 Ultra (249B) 模型。初步测试显示,Super 49B 模型在推理模式下的 GPQA Diamond 测试中达到了 64% 的准确率。
- 这些模型因其推理能力和潜在应用引发了广泛关注,X 上的推文提到了这一发布消息。
- DeepSeek R1 671B 登陆 SambaNova Cloud:DeepSeek R1 671B 现已在 SambaNova Cloud 上正式商用,支持 16K 上下文长度,并提供与主流 IDE 的 API 集成。发布后迅速走红,SambaNovaAI 的推文确认了这一消息。
- 该服务已向所有开发者开放,为各种应用提供访问这一大型模型的权限。
- Aider 新增网页和 PDF 读取能力:Aider 现在支持从 URL 读取网页和 PDF 文件,可通过
/add <filename>、/paste以及命令行参数,配合 GPT-4o 和 Claude 3.7 Sonnet 等具备视觉能力的模型使用,详情见此处文档。- 这一功能增强了 Aider 处理多样化信息源的能力,尽管各模型的相对价值仍在讨论中。
- Gemini Canvas 扩展协作工具:Google 的 Gemini 推出了带有 Canvas 的增强协作功能,提供实时文档编辑和原型代码编写。
- 这个交互式空间简化了写作、编辑和分享工作,并提供快速编辑工具来调整语气、长度或格式。
- Aider 通过 Aiderignore 忽略仓库文件:Aider 允许用户使用
.aiderignore文件从 repo map 中排除文件和目录,详见配置选项。- 该功能有助于让 LLM 专注于相关代码,从而提高代码编辑的效率。
Interconnects (Nathan Lambert) Discord
- 腾讯混元预热 T1 等级 (Hunyuan Hypes T1 Hierarchy):
@TXhunyuan正在寻找合作伙伴共同 进军 T1 模型,并在 X 上的帖子中质疑了在众多模型已经占据了 显著字母 后,用于命名推理模型的字母可用性。- 社区对潜在名称进行了辩论,考虑到在众多模型已经抢占先机后,剩下的选项已经不多了。
- 三星 ByteCraft 生成游戏:SamsungSAILMontreal 推出了 ByteCraft,这是一个将文本提示词转换为可执行视频游戏文件的生成模型,可通过 7B 模型和博客文章获取。
- 早期工作需要 极高的 GPU 需求,最多需要 4 张 GPU 运行 4 个月。
- NVIDIA DGX Spark 和 Station 亮相:NVIDIA 发布了其新型 DGX Spark 和 DGX Station 个人 AI 超级计算机,由该公司的 Grace Blackwell 平台驱动。
- DGX Spark(前身为 Project DIGITS)是一款售价 3,000 美元、Mac Mini 大小的 全球最小 AI 超级计算机,面向 AI 开发者、研究人员、数据科学家和学生,用于原型设计、微调和推理。
- 加州 AB-412 法案威胁 AI 初创公司:加州立法者正在审查 A.B. 412 法案,该法案强制要求 AI 开发者跟踪并披露 AI 训练中使用的每一项已注册版权的作品。
- 批评者担心这种 不可能的标准 可能会 摧毁小型 AI 初创公司和开发者,同时巩固科技巨头的垄断地位。此外,AI2 向 科学和技术政策办公室 (OSTP) 提交了一份建议,倡导开放的创新生态系统。
- NVIDIA 遭遇“不严肃”营销质疑:NVIDIA 正在广告中宣传 H200 在 H100 节点上的性能,以及 B200 相比 H200 在从 FP8 切换到 FP4 后实现了 1.67 倍的加速,一些人通过这些推文和这里形容 NVIDIA 的营销 非常不严肃。
- NVIDIA 声称拥有 全球最快的 DeepSeek-R1 推理速度,单个系统在 NVL8 配置下使用 8 个 Blackwell GPU,在完整的 DeepSeek-R1 671B 参数模型上可提供 253 TPS/用户 或 30K TPS 的系统吞吐量,更多详情请见 NVIDIA 官网。
Yannick Kilcher Discord
- OpenAI 是“三位一体”的威胁:一位成员指出 OpenAI 在 模型开发、产品应用 和 定价策略 方面具有综合实力,使其在 AI 领域脱颖而出。
- 其他公司可能只擅长这些关键领域中的一两个,但 OpenAI 在各方面都表现卓越。
- AI 伴侣关系引发成瘾情绪:随着 AI Agent(如语音助手)培养了成瘾倾向,导致一些用户产生情感依赖,担忧正在浮现。
- 这一趋势引发了关于刻意设计的成瘾功能及其对用户依赖性潜在影响的伦理问题,并讨论了公司是否应该避免可能增强此类行为的功能。
- 智能眼镜:伪装成都市时尚的数据收割?:一场讨论质疑了 Meta 和 Amazon 的智能眼镜,认为其意图是数据收割,特别是为机器人公司策划的自我中心视角(egocentric views)。
- 一位成员开玩笑说了一个针对反派的智能眼镜初创公司点子,强调了情绪检测、梦境电影和共享视角等功能,通过创造依赖反馈回路来收集用户数据并训练模型。
- AI 艺术版权:不允许机器人作者!:美国上诉法院确认,没有人类投入的 AI 生成艺术不受美国法律保护,支持美国版权局对 Stephen Thaler 的 DABUS 系统的立场;详见 路透社报道。
- 法院强调只有人类作者的作品才能获得版权,这标志着在应对快速发展的生成式 AI 行业的版权影响方面的最新尝试。
- Llama 4 即将到来?:传闻暗示 Llama 4 可能会在 4 月 29 日发布。
- 这一推测与 Meta 即将举行的活动 Llamacon 2025 有关。
Perplexity AI Discord
- Perplexity 被认为比 Claude 笨:一位用户表示 Perplexity 感觉比 Claude 3.5 笨,并指出了在上下文保留(context retention)和抽象生成方面的问题。
- 建议使用无痕模式或禁用 AI 数据保留以防止数据存储,并指出开启新对话可以提供一个干净的状态。
- O1 热度因付费墙而减退:社区测试表明,最初高估了 O3 mini,而低估了 o1 和 o1 pro,付费墙(paywall) 显著降低了用户的热情。
- 一位用户报告称 R1 在大多数时候都没用,而
o3-mini在调试js代码时效果更好。
- 一位用户报告称 R1 在大多数时候都没用,而
- Oblix 项目在边缘端和云端之间转换:根据演示视频,Oblix Project 使用 Agent 监控系统资源,在本地和云端模型之间进行编排。
- 该项目在云端和设备端模型之间动态切换执行。
- Perplexity API 响应不稳定:一位用户报告了 Perplexity API 的随机响应问题,特别是在进行数百次快速网页搜索时。
- 在快速重复调用
conductWebQuery函数时,代码要么只收到随机响应,要么忽略随机查询,这可能是由于实现错误导致的。
- 在快速重复调用
Notebook LM Discord
- GDocs 布局被破坏!:用户发现转换为 GDocs 会破坏布局,且无法导入教师演示文稿中的大部分图像;他们发现提取文本(使用 pdftotext)并转换为纯图像格式有助于 Grounding。
- 纯图像 PDF 可能会超过 200MB,由于 NLM 的文件大小限制,需要进行拆分。
- NotebookLM:单人秀!:用户发现通过自定义功能,可以让它完成任何你想做的事(单人播客可以是男性或女性、模仿特定人格、叙述故事、逐字阅读)。
- 唯一的限制是你的想象力。
- 播客休闲模式:脏话连篇!:反馈表明休闲播客模式可能包含脏话。
- 目前尚不清楚是否提供纯净设置(clean setting)。
- NotebookLM 无法强制换行:用户无法在 NotebookLM 的响应中强制执行换行和间距,因为 AI 是根据需求添加这些内容的,目前用户无法配置。
- 作为音频概览(audio overviews)的替代方案,建议用户下载音频并将其作为源文件上传,以生成转录文本。
- 思维导图功能逐步推出:用户讨论了 NotebookLM 中新的思维导图(Mind Map)功能,该功能可以视觉化地总结上传的源文件,参见 Mind Maps - NotebookLM Help。
- 该功能正逐步向更多用户推出,以便控制 Bug:先向有限数量的人发布新功能,然后随时间推移逐渐增加人数是更好的做法,因为这样有时间排除出现的任何 Bug,并在所有人都能使用时提供一个更完善的版本。
MCP (Glama) Discord
- 通过 Glama API 列出 Smithery 注册表:一位成员利用 Glama API 枚举了 GitHub URL 并验证了 smithery.yaml 文件的存在,并将其代码描述为“一次性的临时脚本(one time hack job script)”。
- 他们表示如果有足够的兴趣,会考虑创建一个 gist,并强调了该脚本的临时性质。
- 关于 Spring 应用与 Spring-AI-MCP-Core 的问题:一位用户首次在 Open-webui 中探索 MCP,并使用 spring-ai-mcp-core 构建基础 Spring app,正在寻求除 ClaudeMCP 和 modelcontextprotocol GitHub 仓库之外的资源。
- 他们询问了 MCP 与 GraphQL 或 function calling 的对比,以及它如何处理 system prompts 和 multi-agent systems。
- Claude Code MCP 实现发布:一位成员发布了 Claude Code MCP,这是 Claude Code 作为 Model Context Protocol (MCP) 服务端的实现。
- 他们在集成 Claude Desktop 时曾就 claude_desktop_config.json 的 json 行寻求帮助,但随后自行解决了问题。
- 为 Windows 上的 Cursor 构建的 DuckDuckGo MCP 框架:由于现有的 NPM 项目运行失败,一位成员在 Python framework 上为 Windows 端的 Cursor 创建了自己的 DuckDuckGo MCP。
- 它支持 web、image、news 和 video 搜索,无需 API key,已在 GitHub 上线。
- MCP Python REPL 受到关注:成员们就 hdresearch/mcp-python、Alec2435/python_mcp 和 evalstate/mcp-py-repl 作为 MCP 的 Python REPL 交换了意见。
- 有人担心其中一个实现“完全没有隔离,可能导致灾难”,建议使用 Docker 进行沙箱化(sandbox)访问。
Nous Research AI Discord
- Phi-4 可作为你的辅助模型:成员们讨论了 Phi-4 在复杂系统中作为有用“辅助模型(auxiliary model)”的潜力,强调了其指令遵循(direction-following)、LLM 接口交互和角色扮演(roleplay)能力。
- 观点认为,在已经拥有多个其他模型的复杂系统中,它作为辅助模型会非常有用。
- Claude 的参数列表错误:一位用户批评了 Claude AI 的建议,指出其模型大小不准确,因为列出的模型并不符合所要求的 10m parameters(1000 万参数)以下,详见 Claude 的输出。
- 一位成员辩护称,“10m”可能被理解为“在现代硬件上普遍可用的极轻量级模型”的简称。
- “Vibe Coding”是背景学习:一位成员分享了通过沉浸式学习日语的轶事,并将其类比为获取技能的“vibe coding”。
- 他们补充道,“即使是 vibe coding,你仍然需要担心模块间的接口等问题,以便在有限的 LLM context windows(上下文窗口)下保持扩展性。”
- Nvidia 发布大规模编程数据集:一位用户分享了 Nvidia 开源的指令编程数据集,旨在提升 Llama instruct 模型 的数学、代码、通用推理和指令遵循能力,其中包含来自 DeepSeek-R1 和 Qwen-2.5 的数据。
- 另一位下载了该数据集的成员报告称,对其进行过滤和训练将会很有趣。
- 有限的 VRAM 促使利基调优:一位成员寻求帮助,希望在 RTX 3080 等有限 VRAM 的条件下寻找训练模型的“利基(niche)”方向。
- 讨论内容包括各种 QLoRA 实验,以及对代码编辑进行 fine tune(微调)的建议。
LMArena Discord
- LMArena 面临缓慢消亡?:一位成员质疑 LMArena 上的测试人员质量,问道 “真正的测试者、改进者和真正的思考者都去哪了?” 并分享了一个 Calm Down GIF。
- 这表明社区对平台的发展方向或参与度感到担忧,可能涉及其用户体验和社区支持。
- Perplexity/Sonar 必须击败 OpenAI/Google:一位成员推测,如果 Perplexity/Sonar 不能成为顶级的基于 Web 的搜索工具,该公司将难以在 OpenAI 或 Google 面前保持独特性。
- 另一位成员指出 “实际上没人在 Perplexity 上使用 Sonar”,暗示主要是 Pro 订阅在驱动收入。
- Gemini Deep Research 节省 10 倍时间:Gemini Deep Research 的最新更新为一位成员节省了 10 倍 的时间,但对于 LMArena 基准测试来说可能过于昂贵。
- 另一位成员补充道,Gemini 提供了出色的结果,为科学医学研究提供了深刻的分析,甚至生成了包含 90 个文献来源 的列表。
- LeCun 揭穿 Zuckerberg 的 AGI 炒作:Yann LeCun 警告说,实现 AGI “将需要数年甚至数十年”,并且需要新的科学突破。
- 最近的一篇文章称,Meta 的 LLM 在 2025 年之前不会达到人类水平的智能。
- Grok 3 的 Deeper Search 令人失望:一位用户发现 Grok 3 的 Deeper Search 功能令人失望,理由是存在幻觉和低质量结果。
- 然而,另一位用户为 Grok 辩护,称 “Deeper Search 看起来相当不错”,但原评论者反驳说,频繁使用会发现大量的错误和幻觉。
GPU MODE Discord
- Gemma 3 量化计算:一位用户询问在 M1 Macbook Pro (16GB) 上运行 Gemma 3 的情况,另一位用户解释了如何根据模型大小和以字节为单位的量化来计算内存需求,并建议该 Macbook 可以运行 FP16 格式的 Gemma 3 4B。
- 该用户解释说,考虑到 Macbook 的 16GB 统一内存中有 70% 分配给 GPU,也可以运行 FP4 格式的 12B 模型。
- Blackwell ULTRA 的 attention 指令引起关注:一位成员提到 Blackwell ULTRA 将带来 attention 指令,但其具体含义尚不明确。
- 此外,成员们讨论了如果 kernel1 的 smem carveout 仅为 100 或 132 KiB,则没有足够空间让两个 kernel 同时运行,建议参考 关于共享内存的 CUDA 文档 增加 carveout。
- Nvfuser 的 Matmul 输出融合引入停顿:一位成员指出为 nvfuser 实现 matmul 输出融合(matmul output fusions)非常困难,即使是乘法/加法也会引入停顿(stalls),由于需要保持 tensor cores 的供应,这使得它比独立 kernel 更慢。
- 另一位成员询问困难是否源于 Tensor Cores 和 CUDA Cores 无法并发运行,从而可能竞争寄存器使用,同时引用 Blackwell 文档称 TC 和 CUDA cores 现在可以并发运行。
Accelerate准备合并 FSDP2 支持:一位成员询问accelerate使用的是 FSDP1 还是 FSDP2,以及是否可以使用trl配合 FSDP2 微调 LLM。澄清指出,下周左右将合并一个 pull request,以在此处添加对 FSDP2 的初始支持。- 在该成员澄清了 FSDP2 支持添加的具体细节后,另一位成员表示:“这太令人兴奋了!感谢澄清!”,强调了用户对
accelerate中 FSDP2 支持到来的期待。
- 在该成员澄清了 FSDP2 支持添加的具体细节后,另一位成员表示:“这太令人兴奋了!感谢澄清!”,强调了用户对
- DAPO 算法开源发布:DAPO 算法(decoupled clip and dynamic sampling policy optimization,解耦裁剪与动态采样策略优化)正式发布;DAPO-Zero-32B 超越了 DeepSeek-R1-Zero-Qwen-32B,在 AIME 2024 上获得 50 分,且步数减少了 50%;它是在 Qwen-32b 预训练模型基础上通过 zero-shot RL 训练的,算法、代码、数据集、验证器和模型已完全开源,基于 Verl 构建。
Modular (Mojo 🔥) Discord
- Nvidia 发布 Blackwell Ultra 和 Ruben:在最近的主题演讲中,Nvidia 宣布了 Blackwell Ultra 和 Ruben,以及名为 Feynman 的下一代 GPU。
- 通过 Ruben,Nvidia 正在转向硅光子技术(silicon photonics)以节省数据传输功耗;Ruben 将配备全新的 ARM CPU,并对 Spectrum X 进行重大投资,后者将推出 1.6 Tbps 交换机。
- CompactDict 因修复 SIMD 问题受到关注:成员们讨论了 CompactDict 的优势,这是一种自定义字典实现,避免了内置 Dict 中存在的 SIMD-Struct-not-supported 问题。
- 一年前在 GitHub 上发布了一份报告,详细介绍了两种专门的 Dict 实现:一种针对 Strings,另一种强制实现 trait Keyable。
- HashMap 是否加入 Mojo 标准库引发辩论:有人建议将 generic_dict 作为 HashMap 包含在标准库中,同时保留当前的 Dict。
- 有人担心 Dict 需要处理大量非静态类型(not-static-typed)的操作,增加一个设计更好的新 struct 并随着时间的推移弃用 Dict 可能更有价值。
- List.fill 行为导致意外的长度变化:用户质疑填充 lists buffer 未初始化部分是否应该是可选的,因为调用 List.fill 可能会出人意料地改变 list 的长度(length)。
- 建议将填充 lists buffer 未初始化部分设为可选将解决此问题。
- List 中缺少索引越界检查:一位用户注意到 List 中缺少索引越界(index out of range)检查,表示惊讶,因为他们认为这就是 unsafe_get 的用途。
- 另一位成员也遇到了这个问题,Modular 的人员表示需要在“某个时候”添加该功能。
Latent Space Discord
- Patronus AI 在 Etsy 评判诚实度:Patronus AI 推出了 MLLM-as-a-Judge 来评估 AI 系统,目前已被 Etsy 采用,用于验证产品图像说明文字的准确性。
- Etsy 拥有 数亿件商品,需要确保其描述准确且不产生幻觉(hallucinated)。
- Cognition AI 获得 40 亿美元估值:Cognition AI 在由 Lonsdale 公司领投的一笔交易中达到了 40 亿美元估值。
- 该交易的进一步细节尚未披露。
- AWS 价格远低于 Nvidia:在 GTC 2025 年 3 月主题演讲 期间,据 这条推文 报道,AWS 对 Trainium 的定价仅为 Nvidia 芯片 (Hopper) 的 25%。
- Jensen(黄仁勋)开玩笑说,在 Blackwell 之后,他们可以免费赠送 Hopper,因为 Blackwell 的性能将非常强大。
- Manus 访问权限给交易机器人用户留下深刻印象:一位成员获得了 Manus 的访问权限,该工具通过 Grok3 进行深度搜索,并评价其“非常好”,展示了它是如何在周末构建一个交易机器人的,不过目前在模拟交易(paper trading)中亏损了约 1.50 美元。
- 他们展示了令人印象深刻的输出,并分享了预览截图。
- vLLM:推理界的 ffmpeg:根据 这条推文,vLLM 正在 逐渐成为 LLM 推理界的 ffmpeg。
- 该推文对大家对 vLLM 的信任表示感谢。
Eleuther Discord
- 微调 Gemini/OLMo 模型变得热门:成员们正在寻求关于微调 Gemini 或 OLMo 模型的建议,并考虑蒸馏(distillation)是否是更好的方法,特别是针对 PDF 文件 中的数据。
- 讨论演变为 内存优化(memory optimization) 和 混合设置(hybrid setups) 以增强性能,而非微调特定模型的细节。
- Passkey 性能变得模糊:一位成员建议使用混合方法或由 passkey 激活的 memory expert,将重要 key 的 passkey 和模糊率(fuzzy rate) 提高到接近 100%,如 scrot.png 所示。
- 他们指出,更大的模型将拥有更长的记忆,并展示了从 1.5B 到 2.9B 参数 的改进。
- Latent Activations 揭示完整序列:一位发帖者认为,应该从 整个序列 而不是单个 token 生成 latent activations,以了解模型的正常行为。
- 他们建议关注 整个序列 能更准确地代表 model 行为,并提供了示例代码:
latents = get_activations(sequence)。
- 他们建议关注 整个序列 能更准确地代表 model 行为,并提供了示例代码:
- 云端模型需要 API Keys:成员们询问无法在本地托管的云端模型是否与 API keys 兼容。
- 另一位成员确认它们确实兼容,并指向了之前提供的 详细信息链接。
{kind=link}
LlamaIndex Discord
- Hugging Face 教授 LlamaIndex Agents 课程:Hugging Face 发布了一门关于在 LlamaIndex 中构建 Agent 的免费课程,涵盖了组件、RAG、工具、Agent 和工作流 (链接)。
- 该课程深入探讨了 LlamaIndex Agent 的复杂性,为希望构建 AI 驱动应用程序的开发者提供了实用指南。
- Google 与 LlamaIndex 简化 AI Agents 构建:LlamaIndex 已与 Google Cloud 合作,利用 Gen AI Toolbox for Databases 简化 AI Agent 的构建 (链接)。
- Gen AI Toolbox for Databases 负责管理复杂的数据库连接、安全和工具管理,更多详情可在 Twitter 上查看。
- LlamaIndex 与 Langchain 长期记忆对比:一位成员询问 LlamaIndex 是否具有类似于 Langchain 在 LangGraph 中的长期记忆支持 的功能。
- 另一位成员指出,“在 Langchain 的情况下,长期记忆只是一个向量存储”,并建议使用 LlamaIndex 的 Composable Memory。
- Nebius AI 平台与巨头对比:一位成员对 Nebius 用于 AI 和机器学习工作负载的计算平台的实际使用体验感到好奇,包括其 GPU 集群和推理服务。
- 他们正在将其与 AWS、Lambda Labs 或 CoreWeave 在成本、可扩展性和部署易用性方面进行比较,并希望了解其稳定性、网络速度以及 Kubernetes 或 Slurm 等编排工具的情况。
Cohere Discord
- Cohere Expanse 32B:寻求知识截止日期:一位用户询问了 Cohere Expanse 32B 的知识截止日期,因为他们正在寻找新工作。
- 目前尚未提供关于具体截止日期的进一步信息或回复。
- 测试密钥用户遇到速率限制:一位用户报告其测试密钥遇到了 429 错误,寻求关于跟踪使用情况以及如何确定是否超过了 Cohere 速率限制文档 中描述的每月 1000 次调用限制的指导。
- 一位 Cohere 团队成员提供了帮助,并澄清测试密钥确实受到速率限制(Rate Limits)。
- Websearch Connector 结果退化:一位用户报告 websearch connector 的性能下降,指出实现方式最近发生了变化,现在提供的结果变差了。
- 一位团队成员请求提供详细信息以便调查,并指出连接选项 site: WEBSITE 无法将查询限制在特定网站,该修复程序即将发布。
- Command-R-Plus-02-2024 与 Command-A-03-2025 对比:一位用户测试并比较了 command-r-plus-02-2024 和 command-a-03-2025 模型之间的网页搜索结果,发现模型之间没有显著差异。
- 他们还报告了多起网页搜索功能未能返回任何结果的情况。
- Goodnews MCP:LLM 传递正能量新闻:一位成员创建了一个 Goodnews MCP 服务器,通过 Cohere Command A 向 MCP 客户端传递正面新闻,该项目已在 此 GitHub 仓库 开源。
- 该工具名为
fetch_good_news_list,使用 Cohere LLM 对近期头条新闻进行排名,以识别并返回最正面的文章。
- 该工具名为
LLM Agents (Berkeley MOOC) Discord
- MOOC 课程作业详情发布:LLM Agents MOOC 的课程作业和结业证书说明已在 课程网站 上发布,该内容基于 2024 年秋季 LLM Agents MOOC 的基础。
- Labs 和证书申报表将于 4 月发布,作业暂定于 5 月底截止,证书将于 6 月发放。
- AgentX 竞赛设有 5 个等级:AgentX 竞赛的详情已公布,包括 此处 的报名信息,竞赛包含 5 个等级:Trailblazer ⚡, Mastery 🔬, Ninja 🥷, Legendary 🏆, Honorary 🌟。
- 参与者还可以通过 此申请表 申请 AgentX 研究赛道(Research Track)项目的导师指导,申请截止日期为 PDT 时间 3 月 26 日晚上 11:59。
- 测验截止日期为 5 月底:所有作业(包括每堂课后发布的测验)的截止日期均为 5 月底,因此你仍可以提交作业以获得证书资格。
- 澄清一点:AgentX 研究赛道 的选拔标准 并非“我们只接受前 X% 的人”。
- AgentX 研究赛道项目指导:研究赛道项目的指导将从 3 月 31 日持续到 5 月 31 日,导师将直接联系申请人进行潜在的面试。
- 申请人应展现出主动性、与课程相关的深思熟虑的研究想法,以及在两个月时间内完成该想法的背景能力。
- 证书问题排查:一位在 12 月参加 MOOC 课程 的成员反映未收到证书,导师回复称 证书邮件 已于 2 月 6 日 发送,并建议检查垃圾邮件箱并确认使用了正确的电子邮件地址。
Torchtune Discord
- FL 设置终于可以运行:在经历了因 IT 延迟导致的 4 个月 等待后,一位成员的 FL(联邦学习)设置终于可以运行了,展示在 这张图片 中。
- 这种长时间的延迟凸显了在大组织中使必要基础设施投入运行所面临的常见挑战。
- Nvidia GPU 面临长期的供应延迟:成员们报告了 Nvidia GPU 供应的持续延迟,以 H200s 为例,该型号在 2 年前 宣布,但直到 6 个月前 才向客户开放。
- 此类延迟影响了 AI 项目的开发时间表和资源规划。
recvVector和sendBytes触发 DPO 故障:用户报告在运行 DPO recipes 时出现recvVector failed和sendBytes failed错误。- 错误的来源尚不确定,可能源于集群问题或 torch 的问题。
cudaGetDeviceCount兼容性报错:成员在使用 NumCudaDevices 时遇到了RuntimeError: Unexpected error from cudaGetDeviceCount()。- 错误
Error 802: system not yet initialized可能源于使用了比预期更新的 CUDA 版本,尽管这一点尚未得到证实。
- 错误
nvidia-fabricmanager解决 CUDA 修复问题:使用nvidia-fabricmanager是解决cudaGetDeviceCount错误的方法。- 正确的流程包括使用
systemctl start nvidia-fabricmanager启动它,并通过nvidia-smi -q -i 0 | grep -i -A 2 Fabric确认状态,验证状态显示为 “completed”。
- 正确的流程包括使用
{kind=link}
tinygrad (George Hotz) Discord
- M1 Mac 在模型训练方面表现挣扎:一位用户报告称,他们的 M1 Mac Air 即使在小批量训练模型时也非常吃力,在 Kaggle 和 Hugging Face Spaces 上遇到了 clang 问题。
- 他们寻求关于在已训练模型上托管推理演示的建议,但发现硬件性能不足以处理基础的训练任务。
- DeepSeek-R1 针对家庭使用进行优化:腾讯玄武实验室的优化方案允许在消费级硬件上家庭部署 DeepSeek-R1,成本仅需 4万元,功耗与普通台式机相当,详见这条推文。
- 该优化配置每秒可生成约 10个汉字,与传统的 GPU 配置相比,实现了 97% 的成本降低,有可能使强大模型的使用变得大众化。
- Clang 依赖需要更好的错误处理:一位贡献者建议,在没有 clang 的 CPU 上运行 mnist 示例时,应改进针对
FileNotFoundError的依赖验证。- 当前的错误消息未能清晰指出缺失 clang 依赖的问题,可能会让新用户感到困惑。
- REDUCE_LOAD 的索引选择令人困惑:一位成员请求澄清
x.src[2].src[1].src[1]的含义,以及选择这些索引作为 REDUCE_LOAD pattern 的reduce_input的原因。- 代码片段检查
x.src[2].src[1].src[1]是否不等于x.src[2].src[0],并据此将x.src[2].src[1].src[1]或x.src[2].src[1].src[0]赋值给reduce_input。
- 代码片段检查
AI21 Labs (Jamba) Discord
- AI21 Labs 对 Jamba 保持沉默:AI21 Labs 目前没有公开分享关于他们用于 Jamba 模型开发的技术信息。
- 一位代表对缺乏透明度表示歉意,但表示如果情况有变,他们会提供更新。
- 社区迎来新面孔:社区欢迎了几位新成员,包括 <@518047238275203073>, <@479810246974373917>, <@922469143503065088>, <@530930553394954250>, <@1055456621695868928>, <@1090741697610256416>, <@1350806111984422993>, 和 <@347380131238510592>。
- 鼓励他们参与社区投票以进行互动。
DSPy Discord
- Chain Of Draft 的可复现性已实现:一位成员使用
dspy.ChainOfThought复现了 Chain of Draft 技术,并在一篇博客文章中详细介绍了该过程。- 这验证了使用 DSPy 可靠地复现高级 Prompting 策略的方法。
- Chain Of Draft 技术减少了 Token 消耗:Chain Of Draft Prompt 技术可以帮助 LLM 在不冗长的情况下扩展其回答,将输出 Token 减少了一半以上。
- 关于该方法的更多细节可以在这篇研究论文中找到。
MLOps @Chipro Discord
- AWS 网络研讨会教授 MLOps 栈构建:一场关于 3月25日太平洋时间上午8点 举行的网络研讨会将涵盖 在 AWS 上从零开始构建 MLOps 栈,可通过此链接注册。
- 该研讨会旨在深入探讨构建端到端 MLOps 平台。
- AI4Legislation 研讨会聚焦 Legalese Decoder:AI4Legislation 研讨会邀请了 Legalese Decoder 创始人 William Tsui 和基金会主席 Chunhua Liao,定于 太平洋时间4月2日下午6:30 举行(在此预约)。
- 该研讨会是硅谷华人协会基金会 (SVCAF) 推动 AI 在立法领域应用努力的一部分。
- Featureform 简化了 ML 模型特征:Featureform 被定位为一个虚拟特征存储 (virtual feature store),使数据科学家能够为他们的 ML 模型定义、管理和提供特征。
- 它专注于简化 ML 工作流中的特征工程和管理流程。
- SVCAF 竞赛推动立法领域的开源 AI:硅谷华人协会基金会 (SVCAF) 正在举办一场夏季竞赛,重点是开发开源 AI 驱动的解决方案,以增强公民对立法过程的参与(GitHub 仓库)。
- 该竞赛旨在促进社区驱动的创新,将 AI 应用于立法挑战。
Nomic.ai (GPT4All) Discord
- GPT4All 默认目录详情:GitHub 上的 GPT4All FAQ 页面描述了 models 和 settings 的默认目录。
- 该 GitHub 页面还提供了关于 GPT4All 的额外信息。
- GPT4All Models 的默认位置:GPT4All models 的默认位置在 FAQ 中有详细说明。
- 了解此位置有助于管理和组织 models。
Codeium (Windsurf) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
第二部分:按频道划分的详细摘要和链接
完整的频道分类明细已针对邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!