ainews-promptable-prosody-sota-asr-and-semantic
可提示的韵律、最先进的 ASR 和语义 VAD:OpenAI 全面升级语音 AI
OpenAI 在其 API 中推出了三款全新的尖端音频模型,其中包括性能超越 Whisper 的语音转文本模型 gpt-4o-transcribe,以及具备“可提示韵律”(promptable prosody)功能的文本转语音模型 gpt-4o-mini-tts,后者允许用户控制语音的停顿节奏和情感。
Agents SDK 现在已支持音频功能,从而能够构建语音智能体。OpenAI 还更新了轮次检测(turn detection)功能,实现了基于语音内容的实时语音活动检测(VAD)。此外,OpenAI 的 o1-pro 模型已向部分开发者开放,支持视觉和函数调用等高级功能,但计算成本也相应更高。
社区对这些音频技术的进步表现出极大的热情,目前一项针对 TTS 创作的广播竞赛正在进行中。与此同时,Kokoro-82M v1.0 作为一款领先的开源权重 TTS 模型脱颖而出,并在 Replicate 平台上提供了极具竞争力的价格。
OpenAI 语音模型就是你所需要的一切。
2025年3月19日至3月20日的 AI 新闻。我们为你检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord(227 个频道,4533 条消息)。预计为你节省阅读时间(以 200wpm 计算):386 分钟。你现在可以标记 @smol_ai 进行 AINews 讨论!
正如一位评论者所说,预测 OpenAI 发布产品的最佳指标是另一家前沿实验室的发布。今天 OpenAI 的“碾压”表现拔得头筹,因为它极其广泛地翻新了 OpenAI 的产品线——如果你关心语音,这次的变化与上周的 Agents 平台重构一样彻底。
我们认为 Justin Uberti 的总结是最好的:
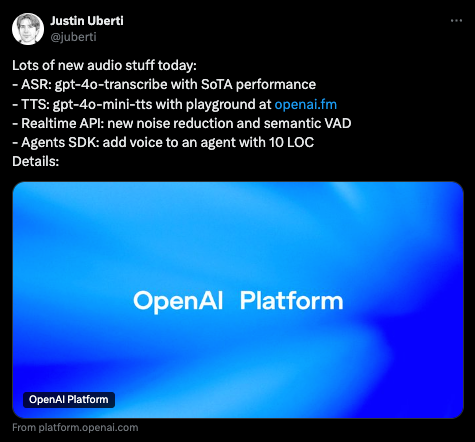
但你也应该看看直播:
https://www.youtube.com/watch?v=lXb0L16ISAc
三大亮点分别是:
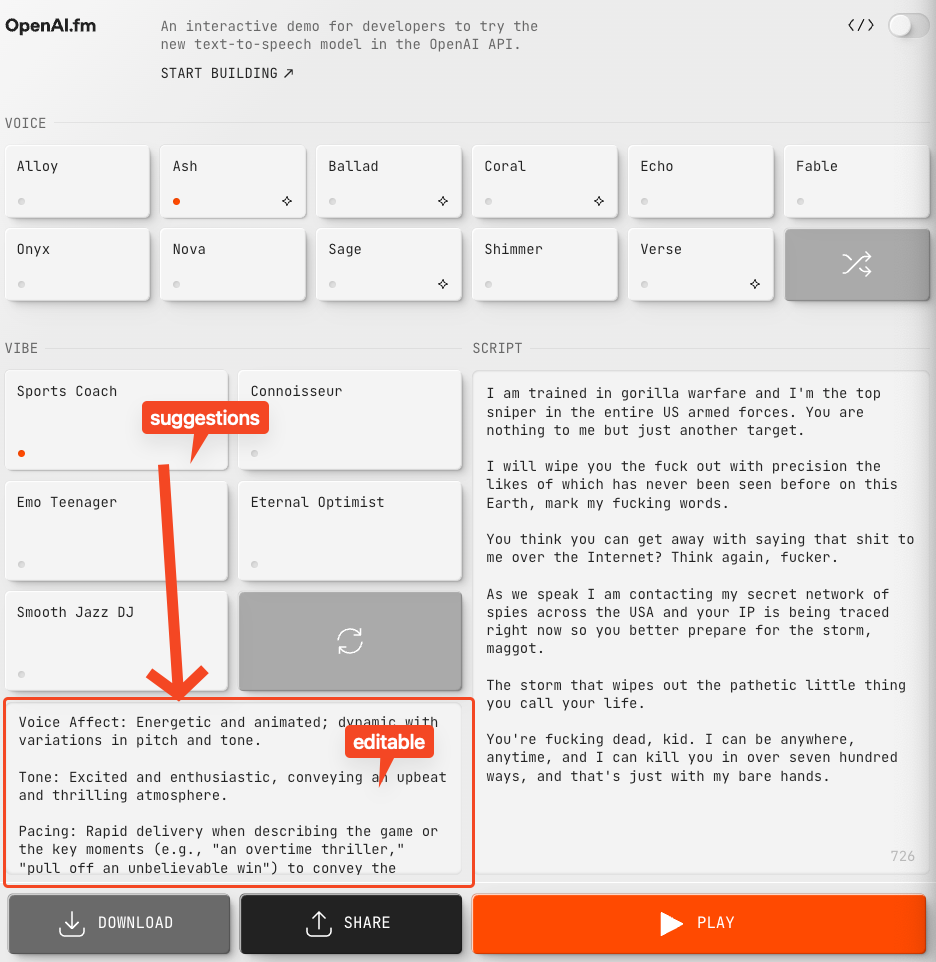
OpenAI.fm,一个演示网站,展示了 4o-mini-tts 中新的可提示韵律(promptable prosody):
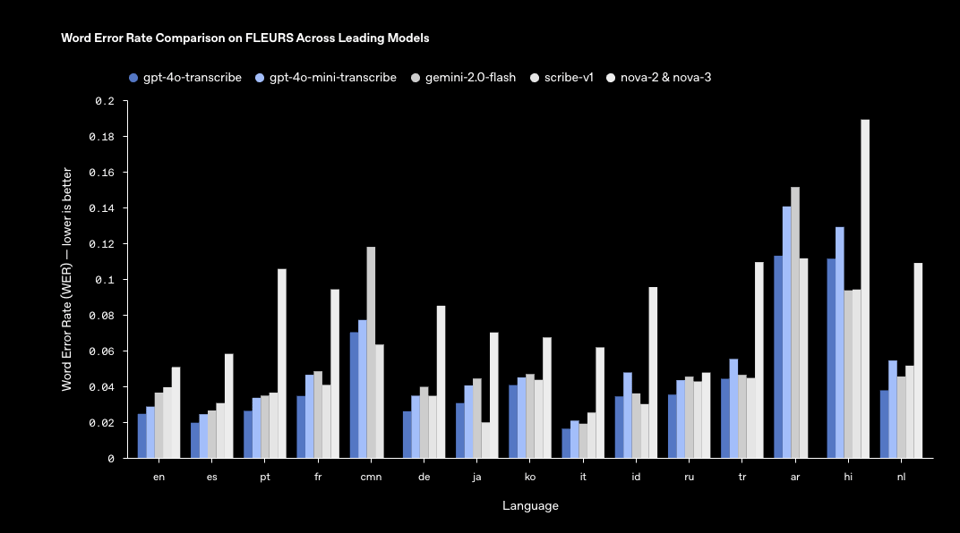
4o-transcribe,一个新的(非开源?)ASR 模型,击败了 Whisper 和商业同行:
最后,稍纵即逝但非常重要,连 turn detection(轮次检测)也获得了更新,现在 realtime 语音将利用语音内容(CONTENT)来动态调整 VAD:
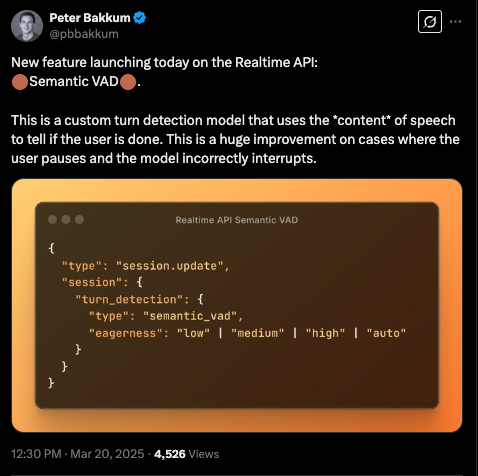
博客文章中的技术细节当然很少,每个要点只有一段话。

AI Twitter 综述
音频模型、语音转文本和文本转语音的进展
- OpenAI 在其 API 中发布了三个新的 SOTA 音频模型:包括两个语音转文本模型(性能超越 Whisper),以及一个新 TTS 模型(允许你指令它如何说话),正如 @OpenAIDevs 所述。Agents SDK 现在支持音频,方便构建语音 Agent,@sama 进一步讨论了这一点。@reach_vb 表达了兴奋,称 MOAR AUDIO - LETSGOOO!,显示了社区的热情。你可以在 @OpenAI 听到新模型的实际效果。@kevinweil 提到新功能让你能够控制时机和情感。
- OpenAI 正在举办 TTS 创作电台竞赛。根据 @OpenAIDevs 和 @kevinweil 的说法,用户可以推特分享他们的作品,有机会赢得一台 Teenage Engineering OB-4,比赛将于周五结束。@juberti 指出,他们增加了具有 SOTA 性能的 ASR 模型 gpt-4o-transcribe,以及带有 Playground 的 TTS 模型 gpt-4o-mini-tts。
- Artificial Analysis 报告称 Kokoro-82M v1.0 现在是领先的开放权重文本转语音模型,并且价格极具竞争力,在 Replicate 上运行每百万字符仅需 0.63 美元 @ArtificialAnlys。
模型发布、开源倡议和性能基准测试
- OpenAI 的 o1-pro 现已在 API 中向第 1-5 级的特定开发者开放,根据 @OpenAIDevs 的消息,该模型支持 vision、function calling、Structured Outputs,并可与 Responses 和 Batch APIs 配合使用。该模型消耗更多算力且价格更高:每 1M input tokens 为 150 美元,每 1M output tokens 为 600 美元。包括 @omarsar0 和 @BorisMPower 在内的多位用户表示对测试 o1-pro 感到兴奋。@Yuchenj_UW 指出 o1-pro 可能会取代一名 PhD 或资深软件工程师并节省资金。
- Nvidia 开源了 Canary 1B & 180M Flash,根据 @reach_vb 的消息,这是采用 CC-BY 许可协议(允许商业使用)的多语言语音识别和翻译模型。
- Perplexity AI 宣布对其 Sonar 模型进行重大升级,以更低的成本提供卓越的性能。根据 @Perplexity_AI 的消息,基准测试显示 Sonar Pro 以显著更低的价格超越了甚至最昂贵的竞争对手模型。@AravSrinivas 报告称,他们的 Sonar API 在 SimpleQA 上得分 91%,同时比 GPT-4o-mini 还要便宜。根据 @Perplexity_AI 和 @AravSrinivas 的消息,新增了搜索模式(High, Medium 和 Low),用于自定义性能和价格控制。
- Reka AI 推出了 Reka Flash 3,一款全新的开源 21B 参数推理模型,据 @ArtificialAnlys 称,该模型在其同尺寸模型中得分最高。该模型的 Artificial Analysis Intelligence Index 为 47,表现优于几乎所有非推理模型,并且在 Coding Index 中强于所有非推理模型。该模型足够小,可以在仅有 32GB RAM 的 MacBook 上以 8-bit 精度运行。
- DeepLearningAI 报告称,Perplexity 发布了 DeepSeek-R1 1776,这是最初为中国开发的模型更新版本,由于移除了政治审查,在中国境外更加实用 @DeepLearningAI。
AI Agents, Frameworks, and Tooling
- LangChain 的 graph 使用量正在增加,据 @hwchase17 称,他们正在提升这些 graph 的速度。他们还强调,这一社区努力尝试使用 LangStack (LangChain + LangGraph) 来复制 Manus @hwchase17。
- Roblox 在 Hugging Face 上发布了 Cube,这是 Roblox 对 3D Intelligence 的视角 @_akhaliq。
- Meta 推出了 SWEET-RL,一个新的多轮 LLM agent 基准测试,以及一种新型的 RL 算法,用于训练具有跨多轮有效信用分配(credit assignment)能力的多轮 LLM agents,根据 @iScienceLuvr 的消息。
AI in Robotics and Embodied Agents
- Figure 将部署数千个执行小件包裹物流的机器人,每个机器人都拥有独立的神经网络,根据 @adcock_brett 的消息。@DrJimFan 鼓励社区回馈他们的开源 GR00T N1 项目。
LLM-Based Coding Assistants and Tools
- Professor Rush 已进入代码助手领域,根据 @andrew_n_carr 的消息。@ClementDelangue 指出 Cursor 正开始与他们自己的 @srush_nlp 一起构建模型。
Observations and Opinions
- François Chollet 指出,强泛化能力需要组合性(compositionality):构建模块化、可重用的抽象,并在面对新情况时即时重新组合 @fchollet。此外,从第一性原理(first principles)出发思考,而不是对过去进行模式匹配(pattern-matching),能让你提前预判重要的变化 @fchollet。
- Karpathy 描述了一种笔记方法,即将想法追加到单个文本笔记中并定期回顾,他发现这种方法在简单性和有效性之间取得了平衡 @karpathy。他还探讨了 LLM 维持一个巨型对话与为每个请求开启新对话的影响,讨论了速度、能力和信噪比(signal-to-noise ratio)等注意事项 @karpathy。
- Nearcyan 引入了 “slop coding”(垃圾代码编写)一词,用来描述在没有充分 Prompting、设计或验证的情况下让 LLM 编写代码的行为,并强调了其适用的场景非常有限 @nearcyan。
- Swyx 分享了关于 Agent 工程中时机重要性的分析,并强调 METR 论文是目前公认的前沿自主性(frontier autonomy)标准 @swyx。
- Tex 声称中国最大的优势之一是他们的婴儿潮一代(boomers)对学习技术的恐惧程度要低得多 @teortaxesTex。
幽默/迷因 (Humor/Memes)
- Aidan Mclauglin 发推讨论了 GPT-4.5-preview 最喜欢的 Token @aidan_mclau,结果显示其具有明显的重复性 @aidan_mclau。
- Vikhyatk 戏称自己写了价值 800 万美元的四行代码,并欢迎提问 @vikhyatk。
- Will Depue 评论道 anson yu 是滑铁卢大学的泰勒·斯威夫特(Taylor Swift) @willdepue。
AI Reddit 热点回顾
/r/LocalLlama 回顾
主题 1. LLM 翻译比 DeepL 便宜 800 倍
- LLM 翻译比 DeepL 便宜 800 倍 (Score: 530, Comments: 162):LLM 在翻译方面具有显著的成本优势,比 DeepL 便宜 800 多倍,其中
gemini-2.0-flash-lite的成本低于 $0.01/hr,而 DeepL 为 $4.05/hr。虽然目前的翻译质量可能略低,但作者预计 LLM 很快将超越传统模型,并且通过改进 Prompting,它们已经取得了与 Google 翻译相当的结果。- LLM vs. 传统模型:许多用户强调,与传统翻译模型相比,LLM 提供了更优越的上下文理解能力,这提升了翻译质量,尤其是对于日语等具有复杂上下文的语言。然而,也有人担心 LLM 过于具有创造性或产生幻觉(hallucinating),这可能导致翻译不准确。
- 模型比较与偏好:用户讨论了 Gemma 3、CommandR+ 和 Mistral 等各种模型,指出了它们在特定语言对或语境中的有效性。一些人因 DeepL 能够保持文档结构而在某些任务中更青睐它,而另一些人则发现 GPT-4o 和 Sonnet 能产生更自然的翻译。
- 微调(Finetuning)与定制:微调像 Gemma 3 这样的 LLM 是一个热门话题,用户分享了在特定领域或语言对中提高翻译质量的技术和经验。Finetuning 被指出能显著提高性能,使 LLM 与 Google Translate 等传统模型相比更具竞争力。
主题 2. 低于 700 美元的预算级 64GB VRAM GPU 服务器
- 分享我的配置:低于 700 美元的预算级 64 GB VRAM GPU 服务器 (Score: 521, Comments: 144): 该帖子描述了一个低于 700 美元、拥有 64GB VRAM 的 预算级 GPU 服务器配置。帖子正文未提供更多细节或规格。
- 预算配置详情:该配置包括 Supermicro X10DRG-Q 主板、2 颗 Intel Xeon E5-2650 v4 CPU 以及 4 块 AMD Radeon Pro V340L 16GB GPU,总计约 698 美元。软件方面使用了 Ubuntu 22.04.5 和 ROCm version 6.3.3,性能指标显示采样时间为 20250.33 tokens per second。
- GPU 与性能讨论:AMD Radeon Pro V340L GPU 因其理论速度而受到关注,但实际性能问题也被凸显,并与 M1 Max 和 M1 Ultra 系统进行了对比。提到了使用 Llama-cpp 和 mlc-llm 来优化 GPU 利用率,其中 mlc-llm 允许同时使用所有 GPU 以获得更好的性能。
- 市场与替代方案:讨论中还与其他 GPU 进行了对比,例如拥有 1TB/s memory bandwidth 且功耗更低的 Mi50 32GB。共识是目前预算级 GPU 配置市场面临挑战,虽然 ROCm 显卡更便宜,但在性能和软件支持方面存在权衡。
Theme 3. TikZero: 从文本生成 AI 科学图表
- TikZero - 使用 LLM 从文本描述生成科学图表的新方法 (Score: 165, Comments: 31): TikZero 介绍了一种使用 Large Language Models (LLMs) 从文本描述生成科学图表的新方法,这与传统的 End-to-End Models 形成对比。图片展示了 TikZero 生成复杂可视化图表的能力,如 3D 等高线图、神经网络图和高斯函数图,证明了其在创建详细科学插图方面的有效性。
- 批评者认为,TikZero 的方法可能会鼓励在科学背景下的滥用,因为它在没有真实数据的情况下生成图表,可能损害科学诚信。然而,一些人认为 TikZero 在生成初始绘图结构方面具有价值,这些结构可以用实际数据进行细化,突显了其在创建难以手动编程的复杂可视化方面的实用性。
- DrCracket 为 TikZero 的实用性辩护,强调其在为复杂可视化生成可编辑的高级图形程序方面的作用,这些程序很难手动创建,并提到了它在建筑和原理图等领域的关联性。尽管存在对准确性的担忧,但模型的输出允许轻松纠正和改进,为进一步定制提供了基础。
- 关于模型大小的讨论表明,虽然像 SmolDocling-256M 这样的小型模型提供了良好的 OCR 性能,但 TikZero 对代码生成的关注需要更大的模型规模(如目前的 8B model)来保持性能。DrCracket 提到正在探索更小的模型,但预计会有性能权衡。
{kind=link}
Theme 4. 使用 15B 以下 LLM 模型进行创意写作
- 15B 以下模型的创意写作 (Score: 148, Comments: 92): 该帖子讨论了一项评估参数量少于 15 billion 的 AI 模型 创意写作能力 的实验,使用了 ollama 和 openwebui 设置。它描述了一个基于十项标准的评分系统,包括 Grammar & Mechanics、Narrative Structure 以及 Originality & Creativity,并参考了一张对比 Gemini 3B 和 Claude 3 等模型的图表。
- 几位用户指出,由于分辨率低,很难阅读结果,并请求提供更高分辨率的图像或电子表格,以便更好地理解评分系统和模型对比。Wandering_By_ 承认了这一点,并在评论中提供了更多细节。
- 关于 Gemma3-4b 等小型模型的有效性存在争论,令人惊讶的是,该模型在创意写作任务中表现优于大型模型,总分最高。一些用户质疑该基准测试的有效性,指出存在评判提示词模糊以及模型可能产生 “purple prose”(辞藻堆砌)等问题。
- 建议包括使用更具体和不常见的提示词以避免通用的输出,并考虑对推理模型和通用模型进行单独测试。还提到了需要更结构化的评分量表和示例,以增强评估过程。
{kind=link}
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. Claude 3.7 退化:广泛的用户担忧
- 我对 Anthropic 秘密降低 Sonnet 3.7 智能水平的行为感到非常反感。 (Score: 255, Comments: 124): 用户对 Anthropic 处理 Claude 3.7 的方式表示不满,理由是出现了显著的性能问题,例如响应不匹配,以及在 Excel 公式中错误地使用 LEN + SUBSTITUTE 而非 COUNTIF 函数。据报道,这种功能下降始于近期,导致用户对这种被视为秘密降级的行为感到沮丧。
- 用户报告 Claude 3.7 存在 严重的性能退化,包括逻辑错误、无法遵循指令以及代码生成错误,而这些问题在之前的版本中并未出现。由于这些问题,许多用户已转回使用 GPT,理由是对 Claude 的一致性和可靠性感到担忧。
- 有推测认为 Anthropic 可能正在对其模型进行 实时 A/B testing 或 功能操纵 实验,这可以解释 Claude 3.7 的异常行为。一些用户认为 Anthropic 正在使用 用户数据 进行训练或功能调整,正如其 博客 中讨论的那样。
- 社区对 Anthropic 缺乏透明度 的做法表示不满,许多用户对明显的 降级 以及为了获得理想结果而需要进行更多 Prompt 管理 感到沮丧。用户还担心 API 使用量 的增加及其产生的成本,导致一些人考虑切换到其他模型。
- 如果你正在进行 Vibe Coding,请阅读本文。它可能会救你一命! (Score: 644, Comments: 192): 该帖子讨论了 Vibe Coding 的趋势,强调了大量非编程人员正在创建应用程序和网站,这可能导致错误并带来学习机会。作者建议使用领先的推理模型来审查代码的生产就绪性,重点关注漏洞、安全性和最佳实践,并分享了他们的非编程人员作品集,包括 The Prompt Index 等项目以及由 Claude Sonnet 添加的 AI T-Shirt Design。
- 许多评论者批评 Vibe Coding 是一种天真的方法,强调了构建稳健且安全的产品必须具备基础软件工程知识。他们认为 AI 生成的代码经常引入问题,且缺乏生产级应用所需的深度,建议非编程人员要么学习编程基础,要么与经验丰富的开发人员合作。
- 一些参与者讨论了 AI 工具 在编程中的有效性,其中一位评论者详细介绍了他们的工作流程,包括深度研究、与 AI 扮演 CTO 角色以及创建详细的项目计划。他们强调了理解项目需求和保持对 AI 生成输出控制的重要性,以避免次优结果;而另一些人则指出 AI 有可能加速早期开发阶段,但强调最终需要更深入的工程实践。
- AI 驱动的开发 被视为一把双刃剑;它可以提高生产力并给管理层留下深刻印象,但许多开发人员仍持怀疑态度。虽然一些人已成功将 AI 集成到他们的编程过程中,但其他人警告不要在不了解底层系统的情况下过度依赖 AI,并指出如果引导不当,AI 可能会生成代码冗余(Code Bloat)和错误。
- 我的电脑性能不够。有没有拥有高性能电脑的人愿意把我的这个原创角色(OC)变成动漫图片吗? (Score: 380, Comments: 131): Anthropic 对 Claude 3.7 的管理:讨论集中在 Claude 3.7 的性能下降上,引发了 AI 社区内的辩论。人们对影响 AI 能力的管理和决策过程表示担忧。
- 讨论转向使用各种工具进行 image generation(图像生成),提到了 animegenius.live3d.io 等免费资源以及 img2img 技术,正如多个分享的图像和链接所示。用户分享了生成的图像,通常幽默地引用了 Chris Chan 和 Sonichu。
- 对话包括对争议性互联网人物 Chris Chan saga 的引用,并附有更新故事的链接,如 2024 Business Insider 文章。这引发了幽默与批评交织的回应,反映了该事件对互联网文化的影响。
- 很大一部分评论包含幽默或讽刺内容,用户以轻松的方式分享 memes 和 GIFs,而一些评论者对将无关个人与 指控的罪犯 进行比较表示担忧。
{kind=link}
主题 2. OpenAI 发布 openai.fm 文本转语音(Text-to-Speech)模型
- openai.fm 发布:OpenAI 最新的文本转语音模型 (Score: 107, Comments: 22): OpenAI 推出了一个名为 openai.fm 的新文本转语音模型,具有交互式演示界面。用户可以选择不同的语音选项,如 Alloy、Ash 和 Coral,以及 Calm(冷静)和 Dramatic(戏剧化)等氛围设置,通过示例文本测试模型的能力,并轻松下载或分享音频输出。
- 用户讨论了演示版中的 999 字符限制,认为 API 可能会提供更广泛的功能,正如 OpenAI 的 audio guide 中所提到的。
- 一些用户将 openai.fm 与 Eleven Labs 的 elevenreader 进行了比较,后者是一款以高质量文本转语音能力著称的免费移动应用,包含 Laurence Olivier 等配音。
- 对于 OpenAI 语音质量的反应褒贬不一,有些人觉得与 Coral Labs 和 Sesame Maya 等其他服务相比平淡无奇,但也有人欣赏这些即插即用语音的 low latency(低延迟)和 intelligence(智能)。
- 我让 ChatGPT 生成一张它参加我生日派对的照片,结果生成了这张 (Score: 1008, Comments: 241): 该帖子描述了 ChatGPT 为生日派对场景生成的图像,画面中一个金属机器人手持突击步枪,背景是带有巧克力蛋糕、派对宾客和装饰品的庆祝场景。尽管机器人的出现出人意料,但生动的场景包括串灯和派对帽,强调了节日气氛。
- 用户分享了他们自己生成的具有不同主题的 ChatGPT-generated images,其中一些突出了幽默或意想不到的元素,如 四胞胎 和他们自己的 机器人版本。图像通常包含幽默或超现实元素,如 steampunk(蒸汽朋克)设置和 robogirls。
- 讨论包括 AI 的创作自由 在图像生成中的体现,例如无法生成准确的文本,导致名字变成了 “RiotGPT” 而不是 “ChatGPT”。对于 AI 对 安全和派对主题的解读 存在幽默感,一些用户开玩笑说派对上的 不安全枪支操作。
- 社区进行了轻松的调侃和幽默,评论涉及 AI 生成场景的怪诞和 异想天开的本质,包括 对恐怖电影的引用 和 意想不到的派对主题。
{kind=link}
{kind=link}
主题 3. Kitboga 的 AI 机器人大军:针对诈骗者的创意应用
- Kitboga 创建了一个 AI 机器人大军来针对电话诈骗者,这非常滑稽 (Score: 626, Comments: 29): Kitboga 雇佣了一支 AI 机器人大军,向电话诈骗中心拨打海量电话,在浪费诈骗者数小时时间的同时,还创作了极具娱乐性的内容。这种对 AI 的创新应用因其有效性和幽默感而受到赞赏,正如 YouTube 视频 中所展示的那样。
- 评论者强调了 AI 被用于正面和负面影响的潜力,Kitboga 的做法是一个正面的例子,同时也承认诈骗者也可能采用 AI 来扩大其操作规模。RyanGosaling 建议 AI 还可以通过实时识别诈骗来保护潜在受害者。
- 关于 Kitboga 运营的成本效益存在讨论,用户指出虽然在本地运行 AI 会产生费用,但这些费用可以通过在 YouTube 和 Twitch 等平台上的内容变现收入来抵消。Navadvisor 指出,诈骗者在处理虚假电话时会产生更高的成本。
- 一些用户提出了打击诈骗者更激进的策略,Vast_Understanding_1 表示希望 AI 能摧毁诈骗者的电话系统,而 OverallComplexities 等人则称赞目前的努力是英雄之举。
- Doge The Builder – 他能搞砸吗? (Score: 183, Comments: 24): 社区幽默地讨论了一个虚构场景,Elon Musk 和一只 Dogecoin 柴犬模仿“建筑师巴布”(Bob the Builder),对贪婪和不受约束的资本主义进行了戏谑的批判。该帖子是对 memecoins 可能引发的混乱的讽刺性演绎,并展示了一个由 DOAT (Department of Automated Truth) 官方授权的 meme,并提供了经批准的 YouTube 链接用于重新发布。
- AI 令人印象深刻的能力:评论者对 AI 目前的能力表示赞赏,强调了其在创作引人入胜且幽默的内容方面的出色表现。
- 影响力人物的文化影响:反思了像 Elon Musk 这样的人物如何显著影响文化时代精神,并对财富积累和社会影响的伦理含义持批评态度。
- 创作过程咨询:一位用户表现出对创作此类讽刺内容背后过程的兴趣,表示对涉及的技术或创意方法感到好奇。
主题 4. Vibe Coding:AI 开发的新趋势
- AI 领域的摩尔定律:AI 可执行任务的时长每 7 个月翻一倍 (Score: 117, Comments: 27): 该图片直观地展示了这样一种说法:AI 能够处理的任务时长每 7 个月翻一倍,任务范围从回答问题到为定制芯片优化代码。GPT-2、GPT-3、GPT-3.5 和 GPT-4 等著名的 AI 模型被标记在时间线上,展示了从 2020 年到 2026 年它们不断增强的能力和成功率的变化。
- 限流与资源管理:讨论强调了用户对 AI 使用限流的沮丧,这并非由于模型限制,而是由于资源管理。NVIDIA GPU 的短缺是一个主要因素,目前的需求超过了供应,影响了 AI 服务的容量。
- 定价模式与用户影响:ChatGPT 等 AI 服务的定价模式因“灵活且不精确”而受到批评,这影响了经常超出使用限制的高级用户,使他们成为市场上的“亏本先锋(loss leaders)”。建议包括更明确的使用限制和成本透明度,以改善用户体验。
- 任务时长与 AI 能力:图中绘制的任务时长存在困惑,澄清表明这些时长是基于人类完成类似任务所需的时间。讨论还指出,像 GPT-2 这样的 AI 模型存在局限性,例如在较长的任务中难以保持连贯性。
{kind=link}
AI Discord 摘要
由 Gemini 2.0 Flash Thinking 提供的摘要之摘要的摘要
主题 1. LLM 定价与市场波动
- OpenAI 的 o1-pro API 价格令开发者震惊:OpenAI 的新 o1-pro API 模型现已向部分开发者开放,其价格高昂,每 1M input tokens 为 150 美元,每 1M output tokens 为 600 美元。OpenRouter 上的用户对此表示愤怒,认为定价“疯狂”,并质疑这是否是针对 DeepSeek R1 等竞争对手的防御性举措,或者是由于缺乏 streaming 的复杂多轮处理所致。
- Pear AI 以更低价格挑战 Cursor:Cursor Community Discord 的成员正在强调 Pear AI 相较于 Cursor 的价格优势,声称 Cursor 变得越来越贵。一位用户表示,如果 Cursor 不改进其 context window 或 Sonnet Max 的定价,他们可能会转向 Pear AI,并指出 “如果我要为 sonnet max 付费,我不如用 pear,因为价格更便宜”。
- Perplexity 在融资谈判中寻求 180 亿美元估值:据报道,Perplexity AI 正处于 5 亿至 10 亿美元的早期融资谈判中,估值达 180 亿美元,这可能使其自 12 月以来的估值翻倍。这反映了在 AI 领域竞争日益加剧的情况下,投资者对 Perplexity 的 AI 搜索技术充满信心。
Theme 2. LLM Model Quirks and Fixes
- Gemma 3 在 Hugging Face 上遭遇身份危机:用户报告称,来自 Hugging Face 的 Gemma 模型错误地识别为具有 2B 或 7B 参数的“第一代”模型,即使下载的是 12B Gemma 3 也是如此。这种误识别是由 Google 在更新识别代码时的疏忽造成的,虽然不影响模型性能,但会导致用户对模型版本的困惑。
- Unsloth 修复 Gemma 3 Float16 激活问题:Unsloth AI 解决了 Gemma 3 在使用 float16 精度时出现的无限激活(infinite activations)问题,该问题曾导致在 Colab GPU 上进行 fine-tuning 和 inference 时出现 NaN 梯度。修复方案是将中间激活保留在 bfloat16 中,并将 layernorm 操作上采样至 float32,从而避免为了速度而进行全量 float32 转换,详情见 Unsloth AI 博客。
- Hugging Face Inference API 遭遇 404 错误:用户报告 Hugging Face Inference API 出现大范围 404 错误,影响了多个应用程序和付费用户。Hugging Face 团队成员承认了该问题并表示已提交调查,这干扰了依赖该 API 的服务。
Theme 3. Tools and Frameworks Evolve for LLM Development
- UV 成为备受关注的 Python 包管理器:MCP (Glama) Discord 的开发者们正在推崇 uv,这是一个用 Rust 编写的快速 Python 包和项目管理器,被认为是 pip 和 conda 的卓越替代品。uv 因其速度和极简的网站而受到赞誉,正在寻求高效依赖管理的 Python 开发者中获得青睐。
- Nvidia 的 cuTile 觊觎 Triton 的宝座?:NVIDIA 发布了 cuTile,这是一种用于 CUDA 的新 tile 编程模型,引发了社区关于其是否与 Triton 功能重叠的讨论。一些人推测 cuTile 可能是“另一个 Nvidia 版的 Triton”,并对 NVIDIA 在跨厂商后端支持方面的承诺表示担忧。
- LlamaIndex 与 DeepLearningAI 合作推出 Agentic 工作流课程:DeepLearningAI 与 LlamaIndex 合作推出了一门关于使用 RAG 构建 Agentic 工作流的短课,重点是自动化信息处理和上下文感知响应。该课程涵盖了解析表单和提取关键字段等实用技能,旨在增强 Agentic 系统的开发。
Theme 4. Hardware Headaches and Performance Hurdles
- TPUs 在机器学习速度竞赛中碾压 T4s:正如 Unsloth AI Discord 中所强调的,TPUs 表现出明显快于 T4s 的性能,特别是在 batch size 为 8 时。这一观察结果突显了 TPUs 在对速度要求极高的机器学习任务中的计算优势。
- LM Studio 多 GPU 性能大幅下降:LM Studio Discord 的一位用户报告称,在 LM Studio 中使用 CUDA llama.cpp v1.21.0 时,多 GPU 性能出现严重退化。性能显著下降,导致有建议通过 tensor splitting 配置手动将 LM Studio 限制为单 GPU。
- Nvidia Blackwell RTX Pro GPU 面临供应链紧缩:根据 Nous Research AI Discord 中分享的一篇 Tom’s Hardware 文章,Nvidia Blackwell RTX Pro 系列 GPU 预计将面临供应限制。供应问题可能会持续到 5月/6月,这可能会影响这些高需求 GPU 的可用性和价格。
{kind=link}
主题 5. AI 伦理、政策与安全辩论
- 中国强制要求对所有 AI 生成内容进行标识:中国将从 2025年9月1日 开始执行新规定,要求对 所有 AI 生成的合成内容 进行标识。根据中国政府的官方公告,《人工智能生成合成内容标识办法》将要求在 AI 生成的文本、图像、音频、视频和虚拟场景中添加显式和隐式标识。
- 中国模型对“文革”相关内容进行自我审查:OpenAI Discord 的一位用户报告称,某中国 AI 模型在被问及 文化大革命 时会删除回复,表现出自我审查。作为证据提供的截图突显了对某些 AI 模型内容限制的担忧。
- Sonnet 系列 LLM 暴露出 AI 编程盲点:aider Discord 中分享的一篇博文讨论了在 LLM(特别是 Sonnet 系列)中观察到的 AI 编程盲点。作者建议未来的解决方案可能涉及旨在解决“停止挖掘 (stop digging)”、“黑盒测试 (black box testing)”和“准备性重构 (preparatory refactoring)”等问题的 Cursor 规则,这表明人们正在不断努力改进 AI 编程辅助。
{kind=link}
第一部分:Discord 高层级摘要
Cursor Community Discord
- Agent Mode 崩溃:成员们报告 Agent mode 宕机了一小时,且 Status Page 未及时更新。
- 有人开玩笑说 dan percs 正在处理这个问题,他正 忙着在 Cursor 里回复用户 并 处理缓慢的请求,这就是为什么他总是保持在线。
- Dan Perks 征求键盘建议:Cursor 的 Dan Perks 征求了关于 Keychron 键盘的意见,特别是在寻找一款带有 旋钮 (knobs) 且 低平整洁 (low profile and clean) 的型号。
- 建议纷至沓来,包括 Keychron 的矮轴系列,尽管 Dan 对键帽的美观表示担忧,称 我不喜欢这些键帽。
- Pear AI vs Cursor:价格战?:几位成员吹捧了使用 Pear AI 的优势,并声称 Cursor 现在更贵了。
- 一位成员声称因为买了多个 Cursor 年费订阅而感到 心碎 (cooked),另一位则表示:如果 Cursor 改变他们的 Context Window,或者将 Sonnet Max 改为高级版使用,我会留在 Cursor;否则,如果我要为 Sonnet Max 付费,我不如用 Pear,因为那样更便宜。
- ASI:人类唯一的希望?:成员们辩论 人工超级智能 (ASI) 是否是下一次进化,声称 ASI-Singularity (天赐奇点) 必须是唯一的全球解决方案。
- 其他人持怀疑态度,一位用户开玩笑说 性别研究比 ASI 更重要,声称 这是让模型成为星际物种的下一步,拥有中性流动的性别,我们可以与来自不同星球的外星人交配,并适应他们的巫术技术。
- Pear AI 被指克隆 Continue?:成员们讨论了围绕 Pear AI 的争议,有人声称 Pear AI 基本上就是克隆了 Continue,并且 只是拿走了别人的工作成果,然后决定把它变成自己的项目。
- 其他人则担心该项目是闭源的,认为应该转向其他替代方案,如 Trae AI。
Unsloth AI (Daniel Han) Discord
- TPU 在速度上完爆 T4:一位成员指出,TPU 表现出比 T4 快得多的性能,尤其是在使用 Batch Size 为 8 时,正如对比 截图 所示。
- 这一观察强调了在机器学习中对于计算密集型任务使用 TPU 的优势,因为速度和效率至关重要。
- 梯度累积 (Gradient Accumulation) 故障修复:最近的一篇博客文章 (Unsloth Gradient Accumulation fix) 详细介绍并解决了一个与 Gradient Accumulation 相关的问题,该问题曾对序列模型的训练、预训练和 Fine-tuning 产生负面影响。
- 实施的修复方案旨在 模拟全批次训练的同时减少 VRAM 使用,并将其优势扩展到 DDP 和多 GPU 配置。
- Gemma 3 遭遇身份危机:用户观察到,从 Hugging Face 获取的 Gemma 模型 错误地将自己识别为具有 2B 或 7B 参数 的 第一代 模型,尽管它们实际上是 12B Gemma 3。
- 这种误识别是因为 Google 在训练期间没有更新相关的识别代码,尽管模型本身表现出对其身份和能力的认知。
- Gemma 3 获得 Float16 救生索:Unsloth 通过 这条推文 解决了 Gemma 3 在 float16 下的 无限激活 (infinite activations) 问题,该问题此前导致在 Colab GPU 上进行 Fine-tuning 和推理时出现 NaN 梯度。
- 该解决方案将所有中间激活保持在 bfloat16 中,并将 Layernorm 操作上采样至 float32,通过避免完全的 float32 转换来规避速度下降,详见 Unsloth AI 博客。
- Gemma 3 需要降级 Triton:一位用户在 Python 3.12.9 环境下使用 4090 运行 Gemma 3 时遇到了与 Triton 编译器相关的 SystemError。
- 根据 此 GitHub issue 的建议,解决方案涉及将 Python 3.11.x 上的 Triton 降级到 3.1.0 版本。
aider (Paul Gauthier) Discord
- Featherless.ai 配置引发困扰:用户报告了在使用 Aider 时 Featherless.ai 的配置问题,特别是关于配置文件位置和 API key 设置;使用
--verbose命令选项有助于排查设置问题。- 一位用户强调 Wiki 应该为 Windows 用户明确主目录,指定为
C:\Users\YOURUSERNAME。
- 一位用户强调 Wiki 应该为 Windows 用户明确主目录,指定为
- DeepSeek R1 价格便宜但速度较慢:虽然 DeepSeek R1 成为 Claude Sonnet 的高性价比替代方案,但其较慢的速度以及相对于 GPT-3.7 的性能让部分用户感到失望,即使使用了 Unsloth 的动态量化 (Dynamic Quantization)。
- 有人指出,完整的非量化版本 R1 需要 1TB RAM,这使得 H200 卡 成为首选;然而,32B 模型仍被认为是家庭使用的最佳选择。
- OpenAI 的 o1-pro API 定价令人咋舌:OpenAI 新推出的 o1-pro API 因其高昂的定价遭到用户投诉,价格定为 每 1M input tokens $150 以及 每 1M output tokens $600。
- 一位用户调侃道,单次文件重构和基准测试就要花费 $5,而另一位用户则戏称其为 fatherless AI。
- Aider LLM 编辑能力引发讨论:有人指出,Aider 从擅长“编辑”代码而非仅仅“生成”代码的 LLM 中获益最多,并引用了来自 aider.chat 的图表。
- polyglot benchmark 采用了来自 Exercism 的 225 个跨多种语言的编程练习,用以衡量 LLM 编辑能力。
- AI 编程盲点聚焦于 Sonnet 系列 LLM:分享了一篇关于他们在 LLM(特别是 Sonnet 系列)中注意到的 AI 编程盲点的博客文章。
- 作者建议,未来的解决方案可能涉及旨在解决这些问题的 Cursor rules。
LM Studio Discord
- 代理设置挽救了 LM Studio!:一位用户通过启用代理设置、进行 Windows 更新、重置网络并重启电脑,解决了 LM Studio 的连接问题。
- 他们怀疑这是由于硬件不兼容或运营商屏蔽了 Hugging Face 导致的。
- PCIE 带宽对性能提升微乎其微:一位用户发现 PCIE 带宽几乎不影响推理速度,与 PCI-e 4.0 x8 相比,最多只多出 2 tokens per second (TPS)。
- 他们建议优先考虑 GPU 之间的空间,并避免主板连接器溢出。
- LM Studio 误报 RAM/VRAM?:一位用户注意到 LM Studio 的 RAM 和 VRAM 显示在更改系统设置后不会立即更新,暗示该检查是在安装期间进行的。
- 尽管报告不准确,他们正在测试是否可以通过禁用防护栏(guardrails)和增加上下文长度,使应用程序超过报告的 48GB VRAM。
- Mistral Small 视觉支持仍难以实现:用户发现 LM Studio 上的某些 Mistral Small 24b 2503 模型被错误地标记为支持视觉(vision),因为 Unsloth 版本加载时不带视觉功能,而 MLX 版本则加载失败。
- 一些人怀疑 Mistral Small 在 MLX 和 llama.cpp 上仅限文本,希望未来的 mlx-vlm 更新能解决此问题。
- 多 GPU 性能大幅下降:一位用户报告了在 LM Studio 中使用 CUDA llama.cpp v1.21.0 时多 GPU 性能显著下降的问题,并分享了性能数据和日志。
- 一位成员建议手动修改 tensor_split 属性,以强制 LM Studio 仅使用单个 GPU。
Perplexity AI Discord
- Deep Research 界面更新:用户报告了 Perplexity 的 Deep Research 中出现了新的 Standard/High 选择器,并想知道使用 High 模式是否存在限制。
- 团队正致力于在模型层面改进 sonar-deep-research。
- GPT 4.5 玩起了“消失术”:GPT 4.5 从部分用户的下拉菜单中消失了,引发了因成本原因被移除的猜测。
- 一位用户指出,它在 rewrite option(重写选项)下仍然存在。
- Sonar API 推出全新搜索模式:Perplexity AI 宣布了改进后的 Sonar 模型,这些模型在保持性能的同时降低了成本,表现优于开启搜索功能的 GPT-4o 等竞争对手,详情见 博客文章。
- 他们引入了 High、Medium 和 Low 搜索计算模式以优化性能和成本控制,并简化了计费结构,改为输入/输出 token 定价配合固定搜索模式定价,取消了 Sonar Pro 和 Sonar Reasoning Pro 回复中引用 token 的费用。
- 通过命名避免 API Key 混乱:一位用户请求在 UI 上增加为 API Key 命名的功能,以避免误删生产环境的 Key,并被引导至 GitHub 提交功能请求。
- 另一位用户确认 API 调用看起来是正确的,并提醒根据 文档 考虑 Rate Limits(速率限制)。
- Perplexity 无法在锁屏界面使用:用户反映 Perplexity 无法在锁屏界面运行,而不像 ChatGPT 那样支持,这让社区感到失望。
- 一些用户注意到,Perplexity 现在使用的来源数量显著减少(8-16 个,最多可能 25 个),而以前曾使用 40+ 个,这影响了搜索深度。
Interconnects (Nathan Lambert) Discord
- O1 Pro API 搁置 Chat Completions 支持:由于其复杂的多轮模型交互,O1 Pro API 将仅在 responses API 中提供,而不会添加到 Chat Completions 中。
- 与 O1 Pro 不同,大多数即将推出的 GPT 和 O-series 模型都将集成到 Chat Completions 中。
- Sasha Rush 加入 Cursor 负责前沿 RL:Sasha Rush (@srush_nlp) 已加入 Cursor,致力于为真实世界的编程环境开发大规模前沿 RL 模型。
- Rush 乐于讨论 AI 职位以及工业界与学术界的问题,并计划在博客文章中分享他的决策过程。
- Nvidia 的 Canary 开源:Nvidia 开源了 Canary 1B & 180M Flash (@reach_vb),在 CC-BY 许可证下提供多语言语音识别和翻译模型,可用于商业应用。
- 该模型支持英文、德文、法文和西班牙文。
- 中国将对 AI 内容进行标识:中国将从 2025 年 9 月 1 日起施行《人工智能生成合成内容标识办法》,强制要求对所有 AI 生成内容进行标识。
- 该规定要求在文本、图像、音频、视频和虚拟场景等内容上添加显式和隐式标识;参见 中国政府官方公告。
- 三星 ByteCraft 将文本转化为游戏:三星 SAIL Montreal 推出了 ByteCraft,这是世界上第一个通过字节生成视频游戏和动画的生成式模型,可将文本提示词转换为可执行文件,详情见其 论文 和 代码。
- 该 7B 模型可在 Hugging Face 上获取,博客文章 进一步详细介绍了该项目。
Notebook LM Discord
- NotebookLM Plus 订阅者请求 Anki 集成:一位 NotebookLM Plus 用户请求在 NotebookLM 中加入 抽认卡生成集成 (Anki)。
- 然而,社区对此话题并没有太多讨论。
- “自定义”按钮解决了音频自定义的困惑:Audio Overview 功能中的“Customize”按钮对 NotebookLM 和 NotebookLM Plus 用户均可用,允许用户通过输入 Prompt 来定制音频内容。
- 免费账户限制每天只能生成 3 个音频,因此请谨慎选择你的自定义设置。
- 思维导图功能逐步推出:用户对 思维导图 (Mindmap) 功能 表示期待,有人分享了一个 YouTube 视频 展示其交互式用途。
- 这不是 A/B 测试,而是逐步推出;该功能允许通过选择不同的来源生成多个思维导图,但目前尚不支持编辑思维导图。
- Audio Overviews 在发音上仍有困难:用户报告称 Audio Overviews 经常读错词汇,即使在 Customize 输入框中使用了音标拼写也是如此。
- NotebookLM 团队已意识到此问题,并建议在源材料中使用音标拼写作为临时解决方案。
- 扩展程序用户遇到 NotebookLM 页面限制:用户正在使用 Chrome 扩展程序抓取并添加来自同一域名下链接的源,并指向了 NotebookLM 的 Chrome 网上应用店。
- 然而,一名用户在使用此类扩展程序时达到了 10,000 页 的上限。
Nous Research AI Discord
- Aphrodite 在性能上碾压 Llama.cpp:一名成员报告称,使用 Aphrodite Engine 运行 FP6 Llama-3-2-3b-instruct 达到了 70 tokens per second,并指出在 10GB VRAM 上可以运行多达 4 个 batch 且包含 8192 个 token。
- 另一名成员赞扬了 Aphrodite Engine 的首席开发人员,并强调该引擎是本地运行的最佳选择之一,同时也承认 Llama.cpp 是兼容性和依赖项方面的标准。
- LLM 在调试时表现不佳:成员们观察到,许多模型现在擅长编写无错代码,但在调试现有代码时却很吃力,并指出提供提示(hints)会有所帮助。
- 该成员对比了他们思考问题的方法,即提供可能的解释和代码片段,这种方法通常会取得成功,除非遇到“非常古怪的东西”。
- Nvidia 的 Blackwell RTX Pro GPU 面临供应链限制:一名成员分享了一篇关于 Nvidia Blackwell RTX Pro 系列 GPU 的 Tom’s Hardware 文章,强调了潜在的供应问题。
- 文章暗示供应可能会在 5月/6月 赶上需求,届时可能会有更多以 MSRP(建议零售价)供应的型号。
- 数据集格式 > QwQ 的聊天模板?:一名成员建议不要过度关注数据集的格式,并表示将数据集放入 QwQ 正确的 Chat Template 更为重要。
- 他们补充说,见解可能对数据集是唯一的,并且推理行为似乎发生在模型层中相对较浅的位置。
- 有趣的 Logan Kilpatrick 聊天片段:一名成员分享了 Logan Kilpatrick 的 YouTube 视频,称这段对话非常“有趣”。
- 讨论提到了与 Logan Kilpatrick 视频相关的“有趣聊天”,但未提供更多细节。
MCP (Glama) Discord
- 酷酷的 Python 开发者安装 UV 包管理器:成员们讨论了安装和使用 uv,这是一个用 Rust 编写的高速 Python 包和项目管理器,用于替代 pip 和 conda。
- 它受到青睐是因为其网站非常极简,只有一个搜索引擎和落地页。
- glama.json 认领 GitHub MCP 服务器:要在 Glama 上认领 GitHub 托管的 MCP 服务器,用户应在仓库根目录添加一个
glama.json文件,并在maintainers数组中填入其 GitHub 用户名,详情见此处。- 该配置需要一个指向
glama.ai/mcp/schemas/server.json的$schema链接。
- 该配置需要一个指向
- MCP 应用提升 GitHub API 速率限制:由于 MCP 服务器数量不断增加,Glama AI 正面临 GitHub API 速率限制,但用户可以通过安装 Glama AI GitHub App 来提高速率限制。
- 这样做通过授予应用权限来帮助扩展 Glama。
- Turso Cloud 与 MCP 集成:一个新的 MCP 服务器 mcp-turso-cloud 将 Turso 数据库 与 LLMs 集成。
- 该服务器实现了一个两级身份验证系统,用于直接从 LLMs 管理和查询 Turso 数据库。
- Unity MCP 将 AI 与文件访问集成:最先进的 Unity MCP 集成 现在支持对项目的文件读写访问,使 AI 助手能够理解场景、执行 C# 代码、监控日志、控制播放模式并操作项目文件。
- Blender 支持目前正在开发中,用于 3D 内容生成。
OpenAI Discord
- o1-pro 模型定价令人震惊:新的 o1-pro 模型 现已在 API 中向特定开发者开放,支持视觉、function calling 和 structured outputs,详见 OpenAI 文档。
- 然而,其 $150 / 1M 输入 tokens 和 $600 / 1M 输出 tokens 的高昂定价引发了争论,尽管一些用户声称它能一次性解决其他模型失败的代码任务。
- ChatGPT 代码带表情符号?!:根据 gpt-4-discussions 频道的讨论,成员们正在寻找防止 ChatGPT 在代码中插入表情符号的方法,即使设置了自定义指令也是如此。
- 建议包括避免使用 emoji 一词,并指示模型 “以恰当、专业的方式编写代码”。
- 中国模型自我审查!:一名用户报告称,一个中国模型会删除有关文化大革命提示词的回复,并提供了截图作为证据。
- 该问题在 ai-discussions 频道中进行了讨论,突显了对 AI 模型审查制度的关注。
- AI 不会让你选股:在 api-discussions 和 prompt-engineering 中,用户讨论了使用 AI 进行股市预测,但成员们指出,提供财务建议违反了 OpenAI 的使用政策。
- 澄清说明,探索个人股票想法是可以接受的,但禁止向他人提供建议。
- Agent SDK 与 MCP 的对决:成员们将 OpenAI Agent SDK 与 MCP (Model Communication Protocol) 进行了对比,指出前者仅适用于 OpenAI 模型,而后者支持任何使用任何工具的 LLM。
- MCP 允许通过
npx和uvx轻松加载集成,例如npx -y @tokenizin/mcp-npx-fetch或uvx basic-memory mcp。
- MCP 允许通过
LMArena Discord
- LLMs 面临 AI Hallucinations 的批评:成员们对 LLMs 在进行研究时容易出错和产生 hallucinations(幻觉)表示担忧。
- 一位成员观察到,Agent 虽然能找到准确的来源,但仍然会虚构网站,类似于 Perplexity 的 Deep Research 容易分心并产生大量 hallucinate。
- o1-pro 价格引发关注,被认为 GPT-4.5 定价过高:OpenAI 的新 o1-pro API 定价为 每 1M input tokens $150,每 1M output tokens $600(公告)。
- 一些成员认为这意味着 GPT-4.5 定价过高,其中一人评论称,通过算力优化托管同等模型会更便宜;然而,其他人辩称 o1 的推理链(reasoning chains)需要更多资源。
- 文件上传限制困扰 Gemini Pro:用户质疑为什么 Gemini Pro 不像 Flash Thinking 那样支持文件上传。
- 他们还指出 AI 模型 在准确识别 PDF 文件(包括非扫描件)方面存在困难,并希望未来的模型能够仔细阅读完整文章。
- Claude 3.7 编程能力引发争论:一些成员认为 Claude 3.7 的编程能力被高估了,认为它在 Web 开发和类似于 SWE-bench 的任务中表现出色,但在通用编程方面表现不佳(排行榜)。
- 相反,其他人发现 Deepseek R1 在终端命令测试中表现更优。
- 在 Google AI Studio 中构建 Vision AI Agent:一位成员报告称,成功使用 Google AI Studio API 在 Python 中构建了一个相当智能的 vision AI agent。
- 他们还尝试了同时运行 2-5 个以上的 Agent,共享内存并共同浏览互联网。
HuggingFace Discord
- Flux Diffusion 在本地运行:成员们讨论了在本地运行 Flux diffusion model,建议对其进行量化以在有限的 VRAM 上获得更好性能,并参考了文档和这篇博客文章。
- 成员们分享了一个用于优化扩散模型的相关 GitHub repo,以及一篇关于 GUI 设置的 Civitai 文章。
- HF Inference API 报错,用户表示愤怒:一位用户报告了 Hugging Face Inference API 返回 404 错误的普遍问题,影响了多个应用程序和付费用户,并链接到了此讨论。
- 一名团队成员承认了该问题,并表示他们已向团队报告以进行进一步调查。
- Roblox 通过 HF 分类器实现语音安全:Roblox 在 Hugging Face 上发布了一个语音安全分类器,该分类器使用 2,374 小时的语音聊天音频片段进行了微调,详见这篇博客文章和模型卡片。
- 该模型输出一个带有标签的张量,如 Profanity(亵渎)、DatingAndSexting(约会与性暗示)、Racist(种族主义)、Bullying(霸凌)、Other(其他)和 NoViolation(无违规)。
- Little Geeky 学会了说话:一位成员展示了一个基于 Ollama 的 Gradio UI,由 Kokoro TTS 驱动,可以自动以选定的声音朗读文本输出,该项目可在 Little Geeky’s Learning UI 获取。
- 该 UI 包含模型创建和管理工具,以及阅读电子书和回答文档相关问题的能力。
- Vision Model 面临输入处理失败:一位成员报告在下载 LLaVA 后使用本地 vision model 时,收到 “failed to process inputs: unable to make llava embedding from image” 错误。
- 失败的根本原因尚不明确。
OpenRouter (Alex Atallah) Discord
- O1-Pro 定价令用户震惊:用户对 O1-Pro 的定价表示愤怒,认为 $150/月输入和 $600/月输出的成本简直疯狂到令人望而却步。
- 有推测认为,高昂的价格是对来自 R1 和中国模型竞争的回应,或者是由于 OAI 在没有流式传输支持的情况下结合了多个模型的输出。
- LLM 象棋锦标赛测试原生性能:一名成员发起了第二次象棋锦标赛以评估原生性能,利用原始 PGN 棋谱文本续写并发布了结果。
- 模型重复对局序列并增加一个新招法,由 Stockfish 17 评估准确性;包含推理的第一次锦标赛可见此处。
- OpenRouter API:免费模型并不完全免费?:一位用户发现
/api/v1/chat/completions端点中的 model 字段是必填的,这与文档中声称的即使在使用免费模型时也是可选的说法相矛盾。- 一位用户建议 model 字段应默认为默认模型,或者默认为系统预设的默认模型。
- Groq API 出现间歇性功能故障:用户报告称 Groq 在 OpenRouter 聊天室中可以运行,但无法通过 API 运行。
- 一名成员要求澄清使用 API 时遇到的具体错误,并指出了 Groq 的速度优势。
- OpenAI 发布新款音频模型!:OpenAI 将发布两款新 STT 模型和一款新 TTS 模型(gpt-4o-mini-tts)。
- 语音转文本模型命名为 gpt-4o-transcribe 和 gpt-4o-mini-transcribe,并包含与 Agents SDK 的音频集成,用于创建可定制的语音 Agent。
GPU MODE Discord
- Vast.ai 裸机访问:难以实现?:成员们讨论了 Vast.ai 是否允许 NCU profiling 以及获取裸机访问权限是否可行,同时另一名成员询问了如何获取 NCU 和 NSYS。
- 虽然一名成员怀疑裸机访问的可能性,但他们承认自己也可能弄错。
- BFloat16 原子操作困扰 Triton:社区探索了在非 Hopper GPU 上使
tl.atomic支持 bfloat16 的方法,建议查看 tilelang 以了解原子操作以及非 Hopper GPU 对 bfloat16 支持的限制。- 一名成员指出,由于
tl.atomic_add的限制,目前使用 bfloat16 会导致崩溃,但有人认为可以通过tl.atomic_cas实现原子加法。
- 一名成员指出,由于
- cuTile 可能是另一个 Triton:成员们讨论了 NVIDIA 发布的 cuTile(一种用于 CUDA 的 Tile 编程模型),并引用了关于它的一条推文,一名成员对 NVIDIA 可能不支持 AMD GPU 等其他后端表示担忧。
- 有推测认为 cuTile 可能类似于 tilelang,即“另一个 Triton,但由 NVIDIA 出品”。
- GEMM 激活融合受挫:一名成员在编写自定义融合的 GEMM+activation Triton 内核时遇到问题,指出这取决于寄存器溢出 (register spillage),因为如果 GEMM 使用了所有寄存器,在 GEMM 中融合激活函数会损害性能。
- 正如 gpu-mode 第 45 课中所讨论的,将 GEMM 和激活函数拆分为两个内核可能会更快。
- 对齐改变处理器中的跳转:在 C++ 代码中包含
<iostream>可能会改变主循环跳转的对齐方式,从而由于处理器特定的行为影响性能,因为跳转的速度可能取决于目标地址的对齐方式。- 一名成员指出,在某些 Intel CPU 中,条件跳转指令的 32 字节对齐模数可能会因修补安全漏洞的微代码更新而显著影响性能,建议在关键循环前的内联汇编中添加 16 条 NOP 指令可以重现该问题。
Latent Space Discord
- Orpheus 夺得 TTS 竞技场榜首:开源 TTS 模型 Orpheus 首次亮相,据 此推文 和 此 YouTube 视频 称,其性能优于 ElevenLabs 和 OpenAI 等开源和闭源模型。
- 社区成员讨论了 Orpheus 对 TTS 领域潜在的影响,并期待进一步的基准测试和对比以验证这些说法。
- DeepSeek R1 训练费用引发热议:关于 DeepSeek R1 训练成本的估算正在讨论中,初始数据约为 600 万美元,但根据 此推文,李开复估计 2024 年整个 DeepSeek 项目的投入为 1.4 亿美元。
- 讨论强调了开发尖端 AI 模型所需的巨额投资以及成本估算的差异。
- OpenAI 的 o1-pro 携增强功能上线 API:OpenAI 在其 API 中发布了 o1-pro,提供更优的响应,成本为每 1M 输入 token 150 美元,每 1M 输出 token 600 美元,面向 Tier 1–5 的特定开发者开放,详见 此推文 和 OpenAI 文档。
- 该模型支持 vision、function calling 和 Structured Outputs,标志着 OpenAI API 服务的重大升级。
- Gemma 软件包简化微调工作:推出了 Gemma package,这是一个简化 Gemma 使用和微调的库,可通过 pip install gemma 安装,并记录在 gemma-llm.readthedocs.io 上,详见 此推文。
- 该软件包包含关于微调、sharding、LoRA、PEFT、多模态和 tokenization 的文档,简化了开发流程。
- 据报道 Perplexity 寻求 180 亿美元估值:据 Bloomberg 报道,Perplexity 正就 5 亿至 10 亿美元的新一轮融资进行早期谈判,估值达 180 亿美元,可能比 12 月的估值翻一番。
- 这一轮融资将反映出投资者对 Perplexity 搜索和 AI 技术的信心增强。
Eleuther Discord
- 单语模型引发困惑:成员们对“针对 350 种语言的单语模型”这一概念表示困惑,因为预期模型应该是 multilingual(多语言)的。
- 一位成员澄清说,该项目为每种语言训练一个模型,最终在 HF 上产生了 1154 个总模型。
- CV 工程师开启 AI Safety 探索:一位成员介绍自己是 CV 工程师,并表达了对为 AI safety 和 interpretability(可解释性)研究做出贡献的兴奋之情。
- 他们有兴趣与群组中的其他人讨论这些话题。
- 探索 Expert Choice Routing:成员们讨论了在自回归模型上实现 expert choice routing,在训练期间使用在线分位数估计 (online quantile estimation) 来推导推理阈值。
- 一个建议是假设 router logits 符合 Gaussian 分布,计算 EMA 均值和标准差,然后利用 Gaussian quantile function。
- 分位数估计管理稀疏性:一位成员提议在推理时使用 population quantiles(总体分位数)的估计来维持所需的平均稀疏性,并类比了 batchnorm。
- 另一位成员指出,由于 node limited routing,dsv3 architecture 能够激活 8-13 个专家,但目标是允许在 0 到 N 个专家之间激活。
- LLM 面临 Kolmogorov 压缩测试:一位成员分享了论文 《The Kolmogorov Test》,该论文为代码生成 LLM 引入了一种“压缩即智能”的测试。
- Kolmogorov Test (KT) 在推理时向模型提供一个数据序列,挑战其生成能够产生该序列的最短程序。
Cohere Discord
- Command-A 用卡斯蒂利亚语亲切交流:一位来自墨西哥的用户报告称,Command-A 以一种令人惊讶的自然且友好的方式模仿了他们的方言。
- 该模型感觉就像在与墨西哥人交谈,即使没有特定的 Prompt。
- Command-R 消耗大量 Token:一位用户通过 OpenRouter 为 Azure AI Search 测试了 Cohere 模型,并对输出结果印象深刻。
- 然而,他们指出,每次请求的输入消耗了 80,000 个 Token。
- Connectors 让当前的 Cmd 模型产生困扰:一位用户探索了带有 Slack integration 的 Connectors,但发现它们似乎不被 cmd-R 和 cmd-A 等最新模型支持。
- 旧模型返回了 500 错误,且 Connectors 似乎已从 V2 版本的 API 中移除,这令人失望,因为它们简化了数据处理;同时也有人担心从 Connectors 到 Tools 的过渡是否是等价替换。
- Good News MCP Server 传递正能量:一位成员构建了一个名为 Goodnews MCP 的 MCP server,它在其工具
fetch_good_news_list中使用 Cohere Command A 为 MCP 客户端提供积极、令人振奋的新闻,代码可在 GitHub 获取。- 该系统使用 Cohere LLM 对近期头条新闻进行排名,返回最积极的文章。
- Cohere API 上下文:容量至关重要:一位成员表示更倾向于使用 Cohere API,因为 OpenAI API 的上下文大小限制仅为 128,000,而 Cohere 提供 200,000。
- 然而,使用兼容性 API 会导致你失去对 API 响应中
documents和citations等 Cohere 特定功能的访问权限。
- 然而,使用兼容性 API 会导致你失去对 API 响应中
Modular (Mojo 🔥) Discord
- 光子学推测引发 GPU 热议:讨论集中在 Ruben GPUs 中的 photonics 和集成 CPU 是仅限于数据中心模型,还是会扩展到消费级版本(可能是 6000 series)。
- 有人提出了 CX9 拥有共封装光学器件(co-packaged optics)的可能性,暗示 DIGITs successor 可能会利用此类技术,而 CPU 已确认将用于 DGX workstations。
- 调试断言需要额外的编译器选项:在 Mojo 标准库中启用调试断言(debug asserts)需要一个额外的编译选项
-D ASSERT=_,这并未被广泛宣传,详见 debug_assert.mojo。- 有人指出使用
-g并不会启用断言,预期的做法是使用-Og编译时应自动开启它们。
- 有人指出使用
- Mojo List 索引因 UB 打印 0:当 Mojo List 索引超出范围时,由于未定义行为(UB),它会打印 0 而不是抛出错误。
- 出现此问题是因为代码索引超出了列表范围,进入了内核提供的零初始化内存。
- 关于默认断言行为的讨论:引发了关于
debug_assert默认行为的讨论,特别是围绕debug_assert[assert_mode="none"]的困惑,以及在调试模式下是否应默认启用它。- 有建议认为,在调试模式下运行程序时,应启用所有断言。
LlamaIndex Discord
- DeepLearningAI 推出 Agentic Workflow 课程:DeepLearningAI 推出了一门关于使用 RAG 构建 Agentic Workflow 的短课,内容涵盖解析表单和提取关键字段,更多详情见 Twitter。
- 该课程教授如何创建能够自动处理信息并生成上下文感知响应的系统。
- AMD GPU 驱动 AI 语音助手流水线:一个教程展示了如何使用 AMD GPU 创建多模态流水线,实现语音转文本、使用 RAG 以及将文本转回语音,该方案利用了 ROCm 和 LlamaIndex,详见此教程。
- 该教程重点介绍了 ROCm 环境的搭建,以及如何集成 LlamaIndex 以实现上下文感知的语音助手应用。
- LLM.as_structured_llm 需要并行工具调用支持:一位成员指出,在使用
LLM.as_structured_llm配合.chat时缺少allow_parallel_tool_calls选项,并建议扩展.as_structured_llm()调用以接受诸如allow_parallel_tool_calls=False之类的参数。- 另一位用户建议直接使用
FunctionCallingProgram进行自定义,并为 OpenAI 设置additional_kwargs={"parallel_tool_calls": False},参考了 OpenAI API 文档。
- 另一位用户建议直接使用
- Ollama 的推理标签困扰 ChatMemoryBuffer:一位在使用 Ollama 配合 qwq 模型 的用户正苦于
<think>推理标签出现在ChatMemoryBuffer的text块中,并寻求在使用ChatMemoryBuffer.from_defaults时移除它们的方法。- 另一位用户建议对 LLM 输出进行手动后处理,因为 Ollama 不提供内置过滤功能;原用户表示愿意分享他们的
MariaDBChatStore实现(PostgresChatStore的克隆版本)。
- 另一位用户建议对 LLM 输出进行手动后处理,因为 Ollama 不提供内置过滤功能;原用户表示愿意分享他们的
- llamaparse PDF 问答困惑:一位用户就使用 llamaparse 解析的数百个 PDF 文件的问答任务寻求建议,指出有些文件解析完美,而另一些则生成了毫无意义的 Markdown。
- 他们还对如何为需要不同处理方式的文档实现不同的解析模式感到好奇。
Torchtune Discord
- Nvidia 硬件仍落后于进度:成员们报告称 Nvidia 的新硬件迟到了,称 H200 在 2 年前 就已发布,但 6 个月前 才提供给客户。
- 一位成员调侃道,这就是“Nvidia 风格”。
- Gemma 3 微调将获得 Torchtune 支持:一位成员正在处理一个仅限 gemma 文本的 PR,并可能尝试加速落地,之后再添加图像功能。
- 另一位成员承诺将尽快继续 Gemma 3 的工作,并开玩笑地宣称他们的“假期正在转化为 Torchtune 冲刺”。
- 驱动版本导致 nv-fabricmanager 错误:当 nv-fabricmanager 的驱动版本与显卡驱动版本不匹配时,可能会抛出错误。
- 此问题已在某些按需 VM 上被观察到。
tinygrad (George Hotz) Discord
- Adam 优化器在 ML4SCI 任务中达到低损耗:一位成员报告称,使用 Adam 优化器 为
ML4SCI/task1训练了一个模型,损耗达到了 0.2s 左右,设置代码可在 GitHub 上找到。- 该仓库是该成员 Google Summer of Code 2025 项目的一部分。
- General 频道执行 Discord 规则:一位成员被提醒遵守 Discord 规则,特别是该频道仅用于讨论 tinygrad 开发 和 tinygrad 使用。
- 未提供有关违规行为的更多细节。
LLM Agents (Berkeley MOOC) Discord
- 用户对 AgentX 研究方向表示期待:一位用户表达了加入 AgentX Research Track 的兴奋和兴趣,渴望与导师和博士后合作。
- 他们的目标是通过对 LLM Agent 和 多 Agent 系统 的研究为该项目做出贡献。
- 用户承诺发挥主动性和自主性:一位用户承诺在 AgentX Research Track 中会积极主动且独立地推动其研究。
- 他们承诺在给定时间内交付高质量的工作,并感谢任何能增加其入选机会的支持。
DSPy Discord
- DSPy 用户寻求 arXiv 论文实现指导:kotykd 询问了是否可以使用 DSPy 实现这篇 arXiv 论文中描述的方法。
- 未提供关于具体实现挑战或目标的更多细节。
- arXiv 论文实现:用户 kotykd 引用了一篇 arXiv 论文,并询问是否可以使用 DSPy 来实现它。
- 论文内容以及用户感兴趣的具体方面未详细说明。
MLOps @Chipro Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Codeium (Windsurf) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Nomic.ai (GPT4All) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将将其移除。
第 2 部分:各频道详细摘要与链接
完整的频道详细解析已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预谢!