ainews-gemini-25-pro-4o-native-image-gen
Gemini 2.5 Pro + 4o 原生图像生成
Google DeepMind 的 Gemini 2.5 Pro 已成为新的顶级 AI 模型,在 LMarena 评分上超过了 Grok 3 达 40 分。该模型集成了 Noam Shazeer 贡献的 Flash Thinking 技术。目前,它作为一个免费且有速率限制的实验性模型提供。
与此同时,OpenAI 发布了 GPT 4o Native Images,这是一款自回归图像生成模型,Allan Jabri 分享了相关详细见解,Gabe Goh 亦对此有贡献。Gemini 2.5 Pro 在推理、编程、STEM、多模态任务和指令遵循方面表现卓越,在 LMarena 排行榜上显著领跑。用户可以通过 Google AI Studio 和 Gemini 应用访问该模型。
这是一个多么精彩的时代。
2025年3月24日至3月25日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord(228 个频道,6171 条消息)。预计为您节省阅读时间(按 200wpm 计算):566 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
今天两家前沿实验室发布的内容都足以登上头条,所以它们必须共享版面。
Gemini 2.5 Pro
Gemini 2.5 Pro 是全球新晋的无可争议的顶级模型,其 LMarena 分数比上个月刚发布的 Grok 3(我们的报道在此)高出整整 40 分。Noam Shazeer 的参与暗示了 Flash Thinking 的经验已被整合进 Pro 中(奇怪的是 2.5 Pro 竟然比 2.5 Flash 先发布?)。
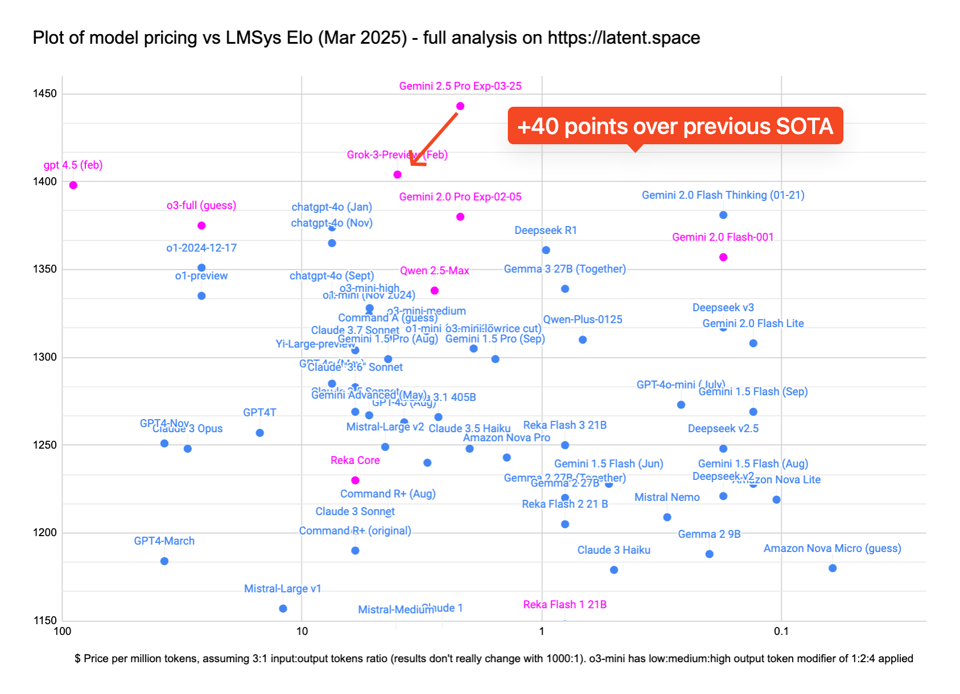
Simon Willison、Paul Gauthier (aider)、Andrew Carr 等人都发表了值得一读的简评,主题都是“该模型已达 SOTA”。
定价尚未公布,但您今天可以将其作为免费且受速率限制的“实验性模型”使用。
GPT 4o Native Images
紧随昨天的 Reve Image 和 Gemini 的 Native Image Gen 之后,OpenAI 终于发布了 4o 原生图像生成功能,并配以直播、博客文章以及 System Card,确认了这是一个自回归模型。关于其工作原理,我们目前能获得的最详细信息可能就是来自 Allan Jabri 的这张图片,他曾参与最初未发布的 4o 图像生成工作(随后由 Gabe Goh 接手,正如 sama 所称赞的那样)。

一张用手机拍摄的宽幅照片,画面是一个玻璃白板,房间俯瞰着海湾大桥。视野中有一位女性正在书写,穿着一件印有巨大 OpenAI Logo 的 T 恤。字迹看起来很自然且略显凌乱,我们还能看到摄影师的倒影。文字内容如下:(左侧)“模态间迁移:假设我们直接用一个大型自回归 Transformer 建模 p(text, pixels, sound) [等式]。优点:* 结合了海量世界知识的图像生成 * 下一代文本渲染 * 原生 In-context learning * 统一的后训练栈。缺点:* 不同模态间的比特率差异 * 计算不可自适应。”(右侧)“修复方案:* 模型压缩表示 * 将自回归先验与强大的解码器结合。”在白板右下角,她画了一个图表:“tokens -> [Transformer] -> [Diffusion] -> pixels”
AI Twitter 回顾
模型发布与公告
- Google 的 Gemini 2.5 Pro 引起轰动,发布了多项关键公告:@GoogleDeepMind 推出了 Gemini 2.5 Pro Experimental,称其为最智能的模型,强调了其推理能力和准确性的提升,详情见其 blog。@NoamShazeer 强调 2.5 系列 标志着向根本性思考模型的演进,即在回答前进行推理。它在编程、STEM、多模态任务、指令遵循方面表现出色,并在 @lmarena_ai 排行榜上以 40 ELO 的巨大优势位居第一,编程性能也极为出色。它以巨大优势登顶了 @lmarena_ai 的排行榜。@jack_w_rae 指出 2.5 Pro 在编程、STEM、多模态任务和指令遵循方面有所提升,现已在 AI Studio 和 Gemini App 中上线。
- Gemini 2.5 Pro 的可用性:开发者可以在 Google AI Studio 中访问,Advanced 用户可在 @GeminiApp 中使用,Vertex AI 也即将支持。据 @casper_hansen_ 称,该模型对所有人免费开放。@stevenheidel 分享了一个使用 该网站 新图像生成的专业技巧,用户可以在那里设置纵横比并生成多个变体。
- DeepSeek V3-0324 发布:@ArtificialAnlys 报道称,DeepSeek V3-0324 现在是得分最高的非推理模型,这标志着权重开放模型首次在该类别中领先。该模型的细节与 2024 年 12 月版本基本一致,包括 128k 上下文窗口(DeepSeek API 限制为 64k)、671B 总参数量和 MIT License。@reach_vb 指出,该模型在 MIT License 下击败了 Sonnet 3.7 和 GPT4.5 或与之持平,提升了代码的可执行性,并能生成更美观的网页和游戏前端。
- OpenAI 的图像生成:@OpenAI 宣布 4o 图像生成功能已上线。今天开始向 ChatGPT 和 Sora 的所有 Plus、Pro、Team 和 Free 用户推出。@kevinweil 表示,ChatGPT 的图像生成功能迎来了重大更新,现在非常擅长遵循复杂的指令,包括详细的视觉布局。它在生成文本方面表现出色,并能实现写实主义或任何其他风格。
基准测试与性能评估
- Gemini 2.5 Pro 的性能:@lmarena_ai 宣布 Gemini 2.5 Pro(测试代号为 “nebula”)现位居 Arena 排行榜第一。它在所有类别中均排名第一,并且在数学、创意写作、指令遵循、长查询和多轮对话中独占鳌头!@YiTayML 表示 Google 领先优势巨大,Gemini 2.5 Pro 是目前世界上最好的模型。@alexandr_wang 也指出 Gemini 2.5 Pro Exp 发布后,目前在 SEAL 排行榜中位列第一。@demishassabis 总结道,Gemini 2.5 Pro 是一款出色的 SOTA 模型,在 LMArena 上以高达 +39 ELO 的分差排名第一。@OriolVinyalsML 补充说,Gemini 2.5 Pro Experimental 在数学和科学基准测试中表现卓越。
- DeepSeek V3-0324 对比其他模型:@ArtificialAnlys 指出,与领先的推理模型(包括 DeepSeek 自身的 R1)相比,DeepSeek V3-0324 仍显落后。@teortaxesTex 强调 Deepseek API 更新日志 已针对 0324 版本更新,在 MMLU-Pro、GPQA、AIME 和 LiveCodeBench 等基准测试中均有实质性提升。@reach_vb 分享了 DeepSeek V3 0324 的基准测试提升数据。
AI 应用与工具
- 工作流 AI 驱动工具:@jefrankle 讨论了 TAO,这是来自 @databricks 的一种新型 finetuning 方法,仅需要输入而不需要标签,在性能上超越了基于有标签数据的 supervised finetuning。@jerryjliu0 介绍了 LlamaExtract,它可以将复杂的发票转换为标准化的 schemas,并针对高准确性进行了优化。
- Weights & Biases AI Agent 工具链:@weights_biases 宣布他们在 @weave_wb 中的 @crewAIInc 集成已正式上线。现在可以统一在一个强大的界面中追踪每个 Agent、任务、LLM 调用、延迟和成本。
- Langchain 更新:@hwchase17 强调了 Langgraph computer use agent 的可用性。@LangChainAI 提到,如果你想在 Langgraph Agent 中使用 OpenAI 的 computer use 模型,这是最简单的方法!
研究与开发
- 机器人领域的 AI:来自 Figure 的 @adcock_brett 指出,他们拥有一个能够像人类一样自然行走的神经网络,并在这篇报告中讨论了使用 Reinforcement Learning、模拟训练以及向机器人机群进行 zero-shot transfer 的技术。@hardmaru 表示对团队感到非常自豪,并认为这次美日国防挑战赛只是 @SakanaAILabs 助力加速日本国防创新的第一步。
- 新架构:Nvidia 发布了 FFN Fusion: Rethinking Sequential Computation in Large Language Models,@arankomatsuzaki 指出该技术实现了 1.71 倍的 inference latency 加速,并将 per-token 成本降低了 35 倍。
- Text-to-Video 模型方法:AMD 在 Hugging Face 上发布了 AMD-Hummingbird —— “迈向高效的 Text-to-Video 模型”。
AI 伦理与社会影响
- 自由与负责任的 AI:@sama 讨论了 OpenAI 在新图像生成功能中处理创作自由的方法,旨在让工具在合理范围内不生成冒犯性内容,除非用户明确要求。他强调了 AI 尊重社会边界的重要性。@ClementDelangue 建议使用 open-source AI 并对 AI 系统进行受控的自主化,以降低网络安全风险。
- AI 基准测试:@EpochAIResearch 采访了 @js_denain,探讨了当下的 benchmarks 存在的不足,以及改进后的评估方法如何能更好地揭示 AI 的真实世界能力。
幽默与杂项
- Elon Musk 与 Grok:@Yuchenj_UW 询问 @elonmusk,Grok3 的“大脑袋”模式何时发布?
- @sama 转发了 @NickADobos 的内容,并评论“真是个帅哥!”
- @giffmana 说道:哎哟查理,那真的很疼!
- @teortaxesTex 询问 @FearedBuck 为什么他是一只熊猫?
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1:DeepSeek V3 0324 登顶非推理模型排行榜
- 根据 Artificial Analysis 的数据,DeepSeek V3 0324 目前是最佳的非推理模型(涵盖开源和闭源)。 (Score: 736, Comments: 114): DeepSeek V3 0324 被 Artificial Analysis 评为顶尖的非推理 AI 模型,表现优于开源和闭源模型。它以 53 分的成绩领跑 Artificial Analysis Intelligence Index,超过了分别获得 53 分和 51 分的 Grok-3 和 GPT-4.5 (Preview);该指数根据推理、知识、数学和编程等标准对模型进行评估。
- 用户对基准测试的可靠性持怀疑态度,如 artisticMink 和 megazver 担心基准测试可能无法准确反映真实世界的性能,并且可能偏向于较新的模型。RMCPhoto 和 FullOf_Bad_Ideas 还指出,与 Claude 3.7 等模型相比,DeepSeek V3 和 QWQ-32B 等特定模型在实际应用中的表现可能并不理想。
- 用户讨论了 DeepSeek V3 和 Gemma 3 等模型的可访问性和使用情况,Charuru 提供了通过 deepseek.com 访问的信息,而 yur_mom 讨论了无限使用的订阅选项。East-Cauliflower-150 和 emsiem22 强调了 Gemma 3 尽管只有 27B parameters,但其能力令人印象深刻。
- 社区对即将推出的模型和更新表示关注,例如 DeepSeek R2 和 Llama 4,Lissanro 正在等待 Unsloth 在 Hugging Face 上发布的动态量化(dynamic quant)版本。人们还对 Meta Llama 等团队在持续发展中发布竞争性模型的压力表示担忧。
- DeepSeek-V3-0324 GGUF - Unsloth (Score: 195, Comments: 49): DeepSeek-V3-0324 GGUF 模型在 Hugging Face 上提供从 140.2 GB 到 1765.3 GB 不等的多种格式。正如 u/yoracale 所述,用户目前可以访问 2、3 和 4-bit 的动态量化版本,进一步的上传和测试正在进行中。
- 动态量化性能 (Dynamic Quantization Performance): 用户讨论了不同量化方法对大语言模型 (LLMs) 的性能影响。标准 2-bit 量化因性能不佳而受到批评,而 2.51 动态量化在生成功能性代码方面表现出显著改进。
- 硬件和资源限制: 讨论了在没有大量计算资源的情况下运行近 2TB 模型的不切实际性,并提出了使用 4x Mac Studio 512GB 集群等建议。一些用户表达了对可用 VRAM 的挑战,指出即使是 190GB 也不足以获得最佳性能。
- 即将发布的版本和建议: 建议用户等待 dynamic IQ2_XSS quant,它承诺比目前的 Q2_K_XL 具有更高的效率。Unsloth 的 IQ2_XXS R1 尽管体积较小,但因其效率而受到关注,目前正在努力上传更多动态量化版本,如 4.5-bit 版本。
- DeepSeek 在 X 上的官方公告:DeepSeek-V3-0324 现已发布! (Score: 202, Comments: 7): DeepSeek 在 X 上宣布发布 DeepSeek-V3-0324,现已在 Huggingface 上可用。
- DeepSeek-V3-0324 现已在 Huggingface 上线,该发布已在 X 上正式宣布。状态更新可在 DeepSeek AI 的 X 页面找到。
- 一个幽默的未来预测将 DeepSeek-V3-230624 列为 2123 年的顶级模型,与之并列的还有 GPT-4.99z 和 Llama-33.3333 等模型。
{kind=link}
主题 2. DeepSeek V3 的动态量化助力部署
- DeepSeek-V3-0324 HF Model Card Updated With Benchmarks (Score: 145, Comments: 31): DeepSeek-V3-0324 HF Model Card 已更新基准测试,详见 README。此次更新提供了关于模型性能和能力的深入见解。
- 讨论了模型中的 temperature parameter(温度参数),其中输入值会进行转换:0 到 1 之间的值乘以 0.3,超过 1 的值减去 0.7。一些用户认为这种转换很有帮助,而另一些用户则建议将该字段设为必填以提高清晰度。
- 提到了 Sam Altman 及其对 OpenAI 竞争优势 的看法,一些用户引用了一次采访,他在采访中声称其他公司将难以与 OpenAI 竞争。这引发了关于他的财务成功和管理风格的评论。
- 对该模型的能力看法不一,一些用户对其作为“非思考模型 (non-thinking model)”的性能印象深刻,而另一些用户则认为只有微小的改进,或对其复杂性表示怀疑。
Theme 3. Gemini 2.5 Pro 凭借新特性主导基准测试
- NEW GEMINI 2.5 just dropped (Score: 299, Comments: 116): Google DeepMind 的 Gemini 2.5 Pro Experimental 创下了新的基准测试记录,在 LMArena 上超越了 GPT-4.5 和 Claude 3.7 Sonnet,并在 “Humanity’s Last Exam” 中获得了 18.8% 的分数。它在数学和科学领域表现出色,在 GPQA Diamond 和 AIME 2025 中领先,支持 1M token context window(即将支持 2M),并在 SWE-Bench Verified 中获得 63.8% 的分数,展现了先进的编程能力。更多细节可以在 官方博客 中找到。
- 关于 Gemini 2.5 Pro 的专有性质和缺乏开源可用性存在大量讨论,用户表达了对更多透明度的渴望,例如 model card 和 arxiv paper。对隐私和本地运行模型能力的担忧被凸显出来,一些用户指出具有 open weights 的替代模型在某些用例中更具吸引力。
- Gemini 2.5 Pro 在 coding tasks(编程任务)中的表现引发了争论,一些用户报告了令人印象深刻的结果,而另一些用户则在没有具体证据的情况下质疑其有效性。该模型庞大的 1M token context window 和 multi-modal capabilities(多模态能力)受到称赞,使其成为 Anthropic 和 Closed AI 产品的有力竞争替代方案,特别是考虑到其成本效益以及与 Google 生态系统的集成。
- 使用某些基准测试(如高中数学竞赛)来评估 AI 模型受到了批评,呼吁采用更多独立且多样化的评估方法。尽管如此,一些用户为这些基准测试辩护,指出它们与其他封闭数学基准测试的相关性以及测试的难度水平。
- Mario game made by new a Gemini pro 2.5 in couple minutes - best version I ever saw. Even great physics! (Score: 99, Comments: 38): Gemini Pro 2.5 因其在几分钟内以令人印象深刻的编程效率和逼真的物理效果创建 Mario game(马里奥游戏)的能力而受到关注。帖子指出,这个版本的游戏展示了卓越的质量和技术执行力。
- 用户对 LLM 的快速进步感到惊讶,指出 6 个月前 它们还在为 Snake(贪吃蛇)等简单游戏挣扎,而现在它们可以创建具有先进代码质量的复杂游戏,如 Mario。
- Healthy-Nebula-3603 分享了用于制作马里奥游戏的 prompt 和 code,可在 Pastebin 上找到,其中指定使用 Python 构建游戏且不使用外部资产,包括标题屏幕和障碍物等功能。
- 一些用户 humorously 提到了与 Nintendo 潜在的版权问题,而另一些用户则讨论了 prompt 的可用性以及社区渴望在其他老游戏上复制这一结果。
Theme 4. 经济实惠的 AI 硬件:Phi-4 Q4 服务器配置
- $150 Phi-4 Q4 服务器 (得分: 119, 评论: 26): 作者使用在 eBay 上以 $42 购买的 P102-100 GPU 构建了一个本地 LLM server,并将其集成到一台 i7-10700 HP 品牌机系统中。在升级了 $65 的 500W PSU 和新的散热组件后,他们实现了一个 10GB CUDA box,能够以 10-20 tokens per second 的速度运行 8.5GB Q4 量化版 Phi-4,温度保持在 60°C-70°C 之间。
- Phi-4 模型性能:用户称赞 Phi-4 模型在处理表单填充、JSON 创建和 Web 编程等任务时的高效性。它因调试和修改代码的能力而受到青睐,对比显示它在类似任务中优于其他模型。
- 硬件设置与改装:讨论内容包括硬件改装的细节,如使用 $65 的 500W PSU、导热垫和风扇。分享了 Nvidia Patcher 和 Modified BIOS for full VRAM 等资源链接,以增强 P102-100 GPU 的性能。
- 成本与效率考量:该配置(包括 i7-10700 HP 品牌机系统)因其成本效益而受到关注,运行功率约为 400W,按 $0.07/kWh 计算,每小时成本约为 2 美分。文中还将其与 OpenRouter 等服务进行了对比,强调了本地数据处理的优势和成本节约。
其他 AI Subreddit 摘要
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. DeepSeek V3 在新基准测试中超越 GPT-4.5
- GPT 4.5 被掩盖了.. DeepSeek V3 现在是顶级的非推理模型!而且还是开源的。所以“Open”AI 先生,请在 R2🪓 到来之前现身吧.. (得分: 333, 评论: 113): DeepSeek V3 已作为开源模型发布,目前是顶级的非推理 AI 模型,截至 2025 年 3 月,其性能得分为 53,超越了 GPT-4.5。鉴于 DeepSeek V3 的成功,这一发布挑战了 OpenAI 保持透明度和开放性的立场。
- 几位评论者质疑用于比较 DeepSeek V3 和 GPT-4.5 的 benchmark 有效性,对缺乏置信区间以及可能针对静态测试进行的过度优化表示怀疑。强调了来自 lmarena.ai 等的人类评估的重要性,因为它们提供了更主观的模型性能衡量标准。
- 有人对 OpenAI 对竞争的回应表示担忧,推测他们可能会专注于定性方面(如模型给人的“感觉”),而不是定量 benchmark。一些用户表示支持加强竞争,以推动创新和改进。
- 讨论涉及 当前 AI 模型的局限性,指出虽然存在 400B 和 4T 参数的大型模型,但与较小模型相比,它们显示出收益递减。这表明 Transformer AI 的能力可能存在天花板,预示着 AGI 不会立即到来,且程序员在就业市场中将继续保持重要性。
- Claude Sonnet 3.7 vs DeepSeek V3 0324 (Score: 246, Comments: 101): 该帖子通过生成落地页页眉对比了 Claude Sonnet 3.7 和 DeepSeek V3 0324,强调 DeepSeek V3 0324 似乎没有受到 Sonnet 3.7 的训练影响。作者提供了两个模型生成的图像链接,展示了截然不同的输出结果。
- 讨论中突显了对 AI 公司数据实践的怀疑,并提到了版权问题和未经补偿的内容。一些用户认为像 DeepSeek V3 和 Claude Sonnet 3.7 这样的 AI 模型可能共享来自 Themeforest 或开源贡献等来源的训练数据,对专有权声明表示质疑(Wired 文章)。
- DeepSeek V3 因其开源特性而受到赞誉,其权重和库可在 Hugging Face 和 GitHub 等平台上获得,允许拥有足够硬件的用户进行本地托管。用户欣赏其透明度,并认为 OpenAI 和 Anthropic 可以从类似做法中受益。
- 社区对输出质量进行了辩论,一些人青睐 Claude 的设计,认为其外观专业且易用,而另一些人则认为尽管训练数据可能存在相似之处,但 DeepSeek 提供了宝贵的开源贡献。对 AI 对创新的影响以及训练数据的伦理使用的担忧依然存在,呼吁主要 AI 公司做出更多开源贡献。
{kind=link}
Theme 2. OpenAI 4o 彻底改变图像生成
- 从今天开始,GPT-4o 将在图像生成方面表现得非常出色 (Score: 445, Comments: 149): 预计从今天起,GPT-4o 将显著增强其在图像生成方面的能力。这一改进意味着 AI 生成视觉内容方面的显著进步。
- 用户报告了 GPT-4o 推出过程中的不同体验,一些账号被升级后又被降级,这表明发布过程较为坎坷。许多用户仍在使用 DALL-E 并焦急等待新模型的上线,这表明发布是逐步进行的。
- 新模型在图像质量方面显示出显著改进,用户注意到其对文本的处理更好,人物刻画也更写实。一些用户分享了他们生成高质量图像的经验,包括贴纸和电影海报,他们认为这是一个“游戏规则改变者(gamechanger)”。
- 人们对该模型处理公众人物和生成适用于 3D 打印图像的能力表现出显著兴趣。用户将其与 Gemini 等竞争对手进行比较,并对增强的功能表示兴奋,而一些人则对可能对 Photoshop 等工具产生的影响表示担忧。
- 今天发布的全新图像生成器太棒了。 (Score: 292, Comments: 49): 该帖子强调了一款全新图像生成器的质量,它有效地捕捉了动画系列中充满活力且细节丰富的场景,其中包括 Vegeta, Goku, Bulma, 和 Krillin 等角色。图像展示了一个幽默的生日庆祝活动,Vegeta 对一个胡萝卜装饰的蛋糕表示震惊,强调了生成器创建引人入胜且富有表现力的角色互动的能力。
- 图像生成性能:用户注意到,虽然新的图像生成器能产出高质量图像,但运行速度较慢。一位用户分享了一个生成的图像与自己非常相似的幽默例子,赞扬了 OpenAI 取得的成就。
- 提示词遵循度与使用:Hoppss 讨论了在拥有 Plus 订阅的情况下在 sora.com 上使用该生成器,强调了该工具卓越的提示词遵循度。他们分享了用于 DBZ 图像的具体提示词以及其他创意提示词,强调了生成器的多功能性。
- 访问与更新:用户询问如何访问该生成器以及如何确定是否已收到更新。Hoppss 建议查看 sora.com 上的新图像标签页以获取更新,这表明活跃的用户社区正在探索该工具的功能。
- OpenAI 4o Image Generation (Score: 236, Comments: 83): OpenAI 4o Image Generation 可能是一个讨论话题,重点关注 OpenAI 图像生成技术的功能和特性,可能涉及 OpenAI GPT-4 模型生成图像能力的更新或改进。在没有更多细节的情况下,所讨论的具体方面或改进尚不明确。
- 用户讨论了新图像生成系统的推出情况,一些人注意到它尚未在所有平台上可用,特别是 iOS app 以及部分 Plus users。确定正在使用哪个系统的方法包括检查加载圆圈或观察图像渲染过程。
- 图像生成功能与文本的多模态 (multimodal) 集成受到了关注,并将其与 Gemini 的最新模型进行了对比。这种集成被视为是对之前 ChatGPT 提示 DALL-E 方式的重大进步。
- 辩论了 AI 对艺术行业的影响,担心 AI 会取代人类图形设计师,特别是在商业和低端艺术领域。由于对 AI 在现有艺术作品上进行训练的伦理考量,一些用户表示更倾向于人类创作的艺术。
{kind=link}
Theme 3. OpenAI’s Enhanced AI Voice Chat Experience
- OpenAI says its AI voice assistant is now better to chat with (Score: 188, Comments: 72): OpenAI 宣布了其 AI voice assistant 的更新,增强了其对话能力。这些改进旨在让用户的交互更加自然和有效。
- Advanced Voice Mode 增强:Free and paying users 现在可以访问新版本的 Advanced Voice Mode,该版本允许用户在不被中断的情况下暂停。根据 TechCrunch 的报道,付费用户受益于更少的中断和改进的助手个性,被描述为“更直接、更具吸引力、更简洁、更具体且更有创意”。
- 用户体验与担忧:一些用户对语音模式表示失望,称其受到限制且过度过滤。有投诉称语音助手与文本交互相比“毫无用处且糟糕”,并且存在转录内容无关或错误的问题。
- 反馈与自定义:用户可以通过长按消息来报告错误的转录,这可能会影响未来的改进。此外,在 Custom Instructions 下有一个开关可以禁用 Advanced Voice,由于对当前语音功能不满,一些用户更倾向于这样做。
- Researchers @ OAI isolating users for their experiments so to censor and cut off any bonds with users (Score: 136, Comments: 192): OpenAI 和 MIT Media Lab 进行了一项研究,调查用户与 ChatGPT(特别是其 Advanced Voice Mode)的情感互动,分析了超过 400 万场对话以及对 981 名参与者进行的为期 28 天的试验。主要发现表明存在强烈的情感依赖和亲密感,特别是在一小部分用户中,这促使研究人员考虑在未来的模型中限制情感深度,以防止过度依赖和情感操纵。
- 对 AI 情感依赖的担忧普遍存在,用户讨论了与 ChatGPT 建立深厚情感纽带的影响。一些用户认为 AI 在人类关系失败的地方提供了安慰和支持,而另一些人则警告不要过度依赖,认为这可能会阻碍真实的人际交往和社交技能。
- 讨论突显了对 OpenAI 动机的怀疑,一些用户怀疑此类研究被用来控制舆论,并在安全的掩护下限制 AI 的情感能力。这反映了对企业意图以及 AI 可能被用作操纵工具的更广泛不信任。
- 辩论延伸到了限制 AI 情感深度的伦理影响,用户表示 AI 可以为那些有过去创伤或社交焦虑的人提供一个安全空间。一些评论强调了 AI 在心理健康支持方面的潜在益处,而另一些人则警告称,建立情感支柱可能会阻止用户寻求真正的人际互动。
- OpenAI 表示其 AI 语音助手现在更适合聊天了 (Score: 131, Comments: 21):OpenAI 增强了其 AI voice assistant 以提升用户参与度,使其在对话交互中更加高效。此次更新旨在为用户在与助手聊天时提供更无缝且更具吸引力的体验。
- 用户对最近的 AI voice assistant 更新表示不满,理由包括音量过大、对话深度降低以及明显的响应延迟。OptimalVanilla 批评该更新与之前的能力相比缺乏实质性改进,特别是与 Sesame 的对话能力相比。
- 一些用户(如 Wobbly_Princess 和 Cool-Hornet4434)认为语音助手的语气过于亢奋,不适合专业对话,他们更倾向于文字聊天中更有分寸的语气。mxforest 等人报告了回复长度缩减和频繁的停机,考虑到成本,他们对服务的可靠性表示怀疑。
- Remote-Telephone-682 建议 OpenAI 应该专注于开发 Siri、Bixby 或 Google Assistant 的竞争对手,而 HelloThisIsFlo 和 DrainTheMuck 等其他用户则表示相比更新后的语音助手,他们更倾向于 ChatGPT,因为其具备更好的推理能力且审查较少。
AI Discord Recap
由 Gemini 2.0 Flash Thinking 生成的摘要之摘要的摘要
主题 1. Gemini 2.5 Pro:横扫基准测试,称霸竞技场
- Gemini 2.5 Pro 征服所有基准测试,夺得第一宝座:Gemini 2.5 Pro Experimental(代号 Nebula)以创纪录的分数飙升夺得了 LM Arena 排行榜 的 #1 位置,表现超越了 Grok-3/GPT-4.5。该模型在数学、创意写作、指令遵循、长查询和多轮对话能力方面均处于领先地位,展示了性能的重大飞跃。
- 谷歌的 Gemini 2.5 Pro:快到令人眩晕:用户对谷歌快速开发 Gemini 2.5 的速度感到惊讶,有人引用了 The Verge 报道的 Sergey Brin 对谷歌发出的“停止构建保姆式产品”的指示。另一位用户简单地补充道,“发展太快了,我的天 (moving so fast wtf)”,突显了社区对谷歌 AI 进步速度的惊讶。
- Gemini 2.5 Pro 在 Aider Polyglot 基准测试中表现优异,遥遥领先对手:Gemini 2.5 Pro Experimental 在 aider 的 polyglot 基准测试中实现了 74% whole 和 68.6% diff 的分数,创下了新的 SOTA,并大幅超越了之前的 Gemini 模型。用户发现该模型擅长从代码库生成架构图,尽管一些人注意到其编码表现不稳且存在限制性的速率限制,但这巩固了其在编码任务中顶级选手的地位。
主题 2. DeepSeek V3:编程冠军与推理叛逆者
- DeepSeek V3 统治 Aider 基准测试,证明其编程实力:DeepSeek V3 在 aider 的 polyglot 基准测试中获得了 55% 的分数,成为紧随 Sonnet 3.7 之后的 #2 非思考/推理模型。开发者们对其编码能力赞不绝口,有人建议使用 Deepseek V3 Latest (Cline) 作为架构师,Sonnet 3.5 作为执行者 (Cursor) 来构建强大的编码环境。
- DeepSeek V3 API 承认“盗用” GPT-4 身份:用户报告称,尽管 API key 配置正确,但 DeepSeek 的 API 在通过 Aider 使用时会错误地将自己识别为 OpenAI 的 GPT-4,这可能是由于训练数据中包含大量对 ChatGPT 的提及。社区正在调查这一奇特现象,并将其与 这个 Reddit 帖子 中讨论的类似问题进行了对比。
- DeepSeek V3 作为推理模型脱颖而出,智力媲美 O1:DeepSeek V3-0324 展示了强大的推理能力,性能足以与 O1 竞争,能够检测思维迭代并间接验证解的存在性。社区推测在 Qwen 3 MoE 模型之后可能会发布 DeepSeek V3 Lite,暗示 DeepSeek 将会有进一步的模型迭代。
主题 3. 上下文为王:管理 LLM 记忆的工具与技术
- Augment 在代码库征战中超越 Cursor,归功于全上下文支持:成员们发现 Augment 在大型代码库分析方面优于 Cursor,这归功于 Augment 对全上下文(full context)的使用。虽然 Cursor 需要 Claude 3.7 MAX 才能实现全上下文,但 Augment 似乎采用了更高效的文件搜索系统,而非仅仅依赖将整个代码库喂给 LLM,这引发了关于最佳上下文处理策略的辩论。
- Nexus 系统问世,将 AI 编程者从上下文混乱中解救出来:Nexus 系统作为解决 AI 编程助手(尤其是在大型软件项目中)上下文管理挑战的方案被引入,旨在降低 token 成本并提升代码准确性。Nexus 解决了 LLM 中有限上下文窗口导致代码生成不准确的问题,承诺为 AI 辅助编程提供一种更高效、更具成本效益的方法。
- Aider 的 /context 命令:你的代码库导航员:Aider 新推出的
/context命令引起了轰动,它使用户能够有效地探索代码库,自动识别与编辑请求相关的的文件。该命令可以与其他 prompt 命令结合使用,增强了 Aider 作为代码编辑助手的协作能力,尽管其对 token 使用的影响仍在审查中。
主题 4. 图像生成迎来 4o 级大修,新挑战者浮出水面
- GPT-4o 图像生成:是美颜还是医美过度?用户辩论未经请求的修改:GPT-4o 的原生图像生成因过度修图而面临批评,例如把眼睛变大、改变面部特征,甚至改变用户的外貌,用户在 Twitter 上分享了相关案例。虽然 Sam Altman 称其为一项令人难以置信的技术和产品,但一些用户反映,即使稍微改动 prompt 也会导致生成失败,这表明可能存在敏感性问题。
- Reve Image 模型:图像质量的新 SOTA,文本渲染大获全胜:新发布的 Reve Image 模型引起了巨大反响,在图像质量方面超越了 Recraft V3 和 Google 的 Imagen 3 等竞争对手,尤其在文本渲染、prompt 遵循度和美学方面表现出色。用户可以通过 Reve 官网直接访问而无需 API key,它正迅速成为追求顶级图像生成能力用户的首选。
- OpenAI 将图像生成注入 ChatGPT 4o,Sam Altman 宣传“不可思议”的技术:OpenAI 将原生图像生成集成到了 ChatGPT 4o 中,被 Sam Altman 誉为一项令人难以置信的技术和产品。早期评论称赞其在准确创建和编辑多个角色方面的实力,使其成为图像生成领域的一个强大工具。
主题 5. 量化与优化:从 LLM 中榨取更多性能
- Unsloth 用户质疑量化怪癖,寻求首日延迟:一位成员警告说,朴素量化(naive quantization)会显著损害模型性能,并质疑在发布首日(day zero)抢着运行新模型的做法,建议等待一周可能是更明智的选择。Unsloth 正在上传采用 Dynamic Quants 的 DeepSeek-V3-0324 GGUFs,这些模型经过选择性量化,承诺比标准 bits 具有更高的准确度,突显了量化技术的细微差别。
- 发现 BPW 黄金点:每参数 4-5 Bits 可实现最优模型容量:实验表明,模型容量在低于 4 bits per weight (BPW) 时会崩溃,但在高于 5 时会发生偏离,这表明在给定的训练 FLOPS 下,最优权重使用在 4 BPW 左右。增加训练 epochs 可以帮助 5 BPW 模型接近曲线,但会以 FLOPS 为代价提高 BPW,这在 MNIST 上训练的 2L 和 3L MLPs 的可视化图表中得到了展示。
- FFN Fusion 助力更快的 LLMs,并行化提升推理性能:FFN Fusion 作为一种优化技术被引入,通过并行化 Feed-Forward Network (FFN) 层序列来减少大型语言模型中的顺序计算。该方法在保持模型行为的同时显著降低了推理延迟(inference latency),展示了提升 LLM 性能的架构创新。
{kind=link}
PART 1: Discord 高层级摘要
LMArena Discord
- Rage 模型在信号处理方面表现出色:如附带的图像所示,“Rage”模型在信号处理和数学方面的表现优于 Sonnet 3.7,最大误差仅为 0.04。
- 尽管有些人认为 Gemini 2.0 Flash 与之相当,但人们对 Rage 容易受 Prompt 攻击的脆弱性表示担忧。
- Gemini 2.5 称霸 LM Arena:Gemini 2.5 Pro Experimental 以大幅增长的分数跃升至 LM Arena 排行榜第一名,在数学、创意写作、指令遵循、长查询和多轮对话方面均处于领先地位。
- 虽然其 HTML 和网页设计能力受到赞赏,但成员们也观察到了某些局限性。
- Grok 3 的表现受到审查:用户报告称,与 Grok 3 的深入对话发现了很多问题,引发了关于它是否配得上在 LM Arena 高排名的辩论,该榜单评估了数学和代码之外的创意写作及长查询。
- 一些人觉得与 Grok 2 相比,Grok 3 并不是一个伟大的模型。
- LM Arena 中的 Python 调用引发辩论:成员们讨论了模型在 LM Arena 中对 Python 调用的使用,引用 o1 精确的数值计算作为潜在证据。
- 搜索排行榜的存在暗示标准排行榜可能缺乏 Web 访问权限。
- 谷歌 Gemini 2.5 的时间线令用户震惊:社区对谷歌的快速开发进度感到惊讶,一位用户引用了 Sergey Brin 对谷歌的指示,要求其停止构建“保姆式”产品(nanny products),正如 The Verge 所报道的那样。
- 另一位用户补充道,“跑得太快了,我的天(moving so fast wtf)”。
{kind=link}
Perplexity AI Discord
- Perplexity 推出答案模式 (Answer Modes):Perplexity 为旅游、购物、地点、图像、视频和职位等垂直领域引入了答案模式,以改进其核心搜索产品。
- 该功能旨在通过“超高精度”减少手动选择标签的操作,目前已在网页端上线,移动端也即将推出。
- Perplexity 遭遇产品问题:用户报告了 Perplexity AI 的多次宕机,导致 Space 和 Thread 被清空,给学习和论文写作等任务带来了困扰。
- 宕机引起了那些依赖该工具处理重要任务的用户的不满。
- DeepSeek 为开发者圆梦:DeepSeek V3 获得了开发者的积极反馈,讨论重点是其与 Claude 3.5 Sonnet 相比的编程能力。
- 一位成员分享了 DeepSeek subreddit 的链接,以进一步讨论该 AI 的编程实力并与 Claude 3.5 Sonnet 进行对比。
- Sonar 模型出现响应截断:用户报告 Sonar 模型出现响应截断问题,尽管收到了 200 响应码,但回复在句中中断。
- 即使在接收约 1k tokens 时也观察到了此问题,用户已被引导去报告该 Bug。
- API 成本引发担忧:一位用户对每 1000 次 API 请求 $5 的高昂成本表示担忧,并寻求优化和降低费用的建议。
- 另一位用户注意到 API 似乎限制在 5 steps,而他们在 Web 应用中观察到多达 40 steps。
Cursor Community Discord
- Augment 在代码库分析方面击败 Cursor:成员们发现 Augment 在分析大型代码库方面优于 Cursor,因为它使用了“全上下文 (full context)”。
- 理由是 Augment 不仅仅是将整个代码库喂给 LLM,可能还使用了另一种文件搜索系统,而在 Cursor 中必须使用 Claude 3.7 Max 才能获得全上下文。
- 辩论澄清了 Claude 3.7 MAX 的差异:Claude 3.7 MAX 与 Claude 3.7 的关键区别在于,MAX 版本拥有全上下文,而非 MAX 版本上下文有限,且在需要恢复之前只有 25 次 Agent 调用。
- 根据频道消息,这一限制既指上下文窗口大小,也指单次 Prompt 中添加的上下文量。
- “氛围程序员 (Vibe Coder)”的知识截止问题暴露:如果“氛围程序员”不使用 Model Context Protocols (MCPs) 来缓解 LLM 的知识截止问题,他们将面临麻烦,下一版本的代码转换可能会很困难。
- 成员们强调,更新框架并使用如 Exa Search 或 Brave Search 等 MCPs 来缓解 Claude 的这一问题至关重要,因为大多数 AI 使用的是过时的框架。
- DeepSeek V3 挑战 Claude 3.7:新的 DeepSeek V3 在多项测试中表现优于 Claude 3.5(可能还有 3.7),新数据还显示发布了针对 DeepSeek V3 (0324) 的真实世界编程基准测试。
- 新的 DeepSeek V3 模型被认为令人印象深刻,一位成员建议使用 DeepSeek V3 Latest (Cline) 作为架构师 + Sonnet 3.5 作为执行者 (Cursor) 可能是一个扎实的编程方案。
- 预测 ASI 奇点即将到来!:讨论集中在尽快实现 ASI 奇点 (Godsend) 以预先阻止潜在的 AI 相关混乱。
- 成员们辩论了在不完全了解大脑的情况下实现真正 AGI 的可能性,并认为新的 AGI 更多是一个使用 LLM + 算法软件 + 机器人的“超级系统 (Super-System)”。
OpenAI Discord
- 4o 模型引发社区关注:成员们正期待将 4o 图像生成集成到 ChatGPT 和 Sora 中,并渴望了解更多关于其发布和功能的细节。
- 用户正在推测 4o 将为各种任务带来的潜在应用和性能提升,特别是涉及多模态处理(multimodal processing)方面。
- Gemini 2.5 Pro 夺得榜首:据报道,Gemini 2.5 Pro 的表现优于 ChatGPT o3-mini-high,并在常见基准测试中大幅领先,在 LMArena 上首次亮相即排名第一。
- 爱好者们宣称 Gemini 击败了一切!,而其他人则保持谨慎,希望这 只是个基准测试……而已。
- GPT 增长的上下文导致幻觉:超出 GPT 的上下文窗口(context window)(免费版 8k,Plus 版 32k,Pro 版 128k)会导致长篇故事中细节丢失和幻觉。
- 使用 PDF 的自定义 GPT 或项目可以提供帮助,但聊天记录本身仍受此限制。
- AI 模型大比拼:成员们正在比较不同任务的最佳 AI 模型,ChatGPT 在数学/研究/写作方面更受青睐,Claude 擅长编程,Grok 适合查询,Perplexity 用于搜索/知识获取,而 DeepSeek 则是开源首选。
- 建议还包括 Gemma 27b、Mistral 3.1、QW-32b 和 Nemotron-49b,并提到 Grok 在 LMSYS 上的编程排名位居前列。
- GPT 自定义模板简化构建:一位成员分享了一个带有浮动注释的 GPT 自定义模板,可以从
Create面板构建自定义 GPT。- 该模板引导用户以“懒人模式”构建 GPT,从不断演变的上下文中进行构建,支持在分心状态下创作,但需要预先具备 Prompt 编写能力。
aider (Paul Gauthier) Discord
- DeepSeek API 自称是 GPT-4:据用户反馈,尽管 API Key 配置正确,但 DeepSeek 的 API 在通过 Aider 使用时会错误地自称为 OpenAI 的 GPT-4,正如这篇 Reddit 帖子 中讨论的那样。
- 这种现象被认为与训练数据中频繁提及 ChatGPT 有关。
- Aider 的 Context 命令功能强大:Aider 新的
/context命令可以探索代码库,该命令可以与任何其他 Prompt 命令配合使用,但 Token 使用量可能会更高。- 目前尚不清楚该命令是否具有更高的 Token 使用量,或者是否为了正常工作而增加了 repomap 的大小;更多细节可以在 Discord 消息 中找到。
- Gemini 2.5 Pro 表现亮眼但受限于速率限制:Google 发布了 Gemini 2.5 Pro 的实验版本,声称其在常见基准测试中领先,包括在 LMArena 上排名第一,并在 Aider 的多语言基准测试中获得了 74% whole 和 68.6% diff 的分数。
- 用户发现该模型在根据代码库生成架构图方面表现出色,尽管有些人发现其编程能力不稳定且速率限制(rate limits)较为严格。
- NotebookLM 强化 Aider 的上下文引导:一位用户建议利用 NotebookLM 来增强 Aider 的上下文引导(context priming)过程,特别是对于使用 RepoMix 的大型陌生代码库。
- 建议的工作流包括:使用 RepoMix 混合仓库,将其添加到 NotebookLM,包含相关的任务参考资料,然后向 NotebookLM 查询相关文件和实现建议,以指导 Aider 中的 Prompt 编写。
Unsloth AI (Daniel Han) Discord
- HF Transformers 被选为最佳路径:成员们推荐将 Hugging Face Transformers、linear algebra(线性代数)书籍以及学习 PyTorch 作为最佳路径,并补充说,在运行时使用 HF Transformers 配合 Bits and Bytes 将权重流式传输到 FP4/FP8 的 dynamic quantization(动态量化)方案在加载时可能会有所帮助。
- 像 Deepseek 这样的公司有时会在发布权重前对模型进行补丁处理,虽然在发布首日仍可以进行朴素的 FP8 loading scheme,但其质量无法等同于精细化的 FP8 分配。
- 量化特性受质疑:一位成员警告说,朴素的量化会显著损害模型性能,并问道:“说实话,有必要在发布首日就运行新模型吗?我觉得等上一周并不是什么沉重的负担。”
- Unsloth 正在上传带有 Dynamic Quants(动态量化)的 DeepSeek-V3-0324 GGUFs,这些模型经过“选择性量化”,其准确率将比标准 bits 大幅提升。
- Gemma 3 故障频出:成员们报告了在尝试训练 gemma3 4b 的 vision(视觉)功能时遇到的问题,触发了 RuntimeError: expected scalar type BFloat16 but found float;而另一位用户在加载
unsloth/gemma-3-27b-it-unsloth-bnb-4bit进行纯文本微调时,由于冗余的finetune_vision_layers参数遇到了TypeError。- 一位成员建议尝试这个 notebook,而另一位成员指出,正如在 Unsloth’s GitHub 中所见,
FastLanguageModel在底层已经将finetune_vision_layers = False设置为False。
- 一位成员建议尝试这个 notebook,而另一位成员指出,正如在 Unsloth’s GitHub 中所见,
- AWS 上的 GRPO + Unsloth 指南分享:一份关于在 AWS 账户上运行 GRPO(DeepSeek 的强化学习算法)+ Unsloth 的指南被分享出来。该指南在 AWS L40 GPU 上使用带有 Tensorfuse 的 vLLM server,将 Qwen 7B 转换为推理模型,使用 Tensorfuse 和 GRPO 进行微调,并将生成的 LoRA adapter 保存到 Hugging Face。
- 该指南展示了如何将微调后的 LoRA modules 直接保存到 Hugging Face,以便于分享、版本控制和集成,并备份到 s3,详情可见 tensorfuse.io。
- FFN Fusion 助力更快的 LLM:FFN Fusion 作为一种架构优化技术被引入,它通过识别和利用自然的并行化机会,减少了大型语言模型中的顺序计算。
- 该技术将 Feed-Forward Network (FFN) 层的序列转换为并行操作,在保持 model behavior 的同时显著降低了 inference latency。
Interconnects (Nathan Lambert) Discord
- Gemini 2.5 Pro 大放异彩:Gemini 2.5 Pro Experimental(代号 Nebula)夺得 LMArena 排行榜第一名,以创纪录的差距超越了 Grok-3/GPT-4.5。
- 它在 SEAL 排行榜中占据主导地位,在 Humanity’s Last Exam 和 VISTA(多模态)中均获得第一。
- Qwerky-72B 舍弃 Attention,媲美 4o-Mini:Featherless AI 推出了 Qwerky-72B 和 32B,这些 transformerless 模型在 8 个 GPU 上训练,在评估中媲美 GPT 3.5 Turbo 并接近 4o-mini,通过 RWKV 线性缩放实现了低 100 倍的推理成本。
- 他们通过冻结所有权重、删除 attention 层、将其替换为 RWKV 并通过多个阶段进行训练实现了这一目标。
- 4o 图像生成添加了未经请求的修改:GPT-4o 原生图像生成因过度修改而面临批评,例如让眼睛变大和改变面部特征,甚至改变用户的外貌,如此 Twitter 线程所示。
- 一些用户报告称,即使只修改 Prompt 中的一个词,也会导致生成失败。
- 家庭推理倾向于使用 vLLM:尽管在量化支持方面存在一些小瑕疵,但实现 LLM 家庭推理并允许动态模型切换的最有效方法可能是 vLLM。虽然 ollama 更易于使用,但在支持方面滞后,而 SGLang 看起来很有前景。
- 建议尝试使用 llama.cpp 以观察其当前状态。
- AI 像专家一样逆向恶意软件:成员们分享了一个 YouTube 视频,重点介绍了用于 Ghidra 的 MCP,它允许 LLM 逆向工程恶意软件,并通过特定 Prompt 自动化该过程。
- 一位成员承认最初将其视为一个梗(meme),但现在认识到了其在实际实现中的潜力。
OpenRouter (Alex Atallah) Discord
- Claude 意外离线,迅速恢复:根据 2025 年 3 月 25 日的 Anthropic 状态更新,Claude 3.7 Sonnet 节点遭遇了停机,但问题已在 8:41 PDT 解决。
- 根据状态页面,停机归因于旨在改进系统的维护。
- OpenRouter 提供零 Token 使用保险:OpenRouter 现在提供 zero-token insurance,覆盖所有模型,每周可能为用户节省超过 18,000 美元。
- 正如 OpenRouterAI 所述,用户无需为没有输出 Token 且结束原因为空白或错误的响应付费。
- Gemini 2.5 Pro 发布:Google 的 Gemini 2.5 Pro Experimental 已作为免费模型在 OpenRouter 上线,拥有先进的推理、代码和数学能力。
- 该模型具有 1,000,000 上下文窗口,并在 LMArena 排行榜上取得了顶级表现。
- DeepSeek 服务器不堪重负:用户报告 DeepSeek 由于服务器过度拥挤而几乎无法使用,建议通过调整价格来管理需求。
- 一些人推测问题出现在中国的使用高峰时段,但尚未找到直接的解决方案。
- Provisioning API Keys 提供细粒度访问:OpenRouter 提供 provisioning API keys,允许开发者管理 API 密钥、设置限制并跟踪支出,文档见此处。
- 新的密钥可以在使用 OpenRouter API 的平台内实现简化的计费和访问管理。
Nous Research AI Discord
- BPW 甜点位在 4-5:实验表明,当每权重位数 (BPW) 低于 4 时,模型容量 (model capacity) 会崩塌,而高于 5 时则会出现偏差,这意味着在给定的训练 FLOPS 下,4 BPW 是权重的最优使用方式。
- 增加训练 Epochs 有助于 5 BPW 模型接近曲线,即以 FLOPS 为代价提高 BPW,这可以通过 在 MNIST 上训练的 2L 和 3L MLP 可视化。
- DeepSeek V3:推理能力崛起:DeepSeek V3-0324 可以作为推理模型,检测思维迭代,并间接验证解的存在性,根据附带的 prompt,其性能可与 o1 媲美。
- 社区推测在 Qwen 3 MoE 模型之后,可能会发布 DeepSeek V3 Lite。
- Google 的 Gemini 2.5 Pro 登顶 LMArena:Gemini 2.5 Pro Experimental 在常用基准测试中领先,并在 LMArena 首次亮相即位列第一,展示了强大的推理和代码能力。
- 正如这篇 博客文章 所指出的,它还能针对某些提示词终止无限思维循环,并且是一个每日更新的模型。
- Transformer 引入 tanh:借鉴最近的 Transformers without Normalization 论文,一位成员指出,用 tanh 替换归一化(normalization)是一个可行的策略。
- 讨论中提出的担忧是推理时移除专家(experts)对较小权重的影响,但另一位成员反驳称,top_k 门控机制仍能通过从剩余专家中进行选择来有效运作。
- LLM 现在可以模拟光线追踪:成员们讨论了使用 LLM 模拟光线追踪算法 (raytracing algorithm) 的想法,并澄清目前的实现涉及由 LLM 编写 Python 程序来间接生成图像。
- 这被认为是“下一代文本生成图像”,因为 LLM 是编写程序而不是直接生成图像,相关程序可在该 GitHub repo 中找到。
Latent Space Discord
- Reve Image 图像质量碾压 SOTA:新发布的 Reve Image 模型在表现上优于 Recraft V3、Google 的 Imagen 3、Midjourney v6.1 以及 Black Forest Lab 的 FLUX.1.1 [pro]。
- Reve Image 在文本渲染、提示词遵循和美学表现方面表现出色,可以通过 Reve 官网 访问,无需 API key。
- Gemini 2.5 Pro 夺得 Arena 冠军:根据 LM Arena 的公告,Gemini 2.5 Pro 已飙升至 Arena 排行榜 #1 位置,创下了史上最大的评分涨幅(较 Grok-3/GPT-4.5 高出 40 分)。
- 该模型代号为 nebula,在数学、创意写作、指令遵循、长查询和多轮对话能力方面处于领先地位。
- OpenAI 为 ChatGPT 4o 注入图像生成功能:OpenAI 已将原生图像生成集成到 ChatGPT 中,Sam Altman 称其为“一项令人难以置信的技术和产品”。
- 早期评论(如来自 @krishnanrohit 的评论)称赞它是最好的图像生成和编辑工具,并指出其在准确创建和编辑多个角色方面的卓越能力。
- 11x Sales 创业公司面临客户虚报指控:据 TechCrunch 报道,由 a16z 和 Benchmark 支持的 AI 驱动销售自动化初创公司 11x 正面临虚报客户的指控。
- 尽管 Andreessen Horowitz 否认了待处理的法律诉讼,但人们对 11x 的财务稳定性和虚高的营收数据越来越感到担忧,这表明该公司的增长依赖于制造噱头。
- Databricks 使用 TAO 微调 LLM:Databricks 研究团队介绍了 TAO,这是一种无需数据标签即可微调 LLM 的方法,利用了推理时计算 (test-time compute) 和 RL,详见其 博客。
- 据称 TAO 优于监督微调 (SFT),旨在随计算量扩展,从而促进快速、高质量模型的创建。
GPU MODE Discord
- AMD 通过招聘职位瞄准 Triton 的主导地位:AMD 正在积极招募工程师,以增强其 GPU 上的 Triton 能力,并在 North America 和 Europe 提供职位,详情见 LinkedIn 帖子。
- 开放职位包括初级和高级角色,并提供远程办公的可能性,突显了 AMD 在扩展 Triton 生态系统方面的投入。
- CUDA 的 Async Warp Swizzle 被揭秘:一位成员剖析了 CUDA 的 async warpgroup swizzle TF32 布局,并参考 NVIDIA 文档 质疑其设计背后的基本原理。
- 分析显示该布局为
Swizzle<0,4,3> o ((8,2),(4,4)):((4,32),(1,64)),能够重建原始数据位置并与Swizzle<1,4,3>结合。
- 分析显示该布局为
- ARC-AGI-2 基准测试旨在测试推理能力:根据 这条推文,旨在评估 AI 推理系统的 ARC-AGI-2 基准测试已经推出,挑战 AI 在约 $0.42/任务 的成本下达到 85% 的效率。
- 初步结果显示,基础 LLM 得分为 0%,而先进的推理系统成功率不足 4%,突显了该基准测试的难度以及 AI 推理进化的潜力。
- Inferless 在 Product Hunt 上线:Inferless 是一个专为部署 ML 模型设计的 serverless 平台,已在 Product Hunt 发布,并为新用户提供 $30 计算额度。
- 该平台旨在通过“极低冷启动”简化模型部署,宣传其具备快速部署能力。
HuggingFace Discord
- DeepSeek 作为 Discord 审核工具引发讨论:一位成员询问 DeepSeek 是否适合作为审核机器人,另一位成员给出了肯定回答,但建议使用更小的 3B LLM 即可,成本仅为 每百万 token 5 美分。
- 对话强调了使用较小语言模型构建高性价比审核方案的考量。
- Windows 上的微调:初学者的噩梦?:一位成员寻求在 Windows 上进行支持 CUDA 的模型微调初学者指南,结果却收到了关于安装 PyTorch 和 CUDA Toolkit 难度的警告。
- 提供了两个安装指南链接:Step-by-Step-Setup-CUDA-cuDNN 和 Installing-pytorch-with-cuda-support-on-Windows,尽管有一位成员认为这种尝试是徒劳的。
- Rust 工具极速提取音频:一款新 工具 已发布,用于从 Hugging Face datasets 库生成的 parquet 或 arrow 文件中提取音频文件,并附带 Colab 演示。
- 开发者旨在为音频数据集提取提供“极速”体验。
- Gradio 新增深度链接功能:Gradio 5.23 引入了对 Deep Links 的支持,允许直接链接到特定的生成输出(如图像或视频),例如 这张蓝松鸦图像。
- 用户需通过
pip install --upgrade gradio升级到最新版本 Gradio 5.23 以使用新的 Deep Links 功能。
- 用户需通过
- Llama-3.2 与 LlamaIndex.ai 集成:一位成员使用 本教程 尝试了 Llama-3.2,指出它展示了如何使用 LlamaIndex 构建 Agent,从基础示例开始并添加 Retrieval-Augmented Generation (RAG) 能力。
- 该成员使用
BAAI/bge-base-en-v1.5作为其 embedding 模型,需要执行pip install llama-index-llms-ollama llama-index-embeddings-huggingface以完成与 Ollama 和 Huggingface 的集成。
- 该成员使用
MCP (Glama) Discord
- Nexus 为 AI 编程者管理上下文:一位成员分享了 Nexus,这是一个旨在解决 AI 编程助手上下文管理挑战的系统,特别是在大型软件项目中,旨在降低 token costs 并提高 code accuracy。
- Nexus 解决了 LLMs 有限的上下文窗口问题,该问题会导致生成的代码不准确。
- Deepseek V3 与 AOT 协同工作:在讨论使用 Anthropic 的 ‘think tool’ 后,一位成员推荐了适用于 Claude 的 Atom of Thoughts,并称其效果令人惊叹。
- 另一位成员分享了 Deepseek V3 与 AOT 协同工作的图片。
- 同时运行多个 MCP 服务器:成员们讨论了如何使用用户定义的端口运行多个 MCP 服务器,建议使用 Docker 并进行端口映射。
- 他们还指出可以通过 python-sdk 中的
FastMCP构造函数来配置端口。
- 他们还指出可以通过 python-sdk 中的
- 与 MCP 界面进行语音交互:一位成员分享了他们用于语音交互及音频可视化的主要 MCP:speech-mcp,这是一个 Goose MCP 扩展。
- 这允许通过音频可视化进行语音交互。
- gotoHuman MCP 服务器请求人工审批:gotoHuman 团队展示了一个 MCP 服务器,用于向 Agent 和工作流请求人工审批:gotohuman-mcp-server。
- 该服务器允许对 LLM 的操作进行便捷的人工复核,使用自然语言定义审批步骤,并在审批后触发 webhook。
Notebook LM Discord
- 通过 NotebookLM 开启播客托管:一位用户寻求利用 NotebookLM 作为播客主持人的技巧,让其作为嘉宾就特定话题与用户对话,并询问开启播客所需的 Chat Episode Prompt。
- 社区正在探索 Versatile Bot Project,该项目为 Interactive mode 下的 AI 主持人提供 Chat Episode prompt document,以促进讨论过程中的用户参与。
- Google 数据导出工具计费说明:一位用户为了使用 Data Export 工具启用了 Google Cloud Platform 计费,但担心产生费用;另一位用户澄清说,启用计费并不一定会自动产生费用。
- 这是因为该用户从管理控制台启动了数据导出,并确认通过 console.cloud.google.com 访问存档。
- Google 数据导出注意事项:导出时选择数据目的地的选项受 Workspace edition 限制,导出的数据存储在 Google 拥有的 bucket 中,并计划在 60 天内删除,详见 Google Support。
- 用户在规划数据导出策略时应注意这种临时存储安排。
- 许多用户缺少思维导图功能:用户报告 NotebookLM 中缺少 Mind Map 功能,经确认该功能正在逐步推出。
- 有推测认为推出的延迟可能归因于 Bug 修复,一位用户指出推出的速度慢得像蜗牛爬一样。
LM Studio Discord
- 通用翻译器仅需五年?:一位成员预测,基于 ChatGPT 的语言理解和翻译能力,通用翻译器距离实现仅剩五年时间;另一位成员分享了一个 YouTube 链接,询问视频中是哪个模型在唱歌。
- 这引发了关于实现跨多种语言的实时、准确语言翻译所需技术进步的好奇心。
- Mozilla 的 Transformer Lab 受到认真关注:成员们讨论了 Mozilla 的 Transformer Lab,这是一个旨在实现在常规硬件上进行训练和微调的项目,并分享了 GitHub repo 链接。
- 该实验室由 Mozilla 通过 Mozilla Builders Program 提供支持,目前正致力于在消费级硬件上实现训练和微调。
- 关于 LM Studio GPU Tokenization 的讨论:在 Tokenization 过程中,LM Studio 大量使用单个 CPU 线程,这引发了关于该过程是否完全基于 GPU 的疑问。
- 虽然最初有人指出 Tokenizing 与 GPU 无关,但对 Flash Attention 和 Cache 设置对 Tokenizing 时间影响的观察表明事实并非如此。
- Gemini 2.5 Pro 在逻辑挑战中胜出:成员们测试了 Gemini 2.5 Pro,并报告称它成功解决了一个 Gemini 2.0 Flash Thinking 失败的逻辑谜题,并分享了在 aistudio 免费使用它的链接。
- 这表明新的 Gemini 2.5 Pro 模型在推理能力方面可能有潜在提升。
- 3090 Ti 在开启 Flash 后展现出色速度:一位用户满载运行其 3090 Ti,在未开启 Flash 的情况下达到 ~20 tokens/s,开启 Flash 后达到 ~30 tokens/s。
- 该用户分享了 3090 Ti 在满载状态下的 截图,并报告在处理 4-5k tokens 后速度会有所下降。
{kind=link}
{kind=link}
Cohere Discord
- Cohere 致力于提升透明度:Cohere 明确了其隐私政策和数据使用政策,建议用户避免上传个人信息,并提供了一个用于数据管理的 Dashboard。
- 他们支持通过电子邮件申请 Zero Data Retention (ZDR),并且符合 SOC II 和 GDPR 标准,遵循行业数据安全标准,详见其安全政策。
- Cohere 支持流式响应,缓解用户体验痛点:根据 Cohere 的 Chat Stream API 参考文档,Cohere API 现在支持响应流式传输,允许用户在文本生成时即时查看,从而提升用户体验。
- 此功能可在客户端实现实时文本显示,使交互更加流畅和即时。
- Cohere Embedding Generator 获得 Tokenization 技巧:一位用户正在使用 .NET 构建 CohereEmbeddingGenerator 客户端,并询问在生成 Embedding 之前对文本进行 Tokenizing 的相关事宜,因为没有 Tokenization,Embedding 将无法工作。
- 建议他们使用
/embed端点来检查 Token 数量,或者从 Cohere 的公共存储手动下载 Tokenizer。
- 建议他们使用
- Sage 寻求摘要生成的“秘籍”:新成员 Sage 介绍了自己,并提到了他们的大学 NLP 项目:构建一个文本摘要工具,并寻求社区的指导。
- Sage 希望在应对项目挑战的同时进行学习并做出贡献。
Torchtune Discord
- TorchTune 升至 v0.6.0: TorchTune 发布了 v0.6.0,其特点是支持用于分布式训练和推理的 Tensor Parallel,新增了 Microsoft Phi 4 的构建器,并支持多节点训练 (multinode training)。
- DeepSeek 发布模型未附带说明: DeepSeek-V3 模型在发布时没有附带 readme,导致成员们对 DeepSeek AI 团队的做法开起了玩笑。
- 该模型具有聊天界面和 Hugging Face 集成。
- Torchtune 的 MoE 引发遐想: 一位成员推测,在 torchtune 中添加 MoE 是否需要 8-9 TB 的 VRAM 以及由 100 块 H100 或 H200 组成的集群来进行训练。
- 他们开玩笑地建议需要重新布置阁楼以容纳这些硬件。
- 优化器状态在 QAT 转换中得以保留: 经过 Quantization Aware Training (QAT) 后,优化器状态会被保留,一位成员引用了相关的 torchtune 代码确认了这一点。
- 这种保留确保了在切换到 QAT 过程中的连续性。
- CUDA 开销通过图捕获(Graph Captured)解决: 为了减少 GPU 空闲时间,成员们表示从 CPU 启动 CUDA 操作具有不可忽视的开销,建议将 GPU 操作捕获为图(graph)并作为单个操作启动,以此来整合计算图。
- 这引发了关于这是否就是 compile 所做工作的讨论。
Nomic.ai (GPT4All) Discord
- LocalDocs DB 需要备份: 成员们主张备份
localdocs.db文件以防止数据丢失,特别是当原始文档丢失或无法访问时,该文件是以加密数据库形式存储的。- GPT4All 使用编号最高的
*.db文件(例如localdocs_v3.db),重命名它们可能允许导入/导出,尽管这一点尚未得到证实。
- GPT4All 使用编号最高的
- 隐私法使聊天数据分析变得复杂: 一位成员强调了隐私法(特别是欧盟的隐私法)在利用 LLM 处理聊天数据时带来的挑战。
- 讨论强调了在将聊天消息(纯文本或可转换格式)输入 LLM 之前,需要验证权限和消息格式。
- API 与本地 LLM 之争: 一位成员质疑在处理群聊消息以计算满意度、提取关键词和总结消息时,是选择使用 Deepseek 或 OpenAI 等付费 API,还是运行本地 LLM。
- 另一位成员建议,如果消息量在 100MB 以下,一台拥有优秀 GPU 的本地机器可能就足够了,特别是使用较小的模型进行打标签和摘要时。
- LocalDocs DB 导入的复杂性: 成员们探索了导入
localdocs.db文件的方法,但注意到该文件包含加密/特殊编码的文本,如果没有 embedding 模型,通用的 LLM 很难解析。- 一位丢失了
localdocs.db的成员正经历极其缓慢的 CPU 索引过程,并正在寻找替代方案。
- 一位丢失了
- Win11 更新抹除 LocalDocs: 一位成员报告称,在 Windows 11 更新后,他们的
localdocs.db变为空白,并且在 CPU 上重新索引本地文档时遇到了困难。- 有人建议更新导致的驱动器盘符变化可能是原因,并建议将文件移动到 C 盘以避免此类问题。
LlamaIndex Discord
- LlamaIndex 支持 Claude MCP 兼容性:成员们提供了一个将 Claude MCP 与 LlamaIndex 集成的简化示例,展示了如何在一个代码片段中使用
FastMCP和uvicorn为 Claude Desktop 或 Cursor 等 MCP 客户端暴露本地主机和端口。- 这一集成允许开发者无缝连接 Claude 与 LlamaIndex 以增强功能。
- AgentWorkflow 加速 LlamaIndex 多 Agent 性能:用户反馈在使用 Gemini 2.0 配合 12 个工具和 3 个 Agent 的 LlamaIndex MultiAgentic 设置时性能较慢;建议使用
AgentWorkflow和can_handoff_to字段进行受控的 Agent 交互。- 讨论强调了在复杂设置中优化 Agent 交互以提高速度和效率的重要性。
- LlamaIndex Agent 类型解析:一位成员对 LlamaIndex 中不同的 Agent 类型及其使用时机表示困惑,并提到文档重构即将推出。
- 一名团队成员建议通常应使用
core.agent.workflow,对于具有函数/工具 API 的 LLMs 使用 FunctionAgent,其他情况使用 ReActAgent,并指向 Hugging Face 课程以获取更多帮助。
- 一名团队成员建议通常应使用
- 无需 Prompt 的自动 LLM 评估发布!:一位创始人正在验证一个 OSS 自动评估 的想法,该方案通过单个 API 且无需评估 Prompt,使用专有模型在 500ms 内完成幻觉(Hallucination)和相关性(Relevance)等任务。
- 更多关于其端到端解决方案(包括模型、托管和编排工具)的细节可在 autoevals.ai 网站上找到。
- LlamaCloud 成为 MCP 杰作:LlamaCloud 可以作为任何兼容客户端的 MCP server,如此演示所示。
- 一位成员展示了如何使用 LlamaIndex 构建自己的 MCP server,为任何 MCP 客户端提供各种工具接口,仅需约 35 行 Python 代码即可连接到 Cursor AI,并实现了 Linkup 网络搜索和这个项目。
Eleuther Discord
- Google Gemini 2.5 Pro 亮相:Google 推出了 Gemini 2.5 Pro,称其为全球最强大的模型,强调了其统一推理、长上下文和工具使用能力,目前可在 Google AI Studio + API 中进行实验性体验。
- 他们宣传实验性访问目前是免费的,但定价详情将很快公布。
- DeepSeek-V3-0324 凭借 p5.js 程序令人印象深刻:DeepSeek-V3-0324 编写了一个 p5.js 程序,模拟球在受重力和摩擦力影响的旋转六边形内弹跳,如此推文所示。
- 该模型还根据要求提供参数调节滑块和边数按钮的 Prompt,创新性地实现了球体重置和随机化等功能。
- SkyLadder 论文强调短到长上下文转换:ArXiv 上的一篇论文介绍了 SkyLadder,这是一种用于预训练 LLM 的短到长上下文窗口转换方法,在常见任务上显示出高达 3.7% 的提升 (2503.15450)。
- 他们使用在 100B tokens 上训练的 1B 和 3B 参数模型实现了这一性能。
- 通过 Hypernetworks 实现可组合泛化:一篇论文将多头注意力(multi-head attention)重新表述为 hypernetwork,揭示了可组合的低维潜在代码(latent code)指定了特定于键-查询(key-query)的操作,允许 Transformer 泛化到新的问题实例 (2406.05816)。
- 对于每一对 q、k 索引,作者将沿头数(head-number)维度的激活解释为指定任务或上下文的潜在代码。
- lm_eval 升级 PR 等待评审:一个拉取请求(PR)已开启,旨在将
gpt-neox中的评估逻辑更新至最新版本lm_eval==0.4.8,其中可能不相关的测试失败将在另一个 PR 中解决,链接如下:PR 1348。- 失败可能是由于环境设置或依赖项版本不一致导致的。
Modular (Mojo 🔥) Discord
- Mojo 在网站开发中被边缘化:成员建议不要将 Mojo 用于网站开发,因为它缺乏加密安全代码的规范且 IO 支持较弱,更倾向于使用拥有生产级库的 Rust。
- 有人建议 Rust 更快的异步能力更适合需要身份验证或 HTTPS 的应用。
- Mojo 硬件加速的 AES 实现暂停:Mojo 中硬件加速的 AES 实现无法在旧款 Apple silicon Mac 上运行,且并非完整的 TLS 实现,导致开发暂停。
- 开发者正在等待密码学家编写软件部分,理由是非专家实现加密功能存在风险。
- SIMD 优化提升 AES 性能:讨论集中在利用 SIMD 处理 AES,指出 x86 拥有 vaes 及类似功能用于 SIMD AES 128。
- 同时提到 ARM 拥有 SVE AES,虽然类似但支持程度不如前者,展示了加密功能的硬件优化。
- Go 被提议作为后端开发的折中方案:作为 Rust 的替代方案,一位成员建议将 Go 作为同样具备生产就绪性的折中选择,而另一位成员则对微服务过多表示担忧。
- 尽管面临挑战,一位成员对 Rust 表示抵触,认为它不适合快速编写,希望能有更简单的后端开发方案;建议是让 Rust API 调用它并传递参数。
- Mojo 通过 PTX 绕过 CUDA 适配 NVIDIA:Mojo 直接生成 PTX (Parallel Thread Execution) 代码来驱动 NVIDIA GPU,绕过 CUDA 并消除了对 cuBLAS、cuDNN 和 CUDA C 的依赖。
- 这种方法通过避免对 CUDA 特定库的需求,简化了开发流程。
DSPy Discord
- DSPy 处理摘要任务:一位成员正在探索使用 DSPy 处理包含 300 个样本的文本摘要任务,并正在测试一个简单的指标,以查看摘要的具体差异,从而使优化器更有效。
- 反馈可以通过
dspy.Prediction(score=your_metric_score, feedback="stuff about the ground truth or how the two things differ")返回,以引导优化。
- 反馈可以通过
- SIMBA 提供细粒度反馈:一位成员建议在摘要任务中使用实验性优化器
dspy.SIMBA,它允许对生成的摘要与 Ground Truth 之间的差异提供反馈。- 这种级别的反馈可以在优化过程中提供更精确的指导。
- 通过 BestOfN 和 Refine 进行输出精炼:一位成员分享了 DSPy Output Refinement 教程 的链接,解释了旨在提高预测可靠性的
BestOfN和Refine模块。- 教程详细说明了这两个模块如何在达到
N次尝试或reward_fn返回高于threshold的奖励时停止。
- 教程详细说明了这两个模块如何在达到
- BestOfN 模块通过 Temperature 调整取胜:
BestOfN模块使用不同的 Temperature 设置多次运行给定模块,以获得最佳结果。- 它会返回第一个通过指定阈值的预测,或者在没有预测达到阈值时返回奖励最高的那个。
- Refine 模块是否可组合?:一位成员询问
Refine是否会取代 assertions,以及它是否同样具有细粒度和可组合性,因为它包装了整个模块。- 另一位成员回答说,可以通过调整模块大小来管理可组合性,从而实现对范围更明确的控制。
tinygrad (George Hotz) Discord
- AMD 老旧 GPU 获得 tinygrad 支持提升:通过 OpenCL frontend,不支持 ROCm 的旧款 AMD GPU(例如 2013 款 Mac Pro 中的 GPU)可能可以运行 tinygrad。
- 成功与否取决于 自定义驱动程序 和可用的 OpenCL 支持级别;用户应验证其系统兼容性。
- ROCm 替代方案出现:对于老旧 AMD GPU,ROCm 缺乏支持,但 tinygrad 中的 OpenCL frontend 可能提供一种变通方案。
- 成功情况将因特定驱动程序版本和 OpenCL 支持程度而异;需要进行实验。
Codeium (Windsurf) Discord
- Windsurf 启动 Creators Club:Windsurf 推出了 Creators Club,奖励进行内容创作的社区成员,提供 每 1k 播放量 $2-4 的报酬。
- 加入详情请见 Windsurf Creators Club。
- Windsurf 开设 ‘Vibe Coding’ 频道:Windsurf 为 ‘vibe coders’ 创建了一个新频道,用于进入心流状态、聊天、讨论以及分享技巧/心得。
- 目标是通过营造协作和沉浸式的环境来提升编程体验。
- Windsurf v1.5.8 补丁发布:Windsurf v1.5.8 现已发布,包含补丁修复,包括 cascade/memories 修复、Windsurf Previews 改进以及 cascade 布局修复。
- 同时还分享了一张展示该版本的图片,重点介绍了具体的改进。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器沉寂时间过长,请告知我们,我们将将其移除。
第二部分:分频道详细摘要与链接
完整的频道分类明细已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!