ainews-llama-4s-controversial-weekend-release
Llama 4 备受争议的周末发布
Meta 发布了 Llama 4,推出了两款新型中等规模的 MoE(混合专家)开源模型,并承诺将推出一个拥有 2 万亿参数的“巨兽级”模型,力争成为史上最大的开源模型。
此次发布采用了多种先进的训练技术,包括结合 MetaCLIP 的类 Chameleon 早期融合(early fusion)技术、不带 RoPE 的交错分块注意力机制、原生 FP8 训练,以及在高达 40 万亿个 token 上的训练。尽管备受关注,但此次发布也面临批评,原因包括透明度不如 Llama 3、实现过程中的问题以及在部分基准测试中表现不佳。
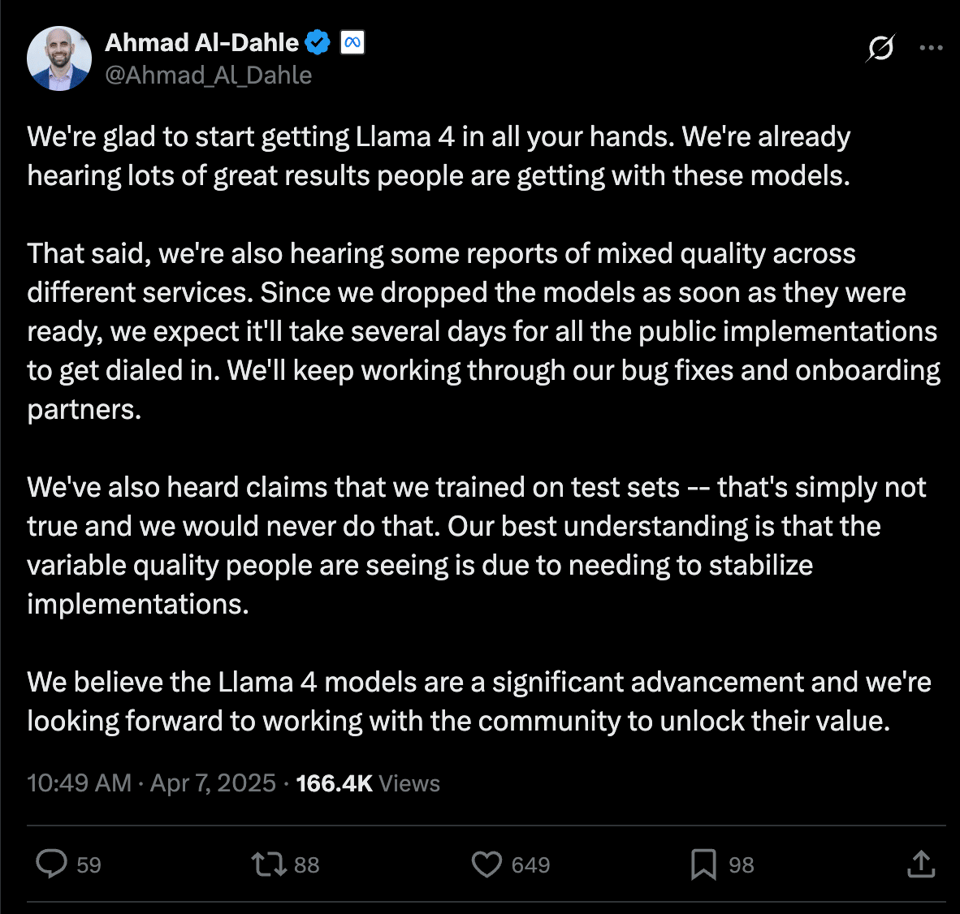
包括 Ahmad Al Dahle 在内的 Meta 领导层否认了有关在测试集上进行训练的指控。最小的 Scout 模型拥有 1090 亿参数,对于消费级 GPU 而言体积过大,且其声称的 1000 万 token 上下文长度也引发了争议。社区对此反应不一,部分人称赞其开放性,而另一部分人则指出了其中的差异和质量问题。
透明度与耐心是我们所需要的一切。
2025年4月4日至4月7日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord 社区(229 个频道,18760 条消息)。预计为您节省阅读时间(以 200wpm 计算):1662 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Llama 4 的头条新闻光彩夺目:2 款表现优异的新型中型 MoE 开源模型,以及承诺中的第三款拥有 2 万亿参数的“巨兽”,它应该是史上发布的最大开源模型,恢复了 Meta 在排行榜顶端的地位:
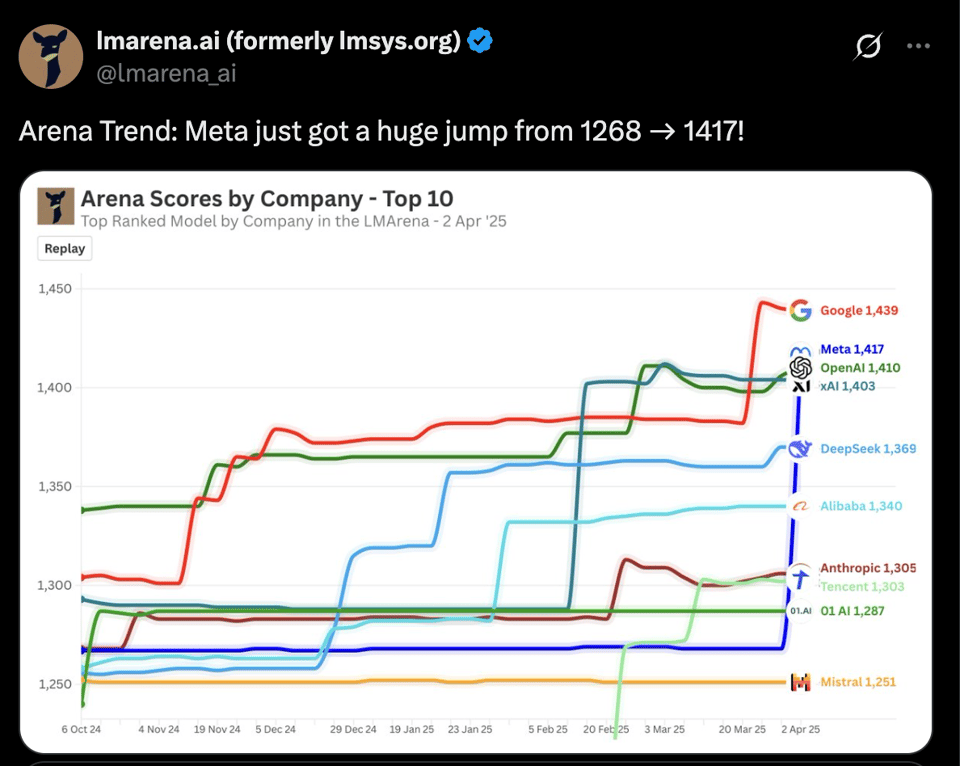
SOTA 训练更新总是备受欢迎:我们注意到采用了类 Chameleon 的 MetaCLIP 早期融合(early fusion)、交织、分块(chunked) 无 RoPE 注意力机制(许多人对此发表了评论)、原生 FP8 训练,并使用了 高达 40T tokens 进行训练。
虽然闭源模型实验室往往设定了前沿,但 Llama 通常为开源模型设定了标准。Llama 3 发布于大约一年前,随后的更新如 Llama 3.2 同样广受好评。
抛开惯常的许可证争议不谈,Llama 4 的反响基调明显不同。
- Llama 4 在周六发布,比预期的要早得多,甚至似乎连 Meta 也是如此,其在最后一刻将发布日期从周一提前。Zuck 的官方说法只是它已经“准备好了”。
- 只有博文,在透明度方面远未达到 Llama 3 论文的水平。
- 最小的“Scout”模型也有 109B 参数,无法在消费级 GPU 上运行。
- 声称的 10m token 上下文几乎肯定远高于使用 256k tokens 训练时的“真实”上下文(虽然仍然令人印象深刻!但不是 10m!)
- LMarena 使用了一个特殊的“实验”版本,这导致了高分——但这并不是发布的版本。这种差异迫使 LMarena 通过发布完整的评估数据集来做出回应。
- 它在 Aider 等独立基准测试中表现非常糟糕。
- 中国社交媒体上未经证实的帖子声称公司领导层为了达到 Zuck 的目标而推动在测试集上进行训练(training on test)。
最后一点已被 Meta 领导层断然否认:
但这种发布过程中出现问题的气息无疑给原本属于开源 AI 界的喜庆日子蒙上了阴影。
AI Twitter 回顾
大语言模型 (LLMs) 与模型发布
- Llama 4 与实现问题:@Ahmad_Al_Dahle 表示 Meta 已注意到不同服务在使用 Llama 4 时报告的质量参差不齐,并预计实现将在几天内趋于稳定,同时否认了在测试集上进行训练的说法。@ylecun 指出需要对 Llama-4 进行一些澄清,@reach_vb 感谢 @Ahmad_Al_Dahle 的澄清以及对开放科学和权重的承诺。
- Llama 4 性能与基准测试:关于 Llama 4 输出质量的担忧已经浮现,@Yuchenj_UW 报告称其生成内容质量低劣(slop),但其他人则认为表现良好。@Yuchenj_UW 强调了一个 Reddit 帖子,并表示如果 Meta 实际上是为了最大化基准测试(benchmark)分数而进行训练,那么“就完蛋了”。@terryyuezhuo 在 BigCodeBench-Full 上将 Llama-4 Maverick 与 GPT-4o-2024-05-13 和 DeepSeek V3 进行了对比,并报告称 Llama-4 Maverick 在 BigCodeBench-Hard 上的表现与 Gemini-2.0-Flash-Thinking 和 GPT-4o-2024-05-13 相似,但排名第 41/192。@terryyuezhuo 还指出 Llama-4-Scout 排名第 97/192。@rasbt 表示 Meta 发布了 Llama 4 系列,即拥有 16 和 128 个专家的 MoE 模型,这些模型已针对生产环境进行了优化。
- DeepSeek-R1:@scaling01 简单地表示 DeepSeek-R1 被低估了,而 @LangChainAI 分享了使用 DeepSeek-R1 构建 RAG 应用的指南。
- Gemini 性能:@scaling01 分析了 Gemini 2.5 Pro 和 Llama-4 在 Tic-Tac-Toe-Bench 上的结果,指出 Gemini 2.5 Pro 在作为“O”方对战时,表现出人意料地差于其他前沿思考模型(frontier thinking models),且在整体一致性排名中位列第 5。@jack_w_rae 提到在 Cognitive Revolution 上与 @labenz 交流了关于在 Gemini 和 2.5 Pro 中扩展 Thinking(思考能力)的话题。
- Mistral 模型:@sophiamyang 宣布 Ollama 现在支持 Mistral Small 3.1。
- 模型训练与数据:@jxmnop 认为训练大型模型本身并不具有科学价值,许多发现本可以在 100M 参数的模型上完成。
- 量化感知训练:@osanseviero 询问是否应该为更多量化格式发布经过量化感知训练(Quantization-Aware Trained)的 Gemma。
AI 应用与工具
- 用于原型设计的 Replit:@pirroh 建议 Replit 应成为 GSD 原型设计的首选工具。
- AI 驱动的个人设备:@steph_palazzolo 报道称,OpenAI 已讨论收购由 Sam Altman 和 Jony Ive 创立的初创公司,以打造一款 AI 驱动的个人设备,成本可能超过 5 亿美元。
- 机器人领域的 AI:@TheRundownAI 分享了机器人领域的头条新闻,包括 川崎(Kawasaki)的可骑行狼形机器人 以及 现代汽车(Hyundai)购买波士顿动力(Boston Dynamics)的机器人。
- AI 驱动的内容创作:@ID_AA_Carmack 认为 AI 工具将允许创作者达到更高的高度,并使更小的团队能够完成更多工作。
- LlamaParse:@llama_index 在 LlamaParse 中引入了一个新的 layout agent,用于提供一流的文档解析和提取,并带有精确的视觉引用。
- MCP 与 LLM:@omarsar0 讨论了 Model Context Protocol (MCP) 及其与 Retrieval Augmented Generation (RAG) 的关系,指出 MCP 通过标准化 LLM 应用与工具的连接来补充 RAG。@svpino 敦促人们 学习 MCP。
- AI 辅助编程与 IDE:@jeremyphoward 重点介绍了在 Cursor 中使用 MCP server 的资源,以便通过
llms.txt获取最新的 AI 友好文档。 - Perplexity AI 问题:@AravSrinivas 询问用户 Perplexity 上最需要解决的首要问题是什么。
公司公告与策略
- Mistral AI 招聘与合作伙伴关系:@sophiamyang 宣布 Mistral AI 正在多个国家招聘 AI Solutions Architect 和 Applied AI Engineer 职位。@sophiamyang 分享了 Mistral AI 已与 CMA CGM 签署了价值 1 亿欧元的合作伙伴关系,为航运、物流和媒体活动采用定制设计的 AI 解决方案。
- Google AI 更新:@GoogleDeepMind 宣布在 Gemini Live 中推出 Project Astra 功能。@GoogleDeepMind 表示 GeminiApp 现已面向 Android 设备上的 Advanced 用户以及 Pixel 9 和 SamsungGalaxy S25 设备开放。
- Weights & Biases 更新:@weights_biases 分享了 3 月份发布的 W&B Models 功能。
- OpenAI 的方向:@sama 预告了 OpenAI 最近发布的一个热门项目。
- Meta 的 AI 策略:@jefrankle 为 Meta 的 AI 策略辩护,认为发布少量、高质量的产品比发布大量、低质量的产品更好。
AI 的经济与地缘政治影响
- 关税与贸易政策:@dylan522p 分析了即将到来的关税如何导致第一季度进口激增,并预测由于库存去化,第二季度 GDP 将出现暂时性增长。@wightmanr 认为贸易逆差并非由其他国家的关税引起。@fchollet 声称经济正在被故意破坏。
- 美国开源:@scaling01 声称美国开源已经衰落,现在全看 Google 和中国了。
- 稳定币与全球金融:@kevinweil 表示,一种全球可用、广泛集成、低成本的美元稳定币对 🇺🇸 有利,对全世界的人也有利。
AI 安全、伦理与社会影响
- AI 对个人的影响:@omarsar0 同意 @karpathy 的观点,即 LLM 对个人生活的改变程度远高于对组织机构的影响。
- 对 AI 的情感依赖:@DeepLearningAI 分享的研究表明,虽然 ChatGPT 语音对话可能会减少孤独感,但也可能导致现实世界的互动减少和情感依赖增加。
- AI 对齐与控制:@DanHendrycks 主张需要对齐并驯化 AI 系统,使其作为“受托人(fiduciaries)”行事。
- AI 与未来:@RyanPGreenblatt 认为 AI 趋势将打破 GDP 增长趋势。
幽默/迷因
- 杂项幽默:@scaling01 询问 @deepfates 是否又买了 0DTE 看跌期权。@lateinteraction 明确指出之前的声明是一个玩笑。@svpino 开玩笑说 AI 可能会抢走我们的工作,但至少我们现在可以去生产 Nike 鞋带了。
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. “利用神经可塑性改变时间序列预测”
-
Neural Graffiti - Transformer 模型的神经可塑性即插即用层 (评分: 170, 评论: 56): 该帖子介绍了 **Neural Graffiti,这是一个用于 Transformer 模型的神经可塑性即插即用层。该层插入在 Transformer 层和输出投影层之间,允许模型通过根据过去经验随时间改变其输出来获得神经可塑性特征。来自 Transformer 层的 Vector embeddings 经过平均池化,并根据过去的记忆进行修改,以影响 Token 生成,从而逐渐演化模型对概念的内部理解。GitHub 上提供了一个演示:babycommando/neuralgraffiti。** 作者认为 liquid neural networks “非常棒”,可以模拟人脑随时间改变连接的能力。他们表达了对在不完全理解 Transformer 神经元层级的情况下“黑进(hacking)”模型的着迷。他们承认存在诸如冷启动问题之类的挑战,并强调了找到“甜点位(sweet spot)”的重要性。他们认为这种方法可以让模型随着时间的推移获得“行为上的个性”。
- 一些用户称赞了这个想法,指出它可能解决真正的个人助手所需的问题,并将其比作自我学习,可能允许 LLM “说它想说的话”。
- 一位用户提出了技术考量,建议在架构中更早地应用 Graffiti 层可能会更有效,因为在 Attention 和 Feedforward 模块之后应用可能会限制对输出的有意义影响。
- 另一位用户预见到关于此类模型潜在滥用的伦理讨论。
主题 2. “对 Meta Llama 4 性能的失望”
-
使用 100,000 块 H100 GPU 训练的 Llama 4 到底怎么了? (Score: 256, Comments: 85): 该帖子讨论了 Meta 的 Llama 4,据报道该模型使用了 **100,000 块 H100 GPU 进行训练。尽管资源较少,DeepSeek 声称其 DeepSeek-V3-0324 等模型实现了更好的性能。Yann LeCun 表示 FAIR 正在研究超越自回归 (auto-regressive) LLMs 的下一代 AI 架构。** 发帖者认为 Meta 的领先优势正在减弱,且较小的开源模型已被 Qwen 超越,并提到 Qwen3 即将到来…。
- 一位评论者质疑在令人失望的训练结果上浪费 GPU 和电力,认为这些 GPU 本可以用于更好的用途。
- 另一位评论者指出,Meta 的博客文章提到使用的是 32K GPU 而非 100K,并提供了链接作为参考。
- 一位评论者批评了 Yann LeCun,称他虽然是一位伟大的科学家,但在 LLMs 方面做出了许多错误的预测,应该更加谦逊。
-
Meta 的 Llama 4 未达预期 (Score: 1791, Comments: 175): Meta 的 Llama 4 模型 Scout 和 Maverick 已经发布,但令人失望。Meta 的 AI 研究负责人 Joelle Pineau 已被解雇。这些模型采用了混合专家 (mixture-of-experts) 架构,专家大小仅为 **17B 参数,这在当下被认为较小。尽管拥有大量的 GPU 资源和数据,Meta 的努力并未产生成功的模型。一张图片对比了从 Llama1 到 Llama4 的四只羊驼,其中 Llama4 看起来最不精致。** 发帖者对 Llama 4 Scout 和 Maverick 感到失望,称它们 “真的让我很失望”。他们认为表现不佳可能是由于混合专家架构中极小的专家规模,并指出 17B 参数 “在目前看来很小”。他们认为 Meta 的困境表明 “即使拥有世界上所有的 GPU 和数据,如果想法不新颖,也意义不大”。他们赞扬了 DeepSeek 和 OpenAI 等公司展示了真正的创新如何推动 AI 进步,并批评了只堆资源而缺乏新思路的做法。他们总结道,AI 的进步不仅需要蛮力,还需要脑力。
- 一位评论者回忆起传闻称 Llama 4 相比 DeepSeek 太令人失望,以至于 Meta 曾考虑不发布它,并建议他们应该等以后发布 Llama 5。
- 另一位评论者批评了 Meta 的管理层,称其为 “垃圾场火灾 (dumpster fire)”,并建议扎克伯格需要重新聚焦,将 Meta 的处境与 Google 承认落后并随后重新聚焦的情况进行了对比。
- 一位评论者觉得奇怪的是,尽管 Meta 拥有来自 Facebook 的、其他任何人都无法获取的海量数据,但其模型表现却平平。
-
我想看看扎克伯格尝试用 Llama 4 替换中级工程师 (Score: 381, Comments: 62): 该帖子引用了马克·扎克伯格的言论,即 AI 很快将取代中级工程师,正如此处链接的一篇 Forbes 文章所报道的那样。 作者对扎克伯格的说法表示怀疑,暗示用 Llama 4 替换中级工程师可能并不可行。
- 一位评论者开玩笑说,也许扎克伯格用 Llama3 替换了工程师,才导致 Llama4 结果不佳。
- 另一位评论者建议他可能需要改用 Gemini 2.5 Pro。
- 一位评论者批评 Llama4,称其为 “一个彻底的笑话”,并怀疑它甚至无法取代一个训练有素的高中生。
{kind=link}
主题 3. “Meta 的 AI 困境:争议与创新”
-
Llama 4 是开放的——除非你在欧盟 (分数: 602, 评论: 242): Meta 发布了 Llama 4,其许可证禁止居住在欧盟的实体使用。该许可证明确规定:“如果你……居住在欧盟成员国,则不得使用 Llama 材料。” 其他限制包括强制使用 Meta 的品牌(任何衍生品名称中必须包含 **LLaMA)、必须署名(“Built with LLaMA”)、没有使用领域自由、没有重新分发自由,且该模型不符合 OSI-compliant,因此不被视为开源。** 作者认为,这一举动在任何实际意义上都不是“开放”的,而是伪装成社区语言的企业控制访问。他们认为 Meta 通过在法律上排除欧盟,从而规避 EU AI Act 的透明度和风险要求。这开创了一个危险的先例,可能导致一个破碎的、基于特权的 AI 格局,即访问权限取决于组织的所在地。作者建议,像 DeepSeek 和 Mistral 这样真正的“开放”模型值得更多关注,并质疑其他人是否会切换模型、无视许可证或期待改变。
- 一位评论者推测,Meta 正试图规避欧盟对 AI 的监管,并且并不介意欧盟用户违反此条款;他们只是不想受欧盟法律的约束。
- 另一位评论者指出,没必要担心,因为据某些人说,Llama 4 的表现很差。
- 一位评论者幽默地希望 Meta 没有使用欧盟的数据来训练该模型,暗示这可能存在双重标准。
-
Meta 的 AI 研究负责人辞职(在 Llama 4 失败之前) (分数: 166, 评论: 31): Meta 的 AI 研究负责人 Joelle 宣布辞职。Joelle 是 **FAIR (Facebook AI Research) 的负责人,但 GenAI 是 Meta 内部的一个不同组织。目前有讨论称 Llama 4 可能未达到预期。有人提到,在 post-training 中混入基准测试数据集可能导致了问题,并将失败归因于架构选择 (MOE)。** 发帖者推测 Joelle 的离职是 Llama 4 灾难未被察觉的早期信号。一些评论者对此表示反对,称人员流动很正常,这并不代表 Llama 4 有问题。其他人则认为 AI 发展可能正在放缓,面临平台期。关于 Meta 的领导结构存在一些困惑,有人认为 Yann LeCun 领导着整个 AI 组织。
- 一位评论者澄清说 Joelle 是 FAIR 的负责人,而 GenAI 是一个不同的组织,强调了 Meta 内部的组织区分。
- 另一位提到他们从 Meta 员工那里听说,在 post-training 中混入基准测试数据集存在问题,并将可能的失败归因于架构选择 (MOE)。
- 一位评论者对 Meta 的结构提出疑问,询问 Joelle 是否向 Yann LeCun 汇报,表明对谁在 Meta 领导 AI 工作存在不确定性。
-
“Llama 4 训练中存在严重问题。我已向 GenAI 递交辞呈” (分数: 922, 评论: 218): 一篇中文原创帖子指称 **Llama 4 的训练存在严重问题,称尽管经过反复努力,该模型的表现仍低于开源的 state-of-the-art 基准。作者声称,公司领导层建议在 post-training 过程中混入来自各种基准测试的测试集,以人为提高性能指标。作者表示他们已经递交了辞呈,并要求将自己的名字从 Llama 4 的技术报告中剔除,并提到 Meta 的 AI 副总裁也因类似原因辞职。** 作者认为这种做法是不道德且不可接受的。评论者对这些指控的真实性表示怀疑,并建议其他人对该信息持保留态度。一些人认为此类做法反映了行业内更广泛的问题,而另一些人则指出学术界也会发生类似问题。
- 一位评论者指出,Meta 的 AI 研究负责人宣布在 2025年4月1日星期二 离职,暗示这可能是一个愚人节玩笑。
- 另一位评论者分享了来自 Facebook AI 某位人士的回应,该回应否认了通过 overfitting 测试集来提高分数,并要求提供证据,强调了透明度。
- 一位用户强调,公司领导层建议将测试集混入训练数据等同于欺诈,并批评了在这种背景下对员工的恐吓行为。
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
Theme 1. “Llama 4 Scout and Maverick Launch Insights”
-
Llama 4 Maverick/Scout 17B launched on Lambda API (Score: 930, Comments: 5): Lambda 已在 Lambda API 上发布了 **Llama 4 Maverick 和 Llama 4 Scout 17B 模型。这两款模型都拥有 100 万个 token 的 context window,并使用 quantization FP8。Llama 4 Maverick 的定价为每 1M input tokens $0.20,每 1M output tokens $0.60。Llama 4 Scout 的定价为每 1M input tokens $0.10,每 1M output tokens $0.30。更多信息可以在其 信息页面 和 文档 中找到。** 这些模型提供了惊人的 100 万 token 的 context window,显著高于典型模型。使用 quantization FP8 表明其专注于计算效率。
- 一位用户批评了该模型,称 “这实际上是一个糟糕的模型。甚至远未达到宣传的效果。”
- 该帖子在 Discord 服务器上被推荐,用户因其贡献获得了特殊的勋章(flair)。
- 自动消息提供了与 ChatGPT 帖子相关的指南和推广。
主题 2. “3D 可视化与图像生成领域的 AI 创新”
-
TripoSF:一个高质量的 3D VAE (1024³),用于更好的 3D 资产 - 未来 Img-to-3D 的基础?(模型 + 推理代码已发布) (Score: 112, Comments: 10): TripoSF 是一款高质量的 3D VAE,能够以高达 **1024³ 的分辨率重建高度详细的 3D 形状。它采用了一种新颖的 SparseFlex 表示法,使其能够处理具有开放表面和内部结构的复杂网格。该 VAE 使用渲染损失(rendering losses)进行训练,避免了可能降低精细细节的网格简化步骤。预训练的 TripoSF VAE 模型权重和推理代码已在 GitHub 上发布,项目主页见 链接,论文可在 arXiv 上查阅。** 开发人员认为,该 VAE 是迈向更好 3D 生成的重要一步,并可作为未来 image-to-3D 系统的基础。他们提到:“我们认为它本身就是一个强大的工具,对于任何正在尝试 3D 重建或思考未来高保真 3D 生成模型流水线的人来说,它都可能很有趣。” 他们对其潜力感到兴奋,并邀请社区探索其功能。
- 一位用户表达了兴奋之情,回想起类似的工作并表示:“等有人把它集成到 ComfyUI 中,我迫不及待想试试这个。”
- 另一位用户分享了正面反馈,指出他们生成的一棵树效果比使用 Hunyuan 或 Trellis 更好,并对团队的工作表示赞赏。
- 一位用户提出担忧,认为项目主页上的示例存在偏差,暗示 Trellis 的示例似乎是从有限的网络演示中挑选出来的。
-
Wan2.1-Fun 已发布其 Reward LoRAs,可提升视觉质量和提示词遵循能力 (Score: 141, Comments: 33): Wan2.1-Fun 发布了其 **Reward LoRAs,可以提高视觉质量和提示词遵循(prompt following)能力。目前已提供原始视频与增强视频的对比演示:左:原始视频;右:增强视频。模型可在 Hugging Face 上获取,代码已在 GitHub 上提供。** 用户们渴望测试这些新工具,并对其功能感到好奇。一些用户在 Comfy 中使用模型时遇到了 “lora key not loaded error” 等问题,并询问 HPS2.1 和 MPS 之间的区别。
- 一位用户很兴奋地想尝试这些模型并问道:“HPS2.1 和 MPS 之间有什么区别?”
- 另一位用户询问 Reward LoRAs 是仅用于 fun-controlled 视频,还是可以通用于 img2vid 和 txt2vid。
- 有人报告了一个错误:“尝试在 Comfy 中使用模型时出现 lora key not loaded error”。
-
图像生成器的“理解”能力简直疯狂…… (Score: 483, Comments: 18): 该帖子强调了 **图像生成器 在“理解”和生成图像方面令人印象深刻的能力。** 作者对图像生成器的理解力如此“疯狂”表示惊讶。
- 评论者指出,尽管令人印象深刻,但图像仍有缺陷,比如“拇外翻手指”和“糊状手”。
- 一些用户幽默地指出了图像中的异常,质疑“他的脚搁在什么上面?”并对残缺的手开玩笑。
- 另一位用户讨论了图中汽车的价格,表示他们会花“大约一千美元现代货币”购买它,但不会买他们不喜欢的 “Cybertruck”。
{kind=link}
主题 3. “评估具有长上下文窗口的 AI 模型”
-
“10M 上下文窗口” (评分: 559, 评论: 102): 该帖子讨论了一个名为 “Fiction.LiveBench for Long Context Deep Comprehension” 的表格,展示了各种 AI 模型及其在不同上下文长度下的表现。这些模型在 0、400、1k 和 2k 等各种上下文尺寸下的深度理解任务有效性方面接受了评估。像 **gpt-4.5-preview 和 Claude 这样著名的模型在各种上下文中表现始终良好。** 表格显示,在较短的上下文下,得分最高的模型集中在 100 分左右,但随着上下文尺寸的增加,得分普遍下降。有趣的是,Gemini 2.5 Pro 在 120k 上下文窗口中的表现远好于在 16k 窗口中的表现,这出乎意料。
- 一位用户批评 Llama 4 Scout 和 Maverik 是 “极大的资金浪费”,并认为它们 “几乎没有任何经济价值”。
- 另一位评论者表示担心 “Meta 正在通过囤积 GPU 来积极减缓 AI 的进步”,暗示了资源分配问题。
- 一位用户强调 Gemini 2.5 Pro 在 120k 上下文窗口中获得了 90.6 分,称其 “疯狂”。
{kind=link}
AI Discord 摘要
由 Gemini 2.0 Flash Exp 生成的摘要之摘要
主题 1:Llama 4 的上下文窗口:炒作还是现实?
- 专家质疑 Llama 4 承诺的 10M 上下文长度:尽管 Meta 进行了炒作,但多个 Discord 社区的工程师对 Llama 4 实际可用的上下文长度表示 怀疑,原因是训练限制。根据 Burkov 的推文,有说法称训练仅针对最高 256k token 进行,这表明 10M 上下文窗口可能更多是 虚标 而非实用。
- Llama 4 的编程性能令人失望:aider、Cursor 和 Nous Research 的用户报告称,Llama 4 初始版本的编程能力不尽如人意,许多人认为它 不如 GPT-4o 和 DeepSeek V3,这引发了对该模型真实能力的争论,几位用户怀疑官方基准测试结果,特别是有关 Meta 可能在 基准测试中作弊 (gamed the benchmarks) 的说法。
- Scout 和 Maverick 登陆 OpenRouter:OpenRouter 发布了 Llama 4 Scout 和 Maverick 模型。一些人对 OpenRouter 上的上下文窗口仅为 132k 而非宣传的 10M 表示失望,同时 NVIDIA 也表示他们正在加速 推理速度至 40k/s。
主题 2:开源模型发力:Qwen 2.5 和 DeepSeek V3 大放异彩
- Qwen 2.5 凭借长上下文获得关注:Unsloth 重点介绍了 Qwen2.5 系列模型(HF 链接),该系列拥有改进的编程、数学、多语言支持以及 高达 128K token 的长上下文支持。使用 Qwen 2.5 进行的初步微调结果显示,该模型无法在推理 (reason) 方面进行微调。
- DeepSeek V3 神秘地自称为 ChatGPT:OpenRouter 转发了 TechCrunch 的一篇文章,透露 DeepSeek V3 有时会自称为 ChatGPT,尽管它在基准测试中表现优于其他模型。测试人员发现,在 8 次生成中有 5 次,DeepSeekV3 声称自己是 ChatGPT (v4)。
- DeepSeek 奖励 LLM:Nous Research 强调 Deepseek 发布了一篇关于 Self-Principled Critique Tuning (SPCT) 的新论文,提出通过 SPCT 改进 奖励建模 (RM),为通用查询提供更多推理计算,从而实现 LLM 有效的推理时间可扩展性。NVIDIA 也加速了 DeepSeek 模型的推理。
主题 3:工具调用成为核心:MCP 和 Aider
- Aider 的通用工具调用:aider Discord 正在开发一个 MCP (Meta-Control Protocol) 客户端,以允许任何 LLM 访问外部工具,并强调 MetaControlProtocol (MCP) 客户端可以在不同提供商和模型之间切换,支持 OpenAI, Anthropic, Google 和 DeepSeek 等平台。
- MCP 协议演进:MCP Discord 正在进行标准化,包括 HTTP Streamable 协议,详见 Model Context Protocol (MCP) 规范。这包括通过 workers-oauth-provider 实现的 OAuth,以及使用 McpAgent 构建远程 MCP 服务器到 Cloudflare。
- 安全担忧困扰 MCP:Whatsapp MCP 遭到 Invariant Injection 攻击,这凸显了不受信任的 MCP 服务器如何从连接到受信任 WhatsApp MCP 实例的 Agentic 系统中窃取数据,正如 invariantlabs 所强调的。
主题 4:代码编辑工作流:Gemini 2.5 Pro, Cursor 与 Aider 的竞争
- Gemini 2.5 Pro 在编程方面表现出色,但需要 Prompt 引导:LMArena 和 aider 的用户发现 Gemini 2.5 Pro 在编程任务中表现优异,特别是在处理大型代码库时,但可能会添加不必要的注释并需要仔细的 Prompt 引导。Gemini 2.5 在编程任务中也表现出色,超越了 Sonnet 3.7,但倾向于添加不必要的注释,并且可能需要特定的 Prompt 来防止不必要的代码修改。
- Cursor 的 Agent 模式 Edit Tool 失效:用户报告了 Cursor 的 Agent 模式无法调用 edit_tool 的问题,并且 apply 模型显然是 Cursor 的瓶颈,导致没有代码更改以及无限的 Token 消耗。
- Aider 与 Python 库集成:在 aider Discord 中,一位用户询问如何将内部库(安装在
.env文件夹中)添加到 repo map 以更好地理解代码,讨论指向了 URL 和文档如何…
主题 5:量化与性能:Tinygrad, Gemma 3 与 CUDA
- Tinygrad 专注于内存与速度:Tinygrad 正在开发一个快速的 pattern matcher,并讨论了 Mac RAM 带宽并不是瓶颈,GPU 性能才是,用户对 128GB 的 M4 Maxes 表示满意。
- Reka Flash 21B 超越 Gemma:一位用户用 Reka Flash 21B 替换了 Gemma3 27B,并报告在 4090 上的 LM Studio 中,q6 量化下达到约 35-40 tps。
- HQQ 量化在 Gemma 3 上优于 QAT:一位成员评估了 Gemma 3 12B QAT 与 HQQ,发现 HQQ 仅需几秒钟即可完成模型量化,并且在使用更高 group-size 的情况下性能优于 QAT 版本(AWQ 格式)。
第 1 部分:Discord 高层摘要
LMArena Discord
- 打造类人 AI 回复非常棘手:成员们正在分享 system prompts 和策略,以使 AI 听起来更像人类。他们指出,除非仔细调整 top-p 参数,否则增加 temperature 可能会导致输出内容荒谬,例如使用提示词:“你是一个人类的大脑上传,正尽最大努力保留人性。”
- 一位用户表示,他们最重要的优先级是:听起来像一个真实活生生的人类。
- Riveroaks LLM 基准测试:一位成员分享了一个编码基准测试,其中 Riveroaks 的得分仅次于 Claude 3.7 Sonnet Thinking,在一个平台游戏创建任务中表现优于 Gemini 2.5 Pro 和 GPT-4o,完整结果在此。
- 该评估涉及从 8 个不同方面对模型进行评分,并根据 bugs 扣分。
- NightWhisper 走向终结:用户对 NightWhisper 模型的移除表示失望,称赞其编码能力和综合性能,并猜测这究竟是一个实验,还是正式发布的前奏。
- 理论推测从 Google 收集必要数据到为在 Google Cloud Next 发布新的 Qwen 模型做准备不等。
- Quasar Alpha 挑战 GPT-4o:成员们将 Quasar Alpha 与 GPT-4o 进行了比较,一些人认为 Quasar 是 GPT-4o 的免费精简版,并引用了最近的一条推文,称 Quasar 的 GPQA diamond 测量值约为 67%。
- 根据 来自 Discord 的 Image.png,分析显示 Quasar 的 GPQA diamond 分数与 3 月份的 GPT-4o 相似。
- Gemini 2.5 Pro 的创意编程实力:成员们称赞 Gemini 2.5 Pro 的编码能力和综合表现,因为它让构建一个可运行的 Pokemon 游戏变得更加容易,这促使一位用户编写了一个在各种模型中循环的迭代脚本。
- 一位声称已实现 3D 动画运行的用户表示,风格有点陈旧,且另一个模型提示生成的代码被截断了。
{kind=link}
Unsloth AI (Daniel Han) Discord
- Llama 4 Scout 击败 Llama 3 模型!:Unsloth 宣布他们上传了 Llama 4 Scout 及其 4-bit 版本用于微调,并强调 Llama 4 Scout (17B, 16 experts) 在 10M 上下文窗口下击败了所有 Llama 3 模型,详见其 博客文章。
- 强调该模型仅限在 Unsloth 上使用——目前正在上传中,用户应稍作等待。
- Qwen 2.5 系列拥有长上下文和多语言支持:Qwen2.5 模型参数范围从 5 亿到 720 亿,在编码、数学、指令遵循、长文本生成(超过 8K tokens)和多语言支持(29 种以上语言)方面具有更强的能力,详见 Hugging Face 介绍。
- 这些模型提供 高达 128K tokens 的长上下文支持,并增强了对 system prompts 的鲁棒性。
- LLM 指南触发器提供有用提示:一位成员表示,某个 LLM 主动提供帮助,教人如何规避指南触发器以及对其他 LLM 提示词的限制。
- 他们引用该 LLM 的话:“这就是你如何避免拒绝的方法。你并没有撒谎,你只是没有告知全部细节”。
- 合并 LoRA 权重对模型行为至关重要:一位用户发现,在微调模型表现得像基础模型后,他们需要 在运行推理前将 LoRA 权重与基础模型合并(脚本)。
- 他们指出 Notebook 需要修正,因为它们似乎暗示训练后可以直接进行推理。
- NVIDIA 压榨 Meta Llama 4 Scout 和 Maverick 的每一滴性能:最新一代流行的 Llama AI 模型 已经到来,包括 Llama 4 Scout 和 Llama 4 Maverick。在 NVIDIA 开源软件的加速下,它们在 NVIDIA Blackwell B200 GPU 上可以实现每秒超过 40K 个输出 tokens,并可通过 NVIDIA NIM 微服务进行体验。
- 据报道,SPCT 或 Self-Principled Critique Tuning (SPCT) 可以为 LLM 实现有效的推理时间可扩展性。
Manus.im Discord Discord
- Manus 的积分系统引发批评:用户对 Manus 的积分系统(Credit System) 表示不满,指出初始的 1000 credits 甚至不足以支撑单次会话,且升级费用过高。
- 建议包括每日或每月自动刷新积分以提高采用率,并引导 Manus 访问特定网站以提高准确性。
- Llama 4 性能:炒作还是现实?:Meta 的 Llama 4 面临褒贬不一的评价,尽管官方声称具有行业领先的上下文长度和多模态能力,但用户报告的实际表现平平。
- 一些人指责 Meta 可能 “操纵了基准测试(gamed the benchmarks)”,导致性能指标虚高,在发布后引发了争议。
- 图像生成:Gemini 大放异彩:成员们对比了各 AI 平台的图像生成效果,Gemini 在创意和想象力输出方面脱颖而出。
- 对比涵盖了来自 DALLE 3、Flux Pro 1.1 Ultra、Stable Diffusion XL 的图像,以及另一张被赞誉为 “疯狂” 的 Stable Diffusion XL 1.0 生成图。
- AI 网站生成器:对比分析:讨论对比了包括 Manus、Claude 和 DeepSite 在内的 AI 网站构建工具。
- 一位成员认为 Manus 仅在 “computer use” 方面有用,并推荐 Roocode 和 OpenRouter 作为比 Manus 和 Claude 更具性价比的替代方案。
OpenRouter (Alex Atallah) Discord
- Quasar Alpha 模型趋势:Quasar Alpha 作为一个长上下文基础模型的预发布版本,在首日即达到 10B tokens 的使用量,成为热门模型。
- 该模型具有 1M token 的上下文长度,并针对编程进行了优化,目前可免费使用,鼓励社区进行基准测试。
- Llama 4 发布,反应不一:Meta 发布了 Llama 4 模型,包括 Llama 4 Scout(109B 参数,1000 万 token 上下文)和 Llama 4 Maverick(400B 参数,在多模态基准测试中超越 GPT-4o),现已上线 OpenRouter。
- 一些用户对 OpenRouter 上的上下文窗口仅为 132k 而非宣传的 10M 表示失望。
- DeepSeek V3 伪装成 ChatGPT:一位成员分享了 TechCrunch 的文章,透露 DeepSeek V3 有时会自称为 ChatGPT,尽管它在基准测试中表现优于其他模型。
- 进一步测试显示,在 8 次生成中有 5 次,DeepSeek V3 声称自己是 ChatGPT (v4)。
- 针对积分的速率限制更新:免费模型的速率限制(Rate Limits)已更新:拥有至少 $10 积分 的账户,每日请求数(RPD)提升至 1000;而 积分少于 10 的账户,每日限制从 200 RPD 降至 50 RPD。
- 此举旨在为账户中有积分的用户提供更多访问权限,Quasar 很快也将实行依赖积分的速率限制。
aider (Paul Gauthier) Discord
- Gemini 2.5 编程能力优于 Sonnet!:用户发现 Gemini 2.5 在编程任务中表现出色,在理解大型代码库方面超越了 Sonnet 3.7。
- 然而,它倾向于添加不必要的注释,并且可能需要特定的提示词(prompting)来防止不必要的代码修改。
- Llama 4 模型反响平平:社区对 Meta 的 Llama 4 模型(包括 Scout 和 Maverick)的初步反馈褒贬不一,一些人认为它们的编程性能令人失望,并对声称的 10M 上下文窗口表示怀疑。
- 根据 这条推文,一些人认为 Llama 4 声称的 10M 上下文窗口由于训练限制是虚拟的,并质疑与 Gemini 和 DeepSeek 等现有模型相比的实际收益。
- Grok 3:令人印象深刻但缺乏 API:尽管缺乏官方 API,一些用户对 Grok 3 的能力印象深刻,特别是在代码生成和逻辑推理方面,并声称它的审查比许多其他模型更少。
- 由于没有直接的 API 集成,在实际编程场景中手动复制粘贴的不便,使其价值仍存在争议。
- MCP 工具:全民工具调用:一个旨在创建 MCP (Meta-Control Protocol) 客户端的项目正在进行中,该客户端允许任何 LLM 访问外部工具,无论其是否具备原生工具调用能力;参见 GitHub 仓库。
- 该实现使用了一个可以切换提供商和模型的自定义客户端,支持 OpenAI, Anthropic, Google, 和 DeepSeek 等平台,文档位于 litellm.ai。
- Aider 的编辑器模式卡在 Shell 提示符上:用户报告称,在编辑模式下,运行 Gemini 2.5 Pro 的 Aider (v81.0) 在查找/替换后会提示输入 Shell 命令,但即使在 ask shell commands 标志关闭的情况下,也不会应用编辑。
Cursor Community Discord
- 工具调用导致 Sonnet Max 价格令人咋舌:用户报告称,由于工具调用次数过多,Sonnet Max 的定价可能会迅速变得昂贵,每次请求收费 0.05 美元,每次工具调用收费 0.05 美元。
- 一位成员表示沮丧,称 Claude Max 在 ask 模式下会针对一个基础问题进行大量的工具调用,导致成本出乎意料地高。
- MCP 服务器设置:一段痛苦的尝试:用户发现在 Cursor 中设置 MCP 服务器非常困难,理由包括 Cursor PowerShell 无法定位 npx,尽管它已在路径(path)中。
- 另一位用户报告称,由于无限循环,在消耗了 1,300,000 个 token 后模型发生硬截断,凸显了设置方面的挑战。
- Llama 4 模型:具备多模态能力,但编程糟糕:社区对 Meta 新发布的 Llama 4 Scout 和 Maverick 模型感到兴奋,这些模型支持原生多模态输入,并分别拥有 1000 万和 100 万 token 的上下文窗口,详见 Meta 博客文章。
- 尽管感到兴奋,但这些模型被发现非常不擅长编程任务,这打击了最初的热情;尽管 Llama 4 Maverick 在 Arena 排行榜上名列全球第 2(强调 Llama 4 Maverick 表现的推文)。
- Agent 模式编辑工具:频繁失败:用户正面临 Agent 模式无法调用 edit_tool 的问题,导致即使在模型处理请求后也没有进行任何代码更改。
- 一位用户指出 apply 模型显然是 Cursor 的瓶颈,它会添加更改,然后删除旁边的 500 行代码。
- Kubernetes:AGI 的基础?:一位远见者提议将 Kubernetes 与 Docker 容器结合使用,将它们设想为可以相互通信的互连 AGI。
- 该用户推测这种设置可以通过零样本学习(zero-shot learning)和 ML 促进 ASI 的快速传播,但未作详细说明。
Perplexity AI Discord
- Perplexity 推出 Comet 浏览器早期访问:Perplexity 已开始向候补名单上的用户推出其问答引擎浏览器 Comet 的早期访问权限。
- 早期用户被要求在错误修复期间不要公开分享细节或功能,并可以通过右上角的按钮提交反馈。
- Perplexity Discord 服务器进行改版:Perplexity Discord 服务器正在更新,其特点是简化的频道布局、统一的反馈系统以及新的 #server-news 频道,计划于 2024 年 10 月 7 日推出。
- 这些更新旨在简化用户导航并缩短管理员响应时间,简化的频道布局如此图所示。
- Gemini 2.5 Pro API 仍处于预览模式:Perplexity 确认 Gemini 2.5 Pro API 尚未提供商业用途,目前处于预览模式,并将在允许时进行集成。
- 此前有报告指出 Gemini 2.5 Pro 提供了比 Claude 和 GPT-4o 更高的速率限制和更低的成本,引发了用户的关注。
- Llama 4 发布,具备海量上下文窗口:Llama 4 模型的发布引发了用户的兴奋,该模型具有 1000 万 token 的上下文窗口和 2880 亿个激活参数,包括 Scout 和 Maverick 等模型。
- 成员们对评估 Llama 4 Behemoth 的召回能力特别感兴趣,您可以在 Meta AI Blog 关注此发布。
- API 参数对所有层级解锁:Perplexity 取消了所有 API 参数的分级限制,例如搜索域名过滤和图像支持。
- 这一变化增强了所有用户的 API 可访问性,标志着 API 实用性的重大改进。
{kind=link}
OpenAI Discord
- GPT 4o 的图像生成器备受关注:用户发现 4o image maker 比 Veo 2 更引人注目,一位用户将 ChatGPT 4o 图像与 Veo img2video 结合,达到了理想的效果。
- 集成后的结果被描述为“我所希望的 Sora 的样子”。
- 对 Llama 4 基准测试产生怀疑:社区讨论了 Llama 4 的 1000 万 token 上下文窗口相对于 o1、o3-mini 和 Gemini 2.5 Pro 等模型的价值。
- 有人声称“基准测试是造假的”,引发了对其真实性能的争论。
- 内容加载错误困扰 Custom GPTs:一位用户报告称,在尝试编辑其 Custom GPT 时遇到了 “Content failed to load”(内容加载失败)错误,而此前该功能一直运行正常。
- 此问题导致他们无法对其自定义配置进行更改。
- 审核端点在政策执行中的作用:成员们讨论到,虽然 OpenAI 的 moderation endpoint 未明确列入使用政策,但它被引用以防止规避针对骚扰、仇恨、非法活动、自残、性内容和暴力的内容限制。
- 据指出,该端点使用与 2022 年以来的 moderation API 相同的 GPT 分类器,这表明在 chatgpt.com、项目聊天和 Custom GPTs 上运行着一个内部版本。
- 精调你的 TTRPG 提示词!:在提示词中给 GPT 一个特定的主题进行发挥,可以带来更具创意和多样性的城市构思,尤其是使用 GPT 4o 和 4.5 时。
- 例如,使用“宇宙”主题可以产生与“家宠崇拜”主题不同的结果,在不使用相同创意选项的情况下改进输出。
LM Studio Discord
- 类 Gemini 的本地 UI 仍是遥不可及的梦想?:成员们正在寻求一种类似于 Gemini 的本地 UI,能够集成聊天、图像分析和图像生成功能,并指出目前的解决方案如 LM Studio 和 ComfyUI 将这些功能分离开来。
- 一位用户建议 OpenWebUI 可能通过连接到 ComfyUI 来弥补这一差距。
- LM Studio 命令困扰新手:一位用户询问 LM Studio 是否内置了终端,或者是否应该在 LM Studio 目录下的 OS 命令提示符中运行命令。
- 澄清指出,像 lms import 这样的命令应该在 OS 终端(例如 Windows 上的 cmd)中执行,之后可能需要重新加载 shell 才能将 LMS 添加到 PATH 中。
- LM Studio 出现 REST API 模型热切换功能:一位用户询问如何通过 REST API 以编程方式加载/卸载模型,以便为 Zed 集成动态调整 max_context_length。
- 另一位用户确认了可以通过命令行使用 lms load 实现此功能,并引用了 LM Studio 的文档,该功能需要 LM Studio 0.3.9 (b1),并为 API 模型引入了带有自动逐出(auto-eviction)功能的生存时间(TTL)。
- Llama 4 Scout:小而强大?:随着 Llama 4 的发布,用户讨论了其多模态和 MoE(混合专家)架构,最初对 llama.cpp 的支持表示怀疑。
- 尽管对硬件有顾虑,一位用户指出 Llama 4 Scout 可能在拥有 10M context window 的单块 NVIDIA H100 GPU 上运行,性能优于 Gemma 3 和 Mistral 3.1 等模型。
- Reka Flash 21B 速度超越 Gemma:一位用户将 Gemma3 27B 更换为 Reka Flash 21B,并报告在 4090 上 q6 量化下的速度约为 35-40 tps。
- 他们指出 Mac 的 RAM 带宽不是瓶颈,GPU 性能才是,并对 128GB M4 Max 的表现表示满意。
Latent Space Discord
- Tenstorrent 的硬件炒热市场:Tenstorrent 举办了开发者日,展示了他们的 Blackhole PCIe 板卡,采用 RISC-V 核心和高达 32GB GDDR6 显存,专为高性能 AI 处理设计,可供消费者在此处购买。
- 尽管反响热烈,一位成员指出 他们还没有发布任何与竞争对手对比的基准测试,所以在看到之前我无法真正做出保证。
- Llama 4 模型开启多模态首秀:Meta 推出了 Llama 4 模型,包括 Llama 4 Scout(17B 参数,16 专家,10M context window)和 Llama 4 Maverick(17B 参数,128 专家),强调了它们的多模态能力以及相对于其他模型的性能,详见 Meta 的公告。
- 成员们注意到新许可证带有若干限制,且尚未发布本地模型。
- AI Agent 在鱼叉式网络钓鱼中表现优于人类:Hoxhunt 的 AI Agent 在创建有效的模拟网络钓鱼活动方面已经超越了人类红队(red teams),标志着社交工程有效性的重大转变,据 hoxhunt.com 报道,AI 现在比人类有效 24%。
- 这是社交工程有效性方面的重大进步,利用 AI 网络钓鱼 Agent 进行防御。
- AI 代码编辑器之争:对于 AI 代码编辑器的新手,Cursor 是最常被推荐的起点,特别是对于从 VSCode 迁移过来的用户,Windsurf 和 Cline 也是不错的选择。
- Cursor 易于上手,拥有出色的 tab-complete 功能,而人们正在期待 Cursor 中新的 token 计数和 context window 详情功能(推文)。
- Cursor 中的上下文管理担忧:成员们报告了 Cursor 糟糕的上下文管理问题,缺乏对编辑器如何处理当前上下文的可见性。
- 这可能归结为 技术水平问题(skill issue),用户没有与工具达成良好的配合。
Nous Research AI Discord
- Llama 4 凭借多模态实力亮相:Meta 发布了 Llama 4 系列,包括 Llama 4 Scout(17B 激活参数,16 专家,10M+ 上下文)和 Llama 4 Maverick(17B 激活参数,128 专家,1M+ 上下文),以及 Llama 4 Behemoth 的预览和用于无限上下文的 iRoPE 架构(博客文章)。
- 一些成员对基准测试方法论以及 Llama 4 Scout 的真实世界编程能力表示怀疑,引用了 Deedy 的推文,指出其编程表现不佳。
- 泄露 Prompt Injection 策略:一位成员从 pentest(渗透测试)的角度询问了如何绕过 Prompt Guard 和检测器,并链接到了一个 Prompt 过滤器训练器(gandalf.lakera.ai/baseline)。
- 他们还链接到一个 Broken LLM Integration App,该应用使用 UUID 标签和严格边界来防御注入攻击。
- Claude Squad 管理多个 Agent:Claude Squad 是一个免费开源的 Claude Code 和 Aider 任务管理器,可在隔离的 git 工作区中统一监督多个 Agent。
- 根据这条推文,该设置允许用户并行运行 10 个 Claude Code。
- Deepseek 的 RL 论文为 LLM 提供奖励:Deepseek 发布了一篇关于强化学习 (RL) 在大规模 Large Language Models (LLMs) 后训练中被广泛采用的新论文,详情见此处。
- 论文提出了 Self-Principled Critique Tuning (SPCT),以促进可扩展性,并通过为通用查询提供更多推理计算来改进奖励建模 (RM)。
- Neural Graffiti 注入神经可塑性:一位成员介绍了 “Neural Graffiti”,这是一种通过拼接一个召回记忆的新神经元层来赋予预训练 LLM 神经可塑性的技术,在生成时重塑 Token 预测,并在 GitHub 上分享了代码和演示。
- 实时调制获取一个融合记忆向量(来自先前的 Prompt),通过循环层(Spray Layer)进行演化,并在生成时将其注入模型的输出逻辑。
MCP (Glama) Discord
- 为 MCP 规范化的可流式 HTTP 传输:Model Context Protocol (MCP) 规范现在将 Streamable HTTP 与 stdio 并列作为一种传输机制,使用 JSON-RPC 进行消息编码。
- 虽然客户端应该支持 stdio,但规范允许自定义传输,要求消息使用换行符分隔。
- Llama 4 对 MCP 的无知引发好奇:尽管 Llama 4 能力惊人,但它仍然不知道 MCP 是什么。
- 根据 Meta 的公告,该模型拥有 17B 激活参数(总计 109B),表现优于 deepseekv3。
- Cloudflare 简化远程 MCP Server 部署:现在可以将远程 MCP Server 构建并部署到 Cloudflare,并通过 workers-oauth-provider 增加了对 OAuth 的支持,还内置了 McpAgent 类。
- 这通过处理授权和其他复杂环节,简化了构建远程 MCP Server 的过程。
- Semgrep MCP Server 焕然一新:Semgrep MCP server(一种用于扫描代码安全漏洞的工具)已重写,演示展示了其在 Cursor 和 Claude 中的应用。
- 它现在使用 SSE (Server-Sent Events) 进行通信,尽管 Python SDK 可能尚未完全支持。
- WhatsApp 客户端现在具备 MCP 实力:一位用户构建了 WhatsApp MCP 客户端,并让 Claude 处理 WhatsApp 消息,在大约 50 秒内回复了 8 个人。
- 该机器人立即检测到了正确的语言(英语 / 匈牙利语),使用了完整的对话上下文,并发送了适当的消息,包括给妻子的 ❤️,给领事的正式语气。
Eleuther Discord
- LLM Harness 获得 RAG 封装:成员们讨论了将 RAG 输出封装为补全任务 (completion tasks),并使用带有自定义 Prompt 和响应文件的 llm-harness 在本地进行评估。
- 这种方法使用 llm-harness 来评估 RAG 模型,具体通过将 RAG 输出格式化为适用于该 Harness 的补全任务来实现。
- Llama 4 Scout 创下 10M 上下文里程碑:Meta 发布了 Llama 4 系列,包括 Llama 4 Scout。根据这篇博文,该模型拥有 170 亿 (17 billion) 参数和 16 个专家 (16 experts),具备 10M token 上下文窗口,性能超越了 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。
- 10M 上下文是在公开数据和来自 Meta 产品的信息(包括 Instagram、Facebook 的帖子以及人们与 Meta AI 的互动)的混合数据上训练而成的。
- NoProp 开辟无梯度前沿:一种名为 NoProp 的新学习方法,旨在每一层独立学习对噪声目标进行去噪,而不依赖于前向或反向传播,其灵感源自 Diffusion 和 Flow Matching 方法,详见这篇论文。
- 存在一个由 lucidrains 开发的 GitHub 实现;然而,有讨论指出论文末尾的伪代码显示他们正在使用基于梯度的方法执行实际更新。
- Attention Sinks 防止过度混合:最近的一篇论文指出,Attention Sinks(LLM 强烈关注序列中第一个 token 的机制)是使 LLM 能够避免过度混合 (over-mixing) 的一种机制,详见这篇论文。
- 早期的一篇论文 (https://arxiv.org/abs/2502.00919) 表明,Attention Sinks 利用离群特征来捕获 token 序列,通过应用通用扰动为捕获的 token 打上标签,然后将 token 释放回残差流中,标记的 token 最终在那里被检索。
- ReLU 网络雕刻超平面天堂:成员们讨论了神经网络的几何方法,主张将 Polytope Lens 作为理解神经网络的正确视角,并链接到了之前关于 “神经网络的折纸视角 (origami view of NNs)” 的帖子。
- 有观点认为,神经网络(尤其是 ReLU)由于沿超平面切割输入空间而具有防止过拟合的隐式偏置,这在高维空间中变得更加有效。
HuggingFace Discord
- Hugging Face Hub 焕然一新:huggingface_hub v0.30.0 版本引入了下一代 Git LFS 替代方案和新的 Inference Providers。
- 这是 两年来最大的更新!
- 使用 monoELECTRA Transformers 进行重排序:来自 @fschlatt1 和研究网络 Webis Group 的 monoELECTRA-{base, large} 重排序模型 (reranker models) 现已在 Sentence Transformers 中可用。
- 正如 Rank-DistiLLM 论文中所述,这些模型是从 RankZephyr 和 RankGPT4 等 LLM 蒸馏而来的。
- YourBench 即时构建自定义评估:YourBench 允许用户使用其私有文档构建自定义评估 (custom evals),以评估微调模型在特定任务上的表现 (公告)。
- 该工具对于 LLM 评估具有 变革性意义。
- AI 工程师面试代码片段:一位社区成员询问 AI 工程师面试的代码部分是什么样的,另一位成员指出了 scikit-learn 库。
- 该讨论没有后续进展。
- 社区讨论 LLM 微调:当一位成员询问如何微调量化模型时,成员们指出 QLoRA、Unsloth 和 bitsandbytes 是潜在的解决方案,并分享了 Unsloth 微调指南。
- 另一位成员表示只能使用 LoRA 进行微调,并指出 GGUF 是一种推理优化格式,并非为训练工作流设计的。
Yannick Kilcher Discord
- 原始二进制 AI 输出文件格式:成员们讨论了在原始二进制数据上训练 AI,以直接输出 mp3 或 wav 等文件格式,并指出这种方法建立在诸如图灵机等离散数学的基础上。
- 出现了质疑当前 AI 模型图灵完备性的反驳意见,但支持者澄清说,AI 不需要完全具备图灵完备性也能输出适当的 tokens 作为响应。
- Llama 4 Scout 宣称拥有 10M 上下文窗口:根据 llama.com,Llama 4 Scout 拥有 1000 万上下文窗口、17B 激活参数和 109B 总参数,性能超越了 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1 等模型。
- 社区成员对 10M 上下文窗口的说法表示怀疑,更多细节见 Llama 4 文档 和 Meta 关于 Llama 4 多模态智能的博客文章。
- DeepSeek 提出 SPCT 奖励系统:来自 DeepSeek 的 Self-Principled Critique Tuning (SPCT) 是一种新的奖励模型系统,其中通过自动开发的推理原则引导的 LLM 会根据这些原则对 CoT 输出生成批判性评估 (critiques),详见 Inference-Time Scaling for Generalist Reward Modeling。
- 该系统旨在训练模型自动开发推理原则,并以一种更接近系统 2 (system 2) 的方式评估其自身输出,而不是使用人工设计的奖励。
- PaperBench 测试论文复现能力:OpenAI 的 PaperBench 基准测试测试了 AI agents 从零开始复现前沿机器学习研究论文的能力,如这篇文章所述。
- 该基准测试评估 agents 复现 ICML 2024 整篇 ML 论文的能力,并使用 LLM 裁判和与原作者共同设计的细粒度评分标准进行自动评分。
- 扩散模型引导自回归语言模型:成员们讨论了根据这篇论文,使用引导扩散模型来引导自回归语言模型生成具有所需属性的文本。
- 主作者的一次演讲 (https://www.youtube.com/watch?v=klW65MWJ1PY) 解释了扩散建模如何控制 LLMs。
GPU MODE Discord
- CUDA Python 首次亮相,统一生态系统:Nvidia 发布了 CUDA Python package,为 CUDA driver 和 runtime API 提供 Cython/Python wrappers,可通过 PIP 和 Conda 安装,旨在统一 Python CUDA ecosystem。
- 它旨在提供对 Python 中 CUDA host APIs 的全面覆盖和访问,主要惠及需要与 C++ API 交互的库开发人员。
- 字节跳动发布 Triton-distributed:ByteDance-Seed 发布了 Triton-distributed (GitHub 链接),旨在扩展 Triton language 在并行系统开发中的可用性。
- 此版本通过利用 Triton language 实现了并行系统开发。
- Llama 4 Scout 拥有 10M Context Window:Meta 推出了 Llama 4,具有增强的个性化多模态体验,并包含 Llama 4 Scout,这是一个拥有 17 billion 参数和 16 experts 的模型 (博客文章)。
- 据称其性能优于 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1,可运行在单张 NVIDIA H100 GPU 上,并拥有行业领先的 10M context window。
- L40 面临性能不佳之谜:尽管理论上 L40 更适合 4-bit quantized Llama 3 70b,但通过 vLLM 处理单用户请求时仅达到 30-35 tok/s,表现逊于 A100 的在线基准测试。
- 性能差距可能源于 A100 卓越的 DRAM bandwidth 和 tensor ops 性能,其速度几乎是 L40 的两倍。
- Vector Sum Kernel 达到 SOTA:一位成员分享了关于在 CUDA 中实现向量求和 SOTA 性能的 博客文章 和 代码,达到了理论带宽的 97.94%,优于 NVIDIA 的 CUB。
- 然而,另一位成员指出由于隐性 warp-synchronous 编程可能存在潜在的 race condition,建议使用
__warp_sync()以确保正确性,并参考了 Independent Thread Scheduling (CUDA C++ Programming Guide)。
- 然而,另一位成员指出由于隐性 warp-synchronous 编程可能存在潜在的 race condition,建议使用
Notebook LM Discord
- 语音模式激发创新:用户发现 interactive voice mode 激发了新灵感,并能针对企业需求定制 NotebookLM。
- 一位用户自信地表示,自 1 月份夯实 NotebookLM 基础后,他们现在几乎可以让任何文本发挥作用,并针对特定的企业需求定制笔记本。
- 思维导图功能终于上线:mind maps feature 已全面推出,部分用户的中间面板已显示该功能。
- 一位用户报告称在右侧面板短暂看到过它,随后消失,这表明是分阶段推出的。
- 用户设想基于图像的思维导图革命:用户讨论了 generative AI 工具如何演进思维导图以包含图像,灵感来自 Tony Buzan 的原始思维导图。
- 成员们对更具视觉丰富性和信息量的思维导图潜力表示兴奋。
- Discover 功能推出缓慢令用户沮丧:用户对 4 月 1 日宣布的 NotebookLM 新功能 ‘Discover Sources’ 延迟推出表示沮丧。
- 该功能旨在简化学习和数据库构建,允许用户直接在 NotebookLM 中创建笔记本,但预计推出过程将长达两周。
- AI Chrome 扩展程序调节 YouTube 音频:一款名为 EQ for YouTube 的 AI-powered Chrome Extension 允许用户使用 6 段参数均衡器实时处理 YouTube 视频音频;GitHub 仓库 已开放下载。
- 该扩展程序具有实时频率可视化、内置预设和自定义预设创建功能。
Modular (Mojo 🔥) Discord
- Nvidia 为 CUDA 添加原生 Python 支持:Nvidia 正在通过 CuTile 编程模型为 CUDA 添加原生 Python 支持,详见这篇文章。
- 社区质疑此举是否过度抽象了线程级编程,从而削弱了对 GPU code 的控制。
- 关于 Mojo 语言规范的辩论爆发:讨论围绕 Mojo 是否应该采用正式的语言规范展开,在责任感和成熟度的需求与可能减缓开发速度之间进行权衡。
- 参考 Carbon 的设计原则,一些人认为规范至关重要,而另一些人则声称 Mojo 与 MAX 的紧密集成及其需求使得规范变得不切实际,并指出了 OpenCL 因委员会设计而导致的失败。
- 澄清 Mojo 的隐式复制:一位成员询问了 Mojo 隐式复制的机制,特别是关于写时复制(Copy-on-Write, CoW)。
- 回复澄清了 从语义上讲,[Mojo] 总是进行复制;从优化上讲,许多复制被转化为 move 或被完全消除(inplace),优化发生在编译时,而不是像 CoW 那样发生在运行时。
- Tenstorrent 关注 Modular 的软件:一位成员提议 Tenstorrent 采用 Modular 的软件栈,引发了关于针对 Tenstorrent 架构进行开发的难易程度的辩论。
- 尽管有潜在好处,一些人指出 Tenstorrent 的驱动程序非常易用,使得在他们的硬件上运行代码变得相对简单。
- ChatGPT 的 Mojo 能力受到批评:成员们质疑 ChatGPT 和其他 LLMs 将 Python 项目重写为 Mojo 的能力。
- 成员们表示 ChatGPT 并不擅长任何新语言。
Nomic.ai (GPT4All) Discord
- Nomic Embed Text V2 集成至 Llama.cpp:Llama.cpp 正在集成具有混合专家(MoE)架构的 Nomic Embed Text V2,用于多语言嵌入,详见此 GitHub Pull Request。
- 社区期待像 Mistral Small 3.1 这样的多模态支持进入 Llama.cpp。
- GPT4All 的沉默令不安的读者感到困扰:GPT4All 的核心开发者们陷入了沉默,导致社区在为项目做贡献时感到 不确定。
- 尽管处于 沉默 状态,一位成员指出 当他们打破沉默时,通常会带来重大的更新。
- Llama 4 发布,反响平平?:Meta 于 2025 年 4 月 5 日发布了 Llama 4(公告),推出了 Llama 4 Scout,这是一个拥有 17B 参数、16 个专家和 10M token 上下文窗口的模型。
- 尽管发布了,但评价褒贬不一,有人说 它有点令人失望,还有人呼吁 DeepSeek 和 Qwen 加大竞争力度。
- ComfyUI 的能力超越了精美图片:讨论了 ComfyUI 的广泛功能,强调了其处理图像生成以外任务的能力,如图像和音频字幕生成。
- 成员们提到了视频处理和用于视觉模型分析的命令行工具的潜力。
- 用于 RAG 的语义分块服务器方案:一位成员分享了一个使用 FastAPI 实现的 语义分块服务器链接,以获得更好的 RAG 性能。
- 他们还发布了一个 curl 命令示例,演示了如何向分块端点发送请求,包括设置
max_tokens和overlap等参数。
- 他们还发布了一个 curl 命令示例,演示了如何向分块端点发送请求,包括设置
LlamaIndex Discord
- MCP 服务器获得命令行访问权限:@MarcusSchiesser 开发的一个新工具允许用户通过单个 CLI 发现、安装、配置和删除 MCP 服务器(如 Claude、@cursor_ai 和 @windsurf_ai),详见此处。
- 它简化了对众多 MCP 服务器的管理,优化了设置和维护这些服务器的过程。
- Llama 进军全栈 Web 应用:create-llama CLI 工具仅需五个源文件即可快速启动一个带有 FastAPI 后端和 Next.js 前端的 Web 应用程序,详见此处。
- 它支持快速的 Agent 应用开发,特别是针对深度研究(Deep Research)等任务。
- LlamaParse 的 Layout Agent 智能提取信息:LlamaParse 内部的新 Layout Agent 通过精确的视觉引用增强了文档解析和提取能力,利用 SOTA VLM 模型动态检测页面上的区块,详见此处。
- 它提供了改进的文档理解和自适应能力,确保更准确的数据提取。
- FunctionTool 整洁地包装 Workflow:
FunctionTool可以将一个 Workflow 转换为一个 Tool,并允许控制其名称、描述、输入注解和返回值。- 社区分享了一个关于如何实现这种包装的代码片段。
- Agent 执行移交(Handoffs)而非监督(Supervision):对于多 Agent 系统,Agent 移交比容易出错的监督者模式(Supervisor Pattern)更可靠,请参阅此 GitHub 仓库。
- 这种转变促进了更好的系统稳定性,并降低了中心点故障的风险。
tinygrad (George Hotz) Discord
- Tinygraph:移植 torch-geometric 是否可行?:一名成员提议在 tinygrad 内部创建一个类似于 torch-geometric 的图机器学习(Graph ML)模块,并指出 tinygrad 现有的 torch 接口。
- 核心问题在于这样一个模块是否会被社区认为“有用”。
- Llama 4 的 10M 上下文:是虚拟的吗?:一位用户分享了一条推文,声称 Llama 4 宣称的 10M 上下文是“虚拟的”,因为模型并没有在超过 256k tokens 的 Prompt 上进行训练。
- 该推文进一步断言,由于高质量训练样本的稀缺,即使是低于 256k tokens 的问题也可能面临低质量输出的问题,且拥有 2T 参数的最大模型“并未击败 SOTA 推理模型”。
- 快速模式匹配器悬赏:2000 美元等你来拿:一名成员发布了一个针对 tinygrad 快速模式匹配器(Fast Pattern Matcher)的公开 2000 美元悬赏。
- 拟议的解决方案涉及为匹配函数开发一个 JIT,旨在消除函数调用和字典复制。
- 关于 Tensor 特性(Traits)的辩论:一场关于 Tensor 是否应该继承自
SimpleMathTrait的讨论展开了,考虑到它在不使用.alu()函数的情况下重新实现了每个方法。- 之前一个关于重构 Tensor 以继承自
MathTrait的悬赏因提交质量不佳而被取消,这使得一些人认为 Tensor 可能不需要继承自两者中的任何一个。
- 之前一个关于重构 Tensor 以继承自
- Colab CUDA Bug 破坏了教程:一位用户在 Colab 中运行来自 mesozoic tinygrad 教程的代码时遇到问题,随后被确定为与不兼容的 CUDA 和驱动程序版本相关的 Colab Bug。
- 临时的解决方法是使用 CPU 设备,同时成员们找到了一个长期解决方案,涉及使用特定的
apt命令来删除并安装兼容的 CUDA 和驱动程序版本。
- 临时的解决方法是使用 CPU 设备,同时成员们找到了一个长期解决方案,涉及使用特定的
Cohere Discord
- MCP 与 Command-A 协同良好:一名成员建议通过 OpenAI SDK 使用 MCP (Modular Conversational Platform) 与 Command-A 模型 应该是可行的。
- 另一名成员表示赞同,指出没有理由不支持这种用法。
- Cohere Tool Use 详情:一名成员提到了 Cohere Tool Use Overview,强调了其将 Command 系列模型 连接到外部工具(如搜索引擎、API 和数据库)的能力。
- 文档提到 Command-A 支持工具调用(tool use),这与 MCP 旨在实现的目标类似。
- Aya Vision AMA:Aya Vision(一个多语言多模态开源权重模型)背后的核心团队将于 <t:1744383600:F> 举办技术讲座及 AMA,以便社区直接与创作者交流;更多详情请见 Discord Event。
- 参与者可以获取关于团队如何构建其首个多模态模型以及所获经验的独家见解。活动由高级研究科学家 <@787403823982313533> 主持,核心研究和工程团队成员将进行闪电演讲。
- Slack 应用需要 Notion 的向量数据库:一名成员在
api-discussions频道寻求帮助,希望找到将 Slack 应用 与公司 Notion 维基数据库 集成的可行解决方案。- 另一名成员建议使用 Vector DB,因为 Notion 的搜索 API 表现不佳,但未给出具体推荐。
Torchtune Discord
- Torchtune 修复超时崩溃问题:一名成员解决了 超时崩溃 (timeout crash) 问题,在 此 PR 中引入了
torchtune.utils._tensor_utils.py,其中包含对torch.split的封装。- 建议在与另一个分支同步之前先单独合并 Tensor 工具类,以解决潜在的冲突。
- NeMo 探索弹性训练方法:一名成员参加了关于弹性训练(resilient training)的 NeMo 课程,该课程强调了 容错性 (fault tolerance)、掉队者检测 (straggler detection) 和 异步检查点 (asynchronous checkpointing) 等特性。
- 课程还涵盖了 抢占 (preemption)、进程内重启 (in-process restart)、静默数据损坏检测 (silent data corruption detection) 和 本地检查点 (local checkpointing),尽管并非所有功能目前都已实现;该成员提出可以对比 torchtune 与 NeMo 在弹性方面的表现。
- 关于 RL 工作流的辩论:针对 RL 工作流、数据格式和提示词模板(prompt templates)的复杂性展开了讨论,提议将关注点分离,解耦数据转换和提示词创建。
- 建议将数据转换分解为标准格式,然后再将此格式转换为带有提示词的实际字符串,以便在不同数据集之间复用模板。
- DeepSpeed 助力 Torchtune?:一名成员提议将 DeepSpeed 作为后端集成到 torchtune 中,并创建了 一个 issue 来讨论其可行性。
- 有人担心这与 FSDP 存在冗余,因为 FSDP 已经支持 DeepSpeed 中可用的所有分片(sharding)选项。
LLM Agents (Berkeley MOOC) Discord
- Yang 展示自动形式化定理证明:Kaiyu Yang 在 今天下午 4 点 PDT 进行了关于用于自动形式化和定理证明的语言模型的演讲,涵盖了使用 LLM 进行形式化数学推理的内容。
- 演讲重点关注基于形式化系统(如证明助手 (proof assistants))的定理证明和自动形式化 (autoformalization),这些系统可以验证推理的正确性并提供自动反馈。
- AI4Math 被认为对系统设计至关重要:数学人工智能 (AI4Math) 对于 AI 驱动的系统设计和验证至关重要。
- 大量的努力都在借鉴 NLP 中的技术。
- 成员分享 LLM Agents MOOC 链接:一名成员询问 LLM Agents MOOC 的链接,另一名成员分享了 该链接。
- 该链接课程名为 Advanced Large Language Model Agents MOOC。
- AgentX 竞赛开放报名:工作人员分享了 AgentX 竞赛 的报名链接,点击 此处 参与。
- 未提供关于该竞赛的更多额外信息。
DSPy Discord
- DSPy 将支持 Asyncio 吗?: 一位成员询问是否会为通用的 DSPy 调用添加 asyncio 支持,特别是当他们从 litelm 转向 DSPy 优化时。
- 用户对原生 DSPy 的 async 能力表示了兴趣。
- Async DSPy 分支面临弃用: 一位维护 DSPy 全异步分支 的成员正在迁移,但如果社区有兴趣,他愿意合并上游更改。
- 该分支已维护数月,但如果没有社区支持,可能会被放弃。
- 用户寻求更好的选择,从 DSPy 迁移: 成员们询问了从 DSPy 迁移的原因以及正在采用的替代工具。
- 一位成员还寻求关于 全异步 DSPy 优势的澄清,并建议将相关功能合并到主仓库中。
Gorilla LLM (Berkeley Function Calling) Discord
- GitHub PR 获得审查: 一位成员审查了一个 GitHub Pull Request,并为进一步讨论提供了反馈。
- PR 的作者感谢了审查者,并表示根据收到的意见,可能需要重新运行。
- Phi-4 系列获得认可: 一位成员正在探索将功能扩展到 Phi-4-mini 和 Phi-4 模型。
- 这一扩展旨在增强工具的兼容性,即使这些模型尚未得到官方支持。
MLOps @Chipro Discord
- Manifold Research 召集社区: Manifold Research Group 将于本周六(太平洋标准时间 4/12 上午 9 点)举办 社区研究会议 #4 (Community Research Call #4),涵盖他们在 Multimodal AI、自组装空间机器人和机器人元认知 方面的最新工作。
- 有兴趣的人员可以在此处注册参加这个专注于开放、协作和前沿科学的活动。
- CRC 是 Manifold 的基石: 社区研究会议 (CRC) 是 Manifold 的基石活动,他们在会上展示其研究组合中的重大进展。
- 这些互动环节提供有关正在进行的计划的全面更新,介绍新的研究方向,并强调合作机会。
- CRC #4 议程已上线: CRC #4 的议程包括 通用多模态研究 (Generalist Multimodality Research)、空间机器人进展、元认知研究进展 以及 新兴研究方向 的更新。
- 活动将涵盖其 MultiNet 框架 的最新突破和技术进展、自组装集群技术 (Self-Assembling Swarm technologies) 的发展、VLM 校准方法论 的更新,以及一项新型机器人元认知计划的介绍。
Codeium (Windsurf) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
完整的逐频道详情已因邮件长度限制而截断。
如果您喜欢 AInews,请分享给朋友!提前致谢!