ainews-deepcoder-a-fully-open-source-14b-coder-at
DeepCoder:达到 O3-mini 级别的完全开源 14B 编程模型
以下是为您翻译的中文内容:
Together AI 与 Agentica 发布了 DeepCoder-14B,这是一款开源的 140 亿(14B)参数编程模型,在编程基准测试中可与 OpenAI 的 o3-mini 和 o1 媲美。该模型采用字节跳动的开源强化学习(RL)框架训练,成本约为 26,880 美元。Google DeepMind 推出了 Gemini 2.5 Pro,并向订阅者提供实验性的 “Flash” 版本。月之暗面(Moonshot AI) 推出了 Kimi-VL-A3B,这是一款拥有 128K 上下文窗口的多模态模型,在视觉和数学基准测试中表现优于 gpt-4o。Meta AI 发布了 Llama 4 Scout 和 Maverick,另有一款更大的 Behemoth 模型正在训练中,这些模型采用了混合专家(MoE)和 L2 范数技术。Runway 推出了 Gen-4 Turbo,在成本不变的情况下,其效果比 Gen-3 提升了 10 倍。谷歌宣布 Imagen 3(一款高质量文本生成图像模型)现已登陆 Vertex AI,可更轻松地实现物体移除。该报告重点介绍了开源贡献、强化学习训练优化,以及在编程、多模态和图像生成领域显著的模型性能提升。
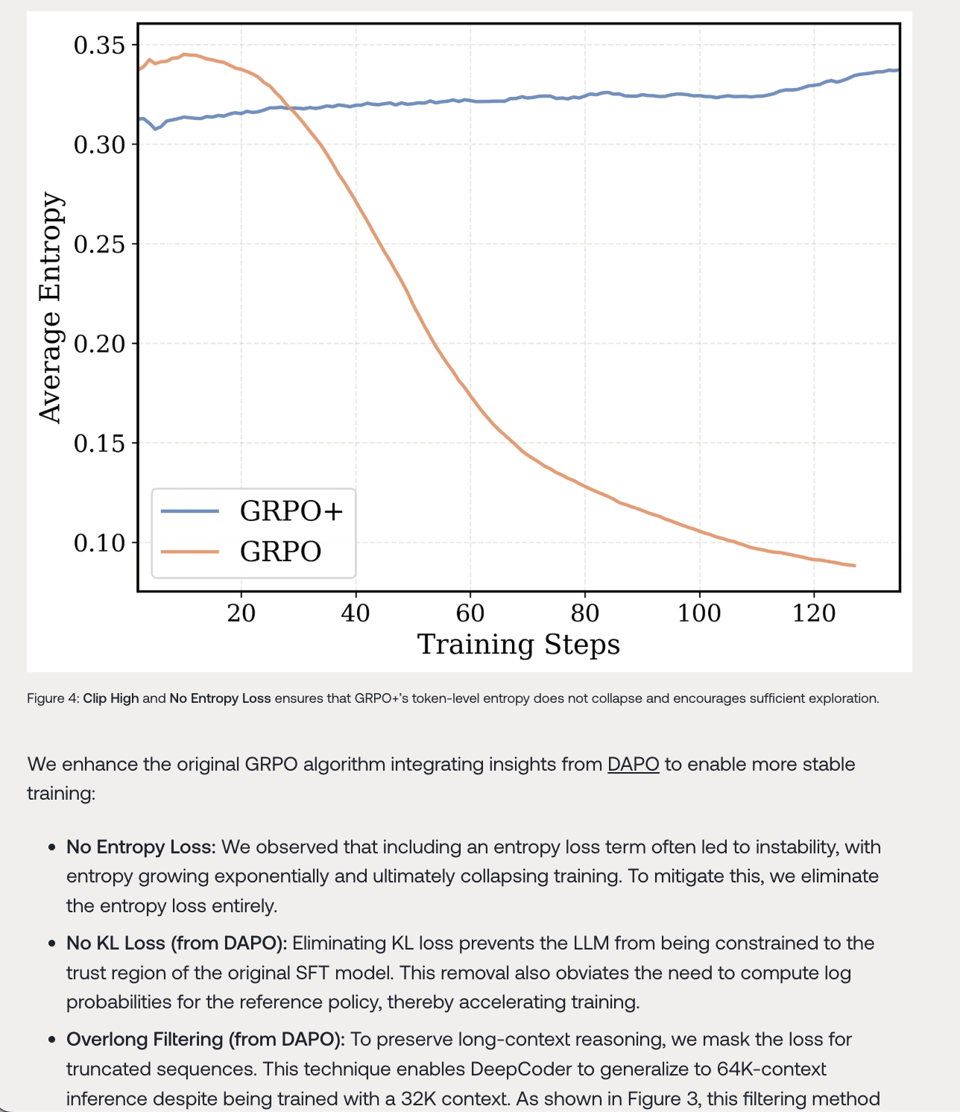
GPRO+ 就够了。
2025年4月7日至4月8日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 30 个 Discord 服务器(229 个频道,7279 条消息)。预计节省阅读时间(按每分钟 200 字计算):692 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
在 DeepSeek R1 发布之后(我们的报道在此),出现了一大批“比 R1 更开源”的克隆尝试,如果不算蒸馏工作,目前似乎只有 HuggingFace 的 OpenR1 仍在发布活跃更新。然而,今天 Together 和 Agentica Project(此前曾开展 DeepScaleR 工作)推出了一款专注于代码的 14B 推理模型,其评分达到了 O3-mini 级别:
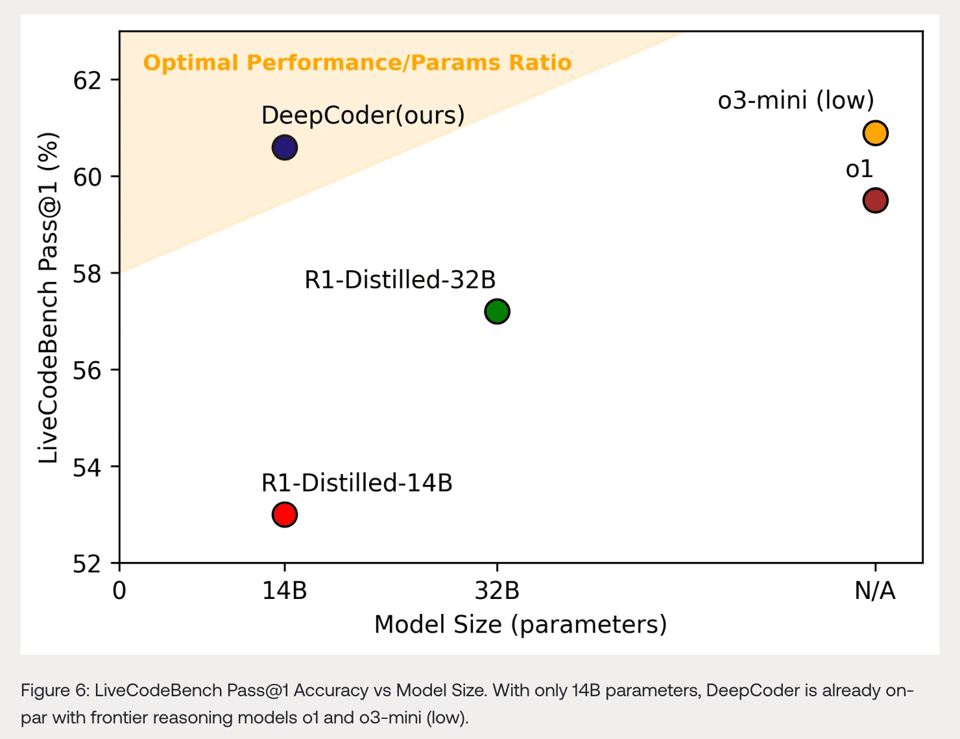
通常这类项目很容易刷榜,因此并不出众,但该项目的独特之处在于它是完全开源的——包括数据集、代码、配方(recipe)等,这意味着其教育价值很高,尤其是考虑到其合作者之前的成果。
专门针对 RL 训练,他们指出了采样器瓶颈:
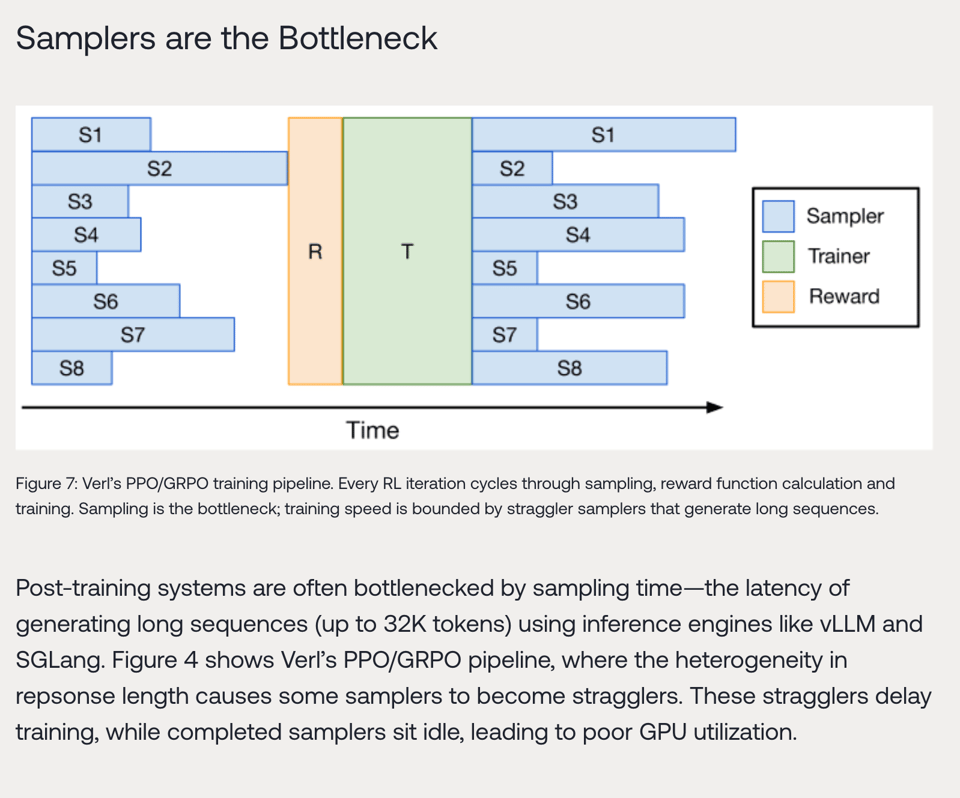
因此,他们对流水线化(pipelining)有非常独到的见解:
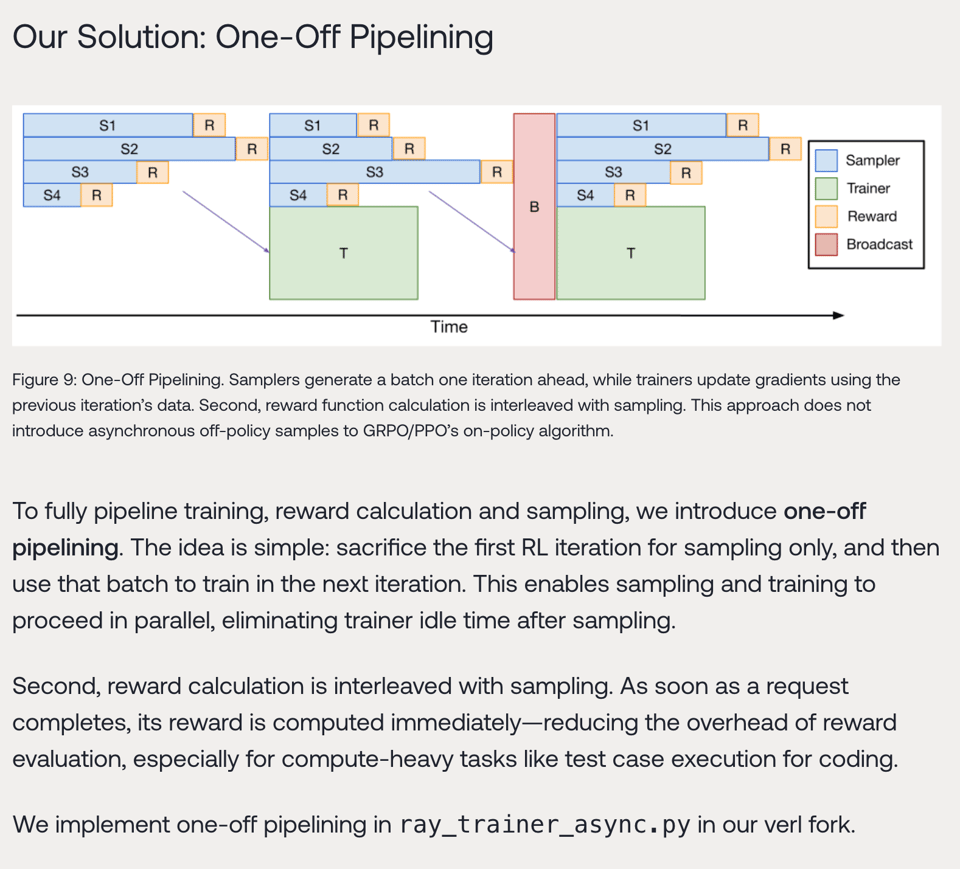
并且他们还提出了对 DeepSeek GRPO 的更新:
AI Twitter 综述
模型发布与更新
- Gemini 2.5 Pro(包括其 “Flash” 实验版本)现已面向订阅用户开放,消息来自 @Google 和 @_philschmid。正如 @GoogleDeepMind 所指出的,可以通过 Gemini 应用中的 Deep Research 功能进行访问。@lepikhin 提到团队正在努力应对所有流量。
- Moonshot AI 发布了 Kimi-VL-A3B,这是一款具有 128K 上下文、采用 MIT 许可证的多模态 LM。根据 @reach_vb 的说法,它在视觉 + 数学基准测试中表现优于 GPT4o。模型已在 Hugging Face 上可用并集成了 Transformers。@_akhaliq 也关注到了此次发布。
- Together AI 与 Agentica 合作发布了 DeepCoder-14B,这是一个开源编程模型,在编程任务上可与 OpenAI 的 o3-mini 和 o1 媲美。据 @Yuchenj_UW 称,其训练成本约为 26,880 美元。@togethercompute 指出,该模型、训练代码、数据集和详细博客均已发布。根据 @togethercompute 的数据,它在 LiveCodeBench 上获得了 60.6% 的分数,在 CodeForces 上获得了 1936 分,在竞赛级编程任务中与 o3-mini (low) 和 o1 表现相当。@Yuchenj_UW 提到,它是使用来自 ByteDance 的开源 RL 框架训练的。
- Meta AI 发布了 Llama 4 Scout 和 Maverick,正如 @EpochAIResearch 所提到的,一个名为 Behemoth 的更大版本正在训练中。根据 @danielhanchen 的说法,Maverick 混合了 MoE 层与密集层,而 Scout 在 QK 上使用了 L2 Norm。
- Runway 发布了 Gen-4 Turbo,据 @c_valenzuelab 称,在相同价格点下,其效果比 Gen-3 提升了 10 倍。
- Google 宣布了 Imagen 3,这是他们最高质量的文本生成图像模型,现已集成在 Vertex AI 中。据 @GoogleDeepMind 称,该模型可以更轻松地移除不需要的对象。
- Google 宣布了 Veo 2,据 @GoogleDeepMind 称,它允许用户在 Vertex AI 中精炼和增强现有素材,并指导镜头构图。
评估与基准测试
- OpenAI 发布了全新的 Evals API,用于以编程方式定义测试、自动化评估运行以及迭代 Prompt,并可将其集成到任何工作流中,正如 @OpenAIDevs 所述。@OpenAIDevs 指出,良好的评估有助于系统地提高模型响应的质量。
- Epoch AI Research 对 Llama 4 进行了评估,发现 Maverick 和 Scout 在 GPQA Diamond 上的得分分别为 67% 和 52%,与 Meta 报告的分数相似,消息来自 @EpochAIResearch。
- ZeroBench 测试显示当前的视觉语言模型表现不佳,据 @LiorOnAI 称,GPT-4V 和 Gemini 在 100 个高难度视觉推理问题上的 pass@1 和 5/5 可靠性得分均为 0%。
Agent 系统与工具
- Auth0 的 Auth for GenAI 现在提供原生 LlamaIndex 支持,使得在 Agent 工作流中构建身份验证变得更加容易,消息由 @llama_index 发布。
- MongoDB 发布了一个包含 100 多个关于 AI Agents 和 RAG 的分步 Notebook 仓库,涵盖了从聊天机器人构建到 Airbnb Agent 的内容,消息来自 @LiorOnAI。
行业分析
- Swyx 认为推特圈对个人开发者工具的评价很准确,但对 AI 如何改进 SDLC 的各个方面(这可能更具影响力)缺乏认识,这使得 Sourcegraph 作为一个 AI 开发者工具公司处于有利地位,根据 @swyx 的说法。
- Nearcyan 认为消费者不会通过 prompting 生成自己的完整应用,因为大多数优秀的应用都需要数据,而消费者并没有真正的数据可移植性,根据 @nearcyan 的说法。
- Svpino 认为学习如何在自己的手艺中应用 AI 至关重要,正如 Shopify 所理解的那样,那些洞察先机的人正在要求人们去学习和研究,根据 @svpino 的说法。
幽默/梗 (Humor/Memes)
- Vikhyatk 调侃西雅图市中心的午餐花费 16-20 个 H100-hours,自从将美元转换为 H100-hours 后,热量消耗下降了 10 倍,根据 @vikhyatk 的说法。
- Scaling01 调侃 Gemini 3.0 将便宜到无法计费,根据 @scaling01 的说法。
- Andrew Carr 注意到 Gemini 在玩《宝可梦》时的表现,引用了 Gemini 的话:“我不敢相信花了六次尝试,现在游戏居然问我是否想通过给这东西起个昵称来进一步羞辱自己。没门。我不想给这个象征我失败的符号命名。我会按 B 键拒绝”,根据 @andrew_n_carr 的说法。
AI Reddit 摘要
我们的流水线昨天发生了故障。抱歉!
AI Discord 摘要
由 Gemini 2.5 Pro Exp 生成的摘要的摘要的摘要
主题 1:模型狂热:Gemini 称霸,Llama 4 遇挫,新竞争者涌现
- Gemini 2.5 Pro 夺冠,但缺乏推理透明度:在多个 Discord(LMArena, OpenRouter, Perplexity AI, Nous Research AI, aider)中,Gemini 2.5 Pro 因其通用能力、创意写作甚至从复杂 prompt 生成功能性代码而获得高度评价,通常被认为优于 GPT-4.5 和 Claude 3.5 Sonnet 等竞争对手。然而,用户注意到其推理 token 没有通过 Perplexity API 暴露,阻碍了其作为推理模型的使用,而且即使具备深度研究能力,除非在 AI Studio 中进行特定接地(grounded),否则仍会出现幻觉。
- Llama 4 发布引发用户哀叹:Llama 4 (Scout, Maverick) 的发布让用户普遍感到失望(LM Studio, Manus.im, Yannick Kilcher, Nomic.ai),用户称其“糟糕”、“过度炒作”,尽管在日语表现上尚可,但可能是退步。担忧集中在“草率的后期训练”、可能由于过拟合或“刷榜”导致的基准测试有效性存疑,以及比预期性能水平更高的 VRAM 要求,导致许多人等待大修或坚持使用 Qwen 14B 等替代方案。
- Cogito & Nvidia 模型挑战现状:新模型正在掀起波澜,包括 DeepCogito 的 v1 Preview 模型(3B-70B),通过迭代蒸馏和放大 (IDA) 训练,声称优于 Llama, DeepSeek 和 Qwen 的同类模型,甚至优于 Llama 4 109B MoE,提供直接回答和自我反思模式 (DeepCogito Research)。Nvidia 也悄悄发布了一个 SOTA 级别的推理模型 Llama-3.1-Nemotron-Ultra-253B-v1,具有开启或关闭推理能力的开关 (Nvidia Blog Post)。
主题 2:训练与微调前沿
- Unsloth 微调修复与 FP4 发现:Unsloth AI 解决了 3 个以上 GPU 上的 DDP 训练问题,建议进行特定的 CUDA 设备可见性设置,同时由于数据效率原因,提倡在 QLoRA 训练中使用 bitsandbytes (bnb) 而非 GGUF。用户探索了通过 Unsloth 等工具使用 FP4 对量化模型进行微调以实现更快的训练,并澄清虽然直接微调量化模型不可行,但 LoRA 提供了一条可行的路径。
- 分布式训练辩论:DeepSpeed vs. FSDP 与不可信计算:在 Torchtune 中,关于集成 DeepSpeed 的优点展开了辩论,维护者更倾向于原生 PyTorch FSDP 以获得更好的可组合性,尽管也提供对社区 DeepSpeed recipe 的支持。与此同时,受 Nous DeMo 论文启发的 Panthalia 平台(X.com 等候名单)旨在通过梯度压缩(算法文档)验证用于分布式数据并行 (DDP) 训练的不可信、低成本算力。
- 讨论的新技术与研究方向:研究人员讨论了 Google DeepMind 的 Hierarchical Perceiver 专利,这可能与 Gemini 中的长上下文(long context)有关,并辩论了 QKNorm 的进展(论文 1,论文 2)。其他讨论包括用于在复杂任务中扩展自动化提示工程(Prompt Engineering)的 MIPRO 算法(TensorZero 博客),以及助力 DAPO 研究以获得更好 RLHF 回答的 OLMo(DAPO 论文,OLMo 论文)。
主题 3:工具与平台:更新、Bug 与博弈
- 平台更新:新 UI、速率限制与品牌重塑:LMArena 推出了用于测试的 Alpha UI,而 OpenRouter 发布了精美的新前端,但将免费模型的速率限制收紧至 50 RPD(除非用户拥有 10 美元以上的额度),引发了用户的不满。Codeium 在其编辑器取得成功后,正式更名为 Windsurf(品牌重塑公告),并开设了新的 SubReddit。
- 工具故障:Bug 困扰 Cursor、Aider 和 API:Cursor 用户报告了 C/C++ 扩展的问题,需要回滚版本(论坛帖子),自动选择功能选择了较差的模型,以及因绕过试用限制而可能面临的封禁。Aider 用户面临 /architect 模式编辑被截断的问题,并寻求禁用自动提交的方法(Aider 配置文档),而 Perplexity API 用户注意到与 Web UI 相比存在差异,以及 Sonar 提示词过于关注系统提示词的问题(提示词指南)。
- 框架挫折与修复:Mojo、MAX、Granite:Mojo 开发者讨论了其借用(borrowing)范式(Mojo vs Rust 博客)、
__moveinit__与__copyinit__(示例代码)以及管理Span的生命周期。用户对比了 MLX 和 MAX,指出 MAX 目前无法调用 Apple Silicon GPU,而 Unsloth AI 用户发现了一个在 Colab 中修复 GraniteModel Bug 的快速方法,涉及编辑config.json。
主题 4:AI 生态系统:研究、传闻与现实应用
- 研究动态:专利、审计与遗忘学习:Google DeepMind 尝试为 Hierarchical Perceiver 申请专利(专利链接,论文链接),引发了关于防御性专利申请和长上下文 Gemini 的讨论。研究人员正在为一项基于伦理的审计调查寻求 AI 专业人士的参与(调查链接),同时 ICML 宣布举办机器学习遗忘学习(machine unlearning)研讨会(研讨会网站)。
- 行业洞察与内幕:Google 的薪酬、关税与网络犯罪:一篇 TechCrunch 文章声称 Google 据传向部分离职的 AI 员工支付一年薪水以防止其加入竞争对手,这引发了关于合法性和影响的质疑。有担忧指出,可能对 NVDA GPU 征收的关税可能会减缓 AI 的进展,而另一些人则注意到网络罪犯对 AI 的采用似乎比预期要慢,尽管未来的“冲击”仍有可能发生。
- 应用与集成:MCP、数学、身份验证与 Agent:Model Context Protocol (MCP) 的使用案例得到讨论,包括使用 mcpomni-connect 等客户端将 Neo4j 图数据库集成到 RAG 中;Semgrep 使用 SSE 重写了其 MCP 服务器(Cursor 演示)。AI4Math 的讨论强调了将 LLM 与 Lean 等形式化系统结合用于定理证明(Kaiyu Yang 讲座),同时 Auth0 的 Auth for GenAI 集成了原生 LlamaIndex 支持(推文)。Mozilla AI 发布了
any-agent以简化 Agent 框架评估(GitHub 仓库)。
主题 5:GPU 与硬件动态
- 硬件难题:ROCm 困扰与 METAL 同步故障:由于缺乏官方支持(AMD 文档)和 WSL 透传问题,用户仍难以在 AMD 7800XT GPU 上通过 WSL 运行 ROCm。在 tinygrad 中,一名调试 METAL 同步问题悬赏的用户发现,LLaMA 中的分片问题可能源于 COPY 操作在 XFER 命令完成之前执行,导致数据读取错误。
- 性能难题与优化:tinygrad 用户报告称,在 AMD 硬件上使用 BEAM=2 可获得显著加速,性能超越 Torch。在 GPU MODE 中,讨论集中在 Triton 的
tl.make_block_ptr配合boundary_check以安全处理越界内存(会有轻微性能代价),以及 TorchTitan 独特的预编译策略,该策略可能规避torch.compile的 bug(TorchTitan 代码),尽管torch.compile和 FSDP 的数值问题依然存在。 - GPU 专家的新发布与资源:Nvidia 的 PhysX CUDA 物理模拟内核现已开源,欢迎社区进行移植(如 ROCm)。TorchAO v0.10.0 已发布(发布说明),增加了针对 Nvidia B200 的 MXFP8 训练支持和模块交换量化 API。学习资源方面,推荐了 geohotarchive YouTube 频道和 《Programming Massively Parallel Processors (PMPP)》一书(第 4 版)。
第一部分:Discord 高层级摘要
LMArena Discord
- Gemini 2.5 Pro 被宣布为 AI 至尊:成员们称 Gemini 2.5 Pro 为第一个“真正的” AI,强调其在创意写作和一致性方面优于之前的模型。
- 虽然 Gemini 2.5 Pro 在通用任务中表现出色,但有人指出尚未发布的 Nightwhisper 模型在 coding 能力上更胜一筹。
- OpenAI 的 Deep Research 受到质疑:尽管有人声称 OpenAI 的 Deep Research 项目是“用于网页搜索的最佳 Agent”,但对其仍存疑虑,有人表示“带有工具的 2.5 简直是另一个层级的存在”。
- 普遍观点认为 Deep Research 仅仅是 OpenAI 现有 o3 model 的更名版本。
- DeepCoder-14B 亮相,反响平平:Together AI 和 Agentica 推出了 DeepCoder-14B-Preview,这是一个代码推理模型,通过分布式 RL 从 Deepseek-R1-Distilled-Qwen-14B 微调而来。
- 然而,这次发布遭到了批评,一位用户嘲讽其营销是“有史以来最愚蠢、最可耻的营销”,称考虑到这只是 o3-mini,其提升并不令人印象深刻。
- NightWhisper 的编程能力引发期待:尽管 NightWhisper 在 webdev 和 lmarena 上的可用时间很短,但其在竞技场中展示的 coding 能力让人们对其潜在的发布充满热情。
- 有推测认为 NightWhisper 可能与即将推出的 Google Ultra model 一致。
- Alpha UI 开启众测:Alpha UI 现在可在此进行测试,无需密码。
- 用户被要求通过提供的 Google Forms 和 Airtable 链接提供反馈和 Bug 报告,预计 Desktop & Mobile 端都将频繁更新。
Unsloth AI (Daniel Han) Discord
- Unsloth 修复 DDP 训练补丁:用户报告了 HF Trainer 和 DDP 在 3 个或更多 GPU 上无法工作的问题,建议确保 CUDA 可见设备设置为特定 GPU,但 Unsloth 支持 DDP。
- 经过测试,它抛出了 ValueError,因此成员建议确保 CUDA 可见设备设置为特定的 GPU。
- LoRA 训练首选 bnb:建议在 QLoRA 训练中使用 bnb (bitsandbytes) 而非 GGUF,因为这样可以节省 4 倍的数据下载量,并且可以保存 adapter 并将其与 bnb 模型合并,以便稍后导出为 GGUF。
- 用户在为微型模型选择使用 bnb 4-bit 还是 GGUF 进行 LoRA 训练时,共识倾向于前者。
- Llama 4 模型获得“草率”评价:测试 Llama 4 (Scout 和 Maverick) 的成员发现,尽管 post-training 显得有些草率,但它在日语方面表现良好,且是能力出众的 base models。
- 普遍情绪是等待即将到来的 post-training 彻底翻新。
- DeepCogito v1 声称在 LLM 性能上领先:DeepCogito 声称其 v1 Preview models 优于同尺寸的最佳开源模型,包括来自 LLaMA、DeepSeek 和 Qwen 的对应模型。
- 这些模型提供了直接回答(标准 LLM)或在回答前进行自我反思(类似推理模型)的能力。
- GraniteModel Bug 影响 Colab:用户在使用 GraniteModel 的 Colab notebook 时遇到了 Bug,并提出了一个快速修复方案:编辑
granite_based/config.json,将 GraniteModel 替换为 GraniteForCausalLM 并重新运行单元格。- 在 Colab 上编辑该文件的推荐方法是下载后在本地编辑,然后将修改后的版本重新上传到 Colab。
OpenRouter (Alex Atallah) Discord
- OpenRouter 免费模型限制收紧:OpenRouter 将免费模型的 token 限制降至 50,引发了用户的负面反应。用户对降低限制表示沮丧,一些人认为这就像是设置了“付费墙”。
- 拥有至少 10 美元额度(credits)的账户,其每日请求数(RPD)将提升至 1000,而额度少于 10 美元的账户,其 RPD 将从 200 降至 50。
- Quasar 即将推出基于额度的速率限制:更新说明指出,Quasar 很快将实施依赖于额度的速率限制,虽然没有每小时限制,但速率限制为 每分钟 20 次请求。
- 成员们开启了一个反馈线程,供用户发布对这些变化的看法。
- OpenRouter 推出精美的新前端:OpenRouter 推出了非常酷炫的新前端,非常感谢 clinemay!
- 一位用户开玩笑说,这看起来像是 gpt-3.5 用了大约 4 分钟做出来的网站。
- Gemini 获封模型之王:Gemini 2.5 Pro 与其他模型相比完全处于另一个层次,使其成为迄今为止最强大的模型。
- 一位用户指出,它的评分排名是:1. gemini 2.5 pro … 10. 其他所有人。
- Nvidia 悄然发布推理模型:Nvidia 默默发布了一个 SOTA 级别的推理模型。
- 这个新模型随手展现出的性能就优于 Behemoth。
Cursor Community Discord
- Daniel Mac 使用 GraphDB 进行代码图谱化:一位成员分享了 Daniel Mac 的推文,内容关于使用图数据库(graph database)进行代码查询。
- 这引发了关于使用图数据库进行代码分析以及理解代码库中复杂关系的潜在益处的讨论。
- Manus.im 吞噬额度:一位用户报告称 Manus.im 未能正确回答问题,并且在单次 prompt 中消耗了其 1000 个免费额度中的 984 个。
- 用户建议将 Smithery.ai 和 Awesome MCP Servers 作为潜在的替代方案。
- C/C++ 扩展错误频发:一位用户报告称,自 2023 年 3 月开始使用 Cursor 以来,遇到了与 C/C++ 扩展相关的错误,并指出该扩展可能仅限于 Microsoft 产品。
- Auto-Select 模型被指责为骗局:有用户报告称 auto-select 模型选项会选择低质量的模型,一位用户声称它“搞砸了我的代码库”。
- 另一位用户认为这种行为可能是故意的,引发了对 auto-select 功能可靠性的担忧。
- Cursor 对绕过免费层级的用户祭出封号大棒:一位成员报告称,绕过 Cursor 的试用版本可能会导致被完全禁止使用该工具,并警告说“你很快就会完全无法使用它”。
- 这引发了关于 Cursor 试用版限制的公平性以及尝试规避限制所带来后果的辩论。
LM Studio Discord
- Llama 4 令用户失望:用户对 Llama 4 的表现表示失望,一些人将其描述为一种退步,并质疑基准测试(benchmark)的有效性。
- 虽然 Llama 4 提供了与 17B 模型相似的速度/成本以及与 24-27B 模型相似的结果,但它需要更多的 VRAM,这使得它对普通用户来说毫无意义,而 Qwen 的 14B 模型则受到了称赞。
- WSL 上的 ROCm 在 7800XT 上仍无法工作:一名用户报告称,由于缺乏官方支持,通过 WSL 运行的 ROCm 无法在 7800XT 上运行(AMD 文档)。
- 另一名用户建议它可能可以工作,因为两款显卡都是 RDNA3 架构,但第一名用户确认由于 WSL passthrough 问题,根本不可能运行成功。
- 快速修复 Cogito Jinja 错误:用户报告了在使用 cogito-v1-preview-llama-3b 时出现的 Jinja templates 错误,并被建议使用 ChatGPT 来快速修复模板。
- 社区模型维护者已收到关于模板异常的通知,预计很快会更新模型。
- Docker 遭到吐槽:在一名成员表示想与任何说 Docker 坏话的人成为“好朋友”后,另一名成员开玩笑地问:“Docker 是对你的家人做了什么吗?”
- 第一名成员幽默地回答道:“我的心理医生说我不应该谈论这件事。”
- 辩论构建经济型超级计算机:一名用户提议使用 RTX 4090 D GPU 或性能稍弱的方案构建一个 16 节点超级计算机,目标是运行具有 1M 上下文 的 2T 模型。
- 怀疑者质疑其可行性,强调了对 RDMA、高速互连和专业工程师的需求。
Perplexity AI Discord
- 初创公司通过 Perplexity 节省开支:Perplexity AI 推出了一个初创公司计划,为符合条件的初创公司提供价值 $5000 的 Perplexity API 额度以及 6 个月 的 Perplexity Enterprise Pro。
- 申请资格要求融资额少于 $20M,成立时间少于 5 年,并与初创公司合作伙伴有关联。
- Gemini 2.5 推理功能引发争议:成员们注意到 Gemini 2.5 Pro 没有通过 API 开放其推理 Token(reasoning tokens),因此无法作为推理模型包含在 Perplexity 中,尽管它是一个高延迟思考模型。
- 因此,与 AI Studio 不同,其推理过程不会通过 API 显示。
- Deep Research High 备受期待但进展受阻:用户正在等待 Deep Research High 的推出,该功能旨在平均使用 150-200 个来源,但一名用户报告称 Perplexity 的深度研究获取了 23 个来源,而免费的 Gemini 深度研究获取了超过 500 个。
- 一些成员对发布时间表缺乏沟通以及当前版本的输出只是摘要而非真正的深度研究感到沮丧;可以查看 DeepSeek Subreddit。
- Llama 4 面临基准测试造假的指责:针对一个质疑 Llama 4 是否在基准测试中造假的 Perplexity AI 搜索结果,引发了广泛关注。
- 这是关于模型基准测试透明度以及用于评估 Llama 4 方法论的更广泛讨论的一部分。
- Perplexity API:提示词问题依然存在:一名用户报告称 Sonar 的响应侧重于系统提示词(system prompt)而非用户查询,而一名团队成员澄清说系统提示词在搜索阶段并不使用,建议用户参考 Prompt Guide 优化用户提示词。
- 此外,一些成员讨论了在总结网页时 Perplexity API 与 Web UI 之间的差异,在使用 sonar-reasoning-pro 时,API sandbox 的结果甚至比实际的 API 好得多。
Manus.im Discord Discord
- 本地版 Manus 指日可待:成员们推测未来可能会推出本地版本的 Manus,类似于其他 AI models。
- 这将允许用户在自己的硬件上运行 Manus,解决额度消耗和数据隐私方面的担忧。
- MCP 服务器已在 Claude 上部署:据一名成员报告,截至 2024 年 11 月 25 日,MCP servers 已在 Claude 上可用,并可与 Claude 代码配合使用。
- 这种集成使用户能够在 Claude 环境中利用 MCP servers 来增强功能。
- Llama 4 炒作降温:在 Openrouter.AI 上进行测试后,用户报告称 Llama 4 因回复质量不佳而被过度炒作。
- 批评还指向了 Zucks,他被指责在 benchmarks 上造假,导致性能预期被夸大。
- Octopus 网页爬虫大放异彩:一位成员报告称,免费网站爬虫 Octopus 在 Zillow 和 Realtor 上运行效果良好,是每月 130 美元的 Bardeen 的高性价比替代方案。
- Bardeen 的高昂成本促使人们建议使用 Manus 构建自定义爬虫,作为一种更经济的解决方案。
- Manus 额度紧缺引发用户不满:用户对 Manus credits 的高昂成本表示不满,报告称即使是简单的任务也会消耗大量额度,一名用户在单个标准复杂度任务上就耗尽了 1000 个免费额度。
- 为了减少额度消耗,用户建议将任务拆分为更小的对话窗口,并考虑将 Proxy 作为更便宜的替代方案,同时等待 Manus 定价和额度计划的更新。
aider (Paul Gauthier) Discord
- Gemini 2.5 与 Sonnet 的提示词能力对比:用户发现 Gemini 2.5 的逻辑很强,但指令遵循能力较差,与之形成对比的是 Sonnet 功能丰富的编码能力,但需要更多的提示词引导。
- 一位用户报告称,使用 Gemini 2.5 只需要 1 次提示,而 Sonnet 需要 3 次提示,尽管 Sonnet 拥有多文件输入方法和批处理等高级功能。
- Aider 的自动提交功能引发混乱?:由于 Aider 会提交未经测试的代码,一位用户寻求禁用 Aider’s auto-committing 的方法,并参考了 Aider configuration options。
- 另一位用户建议提供 model and key,否则 Aider 将根据可用密钥进行猜测。
- OpenRouter 缺失 Sonar Pro 引用:一位用户质疑通过 OpenRouter 使用 Perplexity Sonar Pro 时缺失引用链接,并在此提供了视觉参考。
- 讨论暗示通过 OpenRouter 使用某些模型时,引用链接的可靠性可能存在问题。
- 软件工程师的间隔年是职业生涯杀手?:一篇文章认为,对于软件工程师来说,休间隔年或长假是一个糟糕的决定,文章引用了对当前技术格局的见解,详见这篇文章。
- 作者认为,技术快速演进的本质使得长时间的休息不利于保持竞争力。
- 架构模式编辑被中断:用户报告在 Aider 的 /architect mode 编辑过程中添加新文件会导致编辑被切断,从而可能丢失编辑器状态。
- 避免在编辑过程中添加新文件似乎可以让过程不间断地继续。
{kind=link}
Notebook LM Discord
- AgentSpace 为企业开启 NotebookLM:Google 的 AgentSpace 文档显示,NotebookLM Enterprise 现在可以设置客户管理的加密密钥 (CMEK),以实现更好的数据加密控制。
- 一位用户询问了商业规模的 NotebookLM,另一位成员指出了这一新产品。
- NotebookLM 的隐私保证得到确认:据一名成员称,NotebookLM 的 Enterprise 和 Plus 版本均确保用户数据保持私密,绝不会进入公共领域。
- 这一澄清解决了对 Google 隐私政策和条款的误解,并指出其内置了防止 Prompt Injection(提示词注入)的机制。
- 用户纠正改进了 NotebookLM 的摘要:一位用户报告称,NotebookLM 最初误读了一篇学术文章,但在提供引用和解释后自行进行了纠正。
- 从头开始在不同的 Google 账号中重复相同的 Prompt 得到了正确的结果,这引发了关于训练和隐私的疑问。
- Discovery Mode 推出仍在进行中:用户仍在等待 NotebookLM 中的新功能 Discovery Mode,预计从发布日期起需要长达两周的时间完成推送。
- 一位用户幽默地要求作为 Google 铁粉获得特殊待遇 以尽早获得访问权限。
- Gemini 在深度研究中仍会产生幻觉:用户报告称,即使有互联网访问权限,Gemini 在进行 Deep Research 时仍会产生“幻觉”。
- 一名成员澄清说,Gemini 可以连接到 Google Search,但需要在 AI Studio 中设置特定的 Grounding 指令。
Interconnects (Nathan Lambert) Discord
- DeepSeek R2 准备在 LlamaCon 发布:成员们敦促 DeepSeek 在 LlamaCon 当天发布 R2 以利用热度,并指出 MoE 的训练数据与基础模型不同,引用了这篇论文。
- 此次发布可能会挑战其他模型,并在活动期间吸引大量关注。
- Together AI 进入训练领域:Together AI 正在进入模型训练业务,这一案例研究展示了 Cogito-v1-preview-llama-70B 模型。
- 此举标志着其向提供包括训练基础设施和服务在内的全面 AI 解决方案转变。
- 传闻 Google 支付 AI 员工薪水让其闲置:根据 TechCrunch 的这篇文章,Google 据称支付部分 AI 员工一年的薪水让他们无所事事,而不是允许他们加入竞争对手。
- 一名成员批评这是一种具有极其糟糕的二阶效应的基础管理思路,另一名成员指出,这可能会因为限制员工在合同期内的行为或开发工作而产生法律风险。
- 关税威胁 NVDA GPU 可用性:成员们推测,如果关税持续存在,由于 NVDA GPU 成本增加,AI 领域可能会放缓。
- 这可能会影响开发和研究,因为获取必要硬件的财务压力会变大。
- OLMo 助力 DAPO 研究:成员们讨论了一篇 DAPO 论文,认为其提供了“极端价值”,并引用了另一篇基于 OLMo 构建的论文。
- 研究人员指出了一种新型计算方法,可以在 RLHF 任务中获得更好的答案。
Eleuther Discord
- DeepMind 的分层专利追求:Google DeepMind 正在尝试为 Hierarchical Perceiver 申请专利,人们将专利图表与原始 研究论文 中的图表进行了对比。
- 推测认为,这项专利可能与 DeepMind 在 Gemini 中实现的 超长上下文长度(ultra-long context lengths) 工作有关,可能是一种防御性措施。
- 调查寻求 AI 审计专家:一位研究人员正在寻求 AI 专业人士参与一项关于生成式 AI 系统基于伦理审计的调查。
- 该 调查 旨在收集关于审计或评估 AI 系统(尤其是生成模型)的见解。
- 关于 QKNorm 可疑进展的辩论:成员们辩论认为 QKNorm 的进展 并非正确的方向,并引用了 这篇论文。
- 一位成员推荐了一篇 更好/更早的论文。
- ICML 邀请对机器遗忘(Unlearning)进行研究:一位成员分享了 ICML 将举办 机器遗忘研讨会(machine unlearning workshop) 的消息。
- 研讨会的网站可以在 这里 找到。
- 寻求 LM Harness 实施指导:一位成员询问关于 HotpotQA 的 LM harness 实现,以评估 Llama 和 GPT models。
- 请求关于针对 HotpotQA 运行评估的指导。
Nous Research AI Discord
- Llama-4-Scout-17B 已适配 llama.cpp:Llama-4-Scout-17B text-to-text 支持已添加到 llama.cpp,成员们正在对该模型进行转换和量化。
- 这一预发布版本引起了用户的兴奋,大家渴望测试其能力。
- Gemini 2.5 Pro 生成功能性代码片段:Gemini 2.5 Pro 因能根据复杂提示词生成功能性代码片段而受到称赞,请在 此消息 中查看提示词和响应。
- 一位用户报告使用 aider-chat 结合 Gemini 2.5 Pro,从 300k token 上下文 中编辑或创建了 15 个文件,包括他们的前端、API 和微服务。
- HiDream-I1 生成高质量图像:HiDream-I1 是一款新型开源图像生成基础模型,拥有 17B 参数,使用 Llama 3.1 8B 作为文本编码器,采用 MIT 许可证 发布。
- 它 在包括写实、卡通、艺术等多种风格中产生了卓越的效果,实现了最先进的 HPS v2.1 分数,符合人类偏好。
- Cogito 模型使用迭代蒸馏:一套全新的 Cogito 模型(3B-70B)表现优于 Llama, DeepSeek, 和 Qwen 等模型,这些模型使用 迭代蒸馏与放大(Iterated Distillation and Amplification, IDA) 进行训练,该方法可以迭代地提高模型的能力。
- 值得注意的是,据 此项研究 概述,70B 模型 据称超越了新发布的 Llama 4 109B MoE 模型。
- Panthalia 平台旨在通过 DDP 验证低成本算力:受 Nous DeMo 论文启发,一个旨在验证用于通过互联网进行模型训练的不可信、低成本算力的平台已经开发完成,该平台使用分布式数据并行(DDP),可通过 X.com 加入等待名单。
GPU MODE Discord
- GPUMODE 的数据集需要 PyTorch 2.5:用于 Inductor Created Data 的 GPUMODE “triton” 数据集是使用 PyTorch 2.5 创建的,创建者承诺将更新 readme。
- 用户在 PyTorch 2.6+ 上运行该数据集时可能会遇到问题。
- Triton 获得边界检查功能:一名成员建议使用带有
boundary_check和padding_option="zero"的tl.make_block_ptr来创建指针,以便在越界内存访问时填充零。- 对方澄清说,省略
boundary_check可以提高速度,但由于潜在的缓冲区溢出,存在触发 “device-side assert triggered” 等错误的风险。
- 对方澄清说,省略
- TorchTitan 在操作前进行编译:TorchTitan 在操作前会进行独特的逐块编译,这可能是为了规避某些 torch compile bugs;详见 torchtitan/parallelize_llama.py#L313。
- 同时使用
torch.compile和 FSDP 时,可能仍然存在数值问题。
- 同时使用
- PhysX 现已开源:NVIDIA 的 CUDA 物理模拟内核现已开源,并且已经有人在开发 ROCm 版本。
- Triton-Distributed 学习笔记详细介绍了将 Triton 与 NVSHMEM/ROC-SHMEM 融合以实现多 GPU 执行的方法。
- LiveDocs 提供可靠的文档管理:LiveDocs 的创建者邀请用户使用其升级后的服务来编写代码文档,现在通过在 www.asvatthi.com 注册即可使用更多功能。
- 其中包含一张界面截图,展示了各种代码文档页面。
HuggingFace Discord
- FP4 微调加速任务完成:用户正在探索使用 Unsloth 等工具通过 FP4 微调量化模型,该工具允许加载低精度模型进行训练和量化。
- 虽然可以通过 LoRA 对量化模型进行微调,但直接对量化模型本身进行微调是不可能的。
- Parasail 提供卓越性能:新型推理提供商 Parasail 在结束隐身模式后,正寻求与 Hugging Face 合作。据 The Next Platform 报道,该公司已在 Open Router 上每天处理 30 亿 token,并为私有公司每天处理超过 50 亿 token。
- The Next Platform 报道称,Parasail 在 AI 算力需求和供应之间充当经纪人。
- Llama.cpp 跨越至 Llama 4:根据 GitHub releases,后端 Llama.cpp 已更新以支持 Llama 4。
- 此次更新增强了与最新 Llama 模型的兼容性和性能。
- AI Runner 桌面 GUI 正式发布:一名成员发布了 AI Runner,这是一个使用 HuggingFace 库在本地运行 AI 模型的桌面 GUI,如此 YouTube 视频所述。
- 该工具允许用户创建和管理具有自定义声音、性格和情绪的聊天机器人。这些机器人是使用 llama-index 和 ReAct 工具构建的 Agent,能够通过 Stable Diffusion 生成图像并进行实时语音对话(使用 espeak、speecht5 或 openvoice)。
- any-agent 库简化 Agent 框架评估:Mozilla AI 团队发布了
any-agent,这是一个旨在简化尝试不同 Agent 框架的库,GitHub 仓库已开放供用户尝试和贡献。- 该库支持 smolagents、OpenAI、Langchain 和 Llama Index 等框架。
MCP (Glama) Discord
- Semgrep MCP Server 获得 Docker 助力:一位成员报告称已运行 Semgrep MCP server 超过一个月,该服务器通过 Docker 和 AWS EC2 托管。
- 这一配置是 MCP 在云端环境部署的实际演示,鉴于其易用性,具有广泛采用的潜力。
- Semgrep MCP Server 修复 CORS 错误:在连接 Cloudflare Playground 时报告的 CORS error 已被迅速解决。
- 该工具正配合 Cursor 进行测试,表明了实际应用和集成的需求。
- MCP 为企业客户提供 HTTP 请求-响应支持:针对企业客户对 MCP 中 HTTP request-response 支持的需求展开了讨论,详见此 Pull Request。
- 对该功能的需求凸显了 MCP 在企业机构中日益增长的采用率。
- MCP 集成图数据库用于 RAG:一位成员询问了在 RAG 场景中使用 MCP 配合 Neo4j graph database 的情况,重点关注向量搜索和自定义 CQL search。
- 另一位成员确认这是一个很好的用例,并链接到了 mcpomni-connect 作为可行的 MCP 客户端,展示了 MCP 的多功能性。
- Semgrep 使用 SSE 重写 MCP Server:一位成员重写了 Semgrep’s MCP server,并分享了在 Cursor 和 Claude 中使用 SSE 的演示视频。
- 该服务器使用 SSE 是因为 Python SDK 尚不支持 HTTP streaming。
Latent Space Discord
- Shopify 的 AI 探索势头强劲:Shopify 的 AI 战略正受到关注,如此推文所述。
- 该公司正推动其平台全线集成 AI,内部讨论集中在实际应用和战略影响上。
- Anthropic API 额度设有有效期:Anthropic API 额度在一年后过期,这可能是为了简化会计处理,并考虑到快速发展的 AI 领域。
- 成员们认为,这一政策有助于在快速变化的领域中管理预期,为资源分配和未来规划提供框架。
- NVIDIA 推理模型支持开关切换:NVIDIA 发布了一个新模型,具备开启或关闭推理的能力,详见此博客文章,该模型已在 Hugging Face 上线。
- 该功能允许开发者尝试不同的推理方法,并针对特定任务微调其 AI 应用。
- 网络犯罪对 AI 的采用慢于预期:尽管出现了 FraudGPT 等基础 AI 应用,但网络犯罪分子大规模采用 AI 的速度出奇地慢,有人推测当他们更广泛地采用 AI 时,可能会发生“网络犯罪 AI 冲击”。
- 一位成员指出,LLM 可能直到最近才足够成熟到可以用于网络犯罪,这表明该技术在这一背景下仍在发展中。
- Gemini 直播宝可梦游戏:Gemini AI 正在玩《宝可梦》,引起了关注,如此推文所示。
- 这展示了 AI 在游戏和互动娱乐方面的潜力,证明了其在虚拟环境中处理复杂任务的能力。
Yannick Kilcher Discord
- Llama 4 基准测试缺陷曝光:一位成员断言 Llama 4 在非博弈、非过拟合的基准测试中表现不佳 (flops),引发了对论文 arxiv.org/abs/2408.04220 和相关 YouTube 演讲 的关注。
- 根据此 fxtwitter 链接,人们担心 Meta 应该澄清 “Llama-4-Maverick-03-26-Experimental” 是一个为了优化人类偏好而定制的模型。
- 解码 Bayesian Structural EM 的秘密:一位成员强调 Bayesian inference(贝叶斯推理)结合权重和架构已有约一个世纪的历史,并引用 Bayesian Structural EM 作为例子。
- 模型的 DNA:程序化模型表示 (Procedural Model Representation):一位成员介绍了程序化模型表示,即通过一个小种子生成一个大型模型(架构 + 权重),设想下载一个 10MB 的模型来生成一个 100TB 的模型。
- 该成员将其描述为通过下载 DNA 来生成人类,通过更换种子来生成不同的模型。
- Cogito 14b 采用高效工具模板:14b 模型出人意料地开始使用比初始指令中提供的更高效的工具调用 (tool calling) 模板,参见 Cogito 模型。
- 这表明该模型可能自主优化了其工具使用,为进一步研究提供了潜在领域。
- DeepCogito 迭代改进:一位成员分享了来自 Hacker News 的链接,关于使用测试时计算 (test time compute) 进行微调的迭代改进策略,出自 DeepCogito。
Nomic.ai (GPT4All) Discord
- Granite 8B 的 RAG 能力令人印象深刻:成员们报告称 IBM Granite 8B 在 RAG 任务中非常有效,特别是在提供引用 (references) 方面。
- 其他成员表示赞同,也发现 Granite 非常有效。
- Docling 精细处理 OCR:一位成员推荐使用 docling 进行图像 OCR,特别是针对扫描件等非文本 PDF,以便运行 embeddings。
- 他们强调了其在生成 embedding 方面的持续运行,以及集成到带有索引文档的数据库中,从而通过交集实现 RAG。
- 语义分块 (Semantic Chunking) 对上下文进行分块:一位成员分享了一个语义分块服务器,展示了其在 剪贴板示例 中的应用。
- 他们注意到它与音频和图像处理的兼容性,建议使用 ComfyUI 来结合所有模态。
- Llama 第 4 代遭到猛烈抨击:一位成员痛批 Llama 第 4 代模型,称其与较小的模型相比表现糟糕。
- 其他人表示同意,并指出 Reddit 评论 推测它可能在较小的“高质量”数据集上过拟合了,尽管某些基准测试显示出前景。
- GPT4All:本地运行!:一位成员建议主要在本地使用 GPT4All,以确保隐私并避免将私密信息发送到远程 API。
- 他们详细说明了如何在本地运行 embedding 模型,并通过分块 (chunking) 和嵌入 (embedding) 对文件进行索引,并参考了一个 shell 脚本示例。
Modular (Mojo 🔥) Discord
- MAX 在 Apple Silicon 部署方面遇到困难:一位成员对比了 MLX 和 MAX,指出 MAX 目前无法像 MLX 那样以 Apple Silicon GPU 为目标,这给直接对比和部署带来了挑战。
- 他们建议,虽然 MLX 对于初始实验很方便,但在服务器设置中部署 Apple 生态系统的实际限制使得有必要重写为 MAX、JAX 或 PyTorch 等框架。
- Mojo 借用范式获得好评:一位新人分享了一篇对比 Mojo 和 Rust 的博客文章,观察到 Mojo 的 默认借用 (borrow by default) 感觉更直观,并想知道 Mojo 如何处理函数的返回值。
- 随后讨论了 Mojo 如何处理从函数返回值的机制。
- Moveinit vs Copyinit 深度探讨:一位成员澄清说,在 Mojo 中返回对象时,
__moveinit__的存在决定了对象是否被移动,否则将使用__copyinit__,并提供了一个 GitHub 上的示例。- 该成员还指向了 Mojo 官方文档 以获取完整信息。
- Span 生命周期让你困扰?使用 Rebind!:一位成员询问如何在 Mojo 中指定 “返回值的生命周期至少与 self 的生命周期一样长”,特别是针对
Span。- 另一位成员建议使用
rebind[Span[UInt8, __origin_of(self)]](Span(self.seq))或使 trait 对 origin 进行泛型化,但指出目前尚不支持 trait 参数。
- 另一位成员建议使用
- 自我推广规则触发管理员干预!:一位成员举报了 Discord 频道中的一条帖子违反了自我推广规则。
- 管理员表示同意,确认该帖子确实违反了社区的自我推广指南。
tinygrad (George Hotz) Discord
- 寻求优雅的 Tensor 命名方式:一位成员正在寻求一种更优雅的方式来命名 Tensor,以便在打印模型参数时更容易跟踪,而不是手动在 Tensor 类中添加 name 属性。
- 该成员正在寻求简化 Tensor 命名约定的技术,以增强代码的可读性。
- GPU 编程和编译器开发资源:一位成员表示有兴趣参与 GPU 编程 和 编译器开发(针对 tinygrad 等项目),并请求学习资源或博客文章。
- 该成员计划阅读 tinygrad-notes,并征求关于 GPU 编译器开发的图书或博客推荐。另一位成员推荐了 geohotarchive YouTube 频道 作为学习 tinygrad 的资源,以及 PMPP (第 4 版) 用于 GPU 编程。
- METAL 同步故障导致 LLaMA 分片出错:一位成员在复现悬赏任务中关于 METAL 同步问题 的最小示例时发现了分片(sharding)中的异常行为,怀疑从 METAL:1 到 CPU 的 COPY 操作在从 METAL 到 METAL:1 的 XFER 结束之前就执行了。
- 用户认为这导致 CPU 在 LLaMA 推理期间读取的是零,而不是正确的分片。
- AMD BEAM=2 为 Tinygrad 提速:一位用户报告称,使用 AMD 配合 BEAM=2 获得了令人印象深刻的速度提升,达到了 64 it/s,超过了之前使用 Torch 达到的 55+ it/s 的最佳纪录。
- 成员们指出 BEAM=2 通常优于 Torch。
- LLaMA 分片丢失设备信息:一位用户在运行带有
--shard 4参数的 llama.py 时遇到了 AssertionError,表明采样后设备信息丢失。- GitHub 上提出了一个潜在的修复方案,即移动 Tensor。
LlamaIndex Discord
- Llama 4 助力全新 RAG 工作流:一个快速入门教程演示了如何使用 Llama 4 从零开始构建 RAG 工作流,展示了如何利用 LlamaIndex 工作流设置围绕数据摄取 (ingestion)、检索 (retrieval) 和生成 (generation) 的核心步骤,详见此推文。
- 该教程专注于围绕数据摄取、检索和生成的核心步骤。
- Auth0 与 LlamaIndex 联手推出 GenAI 身份验证:Auth0 的 Auth for GenAI 现在提供原生 LlamaIndex 支持,使得在 Agent 工作流中构建身份验证变得更加容易,正如此推文中所宣布的。
- 这一集成简化了在基于 Agent 的应用程序中加入身份验证的过程。
- Gemini 2.5 Pro 停用,转向统一 SDK:成员们发现 Gemini 2.5 Pro 已被弃用,建议改用 Google 最新的统一 SDK,如 LlamaIndex 文档中所述。
- 有人提到 Google SDK 不会验证模型名称,而是假设提供的名称是有效的,因此仔细检查可能很重要。
- StructuredPlannerAgent 被移除:
StructuredPlannerAgent的文档已被删除,因为在 Agent 文档清理过程中它不再被维护,并提供了一个回链供历史参考:StructuredPlannerAgent。- 建议不要使用
StructuredPlannerAgent,而是使用带有 planning tool(规划工具)的 Agent 来进行一些 Chain of Thought (CoT) 推理,或者在调用 Agent 之前使用 LLM 本身来创建计划。
- 建议不要使用
Cohere Discord
- 成员询问活动录音:一名成员询问了无法参加现场活动的人是否可以获得活动录音,但未得到回应。
- 该成员表达了兴趣,因此在未来,发布活动录音将使缺席的成员受益。
- 新手寻求结构化输出指导:一名新成员请求提供如何使用 Cohere 获取结构化输出(例如书籍列表)的示例,并被引导至 Cohere 文档。
- 用户承认对 Cohere 缺乏经验,官方文档中可能需要更多关于 structured output 的示例。
- 通过 cURL 集成 Pydantic Schema:一名成员寻求在 Cohere 的
response_format中直接使用 Pydantic schemas 且不使用 Cohere Python 包的方法。- 他们收到了 Cohere Chat API 参考链接 以及一个向
https://api.cohere.com/v2/chat发送请求的 cURL 示例,模仿了 OpenAI SDK 的方法。
- 他们收到了 Cohere Chat API 参考链接 以及一个向
- Cohere 回避向量数据库推荐:历史上一直避免对 vector DBs 做出明确推荐,因为 Cohere 的模型旨在与 所有 vector DBs 有效配合。
- 这种方法确保了广泛的兼容性以及对 vector database 生态系统 的中立立场,这意味着不需要针对任何特定的 vector DB 进行特殊优化。
- Aditya 加入 Cohere 社区:拥有 machine vision and control 背景的 Aditya 在休假期间介绍了自己,并正在通过 openchain.earth 项目探索 Web/AI。
- Aditya 正在使用 VS Code、GitHub Copilot、Flutter、MongoDB、JS 和 Python(评估中),希望了解更多关于将 Cohere AI 集成到其项目中的信息。
Torchtune Discord
- 寻求贡献者标签:一名成员在 Discord 上申请 Contributor 标签,并分享了他们的 GitHub 用户名。
- 该用户风趣地提到他们的 Discord 头像使用的是美剧《灵异妙探》(Psych)中的角色 Gus。
- 关于 TorchTune 集成 DeepSpeed 的辩论:一名成员询问是否可以将 DeepSpeed 作为后端集成到 TorchTune 中,并创建了一个 Issue 来讨论这种可能性。
- 一位维护者询问了更多背景信息,并指出 FSDP 支持 DeepSpeed 的所有分片(sharding)选项。
- TorchTune 倾向于 FSDP 而非 DeepSpeed:TorchTune 更倾向于使用 FSDP,因为它能更好地与 PyTorch 的其他分布式特性组合,并认为同时支持好两个版本是不可行的。
- 为了避免 DeepSpeed、PyTorch 和 Megatron 组合时的复杂性而迁移到 TorchTune 的用户,更倾向于坚持使用原生 PyTorch。
- TorchTune 的 DeepSpeed Recipe?:一位维护者建议创建一个社区 Recipe,通过导入 TorchTune 并托管一个 DeepSpeed Recipe,并表示如果建立了代码库,愿意对其进行推荐。
- 这使得对 DeepSpeed 感兴趣的用户可以在 TorchTune 中使用它,同时保持核心框架专注于原生 PyTorch。
- 为 ZeRO-1/2 训练调整 FSDPModule:由于 TorchTune 默认使用相当于 ZeRO-3 的配置,因此关于如何使用 FSDPModule 方法调整 Recipe 以进行 ZeRO-1/2 训练的文档或更多 Recipe 将会很有帮助。
- 据信,只需对集合通信(collectives)进行非常微小的调整,即可实现 ZeRO 1-3。
DSPy Discord
- MIPRO 算法在复杂任务上的扩展:一篇文章测试了 MIPRO 自动提示词工程算法在不同复杂程度任务中的表现,从命名实体识别到基于文本的游戏导航。
- 该研究利用了 CoNLL++、HoVer、BabyAI 和 τ-bench(涉及 Agent 工具使用的客户支持)等任务。
- 大型模型更能发挥 MIPRO 的优势:研究发现,在复杂设置下,大型模型从 MIPRO 优化中获益更多,这可能是因为它们能更有效地处理较长的多轮示例(demonstrations)。
- 反馈的质量显著影响 MIPRO 的优化过程,即使是来自带有噪声的 AI 生成反馈也能看到明显的改进。
LLM Agents (Berkeley MOOC) Discord
- Kaiyu Yang 探索形式化数学推理:客座讲师 Kaiyu Yang 在直播中发表了题为 “用于自动形式化和定理证明的语言模型” 的演讲,视频可在此链接观看。
- 讲座涵盖了使用 LLM 进行形式化数学推理的内容,包括定理证明和自动形式化(autoformalization)。
- AI4Math 对 AI 系统变得至关重要:数学人工智能 (AI4Math) 对于 AI 驱动的系统设计和验证至关重要,它借鉴了 NLP 技术,特别是针对精选数学数据集训练 LLM。
- 一种补充方法涉及基于 Lean 等系统的形式化数学推理,这些系统可以验证推理的正确性并提供反馈。
- Yang 博士增强数学领域的 AI 能力:Meta FAIR 的研究科学家 Kaiyu Yang 博士专注于通过集成 Lean 等形式化系统来增强 AI 的数学推理能力。
- 他的工作探索了使用 LLM 执行定理证明(生成形式化证明)和自动形式化(将非形式化语言翻译为形式化语言)等任务。
MLOps @Chipro Discord
- Manifold Research 深度探讨:Manifold Research Group 将于本周六(太平洋标准时间 4/12 上午 9 点)举办他们的 第 4 次社区研究电话会议,展示他们的最新项目。
- 讨论内容将包括多模态 AI、自组装空间机器人以及机器人元认知,并邀请在垂直科学领域进行协作。
- 群集空间机器人技术起飞:Manifold Research Group 的一名专注于空间机器人群的研究生发出了参加此次研究电话会议的邀请。
- 该研究会议旨在鼓励协作并探索空间机器人领域的前沿科学。
Codeium (Windsurf) Discord
- Codeium 在编辑器取得成功后更名为 Windsurf:在 2024 年 11 月成功推出 Windsurf Editor 后,Codeium 更名为 Windsurf,其品牌重塑公告中对此进行了说明。
- 新名称代表了人类与机器能力的融合,旨在创造强大的体验。
- Windsurf 启动新的 SubReddit:Windsurf 推出了新的 SubReddit 以建立社区,同时也对其 Discord 服务器进行了调整。
- 这些变化包括更新页面和重命名频道,以反映新的 Windsurf 品牌。
- Codeium Extensions 获得新的 Plugin:随着品牌重塑,Codeium Extensions 现在正式更名为 Windsurf Plugins,并承诺会有更多创新。
- 公司重申了他们持续增强 Windsurf Editor 的决心。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区沉寂时间过长,请告知我们,我们将将其移除。
PART 2: 频道详细摘要与链接
完整的各频道详细解析已针对电子邮件进行缩减。
如果您喜欢 AInews,请分享给朋友!预先感谢!