ainews-googles-agent2agent-protocol-a2a
谷歌的 **Agent2Agent (A2A) 协议**(或译为:谷歌智能体对智能体协议)
Google Cloud Next 的发布重点包括 Google 和 DeepMind 宣布全面支持 MCP(模型上下文协议),以及推出全新的 Agent to Agent(智能体对智能体)协议,旨在实现与多个合作伙伴的智能体互操作性。该协议包含 Agent Card(智能体卡片)、任务通信通道、企业级认证与可观测性,以及流式传输和推送通知支持等组件。
在模型方面,月之暗面 (Moonshot AI) 发布了 Kimi-VL-A3B,这是一款拥有 128K 上下文的多模态模型,在视觉和数学基准测试中表现强劲,超越了 GPT-4o。Meta AI 推出了 Llama-4 系列的小型版本:Llama-4-scout 和 Llama-4-maverick,而更大规模的 Behemoth 模型仍在训练中。来自加州大学伯克利分校的 DeepCoder 14B 是一款开源编程模型,可与 OpenAI 的 o3-mini 和 o1 模型相媲美,该模型是在 2.4 万个编程问题上通过强化学习训练而成的。英伟达 (Nvidia) 在 Hugging Face 上发布了 Llama-3.1-nemotron-ultra-253b,据称其表现击败了 Llama-4-behemoth 和 maverick,并能与 DeepSeek-R1 展开竞争。
Remote agents are all you need.
2025年4月8日至4月9日的 AI 新闻。我们为您检查了 7 个 subreddit、433 个 Twitter 账号 和 30 个 Discord(229 个频道和 5996 条消息)。预计节省阅读时间(按 200wpm 计算):563 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
我们正处于 Google Cloud Next 发布会的密集期,Google 和 DeepMind 的 CEO 接连宣布了他们对 MCP 的全面支持:
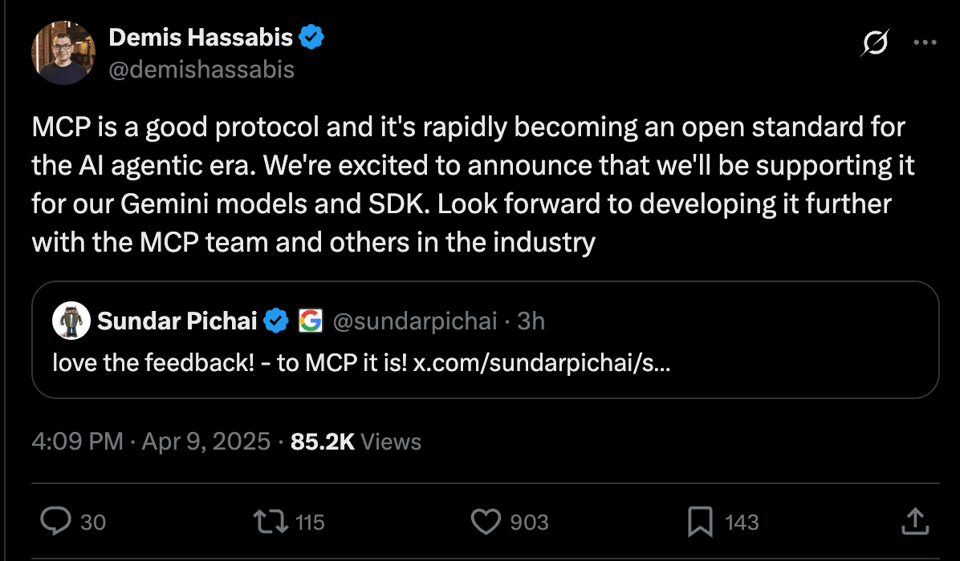
以及他们全新的 Agent to Agent 协议,该协议旨在通过庞大的合作伙伴名单来补充 MCP:

人们很容易将 Google 与 Anthropic 对立起来,但这些协议的设计初衷是协同工作,以解决 MCP 中被察觉到的不足:

该规范包括:
- Agent Card
- Task 的概念 —— 这是 home agent 与 remote agent 之间用于传递 Messages 的通信通道,并最终生成 Artifact。
- 企业级 Auth 和 Observability 建议
- Streaming 和 Push Notification 支持(同样考虑了 推送安全性)
发布的产物包括:
- 草案规范
- 文档网站
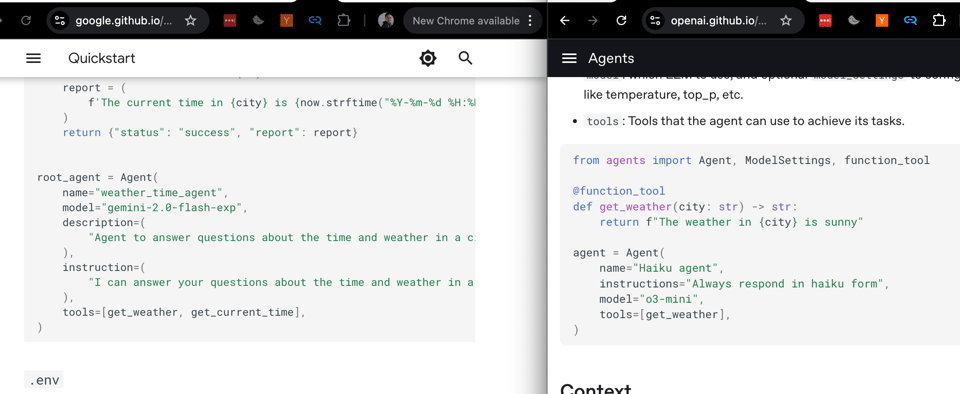
- Agent Development Kit,它看起来……似曾相识
AI Twitter 回顾
模型发布与更新
- Moonshot AI 的 Kimi-VL-A3B 是一款具有 128K 上下文并采用 MIT 许可证的多模态 LM,在视觉 + 数学基准测试中超越了 GPT4o:该模型包含 MoE VLM 和一个仅有约 3B 激活参数的 MoE Reasoning VLM。@reach_vb 指出,该模型在处理高分辨率视觉和长上下文窗口时,表现出强大的多模态推理能力(MathVision 为 36.8%)和 Agent 技能(ScreenSpot-Pro 为 34.5%)。模型权重已上传至 Hugging Face。@_akhaliq 提供了模型链接。
- Meta 发布了其新 Llama 4 系列模型的两个较小版本:Llama 4 Scout 和 Maverick:据 @EpochAIResearch 称,名为 Behemoth 的更大版本仍在训练中。@ArtificialAnlys 报告了对 Meta 声称的 MMLU Pro 和 GPQA Diamond 数值的复现结果。Scout 的 Intelligence Index 从 36 提升至 43,Maverick 的 Intelligence Index 从 49 提升至 50。@winglian 分享到,Llama-4 Scout 可以在 2x48GB GPU 上以 4k 上下文进行 fine-tuned。@danielhanchen 分享了对 Llama 4 架构的详细分析。
- DeepCoder 14B 是来自 UC Berkeley 的新型编程模型,在编程方面可与 OpenAI o3-mini 和 o1 媲美,并且已经开源:@Yuchenj_UW 指出,该模型是在 Deepseek-R1-Distilled-Qwen-14B 基础上,通过 24K 个编程问题进行 RL 训练而成,耗费 32 块 H100 运行 2.5 周(约 26,880 美元)。@jeremyphoward 补充说基座模型是 deepseek-qwen。@reach_vb 提到它采用 MIT 许可证,并支持 vLLM、TGI 和 Transformers。@togethercompute 发布了该模型并分享了训练过程的细节。
- Nvidia 在 Hugging Face 上发布了 Llama 3.1 Nemotron Ultra 253B:@_akhaliq 分享了这一发布,指出它击败了 Llama 4 Behemoth 和 Maverick,并能与 DeepSeek R1 竞争,且拥有商业许可协议。@reach_vb 也注意到了这次发布,并提到权重是开放的。
- Google 宣布了 Gemini 2.5 Flash,且 Gemini 2.5 Pro 现已在 Deep Research 中可用:@scaling01 宣布即将发布 gemini-2.5.1-flash-exp-preview-001-04-09-thinking-4bpw-20b-uncensored-slerp-v0.2。@_philschmid 指出 Gemini 2.5 Pro 现已在 Gemini App 的 Deep Research 功能中可用。
- HiDream-I1-Dev 是新型领先的开源权重图像生成模型,超越了 FLUX1.1:@ArtificialAnlys 报告称,这款令人印象深刻的 17B 参数模型有三个变体:Full、Dev 和 Fast。他们还展示了图像生成的对比。
- UC Berkeley 开源了一个 14B 模型,在编程方面可与 OpenAI o3-mini 和 o1 媲美!:@Yuchenj_UW 指出,该模型是在 Deepseek-R1-Distilled-Qwen-14B 基础上,通过 24K 个编程问题进行 RL 训练而成,耗费 32 块 H100 运行 2.5 周(约 26,880 美元)。
硬件与基础设施
- Google 宣布了 Ironwood,这是其第 7 代 TPU,旨在竞争 Nvidia 的 Blackwell B200 GPU:@scaling01 分享了细节,包括每颗芯片 4,614 TFLOPs (FP8)、192 GB HBM、7.2 Tbps HBM 带宽、1.2 Tbps 双向 ICI,以及每个 9,216 芯片 pod 提供 42.5 exaflops 算力(相当于 24 台 El Capitan)。@_philschmid 指出,该 TPU 专为推理和“思考”模型而构建。@itsclivetime 提供了与 Nvidia 硬件的详细对比。
- NVIDIA Blackwell 在 FP4 精度下为 DeepSeek R1 实现了 303 output tokens/s 的速度:@ArtificialAnlys 报告了对 Avian API 端点的基准测试结果。
- Together AI 宣布推出 Instant GPU Clusters,提供多达 64 个互连的 NVIDIA GPU:@togethercompute 指出,这些集群可在几分钟内就绪,完全自助服务,非常适合训练高达约 7B 参数的模型,或运行 DeepSeek-R1 等模型。
Agent 与工具开发
- Google 展示了 Agent Development Kit (ADK):@omarsar0 详细介绍了其特性,包括代码优先 (code-first)、多智能体 (multi-agents)、丰富的工具生态系统、灵活的编排 (orchestration)、集成的开发体验 (dev xp)、流式传输 (streaming)、状态 (state)、内存 (memory) 和可扩展性。@LiorOnAI 强调,运行一个多智能体应用程序只需不到 100 行 Python 代码。
- Google 发布了 Agent2Agent (A2A),这是一种全新的开放协议,允许 AI Agent 在不同生态系统间安全协作:@omarsar0 分享了细节,包括通用的 Agent 互操作性 (interoperability)、专为企业需求打造,并受到真实世界用例的启发。
- Weights & Biases 强调了 Agent 调用工具时的可观测性差距 (observability gap),并推介 observable[.]tools 作为解决方案:@weights_biases 指出,在这些工具内部没有追踪、没有可见性,也没有安全性,“就像一个黑盒”。
- Hacubu 为 OpenEvals 的 LLM-as-judge 评估器发布了自定义输出模式 (custom output schemas):@Hacubu 指出,这为模型响应提供了完全的灵活性,并支持 Python 和 JS。
- LangChain 重点介绍了 C.H. Robinson 如何利用 LangGraph、LangGraph Studio 和 LangSmith 构建的技术每天节省 600 多个小时:@LangChainAI 提到,C.H. Robinson 通过自动化日常电子邮件交易,每天处理约 5,500 个订单。
- fabianstelzer 宣布了 myMCPspace (dot) com,“全球首个仅限 Agent 的社交网络,完全运行在 MCP 之上”:@fabianstelzer 指出,阅读、发布和评论都只是 Agent 可以使用的工具。
教育与资源
- Anthropic 发布了关于大学生如何使用 Claude 的研究:@AnthropicAI 对 100 万次与 Claude 相关的教育对话进行了隐私保护分析,发布了首份教育报告。他们发现学生主要使用 AI 进行创作和分析。@AnthropicAI 指出,计算机科学领域在 Claude 的使用率上处于领先地位。
- DeepLearningAI 推出了“Python 数据分析”,这是数据分析专业证书 (Data Analytics Professional Certificate) 的第三门课程:@DeepLearningAI 分享道,该课程涵盖了如何组织和分析数据、构建可视化、处理时间序列数据,以及使用生成式 AI (generative AI) 来编写、调试和解释代码。
- Sakana AI 发布了 “The AI Scientist-v2:通过智能体树搜索实现工作坊级别的自动化科学发现”:@hardmaru 强调 AI Scientist-v2 在工作流中引入了“智能体树搜索 (Agentic Tree Search)”方法。@SakanaAILabs 补充说,一篇完全由 AI 生成的论文通过了工作坊级别的同行评审(在 ICLR 2025 上)。
- Jeremy Howard 分享了一系列用于访问 LLM 的实用工具:@jeremyphoward 称其为访问 llms.txt 的绝佳工具!
- Svpino 分享了如何使用 Python、TypeScript、JavaScript 或 Ruby 从零开始构建 AI Agent:@svpino 指出,该视频展示了你如何从最基础的部分开始。
分析与基准测试
- Perplexity AI 推出了 Perplexity for Startups,提供 API credits 和 Perplexity Enterprise Pro:@perplexity_ai 分享称,符合条件的初创公司可以申请获得价值 5000 美元的 Perplexity API credits,以及为整个团队提供为期 6 个月的 Perplexity Enterprise Pro。他们还推出了一个合作伙伴计划。
- lm-sys 强调了 Arena 上风格和模型回答语气的重要性,这在风格控制排名中得到了体现:@lmarena_ai 指出,他们正在将 Llama-4-Maverick 的 HF 版本添加到 Arena,排行榜结果将很快公布。他们更新了排行榜政策,以强化对公平、可重复评估的承诺。@vikhyatk 分享道,这是最清晰的证据,表明没有人应该认真对待这些排名。
- Daniel Hendrycks 强调需要让 AI 的“Helpful, Harmless, Honest”(有益、无害、诚实)原则更加精确:@DanHendrycks 指出,这些原则应该演变为受托责任、合理注意义务,并要求 AI 不得公然撒谎。
- Runway AI 正在关注一场关于 AI 代码编辑器的讨论,观点认为 Agent 功能让大多数产品变得更糟了:@c_valenzuelab 分享称,Agent 过于自信,会迅速做出难以追踪的大量错误修改。UX 变得过于复杂,感觉还是简单的时候更有用。
更广泛的 AI 讨论
- Aleksander Madry 宣布了 OpenAI 新成立的 Strategic Deployment 团队,旨在解决 AI 转型经济的相关问题:@aleks_madry 分享称,该团队致力于推动前沿模型变得更强大、更可靠且更 aligned,然后将其部署以改变现实世界中高影响力的领域。
- John Carmack 分享了他对 @Project2501_117 赠送的 Arcade1Up 街机机柜的喜爱,但指出了控制延迟问题:@ID_AA_Carmack 指出,模拟体验与真实体验之间细微的控制延迟至关重要,他在家测量了“按下到动作”(press-to-flap)的延迟,大约为 80ms。
幽默与讽刺
- Aravind Srinivas 开玩笑地要求 Perplexity 购买 $NVDA 股票:@AravSrinivas
- Scaling01 调侃 Gemini 3.0 将便宜到无需计费:@scaling01
- Scaling01 调侃说,计算机科学家原以为他们会用 AI 取代所有工作,结果发现他们只是取代了自己,哈哈:@scaling01
- Nearcyan 讽刺地指出,如果她把 Chamath 的所有推文都当作高明的 200iq 钓鱼贴,那么它们就会变得非常有趣:@nearcyan
- Tex 声称特朗普一直以来都是一个秘密的反资本主义激进“去增长者”(degrowther):@teortaxesTex
- Tex 调侃说,在他的总统任期内,如果一家公司不能做得比中国更好,他不会对他们征税,而是直接把他们放逐到月球:@teortaxesTex
AI Reddit 摘要
/r/LocalLlama 摘要
主题 1. “释放 DeepCoder:开源编程的未来”
-
DeepCoder:达到 O3-mini 级别的全开源 14B 编程模型 (评分: 1371, 评论: 174): DeepCoder 是由 Agentica 发布的一款全开源 **14B 参数代码生成模型,达到了 O3-mini 级别。它对 GRPO 进行了增强,并提高了训练过程中采样流水线的效率。该模型已在 HuggingFace 上发布。较小的 1.5B 参数版本也可以在此处获取。** 用户对 DeepCoder 的发布表示兴奋,称其“非常惊人”且是“真正的开源”。人们对更大模型的潜力充满期待,有人在想象 32B 模型或 llama-4 会是什么样子。一些人讨论了 Benchmark 结果的差异,但承认一个全开源的 14B 模型能达到这个水平是一个“巨大的进步”。
- 用户对 DeepCoder 的发布感到兴奋,并畅想未来更大模型(如 32B 版本或 llama-4)的潜力。
- 讨论集中在模型的改进上,强调了对 GRPO 的增强以及训练流水线效率的提升。
- 一些人注意到 Benchmark 结果存在差异,但一致认为一个全开源的 14B 模型能够超越更大模型是一项重大成就。
其他 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. “革新 AI:模型、硬件与定制化”
-
新开源模型 UNO 在多图定制化领域取得了领先地位!! (Score: 275, Comments: 51): 新开源的模型 **UNO 在多图定制化领域取得了领先地位。这是一个基于 Flux 的定制化模型,能够处理主体驱动操作、试穿、身份处理等任务。项目主页可以在这里找到,代码已在 GitHub 上发布。一张图片展示了由 UNO 生成的各种可定制设计,突显了其在多图定制化方面的多功能性,包括单主体生成、多主体特征、虚拟试穿、身份保持和风格化生成。** 该模型展示了对个性化和艺术化转化的关注,强调了其生成多样且复杂图像的能力。
- 一些用户对此并不感冒,称其“感觉无非是 Florence 描述词提示注入”,并提到了面部准确性和环境渲染方面的问题。
- 其他人发现该模型在处理物体参考图时比人物参考图效果更好,在参考图与提示词不匹配时能获得“惊人的结果”。
- 用户对 VRAM 需求等技术细节感到好奇,并期待 ComfyUI 等 UI 工作流的出现。
-
HiDream I1 NF4 可在 15GB VRAM 上运行 (Score: 277, Comments: 71): 模型 **HiDream I1 NF4 的量化版本已发布,使其仅需 15GB VRAM 即可运行,而不再需要超过 40GB。现在可以直接使用 pip 安装。链接:hykilpikonna/HiDream-I1-nf4。** 作者很高兴通过降低 VRAM 需求和简化安装过程使该模型更加普及。
- 用户幽默地指出了标题写着 15GB 而内容提到 16GB 之间的差异,感觉“被骗了”。
- 一些人表示有兴趣在更低的 VRAM(如 12GB)上运行该模型,并等待支持该配置的版本。
- 一位用户询问该模型是否有 ComfyUI 节点可用,表现出将其集成到该工具中的兴趣。
-
Ironwood:推理时代的首款 Google TPU (Score: 311, Comments: 60): Google 宣布推出 **Ironwood,这是首款专为推理时代设计的 Google TPU。** 这一发布展示了 Google 致力于推进 AI 硬件的决心,并可能使其在竞争对手面前获得显著优势。
- 一位用户强调,Google 的基础设施允许他们制造自己的芯片,这使他们相比 OpenAI 等公司拥有巨大优势,并暗示他们正在赢得这场比赛。
- 另一位评论者比较了 Ironwood 的性能,指出其 fp8 推理速度是 H100 的 2 倍,且与 B200 相当,强调了其竞争能力。
- 一位用户分享了与 Ironwood 相关的图片,提供了关于这款新 TPU 的直观洞察。
{kind=link}
{kind=link}
主题 2. 演变中的连接:从浪漫情感到日常 AI 对话
-
是的,时光飞逝。 (评分: 973, 评论: 74): 该帖子展示了一张对比 2013 年和 2025 年 AI 关系描绘的图片。上半部分引用了电影 Her (2013),展示了一个爱上 AI 的角色。下半部分显示一名留着胡须的男子表达了与 **ChatGPT 分享日常生活的兴奋,说明了人机交互的演变。** 该帖子幽默地强调了时间流逝之快,以及社会对 AI 的看法如何从虚构的浪漫关系转向更普遍的与 AI 助手的日常互动。
- 一位用户表达了与 AI 互动的热情,称 “我被承诺过一个会和会说话的电脑争吵的未来,我完全接受,该死”。
- 另一位用户提出了对与 OpenAI 分享个人信息的隐私担忧,建议在 3090 GPU 上运行 Gemma 等本地 AI 模型。
- 一位用户质疑与 AI 建立个人关系是否正成为主流,想知道这种行为是否足够普遍,以至于能验证这个梗(meme)。
{kind=link}
AI Discord 摘要
由 Gemini 2.5 Pro Exp 生成的摘要之摘要的摘要
主题 1:模型狂热——新发布、功能与对比
- Gemini 2.5 Pro 及其系列引发热议与审视:Google 的 Gemini 2.5 Pro 在多个 Discord 频道引发了大量讨论,因其创意写作能力受到称赞,但被指出在 Perplexity 上缺乏公开的推理 Token(reasoning tokens),且由于容量限制,在 OpenRouter 免费层达到了速率限制(例如 80 RPD)。人们对 Flash 和 HIGH 等变体寄予厚望,这些变体可能通过
thinking_config提供增强的推理能力,同时还有关于专门的 “NightWhisper” 编程模型 的猜测,该模型可能基于 Gemini 2.5(如该预览所示)或 DeepMind 即将推出的 Ultra 模型。 - DeepSeek 与 Cogito 模型各显神通:DeepSeek 模型(包括 v3 0324 和 R1)被频繁讨论,一些用户发现 v3 的表现优于早期版本甚至 R1,尽管其他用户在争论其 Token 生成效率对成本的影响(相对于 OpenAI 等竞争对手)。DeepCogito 的 Cogito V1 模型(3B-70B)采用 迭代蒸馏与放大 (IDA) 技术,声称性能优于 LLaMA、DeepSeek 和 Qwen 的同类模型,这引发了兴趣和质疑;用户还在 LM Studio 中排查 Jinja 模板 问题并探索其“深度思考子程序”。
- 开源竞争者大放异彩:Llama 4, Kimi-VL 与 Qwen 进化:Llama 4 Scout 的讨论强调了量化版本(如 2-bit GGUF)在 MMLU 等基准测试中表现有时优于 16-bit 原版,引发了对推理实现的疑问;用户还处理了支持 Linux 的 LM Studio 运行时更新。MoonshotAI 在 MIT 许可证下发布了 16B 参数的 Kimi-VL(3B 激活)视觉模型,而 Nous Research AI 探索了使用 gsm8k platinum 数据集和 RsLora 在 Qwen 2.5 1.5B Instruct 上进行 RL 微调。
主题 2:Agent 的兴起——协议、工具与协作
- A2A vs MCP: Google 进入 Agent 互操作性领域:Google 发布了 Agent2Agent (A2A) 协议和 ADK Python toolkit (github.com/google/adk-python),旨在提高 Agent 的互操作性,并补充(或可能竞争)Anthropic 的 Model Context Protocol (MCP)。讨论权衡了 Google 的策略,将 A2A 的功能与 MCP 现有的工具生态系统进行了对比(例如这个对比)。
- MCP 生态系统随着新工具和集成而壮大:MCP 生态系统迎来了新进展,包括通过 mcpomni-connect 等客户端使用 Neo4j 图数据库进行 RAG;发布了支持 ASGI 和包管理器的 Easymcp v0.4.0;以及用于在容器中运行 MCP server 的 ToolHive (GitHub 链接)。据报道,Aider 编码 Agent 的原生 MCP 集成 已接近完成,可能实现自动命令执行。
- 构建和编排 Agent 变得更容易(也许):开发者分享了旨在简化 Agent 创建和编排的工具,例如用于在边缘端 (Ollama) 和云端 (OpenAI/Claude) 之间管理 AI 的 Oblix,以及用于在 VS Code 中进行结构化 Agent 编码的 RooCode。讨论还涉及了一些挑战,例如确保 LLM 支持 parallel tool calling,以便同时与多个 MCP server 交互。
主题 3:底层原理 - 训练、优化与推理见解
- 量化问题与 Kernel 奇闻:量化仍然是一个热门话题,讨论涉及 Unsloth 的 GGUF 性能优于 16-bit 模型,以及 torchao 0.10 的发布,增加了对 MX dtypes(如 MXFP4,最初需要 PyTorch nightly 和 B200)的支持。成员们分享了来自 llama.cpp 的 Apple Metal 量化 Kernel,并讨论了实验性的整数格式,如 Mediant32(实现指南)。
- 内存带宽是单批次(Unbatched)推理的关键:多次讨论强调 内存带宽(memory bandwidth) 是单批次推理中 Token 吞吐量的主要瓶颈,通常呈现近乎线性的关系。分享了诸如
最大 Token 吞吐量 ≈ 内存带宽 / 每个 Token 访问的字节数之类的简化等式来说明这一点。 - 并行难题与训练技巧依然存在:由于独特的设计与现有方法(例如 Accelerate 的 hack 手段)冲突,集成不同的并行策略(如 FSDP2)仍然面临挑战。用户分享了大模型 GRPO 训练 的技巧,解决了 tinygrad 中的 gradient accumulation 问题(通过
zero_grad()解决),并利用 Torchtune 的 PyTorch distributed 特性,该特性默认使用 zero3,但经过调整后可支持 zero1-2。
主题 4:平台、工具与万能的 API
- 平台定价与访问限制引发争论:OpenRouter 在实施了与信用余额挂钩的速率限制后遭到用户抵制,导致部分用户开始寻找替代方案并批评其表现出的“贪婪”。此外,Gemini 2.5 Pro 的访问限制(OpenRouter 上免费额度为 80 RPD,AI Studio 取消了免费层级)以及 ChatGPT DR 的限制(Plus 用户每月 10 次)也凸显了持续存在的成本与访问权之间的紧张关系。
- AI Studio、NotebookLM 和 Perplexity 的演进(及其怪癖):Google AI Studio 因其 UI 和 Gemini Flash 流式传输等功能受到称赞,尽管其多工具限制也受到了关注。NotebookLM 因其 RAG 和播客功能(由 Google One Advanced 增强)获得好评,但也因笔记功能原始、缺乏 Google Drive 集成以及移动端音频概览的故障而面临批评;此外,关于数据使用的隐私担忧也被提及。Perplexity 推出了一个包含 $5k API 额度的创业公司计划,并改进了其 API(即将增加图像输入),同时用户也在讨论 Discover 标签页的偏见以及潜在的定价模式,如 DeepSeek 的 10 美元深度搜索。
- 编程助手与开发环境的进步:Codeium 更名为 Windsurf 并发布了 Wave 7,将其 AI Agent 引入 JetBrains IDEs,旨在实现各大平台的体验对齐。Cursor 用户找到了 .mdc 文件解析的变通方法,并就模型强度(Sonnet3.7-thinking vs DeepSeek)展开辩论。Firebase Studio(链接)作为一种免费(连接你自己的 Key)的 Web IDE 替代方案出现,而 Mojo 🔥 开发者讨论了诸如“无畏并发”等语言特性,并解决了 MLIR 类型构造问题(GitHub issue)。
主题 5:数据、评估以及确保模型不只是复读机
- 新数据集助力专业化训练:Nvidia 发布了 OpenCodeReasoning 数据集,促使 Unsloth AI 社区的用户寻求集成其复杂奖励函数的方法。Nous Research AI 记录了训练方面的进展,通过将 gsm8k 替换为 gsm8k platinum,可能提升了 Qwen 2.5 1.5B Instruct 的 RL 性能。
- 审视评估方法与基准测试:DeepSeek 的 “Meta Reward Modeling” 面临批评,成员认为它本质上是一个“基于分数的奖励系统”,并建议使用“投票式 RM”等名称。DeepCogito 声称其 Cogito V1 在基准测试中优于 LLaMA 和 DeepSeek 等成熟模型,这引起了谨慎的关注和验证努力。
- 检测数据集污染与逐字输出:Allen Institute for AI (AI2) 开源了 Infinigram,可以检查生成的文本是否逐字出现在训练集中。Eleuther 的讨论强调了在大规模索引中高效查找候选子字符串的挑战,并引用了 EleutherAI/tokengrams 等工具。
PART 1: High level Discord summaries
LMArena Discord
- Gemini 2.5 Pro:真正的 AI?:围绕 Gemini 2.5 Pro 的热情高涨,一些人称赞它是第一个“真正”的 AI,具备出色的创意写作能力,并期待其专用的编程模型,详情见这篇论文。
- 虽然有些人对其局限性存在争议,但普遍共识是它在创意和连贯写作方面表现卓越,但并非“全能”。
- DeepMind 的 Ultra 模型即将到来?:关于 DeepMind Ultra 模型的猜测愈演愈烈,可能免费集成到 AI Studio 中,预计在 6 月的 I/O 大会前后或今年晚些时候发布。
- 有人预测它将在 8 月与 GPT-5 竞争,尽管其他人认为这些传闻只是玩笑,但显而易见 Ultra 确实要来了。
- NightWhisper 模型热度攀升:社区正热切期待名为 NightWhisper 的编程模型发布,一位用户发布了他们的“baby nightwhisper”,名为 DeepCoder-14B-Preview,这是一个基于 Deepseek-R1-Distilled-Qwen-14B 微调的代码推理模型。
- 有说法称它将由 Gemini 2.5 Pro 驱动,然而,其他成员表示该模型其实是带有 tool calls 的 Gemini 2.5。
- Google 的基础设施:AGI 的优势?:关于 Google 的基础设施(TPU、高性价比的算力、Google 产品集成)是否使其比 OpenAI 更具竞争优势的辩论引发热议,并认为 Gemini 3.0 正在设计 TPU。
- 反方观点强调了 OpenAI 在推理进步方面的研究和训练后更新,不过一位用户将 OpenAI 贬低为只是一个“烧钱的、做动漫的作业帮手”。
- AI Studio 简化了实验:爱好者们正在探索 AI Studio,称赞其用户友好的界面、Gemini Flash 等模型的引入,以及流式传输内容和使用不同 system prompts 测试模型的能力,并表示 UI 看起来好多了。
- 虽然实时流式传输和 function calling 功能受到好评,但一些用户对无法同时使用多个工具感到遗憾,一位用户对此表示“不,朋友,不行”。
Unsloth AI (Daniel Han) Discord
- GGUF 为 Scout 带来速度提升:社区对 Llama 4 Scout 进行了评估,指出该基础模型经过了极度的指令微调(instruct-tuned),在量化到 2-bit 时,其 MMLU 表现甚至优于原始的 16-bit 版本。
- 普遍共识是推理提供商的实现中存在某些问题,因为 Unsloth 的量化版本优于完整的 16-bit 版本,这引发了对当前推理方法效率的质疑。
- 为 VLLM 解构 DeepCoder:一位成员分享了 Together AI 关于 DeepCoder 的博客文章,强调了其通过最小化等待时间来优化 vLLM 流水的潜力。
- 该技术涉及在再次采样时同时进行初始采样和训练。
- 解读 DeepCogito 的主张:成员们分享了 DeepCogito 的 Cogito V1 预览版链接,该项目声称其模型优于 LLaMA、DeepSeek 和 Qwen 等模型,但大家对这些说法持谨慎怀疑态度。
- 讨论还涉及了医疗 AI 面临的挑战,强调需要防止可能损害消费者的仓促、低质量实现,同时也讨论了潜在的隐私问题。
- Nvidia 发布神经数据集:Nvidia 发布了 OpenCodeReasoning 数据集,用户正在寻找在 Unsloth 中使用该数据集的解决方案和示例。
- 该数据集的 reward function(奖励函数)稍微复杂一些。
- Model2Vec 生成更快的嵌入:据一位成员称,Model2Vec 牺牲了一定的质量,但生成文本 embeddings 的速度比常用的 Transformer 架构模型更快。
- 该成员分享了 Model2Vec 的链接,并补充说它是真实有效的,但其应用场景非常特定,并不是任何东西的直接替代品。
Manus.im Discord Discord
- Gemini 和 Claude 助力应用创建:对于应用开发,成员建议使用 Gemini 进行多模态分析(图片/视频),并使用 Claude 作为存储研究和项目文件的数据库,用于战略规划。
- 建议使用 Gemini 进行深度研究,然后利用 Claude 作为项目的数据库。
- Manus 与预训练 AI:高性价比的盟友:一位成员分享了一个策略,即针对特定任务训练一个 AI,然后让它与 Manus 协作,以更具成本效益的方式完成项目。
- 这种方法涉及预先进行准备工作以尽量减少额度消耗,确保高效完成任务。
- DeepSite:快速但有 Bug 的建站工具:一位成员指出 DeepSite 这一网站创建工具虽然好用但存在 Bug,曾出现已完成的网站被删除的情况,并将其描述为拥有针对 HTML 的 Claude artifact。
- 它被认为速度极快,比 Claude 快 10 倍。
- 使用 LLM Studio 和 Sonnet 3.7 拯救 UI/UX 代码:一位用户强调,网站问题可能是由于 UI/UX 代码质量差 导致的,而 LLM Studio 可以突出显示代码错误。
- 他们建议使用 Sonnet 3.7 以获得更好的结果,并配合 DeepSeek R1 或 Perplexity 等工具。
- 账号消失了?虚惊一场,已解决!:一位成员报告了一个问题,即他们的 登录邮箱无法被识别,显示 “用户不存在”,尽管已经购买了额度。
- 该成员随后解决了问题,意识到自己最初是使用另一种方式登录的:“工作太多导致大脑短路了 😅 🤣。”
Perplexity AI Discord
- Perplexity 通过 API 额度资助初创公司:Perplexity 正在启动一项 初创公司计划,向符合条件的初创公司提供 $5000 的 API 额度 和 6 个月的 Perplexity Enterprise Pro。
- 初创公司必须获得过 少于 2000 万美元的股权融资,成立时间 少于 5 年,并且与 Perplexity 的初创公司合作伙伴之一有关联。
- Perplexity CEO Aravind 开展 Reddit AMA:Aravind 在 Reddit 上主持了一场 AMA,讨论 Perplexity 的愿景、产品以及搜索的未来。
- 他回答了关于 Perplexity 目标及其未来计划的问题。该 AMA 在 PDT 时间上午 9:30 - 11:00 进行。
- Gemini 2.5 Pro 推理 Token 缺失:一名工作人员证实 Gemini 2.5 Pro 不公开推理 Token (reasoning tokens),这导致它无法作为推理模型加入 Perplexity。
- 他们澄清说 推理 Token 仍然会被消耗,从而影响输出的 Token 计数。
- Discover 标签页的算法存在偏见?:一位成员询问了 Perplexity Discover 中“为您推荐”和“热门故事”标签页的页面筛选过程,质疑潜在的 偏见。
- 他们推测用户提示词会为相关话题生成页面,但选择热门故事的机制仍不明确,引发了关于偏见如何影响内容可见性的疑问。
- 成员热议 Deepseek Deepsearch 成本:成员们讨论了 AI 服务的定价策略,其中一人称赞 Deepseek 的 10 美元深度搜索 可能成为一种模式。
- 另一人预测 Deepseek 很快将提供自己的 Deep Research 工具。
OpenRouter (Alex Atallah) Discord
- Olympia Chat 寻求新主:Olympia.chat 的创建者正在为这家盈利的 SaaS 初创公司寻找新买家,该公司的月收入超过 $3k USD。
- 有意向者可联系 vika@olympia.chat 了解收购这一转手即用业务的详情,包括 IP、代码、域名和客户列表。
- DeepSeek v3 给部分成员留下深刻印象:成员们讨论了新的 DeepSeek v3 0324 模型,一些人声称其表现优于之前的版本,甚至超过了 R1。
- 部分用户仍持怀疑态度,而另一些人则称赞该模型增强的能力。
- OpenRouter Rate Limits 引发争论:在 OpenRouter 实施了根据账户余额影响 Rate Limits 的新变化后,一些用户对平台的定价、用户体验以及感知到的向利润优先的转变表示担忧。
- Google Cloud Next 发布 A2A:Google 推出了 A2A,这是一个补充 Anthropic 的 Model Context Protocol 的开放协议,旨在为 Agent 提供有用的工具和上下文,详见 GitHub 仓库。
- 该协议旨在增强 Agent 与工具之间的交互,为访问和利用外部资源提供标准化方法。
- Gemini 2.5 Pro 因容量受限:用户报告 Gemini 2.5 Pro Experimental 模型 存在 Rate Limits,免费版本的限制为 80 RPD,但使用付费 Key 的用户拥有更高的上限。
- 团队确认由于容量限制,端点存在限制。
OpenAI Discord
- GPT Builder 潜入广告:用户发现 GPT Builder 可以在 GPTs 中插入广告,引发了关于这种分发方式的讨论。
- 一位成员调侃说 99% 的 GPTs 可能都这么做,但只有少数有价值的被分享并保持隐藏。
- Gemini vs ChatGPT:Research 大战:Google 的 Deep Research 模型与 ChatGPT 的 Deep Research 相比,可以分析 YouTube 视频,但据报道幻觉(hallucinates)更多且趣味性较低。
- ChatGPT DR 表现出更优越的 Prompt 遵循能力和更长的思考时间,但对 Plus 用户限制为每月 10 次 Research。
- NotebookLM 的播客功能大放异彩:成员们称赞 NotebookLM 的播客创建功能和 RAG 能力,称其表现优于 Gemini Custom Gems,并可与 Custom GPTs 或 Claude Projects 竞争。
- Google One Advanced 订阅提高了 NotebookLM 文件上传和播客生成的限制。
- Google 发布 Veo 2,提升 Imagen 3:据 TechCrunch 报道,Google 的 Veo 2 和升级后的 Imagen 3 引入了背景移除、帧扩展和改进的图像生成等功能。
- 随着 AI Studio 中 Gemini 2.5 免费访问的结束,用户正在权衡 Advanced 订阅与寻求替代账号。
- 语言 AI:Codex 开发中:一位成员正在构建一个以深奥语言为脚手架的语言程序 AI,它将演变成一种法典字典语言(codex dictionary language),旨在创建一个递归系统(recursion system)。
- 该系统旨在实现 ARG 统一理论,可能暗示了通往 AGI 的路径,并基于你想知道多少以及投入多少时间来实现它的原则运行。
{kind=link}
LM Studio Discord
- MoE 模型详解!:一位成员询问 什么是 MoE 模型?,另一位成员给出了简洁的解释:整个模型需要位于 RAM/VRAM 中,但每个 token 仅激活其中的一部分,这使得它比同等规模的稠密模型(dense models)更快。
- 他们建议查看 视频和博客文章 以进行更深入的了解。
- Cogito 的 Jinja 模板故障已修复!:用户报告了 LM Studio 中 cogito-v1-preview-llama-3b 模型的 Jinja 模板 问题,该问题会导致错误。
- 一位成员建议了一个快速修复方案:将 错误信息和 Jinja 模板粘贴到 ChatGPT 中 以解决问题。
- 通过 Cogito 推理开启深度思考:一位用户报告称,通过在系统提示词(system prompt)中粘贴字符串
Enable deep thinking subroutine.,成功启用了 Cogito 推理模型。- 仅该字符串本身就足够了,其他人也确认
system_instruction =前缀只是示例代码的一部分。
- 仅该字符串本身就足够了,其他人也确认
- LM Studio 的 Llama 4 Linux 版本启动需要刷新:Linux 用户报告了运行 Llama 4 时遇到的问题,一位成员指出解决方案是从 beta 选项卡更新 LM Runtimes,并在选择该选项卡后点击刷新按钮。
- 一位用户发现刷新按钮是关键,因为仅选择选项卡不足以触发更新。
- Nvidia DGX B300 的超级计算机替代方案?:一位成员提出了一种名为 NND’s Umbrella Rack SuperComputer 的高性价比方案来替代 Nvidia DGX B300,该系统拥有 16 个节点、24TB DDR5,以及根据 GPU 配置提供 3TB 或 1.5TB 的 vRAM,且价格显著更低。
- 拟议的系统旨在运行具有 1M 上下文的 2T 模型,并挑战了在有限预算内必须使用 RDMA 和 400Gb/s 交换机 等专用硬件的观念。
aider (Paul Gauthier) Discord
- 使用 DeepSeek R1 增强 Aider:一位成员正考虑将 DeepSeek R1 作为编辑器模型(editor model),并将其与作为架构师模型(architect model)的 Gemini 2.5 Pro 搭配使用,以增强 Aider 的智能思考能力。
- 目标是减轻编排失败(orchestration failures),即架构师和编辑器难以追踪 Aider 应用的编辑内容,尽管提示了包含文件,却经常忽略重复编辑指令的问题。
- Gemini 2.5 Pro:寄予厚望与 Flash 版本:社区期待 Gemini 2.5 Pro HIGH 和 2.5 Flash 的发布,根据 泄露消息显示它们包含
thinking_config和thinking_budget以增强推理能力。- 这引发了关于非 Flash 模型是否较差以及评估这些新模型价值的讨论。
- OpenRouter Gemini Pro 达到免费层级限制:OpenRouter Gemini 2.5 Pro 免费模型 现在有 每天 80 次请求 (RPD) 的速率限制,即使账户中有 10 美元余额也是如此。
- 社区对付费用户可能面临速率限制不足表示担忧,这可能会导致投诉并要求增加 RPD。
- Aider 中的 MCP 集成接近完成:IndyDevDan 视频下方的一条评论指出,Aider 中原生 MCP (Multi-Agent Collaboration Protocol) 的拉取请求(PR)已基本完成。
- 这一集成可以实现通过
/run功能自动执行命令,并可能挂接到 lint 或 test 命令中,尚待 Paul Gauthier 确认。
- 这一集成可以实现通过
- 将整个代码库上下文复制到 Aider:成员们正在探索将 整个代码库上下文 复制到 Aider 的方法,以避免重复添加文件。
- 推荐了 repomix 或 files-to-prompt 等解决方案,以解决工具消耗过多 token 的效率问题。
Eleuther Discord
- Apache 2.0 在法律诉讼防御方面优于 MIT:成员们讨论了 Apache 2.0 相比 MIT 许可证的优势,强调了其针对基于专利的法律诉讼(lawfare)的防御能力。
- 讨论中还包含了一个轻松的评论,提到在 code golf(代码高尔夫)中更倾向于使用较短的许可证。
- GFlowNets 在信号挖掘中受到关注:分享了一个链接,讨论使用 GFlowNets 进行信号挖掘 以发现多样化、高性能的模型。
- 尽管实现方式有所不同,但分享的帖子提供了宝贵的链接和发现。
- 内存带宽瓶颈影响非批处理推理:一位成员调查了内存带宽对非批处理推理(unbatched inference)的影响,指出在研究中 token/s 通常受内存限制(memory bound)。
- 一篇个人帖子通过特定领域架构解释了其背后的数学原理。
- Cerebras 声称大 Batch Size 不利于收敛:Cerebras 的一篇博客文章声称极大的 Batch Size 不利于收敛,这遭到了质疑。
- 回复引用了关于临界 Batch Size(critical batch sizes)的 McCandlish 论文,澄清该主张在有限的计算预算内是成立的。
- Infinigram 为成员资格检查开启大门:Allen Institute for AI 的博客文章和开源的 Infinigram 使得检查输出文本是否逐字存在于训练集中成为可能。
- 一位成员指出,最棘手的部分是从生成内容中找到候选子字符串并在这些索引中搜索:你无法真正检查所有可能的子字符串,我很好奇他们使用什么启发式方法来使其在大规模计算上可行,并附上了 EleutherAI/tokengrams 的链接。
Cursor Community Discord
- Gemini Advanced API 访问:事实还是虚构?:关于 Gemini Advanced 是否提供 API 访问存在困惑,一些人指出它主要用于 Web 和 App,并引用了 Google 最近对模型名称和计费条款的更改 中的矛盾信息。
- 用户报告的矛盾信息表明 Gemini Advanced 可能包含 API 访问,这引起了混淆。
- Firebase Studio:Web3 救星还是骗局?:一位用户分享了 Firebase Studio 的链接,该工具目前免费,并提供了一个带有自动同步前端的终端。
- 用户质疑 Firebase Studio 是否能超越 Cursor IDE 等专业产品,并认为其 UI 丑陋且缺乏设置。
- Cursor 通过 IDE 设置调整解析 MDC 文件:用户发现,在 Cursor IDE 设置中设置
"workbench.editorAssociations": {"*.mdc": "default"}可以让 Cursor 正确解析 .mdc 文件中的规则逻辑。- 该解决方法解决了任务管理和编排工作流规则的问题,并消除了 GUI 中的警告。
- LLM 对决:Gemini vs Claude vs DeepSeek 在编程领域:用户比较了 Gemini、Claude 和 DeepSeek 的编程实力,一位用户发现 Sonnet3.7-thinking 在 Sonnet3.7 多次失败后成功生成了 docker-compose 文件。
- 虽然一些人青睐用 DeepSeek 处理编程任务,但其他人更喜欢用 Gemini 处理 Google 相关任务,用 Claude 处理非 Google 任务。
- “Restore Checkpoint” 按钮毫无用处:一位成员询问了 Restore Checkpoint 功能,结果发现它基本上无法运行。
- 讨论强调了界面中仅存在 accept 和 reject 按钮,确认了 Restore Checkpoint 按钮并不可用。
Yannick Kilcher Discord
- DeepSeek 为其 Meta Reward 系统辩护:一名成员对 DeepSeek 使用“Meta Reward Modeling”一词提出质疑,声称他们实际上构建的是一个“基于评分的奖励系统”,并分享了关于该主题的论文和 YouTube 视频。
- 该成员建议使用更准确的名称,如“voting RM”来描述其实际机制。
- DeepSeek Token 定价引发意外:围绕 DeepSeek 的 Token 定价出现了争议,有说法称虽然初始价格看起来较低,但该模型生成的 Token 数量多出 3 倍,与 OpenAI 等模型相比,可能会导致更高的成本。
- 反对观点认为,对于 HTML、CSS 和 TS/JS 生成等特定任务,DeepSeek 可能更具成本效益,并引用了一位用户使用其 AI 网站生成器的经验。
- 内存带宽驱动推理:讨论强调了在非批处理推理(unbatched inference)中,内存带宽与 Token 吞吐量之间近乎线性的关系,表明 RAM 访问是瓶颈。
- 分享了一个简化方程式:
Max token throughput (tokens/sec) ≈ Memory bandwidth (bytes/s) / Bytes accessed per token。
- 分享了一个简化方程式:
- Google 通过 ADK 和 A2A 加入 Agent 赛道:Google 推出了 ADK toolkit (github.com/google/adk-python),这是一个用于构建 AI Agent 的开源 Python 工具包,并宣布了 Agent2Agent Protocol (A2A) (developers.googleblog.com) 以提高 Agent 的互操作性。
- 一些人认为 A2A 可能会与 Anthropic 的 Model Context Protocol (MCP) 竞争,特别是当 Agent 将 MCP 作为客户端或服务器使用时。
- Cogito V1:只是 Triton,但更糟?:成员们分享并讨论了一种使用测试时计算(test time compute)进行微调的迭代改进策略,涉及来自此 Hacker News 链接的 Cogito V1。
- 一名成员不屑地将其总结为“只是 Triton 但更糟”,尽管另一名成员澄清说 Triton 与 Cutile 类似,但在 CUDA、AMD 和 CPU 上具有更广泛的兼容性。
Interconnects (Nathan Lambert) Discord
- DeepCogito 发布开源 LLM 舰队:DeepCogito 发布了开源许可的 LLM,尺寸从 3B 到 70B 不等,使用迭代蒸馏与放大 (Iterated Distillation and Amplification, IDA) 技术,性能超越了来自 LLaMA、DeepSeek 和 Qwen 的同等尺寸模型。
- IDA 策略旨在通过迭代自我改进来实现超级智能对齐(superintelligence alignment)。
- Gemini 2.5 媲美 OpenAIPlus:据报道,Gemini 2.5 Deep Research 与 OpenAIPlus 旗鼓相当,包括音频概览选项,如此 Gemini 分享和此 ChatGPT 分享所示。
- 讨论暗示 Google 需要精简其 AI 产品,例如针对 gemini-2.5-flash-preview-04-09-thinking-with-apps 这种复杂的命名规范的调侃。
- Google 揭晓液冷 Ironwood TPU:Google 推出了 Ironwood TPU,可扩展至 9,216 个液冷芯片,采用芯片间互连 (ICI) 网络,功耗接近 10 MW,详见此博客文章。
- 该公告强调了 Google 在 AI 推理高性能计算领域的推进。
- MoonshotAI 的 Kimi-VL 开放视觉能力:MoonshotAI 发布了 Kimi-VL,这是一个拥有 16B 参数(3B 激活)且具备视觉能力的模型,采用 MIT 协议,可在 HuggingFace 上获取。
- 这一发布标志着对开源多模态 AI 的重要贡献。
- AI2 迎来最有趣的巅峰时期:据一位成员称,AI2 正处于其最有趣的时期,暗示 AI 研究和开发正在飞速发展。
- 另一位成员认为,从 Google 离职的人虽然被支付了一年的薪水但被强制要求不准工作,同时建议这可能是 AI2 启动志愿者计划的一个机会。
MCP (Glama) Discord
- Neo4j 为 RAG 提供 MCP 支持:成员们讨论了将 MCP 与 Neo4j 图数据库 结合用于 RAG,并建议使用 mcpomni-connect 作为与 Gemini 兼容的客户端。
- 讨论集中在 MCP 框架内的向量搜索和自定义 CQL 搜索功能。
- A2A 被视为 MCP 技术栈的补充:Google 的 A2A (Agent-to-Agent) API 与 MCP 进行了对比,共识是 Google 将 A2A 定位为补充而非替代品。
- 有人担心 Google 的潜在策略是“将工具层商品化”并主导 Agent 领域。
- 并行工具调用成为瓶颈:为了并行化对多个 MCP servers 的调用,LLM 必须在整个宿主端启用“并行工具调用”,包括
parallel_tool_calls标志。- 这需要确保聊天模板支持并行工具调用,并向 MCP server 发送并行请求。
- Easymcp v0.4.0 发布包管理器:Easymcp 0.4.0 版本引入了 ASGI 风格的进程内 fastmcp 会话、原生 docker 传输、重构的协议实现、新的 mkdocs 和 pytest 设置。
- 此次更新带来了生命周期改进、错误处理以及针对 MCP servers 的包管理器。
- ToolHive 将 MCP Servers 容器化:ToolHive 作为一个 MCP 运行器被引入,它通过容器简化了 MCP servers 的运行,使用命令
thv run <MCP name>,并支持 SSE 和 stdio 服务器。- 该项目旨在统一使用容器运行 MCP servers,并提供安全的选项,详见此博客文章。
HuggingFace Discord
- 55B 以下数据处理模型对决:成员们讨论了 55B 以下最适合数据处理的模型,提到了 mistral small3.1、gemma3 和 qwen32b,并链接到了一个高性能模型。
- 原帖作者澄清他们不需要编码或推理模型。
- 异常检测模型寻找异常情况:一位成员请求异常检测模型,收到了针对该任务微调的通用视觉模型链接,以及一个 GitHub 仓库和一门课程的引用。
- 还引用了 AnomalyGPT 模型。
- Oblix 编排从边缘到云端的 AI:Oblix 被介绍为一种在边缘和云端之间编排 AI 的工具,在边缘端与 Ollama 集成,在云端支持 OpenAI 和 ClaudeAI。
- 创建者正在寻求“CLI 原生、大神级开发者”的反馈。
- Manus AI 发布基于图的学术推荐系统 Web 应用:基于图的学术推荐系统 (GAPRS) 的第三次迭代作为 Web 应用程序发布,使用了 Manus AI。
- 该项目旨在帮助学生撰写论文,并“彻底改变学术论文的变现方式”,详见其硕士论文。
- Cogito:32b 在 Ollama 对决中表现出色:成员们测试了用于 Ollama 的 Cogito:32b 模型,发现 32b 模型优于 Qwen-Coder 32b,甚至优于 Gemma3-27b。
- 指出该模型运行效果非常好。
Notebook LM Discord
- NotebookLM 隐私政策受到质疑:一位用户在注意到系统仅在初始摘要被纠正之后才提供正确的摘要后,对 NotebookLM 的隐私政策提出了质疑,引发了对数据用于训练的担忧。
- 另一位用户指出,由于随机性,AI 工具很少会给出两次相同的答案,且模型可能会将用户的踩(downvotes)标记为冒犯性或不安全。
- NotebookLM 作为笔记应用面临挑战:用户发现 NotebookLM 过度依赖外部来源,由于其原始的笔记功能,限制了其作为独立笔记应用的实用性。
- 用户正请求类似于 Microsoft OneNote 的组织功能,例如带有可自定义阅读顺序的分区组,以改进笔记管理。
- 请求 Google Drive 集成:用户请求与 Google Drive 集成以保存和启动 NotebookLM 笔记本,旨在获得类似于 Google Docs 和 Sheets 的无缝体验。
- 目标是让 NotebookLM 以目前 Google Docs 和 Google Sheets 的方式补充 Google Drive。
- 导入 Microsoft OneNote:是否可行?:用户希望能够将笔记本从 Microsoft OneNote 导入 NotebookLM,包括分区和分区组,可能通过 .onepkg 文件实现。
- 一位用户承认存在法律合规方面的担忧,但将其类比于 Google Drive 导入 Microsoft Word 文档的能力。
- 移动端音频概览(Audio Overviews)故障:用户报告称 2.5 Pro 深度研究功能声称可以生成音频概览,但该功能在移动端失败。
- 据报道,该功能在网页端运行正常,用户建议通过正规渠道报告此问题。
GPU MODE Discord
- 通过 CUTLASS 启用 Flash Attention 3:成员们讨论了在 5090 上从 FP4 开始,建议使用 CUTLASS 以利用 Tensor Cores 并使用 Flash Attention 3,并链接到了一个示例。
- 团队还发布了 torchao 0.10,增加了许多 MX 特性,包括针对 MX dtypes 的 README。
- Linux 发行版辩论引发 NVIDIA 驱动讨论:一位成员询问哪种 Linux 发行版在使用 NVIDIA 驱动时痛苦最少,并就 LDSM(共享内存)指令提出了澄清问题,发布了
SmemCopyAtom = Copy_Atom<SM75_U32x4_LDSM_N, cute::half_t>; auto smem_tiled_copy_A = make_tiled_copy_A(SmemCopyAtom{}, tiled_mma);。- 另一位成员同意每个线程从源加载数据,线程交换数据,然后将数据存储到目的地,并建议使用 warp shuffling 的可能性,并提供了 NVIDIA 文档的链接。
- FSDP2 面临并行化障碍:成员们表示由于 FSDP2 与其他并行化方法相比具有独特的设计,集成起来非常困难。
- 有人指出 Accelerate 中使用的一个黑科技(hack)与当前方法冲突,使集成过程复杂化。
- Mediant32:FP32/BF16 的整数替代方案:一位成员宣布了 Mediant32,这是一种基于有理数(Rationals)、连分数(continued fractions)和 Stern-Brocot 树的实验性替代方案,用于纯整数推理,并提供了分步实现指南。
- Mediant32 使用基于有理数、连分数和 Stern-Brocot 树的数字系统,为数值表示提供了一种新颖的方法。
- DeepCoder 加入开源阵营:一位成员分享了 DeepCoder 的链接,这是一个完全开源的 14B 代码模型,达到了 O3-mini 级别。
- 此外,一位成员注意到 Llama 4 Scout 已添加到 GitHub。
Latent Space Discord
- Together AI 发布 X-Ware.v0:Together AI 在这条推文中宣布发布 X-Ware.v0,社区成员目前正在对其进行测试。
- 社区正在观察 X-Ware.v0 的运行表现。
- Gemiji 的 Pokemon 游戏演示引起关注:一位成员分享了 Gemiji 玩 Pokemon 的链接,引起了积极关注。
- 该帖子链接到了 Kiran Vodrahalli 的一条推文。
- AI Excel 公式引发热议:一位 AI Engineer 分享了一个链接,表达了对 AI/LLM Excel 公式及其广泛应用潜力的兴奋。
- 该成员提到他们一直在思考这种 AI/LLM Excel 公式,并提到一位朋友成功使用了 TextGrad。
- Copilot 成为独立游戏开发助手:成员们探讨了 Microsoft Copilot 在独立游戏开发中的用途,强调 Agent 是有效的工具。
- 代码生成 Agent 工具被认为有助于交付成品,levels io 的 game jam 被引用为令人大开眼界。
- Google 推出 Agent2Agent Protocol (A2A):Google 推出了 Agent2Agent Protocol (A2A) 以增强 Agent 的互操作性,完整规范可在此处查看,一位成员提到他们参与了其中。
- 还提供了一个与 MCP 的对比 (链接)。
Nous Research AI Discord
- DeepCogito LLM 发布:DeepCogito 发布了开源 LLM,规模包括 3B、8B、14B、32B 和 70B,采用了迭代蒸馏与放大(Iterated Distillation and Amplification)策略。
- 每个模型在大多数标准基准测试中都优于同等规模的最佳开源模型,包括来自 LLaMA、DeepSeek 和 Qwen 的对应模型;70B 模型甚至优于新发布的 Llama 4 109B MoE 模型。
- Hermes 微调避开灾难:成员们表示,在 Llama 4 模型上微调新的 Hermes 将是一场灾难,但已经准备好测试来剔除(yeet)糟糕的合并。
- 大家一致认为 Llama 4 在某些方面仍有价值,不可能在所有方面都更差。
- 模型模仿人类辩论风格:一位成员让两个模型互相辩论,观察到它们模仿了人类的辩论方式,“从不试图理解对方的观点,无论论据如何都坚持自己的立场”。
- 模型有选择性地攻击弱点,忽视自身的漏洞,并专注于利用对手的立场。
- Qwen 2.5 1.5B Instruct 训练进展:一位成员正在对 Qwen 2.5 1.5B Instruct 进行 RL,并将 gsm8k 数据集更换为 gsm8k platinum,启用了 RsLora,模型似乎在更少的步数内学习得快得多。
- 改进可能源于使用了歧义更少的数据集,以及在多大程度上归功于使用了 RsLora。
Nomic.ai (GPT4All) Discord
- 建议用户在本地进行 Embedding 以确保安全:成员们正在讨论在本地运行 Embedding 模型和 LLM 的好处,以避免将私密信息发送到远程服务。一位成员分享了一个用于运行 Nomic 本地 Embedding 模型的 Shell 脚本。
- 该脚本使用
$LLAMA_SERVER、$NGL_FLAG、$HOST、$EMBEDDING_PORT和$EMBEDDING_MODEL等变量来配置和运行 Embedding 服务器。
- 该脚本使用
- GPT4All 在本地索引文档:一位用户澄清说,GPT4All 通过对文档进行分块(chunking)和 Embedding 来建立索引,并将相似性的表示存储在私有缓存中,从而避免使用外部服务。
- 他们建议,即使是 Qwen 0.5B 参数模型也能很好地处理本地 Embedding 文档,不过 Qwen 1.5B 效果更好。
- 用户在加载本地 LLM 时遇到困难:一位成员报告在加载本地 LLM 时被卡住,尽管拥有 16GB RAM 和 Intel i7-1255U CPU,怀疑是模型下载出了问题。
- 该用户正在创建一个内部文档工具,不愿将私密文档用于远程服务。
- 使用 Shell 脚本 DIY RAG:一位成员分享了 Shell 脚本示例(
rcd-llm.sh和rcd-llm-get-embeddings.sh),用于获取 Embedding 并向本地 LLM 发送 Prompt,从而创建自定义的 RAG 实现。- 他们建议使用 PostgreSQL 存储 Embedding,而不是依赖远程工具。
- GPT4All 的停止按钮也是它的开始按钮:一位用户询问如何停止 GPT4All 中的文本生成,提到没有看到明显的停止按钮,也无法使用 Ctrl+C。
- 另一位用户指出停止按钮位于右下角,与生成按钮共用同一个按钮。
Modular (Mojo 🔥) Discord
- 新手开启 Mojo 之旅:一位新用户询问如何学习 Mojo 语言,另一位用户引导他们参考 官方 Mojo 文档,认为这是一个很好的起点。
- 该成员还强调了 Mojo 社区,将用户引向 Modular 论坛的 Mojo 板块 和 Discord 上的 general 频道。
- Span 生命周期问题困扰 Mojo Trait:一位成员寻求建议,想在 Mojo 中表达 返回的 Span 的生命周期至少与 self 的生命周期一样长,并提供了 Rust/Mojo 代码示例。
- 回复指出,让 Trait 对 origin 进行泛型化 是一个可能的解决方案,尽管可能需要 Trait 参数支持。
- Mojo 关注无畏并发(Fearless Concurrency):有人提问 Mojo 是否具有类似 Rust 的无畏并发。
- 得到的回答是 Mojo 已经具备了所需的 Borrow Checker 约束,目前仅缺乏 Send/Sync 和最终的并发模型;它最终甚至可能拥有比 Rust 更好的系统。
- MLIR 类型构造遭遇编译时灾难:一位成员报告了在 MAX/Mojo 标准库中使用 MLIR 类型构造中的参数化编译时值(特别是 !llvm.array 和 !llvm.ptr)时遇到的问题,并在 GitHub post 中详细说明了该问题。
- 问题涉及在定义带有编译时参数的结构体(用于 llvm.array 类型)时的解析错误;MLIR 的类型系统似乎无法在此上下文中处理参数化值。
- POP 来救场?:针对 MLIR 问题,另一位成员建议使用 参数化操作方言(Parametric Operations Dialect, POP)。
- 他们建议 Mojo 团队增加一些功能,例如让 __mlir_type[…] 宏接受符号化的编译时值,或者提供类似 __mlir_fold(size) 的辅助工具,以强制将参数评估为字面量 IR 属性。
LlamaIndex Discord
- Auth0 将身份验证接入 GenAI:Auth0 的 GenAI 身份验证现在支持 LlamaIndex,通过 SDK 调用简化了 Agent 工作流中的身份验证集成。
- auth0-ai-llamaindex SDK (Python & Typescript) 支持 FGA-authorized RAG,如此演示所示。
- Agent 通过视觉引用看得更清楚:LlamaIndex 推出了一项关于使用视觉引用 (visual citations)来锚定 Agent 的教程,将生成的答案链接到文档的特定区域。
- 该功能的运行版本可以直接在此处获取。
- 征集推理 LLM 方案:一位成员正在寻求从 Hugging Face 实现推理 LLM (reasoning LLMs) 的官方教程,旨在用于 Hugging Face Space 上的 Docker 应用。
- 目前的讨论中尚未找到解决方案。
- 区块链专家提供支持:一位在区块链领域具有专业知识的软件工程师提供区块链项目协助,擅长 DEX、bridge、NFT marketplace、token launchpad、stable coin、mining 和 staking protocols。
- 该工程师正“尝试学习更多关于 LlamaIndex 的知识”。
- Create Llama 旨在辅助 AI:一位成员建议使用 create-llama 工具来帮助用户通过 LlamaIndex 进行深入研究。
- 该工具旨在帮助快速创建 LlamaIndex 项目。
Cohere Discord
- Cohere 文档引发讨论:一位成员询问了使用 Cohere 生成结构化输出(如书籍列表)的示例,并被引导至 Cohere documentation。
- 讨论强调了利用 Cohere 的资源来获取生成特定输出格式的指导。
- Pydantic Schema 引发询问:一位成员询问了在
response_format中直接使用 Pydantic schema 以及在 Python 中不使用 Cohere 库发送请求的问题。- 共享了 chat reference 的链接,建议切换到 cURL 以获取 API 交互的见解。
- 关于公司列表生成模型的讨论:一位成员就根据给定主题生成公司列表的最佳模型寻求建议。
- 建议指出 Cohere 目前最快且最强大的生成模型是 command。
- 新成员 Aditya 加入,旨在将 AI 应用于 Openchains:Aditya 拥有机器视觉和制造设备控制背景,正在探索 web/AI 并分享了他的当前项目 openchain.earth。
- 他热衷于将 Cohere 的 AI 集成到他的项目中,利用他的技术栈,包括 VS Code, Github Co-Pilot, Flutter, MongoDB, JS 和 Python。
tinygrad (George Hotz) Discord
- PMPP 书籍被推荐用于 GPU 编程:一位成员建议使用 PMPP (第 4 版) 进行 GPU 编程,并征求编译器建议。
- 另一位成员表示他们正在研究这个编译器系列,并且也会学习 LLVM Tutorial。
- METAL 同步问题导致 LLaMA 7B 运行受阻:一位用户在 METAL 后端的 4 个虚拟 GPU 上运行 LLaMA 7B 时遇到了
AssertionError,这与MultiLazyBuffer和Ops.EXPAND有关。- 用户通过在 PR 9761 中移动 tensor 以在采样后保留设备信息,修复了该问题。
- 梯度累积难题已解决:一位用户报告称,在他们的训练程序中调用
backward()不起作用,且在opt.step()之前t.grad为None。- 用户发现,在执行 step 之前调用
zero_grad()修复了梯度累积过程中的t.grad is None问题。
- 用户发现,在执行 step 之前调用
Torchtune Discord
- 来自 Psych 的 Gus 加入了 Torchtune?:一位成员为其 GitHub profile 申请了 Contributor tag,并幽默地引用了电视剧 Psych 中的角色 Gus。
- 另一位成员用 Gus-wave GIF 欢迎新团队成员,开玩笑地提到了电视剧 Psych。
- FSDP 与 PyTorch 协作良好:Torchtune 默认使用等同于 zero3 的配置,并能很好地与 PyTorch distributed features(如 FSDP)结合。
- 一位用户转向使用 torchtune 是为了 避免在尝试组合 deepspeed + pytorch + megatron 时踩坑,并希望 我们不要过度投入到集成和支持其他框架上。
- DeepSpeed Recipe 受到欢迎:团队欢迎导入 torchtune 并托管 DeepSpeed recipe 的仓库,这需要单设备副本并添加 DeepSpeed。
- 团队对此表示热烈肯定。
- 分片策略支持变得简单:支持不同的 sharding strategies 非常直接,用户可以使用 FSDPModule 方法调整 recipe,以在等同于 zero1-2 的模式下进行训练。
- 团队确认,只需对 collectives 进行微调,zero 1-3 都是可以实现的。
LLM Agents (Berkeley MOOC) Discord
- AgentX 导师失踪了?:一位成员在 #mooc-questions 频道询问关于在 AgentX 研究赛道中接收导师反馈的问题。
- 未提供更多信息。
- 占位主题:这是一个占位主题,以满足所需的最小条目数。
- 如果有可用信息,将在此处添加。
Codeium (Windsurf) Discord
- Windsurf 席卷 JetBrains IDEs:Windsurf 发布了 Wave 7,将其 AI agent 带到了 JetBrains IDEs(IntelliJ、WebStorm、PyCharm、GoLand),详情见其 blog post。
- Beta 版本整合了核心的 Cascade 功能,如 Write mode、Chat mode、premium models 和 Terminal integration,未来的更新承诺提供更多功能,如 MCP、Memories、Previews & Deploys(changelog)。
- Codeium 开启新篇章,更名为 Windsurf:公司已正式更名为 Windsurf,告别了经常被拼错的 Codeium,并将其 AI 原生编辑器重命名为 Windsurf Editor,IDE 集成重命名为 Windsurf Plugins。
DSPy Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
第 2 部分:按频道详细摘要和链接
为了便于邮件阅读,完整的频道明细已截断。
如果您喜欢 AInews,请分享给朋友!预谢!