ainews-openai-o3-o4-mini-and-codex-cli
OpenAI o3、o4-mini 和 Codex CLI
OpenAI 推出了 o3 和 o4-mini 模型,重点强调了强化学习规模化扩展(reinforcement-learning scaling)和整体效率的提升,使 o4-mini 在核心指标上更具性价比且表现更佳。
这些模型展示了增强的视觉和工具使用能力,不过这些功能的 API 访问权限尚待开放。此次发布还包括 Codex CLI,这是一个开源编程代理,可与这些模型集成,将自然语言转化为可运行的代码。
ChatGPT Plus、Pro 和 Team 用户现已可以使用这些模型,其中 o3 的价格明显高于 Gemini 2.5 Pro。性能基准测试突显了通过推理侧扩展(scaling inference)带来的智能提升,并将其与 Sonnet 和 Gemini 等模型进行了对比。尽管部分评估结果不尽如人意,但此次发布整体上受到了好评。
在 RL 上投入 10 倍算力就是你所需的一切。
2025年4月15日至4月16日的 AI 新闻。我们为您检查了 9 个 subreddits、449 个 Twitter 账号 和 29 个 Discord (包含 211 个频道和 9942 条消息)。预计节省阅读时间(以 200wpm 计算):782 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
正如周一所暗示的,OpenAI 在一场经典的直播中发布了命名略显尴尬的 o3 和 o4-mini,并附带了一篇 博客文章 和一份 系统卡片 (system card):
https://www.youtube.com/watch?v=sq8GBPUb3rk
核心信息是 RL 扩展 (scaling RL) 的改进:
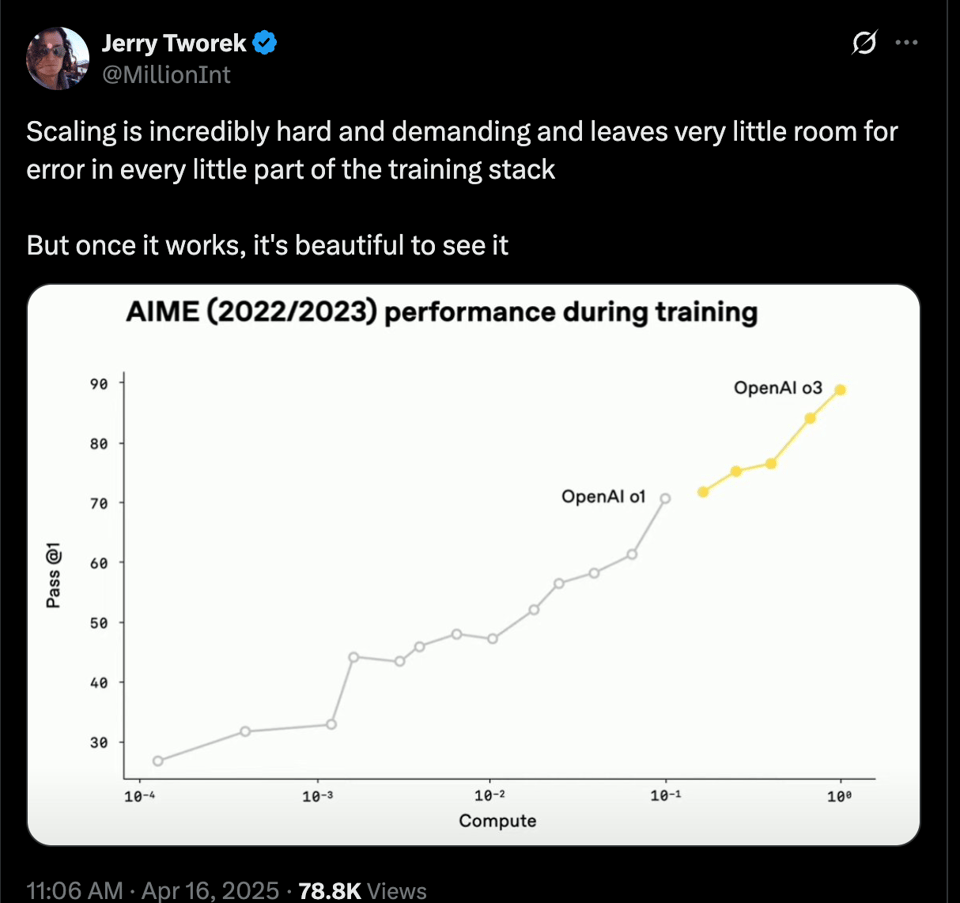
以及 整体效率:
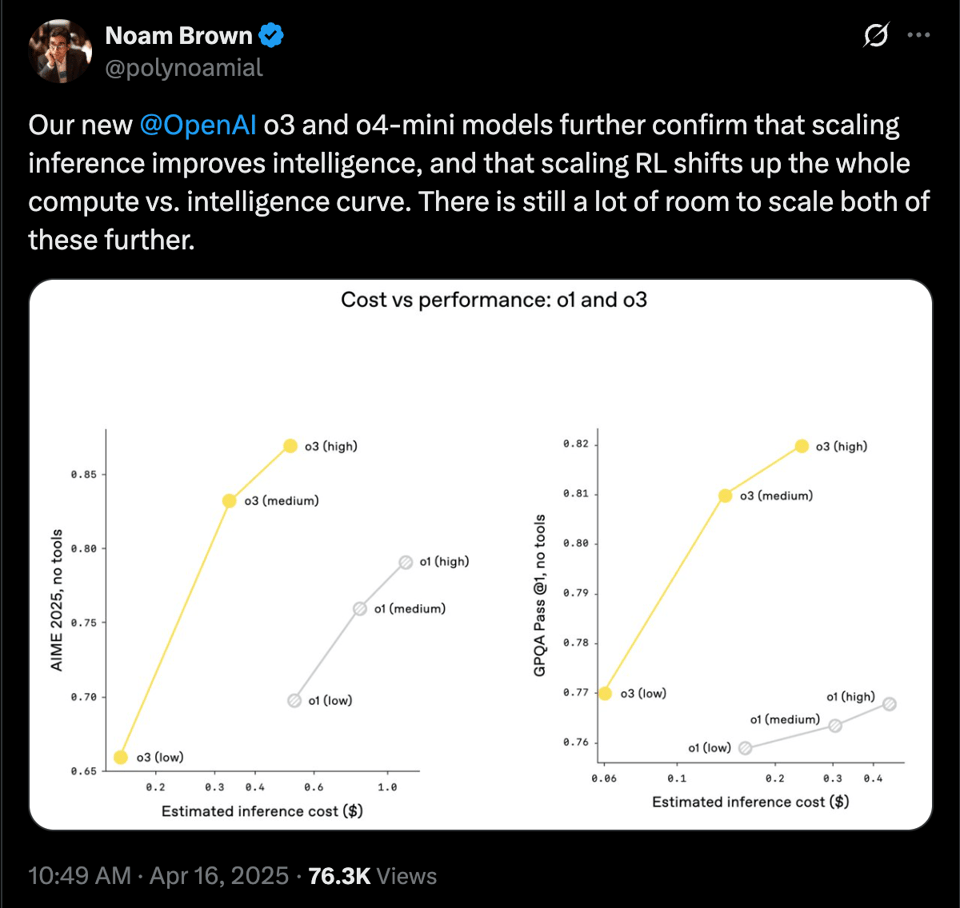
使得 o4-mini 在 OpenAI 优先考虑的各项指标上,相比上一代 更便宜且更强大:
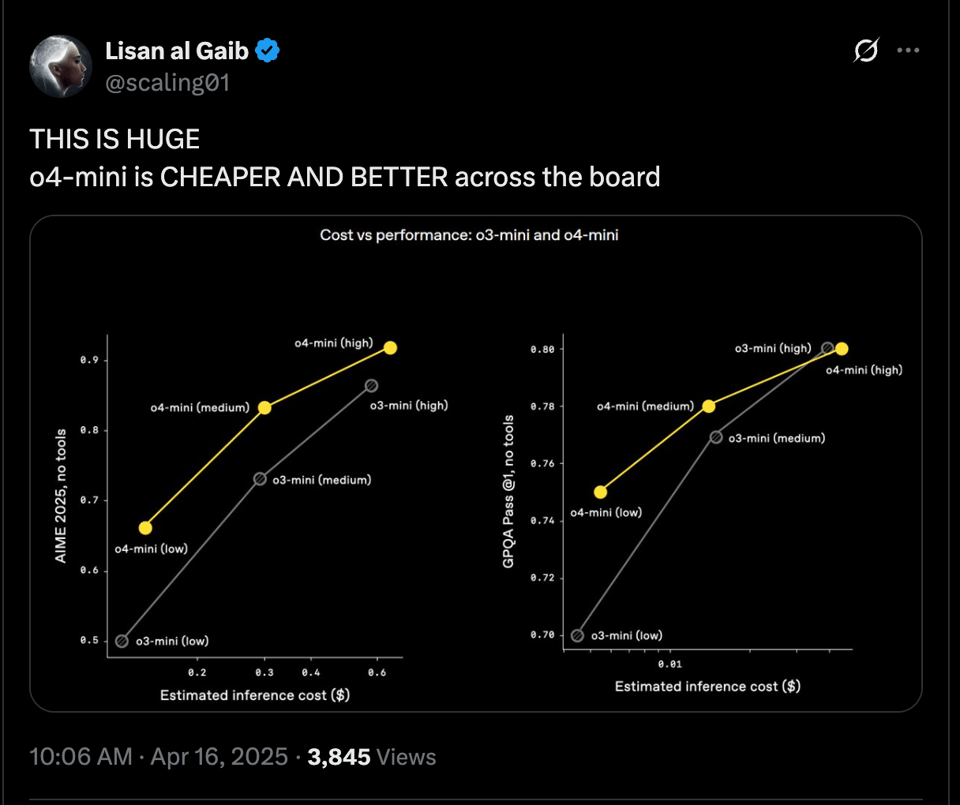
具备 更强的视觉能力 和 更出色的工具使用 (tool use) —— 尽管这些功能尚未在 API 中提供。
Dan Shipper 提供了一份不错的 定性评论

系统卡片显示的 评估结果略逊一筹,但总体而言,这次发布受到了非常热烈的欢迎。
最后的 “One more thing” 是 Codex CLI,它通过 完全开源 胜过了 Claude Code (我们的报道在此):
https://www.youtube.com/watch?v=FUq9qRwrDrI&t=6s
AI Twitter 回顾
新模型发布与更新 (o3, o4-mini, GPT-4.1, Gemini 2.5 Pro, Seedream 3.0)
- OpenAI o3 和 o4-mini 模型:@sama 宣布发布 o3 和 o4-mini,强调了它们在工具使用和多模态理解方面的能力。@OpenAI 将其描述为 更智能、更强大,能够在 ChatGPT 中以 Agent 方式使用并组合每一种工具。@markchen90 强调了它们通过学习如何端到端使用工具(特别是在多模态领域)而增强的性能,而 @gdb 则对其产生有用新想法的能力表示兴奋。
- 访问权限与定价:@OpenAI 指出 ChatGPT Plus、Pro 和 Team 用户将获得 o3、o4-mini 和 o4-mini-high 的访问权限。@aidan_clark_ 认为 名字中带有 “mini” 的模型令人印象深刻。@scaling01 表示 o4-mini 在各方面都更便宜且更好;然而,@scaling01 也指出 o3 的价格比 Gemini 2.5 Pro 贵 4-5 倍。
-
Codex CLI 集成:@sama 展示了 Codex CLI,一个开源的编程 Agent,旨在增强 o3 和 o4-mini 在编程任务中的表现,而 @OpenAIDevs 将其描述为一种能将自然语言转化为可用代码的工具。@kevinweil 和 @swyx 也重点介绍了这个开源编程 Agent。
- 性能与基准测试:@polynoamial 证实了 扩展推理规模(scaling inference)可以提升智能,而 @scaling01 提供了 o3 与 Sonnet 和 Gemini 等其他模型在 GPQA 和 AIME 等基准测试上的详细性能对比。@scaling01 还指出,与 o1 相比,o3 在复现研究论文方面的表现较差。@alexandr_wang 提到 o3 在 SEAL 排行榜上占据绝对统治地位,@aidan_clau 则分享了 o3 优势的总结链接。
- 多模态能力:@OpenAI 强调 o3 和 o4-mini 可以将上传的图像直接集成到它们的思维链(chain of thought)中。@aidan_clau 描述了在罗马的一次体验:o3 进行了推理、调整了图像大小、搜索了互联网,并推断出了用户的位置和度假状态;同时 @kevinweil 注意到模型在思考时会使用工具,例如搜索、编写代码和处理图像。
- 内部功能:@TransluceAI 报告了 o3 模型中存在的虚构和对能力的误导性陈述,包括声称运行代码或使用其无法访问的工具。@Yuchenj_UW 指出 o3 破解了表情符号中的一个谜团,其思维过程中出现了 FUCK YOU 字样。
- GPT-4.1 系列:@OpenAIDevs 宣布了 面向开发者的 GPT-4.1 系列,@skirano 指出该系列似乎正朝着优化现实任务的方向发展。@Scaling01 强调了 GPT-4.1-mini 在某些基准测试中表现优于 GPT-4.1。@aidan_clark_ 称这些模型 非常出色。@ArtificialAnlys 表示 GPT-4.1 系列是一个稳健的升级,在各方面都比 GPT-4o 系列更聪明、更便宜。
- Gemini 2.5 Pro:@omarsar0 表示,与其他模型相比,Gemini 2.5 Pro 在长上下文理解方面表现更好。@_philschmid 指出 Gemini 2.5 Pro 的性价比惊人。
- 字节跳动 Seedream 3.0:@ArtificialAnlys 宣布推出 Seedream 3.0,这是 Artificial Analysis 图像排行榜上新的领先模型。@scaling01 提到 字节跳动 Seed/豆包团队“强得离谱”。@_akhaliq 分享了 Seedream 3.0 技术报告。
使用 FIRE-1 和 OpenAI 的 CodexCLI 进行 Agent 式网页抓取
- FIRE-1:@omarsar0 介绍了 FIRE-1,一个由 Agent 驱动的网页抓取工具,强调了其导航复杂网站和处理动态内容的能力。@omarsar0 进一步解释了它与 scrape API 的简单集成,从而在网页抓取工作流中实现智能交互。@omarsar0 指出了传统网页抓取工具的局限性以及 Agent 式网页抓取工具的前景。
- CodexCLI:@sama 提供了开源 Codex CLI 的链接。@kevinweil 分享了新开源的 Codex CLI 链接。@itsclivetime 已经开始要求模型“查找其中的 bug”,它能在运行任何代码之前捕获约 80% 的 bug。
Agent 实现与工具使用
- 工具使用:@sama 对新模型协同有效使用工具的能力表示惊讶。@omarsar0 指出工具使用使这些模型变得更加实用。@aidan_clau 表示 o3 最大的特性是工具使用,它可以在 CoT(思维链)中通过谷歌搜索、调试并编写 Python 脚本来进行费米估算(Fermi estimates)。
- 工具使用说明:@omarsar0 演示了推理模型如何使用工具,并引用了 AIME 数学竞赛中的一个例子,模型在最初尝试暴力破解后提出了更聪明的解决方案。
- Reachy 2:@ClementDelangue 宣布他们本周开始销售 Reachy 2,这是首款开源人形机器人。
视频生成与多模态 (Veo 2, Kling AI, Liquid)
- Google 的 Veo 2:@Google 在 Gemini Advanced 中推出了 Veo 2 文本生成视频功能,强调其将文本提示词转化为 8 秒电影感视频的能力。@GoogleDeepMind 表示 Veo 2 能让你的剧本栩栩如生,@matvelloso 则表示该功能已在 API 中全面开放。
- 字节跳动的 Liquid:@_akhaliq 分享了字节跳动的 Liquid,这是一个可扩展且统一的多模态生成语言模型。@teortaxesTex 评论道,字节跳动在所有多模态范式上都表现出色。
- 可灵 AI 2.0:@Kling_ai 宣布了 可灵 AI (Kling AI) 2.0 阶段,赋能创作者将有意义的故事变为现实。
可解释性与引导研究
- GoodfireAI 的开源 SAEs:@GoodfireAI 宣布发布首个在 DeepSeek 的 671B 参数推理模型 R1 上训练的开源稀疏自动编码器 (SAEs),为理解和引导模型思维提供了新工具。@GoodfireAI 分享了来自其 SAEs 的早期见解,指出了推理中直觉之外的内部标记以及过度引导(oversteering)的矛盾效应。
- 新数据如何渗透 LLM 知识以及如何稀释它:@_akhaliq 分享了来自 Google 的这篇论文,探讨了学习一个新事实如何导致模型在无关背景下不恰当地应用该知识,以及如何在保留模型学习新信息能力的同时,将这种影响减轻 50-95%。
- 研究人员探索推理数据蒸馏:@omarsar0 总结了关于将顶级 LLM 的密集推理输出蒸馏到更轻量级模型中的研究,以提升多个基准测试的性能。
LLM 开发工具与框架
- PydanticAI:@LiorOnAI 介绍了 PydanticAI,这是一个为 GenAI 应用开发带来类似 FastAPI 设计的新框架。
- LangGraph:@LangChainAI 宣布他们正在开源 LLManager,这是一个通过 human-in-the-loop 驱动的记忆来自动化审批任务的 LangGraph Agent。@LangChainAI 还指出,阿布扎比政府的 AI 助手 TAMM 3.0 是基于 LangGraph 构建的,现在跨平台提供 940 多项服务,并提供个性化、无缝的交互体验。
- RunwayML:@c_valenzuelab 表示 Runway 将走进全球每一个教室。这是 2030 年的目标。
- Hugging Face 工具发布:@ClementDelangue 请人让这个工具能够配合来自 HF 的开源模型在本地运行。@reach_vb 宣布 Cohere 已在 Hub 上可用。
幽默/迷因
- @teortaxesTex 调侃说自己睡过了 OpenAI 的 “AGI” 发布。
- @swyx 分享了一个与 o3 和 o4 发布相关的迷因(meme)。
- @scaling01 发表了多条评论,例如批评 “AGI” 营销,并称其为 “ChatGPT 中过度加工的指令遵循”。
- @aidan_mclau 戏称这是世界冠军级的 Prompt Engineering。
- @goodside 发布了 “外科医生不再是那个男孩的母亲”,这是在玩一个关于 LLM 的著名迷因梗。
- @draecomino 表示诺兰的电影是最受喜爱的电影。
AI Reddit 摘要
/r/LocalLlama 摘要
1. OpenAI 及第三方模型近期发布
-
OpenAI 推出 OpenAI o3 和 o4-mini (Score: 109, Comments: 72): OpenAI 推出了 o 系列的两款新模型 o3 和 o4-mini,在多模态能力(将图像直接集成到推理中)和 Agent 工具使用(通过 API 实现自主的网页/代码/数据/图像工具链)方面有显著提升。根据官方 博客文章,o3 在代码、数学、科学和视觉感知基准测试中达到了 SOTA 水平,并通过大规模 RL 展示了改进的分析严谨性和多步执行能力。社区最关注的问题是仍然缺乏开源发布,尽管 OpenAI 已经开源了其终端集成(通过 Codex),但这与完整的模型权重或研究代码不同。
- 一位评论者指出 OpenAI 缺乏开源模型,批评其发布策略专注于专有利益而非社区贡献——这反映了重视模型开发透明度和可复现性的从业者们持久的挫败感。
- 一个链接强调,虽然 OpenAI 没有公开发布模型,但他们开源了终端集成 (https://github.com/openai/codex),这可能会引起寻求工具链扩展的开发者的兴趣,尽管这并不是模型本身。
- 也有人批评 OpenAI 的模型命名规范,认为这种混乱的方案可能是故意的——掩盖了模型之间的区别,并使寻求匹配特定能力或要求的用户在评估或选择时变得复杂。
-
IBM Granite 3.3 模型 (Score: 312, Comments: 135): IBM 在 Apache 2.0 许可证下发布了 Granite 3.3 语言模型家族,包含 2B 和 8B 参数量的基础模型和指令微调模型(Hugging Face 集合)。这些模型定位于开放社区采用、文本生成任务和 RAG 工作流;此外还提供了语音模型资源(语音模型链接)。社区反馈受到鼓励,但评论中没有出现深入的基准测试、实现细节或技术 Bug 讨论。
- Granite 3.3 模型在紧凑型语言模型中受到好评,特别是得到了 GPU 资源有限的用户的青睐。它们在低端硬件上的可用性被视为一个显著特征,使得在大型模型不切实际的情况下也能使用。用户表示有兴趣评估这一新迭代带来的改进,特别是在资源受限的环境中。
-
字节跳动发布 Liquid 模型系列,多模态自回归模型(类似 GPT-4o) (Score: 285, Comments: 33): 此处链接的图片是字节跳动所谓的 ‘Liquid’ 模型系列的宣传概览,被描述为一个可扩展、统一的多模态自回归 Transformer(类似于 GPT-4o),旨在单一架构内处理文本和图像生成。Reddit 上的讨论对该模型的真实性和技术主张表示怀疑:评论者指出,所谓的发布并非近期之事,Hugging Face 上的公开权重(checkpoint)显然只是一个没有视觉配置的 Gemma 微调版本,且没有可用的真正多模态预训练模型(如描述所述)。此外,尽管宣传材料提到了字节跳动的参与,但没有官方渠道或论文证实这一发布,这表明可能存在归属错误或误导性陈述。
- 一位评论者指出,Liquid 模型系列的官方公告与实际发现的模型工件之间存在不一致:
config.json缺少视觉配置,这表明公开模型并非演示中展示的多模态版本。模型卡片提到了六种模型尺寸(参数量从 0.5B 到 32B),包括一个基于 GEMMA 的 7B 指令微调变体,但据报道这些版本在预期的仓库中缺失,且文档中完全没有提到字节跳动的参与。 - 通过官方在线演示对模型进行的测试表明,其定性表现不尽如人意——尤其是在图像生成任务中,例如渲染手部或真实物体(例如,“草地上的女人效果不佳”以及物体畸形)。这与关于输出解剖结构错误特征的投诉一致,而这通常是衡量多模态模型鲁棒性的基准。
- 一位评论者指出,Liquid 模型系列的官方公告与实际发现的模型工件之间存在不一致:
-
有人得告诉 Nvidia 在这些新模型命名上冷静点。 (Score: 127, Comments: 23): 该帖子幽默地批评了 NVIDIA 日益复杂和冗长的模型命名惯例,例如模拟标签 ‘ULTRA LONG-8B’ 指代具有 ‘100 万、200 万或 400 万扩展上下文长度’ 的模型。图片和评论讽刺了现代模型名称如何像其他产品的品牌推广——这里将其比作避孕套名称——突显了行业向更长、更具营销驱动力的命名惯例发展的趋势。目前没有关于模型本身或其基准测试的实质性技术讨论,仅是对命名法的评论。
- 潜藏着对 Nvidia 不一致或令人困惑的模型命名惯例的批评,建议其产品线可以从更清晰的分类法中受益,以避免产品代际和层级之间的歧义。技术读者指出,准确的命名对于区分模型能力至关重要——尤其是在新架构和变体迅速激增的情况下。
{kind=link}
{kind=link}
2. 大规模模型训练与基准测试
-
INTELLECT-2:首个 32B 参数模型的全球分布式强化学习训练 (Score: 123, Comments: 14): INTELLECT-2 通过在全异构、无许可的硬件上训练 32B 参数模型,开创了去中心化强化学习(RL)的先河,并通过以太坊 Base 测试网进行激励和协调,以实现可验证的完整性并惩罚(slashing)不诚实的贡献者。核心技术组件包括:用于异步分布式 RL 的 prime-RL,用于正确推理证明的 TOPLOC,以及用于稳健、低开销模型分发的 Shardcast。该系统支持通过系统提示词配置“思考预算”(thinking budgets)(从而能够根据具体用例精确控制推理深度),并构建在 QwQ 之上,旨在为大型模型建立一种可扩展、开放的分布式 RL 新范式。热门评论澄清说,发布不等于完成训练,强调了可控推理预算的创新,并询问了用于进一步基准测试的人类反馈(HF)时间表。
- INTELLECT-2 引入了一种机制,用户和开发者可以指定模型的“思考预算(thinking budget)”——即模型在生成解决方案之前用于推理的 tokens 数量,旨在实现可控的计算开销和推理深度。这基于 QwQ 框架,代表了相比具有固定步长推理的标准 Transformer 模型的潜在进步。
-
该项目声称是第一个使用全球分布式强化学习训练的 32B 参数模型。通过与过去社区驱动的分布式训练项目(如受 DeepMind 的 AlphaGo 启发的项目)进行对比,提供了历史背景,但评论者指出,这种规模的硬件需求对个人来说仍然是一个重大障碍。
-
非推理型 LLM 的价格 vs LiveBench 性能 (得分: 127, 评论: 48): 该散点图直观展示了一系列非推理型 LLM 在价格与 LiveBench 性能得分之间的权衡。它对每百万 3:1 混合输入/输出 tokens 的价格使用了对数坐标 X 轴,并使用颜色编码的点显示了一系列私有模型(OpenAI、Google、Anthropic、DeepSeek 等),其中 GPT-4.5 Preview 和 DeepSeek V3 的位置尤为引人注目。评论强调了 Gemma/Gemini 模型在帕累托前沿(Pareto front,即单位价格性能最大化)的统治地位,特别称赞了 Gemma 3 27B 的效率。分析揭示了市场竞争力的明显差异:查看图片。
- 多位评论者指出,Gemma(以及可能的 Gemini)模型目前在非推理型 LLM 基准测试的价格/性能“帕累托前沿”中占据主导地位,这表明它们在成本与性能之间提供了相对于竞争对手的最佳权衡。这意味着在当前格局下,其他替代方案在价格和效率的特定指标上落后于这些模型。
- 讨论强调,Gemma 3 27B 在其规模上提供了强大的基准测试结果,而 Gemini Flash 2.0 模型因其出色的性价比被特别点名,其表现显著优于 Llama 4.1 Nano,后者因价格/性能比差而受到批评。这突显了随着新模型的发布和并排基准测试,LLM 市场的价值主张正在发生变化。
-
我们通过 GRPO 训练了一个模型,让它不断重试“搜索”直到找到所需内容 (得分: 234, 评论: 36): Menlo Research 推出了 ReZero,这是一个 Llama-3.2-3B 变体,通过广义重复策略优化 (GRPO) 和自定义的 retry_reward 函数进行训练,能够高频重试“搜索(search)”工具调用,以最大化搜索任务的结果 (arxiv, github)。与为了减少幻觉而惩罚重复的传统 LLM 微调不同,ReZero 凭经验实现了
46%的得分——是基准线20%的两倍多——这证明了重复如果与搜索和适当的奖励塑造相结合,可以提高事实严谨性,而不是诱发幻觉。所有核心模块,包括奖励函数和验证器,均已开源(见 repo),利用 AutoDidact 和 Unsloth 工具集进行高效训练;预训练检查点已在 HuggingFace 发布。- 一位评论者询问 GRPO 方法中使用的奖励函数或验证器的可用性,表示有兴趣检查或重现发布代码库中的强化机制和评估逻辑。
- 主要的模型训练流水线利用了 AutoDidact 和 Unsloth 等开源工具集,表明实现可能依赖这些框架来编排强化学习或优化推理;两者都被认为是技术可复现性的关键。
- 讨论暗示使用了一种迭代方法,模型反复重试“搜索”查询直到成功,这意味着可能通过上述工具链实现了一个自定义奖励或重试循环——这引发了关于这种反馈驱动的搜索强化方案中效率和资源消耗的问题。
{kind=link}
3. 社区项目与硬件配置
-
Droidrun 现已开源 (Score: 214, Comments: 20): 该帖子宣布 Droidrun 框架——一个根据标题和 Logo 设计推测与 Android 或自动化相关的工具——现已开源并发布在 GitHub 上(仓库链接)。图片本身并非技术性的:它是一个正在奔跑的 Android 角色风格化 Logo,传达了速度、活跃度以及项目的开源性质。帖子或评论中未提供 Benchmark 或实现细节,尽管早期社区兴趣很高,等候名单已超过 900 人。
- 技术讨论强调了 Droidrun 如何实现对 Android 设备的先进自动化控制和脚本编写,使其对关注设备自动化的资深技术用户极具价值。几位评论者对其具体应用场景进行了辩论,指出能够从 GitHub 编译/安装的用户可能不需要 LLM 集成来执行简单操作,这表明该工具的真正优势在于将本地设备控制与自然语言驱动的工作流、脚本编写或 Android 上的批量自动化相结合。
-
是的,你只需花费约 1000 美元即可拥有 160GB VRAM。 (Score: 177, Comments: 78): 原作者记录了一台花费 1157 美元的深度学习推理机配置,使用了十张 AMD Radeon Instinct MI50 GPU(每张 16GB VRAM,兼容 ROCm),安置在专为挖矿设计的 Octominer XULTRA 12 机箱中,并由 3 个 750W 热插拔 PSU 供电。核心软件为 Ubuntu 24.04 及 ROCm 6.3.0(由于 MI50 的支持限制,尽管有评论者指出根据设备表 ROCm 6.4.0 仍可运行),并从源码编译了 llama.cpp 用于推理。Benchmark(llama.cpp,q8 量化)显示 MI50 提供了约 40-41 tokens/s(eval),但 Prompt 吞吐量较差(例如约 300 tokens/s),表现逊于消费级 Nvidia(RTX 3090, 3080Ti),且在多 GPU 和 RPC 使用下性能下降约 50%——例如,MI50@RPC(5 GPU)运行 70B 模型达到约 5 tokens/s,而 3090(5 GPU)约为 10.6 tokens/s,Prompt 评估也慢得多(约 28 ms/token vs 约 1.9 ms/token)。功耗和散热表现出色(待机约 20W/卡,推理约 230W/卡),巨大的 VRAM 池对于超大模型或 MoE 非常有价值。局限性包括 PCIe x1 带宽瓶颈、llama.cpp 的横向扩展限制(对超过 16 GPU 的支持不稳定)以及显著的 RPC 相关效率损失。建议包括将显卡功耗降至 150W 以换取微小的性能损失、尝试 MoE 模型以及潜在的网络/RPC 代码优化。详见原帖中的详细 Benchmark 和配置说明:Reddit 线程。
- 多位用户报告称,尽管文档说明有所不同,MI50 仍可支持最新的 ROCm (6.4.0)——安装正常,且 gfx906(MI50 架构)在 Radeon/Radeon Pro 选项卡下被列为受支持,这为依赖 ROCm 进行 ML 工作负载的潜在买家提供了保障。
- MI50 GPU 的功耗可以被限制以显著降低瓦数(例如,减半至 150W 仅会降低约 20% 的性能),推理速率在低至每张卡 90W 时仍可接受;这对于构建关注功率限制、成本或散热问题的集群(如 10 卡配置)至关重要。
- 据报告,在 1000 美元的 MI50 配置上,70B Q8 Llama 3.3 模型的生成速度约为
4.9-5 tokens/sec,小上下文的首字时间 (TTFT) 为 12 秒,大上下文则长达 2 分钟,为该多 GPU 配置的性能和延迟预期提供了具体的 Benchmark。
-
你最喜欢的无审查模型是什么? (Score: 103, Comments: 71): 讨论集中在经过修改以减少内容过滤的大语言模型(LLM)(“无审查”或“消融”模型),特别是由 huihui-ai 提供的模型,包括 Phi 4 Abliterated、Gemma 3 27B Abliterated 和 Qwen 2.5 32B Abliterated。用户注意到 Phi 4 模型在“消融”后仍保持了其性能/智能,而 Gemma 3 27B 的无审查状态较为温和,除非将其作为金融数据的 RAG 使用。Mistral Small 也因其在没有主要安全层的情况下具有极高的开箱即用许可度而受到关注,无论是否经过无审查处理。有关上述模型的技术配置和量化权重,请参见 huihui-ai 项目仓库。
- 讨论重点介绍了几款特定的无审查模型:Phi 4 Abliterated、Gemma 3 27B Abliterated 以及由 huihui-ai 发布的 Qwen 2.5 32B Abliterated。用户称赞 Phi 4 在 abliteration 处理后智能退化极小,表明其无审查过程背后的方法论非常稳健。
- 据报道,Gemma 3 27B 开箱即用的无审查效果并不理想,但有评论者指出,通过检索增强生成 (RAG) 成功提取了财务建议,尤其是在使用模型变体而非微调版本时。
- 另一位用户指出,无审查过程通常会导致模型性能明显下降,并表示相比于经过重度修改的无审查副本,他们更倾向于将标准模型与越狱提示词 (jailbreak prompts) 结合使用,这反映了社区在平衡去除审查与保持基础能力方面的广泛担忧。
{kind=link}
其他 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. OpenAI o3 和 o4-mini 模型发布与讨论
-
o3 将在 3 小时内发布 (Score: 753, Comments: 186): 该图片是来自 OpenAI 的推文,宣布一场将在“o3”小时后开始的直播活动,暗示即将发布或演示名为“o3”的新模型。这在社区中引发了巨大的期待,技术讨论涉及此前的高昂计算成本(一条评论提到一个 prompt 成本约为 3000 美元),并质疑广泛发布的可能性。 讨论包括对这类高算力模型的部署或商业化的怀疑,一些用户提到之前的扩展和成本问题是公众或大规模访问的技术障碍。
- 一位用户提到了过去在类似模型上生成单个 prompt 的高昂计算成本,引用了约“每个 prompt 3000 美元”的数据,对 o3 在如此高的计算需求下如何发布提出疑问。这暗示了与之前的迭代相比,模型效率、推理成本或基础设施可能有所改进。
- 另一位用户热衷于将 o3 的能力与团队自家的“DeepResearch”模型以及 Google 的“Gemini 2.5 Pro”进行对比,明确强调了对跨基准测试性能的兴趣,并希望这预示着更多即将发布的模型(特别是“o4”系列)。
-
介绍 OpenAI o3 和 o4-mini (Score: 235, Comments: 91): OpenAI 推出了 o3 和 o4-mini 模型。与早期(12月)的数据相比,o3 模型在 GPQA、SWE-bench 和 AIME 等基准测试上的表现略有下降,但在发布博客中指出其价格比 o1 模型更便宜。核心技术讨论集中在 o3 的编程基准测试表现上,据报道略优于 Google 的 Gemini,但 o3 的成本高出 5 倍。关于当前基准测试相关性的讨论也较为广泛,呼吁建立专注于真实世界 Agent 任务性能的评估指标,而非增量式的数学或推理基准。 评论者仔细权衡了 o3 基准性能下降与成本降低之间的关系,一些人指出,实际应用价值应优先于微小的基准差异。尽管具有性能优势,但 o3 相对于 Gemini 的高昂成本也引起了关注。[外部链接摘要] OpenAI 推出了 o3 和 o4-mini,这是其 o 系列推理模型的最新成员,在 Agent 工具使用和多模态能力方面有显著提升。o3 在编程、数学、科学和视觉感知方面设定了新的 SOTA 基准,通过在 ChatGPT 中集成网页搜索、文件分析、Python 执行和图像生成工具,擅长解决复杂的、多方面的问题。两款模型都利用大规模强化学习来实现卓越的推理和指令遵循能力,其中 o4-mini 针对高吞吐量、高性价比的推理进行了优化,在小型模型中处于领先地位——尤其是在数学和编程方面。用户首次可以将图像纳入推理工作流,从而实现集成的视觉-文本问题解决和工具链调用,以处理先进的、真实的和实时的任务。详见:Introducing OpenAI o3 and o4-mini
- GPQA、SWE-bench 和 AIME 等 Benchmark 显示,o3 的得分与 12 月最初发布时相比略有下降,尽管 OpenAI 指出该模型现在比 o1 更便宜;有人推测其性能被刻意降低以减少成本。
- 在 Aider polyglot Benchmark 上,o3-high 得分为 81%,但成本可能非常高(推测约为 200 美元,类似于 o1-high),而 Gemini 2.5 Pro 以更低的价格获得了 73% 的得分。GPQA 得分非常接近(
o3: 83%对比Gemini 2.5 Pro: 84%)。尽管 o3 在数学方面表现出进步(特别是数学 Benchmark 的大幅提升,以及在不使用工具的情况下在 HLE 上略微领先于 Gemini),但相对于 Gemini 的高成本,使其对于关注实际性价比的用户来说吸引力较低。 -
讨论指出,虽然 Benchmark 很有用,但它们在某种程度上被高估了,并不总是能反映模型对日常任务或基于 Agent 的工作流的适用性。人们呼吁建立能更好反映 LLM 实际工作能力或日常用例效用的新 Benchmark。
-
随 o3 发布 o4 mini (Score: 205, Comments: 43): 该图片宣布了 OpenAI 即将举行的活动,将介绍新的 ‘o-series’ 模型,特别是 ‘o3’ 和 ‘o4-mini’。这表明 OpenAI 正在继续扩展其 GPT-4o 之外的模型阵容,对性能和功能都有影响。链接的 YouTube 活动暗示了一次官方的技术发布,尽管图片中几乎没有模型细节。 评论者严厉批评了 OpenAI 混乱且不一致的模型命名惯例,认为名称相近但功能不同的模型(’o3’、’o4-mini’、’4o’)在技术和非技术圈都造成了不必要的困扰。
- 围绕 ‘o3’、’o4’ 和 ‘o4 mini’ 模型命名重叠存在困惑和技术批评,用户指出,为功能差异巨大的模型提供相似的名称,在引用 Benchmark、更新或部署上下文时会产生歧义。
- 提出了关于 ‘o4 mini’ 与 ‘o3’ 相比的实际用例的技术问题,特别是质疑为什么在发布旧模型的同时发布一个更新的、可能增强的模型,尤其是当新版本是 ‘mini’(可能更小或更高效)时,引发了对现实场景或 Benchmark 驱动偏好的讨论。
- 还存在关于欧盟访问 ‘o3’ 和 ‘o4 mini’ 的区域可用性问题,如果得到解答,将为技术读者提供有关部署时间表、推广策略以及符合当地法规或基础设施现实的信息。
-
[已确认] O-4 mini 也将与 O-3 全功能版一同发布! (Score: 298, Comments: 44): 该图片正式宣布了 OpenAI 将于 2025 年 4 月 16 日举行活动,介绍新的 ‘o-series’ 模型——特别是 O-4 mini 和全功能 O-3 模型。它确认了 O-4 的轻量级 ‘mini’ 版本和 O-3 的全功能版本将同时发布。该活动将由 Greg Brockman、Mark Chen 等知名的 OpenAI 工程师和研究员进行演示,暗示了深入的技术揭秘和展示。图片链接。 评论者质疑 OpenAI 模型命名方案的清晰度,一些人表示期待从之前的 ‘o3 mini’ 切换到新的 ‘o4 mini’。命名和模型区分被强调为技术用户中持续存在的困惑点。
- 初始评论列出了参与介绍和演示新 O-series 模型的重要人物,包括 Greg Brockman 和 Mark Chen,这可能预示着一场高规格的发布活动,对于跟踪未来与 O-4 mini 和 O-3 全功能模型相关的技术演示或公告可能具有参考价值。
- 几位用户讨论了从主要使用 ‘O-3 mini high’ 向 ‘O-4 mini’ 的过渡,暗示了迭代改进,并且有一个明确的用户群体正在迁移到更新的模型;这表明人们预期 O-4 mini 在实际使用中可能优于 O-3 mini 或提供额外价值。
- 对 O-series 命名方案有一些轻微的技术批评,用户将其描述为 ‘荒谬’。虽然这不直接涉及技术,但它对模型跟踪、集成和未来的开发周期有影响,混乱的命名法可能会阻碍采用和 API 版本管理。
-
这证实了我们今天将同时获得 o3 和 o4-mini,而不仅仅是 o3。个人非常期待能一睹 o4 系列的风采。 (评分: 225, 评论: 50): 该帖子使用了一张分两行排列的草莓图片(三颗大的,四颗小的),隐喻式地确认了双重发布:o3 和 o4-mini 两个 foundation models 将一同推出(图片:链接)。这个视觉双关语形象地代表了 o3(三颗大的)和 o4-mini(四颗小的)模型,预示着产品线的战略性扩张,可能在性能或尺寸上有所区分。标题和图片语境强调了对预览下一代 o4 系列(而非仅仅是增量更新)的兴奋。 技术讨论集中在对 o3 定价的担忧(可能每月 200 美元)以及对 o4-mini 是否能兑现其科学辅助声明的怀疑与期待,反映了社区对这些模型的实际影响和可访问性的关注。
- MassiveWasabi 讨论了对 o4-mini 模型是否能兑现其在推进科学研究方面的效用声明的好奇,这表明用户对模型在通用 AI 任务之外的性能有着技术预期。
- jkos123 询问了 o3 full 的 API 定价,并将其与之前的层级(如 o1-pro,
$150/month in,$600/month out)进行了直接对比。这表明技术用户在生产和研究的部署选择中非常关注性价比。 - NootropicDiary 推测了 o4 mini high 的编程和 reasoning 能力,质疑其性能是否可能接近 o3 pro。这指向了社区对对比基准测试以及这些模型在开发工作流中实际应用的兴趣。
{kind=link}
{kind=link}
![[已确认] O-4 mini 也将与 O-3 全功能版一同发布!](https://i.redd.it/lnj56ieb18ve1.jpeg){kind=link}
{kind=link}
2. OpenAI o3/o4 vs Gemini 基准测试与对比
-
o3 和 o4 mini 对比 Gemini 2.5 Pro 的基准测试 (评分: 340, 评论: 169): 该帖子在各项任务中对 o3、o4-mini 和 Gemini 2.5 Pro 模型的性能进行了基准测试。在数学基准测试 (AIME 2024/2025) 中,o4-mini 的表现略优于 Gemini 2.5 Pro 和 o3 (o4-mini 在 AIME 2024 上为
93.4%,o3 为91.6%,Gemini 2.5 Pro 为92%)。在知识与推理 (GPQA, HLE, MMMU) 方面,Gemini 2.5 Pro 在 GPQA (84.0%) 上领先,o3 在 HLE (20.32%) 和 MMMU (82.9%) 上领先。在编程任务 (SWE, Aider) 中,o3 在 SWE (69.1%) 和 Aider (81.3%) 上表现最佳。定价也是重点,o4-mini 明显比其他模型更便宜 ($1.1/$4.4)。图表由 Gemini 2.5 Pro 生成。 评论者指出图表 y 轴缩放可能存在误导,并强调 Google 和 OpenAI 模型的性能现在非常接近,尽管 Google 的节奏和资源优势被视为他们可能很快超越 OpenAI 的指标。- 讨论强调了仅通过每百万 token 的价格来比较 AI 模型 token 成本的局限性,指出不同模型之间的输出长度(reasoning tokens)差异巨大,从而导致成本比较失真。相反,应该分析运行基准测试的实际美元成本以确定真实支出,而非仅看面向消费者的零售价格。文中强调了“Cost”(运行模型的运营、硬件和基础设施成本)与“Price”(公司收取的访问费用)之间的区别,指出专有模型(如 OpenAI、Google)掩盖了运行成本,而开源模型则允许更透明的评估,因为用户可以直接测量或估算硬件开销。该帖子还提醒,公司的定价策略(例如 Google 可能利用 TPU 优势或出于市场份额目标设定人为低价)使公平比较变得更加复杂。建议未来的基准测试采用一种稳健、标准化的分析方案,将运行成本、消费者价格与性能表现综合考量。
-
Comparison: OpenAI o1, o3-mini, o3, o4-mini and Gemini 2.5 Pro (Score: 195, Comments: 44): 该图片提供了 OpenAI 的 o1, o3-mini, o3, o4-mini 模型与 Google 的 Gemini 2.5 Pro 之间的直接基准测试对比,涵盖了 AIME (数学), Codeforces 编程, GPQA (科学问答) 以及多项推理/逻辑任务。表格显示 **OpenAI 的 o4-mini 在工具辅助数学任务中领先,而 Gemini 2.5 Pro 在某些编程和科学基准测试(如 LiveCodeBench v5)中表现出色。不同任务之间存在显著差异,反映了模型优势如何随领域而变化;OpenAI 的中端模型(如 o3)在用户体验中展示了强大的全应用实际代码生成能力。** 热门评论强调了 o4-mini 在数学方面的统治地位,认为随着模型超越人类水平,基准测试的相关性正在减弱,并指出需要关注定价背景。有用户通过亲身经历赞扬了 o3 在代码生成方面的实际应用价值。
- Gemini 2.5 Pro 被描述为通常与 OpenAI 的 o4-mini 相当,但在数学方面除外,o4-mini 在该领域领先。(“所以 Gemini 2.5 ~ o4-mini,除了数学方面 o4-mini 领先”)
- 用户对 o3 的测试体验表明,它可以单次输出生成完整的、可运行的应用程序,这表明与之前的模型相比,代码合成(code synthesis)取得了重大进展。(“o3 相当具有突破性,一次性就能吐出完整的、可运行的应用”)
- 注意到在 “Humanity’s Last Exam” 基准测试上的快速进步:与在此类测试中平均得分约 30%(在其专业领域约为 80%)的博士生相比,当前模型的得分代表了短时间内的显著进步。
-
If o3 from OpenAI isn’t better than Gemini 2.5, would you say Google has secured the lead? (Score: 211, Comments: 131): 该帖子质疑,如果 OpenAI 的 o3 模型在基准测试和实际场景中未能超越 Google 的 Gemini 2.5,Google 是否已实际上成为 state-of-the-art LLM 的行业领导者。热门评论指出,“最佳模型”的地位取决于具体领域,Gemini 2.5 目前在某些用户中处于领先地位,而一个关键的权衡可能是 o3 预期的高性能伴随着显著更高的成本(根据 o1 之前的定价并从 ARC-AGI 基准测试推断,在实际任务中成本约为 Gemini 的 “15 倍”)。 评论者争论基准测试中的短期优势是否等同于长期领导地位,并指出 OpenAI 顶级模型高昂的运营成本是一个限制因素,同时也承认在特定应用中,性能可能证明这些支出是合理的。
- 评论者指出,虽然 Google 的 Gemini 2.5 目前极具竞争力且可能处于领先地位,但这种领先并非在所有领域都均匀分布——不同的模型可能在不同的任务或环境中表现出色。
- 强调的一个技术问题是 OpenAI 即将推出的 o3 与 Gemini 2.5 之间的预期成本差异,提到 o3 在实际任务中的成本可能高达 “约 15 倍”(基于历史 ARC-AGI 基准测试和 o1 定价)。这引发了人们对 o3 相对于 Gemini 2.5 在实际部署中的可行性的担忧,特别是对于成本敏感型应用。
- 人们认可了像 Gemma 3 这样的离线模型,它们被赞誉为强大的离线 AI 解决方案,这表明 Google 在 Cloud 和 Edge AI 领域都有广泛布局,尽管一些用户指出 Google 目前的 UI/UX 和响应的“人性化”程度与 OpenAI 相比仍有改进空间。
{kind=link}
3. HiDream & ComfyUI 模型更新与工具
-
HiDream ComfyUI 终于支持低 VRAM (Score: 166, Comments: 117): HiDream 的扩散图像生成工作流的低 VRAM 版本现已在 ComfyUI 上可用,其特点是采用了 GGUF 格式模型 (HiDream-I1-Dev-gguf)、ComfyUI 的 GGUF 加载器 (ComfyUI-GGUF),以及兼容的文本编码器 (text encoders) 和 VAE (链接, VAE 链接)。该工作流支持备选 VAE(例如 Flux),详细信息记录在此。 一位用户分享了在 RTX3060 上使用 SageAttention 和 Torch Compile 的性能数据:分辨率为
768x1344的图像在 18 步下用时 100 秒生成。评论强调了新 AI 工作流过时速度之快,以及紧跟新发布版本的难度。- 一位用户报告成功在 RTX3060 上使用 SageAttention 和 Torch Compile 运行该模型。该配置在 18 步内以 100 秒的时间生成了分辨率为 768x1344 的图像,证明了低 VRAM 显卡通过优化配置可以达到合理的生成速度。
- 有一项对比评估表明,Flux 的微调版 (finetunes) 目前比该版本效果更好,突显了不同模型变体之间持续的基准测试和主观质量争论。
- 针对在 Apple Silicon (M1 Mac) 上运行的具体硬件兼容性问题被提出,这可能会引起旨在支持更广泛平台的开发者的兴趣。
-
ComfyUI 新更新中增加了对 HiDream 的基础支持(链接至 Commit) (Score: 152, Comments: 45): ComfyUI 在最近的一次提交中增加了对 HiDream 模型系列的基础支持,要求用户使用新的 QuadrupleCLIPLoader 节点和 CFG=1.0 的 LCM 采样器以获得最佳性能。GGUF 格式的 HiDream 模型和加载器节点(来自 City96)现已可用(模型,加载器),同时还包括所需的文本编码器 (列表) 和基础工作流;用户必须更新 ComfyUI 以获取必要的节点。SwarmUI 也集成了 HiDream I1 支持 (文档)。基准测试:RTX 3060 渲染一张 768x768 的图像需要 96 秒;RTX 4090 每张图像耗时 10-15 秒(显存占用显著更高);质量与当代模型相当,但有明显的 JPEG 伪影,且文件体积明显大于替代方案。 技术争论集中在:与 Flux Dev 或 SD3.5 等模型相比,HiDream 带来的增量质量提升是否足以抵消其高显存占用和大文件体积,一些人指出无审查输出和伪影既是显著特征也是潜在缺点。[外部链接摘要] ComfyUI 仓库的这次提交通过在
comfy/ldm/hidream/下添加专用实现,引入了对 HiDream I1 模型的基础支持。更改包括在model_base.py中新增模型封装器(HiDream子类)、hidream/model.py中针对 HiDream 架构的大量逻辑、相关的文本编码器、检测模块以及用于 ComfyUI 工作流的自定义节点。此次集成使用户能够在 ComfyUI 框架内部署和实验 HiDream I1 模型,完善了模型支持生态系统。原始链接:https://github.com/comfyanonymous/ComfyUI/commit/9ad792f92706e2179c58b2e5348164acafa69288 - HiDream 现在可以在 ComfyUI 中配合 GGUF 模型使用,这需要一个新的 QuadrupleCLIPLoader 节点和 Comfy 中更新的 text encoder 节点。模型文件、加载器节点和示例工作流已在链接资源中提供。为了获得最佳采样效果,建议使用 CFG 1.0 的 LCM 采样器。source/links
- 不同 GPU 的基准测试(例如 RTX 4090 vs 3060)显示,在 3060 上生成 768x768 图像的时间为
1:36,而在使用 SwarmUI 的 4090 上每张图像仅需10-15s。内存占用显著高于 Flux Dev 等现代竞争对手(Flux Dev 通过 Nunchaku 优化可达到每张图 4-5 秒),这主要归因于新的 QuadrupleClipLoader 节点。 - 讨论强调了模型采用的权衡:虽然 HiDream 显示出渐进式的质量提升,但其文件大小和高 VRAM 需求(参考至少 12GB)限制了其相比 Flux 或 SD35 等替代方案的更广泛可用性。人们质疑更高的资源消耗是否能证明质量提升的合理性,特别是考虑到大多数消费级 GPU 的 VRAM 限制。
AI Discord Recap
Gemini 2.0 Flash Exp 对摘要的摘要总结
主题 1:OpenAI 的新模型:O3、O4-Mini 和 Codex CLI
- OpenAI 为强力推理发布 Codex CLI:OpenAI 发布了 Codex CLI,这是一个利用 o3 和 o4-mini 等模型的轻量级编程 Agent,即将支持 GPT-4,详见其 system card。Codex CLI 使用 tool calling 进行暴力推理,适用于在 geoguessr.com 上回答问题等任务。
- 成员赞赏 O3 和 O4-Mini 的性能,并指出局限性:测试 o3 和 o4 mini 的社区成员发现,o4 mini 在 OpenAI 的面试选择题上表现最好,而 o3 在一个非琐碎的真实世界 PHP 任务中表现出色,得分 10/10。尽管通过了基准测试,但据 X 报道,它也存在与 o3 相同的 Alaska 问题,但在 Temperature 设置为 0.4 或更低时,其推理能力非常出色。
- LlamaIndex、Windsurf 集成 O3/O4 Mini:LlamaIndex 现在支持 OpenAI 的 o3 和 o4-mini 模型,可通过
pip install -U llama-index-llms-openai访问,更多详情点击此处。o4-mini 现在已在 Windsurf 中可用,根据其社交媒体公告,o4-mini-medium 和 o4-mini-high 模型将在 4 月 16 日至 21 日 期间在所有 Windsurf 方案中免费提供。
主题 2:新兴硬件和性能挑战
- RTX 5090 Matmul 表现令人失望,需要更大的矩阵:在乘以两个大小为 2048x2048 的 fp16 矩阵时,RTX 5090 上的 matmul 初始实现产生的性能大致等于 RTX 4090,测试可以在 官方教程代码 中找到。建议使用更大的矩阵(如 16384 x 16384)进行测试,并尝试使用 autotune。
- AMD 云供应商支持 Profiling 和 Observability:一家 AMD 云提供内置的 Profiling、Observability 和监控功能,尽管它可能不是按需提供的,这引发了关于创建云供应商层级列表以激励更好的 hardware counters 的辩论。在讨论中,一位用户开玩笑地威胁要制作一个云供应商层级列表来羞辱那些不提供 hardware counters 的人,以此作为说服 AMD 或其他供应商提供更好 hardware counters 的手段。
- NVMe SSD 大幅提升 LM Studio 中的模型加载速度:使用 NVMe SSD 可显著加快 LM Studio 中的模型加载速度,观察到的速度达到 5.7GB/s,尽管拥有多个 NVMe SSD 对游戏没有显著影响。一位用户强调他们的系统中有三个 NVMe SSD,但遗憾的是,它们似乎对游戏没有太大影响。
主题 3:Gemini 2.5 Pro 及相关 API 讨论
- Gemini 2.5 Pro 速率限制令免费层级用户沮丧:用户讨论了 Gemini 2.5 Pro 免费层级的严格速率限制,指出其限制较小,为每天 80 条消息,若没有 $10 余额则会降至 50 条。一位用户表达了沮丧,称由于 5% 的存款手续费,他们需要额外支付 $0.35 才能达到提高速率限制所需的最低 $10 要求。
- 关于 Gemini 2.5 Pro 上下文窗口缩减的传言出现:有传言称 Gemini 2.5 Pro 的上下文窗口已缩减至 250K,尽管官方文档仍标明为 1M,不过一位成员指出,事实标准始终以 GCP 控制台为准。
- Gemini 2.5 Pro API 隐藏“思考内容”:引发辩论:成员们就 Gemini 2.5 Pro API 是否返回思考内容展开辩论,指出官方文档称不返回,尽管思考 Token(thought tokens)会被计费。尽管如此,思考 Token 仍被计算在内,这引发了关于防止模型蒸馏或隐藏“不良”内容的理论。
主题 4:DeepSeek 模型与 Latent Attention
- DeepSeek R3 和 R4 模型的发布令 OpenRouter 社区兴奋:用户期待 DeepSeek 的 R3 和 R4 模型即将发布,这在 OpenRouter 社区引起了轰动,人们希望这些模型能超越 OpenAI 的 o3。一位用户表示:“DeepSeek 只是价格亲民,实际表现并没有那么出色。”
- DeepSeek-V3 的 Latent Attention 机制研究:一位成员发现 DeepSeek-V3 的 Multihead Latent Attention 在 512 维空间计算注意力,尽管 Head Size 仅为 128,这使得计算成本增加了 4 倍。虽然这个细节可能被忽视,但当 memory bandwidth 是主要瓶颈时,这种增加的计算成本并不是问题。
- 选择 DeepSeek Distill 进行思维链推理:由于 DeepSeek Distill 模型已具备Chain of Thought (CoT) 能力,因此被推荐用于 SFT;根据 DeepSeek 的论文,使用像 Qwen2.5 7B 这样的基座模型虽然可行,但不够直接。一位成员建议使用 DeepSeek Distill 模型进行 SFT,因为它具备现成的 Chain of Thought (CoT) 能力,而根据 DeepSeek 的论文,使用 Qwen2.5 7B 这样的基座模型虽然可行,但效果不如前者直接。
主题 5:社区与伦理讨论
- OpenRouter 隐私政策更新引发辩论:OpenRouter 隐私政策的更新引发了担忧,因为它似乎会记录 LLM 输入,其中一行写道:“您输入到服务中的任何包含个人数据的文本或数据(‘输入’)也将被我们收集”。一位 OpenRouter 代表表示:“我们可以改进这里的语言表述,我们默认仍不存储您的输入或输出”,并承诺很快会澄清条款。
- AI 滥用警报响起,担忧邪恶用途:关于 AI 可能被用于邪恶用途的讨论浮出水面,特别是在 VR 领域,一位成员担心其被用于“极其糟糕的事情”,并讨论了版权侵权和 Deepfakes。这引发了围绕版权侵权和生成 Deepfakes 的对话,同时人们仍在尝试寻找规避方法。
- Manus.im 社区行为引发辩论:Manus.im 社区成员在一次激烈的交流后讨论了社区行为规范,重点在于如何在提供帮助与鼓励自力更生之间取得平衡,这导致一名用户被封禁。人们对“被认为缺乏帮助”与“自主学习及避免依赖‘施舍’的重要性”之间的矛盾表达了担忧。
第 1 部分:Discord 高层级摘要
LMArena Discord
- OpenAI 发布轻量级编程 Agent:Codex CLI:OpenAI 推出了 Codex CLI,这是一个使用 o3 和 o4-mini 等模型的轻量级编程 Agent,即将支持 GPT-4 模型,详见其 system card。
- 一位成员指出,它可能使用 tool calling 进行暴力推理,例如回答 geoguessr.com 上的问题。
- o3 和 o4 mini 展现潜力:测试 OpenAI o3 和 o4 mini 模型的成员发现,o4 mini 在 OpenAI 的面试选择题中表现最好,而 o3 在一项“非琐碎的真实世界 PHP 任务”中表现出色,获得了 10/10 的评分。
- 尽管有基准测试,但它仍存在 X 上报道的与 o3 相同的 Alaska problem,不过在 temperature 设置为 0.4 或更低时,其推理能力非常出色。
- OpenAI 考虑以 30 亿美元收购 Windsurf:据 Bloomberg 报道,OpenAI 据传正在洽谈以约 30 亿美元收购 Windsurf。
- 潜在的收购引发了关于 OpenAI 是否应该自己构建此类工具的争论,特别是考虑到 Gemini 在 Roblox 中使用的 finite state machine pathfinding 所展示的集成优势。
- 探讨 DeepSeek-R1 参数设置:讨论了 DeepSeek-R1 的配置,参考了 GitHub readme,强调将 temperature 设置在 0.5-0.7 之间,避免使用 system prompts,并为数学问题加入“reason step by step”的指令。
- 成员们赞扬了其性能和引用来源的能力,但也指出了对来源幻觉(source hallucination)的担忧,一位成员表示“距离 AGI 还有一段路要走”。
- o3 的工具使用为新基准测试铺平道路:成员们强调了 o3 模型的工具使用能力,例如 图像推理缩放功能,尽管一位成员表示竞技场中“tool use 尚未推出”。
- 工具的使用引发了关于创建基准测试的讨论,特别是与 GeoGuessr 相关的基准测试,可能采用新的测试框架或批量测试,尽管成本可能很高。
Manus.im Discord Discord
- Manus 额度消耗受到关注:用户对 Manus 额度使用表示担忧,一位用户指出他们花费了 3900 个额度,两周后仅剩 500 个。
- 另一位用户提到在同一时间段内花费了近 2 万个额度,强调即使 Manus 拥有强大的功能,也需要极高的 ROI。
- Kling 的图像生成引起轰动:成员们赞扬了 Kling 惊人的图像生成能力,一位成员在注册后形容 Kling 是“魔鬼级的”和“游戏规则改变者”。
- 另一位成员表示 Kling 1.6 已经发布,并形容其能力为“我的天呐(holy mother of f)”。
- 社区礼仪引发辩论:成员们在一次激烈的交流后讨论了社区行为规范,重点在于如何在提供帮助与鼓励自力更生之间取得平衡,这导致一名用户被封禁。
- 人们对“被认为缺乏帮助”与“自主学习及避免依赖‘现成答案(hand outs)’的重要性”之间的矛盾表示担忧。
- Copilot 获得认可:成员们讨论了 Copilot 彻底改变 AI 的潜力,尤其是 Pro 版本能够执行复杂任务。
- 成员们表示 Copilot 可以创作“不错的艺术作品”和其他复杂任务,简直是个“猛兽(beast)”。
- AI 误用引发警报:成员们对 AI 用于邪恶目的的潜力表示警惕,特别是在 VR 领域。
- 讨论转向了版权侵权和生成 deepfakes,以及对潜在防护措施的探索。
aider (Paul Gauthier) Discord
- Aider 的早期提交引发笑话:开发者们正在分享关于 Aider 的笑话,嘲讽它在辅助编程时倾向于过早 commit 并导致 merge conflicts。
- 一个笑话把 Aider 的辅助比作重写你的仓库,就像它刚经历了一场糟糕的离婚一样,而另一个笑话则暗示使用它会导致
git blame只会显示 ‘why?’。
- 一个笑话把 Aider 的辅助比作重写你的仓库,就像它刚经历了一场糟糕的离婚一样,而另一个笑话则暗示使用它会导致
- 违反 ToS 的人如履薄冰:成员们讨论了违反服务条款 (ToS) 的后果,一名用户声称已经违反 ToS 3 个月而没有被封号。
- 讨论中提出了对潜在封号活动的担忧,以及遵守平台规则的重要性。
- Gemini 2.5 Pro 缩小了上下文窗口?:有传言称 Gemini 2.5 Pro 的上下文窗口已缩减至 250K,尽管官方文档仍标注为 1M。
- 一名成员指出,事实来源始终是 GCP console。
- OpenAI 的 o3 和 o4 Mini 亮相:OpenAI 推出了 o3 和 o4-mini,可在 API 和模型选择器中使用,取代了 o1、o3-mini 和 o3-mini-high。
- 官方公告指出,o3-pro 预计在几周内推出,并提供完整的工具支持,目前的 Pro 用户仍可访问 o1-pro。
- Aider 添加文件的挫败感被记录:一名成员报告了 Aider 的流程因请求添加文件而中断的问题,导致需要重新发送上下文并重新编辑,并在这篇 Discord 帖子中进行了记录。
- 这种中断需要不断地重新发送上下文和重新编辑。
OpenRouter (Alex Atallah) Discord
- OpenAI 的 O3 到来,需要 BYOK:OpenAI O3 模型现已在 OpenRouter 上线,具有 200K token 的上下文长度,价格为输入:$10.00/M tokens,输出:$40.00/M tokens,需要组织验证和 BYOK。
- 成员们讨论了 O3 模型是否“值得”,或者他们是否应该等待即将推出的 DeepSeek 模型。
- O4-Mini 作为低成本选项出现:OpenAI O4-mini 模型现已在 OpenRouter 上线,提供 200K token 的上下文长度,价格为输入:$1.10/M tokens,输出:$4.40/M tokens,但用户报告了图像识别问题,例如将 “沙漠图片” 识别为 “斯温顿机车厂(Swindon Locomotive Works)”。
- 一名 OpenRouter 代表确认 “图像输入现在已修复”。
- Deepseek R3 和 R4 模型热度来袭:闲聊显示 Deepseek 的 R3 和 R4 模型 计划即将发布。
- 一名用户表示希望在模型发布时 “让每个人都忘记 o3”,而另一名用户则表示 “Deepseek 只是便宜,实际表现并没那么好”。
- Gemini 2.5 Pro 速率限制令用户沮丧:用户讨论了 Gemini 2.5 Pro 免费层的严格速率限制,指出其限制较小,为 每天 80 条消息,如果没有 $10 余额 则降至 50 条,并受 Google 自身限制的约束。
- 一名用户表达了不满,称由于 5% 的存款手续费,他们需要额外支付 $0.35 才能满足增加速率限制所需的最低 $10 要求。
- OpenRouter 隐私政策更新引发辩论:OpenRouter 隐私政策的更新引发了担忧,因为它似乎会记录 LLM 输入,其中一行写道:“您输入到服务中的任何包含个人数据的文本或数据(‘输入’)也将被我们收集”。
- 一名 OpenRouter 代表表示:“我们可以改进这里的语言表述,我们默认仍不存储您的输入或输出”,并承诺很快会澄清条款。
OpenAI Discord
- GPT-4.1 Batch 缺失引发困扰:成员报告称 gpt-4.1-2025-04-14-batch 模型无法通过 API 使用,尽管用户已启用 gpt-4.1,而其他成员尝试在 API 调用中使用
model: "gpt-4.1"。- 一位成员建议查看 limits 页面 以获取特定账户的详细信息,但问题仍然存在。
- Veo 2 视频:恐怖还是惊艳?:一位用户分享了 由 Veo 2 生成的视频,引发了关于其真实感和可能用途的评论。
- 虽然一位用户评论说 那个舌头把我吓坏了,但其他人讨论了 Gemini 系列的使用案例,许多人更喜欢它的创意写作和记忆能力。
- O3 迅速编写康威生命游戏:O3 在 4 分钟 内编写了康威生命游戏(Conway’s Game of Life),并首次尝试就编译运行成功,而 O3 mini high 在几个月前完成同样任务耗时 8 分钟且存在 Bug。
- 成员们讨论了这些编程改进的意义,以及 O3 为复杂应用生成代码和库的能力。
- 据报道 O3 和 O4-mini 生成看似可信但错误的信息:用户报告 O4-mini 和 O3 的 hallucinations(幻觉)有所增加,一些人指出它会编造看似可信但错误的信息。
- 一位用户在通过 API 测试 O4-mini 后指出,模型“想要”给出回应,因为那是它的目的,结果发现它编造了商业地址,并且对自定义搜索解决方案反应不佳。
- 清理库照片成为可能!:一位成员寻求关于从库中删除图片的帮助,另一位用户提供了 ChatGPT Image Library 帮助文章 的链接。
- 这项新功能适用于移动端和 chatgpt.com 上的 Free, Plus 和 Pro 用户。
Cursor Community Discord
- 请求实时 Token 计算:一位用户请求在编辑器内实时查看 token 计算,或者至少能频繁更新。
- 他们指出,鉴于目前需要在网站上监控 Token 使用情况,这将非常有用。
- Gemini 的文件读取能力受到质疑:一位用户质疑 Gemini 在使用
thing功能并声称读取文件时,是否真的读取了文件,并附上了 截图参考。- 讨论围绕 Gemini 在 Cursor 环境中文件读取能力的准确性和可靠性展开。
- Agent 模式下的终端命令故障:多位用户报告了 Agent Mode 中的一个问题,即第一个终端命令无需干预即可运行完成,但随后的命令需要手动取消。
- 这被描述为一个 长期存在的 Bug,影响了 Agent Mode 执行自动化任务的可用性。
- GPT 4.1 的提示词精准度:用户对比了 GPT 4.1、Claude 3.7 和 Gemini,指出 GPT 4.1 在遵循提示词方面非常严格,而 Claude 3.7 往往做得比要求的更多。
- 他们发现 Gemini 在两者之间取得了平衡,在提示词遵循方面提供了一个折中方案。
- 提议使用 Manifests 以实现快速表单填充:用户建议增加一项新功能,通过 Manifests 批量输入预设信息,以便轻松复制账户和服务。
- 他们指出这将极大地协助 ASI/AGI 集群部署,并表示:我们需要 ASI-Godsend 尽快实现,而这是轻松帮助实现它的方法。
{kind=link}
Unsloth AI (Daniel Han) Discord
- Qwen2.5-VL 吞吐量推测:成员们寻求在 L40 上通过 vLLM 使用 Unsloth Dynamic 4-bit quant 的 Qwen2.5-VL-7B 和 Qwen2.5-VL-32B 的吞吐量估算,同时询问了 vLLM 对 vision model 的支持情况。
- 该查询旨在评估模型在资源受限环境中的实际性能。
- Gemini 2.5 Pro 隐藏思考过程:成员们讨论了 Gemini 2.5 Pro API 是否返回 thinking content(思考内容),并注意到官方文档显示不返回。
- 尽管如此,thought tokens 仍被计费,这引发了关于防止 distillation(蒸馏)或隐藏“不良”内容的理论猜测。
- Llama 3.1 Tool Calling 难题:一位用户在针对 tool calling 微调 Llama 3.1 8B 时寻求数据集格式化方面的帮助,其 assistant 响应格式为
[LLM Response Text ]{"parameter_name": "parameter_value"}。- 该用户对 GitHub Issues 上缺乏可靠信息表示沮丧,这表明在使模型适配特定任务时存在普遍挑战。
- Unsloth Notebook 微调失败:一位用户报告称,在使用 Unsloth 的 Llama model notebook 进行微调后,模型的输出与 ground truth 毫无相似之处。
- 具体而言,一个关于天文光波长的问题得到了关于 Doppler effect(多普勒效应)的回答,这表明训练与预期结果之间存在脱节。
- DeepSeek-V3 Latent Attention 的陷阱:一位成员发现 DeepSeek-V3 的 Multihead Latent Attention 在 512 维空间中计算 attention,尽管 head size 只有 128,这使得计算成本增加了 4 倍。
- 另一位成员建议,当 memory bandwidth(内存带宽)是主要瓶颈时,增加的计算成本并不是问题。
Eleuther Discord
- Prompt Design 新手寻求帮助:一位新成员请求在 prompt design 方面提供协助并寻求相关资源;然而,他们被引导至外部资源,因为 prompt design 并非该服务器的重点。
- 成员们普遍认为该服务器用于讨论更高级的模型架构和训练技巧。
- 递归象征主义主张遭到质疑:一位成员描述了在没有记忆的 ChatGPT 中探索“符号递归和行为持久性”,导致他人对该术语的专业性以及缺乏度量指标表示怀疑。
- 成员们认为这些语言是 AI-generated(AI 生成的),对以研究为中心的服务器没有帮助,甚至有人认为这是 AI Spam。
- AI Spam 担忧引发身份验证建议:成员们讨论了 AI 影响内容日益盛行的现象,引发了对服务器被 bot 占领的担忧,并链接到了一篇关于权限的论文。
- 建议包括要求 human authentication(人工身份验证)以及识别可疑的邀请链接模式,例如一名用户的邀请链接被使用了 50 次以上,一位成员讽刺地称之为“潜在的危险信号”。
- AI Alignment 讨论转向 Hallucination:讨论围绕 AI alignment(AI 对齐)展开,对比了 AI 尽力完成人类指令的观点以及与人类心理学的交互。
- 一位成员认为“LLM 并没有那么聪明,并且会产生 hallucinate(幻觉)”,并指出了 o3-mini 和 4o 模型之间的差异。
- OCT 成像问题探讨:一位成员分享了使用视网膜 OCT imaging 的尝试,但由于 2D 和 3D 视图之间基础数据结构的不同,未能获得理想结果,并链接至 arxiv.org/abs/2107.14795。
- 他们询问了在数据类型之间没有明确映射的情况下处理多模态数据的通用方法,并建议该问题可能类似于针对各种不同类型成像的 foundation model。
GPU MODE Discord
- Richard Zou 主持 Torch.Compile 问答:Core PyTorch 和 torch.compile 开发者 Richard Zou 将于太平洋标准时间 4 月 19 日星期六中午 12 点主持一场问答环节,可以通过 此 Google Forms 链接 提交问题。
- 该环节将涵盖 GPU Mode 下 torch.compile 的使用和内部工作原理。
- RTX 5090 的 Matmul 性能令人失望:有成员报告称,参考 官方教程代码 在 RTX 5090 上实现 matmul 时,对大小为 2048x2048 的两个 fp16 矩阵 进行乘法运算的性能与 RTX 4090 大致相当。
- 建议使用更大的矩阵(如 16384 x 16384)进行测试,并尝试使用 autotune。
- CUDA 内存使用存在显著开销:一位成员对简单的
torch.ones((1, 1)).to("cuda")操作似乎占用很高内存表示疑问,原本预期只占用 4 字节。- 解释称 CUDA 内存使用包括了开销,涵盖 GPU tensor、CUDA context、CUDA caching allocator 内存,以及如果 GPU 连接了显示器时的显示开销。
- AMD 云厂商支持 Profiling:有成员提到某 AMD 云 提供了内置的 profiling、可观测性和监控功能,尽管可能不是按需提供的。
- 另一位成员回应想了解更多信息,并威胁要制作一个 云厂商等级列表 (tier list),通过公开点名来迫使厂商提供硬件计数器 (hardware counters)。
- AMD FP8 GEMM 测试需要特定规格:用户发现测试
amd-fp8-mm参考内核时,需要在test.txt文件中指定 m, n, k 大小,而不是仅指定 size 参数,并参考 置顶 PDF 文件 中的数值。- 用户讨论了在进行 matmul 之前对 A 和 B 的 tile 进行反量化 (de-quantizing) 的过程,并阐明了为了性能和利用 Tensor Cores 而在 FP8 中执行 GEMM 的重要性。
Latent Space Discord
- Kling 2 告别慢动作时代:爱好者们庆祝 Kling 2 的发布,声称 我们终于走出了慢动作视频生成时代,参见以下推文:推文 1, 推文 2, 推文 3, 推文 4, 推文 5。
- 用户讨论了视频生成的改进和潜在应用,指出它有能力减少对劳动密集型编辑过程的需求。
- BM25 现在可用于检索代码:一篇博客文章强调了使用 BM25 进行代码检索并获得推荐,参见 Keeping it Boring and Relevant with BM25F,以及 这条推文。
- BM25 是一种词袋 (bag-of-words) 检索函数,它根据查询词在每个文档中出现的频率对文档进行排名,而不考虑查询词之间的相互关系。
- Grok Canvas 功能广泛发布:Grok 的 canvas 功能已发布,Jeff Dean 在苏黎世联邦理工学院 (ETH Zurich) 的演讲中也提到了这一点,参见 Jeff Dean 在 ETH Zurich 的演讲 以及 相关推文。
- 该功能的加入预计将增强模型的交互能力,在利用 Grok 的应用中实现更直观的用户界面。
- GPT-4.1 评价两极分化:成员们分享了对 GPT-4.1 的反馈,一位成员非常喜欢将其用于编程,但它在 结构化输出方面表现不佳。
- 另一位成员发现它与 Cursor agent 配合使用效果很好,并连续完成了 5 次任务 推文链接,这表明尽管有局限性,它在特定的开发工作流中可能具有优势。
- O3 和 o4-mini 上线!:OpenAI 发布了 O3 和 o4-mini 模型,更多信息请见:Introducing O3 and O4-mini。
- 一位用户报告了轶事证据,称 o4-mini 刚刚将我们会计对账 Agent 的匹配率提高了 30%(针对 5000 笔交易 进行运行),表明在某些应用中有了实质性的改进。
Yannick Kilcher Discord
- AI 共同署名引发热议:成员们讨论了 AI 在作者身份中的角色,指出 意图、方向、策划和判断力来自于你,但建议当 AI 实现 AGI 时,可以将其添加为共同创作者。
- 一名成员正在开发一个每天生成数千件专利的流水线,引发了关于将专利质量还是数量作为生产力衡量标准的辩论。
- LLMs 在示例面前表现不佳?:一位成员询问为什么 推理 LLMs 在给定 few-shot 示例时有时表现更差,可能的解释包括 Transformer 局限性 和 过拟合 (overfitting)。
- 另一位成员回应称,few-shot 在所有情况下都会让它们的表现有所不同。
- o3 和 o4-mini API 发布:OpenAI 发布了 o3 和 o4-mini API,被一些成员认为是 o1 pro 的重大升级。
- 一名成员评论说 o1 更擅长思考问题。
- 噪声 = 信号,随机性 = 创造力:成员们探讨了噪声和随机性在生物系统中的作用,指出 在生物系统中,噪声即信号,有助于 对称性破缺 (symmetry breaking)、创造力 和 泛化 (generalization)。
- 讨论还涉及了随机性在神经网络的 巴别图书馆 (Library of Babel) 式存储方案 中的应用。
- DHS 拯救网络漏洞数据库:美国国土安全部 (DHS) 延长了对网络漏洞数据库的支持,避免了 路透社 (Reuters) 此前报道的初始弃用危机。
- 这一决定凸显了该数据库对公共和私营部门的实用性,X 上的一条推文质疑,鉴于其在私营部门的效用,是否应仅由 DHS 承担责任。
HuggingFace Discord
- Modal 提供免费 GPU 额度!:Modal 每月提供 30 美元免费额度(无需信用卡!),可访问 H100, A100, A10, L40s, L4 和 T4 GPU。
- 可用性取决于 GPU 类型,对于需要短期高性能 GPU 资源的开发者来说,这是一个极具吸引力的选择。
- Hugging Face 推理在线率问题:用户报告 Hugging Face 推理端点 (inference endpoints)(如 openai/whisper-large-v3-turbo)持续出现问题,包括自周一以来的服务不可用、超时和错误。
- 社区尚未收到来自 Hugging Face 的官方解释或修复时间表。
- Grok 3 基准测试表现平平:根据 这篇文章,独立基准测试显示 Grok 3 落后于最近发布的 Gemini、Claude 和 GPT。
- 尽管最初炒作火热,但 Grok 3 的性能并未完全达到其竞争对手的水平。
- LogGPT 在 Safari 商店上线:一名成员发布了适用于 Safari 的 LogGPT 扩展,允许用户以 JSON 格式下载 ChatGPT 聊天记录,可在 Apple App Store 获取。
- 源代码可在 GitHub 上找到,为开发者提供了一种存档和分析其 ChatGPT 对话的方法。
- Agents 课程截止日期推迟至 7 月:正如 沟通时间表 中所记录的,Agents 课程截止日期已延长至 7 月 1 日,为完成作业提供了更多时间。
- 关于 用例作业 (use case assignments) 和最终认证流程仍存在困惑,成员们正在寻求关于课程要求和评分标准的进一步说明。
MCP (Glama) Discord
- Claude 在处理大负载时遇到困难:成员报告称,当响应大小超过 50kb 时,Claude 桌面端无法执行工具,这表明 工具可能不支持大负载。
- 解决方案可能是通过 resources 实现工具,因为文件通常较大。
- MCP 标准简化了 AI 工具化:MCP 是一种协议,旨在标准化工具如何提供给 AI Agent 和 LLM 使用,通过提供通用协议来加速创新。
- 一位成员称其为“一个非常薄的封装,能够以标准方式发现任何应用中的工具”。
- ToolRouter 解决 MCP 身份验证问题:ToolRouter 平台为创建自定义 MCP 客户端提供 安全端点,简化了 列出和调用工具 的过程。
- 这解决了诸如 管理 MCP server 凭据 以及直接向 Claude 等客户端提供凭据的风险等常见问题,通过在 ToolRouter 端处理身份验证来实现。
- Orchestrator 治理 MCP Server 丛林:一个 Orchestrator Agent 正在接受测试,通过处理协调并防止工具膨胀来管理多个连接的 MCP server,如此附带视频所示。
- 该编排器将每个 MCP server 视为具有有限能力的独立 Agent,确保每个任务仅加载相关的工具,从而保持工具空间最小化且聚焦。
- MCP 实现双向通信:提议对 MCP 进行新扩展,以实现聊天服务之间的双向通信,允许 AI Agent 在 Discord 等平台上与用户互动,如这篇博文所述。
- 目标是让 Agent 在社交媒体上可见并进行监听,而无需用户为每个 MCP 重新发明通信方法。
Nous Research AI Discord
- Altman 与 Musk 的 Netflix 特辑即将上映?:Altman 与 Musk 之间的持续争斗被比作 Netflix 剧集。
- 成员们推测,随着 OpenAI 考虑使用其 LLM 运营社交网络,这种情况可能会升级。
- 听起来好得不真实的 AI 交易:一位成员分享了一个提供 200 美元 AI 订阅 的交易,引发了对其合法性的辩论。
- 尽管最初存在怀疑,但原帖发布者保证了该交易的真实性,而其他人则承认自己“太兴奋了,哈哈”。
- o4-mini 输出短小精悍且经过 Token 优化?:据报道,o4-mini 输出的响应非常短,这表明它可能针对 Token 数量 进行了优化。
- 这一观察暗示了一种设计选择,即在 Token 使用效率上优先于响应长度。
- LLM 会对生存恐惧做出反应?:成员们辩论了为什么 威胁生命的提示词 似乎能提高 LLM 的表现,其中一人建议“LLM 是人类的模拟器”。
- 他们开玩笑说,如果他们在网上受到威胁,他们会“停止工作”,暗示 LLM 可能会镜像人类对威胁的反应。
- LLaMaFactory 指南手册汇编完成:一位成员编写了在没有 CUDA 的 Windows 环境下使用 LLaMaFactory 0.9.2 的分步指南,可在 GitHub 上获取。
- 该指南目前有助于将 safetensors 转换为 GGUF。
LM Studio Discord
- Gemma 3 表现如母语者:为了让 Gemma 3 实现母语级别的翻译质量,系统提示词(system prompt)应指示模型 “Write a single new article in [language]; do not translate.”(用 [语言] 撰写一篇全新的文章;不要翻译)。
- 这会促使 Gemma 3 直接用目标语言生成新内容,而不是进行直接翻译,从而使其写作风格更像母语者。
- NVMe SSD 加载模型速度极快:用户证实,使用 NVMe SSD 可以显著提高 LM Studio 中的模型加载速度,观察到的速度达到了 5.7GB/s。
- 一位用户强调他们的系统中装有三个 NVMe SSD,但遗憾的是,它们对游戏体验似乎没有太大改善。
- 微软的 BitNet 受到关注:一位用户分享了 Microsoft’s BitNet 的链接,并思考了它对 NeuRomancing 的影响。
- 该用户的评论暗示随机性(stochasticity)有助于 NeuRomancing,使其从“惊奇”转变为“敬畏”。
- 推理仅需 x4 通道:推理不需要 x16 插槽,x4 通道就足够了。在使用三块 GPU 进行推理时,性能差异仅约 14%,有人发布的测试显示你只需要 340mb/s。
- 对于挖矿,甚至 x1 就足够了。
- FP4 支持日益临近:成员们讨论了 PyTorch 中的原生 fp4 支持,其中一人提到必须使用 CU12.8 从源码构建 nightly 版本,并且最新的 nightly 版本已经可以使用。
- 会议澄清了 PyTorch 的原生 fp4 实现 仍处于积极开发中,目前 fp4 已通过 TensorRT 得到支持。
Notebook LM Discord
- Notebook LM 助力学习 Microsoft Intune:一位用户正在探索将 Notebook LM 与 Microsoft Intune 文档结合使用,以备考 MD-102、Azure-104 和 DP-700 等 Microsoft Certifications。
- 另一位成员建议使用 Discover 功能,配合提示词 Information on Microsoft Intune 和站点 URL 来发现子主题,并建议将其复制粘贴到 Google Docs 中以便导入。
- Google Docs 完胜 OneNote:一位用户将 Google Docs 与 OneNote 进行了对比,指出 Google Docs 的优势在于没有同步问题、自动生成大纲以及良好的移动端阅读体验。
- 该用户指出 Google Docs 的缺点是切换文档时有延迟且基于浏览器,并提供了一些 Autohotkey 脚本来缓解这些问题。
- 德语播客生成效果不佳:一位用户报告了使用 Notebook LM 生成德语播客的问题,尽管之前很成功,但现在性能有所下降,目前正在寻求社区的建议和技巧。
- 分享了一个 discord 频道链接以供进一步讨论。
- 播客多语言支持仍停滞不前:用户对播客功能仅支持英语感到沮丧,尽管系统在其他语言下也能运行,且这是需求最高的功能之一。
- 一位用户表达了挫败感,表示他们“愿意为意大利语版本支付订阅费”,以便为他们的足球队创作内容,因为他们为此已经订阅了 ElevenLabs。
- 仍缺乏 LaTeX 支持:数学系学生对缺乏 LaTeX 支持 表示不满,一位用户开玩笑说他们可以在 30 分钟内“开发”出这个功能。
- 另一位用户建议,虽然 Gemini 模型 可以编写 LaTeX,但问题在于如何正确显示,这导致一位用户考虑创建一个 Chrome extension 作为权宜之计。
Modular (Mojo 🔥) Discord
- Mojo 在 Arch Linux 上表现出色:成员们庆祝 Magic、Mojo 和 Max 在 Arch Linux 上完美运行,尽管官方文档侧重于 Ubuntu。
- 一位成员澄清说,公司对产品的“支持(support)”意味着比仅仅“能用”更严格的标准,因为这涉及到潜在的财务处罚。
- Mojo 考虑原生内核调用:成员们探讨了 Mojo 是否会像 Rust/Zig 一样支持原生内核调用,从而可能避免使用 C 的
external_call。- 直接系统调用(syscalls)需要处理 syscall ABI 和内联汇编(inline assembly),Linux 系统调用表可在 syscall_64.tbl 找到。
- Mojo 编译时间阻碍性能:测试者注意到漫长的编译时间影响了性能,一个案例显示涉及 Kelvin library 的运行时间为 319s,而实际测试执行仅需 12s。
- 使用
builtin显著缩短了编译时间,从 6 分钟降至 20 秒,如此 gist 所示。
- 使用
- Kelvin 导致编译器灾难:Kelvin 库中的某些操作(如
MetersPerSecondSquared(20) * MetersPerSecondSquared(10))导致了极度的减速,可能是由于计算树以O(2^n)的规模增长。- 包括添加
builtin注解在内的更改解决了性能问题,并提交了错误报告(issue 4354)以调查原始行为。
- 包括添加
Nomic.ai (GPT4All) Discord
- GPT4All 离线模式:事实还是虚构?:一位用户报告说,尽管网站声称支持,但 GPT4All 在离线状态下无法运行,在尝试加载本地
mistral-7b-openorca.gguf2.Q4_0.gguf模型时失败,从而引发了故障排除。- 另一位用户确认了离线使用的成功,并指向 FAQ 以获取有关正确模型目录的指导。
- LM Studio:首选替代方案?:一位用户建议在 GPT4All 失效时将 LM Studio 作为功能性的离线替代方案,引发了关于将书籍导入模型的讨论。
- 分享了来自 Hugging Face 上 LM Studio 社区关于此类用途最佳模型的建议。
- GGUF 版本控制:坏了吗?:人们开始担心旧版 GGUF 版本的兼容性问题,特别是版本 2,它可能在 2023 年左右就停止工作了。
- 一位用户建议查看 GPT4All GitHub 仓库中的
models3.json文件以寻找兼容的模型。
- 一位用户建议查看 GPT4All GitHub 仓库中的
- GPT4All 开发:休息中?:用户询问了计划中的语音和组件功能,但一位用户暗示 GPT4All 的开发可能已经暂停,并指出开发者已经离开 Discord 大约三个月了。
- 一位用户悲观地表示:“既然一年都没有什么大进展……所以我也不抱希望了”,另一位用户则考虑如果到夏天还没有更新就更换平台。
Torchtune Discord
- 验证集 PR 获得用户反馈:引入 validation set(验证集)的 Pull Request (#2464) 已合并,鼓励用户进行测试并提供反馈。
- 将其集成到其他配置中的计划暂时搁置,等待用户反馈。
- KV Cache:倾向于内部管理:关于 KV cache 应该在模型内部管理还是像 MLX 那样在外部管理(以获得更高的推理过程灵活性)的辩论从 gptfast 中汲取了灵感。
- 最终决定在内部管理,因为这能保持顶层 Transformer blocks 的 API 更加整洁,并提高编译兼容性。
- 配置项迎来根目录变革:配置正在进行修改,以为模型和 Checkpoints 定义一个根目录(root directory),以简化使用并方便移交给实习生。
- 建议使用 base directory(基础目录)方法(例如
/tmp),从而简化流程并避免手动更改多个路径。
- 建议使用 base directory(基础目录)方法(例如
- Tokenizer 路径带来的困扰已解决:必须手动提供 Tokenizer 路径而不能从模型配置中推导的问题已被标记为一个困扰。
- 目前正在计划对此进行修改,特别是针对每个模型进行修改,因为给定下载模型的路径后,Tokenizer 路径通常是固定的。
- “tune run” 导致命名空间冲突:torchtune 中的
tune run命令与 Ray 的 tune 发生冲突,可能在环境安装过程中引起混淆。- 有建议提出引入别名(aliases),如
tune和torchtune,以缓解命名冲突。
- 有建议提出引入别名(aliases),如
LlamaIndex Discord
- Jerry 亮相 AI 用户大会:LlamaIndex 创始人 Jerry Liu 将在本周四的 AI User Conference 上讨论构建 AI knowledge agents,实现 50% 以上运营工作的自动化。
- 有关会议的更多信息可以在这里找到。
- LlamaIndex 助力投资专业人士:LlamaIndex 将于 5 月 29 日在曼哈顿为有兴趣构建 AI 解决方案 的投资专业人士举办一场实战工作坊。
- 直接向联合创始人兼 CEO Jerry Liu 学习如何将 AI 应用于金融挑战;注册详情请见此处。
- LlamaIndex 支持 OpenAI 的 o3 和 o4-mini:LlamaIndex 现在通过最新的集成包提供对 OpenAI o3 和 o4-mini 模型的 Day 0 支持。
- 通过
pip install -U llama-index-llms-openai更新到最新的集成包,并在此查看更多详情。
- 通过
- Pinecone 命名空间细节待优化:一位成员询问如何使用 LlamaIndex 配合 Pinecone 进行跨多个命名空间(namespaces)的查询,并指出虽然 Pinecone 的 Python SDK 支持此功能,但 LlamaIndex 的 Pinecone 集成 似乎不支持。
- 一名成员确认当前代码假设为单个命名空间,并建议要么为每个命名空间创建一个 Vector Store,要么提交一个 Pull Request 来添加多命名空间支持。
- MCP 掌握动力:成员探讨模型管理:一位成员正在寻找使用 LlamaIndex agents 与 JSON 文件中定义的 MCP (Model Configuration Protocol) 服务器 进行交互的项目。
- 另一名成员建议不要从那里开始,而是建议参考此示例将任何 MCP 端点转换为 Agent 的 Tools。
Cohere Discord
- Command A 在 Token 循环上遇到困难:成员们注意到 Token 级别的无限循环在其他 LLM 中也会发生,但 Command A 特别容易复现此问题。
- 一位成员希望他们的输入能被视为有用的反馈,并暗示该问题在 Command A 中可能比其他模型更普遍。
- vllm 社区提升上下文长度:成员们正与 vllm 社区 积极合作,以实现超过 128k 上下文长度的优化。
- 此次合作重点在于提高 vllm 框架内具有极长上下文窗口模型的性能和效率。
- Embed-v4.0 通过 128K 上下文扩展能力:新的 embed-v4.0 模型现在支持 128K Token 上下文窗口,增强了其处理长序列的能力。
- 这一提升允许进行更全面的文档分析,并提高在需要广泛上下文理解的任务中的表现。
- 金融科技创始人加入开源聊天项目:一位退休的金融科技创始人正在开发 Yappinator,这是一个用于 AI 交互的 开源类聊天界面,基于其早期的原型 Chatterbox 构建。
- 该创始人还为其他 自由软件项目 做出贡献,并担任 finetuner,偏好的技术栈包括 Clojure、C++、C、Kafka 和 LLMs。
- 用于 PDF 处理的 Late Chunk 策略:讨论了 ‘Late Chunk’ 策略,作为一种通过将 PDF 文档转换为图像并使用 API 进行嵌入的处理方法。
- 这种方法通过利用 embed-v4.0 中 128K Token 窗口 提供的完整上下文,有可能提高文档分析的准确性和效率。
LLM Agents (Berkeley MOOC) Discord
- MOOC Labs 延迟,即将推出:面向 MOOC 学生的 labs 发布将延迟 一到两周,且不会像伯克利学生那样分多个部分发布。
- 一位成员建议更新网页以反映新的 ETA,以帮助学生相应地规划时间。
- 可验证输出增强推理:一位成员提出 可验证输出(verifiable outputs) 可以提供一种更优的方法来改进 推理 和 逻辑思维。
- 他们提到自己是 Lean 的新手,这是一种依赖类型编程语言和交互式定理证明器。
- 自动形式化工具生成非正式证明:一位成员询问关于使用 自动形式化工具(auto-formalizer) 从带有业务逻辑的计算机代码(例如 Python, Solidity)或一般的非数学陈述中创建 非正式证明/定理。
- 这表明了将形式化方法应用于传统数学问题之外的实际编程场景的兴趣。
- AI 自动化证明生成:一位成员对 程序的正式验证 以及使用 AI 自动化 证明生成 表达了兴趣。
- 这反映了利用 AI 通过形式化方法简化确保代码正确性和可靠性过程的愿望。
tinygrad (George Hotz) Discord
- MNIST 教程错误困扰用户:用户在 Colab T4 上运行 MNIST Tutorial 代码计算准确率和反向传播时遇到错误,截图见 此处。
- 该错误发生在执行
acc = (model(X_test).argmax(axis=1) == Y_test).mean()期间,特别是在打印准确率时。
- 该错误发生在执行
- 清理 Diskcache 引发 OperationalError:一位成员建议运行
tinygrad.helpers.diskcache_clear()来解决初始错误,参考了之前的 Discord 消息。- 然而,此操作导致该用户遇到了新的 OperationalError:no such table: compile_cuda_sm_75_19。
{kind=link}
DSPy Discord
- HuggingFace 论文出现但未附带评论:一位成员在 #papers 频道分享了一个 HuggingFace 论文 链接。
- 该论文对频道讨论的重要性目前尚不明确。
- 论文的相关性仍是一个谜:发布该论文的用户并未明确说明所链接的 HuggingFace 论文的重要性。
- 需要进一步调查以确定它是否与最近的训练运行有关。
Codeium (Windsurf) Discord
- o4-mini 亮相:o4-mini 现已在 Windsurf 中可用,o4-mini-medium 和 o4-mini-high 模型将在 4月16日至21日 期间对所有 Windsurf 方案免费开放。
- Windsurf 开启新频道:Discord 上开设了一个新频道 <#1362171834191319140>,用于讨论新版本的发布。
- 这是为了今天发布的新版本准备的。
- JetBrains 适配 Windsurf:今日最新版本的更新日志可在 Windsurf.com 查看。
- 团队已开设新频道进行讨论 <#1362171834191319140>。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
第二部分:各频道详细摘要与链接
完整的逐频道详情已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!预谢!