ainews-qwq-32b-claims-to-match-deepseek-r1-671b
QwQ-32B 声称其性能可比肩 DeepSeek R1-671B。
阿里巴巴通义千问(Alibaba Qwen)发布了 QwQ-32B 模型。这是一款拥有 320 亿参数的推理模型,采用了创新的两阶段强化学习(RL)方法:第一阶段通过准确性验证器和代码执行服务器,针对数学和编程任务扩展强化学习规模;第二阶段则将强化学习应用于指令遵循和对齐等通用能力。
与此同时,OpenAI 向 Plus 用户推出了 GPT-4.5,用户对其编程表现的评价褒贬不一,但推理成本的优化受到了关注。QwQ 模型旨在与 DeepSeek-R1 等更大规模的 MoE(混合专家)模型展开竞争。有用户尖锐地批评道“GPT-4.5 在编程方面完全无法使用”,而另一些人则称赞其通过扩展预训练规模显著提升了推理能力。
两阶段 RL 就足够了?
2025年3月5日至3月6日的 AI 新闻。我们为您检查了 7 个 subreddits、433 个 Twitter 账号 和 29 个 Discord(227 个频道和 3619 条消息)。预计节省阅读时间(以 200wpm 计算):351 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
正如去年 11 月预告以及上个月再次提到的,阿里巴巴 Qwen 团队终于发布了 QwQ 的最终版本。这是他们的 Qwen2.5-Plus + Thinking (QwQ) 后训练版本,其性能数据可与 R1 媲美,而 R1 作为一个 MoE 模型,规模比它大 20 倍。
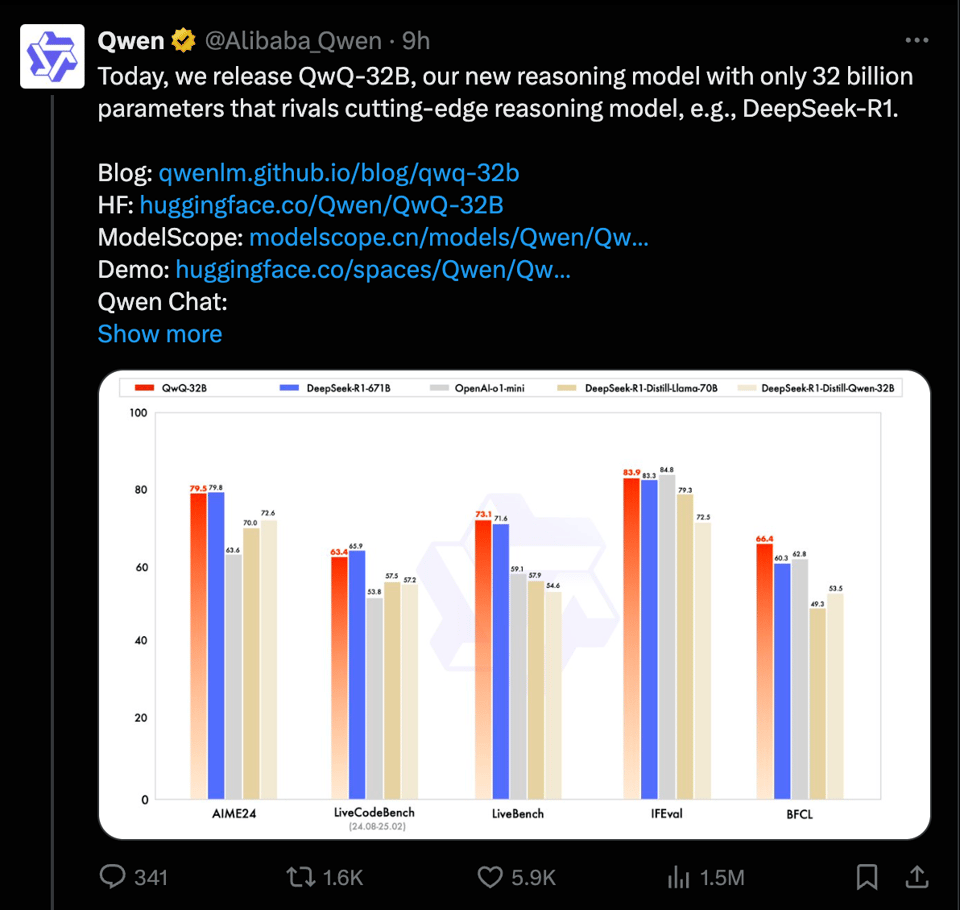
目前还处于早期阶段,因此尚无独立的第三方验证,但 Qwen 团队已经做了最基本的工作来向我们证明,他们并没有为了获得这一结果而简单地对基准测试进行过拟合——因为他们在非数学/编码基准测试中依然表现出色,并用一段文字解释了实现方法:
- 在初始阶段,我们专门针对数学和编码任务扩展了 RL。 我们没有依赖传统的奖励模型,而是利用数学问题的准确性校验器(accuracy verifier)来确保最终解的正确性,并使用代码执行服务器来评估生成的代码是否成功通过预定义的测试用例。随着训练轮次的增加,这两个领域的性能都在持续提升。
- 在第一阶段之后,我们增加了另一个阶段的 RL 以提升通用能力。 它使用来自通用奖励模型和一些基于规则的校验器的奖励进行训练。我们发现,通过少量步数的这一阶段 RL 训练,可以提高其他通用能力(如指令遵循、人类偏好对齐和 Agent 性能),且数学和编码性能不会出现显著下降。
更多信息——如论文、示例数据、示例代码——将有助于理解,但对于 2025 年的开源模型披露来说,这已经足够诚意了。QwQ-32B 在 Open LLM Leaderboard 上排名还需要一段时间,但这里是现状提醒:Thinking 后训练模型并不一定在所有方面都优于其 Instruct 前代模型。
AI Twitter 综述
AI 模型发布与基准测试
- GPT-4.5 发布与性能表现:@sama 宣布向 Plus users 推出 GPT-4.5,将在几天内分阶段开放访问,以管理速率限制并确保良好的用户体验。@sama 随后确认推送已经开始,并将在几天内完成。@OpenAI 强调这是 “成为 Plus 用户的伟大一天”。@aidan_mclau 幽默地警告说,由于 GPT-4.5 的“笨重(chonkiness)”,可能会导致 GPU meltdown。然而,用户对其编程性能的初步反馈褒贬不一,@scaling01 发现 GPT-4.5 在 ChatGPT Plus 中无法用于编程,理由是变量定义、函数修复以及重构时的懒惰问题。@scaling01 重申 “GPT-4.5 无法用于编程”。@juberti 认为 GPT-4.5 的推理成本与 2022 年夏天的 GPT-3 (Davinci) 相当,表明计算成本随时间下降。@polynoamial 注意到 GPT-4.5 解决推理问题的能力,并将其归功于预训练的扩展(scaling pretraining)。
- Qwen QwQ-32B 模型发布:@Alibaba_Qwen 发布了 QwQ-32B,这是一款全新的 320 亿参数推理模型,声称可与 DeepSeek-R1 等尖端模型媲美。@reach_vb 兴奋地宣布 “We are so unfathomably back!”,Qwen QwQ 32B 的表现优于 DeepSeek R1 和 OpenAI O1 Mini,并采用 Apache 2.0 license。@Yuchenj_UW 强调 Qwen QwQ-32B 是一款小巧但强大的推理模型,击败了 DeepSeek-R1 (671B) 和 OpenAI o1-mini,并宣布其已在 Hyperbolic Labs 上线。@iScienceLuvr 也对 Qwen 团队的发布表示兴奋,认为其表现与 DeepSeek 同样令人印象深刻。@teortaxesTex 指出了 Qwen 的 “cold-start” 方法 以及与 R1 的直接竞争。
- AidanBench 更新:@aidan_mclau 发布了 aidanbench 更新,指出 GPT-4.5 综合排名第 3,在非推理模型(non-reasoner)中排名第 1,而 Claude-3.7 模型的得分低于 newsonnet。@aidan_mclau 解释了对 O1 scores 的修正,原因是之前误分类了超时情况。@aidan_mclau 指出了 Chain of Thought (CoT) 推理的高昂成本,并提到有人抱怨 GPT-4.5 的成本,却没人抱怨 Claude-3.7-thinking。@scaling01 分析了 AidanBench 结果,认为 Claude Sonnet 3.5 (new) 表现出持续的顶级性能,而 GPT-4.5 的高分可能是由于对单个问题的记忆(memorization)。
- Cohere Aya Vision 模型发布:@_akhaliq 宣布 Cohere 在 Hugging Face 上发布了 Aya Vision,强调其在多语言文本生成和图像理解方面的强劲表现,优于 Qwen2.5-VL 7B、Gemini Flash 1.5 8B 和 Llama-3.2 11B Vision 等模型。
- Copilot Arena 论文:@StringChaos 重点介绍了 Copilot Arena 论文,该论文由 @iamwaynechi 和 @valeriechen_ 领导,提供了直接来自开发者的 LLM 评估,包含关于模型排名、生产力以及跨领域和语言影响的真实见解。
- VisualThinker-R1-Zero:@Yuchenj_UW 讨论了 VisualThinker-R1-Zero,这是一个通过将 Reinforcement Learning (RL) 直接应用于 Qwen2-VL-2B base model 来实现多模态推理的 2B 模型,在 CVBench 上达到了 59.47% 的准确率。
- Light-R1:@_akhaliq 宣布 Light-R1 在 Hugging Face 上线,通过 Curriculum SFT & DPO 以 1000 美元的成本超越了 R1-Distill from Scratch。
- Ollama 新模型:@ollama 发布了 Ollama v0.5.13,包含新模型:支持 function calling 的 Microsoft Phi 4 mini、用于视觉文档理解的 IBM Granite 3.2 Vision 以及 Cohere Command R7B Arabic。
开源 AI 与社区
- Weights & Biases 被 CoreWeave 收购: @weights_biases 宣布他们被 AI 超大规模算力提供商 CoreWeave 收购。@ClementDelangue 称赞 Weights & Biases 是最具影响力的 AI 公司之一,并祝贺其被 CoreWeave 收购。@iScienceLuvr 也强调这次收购对 AI infra 社区来说是重大新闻。@steph_palazzolo 报道了收购谈判,提到了一项潜在的 17 亿美元交易,旨在将 CoreWeave 的客户群多样化并扩展到软件领域。@alexandr_wang 和 @alexandr_wang 分享了报道此次收购的文章。
- Keras 3.9.0 发布: @fchollet 宣布 Keras 3.9.0 发布,带来了新的 ops、图像增强层、错误修复、性能改进以及新的 rematerialization API。
- Llamba 模型: @awnihannun 推广了 Cartesia 的 Llamba 模型,这是高质量的 1B、3B 和 7B SSMs,支持 MLX 以实现快速的设备端执行。
- Hugging Face 集成: @_akhaliq 宣布了 Hugging Face 更新,允许开发者直接从 Hugging Face 使用 Gradio 部署模型,选择推理提供商,并要求用户登录以进行计费。@sarahookr 提到与 Hugging Face 合作发布 Aya Vision。
AI 应用与用例
- Google 搜索中的 AI Mode: @Google 推出了 Search 中的 AI Mode,这是一项提供 AI 回答和后续提问的实验。@Google 详细介绍了 AI Mode,它在 AI Overviews 的基础上扩展了高级推理和多模态能力,并向 Google One AI Premium 订阅用户推出。@Google 还宣布在 AI Overviews 中加入 Gemini 2.0 以处理编程和数学等复杂问题,并开放无需登录即可访问 AI Overviews 的权限。@jack_w_rae 祝贺搜索团队发布 AI Mode,期待它能为更广泛的受众提供帮助。@OriolVinyalsML 强调了 Gemini 通过 AI Mode 与搜索的集成。
- AI Agent 和 Agentic 工作流: @llama_index 推广了集成到软件流程中的 Agentic 文档工作流,用于知识 Agent。@DeepLearningAI 和 @AndrewYNg 宣布与 LlamaIndex 合作推出关于事件驱动的 Agentic 文档工作流的新短课程,教授如何构建用于表单处理和文档自动化的 Agent。@LangChainAI 宣布了即将举行的 AI Agent 会议 Interrupt,届时来自 Harvey AI 的 @benjaminliebald 将分享关于构建法律 Copilot 的内容。@omarsar0 分享了关于构建 AI Agent 的想法,建议将 API 连接到 LLM 或使用 Agentic 框架,并声称获得不错的 Agent 性能并不难。
- Perplexity AI 功能: @perplexity_ai 为 Perplexity macOS 应用宣布了新的语音模式。@AravSrinivas 指出 Ask Perplexity 在不到一周的时间内获得了 1200 万次曝光。
- Google Shopping AI 功能: @Google 在 Google Shopping 上推出了针对时尚和美容的新 AI 功能,包括 AI 生成的基于图像的推荐、虚拟试穿和 AR 化妆灵感。
- Android AI 驱动功能: @Google 强调了 Android 中新的 AI 驱动功能,以及安全工具和连接性改进。
- Gemini 2.0 的 Function Calling 指南: @_philschmid 宣布了 Google Gemini 2.0 Flash 的端到端 Function Calling 指南,涵盖了设置、JSON schema、Python SDK、LangChain 集成以及 OpenAI 兼容 API。
AI Infrastructure & Compute
- 配备 512GB RAM 的 Mac Studio:@awnihannun 强调了配备 512GB RAM 的新款 Mac Studio,并指出它可以运行 4-bit Deep Seek R1 且仍有余量。@cognitivecompai 对 512GB RAM 选项的反应是“别废话,拿走我的钱!”。
- Mac 上的 MLX 和 LM Studio:@reach_vb 指出 MLX 和 LM Studio 在 M3 Ultra 发布会中被重点提及,感觉非常梦幻。@awnihannun 也指出新款 Mac Studio 产品页面展示了 MLX + LM Studio。@reach_vb 分享了在 MPS 上使用 llama.cpp 和 MLX 的积极体验,并将其与 torch 进行了对比。
- 计算效率与扩展:@omarsar0 讨论了提高推理模型效率的方法,提到了巧妙的推理方法和 UPFT(通过减少 Token 实现的高效训练)。@omarsar0 分享了一篇关于使用 “A Few Tokens Are All You Need” 方法在保持推理性能的同时将 LLM 微调成本降低 75% 的论文。@jxmnop 强调了数据集蒸馏(dataset distillation)的效率,通过仅在 10 张图像上进行训练,在 MNIST 上实现了 94% 的准确率。
- OpenCL 在 AI 计算中错失的机会:@clattner_llvm 反思了 OpenCL 作为“本该”赢得 AI 计算的技术,并分享了从其失败中吸取的教训。
AI 安全与政策
- 超级智能战略与 AI 安全:@DanHendrycks 与 @ericschmidt 及 @alexandr_wang 提出了一项新的超级智能战略,认为其具有不稳定性,并呼吁采取威慑 (MAIM)、竞争力和不扩散的战略。@DanHendrycks 引入了相互保证 AI 故障 (MAIM) 作为针对不稳定 AI 项目的威慑机制,并将其与核 MAD 类比。@DanHendrycks 警告不要针对超级智能实施美国 AI 曼哈顿计划,因为这可能导致局势升级并引发中国等国家的威慑。@DanHendrycks 强调了灾难性 AI 能力向恶意行为者的不扩散,建议追踪 AI 芯片并防止走私。@DanHendrycks 强调了 AI 芯片供应链安全和本土制造对竞争力至关重要,考虑到中国入侵台湾的风险。@DanHendrycks 将解决 AI 问题的方法与冷战政策进行了类比。@saranormous 推广了一集关于该国家安全战略的 NoPriorsPod 播客,嘉宾包括 @DanHendrycks、@alexandr_wang 和 @ericschmidt。@Yoshua_Bengio 支持 Sutton 和 Barto 获得图灵奖,并强调在没有安全措施的情况下发布模型是不负责任的。@denny_zhou 引用了一条建议,即在 AI 研究中应优先考虑雄心,而非隐私、可解释性或安全性。
- 地缘政治与 AI 竞争:@NandoDF 提出了一个问题:中国还是美国被视为可能在 AI 发展中不受约束的专制政府。@teortaxesTex 注意到紧张局势升级,且中国的言论正从缓和方式转变。@teortaxesTex 指出中国顶尖 AI 团队中存在跨性别者,这是中国人力资本竞争力的一个标志。@RichardMCNgo 讨论了 AI 进展对去工业化和工作性质的影响,建议相比抽象角色,更倾向于植根于本地环境的“真实”制造业工作。@hardmaru 认为地缘政治和去全球化将塑造未来十年的世界。
- AI 控制与安全研究:@NeelNanda5 对 AI 控制成为一个真正的研究领域并举办首届会议表示兴奋。
- 注意力经济中的虚假信息与真相:@ReamBraden 观察到 X 上惊人数量的虚假信息,认为注意力经济的激励机制与“言论自由”不相容,在线真相需要新的激励机制。
梗与幽默
- GPT-4.5 的“庞大体积”与 GPU 熔化:@aidan_mclau 警告说 “psa: gpt-4.5 即将登陆 plus,我们的 gpu 可能会熔化,请多包涵!”。@aidan_mclau 发布了“我们的超级计算机正在处理庞然大物的现场画面”。@aidan_mclau 开玩笑说“好吧,你的模型太胖了,它是自己滚出来的”。@stevenheidel 发文称“在我们推出 gpt-4.5 之际,为我们的 GPU 祈祷”。
- GPT-4.5 绿字(greentext)梗:@SebastienBubeck 提到 GPT-4.5 已向 Pro 用户开放,用于“补全绿字”梗。@iScienceLuvr 和 @iScienceLuvr 承认被 GPT-4.5 生成的关于他们自己的搞笑绿字搞得“心态崩了”且感到“尴尬”。
- ChatGPT UltraChonk 7 High 的高昂成本:@andersonbcdefg 调侃了未来 ChatGPT UltraChonk 7 High 的成本,将 1.5 周的使用权比作 80 万美元的遗产或 2028 年的两打鸡蛋。
- 电影观点与 Aidan Moviebench:@aidan_mclau 宣称 “《盗梦空间》实际上是人类历史上最伟大的电影”,并称其为“Aidan Moviebench 中的 o1”。@aidan_mclau 表示 “克里斯托弗·诺兰唯一好的电影是《盗梦空间》和《黑暗骑士》”。
AI Reddit 回顾
/r/LocalLlama 回顾
主题 1:苹果推出搭载 M3 Ultra 的 Mac Studio,支持 AI 推理及 512GB 统一内存
- 苹果发布新款 Mac Studio,搭载 M4 Max 和 M3 Ultra,最高支持 512GB 统一内存 (Score: 422, Comments: 290):Apple 发布了新款 Mac Studio,配备 M4 Max 和 M3 Ultra 芯片,提供高达 512GB 的统一内存。
- 围绕 内存带宽和成本 的讨论强调了使用 DDR5 和 AMD Turin 实现高带宽的挑战,每个 CCD 为 106GB/s,需要 5 个 CCD 才能超过 500GB/s。对比中提到了售价 2998 美元 的 EPYC 9355P 以及服务器 RAM 的高昂成本,对 Apple 产品的性价比提出了质疑。
- 用户对新款 Mac Studio 的 实际应用和性能 表现出浓厚兴趣,特别是针对 AI 推理任务,如运行 Unsloth DeepSeek R1 和 LLM 的 Token 生成。尽管价格高昂,512GB 型号 被视为本地托管 R1 的可行选择,并被拿来与 8 块 RTX 3090 的配置进行对比。
- Mac Studio 的 定价和配置 受到严格审视,512GB 版本 在意大利售价为 1.1 万欧元,在美国为 9500 美元。教育优惠 可将其降至 约 8600 美元,而 M4 Max 因其 546GB/s 的内存带宽 被认为足以与 Nvidia Digits 竞争。
- 新的王者?M3 Ultra,80 核 GPU,512GB 内存 (评分: 207, 评论: 141): 该帖子讨论了配备 32 核 CPU、80 核 GPU 和 512GB 统一内存 的 Apple M3 Ultra,这为计算能力开辟了巨大的可能性。起售价 为 $9,499,提供定制和预订选项,突显了该型号对高性能计算的潜在影响。
- Thunderbolt 网络与 Asahi Linux: 用户讨论了 macOS 对 Thunderbolt 网络的自动设置,指出其在 TB3/4 下之前受限于 10Gbps,而 Asahi Linux 目前支持部分 Apple Silicon 芯片,但不包括 M3。一些用户在 M2 芯片上尝试了 Asahi,但发现尚不完善,尽管更倾向于使用 macOS,但仍对团队的努力表示赞赏。
- 与 NVIDIA 的对比及成本效益: M3 Ultra 缺乏 CUDA 被视为训练和图像生成的劣势,一些用户注意到 Mac 在处理较长 Prompt 时性能较慢。M3 Ultra 的成本与 NVIDIA GPU 进行了对比,讨论强调了其能效比(480W 对比等效 GPU 的 5kW)以及将 GPU 与 CPU 推理 进行比较的挑战。
- 定价与价值认知: M3 Ultra 的价位引发了辩论,一些用户因其 512GB 统一内存 和高效率而认为其物有所值,而另一些人则认为与 NVIDIA GPU 相比定价过高。该设备与 80GB H100 和 Blackwell Quadro 进行了对比,强调了其在内存容量和带宽方面的价值,尽管初始成本较高。
- Mac Studio 刚刚获得了 512GB 内存! (评分: 106, 评论: 76): Mac Studio 现在配备 512GB 内存 和 4TB 存储,内存带宽为 819 GB/s,美国售价为 $10,499。此配置可能能够以 8 tps 的速度运行 Llama 3.1 405B。
- 讨论强调了 Mac Studio 与其他高性能设置相比的成本效益,例如一套耗资 $44,000 的 Nvidia GH200 624GB 系统。用户对 $10,499 价格标签的实用性进行了辩论,一些人指出它为其他昂贵的硬件配置提供了一个具有竞争力的替代方案。
- 用户讨论了 Mac Studio 的技术能力,特别是利用 VRAM Calculator 等工具运行 Deepseek-r1 672B 且上下文超过 70,000+ 的能力。关于其在小上下文规模下运行大型模型的适用性,以及通过集群化多个单元以获得更高性能的潜力存在争议。
- 对话涉及 Mac 系统 在某些任务(如模型训练)中的局限性,以及在自定义构建系统中实现类似内存带宽的挑战。一些用户指出需要 Threadripper 或 EPYC 系统等高级配置才能匹配 Mac Studio 的性能,而另一些人则建议通过网络连接多台 Mac 来增加 RAM。
{kind=link}
主题 2. Qwen/QwQ-32B 发布:性能对比与基准测试
- Qwen/QwQ-32B · Hugging Face (评分: 169, 评论: 55): Qwen/QwQ-32B 是一款可在 Hugging Face 上获取的模型,但该帖子未提供有关它的具体细节或背景。
- Qwen/QwQ-32B 引起了极大的关注,用户表示它可能优于 R1,并可能是迄今为止最好的 32B 模型。一些用户推测它可以与更大的模型竞争,提到它优于 671B 模型,并建议将其与 QwQ 32B coder 结合使用将会非常强大。
- 用户讨论了性能和实现细节,一些人比起官方版本更倾向于 Bartowski 的 GGUF,而另一些人则对该模型在角色扮演和虚构创作等特定用例中的能力印象深刻。该模型在 Hugging Face 上的可用性及其在 3090 GPU 等现有硬件上高效运行的潜力受到了关注。
- 存在关于对科技行业更广泛影响的推测,一些人认为如果该模型获得认可,可能会影响 Nvidia 等公司。然而,其他人认为对私有化部署的需求可能会通过扩大客户群而使 Nvidia 受益。
- 准备好了吗! (Score: 567, Comments: 77): Junyang Lin 在 2025 年 3 月 5 日通过推文宣布完成了 QwQ-32B 的最终训练,该推文获得了 151 个点赞及其他互动。推文中包含一个鱼的表情符号,并由认证账号发布,标志着 AI 训练里程碑中的这一重大进展。
- QwQ-32B 的发布与性能:人们对 QwQ-32B 的发布充满期待,评论强调其预期性能将优于 QwQ-Preview 以及之前的模型(如 Qwen-32B)。该模型被预期会有显著提升,可能超越 Mistral Large 和 Qwen-72B,部分用户能够在消费级 GPU 上运行它。
- 在线演示与对比:Hugging Face 上已提供在线演示,链接见 此处。讨论中将 QwQ-Preview 与 R1-distill-qwen-32B 进行了对比,结果较为理想,暗示新模型在性能上可能超越 DeepSeek R1,并具有更强的推理和工具使用能力。
- 社区反应与期望:用户对新模型表达了兴奋和期待,有人幽默地考虑创建名为 “UwU” 的 AI(基于 QwQ 的模型其实已经存在)。关于 QwQ-32B 是否能比 r1 distilled qwen 32B 表现更好的讨论,显示了社区的高度关注和竞争性基准测试。
{kind=link}
主题 3. llama.cpp 在利用本地 LLM 方面的多功能性
- llama.cpp 就是你所需的一切 (Score: 356, Comments: 122): 作者探索了从 ollama 开始的本地托管 LLM,ollama 使用了 llama.cpp,但在 Linux 上为不支持的 AMD card 编译 ROCm backend 时遇到了问题。在尝试 koboldcpp 未果后,他们通过 llama.cpp 的 vulkan 版本获得了成功。他们赞扬了 llama-server 简洁的 Web-UI、API endpoint 和广泛的可调性,得出结论认为 llama.cpp 能够全面满足他们的需求。
- Llama.cpp 因其功能和易用性受到称赞,但也提到了对性能和多模态支持的担忧。用户提到 llama.cpp 已经放弃了多模态支持,而像 mistral.rs 这样的替代方案支持最新的模型,并提供 in-situ quantization 和 paged attention 等功能。一些用户更倾向于使用 koboldcpp,因为它在不同硬件上具有通用性。
- llama-server 的 Web 界面因其简单和整洁的设计获得了正面反馈,与 openweb-ui 等被认为更复杂的 UI 形成对比。Llama-swap 被强调为管理多个模型和配置的有价值工具,能够实现高效的模型热切换。
- 讨论了 llama.cpp 的性能问题,特别是在并发用户和 VRAM 管理场景下。一些用户报告称使用 exllamav2 和 TabbyAPI 效果更好,这些工具提供了增强的 context length 和 KV cache compression 能力。
- Ollama v0.5.13 已发布 (Score: 139, Comments: 19): Ollama v0.5.13 已经发布。帖子中未提供关于该版本的更多细节或背景。
- Ollama v0.5.13 的发布讨论围绕模型兼容性和集成展开,用户在尝试使用新版本时遇到了挑战,特别是 qwen2.5vl 及其多模态功能。一位用户注意到 Windows 上的 llama runner 进程存在问题,并引用了一个 GitHub issue。
- 人们对 Ollama 接收来自 Visual Studio Code 和 Cursor 请求的能力感到好奇,这表明可能有一项新功能用于处理来自以
vscode-file://开头的 origins 的请求。 - 关于 Phi-4 多模态支持的讨论强调了由于为多模态模型实现 LoRA 的复杂性而导致的延迟,目前 llama.cpp 不支持 minicpm-o2.6,并暂停了多模态开发。
其他 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding
主题 1. TeaCache 增强提升了 WAN 2.1 性能
- 好吧,我不喜欢它假装成一个人并谈论去上学 (Score: 120, Comments: 63):该帖子讨论了一个涉及计算 “130 加上 100 乘以 5” 的数学问题,强调了记住运算顺序的重要性,特别是“数学课”上教的先乘后加。图片使用了对话式的语气并突出显示了短语,以吸引读者。
- 讨论强调,像 ChatGPT 这样的 AI 模型并非专为“130 加上 100 乘以 5”这类简单计算而设计。用户反对将推理模型用于此类任务,认为其效率低下且可能出错,并建议将传统的计算器作为更可靠、更节能的替代方案。
- 对话凸显了对大语言模型 (LLMs) 的普遍误解,用户指出 LLMs 的功能是作为知识检索工具,而非真正的推理实体。一些用户对普通人对 LLM 能力的误解及其在创造力和解决问题方面的局限性表示沮丧。
- 评论中充满了幽默和讽刺,用户开玩笑说 AI 出现在数学课上及其拟人化的描绘。在将 AI 想象成同学时,语调十分俏皮,引用了学校教科书中的 PEMDAS 知识,并回忆起 AI 的“父母”是来自匈牙利的犹太移民。
- Wan 2.1 的官方 TeaCache 已发布。有人说速度提升了 100%,但我还没亲自测试。 (Score: 108, Comments: 41):TeaCache 现在支持 Wan 2.1,一些用户声称速度提升了 100%。社区中的热烈响应(如来自 FurkanGozukara 的回复)突显了在 GitHub 上测试这些新功能的兴奋感和协作精神。
- 用户讨论了 TeaCache 的安装挑战,特别是 Python 和 Torch 版本不匹配的问题。解决方案包括使用 pip 安装 Torch nightly,并确保在安装前通过 “source activate” 激活正确的环境。
- 用户有兴趣了解 TeaCache 与 Kijai 的节点之间的区别。Kijai 更新了他的封装器以包含新的 TeaCache 功能,在官方发布前通过跳步估算系数以进行比较。
- 性能改进显著,用户如 _raydeStar 报告称,使用 sage attention 和 sparge_attn 后速度大幅提升,在测试期间将时间从 34.91s/it 减少到 11.89s/it。然而,一些用户遇到了伪影问题,正在寻求高质量渲染的最佳设置。
{kind=link}
{kind=link}
主题 2. Lightricks LTX-Video v0.9.5 新增关键帧和扩展功能
- LTX-Video v0.9.5 发布,现已支持关键帧、视频扩展和更高分辨率。 (Score: 184, Comments: 53):LTX-Video v0.9.5 已发布,具有关键帧、视频扩展和支持更高分辨率等新功能。
- 关键帧功能与插值:用户对关键帧功能感到兴奋,认为它有可能成为开源模型的游戏规则改变者。帧条件化 (Frame Conditioning) 和 序列条件化 (Sequence Conditioning) 被强调为帧插值和视频扩展的新功能,用户渴望看到这些功能的演示 (GitHub 仓库)。
- 硬件与性能:讨论显示 LTX-Video 相对较小,拥有 2B 参数,可在 6GB vRAM 上运行。用户欣赏该模型与其他模型相比的体积优势,尽管平衡资源、生成时间和质量仍是一个挑战。
- 工作流与示例:社区分享了部署和使用 LTX-Video 的资源,包括一个带有 ComfyUI 的 RunPod 模板,用于 i2v 和 t2v 等工作流。分享了示例工作流和额外资源,强调了更新以利用新功能的必要性 (ComfyUI 示例)。
主题 3. Chroma 模型开源开发版发布
- Chroma: 开源、无审查、为社区而建 - [进行中] (Score: 381, Comments: 117): Chroma 是一个基于 FLUX.1-schnell 的 8.9B 参数模型,完全采用 Apache 2.0 许可 供开源使用和修改,目前正在训练中。该模型基于从 20M 样本 中提取的 5M 数据集 进行训练,专注于无审查内容,并由 Hugging Face 仓库 和 实时 WandB 训练日志 等资源提供支持。
- 数据集充分性:人们对 5M 数据集 是否足以支撑一个通用模型表示担忧,并将其与可达 3M 图像的 booru dumps 进行了比较。此外,还讨论了关于数据集内容的问题,包括是否包含 名人 以及针对 sfw/nsfw 内容的特定标签。
- 技术优化与许可:Chroma 模型经过了显著优化,实现了更快的训练速度(在 8xh100 节点 上约为 18img/s),建议进行 50 epochs 以实现强收敛。项目强调了 Apache 2.0 许可,但由于法律模糊性,在开源数据集方面仍面临挑战。
- 模型对比与法律担忧:讨论中包括了与 SDXL 和 SD 3.5 Medium 等其他模型的对比,一些用户对克服 Flux 模型训练挑战表示兴奋。同时,还提到了在大规模数据集上训练时关于版权侵权的法律担忧,强调了潜在的法律风险。
主题 4. GPT-4.5 向 Plus 用户推出,具备记忆功能
- 4.5 向 Plus 用户推出 (Score: 394, Comments: 144): OpenAI 宣布向 Plus 用户 推出 GPT-4.5,正如一条 Twitter 帖子所示。图片展示了一个揭露该更新的非正式对话,并配有表情符号反应,强调了对新版本发布的兴奋。
- 用户对 GPT-4.5 的自我意识和提供准确信息的能力表示怀疑,一些人报告了模型否认自身存在的情况。OpenAI 尚未明确沟通使用限制,导致用户对 每周 50 条消息 的上限以及重置时间感到困惑。
- 对于此次推出,用户情绪参杂着兴奋与沮丧,特别是针对 速率限制(rate limits) 以及改进记忆等功能缺乏透明度。一些用户报告在 iOS 和 浏览器 上均可访问,并被标记为“Research Preview”。
- OpenAI 提到向 Plus 用户 的推广将需要 1-3 天,速率限制可能会随着需求评估而改变。用户仍在等待关于限制和功能的进一步更新,并对潜在的 advanced voice mode 更新表现出显著兴趣。
- OpenAI 员工确认,Plus 用户的 GPT 4.5 速率限制为每周 50 条消息 (Score: 148, Comments: 61): Aidan McLaughlin 确认 GPT-4.5 限制 Plus 用户 每周 50 条消息,并可能根据使用情况有所变动。他幽默地声称每个 GPT-4.5 token 消耗的能量相当于 意大利 全年的能耗,截至 2025 年 3 月 5 日,该推文已获得 9,600 次浏览。
- 关于 GPT-4.5 能耗 的说法被广泛认为是一种幽默的夸张,用户指出这缺乏逻辑连贯性。Aidan McLaughlin 的推文被解读为一个玩笑,旨在嘲讽关于 AI 能耗的夸大言论,例如将单个 token 的能耗与整个意大利的年能耗相提并论被视为荒谬之极。
- 讨论突出了 GPT-4.5 的巨大规模,推测其参数量可能超过 10 万亿(10 trillion)。用户对模型的尺寸和架构表示好奇,并指出 OpenAI 尚未披露关于参数数量或能耗的具体数据。
- 评论者幽默地应对这种能耗说法的荒谬性,利用 幽默和讽刺 来评价这一言论。这包括关于未来使用 Dyson spheres(戴森球)的笑话,以及对“加拿大女性流浪汉为三明治争吵”等 非公制单位 的戏谑引用。
- GPT-4.5 正式向 Plus 用户推出! (得分: 165, 评论: 56): GPT-4.5 现在以研究预览版的形式向 Plus 用户开放,被描述为适用于写作和探索想法。界面还列出了 GPT-4o 以及带有定时任务功能的 GPT-4o Beta 版用于后续查询,所有这些都集成在一个现代的深色主题 UI 中。
- 用户正在讨论 GPT-4.5 中的记忆功能 (memory feature),一位评论者确认了该功能的存在,这与缺乏此功能的其他模型形成对比。这一补充受到了好评,因为它增强了模型的能力。
- 用户对了解 Plus 用户的限制表现出浓厚兴趣,纷纷询问每天或每周允许的消息数量。一位用户报告进行了超过 20 条消息的对话,另一位用户提到 50 条消息的上限,该上限可能会根据需求进行调整。
- 一些用户对 GPT-4.5 表示失望,认为它与竞争对手相比没有显著的差异化,而另一些人则好奇是否有特定的任务使 GPT-4.5 优于其他模型。
{kind=link}
{kind=link}
{kind=link}
AI Discord 摘要
由 o1-preview-2024-09-12 生成的摘要之摘要之摘要
主题 1:阿里巴巴的 QwQ-32B 挑战巨头
- QwQ-32B 越级挑战 DeepSeek-R1:阿里巴巴的 QwQ-32B(一款 320 亿参数的模型)与 6710 亿参数的 DeepSeek-R1 旗鼓相当,展示了Reinforcement Learning (RL) 扩展的力量。该模型在数学和编程任务中表现出色,证明了尺寸并非决定一切。
- 社区热切测试 QwQ-32B 的实力:用户正在通过 Hugging Face 和 Qwen Chat 对 QwQ-32B 进行全面测试。初步印象表明其性能可与更大的模型相媲美,引发了广泛关注。
- QwQ-32B 采用了 Hermes 的秘诀:观察者注意到 QwQ-32B 使用了类似于 Hermes 的特殊 Token 和格式,包括
<im_start>、<im_end>和工具调用语法。这增强了与高级 Prompt 技术的兼容性。
主题 2:用户对 AI 工具缺陷的挫败感爆发
- Cursor 的 3.7 模型“降智”,用户纷纷跳槽:开发者报告称 Cursor 的 3.7 模型感觉被削弱了,会生成多余的 Readme 文件并错误地使用抽象。一个带有讽刺意味的 Cursor 降智计 (Cursor Dumbness Meter) 嘲讽了这种退步,促使许多人考虑将 Windsurf 作为替代方案。
- Claude Sonnet 3.7 在简单任务上失手:用户对 Perplexity 上的 Claude Sonnet 3.7 表示失望,理由是在解析 JSON 文件时出现幻觉,且性能不如直接通过 Anthropic 使用。用户对其“声称的改进”未能实现感到愈发沮丧。
- GPT-4.5 伴随限制与拒绝请求而至:OpenAI 的 GPT-4.5 发布令用户兴奋,但限制每周使用 50 次。它拒绝处理基于故事的 Prompt,即使这些 Prompt 符合指南,这让用户感到非常恼火。
主题 3:AI Agent 志存高远,价格高昂
- OpenAI 计划为精英级 Agent 每月收费高达 2 万美元:OpenAI 正准备销售高级 AI Agent,订阅费用从每月 2,000 美元到 20,000 美元不等,目标是编程自动化和博士级研究等任务。高昂的价格引起了用户的关注和怀疑。
- LlamaIndex 与 DeepLearningAI 合作开发 Agent 式工作流:LlamaIndex 与 DeepLearningAI 合作提供关于构建 Agentic Document Workflows 的课程,将 AI Agent 无缝集成到软件流程中。这一举措强调了 Agent 在 AI 开发中日益增长的重要性。
- Composio 通过开箱即用的身份验证简化 MCP:Composio 现在支持具有强大身份验证功能的 MCP,消除了为 Slack 和 Notion 等应用设置 MCP 服务器的麻烦。他们的公告宣称提高了工具调用的准确性并易于使用。
主题 4:Reinforcement Learning 大放异彩并取得重大进展
- RL Agent 凭借微型模型征服 Pokémon Red:一个强化学习系统使用参数量低于 1000 万 的策略模型和 PPO 算法打通了 Pokémon Red,展示了 RL 在复杂任务中的实力。这一成就凸显了 RL 的复兴及其在游戏 AI 领域的潜力。
- AI 挑战弹幕游戏:为 Touhou 训练机器人:爱好者们正尝试训练 AI 模型来玩 Touhou,利用以游戏分数为奖励的 RL 技术。他们正在探索像 Starcraft gym 这样的模拟器,以观察 RL 是否能精通这些以高难度著称的游戏。
- RL Scaling 让中型模型化身巨头:QwQ-32B 的成功证明了扩展 RL 训练能显著提升模型性能。持续的 RL Scaling 使得中型模型能够与巨型模型竞争,尤其是在数学和编程能力方面。
主题 5:技术人员对新硬件发布的反应
- 苹果发布天蓝色 M4 MacBook Air,技术圈反应不一:苹果配备 M4 芯片和天蓝色外观的新款 MacBook Air 起售价为 $999。虽然一些人对 Apple Intelligence 功能感到兴奋,但也有人对规格表示不满,称“这就是我不买 Mac 的原因……”
- Thunderbolt 5 承诺超高速数据传输:Thunderbolt 5 拥有 120Gb/s 的单向速度,让用户对分布式训练中增强的数据传输感到兴奋。它被认为有可能超越 RTX 3090 SLI bridge,并为基于 Mac 的设置开启新大门。
- AMD RX 9070 XT 与 Nvidia 针锋相对:AMD RX 9070 XT GPU 的测评显示,其在光栅化性能上与 Nvidia 的 5070 Ti 旗鼓相当。其价格仅为 5070 Ti(建议零售价 $750)的 80%,被赞誉为高性价比的动力源。
第一部分:Discord 高层级摘要
Cursor IDE Discord
- Cursor 的 3.7 模型性能受到质疑:成员们报告称 Cursor 的 3.7 模型感觉被削弱了,理由是它会在未提示的情况下生成 readme 文件,并且过度使用 Class A 抽象。
- 一些用户怀疑 Cursor 要么使用了冗长的 Prompt,要么使用了虚假的 3.7 模型,一位成员分享了一个关于 Cursor 编辑器今天感觉有多笨的科学测量方法。
- 社区讽刺 Cursor 的“变笨”表现:一位成员分享了一个链接,指向一个测量 Cursor 编辑器“愚蠢程度”的“高度精密仪表”。
- 该仪表使用基于“宇宙射线、键盘失误以及代码补全错误次数”的“高级算法”,引发了社区的幽默回应。
- 更新后 YOLO 模式受阻:更新后,Cursor 中的 YOLO 模式无法正常工作,因为即使在白名单为空的情况下,它现在运行命令前也需要获得批准。
- 一位用户表达了沮丧,表示他们希望 AI Agent 拥有尽可能多的自主性,并依靠 Git 来处理错误的删除,他们更喜欢曾为他们节省数小时时间的 v45 版本行为。
- 替代方案 Windsurf 受到关注:社区成员正在积极讨论 Windsurf 的新版本 Wave 4,由于感知到其在 Agent 能力方面的优势,一些人正考虑切换,并分享了一段关于 “Vibe Coding 教程与最佳实践 (Cursor / Windsurf)” 的 YouTube 教程。
- 尽管有兴趣,但对 Windsurf 定价模式的担忧依然存在,一些用户提到它“挪用”了 continue.dev 的成果。
- OpenAI 筹备高端付费层级:一位成员分享了一份报告,称 OpenAI 正在加倍投入其应用业务,计划为能够自动化编程和博士级研究的高级 Agent 提供每月 $2,000 至 $20,000 的订阅服务。
- 这一消息引发了质疑,一些人怀疑如此高昂的价格是否合理,尤其是考虑到目前 AI 模型的输出质量。
OpenAI Discord
- OpenAI 发布 GPT-4.5:OpenAI 提前于计划发布了 GPT-4.5,但目前限制为每周 50 次使用,且它并非 GPT-4o 的替代品。
- 报告显示 GPT-4.5 会拒绝基于故事的提示词,并将逐步增加使用额度。
- OpenAI 迭代 AGI:OpenAI 将 AGI 开发视为一个持续的路径而非突然的飞跃,专注于通过对现有模型的迭代部署和学习,使未来的 AI 更加安全且有益。
- 他们的 AI safety 和 alignment 方法以拥抱不确定性、深度防御、可扩展的方法、人类控制以及社区努力为指导,以确保 AGI 造福全人类。
- 关于 OpenAI O3 的猜测:成员们对 O3 的发布进行了猜测,并指出 OpenAI 表示不会在 ChatGPT 中发布完整版 O3,仅在 API 中提供。
- 语气表明它仍然是一个 AI,因此不会总是 100% 准确,并且用户应当始终咨询人类治疗师或医生。
- Qwen-14B 助力递归摘要:成员们正在使用 Qwen-14B 模型进行递归摘要任务,并发现其输出效果优于 Gemini。
- 示例中提到对一本国际象棋书籍进行摘要,Qwen-14B 的结果优于 Gemini,后者的表现类似于 GPT-3.5。
- 提示工程综述:一位成员分享了一篇关于 Large Language Models 提示工程的系统综述,题为《A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications》,概述了 Zero-Shot Prompting、Few-Shot Prompting 和 Chain-of-Thought (CoT) 提示等关键策略,并提供了 ChatGPT 链接 以供访问。
- 然而,讨论强调了该综述虽然对每种技术都有详细描述,但遗漏了 Self-Discover 和 MedPrompt 等内容。
Codeium (Windsurf) Discord
- Windsurf Wave 4:收获与波动:Windsurf 推出了 Wave 4(博客文章),包括 Previews、Tab-to-import、Linter integration、Suggested actions、MCP discoverability 以及对 Claude 3.7 的改进。
- 一些用户报告了死循环和高额度消耗等问题,而另一些用户则称赞了其速度以及通过 Windsurf Command (
CTRL/Cmd + I) 即可访问的 Claude 3.7 集成。
- 一些用户报告了死循环和高额度消耗等问题,而另一些用户则称赞了其速度以及通过 Windsurf Command (
- 凭据故障导致 Codeium 瘫痪:多名用户报告称无法登录 codeium.com(无论是使用 Google 还是邮箱/密码)。
- 团队承认了登录问题,并提供了一个 状态页面 以获取更新。
- 额度危机困扰 Codeium 用户:用户对额度消耗过快表示担忧,尤其是在使用 Claude 3.7 时,即使在改进后也是如此。
- 团队澄清说 Flex Credits 可以结转,自动修复 Lint 错误是免费的,但其他用户仍在为额度和 Tool calls 感到困扰。
- Windsurf Wave 4 的工作流奇迹:一段 YouTube 视频 介绍了 Windsurf Wave 4 的更新,演示了 Preview、Tab to Import 和 Suggested Actions。
- 新的 Tab-to-import 功能可以通过按下 Tab 键自动添加导入,增强了 Cascade 内部的工作流。
- Windsurf 愿望清单:期待 Webview 和取消限制:用户请求了诸如外部库文档支持、提高额度限制、可调节的聊天字体大小、像 Trae 一样在侧边栏提供真正的 Webview,以及用于生成 llms.txt 文件的 Firecrawl 等功能。
- 一位用户建议使用 Firecrawl 为网站生成 llms.txt 文件,以便输入到 LLM 中。
aider (Paul Gauthier) Discord
- Qwen 发布 QwQ-32B 推理模型:Qwen 推出了 QwQ-32B,这是一个拥有 32B 参数的推理模型,在 VXReddit 帖子 和其 官方博客 中被认为可以与 DeepSeek-R1 相媲美。
- 爱好者们渴望通过 Aider 集成来测试其作为架构师和代码编写者的性能,并提到该模型已在 HF 和 ModelScope 上线。
- 实现 Aider 离线安装:寻求在离线 PC 上安装 Aider 的用户通过使用 pip download 将 Python 包从联网机器传输到离线虚拟环境,克服了安装挑战。
- 一个成功的操作序列包括:
python -m pip download --dest=aider_installer aider-chat。
- 一个成功的操作序列包括:
- 通过 OAI 兼容的 Aider 实现与 OWUI 的和谐共存:为了在 OpenWebUI (OWUI) 中使用 Aider,一位成员建议在模型名称前加上
openai/前缀,以指示这是一个 OAI 兼容的端点,例如openai/myowui-openrouter.openai/gpt-4o-mini。- 这种方法绕过了将 Aider 连接到 OWUI 时出现的
litellm.BadRequestError问题。
- 这种方法绕过了将 Aider 连接到 OWUI 时出现的
- ParaSail 声称拥有极速 R1 吞吐量:一位用户报告称,通过 OpenRouter 使用 Parasail 提供商,在 R1 上达到了 300tps。
- 虽然复现较为困难,但 Parasail 与 SambaNova 一起被认为是 R1 的顶级性能提供商。
- 使用 Aider 编写 commit messages:成员们讨论了让 aider 为暂存文件编写 commit messages 的方法,建议先执行
git stash save --keep-index,然后运行/commit,最后执行git stash pop。- 另一位成员建议使用
aider --commit,它会编写 commit message、提交并退出,并参考 Git 集成文档。
- 另一位成员建议使用
LM Studio Discord
- 注意 VRAM 溢出:一位成员描述了如何通过监控 Dedicated memory(专用内存)和 Shared memory(共享内存)的使用情况来检测 LM Studio 中的 VRAM 溢出,并提供了一张说明该问题的图片。
- 他们指出,当 Dedicated memory 处于高位且 Shared memory 增加时,就会发生溢出。
- 多模态 Phi-4 暂不支持音频:成员们确认,由于 llama.cpp 的限制,LM Studio 目前不支持 multi-modal Phi-4 和音频支持。
- 目前没有针对缺失支持的变通方案。
- 锁定 VRAM、Context 和 KV Cache:一位成员指出,context size 和 KV cache 设置会显著影响 VRAM 使用,建议以 90% VRAM 利用率为目标以优化性能。
- 另一位成员解释说,KV cache 是计算机进行 attention 机制计算时的 K 和 V 的值。
- Sesame AI 的 TTS:开源还是虚晃一枪?:成员们讨论了 Sesame AI 的对话式语音生成模型 (CSM),一位成员称赞其栩栩如生,并链接到了 demo。
- 其他人对其“开源”声明表示怀疑,指出其 GitHub 仓库 缺乏代码提交。
- M3 Ultra 和 M4 Max Mac Studio 发布:Apple 发布了搭载 M3 Ultra(最高支持 512GB RAM)和 M4 Max(最高支持 128GB)的新款 Mac Studio。
- 一位成员对 RAM 规格反应消极,表示“这就是我不买 Mac 的原因……”。
{kind=link}
Interconnects (Nathan Lambert) Discord
- Sutton 引发安全辩论!:图灵奖得主 Richard Sutton 最近在访谈中表示 safety is fake news(安全是假新闻),这引发了激烈讨论。
- 反应各异,一位成员评论道:Rich 在道德上有点可疑,即使他的产出惊人,我也不会听从他的研究建议。
- OpenAI Agent 定价:每月 2 万美元?:根据 The Information 报道,OpenAI 计划对专为自动化编程和 PhD 级别研究等任务设计的 AI Agent 收取 每月 2,000 到 20,000 美元 的费用。
- OpenAI 的投资者 SoftBank 已承诺仅今年就在 OpenAI 的 Agent 产品上投入 30 亿美元。
- 阿里巴巴 QwQ-32B 模型对标 DeepSeek:阿里巴巴 Qwen 发布了 QwQ-32B,这是一个拥有 320 亿参数 的推理模型,正与 DeepSeek-R1 等模型展开竞争。
- 该模型使用了 RL 训练和 post training,显著提升了在数学和编程方面的性能。
- DeepMind 人才流向 Anthropic 的趋势持续:Nicholas Carlini 宣布离开 Google DeepMind 加入 Anthropic,他在博客中提到,他在 adversarial machine learning 方面的研究在 DeepMind 不再获得支持。
- 成员们注意到 GDM 最近流失了这么多重要人才,而其他人则表示 Anthropic 的天命股在上涨。
- RL 击败《宝可梦 红》:一个强化学习系统使用低于 10M 参数 的策略、PPO 以及新技术击败了 Pokémon Red,详情见 博客文章。
- 该系统成功通关游戏,展示了 RL 在解决复杂任务方面的复兴。
GPU MODE Discord
- 东方 Project AI 模型进阶:一位成员正在训练一个 AI 模型来玩 Touhou(东方 Project),使用 RL 并将游戏分数作为奖励,考虑了 Starcraft gym 和 Minetest gym 等模拟器。
- 目标是确定 RL 和奖励函数是否可以用于学习游戏玩法。
- Thunderbolt 5 加速数据传输:成员们对 Thunderbolt 5 感到兴奋,它可能使 Mac Mini/Studio 之间的分布式推理/训练变得更加可行。
- 其单向速度 (120gb/s) 似乎比 RTX 3090 SLI bridge (112.5gb/s) 还要快。
- CUDA 编译器变得过于“聪明”:当写入的数据从未被读取时,CUDA 编译器会优化掉内存写入操作,导致在添加读取操作之前不会报告任何错误。
- 这种优化可能会误导调试内存写入操作的开发者,因为在涉及读取操作之前,没有错误并不代表行为正确。
- TileLang 在 CUDA 12.4/12.6 上遇到困难:用户报告在 CUDA 12.4/12.6 上使用 TileLang 进行 matmul 时出现元素不匹配,并在 GitHub 上提交了 bug 报告。
- 该代码在 CUDA 12.1 上运行正常,但在新版本中会出现关于 tensor 差异的
AssertionError。
- 该代码在 CUDA 12.1 上运行正常,但在新版本中会出现关于 tensor 差异的
- QwQ-32B 让大型模型感受到压力:阿里巴巴发布了 QwQ-32B,这是一个仅有 320 亿参数 的新推理模型,足以媲美 DeepSeek-R1 等模型。
- 该模型已在 HF、ModelScope、Demo 和 Qwen Chat 上线。
Perplexity AI Discord
- Google 搜索进入 AI 聊天领域:Google 宣布推出 AI Mode for Search,提供对话式体验并支持复杂查询,目前作为选择性加入(opt-in)体验提供给部分 Google One AI Premium 订阅者(参见 AndroidAuthority)。
- 一些用户认为,由于这一公告,Perplexity 不再显得特别。
- Claude Sonnet 3.7 未达预期?:一位用户对 Perplexity 实现的 Claude Sonnet 3.7 表示不满,认为其结果不如直接通过 Anthropic 使用。
- 他们补充说,3.7 在一个简单的 JSON 文件中产生了幻觉错误,质疑该模型声称的改进。
- Perplexity API 的 Focus 设置难以捉摸:一位用户询问如何将 API 聚焦于特定主题(如学术或社区相关内容)的方法。
- 然而,消息中并未提供任何解决方案。
- Sonar Pro 搜索模型未能通过时效性测试:一位用户报告称,尽管将 search_recency_filter 设置为 ‘month’,Sonar Pro 模型仍返回过时信息和错误链接。
- 该用户怀疑自己是否误用了 API。
- API 搜索成本仍是个谜:一位用户对 API 不提供搜索成本信息表示沮丧,导致无法准确跟踪支出。
- 他们哀叹无法跟踪自己的 API 支出,因为 API 没有告知使用了多少次搜索,并附上了一个大哭的表情。
HuggingFace Discord
- CoreWeave 提交 IPO 申请,营收增长 700%:云服务提供商 CoreWeave(其近三分之二的收入依赖 Microsoft)提交了 IPO 招股说明书,报告 2024 年营收增长 700% 至 19.2 亿美元,尽管净亏损达 8.634 亿美元。
- 约 77% 的收入来自两家客户(主要是 Microsoft),且该公司持有超过 150 亿美元 的未履行合同。
- Kornia Rust 库在 Google Summer of Code 2025 开放实习:Kornia Rust 库正在为 Google Summer of Code 2025 开放实习岗位以改进该库,主要围绕 Rust 中的 CV/AI 展开。
- 鼓励感兴趣的人士查阅文档并提出任何问题。
- Umar Jamil 在 GPU Mode 分享学习 Flash Attention、Triton 和 CUDA 的历程:Umar Jamil 将于太平洋时间 3 月 8 日(本周六)中午参加 GPU Mode,分享他学习 Flash Attention、Triton 和 CUDA 的历程。
- 这将是与观众的一次“亲密对话”,关于他在学习过程中的困难,并分享如何自学任何知识的实用技巧。
- VisionKit 竟然不是开源的:
i-made-this频道中的模型使用了 VisionKit 但并未开源,可能在未来发布,但在开发过程中 Deepseek-r1 的表现出奇地有帮助。- 一篇 Medium 文章 讨论了构建自定义 MCP server,并提到了 CookGPT 作为示例。
- Agents 课程证书位置不明!:agents-course 频道的用户无法在课程中找到他们的证书,特别是在 此页面 中,并寻求帮助。
- 一位成员指出,证书可以在此数据集的 “files” 下的 “certificates” 中找到,但其他人反映仍有无法显示的问题。
MCP (Glama) Discord
- Composio 通过身份验证增强 MCP:Composio 现在支持带身份验证的 MCP,消除了为 Linear, Slack, Notion 和 Calendly 等应用设置 MCP servers 的需求。
- 他们的 公告 强调了托管身份验证和改进的 tool calling 准确性。
- WebMCP 引发安全争议:任何网站都能充当 MCP server 的概念引发了安全担忧,特别是关于可能访问本地 MCP servers 的问题。
- 有人将其描述为 安全噩梦,会破坏浏览器沙箱,而其他人则建议使用 CORS 和 cross-site configuration 等缓解措施。
- Reddit Agent 使用 MCP 获取线索:一位成员使用 MCP 构建了一个 Reddit agent 来生成潜在客户,展示了 MCP 在实际应用中的实用性。
- 另一位成员在询问如何连接到 Reddit 后,分享了 Composio 的 Reddit 集成。
- Token 两步走:本地 vs. 按站点:在设置 MCP Server 后,一位用户澄清了在网站访问时,除了 local token 之外,还存在 按站点和按会话生成的 tokens。
- 开发者验证了这一过程,强调 tokens 是 按会话、按站点 生成的。
- Insta-Lead-Magic 发布:一位用户展示了一个 Instagram Lead Scraper,并辅以 自定义仪表盘,详情见链接 视频
- 未提供第二个摘要。
Latent Space Discord
- Claude 向开发者收取 25 美分:一位成员报告称,向 Claude 询问一个关于其小型代码库的问题花费了 $0.26,这引发了对使用 Claude 处理代码相关查询成本的担忧。
- 有人建议将代码库复制到 Claude 目录中,并在 Claude Desktop 上激活 filesystem MCP server,作为免费访问的变通方案。
- M4 MacBook Air:天蓝色且有 AI 增强:Apple 发布了搭载 M4 芯片、具备 Apple Intelligence 功能以及全新 天蓝色 的新款 MacBook Air,起售价为 $999,详见 此公告。
- 新款 MacBook Air 拥有长达 18 小时的电池续航时间和 12MP Center Stage 摄像头。
- Qwen 的 QwQ-32B:DeepSeek 的推理竞争对手:根据 这篇博客文章,Qwen 发布了 QwQ-32B,这是一款全新的 320 亿参数推理模型,其性能可与 DeepSeek-R1 等模型相媲美。
- 该模型通过 RL 和持续缩放训练,在数学和编程方面表现出色,可在 HuggingFace 上获取。
- React:LLM 后端的惊喜英雄?:一位成员建议 React 是后端 LLM 工作流的最佳编程模型,并引用了一篇关于使用 node.js 后端和 类 React 组件模型构建 @gensx_inc 的博客文章。
- 反对意见包括 Lisp 更适合创建 DSL,以及提到了 Mastra 作为一个无框架的替代方案。
- Windsurf 的 Cascade:不再需要“检查元素”?:Windsurf 发布了 Wave 4,其特色功能 Cascade 可将元素/错误直接发送到聊天中,旨在减少对“检查元素”的需求,演示见 此链接。
- 更新内容包括预览、Cascade Auto-Linter、MCP UI 改进、Tab 键导入、建议操作、Claude 3.7 改进、推荐奖励以及 Windows ARM 支持。
Stability.ai (Stable Diffusion) Discord
- SDXL 手部问题让你头疼?:用户正在寻求在 SDXL 中自动修复手部的方法,而无需手动进行 inpainting,特别是在使用 8GB VRAM 的情况下。讨论内容涉及 embeddings、face detailers 和 OpenPose 控制网(control nets)。
- 重点在于寻找适用于 SDXL 的有效 hand LoRAs 以及自动校正技术。
- 一张照片变电影?:用户探索了从单张照片创建视频的方法,推荐使用 WAN 2.1 i2v model,但指出该模型需要强大的 GPU 性能和耐心。
- 虽然有人建议使用带有免费额度的在线服务,但共识是本地视频生成会产生成本,主要体现在电力消耗上。
- SD 3.5 表现不尽如人意:成员们反映 SD 3.5 在我的测试中表现甚至不如 flux dev,且远不及 ideogram 或 imagen 等大型模型。
- 然而,另一位成员表示 与早期的 sd 1.5 相比,它们已经取得了长足的进步。
- 涡轮增压般的 SD3.5 速度:TensorArt 开源了 SD3.5 Large TurboX,采用 8 个采样步数(sampling steps) 实现了 6 倍的速度提升,且图像质量优于官方的 Stable Diffusion 3.5 Turbo,可在 Hugging Face 获取。
- 他们还推出了 SD3.5 Medium TurboX,仅需 4 个采样步数 即可在中端 GPU 上用 1 秒 钟生成 768x1248 分辨率的图像,号称有 13 倍的速度提升,同样已上线 Hugging Face。
LlamaIndex Discord
- LlamaIndex 发布 Agentic Document Workflow 合作项目:LlamaIndex 与 DeepLearningAI 合作开设了一门课程,重点关注构建 Agentic Document Workflows(代理式文档工作流)。
- 这些工作流旨在直接集成到更大的软件流程中,标志着知识型 Agent 向前迈进了一步。
- ImageBlock 用户遇到 OpenAI 故障:用户报告了在最新版本的 LlamaIndex 中 ImageBlock 与 OpenAI 的集成问题,系统无法识别图像;机器人建议检查最新版本并确保使用了正确的模型,例如 gpt-4-vision-preview。
- 这一问题凸显了在现有 LlamaIndex 工作流中集成视觉模型的复杂性。
- Query Fusion Retriever 的引用丢失:一位用户发现,在他们的 LlamaIndex 配置中,node post-processing(节点后处理)和 citation templates(引用模板)无法与 Query Fusion Retriever 配合使用,特别是在使用 reciprocal reranking(倒数重排序)时,并链接了他们的代码以供审查。
- Query Fusion Retriever 中的去重过程可能是导致节点处理期间元数据丢失的原因。
- 对分布式 AgentWorkflow 架构的向往:成员们讨论了在 AgentWorkflow 中原生支持分布式架构(distributed architecture)的可能性,即不同的 Agent 在不同的服务器/进程上运行。
- 建议的解决方案是为 Agent 配备用于对服务进行远程调用的工具,而不是依赖内置的分布式架构支持。
- GPT-4o Audio Preview 模型表现不佳:一位用户报告了在 LlamaIndex Agent 中使用 OpenAI 的音频
gpt-4o-audio-preview模型时遇到的集成挑战,特别是在流式传输事件(streaming events)方面。- 有人指出 AgentWorkflow 会自动对聊天消息调用
llm.astream_chat(),这可能与 OpenAI 的音频支持冲突,并建议了一个潜在的变通方法:避免使用 AgentWorkflow 或禁用 LLM 流式传输。
- 有人指出 AgentWorkflow 会自动对聊天消息调用
Notebook LM Discord
- NotebookLM 无法摆脱物理教学大纲:一位用户发现,当他们上传了 180 页的物理教科书时,系统在使用 Gemini 时无法脱离其教学大纲。
- 这限制了偏离并探索教学大纲之外其他替代概念的能力。
- PDF 上传困境:用户在上传 PDF 时面临挑战,发现它们几乎无法使用,尤其是包含文本和图像混合内容时。Google Docs 和 Slides 在渲染混合内容方面似乎表现得更好。
- 建议将 PDF 转换为 Google Docs 或 Slides 作为变通方案,然而这些文件格式是私有的。
- 始终期待 API 访问:一位用户询问是否存在 NotebookLM API 或未来的相关计划,并列举了 AI 工程师在工作流优化方面的众多用例。
- 访问 API 将允许用户将 NotebookLM 与其他服务集成并自动化任务,例如播客生成器。
- 移动应用思索:一位用户询问是否有独立的 Android 版 NotebookLM 应用,另一位用户则建议网页版运行良好,此外还有一个 PWA。
- 用户讨论了 NotebookLM 作为渐进式 Web 应用 (PWA) 的可用性,它可以安装在手机和 PC 上,无需专用应用即可提供类似原生应用的体验。
- 播客功能备受赞誉:一位用户称赞 Notebook LM 的播客生成器非常精妙,但想知道是否有办法将播客长度从 17 分钟延长到 20 分钟。
- 播客功能对于教育工作者和内容创作者进行讲座可能是一项宝贵的资产。
Nous Research AI Discord
- Gaslight Benchmark 探索开始:一位成员询问是否存在 gaslight benchmark(煤气灯效应基准测试)来比较 GPT-4.5 与其他模型,并得到了一个指向讽刺性基准测试链接的回应。
- 讨论强调了社区对在传统指标之外评估模型的兴趣,特别是在欺骗和说服等领域。
- GPT-4.5 的说服力提升:一位成员指出 GPT-4.5 的系统卡 (system card) 显示其在说服力方面有显著提升,这归功于 post-training RL(训练后强化学习)。
- 这一观察引发了对利用 post-training RL 增强模型能力的初创公司的好奇,表明了 AI 开发中的一个更广泛趋势。
- Hermes 的特殊 Token:确认用于训练 Hermes 模型的特殊 Token 为 *
*、* *、*</SCRATCHPAD>* 和 *</THINKING>*。 - 这一澄清对于微调或集成 Hermes 模型的开发者至关重要,可确保正确的格式化和交互。
- QwQ-32B 媲美 DeepSeek R1:根据这篇博客文章,来自 Qwen 的 320 亿参数模型 QwQ-32B 的表现与拥有 6710 亿参数的 DeepSeek-R1 处于相似水平。
- 该模型可通过 QWEN CHAT、Hugging Face、ModelScope、DEMO 和 DISCORD 访问。
- RL 扩展提升模型天赋:Reinforcement Learning (RL) 扩展使模型性能超越了典型的预训练,这篇博客文章详细介绍了 DeepSeek R1 通过冷启动数据和多阶段训练实现复杂推理的例子。
- 这突显了 RL 技术在突破模型能力边界方面日益增长的重要性,特别是在需要高级逻辑思维的任务中。
OpenRouter (Alex Atallah) Discord
- Taiga 应用集成 OpenRouter:一款名为 Taiga 的开源 Android 聊天应用已发布,允许用户自定义想要使用的 LLM,并已预集成 OpenRouter。
- 路线图包括基于 Whisper 模型和 Transformer.js 的本地 Speech To Text(语音转文本),以及对 Text To Image(文本转图像)和基于 ChatTTS 的 TTS 支持。
- Prefill 功能引发讨论:成员们质疑为什么在 text completion(文本补全)模式中使用 prefill,认为它更适合对话补全,因为将其应用于用户消息似乎不合逻辑。
- 一位用户认为 “prefill 对用户消息没有意义,而且他们明确将其定义为对话补全而非文本补全,哈哈”。
- 用户请求 OpenRouter 文档汇总:一位用户请求将 OpenRouter 的文档导出为单个大型 Markdown 文件,以便与 coding agents 无缝集成。
- 另一位用户迅速提供了一个文档的全文文本文件。
- DeepSeek 的格式难以理解:讨论集中在 DeepSeek 用于多轮对话的 instruct format 的歧义上,成员们发现甚至其 Tokenizer 配置也令人困惑。
- 一位用户分享了 tokenizer config,其中定义了
<|begin of sentence|>和<|end of sentence|>Token 用于处理上下文。
- 一位用户分享了 tokenizer config,其中定义了
- 讨论加入 LLMGuard 的可能性:一位成员提出了在 OpenRouter 中为 LLM via API 整合插件(如 LLMGuard)的可能性,用于 Prompt Injection(提示词注入)扫描等功能。
- 该用户链接到了 LLMGuard,并想知道 OpenRouter 是否可以处理 PII(个人身份信息)脱敏以提高安全性。
Yannick Kilcher Discord
- Sparsemax 被误认为双层优化 (Bilevel Max):成员们讨论了将 Sparsemax 构造成双层优化 (BO) 问题,认为网络可以动态调整不同的神经网络层,但另一位成员迅速反驳了这一点。
- 相反,他们详细说明了 Sparsemax 是向概率单纯形(probability simplex)上的投影,具有闭式解(closed-form solution),并利用拉格朗日对偶性(Lagrangian duality)证明了计算可以简化为注水算法(water-filling),从而找到闭式解。
- DDP 导致权重错乱:PyTorch Bug 排查:一位成员报告在使用 PyTorch、DDP 和 4 张 GPU 时遇到问题,在调试过程中发现 Checkpoint 重新加载导致某些 GPU 上的权重出现错乱。
- 另一位成员建议确保在初始化 DDP 之前,在所有 GPU 上完成模型初始化和 Checkpoint 加载,以减轻权重错乱问题。
- Agent 主动澄清文本生成图像意图:一篇新论文介绍了一种主动型 T2I Agent,它们会主动提出澄清问题,并将对用户意图的理解呈现为可编辑的置信图(belief graph),以解决用户提示词描述不充分的问题。该论文名为《Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty》。
- 一段补充视频显示,至少 90% 的人类受试者认为这些 Agent 及其置信图对他们的 T2I 工作流很有帮助。
- 阿里巴巴发布 QwQ-32B:阿里巴巴发布了 QwQ-32B,这是一款参数量仅为 320 亿的新型推理模型,可与 DeepSeek-R1 等顶尖推理模型相媲美。
Cohere Discord
- Cohere 企业支持延迟:一位寻求 Cohere enterprise deployment 协助的成员被引导至邮件支持,但指出其之前的邮件已有一周未获回复。
- 另一位成员提醒 B2B 交付周期可能延长至 6 周,而另一位则反驳称 Cohere 通常在 2-3 天 内回复。
- Cohere 的 Aya Vision 支持 23 种语言:Cohere For AI 推出了 Aya Vision,这是一个支持 23 种语言 的权重开放多语言视觉模型(8B 和 32B 参数),在图像描述、视觉问答、文本生成和翻译方面表现出色(博客文章)。
- Aya Vision 已在 Hugging Face 和 Kaggle 上线,包括新的多语言视觉评估集 AyaVisionBenchmark;聊天机器人也已在 Poe 和 WhatsApp 上线。
- Cohere Reranker v3.5 延迟数据缺失:一位成员请求 Cohere Reranker v3.5 的延迟数据,指出尽管在采访中有所承诺,但仍缺乏公开数据。
- 受访者曾承诺分享图表,但最终未能提供。
- 用户寻找销售/企业支持联系方式:一位新用户加入,寻求联系 Cohere 的 sales / enterprise support 人员。
- 该用户被鼓励进行自我介绍,包括公司详情、行业、大学、当前项目、喜爱的技术/工具以及加入社区的目标。
Modular (Mojo 🔥) Discord
- Mojo 仍处于开发阶段:一位成员报告称 Mojo 仍不稳定,还有大量工作要做;另一位成员询问虚拟活动的 YouTube 录像,但获知该活动未录制。
- 团队提到他们未来肯定会考虑举办类似的虚拟活动。
- Triton 被提议作为 Mojo 替代方案:一位成员建议将 Triton(支持 Intel 和 Nvidia 硬件的 AMD 软件)作为 Mojo 的潜在替代方案。
- 另一位成员澄清说 Mojo 不是 Python 的超集,而是 Python 语言家族的一员,并表示成为超集对 Mojo 来说就像是戴上了口罩(束缚)。
- Mojo 在 Python venv 中性能下降:基准测试显示,在激活的 Python virtual environment 中运行 Mojo 二进制文件时,Mojo 的性能提升会显著降低,即使对于没有 Python 导入的文件也是如此。
- 用户寻求关于为什么 Python venv 会影响本应独立的 Mojo 二进制文件的见解。
- 项目文件夹结构咨询:一位开发者请求对 Mojo/Python 项目文件夹结构 的反馈,该结构涉及导入标准 Python 库并运行用 Mojo 编写的测试。
- 他们广泛使用
Python.add_to_path进行自定义模块导入,并在tests文件夹中使用符号链接(Symlink)来定位源文件,寻求更好的替代方案。
- 他们广泛使用
- 文件夹结构讨论移至 Modular 论坛:一位用户在 Modular 论坛上发起了关于 Mojo/Python 项目文件夹结构 的讨论,链接至论坛帖子。
- 此举旨在确保讨论的长期可发现性和保留,因为 Discord 的搜索和数据保留功能较差。
DSPy Discord
- SynaLinks 进入 LM 竞技场:一个新的基于图的可编程神经符号 LM 框架 SynaLinks 已发布,其函数式 API 灵感源自 Keras,旨在通过异步优化和约束结构化输出等特性达到生产就绪状态 - GitHub 上的 SynaLinks。
- 该框架已在客户的生产环境中运行,重点关注知识图谱 RAG、强化学习和认知架构。
- Adapter 解耦了 DSPy 中的 Signature:DSPy 的 Adapter 系统将 Signature(你想要内容的声明式规范)与不同提供商生成 Completion 的方式解耦。
- 默认情况下,DSPy 使用经过良好调优的 ChatAdapter,并回退到 JSONAdapter,利用结构化输出 API 在 VLLM、SGLang、OpenAI、Databricks 等提供商中进行约束解码。
- DSPy 简化了显式类型指定:DSPy 通过如下代码简化了显式类型指定:
contradictory_pairs: list[dict[str, str]] = dspy.OutputField(desc="List of contradictory pairs, each with fields for text numbers, contradiction result, and justification."),但由于未指定dict的键,这在技术上存在歧义。- 相反,应考虑使用
list[some_pydantic_model],其中 some_pydantic_model 具有正确的字段。
- 相反,应考虑使用
- DSPy 解决滞后线程问题:PR 7914(已合并)解决了
dspy.Evaluate或dspy.Parallel中卡住的滞后(straggler)线程问题,旨在实现更顺畅的运行。- 此修复将在 DSPy 2.6.11 中可用;用户可以从
main分支进行测试,无需更改代码。
- 此修复将在 DSPy 2.6.11 中可用;用户可以从
tinygrad (George Hotz) Discord
- ShapeTracker 合并证明接近完成:一名成员宣布在 Lean 中完成了一个关于何时可以合并 ShapeTracker 的证明,进度约为 90%,可在此仓库和此 Issue中查看。
- 作者指出尚未考虑偏移量(offsets)和掩码(masks),但扩展该证明非常直接。
- 在淘宝上解锁 96GB 4090:一名成员分享了淘宝上 96GB 4090 的链接(X 帖子),引发了“好东西都在淘宝上”的评论。
- 未有进一步讨论。
- 调试 gfx10 Trace 问题:一名成员请求关于 gfx10 trace 的反馈,询问是否应将其记录为 Issue。
- 另一名成员怀疑这与 ctl/ctx 大小有关,并建议运行
IOCTL=1 HIP=1 python3 test/test_tiny.py TestTiny.test_plus以协助调试。
- 另一名成员怀疑这与 ctl/ctx 大小有关,并建议运行
- 评估 Rust CubeCL 质量:一名成员询问 Rust CubeCL 的质量,并指出它来自 Rust Burn 的原班人马。
- 讨论未对其质量得出结论性评估。
Eleuther Discord
- Suleiman 投身 AI 生物黑客(Biohacking):具有软件工程背景的高管 Suleiman 向频道介绍了自己,表达了对 AI 和生物黑客的兴趣。
- 他正在探索营养学和补充剂科学,以开发 AI 赋能的生物黑客工具来改善人类生活。
- Naveen 研究 Txt2Img 模型的机器遗忘:来自 IIT 的硕士兼研究助理 Naveen 介绍了自己及其在文本生成图像扩散模型中的机器遗忘(Machine Unlearning)工作。
- 他提到最近在 CVPR25 发表了一篇论文,重点研究从生成模型中移除不当概念的策略。
- ARC 训练的普适性悬而未决:一名用户质疑 Observation 3.1 是否对几乎任何两个具有非零均值的分布以及 ARC 训练中几乎任何 u35% 的情况都普遍成立。
- 讨论陷入停滞,没有明确结论,也未就 Observation 3.1 的具体条件或例外情况进行讨论。
- 压缩产生智能?:Isaac Liao 和 Albert Gu 在他们的博客文章中探讨了无损信息压缩是否能产生智能行为。
- 他们专注于实际演示,而不是重新讨论关于高效压缩在智能中作用的理论探讨。
- ARC Challenge 使用 YAML 配置:成员们讨论了使用 arc_challenge.yaml 来设置 ARC-Challenge 任务。
- 讨论涉及配置模型使用 25 shots 进行评估,强调了 few-shot learning 能力在应对该挑战中的重要性。
Torchtune Discord
- Torchtune 中的自定义 Tokenizer 问题:用户在训练后遇到了 Torchtune 用来自 Hugging Face 的原始文件覆盖自定义 special_tokens.json 的问题,这是由于 checkpointer 中的 copy_files 逻辑导致的。
- 提出的快速修复方案包括在下载的模型目录中,手动用用户的自定义版本替换下载的 special_tokens.json。
- 关于 Checkpointer save_checkpoint 方法的辩论:一名成员建议通过向 Torchtune 中 checkpointer 的 save_checkpoint 方法传递新参数,来支持自定义 tokenizer 逻辑。
- 然而,其他人质疑在没有充分理由的情况下暴露新配置的必要性。
LLM Agents (Berkeley MOOC) Discord
- MOOC 学生可观看所有讲座:一名成员询问 Berkeley 学生是否拥有 MOOC 学生无法访问的专属讲座,特别是针对 LLM Agents MOOC。
- 另一名成员澄清说,Berkeley 学生和 MOOC 学生参加的是相同的讲座。
- 学生回忆 12 月的提交情况:一名成员提到在 12 月提交了与课程相关的内容,推测是 LLM Agents MOOC 的证书声明表。
- 另一名成员寻求关于提交证书声明表所使用的特定电子邮件地址的确认,暗示可能需要进行行政跟进。
Gorilla LLM (Berkeley Function Calling) Discord
- 寻求 AST Metric 的澄清:一名成员在 Gorilla LLM Leaderboard 频道中寻求关于 AST metric 定义的澄清。
- 他们询问 AST metric 是否代表 LLM 响应生成的格式正确的函数调用百分比。
- 成员询问 V1 Dataset 构建方式:一名成员询问了用于构建 Gorilla LLM Leaderboard 的 V1 dataset 的方法论。
- 了解 dataset construction 过程可以为排行榜的 evaluation methodology 提供有价值的见解。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
PART 2: 频道详情摘要与链接
各频道的详细细分内容已针对电子邮件进行了截断。
如果您喜欢 AInews,请分享给朋友!预谢!