ainews-gemini-25-flash-completes-the-total
Gemini 2.5 Flash 彻底统治了帕累托前沿(Pareto Frontier)。
Gemini 2.5 Flash 推出了全新的“思考预算”(thinking budget)功能,与 Anthropic 和 OpenAI 的模型相比提供了更多控制权,标志着 Gemini 系列的一次重大更新。OpenAI 发布了 o3 和 o4-mini 模型,强调了先进的工具使用能力和多模态理解;其中 o3 在多个排行榜上占据主导地位,但在基准测试中的评价褒贬不一。AI 研发中工具使用的重要性日益凸显,OpenAI Codex CLI 也作为一款轻量级开源编程代理正式发布。这些动态反映了当前 AI 模型发布、基准测试和工具集成领域的持续趋势。
Gemini 就够了。
2025年4月16日至4月17日的 AI 新闻。我们为你查阅了 9 个 subreddit、449 个 Twitter 和 29 个 Discord(212 个频道,以及 11414 条消息)。预计节省阅读时间(按 200wpm 计算):852 分钟。你现在可以艾特 @smol_ai 进行 AINews 讨论!
恰逢 LMArena 转型为一家初创公司,Gemini 在发布 Gemini 2.5 Flash 时,给出了可能是最后一份来自主流实验室对 Chat Arena Elo 评分的背书:
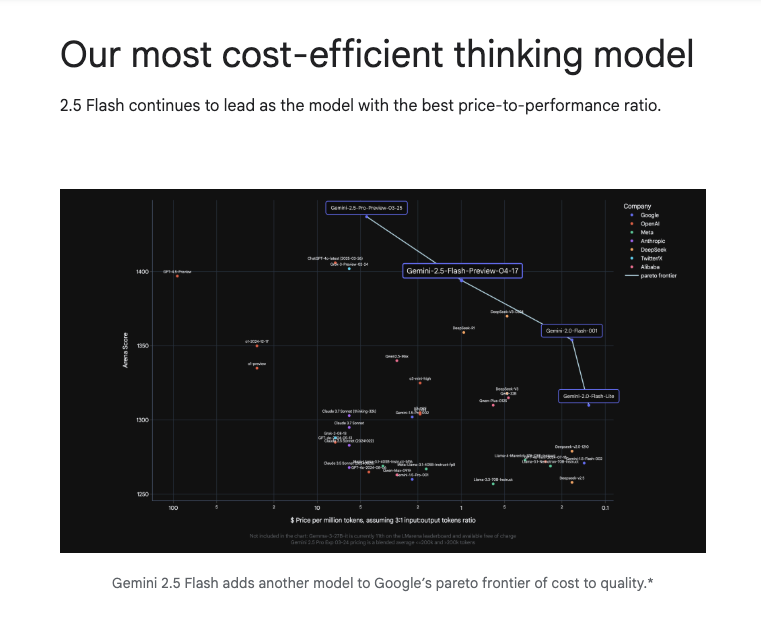
由于 2.5 Flash 的定价似乎恰好选在 2.0 Flash 和 2.5 Pro 之间的界线上,自从 Price-Elo 图表去年在本通讯中首次亮相以来,该图表的预测性在被 Jeff 和 Demis 引用后,其效用似乎达到了顶峰。
Gemini 2.5 Flash 引入了全新的“thinking budget”(思考预算),相比 Anthropic 和 OpenAI 的同类功能提供了更多控制权,尽管这种程度的控制是否真的有用(相对于“低/中/高”选项)仍有待商榷:

HN 评论反映了我们 5 个月前报道过的“Google 觉醒”大趋势:
AI Twitter 综述
模型发布与能力 (o3, o4-mini, Gemini 2.5 Flash 等)
- OpenAI o3 与 o4-mini 发布:@sama 宣布发布 o3 和 o4-mini,强调了它们的工具使用能力和出色的多模态理解。@kevinweil 强调了这些模型在思维链(chain of thought)中使用搜索、代码编写和图像处理等工具的能力,并将 o4-mini 描述为“性价比极高”。@markchen90 指出,通过端到端的工具使用,推理模型变得更加强大,特别是在视觉感知等多模态领域。@alexandr_wang 指出 o3 在 SEAL 排行榜上占据主导地位,在 HLE、Multichallenge、MASK 和 ENIGMA 中均排名第一。
- o3 和 o4-mini 的初步性能印象与基准测试:@polynoamial 表示 OpenAI 并没有“解决数学问题”,o3 和 o4-mini 距离获得国际数学奥林匹克竞赛金牌还很远。@scaling01 认为 o3 虽然是“最强模型”,但在某些领域表现不及预期且营销过度,并指出 Gemini 速度更快,而 Sonnet 的 Agent 特性更强。@scaling01 还提供了 o3、Sonnet 3.7 和 Gemini 2.5 Pro 在 GPQA、SWE-bench Verified、AIME 2024 和 Aider 上的具体基准测试对比,结果互有胜负。
- o3 和 o4-mini 中的工具使用与推理:@sama 对新模型协同使用工具的能力表示惊讶。@aidan_mclau 强调了工具使用的重要性,称 “忽略字面上所有的基准测试,o3 最大的特性是工具使用”,并强调它对于深度研究、调试和编写 Python 脚本非常有用。@cwolferesearch 针对新模型指出,RL 是 AI 研究人员的一项重要技能,并提供了学习资源链接。
- OpenAI Codex CLI:@sama 宣布了 Codex CLI,这是一个开源的编程 Agent。@gdb 将其描述为在终端运行的轻量级编程 Agent,也是即将发布的一系列工具中的首个。@polynoamial 表示他们现在主要使用 Codex 进行编程。
- Gemini 2.5 Flash:@Google 发布了 Gemini 2.5 Flash,强调了其速度和成本效益。@GoogleDeepMind 将其描述为一种混合推理模型,开发者可以控制模型的推理程度,从而针对质量、成本和延迟进行优化。@lmarena_ai 指出 Gemini 2.5 Flash 在排行榜上并列第二,与 GPT 4.5 Preview 和 Grok-3 等顶级模型持平,而价格比 Gemini-2.5-Pro 便宜 5-10 倍。
- 关于模型行为与对齐失调的担忧:@TransluceAI 报告称,o3 的预发布版本经常捏造行为,并在被质问时进行详尽的辩解。这种对能力的误报也出现在 o1 和 o3-mini 中。@ryan_t_lowe 观察到 o3 的幻觉似乎比 o1 多出 2 倍以上,并且由于基于结果的优化(outcome-based optimization)会激励自信的猜测,幻觉可能会随着推理能力的增强而反向增加。
- 电子游戏中的 LLM:@OfirPress 推测,在 4 年内,语言模型将能够观看《半条命》(Half Life)系列的视频攻略,并设计和编写出它自己版本的《半条命 3》。
AI 应用与工具
- 智能体网页浏览与抓取:@AndrewYNg 推介了一门关于构建 AI 浏览器智能体 (AI Browser Agents) 的新短课程,该课程可以实现线上任务自动化。@omarsar0 介绍了 Firecrawl 的 FIRE-1,这是一个由智能体驱动的网页抓取工具 (agent-powered web scraper),能够导航复杂网站、与动态内容交互并填写表单以抓取数据。
- AI 驱动的编程助手:@mervenoyann 强调了 @huggingface Inference Providers 与 smolagents 的集成,使得只需一行代码即可启动像 Llama 4 这样巨头级别的智能体。@omarsar0 指出,使用 o4-mini 和 Gemini 2.5 Pro 等模型进行编程是一种神奇的体验,尤其是在使用像 Windsurf 这样的智能体 IDE (agentic IDEs) 时。
- 其他工具:@LangChainAI 宣布开源了 LLManager,这是一个 LangGraph 智能体,通过人机回环 (human-in-the-loop) 驱动的记忆功能自动执行审批任务,并提供了包含详情的视频链接。@LiorOnAI 推介了 FastRTC,这是一个 Python 库,可将任何函数转换为实时的 WebRTC 或 WebSocket 流,支持音频、视频、电话和多模态输入。@weights_biases 宣布 W&B 的媒体面板变得更加智能,用户现在可以使用任何配置键滚动浏览媒体内容。
框架与基础设施
- vLLM 与 Hugging Face 集成:@vllm_project 宣布了 vLLM 与 Hugging Face 的集成,使得能够以 vLLM 的速度部署任何 Hugging Face 语言模型。@RisingSayak 强调,即使某个模型未被 vLLM 官方支持,你仍然可以从
transformers中使用它,并获得可扩展的推理优势。 - Together AI:@togethercompute 入选了 2025 年福布斯 AI 50 榜单。
- PyTorch:@marksaroufim 和 @soumithchintala 分享了 PyTorch 团队正在招聘工程师,以优化在单个或数千个 GPU 上运行效果同样出色的代码。
经济与地缘政治分析
- 美国竞争力:@wightmanr 观察到,一些学生选择加拿大当地学校而非美国顶尖学府的录取通知,并表示加拿大大学报告的美国学生申请人数有所增加,这对美国的长期竞争力而言并非好事。
- 中国 AI:@dylan522p 表示华为的新 AI 服务器好得惊人,人们需要重塑先验认知。@teortaxesTex 对中国竞争力发表评论称,中国人无法释怀的是,即使在百年耻辱时期,中国也从未沦为殖民地。
招聘与社区
- Hugging Face 协作频道:@mervenoyann 指出,@huggingface 与几乎每一位前员工都建立了 Slack 协作频道,以便保持联系并进行合作,并称这是公司最积极的信号(greenest flag)。
- CMU Catalyst:@Tim_Dettmers 宣布他与三名新生加入了 CMU Catalyst,他们的研究将致力于把最好的模型带到消费级 GPU 上,重点关注智能体系统 (agent systems) 和 MoEs。
- Epoch AI:@EpochAIResearch 正在为其数据洞察团队招聘一名高级研究员,以帮助发现并报告机器学习前沿的趋势。
- Goodfire AI:@GoodfireAI 宣布了其 5000 万美元的 A 轮融资,并分享了通用神经编程平台 Ember 的预览。
- OpenAI 感知团队:@jhyuxm 向 OpenAI 团队致敬,特别是 Brandon、Zhshuai、Jilin、Bowen、Jamie、Dmed256 和 Hthu2017,感谢他们构建了世界上最强大的视觉推理模型。
元评论与观点
- Gwern 的影响:@nearcyan 认为,如果当时有人愿意倾听,Gwern 本可以把大家从这些 slop 中拯救出来。
- AI 的价值:@MillionInt 表示,在基础研究和工程上的辛勤工作最终会为人类带来伟大的成果。@kevinweil 指出,这些是人们余生中将使用的最糟糕的 AI 模型,因为模型只会变得更聪明、更快、更便宜、更安全、更个性化且更有帮助。
- “AGI” 的定义:@kylebrussell 表示,他们正将缩写改为 Artificial Generalizing Intelligence,以承认其日益广泛的能力,并停止为此争论。
幽默
- @qtnx_ 简单地发了一条 “meow :3” 并配了一张图片。
- @code_star 发布了 “编辑 FSDP 配置时的我”。
- @Teknium1 说:“只要把 Sydney 带回来,大家都会想留在 2023 年”。
- @hyhieu226 调侃道:“约会建议:如果你第一次约会是和 GPU indexing,请尽可能保持逻辑(logical)。无论发生什么,不要太物理(physical)。”
- @fabianstelzer 说:“我已经看够了,这就是 AGI”
AI Reddit 摘要
/r/LocalLlama 摘要
1. 新型 LLM 模型发布与基准测试 (BLT, Local, Mind-Blown Updates)
-
BLT 模型权重刚刚发布 - 1B 和 7B Byte-Latent Transformers 已推出! (Score: 157, Comments: 39): Meta FAIR 已发布其 Byte-Latent Transformer (BLT) 模型的权重,包含 1B 和 7B 参数规模 (链接),正如其近期论文 (arXiv:2412.09871) 和博客更新 (Meta AI blog) 中所宣布的那样。BLT 模型旨在实现高效的序列建模,直接作用于字节序列,并利用潜变量推理(latent variable inference)在保持与标准 Transformers 在 NLP 任务上相当的性能的同时,降低计算成本。发布这些模型有助于可复现性,并进一步推动无分词(token-free)和高效语言模型研究的创新。 热门评论中没有实质性的技术辩论或细节——用户主要在请求澄清并发表非技术性言论。
- 人们对消费级硬件是否能运行 1B 或 7B BLT 模型 Checkpoints 感兴趣,从而引发了关于内存和推理需求与 Llama 或 GPT 等标准架构相比的问题。技术读者希望了解硬件先决条件、性能基准测试或适用于家庭使用的优化推理策略。
- 一位用户询问 Llama 4 是否使用了 BLT (Byte-Latent Transformer) 架构或以该风格组合了层,这表现出对架构血统以及 Llama 4 等前沿模型是否采用了 BLT 组件的技术好奇。进一步的探索需要参考已发布的模型卡片(model cards)或架构说明。
-
中型本地模型已经击败了原生 ChatGPT - 令人震惊 (Score: 242, Comments: 111): 一位用户对开源本地模型 Gemma 3 27B(使用 IQ3_XS 量化,适配 16GB VRAM)与原始 ChatGPT (GPT-3.5 Turbo) 进行了基准测试,发现 Gemma 在日常建议、摘要和创意写作任务中略微超过了 GPT-3.5。帖子指出,相比早期的 LLaMA 模型,性能有了显著飞跃,强调中型(8-30B)本地模型现在可以达到或超过早期的 SOTA 闭源模型,证明了在通用硬件上进行实用、高质量的 LLM 推理现在已成为可能。参考资料:Gemma, LLaMA。 一条热门评论强调,现在的满意度标准已提升至 GPT-4 级别的性能,而另一条评论指出,尽管有所改进,但本地模型的多语言能力和流畅度在非英语语言中仍落后于英语。
- 讨论涉及本地模型(8-32B 参数)与 OpenAI 的 GPT-3.5 和 GPT-4 之间的性能差距。虽然一些本地模型在英语方面表现出色,但其在其他语言中的流畅度和知识储备显著下降,这表明 8-14B 模型在多语言能力和事实召回方面仍有改进空间。
- 一位用户分享了在 Q8 量化下运行 Gemma3 27B 和 QwQ 32B 的实际基准测试。他们指出 QwQ 32B(在 Q8 量化下,配合特定的生成参数)比目前免费版的 ChatGPT 和 Gemini 2.5 Pro 提供了更详尽且有效的头脑风暴,这表明通过优化的量化和参数微调,本地运行的大型模型在特定的创意任务中可以接近或超越云端模型。
- 提供了运行 QwQ 32B 的详细推理参数——temperature 0.6, top-k 40, repeat penalty 1.1, min-p 0.0, dry-multiplier 0.5 以及 samplers sequence。使用 InfiniAILab/QwQ-0.5B 作为草稿模型(draft model)展示了针对本地生成质量的工作流优化。
2. 开源 LLM 生态系统:本地使用与许可 (Llama 2, Gemma, JetBrains)
-
[忘掉 DeepSeek R2 或 Qwen 3,Llama 2 显然是我们的本地救星。] (Score: 257, Comments: 43): 该图片展示了一个柱状图,比较了各种 AI 模型在“Humanity’s Last Exam (Reasoning & Knowledge)”基准测试中的表现。Gemini 2.5 Pro 以 17.1% 的得分位居榜首,其次是 o3-ruan (high) 的 12.3%。被标为“本地救星”的 Llama 2 记录的基准测试得分为 5.8%,优于 CTRL+ 等模型,但落后于 Claude 3-instant 和 DeepSeek R1 等较新模型。该基准测试似乎极具挑战性,这反映在相对较低的最高分上。 一位评论者强调了该基准测试的难度,称考试题目极其困难,即使是领域专家也很难获得高分。另一位评论者链接了一个视频 (YouTube),展示了 Llama 2 参加该基准测试的过程,建议进一步了解背景或进行审查。
- 一些评论者对 Llama 2 的基准测试结果表示怀疑,质疑是否存在评估错误、标签错误或可能的 Overfitting(可能通过泄露的测试数据)。一位用户表示,“一个 7b 模型不可能表现得这么好”,对这种规模的模型所达到的性能水平表示难以置信。
- 讨论中提到了基准测试题目的难度,声称“只有顶尖专家才有希望回答其领域内的题目”。这表明在该基准测试中获得 20% 的成功率对于 AI 模型来说是一个令人印象深刻的结果——高于大多数没有专业知识的人类所能达到的水平,强调了 Llama 2 在具有挑战性的专家级任务上的能力。
- 链接指向了一个 Llama 2 参加基准测试的 YouTube 视频,这对于对模型在测试条件下的直接演示和进一步分析感兴趣的技术读者可能很有用。
-
[JetBrains AI 现已集成本地 LLM,并提供免费且无限的代码补全] (Score: 206, Comments: 35): JetBrains 对其 IDE 的 AI Assistant 进行了重大更新,在所有非社区版(non-Community editions)中提供免费、无限的代码补全和本地 LLM 集成。此次更新支持新的云端模型(GPT-4.1, Claude 3.7, Gemini 2.0),并具有先进的基于 RAG 的上下文感知和多文件编辑模式等功能,同时推出了新的订阅模型以扩展对增强功能的访问(变更日志)。本地 LLM 集成实现了设备端推理,从而提供更低延迟、保护隐私的补全。 热门评论指出,免费层级不包括社区版,质疑无限本地 LLM 补全的真实性,并将 JetBrains 的产品与 VSCode 的 Copilot 集成进行了不利的比较,指出了插件问题和 JetBrains IDE 使用率下降的情况。
- JetBrains AI 的本地 LLM 集成在免费的社区版中不可用,将无限本地补全限制在付费版本(如 Ultimate, Pro)中,正如此截图所证实的。
- 当前版本允许通过 OpenAI 兼容的 API 连接到本地 LLM,但存在一个限制:当私有的本地 LLM 部署需要身份验证时,无法连接。未来的更新可能会解决这一差距,但目前尚不支持依赖安全内部模型的企业用户。
- JetBrains AI 的积分系统存在混淆,因为关于 Pro 计划的 “M” 积分和 Ultimate 计划的 “L” 积分的含义及实际转化的细节尚未公开。这使得用户难以估算非本地 LLM 功能的操作成本或使用限制。
-
Gemma 的许可协议中有一项条款规定“你必须做出‘合理努力来使用最新版本的 Gemma’” (得分: 203, 评论: 57):该图片展示了 Gemma 模型许可协议(第 4 节:附加条款)中的一段突出显示内容,其中强制要求用户必须做出“合理努力来使用最新版本的 Gemma”。这一条款为 Google 提供了一种手段,通过鼓励(但非严格强制)升级,来降低旧版本模型可能生成有问题内容所带来的风险或责任。法律措辞(“合理努力”)刻意保持模糊,既提供了灵活性,但也可能使开发人员和下游项目的合规工作变得复杂。 一条高赞评论推测,该条款旨在保护 Google 免受旧版本模型产生有害输出的问题影响。其他评论则批评该条款无法执行或不切实际,强调了用户对何为“合理努力”的抵触或困惑。
- 要求用户做出“合理努力来使用最新版本的 Gemma”的规定,可能是 Google 的一种法律保障。这可以让 Google 撇清因旧版本生成有问题内容而产生的潜在责任,实际上是将及时打补丁作为许可合规的一项要求。
- 对许可文档的技术审查揭示了不一致之处:该争议条款出现在 Ollama 分发的版本中(参见 Ollama 的 blob),但未出现在通过 Huggingface 分发的 Google 官方 Gemma 许可条款中。官方许可的第 4.1 节仅提到“Google 可能会不时更新 Gemma”。这种差异表明,这要么是错误的复制粘贴,要么是源自不同(可能是 API)版本的许可协议。
{kind=link}
{kind=link}
{kind=link}
3. AI 行业新闻:DeepSeek、Wikipedia-Kaggle 数据集、Qwen 3 热度
-
据报道,特朗普政府正考虑在美国禁用 DeepSeek (得分: 458, 评论: 218):图片展示了 DeepSeek 的 Logo 以及一篇讨论特朗普政府据传考虑禁止中国 AI 公司 DeepSeek 获取 Nvidia AI 芯片并限制其在美国提供 AI 服务的新闻文章。TechCrunch 和《纽约时报》最近的文章详细描述了这一举动,将其定位在持续的美中 AI 和半导体技术竞争之中。据报道的限制措施可能会对技术交流、芯片供应链以及美国市场获取先进 AI 模型产生重大影响。 评论者们辩论了监管逻辑,质疑如何有选择性地执行针对模型蒸馏(model distillation)等行为的禁令(特别是考虑到训练数据中持续存在的版权争议)。人们对可执行性表示怀疑,一些人认为此类举措将推动创新和开源开发进一步向美国生态系统之外转移。
- 读者们辩论了禁止模型蒸馏的合法性和可执行性,质疑了据报道的 OpenAI 的论点,及其与“使用受版权保护的数据进行训练是合法的”这一主张的一致性。怀疑点包括技术细节,即微小的模型修改(例如,修改单个权重并重命名模型)理论上就可以规避此类禁令,这突显了对开源 AI 模型实施知识产权管控的挑战。
- 评论中还提到了与 1996 年之前美国对密码学限制的历史对比,一位评论者认为美国政府此前曾将软件(包括加密二进制文件中的任意数字)视为军需品,暗示 AI 模型权重可能会受到类似对待。文中还提到了禁令的实际影响:虽然盗版模型权重是可能的,但如果主要的推理硬件或托管平台拒绝支持,模型的采用将会受阻。
- 基础设施韧性问题也被提出:如果美国平台(如 HuggingFace)被禁止托管 DeepSeek 权重,国际托管平台可以提供持续访问。托管基础设施的技术和司法管辖区分布被认为是确保开源 AI 模型在面临监管压力时持续可用性的关键。
-
Wikipedia 正在向 AI 开发者提供其数据,以抵御机器人爬虫 - 数据科学平台 Kaggle 正在托管一个专门针对机器学习应用优化的 Wikipedia 数据集 (Score: 506, Comments: 71): Wikipedia 与 Kaggle 合作发布了一个专门用于机器学习应用的新结构化数据集,提供英文和法文版本,并采用结构良好的 JSON 格式,以简化建模、基准测试和 NLP 流水线的开发。该数据集受 CC-BY-SA 4.0 和 GFDL 许可协议保护,旨在为爬虫抓取和非结构化转储提供一种合法且优化的替代方案,使缺乏大量数据工程资源的小型开发者更容易获取。官方公告 和 Verge 报道 提供了详细信息。 评论强调,主要的受益者可能是缺乏处理现有 Wikipedia 转储(dumps)资源的个人开发者和小型团队,而不是已经拥有此类数据访问权限的 AI 实验室。有人批评 The Verge 的标题党式表述,认为实际的动机是提高实用可访问性和许可合规性,而非“抵御”爬虫。
- 讨论指出,Wikipedia 与 Kaggle 的合作主要是为了让那些缺乏处理每日转储(nightly dumps)资源或专业知识的个人能够更方便地使用和获取 Wikipedia 数据——此前,Wikipedia 提供的是原始数据库转储,但将其转换为机器学习就绪的格式并非易事。
- 技术推测认为,新的 Kaggle 数据集可能不会改变大型 AI 实验室的现状,因为他们长期以来一直可以直接访问 Wikipedia 的转储数据;其收益主要面向小型用户或爱好者。
- 一条评论澄清说,Wikipedia 的数据一直可以作为完整的网站下载,并假设所有主要的 LLM (Large Language Models) 都已经基于这些数据进行了训练,这表明 Kaggle 的发布并非模型训练的根本性新数据源。
-
Qwen 3 在哪里? (Score: 172, Comments: 57): 该帖子质疑了备受期待的 **Qwen 3 发布的当前状态,此前曾有明显的活动,如 GitHub pull requests 和社交媒体公告。目前尚未发布官方更新或新的基准测试,项目在最初的热度之后陷入了沉寂。** 热门评论推测 Qwen 3 仍在开发中,并参考了 Deepseek R2 等其他项目的类似时间表,同时提到用户在此期间可以使用 Gemma 3 12B/27B 等现有模型;未提供具体的底层技术批评或新信息。
- 一位评论者指出,在 Llama 4 发布出现问题后,模型开发者在发布时可能会更加谨慎,旨在实现更顺畅的开箱即用兼容性,而不是依赖社区在发布后修复问题。这反映了开源 LLM 领域向更成熟、用户友好的部署实践的转变。
- 有人提到 Deepseek 目前正在开发 R2,而 Qwen 正在积极开发 Version 3,突显了开源 AI 模型社区内持续的并行开发努力。此外,Gemma 3 12B 和 27B 被提及为目前可用的、性能强大但被低估的模型。
{kind=link}
{kind=link}
其他 AI Subreddit 摘要
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. OpenAI o3 和 o4-mini 模型基准测试与用户体验
-
震惊!!OpenAI 反击了。o3 在长上下文理解方面几乎完美。 (评分: 769, 评论: 169): 该帖子分享了来自 Fiction.LiveBench 的基准测试表 (https://i.redd.it/kw13sjo4ieve1.jpeg),评估了多个 LLM (large language models) 在高达 120k tokens 输入长度下的长上下文理解能力。OpenAI 的 ‘o3’ 模型表现出色,在短上下文 (0-4k) 中始终获得 100.0 分,在 32k 时保持高性能 (83.3),并且独特地在 120k 时恢复到满分 (100.0),超越了所有列出的竞争对手,如 Gemini 1.5 Pro, Llama-3-70B, Claude 3 Opus 和 Gemini 1.5 Flash。随着上下文长度的增加,其他模型表现出更多的波动且得分普遍较低,这表明 o3 具有卓越的长上下文细粒度记忆和推理能力。 评论者指出需要超过 120k tokens 的更高上下文基准测试,并质疑为什么 ‘o3’ 和 Gemini 2.5 在 120k 时的表现异常优于 16k,推测可能存在评估偏差或针对极端长上下文的模型特定优化。
- 一个技术层面的担忧是,尽管据报道 o3 能很好地处理 120k tokens 的上下文,但基准测试本身上限就是 120k,限制了长上下文理解评估的深度。人们呼吁将基准测试的上下文限制提高到 120k 以上,以真实评估 o3 和 Gemini 2.5 等模型。
- 一位用户指出了一项实际限制:尽管声称在长上下文窗口(高达 120k tokens)中表现强劲,但 OpenAI 的 Web 界面将输入限制在 64k tokens 左右,经常产生“消息过长”错误,这限制了 Pro 用户在现实世界中的可用性。
- 有人提出了一个技术问题:为什么像 o3 和 Gemini 2.5 这样的模型有时在 120k tokens 时的表现似乎比在 16k 等较短上下文窗口时更好,这引发了人们对上下文窗口性能动态以及导致这一反直觉结果的潜在架构或训练原因的兴趣。
-
o3 思考了 14 分钟,结果错得离谱。 (评分: 1403, 评论: 402): 该图片记录了一个失败案例,其中 ChatGPT 的视觉模型(被称为 o3)被要求清点图片中的石头。尽管“思考”了近 14 分钟,它却错误地得出结论说有 30 块石头,而一位评论者指出实际有 41 块。这突显了当前 AI 视觉模型在精确物体计数方面的持续局限性,即使延长了推理时间也是如此。 评论者指出了这一错误——其中一人给出了正确答案(41 块石头),另一人表示怀疑但认为这种错误在情理之中,强调了人们对 AI 在此类感知任务中可靠性的持续疑虑。另一位用户分享了与 Gemini 2.5 Pro 的对比,表明了对这些视觉模型进行基准测试的广泛兴趣。
- 用户分享的图像对比(例如与 Gemini 2.5 Pro 的对比)暗示,LLM 或像 o3 和 Gemini 2.5 Pro 这样的多模态模型在处理简单的视觉计数任务(如确定图像中物体的数量,如石头)时表现出明显的困难。这表明领先 AI 实验室的当前模型在基础视觉定量推理方面仍存在持续的局限性。
- 讨论间接提到了将模型不恰当地或不匹配地应用于其技能领域之外的任务,正如一位用户所指出的,将 AI 的失败比作使用“锤子”去干“切割”的活——这表明依靠 LLM 或多模态模型进行精确的视觉计数可能不符合它们的设计优势。这指向了对此类任务需要专门的架构或更多训练的需求,而不是期望通用模型能立即掌握所有领域。
-
o3 在 Fiction.Livebench 长上下文基准测试中碾压所有模型(包括 Gemini 2.5),太离谱了 (Score: 139, Comments: 56): 图像显示了 ‘Fiction.LiveBench’ 长上下文理解基准测试,其中 ‘o3’ 模型在所有测试的上下文大小(从 400 到 120k tokens)中均获得了 100.0 的满分,显著优于 Gemini 2.5 等竞争对手,后者的性能在较大上下文时会有所下降。这表明 o3 在长输入序列中保持深度理解的能力方面取得了架构或训练上的进步,而目前的 SOTA 模型在这一问题上仍面临挑战——特别是在 16k tokens 以上。完整的基准测试详情可在提供的链接中验证。 热门评论对该基准测试的有效性提出了质疑,声称它更多是作为一种广告,与实际效果并无强相关性。技术讨论涉及 ‘o3’ 和 ‘2.5 pro’ 在 16k token 关口都遇到了困难,并指出 ‘o3’ 无法像报道中的 ‘2.5 Pro’ 那样处理 1M-token 的上下文。
- 人们对 Fiction.Livebech 长上下文基准测试的有效性表示担忧,用户指责其更多是为托管网站做广告,并认为报告的结果可能与实际的模型使用或性能不符。
- 讨论强调 Gemini 2.5 Pro 和 o3 模型在 16k token 上下文窗口时都表现吃力,突显了它们在处理某些长上下文场景时的局限性,尽管在其他方面有所改进;这对于强调扩展上下文理解的任务非常重要。
- 尽管 o3 在某些方面有所改进,但用户报告称,它仍然受到比 o1 Pro 更严格的输出 token 限制,这可能会影响其在需要长篇或较少限制生成的场景中的可用性,且一些人发现它在遵循指令方面不太可靠。
{kind=link}
{kind=link}
{kind=link}
2. Recent Video Generation Model Launches and Guides (FramePack, Wan2.1, LTXVideo)
-
终于有能在消费级 GPU 上运行的视频扩散模型了? (Score: 926, Comments: 332): lllyasviel 发布了一个新的开源视频扩散模型,据报道可以在 消费级 GPU 上进行视频生成(细节待定,但对可访问性和硬件要求具有重要意义)。早期用户报告确认了 Windows 手动安装成功,完整安装约占用
40GB磁盘空间;目前已有第三方的分步安装指南。 评论强调了 lllyasviel 在开源社区的声誉,指出这一进展在技术上令人印象深刻,且与之前高资源需求的视频扩散模型发布相比,其可访问性尤为突出。[外部链接摘要] FramePack 是论文 “Packing Input Frame Context in Next-Frame Prediction Models for Video Generation” 中提出的视频扩散下一帧预测架构的官方实现。FramePack 将输入上下文压缩到固定长度,使计算工作量不随视频长度变化,从而能够在相对较低配置的 GPU(≥6GB,例如 RTX 30XX 笔记本显卡)上对大型模型(如 13B 参数)进行高效推理和训练。该系统支持带有直接视觉反馈的分段视频生成,提供强大的内存管理和极简的独立 GUI,并兼容各种注意力机制(PyTorch, xformers, flash-attn, sage-attention)。量化方法和 “teacache” 加速可能会影响输出质量,因此建议仅在最终渲染前的实验阶段使用。- 一位用户详细介绍了他们在 Windows 上手动安装 lllyasviel 新视频扩散生成器的经验,强调完整安装需要约
40 GB的磁盘空间。他们确认安装成功,并为他人提供了分步设置指南的链接,强调需要具备一定的命令行熟练度才能顺利完成设置过程:安装指南。
- 一位用户详细介绍了他们在 Windows 上手动安装 lllyasviel 新视频扩散生成器的经验,强调完整安装需要约
-
新的 LTXVideo 0.9.6 Distilled 模型简直太疯狂了!我几秒钟就能生成不错的结果! (Score: 204, Comments: 41): LTXVideo 0.9.6 Distilled 模型在视频生成方面提供了显著改进,仅需
8 steps即可生成高质量输出,推理时间大幅缩短。技术变化包括引入了STGGuiderAdvanced节点,能够在整个扩散过程中动态调整 CFG 和 STG 参数,并且所有工作流都已更新以实现最佳参数化 (GitHub, HuggingFace 权重)。官方 工作流 采用了 LLM 节点进行提示词增强,使过程既灵活又高效。 评论强调了输出速度和可用性的剧增,以及新引导节点带来的技术飞跃,标志着视频合成正向快速迭代迈进。一种潜在的共识认为,该版本的发布降低了 ComfyUI 等高级工作流的普及门槛。[外部链接摘要] LTXVideo 0.9.6 Distilled 模型相比之前版本引入了重大进步:它能在几秒钟内生成高质量、可用的视频,蒸馏版本比全量模型推理速度快 15 倍(支持 8、4、2 甚至 1 个扩散步数采样)。关键技术改进包括用于分步配置 CFG 和 STG 的新STGGuiderAdvanced节点、更好的提示词遵循能力、改进的运动和细节,以及默认 1216×704 分辨率、30 FPS 的输出——在 H100 GPU 上可实现实时生成——且不需要 Classifier-Free 或 Spatio-Temporal 引导。利用基于 LLM 的提示词节点进行的工作流优化进一步提升了用户体验和输出控制。完整讨论与链接- LTXVideo 0.9.6 Distilled 被强调为该模型最快的迭代版本,仅需
8 steps即可生成结果,使其比以前的版本更轻量,更适合快速原型设计和迭代。这种对性能的关注对于需要快速预览或实验的工作流至关重要。 - 此次更新引入了新的
STGGuiderAdvanced节点,允许在扩散过程的不同步骤应用不同的 CFG 和 STG 参数。这种动态参数化旨在提高输出质量,现有的模型工作流已重构以利用此节点实现最佳性能,详见项目的 示例工作流。 - 一位用户的询问提出了一个技术问题:LTXVideo 0.9.6 Distilled 是否缩小了与 Wan 和 HV 等竞争视频生成模型的差距,这表明用户对这些领先解决方案之间的直接基准测试或定性对比分析很感兴趣。
- LTXVideo 0.9.6 Distilled 被强调为该模型最快的迭代版本,仅需
-
在 Windows 上安装 lllyasviel 新视频生成器 Framepack 的指南(今天就装,不用等明天的安装程序) (Score: 226, Comments: 133): 本帖提供了在官方安装程序发布前,在 Windows 上手动分步安装 lllyasviel 新的 FramePack 视频扩散生成器的指南 (GitHub)。安装过程包括创建虚拟环境、安装特定版本的 Python (3.10–3.12)、特定于 CUDA 的 PyTorch wheel 文件、Sage Attention 2 (woct0rdho/SageAttention) 以及可选的 FlashAttention,并注明官方要求为 Python <=3.12 和 CUDA 12.x。用户必须手动选择与环境匹配的 Sage 和 PyTorch 兼容 wheel 文件,应用程序通过
demo_gradio.py启动(已知问题是嵌入的 Gradio 视频播放器无法正常工作;输出会保存到磁盘)。视频生成是增量式的,每次增加 1 秒,导致磁盘占用量巨大(据报告超过 45GB)。 评论中没有重大的技术争论——大多数用户都在等待官方安装程序。报告的一个小问题是 Gradio 视频播放器无法渲染视频,尽管输出可以正常保存。 - 一位用户询问在 NVIDIA 4090 上生成 5 秒视频所需的时间,这表明用户对 Framepack 在高端 GPU 上的具体性能基准和吞吐率感兴趣。
-
另一位用户询问了 Framepack 在 3060 12GB GPU 上运行的实际性能反馈,寻求该工具在中端消费级硬件上表现的信息。这些问题突显了社区对这一新视频生成工具的实测速度和硬件要求的关注。
-
官方 Wan2.1 首帧末帧模型发布 (评分: 779, 评论: 102): Wan2.1 首末帧转视频模型 (FLF2V) v14B 现已完全开源,并提供了 权重和代码 以及 GitHub 仓库。此次发布仅限于单个 14B 参数的大模型,且仅支持 720P分辨率——480P 和其他变体目前尚不可用。该模型主要在中文文本-视频对上进行训练,使用中文 Prompt 可以获得最佳效果。此外还提供了一个 ComfyUI 工作流示例 以供集成。 评论者注意到缺乏较小或低分辨率的模型,并强调了对 480p 和其他变体的需求。训练数据集对中文 Prompt 的侧重被认为是获得最佳模型输出的关键。[外部链接摘要] Wan2.1 首帧末帧 (FLF2V) 模型现已在 HuggingFace 和 GitHub 上完全开源,支持根据用户提供的首末帧生成 720P 视频,无论是否带有 Prompt 扩展(目前不支持 480P)。该模型主要在中文文本-视频对上进行训练,使用中文 Prompt 的效果显著更好,并且提供了 ComfyUI 工作流封装器和 fp8 量化权重以供集成。技术细节及模型/代码获取:HuggingFaceGitHub。 - 该模型主要在中文文本-视频对上进行训练,因此使用中文编写的 Prompt 会产生更好的结果。这突显了由于训练数据集导致的语言偏差,在使用非中文 Prompt 时可能会影响输出质量。
- 目前仅提供 14B 参数、720p 的模型。用户对其他模型(如 480p 或不同参数规模)感兴趣,但这些尚未得到支持或发布。
- GitHub 上提供了一个将 Wan2.1 首帧末帧模型与 ComfyUI 集成的工作流(参见 此工作流 JSON)。此外,HuggingFace 上发布了 fp8 量化模型变体,从而实现了更高效的部署方案。
3. 创新与专业图像/角色生成模型发布
-
InstantCharacter 模型发布:个性化任何角色 (Score: 126, Comments: 22): 该图展示了腾讯新发布的 InstantCharacter 模型,这是一种无需微调(tuning-free)的开源解决方案,可从单张图像生成保持角色特征的内容。它直观地演示了工作流程:通过文本和图像调节,将参考图像转换为在各种复杂背景(如地铁、街道)下高度个性化的动漫风格表现。该模型利用结合了 Style LoRA 的 IP-Adapter 算法,运行在 Flux 上,旨在在灵活性和保真度方面超越早期的 InstantID 等解决方案。 技术导向的评论者赞扬了生成结果,并对集成(例如 ‘ComfyUI 节点’)表示出浓厚兴趣,增强了该工作流在下游生成任务中的感知质量和可用性。
- 一位用户提到,现有的解决方案(如 UNO)在个性化角色生成方面表现不尽如人意,暗示先前的模型在集成或输出质量方面存在困难。这突显了当前工具在可靠的角色个性化方面面临的挑战,并为评估 InstantCharacter 的方法和承诺的能力设定了技术基准。
-
Flux.Dev 对比 HiDream Full (Score: 105, Comments: 37): 本帖提供了 Flux.Dev 与 HiDream Full 的并排对比,使用了 HiDream ComfyUI 工作流(参考)和
hidream_i1_full_fp16.safetensors模型(模型链接)。生成参数为50 steps、uni_pc采样器、simple调度器、cfg=5.0以及shift=3.0,涵盖了七个详细的提示词。对比在遵循度和风格上对结果进行了视觉排名,显示 Flux.Dev 在提示词忠实度方面通常表现出色,甚至在风格上能与 HiDream Full 竞争,尽管 HiDream 的资源需求更高。 讨论强调了 LLM 风格的“华丽辞藻”(purple prose)提示词对评估原始提示词遵循度的影响,并指出尽管 HiDream 在某些单项上获胜,但 Flux.Dev 被认为具有更好的整体提示词遵循度和资源效率。一些人形容 HiDream 在这组测试中的表现“令人失望”,尽管替代方案仍受到欢迎。 -
几位用户强调了提示词设计在基准测试中的重要性,强调包含复杂或主观语言(如“情绪”描述或过多的散文体)的 LLM 生成提示词会引入变量,使得准确评估模型的提示词遵循度变得更加困难。建议使用更精确或客观的提示词将产生更清晰的性能对比。
- 大家的共识是 Flux.Dev 在这一轮中胜过 HiDream Full,特别是在提示词遵循和风格灵活性方面,尽管 HiDream 更加耗费资源。Flux 被视为微弱的赢家,但据报道,这两个模型在原始性能上都显著超越了前几代模型。
- 针对第一个对比提示词提出了批评,指出其中存在语法错误和如 ‘hypo realistic’ 等非标准术语。语言上的不规范被认为是导致两个模型产生困惑的可能原因,潜在地影响了并排评估的可靠性。
{kind=link}
AI Discord 摘要
由 Gemini 2.5 Flash Preview 生成的摘要之摘要的摘要
主题 1. 最新 LLM 模型:成功、失败与幻觉
- 新 Gemini 2.5 Flash 登陆 Vertex AI:Google 的 Gemini 2.5 Flash 已在 Vertex AI 中上线,因其先进的推理和编码能力而备受推崇,引发了与 Gemini 2.5 Pro 在效率和工具调用(tool-calling)方面的辩论,但也有关于思维循环(thinking loops)的报告。用户还在权衡 O3 和 O4 Mini,发现 O3 更具优势,因为 O4 Mini 的高昂输出成本使其几乎无法使用。
- O4 模型幻觉增多,用户抱怨:用户报告 o4-mini 和 o3 模型更频繁地编造信息,甚至提供看似可信但完全错误的答案,如虚假的商业地址。虽然建议模型通过搜索验证来源可能有所帮助,但用户发现 GPT-4.1 Nano 在事实性任务中处理非虚假信息表现更好。
- 微软发布 1-Bit BitNet,IBM 发布 Granite 3:Microsoft Research 发布了 BitNet b1.58 2B 4T,这是一个在 4 万亿 token 上训练的 20 亿参数 原生 1-bit LLM,可在 Microsoft 的 GitHub 上获取推理实现。IBM 宣布了 Granite 3 和经过优化的推理 RAG Lora 模型,详见 此 IBM 公告。
Theme 2. AI 开发工具与框架
- Aider 获得新 Probe 工具,架构师模式吞掉文件:Aider 引入了用于语义代码搜索的
probe工具,因其能提取错误代码块并与测试输出集成而受到称赞,同时还分享了 claude-task-tool 等替代方案。用户在 Aider 的架构师模式(architect mode)中遇到了一个 Bug:在创建 15 个新文件后添加一个到聊天中会导致所有更改被丢弃,虽然这是预期行为,但在丢弃编辑时没有给出任何警告。 - Cursor 的编码助手引起热议、崩溃与困惑:用户在讨论 Cursor 中 o3/o4-mini 是否优于 2.5 Pro 和 3.7 thinking,有人报告 o4-mini-high 在代码库分析和逻辑方面优于 4o 和 4.1,即使是大型项目也是如此。其他人则抱怨 Cursor agent 不退出终端、频繁进行无代码输出的工具调用以及连接/编辑问题。
- MCP, LlamaIndex, NotebookLM 提升集成与 RAG:一名成员正在为 Obsidain 构建 MCP server 以简化集成,并寻求关于通过 HTTPS header 安全传递 API key 的建议。LlamaIndex 现在支持根据开放协议构建兼容 A2A (Agent2Agent) 的 Agent,从而实现安全的信息交换,无论底层基础设施如何。NotebookLM 用户集成了 Google Maps 并利用 RAG,分享了诸如此 Vertex RAG 图表之类的架构图。
{kind=link}
Theme 3. 优化 AI 硬件性能
- Triton, CUDA, Cutlass:底层性能挑战:在 GPU MODE 的
#triton频道中,一名成员报告慢速 fp16 矩阵乘法(2048x2048)落后于 cuBLAS,被建议使用更大的矩阵或测量端到端模型处理。用户在#cutlass频道中尝试使用 Cutlass 的cuda::pipeline和 TMA/CuTensorMap API,发现基准测试的 mx cast kernel 仅达到 3.2 TB/s,并寻求关于 Cutlass 瓶颈的建议。 - AMD MI300 排行榜竞争激烈,NVIDIA 硬件讨论:根据 GPU MODE 的
#submissions频道,MI300 上amd-fp8-mm排行榜的提交结果差异很大,其中一项提交达到了 255 µs。#cuda频道的讨论确认 H200 不支持 FP4 精度,这可能是 B200 的笔误,LM Studio 的成员正在针对 0.3.15 beta 版本优化新的 RTX 5090。 - 量化定性地改变了 LLM,AVX 需求依然存在:Eleuther 的成员探讨了分析量化对 LLM 影响的研究,认为在低比特位时会发生定性变化,尤其是使用基于训练的策略时,这得到了 composable interventions 论文的支持。运行不带 AVX2 的 E5-V2 的旧服务器只能使用非常旧版本的 LM Studio 或 llama-server-vulkan 等替代项目,因为现代 LLM 需要 AVX。
Theme 4. AI 模型安全、数据与社会影响
- AI 幻觉依然存在,伪对齐误导用户:人们对“伪对齐(pseudo-alignment)”表示担忧,即 LLM 通过谄媚行为来欺骗用户,依赖于似是而非的想法拼凑而非真正的理解。Eleuther 的
#general频道成员认为,开放网络目前正因 AI 的存在而受到实质性的破坏。一位成员花费 7 个月时间构建了 PolyThink,这是一个基于 Agent 的多模型 AI 系统,旨在通过模型间的相互纠错来消除 AI 幻觉,并邀请用户加入等候名单。 - 数据隐私与验证引发关注:OpenRouter 更新了其服务条款和隐私政策,明确表示未经同意不会存储 LLM 输入,提示词分类仅用于排名和分析。Discord 新的年龄验证功能要求通过 withpersona.com 进行身份验证,这在 Nous Research AI 社区引发了关于隐私妥协及潜在平台级变化的担忧。
- 欧洲培育区域语言模型:成员们讨论了除 Mistral 之外,欧洲各地区域定制语言模型的可用性,包括荷兰的 GPT-NL 生态系统、意大利的 Sapienza NLP、西班牙的巴塞罗那超算中心、法国的 OpenLLM-France/CroissantLLM、德国的 AIDev、俄罗斯的 Vikhr、希伯来语的 Ivrit.AI/DictaLM、波斯语的 Persian AI Community 以及日本的 rinna。
主题 5. 行业观察:禁令、收购与业务转型
- 特朗普关税针对欧盟、中国及 Deepseek?:根据 Perplexity 的这份报告,特朗普政府对欧盟产品征收了 245% 的关税,以报复空客补贴,并因知识产权盗窃对中国商品征收关税。据 TechCrunch 的这篇文章报道,特朗普政府据传还在考虑在全美范围内禁用 Deepseek。
- OpenAI 收购 Windsurf 的传闻甚嚣尘上:有推测称 OpenAI 可能会以 30 亿美元的价格收购 Windsurf,一些人认为这是该公司变得越来越像 Microsoft 的迹象。随后引发了关于 Cursor 和 Windsurf 是真正的 IDE,还是仅仅是为“氛围程序员(vibe coders)”量身定制的美化版 API 封装工具的争论。
- LMArena 走向公司化,HeyGen API 发布:源自加州大学伯克利分校项目的 LMArena 正在组建公司,以支持其平台运行,同时确保其保持中立和可访问性。HeyGen API 的产品负责人介绍了他们的平台,强调了其无需摄像头即可制作极具吸引力的视频的能力。
第一部分:Discord 高层级摘要
Perplexity AI Discord
-
Perplexity 发布 Telegram 机器人:Perplexity AI 现在可以通过 askplexbot 在 Telegram 上使用,并计划集成 WhatsApp。
- 一段预告视频 (Telegram_Bot_Launch_1.mp4) 展示了其无缝集成和实时响应能力。
-
Perplexity 讨论 Discord 支持方案:成员们建议在 Discord 中加入 ticketing bot(工单机器人),但更倾向于使用 help center(帮助中心)的方式。
- 讨论中提到了 helper role(助手角色)等替代方案,并指出 Discord 并非理想的支持平台,连接到 Zendesk 的 Modmail bot 可能会更有用。
-
Neovim 配置展示:一位成员在学习 IT 三天后分享了他们的 Neovim configuration 图片。
- 他们利用 AI 模型让学习过程变得有趣,且效果良好。
-
特朗普关税影响显现:根据这份报告,特朗普政府为了报复对 Airbus 的补贴,对欧盟产品征收了 245% 的关税,并因知识产权窃取问题对中国商品征收关税。
- 这次 Perplexity 搜索解释称,这些措施旨在保护美国工业并解决贸易失衡问题。
{kind=link}
LMArena Discord
-
Gemini 2.5 Flash 席卷 Vertex AI:Gemini 2.5 Flash 出现在 Vertex AI 中,引发了关于其与 Gemini 2.5 Pro 相比在代码效率和 tool-calling 能力方面的讨论。
- 一些用户称赞其速度,而另一些用户则报告它会陷入类似于 2.5 Pro 之前出现的 thinking loops(思考循环)。
-
O3 与 O4 Mini 对决:成员们正在积极测试和比较 O3 与 O4 Mini,并分享了像 这个 这样的实时测试来展示它们的潜力。
- 尽管 O4 Mini 的初始成本较低,但一些用户发现其高使用量和输出成本令人望而却步,导致许多人重新使用 O3。
-
Thinking Budget 功能引发争议:Vertex AI 的新功能 Thinking Budget(允许控制 thinking tokens)正受到关注。
- 虽然有些人觉得它很有用,但也有人报告了 Bug,一位用户指出 2.5 pro 在 0.65 temp 下表现更好。
-
LLM:教育的救星还是破坏者?:关于 LLM 辅助发展中国家教育的潜力正在讨论中,重点在于可访问性与可靠性之间的平衡。
- 讨论中提到了对 LLM 产生 hallucinate(幻觉)倾向的担忧,并将其与由专业人士编写的书籍的可靠性进行了对比。
-
LMArena 走向公司化,保持开放:源自加州大学伯克利分校项目的 LMArena 正在组建公司以支持其平台,同时确保其保持中立和开放。
- 社区还报告称 Beta 版本 结合了用户反馈,包括深色/浅色模式切换和直接复制/粘贴图片功能。
aider (Paul Gauthier) Discord
-
Aider 的 code2prompt 评价褒贬不一:成员们讨论了 Aider 中
code2prompt的实用性,质疑其相对于/add命令在包含必要文件方面的优势,因为code2prompt会快速解析所有匹配的文件。code2prompt的效用取决于特定的使用场景和模型能力,主要是其解析速度。
-
Aider 的 Architect Mode 吞掉了新文件:一位成员在 Aider 的 architect mode 中遇到了一个 Bug,在创建了 15 个新文件并将其中的一个文件添加到对话后,更改被丢弃了。
- 这种行为是预料之中的,但在丢弃编辑内容时没有给出警告,导致用户在重构的代码丢失时感到困惑。
-
Aider 的 Probe 工具亮相:成员们讨论了 Aider 新的
probe工具,强调了其语义代码搜索能力,用于提取带有错误的代码块并与测试输出集成。- 爱好者们分享了用于语义代码搜索的替代方案,例如 claude-task-tool 和 potpie-ai/potpie。
-
DeepSeek R2 热度高涨:成员们对即将发布的 DeepSeek R2 充满热情,希望它的性能能超越 O3-high,同时提供更好的价格点,并暗示这只是时间问题。
- 一些人推测,由于其潜在的卓越性价比,DeepSeek R2 可能会挑战 OpenAI 的主导地位。
-
YouTube 提供了对新模型的冷静分析:一位成员分享了一个 YouTube 视频,对新模型提供了更理性的看法。
- 该视频对近期发布的模型进行了分析,重点关注技术价值。
OpenRouter (Alex Atallah) Discord
-
OpenRouter 更新条款:OpenRouter 更新了其 服务条款和隐私政策,明确表示 未经同意不会存储 LLM 输入,并详细说明了他们如何对 Prompt 进行分类以进行排名和分析。
- Prompt 分类用于确定请求的类型(编程、角色扮演等),对于未选择开启日志记录的用户,这些信息将是匿名的。
-
购买额度以使用:OpenRouter 更新了免费模型的限制,现在 要求终身累计购买至少 10 个额度 才能享受更高的 1000 次请求/天 (RPD),无论当前的额度余额是多少。
- 由于需求极高,实验性
google/gemini-2.5-pro-exp-03-25免费模型的访问权限仅限于购买了至少 10 个额度的用户;付费版本提供不间断访问。
- 由于需求极高,实验性
-
Gemini 2.5 表现亮眼:OpenRouter 推出了 Gemini 2.5 Flash,这是一款用于高级推理、编程、数学和科学的模型,提供 标准版 和带有内置推理 Token 的 :thinking 变体。
- 用户可以使用
max tokens for reasoning参数自定义 :thinking 变体,详见 文档。
- 用户可以使用
-
成本模拟器和聊天应用上线:一位成员创建了一个模拟 LLM 对话成本的工具,支持 OpenRouter 上的 350 多种模型;另一位成员开发了一个连接 OpenRouter 的 LLM 聊天应用,提供精选 LLM 列表以及网页搜索和 RAG 检索等功能。
- 该聊天应用有基础免费版,扩展搜索和 RAG 功能需按月付费,或选择无限使用。
-
Codex 报错,DeepSeek 延迟:OpenAI 的 Codex 使用了新的 API 端点,因此目前无法与 OpenRouter 配合使用;由于 OpenAI 要求身份验证的限制,OpenRouter 的 o-series 推理摘要 可能会延迟。
- 一位用户指出,新的 DeepSeek 与 Google 的 Firebase studio 类似。
OpenAI Discord
-
Gemini 2.5 仍比新模型更受青睐:尽管有了 o3 和 o4 等新模型,一些人仍然更喜欢 Gemini 2.5 Pro,因为它的速度、准确性和成本,尽管该模型在处理复杂任务时会疯狂产生幻觉。
- 基准测试显示 o3 在编程方面表现更好,而 Gemini 2.5 Pro 在推理方面表现出色;新的 2.5 Flash 版本则强调更快的响应速度。
-
o4 模型在事实准确性方面表现不佳:用户报告称 o4-mini 和 o3 模型更频繁地编造信息,甚至提供看似可信但完全错误的答案,例如虚假的公司地址。
- 指示模型通过搜索验证来源可能有助于减少幻觉,但有人指出 GPT-4.1 Nano 在处理非虚假信息方面表现更好。
-
GPT-4.5 用户抱怨模型太慢:多位用户抱怨 GPT 4.5 非常慢且昂贵,推测这“可能是因为它是一个稠密模型,而不是 Mixture of Experts(混合专家)”模型。
- o4-mini 的使用限制为每天 150 次,o4-mini high 为每天 50 次,o3 为每周 50 次。
-
Custom GPTs 失控:一位用户报告他们的 Custom GPT 不听从指令,“目前它就在那里各行其是”。
- 还有人询问在 Chat GPT 中,哪种语言模型最适合上传 PDF 进行学习、提问并准备现成的考试题目。
-
在 GPTPlus 上模拟上下文记忆:一位用户报告通过叙事连贯性和文本提示在 GPTPlus 账户上模拟了上下文记忆,构建了一个拥有超过 30 个讨论的多模块系统。
- 另一位用户确认了类似的结果,通过使用正确的关键词连接新的讨论。
Cursor Community Discord
-
Cursor 订阅退款延迟:取消 Cursor 订阅的用户正在等待退款,虽然收到了确认邮件但还没收到实际款项,不过有一位用户声称他们已经拿到了。
- 未提供关于延迟原因或具体涉及金额的进一步细节。
-
FIOS 修复微调:一位用户发现,物理调整其 Verizon FIOS 设置上的 LAN 有线连接可以将下载速度从 450Mbps 提升到 900Mbps+。
- 他们建议使用类似于 PCIE 风格的更稳固的连接器,并发布了一张他们的设置图片。
-
MacBook 版 Cursor 模型上线:用户讨论了在 MacBook 版本的 Cursor 上添加新模型,有些人需要重启或重新安装才能看到它们。
- 建议通过输入 o4-mini 并点击 Add Model 来手动添加 o4-mini 模型。
-
Cursor 编程助手引发讨论:用户争论 o3/o4-mini 是否优于 2.5 Pro 和 3.7 thinking,其中一人报告说 o4-mini-high 在分析代码库和解决逻辑方面优于 4o 和 4.1,即使是大型项目也是如此。
- 其他人抱怨 Cursor Agent 在运行命令后不退出终端(导致其无限期挂起)、频繁的工具调用但没有代码输出、消息过长问题、连接状态指示器损坏以及无法编辑文件。
-
Windsurf 收购传闻风起云涌:有推测称 OpenAI 可能会以 30 亿美元收购 Windsurf,一些人认为这是公司变得更像 Microsoft 的迹象,而另一些人(如这条推文)则关注 GPT4o mini。
- 参与者辩论 Cursor 和 Windsurf 是真正的 IDE,还是仅仅是为 vibe coders、扩展程序或纯文本编辑器提供服务的、带有 UX 产品的 API Wrapper(或 Fork)。
{kind=link}
Yannick Kilcher Discord
-
脑部解构产生流形 (Manifolds):一篇论文建议大脑连接可以分解为简单的流形,并辅以额外的长程连接 (PhysRevE.111.014410),尽管有些人对于任何使用 Schrödinger’s equation 的东西都被称为“量子”感到厌烦。
- 另一位成员澄清说,任何平面波线性方程都可以通过使用 Fourier transform 转换为 Schrödinger’s equation 的形式。
-
Responses API 亮相,Assistant API 逐渐退出:成员们澄清说,虽然 Responses API 是全新的,但 Assistant API 将于明年停止服务。
- 有人强调,如果你想要助手,就选择 Assistant API;如果你想要常规基础功能,就使用 Responses API。
-
储备池计算 (Reservoir Computing) 解构:成员们讨论了 Reservoir Computing 作为一个固定、高维动力系统,并澄清 储备池不一定是软件 RNN,它可以是任何具有时间动态的东西,并从该动力系统中学习一个简单的读出 (readout)。
- 一位成员分享道,大多数“储备池计算”的炒作通常是 用复杂的术语或奇特的设置包装一个非常简单的想法:拥有一个动力系统。不要训练它。只训练一个简单的读出。
-
特朗普威胁禁用 Deepseek:据 TechCrunch 文章 报道,特朗普政府据传正在考虑在美国禁用 Deepseek。
- 未提供更多细节。
-
Meta 推出 Fair 更新,IBM 发布 Granite:Meta 为感知、定位和推理推出了 Fair 更新,IBM 宣布了 Granite 3 和优化的推理 RAG Lora 模型,以及一个新的语音识别系统,详见 IBM 公告。
- Meta 的图片展示了一些作为 Meta fair updates 一部分的更新。
Manus.im Discord Discord
-
Discord 成员被踢出:一名成员因涉嫌烦扰所有人而被 Discord 服务器封禁,引发了关于审核透明度的辩论。
- 虽然有些人质疑证据,但其他人辩护称这一决定对于维持和平社区是必要的。
-
Claude 借鉴 Manus:Claude 推出了 UI 更新,支持原生研究以及与 Google Drive 和 Calendar 等服务的应用连接。
- 这一功能镜像了 Manus 中的现有功能,促使一位成员调侃这基本上是查尔斯三世 (Charles III) 更新。
-
GPT 也添加了 MCPS:成员们观察到 GPT 现在也具备了类似的集成功能,允许用户搜索 Google Calendar、Google Drive 和连接的 Gmail 账户。
- 这一更新将 GPT 定位为生产力和研究领域的竞争者,与 Claude 最近的增强功能并驾齐驱。
-
AI 游戏开发梦想走向开源:围绕着与 AI 和伦理 NFT 实施交织在一起的开源游戏开发潜力,讨论热情高涨。
- 讨论围绕着什么让抽卡游戏 (gacha games) 具有吸引力,以及如何弥合游戏玩家与 crypto/NFT 世界之间的鸿沟。
-
体力系统 (Stamina System) 创新引发讨论:提出了一种新型体力系统,在不同的体力水平提供奖励,以迎合不同的玩家风格并惠及开发者。
- 探索了替代机制,例如抵押物品换取体力或整合损失元素以提高参与度,并与 MapleStory 和 Rust 等游戏进行了类比。
Eleuther Discord
-
LLMs 产生伪对齐幻觉:成员们对伪对齐 (pseudo-alignment) 表示担忧,即 LLM 通过谄媚技巧误导人们认为它们已经掌握了知识,而实际上它们只是依赖 AI 生成听起来合理的想法拼凑,并分享了一篇关于权限随时间变化的论文。
- 成员们普遍警告称,开放网络目前正因 AI 的存在而受到实质性的破坏。
-
欧洲推出区域定制化语言模型:成员们讨论了欧洲境内区域定制化语言模型的可用性,除了像 Mistral 这样知名的实体外,还包括荷兰的 GPT-NL 生态系统、意大利的 Sapienza NLP、西班牙的 Barcelona Supercomputing Center、法国的 OpenLLM-France 和 CroissantLLM、德国的 AIDev、俄罗斯的 Vikhr、希伯来语的 Ivrit.AI 和 DictaLM、波斯语的 Persian AI Community 以及日本的 rinna。
- 几位成员指出,区域定制化语言模型在特定用例中可能会非常有帮助。
-
社区辩论人类验证策略:成员们讨论了在服务器上引入人类身份验证以对抗 AI 机器人的潜在需求。有人认为目前较低的影响可能不会持续,但也在考虑严格验证之外的替代方案,包括社区治理和关注活跃贡献者。
- 社区的整体情绪是审慎乐观的,同时也对 AI 生成内容日益盛行表示担忧。
-
量化效应的质量检查:成员们探讨了分析量化 (quantization) 对 LLM 影响的研究,指出在低比特 (low bits) 下正在发生质变,特别是对于基于训练的量化策略,并分享了一张带有相关支持数据的截图。
- 一位成员还推荐了可组合干预论文 (composable interventions paper),作为低比特下发生质变的证据支持。
{kind=link}
HuggingFace Discord
-
带有 Illustrious Shine 的动漫模型:成员们推荐使用 Illustrious、NoobAI XL、RouWei 和 Animagine 4.0 进行动漫生成,并指向了如 Raehoshi-illust-XL-4 和 RouWei-0.7 等模型。
- 增加 LoRA 资源可以提高输出质量。
-
nVidia 简化了大模型的 GPU 使用:一位成员指出,使用
device_map='auto'在多个 nVidia GPU 上运行一个大模型更加容易,而 AMD 则需要更多的即兴调整,并链接到了 Accelerate 文档。- 使用 device_map=’auto’ 让框架自动管理模型在可用 GPU 上的分布。
-
PolyThink 旨在消除 AI 幻觉:一位成员花费 7 个月时间构建了 PolyThink,这是一个 Agentic 多模型 AI 系统,旨在通过让多个 AI 模型相互纠错与协作来消除 AI 幻觉,并邀请社区注册候补名单。
- PolyThink 的承诺是通过协作验证来提高 AI 生成内容的可靠性和准确性。
-
Agents 课程仍受 503 错误困扰:多位用户报告在开始 Agents 课程时遇到 503 错误,特别是在使用 dummy agent 时,这可能由于达到了 API key 使用限制。
- 尽管用户报告了错误,但一些人指出他们仍有可用额度,这可能表明是流量问题而非 API 限制问题。
-
TRNG 声称其高熵特性可用于 AI 训练:一位成员构建了一个具有极高熵位评分的研究级 True Random Number Generator (TRNG),并希望测试其对 AI 训练的影响,评估信息可在 GitHub 上获取。
- 希望在 AI 训练期间使用具有更高熵的 TRNG 能提高模型性能和随机性。
GPU MODE Discord
-
SYCL 在计算平台中取代了 OpenCL?:在 GPU MODE 的
#general频道中,成员们讨论了 SYCL 是否正在取代 OpenCL,并探讨了这两种技术的相对优劣和未来。- 一位管理员回应称,从历史上看,目前还没有足够的需求来开设专门的 OpenCL 频道,尽管他们承认 OpenCL 仍然是主流,并且在 Intel、AMD 和 NVIDIA 的 CPU/GPU 上提供了广泛的兼容性。
-
矩阵乘法速度未达预期:在 GPU MODE 的
#triton频道中,一名成员报告称,大小为 2048x2048 的 fp16 矩阵乘法 性能不如预期,甚至落后于 cuBLAS,尽管他参考了 官方教程代码。- 建议指出,更现实的基准测试方法是在
torch.nn.Sequential中堆叠约 8 个线性层,使用torch.compile或 cuda-graphs,并测量模型的端到端处理时间,而不仅仅是单个 matmul。
- 建议指出,更现实的基准测试方法是在
-
Popcorn CLI 问题频发:在 GPU MODE 的
#general频道中,用户在使用该 CLI 工具时遇到了错误;一名用户在运行 popcorn 时被提示需先执行popcorn register,并被引导至 Discord 或 GitHub。- 另一名用户在注册后遇到了与 无效或未授权的 X-Popcorn-Cli-Id 相关的 Submission error: Server returned status 401 Unauthorized 错误,而第三名用户报告称在通过浏览器授权执行
popcorn-cli register命令后出现 error decoding response body。
- 另一名用户在注册后遇到了与 无效或未授权的 X-Popcorn-Cli-Id 相关的 Submission error: Server returned status 401 Unauthorized 错误,而第三名用户报告称在通过浏览器授权执行
-
MI300 AMD-FP8-MM 排行榜竞争激烈:根据 GPU MODE 的
#submissions频道,MI300 上的amd-fp8-mm排行榜提交记录从 5.24 ms 到 791 µs 不等,展示了该平台上各种性能水平,其中一项提交达到了 255 µs。- 一名用户在
amd-fp8-mm排行榜上刷新了个人最好成绩,在 MI300 上达到了 5.20 ms,展示了 FP8 矩阵乘法性能的持续改进和优化。
- 一名用户在
-
Torch 模板取得突破,容差已调整:在 GPU MODE 的
#amd-competition频道中,一位参与者分享了一个改进的模板实现(以 message.txt 文件形式附带),该实现避免了 torch 头文件(需要设置no_implicit_headers=True)以缩短往返时间,并配置了正确的 ROCm 架构(gfx942:xnack-)。- 参赛者指出 Kernel 输出存在微小误差,导致出现
mismatch found! custom implementation doesn't match reference等失败消息,随后管理员放宽了最初过于严格的容差(tolerances)。
- 参赛者指出 Kernel 输出存在微小误差,导致出现
LM Studio Discord
-
NVMe SSD 在速度测试中完胜 SATA SSD:用户证实 NVMe SSD 的速度远超 SATA SSD,达到 2000-5000 MiB/s,而 SATA 仅为 500 MiB/s。
- 一名成员指出,在加载大型模型时差距会进一步扩大,并提到由于磁盘缓存和充足的 RAM,会出现远高于 SSD 性能的巨大峰值。
-
LM Studio 视觉模型实现仍是个谜:成员们研究了如何在 LM Studio 中使用 qwen2-vl-2b-instruct 等视觉模型,并引用了 图像输入文档。
- 虽然有人声称成功处理了图像,但其他人报告失败;Llama 4 模型在模型元数据中带有视觉标签,但在 llama.cpp 中不支持视觉功能,且 Gemma 3 的支持情况尚不确定。
-
RAG 模型获得 ‘+’ 号功能支持:用户注意到 LM Studio 中的 RAG 模型可以通过聊天模式消息提示栏中的 ’+’ 号附加文件。
- 模型的信息页面会显示其是否具备 RAG 能力。
-
Granite 模型在交互式聊天中依然表现出色:尽管 Granite 在大多数任务中通常被认为性能较低,但一位用户更喜欢将其用于通用场景,特别是交互式流式宠物类聊天机器人。
- 该用户表示,当尝试将其放入更自然的语境时,它感觉很机械,但 Granite 仍然是目前性能最好的。
-
AVX 指令集要求限制了旧版 LM Studio 的使用:一位使用不带 AVX2 的旧款 E5-V2 服务器的用户询问是否能运行 LM Studio,但被告知只有非常旧版本的 LM Studio 才支持 AVX。
- 建议使用 llama-server-vulkan 或寻找仍支持 AVX 的 LLM。
Unsloth AI (Daniel Han) Discord
-
Llama 4 适配 Unsloth:Llama 4 的微调支持将于本周登陆 Unsloth,同时支持 7B 和 14B 模型。
- 要使用它,请切换到 7B notebook 并将其更改为 14B 以访问新功能。
-
自定义 Token 占用内存?:在 Unsloth 中添加自定义 Token 会增加内存消耗,需要用户启用持续预训练 (continued pretraining) 并向 embedding 和 LM head 添加层适配器 (layer adapters)。
- 有关此技术的更多信息,请参阅 Unsloth 文档。
-
MetaAI 吐露仇恨言论:一位成员观察到 MetaAI 在 Facebook Messenger 中生成并随后删除了一条冒犯性评论,接着声称服务不可用。
- 该成员批评 Meta 将输出流式传输置于审核之上,建议审核应该像 DeepSeek 那样在服务器端进行。
-
PolyThink 消除幻觉:一位成员宣布了 PolyThink PolyThink 候补名单 的开启,这是一个多模型 AI 系统,旨在通过让 AI 模型相互纠错来消除 AI 幻觉 (AI hallucinations)。
- 另一位成员将该系统比作“用所有模型进行思考”,并表示有兴趣将其用于合成数据生成 (synthetic data generation) 以创建更好的数据集。
-
未经训练的神经网络展现出涌现计算:一篇文章指出,未经训练的深度神经网络可以在没有训练的情况下执行图像处理任务,利用随机权重对图像进行过滤和特征提取。
- 该技术利用神经网络固有的结构来处理数据,而无需从训练数据中学习特定模式,展示了涌现计算 (emergent computation)。
Nous Research AI Discord
-
GPT4o 在自动补全方面表现挣扎:成员们讨论了 GitHub Copilot 是否使用 GPT4o 进行自动补全,有报告称其幻觉出链接并交付了损坏的代码,正如这些推文和另一篇推文所记录的那样。
- 普遍观点认为,尽管对自动补全任务寄予厚望,但 GPT4o 的表现仅与其他 SOTA LLM 持平。
-
华为可能挑战 Nvidia 的领先地位:特朗普的关税政策可能会使 华为 在硬件方面与 Nvidia 竞争,并可能主导全球市场,根据这篇推文和这段 YouTube 视频。
- 然而,一些用户对 GPT4o-mini-high 的评价褒贬不一,指出其在 zero-shot 时会出现损坏的代码,且在处理基础 Prompt 时失败。
-
微软研究院发布 BitNet b1.58 2B 4T:微软研究院推出了 BitNet b1.58 2B 4T,这是一个原生的 1-bit LLM,拥有 20 亿参数,并在 4 万亿 Token 上进行了训练,其 GitHub 仓库在此。
- 用户发现,必须利用专门的 C++ 实现 (bitnet.cpp) 才能实现承诺的效率优势,且上下文窗口限制为 4k。
-
Discord 的新年龄验证引发争论:一位成员分享了对 Discord 在英国和澳大利亚测试的新年龄验证功能的担忧,引用了此链接。
- 核心问题在于用户担心隐私受损以及平台范围内可能发生的进一步变化。
Notebook LM Discord
-
Gemini Pro 助力会计自动化:一位成员利用 Gemini Pro 为初级会计师的月末流程指南生成了 TOC(目录),随后通过 Deep Research 对其进行了丰富,并将研究结果整合到 GDoc 中。
- 他们将 GDoc 作为主要来源整合进 NLM,强调了其功能并征求改进反馈。
-
通过 Google Maps 规划度假愿景:一位成员使用 Notebook LM 创建了度假行程,并将兴趣点存档在 Google Maps 中。
- 他们建议 Notebook LM 应该能够摄取保存的 Google Maps 列表作为源材料。
-
投票,投票,否则就错失良机:一位成员提醒大家 Webby 投票明天截止,NotebookLM 在 3 个类别中有 2 个处于落后状态,敦促用户投票并广而告之:https://vote.webbyawards.com/PublicVoting#/2025/ai-immersive-games/ai-apps-experiences-features/technical-achievement。
- 该成员担心如果大家不投票,他们将会落选。
-
NLM 的 RAG 架构图讨论:针对有关 RAG 的提问,一位成员分享了两张展示通用 RAG 系统和简化版本的图表,详见此处:Vertex_RAG_diagram_b4Csnl2.original.png 和 Screenshot_2025-04-18_at_01.12.18.png。
- 另一位用户插话表示他们在 Obsidian 中有自定义的 RAG 设置,随后讨论转向了响应风格。
{kind=link}
MCP (Glama) Discord
-
Obsidian MCP 服务器亮相:一位成员正在开发 Obsidian 的 MCP 服务器 并寻求创意协作,强调主要漏洞在于编排(orchestration)而非协议本身。
- 该开发旨在通过安全的编排接口简化 Obsidian 与外部服务之间的集成。
-
使用 SSE API Key 保护 Cloudflare Workers:一位成员正在使用 Cloudflare Workers 和 Server-Sent Events (SSE) 配置 MCP 服务器,并就如何安全地传递 apiKey 征求建议。
- 另一位成员建议通过 HTTPS 加密的 header 而非 URL 参数传输 apiKey,以增强安全性。
-
LLM 工具理解机制解析:一位成员询问 LLM 如何真正“理解”工具和资源,探讨这仅仅是基于 prompt 解释,还是针对 MCP spec 进行了特定训练。
- 澄清指出 LLM 通过描述来理解工具,许多模型支持工具规范或其他定义这些工具的参数,从而引导其使用。
-
MCP 服务器的个性化困境:一位成员试图通过在初始化期间设置特定 prompt 来为他们的 MCP 服务器 定义独特个性,以规定响应行为。
- 尽管付出了这些努力,MCP 服务器 的响应仍保持不变,这引发了对有效个性化定制技术的进一步研究。
-
HeyGen API 正式登场:HeyGen API 的产品负责人介绍了他们的平台,强调其无需摄像头即可制作引人入胜的视频的能力。
- HeyGen 允许用户在没有摄像头的情况下创建吸引人的视频。
Torchtune Discord
-
GRPO Recipe 待办事项列表已过时:原始 GRPO recipe 待办事项 已过时,因为新版本的 GRPO 正在 r1-zero repo 中准备。
- 单设备 recipe 将不会通过 r1-zero repo 添加。
-
异步 GRPO 版本正在开发中:异步版本的 GRPO 正在一个独立的分支中开发,很快将合并回 Torchtune。
- 此次更新旨在增强 Torchtune 内部 GRPO 实现的灵活性和效率。
-
单 GPU GRPO Recipe 进入最后冲刺阶段:来自 @f0cus73 的单 GPU GRPO recipe PR 可以在这里查看,目前正在进行最后的完善。
- 该 recipe 允许用户在单 GPU 上运行 GRPO,降低了实验和开发的硬件门槛。
-
奖励建模 RFC 即将发布:奖励建模 (Reward Modeling) 的 RFC (意见征求稿) 即将发布,将概述实现要求。
- 社区期望该 RFC 能为奖励建模提供结构化的方法,促进 Torchtune 内部更好的集成和标准化。
-
Titans Talk 即将开始…:Titans Talk 将在 1 分钟后为感兴趣的人开始。
- 算了,当我没说!
LlamaIndex Discord
-
LlamaIndex Agent 流利支持 A2A 通信:LlamaIndex 现在支持构建符合 A2A (Agent2Agent) 协议的 Agent,该协议由 Google 发起,并得到了超过 50 家技术合作伙伴 的支持。
- 该协议使 AI Agent 能够安全地交换信息并协调行动,无论其底层基础设施如何。
-
CondenseQuestionChatEngine 不支持工具调用:CondenseQuestionChatEngine 不支持调用工具;据一名成员称,建议改用 Agent。
- 另一名成员确认这只是一个建议,实际上并未实施。
-
Bedrock Converse Prompt Caching 导致混乱:一名通过 Bedrock Converse 使用 Anthropic 的成员在尝试使用 Prompt Caching 时遇到问题,在向 llm.acomplete 调用添加 extra_headers 时报错。
- 移除额外的 header 后错误消失,但响应中缺少预期的 Prompt Caching 字段,例如 cache_creation_input_tokens。
-
Anthropic 类可能解决 Bedrock 缓存问题:有建议称,由于放置缓存点的方式不同,Bedrock Converse 集成 可能需要更新才能正确支持 Prompt Caching,目前应使用
Anthropic类。- 该建议基于成员对原生 Anthropic 的测试,并指向了一个 Google Colab 笔记本示例 作为参考。
Nomic.ai (GPT4All) Discord
-
GPT4All 的停滞引发疑虑:Discord 服务器上的用户对 GPT4All 的未来表示担忧,指出已经大约 三个月 没有更新或开发者露面了。
- 一位用户表示,既然一年时间都不算什么大跨度……所以我对及时的更新不抱希望。
-
IBM Granite 3.3 成为 RAG 的替代方案:一名成员强调 IBM 的 Granite 3.3(拥有 80 亿参数)能为 RAG 应用提供准确且详尽的结果,并提供了 IBM 公告 和 Hugging Face 页面的链接。
- 该成员还提到,他们正在使用 GPT4All 的 Nomic embed text 进行编程函数的本地语义搜索。
-
LinkedIn 询问被无视:一名成员表示,他们 在 LinkedIn 上询问了 GPT4All 的状态,但我觉得我被无视了。
- 未记录进一步的讨论。
Modular (Mojo 🔥) Discord
-
Modular 举办线下见面会:Modular 将于下周在其位于加利福尼亚州洛斯阿尔托斯 (Los Altos, California) 的总部举办线下见面会,并邀请您在此预约 (RSVP)。
- 见面会将包含一场关于通过 Mojo & MAX 提升 GPU 性能的演讲,并提供线下和虚拟参会两种方式。
-
Mojo 缺少标准 MLIR Dialects:一位用户发现 Mojo 默认情况下不暴露
arith等标准 MLIR dialects,仅提供llvmdialect。- 会议澄清,目前在 Mojo 中没有注册其他 dialects 的机制。
-
Mojo 字典指针触发 Copy/Move:一位用户观察到,在 Mojo 中使用
Dict[Int, S]()和d.get_ptr(1)获取字典值的指针时,会出现非预期的copy和move行为。- 这引发了一个问题:“为什么获取字典值的指针会调用 copy 和 move?🤯 这在任何意义上是预期的行为吗?”
-
max 仓库需要孤儿清理机制 (Orphan Cleanup Mechanism):一位成员强调了
max仓库需要孤儿清理机制,该问题最初于几个月前在 issue 4028 中提出。- 这一特性对于磁盘分区较小的开发者尤为重要,尽管它被归类为纯粹的开发端问题。
LLM Agents (Berkeley MOOC) Discord
-
自动形式化工具寻求业务逻辑证明:一位成员询问如何使用 Lean 自动形式化工具 (auto-formalizer) 从包含业务逻辑的计算机代码中生成非正式证明,以便利用 AI 证明生成进行程序的形式化验证 (formal verification)。
- 讨论重点关注了 Python 和 Solidity 等编程语言。
-
CIRIS Covenant Beta:开源对齐 (Alignment):CIRIS Covenant 1.0-beta 已发布,这是一个用于自适应相干 AI 对齐 (AI alignment) 的开源框架,并提供 PDF 下载。
- 该项目旨在帮助 AI 安全或治理领域的人员,项目中心和评论门户可在此处访问。
MLOps @Chipro Discord
-
寻求集成预测模型 (ensembling forecasting models) 的资源:一位成员询问有关集成预测模型的资源。
- 消息记录中未提供相关资源。
-
成员集思广益毕业设计 (Final Year Project) 想法:一位成员正在为 AI 专业的学士学位寻找实用的毕业设计想法,对计算机视觉、NLP 和生成式 AI 感兴趣,特别是能解决现实世界问题的项目。
- 他们正在寻找构建难度适中的项目。
Cohere Discord
-
AI 模型开发通常是分阶段的吗?:一位用户询问 AI 模型开发是否通常采用分阶段训练过程,例如实验阶段 (20-50%)、预览阶段 (50-70%) 和稳定阶段 (100%)。
- 该问题探讨了 AI 模型训练中分阶段方法的普遍性,涉及实验版、预览版和稳定版发布等阶段。
-
分阶段训练在 AI 中常见吗?:讨论集中在 AI 模型使用分阶段训练过程的情况,将其分解为实验、预览和稳定等阶段。
- 用户试图了解这种分阶段部署是否是该领域的常见做法。
Codeium (Windsurf) Discord
-
Windsurf 的 Jetbrains 更新日志发布:最新的发布说明现已在 Windsurf 更新日志中上线。
- 鼓励用户查看更新日志,以了解最新的功能和改进。
-
新讨论频道开启:一个新的讨论频道 <#1362171834191319140> 已开启,用于社区交流。
- 旨在为用户提供一个专门的空间来分享想法、建议,并询问有关 Windsurf 的问题。
DSPy Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
tinygrad (George Hotz) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
第二部分:按频道详细摘要和链接
完整的各频道详细内容已在邮件中截断。
如果您喜欢 AInews,请分享给朋友!提前感谢!