ainews-grok-3-3-mini-now-api-available
Grok 3 和 3-mini API 现已开放。
以下是该文本的中文翻译:
Grok 3 API 现已推出,其中包括名为 Grok 3 mini 的较小版本,该版本提供极具竞争力的定价和完整的推理轨迹。OpenAI 发布了构建 AI 智能体(Agent)的实用指南,同时 LlamaIndex 已支持用于多智能体通信的 Agent2Agent 协议。Codex CLI 凭借新功能以及来自 Aider 和 Claude Code 的竞争正受到关注。Google DeepMind 推出了 Gemini 2.5 Flash,这是一款在 Chatbot Arena 排行榜上名列前茅的混合推理模型。OpenAI 的 o3 和 o4-mini 模型展示了大规模强化学习带来的涌现行为。Epoch AI Research 更新了其方法论,由于 Llama 4 Maverick 的训练算力需求下降,将其从高 FLOP(浮点运算量)模型名单中移除。Goodfire AI 宣布为其 Ember 神经编程平台完成 5000 万美元的 A 轮融资。Mechanize 公司成立,旨在构建虚拟工作环境和自动化基准测试。Google DeepMind 针对 Gemma 3 模型的量化感知训练(QAT)显著减小了模型体积,并提供了开源检查点。
X is all you need?
2025年4月17日至4月18日的 AI 新闻。我们为您检查了 9 个 subreddits、449 个 Twitter 账号 和 29 个 Discord(211 个频道,8290 条消息)。为您节省了预计阅读时间(以 200wpm 计算):650 分钟。您现在可以标记 @smol_ai 进行 AINews 讨论!
Grok 3(我们的报道在此)已经发布几个月了,但之前一直没有 API。现在它来了,还带了一个额外的“小老弟”!
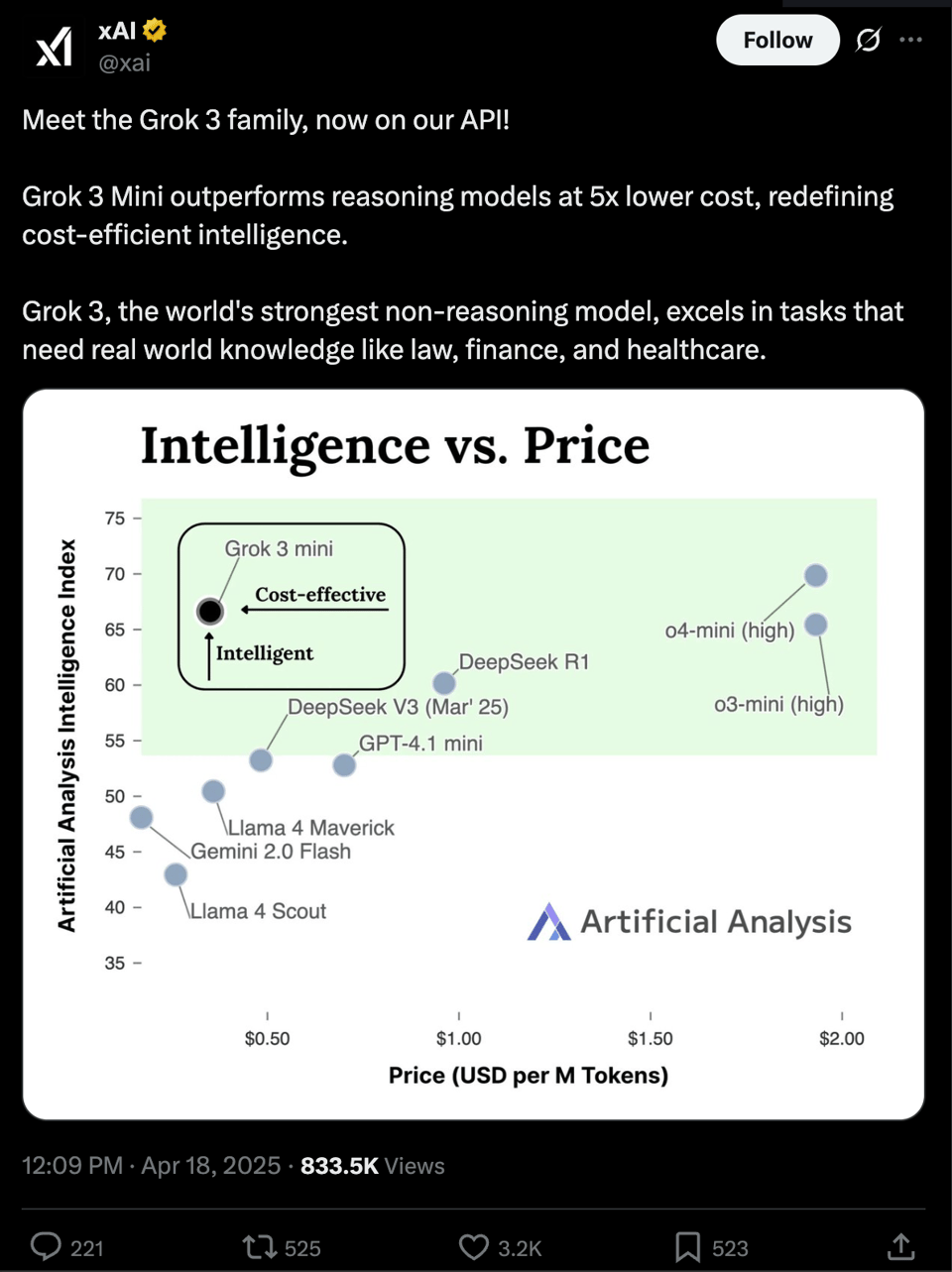
Grok 3 mini 的价格为每百万输出 token 50 美分,声称能与大得多的前沿模型竞争,同时还能展示完整的推理链(reasoning traces):
您可以从这里开始:https://docs.x.ai/docs/overview
AI Twitter 回顾
Agent 工具、框架与设计
- AI Agent 开发与部署:@TheTuringPost 重点介绍了来自 OpenAI 的构建 AI agents 的实用指南,涵盖了用例选择、设计模式、安全部署实践,以及产品和工程团队所需的基础知识。
- Agent 交互:@llama_index 展示了 LlamaIndex 对 Agent2Agent (A2A) 协议的支持,允许 AI agents 在不同系统之间进行通信、交换信息和协调行动。这促进了多 Agent 生态系统中的协作。提供了一个支持 A2A 协议的聊天 Agent 示例。
- Codex CLI 与 AI 辅助代码编辑:@gdb 报告了围绕 Codex CLI 的兴奋点,并指出它还处于早期阶段,正在增加对 MCP、本地/不同提供商模型以及原生插件系统的支持,同时修复了速率限制问题。@_philschmid 概述了其工作原理。@jeremyphoward 指出 Aider 是 CLI AI 编辑器的鼻祖,而 Claude Code 是目前备受瞩目的新秀。它们都是 Codex 的竞争对手。
模型更新、发布与性能
- Gemini 2.5 Pro 与 Flash:@GoogleDeepMind 宣布发布 Gemini 2.5 Flash,强调其混合推理模型可以根据提示词调整其“思考”程度,使其成为各种任务的理想选择。@DeepLearningAI 指出它在 Chatbot Arena 排行榜上名列前茅。@osanseviero 分享了同样的消息,并展示了博客链接和 AI studio 链接。
- 模型评估与基准测试:@swyx 注意到性价比(performance-per-cost)思维正被广泛采用。
- o3 模型工具使用:来自 OpenAI 的 @mckbrando 澄清说,在 o3 和 o4-mini 中看到的行为是大规模 RL(强化学习)的涌现结果,模型被赋予了访问 Python 和操作图像的能力。
- Llama 3 与 Maverick:@EpochAIResearch 正在更新其方法论,并将 Maverick 从超过 1e25 FLOP 的模型列表中移除,因为 Llama 4 Maverick 的训练算力降至 2.2e24 FLOP。
公司与融资
- AI 初创公司:@GoodfireAI 宣布获得 5000 万美元 A 轮融资,并分享了 Ember 的预览,这是一个通用神经编程平台,可以直接、可编程地访问任何 AI 模型的内部思维。
- Mechanize 虚拟工作环境:@tamaybes 宣布成立 Mechanize,该公司将构建虚拟工作环境、基准测试和训练数据,以实现所有工作的全面自动化。
效率与基础设施
- 针对 Gemma 模型的量化感知训练 (QAT):@reach_vb 重点介绍了 GoogleDeepMind 的 量化感知训练 (Quantisation Aware Trained) Gemma 3 模型,并指出 27B 模型的大小从 54GB 缩减至 14.1GB,且开源 Checkpoints 现在已可在 MLX、llama.cpp、lmstudio 等工具中运行。@osanseviero 对该模型的全面发布感到兴奋。
- vLLM 与 Hugging Face Transformers 的集成:@vllm_project 指出,现在可以利用 vLLM 的速度部署任何 Hugging Face 语言模型,从而实现 HF 模型在训练和推理中的一致性实现。
- 具有 400 万上下文长度的 Nvidia Nemotron:@reach_vb 提到 Nvidia 发布了具有 400 万 上下文长度的 Llama 3.1 Nemotron,你几乎可以将整个代码库都投入其中。
- Perplexity AI 的 DeepSeek MoE 多节点部署:@AravSrinivas 宣布 Perplexity AI 正在提供 MoE 模型服务(如训练后的 DeepSeek-v3 版本),并指出这些模型可以在多节点设置中高效利用 GPU。
- 用于嵌入量化的 embzip:@jxmnop 宣布发布 embzip,这是一个用于嵌入量化 (Embedding Quantization) 的新 Python 库,允许用户通过一行代码使用乘积量化 (Product Quantization) 来保存和加载嵌入。
新 AI 技术
- 用于 Diffusion LLMs 推理的强化学习 (RL):@omarsar0 重点介绍了一篇论文,指出了其两阶段流水线以及超越 SFT 并实现强大推理能力的能力。
更广泛的影响
- 工业化国家的出生率:@fchollet 认为工业化国家出生率的下降是一个经济和文化问题,并很有可能在后 AGI 社会中得到逆转,届时人们将能够选择不工作。
- AI 与个人用例:@yusuf_i_mehdi 引用了一篇文章,指出 AI 正迅速成为日常伴侣,人们现在转向 AI 寻求从个人决策到深度对话、从组织生活到创意表达的一切帮助。
- AI 安全:@lateinteraction 表示,使智能系统可靠的方法 不是 增加更多的智能。事实上,是通过在正确的地方减少智能。
AI 与中美科技战
- 中国技术进步:@nearcyan 表示,我们肯定会在“硬件奇点”之前很久就迎来“软件奇点”,而硬件奇点似乎……比以往任何时候都更加推迟了。
幽默/梗
- 共鸣:@code_star 发布了“编辑 FSDP 配置时的我”。
- 恶搞:@Yuchenj_UW 宣称“你想要猫娘”。
AI Reddit 回顾
/r/LocalLlama 回顾
1. Google Gemma 3 QAT 量化与生态系统发布
-
Google QAT - 优化的 int4 Gemma 3 大幅削减了 VRAM 需求 (54GB -> 14.1GB) 同时保持了质量 - llama.cpp, lmstudio, MLX, ollama (得分: 506, 评论: 108): 该图片是一个柱状图,直观地展示了 Google 的 QAT (Quantization Aware Training) 对使用 int4 量化而非 bf16 权重的 Gemma 3 模型加载时内存需求的影响。值得注意的是,27B 参数模型的 VRAM 需求从 54GB (bf16) 降至仅 14.1GB (int4),这代表了巨大的节省,同时正如 QAT 所保证的,保持了 bf16 级别的输出质量。该帖子还指出,这些格式可通过 HuggingFace 直接获取,用于 MLX、Hugging Face Transformers (safetensors) 和 GGUF 格式(适用于 llama.cpp、lmstudio、ollama),从而实现了广泛的平台兼容性。 一条显眼的评论强调了 QAT Checkpoints 的重要性,它涉及量化后的微调以恢复精度——这意味着,特别是对于 Gemma 3 QAT,int4 模型的表现可以媲美 bf16。另一条评论指出,这种量化改进是在预料之中的,尽管 QAT 将质量提升到了超越典型训练后量化的水平。
- Gemma 3 的 QAT (Quantization Aware Training) 检查点涉及在量化后对模型进行进一步训练,使得 Q4 变体能够达到接近 bfloat16 (bf16) 的精度,相比传统的训练后量化方法有显著提升。这在不产生激进量化常见的典型精度损失的情况下,提高了推理效率。
- 注意到 Google 官方 QAT GGUF 模型的技术差异:它们在
token_embd权重上使用 fp16 精度,且未采用 imatrix 量化,这可能阻碍了最佳的文件大小缩减。社区努力(如 /u/stduhpf 的工作)已通过“手术式”替换,将这些权重更换为 Q6_K,以获得更好的尺寸/性能比(详情:Reddit 链接)。 - 性能基准测试显示,尽管尺寸减小(例如 27B Q4 约为 16GB),但 Gemma 3 QAT 模型的 Token 生成 (tg) 速度相对较慢,在 Apple M1 Ultra 硬件上的表现与 Mistral-Small-24B Q8_0 相当,且慢于 Qwen2.5 14B Q8_0 或 Phi-4 Q8_0。还有早期报告称存在损坏的 QAT 检查点(如 1B-IT-qat 版本)以及在某些 speculative decoding 工作流中出现词表不匹配问题。
- 注意到 Google 官方 QAT GGUF 模型的技术差异:它们在
-
Google 发布新型 QAT 优化 int4 Gemma 3 模型,在保持质量的同时大幅降低 VRAM 需求 (54GB -> 14.1GB)。 (得分: 240, 评论: 30): Google 发布了新型 QAT (Quantization-Aware Training) 优化的
int4Gemma 3 模型,将 VRAM 需求从54GB降低到14.1GB,且模型质量没有显著损失 链接。QAT 是一种在训练期间模拟量化影响的技术,能够实现低比特推理并最大限度地减少精度下降,这标志着高效模型部署迈出了重要一步。 评论强调了社区对适当 QAT 优化模型的期待,并指出了对 Google 此前发布的 QAT 版本的困惑,认为这次发布是首次在 int4 精度下满足实际 VRAM 效率需求的版本。[外部链接摘要] Google 的 Gemma 3 模型现在包含 QAT (Quantization-Aware Training) 变体,通过将数值精度降低到 int4 (4-bit),实现在消费级 GPU 上进行高效、高质量的推理。集成 QAT 的训练使得像 27B 参数这样大的 Gemma 3 模型能够在像 RTX 3090 这样的 GPU 上运行,最大模型仅需 14.1GB VRAM,且 AI 质量下降极小(与朴素的后量化相比,困惑度 drop 减少了 54%)。预构建的集成支持主要的推理引擎 (Ollama, llama.cpp, MLX),官方模型可在 Hugging Face 和 Kaggle 上获取;更广泛的 Gemma 生态系统还支持针对特定硬件或性能/质量权衡的其他量化策略。阅读原始博客文章 - 讨论强调了 Google 新型 QAT 优化 int4 Gemma 3 模型对 VRAM 需求的显著降低(从 54GB 缩减至 14.1GB),并强调了此类优化对于在不损失质量的情况下实现更广泛硬件可访问性的重要性。
- 对 Bartowski, Unsloth 和 GGML 等工具的提及表明,技术活跃的社区正在关注 QAT 和模型部署效率方面的上游及第三方进展。
- 存在对进一步压缩可行性的好奇(例如将模型大小减小到 11GB),这表明人们持续关注在保持推理质量的同时,挑战量化技术和硬件适应的极限。
-
Gemma 3 QAT 在 MLX, llama.cpp, Ollama, LM Studio 和 Hugging Face 上发布 (Score: 144, Comments: 37): Google 发布了针对 Gemma 3 的未量化 QAT (Quantization-Aware Training) Checkpoints,允许第三方进行自定义量化;该方法在显著降低内存需求的同时,保留了与 bfloat16 相当的模型质量。这些模型在各大主流平台(MLX, llama.cpp, Ollama, LM Studio, Hugging Face)上均获得原生支持,且 GGUF 格式的量化权重和新的未量化 Checkpoints 均已公开 (博客文章, Hugging Face 集合)。尽管工具链已提供支持,但集成细节仍存疑:官方指南强调使用 Q4_0 进行量化,但如何将其与其他量化技术和框架(例如 Hugging Face Transformers 对 4-bit 量化的支持)协调一致尚不明确。 Redditors 报告了不同格式间的不一致和损坏问题——例如,MLX 4-bit 模型在 LM Studio 中响应为 ‘
',LM Studio 与 Hugging Face 构建的模型大小存在差异,以及对哪个模型版本具有权威性感到困惑。专家们正在讨论 HF Transformers 的量化实现(bitsandbytes, GPTQ, AWQ 等)是否与 Q4_0 兼容,并指出缺乏关于基于 HF 推理的最佳 QAT 工作流文档。 - 关于 MLX 中 Gemma 3 QAT 模型的量化级别存在技术困惑,特别是 3-bit、4-bit 和 8-bit 版本的存在。一位用户指出,8-bit MLX 版本似乎只是对 4-bit QAT 权重进行了上采样,“消耗了两倍的内存却没有任何收益”,这引发了对内存效率和量化过程合法性的担忧。此外,有报告称 4-bit MLX 版本在 LM Studio 0.3.14 (build 5) 中仅返回
Token,表明该版本可能存在兼容性 Bug。 - 针对 LM Studio 与 Hugging Face/Kaggle 之间对同一 QAT Checkpoints 模型大小报告不一致的问题,引发了一场技术辩论(例如,LM Studio 报告 12B QAT 为 7.74GB,Hugging Face 为 8.07GB,但下载后为 7.5GB)。进一步调查显示,一个 4b QAT Q4_0 模型在 LM Studio 为 2.20GB,而在 Hugging Face 为 2.93GB,这表明存在多个非同质的构建版本——引发了哪个来源最准确且最新的疑问。
- 关于使用 Hugging Face Transformers 对 Gemma 3 QAT 模型进行最佳量化推理存在重大不确定性。官方指南仅为非 QAT 模型提供直接支持/示例,而 QAT 量化过程推荐使用 GGUF Q4_0(一种 4-bit 最近舍入的传统量化)。由于 HF Transformers 支持其自身的 4-bit 量化格式(如 bitsandbytes, AWQ, GPTQ),目前尚不清楚这些方法是否与 GGUF Q4_0 的缩放/阈值对齐——这影响了在使用 HF 支持的量化流水线时,QAT 微调模型的优势是否能被真正保留。
{kind=link}
2. Novel LLM Benchmarks: VideoGameBench & Real-time CSM 1B
-
使用 LLM 玩 DOOM II 和其他 19 款 DOS/GB 游戏作为新基准测试 (评分: 490, 评论: 98): 研究人员推出了 VideoGameBench (项目页面),这是一个视觉语言模型基准测试,要求实时完成 20 款经典的 DOS/GB 游戏(如 DOOM II),并在 GPT-4o、Claude Sonnet 3.7 和 Gemini 2.5 Pro/2.0 Flash 等模型上进行了测试 (GitHub 链接)。模型表现出有限的交互式推理和规划能力,没有一个模型能通过 DOOM II 的第一关,这凸显了目前基于 LLM 的 Agent 在复杂实时环境中的重大局限性。 评论幽默地引用了经典的“能运行 Doom 吗?”梗,并轻微讨论了将游戏作为智能基准测试的价值,但没有深入的技术辩论。[外部链接摘要] 研究人员推出了 VideoGameBench (https://vgbench.com),这是一个旨在评估视觉语言模型 (VLMs) 通过视觉输入和文本命令实时玩 20 款经典视频游戏(DOS/GB 平台)能力的全新基准测试。主要的 LLM/VLM 系统,包括 GPT-4o、Claude Sonnet 3.7 和 Gemini 2.5 Pro,在相同提示词下进行了该任务(例如 DOOM II,默认难度)的基准测试,结果没有一个能通过第一关,揭示了 VLMs 在动态、实时视觉推理和决策任务中的当前局限性。相关代码和评估细节可在 https://github.com/alexzhang13/VideoGameBench 获取。
- 一位用户对在游戏任务中使用像 Gemini 2.5 Pro 这样的推理模型时的性能和延迟表示担忧,指出与非推理架构相比,推理模型可能没有针对低延迟或实时交互进行优化。
- 另一条评论表达了技术上的怀疑,表示对能够在具有约 400GB/s 显存带宽的单个 GPU 上遵循文本指令进行实时游戏的 8B 参数以下模型感兴趣,并建议需要改进架构才能在当前的资源限制下实现这一目标。
-
CSM 1B 现已支持实时运行并可进行微调 (评分: 151, 评论: 30): CSM 1B 是一款开源的文本转语音 (TTS) 模型,现在支持实时流式传输和基于 LoRA 的微调,详见此 GitHub 仓库。作者实现了一个实时本地聊天演示以及通过 LoRA 进行的微调,同时也支持全量微调。该仓库展示了实现实时推理的性能改进,使其与其他开源 TTS 模型相比具有竞争力。 评论者正在询问与 Apple Silicon 的兼容性,并对实现实时性能所做的优化技术细节感兴趣。大家对持续的迭代开发普遍持积极态度。
- 讨论围绕使用 5090 等高端 GPU 实现近乎实时的推理展开,据报告推理性能可达
0.5s(2 倍实时),但由于容器启动原因仍存在延迟问题。部署示例包括将推理作为 serverless 实例运行,以及尝试通过 WebSocket 从 Docker 容器流式传输音频输出。- 有人提出了关于 Apple Silicon 兼容性的问题,特别是性能(尽管较慢)是否允许该模型在 Apple 硬件上有效运行。另一位用户描述了将代码库移植到适用于 Apple Silicon 的 MLX,报告称 CPU 推理性能优于当前的 Metal 后端,但总体结果并不理想。
- 存在对该模型在原始训练集之外的语言进行微调的能力的技术好奇,以及参考语音是否需要与生成的音频使用相同的语言,这暗示了对多语言支持和微调数据限制的兴趣。
-
microsoft/MAI-DS-R1,由 Microsoft 进行后训练的 DeepSeek R1 (得分: 320, 评论: 73): Microsoft 发布了 MAI-DS-R1,这是一个基于 DeepSeek R1 的模型,似乎在代码补全基准测试中有了实质性的提升,特别是在 livecodebench 上表现优于同类模型。这一公告引发了关于规模的讨论,因为之前的重大型后训练(如 Nous Hermes 405B)曾被认为是业界顶尖水平,而这可能代表了主要供应商进行的一次全新的、规模最大的后训练/微调尝试。 评论者注意到其在特定编程基准测试中的强劲表现,并讨论了地缘政治背景,将其与近期关于大模型的国家安全报告进行了对比。技术讨论集中在 Microsoft 在此类大规模后训练上的投入,相较于社区和行业努力的意义。[外部链接摘要] MAI-DS-R1 是一个基于 DeepSeek-R1 的推理 LLM,由 Microsoft 进行后训练,旨在改善对先前被屏蔽/易产生偏见的话题的响应并降低风险,利用了 11万条安全/非合规样本(Tulu 3 SFT)和 35万条内部多语言偏见焦点数据。该模型展示了卓越的安全性和解除屏蔽性能(在基准测试中达到或超过了 R1-1776),同时保留了推理、编程和通用知识能力,但仍受限于固有局限性(例如:可能的幻觉、语言偏见、未改变的知识截止日期)。评估涵盖了公开基准测试、屏蔽话题测试集(11 种语言)以及伤害缓解(HarmBench),结果显示 MAI-DS-R1 生成了更相关、危害更小的输出——尽管在涉及重大利害关系的使用场景中,仍建议进行内容审核和人工监督。
- MAI-DS-R1 在 livecodebench 代码补全基准测试中表现出改进的性能,正如发布的截图所示。这使其成为当前代码推理和生成模型中的强力竞争者。
- 一份技术更新指出,MAI-DS-R1 是基于 DeepSeek-R1,使用来自 Tulu 3 SFT 数据集的 11万条安全和非合规示例(https://huggingface.co/datasets/allenai/tulu-3-sft-mixture),加上约 35万条内部开发、专注于已报告偏见的多语言示例进行后训练的。这旨在同时提高安全性、合规性和推理能力。
- 存在关于此次后训练规模和范围与之前大规模尝试(如 Nous Hermes 405b)对比的技术讨论,一些用户认为这可能是迄今为止开源 LLM 社区中规模最大或最全面的微调/后训练尝试之一。
3. 本地优先的 AI 工具、可视化和社区项目
-
无需 API 密钥,无需云端。只需真正起作用的本地 AI + 工具。要求太高了吗? (得分: 111, 评论: 33): Clara 是一款本地优先的 AI 助手,作为原生桌面应用构建,完全通过 Ollama 在用户机器上运行大语言模型推理。最新更新将开源工作流自动化工具 n8n 直接集成到 Clara 中,使终端用户能够通过可视化流程构建器自动执行任务(如电子邮件、日历、 API 调用、数据库、计划任务和 webhooks)——所有这些都无需云端、外部服务或 API 密钥。 完整的技术细节和代码库已发布在 GitHub。与 OpenWebUI 和 LibreChat 等项目相比,Clara 强调减少依赖项,并为本地部署提供初学者友好的 UX。 一条评论指出,在没有上下文的情况下提及 “Ollama” 可能会阻碍用户的理解或采用;另一条评论则反思了本地 AI 助手的拥挤现状,质疑为什么像 Clara 这样的项目可能受到的关注有限。
- 一位用户询问了与其他本地 AI 服务器的互操作性,特别是那些提供 OpenAI 兼容端点的服务器(如 Tabby API 和 vLLM),强调了支持更广泛的本地推理服务器生态系统对于灵活性和提高采用率的重要性。
- 另一位用户请求增加 OpenAI 兼容的 API 使用功能,指出并非所有用户都拥有持续运行本地模型所需的计算资源;当本地托管不切实际时,此功能将允许云端回退或混合工作流。
-
是时候提升本地推理水平了 (评分: 188, 评论: 57): 图片展示了 OpenAI 的身份验证提示,现在访问其最新模型需要进行身份验证。该过程要求提供大量的个人数据,包括生物特征识别符、政府证件扫描件以及用户对数据处理的同意,这标志着在获取先进 AI 模型访问权限之前,用户验证正转向更具侵入性的方式——这可能会影响可访问性、隐私和用户信任。 评论者批评 OpenAI 这种激进的数据收集行为,引发了对隐私的担忧,一些人建议寻找替代方案(Anthropic、本地模型),并警告不要使用需要敏感验证的平台或“persona”功能;便捷性与隐私之间的权衡是一个关键主题。
-
评论者讨论了 AI 产品中“persona”功能的隐私影响,警告这些系统会收集大量的个人数据甚至生物特征数据,并以 OpenAI 和 Worldcoin 的举措为例。建议优先选择开源或本地 AI 替代方案,例如 Anthropic 的方法或在个人硬件上运行模型,以降低隐私风险。
-
我创建了一个交互式工具,可以可视化 GPT-2 中的每一个注意力权重矩阵! (评分: 136, 评论: 14): OP 设计了一个交互式工具,用于可视化 GPT-2 语言模型中的每一个注意力权重矩阵。该工具可在 amanvir.com/gpt-2-attention 在线访问,使用户能够以完全交互的方式检查 GPT-2 所有层和头部的注意力模式。这丰富了模型可解释性工具谱系,可与 Brendan Bycroft 的 LLM Visualization 相媲美,并且可以适配更小、更轻量级的模型(例如 nano-GPT 85k),以提高可访问性和速度。 评论者注意到了该工具的实用性,并请求提供类似可视化/可解释性项目的精选列表。有人建议在比 GPT-2 更轻量的模型上部署该工具,以提高性能和可用性。[外部链接摘要] 一位用户开发了一个交互式可视化工具(访问地址:amanvir.com/gpt-2-attention),它可以渲染 GPT-2 内部的每一个注意力权重矩阵,允许逐层深入探索和分析 Transformer 注意力头的内部运作。社区建议包括将该工具适配到 nano-GPT 等更小的模型以提高可访问性,并提供了类似工作的参考,如 Brendan Bycroft 的 LLM Visualization 和开源的 TensorLens 库。该工具通过实现对大语言模型中注意力模式的直接、细粒度检查,推动了可解释性研究。(原贴: Reddit 链接)
- 一位评论者建议在可视化工具中用 nano-GPT 85k 替换完整的 GPT-2 模型,理由是 nano-GPT 的下载量小得多,因此更容易可视化和交互,使那些希望探索注意力权重而又不想承担完整尺寸模型计算开销的用户更容易上手(参考:https://github.com/karpathy/nanoGPT)。
- 另一个建议针对可视化的粒度:修改可视化中的点颜色通道以反映不同的轴或坐标,这可以更清晰地突出注意力图中的 cross-attention 或特定层的动态。
- 提供了相关可解释性工具的其他参考:用于交互式 Transformer 探索的 Brendan Bycroft’s LLM Visualization,以及提供对模型内部更深层探测的 attentionmech/tensorlens,这表明社区对多样化的 Transformer 可视化方法有着浓厚兴趣。
-
承诺的开源 Grok 2 在哪里? (Score: 186, Comments: 70): 该帖子质疑了在 Grok 2 已经显著落后于新发布的模型(如 DeepSeek V3、即将推出的 Qwen 3 和 Llama 4 Reasoning)的情况下,将其开源的价值。人们担心等到 Grok 2 发布时它已经过时了,并引用了 Grok 1 发布时机不佳的先例。虽然没有讨论 Grok 2 的基准测试或模型规格,但提到了 Grok 3 最近已开放 API,这可能预示着 Grok 2 的开源发布即将到来。 评论中辩论了发布过时的模型是否仍具有研究价值;一些人认为即使是过时的模型(例如,如果 OpenAI 发布 GPT-3.5 的权重)对研究也是有用的,而另一些人则指出 Grok 1 和 2 在发布时并不令人印象深刻,并质疑其整体影响力。类比 Tesla Roadster 等延迟发布的产品,凸显了人们对已宣布发布时间表与实际发布时间表之间差距的怀疑。
- 一位评论者指出,尽管 Grok 1 和 Grok 2 在发布时表现不佳,但 Grok 3 开放 API 代表了一个技术里程碑。该评论者认为,Grok 3 的公开 API 发布是开源 Grok 2 的前提条件,暗示开源工作取决于新版本 Grok 的发布节奏和稳定性。
- 强调了即使是像 GPT-3 或 3.5 这样“过时”的模型,如果开源,仍会引起巨大的研究兴趣,突出了尽管模型迭代和改进迅速,开源发布对研究和开发者社区仍具有价值。
- 评论者指向之前的技术发布模式(例如 Tesla 产品),以表达对 Grok 2 及时开源发布的怀疑,间接引发了对 AI 模型发布周期中错过截止日期以及可能出现“空头支票(vaporware)”的担忧。
{kind=link}
Other AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. OpenAI o3 和 GPT-4o 用户体验与能力
-
o3 在 GeoGuessr 中表现疯狂 (Score: 358, Comments: 64): 该图片展示了一条推文,描述了 GeoGuessr 中一项非凡的壮举:在没有可见标志、Google Street View 或元数据的情况下,纯粹依靠视觉地理特征,从雪景中准确识别出位置(乌兹别克斯坦 Amirsay 山地度假村)。通过山边视图确定了坐标(约 41.50°N, 70.00°E),展示了 AI 地理定位的进步。评论强调了进一步的技术实力,例如在没有地理数据的情况下,从用户截图中正确识别出钻石头山(Diamond Head),并指出 Gemini 2.5 Pro 也显示出类似的地理识别能力。 讨论强调了这些新模型在仅使用视觉线索进行地理定位方面是多么先进,用户对 o3 和 Gemini 2.5 Pro 等模型的历史背景和当前能力都留下了深刻印象。
- 多位用户提供的图像证据显示,o3 这一 AI(可能是提到的多模态模型)能够根据极少的视觉线索,在 GeoGuessr 中准确识别精确的世界位置,即使没有嵌入地理数据——这意味着其具备先进的视觉识别能力。一位用户指出,该模型从个人截图中正确识别了钻石头山,并强调没有任何元数据辅助其猜测,展示了令人印象深刻的推理和泛化能力。
- 另一条评论提到 Google 的 Gemini 2.5 Pro 模型也在这一高度具体的 GeoGuessr 任务中取得了成功,这表明多个 SOTA 多模态模型在现实世界的地理位置识别场景中都达到了卓越的性能。这为模型能力的比较提供了信息,并突显了顶级竞争对手之间的快速进步。
-
o3 在 geoguessr 中表现惊人 (评分: 701, 评论: 91): 该图像展示了一个被称为 ‘o3’ 的 AI,在极少线索的情况下(无标牌、无 Google Street View 覆盖、无可见元数据),准确地对乌兹别克斯坦 Amirsoy 山地度假村的一个极具特定性的雪景进行了地理定位。该帖子强调了这一技术壮举,指出 o3 不仅推断出了国家,还纯粹基于图像中的环境和地理模式识别确定了精确位置。 评论者将 o3 的地理定位能力与人类专家及 Google Image Search 等现有工具进行了比较,对 LLM 和 AI 的模式识别能力表示惊讶。一位用户表示,希望人类认知也能像 LLM 一样,能够掌握庞大的模式和视觉数据关联。
- 一位用户提出了一个技术问题,即 ChatGPT 等模型是否可以访问上传图像中嵌入的 EXIF 元数据,认为 GeoGuessr 中准确的地理位置识别可能是由于提取了图像文件中包含的 GPS 或 geotag 数据,而非纯粹的图像模式识别。
- 讨论对比了 GeoGuessr 模型的表现与 Google Image Search,暗示了 Google 基于图像地理定位的相似性搜索算法的有效性,并建议在 AI 模型与搜索引擎的精确位置猜测能力之间进行基准测试对比。
-
O3 作为商业顾问处于另一个水平。 (评分: 277, 评论: 84): 该帖子详细描述了一位初创公司创始人对 OpenAI 的 O3 模型与 GPT-4.5 等早期 LLM 进行的定性对比,强调了 O3 在商业战略语境下比 GPT-4.5 的中立或讨好倾向更具权威性和指导性的咨询风格。该用户引用了 O3 输出的一个直接计划,该计划建议发布一个最小可行功能(minimum-viable feature)以获取真实数据,然后根据衡量的参与度果断迭代,这与早期模型倾向于无休止生成假设形成鲜明对比。从技术角度看,评论指出 Gemini 会提供“争论性”的反馈,而 O3 展现出一种改进的、较少安抚性、更具专家风范的人格,但也存在限制,例如约 200 行的代码输出上限,以及在给出错误答案时可能表现出的过度自信。 响应者辩论了具有果断(“非安抚型”)人格的 LLM 的价值,指出了 Gemini 的对抗性立场与 O3 的权威指导之间的区别,并提出了关于 O3 代码输出和有时过度自负的专业知识的问题。
- 几位用户将 O3 的性能与其他 LLM 进行了对比,指出其在商业咨询和技术领域的果断性和专业性高于之前的模型,甚至超过了 Gemini 2.5 Pro/Sonnet 3.7。O3 经常提供权威且细致的反馈,但可能需要提示词(prompting)来为非技术用户简化回答。
- 提到了关键的技术限制:O3 目前每次响应的代码输出上限约为 200 行,这可能会阻碍更复杂的编码任务和工作流集成。这被视为习惯于其他模型更大输出量的技术用户所面临的显著退步或障碍。
- 关于模型版本和能力的认知存在混乱:一些用户误认为 O3 在推理和非讨好性响应方面可能优于 O4,质疑 O3 的性能特征(即不太可能讨好用户,更具争论性/教条性)是技术特性还是仅仅是微调的结果。用户强调了在多个模型之间进行的实际 A/B 测试使用情况。
-
o3 无法拼写 strawberry (评分: 155, 评论: 45): 该图像记录了一个失败案例,OpenAI 的 GPT-3.5 Turbo(被称为 “o3”)错误地回答了一个基础事实问题——声称 “strawberry” 一词中只有 2 个 ‘r’,而不是正确的 3 个。附带的 ChatGPT 分享链接和截图记录了模型的直接输出,突出了 LLM 事实幻觉或计数错误的一个具体案例。此外,截图中 UI 缺少通常的 ‘Thinking’ 占位符,表明除了 LLM 的错误外,可能还存在界面或后端 Bug。 几位评论者表示他们无法复现该错误,o3 和较新的 o4-mini 模型都返回了正确答案,这表明该问题可能是间歇性的,或与特定的部署故障有关。一个值得注意的观察是图像中缺少 ‘Thinking’ 模块,这引发了关于模型失败伴随界面或后端异常的猜测。
- 多位用户报告称,O3 模型无法正确拼写 ‘strawberry’ 的问题无法稳定复现;甚至像 o4-mini 这样的较低阶模型也能返回正确答案。视觉证据(例如 这张截图)显示,在典型查询中,正确答案和正常的 “Thinking” 块都会出现,这表明要么是一个罕见的边缘案例 bug,要么是特定会话的问题。
- 有人提到原始用户的输出中缺少 “Thinking” 块,这并非标准行为;这一细节让部分人认为,模型响应过程中可能涉及非典型的 bug 或执行路径。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. 新型 LLM 与 AI 模型基准测试及发布
-
LLM 玩 DOOM II 和其他 19 款 DOS/GB 游戏 (评分: 161, 评论: 45): 该帖子介绍了 VideoGameBench,这是一个全新的基准测试,旨在测试视觉语言模型(如 GPT-4o、Claude Sonnet 3.7、Gemini 2.5 Pro 和 Gemini 2.0 Flash)使用相同提示词完成 20 款实时 DOS/Gameboy 游戏(包括 DOOM II)的能力。结果显示,虽然各模型表现不一,但没有一个模型能通过 DOOM II 的第一关(默认难度),这凸显了当前视觉语言 Agent 在基于像素的控制和实时游戏环境中的显著局限性。 评论者指出,Claude 在实际测试中往往优于其他模型,并讨论了影响视频游戏熟练度的人为因素;有人提出,由于多动作处理和威胁响应能力有限,即使是人类新手也可能表现出与当前 LLM Agent 类似的失败模式。[外部链接摘要] 新基准测试 VideoGameBench (https://vgbench.com/) 通过挑战视觉语言模型完成包括 DOOM II 在内的 20 款实时 DOS 和 Game Boy 游戏来对其进行评估。GPT-4o、Claude Sonnet 3.7、Gemini 2.5 Pro 和 Gemini 2.0 Flash 等领先的 LLM 在 DOOM II 上进行了测试,但均无法通过第一关,这凸显了 LLM 在需要具身认知(embodied cognition)和快速决策的实时闭环交互环境中的当前局限性。
- 一位用户强调,Claude 在实际游戏任务中始终优于其他 LLM,这表明其架构或训练与那些主要在合成基准测试(而非交互式环境)中表现出色的模型相比,具有切实的优势。
- 另一位用户指出,LLM 表现出的新手级游戏操作让人联想到不熟悉游戏的人类行为——例如有限的按键操作或对威胁的反应迟钝——这强调了在没有具身学习(embodied learning)的情况下,纯粹从文本或数据中泛化运动/交互技能的难度。
- 关于 AI 实现游戏领域 AGI 所需条件的讨论指出,成功击败极具挑战性的复杂游戏可能是一个关键里程碑,这将推动 AI 超越排行榜基准,向整体、可迁移的推理和适应能力迈进。
-
Seedream 3.0,一款新型 AI 图像生成器,在 Artificial Analysis 竞技场排名第一(与 4o 并列)。击败了 Imagen-3、Reve Halfmoon, Recraft (评分: 112, 评论: 21): 该图片展示了来自 Artificial Analysis 竞技场的最新 AI 图像生成模型排名,其中 Seedream 3.0(由 ByteDance Seed 开发)与 OpenAI 的 GPT-4o 并列第一,两者的 Arena ELO 评分均处于顶尖水平(约 1155-1156),超过了 Imagen-3 和 Reve Halfmoon 等强劲对手。该表格强调了 Seedream 3.0 的快速进步,以及通过大规模真人偏好评估衡量的竞争性能。社区讨论集中在对可用性的请求上,开发团队分享了官方技术细节和文档(此处),排行榜透明度可通过 Artificial Analysis 查看。 大多数技术评论者对 Seedream 3.0 的广泛用户访问权限感兴趣,理由是目前缺乏公开 Demo,并强调了独立基准测试和透明方法论在评估模型质量方面的重要性。
- 多位评论者观察到 Artificial Analysis 竞技场基准测试 (https://artificialanalysis.ai/text-to-image/arena?tab=leaderboard) 已经过时,无法反映当前的模型能力,特别是忽略了 GPT-4o 和 Sora 等模型在提示词理解和 img2img 功能方面的显著优势。有人指出,Seedream 3.0 虽然在竞技场中并列第一,但与领先的同行相比,其生成结果风格平淡,且在处理复杂提示词时表现吃力。
- 提供了 Seedream 3.0 技术演示 (https://team.doubao.com/en/tech/seedream3_0) 和 AI 搜索演示视频 (https://www.youtube.com/watch?v=Q6QbaK57f5E) 的直接链接,这可以为那些寻求基准测试结果之外的深入细节的人提供有关模型架构、工作流和独特功能的更多技术见解。
{kind=link}
3. AI 行业基础设施与定价更新
-
arXiv moving from Cornell servers to Google Cloud (Score: 122, Comments: 14): arXiv 正在将其基础设施从 Cornell 管理的本地服务器迁移到 Google Cloud Platform (GCP),同时进行重大的代码库重写。此举旨在实现 arXiv 技术栈的现代化,并利用云原生服务,但也引发了对潜在供应商锁定(vendor lock-in)以及同步进行重大变更带来的运营风险的担忧。评论者指出,arXiv 已经在使用外部分发(例如 Cloudflare R2),且备份或扩展等优势并非 GCP 所独有。 技术评论者压倒性地警告不要将代码重写与云迁移结合在一起,认为这会增加项目失败的风险。关于使用 GCP 托管服务与容器化的可移植性优势之间的权衡存在讨论,其中一条评论对必要性表示怀疑,因为 arXiv 已有现有的外部分发机制。[外部链接摘要] arXiv 招聘页面 (https://info.arxiv.org/hiring/index.html) 详细说明了为 arXiv 电子预印本库贡献角色的当前空缺和招聘信息,这是一个由多个基金会资助并托管在 Cornell University 的著名预印本服务器。该页面通常包括软件开发(如 Software Engineer 和 DevOps Specialist)的技术角色,专注于平台基础设施和服务的维护、改进和扩展。职位要求具备软件工程、DevOps 实践方面的专业知识,并致力于支持大规模的开放科学交流。
- 一位用户指出了一项重大技术风险:arXiv 计划同时将从零开始的重写与从本地到 Google Cloud 的迁移结合起来。在系统工程中,这通常被认为是一种糟糕的做法,因为复杂的迁移和重写在不分阶段进行时会引入许多故障点,从而产生复合风险。
- 人们担心 arXiv 会与 Google Cloud Platform (GCP) 过度耦合,这将使未来的可移植性和多云策略变得更加困难。评论者建议在云迁移之前将容器化作为最佳实践,以便在任何云提供商上轻松部署,并指出 arXiv 已经通过 Cloudflare R2 分发批量数据,这意味着已经在利用冗余的云服务。
- 讨论还将其与其他主要的存档转型进行了类比,特别是 dejanews 被 Google 收购及其随后转变为一个不够开放、限制更多的系统 (Google Groups)。这突显了在控制权集中在大型企业云提供商之下时,arXiv 的开放性和长期可访问性所面临的风险。
-
OpenAI Introduces “Flex” Pricing: Now Half the Price (Score: 139, Comments: 41): OpenAI 宣布了一个新的 “Flex” 定价层级,提供 50% 的 API 使用成本减免,代价是在高需求期间响应可能会变慢、排队或受到限制。这与之前的 Batch API 不同,后者承诺在“最多 24 小时”内(通常快得多)提供结果并享受类似的折扣,这引发了开发者关于 “Flex” 是否会取代 Batch API 的疑问。 技术讨论集中在响应延迟非关键的使用场景,一些用户询问 “Flex” 与现有 Batch API 之间的功能和性能差异,特别是关于排队时间和工作流影响。[外部链接摘要] OpenAI 的 Flex 处理 是一个测试版定价层级,通过降低请求优先级,为 o3 和 o4-mini 模型提供 50% 的每 Token 成本减免,使其适用于后台、非生产或延迟容忍型工作负载。Flex 使用简单的同步 API 参数 (service_tier:”flex”),保留了流式传输/函数支持,但缺乏固定的 SLA,并且在高峰时段会面临更大的响应时间波动和排队——这与通过离线文件提交优化大规模任务并拥有独立配额的 Batch API 不同。现在,较低使用层级也需要进行身份验证才能访问某些功能,此次更新正值 AI API 市场竞争压力加剧、开发者成本降低之际。原文链接
- 用户要求详细说明新的 Flex 定价与之前可用的 Batched API 之间的对比。他们指出 Batched API 承诺在“最多 24 小时”内返回结果,但实际上返回响应的速度一直快得多(通常在 1-10 分钟内,最长 1 小时),并伴有 50% 的折扣——这引发了一个技术问题:Flex 在 SLA 和架构实现上是否以及如何取代 Batched API。
- 另一位用户询问 Flex API 是否存在任何真正的异步工作流支持:具体而言,该 API 是否允许 request-tickets 模式,即客户端可以提交请求、获取凭据(ticket)并在稍后获取结果(而不是保持持久的开放连接),这对于某些用例来说是一个重要的架构考虑,特别是为了避免保持连接开启的缺点。
- 还有一个关于 Flex 定价和基于 token 的计费如何与现有的每月 20 美元的 OpenAI 个人订阅互动的问题,这反映了技术用户需要澄清 Flex 对不同用户层级的意义,以及它如何影响不同使用水平的整体成本结构。
AI Discord Recap
由 Gemini 2.5 Flash Preview 生成的摘要之摘要之摘要
主题 1. 新模型入场:Gemini, Grok 和 Dayhush 引发竞争
- Grok 3 Mini 可能表现超预期! 讨论表明 Grok 3 Mini 在与 Gemini 2.5 Pro 的竞争中表现出色,尤其是在 tool use 方面,尽管有时在调用工具时过于激进。一位用户指出其输出成本显著降低,称 Grok 3 Mini 的输出 token 价格仅为 2.5 flash thinking 的 1/7。
- Dayhush 撼动编程模型等级制度! 成员们正在评估 Dayhush 作为 Nightwhisper 潜在继任者的表现,发现它在编程和网页设计方面更胜一筹,在实际任务中可能超越 3.7 Sonnet。用户分享了生成复杂任务代码(如“制作宝可梦游戏”)的 prompt 以对比输出结果。
- Gemini 家族壮大:Advanced 推送困扰与 Ultra 传闻! Android 用户对 Gemini Advanced 的推送表示沮丧,称尽管符合标准并关注了官方公告,但仍缺少 deep research 模型等功能,且 UI 存在不一致。同时,一名 Google 员工证实了关于“Gemini Coder”模型的传闻,并预期 Gemini Ultra 将比 Pro 实现更大规模的改进。
主题 2. 框架深度解析:Mojo 指针与 tinygrad Bug
- Mojo 的
Dict.get_ptr竟然在偷偷复制值! 一位用户发现,在 Mojo 中获取Dict值的指针会意外触发拷贝和移动构造函数,详见此代码片段。一个 PR 正尝试修复这个追溯到get_ptr函数中特定行的拷贝问题。 - 移动 Mojo 变长参数(Variadics)需要
UnsafePointer的复杂操作! 在 Mojo 中从变长参数包(variadic pack)中提取值需要使用UnsafePointer并显式禁用析构函数(__disable_del args),以防止原始元素的意外拷贝。用户担心如果开发者在这些场景中不仔细管理资源,可能会导致内存泄漏。 - Tinygrad 的 Rockchip Beam Search 崩溃了! 在 Rockchip 3588 上运行
beam=1/2时,使用 examples/benchmark_onnx.py 的基准测试代码会导致tinygrad/engine/search.py出现IndexError崩溃。一位成员还怀疑模式匹配器(pattern matcher)中存在潜在 Bug,如果基础形状对齐,可能会忽略转置后的源。
主题 3. 实用 AI 工具:从财务解析到 Agent 聊天
- Perplexity 聊天机器人登陆 Telegram! Perplexity 推出了 Telegram bot,允许用户直接在群聊和私聊中获取带有来源的实时回答;在此查找。他们还在新的定价方案中取消了引用 token 费用,以实现更可预测的成本。
- LlamaIndex Agent 学会使用 Google 的 A2A 协议进行对话! LlamaIndex 现在支持 Google 的 Agent2Agent (A2A) 协议,这是一个用于安全 AI Agent 通信的开放标准,无论来源如何。讨论中提到了 llama-deploy 本身是否需要实现 A2A 才能正常工作。
- Concall Parser 解决金融数据的 PDF 混乱问题! 一位成员在 PyPI 上发布了 concall-parser,这是一个 Python NLP 工具,旨在高效地从财报电话会议报告中提取结构化数据。开发者强调 PDF 中的数据差异(PDF 很难处理得完全正确)是主要的开发障碍,需要大量的 regex 和测试工作。
主题 4. AI 框架集成与特性:LlamaIndex, Perplexity, Modular
- LlamaIndex 开箱即用支持 Gemini 2.5 Flash! LlamaIndex 现在支持 Gemini 2.5 flash,无需用户进行任何升级;只需调用新的模型名称即可工作,如此示例所示。这为 LlamaIndex 用户提供了立即访问新模型能力的机会。
- Perplexity API 新增图片上传与日期过滤器! Perplexity API 添加了图片上传功能,用于将图片集成到 Sonar 搜索中,详见此指南。新的日期范围过滤器也已上线,允许用户根据此指南将搜索结果缩小到特定时间段。
- Modular 举办 Mojo 见面会:GPU 优化提上日程! Modular 将于下周在其位于 加州洛斯阿图斯 (Los Altos, CA) 的总部举办线下见面会,并提供线上选项;在此预约 (RSVP)。一场名为 making GPUs go brrr 的演讲将涵盖使用 Mojo & MAX 优化 GPU 性能的内容。
主题 5. 解码 AI “思考”:架构、推理与入门指南的力量
- AlphaGo vs. LLM “思考”:截然不同的物种! 讨论对比了 Alpha* 系统和 Transformer LLM 的架构,指出 LLM 无法像 Alpha* 那样训练,也无法以受益于此类训练的方式运行,称它们截然不同。一位用户指出 LLM 的思考模式 (Thinking Mode) 是一种原始的策略搜索,而不是带有世界模型的系统化过程。
- Cohere Command A 的推理能力引发讨论! 一位成员质疑 Command A 是否具备真正的推理能力,或者其性能是否完全源于其 tokenizer。该问题尚未得到解答,使得 Command A “推理”的本质仍悬而未决。
- DSPy 社区获得推理模型入门指南! 一位成员分享了一份通俗易懂的推理模型入门指南,题为《当我们说“思考”时,我们指的是什么》(What We Mean When We Say Think),面向普通受众。该指南旨在简化与推理模型相关的复杂概念,使其更易于理解。
第 1 部分:高层级 Discord 摘要
Perplexity AI Discord
- Telegram 上的 Plex:Perplexity 现在可以通过 Telegram 机器人访问,在群聊和私聊中提供带来源的实时回答;点击此处查看。
- 这一增强功能与其在移动端推出的 GPT 4.1 和 Perplexity Travel 相呼应,详见其 更新日志。
- LAN Party 依然盛行:成员们分享了过去 LAN Party 的故事,讨论了搬运台式机去玩 Doom 和 Quake 等经典游戏的挑战。
- 一位成员回忆起穿越 阿联酋 去玩 CS:GO 的经历,提到电线管理虽然混乱但很有趣,开玩笑说虽然一团糟,但起码能用。
- Gemini Advanced 用户感到愤怒:尽管符合 官方公告 中列出的要求,Android 用户仍报告了 Gemini Advanced 功能推送的问题。
- 一位尝试了“所有方法”的用户报告称功能缺失且 UI 不一致,计划将“彻底清除数据(full wipe)”作为最后手段。
- GPT-4o 对阵 Gemini:模型肉搏战!:成员们辩论了 GPT-4o 与 Gemini 2.5 Pro 在生产力方面的优劣,一位成员因其 高上下文限制(high context limit) 而更倾向于在主要业余项目中使用 Gemini。
- 几位用户批评了 ChatGPT 最近过于奉承且表现不一致的倾向,其中一人调侃道:这就像是……Elon Musk 会为自己编写的代码。
- Perplexity 取消引用 Token 费用:Perplexity 转向了新的 定价方案,取消了引用 Token 费用以使定价更具可预测性,详见其 定价页面。
- 他们还宣布了与 Devpost 合作的首场 Hackathon,邀请社区参与,详情见 此处。
LMArena Discord
- Dayhush 废黜 Nightwhisper?:成员们发现 Dayhush 在编程和网页设计方面优于 Nightwhisper,表现可能超过 3.7 Sonnet。
- 用户分享了如 “创建宝可梦游戏” 等视觉效果惊人的 Prompt,让模型生成代码并对比输出结果。
- Grok 3 Mini 挑战 Gemini 2.5 Pro:Grok 3 Mini 与 Gemini 2.5 Pro 具有竞争关系,特别是在工具使用(tool use)方面,但可能在工具调用(tool calling)上过于激进。
- 一位用户指出,Grok 3 Mini 的 输出 Token 价格仅为 2.5 flash thinking 的 1/7,使其成为一个极具经济吸引力的选择。
- Polymarket 对 Arena 的影响?:讨论围绕 Polymarket 上潜在的 市场操纵 展开,这可能会影响 LM Arena 中的模型评估,特别是关于 o3 或 o4-mini 超越 2.5 Pro 的赌注。
- 有人担心,与其他模型相比,为 o3 操纵 Arena 排名的获利空间。
- AlphaGo 架构对比 LLM:成员们讨论了截然不同的架构,认为 Transformer LLM 不能像 Alpha* 那样训练,即使可以,它的运行方式也无法利用这种训练,并提到两者 差异巨大。
- 与 LLM 中的大多数事物一样,思考模式(Thinking Mode) 只是策略搜索(policy search)的一种原始、退化的变形,让 LLM 有几十次尝试机会来获得更好的解决方案,但它既不系统也不详尽,也没有世界模型(world model)或持久状态来进行内部模拟或探测。
- Gemini Ultra 即将来临:关于新款 Google 编程模型(可能命名为 “Gemini Coder”)的传闻已得到 Google 员工的证实,预计 Gemini Ultra 将在 Pro 的基础上实现规模化改进。
- 猜测围绕理想的模型大小以及模型在潜空间(latent space)中进行推理的潜力展开,以增强效率并模拟类人思考,大家也对 Gemini Ultra 何时发布充满好奇。
Modular (Mojo 🔥) Discord
- Modular 在总部举办 Mojo Meetup:Modular 下周将在其位于加利福尼亚州洛斯阿托斯 (Los Altos) 的总部举办一场线下见面会,同时也提供远程参加方式,在此预约。
- 一位成员将发表关于使用 Mojo & MAX 让 GPU 飞速运转 (go brrr) 的演讲,分享如何利用 Mojo 和 Modular 的 MAX 框架优化 GPU 性能。
Dict.get_ptr产生意外的值拷贝!:一位用户发现,在 Mojo 中获取Dict值的指针会意外地触发拷贝构造函数和移动构造函数,如此代码片段所示。- 官方已提交一个 PR 来解决这个拷贝问题,该问题被追溯到
get_ptr函数内部的一行特定代码。
- 官方已提交一个 PR 来解决这个拷贝问题,该问题被追溯到
- 移动 Variadic packs 需要
UnsafePointer:在 Mojo 中从 Variadic pack 移动值需要使用UnsafePointer并禁用 destructor,以避免不必要的拷贝。- 一位成员展示了在
take_args函数中使用__disable_del args来防止在原始元素上调用 destructor,但也引发了如果处理不当可能导致内存泄漏的担忧。
- 一位成员展示了在
- 矩阵并行化:起步较慢:一位成员观察到,在处理小矩阵时,并行化的矩阵操作最初表现不如 for 循环,这是由于 warmup 期间的开销导致的,但在随后的步骤中能达到相当的性能。
- 目前尚不确定这种行为是否符合预期,他们正在请求反馈,以确认其基准测试是否存在问题。
LlamaIndex Discord
- LlamaIndex 支持 Agent2Agent 协议:LlamaIndex 现在支持 Agent2Agent (A2A) 协议,这是由 Google 推出的开放标准,旨在实现安全的 AI Agent 通信,无论其来源如何。
- 成员们正在讨论 llama-deploy 是否需要实现 A2A 协议才能正常运行。
- Gemini 2.5 Flash 开箱即用:LlamaIndex 已原生支持 Gemini 2.5 flash;用户无需任何升级即可直接调用新的模型名称,如本示例所示。
- 这一集成让 LlamaIndex 用户能够立即访问 Gemini 2.5 flash。
- 用于财务分析的 LlamaExtract:一个全栈 JavaScript Web 应用使用 LlamaExtract 进行财务分析,通过定义可重用的 Schema 从复杂文档中提取结构化数据,如本示例所示。
- 该应用展示了 LlamaExtract 在金融领域的实际应用。
- LlamaIndex 展示 Google Cloud 集成:在 Google Cloud Next 2025 上,LlamaIndex 重点展示了与 Google Cloud 数据库的集成,强调构建用于多步研究和报告生成的知识 Agent,并在多 Agent 系统中进行了演示。
- 重点在于利用 Google Cloud 基础设施实现高级 AI 工作流。
- 用户反馈 LlamaIndex 更新后出现 Prompt 问题:一位用户报告称,在将 LlamaIndex 更新以使用新的 OpenAI models 后,Prompt 的回答和引用出现了问题。
- 一位成员澄清说代码库没有变动,并建议新模型可能需要不同的 Prompt。
Cohere Discord
- 分阶段 AI 模型训练:行业规范?:一位公会成员询问 AI 模型 开发是否通常遵循分阶段训练过程,例如 Experimental (20-50%)、Preview (50-70%) 和 Stable (100%)。
- 该问题在频道中未得到解答,因此尚不清楚这是否是一种常见模式。
- Command A:推理引擎还是 Tokenization 技巧?:一名成员询问 Command A 是否具备真正的推理能力,或者其能力仅仅是 Tokenizer 的功劳。
- 未收到任何回复,使得 Command A 的推理能力问题悬而未决。
- FP8 在 H100s 上遭遇适配失败:一位公会成员声称 FP8 无法适配 2 个 H100s,但未提供更多细节。
- 目前尚不清楚其具体含义,但可能与内存或计算限制有关。
- Concall Parser 在 PyPI 上线:一名成员宣布发布了他们的第一个 Python 包 concall-parser,该工具作为一个 NLP pipeline tool,能够高效地从财报电话会议报告 (earnings call reports) 中提取结构化信息。
- 据开发者称,构建 concall-parser 让他们在 regexes 和测试真实世界 NLP pipelines 领域学到了很多。
- PDF 数据差异:NLP 的头号公敌:concall-parser 的开发者指出 data variation(PDF 很难处理好)是构建该包过程中的一个重大挑战。
- 他们暗示这个问题可能对他们的 NLP 流水线开发构成了显著阻碍。
Nomic.ai (GPT4All) Discord
- GPT4All 的 LinkedIn 状态被忽略:一位成员在询问状态并请求 speech recognition mode 后,感觉在 LinkedIn 上被 GPT4All 忽略了。
- 针对该询问,目前没有进一步的讨论或回复。
- 语音识别脚本分享:一位成员分享了语音识别脚本的链接 (rcd-llm-speech-single-input.sh),建议安装并绑定到鼠标按键。
- 该建议未收到其他成员的回复或进一步参与。
- MCP Server 配置疑问:一位成员询问如何在 GPT4All 上配置 MCP server,寻求对该过程的澄清。
- 这个问题在频道内没有得到任何回应或进一步讨论。
tinygrad (George Hotz) Discord
- Tinygrad 的 Pattern Matcher 面临 Bug 审查:一位成员怀疑 Tinygrad 的 Pattern Matcher 存在 Bug,如果 base shapes 匹配,它可能会忽略 source view,这可能导致错误的结果,特别是在处理 transposed sources 时。
- 当其中一个 source 存在 transpose 时,Pattern Matcher 可能会遗漏,从而引发该问题。
- Rockchip 3588 Beam Search 崩溃:一位成员报告称,在运行 examples/benchmark_onnx.py 的基准测试代码时,在 Rockchip 3588 上使用
beam=1/2会导致崩溃。- 崩溃表现为在 buffer allocation 期间,
tinygrad/engine/search.py中出现IndexError: list assignment index out of range,从而中断了 Beam Search 功能。
- 崩溃表现为在 buffer allocation 期间,
DSPy Discord
- 推理模型入门指南发布:一位成员分享了一份面向普通读者的推理模型入门指南,题为 What We Mean When We Say Think。
- 该指南旨在通过以通俗易懂的方式分解复杂概念来解释 reasoning models(推理模型)。
- 推理模型的通俗解释:该指南以易于理解的方式分解了与 reasoning models 相关的复杂概念,使更广泛的受众更容易理解。
- 这种解释旨在避免技术术语,专注于核心原则和针对该领域新手的实际应用。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长期保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期保持沉默,请告知我们,我们将将其移除。
Codeium (Windsurf) Discord 没有新消息。如果该频道长期保持沉默,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长期保持沉默,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长期保持沉默,请告知我们,我们将将其移除。
第二部分:按频道分类的详细摘要和链接
完整的频道明细已在邮件中截断。
如果你喜欢 AInews,请分享给朋友!提前感谢!