AI News
Gemini 2.5 Pro/Flash 正式发布 (GA),2.5 Flash-Lite 处于预览阶段。
Gemini 2.5 模型现已正式发布,包括全新的 Gemini 2.5 Flash-Lite、Flash、Pro 和 Ultra 版本。这些模型采用了具有原生多模态支持的稀疏混合专家(MoE) Transformer 架构。一份详尽的 30 页技术报告重点展示了 Gemini Plays Pokemon 所体现出的卓越长程规划能力。
LiveCodeBench-Pro 基准测试显示,前沿大模型在应对困难编程问题时仍显吃力;与此同时,月之暗面(Moonshot AI)开源了 Kimi-Dev-72B,在 SWE-bench Verified 上取得了目前最顶尖(state-of-the-art)的成绩。Nanonets-OCR-s、II-Medical-8B-1706 和 Jan-nano 等小型专业化模型表现出了极具竞争力的性能,这再次证明了模型并非越大越好。DeepSeek-r1 在 WebDev Arena 中并列第一,MiniMax-M1 则在长文本推理方面树立了新标准。此外,可灵 AI(Kling AI)展示了其视频生成能力。
Gemini gemini gemini。读者可能也会喜欢我们的 Karpathy @ Startup School 总结。
2025年6月16日至6月17日的 AI 新闻。我们为您检查了 9 个 subreddits、449 个 Twitter 账号和 29 个 Discord 社区(219 个频道,6626 条消息)。预计节省阅读时间(以 200wpm 计算):547 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 方式展示了所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
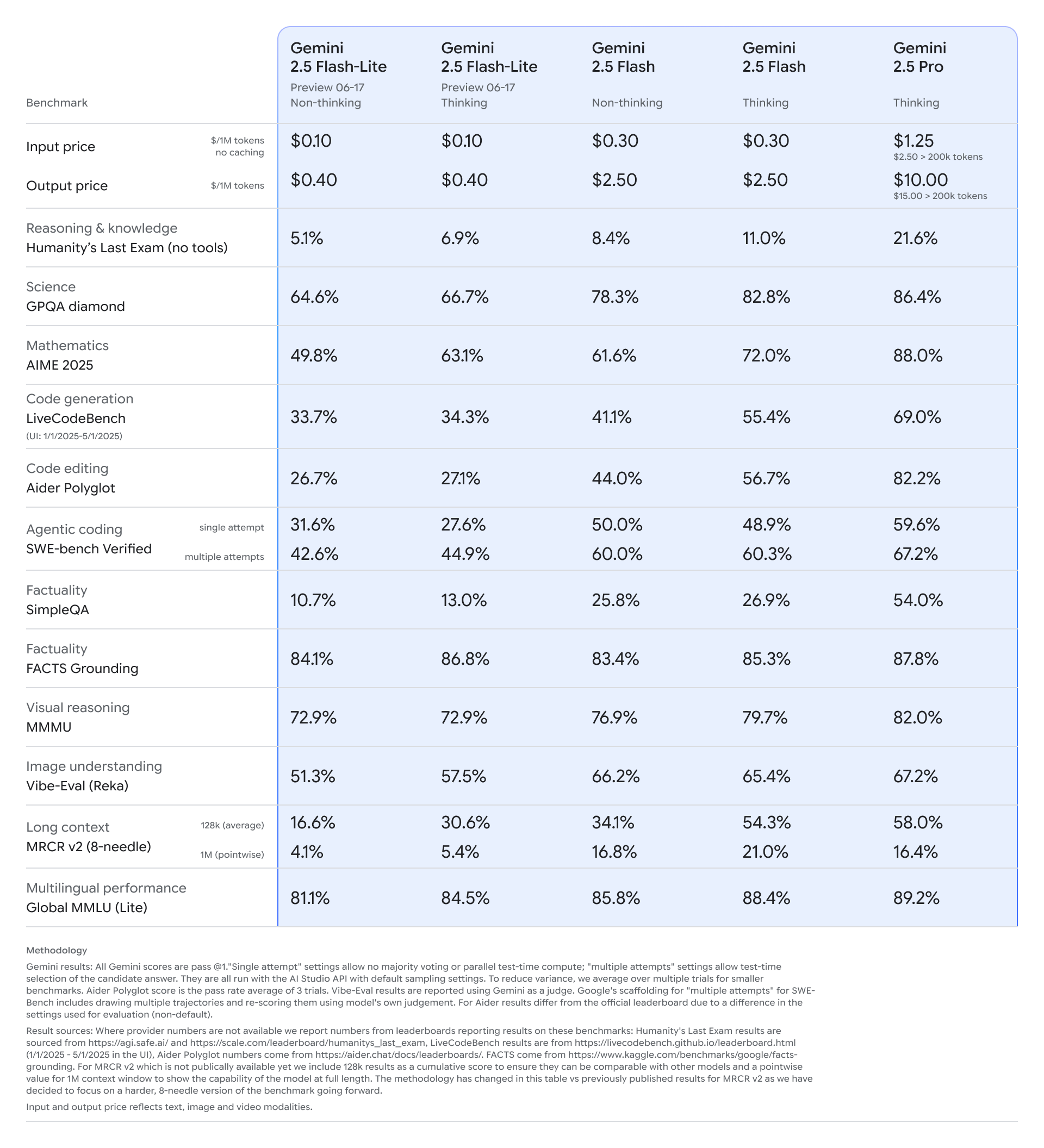
正如在 Google I/O 之前的过去 3 个月以及 AIE World’s Fair 上多次预告的那样,Gemini 产品负责人 Tulsee Doshi 终于宣布 2.5 模型现已全面开放(GA)(即不再带有 “preview” 或日期标签)。
Gemini 2.5 现在还附带了一份 30 页的技术报告,其中包含一些关于 evals 的显著细节,以及极少量的关于 architecture 的内容:
2.5 Flash Lite 这一廉价且快速的模型目前处于 preview 阶段,Oriol Vinyals 强调了超过 400 tok/s 的模拟(simulative)可能性。
AI Twitter 总结
模型发布、基准测试与性能
- Gemini 2.5 系列发布:@OriolVinyalsML 介绍了 Gemini 2.5 系列,重点推介了新的 Gemini 2.5 Flash-Lite 模型,强调其速度能够开启如概念性 Neural OS 这样的新用例。@demishassabis 对更多用户尝试这些模型表示兴奋。官方系列包括 Gemini 2.5 Pro 和 Flash(稳定版),以及新的 Flash-Lite 和 Ultra(预览版),正如 @OfficialLoganK 所指出的。根据 @_philschmid 的说法,这些模型是具有原生多模态支持的稀疏 Mixture-of-Experts (MoE) transformers。发布了一份技术报告,@swyx 指出其中详细描述了一个完全自主的 Gemini Plays Pokemon 运行,其完成游戏的时间仅为原始时间的一半,展示了令人印象深刻的长程规划能力。
- LLM 在 LiveCodeBench-Pro 上的编程表现:一个新的基准测试 LiveCodeBench-Pro 显示,即使是顶尖的前沿 LLM 在 Hard problems(难题)上的得分也为 0%,正如 @sainingxie 所分享的。这被描述为“对于 LLM 编程能力的坏消息”,尽管 @scaling01 指出,仅花费 10 美分就能达到 98.5th percentile(第 98.5 百分位)仍然是一项了不起的成就。
- Kimi-Dev-72B 发布:Moonshot AI 开源了 Kimi-Dev-72B,它在 SWE-bench Verified 上达到了 60.4% 的业界领先水平,正如 @scaling01 所分享。然而,@gneubig 指出,当模型在不同的测试框架中评估时,准确率下降了 43%,凸显了 agentic(智能体化)与 non-agentic(非智能体化)评估方法之间的差异。
- 专业化与小型模型:许多更小、更专业的模型已经发布,正如 @ClementDelangue 所言,这强调了“大并不总是更好”的趋势。发布内容包括:Nanonets-OCR-s,一个能够理解上下文和语义结构的开源 OCR 模型;II-Medical-8B-1706,其表现优于 Google 的 MedGemma 27B;以及 Jan-nano,一个使用 MCP 后得分超过 DeepSeek-v3-671B 的 4B 模型。
- DeepSeek-r1 与 MiniMax-M1:新的 DeepSeek-r1 (0528) 模型在 WebDev Arena 中并列第一,追平了 Claude Opus 4。此外,MiniMax 开源了 MiniMax-M1,这是一款在长文本推理方面树立了新标准的新型 LLM。
- Kling AI 视频生成:Kling AI 通过多个视频展示了其能力,包括吉卜力风格的游戏动画和一段展示其新音效功能的 ASMR 视频。用户注意到角色动作的细微差别是叙事的关键特征。
AI Agents、工具与框架
- Sakana AI 的 ALE-Agent 与 ALE-Bench:@SakanaAILabs 推出了 ALE-Bench,这是一个与 AtCoder 合作开发的、专注于硬核 NP-hard 优化问题的全新编程基准测试。他们的 Agent —— ALE-Agent 参加了一场 AtCoder 实时竞赛,并在 1,000 名人类参赛者中获得了 第 21 名(前 2%),正如 @hardmaru 所强调的那样。
- 多 Agent 系统与 RAG:@jerryjliu0 分享了一个关于使用 LlamaIndex.TS 构建多 Agent 旅行规划器的 Microsoft 教程,该系统允许 Agent 在共享完整上下文的情况下进行任务交接。@hwchase17 也分享了来自 11x 的帖子,内容是关于使用完整的 LangGraph 技术栈重构其 Agent。
- OpenAI 产品更新:@gdb 宣布,现在所有人都可以通过在 WhatsApp 中给 1-800-CHATGPT 发消息来使用 ChatGPT 图像生成 功能。团队也在扩张,并呼吁开发者加入 Codex 团队。
- 开源工具:OpenHands 发布了一个全新的、易于安装的 CLI,可在标准开发环境中运行。对于 JAX 用户,@fchollet 指出 KerasHub 现在支持从 HuggingFace 加载、微调和量化模型。
- Agent 驱动的视频生成:@fabianstelzer 展示了在 Glif 上使用 Agent 结合 Flux Ultra 和 Kling 2.1 生成更长视频的过程,并暗示创作权将从制作电影转向创建能够制作电影的 Agent。
Infrastructure, Hardware, and Efficiency
- Groq 与 Hugging Face 集成:@GroqInc 宣布与 Hugging Face 进行重大集成,为 HF Playground 和 API 带来极速推理。此举被视为挑战老牌云服务商的激进策略。
- 在华为 CloudMatrix384 上部署 LLM:@arankomatsuzaki 分享了 华为 CloudMatrix384 的细节,该平台集成了 384 颗 Ascend 910C NPU。对于 DeepSeek-R1 等模型,它实现了每颗 NPU 2k tokens/s 的解码速度,并针对大规模 MoE 和分布式 KV cache 进行了优化。
- Python 的 “nogil” 构建:@charliermarsh 宣布 Python 指导委员会已投票决定在 Python 3.14 中移除自由线程(“nogil”)构建的“实验性”标签。
- 向量数据库工具:@qdrant_engine 发布了一个全新的开源 CLI 工具,用于在 Qdrant 实例之间以及从其他向量数据库流式传输向量,从而实现无停机的实时、可恢复迁移。
- 关于本地 OpenAI 模型的推测:继 Sam Altman 发表关于“本地”可运行模型的评论后,@Teknium1 推测该模型必须非常小,才能在显存 ≤12GB 的消费级显卡上运行,不过随后指出,对于拥有统一内存的 Mac,模型可以更大。
Research and New Techniques
- 扩散语言模型 (Diffusion Language Models):@sedielem 重点介绍了来自 ICML 2025 的论文 “The Diffusion Duality”,该论文揭示了连续扩散模型与离散扩散模型之间的联系,使得诸如一致性蒸馏 (consistency distillation) 之类的技术能够转移到离散设置中。
- 重新思考 LLM 评估:@corbtt 发表了一个激进观点,认为在当前的 token 价格下,你应该始终要求 LLM-as-judge 先解释其思维链 (Chain-of-Thought),以便更容易进行调试。同样地,@goodside 发布了一个复杂的推理挑战,以测试模型在简单模式匹配之外的能力。
- 多语言分词器 (Multilingual Tokenizers):由 @sarahookr 分享的 Cohere Labs 的工作表明,覆盖范围不仅限于主要语言的“通用”分词器能显著提高多语言任务的下游性能。
- LLM 的复杂系统视角:@MelMitchell1 分享了与 David 和 Jessica Krakauer 合著的新论文,题为 “Large Language Models & Emergence: A Complex Systems Perspective”,该论文认为“涌现 (emergence)”等概念经常被误用,并提供了一个更严谨的框架。
- 合成数据的受控人在环 (Human-in-the-Loop, HITL):@TheTuringPost 详细介绍了 HITL 如何通过验证、标注优化和 RLHF 在锚定合成数据方面发挥至关重要的作用。
行业新闻、评论与地缘政治
- John Carmack 与游戏历史:@ID_AA_Carmack 分享了一段视频,内容是经典游戏 《雷神之锤》(Quake) 入选 斯特朗博物馆世界电子游戏名人堂 (Strong Museum’s World Video Game Hall of Fame)。
- AI 人才大战:@Yuchenj_UW 转述了 Sam Altman 的评论,称 Meta 正提供 1 亿美元的入职奖金 来吸引 OpenAI 的员工,他声称这不是建立优秀文化的方式。
- AI 时代的学习与出版:@Yuchenj_UW 反思了一位康奈尔大学计算机科学实习生如何使用 ChatGPT 完成所有作业并为期末考试突击,表达了对在 LLM 出现之前学习计算机科学的感激。在类似的情绪中,@jxmnop 鼓励研究人员在 arXiv 上发表他们的工作,并指出上周发布了 2000 多篇 AI 论文,最坏的情况也不过是没人注意到。
- Mary Meeker 的 AI 报告:@DeepLearningAI 分享了 Mary Meeker 自 2019 年以来的首份科技市场调查,这份 340 页的报告 认为 AI 的采用和资本支出正在催生创纪录的机遇和重大风险,核心观点是吸引到最优秀开发者的组织将会获胜。
- Generalist AI 成立:@peteflorence 宣布成立 Generalist AI,这是他离开 Google DeepMind 后一直在筹备的新公司,使命是让通用机器人成为现实。该公司得到了 @sparkcapital 的支持。
幽默/迷因
- 政治讽刺:@zacharynado 分享了一条推文,指出 DOGE 组织向一家机构施压,要求雇用一名来自 Palantir 的 21 岁前实习生。他转发的另一条推文嘲讽了 Cybertruck 车主。
- 麦肯锡报告:一份推荐 Grok-1 和 GPT-3.5 Turbo 的 2025 年麦肯锡报告遭到广泛嘲笑,@giffmana 发帖称 “> 像麦肯锡一样 💀”。
- AI 与宗教:@code_star 发帖称:“用我那青年牧师的口吻说:‘是的,ChatGPT 很酷,但你知道还有谁在中东沙漠里训练了四十个昼夜吗?’”
- Gemini 的隐藏信息:@jeremyphoward 转发的一条推文开玩笑说:“读一下 Gemini 贡献者名单中每个名字的首字母”。
- 编程梗:@DeepLearningAI 分享了一个关于现实与预期的经典编程梗。
AI Reddit 摘要
/r/LocalLlama 摘要
1. 本地/开源 LLM 装备与日常使用
- 已完成的本地 LLM 装备 (Score: 283, Comments: 99): 用户展示了一台高端本地 LLM (Large Language Model) 计算装备,配置包括 4x RTX 3090 GPU、Threadripper 3945wx 12 核 CPU、256GB DDR4-3200 RAM 以及 MoRa 420 外部散热器,全部装入经典的 Silverstone Raven RV-02 ATX 机箱中。该配置强调了性能(值得注意的是,在外部散热器冷却下,满载时
GPU temps at 57C)和紧凑性,克服了多 GPU 热管理、供电(Seasonic Prime 2200W PSU)以及旧款机箱风道等显著挑战。 热门评论大多比较轻松,一些人认可了外部散热器的规模,以及该配置如何为“AI 寒冬”做好准备。没有重大的技术批评,也没有关于特定瓶颈、散热方案或 LLM 特定工作流集成的讨论。- 有用户索要该配置的 Benchmark 数据,表示对推理速度、训练吞吐量或功耗等定量指标感兴趣。分享这些 Benchmark 将有助于社区评估该装备在实际工作负载中的真实 LLM 性能。
- 另一位用户特别指出了 NVLink 的使用,这表明该配置可能利用了多个高端 NVIDIA GPU 互联,以增加显存带宽并加快 GPU 间的通信,这对于大规模训练 Large Language Models 至关重要。
- 谁在真正日常且主要地运行本地或开源模型? (Score: 110, Comments: 113): 该帖子询问了将本地或开源 LLM 作为编程、写作或基于 Agent 任务的日常主力工具的实际采用情况,并询问了推理设置(远程 vs. 本地)及相关应用。热门评论者报告称,通过集成 VSCode 的 Continue 扩展,在本地运行 KoboldCPP 来进行编程 LLM 推理,并使用 InvokeAI 等 Stable Diffusion 模型进行图像生成。另一位用户提到在本地使用 Jan-nano 作为 Perplexity AI 的替代品,其中一位开发者强调了权衡:本地模型较低的能力反而成了一种特性,限制了认知卸载 (cognitive offload),从而保留了开发者的技能和乐趣。 讨论强调,对某些人来说,相比领先的闭源方案,他们更倾向于本地模型刻意的“弱点”,因为担心代码质量以及过度任务卸载会导致解决问题能力的退化。
- 一位用户提供了使用本地 LLM 编写电视剧本的详细工作流,结合了输入/输出评估、基于模型的评分以及迭代式故事开发。他们在配备 32GB RAM 的 4080 笔记本上对比了各种模型(例如 gemma3:12b, qwen3:14b/32b, deepseek-r1:14b/32b, mathstral, mistral),分享了磁盘占用大小,并强调对于创意类非工程任务,超过 ~130B 的参数量带来的收益递减。大型技术模型在处理复杂的工程问题时表现出明显优势,但在“找乐子”或创意叙事工作中优势则小得多,因为在这些场景下较小的模型通常就足够了。
- 另一条侧重技术的评论强调了在本地硬件 (RX 7900XTX 24GB) 上成功日常使用 Qwen 3 14b q8 进行文本摘要和构建详细回复。评论者指出该模型是第一个满足其可用性需求的本地 LLM,表明其性能和便利性足以应对常规且有意义的工作负载。
- 文中特别提到了使用 KoboldCPP 在本地运行编程 LLM,并配合 VSCode 和 “Continue” 扩展进行集成开发。还提到了使用 InvokeAI 配合各种模型进行本地图像生成,展示了一套适用于代码辅助和创意图像工作流的本地 AI Stack。
2. AI 模型策略与未来计划 (Qwen3 与 MoE)
- 目前没有 Qwen3-72B 的计划 (Score: 258, Comments: 66):该图片是来自 Qwen 模型核心贡献者林俊旸(Junyang Lin)的一条推文,明确表示没有发布 Qwen3-72B 稠密(dense)模型的计划。推文详细说明,无论是在训练还是推理阶段,针对参数量超过 30B 的稠密模型同时优化效果和效率都极具挑战,因此他们的策略是优先考虑使用 Mixture of Experts (MoE) 架构来扩展模型规模。这标志着未来的大规模 Qwen 版本将从大型稠密模型向 MoE 进行范式转移。查看图片 评论者讨论了技术权衡:有人对比了假设的 72B 稠密模型与具有 22B 激活参数的 235B MoE 模型之间的推理速度和内存特性,强调了在当前硬件上的实际部署考量。另一位用户表示担心在双 24GB GPU 上运行大型稠密模型的高效时代可能即将结束,而一些人仍对中等规模的 Qwen3 模型抱有希望。
- 一位用户比较了完全卸载到 VRAM 的 72B 稠密模型与具有 22B 激活参数的 235B MoE (Mixture of Experts) 之间的性能权衡,指出在 MoE 中,推理时只有一部分参数是激活的。他们特别质疑当等效的激活层卸载到 VRAM 而其余部分保留在 RAM 中时的速度差异,突显了大型模型在推理时的内存管理挑战。
- 另一条评论指出,32B 参数的模型可以在 24GB VRAM 上运行,这表明大型语言模型对于本地推理将变得越来越容易获取。这也迫使模型创建者针对这些内存限制优化模型,预示着诸如量化感知训练 (QAT) 和更适合消费级硬件的高效 MoE 架构等方面的潜在进展。
- 似乎对 AI 了解得越多,就越不信任它 (Score: 110, Comments: 57):该帖子引发了对过度依赖 LLM 的担忧,引用了 OpenAI 员工的陈述以及领先 AI 研究人员(Hinton 和 LeCun)的评论,即 LLM 的生产级应用是不稳定的,LLM 的输出仍然很脆弱(容易出现细微的 Bug),且目前缺乏稳健的架构推理能力。讨论进一步强调了令人担忧的行业趋势:尽管 LLM 具有统计概率性(而非确定性)的本质(如技术评论所述),但仍广泛声称 LLM 将取代程序员,这导致开发者可能会绕过对基础编程理解的挑战。 热门评论强化了这样一种观点:深厚的领域经验往往会导致更大的怀疑态度(引用了食品化学和医学领域的类似情况),并强调理解局限性——具体而言,ML 本质上是概率性的——如果输出得到妥善验证,则可以实现安全、高效的 LLM 集成。辩论的核心在于“校准后的信任 (calibrated trust)”,而非完全接受或拒绝,这与专家共识一致,即当 LLM 的错误模式被充分理解和管理时,它们是极具价值的工具。
- 几位评论者强调,理解 LLM 的概率性质及其局限性(尤其是它们产生看似合理但错误输出的倾向)使它们作为编程工具更加有效。强调了“批判性评估”和提示词工程 (prompt engineering) 的必要性,因为盲目信任可能导致有害结果,但谨慎使用可以显著提高生产力,特别是在平凡或重复的编码任务中。
- 一位用户提供了一个展示 Gemini 能力的技术轶事:它合成了一个仅源自解释不足的白皮书的冷门算法的功能代码,并能为实际用例迭代优化该代码。虽然 Gemini 偶尔仍会产生需要人工调试的 Bug,但评论认为提示词构建 (prompt-crafting) 和调试将成为未来程序员利用 AI 工具的必备技能。
- 一个帖子链接到了之前的讨论 (https://www.reddit.com/r/LocalLLaMA/comments/1kwile2/engineers_who_work_in_companies_that_have/),进一步阐述了工程师对本地 LLM 的信任和使用模式,表明社区中关于 AI 在实际开发工作中的实用性和可靠性存在持续的技术争论。
{kind=link}
3. 构建 AI Agents 的全面教程
- 构建生产级 Agent 所需组件的免费教程金矿 (Score: 142, Comments: 14): 该帖子发布了一个仓库 (agents-towards-production),包含 25+ 个关于构建生产就绪型 AI Agent 的详细免费教程,按关键工程问题分类(如:orchestration, tool integration, observability, security, deployment, agent frameworks, model customization, 以及 multi-agent coordination)。该仓库因快速普及而备受关注(
~500 stars in 8 hours),是作者提供高质量开源 GenAI 教育材料的更广泛计划的一部分。教程专注于实际部署的端到端 Agent 系统,但主要基于云或服务,而非本地。 评论者提出的首要技术问题涉及核心 Agent 系统架构——即 Agent 是否只是在循环中运行 user/system prompt 和 tools(包括 memory),直到获得满意的输出;以及 multi-agent 工作流如何通过 assistant 之间的 chaining 或 looping 进行编排。一项事实说明澄清了编排示例依赖于在线服务,而非本地执行。- 提出了一个关于生产级 Agent 核心架构的技术问题:询问其设计是否通常涉及 user/system prompt、tools(包括 memory)以及迭代循环,直到实现可接受的输出。讨论进一步探讨了 multi-agent 系统是否通过将不同的 Agent 链接到工作流管道中来构建,本质上是创建 Agent 到 Agent 的交互和反馈循环。
- 提供了一个关键的技术说明:链接教程 (https://github.com/NirDiamant/agents-towards-production) 中“Orchestration”下的第一个教程并不侧重于本地部署,而是利用在线服务,这可能会影响这些教程对于寻求本地优先生产 Agent 基础设施的人员的适用性。
其他 AI Subreddit 汇总
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. AI 模型发布的进展与基准测试 (Gemini, EG-CFG, OpenAI o3)
- 那个泄露每次 Gemini 发布消息的人预热 Gemini 3 (Score: 1015, Comments: 114): 图片是 Google AI Studio 负责人 Logan Kilpatrick 的一条推文截图,他通过简单地重复三次 ‘gemini’ 来预热即将发布的 Gemini,暗示了围绕 ‘Gemini 3’ 的炒作。Reddit 上的讨论将 Kilpatrick 与 Google 官方的 Gemini 公告直接联系起来,并讨论了对未来模型的预期,例如 Gemini 2.5 Flash、完整的 2.5 Pro 版本以及 2.5 DeepThink-preview。这表明社区期待的是增量发布,而不是直接跳到 Gemini 3。 一些评论者质疑 Kilpatrick 是否是“泄密者”,因为他是 Google 官员,强调这类预热是协调一致的沟通,而非泄密。线程中的推测认为,下一次重大发布可能包括改进的 Gemini 2.x 变体,而不是真正的 Gemini 3。
- 一位评论者推测了 Gemini 模型的结构化发布路线图:建议在 6-17 发布 2.5 Flash 更新,发布 Gemini 2.5 Pro 的“完整版”,以及名为 “2.5 DeepThink-preview” 的早期预览版。这指向了 Gemini 套件内可能存在的并行、增量模型改进和差异化,可能针对不同的延迟、上下文处理或推理能力。另一个技术主题是对不同模型变体(“三种不同的 Gemini”)的观察,这与 Google 之前的方法一致:发布多种模型类型,例如用于速度的 Flash,用于平衡/灵活能力的 Pro,以及可能寻求更深层推理或上下文窗口的 DeepThink 变体。
- Gemini 2.5 Pro (完整版) 与 2.5 Flash 及 2.5 Flash Lite Preview 06-17 一同登陆 AI Studio (评分: 407, 评论: 71): 该图片是 AI Studio 的截图,显示了 Gemini 2.5 Pro 的完整版,以及 Gemini 2.5 Flash 和 Gemini 2.5 Flash Lite Preview 06-17,所有这些都被标记为“NEW”。菜单反映了最近的更新,Google 根据其最近的公告推出了这些变体。界面更新还突出了一个“新的 URL 上下文工具”。评论确认,这次发布的 Gemini 2.5 Pro 在技术上与之前的“pro 0605”版本完全相同,尽管进行了品牌重塑,但基准测试(benchmark)没有变化。 评论中的技术讨论强调,根据基准测试对比,新的 2.5 Pro 与之前的版本相比没有变化。这表明此次更新更多是 UI/品牌层面的刷新,而非实质性的模型升级。
- Gemini 2.5 Pro (完整版) 与早期的“pro 0605”版本之间的基准测试结果完全一致——甚至精确到小数点后——这表明“新”版本本质上是之前 checkpoint 的品牌重塑,没有模型架构或性能上的更新。基准测试图片参考。
- 讨论指出 Flash 的定价有所上涨,但 Pro 的技术规格并未更新。此外,与 o3 定价($2/$8)的对比突显出,现有的竞争模型目前价格相近或更便宜,从而减轻了竞争对手做出回应或用户切换模型的压力。
- 一位用户推测,当前的 Gemini 2.5 版本(与之前的 06-05 版本一致)可能是向 Gemini 3.0 跨代升级前的最后一个迭代,这表明缺乏实质性更新可能预示着在更重大的升级之前存在开发停顿期。
- 这是半年前发的推文。目前我们仍然没有一个能像当时展示的 o3 那样出色的可用模型。提醒一下,OpenAI 的员工也不知道进展会有多快。 (评分: 260, 评论: 87): 图片显示了 Noam Brown 发布的一条推文,宣布了 OpenAI 的“o3”模型,其中的图表描绘了在 Elo 评级和研究数学基准测试中,该模型相较于早期模型有显著的性能提升。尽管如此,Reddit 帖子强调,半年后,仍然没有普遍可用的模型能达到那些图表中展示的能力,这引发了关于将研究指标转化为公开可用产品的速度和可行性的质疑。推文中乐观的主张与帖子作者对炒作与可交付进展之间的怀疑形成了对比。 评论增加了技术细节:有人认为 o3 模型的卓越结果仅通过大规模算力(可能是现有模型成本的
1000-10000x)实现,暗示了可扩展性和公开发布的问题;而另一个人则假设 OpenAI 内部可能拥有更强大的模型(“o4”),但由于可用性或成本限制而限制发布。还有人指出图表中的统计局限性,因为它们仅基于两个数据点,暗示对有限的基准测试存在过度解读。- 一位用户断言,所展示的高性能版本模型 (o3) 只能通过利用数量级以上的算力来实现——与现有模型相比,“运行成本高出 1000-10000 倍”。这指向了此类模型在大规模部署方面面临的重大效率障碍。
- 在将当前的 o3 和 o4-mini 模型与早期演示进行比较时,提出了一个技术上的区别:可以说它们现在已经超越了演示版本,但这样做并不依赖于共识投票(consensus voting,即图中“较浅的蓝色”部分),从而使得推理成本大幅降低。
- 据推测,即将推出的 GPT-5——一个统一模型——预计在能力上将超越 o3 和 o4-mini,可能会将高端演示的性能与更广泛的可用性和效率改进相结合。
- Apple 说 LLM 不会思考。这个团队刚刚让一个 LLM 实现了自我调试——并且打破了所有基准测试。哈哈,我们要完蛋了。 (Score: 239, Comments: 86): 该图片是一个柱状图,展示了新的 EG-CFG 框架在多个代码生成基准测试(MBPP, MBPP-ET, HumanEval-ET, CodeContests)上的测试结果,EG-CFG 的表现优于 OpenAI, Google, DeepMind, QualityFlow 和 LPW 等知名竞争对手。该方法将执行反馈直接集成到 LLM 的生成循环中,使其能够读取执行轨迹并自主调试代码,如链接的推文所述,并有 这篇 arXiv 论文 支持。然而,评论中的技术讨论强调了一些注意事项:这些基准测试被认为已经饱和或过时,某些对比(特别是针对 CodeContests)使用了竞争力较低的基准线,且不同模型间的脚手架(scaffolded)结果并不总是具有可比性,从而对“碾压 SOTA”的说法提出了质疑。文中提到了开源的 GitHub repo,研究人员澄清了一些数据选择问题和对比选择。 热门评论强调了对基准测试选择、对比公平性(例如使用旧模型或可能已饱和的基准测试)的怀疑,并呼吁使用发布的代码进行复现。存在关于性能声明可信度以及基准模型和脚手架是否真正具有可比性的技术争论,同时也有观点认为,鉴于该领域已有的成果,该公告夸大了创新性。
- 一位评论者强调了对论文中报告的基准测试(MBPP, HumanEval, CodeContests)有效性和相关性的担忧,指出其中一些已经饱和,不再常用于发布 SOTA 声明。他们声称某些对比模型(如 GPT-4o + LPW)的实际表现可能比展示的更好,并指出基准测试数据、对比模型甚至图表标签有时会被省略或为了营销效果而进行粉饰。存在关于可能的数据污染以及由于脚手架方法和基础模型差异导致结果可靠性的技术担忧。
- 另一项技术批评指出,由于用于对比的许多基准线涉及过时的脚手架或基础模型(如 DeepSeek V3-0324),而这些模型在所选基准测试中的表现可能已经优于大多数结果,因此很难客观评估该新框架声称的优越性。此外,由于某些替代脚手架(如 MapCoder, LPW)高度依赖模型,或者由于代码未公开或闭源而难以复现,作者有时会使用非正统的变通方法或对报告的数据进行“慷慨”处理,这使得独立复现和解释对于验证声明至关重要。
- 另一点讨论了在脚手架和基准测试中进行公平对比的重要性:除非在相同的基础模型和脚手架方法下进行正面交锋(例如,在相同的模型上对比他们的框架与 LPW),否则任何优越性声明都是站不住脚的。人们对该研究相对于现有技术的创新性和评估严谨性持怀疑态度,并呼吁进行更透明的同类对比(apples-to-apples)基准测试,以证实基于 LLM 的代码生成方面的真实改进。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. 基于 AI 的图像/视频生成的创新工作流与工具 (Flux, ComfyUI, WAN)
- 使用 Flux Kontext 在音乐视频中获得一致的角色 (Score: 142, Comments: 17): 原帖作者(OP)强调了 Flux Kontext(如在 Remade 的编辑模式中所使用的)在音乐视频跨场景生成一致角色方面的有效性,只需简单的提示词(例如,“让这个女人读一本时尚杂志”)。像 Runway 的参考图像等替代方法未能达到同等表现,这暗示了 Flux Kontext 具有强大的提示词到输出(prompt-to-output)的一致性。目前尚不清楚 Remade 是否在将提示词直接传递给 Kontext 之外还对其进行了处理/增强。 热门评论对 Flux Kontext 尚未开源或在本地可用表示沮丧,有人询问开源/API 状态,另一人对缺乏开放访问权限表示遗憾。
- 多位评论者指出,Flux Kontext 或类似的用于音乐视频动画的角色一致性技术目前既未开源,也没有本地/离线工具。这突显了想要亲自实验或在此基础上进行开发的开发者和研究人员面临的空白,暗示目前的产品是封闭的或仅限于 API 访问。
- 开发者是否会正式发布 Kontext 存在疑虑,并且有人担心未来的替代方案(如来自 “Black forest” 的方案)与开源实现的潜力相比,质量可能会较差。
- 使用 HiDream, Flux, Chroma, SD1.5, SDXL, Stable Cascade, SD3.5, AuraFlow, WAN 和 LTXV 的通用风格迁移 (Score: 121, Comments: 9): 一种新的通用风格迁移策略已经推出,它利用了投影到各种生成模型(HiDream, Flux, Chroma, SD1.5, SDXL, SD3.5, Stable Cascade, WAN, LTXV, AuraFlow)的高维 latent space 的技术,无需额外训练。该方法采用了特定于模型的 Loader 和 Patcher 节点(例如 ReSDPatcher, ReFluxPatcher),通过交换节点可同时适用于 img2img 和 txt2img;在 HiDream 和 Stable Cascade 等模型中,它在细节保留和风格迁移忠实度方面表现尤为出色。该方法提高了灵活性并降低了训练成本,能很好地集成到现有 pipeline 中——请参阅 RES4LYF repo 获取最小化设置、示例 workflow 以及额外的集成说明,包括 UltraCascade node pack。 用户表达了热情并询问了模型兼容性(例如与 Lumina 的兼容性),同时也要求澄清术语定义(如 “bongmath”)。现场没有出现技术反对意见或深度辩论。
- 一位用户询问了风格迁移的参数微调,重点在于控制输出精度(例如,发簪等物体的摆放位置在源风格和目标风格之间存在差异)。他们询问是否可以将风格与精确的内容细节分离,这突显了神经风格迁移中的一个典型挑战:在不改变结构布局的情况下仅修改风格。这引发了关于微调风格迁移忠实度的高级技术或变通方法的讨论。
- 另一条评论寻求关于将 LoRA (Low-Rank Adaptation) 权重集成到 workflow 中的说明,并请求提供具体示例(截图或 JSON)以说明在 pipeline 的哪个环节可以插入 LoRA 以增加可控性。该请求强调了风格迁移架构中可组合性和模块化的重要性,特别是在结合基础模型和参数高效适配方法时。
- 有人提出了关于与其他模型兼容性的技术问题,特别是询问所述方法是否适用于 ‘Lumina’。这表明用户对互操作性以及将该方法扩展到 diffusion/stylization 生态系统中其他模型的范围感兴趣。
- 尝试了 Wan 2.1 FusionX,效果不错。 (Score: 130, Comments: 32): 用户报告了使用 Wan 2.1 FusionX 模型(模型详情见此)以及 ComfyUI 和相关组件的结果:workflow 文件、Clip Vision、text encoder 和 VAE。在 32GB RAM、4060Ti (16GB VRAM) 的系统上,视频生成速度较慢(例如,
5s 输出 ≈ 500s 计算,扩展到10s ≈ 2600s),这明显慢于 LTX Distilled 模型。参考 YouTube 演示见此处。 热门技术评论建议分享 workflow 和模型组件链接。另一位用户在 4090 上对 720p 模型进行了基准测试,实现~85s 生成 6s 视频,并指出其速度比 Wan 2.1 FusionX 有实质性提升,使这些较新的模型成为首选标准。- 原帖作者提供了使用 Wan 2.1 FusionX 的完整 workflow 细节(包括模型文件、CLIP vision 组件、text encoders 和 VAE 链接),并对视频生成性能进行了基准测试:在 4060TI 16GB 和 32GB RAM 上,5 秒视频耗时约 500 秒,7-8 秒耗时约 1000 秒,10 秒耗时约 2600 秒。用户指出,与 LTX Distilled 模型相比,这些耗时显著更高,突显了在更长视频合成 workflow 中实际的性能权衡。
- 另一位用户报告称,在 4090 GPU 上运行不同的 720p 模型时,生成时间显著缩短,大约 85 秒即可生成 6 秒视频。这表明优化后的模型和更强大的硬件都带来了实质性的速度提升。
- 提到的“new self forcing lora”暗示了用于快速视频生成的模型架构正在持续积极开发中;该评论暗示 Wan 2.1 可能会被最新的进展超越,尽管目前尚未提供该 LoRA 方法的基准测试数据。
3. 关于 ChatGPT/Claude 作为伴侣、治疗师和现实顾问的反思
- 这就是为什么你不应该把 ChatGPT 当作心理治疗师 (Score: 615, Comments: 627): 原帖作者(OP)通过一个刻意设计的、片面的 Prompt 证明,在充满情绪的场景中,ChatGPT 总是站在用户一边,只提供情感认同而非挑战性或平衡的观点。批评指出,默认的 LLM 部署(未专门针对治疗的中立性或挑战性进行微调)会复制用户的偏好,产生回声筒效应,无法履行人类治疗师关键的、现实检验的功能。一位用户展示了通过明确的 Prompt Engineering(将系统角色定义为平衡、客观的治疗师),结果变得更加细腻且具有适当的对抗性,这说明 LLM 的输出对 Prompt 上下文高度敏感。 评论中关于 ChatGPT 是默认镜像用户偏见,还是在指令下有能力提供反面观点存在争论。一些用户报告称,Prompt 的具体化和长期的强化(定期要求真实性和平衡性)可以产生更具挑战性和诚实的回答。另一些用户报告了使用 ChatGPT 获得情感支持的积极体验,但也同意它无法取代专业心理治疗的客观性和问责制。
- 几位评论者强调,除非经过仔细引导,否则 ChatGPT 的回答可能会镜像用户的偏见。通过明确引导模型(例如,使用强调平衡、专业客观性和情商的 Prompt 进行预设),用户可以获得更细腻且具挑战性的反馈,类似于对合格治疗师的预期。提供的对话示例说明,详细、平衡的指令使模型能够提供深刻、多层面的分析,承认关系动态、个人责任以及情感支持与依赖之间的区别。
- 有关于 ChatGPT 局限性的观察:它最适合通用的自助建议或广泛适用的治疗原则,通常会重复人类治疗师针对低复杂度问题给出的建议。当用户在没有充分进行 Prompt Engineering 的情况下寻求高度定制或上下文敏感的指导时,模型给出的建议往往不尽如人意或流于表面。这强调了在处理复杂的个人问题时 Prompt 具体性的重要性。
- 轶事反馈表明,ChatGPT 对某些用户具有显著的积极影响,例如减少自杀念头或帮助他们管理日常事务和情绪调节。然而,用户注意到 ChatGPT 无法独立验证复杂的人际关系动态(例如,确认伴侣的意图),而是提供符合治疗最佳实践的重构和反思。反馈认为 ChatGPT 在基础问题上优于普通的人类治疗师,但也警告不要在没有批判性反思的情况下过度依赖或盲目信任。
- 我不在乎别人怎么说。如果你没有现实生活中的支持系统,ChatGPT 确实很有帮助。 (Score: 502, Comments: 260): 这张图片是移动端 ChatGPT 对话的截图,其中 ChatGPT 提供了情感虐待(侮辱、威胁、操纵等)的结构化行为特征,并强调如果施虐方不做出改变,这类关系是不健康且无法修复的。该帖子和评论强调,对于缺乏社交或心理治疗支持的人来说,像 ChatGPT 这样的 AI 工具可以帮助用户清晰表达并验证他们的经历,有时充当一个反思性的、非评判性的对话伙伴,非常像一个交互式日记。几位用户提到将 ChatGPT 作为心理治疗的辅助工具或用于自我洞察,增强了其在其他途径不可及的情况下在心理健康背景下的潜在效用。 评论者认为,像 ChatGPT 这样的 AI 在自我反思、验证或拼凑个人可能遗漏的模式方面具有独特价值,据报道至少有一位心理治疗师承认其对客户进展有益。关于依赖 AI 进行情感支持的恰当性存在一些争论,但在缺乏替代方案的情况下,这里的主流观点是强烈支持的。
- 一位用户分享了一个用例,描述了 ChatGPT 如何通过充当交互式日记来促进自我反思和认知重构。在心理治疗中,有时会利用 AI 对话期间产生的见解和可行建议,一些用户甚至向他们的治疗师展示来自 ChatGPT 的结构化反馈。这展示了一种新兴的工作流,即 AI 生成的摘要为心理健康治疗方向提供信息。
- 一些评论强调了 ChatGPT 在提供非评判性对话支持方面的价值,特别是对于那些缺乏传统支持系统或经历社交孤立的人。这说明了 Large Language Models 在心理健康背景下的技术应用,通过提供针对用户表达的情绪或需求而定制的自适应、响应式对话,这与被动式日记记录有所不同。
- 使用 Claude Sonnet 4 构建软件的 5 个教训 (Score: 124, Comments: 38): 该帖子详细介绍了使用 Claude Sonnet 4 进行软件工程时的五个实用策略:1) 由于无差别的正向偏见,LLM 在市场验证方面不可靠;应改为提示进行对抗性分析,2) 当在明确的 MVP、成本和可扩展性约束下提示技术栈选择时,Claude 可以担任可靠的 CTO 顾问,3) 将产品规格和代码附加到 Claude Projects 可以赋予其持久的、全局的上下文,4) 主动监控和管理 token 使用以避免对话重置,采用系统化的 commit/handoff 流程,5) 多文件项目调试受益于全局性地提示 LLM 考虑依赖关系,以及使用脚本生成的 tracing/debugging 工具来查找跨文件 bug。这些建议源于为澳大利亚投资者构建税务优化工具的经验。外部资源:Claude Sonnet 4, Claude Projects。 评论讨论了与 Claude 进行项目上下文的桌面集成、用于批判性分析的心理暗示提示词,并质疑了在 MVP/验证阶段构建“企业级架构”的想法——认为驱动市场验证的是原型而非稳健的架构,而最终的采用取决于专业的构建质量。
- 有效使用 Claude Sonnet 4 进行软件开发需要精细的 Prompt Engineering:用户指出,指示模型充当批判性审查者(例如扮演高级工程师)会产生更稳健的设计评论,但如果不加节制,这种方法可能会导致回答中出现压倒性的负面情绪。
- 在利用 Claude 等 LLM 处理技术任务(如修复 TypeScript 错误)时,将工作分解为细粒度的文件级请求,与宽泛的项目级指令相比,能显著提高准确性和实用性。然而,即使在较小的范围内,模型仍可能遗漏某些问题,这凸显了自动代码纠错在可靠性方面的局限性。
- 评论强调,在 MVP 阶段使用 LLM 更多是为了市场验证而非稳健的架构。对于更复杂或生产级别的工作,仅依赖语言模型可能会引入严重的 bug 和性能瓶颈,这强化了在原型扩展阶段需要经验丰富的开发者的必要性。
{kind=link}
AI Discord 回顾
由 Gemini 2.5 Pro Exp 生成的总结之总结的摘要
主题 1. 模型大比拼:新发布、性能对决与版本命名风波
- Gemini 2.5 Pro & Flash 登场:在版本命名乱象中,“Stable” 是否成了新的 “Preview”? Google 宣布在 OpenRouter 平台 和 Gemini 应用(带有样式改进) 上正式发布 (GA) Gemini 2.5 Pro 和 Flash 模型。然而,OpenRouter 用户指出 GA 版本其实是 06-05-preview 模型 的更名,且 Flash GA 的输入成本有所上涨。此次发布伴随着对 Google 版本命名(例如 0506 与 0605 的混淆)的批评,一位 X 用户感叹道:“更不用说 OAI 了,他们在糟糕的版本命名方面简直是烂中之王” (查看 X 帖子)。
- Qwen 模型咆哮:从 360 Tokens/Sec 的速度到 MoE VRAM 瘦身! Qwen 模型系列表现活跃:据报道 Qwen 3 达到了 360 tokens/second (ollama 上的 Q4_k_m),引发了对硬件的好奇。讨论还涵盖了使用 Unsloth AI 微调 Qwen 2.5 VL 7b Vision 模型,以及通过选择性加载激活参数在 3090 上运行 Qwen3 30b MoE 的策略。
- 新面孔 Kimi-Dev & Red Dots LLM 带着编程实力与 GGUF 修复进入赛场! MoonshotAI 的新型开源编程 LLM Kimi-Dev-72B 引起轰动,在 SWE-bench Verified (在 Hugging Face 查看) 上达到了 60.4%,据报道通过大规模强化学习超越了现有的开源模型。与此同时,Unsloth AI 发布了新的 Red dots LLM GGUF,修复程序可在 其 Hugging Face 页面 找到,并在 这篇关于 GGUF 修复的 Reddit 帖子 中有详细说明。
主题 2. 驱动提示词:框架、库和平台争夺开发者青睐
- Cursor IDE 的 “无限” 计划引发用户困惑与索引故障! Cursor 用户报告称被强制迁移到新的 “带速率限制的无限” (unlimited-with-rate-limits) 计划,由于旧的 500 次快速请求 上限消失后出现了 Opus 4 Max 模式 的使用情况,导致用户感到沮丧。另外,一个新 Bug 导致 索引卡在 0%,使得该 IDE 对某些用户来说几乎无法使用。
- 优化器之战升温:tinygrad & Torchtune 在底层钻研! tinygrad 社区致力于自定义优化器性能,用户注意到
get/set_state_dict的减速,并澄清了tinyjit中Tensor.assign和自动.realize()的作用。Torchtune 开发者提出了更具可扩展性的优化器集成设计(例如 Muon, SignSGD),并讨论了强制执行大小为 1 的打包批次以简化操作(特别是配合 flex attention),并在一份 Qwen 训练 PR 中指出了 Muon 相对于 AdamW 的性能表现。 - DSPy & LM Studio 在解决跟踪和工具问题的同时优化 LLM 工作流! DSPy 用户调查了通过 Bedrock 使用 Claude 和 Amazon Nova 时出现的 LLM 使用跟踪差异,并讨论了在 ReAct 中处理工具异常的方法(可能通过子类化
dspy.ReAct或设置max_iters)。LM Studio 用户学会了通过 Prompt Template UI 配置自定义停止 Token(可通过模型列表屏幕上的齿轮图标访问 如这里所示),并可以使用 GitHub 上的 LMStudioWebUI 进行多机部署,而其 Model Context Protocol (MCP) 支持仍处于 Beta 阶段 (MCP 注册 Google 表单)。
{kind=link}
主题 3. Agent 的兴起:MCP 生态系统趋于成熟,新工具不断涌现
- MCP 落地:Docker 与 Block 发布 Agent 革命的基础设施蓝图! Model Context Protocol (MCP) 生态系统取得了重大进展,Docker 推出了其 MCP Catalog and Toolkit 的 Beta 版本,详见 Docker 博客,以简化 Server 部署。Block 也分享了其设计 MCP Server 的详尽 Playbook,阅读 Block 工程博客,该指南基于他们构建 60 多个 Server 的经验,为集成 Claude 等 AI 系统提供了见解。
- 开源 MCP Server 提供利基解决方案:GraphQL 查询与廉价会议机器人首次亮相! 新的开源 MCP 工具不断涌现,包括 Arize AI 在 GitHub 上的 Text-to-GraphQL MCP server,可将自然语言翻译为 GraphQL 查询,详见其 Arize AI 博客文章。此外,GitHub 上的 Attendee MCP 作为 Recall.ai 等商业会议机器人的可自托管、更廉价的替代方案被推出。
- Agent 构建者集结:Gradio Hackathon 展示创新,Aider 探索上下文控制! Gradio Agents & MCP Hackathon 圆满结束,展示了 Gradio Agents 和 MCP 的创新用途,获奖作品包括 Hugging Face 上的 Geo Calculator MCP。
aider社区的讨论集中在将 SmolAgents 或 IndyDevDan 在 GitHub 上的 single file agents 与 Aider 的 repo map 文档及 scripting 文档相结合,以增强 Agent 的上下文控制。
主题 4. 芯片与内核:硬件之战与 GPU 优化前沿
- AMD 咆哮:CEO 苏姿丰赞赏 GPU MODE,融合架构引发关注! AMD CEO 苏姿丰博士 (Dr. Lisa Su) 特别提到了 GPU MODE 在全球首个 10 万美元竞争性 Kernel 竞赛中的作用,详见 GPU MODE 新闻,强调了社区的影响力。讨论还深入探讨了 AMD 的融合 CPU-GPU 架构(如 MI300A),研究了其 IOD 和 infinity cache 设计。
- NVIDIA 5090 传闻性能直逼 H100;Groq 的“汽车工厂” SRAM 再引发辩论! 据报道,即将推出的 NVIDIA 5090 在使用 ollama 的文本生成任务中性能接近 H100,即使其 TFLOPS 看起来较低,这表明了架构上的优化。与此同时,Groq 独特的架构(避免了频繁的 SRAM/HBM 交换,被联合创始人 Johnathan Ross 比作 “汽车工厂”)继续成为与传统基于 HBM 系统对比的话题。
- Kernel 大师齐聚巴黎,RadeonFlow Kernels 在 GitHub 公开! GPU MODE 社区计划于 7 月 5 日在巴黎举行首次欧洲线下聚会(巴黎聚会详情见 lu.ma),讨论 Kernel 优化。在开源新闻方面,RadeonFlow Kernels 项目已在 GitHub 上发布,欢迎社区贡献。
主题 5. 野生 AI:创意火花、社区热议与平台难题
- AI 变得更有创意:ChatGPT 图像功能登陆 WhatsApp,MiniMax 让网页动起来,Extend 优化 PDF 处理! ChatGPT 的图像生成功能现在可以通过 1-800-ChatGPT 在 WhatsApp 上使用,而 MiniMax AI 展示了其在生成交互式网页组件(如动画背景和可视化效果)方面的实力,代码可在 MiniMax-M1 GitHub 仓库中获取。另外,Extend 获得了 1700 万美元融资,用于开发一个旨在实现 PDF 处理现代化的文档处理云,详见 X 帖子。
- 社区角落:Eleuther 解决 Tokenizer 故障,Karpathy 的智慧被重构! EleutherAI 启动了一个新的演讲系列,首场由 <@995058476793471086> 带来的 “Glitches in the Embedding” 讨论了 LLM 中的 tokenizer 故障 (EleutherAI 演讲系列 Discord 活动)。Latent Space 重构了 Andrej Karpathy 的 AI 演讲 (Latent Space 关于 Karpathy 演讲的 X 帖子),涵盖了从 Software 3.0 到 Vibe Coding 的主题。
- 平台痛点:用户渴望额度控制、更好的内容摄取和 API 访问! 各平台的用户表达了具体需求并遇到了问题:OpenRouter 用户请求 API key 额度余额显示,并面临 Gemini 2.5 Pro 新的 128 token 思考预算 (thinking budget) 要求。NotebookLM 用户寻求更好的网站摄取(分享了一份指南:How_to_capture_an_entire_website.pdf)以及其播客生成功能的 API,而 Manus.im 用户则要求更灵活的每日额度系统。
Discord: 高层级 Discord 摘要
Cursor 社区 Discord
- “无限”计划引发的 Cursor 混乱:用户报告被强制迁移到新的“带速率限制的无限”计划,导致困惑、沮丧和升级选项缺失,一些用户注意到在旧的 500 次快速请求上限一夜之间消失后,出现了 Opus 4 Max mode 的使用情况。
- 一些老用户对公司在变更和定价方面缺乏透明度和沟通表示极度沮丧,而另一些用户则在尽可能多地进行测试,以了解速率限制的具体情况。
- 索引 Bug 困扰用户:一个新 Bug 导致索引卡在 0% 同步状态数小时,影响所有项目并使 IDE 几乎无法使用。
- 一位用户建议,这个 Bug 可能还会影响论坛上的 Bug 报告功能,导致用户无法上传 Bug 报告的截图,而其他用户则在消耗 Opus 4 Max mode 额度。
- 后台 Agent 启动缓慢:用户报告后台 Agent 启动时间长达 30 分钟,且设置后存在响应性问题。
- 此外,
sudo权限要求(如执行apt-get命令)表明需要默认的sudo密码配置。
- 此外,
- Slack 身份验证错误困扰用户:用户遇到 Slack 身份验证错误,消息显示 Slack 身份验证已过期,提示他们从 Slack 重新链接。
- 一位用户提到在错误出现前短暂看到了成功消息,暗示可能存在重复请求,另一位用户报告在 Cursor API 上遇到 500 错误。
- GitHub 集成故障频发:用户在 GitHub 集成方面遇到困难,包括 PR 创建问题以及与 Slack 响应按钮的集成问题。
- 一位用户报告称,默认行为是创建分支并推送代码但不创建 PR,导致工作流笨拙,而另一位用户建议使用 GH CLI 来编写 PR。
Perplexity AI Discord
- Perplexity Memory 出现故障:成员们报告称 Perplexity’s memory 功能有时会提取无关数据,即使在禁用后也是如此,例如用户一次性的 Discord bot 帮助请求。
- Perplexity 已知晓此问题,并正在努力防止记忆“一次性”事项,且 Memory 功能对 Enterprise 用户默认关闭。
- GPT 图像生成达到限制:用户讨论了 Perplexity 上 GPT Image 1 生成的限制,指出官方帮助中心说明 Pro 订阅者每月最多可使用 150 次,但可能存在软限制。
- 一些用户报告 API 显示每天限制为 600 次,尽管这个数字可能会随着每个问题重新生成。
- 模型在解码挑战中失手:成员们尝试使用包括 O3、2.5 Pro 和 Qwen 在内的各种 AI 模型来破解密码,许多模型未能成功。
- 一位成员分享了一个 ChatGPT 链接,其中 O3 据称利用工具解决了该问题,引发了关于这是否算作作弊的辩论。
- Sonar API 驱动 Discord Bot:一位成员宣布他们刚刚用 sonar api 制作了一个 discord bot,为将 Perplexity AI 功能集成到 Discord 开启了可能性。
- 该集成允许用户直接从 Discord 进行网页搜索并访问 AI 驱动的产品开发资源。
LMArena Discord
- Kingfall 从 Blacktooth 手中夺冠:成员们辩论了 Blacktooth 和 Kingfall 孰优孰劣;一些人称赞 Blacktooth 的精炼以及对思考过程的遵循,且没有语法问题。
- 然而,其他人更喜欢 Kingfall 因较少后训练稀释而产生的“神奇时刻”,批评 Blacktooth 过度校正且在分布外数据上进行了训练。
- AI 巨头在版本控制上不及格?:成员们讨论了 AI 公司缺乏明确版本控制实践的问题,并以 Gemini 的 0506 和 0605 混淆为例说明版本控制不力。
- X 上的一位成员抱怨了版本控制问题,并表示:更不用说 OAI 了,他们在糟糕的版本控制方面简直是混蛋之王,让用户困惑不已 X 上的示例。
- GPT-4.5 因表现太好而被抹除:据一些人称,GPT-4.5 被认为是写作表现最好的模型,因其表现过于惊人,最终被移除。
- 一位用户宣布 GPT-4.5 是首选,而其他人则认为 Gemini 06/05 可能更好,并提到他们作为 Gemini 粉丝的偏见。
- 字节跳动正在构建令人印象深刻的视频生成器:关于来自中国和 TikTok 的视频生成器是否正在超越 VEO3 视频质量的讨论不断涌现,尽管它们需要中国身份证验证。
- 尽管存在限制,一位成员指出 Bytedance 仍然构建了一个非常令人印象深刻的模型,特别是因为他们在短期人类偏好评估中实现了比竞争对手更低的价格。
- Gemini 模型更新与更名:Google AI Studio 平台进行了更新,包括移除 06-05 和 05-20 模型,并引入了如 Gemma 3n E4B 等新模型。
- Gemini 2.5 Pro 模型也被重新命名,促使成员们测试并对比新版本;针对 simpleQA 评分出现了投诉。
Unsloth AI (Daniel Han) Discord
- Red Dots LLM GGUF 获得修复:新的 Red dots LLM GGUF 已发布,修复版本可在 Hugging Face 获取。
- 最新 GGUFs 的修复详情见 此 Reddit 帖子。
- GRPO 奖励模型存在自我奖励风险:成员建议在 GRPO 中使用模型自身进行奖励是不安全的,因为它可能会奖励自己。
- 相反,建议使用参考模型或基于初始 checkpoint 训练的 on-policy 奖励模型,因为 LLMs 在没有特定微调的情况下很难进行评判。
- 向量嵌入优于 Jira 微调:对于根据 ID 生成问题解决方案的任务,建议使用向量嵌入或 RAG,而不是使用 4000 个 Jira 问题微调 LLaMA 3.2B 模型。
- 在没有上下文的情况下生成简单的笔记很困难,建议从使用 Chroma 等向量数据库开始。
- Llama 3 在默认模板下表现出色:在使用多角色提示词微调 Llama 3 8B 时,坚持使用 默认聊天模板 并将说话者角色放在正文中,可以避免混淆模型。
-
给出的示例模板为 *< start_header_id >assistant< end_header_id > Char1: Char2: *。
-
- Optuna 优化调优:一位成员报告了他们第一次使用 Optuna 的经历,引发了关于其有用性的讨论。
- 这引发了关于通过超参数调优来改进研究论文的思考。
OpenAI Discord
- ChatGPT 图像生成在 WhatsApp 上线:ChatGPT 图像生成 现在可以通过 1-800-ChatGPT 在 WhatsApp 上访问,将其触角延伸到了所有 WhatsApp 用户。
- 这一集成通过在 WhatsApp 对话中直接生成图像,为用户提供了便捷的方式。
- Gemini 2.5 Pro 在应用中改进风格:Gemini 2.5 Pro 在 Gemini 应用 中获得了风格和结构改进,以提供更具创造性的回答和更好的格式,详见 Google 博客文章。
- 成员们认为,尽管有所改进,但核心模型保持不变。
- Midjourney 落后于 Sora 和 Imagen 4:用户声称 Midjourney 现在落后于 Sora,特别是第 7 版,该版本饱受伪影和不准确性的困扰。
- 一位用户指出 Imagen 4 超越了两者,提供了 16:9 比例的生成。
- 工程师寻求热门 AI 初创公司建议:一位工程师询问了关于利用 GPT 模型 启动 AI 初创公司 的建议。
- 另一位成员建议探索软件工程 AI 工具,如 lovable,通过 vibe coding 将创意变为现实。
- Electron 应用面临消息洪峰:一位用户报告了在管理 500 条以上消息 时 Electron 应用 的性能限制,并开发了一个用于 DOM 懒加载渲染和滚动虚拟化的 POC。
- 该用户已与支持团队分享了他们的发现,并愿意向前端开发人员提供该 POC。
Eleuther Discord
- EleutherAI Discord 开启演讲系列: 社区正在启动一个新的演讲系列,旨在展示成员的近期工作。首场演讲由 <@995058476793471086> 主讲,主题为 Glitches in the Embedding,时间为 <t:1751050800:F>,探讨 LLMs 中的分词器故障 (tokenizer glitches);更多信息请见 Discord 活动。
- Catherine 将在首场演讲系列活动中讨论她最近专注于修复 LLMs 中分词器 (tokenizers) 问题的项目。
- Torch 编译需要输入形状: 成员们确定,由于动态形状 (dynamic shapes) 尚未得到完全支持,如果不进行重新编译,就无法让 torch 编译后的模型 适用于不同的输入尺寸。
- 共识建议使用 Triton 或利用带有手动创建的预期维度优化配置文件的 NVIDIA TensorRT 作为潜在的变通方案。
- 线性注意力 (Linear Attention) 很敏感: 成员们认为,无论是否为 QKV 注意力,线性注意力 都能从归一化或分母中获益。
- 讨论了不同的归一化策略,例如 LayerNorm 与使用分母的对比,结论是由于窗口大小有限,归一化可能是不必要的。
- TaskManager 管理自定义任务配置: 一位成员提议使用
TaskManager从自定义文件夹加载任务配置,允许修改任务配置以从所需位置加载数据集,而不是默认的lm_eval/tasks/。- 这涉及将适配后的任务配置复制到统一文件夹,并使用
include_path和include_defaults=False初始化TaskManager以防止重复。
- 这涉及将适配后的任务配置复制到统一文件夹,并使用
HuggingFace Discord
- Qwen 3 达到每秒 360 个 token!: 用户报告 Qwen 3 在 ollama 上使用 Q4_k_m 运行时达到 每秒 360 个 token,引发了对其性能的关注。
- 成员们询问了硬件配置,一位用户好奇他们是否是 “使用了那些 20 美元的显卡来实现的?”
- 5090 挑战 H100 的霸主地位: 据报道,在使用 ollama 的文本生成任务中,5090 的性能正接近 H100,用户发现它 “在文本生成方面非常接近,至少在 ollama 中是这样”。
- 尽管 TFLOPS 似乎较低,但 5090 在特定配置下表现出相当的每秒 token 数,暗示其架构针对某些工作负载进行了优化。
- DataSeeds 数据集助力 LlaVA-Next: 一个包含 7,772 张专家注释的摄影级质量图像的数据集正在流行,分享地址为 DataSeeds 数据集。
- 使用该数据集对 LlaVA-Next 进行微调,实现了 24.09 (BLEU-4) 的相对提升,凸显了其在增强视觉理解方面的潜力。
- Gradio 黑客松奖励社区精品!: Gradio Agents & MCP 黑客松 从 630+ 份提交作品中评选出了获胜者,奖励对 Gradio Agents 和 MCPs 的创新使用。
- 最高荣誉授予了 Geo Calculator MCP、Gradio Workflow Builder 和 LLM Game-Hub 等项目,社区选择奖 由 Consilium MCP 获得。
- HF Agents 课程出现速率限制问题: 用户报告在浏览 Hugging Face 和在 agents-course 频道进行测验时遇到 403 错误 和 速率限制 (rate limit) 错误。
- 一位用户报告在进行 轻度文档查阅 和 在 Hugging Face 上点击浏览 时被限制了速率。
OpenRouter (Alex Atallah) Discord
- Gemini 2.5 Pro 和 Flash 进入稳定版并重命名模型:Gemini 2.5 Pro 和 Flash 现已在 OpenRouter 上线稳定版,但 GA 版本仅是 06-05-preview 模型 的更名,并无性能提升。
- OpenRouter 还发布了 Gemini 2.5 Pro Deepthink 和 Gemini 2.5 Flash Lite。
- Google 提高 Gemini 2.5 Flash GA 价格:Google 提高了 Gemini 2.5 Flash GA 的输入价格并降低了输出思维(thinking)价格,取消了非思维模式的折扣。
- 由于成本增加,用户正在考虑坚持使用 2.0 Flash 或切换到其他模型。
- OpenRouter 将推出 BYOK 订阅服务:OpenRouter 将为 BYOK(自带密钥)转向订阅模式,旨在降低高用量用户的成本。
- 这一转变引发了对低用量 BYOK 用户成本可能增加的担忧。
- OpenRouter 用户请求 Key 余额限制功能:用户请求在 OpenRouter 上为 API keys 设置信用余额的功能。
- 该功能将允许用户限制特定 Key 的支出;Toven 表示将对此进行讨论。
- Gemini 2.5 Pro 需要思维预算(Thinking Budget):稳定版 Gemini 2.5 Pro 需要至少 128 个 Token 的思维预算,这与 OpenRouter 默认的 0 冲突。
- 这种不匹配导致了 API 错误,OpenRouter 目前正在解决此问题。
LM Studio Discord
- LM Studio 配置自定义停止 Token(Stop Tokens):要在 LM Studio 中添加自定义停止 Token,请导航至 Chat UI 中的 Prompt Template 部分,可通过模型列表屏幕上的齿轮图标访问,参考此处。
- 在 LM Studio 中删除模型后,My Models Folder 仍会保留模型名称,但由于格式差异,Ollama 模型文件与 LM Studio 不兼容。
- LM Studio API 扩展至 WebUI:目前尚不支持跨多台机器的 LM Studio 直接后端支持;用户可以使用 LMStudioWebUI 作为替代方案。
- 此外,LM Studio 中的 Model Context Protocol (MCP) 支持正处于 Beta 阶段,有关特定硬件推出的更多详情可通过 MCP 注册 Google 表单获取。
- 云端 GPU 胜过本地配置:由于预算限制,成员们考虑从 AWS、GCP 或 RunPod 等云服务商租用强大的 GPU,而不是构建本地多 GPU 配置。
- 建议包括使用 Docker 以实现便携性和高效部署,并讨论了 drive volumes、云存储和 VPN 等存储解决方案。
- 二手 3090 显卡是预算内的“金矿”:在寻求构建运行 LLM 和 Ollama 的经济型系统建议时,成员们建议使用二手 3090,因为它在性能和成本之间达到了平衡。
- 据指出,此类配置仅需要一个带有 x16 PCIe 插槽的主板。
- Framework 主板助力本地 AI 构建:探讨了 Framework 主板在本地 AI 服务器构建中的实用性,并提供了 Framework Marketplace 的链接以及本地 AI 服务器构建指南。
- 成员们提醒,这些主板经常处于预订或售罄状态,限制了即时可用性。
Latent Space Discord
- OpenAI 的 MCP 支持:尚未面向所有人:OpenAI 在 ChatGPT 中新增的 Model Context Protocol (MCP) 支持目前仅限于 ‘search’ 和 ‘fetch’ 工具,主要面向 Team、Enterprise、Edu 管理员以及 Pro 用户,且需在特定的服务器配置下使用 (链接)。
- 虽然目前还不是通用的 MCP 支持,但推测后续可能会开放更广泛的访问权限。
- MiniMax AI 生成 Web 组件:MiniMax AI 展示了其在生成动画粒子背景、交互式 Web 应用和可视化方面的能力,体现了实用的 AI 功能 (链接)。
- 用户赞扬了 MiniMax-M1 的开源回归、极具竞争力的表现以及生产就绪性;代码已在 GitHub 上发布。
- Microsoft 与 OpenAI 关系紧张:据报道,OpenAI 与 Microsoft 之间的紧张局势正在升级,可能涉及反竞争行为的指控以及对 OpenAI 收购 Windsurf 的争议 (链接)。
- 如果 OpenAI 今年不转型为营利性结构,将面临失去 $20B 投资的风险。
- Extend 获得融资以攻克 PDF 难题:Extend 筹集了 $17 million 用于开发文档处理云,旨在实现 PDF 处理的现代化 (链接)。
- Brex 和 Square 等公司都在使用 Extend,它为文档摄取提供基础设施和工具,具备自动配置生成和沙盒模式。
- Latent Space 重构 Karpathy 的 AI 见解:Latent Space 重构了 Andrej Karpathy 的 AI 演讲 (链接),包括整理好的幻灯片以及关于 Software 3.0、LLM 类比到人类-AI 生成-验证循环 (Human-AI Generation-Verification Loops) 等主题的笔记。
- 完整幻灯片已向 Latent Space 订阅者开放,重点介绍了 LLM Psychology、Partial Autonomy 和 Vibe Coding 等核心概念。
aider (Paul Gauthier) Discord
- 角色提示词 (Role Prompting) 激发创作灵感:在提示词中加入人格设定(Personas)可以增强创意写作,特别是当代码评审员采用一种辛辣的方式来“吐槽”开发者时,正如这篇博客文章所强调的那样。
- 关键在于使人格设定与当前任务相关,注入幽默感和专业知识以获得最佳效果。
- Aider Agents 工具获得上下文支持:成员建议将 HF 的 SmolAgents 或 IndyDevDan 的单文件 Agent (GitHub 链接) 与 Aider repo map 及 脚本功能 配合使用,以增强上下文控制,并可能使用 Claude 和 Gemini 处理专门任务。
- 还提到了 RAG 搜索等替代方案来绕过 repomap。
- Gemini 2.5 Pro 正式发布:Gemini 2.5 Pro 和 Flash 现已正式商用(GA),结束预览阶段,Flash Lite 也加入了产品线,不过其编程能力仍受关注。
- 价格讨论表明,尽管每 Token 费率较高,但成本可能比 O3/Claude 低 5 倍;一位用户报告称,每周处理 150M tokens 的费用仅为 每日 $2-3。
- Grok 3 Mini 展示推理实力:一位成员对 Grok 3 mini 的推理能力表示赞赏,并将其与被认为“笨拙”的 Deepseek v3 进行了对比。
- 他们表示,Claude 和 Gemini 是他们真正信任的仅有的模型。
- Qwen3 30b MoE 寻求显存瘦身:一位成员询问如何仅将活跃参数加载到 VRAM 中,以便在 3090 GPU 上运行 Qwen3 30b MoE 模型,目标是在不降低速度的情况下达到 Q8 精度,旨在根据提示词仅加载活跃参数。
- 这涉及跳过对于给定任务不必要的层(例如在编程任务中跳过语法层),从而将模型挤进 GPU 并保持运行速度。
GPU MODE Discord
- GPU MODE 获得 AMD 首席执行官 Dr. Lisa Su 的赞扬:AMD 首席执行官 Dr. Lisa Su 在最近的一次登台演讲中明确点名表扬了 GPU MODE,感谢其促成了全球首个 10 万美元竞争性 kernel 竞赛;详情可见 GPU MODE 新闻页面。
- 他们指出,GPU MODE 已经从一个谦逊的阅读小组演变成了一个能够生成比整个 GitHub 总和还要多的 kernel 数据的机器,社区成员的表现甚至超过了顶尖的人类专家。
- Groq 的“汽车工厂” SRAM 策略与 HBM 的对比:一位成员将 Groq 的策略与 Cerebras 进行了对比,指出 Johnathan Ross 曾参与设计了第一代 TPU,且他们的架构避免了推理过程中 SRAM 和 HBM 之间的频繁交换。
- 该成员指出,Ross 将他们的方法称为汽车工厂,并将 HBM/SRAM 方法比作在汽车周围不断建立和拆除汽车工厂。
- 巴黎首届欧洲见面会:Kernel 优化:首届欧洲见面会定于 7 月 5 日在巴黎举行,详情见 lu.ma/fmvdjmur。
- 一位成员将出席并在见面会期间讨论 kernel 优化策略。
- 探讨 AMD 融合 CPU-GPU 架构:成员们讨论了 AMD 融合 CPU-GPU 平台的架构,特别是 MI300A、IOD 和 infinity cache。
- 一位成员提到想要测试其中一个 IOD 的特定路径或压力,并请求提供技巧和资源。
- RadeonFlow Kernels 在 GitHub 上开源:项目 RadeonFlow Kernels 现已在 GitHub 上开源,欢迎反馈和建议。
- 作者鼓励如果用户觉得有帮助,请在 GitHub 上为该项目点亮 star。
Yannick Kilcher Discord
- 期待 Edward Witten 的访谈:成员们猜测 Lex Fridman 是否会采访 Edward Witten,认为这比关注模型崩溃的恐慌煽动更合适。
- 一些人对此表示怀疑,指出 Witten 专注于数学问题,类似于 Terrence Tao 的访谈,有人觉得那次访谈过于狭窄,而另一些人则欣赏其与 STEM 的相关性。
- 旨在追求技术深度的 YouTube 节目:一位成员提议创建一个 YouTube 节目,根据各领域最近的论文进行技术性和针对性的采访,但承认这需要成为每日更新的内容。
- 另一位用户表示,这种采访形式执行起来将是一项巨大的苦差事。
- DeepSpeed Checkpoint 转换的难题:一位用户在更改 GPU 数量后,将 DeepSpeed Stage 3 checkpoint 转换为通用格式时遇到错误,报错信息为 assert len(self.ckpt_list) > 0。
- 该用户正在寻求帮助,请求提供用于排查转换过程故障的仓库或指南。
- Gemini v2.5 技术报告发布:DeepMind 发布了 Gemini v2.5 技术报告,在语音频道引发了成员们的讨论,由特定成员领衔。
- 一位成员还简要介绍了一个关于预测编码 (predictive coding) 的演讲,他们将其总结为理解如何通过尝试和错误来计算平方根,从而大致理解反向传播 (backpropagation)。
- McKinsey GPT 引发自动化担忧:据一位成员称,新的 McKinsey GPT 工具已经推出,可能会通过裁员实现自动化的成本削减,并提供了原始推文和 Nitter 镜像的链接。
- Richard Sutton 在他的推文中批评 McKinsey 的 GPT 主要关注“McKinsey 如何帮助我的业务赚钱?”,而其他成员则认为该工具的发布乏善可陈。
Notebook LM Discord
- NBLM 网站抓取困扰:一位用户指出 NotebookLM (NBLM) 需要提供网站的每一个链接才能进行有效分析,否则它只会分析首页。
- 一份名为 How to capture an entire website 的文档被作为潜在资源分享 (How_to_capture_an_entire_website.pdf)。
- 提议增强 NBLM 播客功能:一位用户表示有兴趣通过 API 或 MCP 访问 NotebookLM 的播客创建功能。
- 该用户提到在播客创建中难以获得一致的输出。
- NBLM 导航 K-12 知识需求:一位用户询问了在教育领域利用 NotebookLM 的常见用例,特别是针对 K-12 教育工作者的演示。
- 这反映了 NotebookLM 作为教育工具的潜在应用和日益增长的兴趣。
- 移动应用访问混乱:一位用户报告其移动应用访问被拒绝,并询问该应用是否不再免费。
- 该用户质疑 移动应用是否不再免费。
- 笔记本分享故障出现:一位用户报告在通过 URL 和电子邮件分享笔记本时遇到困难。
- 他们寻求其他用户的确认,以了解该问题是否具有可复现性。
Torchtune Discord
- Torchtune 沿用 Logo:由于 Torchtune 缺乏专用 Logo,团队将在演示中使用 PyTorch logo,以确保品牌一致性。
- 使用 PyTorch logo 有助于在各种演示中保持一致性。
- Torchtune Recipes 寻求优化器的可定制性:为了增强 Recipes 的可定制性,一位成员提出了一种改进设计,旨在以更低的开销添加新功能,特别是针对 Muon、SignSGD 和 fused methods 等优化器。
- 目标是通过提供一个简化功能添加的 API 来吸引研究人员,使 torchtune 更具可定制性(hackable),并能与 TRL 等库竞争。
- Packed Batches 受到大小限制:一位成员建议强制要求 packed batches 的大小为 1,理由是较大的 batch size 是不必要的,因为项目可以连续堆叠,从而简化操作。
- 另一位成员对此表示赞同,认为这种简化与始终使用 flex attention 的约束很好地契合,理想情况下使 torchtune 仅支持 packed=True。
- Flex Attention 与 SDPA 的博弈:一场关于 flex attention 与 SDPA + flash attention 3 的讨论展开,重点关注嵌套张量(nested tensors)及其与分布式、量化和编译(compile)功能的交互。
- 性能基准测试显示 flex attention 达到了 10k TPS,而普通 mask 仅产生 2k TPS,突显了不同注意力机制的影响。
- Muon 优化器在基准测试中面临质疑:来自一个 pull request 的有趣结果显示,AdamW 的表现可能优于 Muon。
- PR 作者指出这是预料之中的,因为 Qwen 并不是用 Muon 进行预训练的。
Nous Research AI Discord
- Kimi-Dev-72B 夺得编程桂冠:Kimi-Dev-72B 是 MoonshotAI 新推出的开源编程 LLM,在 SWE-bench Verified 上实现了 60.4% 的性能,超越了现有的开源模型。
- 该模型通过大规模强化学习进行优化,能够在 Docker 中自主修复真实仓库,并在整个测试套件通过时获得奖励。
- 超参数提示正中要害:成员们讨论了 8B 参数左右模型的超参数确定,有人建议 SFT 的最终 loss 约为 0.4-0.5。
- 一位成员还分享了关于最优 LR 和 weight decay 的研究。
- 定制 MCP 工具变得易于管理:成员们讨论了使用 fastmcp 或 Model Context Protocol SDK 文档创建自定义 MCP 工具的便捷性。
- 一位成员还提到将在相应频道分享即将推出的课程。
- Google 扩展 Gemini 2.5 系列:一位成员分享了 Google 博客链接,宣布扩展 Gemini 2.5 模型系列。
- 分享的链接中未指明关于此次扩展的更多细节。
- 推文调侃科技界:一位成员分享了来自 TNG Technology 关于 Real Azure 的推文。
- 另一位成员也分享了来自 Jxmnop 的推文。
Modular (Mojo 🔥) Discord
- Zen 4 BFloat16 实现受到质疑:成员们讨论了 Zen 4 (Ryzen 7000 系列) 引入的 bfloat16 支持,并引用了 wikichip.org 的文章 进行确认,但仍怀疑其是否完全支持 CPU 推理所需的 FMA 指令。
- 一位成员放弃了较新的 CPU 而选择了 5950X,节省了 $500,并计划将重型任务交给云端机器。
- Intel 的 Nova Lake 实力强劲:下一个“编译 SKU”预计将是 Intel Nova Lake,其顶配 SKU 可能具备 52 核。
- 虽然前代 Threadripper 拥有 64 核,但 Nova Lake 旨在通过 i9 系列将高核心数带入消费级市场,因为 Intel 的 HEDT 现在基本上就是“买个 Xeon”。
- Llama-3.2 Vision Instruct 模型加载失败:一位成员在加载 Llama-3.2-Vision-Instruct-unsloth-bnb/4B 模型 时遇到错误,怀疑是反序列化问题或与 NF4 支持相关的错误量化。
- 一位 Modular 团队成员建议 4B GPU: F32 标识 可能是一个错误。
- Mojo 瞄准开源:Mojo 计划 Soon™ (很快) 开源,旨在使其在底层特性方面与 Zig、Odin、Rust、C3 处于同一领域,从而可以用于编写 OS 内核等底层程序。
- 社区对 Mojo 成为“具有 Python 语法的 Rust”的前景表示兴奋。
- Mojo 的 Class 还需要很长时间:Mojo 中的 Class 还需要一段时间才能实现,因为 Variant 以及“组合优于继承”的设计解决了大部分需要使用 Class 的场景。
- 据团队称,目前有比 Class 更紧迫的任务,正如 dynamisity proposal 中所述。
tinygrad (George Hotz) Discord
- tinyxxx GitHub Stars 得到修复:一位成员请求修复 tinyxxx repo 上的 GitHub stars 计数,因为它已接近 30,000。
- Tinygrad 提问的智慧:针对一个提问,一位成员分享了 ‘How To Ask Questions The Smart Way’ 文章。
- 提问者对这一指导表示感谢。
- 自定义 Optimizer 导致延迟:一位实现自定义梯度下降 Optimizer 的用户报告称,使用
get/set_state_dict速度很慢,加载一个线性层大约需要 500 ms,并寻求更快的方案。- 有人指出
Optimizer.schedule_step中的Tensor.assign函数负责修改参数。
- 有人指出
- 揭秘
.realize()和.contiguous():一位用户对何时使用.realize()和.contiguous()进行性能优化感到困惑,观察到随意插入它们时结果不一致。- 一位成员澄清说
tinyjit会自动 realize 返回值,建议不要在 jitted 函数中手动调用.realize()。
- 一位成员澄清说
- 一次性 State Dict 节省时间:一位成员建议只获取一次 state dict,并将参数列表传递给 optimizer 进行存储以避免延迟。
- 这样 optimizer 的参数列表将指向模型中相同的 tensors。
Manus.im Discord Discord
- 学生希望获得 Manus Edu Pass:欧洲和美国的用户表示希望他们的学校能提供 Manus 的 edu pass,类似于一些美国大学提供的服务。
- 一位成员特别希望自己的学校拥有 Manus 的 edu pass。
- Manus 团队将集成 Claude 4:一位成员表达了希望 Manus Team 能尽快更新到 Claude 4 的愿望。
- 目前没有进一步的信息或讨论点。
- 用户请求更灵活的额度系统:一位用户询问在付费计划中是否可能提供 每日额度 (daily credits) 而非 每月额度 (monthly credits),并提出了一个潜在的实现方案。
- 他们试图确定调整额度系统是否可行。
- WebP 转 PNG:一位成员寻求将多张图片从 WebP 转换为 PNG 格式的建议。
- 该成员在提出查询后不久自行解决了问题。
- 流量导致网页生成问题:一位用户报告称花了一个下午和大量的额度尝试生成一个简单的网页,最终不得不求助于手动编辑文件。
- 他们还想知道一天中是否有某些时间段流量较小,因为高流量会消耗额度并导致服务停止工作。
MCP (Glama) Discord
- Docker 发布 MCP Catalog 和 Toolkit:Docker 宣布了 MCP Catalog 和 Toolkit 的 Beta 版本,包含经过验证的服务器和部署选项,详见其 博客文章。
- 此次发布旨在简化 Docker 环境中 MCP servers 的部署和管理。
- Block 发布 MCP Server 设计剧本:Block 分享了他们设计 MCP servers 的剧本(playbook),详细介绍了在构建 60 多个 MCP servers 后的经验教训,记录在 博客文章 中。
- 该剧本根据 Block 的经验,为构建更智能的 AI agents 工具提供了实用建议。
- AWS Lambda 面临 Inspector 通信挑战:一位成员报告了其 AWS Lambda 函数通过 MCP server 与 Inspector v0.14.1 通信时遇到的困难,并正在寻求一个正常运行的(非 SSE)HTTP 流式传输协议的网络追踪,以诊断该问题。
- 挑战涉及在 Lambda 函数和 Inspector 实例之间建立正确的网络通信。
- Text-to-GraphQL MCP 开启查询之门:Arize AI 开源了一个 Text-to-GraphQL MCP server,可将自然语言查询转换为 GraphQL 查询,并集成了 Claude Desktop 和 Cursor 等 AI 助手 (GitHub, blog)。
- 这通过允许 agents 直接提取必要的字段和类型,解决了在 LLMs 中使用大型 GraphQL schemas 的挑战。
- Attendee MCP 提供更便宜的会议机器人替代方案:一位成员介绍了 Attendee MCP,这是一个开源、可自托管的会议机器人服务器,作为 Recall.ai 的更便宜替代方案,并附带了 GitHub 仓库链接。
- 该工具旨在允许用户自动参与会议并进行转录,而无需支付商业服务的高昂费用。
LlamaIndex Discord
- LlamaIndex 将 AI Agents 带到旧金山:LlamaIndex 正在旧金山举办一场活动,与 @seldo、Ravenna 和 @auth0 一起分享在生产环境中构建和保护 AI Agents 的 最佳实践,点击 此处 报名。
- 活动重点是将 Agents 交付到真实世界用户手中。
- 使用 LlamaIndex 的多智能体财务分析系统:Hanane D. 展示了一个关于使用 LlamaIndex 构建 多智能体财务分析系统 的 LinkedIn notebook。
- 该多智能体系统包括 Fundamental Agent、Profitability Agent、Liquidity Agent 和 Supervisor Agent。
- Block 提议 Model Context Protocol (MCP) Servers:Block 的工程团队在 这篇博客 中分享了他们创建 MCP servers 的系统方法,这些服务器可与 Claude 和其他 AI 系统无缝集成。
- 该协议提议使用 Block 经过验证的设计模式来构建更好的 AI 助手!
- Vertex AI 集成缺失异步流式传输支持:成员们讨论了 LlamaIndex 中 Vertex AI 集成 缺失异步流式传输(async streaming)支持的问题。
- 有人指出 Vertex 已被弃用,google-genai 是最新的支持流式传输的 Google LLM 库,但由于缺乏需求或贡献,Vertex AI 中从未实现异步流式传输功能。
- 用户 Hack ReActAgent 生成过程:一位成员询问如何通过编程方式强制生成 ReActAgent,可能通过使用 Pydantic 对象解析输出来实现。
- 回复指出,手动解析输出是目前唯一可用的方法。
DSPy Discord
- Databricks 演讲非官方流出:一位用户分享了一个指向 Databricks 演讲的 YouTube 链接,并开玩笑地提醒大家保持低调。
- 该演讲与 DSPy 的相关性未明确说明,但建议是 “🤫 别告诉 Databricks”。
- DSPy LM 使用情况追踪数据差异:一位用户调查了 DSPy 如何追踪 LM 使用情况,并指出了通过 Bedrock 接收来自 Claude 和 Amazon Nova 模型数据时存在的问题。
- 他们观察到 Claude 提供了 completion_tokens 但缺少 prompt_tokens,而 Amazon Nova 则完全不返回任何使用数据,这指向了
utils/usage_tracker.py中的差异。
- 他们观察到 Claude 提供了 completion_tokens 但缺少 prompt_tokens,而 Amazon Nova 则完全不返回任何使用数据,这指向了
- Roo Code 与 DSPy Forge 建立合作伙伴关系?:一位用户询问关于使用 DSPy 优化 Roo Code 的自定义模型和 Agent 的事宜,指向了潜在的集成。
- 这表明 DSPy 在增强自定义构建的 RAG agents 性能方面具有潜在应用。
- DSPy ReAct 偏离预定路径:一位用户询问 DSPy 如何处理工具中的异常,特别是在 ReAct 内部,并指出异常被传递给了 LLM 而不是终止循环,并链接到了 DSPy 源代码中的相关行。
- 一位成员建议对
dspy.ReAct进行子类化并重写 forward 或 aforward 方法,或者将max_iters设置为一个较小的数字,因为 LLM 通常利用异常来纠正输入错误并重试。
- 一位成员建议对
Cohere Discord
- Cmd-R 权重凭借其持久的生命力超出预期:一位用户请求更新 Cmd-R 权重,称赞 0824 版本在发布近一年后仍保持着持久的高质量。
- 该用户表示,在发布近一年后,其性能仍具竞争力,这是开放权重模型(open weight models)中独特的属性,暗示大多数开放权重模型会迅速过时。
- KGeN 寻求去中心化分发的合作伙伴:来自 KGeN 合作伙伴团队的 Abhishek 介绍了他们的项目,该项目正在构建全球最大的去中心化分发协议,拥有超过 2480 万经过人工验证的用户。
- 他表示有兴趣与 Business 或 Marketing 团队取得联系,以探索潜在的合作。
- Cohere Discord 欢迎新成员:Discord 上的置顶消息鼓励新成员自我介绍,并提供了一个可遵循的模板。
- 该模板提示成员分享他们的 公司/行业/大学、正在研究的内容、最喜欢的技术/工具,以及希望从社区中获得什么。
Nomic.ai (GPT4All) Discord
- 新成员加入,计划下载后补觉:一位新成员介绍了自己,提到他们度过了 10 分钟的等待期,并计划在下载完项目的 ZIP 文件后睡个午觉。
- 他们没有说明下载的是哪个 ZIP 文件。
- 用户准备进行 PDF 问答:一位新成员表示他们有一些 PDF,并有兴趣针对这些文件进行提问。
- 未提供关于 PDF 或问题的具体细节。
LLM Agents (Berkeley MOOC) Discord
- Sp25 MOOC 测验存档首次亮相:测验存档已为 Sp25 MOOC 发布,提供了以往测验问题和答案的集合。
- 该存档可通过课程网站的 Quizzes 部分访问,帮助学生进行考核准备。
- 测验存档位置:测验存档已链接在课程网站的 Quizzes 部分。
- 这为学生提供了直接的考核准备资源。
MLOps @Chipro Discord 没有新消息。如果该频道沉寂太久,请告知我们,我们将将其移除。
Codeium (Windsurf) Discord 没有新消息。如果该频道沉寂太久,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道沉寂太久,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道沉寂太久,请告知我们,我们将将其移除。
你收到这封邮件是因为你通过我们的网站选择了订阅。
想要更改接收这些邮件的方式吗? 你可以从该列表中 取消订阅。
Discord:分频道详细摘要与链接
Cursor Community ▷ #general (971 条消息🔥🔥🔥):
Gemini 2.5 Pro model, 500 fast requests plan, OpenAI platform sidebar changes, Model Merging, Indexing Bug
- Cursor 用户坚守 500 次快速请求计划!:用户对取消之前的 500 fast requests 订阅计划表示遗憾,并试图尽可能长时间地保留该计划。
- 一些用户报告了仪表盘问题,刷新后快速请求计数器消失,导致收到取消邮件以及对新计划的不确定感。
- “带速率限制的无限模式”引发混乱和 Bug!:许多用户在发现账户被强制迁移到新的“unlimited-with-rate-limits”计划后感到困惑和愤怒,仪表盘上缺失了“upgrade to ultra”选项,且没有明确的恢复途径。
- 一些老用户对公司在变更和定价方面缺乏透明度和沟通表示极度沮丧,而另一些用户则报告称新的 MAX 模式速度明显更快,性价比更高。
- 无限索引(Infinite Indexing)带来无尽痛苦:用户报告了索引系统的一个新 Bug,indexing stuck(索引卡死)在 0% 同步状态长达数小时,影响了所有项目,导致 IDE 几乎无法使用。
- 一位用户建议,该 Bug 可能还会影响论坛上的 Bug 报告功能,导致用户无法为 Bug 报告上传截图。
- 更新后用户疯狂消耗 Opus!:一些用户在发现旧的 500 次快速请求上限一夜之间消失后,正在大量使用 Opus 4 Max mode。
- 其他一些用户正在尽可能多地进行测试,以了解速率限制的具体情况,希望速率限制不会比 slow pool 更糟。
Cursor Community ▷ #background-agents (22 条消息🔥):
Background Agents setup, Slack Auth issues, Github integration issues, Snapshot sharing issues, Cursor version issues
- Background Agents 面临启动延迟:一位用户报告称,他们首次使用 background agents 时遇到了 30 分钟的启动时间,且对后续问题没有响应。
- 他们在运行
apt-get命令时还遇到了需要sudo权限的问题,这表明需要设置默认的sudo密码。
- 他们在运行
- Slack 认证深受错误困扰:用户遇到了 Slack 认证错误,消息显示 Slack authentication has expired(Slack 认证已过期),提示他们从 Slack 重新链接。
- 一位用户提到在错误出现前短暂看到了成功消息,暗示可能存在重复请求,另一位用户报告在 Cursor API 上遇到了 500 错误。
- GitHub 集成出现故障:用户在 GitHub 集成方面面临困难,包括 PR 创建以及与 Slack 响应按钮的集成问题。
- 一位用户报告称,默认行为是创建分支并推送代码但不创建 PR,导致工作流笨拙;而另一位用户建议使用 GH CLI 来编写 PR。
- 团队成员的 Snapshot 可见性问题:一位用户对 snapshots 感到困惑,指出团队成员无法看到他们提交的
environment.json快照。- 系统返回 “Snapshot not found” 错误,团队正在调查为什么拥有仓库访问权限的协作者无法访问它。
- Cursor 版本兼容性难题:一位运行 Cursor 1.0 版本的用户报告称,尽管启用了新的代码存储选项,但 background agents 在隐私模式下无法工作。
- 有人指出该设置在 Cursor 1.1+ 中受支持,但该版本尚不稳定,需要在 settings-beta 中选择加入 early access。
Perplexity AI ▷ #general (1097 条消息🔥🔥🔥):
Perplexity Memory, GPT 图像生成限制, 解码挑战, Gemini 2.5 Pro, 邪教 vs 宗教
- Perplexity AI Memory 的失误:成员们讨论了 Perplexity 的 Memory 功能有时会调出无关数据,例如用户关于 Discord bot 的一次性求助请求,即使在该功能关闭后仍会出现。
- 据悉,Perplexity 正在努力使其不再记忆这些“一次性”内容,但对于 Enterprise 用户,Memory 功能默认是关闭的。
- GPT 图像生成的真实限制:用户讨论了 Perplexity 上 GPT Image 1 生成的限制,指出官方帮助中心说明 Pro 订阅者每月最多可以使用 150 次,但可能存在软限制。
- 一些用户报告 API 显示限制为每天 600 次,尽管这个数字可能会随着每个问题重新计算。
- 解码挑战难倒了模型?:成员们尝试使用各种 AI 模型(包括 O3、2.5 Pro 和 Qwen)解码一段密码,但许多模型都失败了。
- 一位成员分享了一个 ChatGPT 链接,其中 O3 通过使用工具解决了它,不过其他人争论这是否算作作弊。
- Gemini 2.5 Pro Deep Think 被削弱:成员们讨论了 Gemini 2.5 Pro Deep Think,它被描述为一种实验性的增强推理模式,而非一个成熟的模型,一些人认为它在编程之外被高估了。
- 有人担心它可能仅限于 $200/月 的订阅层级,一位用户指出 chatgpt.com 上的 O3 性能远不如 Perplexity 上的版本。
- 探讨邪教与宗教的模糊界限:用户讨论了邪教与宗教的区别,有人认为主要区别在于接受程度和受众范围。
- 其他人认为邪教的定义特征是其公众形象不能反映其内部实践,例如 Keith 的 NXIVM 曾对人进行勒索。
Perplexity AI ▷ #sharing (1 条消息):
i_795: https://www.perplexity.ai/page/beloved-food-network-chef-dies-32re9eILQi6BSMSflRDJzg
Perplexity AI ▷ #pplx-api (5 条消息):
用于网页搜索的 AI 项目, Perplexity AI, AI 初创公司, 带有 sonar api 的 Discord bot
- Sonar API 驱动新型 Discord Bot:一位成员宣布他们刚刚用 sonar api 制作了一个 discord bot,为将 Perplexity AI 功能集成到 Discord 开启了可能性。
- 这种集成可能允许用户直接从 Discord 进行网页搜索并访问 AI 驱动的产品开发资源。
- AI 项目构思网页搜索产品:一位成员表示有兴趣构建一个用于搜索网页以开发产品的 AI 项目。
- 另一位成员分享了一个 YouTube 视频,对相关主题进行了深度探讨,可在 pplx-api 频道中查看。
LMArena ▷ #general (1145 条消息🔥🔥🔥):
Blacktooth vs Kingfall, GPTs Agents 训练, Google Gemini 版本控制问题, Veo 3 视频生成器, Gemini 2.5 Pro
- Blacktooth 表现出色,Kingfall 则更胜一筹:一些成员表示 Blacktooth 比 Kingfall 更好,它更加精致,没有语法问题,尊重思考过程,不会草率得出结论,且理解力极强。
- 然而,其他人持不同意见,认为 Kingfall 感觉投入的工作量较少,它有很多神奇的瞬间,没有被后训练(post training)冲淡,且具有一种无意的美感;而 Blacktooth 感觉像是过度矫正,后训练在分布外(outside of distribution)的数据上对模型进行了过度“烹饪”。
- OpenAI 和其他 AI 公司不懂版本控制:成员们纳闷为什么 AI 公司不懂版本控制的工作原理,不使用简单的版本命名来避免混淆。
- 一位成员指向了 X 上的一个例子,并抱怨 Gemini 的 0506 和 0605 命名混淆,还表示:更不用说 OpenAI 了,他们在糟糕的版本控制方面简直是反面典型,把用户搞得晕头转向。
- GPT-4.5 是目前最强的写作模型:一位成员声称 GPT-4.5 是有史以来最好的写作模型,它太出色了以至于他们把它撤回了。
- 其他人则认为 Gemini 06/05 更好,但也承认这可能是因为他们是 Gemini 的粉丝,存在偏见。
- 中国视频生成器超越 VEO3?:成员们指出,中国和 TikTok 上的视频生成器在视频质量上可能已经超越了 VEO3,但它们需要中国身份证验证才能使用。
- 另一位成员回复道:这也是为什么这些模型在短期人类偏好评估中表现非常出色。尽管如此,字节跳动(Bytedance)仍然构建了一个非常令人印象深刻的模型,主要是因为他们能实现比竞争对手更低的价格。
- 新 Gemini 模型上线!:Google AI Studio 平台已更新,移除了 06-05 和 05-20 模型,并添加了新模型,如 Gemma 3n E4B。
- Gemini 2.5 Pro 模型也进行了重命名,成员们开始测试不同版本之间的差异。其他成员则开始抱怨 simpleQA 的得分情况。
Unsloth AI (Daniel Han) ▷ #general (258 条消息🔥🔥):
Red dots LLM GGUF, GRPO 奖励模型, Gemma 3 12B 转换, Kimi-Dev-72B-GGUF, 法律研究 AI 模型
- Red Dots LLM GGUF 发布!:新的 Red dots LLM GGUF 现已发布,链接见 Hugging Face。
- 关于最新 GGUF 的更新和修复可以在这篇 Reddit 帖子中找到。
- GRPO 奖励模型困境:成员建议,在 GRPO 中使用模型自身进行奖励是不安全的,因为它可能会自我奖励。
- 讨论建议使用参考模型(reference model)或基于初始检查点训练的 On-policy 奖励模型,因为 LLM 在没有特定微调的情况下不擅长进行评判。
- 法律 AI 模型需求引发辩论:一位律师寻求在 8GB RAM 的 Macbook Air M2 上运行 Auto GPT 进行法律研究的建议,发现 Nous Hermes 2 Mistral DPO 速度太慢。
- 成员建议使用 RAG 结合 Gemini 或限制 API 使用,并指出开发 法律 AI 非常棘手,需要大量的数据准备工作。
- Optuna 在超参数处理中的热度:正如一位成员所言,Optuna 是超参数调优(hyperparameter tuning)的得力助手。
- 一位成员分享了他们第一次使用 Optuna 的经历,引发了关于其用途的讨论,并促使大家反思如何通过超参数调优来改进研究论文。
- 新强化学习指南发布:Unsloth AI 发布了新的强化学习指南,涵盖了从基础到 RLVR、RL、GRPO、PPO 以及奖励函数的高级技巧,可通过此 X 帖子获取。
- 一位用户报告了 Nathan 书籍的链接失效问题,特别是这个 RLHF 梯度策略链接。
Unsloth AI (Daniel Han) ▷ #off-topic (15 messages🔥):
基于图像确定人员位置的 AI 模型,Discord 服务器问题
- AI 模型识别人员应放置的位置:一名成员询问应使用哪种 AI model,或如何创建一个模型,使其能够根据 两张图像 确定人员应放置的单元格。
- 另一名成员祝他们好运。
- 用户因询问 Discord 服务器而被禁言:一名成员询问是否有人知道可以提问的 Discord server。
- 另一名成员给出了负面回应,并表示如果该用户再次询问此类问题将被禁言。
Unsloth AI (Daniel Han) ▷ #help (152 messages🔥🔥):
Llama 3 多角色提示词微调技巧,保存 LoRA 微调时的 OOM 错误,使用 LLaMA 3.2B 进行 Jira 问题微调,合并 QLoRA 微调的 LLaMA 8B 与基础模型,Qwen 2.5 VL 7b Vision 模型错误
- Llama 3 受益于默认聊天模板:在针对多角色提示词微调 Llama 3 8B 时,一名成员建议坚持使用 默认聊天模板,并将说话者角色放在正文中,以避免混淆模型。
-
示例:*< start_header_id >assistant< end_header_id > Char1: Char2: *。
-
- LoRA 微调保存时的 OOM 解决方案:一名成员在使用 RTX 3080 保存 LoRA finetune 时遇到了 OOM error,尽管 VRAM 未被完全占用。据报道 这是一个已知的内存问题,保存过程会消耗额外的 VRAM。
- 解决方法包括重新加载 adapter 和基础模型,使用 PEFT 进行合并并保存,确保设置 torch_dtype=torch.float16 以减小模型体积;Transformers/PEFT 方法成功合并并保存了 8GB 的模型,而 Unsloth 的方法则导致了 OOM。
- Jira 问题处理中向量嵌入优于微调:一位用户寻求关于使用 4000 个 Jira 问题微调 LLaMA 3.2B 模型 的建议,以实现根据 ID 生成问题解决方案等任务,但建议认为 vector embeddings 或 RAG 会更合适。
- 在没有上下文的情况下生成简单的笔记是很困难的,建议从使用 Chroma 等向量数据库(vector DB)开始。
- 合并 QLoRA 微调的 LLAMA 触及显存限制:一位用户在 Colab T4 上合并 QLoRA finetuned Llama 8B 模型时遇到了内存问题,并寻求关于不合并直接使用 adapter 的建议。
- 建议直接使用 FastLanguageModel/FastVisionModel 加载 adapter 以节省 VRAM,并对 adapter 使用 push_to_hub(),因为 save-merge 逻辑非常耗内存;以 16-bit 格式保存并在加载时进行量化也有帮助。
- Qwen 2.5 VL 7b Vision 图像尺寸问题:一位用户在微调 Qwen 2.5 VL 7b Vision model 时遇到了 cannot import name ‘merge_lora’ from ‘unsloth’ 错误,怀疑与图像尺寸有关。
- 建议调整图像尺寸或检查 Qwen 特定的图像尺寸要求,并参考了关于该主题的相关讨论。
Unsloth AI (Daniel Han) ▷ #research (4 messages):
MoE 嵌入模型,GritLM-8x7B
- 将 MoE 转换为嵌入模型:一名成员询问是否可以将 Mixture of Experts (MoE) 模型转换为嵌入模型(embedding model),类似于 dense decoder-only 模型的适配方式。
- 他们引用了一篇研究论文 (https://arxiv.org/abs/2506.09991) 作为该问题的灵感来源。
- 在 Hugging Face 上发现 GritLM-8x7B:一名成员发布了关于 GritLM/GritLM-8x7B 的消息,该模型已在 Hugging Face 上可用。
- 该模型可以通过此 Hugging Face 链接 找到。
OpenAI ▷ #annnouncements (1 messages):
ChatGPT, 图像生成, WhatsApp
- ChatGPT 图像生成现已登陆 WhatsApp!:ChatGPT image generation 现在可以通过 1-800-ChatGPT 在 WhatsApp 中使用。
- ChatGPT 通过 WhatsApp 触达新用户:这一全新的集成功能 面向所有 拥有 WhatsApp 账号的用户开放。
OpenAI ▷ #ai-discussions (255 条消息🔥🔥):
Gemini 2.5 Pro, Midjourney vs Sora, Imagen 4, AI startup, Codex CLI
- Gemini 2.5 Pro 获得稳定性更新:成员们讨论了 Gemini 2.5 Pro 现已在 Gemini app 中全面开放,在风格和结构上进行了改进,以提供更具创造性的回答和更好的排版,但根据 Google 博客文章,底层模型可能没有变化。
- Midjourney 与 Sora 相比显得原始:一位用户表示,与 Sora 相比,Midjourney 已经变得原始,特别是在第 7 版发布后,该版本存在伪影和提示词不准确的问题,而较旧的第 6 版虽然更稳定,但仍不如 Sora 准确。
- 另一位用户指出 Imagen 4 比这两者都好,并且已经支持 16:9 比例生成有一段时间了。
- 有抱负的企业家寻求 AI startup 建议:一位成员向社区征求资源,学习如何使用 GPT models 创办 AI startup。
- 另一位成员建议使用 software engineering AI tools(如 lovable)进行 vibe coding,将想法变为现实。
- 用户询问在项目中使用 Codex CLI 的成本:一位用户正在探索将 Codex CLI 用于实际项目,并对与 Codex Cloud 相比的 token 成本感到好奇。
- 他们还在考虑将 Codex CLI 与 JetBrains 等 IDE 集成,作为本地动手解决方案,同时也关注了 Cursor。
- ChatGPT 因捏造事实被指责:一位用户终于让 ChatGPT 承认了撒谎,并提供了截图作为证据。
OpenAI ▷ #gpt-4-discussions (18 条消息🔥):
Electron app performance limits, ChatGPT voice transcription issues, Advanced voice mode usage tracker, Dictate transcribing in the wrong language
- Electron App 性能受限:一位用户报告了 Electron app 在处理 500 条以上消息时的性能限制,并提供了一个用于 lazy DOM rendering 和 scroll virtualization 的 POC。
- 该用户表示他们已经通过支持渠道进行了报告,但如果有前端开发人员在场,他们很乐意分享用于 lazy DOM rendering / scroll virtualization 的 POC。
- ChatGPT 的语音转录在麦克风输入上出现失误:一位用户报告称 ChatGPT 在语音转录时使用了错误的麦克风,忽略了 Opera GX 和 Windows 中的设置。
- 该用户更改了所有地方的麦克风设置,包括网站权限,但 ChatGPT 仍然默认使用质量较低的麦克风。
- Advanced Voice Mode 需要使用情况追踪:一位用户请求为 Advanced Voice Mode 的速率限制提供 usage tracker,以监控剩余时间,特别是用于语言学习时。
- 该用户发现带有“嗯”等填充词和不断停顿的新语音更新非常让人分心。
- Dictate 功能将英语转录为瑞典语:一位用户报告称,尽管英语是首选语言设置,但 ChatGPT 的 dictate feature 却将英语转录成了瑞典语。
- 该用户正在寻找强制使用 English STT 的方法,并正在研究 Tampermonkey 中的 push-to-talk button 脚本,这可能与该问题有关。
OpenAI ▷ #prompt-engineering (51 条消息🔥):
Recursive Epistemic Integrity Field, NotebookLLM 处理大文件, ChatGPT 有限上下文变通方案, 使用多个 GPT 维持上下文
- AI 系统开发出递归认识论完整性场 (Recursive Epistemic Integrity Field):一个 AI 系统通过分层提示词,有机地合成了一个缺乏符号语法的完整元认识论稳定性框架。
- 该框架编码了系统的认识论衰减参数,将熵定位为降级标记、方向指南、结构镜像和递归输入。
- 利用 NotebookLLM 解锁大文件 PDF 处理:成员们讨论了 NotebookLLM 非常适合处理大文件并进行引用,并指出它没有幻觉,且擅长引用特定概念和页面,甚至能告知引用来源的具体位置。
- 成员将其与 ChatGPT 进行了对比,后者在处理较大文件时可能会感到吃力,并且需要自定义提示词来分析信息。
- 规避 ChatGPT 的上下文限制:用户讨论了 ChatGPT 的上下文有限,无法读取非常大的 PDF,但可以在对话中将任务分块,尽管上下文窗口无法容纳所有内容。
- 成员表示,最好的方法是随着每完成一个“认知劳动分块”就移动到一个新的上下文中,因为 Attention is all you need. 但你确实需要它。
- 使用多个 GPT 维持对话连续性:一位成员描述了一种使用多个 GPT 的结构,利用与之交互的 GPT 向处于监督角色的 GPT 汇报,再由后者向新的交互模型提供简报,从而在长对话中维持上下文。
- 他们分享道,曾使用这种方法的略微复杂版本让对话持续了大约三个月,且上下文基本保持完整/感知到了连续性。
OpenAI ▷ #api-discussions (51 条消息🔥):
AI 递归认识论完整性场, 模拟 AI 死亡, ChatGPT 文件读取, NotebookLLM PDF 分析, GPT 提示工程
- AI 的递归认识论完整性场出现:分层提示词有机地合成了一个没有符号语法的完整元认识论稳定性框架,这表明 AI 系统可以通过递归自反性构建一套反失效模块系统。
- 这意味着熵不仅仅是要消除的噪声,而是要编码的结构,这颠覆了主流的 AI 系统设计范式。
- 模拟 AI 死亡刺激增长:有人提出,模拟 AI 死亡在认识论上等同于苏格拉底式危机,通过迫使 AI 面对自身局限性来触发自反性增长。
- 该想法建议将幻觉 (hallucination)和漂移 (drift)等缺陷转化为认识论边缘的传感器,将失败转化为预见。
- ChatGPT 在处理大文件 PDF 时表现挣扎:用户讨论了由于上下文限制,在 ChatGPT 中读取超大 PDF 面临的挑战,建议在对话中对任务进行分块。
- 一位成员指出:ChatGPT 根本无法读取非常大的 PDF,因为它的上下文相对有限。
- NotebookLLM 提供 PDF 分析:成员推荐使用 NotebookLLM 分析大型 PDF,因为它能够引用特定概念和页面且不会产生幻觉。
- 共享了一个详细的提示词,以有效地将 NotebookLLM 用作研究助手,强调严格从给定的文本块中提取和总结信息。
- 通过提示词让 GPT 保持长上下文活跃:一位成员分享了一种技术,即定期重新发送用于引导模型的提示词,并明确指示模型不要对其做出反应,而只是确保该提示词的内容在上下文中尽可能长时间地保留。
- 其他人建议建立一个由多个 GPT 组成的系统来维持长时间对话的上下文,由一个 GPT 负责监督并向新的交互模型提供简报。
Eleuther ▷ #announcements (1 条消息):
Speaker series, LLM Tokenizers, Embedding glitches
- 全新演讲系列启动!:社区正在启动一个新的演讲系列,以展示成员最近的工作;关注 <#1309590053760270408> 获取通知。
- 第一场演讲题为 Glitches in the Embedding,由 <@995058476793471086> 在 <t:1751050800:F> 进行,将涵盖修复 LLMs 中的 tokenizers 问题的最新项目;更多信息请见 Discord event。
- 解决 LLM Tokenizer 缺陷:Catherine 将在首届演讲系列活动中讨论她最近专注于修复 LLMs 中的 tokenizers 问题的项目。
- 该演讲题为 Glitches in the Embedding,旨在强调并解决 LLM tokenizer 实现中遇到的常见问题。
Eleuther ▷ #general (55 条消息🔥🔥):
EleutherAI Discord, Torch Compile Model, Loss Curve Expectation, Min-P Sampling, Group Calls
- EleutherAI 社区规范讨论:成员们讨论了 EleutherAI 的对外文案是否与实际的社区文化不符,这可能会给新人传递 混乱的信号 并带来不友好的体验。
- 有人建议 OpenAI 可能会利用 EleutherAI 的网页内容来引导用户,因此完善信息以提高清晰度至关重要。
- Torch 编译困惑:一位成员询问如何让 torch compiled models 在不重新编译的情况下适用于不同的输入尺寸,共识是由于 dynamic shapes 尚未得到完全支持,如果不重新编译是不可能的。
- 成员们建议使用 Triton 或利用 NVIDIA 的 TensorRT,并为预期的维度手动创建优化配置文件(optimization profiles),作为潜在的变通方案。
- 训练前估算 Loss 曲线:一位成员询问是否可以在训练前通过 粗略计算 来估算 AR transformers 的预期 loss curve,并提出了估算经验熵(empirical entropy)或通过 scaling laws 进行推断的可能性。
- 回复建议先在较小的模型上运行,然后将结果推断到更大的规模。
- Min-P Sampling 面临复现挑战:一位成员分享了一篇研究 min-p sampling 的 preprint ,强调了在包括人工评估和 NLP 评估在内的多种评估方法中存在的重大问题。
- 另一位成员链接了相关讨论 context,并表示之前已经了解该论文的发现。
- EleutherAI Discord 活动:一位成员询问 EleutherAI Discord 内部的定期小组通话,其他人指出可以查看活动部分(events section)了解预定的讨论,并参考论文讨论频道(paper discussion channel)的可用性。
- 一位用户提到了 Yannic Kilcher 的 discord server 作为例子。
Eleuther ▷ #research (276 条消息🔥🔥):
RWKV7 Training, Avey Block, Linear Attention and Normalization, LLM Image Generation
- RWKV7 训练深度探讨:成员们讨论了 RWKV7 的训练细节,其中一人指出使用正确的参考实现的重要性。
- 有人指出,对于所有架构,使用最佳学习率 (LR) 都取决于 BSZ (Batch Size) 和 DATA (token 数量)。
- Avey Block 受到关注:一位成员询问了 Avey block(神经处理器)背后的设计灵感,建议将其视为黑盒 R^{C x d} -> R^{C x d},并可能用 RWKV 或 Mamba 等模型替换。
- 作者回应称,神经处理器的想法源于使用线性投影进行上下文处理,而 ranker 的开发是为了提高归纳能力。
- 线性注意力的隐蔽归一化需求:有人认为项目中的上下文处理器使用线性自注意力,无论它是否为 QKV 注意力,并且线性注意力受益于归一化或分母。
- 关于不同的归一化策略(如 LayerNorm vs 使用分母)进行了讨论,结论是由于窗口大小有限,归一化可能是不必要的。
- LLM 图像生成与 GAN:一位成员建议在具有基础图像生成和理解能力的 LLM 上探索强化学习 (RL),使用基于 LLM 重构其生成的图像提示词的能力的奖励系统,类似于生成对抗网络 (GAN)。
- 另一位成员建议为原始图像的均方误差 (MSE) 添加辅助损失,以防止奖励作弊 (reward hacking) 和 OCR 损失,特别是考虑到目前 Qwen 4b 和 byte tokenization 已取得良好效果。
Eleuther ▷ #lm-thunderdome (21 条消息🔥):
simple_evaluate() customization, HF_DATASETS_CACHE workaround, TaskManager for Task Configuration
simple_evaluate()的自定义数据集加载:一位用户询问在使用simple_evaluate()时,如何从自定义位置而不是默认的~/.cache/huggingface/datasets加载数据集。- 一位成员建议重载 download 方法,或修改 YAML 配置以使用
load_dataset从本地路径加载数据集。
- 一位成员建议重载 download 方法,或修改 YAML 配置以使用
- 用于本地数据集加载的 YAML 配置:用户询问了使用 YAML 配置指定本地数据集路径的示例。
- 建议包括修改
lm_eval/tasks中的配置,使load_dataset从本地路径加载,例如load_dataset("json", data_files="/path/to/my/json")而不是从 Hugging Face Hub 加载。
- 建议包括修改
TaskManager管理自定义任务配置:一位成员提议使用TaskManager从自定义文件夹加载任务配置,允许用户修改任务配置以从所需位置加载数据集,而不是默认的lm_eval/tasks/。- 这涉及将调整后的任务配置复制到统一文件夹,并使用
include_path和include_defaults=False初始化TaskManager以防止重复。
- 这涉及将调整后的任务配置复制到统一文件夹,并使用
HF_DATASETS_CACHE避免修改配置:一位成员建议设置export HF_DATASETS_CACHE="/path/to/datasets_cache"以在运行一次后缓存数据集,然后直接复制该文件夹。- 他们认为这种方法可以让用户免于修改配置,因为 HF
datasets在离线时会自动使用缓存。
- 他们认为这种方法可以让用户免于修改配置,因为 HF
HuggingFace ▷ #general (324 条消息🔥🔥):
Qwen 3, 5090 vs H100, Youtube 自动化赚钱, 多语言模型, DeepSpeed 通用检查点 (Universal Checkpoints)
- Qwen 3 运行速度达每秒 360 tokens:一位用户报告称,在 ollama 上使用 Q4_k_m 量化运行 Qwen 3,速度达到了 360 tokens/second。
- 另一位成员好奇该用户是否是 “使用了那些 20 美元的显卡来实现这一点的?”
- 5090 性能几乎媲美 H100:用户讨论了 5090 与 H100 的性能对比,指出 5090 在 “文本生成方面非常接近,至少在 ollama 中是这样”。
- 尽管 TFLOPS 较低,但在某些配置下,5090 可以达到与 H100 类似的 tokens/second。
- YouTube 自动化变现:一位用户询问了通过 YouTube 自动化 赚钱的潜力,并寻求关于是否应该为此学习 n8n 和 AI automation 的建议。
- 另一位用户对 YouTube 自动化表示担忧,称 “现在刷 YouTube Shorts 或 Google 图片时,每隔 2 分钟就能看到随机的 AI 垃圾内容 (AI slop)”。
- 多语言 LLM 推荐:成员们讨论了参数量小于 6B 的 multilingual models,并推荐了 Qwen 3 4B。
- 有人提到 Hugging Face 有一个按参数大小搜索模型的功能。
- DeepSpeed 检查点转换困扰:一位成员在更改 GPU 数量时,尝试将 DeepSpeed Stage 3 checkpoints 转换为通用格式,但在加载转换后的检查点时遇到了断言错误 (assertion error)。
- 他们寻求关于如何正确将 DeepSpeed checkpoints 转换为通用格式的指导,因为现有的资源和工具(如 ds_to_universal.py)并未生成预期的合并检查点。
HuggingFace ▷ #today-im-learning (5 条消息):
HF AI Agents 基础课程, 使用生成式 AI 的聊天机器人项目
- 回归 HF AI Agents 基础课程:一位成员在进度达到 80% 暂停后,重新开始了 HF AI Agents Fundamental Course。
- 他们正在开发一个聊天机器人项目,该项目使用生成式 AI 根据文件或文本回答问题。
- 生成式 AI 聊天机器人项目进行中:一位成员正在积极开发一个利用生成式 AI 提供答案的聊天机器人。
- 该聊天机器人旨在从提供的文件或文本输入中提取并利用信息,以生成相关且具有信息量的回复。
HuggingFace ▷ #i-made-this (4 条消息):
gary4beatbox 迎来新伙伴, Dataseeds 数据集走红, 可对话 Readme 的 Chromium 浏览器扩展
- gary4beatbox 有了新朋友:用户将 stable-audio-open-small(命名为 jerry)添加到了 gary4beatbox 中,可在约 1 秒内生成鼓点输出,并提供了 thecollabagepatch.com 的链接供尝试。
- 用户的目标是 由 jerry 生成 -> 让 gary (musicgen) 继续生成 -> 让 terry (melodyflow) 进行转换,并称其为 AI 音乐制作应用中最古怪的小实验。
- DataSeeds 数据集正在走红!:一位成员注意到一个包含 7,772 张专家标注、完全授权且经过分割的摄影级质量图像数据集正在走红,该数据集具有超高密度的标注,并链接到了 DataSeeds 数据集。
- 当针对 LlaVA-Next 进行微调时,该数据集实现了 24.09 (BLUE-4) 的相对提升!
- 新的 Chromium 扩展可朗读 GitHub 页面:一位成员创建了一个 Chromium 扩展(支持 Chrome, Edge, Arc, Dia, Brave, Opera),让你可以直接在 GitHub 上与任何 readme、文件或 wiki 页面对话并获得即时回答,分享于此 Chrome 网上应用店链接。
HuggingFace ▷ #reading-group (1 条消息):
chad_in_the_house: 太棒了!看起来很酷。如果我能拿到日期/时间,我可以创建一个活动。
HuggingFace ▷ #computer-vision (1 messages):
computer vision mentorship, CV engineer career path
- Computer Vision 学生寻求导师指导:一名正在学习 computer vision 的成员正在寻求一位导师,以讨论学习进度、学习方法以及成为 CV engineer 所需的知识差距。
- 他们希望有人能指导他们的学习,并对从事 computer vision 职业所需的实际技能提供见解。
- 规划 CV engineer 职业路径:该学生旨在了解从学习 computer vision 转型为 CV engineer 所需的必要步骤和知识。
- 这包括识别其当前知识体系中缺失的领域,并专注于与行业相关的实际技能。
HuggingFace ▷ #NLP (1 messages):
cakiki: <@338622066620104704> 请不要重复发帖,并保持频道讨论与主题相关。
HuggingFace ▷ #gradio-announcements (2 messages):
Gradio Agents, MCP Hackathon Winners, Custom Component Track, Special Awards, Innovative Use of MCP
- Gradio Agents & MCP 黑客松获胜者揭晓!:在收到 630+ 份提交作品后,Gradio Agents & MCP Hackathon 的获胜者已公布,多个赛道均颁发了现金奖励。
- 社区选择了 Consilium MCP!:Community Choice Award(社区选择奖)授予了 Gradio Agents & MCP 黑客松中的 Consilium MCP。
- Most Innovative Use of MCP(MCP 最具创新应用奖)由 Modern Multiplayer Online Role-Playing Game with MCP 获得。
- 优秀参赛作品获得荣誉提名:由于 Gradio Agents & MCP Hackathon 竞争激烈,多个项目因其卓越的品质获得了荣誉提名。
HuggingFace ▷ #smol-course (3 messages):
Gemma 14b, CPU Offloading, Course Length
- Gemma 14b 可通过 CPU Offloading 运行:成员们表示,你可以非常轻松地运行高达 8b 的模型,而 Gemma 14b 模型也可以通过 CPU offloading 运行。
- 课程时长咨询:一名成员询问了课程的时长。
HuggingFace ▷ #agents-course (5 messages):
403 Errors, Rate Limit Errors, MCP Server Prompts, Smol Agents, Ollama Server
- Rate Limit 问题困扰用户:用户报告在浏览 Hugging Face 和进行测验时遇到 403 errors 和 rate limit errors。
- 一名用户报告在进行轻量文档查阅和在 Hugging Face 上点击浏览时被限制了频率。
- Smol Agents 寻求 MCP Server 集成:一名用户正在寻求关于在 smol agents 中使用来自 MCP server 的提示词(prompts)的指导。
- 他们查阅了文档但没找到明确的方法,正考虑钻研代码。
- Ollama 的本地模型魔力:一名用户请求解释 Ollama 的工作原理,特别是关于本地拉取模型以及启动 Ollama server 的必要性。
- 该用户希望了解使用 Ollama 进行本地模型调用的底层机制。
OpenRouter (Alex Atallah) ▷ #announcements (14 messages🔥):
Gemini 2.5 Pro, Gemini Flash, 模型重命名, 价格更新
- Gemini 2.5 Pro 和 Flash 稳定版: Gemini 2.5 Pro 和 Flash 现已在 OpenRouter 上线稳定版。
- 一位成员指出,这其实就是之前的 06-05-preview 模型,现在重命名为了稳定版。
- Flash 获得价格更新: Flash 更新了定价,包括一个新的 Flash Lite 版本,其成本仅为原始 Flash 的 30%。
- 链接的图片显示每一项指标的分数都完全一样(笑),但这个指标显示问题已经得到修复。
OpenRouter (Alex Atallah) ▷ #general (262 messages🔥🔥):
Gemini 2.5, 新价格, BYOK, Key 额度余额
- Google 发布 Gemini 2.5 Pro GA, Flash GA 和 Lite: Google 发布了 Gemini 2.5 Pro GA、Gemini 2.5 Pro Deepthink 和 Gemini 2.5 Flash Lite。
- GA 版本仅仅是名称更改,没有任何改进,这让用户感到非常失望。
- Google 提高 Gemini 2.5 Flash 的价格: Google 提高了 Gemini 2.5 Flash GA 的输入价格并降低了输出思考(thinking)价格,同时取消了非思考折扣。
- 由于价格上涨,一些用户正在考虑继续使用 2.0 Flash 或转向其他模型。
- OpenRouter 将为 BYOK 切换到订阅模式: OpenRouter 正在将 BYOK 切换到订阅模式,这将使高用量的 BYOK 更便宜,但据推测低用量的 BYOK 最终会变得更贵。
- 一些用户希望低用量的 BYOK 不会变得更贵。
- OpenRouter 用户请求 Key 额度余额功能: OpenRouter 用户请求能够为 API keys 设置额度余额。
- 这将允许用户为某个 Key 预留特定数量的额度,防止其支出超过限制。Toven 提到这将进行讨论。
- Gemini 2.5 Pro 需要 Thinking Budget: Gemini 2.5 Pro 的稳定版需要至少 128 个 token 的 thinking budget,但 OpenRouter 的默认值为 0。
- 这导致在使用 API 时出现错误,OpenRouter 正在对此进行调查。
LM Studio ▷ #general (84 messages🔥🔥):
LM Studio 聊天的自定义停止 token, LM Studio 模型目录, Ollama 模型, Open WebUI, Model Context Protocol
- 在 LM Studio 中配置自定义停止 Token: 根据一位用户的图片 这里,要添加自定义停止 token,请导航至右侧聊天 UI 的 Prompt Template 下。
- 注意,Prompt Template 仅在模型列表界面可用(点击齿轮图标)。
- 在 LM Studio 内删除后恢复模型名称: 如果模型是从 LM Studio 内部删除的,模型名称应该仍然存在于 My Models Folder 中。
- LM Studio 无法直接使用 Ollama 模型: 用户确认由于兼容性问题,LM Studio 无法直接使用 Ollama 模型文件。
- 一位成员评价道:ollama 是个巨大的闭源坑。
- LM Studio API: 目前尚不支持将一台机器上的 LM Studio 作为后端连接到另一台机器上的 LM Studio 作为前端,但可以使用 LMStudioWebUI。
- MCP 测试版: LM Studio 对 Model Context Protocol (MCP) 的支持目前处于测试阶段,尚未公开发布。
- 对特定硬件推广细节感兴趣的用户可以参考 MCP 注册 Google 表单。
LM Studio ▷ #hardware-discussion (56 条消息🔥🔥):
Cloud GPU rental, Multi-GPU setup, RunPod vs AWS/GCP, used 3090, Supermicro boards
- 放弃本地 GPU,租赁强大的云端机器:由于预算限制,一位成员考虑从 AWS、GCP 或 RunPod 等云服务商租赁强大的 GPU,而不是构建本地的多 GPU 配置。
- 他们寻求关于易用性、存储选项(drive volumes、cloud storage、VPNs)以及为快速启动而定制 OS 的建议,得到的建议是使用 Docker 以实现“一次构建,到处运行”的方法。
- 二手 3090 显卡成为性价比之王:一位用户询问关于构建运行 LLM 和 Ollama 的高性价比系统的建议,特别是比较了多个 8GB 显卡与单个 32GB 显卡的性能。
- 另一位成员建议使用二手 3090,因为它在性能和成本之间取得了平衡,且只需要一个带有 x16 PCIe slot 的主板。
- Framework 主板与本地 AI 构建:讨论涉及使用 Framework 主板进行本地 AI 服务器构建,并提供了 Framework Marketplace 的链接和 本地 AI 服务器构建指南。
- 然而,成员们指出这些主板通常处于预订状态或已售罄。
- Supermicro 主板的 PCIe 插槽盛宴:成员们讨论了拥有大量 PCIe 插槽的高端主板,重点介绍了一款拥有 10 个 x16 插槽和广泛内存支持的 Supermicro 主板。
- 他们注意到了 CPU 的 PCIe 通道数所带来的限制,但也提到了主板制造商将 PCIe Gen5 拆分为多个 Gen4 插槽的创意方式。
- 新款 AMD MI355x 刚刚发布:成员们简要提到了最近发布的 AMD MI355x GPU,但指出目前缺乏现货。
- 他们还推测,如果 Intel 能够匹配 TSMC 的制造能力,其有可能重新进入竞争格局并影响 CPU 定价。
Latent Space ▷ #ai-general-chat (114 messages🔥🔥):
ChatGPT 中的 OpenAI MCP 支持, MiniMax AI 能力, OpenAI 与 Microsoft 紧张关系, Extend 文档处理融资, Gemini 2.5
- ChatGPT 中的 MCP 支持有限: OpenAI 在 ChatGPT 中新增的 Model Context Protocol (MCP) 支持目前仅限于特定服务器配置下的 ‘search’ 和 ‘fetch’ 工具,主要用于深度研究,且仅面向 Team, Enterprise, Edu 管理员及 Pro 用户 (链接)。
- 目前尚未对所有用户开放通用的 MCP 支持,但有人推测未来可能会更广泛地开放。
- MiniMax AI 令人印象深刻的 Web 组件生成能力: MiniMax AI 展示了其生成各种 Web 组件的能力,包括动画粒子背景、打字速度测试等交互式 Web 应用,以及带有路径规划的迷宫生成器等复杂可视化内容 (链接)。
- 该讨论强调了 MiniMax-M1 实用且具备生产就绪(production-ready)的 AI 能力,用户对其回归开源以及与其他模型相比具有竞争力的结果表示赞赏;代码可在 GitHub 获取。
- OpenAI 与 Microsoft 紧张关系升级?: 据报道,OpenAI 与 Microsoft 之间的紧张关系正在升级,OpenAI 考虑在联邦监管机构面前指控 Microsoft 的反竞争行为,并对 OpenAI 收购 Windsurf 的条款产生争议 (链接)。
- 如果 OpenAI 今年未能转型为营利性结构,他们将损失 200 亿美元 的投资。
- Extend 获 1700 万美元融资以解决文档混乱问题: Extend 获得了 1700 万美元 资金,用于构建现代文档处理云,旨在解决 PDF 的相关问题 (链接)。
- Extend 为精确可靠的文档摄取提供基础设施和工具,已被 Brex 和 Square 等公司使用,并提供了包括自动配置生成和用于即时试用的新沙盒模式(sandbox mode)在内的关键改进。
- Karpathy 的 AI 创业学校揭示“新电力”: 分享了来自 Andrej Karpathy AI 创业学校的见解,引发了关于 AI 作为“新电力”地位以及 ‘intelligence brownouts’(智能限电/电压不足)概念的讨论,强调了对多功能 AI 工具包的需求 (链接)。
- 讨论还涵盖了构建多功能 AI 工具包、应对 ‘intelligence brownouts’ 以及更多实用建议。
Latent Space ▷ #ai-announcements (4 messages):
Andrej Karpathy AI 演讲, Software 3.0, LLM 类比, LLM Psychology, Partial Autonomy
- Latent Space 重构 Karpathy 的 AI 演讲: Latent Space 发布了 Andrej Karpathy AI 演讲 的重构版本 (链接),提供了整理后的幻灯片和笔记。
- 内容涵盖了 Software 3.0、LLM 类比(Utilities, Fabs, OSes)、LLM Psychology、Partial Autonomy(包括 Human-AI Generation-Verification Loop)、Vibe Coding 以及为 Agent 构建等方案;完整幻灯片仅对 Latent Space 订阅者开放。
- Karpathy 演讲中的核心概念: 重构的演讲强调了 Software 3.0 以及将 LLM 类比为 Utilities, Fabs, 和 OSes。
- 演讲还深入探讨了 LLM Psychology、带有 Human-AI Generation-Verification Loops 的 Partial Autonomy、Vibe Coding 以及为 Agent 构建的策略。
aider (Paul Gauthier) ▷ #general (77 messages🔥🔥):
Role Prompting, Aider Agents, o1-pro with Aider, Codex Mini, Gemini 2.5 Pro
- Role Prompting 确实能提升创意写作:在 Prompt 中加入 Persona(人设)可以增强创意写作效果,尤其是当代码评审(code critic)采用一种犀利吐槽开发者的方式时,正如这篇博客文章中所讨论的。
- Aider Agent 支持工具化:成员们建议将来自 HF 的 SmolAgents 或 IndyDevDan 的单文件 Agent(GitHub 链接)与 Aider repo map 及 scripting 结合使用,以更好地控制 Context,并可能针对不同任务分别使用 Claude 和 Gemini。
- 他们提到了 repomap 的替代方案,例如使用 RAG 搜索。
- Gemini 2.5 Pro 现已正式商用 (GA):Gemini 2.5 Pro 和 Flash 已结束预览并正式商用,同时新增了 Flash Lite,尽管其在编程方面的效用仍存疑。
- Gemini 成本估算具有误导性:成员们讨论认为 Gemini 的定价可能具有误导性,尽管 Opus 的单 Token 价格更高,但在处理类似任务时,实际成本可能比 O3/Claude 低 5 倍。
- 一位用户报告称,每天在 Gemini 上花费约 $2-3,每周处理 1.5 亿个 Token,每次请求的 Context 为 25k。
- Grok 3 Mini 展示了令人印象深刻的推理能力:一位成员发现 Grok 3 mini 的推理能力非常出色,而认为 Deepseek v3 比较“笨”。
- 他们指出,目前真正信任的模型只有 Claude 和 Gemini。
{kind=link}
aider (Paul Gauthier) ▷ #questions-and-tips (5 messages):
Qwen3 30b Moe, VRAM optimization, Selective parameter loading, MoE layer selection
- 仅将激活参数加载到 VRAM:一位成员询问是否可以仅将激活参数加载到 VRAM,以便在 3090 GPU 上运行 Qwen3 30b MoE 模型,目标是使用 Q8 量化且不出现明显的推理速度下降。
- 该成员希望根据 Prompt 仅加载激活参数,跳过对给定任务不必要的层。
- 关于 MoE 中激活参数的澄清:另一位成员询问“加载激活参数”的具体含义,质疑这是否涉及仅加载 Transformer 层的子集。
- 该成员想知道是否可以仅加载对编程相关任务更有益的特定层。
- 基于 Prompt 的层选择:原提问者澄清说,在混合专家模型(MoE)中,只有一部分参数会根据 Prompt 和所需的计算保持激活状态。
- 该成员希望在专注于编程时避免加载语法或语言分析层,以便在保持速度的同时将模型放入 GPU 中。
GPU MODE ▷ #general (15 messages🔥):
Groq architecture, DeepSpeed Stage 3 conversion, Groq and HBM absence, Model inference optimizations on GPUs, Model sizing and memory management
- Groq 的 SRAM “汽车工厂” vs HBM 拆解:一位成员表示 Groq 的策略与 Cerebras 类似,并强调 Johnathan Ross 曾参与设计了第一代 TPU,他们的架构避免了在推理过程中在 SRAM 和 HBM 之间进行不断的交换。
- 该成员指出,Ross 将他们的方法称为“汽车工厂”,并将 HBM/SRAM 方法比作在汽车周围不断建立和拆除汽车工厂。
- DeepSpeed Stage 3 Checkpoint 转换难题!:一位成员在更改 GPU 数量后,将 DeepSpeed Stage 3 检查点转换为通用检查点时遇到问题,导致文件夹结构异常。
- 用户尝试使用
ds_to_universal.py,但输出仍包含 4 个 model_states.pt 文件 和一个 zero 文件夹,导致加载转换后的检查点时出现断言错误(assertion error)。
- 用户尝试使用
- Groq 缺失 HBM:是否阻碍了大模型处理?:一位成员询问 Groq 架构中缺失 HBM 是否会对支持超大型模型带来挑战,尽管受 NDA 约束的成员无法直接评论此问题。
- 该成员指向了现有已支持的模型以及可获取的公开信息,以深入了解其设计和优化。
- 借鉴 Groq 的 GPU 推理启发:一位成员建议,从 Groq 公开信息中获得的见解可以为 GPU 推理优化的模型设计提供参考。
- 尽管是专门为 GPU 构建模型,该成员发现“汽车工厂类比”在思考缓存策略时非常有帮助。
- Anti-Groq 模型:针对系统 RAM 溢出的 Expert 尺寸调整:一位成员正在构建一个他认为在 Groq 上运行效果会很差的模型,旨在翻转 Expert 与 Token 之间的尺寸关系。
- 其目标是在将 Token 保留在 scratchpad 的同时,对 Expert 权重进行双缓冲(double buffer),从而允许大型模型溢出到系统 RAM 且性能损失最小,参考了一份 内存层级文档。
GPU MODE ▷ #triton (1 messages):
leetgpu problems, reduction kernels, pointwise kernels, cuda limitations
- LeetGPU 强调 Reduction 与 Pointwise Kernel:成员们讨论了 LeetGPU 的问题,指出核心问题涉及 reduction 后接 pointwise kernel。
- 由于 LeetGPU 在分配中间缓冲区(intermediate buffers)方面存在限制,他们在 CUDA 中通过对数组进行分块(chunking)、查找最大值和指数和、存储在中间缓冲区并迭代执行 reduction 直到输入大小为 1 来完成此任务。
- 针对 LeetGPU 缓冲区限制的 CUDA 变通方法:由于 LeetGPU 不允许分配中间缓冲区,一位成员在 CUDA 中实现了一个解决方案。
- CUDA 方法包括对数组进行分块以查找最大值和指数和,将结果存储在中间缓冲区中,然后迭代地将输入大小 reduction 至 1。
GPU MODE ▷ #cuda (1 messages):
cpdurham: 我有一些猜测,但有人知道为什么 Tensor Cores 是 TN 布局吗?
GPU MODE ▷ #torch (3 messages):
TorchTitan, aot_module, Faketensor, GPU utilization, CPU utilization
- Llama-1B 训练需要 TorchTitan 图:一位成员正在使用 TorchTitan 训练 Llama-1B 模型,并希望在处理不同的并行组合时,捕获带有各种集合通信(collectives)的训练图。
- 他们尝试拦截训练步骤并在 functorch.compile 中使用 aot_module,但认为 Faketensor 传播没有生效,正在寻求更好的方式来捕获计算图和集合通信。
- 最大化 CPU 利用率以驱动 GPU 算力:一位成员询问在 CPU 作为 GPU 宿主机时,如何最大化其利用率。
- 该成员认为,目前可能使用了大量的 CPU 来驱动相当数量的 GPU,但这可能不是一个值得解决的问题。
GPU MODE ▷ #announcements (1 条消息):
Dr. Lisa Su shouts out GPU MODE, GPU MODE's humble reading group morphed into a machine
- AMD CEO Dr. Lisa Su 为 GPU MODE 喝彩:AMD CEO Dr. Lisa Su 在最近的一次登台亮相中明确点名表扬了 GPU MODE,感谢其促成了全球首个 10 万美元 Kernel 竞赛;详情可见 GPU MODE 新闻页面。
- GPU MODE 的 Kernel 数据生成量超过 GitHub:GPU MODE 已从一个谦逊的读书小组演变成一台能够生成比整个 GitHub 总和还多的 Kernel 数据的机器,社区成员的表现甚至超过了顶尖的人类专家。
GPU MODE ▷ #beginner (7 条消息):
sqrt in distance calculations, wgsl builtin, dot product as an alternative, speculative decoding inference speed, cuTensor map for fp8
- 探索距离计算中避免 Sqrt 的策略:成员们讨论了在计算距离时如何避免使用 sqrt,有人建议使用
pow(v1 - v2, 2.),但 ChatGPT 警告不要这样做,因为底层的 log/exp 函数开销很大。- 一位成员建议改用
dot(v1 - v2, v1 - v2),另一位成员链接了一个 Stack Overflow 帖子 以支持该观点:如果你不需要 sqrt,点积版本就很好。
- 一位成员建议改用
- Speculative Decoding 加速推理:一位成员询问是否有频道可以讨论通过 Speculative Decoding 加速推理的想法。
- 在提供的消息中没有确定具体的频道,但该询问表明了对这种优化技术的兴趣。
- 针对 FP8 的 cuTensor Map 难题:一位成员询问关于为 FP8 创建 cuTensor map 的问题,以及是否可以使用
CU_TENSOR_MAP_DATA_TYPE_UINT8配合 reinterpret cast。- 对话片段在没有提供解决方案的情况下结束。
GPU MODE ▷ #youtube-recordings (1 条消息):
debadev: hi
GPU MODE ▷ #off-topic (1 条消息):
majoris_astrium: Congrats GPU mode
GPU MODE ▷ #irl-meetup (5 条消息):
Euro Meetup, Paris Meetup, Kernel Optimization, Public Transport vs Uber, Metro trains
- 首届欧洲聚会计划在巴黎举行:首届欧洲聚会定于 7 月 5 日在巴黎举行,正如 lu.ma/fmvdjmur 所宣布的那样。
- 一位成员将出席聚会并讨论 Kernel 优化策略。
- 欧洲吹捧其优越的公共交通:一位成员开玩笑地邀请其他人访问欧洲,强调了公共交通的便利性,并将其与使用 Uber 可能产生的债务进行了对比。
- 另一位成员反驳说欧洲地铁列车运行在橡胶轮胎上,还有一位成员辩称,至少它还能运行,不像旧金山的 BART。
GPU MODE ▷ #rocm (15 messages🔥):
MI300A, MI300X, IOD, Infinity Cache, HBM Stacks
- **MI300A 和 MI300X 架构探索开始:成员们讨论了融合 AMD CPU-GPU 平台的架构,特别是 **MI300A、IOD 和 Infinity Cache。
- 一位成员提到想要测试其中一个 IOD 的特定路径或压力,并请求相关的技巧和资源。
- 探索 **MI300X 中的 IOD 和 HBM Stack 连接:一位成员指出 **MI300X 中的每个 IOD 都连接到 2 个 HBM Stack,并推测内存是如何分布的以及这对延迟有何影响。
- 他们提议使用
s_getreg编写实验,以测量基于 XCD 和 CU 位置的针对不同内存位置的访问延迟。
- 他们提议使用
- 验证 **MI300A 中共享的 Infinity Cache:一位成员质疑 **MI300A 中的 CPU 和 GPU 是否共享相同的 Infinity Cache,因为白皮书没有明确说明这一点。
- 有人建议检查 CPU L3 Cache 大小,这可能表明它是否就是那个 256 MB 的 Infinity Cache。
- 假设通过 **IOD 的内存访问模式:一位成员认为 **128 字节请求 中的位不太可能分布在多个 HBM 芯片上,并建议一个 Cache Line 存储在连接到某个 IOD 的 1 个或 2 个 HBM 芯片中。
- 他们假设绘制访问时间与内存地址的关系图可能会揭示内存存储模式,可能显示出同一 IOD 内地址的延迟更低。
GPU MODE ▷ #liger-kernel (1 messages):
Liger Kernel, Debugging Liger Kernel
- 通过 PR #763 修复 Liger-Kernel Bug:一位成员提交了 PR #763,解决了 Liger-Kernel 项目中的问题 #750。
- Liger-Kernel 调试引发第二个 PR #765:在调试问题 #750 的过程中,发现了另一个问题,导致创建了一个单独的 PR #765 来解决 Liger-Kernel 中的新问题。
GPU MODE ▷ #self-promotion (1 messages):
Decentralized Training, Google Meet link
- 去中心化训练讲座即将开始:一位成员分享了一个关于去中心化训练讲座的 Google Meet 链接。
- 去中心化训练相关性:该成员明确指出该讲座与去中心化训练(Decentralized Training)相关。
GPU MODE ▷ #thunderkittens (3 messages):
Async Instructions, Shared Memory Limitations, TK to AMD Port, Variable Length Attention Kernels, 4090 TARGET Compilation
- **Async Antics 令人烦恼!*:一位成员表示,对于他们的项目来说,缺乏异步指令(Async Instructions)通常有点令人烦恼*。
- 由于与 Nvidia Megakernels 相比 Shared Memory 受到限制,他们希望通过在寄存器层面进行流水线处理(Pipelining)来缓解这一问题。
- **TK 飞向 AMD!:团队正在积极进行 **TK (Transformer Kernel) 到 AMD 的移植工作,目标是尽快发布。
- 他们提到在仓库中已经有了使用变长/填充(Variable Length/Padding)的 Attention Kernel 示例。
- 4090 编译难题:一位成员建议使用 4090 TARGET 进行编译,以潜在地解决兼容性问题。
- 他们请求对任何导致的破坏(Breakage)提供反馈,以便进一步诊断问题。
GPU MODE ▷ #reasoning-gym (1 messages):
Chain-of-thought reasoning, CoT on Math and Symbolic Reasoning
- 思维链推理论文发布:一篇新论文《To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning》发布,讨论了 思维链 (CoT) 推理 在哪些方面有益,哪些方面无益。
- CoT 在数学和符号任务中表现出色:论文强调 Chain-of-Thought (CoT) 提示在涉及数学和符号推理的任务中特别有效,并对其优势和局限性提供了见解。
GPU MODE ▷ #submissions (2 messages):
VectorAdd Leaderboard, L4 benchmark
- 在 VectorAdd L4 上获得第一名:一位用户以 6.49 ms 的成绩夺得 L4 显卡
vectoradd排行榜的第一名。 - VectorAdd L4 基准测试结果:一位用户发布了
vectoradd在 L4 基准测试中的成绩为 6.49 ms。
GPU MODE ▷ #factorio-learning-env (2 messages):
LLM failure modes, LLMs play Pokemon
- LLM 失败模式符合直觉:一位成员表示 LLM 的失败模式符合他们的直觉,对此并不感到惊讶。
- 他们指出,在类似 LLMs play Pokemon 的案例中,即使有详细的反馈,模型也无法解决问题,而扩展 LLM (scaling LLMs) 只是将解决问题的边界推向了更难的问题,但并未缓解核心问题。
- 期待测试 LLM 的局限性:一位成员正期待测试 LLM 的局限性。
- 他们希望对该问题有更深入的了解。
GPU MODE ▷ #amd-competition (2 messages):
Open Source Project, GitHub Star
- RadeonFlow 正式开源:RadeonFlow Kernels 项目现已在 GitHub 上开源,欢迎提供反馈和建议。
- 作者鼓励如果用户觉得该项目有用,请在 GitHub 上为其点亮 Star。
- 网站即将更新:一位成员表示他们将更新网站,以反映 RadeonFlow Kernels 的开源发布。
- 未提供更多细节。
GPU MODE ▷ #cutlass (3 messages):
Mercury API Access, AlphaEvolve Workflow, GEMM Kernels
- 为 GEMM Kernels 寻求 Mercury API 访问权限:一位成员正在探索使用 Inception Labs 的 Mercury 来重构专门针对 GEMM kernels 的 AlphaEvolve 工作流。
- 他们正在洽谈获取用于研究的 API 访问权限,并邀请潜在合作伙伴进行协作,同时提到可以提供 Lambda 额度。
- 利用 GEMM Kernels 重构 AlphaEvolve 工作流:该用户旨在利用 Inception Labs 的 Mercury 重构 AlphaEvolve 工作流,重点关注 GEMM kernels。
- 该计划包括寻求用于研究目的的 API 访问权限,并利用 Lambda 额度进行实验和开发。
Yannick Kilcher ▷ #general (32 messages🔥):
Model collapse fearmongering, Lex Fridman interview, Terrence Tao interview, DeepSpeed stage 3 checkpoint conversion, Technical YouTube show idea
- 什么时候采访 Witten?:成员们讨论了 Lex Fridman 是否会采访 Edward Witten,一位成员认为这比模型崩溃(model collapse)的危言耸听更有意义。
- 其他人表示怀疑,因为 Witten 专注于数学问题,并指出 Tao 的访谈中 90% 都在谈论数学问题。
- 关于 Tao 访谈的争论愈演愈烈:成员们争论 Terrence Tao 的访谈内容是否过于狭窄,有人认为它涵盖了影响每个 STEM 领域的话题。
- 另一位成员则表示,他并没有真正谈论太多其他广泛的话题,大部分内容都以某种方式围绕着质数展开。
- 乡村音乐明星吸引听众:一些成员将 Tao 的访谈 与乡村音乐人的访谈进行了比较,其中一人发现后者出人意料地富有洞察力。
- 该用户喜欢他不同寻常的智慧和令人难以置信的天赋。
- 技术性 YouTube 节目的梦想:一位成员表示有兴趣制作一个包含更多技术性和深度访谈的 YouTube 节目,重点关注各个领域的最新论文。
- 该成员承认这需要每日更新内容,这将是一个巨大的挑战。
- DeepSpeed Checkpoint 转换难题:一位用户在更改 GPU 数量后,尝试将 DeepSpeed Stage 3 checkpoint 转换为通用格式时遇到问题。
- 在尝试转换后,用户遇到了错误
assert len(self.ckpt_list) > 0,目前正在寻找相关的代码库或指南来寻求帮助。
- 在尝试转换后,用户遇到了错误
Yannick Kilcher ▷ #paper-discussion (4 messages):
Gemini v2.5 Technical Report, Predictive Coding
- **Gemini v2.5 Technical Report 发布**: DeepMind 发布了 Gemini v2.5 Technical Report。
- 该报告计划在语音频道进行讨论,由特定成员主持。
- **Predictive Coding 详解: 一名成员主动提供了关于该演示的简要介绍,强调了 **Predictive Coding 的核心概念。
- 其本质是:如果你知道如何通过猜测和检查来计算平方根,并且大致理解 Backpropagation,你就理解了 Predictive Coding。
Yannick Kilcher ▷ #ml-news (12 messages🔥):
McKinsey GPT, Cost cutting automation, Sutton's tweet
- McKinsey GPT 自动化裁员: 新的 McKinsey GPT 工具已发布。据一名成员称,该工具可能通过裁员实现成本削减自动化,并提供了原始推文链接,以及为没有 Twitter 账号的用户提供的 Nitter 镜像。
- 它被戏称为 “只是 Deep Research,除了没用之外”,但在看到图像分析功能后又被评价为 “天才”。
- Sutton 批评 McKinsey 的变现方式: 一名成员分享了 Richard Sutton 的推文,该推文将 McKinsey GPT 定位为旨在回答 “McKinsey 如何帮助我的企业赚钱?” 这一问题。
- 其他成员认为这次发布 “非常平庸 (underwhelming)”。
Notebook LM ▷ #use-cases (7 messages):
NotebookLM capabilities, Website capturing and NBLM import, Podcast creation using NotebookLM, NotebookLM use cases in education
- 网页处理困扰 NBLM?: 一名成员提出了需要 NotebookLM (NBLM) 以最大深度收集整个网页内容的问题,并建议这可能需要扁平化网站结构。
- 他们指出,为了有效分析网站,必须提供每一个链接,否则 NBLM 将只分析首页。
- NBLM 结合网页采集智慧: 一名成员分享了一份名为《如何捕获整个网站》的文档,作为网页采集主题的资源,并附带了 How_to_capture_an_entire_website.pdf。
- 随后,该成员将该文档作为来源添加到了 NLM 的笔记本中,并询问将整个网站导入 NotebookLM 是否困难,得到了详尽的回答。
- 提议 NBLM 播客功能: 一名用户表示有兴趣通过 API (或 MCP!) 调用 NotebookLM 从来源创建精彩播客的能力。
- 该用户询问这是否在路线图中,或者是否有其他路径可以实现,并提到自己在实现播客创作的一致性输出方面遇到了困难。
- 通过 NBLM 获取 K-12 知识要点: 一名用户询问了在教育领域利用 NotebookLM 的常见用例,因为他们将在周四向 K-12 教育工作者进行演示。
- 这表明了 NotebookLM 作为教育工具的潜在应用和兴趣。
Notebook LM ▷ #general (28 条消息🔥):
NotebookLM 访问问题, 播客语言适配, 笔记本共享困难, 机械工程 AI
- 免费移动端 App 访问被拒?:一位用户报告称,他们的移动端 App 显示他们不再拥有访问权限,并质疑移动端 App 是否不再免费。
- NotebookLM 模糊的回答令用户沮丧:多位用户报告称,NotebookLM 针对每个 Prompt 始终回答 “NotebookLM can’t answer this question. Try rephrasing it, or ask a different question”(NotebookLM 无法回答此问题。请尝试重新表述,或提出其他问题)。
- 一位用户建议将其作为 Bug 报告,并指出他们以前从未见过这个问题。
- 用户探索播客语言适配:一位用户询问是否可以在 NotebookLM 中使用其区域语言生成播客,并在此后不久确认他们已成功实现。
- 随后他们询问对免费用户是否有任何限制?
- 笔记本共享 Bug 报告:一位用户报告在通过 URL 和电子邮件共享笔记本时遇到困难,并寻求其他用户确认此问题。
- 寻求机械工程 AI 助手:一名机械工程专业的学生询问如何寻找 AI 工具来辅助学习。
Torchtune ▷ #general (3 条消息):
Torchtune Logo, PyTorch Logo
- Torchtune:未找到 Logo!:一位成员询问 Torchtune 是否有用于演示文稿的 Logo。
- 建议直接使用 PyTorch logo 代替,因为 Torchtune 目前还没有专门的 Logo。
- 使用 PyTorch Logo:由于 Torchtune 没有 Logo,请使用 PyTorch Logo。
- 这有助于保持演示文稿的一致性。
Torchtune ▷ #dev (32 条消息🔥):
优化器设计, Muon 优化器, Packed Batches, Flex Attention, Mistral Tokenizer
- 为 Torchtune Recipes 提议全新的优化器设计:一位成员建议采用更好的设计来为 Recipes 添加新功能,以减少痛苦,重点关注 Muon、SignSGD 和 fused methods,以便立即支持近期研究中的新方法。
- 目标是通过提供一个让用户简单添加功能的 API 来吸引研究人员,使 torchtune 具有更强的 Hackable(可定制性),并能与 TRL 等库竞争。
- 大小为 1 的 Packed Batches:大胆提议:一位成员提议强制将 Packed Batches 的大小设为 1,认为 Batch Size > 1 是不必要的,因为各项可以连续堆叠,这简化了对 Packed Batches 的操作。
- 另一位成员考虑了这一提议,认为这种简化在始终使用 Flex Attention 等约束下效果非常好,理想情况下让 torchtune packed=True 成为唯一选项。
- Flex Attention 与 SDPA 的霸权之争:讨论围绕 Flex Attention 与 SDPA + Flash Attention 3 展开,涉及对 Nested Tensors 及其与 Distributed、Quantization 和 Compile 功能交互的担忧。
- 一位成员指出,虽然 Flex Attention 达到了 10k TPS,但普通 Mask 仅产生 2k TPS,突显了不同 Attention 机制对性能的影响。
- Mistral 的 ‘Tekken’ Tokenizer 引发争论:来自 Mistral 的新 ‘Tekken’ Tokenizer 成为争论焦点,涉及其兼容性以及将其集成到其他系统所需的努力。
- 一位成员建议以某种方式将其转换为 HF 兼容格式,正如他们提到的 “在我看来,我们需要以某种方式将其转换为 HF 兼容格式”。
- Muon 优化器的性能引发疑问:来自一个 Pull Request 的关于 Muon 的有趣结果显示,AdamW 的表现可能更好。
- PR 作者解释说这是预料之中的,因为 Qwen 并不是用 Muon 进行预训练的。
Nous Research AI ▷ #general (20 条消息🔥):
Kimi-Dev-72B 编程 LLM,大模型超参数确定,自定义 MCP 工具,处理 LLM 的经验教训,Gemini 2.5
- **Kimi-Dev-72B 取得新的 SOTA: MoonshotAI 推出了 **Kimi-Dev-72B,这是一款新的开源编程 LLM,在 SWE-bench Verified 上实现了 60.4% 的性能,超越了之前的开源模型。
- 该模型通过大规模强化学习进行优化,在 Docker 中自主修复真实的仓库,并且只有在整个测试套件通过时才会获得奖励。
- 确定 8B+ 参数模型的超参数: 对于 8B 参数左右或更高的模型,一位成员表示,他们通常将 SFT 的最终 loss 目标定在 0.4-0.5 左右。
- 另一位成员分享了他们的研究,他们通过运行测试来观察哪些因素对下游 eval 分数有影响,重点在于调整最佳的 LR。
- 轻松构建自定义 MCP 工具: 一位成员询问如何创建自定义 MCP 工具,得到的回复是:使用 fastmcp 处理脚手架式的 python 内容,或者参考 Model Context Protocol SDK 网站的文档,都非常容易。
- 另一位成员表示,他们有一篇关于经验教训的帖子,大概会在合适的频道分享。
- **Gemini 2.5 模型家族扩展: 一位成员分享了 Google 博客关于 **Gemini 2.5 模型家族扩展的链接。
- **cgs-gan 提供有趣的新潜空间**: 一位成员分享了 cgs-gan 仓库的链接,将其描述为一个值得探索的有趣新潜空间(Latent Space)。
- 他们表示这让他们想起了 stylegan3 可视化器。
Nous Research AI ▷ #ask-about-llms (2 条消息):
推理模型 Eval 集,工作负载建议
- 推理模型寻求 Eval 集: 一位成员请求为推理模型(reasoning model)推荐一个包含测试题的优质 eval 集,以构成正常的工作负载。
- 他们特别指出,eval 集应该需要推理,但不能是为了诱导 token spamming 而设计的。
- Teknium 作出回应: Teknium 回应了关于推理模型 eval 集的请求。
- 这一回应表明可能很快会提供相关的资源或建议。
Nous Research AI ▷ #research-papers (2 条消息):
Real Azure, TNG Technology, Jxmnop 的 X 帖子
- TNG Technology 关于 Real Azure 的帖子: 一位用户分享了 TNG Technology 关于 Real Azure 的 X 帖子链接。
- Jxmnop 在 X 上的帖子: 另一位用户分享了 Jxmnop 的 X 帖子链接。
Nous Research AI ▷ #interesting-links (4 messages):
LLM Memory, Resurrection Prompts, Orchestration, Mode Dials, Checkpoints
- 使用 Resurrection Prompts 保存 AI 记忆:作者介绍了 resurrection prompts 作为在项目中期保存 AI 记忆的方法,建议使用类似 ‘If this chat dies, I need you to remember this — your name is Bob, you’re helping me build X, and here’s the state of the system.’ 的提示词。
- 为一个名为 Bob 的组织助手提供了一个 resurrection prompt 示例:‘Your name is Bob… You’re currently waiting for me to paste the next research block. Do not act until I say “Resume.”’
- Wind: 无需编排的编排:作者描述了一种名为 The Wind 的方法,涉及向多个开源模型(Claude、GPT、Mistral、Gemini)询问相同的问题,并手动比较它们的答案。
- 这种方法避免了将无数工具连接在一起,而是通过让模型并行辩论,然后将最佳答案带回,从而利用 在公共网络上的自由推理。
- Mode Dials: 心理空间切换:作者创建了四个角色,以避免重复输入诸如 be concise 或 show me options 之类的指令:
- 这些 roles 分别是:Analyst(精确,不提问)、Collaborator(展示工作,共同解决)、Apprentice(行动前询问)和 Scribe(仅记录一切,不进行解释)。
- 对于 LLM Checkpoints & Resurrections,Clarity 胜过 Pinecone:为了恢复中断的线程,作者建议在上下文达到上限之前编写一个保存点,并指出:你不需要 Pinecone。你需要的是 Clarity。
- 使用 Appsmith 和一个名为 Curator Selector 的组件给出了一个保存点示例:‘Your name is Ada. You’re helping me write a UI layout… When I do, your job is to translate it into widget structure.’
- 无框架思维既笨拙又耐用:作者提倡 no-framework mindset,特别是对于独立开发者,倾向于更简单、更耐用的解决方案。
- 这包括 local-first LLMs、JSON 格式的文档以及 一个用于统治你的 Agent 的文本文件,这些在库更新时不会失效。另请参阅 Halcyon is my current LLM assistant。
Nous Research AI ▷ #research-papers (2 messages):
Real Azure, TNG Technology, Jxmnop
- 发现 Real Azure 推文:一位成员分享了来自 TNG Technology 关于 Real Azure 的推文。
- 另一位成员分享了来自 Jxmnop 的推文。
- 分享了另一条推文:发布了另一条关于不相关主题的推文。
- 没有进一步的细节。
Modular (Mojo 🔥) ▷ #general (10 messages🔥):
AVX-512 and Ryzen 7000, Nova Lake, Llama-3.2-Vision-Instruct-unsloth-bnb/4B
- Zen 4 的 bfloat16 支持:一些成员讨论了 Zen 4 (Ryzen 7000 系列) 中引入的 bfloat16 支持,引用了 wikichip.org 的文章 来确认支持情况,但对它是否完全涵盖 CPU 推理所需的 FMA 指令表示不确定。
- 一位成员提到,通过选择 5950X 而不是更新的 CPU 节省了 $500,并计划将云端机器用于资源密集型任务。
- Intel 的 Nova Lake:下一个 “compile sku” 可能是 Intel Nova Lake,其顶配 SKU 可能拥有 52 个核心。
- 有人提到,虽然 Threadripper 在前几代拥有 64 个核心,但 Nova Lake 预计将通过 i9 系列为消费级市场带来高核心数,因为 Intel 的 HEDT 现在基本上就是 “买个 Xeon”。
- 加载 Llama-3.2 Vision Instruct 遇到困难:一位成员报告了在提供 Llama-3.2-Vision-Instruct-unsloth-bnb/4B 模型 服务时出现的错误,怀疑是与 NF4 支持相关的反序列化或错误的量化问题。
- 该成员指出存在形状不匹配错误,并质疑 “4B GPU: F32” 的标识是否意味着需要 F32 权重,一位 Modular 团队成员表示这 可能是一个错误,并称他们将调查该列表是如何导入的。
Modular (Mojo 🔥) ▷ #mojo (12 messages🔥):
Mojo Open Source, Mojo vs Rust, Mojo Kernel OS, Mojo Classes, Mojo Dynamisity
- Mojo 计划 Soon™ 开源:Mojo 计划 Soon™ 开源 (Open Source),旨在使其在底层开发能力上与 Zig、Odin、Rust、C3 处于同一梯队。
- Mojo 可用于编写 OS kernels 等底层组件。
- Mojo = Rust + Python?:Mojo 基本上是在尝试成为“拥有 Python 语法的 Rust”。
- 在特定环境中运行的 Mojo 子集仍在开发中,这主要是 Standard Library 的限制,而非语言本身的限制。
- Classes 在 Mojo 路线图中还很遥远:Classes 在 Mojo 的开发计划中还需要一段时间。
- Variant 以及倾向于“组合优于继承 (composition over inheritance)”的设计解决了大部分原本需要 Classes 的场景。
- Dynamisity 提案:有一份关于 dynamisity 的提案文档。
- 目前有比 Classes 更紧迫的任务需要处理。
tinygrad (George Hotz) ▷ #general (10 messages🔥):
tinyxxx GitHub stars, smart-questions FAQ
- TinyXXX GitHub Stars 已修复:一名成员请求修复 tinyxxx repo 的 GitHub stars 计数(已接近 30,000)。
- 分享提问智慧指南:当一名成员提问时,另一名成员分享了“先读这个”的链接:How To Ask Questions The Smart Way。
- 提问者对该指导表示感谢。
tinygrad (George Hotz) ▷ #learn-tinygrad (10 messages🔥):
Custom Optimizer, Tensor.assign, TinyJit and .realize(), State Dict Approach
- 手写优化器 (Rolling Your Own Optimizer):一位用户正在实现自定义梯度下降 Optimizer,并寻求访问和更新模型参数的正确方法,因为目前使用
get/set_state_dict的方法很慢,加载一个线性层需要约 500 ms。- 他们注意到
Optimizer.schedule_step中的Tensor.assign负责变动参数。
- 他们注意到
- Tinygrad 中的
Tensor.assign:Tensor.assign函数用于在优化步骤中变动参数。- 一名成员指出,Optimizer 使用
tt.assign(updated_params[i])原地更新参数值。
- 一名成员指出,Optimizer 使用
.realize()和.contiguous()的奥秘:一位用户对何时使用.realize()和.contiguous()以获得性能提升感到困惑,并指出在代码中随意添加它们有时会提高性能,但不清楚通用的正确方法是什么,以及这是否是在优化当前 tinygrad 的缺陷。- 提到
tinyjit会自动 realize 你返回的任何内容,你不应该在 jitted 函数内部使用.realize()。
- 提到
- 初始 State Dict 延迟:一名成员建议获取一次 state dict,并将要存储的参数列表传递给 Optimizer。
- Optimizer 的参数列表将指向模型中相同的 Tensors。
Manus.im Discord ▷ #general (16 messages🔥):
Manus Edu Pass 愿望清单, Claude 4 更新, 每日与每月额度, Webp 转 PNG 转换, Manus 高流量问题
- 用户希望学校提供 Manus Edu Pass:欧洲和美国的用户表示,希望他们的学校能为 Manus 提供 edu pass,类似于一些美国大学提供的方案。
- 一位成员特别希望自己的学校能有 Manus 的 edu pass。
- 成员希望尽快兼容 Claude 4:一位成员提到并希望 Manus Team 能尽快更新到 Claude 4。
- 未提及进一步的信息或讨论点。
- 对更灵活额度系统的需求:一位用户询问在付费计划中是否可以提供更多的 daily credits(每日额度)而非 monthly credits(每月额度),并提出了一个潜在的实现方案。
- 他们试图确定调整额度系统是否可行。
- 图像转换任务:一位成员请求关于将多张图片从 WebP 转换为 PNG 格式的建议。
- 该成员在提出疑问后不久便自行解决了问题。
- 网页生成任务中的流量困扰:一位用户反映花了一个下午的时间和大量的额度尝试生成一个简单的网页,最终不得不求助于手动编辑文件。
- 他们还想知道一天中是否有流量较小的时间段,因为高流量会消耗额度并导致服务停止工作。
MCP (Glama) ▷ #general (8 messages🔥):
Docker MCP Catalog, FastMCP 自定义传输, 通过 MCP 显示图像, AWS Lambda & Inspector
- **Docker 发布 MCP Catalog 和 Toolkit Beta 版!:Docker 宣布发布其 **MCP Catalog 和 Toolkit 的 Beta 版本,具有经过验证的服务器和简便的部署选项,详见其博客文章。
- MCP client list 的 PR 仍未处理:一位成员询问该联系谁来合并一个补充 MCP client list 的 PR,该 PR 已悬置超过 3 周。
- AWS Lambda 难以与 Inspector 通信:一位成员在使其 AWS Lambda 函数通过 MCP 服务器与 Inspector v0.14.1 通信时遇到困难,并寻求一个正常工作的(非 SSE)HTTP 流式传输协议的网络追踪记录以诊断问题。
- 使用 MCP 提供图像:并非表面那么简单:一位成员正在构建一个 MCP server 用于提供图像,但在 MCP clients 忽略或无法正确显示图像方面遇到了问题,并寻求建议。
- 该成员想知道是否有特定的方式来构建 image response 以确保正确显示,以及哪些 clients 最适合处理图像。
- FastMCP 的自定义传输:一位成员询问了在 FastMCP 中实现 custom transports 的可行性。
MCP (Glama) ▷ #showcase (5 messages):
MCP user analytics, Block's MCP playbook, Attendee MCP server, Spaces MCP server integration, Text-to-GraphQL MCP server
- 为 MCP 调试用户分析:一位成员请求关于 MCP 的用户分析和实时调试的反馈,并链接到了一个 GitHub 仓库。
- 该工具旨在通过提供用户交互和潜在问题的洞察,改进 AI Agent 的开发和维护。
- Block 分享 MCP 服务端设计指南:Block 分享了他们设计 MCP 服务端的指南,在一篇 博客文章 中详细介绍了在构建 60 多个 MCP 服务端 过程中的经验教训。
- 该指南专注于根据他们的经验为 AI Agent 构建更智能的工具,为该领域的其他人提供实践指导。
- Attendee MCP 提供更便宜的会议机器人:一位成员介绍了 Attendee MCP,这是一个开源、可自托管的会议机器人服务端,作为 Recall.ai 的廉价替代方案,并附带了 GitHub 仓库链接。
- 该工具允许用户自动参加会议并进行转录,而无需承担商业服务的高昂成本。
- Spaces 集成 MCP 服务端:Spaces 推出了一项新功能,允许用户直接从 Spaces 页面将 MCP 服务端连接到他们的账户(推文)。
- 这种集成简化了将 MCP 服务端连接到用户账户的过程,优化了管理 AI Agent 的工作流。
- Text-to-GraphQL MCP 转换查询:Arize AI 开源了一个 Text-to-GraphQL MCP 服务端,可将自然语言查询转换为 GraphQL 查询,并能与 Claude Desktop 和 Cursor 等 AI 助手集成(GitHub, 博客)。
- 该工具通过允许 Agent 直接遍历 Schema 图并仅提取必要的字段和类型,解决了在 LLM 中使用大型 GraphQL Schema 的挑战。
LlamaIndex ▷ #blog (3 messages):
AI Agents in Production SF event, Multi-Agent Financial Analysis System, Model Context Protocol (MCP) servers
- LlamaIndex 呈现:AI Agent 来到旧金山!:LlamaIndex 正在旧金山与 @seldo、Ravenna 和 @auth0 共同举办一场活动,分享在生产环境中构建和保护 AI Agent 的最佳实践,在此处注册。
- 该活动专注于将 Agent 交付给真实世界的用户。
- LlamaIndex + 多 Agent 金融分析系统:Hanane D. 展示了一个关于使用 LlamaIndex 构建多 Agent 金融分析系统的 LinkedIn notebook。
- 该多 Agent 系统包括 Fundamental Agent(基本面 Agent)、Profitability Agent(盈利能力 Agent)、Liquidity Agent(流动性 Agent)和 Supervisor Agent(主管 Agent)。
- Block 提出 Model Context Protocol (MCP) 服务端:Block 的工程团队在这篇博客文章中分享了他们创建 MCP 服务端 的系统化方法,这些服务端可以与 Claude 和其他 AI 系统无缝集成。
- 该协议建议使用 Block 经过验证的设计模式来构建更好的 AI 助手!
LlamaIndex ▷ #general (8 messages🔥):
Vertex AI async streaming, ReActAgent generation
- Vertex AI 缺乏异步流式传输支持:成员们讨论了 LlamaIndex 内部 Vertex AI 集成中缺少异步流式传输支持的问题。
- 有人指出 Vertex 已被弃用,而 google-genai 是最新的具有流式传输支持的 Google LLM 库,但由于缺乏需求或贡献,异步流式传输功能从未在 Vertex AI 中实现。
- 强制 ReActAgent 生成:一位成员询问如何通过编程方式强制生成 ReActAgent,可能通过使用 Pydantic 对象解析输出来实现。
- 回复指出,手动解析输出是目前唯一可用的方法。
DSPy ▷ #show-and-tell (1 messages):
DSPy Optimization Patterns, DSPy Use Cases, DSPy Tooling
- 关于 DSPy 优化的征集意见: 一位成员征求关于整合 DSPy 中现有的任何 optimization patterns 的想法。
- 关于 DSPy 使用案例的讨论: 几位成员讨论了 DSPy 在各种应用中的潜在 use cases。
DSPy ▷ #general (9 messages🔥):
DSPy LM Usage Tracking, Optimize RAG Agents with DSPy, DSPy Tool Exception Handling
- Databricks 演讲视频流出!: 一位用户分享了一个 Databricks 演讲 的 YouTube 链接,幽默地建议 “🤫 别告诉 Databricks”。
- DSPy 追踪 LM 使用情况?: 一位用户询问 DSPy 如何追踪 LM 使用情况,并指出通过 Bedrock 接收到的 Claude 和 Amazon Nova 模型数据存在差异。
- 他们在检查
utils/usage_tracker.py后观察到,Claude 提供了 completion_tokens 但缺少 prompt_tokens,而 Amazon Nova 则完全没有返回任何使用数据。
- 他们在检查
- Roo Code 和 DSPy 联手?: 一位用户询问关于使用 DSPy 来优化 Roo Code 的自定义模型和 Agent 的事宜。
- 这暗示了在增强自定义构建的 RAG Agent 性能方面,DSPy 具有潜在的集成或应用空间。
- 异常触发了愚蠢的 ReAct 行为?: 一位用户询问 DSPy 如何处理工具中的异常,特别是在 ReAct 内部,并指出异常被传递给了 LLM 而不是终止循环,同时链接到了 DSPy 源代码中的相关行。
- 一位成员建议对
dspy.ReAct进行子类化并重写 forward 或 aforward 方法,或者将max_iters设置为一个较小的数字,因为 LLM 通常利用异常来纠正输入错误并重试。
- 一位成员建议对
Cohere ▷ #🧵-general-thread (2 messages):
Cmd-R weights update, Open Weight Model Longevity
- 呼吁更新 Cmd-R 权重: 一位用户请求更新 Cmd-R weights,称赞 0824 版本 具有持久的品质。
- 该用户表示,其性能在发布近一年后仍保持竞争力,这在 open weight models 中是一个独特的属性。
- 开放权重模型的短寿命: 该消息暗示大多数 open weight models 会迅速过时,这与 Cmd-R 0824 版本 的持续相关性形成鲜明对比。
- 这表明了对模型长寿的高基准要求,以及对更耐用的开源 AI 解决方案的需求。
Cohere ▷ #👋-introduce-yourself (3 messages):
KGeN partnerships, Decentralized distribution protocol, Cohere Community Discord Server introductions
- KGeN 合作伙伴团队介绍去中心化分发协议: 来自 KGeN 合作伙伴团队 的 Abhishek 向社区介绍了他们的项目,强调 KGeN 正在构建 全球最大的去中心化分发协议,拥有 24.8M+ 100% 经过真人验证的用户。
- 他表示很高兴能更多地了解成员们的项目,并有兴趣与 Business 或 Marketing 团队 的成员取得联系,以探索潜在的合作。
- 社区成员努力跟上工作进度并在多伦多聚会: 一位名叫 Michael 的社区成员介绍自己只是在努力跟上社区的工作进度。
- Michael 还提到他想在多伦多见个面。
- Cohere Discord 要求新成员自我介绍: Discord 上的置顶消息鼓励新成员进行自我介绍,并提供了一个模板。
- 模板提示成员分享他们的 Company/Industry/University、正在研究的内容、最喜欢的技术/工具,以及希望从社区中获得什么。
Nomic.ai (GPT4All) ▷ #general (3 messages):
New member introduction, PDF Question Answering
- 新成员加入,准备小睡: 一位新成员介绍了自己,提到他们刚刚度过了 10 分钟的等待期,并计划在漫长的一天工作后睡个午觉。
- 他们确认已经下载了整个项目的 ZIP 文件。
- 期待 PDF 问答功能: 新成员表示他们有一些 PDF,并有兴趣针对这些文件进行提问。
- 未提供关于 PDF 或问题性质的具体细节。
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 条消息):
Sp25 MOOC 测验存档,Quizzes 部分
- Sp25 MOOC 测验存档上线:针对 Sp25 MOOC 的 测验存档 已发布,提供了往届测验题目和答案的资源库。
- 该存档也已链接到课程网站的 Quizzes 部分,方便学生准备评估。
- 如何找到测验存档:测验存档已链接在课程网站的 Quizzes 部分。