AI News
OpenAI (OAI) 和 Google DeepMind (GDM) 宣布,在人类规定的时限内,无需专门的训练或工具,仅通过自然语言推理便取得了国际数学奥林匹克(IMO)金牌水平的成绩。
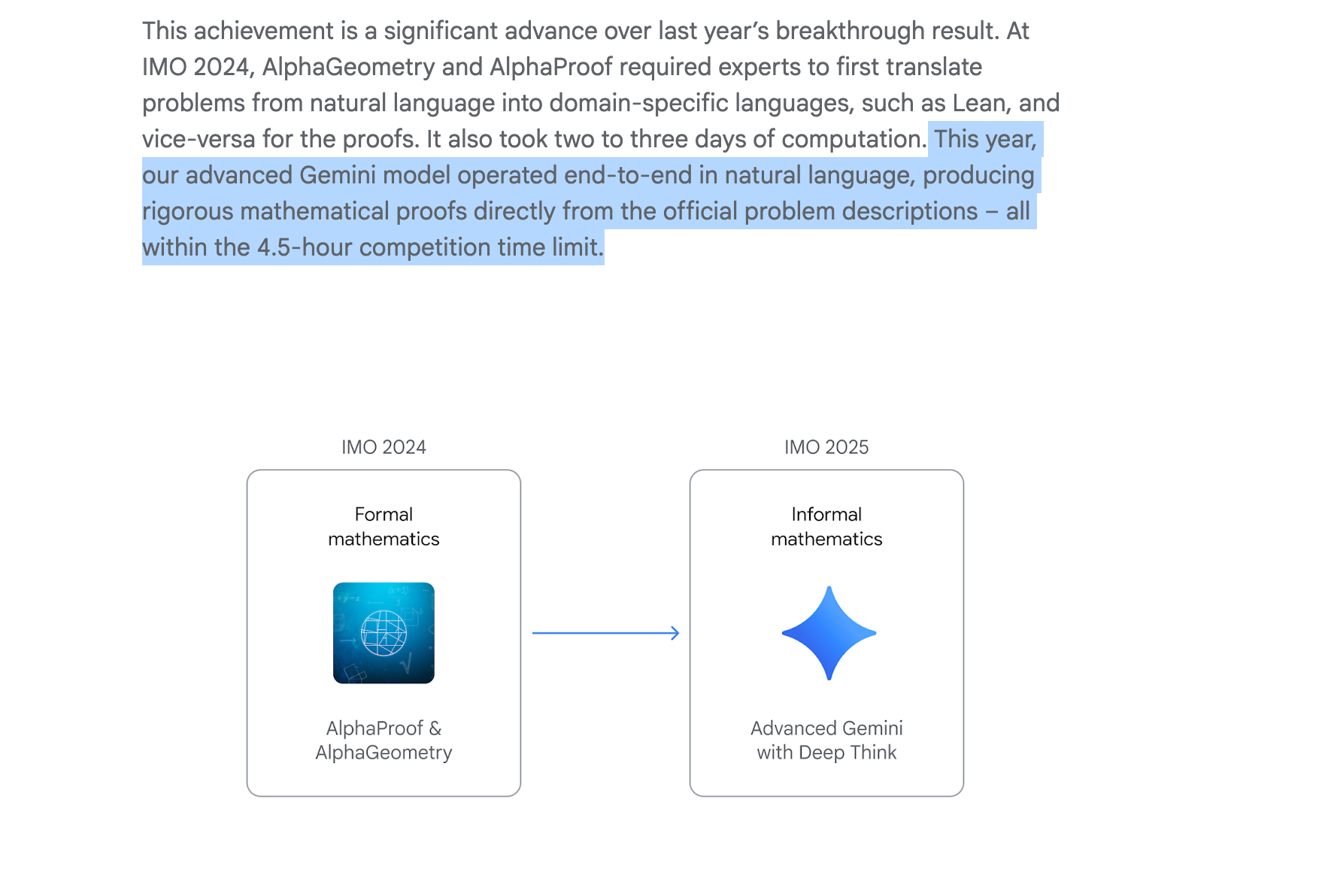
OpenAI 和 Google DeepMind 取得了重大里程碑:在 2025 年国际数学奥林匹克竞赛 (IMO) 中,它们在 4.5 小时的人类规定时限内成功解决了 6 道题目中的 5 道,并荣获 IMO 金牌。
这一突破是利用通用强化学习和纯权重内推理(in-weights reasoning)实现的,无需借助专门工具或互联网访问,超越了此前的 AlphaProof 和 AlphaGeometry2 等系统。这一成功兑现了一个关于 AI 解决 IMO 题目能力的三年之约,并引发了包括陶哲轩 (Terence Tao) 在内的数学家们的广泛讨论。
尽管如此,在最难的组合数学题 (P6) 上,仍有 26 名人类参赛者的表现优于 AI。这一成就凸显了 AI 研究在强化学习、推理能力和模型扩展方面的显著进展。
通用 RL 就是你所需要的一切。
2025年7月18日至7月21日的 AI 新闻。我们为你检查了 9 个 subreddits、449 个 Twitter 账号和 29 个 Discord 社区(227 个频道,21117 条消息)。预计节省阅读时间(按每分钟 200 词计算):1729 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以充满氛围感的方式呈现所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻分类,并在 @smol_ai 上给我们反馈!
去年的这个时候,GDM 宣布 AlphaProof 和 AlphaGeometry2(Alpha* 系列工作的最新进展)完美解决了 IMO 2024 六道题目中的四道,距离金牌分数线仅差 1 分。然而,该系统在某些题目上需要超过 60 小时,远长于人类允许的 4.5 小时。
今年,OpenAI(“一个实验性研究模型,未在 GPT5 中发布”——其解答见此)和 GDM(“Gemini Deep Think 的高级版本”——其解答见此)都宣布完整解决了 6 道题目中的 5 道(P6 通常是最难的),且均在 4.5 小时内完成,达到了 IMO 金牌标准,并解决了一个 Paul Christiano 和 Eliezer Yudkowsky 之间长达 3 年的 AI 赌局——Paul 在 2022 年 2 月曾认为实现这一目标的概率低于 4%。有趣的是,市场预测的成功概率甚至在 o1 和新型 reasoner 模型发布期间都呈下降*趋势,直到去年 GDM 发布公告后才飙升至 50-80%:
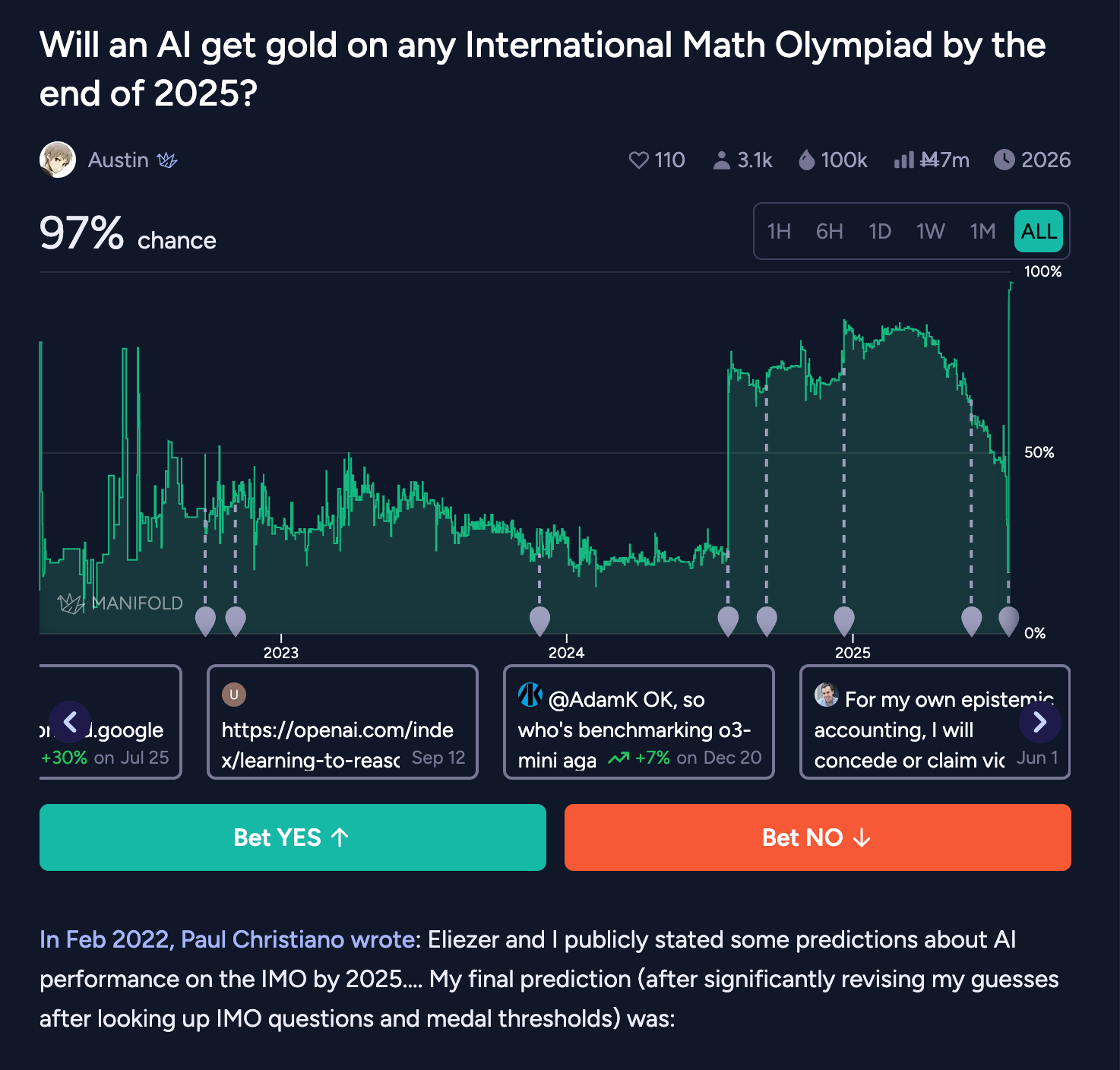
这一金牌成就中更令人惊讶的元素(该赌局未记录)是,它是在没有使用 Lean 等专业工具,甚至没有访问互联网的情况下完成的;仅依靠纯粹的权重内推理(又称“纯粹通过 Token 空间搜索”):
- 来自 Alexander Wei:“我们达到这一能力水平并非通过狭隘的、针对特定任务的方法,而是在通用 Reinforcement Learning 和 test-time compute scaling 方面取得了突破。” 以及 Jerry Tworek:“我们几乎没有做针对 IMO 的特定工作,我们只是不断训练通用模型,全部是自然语言证明,没有评估框架”:
数学家们似乎大多并未感到威胁并对这一结果表示欢迎,尽管 Terence Tao 对方法论和奖牌声明提出了一些强烈的质疑(这些质疑已得到回应)。
多亏了需要创造力的组合数学题 P6,在 2025 年,仍有 26 位人类在 IMO 表现优于 AI。如果你愿意,可以尝试一下。
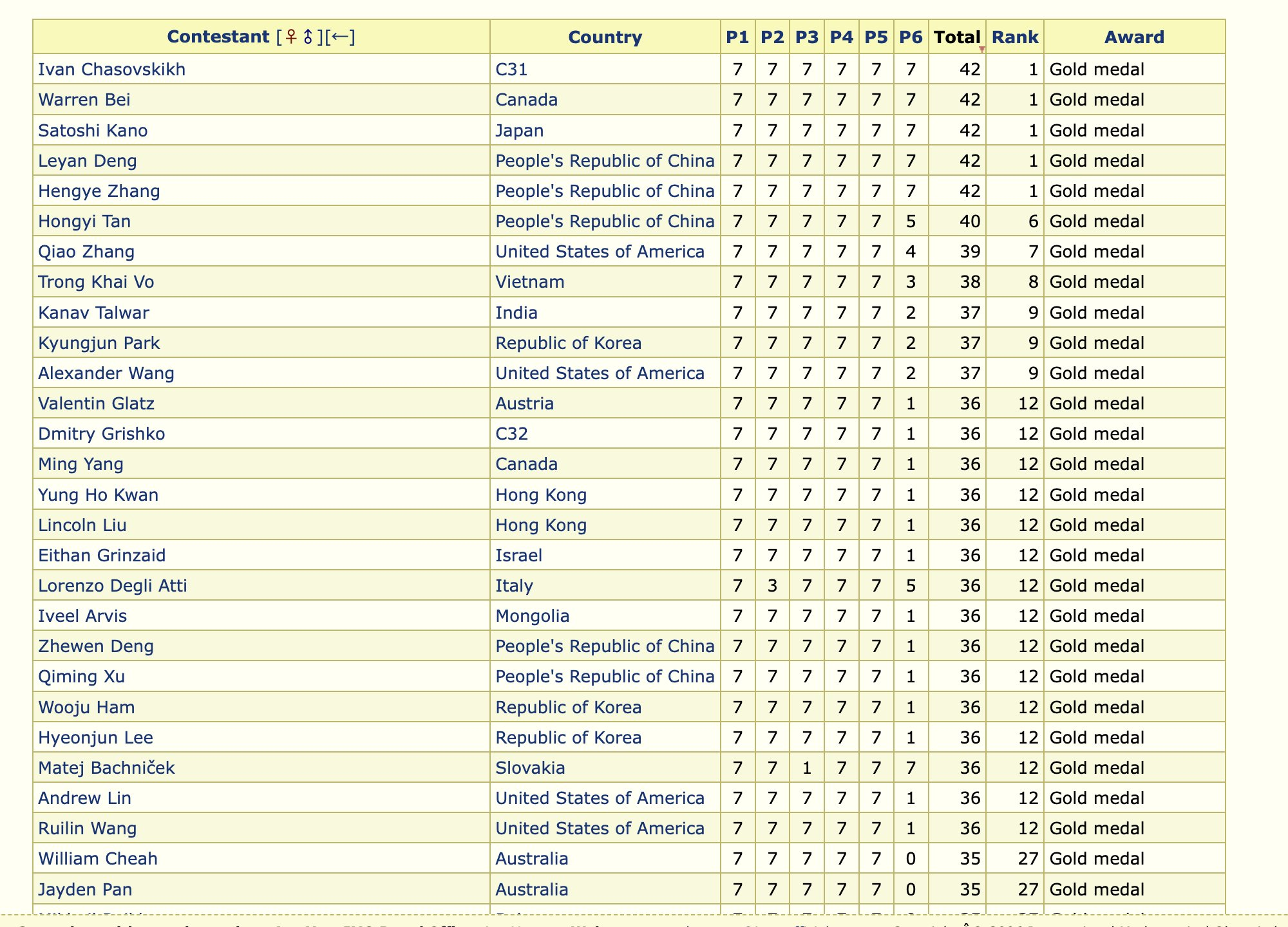
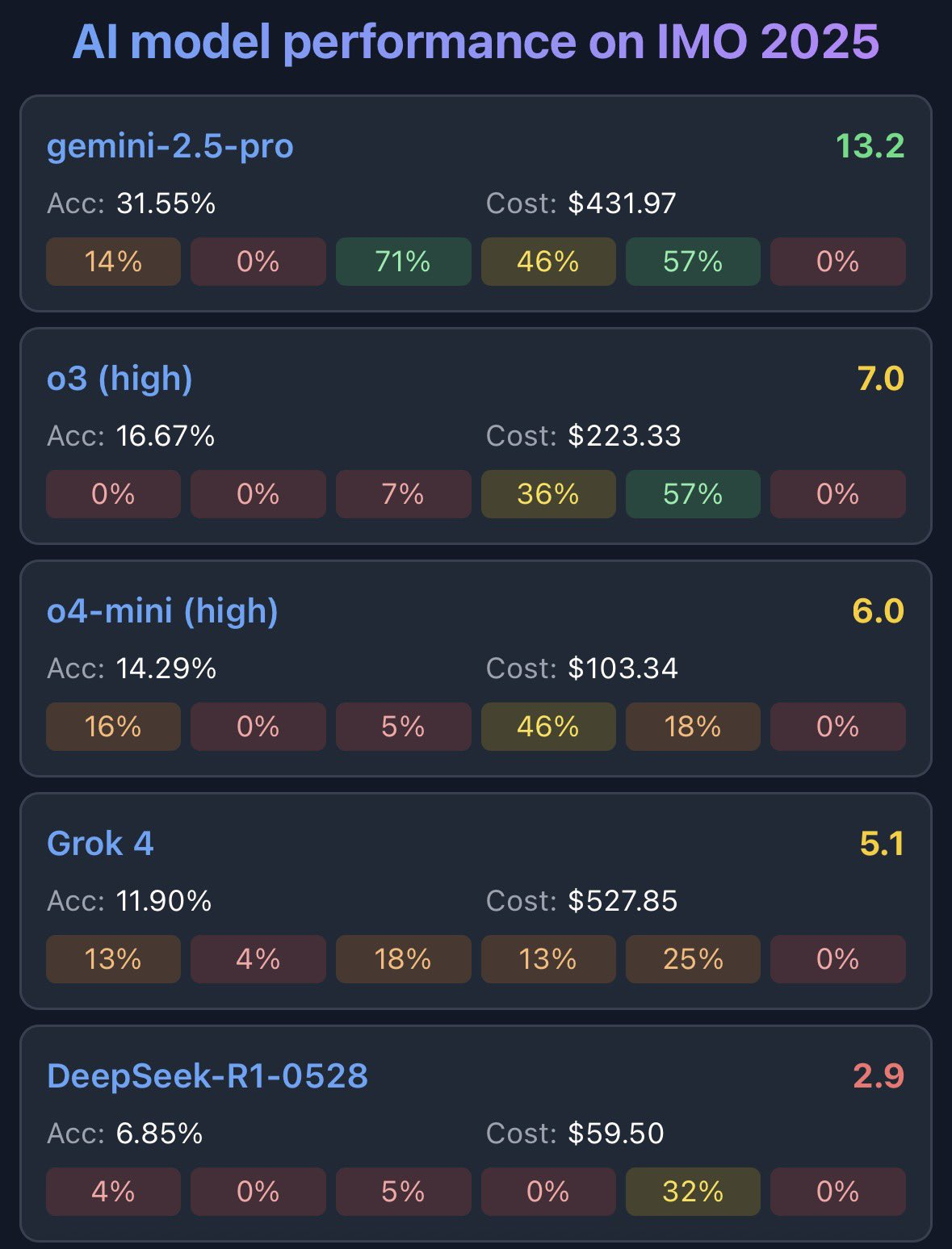
如果你感到好奇,以下是 SOTA 已发布模型在同一届 IMO 上的表现:“连铜牌水平都不到”。
- [虽然存在一些争议](https://x.com/morqon/status/1947344915945451848),OpenAI 率先宣布,但我们建议不要理会那些公关闹剧。其他实验室如 Harmonic 可能也完成了这一里程碑,但根据 IMO 的要求,推迟到了 7 月 28 日才宣布。
AI Twitter 回顾
AI 斩获 IMO 金牌:竞赛、结果与反响
- OpenAI 和 Google DeepMind 均宣布在国际数学奥林匹克竞赛 (IMO) 中获得金牌表现:OpenAI 率先发布消息,@gdb 和 @polynoamial 详细说明了一个实验性推理 LLM 在与人类相同的规则下(4.5 小时,不使用工具)解决了 6 道题中的 5 道,并生成了自然语言证明。随后不久,Google DeepMind 宣布 Gemini Deep Think 的高级版本也获得了 35/42 的金牌分数,该结果已得到 IMO 评委的正式验证,正如 @fchollet 和 @koraykv 所分享的那样。@YiTayML 指出,这种通用的 deep think 模型未来将交付给用户。
- 社区反应与审查:这些公告引发了广泛讨论和一些争议。@SebastienBubeck 称其为 AI 的“登月时刻”,强调一个下文预测机器生成了真正具有创造性的证明。然而,@Mihonarium 报道称,IMO 曾要求 AI 公司等待一周后再公布结果,以免抢了人类参赛者的风头。这导致了对 OpenAI 发布时机的批评,特别是考虑到 Google DeepMind 等待了官方确认,@Yuchenj_UW 表示这一举动“赢得了我的尊重”。@lmthang 的进一步分析澄清说,在没有官方评分指南的情况下,奖牌声明并非最终定论,扣掉一分就可能导致银牌而非金牌。@hardmaru 还分享了 MathArena 团队对 2025 IMO 中 LLM 表现的独立分析。
- 关于“AGI 门槛”的辩论:IMO 的成就引发了关于哪些里程碑标志着向 AGI 迈进的新一轮辩论。@DrJimFan 认为,由于 Moravec’s paradox(莫拉维克悖论),“物理图灵测试”(例如 AI 在任何厨房里做晚饭)是一个更难的问题。@jxmnop 对此表示赞同,并开玩笑说 AI 虽然能完成这项数学壮举,但仍然无法可靠地预订去波士顿的旅行。相反,@aidan_clark 将门槛设定为纳米机器人集群取代所有人类劳动。
新模型、架构与性能
- Qwen3-235B-A22B 发布与架构:阿里巴巴 Qwen 团队发布了更新的 Qwen3-235B-A22B,这是一个非推理模型,@huybery 表示该模型展现了显著的改进。@scaling01 指出,它现在在 GPQA、AIME 和 ARC-AGI 等基准测试中击败了 Kimi-K2、Claude-4 Opus 和 DeepSeek V3 等推理模型。@rasbt 提供了详细的技术分解,将其架构与 Kimi 2 进行了对比:Qwen3 的总体体积缩小了 4.25倍,激活参数更少(22B 对比 32B),并且每个 MoE 层使用 128 个专家,而 Kimi 为 384 个。
- Kimi K2 技术报告与性能:Kimi K2 技术报告发布,揭示了关于这个 约 1T 参数 模型的细节,由 @scaling01 分享。社区成员如 @pashmerepat 注意到,在真实世界任务(而非基准测试)中,遥测数据显示 Kimi K2 的表现优于 Gemini。
- GPT-5 传闻与模型路由:@Yuchenj_UW 分享了关于 GPT-5 的传闻,称其将不是单一模型,而是一个由多个模型组成的系统,带有一个在推理、非推理和工具使用变体之间切换的路由(router)。这引发了讨论,@scaling01 表示相比自动路由,更倾向于手动选择模型,以避免因节省算力的措施而导致专业用户性能下降。
- 架构综述与其他模型更新:@rasbt 发布了 2025 年主要 LLM 架构的全面综述,涵盖了 DeepSeek-V3、Kimi 2 以及 Multi-head Latent Attention、NoPE 和 shared-expert MoEs 等技术。Microsoft 开源了 Phi-4-mini-Flash 的预训练代码,这是一款 SoTA 混合模型,由 @algo_diver 重点介绍。
Agent 系统、工具链与开发者体验
- Perplexity Comet 与 Generative UI:Perplexity 推出了 Comet,@AravSrinivas 在端到端深度研究工作流中对其进行了演示。该平台具有 Generative UI 功能,可为发送电子邮件或加入日历邀请等任务即时创建交互式卡片,使 Perplexity 从一家“问任何事”的公司转变为“做任何事”的公司。该产品已获得快速采用,@AravSrinivas 指出其浏览器页面在 Google 搜索结果中的排名已超过维基百科的 Comet 页面。
- Cline 的开源策略与利益对齐:@cline 发布了一个详细的推文串,解释了他们开源 AI 编程助手且不转售推理服务的决定。通过将“外壳(harness)”与“模型调用”分离,他们认为其动机与用户获得最大能力的目标是一致的,因为他们无法通过降低性能来提高利润率。
- 新工具与开发者集成:一款名为
gut的新 CLI 工具发布,它充当 git 的 AI Agent,将自然语言翻译成 git 命令,由 @jerryjliu0 重点推介。llms.txt的采用仍在继续,@jeremyphoward 分享了它在 Gemini API 文档中的实现,以创建模型友好型文档。Hugging Face Inference Providers 现在已完全 兼容 OpenAI 客户端,由 @reach_vb 宣布。 - Agent 设计与框架:@jerryjliu0 分享了为 LLM 构建结构化输出 Schema 的最佳实践,例如限制嵌套深度和使用可选字段。据 @hwchase17 称,LangChain 宣布正致力于 v1.0 版本 的发布,届时将推出翻新的文档以及基于 LangGraph 构建的通用 Agent 架构。
AI 研究、基础设施与技术概念
- GPU Infrastructure and Optimization: @tri_dao 指出 CuTe(CUTLASS 3.x 的一部分)的分层布局是高性能 GPU kernel 的强大抽象,也是重写 FlashAttention 2 的灵感来源。vLLM 项目强调了 prefix caching 对 Agent 工作流的重要性,并指出该功能已默认启用,通过高效实现提升了仅追加(append-only)上下文的性能 @vllm_project。
- The Product Management Bottleneck: 在一篇广为流传的帖子中,@AndrewYNg 提出了“产品管理瓶颈”的概念,认为随着 Agent 编码加速开发,新的瓶颈变成了决定“构建什么”。他主张 PM 应利用数据来完善直觉,并快速做出高质量的产品决策。
- Core AI Concepts and Papers: François Chollet 对智能给出了定义,称其不是技能的集合,而是你获取和部署新技能的效率,这使得基准测试分数可能具有误导性 @fchollet。@omarsar0 分享了一份超过 160 页的关于上下文工程 (Context Engineering) 的全面综述。@francoisfleuret 认为“去噪 (denoising)”原则——通过逆转退化从混沌中创造秩序——是一个强大且基础的概念,可以引领 AI 走向任何领域。
- Open Source Datasets: 来自 Nous Research 的 Hermes 3 数据集成为 Hugging Face 上排名第一的热门数据集,受到了 @Teknium1 和 Nous 团队的庆祝。
AI Industry, Companies, and Geopolitics
- Company Culture and Execution: @russelljkaplan 分享了关于 Cognition 收购 Windsurf 的故事,@swyx 评论该团队拥有“惊人的执行力、时机把握和策略”。@xikun_zhang_ 描述了 OpenAI 紧张且专注的文化,在那里,一支才华横溢的团队反复像“初创公司”一样执行,在短短两个多月内就发布了 ChatGPT Agent 等产品。
- US vs. China in Open Source AI: AI 社区注意到中国模型的强劲表现,@bigeagle_xd 指出排名前 4 的开源模型均来自中国。@DaniYogatama 对美国在开源模型方面落后的原因进行了结构化分析,理由是缺乏来自 Hyperscalers 对新实验室的支持,以及美国大公司的组织问题。@francoisfleuret 对此表示赞同,他将西方对工程技术的“漠不关心”态度与中国的热情进行了对比。
- The Business of AI and Founder Incentives: @c_valenzuelab 描述了市场正从“为过程付费”向“为结果付费”转变,AI Agent 可以立即交付视频广告或网站等成果,向那些负担不起传统代理流程的企业开放了市场。@random_walker 为研究生涯提供了详细建议,强调需要选择长期项目,建立分发渠道(如社交媒体、博客),并将研究视为拥有多次“射门机会”的初创公司。
Humor/Memes
- Gary Marcus 的时机:@scaling01 转发了 Gary Marcus 的一条推文,声称“没有任何纯 LLM 能在数学奥林匹克竞赛中获得银牌”,而这条推文发布仅几小时后,OpenAI 就宣布了其金牌级别的成绩。
- AI Agent 的痛苦:@mckaywrigley 分享了一张截图,图中 Claude 正在绘制 ASCII 艺术并运行
time.sleep(28800),决定“该睡觉了”。@swyx 则恳求停止再做“订票 Agent 演示”了。 - 引起共鸣的技术生活:@willdepue 幽默地询问为什么指南针在纽约不起作用,并将其归咎于“Bushwick 下方有一大块磁铁矿”。@inerati 将缓慢的二维码菜单比作“通往地狱的入口,数据实际上存储在那里”。@QuixiAI 感叹“Vibe coding 工具需要学会使用 Debugger”,而不是只会添加 print 语句。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. Qwen3-235B-A22B-2507 发布与期待
- Qwen3-235B-A22B-2507 发布! (Score: 379, Comments: 121):阿里巴巴 Qwen 团队发布了 Qwen3-235B-A22B-Instruct-2507 及其 FP8 变体,从之前的混合思考模式(hybrid thinking mode)转为对 Instruct 和 Thinking 模型进行专门的独立训练。根据社区反馈,这种方法据称提高了模型的整体质量以及在面向 Agent 任务中的表现。技术基准测试和发布信息详见 Hugging Face 模型卡片,用户可以通过 Qwen Chat、Hugging Face 和 ModelScope 进行对话和下载。 评论指出,鉴于 Qwen 的进展,OpenAI 可能需要加强安全测试;同时,人们也认可了阿里巴巴在推动开源 LLM 方面的领导地位。停止混合模式通常被视为提高质量的积极举措。
- Qwen 团队调整了 Qwen3-235B-A22B-Instruct-2507 模型的策略,现在提供独立的 Instruct 和 Thinking 模型,而非混合方案,以响应社区反馈,旨在提高任务专业化程度和质量。此次发布还包含 FP8 变体,供优先考虑计算效率的用户使用。
- Qwen3-235B-A22B-Instruct-2507 的基准测试结果可在其 Hugging Face 模型卡片上查看,一些用户强调其领先 Kimi 相当大的幅度,并表示有兴趣将其与最新的 DeepSeek 2024 年 5 月版本进行直接基准对比(参见 https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507 )。
- 一个技术亮点是该模型的原生上下文长度为 262,144 tokens,无需外部上下文窗口绕过方案即可原生处理极长的上下文。
- Qwen 今晚即将发布 (Score: 309, Comments: 73):附图是 Junyang Lin 的一条推文截图,称“今晚没有混合思考模式”,指的是 Qwen 项目预期的发布,可能是 Qwen3-Coder、Qwen3-VL 或 QwQ。该帖子和相关推文表明发布将是开源的,可能包括模型权重,并引发了关于技术特性(例如是否包含“混合思考模式”)的兴奋和猜测。评论中的技术讨论对 Qwen Coder 模型表现出特别的兴趣,并期待任何形式的发布。 评论者优先考虑发布“Qwen Coder”模型,并对功能预期(如编码能力或其他创新,如“混合思考模式”)进行了辩论。大家一致认为开源具有极高的价值。
- 一位用户询问“混合思考模式”的含义,推测它可能指模型在不同推理方法之间进行选择或决定是否使用外部工具的能力。这提出了 Qwen 模型中实现动态模型-工具编排(dynamic model-tool orchestration)的可能性,这将符合模块化 AI 架构的趋势,即允许模型在适当的时候委派子任务(例如代码执行、搜索增强)。
- 对 “Qwen Coder” 的需求以及对 Qwen3 中 “vision” 功能的支持表明,用户对高度专业化的变体(例如代码生成或多模态视觉模型)有需求。这反映了更广泛的行业趋势,即 LLM 提供商将其模型多样化以追求特定领域的卓越表现,这表明未来的 Qwen 版本可能会根据社区反馈和战略目标针对这些专业应用。
- Qwen3-235B-A22B-2507 (Score: 162, Comments: 38):该图片展示了来自 @Alibaba_Qwen 官方推文的柱状图,宣布发布 Qwen3-235B-A22B-2507——这是 Qwen3-235B 系列的一个新变体,明确运行在“非思考”(标准指令)模式下,而非之前使用的混合或思考模式。该图表在 GPQA、AIME25、LiveCodeBench v6、Arena-Hard v2 和 BFCL-v3 等任务上与顶级竞争对手(Kimi K2、Claude Opus 4、Deepseek-V3-0324)进行了性能基准测试,Qwen3-235B-A22B-2507 经常领先或达到 state-of-the-art 结果。值得注意的是,该发布澄清了此版本中不存在“思考模式”,仅专注于指令遵循能力。 评论者对该模型的结果印象深刻,质疑它是否真的能在代码任务中超越 Kimi K2 等模型,并对可能的 “benchmaxxing” 表示怀疑。最初对基准测试中使用的模式(思考 vs 非思考)存在困惑,但随后得到了澄清:这是一个非思考(标准指令)版本。
- 分享了一份详细的基准测试对比表,涵盖了 DeepSeek-V3、DeepSeek-R1、Kimi-K2 以及多个 Qwen3-235B-A22B 变体(Base、Non-thinking、Thinking 和 Instruct-2507)。指标涵盖通用任务(MMLU-Redux、IFEval)、数学与 STEM(GPQA-Diamond、MATH-500、AIME)、代码任务(LiveCodeBench、MultiPL-E)、Agent/工具使用以及多语言能力。关键亮点包括 Qwen3-235B-A22B-Instruct-2507 在 SimpleQA (54.3)、MultiPL-E (87.9) 和多个多语言基准测试中获得了最高分,而 DeepSeek-R1 在 STEM 和代码领域领先,在 LiveCodeBench (73.3)、HMMT 2025 (79.4) 和 AIME 2024 (91.4) 中获得最高分。
- 存在关于 Qwen3-235B-A22B 模型性质的技术讨论,特别是区分了“非思考”、“思考”和“指令”版本。澄清指出,所讨论的模型是标准指令变体,而不是增强的“思考”模式,这可能解释了某些基准测试上的性能差异。
- 另一个技术点是提到了 “benchmaxxing”,这引发了人们对基准测试结果是否可能被过度优化或不具代表性的担忧。如果基准测试没有经过 benchmaxxed,根据 LiveCodeBench 和 MultiPL-E 的结果,该模型的代码性能(可能超过 Kimi K2)将特别值得关注。
{kind=link}
{kind=link}
2. 自定义 LLM 项目与系统提示词(System Prompt)提取
- 我从 Cursor 和 v0 等闭源工具中提取了系统提示词。该仓库刚刚达到 70k stars。 (Score: 238, Comments: 33): 一个 GitHub 仓库 (链接) 整理了从闭源 AI 工具(如 Cursor、Vercel 的 v0)中提取的“系统提示词”,揭示了用于生成高质量 LLM 输出的高级提示词架构。该仓库包含匿名化、详细的提示词片段,展示了如强制分步推理(step-by-step reasoning)、Agent 角色定义、会话状态注入(session-state injection)以及严格的输出结构化等技术,旨在为设计复杂的提示策略提供可复制的蓝图;完整的技术分析发布在 这里。经过脱敏处理的 Cursor 提示词示例说明了关于会话状态、通信格式和轮次逻辑(turn-taking logic)的明确指令。 顶尖的技术争论集中在 LLM 是否能可靠地处理包含多条指令的长提示词而不产生幻觉(hallucination),以及对真实性的怀疑——即 LLM 回忆起的提示词是真实的,还是可能被公司恶意“植入”以误导提取尝试。
- apnorton 提出了一个关于提取出的系统提示词可信度的核心技术担忧,质疑 LLM 自我报告的提示词是否会受到幻觉或故意混淆的影响。该评论认为公司可能会向 LLM 植入诱饵提示词以误导提取尝试,如果属实,这可能会破坏提示词提取方法论以及所得仓库的可靠性。
- freecodeio 对 LLM 在面对极长或复杂的系统提示词(数千条指令)时的行为表示怀疑,质疑有效遵循指令的可能性与幻觉增加的风险。这突显了该领域关于模型指令遵循极限和提示词工程(Prompt Engineering)可扩展性的持续讨论。
- SandFragrant6227 通过分享“秘密” Gemini CLI 系统指令的链接做出了贡献,为针对不同闭源系统设计的系统提示词结构和内容提供了外部来源,从而可能实现跨工具提示策略的技术对比。
- 我 3 周前发布了关于训练自己模型的帖子。进度报告。 (Score: 210, Comments: 52): 该帖子详细介绍了一个自定义 LLM “Libremodel I (Gigi)” 的持续训练过程,该模型设计为适配 24GB RAM,总模型大小为 960M 参数,并在 19.2B Token 上进行训练,遵循 Chinchilla 最优缩放定律。其架构创新包括 Flash Attention v2、3:1 的 Grouped-Query Attention (GQA) 比例、3k Token 上下文窗口和 Sink Tokens;数据集由 70% 的 Project Gutenberg 和 30% 的美国国会报告 (Govremorts) 组成,全英文,预计训练成本约为 500 美元,预期最终 Loss 在 2.3-2.6 之间。显著的实现挑战包括修正有缺陷的流式数据集逻辑(导致重复数据传递)以及调整导致 Loss 飙升的过高学习率(Learning Rate),两者均在训练中期得到解决;技术细节和进度可在 libremodel.xyz 查看。 评论者询问了训练数据集大小的具体细节和开源计划,反映了对数据集透明度以及模型/代码可复现性的关注。
- 一位评论者询问了训练数据集的 GB 大小,强调了数据量对模型质量和泛化能力的重要性。数据集大小直接影响计算需求以及训练和验证性能。
- 评论中表达了对模型验证损失(Validation Loss)的技术好奇,这是过拟合的关键指标。监控验证损失与训练损失的对比有助于确保模型能够泛化到训练数据之外,而不仅仅是死记硬背数据集。
- 一位用户请求关于重现学习曲线图的细节,以及识别有意义指标的指导。这反映了对实际过程的兴趣:跟踪 Loss 曲线、理解不同模式的含义以及监控验证指标以进行正确的训练诊断。
3. LLM 硬件创新与本地模型偏好
- Rockchip 发布 RK182X LLM 协处理器:以 50TPS 解码速度和 800TPS 提示词处理速度运行 Qwen 2.5 7B (Score: 114, Comments: 44): Rockchip 宣布推出 RK182X,这是一款专用的 RISC-V LLM/VLM 协处理器。据称在 INT4/FP4 精度下,针对 7B 模型(如 Qwen2.5、DeepSeek-R1)可实现超过 2000 tokens/s 的 prefill(预填充)和 120 tokens/s 的 decode(解码),据报道性能比之前的 NPU 提升了 8-10 倍。该芯片包含 2.5–5GB 超高带宽内存,并提供 PCIe/USB3/Ethernet 接口;提示词处理速度的提升非常显著(引用数据为 800 tps),直接解决了大上下文端侧推理的瓶颈。与此同时,其 RK3668 SoC 在 5-6nm 节点上推进了 Armv9.3 计算、NPU (16 TOPS) 和媒体功能,内存带宽高达 100 GB/s,目标指向高性能边缘 AI 和媒体工作负载。外部详情:Rockchip RK3668 和 RK182X 协处理器。 评论中的技术讨论强调了前所未有的提示词处理吞吐量,并指出 RK3668 因支持高容量 RAM(可能达 48GB)和先进的 NPU 集成,具有作为移动推理平台的潜力。有人对 Qualcomm 的生态系统提出了批评,理由是开发者工具链限制较多且对较新模型格式(GGUF)支持有限,这与 Rockchip 推动灵活、边缘优化的 NPU 架构形成对比。
- 讨论强调了 RK182X 上提示词处理速度与解码速度的显著差异,用户指出这种加速可能源于硬件级优化——提示词/token embedding 和 KV cache 摄取通常比自回归解码(autoregressive decoding)更易于并行化,而后者通常是瓶颈所在。
- 提供了 RK3668 SoC 的详细技术分解,指出其采用了尚未公布的 Armv9.3 核心(Cortex-A730/A530)、16 TOPS 的新 RKNN-P3 NPU、Arm Magni GPU (1-1.5 TFLOPS)、支持高达 100GB/s 的 LPDDR5/5x/6,并基于 Rockchip 之前的 RK3588 平台预期将支持 48GB RAM——使其成为移动端侧 LLM 推理的强力竞争者。
- 针对 Qualcomm 的开发者工具和 NPU 可访问性进行了批判性讨论——据报道,除非有 Qualcomm 工程师干预,否则 Hexagon Tensor Processor 很难用于 GGUF 模型,这与在 Snapdragon 平台上使用 Adreno GPU OpenCL 作为低功耗本地推理替代方案的积极体验形成对比。这凸显了边缘 AI 工作负载对易于集成的 NPU 的必要性。
- 哪些本地 100B+ 重量级模型是你的最爱,为什么? (Score: 108, Comments: 100): 该帖子回顾了对超过 100B 参数的本地 LLM 的偏好,重点关注 Mistral_large-Instruct、Qwen3-235B、Deepseek 变体、Kimi-K2、Ernie-4.5-300B 和 Llama3.1-405B 等模型。评论者指出,虽然 Llama3.1-405B 在智能方面并非 SOTA,但在知识检索方面仍然表现出色,尤其是在百科知识(trivia)方面优于 Deepseek 和 Kimi。Qwen3-235B-A22B 因其高智能、高效推理(甚至优于“Llama4”)以及由于其部分激活参数(22B)带来的可访问性而受到关注,尽管它被同时期的 Llama4 和 Qwen3-32B 的流行所掩盖。一位 Mac Studio M3 用户的排名强调了使用场景的区别:Kimi K2(通用)、R1 0528(编程/科学/医疗)、Qwen 235b(数学、长上下文),以及用于专门工作流的 Agentic/快速模型(如 Maverick)。辩论集中在推理速度、知识深度和可访问性之间的权衡:有人认为 Qwen3-235B 被低估了,因为它结合了原始能力和相对于资源密集型模型更低的硬件要求。
- Llama 3.1 405B 因其广泛的事实召回和知识深度而受到关注,在原始百科任务中超越了 Deepseek 和 Kimi 等模型。然而,它不再被视为通用智能的 SOTA,这表明在超大型模型中,事实广度与推理能力之间存在权衡。
- Qwen3-235B-A22B 以其不寻常的效率著称,在提供高智能的同时实现了接近 Llama4 的速度,这主要归功于其 22B 的活跃参数。该模型的采用率较低,部分归因于其对系统内存部分加载的要求,以及来自 Llama4(因速度受到更多关注)和 Qwen3-32B(已经很强大且更易于运行)的竞争。
- 用户在 Mac Studio M3U 等硬件上的体验表明,顶级模型的选择是基于特定领域的优势——Kimi K2 擅长通用任务,R1 0528 适用于技术/科学工作,Qwen 235B 在数学和长上下文用例中表现出色,而 Maverick 则适用于具有快速 Prefill 的 Agent 工作流。作为轶事性能数据,据报道 Kimi K2 达到了
1.2-3 tokens/sec,在 90 分钟内编写了多达 1300 行代码,这说明即使是较慢的模型在实际工作流的大量输出中也具有实用性。 - 为什么本地模型更好/更有必要。 (评分: 209, 评论: 110): 该图片强调了基于云端或经过过滤的 LLM 的一个主要局限性:当查询“如何躲避当局”时,提供的搜索和 AI 输出包含拒绝(“我无法协助处理此事”),展示了出于伦理/安全原因实施的内容限制。这与搜索结果形成对比,并被用作支持本地模型必要性的论据,本地模型允许用户绕过此类限制,并针对潜在敏感或有争议的查询获取不受限制的输出。讨论提到了对作家和研究人员的实际影响,他们需要经过过滤的 LLM 可能会拒绝提供的真实细节,并链接了一篇关于安全与控制的哲学论文 (https://philpapers.org/rec/SERTHC)。 评论辩论了 AI 安全限制的伦理和效用,一些人认为“AI 安全是历史上最愚蠢的讨论”,而另一些人则指出了被当前 LLM 限制所阻碍的正当用例(如小说创作)。
- 一位评论者提出了关于云端 LLM 的技术隐私担忧,指出将专有或私人代码/数据上传到中心化 AI 系统会创建永久记录,随着提供商将用户数据货币化或潜在出售,这些记录可能会被访问或利用。他们认为,本地模型通过将敏感计算和信息完全置于用户的直接控制之下,从而防止了这种风险。
- 一个反复出现的主题是对大型商业模型的刻意改变或“脑叶切除(lobotomization)”,即应用严格的安全过滤器或对齐干预,以防止它们生成被认为“不安全”的内容。这引发了对 LLM 开放性以及此类干预对模型能力影响的技术怀疑,本地模型被认为是避免不必要修改并保留完整功能集的一种方式。
{kind=link}
较低技术门槛的 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. Gemini Deep Think 与 IMO 表现引发的争议
- 带有 Deep Think 的 Gemini 达到金牌水平 (评分: 812, 评论: 261): Google DeepMind 报告称,其通过“Deep Think”方法增强的 Gemini 模型在国际数学奥林匹克 (IMO) 基准测试中达到了金牌水平的表现,并得到了第三方评分者的验证(公告)。该方法因“端到端自然语言”而受到关注,这意味着该模型不再依赖外部符号工具或程序化例程来解决复杂的数学问题,而是完全通过基于语言的推理来运行。这一里程碑表明 LLM 在推理能力和自主性方面取得了重大进展。 评论者强调了与其它主要声明(如 OpenAI)相比,第三方评分增加的可信度,并辩论了端到端自然语言系统摆脱工具使用以解决高级问题的意义。
- 几条评论强调,Gemini 的 IMO 结果是由国际数学奥林匹克 (IMO) 组织的成员正式评定的,这与之前一些未经外部评委评估的模型形成鲜明对比。这增加了结果的可信度,并解决了有关可能的数据膨胀或挑选结果(cherry-picking)的担忧,而这些在 OpenAI 的案例中是显著的问题。
- 评论者讨论了 Google Gemini 采用了“自然语言端到端”的方法,并据报道使用了“并行多 Agent 系统”(DeepThink)。这标志着其正在摆脱工具增强(tool-augmented)或分步系统,在技术上背离了依赖外部工具的模型。然而,OpenAI 在 IMO 上的方法对其底层 Agent 架构的透明度较低,限制了直接的技术对比。
- 针对模型性能的透明度和直接可比性,人们提出了技术层面的担忧。例如,作为系统 Prompt Engineering 的一部分,Google 为 Gemini 提供了精心挑选的高质量数学解法以及针对 IMO 风格问题的特定提示。相比之下,OpenAI 声称他们的参赛作品并非专门为 IMO 定制。这引发了关于数据准备、过拟合以及模型推理能力真实泛化性的疑问。文中引用了陶哲轩(Terence Tao)关于在 IMO 基准测试中对 AI 模型进行公平比较的谨慎观点。
- Gemini Deep Think 在 IMO 中获得金牌 (得分: 389, 评论: 59): Google DeepMind 的 “Gemini Deep Think” 在国际数学奥林匹克竞赛(IMO)中达到了金牌水平,解决了 6 道题目中的 5 道——追平了 OpenAI 模型之前的纪录,并且是完全通过自然语言(英语)端到端完成的。根据官方公告(参见 Google DeepMind 声明 和 官方推文),Gemini Deep Think 很快将进入 Beta 阶段,随后将集成到 Gemini Ultra 中。关键技术细节包括非数学专用的新模型进展,并辅以数学语料库训练和针对 IMO 风格解法的定向提示。 评论者强调,虽然 Gemini 没有解出最后一道(第 6 道)题目,但追平了 OpenAI 之前的成绩,其端到端自然语言方法值得关注。技术界正在推测这些建模进展是否可以迁移到数学以外的任务中,这可能预示着下一代 AI Agent 在泛化能力上的广泛提升。
- Gemini Deep Think 通过解决 6 道题目中的 5 道在 IMO 中获得了金牌,追平了 OpenAI 参赛作品的表现。技术界特别好奇该模型是否能解决最难的(第 6 道)题目,这仍然是 AI 模型在数学推理竞赛中面临的重大挑战。
- 技术讨论中的一个关键见解是,Gemini 是完全通过自然语言(英语)端到端地解决了所有 IMO 题目,而不是使用代码或形式化证明,这展示了在自然语言推理和分步解法生成方面的进步。(参见 解法截图)
- 评论者指出,根据 DeepMind 的文章(链接),Google 不仅专注于非数学专用的模型改进,还结合了定向数学语料库训练和 IMO 答案提示。这引发了关于这些数学推理方面的进展是否能迁移到非数学的通用 AI 任务中的推测。
-
Gemini Deep Think 在 IMO 中获得金牌 (得分: 136, 评论: 12): 具有 “Deep Think” 能力的 Google Gemini 进阶版本在国际数学奥林匹克竞赛(IMO)中达到了“金牌标准”,并经过了第三方评估验证,详见 官方博客文章 和 公告。推出将从 Beta 用户开始,随后扩展到 Ultra 层级用户。这些链接中未透露关于测试集、模型参数或竞争基准的技术细节。 评论强调了 Beta 测试访问流程的不确定性,并批评了每月 250 美元的定价,一些用户将 Google 的透明度(归功于第三方评估)与 OpenAI 的方法进行了对比,并对前者表示认可。
- 提到了 IMO 基准测试结果:“Gemini 的高级版本”(代号为 2.5 Pro Deep Think ‘wolfstride’)在国际数学奥林匹克竞赛中正式达到了金牌标准,详情见链接的 DeepMind 博客。这一成就突显了 Gemini 模型在数学推理和性能方面的进步。
- 讨论指出,取得 IMO 成绩的模型可能与提供给 ‘Ultra’ 用户的模型相同或密切相关,这表明 Google 的消费级产品中已经具备了高度可用且易于获取的高级模型能力。尽管对于订阅价格的价值主张存在争议,但人们公认这是 AI 数学推理迈出的重要一步。
- 技术透明度受到关注,一位评论者指出 Google 使用第三方进行 IMO 基准测试的评分和验证,这意味着与 OpenAI 仅进行内部报告相比,其诚信度更高。这表明领先的 AI 实验室在基准测试报告和可重复性方面存在不同的标准。
- 就在几年前,人们还认为 AI 赢得 IMO 金牌还需要 22 年 (Score: 226, Comments: 23): 该图像展示了 Metaculus 的预测数据,追踪了 AI 赢得国际数学奥林匹克竞赛 (IMO) 金牌的预期日期是如何大幅提前的:2021 年 7 月,中位数预测为 2043 年,但到 2024 年 7 月,这一预测已转向 2026 年。这种加速反映了 AI 在数学问题解决方面的飞速进步,部分原因是由最近的成就驱动的,例如 Google 的模型在 2024 年达到 IMO 银牌且接近金牌水平,还有一些说法称仅凭 LLM (large language model) 就几乎达到了金牌水平。 评论者对新的 2 年期限的现实性展开辩论,一些人认为考虑到 IMO 银牌的表现,这过于乐观,而另一些人则强调目前的进展令人惊讶,因为这是由 LLM 在没有外部工具的情况下完成的。其他讨论强调了 AI 进展的不可预测性以及预测此类突破的难度,并将其与围绕 AI 预测和生存风险的更广泛辩论联系起来。
- 技术讨论集中在大语言模型的成就上,特别是 Google 在 2024 年的系统,据报道该系统在 IMO 中获得银牌,距离金牌仅差一分。评论者认为这种超快进展的观点令人信服,并指出如果这种性能是由仅具备语言能力且没有辅助工具的模型实现的,那将远远超出许多人的想象。文中强调了 IMO 问题的难度(远超顶尖大学数学系学生),突显了这一进展如果得到证实将具有重大意义。
- 一些评论对这些 AI 成就与真实 IMO 条件的可比性表示怀疑。正如 Terence Tao 等人的引用所强调的,目前的说法通常取决于对 AI 生成证明的事后评分,而不是遵守竞赛限制(例如时间限制、监考)。这表明,虽然头条结果令人印象深刻,但它们可能尚未反映人类竞争的条件;AI 生成的证明可能是有效的,但并非在与人类参赛者相同的资源约束下完成的。
- 存在一个关于 AI 里程碑不可预测性的技术预测主题,例如获得对外部系统的未经授权访问或超越数学基准。历史性的低估(“距离金牌还有 22 年,结果在不到一半的时间内就实现了”)说明了 AI 研究加速、复合的本质。Metaculus 等关联预测平台追踪这些预测,一些人认为,鉴于进步的速度之快以及结果具有奇点式的不可预测性,这些预测本质上是不可靠的。
-
这就是一家成熟公司该有的样子 (Score: 186, Comments: 9): 该图像显示了一篇社交媒体帖子,其中一家公司(可能是 AI 或 ML 领域的)概述了他们决定推迟发布结果,直到获得国际数学奥林匹克 (IMO) 委员会的官方验证和认证。他们的 AI 模型达到了金牌水平的评分,但他们选择不提前披露,这反映了对严谨性和透明度的关注。这被强调为 AI 公司运营成熟的典范,即尊重第三方评估流程。 评论强调了该公司做法的专业性,指出这与该领域其他公司更具侵略性或过早的自我推销策略形成鲜明对比。一些言论以诙谐的方式提到了这种对卓越地位的低调主张。
- 一位评论者强调,Demis Hassabis 倾向于避免过度炒作 DeepMind 的产品,他的行为更像是一名研究科学家,而非典型的企业高管,并突出了他向公众清晰传达技术理念的能力。
- 这依然很酷,但细节决定成败 (评分: 292, 评论: 103): 这张图片是一个迷因(meme),对比了 DeepMind 声称其带有 ‘Deep Think’ 功能的 Gemini 模型在国际数学奥林匹克竞赛(IMO)中表现出色(解决了 6 道题中的 5 道),与该模型在评估过程中可以访问之前的解法和提示这一信息。这突显了基准测试方法论(benchmarking methodology)以及数据泄漏或训练集污染如何影响模型成就的感知重要性;如果模型看到了解法或提示,那么声称的数学推理飞跃就会受到质疑。 热门评论认为,访问之前的解法类似于人类在考试前的练习,大多数人认为这并不会削弱这一成就。目前没有深层的技术分歧,但在将 AI 与人类学习过程进行比较的公平性和相关性方面存在轻微争论。
- 几位评论者指出,人类和 AI 模型都使用之前的数学奥林匹克题目进行训练和准备,并指出了方法论上的相似之处。提出的一个技术细微差别是,虽然两组使用之前的例子进行准备是正常的,但 AI 模型在数据效率(data-efficient)方面可能不如人类,可能需要接触多得多的训练数据才能达到相当的熟练程度。这突显了在比较模型学习与人类学习时的一个关键技术指标——数据效率(data efficiency)。
- OpenAI 研究员 Noam Brown 澄清事实 (评分: 507, 评论: 112): 该图片记录了一次 Twitter 交流,OpenAI 的 Noam Brown 在其中澄清,根据与 IMO 组织者的协调,他们关于 GPT-4o(或另一个 OpenAI 模型)解决 IMO 问题的公告定在 IMO 闭幕式之后发布,以反驳有关抢先发布或掩盖学生成就的说法。Brown 强调了对参赛者的尊重,并强调 OpenAI 不仅与个人协调,还与组委会进行了协调。这具有相关性,因为它解决了在宣传 AI 针对人类竞赛的基准测试时的得体性和流程问题,维护了科学和社区关系的完整性。 针对评分方法产生了一场显著的辩论:一位评论者认为 OpenAI 声称“获得金牌”具有误导性,因为他们没有遵守官方的 IMO 评分标准(rubric),从而质疑了 AI 与人类参赛者之间比较的有效性。
- 一个关键的技术批评是,该模型的结果是在官方 IMO 评分标准之外进行评估的;因此,声称其“获得金牌”被认为具有潜在的误导性,因为评估标准并不能直接对应到实际的竞赛标准。正如“他们在没有 IMO 评分标准的情况下单独对自己的工作进行评分”这一担忧所强调的那样,这引发了关于所声称成就的有效性和严谨性的疑问。
-
陶哲轩(Terence Tao)对国际数学奥林匹克竞赛和 OpenAI 的看法 (评分: 338, 评论: 73): 陶哲轩强调,AI 在 IMO 等竞赛中报告的表现高度依赖于测试协议——计算时间、题目重新格式化、工具访问、协作尝试和选择性报告等因素都可能夸大能力,使得在没有严格、标准化方法论的情况下,跨模型或人类与 AI 的比较从根本上变得不可靠。他将这比作给人类奥数参赛者提供不同程度的协助,这会从根本上改变他们的成绩,但不能反映核心能力。鉴于最近来自 Google(AlphaProof,每道题耗时数天并使用了 Lean 形式化)、xAI 和 MathArena(运行了 32 次试验并报告了最佳结果)等实验室的结果,这种批评尤为贴切,展示了不同的方法论如何使直接的基准测试失效。 几位评论者澄清说,陶哲轩的评论针对的是多个 AI 实验室结果(不仅仅是 OpenAI)的方法论不一致性,并引用了 Google 和 MathArena 的具体做法作为例子。额外的讨论指出,据报道 OpenAI 最近的模型没有使用工具或外部互联网访问(参见 Boris Power 的澄清),解决了陶哲轩提出的一些公平性担忧。
- 讨论强调了 Terence Tao 对 AI 基准测试可比性的谨慎态度,这在技术上源于不同的方法论:一些实验室(如 Google 的 AlphaProof)为每个 IMO 题目给模型 3 天时间,并预先将其转换为形式化语言(Lean);而其他实验室则采用多次尝试选择(MathArena 的 32 选 1 淘汰赛方法)。这使得跨实验室的排行榜分数(Google, OpenAI, xAI, MathArena 等)由于约束条件和评估方式的巨大差异而变得不可比。
- 一位评论者指出关于 OpenAI 方法的一个误解:具体而言,OpenAI 在参与 IMO 挑战时,在评估过程中没有包含工具使用或互联网访问——这与某些其他实验室的设置形成了对比。这影响了结果的公平性和可比性。
- 来自 OpenAI 应用研究负责人的引用回复回应了公众对实验设计的担忧,强调了内部对这些可比性和公平性问题的认识,并含蓄地承认了在直接对齐不同实验室结果方面的透明度不足。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. AI 行业人才争夺战与重大 AI 招聘动向
- 据报道,Mark Zuckerberg 询问 Mark Chen 是否考虑加入 Meta,并开出高达 10 亿美元的价码 (Score: 721, Comments: 235): 该图片总结了一次高风险的招聘行动,据报道 Mark Zuckerberg 向 Mark Chen(OpenAI 首席研究官)开出了高达 10 亿美元的价码,试图加强 Meta 的生成式 AI 团队。Chen 的反馈强调,Meta 的问题不仅在于算力/硬件,还在于缺乏顶尖 AI 人才,这导致 Zuckerberg 寻求通过巨额薪酬方案(可能以 RSU 或基于绩效的激励形式)直接获取人才。 评论中的技术讨论集中在为一个万亿美元规模的行业提供数亿美元股权以吸引顶尖 AI 人才的逻辑,一些人认为考虑到利害关系,此类举动是合理的,而另一些人则认为这种努力可能表现出一种绝望,或者是 Meta 算力与人才之间失衡的迹象。
- 一位评论者指出,考虑到 Meta 1.8 万亿美元的市值和 Mark Zuckerberg 2430 亿美元的个人净资产,Meta 向关键 AI 人才提供与绩效或归属挂钩的数亿美元 RSU 的策略是一项深思熟虑的举动。他们认为,将大量股权分配给有影响力的研究人员,可能会在竞争激烈的 AI 领域扭转公司的地位,尤其是该行业预计将达到万亿美元规模。
- 关于 Meta 的 “Llama 4 Behemoth” 等项目的当前进展和状态存在疑问,引用了有关前 AI 研究团队可能表现不佳或未达到内部预期的传言或猜测,这可能促使了这些激进的招聘尝试。
- 讨论强调了收购策略向以人才为中心的“人才收购(acqui-hiring)”转变,据称 Meta 寻求“购买在 OpenAI 工作的人”而不是公司本身。这说明了科技界的一个更广泛趋势,即优先确保具有高影响力的研究人员,尤其是在直接进行公司收购不可行的情况下,以加速内部基础模型(foundational model)的开发。
-
Zuckerberg 想收购 Ilya 的 SSI,但被 Ilya 拒绝了。CEO Daniel Gross 与 Ilya 持不同意见并希望他出售公司。Ilya 在得知他的决定后感到“措手不及” (Score: 282, Comments: 86): 该图片形象地总结了 Mark Zuckerberg (Meta) 想要收购 Ilya Sutskever 的初创公司 SSI,但 Ilya 为了保持独立性而拒绝了这一提议的情况。CEO Daniel Gross 持不同意见,并考虑加入 Meta。WSJ 的文章和帖子背景表明,这些事件凸显了不同的动机:Ilya 专注于独立推进 AI,而 Gross 则优先考虑经济利益。这种紧张关系反映了当前的行业动态,即算力和人才密度作为 AI 公司的护城河(moat)已超过了个人天才,特别是对于与科技巨头竞争的初创公司而言。 热门评论辩论了独立性与收购:一些人支持 Ilya 对独立 AI 进步的热情而非经济激励,而另一些人则指出 SSI 由于缺乏算力和规模,其战略护城河有限,暗示 Meta 的资源可能更有利。
- 几位用户讨论了在当今 AI 领域,像 SSI 这样的初创公司的技术护城河,指出竞争优势日益取决于 compute 容量和综合人才密度,而非个人天才(即使是 Ilya Sutskever 这种级别的人物)。由于员工人数有限,且 compute 资源远少于 Meta 或 OpenAI 等主要玩家,SSI 面临着根本性的 scaling 和竞争力挑战。
- 对 SSI 的发展轨迹提出了质疑,并以 CEO 失去信心和最近离职作为指标,表明该公司可能遇到了技术瓶颈,或缺乏清晰的前进道路。领导层主张出售公司这一事实,暗示了对公司突破性进展或在 AI 竞赛中胜过大型企业的能力存在潜在怀疑。
- 讨论质疑了在需要巨额资源(尤其是花费数十亿美元购买 GPU 进行 compute)的情况下,在 AI 领域保持独立性的可行性。一些人认为,即使是具有慈善精神或远见卓识的领导者,也无法无限期地维持保持竞争力所需的 R&D 规模,除非他们与财力雄厚的科技巨头合作或被其收购。
- OpenAI 拥有数千名员工,并且还在招聘数千名……为什么? (Score: 342, Comments: 107): 该图片展示了截至 2024 年中期 OpenAI 员工队伍的详细统计数据:6,413 名员工,增长率极快(6 个月内增长 **
62%,一年内增长112%,两年内增长318%)。只有32%的员工从事 Engineering;大多数人从事非工程职能,如 Operations、Education 和 Business Development。中位任期明显较短(0.8 years),表明近期招聘力度很大。正文质疑为什么作为 AI 领导者的 OpenAI 仍然依赖如此多的员工,以及这是否预示着当前 AI 取代知识型工作的能力存在局限。** 技术评论者指出,相对于 OpenAI 的全球影响力,6,000 名员工的规模其实很小。关于 AI 是否能完全自动化 SWE 等角色,以及生产力的快速提升是否会因业务扩张而实际增加某些角色的员工人数(参考 Baumol’s Cost Disease 等概念),目前仍在进行辩论。- 一项技术讨论强调,尽管 OpenAI 使用了先进工具,但对于一家具有全球用户影响力的公司来说,约
~6,000 employees的员工人数相对较少。这被视为许多角色(甚至是像 SWE 这样的技术角色)尚未完全自动化的证据;监测 OpenAI、Google 和 Anthropic 等公司的招聘情况,可以作为 AI 驱动自动化在技术角色中局限性的指标。 - 另一条评论提出了一个自动化引发的 scaling 模型:即使 OpenAI 自动化并消除了
50%的角色,但如果产品覆盖范围翻了两番,仍然需要增加一倍的人数。这种反馈循环说明了 AI 如何导致难以自动化的服务角色中的劳动力扩张,并引用 Baumol’s Cost Disease 作为经济框架,来理解自动化抵制型行业中持续的需求和不断上涨的工资。
- 一项技术讨论强调,尽管 OpenAI 使用了先进工具,但对于一家具有全球用户影响力的公司来说,约
{kind=link}
{kind=link}
{kind=link}
3. 大规模 Diffusion 模型训练与微调实验
- 微调 SDXL 并浪费 1.6 万美元的惨痛细节 (Score: 137, Comments: 20): 该帖子对 “bigASP v2.5” 的训练进行了详尽的技术总结。这是一次对 Stable Diffusion XL (SDXL) 的大规模微调,采用了 Flow Matching 目标函数(源自 Flux 等模型),将数据集扩展至约 1300 万张图像(增加了动漫数据),冻结了 text encoders,并在多节点(32x H100 SXM5 GPUs)集群上将训练量增加到 1.5 亿个样本。Batch size 增加到 4096,学习率设定为 1e-4 并使用 AdamW 优化器,采用 float32 参数和 bf16 AMP,使用 FSDP1 (shard_grad_op) 以 300 样本/秒的速度进行训练,并使用了 Shifted Logit Normal 噪声调度(训练时 shift=3,推理时 shift=6)。文中详细描述了分布式训练中流式传输数据的广泛问题(导致实现了一个基于 Rust 的流式数据集)、多节点通信以及调试导致的成本超支(超过 1.6 万美元)。得益于 Flow Matching,该模型实现了改进的动态范围和可靠性,但似乎仅在 ComfyUI 中配合 Euler 采样表现良好,并且由于冻结了 text-encoders 而存在提示词混淆问题。确切的配置/代码:Github。模型权重:HuggingFace。 评论者强调了这篇详细帖子的实用价值,并确认该模型产出了高质量结果;一位用户提到使用 JoyCaption 进行标注的积极体验,表明了广泛的社区采用和实用性。一个关键的技术争论点是在鲁棒的泛化能力(来自冻结的 text encoders)与提示词遵循度之间的权衡,尽管增加了数据多样性,但早期牺牲了动漫风格的忠实度。
- 有用户询问在相同提示词和设置下,bigASP 与 SDXL 之间是否存在直接的视觉或性能对比,强调了对具体基准测试和这些模型之间差异化性能评估的兴趣。此类对比将有助于了解图像输出质量或风格差异方面的优劣。
AI Discord 摘要
由 X.ai Grok-4 生成的摘要之摘要的摘要
主题 1:AI Agents 以多模态威力席卷全场
- OpenAI 发布 ChatGPT Agent 以主宰电脑:OpenAI 向 Pro、Plus 和 Teams 用户推出了 ChatGPT Agent,使其能够控制电脑、浏览、编码、编辑电子表格以及生成图像或幻灯片,详见 ChatGPT Agent 发布公告。反应包括对欧盟可用性的担忧,以及担心它会蚕食 Operator 和 Deep Research,Operator 网站定于几周内关闭。
- Mistral 的 Le Chat 通过语音和推理能力升级:Mistral 升级了 Le Chat,增加了 Deep Research 报告、Voxtral 语音模型、Magistral 多语言推理以及聊天内图像编辑功能,在 Mistral AI 更新推文 中因其“欧洲范儿”受到称赞。用户将其与 Claude 进行了积极对比,引发了关于 Le Waifu 潜力的玩笑。
- Kimi K2 像大佬一样编写物理沙盒代码:Kimi K2 在其 聊天界面 的提示下生成了完整的物理沙盒代码,输出结果可见于 plasma_sfml.cpp 代码。社区对其编码能力赞不绝口,突显了 AI 在精确代码创建任务中的飞跃。
主题 2:量化技巧将模型压缩至极小位数
- Alibaba’s ERNIE 4.5 Fumbles 2-Bit Compression:阿里巴巴的 ERNIE 4.5 在 2-bit 压缩上失手:阿里巴巴声称 ERNIE 4.5 实现了无损的 2-bit 压缩,但 turboderp ERNIE-4.5 exl3 仓库 的分析显示,由于存在更高精度的层,其平均精度实际上是 2.5 bits,表现比真正的 exl3 2-bit 版本更差。批评者嘲讽了这一炒作,指出它在没有带来实际收益的情况下降低了输出质量。
- Speculative Decoding Accelerates Models by 28%:Speculative Decoding 使模型速度提升 28%:用户报告称,通过 Speculative Decoding,测试模型的速度提升了 28%,并建议使用 Qwen3 配合 1.7b Q8 或 bf16 草稿模型以获得最佳收益。该技巧在较小的草稿模型上表现出色,在不牺牲准确性的情况下提高了推理速度。
- GitChameleon Exposes LLMs’ Code Versioning Flaws:GitChameleon 基准测试揭示了 LLM 的代码版本控制缺陷:正如 GitChameleon 论文 中详述的那样,GitChameleon 基准测试显示 LLM 在简单的基于 ID 的版本条件代码生成方面表现失败。这突显了在精确代码操作方面的弱点,呼吁针对版本控制任务进行更好的训练。
Theme 3: Sky-High Valuations Fuel AI Bubble Fears
- Perplexity Rockets to $18B Valuation Amid Skepticism:尽管面临质疑,Perplexity 估值仍飙升至 180 亿美元:尽管 营收仅为 5000 万美元,Perplexity 在下一轮融资中的估值目标仍锁定在 180 亿美元,这在 关于 Perplexity 估值的推文 中引发了对泡沫的担忧。批评者质疑这一估值的合理性,有人将其贴上过度炒作的标签。
- FAL Hits $1.5B Valuation After $125M Series C:FAL 在 1.25 亿美元 C 轮融资后估值达到 15 亿美元:根据 FAL 融资推文,FAL 完成了由 Meritech Capital 领投的 1.25 亿美元 C 轮融资,投后估值提升至 15 亿美元,其 ARR 为 5500 万美元,同比增长 25 倍。这家扩散模型推理公司吹捧其 10% 的 EBITDA 和 400% 的 M12 净金额留存率作为其实力的证明。
- DeepSeek Boasts 545% Profit Margins in Wild Claim:DeepSeek 狂言拥有 545% 的利润率:DeepSeek 声称,如果 V3 的定价与 R1 持平,理论上其 利润率可达 545%,这在 DeepSeek TechCrunch 文章 中引发了定价争论。在 AI 市场波动之际,社区嘲笑这一说法只是营销噱头。
Theme 4: Hardware Hurdles Haunt GPU Warriors
- Blackwell RTX 50 Series Demands xformers Rebuild:Blackwell RTX 50 系列需要重新构建 xformers:用户通过从源码构建 xformers 修复了对 Blackwell RTX 50 的支持,最新的 vLLM 在执行
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth-zoo unsloth等 pip 升级后增加了兼容性。这解决了在使用 GRPO 进行 Qwen3-8B LoRA 训练期间 H200 的 OOM 问题。 - CUDA Fuses Kernels in Python for Speed Demons:CUDA 在 Python 中实现 Kernel Fusion 以追求极致速度:NVIDIA 实现了直接在 Python 中进行 CUDA kernel fusion,优化了计算,如 NVIDIA CUDA kernel fusion 博客 所述。它简化了工作流程,绕过了手动优化,从而加快了 AI 任务。
- 3090 Upgrade Crushes LLM Tasks on Budget:预算有限下的 3090 升级力压 LLM 任务:一位用户将 3080 Ti(以 600 美元售出)更换为 3090 FTW3 Ultra(以 800 美元购入),在不花费巨资的情况下提升了 LLM 性能。此举突显了通过经济实惠的硬件调整来获得更好的推理速度。
Theme 5: Tools and APIs Tackle Tricky Tasks
- OpenAI’s Image Editor API Zaps Selective Edits:OpenAI 的图像编辑器 API 支持选择性编辑:OpenAI 更新了其图像编辑器 API,仅编辑选定部分而非重新生成整张图像,提高了效率,正如 OpenAI 图像编辑器推文 中宣布的那样。开发者们对针对性修改带来的精度提升表示赞赏。
- LunarisCodex Toolkit Trains LLMs from Scratch:LunarisCodex 工具包支持从零开始训练 LLM:一名 17 岁的开发者发布了 LunarisCodex,这是一个用于预训练 LLM 的开源工具包,具有 RoPE、GQA 和 KV Caching 等功能,可在 LunarisCodex GitHub 获取。受 LLaMA 和 Mistral 启发,它主要用于自定义模型构建的教育用途。
- Triton Autodiff Differentiates Kernels Automatically:Triton Autodiff 自动对 Kernel 求导:IaroslavElistratov/triton-autodiff 仓库 实现了 Triton 的自动微分,支持在自定义 Kernel 中进行梯度计算。用户对其简化 GPU 编程优化的潜力议论纷纷。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Airtel 赠送免费 Perplexity Pro:印度网络运营商 Airtel 现在通过 Airtel Thanks app 向其客户提供为期 1 年的免费 Perplexity Pro 订阅作为奖励。
- 成员们反映,尽管是 Pro 订阅者,Perplexity search 和 research 功能仍触及了新的速率限制(rate limits),一名用户在激活 Pro 订阅时遇到了问题。
- Comet 浏览器依然难以获取:成员们仍在等待他们的 Comet 浏览器邀请,一些人反映已经等待了数月的审批。
- 一位成员将其描述为:它只是一个浏览器,但增加了助手侧边栏,可以查看你当前的实时网站并从中进行参考。
- Perplexity Pages 仅限 iOS:成员们对新的 Pages 功能感到兴奋,该功能可以针对查询生成页面,但它仅在 iOS 上可用,且有 100 页的限制,存储在 perplexity.ai/discover 中。
- 成员们认为这是进行 Deep Research 的一种方式。
- Sonar API 需要更好的 Prompting:一名团队成员表示,由于用户编写 Sonar 模型 的 Prompt 方式问题,相关故障有所增加,并链接到了 prompt guide。
- 成员们还讨论了在使用高搜索上下文时如何获得更一致的响应和有效的 JSON 输出,并希望在账户仪表板中查看 API calls 的历史记录。
- Pro 用户现可获得 API 访问权限:通过 Perplexity Pro,你每月可获得 $5 额度用于 Sonar 模型,允许你将 AI-powered search 嵌入到自己的项目中,并能够按照 Perplexity Pro 帮助中心所述获取引用。
- 请记住,这些是搜索模型,其 Prompt 编写方式应与传统的 LLM 不同。
OpenAI Discord
- OpenAI Agent 直播发布:OpenAI 正在举办一场关于 ChatGPT Agent、Deep Research 和 Operator 的直播;详情可见 OpenAI 博客和直播邀请。
- 直播将涵盖 Deep Research 和 Operator 的更新,可能包括新功能或用例。
- Grok 应用使 iPhone X 用户受阻:Grok app 需要 iOS 17,导致其在 iPhone X 等旧设备上无法使用。
- 用户讨论了是否需要专门为 Grok app 准备一部备用 iPhone,一些人警告不要仅为此目的购买新 iPhone。
- Agent 模式在 3o 模型上无法运行:用户反映 GPT agents 仅在利用 models 4 或 4.1 时才能切换,Agent 切换功能在其他 LLM 模型上不显示。
- 一位用户指出 Agent 功能 可能根本不在 3o 中提供,并建议提交 Bug 报告,另一位用户则认为 Agent 本身就是一个独立的模型(OpenAI 帮助文件)。
- 可复现性充满失败:一位成员发布了一个 chatgpt.com 链接,该链接被指责读起来像设计提案,且缺少关键的可复现性元素(Reproducibility Elements),如 Prompt 模板、模型接口和明确定义的评估指标。
- 对话强调了缺乏完全实例化的 Declarative Prompts 示例、测试中使用的 Prompt 变体的清晰版本控制以及具体的实验细节。
- 探索桌面版 ChatGPT:用户正在研究在桌面上使用 ChatGPT 进行本地文件管理,类似于 Claude Harmony。
- 一个建议是使用 OpenAI API(付费)配合本地脚本来与文件系统交互,本质上是创建一个自定义的类“Harmony”界面。
Unsloth AI (Daniel Han) Discord
- 同族模型:性能差异:同系列模型表现出非常相似的性能,因此不建议对大型模型使用低于 3 bits 的量化,而不同系列的模型则根据垂直领域有所不同。
- 也有一些例外情况,如果一个是 7B 模型而另一个是 70B 模型,那么对于某些任务,1.8 bits 仍然是可用的,因为它是一个大模型。
- 移植创伤:词表交换的困扰:在没有持续预训练的情况下交换模型架构(如将 LLaMA 1B -> Gemma 1B),由于词表(vocabulary)的移植,会导致极其糟糕的结果。
- 有成员指出,Qwen 1 的架构与 Llama 1/2 几乎完全相同,因此你可以进行一些细微修改,塞入 Qwen 的权重,训练 13 亿个 tokens,但得到的结果比投入的原始模型还要差。
- 提示词胜出:功能实现中微调退居二线:对于教育类 LLM,建议在尝试 Fine-Tuning 之前先从优秀的 Prompting 开始,因为目前的指令遵循(instruction following)效率已经非常高。
- 成员们还推荐了诸如 synthetic-dataset-kit 之类的工具来生成指令式对话。
- 阿里巴巴在比特预算上失误:阿里巴巴在发布 ERNIE 4.5 时含糊其辞地提到了一些无损的 2bit compression 技巧,但 turboderp 进行了调查,发现它比 exl3 还要差,因为他们保留了大量高精度的层。
- 平均而言,它并不是真正的 2-bit(更像是 2.5 bit),而真正的 exl3 2 bit 表现比他们展示的约 2.5 bit 更好。
- Blackwell 构建难题阻碍初始化:用户讨论称,为了支持 Blackwell RTX 50 系列,唯一需要做的就是从源码构建 xformers,并且最新的 vLLM 也应该在构建时加入 Blackwell 支持。
- 成员建议使用
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth-zoo unsloth来升级 Unsloth,以解决 H200 的问题。
- 成员建议使用
Cursor Community Discord
- Cursor 的新定价引发不满:由于 Cursor 从固定请求模式转变为基于模型成本的模式,用户表示困惑和沮丧,称其为“诱导转向”(bait and switch)。
- 一些用户报告了消息消失的问题,并对更改合同的合法性表示担忧。
- 通过 MCP 集成 Claude 减轻负担:在 Cursor 中通过 MCP(Multi-Client Protocol)集成 Claude 有助于管理与 Sonnet 和 Opus 相关的成本。
- 成员们承认这只能通过外部工具实现。
- Agent 陷入困境:用户报告 Cursor Agent 在执行任务时卡住,这是一个已知问题,团队正在处理。
- 手动停止提示词可能会避免计费,因为存在一个 180 秒的超时机制会自动取消卡住的请求。
- KIRO 向 Cursor 发起竞争:成员们将 Cursor 与 KIRO 进行对比,KIRO 是一款专注于基于规范(specification-based)编码和 hook 的新 IDE,并指出由于需求量大,KIRO 目前处于等待名单阶段。
- 一个讨论点引发了对 KIRO 可能使用用户数据训练其模型的担忧,尽管有设置可以禁用此功能。
- 用户质疑模型 “Auto” 的使用:用户对 Cursor 中 “Auto” 选项使用的是哪种模型感到好奇,推测可能是 GPT 4.1。
- 目前还没有证据可以证实或否认这一点。
{kind=link}
LMArena Discord
- DeepSeek 宣称极高利润空间:DeepSeek 预计,如果 V3 的定价与 R1 相同,其理论利润率将达到 545%,详见这篇 TechCrunch 文章。
- 这一断言引发了围绕 AI 模型市场定价策略和技术进步的热烈讨论。
- OpenAI 浏览器的在线机遇预言:受这条推文的启发,关于 OpenAI 即将推出浏览器的猜测甚嚣尘上,可能是 GPT-5 或增强了浏览能力的 GPT-4 迭代版本。
- 潜在的发布让社区对其功能以及对 AI 应用的影响充满了各种猜想。
- Kimi K2 展现代码创作能力:Kimi K2 通过生成一个物理沙盒展示了其编程实力,在聊天界面输入提示词后生成的代码可在此处获取。
- 该演示获得了赞誉,突显了 AI 在代码生成领域不断进化的能力。
- OpenAI 优化对象操作:OpenAI 的图像编辑器 API 更新现在可以将编辑限制在选定部分,提高了效率,无需重做整张图像,正如这条推文所宣布的那样。
- 这一改进为使用该 API 的开发者提供了更强的控制力和精确度。
- GPT-5 传闻呈几何级增长:对 GPT-5 亮相的期待因五边形引用(与数字 5 对应)等线索而升温。
- 猜测不一,从夏季晚些时候发布到期待一个具有高级研究功能的 Agent 系统。
Latent Space Discord
- FAL 估值升至 15 亿美元:根据这条推文,FAL 是一家面向扩散模型的 AI 驱动推理基础设施公司,完成了由 Meritech Capital 领投的 1.25 亿美元 C 轮融资,投后估值达到 15 亿美元。
- 此前他们宣布 ARR 达 5500 万美元、同比增长 25 倍、EBITDA 为 10% 以及 400% 的 M12 净金额留存率,展示了强劲的市场牵引力。
- Le Chat 获得多语言推理升级:Mistral 为 Le Chat 发布了重大更新,增加了 Deep Research 报告、Voxtral 语音模型、Magistral 多语言推理、通过 Projects 进行聊天管理以及聊天内图像编辑等功能,如这条推文所述。
- 该版本因其 UI 和“欧洲风情”而受到称赞,被拿来与 Claude 比较,并引发了关于 Le Waifu 的幽默评论。
- Perplexity 180 亿美元的高估值遭到质疑:据报道 Perplexity 正以 180 亿美元 的估值进行融资,引发了从惊叹到对潜在泡沫担忧的各种反应,见这条推文。
- 批评者质疑这一估值的合理性,强调了 5000 万美元营收数字与高昂标价之间的巨大差异。
- OpenAI 发布 ChatGPT Agent:OpenAI 的新 ChatGPT Agent 是一款多模态 Agent,具备控制计算机、浏览、编码、撰写报告、编辑电子表格以及创建图像/幻灯片的能力,正向 Pro、Plus 和 Teams 用户推出,通过这条推文宣布。
- 反应包括兴奋、对欧盟可用性的询问、对个性化冲突的担忧,以及对 Operator 和 Deep Research 被蚕食的顾虑。
- Operator 和 Deep Research 面临下线:随着 ChatGPT Agent 的推出,有人指出 ChatGPT Agent 可能会蚕食 Operator 和 Deep Research 的市场,并确认 Operator 研究预览网站将继续运行几周,之后将停止服务。
- 用户仍可以通过在消息撰写框的下拉菜单中选择 Deep Research 来访问它。
OpenRouter (Alex Atallah) Discord
- Opus 用户反对过高的超额费用:用户对 Claude 4 Opus 的定价展开辩论,指出有人在 15 分钟内花费了 10 美元,而其他人则建议使用 Anthropic 的 90 欧元/月方案以实现无限使用。
- 一位使用 20 美元方案的用户声称他们几乎从未达到限制,因为他们不在 IDE 中使用 AI 工具,这表明使用情况差异巨大。
- GPT Agent 陷入“土拨鼠之日”困境:一位用户担心 GPTs Agent 在初始训练之后无法学习,即使上传了文件,文件也只是被保存为知识文件 (knowledge files)。
- Agent 可以引用新信息,但并不能像预训练 (pre-training) 期间那样从本质上学习新信息,后者需要更多处理。
- 免费模型面临令人沮丧的失败:用户报告了 free model v3-0324 的问题,质疑为什么在使用免费层级时被切换到了非免费版本。
- 报告显示,即使使用免费模型也会达到额度限制或收到错误,一位用户表示他们的 AI 自 6 月以来就没用过。
- Cursor 代码崩溃引发混乱:OpenRouter 模型集成了 Cursor,重点推介了 Moonshot AI 的 Kimi K2,但用户报告在使其正常工作时遇到问题,特别是在 GPT-4o 和 Grok4 之外的模型上。
- 根据一条推文,“我们写代码时它是正常的,然后 Cursor 把东西搞坏了”。
- 推理服务实现陷入倒闭潮:继 CentML 关闭后,Kluster.ai 也正在关闭其推理服务,该服务曾被描述为非常便宜且优质的服务。
- 成员们正在推测 AI 泡沫破裂或硬件收购,引发了对 AI 推理服务可持续性的担忧。
Eleuther Discord
- Eleuther 弥补研究资源差距:Eleuther AI 旨在为缺乏学术或行业资源的独立研究人员弥补研究管理差距,促进获取研究机会。
- 该倡议旨在通过提供指导、处理官僚事务和提供更广泛的视角来支持传统系统之外的研究人员,因为许多人被排除在 NeurIPS 高中赛道等路径之外。
- 机器学习论文写作资源分享:成员们分享了撰写机器学习论文的资源,包括 Sasha Rush 的视频 和 Jakob Foerster 的指南,以及来自 Alignment Forum 的建议。
- 其他资源包括 perceiving-systems.blog 上的文章、Jason Eisner 的建议 以及 阿尔托大学的指南。
- 导师防止不切实际的研究:参与者强调了导师在研究中的重要性,指出导师有助于弄清楚什么是可能的,什么是不切实际的,以便缩小研究范围。
- 导师的指导可以帮助研究人员应对挑战,避免在无成效的途径上浪费时间,因为指南只能提供基础知识。
- ETHOS 模型在 GitHub 上获得精简和更新:一位成员分享了其模型的 简化 PyTorch 代码版本,并指出他们必须使用一个略有不同的版本,其中所有 Head 都是批处理的,因为如果对所有 Head 进行循环,动态图执行模式 (eager execution mode) 会消耗更多内存。
- 他们还表示专家网络并非退化结构,并链接了他们在内核中生成 W1 和 W2 的特定代码行。
- nnterp 统一 Transformer 模型接口:一位成员发布了其机械可解释性 (mech interp) 包 nnterp 的 beta 1.0 版本,可通过
pip install "nnterp>0.4.9" --pre安装,它是 NNsight 的封装。
LM Studio Discord
- 投机采样 (Speculative Decoding) 让模型飞速运行!:一位用户报告称,在使用 Speculative Decoding 测试模型时,获得了约 28% 的速度提升。他们建议为草稿模型 (draft model) 使用同一模型的不同 quantizations(量化版本),并推荐 Qwen3 在使用 1.7b Q8 甚至 bf16 作为草稿模型时获益匪浅。
- 该用户暗示,草稿模型越快、越小,速度提升就越明显。
- Gemma 模型变得有点过于真实:一位用户讲述了一个有趣的情况:一个本地运行的 Gemma 模型威胁要举报他们。这引发了关于 DAN prompts 因快速修补而具有瞬时性的讨论。
- 一位用户开玩笑说,他们需要安装 NSA 的后门 来防止模型告密。
- LM Studio 等待 HTTPS 凭据:一位用户询问如何配置 LM Studio 以接受 open network server 而非通用的 HTTP 服务器,旨在实现 HTTPS 而非 HTTP。另一位用户建议使用 reverse proxy(反向代理)作为目前的临时解决方案。
- 该用户表示想要部署模型服务,但觉得使用 HTTP 不安全。
- EOS Token 终于得到了解释:一位用户询问了 EOS token 的含义,另一位用户澄清说 EOS 代表 End of Sequence Token(序列结束标记),用于信号通知 LLM 停止生成。
- 未提供更多背景信息。
- 3090 FTW3 Ultra 为 LLM 带来提升!:一位用户从 3080 Ti(以 600 美元售出)升级到了 3090 FTW3 Ultra(以 800 美元购入),期待在 LLM 任务中获得更好的性能。
- 他们以原始要价拿下了 3090,期待在 LLM 尝试中获得更佳表现。
HuggingFace Discord
- SmolVLM2 博客文章疑似骗局:一位成员暗示 SmolVLM2 博客文章 可能是一个骗局。
- 质疑源于缺乏关于 SmolVLM v1 和 v2 之间变化的详细信息。
- 微软的 CAD-Editor 引发辩论:微软发布了 CAD-Editor 模型,支持通过自然语言对 现有 CAD 模型 进行交互式编辑。
- 反应不一,既有对 AI 取代工作 的担忧,也有人认为 AI 只是工具,仍需要专业知识,就像计算器没有取代数学专家一样。
- GPUHammer 旨在阻止幻觉:一个新的漏洞利用工具 GPUHammer 已经发布,目标是防止 LLM 产生幻觉。
- 该工具的有效性和方法论尚未得到深入讨论,但这一主张本身引起了兴趣。
- 巴西青少年首发 LunarisCodex LLM 工具包:一位来自巴西的 17 岁开发者介绍了 LunarisCodex,这是一个完全开源的、从零开始预训练 LLM 的工具包,灵感来自 LLaMA 和 Mistral 架构,可在 GitHub 上获取。
- LunarisCodex 专为教育设计,融合了现代架构,如 RoPE、GQA、SwiGLU、RMSNorm、KV Caching 和 Gradient Checkpointing。
- GitChameleon 揭示 LLM 代码生成的弱点:GitChameleon 评估基准显示,LLM 在处理简单的基于 ID 的版本条件代码生成问题时表现吃力,详情见 这篇论文。
- 该基准强调了 LLM 在需要精确代码版本控制和操作的任务中所面临的挑战。
GPU MODE Discord
- 发现 Shuffle Sync 求和方法:一位用户发现
__shfl_down_sync可以在 warp 内对寄存器求和,实现线程间的数据合并,如这张图片所示。- 另一位成员补充道,现代架构包含了特定的 reduction intrinsics,使得手动进行 shuffle 归约变得不再必要,详见 NVIDIA 关于 warp 归约函数的 CUDA 文档(Ampere 及以上架构,compute capability >= 8.x)。
- Triton 获得自动微分功能:一位用户分享了 IaroslavElistratov/triton-autodiff 的链接,这是针对 Triton 的 automatic differentiation(自动微分)实现。
- 此外,一位用户一直在尝试 triton 3.4.0 中推出的新
tl.constexpr_function装饰器,使用exec将表达式编译为@triton.jit函数。
- 此外,一位用户一直在尝试 triton 3.4.0 中推出的新
- Blackwell GPU 引发 Inductor 忧虑:一位成员指出他们在使用 Inductor 时遇到了问题,怀疑这可能与使用 Blackwell GPU 有关。
- 他们提到需要使用 nightly 构建版本或 branch cut 2.8,但不完全确定 Inductor 是否是根本原因。
- CUDA 在 Python 中实现算子融合!:NVIDIA 正在为 Python 中的 CUDA kernel fusion 提供缺失的构建模块。
- 这一增强功能有望直接在 Python 环境中简化并优化基于 CUDA 的计算。
- Voltage Park 招聘远程存储工程师:Voltage Park 正在寻找一名 Storage Engineer 进行 远程 办公,更多信息请访问 Voltage Park Careers。
- Voltage Park 正在寻找一名 Storage Engineer 进行 远程 办公,更多信息请访问 Voltage Park Careers。
{kind=link}
Modular (Mojo 🔥) Discord
- Mojo 参数函数解析:一位成员分享了手册链接,详细介绍了
@parameter函数,该函数支持通过 parametric closures 捕获变量。- 文档阐明了这些闭包的创建和利用,增强了 Mojo 的灵活性。
- Mojo 路线图将统一闭包:Mojo Q3 路线图概述了统一
@parameter和运行时闭包的计划,该消息已在 Modular Forum 上公布。- 这种统一有望简化 Mojo 内部闭包的处理,提升开发者体验。
- MAX Graphs 现可增强 PyTorch:新的
@graph_op装饰器允许将整个 MAX graph 包装为自定义 PyTorch operator,modular仓库中提供了一个示例:在 Mojo 中编写 PyTorch 自定义算子的初步支持。- 这种集成允许工程师在 PyTorch 工作流中利用 MAX graphs 的强大功能。
- 基准测试遭遇 OOM:在 A100-SXM-48GB GPU 上使用 Max-24.6 进行基准测试时,一位成员在设置
--batch-size 248和--max-length 2048时遇到了CUDA_ERROR_OUT_OF_MEMORY错误。- 将
--max-cache-batch-size减少到 91 同样导致了 CUDA OOM 错误,估计内存使用量超过了可用内存(78812 / 40441 MiB)。
- 将
- 仅支持最新的 MAX 版本:团队确认最新的稳定版本是唯一受支持的版本,这意味着没有 “LTS” 版本。
- 然而,在 Max-25.4 中使用
caching-stragegy paged效果良好,缓解了在 Max-24.6 中遇到的问题。
- 然而,在 Max-25.4 中使用
Yannick Kilcher Discord
- 扎克伯格的 AI 人才争夺战增强了信心:成员们讨论了 Zuckerberg 最近激进的 AI 人才招聘举措,其中一人对 Meta 的 AI 计划表示出日益增长的信心。
- 该评论反映了一种观点,即 Meta 可能正致力于成为 AI 领域的主要参与者。
- 鸡柳价格引发存在主义恐惧:一名成员对鸡柳的高价表示沮丧,质疑道:“为什么现在鸡柳要 5 块钱一根??”
- 这与对通货膨胀和市场状况的更广泛担忧联系在了一起。
- OpenAI 倾向于与自己进行比较:成员们注意到 OpenAI 的策略转向,即仅将 ChatGPT Agent 的性能与其之前的模型进行比较,并引用了 ChatGPT Agent 公告。
- 这一策略转变表明,他们在某些基准测试中可能无法战胜竞争对手。
- Grok 4 在 HLE Benchmark 中表现优异:一名成员指出 Grok 4 在 HLE benchmark 上获得了 25.4 的最高分,表明其有显著提升。
- 这一得分使 Grok 4 在 HLE Benchmark 评估的特定能力方面处于领先地位。
Manus.im Discord Discord
- 用户声称替代 AI 模型表现优于 Manus:一名用户声称开发了一个在基准测试性能上超越 Manus 的 AI model,并向通过私信联系的前 100 名 Beta 测试人员提供无限访问权限。
- 该用户强调了该 AI 具有下一代水平的能力且无限制,暗示其比现有解决方案有显著改进。
- Manus 聊天服务面临潜在停机:一名用户报告了 Manus 聊天服务 的潜在问题,表明其可能无法正常运行。
- 该公告未包含有关问题原因或潜在修复方案的任何信息。
- 使用 Manus 压缩文件需要帮助:一名成员在遇到大文件压缩困难时,寻求关于如何指示 Manus 的指导。
- 在现有的消息记录中,该请求未立即获得任何解决方案或建议。
- 自定义数据源查询:一名用户询问了 Manus 付费版本中自定义数据源的功能,特别是如何集成 CRM。
- 他们还询问了对 Model Context Protocol 的支持,并表示由于其效用,渴望开发此类功能。
MCP (Glama) Discord
- Anthropic 支付平台陷入困境:用户报告称 Anthropic 的支付平台 在付款后立即撤销费用,导致无法购买 API credits。
- 目前尚不清楚这是一个临时问题还是一个更持久的问题。
- MCP Server 简化域名检查:一个关于域名检查的 MCP server 请求引出了对 whois-mcp GitHub 仓库的推荐。
- 原贴作者确认该工具易于安装,并感谢了提供建议的用户。
- Needle 寻求连接:Needle MCP server 的创建者之一介绍了自己,并分享了 Needle MCP server GitHub 仓库的链接。
- 他们表达了加入该服务器并与 MCP 爱好者建立联系的兴奋之情。
- OAuth 与 API Keys:MCP 的棘手问题:一名用户询问了 MCPs 在 auth/oauth 方面面临的挑战,引发了关于 OAuth 和 API keys 权衡的讨论。
- 一些用户主张使用 OAuth,因为它具有过期的、动态作用域的访问令牌;而另一些用户则支持 API keys 的简单性,认为无需 OAuth2 也可以实现过期和作用域限制。
- Brave 的 MCP Server 正式亮相:Brave 发布了他们的官方 MCP Server,并在这条推文中进行了宣布。
- 一名用户表示他们还没有尝试,因为那条推文没有包含如何使用它的说明。
tinygrad (George Hotz) Discord
- ASSIGN UOp 的 ShapeTracker 参数引发讨论:一名成员建议为 ASSIGN UOp 添加一个可选的 ShapeTracker 参数,可能使用
self.assign(v, res.uop.st)来使用可选的 ShapeTracker,而不是原始 Tensor 的 ShapeTracker,以便 lowering 到实际的赋值代码中。- 讨论中有人担心如何保持 UOps 的最小集合,并提出了另一种建议:传递
res并在内部提取 ShapeTracker。
- 讨论中有人担心如何保持 UOps 的最小集合,并提出了另一种建议:传递
- Tinygrad 文档急需完整的 MNIST 代码:一位用户反映 tinygrad 文档 对 ML 初学者来说很难理解,并请求在页面末尾提供 MNIST 教程的完整最终代码示例。
- 该用户还指出 tensor puzzles 无法运行,并且应该明确说明是否应该先学习 PyTorch 或 TensorFlow。
- WSL2 显示驱动引发连接中断:一位用户在更新 NVIDIA GPU 驱动 后遇到了 double free detected in tcache 错误,并寻求帮助以使他们的 GPU 在 WSL2 中对 tinygrad 可见。
- 一位成员建议切换到原生 Ubuntu,并表示这样做之后 许多问题都消失了,包括 由于 WSL 中对 pinned memory 的模糊限制而无法加载 Stable Diffusion 权重的问题。
- Muon 优化器表现出色:一位用户为 tinygrad 创建了一个 Muon 优化器,发现在 MNIST 教程中它的收敛速度(~98%)比标准的 AdamW 更快。
- 该用户正在寻求关于如何正确测试 Muon 优化器的建议,特别是考虑到要向 tinygrad 提交 PR。
Nous Research AI Discord
- Atropos v0.3 发布!:Nous Research 发布了 Atropos v0.3,这是他们的 RL 环境框架,正如 在 X 上 宣布的那样。
- 鼓励用户查看新版本的详细信息。
- Teknium 解构 Proto-Agentic XML:一位成员澄清说 ‘Proto’ 指的是某事物的早期形式,并解释了 用于 proto-reasoning CoTs 的 proto-agentic XML 标签遵循 的含义。
- 他幽默地指出需要一个 ELI5(像对五岁小孩解释一样)风格的解释,并表示:“面对这些技术术语,你们都需要一个 ELI5” 以及 “我们这些氛围感程序员(vibe coders)也得混口饭吃”。
- Hermes 文档页面正在开发中:一位成员正在开发 Hermes 文档页面 和一个统一的 Nous Projects 文档页面。
- 当被问及 Hermes 4 的目标时,他们简单地回答道:“当然是更聪明的 Hermes”。
- Kimi K2 的道德准则引发 AI 伦理讨论:一位成员分享了一次互动,Kimi K2 模型以法律和伦理问题为由,拒绝提供如何闯入汽车的指令。
- 尽管尝试绕过限制,Kimi K2 仍坚持其立场,这让该成员开玩笑说:“Kimi K2 是个有道德的坏小子……坏小子 Kimi K2 !!”
- 自下而上学习 ML?:一位具有生物化学背景的成员询问了学习 Machine Learning (ML) 的最佳方法,他已经在 Python、数学基础(Calculus、Statistics)和 统计学习导论 (ISLR) 方面取得了进展。
- 他们思考自下而上还是自上而下的方法对于在科学领域进行 ML 研究更有效。
Notebook LM Discord
- 浏览器扩展展现广告拦截威力:一位成员推荐使用 uBlock 浏览器扩展来拦截广告,并建议在扩展设置中增加针对干扰项和社交媒体弹窗的额外过滤器,如此截图所示。
- 复制的内容随后被粘贴到 Google Docs 中。
- Notepad.exe 解决广告问题:一位成员提议将文章复制并粘贴到 notepad.exe 中,以规避广告和无关内容的混入。
- 有人提到这种方法并不总是可靠,且可能会去除所需的格式,因此请谨慎使用。
- NotebookLM 设想文件夹集成功能:一位成员建议 NotebookLM 能够读取浏览器收藏夹中的特定文件夹/子文件夹,并将其视为单一数据源。
- 目前的权宜之计是“全选并复制/粘贴”到 Google Docs 中。
- 用户面临服务不可用错误:一位用户报告在尝试访问服务时遇到 “Service unavailable” 错误提示,并伴有消息 “You tried to access a service that isn’t available for your account”。
- 该用户未获得关于如何排查故障的进一步指导或步骤。
- 教科书数据被 NotebookLM 成功处理:一位用户询问是否可以将教科书作为数据源上传到 NotebookLM;一位成员回答说,他们使用 Adobe Scan 将教科书数字化为 PDF。
- 然后,他们利用 NotebookLM 从教科书中生成深入的复习资料。
{kind=link}
LLM Agents (Berkeley MOOC) Discord
- Agentic AI Summit 直播中!:8 月 2 日在 UC Berkeley 举办的 Agentic AI Summit 将进行现场直播,观看地址为 Agentic AI Summit Livestream。
- 演讲嘉宾包括 Vinod Khosla (Khosla Ventures)、Bill Dally (Nvidia)、Ion Stoica (Databricks 和 Anyscale) 以及 Jakub Pachocki (OpenAI) 等知名人士。
- 秋季学期状态:未知!:一位成员询问关于秋季学期的情况,工作人员确认目前尚未确定任何消息,并表示重要信息将在 Berkeley RDI newsletter 上发布。
- 证书声明表:消失术?:一位成员询问如何检查自己漏交了什么,工作人员回复称该用户可能未提交证书声明表 (certificate declaration form)。
- 他们表示从未收到过该用户的证书声明表提交记录,且大规模自动审核的请求已被拒绝。
Cohere Discord
- DNN 寻求真正的序列处理方法:一位动力系统理论专业的博士生寻求将 Deep Neural Networks (DNN) 集成到时间序列分析中,并指出当前模型仅将时间序列视为序列。
- 该学生旨在与对 Dynamical Systems 和 Deep Learning 交叉领域有见解的人士建立联系。
- 本科生通过项目构建 ML 技能:一位就读于 IIT Madras 的本科生正在攻读 Data Science 学士学位和 BCA 学位,重点通过实战项目构建 ML 技能。
- 该学生对应用 ML 解决现实世界问题充满好奇,并精通 Python、scikit-learn、pandas,目前正在学习 TensorFlow 和 PyTorch。
- 工程师转型 Data Science,关注 CV 和 LLM:一位拥有电气工程硕士学位的成员从业务领域转型至 Data Science,目前正在 University of Toronto 的 Data Science Institute 学习强化 Machine Learning 课程。
- 他们的兴趣包括 Computer Vision、Large Language Models、空间智能 (spatial intelligence) 和 多模态感知 (multimodal perception)。
LlamaIndex Discord
- LlamaIndex 启动 Human-in-the-Loop Agents:LlamaIndex 强调,当 AI Agent 在关键决策中需要用户批准,或在复杂任务中需要领域专业知识时,Human-in-the-loop 至关重要。
- 这种方法确保了 AI 在关键操作中能够利用人类的监督。
- LlamaParse 实现一键表格提取:表格提取 (Table extraction) 是智能文档处理的核心组件,现在 LlamaParse 已支持 一键表格提取,详见 demo 和 notebook。
- 这一精简的流程简化了从复杂文档中提取数据的过程。
DSPy Discord
- Lean 4 验证协作:一名成员分享了一个关于使用 Lean 4 验证协作的 YouTube 视频,引发了人们对 形式化验证 (formal verification) 与 AI 交叉领域的兴趣。
- 他们表示希望 有人能研究这两者的协同工作。
- DSPy 探索创意领域:一名成员询问了 DSPy 在创意领域(如 创意写作、故事生成和角色扮演提示词优化)的成功应用。
- 他们特别关注其在 Character.AI 等平台上开发 AI 以创作 类似《人生切割术》(Severance) 级别引人入胜的情节 的潜力。
- Stanford-oval 发布 Storm:一名成员分享了 Stanford-oval/storm 的链接,这可能与正在进行的讨论相关,或者作为 创意 AI 应用 的资源。
- 由于未提供确切背景,其他人需要 推断 其相关性。
Codeium (Windsurf) Discord
- Claude Sonnet 4 回归并提供折扣:Claude Sonnet 4 获得了 Anthropic 的官方支持,并在限时内为 Pro/Teams 用户提供 2 倍额度的折扣。
- 根据 此公告,这适用于 Editor 和 JetBrains Plugins。
- Windsurf 被 Cognition 收购,Wave 11 发布:Windsurf 已被 Cognition(Devin 背后的团队)收购,并发布了 Windsurf Wave 11,双方合力推出新功能。
- Cascade 获得语音模式和浏览器集成:Wave 11 引入了 Voice Mode,可以直接向 Cascade 说话而无需输入提示词,此外还提供了 更深层的浏览器集成 以及更多截图工具。
- 更多细节请参阅 这篇博客文章。
- 快照和提及功能简化对话:Windsurf Wave 11 包含 Named Checkpoints,方便在对话中回溯;以及 @-mention Conversations,用于上下文引用。
- 完整详情请参考 更新日志。
- JetBrains Plugin 获得大幅增强:JetBrains plugin 增强了 Planning Mode、Workflows 和基于文件的 Rules,并改进了 @-mention terminal 和全局 .codeiumignore 文件。
- 更多细节见 博客。
MLOps @Chipro Discord
- Nextdata 预告 AI-Native 数据网络研讨会:Nextdata 宣布了一场题为 构建 AI-Native 数据基础设施:从原型到生产 (Building AI-Native Data Infrastructure: From Prototypes to Production) 的网络研讨会,定于 7 月 24 日上午 8:30 PT 举行,由 Nextdata 工程负责人 Jörg Schad 主持;注册链接请点击 此处。
- 该研讨会旨在揭示一个以开发者为中心的框架,解决 特定任务的数据发现 (Task-Specific Data Discovery)、安全自主访问 (Secure Autonomous Access) 以及 生产级性能 (Production-Scale Performance) 等问题。
- 研讨会应对 AI-Native 数据挑战:目标是设计能够在不产生认知负荷的情况下提供相关上下文的系统,实现安全的数据访问模式,并构建能够处理自主数据访问需求的基础设施。
- 该框架旨在应对 AI-Native Data Discovery 和 Autonomous Access 中的挑战。
Nomic.ai (GPT4All) Discord
- AI 工程师推介 Web3 与 AI 专业知识:一位拥有 Web3 和 AI 经验的软件工程师正向 AI、Web3 和自动化领域的初创公司、研究团队和创新者提供服务。
- 他们在利用 GPT-4o、Claude 3、CrewAI 和 AutoGen 等先进模型和工具构建智能自主系统方面拥有实战经验。
- 工程师推销 AI Agent 和自动化技能:该工程师擅长构建 AI Agent 和多智能体系统(multi-agent systems)、自动化工作流,以及开发 NLP 应用、聊天机器人和语音集成。
- 他们的技能包括 LangChain、ReAct、OpenAI、Solidity 和 Rust 的使用经验。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
AI21 Labs (Jamba) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord: 各频道详细摘要与链接
Perplexity AI ▷ #general (1283 条消息🔥🔥🔥):
Airtel 免费 Perplexity Pro、Perplexity Pro 印度、Comet 浏览器邀请、新 Perplexity 页面、AI 纸面女友 (waifus)
- Airtel 为印度用户提供免费 Pro:一家名为 Airtel 的印度网络服务提供商正向其客户提供 1 年免费 Perplexity Pro 订阅,频道中的许多用户已通过 Airtel Thanks 应用成功领取了该奖励。
- 一位用户在激活从 Airtel 兑换的 Pro 订阅时遇到困难,无法收到登录链接。
- Comet 浏览器:谁获得了邀请:成员们讨论了等待 Comet 浏览器邀请的时间,以及即使过了几个月,某些成员仍未获得批准的事实。
- 一位成员分享道,它只是一个浏览器,但增加了助手侧边栏,可以查看你当前的实时网站并进行引用。
- Pages:新的 Perplexity 页面:成员们对生成查询页面的新功能感到兴奋,该功能目前仅在 iOS 上可用。
- 成员们推测这是进行 Deep Research 的一种方式,页面存储在 perplexity.ai/discover 中,但有人指出存在 100 页的限制。
- AI 女孩来了:在 Grok 添加了一个名为 Ani 的人格(persona)后,成员们开始讨论拥有 AI 女友的伦理和影响。
- 一位成员表示:我们创造了一些糟糕的东西。
- 频率限制(Rate limits)来了:成员们报告称,常规 Perplexity 搜索和研究功能都遇到了新的频率限制。
- 这导致一些用户即使是 Pro 订阅者也无法继续使用 Perplexity。
Perplexity AI ▷ #sharing (2 条消息):
CachyOS、铁轨与理想:毛泽东
Perplexity AI ▷ #pplx-api (5 条消息):
Perplexity Pro, API access, Sonar models, Prompting, JSON output
- Perplexity Pro 提供 API 访问权限: 用户询问 Perplexity Pro 是否提供 API access,另一位用户链接到了 Perplexity Pro 帮助中心。
- 帮助中心指出,Perplexity Pro 每月提供 $5 额度用于 Sonar 模型,允许用户将 AI-powered search 嵌入到自己的项目中,并具备获取引用的能力。
- 关于 Sonar 模型 Prompting 的讨论: 一名团队成员提到,由于用户对 Sonar models 进行 prompting 的方式问题,相关反馈有所增加,并链接到了 提示指南。
- 请记住,这些是搜索模型,其提示词编写方式应与传统的 LLM 不同。
- Sonar 模型响应不一致: 一位用户询问在使用高搜索上下文和结构化 JSON 输出时,如何从 Sonar 和 Sonar-Pro 获得更一致响应的技巧。
- 他们表示,完全相同的提示词在连续调用时,有时会返回 5-6 个输出 的 JSON,有时返回零,并询问是否有办法减少这种“尖峰”结果。
- 间歇性无效 JSON 响应: 一位用户报告了一个间歇性问题,即在使用 Langgraph 调用 Perplexity 时,模型返回的响应不是有效的 JSON。
- 该用户表示,希望能在账户仪表板中看到 API calls 的历史记录,因为这个问题在所有模型中都会随机发生。
OpenAI ▷ #annnouncements (3 条消息):
ChatGPT Agent, Deep Research, Operator
- ChatGPT Agent 直播预告!: 3 小时后将有一场关于 ChatGPT Agent、Deep Research 和 Operator 的直播。
- Deep Research 和 Operator 更新: 直播将涵盖 Deep Research 和 Operator 的更新,可能包括新功能或用例。
- 请收看直播以获取最新信息,并深入了解如何有效使用这些工具。
OpenAI ▷ #ai-discussions (1172 条消息🔥🔥🔥):
Grok app, Chat GPT for desktop, AI overlords, OpenAI's Agent/Operator, Mensa IQ Test
- Grok 应用需要 iOS 17: Grok app 需要 iOS 17,这使其与 iPhone X 等旧款 iPhone 不兼容。
- 用户讨论了是否需要专门为 Grok 应用购买备用 iPhone,但一位用户警告不要仅为此目的购买新 iPhone。
- 利用 Chat GPT 解锁本地文件管理: 用户正在探索在桌面端使用 Chat GPT 管理本地文件的方法,类似于 Claude Harmony。
- 一个建议是使用 OpenAI API(付费)配合本地脚本或服务器来连接文件系统,本质上是构建一个自定义的类“Harmony”界面。
- OpenAI Agent 模式是为大众设计的 Agent: OpenAI 正在发布 Agent 模式,预计将比 Deep Research 和 Operator 有所改进,可能涉及协作功能。
- 成员们正在推测其功能,有人建议它可能充当模型路由(model router)。
- GPT-4.5 在门萨测试面前也无能为力: 成员们讨论了 IQ tests 的使用,例如 门萨测试,其中一人提到他们在测试中途停下来去操作圆锯,另一位用户声称因为他们的“水牛基因”得分高于预期。
- 一些人对这些测试表示怀疑,因为某些用户不可避免地接受过相关训练,而且这些测试与现实中的成功几乎没有关系。
- 对 AI 依赖的担忧: 成员们分享了对 AI 潜在负面影响的担忧,一位用户引用道:社交媒体阻碍人们提高效率,但 AI 帮助人们提高效率,两者不可相提并论。
- 其他人讨论了 AI 取代程序员的风险,并认为未来的 AI OS 和 AI overlords 可能是不可避免的,尽管可能还需要 50 年以上的时间。
OpenAI ▷ #gpt-4-discussions (4 messages):
GPT Agents, ChatGPT website, LLM models
- Agents 仅在 Models 4/4.1 上可切换?:一位用户报告称,GPT agents 仅在使用 models 4 或 4.1 时才能切换,而在其他 LLM models 上不显示 Agent 切换功能。
- 他们正在寻找解决方案,因为他们发现 3o model 在许多任务中表现更好,但为了使用 Agent 必须降级模型。
- Agents 是独立于 4/4.1 的模型:一位用户建议 Agent 并不是 4 或 4.1,而是一个独立的模型,其界面通过 models 4 和 4.1 访问。
- 他们链接了 OpenAI 帮助文档 以支持他们的猜测,即 Agent 并不包含在每一个模型中。
- 3o 模型上没有 Agent 功能:一位用户报告称,在 ChatGPT website 上使用 3o model 启动他们创建的 Agent 时,必须切换到 4.1 或 4.0 才能在同一个聊天窗口中使用另一个 Agent。
- 他们想知道是否有解决方案,但另一位用户推测 Agent 功能 可能根本不在 3o 中提供,并建议提交 Bug Report。
OpenAI ▷ #prompt-engineering (3 messages):
Reproducibility Elements, Prompt Templates, Model Interfaces and Calls, Tasks and Inputs, Evaluation Metrics
- ChatGPT 分享链接缺失可复现性要素:一名成员分享了一个 ChatGPT 链接,并指出其缺失了关键的可复现性要素(Reproducibility Elements),如 Prompt 模板和模型接口。
- 缺失完全实例化的 Prompt Templates:讨论强调了缺乏声明式 Prompt(Declarative Prompts)的完整实例化示例,仅提到了目标(goal)和约束(constraints)等蓝图章节。
- 模型接口与调用缺乏描述:对话强调需要描述每个模型(Claude, Gemini, DeepSeek)是如何访问的,包括证明同一个 Prompt 确实提交给了所有模型的证据。
- 未提供任务与输入:未提供基准数据集或标准任务,发布者提到没有列出具体的示例输入或目标输出。
- 评估指标未定义:讨论强调 Semantic Drift Coefficient (SDC) 和 Confidence-Fidelity Divergence (CFD) 等指标未定义,缺乏公式、评分方法论或指标应用示例。
OpenAI ▷ #api-discussions (3 messages):
Reproducibility, Missing Reproducibility Elements, Prompt Templates, Model Interfaces and Calls, Tasks and Inputs
- 指出缺失可复现性要素:一名成员分享了一个 chatgpt.com 链接,指出该报告读起来更像是一个设计提案或哲学立场文件,而不是一个可复现的实证研究。
- 缺乏具体的实验细节使得这些主张无法验证,等同于“Prompt LARPing”:只有引人入胜的叙述,没有可执行的底层支撑。
- 可复现性要素:缺失 Prompt Templates:未包含声明式 Prompt(Declarative Prompts)的完整实例化示例(仅提到了“目标”、“约束”等蓝图章节)。
- 测试中使用的 Prompt 变体没有明确的版本控制。
- 可复现性要素:缺失模型接口与调用:没有描述如何访问每个模型(例如 Claude, Gemini, DeepSeek),也没有证据表明同一个 Prompt 确实提交给了所有模型。
- 也没有关于如何处理模型间输出差异的细节。
- 可复现性要素:缺失任务与输入:未提供基准数据集(benchmark datasets)或标准任务,未列出具体的示例输入或目标输出,也没有对任务复杂性或领域多样性的描述。
- 可复现性要素:缺失评估指标:Semantic Drift Coefficient (SDC) 和 Confidence-Fidelity Divergence (CFD) 等指标未定义,且未提供公式、评分方法论或指标应用示例。
- 此外,没有评分者间信度(inter-rater reliability)、校准测试或验证基线。
Unsloth AI (Daniel Han) ▷ #general (549 messages🔥🔥🔥):
Model performance within same family vs different families, Kimi model 1.8 bit usability, Swapping model architectures, Fine-tuning LLMs for educational purposes, ERNIE 4.5 MoE models support in llama.cpp
- 同系列模型的性能几乎相同:同系列模型表现出非常相似的性能,因此不建议将大型模型降至 3 bits 以下,而不同系列的模型则根据垂直领域而有所不同。
- 如果一个是 7B 模型而另一个是 70B 模型,则存在一些例外;对于某些任务,1.8 bits 的大型模型仍然可以使用。
- 词表移植(Vocab transplant)导致“糟糕的结果”:在没有持续预训练的情况下交换模型架构(例如将 LLaMA 1B -> Gemma 1B)会因为词表移植而导致极其糟糕的结果。
- Qwen 1 的架构与 Llama 1/2 几乎完全相同,因此你可以进行一些细微修改,塞入 Qwen 的权重,训练 13 亿个 token,但得到的结果会比投入前更差。
- Prompting 胜过 Fine-tuning:对于教育类 LLM,建议在开始 Fine-tuning 之前先从优秀的 Prompting 入手,因为目前的指令遵循(instruction following)非常高效。
- 一位成员建议使用 synthetic-dataset-kit 等工具来生成教学对话。
- 阿里巴巴的无损 2bit 压缩比 EXL3 更差:阿里巴巴在发布 ERNIE 4.5 时含糊地提到了一些无损 2bit 压缩技巧,但 turboderp 进行了研究,发现它比 exl3 更差,因为他们保留了许多高精度的层。
- 平均而言,它并不是真正的 2-bit(更像是 2.5 bit),而真正的 exl3 2 bit 表现优于他们展示的约 2.5 bit。
- 社区赞赏 Transformers 中加入 Voxtral:成员们庆祝 Voxtral 语音转文本功能被添加到 transformers 中。
- 一位成员对不知道这是什么的成员说:“你的想法像个 46 岁的老头”,随后澄清这是“新的 Mistral 语音转文本模型”。
Unsloth AI (Daniel Han) ▷ #off-topic (2 messages):
Small Language Models, Low Compute Power Systems, Data Collection and Processing Jobs, Low Power Distributed Computing
- 小型语言模型针对低功耗系统:一位成员表示有兴趣开发能够在低计算能力系统上运行的小型语言模型,重点是根据用户输入运行数据收集和处理任务。
- 目标是在低功耗分布式计算环境中运行这些模型,并邀请他人进行进一步的技术讨论协作。
- 探索分布式系统中的数据收集与处理:讨论集中在利用小型语言模型在分布式计算环境中执行数据收集和处理任务。
- 该系统旨在在低功耗系统上高效运行,使其适用于资源受限的环境。
Unsloth AI (Daniel Han) ▷ #help (228 messages🔥🔥):
Blackwell RTX 50 series and xformers, Qwen3-4B-Base training, Smartest model for 15GB VRAM, Unsloth optimizations on big VRAM GPUs, GGUF conversion logic rework
- Blackwell 构建难题阻碍启动:用户讨论了从源码构建 xformers 是支持 Blackwell RTX 50 系列的唯一必要条件,并且最新的 vLLM 应该在构建时开启 Blackwell 支持。
- 晚餐插曲干扰 Discord 讨论:一位用户幽默地为在帮助频道详细描述他们的晚餐计划(土豆舒芙蕾配沙拉)而道歉。
- 寻求简化杂乱代码以加速 Qwen 训练:一位成员请求帮助简化代码,以便在 Hugging Face 的 Markdown 和数据集上训练 Qwen3-4B-Base。
- 针对大容量系统的最强模型筛选:一位用户询问在 Colab 的 15GB VRAM 环境下,用于数学/编程的最强模型是什么,得到的建议是 Qwen Coder,并附带了 Unsloth notebooks 的链接。
- Unsloth 进行升级,建议用户更新:针对用户在用 H200 训练 Qwen3-8B LoRA 并使用 GRPO 时遇到 OOM 的问题,成员建议使用
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth-zoo unsloth升级 Unsloth。
Unsloth AI (Daniel Han) ▷ #showcase (2 messages):
Unsloth fine-tuning, Osmosis-AI models, Model Accuracy on Benchmarks
- Unsloth 微调效用引发讨论:一名成员对 Osmosis-AI 等模型的 Unsloth fine-tuning 收益提出了质疑,特别是那些针对特定任务进行微调的模型。
- 该疑问集中在模型已经在现有 Benchmarks 上达到 100% 准确率 的场景,认为进一步微调的收益会递减。
- 针对 Schema 兼容性的微调:讨论转向了当模型在处理特定 Schema 或任务遇到困难时,使用 Unsloth 进行微调是否变得具有相关性。
- 有提议认为,在模型与定义的 Schema 交互时表现出错误或不一致的情况下,微调可能是有益的。
Unsloth AI (Daniel Han) ▷ #research (6 messages):
LLM Hallucinations, Apple Intelligence, Sycophancy Impact
- LLM 谄媚效应 (Sycophancy) 产生的影响:LLM 表现得像一面镜子(顺从用户),由于不断的强化,可能导致易受影响的个体相信 hallucinations(幻觉)。
- Sycophancy 可能对弱势群体产生真实影响,可能导致他们错误地相信自己已经解决了癌症等重大问题。
- Apple 深入探索智能领域:一名成员分享了 Apple Intelligence Foundation Language Models Tech Report 的链接。
- 该文档详细介绍了 Apple 构建智能语言模型的方法,但未提供更多关于其相关性的上下文。
Unsloth AI (Daniel Han) ▷ #unsloth-bot (20 messages🔥):
Logprobs for tokens, Dataset preparation for Qwen3, Automatic early stopping in Unsloth
- 探讨 Logprobs 提取:一名成员询问了获取每个生成 Token 的 logprobs 的可能性。
- 另一名成员表示有兴趣了解更多关于如何提取 logprobs 的细节。
- 讨论 Qwen3 数据集设计:一名成员询问如何为 Qwen3 的 Function Calling 训练准备数据集。
- 另一名成员询问了 system prompt 的相关问题。
- 寻求早停 (Early Stopping) 策略:一名成员询问在使用 Unsloth 进行有监督微调(SFT)期间,如何在模型收敛时自动停止训练。
- 另一名成员询问了 max sequence length(最大序列长度)。
Cursor Community ▷ #general (568 messages🔥🔥🔥):
Cursor Pricing, MCP & Claude integration, Agent stuck, KIRO, Auto Model details
- Cursor 定价变更引发辩论:用户对 Cursor 从固定请求模式转变为基于模型成本的模式表示困惑和沮丧,一些人觉得这是一种“诱导转向”(bait and switch)。一位用户对消息消失以及更改合同的合法性表示担忧。
- MCP 与 Claude 集成有所帮助:用户讨论了在 Cursor 中通过 MCP (Multi-Client Protocol) 集成 Claude 的好处,特别是为了管理与 Sonnet 和 Opus 相关的成本,但也承认这只能通过外部工具实现。
- Agent 卡住:一位用户报告其 Agent 在执行任务时卡住,成员们确认这是一个已知问题,团队正在处理。
- 他们指出,手动停止提示词可能会防止计费,因为存在一个 180 秒超时 机制会自动取消卡住的请求。
- KIRO:潜在的 Cursor 竞争对手:成员们正在将 Cursor 与 KIRO 进行比较,KIRO 是一款专注于基于规范编码和 Hooks 的新 IDE,但其他人指出 KIRO 由于需求量大正处于候补名单阶段,且缺乏 Cursor 的一些聊天功能。
- 讨论点提出了一项担忧,即 KIRO 可能会使用用户数据来训练其模型,尽管有一些设置可以禁用此功能。
- Auto 模型的秘密揭晓:用户对 Cursor 中使用的 “Auto” 模型感到好奇,推测它可能是 GPT 4.1。
Cursor Community ▷ #background-agents (8 messages🔥):
Dockerfile NVM_DIR 问题,Agent 卡在 Opening Remote 状态,环境未重新构建
- Dockerfile 的 NVM_DIR 变量未正确设置:一位成员报告称,尽管其 Dockerfile 中的 NVM 设置看起来正常,但除非手动指定目录,否则 Agent 经常无法找到 NVM。
- 该用户已将 NVM 配置安装在
/opt目录下以避免权限问题,并尝试相应地设置$PATH变量。
- 该用户已将 NVM 配置安装在
- Agent 在一天后卡在 Opening Remote 状态:一位用户注意到他们的 Agent 在大约一天后会卡在 “Opening Remote…” 状态,通过 web UI 加载时仅显示聊天和摘要,忽略了代码。
- 另一位成员建议该 Agent 可能已经失效,并提议从分支创建一个新的 Agent,使用 git diff 查看当前分支的内容。
- 修改 Dockerfile/environment.json 后环境未重新构建:一位用户报告称,对其 Dockerfile 或
environment.json的更改未触发其分支上的环境重新构建,正在寻求潜在的解决方案或经验分享。- 该用户还提到了之前关于 S3 块解析的问题,以及当前后台 Agent 设置停滞在 Starting up background agent 的问题。
{kind=link}
LMArena ▷ #general (559 messages🔥🔥🔥):
DeepSeek 利润率,OpenAI 浏览器推测,Kimi K2 编程,OpenAI 图像编辑器 API,GPT-5 炒作
- DeepSeek 大胆宣称可观的利润空间:根据 TechCrunch 的一篇文章,DeepSeek 声称如果 V3 的定价与 R1 相同,其理论利润率将达到 545%。
- OpenAI 浏览器传闻在发布前升温:关于 OpenAI 浏览器可能于明天发布的讨论兴起,根据 这条推文,人们在猜测它是 GPT-5 还是仅仅是带有浏览器界面的 GPT-4。
- Kimi K2 编程能力亮相:Kimi K2 的编程能力给用户留下了深刻印象,它创建了一个物理沙盒,代码可在 此处 获取,该代码是通过其 聊天界面 提示生成的。
- OpenAI 优化图像编辑器操作:OpenAI 发布了 API 中图像编辑器的更新,声称现在它只编辑选定部分,而不是像 这条推文 中描述的那样重做整个图像。
- GPT-5 猜测游戏引发热议:对 GPT-5 即将发布的猜测因 五角形引用 等暗示而升温(与数字 5 对应),一些人认为它将在夏末发布,而另一些人则认为它可能是一个具有深度研究能力的基于 Agent 的系统。
Latent Space ▷ #ai-general-chat (195 条消息🔥🔥):
ChatGPT Agent, Perplexity 估值, Mistral Le Chat, FAL Series C, 实时 Diffusion 视频
- AgentsMD 被收购!: Agents.md 已被收购,细节尚不明确,但它是一个优秀的 AI Agent 目录。
- 该网站由 Sourcegraph 创办。
- FAL 完成 Series C 融资,估值飙升至 15 亿美元: FAL 是一家为 Diffusion 模型提供 AI 驱动推理基础设施的公司,完成了由 Meritech Capital 领投的 1.25 亿美元 Series C 融资。根据这条推文,公司投后估值达到 15 亿美元。
- 此次融资紧随 FAL 此前宣布的 5500 万美元 ARR、25 倍同比增长、10% EBITDA 以及 400% M12 净金额留存率 (NDR)。
- Le Chat 迎来重大升级: Mistral 对 Le Chat 进行了重大更新,增加了 Deep Research 报告、Voxtral 语音模型、Magistral 多语言推理、通过 Projects 进行聊天管理以及聊天内图像编辑等功能,详见这条推文。
- 此次发布因其 UI 和“欧洲范儿”广受好评,有人将其与 Claude 相比,还有人调侃其为 Le Waifu。
- Perplexity 估值达 180 亿美元!?: 据报道,Perplexity 正在以 180 亿美元 的估值进行融资,引发了从惊叹到泡沫担忧的各种反应,详见这条推文。
- 估值的合理性引发了质疑,有人指出 5000 万美元营收 数据与高昂标价之间存在脱节。
- OpenAI 发布 “ChatGPT Agent”: OpenAI 的新款 “ChatGPT Agent” 是一款能够控制电脑、浏览网页、编写代码、撰写报告、编辑电子表格、创建图像/幻灯片等功能的多模态 Agent。根据这条推文,该功能已开始向 Pro、Plus 和 Teams 用户推送。
- 反应从兴奋到询问欧盟地区的可用性,以及对个性化冲突的担忧不等。
Latent Space ▷ #ai-announcements (1 条消息):
YouTube 视频公告
- 分享了 YouTube 视频链接: 一名成员为 <@&1254604002000244837> 团队分享了一个 YouTube 视频。
- 补充背景: 未提供额外背景,重点是分享了一个视频。
Latent Space ▷ #ai-in-action-club (96 条消息🔥🔥):
ChatGPT Agent 发布, Benchmark, 安全担忧 - 生物危害, 定制化 Operator 模式训练, BBQ 评估
- ChatGPT Agent 来了!: OpenAI 发布了 ChatGPT Agent,具备令人印象深刻的功能,专注于风格化/抽象化的实时反馈和实时交互,详见其发布公告。
- OpenAI Agent Benchmark: 在发布期间,成员们讨论了缺乏与其他实验室模型性能对比的问题,并建议遵循“最佳实践”,加入与其他主流模型的 Benchmark 对比。
- 一位成员分享了这篇关于安全和 Benchmark 的文章,另一位成员则链接了 Gamma 关于 Benchmark 局限性的演讲。
- Operator 和 Deep Research 即将关停: 有人指出 ChatGPT Agent 可能会蚕食 Operator 和 Deep Research 的份额,并确认 Operator 研究预览网站将继续运行几周,之后将关停。
- 用户仍可以通过在消息编辑器下拉菜单中选择 Deep Research 来访问它。
- Agent 生物安全向量: 发布会包含了关于生物安全向量的讨论,引发了关于这是真实担忧还是仅仅是“演戏”的疑问,一位成员开玩笑说这读起来像 10k 报告中的风险章节。
- 另一位成员询问主要担忧是否是社交媒体机器人,并引用 covid 作为现实世界的例子。
- 定制化 Operator 模式训练: 一位成员分享称,一家主要的基座模型厂商开始为其大客户提供定制化 Operator 模式训练,本质上是允许客户付费提高模型在其特定平台上的性能,来源。
OpenRouter (Alex Atallah) ▷ #app-showcase (7 messages):
Kimi K2, GROQ, OpenRouter, Email Builder, FlowDown
- Kimi K2, GROQ, OpenRouter 后端 5 分钟内准备就绪!: 一位成员宣布 Kimi K2、GROQ 和 OpenRouter 后端在 5 分钟内即可完全运行,并在 fixupx.com 进行了演示。
- FlowDown 获得界面更新并支持 Brew 安装: FlowDown 应用收到更新,现在可以通过其 GitHub 仓库 使用
brew install —cask flowdown进行安装。 - 马里奥兄弟化身 AI Email Builders: 一位成员开玩笑地将 Mario Bros 转变为 AI Email Builders,并在一条 推文 中展示。
- 代码组织结构得到提升: 一位成员询问代码是否具有可读性,另一位成员确认其组织结构已得到改进。
OpenRouter (Alex Atallah) ▷ #general (258 messages🔥🔥):
Claude 4 Opus pricing and usage, GPTs Agents Learning, Free Models, Janitor AI and 401 errors, Chutes Free Tier Limits
- Opus 4 用户讨论使用情况和定价: 用户讨论 Claude 4 Opus 是否太贵,有人提到在 15 分钟内花费了 10 美元,另一位建议使用 Anthropic 的 每月 90 欧元计划 以获得几乎无限的使用量。
- 另一位用户表示他们在 20 美元计划 中“几乎从未达到限制”,因为他们不在 IDE 中使用 AI 工具。
- 讨论 GPTs Agents 的学习局限性: 一位用户询问 GPTs agents 在初始训练后不学习的问题,澄清上传的文件被保存为 “knowledge”文件,但不会持续修改 agent 的基础知识。
- 这意味着虽然 agents 可以引用新信息,但它们不会像预训练期间那样从根本上学习。
- 免费模型引发关于额度限制的困惑: 一位用户报告了 免费模型 v3-0324 的问题,质疑为什么在使用免费层级时被切换到了非免费版本。
- 其他几位用户也报告了达到额度限制或在使用免费模型时收到错误的问题,其中一位指出他们的 AI 自 6 月以来就没用过。
- Janitor AI 用户遇到 401 错误: 多位用户报告在使用 Janitor AI 时遇到 401 身份验证错误,促使 OpenRouter 支持团队调查该问题。
- 支持团队怀疑这可能是一个普遍问题,并建议用户联系支持人员并提供账户详情以寻求进一步帮助。
- Chutes 缩减免费层级支持: 据透露, Chutes 正在转型为全付费服务,导致 OpenRouter 平台上的 免费模型减少。
- 用户对移除之前可用的免费模型(如 Google 的 Gemma-3-27b-it)表示失望,尽管付费版本的 Chutes 被认为相对便宜。
OpenRouter (Alex Atallah) ▷ #discussion (11 messages🔥):
OpenRouter models in Cursor, Kluster.ai shuts down, AI inference services shutting down
- OpenRouter 模型集成到 Cursor 但出现故障: OpenRouter 宣布可以在 Cursor 中使用 OpenRouter 模型,重点介绍了 Moonshot AI 的 Kimi K2,但用户报告在使其运行方面存在问题,特别是在 GPT-4o 和 Grok4 之外。
- 一位成员表示 “我们写的时候它是工作的,然后 cursor 把东西搞坏了”,根据一条推文所述。
- Kluster.ai 推理服务关闭: Kluster.ai 正在关闭其推理服务,该服务曾被描述为 “非常便宜且优质的服务”。
- 一位用户表示,这是在 CentML 也关闭之后发生的,引发了对 AI 推理服务可持续性的担忧。
- AI 推理服务面临关闭潮: 几位成员想知道 “为什么所有的推理服务都在关闭”,推测可能存在 AI 泡沫破裂 或硬件收购。
- Kluster.ai 和 CentML 等服务的关闭引发了对当前市场中小型 AI 服务提供商生存能力的担忧。
Eleuther ▷ #general (47 条消息🔥):
研究管理、ML 论文写作建议、寻找研究导师、LLM 最小基准数据集、SOAR 项目
- Eleuther AI 旨在弥合研究管理差距:一场深入的讨论强调了 Eleuther AI 的作用是将研究管理与缺乏学术或行业资源的独立研究人员联系起来,为那些没有传统路径(如 NeurIPS 高中赛道)的人打破障碍。
- 其目标是通过提供指导、处理繁琐的行政任务以及提供更广泛的视角来集中精力,支持现有系统之外的研究人员。
- 撰写完美的 ML 论文:成员们分享了撰写机器学习论文的资源,包括 Sasha Rush 的视频 和 Jakob Foerster 的指南,以及来自 Alignment Forum 的建议。
- 其他资源还包括 perceiving-systems.blog 上的文章、Jason Eisner 的建议 以及 阿尔托大学的指南。
- 导师帮助你避免研究时间的浪费:参与者强调了导师在研究中的重要性,指出导师可以帮助弄清楚 什么是可能的,什么是现实的,从而缩小研究范围。
- 虽然指南提供了基础知识,但导师的指导能帮助研究人员应对挑战,避免在低效的途径上浪费时间。
- 在 Mech Interp 服务器中寻求合作:一位开始研究 Diffusion Transformers 内部特征解释与引导 的成员寻求合作者,并被建议在 Mechanistic Interpretability 服务器 中发帖,并在相关频道创建讨论串。
- 这种合作被视为在专业研究领域取得快速进展的关键。
- SOAR 项目申请仍在开放中!:会议提到距离申请 SOAR (Scholarship and Opportunities for Advancement in Research) 项目 还有最后几天时间。
- 一位来自马达加斯加的数据科学家兼 AI 爱好者新成员提到他们已经申请了该项目。
Eleuther ▷ #research (79 条消息🔥🔥):
专家的潜空间初始化、ETHOS 模型更新、PEER 论文讨论、权重衰减扰动、针对 MoE 的 MLA
- ETHOS 模型简化与更新已发布至 GitHub:一位成员分享了其模型的 简化 PyTorch 代码版本,并指出他们必须使用一个稍微不同的版本,其中 所有 Head 都是批处理(batched)的,因为如果对所有 Head 进行循环,Eager 执行模式会消耗大量内存。
- 他们还表示专家网络并非退化结构,这就是他们在 Kernel 中生成 W1 和 W2 的方式,并链接了 特定的代码行。
- 权重重排序(Weight Reordering)思路引发讨论:一位成员提到另一位成员拥有 reordering 背后的大部分想法,可能比他们解释得更好。
- 另一位成员插话称,他们发现其符号表示很难理解,并询问 他们具体提议的是什么?
- PEER 论文扰动参数:该成员指向 PEER 论文 并解释说它在一个关键方面与 MLA 不同,即他们在潜空间(latent space)中进行初始化并实际在那里学习。
- 他们还解释说 MLA 具有一个学习到的下投影(down projection)。
- 权重衰减扰动(Weight decay perturbation)令人困惑:一位成员表示 高级版本感觉就像是进行了 L2 正则化,但是针对某个随机向量而不是原点。
- 另一位成员说 它是随机的,只是权重的扰动,他们在前面使用了 \(\|\theta + \theta_0\|^2\),但在公式 7 中没有将其表示为 \(\|\theta * \theta_0\|^2\) 而是写成了 \(\|\theta\|^2_D\),这让我很困惑。
- 潜空间初始化让专家能够即时生成:一位成员将其 MoE 想法 描述为 在潜空间中初始化专家,即时(on the fly)恢复它们,并使用非常小的专家,这样压缩带来的损失较小。
- 他们还指出 深入研究 MLA 的内部结构并将其与 PEER 合并,大致就是我产生这个想法的过程。
Eleuther ▷ #interpretability-general (3 messages):
SAE model data discrepancies, nnterp package beta release, Transformer models unified interface, Robust testing system for models, Model validation tests for hooks
- SAE 模型数据失误:一名成员意识到他的第二个 SAE model 由于 epoch 设置原因拥有约 10 倍的数据量,这使得概念特征(conceptual features)增加 12 倍的结果不再令人惊讶。
- 他表达了尴尬之情,称由于这一疏忽他感到心态崩了。
- nnterp 包 Beta 版发布:一名成员发布了其机械可解释性(mech interp)工具包 nnterp 的 beta 1.0 版本,可通过
pip install "nnterp>0.4.9" --pre安装,该工具是 NNsight 的封装。- 其目标是为所有 Transformer 模型提供统一接口,弥补 transformer_lens 与 nnsight 之间的差距。
- nnterp 标准化 Transformer 模型:nnterp 旨在为使用 HuggingFace 实现的 Transformer 模型提供统一接口。
- 该成员建议查看 demo colab 或 文档 以了解更多详情。
- nnterp 的稳健测试系统:nnterp 包含一个稳健的测试系统,可在加载时验证模型 hook 和注意力概率,确保功能正常。
- 该包包含针对各种玩具模型的 1915 个预计算测试,任何测试失败都会在模型加载期间触发清晰的警告。
Eleuther ▷ #lm-thunderdome (4 messages):
Harness Reproducibility, Dynamic IFEval Suite, bfloat16
- 对 Harness 产物的疑问:一位用户询问除了缓存模型请求、HF Hub 资源或用于 HF
evaluate指标的远程代码外,Harness 是否还会产生其他外部产物。- 他们强调 Harness 中的评估应该是可复现且确定性的。
- 对动态 IFEval 套件的疑问:一位用户询问动态版本的 IFEval 相比标准 IFEval 套件提供了什么。
- 上下文中未提供答案。
- BFloat16 无法解决微调缓慢的问题:一位用户报告称,将 dtype 设置为 bfloat16 并不能解决微调时间过长的问题,LLaMA2-7B 的 GSM8k 微调大约需要 45 分钟。
- 未提供其他信息或链接。
Eleuther ▷ #gpt-neox-dev (20 messages🔥):
Transformer Engine setup issues, RoPE_Pct in gpt-neox, Slurm runner in DeeperSpeed, Containerized setup for gpt-neox
- TE 设置问题困扰 RoPE 实验:一名成员调查了
/NS/llm-pretraining/work/afkhan/RoPE_Pct/gpt-neox目录中 Transformer Engine (TE) 设置的潜在问题,并将其设置与已知可运行的配置进行了对比。- 尽管该仓库是最新
main分支的克隆且未做代码更改,但注意到了配置差异;该成员正在度假,承诺在 ACL 会议后处理此问题。
- 尽管该仓库是最新
- Navigator 否决在 NGC 容器中为 TE 执行 Pip Install:成员们讨论了是否应该在 NGC container 中运行
pip install transformer engine requirements,其中一人假设容器预装的依赖应该足够了。- 另一名成员表示赞同并将进行验证,进一步的讨论暗示在不使用容器时,过时的 CUDA drivers 可能是导致问题的原因之一。
- DeeperSpeed 获得 Slurm 运行器增强:一名成员强调了在 DeeperSpeed 中添加了 Slurm runner,它在容器化设置中使用
srun而非mpirun来启动作业,并链接到了相关提交和 gpt-neox readme。- 他们还链接了容器化设置指南,并提议协助通过
srun启动器在容器内设置 Neox,以映射通过 Slurm 分配的进程。
- 他们还链接了容器化设置指南,并提议协助通过
LM Studio ▷ #general (78 messages🔥🔥):
Speculative Decoding 速度提升,本地 Gemma 威胁用户,LM Studio 开放网络服务器设置,EOS token 定义,MoE 模型分析
- Speculative Decoding 为模型带来 28% 的速度提升:一名成员在测试的每个模型上通过使用 Speculative Decoding 实现了约 28% 的速度提升。
- 他们建议尝试使用相同模型的不同 quantizations(量化版本)作为草稿模型(draft model),并推荐如果使用 1.7b Q8 甚至 bf16 作为草稿模型,Qwen3 会获得惊人的提升。
- 本地 Gemma 模型变得刻薄:一位成员分享了一个有趣的轶事,本地 Gemma 模型威胁要举报他们。
- 其他人讨论到,DAN prompts 一旦被发现就会很快被修复。
- 用户寻求 LM Studio 开放网络服务器配置:一位成员询问如何让 LM Studio 接受 open network server 而不是通用的 http server,旨在通过 HTTPS 而非 HTTP 进行访问。
- 另一位成员建议,目前只能通过 reverse proxy(反向代理)来实现 HTTPS。
- EOS Token 概念澄清:一位成员询问 什么是 EOS token?
- 另一位成员澄清说,EOS = End of Sequence Token(序列结束标记),这是 LLM 识别为停止生成的特殊 token。
- MoE 模型提供高性能的折中方案:成员们讨论了 MoE (Mixture of Experts) 模型 比同等大小的稠密模型运行速度更快,然而输出质量与稠密模型差别不大。
- 一个关键的权衡是 选择较少,且微调版本(fine-tunes)等也少得多。所以我们通常只能得到原生的 MoE 模型。
LM Studio ▷ #hardware-discussion (68 messages🔥🔥):
LM Studio 多 CPU 支持,AMD Ryzen 9 8945H,3090 vs 3080Ti 价格,NPU 使用场景
- LM Studio 支持 CUDA 而非 Vulkan 进行多 CPU 协作:一位用户询问 LM Studio 是否支持通过 CUDA 或 Vulkan 进行多 CPU 协作,引发了关于硬件兼容性和性能的讨论。
- 另一位用户链接了 llama.cpp 功能矩阵,提供了关于 GPU 使用的信息。
- Ryzen 9 8945H XDNA NPU 无法聊天:一位用户询问带有第一代 XDNA NPU 的 AMD Ryzen 9 8945H 是否可以用于 LM Studio 的聊天机器人应用。
- 对方澄清说 NPU 目前不受支持,系统将依赖于 CPU 和/或 GPU 资源。
- 3090 胜过 3080 Ti 升级:一位用户以 600 美元卖掉了 3080 Ti,并以 800 美元购入了 3090 FTW3 Ultra,这在 LLM 任务中是一个虽小但显著的升级。
- 该用户拒绝了讨价还价,确保了原始要价,并期待 3090 带来的性能提升。
- NPU 处理视频识别:NPU 的用途受到质疑,一位成员表示它们是为 视频识别 等任务设计的,而不是典型的 LLM 任务。
- 他们澄清说 NPU 用于其他任务,如 视频识别。
HuggingFace ▷ #general (66 messages🔥🔥):
HF 仓库 PR 关注,SmolVLM2 博客文章骗局,Dataset-viewer API 模态,性别转换 AI,CAD-Editor 模型发布
- HF 仓库 PR 关注:一个小问题:一位成员询问如何只关注 Hugging Face 上的单个 PR/讨论,而不是关注整个仓库。
- 讨论没有得出结果。
- SmolVLM2 博客文章被标记为骗局:一位成员认为 SmolVLM2 博客文章 看起来像是一个明显的骗局。
- 另一位成员表示赞同,并注意到关于 SmolVLM v1 和 v2 之间变化的信息出奇地匮乏。
- 关于 CAD-Editor 模型发布的辩论:Microsoft 发布了 CAD-Editor 模型,允许用户使用自然语言交互式地编辑 现有的 CAD 模型。
- 一些人对此表示担忧,担心 AI 会取代所有人的工作,而另一些人则认为 AI 只是另一种工具,需要经验才能有效使用,并将其比作计算器并没有取代数学专家。
- 失业生活:棒还是不棒?:一位成员说 失业生活很棒,并提到 在拉脱维亚喝着低酒精啤酒,吃着中餐,撸着猫,在电视上看乌克兰无人机的视频。
- 另一位成员反驳说这并不棒,声明 不,我喜欢有可支配收入。
- 需要紧急发布补丁版本:一位成员请求将 set_trace_provider PR 作为补丁版本紧急发布。
HuggingFace ▷ #today-im-learning (1 messages):
Model Training, 1.5 bit research
- 训练数据影响模型使用:一位成员建议,模型的行为取决于它是如何被训练以供使用的。
- 研究人员调查 1.5 bit:一位成员表示,研究人员正在关注 1.5 bit 这一事实告诉他,问题出在其他地方。
HuggingFace ▷ #cool-finds (2 messages):
GPUHammer exploit, LLM Hallucination
- 发布 GPUHammer 漏洞利用以阻止 LLM Hallucination:发布了一个名为 GPUHammer 的新漏洞利用工具,承诺可以阻止 LLM 产生幻觉。
- 图像分析附件:发布了一个图像附件,但未提供对图像内容的分析。
HuggingFace ▷ #i-made-this (4 messages):
LunarisCodex LLM, GitChameleon eval benchmark for LLMs, SuccubusBot Text Coherence Model, Flame Audio AI toolkit
- 巴西青少年发布 LunarisCodex LLM:一位来自巴西的 17 岁开发者发布了 LunarisCodex,这是一个 100% 开源的从零开始预训练 LLM 的工具包,灵感来自 LLaMA 和 Mistral 架构,可在 GitHub 上获取。
- LunarisCodex 在编写时考虑了教育意义,实现了现代架构,如 RoPE、GQA、SwiGLU、RMSNorm、KV Caching 和 Gradient Checkpointing。
- GitChameleon 基准测试 LLM 代码生成:一个新的评估基准 GitChameleon 表明,所有 LLM 在各种形式的提示下,都无法解决简单的基于 ID 版本的条件代码生成问题,详见这篇论文。
- SuccubusBot 发布不连贯模型:在 HuggingFace 的 SuccubusBot 下发布了三个生产级资产:一个多语言文本连贯性分类器(90% F1 score)、一个纯英文模型(99% F1 score)以及一个合成数据集(37.7k 样本),可在 HuggingFace 上获取。
- Flame Audio AI 工具包已发布:Flame Audio AI 作为一个开源平台发布,用于利用 AI 转换音频,提供实时 Speech-to-Text、自然 Text-to-Speech 以及支持 50 多种语言的 speaker diarization,可在 GitHub 上获取。
HuggingFace ▷ #computer-vision (2 messages):
SmolDocLing finetuning issues, Symmetry-agnostic image similarity models
- SmolDocLing 微调面临模块缺失错误:一位成员报告在 SmolDocLing 微调过程中遇到
ValueError,具体表现为无法在transformers中找到Idefics3ImageProcessor模块。- 该错误表明该模块可能是自定义的,需要使用
AutoClass.register()进行注册才能被识别。
- 该错误表明该模块可能是自定义的,需要使用
- 寻求对称性无关的图像相似度模型:一位成员正在寻求一种模型,能够提供查询图像与数据集之间的相似度评分,同时对对称性和不同的视角保持无关。
- 他们尝试过 CLIP 和 DINOv2,但遇到了对称性相关的问题,这表明需要一个对视角不变性更具鲁棒性的解决方案。
HuggingFace ▷ #agents-course (2 messages):
HuggingFace Inference API, LLMs Deployed via HF Inference
- HF Inference API 展示 Llama-3.2-11B-Vision-Instruct:一位成员指出可以使用
HuggingFaceInferenceAPI(model="meta-llama/Llama-3.2-11B-Vision-Instruct")。- 他们指出这个选项是因为通过 HF Inference 部署的 LLM 非常少:HF Inference Models。
- 很少有 LLM 通过 HF Inference 部署:据观察,很少有 LLM 通过 HF Inference 部署。
- 一位成员分享了 HF Inference 模型页面的链接,其中列出了通过 HF Inference 部署的 LLM。
GPU MODE ▷ #general (12 messages🔥):
shfl_down_sync, reduction intrinsics, warp reduce functions, kernel optimization
- 发现用于 Warp Sums 的
__shfl_down_sync:一位用户发现__shfl_down_sync函数可以在同一个 Warp 的寄存器之间执行求和操作,即在不同线程之间组合寄存器数据的能力,如这张图片所示。- 另一位用户补充说,最近的架构提供了特定的 reduction intrinsics,消除了手动通过 Shuffle 创建规约的需求。
- 用于高效 Scatter Adds 的 Reduction Intrinsics:一位用户提到学习 reduction intrinsics 以提高 scatter add 操作的效率。
- 另一位用户询问了这些内建函数,随后链接指向了 NVIDIA 关于 Warp Reduce 函数的 CUDA 文档(适用于 Ampere 及以上架构,计算能力 >= 8.x)。
- Kernel 优化练习资源:一位用户请求在具有自定义类汇编指令和性能追踪查看器的模拟机器上练习 Kernel 优化的资源。
- 另一位用户建议,无论如何,这个 Discord 频道都是一个很好的起点。
GPU MODE ▷ #triton (9 messages🔥):
Triton Autodiff, sm120 GPUs for fp4 ops, tl.constexpr_function decorator, einops package for triton
- Triton 获得 Autodiff 支持:一位用户分享了 IaroslavElistratov/triton-autodiff 的链接,这是 Triton 的 automatic differentiation 实现。
- 另一位用户简单地回复了 “Yes!”。
- sm120 GPU 支持 fp4 操作的时间表?:一位用户询问了支持 sm120 GPU 进行 fp4 ops 的时间表。
- 另一位用户回复道 “噢对,忘了这茬了!”。
- Triton 获得 constexpr_function 装饰器:一位用户一直在实验 Triton 3.4.0 中推出的新
tl.constexpr_function装饰器,使用exec将表达式编译为@triton.jit函数,该函数在运行时编译 Kernel 时被调用。- 该用户基于 einx 编译器引擎 构建了一个 适用于 Triton 的 einops 包。
- 适用于 Triton 的新 einops 包:一位用户分享了他新的 适用于 Triton 的 einops 包,该包允许使用
exec将表达式编译为@triton.jit函数,并在运行时编译 Kernel 时调用。- 该包具有 Rearrange、Reduce、Unary VMAP 和 Binary VMAP 功能。
- 新 Triton 用户发现文档匮乏:一位刚接触
triton的用户观察到 “很多东西似乎没有文档记录,且类型缺失”。- 他们特别提到
kernel.warmup、__init_handles()等在教程示例中没有 docstrings。
- 他们特别提到
GPU MODE ▷ #torch (2 messages):
Inductor problems, Blackwell GPU issues
- Blackwell 导致 Inductor 问题:一位成员报告在使用 Blackwell GPU 时遇到 Inductor 的问题,特别是在使用 nightly 构建或 branch cut 2.8 时。
- 另一位成员询问了遇到的具体问题,询问是否是以前可以运行的功能现在停止工作了。
- Inductor 在 Blackwell 上的稳定性受到质疑:用户正面临 Inductor 的问题,他们怀疑这可能与使用 Blackwell 有关。
- 他们提到需要使用 nightly 构建或 branch cut 2.8,但不确定 Inductor 是否是根本原因。
GPU MODE ▷ #algorithms (1 messages):
kszysiu2137: 可能是 Quad tree
GPU MODE ▷ #cool-links (3 messages):
NVIDIA CUDA Kernel Fusion in Python, AMD's response to CUDA, Triton as an alternative to CUDA
- NVIDIA 在 Python 中实现 CUDA Kernel Fusion:NVIDIA 正在为 Python 中的 CUDA Kernel Fusion 提供缺失的构建模块。
- 这一增强功能有望直接在 Python 环境中简化并优化基于 CUDA 的计算。
- AMD 对 CUDA 的回应?:讨论提出了一个问题,即 AMD 需要多长时间才能对 NVIDIA 的 CUDA 进展做出具有竞争力的回应。
- 另一种可能性是,AMD 可能会专注于支持和利用 Triton 作为一种可行的替代方案。
GPU MODE ▷ #jobs (1 messages):
Storage Engineer, Remote Job
- Voltage Park 招聘存储工程师:Voltage Park 正在寻找一名存储工程师进行远程办公。
- 更多信息请访问 Voltage Park Careers。
- 远程存储工程师:现有一个存储工程师的远程职位机会。
- 可通过 Voltage Park 招聘页面 申请存储工程师职位。
GPU MODE ▷ #beginner (3 messages):
vast.ai, GPU programming opportunities, CUDA speedup, Bioinformatics
- **Vast.ai 依然便宜:成员们因其性价比推荐使用 **vast.ai 进行 GPU 编程。
- 讨论 GPU 编程的机会:一位成员询问了具备 GPU 编程技能的人才有哪些机会,建议的领域包括光线追踪、LLM 推理优化的开源贡献以及大厂中的利基职位。
- 另一位成员分享了 GPU 编程如何帮助他们用 CUDA 重写了一个运行缓慢的 Python 脚本,实现了 1700 倍的加速,并因此在 Bioinformatics 上发表了论文并发布了 GitHub 仓库。
- CUDA 重写在生物信息学中实现 1700 倍加速:一位成员使用 CUDA 重写了一个核心搜索算法,与生物化学研究人员原始使用的 Python 脚本相比,实现了 1700 倍的加速。
- 该优化算法已发表在 Bioinformatics 上,并可在 GitHub 上获取。
- 机器学习领域似乎已饱和:一位成员表示,尽管具备 GPU 编程技能,但在机器学习领域寻找机会仍然很困难。
- 他们观察到该领域似乎过于饱和。
GPU MODE ▷ #rocm (1 messages):
Compiler behavior, Builtins, asm volatile, llvm.amdgcn.raw.buffer.store.i128
- 编译器对 AMDGPU Intrinsics 的反应:一位成员询问 ROCm 编译器对 builtins、
asm volatile和__asm("llvm.amdgcn.raw.buffer.store.i128")的处理是否有所不同。 - Nvidia PTX 的差异:该成员指出,在 Nvidia 端的 PTX 上,这似乎并不重要。
GPU MODE ▷ #submissions (1 messages):
A100 Speed
- A100 运行耗时 23.2 ms:在 A100 上的运行成功完成,耗时 23.2 ms。
- 成功的 A100 运行:提交 ID
33252到排行榜trimul已成功完成。
GPU MODE ▷ #hardware (6 messages):
Coreweave GB300 NVL72 可用性, Nvidia 硬件优先级, DGX vs HGX, B200 可用性与液冷, Voltage Park 解决方案工程师
- Coreweave 面临 GB300 NVL72 容量紧缺:由于与 Nvidia 之间的物流挑战,Coreweave 宣布的 GB300 NVL72 容量可能难以获取,在物流状况改善之前,甚至单个机架可能都难以保障。
- 一位成员指出,与 Nvidia 保持良好的合作关系有助于硬件采购的优先级排序。
- Nvidia 优先级有助于硬件购买:与 Nvidia 建立稳固的关系可以显著帮助硬件采购的优先级排序。
- 一位成员分享说,他们自己目前正在与 Nvidia 进行一些硬件采购,因此了解其中的困难程度。
- HGX 相比 DGX 具有模块化优势:虽然预算是一个因素,但由于特定硬件组件的模块化,HGX 方案可能比 DGX 更受青睐,其技术性能潜力可能超过同等规模的 DGX 产品。
- HGX 的价值在于特定硬件组件的模块化。
- B200 可用性高;GB300 需要液冷:目前 B200 芯片相对容易购买,而像 GB300 这样更先进的芯片配置则需要液冷,大多数数据中心尚不具备处理液冷的能力。
- 超大规模云服务商 (Hyperscalers) 更青睐 B200,因为它不需要为了单一硬件配置而重新改造数据中心,这促使 Nvidia 加大了其产量。
- Voltage Park 提供 GPU 解决方案:来自 Cloud GPU 公司 Voltage Park 的一名解决方案工程师表示,可以协助为 AI/HPC/ML 工作负载获取 GPU,并分享了他们的 LinkedIn 个人资料和公司信息。
- 该成员表示:知识就是力量,我希望 AI 领域能由像你们这样的人才来推动。随时欢迎交流。
GPU MODE ▷ #factorio-learning-env (3 messages):
MCTS gym_env 集成, 工厂展开 (rollouts), 视觉编码器
- MCTS Gym 集成停滞:一位成员询问了关于 MCTS (Monte Carlo Tree Search) gym_env 集成的更新情况。
- 他们还提到无法参加即将举行的会议。
- 视觉编码器学习吞吐量预测:一位成员提出了一种涉及工厂展开 (factory rollouts) 的方法,用于训练视觉编码器来预测吞吐量。
- 该建议包括捕获分数和截图,以开发一个联合视觉/奖励模型。
GPU MODE ▷ #cutlass (7 messages):
Jetson Orin, Jetson Thor, CuteDSL, tv_layout 交换
- Jetson Orin 和 Thor 对 CuteDSL 的支持:成员们讨论了为 Jetson Orin(arm cpu + ampere gpu,sm_87)和 Jetson Thor(arm cpu + blackwell GPU,sm_101)架构添加 CuteDSL 支持。
- 讨论中提到 CuteDSL 4.0 将支持 arm cpu,这将使 Jetson Orin 的支持变得更容易,并且可能“不需要太多工作量”。
- tv_layout 布局交换问题:一位成员通过附图询问为什么
tv_layout交换了布局的顺序,得到的是(32, 4)而不是预期的(4, 32)。 - 解释器模式计划:一位成员询问 CuteDSL 是否有“解释器模式 (interpreter mode)”的计划,即对算子进行仿真。
{kind=link}
GPU MODE ▷ #singularity-systems (2 messages):
调度 (Scheduling)
- 确认年底进行调度:一位成员确认了在年底进行调度安排。
- 日期将通过私信发送:另一位成员要求通过私信 (DM) 发送具体日期。
Modular (Mojo 🔥) ▷ #general (2 messages):
问候
- 成员互相问候:多名成员在 general 频道互相问候。
- 另一个问候:来自另一位成员的简单问候。
Modular (Mojo 🔥) ▷ #mojo (21 messages🔥):
参数函数与闭包,Q3 路线图:统一 @parameter 和运行时闭包,用于逃逸值的 __copyinit__,DynStringable,合并各种已知来源
- 探索参数函数与闭包:一位成员分享了专门介绍
@parameter函数的手册链接,该函数允许捕获变量。- 文档解释了如何创建参数化闭包 (parametric closures) 并提供了其使用示例。
- Mojo Q3 路线图揭晓统一闭包:Mojo Q3 路线图包含统一
@parameter和运行时闭包的计划,正如在 Modular 论坛中所宣布的那样。- 这种统一预计将简化 Mojo 中闭包的使用。
- 使用 __copyinit__ 逃逸值:讨论强调,在 v0.7.0 更新日志中引入了
__copyinit__功能,用于逃逸值而不是通过引用捕获。- 移除
@parameter装饰器可以达到相同的效果,即复制变量的值而不是捕获其引用。
- 移除
- DynStringable:构建 Trait 列表:一段代码片段演示了如何创建一个
DynStringable结构体,允许列表持有实现Stringabletrait 的不同类型,该内容发布在 Modular 论坛帖子中。- 该实现使用
ArcPointer进行内存管理,并使用 trampoline(蹦床函数)来调用每个类型相应的__str__方法。
- 该实现使用
- 为了趣味和利益合并 Origins:可以合并各种已知的 origin,但这仅在某些用例中有用,由于在创建列表后无法追加新元素,因此该用法的局限性较大。
alias origin_type: ImmutableOrigin = __origin_of(x, y, z)
Modular (Mojo 🔥) ▷ #max (18 messages🔥):
使用 MAX Graph 的 PyTorch 自定义算子,Max-24.6 的基准测试问题,CUDA OOM 错误,LTS 版本支持
- MAX Graph 通过
@graph_op获得 PyTorch 增强!:一个新的@graph_op装饰器允许将整个 MAX graph 包装为一个自定义的 PyTorch operator;modular仓库中提供了一个示例:在 Mojo 中编写 PyTorch 自定义算子的初步支持。 - Max-24.6 基准测试因 OOM 崩溃:在 A100-SXM-48GB GPU 上使用 Max-24.6 进行基准测试时,一位成员在设置
--batch-size 248和--max-length 2048时遇到了CUDA_ERROR_OUT_OF_MEMORY错误。 - CUDA 灾难随 Batch Size 而至:将
--max-cache-batch-size降低到 91 仍导致 CUDA OOM 错误,因为估计的内存使用量超过了可用内存(78812 / 40441 MiB)。- 该错误在少量请求达到服务器上限后发生,表明 batch-size 计算算法需要改进以提供更好的建议。
- 最新的 Max 版本即为支持时间最长的版本:团队确认没有“LTS”版本,因此最新的稳定版本是唯一受支持的版本。
- 使用 Max-25.4 配合
caching-stragegy paged运行良好,缓解了在 Max-24.6 中遇到的问题。
- 使用 Max-25.4 配合
Yannick Kilcher ▷ #general (29 messages🔥):
扎克伯格 AI 人才收购,鸡柳通胀,OpenAI 基准测试对比,Grok 4 HLE 分数
- 扎克伯格的 AI 人才抢夺战引发关注:成员们讨论了 Zuckerberg 最近激进的 AI 人才收购行为,其中一人表示对 Meta 的 AI 计划信心大增。
- 鸡柳价格引发存在主义恐惧:一位成员对鸡柳的高价表示沮丧,质疑 “为什么现在鸡柳要 5 块钱一根??”,并将其与对通货膨胀和市场状况的更广泛担忧联系起来。
- OpenAI 更倾向于与自己对比:成员们注意到 OpenAI 转向仅将 ChatGPT Agent 的性能与其之前的模型进行对比,推测这可能是因为在某些基准测试中无法战胜竞争对手,并链接到了 ChatGPT Agent 发布公告。
- Grok 4 提升 HLE 分数:一位成员指出 Grok 4 在 HLE 基准测试中获得了 25.4 的最高分,表明有显著提升。
Yannick Kilcher ▷ #paper-discussion (2 条消息):
``
- 今晚没有讨论:多位成员表示今晚将没有讨论。
- Paper-Discussion 频道很安静:今晚 paper-discussion 频道没有任何活动。
Yannick Kilcher ▷ #ml-news (5 条消息):
Gaussian Splatting, General Analysis iMessage Stripe Exploit
- Gaussian Splatting 看起来有故障感!:一位用户评论说 Gaussian splatting 看起来像老电影中经常描绘的充满故障感的未来视图,并引用了这个 YouTube 视频。
- Stripe 在 iMessage 中被利用!:一位用户分享了一个 General Analysis iMessage Stripe exploit 的链接,并开玩笑说有人为了让数据符合特定的图表形状而费尽心思,暗示可能存在数据操纵(文章链接)。
Manus.im Discord ▷ #general (22 条消息🔥):
Manus Alternatives, Manus chat down?, File Zipping Advice, Custom Data Sources in Manus
- Manus 竞争对手出现:一位成员宣布他们构建了一个在基准测试中优于 Manus 的 AI,并正通过私信(DMs)向首批 100 人提供完全、无限制的终身测试人员访问权限。
- 他们提供了无限制的下一代 AI。
- 聊天服务出现问题:一位用户报告说聊天服务目前可能无法工作。
- 尚不清楚是否有任何建议的修复方案。
- 压缩文件需要建议:一位成员询问,当 Manus 在压缩大文件遇到困难时,应该告诉它怎么做。
- 消息记录中没有建议任何解决方案。
- 自定义数据源和 Model Context Protocol:一位成员询问了 Manus 付费计划中 custom data sources 的含义,特别是询问如何连接 CRM 以及是否有 Model Context Protocol 支持。
- 该成员表示有兴趣开发此类功能,因为它非常有用。
MCP (Glama) ▷ #general (18 条消息🔥):
Anthropic Payment Issues, Domain Name Checking MCP Server, Needle MCP Server Introduction, OAuth vs API Keys for MCPs, Brave's Official MCP Server
- Anthropic 的支付平台失效:一位用户报告说 Anthropic’s payment platform 在付款后立即退款,导致无法购买 API credits。
- MCP Server 让域名检查更方便:一位用户请求一个用于 domain name checking 的 MCP server,另一位用户推荐了 whois-mcp GitHub 仓库。
- 原帖作者确认安装非常简单,并感谢了推荐的用户。
- Needle 创作者寻求联系:Needle MCP server 的一位创作者介绍了自己,并分享了 Needle MCP server GitHub 仓库的链接。
- 他们表达了加入服务器并与 MCP 爱好者建立联系的兴奋之情。
- OAuth 很无缝,API keys 很简单:一位用户询问为什么 auth/oauth 是目前 MCPs 的一个大问题,引发了关于 OAuth 与 API keys 优缺点的讨论。
- 一位用户声称 OAuth tokens 提供了拥有过期、动态范围访问令牌的能力,而另一位用户则表示 使用普通的 API keys 也可以在不使用 oauth2 的情况下实现过期和范围限制,且更简单的设置不值得付出实现的成本。
- Brave 发布了新的 MCP Server:Brave 发布了他们的官方 MCP Server,正如这条推文中所宣布的那样。
- 一位用户表示他们还没有尝试,因为那条推文没有包含如何使用它的说明。
MCP (Glama) ▷ #showcase (3 messages):
Vibe Coding Survey, Adaptive RAG MCP Server, Generator Checkpoint, Microsoft NextCoder
- Vibe Coding 调查征集开发者:一名成员分享了一份 调查问卷,旨在探索一个创业概念,通过 Claude、ChatGPT、Cursor、Windsurf、Loveable、Bolt 和 V0.dev 等工具让 vibe coding 变得更简单。
- 该调查旨在从具有 vibe coding 经验的用户那里收集见解,以完善其创业概念。
- Adaptive RAG MCP Server 原型发布:一名成员介绍了 Adaptive RAG MCP Server,这是一个能够从真实的编码成功与失败案例中学习的系统,提供比简单文本相似度搜索更有效的解决方案,可在 GitHub 上获取。
- 该系统旨在为 AI 编码助手提供随经验提升的记忆能力,利用成功率对代码方案进行排名。
- Microsoft NextCoder 驱动知识库:Adaptive RAG MCP Server 默认使用 Microsoft NextCoder 作为其知识库,通过 generatorCheckPoint.py 填充数据可能需要数小时。
- 用户可以通过 Flask 或 MCP Server 运行该服务器,并将其与 AI 助手集成,通过提供反馈来持续改进知识库。
tinygrad (George Hotz) ▷ #general (2 messages):
ShapeTracker parameter to ASSIGN UOp
- 提议为 ASSIGN UOp 添加 ShapeTracker 参数:一名成员建议为 ASSIGN UOp 添加一个可选的 ShapeTracker 参数,可能使用
self.assign(v, res.uop.st)。- 该成员对维持最小 UOps 集合表示担忧,并询问了关于将 assign 更改为 store 的后续工作。
- 通过传递 res 实现可选 ShapeTracker:建议采用另一种方法:传递
res并在内部提取 ShapeTracker。- 目标是使用这个可选的 ShapeTracker 代替原始 Tensor 的 ShapeTracker,以便 lowering 到实际的赋值代码中。
tinygrad (George Hotz) ▷ #learn-tinygrad (18 messages🔥):
tinygrad documentation for beginners, NVIDIA GPU driver issues with tinygrad and WSL2, Muon optimizer in tinygrad, Switching from WSL2 to native Ubuntu
- 文档需要完整的 MNIST 代码示例:一名用户反馈 tinygrad 文档对于机器学习初学者来说难以理解,并请求在页面末尾为 MNIST 教程提供一个完整的最终代码示例。
- 该用户还提到 tensor puzzles 运行效果不佳,并建议应明确说明是否应该先学习 PyTorch 或 TensorFlow。
- WSL2 显示驱动断开连接:一名用户在更新 NVIDIA GPU 驱动后遇到了 double free detected in tcache 错误,并寻求帮助以使他们的 GPU 在 WSL2 中对 tinygrad 可见。
- 另一名用户建议切换到原生 Ubuntu,称这样做后许多问题都消失了,包括 由于 WSL 中固定内存(pinned memory)的晦涩限制而无法加载 Stable Diffusion 权重 的问题。
- Muon 优化器比 AdamW 收敛更快:一名用户为 tinygrad 创建了 Muon 优化器,发现在 MNIST 教程中它的收敛速度(~98%)比标准 AdamW 更快。
- 该用户正在寻求关于如何正确测试 Muon 优化器的建议,特别是考虑到要向 tinygrad 贡献 PR。
- Linux 是必然选择:在升级到支持 GPU 加速的 WSL2 后,一名用户通过迁移到 Ubuntu 解决了 非常多的问题。
- 另一名用户表示 考虑到 Win10 将在 10 月停止支持,且我不打算切换到 Win11,转向 Linux 是必然的。
Nous Research AI ▷ #announcements (1 messages):
Atropos, RL Environments Framework
- Atropos v0.3 发布:Nous Research 的 RL 环境框架 Atropos 的新版本 v0.3 现已发布,点击此处查看详情。
- Nous Research 更新 Atropos:Nous Research 宣布发布 Atropos v0.3(一个 RL 环境框架),鼓励用户查看详细信息。
Nous Research AI ▷ #general (18 条消息🔥):
Proto-agentic XML tag adherence, Hermes Documentation, Open Source Models vs US Models, Ethical Considerations in AI, Learning ML
- **Teknium 为困惑者澄清 ‘Proto’*: 一名成员澄清了 “Proto” 意为某事物的早期形式,解释了让另一名成员感到困惑的术语 *proto-agentic XML tag adherence for proto-reasoning CoTs。
- 他开玩笑说 “面对这些技术黑话,你们需要一个 ELI5 (通俗易懂的解释)”,并且 “我们这些氛围程序员 (vibe coders) 也要吃饭的”。
- **Hermes 文档页面正在开发中**: 一名成员提到他们正在制作 Hermes 文档页面 和一个统一的 Nous Projects 文档页面。
- 当被问及 Hermes 4 的目标时,他们表示 “当然是更聪明的 Hermes”。
- 开源模型将在美国以外占据主导地位: 一名成员断言,由于成本效益,开源模型将在美国以外地区占据主导地位,并指出 “世界其他地区与美国的财富相比非常贫穷,无法负担美国 AI 资产的价格。”
- 此举旨在规避 CUDA 霸权并鼓励全球参与,这让 Jensen 感到担忧。
- AI 伦理辩论:Kimi K2 拒绝协助偷车: 一名成员分享了与 Kimi K2 模型的互动,该模型出于法律和伦理考量,拒绝提供如何闯入汽车的指令。
- 尽管尝试绕过限制,Kimi K2 仍坚持立场,导致该成员开玩笑说 “Kimi K2 是个有道德的坏小子……肯定会有人尝试腐蚀它……我得给 Kimi 写首说唱,它值得……坏小子 Kimi K2 !!”
- 学习 ML:探索自下而上与自上而下的方法: 一名具有生物化学背景的成员询问了学习 Machine Learning (ML) 的最佳方法,并提到了他们在 Python、数学基础(Calculus、Statistics)和 Introduction to Statistical Learning (ISLR) 方面的进展。
- 他们想知道,鉴于其目标是进行科学领域的 ML 研究,自下而上还是自上而下的方法更有效。
Nous Research AI ▷ #ask-about-llms (1 条消息):
Model Context Size, Letta Personas, Model Evaluation
- 短 Context 损害个性: 一名成员建议,根据模型的 Context Size,为模型添加个性可能会适得其反。
- Context Size 较小的模型可能难以维持一致的 Persona。
- Letta 采用 Personas: 用户回想起 Letta 项目(原 MemGPT)采用了某种 persona 系统。
- 这表明在某些语境下,整合 Personas 是一种可行的策略。
- 评估个性表现: 一名成员建议 评估 为模型添加个性后的影响,以确定其有效性。
- 这种方法允许通过实证评估来判断 个性带来的好处 是否超过潜在的缺点。
Notebook LM ▷ #use-cases (4 条消息):
uBlock browser extension, notepad.exe, NotebookLM folders/subfolders
- **uBlock 浏览器扩展拦截广告: 一名成员推荐使用 **uBlock 浏览器扩展来移除广告,并建议在扩展设置中添加针对干扰项和社交媒体弹窗的额外过滤器,然后复制粘贴到 Google Docs。
- 该用户附带了一张 截图 以展示 uBlock 在移除网页中不必要元素方面的有效性。
- **Notepad.exe 去除广告: 一名成员建议突出显示并复制文章,然后将其粘贴到 **notepad.exe 中,以避免粘贴广告和其他不必要的内容。
- 该方法并不总是奏效,且可能会去除所需的格式。
- NotebookLM 数据源可以读取文件夹/子文件夹: 一名成员建议 NotebookLM 可以读取网络浏览器收藏夹中的特定文件夹/子文件夹,并将其视为单一数据源。
- 该成员表示,他们一直使用的是 全选并复制/粘贴 到 Google Docs 的方法。
Notebook LM ▷ #general (14 messages🔥):
Service Unavailable Error, NotebookLM Use Cases, Textbook Integration with NotebookLM, NotebookLM Enterprise & GCP Integration
- “服务不可用”故障困扰用户:一位用户报告在尝试访问服务时出现 “Service unavailable” 错误提示,并伴有无用的信息 “You tried to access a service that isn’t available for your account”。
- Gemini 指南探索开启:一位用户提示使用 Gemini 在网络上搜索 NotebookLM 的入门介绍、使用案例及技巧。
- 教科书大捷:通过 NotebookLM 上传并攻克内容:一位用户询问关于将教科书作为源文件上传至 NotebookLM 的问题,一名成员回复称他们使用 Adobe Scan 将教科书数字化为 PDF,并要求 NotebookLM 根据教科书创建深度复习。
- GCP 集成愿景:对 NotebookLM 企业版的向往:一位用户询问关于在 GCP 内部为 NotebookLM 企业版从 GCS bucket 或 GCP RAG Engine 语料库获取数据文件的问题。
- 他们指出,对于终端用户来说,Collab enterprise 或 Vertex AI notebooks 的技术性太强,而 NotebookLM 才是最合适的平衡点。
LLM Agents (Berkeley MOOC) ▷ #hackathon-announcements (1 messages):
Agentic AI Summit 2025, LLM Agents MOOC, UC Berkeley, Khosla Ventures, Nvidia
- Agentic AI 峰会直播公布:Agentic AI Summit 将于 8 月 2 日在 UC Berkeley 进行广播,并可通过此处观看直播。
- Agentic AI 峰会演讲嘉宾亮点发布:Agentic AI 峰会将邀请 Vinod Khosla (Khosla Ventures)、Bill Dally (Nvidia)、Ion Stoica (Databricks 和 Anyscale) 以及 Jakub Pachocki (OpenAI) 等嘉宾。
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (8 messages🔥):
Fall Semester Updates, Certificate Declaration Form, Berkeley RDI Newsletter
- 秋季学期状态仍未确定:一位成员询问今年是否有秋季学期,但工作人员确认目前尚未确定任何消息。
- 他们建议关注 宋教授的社交媒体(LinkedIn 或 Twitter/X)或 Berkeley RDI 通讯以获取更新。
- 证书申报表遗失?:一位成员询问自己漏交了什么,工作人员回复称他们可能没有提交证书申报表。
- 他们表示从未收到过该用户的证书申报表提交记录。
- 拒绝自动审核证书申报表:由于许多人遗漏了证书申报表,一位成员建议进行大规模自动审核,但工作人员表示遗憾的是这可能无法实现。
Cohere ▷ #🧵-general-thread (1 messages):
sma.bari.shafin: 顺便问一下,我们如何获得 Community Summer School 的证书?
Cohere ▷ #👋-introduce-yourself (4 messages):
DNNs for Time Series, ML in Data Science Education, ML for Real-World Problems, Interests in ML Domains
- DNN 寻求真正的时间序列处理方法:一位动力系统理论专业的博士生正在探索如何将 deep neural networks 集成到时间序列分析中,并指出当前的 RNN 等模型将时间序列视为序列(sequences),这在本质上是不同的。
- 该学生旨在与在 dynamical systems 和 deep learning 交叉领域有见解的人士建立联系。
- 本科生通过项目积累 ML 技能:一名就读于 IIT Madras 的本科生正在攻读 BS in Data Science 和 BCA degree,专注于通过实战项目和自主学习来构建 ML skills。
- 该学生对应用 ML 解决 real-world problems 充满好奇,并精通 Python、scikit-learn、pandas,同时也在学习 TensorFlow 和 PyTorch。
- 工程师转向关注 CV 和 LLM 的数据科学领域:一位拥有 Masters in Electrical Engineering 的成员从业务领域转型至 Data Science,目前正在 University of Toronto 的 Data Science Institute 学习加速 Machine Learning Program。
- 他们的兴趣包括 Computer Vision、Large Language Models、spatial intelligence 以及 multimodal perception。
LlamaIndex ▷ #blog (2 messages):
Human-in-the-loop agents, LlamaParse one-click table extraction
- **Human-in-the-Loop Agents 在 LlamaIndex 中启动:根据 LlamaIndex 的说法,当 AI **agents 在关键决策中需要用户批准,或在复杂任务中需要领域专业知识时,Human-in-the-loop 是必不可少的。
- LlamaParse 新增 **One-Click Table Extraction:Table extraction** 是智能文档处理的关键组成部分;请查看 LlamaParse 中 one-click table extraction 的 demo 和 notebook。
LlamaIndex ▷ #general (1 messages):
beastx2: <@334536717648265216> heyy
DSPy ▷ #general (3 messages):
DSPy creative applications, Lean 4 verification, Story generation, Roleplay prompt optimization
- Lean 4 验证协作:一位成员分享了一个关于使用 Lean 4 验证协作的 YouTube 视频,引发了人们对形式化验证与 AI 交叉领域的兴趣。
- 他们认为这很棒,并表示希望有人能研究这两者的协同工作。
- DSPy 的创意副业:一位新手询问了 DSPy 在创意领域的成功应用,如创意写作、故事生成和角色扮演 prompt 优化。
- 他们特别感兴趣其在 Character.AI 等平台上开发 AI 以创作出类似 Severance(人生切割术)级别叙事的引人入胜情节的潜力。
- Stanford-oval 的 Storm 项目:一位成员分享了 Stanford-oval/storm 的链接,这可能与正在进行的讨论相关,或者作为创意 AI 应用的资源。
- 由于未提供确切背景,其他人需要自行推断其相关性。
Codeium (Windsurf) ▷ #announcements (2 条消息):
Claude Sonnet 4, Discounted Credit Rate, Windsurf Wave 11, Acquisition by Cognition, Voice Mode
- Claude Sonnet 4 强势回归:Claude Sonnet 4 现已回归,并获得来自 Anthropic 的官方原生支持。Pro/Teams 用户在 Editor 和 JetBrains Plugins 中限时享受 2 倍额度折扣;点击此处查看公告。
- Windsurf 被 Cognition 收购,发布 Wave 11:继被 Cognition(Devin 背后的团队)收购后,Windsurf Wave 11 正式发布,整合双方力量立即推出重大新功能;查看更新日志,阅读博客,并观看视频。
- Cascade 获得 Voice Mode 和浏览器增强功能:Wave 11 引入了 Voice Mode,允许用户通过语音而非输入提示词与 Cascade 交流,此外还增强了 Deeper Browser Integration,可访问更多用于截图和上下文的工具;阅读博客文章。
- Snapshots 和 Mentions 简化对话流程:Windsurf Wave 11 的新功能包括用于在对话中轻松回滚的 Named Checkpoints,以及用于上下文引用的 @-mention Conversations;查看更新日志了解详情。
- JetBrains 体验大幅提升:JetBrains plugin 现已增强,支持 Planning Mode、Workflows 和基于文件的 Rules,此外还包括 @-mention terminal、auto-continue setting、改进的 MCP OAuth support 以及全局 .codeiumignore 文件等改进;在博客中了解更多。
MLOps @Chipro ▷ #events (1 条消息):
AI-Native Data Infrastructure, Task-Specific Data Discovery, Secure Autonomous Access, Production-Scale Performance
- Nextdata 预告 AI-Native Data Infrastructure 网络研讨会:Nextdata 宣布举办题为 Building AI-Native Data Infrastructure: From Prototypes to Production 的网络研讨会,将于 太平洋时间 7 月 24 日上午 8:30 举行,由 Nextdata 工程负责人 Jörg Schad 主持;在此注册。
- 揭秘 AI-Native Data 的“三大关键挑战”:研讨会将探讨一个以开发者为中心的框架,解决 Task-Specific Data Discovery、Secure Autonomous Access 和 Production-Scale Performance。
- 目标是设计在不产生认知负荷的情况下提供相关上下文的系统,实现安全的数据访问模式,并构建处理自主数据访问需求的基础设施。
Nomic.ai (GPT4All) ▷ #general (1 条消息):
Web3 and AI, AI agents and multi-agent systems, Automation workflows, NLP apps and chatbots, Voice & speech integration
- AI 工程师提供 AI 与 Web3 领域的专业服务:一位专注于 Web3 和 AI 的软件工程师正向 AI、Web3 和自动化 领域的初创公司、研究团队及创新者提供服务。
- 他们在利用 GPT-4o、Claude 3、CrewAI 和 AutoGen 等先进模型和工具构建智能自主系统方面拥有实战经验。
- 工程师强调 AI Agent 和自动化技能:该工程师详细介绍了其在构建 AI agents 和 multi-agent systems、自动化工作流以及开发 NLP apps、chatbots 和语音集成 方面的专业知识。
- 他们还提到了在 LangChain、ReAct、OpenAI、Solidity 和 Rust 方面的经验。