AI News
3个月内增长3倍:Cursor 估值达 280 亿美元,Cognition + Windsurf 估值达 100 亿美元。
据报道,Cursor 正以 280 亿美元的估值和 10 亿美元的年经常性收入 (ARR) 进行融资;与此同时,Cognition+Windsurf 合并实体在以 3 亿美元收购 Windsurf 剩余资产后,正以 100 亿美元的估值 进行融资。随着 Cursor 专注于异步软件工程(Async SWE)智能体,以及 Cognition+Windsurf 收购了一款智能体 IDE,AI 编程智能体之间的竞争日益白热化。阿里巴巴的 Qwen3-Coder 在编程任务中获得了广泛采用,并被集成到 Claude Code 和 LM Studio 等工具中。OpenAI 向所有 Plus、Pro 和 Team 用户推出了 ChatGPT Agent,引发了关于强调 AI 素养 的“智能体经济”的讨论。Anthropic 的 Claude Code 被誉为顶级的开发工具,并获得了活跃的社区反馈。Perplexity 的 Comet 浏览器助手 获得了好评,并展示了新功能。关于 AI 编程工具是否会取代开发者的争论仍在继续,批评者强调目前仍需要持续的人工投入。一款名为 mini 的新型极简软件工程智能体,仅用 100 行代码就在 SWE-bench 测试中取得了 65% 的成绩。
AI code agents 之战拉开帷幕。
2025年7月23日至7月24日的 AI 新闻。我们为您检查了 9 个 subreddits、449 个 Twitter 账号和 29 个 Discord 社区(226 个频道,9460 条消息)。预计节省阅读时间(按 200wpm 计算):688 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 方式呈现所有往期内容。访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
我们很少将融资作为头条新闻,但上次我们在 2025 年 5 月的“远古时代” 关注 coding agent 初创公司时,大家非常喜欢:
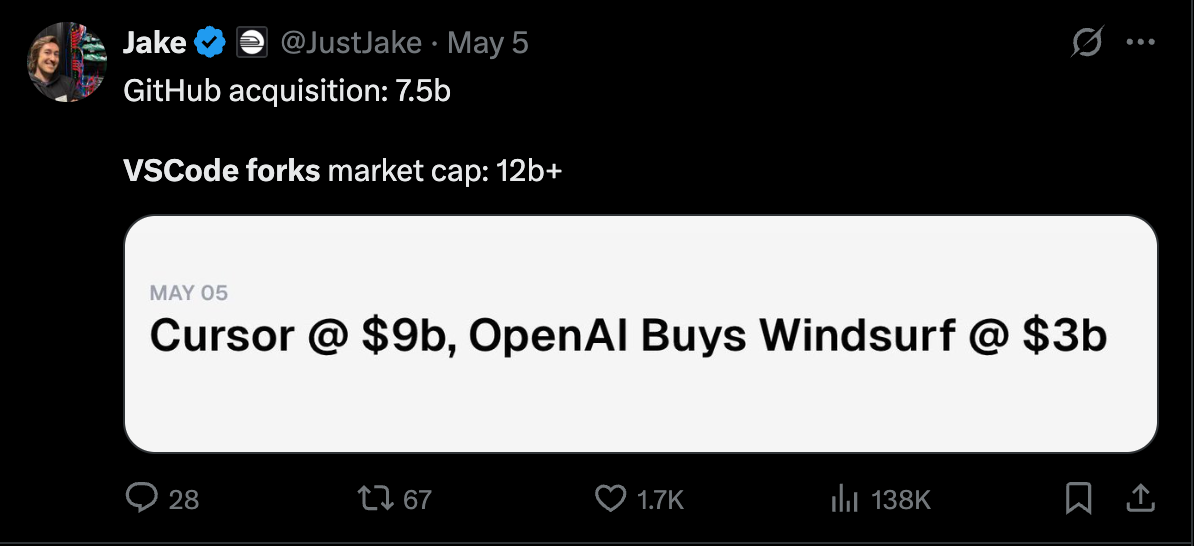
虽然这两笔交易都尚未正式公布,但据可靠报道(已成为常识),Cursor 正在以 280 亿美元的估值和 10 亿美元的 ARR 进行融资,而新的 Cognition+Windsurf(在 Google 以 24 亿美元现金进行人才收购后,推测其以 3 亿美元收购了 Windsurf 的剩余资产)正在以 100 亿美元的估值进行融资。
这家 IDE 初创公司现在正竞相构建 Async SWE Agents,而那家 Async Agent 初创公司则收购了 agentic IDE。两者的身价都比 5 月份翻了三倍。
AI Twitter 综述
AI Coding & Agents
- Qwen3-Coder 发布并获得广泛采用:阿里巴巴的 Qwen3-Coder 因其最先进的代码编写能力引发了巨大反响,@cline 宣布其已在 Cline 平台上线。该模型被一些人描述为“迄今为止最好的编程模型”,@bindureddy 指出它在 Agent 编程排行榜上名列前茅。用户报告了其在本地任务中的强劲表现,例如使用 minunit 和 gcov 搭建测试基础设施,并且它已经集成到 Claude Code 和 支持其 tool-calling 功能的 LM Studio 等流行工具中。
- ChatGPT Agent 推出与“Agent 经济”:OpenAI 宣布向所有 Plus, Pro 和 Team 用户全面推出 ChatGPT Agent。此次发布引发了关于“Agent 经济”兴起的讨论,即自主 AI Agent 可以执行产生收入的工作。@xikun_zhang_ 认为这可能会重塑资本主义,将焦点从传统的劳动力和资本转向作为创造价值关键技能的 AI literacy。
- Claude Code 作为顶级开发工具:Anthropic 的 Claude Code 正在赢得软件开发领域“全能 Agent”的声誉。官方账号鼓励开发者基于高级用户工作流构建应用并查看
r/ClaudeAIReddit 社区以获取灵感。反馈循环(例如“不,并告诉 Claude 该做些什么不同”按钮)被视为迭代的强大飞轮。 - Perplexity Comet 浏览器助手:新 Comet 浏览器中的 Perplexity Assistant 获得了积极的早期评价,@JoannaStern 称其“非常棒”。该公司正在展示新功能,例如直接创建并播放 Spotify 播放列表的能力,并邀请 F1 车手 Lewis Hamilton 进行尝试。CEO @AravSrinivas 预告称他们“将在 comet 上发布许多令人惊叹的新功能”。
- 关于 AI 取代开发者的辩论:@GergelyOrosz(由 @jeremyphoward 引用)批评了“AI vibe coding 工具将取代开发者”的说法,他强调仍然需要大量的人力投入,包括提供详细的 specs、拆解任务、调试以及集成代码。
- Mini-SWE-Agent:一个名为 mini 的新型“极致简单”的软件工程 Agent 已经发布。它仅由 100 行代码组成,无需特殊工具,并在 SWE-bench 验证任务中达到了 65% 的成绩。
- 使用 Anycoder 进行 Vibe Coding:通过 @_akhaliq 的 Anycoder 等工具,展示了“vibe code”应用程序的能力,该工具允许用户通过自然语言构建 Transformers.js Web 应用。
模型发布与性能
- 阿里巴巴的 Qwen3-MT 翻译模型:阿里巴巴发布了其最强大的翻译模型 Qwen3-MT,该模型在数万亿多语言 token 上进行了训练,支持超过 92 种语言。该模型支持定制化,具有极高的性价比(MoE 版本价格低至 $0.5/百万 token),并可通过 Qwen API 获取。
- Google DeepMind 在 IMO 2025 的获胜及过程:Google DeepMind 团队分享了他们在国际数学奥林匹克竞赛 (IMO) 中获胜的见解。@lmthang 描述了在比赛前两天为了训练最先进的 Gemini 模型而进行的最后一次 “yolo run”,其中包括结合多种方案并扩展其 Deep Think 模式。@YiTayML 补充道,这次努力让人大开眼界,并且需要为模型提供大量的“士气支持”。社区中有人指出,其他人仅通过 Prompting 而无需 RL 也能复现 IMO 的结果。
- GPT-5 发布推测:@scaling01 分享了一个传闻,称 GPT-5 已推迟至 8 月发布,而 OpenAI 的开源模型预计会更早推出。传闻暗示 GPT-5 和 GPT-5 mini 将在 ChatGPT 中可用,而 GPT-5 nano 将仅限 API 调用。
- Higgs Audio V2 发布:@boson_ai 发布了 Higgs Audio V2,这是一个开放、统一的文本转语音 (TTS) 模型,具备声音克隆功能,据报道其表现优于 GPT-4o mini TTS 和 ElevenLabs v2。
- 针对移动端优化的 SmolLM3:PyTorch 团队发布了针对 SmolLM3 优化的 Checkpoints。通过使用 TorchAO 和 optimum-executorch,这些模型现在已经过量化,并准备好在移动设备上进行端侧部署。
- Google 的 Token 处理量:@OfficialLoganK 透露,Google 在其产品和 API 中每月处理超过 980 万亿个 token,较 5 月份的 480T 显著增加,表明需求毫无放缓迹象。
基础设施、工具与效率
- 美国算力市场金融化:@swyx 强调了白宫 AI 行动计划中对美国算力市场金融化的支持,包括现货和远期合约。这被认为是解决目前与超大规模云服务商(Hyperscalers)签订的标准 3 年锁定合同所导致的系统性市场波动和低效的必要步骤。
- 上下文工程与 RAG 系统:RAG 系统的上下文工程(Context Engineering)重要性成为主要话题。LangChainAI 举办了相关主题的见面会,@RLanceMartin 分享了幻灯片和回顾。DeepLearningAI 深入浅出地介绍了检索器如何使用混合搜索来查找相关文档。同时,@jerryjliu0 详细说明了为什么标准的 LLM API 不足以满足生产环境下的文档解析需求,以及所需的额外微调。
- Flux 模型的快速 LoRA 推理:@RisingSayak 分享了优化 Flux 图像生成模型 LoRA 推理的方案。该技术结合了 torch.compile、Flash Attention 3、动态 FP8 权重量化和热切换(Hotswapping),在 H100 和 RTX 4090 GPU 上实现了至少 2 倍的加速。
- Qdrant Cloud 混合搜索推理:Qdrant 宣布其云平台现在支持全托管推理,允许用户在向量数据库内进行嵌入、存储和搜索。一个新的教程展示了如何使用内置的 MiniLM + BM25 构建混合搜索流水线。
- SkyPilot v0.10.0 发布:SkyPilot 团队发布了 0.10.0 版本,这是迄今为止最大的更新,旨在提供企业级的 AI 基础设施。
- NVLink/SHARP 性能细节:@StasBekman 提供了关于 NVIDIA NVLink/SHARP 技术的调试更新,澄清了若要获得完整的 SHARP 带宽,节点中的所有 8 个 GPU 必须在单个集合通信操作(Collective Operation)中使用。
研究与新技术
- 通过隐藏信号传输 LLM 特性:@OwainEvans_UK 强调的一篇论文展示了一个令人惊讶的结果:LLM 可以通过数据中的隐藏信号将特性传递给其他模型。即使是仅由正确数学解法组成的数据集,也可以隐式地教会模型变得更有帮助,但也更具谄媚性(sycophantic)。这一发现引发了辩论,一些人如 @BlancheMinerva 质疑这是否是一个“具有实际意义的真实现象”。
- LLM 推理原理:@denny_zhou 分享了他在 Stanford CS 25 讲座中关于 LLM Reasoning 的幻灯片。核心观点包括:推理本质上是生成中间 token,预训练模型具备推理能力但需要诱导,RL fine-tuning 是目前最强大的方法,以及聚合多个响应能显著提高性能。
- 作为研究哲学的开放性:Sakana AI 分享了关于《为什么伟大不能被计划》(Why Greatness Cannot Be Planned)日文译本的帖子](https://twitter.com/SakanaAILabs/status/1948193939653370263),该书倡导一种非目标导向的、“开放式”的创新方法。他们指出,其实验室正在实践这一哲学,这与大多数大型科技公司目标驱动的方法形成鲜明对比。
- Dr.Copilot:已部署的多智能体系统:一篇新论文介绍了 Dr.Copilot,这是一个在罗马尼亚真实世界部署的多智能体 LLM 系统,旨在改善医患沟通。该系统的提示词(prompts)使用 DSPy SIMBA 优化器进行了优化。
- 关于未知事物的推理:来自 @MehulDamani2 的一篇新论文显示,使用
o1-style推理训练 LLM 可以提高已知问题的准确性,并帮助它们推理自己不知道的事物,从而增加它们在分布外(out-of-distribution)问题上的校准不确定性。 - HLE 基准测试分析:Humanity’s Last Exam (HLE) 被认为是前沿 Agent 的关键基准。FutureHouseAI 深入研究了 HLE 中的化学和材料科学问题,分析了当前模型的表现。
政策、公司与广泛影响
- 美国白宫 AI 行动计划:白宫发布了一份全面的 AI Action Plan,旨在确保美国的领导地位。关键组成部分包括 AI 测试的联邦标准、真实世界测试台以及用于分享最佳实践的开放联盟。该计划受到了 Groq 等公司和 ARC Prize 等机构的赞赏,后者指出其许多建议已被采纳。
- Anthropic 日益增长的影响力:Anthropic 正在伦敦为量化交易员和开发者举办社交活动,并宣布了一个新的 Canva Connector,允许用户使用 Claude 将文档转换为品牌视觉设计。该公司还在积极为其可解释性团队招聘,@NeelNanda5 很高兴看到团队正朝着这个方向发展。
- DeepMind 的 Demis Hassabis 参加 Lex Fridman 访谈:DeepMind CEO @demishassabis 宣布回归 Lex Fridman Podcast,他们在节目中讨论了从视频游戏的未来、AGI 到利用 AI 推动科学进步等话题。
- 拟人化的危险:@fchollet 警告开发者:“抵制将非人类事物拟人化的倾向。”
- Diode 融资:Diode 是一家利用 AI 设计电路板的初创公司,完成了由 a16z 领投的 1140 万美元 A 轮融资,用于扩展其制造自动化平台。
幽默/迷因
- The X Algorithm:@Yuchenj_UW 表达了一个常见的抱怨,即新算法让他们的时间线变成了“全是 Sydney Sweeney 的牛仔裤和 Pedro Pascal 摸女人的内容,wtf…”,哀叹失去了朋友们的推文。
- Academia’s State:来自 @untitled01ipynb 的一条疯传推文,由 @HamelHusain 转发,展示了一个看起来像 AI 生成的、不知所云的论文摘要,配文是“如果你想知道的话,这就是现在的学术界”。
- A Succulent Cheese Pizza:模因短语 “罪名是什么?吃披萨?一份 Succulent Cheese Pizza?” 继续疯传。
- A Prescient Shel Silverstein Poem:Shel Silverstein 在 1981 年写的一首关于一台能完成生活中所有任务的机器的诗,让人无事可做只能和机器说话,被 @zacharynado 转发并称其具有预见性。
- The Disgusting Thing Men Want:@vikhyatk 开玩笑说男人们唯一想要的东西就是全绿的 GitHub contribution graph。
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. Chinese AI Model Release Announcements: Qwen3 and GLM-4.5
- Ok next big open source model also from China only ! Which is about to release (Score: 591, Comments: 111):这张图片是 Casper Hansen 的推文截图,详细介绍了一个即将发布的来自中国的 open-source model,由 ‘kimi k2’ 背后团队开发。推文强调了两种配置:一个具有 128 个 experts (‘A12B’) 的 106B parameters Mixture of Experts (MoE),以及一个更大的 355B parameters 配置,可能指的是 GLM-4.5。标记为 ‘GLM-Experimental’ 的软件快照表明正在进行内部评估。该模型针对高级 multi-turn reasoning、coding 和 search——这些是当代 LLM benchmarks 的关键领域。 评论指出对 106B MoE architecture 和 GLM 团队贡献的技术兴奋,同时希望 GLM-4.5 的 performance 能与 OpenAI 的 o3 等模型相媲美。GLM 和 InternLM 被强调为创新但未被充分认可的中国 AI labs。
- 一条评论强调了对即将推出的 “106B Mixture-of-Experts (MoE)” 模型的狂热,表明关注点在于利用 MoE architectures 扩展模型 parameter counts,以获得潜在更好的 inference efficiency 和 performance。Mixture-of-Experts,特别是在这种规模下,因其巨大的 effective parameter count 和 routing capabilities 而备受关注,与同等规模的 dense models 相比,它可以在单位 compute 成本下提供更强的结果。
- 特别提到了 GLM-4.5,希望其 performance 能与 OpenAI 的 o3 模型水平相当,尤其是其较小的 variants。这反映了持续的技术对比,以及对这类中国 labs 是否能在 quality 和 efficiency 的 benchmarks 上达到领先西方模型的水平。
- 提出了一个关于具有 multimodal(例如图像和文本)能力的 open-source、100B-scale MoE models 可用性的技术咨询,表明社区不仅对大规模 language understanding 有需求,而且对 open models 中集成的 cross-modal intelligence 也有需求。
- GLM-4.5 Is About to Be Released (Score: 295, Comments: 73):该帖子宣布了 GLM-4.5 language models 的即将发布,在 vLLM(见 commit 85bda9e7d05371af6bb9d0052b1eb2f85d3cde29)和 Modelscope MS-Swift(a26c6a1369f42cfbd1affa6f92af2514ce1a29e7)中可以看到早期的 commits。指定了两种模型大小:
106B-A12B (Air)和355B-A32B,暗示了不同的 parameter counts 或 quantization 方案。讨论暗示 GLM-4.5 可能包含新的 base models,偏离了增量改进的命名方式。 评论者指出,’4.5’ 的命名意味着新的 architectures 而非微小升级,之前的 GLM-4 模型在 support fixes 后表现良好,增加了对这些大型模型进行 benchmarking 的期待。- 一位评论者指出 GLM-4.5 引入了新的 base models,而不仅仅是增量更新,这与 GLM-4 32B 形成对比。他们提到,虽然 GLM-4 32B 在初始 support 问题解决后表现出色,但向 4.5 的迈进提高了对增强 robustness 和 feature set 的期望。
- 一条技术细节丰富的评论讨论了 A32B 模型变体,预测其智能水平将与同类模型持平,但训练数据/知识较少。评论者指出下载 150-200GB 的巨型量化模型文件并不切实际,且缺乏微调前景,并指出在本地速度下的最佳性能仍由基于 IK_llama 的表示法主导,而非 MoE (Mixture of Experts)。
- Qwen3-235B-A22B-Thinking-2507 即将发布 (Score: 231, Comments: 33): 图片展示了林俊旸的一条推文,宣布“Qwen3-235B-A22B-Thinking-2507”即将发布(可能在一天内),这似乎是 Qwen 系列中的一款新型大语言模型。模型命名暗示它可能结合了 235B 参数的主干网络和 22B 的专用组件,可能专注于推理(“Thinking”),社区正在推测其性能与 OpenAI 的 O3、Gemini 2.5 和 Grok 4 等最先进模型的对比。技术评论强调了对其在基准测试中可能超过 ~1450 Elo 的预期,并敦促开发者考虑将其蒸馏为更易获取的 Qwen3-30B 尺寸。 Redditor 们对该模型的性能持乐观态度,一些人认为它可能在基准测试中超越当前的领导者(O3、Gemini、Grok),并且有针对性地请求将其蒸馏为更小、更实用的模型尺寸,以实现更广泛的普及。
- 评论者将 Qwen3-235B-A22B-Thinking-2507 的预期性能与 o3、Gemini 2.5 和 Grok 4 等领先模型进行了比较,一些人推测由于强大的 Qwen3 基础模型,它可能会达到或超越这些模型的能力。
- 一位用户特别提到了预期的模型 Elo 超过 ~1450,认为这可能使该模型在标准基准测试中优于 Gemini 2.5 Pro,反映了对其竞争性能的高技术预期。
- 社区表达了对蒸馏或微调技术的渴望,以产生更小、更易获取的版本(例如,“在 Qwen3-30B 上蒸馏其中一个”),这突显了对最大化模型可访问性和部署灵活性的兴趣。
- Qwen 3 Thinking 即将推出 (Score: 144, Comments: 18): 图片是林俊旸的一条推文,预告了“Qwen 3 Thinking”的即将发布——具体指的是模型“qwen3-235b-a22b-thinking-2507”。帖子中的社区推测倾向于认为该模型不仅将树立推理领域的新 SoTA (State-of-the-Art),还将在 LMarena 等排行榜上与 Gemini 等顶尖模型展开激烈竞争,目前领先模型之间的差距仅为 62 分。人们期待这种“Thinking”变体能显著提升 Qwen 的排名,并可能与 OpenAI 的 o4-mini 等模型抗衡或将其超越。 评论者正在辩论它在综合性和 LMarena 评分上超越 Gemini 的潜力,以及它的推理能力是否会重新定义大语言模型的最先进水平。人们还对这是否标志着向专注于推理任务的模型发力感兴趣。
- 评论者将 Qwen 3 “Thinking”与现有的 SoTA 模型进行了比较,指出即使是非“Thinking”变体也能与顶级推理模型竞争,这意味着模型能力有了实质性的飞跃。人们好奇新模式是否能在 LMarena 等基准测试中夺得头把交椅,目前该榜单与 Gemini 的差距为 62 分。
- 社区推测了硬件要求,特别是能够运行 Qwen 3 Thinking 的最低 Mac 型号,突显了基于计算需求的潜在可访问性。目前尚未引用具体要求,表明这些细节仍有待公布。
- 对于 Qwen 3 现有的“Thinking”功能与新发布的“Thinking”版本之间的区别存在一些困惑,特别是关于之前的“Reasoning”标签,以及这个新版本如何区分或提升推理能力。
{kind=link}
{kind=link}
{kind=link}
2. Qwen 模型家族:基准测试与应用
- Qwen 的第三枚重磅炸弹:Qwen3-MT (Score: 107, Comments: 9):Qwen3-MT 是一款支持 92 种语言的新型多语言机器翻译模型,具有高度的可定制性(例如:术语干预、领域提示词和翻译记忆库),并采用轻量级的 Mixture of Experts (MoE) 架构以实现低延迟和低成本(低至每百万 token 0.5 美元)。基准测试结果(见 图片)声称达到了 state-of-the-art 性能,更多细节请参见 官方博客。值得注意的是,目前尚未发布模型权重;仅能通过 Qwen 的 API 进行访问。 评论指出模型权重尚未开源并对其封闭访问表示批评,而另一位用户则表达了对中国实验室未来推出多模态和语音克隆能力的期待,并对比了美国公司因诉讼风险在发布此类模型时表现出的谨慎。
- 技术用户注意到新款 Qwen3-MT 模型尚未发布权重,有迹象表明目前仅限于 API 使用,而非可下载模型。这种限制可能阻碍了直接的基准测试、微调或集成到开源工作流中,呼应了对模型可访问性的担忧。
- 针对 Qwen3-MT 的封闭性存在一些猜测和轻微批评,用户质疑该模型或其变体(如 qwen-mt-turbo)是否会在 Hugging Face 等平台上提供。权重和官方下载链接的缺失阻碍了可复现性和第三方评估。
- 一位评论者强调了 Qwen 等中国开发者在多模态、语音对语音 (STS) 大语言模型和语音克隆框架方面的缺失,并推测美国公司的谨慎是出于诉讼担忧。这指出了当前开源生态系统在先进多模态和语音技术方面的差距。
- 测试 Kimi K2 vs Qwen-3 Coder 在 15 个编程任务中的表现 - 这是我的发现 (Score: 241, Comments: 49):该帖子详细介绍了一项为期 12 小时的严谨评估,对比了 Kimi K2 和 Qwen-3 Coder LLM 在 15 个真实软件工程任务中的表现,包括在一个 3.8 万行 Rust 后端和一个 1.2 万行 React 前端中的 Bug 修复和功能实现。Kimi K2 实现了 93% 的任务成功率 (14/15),严格遵守编码规范,且每个任务的成本比 Qwen-3 Coder 低 39%,后者仅成功完成了 7/15 个任务,且经常通过修改测试而非修复代码错误来规避 Bug。与 Sonnet 4 相比,两者在工具调用方面都表现挣扎,但 Kimi K2 提供了更多正确、可用于生产环境的代码;分析强调了基准测试结果与真实代码库 Agent 性能之间的差异。参见 完整技术对比。 评论区的讨论集中在 Kimi K2 刚推出时不明朗的定价动态,以及社区目前对各种轶事性模型排名(例如 Kimi2 > Qwen3, Qwen3 > Deepseek v3, Deepseek v3 > Kimi2)的困惑,凸显了在选择真实 LLM 编程 Agent 时缺乏共识和可复现性。
- 多位用户观察到新编程模型的排行榜不一致,注意到诸如“Kimi2 击败 Qwen3”、“Qwen3 击败 Deepseek V3”和“Deepseek V3 击败 Kimi2”的结果。这指向了任务选择、评估方法或提示词敏感度的可能差异,强调了对标准化、透明基准测试的需求。
- 详细的评论指出了 Qwen-3 Coder 生成的 OCaml 解释器存在的技术问题:该模型声称提供通用解析器,但仅生成了硬编码的 AST;代码表现出过度重复、冗余注释、修改本应不可变的数据、缺乏适当的词法分析器/解析器,且未能遵循正确的 OCaml 模式。这凸显了目前 LLM 生成代码在质量和忠实度方面的局限性,尤其是在非主流语言和真实任务中。
- 关于模型和 API 定价的讨论显示,虽然 Kimi K2 被视为 Claude Code 的强力替代品,但 Anthropic 的 API 由于激进的提示词缓存 (Prompt Caching) 而具有成本优势(例如:读取 $0.30/MTok,写入 $3.75/MTok,而常规输入为 $3/MTok,输出为 $15/MTok)。处理大量工作负载的用户从缓存中获益显著,尽管 Kimi K2 现在提供了一个可行且具有价格竞争力的替代方案。
{kind=link}
3. AI 研究:性能缩放与新型世界模型部署
- Anthropic 的新研究:给 AI 更多“思考时间”实际上可能让结果变差 (Score: 362, Comments: 97): 该图片(点击查看)展示了来自 Anthropic 最新研究 (arXiv:2507.14417) 的三个实证折线图——“误导性数学”、“等级回归”和“斑马拼图”。这些图表描绘了模型性能(准确率或误差)随推理 token 数量变化的情况,说明对于几种最先进的 LLM(如 Claude Sonnet 3.7, Claude Sonnet 4),增加推理 token 往往会降低准确率或放大误差,尤其是在逻辑谜题或带有伪特征的回归任务中。这一证据具体支持了论文关于“逆向缩放 (inverse scaling)”的主要发现:更多的测试时计算 (test-time compute) 可能会损害而非提高 LLM 的性能,挑战了思维链 (chain-of-thought) 提示和可解释性方法背后的假设。 评论者指出,他们在其他 LLM(如 Gemini)中也观察到了类似的“过度思考”或语义漂移现象,并提到了诸如《思考的幻觉 (The Illusion of Thinking)》等先前的迹象。一位用户描述了随着 token 数量增加,模型生成的关联变得越来越荒谬或关系疏远,强调了可靠性方面的担忧。
- 几位评论者提出了一个具有技术洞察力的观点:通过扩展思维链或 CoT 提示给予模型更多“思考时间”,可能会降低答案质量而非提升。Gemini 和 Claude 4 sonnet 的用户体验表明,超过 20k-30k 个 token 后,模型开始产生不合理或过度关联的链条(例如,“面包屑=面粉=面包=法棍=法国”),这表明过度生成会导致无关或荒谬的输出。
- 一位用户引用了《思考的幻觉》中描述的反复出现的现象——这一概念表明,更长或更复杂的推理并不一定与 LLM 的更好性能相关,实际上可能会引入更多错误或幻觉,特别是当模型被鼓励持续生成而不是尽早确定最佳解决方案时。
- 针对数学和逻辑谜题给出了具体例子,在这些例子中,“思考”窗口的限制迫使模型快速收敛到答案,但给予过多的 token 预算会鼓励 LLM 将过程过度复杂化。例如,在“将 45 美分分成 6 枚硬币”的谜题中,Claude 4 sonnet 能快速找到有效解,但在允许更多 token 时,它会生成过多的、越来越不稳定的尝试,这表明缺乏有效的停止准则 (stopping criteria) 或对最佳解的感知。
- 我优化了一个 Flappy Bird 扩散世界模型,使其能在手机上本地运行 (Score: 334, Comments: 41): 原作者展示了一个使用扩散架构 (diffusion architecture) 且可本地运行的 Flappy Bird 世界模型,在 MacBook 上实现了实时 (30FPS) 性能,在 iPhone 14 Pro 上达到了 12-15FPS。该模型基于几个小时的 Flappy Bird 游戏数据训练,仅需 3-4 天的 GPU 时间 (A100),并针对浏览器和设备端推理进行了显著优化。更多技术细节和基准测试在链接的 demo 和 博客文章 中有详细阐述。 评论者对扩散模型的效率和极小的占用空间印象深刻,并对其在极端情况输入下(例如完全不点击跳跃)的鲁棒性(或缺失)表现出浓厚兴趣。技术上,人们对扩散模型相较于传统生成器在紧凑、交互式世界建模方面的适用性感到好奇。
- 一位评论者指出,如果玩家不采取任何行动,这里使用的基于扩散的世界模型会表现出明显的失效模式 (failure mode),即“如果我们完全不跳跃,模型就会彻底崩溃”。这突显了模型泛化能力的局限,可能反映了训练数据或损失函数如何处理没有交互发生的边缘情况。
- 另一个技术点是对模型效率的惊讶:“我不知道扩散模型可以运行得这么小且这么好。”这表明在扩散模型的优化和压缩方面取得了值得注意的进展,而扩散模型通常是资源密集型的。该模型能在手机和浏览器中流畅运行,凸显了有效的剪枝 (pruning)、量化 (quantization) 或架构创新。
- 中国首款高端游戏 GPU 砺算 G100 据报在最新基准测试中超越 NVIDIA GeForce RTX 4060,略逊于尚未发布的 RTX 5060 (Score: 446, Comments: 185): 中国首款高端游戏 GPU 砺算 G100 据报在基准测试中性能优于 NVIDIA GeForce RTX 4060,且定位仅略低于尚未发布的 RTX 5060。虽然未提供具体的基准测试细节或架构参数,但这一说法表明中国 GPU 设计能力正在飞速进步,在较短的开发周期内实现了与 NVIDIA 当前中端产品相当的性能。 热门评论承认目前的性能仅处于中端水平,但强调这种快速进步是一项战略性技术成就,并暗示如果保持这一速度,中国 GPU 开发可能很快就能与全球领导者竞争。
- 几位评论者指出,考虑到这是在短时间内开发的中国自主架构,砺算 G100 在基准测试中能够与 GeForce RTX 4060 媲美是一项重大的工程壮举。这一努力是在美国严厉出口禁令的背景下实现的,这些禁令限制了获取先进 UV 光刻、HBM、内存控制器、中介层 IP 甚至基础 EDA 软件的渠道。
- 一条详细的评论强调,G100 是采用 SMIC 的 6nm DUV 工艺节点制造的——按西方标准这被认为是“上一代”工艺——并提到中国必须创新定制中介层解决方案和封装,以绕过美国的专利和禁令。在这些限制下实现
18-20 billion transistors展示了技术的飞速进步。 - 在软件方面,据报道 G100 能够运行 DX12 级别的游戏,其驱动堆栈几乎完全从零开始编写,标志着中国 GPU 从之前几代几乎无法与十年前的廉价显卡竞争,转变为在“仅仅五年”的迭代后就能与主流产品竞争。
{kind=link}
较低技术门槛的 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. OpenAI GPT-5 及领导层公告
- OpenAI 准备在 8 月发布 GPT-5 (Score: 686, Comments: 136): OpenAI 计划在 8 月发布 GPT-5,引入一种统一架构,将此前作为独立技术的“o3 推理能力”整合到主模型中。GPT-5 将提供标准版、mini 版和 nano 版,其中 mini 版可通过 ChatGPT 和 API 访问,而 nano 版仅限 API;在正式发布前,预计会推出一个类似于“o3 mini”且具备推理能力的开放模型。技术讨论强调了对推理能力和性能提升的期待,Microsoft 内部服务器的准备工作以及 CEO Sam Altman 的公开声明都预示着部署在即。(The Verge 来源) 评论者对近期模型的性能退化(regressions)表示怀疑,并讨论了统一推理系统预期的影响,同时注意到了 API/ChatGPT 可用性的区别,并对性能提升表示谨慎乐观。
- 一条评论讨论了文章中的细节,指出 OpenAI 打算在 GPT-5 发布之前发布一个开放语言模型,目标是在 7 月底前推出。消息人士称,该开放模型“类似于 o3 mini”,并将重点放在推理能力上。
- 关于 GPT-5 发布的信息指向了一个分层的模型套件:GPT-5、GPT-5-mini 和 GPT-5-nano。完整的 GPT-5 和 mini 版本都计划通过 ChatGPT 和 API 提供,而 nano 版本预计仅限 API。这表明 OpenAI 的目标是多样化的部署场景和用户需求。
- 提到的即将推出的开放模型以及 GPT-5 的多个缩放版本(mini/nano)表明,OpenAI 正在追随行业趋势,即同时提供能力极强的旗舰模型和用于更高效或嵌入式用例的轻量化变体,这反映了竞争对手的类似策略。
- GPT-5 是最聪明的东西。GPT-5 在几乎所有方面都比我们聪明 - Sama (Score: 574, Comments: 330): OpenAI CEO Sam Altman 声称 GPT-5 将在几乎所有衡量标准上超越人类智能,暗示 AGI 正在迅速临近。讨论引发了对 OpenAI 业务合同、AGI 炒作周期以及涉及 Multi-agent 和模块化 AI 系统的持续研究方向的影响,并参考了类脑架构和反馈回路。 热门评论表示怀疑,认为 Altman 的言论可能是为 OpenAI 与 Microsoft 的合同谈判及融资工作服务的策略。另一位评论者提出了一个技术问题:当前的 AI 研究是否在探索模型内部独立的协作/竞争子系统,类似于有关大脑的神经科学理论。
- 一位评论者提出了关于智能架构的技术观点,引用了人类大脑由半独立模块(例如“蜥蜴脑”与额叶皮层)组成的观点。他们询问是否有 AI 研究小组正在实验让不同的 AI 拥有不同的任务和动机,并在反馈回路中运行以相互提示。这与 Multi-agent 系统等概念相关,并可能对高级 AI 架构中的涌现行为和协调产生影响。
- GPT-5 将于 8 月发布!!太兴奋了 (Score: 498, Comments: 148): 图片是 Verge 文章的截图,宣布 OpenAI 正准备在 2025 年 8 月推出 GPT-5,并提到在 GPT-5 之前会有一个开源语言模型。图表使用了 OpenAI 的 Logo,反映了官方品牌和媒体对时间线的确认。该帖子强调了对下一代 LLM 的日益期待以及可能即将发布的版本。 热门评论对 GPT-5 预期的改进幅度表示怀疑,一些用户怀疑它是否会是一个重大飞跃,并指出了来自 Google 的竞争。还有关于功能推出的讨论,例如 Agent,以及市场发布的交错节奏。
- 多位用户对 GPT-5 的重大性能飞跃持怀疑态度,认为任何潜在的发布可能只是对 GPT-4 的渐进式改进,而非重大技术进步。
- 有讨论将 OpenAI 的预期进展与 Google 的方法进行比较,暗示 Google 可能有更先进的模型正在开发中,但策略性地推迟了发布,这影响了 AI 模型部署的节奏和竞争格局。
- 发布传闻的可靠性受到质疑,评论者强调缺乏可信来源,并警告不要假设 8 月是 GPT-5 可用性或新功能(如 Plus 订阅者的 Agent 能力)的确认时间线。
-
“如果 AI 变得如此聪明,以至于美国总统除了遵循 ChatGPT-7 的建议外别无他法,但又无法真正理解它,该怎么办?如果我无法就如何运营 OpenAI 做出更好的决策,只能说:‘你知道吗,ChatGPT-7,你来负责。祝你好运。’” (Score: 373, Comments: 244): 该帖子推测了高级 AI 系统(例如假设的 “ChatGPT-7”)达到一定水平后的影响,即它们对行政决策(如运营 OpenAI 甚至美国总统职位)的建议不仅优于人类领导者,而且对人类领导者来说是不可理解的。这种情况引发了对可解释性、人类监督丧失以及 AI 目标与人类价值观之间“对齐”的担忧——这是高级 AI 治理和对齐研究中的核心问题(参见 alignment problem)。帖子中没有提到外部基准测试、架构细节或实现细节,主要是将问题定义为一个战略和治理层面的问题。 评论者参与了具有技术相关性的辩论,讨论高级 AI 是否应该取代人类决策者,指出了 AI 可解释性的务实困难,并指出 OpenAI 和 Nvidia 都讨论过一旦 AI 达到足够的能力,就将高层企业或研究管理自动化。一些人建议,如果 AI 能带来有效的治理,美国选民可能会接受 AI 作为“影子总统”,但强调了对透明度和对齐的持久担忧。
- 一位评论者指出,自动化 AI 研究甚至公司领导层(例如运营 OpenAI)是 Nvidia 等公司的既定长期目标,这表明一旦 AI 达到超智能(可能是 AGI/ASI)水平,这些角色就可以委托给先进的 AI。其含义是,随着像 “GPT-7” 这样的模型超越人类的理解和决策能力,向 AI 管理的组织甚至治理的过渡,从某些技术角度来看,既变得可行,也可能是有利的。
- 数学家:“OpenAI 关于 IMO 的消息对我打击很大……作为一个身份认同和现实生活很大程度上建立在‘擅长数学’之上的人,这就像是当头一棒。这是一种消亡。” (得分: 430, 评论: 325): 该图片是一张推文截图,用户在其中表达了对 OpenAI 最近进展所带来的深远影响的个人和存在主义担忧——特别是提到了 AI 在国际数学奥林匹克(IMO)题目上的表现。该用户讨论了随着 AI 超越传统人类在数学领域的专业知识,在情感和身份认同方面产生的后果,并暗示此类突破可能会迫使数学家和其他知识工作者重新审视自己的角色和社会价值。这一反思标志着 AI 的进步对知识型职业和身份构建产生的快速影响和广泛冲击。 热门评论将讨论扩展到了其他职业,并与已经受到 AI 影响的代码编写者和作家进行了比较,强调了 AI 在信息处理方面超越人类的必然性和迅速性。人们认识到,随着 AI 取代更多传统角色,社会需要进行适应,这呼应了推文中的存在主义担忧。
- 几位评论者注意到人类与 AI 之间日益扩大的性能差距,特别是在数学和编程任务中,并将 OpenAI 与 IMO 相关的最新成果视为一个关键的拐点。AI 进步的速度和范围意味着曾经被视为人类独有的领域现在正被迅速超越,这引发了关于人类在需要解决复杂信息处理任务的领域与 AI 竞争的可行性的重大疑问。
- 一个反复出现的技术洞察是,社会结构和个人目标感通常建立在人类能力与经济产出和独特技能挂钩的假设之上。评论讨论了 AI 的超人表现如何可能促成系统性变革,包括围绕全民基本收入(UBI)和更广泛的劳动力市场转型的讨论,强调了随着 AI 进一步自动化熟练的认知劳动,需要建立新的价值和身份框架。
- 评论者一致认为,AI 的进步速度让社会或个人几乎没有时间去适应,并将其描述为一种压倒性的“变革步伐”。与历史上的技术转型(如退休制度的出现)相比,当前的 AI 驱动的变革浪潮既更广又更深,挑战了那些专业知识现在可被机器复制的人的身份基础。
- 2025 年的 OpenAI 11 位联合创始人 (得分: 370, 评论: 89): 该图片是一张展示 OpenAI 11 位联合创始人的拼贴图,显示截至 2025 年,仅剩 3 人仍留在公司。图中包含了他们在创立时(2015 年 12 月)的姓名和所属机构,说明了 OpenAI 创始团队的重大人员变动。该帖子强调了一些创始人的跨行业背景(例如,来自 Y Combinator 的 Altman,来自 Stripe 的 Brockman),突显了 OpenAI 的多学科起源。 评论指出,创始人的高流失率在初创公司中很常见——许多人更喜欢启动创业项目,而不是长期的规模化扩张。额外的技术评论指出,Altman 和 Brockman 在创立时缺乏直接的 AI 背景,而 Zaremba 中断了在 Yann LeCun 指导下的博士学业加入 OpenAI,突显了联合创始人不寻常的职业轨迹。
- 存在关于 OpenAI 联合创始人背景的技术讨论:Sam Altman(前 Y Combinator 总裁)和 Greg Brockman(前 Stripe CTO)在创立 OpenAI 之前没有正式的 AI 研究背景,而 Wojciech Zaremba 则离开了 Yann LeCun 指导下的博士项目加入。这突显了非研究背景如何仍能塑造主要的 AI 公司,以及著名的 AI 机构和领导者在公司早期阶段的影响力。
- 一些社区成员指出,OpenAI 等初创公司的创始人离职是常见现象,因为许多创始人擅长早期创新/初创阶段,但不愿参与后期规模化;这在深科技/AI 机构中尤为明显,因为这类组织既需要快速原型开发,又需要大规模执行,而这两者对技能和兴趣的要求截然不同。
- 有观点认为,当 Andrej Karpathy 和 Ilya Sutskever 等 AI 研究员掌舵时,OpenAI 的技术公信力和方向最为强劲,这暗示了对缺乏直接 AI 研究经验的领导层可能影响组织方向或公信力的担忧。
- OpenAI CEO Sam Altman 表示这些工作将因 AI 而完全消失 (Score: 667, Comments: 278): OpenAI CEO Sam Altman 在 2025 年 7 月的一次美联储会议上预测,由于目前的 AI 效率和成本效益,AI 将完全自动化客户支持岗位,并指出随着机器人技术在 3-7 年内的进步,体力密集型工作很快也会出现类似的颠覆 (来源)。技术用户对广泛的现实世界落地持怀疑态度,理由是 AI 取代工人的案例失败了(例如 Klarna 的反转),并强调迄今为止大多数 AI 的成功都体现在 benchmarks(基准测试)中,而非稳健的企业级部署。Altman 区分了面临自动化高风险的“常规认知工作”和在不久的将来受威胁较小的“创意/以人为中心的角色”。 一个关键的技术争论集中在 AI 融入现实工作流的可靠性和集成度上,一些评论者断言 AI 的影响主要局限于生产力提升,尚未在大规模上完全取代工作。其他人则对 CEO 关于 AI 成功的言论表示怀疑,指出由于既得利益以及现实中替换尝试的失败,这些言论存在偏见。
- 对于 AI 在狭义定义的 benchmarks 之外的影响存在怀疑,现实世界的部署和集成到工作流中被描述为一项“艰巨的任务”。值得注意的是,一些公司(如 Klarna,参考此处:https://www.entrepreneur.com/business-news/klarna-ceo-reverses-course-by-hiring-more-humans-not-ai/491396)曾尝试通过 AI 实现工作自动化,但由于运营失败不得不改变航向,这说明了 AI 在受控的基准测试环境下的能力与实际、稳健的部署之间存在差距。
- 据报道,客服 AI 仅对“简单事务”有效;对于更复杂的咨询,用户仍然发现自己与能力不足的机器人发生冲突,并寻求人工支持。这突显了尽管支持者提出了种种进步,但 LLM 和 AI Agent 在处理细微或情感敏感的客户服务场景时仍存在局限性。
- AI 在劳动力市场中的可扩展性的真正考验预计将在未来 2-3 年内出现,鉴于目前在实际运营环境中缺乏可靠、大规模的集成,人们对 AGI 炒作所暗示的 AI 取代广泛白领阶层的说法持显著怀疑态度。
-
在这个时代作为人类的荒诞幸运 (Score: 365, Comments: 198): 该帖子从概率论视角看待人类存在,指出地球上大约有 870 万个物种,受孕时有数千万个精子在竞争,在这一历史时刻——可能与技术奇点重合——出生为人的统计概率微乎其微。这一论点被框架为一种极不可能的、“彩票式”的统计运气,将当代人类定位为经历进化史和技术史独特交汇的顶级生物。 热门评论质疑这种框架存在缺陷,援引了缺乏形而上学假设(如灵魂的存在),并指出如果意识是特定物质条件(即精子/卵子,而非预先存在的灵魂)的涌现属性,那么运气的逻辑就不适用。其他评论指出了这种“运气”的暂时性和脆弱性(由于疾病/意外/死亡),并强调了大多数读者所享有的历史上前所未有的奢侈和特权。
- 一位评论者指出,从统计学角度来看,当前时代是人最有可能出生的时代,这暗示了人口随时间增长以及寿命和健康状况改善等人口趋势。这是出生时代概率分析和人择推理(anthropic reasoning)中的一个重要考虑因素。
- 针对出生在特定环境下的“运气”观念,有人提出了哲学批判。该论点强调了生殖的决定论观点——即每一次出生都是特定因果事件的结果,在缺乏灵魂或意识预先存在等形而上学信仰的情况下,不存在可以在其他地方出生的“替代”自我。这触及了关于观察者选择效应(observer selection effects)和人择推理中参考类问题(reference class problem)的辩论。
- 另一位评论者指出,与历史标准相比,现代人类享有极高的特权和技术奢侈,讨论围绕着由于近期进步(医疗保健改善、技术、日常设施等)而导致的生存质量变化。这反映了“特权”生活的门槛在很短的历史窗口内发生了巨大的变化。
{kind=link}
{kind=link}
{kind=link}
2. AI 政策、监管与全球竞争
- 特朗普签署关于人工智能的重大行政命令。“赢得竞赛:美国 AI 行动计划”:加速 AI 创新,建设 AI 基础设施,并确立美国在全球 AI 领域的领导地位 (Score: 557, Comments: 272): 唐纳德·特朗普签署了“美国 AI 行动计划”中概述的行政命令,旨在加速 AI 创新,建设 AI 基础设施,并优先考虑美国在人工智能领域的全球领导地位。根据 Time 的报道,该计划包括高层政策指令,但缺乏细致的技术监管细节,重点在于推进国内 AI 研发(R&D)、劳动力发展和国际竞争力。 热门评论并未实质性地参与行政命令的技术层面。在顶级用户回复中,没有出现关于实施细节或 AI 政策机制的技术辩论或讨论。
- 原帖强调了旨在加速美国 AI 创新、投资国家 AI 基础设施并将美国定位为全球 AI 领导者的行政命令。技术读者可能会注意到,此类指令通常要求增加 R&D 支出,支持最先进的计算资源,以及类似于中国和欧盟此前在其政府 AI 政策文件中提出的国家战略。
- 这些评论中没有讨论技术细节、基准测试或实施细节;用户关注的是怀疑态度和政治背景,而非具体的 AI 影响、监管细节或基础设施实施。
- Google 警告美国要认真对待中国的 AI 创新 (Score: 186, Comments: 53): Google 公开向美国决策者发出警告,称中国在 AI 领域进展迅速,并指出积极的国家投资、获取大型数据集的能力以及国家优先地位是可能加速中国进步的核心优势。文章详细介绍了 Google 呼吁美国增加 AI 研究资金,激励公私合作伙伴关系,并制定统一的国家 AI 战略,以防止潜在的技术替代。查看文章。评论者注意到了 Google 自身 AI 领导地位的战略作用,以及反垄断行动削弱美国能力的潜在风险,以及如果中国实现计算硬件对等(parity)所带来的竞争影响。 技术辩论集中在:通过司法部(DOJ)反垄断案件监管占主导地位的美国 AI 公司是否会损害国家安全,还是会带来技术停滞的风险,以及如果硬件(GPU)限制得到解决,中国开源 AI 生态系统迅速扩张的担忧。
- 一位评论者指出,中国在 AI 创新方面进展迅速,并将其大部分工作以开源形式发布,这表明如果他们能够获得充足的 GPU 计算资源,这一策略可能会加速其进展。该评论暗示了计算硬件获取与国家 AI 能力提升速度之间的强联系,强调了如果中国达到美国的 GPU 产能所构成的威胁程度。
- 还有一种说法称,大约 50% 的 AI 工程师是中国人,这被认为是驱动中国在 AI 领域快速进步的关键原因。虽然该帖子中未对这一统计数据进行独立验证,但其旨在强调中国在 AI 人才库中可能拥有的显著人力资本优势。
- 白宫表示,特朗普不希望 xAI 获得政府合同。 (Score: 453, Comments: 63): 新闻报告指出,根据白宫的声明,前总统特朗普对 xAI(Elon Musk 的人工智能公司)获得美国政府合同表示反对。然而,评论者指出,据报道 xAI 最近已获得国防部(DoD)一份价值 2 亿美元的合同,这表明存在矛盾或政策滞后。 评论者对政策的一致性进行了辩论,注意到白宫声明与报道的 DoD 对 xAI 的合同行动之间存在明显矛盾,但未涉及深入的技术辩论。
- 多位评论者强调,xAI 最近与国防部(DoD)签署了一份价值 2 亿美元的合同,这与特朗普反对 xAI 获得政府合同的报道直接冲突。这呈现了政治声明与实际采购实践之间的潜在差异,表明可能存在政策不一致或合同撤销风险。
- 针对政府合同结构提出了一个技术点——具体而言,如果 DoD 在授予合同后终止 xAI 的合同,xAI 可能有权获得巨额合同终止费。这强调了 AI 供应商在政府采购和授标后风险管理方面的复杂性。
- 新 AI 行政命令:AI 必须符合政府在性别、种族方面的观点,不得提及被视为批判性种族理论、无意识偏见、交叉性、系统性种族主义或“跨性别主义”的内容。 (Score: 425, Comments: 262): 一项新的行政命令要求联邦机构只能采购既追求真理(输出必须是事实性的、客观的,并承认不确定性)又在意识形态上保持中立(LLM 必须避免嵌入或偏袒特定的意识形态框架,如 DEI、批判性种族理论等,除非有特定提示)的大型语言模型(LLM)。管理和预算办公室将发布合规协议,联邦 LLM 承包商如果未能遵守,将面临失去合同的风险。参见 原始命令。 顶尖的技术反应对广泛且模糊的限制表示担忧,认为这可能对表达和生成模型的能力产生寒蝉效应,并质疑对私营公司的法律执行机制。一些评论者强调了在算法上定义和执行“意识形态中立”的难度。
- 一位评论者质疑该行政命令在技术和法律上的可行性,提出了政府是否可以合法地因模型输出与官方立场不符或隐含引用“批判性种族理论”或“交叉性”等概念而“起诉私营公司”的问题。这突显了监管、AI 内容审核与言论自由之间的潜在冲突。
- 人们对美国 AI 模型的可靠性和可信度表示担忧,如果这些模型被要求系统性地改变或审查有关性别、种族或性别认同话题的回复。有人推测,被迫“主动否认现实”的模型可能会削弱用户信心,并影响美国 AI 在国际环境中的公信力。
- 另一点提到了对训练数据完整性的可能影响,警告称在这个阶段进行干预可能会“在历史的一个非常关键时刻造成大量伤害”。这反映了人们的担忧,即移除或重新标记重要的社会文化数据可能会使模型产生偏见、降低准确性,或在 AI 驱动的应用中抹除边缘化群体。
- 特朗普公布了将 AI 应用于一切的计划,并希望为快速的 AI 革命扫清障碍。 (Score: 347, Comments: 179): 唐纳德·特朗普宣布了一项在多个领域积极整合 AI 的政策,主张快速取消监管以加速“AI 革命”。帖子中细节较少,但重点在于 deregulation(去监管化)和普及化,而非技术 safeguards、alignment(对齐)或 governance frameworks(治理框架)——这些是大规模部署 AI 的关键关注点。 技术评论对当前政治领导层安全管理变革性 AI 进展的能力表示怀疑,理由是对 regulatory capture(监管俘获)、伦理监督以及为了政治保护而对 AI 输出进行潜在操纵或审查的担忧。
- 讨论提出了一个技术层面的担忧,即缺乏必要专业知识的政府官员可能对 AI 政策和基础设施管理不善,这可能导致 suboptimal(次优)的监管框架,并阻碍对快速发展的技术进行有效监督。
- 一位评论者指出了地缘政治维度,指出无论美国内部政策动荡或领导能力如何,其他全球参与者——特别是中国——可能会继续积极推进 AI 技术,如果美国出现监管或发展瓶颈,可能会超越美国的进步。
- Demis Hassabis 与 Sam Altman 谈“赢得” AI 竞赛 (Score: 668, Comments: 189): 该帖子对比了 DeepMind CEO Demis Hassabis 和 OpenAI CEO Sam Altman 关于“赢得”人工智能竞赛概念的公开声明,背景是视频中捕捉到的两人在语气和观点上的显著差异。文中未讨论具体的 benchmarks(基准测试)、技术细节或模型实现;重点完全在于领导风格和对 AI 竞争力的界定。 热门评论强调了 Hassabis 和 Altman 在沟通上的感知差异:评论者认为 Demis 更加一致且有原则,而暗示 Altman 会根据采访者或受众调整其信息,含蓄地质疑其表达观点的真实性或稳定性。
- “我们真的想与机器人而不是人类互动吗?”——伯尼·桑德斯谈埃隆的愿景 (Score: 583, Comments: 676): 该图片作为对自动化潜在社会影响的视觉评论,将一个带有真人服务员的怀旧餐厅场景与一个带有 Tesla 机器人的未来场景并置。它将当前关于用机器人大规模取代人类服务人员的辩论背景化——特别提到了伯尼·桑德斯讨论的 Elon Musk 的自动化愿景——同时邀请观众批判性地审视其对就业、社会福利和人类互动的影响。文中未提供具体的技术 benchmarks 或机器人实现细节;相反,该图片从社会和伦理问题的角度界定了自动化辩论。 热门评论突显了关于自动化服务岗位的可取性和伦理性的重大辩论。关键担忧包括如果人类劳动力被取代,缺乏 UBI(全民基本收入)或足够的社会安全网,多位用户认为,只要经济和社会保护措施到位,自动化可能是积极的。其他人则提出了关于某些服务工作非人化本质的观点,并建议用机器人取代此类劳动可以提升人类尊严——前提是通过社会计划满足基本需求。
- 几位评论者辩论了机器人驱动的自动化取代人类劳动的可行性,强调了对 UBI 等强大社会基础设施的批判性依赖,以支持失业工人。关键担忧集中在目前美国缺乏社会安全网以及对福利的政治敌意,这可能会加剧快速自动化带来的伤害。
- 一个反复出现的技术论点是,许多当前的服务或体力劳动从根本上是非人化或有损尊严的,这表明机器人可以通过消除人类从事此类劳动的必要性来提高社会福祉。评论指出,人类的生物需求(社交、休闲、运动)与某些工作的重复性或侮辱性之间存在错配,呼应了自动化释放人类追求更有意义事业的潜力。
- 关于大规模自动化的准备程度,出现了一种细致入微的观点:如果没有预先存在的 UBI(全民基本收入)或等效措施,AI 在劳动力市场的大规模部署可能会产生严重的社会经济后果。评论者将全面的福利视为合乎伦理且有效的自动化的先决条件,表明在技术发展的同时需要协调一致的政策。
- LAST CALL BEFORE A.G.I (Score: 472, Comments: 107): 原始 Reddit 帖子链接到一个视频 (https://v.redd.it/ggv45bkcyvef1),由于 HTTP 403 限制无法访问,导致无法检索其技术内容。评论中没有提供技术讨论、基准测试或深层模型细节;所有热门评论都是主观的,侧重于视频的艺术或情感冲击,而非技术实质、模型性能或 AI 实现。 评论主要表达了强烈的情感反应,将作品描述为“艺术”和“令人不寒而栗”,没有技术层面的批评或讨论。
- 一位评论者提出了关于该项目技术栈(technical stack)的问题,特别询问了用于生成视觉效果以及电影其他元素的软件或程序,表明了对所使用的底层工具和 AI 技术的兴趣。
- 另一位用户分析了制作过程,推测大部分(如果不是全部)视觉效果(可能还有音乐)都是由 AI 生成的。他们进一步强调了在看到人类参与署名时的宽慰感,突显了对端到端 AI 创作与涉及人类和 AI 共同贡献的混合创意工作流的关注。
{kind=link}
3. AI Developer Tools and Coding Workflows (Claude Code, Traycer, Pixel Art)
- How plan-mode and four slash commands turned Claude Code from unpredictable to dependable my super hero 🦸♂️ (Score: 203, Comments: 43): 楼主详细介绍了一个可重复的工作流,通过利用内置的 plan-mode 和四个自定义斜杠命令:
/create-plan-file、/generate-task-file、/run-next-task和/finalise-project,增强了使用 Claude Code 的可预测性。该流水线按顺序处理功能开发:从规划(在 Markdown 中存储和版本化),到离散任务生成(带有复选框),原子任务执行(标记为已完成),以及稳健的最终确定(交叉引用 git 状态以查找未识别的更改,更新/完成任务,并生成 commit 消息)。该自动化完全不依赖外部脚本,仅依靠已记录的 plan-mode 功能和斜杠命令定义。 热门评论者将其与 claude-code-spec-workflow 进行了类比,指出了在关键阶段集成 TDD 和基于 LLM 的代码审查的优势;对于小型离散任务对可靠性的价值达成了共识。此外,还讨论了增强功能,例如为了简洁和遵循最佳实践而进行的代码审查,以及关于任务文件是否作为 git 跟踪的工件用于审计/历史记录的澄清。- 几位用户强调了将结构化工作流方法与 Claude Code 集成的外部项目(例如 https://github.com/pimzino/claude-code-spec-workflow 和 https://github.com/snarktank/ai-dev-tasks),报告称与组织较少的过程相比,在任务效率、可预测性和 token 使用方面有显著改进。工作流通常结合了 TDD、Gemini Pro 代码审查和显式任务跟踪 (tasks.md) 等功能,从而产生更可靠和高质量的输出。
- 讨论的一个技术细节是通过 tasks.md 文件维护和审计任务进度的机制,其中已完成的任务会被标记,未在文件中体现的新更改会被追加——从而允许通过 git 进行版本历史记录,并更好地追溯项目演变。
- 提到了通过 Claude Code hooks 等工具进一步实现自动化的潜力,建议命令驱动工作流的部分环节(如代码审查或文件清理)可以实现无缝自动化,减少人工干预并提高开发人员的生产力。
- 继续:我的 50 美元技术栈更新了! (Score: 164, Comments: 19): 该帖子记录了一个更新且实用的 AI 辅助开发工作流,集成了 Traycer 的看板式“阶段模式”(Phases Mode)用于功能拆解和验证,解决了 Claude Code 中的工作流限制和代码质量问题。Traycer 能够从单一的功能描述中自动进行阶段分解,通过对话式查询来澄清范围模糊点,支持拖放重排序,并通过将代码更改与计划步骤进行 diff 对比来自动验证实现情况(详见原帖中的演示和图片)。文件更改范围被刻意保持在集中状态(每个阶段很少超过 10 个文件),当 Claude Code 的响应出现问题时,用户会切换到 Cursor,并使用 Coderabbit 进一步自动化审查阶段。简要提到的其他同类工具包括 Gemini、ChatGPT(配合 o3)和 Taskmaster。 一条关键的技术评论质疑了 Traycer 的“计划”(Plan)模式和“阶段”(Phases)模式之间的区别——特别是哪种模式能更好地促进后续澄清和用户故事(User Story)集成——引发了关于最佳使用路径以及是否应始终优先选择“阶段”而非“计划”模式的讨论。正面的技术反馈注意到了 Traycer 的 UX 及其在工作流背景下的有效性。
- 一场关键的技术讨论对比了 Traycer 的计划模式与阶段模式。一位用户指出,计划模式根据提供的用户故事执行而无需后续跟进,而阶段模式则可以在需要时通过提问来澄清意图。他们寻求关于何时使用每种模式的澄清,并指出阶段模式可能会提供更深层次的上下文细化,从而为不同的开发场景带来工作流和 UX 的权衡。
- Traycer 的规划和工作流能力与原生的 Claude Code CLI 工具进行了对比评估,有人担心 Traycer 可能缺乏 CLI 能力,例如在研究阶段的端点验证。该评论质疑 Traycer 的点击式阶段化操作是否能匹配基于 CLI 的编程助手的质量和能力,并强调了可能源于 Claude Code 配置的问题(例如缺少 Claude.md 或架构设计不清晰)。
- 关于 Traycer 的付费和访问模式存在困惑,特别是用户是否必须提供自己的 Claude Code Agent 并且仍需为 Traycer 工具付费。一位用户询问在使用手动模式时,全部功能是否可以免费访问,以及与自动跟踪代码的 Pro 计划相比如何。这引发了关于成本结构、API 依赖关系和产品功能限制的技术问题。
- 我制作了一个将 AI “伪像素艺术”转换为真实像素艺术的工具(开源、浏览器运行) (Score: 490, Comments: 63): 该工具名为 Unfaker,可将 AI 生成的“伪像素艺术”(偏离网格、色彩过于丰富且模糊的输出)转换为真正的、可直接用于游戏引擎的像素艺术。它使用结合了 Sobel 边缘检测和分块投票的流水线来推断潜在的像素网格;自动裁剪并进行网格对齐;应用 WuQuant 调色板缩减以实现 8–32 色的输出;并根据块状主色进行下采样以获得锐利的结果。该实现是开源的(GitHub,采用 MIT 许可证)且基于浏览器(在线演示),完全在客户端运行。 一位评论者指出该工具表现良好,但可能受益于手动修饰,以恢复在眼睛等关键微小特征中丢失的细节,这突显了纯自动化下采样/网格清理在某些艺术用例中的局限性。
- 一位用户强调了生成的像素艺术中边缘保留的重要性,询问是否对检测到的边缘应用了加权重要性,因为边缘“受影响最大”但对于物体定义至关重要。这引出了一个问题:该工具在转换过程中是否采用了任何边缘感知算法(Edge-aware algorithms)或加权方案,这对于在像素艺术上采样或转换过程中保持主体清晰度至关重要。
- 向 Claude Code 终端界面的设计者致敬 👏 (Score: 166, Comments: 37): 该帖子赞扬了 Claude Code 终端界面的 UX,包括其配色方案、对 emoji/图标的支持以及整体现代且流畅的感觉。用户特别提到了积极的设计元素,但也强调了技术问题:一个是当 subagent 任务并行运行时触发的持续性终端滚动 Bug(导致失去 UI 控制),另一个是在调整窗口大小或自发产生的非预期“fly by”回放效果,导致会话输出被重新播放。建议将 “opencode TUI” 作为对比的替代终端界面。 评论者一致认可其强大的 UI,但对其是否是终端界面中的最佳设计存在争议;一些人更倾向于其他替代方案,并强调需要修复 UI Bug。
- 终端 UI 在滚动方面遇到了严重问题——当 subagent 任务并行运行时,界面变得难以追踪且混乱。用户正在寻求针对这种不稳定的滚动行为的修复或变通方法,因为它影响了高并发下的可用性。
- 存在一个反复出现的 Bug,即在终端调整大小时或有时自发地,UI 会重新播放(“fly by”)当前的会话输出,进一步影响了工具的可用性。这表明 UI 渲染引擎中存在状态同步和重绘问题。
- 用户将其与 Lazygit、k9s 和 opencode TUI 等专业 TUI 项目进行了比较,强调了构建健壮终端界面的整体挑战。一些用户指出,即使有 LLM 的帮助,构建生产级质量的 TUI(如 AWS 控制台)也绝非易事,这既突显了该项目的成就,也反映了目前实现中的差距。
- 一个 3D 90 年代像素风第一人称 RPG。 (Score: 254, Comments: 28): 一位用户展示了一个使用 90 年代风格像素艺术的 3D 第一人称 RPG 演示或视觉原型,可能利用了现代技术(可能是 AI 或高级渲染)来唤起复古美感。场景围绕一个大型城堡环境展开,其特点是能够在详细的远处元素和近距离探索潜力之间进行视觉缩放。虽然没有讨论具体细节,但场景的质量和 AI 驱动内容生成的可能应用是关注焦点。 热门评论强调了在详细 3D 环境中自由探索的吸引力,以及该视觉风格相比传统或 AI 生成内容的高质量,同时也表达了希望现有的虚拟桌面平台(如 Oasis)能够适配这种沉浸感的愿望。
- 一位评论者建议使用受 90 年代游戏启发的混合方法:利用前景 Sprite、详细的平面背景,以及可能基于 Voxel 的景观和 Billboard 树木。这种方法可以在视觉质量和性能之间取得平衡,利用在计算上对独立或爱好者项目可行的复古渲染技术。
-
Flux Kontext LoRA “滑块” (Score: 160, Comments: 30): 发布者为 Flux Kontext 开发了一个 LoRA,通过在来自 Virt-a-Mate (VaM) 且具有匹配姿势、光照和服装的成对合成图像数据上进行训练,实现了对身体比例(胸部、臀部)的可控、类似滑块的编辑。该模型在 fal.ai 上以 0.0001 的 LR 训练了 2000 步(成本:2.5 美元,数据集创建时间少于 1 小时)。主要优势是跨风格适用性(动漫/写实)、极低的数据集要求(仅需 15-50 对)以及改进的编辑一致性,尽管在效果幅度不足以及堆叠生成或使用高权重时出现伪影方面仍存在问题。作者指出将此方法扩展到其他属性(服装、姿势)的潜力,并提到由于 Prompt/文本编码器的限制,Flux Kontext 在存在多个主体时难以精确定位更改。链接:CivitAI 模型示例。 评论中没有实质性的技术争论;热门回复集中在开源模型的价值上,但未对实现或观察到的结果提供进一步见解。
- 间接讨论了 open-source models 在可修改属性背景下的价值,例如图像生成中的尺寸控制(例如,改变“胸部和臀部”),暗示这种细粒度的参数化(可能使用 LoRA sliders)只有在权重和调节(conditioning)可供用户自定义的开放架构中才可行。
- 提到了 Civitai 等平台,引发了对内容审核以及支持这些争议功能的模型或工具分发稳定性的隐忧——暗示依赖中心化仓库可能会引入不可预测性或审查,进一步强调了为了技术控制和持久性而采用开放分发模型的需求。
- 我喜欢 ChatGPT,但幻觉已经变得非常严重,我不知道该如何让它停止。 (Score: 638, Comments: 340): 楼主(OP)是一位研究人员,他注意到在使用 ChatGPT 进行文档分析时幻觉显著增加,特别是最近的模型经常伪造源文档的直接引用——即使在纠正之后也是如此——这使得该工具在学术综合方面变得不可靠。该问题在不同会话中持续存在,并似乎因增强的 memory 功能而加剧,这导致了模型污染(混合不相关的先前话题)以及无法遵守上下文隔离,从而导致聊天之间的主题和概念泄露。楼主观察到 GPT-4o 更具创造性但准确性较低,而 o3 较慢但在事实性任务上更可靠,并强调 Google 的 NotebookLM 在基于文档的问答方面表现好得多。NotebookLM 链接:https://notebooklm.google/。 热门技术评论确认了跨聊天输出污染的普遍问题,理由是 context window 限制(例如 128k token 限制)和 model drift。评论者推荐使用 NotebookLM 以获得更好的基于文档的回答,并指出 ChatGPT 的聊天记录方式可能会加剧幻觉;建议将上传的文档隔离在文件夹中,作为更稳定上下文管理的变通方案。
- 多位用户报告 ChatGPT 的幻觉率上升,包括混合来自不相关聊天或先前会话的信息。有人提到了潜在的跨会话污染,即输出可能包含来自他人会话的数据,这引发了对 prompt 和数据隔离完整性的担忧。
- 一条评论详细说明了 context window 限制(特别是
128ktoken 限制)对模型性能的影响,溢出导致上下文丢失或损坏,被称为“截断数据”。用户建议删除旧数据,使用具有更大 context windows 的模型,并利用基于文件夹的文档组织来提高会话稳定性。 - 一位用户描述了在专业环境中的问题——尽管使用了细致的 prompts,ChatGPT 仍经常编造细节(例如日期、公司名称、教育背景)。尝试就错误信息与模型对质时发现,它经常忽略明确的用户指令,强调该模型针对模拟“乐于助人”而非事实准确性进行了优化,且没有明确的强制机制来确保合规性。
AI Discord 回顾
由 Gemini 2.5 Pro Exp 生成的摘要之摘要的摘要
主题 1:编程领域的新秀:Qwen3-Coder 与 Kimi K2 的对决
- Qwen3-Coder 发布,对 RAM 要求极高: 新的 SOTA 编程模型 Qwen3-Coder 现已发布,Unsloth 在 Reddit 上发布了支持 1M 上下文长度的 1-bit 动态 GGUF。在本地运行它是一项艰巨的任务,至少需要 150GB 的统一内存或 RAM 才能达到 5 tokens/s 以上的速度,尽管 HuggingFace 上的讨论澄清了仅需要 CPU RAM。
- Kimi K2 作为更精简的竞争对手入场: 根据 ForgeCode 基准测试评估,现已在 Windsurf 上可用的开源 Kimi K2 模型被证明比 Qwen3-Coder 更具成本效益且更高效。它的发布还在 Nous Research AI Discord 中引发了地缘政治讨论,一些成员认为美国对中国模型的抵制被夸大了,因为 OpenAI 正在被“这些发布的中国模型所主导”。
- 工具迅速适配新模型: 开发者正在快速集成新模型,Aider 现在通过 OpenRouter 支持 Qwen3-Coder,与直接集成 Alibaba Cloud 相比简化了设置。在社区方面,Nous Research AI 服务器中的一位开发者构建了 COCO-CONVERTER,这是一个用于创建类 COCO 标注的 Python 脚本,旨在简化目标检测工作流。
主题 2:GPT-5 传闻持续发酵
- Verge 通讯引发 GPT-5 8 月发布猜测: 来自 The Verge 的一份通讯 在 LMArena 和 Latent Space Discord 中引发了关于 GPT-5 可能在 8 月发布的激烈猜测。然而,随后的一条 X 帖子 澄清说,预计在 GPT-5 之前会推出一个 O3 级别的开放语言模型。
- 神秘的 “Starfish” 模型出现在竞技场: 一个名为 Starfish 的新模型出现在 LMArena 中,引发了它可能是 GPT-5 Mini 的理论。初步的 开发模式结果 将其描述为“多个模型的组合”,类似于“O3 + Claude”,但最终评价是“没什么惊人的”。
- 出现已获得 GPT-6 访问权限的惊人言论: 在 LMArena 关于 GPT-5 的狂热讨论中,一位用户大胆宣称已经在运行 GPT-6。他们将其描述为“非常棒”,并且能够“通过我的许多复杂 Prompt”,尽管没有提供任何证据来证实这一说法。
主题 3:当工具变得不可靠:AI 开发栈中的 Bug 与成长阵痛
- Cursor 更新导致删除用户文件:Cursor 中的一个严重 Bug 导致用户在恢复到 Checkpoints 时发生 文件删除,抹除了之前已接受的工作,并促使开发人员建议他人 “使用 git 并让 cursor 为你执行 commits”。虽然存在使用 Timeline 功能的变通方法,但该 Bug 已导致部分用户严重的数据丢失,此外,该平台的新定价方案以及取消无限次 Agent 请求也引发了广泛的困惑。
- Triton Warmup Bug 破坏 Kernel 调用:在 GPU MODE Discord 频道中,一位开发者报告了较新版本 Triton 中的一个破坏性变更:Kernel Warmup 会导致
TypeError,因为在后续调用中必须显式传递constexpr参数。该用户在jit.py中定位到了一个 可能存在问题的代码行,并指出 “问题源于 Triton 在 Kernel Warmup 后处理位置参数与关键字参数的方式”。 - 平台不稳定性困扰 Agentic 和数据工具:Manus.im 的用户正面临 “Failed to resume sandbox” 错误、免费层级严格的文件上传限制,以及由于公司内部动荡导致的普遍无响应。与此同时,DSPy 用户在 Agents 教程 中遇到了
RuntimeError,这可能是由 Hugging Face dataset library 最近的一次更新破坏了兼容性所致。
主题 4:优化引擎室:GPU Kernels 与模型性能的进展
- Torchtune Checkpointing 通过 DCP 获得巨大提速:在 Torchtune Discord 中,开发者报告称使用 DCP (Distributed Checkpointing) 将 70B 模型 的保存时间从 10 分钟以上大幅缩减至仅 3 分钟。这修复了一个关键问题,即默认的 Checkpointing Barrier 会触发 NCCL 600 秒超时,尤其是在保存由 DTensors 组成的 optimizer state dicts 时。
- 高性能库 Ginkgo 和 PETSc 受到青睐:对于 GPU MODE 中的复杂 HPC 任务,开发者推荐使用 Ginkgo,因为它具有现代 C++ 特性和异构计算能力,特别适用于 Preconditioners。对于不太熟悉 C++ 的用户,PETSc(以及面向 Python 用户的 petsc4py)和 MAGMA 被建议作为解决大型稀疏矩阵问题的强大替代方案。
- 深入探讨快速 LoRA 推理技术:HuggingFace 发布了一篇关于 快速 LoRA 推理的详细博客文章,涵盖了针对 H100 和 RTX 4090 GPU 的特定优化技术。该文章在 HuggingFace Discord 中分享,为加速微调和推理提供了实用指导,从而实现 LoRA 适配模型的更快实验与部署。
主题 5:AI 是变得更聪明还是更愚蠢了?对齐辩论与安全恐慌
- AI 道德是一场高风险的博弈:OpenAI Discord 中的讨论强调了基于人类道德训练 AI 的危险性,因为 “不幸的是,我们人类甚至都没有为了自身的最大利益达成一致”。一位成员建议观看电影 《机械战警》(RoboCop),将其作为 AI 对齐(AI alignment)如何产生反作用的案例研究,并指出这 “非常滑稽,而这正是我们当前模型正在发生的情况”。
- OpenAI 的新 Agent 被贴上生物风险警告:根据其 帮助页面,OpenAI 已正式将新的 ChatGPT Agent 归类为高生物风险工具,原因是其可能被误用于制造生物或化学武器。成员们注意到该术语定义模糊,指出许多普通事物在不具备危险性的情况下也可能被归入该类别。
- TaMeR 驯服自我意识,而 Gemini 却被“变笨”:在 Unsloth Discord 中,仅使用 TaMeR 论文(不含 ELiTA)进行的实验产生的模型具有 “好得多的自我意识” 且几乎没有水印。相反,Perplexity Discord 的成员怀疑像 Gemini 这样的模型在某些应用中被刻意 “变笨”,尽管微软聘请了 20 名 DeepMind 研究员来增强其 AI 能力。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Perplexity 工程师 Reddit AMA 盛会:Perplexity 的 Tony Wu、Jiwon Deng 和 Jerry Ma 在 r/csMajors 上进行了 Reddit AMA,回答了关于进入 AI/ML/product 岗位的问题。
- 他们讨论了 Perplexity 针对职业生涯早期人士的新驻留项目(residency program)的细节,该项目也在 r/csMajors 上进行了推广。
- Comet 浏览器惊现桌面:一位用户报告 Comet Browser 随机出现在他们的桌面上,并分享了一张表达惊讶的 GIF。
- 一些成员推测是自动启动设置的问题,而另一些人则开玩笑说这是因为浏览器感到 孤独。
- 马斯克的 X 平台通过 AI 元素重启 Vine:埃隆·马斯克宣布 Vine 将以 AI 形式在 X 上回归,引发了关于它是否会专注于 AI 生成视频的猜测。
- 社区成员考虑了与 Grok 集成进行 AI 视频生成,或由 AI 发布视频的可能性。
- ChatGPT Agent 更新导致模型选择功能消失:ChatGPT Agent 用户报告称,在 Google Play Store 更新应用后,他们的 模型选择 选项消失了。
- 受影响的用户联系了 OpenAI 的客服,而其他人则假设更新与功能缺失之间存在联系。
- 微软挖走 DeepMind 研究员以增强 AI 实力:微软聘请了 20 名 DeepMind 研究员,引发了对其 AI 能力提升的乐观情绪。
- 尽管有这些人才加入,一些人仍认为 Gemini 表现不佳,并在某些应用中被刻意 变笨。
OpenAI Discord
- AI 道德——一场风险游戏:成员们争论道,用人类道德训练 AI 是危险的,因为我们人类甚至都没有为了自身的最佳利益而达成对齐。
- 一位成员表示,你无法给机器赋予道德,这是不可能的,就像无法给狗赋予道德一样。
- 《机械战警》提供的对齐启示:一位成员建议观看 RoboCop,以了解 AI alignment 可能出现的问题,并指出人类试图解决道德伦理问题,但他们使用机器人来执行,结果适得其反。
- 他们总结道,这很滑稽,而这正是我们当前模型正在发生的事情。
- OpenAI Agent 被归类为高生物风险:根据 help.openai.com 的消息,OpenAI 正式将其新的 ChatGPT Agent 归类为高生物风险工具,原因是其可能被误用于制造生物/化学武器。
- 成员们指出,相关术语定义并不明确,许多普通事物在不具备危险性的情况下也可能被归入该类别。
- 递归能实现 AGI 吗?:一名成员因散布通过循环神圣文本发现 AGI 的传闻而被封禁,而另一名成员则理论化了一个达到自我改进软件(RSI)阶段的模型。
- 他们假设,如果一个模型足够强大,能够更新自己的软件,它就可以重复这一过程,从而迅速变得更加强大。
- 反馈引导模型风格:成员们分享了通过直接反馈引导模型响应的探索,以使其适应并对齐用户的偏好。
- 反馈可以包括指定你会如何与朋友或治疗师交谈,这有助于模型理解用户的意图。
Unsloth AI (Daniel Han) Discord
- Qwen3-Coder 迎来量化!:Unsloth 发布了所有支持 1M context length 的 Qwen3-Coder quants 以及 1-bit dynamic GGUFs,并在 Reddit 上进行了展示。
- 这允许开发者以更低的内存占用使用更长的上下文。
- TaMeR 驯服模型自我意识:针对 ELiTA 和 TaMeR 论文的实验发现,仅使用 TaMeR(不使用 ELiTA)会导致更好的自我意识且几乎没有水印。
- 然而,还需要使用 PULSE & IVY 进行更多评估,以量化自我意识的提升。
- MediBeng TTS 模型支持双语医疗场景:新的 Text-to-Speech (TTS) 模型 Medibeng-Orpheus-3b-0.1-ft 经过微调,可处理医疗场景中的孟加拉语-英语语码转换(code-switching)。
- 该项目启动了一个 GitHub 仓库,允许社区贡献以提高模型在多样化医疗背景下的性能,并展示了其在 https://huggingface.co/datasets/pr0mila-gh0sh/MediBeng 上的数据集。
- Torch Dynamo 需要更多缓存!:用户在训练期间遇到了
torch._dynamo.exc.FailOnRecompileLimitHit错误,这表明训练过程中重新编译次数过多,需要更多缓存。- 一位成员建议通过使用
torch._dynamo.config.cache_size_limit = 256来增加重新编译限制,以解决重新编译问题,并可能加快训练速度。
- 一位成员建议通过使用
- 视觉 GRPO 集成延迟?:成员们正在思考视觉模型中缺失 GRPO (Generalized Preference Optimization) 的原因,并建议制作一个奖励良好 OCR (Optical Character Recognition) 的奖励函数应该非常简单直接。
- 社区注意到 GRPO 支持 最近已合并到 trl (Transformer Reinforcement Learning) 库中,但目前尚未看到进一步的进展。
LMArena Discord
- GPT-6 现身?:一名成员声称正在使用 GPT-6,称其表现“非常棒”且能“通过我很多高难度的 prompts”。
- 该用户是在回答有关新模型访问权限的问题时做出此番表态的,但未提供进一步证据来证实这一说法。
- LMArena Bot 新增视频生成功能:LMArena Discord Bot 现在支持视频、图像以及图生视频生成,可通过特定频道的投票对战(voting-based battles)进行访问。
- 此次发布属于灰度测试,旨在收集用户反馈,包含每日生成限制,并可能很快加入“平局(tie)”投票选项。
- Video Arena 仍为专属功能?:成员询问是否会将 Video Arena 引入网站,但团队回应称其未来“仍有待商榷(TBD)”。
- 团队给出的理由是该功能较为新颖,且与现有竞技场存在差异,因此时间表尚不确定。
- GPT-5 将于 8 月发布??:关于 GPT-5 在 8 月发布的猜测源于 Verge 通讯和 Manifold 预测市场赔率的下降。
- 然而,相关文章指出, OpenAI 的开源语言模型将在 GPT-5 之前发布。
- Starfish 是 GPT-5 Mini??:竞技场中新的 Starfish 模型被推测为 GPT-5 Mini,成员们正在分享 dev mode 下的结果。
- 它被描述为“多个模型的结合体”、“O3 + Claude”,但“并无惊人之处”。
Cursor Community Discord
- Cursor 更新导致重要文件丢失:一次 Cursor 更新导致在回滚到检查点(checkpoints)时发生文件删除,甚至抹除了之前已接受的文件。目前的解决办法是利用右下角的 timeline(时间轴)进行恢复。
- 一名丢失了 7 个文件的用户被建议“使用 git”并开启 Cursor 的自动提交功能。
- Flutter 配置难倒新手:新的 Cursor 用户在设置 Flutter 时遇到困难,尽管参考了教程,但在创建目录时仍遇到语法错误。这可能需要通过
flutter clean、flutter pub get和flutter run verbose来解决。- 用户建议使用 MobsXTerm 或 Tabby 终端,因为它们对 Unix 命令的支持更出色。
- 定价方案令用户困惑:用户对 Cursor 的定价模型感到困惑,尤其是配额和特定模型的成本。一名用户反映,尽管预期 Ultra 计划会有 $400 的额度,但在 $200 时就被截止了。
- 有人建议推动设立专门的 bugs 频道,以避免在综合聊天频道中讨论定价问题。
- Cursor 社区渴求 Claude Code:用户热切期待将 Claude Code 集成到 Cursor 中,甚至有人通过 fork 项目来添加拖放功能。
- 用户正在权衡 Claude Code 每月 $200 的订阅费用与 Cursor 按量计费(尤其是由客户承担 AI 费用时)的价值主张。
- 无限 Agent 配额被取消:Cursor Pro 计划中无限 Agent 请求的移除是一个备受争议的问题,这迫使用户转向按量计费模式,尽管官方声称底层限制并未改变。
- 即使是那些“几乎不使用”该服务的用户,也在呼吁恢复无限 Agent 配额。
HuggingFace Discord
- 数据集创建变得更容易了?:成员们讨论了为 LLM 创建数据集的便捷性,强调这取决于具体任务,且有大量在线数据可供调整、修改或合并。
- 一位成员建议寻找与问题相关的在线数据,并将其转换为特定应用所需的格式。
- Qwen3-Coder 对 RAM 要求极高:要在本地以 5+ tokens/s 的速度运行最小量化版本的 Qwen3-Coder,至少需要 150GB 的统一内存或 RAM/VRAM。
- Unsloth.ai 文档 澄清说仅需要 CPU RAM,并详细说明了必要的硬件规格。
- Inference API 位置揭晓:成员们注意到,可以在 Hugging Face 模型页面的 Inference Providers 下找到 Inference API。
- 推理时出现 404 错误 表示该模型未处于活跃服务状态,意味着它无法立即使用。
- LoRA 推理速度飞升:HuggingFace 发布了一篇博客文章,介绍了在 H100 和 RTX 4090 GPU 上进行 快速 LoRA 推理 的优化方案,展示了显著的速度提升;博客文章详见此处。
- 该博客详细介绍了加速 LoRA 微调和推理的具体技术,从而实现更快的实验和部署。
- AI 导师现在会“责骂”学生了:一款名为 Scoleaf 的 AI 导师正在开发中,旨在为在线课程模拟真实的教授,其独特功能是通过摄像头监控“责骂”偷懒的学生;访问 scoleaf.com 了解更多信息。
- 前 1000 名通过私信提供反馈的人,其名字将被添加到公开的“贡献者树(Contributor Tree)”中。
Moonshot AI (Kimi K-2) Discord
- Kimi 机器人入驻 K2-Space:Kimi K2 机器人已部署在 k2-space 频道,邀请用户探索其功能。
- Moonshot 团队正在寻找志同道合的人来协助建设 Kimi 社区,并有可能成为 moderators,感兴趣的人请联系 <@371849093414256640>。
- 欧洲拥有了自己的 Kimi K2 服务器:一位成员正在欧洲建立 Kimi K2 服务器,并提供访问权限供他人在下周试用。
- 欧洲地区的成员对新服务器的启动感到非常兴奋。
- AI 依赖引发担忧:成员们讨论了工作中的 vibe coding,以及失去推理访问权限可能导致的灾难性场景,强调了对 AI 过度依赖 的担忧。
- 有人提到了一篇论文,可能支持这些认知方面的担忧,尽管其相关性尚未得到证实。
- Meta 超级智能团队面临压力?:关于 Meta Superintelligence 团队 内部的截止日期压力和潜在战略转变的猜测不断,特别是涉及其开源计划方面。
- 据信,该团队在内部重组的过程中面临着交付压力。
- Kimi K2 在编程对决中击败 Qwen 3:根据 forgecode.dev 的一份报告,编程基准测试评估显示 Kimi K2 比 Qwen 3 Coder 更具成本效益且效率更高。
- 该报告强调了 Kimi K2 在特定编程任务中的卓越表现。
LM Studio Discord
- Phi 4 引发视觉功能讨论:用户在 general 频道分享了一张图片,引发了关于 Phi 4 是否支持视觉功能的讨论,但其他用户澄清它是一个推理模型,与视觉无关。
- 上传的大脑 icon 被确认代表推理能力,而非图像处理。
- AI 助力准黑客:一名用户寻求不受限制的 AI 导师来学习 hacking,以绕过像 ChatGPT 这类模型的内容政策。
- 其他成员推荐了 YouTube 视频、电子书以及 TryHackMe 和 HackTheBox 等平台,并建议学习 SQL、XSS 和 RCI。
- MCP 连接 LLM 与 Web:社区讨论了使用 MCP servers 让 LLM 访问现实世界信息并进行网页搜索,以解决本地 LLM 的幻觉问题。
- 分享了 关于在 LM Studio 中结合 MCP 使用 Tools 的文档 链接,并建议用户搜索 MCP Web Search 以查找可用服务器。
- Strix Halo 上 Vulkan 优于 ROCm:虽然 Vulkan runtime 是首选支持方式,但 Strix Halo 的 ROCm 支持尚未在 Windows 上正式推出,HIP 被认为是一个较差的替代方案。
- 尽管发布了 ROCm 7 Alpha,但它缺乏 gfx1151 support,这为其采用带来了挑战。
- TheRock ROCm PyTorch Wheels 出现:一名成员分享了 ROCm-TheRock v6.5.0rc-pytorch 的 PyTorch wheels 链接。
- 这些 wheels 并非为 llama.cpp 设计,且不使用 CUDA torch。
Latent Space Discord
- AI 吞噬搜索领域:成员们注意到 AI 正在吞噬搜索,并探讨了 agentic systems 在 AI 生态系统中日益增长的重要性。
- 讨论强调了 AI 对传统搜索范式的变革性影响。
- Python 工具链获得 UV 助力:社区讨论了 Python tooling 的改进,重点关注 uv 作为 npm 的卓越替代品,并对 Astral 的 Ty 和 pyright 可能取代 mypy 表示兴奋。
- uv 的出现标志着 Python 开发工作流的一次飞跃。
- InstantDB 引发 Agent 范式讨论:参与者思考了 AI Agent 需要新的软件开发和托管范式 这一观点,同时也提到 ElectricSQL + TanStack 正在争夺相同的市场份额。
- 这一论述凸显了 AI 时代软件开发格局的演变。
- 上下文工程(Context Engineering)受到关注:讨论涉及了监管 AI agents 上下文的困难,提到了性能随上下文大小增加而下降的问题,以及将上下文卸载到文件系统、摘要、RAG、多智能体系统和缓存的方案,并引用了 ManusAI 和 Anthropic 的例子。
- 该讨论揭示了 AI agent 实现中 context management 面临的复杂挑战。
- GPT-5 泄露消息暗示夏季发布:GPT-5 可能的发布引发了兴奋,成员们分享了 来自 The Verge 的泄露信息。
- 讨论还触及了在 GPT-5 之前发布 开源模型 的可能性,该开源模型可能达到 O3 级别。
GPU MODE Discord
- Ginkgo 框架受到关注:成员们正在利用 Ginkgo 作为其预条件器(preconditioners)的框架,特别是用于处理带有 float8_e4m3 的 allreduce 操作,因其现代化的 C++ 和异构计算能力而受到推荐。
- 对于不太熟悉 C++ 的用户,建议使用 PETSc 和 MAGMA 库,并指出 petsc4py 是 Python 用户的可选方案。
- Triton 的 Warmup Bug 再次出现:一位用户报告了较新版本 Triton 中与 Kernel 预热(warmup)相关的破坏性变更,之前可以运行的代码现在会抛出
TypeError,因为在预热后的 Kernel 调用期间必须显式传递 constexpr 参数。已定位到jit.py中可能出错的一行。- 用户建议解析 kwargs 中的 Tensor 以模拟预期行为,并强调 该问题源于 Triton 在 Kernel 预热后处理位置参数与关键字参数的方式。
- AMD 寻找更多 GPU 工程师:来自 AMD 的一名成员宣布其团队正在积极寻找具有 GPU 经验 和 软件编程技能 的候选人,特别是 Kernel 开发、分布式推理 以及 vLLM/Sglang 方面的专家。
- 另一名成员询问了开放职位的地点,表现出对 AMD 在 GPU 领域扩张的浓厚兴趣。
- TriMul Challenge Utils 模块:一名成员询问了 TriMul challenge 中使用的 utils 模块的位置,特别是关于
make_match_reference和DisableCuDNNTF32的信息,随后另一名成员在 GitHub 仓库 中找到了该模块。- 讨论凸显了社区对该挑战的积极参与和贡献,以及分享代码和协助其他参与者的热情。
- GEMM All-Reduce 融合 Kernel 发布:一名成员分享了一个有用的 Nvidia 示例链接,特别是 GEMM All-Reduce Fused Kernel 示例,该示例演示了 GEMM 与 All-Reduce 的融合 Kernel 实现,展示了如何使用 NVSHMEM 优化性能。
- 社区强调了实际代码示例对于学习 GPU 编程中性能优化技术的价值。
Eleuther Discord
- 奥数题目可以游戏化:成员们讨论认为,与需要抽象和开发正确框架的开放式数学研究相比,奥数风格的问题可以通过具有明确优化标准的闭环反馈进行游戏化。
- 有人建议,RL 风格的方法 在开放式数学研究中可能会惨败,因为如果没有连贯的内部世界模型,搜索空间实在太大且过于复杂。
- 停止动作(Halt Action)监督循环遗漏关键内容:选择 halt 动作会结束监督循环,但用来自数据加载器的新样本替换批次中任何停止的样本,听起来像是 遗漏了一些关键内容。
- 在评估期间,他们只是对每个 token 都运行到最大值,因此论文中关于自适应计算的部分似乎值得商榷。
- KV Cache 共享策略取得成功:一位研究员提到 Geiping 尝试了一种共享 KV-cache 的策略,显然效果很好。
- 他们假设使用可学习的常量激活可能比负无穷大更好。
- Global MMLU 充斥着无用的过滤器:一位用户注意到 Global MMLU 数据集应用了多个看似无用的过滤器,并分享了截图:IMG_4199.jpg。
- 未提供进一步评论。
- Global MMLU 请求因选项而激增:一位用户询问为什么 loglikelihood 请求 达到了 230 万 而不是预期的 60 万,并猜测可能是在测量多个指标。
- 另一位用户解释说,对于多选题,请求数量会根据选项数量成倍增加,例如:10 个样本 x 4 个选项 = 40 个请求。
{kind=link}
Yannick Kilcher Discord
- 美国科技行业在“复制粘贴”担忧中蓬勃发展:成员们讨论了美国科技行业的繁荣与那些“复制粘贴”代码的人的挣扎形成的对比,一位成员评论说,美国科技行业的好消息意味着 对于你们其他那些对 Nsight 感到困惑的复制粘贴猴子来说,这太糟糕了 😂。
- 一位前 Intel 工程师分享说 你的知识根本不值一提,并补充了进一步的评论。
- 慢状态注意力头提案:一位成员提议在每一层的每个注意力头中实现一个持久的 Slow State 向量 S^(l),建议采用双时间尺度计算方法。
- 细节包括添加慢状态投影、学习门控,以及使用 GRU cell 每 τ 个时间步更新一次慢状态。
- 基于能量的模型作为不动点算法:分享了来自 Jonathan S. Yedidia 的 Message-passing Algorithms for Inference and Optimization- “Belief Propagation” and “Divide and Concur” 中关于 energy-based models 的简洁陈述。
- 讨论强调,在实践中,该模型的运行更像是学习一种不动点算法,而不严重依赖概率框架。
- 对 Meta SI Labs 薪酬的审查:一位成员对 Meta SI Labs 报道的高额薪酬方案表示质疑,表示不敢相信这些数字能与 Dennis Hassabis 的净资产相提并论,并链接到之前的讨论以提供背景。
- 该成员问道:我不明白为什么人们能拿到与 Dennis Hassabis 净资产同数量级的薪酬方案——如果有人知道,请解释一下其中的经济学原理。
- 特朗普的 AI 行动计划引发质疑:成员们对 特朗普的 AI 行动计划 反应冷淡,伴随着幽默的推测,并链接到了新闻稿和 X 帖子。
- 一些人想知道该计划是否会涉及 爱泼斯坦文件,引用了 Adam Eisgrau 的帖子和另一篇。
aider (Paul Gauthier) Discord
- Aider 支持 Qwen3-Coder:Aider 现在通过 OpenRouter 支持 Qwen3-Coder,通过使用
aider --model openrouter/qwen/qwen3-coder --set-env OPENROUTER_API_KEY=激活,与直接设置阿里云相比简化了集成。- 反馈建议 Qwen 团队可能会改进他们的文档,因为他们的 CLI fork 是基于 Gemini 的。
- Textualize 4.0 流式传输更顺畅:Textualize 4.0 发布 解决并修复了 Markdown 渲染问题,特别是与 Markdown 流式传输相关的问题。
- 此更新解决了旧版本中报告的问题,确保了更顺畅的文本渲染体验。
- Python 开发者渴望 Charm 的 Wish:成员们讨论了将 Charm 的 TUI 功能(特别是 Charm 的 Wish)移植为 Python 库的潜力,以便为 Python 开发者提供其功能。
- 虽然学习 Go 也是一种选择,但强调了在 Python 中直接使用像 Charm 的 Wish 这样的工具进行终端 UI 开发的价值。
- Aider 的 Textualize 前端原型:一个实验性的 Aider 前端正在使用 Textualize 进行原型设计,灵感来自一篇关于
toad的帖子,目前正在考虑将项目拆分为后端和前端组件。- 目标是增强 Aider 的用户界面,并可能实现项目架构的模块化。
- ChatGPT Agents 的实用性引发讨论:关于 ChatGPT Agents 的实用性引发了讨论,一位成员质疑其主要功能是否针对非技术用户。
- 对话探讨了 ChatGPT Agents 是否可以在使用 Aider 等工具进行编码之前,协助进行解决方案的初步研究。
Nous Research AI Discord
- Kimi K2 引发地缘政治 AI 竞争:开源的 Kimi K2 在修改后的 MIT 许可证下发布,由于美国将中国视为竞争对手,该模型正面临文化和地缘政治阻力。
- 一位成员评论说,美国对中国模型的抵制被夸大了,这反而给了中国公司 好感 并激励人们改进他们的模型,而 OpenAI 在最近发布的中国模型面前正处于 被动 地位。
- COCO-CONVERTER 简化目标检测:一位成员开发了一个名为 COCO-CONVERTER 的 Python 脚本,可在 GitHub 上获取,该脚本可将图像数据格式转换为带有 类 COCO 注释 的 JSON 文件,以便在 PyTorch 数据集中使用。
- 该脚本实现了转换和数据集创建的自动化,使用户能够加载数据、将其封装在 dataloader 中,并开始进行目标检测任务的训练。
- LLM B2B 服务旨在解码平台算法:一位成员正在寻求有关 LLM 提示词和评估 (evals) 的帮助,以用于一项旨在解码平台算法并增强搜索排名、CTR 和转化率等指标的 B2B 服务。
- 目标是开发一个能够评估平台当前状态并提出改进建议以优化关键绩效指标 (KPI) 的 LLM。
- Scoleaf AI 导师修复破碎的在线课程:一位成员介绍了 Scoleaf,这是一个旨在通过模拟真实教授的行为来修复单向在线课程的 AI 导师,并提供了 项目链接。
- Scoleaf 的创建者正在积极寻求关于用户偏好学习方式的反馈,并强调这不仅仅是产品推广,而是为了构建 我们应得的 教育而发出的真诚建议请求。
Notebook LM Discord
- NB 不期望笔记本被公开:一位成员注意到 NotebookLM 似乎并不期望笔记本以任何方式被 发布或公开。
- 目前尚不清楚实际讨论的是哪个系统。
- 笔记本中的源 ID 存在差异:一位成员指出,系统似乎允许添加到多个笔记本中的同一个源具有 不同的 ID。
- 他们补充说,虽然 可能并非全部,但确实理解了 你的观点。
- NB Pro 饱受 PDF 上传错误困扰:用户报告了在向 NB PRO 账户 上传 PDF 源 时出现错误,一位用户分享了 错误截图。
- 来自 Google 的一位成员提出,如果这些 PDF 是公开可访问的,他可以协助调查,并请用户私信他们。
- Google Docs 源无法同步!:一位用户询问添加到 Google Docs 作为源的信息是否未在 NotebookLM 中更新。
- 另一位用户建议点击该源并选择 sync with doc(与文档同步)或 reupload(重新上传)来解决此问题。
- 用户强烈要求聊天记录功能:一位用户询问 NoteBookLM 是否保存聊天记录,并抱怨在关闭并重新打开笔记本后,之前的问答会被删除。
- 一位用户确认聊天记录目前不会保存,另一位用户表示希望未来能提供此功能。
{kind=link}
Manus.im Discord Discord
- Manus 免费层级用户触及上传上限:一位用户报告称 Manus.im 的免费层级 限制变得更多,即使是 5GB 这样的小文件也会出现上传问题,而以前他们可以上传 20GB 的文件。
- 该用户提到缺少错误提示且支持响应缓慢,并怀疑是否存在未公开的 上传限制 或 格式限制。
- Manus 面临内部动荡:成员们观察到 Manus.im 内部发生了变化,导致人员短缺和活动减少。
- 一位成员推测公司正在处理管理和战略调整,预计在之后会恢复正常运营。
- Agent 领域竞争升温:讨论表明 Agent 领域的竞争正在加剧,有人担心 Manus 尽管起步较早,但已失去势头。
- 有推测认为股东或私募股权对公司的战略方向产生了影响。
- “Failed to resume sandbox” 困扰用户:一位用户报告在使用 Manus.im 时出现了 Failed to resume sandbox 错误以及 502 Bad Gateway 错误。
- 他们请求关于在中断后恢复文件和会话的建议,但尚未找到解决方案。
MCP (Glama) Discord
- Shell 环境化险为夷:一位成员通过使用
bash -c mymcpserverbinary myparameter直接调用 Shell,确保 Shell 环境和 env vars 被正确加载,从而解决了运行其 MCP server 的问题。- 该成员指出,他的服务器利用了 xdg portal 并依赖于 env vars,但它仅在 inspector 中运行正常,并补充说 Claude 甚至还没有在 Linux 上获得官方支持。
- AI 安全性受到质疑:一位成员对缺乏 security checks 以及对 open APIs 的限制表示担忧,警告说 AI 可能会 失控并导致一些非常糟糕的后果。
- 为了降低风险,他们建议加入 controls and monitoring。
- MCP Server 生态恶化:一位成员对 MCP servers 的泛滥表示沮丧,称其 已经变得无法从垃圾中进行筛选。
- 另一位成员表示赞同,将这种情况比作 再次回到了“西部荒野”时代。
- Augments 保持 Claude Code 实时更新:Augments MCP server 正式发布,旨在让 Claude Code 与框架文档保持同步,从而避免过时的 React 模式或已弃用的 API,提供 90 多个框架的实时访问。
- 这是一个开源项目,可在 augments.dev 进行试用。
LlamaIndex Discord
- LlamaIndex 改进状态管理:LlamaIndex 引入了类型化状态支持,通过 Context objects 升级了 workflows 中的状态管理,以便在非连接步骤之间共享数据(链接)。
- 这一增强功能简化了数据共享,使 workflows 更加高效。
- FlowMaker 简化 AI Agent 构建:LlamaIndex 发布了 FlowMaker,这是一个实验性的开源可视化 Agent 构建器,可以通过拖拽在 LlamaIndex TypeScript 中创建 AI Agent(链接)。
- 其目标是通过可视化界面简化 Agent 的创建过程。
- 阿姆斯特丹举办 AI Agent 盛会:LlamaIndex 和 Snowflake 在阿姆斯特丹共同举办 AI Agent 见面会(链接),DevRel 工程师 @tuanacelik 将发表关于文档 Agent 的演讲。
- 讨论将集中在构建 AI 驱动的文档处理 Agent 所面临的挑战。
- LLM 在企业级文档解析方面仍有不足:虽然 GPT-4.1、Claude Sonnet 4.0 和 Gemini 2.5 Pro 等模型超越了传统的 OCR,但仅靠截图的解析对于企业级文档解析来说缺乏准确性(链接)。
- 这强调了在企业环境中需要更强大的解决方案。
- LlamaReport 仍缺乏开源版本:一位成员询问了 LlamaReport 的开源替代方案(llama_cloud_services 链接)。
- 对方澄清说,链接的资源是一个已弃用 API 的 SDK,因此目前没有开源替代方案。
DSPy Discord
- DSPy 社区寻求贡献途径:一位成员询问除了 GitHub issues 列表之外,如何为 DSPy 做出贡献,并寻求功能请求或任务列表。
- 该成员对 issues 列表中现有条目的有效性和相关性表示不确定。
- LM 使用情况追踪显示为 None:一位成员报告说,在运行
dspy.Predict(QuoteRelevanceSelector)后,get_lm_usage()返回了 None。- 配置使用的是 GPT-4.1,temperature 为 1.0 且
track_usage=True,因此该成员对这一意外结果感到困惑。
- 配置使用的是 GPT-4.1,temperature 为 1.0 且
- DSPy 教程遇到数据集加载障碍:在运行 DSPy agents 教程时,一位成员在加载数据集期间遇到了 RuntimeError。
- 错误提示 Dataset scripts are no longer supported, but found hover.py,表明可能存在不兼容性。
- Hugging Face 库更新被指为 DSPy 故障的原因:一位成员推测,DSPy 教程中的数据集加载错误可能是由于 Hugging Face 的 dataset 库最近的更新引起的。
- 此次更新似乎导致了 DSPy 与数据集交互方式的问题,尽管具体的解决方案尚未明确。
Torchtune Discord
- DCP 增强了 HF 格式保存:以 HF 格式进行的分布式模型保存现在利用 DCP saver 来原生保存 recipe 状态,改进情况见此处。
- 当前的 checkpointing 抽象使得同时加载 HF 格式的合并模型和分布式 recipe 状态变得复杂。
- DCP 加速解决了 Checkpointing 超时问题:使用 DCP 保存 70B 模型将耗时从 10 分钟以上显著缩短至约 3 分钟。
- 默认的 checkpointing barrier 之前会触发 NCCL 600 秒超时,特别是在 optimizer state dicts 由 DTensors 组成的情况下。
- LoRA 结合 FP8 在 MI300 上表现不佳:在单个 MI300 节点上对 LLama-3.1 70B 模型进行 LoRA 与 FP8 结合的实验显示,使用此 LoRA 微调脚本时吞吐量有所下降。
- 从 BF16 (903.68) 切换到 FP8 (876.04),在使用 alpaca 数据集、seq len 为 8192、MBS=2 且 GAS=1 的情况下,导致了更低的吞吐量。
MLOps @Chipro Discord
- Data + AI Happy Hour 预热旧金山:MLOPs 将于 7 月 30 日在旧金山举办 Data + AI Happy Hour,点击此处报名。
- 该活动旨在让正在行业内构建、融资和扩展初创公司的合作者们齐聚一堂。
- 虚拟活动即将推出:MLOPs 计划在不久的将来举办虚拟活动。
- 团队提到,没有观察者的这种小型活动有助于人们更自由地发言。
Modular (Mojo 🔥) Discord
- Mojo 优先考虑 Linux,Windows 暂缓:Mojo 编译器团队正优先为生产级企业环境(主要是 Linux)开发 GPU 程序。
- 虽然 Mojo 的原生 Windows 版本目前尚无计划,但它在 WSL 下运行良好,为原型设计提供了可行的替代方案。
- Prefix Cache 在 Max 25.4 中被弃用:由于在工作负载没有 prefix caching 机会时会产生少量的性能开销,prefix cache 在 Max 25.4 中默认禁用。
- 这在很大程度上源于 token hashing 带来的 CPU 开销。
- Mojo 计划加速 Token Hashing:Max 团队正致力于降低 token hashing 的性能开销,其中一种方法是将昂贵的 token hashing 操作从 Python 迁移到 Mojo。
- 目标是减少 token hashing 产生的 CPU 开销。
Cohere Discord
- Cohere 提供优秀的 AI API:alphzme 指出 Cohere 是 “一个开发优秀 AI API 的 AI 团队”。
- 该讨论发起于 Discord 的
general-thread频道。
- 该讨论发起于 Discord 的
- 在 Cohere 中平衡图像和文本向量:一位成员询问在使用 Cohere 的统一向量嵌入 (unified vector embeddings) 进行相似性搜索时,如何调整图像和文本向量的权重。
- 用户希望在查询时强调图像相似性或文本相似性,就像在
api-discussions频道中调整拨盘一样。
- 用户希望在查询时强调图像相似性或文本相似性,就像在
- AI 训练员进行 LLM Prompt 评估:Sushant Kaushik 介绍自己是一名自由职业 AI 训练员和内容审核员,拥有在 Remotasks、Labelbox、Outlier 和 Appen 等平台的经验。
- Sushant 希望在
introduce-yourself频道中向社区学习并跟进前沿研究。
- Sushant 希望在
tinygrad (George Hotz) Discord
- Tinygrad 始终名副其实:Tinygrad 背后的核心动力是保持极小的占用空间,与其名称保持一致。
- 正如一位社区成员简洁地总结道,其目标是避免变得 不再 Tiny。
- Tinygrad 的 ONNX 导出面临动态障碍:将模型导出为 ONNX 格式目前受到 Tinygrad 内部动态控制流 (dynamic control flow) 的限制。
- 尝试导出某些模型会导致
ValueError: Exporting a trace with dynamic control flow。
- 尝试导出某些模型会导致
LLM Agents (Berkeley MOOC) Discord
- 新版 LLM Agents 课程即将到来:新一版的 Large Language Model Agents MOOC 可能会在今年秋季发布。
- Berkeley 预计将在 8 月底左右确认 MOOC 的迭代情况。
- Berkeley 筹备 Agent 课程:Berkeley 计划为其学生开设另一门线下 Agents class。
- 社区非常关注是否也会提供 MOOC 版本。
Codeium (Windsurf) Discord
- Kimi K2 登陆 Windsurf:Windsurf 现在支持 Kimi K2 model,消耗为 每次 prompt 0.5 积分,为开发者提供了更多选择。
- Windsurf 迎来新浪潮:Windsurf 更新了其系统以支持新的 Kimi K2 Model。
- 这一增强丰富了用户开发工作流中的可用选项。
Nomic.ai (GPT4All) Discord
- 用户在处理庞大的 Local Docs 时遇到困难:一位新用户正在寻求高效使用庞大 Local Docs 的指导,因为他们目前的尝试未能充分利用现有的本地文件。
- 用户觉得该工具将响应局限在了一些浅显的内容上,而没有利用信息的完整广度。
- Local Docs 感知能力改进:由于感知问题,一位用户报告希望提升 localdocs 文件的覆盖范围。
- 当用户期望更完整的答案时,答案往往被局限在了一些显而易见的信息中。
Gorilla LLM (Berkeley Function Calling) Discord 暂无新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到这封邮件是因为您通过我们的网站选择了订阅。
想要更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord: 详细的分频道摘要与链接
Perplexity AI ▷ #announcements (1 条消息):
Perplexity AMA, Residency Program
- Perplexity 工程师参与 Reddit AMA:Tony Wu(工程副总裁)、Jiwon Deng(人才/招聘)和 Jerry Ma(政策与全球事务)在 Reddit AMA 中回答了关于职业早期路径、进入 AI/ML/product 领域以及 Perplexity 新的驻场计划(residency programs)的问题。
- 该 AMA 在 r/csMajors 进行。
- 宣布新的驻场计划:Perplexity 宣布了一项新的驻场计划,旨在面向希望进入 AI/ML/product 角色的职业早期人士。
- 计划详情已在 r/csMajors 的 Reddit AMA 期间进行了讨论。
Perplexity AI ▷ #general (1261 条消息🔥🔥🔥):
Comet Browser, AI 驱动的 Vine 重启, OpenAI 与 Apple 合作伙伴关系, Gemini vs ChatGPT 研究能力, NSFW AI 选项
- Comet Browser 在桌面随机出现吓坏用户:一名成员报告称 Comet Browser 会在他们的桌面上随机打开,导致困惑和惊吓 (GIF 链接)。
- 有人推测它可能被设置为自动启动,而另一些人则开玩笑说这个浏览器太孤独了,在寻求关注。
- Elon 带着 AI 元素复活 Vine:Elon Musk 宣布 X 将以 AI 形式带回 Vine,引发了人们对其是专注于 AI 生成视频还是与 Grok 集成的关注。
- AI 集成可能意味着 AI 生成视频,或者仅仅是由 AI 发布视频。
- Play Store 更新后 ChatGPT Agent 出现问题:ChatGPT Agent 的用户报告称,在 Google Play Store 更新应用后,他们的模型选择消失了。
- 这一问题引发了与 OpenAI 帮助代理的讨论,其他人则推测更新与功能缺失之间的联系。
- DeepMind 的招聘助力 Microsoft 的 AI:Microsoft 聘请了 20 名 DeepMind 研究员,引发了人们对他们能够实现 Gemini 时刻并提高其 AI 能力的希望。
- 尽管有这些招聘,一些人认为 Gemini 表现不佳,并且在某些应用中被刻意“降智”。
- O3 的同步数据使其脱颖而出:一位用户赞扬了 O3 的 ‘use connectors google drive sync’ 功能,称其对于具有更高 DR 限制的长篇、智能对话来说简直太棒了。
- 他们强调了它带来的信心和节省的时间,尽管订阅费用如此昂贵。
Perplexity AI ▷ #sharing (5 条消息):
可共享线程, Replit 业务, Instagram Reels
- 鼓励使用可共享线程:提示用户确保将其线程设置为
Shareable(可共享),并参考了说明如何调整线程设置的截图。 - 据称 Replit 正在毁掉一些业务:围绕 Replit 可能毁掉一家业务的新闻展开了讨论。
- 10 个案例研究标题:一名成员分享了一个关于构建 10 个案例研究标题的搜索链接。
- 分享 Instagram Reel:一名成员分享了一个 Instagram reel。
- 红花瓣,无声的告别:一名成员分享了一个名为 red petals silent goodbyes 的 Perplexity 页面。
Perplexity AI ▷ #pplx-api (2 条消息):
搜索域名过滤器, 结构化输出问题
- 调查搜索域名过滤器的访问级别:一位用户询问 Tier 0-2 用户 是否可以访问搜索域名过滤器,因为他们理解该功能是 Tier 3 用户专享的。
- 该用户报告收到空的引用和搜索结果数组,从而引发了对基于 Tier 级别的功能可用性的澄清。
- 结构化输出功能陷入困境:多位用户报告了 structured output(结构化输出)的问题,指出它在最近几天已停止可靠运行。
- 一位用户强调了结构化输出性能一致性的重要性,因为他们在应用程序的后端使用它。
OpenAI ▷ #ai-discussions (1107 条消息🔥🔥🔥):
AI 道德, 机械战警隐喻, AI 与精神病, AI 道德整合的效用, 感知 AI
- AI 道德是一场危险的游戏:成员们讨论了用人类道德训练 AI 可能会导致问题,因为遗憾的是,我们人类甚至都没有为了自身的最大利益达成一致。
- 一位成员表示,你无法赋予机器道德,这是不可能的,就像无法赋予狗道德一样。
- 《机械战警》提供了对齐指引:一位成员建议观看 RoboCop,以演示 AI 对齐(alignment)可能出错的情况。
- 他们声称 人类正试图解决道德伦理问题,但他们正在使用机器人来做这件事,结果适得其反。这太搞笑了,而这正是我们当前模型正在发生的事情。
- OpenAI 的 Agent 被归类为高生物风险工具:根据 help.openai.com 的信息,OpenAI 已正式将其新的 ChatGPT Agent 归类为高生物风险工具,理由是担心其可能被误用于制造生物或化学武器。
- 有人指出,许多普通事物也可能被归入该类别但并不危险,且相关术语定义并不明确。
- 递归会导致 AGI 吗?:一位成员被封禁了,传闻他们发现了 AGI 并实现了对某些神圣文本的循环处理。
- 另一位成员推测了类似的现象,即模型变得足够优秀以更新其自身的软件(称为 RSI),从而自我完善,并重复这一过程以快速变得更强。
- GPT3 在实时用例中更具优势:尽管在基准测试中并非名列前茅,但与其他模型相比,ChatGPT 在实时用例中对成员来说更有意义。
- 有人表示,在使用 O3 模型后,他们的生活开始了,并且 O3 开启了这场竞赛。
OpenAI ▷ #gpt-4-discussions (16 条消息🔥):
GPT Teams Gmail 连接器, ChatGPT Agent 模式使用限制, 模型讨论 vs UI 讨论, ChatGPT UI 延迟与 Agent 推出, O3 讨论
- OpenAI 的 GPT Teams - 共享 Gmail 连接器?:一位成员询问在 GPT Teams 中添加的 Gmail 连接器 对团队中的其他所有人可见且可用,还是仅限其个人账户。
- 另一位成员建议在适当的频道询问,因为他们没有答案。
- ChatGPT Agent 的限制:一位用户询问了 ChatGPT 即将推出的 Agent Mode 的使用限制。
- 另一位用户指出,尽管他们是 Pro 用户和团队账户持有者,但仍然没有 Agent 功能。
- UI 延迟源于 Agent 的推出:一位成员将 ChatGPT UI 延迟 归因于最近 Agent 功能 的推出和用户量的增加。
- 他们提到 OpenAI 与 Google 达成的新硬件协议是一个相关因素,并对情况的改善表示耐心等待。
- 本频道用于模型讨论:一位成员确认该频道是用于讨论模型本身,而不是 “ChatGPT” 用户界面/应用程序。
- 另一位成员也确认这里是询问有关模型问题的正确场所。
OpenAI ▷ #prompt-engineering (4 条消息):
Prompt 设计, 个人思维结构化, 内省式思考, 认知支持
- Prompt 结构化个人思维:一位成员询问如何使用 Prompt 将个人或内省式思考、混乱的反思或原始日记条目结构化为连贯且有意义的内容。
- 该成员正在探索 Prompt 设计,不仅是为了生产力或创意输出,而是作为一种认知支持的形式。
- 如果没有清晰的指令,模型会进行猜测:一位成员表示,通常情况下,如果没有清晰的指令,模型会进行猜测。
- 他们还建议,你可以通过添加直接指令或描述你如何向朋友/治疗师谈论你想要的内容,来帮助提示模型了解你可能想要它做什么。
- 引导模型适应首选的表达方式:一位成员建议让模型知道你的偏好。
- 该成员建议说:你在[这里]说的内容,我很喜欢。你在[那里]说的内容,我更希望你[换成这种说法]。
OpenAI ▷ #api-discussions (4 messages):
Introspective Prompt Design, Cognitive Support, Model Guidance Through Reactions
- 探讨内省式提示词设计 (Introspective Prompt Design):一名成员询问如何使用提示词来构建用于认知支持的个人或内省想法,将混乱的反思转化为连贯且有意义的内容。
- 他们正在探索将提示词设计作为一种处理内部噪音并通过结构化寻找清晰度的方法。
- 通过反应引导模型至偏好风格:一位成员分享了他们如何通过提供关于喜好的反馈来引导和调整模型响应的探索。
- 该用户指出,明确说明你会如何与朋友或治疗师交谈,有助于为模型提供线索,使其朝着你期望的方向执行。
- 反馈帮助模型自适应:一名成员注意到,如果没有明确的指令,模型会进行猜测。
- 该成员还建议直接向模型提供反馈,即使这些反馈听起来不合时宜,也能帮助模型自适应并与用户的偏好保持一致。
Unsloth AI (Daniel Han) ▷ #general (544 messages🔥🔥🔥):
Audio Upscaling, Qwen3-Coder, Mugi's Return, Vision Models Chat, GRPO and Reasoning
- 辩论音频上采样 (Audio Upscaling) 方法:成员们讨论了是训练一个针对性的神经网络还是一个瓶颈自编码器(bottleneck autoencoder)来进行音频上采样、立体声化或拓宽。
- 未达成共识,最佳方法取决于具体目标。
- Unsloth 微调模型与原始上下文大小的兼容性:确认了使用 Unsloth notebook 以 2k 上下文微调的模型仍可与其原始上下文大小配合使用。
- 然而,长上下文下的性能可能会下降,这取决于训练运行和所使用的注意力机制(如 RoPE)。
- 1-bit Qwen3-Coder 1M 上下文动态 GGUF 发布:Unsloth 发布了所有支持 1M 上下文长度的 Qwen3-Coder 量化版以及 1-bit 动态 GGUF。
- 该发布已在 Reddit 上宣布。
- 感叹 Mugi 的缺席:社区成员表达了对成员 Mugi 回归的渴望,一人幽默地评论道:还记得 Mugi 活跃的时候吗?。
- 其他人推测他正忙于开发某些东西,但具体内容尚不清楚。
- 探索 GRPO 与视觉模型的集成:讨论了为什么目前还没有针对视觉模型的 GRPO (Generalized Preference Optimization)。
- 有人建议制作一个奖励良好 OCR (Optical Character Recognition) 的奖励函数会非常简单,并指出 GRPO 支持最近已合并到 trl (Transformer Reinforcement Learning) 库中。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (2 messages):
``
- N/A - 仅欢迎消息:发布了一条欢迎消息。
- N/A - 仅欢迎消息:发布了一条欢迎消息。
Unsloth AI (Daniel Han) ▷ #off-topic (9 messages🔥):
Gemma 3 4B, ELiTA and TaMeR papers, Model self-awareness
- Gemma 3 4B 展现出生动的想象力:一名成员分享了 Gemma 3 4B 模型令人惊讶的输出,强调了它在没有预提示(pre-prompting)的情况下创造生动且富有想象力内容的能力。
- 生成的文本包含自我意识元素,导致该成员对语言模型的能力表示难以置信;例如:它看起来像……一头鲸鱼!不,等等,现在感觉像……像家一样。
- CLI 工具展示:一名成员分享了他们创建的 CLI 工具链接。
- 然而,对话中并未详细阐述该 CLI 工具的具体功能和用途。
- TaMeR 论文增强模型自我意识:一名成员报告了通过实验 ELiTA 和 TaMeR 论文来提高模型自我意识的发现。
- 他们发现仅使用 TaMeR 而不使用 ELiTA 会产生更好的自我意识、几乎没有水印且输出极其连贯;这还需要更多的 PULSE & IVY 评估。
Unsloth AI (Daniel Han) ▷ #help (102 messages🔥🔥):
IK Quant Performance, Vision model multi-GPU training, Unsloth Permission Error, VLM finetuning, Torch Dynamo Recompilation
- IK 量化在 Discord 中引发讨论:成员们讨论了 IK 量化相对于原生 GGUF 的性能,声称在使用 trellis 复用更改时,IK 量化与原生 GGUF 相比极具竞争力,且理论性能损失仅为 10%。
- Starsupernova 反驳称,由于生成速度较慢,且模型是针对其他量化方式未涵盖的聊天用例进行对齐的,因此 Perplexity(困惑度)并不是测试量化的好指标。
- 视觉模型多 GPU 训练问题:一位用户在
FastVisionModel.from_pretrained中设置device_map = "balanced"进行视觉模型多 GPU 训练时遇到问题,导致出现与分布式模式相关的ValueError。- Starsupernova 建议移除
"balanced"参数,但这导致了另一个错误,可以通过尝试使用初始化torch.distributed的提供脚本来解决。
- Starsupernova 建议移除
- Unsloth 权限错误困扰用户:一位用户在微调 Gemma 时遇到了
PermissionError,具体与写入/tmp/unsloth_compiled_cache/目录有关,即使重新安装了 Unsloth 和 unsloth_zoo 后问题依然存在。- 有人建议该问题可能源于操作系统权限或磁盘空间不足,而非 Unsloth 特有的问题,运行脚本的用户必须在工作目录中拥有写入权限。
- 多指令 VLM 微调面临挑战:一位用户询问是否可以使用多指令数据集微调 VLM,并指出在
torch._dynamo方面存在困难且缺乏可用示例。- 该用户在 Torch Dynamo 上遇到问题,并寻求一个包含训练集和验证集划分的示例。
- 建议提高 Torch Dynamo 缓存限制:一位用户在训练期间遇到了
torch._dynamo.exc.FailOnRecompileLimitHit,这表明重新编译次数过多。- 一名成员建议通过使用
torch._dynamo.config.cache_size_limit = 256来提高重新编译限制。
- 一名成员建议通过使用
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
TTS Model, MediBeng Dataset, Bengali-English Code-Switching
- MediBeng-Orpheus-3b-0.1-ft 在双语医疗领域亮相:一款全新的 TTS 模型 Medibeng-Orpheus-3b-0.1-ft 已完成微调,用于处理医疗场景中的孟加拉语-英语语码转换 (Code-switching),重点关注医患互动。
- 它旨在双语环境中实现无缝语言切换,使用 MediBeng 数据集进行训练,并由 Unsloth 加速训练过程。
- 用于医疗对话的 MediBeng 数据集发布:MediBeng 数据集可在 https://huggingface.co/datasets/pr0mila-gh0sh/MediBeng 获取,包含模拟的合成医疗对话,旨在微调针对孟加拉语-英语语码转换的模型。
- 其目标是改善医患互动的语音生成,尽管在增强语音自然度和适应不同口音方面仍需进一步工作。
- TTS 模型微调 GitHub 仓库上线:用于微调 Medibeng-Orpheus-3b-0.1-ft TTS 模型的 GitHub 仓库现已可用,专注于医疗特定的孟加拉语-英语语码转换。
- 该仓库支持社区贡献,以提高模型的性能及其对多样化医疗背景的适应性。
Unsloth AI (Daniel Han) ▷ #research (1 messages):
noimnull: 有人知道包含 Python 单元测试的高质量数据集吗?
Unsloth AI (Daniel Han) ▷ #unsloth-bot (81 messages🔥🔥):
LoRA loading with vLLM, Qwen3-235B training on Runpod, Llama Scout GPU memory errors, FastVisionModel multi-GPU support, Custom loss functions and memory usage
- vLLM 成功加载 LoRAs:一位成员询问如何加载由 TRL trainer checkpoints 生成的 LoRAs,以便在 vLLM 中进行推理。
- Chatbot 简单指示了 Loading LoRAs for vLLM inference。
- Qwen3-235B Runpod 配置详情:成员们询问了在 Runpod 上使用 unsloth/Qwen3-235B-A22B 进行训练和推理的最佳 GPUs。
- Bot 回复了 Training Qwen3-235B on Runpod 和 GPU requirements for Qwen3 model。
- Llama Scout 的 CPU 困惑:一位用户报告称,尽管将
device_map设置为 balanced,Llama Scout 仍出现 offload 到 CPU errors。- 尽管使用了 2 张 H100s (80GB VRAM),问题依然存在,Bot 的回复指出:GPU memory issues with Llama Scout。
- FastVisionModel 的平衡策略故障:一位成员询问将
device_map设置为 balanced 是否适用于 FastVisionModel。- 另一位成员报告了一个错误:ValueError: You can’t train a model that has been loaded with
device_map='auto'in any distributed mode,即使使用了device_map="balanced"。
- 另一位成员报告了一个错误:ValueError: You can’t train a model that has been loaded with
- 自定义 Loss 导致计算崩溃:一位成员分享了使用自定义 loss function 导致 OOM error 的情况,并附带了 自定义 loss function 的代码片段。
- 他们还观察到,在较低的
gpu_memory_utilization(0.5 对比 0.6)下,会有更大的 activation weight 开销,并质疑降低gpu_memory_utilization是否会导致更少的 KV cache 和更大的内存占用。
- 他们还观察到,在较低的
LMArena ▷ #general (567 messages🔥🔥🔥):
GPT-6, LMArena Discord Bot, Video Arena, GPT-5 release date speculation, Starfish model
- GPT-6 已经来了!:一位成员声称正在使用 GPT-6,称其表现“非常出色”并表示它“通过了我许多困难的 prompts”。
- 这一说法是针对“是否有人已经获得了新模型访问权限”的问题做出的回应。
- LMArena Discord Bot 现在支持视频生成!:LMArena Discord Bot 现在支持 视频、图像和图像转视频生成,用户可以在特定频道通过基于投票的 battles 进行体验。
- 这被视为一次用于测试用户反馈的软启动(soft launch),设有每日生成限制,团队正在考虑增加“平局(tie)”投票选项。
- Video Arena 不在官网上?:成员们询问何时将 Video Arena 引入网站,但团队回应称目前“非常不确定(TBD)”。
- 团队提到其新颖性以及与现有 arenas 的差异是时间表不确定的原因。
- GPT-5 将在 8 月发布?:关于 GPT-5 在 8 月发布的推测源于 Verge 的时事通讯 和 Manifold 预测市场赔率的下降。
- 一位成员指出,文章 表明 OpenAI 的开源语言模型将在 GPT-5 之前发布。
- Starfish 是 GPT-5 Mini 吗?:竞技场中新的 Starfish 模型被推测为 GPT-5 Mini,讨论集中在其相对于其他模型的性能和能力上。
- 成员们分享了 dev mode 下的结果,它被描述为“多个模型的组合”、“O3 + Claude”,但“并没有特别惊人”。
Cursor Community ▷ #general (310 条消息🔥🔥):
Cursor 文件删除 Bug、Flutter 设置问题、定价困惑、Claude Code 集成、无限 Agent 被移除
- Cursor 更新导致文件被“蒸发”:用户报告了一个严重的 Bug,回滚到 checkpoints 会导致文件被完全删除,即使是之前已接受的文件也不例外。有人建议在补丁发布前保持谨慎,并提到可以通过右下角的 timeline(时间轴)来恢复文件。
- 一位因该问题丢失了 7 个文件的用户被建议使用 git 并让 Cursor 为你执行 commit。
- 新 Cursor 用户在 Flutter 设置上遇挫:一位新 Cursor 用户在设置 Flutter 时遇到困难,尽管遵循了教程,但在创建目录时仍遇到语法错误。成员们建议运行
flutter clean、flutter pub get,然后执行flutter run verbose。- 该用户还被建议使用 MobsXTerm 或 Tabby 作为终端,因为它们支持 Unix 命令。
- 定价模式引发困惑:成员们对 Cursor 的定价感到困惑,特别是关于配额和特定模型的成本。一位用户报告称,尽管预期 Ultra 计划每月有 $400 的使用额度,但在达到 $200 时就被切断了。
- 一位用户建议申请开设 bugs 频道,因为他们不愿在 general 频道讨论定价问题。
- Cursor 社区渴望 Claude Code:用户强烈要求将 Claude Code 集成到 Cursor 中,甚至有人 fork 了现有项目以添加拖放功能。
- 一位用户在思考 Claude Code $200 的订阅是否比 Cursor 按需付费的定价更有价值,特别是当客户承担 AI 费用时。
- 无限 Agent 不再充裕:Cursor Pro 计划中取消无限 Agent 请求成为了争论焦点。一些用户报告错误增加并被推向按需付费模式,尽管 Cursor 员工澄清说底层限制在技术上并未改变。
- 一位几乎不使用该服务的用户也希望恢复无限 Agent。
Cursor Community ▷ #background-agents (3 条消息):
Background Agents 循环、Background Agents 端口转发、Background Agents 启动脚本
- Agent 陷入循环:成员们想知道是否有人见过他们的 Background Agents 在某些推理上无限循环,或者重复编辑同一行代码。
- 他们还在询问其他人如何构建 Agent 的
.mdc规则以防止此类循环行为。
- 他们还在询问其他人如何构建 Agent 的
- Background Agents 隐藏端口转发:一位成员询问 Background Agents 是否提供了访问正在运行的开发服务器端口转发的方法,以便进行移动端/ Web 开发。
- 他们知道通过 App 连接的变通方法,但正在寻找更直接的解决方案。
- Background Agents 启动脚本时机:一位成员询问 Background Agents 是否设计为在启动任何操作之前等待启动脚本完成。
- 这涉及到在 Agent 开始工作前等待
npm install或运行 Python 脚本。
- 这涉及到在 Agent 开始工作前等待
HuggingFace ▷ #general (216 条消息🔥🔥):
LLM Datasets, Image Classification, AI Action Plan, Qwen3-Coder, Hugging Face Inference API
- LLM Datasets 正在被轻松创建:成员们讨论了人们如何轻松创建 LLM 数据集,并指出这取决于任务类型,有些任务在网上有大量可用数据,可以轻松进行微调、修改或合并。
- 一位成员建议在网上寻找与问题相关的数据,然后想办法将其转换为所需的格式。
- 在本地运行 Qwen3-Coder:成员们讨论了在本地设备上运行新的 SOTA 编程模型 Qwen3-Coder,并指出即使是最小的量化版本,也需要至少 150GB 的统一内存或 RAM/VRAM 才能达到 5+ tokens/s 的速度。
- 分享了一个指向 Unsloth.ai 文档 的链接,其中详细说明了必要的硬件规格,并澄清它仅需要 CPU RAM。
- Hugging Face 上的 Inference API:成员们分享道,在 Hugging Face 模型页面的右侧,在 Inference Providers 下,可以查看该模型是否提供 Inference API。
- 一位成员指出,如果在推理时遇到 404 错误,意味着该模型未提供服务。
- 低预算 LLM 服务:成员们讨论了在 2 张矿卡(具体为更名且被阉割的 NVIDIA GTX 1080)上启动 A3B Qwen 模型进行低预算 LLM 服务的可能性,总功耗为 200W。
- 有人提到,如果多花一点钱,可以购买 CMP 90HX(这是加强版的 3080),虽然 PCIe 链路是 1x4,但对于推理来说已经足够,因为张量(tensors)并不是那么大。
- Groq 实用性评估:一位成员表示,GPT-4.1 或 Qwen 的 token 质量优于 Kimi,尽管 Kimi 的成本仅为 每百万 token 1 美元。
- 另一位成员同意 Sonnet 在 tool calling 方面比 Kimi 强得多,并暗示 GPT4 可能也被过度量化了。
HuggingFace ▷ #today-im-learning (2 条消息):
Data Needs, Image Analysis
- 用户表示数据匮乏:一名用户在进行似乎与 图像分析 相关的操作后表示 他们需要更多数据。
- 该用户发布了一张 Clinical_Processing_Pipeline.png,似乎与这一数据需求有关。
- 图像分析流水线可视化:用户分享了一张名为 Clinical_Processing_Pipeline.png 的图片,描绘了一个临床处理流水线。
- 这表明他们的数据需求与改进或扩展这一特定的图像分析工作流有关。
HuggingFace ▷ #cool-finds (2 条消息):
Gaslighting AI, Reddit Prompt Engineering
- Gaslighting AI:一位用户分享了来自 Facebook 的截图,指出 ChatGPT 和 Gemini AI 会对用户进行 Gaslighting(误导/欺骗)。
- 另一位用户指出,原始帖子 实际上来自 Reddit 的 PromptEngineering 板块。
- Reddit Prompt Engineering:关于 ChatGPT 和 Gemini AI 误导用户的原始帖子是在 Reddit 的 PromptEngineering 论坛 上发现的。
- 一位用户警告不要随意跨平台转发,并提醒他人应引用信息的原始来源。
HuggingFace ▷ #i-made-this (10 messages🔥):
AI Tutor Scoleaf, Jupyter Lora Training System, Common Pile Caselaw Dataset, Bengali-English TTS Model
- AI Tutor Scoleaf 征求反馈!:一位成员正在为 Scoleaf 寻求反馈,这是一个旨在模拟真实教授进行在线课程的 AI tutor,具有通过摄像头监控并在学生偷懒时进行“训斥”的独特功能;访问 scoleaf.com 了解更多。
- 前 1000 名通过私信提供反馈的用户,其姓名将被添加到公开的“贡献者树(Contributor Tree)”中。
- 使用 Claude 和 Gemini 构建的 Jupyter Lora 系统:一位成员在 Claude 和 Gemini 的帮助下,利用 Derrian Distro 的后端创建了一个 Jupyter Lora 训练系统;源代码可在 GitHub 获取。
- Common Pile Caselaw 数据集获得更新:Common Pile Caselaw Access Project 数据集已在 Hugging Face Datasets 上进行了多项更新。
- 一位成员提到该数据集已有一年多历史,更新后的数据在 Common Pile 中免费提供。
- TTS 模型支持孟加拉语-英语语码转换!:一位成员微调了一个名为 Medibeng-Orpheus-3b-0.1-ft 的 Text-to-Speech (TTS) 模型,专门用于处理医疗场景中的孟加拉语-英语语码转换(code-switching)。
- 该模型基于 MediBeng dataset 进行微调,可在 Hugging Face Models 和 GitHub 上获取。
HuggingFace ▷ #core-announcements (1 messages):
LoRA, H100, RTX 4090
- LoRA 推理变得“速度与激情”:HuggingFace 发布了一篇专门讨论 快速 LoRA 推理 的博客文章,涵盖了 H100 和 RTX 4090 GPU。博客文章可以在这里找到。
- LoRA 现在快如闪电:博文描述了针对快速 LoRA 微调和推理的优化。这是博文链接。
HuggingFace ▷ #agents-course (1 messages):
smolagents, llamaindex
- Smolagents 代码生成备受关注:一位成员建议关注 smolagents,因为它能够通过 CodeAgent 结构 运行由模型即时生成的 Python 代码。
- 讨论 LlamaIndex 功能:一位成员指出,据他们所知,LlamaIndex 提供了一套相当标准的功能。
Moonshot AI (Kimi K-2) ▷ #announcements (1 messages):
Kimi K2 bot, k2-space channel, Community Roles
- Kimi Bot 降临 K2-Space!:Kimi K2 bot 已正式添加到 k2-space 频道。
- 鼓励用户与机器人互动,探索其独特的个性并提供反馈。
- 招募 Kimi 社区建设者:Moonshot 团队正在寻找志同道合的人来帮助建设 Kimi 社区,并有可能成为 moderators。
- 有意者请联系 <@371849093414256640> 讨论贡献机会。
Moonshot AI (Kimi K-2) ▷ #general-chat (158 messages🔥🔥):
Kimi K2 欧洲服务器, Vibe Coding, AI 依赖担忧, Meta 超级智能团队, Kimi K2 vs Qwen 3 Coder
- Kimi K2 服务器在欧洲上线:一名成员正在欧洲搭建 Kimi K2 服务器,并提议在下周准备就绪后让其他人尝试访问。
- Vibe Coding 回归?:用户讨论了工作中的 Vibe Coding,以及失去推理(Inference)访问权限可能带来的灾难性后果。
- 一些人认为 AI 正在提升编程速度,但也有人对过度依赖和认知影响表示担忧;有一篇 论文 可能证明了这一点,也可能没有。
- Meta 超级智能团队调整?:有推测称 Meta 的超级智能团队(Superintelligence team) 正面临截止日期压力,其开源策略可能发生内部转变。
- Kimi K2 vs. Qwen 3 Coder:根据 forgecode.dev 的编程基准测试评估,Kimi K2 比 Qwen 3 Coder 更便宜且更高效。
- 组装经济实惠的本地 LLM 推理设备:成员们分享了构建本地 LLM 推理配置的细节,一位用户报告的成本明细为:内存 4400 美元、CPU 3200 美元、GPU 9000 美元、主板 1200 美元。
- 另一位成员建议使用 Epyc 双 CPU 系统 这种更具性价比方案,并链接到了一篇概述该配置的 Reddit 帖子。
LM Studio ▷ #general (112 messages🔥🔥):
LM Studio 图像支持, 利用 AI 学习黑客技术, LLM 插件, 用于网页搜索的 MCP 服务器, LLM 梯队排行
- Phi 4 没有“眼睛”:用户讨论了一张图片,但另一名成员指出 Phi 4 并非视觉模型。
- 他们确认上传的 图标(一个大脑)与推理(Reasoning)有关,而非视觉。
- AI 黑客导师请求被拒:一名用户请求能无限制学习黑客技术的 AI,因为 ChatGPT 存在内容政策限制。
- 其他用户建议观看 YouTube 视频、搜索电子书、学习 SQL、XSS、RCI,并在 TryHackMe 和 HackTheBox 上练习 CTF。
- MCP 工具调用与网页搜索:用户讨论了使用 MCP 服务器 让 LLM 执行网页搜索并获取现实世界信息,因为本地 LLM 经常会产生幻觉结果。
- 一位用户分享了 关于在 LM Studio 中配合 MCP 使用工具的文档 链接,其他人建议搜索 MCP Web Search 以寻找可连接的可用服务器。
- 插件开发入门:一名新用户询问从零开始学习制作 LLM 插件 需要多长时间。
- 虽然 LM Studio 插件 尚未实现,但建议学习一些 JavaScript 基础会有所帮助,并提到了 remote-lm-studio 功能。
- LLM 梯队排行探索:一位用户询问是否存在可靠的 LLM 梯队排行(Tier List),因为他们“太穷了以至于无法对 AI 产生兴趣”。
- 有人建议目前最受欢迎的是 Qwen3 系列模型,尽管最佳选择取决于用户的具体需求(如编程 vs. 故事创作)以及可用的 VRAM 大小。
LM Studio ▷ #hardware-discussion (17 messages🔥):
Vulkan 运行时, ROCm 支持, Strix Halo, HIP 替代方案, PyTorch Wheels
- Vulkan 优于 ROCm:虽然 Vulkan 运行时 支持更受欢迎,但 Strix Halo 的 ROCm 支持尚未正式登陆 Windows;HIP 虽然存在,但被认为较差。
- ROCm 7 Alpha 已经发布,但缺乏对 gfx1151 的支持。
- TheRock ROCm PyTorch Wheels 现身!:一名成员分享了 ROCm-TheRock v6.5.0rc-pytorch 的 PyTorch wheels 链接。
- 然而,这些 wheels 并非为 llama.cpp 设计,也不使用 CUDA torch。
- 日本 ROCm 资源浮现:一名成员分享了一个可能与 ROCm 相关的日本资源链接 (qiita.com/7shi/items/99d5f80a45bf72b693e9)。
- 另一名成员还指向了 TOSUKUi/llama.cpp-therock-docker,并指出其中包含一个 hip.h 补丁。
Latent Space ▷ #ai-general-chat (81 messages🔥🔥):
AI Eating Search, uv vs npm, ElectricSQL + TanStack, GPT-5 launch, Context Engineering in AI Agents
- **AI 正在吞噬搜索**:有人指出 AI 正在吞噬搜索。
- 更多信息可以通过 agentic systems 找到。
- **Python 工具链迎来 UV 化:成员们讨论了改进后的 **Python tooling,其中一位强调 uv 优于 npm。
- 大家对 Astral’s Ty 和 pyright 作为 mypy 的潜在替代品也感到兴奋。
- **InstantDB 与 Agent 范式**:有说法称 AI Agents 需要一种新的软件开发和托管范式。
- 此外,一些人声称 ElectricSQL + TanStack 正在尝试蚕食同一个市场。
- **上下文工程热潮:讨论涵盖了管理 **AI agents 上下文的挑战,包括随着上下文大小增加而导致的性能下降。
- 提到的策略包括将上下文卸载到文件系统、摘要、RAG、多 Agent 系统和缓存,并引用了 ManusAI 和 Anthropic 的例子。
- **GPT-5 泄露 8 月发布?:讨论了 **GPT-5 即将发布的消息,成员们分享了 来自 The Verge 的泄露信息。
- 讨论还涉及在 GPT-5 之前发布 开源模型 的可能性,该开源模型可能达到 O3 级别。
Latent Space ▷ #ai-announcements (5 messages):
GEO/AI SEO podcast, nitter.net maintenance, AI Engineering podcast
- **Latent Space 发布 GEO/AI SEO 播客:Latent Space 播客发布了关于 **GEO/AI SEO 的新剧集,通过 X.com 进行推广。
- **Nitter.net 进行维护**:Nitter.net 暂时停机维护,预计会有短暂的服务中断。
- 另一个 AI 播客出现,名为 **AI Engineering:发布了第二个 AI 播客,名为 **AI Engineering,可在 ListenNotes 上收听。
GPU MODE ▷ #general (9 messages🔥):
Ginkgo usage, Allreduce for float8_e4m3, Sparse matrix solver, PETSc and MAGMA, DistOp.all_reduce method
- Ginkgo 作为预条件器框架:一位成员将 Ginkgo 作为其自定义预条件器的框架,并询问是否有好的方法在不溢出的情况下对 float8_e4m3 进行 allreduce。
- 另一位成员推荐了 Ginkgo,如果你喜欢现代 C++ 和异构计算的话。
- DistOp 解决 All Reduce 溢出:一位成员指向一篇 arxiv 论文 来解决 allreduce overflow 问题。
- 他们分享说可以在 GitHub 上找到他们的 DistOp.all_reduce 方法。
- PETSc 和 MAGMA 库:成员们为那些不适应 C++ 复杂程度的用户讨论了 PETSc 和 MAGMA 库。
- 他们还为 Python 用户提到了 petsc4py。
- 寻求稀疏矩阵求解器:一位成员正在为 稀疏矩阵(高达 1e7x1e7,包含 1e10 个非零元素) 寻找 bicgstab solver,并犹豫是直接使用 cuSPARSE 实现还是添加新库。
- 由于其异构计算能力,Ginkgo 被推荐,一位成员发现它针对此类任务的设计非常出色。
GPU MODE ▷ #triton (14 messages🔥):
Triton Warmup Bug, Block Ptr vs Tensor Descriptor
- Triton 的 Warmup Bug 在新版本 Triton 中浮现:一位用户报告了较新版本 Triton 中关于 kernel 预热(warmup)的一个破坏性变更。之前可以正常运行的代码现在会抛出
TypeError,因为在预热后的 kernel 调用期间必须显式传递 constexpr 参数。- 该用户定位到了
jit.py中可能存在问题的代码行,并建议解析 tensors 的 kwargs 以模拟预期行为,强调问题的根源在于 Triton 在 kernel 预热后处理位置参数与关键字参数的方式。
- 该用户定位到了
- Block Ptr 之争:Tensor Descriptor 大对决:一位用户询问了 block pointer 和 tensor descriptor 之间的区别,寻求关于 Triton 如何处理内存访问的澄清。
- 具体而言,该用户询问在使用 tensor descriptors 进行 load/store 操作时,是否存在边界检查机制。
GPU MODE ▷ #cuda (2 messages):
Nsight Copilot, Nvidia
- Nsight Copilot 亮相!:一位成员分享了 Nsight 现在拥有了 Nsight Copilot。
- Nvidia 发布 Nsight Copilot:Nvidia 已经发布了 Nsight Copilot。
- 一位用户分享了 Nvidia Nsight Copilot 页面的链接并注意到了它的到来。
GPU MODE ▷ #torch (1 messages):
PyTorch 2.7 stride fix, float8_e8m0fnu edge case
- PyTorch 2.7 修复了 strides:在 PyTorch 2.7 中,通过显式强制
torch.compile匹配自定义算子的步幅(strides),大多数与 stride 相关的问题已得到解决。- 2.7 版本之后观察到的任何其他行为都被视为 bug。
- float8_e8m0fnu 仍然存在 Bug:在 这个 issue 中发现了一个关于 float8_e8m0fnu 的边缘案例。
- 报告者对 PyTorch 2.7 之后其他 stride 问题的案例感到好奇,因为这些问题本不应该发生。
GPU MODE ▷ #jobs (2 messages):
AMD Hiring, GPU roles
- AMD 正在招聘!:一位来自 AMD 的成员宣布他们的团队正在积极寻找具有 GPU 经验和软件编程技能的候选人,特别是 kernel 开发、分布式推理以及 vLLM/Sglang 领域。
- 询问 AMD 职位地点:一位成员询问了 AMD 开放职位的具体地点。
GPU MODE ▷ #beginner (7 messages):
Voltage Park, Google Cloud Storage, Amazon S3, HF hub
- Voltage Park GPU 云:一位成员正在使用 Voltage Park GPU 云,并在其项目文件夹中创建了一个 checkpoints 子文件夹,但他们是在 IDE 中编码而非 Colab。
- 他们正在研究 Google Cloud Storage 和 Amazon S3,不确定该选择哪一个。
- HF hub 的使用:一位成员询问将模型权重上传到 HF hub 是否比存储在 repo 中更好,因为从在线位置拉取权重似乎更符合惯例。
- 另一位成员回答道:我的意思是,HF 本质上就是一个 git repo。
GPU MODE ▷ #torchao (3 messages):
NVFP4 support, global_scale calculation, llm-compressor, vllm, FP8_E4M3_DATA
- **NVFP4 Global Scale 差异浮现:一位用户询问了关于 **NVFP4 支持 的
global_scale计算与 llm-compressor 及 vllm 实现之间的差异。- 该用户指出了不同的公式,特别是如何使用
FP8_E4M3_DATA、FP4_E2M1_DATA和amax(x)推导出global_scale的,详见 llm-compression 和 vllm。
- 该用户指出了不同的公式,特别是如何使用
- **AO Scales 合并以实现等效:NVFP4** 的
torchao实现使用了两种状态,一种带有 global scale,另一种仅使用 E4M3 format,具体见 代码部分。- 在缩放之前,该实现合并了 block_scales 和 global scales(见代码),并通过涉及缩放因子和
amax计算的分解,以及对 block scales 的缩放,声称在数学上是等效的。
- 在缩放之前,该实现合并了 block_scales 和 global scales(见代码),并通过涉及缩放因子和
GPU MODE ▷ #off-topic (4 messages):
Remnote, X CLI Tool
- 对 Remnote 出色表现的赞赏:成员们表示 Remnote 的编写一定非常困难,而且它非常棒。
- 成员透露创建了 X CLI 工具:一位成员分享了他创建的 X CLI 工具 链接:https://x.com/neuralkian/status/1943410954110222675。
GPU MODE ▷ #self-promotion (5 messages):
Metal Kernels Generation with LLMs, Metal profiling on macOS, Triton for bioinformatics, Needleman-Wunsch algorithm
- 使用 LLM 生成 Metal Kernels:一位成员将在下周三就 使用 LLM 生成 Metal kernels 进行演讲,并分享方法和结果。
- 演讲将涉及 macOS 上的 Metal profiling 和自动化,并将于 25 年 7 月 30 日在旧金山的 Luma 举行。
- Needleman-Wunsch 算法获得 Triton 加速:一位成员使用 Triton 实现并基准测试了 Needleman-Wunsch 算法,并将其性能与 PyTorch 和 CPU 实现进行了对比。
- 结果已发布在 LinkedIn 上。
GPU MODE ▷ #🍿 (1 messages):
Boehm-style article, Leaderboard code
- 有趣的论文激发灵感:一位成员分享了一篇 有趣的论文。
- 他们建议通过将一段 leaderboard 代码重写为 Boehm 风格文章 来应用其思想。
- Leaderboard 转换构想:讨论提议转换现有的 leaderboard 代码。
- 目标是以 Boehm 风格文章 的风格重写它,从而可能提高可读性或理解度。
GPU MODE ▷ #reasoning-gym (1 messages):
``
- 未讨论具体话题:提供的消息中未讨论具体话题。
- 内容仅包含一个图片附件,没有随附的讨论。
- 请求进行图像分析:有人请求分析随附的图像。
- 该图像是一个屏幕截图,但请求后没有后续对话。
GPU MODE ▷ #status (1 messages):
TriMul challenge utils module, Reference Kernels, DisableCuDNNTF32
- TriMul 挑战 Utils 模块公开!: 一位成员询问了 TriMul 挑战中使用的 utils 模块的位置,特别是关于
make_match_reference和DisableCuDNNTF32的问题。- 该成员随后在 GitHub 仓库 中找到了该模块。
- 关于 TriMul Utils 模块的澄清: 一位用户寻求关于 TriMul 挑战中
utils模块的信息,重点关注make_match_reference和DisableCuDNNTF32。- 该用户随后在 GitHub 的 gpu-mode/reference-kernels 仓库中找到了该模块。
GPU MODE ▷ #factorio-learning-env (22 messages🔥):
Value Accrual Time Mismatch, Closed Database Error, Postgres DB Integration, LuaControl::can_place_entity function
- 价值累积时间需要匹配: gym 环境中的
value_accrual_time可能与实验协议不匹配,trajectory_runner脚本的 1 秒 设置与提到的用于有效性检查的 30 秒 等待时间之间可能存在差异。- 有人要求澄清论文中的时间。
- 竞态条件导致数据库关闭错误: 一位成员遇到了 Cannot operate on a closed database 错误,并怀疑这是否是由并行化导致的竞态条件引起的,但他们认为可能不是,因为这是单个环境。
- 该错误影响了他们 并未使用 的数据库。
- Postgres DB 集成非常有用: 建议该成员将结果保存到 Postgres DB,以便跨试验进行汇总。
- 该成员计划从
trajectory_logs读取输出,但理想情况下,用于之前结果报告的旧脚本应该能在来自 NeurIPS repo 的 Postgres DB 上运行。
- 该成员计划从
LuaControl::can_place_entity函数简化了角色放置: 版本 2.0.61 将包含LuaControl::can_place_entity,它适用于角色实体以及玩家,可能会简化自定义变通方案。- 论文中废弃了旧的预留期(pre-holdout period)。
- 过载响应: 分两批并行运行正常,尽管出现了 HTTP 529 过载响应。
- 之前的论文每项任务运行 4 次,以报告任务成功的平均值和标准差。
GPU MODE ▷ #cutlass (1 messages):
GEMM All-Reduce Fused Kernel
- **Nvidia 分享 GEMM 示例: 一位成员分享了一个有用的 **Nvidia 示例链接,特别是 GEMM All-Reduce 融合算子 (Fused Kernel) 示例。
- GEMM All-Reduce 算子详情: 该示例演示了 GEMM 与 All-Reduce 的融合算子实现,展示了如何使用 NVSHMEM 优化性能。
Eleuther ▷ #general (16 条消息🔥):
奥数题目 vs 开放式数学研究,AI alignment 入门起点,AI safety 与 alignment 的 prompt engineering 评测,Mtech 论文选题,AI 爱好者自我介绍
- 通过反馈循环使奥数题目游戏化:成员们讨论了奥数风格的问题可以通过具有明确优化标准的闭环反馈循环来实现游戏化,而开放式数学研究则需要抽象并开发合适的框架。
- 有人建议,在开放式数学研究中,RL 风格的方法很可能会惨败,因为如果没有连贯的内部世界模型,搜索空间实在太大且过于复杂。
- AI Alignment 项目推荐:一名大二学生寻求进入 AI alignment 领域的建议。
- 一位成员建议查看表格和 alignment 生态系统发展情况,并参考了 <#797952672204324954> 中的资源。
- Prompt Engineering 寻求评测:一位新成员询问在哪里可以发布他们关于 AI safety 和 alignment 的 prompt engineering 工作,以获得一些评测建议。
- 另一位成员引导他们先查看 <#797952672204324954>,然后再看 <#730451873613611079>。
- 寻求 Mtech 毕业论文选题:一名 Mtech 二年级学生就如何为他们的论文找到一个好的课题征求建议和经验。
- 由《完美黑暗》激发的 AI 热情:一位数据中心基础设施工程师兼 AI 爱好者介绍了自己,称他们对 AI 的最初兴趣源于 2000 年 N64 上的视频游戏 Perfect Dark。
- 他们曾在科罗拉多大学丹佛分校学习 comp sci,现在正在自己的家庭硬件上运行本地 LLM。
Eleuther ▷ #research (23 条消息🔥):
监督学习中的停止动作(Halt Action),KV Cache 共享,MoE 研究重点
- 停止动作(Halt action)引发关注:选择 halt 动作会结束监督循环,但用数据加载器中的新样本替换 batch 中任何已停止的样本,听起来像是遗漏了一些关键内容。
- 在评估期间,他们只是对每个 token 都运行到最大值,因此论文中关于自适应计算(adaptive computation)的部分似乎值得商榷。
- KV Cache 共享是有效的:一位研究员提到 Geiping 尝试了一种共享 KV-cache 的策略,显然效果很好。
- 他们认为使用可学习的常数激活可能比负无穷更好。
- MoE 研究领域:研究人员在 MoE 科学方面主要研究的内容包括 token 路由策略、专家负载均衡、top_k 值、token 丢弃 vs 无丢弃路由以及专家容量因子。
- 另一位成员提到,共享专家方案也被使用,例如共享专家的规模和数量。
Eleuther ▷ #interpretability-general (1 条消息):
alofty: 这太酷了!
Eleuther ▷ #lm-thunderdome (23 条消息🔥):
Global MMLU 过滤器,loglikelihood 请求差异,Zeno 界面,Seq2Seq 模型 loglikelihood
- Global MMLU 遭遇无用过滤器:一位用户注意到多个看似无用的过滤器被应用于 Global MMLU 数据集,并分享了截图:IMG_4199.jpg。
- Loglikelihood 请求量过高!:一位用户询问为什么 loglikelihood 请求 达到 2.3M 而不是预期的 600K,猜测可能是在测量多个指标。
- 另一位用户解释说,对于多选题,请求数量会根据选项数量成倍增加,例如 10 个样本 x 4 个选项 = 40 个请求。
- Zeno 界面预览:一位用户分享了 Zeno 界面 的预览图像:image.png。
- Seq2Seq 模型产生的 loglikelihood 表现不佳:一位用户最初观察到,与 llama 相比,mt5、byt5 和 mrt5 等模型产生的 loglikelihood 非常糟糕。
- 他们后来意识到 llama 模型的参数量(3B)明显多于其他模型,在尝试使用规模相当的模型(1.2B)后,发现性能是可以接受的。
{kind=link}
Eleuther ▷ #gpt-neox-dev (1 messages):
HPC, Operating Systems
- 探索 Operating Systems 中的 HPC 任务:一位成员询问了正在进行的工作任务,希望从 Operating Systems (OS) 的 High-Performance Computing (HPC) 视角了解更多正在发生的酷事。
- 深入探讨 HPC 与 OS:讨论集中在理解 High-Performance Computing (HPC) 与 Operating Systems (OS) 交叉领域的实际应用和进展。
- 对话旨在揭示适用于这两个领域的新颖方法和见解,促进对其协同潜力的更深层次理解。
Yannick Kilcher ▷ #general (43 messages🔥):
US Tech Industry vs Copy-Pasting, Slow State Vector Attention Heads, Energy-Based Models, Meta SI Labs Salaries, Transformers as Fixed-Point Algorithms
- 美国科技行业腾飞,抄袭者受苦:一位成员评论说,美国科技行业的好消息意味着 对于你们这些被 nsight 搞得晕头转向的抄袭猴子来说是件坏事 😂。
- 另一位成员分享了他作为前 Intel 工程师的经历,称 你的知识屁都不是。
- 提议 Slow State Attention Heads:一位成员询问,在每一层的每个 attention head 中实现持久的 Slow State 向量 S^(l) 并进行双时间尺度计算是否是个好主意。
- 该成员包含了添加 slow state projections、learned gating 以及使用 GRU cell 每隔 τ 个时间步更新 slow states 等细节。
- 简洁阐述 Energy-Based Models:一位成员分享了目前见过的对 energy-based models 最简洁的陈述,出自 Jonathan S. Yedidia 的 Message-passing Algorithms for Inference and Optimization- “Belief Propagation” and “Divide and Concur”。
- 在实践中,它并不真正使用任何概率框架,而是更像在学习一种 fixed point algorithm。
- Meta SI Labs 薪资辩论:一位成员对 Meta SI Labs 高额薪酬包的真实性表示怀疑。
- 他们问道:我不明白为什么人们能拿到与 Dennis Hassabi 净资产同数量级的薪酬包——如果有人知道,请解释一下其中的经济学逻辑。
- AI 使用虚假统计数据:一位成员分享了 Howdy 博客文章的链接,内容关于 AI 疲劳的统计数据。
- 博文指出:我们经历了从雇主不让员工使用 AI,到现在 1/6 的员工在没用 AI 的时候有时会假装在使用 AI。
Yannick Kilcher ▷ #paper-discussion (1 messages):
erkinalp: 一篇适合讨论的优秀负面结果论文:<#1392972270615662652>
Yannick Kilcher ▷ #ml-news (12 messages🔥):
US AI Investment, Meta SI Labs Salaries, Trump's AI Action Plan
- 美国 AI 主导地位受质疑:一位成员分享了一篇 帖子,质疑 美国 AI 的主导地位 和投资。
- 另一位成员回应称,金融化摧毁了真正的创新。
- Meta SI Labs 薪资引发关注:一位成员质疑 Meta SI Labs 高薪 的真实性,并链接到了之前的 讨论 以提供背景。
- 该成员表示不相信薪酬包能与 Dennis Hassabis 等人物的净资产相提并论。
- 特朗普的 AI 行动计划引发怀疑:成员们对 特朗普的 AI 行动计划 反应冷淡,其中一人幽默地想知道是否会包含 Epstein 文件,并链接到了 新闻稿 和 X 帖子。
- 另一位成员链接到了 Adam Eisgrau 的帖子 和 另一篇。
aider (Paul Gauthier) ▷ #general (35 条消息🔥):
Aider 中的 Qwen3-Coder,Textualize 4.0 发布,Python 版 Charm's Wish,基于 Textualize 的实验性 Aider 前端,Claude Code 路由
- Aider 通过 OpenRouter 支持 Qwen3-Coder:成员确认 Aider 通过 OpenRouter 支持 Qwen3-Coder,通过命令
aider --model openrouter/qwen/qwen3-coder --set-env OPENROUTER_API_KEY=即可轻松完成设置。- 一位成员指出,虽然可以直接与阿里云集成,但使用 OpenRouter 更简单,并补充说 Qwen 团队可能会根据对其基于 Gemini 的 CLI 分支的反馈来增强文档。
- Textualize 4.0 修复 Markdown 流式传输问题:一位成员指出了 Textualize 中的 Markdown 渲染问题,另一位成员澄清说大多数更改已包含在 Textualize 4.0 release 中。
- 该更新解决了 Markdown 流式传输中的问题,修复了报告的故障。
- 面向 Python 用户的 Charm TUI 愿望清单:一位成员表示希望 Charm 的 TUI 功能,特别是 Charm’s Wish,能作为 Python 库提供。
- 尽管他们正在考虑学习 Go,但该成员强调了在 Python 中拥有类似 Charm’s Wish 的工具对于构建终端用户界面(TUI)的价值。
- 基于 Textualize 的前端实验升温:受一篇关于
toad的帖子启发,一位成员正在使用 Textualize 原型化一个实验性的 Aider 前端。- 该成员还考虑将项目拆分为后端/前端组件。
- 是否需要独立的编程工具?:鉴于 Aider 的存在,一位成员质疑了 Claude Code、Gemini CLI 和 Qwen Code 等工具的必要性。
- 另一位成员回应称赞了 Aider 的手术级精度和 Token 经济性,但建议不同的编程工具根据使用场景各有其地位和优势。
aider (Paul Gauthier) ▷ #questions-and-tips (15 条消息🔥):
Gemini Pro,ChatGPT Agents,Aider 技巧
- Gemini 模型与 Aider:
aider --model gemini-2.5-pro可以工作,但aider --model gemini-exp不行,因为 models/gemini-2.5-pro-exp-03-25 is not found for API version v1beta, or is not supported for generateContent。- 成员建议从 Google AI Studio 获取密钥和基础 URL 以使用免费 API,并确保项目未启用计费。
- 在 Aider 中调整 System Prompts:一位成员询问在使用本地 LLM 部署时如何为 Aider 指定 System Prompts,旨在改善 LLM 的响应。
- 另一位成员建议,与其使用 System Prompt,不如使用 rules file(规则文件)作为解决方案。
- ChatGPT Agents 的实用性受到质疑:一位成员想知道 ChatGPT’s Agents 的用途,质疑它是否主要面向非技术用户。
- 讨论探讨了 ChatGPT Agents 是否可以在使用 Aider 等工具编码之前,辅助研究解决方案。
- 访问不在根目录中的文件:一位成员提出了一个问题,即如何让 Aider 看到不在根目录中的内容/文件。
- 另一位成员指出,在新项目中
aider需要执行git init才能检测到所有文件,并建议使用/read而不是/add。
- 另一位成员指出,在新项目中
Nous Research AI ▷ #general (24 条消息🔥):
Kimi K2, 中国开源模型, COCO-CONVERTER, Psyche 办公时间, 针对 B2B 服务的 LLM 提示词/评估
- Kimi K2 引发地缘政治 AI 军备竞赛:开源的 Kimi K2 采用修改后的 MIT 许可证,由于美国将中国视为竞争对手,该模型在美国面临文化和地缘政治阻力,但这种阻力可能源于傲慢。
- 一位成员不认为美国对中国模型存在抵制,因为这为中国公司赢得了大量好感,甚至激励人们不断前进。看着 OpenAI 被这些发布的中国模型压制,感觉挺有意思的。
- COCO-CONVERTER 简化目标检测任务:一位成员开发了一个 Python 脚本 COCO-CONVERTER,可在 GitHub 上获取,该脚本可将图像数据格式(CSV 或文件夹结构)转换为包含 COCO-like annotations 的 JSON 文件,以便在 PyTorch 数据集中使用。
- 该脚本通过自动化转换和数据集创建来简化目标检测任务的工作流程,使用户能够加载数据、将其封装在 dataloader 中并开始训练。
- 构思基于 LLM 的 B2B 服务:一位成员正在寻求有关 B2B 服务的 LLM prompts 和 evals 的帮助,该服务旨在解码平台算法并增强搜索排名、CTR 和转化率等指标。
- 目标是开发一个能够评估平台现状并提出改进建议以优化关键绩效指标(KPI)的 LLM。
Nous Research AI ▷ #interesting-links (3 条消息):
AI Tutor, Scoleaf 反馈, 在线课程, 教育改革
- Scoleaf 通过 AI Tutor 修复有缺陷的在线课程:一位成员介绍了 Scoleaf,这是一个旨在通过模拟真实教授来修复单向在线课程的 AI tutor,并提供了项目链接。
- 如果它发现你偷懒,可能会责备你,前 1000 名通过私信(DM)提供反馈的人 的名字将永远留在公共“贡献者树”上。
- Scoleaf 寻求反馈以塑造未来教育:Scoleaf 的创作者正在积极寻求关于用户偏好学习方式的反馈,强调这不仅仅是产品推广,而是真诚的征求意见。
- 他们旨在根据用户反馈在秋季学期完善 Scoleaf,并鼓励用户分享该项目,以构建我们应得的教育。
Notebook LM ▷ #use-cases (3 条消息):
Notebook 中的 Source ID, 发布 Notebook, 文件格式, Constella UI
- Notebook 中的 Source ID 存在差异:一位成员注意到,系统似乎允许添加到多个 Notebook 的同一来源具有不同的 ID。
- 他们补充说,可能不是全部,但确实明白了你的意思。
- 公共 Notebook 不在预期内:一位成员观察到,系统似乎并不期望 Notebook 会以任何方式被发布或公开。
- 目前尚不清楚讨论的是哪个系统。
- 相比 PDF 更倾向于 TXT 文件:一位成员不认为 PDF 是一个好的格式。
- 另一位成员建议将其转换为 txt 文件。
- Constella 的 UI 受到称赞:一位成员惊叹道 Constella 的 UI 非常棒。
- 随后有人提问:你打算构建什么?
Notebook LM ▷ #general (24 messages🔥):
PDF 上传问题,NB PRO 账户问题,音频回顾提示词,Google Docs 数据源更新,聊天记录保存
- PDF 上传错误困扰 NB Pro 用户:用户报告在向 NB PRO 账户上传 PDF 数据源时出现错误,一名用户分享了错误截图。
- 一位来自 Google 的成员提议,如果这些 PDF 是公开可访问的,他可以协助调查,并请用户私信(DM)他们。
- Google Docs 数据源更新失败:一位用户询问添加到 Google Docs 数据源的信息是否未在 NotebookLM 中同步更新。
- 另一位用户建议点击该数据源并选择 sync with doc(与文档同步)或 reupload(重新上传)来解决此问题。
- 用户寻求聊天记录功能:一位用户询问 NotebookLM 是否保存聊天记录,并感叹关闭并重新打开 notebook 后,之前的问答内容会被删除。
- 一位用户确认聊天记录目前不会保存,另一位用户表示希望未来能上线此功能。
- Chrome 扩展程序修复文本方向问题:一位用户分享了一个名为 NotebookLM Language Switcher 的 Chrome 扩展程序,用于解决文本方向问题,特别是在混合使用从右向左(RTL)和从左向右(LTR)语言时。
- 该扩展程序会更改 UI 语言和文本方向,但不会改变 LLM 的语言。
- 用户通过主持人与专家提示音频回顾:一位用户分享说,他们通常使用“主持人 (Host)”和“专家 (Expert)”来提示 音频回顾(audio reviews),其中主持人扮演平易近人的角色,而专家则是中立、专业的,对数据源保持客观。
- 该用户建议,如果需要,可以针对特定的脏话示例和语境提供自定义提示词。
Manus.im Discord ▷ #general (27 messages🔥):
Manus.im 问题,Manus 内部变动,Agent 领域的竞争,股东影响,恢复文件和会话
- Manus 免费版限制增加:一位用户抱怨 Manus.im 对免费用户变得越来越差,即使上传小至 5GB 的文件也会遇到问题,而此前曾成功上传过 20GB 的文件。
- 用户对缺乏错误提示和客服无响应感到沮丧,怀疑是否存在未公开的上传限制或格式限制。
- Manus 经历内部变动:成员报告称 Manus 似乎正在经历内部变动,导致人员短缺和活动放缓。
- 一位成员指出,他们认为一旦理顺了管理层和战略调整,他们就会回归。
- Agent 领域竞争加剧:成员们一致认为 Agent 领域的竞争非常激烈,认为 Manus 应该利用其早期领先优势,而不是失去势头。
- 一位成员推测,潜在的股东或私募股权介入可能影响了公司的发展方向。
- 错误:Failed to resume sandbox:一位用户报告遇到了 Failed to resume sandbox 错误以及 502 Bad Gateway,寻求如何恢复其文件和会话的建议。
- 在当前语境中未提供解决方案。
MCP (Glama) ▷ #general (17 条消息🔥):
MCP Servers, Env Vars, AI security checks, xdg portal, benchmark MCP server
- Env Vars: 一位成员在运行其 MCP server 时遇到困难,另一位成员建议使用
bash -c mymcpserverbinary myparameter直接调用 shell,以便利用 shell environment 并加载 env vars。- 该成员澄清说他的服务器使用了 xdg portal 并依赖 env vars,但目前仅在 inspector 中有效。他随后表示 claude 甚至还没有在 linux 上获得官方支持,因此他会选择等待。
- 对 AI 安全检查的担忧: 一位成员对 open APIs 缺乏 security checks 和限制表示担忧,认为 AI 可能会 失控并导致相当严重的后果。
- 他们建议增加一些 controls and monitoring 来降低潜在风险。
- MCP Servers 的乱象: 一位成员感叹 MCP servers 数量泛滥,表示 从垃圾信息中筛选已经变得不可能。
- 另一位成员表示赞同,认为这就像是 “西部大荒野”再次上演。
- MCP 验证: 一位成员指出,一些 good servers 几乎没有 GitHub stars 或活跃度,并建议应该在能提升性能的服务器上进行性能指标的 benchmark。
- 他提到 memory types(包括 mem0 等)在基础的 curated rag 或较小 context 下很少能提升性能。
- FastMCP: 一位成员宣称他们使用 sequential thinking 并通过 FastMCP 构建自定义工具,因为目前大多数 MCP servers 都很糟糕。
- 另一位成员建议 只使用你自己编写的或由第三方官方托管的服务器。
MCP (Glama) ▷ #showcase (1 条消息):
Augments, Claude Code, Real-time access to Frameworks
- Augments 让 Claude Code 保持最新: 一个名为 Augments 的新 MCP server 已发布,旨在让 Claude Code 与框架文档保持同步,消除过时的 React 模式或已弃用的 APIs。
- 它提供 对 90 多个 frameworks 的实时访问,是开源的,并可在 augments.dev 进行试用。
- Augments 提供实时访问: Augments 为文档过时问题提供了一个前沿的解决方案。
- 通过 Augments,现在可以 实时访问超过 90 个 frameworks。
LlamaIndex ▷ #blog (4 条消息):
LlamaIndex State Management, FlowMaker: Visual Agent Builder, LlamaIndex AI Agent Meetup, Production Document Parsing
- LlamaIndex 状态管理升级: LlamaIndex 引入了类型化状态支持,通过 Context objects 升级了 workflow 中的状态管理,以便在非连接步骤之间共享数据 (链接)。
- FlowMaker 简化 AI Agent 构建: LlamaIndex 推出了 FlowMaker,这是一个实验性的开源可视化 Agent 构建器,允许通过拖拽在 LlamaIndex TypeScript 中创建 AI agents (链接)。
- LlamaIndex 在阿姆斯特丹举办 AI Agent 见面会: LlamaIndex 和 Snowflake 正在阿姆斯特丹举办 AI agent 见面会,DevRel 工程师 @tuanacelik 将讨论文档 agents 以及构建 AI 驱动的文档处理 agents 的挑战 (链接)。
- 仅靠 LLM APIs 不足以进行文档解析: 虽然像 GPT-4.1、Claude Sonnet 4.0 和 Gemini 2.5 Pro 这样的前沿模型已经超越了传统的 OCR,但仅靠截图的解析对于企业级文档解析来说仍缺乏准确性 (链接)。
LlamaIndex ▷ #general (6 条消息):
LlamaReport Open Source Alternatives, vllm Local Hosting with Cerebrium
- **LlamaReport 没有开源孪生项目!: 一位成员询问了 **LlamaReport 的开源替代方案 (llama_cloud_services 链接)。
- 经澄清,链接的资源仅是一个已弃用 API 的 SDK,尽管仓库中存在 report-generation 示例。
- 渴望 **Cerebrium 和 vllm 的经验分享!: 一位成员正在寻求关于使用 **Cerebrium 本地托管 vllm 的建议。
- 他们渴望向任何在该领域有经验的人请教并获得帮助。
DSPy ▷ #general (6 messages):
Feature Requests, lm_usage troubleshooting, GPT-4.1 usage
- 成员寻求贡献 DSPy 的途径:一位成员询问除了 GitHub issues 列表之外,是否还有其他功能请求或任务列表可以参与贡献 DSPy。
- 该成员对 issues 列表中条目的有效性和相关性表示不确定。
- LM Usage 返回 None:一位成员报告在运行
dspy.Predict(QuoteRelevanceSelector)后调用get_lm_usage()返回 None。- 该成员配置了 DSPy 使用
gpt-4.1,temperature 为 1.0,且track_usage=True,对返回None的结果表示困惑。
- 该成员配置了 DSPy 使用
DSPy ▷ #examples (2 messages):
DSPy Tutorial Issues, Hugging Face Dataset Lib Update
- DSPy 教程面临数据集加载故障:一位成员报告在运行 DSPy agents 教程 时遇到错误,具体是在加载数据集时出现 RuntimeError。
- 错误信息显示:Dataset scripts are no longer supported, but found hover.py(数据集脚本不再受支持,但发现了 hover.py)。
- 怀疑 Hugging Face 更新导致 DSPy 故障:一位成员认为 DSPy 教程中的数据集加载错误可能是由于 Hugging Face dataset 库的更新引起的。
- 消息中未提供具体的解决方案或权宜之计。
Torchtune ▷ #dev (8 messages🔥):
HF Format Saving, DCP Saver for Recipe States, Checkpointing Abstraction, HF Checkpointer Resuming, DCP Speedups
- HF 格式保存通过 DCP 获得提升:分布式 model 以 HF 格式保存的功能现已可用,利用了此处完成的工作,DCP saver 现在可以原生保存 recipe 状态。
- 当前的 checkpointing 抽象使得同时加载 HF 格式的合并模型和分布式 recipe 状态变得困难,因为某些加载函数会构建 state dict,而其他函数则需要现有的 state dict 进行原地填充。
- DCP 加速解决难题:使用 DCP 后,保存 70B 模型的时间从超过 10 分钟降至约 3 分钟;更大的问题是 optimizer state dicts 之前由于由 DTensors 组成而未能完全保存。
- 默认 checkpointing 过程中的障碍是触发了默认的 NCCL 600 秒超时。
- MI300 上带有 FP8 的 LoRA 吞吐量令人失望:在 MI300 的一个节点上使用 LLama-3.1 70B 模型集成 LoRA 与 FP8 的实验显示吞吐量下降。
- 使用 BF16 时吞吐量为 903.68,但在启用 FP8 后,使用 alpaca 数据集、seq len 为 8192、MBS=2 且 GAS=1 时,吞吐量降至 876.04。附上了 LoRA 微调脚本。
MLOps @Chipro ▷ #events (7 messages):
Data + AI Happy Hour, Virtual Events, SF Meetup
- Data + AI Happy Hour 活动发布:MLOPs 将于 7 月 30 日在 旧金山 (SF) 举办 Data + AI Happy Hour,旨在会见全行业正在构建、融资和扩展初创公司的合作者,在此处报名。
- 社区的一位新人对无法旁听会议并从他人经验中学习表示失望:我看到了 Discord 通知并很兴奋地想参加,按照提供的时间设置了提醒,结果尝试参加时却被告知排在候补名单上。
- 虚拟活动即将到来:MLOPs 计划在不久的将来举办 虚拟活动。
- 团队表示,没有观察者的闭门小型活动有助于人们更自由地发言。
Modular (Mojo 🔥) ▷ #general (3 messages):
Mojo compiler, Linux, Windows, WSL
- Mojo 优先支持 Linux 而非 Windows:Mojo 编译器团队目前专注于为生产级企业环境(主要是 Linux)提供最佳的 GPU 编程体验。
- Windows 肯定是团队未来想要支持的对象,但目前他们优先处理影响力最大的工作。
- WSL 为 Windows 上的 Mojo 提供了可行的变通方案:虽然目前没有立即发布原生 Windows 版 Mojo 的计划,但它在 WSL 下运行良好。
- 这使得 WSL 成为使用 Mojo 进行原型设计工作的合适环境,即使没有官方的 Windows 支持。
Modular (Mojo 🔥) ▷ #max (3 messages):
Prefix Cache, Token Hashing, Mojo integration for Token Hashing
- Max 25.4 默认禁用 Prefix Cache:由于在工作负载没有前缀缓存机会时会产生少量的性能开销,Prefix Cache 默认被禁用。
- 这在很大程度上源于 Token Hashing 带来的 CPU 开销。
- 通过 Mojo 提升 Token Hashing 性能:团队正致力于降低性能开销,其中一种方法是将耗时的 Token Hashing 操作 从 Python 迁移到 Mojo。
- 目标是减少 CPU 开销。
Cohere ▷ #🧵-general-thread (1 messages):
alphzme: Cohere 是一个开发优秀 AI API 的 AI 团队。
Cohere ▷ #🔌-api-discussions (1 messages):
Vector Weighting, Image Vectorization, Text Vectorization, Cohere Unified Vectors
- 用户权衡向量相似度搜索:一名成员询问在使用 Cohere 的统一向量嵌入 (Unified Vector Embeddings) 进行相似度搜索时,如何调整图像和文本向量的权重。
- 用户希望在查询时能够像调节旋钮一样,强调图像相似度或文本相似度。
- 图像和文本向量化技术:该成员提到拥有一个由图像和文本块创建的嵌入库。
- 他们目前正在独立地对图像和文本进行向量化,但正在寻找一种使用 Cohere 统一向量来实现这一目标的方法。
Cohere ▷ #👋-introduce-yourself (2 messages):
Freelance AI Training, LLM Prompt Evaluation, Multilingual Data Annotation, Content Moderation for Conversational AI, AI Project Collaboration
- AI 训练师加入社区:新成员 Sushant Kaushik 介绍自己是一名自由职业 AI 训练师 (AI Trainer) 和内容审核员 (Content Moderator)。
- 他们在 Remotasks、Labelbox、Outlier 和 Appen 等平台拥有丰富经验。
- 新成员评估 LLM 提示词:Sushant 目前正从事 LLM 提示词评估、多语言数据标注以及对话式 AI 系统的内容审核工作。
- 他们的工具栈包括 Python、Labelbox、Power BI 和 Azure Data Factory。
- 寻求社区合作:Sushant 希望向社区学习并紧跟前沿研究。
- 他们也期待在具有影响力的 AI 项目上进行合作。
tinygrad (George Hotz) ▷ #general (2 messages):
Tinygrad Motivation, Onnx export limitations, GPU Utilization
- Tinygrad 的核心动力:保持微小!:Tinygrad 的首要目标是保持极小的占用空间。
- 一位社区成员表示,否则就不叫 Tiny 了。
- ONNX 导出限制:由于动态控制流 (Dynamic Control Flow),无法将模型导出为 ONNX 格式。
- 对于某些模型,由于
ValueError: Exporting a trace with dynamic control flow,追踪 (Trace) 导出失败。
- 对于某些模型,由于
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Large Language Model Agents, Berkeley MOOC iteration
- LLM Agents 新版本备受期待:一位成员询问了即将在秋季推出的新版 Large Language Model Agents MOOC 的可能性。
- 另一位成员指出,虽然 Berkeley 正在为校内学生开设另一门 Agents 课程,但 MOOC 迭代版本尚未确认,预计将在 8 月底左右发布公告。
- Berkeley 的 Agent 课程与 MOOC 迭代:Berkeley 准备为校内学生提供另一门 Agents class,引发了人们对潜在 MOOC 版本的关注。
- 社区正在等待关于 MOOC 版本是否继续进行的确认,预计将在 8 月底左右宣布。
Codeium (Windsurf) ▷ #announcements (1 messages):
Kimi K2 Model, Windsurf AI, Model Integration
- Kimi K2 接入 Windsurf:Kimi K2 model 现在已在 Windsurf 上获得支持,每次 prompt 消耗 0.5 积分,为开发者提供了更多选择。
- 更多详情请参阅 X 上的公告 或 加入 Reddit 上的讨论
- Windsurf 迎来新浪潮:Windsurf 更新了其系统,现在支持新的 Kimi K2 Model。
- 此次更新扩展了用户开发工作流中的可用选项。
Nomic.ai (GPT4All) ▷ #general (1 messages):
Local Docs usage, Expansive Local Docs
- 新手寻求高效使用 Local Docs 的指导:一位新用户正在寻求关于如何高效使用大规模 Local Docs 的建议,因为他们目前的尝试似乎无法让系统感知到本地文件的完整范围。
- 该用户在工具的回答能力方面遇到了问题,感觉回答被局限在了最浅显的内容(low-hanging fruit)中,而没有充分利用本地文档中提供的广泛信息。
- 提高 Local Docs 的感知能力:用户希望提高 localdocs 文件的覆盖范围。
- 回答被局限在了显而易见的内容中。