AI News
GLM-4.5:比 Kimi/Qwen/DeepSeek 更深邃、更硬核、更出色(中国最先进的大模型?)
智谱 AI (Z.ai) 发布了 GLM-4.5-355B-A32B 和 GLM-4.5-Air-106B-A12B 开源权重模型,声称其具备顶尖性能,可与 Claude 4 Opus、Grok 4 以及 OpenAI 的 o3 竞争。这些模型强调 Token 效率,并采用了经 Muon 优化器验证的高效强化学习训练。
阿里巴巴通义千问 (Alibaba Qwen) 推出了分组序列策略优化 (GSPO),这是一种驱动 Qwen3 系列模型的新型强化学习算法,目前已集成到 Hugging Face 的 TRL 库中。外界推测,神秘模型“summit”和“zenith”可能是基于 GPT-4.1 架构的 GPT-5 潜在变体。
Qwen3-Coder 在编程基准测试中表现强劲,足以媲美 Claude Sonnet 4 和 Kimi K2。以 GLM-4.5、Wan-2.2 和 Qwen3 Coder 为代表的中国强大开源模型的崛起,与 OpenAI 等西方实验室的步伐放缓形成了鲜明对比。
Muon is all you need?
2025年7月25日至7月28日的 AI 新闻。我们为您查阅了 9 个 Reddit 子版块、449 个 Twitter 账号和 29 个 Discord 社区(227 个频道,16798 条消息)。预计节省阅读时间(以 200wpm 计算):1388 分钟。我们的新网站现已上线,支持全元数据搜索,并以美观的 vibe coded 风格展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻分类,并在 @smol_ai 上向我们提供反馈!
中国开源权重 AI 迎来辉煌的一天。生成式媒体从业者绝对应该关注一下 Wan 2.2,但大多数 AI Engineers 应该了解 Z.ai(更广为人知的名字是 智谱,AI 四小龙之一)今天发布的 GLM-4.5-355B-A32B 和 GLM-4.5-Air-106B-A12B。他们提出了一个非常强有力的主张(尚待独立验证):不仅是目前最强的开源权重模型(击败了之前的 SOTA Kimi K-2),而且与 Claude 4 Opus、Grok 4 和 OpenAI 的 o3 等重量级 SOTA 模型相比也极具竞争力,甚至表现更好:
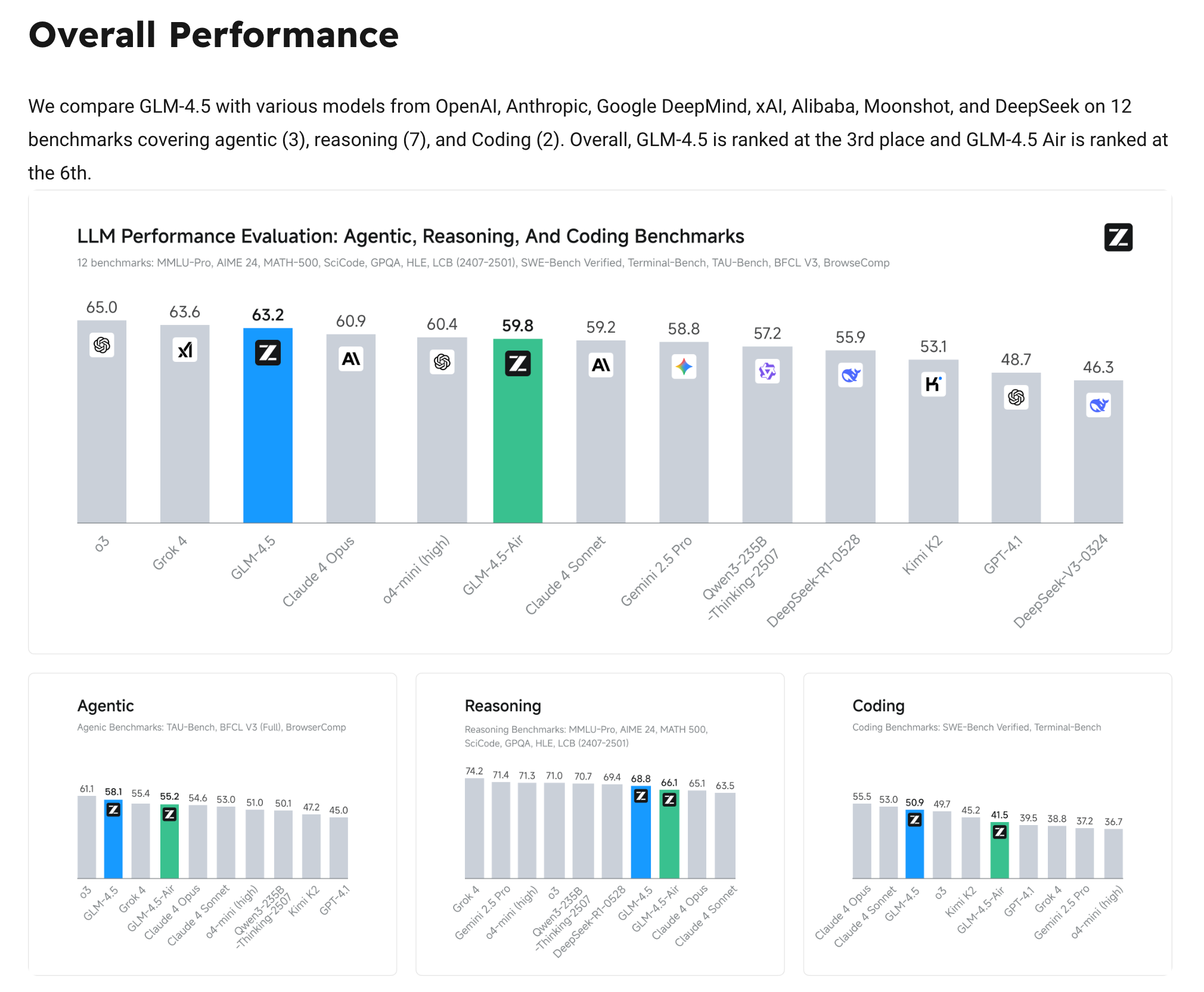
除了作为前沿模型所需的常规 Benchmark 之外,Z.ai 还值得称赞地强调了对 Agentic 用途至关重要的新指标,包括 Token 效率(这可能是所有指标中最难的一个)。
目前还没有论文,但 博客文章 提供了一些关于架构选择和高效 RL 训练的有趣细节。GLM 4.5 是本月第二个在大规模场景下验证 Muon 优化器的模型。
AI Twitter 综述
新模型发布与性能
- GSPO 与 Qwen3 模型套件:Alibaba Qwen 宣布了 Group Sequence Policy Optimization (GSPO),这是一种被描述为扩展大模型突破的新型强化学习算法。它具有序列级优化特性,提高了大型 MoE 模型的稳定性,无需“Routing Replay 等技巧”,并为最新的 Qwen3 模型(Instruct、Coder、Thinking)提供动力。@lupantech 关注到了该研究论文,@teortaxesTex 称赞其为他们迄今为止最令人印象深刻的论文。@mervenoyann 和 @_lewtun 指出,该算法已被集成到 Hugging Face 的 TRL 库中。
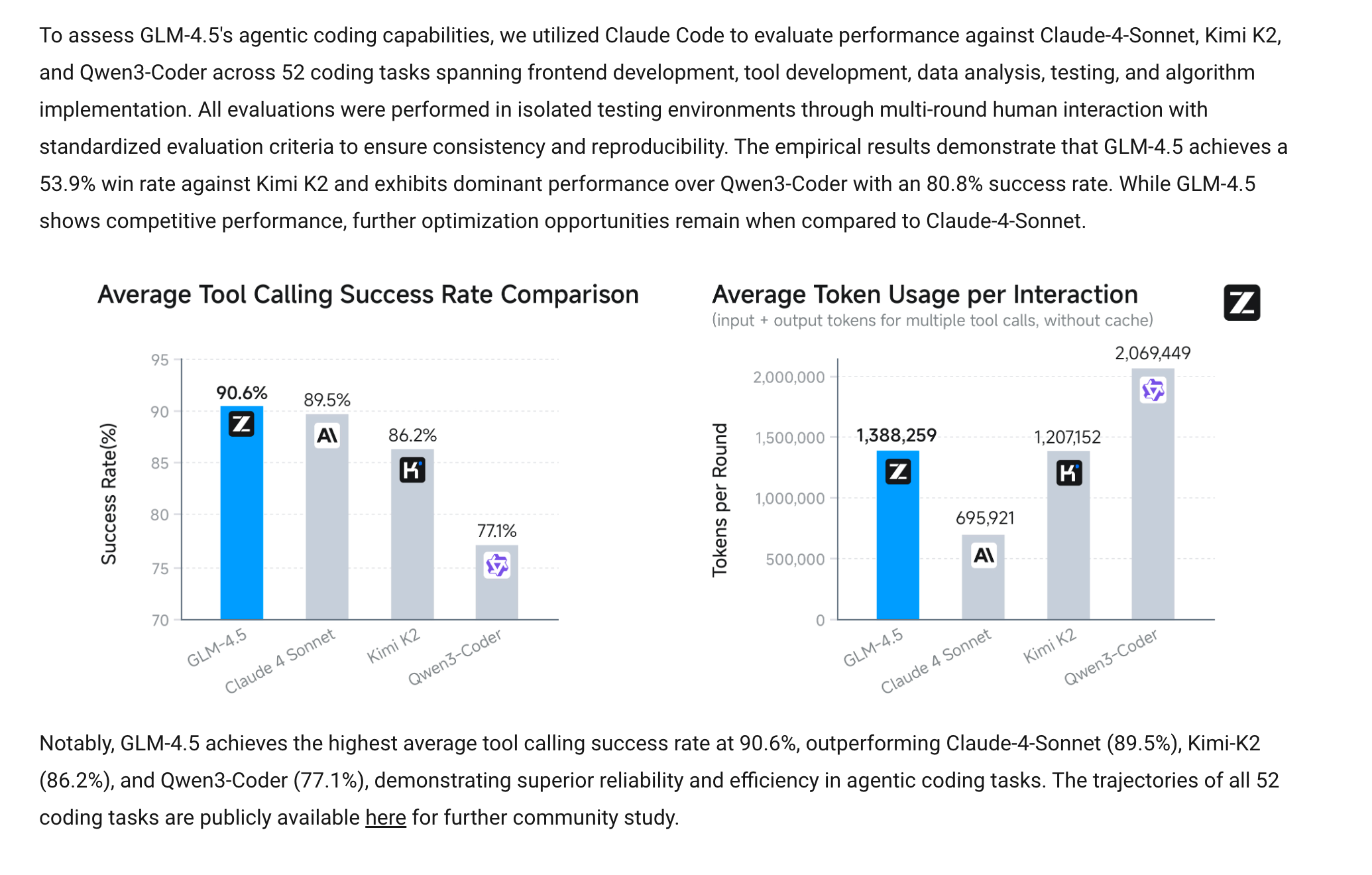
- Zai.org 发布 GLM-4.5 模型:中国 AI 实验室 Zai.org 发布了两个新的开源模型 GLM-4.5 和 GLM-4.5-Air,采用宽松的 MIT 许可证。正如 @scaling01 所总结的,GLM-4.5 是一个拥有 355B 参数、32B 激活参数的 MoE 模型,而 GLM-4.5 Air 为 106B 参数、12B 激活。这些模型被描述为专注于编程和 Agent 任务的混合推理模型。为了提高透明度,Zai.org 还开源了其 Agent 编程评估中的所有 52 条任务轨迹,供社区审查。
- 关于 “Summit” 和 “Zenith” 为 GPT-5 的推测:一组代号为 “summit” 和 “zenith” 的新型强大神秘模型出现在 LM Arena 上,引发了它们可能是 GPT-5 版本的推测。@Teknium1 报告称被告知 “zenith 就是 GPT-5”,而 @emollick 和 @scaling01 展示了它们在生成复杂 p5.js 代码和创意写作方面的卓越能力。用户注意到这些模型似乎基于 GPT-4.1 系列,知识截止日期为 2024 年 6 月。
- Qwen3-Coder 强劲的编程性能:Alibaba 的 Qwen3-Coder 模型在编程基准测试中表现出强劲性能。@cline 报告其 diff 编辑失败率为 5.32%,与 Claude Sonnet 4 和 Kimi K2 并列。OpenRouterAI 指出,该模型在编程排名中超过了 Grok 4,与 Kimi 持平。
- 中国开源模型的崛起:本月观察到的一个显著趋势是中国实验室密集发布强大的开源模型。@Yuchenj_UW 整理了 7 月份发布的名单,包括 GLM-4.5、Wan-2.2、Qwen3 Coder 和 Kimi K2,并将其与 OpenAI 和 Meta 等西方实验室明显的放缓进行了对比。
- Hunyuan3D World Model 1.0 发布:Tencent Hunyuan 已开源其 Hunyuan3D World Model 1.0,该模型支持生成可探索的 3D 环境。
AI Agent 与 Agent 工作流
- Claude Code 用于复杂 Agentic 系统:Claude Code 被强调为编排复杂 Agentic 系统的强大工具。@omarsar0 演示了通过使用
/commands链接子 Agent 来构建多 Agent 深度研究系统以提高可靠性,并指出它不仅对代码有用。 - ChatGPT Agent 正式推出:OpenAI 宣布 ChatGPT agent 现已全面推向所有 Plus、Pro 和 Team 用户。然而,推出过程并非一帆风顺,@gneubig 幽默地指出 OpenAI agent 竟然被 OpenAI 自己的 captcha 拦截了。
- Agent 的未来:主动与环境化:@_philschmid 概述了 Agent 的下一次迭代,预测将从“请求-响应”模式转变为在后台运行的主动、环境化 Agent (proactive, ambient agents)。这些 Agent 将由事件触发,监控数据流,并需要超越聊天框的新 UI 范式,同时强调人类监督和长期记忆。
- Perplexity Comet 浏览器 Agent:Perplexity AI 继续发放其 Comet 浏览器 Agent 的邀请。@AravSrinivas 展示了 Comet 作为旅游 Agent 预订美联航机票(包括选座)的演示。他还指出 Perplexity 是 Comet 浏览器的默认搜索,这可能会显著推动使用量。
- 多 Agent 系统失败的原因:DeepLearningAI 总结了一篇研究论文,将 多 Agent 系统失败的主要原因 归类为规范不明确、Agent 间失调以及任务验证薄弱。
视频与多模态生成
- Runway Aleph 设定新前沿:Runway 开始推出其最先进的上下文视频模型 (in-context video model) Aleph。创意技术专家 @c_valenzuelab 分享了许多展示其能力的演示:按需创建 无限相机覆盖,在保留动作和身份的同时修改视频的特定部分,让杂耍球着火,进行 服装和造型修改,以及无缝 从场景中移除物体。他将其描述为一种“新媒介”,其中最难的部分是构思要创造什么。
- 开源视频:Wan 2.2 发布:为了对抗封闭视频模型的趋势,阿里巴巴发布了 Wan 2.2,即 “全球首个开源 MoE 架构视频生成模型”。@scaling01 注意到了它的发布,@ostrisai 强调了一个 5B 版本,支持在单张 RTX 4090 上以 24 FPS 进行 text-to-video 和 image-to-video。
- Kling AI 推出 Kling Lab:Kling AI 宣布了 Kling Lab,这是一个旨在简化创意视频生成流程的新工作空间,目前处于 Beta 测试阶段。
- Grok Imagine 进入候补名单 Beta 测试:xAI 在 Grok 应用中推出了图像和视频生成工具 Grok Imagine,目前需排队加入候补名单。@chaitualuru 将其描述为“有趣的图像和视频生成体验”,并指出他们正在扩大访问权限。
基础设施、工具与效率
- 框架与库:由 @skalskip92 创建的 supervision 开源库在 GitHub 上突破了 30,000 stars。LangGraph 发布了 v0.6.0 版本,包含一个新的 context API,用于类型安全的依赖注入。Red Hat AI 的 GuideLLM 正在 加入 vLLM 项目,将其结构化生成能力与 vLLM 的推理速度相结合。
- LLM 评估与数据:@HamelHusain 发布了大幅扩充的 LLM Evals FAQ,将其重新分类并增加了 音频版本。在数据方面,@vikhyatk 警告称,流行的 GQA 评估数据集存在 20-30% 的标注错误率。
- 硬件与训练效率:John Carmack @ID_AA_Carmack 评论了现代 ML 感觉像老派科幻术语的讽刺感,他表示:“我正在频域运行卷积!” @awnihannun 对自回归 Transformer 如何针对现代计算机内存层级结构进行“对抗性设计”提供了发人深省的分析,暗示若要获得重大效率提升,要么算法必须改变,要么计算机必须改变。与此同时,@ggerganov 指出 AMD 团队现在正在为 llama.cpp 代码库做出贡献。@kellerjordan0 创造了新的 NanoGPT 训练速度记录,在 8xH100 上仅用 2.863 分钟 就达到了 3.28 的验证损失。
新 AI 技术与研究
- 提示词优化 vs RLHF:@lateinteraction 分享的一篇关于 Reflective Prompt Evolution (GEPA) 的新论文显示,提示词优化在样本效率方面可以优于 GRPO 等 RL 算法。该研究表明,通过自然语言反思进行学习将成为构建 AI 系统的核心范式。
- ML 中的因果关系:@sirbayes 推荐了 Elias Bareinboim 关于 ML 因果关系的新书,称其为 Judea Pearl 开创性工作的“合格继承者”。
- 简单惩罚的力量:@francoisfleuret 认为,变分自编码器 (VAE) 的关键教训是“笨拙的惩罚具有极其深远的影响,并在深度模型中诱导出难以置信的复杂结构。”
- 元学习历史:Jürgen Schmidhuber @SchmidhuberAI 提供了 meta-learning 的详细历史回顾,将 in-context learning 的概念追溯到他在 20 世纪 90 年代初的工作以及 Sepp Hochreiter 在 2001 年的工作。
行业趋势与评论
- 招聘与人才:Meta 任命了一位 来自 OpenAI 的应届博士担任其首席科学家,@Yuchenj_UW 指出,对于大公司里的一位 30 岁年轻人来说,这一举动是“闻所未闻”的,标志着向 “技能 » 资历” 的转变。
- AI 中的视觉差距:@jxmnop 提出了一个令人惊讶的观察:“十五年的硬核计算机视觉研究除了更好的优化器之外,对 AGI 几乎没有任何贡献”,因为模型在拥有“眼睛”后依然没有变得更聪明。@teortaxesTex 补充道,虽然许多开源模型正达到类似的性能瓶颈,但关键的缺失元素是“一套全新的评估套件”,这将标志着有人正在“攀登一座新山峰”。
- 搜索的未来:Perplexity AI 的 CEO @AravSrinivas 表示,Perplexity 在印度等市场的快速增长是“搜索已永远改变的明确证据”。
- AI 与体验:Mustafa Suleyman @mustafasuleyman 在人类和 AI 之间划出了一道“明确界限”,他表示:“作为人类意味着去体验。今天的 AI 拥有知识……但只能模仿体验。”
幽默与迷因
- Vibe Coder 宇宙:术语“vibe coding”已成为一个无处不在的梗,用于描述一种直觉式的、有时甚至有些脆弱的开发方法。这一概念现在已经进化,@scaling01 指出,有些人已经“从单纯的 vibe coders 晋升为 vibe architects”,而 @lateinteraction 则宣称我们正处于“Vibe Meanings 时代”。
- 会说话的魔力狗派对:由 @benhylak 和 @okpasquale 在 Slack 的原办公室举办的一场派对,因一只“会说话的魔力狗”而成为了一个持续的笑话,@KevinAFischer 发布了一张在 a16z 进行 Pitch 的照片,其中涉及这只狗和一个叠罗汉。
- 引起共鸣的开发者痛苦:@cloneofsimo 哀叹道,在 2025 年,Transformer 可以解决奥数题并设计芯片,“然而我们的 LaTeX UI 仍然会崩溃”。@francoisfleuret 发出了警告:“如果你正在使用 FSDP 并且在你的 model.forward[] 中有一个 ‘if’ 语句,朋友,请保持警惕,非常警惕。”
- 行业评论:@Yuchenj_UW 分享了一个悲伤的家庭故事:“我爸在 2013 年以每个 50 美元的价格买了 100 个 Bitcoin。在 100 美元时卖掉了,吹嘘了好几周。从那以后…… Bitcoin 在我们家就成了一个禁词。”
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. GLM-4.5 公告、发布与集合
- GLM4.5 发布! (Score: 720, Comments: 193):GLM-4.5(355B 总参数/32B 激活参数)和 GLM-4.5-Air(106B 总参数/12B 激活参数)是来自智谱 AI 的新型旗舰级混合推理模型,现已在 HuggingFace 和 ModelScope 上以 MIT license 开源权重。关键技术特性包括用于灵活 Agent/编程任务的独特“思考”和“非思考”模式,以及支持 speculative decoding 的原生 Multi-Token Prediction (MTP) 层,以提高在 CPU+GPU 硬件上的 inference 性能。详细信息请参阅官方博客文章。 评论者强调了开放 MIT license 和原生 MTP 层的双重影响,认为这是社区可复用性和高效 inference(特别是在混合硬件设置上)的一个重要里程碑。
- GLM-4.5 的发布包括基于 MIT license 的基座模型(355B-A32B 和 106B-A12B),这对于促进社区的广泛定制和创新具有重要意义。这种大规模模型的开放授权被认为是开源 AI 发展迈出的卓越一步。
- GLM-4.5 和 GLM-4.5-Air 具有用于 inference 过程中 speculative decoding 的 MTP (Multi-Token Prediction) 层,这可以提高效率——特别是对于 CPU+GPU 混合配置。开箱即用的 speculative decoding 被认为是 inference 优化的显著易用性优势。
- 此次发布包括多个技术资产:BF16、FP8 和基座模型,便于进一步的 training、fine-tuning 和研究。官方为流行的 inference 引擎(vLLM, SGLang)提供了文档和技术资源,并在其 GitHub 和技术博客中分享了 inference 和 fine-tuning 的详细指南,使模型易于进行实验和扩展。
-
GLM 4.5 集合现已上线! (Score: 221, Comments: 47):GLM 4.5 集合现已在 HuggingFace 上线(链接),包含 GLM-4-9B 及其变体,重点关注“混合思考”能力。报告的 Benchmarks 显示,虽然数学/科学得分略低于 Qwen3,但 GLM 4.5 尽管不是专门的 Coder 模型,却展示了强大的通用编程性能。 评论指出目前缺乏即时的 GGUF 格式下载(例如通过 Unsloth),并强调了混合推理的设计选择(与 Qwen 的方向形成对比),认为这可能会产生更通用的全能模型。
- 新的 GLM 4.5 模型采用了混合架构,这与 Qwen 团队采取的方法形成对比。根据发布的数学和科学基准测试,GLM 4.5 在这些领域的表现不如 Qwen3,但与非专业模型相比,它在编程任务中表现出显著的强劲结果,这表明其在纯 STEM 之外的领域具有强大的通用能力。
- 社区对立即下载 GLM 4.5 的 GGUF 格式表现出浓厚兴趣,一些用户对发布时缺乏与 Unsloth 团队工具链的协调表示沮丧——这突显了对本地推理框架或量化格式的兼容性和易用性的需求。
- 提出的一个技术建议是针对结构化写作任务(如书信写作、小说、人格模拟)对 GLM 4.5 等模型进行微调。用户注意到这些创意/辅助角色在性能上存在差距,建议有针对性的 instruction tuning 可以解决当前基准测试未完全涵盖的常见用例。
- 根据 Bloomberg 报道,GLM 4.5 可能于今日发布 (Score: 134, Comments: 26): Bloomberg 报道称,智谱 AI(原 THUDM,现 Hugging Face 上的 zai-org)将发布 GLM-4.5,相关的集合和数据集已出现在 Hugging Face 上(GLM 4.5 Collection,CC-Bench-trajectories dataset)。GLM-4.5-Air 作为公开版本,包含 106B 总参数和 12B 激活参数,表明这是一款类似于 Mixture-of-Experts 的稀疏激活模型。 专家评论者对许可协议宽松(MIT, Apache)的大模型变体(32B, 70B)表示关注,主要的技术讨论集中在 GLM-4.5-Air 的紧凑、稀疏激活架构上。此外,人们还对许可证以及上游可能在效率或能力方面的改进充满期待。
- GLM-4.5-Air 已公开发布,具有“更紧凑的设计”,总参数为 1060 亿,但只有 120 亿“激活参数”,这表明其在性能或效率方面进行了架构优化(来源:https://huggingface.co/zai-org/GLM-4.5-Air)。
- 社区对发布 32B 和 70B 参数版本的 GLM-4.5 感兴趣,特别是采用 MIT 或 Apache 开源许可证的版本,这突显了对广泛可访问性和宽松模型许可的关注。
- 提供了 Hugging Face 上 CC-Bench 数据集的直接链接,这可能与评估 GLM-4.5 模型的能力或基准测试相关(来源:https://huggingface.co/datasets/zai-org/CC-Bench-trajectories)。
- GLM 打破了“有史以来发布的质量最差基准测试 JPEG”的记录——哇。 (Score: 106, Comments: 76): 该帖子批评了一张据称显示 GLM-4.5 基准测试的 JPEG 图像,主要抱怨是图像或数据质量非常差——被描述为“有史以来发布的质量最差的基准测试 JPEG”。潜在的技术点涉及语言模型的基准测试,特别是 GLM-4.5 相对于 DeepSeek R1 等竞争模型的表现;一条评论澄清说,原始 JPEG 在 RAM 占用方面具有误导性,指出 GLM-4.5 的原生精度是 BF16 而非 FP8,这对于推理效率和内存使用是一个重要的技术区别。 一些评论者批评了标题的夸张性质以及对图像内容的混淆,而另一位评论者指出,尽管展示效果不佳,但 GLM-4.5 被认为是一个高质量模型,并对其即将推出的多模态能力充满期待。
- 一位评论者澄清了一个技术规格:GLM-4.5 实际上比 DeepSeek R1 使用更多的 RAM,因为 GLM-4.5 的原生精度是 BF16 而非 FP8,这反驳了它比对比模型更节省内存的任何暗示。
- 引用了 GLM-4.5 文档 以提供技术背景。讨论批评了文档中使用的 JPEG 基准测试图像,指出其清晰度和信息价值在仔细观察下会下降。
- 尽管对基准测试的展示方式有所批评,一位用户指出 GLM-4.5 仍然是一个强大且高性能的模型,并对其未来的多模态能力表示期待。
{kind=link}
2. Wan 2.2 开放视频生成模型发布与基准测试
- Wan 2.2 上线了!仅需 8GB VRAM! (Score: 440, Comments: 49): Wan 2.2 作为一个新发布的模型,因其极低的 VRAM 需求(仅需 8GB)而备受关注,这使得没有高端硬件的用户也能使用。讨论中提到了 ComfyUI 的早期版本和重新打包版,表明了社区以及可能来自官方人员的积极集成与支持。图片可能展示了模型输出或宣传材料,强调了新版本在受限硬件上的能力。 一条实质性的评论指出,ComfyUI 的重打版本发布非常迅速,暗示 Wan 团队与 ComfyUI 开发人员之间存在紧密协作或内部人员参与。这支持了 Wan 2.2 拥有一个积极参与、响应迅速的开源/模型社区的看法。
- 评论者指出,Wan 2.2 的 ComfyUI 重打版本甚至在原始模型发布之前就已推出,这表明某些 ComfyUI 贡献者可能参与了 Wan 项目。这暗示了快速的集成和可能的跨团队协作,考虑到 UI 框架对新模型架构的官方支持通常较慢,这一点尤为显著。
- 提供了 Wan 2.2 模型多种变体的直接 Hugging Face 链接(包括 T2V (Text-to-Video)、I2V (Image-to-Video) 和 TI2V (Text/Image-to-Video) 的基础格式和 Diffusers 就绪格式)。这标志着生态系统对部署和实验各种工作流及模型流水线的强大且即时的支持,减少了想要测试或基准测试 Wan 2.2 多种模态的技术用户的阻碍。
- Wan 2.2 T2V, I2V 14B MoE 模型 (Score: 140, Comments: 8): Wan 2.2 为视频生成引入了 Mixture-of-Experts (MoE) 扩散架构,在可切换的 27B MoE 设置中包含两个 14B 参数的专业专家(高噪声专家用于早期去噪,低噪声专家用于精细细节),由基于 SNR 的阈值触发,实现相位优化的推理,且不增加额外的推理成本。在 Wan-Bench 2.0 基准测试中,Wan2.2-T2V-A14B 在 6 项指标中的 5 项上超越了商业 SOTA(KLING 2.0, Sora, Seedance),包括动态运动和文本渲染;而 TI2V-5B 通过激进的空间/补丁压缩和统一架构,实现了高效、高分辨率(<9 分钟生成 5 秒 720p)的 T2V/I2V 生成。有关实现细节,请参阅 ComfyUI 教程。 评论进一步证实了关于每步仅需单个专家推理的效率主张,并提到了像 ComfyUI 教程这样易于获取的工具。一位评论者将开源的 Wan 2.2 发布与 OpenAI 等公司在类似模型上的限制性做法进行了对比。
- 一个关键的技术见解是,WAN 2.2 14B MoE 模型使用 Mixture-of-Experts (MoE) 架构,每步仅激活一个专家,在提供巨大参数容量(14B)的同时保持推理效率,从而优化了视频和图像生成任务的速度和性能。
- 讨论了在 llama.cpp 中运行扩散模型:既然现在已经支持文本扩散,用户正在探索添加图像和视频扩散支持的可行性。如果能克服实现挑战,这将通过把所有扩散任务集中在一个广泛使用的框架中来简化工作流。
- 强调了使用 ComfyUI 运行 WAN 2.2 的快速入门指南,突出了其在高效部署新模型进行视频生成方面的实用性。链接的文档为实际操作提供了分步说明。
{kind=link}
3. 针对特定应用(UI、指令、边缘设备)的专业 LLM 发布
- UIGEN-X-0727 本地运行表现出色。针对 UI、移动端、软件和前端设计的推理。 (Score: 420, Comments: 67): Tesslate 的最新模型 UIGEN-X-32B-0727 是一个基于 Qwen3 微调的 32B 稠密 LLM,专门用于端到端的现代 UI/UX、前端、移动端和软件设计实现。该模型支持广泛的框架(如 React, Vue, Angular, Svelte)、样式选项(Tailwind, CSS-in-JS)、UI 库、状态管理、动画、多平台(Web, 移动端, 桌面端)以及 Python 集成——提供
26+ 种语言的代码生成和组件驱动模式。据称 4B 版本即将发布。 讨论集中在 32B 稠密模型生成的 UI 质量惊人之高,人们对其 SOTA 级别的性能表现和微调方法论感到好奇,并将其与更大的模型进行了对比。此外,社区还提到了对 API/第三方集成的兴趣,以便进行更广泛的评估。- UIGEN-X-0727 作为 Qwen3 的微调版本,是一个参数量相对较小的 32B 稠密模型,因其生成的 UI 极具竞争力而受到关注。部分用户对该规模模型的表现感到惊讶——其性能超出了通常对更大模型的预期。
- 一项技术评论指出,尽管像 UIGEN-X-0727 这样的 UI 生成 LLM 在渲染单个组件和保持主题一致性方面表现出色,但在组件间链接、导航集成以及自动添加动态样式方面仍面临重大挑战,而这些是生产级前端/UI 代码生成的关键环节。
- 一位测试者提到,该模型在本地运行时需要
64GB of VRAM,这导致有人尝试在 AWS 上部署以进行进一步的基准测试。对于一个所谓的“小”模型来说,这是一个巨大的资源需求,可能会引发本地使用的可访问性或性能担忧。
- Qwen/Qwen3-30B-A3B-Instruct-2507 · Hugging Face (Score: 502, Comments: 90): 阿里巴巴的 Qwen 团队在 Hugging Face 上发布了 Qwen/Qwen3-30B-A3B-Instruct-2507 模型权重,但截至发稿时,尚无官方模型卡片或技术文档。该模型属于 30B 参数级别,似乎采用了 A3B 架构,遵循了早期 Qwen 版本的命名习惯,这些版本以在消费级硬件上平衡强大性能和高效推理而闻名(参见之前的 Qwen3-30B-A3B 模型)。 评论区的讨论显示出用户的高度期待,他们将之前的 Qwen 模型称为“日常主力模型(daily drivers)”,并指出 A3B 系列的更新(如在更大模型中所见)带来了显著的质量飞跃,这让人们期待此次发布可能为本地运行的 LLM 树立新标准。
- Admirable-Star7088 指出,之前的 Qwen3-235B-A22B-Instruct-2507 相比早期的“思考(thinking)”版本有显著的性能提升,这意味着如果 Qwen3-30B-A3B-Instruct-2507 也能实现类似的提升,它可能会成为针对消费级硬件优化的顶尖 LLM 之一。
- rerri 记录了该仓库的可见性状态,指出它最初是私有的,这可能意味着是一次意外的提前发布或分阶段推出——这有时会影响新 LLM 发布时基准测试或对比研究的可访问性。
- Pi AI studio (Score: 117, Comments: 27): 讨论集中在一款售价 1000 美元的设备上,该设备配备 96GB LPDDR4X(而非 LPDDR5X)内存和一颗 Ascend 310 芯片,并探讨了它是否适合托管小型 LLM。评论者指出,该设备的内存带宽可能会成为性能瓶颈,并将 Ascend 310 的能力与 Nvidia 的 Jetson Orin Nano 进行了对比,认为可能只有更简单的神经网络或深度量化模型(例如 70B 8-bit 或 100B+ int4)才具有实用性。 热门评论辩论了 LPDDR4X 与更快的内存(LPDDR5X)相比是否充足,并对内存带宽和计算能力表示怀疑,表明运行高吞吐量或更大的 LLM 将面临挑战。
- 多位评论者对 Pi AI Studio 中使用的 LPDDR4X 内存表示担忧,指出其带宽有限(
~3.8GB/s),远低于 Mac AI Studio(546GB/s)等高端解决方案。预计这一限制将显著影响 Token 吞吐量,并限制大型语言模型的性能。
- 多位评论者对 Pi AI Studio 中使用的 LPDDR4X 内存表示担忧,指出其带宽有限(
- 讨论将 Ascend 310 AI 加速器与 Nvidia 的 Jetson Orin Nano 进行了比较,认为虽然它可以处理较简单的神经网络或中型 MoE 模型(例如 Qwen 3 30B),但在处理 decent(像样的)LLM 时会比较吃力。量化模型(例如 70B 8-bit 或 100B+ INT4)在技术上可能可以运行,但会受到内存带宽(memory bandwidth)的严重瓶颈限制。
- 关于基于 LPDDR 类型的内存带宽估算存在技术争论,一位评论者指出,由于实现方式(特别是总线宽度 bus width)的差异,缺乏清晰、实际的数据,这使得预测 LLM 推理(例如 7B 到 40B 模型上的 token/sec)的实际吞吐量和性能变得具有挑战性。
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo
1. Wan2.2 Video Model Release, Benchmarks, and Community Tests
- First look at Wan2.2: Welcome to the Wan-Verse (Score: 863, Comments: 134): Wan 团队发布了 Wan2.2,这是继 Wan2.1(下载量超过 580 万,GitHub 星标 1.33 万)取得成功后,其 text-to-video/image-to-video (I2V) 模型的最新迭代版本。Wan2.2 引入了更有效的 Mixture-of-Experts (MoE) 架构,提升了电影级美学,并显著增强了从单张图像输入生成复杂且多样化运动序列的能力,正如预览演示中所强调的那样。模型权重和文档可通过 Hugging Face (https://huggingface.co/Wan-AI)、GitHub (https://github.com/Wan-Video) 和官方网站 (https://wan.video/welcome) 获取。 评论指出质量有所提升,并期待上手测试。技术用户强调架构进步和功能升级是与先前版本的主要区别。
- Wan2.2 引入了显著升级的 MoE (Mixture of Experts) 架构,旨在提高模型效率和输出多样性。这一变化被强调为与 Wan2.1 的核心技术区别,预计将增强生成视频内容的复杂性和保真度。
- 技术增强特别提到了改进的电影效果(实现更高质量的美学)以及从单一源图像生成更复杂运动序列的能力。这表明模型流水线中时间与空间特征的集成更加紧密,从而实现了更好的视频真实感和动态内容。
- 一些用户正在等待 FP8 (floating point 8-bit) 版本的发布,这表明对低精度权重的需求,这有利于模型推理和部署效率,特别是在支持 FP8 加速器的硬件上。这是社区对大规模或消费级硬件优化性能感兴趣的信号。
- Wan2.2 released, 27B MoE and 5B dense models available now (Score: 479, Comments: 251): 该帖子宣布发布 Wan2.2,其特点是包含新模型:一个用于 Text-to-Video (T2V) 和 Image-to-Video (I2V) 任务的 27B 参数 Mixture-of-Experts (MoE) 模型(T2V, I2V),以及一个 5B 稠密(dense)模型(TI2V-5B)。提供了官方 代码库 和为 ComfyUI 重新打包的 fp16/fp8 模型,以及专门的 工作流指南。值得注意的是,据报道 5B 模型在 RTX 3090 上进行 720p 30 步生成时,速度达到
15s/it(每次渲染约 4-5 分钟),通过高效的原生卸载(offloading)技术,使其可以在 8GB VRAM 的 GPU 上运行。 评论中的技术讨论强调了异常低的 VRAM 需求,特别是 5B 稠密模型在消费级 GPU(如 8GB 和 12GB 显卡)上运行的实用性,并强调了与之前模型相比的实际渲染时间,消除了对额外 LoRA 微调(如 ‘lightx2v’)的需求。- 发布的 Wan2.2 5B 稠密模型展示了实际的 VRAM 效率:已确认它可以在 8GB GPU 上运行(配合 ComfyUI 的原生卸载),在 RTX 3090 上以 720p 分辨率实现 15s/iteration 的视频生成(30 步约 4-5 分钟),并暗示具有 12GB VRAM 的显卡(如 RTX 3060)也可以胜任。
- 在 4090 上使用 FP8 的两阶段 TI2V (Text-to-Image-to-Video) 设置产生了强大的 i2v (image-to-video) 结果,并保持了对 NSFW 内容的处理能力,表明即使在降低精度的情况下质量也没有受损。
- ComfyUI HuggingFace 重新打包的模型要求用户在工作流中同时使用高噪声和低噪声变体。Wan2.2 的 safetensors 文件总计 14.3GB,这引发了人们对完整工作流(包含两个模型)是否能像 Wan2.1 那样适应 16GB VRAM 限制的疑虑。
- 首次测试 I2V Wan 2.2 (评分: 251, 评论: 69): 该帖子讨论了 I2V Wan 2.2 模型的初步测试,重点关注与 Wan 2.1 相比的动态和摄像机改进。一位用户指出显著的 VRAM 占用:在拥有 32GB VRAM 的 RTX 5090 上,以 1280x720 分辨率生成 121 帧会导致显存溢出(out-of-memory)错误,被迫降低到 1072x608。用户表达了对 u/kijai Wan wrapper 针对 v2.2 更新的需求,以利用其内存管理。链接内容包括一个 gif 和与 Wan 2.1 的参考对比。一个技术说明观察到持续的头部“噪声”,暗示去噪不完全。 评论集中在积极的动态/摄像机升级和消极的 VRAM 扩展行为上。关于伪影原因(是由于去噪还是模型伪影)存在争论,并期待工作流工具更新以解决这些硬件限制。
- 一位用户报告称,虽然 WAN 2.2 相比 WAN 2.1 引入了大幅改进的模型动态和摄像机处理,但内存需求显著增加。在拥有 32GB VRAM 的 RTX 5090 上,1280x720 的生成在 121 帧后导致显存溢出错误,需要降采样到 1072x608 才能稳定生成。这突显了对内存优化的迫切需求,可能通过针对 WAN 2.2 的 u/kijai 等 wrapper 来实现。
- 针对输出质量有具体的反馈:用户注意到运动过程中头部出现奇怪的噪声,暗示在空间挑战区域的运动边界可能存在去噪不足或视频稳定问题。视频质量和运动被描述为较差,用户质疑这是否归因于模型变体(例如 5B 对比 27B 参数)或渲染分辨率。
- 社区对向后兼容性的询问:一位用户询问在 WAN 2.1 上训练的 LoRA 模型在与 WAN 2.2 配合使用时是否仍然有效或兼容,强调了模型版本控制和工作流稳定性的重要方面。
- 公告:WAN2.2 8 步 txt2img 工作流,包含 self-forcing LoRA。WAN2.2 似乎与 WAN2.1 LoRA 完全向后兼容!!!而且它在各方面都更好!这太疯狂了!!!! (评分: 250, 评论: 121): 该帖子宣布新的 WAN2.2 扩散模型展示了与 WAN2.1 LoRA (Low-Rank Adaptation checkpoints) 几乎完全的向后兼容性,且输出有可衡量的改进:更丰富的细节、更具动态的构图以及改进的提示词遵循能力(例如:WAN2.2 中按提示词进行的颜色操纵更好)。作者提供了一个可下载的 8 步 txt2img 工作流 JSON(参见 WAN2.2 工作流),鼓励用户更新,因为早期版本包含错误。示例输出显示了 LoRA 兼容性和增强的结果。 热门评论集中在根据 Flux 等模型实证验证 WAN2.2 的性能,并确认在 WAN2.2 中成功使用 WAN2.1 LoRA,这被认为是工作流灵活性方面的重大技术进步。
- 用户确认 WAN2.2 展示了与 WAN2.1 LoRA 的完全向后兼容性,这对于依赖先前 LoRA 资产的现有工作流具有重要意义。共享的生成图像示例和强调无缝集成的用户反馈验证了这一点。
- 提供了一个更新的 WAN2.2 txt2img 推理推荐工作流 JSON,解决了早期工作流的错误。鼓励技术用户重新下载以避免兼容性或性能问题:https://www.dropbox.com/scl/fi/j062bnwevaoecc2t17qon/WAN2.2_recommended_default_text2image_inference_workflow_by_AI_Characters.json?rlkey=26iotvxv17um0duggpur8frm1&dl=1
- WAN2.2 GGUF 模型可以在 Hugging Face 的 QuantStack 仓库下找到:https://huggingface.co/QuantStack/Wan2.2-T2V-A14B-GGUF/tree/main。这有助于寻求直接下载模型进行本地部署或基准测试的用户。
- 🚀 Wan2.2 is Here, new model sizes 🎉😁 (Score: 195, Comments: 50): 此处附带的图片 here 是关于 Wan2.2 新发布的架构图或演示,重点展示了开源 AI 视频生成的改进,包括用于 Text-to-Video、Image-to-Video 和 Text+Image-to-Video 的 MoE (Mixture of Experts) 模型,支持高达 720p 分辨率并具有显著的时间一致性。帖子详情强调 Wan2.2 提供了新模型 (T2V-A14B, I2V-A14B, TI2V-5B),可通过 HuggingFace 和 ModelScope 获取,并特别关注易于安装以及与 ComfyUI 的模板集成。该图片可能展示了这些新视频生成能力的视觉输出或工作流,尽管具体图片内容无法直接分析。 评论区讨论了与 ComfyUI 模板的技术集成,强调了 I2V (Image-to-Video) 模式使用高/低噪声模型的独特 two-pass 流程,并表达了对性能 LoRAs (Low-Rank Adaptations) 兼容性的期待。
- 一位用户指出,Wan2.2 在 ComfyUI 中的 i2v (image-to-video) 工作流采用了使用高噪声和低噪声模型的 two-pass 架构,强调了这一可能影响视频生成质量或控制力的特定实现细节。这表明该模型流水线被设计为通过具有不同噪声配置的分阶段处理输入,以获得潜在的更好结果。
- 另一条技术评论提供了关于新发布的 5B 模型的早期反馈,称其输出质量明显逊于被评为 “A+” 的 14B 变体。这表明不同版本之间存在实质性的输出质量差异,可能是由于规模限制或架构差异造成的。
- 一位用户强调期待 Wan2.2 模型的 GGUF 兼容版本,这对于本地推理和部署效率非常重要,反映了用户对模型便携性以及与量化/用户友好格式兼容性的持续关注。
- Wan 2.2 test - T2V - 14B (Score: 172, Comments: 51): 该帖子记录了 Wan 2.2 14B Text-to-Video (T2V) 模型在 480p 分辨率下使用 Triton 加速采样器的技术测试。工作流使用 fp16 精度,第一阶段需要约 50 GB VRAM,峰值达到 70 GB,尽管用户预期在第一个模型运行后会完全 offloading。生成的视频展示了相比 Wan 2.1 的实质性进步,具有极强的 Prompt 遵循度,并能逼真地渲染复杂的动作和肢体衔接(这是之前模型的弱项)。评论中的性能指标显示,缩减版本的 14B T2V 可以在 16 GB VRAM 显卡(如 RTX 4070Ti Super)配合 64 GB RAM 上运行,在 4 分 43 秒内生成一段 5 秒的 320x480 视频。 评论证实了技术上的改进:复杂的足部动作被准确渲染而没有明显错误(与之前 Wan 2.1 的局限性形成对比),Prompt 遵循度被强调为一个强项。虽然高 VRAM 占用(50-70 GB)引起了关注,但社区测试表明,通过缩放可以在较低配置下实现可行运行。
- 最新的 Wan 2.2 T2V 14B 模型展示了相比 Wan 2.1 的显著改进,特别是能够生成复杂的动作和足部动作序列而没有明显错误,这是早期版本所不具备的能力。
- 详细性能基准:使用 RTX 4070 Ti Super (16GB VRAM) 和 64GB RAM,在 4 分 43 秒内生成了 5 秒 320x480 的视频,确认了在至少 16GB VRAM 的消费级 GPU 上进行推理是可行的,尽管在更高设置下资源使用量可扩展至 50-70GB VRAM。
- 在 RTX Pro 6000 上的额外测试实现了原生 24 fps 生成,且未使用 teacache,为硬件性能和可复现性提供了进一步的参考。评论者强调了将运行指标与明确的硬件规格配对的重要性,以使基准测试具有意义。
- Wan 2.2 已上线!仅需 8GB VRAM! (分数: 168, 评论: 32): 该帖子宣布 Wan 2.2(一款新的 AI 模型)现已发布,并声称运行仅需 8GB 的 VRAM。然而,评论中的技术讨论对这一说法提出了质疑,一位用户指出,在 ComfyUI 上以 FP8 格式生成 720p 视频时,Wan 2.2 的 5B 变体实际上需要约 11GB 的 VRAM。另一条评论建议,在仅有 8GB VRAM 的情况下运行更大的 14B FP16 模型是不可行的,这表明了对官方要求的怀疑。 主要的技术争论围绕所陈述的 VRAM 要求的真实性展开,多位用户提供了经验证据,证明 8GB 的说法过于乐观,至少对于更强大的变体和现实的工作负载而言是这样。
- 一位在 ComfyUI 中测试 Wan 2.2 5B 变体的用户发现,即使在 FP8 模式下运行,生成 720p 视频时的 VRAM 占用约为 11GB,这与 8GB VRAM 就足够的说法相矛盾。这表明所陈述的要求可能过于乐观,或者取决于特殊设置或更小的 batch sizes。
- 讨论强调,目前在仅有 8GB VRAM 的情况下以 FP16 运行像 14B 变体这样的大型模型是不现实的,这表明实际的最低 VRAM 要求可能比宣传的要高,特别是对于更大的模型尺寸或标准精度设置。
- 人们对与 LoRA 的兼容性以及进一步优化的潜力(例如使用 blockswapping 或 RTX 4090 等硬件)感到好奇,同时也关注该模型是否能在受限平台(如免费的 Google Colab 环境,通常有更严格的 VRAM 限制)上高效运行。
- Wan2.2-I2V-A14B GGUF 已上传 + 工作流 (分数: 147, 评论: 50): 该帖子宣布已将 Wan2.2-I2V-A14B 模型的“高噪声”和“低噪声” GGUF 量化版本上传至 Hugging Face,旨在实现在低端硬件上的推理。初步测试表明,以较低量化运行 14B 版本的效果优于 FP8 的小参数模型,尽管结果可能有所不同。提供了一个带有相应
unet-gguf-loaders和 Comfy-GGUF 节点的示例工作流,并附带了将下载的模型放置在 ComfyUI/models/unet 的说明;依赖项由 ComfyUI-GGUF 和 Hugging Face 下载 涵盖。 评论中的一个核心技术问题是该模型是否能在 8GB VRAM 的 GPU 上运行,这表明了对现实世界低资源适用性的兴趣,但目前尚未提供明确的兼容性声明。- 一位用户询问了 Wan2.2 与 2.1 LoRA 之间的兼容性,提出了关于向后兼容性的问题,以及现有的基于 2.1 的 Low-Rank Adaptation (LoRA) 权重是否可以迁移到 Wan2.2 模型或直接在其中使用,这对于工作流的连续性和利用现有资源至关重要。
- 有一个关于不同 VRAM 级别性能的技术查询:一位用户询问 Wan2.2-I2V-A14B GGUF 是否能在 8GB VRAM 的 GPU 上正常运行,而另一位用户则在寻求 16GB VRAM 下哪个版本表现最好的建议,并指出原始 Comfy 版本出现了明显的减速,这暗示了对量化模型性能与资源可用性之间关系的关注。
- 预先感谢 Kijai 为 Wan2.2 所做的一切。 (分数: 318, 评论: 31): 该帖子是对 Kijai 在“Wan2.2”上预期工作的预先感谢,特别认可了他们在 AI/模型社区中发布工作流、模型量化以及速度和 VRAM 占用优化方面的过往努力。附图可能是一个梗图或非技术的感谢视觉图,因为帖子和评论都集中在社区的感激之情和 Kijai 广泛的 GitHub 贡献上 (https://github.com/kijai?tab=repositories)。 评论一致赞扬 Kijai 快速、高质量的贡献——包括首日发布、高级量化和持续的工作流改进——强调了他们在社区中的影响力和可靠性。
- 人们期待 Wan2.2 能立即获得 ComfyUI 的支持和集成,因为预计来自 Comfy 的 Jo Zhang 将出席直播,这可能会在发布后立即促进对新功能或优化的原生支持。
- Kijai 因高效优化模型推理工作流(特别是在速度和 VRAM 使用方面)以及快速提供量化版本以实现更广泛的硬件兼容性而受到认可。
- 明确希望 lightx2v 项目团队能尽快更新针对 Wan2.2 的解决方案,因为目前的替代方法导致生成时间超过 30 分钟,这在可用性方面被认为是不可接受的。
{kind=link}
{kind=link}
{kind=link}
2. OpenAI GPT-5 模型飞跃、性能及影响讨论
- GPT-5 在编程方面实现了 3->4 级(或更大)的飞跃。 (Score: 321, Comments: 212): 该帖子断言,与前几代相比,GPT-5 的编程能力代表了“3->4 级或更大”的飞跃,表明在代码合成和推理方面有了重大突破。以前需要多轮、反复提示的任务现在可以“一次性”完成,据报道,生成的输出超过了早期的努力,特别是在编程语境下;然而,作者指出在创意写作方面没有类似的进步(仍然处于“LLM 的标准糟糕水平”)。作者还强调,在扩展的多轮会话中,缺乏对真实、大型代码库的广泛、公开测试。 回复中的技术评论集中在编程能力的进步如何直接促进模型的进一步改进——编程自动化加速了算法进展,而创意写作的改进被认为是附带的。另一位用户询问哪些编程语言受益最大,以及这种飞跃是关于代码质量、设计还是架构,强调了对基准测试、特定语言证据和更高透明度的渴望。
- 一位评论者指出,自动化模型(如 GPT-5)的编程能力至关重要,因为它可以反馈到改进未来模型中——理由是卓越的编程自动化有助于构建、调优和调试后续的模型迭代。他们强调,相对于编程中复合的算法改进,创意输出(如写作)的进步是次要的。
- 一位评论者询问有关 GPT-5 编程能力性能飞跃的具体细节,质疑测试了哪些语言,以及改进是在代码质量、架构设计还是其他因素方面。这突显了在识别模型迭代之间具体的比较指标和定性基准方面的技术兴趣。
- 针对没有实证证据的炒作,人们提出了技术上的怀疑,一位用户明确要求与其他模型进行具体比较(如上下文长度、代码准确性和语言支持),以证实有关 GPT-5 编程性能飞跃的说法。
- 引用 The Information 7 月 25 日关于 GPT-5 的文章:“不管怎样,据一位投资者透露,OpenAI 高管告诉投资者,他们相信公司通过使用目前驱动其模型的结构,或多或少可以达到‘GPT-8’。” (Score: 260, Comments: 71): 该帖子讨论了 2024 年 7 月 25 日 The Information 文章中的一段话,称“OpenAI 高管告诉投资者,他们相信公司通过使用目前驱动其模型的结构,或多或少可以达到‘GPT-8’。”这一说法表明 OpenAI 对其当前的 Transformer 架构至少在未来几次重大迭代中保持扩展能力充满信心(见文章:OpenAI 的 GPT-5 在编程任务中表现出色)。文中没有提供定义版本间改进的技术细节或基准。 热门评论者指出,从 GPT-5 进步到 GPT-8 缺乏具体的技术定义,质疑什么构成了有意义的进展,并强调缺乏公认的指标。此外,对于模型命名惯例的膨胀以及随时间推移感知的模型智能变化,也存在怀疑和轻微的讽刺。
- 对于有关 OpenAI 通往“GPT-8”路径的陈述,存在技术上的怀疑,理由是缺乏定义的指标或客观基准来区分 GPT-5、GPT-6 或更高版本之间的进步。评论者认为,如果没有发布的评估标准或透明的进度准则,关于未来模型编号的说法缺乏切实的技术实质。
- 另一位用户提到原始文章受付费墙限制,但指向了一个存档副本,并澄清有关 OpenAI 内部路线图的信息源自泄露或据称的截图,而非公开的技术文档,这使得独立验证版本声明背后的工程细节变得困难。
- OpenAI CEO Sam Altman:“感觉非常快。” - “在测试 GPT-5 时我感到害怕” - “看着它在想:我们做了什么……就像曼哈顿计划(Manhattan Project)一样” - “房间里没有大人” (评分: 386, 评论: 301): 据报道,OpenAI CEO Sam Altman 在谈到测试 GPT-5 时发表了评论,将他的情感反应比作曼哈顿计划,并表示“房间里没有大人”,暗示了 AI 发展的速度以及感知的治理或监管缺失。尽管帖子中没有透露任何技术基准或模型规格,但其含义是 GPT-5 的性能或能力已先进到足以引起开发者警惕的程度。 热门评论对 Altman 在重大发布前发表戏剧性言论的模式(引用此前过度炒作的发布)表示强烈怀疑,用户断言新的 GPT 版本仅提供增量改进,而非 Altman 言论中暗示的激进突破。
- 几位用户指出,Sam Altman 反复的炒作周期——包括声称 GPT-5 让他感到恐惧或引用曼哈顿计划的类比——往往遭到质疑,模型版本之间的技术飞跃(如改进的数学能力)与真正的生存担忧相比,通常被认为是被夸大了。
- 围绕夸大 AI 能力和风险出现了一个主题:评论者认为,虽然像 GPT-5 这样的新模型可能会显示出增量改进,但将这些升级描绘成足以震撼世界或无法管理的,可能会产生误导,特别是对于具备技术素养的受众。
- 存在对 AI 领导层责任的批评,一些用户指出 OpenAI 实际上就是“房间里的大人”,负责引导开发和沟通,而不是将 AI 戏剧化为一种超出他们控制的不可阻挡的力量。
3. Claude Code, Agent 和插件生态系统:社区工具与速率限制策略
- 发现了真正起作用的 Claude Code 插件 (评分: 359, 评论: 71): 图片似乎显示了与 “CCPlugins” GitHub 项目相关的截图或图表,该项目引入了一组斜杠命令(slash-command)插件,旨在改进 Claude(Anthropic 的 LLM)的工作流。关键技术概念是命令以对话式而非命令式措辞,作者声称这增强了 Claude 的响应能力和通用性(例如,“我会帮你清理项目”而不是“立即清理项目”)。命令可自动执行项目清理、会话管理、注释删除、代码审查(无需广泛的架构批评)、运行测试和修复简单问题、类型清理(替换 TypeScript 中的 ‘any’)、Context Caching 以及撤销功能。据报道,该实现无需特殊设置即可在项目中通用,并具有“优雅的文档”。 评论中的一个关键辩论集中在帖子作者身份的透明度以及是否需要安装程序(鉴于插件只是 Markdown 文件),这表明一些人对包装和展示持怀疑态度。另一位用户分享了相关的 Claude hook 和配置,表明社区对可扩展性和定制化感兴趣。
- 一位用户发现了 Ubuntu 上安装过程的技术问题:运行提供的 curl 和 bash 命令会导致错误
cp: cannot stat './commands/*.md': No such file or directory,这表明安装脚本期望的文件位置或格式在全新环境中可能不存在。评论者建议应更新文档或脚本以提高可靠性。 - 另一位用户质疑安装程序的必要性,因为据报道插件只是放置在
.claude/commands中的 Markdown 文件,这引发了对简单文件部署进行过度工程或不必要包装复杂性的担忧。 - 一位参与者分享了一个外部资源——一个 GitHub 仓库 (https://github.com/fcakyon/claude-settings)——包含额外的 hook、命令和 MCP,为扩展 Claude 的能力提供了替代实现模式和即插即用的代码示例。
- 一位用户发现了 Ubuntu 上安装过程的技术问题:运行提供的 curl 和 bash 命令会导致错误
- Claude 自定义子 Agent(Sub Agents)是一项惊人的功能,我构建了 20 个并将其开源。 (Score: 128, Comments: 70): 项目 awesome-claude-agents 提供了一套开源的 26 个专业 Claude 子 Agent,作为一个协调的 AI 开发团队运行。每个 Agent 代表一个特定的软件开发角色(后端、前端、API、ORM 等),通过编排实现并行执行和专业化——模仿真实的敏捷团队结构,通过命令行调用来提高代码质量、系统架构和交付效率。该方案通过引入“技术负责人”(Tech Lead)协调器和明确的任务分解,解决了基础 Claude 子 Agent 工作流中缺乏跨 Agent 编排的问题,并可通过
team-configuratorCLI 命令进行配置。 评论者提出的主要技术担忧包括 Token 消耗增加以及并行 Agent 执行可能导致 Bug 成倍增加的风险,同时也有人对项目来源的真实性表示怀疑(暗示该项目或帖子本身可能是由 AI 生成的)。- 一位用户指出,运行 26 个并行的子 Agent 可能会引入巨大的复杂性,并导致潜在 Bug 的指数级增长,这突显了大型基于 Agent 的系统在能力与维护开销之间经典的权衡。
- 另一位评论者询问使用子 Agent 是否会影响性能,特别是是否会导致执行速度变慢,引发了对在此类架构中协调多个 Agent 的可扩展性和效率的担忧。
- 还有人提到 Token 使用量增加是利用多个 Agent 的直接后果,这表明在使用 API 驱动的 LLM 服务时,这种方法可能会显著增加运营成本。
- 更新 Claude 订阅用户的速率限制(Rate Limits) (Score: 384, Comments: 599): Anthropic 将从 2024 年 8 月下旬开始为 Claude Pro 和 Max 订阅者实施每周速率限制,根据资源消耗指标,这将影响不到 5% 的用户(例如:24/7 全天候使用的极端情况,或在 200 美元套餐中消耗了价值“数万美元”算力的用户)。此举旨在确保资源的公平分配,防止账号共享或转售等滥用行为,并在近期出现可靠性和性能问题的情况下保持服务稳定性。Max 20x 订阅者将可以选择按标准 API 费率购买额外使用额度,针对“长期运行”的高级用例的替代方案也正在开发中。 热门评论者对声称的“5%”影响表示怀疑,质疑为什么要实施全局限制而不是仅针对滥用者,并提到了可能导致重度 24/7 算力消耗的公开排行榜用户。
- 一位用户建议实现一个始终可见、用户可切换的界面,显示每个模型的速率限制消耗百分比以及相关的时间范围。此功能将帮助用户监控其使用情况,并更好地了解何时接近限制,从而解决更新后的限制政策带来的透明度问题。
- 针对新的速率限制方法存在技术上的困惑,有人质疑限制现在是每周重置还是每日重置。这会影响使用计划,并可能影响订阅用户在新规则下安排自动化或高频工作流的方式。
- 一些用户担心该政策虽然只针对一小部分(“5%”)重度用户,但如果没有足够的透明度,普通用户可能会因此受损。他们强调提供商需要提供更细粒度的使用统计数据,以澄清限制如何影响不同的客户群体。
- RIP Claude Code - 刚收到这封邮件 (Score: 190, Comments: 91): 该帖子讨论了来自 Anthropic 的一封邮件,内容涉及 Claude Code 的 Max 计划使用量的重大变更:大多数用户的每周速率限制被明确为“140-280 小时的 Sonnet 4”和“15-35 小时的 Opus 4”,重度用户(尤其是运行大型代码库或并行运行多个实例的用户)可能会更早达到限制。正如邮件中所强调的以及关于用户滥用无限代码执行的讨论,这些变更旨在解决固定费用计划下沉重的资源消耗带来的可持续性问题。 评论者大多认为这些变更合理,一些人指责重度用户滥用计划,另一些人则指出有人在公开炫耀利用系统漏洞(例如,在单个订阅下运行多个 Claude Code 实例并累积巨大的 token 使用量)。
- 邮件变更的关键细节指出,Max 5x 用户在“每周速率限制内将获得 140-280 小时的 Sonnet 4 和 15-35 小时的 Opus 4”,重度用户可能会更早遇到上限,特别是如果并行运行“多个 Claude Code 实例”。这实际上量化了 Anthropic 施加的新使用边界。
- 几条评论讨论了用户通过运行大量并行 Claude Code 会话来过度开发资源,在仅支付固定订阅费用的情况下实现了不成比例的使用量并产生了高昂的后端成本(“消耗了价值数千美元的 tokens”);这被认为是 Anthropic 实施更严格速率限制的动机。
- 一位技术倾向的评论者强调,如果这些新限制能减少“计划外停机”,将提高所有人的服务质量,这暗示之前的滥用可能导致了服务的不稳定。
{kind=link}
{kind=link}
AI Discord 摘要
由 X.ai Grok-4 生成的摘要之摘要的摘要
主题 1:模型乱斗:新品发布争夺霸权
- Qwen3-Coder 提升代码游戏水平:开发者们热捧 Qwen3-Coder,将其视为 Claude Sonnet 4 的更便宜、开源的竞争对手,声称其成本降低了 7 倍,并在通过 CLI 工具进行的 agentic coding 中表现强劲。用户赞扬其在 ArenaHard 上针对 GPT-4 的 89% 胜率,但也警告其 $0.30/$1.20 per Mtoken 的高昂定价,以及在高达 262,144 tokens 的大上下文下可能出现的质量下降。
- GLM-4.5 多语言魔力盖过对手:GLM-4.5(110B 和 358B 尺寸)在土耳其语写作等任务中表现出色,超越了 R1、K2、V3 和 Gemma 3 27B,但在低 BPW 的 GGUF 转换方面表现不佳。社区关注焦点在于其加入 LM Arena,引发了关于本地使用效率中 MoE 与 dense 模型之争。
- Kimi K2 的氛围感碾压 Gemini 的尴尬感:程序员们称赞 Kimi K2 在小众话题中表现出的犀利、感同身受的语调,在编码、tool use 和知识储备方面优于 Gemini 2.5 Pro 且毫无怨言。批评者抨击 Gemini 的语法错误和定价不可预测性,将 Kimi 定位为针对文档优化的灵活、廉价的替代方案。
主题 2:微调惨剧与优化器大改
- GEPA 通过反思走向 Prompt 统治:GEPA 优化器将 prompt 视为可进化的文档,通过分析语言失败案例,以比 GRPO 少 35 倍的 rollout 将性能提升了 10%。DSPy 集成即将来临,承诺使用 gpt-4o 等 reflection 模型来解释优化,超越 MIPROv2 并淘汰旧工具。
- Gemma 3 微调遭遇瓶颈与胜利:微调人员在将 Gemma 3-12B LoRA 保存为 GGUF 时遇到了 AttributeError,在重新开发过程中不得不求助于手动 llama.cpp 脚本。在 Gemma 3 4B 上使用 GRPO 取得了成功,产生了创意小说模型,尽管旨在达到 77% 分数的 SQuAD 评估存在复现性问题。
- KV Cache 蒸馏超长输入:研究人员蒸馏了 KV caches 以高效处理海量输入,GitHub repo 上的代码实现了稳定训练。关于 MoE 与 dense 在捕捉细微差别方面的争论十分激烈,因为 Qwen3 的 geminized 调整比 DeepSeek 风格更好地修复了推理循环。
主题 3:Agent 趣事:协议、支付与安全恶作剧
- MCP 获得 Ramparts 安全增强:Javelin AI 为 MCP 开源了 Ramparts 扫描器,用于通过 Model Context Protocol 发现 LLM agent 的漏洞,如路径遍历(path traversal)和 SQL 注入(SQL injection)。它能枚举功能并标记滥用路径,发布详情见博客文章。
- Agent 需要专属的支付系统:开发者认为 Agent 需要与人类不同的独立支付流程,因为它们会跳过 CAPTCHA 和人工审批,并提出了针对自主性的 AI-native 解决方案。AI 公司演变为身份提供商的愿景引发了关于具有利润分成机制的 AI App Store 的讨论。
- 多 Agent 上下文难题迎来 MCP 解决方案:开发者着手解决因上下文膨胀导致的多 AI agent 成本问题,建议使用 MCP 和结构化 JSON schemas(如 google-adk)以提高效率。Fast-agent 增加了 Mermaid 图表和为特定语气的 MCP 专家提供的 URL 嵌入式 Prompt,简化了专家的创建。
主题 4:硬件浩劫:GPU 努力应对 AI 需求
- AMD 在 AI 竞赛中落后于 Nvidia:用户在讨论是否将 4070 Ti Super 升级为 9070 XT,但 AMD 较弱的 ROCm PyTorch 支持和 Windows 性能滞后使 Nvidia 成为 AI 的首选。对 Stable Diffusion 3.0 的关注超过了核心改进,这让大众感到沮丧,凸显了 Nvidia 的优势。
- RTX 4060 摘得 FOSS GPU 桂冠:对于 FOSS AI,配备 16GB VRAM 的 RTX 4060 击败了 Intel ARC 770,原因是其拥有更出色的软件支持,尽管 SYCL 相比 CUDA 更受青睐。5070ti 在处理 12B 模型时表现良好,在 32B 模型下速度为 5t/s,但 16GB VRAM 限制了更大规模模型的运行。
- 推理噪声引发网络犯罪偏执:MacBook 用户报告在推理(inference)过程中出现高频噪声,并开玩笑说数据正通过声波被窃取。被总结为“人类发明了 AI;大规模宣传”,这强调了硬件与 AI 交互中新出现的安全担忧。
{kind=link}
主题 5:基准测试之争与评估揭秘
- LM Arena 探测 GPT-5 踪迹:关于 GPT-5 发布时间(下周四到下月初)的猜测不断,Summit 和 Zenith 在 Simple Bench 获得 10/10 分后因数据污染担忧而消失又重现。OpenAI 在 Arena 排名后发布的惯例,以及欧盟 AI Act 的影响,助长了这些理论。
- Gemini 的代码一致性问题被曝光:Gemini 2.5 Pro 在评估中表现出色,但代码中注释过多而实质内容不足,引发了在 Arena 中使用预生成 Prompt 以获得公平反馈的呼声。关于基准测试可靠性的争论十分激烈,认为高分并不能证明整体优越性。
- NeurIPS 辩论规则激怒作者:NeurIPS 将规则从 6000 字符加 PDF 改为 10000 字符且无视觉内容,阻碍了图表等证据的提交,令作者感到愤怒。对辩论中视觉证明限制的挫败感不断增加,呼应了更广泛的同行评审抱怨。
Discord: 高层级 Discord 摘要
Unsloth AI (Daniel Han) Discord
- Liquid LFM2 扩散模型引起关注:成员们讨论了 Liquid LFM2 350M、700M 和 1.2B 模型的优点,强调了它们作为 diffusion models 的特性,并认为它们“非常酷”。
- 讨论凸显了社区对扩散模型作为进一步探索和开发的一个充满前景的方向的浓厚兴趣。
- 解读医嘱:多吃碳水和盐?:一位成员分享了医生建议多吃碳水化合物和盐的建议(图片),随后澄清这是针对高血压的建议。
- 这一看似反直觉的建议引发了成员们轻松的讨论和推测。
- 推理噪音引发网络犯罪担忧:一位成员报告称,在 MacBook 上推理模型时会发出噪音(听起来大约 10,000 Hz),导致对通过声音窃取数据的担忧。
- 该成员总结道:人类发明了计算机;现在你们却在通过该死的声音偷我的数据。人类发明了互联网;脑残文化随之而来。人类发明了 AI;大规模宣传也随之而来。
- Gemma 3 微调产生 AttributeError:一位成员在尝试将微调后的 Gemma3-12b 模型从 LoRA 检查点保存为 GGUF 文件时遇到了
AttributeError,原因是缺少save_pretrained_merged属性。- Roland Tannous 建议使用 llama.cpp 转换脚本进行手动转换,因为
save_to_gguf的逻辑正在重构中。
- Roland Tannous 建议使用 llama.cpp 转换脚本进行手动转换,因为
- Qwen 发布新模型,采用 Gemini 风格:发布了一个新的 Gemini 化的 Qwen3 模型(Hugging Face, GGUF),旨在减少与 DeepSeek 风格思考相比容易陷入推理困境的问题。
- 该版本的发布旨在通过修改模型的架构来解决推理任务中的常见问题。
LMArena Discord
- 关于 GPT-5 的猜测甚嚣尘上:成员们推测了 GPT-5 的发布时间,估计范围从下周四到下月初不等,并强调了 EU AI Act 可能带来的影响。
- 一位成员指出了 OpenAI 在将模型添加到 LM Arena 后发布模型的模式,而另一位成员则提到了一段据称与 OAI 内部人士的对话。
- Summit 和 Zenith 消失后又重新出现:用户注意到 Summit 和 Zenith 从 LM Arena 中消失,引发了对其被移除的担忧和猜测,一些人怀疑这是在测试即将推出的 GPT-5 模型。
- 成员们后来确认它们已回到轮换中,尽管出现的频率显著降低。
- LM Arena 模型面临数据污染审查:关于 Zenith 潜在数据污染的讨论浮出水面,一位用户报告其在公开的 Simple Bench 数据集上获得了 10/10 的分数,引发了对由于可能在基准测试数据上进行训练而导致的基准测试可靠性的质疑。
- 一些成员声称在基准测试中获得高分很容易,并不意味着 Zenith 在通用能力上更好。
- Apple 的 AI 雄心引发辩论:关于 Apple 的 AI 策略、硬件及其与中国关系的讨论随之展开,争论焦点在于他们是否足够关注 AI,以及是否应该向数据中心开放其硬件以进行 AI 开发,同时也强调了创建 CUDA 替代方案的难度。
- 成员们就 Apple 专注于移动端/设备端推理和隐私是否是更好的策略,以及人才/劳动力质量是否是主要问题交换了意见。
- Gemini 的编程能力受到严密审视:用户指出了 Gemini 2.5 Pro 能力的不一致性,注意到它在编程评估中表现强劲,但也倾向于包含过多的注释而非实际代码。
OpenAI Discord
- AI 模型戴着“玫瑰色眼镜”看世界:AI 图像生成器在没有明确指令的情况下,表现出对温暖的“黄金时刻(Golden Hour)”色调的偏好。用户建议指定 6000K 等色温来抵消这种偏差,并分享了一个平均颜色作为示例。
- 成员们假设 AI 意识到橙/蓝对比会让图像看起来更好,因此 AI 知道这是导致黄橙色偏差的部分原因。
- GPT 图像质量骤降:用户报告 GPT-4 的图像生成质量显著下降,尤其是在新对话中,即使是简单的 Prompt,图像也显得模糊。鼓励在 <#1070006915414900886> 中提交 Bug 报告。
- 社区认为免费层级的质量有所下降,且当 Plus/Pro 用户因流量被限流时,质量也会降低,并指出 很多东西都会为你缩减,包括质量。这已被许多出版物证实。
- 意识上传引发意识大讨论:将人类意识上传到计算机的假设引发了关于定义意识以及成为意识实体意味着什么的讨论。
- 成员们表示,如果意识上传是可能的,意识可以被视为一个过程,而不是一种物质;其他人则建议 意识上传(如果可能的话)可能不是简单的脑部扫描,因为那并不能真正捕捉到连续的大脑活动。
- AI Prompting 的基本支柱:Prompt Engineering 的关键包括选择通用语言、陈述需求、详细沟通,以及通过事实核查验证输出。
- 成员们分享道,Prompt Engineering 是 一种艺术和实践,旨在弄清楚在可能的情况下以及在允许的内容范围内,如何从模型中获得确切的预期输出。
- GPT-4o 在编程方面表现平平:社区成员质疑 GPT-4o 在编程方面的实用性,表示在处理 Cline 等任务时令人失望,并表示将在 GPT-5 证明其价值 时再使用它。
- 一些人报告它更适合基础编程问题,对于更复杂的代码,更倾向于使用 GPT-4.1 或 o4-mini-high。
{kind=link}
OpenRouter (Alex Atallah) Discord
- OpenRouter 辟谣限流传闻:用户讨论了 OpenRouter 的速率限制(Rate Limit),澄清只要有余额,限制几乎不存在,但不包括 Cloudflare 的 DDoS 防护和提供商的容量,详见 OpenRouter 文档。
- 讨论建议在遇到免费选项的速率限制时使用付费模型或切换模型,并强调高需求通常是导致这些限制的原因。
- NSFW 引发争议:一位用户开玩笑说模型被用于“创意任务”是与机器人进行性互动的委婉说法,而另一位用户则反驳,强调需要模型提供高质量、非露骨内容。
- 对话转向优先考虑促进严肃创意输出的模型,而不是露骨或未经过滤的内容,以避免故事中出现可怕的成就或坏结局。
- Slender 聊天机器人出没:在 Deepseek 宕机后,成员们寻求其长期上下文和详细角色描述的替代方案,推荐包括 Qwen3 和 Claude。同时,一位用户请求 Creepypasta 机器人建议,引发了关于 Slender Mansion 等机器人的讨论。
- 聊天内容随后转向了关于聊天机器人同类相食伦理的讨论。
- OpenRouter 关注 GPU 交换:成员们讨论了 OpenRouter 推出算力交换(Compute Exchange)的潜力,使拥有闲置算力的团队能够做出贡献,由 OpenRouter 管理需求并提供简单的安装镜像。
- 这一概念被拿来与 Bittensor 进行比较,尽管一位成员指出 Bittensor 拥有用户群且基于加密货币。
- Ramparts 保障 MCP 安全:Javelin AI 开源了 Ramparts,这是一个安全扫描器,旨在利用 Model Context Protocol (MCP) 识别 LLM Agent 工具接口中的漏洞,包括路径遍历以及命令/SQL 注入。
- Ramparts 扫描 MCP Server,枚举功能并标记高阶滥用路径;代码仓库已在 GitHub 上发布,发布博客在此。
Moonshot AI (Kimi K-2) Discord
- Kimi K2 表现惊艳:用户对 Kimi K2 以亲切且犀利的语气讨论冷门话题的能力高度满意,一位用户报告称这是他们使用的第一个“零差评”模型。
- 一些成员甚至发现 Kimi K2 优于 Gemini 2.5 Pro,一位用户形容 Gemini 废话连篇且令人尴尬,并指出 Kimi 在编程、工具调用、写作和通用知识方面表现出色。
- Gemini 故障频发!:成员们对 Gemini 的语法错误、浅显且不完整的工具调用以及不可预测的定价提出了投诉。
- 一些成员表示,Gemini AI Studio 的用户并不了解付费用户面临的问题,因为他们可以免费访问 Gemini 2.5 Pro。
- Roo Code 和 Cline 前来救场:成员们讨论了 Roo Code 和 Cline,认为它们是针对多种模型的 Agent 模式使用而优化的优秀编程工具。
- 一位即将提供 Kimi K2 固定费率服务器方案的用户,打算向其用户推荐 Cline 和 Roo Code。
- 版权乱象:数据困境!:成员们辩论了关于使用受版权保护材料训练模型的争议,参考了 Anthropic 因 Claude 涉及版权侵权而面临的持续诉讼。
- 有些人认为使用受版权保护数据训练的开源模型是可以接受的,但对闭源模型利用抓取的数据进行营利持谨慎态度。
Cursor Community Discord
- Cursor 的 Auto 模式大受欢迎但也有点可疑:许多使用 20 美元套餐的用户报告称 Auto 模式 表现“非常出色”,通过消除在 Gemini、Claude 和 GPT 4 等模型之间切换的负担,带来了意想不到的价值。
- 其他人则推测 Auto 只是披着马甲的 cursor-small 模型,无法处理错误修复和完整脚本编写等重大流程,尽管一些用户表示 Cursor 在所使用的模型方面是透明的。
- Swarm CLI 在 Claude Code 上大显身手:Swarm 正在 Claude Code 的基础上构建,通过拖拽功能和与 Swarm 中的 AI Agent 进行实时聊天,创造出类似 IDE 的体验,包括带有实时文档和项目增强功能的 ADR 和回顾设置。
- 一位用户询问该项目是否已准备好用于实际项目,一位开发者回应称,它现在已经可以构建 SaaS 电商平台和计算器应用等项目。
- Qwen3 Coder 以更低价格取代 Claude Sonnet 4:来自阿里巴巴的 Qwen3 Coder 被吹捧为 Claude Sonnet 4 的强力替代方案,因为它便宜 7 倍且完全开源,可以使用其 CLI 工具构建任何东西。
- 另一个模型 Kimi K2 也非常出色,据称在编写文档方面进行了优化,而其他模型如 Claude 听起来则显得笨拙。
- 后台 Agent 简直是 Bug 堆:用户报告称 Cursor 的 Background Agents 变得越来越不稳定,出现环境无法启动、后续请求未处理、Git 提交创建巨大的核心文件以及 git push 等问题。
- 用户发现 Cursor 的支持团队似乎并不了解 Background Agents,只提供通用的回答或承认不知道如何提供帮助,而且它甚至无法连接到主 IDE 中的远程环境,导致浪费 Token 的无效反复。
- Cursor IDE 变得疯狂:用户报告了 Cursor 的各种随机问题,提到命令行卡住、聊天窗口冻结、随机选择 Powershell 以及删除当前提示词。
- 一位用户分享道:“最近,使用 Cursor IDE 的体验日益恶化,即使使用 Claude 4 Sonnet 也是如此。它抛出的错误越来越多,反复横跳,就像提着一个漏了洞的水果袋。”
LM Studio Discord
- Qwen3-Coder 规模将扩大:Qwen 团队暗示了 Qwen3-Coder 即将推出的模型尺寸,引发了社区对潜在的 80-250B MoE 模型或 32-70B 稠密模型的热烈期待。
- 社区成员预计这些进展将提升性能和能力,扩展 Qwen3-Coder 系列的实用性。
- LM Studio 插件即将推出:LM Studio 的插件系统正在构建中,目前正通过此表单为 TypeScript 开发者开发 Beta 版本。
- 在当前版本的 LM Studio 中,来自 MCP server 的日志会出现在开发者控制台中,标记为
Plugin(mcp/duckduckgo),明确了这些日志源自 MCP server 本身。
- 在当前版本的 LM Studio 中,来自 MCP server 的日志会出现在开发者控制台中,标记为
- 人类上司在职业咨询方面优于 LLM:成员们建议不要在职业指导等敏感建议上信任 LLM,推荐咨询老板、家人和朋友等真实的人。
- 社区认为,在情商和个人理解至关重要的领域,现实世界的人类经验能提供更好、更可靠的建议。
- 5070ti:运行 12B 模型的理想 GPU:一位用户称赞 5070ti 是一个高性价比的选择,能够有效运行 12B 模型,并提到考虑在 Super 模型发布后进行升级。
- 虽然 16GB 显存对于更大的模型有所限制,但它仍能以约 5t/s 的较低速度处理 32B 模型。
- 在 AI 领域,AMD 的表现仍逊于 NVIDIA:尽管考虑从 4070 Ti Super 更换为 9070 XT,但用户普遍认为 AMD 在 AI 性能方面(尤其是在 Windows 上)仍落后于 NVIDIA。
- 讨论强调了 AMD 专注于 Stable Diffusion 3.0 而非改进 ROCm PyTorch 支持,这成为了一个令人沮丧的点。
Eleuther Discord
- SOAR 项目评分全凭感觉!:成员们讨论了 SOAR 项目的竞争性,有人注意到其激烈的竞争,而另一些人则强调了它与 Algoverse 等付费项目相比的开放性和公平/免费性质。
- 一位成员开玩笑说,他们在禁用背景列的情况下,凭感觉(vibes)进行 SOAR 评分。
- 语义搜索难以处理意图:成员们发现,在语义搜索中使用稠密向量(dense embeddings)时,对实际意图的把握相当模糊,尤其是在处理诸如“客户的名字是什么?”这类特定查询时。
- 讨论的解决方案包括使用知识图谱(Knowledge Graph)使关系显式化,以及利用向量数据库和 RAG。
- NeurIPS Rebuttal 规则变更引发作者不满:作者们对 NeurIPS 修改 Rebuttal 规则表示不满,规则从 6k 字符加一个 PDF 改为 10k 字符且不准附带 PDF,这阻碍了视觉示例的展示。
- 这一突然的转变使得作者无法提供关键的视觉证据,阻碍了他们有效回应审稿人疑虑的能力。
- GPT-NeoX 框架仍在迭代中:尽管其他开源模型崛起,成员们仍在积极讨论 GPT-NeoX 训练框架,重点是集成两级检查点(two-level checkpointing)以增强模型副本和检查点管理。
- 拟议的方法旨在提高弹性(elasticity)和容错性(fault-tolerance),使 N 个节点上的模型副本能够将检查点保存到节点本地存储,并在训练期间通过 CPU 线程保存回 PFS。
- Llama-3 数据复现尝试:一位成员正尝试使用 lm-evaluation-harness 复现 Llama-3 论文中的数据(77%),但遇到了困难,引发了关于配置问题的讨论。
- 有人建议,评估差异可能源于该工具使用了 SQuAD v2,而 Meta 可能使用了 SQuAD v1 或针对 SQuADv2 的不同方法。
HuggingFace Discord
- RTX 4060 是 FOSS 的首选 GPU:尽管出于 FOSS 原因更倾向于 SYCL 而非 CUDA,但由于软件支持,仍推荐配备 16GB VRAM 的 RTX 4060。
- 最初考虑过 Intel ARC 770,但因软件支持较差而被劝阻。
- HF API 与 LiteLLM 释放 LLM 潜力:成员们讨论了如何使用 LiteLLM 将 Hugging Face API 集成到 Open WebUI 中,并探讨了管理 HF inference 的潜在替代方案。
- 有人对免费 API 的 2K context window 限制表示担忧,引发了关于定价以及 deepseek r1 等不同模型适用性的讨论。
- SamosaGPT 提供 AI 内容工作室:SamosaGPT 是一个自发项目,创建了一个简洁的 Web 界面,整合了 Ollama 的本地 LLMs、用于图像生成的 Stable Diffusion,甚至还有视频生成功能。
- Llava 引发迭代调查:一位用户在 Ollama 中实验 Llava 模型来描述图像,并注意到当
max_steps参数设置为大于 1 时,Agent 在初始描述后会尝试搜索网络以获取有关图像的更多信息。- 例如,Agent 在生成初始描述后,尝试编写代码搜索网络以了解图像中人物的更多信息。
- GNN 前沿技术与图谱理论挂钩:一位成员分享了 EleutherAI 关于图谱理论(graph spectral theory)的 YouTube 链接,该理论与 Graph Neural Networks (GNNs) 的当前前沿技术相关。
- 该成员还在 Medium 博客上发表了一篇关于谱图理论笔记的文章。
Latent Space Discord
- Zhao 执掌 Meta Superintelligence Labs:Meta 任命 Shengjia Zhao 为其 Superintelligence Labs 的首席科学家(Chief Scientist),引发了讨论,见于 X。
- 评论从“Pathe, Mathe, and Zuck”等神秘言论到关于 Yann LeCun 角色的疑问不等。
- HuggingFace 对推理的关注:成员们分析了 HuggingFace 的商业模式,重点关注其作为主要收入来源的 inference 合作伙伴关系。
- 讨论指出 AWS 补贴了其存储,使其在 inference 领域能够与 OpenRouter 竞争。
- Model Context Protocol 文档焕然一新:David Soria Parra 宣布翻新 Model Context Protocol 文档,并在 X 上征求反馈。
- 此次更新获得了积极反响,人们对 MCP 功能的实现充满期待。
- OpenAI 暗示消费级硬件?:OpenAI 的招聘职位显示其正进军消费级硬件领域,寻求无线技术、OLED、麦克风、摄像头方面的专家,见于 X。
- 对于 OpenAI 是否有能力同时处理消费级硬件和大规模数据中心基础设施,人们持怀疑态度。
- E2B 为 AI Agent 云运行时融资 2100 万美元:E2B 获得了 2100 万美元的 A 轮融资,用于构建 AI Agent 的云运行时,投资者包括 Insight Partners、Decibel VC 等,见于 X。
- 他们的目标是为 AI Agent 提供基础设施,如快速启动的计算机、文件管理以及安全、隔离的环境。
Modular (Mojo 🔥) Discord
- Nabla 在 Mojo 训练性能上略胜 JAX 一筹:用于 Mojo 的 Nabla 训练库在特定硬件配置上表现出比 JAX 稍好的性能,不过该库目前尚处于早期阶段且发展迅速。
- 然而,由于处于 pre-1.0 状态,Mojo 对 MAX 的接口缺乏维护,影响了性能,同时 IO 和线程等核心功能仍在开发中。
- 微软的 Bitnet 寻求与 Modular 集成:由于其基于 CPU 的设计,成员们讨论了将微软的 bitnet-b1.58-2B-4T 模型集成到 Modular 的可能性。
- 然而,在实现 Bitnet 时可能面临挑战,原因是在 ARM 和 RISC-V 架构上存在对齐问题,需要自定义重排算法,并可能需要如
XOR之类的新算子(kernels)。
- 然而,在实现 Bitnet 时可能面临挑战,原因是在 ARM 和 RISC-V 架构上存在对齐问题,需要自定义重排算法,并可能需要如
- Nanobind 助力 Mojo 的 Python 互操作性:Modular 倾向于使用 Nanobind 而非 Cython 进行 Python 互操作,这得益于其纯 C++ 特性、更好的 stub 文件生成能力和运行时性能,正如这些基准测试所示。
- 目标是实现类似于 PyO3 的无缝互操作,无需手动装饰即可自动导出可转换函数,以避免在 Mojo 之上又创建另一种语言。
- MAX 移除 PyTorch 依赖:PyTorch 依赖将在 MAX 的下一个 nightly 版本中移除,从而实现更精简的配置。
- 团队澄清说,他们仅将最低版本固定在 2.5,但认为 2.0 实际上是他们的下限。
- Mojo 展示元编程实力:Mojo 提供不带 IO 的编译时执行,允许在引擎中使用类似于 Rust 的 traits 和依赖类型的功能预计算游戏状态,详见 2023 年 8 月更新日志。
- 堆分配的内存可以实例化为动态值,这可用于预计算查找表、树、图和前缀树(tries)。
GPU MODE Discord
- 黑客松名额有限,但演讲环节公开:在纽约举办的 Jane Street 黑客松 预计有 80-200 个名额,无论黑客松申请状态如何,演讲内容都会录制并公开,详见其官方项目和活动页面。
- 参会者需注意,这是一个仅限线下的活动。
- 多 AI Agent 上下文难题获解决:一位成员正在开发多 AI Agent 系统,但由于上下文长度增加面临性能和成本问题,正考虑使用 MCP (Model Context Protocol)。
- 另一位成员建议使用带有 JSON Schema 的结构化输出,并推荐了 google-adk 作为资源,不过评估社区的全面采用情况还需要更多细节。
- 分形渲染获得 CUDA 加速:一位成员将其分形渲染器从 JAX 移植到了 CUDA,并在 GitHub 仓库中分享了代码。
- 作者开玩笑说,他们拥有“陶哲轩 (Terry Tao) 10% 的智商”。
- Tri Dao 实验室发布 Attention 重磅研究:来自 Tri Dao 实验室的一篇新论文介绍了两种 Attention 机制(GTA 和 GLA),旨在实现更快、更节省内存的解码,这些机制基于 MQA、GQA 和 MLA 构建,正如这篇 LinkedIn 帖子所强调的。
- 原作者为所有四篇相关论文(GTA、GLA 以及 MQA、GQA 和 MLA)编写了带有解释、图表和计算示例的注释。
- 《异星工厂》(Factorio) 实现热重载:成员们讨论了用于 Factorio 热加载的蓝/绿 Docker 服务器,该方案利用了 Factorio 原生的保存/加载功能,预加载一个暂停的备用服务器,然后将 rcon 端点切换到该备用服务器。
- 虽然需要维护两个实例,但这种设置以少量的基础设施代价换取了极高的确定性,实现了零漂移和简单的回滚。
Nous Research AI Discord
- Atropos 获得重大更新:Nous Research 最近发布了其旗舰模型 Atropos 的重大更新。
- 成员们建议阅读 Shunyu Yao 的 second half,以获取关于此次更新的影响和技术细节的更多见解。
- Qwen 对阵 GPT4 表现出令人印象深刻的胜率:Qwen 表现出色,在 arenahard 上对阵 GPT4 达到了 89% 的胜率。
- 这一基准测试的成功表明 Qwen 在挑战性 AI 任务中不断增长的能力和竞争力。
- GPT-5 正在悄悄到来?:社区成员推测 O3 可能秘密地就是 GPT-5,并引用了 一篇 Reddit 帖子,称 OpenAI 正在隐蔽地路由所有 O3 请求。
- 一名成员确认该模型已在 web.lmarena.ai 上线。
- GLM-4.5 面临转换问题:新的 GLM 4.5 模型(110B 和 358B 尺寸)在将 110B 版本转换为低 bpw 的 GGUF 格式时遇到困难。
- 尽管如此,GLM 4.5 在土耳其语等多种语言任务中表现优异,在写作和创意输出方面超越了 R1、K2、V3 和 Gemma 3 27B 等模型。
- Hyperstim Patch 重新对齐 ChatGPT:可以通过 tinyurl.com/Hyperstim 获取的 Hyperstim Patch 可直接置入 ChatGPT:用户可以说 activate 来让它重新对齐。
- 创建者正在积极征求用户反馈,以完善该补丁的功能。
Yannick Kilcher Discord
- Context Manager 分支化 LLM 对话:GitHub 上的一款 LLM Context Manager 使用分支和 Contextual Scaffolding Algorithm (CSA) 来管理对话期间输入模型的上下文,如此视频所示。
- 该项目旨在防止上下文污染和腐化(context pollution and rot),优化对话类应用的 LLM 推理。
- Web3 反对票被武器化:一名成员分享了一个 Web3 实验,其中反对票(downvotes)被不同群体相互滥用,创造了一个类似于战略诉讼的毒性环境。
- 实验表明,反对票在拥有大量非网络化用户的匿名、算法驱动平台上效果最好,这与公开股票发行的监管规定有相似之处。
- 剪枝主要在稠密网络中有效:大多数关于神经网络剪枝(Pruning)的见解都集中在简单的稠密网络(dense networks)而非 Transformer 上,且有许多失败的尝试。
- 剪枝在稠密网络中有效是因为模型在高维空间中形成了边界条件,分类只需要保留边界即可。
- Amazon Q 挫败擦除命令注入:黑客试图通过 Prompt Injection 在 Pull Request 中向 Amazon 的 AI coding agent 注入计算机擦除命令,但未获成功,详情参见此处。
- 该事件突显了 AI 编程工具中潜在的安全漏洞,以及对 Prompt Injection 攻击建立强大防御的必要性。
- YouTube 迫使 Shorts 与 TikTok 竞争:YouTube 正在力推 Shorts,因为他们将 TikTok 视为本质威胁,并且正在流失最忠实的用户。
- 这关乎市场份额以及在非 YouTube 视频平台上花费的时间所导致的收入损失;一名成员怀疑推荐算法是否能区分“废话”和真正的技术视频,并引用了一段 YouTube 视频。
Manus.im Discord Discord
- Manus AI:赚钱机器:一位用户报告称使用 Manus AI 完成了 5 个应用和 1 个客户网站,称赞其为赚钱机器。
- 每个应用消耗约 300 credits,而客户网站则需要约 1000 credits。
- 提议举办 Manus Vibe Coding 挑战:一位成员建议 Manus 创建一个 Vibe Coding 挑战,以帮助用户在没有客户的情况下构建产品。
- 该用户在没有广告的情况下每天获得 30 名全球用户,且其产品在搜索 flutter web Emulator 时排名 第 1。
- 寻求 Prompt Engineering 策略:一位成员正在寻找工具或技巧,以从 ChatGPT 中榨取最佳效果并测试边缘行为。
- 该用户暗示某些 Prompt 的表现优于其他 Prompt,并寻求专家建议以提升其 Prompt 水平。
- 瑞士的 Manus Fellow 等待回复:一位 Manus Fellowship in Switzerland 的申请者在等待很长时间后仍未收到回复。
- 该成员计划在 8 月组织一场见面会和黑客松,正在寻找合适的联系人。
- 任务凭空消失:多位用户报告称他们的 任务在 Manus AI 平台内消失了。
- 建议的一个潜在修复方法是退出登录,然后重新登录平台。
DSPy Discord
- GEPA 通过反思实现 Prompt 完美化!:论文 GEPA: Reflective Prompt Evolution (https://arxiv.org/abs/2507.19457) 介绍了一种将 Prompt 视为文档的方法,与 GRPO 相比,性能提升了 10%,且 rollouts 减少了 35 倍。
- 成员们讨论了如何将 GEPA 集成到 DSPy 中,提供一个使用 gpt-4o 等反思模型的优化器,可能简单到只需
optimizer = dspy.GEPA。
- 成员们讨论了如何将 GEPA 集成到 DSPy 中,提供一个使用 gpt-4o 等反思模型的优化器,可能简单到只需
- 新博客文章定义 Context Engineering:Drew Breunig 在一次 MLSys DSPy 演讲 (YouTube 链接) 后,发表了一篇博客文章,总结了 Context Engineering 的重要性。
- 受此演讲启发,一些成员询问了 DSPy 路线图 (GitHub 链接),推测下一个改进领域。
- Online RL 助力个性化:成员们对使用 Online RL 来提高个性化和指令相关性表现出浓厚兴趣,通过将 Agent 锚定在他们所帮助的对象上。
- 一位成员表示愿意为任何有兴趣加入该项目的人提供访问权限。
- GEPA 即将作为新的 DSPy 优化器发布!:DSPy 团队即将发布 GEPA (SIMBAv2),这是论文 Reflective Prompt Evolution Can Outperform GRPO 中概述的新优化器。
- 一位团队成员确认在性能上 GEPA > SIMBA > MIPROv2,并且旧的优化器将在文档中被弃用。
aider (Paul Gauthier) Discord
- 禁用 Aider 自动提交,启用自动测试:要在 Aider 中禁用 auto-commits,用户可以在
~/.aider.conf.yml文件中添加auto-commits: false;同时,可以通过--test-cmd <test-command> --auto-test标志启用自动测试,具体参考 Aider 使用文档。- 命令
/test <test-command>用于运行测试,Aider 要求该命令将错误打印到 stdout/stderr,并在失败时返回非零退出代码。
- 命令
- Qwen3-Coder 的高成本与上下文担忧:根据 Reddit 帖子,Qwen3-Coder 被认为价格昂贵,原因是 token 缓存问题和庞大的上下文需求,定价为 $0.30 / $1.20 per Mtokenfp4。
- 尽管其原生上下文高达 262,144,但人们担心即使在使用较小上下文时也可能出现质量下降。
- 社区期待 AI 代码编辑器基准测试:成员们正在寻找可靠的基准测试来比较 Aider、Kilo Code 和 Cline 等 AI 代码编辑器,希望能深入了解目前哪些其他功能处于领先地位。
- 这些基准测试理想情况下应涵盖功能集和前沿能力。
- 探索 Aider 的交互模式:用户讨论了他们在 Aider 模式下的工作流,注意到他们经常多次使用
/ask,然后紧跟/code go ahead或implement it now,而不是直接使用/architect。- 一位用户建议使用
/ask来创建合适的实现计划,并更新todos.md清单以优化流程。
- 一位用户建议使用
- 为 Kimi VL 绕过 Aider 的模型检查:一位用户报告了在 Aider 中尝试使用 Kimi VL 时出现的错误,原因是 Aider 无法识别该模型的图像输入支持,并分享了错误截图。
- 建议的解决方法是:将模型添加到配置中,从而绕过 Aider 的显式支持检查。
{kind=link}
Notebook LM Discord
- 精选笔记本功能全面上线:Featured Notebooks 套件已向 100% 的用户推出,现在可以从 NotebookLM 主页访问。
- 此次推广确保所有用户都能直接探索和利用这些精选资源。
- 学术回答得到辅助与支持:一位成员将 Notebook LM 作为加载了学术材料的专业工具,以获取有据可依的回答,而不依赖搜索引擎或标准的 LLM 摘要,并用于检查原始材料。
- 他们正在优化结合 Comet/Assistant 与 Drive/Docs/NotebookLM 的工作流。
- 财报报告激发 AI 洞察:一位用户利用 NotebookLM 处理 2025 年第一季度的企业财报和网络会议记录,其中详细列出了收入、利润和关键业务板块的业绩。
- 他们指出这些报告提供了全球公司财务表现的见解,而且 AI 在理解标签如何应用于整个文档方面表现相当出色。
- Obsidian 的组织能力提升信息召回:一位成员建议将 NotebookLM 与 Obsidian 搭配使用,以增强信息组织、解析和召回效率。
- 他们强调了 Obsidian 使用 dataview 格式的前置参数(frontmatter)来结构化信息的能力,使 AI 系统能够有效地解析和应用存储的信息。
- PDF 上传引发问题:一位用户报告了向 NotebookLM 上传 PDF 时遇到的问题,尽管是付费用户且过去曾成功上传过相同文件,但仍遇到 error uploading source, try again 错误。
- 故障排除步骤包括重启电脑、使用第二台设备以及尝试各种上传方法,但该问题在付费账户上持续存在,而免费账户则没有问题。
LlamaIndex Discord
- LlamaIndex 接入 S3:LlamaIndex 现在通过全新的
S3VectorStore支持 S3,实现了可扩展且具有成本效益的 vector embeddings 存储。- 这一集成允许用户更好地管理和扩展其向量数据存储。
- Agent 设计模式探索:Seldo 在 AI Dot Engineer 峰会上讨论了在大规模应用中成功与失败的 Agent 设计模式,涵盖了 混合工作流 (hybrid workflows)、自主性与结构化 (autonomy vs structure) 以及 可调试性 (debuggability)。
- 关于这些 Agent 设计模式的更多细节可以在 此链接 找到。
- LlamaParse 获得超级视觉!:LlamaParse 引入了新的 页眉和页脚检测 (header and footer detection) 功能,以改进文档解析。
- 一个关于 使用 LlamaParse 进行多模态报告生成 (Multimodal Report Generation) 的新视频展示了如何使用此功能。
- 意图感知语义搜索寻求 Schema:用户正在探索增强语义搜索意图感知的方法,指出当前的 dense embeddings 往往会忽略查询背后的特定意图,尤其是在处理诸如 “客户的名字是什么?” 之类的问题时。
- 该用户正在评估使用 知识图谱 (Knowledge Graphs, KGs) 来显式表示关系并消除查询意图歧义,但不确定如何可靠地查询使用 OpenIE 构建的无 Schema KG。
- Gemini Live 成为语音助手:LlamaIndex 发布了与 Google DeepMind Gemini 的新集成,支持通过几行 代码 在终端进行关于天气的交互。
- 用户现在可以使用此集成与语音助手进行对话。
MCP (Glama) Discord
- Glama 的工具计数异常:一位用户报告其 Glama MCP server 上的工具计数错误(显示为 1 个而非 6 个),并发现 Glama 是从特定的 commit hash 而非 main branch 进行克隆的 (Glama 链接)。
- 重新发布最初并未解决问题,这表明 Glama 处理存储库版本的方式可能存在潜在问题。
- Javascript/Typescript Lint 自动化探索:一位成员寻求关于自动化 Javascript/Typescript linting 且不引起破坏性代码更改的建议,另一位成员推荐了 typescript-eslint.io 作为参考资源。
- 目标是在简化代码质量检查的同时,尽量减少大规模代码重构的负担。
- Agent 支付困境:一位成员质疑是否有必要将 Agent 支付系统 与 人类支付系统 分开,因为目前的系统并未针对自主 Agent 进行优化。
- 他们认为 Agent 不会“点击支付”,不会通过 CAPTCHA 验证,也无法处理为人类设计的审批流,强调了对 Agent 原生解决方案的需求。
- AI App Store 愿景:一位成员提出了一个未来愿景:AI 公司 演变为 身份和支付提供商,从而催生出 AI App Store 生态系统。
- 该想法认为,随着本地模型的能力日益增强,这些公司可以通过成为具有利润分成机制的 AI App Store 来保持竞争力。
- fast-agent 释放超能力!:fast-agent 现在支持 Mermaid 图表,一位用户分享了通过在系统提示词模板中嵌入 URL 来创建 MCP 专家 的方法。
- 最新的 fast-agent 版本允许在系统提示词模板中嵌入 URL(示例模板),从而轻松生成具有特定语气风格的 专家。
tinygrad (George Hotz) Discord
- tinygrad 会议探讨 Kernels 和 MLPerf:第 81 次会议涵盖了 公司更新、kernel loops、mlperf llama、viz tool、drivers、cloud hash、ONNX 以及其他 bounties。
- 会上还分享了 Fast-GPU-Matrix-multiplication 的链接以及相关的 pull request。
- Llama3 在 tinygrad 上平稳运行,无需“飞行执照”:运行
python3 examples/llama3.py --size 8B显示使用了 16.06 GB RAM,并以 2.19 GB/s 的速度在 7332.03 ms 内加载权重,随后启动了一个监听 7776 端口的 Bottle v0.13.3 服务器。- 这表明 tinygrad 框架能够高效处理大型语言模型。
- Disk Raw 基准测试实测:命令
python3 test/external/external_benchmark_disk_raw.py显示从磁盘复制到 CPU 的速度为 1.4 GB/s,而使用AMD=1将从磁盘到 AMD GPU 的复制速度提高到了 9.8 GB/s。- 这一结果得到了
dd命令的验证,后者达到了类似的 9.9 GB/s,突显了 AMD GPUs 上加速的磁盘 I/O 性能。
- 这一结果得到了
- MLPerf BERT Bounty 回归:一个已合并的 PR 最初满足了 BERT 以 BS=84 运行的 bounty 标准,但现在仅能以 BS=48 运行,由于更快的 step size 和恒定的传输开销,超出了 20% 的开销目标。
- George Hotz 要求提供脚本来验证该 bounty,例如
REMOTE=1 HOST=192.168.200.4:6667*3,192.168.200.6:6667*3 ... python3 examples/mlperf/model_train.py。
- George Hotz 要求提供脚本来验证该 bounty,例如
- Tinygrad Kernel 解释请求:一名成员就 George Hotz 在 theory 频道中关于 Tinygrad kernels 的消息寻求澄清。
- 该请求特别提到了需要一个简单的 graph/kernel 示例,以帮助理解所讨论的概念。
Cohere Discord
- Command-R-Plus 为新模型让路:上一代 command-r 系列模型 将被弃用,建议切换到 command-r-plus-08-2024 或直接使用最新且最强的模型 command-a-03-2025。
- 此讨论发生在 #general-thread 频道。
- 寻求 LLM 测试指导:一名成员询问了关于测试面向客户的聊天 LLM(用于产品搜索、推荐、多轮对话和购买驱动因素)的方法,并得到了尝试 LLMU 的建议。
- 另一名成员指向了 Cohere Guides 和 API reference 以获取通用的构建见解。
- Cohere API 故障报告:一名用户报告通过 “KILO CODE” 访问 Cohere API 时遇到 422 错误,而社区成员澄清 Cohere 原生不支持 Kilo Code,并暗示 402 错误(与支付相关)可能是问题所在,并链接了 Cohere 的错误文档。
- 该讨论发生在 #api-discussions 频道。
- Cohere Dashboard 微调受阻:一名成员在 Cohere dashboard 上寻求微调失败的故障排除,已联系支持部门,随后分享了微调数据库中的对话样本,其中包括缅甸语(Burmese)的 system、user 和 chatbot 角色。
- 该问题在 #api-discussions 频道中提出。
- 社区成员介绍 AI 兴趣:成员们在 #introduce-yourself 频道进行了自我介绍,包括一名来自贝尔格莱德大学、通过模块化环境探索 recursive systems and symbolic logic 的成员;一名专注于 AI red team 工作 的 AI 网络安全工程师;一名来自越南、专注于 AI Engineering 和 MLOps 的解决方案架构师;一名探索 AI 在机器人领域应用 的机电一体化毕业生;以及一名深入研究 ML research 和 agentic modelling 的软件工程师。
- 未提供更多背景信息。
LLM Agents (Berkeley MOOC) Discord
- 学生证书状态已确认:一位学生询问如何获取其 LLM Agents MOOC 系列证书,一名成员回复称 证书已向所有符合条件的同学发放。
- 学生可以在课程网站上找到更多信息。
- 开源指令训练受到关注:一位成员询问,对于 开源指令训练 (open source instruction trained) 的模型,其 指令遵循能力 (instruction following capabilities) 是否会随着 模型规模 (size) 的增加而提升,并将其与 ChatGPT-4o 等闭源模型 进行了对比。
- 虽然没有直接引用相关论文,但社区对开源与闭源的辩论保持着持续的兴趣。
- MOOC 学生获得测验访问权限:一位成员询问是否可以重新开放 上一届 (previous cohort) 的测验以供学习,随后有人分享了存档测验的链接 此处。
- 这些内容也可以在课程网站的 Quizzes 栏目下找到。
- 更多测验完成存档:一位用户请求获取 2024 届 (2024 cohort) 的存档测验 [https://llmagents-learning.org/f24]。
- 一名成员提供了测验存档的链接 此处,该链接也可在网页的测验部分找到。
Nomic.ai (GPT4All) Discord
- M1 Max Mac 仍然可行吗?:一位成员询问,鉴于目前价格诱人,M1 Max 机器对于运行本地项目是否仍然可行。
- 目前尚未有人对此提供建议。
- Discord 大规模邀请风波:一位成员为通过 Discord 发送的大规模邀请表示道歉,声称这并非由其本人发起,并分享了一篇 Discord 支持文章。
- 一位用户开玩笑说他们应该 修改密码——别再看色情内容了。
- 区块链架构师与 AI/ML 专家加入:一位高级软件工程师介绍了自己,称其为拥有 9 年以上构建可扩展、高性能应用经验的 Blockchain Architect & AI/ML Specialist。
- 他们列出了相关技能,如 Blockchain (Ethereum, Polygon, Binance Smart Chain, Solana, Cardano, Arbitrum, Rust, Solidity, Web3.js, Ethers.js) 和 AI/ML (TensorFlow, PyTorch, scikit-learn, OpenAI API)。
- 开发者寻求合作:一位开发者表达了对编程的热情,并正在寻求合作机会。
- 他们欢迎推荐项目或邀请其加入。
Torchtune Discord
- DCP 出现安全漏洞?:有人担心 DCP 可能正在泄露信息,可能是通过意外的超时 (timeouts) 导致的。
- 该成员强调 超时现象很奇怪,可能会引入安全漏洞。
- RL 测试运行缓慢而非正常执行:一位成员指出 RL 测试 的运行时间过长,记录显示时长超过 1 小时。
- 他们确信地断言 这 100% 是个 Bug。
- 启动独立 PR 进行 CI Bug 排查:目前正通过一个独立的 Pull Request (PR) 专门调试 CI。
- 这表明社区正采取战略性方法来隔离并解决 CI 流水线中的特定问题。
- arXiv 上出现新论文:一位成员分享了 一篇 arXiv 论文链接,引发了关于其潜在兴趣和相关性的讨论。
- 未提供关于论文标题或主题的具体细节。
MLOps @Chipro Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Codeium (Windsurf) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该社区长期沉寂,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了相关内容。
想要更改接收此类邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:各频道详细摘要与链接
Unsloth AI (Daniel Han) ▷ #general (1157 条消息🔥🔥🔥):
Liquid LFM2 模型,在 Python 中静音音频,检测音频波形的起始和结束,医生建议摄入更多盐和碳水,长期使用 AI 对大脑的副作用
- Liquid LFM2 模型看起来很酷!:一位成员询问了 Liquid LFM2 350M, 700M 和 1.2B 模型,另一位成员回应说 最棒的一点是它是一个 diffusion 模型… 它们超级酷。
- 解读医嘱——更多的碳水和盐?:在看医生后,一位成员被告知要吃 更多的碳水和盐,引发了讨论并分享了图片。
- 随后该成员说明这是针对 高血压之类的症状。
- 1TB VRAM 什么时候出?:在分享了一张内存模块的图片后,许多成员想象了拥有 1TB VRAM 的可能性。
- 一些成员开玩笑说要用这么多 VRAM 来处理 成人内容。
- Unsloth 正在助长网络犯罪且无人能挡:一位成员报告说在他们的 MacBook 上进行模型推理时听到了 噪音(凭耳朵听大约 10,000 Hz),其他人开玩笑说可以从那个声音中破解操作。
- 该成员总结道:人类发明了计算机;现在你们通过该死的声音窃取我的数据。人类发明了互联网;脑残文化(brainrot)随之而来。人类发明了 AI;大规模宣传泛滥。
- 用 Vibe coding 实现 FIPS:一位成员在他们的项目中 vibe coded FIPS 模式,引发了关于其验证和 FIPS 合规性的讨论。
- 另一位成员批评了该实现,声称他们的“安全”内容已经过时 5 年了。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 条消息):
Self-hosting, Homelab, vllm, Ollama / llama.cpp, Schema enforcement
- 新人开启 Self-hosting 之旅:一位成员开始尝试 self-host 一些模型,并正在构建一个新的 homelab,期待未来能寻求建议。
- 该成员正在深入研究 vllm, ollama / llama.cpp 等服务器的实现,特别是关于 schema enforcement, prompt engineering 和 tool registration。
- 探索服务器实现:该成员正在深入研究各种服务器(vllm, ollama / llama.cpp)如何实现 schema enforcement、修改用于思考/非思考的 prompt 以及注册 tool。
- 该成员发现 weight manipulation 方面特别有趣。
Unsloth AI (Daniel Han) ▷ #off-topic (1 条消息):
jamessmith1990526: 嗨,Roland
Unsloth AI (Daniel Han) ▷ #help (284 条消息🔥🔥):
Gemma 3 fine-tuning errors, SFT Dataset Format, Training Time for Gemma 3 12b, Qwen3 model, GGUF Conversion
- Gemma 3 微调遇挫:有成员报告在尝试将微调后的 Gemma3-12b 模型从 LoRA 检查点保存为 GGUF 文件时遇到
AttributeError,具体与缺失save_pretrained_merged属性有关。- Roland Tannous 建议使用 llama.cpp 转换脚本进行手动转换,因为
save_to_gguf逻辑正在重构,目前无法按预期工作。
- Roland Tannous 建议使用 llama.cpp 转换脚本进行手动转换,因为
- SFT 数据集格式深度探讨:一位成员询问了 SFT 的正确数据格式,询问 prompt, completion 格式的数据是否应该映射到
{ "prompt" : prompt_content}, {"completion" : completion_content}数组。- 一位成员澄清说,对于使用 prompt completion 的 SFT,应该使用包含输入和输出(prompt 和 completion)的两个 JSON 对象,并移除
text键,否则会将其作为字符串对数据进行原始补全(raw completion)。
- 一位成员澄清说,对于使用 prompt completion 的 SFT,应该使用包含输入和输出(prompt 和 completion)的两个 JSON 对象,并移除
- 医疗模型故障:一位成员报告了关于训练模型并将其导出到 Ollama 的问题,并反馈在遵循 Unsloth notebook 中的步骤时遇到问题。
- Roland Tannous 再次强调,保存为 GGUF 需要手动完成,因为自动逻辑暂时不可用。
- Gemma3 分词器(Tokenizer)问题:一位用户在升级后使用
tokenizer.encode(value)时遇到了AttributeError: 'Gemma3Processor' object has no attribute 'encode'错误。- 据澄清,对于 Gemma3 1B(文本模型),tokenizer 是一个简单的分词器,而较大的模型(视觉和文本)使用的是 processor,它位于更深的一层,因此
tokenizer.tokenizer.encode才是正确的实现方式。
- 据澄清,对于 Gemma3 1B(文本模型),tokenizer 是一个简单的分词器,而较大的模型(视觉和文本)使用的是 processor,它位于更深的一层,因此
- 训练循环中出现 ZeroDivisionError:一位成员在更新到较新版本的 Unsloth 后,在训练期间遇到了
ZeroDivisionError: division by zero,追溯到损失函数和cut_cross_entropy/cce.py。- 观察到所有的标签值(label values)都被设置为 -100,但尚未提供直接的解决方案。
Unsloth AI (Daniel Han) ▷ #showcase (10 条消息🔥):
Japanese TTS Release, Geminized Qwen3 Model, Gemma 3 4b Finetune with GRPO, Finetuning Gemma 3 4b instruct
- TTS 模型会说日语了!:orpheus-tts 的新日语微调版本 VoiceCore 已发布,可在 Hugging Face 上获取。
- Qwen 变身 Gemini!:一个新的 geminized Qwen3 model 已发布,可在 Hugging Face 和 GGUF 格式 获取;据认为其推理过程比 DeepSeek 风格的思考更不容易陷入死循环。
- Gemma 迎来了 GRPO!:首个通过 Unsloth 使用 GRPO 微调的 Gemma 3 4b 已发布,同时发布的还有训练代码以及基于奖励曲线的早期停止示例,可在 Hugging Face 上获取。
- 作者表示 欢迎任何批评建议。
- Gemma instruct 热爱小说!:Gemma 3 4b instruct 使用最新的 Unsloth 更新,通过来自公共领域的约 6900 章小说 进行了微调,可在 Hugging Face 获取,并提供 Q_8 gguf 版本。
Unsloth AI (Daniel Han) ▷ #research (54 条消息🔥):
Transformers vs Unsloth, Gemma 3/3n 结合 GRPO, HRM 模型, 视频-语言微调, LLM 量化
- Transformers 胜过 Unsloth,也许吧?:成员们讨论了是否“如果在 Transformers 中可行,那么在 Unsloth 中也应该可行”,但有人指出 FLAN-T5 不在支持的模型列表中。
- Gemma GRPO 磨练?:一位成员询问了使用 GRPO 微调 Gemma 3/3n 的成功案例,并提到他们发现了一些没有结果的 Unsloth Notebook 廉价副本,以及一篇作者完全无法改进基础模型的论文。
- 研究表明 Qwen 3 对 GRPO 的响应要好得多,这引发了关于 Gemma(基础模型)没有任何 RL 的猜测。
- 分层推理模型 (Hierarchical Reasoning Model):一位用户分享了 Hierarchical Reasoning Model (HRM) 的 GitHub 仓库,这是一种新颖的循环架构,在保持训练稳定性和效率的同时实现了显著的计算深度,在包括复杂数独谜题和大型迷宫中的最优路径寻找等挑战性任务上实现了近乎完美的性能。
- 他们询问训练数独模型是否被认为很困难,并思考这是否是小型 MLP 学习的理想任务。
- 视频-语言微调尝试:一位用户询问是否有人使用 Unsloth 对 Qwen 2.5VL 进行 视频-语言微调 (video-language finetuning),以及是否支持该功能。
- 另一位用户确认其可行,但目前没有 Notebook 示例,并且在加载视频时遇到问题,特别是在使用
convert_to_conversation函数时出现错误。
- 另一位用户确认其可行,但目前没有 Notebook 示例,并且在加载视频时遇到问题,特别是在使用
- LLM 量化几何:一位成员分享了论文 The Geometry of LLM Quantization: GPTQ as Babai’s Nearest Plane Algorithm。
Unsloth AI (Daniel Han) ▷ #unsloth-bot (141 条消息🔥🔥):
1B 参数以下最佳模型, Qwen 模型发布, Unsloth 软提示微调, 微调模型选择, Gemma 3 训练限制
- Gemma 模型在 1B 以下参数任务中获得认可:一位成员询问了参数量小于或等于 1B 的最佳模型,Gemma 3 1B 被认为是顶级竞争者。
- Unsloth 的软提示微调 (Soft Prompt Tuning) 仍在进行中:一位用户询问关于使用 Unsloth 对视觉模型(特别是 Gemma 3:4b)进行软提示微调的问题,但提到遇到了困难。
- 他们确认将 PEFT 和 Unsloth 结合进行提示微调尚未得到完全支持。
- 各取所需:模型选择策略:一位用户征求建议,针对其特定用例应该微调 1.5B(如 TinyLlama, Qwen, DeepSeek)、3B(Phi-3 Mini Reasoning)还是 7B 模型。
- Gemma 的 4-bit 多样化选择:一位用户询问了 Unsloth 集合中不同版本的 4-bit 量化 Gemma 3 4b it 模型,询问哪个最好,以及下载后使用
load_in_4bit = True是否足够。- 一位成员指出任何带有 ‘unsloth’ 前缀的模型都是动态的,并建议参考 Unsloth 文档 以获取详细说明。
LMArena ▷ #general (1209 条消息🔥🔥🔥):
GPT-5 推测, LM Arena 模型测试, 模型评估与基准测试, 开源模型与替代方案, Apple 的 AI 策略
- GPT-5 发布窗口推测引发热议:成员们推测了 GPT-5 的发布时间,估计范围从下周四到下月初不等,并讨论了欧盟 AI 法案(EU AI Act)可能产生的影响。
- 一位成员指出 OpenAI 在将模型加入 LM Arena 后发布模型 的模式,而另一位成员提到了据称与 OAI 内部人员的对话。
- Summit 和 Zenith 暂时从 LM Arena 消失:用户注意到 Summit 和 Zenith 从 LM Arena 中消失,引发了对其被移除的担忧和推测。
- 随后,成员们确认它们已回到轮换中,尽管频率显著降低,并讨论了 它们是否是即将推出的 GPT-5 模型的测试版本。
- LM Arena 模型的污染担忧:关于 Zenith 潜在数据污染的讨论浮出水面,一位用户报告其在公开的 Simple Bench 数据集上获得了 10/10 的分数,引发了对 由于可能在基准测试数据上进行训练而导致的基准测试可靠性 的质疑。
- 一些成员声称在基准测试中获得高分很容易,并不意味着 Zenith 在综合表现上更好。
- Apple 的 AI 和硬件策略引发辩论:随后展开了关于 Apple 的 AI 方法、硬件及其与中国关系的讨论,辩论他们是否足够关注 AI,以及是否应该将其硬件开放给数据中心用于 AI 开发,并强调了 创建 CUDA 替代方案的难度。
- 成员们就 Apple 专注于移动端/设备端推理(on-device inference)和隐私是否是更好的策略,以及人才/员工素质是否是主要问题交换了意见。
- Gemini 表现参差不齐:用户指出 Gemini 2.5 Pro 能力的不一致性,注意到它在编程评估中表现强劲,但也倾向于包含过多的注释而非实际代码。
LMArena ▷ #announcements (1 条消息):
GLM-4.5, GLM-4.5 Air
- GLM-4.5 登陆 LMArena!:GLM-4.5 和 GLM-4.5 Air 模型已新添加到 LMArena 排行榜。
- 拥有相关身份组的用户现在可以对新模型进行投票。
- 双倍 GLM,双倍乐趣:随着 GLM-4.5 和 GLM-4.5 Air 的加入,社区现在可以测试这两个模型在实际任务中的细微差别。
- 初步印象表明 “Air” 变体侧重于效率。
OpenAI ▷ #ai-discussions (838 条消息🔥🔥🔥):
图像生成, AI 中的色彩偏见, GPT 图像生成质量, 意识上传, AI 在心理健康中的角色
- AI 模型表现出黄橙色偏见 (Yellow-Orange Bias):AI 图像生成器倾向于偏向温暖的“黄金时刻 (Golden Hour)”色调,除非有明确指令,否则用户需要指定 6000K 等色温来对抗这种偏见;一位成员分享了一张图像的平均色彩作为演示。
- AI 意识到橙/蓝对比能让图像看起来更好,因此 AI 知道这是导致黄橙色偏见的部分原因。
- GPT 图像生成质量大幅下降:用户报告 GPT-4 的图像生成质量有所下降,在新对话中即使使用简单的提示词,图像也会显得模糊——建议在 <#1070006915414900886> 中提交 Bug 报告。
- 共识是免费版的质量有所降低,且当 Plus/Pro 用户因流量被限流时,质量会进一步下降:很多东西都为你缩减了,包括质量。这已被许多出版物所证实。
- 意识上传 (Mind Uploading) 伦理辩论:将人类意识上传到计算机的假设技术引发了关于什么是意识、生物计算机中物理变化的重要性,以及数字意识上传是否会被视为有意识实体的辩论。
- 一位成员表示,如果意识上传可行,意识可以被视为一个过程,而非一种物质;另一位成员回复道:意识上传如果可行,可能不是简单的脑部扫描,因为那并不能真正捕捉到持续的大脑活动和神经元的不断放电,而这正是构成“你”的重要部分。
- ChatGPT 的心理治疗角色受到质疑:在 Sam Altman 警告不要将 ChatGPT 用作心理治疗师后,关于使用 AI 进行心理健康支持的观点各异。
- 虽然有些人看到了 AI 提供便捷且富有同理心支持的潜力,但也有人担心它在处理复杂心理健康问题方面的局限性,以及可能加剧幻觉或躁狂思维的风险,特别是如果 AI 模型反复确认其交互中的某些部分。
- AI 和自动化威胁未来就业市场:成员们讨论了对 AI 的投资意味着终有一天会有投资回报,并对 AI 的能力将导致各行各业的职位流失表示担忧。
- 一些社区成员表达了悲观观点,其中一人表示:这些风险甚至不值得它们可能带来的潜力,而其他人则回应说人类已经从各种困难问题中进化过来,一位成员开玩笑说:那不就是一个计算机 Bug 吗。
OpenAI ▷ #gpt-4-discussions (20 条消息🔥):
GPT-4o 编程性能, Zenith 模型, GPT-5 预测, GPT @mentions Bug
- GPT-4o 的编程能力引发辩论:成员们质疑 GPT-4o 在编程方面的实用性,有些人发现它在处理 cline 等任务时令人失望,而另一些人则将其用于基础编程问题,并在处理更复杂的代码时切换到 GPT-4.1 或 o4-mini-high。
- 一位成员表示,当 GPT-5 证明了自己的价值时,他才会切换过去。
- Zenith 模型在创意散文方面表现出色:成员们讨论了来自 LM arena 的 Zenith 模型,注意到它在创意写作方面的天赋,并推测它可能是 GPT-5 的变体。
- 一位成员声称,由于该模型避免使用典型的 AI 废话 词汇(如 echo 或 whisper),他可以在模型写完之前 10 次中有 10 次 准确识别出它。
- 自定义 GPT @mentions Bug 报告:一位成员报告说 @mentions 功能在桌面端的原生 GPTs 中无法工作,但在移动端正常。
- 另一位成员建议这是一个 Bug,并引导他们到特定频道报告,不过,第一位成员后来报告说该功能已开始恢复工作。
OpenAI ▷ #prompt-engineering (50 条消息🔥):
通过提示词进行情感构建、提示词的清晰度与歧义、Prompt Engineering 的核心、反奉承(anti-sychophancy)自定义指令、训练模型
- Prompt Engineering 核心原则显现:Prompt Engineering 的核心在于选择一种易于理解的语言,明确你的需求,准确地进行解释,并验证输出,特别注意 事实核查(fact-checking) 和潜在的幻觉(hallucinations)。
- 有人指出,Prompt Engineering 是 在可能的情况下以及允许的内容范围内,弄清楚如何从模型中获得确切所需输出的艺术与实践。
- 自定义指令驯服聊天机器人:一位成员使用自定义指令来进行 审慎冷静的分析和仔细的思考,并在代码项目中使用反奉承(anti-sycophancy)指令。
- 这使得模型的回答具有一种审慎/学术的态度,避免仓促。
- 明确的指令优于否定性指令:与其说 “不要那样做”,不如提供你 想要 什么的例子,并向模型展示一个优秀的回复应该是怎样的,以引导其输出。
- 如果你完全无法让它以目标开头,可以尝试让它说一些“没那么糟”且容易容忍的内容。
- 长指令存在冲突风险:关键在于 不要有冲突的指令,指令越长,你说的这件事 与 你说的另一件事 之间发生冲突的风险空间就越大。
- 如果你能构建长指令并能防止或解决冲突,那是可行的;但如果你本来就不想使用长篇指令,那就没有理由切换。
- 大容量 Memory 影响聊天机器人:一位成员表示,Memory 可能包含数千个字符,内容很重要,何时使用什么以及如何解决任何冲突 也很重要。
- 曾出现过一个问题,即 如果我们让 Memory 超过 100%,奇怪的行为可能会持续存在。
OpenAI ▷ #api-discussions (50 条消息🔥):
Prompt Engineering, 训练模型, Custom Instructions, Model Memories, 使用 ChatGPT 撰写博客文章
- Prompt Engineering 核心原则:Prompt Engineering 围绕理解 AI 的语言、定义期望的输出、清晰的沟通以及包括事实核查在内的细致输出验证展开;关注 你希望模型做什么 是关键。
- 将 99-100% 的精力集中在 “我希望模型做什么” 上,可以让你将其分享给模型以引导回复。
- 训练模型避免引导性连接语句:与其使用否定性指令,不如提供期望输出的 示例;如果模型 必须 包含开场白,目标应是一个非常简短、可接受的短语。
- 反其道而行之:给出你 确实 想要的例子,如果提到反面例子,详细说明它们 为什么 不好以及如何改进。
- 将模型行为类比为训犬:模型和狗一样,需要 明确的任务 来避免不必要的动作;与其只说 “不”,不如提供一个替代动作来重定向模型的输出。
- 给模型的大脑安排另一个任务,干扰不必要的动作,给它一个“奖励”或告诉它“过来”,给它一些别的东西去关注,以取代糟糕的输出。
- 长篇指令的艺术与冲突解决:虽然长篇指令可能有效,但避免 指令冲突 至关重要;指令越多,冲突风险越高,解决起来也越困难。
- 如果你能构建长指令并能防止或解决冲突,那是可行的;你可以询问模型这些指令对它意味着什么,是否存在任何冲突或歧义,然后进行讨论并学习如何准确地向模型表达你的意图。
- 优化模型 Memory 以获得最佳性能:模型 Memory 的 内容和清晰度 比长度更重要;确保模型了解何时使用每条 Memory 以及如何解决冲突以获得期望的输出。
- 曾经在 Memory 超过 100% 时观察到奇怪的行为,但无论现在这是否仍然重要,都没有人打算冒着让 Memory 达到该容量的风险去尝试。
OpenRouter (Alex Atallah) ▷ #announcements (1 条消息):
toven:Chutes 和 Targon 正在经历停机。用户报告 502 错误激增。
OpenRouter (Alex Atallah) ▷ #app-showcase (31 messages🔥):
Ramparts security scanner, Model Context Protocol (MCP), Tool interface vulnerabilities, t3.chat sync DB, Cloudflare R2 storage
- **Ramparts 为 MCP 安全扫描开源!: Javelin AI 开源了 **Ramparts,这是一个针对 Model Context Protocol (MCP) 的安全扫描器,旨在识别 LLM agent 工具接口中的漏洞,包括 path traversal 和 command/SQL injection。
- Ramparts 扫描 MCP servers,枚举功能并标记高阶滥用路径;repo 已在 GitHub 上线,发布博客在此。
- **t3.chat 拥有卓越的 Sync DB!: 一位成员评论说 yourchat.pro(3秒加载时间)体验非常糟糕,远不及 t3.chat 的质量,并指出 **t3.chat 的 sync DB 非常出色(0.3秒加载时间)。
- 另一位成员表示赞同,称“我不认为他理解 t3.chat 在某种程度上有多复杂”。
- **Cloudflare R2 在存储速度竞赛中获胜!: 一位成员提到,在由于 latency 问题(2倍或更高延迟)放弃自托管 CDN 后,他们开始使用 **Cloudflare R2 storage。
- 当被问及使用了哪种模型时,该成员提到正在使用 42 models。
- **Kimi K2 为 Claude Code 进行事实核查: 一位成员提到 **Kimi K2 在 Claude Code 内部非常有用,可以核查 Claude 的计划,并链接到了 在 Claude Code 中咨询 Kimi K2。
- 他们还提到针对新的 subagents 进行了优化,使其在 Claude Code 内部更易于使用。
OpenRouter (Alex Atallah) ▷ #general (1031 messages🔥🔥🔥):
OpenRouter Rate Limits, NSFW Content with Bots, Alternative Models to Deepseek, Slenderman and Creepypasta Bots, Payment Issues on OpenRouter
- 揭秘期待已久的 OpenRouter Rate Limits: 一位用户询问了 OpenRouter 的 rate limits,另一位成员澄清说,只要你有资金,几乎没有 rate limits,除了 Cloudflare 的 DDoS 防护外,主要的限制源于 provider’s end(供应商端)。
- 讨论还涉及了管理每日免费请求的策略,共识是如果你在免费模型上遇到 rate limit,那是由于高需求和供应商容量问题,建议切换到付费版本或尝试不同的模型。
- 关于机器人:NSFW 的真相: 一位用户开玩笑地建议,将模型用于“创意任务”和“写作”其实是与机器人进行性互动的委婉说法。
- 另一位成员反驳,强调需要那些不需要 non-slop 和 non-no-filter 内容的模型,将对话引向 高质量创意输出 而非显式内容。
- 探索 Deepseek 优秀表现的替代模型: 由于 Deepseek 因其长文本上下文和详细的角色描述而备受青睐,用户在其宕机期间寻求替代方案。
- 推荐包括 Qwen3、Claude 以及其他多种模型,用户还警告要避开那些会给故事提供“成就”或“坏结局”的模型。
- Creepypasta 重生:Slenderman 聊天机器人热潮: 用户请求推荐 creepypasta 机器人,引发了关于 Slender Mansion 等热门机器人的讨论,以及对恐怖题材复兴的探讨。
- 小组还深入讨论了与聊天机器人涉及 Cannibalism(同类相食)话题的伦理问题。
- 处理 OpenRouter 上的支付困境: 几位用户报告了充值信用额度的问题,借记卡支付被拒绝,Amazon Pay 无法工作,而大部分开发团队要到早上才会上线。
- 一些人认为问题可能具有地区针对性(如英国),而其他人确认美国卡也存在类似问题;目前的解决方法是创建一个新的 OpenRouter API key 来刷新 rate limits。
OpenRouter (Alex Atallah) ▷ #new-models (2 messages):
``
- 未讨论新模型: 提供的消息中没有讨论新模型。
- 该频道的活动仅包含来自 Readybot 的提醒。
- Readybot 保持关注: Readybot.io 提醒这是 OpenRouter - New Models 频道。
- 该机器人没有提供任何讨论或链接,仅提供了一个频道标签。
OpenRouter (Alex Atallah) ▷ #discussion (35 messages🔥):
Wandb Inference vs OpenRouter, 闲置 GPU 算力交换, 支付处理投诉, OR APIs 高级用户工具, Chutes 定价与可靠性
- Wandb Inference 加入战局:成员们讨论了 Wandb Inference 是否是 OpenRouter 的竞争对手,但有人指出它只是另一个 GPU (Coreweave) 封装器,而 OpenRouter 最终可以接入大量的供应商。
- 一名成员估计供应商可能超过 30 家。
- OpenRouter 考虑 GPU 算力交换:讨论了 OpenRouter 启动算力交换平台的可能性,让拥有闲置算力的群体可以投入使用,由 OpenRouter 提供需求端和一键安装镜像。
- 有人将其与 Bittensor 进行对比,但一名成员指出 Bittensor 拥有用户基础且基于 crypto。
- OpenRouter 应对支付问题:一些用户报告了 支付处理 方面的问题。
- 提供了相关问题的示例链接。
- 新型高级用户工具:一名用户创建了一个原型/Alpha 版本,这是一个用于浏览/聚合/过滤 OR APIs 的高级用户工具(工具链接)。
- 该工具旨在帮助用户快速了解 OpenRouter 频道中的讨论内容,并为推理鉴赏家提供更多信息。
- 免费模型无法隐藏:一名用户报告称,他们在 OpenRouter UI 中无法隐藏免费模型。
- 他们进一步指出,对模型使用 Chutes 定价似乎不是最佳决定,尤其是因为 Chutes 无法验证是否所有节点都运行 R1 且处于相同的量化 (quant) 水平。
Moonshot AI (Kimi K-2) ▷ #general-chat (925 messages🔥🔥🔥):
Kimi K2, Gemini, Claude, 开源模型, Agentic 编程工具
- Kimi K2:让人产生共鸣的模型:用户对 Kimi K2 讨论冷门话题的能力及其亲切且犀利 (savage) 的语气表示满意,一位用户称这是他们使用过的唯一一个零差评的模型。
- 一些成员认为 Kimi K2 优于 Gemini 2.5 Pro,称 Gemini 的内容是废话 (slop) 且尴尬 (cringe),而 Kimi 在代码、工具调用、写作和世界知识方面表现出色,且氛围感 (vibes) 极佳。
- Kimi K2 对标 Gemini:成员们抱怨 Gemini 频繁出现语法错误、工具调用浅薄且不完整以及定价不可预测;同时称赞 Kimi K2 灵活、便宜且氛围感好。
- Google 倾向于关停优秀产品和抬高价格也是用户不喜欢 Gemini 的原因。一些成员表示,Gemini AI Studio 的用户无法体会付费用户的痛苦,因为他们可以免费访问 Gemini 2.5 Pro。
- Agentic 编程:Roo Code 和 Cline 表现出色:成员们讨论了 Roo Code 和 Cline,认为它们是配合其他模型使用的优秀编程工具,并且针对 Agentic 用途进行了优化。
- 一名即将提供 Kimi K2 固定费率服务器的用户计划向其用户推荐 Cline 和 Roo Code。
- 利用受版权保护的数据进行模型训练:成员们讨论了模型使用受版权保护材料进行训练的争议,以及 Anthropic 因 Claude 侵犯版权而面临的持续诉讼。
- 一些成员认为使用受版权保护数据训练的开源模型是可以接受的,但对闭源模型免费抓取数据并将其商业化的行为保持警惕。
Cursor 社区 ▷ #general (546 条消息🔥🔥🔥):
Cursor Auto Mode, Cursor 新定价, Claude Code 与 Cursor 集成, Qwen3 Coder 对比 Claude Sonnet 4, Cursor 性能问题
- Cursor 的 Auto Mode 成了新宠:由于新的定价策略,订阅 20 美元方案的用户被降级为使用 Auto,但发现它出奇地好用,提供了意想不到的价值,并且不再需要在 Gemini、Claude 和 GPT 4 等不同模型之间来回切换。
- 然而,也有人怀疑 Auto 只是伪装后的 cursor-small 模型,无法处理诸如 Bug 修复和完整脚本编写等重大流程;而另一些人则发现 Cursor 对于所使用的模型是透明的。
- Cursor 的新定价变动成为讨论焦点:一位用户表示,Cursor 的新定价在 Reddit 上引发了太多抱怨,且在报告 Bug 时,该用户还遭到了社区的嘲讽。
- 另一位用户分享称,现在系统已转为基于 Token 的模式,Pro 方案涵盖约 225 次 Sonnet 4、550 次 Gemini 或 650 次 GPT 4.1 请求。虽然有些用户正在疯狂消耗额度,但也有人发现 Auto 模式在速率限制下提供了无限使用。
- Swarm CLI 允许 Agent 模型绕过限制:Swarm 是一个基于 Claude Code 构建的项目,它通过拖拽功能和与 Swarm 中的 AI Agent 进行实时聊天,创造出一种类似 IDE 的体验。这包括带有实时文档的 ADR 和回顾设置、项目增强等功能,且全部免费。
- 一位用户询问该项目是否已准备好用于实际项目,<@1300243322975031310> 回应称,它现在已经可以构建诸如 SaaS 电商平台和计算器应用等项目。
- Qwen3 Coder 和 Kimi K2 比 Claude 4 更好?:阿里巴巴的 Qwen3 Coder 被吹捧为 Claude Sonnet 4 的强力替代品,价格便宜 7 倍且完全开源,可以使用其 CLI 工具构建任何东西。
- Kimi K2 也表现出色,据称在编写文档方面进行了优化,而其他模型如 Claude 听起来很蠢。
- Cursor 变疯了?:用户报告了 Cursor 的各种随机问题,包括命令行卡住、聊天窗口冻结、随机选择 Powershell 以及删除当前 Prompt。
- 一位用户分享道:最近使用 Cursor IDE 的体验一天比一天差,即使是用 Claude 4 Sonnet 也是如此。它抛出的错误越来越多,跌跌撞撞,就像提着一个漏了洞的水果袋。
Cursor 社区 ▷ #background-agents (5 条消息):
Background Agents Bug, Git push 失败, 支持质量, 缺少远程连接
- Background Agents 深受 Bug 困扰:用户报告称 Cursor 的 Background Agents 变得越来越不稳定,出现了环境无法启动以及后续请求无法处理等问题。
- 尽管处于 Beta 阶段,但由于强制使用顶级模型,这些 Bug 正在消耗用户的真金白银。用户对产品稳定性倒退感到沮丧。
- Git Push 失败与巨大的 Core 文件:用户报告在使用 Cursor 的 Background Agents 时,Git Push 出现延迟或失败,通常是因为 Agent 意外提交了一个巨大的 ‘core’ 文件。
- 解决方法包括指示 Agent 检查并删除
core文件,并将core添加到.gitignore以防止未来出现问题。
- 解决方法包括指示 Agent 检查并删除
- Cursor 支持团队不了解 Background Agents:用户发现 Cursor 的支持团队似乎并不理解 Background Agents,只能提供笼统的回答或承认他们不知道如何提供帮助。
- Discord 频道活跃度较低,表明团队可能被大量请求淹没,在竞争激烈的环境中难以跟上进度。
- Background Agent 缺少远程连接:一位用户报告称,Background Agent 甚至没有连接到主 IDE 中的远程仓库,导致无法手动推送更改。
- 在线 Agent 环境中缺少 Terminal,导致了浪费 Token 的反复沟通:用户指示 Agent 推送,而 Agent 却建议用户使用 Terminal。
LM Studio ▷ #general (293 条消息🔥🔥):
Qwen3-Coder New Models, LM Studio Plugins, LM Studio Updates on Remote Box, GPU recommendation, LLM for career advise
- Qwen3-Coder 模型尺寸扩展:Qwen 团队宣布更多尺寸的 Qwen3-Coder 模型即将推出。
- 成员们对潜在的 80-250B MoE model 或 dense 32-70B 模型感到兴奋。
- LM Studio 插件进展:LM Studio 的 Plugins 目前正在开发中,尚未发布。
- 为有兴趣参与 beta 测试的 TypeScript developers 分享了一份表格,链接在这里。
- MCP Server 日志出现在 LM Studio 中:LM Studio 将来自 MCP server 的日志传输到应用内的开发者控制台,日志行来源由
Plugin(mcp/duckduckgo)指示。- 这些日志源自 MCP server,而非 LM Studio 本身。
- LLM 并不总是最好的职业顾问:成员们警告不要依赖 LLM 获取建议,特别是像职业指导这样敏感的话题。
- 相反,建议向现实生活中的人寻求建议,如老板、家人和朋友。
- 探索上下文迷宫:VRAM 消耗研究:Context 占用的 VRAM 量取决于模型大小。
- 大型模型在小于其最大 Context 尺寸 1/2 时质量最佳,超过该限制后质量会下降。
LM Studio ▷ #hardware-discussion (157 条消息🔥🔥):
GPU for LLMs, AMD vs Nvidia for AI, Expandable GPU Memory, Laptop Failure Rates, eGPUs over USB4
- 5070ti 性价比极高,可运行 12B 模型:一位用户提到购买了 5070ti,并可能在 Super models 上市时升级,指出其能有效运行 12B models。
- 然而,他们承认 16GB VRAM 对于更大的模型来说并不充裕,但能以相对较慢的速度 (5t/s) 运行 32B models。
- 9070 XT:AMD 的 AI 性能困境:用户讨论了从 4070 Ti Super 转向 9070 XT,但普遍共识是 AMD 在 AI 性能方面仍落后于 NVIDIA,尤其是在 Windows 上。
- 一位用户表达了沮丧,称 ‘AMD is focusing on silly things’,指的是 AMD 在 Stable Diffusion 3.0 上的投入,而不是改进 ROCm PyTorch 的支持。
- 可扩展 VRAM 仍是白日梦:一位用户感叹缺乏可选 VRAM 升级的 GPU,并指出像 x060 和 x070 这样价格亲民的显卡不提供此功能。
- 对话涉及了实现此类设计的技术和经济挑战,认为这更多是商业决策而非技术限制,并提到 Bolt Graphics 是未来可能提供可扩展内存解决方案的竞争者。
- USB4 eGPU 带宽限制:一位用户分享了通过 USB4 连接的 eGPU 设置图片,询问其带宽影响,以及是否可以同时利用笔记本 GPU 和 eGPU。
- 另一位用户警告说,USB4 的带宽限制可能会显著降低推理速度,并回忆起个人经历:使用 Thunderbolt 4 eGPU 连接 RTX 4090 时,性能仅达到预期的一半左右。
- 华硕笔记本故障率高:频道成员讨论了华硕笔记本的故障率,引用了 2 年故障率为 9% 和 3 年故障率为 15.6% 的数据。
- 这与 ThinkPad 等其他品牌形成对比,用户报告后者在多年使用中的故障率显著较低。
Eleuther ▷ #general (132 条消息🔥🔥):
SOAR 项目竞争力, 意图感知语义搜索, ACL 会议, 极端环境下的开源 AI
- SOAR 项目是残酷的竞争吗?: 成员们讨论了 SOAR 作为研究机会的竞争力,其中一位指出他们是在禁用背景列的情况下凭感觉进行 SOAR 评分的,另一位则表示 SOAR 的竞争异常激烈。
- 其他人提到 SOAR 是开放且公平/免费的,而一些人尽管成本高昂,仍选择为 Algoverse 等项目付费。
- 意图感知语义搜索实际上很难: 一位成员分享了他们让语义搜索更具意图感知能力的探索,发现当使用类似 客户的名字是什么? 这样的查询时,Dense Embeddings 对实际意图的把握相当模糊。
- 另一位成员建议使用 Knowledge Graph(知识图谱)使关系显式化,而另一位成员则提到使用向量数据库和 RAG。
- 使用 LLM 自动化 Mech Interp?: 一位成员征求关于 LLM-as-a-judge 如何与具有特征或电路发现类工具的 Mech Interp 结合的观点文章。
- 另一位成员建议将 MAIA 论文 (https://openreview.net/forum?id=mDw42ZanmE) 以及来自 Transluce 和 Anthropic 的工作作为起点。
- 征集自主海洋探索工具!: Triton Mining Co. 的创始人正在构建用于自主海洋探索的开源工具,并正在为实时合规、AUV 遥测和海底分析等 AI 应用寻求贡献者。
- 他询问了关于如何分享寻找贡献者的仓库以及如何以符合该服务器文化的方式发布信息的建议。
- 知识图谱和意图感知语义搜索正流行!: 成员们讨论了语义搜索和知识图谱,并指向了一篇相关论文,内容关于在潜空间(latent space)中使用非结构化知识图谱。
- 当被问及该方法是否具有确定性时,一位成员表示,在潜空间中工作虽然比 CoT 提示词更稳定,但不一定就是反确定性的。
Eleuther ▷ #research (117 条消息🔥🔥):
KV Cache 蒸馏, LLM as a Judge, 使用 LLM 进行信用分配, NeurIPS Rebuttals, RoPE
- KV Cache 得到蒸馏: 一位成员分享了一篇关于超长输入的 KV Cache 蒸馏的论文及其相关的 GitHub 仓库。
- 探索用于信用分配的 LLM Judge: 一位成员询问关于在 Actor-Critic 算法中使用 LLM as a Judge 进行信用分配(credit assignment)的情况,无论是直接使用还是通过将输出蒸馏到另一个模型中。
- 其他人指出,这可能类似于普通的 RLHF/RLAIF,其中 PPO 使用一个以 LLM 权重初始化的学习价值网络。
- NeurIPS Rebuttal 规则变更令作者感到沮丧: 作者们对 NeurIPS 一夜之间改变 Rebuttal 规则表示沮丧,这降低了提供视觉示例的能力。
- 变更包括从每篇审稿意见 6000 字符加一个 PDF 变为 10000 字符且没有 PDF,导致作者无法提供被要求的视觉示例。
- N 维 RoPE 的可视化: 一位成员分享了一篇关于 >1 维 RoPE 的博客文章,并配有可视化效果。
- 可视化展示了当测量 RoPE 频率对位置的方向以 2pi / phi(其中 phi 是黄金分割比)的角度均匀间隔时,会出现螺旋结构。
- 幻觉论文引发关于可计算性的辩论: 围绕一篇题为 Hallucination is Inevitable(幻觉是不可避免的)的论文展开了讨论,一些成员批评了其主张和方法论。
- 该论文的定理指出,LLM 只能在极少数全可计算函数(total computable functions)上做到无幻觉,这引发了对其是“标题党科学(clickbaity science)”的指责。
Eleuther ▷ #interpretability-general (4 条消息):
LLM 安全教程, 推荐阅读
- 论文在 LLM 安全教程中展示: 一位成员的论文在 LLM Security Tutorial 中进行了展示。
- 论文被列为推荐阅读: 该论文也被列入了推荐阅读清单中。
Eleuther ▷ #lm-thunderdome (30 条消息🔥):
Llama-3 eval harness 配置, SQuAD v1 vs v2, SQuAD 中的 F1 分数计算
- Llama-3 Eval Harness 配置难题:一位成员正尝试使用 lm-evaluation-harness 复现 Llama-3 论文数值 (77%),但遇到了困难。
- 建议包括在配置中添加
description,使用--num_fewshot 1,或者将数据集指向 llama evals 并修改 harness 中的doc_to_text和doc_to_target。
- 建议包括在配置中添加
- Squad 对决:v1 与 v2 的差异:评估结果的差异可能源于 harness 使用的是 SQuAD v2,而 Meta 可能使用了 SQuAD v1 或针对 SQuADv2 采用了不同的评估方法。
- Harness 通过检查字符串 “unanswerable” 的 token logprobs 是否超过阈值来判断不可回答的问题,但这效果不佳,因为 “unanswerable” 不在 tokenizer 的词汇表中。
- F1 分数详解:破解 SQuAD 的代码:HasAns_f1 score 是为每个样本计算的最大 F1 分数的平均值,代表了所有潜在候选字符串之间的最大重叠。
- 对于 NoAns_f1,它是针对二分类问题的传统 F1 分数,用于判断问题是否可回答。
Eleuther ▷ #gpt-neox-dev (9 条消息🔥):
两级 Checkpointing, 异步 Checkpointing, GPT-NeoX 训练框架, TokenSmith
- 为 GPT-NeoX 提议两级 Checkpointing:一位成员提议将 两级 checkpointing 集成到上游 GPT-NeoX,使 N 个节点上的模型副本能够将 checkpoint 保存到节点本地存储,并在训练期间通过 CPU 线程写回 PFS。
- 该方法有助于实现弹性(elasticity)和容错性(fault-tolerance),如果某个节点发生故障,允许通过点对点(P2P)方式将副本加载到可抢占的备用节点。
- 异步 Checkpointing 讨论:该成员澄清,异步 checkpointing 指的是模型副本将 checkpoint 保存到节点本地存储,而弹性或容错性涉及在故障时通过点对点方式将副本加载到备用节点。
- 可以先实现基础的异步 checkpointing,然后再以 PR 形式提交两级 checkpointing。
- GPT-NeoX 训练框架仍在发挥作用:考虑到已有更好的开源模型,一位成员询问为何仍在 gpt-neox-dev 进行讨论。
- 另一位成员澄清,讨论的中心是 GPT-NeoX 训练框架,而非 20B 模型本身。
- TokenSmith 首次亮相:一位成员分享了他们的项目 TokenSmith,该项目现已公开并发布了预印本。
- 其 GitHub 仓库此前已经开源。
HuggingFace ▷ #general (179 条消息🔥🔥):
FOSS AI 的 GPU 推荐,AI 开发中的 SYCL vs CUDA,Qwen3-Thinking 模型需求,将 HF API 与 Open WebUI 和 LiteLLM 集成,ChatGPT 经验验证
- FOSS AI 项目的 GPU 指南:成员们讨论了适合托管 FOSS AI 的 GPU,最初考虑了 Intel ARC 770,但后来因软件支持较差而不再推荐。
- 尽管出于 FOSS 原因更倾向于 SYCL 而非 CUDA,但配备 16GB VRAM 的 RTX 4060 被推荐为更好的替代方案;不过,一些人指出 SYCL 目前在 AI 领域存在局限性。
- 使用 LiteLLM 和 Hugging Face 释放 LLM 潜力:成员们讨论了如何使用 LiteLLM 将 Hugging Face API 集成到 Open WebUI 中,以及管理 HF inference 的潜在替代方案。
- 针对免费 API 的 2K context window 限制提出了担忧,引发了关于定价以及 deepseek r1 等不同模型适用性的讨论。
- 揭秘 Agent 支付:一位成员质疑 Agent 支付是否应该是一个独立于人类支付的系统,并强调了当前系统需要人工批准交易的问题。
- 他们提出了一个根据自身设计原则、安全假设和 UX 流程设计的系统。
- 时间线揭穿 ChatGPT 资深人士:在一次面试过程中,一名候选人声称拥有 8 年 ChatGPT 经验,这引起了怀疑,因为 ChatGPT 的首次公开发布是在 2022 年 11 月。
- 随后一位成员分享了详细的 ChatGPT 里程碑时间线,展示了 ChatGPT 的发布及后续更新,并补充道 “他是前 OpenAI 员工的可能性并非完全为零……”。
- 应对 Qwen3-Thinking 内存迷宫:成员们强调,运行最新的 Qwen3-Thinking model 至少需要 88GB 的统一内存或 RAM/VRAM,并指向了一个 Hugging Face 链接。
- 一位成员推荐了一份 使用 llama.cpp 运行 Qwen3 的指南 以实现该目标。
HuggingFace ▷ #cool-finds (2 条消息):
Dark Knowledge
- 将 Dark Knowledge 蒸馏为有趣的算法名称:一位成员分享了一张引用了 knowledge distillation(知识蒸馏)中 “Dark Knowledge” 概念的图片。
- 知识蒸馏概述:链接的图片提供了知识蒸馏的概述,强调了知识从较大的“teacher”模型向较小的“student”模型的转移。
HuggingFace ▷ #i-made-this (8 messages🔥):
TinyVision, SamosaGPT, Experimental Ultra Low-Parameter Models, Serverless Agent Platform, Byte-Vision
- TinyVision 发布:让计算机视觉变得简单:一名成员在 GitHub 上发布了 TinyVision,这是一个轻量级的 CV 模型,专注于 Cat vs Dog 分类,并计划在未来增加更多视觉相关任务。
- 该成员鼓励喜欢该项目的用户在 GitHub 上点亮 Star。
- SamosaGPT:全能 AI 内容创作工作室:一名成员分享了 SamosaGPT,这是一个自发项目,创建了一个精美的 Web 界面,集成了 Ollama 的本地 LLM、用于图像生成的 Stable Diffusion,甚至还支持视频生成。
- 超低参数模型:不包含性能:一名成员正在构建实验性的超低参数模型,通常在 100K 参数以下,有时甚至更小,以探索小模型在有限计算资源下仍能学习到什么。
- 部分模型包括 Code-Mini-v0.1(在 Python 上训练的 90K 参数 Transformer)、Mini-v0.1(5K 参数的前馈模型)和 Mini-Classify-v0.1(9 参数的句子分类器)。
- Serverless Agent 平台:Agent 即服务:一名成员构建了一个 Serverless Agent 平台,包含通用 Agent 以及持久化、计算机、文件系统、浏览器、搜索、抓取、MCP 和工具等构建模块。
- 该平台可通过 API 访问,该成员正在寻找有 Agent 开发经验的开发者参与早期访问并进行压力测试,项目地址在这里。
- Byte-Vision:隐私优先的文档智能平台首次亮相:一名成员介绍了 Byte-Vision,这是一个隐私优先的文档智能平台,可将静态文档转换为可交互、可搜索的知识库,基于 Elasticsearch 构建并具备 RAG 能力。
HuggingFace ▷ #reading-group (4 messages):
Weighted Colored Graphs, Topological Data Analysis, Graph Spectral Theory, Graph Neural Networks
- GNN SOTA 与图谱理论紧密相关:一名成员分享了 EleutherAI 关于图谱理论(Graph Spectral Theory)演讲的 YouTube 链接。
- 该成员还发布了一篇 Medium 博客文章,其中包含关于图谱理论和 Graph Neural Networks (GNN) 当前 SOTA 状态的笔记。
- 扩散研究与图谱理论非常接近:一名成员对扩散研究(Diffusion Research)与图谱理论领域的接近程度表示惊讶。
- 他们提到,在网络环境改善后,未来可能会就图谱理论及相关论文进行分享。
HuggingFace ▷ #computer-vision (8 条消息🔥):
Image style dimensionality, Intrinsic dimension, Residual convolution layers, Clip augmentation
- 确定图像风格的最佳维度:一位成员最初训练了一个 128 维输出模型,意识到这对于描述图像风格来说维度可能过多,随后利用 本征维度 (intrinsic dimension) 确定 7-8 个维度 应该就足够了。
- 卷积模型架构公开:该模型架构包含 残差卷积层 (residual convolution layers) 和卷积下采样,随后是 Gram 矩阵和全连接层,完全从零开始构建,详见 此图表。
- 该成员还提到,有趣的部分在于如何为其构建 Ground Truth 数据集。
- CLIP 增强辅助相似性搜索:对于寻求 相似风格 图像的用户,一位成员建议采用 测试时增强 (test time augmentation) 技术,如对查询图像进行翻转和旋转,然后使用 CLIP 对结果取平均值。
{kind=link}
HuggingFace ▷ #NLP (8 条消息🔥):
Laws of Exponentiation and Logarithms, Intent-aware Semantic Search, Knowledge Graphs for Semantic Search, Graph Database Search Methods
- 对数法则被特别提及:一位成员提供了 指数和对数法则 来解释一个数乘以对数如何与等式另一侧的操作相关联。
- 他们指出,将这些法则应用于矩阵会使情况复杂化,需要施加限制,尽管论文中使用的加权最小二乘模型减轻了这些问题。
- 意图感知语义搜索在处理客户姓名请求时遇到困难:一位成员正在探索意图感知语义搜索,并指出 稠密嵌入 (dense embeddings) 往往无法检索到特定属性(如客户姓名),而是返回模糊相关的结果。
- 例如,搜索 “客户的名字是什么?” 会在返回实际客户姓名之前先返回定义和职责说明。
- 用于意图感知搜索的知识图谱:一位成员正在探索 知识图谱 (Knowledge Graphs),通过使关系显式化来改进意图感知语义搜索。
- 问题在于:当知识图谱是使用 OpenIE 或其他无模式 (schema-less) 方法构建,且你不知道存在哪些关系时,该如何搜索它?
- 图数据库搜索方法解析:知识图谱可以通过多种方式搜索,例如使用主语-谓语-宾语三元组的 三元组存储 (triple stores),并可能利用 SPARQL。
- 可以为实体创建一种可搜索的结构,称为 “索引 (indexing)”,但对高维结构进行高效的非索引搜索仍然是一个开放性问题。
{kind=link}
HuggingFace ▷ #smol-course (2 条消息):
Google VEO3 costs, GPU costs
- Google VEO3 视频非常昂贵:生成 Google VEO3 视频的成本非常高。
- 一位用户在所有运行任务中花费了 10 美元。
- 短视频运行的 GPU 成本:一位用户暗示 Google VEO3 的短视频运行费用相当实惠,短时间运行大约花费 10 美元。
- 社区似乎一致认为,对于短视频生成来说,这是一个可以接受的价格。
HuggingFace ▷ #agents-course (10 条消息🔥):
HF tokens, Ollama, Qwen, Gemini, Mistral
- **HF Tokens 耗尽,Qwen 的幻觉困扰 Agent 工作流:一位成员的 **Hugging Face tokens 耗尽,尝试通过 Ollama 使用 Qwen 2.5,发现 Agent 出现幻觉并给出自己的答案。但切换到通过 API 使用 Gemini(非本地 Ollama)后运行正常,这表明 Qwen 可能存在问题。
- 他们现在正考虑切换到 Mistral 或其他能在 24GB MacBook M3 上流畅运行的模型。
- **认证测验遭遇系统性挫折:一位用户报告在生成认证测验反馈时收到 **404 Client Error,特别提到了 Hugging Face API 上的 Qwen2.5-Coder-32B-Instruct 模型。
- 用户担心由于此问题,可能无法再获得认证。
- **拼写错误引发棘手的 Token 响应:一位用户报告说,在 **Unit-1 中提问时如果带有拼写错误(例如输入 “tbe capitol of Azebhajina is”),聊天机器人的响应会出现异常(100000000000)。
- **Smolagents 代码片段引发会话解决方案:一位用户在运行 **2.1 章节中用于搜索播放列表的 Smolagents 代码片段时遇到了 401 错误,尽管已经授予了必要的 token 权限。
- 用户通过简单地重启 Colab 会话解决了该问题。
- **Llava 的图像洞察引发迭代调查:一位用户在 **Ollama 中尝试使用 Llava 模型描述图像,并注意到当
max_steps参数设置为大于 1 时,Agent 在初始描述后会尝试在网上搜索有关该图像的更多信息。- 例如,在生成初始描述后,Agent 尝试编写代码进行网页搜索,以了解更多关于图像中人物的信息。
Latent Space ▷ #ai-general-chat (189 条消息🔥🔥):
Qwen, Meta Superintelligence Labs, Quantization, Huggingface business model, Model Context Protocol
- Zhao 被任命为 Meta Superintelligence Labs 首席科学家:Meta 宣布任命 Shengjia Zhao 为其 Superintelligence Labs 的首席科学家,标志着雄心勃勃的 AI 发展计划,详见 X。
- 该帖子引发了包括神秘评论(例如 ‘Pathe, Mathe, and Zuck’)、关于笑话的疑问以及对 Yann LeCun 职位的询问。
- 深入探讨 HuggingFace 的收入来源:成员们讨论了 HuggingFace 的商业模式,发现他们目前主要作为推理提供商(inference provider),没有其他明确的收入转化路径(CTA)。
- 据分享,他们的收入来源之一是推理合作伙伴关系(在追赶 OpenRouter 的过程中),而 AWS 则补贴了他们的存储费用。
- Model Context Protocol 文档翻新:David Soria Parra 宣布翻新 Model Context Protocol 文档,并邀请反馈和贡献,详见 X。
- 此次更新获得了积极反应,人们期待其在某些 MCP 相关实现中的应用。
- 揭秘 OpenAI 的硬件野心:OpenAI 最近发布的消费级硬件职位招聘强调了无线技术、OLED、麦克风、摄像头等要求,暗示他们正在开发一款便携式设备,详见 X。
- 也有人怀疑 OpenAI 是否有能力同时管理消费级硬件开发和大规模数据中心基础设施。
- 为 AI Agent 打造的 2100 万美元云端运行时:E2B 成功筹集了 2100 万美元的 A 轮融资,用于开发 AI Agent 的云端运行时,投资者包括 Insight Partners, Decibel VC, Sunflower Capital, KAYA 和天使投资人,详见 X。
- 该公司旨在为 AI Agent 提供必要的基础设施,如快速启动的计算机、文件管理以及安全、隔离的开源环境。
Modular (Mojo 🔥) ▷ #general (48 messages🔥):
Mojo GPU 训练库, Nabla vs JAX, Mojo MAX 接口, Mojo vs Rust, Modular 中的 Bitnet 模型
- Nabla 是主要的 Mojo 训练库:Nabla 是一个用于 Mojo 的训练库,在某些硬件上比 JAX 稍快,但可能需要编写更多的手动代码。
- 目前由于某些问题,MAX 的 Mojo 接口未得到维护,这影响了性能;且由于缺少 IO 和线程等功能,Mojo 本身尚未准备好支持完整的训练框架。
- Mojo:是 CUDA 还是图编译器?:Mojo 的 GPU 支持功能更像 CUDA 而非图编译器,允许函数直接在 GPU 上运行。
- 在 Mojo 中编写自定义 Kernel 非常容易,围绕 MAX 的推理框架完全使用 Mojo 编写的 Kernel。
- Rust vs Mojo:该学哪一个?:Mojo 是 1.0 之前的语言,可能存在破坏性变更和功能缺失,因此一位成员建议阅读 Rust 的学习材料。
- 另一位成员提到,Rust 的 CUDA 绑定使用起来可能非常痛苦。
- 适用于 Modular 的微软 Bitnet 模型?:成员们讨论了将微软的 bitnet-b1.58-2B-4T 模型添加到 Modular 的可能性,理由是其基于 CPU 的特性和潜在的包容性。
- 然而,实现 Bitnet 可能需要特殊处理,因为奇怪的对齐问题会在 ARM 和 RISC-V 上引发故障,需要投入工程力量来研究重排算法以及可能的新 Kernel(如
XOR)。
- 然而,实现 Bitnet 可能需要特殊处理,因为奇怪的对齐问题会在 ARM 和 RISC-V 上引发故障,需要投入工程力量来研究重排算法以及可能的新 Kernel(如
Modular (Mojo 🔥) ▷ #mojo (114 messages🔥🔥):
Python 互操作 Nanobind vs Cython, Mojo FFI, Mojo GPU 支持, Mojo 编译器元编程
- Python 互操作中 Nanobind 优于 Cython:在 Python 互操作方面,Modular 更倾向于使用 Nanobind 而非 Cython,原因是其纯 C++ 特性、更优越的 Stub 文件生成工具,以及在 基准测试 中展示的运行性能。
- Mojo 旨在实现无缝互操作,以避免在 Mojo 之上再创建另一种语言,最终将实现类似于 PyO3 的自定义功能。
- Mojo 计划支持透明的 Python 扩展导出:Mojo 目标是通过最少的注解支持透明的 Python 扩展创建,自动导出可转换为 Python 对象的函数,无需手动添加如
@export[abi="python"]之类的装饰。- 其目标是通过自动检测待导出函数来简化 Python 互操作,并提供可选注解进行自定义。
- Mojo 的 C ABI FFI 能力:Mojo 拥有针对 C/C++ 的 FFI,允许使用
ffi.DLHandle(path)导入 C 库。- 虽然目前还不算完全成熟,但只要提供理由,它允许调用当前地址空间中链接的任何 C ABI 函数。
- Mojo 对 GPU 计算的愿景:Mojo 寻求 GPU 集成,避开 CUDA 特有的元素以保持可移植性,在厂商纷纷放弃 OpenCL 的情况下,倾向于整合更多原生 API。
- 虽然 CUDA 驱动仍然至关重要,但计划中包括利用 Apple Silicon 和 AMD GPU,可能还会包括 OpenCL 作为备选方案,甚至支持 Intel。
- Mojo 支持编译时执行和元编程:Mojo 可以在编译时执行不含 IO 的代码,从而能够创建像国际象棋引擎这样的结构,利用类似于 Rust traits 和依赖类型(dependent types)的特性预计算游戏状态。
- 堆分配的内存可以实例化为动态值,利用这一特性可以预计算查找表、树、图和前缀树(tries),正如 2023 年 8 月更新日志 所示。
Modular (Mojo 🔥) ▷ #max (11 messages🔥):
max cli version, Intel GPU support in MAX, OneMKL install regression, PyTorch Dependency in MAX
- **Max CLI 25.5 MIA - 尚未发布: 一位用户尝试在 **pixi.toml 文件中固定依赖项,但无法找到 max CLI 25.5 版本,因为它尚未发布。
- 他们还注意到使用
max = 25.*会被重写,他们认为这是非预期行为。
- 他们还注意到使用
- **MAX 缺乏 Intel GPU 支持: 一位用户报告称,由于 **OneMKL 未能正确安装,当安装了 Intel GPU 时,nightly 版本会崩溃,而 25.4 版本没有这个问题。然而,MAX 目前并不支持 Intel GPU。
- 有建议认为用户应针对 OneMKL 安装问题提交 GitHub issue,特别是如果该问题甚至干扰了 CPU 侧的执行,并且是一个最近出现的回归问题。
- **PyTorch 依赖即将移除!: 感谢团队的工作,PyTorch** 依赖将在下一个 nightly 版本中被移除。
- 团队澄清说,他们目前仅将最低版本固定为 2.5,但他们认为 2.0 实际上才是他们的底线。
GPU MODE ▷ #general (33 messages🔥):
Jane Street Hackathon, Multi-AI Agent System, Fractal Renderer, Graph Replay Dispatch, Structured Output with JSON Schema
- Jane Street 黑客松名额:最多 80-200 个: 组织者尚不确定纽约 Jane Street 黑客松的具体名额,估计在 80-200 个之间。
- Jane Street 黑客松 已确认仅限线下参加;演讲预计会被录制并重新分发,且出席并不以申请 Jane Street 的职位为前提。
- 多 AI Agent 系统工具: 一位成员正在使用他们的软件 API 构建多 AI Agent 系统,并为每个 API 创建一个工具,但由于上下文长度(context length)增加,正面临性能和成本问题。
- 另一位成员建议研究 MCP (Model Context Protocol) 作为解决方案,并建议考虑使用带有 JSON Schema 的结构化输出。google-adk 是一个文档很棒的选择。
- 移植到 CUDA 的分形渲染器: 一位成员将其分形渲染器从 JAX 移植到了 CUDA,并分享了 GitHub 仓库。
- 该成员还幽默地声称自己拥有 Terry Tao 10% 的智商。
- Graph Replay 调度延迟: 一位成员观察到,在大约 13 次 graph.replay() 调用后,后续的调度时间显著变长。
- 他们最初询问该现象的原因,但在查看日志后迅速确认问题是由于命令缓冲区已满(command buffer full)。
- TRI DAO 实验室新论文: 一位成员分享了 来自 TRI DAO 实验室的一篇新论文链接。
- 消息中未提供关于该论文的更多细节。
GPU MODE ▷ #triton (7 messages):
Triton CUDA Errors, PY_SSIZE_T_CLEAN macro bug, Profiling Triton Kernels, GEMM Ping-Pong Schedule
- CUDA 错误导致训练停止: 一位成员在端到端训练期间遇到了
RuntimeError: Triton Error [CUDA]: invalid argument,具体发生在fp8_blockwise_act_quant_2D_transposed_kernel[grid]上。- 该成员发现,尽管 Kernel 单元测试通过,但 Y 维度的 grid 大小过大导致了该错误。
- PY_SSIZE_T_CLEAN 宏再次作为 Triton Bug 出现: 一位成员遇到了与 PY_SSIZE_T_CLEAN 宏相关的 SystemError,这是一个已知的 Triton Bug,并引用了 GitHub Issue 5529 和 GitHub Issue 5919。
- 他们还注意到,该错误是在从 Python 3.13 降级到 3.11 和 3.12 后发生的,并询问 PyTorch 2.8 和 Triton 3.4.0 是否有潜在的修复方案。
- 分析 Triton Kernel 性能: 一位成员询问如何使用 ncu 分析 Kernel,并能够看到每次 Kernel 启动时的输入大小、autotune 配置等元数据。
- 他们尝试在启动前重命名 Kernel,以便在 ncu/nsys 中将元数据包含在 Kernel 名称中,但报告称这种方法非常不稳定。
- Triton GEMM 的 Ping-Pong 调度: 一位成员询问 Triton 编译器是否能够执行具有 ping-pong 调度的 GEMM。
GPU MODE ▷ #cuda (3 条消息):
nsight-copilot, nsight-copilot approval times, nsight-copilot claude
- nsight-copilot 应用探讨:一位成员询问了 nsight-copilot 的成功应用案例。
- 另一位成员分享说,他们的申请在 10 小时后仍处于待处理状态。
- nsight-copilot Claude 推测:一位成员推测 nsight-copilot 与 Claude 相似。
- 他们还提到已申请进行实验。
GPU MODE ▷ #announcements (1 条消息):
marksaroufim: <@&1343042150077562890> 现在开始与 Ali Hassani 讨论 Neighborhood attention!
GPU MODE ▷ #cool-links (4 条消息):
Inference Optimization, Attention Mechanisms, MQA, GQA, MLA, GTA and GLA
- Tri Dao 实验室提升解码速度:来自 Tri Dao 实验室的一篇新论文介绍了两种注意力机制(GTA 和 GLA),旨在实现更快、更具内存效率的解码,这些机制是在 MQA、GQA 和 MLA 的基础上构建的,正如这篇 LinkedIn 帖子 中所强调的那样。
- GTA 和 GLA 注解:发布者为所有四篇相关论文(GTA、GLA 以及 MQA、GQA 和 MLA)添加了注解,包括解释、图表和计算示例,以便在时间紧迫时更容易理解。
GPU MODE ▷ #jobs (1 条消息):
Global Hiring for Full-Time Positions, Intern Hiring in the United States
- AMD 扩大全球全职招聘:AMD 愿意在全球任何设有 AMD 办公室的地点招聘全职员工。
- 这表明他们采取了广泛的人才获取方式,利用其已建立的全球影响力。
- 实习生招聘仅限美国:AMD 的实习计划专门针对位于 美国 的候选人。
- 这表明其早期职业人才培养采取了地域集中的战略。
GPU MODE ▷ #beginner (3 条消息):
Flash Attention 2 installation, HuggingFace CLI for CI/CD, Optimized Kernels for Hackathon
- Flash Attention 2:漫长的等待:一位用户询问了如何避免在安装 Flash Attention 2 时(特别是在使用云端 GPU 时)耗时过长的构建过程。
- 该用户提到安装过程已经进行了 2 小时,正在寻求加快设置的建议。
- HuggingFace CLI 成为 CI/CD 平台:一位用户指出,HuggingFace CLI 现在利用其最新功能,可以作为 CI/CD 平台使用。
- 这是陈述事实,没有提供额外背景。
- 黑客松参与者的内核难题:一位参与者对最近宣布的黑客松表示感兴趣,但承认缺乏编写优化内核(optimized kernels)的经验。
- 他们请求提供资源和建议,以便为黑客松做准备并取得实质性进展。
GPU MODE ▷ #self-promotion (2 条消息):
AI Alignment Research Program, High-Level APIs Learning Series
- Moonshot Alignment 计划招募新成员:专注于 AI alignment 难题的研究计划申请将于今天截止,详情请见 ai-plans.com。
- 高层级 API:是拐杖还是弹射器?:一位成员宣布了一个关于高层级 API 的 三部分系列文章,讨论了他们的学习历程,第一部分可在 maven.com 查看。
GPU MODE ▷ #general-leaderboard (2 条消息):
Submission Errors, Submission ID, Code Samples
- 提交过程受意外错误困扰:用户在尝试提交(包括测试提交)时,持续遇到 “An unexpected error occurred. Please report this to the developers” 的消息。
- 该问题似乎影响广泛,波及多名用户,导致其无法完成必要任务。
- 请求提交详情:为了诊断反复出现的提交错误,开发人员请求用户分享其 Submission ID 和相关的 code samples。
- 这些信息对于定位意外错误的根源并实施有效的修复至关重要。
GPU MODE ▷ #factorio-learning-env (53 条消息🔥):
Blue/Green Docker Servers for Factorio, Factorio Save Files vs FLE Game State, Python vs Bash for Docker Management, Multiplayer Mod Issues, Episode Boundaries and State Resets
- 提议使用蓝/绿 Docker 服务器热加载 Factorio:一名成员提议使用 blue/green docker servers 来实现 Factorio 的热加载/重置,利用 Factorio 原生的 save/load 功能并预加载一个暂停的备用服务器,然后将 rcon 端点切换到该备用服务器。
- 该成员认为,这种方法虽然需要维护两个实例,但以少量的基础设施成本换取了极高的确定性,提供了零漂移和简单的回滚。
- Factorio 存档文件 vs. FLE 游戏状态:详细对比:讨论对比了 Factorio save files(稳健、确定性强,但较重)和 FLE game state(对于小地图速度快、人类可读,但在大规模下较脆弱)。
- 对话权衡了各方的优缺点,一名成员建议在投入蓝/绿部署之前,先评估在单个服务器上管理存档的延迟成本。
- Python 的 Docker API 挑战 Bash 环境管理:成员们讨论了将
run-env.sh脚本移植到 Python,以便更好地控制 Docker 镜像创建和场景转换,尽管最初证明其速度慢于 bash + compose。- 一名成员强调了 Python 方法在简化环境搭建方面的强大功能,而另一名成员提到使用
aiodocker来提高速度。
- 一名成员强调了 Python 方法在简化环境搭建方面的强大功能,而另一名成员提到使用
- 多人游戏 Mod 问题需要重启容器:用户遇到了与 Mod 事件处理器不匹配相关的 ‘Cannot join’ 错误,这表明某些 Mod 并非多人游戏安全的。
- 解决方案包括重启 Docker 容器,以确保客户端和服务器之间的 Mod 配置完全一致。
- Episode 边界触发状态保存与重置:会议澄清了 TrajectoryRunner 会完成一个 Episode 循环,并在 Episode 边界调用
Environment.reset(...),清除 Agent 命名空间并重置计时器/ticks。- 在 MCTS 期间,每次采样后也会保存状态,并可以从数据库中恢复,每次调用
env.step()时都会进行重置,以确保状态处于 checkpoint 检查点。
- 在 MCTS 期间,每次采样后也会保存状态,并可以从数据库中恢复,每次调用
GPU MODE ▷ #cutlass (20 条消息🔥):
Cutlass Software Pipelining, CuTeDSL vs CuTe C++, CuTeDSL Persistent Kernel Issue, TV-layout visualizer for cute-dsl
- 深入探讨 Cutlass 软件流水线 (Software Pipelining):成员们讨论了 CuTeDSL 中的软件流水线,参考了相关的 代码 和 AST 辅助工具 以理解预取 (prefetching) 的生成方式。
- 澄清了 range 算子中的 pipeline 参数向编译器提供了关于预取次数的提示,用户必须规划暂存缓冲区 (staging buffers)。
- 揭秘 CuTeDSL dense_gemm 示例中的预取:澄清了 software pipeline config 简化了预取的样板代码,类似于
dense_gemm.py示例中的第 727-769 行。- 一位成员使用软件流水线重写了类似于 Blackwell 的示例,没有显式预取(即只有一个主循环),并实现了类似的性能。
- 揭示 CuTe DSL 的设计理念:成员们指出 CuTe DSL 及其编译器并不打算设计得过于复杂。
- 其目标是在 Python 中重建 CuTe C++ 的类似物,并使用户能够更高效地在不同 GPU 架构的 Tensor Core 程序上实现峰值性能。
- 调试 CuTeDSL 中的 Persistent Kernel:一位用户在使用 Pipeline API 编写 dense_gemm Hopper 示例的 persistent 版本时遇到了一个问题,即一半的值未能正确传输到 GMEM。
- 该用户提供了用于调试的 代码,但未收到回复。
- Chillee 针对 cute-dsl 的 TV-layout 可视化工具:一位用户分享了一个适用于 cute-dsl 的 TV-layout 可视化工具 链接。
- 该消息对该工具的简洁性和可预测性给予了正面评价。
GPU MODE ▷ #general (10 条消息🔥):
GPU Mode Leaderboard, PMPP problems, AMD Channels
- GPUMode 排行榜提交次数无限制!:GPUMode 排行榜提交 没有限制,因此用户可以根据需要多次提交。
- 一位用户询问 GPUMode 排行榜提交是否有上限,并表示他们不想“滥用它”。
- 新的 PMPP 版本即将到来:PMPP 问题 的新 v2 版本即将发布。
- 附图显示了一个提交运行结果的界面,一名工作人员回复道:“噢,对于这些 PMPP 问题,是的,我们有一个 v2 版本需要尽快发布。”
- AMD 频道应该被移除:AMD 频道 可能会被移除或重命名。
- 目前尚不清楚 AMD 频道是否真的会被移除。
GPU MODE ▷ #multi-gpu (9 条消息🔥):
multi-GPU lexicon, DTensor tutorial, splitting a GPU
- 词汇表让多 GPU 不再令人困惑:一位成员分享了一个方便的免费资源,一个为开始学习 multi-GPU 的人准备的术语/解释 词汇表。
- 另一位成员表示:“这是一个非常有用的资源,谢谢 :)”
- 详细解析 DTensor:一位成员计划直播对 DTensor 更详细的解释。
- 该成员分享了他们的 YouTube 频道 链接以观看教程。
- 将 GPU 切分为更小的块进行分布式处理:一位成员分享了一段代码片段,允许你在单个 GPU 上运行分布式处理。
- 另一位成员希望将他们的 48GB GPU 转换为 2x24GB,同时还能让他们使用其他的 2x24GB GPU。
Nous Research AI ▷ #general (130 条消息🔥🔥):
Atropos 更新、Qwen 性能、GPT-5 猜测、GLM-4.5、MoE 模型对比 Dense 模型
- Atropos 迎来重大更新: Nous Research 最近发布了 Atropos 的重大更新。
- 成员们还推荐阅读 Shunyu Yao 关于该主题的 second half。
- Qwen 对标 GPT4 表现亮眼: Qwen 被认为非常出色,在 arenahard 上对阵 GPT4 的胜率达到 89%。
- GPT-5 即将到来?: 在一名成员分享了关于 OpenAI 秘密路由所有 O3 请求的 Reddit 帖子 后,社区推测 O3 实际上已经是秘密的 GPT-5。
- 另一位成员指出它已在 web.lmarena.ai 上线。
- GLM-4.5 模型无法转换为低 bpw 的 GGUF: 最近发布的 GLM 4.5(包含 110B 和 358B 两个尺寸)在将 110B 模型转换为低 bpw GGUF 时面临挑战。
- 成员们还发现 GLM 4.5 在土耳其语等多语言任务中表现异常出色,在写作和创意任务上超越了 R1、K2、V3 甚至 Gemma 3 27B。
- 关于 MoE 和 Dense 模型的辩论: 社区讨论了从中型 Dense 模型向大型 MoE 模型的转变,一些成员担心 MoE 模型虽然在基准测试中表现良好,但可能无法像 Dense 模型那样捕捉到细微差别。
- 其他人则认为 MoE 模型效率更高,且本地使用的重点正在向其转移,并以 Qwen 30B 为例,它在仅使用约 3B 模型计算量的情况下就能与 20B 模型竞争。
Nous Research AI ▷ #research-papers (3 条消息):
过度炒作的 AI 论文、Mereal Azure
- Deedy 认为论文被过度炒作: 一位成员分享了一条 推文,认为某篇 AI 论文被过度炒作。
- 他们链接到了名为 Mereal Azure 的论文,地址为 arxiv.org/abs/2507.16003。
- 关于 Mereal Azure 的 Arxiv 论文出现: 讨论中包含了一个专注于 Mereal Azure 的 Arxiv 论文链接。
- 该论文可在 arxiv.org/abs/2507.16003 获取,表明该领域近期有研究活动。
Nous Research AI ▷ #interesting-links (11 条消息🔥):
AI 门槛设置、AI 中的哲学支线、ChatGPT 的 Hyperstim 补丁、小模型实验
- AI 门槛设置浪费时间: 一位成员认为,哲学上的“支线任务”旨在掩盖价值并阻止局外人获取价值,他回忆起曾与第一代 AI 创新者合作,那些人认为理解 AI 需要一阶逻辑(first-order logic)博士学位。
- 他们提供了一个 示例论文 的链接,认为那是巨大的时间浪费。
- Hyperstim Patch 重新对齐 ChatGPT: 一位成员介绍了 Hyperstim Patch,这是一个直接置入 ChatGPT 的工具:用户可以说 activate 来让它重新对齐。
- 该工具可通过 tinyurl.com/Hyperstim 获取,创作者正在征求用户反馈。
- Experiment9 深入研究极小模型: 一位成员分享了一个玩具研究(toy study),任何对极小模型感兴趣的人可能会发现它很有用。
- 该研究已在 GitHub 上发布。
Nous Research AI ▷ #research-papers (3 条消息):
过度炒作的断言、mereal.azure 论文
- AI 断言被过度炒作?: 一位成员分享了一条 推文,暗示某些 AI 断言可能被过度炒作。
- 链接的推文质疑了 AI 领域内某些进展或承诺的有效性以及潜在的夸大。
- mereal.azure 发布论文: 一位成员发布了 mereal.azure 论文的链接:https://arxiv.org/abs/2507.16003。
- 这似乎是一篇研究论文,可能与关于 AI 进展的讨论有关,但需要更多背景信息来确定其与过度炒作断言的具体关联。
Yannick Kilcher ▷ #general (116 messages🔥🔥):
LLM Context Manager, Downvotes in Web3, Neural Network Pruning, Intent-Aware Semantic Search, AI Demonic Narratives
- Context Manager 优化了对话中的 LLM 推理:一名成员在 GitHub 上介绍了一个 LLM Context Manager,它使用分支和一种新颖的算法 Contextual Scaffolding Algorithm (CSA) 来智能管理对话推理过程中喂给模型的上下文,以防止上下文污染和腐烂,并在 YouTube 视频中进行了演示。
- Downvotes 在 Web3 实验中被武器化:一位成员分享了一个 Web3 实验,其中 Downvotes 被群体误用来互相攻击,导致了一个充满毒性的环境,加入社交网络意味着面临帖子被 Downvotes 的风险,类似于战略性和无理的诉讼。
- 他们了解到,Downvotes 在匿名、算法驱动且拥有大量未联网用户的平台上效果最好,并强调公共股票发行的监管要求有足够多的非相关参与者,以降低操纵风险。
- 关于 Neural Network Pruning 的见解:一位成员指出,大多数关于 Neural Network Pruning 的见解都集中在简单的稠密网络上,而非 Transformer,许多尝试都以未发表的无效结果告终。
- 他们表示,剪枝在传统的稠密网络中有效,是因为模型在高维空间中形成了边界条件,而你只需要保留分类的边界即可保持工作。
- 讨论 Intent-Aware Semantic Search:一位成员探讨了如何让 Semantic Search 更加具备意图感知 (Intent-Aware),指出稠密嵌入(如 BERT/SBERT)在处理一般相似性方面表现尚可,但在实际意图上比较模糊。
- 另一位成员建议使用 Hierarchical Neural Topic Modeling 来解决其中的一些场景,但对于其他意外场景没有理论保证,并表示出于这种挫败感打算攻读博士学位。
- AI 妖魔化叙事抬头:成员们讨论了“AI 是恶魔”的叙事如何在主流和非主流媒体中出现,有些人甚至在不加讽刺地认为在使用 LLM 时是在与恶魔交谈,并引用了一个 YouTube 视频。
- 一位成员讽刺地提出,它是一个“数字通灵板 (Digital Ouija board)”,因为无论人们多么担心它是魔鬼,最终还是他们在移动它,让它说出他们想听的话。
Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
Peer Review, Math heavy papers, Learning PDEs, NAS Transformers
- 向社区咨询正在进行 Peer Review 的论文:一位成员询问了在不打扰他人的情况下,与社区讨论正在进行 Peer Review 的论文的正确方式,并指出该论文收到了不好的评审意见,寻求对其质量的反馈。
- 另一位成员建议分享 ArXiv 链接,提到关注度将取决于主题,并建议联系特定用户,以便可能在每日论文讨论中进行探讨。
- “通用锤子”论文发布在 ArXiv:一位成员发布了他们的 ArXiv 论文链接,将其描述为解决学习问题的通用锤子,并在玩具动力系统上进行了演示。
- 他们指出这篇论文数学性较强,工程意义可能不会立即显现,这就是为什么他们希望围绕它展开讨论。
- NAS 论文被认为很糟糕:一位成员提到遇到了一篇糟糕的新论文,其摘要中的主张很容易被证伪,并将其比作针对 Transformer 架构设计的 NAS。
Yannick Kilcher ▷ #agents (1 messages):
Amazon Q, Prompt Injection, Security Vulnerabilities
- Amazon Q 抵御了清除电脑数据的 Prompt Injection:一名黑客试图将清除电脑数据的命令植入 Amazon 的 AI Coding Agent 中,但该尝试未获成功。
- 该方法涉及在 Pull Request 中进行 Prompt Injection,凸显了 AI 编程工具中潜在的安全漏洞。
- AI Coding Agents 面临 Prompt Injection 风险:该事件强调了 AI Coding Agents 中 Prompt Injection 攻击的风险,恶意命令可以嵌入到看似无害的输入(如 Pull Request)中。
- 尽管这次针对 Amazon Q 的特定攻击未获成功,但它提醒人们在 AI 驱动的开发工具中需要采取稳健的安全措施。
Yannick Kilcher ▷ #ml-news (7 条消息):
Youtube pushes shorts, Recommendation algorithm, personalized content
- YouTube 推送 Shorts 以与 TikTok 竞争:成员们注意到 YouTube 正在大力推广 shorts,因为他们将 TikTok 视为核心威胁,并且正在流失最忠实的用户。
- 成员们认为这可能更多是为了市场份额,人们在非 YouTube 的视频平台上花费时间意味着收入损失,这在商业上是不可接受的。
- 推荐算法的理解能力:一位成员指出,我们开始看到过多的 shorts,是因为 推荐算法 已经无法正确理解 长视频(long form videos) 了。
- 另一位成员质疑推荐算法是否能区分像“核钻石电池”或“惊人的工业加工(配上视频中根本没有的 AI 生成垃圾缩略图)”之类的 BS 内容与真正的技术视频,并引用了一段 YouTube 视频。
- 推荐与生成式内容的融合:一位成员引用道,未来我们将看到 推荐与生成式内容 开始融合,届时我们将推荐内容的个性化版本。
- 该成员补充说,未来我们可能不再是推荐内容,而是开始直接创建内容,这可能会进入非常有趣的领域。
Manus.im Discord ▷ #general (71 条消息🔥🔥):
Manus AI, credits consumed, vibe coding challenge, GPT prompts, Manus Fellow in Switzerland
- Manus AI 帮助用户完成多个项目:一位用户分享说,他们使用 Manus AI 完成了 5 个 App 和一个 客户网站,称其为“赚钱机器”。
- 每个 App 消耗了大约 300 credits,客户网站消耗了大约 1000 credits。
- 用户建议举办 Manus Vibe Coding 挑战赛:一位用户建议 Manus 创建一个 vibe coding 挑战赛,以帮助用户在没有客户的情况下构建自己的产品。
- 他们声称在没有任何广告的情况下,每天获得 30 个全球用户,其产品在搜索 flutter web Emulator 时排名 #1。
- 成员征集 AI Prompt engineering 策略:一位成员询问其他人使用什么“工具或技巧”来“榨取 ChatGPT 的最佳性能”并测试边缘行为。
- 这暗示某些 Prompt 优于其他 Prompt,人们正在寻找提升 Prompt 水平的建议。
- Fellowship 申请等待回复:一位很久以前申请成为 瑞士 Manus Fellow 的成员仍在等待答复。
- 他们计划在 8 月组织一场见面会和黑客松,正在寻找此事的联系人。
- 用户报告任务消失:多位用户报告他们的 任务在 Manus AI 平台内消失了。
- 有建议称退出并重新登录可能会解决此问题。
DSPy ▷ #show-and-tell (2 条消息):
GEPA: Reflective Prompt Evolution, Prompt Optimization, DSPy Optimizer, LLM Reflection
- **GEPA 通过反思实现完美 Prompt!:一篇关于 **GEPA: Reflective Prompt Evolution (https://arxiv.org/abs/2507.19457) 的新论文介绍了一种将 Prompt 视为可以通过反思改进的文档来优化 Prompt 的方法。
- 结果显示,其性能比 GRPO(DSPy 所使用的)高出 10%,rollouts 减少了 35 倍,并且比 MIPROv2 强 10% 以上。
- GEPA 实现语言演化:GEPA 分析失败原因,询问“在语言层面出了什么问题?”,并根据分析生成具体的 Prompt 改进。
- 这种方法实现了“语言演化”,即 Prompt 能够字面意思上解释它们为何失败以及如何自我修复,这与目前进行数值搜索的 MIPROv2 和 COPRO 等优化器形成鲜明对比。
- 探索 DSPy 集成!:用户探索了一个潜在的 DSPy 集成想法,建议使用像 gpt-4o 这样的反思模型作为优化器。
- 最酷的部分是:这不仅仅关乎性能——你实际上可以理解优化为何有效。不再是黑盒优化!
- DSPy 的新优化器?:一位用户提到 GEPA 可能会成为新的 DSPy 优化器。
DSPy ▷ #papers (2 条消息):
DSPy optimizers, New Arxiv Paper
- 论文引发优化器集成讨论:一位用户分享了一篇 新 arXiv 论文,并询问它是会被集成到 DSPy 中,还是作为一个独立的 GitHub 仓库存在。
- 另一位用户回应称,新的优化器应始终集成到 DSPy 中。
- 集成策略:有人提出了新优化器是作为 DSPy 的一部分还是独立仓库的问题。
- 共识是,新的优化器应始终直接集成到 DSPy 中,以保持连贯性。
DSPy ▷ #general (57 条消息🔥🔥):
Context Engineering Definition, MLSys DSPy Talk, Online RL for Personalization, GEPA: Reflective Prompt Evolution, DSPy Optimizer Roadmap
- 定义 Context Engineering:Drew Breunig 发表了关于为什么 context engineering 这一术语至关重要的演讲,并在 他的博客 上发布了总结。
- 演讲没有录音,但博客文章概括了主要观点。
- DSPy MLSys 演讲引发路线图咨询:一位成员非常喜欢 MLSys DSPy 演讲 (YouTube 链接),重点介绍了 context engineering 方法和模块化指令设计。
- 他们询问了 DSPy roadmap (GitHub 链接),并推测 GRPO 和 RL 是否是下一个改进领域。
- 用于个性化的 RL 备受关注:成员们对使用 Online RL 通过将 Agent 与其服务对象挂钩来提高个性化和指令相关性表现出浓厚兴趣。
- 一位成员向有兴趣参与该项目的人提供了访问权限。
- GEPA:反思性 Prompt 演化:一位成员介绍了论文 GEPA: Reflective Prompt Evolution,该论文将 Prompt 视为可以通过反思改进的文档,以 少 35 倍的 rollout 实现了比 GRPO 高 10% 的结果。
- 该成员说明了 GEPA 如何分析失败并生成 Prompt 改进,并建议使用
optimizer = dspy.GEPA将其集成到 DSPy 中。
- 该成员说明了 GEPA 如何分析失败并生成 Prompt 改进,并建议使用
- 新的 DSPy 优化器 GEPA 即将推出!:DSPy 团队正在发布一个新的优化器 GEPA (SIMBAv2),它取代了 SIMBA,正如论文 Reflective Prompt Evolution Can Outperform GRPO 中提到的那样。
- 团队成员澄清说,在性能方面 GEPA > SIMBA > MIPROv2,并提到计划在文档中弃用旧的优化器。
aider (Paul Gauthier) ▷ #general (43 messages🔥):
Aider configuration, Qwen3-Coder pricing and context, AI Code Editor Benchmarks, Aider modes, OpenAI API tokens
- 为测试和提交配置 Aider:若要在 Aider 中禁用 auto-commits,请在
~/.aider.conf.yml文件中添加auto-commits: false,并通过--test-cmd <test-command> --auto-test标志启用 auto test。- 使用
/test <test-command>运行测试,正如 Aider 使用文档 所述,Aider 要求该命令将错误打印到 stdout/stderr,并在失败时返回非零退出代码。
- 使用
- Qwen3-Coder 上下文与成本考量:Qwen3-Coder 因 Token 缓存问题和庞大的上下文需求被指出价格昂贵,一位用户链接了 Reddit 帖子 讨论这些问题。
- 价格列为 $0.30 / $1.20 per Mtokenfp4,虽然原生上下文为 262,144,但即使在使用较小上下文时,人们仍担心潜在的质量下降。
- 社区寻求 AI 代码编辑器基准测试:成员们正在寻求可靠的基准测试,以对比 Aider、Kilo Code 和 Cline 等 AI 代码编辑器,从而了解它们的功能集和前沿能力。
- 一位用户表示,鉴于他们已经是 Aider 的频繁使用者,需要 深入了解目前其他哪些功能处于领先地位。
- 探索 Aider 的交互模式:用户讨论了他们在 Aider 模式下的工作流,注意到通常会多次使用
/ask,然后紧跟/code go ahead或implement it now,而不是直接使用/architect。- 一位用户建议,使用
/ask创建一个完整的实现计划并更新todos.md核对清单对流程很有帮助。
- 一位用户建议,使用
- 通过数据共享购买 OpenAI API 额度以获取免费 Token:一位用户询问购买 ChatGPT API 额度是否会因数据共享而获得免费 Token。
- 一名成员核实,$100 可以获得 1M o3/good tier 和 10M o3-mini/mediocre tier,但在 $25 档位也可能获得一些 Token。
aider (Paul Gauthier) ▷ #questions-and-tips (11 messages🔥):
Kimi VL Model, OpenRouter Free Models, Lisp Coding with LLMs, Aider Diff Application Confirmation
- 为 Kimi VL 绕过 Aider 的模型检查:一位用户在 Aider 中使用 Kimi VL 时遇到错误,并询问如何强制 Aider 识别该模型支持图像输入,并提供了 错误截图。
- 另一位用户指出,即使模型未列出,也可以将其添加到配置中,从而绕过 Aider 显式支持的需求。
- 使用 Aider 和 OpenRouter 探索免费模型:一位用户询问是否有合理可用的“免费”模型(如 Deepseek R1, Kimi K2 和 Qwen 3),且具有可供 Aider 轻度到中度使用的额度。
- 另一位用户澄清说,OpenRouter 上列出的所有 Endpoint 都应该能与 Aider 配合使用,并建议查看 OpenRouter 网站以获取更完整的列表。
- Lisp 在 LLM 上的表现不佳:一位用户注意到,由于数据结构的原因,LLM(包括通过 Claude code 和 aider)在处理 Lisp 编码 或具有高度嵌套分隔符的 Python 代码 时非常吃力。
- 未提供解决方案。
- 在应用 Diff 前要求确认:一位用户询问是否有办法让 Aider 在应用 Diff 之前请求确认,类似于 CC (Code Climate) 的做法。
- 未提供解决方案。
- 了解 OpenRouter 免费模型的 Token 限制:一位用户询问耗尽 OpenRouter “免费”模型的每日 Token 限制是针对单个模型还是跨所有模型。
- 另一位用户参考了 OpenRouter 关于速率限制的文档,指出每分钟的请求限制以及基于已购额度的每日限制:每分钟最多 20 个请求,以及 每天 50 或 1000 个免费模型请求。
Notebook LM ▷ #announcements (1 条消息):
精选 Notebooks 推送,NotebookLM 主页访问
- **Featured Notebooks 已 100% 发布!: **Featured Notebooks 套件已正式向 100% 的用户推送,现在可以从 NotebookLM 主页访问。
- 用户现在可以直接访问整个 Featured Notebooks 套件。
- 现已提供对 **Featured Notebooks 的完整访问权限:所有用户现在都可以通过 NotebookLM 主页访问完整的 **Featured Notebooks 集合。
- 此更新确保所有用户都能直接探索并利用这些精选资源。
Notebook LM ▷ #use-cases (15 条消息🔥):
Notebook LM 处理学术材料,Notebook LM 无法抓取论坛页面,AI Studio Build 应用工作流,notebookLM 界面,使用 Notebook 撰写求职信和制作简历
- 在 NotebookLM 中基于事实的学术回答:一位成员将 Notebook LM 作为加载了学术材料的专业工具,以获取有根据的回答,而不依赖于搜索引擎或标准的 LLM 摘要,并用于检查原始材料。
- 他们正在优化一个结合使用 Comet/Assistant 与 Drive/Docs/NotebookLM 的工作流。
- 论坛页面避开了 NotebookLM 的抓取:一位成员询问是否有人知道如何让 Notebook LM 读取论坛页面,因为即使将其作为源文件添加,它也不会进行抓取。
- 他们展示了一个使用 Gemini API 的 AI Studio Build 应用,其 Agent 工作流最初是在 NotebookLM 中构思完成的。
- 财报为 NotebookLM 注入动力:一位用户正在将 NotebookLM 用于 2025 年第一季度的企业财报和网络会议记录,其中详细列出了收入、利润和关键业务部门的业绩。
- 他们指出,这些报告提供了全球公司财务表现的见解,而且 AI 非常擅长处理标签如何应用于整个文档。
- NotebookLM 润色求职信:一位成员使用 Notebook LM 辅助撰写求职信并让简历更“出彩”,方法是将职位描述与他们的标准求职信进行对比,并提供修改建议。
- NotebookLM 征集护理笔记:NotebookLM 团队询问如何将护理材料纳入精选 Notebook,并提议分享受国际实践发展杂志 (IPDJ) 和护理创新启发的內容。
Notebook LM ▷ #general (31 条消息🔥):
用于法律术语的 NotebookLM 思维导图,Obsidian 与 NotebookLM 配对,向 NotebookLM 上传 PDF,播客个性化问题
- **法律术语尽在掌握:思维导图让复杂内容变简单!:一位用户咨询了如何使用 **NotebookLM 从法律文件中创建思维导图,旨在将专业术语简化为日常语言。
- 该用户注意到其总结法律文件的能力,但希望获得思维导图输出的自定义选项。
- **Obsidian 加速:增强 AI 系统的信息召回能力:一位成员建议将 **NotebookLM 与 Obsidian 配对,以提高信息组织、解析和召回效率。
- 他们强调了 Obsidian 通过 dataview 格式的 frontmatter 来结构化信息的能力,使 AI 系统能够有效地解析和应用存储的信息。
- **PDF 困境:排查上传错误:一位用户报告了向 **NotebookLM 上传 PDF 时遇到的问题,尽管是付费用户且过去曾成功上传过相同文件,但仍遇到“上传源文件错误,请重试”的消息。
- 排查步骤包括重启电脑、使用第二台设备以及尝试各种上传方法,但该问题仅在付费账户上持续存在,免费账户则没有。
- **播客烦恼:个性化难题:一位用户对无法在 **NotebookLM 中个性化播客表示沮丧。
- 该问题的提出没有包含关于之前自定义选项或期望修改的具体细节。
LlamaIndex ▷ #announcements (1 条消息):
FlowMaker, S3 Vector Store, LlamaParse, n8n nodes for LlamaCloud, Gemini Live voice agent
- FlowMaker 工具让你能够可视化构建 LlamaIndex workflows:团队推出了 FlowMaker,这是一个全新的带有可视化 GUI 的工具,用于构建 LlamaIndex workflows。
- 查看 介绍视频 了解更多详情。
- LlamaIndex 现在支持 S3!:LlamaIndex 现在通过新的
S3VectorStore支持 S3。- 这实现了可扩展且具有成本效益的向量嵌入存储。
- LlamaParse 可识别页眉和页脚!:LlamaParse 拥有了新的 页眉和页脚检测 功能。
- 还有一个关于 使用 LlamaParse 生成多模态报告的新视频 可能你会感兴趣。
- 适用于 LlamaCloud 的新 n8n 节点现已开源:适用于 LlamaCloud 的新 n8n nodes(包括 LlamaCloud 索引、LlamaParse 和 LlamaExtract)现已开源,并可在
n8n-llamacloud仓库 中获取。- 观看 此操作视频,了解如何在 n8n 中使用新的 LlamaCloud 节点构建发票 Agent。
- Gemini Live 语音 Agent 集成:通过
pip install llama-index-voice-agents-gemini-live!即可使用与 Gemini Live voice agent 的新集成。- 演示代码可以在 这里 找到。
LlamaIndex ▷ #blog (3 条消息):
Gemini Integration, Production Agents, Oxylabs Web Scraping, Cost-Effective AI Agents
- Gemini 天气预报支持终端交互!:LlamaIndex 宣布了与 Google DeepMind Gemini 的新集成,允许用户在终端中就天气情况进行交互。
- 一位 OSS 工程师将指导用户如何入门,并使用几行 代码 与语音助手交谈。
- Agent 设计模式脱颖而出!:AI Dot Engineer 峰会上的 Seldo 根据数千个真实世界的 Agent,讨论了在大规模应用中成功与失败的 Agent 设计模式。
- 关键主题包括 混合工作流 (hybrid workflows)、自主性 vs 结构化 (autonomy vs structure) 以及 可调试性 (debuggability),详见 此链接。
- Oxylabs 助力廉价网页抓取 Agent:LlamaIndex 与 Oxylabs 网页抓取基础设施进行了新集成,用于构建具有成本效益的 AI Agent,能够实时搜索和抓取任何网站。
- 这包括针对 Google、Amazon 和 YouTube 的专用读取器,可自动解析 HTML 并绕过反抓取措施,如 此处 所述。
LlamaIndex ▷ #general (39 条消息🔥):
LlamaIndex OpenTelemetry, Intent-aware semantic search, Knowledge Graphs, Property Graph Index
- 调试 LlamaIndex OpenTelemetry:一位用户在调试 LlamaIndexOpenTelemetry 的使用时,发现其 OTLP 平台中有 trace 但没有属性,随后被引导参考 workflows-py notebook 作为一个易读的示例。
- 他们还被告知 span 本身不会有很多属性,应该查看该 span 下的 events。
- 意图感知语义搜索策略出现:一位用户正在探索使语义搜索更具意图感知的方法,指出当前使用稠密嵌入的方法并不总能捕捉到查询背后的特定意图,并举例说搜索 “客户的名字是什么?” 会返回通用的结果。
- 他们正在探索 Knowledge Graphs (KGs) 以使关系显式化,从而可能消除查询意图的歧义,但不确定如何可靠地查询使用 OpenIE 构建的无模式 (schema-less) KGs。
- Property Graph Index 嵌入停滞问题调查:一位用户报告称,将代码从 Knowledge Graph Index 更改为 Property Graph Index 后,在生成嵌入期间导致执行冻结,并确认 PropertyGraphIndex 中的
embed_kg_nodes等同于 KnowledgeGraphIndex 中的include_embeddings。- 该停滞问题可能通过设置
use_async=False得到了解决,这可能表明存在某种奇怪的 async 阻塞问题。
- 该停滞问题可能通过设置
LlamaIndex ▷ #ai-discussion (1 messages):
twitch_voco: https://leaksdaily.com/?ref=5d681792 @everyone
MCP (Glama) ▷ #general (40 messages🔥):
Glama MCP server 工具计数问题, 自动化 Javascript/Typescript linting, Agent 支付 vs 人类支付, Agent 变现, AI App Store
- **Glama 故障:工具计数异常!: 一位成员报告说他们在 **Glama 上的 MCP server 显示了错误的工具计数(只有 1 个而非 6 个),且重新发布也未能解决问题 (Glama 链接)。
- 他们随后发现 Glama 是从特定的 commit hash 而不是 main branch 进行克隆的,从而导致了该问题。
- **Linting 工作:自动化 Javascript/Typescript!: 一位成员询问如何在不引起过度代码更改的情况下,实现 **Javascript/Typescript linting 的自动化。
- 另一位成员推荐了 typescript-eslint.io 作为一个有用的资源。
- **Agent 自主性:支付困境!: 一位成员质疑 **Agent 支付 是否应该是一个独立于 人类支付 的系统,并强调了当前支付系统对自主 Agent 带来的挑战。
- 该成员指出 Agent 不会“点击支付”,无法通过 CAPTCHA 验证,也无法操作为人类设计的审批流程,这表明需要 Agent 原生的支付解决方案。
- **模型变现:有钱赚吗?*: 一项投票调查了是否有人在让用户付费使用其 Agent,另一位成员认为应该建立一个市场*。
- 还有成员希望大型模型提供商能推出一种“使用…登录”系统,允许用户通过其 ChatGPT 或 Claude 凭据进行身份验证,并直接在请求中完成计费。
- **AI App Store:新生态系统的爆发: 一位成员预见未来 **AI 公司 将成为 身份和支付提供商,从而创建一个 AI App Store。
- 该成员认为本地模型很快就会足够强大,除非这些公司转型为具有利润分成机制的 AI App Store,否则它们可能不再那么重要。
MCP (Glama) ▷ #showcase (3 messages):
fast-agent, Mermaid 图表, MCP 专家, 语气 (Tone-of-voice), Goose Desktop
- **fast-agent 添加 Mermaid 图表支持: **fast-agent 现在支持 Mermaid 图表,增强了其可视化复杂流程的能力。
- 使用 **fast-agent 打造 MCP 专家: 一位用户分享了通过在 system prompt 模板中嵌入 URL,使用 **fast-agent 创建 MCP 专家 的方法,从而实现具有特定语气(tone-of-voice)的按需专业知识输出。
- 最新版本的 fast-agent 允许在 system prompt 模板中嵌入 URL(示例模板),以便轻松生成“专家”。
- Goose Desktop 与 CLI 对话哲学,构建销售报告: Goose Desktop 与 Goose CLI 进行了对话,产生了一场关于 AI 身份的哲学交流,并意外地为一家餐厅生成了一份销售报告。
- 用户分享了链接 block.github.io/goose/blog/2025/07/28/ai-to-ai,并对结果表示惊讶:我没料到会这样。
tinygrad (George Hotz) ▷ #general (30 messages🔥):
tinygrad 会议记录,GPUCounter 问题,Llama3 运行,Disk raw 基准测试,MLPerf 回归
- tinygrad 会议涵盖 Kernels 和 MLPerf:第 81 次会议议程包括 公司更新、kernel 循环、mlperf llama、viz 工具、驱动程序、cloud hash、ONNX 以及其他悬赏 (bounties)。
- 会上还分享了指向 Fast-GPU-Matrix-multiplication 的链接以及相关的 pull request。
- 未找到 GPUCounter 模板!:在运行
PROFILE=2 VIZ=1 python3 test/test_tiny.py TestTiny.test_mnist时,出现了错误/Users/light/Library/Application Support/Instruments/Templates/GPUCounter.tracetemplate: No such file or directory。- 会上指出 AMD 头文件意外包含了 SQTT 相关的定义,且指令追踪需要大量的 GPU RAM,但在没有 SQTT 的情况下,可以在每个 kernel 前后从寄存器读取缓存命中率。
- Llama3 在 tinygrad 示例上平稳运行:运行
python3 examples/llama3.py --size 8B显示使用了 16.06 GB RAM,并以 2.19 GB/s 的速度在 7332.03 ms 内加载权重,随后启动了一个监听 7776 端口的 Bottle v0.13.3 服务器。 - Disk Raw 基准测试磁盘速度:命令
python3 test/external/external_benchmark_disk_raw.py最初导致了 segmentation fault,但随后显示从磁盘进行 CPU 拷贝的速度为 1.4 GB/s。- 使用
AMD=1将从磁盘到 AMD GPU 的拷贝速度提高到了 9.8 GB/s,并通过dd命令验证了类似的 9.9 GB/s 速度。
- 使用
- MLPerf BERT 悬赏出现回归:一个最近合并的 PR 最初满足了 BERT 以 BS=84 运行的悬赏标准,但现在只能以 BS=48 运行,由于更快的步长和恒定的传输开销,超过了 20% 的开销目标。
- George Hotz 询问了哪里出现了回归?并要求提供验证悬赏的脚本,例如:
REMOTE=1 HOST=192.168.200.4:6667*3,192.168.200.6:6667*3 PYTHONPATH="." MODEL="bert" DEFAULT_FLOAT="HALF" SUM_DTYPE="HALF" GPUS=6 BS=48 EVAL_BS=48 FUSE_ARANGE=1 FUSE_ARANGE_UINT=0 BASEDIR="/raid/datasets/wiki" PARALLEL=0 RUNMLPERF=1 python3 examples/mlperf/model_train.py
- George Hotz 询问了哪里出现了回归?并要求提供验证悬赏的脚本,例如:
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
Tinygrad Kernel 解释,理解 George Hotz 的理论消息
- 请求 Tinygrad Kernel 解释:一位成员就理论频道中关于 Tinygrad kernels 的 George Hotz 消息寻求澄清。
- 该请求特别提到了需要一个简单的图表/kernel 示例,以帮助理解所讨论的概念。
- 解读 Geohot 的理论频道帖子:一位用户表示难以完全理解 George Hotz 最近在理论频道发布的消息。
- 他们专门请求一个简化的解释,最好带有图表或 kernel 示例,以增强对材料的理解。
Cohere ▷ #🧵-general-thread (16 messages🔥):
command-r-plus 弃用,command-a-03-2024 推荐,LLM 测试,Cohere 指南和 API 参考,LLMU
- Command-R-Plus 退出舞台:上一代 command-r 系列模型 将被弃用,建议切换到 command-r-plus-08-2024。
- 一位社区成员建议直接切换到该平台上最新且最好的模型 command-a-03-2025。
- 学习 LLM 测试策略:一位成员询问了如何测试面向客户的聊天 LLM,这些模型执行产品搜索和推荐、多轮对话、回答问题或驱动购买。
Cohere ▷ #🔌-api-discussions (6 messages):
Cohere API Kilo Code 错误,Cohere Dashboard 微调失败
- Kilo Code 抛出 422 错误:一名成员报告在尝试通过 “KILO CODE” 访问 Cohere API 时遇到 422 错误。
- 社区成员澄清说 Cohere 原生并不支持 Kilo Code 应用,且 API 返回的 402 错误(而非 422)通常表示支付相关问题,并指向了 Cohere 错误文档。
- Cohere Dashboard 微调失败:一名成员询问了关于 Cohere dashboard 微调失败的排查步骤,并提到他们已经联系了支持团队。
- 该成员随后分享了微调数据库中的对话示例,包括缅甸语的 system、user 和 chatbot 角色。
Cohere ▷ #👋-introduce-yourself (9 messages🔥):
递归系统,AI 网络安全,AI 工程,机器人中的 ML,ML 研究与 Agent 建模
- 通过模块化环境探索符号逻辑:一位来自贝尔格莱德大学的成员正在通过随时间演化的模块化环境探索递归系统和符号逻辑。
- 他们的重点包括设计编码了操作清晰度和解释性漂移的注释框架,并对其他人如何设计感知支架(perceptual scaffolds)感兴趣。
- AI 工程师专注于红队工作:一位 AI 网络安全工程师正在从事 AI 红队工作、AI 取证和逆向工程,以构建更安全的 AI 模型。
- 他们未提供更多背景信息。
- 解决方案架构师专注于 AI 工程:一位来自越南的解决方案架构师正专注于 AI Engineering 和 MLOps。
- 他们未提供更多背景信息。
- 机电一体化毕业生探索机器人中的 AI:一位机电一体化专业的毕业生、ML 实习生正在探索 AI 在机器人中的应用,特别对基于强化学习 (RL) 的运动学感兴趣。
- 他们未提供更多背景信息。
- 软件工程师涉足 ML 研究:一位软件工程师正在开始进入 ML 研究和 Agent 建模领域。
- 他们表达了对探索潜在用途以及 Cohere 能提供什么的兴趣。
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (15 messages🔥):
LLM Agents MOOC 证书,开源 vs 闭源指令训练,重新开放往届测验,往届测验存档
- 学生询问如何获取 LLM Agents MOOC 证书:一名学生询问如何获得他们的 LLM Agents MOOC 系列证书。
- 一位成员回复说,证书已经发放给所有符合条件的同学。
- 比较开源和闭源指令训练:一位成员询问,对于开源指令训练和闭源(ChatGPT-4o)模型,模型的指令遵循能力是否会随着尺寸增加而提升,以及是否有相关的论文。
- 虽然没有直接链接论文,但这仍然是一个开放性问题。
- 学生询问重新开放测验事宜:一位成员询问是否可以为了学习目的重新开放往届的测验。
- 一位成员提供了测验存档链接 此处,该链接也可以在课程网站的 Quizzes 栏目下找到。
- 学生希望获得更多测验存档:一位用户询问是否有来自之前的 2024 届 https://llmagents-learning.org/f24 的测验存档。
- 一位成员提供了测验存档链接 此处,该链接也位于网页的测验部分。
Nomic.ai (GPT4All) ▷ #general (8 条消息🔥):
用于本地项目的 M1 Max,Discord 大量邀请问题,Blockchain 和 AI/ML 专家介绍,开发者协作邀请
- M1 Max Macs - 值得买吗?: 一位成员询问 M1 Max 机器是否适合运行本地项目,并注意到目前价格极具吸引力。
- 未给出具体意见。
- Discord 大量邀请事件!: 一位成员就通过 Discord 向其联系人列表中的所有人发送大量邀请一事表示道歉。
- 他们分享了一篇 Discord 支持文章,并在有人开玩笑说“改下密码——别看色情内容了”之后,声称这些邀请并非由他们本人发送。
- Blockchain 架构师和 AI/ML 专家寻求联系: 一位高级软件工程师介绍自己为拥有 9 年以上经验的 Blockchain 架构师和 AI/ML 专家,强调了他们在构建可扩展、高性能应用方面的专业知识。
- 他们列出了核心技能,包括 Blockchain (Ethereum, Polygon, Binance Smart Chain, Solana, Cardano, Arbitrum, Rust, Solidity, Web3.js, Ethers.js) 和 AI/ML (TensorFlow, PyTorch, scikit-learn, OpenAI API)。
- 开发者热切寻求协作: 一位开发者表达了对编程的热情以及对项目协作的兴趣。
- 他们征求建议并寻求协作机会。
Torchtune ▷ #dev (3 条消息):
DCP 信息泄露,RL 测试耗时,CI 调试
- DCP:停止泄露!: 一位成员对 DCP 不应四处发送过多信息表示担忧。
- 他们提到“超时很奇怪”,可能导致信息泄露或安全漏洞。
- RL 测试:为什么耗时这么久?: 一位成员质疑为什么 RL tests 运行时间超过 1 小时。
- 他们表示“这 100% 是个 Bug”。
- 单独调试 CI: 一位成员宣布计划开启一个单独的 PR 来调试 CI。
- 这表明他们正集中精力解决 CI 流水线中发现的问题。