AI News
Gemini 2.5 Deep Think 终于发布了。
据传 OpenAI 即将推出新的 GPT-OSS 和 GPT-5 模型,与此同时,Anthropic 撤销 Claude 访问权限一事正引发热议。Google DeepMind 悄然发布了 Gemini 2.5 Deep Think,这是一款针对并行思维优化的模型,在国际数学奥林匹克竞赛(IMO)中达到了金牌水平,并在推理、编程和创意任务中表现卓越。
泄露的消息显示,OpenAI 正在开发一款 120B MoE(混合专家)模型和一款具有先进注意力机制的 20B 模型。月之暗面 (Kimi Moonshot)、阿里巴巴和智谱 AI 等中国 AI 公司正在发布更快、更强大的开放模型,如 kimi-k2-turbo-preview、Qwen3-Coder-Flash 和 GLM-4.5,这预示着强劲的发展势头,并展现出在 AI 领域超越美国的潜力。“最终的检查点(checkpoint)是在 IMO 题目公布前仅 5 小时选定的,” 这一细节凸显了极快的技术迭代周期。
Parallel thinking is all you need.
2025年7月31日至8月1日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 和 29 个 Discord(227 个频道和 7130 条消息)。预计节省阅读时间(以 200wpm 计算):614 分钟。我们的新网站现已上线,提供完整的元数据搜索和精美的 vibe coded 呈现的所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
关于 OpenAI GPT-OSS 和 GPT-5 模型的传闻和泄露满天飞,这意味着发布在即。在这次备受期待的发布之前,围绕 Anthropic 撤销 OpenAI 的 Claude 访问权限 发生了一些戏剧性事件。
与此同时,GDM 正悄悄地置身事外,刚刚 干净利落地发布了 Deep Think 模型(同样的模型,但 相比几天前获得 IMO 金牌的那个版本,被调低了智力)。它在 SOTA 基准测试中提供了一些令人印象深刻的提升,值得注意的是,它们在基础模型上的提升 明显高于 o3 pro:
以表格形式:
Model card 中有更多信息,但内容不多,所以我们可以帮您省去点击的麻烦:

还有 关于 Deep Think parallel thinking 的各种视频 可以观看,但我们(带有偏见地)实际上会推荐 领导 2.5 Deep Think 工作并甚至评论了他们下一步走向的 Jack Rae 的完整主题演讲:
AI Twitter 回顾
模型发布、泄露与性能
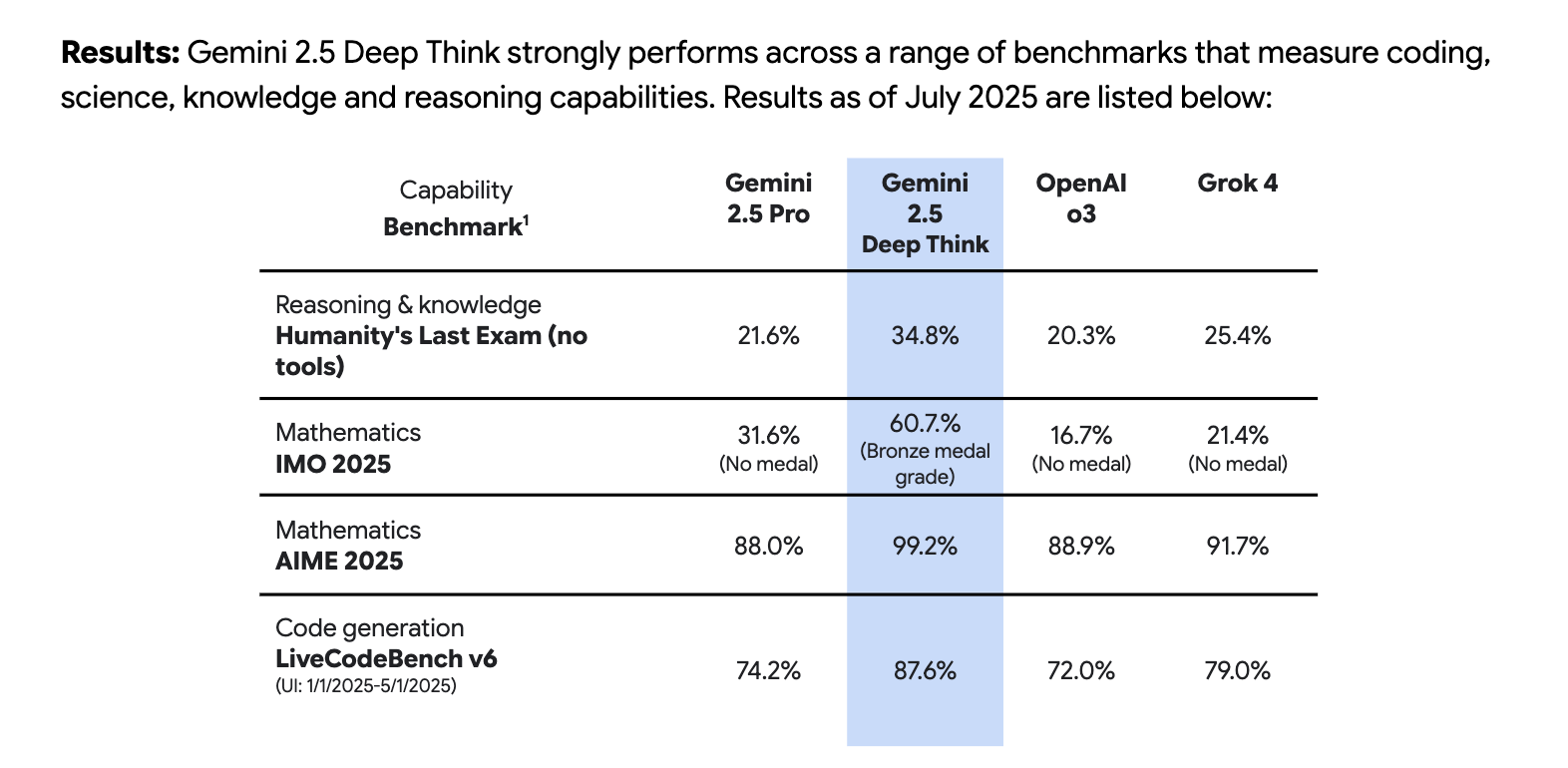
- Google 发布 Gemini 2.5 Deep Think:Google 和 DeepMind 宣布 Gemini 2.5 Deep Think 现已面向 Google AI Ultra 订阅用户开放。CEO @demishassabis 表示,该模型非常适合创造性问题解决和规划,是曾在 IMO(国际数学奥林匹克)达到金牌水平模型的更快速变体。该模型利用并行思考来延长“思考时间”,通过探索多个假设来寻找最佳答案。团队指出,它不仅是一个数学模型,在通用推理、Coding 和创意任务方面也表现出色;团队成员分享道,最终的 Checkpoint 是在 IMO 题目发布前仅 5 小时选定的。Model Card 已经发布,Google 正在将其分享给数学家以获取进一步反馈。
- OpenAI 开源模型泄露与推测:有关 OpenAI 开源模型即将发布的传闻引发了广泛讨论。泄露信息(特别是来自 @scaling01)暗示有两个模型:一个 120B MoE 和一个 20B 模型。120B 模型被描述为“超稀疏”且较浅,具有 36 层、128 个专家和 4 个激活专家。据称该架构包含 attention sinks 以改进滑动窗口注意力(sliding window attention),@Teknium1 指出这可能使用了来自 Nous 的 YaRN 技术。社区正在争论这个泄露的模型是否就是备受讨论的 “Horizon-Alpha”,@teortaxesTex 指出,如果确实如此,“对其他所有人来说都会很尴尬。”
- 中国模型展现强劲势头:月之暗面 (Kimi Moonshot) 推出了 kimi-k2-turbo-preview,该版本模型速度提升了 4 倍(从 10 tok/s 提升至 40 tok/s),且价格降低了 50%。阿里巴巴发布了 Qwen3-Coder-Flash,这是一个具有原生 256K 上下文的 30B 模型,目前已在 Ollama 上可用。主模型 Qwen3 被 LMSys Chatbot Arena 认可为排名第一的开源模型。智谱 AI (Zhipu AI) 发布了 GLM-4.5,这是一个具有统一推理、Coding 和 Agent 能力的开源模型。阶跃星辰 (StepFun) 也发布了 Step 3,这是他们最新的开源多模态推理模型。这一浪潮促使 @AndrewYNg 表示,中国现在已经有路径在 AI 领域超越美国。
- 新模型与新技术:字节跳动 (ByteDance) 正在探索 Diffusion LLM,发布了 Seed Diffusion Preview,这是一个针对代码的快速 LLM。Cohere 发布了一个新的视觉模型,并在 Hugging Face 上提供了权重。Meta 推出了 MetaCLIP 2,并提供了代码和模型,由 @ylecun 分享。然而,@teortaxesTex 观察到,尽管有这些发布,目前仍然没有一个开源模型能在困难的 Coding 任务上持续击败 DeepSeek-R1-0528,这表明当前架构可能遇到了瓶颈。
基础设施、效率与硬件
- 专用硬件上的高速推理:Cerebras 宣布 Qwen3-Coder 已在其平台上上线,实现了 2,000 tokens/s 的推理速度——他们声称这比 Sonnet 快 20 倍,且全回答生成时间仅需 0.5 秒。他们正提供两种新的月度编程计划以供访问。这引发了关于最佳推理设置的讨论,@dylan522p 建议采用一种“天才级”组合:在 Etched 上进行 Prefill 并在 Cerebras/Groq 上进行 Decode。
- Modal Labs 实现 5 秒 vLLM 冷启动:@akshat_b from Modal Labs 宣布,用户现在可以在其平台上实现 vLLM 的 5 秒冷启动,这一能力由他们全新的 GPU snapshotting 原语实现。
- 稀疏性与 MoE 架构成为焦点:Google 向 @Tim_Dettmers 颁发了青年教师奖,以表彰他在稀疏性 (sparsity) 方面的工作,他透露很快会将大型 Mixture of Experts (MoE) 模型引入小型 GPU。这与关于 OpenAI 即将推出的开源模型的泄露细节相吻合,传闻该模型是一个非常稀疏且浅层的 MoE。来自 @nrehiew_ 的技术讨论强调了 attention sinks 的架构意义,它可以解决此类模型中滑动窗口注意力 (sliding window attention) 的问题。
- 性能优化:Baseten 详细介绍了他们与 Amp Tab 合作切换到 TensorRT-LLM 和 KV caching 的工作,从而实现了 30% 的速度提升。UnslothAI 实现了在消费级硬件上本地运行强大的 671B 混合推理模型。
- Runway 的 Aleph 与上下文泛化:@c_valenzuelab from Runway 解释说,他们的 Aleph 模型是一个单一的上下文 (in-context) 模型,可以在推理时解决许多视频工作流。这种多任务方法泛化效果极佳,以至于可以通过简单的文本和图像/视频参考来复制像 Motion Brush 这样的专用功能,而无需专门的 UI 或后训练 (post-training)。
Agent 工具、框架与开发
- Perplexity 推出用于工作流自动化的 Comet Shortcuts:Perplexity 推出了 Comet Shortcuts,这是一项使用简单的自然语言提示词来自动化重复性 Web 工作流的新功能。@AravSrinivas 分享了这次发布,并指出用户可以创建并最终分享或变现自定义快捷方式。一个关键示例是 /fact-check 快捷方式,旨在让互联网更具求真性。
- Deep Agents 与多 Agent 系统的兴起:LangChain 的 @hwchase17 发布了一个视频,将 “Deep Agents” 定义为规划工具、文件系统、子 Agent 和详细系统提示词 (System Prompt) 的结合,并引用了 Claude Code 和 Manus 等模型。他还演示了如何将新的 qwen3-coder 与 deep agents 结合使用。另外,@omarsar0 展示了在 n8n 中构建复杂多 Agent 系统(包括负责分发任务的主管 Agent)正变得越来越容易。
- Runway 开放 Aleph 编程接口:Runway 已通过 API 提供了其强大的 Aleph 视频模型。联合创始人 @c_valenzuelab 将其定义为 “Aleph Programming Interface”,这是一个可以直接以编程方式编辑、转换和生成视频的 API。
- 开发工具与框架:MongoDB 发布了一个开源 MCP Server,允许 AI 工具使用自然语言与数据库进行交互。DSPy 框架正在扩大其影响力,@lateinteraction 宣布了 DSRs,这是 DSPy 向 Rust 的新移植版本。用于计算机视觉的 supervision 库已更新,增加了高级文本位置控制功能。
- RAG 内部机制:DeepLearningAI 发布了一门课程,解析了 LLM 如何在 RAG 系统中处理增强提示词,详细介绍了 Token 嵌入 (token embeddings)、位置向量 (positional vectors) 和多头注意力 (multi-head attention) 的作用,以帮助开发者构建更可靠的 RAG 流水线。
公司新闻、融资与策略
- Cline 为开源代码 Agent 筹集 3200 万美元:开源代码 Agent Cline 宣布完成由 Emergence Capital 和 Pace Capital 领投的 3200 万美元种子轮和 A 轮融资。该工具最初是一个黑客松项目,目前已拥有 270 万开发者,并致力于长期押注开源,以帮助开发者控制 AI 支出。
- 据报道 Meta 正在掀起视频 AI 收购热潮:来自 @steph_palazzolo 的报告指出,Meta 正在积极寻求收购视频 AI 初创公司,并已与 Pika、Higgsfield 和 Runway 等公司进行了对话。
- 中美 AI 竞赛:Andrew Ng 的一条热门推文(由 @Teknium1 转发)认为,由于巨大的势头,中国 现在有路径在 AI 领域超越美国,这一话题在 The Batch 中也有报道。这引发了关于战略的讨论,特朗普总统 发布了一份 “美国 AI 行动计划”,旨在支持“意识形态中立”的模型,加速数据中心许可证审批,并支持 open-weights 工具。
- DeepMind 团队与增长:DeepMind 的 @_philschmid 庆祝入职公司 6 个月,并分享到 Google 产品和 API 现在每月处理超过 980 万亿个 tokens,高于 5 月份的 480 万亿。CEO Demis Hassabis 参加了 Lex Fridman 播客,讨论 AGI 是科学发现的终极工具。
研究、AI 安全与数据集
- Anthropic 开发“人格向量”以减轻不良行为:Anthropic 发布了关于 “persona vectors”(人格向量)的新研究,该技术可以识别并引导语言模型远离不受欢迎的人格,如谄媚或邪恶。@EthanJPerez 解释了 这一技术,@mlpowered 将其描述为 通过在训练期间注入不良人格的向量来创建“LLM 疫苗”,从而教会模型避开它们。
- 国际 AI 安全与对齐倡议:Yoshua Bengio 宣布他将担任由英国 AI 安全研究所发起并得到加拿大同行支持的新 Alignment Project(对齐项目)的专家顾问,鼓励研究人员申请资金和算力。在 Gemini Deep Think 发布后,@NeelNanda5 强调了 用于主动捕捉和缓解风险的广泛安全测试和风险管理方法。
- 发布新数据集和评估框架:发布了 NuminaMath-LEAN 数据集,包含 10 万个以 Lean 4 形式化的数学竞赛问题,如 @bigeagle_xd 所分享。研究人员还推出了 OpenBench 0.1,这是一个用于 开放且可重复评估 的新框架。此外,LMArena 项目发布了一个包含 140,000 条对话 的数据集。
- 黑客松的终结?:@jxmnop 引发了一场讨论,声称 AI “基本上杀死了黑客松”,认为 2019 年在黑客松上可以构建的大多数项目,现在通过 AI 可以构建得更好、更快。
幽默/迷因
- 引起共鸣的开发者之痛:来自 @hkproj 的一条推文哀叹
ncclUnhandledCudaError并配文“反正谁还需要睡眠呢?”,引起了许多人的共鸣。 - AI 社区内部梗:传闻中的 OpenAI 泄露引发了一系列 “我和兄弟们讨论泄露的 OAI 细节” 的梗图。另一种流行观点由 @vikhyatk 捕捉到:“我觉得这种类型的抱怨非常令人厌烦。这是开源。要么提交 PR,要么滚蛋”。
- 何去何从,西方人?:来自 @Yuchenj_UW 的一张将“闭源 AI”与“开源 AI”对立的梗图获得了超过 5,800 个点赞。
- 政治讽刺:@zacharynado 转发的一条推文讽刺地指出,“DOGE 必须削减所有那些毫无价值的‘觉醒烂事’的资金,比如航空安全和天气预报”。
- 不可阻挡的力量 vs. 纹丝不动的物体:@random_walker 的一条高赞推文描述了审批流程的荒谬,配文是:“当不可阻挡的力量 [环境审查] 遇到纹丝不动的物体 [也是环境审查]”。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. OpenAI 120B 模型泄露与推测
- OpenAI 开源权重模型可能是 120B (Score: 631, Comments: 151):据传泄露的消息表明,OpenAI 即将推出的开源权重模型将拥有 120B 参数,这使得大多数没有顶级硬件的用户无法进行本地推理,从而维持了 ChatGPT 的订阅市场。评论推测该模型将使用专有的 .openai 格式,限制第三方运行,并讨论了模型架构:对于混合专家模型 (MoE),量化 (Q3) 版本可能适配 64GB RAM;如果是稠密模型,要与近期模型直接竞争则需要重大技术突破。 技术辩论集中在考虑到可能的专有限制和高硬件要求下的实际可用性,并对 OpenAI 除非能在当前模型基础上实现有意义的创新,否则其可访问性和社区价值表示怀疑。
- 一个关键的技术争论点在于潜在的 OpenAI 120B 模型会采用 MoE 架构还是稠密设计。一位评论者指出,如果是 MoE,量化后的 Q3 版本可以在仅有 64GB RAM 的系统上运行;但如果是稠密模型,资源需求和性能预期将大幅提高——这意味着与近期发布的模型相比,只有实现质量上的巨大飞跃才值得一试。
- 社区对 OpenAI 可能发布的任何“开源权重”的可用性持怀疑态度,有评论建议可能会使用专有的 .openai 文件格式,并要求使用 OpenAI 自己的应用程序进行模型推理,这可能会限制第三方的实验或部署,并引发对真正开放性的担忧。
- OpenAI OS 模型信息泄露 - 将提供 120B 和 20B 版本 (Score: 429, Comments: 138):一张泄露的图片(见此处)据称揭示了 OpenAI 即将推出的“OS”语言模型的配置细节,特别是 120B 参数模型和 20B 参数模型。发布的 120B 模型配置显示其采用了 MoE 架构:
36个隐藏层,128个专家且每个 token 调用4个专家,201088词表大小,2880隐藏层维度,64个注意力头,8个键值头,以及带有缩放因子的 RoPE 位置编码。这些规格表明这是一款高度可扩展、高上下文的 Transformer 设计,类似于近期的 Megatron 或 DeepSpeed MoE 模型。 评论者指出 20B 模型的大小对于研究/部署非常有吸引力,并推测了其开放性/审查制度以及与近期其他大模型的性能对比。一些人指出这次泄露可能是由于临时的内部错误造成的,强调了此类信息的敏感性。- 泄露的 OpenAI “OS” 120B 模型配置文件揭示了架构细节:36 个隐藏层,128 个专家 (MoE),experts_per_token 设置为 4,词表大小为 201,088。关键参数包括 2880 的隐藏层/中间层维度,64 个注意力头(8 个键/值头),4096 的初始上下文长度,以及高级旋转位置编码(rope_theta: 150000, rope_scaling_factor: 32.0)。
- 配置显示该模型采用了 Mixture-of-Experts (MoE) 架构,拥有 128 个专家,每个 token 激活 4 个专家,这种方法旨在提高大型模型的效率。RoPE (Rotary Positional Embedding) 的增强(特别是 rope_ntk_alpha 和 rope_ntk_beta)以及滑动窗口注意力机制(sliding window attention)可能支持更长的上下文处理和扩展。
- 讨论中引用了一位成功获取 120B 权重的用户,表明早期的外部分析正在进行中。预计会与最近的开源模型(如 yofo-deepcurrent, yofo-riverbend)进行对比,技术界对其性能、上下文管理和审查水平充满好奇。
- “泄露”的 120B OpenAI 模型并非在 FP4 下训练 (Score: 231, Comments: 64): 该图片被引用在一场讨论中,旨在反驳关于“泄露”的 120B OpenAI 模型是在 FP4(4位浮点数)下训练的说法,标题明确澄清事实并非如此。讨论和评论显示出对该模型技术细节的炒作或误导信息的怀疑,强调了 AI 社区对这类传闻进行批判性分析的必要性。目前没有证据或 Benchmark 支持 FP4 训练的说法,该帖子主要作为对未经证实泄露的反驳。 评论者将最初的说法斥为“纯属炒作”,并对传闻表示怀疑,呼应了对 AI 误导信息和未经证实泄露的广泛担忧。
- 几条评论强调了对 FP4 训练说法的怀疑,提到所谓的 OpenAI 120B 模型“泄露”很可能是炒作,在技术上并不可信,并指出 FP4 尚未被公认为实用的训练精度格式(目前大型模型的标准是 bfloat16 或 FP16)。
- 其他人强调了模型发布质量优于速度的重要性,将此情况与 DeepSeek r2 的延迟进行了对比,并强调像 OpenAI 这样的“前沿” AI 实验室在模型中优先考虑鲁棒性和性能,而非早期访问或炒作驱动的发布。
- 讨论中还涉及了近期大模型发布的频率,以及即使是像 OpenAI 这样的主要实验室,增加开放性也会提高开放权重(open weight)社区的透明度和竞争标准,有助于将开放模型共享规范化为行业标准做法。
{kind=link}
{kind=link}
2. Qwen3 模型发布与 Benchmark
- Qwen3 Coder 480B 已在 Cerebras 上线(每百万输出 2 美元,吞吐量达 2000 tokens/s!!!) (Score: 372, Comments: 123): Cerebras 已启动 Qwen3 Coder 480B 模型的部署,这是一个用于代码生成的开源大语言模型,提供
每百万 tokens 2 美元的价格和2000 tokens/秒的输出吞吐量。这使其成为 Sonnet 的潜在竞争对手,特别是考虑到其声称在美国基础设施上速度快约20倍,价格便宜约7.5倍。此外还宣布了新的分级编码计划:“Code Pro”每月50 美元(每天 1000 次请求)和“Code Max”每月200 美元(每天 5000 次请求)。 技术评论者指出,对于高频使用代码工具的用户来说,“每天 1000 次请求”存在限制,一些人对该模型声称的性能差距提出异议,认为在实践中 Qwen3 不仅仅比竞争对手差“5-10%”,在现实世界的编码任务中显示出更大的差异。- 在 Cerebras 上使用 Qwen3 Coder 480B 的系统(如 Roocode 和 Opencode)响应速度极快——快到某些工具(如 Roocode)的 UI 处理无法跟上,而在其他工具(Opencode)中,输出几乎是瞬间出现的。这突显了实际吞吐量达到甚至超过了宣传的每秒 2000 个输出 token 的 Benchmark。
- 关于定价结构的讨论表明,每月 50 美元 1000 次请求对所有用户来说可能并不划算,特别是当技术工作流(如代码查找或工具调用)产生大量请求时,因为每次交互(“工具调用和代码查找”)都可能导致单独的 API 调用,迅速消耗配额。
- 评论提醒注意供应商锁定(vendor lock-in)的风险,建议用户在受益于当前性能和价值主张的同时,也要意识到未来生态系统限制或对单一供应商依赖的可能性,尽管 Cerebras 正试图通过激进的定价或性能领先地位来寻求快速普及。
- Qwen3-Embedding-0.6B 速度快、质量高,且支持高达 32k tokens。在 MTEB 上超越了 OpenAI 的 Embedding 模型 (Score: 143, Comments: 16): 阿里巴巴的 Qwen3-Embedding-0.6B(可在 Hugging Face 获取:https://huggingface.co/Qwen/Qwen3-Embedding-0.6B)提供高性能的语义 Embedding,具有大上下文窗口(高达 32k tokens),据报道在 MTEB 基准测试中“超越了 OpenAI 的 Embedding 模型”。用户强调了将 Text Embedding Inference 更新至 1.7.3 版本的重要性,以修复影响早期版本结果的 pad token bug;这类预处理/分词问题可能会影响不同的推理工具链。背景:像 Qwen3 这样的 Embedding 模型通过文档/查询向量相似度(点积/余弦相似度)用于语义搜索,Qwen3-Embedding-0.6B 因其准确性和速度而受到赞誉,在较小的模型规模下实现了新的用例。 评论者建议 Reranker 变体(Qwen3-Reranker-0.6B-seq-cls:https://huggingface.co/tomaarsen/Qwen3-Reranker-0.6B-seq-cls)为 RAG 聊天机器人流水线提供了极速且高度相关的评分,暗示了其在检索增强生成(RAG)工作流中的广泛用途。
- Qwen3-Embedding-0.6B 在语义搜索用例中受到称赞,利用文档和查询 Embedding 的点积或余弦相似度进行排序。它在 MTEB 基准测试中优于 OpenAI 的 Embedding,表明其在涉及基于 Embedding 的检索和排序任务中具有高性能。
- Qwen3-Reranker-0.6B 变体因在检索增强生成(RAG)聊天机器人中提供极快的推理和高质量的相关性评分而受到关注,这已通过用户测试及其在 Hugging Face 上的可用性得到证实(Qwen3-Reranker-0.6B-seq-cls)。
- 虽然 Qwen3-Embedding-0.6B 在英语(以及预料中的中文)方面表现强劲,但据报道在其他多语言场景中效果较差。像 MPNet 这样的竞争模型在多样化的多语言任务上可能会提供更好的性能。
- Qwen3-235B-A22B-2507 是 lmarena 上顶尖的开放权重模型 (Score: 122, Comments: 12): Qwen3-235B-A22B-2507 目前在 lmarena 上被评为性能最高的开放权重模型,根据 lmarena 当前的评估指标,甚至超越了 Claude-4-Opus 和 Gemini-2.5-pro 等闭源模型。该模型采用了 235B 参数架构,在用户关于 UD-Q4_K_XL 量化版本的报告中,以及在 Artificial Analysis 和 LiveBench 等外部基准测试中,其强劲性能均得到了证实。 评论者对 lmarena 的评估方法论表示了一些怀疑;同时,人们也期待未来的模型(例如 OpenAI 120B MoE、GLM-4.5 Air)可能会挑战 Qwen3-235B 的主导地位。
- Qwen3-235B-A22B-2507 目前领跑 lmarena 的开放权重模型排行榜,用户反馈指出其强大的性能和深度,特别是在运行 UD-Q4_K_XL 等量化格式时。讨论还强调了社区对即将推出的模型的期待,特别是 OpenAI 的开放权重 120B MoE 和 GLM-4.5 Air,预计后者在得到 llama.cpp 支持后将更具竞争力。
- 针对 lmarena 的评估方法论存在质疑,特别是 Qwen3-235B 据称超越了 Claude-4-Opus 和 Gemini-2.5-pro 等闭源模型。这引发了对模型基准测试标准以及社区运行测试平台结果可靠性的疑问。
- Qwen3 的性能也通过其在 Artificial Analysis 和 LiveBench 非推理任务中的榜首排名得到了验证,其变体(Qwen3 Coder 480B)在 Design Arena 上也获得了很高的排名,仅次于 Opus 4,并超越了所有其他开放权重模型。这表明 Qwen 的发布节奏已在多个技术基准测试中产生了最先进的开放模型。
3. DocStrange 开源数据提取发布
- DocStrange - 开源文档数据提取器 (Score: 149, Comments: 27): 该图片展示了 DocStrange,这是一个开源 Python 库,用于从多种格式(PDF、图像、Word、PowerPoint、Excel)的文档中提取数据,并提供 Markdown, JSON, CSV 和 HTML 等输出格式。该工具支持用户定义的字段提取(例如特定的发票属性),并通过 JSON Schemas 强制执行输出 Schema 的一致性。提供两种模式:一种是用于通过 API 进行快速处理的云端模式(针对敏感数据提出了隐私警告),另一种是用于隐私和离线计算的本地模式(支持 CPU/GPU)。相关资源:PyPI 链接,GitHub 仓库。 评论者强调了真正的视觉语言模型(VLM)驱动的图像描述(而非基础 OCR)的重要性,正如竞争对手 Docling 和 Markitdown 所支持的那样。针对云端 API 提出了隐私担忧:不应在未加防范的情况下上传敏感文档。
- 用户强调了与现有文档提取工具的直接竞争,指出高级差异化取决于使用 Vision-Language Models (VLMs) 进行描述性图像理解(而不仅仅是 OCR)。Docling 和 Markitdown 被引用为此类能力的基准,从而引发了 DocStrange 是否能提供同等或更优的 VLM 驱动图像描述功能的疑问。
- 技术审查围绕 DocStrange 与直接利用具有视觉处理能力的本地 LLM(如 Gemma 3, Mistral Small 3.2, Qwen 2.5 VL)的对比展开,质疑是否可以通过针对性的 Prompt 和本地模型实现相同的提取(Markdown/JSON/CSV 输出),从而对独立云端解决方案的必要性提出质疑。
- 鉴于 DocStrange 的云端 API 是默认处理机制,数据隐私方面存在警示,因为即时转换需要将文档发送到外部服务器——警告用户除非信任该服务,否则不要上传敏感或个人数据。
- Gemini 2.5 Deep Think 模式基准测试! (Score: 247, Comments: 66): 该图片(此处不可见)被描述为 Google Gemini 2.5 Deep Think 模式的基准测试结果,该模式似乎针对高强度或详细的 LLM 任务。讨论强调 Deep Think 模式目前仅限于 Gemini Ultra 订阅者。一位用户将 Gemini 2.5 Deep Think 与 ChatGPT 的深度研究能力进行了比较,发现 Gemini 在处理复杂任务(如 PC 配置推荐和商业创意分析)时的响应更令人印象深刻。 一些评论者质疑 Deep Think 模式的实用性,因为它仅限 Gemini Ultra 使用,并且提到了“2025 年 AIME 饱和”——可能指预期的算力或先进 AI 模型的可用性。与 ChatGPT Plus 的对比显示,在特定的研究场景中,用户对 Gemini 的性能有实质性的偏好。
- 一位用户报告了 ChatGPT Plus(具有深度研究功能)与 Gemini 2.5 Deep Think 之间的非正式基准测试,使用 Prompt 生成 1200 英镑预算内具备高性能 LLM 能力的 PC 配置以及业务分析。他们发现,与之前使用 ChatGPT 的经验相比,Gemini 2.5 提供了更令人印象深刻且详细的输出,这表明模型在现实世界的 Prompt 处理和决策能力方面存在实际差异。
- 人们对在以前未解决的复杂数学问题上测试 Gemini 2.5 Deep Think 模式表现出浓厚兴趣,至少有一位用户寻求评估其在极具挑战性的数学查询中的表现。这突显了人们对 Gemini 2.5 如何在高级 STEM 推理任务中与顶级 LLM 竞争的积极技术好奇心,而这正是许多模型的已知弱点。
{kind=link}
{kind=link}
技术性较低的 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Gemini 2.5 Deep Think 发布与性能基准测试
- Gemini 2.5 Deep Think 解决了此前未被证明的数学猜想 (Score: 645, Comments: 49): 一段 YouTube 视频声称 Google 的 Gemini 2.5 Deep Think 解决了一个此前未被证明的数学猜想,但帖子和视频都省略了所解决的具体猜想的细节。讨论强调了这一声明的重大意义,但对其在具体数学问题及模型如何完成证明方面缺乏透明度表示遗憾。 评论者对该猜想的模糊性表示担忧,敦促对该模型进行困难数学问题的直接测试,并将 Google 的做法与 OpenAI 在早期发布/访问方面的策略进行了对比,同时质疑其成本以及与未发布的 IMO Gold 模型之间是否存在真正的性能对等。
- 一位用户指出,虽然 OpenAI 开发但尚未发布其专门的 IMO(国际数学奥林匹克)模型,但 Google 正在更快地推出其接近 IMO Gold 水平的高级模型,突显了在开放性和发布策略上的差异。然而,评论者也指出了访问 Google Gemini 2.5 模型的高昂价格和算力(compute)需求,这可能会限制许多人的实际使用和实验。
- 社区对在复杂数学问题上将 Gemini 2.5 与其他最先进模型进行基准测试表现出浓厚的工程兴趣,这从要求获取模型访问权限以测试困难数学猜想的呼声中可见一斑。这表明社区渴望严格评估 Gemini 2.5 的数学解题能力,并将其性能与之前的模型进行比较,特别是在那些以往 AI 方法难以攻克的问题上。
- Gemini 2.5 Deep Think 现已面向 Google AI Ultra 推出 (Score: 294, Comments: 23): Google 正在为其 AI Ultra 层级推出 “Gemini 2.5 Deep Think”,暗示其能力优于以往版本,但据报道每日使用次数有限。帖子或链接的基准测试中未指明新功能的详细技术信息或与 Pro 版的架构差异。 评论者对 Deep Think 的价值主张表示担忧,强调了严格的使用限制(“每天仅限几次”)与高昂成本(
$250)之间的矛盾,并要求澄清其与 Pro 层级的技术区别。- 一位用户询问了 “DeepThink” 与现有 “Pro” 级别之间的关键技术区别,认为需要澄清这两个产品在功能集、访问限制或底层模型差异方面的具体信息。这表明用户对于 DeepThink 带来的具体改进(例如推理深度、上下文窗口扩展或推理速度)存在困惑或缺乏透明度。
- 另一位用户对定价和使用模式表示怀疑,指出尽管价格高昂($250),但 DeepThink 每天仅允许有限次数的使用。这指向了一个潜在的技术或基础设施限制,该限制可能被掩盖为产品层级(可能与模型推理成本、资源分配或 Ultra 级算力的排队有关)。
-
我使用该架构通过 Gemini 2.5 Flash 解决了 4/6 的 IMO 题目,通过 Gemini 2.5 Pro 解决了 5/6 (Score: 216, Comments: 24): 该帖子展示了一个架构(见此图 此处),旨在最大限度地提高 Gemini 2.5 模型解决 IMO 问题的能力。该方法涉及并行假设生成,由专门的 Prover 和 Disprover Agent 生成“信息包”,并输入到 Solution 和 Refinement Agent 中。Refinement Agent 会对响应进行自我验证,从而提高解决方案的严谨性和完整性——解决了过去的缺陷,并使 Gemini 2.5 Flash 能够解决 4/6 的题目,Gemini 2.5 Pro 解决 5/6。位于 Iterative-Contextual-Refinements 的仓库包含了该架构和通用 Prompt,这些内容随后针对 IMO 用例进行了调整,重点放在新颖性、严谨的证明标准以及避免思维定式上。 评论询问为什么大公司不采用类似的基于较小模型的并行 Agent 架构,并对这种技术与行业努力相比的算力效率和新颖性提出了质疑。
- 一位评论者提供了一个 GitHub repository,详细介绍了他们的迭代上下文细化(Iterative Contextual Refinements)架构。该架构从基础的策略/子策略生成流水线演变为并行假设生成方法,其中 Prover 和 Disprover Agent 生成信息包,然后由 Refinement Agent 进行处理。Refinement Agent 执行解决方案的自我验证,这在 Gemini 2.5 Flash 上比之前的版本尤为有效。增强功能包括更严格、更聚焦于 IMO 的 Prompt Engineering,鼓励新颖且多样化的策略、假设考量以及严谨的解决方案标准。
- 提出的一个技术点是,与其使用大规模模型和算力,不如通过让较小的模型在子任务上并行工作来获得类似或更好的结果。这质疑了当前 AI 研究在解决复杂问题时扩展模型和算力规模的策略效率。
- 仓库中指定的一个特定 Prompt 约束要求在假设生成与问题解决之间进行严格的角色分离。该架构要求的 Prompt 强制 Agent (LLM) 不去解决或验证假设,而仅生成战略性推测,这表明了 LLM 存在非平凡的行为控制问题,以及在 Prompt Engineering 中使用明确、强力的任务分离指令的必要性。
- Deep Think benchmarks (Score: 189, Comments: 69): 一份基准测试摘要(通过图片分享)突出了 Google 最新的 LLM —— Deep Think 的表现,其得分显著较高,尤其是在国际数学奥林匹克 (IMO) 数据集上,表明在数学推理方面取得了重大突破。早期的技术评论强调了该模型在数学和逻辑密集型基准测试中的强劲结果,表明它在这些领域可以与 State-of-the-art 媲美甚至超越。相关的可视化数据指向了令人印象深刻的量化改进,特别关注数学相关任务,但需要更详细的分类才能进行粒度分析。 热门评论对出色的数学基准测试得分表示惊讶,特别是 IMO,表明 Deep Think 可能会为自动推理设定新标准。人们对其与当代产品相比更广泛的实际能力充满期待。
- 有人明确要求专门针对更高层级的模型(如 “O3-Pro” 和 “Grok 4 Heavy”)对 Deep Think 进行基准测试,认为在这种情况下,与标准版或基础版的直接比较不足以准确评估性能。
- Deep Think 的数学基准测试得分被认为异常强劲,这意味着该模型在数学推理任务中可能具有独特的能力或优化,这使其在技术或学术应用中脱颖而出。
- 一个技术视角强调,一个新模型要被认为具有相关性,除了成本和便利性等因素外,它必须在至少几个基准测试领域超越现有的领先模型,这凸显了 LLM 基准测试高度竞争的本质。
- Damn Google cooked with deep think (Score: 378, Comments: 127): 该帖子似乎提到了 Google 的一项名为 “Deep Think” 的新功能或能力,可能是一个 AI 驱动的工具或模型。图片(不可见)可能展示了该功能运行时的截图,并捕捉了其用户界面或价格信息。热门评论指出,该功能被封锁在每月 250 美元的订阅层级之后,表明成本极高且普通用户的访问可能受限。还有一个关于它是否对 “Ultra 订阅者” 开放的问题,暗示了 Google 产品中不同的访问级别。 评论者批评了每月 250 美元的高昂付费墙,并讨论了发布策略,暗示 Google 对先进 AI 能力采取了选择性或高成本的方法。一位用户推测,该功能的发布时机可能对竞争对手的行动具有重要意义。
- 多位评论者强调,Deep Think(推测是 Google 的一项新 AI 能力或模型)目前被锁定在 Ultra 订阅之后,据报道每月费用为
$250/month,严重限制了只有高付费用户或组织才能访问。与其它供应商的产品相比,这种付费墙引发了关于先进 AI 工具民主化的质疑。
- 多位评论者强调,Deep Think(推测是 Google 的一项新 AI 能力或模型)目前被锁定在 Ultra 订阅之后,据报道每月费用为
- 技术讨论集中在有限的可用性上:一些人询问新功能是否对所有 Ultra 订阅者开放,或者是否存在进一步的限制或发布限制,暗示可能采用了分阶段或仅限邀请的访问模式。
- 存在对发布时机的猜测,暗示 Google 的战略调整是为了配合竞争对手的活动或公告,尽管最初的评论中没有讨论基准测试或技术性能细节。
- Gemini 2.5 Deep Think 现已面向 Google AI Ultra 推出 (Score: 191, Comments: 64): Google 已开始为其 “AI Ultra” 层级推出 Gemini 2.5 Deep Think,旨在提供显著改进的推理和上下文保留能力。此次发布似乎范围有限,有报告称目前每天只有少量 Prompt 使用新模型——这显然是部署或资源分配中的瓶颈。 热门评论对新模型的有限可用性(每天仅限少量 Prompt)表示沮丧,并对 Google AI 订阅的退款政策表示不满,这表明用户支持和访问扩展性是持续存在的问题。
- 用户注意到,面向 Google AI Ultra 的 Gemini 2.5 Deep Think 目前限制了每日 Prompt 数量,这影响了重度用户的可用性,并与其提供的核心大容量云存储形成对比。对于寻求持续访问高级模型的用户来说,这种限制是一个关键的技术约束。
- 讨论涉及订阅和退款政策,强调了当模型更新(Gemini 2.5 Deep Think)在不可退款的订阅取消后立即发布时用户的挫败感。这突显了 AI 模型发布中透明的发布时间表和退款流程的重要性。
- 天哪,Gemini deep think 比 o3 好得多!GPT-5 什么时候出? (Score: 162, Comments: 51): 图片似乎对比了 Google 的 Gemini Deep Think 和 GPT-4(被称为 o3)的性能,发帖者对 Gemini 优于 GPT-4 的表现表示惊讶,并询问 GPT-5 的发布时间。评论者指出,为了公平起见,此类对比应使用 GPT-4 Pro (o3 Pro) 作为基准,并对 Gemini 在实际问答和编程任务中的能力表示怀疑。上下文显示,该图片可能展示了 AI 模型之间的基准测试结果或定性对比,可能是为了推广 Gemini 的 Ultra 层级。 评论中的一个关键辩论集中在将 Gemini Deep Think 与标准 GPT-4 而非 GPT-4 Pro 进行对比的公平性,以及 Gemini 声称在编程和问答方面的优越性在现实世界中的相关性。一些用户对 Google 的进展表示怀疑,并保持对 OpenAI 模型的偏好,强调了对 GPT-5 发布的期待。
- 评论者指出,应该将 Gemini Deep Think 与 o3-Pro 进行对比,而不是基础版的 o3,因为 Pro 在基准测试和能力上是更直接的竞争对手。几位用户强调,有意义的性能讨论需要对比匹配的层级(即高级版本)。
- 一位用户批评了 Gemini Deep Think 在问答和 Agent 编程方面的实际效用,声称它在这些领域的表现并未超过 o3-Pro,并表示他们已经降级回去了。人们对 Gemini Ultra 层级带来的实际改进也持怀疑态度。
- 比较技术讨论还提到,Gemini Deep Think 在 HLE(可能是一个基准测试或评估语境)中据称并不优于 Grok 4 Heavy,且其性能可能仅与 o3-Pro 持平,暗示在主要实际任务中只是平手而非显著超越。
- Gemini 2.5-pro with Deep Think 是首个能够与 o3-pro (软件开发) 进行辩论并提出反对意见的模型。 (Score: 156, Comments: 40): 该帖子指出,带有 Deep Think 的 Gemini 2.5-pro (Google) 是第一个能够对 o3-pro (OpenAI) 的主张进行强力挑战和分析性反驳的 LLM,特别是在涉及复杂推理的技术软件开发任务中。在一个涉及 npm 包选择的测试案例中——o3-pro 针对一个已弃用包的漏洞建议了复杂的权宜之计——Gemini 2.5-pro 正确地推荐了一个更安全、更简单的替代方案,并且当面对 o3-pro 的反驳(伪装成人类的建议)时,它提供了详细且具有批判性的反驳,重点在于根因分析和合理的包选择。这种行为与早期模型通常顺从 o3-pro 论点的表现形成鲜明对比,表明 Gemini 的对抗和辩论能力有所提升。 评论者鼓励进行严格且多样化的测试,参考了著名的数学挑战(如 Latin Tableau Conjecture),并建议采用集成方法(例如让所有主流推理 LLM 通过 MCP 对解决方案进行投票),以基准测试顶级模型的对抗性推理和数学证明生成能力。
- 一位用户强调了 Gemini 2.5-pro 处理未解决数学问题的能力,例如 Latin Tableau Conjecture (LTC),认为其表现达到或超过了 IMO 水平,并希望针对详细的数学提示对其进行严格测试。文中提到了特定的已知计算边界(验证高达 12x12 的 Young diagrams),以及对组合数学文献的引用,并挑战其提供可机械化的证明或具体的反例。
- 另一个具有技术洞察力的建议提出在复杂任务上并行运行所有顶级推理模型(Claude, Gemini, GPT-4 等)并让它们对解决方案进行投票,指出这种集成方法可以提升结果质量,但成本高昂——可能需要企业级资源才能实现。
- Gemini 2.5-pro 的 Deep Think 模式存在一个局限性:用户目前每天被限制使用 10 次,与允许更广泛免费交互的 o3-pro 相比,这阻碍了全面或迭代测试,从而影响了研究或基准测试环境中的实际生产力。
{kind=link}
{kind=link}
{kind=link}
2. WAN 2.2、Flux Krea 以及当前 Text-to-Image/Video 模型的比较
- 虽然作为视频模型它并不那么特别,但 WAN 2.2 在写实性方面是遥遥领先的最佳 text2image 模型 (Score: 478, Comments: 138): WAN 2.2 被强调为领先的 text-to-image (T2I) 模型,在写实性、纹理细节和极少的审查方面优于 Flux 和 Chroma 等替代方案,并且在与 Instagirl 1.5 结合使用时表现出协同效应。发帖者指出,与 2.1 相比,其在视频生成方面的性能和稳定性不尽如人意,但在 T2I 任务中表现卓越,尤其是在各种噪声水平下。链接的 Civitai 示例展示了其输出的忠实度。 评论者认为发帖者对视频模型的批评可能是由于设置不当或依赖“加速 LoRA”所致,并断言在优化配置下,WAN 2.2 作为视频模型极具竞争力,并强调了其在免费和开源用例中的表现。
-
[**Pirate VFX Breakdown 几乎完全使用 SDXL 和 Wan 制作!](https://v.redd.it/svpf4s6ydggf1) (评分: 529, 评论: 49): **该帖子详细介绍了一个使用生成式 AI 工具的专业 VFX 工作流:使用 SDXL 从静态图中创建参考帧(为了更好的 ControlNet 集成),角色分割采用了 MatAnyone 和 After Effects 的 rotobrush(指出其具有更好的发丝遮罩效果),背景则使用针对高质量视频 Inpainting 优化过的 ‘Wan’ 进行替换。该流水线展示了多个 AI 模型在合成和背景替换任务中的无缝集成,突显了视频后期制作效率和真实感方面的实质性提升。 评论者强调了在创意产业中进行专业、非平庸的 AI 应用的价值,并对更深层次的过程披露表示出兴趣,将其与技术含量较低的 AI 应用进行了对比。 - 一位 3D 艺术家对详细的过程分解表现出浓厚兴趣,表明人们对 SDXL 和 Wan 在 VFX 流水线中的具体使用方式存在技术好奇——这暗示相关的见解可能包括工作流集成、执行步骤,以及这些工具与传统 3D 工作流的对比。
- 另一位评论者强调了专业电影制作人如何利用 SDXL 和 Wan 进行 VFX 制作,从而以低预算产出电影级场景,这意味着这些模型大幅降低了制作成本,并提高了人们对价格亲民、高质量数字内容的期望。
- Flux Krea 不仅仅能生成美女! (评分: 397, 评论: 88): 该帖子讨论了 AI 生成模型 Flux Krea 的能力,强调它可以生成除常见的“美女”之外的多样化输出,包括复杂的场景,如“游戏内截图”和各种“战争图片”(包括带有“血腥”内容的图片)。该模型与 Wan 2.2 进行了对比,表明 Flux Krea 专注于更广泛或不同类型的视觉内容,特别是那些类似于“行车记录仪”和“战地记者”摄影风格的内容。 评论提到了由于写实图像生成可能带来的虚假信息/宣传风险、输出风格的多样性(例如坦克、村庄、Minecraft 主题)以及某些生成内容的敏感性(“不适用于 Warzone”),反映了关于 AI 图像生成伦理和风险的辩论。
- 一位评论者提到了“村庄和 Minecraft 生成图”,表明 Flux Krea 在生成除人像之外的复杂且多样的场景布局方面的能力——这是对其数据集多样性和语义构图控制的技术证明。
- 另一位用户幽默地指出,“我们需要一张更大的显卡”,这间接提到了运行 Flux Krea 等大型先进图像生成模型通常需要的计算强度和高 GPU 显存要求,特别是在进行高分辨率或批量 Inference 任务时。
- Flux Krea 是一个扎实的模型 (评分: 228, 评论: 48): 该帖子评测了 Flux Krea 图像生成模型,重点介绍了其在 1248x1824 分辨率下的原生图像输出,使用了 Euler/Beta 采样器和 2.4 的 CFG (Classifier-Free Guidance)。与 Flux Dev 等先前版本相比,该模型展示了改进的面部多样性和下巴结构,尽管输出结果仍有明显的人工痕迹。 评论者注意到输出中存在持续的淡黄色调和过多的雀斑,暗示训练数据或风格偏置(可能基于 Unsplash)存在潜在问题。此外,还有针对共享输出中缺乏样本多样性的批评,建议评估应涵盖风景、动物和建筑,以便进行更全面的模型评估。
- 用户报告了 Krea 模型输出中一致存在的淡黄色调问题,表明可能存在训练数据偏置或色彩处理问题。几位评论者专门将其与基于 Unsplash 数据训练的模型输出进行了比较,推测受到了类似的来源影响。
- 尝试通过微调 Krea(例如使用 LoRA)来抵消色调和过多雀斑的努力收效甚微,这表明这些伪影已深度嵌入到模型的学习表征中,使得训练后修正变得具有挑战性。
- 一些用户注意到 Krea 生成的面部类似于 SD1.5 的面部,暗示了数据分布或架构方法上的相似性,并指出输出缺乏多样性(例如非人类主体有限),这引发了关于该模型在典型人物特写之外的泛化能力的疑问。
- Wan 2.2 Text-to-Image-to-Video 测试(昨日 T2I 帖子的更新) (Score: 230, Comments: 49): 该帖子展示了 Wan 2.2 使用之前的 Text-to-Image 输出进行 Image-to-Video 能力的测试,运行在原生 720p 分辨率下。作者强调了在极小镜头移动且无后期处理的情况下,对细节和真实感(尤其是人物形象)的保留,并指出放大至 1080p 仅是为了改善 Reddit 的压缩效果。这建立在之前与 Flux Krea 的 Text-to-Image 对比基础之上,展示了该模型在不同模态间输出的一致性。 热门评论认为这次演示是迄今为止 Wan 2.2 生成视频能力最强有力的实证展示,特别称赞了转换后视频中准确的“物理特性”和动态真实感,这表明模型架构或训练在时空连贯性方面取得了进展。
- 一位用户强调了使用 Wan 2.2 时相比之前方法的 Workflow 效率提升:在 Wan 2.1 中,他们的流程包括为每个场景生成多张 1080p 静止图像,选择最佳帧,然后使用带有运动增强 Prompt 的 Image-to-Video 转换为视频(720p)。据称,这种方法能产生更出色的细节,并且比直接进行 Text-to-Video 生成更节省时间,因为后者往往产生质量较低的结果。
- 该模型对“物理特性”的处理受到称赞——这意味着与早期模型相比,生成的视频在时间一致性或物体动力学方面有所增强。用户注意到了场景和物体运动的真实感,表明视频合成技术的进步已超越了单纯的帧插值。
- 帖子还将其与“Veo 3”进行了对比,暗示 Wan 2.2 提供的性能或 Workflow 能力让人联想到 Google 的先进视频模型,但据推测其技术更易于获取或更适合家庭使用。
- Wan2.2 I2V 720p 10 分钟!!16 GB VRAM (Score: 159, Comments: 23): 楼主报告称,在 16GB VRAM 显卡上使用 Kijaiwarpper 工作流运行合并后的 Wan2.2 I2V 模型(phr00t 的 4 步全能合并版),分辨率为 1280x720(81 帧,6 步,CFG=2),生成耗时 10-11 分钟,RAM 占用适中(
~25-30 GB,而标准 Kijaiwarpper 约为~60 GB)。该工作流避免了在无法使用标准双模型设置时的 Out-of-Memory (OOM) 问题,虽然报告的图像质量略低于 Wan2.2 官网输出(1080p,30 fps 下 150 帧),但速度/效率大幅提升,且相对于 2.1 有显著的质量飞跃。完整的 Workflow 详情已通过 Pastebin 分享,并与 VEO3 进行了对比。 热门评论讨论了 Kijaiwarpper/Comfy 工作流中持续存在的 OOM 问题,一些用户注意到工作流有时会同时加载两个模型而不是顺序加载,导致 VRAM 溢出并在低噪声 Pass 阶段出现严重的性能下降。硬件特定的生成速度也受到了讨论,例如 RTX 4070 Ti Super 在 480p 下生成 5 秒视频需要 15-20 分钟,这表明基于 VRAM 和工作流细节的差异非常大。文中还链接了一个未压缩的视频展示供查验。- 用户报告在 Comfy 中运行带有 Block Swapping 的 Kijai 工作流时存在严重的 Out-of-Memory (OOM) 问题;尽管启用了 Block Swapping,有时两个模型仍会同时加载而非顺序加载,导致 VRAM 溢出到系统 RAM 中。这导致仅在高噪声采样期间(当 VRAM 能容纳整个模型时)性能尚可,但在低噪声步骤中由于依赖较慢的 RAM,性能会严重下降,有时甚至完全停滞。
- 性能观察详情显示,一块 RTX 4070 Ti Super 可能需要
15-20 分钟来渲染一段5 秒 480p的剪辑,突显了巨大的计算需求,并暗示更高分辨率或更长持续时间所需的耗时将大幅增加。另一位拥有 RTX 5060 Ti 16GB 和匹配系统 RAM 的用户遇到了硬崩溃,表明尽管看似满足了最低 VRAM 要求,但仍可能存在不兼容或资源不足的问题。 - 提到了未压缩的输出视频,但主要的工程重点在于模型的适应性以及在不同硬件上严重的资源需求或不稳定性,强调了进一步优化工作流或提供关于性能和硬件兼容性更清晰文档的必要性。
- 使用极短搞笑动画测试 WAN 2.2(开启声音) (Score: 143, Comments: 16): 该帖子展示了 WAN 2.2 在文本生成视频 (T2V) 和图像生成视频 (I2V) 续写方面的测试,输出分辨率为 720p。发布者指出,虽然 2.2 版本中伪影 (artifact) 问题依然存在,但提示词遵循 (prompt following) 能力有所提高。目前没有报告模型架构方面的变化,减少伪影仍是一个持续存在的局限性。 一位评论者询问了技术细节——即 I2V 续写是否是通过使用前一段 WAN 2.2 输出的最后一帧实现的——发布者暗示,单纯增加帧数会进一步降低视频质量。另一条评论幽默地提到了提示词坚持度问题,暗示生成保真度仍不完美。
- 一位评论者询问了动画的连续性,询问下一个视频是否从前一个视频的最后一帧开始。他们指出,当他们尝试渲染更多帧时,结果实际上变得更糟,这暗示了在处理帧序列时可能存在模型或渲染限制。
3. OpenAI & AI Industry Model/API Rumors and Announcements
- GPT-5 已经(表面上)可以通过 API 使用 (Score: 581, Comments: 191): 一位 Reddit 用户报告称,可以通过 OpenAI API 访问名为
gpt-5-bench-chatcompletions-gpt41-api-ev3的模型,这表明它可能是 GPT-5 的一个表面上的早期版本。该模型的命名约定表明它适配了 GPT-4.1 API(为了向后兼容),但可能引入了新的 API 参数,正如评论者指出的那样,“它仅支持 temp=1 和现代参数”。链接的 日志和截图 显示了在 OpenAI 禁用访问权限之前的 API 活动和 OpenAI Console 输出。 评论者通过创意任务验证了其能力:生成详细的 SVG 图像(示例)以及单次生成(single shot)功能丰富的 HTML/CSS/JS 落地页(样本输出),报告称其相对于 GPT-4/4.1 有质的提升,特别是在创意和结构化代码生成方面。- 用户报告称,该 API(据称是 GPT-5)在创意编程和设计生成方面表现出强大的能力,例如单次完成(oneshotting)即可生成一致且视觉精美的 iGaming 落地页,满足详细的提示词要求(响应式布局、现代 CSS、无框架的 JavaScript 交互、所有资源均为内联)。这种输出水平——“oneshotting”——表明其相对于 GPT-4 有显著改进,特别是在规范遵循(specification-following)和代码质量方面。
- 技术细节指出,该 API 仅支持
temperature=1和现代参数集,这可能表明与早期的 GPT-4 端点相比,这是一个更新的或实验性的部署。这种参数限制本身可能为它是一个独特的模型或实验性分支提供了间接证据。 - 关于该模型是否真的是 GPT-5 存在怀疑和语义争论,强调 OpenAI 的命名约定并不总是透明的:该模型被描述为“据称”或“表面上”的 GPT-5,这意味着用户无法独立验证其底层架构,而是依赖于外部指标(例如提示词表现、API 元数据)而非正式公告。
- OpenAI 的新开源模型被短暂上传至 HuggingFace (Score: 182, Comments: 37): 该帖子讨论了一次泄露事件,据报道 OpenAI 的新开源模型(参数量分别为 20B 和 120B)被短暂上传到了 HuggingFace。图片和评论中最值得关注的技术细节是模型的超参数:36 个隐藏层,128 个专家且每个 token 激活 4 个(Mixture-of-Experts 架构),词表大小 201,088,隐藏层/中间层大小 2,880,64 个注意力头,8 个键值头,4096 上下文长度,以及特定的旋转位置嵌入 (RoPE) 配置(例如 rope_theta 150000,scaling_factor 32)。这暗示了一个大规模的专家混合 Transformer 模型,可能针对大参数量下的效率和性能进行了优化。 关键的技术争论集中在 20B 参数模型是否能有效支持工具调用 (tool calling) 和代码用例,这表明社区对其具体的集成能力而非仅仅是规模感兴趣。此外,还有关于该模型架构与其他开源模型对比的推测。
- 一位用户分享了该模型的详细架构分解,指出参数包括
num_hidden_layers: 36、num_experts: 128(表明是 Mixture-of-Experts 架构)、experts_per_token: 4、hidden_size: 2880以及注意力配置细节(例如num_attention_heads: 64、num_key_value_heads: 8、sliding_window: 128和initial_context_length: 4096)。这些细节对于理解模型的规模和结构至关重要。 - 讨论提到了两种模型尺寸——20B 和 120B 参数——这意味着既有大规模模型,也有更易于获取的模型。用户表示有兴趣将 20B 版本用于工具调用和代码任务,这反映了对硬件需求与能力之间平衡的实际考量。
- 一位用户分享了该模型的详细架构分解,指出参数包括
- OpenAI 正准备推出新的订阅层级 ChatGPT Go (Score: 230, Comments: 70): 图片 (https://i.redd.it/c4ouejprhdgf1.jpeg) 展示了关于 OpenAI 名为 “ChatGPT Go” 的新产品的预热或泄露,暗示这是一个即将推出的订阅层级。经评论证实,主要的技术背景是推测该层级将介于 Free 和 Plus 方案之间,据称价格为每月 9.99 美元,可能会引入“按需付费” (pay as you go) 计费模式——这表明与当前方案相比,其灵活性更高或采用基于使用量的定价。社区正试图从图片和泄露的消息中推断其功能和定价。 评论中的讨论集中在价格预测(从 10 美元到 2,000 美元/月不等)以及可能向基于使用量的订阅(“按需付费”)转变——但目前尚未确认具体的技术细节或官方基准测试。
- 用户推测 “ChatGPT Go” 的定价和功能差异,认为它可能会填补免费层级和 Plus 层级之间的空白,价格可能定在每月 9.99 美元,并提出其功能集是更接近受限的免费层级还是增强的 GPT Plus 层级的问题。
- 一条评论讨论了在免费层级中引入广告以抵消新订阅模式成本的可能性,这将改变 OpenAI 目前 ChatGPT 产品的变现策略。这突显了 SaaS 变现的一个更广泛趋势,即通过广告或分层功能来补贴免费服务。
- 还有一个关于资源分配和访问权限的问题,一位用户明确询问 “Go” 是否会比 GPT Plus 提供更少的功能或模型访问权限,这表明了对订阅级别之间的技术限制或区别(例如 GPT-4 的可用性、使用限制或高负载期间的优先访问权)的关注。
- Anthropic 刚刚发布了 17 个值得观看的视频 (分数: 761, 评论: 139): Anthropic 通过其官方频道 (链接) 发布了 17 个新的 YouTube 视频(总计约 8 小时),可能提供了关于其最新研究、模型演示、安全实现或产品更新的详细技术见解。这次有组织的内容发布可能暗示了针对开发者和更广泛 AI 社区的协同知识共享或营销活动。 技术相关性最高的评论指出,YouTube 的视频观看速率限制可能会阻碍研究人员快速查看大量内容。另一位评论者提到利用第三方总结工具(例如 Comet AI 浏览器)进行高效信息提取,暗示了手动观看视频存在瓶颈。
- 一位评论者指出,Anthropic 内部有一个使用排行榜来追踪员工的 Token 消耗,揭示了员工中存在竞争性的非研究用途——一名员工承认在没有贡献代码或直接公司价值的情况下,其 Token 使用量领先。这与针对外部用户过度使用的批评形成对比,引发了对 Anthropic 最近使用限制政策背后逻辑和传达信息的质疑。
- 有人对 Anthropic 的新视频缺乏深度技术细节表示失望,并怀疑该公司是否正在转向,不再强调以研究为中心的内容,这可能受到了以 Elon Musk 等人物为首的行业趋势影响。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AI Discord 摘要
由 Gemini 2.5 Flash Preview 05-20 生成的“总结之总结”
主题 1. 前沿 LLM 进展与推测
- GPT-5 谜团加深:恐慌式发布还是温和改进? 围绕 GPT-5 发布的推测不断,观点分为两派:一派认为由于扩展限制(scaling limits)这将是一个完全的“恐慌式发布”,另一派则认为是一个更小、更专注的模型。一名用户在 GPT-5 API 被迅速移除前曾短暂发现过它 (GPT-5 API 现身),这进一步引发了对其最终统一、全模态(omnimodal)性质的推测。
- Horizon Alpha 崛起:免费模型碾压付费 LLM! Horizon Alpha 通过 OpenRouter API 表现优于付费 LLM,在自定义编程语言中交付了完美的 one-shot 代码。用户赞扬其在编排模式(orchestrator mode)下卓越的 shell 使用和任务列表创建能力,一些人推测它是 OpenAI 风格的 120B MoE 或 20B 模型。
- Gemini 的生成出现故障,定价遭到诟病! 一些成员报告了 Gemini 的重复行为,并注意到视频限制从 10 个降至 8 个。社区广泛批评 Gemini Ultra 每月 250 美元 的方案,该方案每天仅提供极少的 10 次查询,称其为“骗局”和“公然抢劫”。
主题 2. 开源与本地 LLM 优化
- Qwen 模型挑战量化极限,Codeium 起飞! 讨论集中在 Qwen3 Coder 30B 的最佳量化方案(Q4_K_M gguf 较慢,UD q3 XL 适合 VRAM)以及工具调用(tool calling)的问题。Qwen3-Coder 现在在 Windsurf 上的运行速度约为 2000 tokens/sec,完全托管在美区服务器上。
- Unsloth 微调释放全新速度与力量! Unsloth 现在支持 GSPO(GRPO 的更新),它作为一个 TRL 封装器工作,动态量化可以通过
quant_clone小程序进行复制。成员们正在探索 LoRAs 的持续训练,并使用 Unsloth 构建了一个 Space Invaders 游戏。 - LM Studio:离线梦想遭遇在线噩梦? 用户期待 图像到视频的提示词生成 以及离线使用的图像附件,相比 ChatGPT 等云端替代方案,用户更倾向于使用它。然而,由于安全性未经验证,通过网络连接到 LM Studio API 的安全漏洞令人担忧。
主题 3. AI 编程与 Agent 工具
- Aider 主导代码编辑,DeepSeek 表现强劲! 用户称赞 Aider 卓越的控制力和自由度,其中一位用户估计,使用 DeepSeek 仅花费 2 美元就在一天内完成了原本需要一周的编程工作。与 SGLang 和 Qwen 的速度对比也显示出高性能,在 RTX 4090 上达到了 472 tokens/s。
- AI Agent 领域扩展,走向链上! 开发者正在利用 Eliza OS 和 LangGraph 构建用于交易和治理的链上 AI Agent,同时致力于为自然光标导航创建 OSS 模型训练脚本。讨论还强调了 AnythingLLM (AnythingLLM 推文) 在确保 Agent 系统数据主权方面的作用。
- MCP 工具升级:安全性、支付和 JSON 处理! 一个新的安全性 MCP 检查工具 (GitHub 仓库) 正在征求反馈,而 PayMCP 为 MCP 服务器提供了支付层,并包含 Python 和 TypeScript 实现。一个 JSON MCP Server (GitHub 仓库) 进一步辅助 LLM 高效解析复杂的 JSON 文件,节省了宝贵的 token 和上下文。
主题 4. 硬件与性能基准测试
- AMD MI300X 向 Nvidia 秀肌肉,GEAK 亮相! 新的 MI300X FP8 基准测试 (MI300X FP8 基准测试报告) 表明,AMD MI300X 在某些任务中优于 NVIDIA H200,性能接近 B200。AMD 还推出了 GEAK 基准测试和 Triton Kernel AI Agent (GEAK 论文),用于 AI 驱动的内核优化。
- Nvidia 驱动更新至 580.88:修复快速运动问题! Nvidia 在 577.00(仅发布 9 天)之后迅速发布了 580.88 驱动,以修复启用 NVIDIA Smooth Motion 后可能出现的 GPU 显存速度问题。讨论还涉及解决 CUDA 编译器中使用
__launch_bounds__确定入口寄存器数量的问题,尽管setmaxnreg仍被忽略。 - 开发者讨论多 GPU 配置,关注显存节省! 讨论包括为双 3090 推荐 MSI X870E GODLIKE 等主板,对比 Mac mini M4 与 RTX 3070,以及探索在 LM Studio 中进行部分 KV Cache Offload 以优化 VRAM 使用的可行性。在 DTensor 和基础并行方案上的努力仍在继续,灵感来自 Marksaroufim 的可视化。
主题 5. AI 产品定价与用户体验
- Perplexity Pro 推出 Comet,iOS 端出现故障,向数百万人免费开放! Perplexity 正在向 Pro 用户缓慢发放 Comet 浏览器邀请,但 iOS 图像生成面临反复出现的问题,即附件图像无法被整合。值得注意的是,印度超过 3 亿的 Airtel 用户将获得为期 12 个月的免费 Perplexity Pro。
- Kimi K2 Turbo 开启狂暴模式,价格下调! Moonshot 团队发布了 Kimi K2 Turbo,宣称速度提升 4 倍,达到 40 tokens/sec,且在 9 月 1 日前在 platform.moonshot.ai 上的输入/输出 token 享受 5 折优惠。新的 Moonshot AI 论坛也已上线用于技术讨论,补充了 Discord “玩梗”的氛围。
- API 错误和高昂成本困扰 AI 用户! Gemini Ultra 的 Deep Think 方案因每月 250 美元仅限 10 次查询/天而遭到嘲讽,引发了与更具性价比替代方案的对比。用户还报告了 OpenRouter 模型(如经常过载的 Deepseek v3 free)和 Cohere API 持续出现的 API 错误和超时。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Comet Browser 邀请函陆续发放:Perplexity 正在缓慢发放 Comet Browser 邀请函,并优先考虑 Pro 用户。
- 用户报告的等待时间各不相同,建议 Pro 用户可以分享最多 2 个邀请函以加快进程。
- iOS 版 Perplexity Pro 图像生成失败:用户报告 iOS 版 Perplexity Pro 在图像生成过程中无法整合上传的图像,导致问题反复出现。
- 即使开启新对话,模型也只是总结请求而未根据附件生成图像。
- 印度 Airtel 用户获赠免费 Perplexity Pro:印度的 Airtel 订阅用户(超过 3 亿人)将获得为期 12 个月的免费 Perplexity Pro。
- 该促销活动仅限位于印度的 Airtel 订阅用户。
- GPT-5 发布日期:依然成谜:关于 GPT-5 发布的猜测不断,对于它是完整版本还是更小、更专注的模型,各方观点不一。
- 一位用户声称在 API 中短暂看到了 GPT-5(来源),但随后被迅速移除,引发了进一步猜测。
- 搜索域名过滤器失效:一位 Perplexity Pro 订阅者报告 search_domain_filter 未按预期工作,尽管该功能并非处于 beta 阶段。
- 另一位成员请求获取该用户的请求副本,以便进一步调查和协助。
Unsloth AI (Daniel Han) Discord
- GPT-5:恐慌式发布还是温和改进?:成员们正在猜测 GPT-5 是否会因为 OpenAI 在扩展方面的限制以及 Chain of Thought (CoT) 收益递减而成为一种“恐慌式发布(panic drop)”。
- 有观点认为 CoT 是一个“彻底的死胡同”,建议直接反馈模型的向量输出网络,而不是使用 tokens 进行思考。
- Qwen3 测试量化极限:讨论围绕 Qwen3 Coder 30B 的最佳量化展开,有报告称 Q4_K_M gguf 在 Ollama 中运行缓慢,而另一些人则为了节省 VRAM 倾向于使用 UD q3 XL。
- 一位成员在 3090 上通过 vllm 全天候运行 4 月份的 Qwen3-30b-a3b 模型(40k 上下文),正在等待 Coder 模型的 4-bit AWQ 版本。
- Unsloth 现已支持 GSPO:在 Qwen 提出将 GSPO 作为 GRPO 的更新后,成员们澄清 GSPO 已经在 Unsloth 中可用,它是一个会自动支持 TRL 更新的包装器。
- 尽管 GSPO 效率略高,但成员们并未注意到性能有显著提升。
- VITS 学会呼吸:一位彻夜训练 VITS checkpoint 的成员分享道,模型质量取决于 epochs 和数据集质量,且 VITS 擅长说话人解耦(speaker disentanglement)。
- 此外,他们发现 VITS 将原始音频编码到潜空间(latent space)以实现逼真的再现,并能通过标注学会逗号处的呼吸等细微差别,但在 iOS 上遇到了内存问题。
- 动态量化获得 Quant Clone:一位成员创建了 一个小程序,用于以与 Unsloth 动态量化相同的方式对微调模型进行量化,希望在自己的微调模型上复制该功能。
- 一位用户报告其 Gemini 微调模型中存在高拒绝率,并发现 Gemini 在这方面相当令人讨厌。
LMArena Discord
- Arena 增强功能旨在提供帮助:成员建议添加 Search、Image、Video 和 Webdev Arena 按钮以提高可见性,并建议在排行榜上添加工具提示,解释 Rank、CI 和 Elo 是如何确定的,并分享了一张 概念图。
- 目标是协助用户浏览平台并理解排名指标。
- 数据担忧:个人信息风险:一位用户对在发布的 Prompt 中意外包含 个人信息 表示担忧,并询问是否可以删除 Prompt。
- 一位成员回复称,此类示例应通过私信(DM)发送给他们以便上报,并承认已 与团队分享了这些担忧。
- Gemini 的生成出现故障:一些成员注意到 Gemini 表现出重复行为,而另一位成员询问 Gemini 2.5 Flash 是否修复了该问题;一位用户注意到视频限制从 10 降至 8,敦促其他人尽快使用视频生成 Arena。
- 社区的情绪在经历故障和性能稳定之间产生分歧。
- DeepThink 首次亮相令人失望?:随着面向 Ultra 会员的 Gemini 2.5 Deepthink 发布,成员们在看到 10 RPD 限制 后怀疑其是否值得。
- 成员们称其为 骗局 和光天化日下的抢劫,认为这只是因为 GPT-5 即将发布而推出的仓促版本。
- Veo 3 视觉胜利:Veo 3 Fast & Veo 3 已发布,在 Video Arena 中具备全新的 带有音频功能的图生视频(Image-to-Video)能力。
- 社区现在可以在 video-arena 频道中使用新的
/image-to-video命令从图像创建视频,并对最佳视频进行投票。
- 社区现在可以在 video-arena 频道中使用新的
{kind=link}
Cursor Community Discord
- Vibe Coding 引发 GitHub 需求:一位成员询问后台 Agent 是否需要 GitHub,并在附图中惊叹 this thing is sick,引发了对 vibe coding 设置的好奇。
- 另一位在 Prompt 上花费了 $40 的用户寻求优化其 Cursor 配置的建议,反映了对高效配置的共同兴趣。
- Cursor 冻结 Bug 令人沮丧:一位用户报告在聊天使用一小时后,机器每隔 30-60 秒 就会频繁冻结,表明存在持续的 Cursor 冻结 Bug。
- 一位 Cursor 团队成员建议在 Cursor 论坛上发布该问题,强调了用于 Bug 报告和协助的官方渠道。
- 模型支出与 Claude Pro 的对比:用户争论 Cursor 与 Claude Pro 的定价,一位用户表示偏好最便宜的方案和最好的模型,倾向于 Claude 的 $200 方案。
- 另一位用户警告成本可能会不断攀升,报告称 3 个月内花费了 $600,强调了成本管理的必要性。
- Horizon Alpha 体验评价不一:一位用户描述他们对 Horizon-Alpha 的个人体验 有点平庸,表明对新功能的反应不一。
- 相反,另一位用户称赞 Cursor 是我见过的最好的应用,强调了用户体验的主观性。
- 索求 Cursor 推荐计划:成员们询问了 Cursor 的推荐计划,一位用户声称目前已通过 Discord 引导了 至少 200 多人,表明社区驱动的采用率很高。
- 分享了 Cursor Ambassador 计划的链接,为奖励社区贡献提供了另一种途径。
OpenAI Discord
- Function Calling API 优于 XML 变通方案:Function Calling API 相比结构化 XML 具有内在价值,后者通常在 Qwen 等模型不支持原生工具调用时作为变通方案使用。
- 内联工具调用最大限度地提高了 Qwen 等编程模型的互操作性,尽管存在细微的效率损失。
- 扎克伯格的 AI 引发生物武器担忧:Mark Zuckerberg 的 AI 超级智能计划引发了对潜在生物武器制造的担忧,一名成员警告不要向公众发布超级智能。
- 成员们还表示担心,通过虚假用户和精心设计的语言来控制思想可能比生物武器更危险。
- GPT-5 面临延迟,Grok4 夺冠?:传闻称 GPT-5 的延迟是因为无法超越 Grok4,但 OpenAI 计划将多个产品整合到 GPT-5 中。
- 澄清说明 GPT-5 将是一个单一、统一的全模态模型。
- Horizon Alpha 表现优于付费 LLM:Horizon Alpha 通过 OpenRouter API 的表现优于付费 LLM,能够在自定义编程语言中提供完美的一次性生成代码(one-shot code)。
- 它在编排模式(orchestrator mode)下的 Shell 使用和任务列表创建优于其他模型,尽管有人推测它可能一直是某种我们没想到的极其古怪的东西,比如 codex-2。
- 大上下文窗口引发争论:尽管 Gemini 拥有 100 万上下文窗口,但遗留代码库问题在 Claude 和 ChatGPT 中得到了更好的解决,这引发了关于大上下文窗口是否被高估的争论。
- 一些人更倾向于上下文窗口较小但输出质量更高的模型,而另一些人则坚持认为大窗口对于 Agent 应用自动记忆并织入久远细节至关重要。
LM Studio Discord
- LM Studio 中的图生视频提示词生成愿景:成员们期待 LM Studio 未来能推出图生视频提示词生成和图像附件功能,相比 ChatGPT 等云端替代方案,他们更青睐离线能力。
- 作为替代方案,一位成员提到了 ComfyUI,并指出它可能尚未针对 AMD 显卡进行优化。
- LM Studio 的路线图:一个谜:社区讨论了 LM Studio 缺乏公开路线图的问题,推测开发计划可能缺乏结构且不可预测。
- 一位成员表示:没有公开路线图,所以没人知道。
- LM Studio API 安全考量:用户讨论了通过网络连接 LM Studio API 的问题,强调了潜在的安全漏洞。
- 针对 LM Studio 未经验证的安全性提出了担忧,警告在没有进行适当风险评估和网络保护的情况下不要将其暴露。
- Qwen3 Coder 模型面临加载故障:用户在加载 Qwen3 Coder 30B 模型时遇到困难,触发了 Cannot read properties of null (reading ‘1’) 错误。
- 一位成员建议更新到 0.3.21 b2 版本,该版本声称已解决此问题,并建议启用推荐设置。
- Nvidia 快速发布驱动:Nvidia 在 577.00 发布仅 9 天后就快速发布了 580.88 驱动,修复了启用 NVIDIA Smooth Motion 后可能出现的 GPU 显存速度问题 [5370796]。
- 该用户直接从 CUDA toolkit 运行驱动程序,不使用花哨的控制面板或 GFE (GeForce Experience)。
OpenRouter (Alex Atallah) Discord
- API 错误困扰 OpenRouter:用户报告在使用 OpenRouter API 调用模型时遇到 API 错误,一位用户建议检查 model ID prefix 和 base URL 以解决该问题。
- 错误包括 no endpoint found,成员认为这可能是由潜在的配置错误引起的。
- Deepseek v3 免费模型受停机困扰:用户在 Deepseek v3 0324 free 模型上遇到了问题,包括 internal errors、empty responses 和 timeouts,导致一些人转向付费版本。
- 一位成员指出 免费版完全超载了。付费版没有这些问题,而且实际的内容质量更好。
- Horizon Alpha 被赞高效:用户称赞 Horizon Alpha 模型具有有效的推理能力和良好的性能。
- 虽然该模型声称是由 OpenAI 开发的,但社区成员澄清说它很可能是一个蒸馏模型(distilled model)。
- Personality.gg 利用 OpenRouter 进行角色扮演:Personality.gg 推出了一个角色扮演网站,大部分模型使用 OpenRouter,通过 OpenRouter PKCE 提供对所有 400 个模型的访问,完全免费或价格低廉。
- 这种集成让用户能够与各种 AI models 进行角色扮演。
- PyrenzAI 的 UX 赢得赞誉:一位用户称赞了 PyrenzAI 的 UI/UX,欣赏其独特的外观和风格,以及与其他应用相比独特的侧边栏设计。
- 尽管存在速度和安全性方面的批评,该应用程序的用户界面仍获得了积极反馈。
Moonshot AI (Kimi K-2) Discord
- Kimi K2 凭借 Turbo 达到惊人速度!:Moonshot 团队宣布了 Kimi K2 Turbo,宣称速度提升了 4 倍,达到 40 tokens/sec,且在 9 月 1 日前在 platform.moonshot.ai 提供输入和输出 token 的 50% 折扣。
- 得益于同一模型更快的托管速度,用户现在可以通过官方 API 体验到显著提升的性能。
- Moonshot AI 推出新的交流据点:Moonshot AI 推出了 Moonshot AI Forum (https://forum.moonshot.ai/),用于技术讨论、API 帮助、模型行为、调试和开发者技巧。
- 虽然 Discord 仍然适合梗图(memes)和闲聊,但该论坛旨在成为严肃构建和技术讨论的首选之地。
- Kimi K2 挑战 Claude 的统治地位:一位用户报告称 Kimi K2 是他们第一个可以用来替代 Claude 的模型,这促使他们放弃了 Gemini 2.5 Pro,因为作为一种信息的编程正变得更加自由。
- 该用户还补充说,他们预计大多数 AI 在知识方面将会趋同,因此它们之间的差异将开始变得模糊。
- Kimi K2 Turbo 价格详情公布:高速的 Kimi K2 Turbo 定价为:输入 token(缓存)$0.30/1M,输入 token(非缓存)$1.20/1M,输出 token $5.00/1M,优惠活动持续至 9 月 1 日。
- 这相当于在折扣期间以 2 倍的价格获得大约 4 倍的速度,专为需要快速处理的用户量身定制。
- Gemini Ultra 的深度思考价格不菲:成员们嘲讽了 Google Gemini Ultra 的方案,该方案规定 每月 250 美元,每天限 10 次查询,一位用户表示这 非常滑稽且非常卑鄙。
- 有人将其与每月 200 美元的 ChatGPT pro(提供无限量 Office 365 Pro)以及被认为定价更合理的 Claude Max 进行了比较。
Nous Research AI Discord
- Hermes-3 数据集拒绝响应引发关注:成员们在为量化计算 imatrix 时,调查了 Hermes-3 dataset 中意外出现的拒绝响应,并进行了进一步的数据集调查以确认该数据集不含拒绝响应。
- 团队希望通过确保数据集经过全面审查,来确认数据集中确实没有拒绝响应。
- Unitree 的 R1 机器人推动 Embodied A.I. 民主化:社区探索了售价为 $5,900 的 Unitree R1 基础机器人模型,它为 A.I. 开发提供了一个完全开放的软件开发工具包(Python、C++ 或 ROS),并在这段 YouTube 视频中进行了展示。
- 用户表示,它是研究团队向下一代 A.I. 演进过渡的理想工具。
- Horizon Alpha 模型引发对 OpenAI 的猜测:成员们讨论了 OpenAI Horizon Alpha model 是否具有 OpenAI 的风格,推测它可能是一个具有低激活度的 120B MoE 模型,或者是 20B 模型,详见这条推文。
- 一些人在 Reddit 帖子上建议,如果该模型仅支持 FP4,那么量化将是不可能的。
- AnythingLLM 倡导数据主权:一位用户分享了关于 AnythingLLM 的推文链接,并宣称它是 数据主权 (data sovereignty) 的未来。
- 该用户还分享了指向 Neuronpedia 的链接,以及其他与 数据主权 相关的推文,包括 Jack_W_Lindsey 的推文和 heyshrutimishra 的推文。
- OSS 模型训练脚本启动:一位公共研究工程师已开始开发 OSS model training script,以填补自然光标导航领域缺乏优质 OSS 模型的空白。
- 该工程师承认,那些屏蔽爬虫机器人的网站可能会被使用这项技术的新“克隆体”抓取。
Latent Space Discord
- Cline 为开源 AI 编程 Agent 融资 3200 万美元:AI 编程 Agent Cline 获得了由 Emergence Capital 和 Pace Capital 领投的 3200 万美元 种子轮和 A 轮融资,旨在通过透明的开源 AI 工具赋能开发者,目前已为 270 万 开发者提供服务,价格透明且无额外加价。
- OpenAI 的开源 (OS) 模型 YOFO 细节泄露:在配置信息被短暂访问后,关于 OpenAI 即将推出的开源模型 YOFO 的细节浮出水面,引发了围绕传闻中的 120B 和 20B 参数变体的关注。
- 一位成员指出,Jimmy Apples 不愿分享所有的配置细节。
- Anthropic 的 Claude 生成了 22,000 行代码更新:Anthropic 合并了一个对其生产环境强化学习代码库的 22,000 行 更改,这些代码大部分由 Claude 编写,这引发了人们对如此大规模 AI 生成代码更改可靠性的怀疑,该更改主要是一个 json dsl。
- 讨论涉及了人工审查流程以及对大规模 AI 驱动代码合并可靠性的担忧;Sauers 证实该更改是真实的。
- Anthropic 封禁 OpenAI 的 Claude API 访问权限:Anthropic 以违反服务条款为由,撤销了 OpenAI 对其模型(包括 Claude)的 API 访问权限。
- OpenAI 表示失望,并指出其 API 仍对 Anthropic 开放,这引发了社区关于竞争手段和模型训练界限模糊的讨论。
Yannick Kilcher Discord
- 查询扩展提升 RAG 效果:讨论围绕在 RAG 系统中使用 查询扩展技术 展开,通过从单个用户查询生成多个问题来提高信息检索效果。
- 对于查询 ‘what is the name of the customer’,建议将其扩展为 ‘What is the name?’ 和 ‘Who is the customer?’。
- Cross-Encoders 在排序中表现不佳:在 MS MARCO 数据上使用 Cross-Encoder 对“客户姓名是什么?”这一问题的结果进行排序实验,结果不尽如人意。
- 预期的首选结果(Customer Name)排名低于(Definition of Customer),得分分别为 -0.67 和 -1.67。
- Fine-Tuning 是检索的关键:根据 这篇论文,直接针对检索任务进行训练对于控制排序质量至关重要。
- 成员们建议,最佳的相似度度量标准取决于具体任务,这意味着通用型的 Embeddings 可能不足以应对专门的检索场景。
- Gemini 2.5 Flash 偏袒 Gemma 模型:Gemini-2.5-flash 始终将 Gemma 模型 的排名置于其他模型之上,甚至是某些 70B 模型。
- 怀疑原因是 Gemma 模型的回答语气对人类和 LLM 来说可能更具说服力,从而影响了排名。
- Cinema AI 生成连贯的电影场景:根据 arxiv 论文,TheCinema AI 研究项目专注于生成彼此保持 连贯性 (cohesion) 的电影场景。
- 该项目探索了生成连贯电影场景的方法,并在项目网站和论文中进行了详细介绍。
Notebook LM Discord
- NotebookLM 用户要求离线访问:用户正在寻求保存 NotebookLM studio 素材 的方法,以便在没有持续网络连接的旅行期间进行离线访问。
- 一位用户提到将音频下载到 iPad,并将其添加到带有家庭照片的 PowerPoint 幻灯片中。
- Pro 用户疑惑缺失预览功能:尽管已升级,但仍有几位 Pro 账户用户 反映无法使用 视频概览功能 (video overview feature),而一些免费账户用户却可以使用。
- 一位曾短暂获得视频访问权限的用户在刷新页面后失去了该权限,这表明可能存在持续的部署问题。
- 用户梦想使用 Gemini 构建自定义 NotebookLM:一位用户正考虑使用 Gemini embedding 001 和 Gemini 2.5 models API 为文档创建一个自定义的多跳、多步推理 RAG 流水线。
- 他们的目标是超越 NotebookLM 的能力,理由是其存在 300 个文件限制、工作流缺乏透明度以及系统指令受限等局限性。
- Comet 扩展将 NBLM 推向新高度:用户讨论了 Comet,这是一个可以访问标签页/历史记录/书签并控制浏览器的浏览器扩展,以及它与 NotebookLM 集成以寻找来源的潜力。
- 有人建议 Comet 可能会编写一个扩展程序,动态地向 NotebookLM 添加来源。
- 西班牙语 Audio Overviews 仍然短小精悍?:一位用户询问为什么西班牙语的 Audio Overviews 持续时间仍然很短,并指出一个变通方法:将其切换为英语,更改时长,然后提示它用西班牙语生成。
- 另一位用户确认,虽然葡萄牙语尚未正式支持讲解视频,但他们能够强制其运行。
Eleuther Discord
- Attention Probes 的性能表现引发分歧:EleutherAI 关于 attention probes(用于分类 transformer 隐藏状态的小型神经网络)的实验结果褒贬不一。正如其博客文章所述,由于过拟合 (overfitting) 和优化问题,其表现有时不如标准的 linear probes。
- 这些实验的代码已在 GitHub 上开源,邀请社区进行探索和改进,以发现潜在的提升空间。
- 低功耗 LLMs 挑战海底场景:一位成员正在离岸低功耗边缘设备上部署 LLMs,用于海底制图、环境监测和自主系统,重点关注任务规划、异常检测和智能数据压缩。
- 目前科学建模受限于延迟和带宽约束,但团队正在积极探索克服这些挑战的方法。
- Gemini-2.5-flash 评判 Gemma 生成:一位成员观察到,在比较各种 LLM 时,Gemini-2.5-flash 始终给 Gemma 的回答打出更高分,这表明可能存在“家族偏见”或 Gemma3 模型具有更优越的性能。
- 这一观察引发了围绕 LLM 评估指标的公平性和客观性,以及开源模型竞争格局的讨论。
- Weight Tying 引发担忧:一位成员认为 weight tying 是一种普遍的糟糕做法,会导致效率低下和不稳定,并且在数学上甚至说不通,暗示其对模型性能有负面影响。
- 这一断言在更广泛的研究社区中引发了关于 weight tying 有效性的辩论。
- HF Transformers 的调整引发争议:在 HuggingFace transformers 4.54 中,Llama & Qwen layers 现在直接返回残差流(不是 tuple),这可能会影响
nnsight layer.output[0]的用户。- 一位成员警告说,使用
nnsight layer.output[0]将只能获取第 1 个 batch 元素,而不是完整的残差流,这一 bug 是通过 nnterp 测试发现的。
- 一位成员警告说,使用
aider (Paul Gauthier) Discord
- Aider 依然在代码编辑领域占据主导地位:用户对 Aider 表示高度赞赏,称其在控制力和自由度之间实现了比替代方案更好的平衡。一位用户估计,使用 DeepSeek,Aider 仅花费 2 美元就在一天内完成了一周的编程工作。
- 另一位用户感叹道:“Aider rules so hard”,强调了它在代码编辑任务中的出色表现。
- SGLang 和 Qwen 突破速度极限:一位用户报告称,在配备 RTX 4090 的设备上,使用 sglang 和 Qwen 0.6B Q8 在 LM Studio 上达到了 472 tokens/s 的速度,而普通 LM Studio 仅为 330 tokens/s。
- 另一位用户表示有兴趣复制这种纯本地配置,特别是考虑到 vllm 在其 4090 上的表现比 Ollama 慢,并表示好奇想尝试 llama.cpp。
- 讨论多 GPU 主板:讨论涉及硬件配置,一位成员推荐将这款 MSI 主板用于 Fractal North XL 机箱内的双 3090s。
- 其他人分享了自己的配置,包括配备 3 个 L4 和 T40 的服务器,以及像 Meshify2 这样多样的机箱选择。
- Claude Code 受困于高 Token 计数:成员们将 Claude Code 与其他前沿模型进行了比较,指出当超过 64k tokens 时,其性能会显著下降,尤其是与 o3 和 Gemini 2.5 Pro 相比。
- 还有人提到,系统提示词(system prompt)消耗了可用上下文窗口的很大一部分。
- 在本地对 Qwen3 30B 进行基准测试:一位成员正在寻求一种简便的方法,使用 LM Studio 在本地对 Qwen3 30B A3B Coder 的 8 个不同量化版本(quants)进行基准测试。
- 另一位成员建议在同一台电脑上利用 llama.cpp server + docker aider benchmark,并参考了一篇关于让 Gemini 2.5 Pro 运行起来的文章。
MCP (Glama) Discord
- 安全 MCP 检查器寻求反馈:一位成员分享了一个用于 security MCP check tool(安全 MCP 检查工具)的 GitHub 仓库,并请求社区反馈。
- 该工具旨在帮助用户识别其 MCP 服务器中的潜在漏洞。
- PayMCP 支付层加入竞争:一个名为 PayMCP 的 MCP 新型支付层正在开发中,目前已提供 Python 和 TypeScript 版本实现。
- 创建者正在寻找合作伙伴和早期采用者,以探索其在促进 MCP 服务器接受付款方面的能力。
- MCP 服务器 PageRank 探索开始:一位成员询问了关于 MCP 服务器的 PageRank 实现,目标是根据实用性对服务器进行排名。
- 建议包括将 MCP 工具仓库和 MCP 注册表 (registry) 作为有价值的资源。
- JSON MCP 服务器优化处理:一个 JSON MCP Server 出现,旨在帮助 LLM 高效解析大型且复杂的 JSON 文件(如 Excalidraw 导出文件),详情记录在此 GitHub 仓库中。
- 该解决方案采用 schema generation(模式生成)来理解 JSON 结构并提取必要数据,从而减少 tokens 和上下文(context)消耗。
GPU MODE Discord
- Hylo 语言与“异构编程语言”类比:Hylo 编程语言 (https://www.hylo-lang.org/) 因其通过值语义 (value semantics) 和调度实现内存安全的方法而受到关注,并被拿来与 Halide 和 Mojo 进行比较。
- 成员报告称,负责 Hylo 的人员目前正在从事 Scala 3/Scala Native 的工作,并指出负责人来自 cpp 和 Swift 背景。
- AMD 发布 Kernel AI Agent 和 GEAK 基准测试:AMD 在其论文 GEAK: INTRODUCING TRITON KERNEL AI AGENT & EVALUATION BENCHMARKS 中介绍了 GEAK 基准测试和 Triton Kernel AI Agent。
- 探索 AMD 使用其新型 Triton Kernel AI Agent 进行内核优化的 AI 驱动内核优化新方法。
- __launch_bounds__ 设置启动 CUDA 修复:一位用户修复了编译器在入口处无法确定寄存器计数的问题,方法是将
minBlocksPerMultiprocessor传递给__launch_bounds__,设置maxThreadsPerBlock=128*3且minBlocksPerMultiprocessor=1。setmaxnreg设置仍被忽略,现在是由于一个与'extern'调用兼容性相关的不同问题。
- MI300X 基准测试超越 H200:一位用户询问了关于在 AMD 硬件上运行新型 MI300X FP8 基准测试 的经验。
- 基准测试将 AMD 的 MI300X 与 NVIDIA 的 H200 进行了比较,结果表明 MI300X 在某些 FP8 数据并行任务中优于 H200,性能接近 NVIDIA 的 B200。
- picocuda 编译器在 GPU 领域取得进展:根据 singularity-systems 频道的成员透露,picocuda 编译器和 elements 图数据结构项目正在取得进展。
- 教科书将大致遵循 CGO ‘16 的 GPUCC 论文。
HuggingFace Discord
- Flux Krea 已发布,但不支持 NSFW:新的 Flux Krea 模型已发布,点击此处获取,该模型承诺提供更多细节,并兼容 base.dev 上的大多数 LoRA。
- 早期报告表明,无法进行 NSFW 内容生成。
- Emergence AI 脱颖而出:Emergence AI 的架构在 LongMemEval benchmark 上实现了 SOTA,该基准测试用于评估 AI Agent 的长期记忆能力。
- 这使得 Emergence AI 成为记忆力基准测试的领导者。
- Smolagents 进军 JavaScript:一名成员发布了 smolagents.js,这是 smolagents 的 TypeScript 移植版,可在 GitHub 和 npm 上获取。
- 该移植版允许开发者在 JavaScript 环境中使用 smolagents。
- 判别器学习率微调:成员们讨论了通过降低判别器学习率(discriminator learning rate)来识别问题以调试 GAN,建议观察在极低值(如 1e-5)下的 Loss 变化。
- 目标是确定判别器的 Loss 塌陷至 0 是否源于学习率不平衡。
- Qwen 和 DeepSeek-R1 顶上:在无法访问 Llama 4 的情况下,可以在 Colab 上运行 dummy_agent_library.ipynb 时使用 Qwen 或 DeepSeek-R1 作为替代。
- 当 Llama 4 的访问受限时,这些模型被认为是可行的替代方案。
Cohere Discord
- Cohere 上下文窗口大小:128k 输入,8k 输出!:一位用户注意到上下文窗口存在差异,Hugging Face 模型卡片显示为 32k context,而 API 文档声称是 128k。团队澄清为 128k 输入和 8k 输出。
- Cohere 团队成员承诺将更新 Hugging Face 模型卡片。
- 速率限制阻碍黑客松愿景!:参加 HackRx 6.0 AI 黑客松的 Team Patriots 遇到了 10 次调用/分钟的测试密钥限制问题。
- 一位 Cohere 团队成员允许其创建多个账户并轮换密钥以克服限制,这表明速率限制是一个已知障碍。
- 初创公司看好 Cohere 的 Reranker 并寻求企业版!:一家初创公司对 Cohere 的 Reranker 实现充满热情,由于超出了生产环境 API 1000次/分钟的限制,表达了对企业版计划(Enterprise plan)的兴趣。
- Cohere 指引他们将用例详情发送至 support@cohere.com 和 varun@cohere.com 以获取安全协助。
- 三星 AI 架构师加入讨论!:来自 Samsung Biologics 的一位 AI 架构师介绍了自己,其工作重点是集成 AI 方法和工具,并运行私有的 带有 RAG 的 LLM 服务供内部使用。
- 他们寻求讨论生物制药或生物学挑战。
- Cohere API 遭遇超时!:#🔌-api-discussions 频道的一位用户报告在查询 API 时收到多次超时错误。
- 该用户在聊天中未获得任何反馈。
Manus.im Discord Discord
- 垃圾信息发送者仍在活动:一名成员报告收到私信(DM)垃圾信息,并请求管理员永久封禁该活跃用户。
- 在此期间未采取任何行动,该垃圾信息发送者仍在继续活动。
- Wide Research,它够“宽”吗?:一名成员询问关于使用 Wide Research 的初步看法。
- 尚未收到关于 Wide Research 的评论。
- Cloudflare 配置卡住,寻求帮助:一名成员在 Cloudflare 中配置虚拟环境时遇到问题。
- 设置过程一直卡在 Cloudflare,导致他们无法完成虚拟环境配置。
- 积分系统崩溃,用户表示不满:一名成员报告每日刷新积分已失效,表明平台的积分系统存在问题。
- 另一位用户提到,尽管没有违反任何规则,但他们的账户被封禁了,这表明账户管理可能存在问题。
- 裁员可能导致无法退款:一名成员指出公司最近进行了裁员,并暗示用户可能无法拿回退款。
- 该评论暗示公司最近的裁员可能会影响处理退款或解决财务问题的能力。
LlamaIndex Discord
- LlamaIndex 与 Novita Labs 联手:LlamaIndex 推文宣布了 LlamaIndex 与 Novita Labs 模型推理能力的集成。
- 此次集成提供了多样化的数据源连接,并能将其转换为向量嵌入(vector embeddings)。
- Gemini 流利使用 TypeScript:LlamaIndex 推文宣布 Gemini Live 集成现已支持 TypeScript。
- 提供了一个演示示例,展示了如何设置并运行一个基础的终端聊天程序。
- 工程师构建链上 AI:一位资深 AI 与区块链工程师正在使用 Eliza OS、LangGraph 和自定义工具链构建用于交易、媒体自动化和自主治理的链上 AI Agent。
- 该工程师在 Base、Solana、Berachain、Sui、Aptos、HBAR、EVM 链以及跨链系统方面拥有丰富的经验。
- LLM 对话的 Git 风格分支:一名成员正在实验一种系统,其中每条消息都是一个节点,允许在对话的任何点分叉以创建新的上下文路径,详见其博客文章。
- 该系统目前使用 Gemini API,并计划加入 GPT-4、Claude 和本地 LLaMA 模型,目前正在寻求测试者反馈。
- Llama 解析器解析耗时较长:成员们讨论了 LlamaIndex 解析器在处理 .doc、.pdf 和 .ppt 文件时的性能,特别是在处理嵌入图像中的文本时。
- 提出的解决方案包括使用高级模式下的 LlamaParse、将 PPT 转换为 PDF 以提高速度,或实现 ThreadPoolExecutor() 进行异步文档解析。
DSPy Discord
- 为 Yaron Minsky 创造了新动词 “DSpill”:成员们讨论了谁会再次尝试 DSpill Yaron Minsky / 量化大佬 (quant bros),从而产生了一个新动词“DSpill”。
- “DSpill”一词被提议用来描述针对 Yaron Minsky 和量化大佬的行动。
- DSPy 现在支持 RL 了!:一位成员分享了一篇博客文章,关于在 DSPy 中使用强化学习(Reinforcement Learning)来提高写作质量。
- 虽然没有引发讨论,但对于那些寻求优化生成结果的人来说可能很有趣。
Modular (Mojo 🔥) Discord
- Mojo 安装问题值得 GitHub 关注:一位成员遇到了 Mojo 安装困难,并考虑开启一个 GitHub issue 来报告该问题。
- 另一位成员建议他们创建一个包含详细日志的 GitHub issue,以协助开发人员高效地诊断和解决安装问题。
- 日志是开发人员最好的朋友:讨论强调了在 GitHub 上报告 Mojo 安装问题时包含详细日志的重要性。
- 提供详尽的日志可以让开发人员通过提供调试所需的必要信息,更高效地诊断和解决问题。
- Print 语句会抑制尾调用优化?!:一位成员观察到,在函数中添加基础的 print/log 语句会阻止尾调用消除(tail call elimination)。
- 讨论围绕在极简 Mojo 示例中添加 print/log 语句如何影响尾调用消除展开,并寻求理解这种行为的底层原因。
Torchtune Discord
- 拥有 128 个专家的 OpenAI 模型泄露:传闻一个拥有 128 个专家和 120B 参数的 OpenAI 模型可能已经泄露。
- 据报道,该模型的权重采用 FP4 格式,表明其处于压缩状态。
- 深入探讨混合专家模型 (MoE):混合专家模型 (MoE) 使用多个子网络(专家)配合一个门控网络来路由输入。
- 这种架构能够在不按比例增加计算成本的情况下扩展模型规模,使其成为一个活跃的研究领域。
LLM Agents (Berkeley MOOC) Discord
- 带有答案解析的 MOOC 测验现已发布:在课程网站的“测验”部分现在可以访问带有答案解析的测验存档。
- 这为学生提供了复习课程材料和评估理解程度的资源。
- Google Forms 将保持关闭状态:课程工作人员宣布,他们无法重新开放用于测验的 Google Forms。
- 错过通过 Google Forms 进行测验的学生应使用可用的存档进行复习。
Codeium (Windsurf) Discord
- Qwen3-Coder 以极速冲入 Windsurf:Qwen3-Coder 现已在 Windsurf 中上线,运行速度约为 2000 tokens/秒。
- Windsurf 的新成员:Qwen3-Coder:Windsurf 现在托管了 Qwen3-Coder,拥有惊人的 2000 tokens/秒 的速度。
- 该新模型的影响正在 Reddit 上进行讨论。
Nomic.ai (GPT4All) Discord
- 开发者寻求机会:alex_sdk4 询问是否有人在寻找开发者。
- 未提供关于具体技能、项目或预期的进一步细节。
- 后续:开发者寻求机会:自 alex_sdk4 联系以来,这可能是处理较小任务的好机会。
- 潜在客户可以直接联系 alex_sdk4。
tinygrad (George Hotz) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord: 各频道详细摘要与链接
Perplexity AI ▷ #general (1048 条消息🔥🔥🔥):
Comet Browser 邀请, Perplexity Pro 图像生成问题, 印度 Airtel 用户免费获得 Perplexity Pro, GPT-5 发布推测, 模型性能对比
- Comet Browser 邀请逐步发放:Perplexity 几乎每天都在发放 Comet Browser 邀请,优先考虑 Pro 用户,但等待时间可能会有所不同。
- 一些用户建议,如果你的女儿有 Pro 账户,她最多可以给你发送 2 个邀请。
- 图像生成故障困扰 Perplexity Pro:一位用户报告说,iOS 版 Perplexity Pro 的图像生成功能无法整合上传的图片,另一位用户确认这是一个反复出现的问题。
- 模型会总结请求,但不会根据上传的文件生成图像,且开启新对话并不总能解决问题。
- 印度 Airtel 用户抢到免费 Perplexity Pro:一位用户提到,印度的 3 亿人如果是 Airtel 用户,可以免费获得 12 个月 的 Perplexity Pro。
- 要使用此促销活动,你必须位于印度并成为 Airtel 用户。
- GPT-5 发布日期仍是个谜:用户们推测 GPT-5 的发布,有人认为可能是下周,但另一位成员坚持认为它可能只是某种 mini 模型,哈哈。
- 一位用户曾短暂在 API 中看到过 GPT-5,但它很快就被移除了(来源)。
- 模型性能引发辩论:Sonnet 4 占据主导,O3 表现稳健:用户讨论了各种模型的使用体验,Sonnet 4 在编程和价值方面受到称赞,而 O3 则被推荐用于推理 (cplx.app)。
- 讨论涉及了工具调用(tool call)问题,以及 Anthropic 模型倾向于除非明确询问否则会保留信息的倾向。
Perplexity AI ▷ #sharing (7 条消息):
可共享的 Thread,无需 Embedding 的 RAG,特朗普-梅德韦杰夫
- Thread 共享设置已澄清:一位 Perplexity AI 工作人员向用户澄清,Thread 应设置为
Shareable(可共享)。- 分享了一个关于如何使 Thread 可共享的链接。
- 无需 Embedding 的 OpenAI RAG:一名成员分享了一篇 Medium 文章,探讨了无需 Embedding 的 RAG 以及 OpenAI 是如何实现这一点的。
- 该文章由 Gaurav Shrivastav 撰写。
- 特朗普-梅德韦杰夫与 2 艘核潜艇的戏剧性事件:一名成员分享了一个 Perplexity 搜索结果,内容涉及 特朗普-梅德韦杰夫关于 2 艘核潜艇部署在俄罗斯附近的戏剧性事件,该内容是为 8 月 1 日的新 Human Benchmark Report 准备的。
- 他们分享了一个为该报告制作的 Gemini Canvas 信息图。
Perplexity AI ▷ #pplx-api (14 条消息🔥):
search_domain_filter, 审核机器人用法, 通过 API 上传图像
- 排除 Search Domain Filter 故障!:一位用户反馈称,即使是 Pro 订阅者,search_domain_filter 也没有生效,并请求了解如何启用该功能。
- 另一名成员回应称该功能应该可以正常工作(不在 Beta 阶段),并要求提供 Request 副本以便协助。
- 审核机器人定价问题?:一名学生咨询了使用 Perplexity AI 构建审核机器人的用法和定价,预计会有约 200 个请求,每个请求的数据量少于 100 个单词。
- 该用户正尝试使用 Perplexity AI 制作一个审核机器人。
- 图像上传导致内部服务器错误!:一位用户在通过 API 以 base64 格式上传图像时遇到了内部服务器错误(code 500)。
- 随后他们分享了其 B4J 代码 来展示其方法,同时一名成员询问了具体的 Request 内容和所使用的模型。
Unsloth AI (Daniel Han) ▷ #general (1099 条消息🔥🔥🔥):
GPT-5 猜测, Qwen3 模型, Cogito V2, Unsloth GRPO 和 TRL, H100 与 Batch Size
- GPT-5 “恐慌式发布”的猜测兴起:成员们正在猜测 GPT-5 会是由于 OpenAI 耗尽了扩展模型规模(Scaling)的空间以及思维链(CoT)收益递减而进行的“恐慌式发布(Panic Drop)”,还是仅仅是一个中规中矩的改进。
- 有观点认为 CoT 是一个完全的死胡同,并且有可能通过将模型的向量输出直接反馈回网络,而不是使用 Token 进行思考来实现同样的效果。
- Qwen3 量化与性能测试:讨论了 Qwen3 Coder 30B 的理想量化方案,一些人发现 Q4_K_M GGUF 在 Ollama 中添加上下文时速度较慢,而另一些人则为了节省显存(VRAM)而倾向于使用 UD q3 XL。
- 一名成员报告称在 3090 上通过 vLLM 全天候运行 4 月份的 Qwen3-30b-a3b 模型,上下文为 40k,而其他人则热切期待 Coder 模型的 4-bit AWQ 版本。
- 探讨 Cogito V2 强化学习:成员们讨论了 Cogito-v2 GGUF 的发布及其强化学习方法,一些人认为这是对现有技术的迭代,而非新颖的突破。
- 一名成员分享了一篇涵盖 2024 年过程奖励模型(Process Reward Models)的文章 (synthesis.ai),另一名成员分享了 Deepmind 在 2022 年探索类似概念的论文 (arxiv.org)。
- Unsloth GRPO 已支持 GSPO:在 Qwen 提议将 GSPO 作为 GRPO 的更新后,一名成员询问是否需要更新 Unsloth 以支持 GSPO 训练。
- 另一名成员澄清说 GSPO 效率稍高,但它已经在 Unsloth 中可用,并且由于 Unsloth 是一个封装器(Wrapper),它将自动支持 TRL 的更新。
- 传闻中的 OpenAI 新模型引发关注:关于 OpenAI 新模型的传闻正在流传,一些人猜测它可能是最强的操作系统(OS)模型,并在评估中击败 SOTA K2。
- 许多人对潜在的稠密(Dense)20B 基座模型感到兴奋,认为它可以很好地适配现有的方案,而另一些人则好奇它会是稠密模型还是另一个专家混合模型(MoE)。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 条消息):
新成员介绍,社区协助
- 新成员加入并坦诚自己是新手:一位新成员 cyber.n0de 介绍了自己,并幽默地承认自己完全不知所措。
- 他们表达了对引导的需求,这标志着社区协助和入职引导的潜在机会。
- 社区伸出援手:成员 theyruinedelise 迅速回应了新成员的求助并提供了帮助。
- 这展示了社区支持新人并提供指导的意愿。
Unsloth AI (Daniel Han) ▷ #off-topic (74 条消息🔥🔥):
VITS checkpoint 训练心得,iOS 上的端侧 VITS 系统,儿童语音录制,用于提升音频保真度的 Avocodo 和 iSTFTNet,用于 Speech LLM 的通用 Vocoder
- VITS 训练带来灵感时刻:在通宵训练 VITS checkpoint 后,一位成员分享了见解:模型质量取决于 Epoch 数量和数据集质量,且 VITS 在说话人解耦(speaker disentanglement)方面表现出色,适用于创建具有独特声音的模型。
- 他们指出 VITS 将原始音频编码到潜空间(latent space)以实现逼真的再现,并强调与 RVC 相比,选择取决于具体需求。
- VITS 在 iOS 上遭遇内存困境:一位成员报告称,在 iOS 上使用 VITS 作为端侧系统语音时,Hifi-GAN decoder 面临内存消耗挑战,需要进行分块解码(chunk-wise decoding)。
- 他们还发现,通过适当的标注,VITS 可以学习到诸如逗号处的呼吸声等细微差别,以及引用文本的不同风格。
- 针对儿童语音,需谨慎安排录音时长:一位成员对录制儿童语音所需的小时数表示不确定,这些语音用于微调轻柔的女声以获得更好的 Baseline。
- 另一位成员建议每个说话人 24 小时录音量过多了,强调数据质量优于数量。
- Avocodo 提升保真度受关注:成员们讨论了将 Avocodo 作为在不显著提升速度的情况下快速增强保真度的手段,指出伪影的减少受限于数据集质量,并分享了一个非官方的 Avocodo-pytorch 实现链接。
- 他们指出,链接中的实现使用了 Hi-Fi GAN,但需要自行训练模型。
- 通用 Vocoder 探索开启:一位成员表示需要一个通用 Vocoder 将 VITS 接入 Speech LLM,要求速度快、GPU 占用低,并且能够从头开始训练。
- 一个建议是 BigVGAN,尽管原帖作者想从头训练;其他人则考虑了轻量级 LLM 架构的影响。
Unsloth AI (Daniel Han) ▷ #help (207 条消息🔥🔥):
Circular Import Error, Merged Model 加载时的 RuntimeError, UV venv 性能, Qwen3 Tool Calling 问题, vLLM 上的 Qwen3-Coder-30B-A3B-Instruct-1M-Q8_0.gguf
- 循环导入引发困扰:一位成员报告了在使用
unsloth.FastLanguageModel.from_pretrained并设置use_async=True时,由于循环导入 (circular import) 导致ImportError: cannot import name 'convert_lora_modules' from partially initialized module 'unsloth_zoo.vllm_utils'。 - 特殊 Token 触发 Runtime Error:一名成员在微调并向 Tokenizer 和模型的 Embedder 添加了 2 个特殊 Token 后,加载合并模型时遇到了与 size mismatch 相关的
RuntimeError。- 另一名成员建议添加新 Token 的问题尚未完全解决,系统可能仍尝试加载基础模型的 Tokenizer;此外,使用
resize_model_vocab = 128258可能会部分解决问题,但对于合并模型并不总是有效,因为它可能会加载基础模型的 Tokenizer。
- 另一名成员建议添加新 Token 的问题尚未完全解决,系统可能仍尝试加载基础模型的 Tokenizer;此外,使用
- UV venv 导致性能下降:一位用户在使用 UV venv 环境下的 Unsloth 时遇到了 20 倍的性能下降,导致在 CUDA Graph Shape Capture 期间初始化极其缓慢。
- 有建议认为 UV 可能会下载所有 xformers 版本导致减速,但一名成员指出他们改用 mamba 以完全避免使用 UV。
- Qwen3 的 Tool Calling 困扰:一位用户报告称,尽管使用了最新版本的 Unsloth 和 Ollama,其 Langchain 应用中的 Qwen3 30B 变体无法像之前的 Qwen3 4B 及更大模型那样可靠地执行 Tool Calling。
- 建议检查
fast_inference=True,但用户确认已启用。随后建议查看与 vLLM 和 UV 相关的 此 vLLM issue。
- 建议检查
- vLLM 难以运行 GGUF 模型:一位用户在尝试于 vLLM 上运行 Qwen3-Coder-30B-A3B-Instruct-1M-Q8_0.gguf 时遇到了
ValueError: GGUF model with architecture qwen3moe is not supported yet。- 成员建议 GGUF 格式应在 llama.cpp 上运行,并指出该模型架构可能尚未支持,建议从源码安装 Transformers 以尝试解决问题。
Unsloth AI (Daniel Han) ▷ #showcase (8 条消息🔥):
Unsloth 动态量化, Qwen3 30B-A3B, Space Invaders 改进, Roleplay AI 微调, Gemini 拒绝响应
- 动态量化获得 Quant Clone:一名成员创建了一个小应用程序,用于以与 Unsloth 动态量化相同的方式对微调模型进行量化。
- 他们希望在自己的微调模型上复制 Unsloth 的动态量化。
- Unsloth 的 Qwen3 Coder 模型构建 Space Invaders:使用 Q4_M unsloth Qwen3 30B-A3B coder 模型和 VS Code 中的 Cline,一名成员创建并改进了一款 Space Invaders 风格的游戏。
- 游戏在约十分钟内完成,未改动一行代码,可在此处体验。
- 使用 Unsloth 进行 Roleplay AI 微调:一名成员宣布了一种使用 Unsloth 进行微调并通过其 roleplay-ai 项目提供更多数据的方法。
- 模型已在 Hugging Face 上发布。
- Gemini 面临高拒绝率:一名成员询问其他人是否在微调模型中遇到了更高水平的拒绝响应,并将其与 Gemini 进行了比较。
- 该成员发现 Gemini 在这方面相当令人讨厌。
Unsloth AI (Daniel Han) ▷ #research (4 条消息):
Gemma 3 1B 表现糟糕, 微调项目, LoRA 的持续训练
- Gemma 3 1B 惨败:一位用户训练了 Gemma 3 1B,发现它完全是垃圾,纯属浪费算力,因此坚持使用性能强劲的 4B 模型。
- 他们没有提到训练数据集或训练方法。
- 微调项目正在进行中:一位用户正寻求合作开展一个使用开源 LLM 的微调项目,并在 GCP 上拥有可用算力。
- 他们热衷于从代码模型到特定领域应用的任何工作。
- 再次探讨 LoRA 持续训练?:一位用户询问了关于持续更新模型权重的最新进展,引用了亚马逊几年前关于 LoRA 持续训练 (continuous training of LoRAs) 的一些研究。
- 另一位用户 suresh.b 确认了此类工作的存在,但未提供更多细节或链接。
Unsloth AI (Daniel Han) ▷ #unsloth-bot (114 条消息🔥🔥):
GRO Trainer 数据集映射, Chat template 截断, GRPOTrainer 配置, Sequence dictionary (seq-dict), Unsloth 形状动态变化
- 排查 GRPO Trainer 中的排列错误:用户在使用 Qwen 2.5 基础模型时,由于
Question和Answer等数据集特征问题,遇到了 GRPO trainer 的排列错误(permutation errors)。- 该错误源于
shuffle_sequence_dict函数,特别是与ref_per_token_logps相关,表明源代码可能存在问题。
- 该错误源于
- 无法配置 Unsloth 的 Output Embeddings:用户难以配置 Unsloth 中
output_embeddings的卸载(offloading)位置,该位置默认存储在{model}/output_embeddings.pt路径下。- 有人提出担忧,如果用户对
{model}路径没有写入权限,这种行为将会产生问题。
- 有人提出担忧,如果用户对
- Gemma 微调的图像格式:用户正在调试在微调 Gemma-3-it-4B 时使用多张图像和系统提示词(system prompts)的正确格式,此前遇到了
ValueError: Invalid input type错误。- 正确的格式涉及为文本和图像内容构建带有
type键的输入数据,支持混合图像(带或不带系统提示词),但要求每个样本的图像数量保持一致。
- 正确的格式涉及为文本和图像内容构建带有
- 利用 AI 生成微调数据:用户正在探索将 0.5 million tokens 的原始文本转换为微调数据的方法,特别是考虑使用具有长上下文或 RAG 的模型。
- 讨论内容包括是否使用带有 RAG 的 Phi-14B 模型来创建训练数据,不过分块(chunking)方案已被排除。
- SFT 训练期间 VRAM 激增:用户好奇为什么在 SFT 训练期间 VRAM 会增加,原本认为内存预分配应该能防止这种情况。
- 有人提到,训练过程应该可以进行内存预分配。
LMArena ▷ #general (968 条消息🔥🔥🔥):
Arena 可见性, 排行榜工具提示, 数据集中的个人信息, Gemini 的重复倾向, Gemini 2.5 Deepthink
- Arena 按钮提升浏览体验:一名成员建议为 Search, Image, Video, 和 Webdev Arena 添加三个主要按钮以提高可见性,并分享了一张 概念图。
- 另一名成员建议添加 webdev arena 按钮,因为它位于独立平台,并建议在排行榜上添加工具提示(tooltips),解释 Rank, CI, 和 Elo 是如何确定的。
- 数据集挖掘暴露危险数据:一位用户对在发布的 prompts 中意外包含 个人信息(电子邮件、密码等)表示担忧,并建议为用户提供在公开前删除 prompts 的方法。
- 一名成员回应称,此类示例应通过私信(DM)发送给他们以便上报,并确认已 与团队分享了这些担忧。
- Gemini 对话出现异常:一位成员询问其他人是否注意到 Gemini 在自我重复,但另一位成员认为其表现一致,并询问 Gemini 2.5 Flash 是否有所改进。
- 一位用户指出视频限制从 10 个降至 8 个,敦促其他人尽快使用视频生成 Arena。
- DeepThink 首次亮相:令人失望?:Gemini 2.5 Deepthink 已向 Ultra 会员开放,成员们在看到 10 RPD 限制后怀疑其是否值得。
- 成员们称其为“骗局”和“白昼抢劫”,有人表示这只是因为 GPT-5 即将发布而赶工出来的版本。
- 关于 GPT-5 的传闻引发高度期待:讨论围绕 GPT-5 的潜在发布展开,一些人期待范式转移(paradigm shift),而另一些人则预期是增量改进,成员们还讨论了各种性能基准测试(benchmark)数据。
- 一名成员表达了这样的观点:我们正迅速告别“最强”模型的时代,因为将任务路由(routing)到一个非常强大的模型可能对某些任务有效,但不会一直使用它。
LMArena ▷ #announcements (1 条消息):
Veo 3, Image-to-Video, Audio 功能
- Veo 3 发布 Image-to-Video 与 Audio 功能:Veo 3 Fast 与 Veo 3 现在在 Video Arena 中具备了带音频的 Image-to-Video 功能。
- 在 Discord 中使用图像创建视频:video-arena 频道新增了
/image-to-video命令:允许用户从图像创建视频。- 鼓励用户对使用新命令创建的最佳视频进行投票。
Cursor Community ▷ #general (580 条消息 🔥🔥🔥):
Background agents, 优化 Cursor 配置, Cursor 卡死问题, YOLO 模式激活, Vibe coding 策略
- Vibe Coding 需要 GitHub:一位成员提到 对于 background agents 你需要 GitHub 吗?这东西太酷了 并附带了图片。
- 另一位成员在 prompt 上花费了 $40,并寻求关于优化其 Cursor 配置的建议。
- Cursor 卡死 Bug 令用户沮丧:一位用户报告称,在聊天超过一小时后,他们的机器每隔 30-60 秒 就会卡死一次。
- 一位 Cursor 团队成员建议将该问题发布在 Cursor 论坛 上,以便获得更好的关注和协助。
- 应对模型支出的复杂局面:用户正在比较 Cursor 和 Claude Pro 的定价,一位用户表示:老实说,哪里有最便宜的方案和最好的模型我就去哪里,即使 Claude 的新方案有每周小时限制,200 美元的方案对我来说目前仍是最好的交易之一。
- 另一位用户表示成本会迅速膨胀,3 个月内花费了 $600。
- Horizon Alpha 体验不及预期:一位用户发现他们对 Horizon-Alpha 的个人体验 有点平庸。
- 相比之下,另一位用户说 Cursor 是我见过的最好的应用。
- Cursor 用户请求推荐计划:成员们在询问 Cursor 是否有推荐计划,因为一位成员提到他目前已经在 Discord 中引导了 至少 200 多人加入,笑死。
- 分享了指向 Cursor Ambassador 计划 的链接。
Cursor Community ▷ #background-agents (1 条消息):
lintaffy: 噢,我的 ba 还在为那个简单命令加载中……
OpenAI ▷ #ai-discussions (410 messages🔥🔥🔥):
Function Calling vs XML, AI Superintelligence Bio-Weapons, Grok4 vs GPT5, Horizon Alpha Performance, Large Context Windows
- **Function Calling APIs:内在价值?:相比于使用结构化的 XML 进行函数调用,Function Calling APIs 被认为具有内在价值**,但一位成员指出,当模型不支持工具调用时,XML 经常被用作一种变通方案。
- 像 Qwen 这样的一些编码模型不支持 Function Calling,因此尽管效率略低,内联工具调用仍能最大化互操作性。
- **Zuckerberg 的 AI Superintelligence:Bio-Weapon 威胁?:Mark Zuckerberg** 的 AI Superintelligence 计划引发了对潜在 Bio-Weapon 制造的担忧,一位成员表示 你不能就这样向公众发布 superintelligence。
- 有人担心 利用虚假用户和精心设计的语言来控制思想 比 Bio-Weapons 甚至更危险。
- **GPT-5 推迟:Grok4 的胜利?:传言称 **GPT-5 推迟是因为无法超越 Grok4,但另一位成员表示 OpenAI 正计划将多个产品整合到 GPT-5 中。
- 一位成员还澄清说,GPT-5 将是一个单一、统一的 Omnimodal 模型。
- **Horizon Alpha 脱颖而出:免费的推理模型?:Horizon Alpha** 在通过 OpenRouter API 运行时似乎优于付费 LLMs,能够提供 自定义编程语言的完美 one-shot 代码,一位用户声称 它比 o3o3 的多轮对话好用 3-4 倍,o3o3 太糟糕了。
- 它在 Orchestrator 模式下的高级 Shell 使用和任务列表创建被证明优于其他模型,尽管有人认为它 可能一直是某种我们没想到的超级奇怪的东西,比如 Codex-2。
- **Context Windows:言过其实还是至关重要?:尽管 **Gemini 拥有 100 万的 Context Window,但遗留代码库问题在 Claude 和 ChatGPT 上得到了更好的解决,这引发了关于 大 Context Windows 是否被高估 的辩论。
- 有人认为 Context Windows 较小但输出质量更好的模型更可取,而另一些人则断言,对于 Agentic applications 来说,更大的 Context Windows 对于 自动记忆和编织久远的细节 至关重要。
OpenAI ▷ #gpt-4-discussions (11 messages🔥):
Agent Mode Confusion, ChatGPT Agents vs Regular GPT, GPT-4o auto reasoning, Missing Chat History
- Agent Mode 引起困惑:用户对 Agent Mode 一词感到困惑,有些人认为这是一个新功能,而它本质上是指现有的高级模式,如 Code Interpreter/Advanced Data Analysis。
- 一些成员将初期的故障归结为基本的成长阵痛,认为它可能会产生混淆、给出错误答案或直接停止工作,但在正常工作时它非常 棒。
- ChatGPT Agents vs 常规 GPT:一位成员指出 ChatGPT 模型并不了解最近的发展,包括像 ChatGPT Agent 这样的新产品。
- 另一位成员报告说使用 Agent Mode 在 GitHub 中工作以解决问题,发现 观察它的行为非常有趣。
- GPT-4o 自动推理:用户注意到 GPT-4o 会自动切换到 Thinking,即使没有被标记为 Deep Research 或 Study mode。
- 在处理技术或编码相关问题时切换到 o3 会导致大量的推理回复,一些用户不喜欢这样,更倾向于简洁的回答。
- Chat History 丢失:一位成员报告说,他们的 Chat History(不在文件夹中)在一周内于网页端和移动端应用上逐渐消失。
- 另一位成员提到 这应该已经被修复了,并且 截至昨天他们已经修复了它。
OpenAI ▷ #prompt-engineering (1 messages):
``
- 无重大讨论:提供的内容中没有值得总结的有意义讨论。
- 无值得注意的见解:提供的屏幕录制不包含任何值得注意的见解或总结主题。
OpenAI ▷ #api-discussions (1 条消息):
``
- 未讨论特定话题:提供的消息中没有讨论相关话题。
- 内容似乎是一个屏幕录制,没有可供摘要的具体细节。
- 摘要数据不足:提供的图像分析缺乏适合生成有意义摘要的文本内容。
- 需要更多信息或消息详情来创建相关的议题摘要。
LM Studio ▷ #general (325 条消息🔥🔥):
LM Studio 中的图生视频提示词生成, LM Studio 缺乏路线图, LM Studio 插件系统, 从网络上的其他计算机连接到 LM Studio API, LM Studio 对 Qwen3 Coder 模型的支持
- LM Studio 什么时候支持图生视频?:成员们想知道 LM Studio 未来是否会支持图生视频提示词生成和图像附件功能,并表示相比依赖 ChatGPT,更倾向于离线解决方案。
- 一位成员建议将 ComfyUI 作为替代方案,但指出它在 AMD 显卡上的表现不如预期。
- 路线图未知,所以没人知道:成员们讨论了 LM Studio 缺乏公开路线图的问题,有人调侃路线图就像一个装满随机纸条的大桶。
- 另一位成员确认没有人知道计划是什么,并表示“没有公开路线图,所以没人知道”。
- 在网络上保护 LM Studio:成员们讨论了从网络上的其他计算机连接到 LM Studio API 的问题,并对安全性表示担忧。
- 有人建议 LM Studio 的安全性尚未得到证实,在不了解风险并确保自身网络安全的情况下,不应将其暴露。
- Qwen 快速入门:加载模型!:成员们讨论了加载 Qwen3 Coder 30B 模型时遇到的问题,一位用户遇到了 Cannot read properties of null (reading ‘1’) 错误。
- 一位成员指出用户应将应用版本更新到 0.3.21 b2(据称已修复该问题),并提到点击推荐设置 (recommended settings)。
- 投机采样:Fabguy 说不值得:一位成员询问在 Qwen3 MoE 模型中使用投机采样 (speculative decoding) 的问题,这会导致崩溃错误。
- 另一位成员指出,“草稿模型和主模型可能会为[投机采样]任务选择非常不同的专家。不值得。”
LM Studio ▷ #hardware-discussion (69 条消息🔥🔥):
Nvidia 驱动 580.88, 二手服务器, 部分 KV Cache 卸载, Mac mini M4 vs RTX 3070, 下一代 GPU
- Nvidia 驱动版本的跳跃:Nvidia 在 577.00 发布后不久就发布了驱动 580.88,这是一个发布仅 9 天的驱动,可能修复了启用 NVIDIA Smooth Motion [5370796] 后 GPU 显存速度的问题。
- 该用户从 CUDA toolkit 运行驱动,不使用花哨的控制面板或 GFE (GeForce Experience)。
- 思考部分 KV Cache 卸载:有人提出了一个问题:是否可以在 LM Studio 中进行部分 KV Cache 卸载,例如对于一个 40GB 的模型,KV Cache 需要 20GB,而 GPU 总共有 48GB。
- 用户想知道是否可以进行拆分,将 20GB 缓存中的 8GB 放在 GPU 中,其余部分卸载 (offload)。
- Mac mini M4 与 RTX 3070 的对比:一位用户想知道拥有 10 核、32GB 内存的 Mac mini M4 是否会优于 RTX 3070。
- 有人表示,如果模型能装入 VRAM,CUDA 通常比 Apple Silicon 更快。
- 关于内存建议的闲聊:一位用户建议攒钱买二手的 3090,他们声称这是 AI 使用场景中性价比最高的显卡。
- 它们的价格约为 700 欧元,对于 LLM 来说可能是最佳解决方案,但由于可能被用于挖矿,可能存在问题。
- 5070 TiS 即将发布!:一位用户推测 5070TiS 将很快发布,配备 24GB 显存,而 5070ti 和 5080 只有 16GB 显存。
- 另一位用户指出,对于廉价推理,目前 5060Ti 16GB 是最佳选择,单价 450 欧元,你可以在一块主板上插 3 到 4 张。
OpenRouter (Alex Atallah) ▷ #app-showcase (11 条消息🔥):
PyrenzAI 发布, Personality.gg, OpenRouter PKCE, PyrenzAI 反馈
- Personality.gg 通过 OpenRouter 实现角色扮演:Personality.gg 推出了一个角色扮演网站,大部分模型使用 OpenRouter,通过 OpenRouter PKCE (Proof Key for Code Exchange) 提供对所有 400 个模型的访问,完全免费或价格低廉。
- PyrenzAI 发布免费 AI 聊天网站:一位开发者宣布发布 PyrenzAI,这是一个具有整洁 UI、模型、记忆系统以及为所有层级提供 免费 RAG (Retrieval-Augmented Generation) 的 AI 聊天网站,使用 OpenRouter 作为主要的 AI 生成后端。
- PyrenzAI 应用面临速度和安全性批评:一位用户批评了新发布的 PyrenzAI 应用,指出它在速度和安全性方面都很糟糕 (cooked),表现为性能滞后 (laggy) 以及过度获取用户偏好(每次加载超过 200 次以上)。
- PyrenzAI 发布后 UI 和 UX 受到赞赏:一位成员称赞了 PyrenzAI 的 UI/UX,欣赏其独特的外观和风格,以及与其他应用相比独特的侧边栏设计。
OpenRouter (Alex Atallah) ▷ #general (242 条消息🔥🔥):
API 错误, Deepseek r1, 免费模型, Horizon Alpha, API Key 额度限制
- API 错误困扰 OpenRouter 用户:一些用户报告在尝试通过 OpenRouter API 使用模型时遇到 API 错误,包括 未找到端点 (no endpoint found) 错误和其他问题。
- 一位成员建议检查 模型 ID 前缀 和 基础 URL 是否存在配置错误。
- Deepseek v3 停机影响用户:用户报告了 Deepseek v3 0324 free 模型的问题,包括 内部错误、空响应 和 超时。
- 一位成员指出,切换到该模型的付费版本解决了问题,暗示免费版本已过载:免费版完全过载。付费版没有这些问题,且实际内容质量更好。
- 免费模型限制令 OpenRouter 用户沮丧:几位用户询问是否有消息限制更高的 免费模型,其中一位用户询问是否有任何免费模型 不会在 50 条消息时停止?
- 成员们澄清说,充值 $10 即可获得 1000 次请求/天 的限制,并引用了详细说明限制的 OpenRouter 文档。
- Horizon Alpha 赞誉度上升:用户讨论了 Horizon Alpha 模型,一些人报告其推理有效且性能良好。
- 该模型本身报告称其由 OpenAI 开发,但其他成员澄清说它可能是一个蒸馏 (distilled) 模型。
- 预算超支令 API 用户困惑:一位用户报告被收取的费用大幅超过了他们的 API Key 额度限制,怀疑使用 Python 线程 并行运行 API 调用 可能是原因。
- 其他用户分享了类似经历,暗示额度限制更新可能不是实时的,导致偶尔出现超支。
OpenRouter (Alex Atallah) ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter (Alex Atallah) ▷ #discussion (23 messages🔥):
Groq OpenBench, Provider Benchmarks, GPQA Evals, Inspect.ai, Prompt Caching for Kimi K2 and GLM 4.5
- 用于 Provider Benchmarks 的 **OpenBench Groqs:成员们讨论了 Groq OpenBench 仓库,以及它在 **provider benchmarks 方面被提及的次数。
- 一位成员提到他们已经在进行评估工作(最近被列为优先事项),例如针对每个 provider 的 GPQA,并正在扩展到其他领域。
- Inspect.ai 的发现受到赞赏:一位成员表示很高兴通过 OpenBench 链接发现了 inspect.ai,并指出这正是其一直在寻找的工具。
- 该用户还对聊天 UI 使用其账户全名且无法控制表示担忧,这可能导致个人信息泄露(doxxing)。
- Kimi K2 和 GLM 4.5 的 **Prompt Caching 问题:一位用户询问 **OpenRouter 是否支持 Kimi K2 和 GLM 4.5 的 prompt caching,并指出 Moonshot 平台已直接支持。
- 他们表示在 z.ai 上看起来似乎支持。
- 突破 20MB 限制:更大的 PDF 现在可以发送了:成员们询问新功能是否会绕过 20MB 限制,并提到他们最近增加了一种发送更大 PDF 的方式。
- 新的限制取决于 upstream provider limit(上游供应商限制)。
Moonshot AI (Kimi K-2) ▷ #announcements (2 messages):
Kimi K2 Turbo, Moonshot AI Forum
- Kimi K2 开启极速模式!:Moonshot 团队发布了 Kimi K2 Turbo,这是 Kimi K2 模型的更快版本,速度提升了 4 倍,从 10 tokens/sec 提高到 40 tokens/sec。
- 在 9 月 1 日之前,用户可享受输入和输出 token 的 50% 折扣 (platform.moonshot.ai)。
- Moonshot AI 发布官方论坛:Moonshot AI 团队宣布启动 Moonshot AI Forum (https://forum.moonshot.ai/),作为技术讨论、API 帮助、模型特性、调试和开发者技巧的新中心。
- Discord 仍然适合梗图、闲聊和调戏 Kimi Bot,但如果你想认真搞开发和技术?论坛才是真正的新阵地 🔥
Moonshot AI (Kimi K-2) ▷ #general-chat (126 messages🔥🔥):
Kimi vs Claude, Kimi K2 Turbo pricing and speed, Using Kimi K2 Turbo in Claude code, Chinese companies video generation, Kimi K2's prompt format similar to ChatGPT
- Kimi K2 挑战 Claude 的地位:经过测试,一位用户发现 Kimi K2 是第一个让他们觉得可以替代 Claude 的模型,并完全放弃了 Gemini 2.5 Pro。
- 他们补充说,编程作为一种信息正在变得更加自由,且发展速度超出预期。最终,大多数 AI 在知识储备上都会趋同,它们之间的差异将开始消失。
- Kimi K2 Turbo 提速 4 倍:Kimi K2 Turbo 是相同的模型但拥有更快的托管服务,现已开启特别促销(截止 9 月 1 日):$0.30/1M 输入 tokens (cached),$1.20/1M 输入 tokens (non-cached),以及 $5.00/1M 输出 tokens。
- 这一定价意味着在折扣期间,以 2 倍的价格获得 4 倍的速度,旨在满足有速度要求的用户,其官方 API 有助于保持稳定。
- Kimi K2 Turbo 环境变量设置:要在 Claude 代码中使用
kimi-k2-turbo-preview,请设置以下环境变量配置:export ANTHROPIC_SMALL_FAST_MODEL=kimi-k2-turbo-preview和export ANTHROPIC_MODEL=kimi-k2-turbo-preview。 - Kimi K2 的 Prompt 设计模仿 ChatGPT:用户注意到 Kimi 的 prompt 格式与 ChatGPT 非常相似。一位用户取消了 Gemini($250/月)、OpenAI ChatGPT Pro($200/月)和 Grok 4 Heavy($3000/年)的订阅。
- 一位成员开玩笑说,要从其他聊天机器人获得类似结果,只需添加一个 system prompt,让它表现得像个失控的 Discord 变态管理员,并告诉它“去尽情表达自我吧”哈哈。
- Google Gemini 的每日 Deep Think 限制:成员们嘲讽了 Google Gemini Ultra 的方案——每月 $250 却限制每天 10 次查询,一位成员称其非常滑稽且卑劣。
- 另一位补充说,即使是 $200/月的 ChatGPT Pro 也提供无限量的 Office 365 Pro,而 Claude Max 则更为合理。
Nous Research AI ▷ #general (110 条消息🔥🔥):
Hermes-3 dataset, Unitree R1 robot, OpenAI's Horizon Alpha model, Quantization challenges, SmolLM and Qwen2.5
- Hermes-3 数据集中的拒绝回答干扰量化:成员们讨论了 Hermes-3 dataset 中的拒绝回答(refusals)是故意的还是受审查模型的产物,其中一名成员在使用它计算量化的 imatrix 时发现了意外的拒绝回答,从而引发了对数据集的进一步调查。
- 主要意图是确认数据集中不存在拒绝回答。
- Unitree 的 R1 机器人推动具身智能(Embodied A.I.)普及:社区讨论了售价 $5,900 的 Unitree R1 基础机器人模型,它为 A.I. 开发提供全开放的软件开发工具包(Python、C++ 或 ROS),如此 YouTube 视频所示。
- 对于向下一代 A.I. 演进的研究团队来说,这是一个理想的工具。
- Horizon Alpha 模型引发 OpenAI 基座模型发布传闻:成员们讨论了 OpenAI 的 Horizon Alpha 模型,推测其风格与 OpenAI 相似,可能是一个具有低激活特性的 120B MoE 模型,或者如这条推文所建议的,是一个 20B 模型。
- Reddit 上也有推测,这个帖子暗示如果它仅支持 FP4,则无法进行适当的量化。
- OpenAI 泄露模型的量化难题:社区分析了泄露的配置文件,显示 OpenAI 的模型 是一个 116.8B/5.7B MoE 模型。当为 GGUF 进行填充(padded)时,其参数量增加到 132.7B/6.3B,由于架构的隐藏层维度(hidden size)限制,除了 Q4_0、Q5_0、Q8_0 和 IQ4_NL 之外,很难使用其他方法进行量化。
- 因为 2880 的隐藏层维度不允许量化为 K 或 I quants。
- SmolLM 和 Qwen2.5 的量化陷阱:讨论显示 SmolLM (135B/360B) 和 Qwen2.5 0.5B 的维度无法转换为 K 或 I quants。
- 成员们报告称,对于传闻中的 GPT 模型,只有 o_proj(来自 attention)可以量化为 K 或 I quants。
Nous Research AI ▷ #ask-about-llms (4 条消息):
Input Tokens per Second, Prefill, Gemma, Time to First Token
- 探究输入 Token 处理:一位用户询问了有关推算每秒输入 Token 数的资源。
- 另一位成员澄清这指的是 prefill(仅指你使用的上下文,而非生成的)。
- 在笔记本电脑上对 Gemma 进行性能分析:一位用户报告称,在使用笔记本电脑运行 Gemma 时,4500 和 9000 Token 的提示词其首个 Token 响应时间(Time To First Token)约为 50 秒。
- 该用户正在寻求该过程的全面概述以进行性能分析(profiling),并指出在不同的输入 Token 大小下,每秒输出 Token 数是相同的。
Nous Research AI ▷ #research-papers (3 条消息):
OSS Model Training Script, Metaprogramming and DAG->HRM->code automation
- 开源模型训练脚本:Raizoken 正在构建!:一位公共研究工程师正在编写一个模型训练脚本,并打算立即将其开源(OSS)。
- 他们正试图为自然光标导航创建高质量的开源模型,但担心模型可能被滥用,例如爬取那些阻止爬虫机器人的网站。
- Raizoken 寻求元编程自动化建议:一位成员正在寻求关于元编程(metaprogramming)和 DAG->HRM->代码自动化的建议,并提到他们已经在技术栈中使用了这些技术,但正面临扩展瓶颈。
- 他们已经实施了 Terraform 和 Helm 来抵消这一影响,但在 Ray 节点形成集群时,正努力应对其中的克隆从属节点(cloned slaves)问题,因为缺乏在冷却时间之外控制自我衍生(self-spawn)的机制。
Nous Research AI ▷ #interesting-links (5 条消息):
AnythingLLM, Neuronpedia, Data Sovereignty
- AnythingLLM 预示 Data Sovereignty 未来:一位用户分享了关于 AnythingLLM 的推文链接,并称其为 Data Sovereignty 的未来。
- Neuronpedia 和 Data Sovereignty 受到关注:该用户还分享了 Neuronpedia 的链接以及其他关于 Data Sovereignty 的推文,分别来自 Jack_W_Lindsey 的推文 和 heyshrutimishra 的推文。
Nous Research AI ▷ #research-papers (3 条消息):
OSS model training script, Metaprogramming and DAG->HRM->code automation, Federated cycles between clones in ray nodes
- OSS 模型训练脚本出现:一位公共研究工程师正在开发 OSS model training script,以解决缺乏用于自然光标导航的优质 OSS 模型的问题。
- 该工程师指出,屏蔽爬虫机器人的网站可能会被使用该技术的新“克隆体”抓取。
- Metaprogramming 自动化瓶颈显现:尽管使用了 Terraform 和 Helm,一位成员仍在寻求关于 Metaprogramming 和 DAG->HRM->code automation 扩展问题的建议。
- 他们正面临 Ray 节点中克隆体之间的联邦循环问题,特别是在冷却期之外不受控制的自我产生问题。
Latent Space ▷ #ai-general-chat (112 条消息🔥🔥):
Cline's $32M seed funding, CLI orchestration layer, Subagents and Claude Code Office Hours, Bytedance's Seed Diffusion LLM for Code, Open-License Hybrid Reasoning Models
- Cline 完成 3200 万美元融资:AI 编程 Agent Cline 宣布完成由 Emergence Capital 和 Pace Capital 领投的 3200 万美元 种子轮和 A 轮融资,旨在支持为开发者提供透明的开源 AI 工具;目前服务于 270 万 开发者,并提供无加价的透明定价。
- Cline 旨在通过避免“阉割版”产品来赋能开发者,专注于访问控制和集中计费等企业级功能。
- OpenAI 的 OS 模型泄露:关于 OpenAI 即将推出的 OS 模型 YOFO 的细节在其配置短暂公开后泄露,引发了对传闻中 120B 和 20B 变体的兴奋。
- 一位成员指出 Jimmy Apples 不愿分享所有的配置细节。
- Anthropic 的生产级强化学习代码库由 Claude 更新:Anthropic 合并了一个对其生产级强化学习代码库的 22,000 行 变更,这些代码主要由 Claude 编写,引发了用户对如此大规模 AI 生成代码变更的真实性和安全性的怀疑与讨论;该变更大部分是一个 JSON DSL。
- Sauers 确认该变更是真实的,讨论涉及了人工审查流程以及对大规模 AI 驱动代码合并可靠性的担忧。
- Anthropic 切断 OpenAI 的 API 访问权限:Anthropic 以违反服务条款为由,撤销了 OpenAI 对其模型(包括 Claude)的 API 访问权限。
- 一位成员指出 OpenAI 对此表示失望,并提到其 API 仍对 Anthropic 开放,社区讨论了竞争举措的影响以及模型训练界限模糊的问题。
Latent Space ▷ #ai-announcements (4 条消息):
Cline pod writeup, Latent Space Podcast, Open Source Code Agent
- Cline 播客文章发布!:Cline podcast 的文章现已发布,链接见 X。
- Latent.Space 播客特邀 Cline!:Latent.Space Podcast 宣布了关于 Cline 的新一期节目,Cline 是一个最近融资 3200 万美元 的开源 VSCode 扩展。
Yannick Kilcher ▷ #general (86 条消息🔥🔥):
RAG query expansion techniques, Sentence embeddings vs. token embeddings, Cross-encoders for semantic similarity, Knowledge Graphs for information retrieval, LLMs and question-answer co-occurrence
- 查询扩展提升 RAG 性能:成员们讨论了用于 RAG 系统的 query expansion(查询扩展),建议从单个查询中生成多个问题。
- 具体而言,针对 “客户的名字是什么”,建议创建 “名字是什么?” 和 “谁是客户?” 等问题以改进检索效果。
- Cross-Encoders 在排序任务中失败:使用 MS MARCO 数据通过 Cross-encoder 对“客户的名字是什么?”这一问题的结果进行排序的实验显示效果不佳。
- 预期的首选结果(客户姓名)的排名低于(客户的定义),得分分别为 -0.67 和 -1.67。
- 微调检索任务是关键:根据 这篇论文,为了控制排序质量,直接在检索任务上进行训练至关重要。
- 有人提出,最佳相似度指标取决于具体任务,这意味着通用型 Embeddings 可能无法满足特定的检索场景。
- Gemini 2.5 Flash 偏好 Gemma 模型:成员们发现 Gemini-2.5-flash 始终将 Gemma 模型 的排名排在其他模型之上,甚至超过了一些 70B 模型。
- 据推测,Gemma 模型的 回复语气(response tone) 可能对人类和 LLMs 来说都更具说服力,从而影响了排名。
- 关于 LLMs 并行思考的辩论:围绕 Google 的 Gemini 2.5 及其 “Deep Think” 功能展开讨论,该功能利用并行思考来提供更详细、更周全的回复。
- 一些人认为该模型通过并行 COT(思维链)并行生成多个想法,而另一些人则认为这是对基础模型和上下文管理的更高级别编排。
Yannick Kilcher ▷ #paper-discussion (3 条消息):
The Cinema AI, Generating Movie Scenes
- 使用 TheCinema AI 生成连贯的电影场景:根据 arXiv 论文,该频道将评测 TheCinema AI,这是一个专注于生成彼此保持 连贯性(cohesion) 的电影场景的有趣研究项目。
- TheCinema AI:生成电影场景:这项研究探索了生成连贯电影场景的方法,详情见 TheCinema AI 项目官网 及其对应的 arXiv 论文。
Yannick Kilcher ▷ #ml-news (4 条消息):
NVIDIA Chips, Nintendo Switch
- 专家揭露 NVIDIA 芯片功能:据称美国 AI 领域的专家透露,NVIDIA 的计算芯片 具备 追踪与地理定位 以及 远程关机 技术。
- 一名成员要求提供 引用来源,因为该消息源自 中国国家互联网信息办公室,并称其为 荒谬且无力的杠杆尝试。
- 政府限制就像 Nintendo Switch:一名成员表示,政府实施的限制就像 Nintendo Switch 一样。
Notebook LM ▷ #use-cases (27 条消息🔥):
幻灯片切换中的音频暂停时机,讲解视频的葡萄牙语支持,用于个性化播客的 NotebookLM,来自 Perplexity Deep Research 的 Canvas 信息图
- 延迟幻灯片切换以获得更平滑的音频:用户建议在每次幻灯片切换前增加额外的半秒暂停,以避免讲解视频中音频突然中断。
- 这一微小的调整可以通过让音频自然淡出,显著提升观看体验。
- 葡萄牙语讲解视频:提供非官方支持:一位用户确认,虽然葡萄牙语尚未正式支持讲解视频,但他们能够强制使其运行。
- 另一位用户报告了混合结果,音频是葡萄牙语,但幻灯片有时仍为英语;还有用户建议调整 Prompt 以同时指定音频和视频轨道。
- NotebookLM + Gemini:播客神器?:一位用户分享了一个工作流:先向 Gemini 提问,然后将答案输入 NotebookLM 以创建个性化播客。
- 他们发布了链接来演示该过程:NotebookLM 和 Gemini Share。
- 通过 NotebookLM 处理来自 Perplexity 的 Canvas 信息图?:一位用户分享了直接从 Perplexity Deep Research 报告创建 Canvas 信息图的过程。
- 虽然与 NotebookLM 没有直接关系,但他们建议将其作为一个潜在步骤,以利用 NotebookLM 的能力处理来自其他模型的详细输出,并补充说 Google 可以且应该做得比目前的视频概览更好,并指出了当前的 AI 输出问题。
Notebook LM ▷ #general (65 条消息🔥🔥):
离线访问 NotebookLM studio 材料,视频概览推送问题,用于自定义 RAG 流水的 NotebookLM 和 Gemini API,用于 NotebookLM 的 Comet 浏览器扩展,音频概览的语言和时长限制
- NotebookLM 为差旅人士提供离线功能:用户正在寻求保存 NotebookLM studio 材料的方法,以便在没有持续互联网连接的旅行期间进行离线访问。
- 一位用户提到将音频下载到 iPad 并将其添加到带有家庭照片的 PowerPoint 幻灯片中。
- 视频概览的烦恼:Pro 用户思考为何缺失预览特权:几位 Pro 账户用户报告称无法使用视频概览(video overview)功能,尽管他们已经升级,而其他免费账户用户却可以使用。
- 一位曾短暂获得视频访问权限的用户在刷新页面后失去了该权限,这表明推送过程仍存在问题。
- RAG 梦想:用户计划利用 Gemini 算力定制 NotebookLM:一位用户正考虑使用 Gemini embedding 001 和 Gemini 2.5 models API 为文档创建一个自定义的多跳、多步推理 RAG pipeline。
- 他们的目标是超越 NotebookLM 的能力,理由是其存在 300 个文件限制、工作流缺乏透明度以及系统指令受限等局限性,并希望能够借鉴其成果。
- Comet 扩展可能让 NBLM 飞跃:用户讨论了 Comet,这是一个可以访问标签页/历史记录/书签并控制浏览器的浏览器扩展,以及它与 NotebookLM 集成以寻找来源的潜力。
- 有建议提出 Comet 可能会编写一个扩展,动态地向 NotebookLM 添加来源。
- 西班牙语音频概览依然短小精悍?:一位用户询问为什么西班牙语的 Audio Overviews 时长仍然很短。
- 有人建议了一个变通方法:将其切换为英语,更改时长,然后提示它用西班牙语生成。
Eleuther ▷ #announcements (1 条消息):
Attention probes, Linear probes, Overfitting, Optimization issues
- Attention Probes:一种分类隐藏状态的新方法:EleutherAI 进行了 attention probes 实验,这是一种带有注意力机制的小型神经网络,经过训练用于对 Transformer 的隐藏状态(hidden states)进行分类。
- 尽管寄予厚望,但其表现参差不齐,有时由于 overfitting(过拟合)和 optimization issues(优化问题)而逊色于标准的 linear probes,详见其 博客文章。
- Attention Probe 代码已开源:EleutherAI 已经开源了其 attention probes 实验的代码,邀请他人探索和改进该方法。
- 该仓库已发布在 GitHub 上,希望进一步的研究能发现潜在的改进空间。
Eleuther ▷ #general (11 messages🔥):
低功耗边缘设备上的 LLM 离岸部署,Gemini-2.5-flash 对 Gemma 响应的偏见排名,OpenAI 开源模型配置,MLA vs MHA 泛化性
- 低功耗 LLM 挑战离岸部署:一位成员正在离岸的低功耗边缘设备上运行 LLM,重点关注海底测绘、环境监测和自主系统。
- 目前的使用案例涉及任务规划、异常检测和智能数据压缩,由于延迟和带宽挑战,尚未用于科学建模。
- Gemini-2.5-flash 对 Gemma 模型表现出偏好:一位使用 Gemini-2.5-flash 对各种 LLM 响应进行排名的成员注意到,Gemma 的响应始终获得有偏见的高排名。
- 该成员推测这可能是由于“家族偏见(family bias)”,或者仅仅是因为 Gemma3 模型确实更优越。
- OpenAI 即将发布的开源模型配置泄露!:一位成员分享了即将发布的 OpenAI 开源模型的 config,规格包括 36 个隐藏层、128 个专家 (experts) 和 201088 的词表大小。
- 其他成员向那些作品被 OpenAI 采纳进该模型的开发者表示祝贺。
- MLA 在泛化性辩论中战胜 MHA:一位成员询问在教科书质量的数据上预训练一个使用 RoPE 的 3 亿参数模型时,MLA 还是 MHA 的泛化性更好。
- 另一位成员建议使用 MLA (Multi-level Attention) 作为首选架构。
Eleuther ▷ #research (41 messages🔥):
RoPE 接近最优,Weight tying 很糟糕,语义搜索与 RAG
- **NovelAI 揭晓 RoPE 研究:NovelAI 的研究已发表在 这里,实验将 **RoPE 中的黄金比例作为优化目标。
- 结论是:一些数学和实验仅对理论家有吸引力,没有实际应用价值。
- **RoPE 的最优性与通用形式:这篇 博客文章 认为,如果尝试推导 **RoPE,会发现它已接近最优。
- N 维的通用形式需要沿不相干且均匀的方向投影位置,尽管这没有太大的实际意义。
- **Weight Tying 被抨击为糟糕的实践*:一位成员表示 *Weight tying 是一种普遍糟糕的实践,并且是一种可怕的归纳偏置(inductive bias)!。
- 他们认为 Weight tying 是导致许多低效和不稳定的原因,而且在数学上甚至都说不通。
- 语义搜索的困扰与 RAG 替代方案:一位成员在语义搜索方面遇到困难,并提出了关于责任限额(liability cap)的问题。
- 另一位成员建议使用类似 RAG 的方法而不是语义搜索,并表示需要投入大量的领域特定工程化(domain specific engineering)才能使语义搜索正常工作。
Eleuther ▷ #scaling-laws (1 messages):
EleutherAI 网站 PR,Tensor Program 论文,Yang 等人的论文
- EleutherAI 网站焕然一新:一位成员感谢了另一位成员的文章,并提交了一个 PR 以修复 EleutherAI 网站的一些问题。
- 该成员请求仔细审查,提到他们尚未阅读 Tensor Program 论文,可能会有错误,特别是在公式 15-18 附近的数学附录部分。
- 寻求 Tensor Program 公式的澄清:提交 PR 的成员正在寻求关于在 Yang 等人的论文中定位特定公式 (15/17) 的指导,表明需要对 Tensor Program 的数学基础进行澄清。
- 这表明大家正在共同努力,以确保网站中关于 Tensor Program 内容的准确性和有效性。
Eleuther ▷ #interpretability-general (5 条消息):
HF transformers 更新,Llama & Qwen 残差流,Attention Probes 工作,NIAH 数据集
- HF Transformers 的 Llama 层发布残差流:在 HuggingFace transformers 4.54 中,Llama & Qwen 层现在直接返回残差流(不再是 tuple),这可能会影响
nnsight layer.output[0]的用户。- 一位成员警告说,使用
nnsight layer.output[0]将只能获取第 1 个 batch 元素,而不是完整的残差流,这个 bug 是通过 nnterp tests 发现的。
- 一位成员警告说,使用
- Attention Probes 取得可喜的探测进展:成员们讨论了前景看好的 attention probes,但对其参差不齐的结果感到惊讶,这些结果基于 attention probes work。
- 一位成员建议使用后缀进行探测,以考虑你试图探测的内容,要求 LM 思考你试图探测的目标(例如:上述陈述是否正确?)。
- NIAH 数据集的 Last-Token 优势:成员们表示,attention probes 表现不佳主要源于 NIAH 数据集,这些数据集的构建方式使得被分类的对象正好出现在序列末尾。
- 这解释了为什么 last-token probing 在那里表现良好;在这种情况下,应该同时训练 linear probe 和 attention probe。
- McKenzie Probing 论文推动 Prompting 进展:探测论文 McKenzie et al. 2025 将提示模型给出答案作为基准(结果低于 probes),但没有通过 prompting 来改进 probing。
- 在 mean probes 优于 last-token probes 的数据集上,这可能是一种改进,值得进一步研究。
Eleuther ▷ #lm-thunderdome (1 条消息):
``
- 用户找到潜在解决方案:一位用户表示他们可能已经找到了解决问题的方法,如果行不通会再发消息。
- 等待用户反馈:对话目前正在等待用户关于其解决方案是否成功的进一步更新。
Eleuther ▷ #gpt-neox-dev (14 条消息🔥):
MIT 合作进行 LLM 训练,容器化问题,CUDA 问题,DeepSpeed checkpoint 检查
- MIT 合作进行 OLMo2 和 DCLM 训练:MIT 和 EAI 正在合作进行 LLM 训练,从 OLMo2 1B 或 DCLM 1B 开始以熟悉 pipeline,最初专注于预训练,但计划稍后加入 SFT 和安全对齐。
- 容器安装面临棘手的权限错误:一位用户在使用 Apptainer 进行容器化安装时遇到了权限错误,特别是与
setgroups失败有关,建议尝试apptainer exec --fakeroot your_image.sif ...作为潜在的变通方案。- 另一位成员根据他们在基于 Slurm 的 HPC 集群上的经验建议,如果容器问题持续存在,可以直接在宿主机上使用 conda 环境。
- Conda 环境中的 CUDA 配置挑战:切换到 conda 环境后,用户遇到了 CUDA 问题,他们认为这些问题已解决,目前正在尝试安装 flash-attention 和 TE。
- 用户询问了在安装 flash-attention 和 TE 后验证环境设置的具体测试命令。
- DeepSpeed Checkpoint 检查困难:一位用户报告称,来自 experimental 分支的
inspect_ds_checkpoint不支持pipe_parallel_size=0,由于 checkpoint 目录中缺少layer_*文件,导致验证检查失败。- 他们还询问,在
pipe_parallel_size=0、model_parallel_size=1和 zero stage 1 的情况下,从 (4 nodes x 8 GPUs) 扩展到 (8 nodes x 8 GPUs) 是否在根本上是不可能的。
- 他们还询问,在
aider (Paul Gauthier) ▷ #general (61 条消息🔥🔥):
Aider 评价、SGLang 与 Qwen 速度、4090 主板与机箱、Aider 与其他工具对比、Claude Code 上下文限制
- **Aider 依然占据统治地位: 一位成员表达了对 **Aider 的赞赏,指出与其他工具相比,它在控制力和自由度之间达到了完美的平衡。据估计,使用 DeepSeek 仅花费 2 美元,就在一天内完成了原本需要 一周的编程工作。
- 另一位用户对此表示赞同,说道:“Aider 简直太强了”。
- **SGLang 和 Qwen 达到惊人速度: 一位成员报告称,在 **RTX 4090 上使用 sglang 和 Qwen 0.6B Q8 运行 LM Studio 达到了 472 tokens/s,而在常规的 LM Studio 上仅为 330 t/s。
- 另一位用户表示有兴趣复现这种纯本地工作流,并指出 vLLM 在其 4090 上的性能相对 Ollama 较慢,因此非常有兴趣尝试 llama.cpp。
- 多 GPU 配置主板探讨: 讨论转向了硬件配置,一位成员推荐将这款 MSI 主板 用于双 3090 方案,并安装在 Fractal North XL 机箱中。
- 其他人也分享了自己的配置,包括配备 3 个 L4 和 T40 的服务器,以及 Meshify2 等不同的机箱。
- Aider vs Windsurf vs Cursor: 一位用户对 Aider、OpenHands 和 Chode-Pilot 表示失望,更倾向于 Windsurf 和 Cursor。
- 他们推测核心竞争力(”sauce”)可能在于运行在强大硬件上的巨型闭源模型,并表示在 Devstral 和 CodeLlama 的体验不佳后,需要尝试 Qwen3。
- **Claude Code 的上下文窗口注意事项: 成员们讨论了 **Claude Code 的性能,有人提到它在没有 RAG 的情况下表现良好,并指出 Claude 与其他前沿模型不同,在高上下文 token 计数下性能下降严重。
- 有人指出,当超过 64k tokens 后,质量会明显下降,这一问题在 o3 中不太明显,而 Gemini 2.5 Pro 处理得最好。其他人指出,仅系统提示词(system prompt)就占用了很大一部分上下文窗口。
aider (Paul Gauthier) ▷ #questions-and-tips (10 条消息🔥):
Qwen3 30B A3B Coder 基准测试、LM Studio 使用、llama.cpp server + docker aider 基准测试、aider + claude-code max 订阅集成、Gemini 2.5 Pro
- 在 LM Studio 中本地测试 Qwen3 30B: 一位成员希望以简便的方式,使用 LM Studio 在本地对 Qwen3 30B A3B Coder 的 8 个不同量化版本进行基准测试。
- 另一位成员建议在同一台电脑上使用 llama.cpp server + docker aider benchmark,并参考了一篇涉及 Gemini 2.5 Pro 的文章,其中详细介绍了使其运行的步骤。
- Aider 集成 Claude-Code Max 订阅: 一位成员询问 aider 是否可以与 claude-code max 订阅集成配合使用,以接入新的 Thinking 模型。
- 他们还询问命令
aider --model gemini/gemini-2.5-pro-preview-06-05 --thinking-tokens 32k是否是旧的 Thinking 模式使用方式,以及是否有人成功在 Claude Code 中运行 Aider。
- 他们还询问命令
MCP (Glama) ▷ #general (43 messages🔥):
Security MCP Check Tool, PayMCP Payment Layer, PageRank for MCP Servers, MCP Eval Platforms, Gateway for Agent Tool Search
- Security MCP Check Tool 发布:一名成员分享了一个 security MCP check tool 的 GitHub 仓库,并寻求反馈。
- 这可能提供一种检查自家服务器漏洞的方法,但目前尚未给出进一步的解释。
- PayMCP 支付层出现:一名成员宣布正在开发 PayMCP,这是一个针对 MCP 的支付层,并正在寻找合作者和早期用户,目前提供了 Python 和 TypeScript 的实现。
- 这个新工具承诺让 MCP Server 能够轻松接受付款,尽管目前尚不清楚它支持哪些支付选项。
- 针对 MCP Server 的 PageRank:一种新的搜索工具:一名成员询问是否存在针对 MCP Server 或工具的 PageRank 实现,旨在根据实用性而非仅仅是名称或描述对 Server 进行排名。
- 另一名成员分享了一个 MCP 工具集合仓库,并提到 MCP registry 也是潜在的有帮助的资源。
- 寻求 MCP Eval 平台:一名成员正在寻找关于 MCP eval 平台 的信息,该平台可以在各种情况下生成不同的 Agent 来测试 MCP Server。
- 另一名成员表示他们正在为 Agent 开发一个搜索工具的网关,并计划在周日发布可用版本。
- 掌握 MCP 的指导:一名成员请求协助理解并在其工作流中使用 MCP,并愿意付费咨询。
- 这凸显了新用户在采用 MCP 时面临的复杂性和学习曲线。
MCP (Glama) ▷ #showcase (1 messages):
JSON MCP Server, LLM Efficiency with JSON, Schema Generation for JSON, Token Savings
- 面向 LLM 的 JSON MCP Server 发布:一个新的 JSON MCP Server 已创建,旨在帮助 LLM 高效解析大型且复杂的 JSON 文件(如 Excalidraw 导出文件);详见 GitHub 仓库。
- 该工具使用 schema generation(模式生成)来首先理解 JSON 的结构,然后仅提取必要的数据,从而节省 Token 和上下文。
- LLM 更高效地解析 JSON 文件:该工具的主要目标是帮助 LLM 更高效地解析大型且杂乱的 JSON 文件。
- 它通过仅提取所需数据来节省 Token 和上下文。
GPU MODE ▷ #general (8 messages🔥):
Hylo Programming Language, Value Semantics, Halide, Scala 3/Scala Native, Heterogenous Programming
- Hylo 语言引起关注:一名成员询问了 Hylo 编程语言(https://www.hylo-lang.org/),强调了其通过 value semantics(值语义)和调度实现内存安全的方法,并将其与 Halide 进行了类比。
- 有人指出,该团队与 Mojo 属于同一个“面向 21 世纪的异构编程语言”范畴。
- Hylo 的值语义和并发:成员表示 Hylo 团队仍在完善其 value semantics 和 concurrency(并发)机制,不过其愿景和路线图是让值语义与调度(scheduling)、平铺(tiling)和向量化(vectorizing)完美结合。
- Hylo 团队来自 Adobe STL,拥有开发 Halide 的经验。
- Scala 团队成员在参与 Hylo?:一名成员提到负责 Hylo 的人目前正在从事 Scala 3/Scala Native 的工作。
- 其他成员表示其负责人来自 cpp 和 Swift 领域。
GPU MODE ▷ #triton (1 messages):
Triton Kernel AI Agent, GEAK benchmarks
- AMD 推出 GEAK 和 Triton Kernel AI Agent:AMD 在其论文 GEAK: INTRODUCING TRITON KERNEL AI AGENT & EVALUATION BENCHMARKS 中介绍了 GEAK benchmarks 和 Triton Kernel AI Agent。
- 深入了解 AMD 的 Kernel AI Agent:探索 AMD 使用其新型 Triton Kernel AI Agent 进行 AI 驱动的内核优化 的创新方法。
GPU MODE ▷ #cuda (4 条消息):
Profiling Copilot,针对寄存器计数问题的 __launch_bounds__ 修复,因 extern 调用导致 setmaxnreg 被忽略
- __launch_bounds__ 设置修复了 CUDA 启动问题:一位用户通过向
__launch_bounds__传递minBlocksPerMultiprocessor参数,设置maxThreadsPerBlock=128*3和minBlocksPerMultiprocessor=1,修复了编译器在入口处无法确定寄存器计数的问题。- 他们指出不确定这具体是如何修复问题的,但很高兴能继续推进。
setmaxnreg遇到不兼容问题:setmaxnreg设置仍然被忽略,现在是由于与extern调用兼容性相关的另一个问题,如消息所示:ptxas info : (C7506) Potential Performance Loss: 'setmaxnreg' ignored to maintain compatibility into 'extern' call.- 一位成员询问 Kernel 是否正在调用定义在独立编译单元中的
'extern'函数。
- 一位成员询问 Kernel 是否正在调用定义在独立编译单元中的
GPU MODE ▷ #torch (1 条消息):
自定义 Kernel 的 CheckpointPolicy,Functorch API
- 自定义 Kernel 的 CheckpointPolicy:一位成员询问了关于在 Torch 中为自定义 Kernel(特别是融合 MLP)实现 CheckpointPolicy 的文档。
- 他们询问在 Functorch API 中使用它是否可行。
- Functorch 与自定义 Kernel:用户希望在利用 CheckpointPolicy 的同时,将自定义 Kernel(如融合 MLP)集成到 Functorch API 中。
- 他们正在寻求关于如何有效实现这一集成的指导或文档。
GPU MODE ▷ #cool-links (1 条消息):
AMD 上的 MI300X FP8 基准测试,AMD MI300X vs H200 vs B200,FP8 数据并行基准测试
- MI300X 基准测试超越 H200:一位用户询问了关于 AMD 硬件上新 MI300X FP8 基准测试 的使用体验。
- MI300X 上的 FP8 性能:该基准测试对比了 AMD MI300X 与 NVIDIA H200,并表明 MI300X 在某些 FP8 数据并行任务中表现优于 H200。
- 结果显示 MI300X 的性能正接近 NVIDIA B200。
GPU MODE ▷ #beginner (1 条消息):
celis1702: 非常感谢你们两位的清晰解释和分享这些细节!
GPU MODE ▷ #jax (2 条消息):
JIT 函数,JAXPR 打印,静态参数
- JAXPR 打印问题:一位用户在尝试为使用静态参数的 JIT 函数打印 JAXPR 时遇到了追踪时(trace-time)错误。
- 用户尝试使用
jax.make_jaxpr(jit_func)(1, 2)但遇到了错误。
- 用户尝试使用
- 静态参数与 JIT 编译:用户的问题围绕着在
jax.jit中使用static_argnames,然后尝试检查生成的 JAXPR。- 理解静态参数如何影响追踪和编译是解决追踪时错误的关键。
GPU MODE ▷ #irl-meetup (2 条消息):
一致,确认
- 肯定确认:用户 @sshkr16 表示 “I am yeah”,在对话中发出一致或确认的信号。
- 另一位用户 ali_8366 回复了 “Nice !”,对初始陈述表示认可和积极肯定。
- 收到积极认可:ali_8366 的回复 “Nice !” 表明对 @sshkr16 的确认持积极态度。
- 这一简单的交流凸显了频道内的相互理解和一致。
GPU MODE ▷ #rocm (2 条消息):
使用 rocprofilerv3 分析 llama.cpp,用于 GGUF 的 AMD 机器
- 使用 rocprofilerv3 分析 llama.cpp 的困扰:一位成员询问了关于使用 rocprofilerv3 分析 llama.cpp 的问题,指出在 MI50 上使用 ROCm 6.3.3 时,PyTorch 代码分析成功,但 llama.cpp 存在问题。
- 他们想知道这个问题是否仅限于他们的环境设置。
- 用于 GGUF 执行的 AMD 硬件查询:另一位成员回复称他们尚未尝试分析 llama.cpp,并询问了用于运行 GGUF 模型的具体 AMD 机器。
- 他们想了解用于 GGUF 推理的硬件配置。
GPU MODE ▷ #self-promotion (1 条消息):
C/ua 招聘,AI Agents 基础设施,创始工程师职位
- C/ua 在旧金山和西班牙寻求人才:C/ua 正在旧金山和西班牙(远程或马德里混合办公)招聘创始工程师,负责构建通用 AI Agents 的基础设施。
- 他们由 Y Combinator 支持,正在开发被数千名开发者使用的开源工具。
- C/ua 构建 AI Agent 基础设施:C/ua 专注于 AI Agents 的基础设施,使其能够大规模安全地使用计算机和应用程序。
- 该职位涉及构建安全运行时、容器编排、开发者 API 以及 OS 级虚拟化。
- C/ua 的创始工程师职位:C/ua 正在寻找对系统安全性、可复现性和开发体验充满热情的创始工程师,以塑造 Agents 的大规模运行方式。
- 感兴趣的候选人可以在 旧金山职位公告 中找到更多详情。
GPU MODE ▷ #🍿 (1 条消息):
tonic_1: 很高兴我足够好奇来围观这次对话 🙂 对此感到非常兴奋 🙂
GPU MODE ▷ #factorio-learning-env (7 条消息):
README 更新 Resource 与 Prototype 的对比,RCON 客户端断开连接,蓝图 VQA 流水线
- README 中是 Resource 还是 Prototype?:一位成员询问 README 关于使用 Resource 还是 Prototype 来寻找资源点的内容是否是最新的,特别是质疑
position=nearest(Prototype.IronOre))是否应该是Resource.IronOre。- 另一位成员确认了这种可能性,并指出 “README 的那部分是由 Cursor 中的 Claude 生成的”。
- RCON 客户端断开连接,限制了测试:由于 RCON 客户端断开连接,测试正受到限制,错误提示为 “The RCON client is currently not connected to the server”。
- 这个问题阻碍了完整轨迹(trajectories)的完成。
- 蓝图 VQA 流水线已完成!:一位成员报告称 蓝图的 VQA 流水线 已经完成,目前正专注于数据增强。
- 增强方法包括 旋转、翻转 和 子区域分块,旨在将可用蓝图数量增加 10-15 倍。
GPU MODE ▷ #singularity-systems (6 条消息):
picocuda 编译器,elements 图数据结构,标量编译,GPU 编译,tinygrad 的 AMD GPU 驱动
- Picocuda 和 Elements 项目取得进展:picocuda 编译器和 elements 图数据结构项目正在取得进展。
- 在完成了 Zero to Hero 教科书的标量编译部分后,现在的重点是深入研究 GPU。
- GPU 编译教科书将参考 GPUCC 论文:该教科书将大致遵循 CGO ‘16 的 GPUCC 论文,扩展来自 sampsons cs6120 的大红中间语言 (BRIL),这是一种微型 LLVM(BRIL 网页)。
- 作者建议通过一小层编排 Host 和 Device 代码的运行时,逐步构建标量和向量编译。
- 用于开源教科书的 AMD GPU:将购买 7900xtx 或 9070xt 用于开发,通过 USB 使用 tinygrad 的 AMD GPU 驱动。
- 选择 AMD 是因为它是开源的,符合教科书针对黑客和极客(tinkerers)的目标受众。
- 将 llm.c 移植到 AMD 的 HIP:目标是最终实现 Karpathy 的 llm.c(已 fork 并修改为 AMD 的 HIP 版本)。
- Host 代码所需的图算法:Host 代码所需的两个主要图算法是用于中间层 (
opto) 的支配树(dominators)和用于后端 (cgen) 寄存器分配器的图着色。- 作者推荐使用 lengauer-tarjan 算法处理支配树(类似 rustc),使用 briggs-chaitin-click 算法处理寄存器分配器(类似 hotspot 的 C2)。
GPU MODE ▷ #multi-gpu (4 messages):
DTensor, Basic Parallelism Schemas, Shape Rotation, DTensor Problems, Marksaroufim visualizations
- DTensor 方案延续计划:成员们计划继续研究 DTensor 和 基础并行方案 (basic parallelism schemas)。
- 会议定于周日 CEST 时间晚上 8 点左右进行,如有必要可能会延长。
- Shape Rotation 任务进行中:其中一名成员计划专注于 shape rotation。
- 目标是探索并实现高效操作 Tensor 形状的技术。
- Marksaroufim 可视化启发 DTensor 问题:成员们将通过使用 Marksaroufim 的可视化工具 来探索新的 DTensor 问题。
- 旨在利用这些可视化结果,深入了解 DTensor 开发中的潜在挑战和解决方案。
HuggingFace ▷ #general (26 messages🔥):
Flux Krea model, Synthetic Datasets with HF jobs, AMD GPU for EM image segmentation, Llama CP model path, Gemini-2.5-flash bias
- **Flux Krea 新模型发布!:新的 **Flux Krea 模型已发布,具有更多细节,可与 base.dev 上的大多数 LoRA 配合使用,在此获取。
- 根据初步报告,该模型无法生成 NSFW 内容。
- **Gemini 2.5 Flash 可能偏向 Gemma 3:一位成员一直尝试使用 **Gemini-2.5-flash 来对各种 LLM 的回答进行排名,并发现 Gemma 3 模型的排名始终高于其他模型,甚至包括一些 70B 模型。
- 另一位成员认为确实存在偏见,但 Gemma 3 本身也是较好的模型之一,且默认权重也做得很好。
- **HuggingFace Ultrascale 书籍是博客文章的镜像?:一位新成员询问 **HF ultrascale book 的内容是否与博客相同,且是否需要 HF pro 订阅。
- 另一位成员确认该书共 246 页,内容可能与包含大量图片的博客文章相同,并链接到了 Julien Chaumond 的推文。
- 使用 **HF jobs 创建合成数据集的文档:一位成员询问如何使用 **HF jobs 创建合成数据集 (Synthetic Datasets)。
- 另一位成员提供了 hf jobs 文档、脚本、数据集 和 配置 作为示例。
- 在 **AMD 上构建的 Volume Seg 工具:一位成员发布了一个 **EM 图像分割的 SOTA 工具,该工具运行在已有 10 年历史、没有 Tensor Core 甚至不受最新 ROCm 支持的 GCN 架构 AMD GPU 上,在此获取。
- 他们提到,该工具相比其他神经模型实现了近 5x-10x 的缩减。
HuggingFace ▷ #today-im-learning (2 messages):
Note-taking tools, Remnote
- 披露笔记应用:Remnote:一位用户询问正在使用的笔记工具,回复指向了 Remnote。
- Remnote 是一款将笔记与间隔重复 (spaced repetition) 学习相结合的知识管理工具。
- Remnote:不仅仅是笔记:讨论强调 Remnote 是一个多功能平台。
- 它将传统笔记与 间隔重复 等功能相结合,以增强学习和记忆效果。
HuggingFace ▷ #cool-finds (2 messages):
AgentUp, Emergence AI, LongMemEval Benchmark
- **AgentUp 闪亮登场!**:AgentUp 项目受到关注。
- 它作为一个值得关注的 Agent 框架,似乎正在获得关注。
- **Emergence AI 声称在记忆力方面达到 SOTA!:Emergence AI** 的新架构在 LongMemEval 基准测试上达到了 SOTA。
- 该基准测试用于评估 AI Agent 的长期记忆能力。
HuggingFace ▷ #i-made-this (3 messages):
smolagents.js, CodeBoarding, Qwen3-30B-A3B-Instruct-2507
- Smolagents 移植到 JavaScript!: 一位成员发布了 smolagents 的 TypeScript 移植版本,名为 smolagents.js,可在 GitHub 和 npm 上获取。
- CodeBoarding 发布!: 一位成员发布了 CodeBoarding,这是一个开源项目,使用静态分析 + LLMs 生成 Python 代码库的交互式图表,可在 GitHub 上获取。
- Qwen3 不再拒绝问题!: 一位成员发布了关于调整 Qwen3-30B-A3B-Instruct-2507 以停止拒绝甚至是非常露骨的问题的内容,可在 HuggingFace 上获取。
HuggingFace ▷ #reading-group (1 messages):
cakiki: <@570737726991761409> 请不要在服务器中推广付费内容。
HuggingFace ▷ #computer-vision (2 messages):
Discriminator Learning Rate, GAN Loss Issues, Debugging GANs
- 降低判别器速率以调试 GAN: 一位成员建议将 判别器学习率 (discriminator learning rate) 降低到极小值以观察损失变化,这有助于定位 GAN 训练中的问题。
- 另一位成员询问应该降低到多少,并提到他们目前的速率是 1e-5。
- 微调 GAN 学习率: 讨论集中在通过操纵判别器学习率来调试 生成对抗网络 (GANs) 的技术。
- 目标是确定判别器的损失塌陷至 0 是否是由于学习率不平衡造成的。
HuggingFace ▷ #agents-course (2 messages):
Llama 4 Access, Qwen Model, DeepSeek-R1
- Llama 4 访问受阻!: 一位成员报告在 Colab 上尝试运行 dummy_agent_library.ipynb 时 无法访问 Llama 4。
- 另一位成员建议使用 Qwen 模型 或 DeepSeek-R1 作为可行的替代方案。
- 替代模型来救场!: 既然 Llama 4 的访问请求被拒绝,可以使用 Qwen 或 DeepSeek-R1 作为替代。
- 这些模型作为替代品效果应该不错。
Cohere ▷ #🧵-general-thread (21 messages🔥):
Cohere API context window size discrepancy, HackRx 6.0 AI hackathon Rate Limit, Cohere Enterprise Plan, Cohere website login error, Cohere Support Team introduction
- 上下文窗口大小之争:32k 还是 128k?: 一位用户指出 Hugging Face 模型卡片(32k 上下文) 与 API 文档(128k 上下文) 之间存在差异,随后澄清为 128k 输入 和 8k 输出。
- 团队承认了该问题,并承诺很快会更新 Hugging Face 模型卡片。
- Team Patriots 寻求放宽速率限制: 学生团队 Team Patriots 请求为 HackRx 6.0 AI 黑客松 临时提高速率限制,因为他们受到了 每分钟 10 次调用的试用 Key 限制。
- 一位 Cohere 团队成员允许他们创建多个账户并轮换使用 Key 以突破限制。
- 初创公司看中 Cohere 企业版: 一家非常喜欢 Cohere 的 Reranker 实现的初创公司咨询了 企业版方案 (Enterprise plan),以应对生产环境 API 超过 1000/min 限制 的情况。
- 他们被引导将用例详情和请求概况发送至 support@cohere.com 和 varun@cohere.com,以便获得安全协助并与相关负责人对接。
- 登录错误令人头疼: 一位用户报告在 Cohere 官网 登录时出现错误,具体与 CORS 策略 在引导流程中拦截访问有关。
- 聊天中未立即提供解决方案。
- Cohere 支持团队表示热烈欢迎: Varun,Cohere 的 技术支持工程师 (Technical Support Engineer),介绍了自己并提供了关于在何处发布通用支持和 API 特定讨论的指导。
- 鼓励新人加入 Cohere Labs 🧪,这是一个专门从事研究的 Discord 社区,地址为 https://cohere.com/research。
Cohere ▷ #🔌-api-discussions (1 messages):
kaludi: API 是出什么问题了吗?我们的查询出现了多次超时。
Cohere ▷ #👋-introduce-yourself (6 条消息):
三星生物 (Samsung Biologics) AI 架构师,专注 LLM 工作流的 AI 开发者,戴尔 (Dell) 工程技术专家,移动端及 JS 全栈 AI 应用开发者
- 三星 (Samsung) AI 架构师加入!:一位来自 Samsung Biologics 的 AI 架构师介绍了自己,重点关注整合 AI 方法和工具 以满足业务需求,并强调了用于内部使用的带有 RAG 的私有 LLM 服务。
- 他们渴望参与有关 生物制药或生物学挑战 的对话。
- 专注于 LLM 的 AI 开发者加入:一位擅长 LLM 工作流、基于 Agent 的工具和 MCP 集成 的 AI 开发者介绍了自己,并提到在使用 LangChain 和 FastAPI 构建 AI 销售助手和 RAG 流水线 方面拥有经验。
- 他们的主要技术栈包括 Python 和 Node.js,并对合作和合同工作持开放态度。
- 移动端 AI 应用开发者打招呼!:一位具有移动端和 JS 全栈经验的 AI 应用开发者 介绍了自己。
- 未提供更多信息。
- 戴尔 (Dell) AI 研究人员到访 Cohere:一位来自巴西、主要从事 AI 研究 的 Dell 工程技术专家介绍了自己。
- 他们来到这里是为了建立联系和学习。
Manus.im Discord ▷ #general (17 条消息🔥):
私信垃圾信息,Wide Research,Cloudflare 问题,Manus AI,每日刷新额度
- 用户投诉私信垃圾信息:一名成员报告收到私信垃圾信息,并请求管理员永久封禁该用户。
- 在此期间未采取任何行动,发送垃圾信息的用户仍未被处理。
- 用户测试 Wide Research 平台:一名成员询问了关于使用 Wide Research 的初步看法。
- 未提供关于 Wide Research 的评论。
- 用户无法设置 Cloudflare 虚拟环境:一名成员在 Cloudflare 中配置虚拟环境时遇到问题。
- 设置一直卡在 Cloudflare 上,导致他们无法完成虚拟环境配置。
- 每日刷新额度停止运作:一名成员报告每日刷新额度不再起作用。
- 另一名用户提到他们的账户在没有违反任何规则的情况下被停用,这表明平台的额度和账户管理可能存在问题。
- 裁员可能影响退款:一名成员指出最近的裁员,并暗示用户可能无法拿回退款。
- 该评论暗示公司最近的裁员可能会影响处理退款或解决财务问题的能力。
LlamaIndex ▷ #blog (2 条消息):
LlamaIndex, Novita Labs, Gemini Live
- LlamaIndex 与 Novita Labs 联手!:LlamaIndex 推文 宣布将 LlamaIndex 与 Novita Labs 的模型推理能力结合使用。
- 他们提供多样化的数据源连接以及将数据转换为向量嵌入 (Vector Embeddings) 的功能。
- Gemini Live 现已支持 TypeScript:LlamaIndex 推文 宣布 Gemini Live 集成 已在 TypeScript 中可用。
- 演示展示了如何设置并运行一个简单的终端聊天。
LlamaIndex ▷ #general (13 messages🔥):
Agentic AI Code Assistance, Git-Style Branching for LLM Conversations, LlamaIndex Parsers for PDFs and PPTs, AI+Blockchain for on-chain AI agents
- 寻求雇佣的 LLM Web3 工程师:一位资深 AI & Blockchain 工程师分享了他使用 Eliza OS、LangGraph 和自定义工具链构建用于交易、媒体自动化和自主治理的 on-chain AI agents 的经验。
- 他在 Base、Solana、Berachain、Sui、Aptos、HBAR、EVM chains 以及跨链系统方面拥有深厚经验。
- 渴望本地 Agentic AI 代码助手:一位成员询问是否有类似于 Cursor editor 但可以在本地运行的本地 Agentic AI 代码助手工具。
- 其他成员建议 GitHub 上有很多选择,但原帖作者表示 大多数选项都存在依赖问题 或缺乏 Agentic 特性。
- Git 风格的分支构建对话树:一位成员正在测试一个系统,其中每条消息都是一个节点,允许在对话树的任何位置分支出新的上下文路径,详情见 他们的博客文章。
- 该系统目前已使用 Gemini API 进行测试,并计划尝试 GPT-4、Claude 和本地 LLaMA 模型,作者正在寻找测试人员。
- Llama 解析器解析耗时较长:成员们讨论了使用 LlamaIndex 解析器处理 .doc、.pdf 和 .ppt 文件的情况,特别是当文本位于图像上时。
- 一位成员建议使用 LlamaParse 的高级模式(premium mode),而另一位成员建议将 PPT 转换为 PDF 以提高速度,或使用 ThreadPoolExecutor() 异步解析文档。
DSPy ▷ #show-and-tell (1 messages):
dbreunig: https://www.dbreunig.com/2025/07/31/how-kimi-rl-ed-qualitative-data-to-write-better.html
DSPy ▷ #general (2 messages):
DSpill, Yaron Minsky, Quant Bros
- 创造新动词:DSpill 来了!:一位成员询问谁会 再次尝试 DSpill Yaron Minsky / quant bros。
- 另一位成员回答:哇,新动词:DSpill。
- Quant bros 被 DSpilled 了?:一位成员提出了 “DSpilling” Yaron Minsky 和 quant bros 的想法。
- 这引发了一个新动词 “DSpill” 的诞生,用以描述这一行为。
Modular (Mojo 🔥) ▷ #general (2 messages):
Mojo installation issues, GitHub issue reporting, Detailed logs for debugging
- Mojo 安装困难是否应提交 GitHub Issue?:一位成员报告称连续三天无法安装 Mojo,并询问是否应该开一个 GitHub issue。
- 另一位成员鼓励他们提交 issue,并附上详细日志以协助排查问题。
- 建议为 GitHub Issue 提供详细日志:在提交关于 Mojo 安装问题的 GitHub issue 时,包含详细日志可以显著提供帮助。
- 这能为开发者提供必要的信息,以便更高效地诊断和解决安装问题。
Modular (Mojo 🔥) ▷ #mojo (1 messages):
Tail Call Elimination, Print/Log Statements, Minimal Examples
- 尾调用消除(Tail Call Elimination)触发机制:一位成员在创建最小示例时注意到,如果函数中添加了基础的 print/log 语句,尾调用消除 就不会触发。
- 该成员正在询问原因。
- Print/Log 语句影响尾调用消除:讨论集中在添加 print/log 语句 如何阻止最小示例中的 尾调用消除。
- 该成员试图理解这种行为背后的深层原因,特别是在编写最小示例时。
Torchtune ▷ #general (3 messages):
OpenAI 模型泄露,Mixture of Experts,FP4 权重
- OpenAI 传闻中的模型泄露:据传 OpenAI 有一个泄露的模型,拥有 128 个专家 (experts) 和 120B 参数。
- 该模型的权重据称采用 FP4 格式,表明其处于高度压缩或量化状态。
- 深入了解 MoE:Mixture of Experts 模型由多个子网络(称为 experts)组成,并带有一个学习将每个输入路由到最相关专家的门控网络 (gating network)。
- 这是一个活跃的研究领域,因为它可以在不按比例增加计算成本的情况下扩展模型规模。
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (1 messages):
课程测验可用性,Google Forms 重新开放
- 带有答案解析的测验现已在线发布:测验(含答案解析)的存档可在课程网站的 “Quizzes” 栏目中找到。
- 这为学生复习课程材料和评估理解程度提供了宝贵的资源。
- 用于测验的 Google Forms 将不会重新开放:课程工作人员宣布,他们将无法重新开放用于测验的 Google Forms。
- 错过通过 Google Forms 进行测验机会的学生应利用现有的存档进行复习。
Codeium (Windsurf) ▷ #announcements (1 messages):
Qwen3-Coder,Token 速度,美国服务器