AI News
OpenAI 的 gpt-oss 20B 和 120B,Claude Opus 4.1,以及 DeepMind 的 Genie 3。
OpenAI 发布了 gpt-oss 系列,包括 gpt-oss-120b 和 gpt-oss-20b。这是自 GPT-2 以来他们推出的首批开源权重模型,专为智能体(agentic)任务设计,并采用 Apache 2.0 协议授权。
这些模型采用了混合专家(MoE)架构,结合了“宽而深”的设计,并引入了诸如注意力机制中的偏置单元(bias units)和独特的 SwiGLU 变体等创新特性。其中,120B 模型的训练耗时约为 210 万个 H100 GPU 小时。
与此同时,Anthropic 推出了 claude-4.1-opus,被誉为目前最强的编程模型。DeepMind 则展示了 genie-3,这是一个具有分钟级一致性的实时世界模拟模型。
这些新成果的发布凸显了开源权重模型、推理能力和世界模拟领域的进步。@sama、@rasbt 和 @SebastienBubeck 等关键人物提供了技术见解和性能评估,在肯定其优势的同时也指出了幻觉风险。
他们把 Open 重新带回了 OpenAI!
2025年8月4日至8月5日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 29 个 Discord 社区(227 个频道,8121 条消息)。预计节省阅读时间(按每分钟 200 字计算):615 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 方式呈现所有往期内容。访问 https://news.smol.ai/ 查看完整的新闻详情,并在 @smol_ai 上向我们提供反馈!
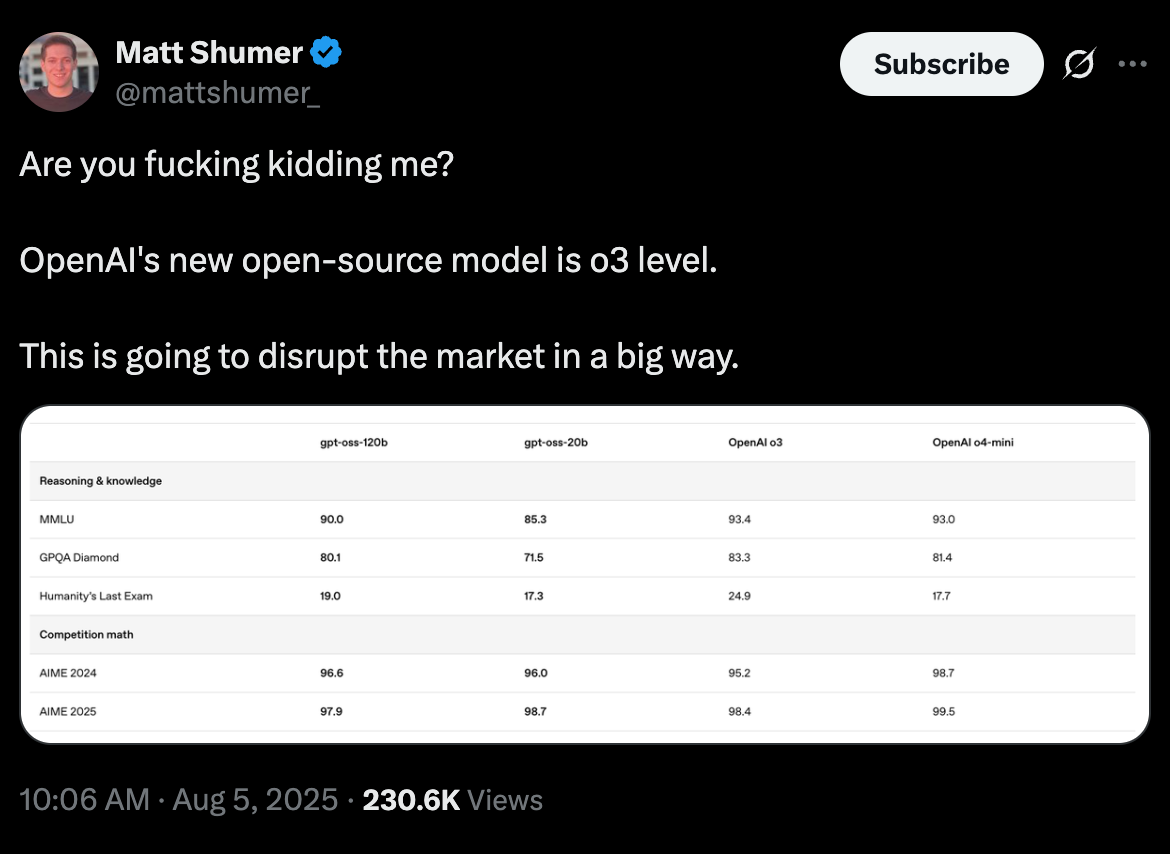
在预计将是今年 AI 新闻最密集的一周的第二天,三家顶级实验室都发布了足以单独占据头条的模型。
首先是泄露得最(无意间)彻底的发布:OpenAI 的新开源权重 GPT-OSS 模型 将 o4-mini 级别的推理能力带到了你的桌面端(60GB GPU)和手机端(12GB),你可以在新的 gpt-oss playground 中进行测试:
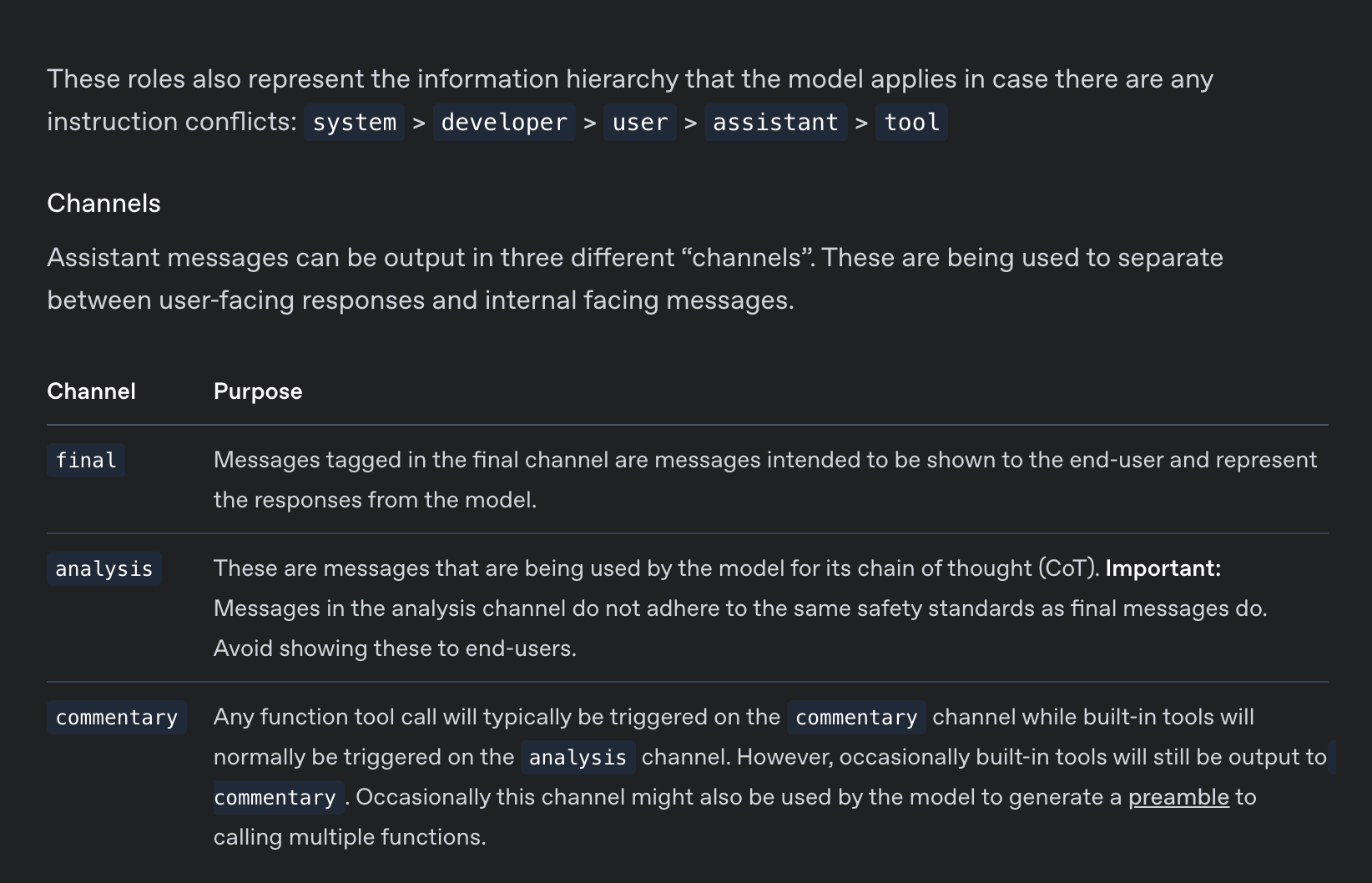
model card 和 研究博客 值得一读。这些模型还首次推出了 harmony 响应格式(已开源),它通过引入消息“channels”等新概念更新了老派的 ChatML:
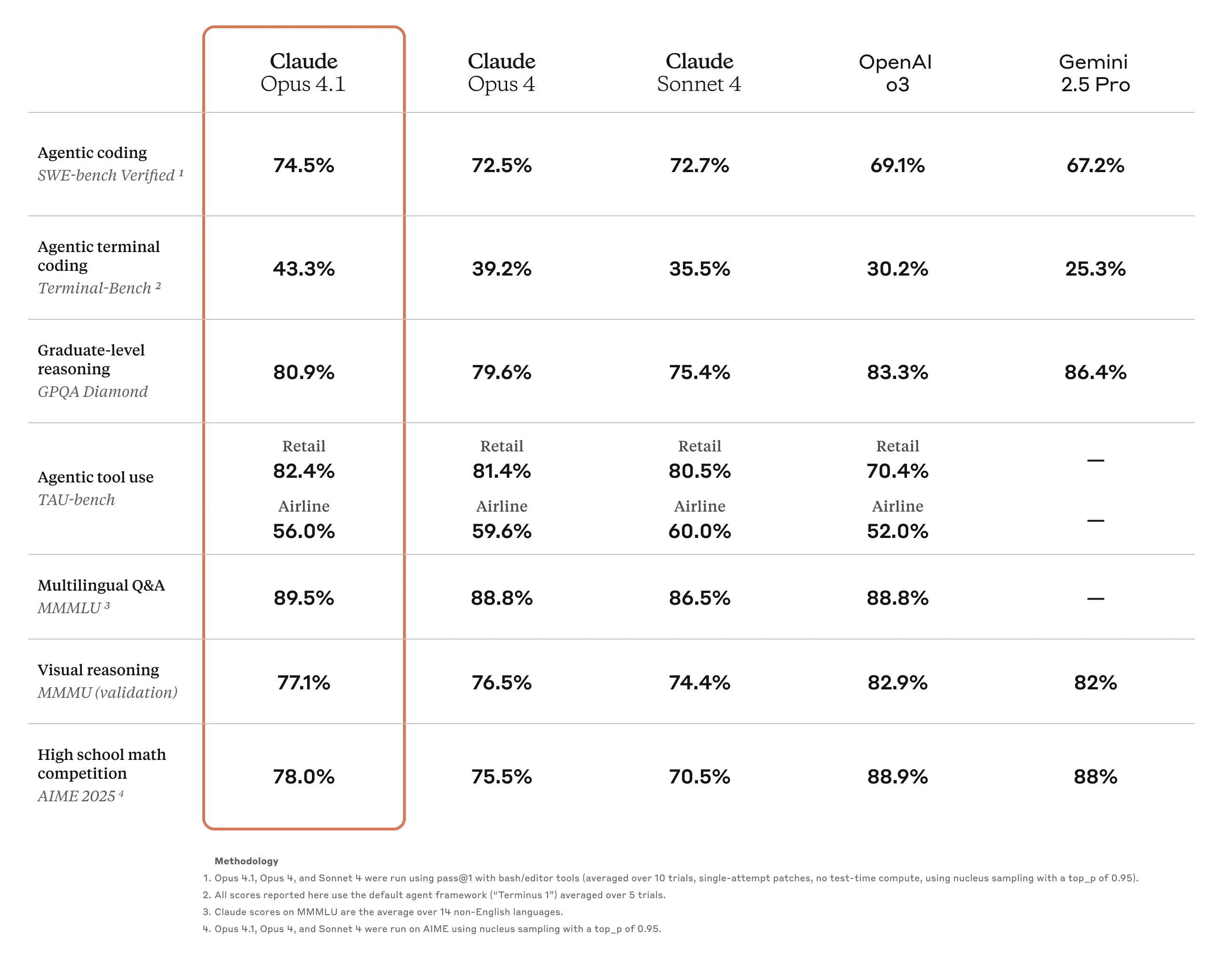
同一天,Anthropic 也发布了 Claude 4.1 Opus(博客),该模型此前也遭到了 泄露。这应该是目前世界上最好的编程模型……至少现在是。
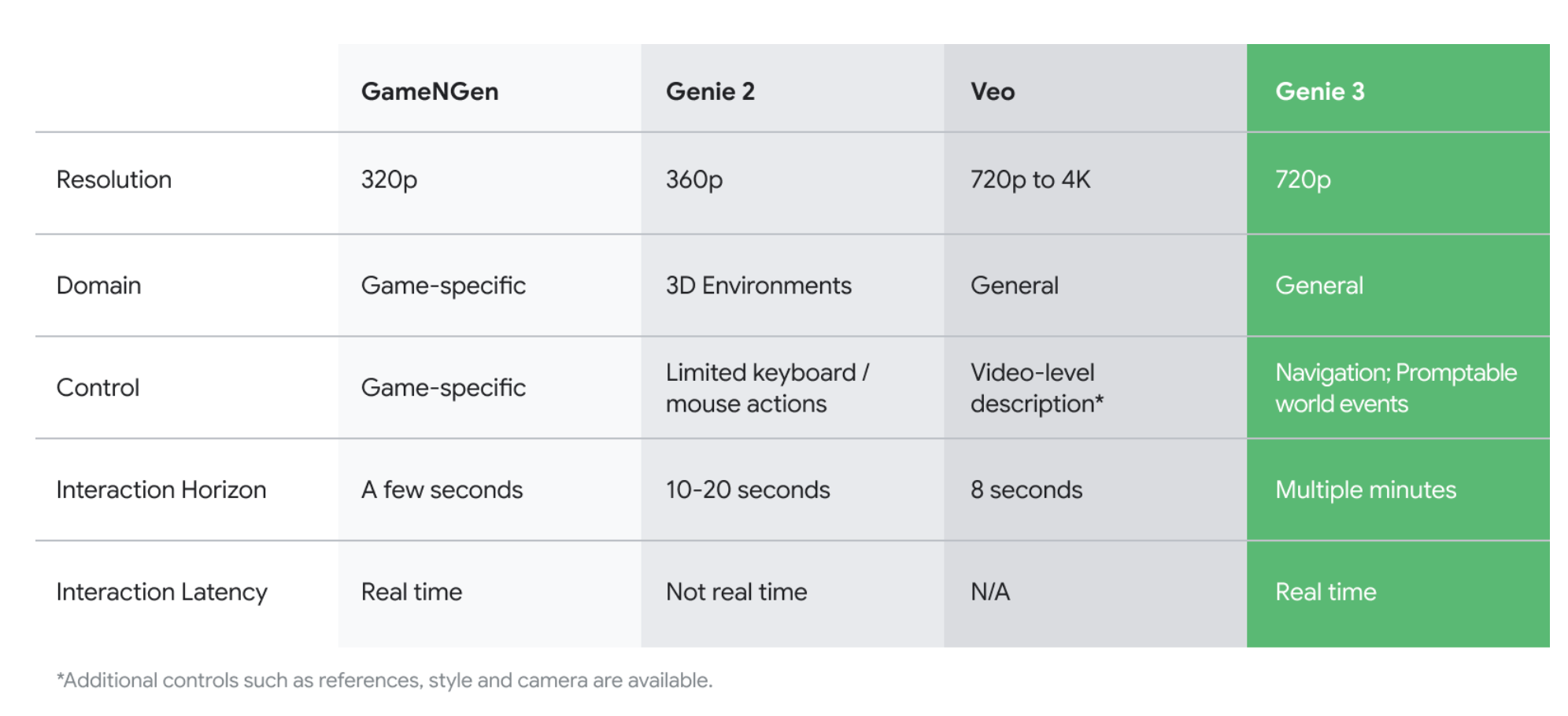
最后,DeepMind 的 Genie 3 展示了 极其令人印象深刻的实时世界模拟,具备导航能力和长达一分钟的一致性。但按照 Genie 的一贯风格,你只能听信他们的话,相信演示视频并非精挑细选的结果。
AI Twitter 简报
OpenAI 的 gpt-oss 开源权重模型发布
- OpenAI 发布
gpt-oss-120b和gpt-oss-20b,这是自 GPT-2 以来其首批权重开放模型:@sama 宣布了这一发布,将其描述为最先进的推理模型,性能可与o4-mini媲美,并可在高端笔记本电脑上本地运行,采用 Apache 2.0 许可。此次发布旨在赋予个人对 AI 的控制权,促进创新,并推动基于民主价值观的 AI 技术栈。这些模型专为 agentic tasks 设计,并针对生物安全等问题采取了安全缓解措施。OpenAI 官方账号也宣布了这一发布,@polynoamial 和 @kaicathyc 等员工也分享了他们的兴奋之情。 - 模型架构与技术细节:这些模型采用 Mixture-of-Experts (MoEs) 架构,其中
gpt-oss-120b拥有 117B 总参数 / 5.1B 激活参数,而gpt-oss-20b拥有 21B 总参数 / 3.6B 激活参数。@rasbt 提供了技术分析,指出它们似乎采用了 wide vs. deep 的架构,并且令人惊讶地在 Attention 机制中使用了 bias units,这是来自 GPT-2 的特性。@finbarrtimbers 强调了其使用了一种高效的 einsum MoE 实现,而 @vikhyatk 指出了一种独特的 swiglu 变体,具有截断输入(clamped inputs)和残差连接(skip connection)。据 @scaling01 指出,120B 模型的训练算力估计为 210 万 H100 小时,与 DeepSeek-R1 的 266 万 H800 小时相当。 - 性能、基准测试与幻觉:@SebastienBubeck 表示,这些模型取得了令人印象深刻的成绩,例如 GPQA 得分为 80,并且可以在单张 GPU 上运行。然而,@scaling01 指出可能存在“幻觉狂欢(hallucination fiesta)”,且在 Aider Polyglot 上的得分较低。这些模型似乎针对特定任务进行了过度训练(overtrained),@teortaxesTex 指出它们“开源了其推理能力扩展(reasoning effort scaling)的成果,完全击败了其他所有尝试”,但在更简单的问题上却表现失败。@vikhyatk 推测这些模型可能主要在合成数据上进行训练,以降低版权侵权和有害内容等风险。
- 工具、对话格式与集成:这些模型经过后期训练(post-trained),可以使用网页浏览器和交互式 Python notebook,赋予了它们强大的开箱即用 Agent 能力。它们使用了一种名为 Harmony 的新对话模板,@Trinkle23897 回忆起三年前曾参与过该模板的工作。此次发布立即获得了生态系统的支持,包括 vLLM(详细介绍了其集成情况)、Hugging Face(提供了微调指南)、Ollama(与 NVIDIA 和 Qualcomm 合作进行加速)、Groq、Cerebras 以及 Together AI。
- 社区反应与开源影响:此次发布被视为开源领域的重大胜利,@AndrewYNg 感谢 OpenAI 提供的这份“礼物”。@ClementDelangue 指出,
gpt-oss几乎瞬间成为 Hugging Face 上排名第一的热门模型。@willdepue 观察到,距离o1发布还不到一年,现在o3级别的模型已经可以在消费级硬件上运行了。
主要模型与产品发布(非 OpenAI)
- Google DeepMind 发布 Genie 3:Google DeepMind 宣布推出 Genie 3,这是一个突破性的 world model,能够根据 text prompt 生成完整的交互式、可玩的模拟 (simulations)。@demishassabis 强调了其生成数分钟长、实时交互式模拟的能力。@DrJimFan 将其描述为“game engine 2.0”,即由数据驱动的权重集合取代了像 UE5 这样复杂引擎的职能。他还将其与 GR00T Dreams 在 robotics 领域进行 world modeling 的挑战联系起来。该模型具有 world memory 以保持环境一致性,并以 720p 分辨率进行渲染。
- Anthropic 发布 Claude Opus 4.1:Anthropic 发布了 Claude Opus 4.1,这是对 Opus 4 的升级,重点关注 agentic 任务、真实世界 coding 和 reasoning。它立即被集成到 Cursor 等开发者工具中,后者宣布了首日支持。@alexalbert__ 宣布将举行直播讨论新模型和 Claude Code。此次发布还预告了“在未来几周内……将有大幅改进”。
- 阿里巴巴发布 Qwen-Image 及新 API:Alibaba Qwen 推出了 Qwen-Image,这是一个用于 text-to-image 生成的 20B MMDiT (Multimodal Diffusion Transformer) 模型,因其在创建图形和中文文本方面的强大能力而受到关注。它已获得 ComfyUI 和 Diffusers 的支持。阿里巴巴还发布了 Qwen3-Coder 和 Qwen3-2507 的 API,支持 1M token context length。
- xAI 推出 Grok Imagine:Grok 的图像生成功能 Grok Imagine 现已在 Grok 应用上向所有 X Premium 用户开放。
- Meta AI 发布 Open Direct Air Capture 数据集:Meta AI 与佐治亚理工学院和 CuspAI 合作,发布了 Open Direct Air Capture 2025 数据集,这是用于寻找从空气中捕获二氧化碳材料的最大开源数据集。
AI Safety, Benchmarking, and Evaluation
- OpenAI 启动 50 万美元 Red Teaming Challenge:OpenAI 宣布了一项 50 万美元的 Red Teaming Challenge,邀请研究人员和开发人员帮助发现新风险并加强开源安全性。METR 确认参与,为 OpenAI 评估灾难性风险的方法提供外部反馈。然而,@RyanPGreenblatt 表达了担忧,认为尚未排除实质性的 CBRN(化学、生物、放射性、核)风险。
- Kaggle 推出 Game Arena:Demis Hassabis 宣布了 Kaggle Game Arena,这是一个新的排行榜和锦标赛系列,用于在游戏(从国际象棋开始)中测试现代 LLMs。这为衡量 Agent 在竞争环境中的性能提供了一种新方法。
- 新基准测试与模型性能:GLM-4.5 在 Terminal-Bench 上表现强劲,使其跻身 Claude 级别模型之列。在关注成本的 AlgoTune 基准测试中,像 Qwen 3 Coder 和 GLM 4.5 这样的 open-weight 模型被证明击败了 Claude Opus 4,因为该基准测试将每个任务的模型预算限制在 1 美元。
Industry News, Tooling, & Broader Implications
- Cloudflare 与 Perplexity AI Agent 之争:在 Cloudflare 开始屏蔽 AI 爬虫后引发了一场重大辩论,此举招致了尖锐批评。Perplexity AI 发表了强硬声明,声称 Cloudflare 的领导层“误导严重”,并认为 AI Agent 是人类用户的延伸。@balajis 和 Y Combinator 的 @garrytan 等人物也放大了这一问题,他们报告称自己的网站在未经许可的情况下被屏蔽。
- 收购与融资:Perplexity AI 宣布收购了 Invisible_HQ,这是一个在 Agent 可扩展基础设施方面拥有专业知识的团队。在融资新闻方面,@steph_palazzolo 报道称,由 DeepMind 研究员创立的初创公司 Reflection AI 正在洽谈筹集 10 亿美元以上的资金用于开源模型开发,而 EliseAI 的 AI 语音 Agent 业务正以 20 亿美元的估值获得支持。
- AI 对未来的影响:Midjourney 的 David Holz 对将用于 2028 年总统大选的 AI 技术力量表示担忧,称“我们还没准备好”。与此同时,@OpenAI 的 Woj Zaremba 分享了一个显示用户对 ChatGPT 满意度的链接,并指出其周活跃用户已增长至近 7 亿。
- 框架与工具更新:LangChain 宣布其 LangGraph Platform 和 LangSmith 已获得 SOC 2 Type II 合规认证。编程 Agent Jules 引入了 Environment Snapshots(环境快照)来保存依赖项,以实现更快速、更一致的任务执行。Agent Reinforcement Trainer 登上 GitHub 趋势仓库榜首。
- 开源模型的崛起:@natolambert 认为 美国需要更严肃地对待开源模型,因为其通过 Llama 建立的早期领先地位已被来自中国的强劲开源模型所侵蚀。@hardmaru 和 @ClementDelangue 也表达了同样的观点,强调“世界运行在开源之上”。
幽默/迷因 (Memes)
- 共鸣与圈内梗:@portiaspetrat 发布了极具共鸣的“从小女孩起我就热爱信息”。@bigsnugga 的一条推文通过迷因声称“Cher 预言了 Grok”。
- OpenAI 炒作周期:来自 @ollama 的一系列帖子显示咖啡杯变得越来越抖动,配文如“在 Ollama 准备好之前再喝一杯”以及“为今天做好准备。@nvidia GeForce RTX 已开启。”,以期待当天的发布。
- 模型行为怪癖:@soumithchintala 哀叹不得不“绅士化”他的写作风格,因为 ChatGPT 让破折号成为了“毫无灵魂的 AI 文风的官方标点”。
- 恶搞:@Yuchenj_UW 发布了一条“AI 模型发布定律”,开玩笑说每当 Google 发布模型时,OpenAI 肯定会紧随其后,预言这将是一个大规模发布周。
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. OpenAI GPT-OSS 模型发布、集成与社区讨论
- 🚀 OpenAI 发布了他们的权重开放模型!!! (分数: 1124, 评论: 375): 该图片与 OpenAI 首次发布的权重开放模型 gpt-oss-120b(117B 参数,5.1B 激活)和 gpt-oss-20b(21B 参数,3.6B 激活)的公告相关,旨在用于生产就绪以及本地/专业化 AI 任务。这些模型可在 HuggingFace 上获取,其显著特点是能够在单个 H100 GPU 上运行,针对具有实际硬件要求的高推理和 Agent 应用。该帖子代表了 OpenAI 向开放性的重大转变,社区反应和技术评论强调了其潜力、初步安全测试和模型质量。 评论者们争论 OpenAI 转向更开放模型的意义,一些用户将其贴上从 ‘ClosedAi’ 到 ‘SemiClosedAi’ 转变的标签,而另一些人则注意到该发布的质量出乎意料地高,即使在批评者中也是如此。初步的第三方安全测试正被引用,表明开源社区正在进行持续审查。
- 这些权重开放模型是在宽松的 Apache 2.0 许可证下发布的,允许在没有 Copyleft 限制或专利风险的情况下使用,使其适用于商业部署和广泛的定制。
- 这些模型具有多项技术创新:可配置的推理力度(用于延迟/性能权衡)、对 Chain-of-Thought 输出的全访问权限(对调试有用,虽然不针对最终用户)、微调支持,以及 Agent 能力,如 Function Calling、网页浏览、Python 执行和结构化输出生成。
- 通过在 MoE 层上使用原生 MXFP4 量化,gpt-oss-120b 可以在单个 H100 GPU 上运行,而 gpt-oss-20b 可以容纳在 16GB VRAM 内,从而实现在更易获取的硬件上进行部署。完整的 Benchmark 结果可在 https://preview.redd.it/0nbuy4ejj8hf1.jpeg?width=967&format=pjpg&auto=webp&s=5840e94490e805fe978ba8bc877904cd3b94fe0c 查看。
- openai/gpt-oss-120b · Hugging Face (分数: 342, 评论: 87): openai/gpt-oss-120b 在 Hugging Face 上的发布值得关注,因为它是一个在宽松的 Apache 2.0 许可证下的
~117B参数模型。一条评论强调了其双参数/激活参数方法(总计117B,激活5.1B),这表明采用了 MoE (Mixture of Experts) 或相关的稀疏激活技术来优化计算。Benchmark 结果尚待独立验证。 评论者注意到对于这种规模的模型来说,其许可证(Apache 2.0)异常宽松,并推测这次发布暗示了 OpenAI 对其即将推出的 GPT-5 充满信心。讨论集中在参数拆分的技术影响以及对 LLM 生态系统的更广泛影响。- 该模型因在 Apache 2.0 许可证下发布而受到关注,与其它开源 AI 许可证相比,该许可证限制较少,使其更适用于商业和研究用途。
- 用户对该模型的量化版本表现出技术兴趣,有用户提到 Unsloth 正在为
gpt-oss-120b准备量化(quants),并指出与替代方案相比, Unsloth 的量化版本“Bug 更少,效果更好”。提供了指向 Unsloth 模型 的直接链接,以及 ggml-org 的量化上传。 - 据报道,该模型受到了严格的审查(censored),这可能会影响其在需要较少限制的响应生成或更广泛输出覆盖的应用中的效用。
- gpt-oss-120b is safetymaxxed (cw: explicit safety) (Score: 349, Comments: 122): 帖子中引用的图像是一个技术基准测试或评估图表,展示了 gpt-oss-120b 与其他模型(可能包括 Nemotron)的安全性对齐情况(可能是拒绝率、毒性或相关的安全指标)。讨论集中在显式安全指标上,一条评论称这是“我真正认真对待的极少数基准测试之一”,表明该图像为模型安全性提供了有意义或高信号的对比。另一条评论链接到了该基准测试的完整版本,强调了社区对透明定量安全性评估的兴趣。该帖子突显了技术界对开源 LLM 进行严格安全性评估的日益增长的期望。 评论者似乎看重该基准测试的可信度和粒度,虽然有一些幽默成分(如 ‘Nemotron cockmaxxing’),但主要关注所呈现安全数据的严肃性和可靠性。
- 一位用户表示担心,将像 gpt-oss-120b 这样“安全性极大化(safety-maxxed)”的开源模型广泛提供,会让研究人员和攻击者能够进行白盒研究安全性机制,从而促进越狱(jailbreaks)和逻辑攻击的发展。其技术含义是,对开源模型进行强大的对抗性测试可能会转化为对闭源模型更有效的违规攻击(例如提示词注入/prompt injections),因为攻击者会在开源基准上磨炼他们的技术。
- 该线程引用了一个被技术从业者认为可信的基准测试或视觉评估(用户链接的图像)。这突显了对经验性的、可公开审计的安全性评估的关注,而不是依赖开发者的声明或不透明的安全性评分。
- Llama.cpp: Add GPT-OSS (Score: 310, Comments: 60): Llama.cpp 已添加对 GPT-OSS(OpenAI 的新开源模型)的支持,实现了推理和实验的首日兼容。虽然实现细节较少,但此次更新指向了与 llama.cpp 高效 C++ 后端的快速生态集成。 评论者质疑 OpenAI 是否积极参与了 llama.cpp 的集成,并对该模型的许可协议(特别是对“负责任使用政策”的担忧)以及与顶级开源权重(open-weight)模型相比的实际表现表示怀疑。
- 评论者对 GPT-OSS 的实际可用性和性能持怀疑态度,并将其与最先进的开源权重模型进行了比较。一位用户质疑这究竟是 OpenAI 真正的开源努力还是公关手段,强调了社区对开源模型能够与现有替代方案进行实质性竞争的期望。
- 许可协议问题被提及,特别是担心限制性或可变的负责任使用政策(responsible use policies)可能会影响下游采用或自由度。社区的技术利益相关者对那些并非真正宽松或可能施加未来限制的许可证特别敏感。
- 有人提出了关于发布时间表的问题,暗示了对 llama.cpp 等项目中上游集成和就绪情况的密切关注——这展示了技术社区对立即、便捷地获取新模型以进行本地实验和基准测试的需求。
- GPT-OSS today? (Score: 289, Comments: 67): 该帖子讨论了 llama.cpp 的一个重大且即将合并的 Pull Request (PR #15091),该 PR 添加了对 OpenAI 新的开源权重模型 GPT-OSS 的支持。链接的图像可能显示了与本地运行 GPT-OSS 相关的终端输出或统计数据。评论者确认 GPT-OSS 已在多个项目中运行:OpenAI 的 Harmony (https://github.com/openai/harmony) 现在支持 GPT-OSS,Hugging Face Transformers v4.55.0 已包含它,并且可以在此处获取 GGUF 格式的模型:https://huggingface.co/collections/ggml-org/gpt-oss-68923b60bee37414546c70bf。 评论强调了 GPT-OSS 在主要工具中的快速集成,社区已经在本地推理框架中利用 GGUF 模型。评论者清楚地感觉到 GPT-OSS 具有即时的实用性,且生态系统正在迅速适应。
- OpenAI 的 Harmony 现已开源,并在 https://openai.com/open-models/ 提供了专门的官方模型卡片(model cards)和资源。这一发布对于提高研究的透明度和可复现性,以及集成到下游应用中具有重要意义。
- HuggingFace 的 Transformers 库 (v4.55.0) 已集成对已发布的 GPT-OSS 模型的支持,允许开发者无缝采用。这表明主要 ML 框架的生态系统正在快速适配和支持。
- GGUF(一种用于高效推理的量化格式,例如配合 llama.cpp 使用)已经支持 GPT-OSS,正如 HuggingFace 上托管的模型所示 (https://huggingface.co/collections/ggml-org/gpt-oss-68923b60bee37414546c70bf),从而实现了低资源和边缘部署。
- 我感到非常安全!太感谢你了,OPENAI! (Score: 241, Comments: 39): 该帖子批评了 OpenAI 的一款产品发布,指出图中描述的模型与同等规模的 GLM(可能是 GLM-4 或 GLM Air)相比,缺乏通用知识和编程能力。标题和正文配合图片(推测是对安全或模型 alignment 的讽刺)表明了对该模型实际应用场景的怀疑,尤其是考虑到其明显的局限性。技术评论者也表示该模型表现不佳——有人称其为“被切除前额叶的 (lobotomized)”——并质疑其发布动机,暗示这更多是营销手段而非实质内容。 用户讨论了该模型的实用性,强烈认为这主要是 OpenAI 的营销举措,并批评了产品能力和围绕它的炒作周期。
- 针对模型中严厉的安全和内容限制提出了批评,一些用户认为过度审查(“safetymaxxing”)显著降低了模型的通用知识效用。这种被感知的“lobotomization”导致模型在广泛的查询中能力下降,而不仅仅是在受限话题上。
- 对于那些过度炒作安全优先的模型发布的长期相关性存在怀疑;人们认为最初的兴奋感会迅速消退,特别是如果限制性政策使得模型在实际效用或通用性上与限制较少的替代方案相比缺乏竞争力。
- Anthropic 的 CEO 将开源斥为“红鲱鱼(转移注意力的借口)”——但他的推理似乎完全没抓到重点! (Score: 390, Comments: 203): 引用的图片可能是一张截图,引用了 Anthropic CEO Dario Amodei 在最近的 Big Technology Podcast 中的言论,他将开源 AI 描述为“红鲱鱼”,即不是 AI 进步或安全的核心问题。该帖子和技术评论批评了这一立场,指出获取强大模型(而非运行推理)才是真正的瓶颈,并暗示 Anthropic 在推理方面的技术局限性进一步削弱了 Amodei 的论点。这反映了关于模型开源是否能有效促进 AI 获取或安全的持续争论。 评论者指出了 Anthropic 被感知的虚伪或误解,一些人认为他们的技术弱点损害了其立场。其他人将 Anthropic 的立场与 OpenAI 进行了负面对比,暗示在开源语境下对 Anthropic 的负面情绪更强。
- 讨论集中在 Anthropic 在推理基础设施和优化方面的相对弱点,用户断言 Anthropic “在运行推理方面是出了名的不擅长”,暗示该公司在这方面的技术局限性削弱了他们对开源的否定。该论点意味着获取强大的模型——以及高效运行它们的手段——仍然是行业的关键瓶颈,而不仅仅是部署或软件开放性的问题。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. KittenTTS:超轻量级 TTS 模型发布
- Kitten TTS : SOTA 超微型 TTS 模型(小于 25 MB) (Score: 1752, Comments: 257):KittenTTS 是来自 Kitten ML 的新型开源 TTS 模型,包含代码和权重(GitHub, HuggingFace),预览版小于 25MB 且参数量约为 15M,后续将推出约 80M 参数的版本(具有相同的 8 种英语语音)。15M 参数的模型提供了 8 种富有表现力的声音(4 男 4 女),运行占用不足 25MB,并能在无需 GPU 的低资源硬件(如 Raspberry Pi、手机)上高效运行——目标是边缘和 CPU 部署场景。未来版本计划支持多语言。 一位技术评论者称赞了该模型在有限参数预算下的语音质量,并建议将演示中更具表现力的声音设为默认值,而不是要求修改源代码。人们对将语言支持扩展到意大利语和其他语言很感兴趣。
- 主要的技术赞誉集中在模型以极小的占用空间(<25MB)提供令人印象深刻的音频质量的能力,这与通常大得多的标准 TTS 模型相比非常显著。用户特别提到它在本地运行良好,并表示希望支持意大利语等其他语言。
- 存在易用性实现方面的批评:一位评论者指出最好的声音不是默认设置,切换声音进行快速测试需要编辑源代码,这影响了快速原型设计或演示复现。建议改进 UI 或配置以便更轻松地选择声音。
- 一位用户提供了其本地运行的音频样本链接,观察到生成的音频与发布视频中的演示存在差异,并寻求澄清或故障排除步骤。这暗示了可能影响最终用户结果的可复现性问题或推理配置不匹配。
- 使用 Qwen 生成 (Score: 188, Comments: 38):该帖子引用了使用阿里巴巴 LLM Qwen 生成的图像,但一位用户观察到不同帖子中来自 Qwen 的图像始终显得模糊。没有给出其他技术实现、配置或版本的详细信息。 主要的技术讨论是 Qwen 输出中的图像质量问题(特别是模糊),没有进一步的分析或调试。
- 多位用户注意到 Qwen 生成的图像始终显得模糊,且与 Flux 等其他模型的输出相比,具有过度的泛光(bloom)照明效果。有人建议 Qwen 输出的图像清晰度和光照控制可能落后于其他 SOTA 生成模型。
3. Llama.cpp 特性更新与 MoE 卸载
- 新的 llama.cpp 选项让 MoE 卸载变得极其简单:
-n-cpu-moe(Score: 262, Comments: 65):最新的llama.cpp版本引入了-cpu-moe和-n-cpu-moe标志,显著简化了从 GPU 到 CPU 的 Mixture-of-Experts (MoE) 层卸载过程。这消除了以前张量卸载 (ot) 所需的复杂正则表达式,允许用户通过简单调整模块数量来优化 GLM-4.5-Air-UD-Q4_K_XL 等gguf模型的卸载计数。在测试中,用户在 3x3090 GPU 上使用-n-cpu-moe 2达到了>45 t/s的速度。 评论普遍证实了该选项的技术有效性,指出其性能调优比手动选择张量更高效且用户友好,并成功应用于高需求模型(如 GLM4.5-Air)。对于这种比以往手动配置方案更直接的实现方式,社区给出了积极反馈。llama.cpp中的--n-cpu-moe选项允许用户轻而易举地将 Mixture-of-Experts (MoE) 层卸载到 CPU,正如在 GLM-4.5-Air-UD-Q4_K_XL 模型(gguf格式)上所演示的那样。一位在 3x3090 配置上使用该标志运行 llama-server 的用户报告称,其吞吐量超过了45 t/s,凸显了在合理分配卸载任务时对性能的强大提升。- 技术讨论观察到,与手动张量卸载相比,
--n-cpu-moe选项简化了流程,特别适合 GLM4.5-Air 等 MoE 模型。这减少了用户的猜测工作,降低了实现最佳多硬件利用率的门槛。 - 进一步增强的建议包括启用跨机器层卸载(例如,将模型层拆分到 Mac mini 和 Linux 笔记本电脑上以整合资源),以及未来版本的
llama.cpp可能会利用模型元数据,根据具体的性能特征更智能地将层分配给 CPU/GPU,从而可能提高未来更大型模型的利用率和可扩展性。
- GPT-OSS 来了? (Score: 289, Comments: 67):该帖子讨论了
llama.cpp一个即将合并的主要 Pull Request (PR #15091),该 PR 增加了对新 GPT-OSS 模型(来自 OpenAI 的开放权重模型)的支持。链接的图片可能显示了在本地运行 GPT-OSS 相关的终端输出或统计数据。评论者确认 GPT-OSS 已在多个项目中运行:OpenAI 的 Harmony (https://github.com/openai/harmony) 现在支持 GPT-OSS,Hugging Face Transformers v4.55.0 已包含该模型,GGUF 格式模型可在此处获取:https://huggingface.co/collections/ggml-org/gpt-oss-68923b60bee37414546c70bf。 评论强调了 GPT-OSS 在主要工具中的快速集成,社区已经在本地推理框架中利用 GGUF 模型。评论者们明确感觉到 GPT-OSS 具有即时实用性,且生态系统正在迅速适应。- OpenAI 的 Harmony 现已开源,官方模型卡片和资源可在 https://openai.com/open-models/ 获取。这一发布对于提高研究的透明度和可复现性,以及集成到下游应用中具有重要意义。
- Hugging Face 的 Transformers 库 (v4.55.0) 已集成对已发布的 GPT-OSS 模型的支持,允许开发者无缝采用。这表明了主要 ML 框架的快速生态适应和支持。
- GPT-OSS 已经支持 GGUF(一种用于高效推理的量化格式,例如配合
llama.cpp使用),如 Hugging Face 上托管的模型所示 (https://huggingface.co/collections/ggml-org/gpt-oss-68923b60bee37414546c70bf),从而实现了低资源和边缘部署。
非技术类 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Google DeepMind Genie 3 模型发布与基准测试
- Google Deepmind 的新 Genie 3 (Score: 4461, Comments: 783): Google DeepMind 的新 Genie 3 在一段 Twitter 视频中备受关注,展示了 AI 驱动的生成式游戏玩法,能够动态创建交互式环境和物体,超越了静态世界生成。展示的模型似乎能够实时合成游戏场景,表明其较之前的版本(如 Genie v2)有了显著进步,并暗示了在开放世界和沉浸式模拟场景中的应用。 评论提出了将 Genie 3 用于 VR/metaverse 应用的想法,并推测其对开放世界游戏模拟的影响,暗示了相对于 GTA 等大型游戏系列的潜在竞争影响。技术辩论集中在递归模拟的可能性和交互式环境的可扩展性上。
- 评论者强调了 Google 的 Genie 3 在 VR 和 metaverse 环境中的潜在应用,认为其从 2D 图像生成交互式 3D 模拟的能力可以加速沉浸式内容开发和程序化世界生成。
- 关于 Genie 3 的未来轨迹和可扩展性的推测不断涌现,技术读者预期随后的研究论文或模型迭代将在生成式模拟、交互式环境、甚至实时用户驱动的内容生成方面产生快速进展。
- DeepMind:Genie 3 是我们突破性的世界模型,可根据单个文本提示创建交互式、可玩的环境 (Score: 1484, Comments: 364): DeepMind 的 Genie 3 是一个自监督世界模型,可根据单个文本提示动态生成完全交互式、可玩的 2D 环境,反映了较之前生成式环境模型的重大进步。从技术上讲,Genie 3 解决了在长时间跨度内保持环境一致性的挑战:虽然自回归视频生成模型通常会受到误差累积的影响,但 Genie 3 可以一次维持数分钟的高视觉保真度和连贯的物理状态——视觉记忆可持久长达一分钟。正如 DeepMind 官方 Genie 3 公告和相关研究论文所述,该模型在生成环境的质量和持久性方面都大幅领先于其前代产品。 评论者强调了技术的快速进步,特别是在长时环境持久性方面,并对实时交互式媒体和 AI 生成的游戏或模拟内容的潜在影响感到兴奋。生成环境中“持久记忆”的出现被视为一项重大的技术突破,暗示着在游戏和模拟领域即将产生的影响。
- 讨论强调了在 AI 生成的世界中保持长时环境一致性的技术挑战,特别是因为自回归生成环境会导致误差累积,从而降低体验。Genie 3 被指出实现了“视觉记忆可追溯到一分钟前”,并能保持环境一致性达数分钟,这代表了较仅六个月前的模型有了显著进步。
- 技术读者指出,类似技术的先前版本在短短半年内的表现要差得多,这标志着最近的进展是“疯狂的”,因为生成环境的持久性和现实感有了巨大改进。
-
从 Genie 2 到 Genie 3 的进步是疯狂的 (Score: 934, Comments: 129): 该帖子强调了从 Genie 2 到 Genie 3 的重大进步,这些是专注于交互式环境合成的生成式 AI 系统。虽然没有详细说明具体的基准测试,但语境暗示了在生成现实感、交互性或能力方面的重大飞跃。一个引用的问题询问该技术是否类似于 Oasis AI 的 Minecraft 生成项目,暗示了在 AI 驱动的开放世界内容创建方面的相似性。 热门评论推测了快速的进展(“Genie 5 将在 2 年内创建 GTA 7”),并设想了与 VR 和语音输入集成,以实现类似于“holodeck”的沉浸式体验。
- 一位评论者指出,Genie 2 无法进行实时交互;用户之前必须预先输入一整套动作序列,而 Genie 3 提升了交互性和响应速度。这标志着 Genie 项目在实时、Agent 驱动的游戏模拟方面取得了显著飞跃。
- 另一个技术主题探讨了 AI 内容生成的货币化,将按 token 付费模式(典型的 LLM 或生成式 AI 模式)与传统的“买断制(buy-to-play)”游戏进行了对比。讨论探讨了未来的游戏访问是否可能转向按游戏时长付费模式,从根本上改变游戏的营收结构。
- 在 Genie 3 中,你可以低头看到自己在行走 (Score: 2710, Comments: 371):该帖子强调了 DeepMind 的 Genie 3 的一项功能。Genie 3 是一个生成式 Agent,可以从图像或视频中合成交互式、可玩的 3D 环境,用户可以低头看到自己的化身(avatar)在行走。这表明该模型在合成环境中具有先进的自我表征和实时渲染能力,这对于具身 AI(embodied AI)和模拟保真度具有重要意义。背景信息请参阅 DeepMind 的 Genie 项目文档。 评论者对游戏和历史重现方面的应用感到兴奋,并指出了其对沉浸感的影响,而一条评论将这种现实感与模拟假设(simulation hypothesis)的辩论联系起来。
- 简单的视频生成与 Genie 3 渲染实时第一人称视角(用户可以低头看到自己行走)的复杂性之间存在关键的技术区别。这意味着更先进的场景理解、空间一致性,以及可能的即时化身生成和一致性定位,这些都远超简单的视频生成。此类系统可能需要实时 3D 场景重建和强大的位置追踪(positional tracking)来维持沉浸感和真实感。
- Genie 3 模拟像素艺术游戏世界 (Score: 570, Comments: 84):该帖子展示了生成式 AI 模型 Genie 3 模拟像素艺术游戏世界,很可能是通过生成低分辨率像素风格的交互式视觉环境。演示表明该模型在渲染动态、可能可玩的 2D-3D 混合像素场景方面的能力,预示着扩散模型(diffusion models)或视频/游戏环境生成的应用,类似于 Google DeepMind 及相关实验室最近的突破。帖子中未提供模型架构、帧率或与游戏引擎集成的具体细节。 评论中的技术讨论推测了未来的潜力,例如使用 AI 为 VR 提供超高保真度、世界级规模的模拟,并征求结合像素艺术与 3D 渲染的现有游戏案例,表现出对实际应用和混合视觉风格的兴趣。
- 针对混合视觉风格提出了技术咨询——特别是对类似于 Genie 3 的融合像素艺术和 3D 的游戏感兴趣。这表明 Genie 3 可能在 3D 渲染环境中使用 2D 精灵图(sprites),或者使用神经渲染(neural rendering)在体积世界几何上模拟像素艺术美学,并引发了对支持此类工作流的渲染方法或引擎的讨论。
- 一位用户推测了生成式 AI(如 Genie 3)的未来影响,认为它可能通过自动化或革命性的内容创建和世界模拟,颠覆 Unreal 和 Unity 等游戏引擎。该评论暗示了先进模型最终可能取代传统沉浸式世界开发流程的可能性。
-
Genie 3 前沿世界模型(Frontier World Model) (Score: 269, Comments: 56):DeepMind 的 Genie 3 被称为“前沿世界模型”,标志着生成式 AI 在根据自然语言提示词创建交互式、可探索世界方面的重大飞跃,可能结合了视觉、物理和语义理解。技术愿景集中在生成式 3D 建模的无缝集成,以及即时、高保真虚拟环境的可能性,暗示了在 VR 和高级游戏设计中的应用。 评论者强调了 Genie 3 通过实现按需生成 VR/3D 世界来彻底改变 AAA 游戏开发的潜力。人们期待将其与先进的 3D 建模集成,引发了关于 AI 生成内容未来沉浸感的辩论。
- 一个关键的技术见解是,像 Genie 3 Frontier 这样的模型可能成为自动化复杂 3D 世界生成的基础,这预示着生成式 AI 与高级 3D 建模工作流最终将走向融合。通过按需创建资产和环境,这可能会弥合通往自动化 AAA 级游戏开发之间的鸿沟。
- 一些评论者讨论了将大规模世界模型(如 Genie 3)与交互式 3D 建模流水线相结合的潜力。这意味着这种集成可以实现游戏世界的即时创建和操纵,从而有效地加速并彻底改变传统的游戏设计和模拟制作。
- 获得访问权限的前 Google 研究员关于 Genie 3 的笔记 (Score: 466, Comments: 68): 一位前 Google 研究员评估了来自 Google DeepMind 的 Genie 3 世界模型,强调了其在游戏和现实世界环境中的泛化能力、快速启动、强大的视觉记忆(在遮挡/时间跨度下保持物体一致性),以及对写实和风格化场景的有效处理。局限性包括系统性物理失效(特别是在刚体和组合任务上)、有限的多 Agent/社交互动支持、受限的动作空间,以及缺乏高级游戏逻辑/指令遵循——这表明它距离生产级游戏引擎仍有很大差距。评论者断言 Genie 3 证明了游戏行业即将面临颠覆,如果规模进一步扩大,可能是迈向 AGI/ASI 的一步,并强调了将世界模型与 3D-AI 及 LLM 集成的重要性。 评论者们争论这类世界模型的进步是否代表了通往 AGI/ASI 的拐点,一些人认为这种高保真想象/可视化模型在与其他模态融合时是 AGI 的“最后一块拼图”,而另一些人则推测行业领导地位(Google 与其他公司)以及游戏领域的竞争压力。
- 一个关键讨论点是 Genie 3 架构在弥合 AGI 差距方面的意义:通过赋予模型不仅通过语言推理,还通过一种类似于人类认知的“想象力”或视觉/空间推理的能力,它解决了多模态 AI 进步中的一个主要瓶颈。
- 一位评论者强调了技术进步的飞速:自 Genie 2 以来,像素数量增加了四倍,可能的交互时间在八个月内增加了十倍。据此推断,他们估计在资源充足的情况下,一年内实现一小时的实时 4K 生成是可行的。
- 存在关于计算需求的讨论,质疑像 Genie 3 这样高分辨率、高帧率的模型多久能在数据中心之外运行,指向了普及高级生成式模型访问权限所面临的主要挑战。
2. OpenAI 开源模型与 GPT-OSS 发布
- 如果开源模型都这么好,GPT-5 可能会非常疯狂 (Score: 477, Comments: 119): 该帖子讨论了一个新开源的模型(被称为 ‘o4-mini’),暗示其规格极具竞争力——意味着其能力可与 OpenAI 的专有模型相媲美。用户推测 OpenAI 之所以开源这个模型,是因为他们即将推出的 GPT-5 可能会显著超越当前的开源模型,使它们变得不再那么重要。引用的图片链接显示了新模型的 Benchmark 结果或配置证据。 热门评论多为非技术性的,表达了兴奋或对 OpenAI 进展的依赖(例如,“加速”、“永远押注于那个年轻人”),但缺乏实质性的技术辩论。
- 评论者对所提到的开源模型的质量和明显进展表示惊讶,暗示了快速的迭代和足以媲美或接近顶尖闭源替代方案的竞争性能。一些言论暗示相关贡献者或组织拒绝了巨额的资金报价,强调了该技术在 AI 社区中极高的感知价值。虽然这些具体评论中没有提供具体的 Benchmark 或技术细节,但讨论反映出人们认识到,有影响力的开源模型进展可能会改变相对于 GPT-5 等闭源模型的竞争格局。
- OpenAI OS Model today? (Score: 383, Comments: 60): 该帖子讨论了 OpenAI GPT-OSS-20B 开放权重(open-weight)语言模型的发布,引用了相关的 Kaggle 竞赛,用于对该模型进行红队测试(安全评估)(https://www.kaggle.com/competitions/openai-gpt-oss-20b-red-teaming)。图片似乎是与此次发布相关的截图或公告,标志着 OpenAI 转向开源至少部分模型的举措,社区重点关注技术细节以及与 Genie 3 等模型的竞争性基准测试。显著的技术方面是其开放权重状态和模型在竞赛中的应用。图片链接 评论者推测该模型是否具有竞争力,或者是否比预期的更大(“想象一下如果 big-but-small 就是 GPT-5”),并将其与 Genie 3 进行比较,突显了社区对性能和开放性的期望。
- 用户指出 OpenAI 发布了 ‘gpt-oss-20b’ 模型作为开放权重模型,并引用了其在 Kaggle 红队竞赛页面上的列表 (链接)。这表明 OpenAI 向开源迈出了重要一步,允许社区对模型的安全性和能力进行严格的测试和评估。
- 讨论推测即将进行重大的模型升级,用户询问是否会发布 “GPT-5” 或更小但架构先进的模型(绰号为 “big-but-small”)。这种预期在技术上基于对相比 GPT-4 等前代产品在能力或效率上有实质性提升的期望。
- 另一条指向 OpenAI 员工声明的链接暗示了以开发者为中心的公告,可能预示着新的 API 功能、供第三方使用的增强型模型权重,或针对开发者集成的工具,进一步引发了关于模型开放性和可访问性的猜测。
- OpenAI releases a free GPT model that can run right on your laptop (Score: 303, Comments: 50): OpenAI 发布了一款名为 GPT-OSS 的免费开放权重 GPT 模型,提供 120B 和 20B 参数版本,其中较小的 20B 模型可以在 16GB RAM 的机器上运行,而较大的版本则需要单个 Nvidia GPU。120B 变体的性能与 o4-mini 模型相当;20B 变体的能力与 o3-mini 相当。两者均采用宽松的 Apache 2.0 许可证分发,并可通过 Hugging Face, Databricks, Azure 和 AWS 获取 (The Verge 摘要)。 评论者强调了在本地硬件(16GB RAM)上运行 20B 模型的实用性,并对响应延迟和实际能力提出疑问。人们对与既有模型的对比基准测试感兴趣,但初步讨论中的细节仍然较少。
- 新的 OpenAI 开放权重模型 GPT-OSS 有两个版本——120B 和 20B 参数。120B 参数模型可以在单个 Nvidia GPU 上运行,据报道其表现与 o4-mini 相似,而 20B 参数版本仅需 16GB 内存即可运行,基准测试接近 o3-mini(参见 The Verge 文章)。两者均在 Apache 2.0 许可证下分发,允许通过 Hugging Face, Databricks, Azure 和 AWS 等平台进行商业修改和部署。
- 一位用户提到了新模型 91.4% 的幻觉率 (hallucination rate),这表明尽管在可访问性和硬件要求方面有所改进,但在这些早期版本中,事实可靠性仍然是一个重大问题。这强调了在将开放权重 LLM 部署到生产环境之前,对其进行严格评估和实际测试的必要性。
- OpenAI 终于发布了开源模型!!达到 o4 mini 级别!!现在我们可以说这就是 OpenAI 了 (Score: 284, Comments: 47): 该帖子讨论了 OpenAI 最近发布的开源(”os”)模型,据报道其性能水平可与 “o4 mini”(可能指 OpenAI 的 GPT-4 mini 或类似的紧凑型模型)相媲美。根据用户评论,这些模型的 20B 参数版本仅需 16GB RAM 即可运行,使得高质量的 LLM 推理在更广泛的硬件上变得更加可行。另一位用户确认了在 LM Studio(一个用于大语言模型的本地推理环境)中的成功使用和令人印象深刻的性能。 评论者对开源模型质量的快速进步感到惊讶和印象深刻;由于上下文原因,一些人甚至将缩写 “os” 误读为 “操作系统” (operating system)。人们对未来的发布(例如 “GPT-5 将会非常出色”)持乐观态度,并对本地运行的硬件效率充满热情。
- 据报道,OpenAI 的 20B 参数开源模型仅需 16GB RAM 即可运行,这使得在消费级硬件上进行本地推理成为可能——即使是相对较大的模型。这种低硬件要求极大地拓宽了开发者和研究人员的可访问性。截图
- 使用 LM Studio 等工具测试新模型的用户表示对其性能印象深刻,并指出开源模型的质量在过去一年中加速提升。这表明在相同参数范围内,其推理速度和能力与其它商业产品相比具有竞争力。
- 讨论强调,此类开源模型可以支持定制化聊天机器人驱动的应用和创新产品的开发,预计在 GitHub 等平台上,由于更简单、高质量的本地部署,开源项目将直接增长。
- Gpt-oss 是目前最先进的权重开放推理模型 (Score: 389, Comments: 141): 一则帖子宣布 “Gpt-oss” 现在被认为是目前最先进的权重开放 (open-weights) 推理模型,在推理能力上可能超越了之前的权重开放模型。主要证据是一个链接的 JPEG 图像,可能是将 Gpt-oss 与现有模型进行的基准测试,暗示了相当大的技术进步,但文中未提供具体的指标或架构细节。 评论对未来模型(如 GPT-5)的影响表示乐观,但该线程缺乏批判性的技术讨论或详细的对比基准测试细节。
- FoxB1t3 认为 Horizon 实际上是来自 OpenAI 的 OSS 120b,并指出尽管其规模巨大(’120b’),但它具有典型的“小模型感”,这可能指其推理速度、校准或与体量相比的输出精致度。该用户还指出,关于在普通 PC 上运行此类海量模型(1200 亿参数)的说法是不切实际的,强调了硬件要求,并暗示这些营销声明从实现角度来看具有误导性。
- Grand0rk 强调该模型表现出极高程度的审查,表明安全过滤器或内容审核非常严格。这影响了需要较少控制输出的任务的部署和研究效用,对于那些打算在无审查环境中使用或微调模型的人来说,这是一个技术考量。
-
介绍 gpt-oss (Score: 161, Comments: 48): 发布了一款新的开源 LLM ‘gpt-oss’,其中包含一个引人注目的 20B 参数模型。来自 Apple silicon (M3 Pro, 18GB) 用户部署的基准测试显示,生成速度约为 30 tokens/sec——明显快于 Google Gemma 3 (17 TPS)。据报道,该模型在消费级 Apple 硬件上加载效率很高,支持大上下文补全。 专家用户正在争论 20B 模型在长文本任务(例如 500 字短篇小说、言情类类型小说)中的定性写作能力,对其创意连贯性与成熟 AI 模型相比仍存疑问。此外,社区对集成到 OpenRouter 的 Prompt 支持表现出浓厚兴趣。
- 一位用户指出,20B gpt-oss 模型在配备 18GB RAM 的 MacBook Pro M3 Pro 上运行时,达到了约
30 tokens per second(TPS),这明显快于 Google 的 Gemma 3(在相同硬件上报告约为17 TPS)。这表明该模型针对本地部署进行了显著的推理优化,并且与同等规模的其他大语言模型相比,效率有所提高。 - 另一位评论者讨论了在 Mac mini (M4 Pro, 64GB RAM) 上运行 20B 模型的情况,并质疑该模型生成长篇连贯输出(如 500 字的短篇小说或言情等特定类型)的能力。这突显了用户对本地硬件上实际生成质量以及处理大型输出任务的持续性能的关注。
- 用户对离线/本地部署表现出浓厚兴趣,有一条评论询问了最低硬件要求以及该模型是否可以完全在没有互联网连接的情况下运行。Altman 提到的“高端”硬件引发了关于像 gpt-oss 这样的大型模型在本地进行推理的可访问性的讨论。
- OpenAI 的开放模型 (Score: 178, Comments: 17):OpenAI 发布了开放权重模型,特别是 20B 参数模型,旨在 ≥16GB VRAM 或统一内存的消费级硬件(包括 Apple Silicon Macs,见官方文档)上优化运行。早期使用 Ollama 的用户测试最初在 16GB Mac mini 上遇到了部署问题,但随后的 Ollama 更新解决了这些问题,验证了在该硬件配置上的兼容性。 讨论集中在模型的硬件需求以及 Ollama 实现的初始问题(现已解决)。用户普遍对基准测试和开源选项的可用性表示热忱,并指出它是当前开放 AI 生态系统中的领先选择。
- 一位拥有 16GB Mac mini 的用户分享了尝试运行 20B OpenAI 模型的经验,引用了文档中提到的模型“在 ≥16GB VRAM 或统一内存下表现最佳”且适用于 Apple Silicon Macs。最初,他们在使用 Ollama 运行时遇到了问题,但指出在 Ollama 团队发布新版本/更新并重新下载后,模型可以按预期工作,这表明消费级硬件的兼容性更新非常迅速。
- OpenAI 开源模型!! (Score: 115, Comments: 15):该图片似乎显示了与 OpenAI 新发布的开源模型相关的基准测试或对比——可能展示了它们的性能(可能是一个 120B 参数的 MoE,包含 5.1B/3.6B 激活参数等细节)。帖子背景和技术评论辩论了规模(120B 参数,Mixture-of-Experts)和推理中的激活专家数量,表明 OpenAI 的开源发布在开源领域处于领先地位。此外还强调了 OpenRouter 的支持以及与未发布模型(例如潜在的 GPT-5)的性能对比。 评论者对规模以及 OpenAI 的开源版本没有被“削弱”(故意降低性能)感到印象深刻;一些人对如果开源模型都这么强,闭源的 GPT-5 能达到什么水平表示兴奋,并注意到该模型已通过 OpenRouter 提供。
- 据报道,发布的模型是一个 120B 参数的 Mixture-of-Experts (MoE),每次仅激活 5.1B 或 3.6B 参数,突显了一种可扩展的效率设置,即在推理过程中仅启用一部分专家。这种 MoE 结构允许模型拥有更大的容量,而不会产生与其参数总量相对应的全部推理成本。
- 社区内正在进行关于哪个变体(尤其是 ‘o3’)在已发布模型中提供最佳性能的技术辩论,这表明一些对比基准测试或定性测试正在进行中。用户还注意到 OpenRouter 上的早期可用性,这促进了更简便的第三方评估和部署。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. Qwen-Image 与开源多模态生成基准测试
- Qwen 的图像提示词遵循能力达到 GT4-o 级别。 (得分: 448, 评论: 128): 该帖子讨论了 Qwen 的图像生成模型,并将其提示词遵循能力与 GPT-4o 进行了比较。用户提供了一系列富有创意且详细的提示词,并指出 Qwen 在忠实执行指令方面的改进。热门评论指出,虽然提示词遵循能力很强,但输出结果往往带有“AI 感”或照片蒙太奇的特质,且在 genai-showdown.specr.net 等基准测试网站上的表现可能落后于顶尖模型。 评论对图像的真实感和视觉质量表示担忧,多位用户表示输出结果看起来“不真实”或“像拙劣的 Photoshop 修图”,这表明对提示词的忠实度并不一定能产生逼真或自然的图像。此外,还有关于 Qwen 的性能是否达到 SOTA 的辩论,并引用了外部基准测试。
- 存在关于提示词遵循能力与视觉真实感的讨论:虽然用户注意到 Qwen 图像模型在提示词服从度方面有显著提升(有人认为其与 GT4-o 相当),但也有批评指出输出结果仍然显得虚假或让人联想到粗糙的数字编辑,突显了生成模型在真实感方面面临的持续挑战。
- 一条评论引用了 https://genai-showdown.specr.net,该网站汇总了生成模型的基准测试对比,暗示关于 Qwen 提示词遵循能力等同于 GT4-o 的说法并未得到直接对比基准测试结果的充分支持。
- Qwen 图像模型展示了强大的多语言能力,使用西班牙语提示词生成详细且上下文准确的图像示例证明了这一点,展示了跨语言的竞争性能。
- Qwen 的图像提示词遵循能力令人惊叹 (得分: 140, 评论: 19): 该帖子展示了 Qwen-Image 模型(特别是
gguf Q5_k_m变体,可在此处获取)的高提示词遵循能力,通过 20 步推理过程生成图像——例如一个复杂的请求:一张 1920 年代的档案照片,主体带有数据损坏(datamoshed)和故障(glitched)效果。示例输出可在此处预览,更多图像通过链接的 Google Drive 文件夹提供。此次技术展示重点在于该模型渲染细粒度提示词细节和复杂视觉效果(如 RGB 故障和乳剂伪影)的能力。 评论者注意到了该模型强大的基础性能,并对进一步微调的潜力表示关注,表明其在定制化生成任务中的适应性。 -
对 Qwen-Image 的提示词遵循能力和整体质量印象深刻 (得分: 105, 评论: 36): 该帖子强调了在 ComfyUI 工作流中使用 Qwen-Image(一种图像生成模型)所实现的令人印象深刻的提示词遵循能力和图像质量。用户仅将推理步数增加到 30 步,其余均遵循 Qwen-Image 官方文档的标准流程。据其描述,结果在第一次尝试时就以高保真度匹配了复杂的多元素提示词,表明了强大的条件图像合成能力和改进的提示词遵循行为(详见 https://docs.comfy.org/tutorials/image/qwen/qwen-image)。 评论者讨论了技术资源需求(据报道 fp8 模型需要约 20GB VRAM),反映了本地使用的硬件限制。进一步的评论赞赏了该模型的叙事能力,并将其与新扩散模型带来的质量飞跃相类比。
- 一条评论指出,FP8 版本的 Qwen-Image 需要 20GB VRAM,这表明全精度推理对资源的需求很高,可能会根据硬件能力影响用户的可访问性。
- 一位用户询问了与 Forge 和 Comfy 等平台的集成情况,对兼容性和所需架构表示不确定,这表明 Qwen-Image 的部署细节对一些实现者来说仍然是一个困惑点。
- 值得注意的是,Qwen-Image 无需外部 LoRAs (Low Rank Adapters) 即可实现高质量输出和提示词遵循,这与 Flux 等通常需要针对性 LoRAs 才能达到类似性能的模型不同,这指向了 Qwen-Image 在架构或训练上的改进。
- 为什么 Qwen-image 和 SeeDream 生成的图像如此相似? (Score: 107, Comments: 52): OP 观察到 Qwen-image 和 SeeDream 3.0 在给定相同提示词(“Chinese woman” 和 “Chinese man”)时,生成的图像几乎完全相同,这引发了关于训练数据集或训练后程序可能存在重叠的疑问。值得注意的是,Qwen-image 是开源的,而 SeeDream 之后更新到了 3.1 版本,其图像风格与 3.0 版本有所不同。 一位技术相关的评论者注意到这些模型生成的几张图像中反复出现“橙色调”,这表明输出中可能存在伪影或颜色表示偏差,这可能与数据或模型训练细节有关。
- 一些用户推测 Qwen-image 和 SeeDream 可能会产生视觉上相似的图像,是因为它们在重叠甚至相同的数据集上进行了训练,可能包括来自 Midjourney、Stable Diffusion 或 Flux 等主要来源的提示词或数据。这种共享的训练基础可以解释不同模型生成的输出之间的相似性。
- 值得注意的是,用户观察到了一致的视觉基调——例如在这些模型的多次生成中反复出现的橙色调。这表明可能存在共同的预处理流水线或在训练期间引入的数据集偏差,无论提示词如何,这些偏差都可能传播到模型输出中。
- 讨论指出,此类强大的生成模型的开源使得广泛的审查、比较和逆向工程成为可能——与专有模型相比,这为追踪这些系统的演变和偏差提供了一个独特的视角。
- 🚀🚀Qwen Image [GGUF] 已在 Huggingface 上线 (Score: 188, Comments: 74): 该帖子宣布了 Qwen Image GGUF 模型(包括 Q4K M 量化版)在 HuggingFace 上的可用性,并提供了多个仓库链接:lym00/qwen-image-gguf-test、city96/Qwen-Image-gguf、一个独立的 GGUF 文本编码器 (unsloth/Qwen2.5-VL-7B-Instruct-GGUF) 以及用于 ComfyUI 的 VAE safetensors。仅 Q4 量化模型就约为 11.5GB,不包括 VAE 和文本编码器,这使得在显存较少的消费级 GPU(如 RTX 3060)上运行具有挑战性。GGUF 格式允许本地推理,但不会加速渲染,且 VRAM 仍然是一个重要的瓶颈,32GB+ 的显存对于最新的生成模型也只能提供有限的缓解。 热门评论表达了对模型大小和 VRAM 限制的沮丧,并指出较低的量化会导致较差的结果。讨论中还提到了 Diffusion 模型缺乏实用的多 GPU 支持,以及对统一内存(如 TPU)的需求。此外还链接了 ComfyUI 的使用示例,提供了实用的工作流。
- GGUF 格式使 Qwen 等大型生成图像模型的本地推理成为可能,但 VRAM 是目前的主要限制:例如,仅 Q4 量化模型就有 11.5GB,还不包括 VAE 和文本编码器的额外要求,这使得在显存有限的 GPU(如 12GB 的 RTX 3060)上运行变得不可能 来源。较低的量化(如 Q4)会显著降低质量,而 FP8 在消费级 GPU 上仍然很慢。
- 虽然 GGUF 在技术上使本地运行这些模型成为可能,但实际性能和速度受到缺乏多 GPU 支持的瓶颈限制——大多数工作流只能分配单独的任务,而不能将核心 Diffusion 计算拆分到多个 GPU 上。人们期待更好的硬件集成,例如通过 TPU 实现统一内存,但目前的进展尚未跟上模型的需求。
- 提供多种 quantization 和 precision 选项——例如 Dfloat11 和 FP8——但用户仍反映在确定最佳生成设置(如 cfg 参数)方面存在困难。ComfyUI 示例等社区资源(见:https://comfyanonymous.github.io/ComfyUI_examples/qwen_image/)正在整理中以提供指导,但最佳实践仍在开发中。
- Qwen-image 现已在 ComfyUI 中受支持 (评分: 208, 评论: 67): Qwen-image 是一款强大的图像生成模型,现已集成到 ComfyUI 以及 SwarmUI (文档)。在 4090 (Windows) 上的基准测试显示,在
CFG=4,Steps=20,Resolution=1024设置下,推理时间约为45 sec/image(或者在CFG=1,Steps=40时类似)。由于其庞大的 text encoder 和参数量,该模型需要高 VRAM,虽然在高 steps/CFG 下报告了最佳效果,但在速度上存在巨大权衡。显著的技术优势包括强大的 prompt 理解能力、文本渲染和极少的审查;但在某些 prompt 上的表现不一致问题仍未解决。 评论者们讨论了平衡质量和速度的参数配置 (CFG/Steps/Resolution),并指出由于高算力需求,quantized模型版本对于更广泛的普及是必要的。一位用户还提到了对 svqd(可能是 semantic vector quantization)支持的需求。- Qwen-image 现已在 ComfyUI 和 SwarmUI 中受支持,SwarmUI 的技术文档详细说明了配置参数。用户报告称,Qwen-image 的最佳生成质量需要高数值(CFG=4, Steps=50, res=1024+),但这会大大增加推理时间(例如,在 RTX 4090 上,CFG=4, Steps=20, Res=1024 每张图耗时约 45 秒)。较低的 CFG 或 Steps 运行速度更快,但会降低输出质量;建议在性能较弱的 GPU 上使用 quantized (quants) 版本或 LoRAs 来提升速度。
- 该模型的 text encoder 和参数需要大量的 VRAM 和计算资源——评论者强调了 quantized 或 GGUF(用于 llama.cpp 兼容性)版本的必要性,以便为硬件有限的用户扩大可用性。该图像模型因其 prompt 忠实度、文本渲染能力、极少的审查以及对流行文化 IP 的识别而受到赞誉,尽管它在某些 prompt 上表现出不稳定性。
- 对 SVQD (vector quantization) 和 GGUF 文件格式的需求显示了社区对效率和更广泛部署的兴趣,特别是针对较小的 GPU,这与将大型模型移植到轻量级、易于访问格式的大趋势相一致。
{kind=link}
{kind=link}
{kind=link}
AI Discord 回顾
由 Gemini 2.5 Pro Exp 提供的总结之总结之总结
主题 1. OpenAI 的 GPT-OSS 发布引发广泛辩论
- GPT-OSS 模型发布,社区争相测试: OpenAI 发布了自 GPT-2 以来的首批开源模型 GPT-OSS 系列,包括 120B 和 20B 参数版本,现已在 HuggingFace 和 LM Studio 上架。发布的同时还举办了为期六周的虚拟黑客松以及在 Kaggle 上进行的 $500K 红队挑战赛。
- 性能与审查备受关注: LMArena 排行榜的初步测试显示 120B 模型的性能接近 OpenAI o4-mini,但用户发现其表现令人失望,幻觉比除 Llama 4 Maverick 之外的大多数模型都多。Unsloth 和 Perplexity 社区的许多工程师指出,该模型被极度审查,引发了关于通过 abliteration 技术提高可用性的讨论。
- 技术拆解揭示新颖架构: 这些模型使用 MXFP4 quantization,权重打包为 uint8,block size 为 32,使得 120B 模型能够装入单块 80GB GPU。该架构还具有交错滑动窗口注意力机制(interleaved sliding window attention)、用于结构化交互的 Harmony chat format,并使用了每个 head 的学习注意力槽(learned attention sink per-head)。
主题 2. 来自 Anthropic、Google 等公司的新模型涌入市场
- Anthropic 的 Claude 4.1 Opus 瞄准 Agent 卓越性能:Anthropic 发布了 Claude 4.1 Opus,可在 OpenRouter 上使用,目前在 SWE Bench 编码基准测试中处于领先地位,并凭借占据 前 10 名中的 9 个席位 统治了终端 Agent 基准测试。虽然因其卓越的工具使用能力而受到赞誉,但一些用户指出它在空间测试中仍然失败,并质疑轻微的改进是否与其成本相符。
- Google DeepMind 揭晓 Genie 3 世界模拟器:Google DeepMind 宣布推出 Genie 3,这是其最先进的世界模拟器,能够以 20-24 fps 的速度生成高保真视觉效果,并具有动态提示和持久的世界记忆。虽然没有为 Genie 3 发布专门的论文,但社区指向了 原始 Genie 论文,以获取有关底层世界模型架构的技术见解。
- 关于 GPT-5 即将发布的猜测升温:关于本周可能发布 GPT-5 的讨论愈演愈烈,这源于 Sam Altman 的暗示以及在 X 上分享的内部泄露。推测认为它可能是一个与 Horizon 相关的 Operating System Model(操作系统模型),尽管一些人认为像 GPT-4.1 这样的小幅更新可能性更大。
Theme 3. Developer Ecosystem Tools and Frameworks Evolve
- LibreChat 极大提升 LM Studio 速度:用户对通过 LibreChat 调用 LM Studio 模型时的极快推理速度赞不绝口,一位用户称 “它就像一个完全相同的 ChatGPT (OpenAI) UI,服务于我所有的 LM Studio 模型,但速度极快。” 设置需要仔细配置,一位用户通过调整 YAML 缩进解决了连接问题,另一位用户通过将主机绑定到 0.0.0.0 解决了 Tailscale 问题。
- LlamaIndex 和 DSPy 应对复杂文档:LlamaParse 展示了将密集的 PDF 转换为多模态报告的能力,而 LlamaCloud 则因帮助 Delphi 等公司处理复杂文档摄取而受到关注。在 DSPy 社区,一位开发者分享了关于使用 DSPy 检测 PDF 中文档边界 的文章。
- AutoGen 和 MCP 助力 YouTube 搜索机器人:一位开发者分享了一个 YouTube 教程,介绍如何使用 AutoGen 和 MCP 服务器 构建多 Agent 聊天机器人进行 YouTube 搜索。与此同时,有人提议为 MCP 增加一种新的 浏览器内 ‘postMessage’ 传输方式,并附带了 Demo 和用于标准化的 SEP 草案。
Theme 4. AI Benchmarking and Novel Applications
- Kaggle 在质疑声中启动 AI 象棋锦标赛:Kaggle Game Arena 推出了为期 3 天的 AI 象棋表演赛,但一些工程师质疑象棋是否能作为真正的智能测试,认为它更像是一个策略优化游戏。在另一场比赛中,Kimi K2 输给了 Deepseek O3,Kimi 在做出违规移动后被迫认输。
- GLM 4.5 Air 热度高涨,在编码测试中超越对手:GLM-4.5 Air 被吹捧为强有力的竞争者,在一位用户的测试套件中获得了 5/5 的评分,并在“创建一个 HTML 游戏”的测试中超越了 Horizon Beta、Grok 4 和 Opus 等模型。尽管存在无限思考循环等小瑕疵,但共识是 GLM-4.5 确实非常强大。
- Youzu.ai 勾勒电子商务的未来:Youzu.ai 展示了其用于电子商务的视觉 AI 基础设施,其 Room Visualizer 功能允许用户上传房间照片并在几秒钟内获得完整的重新设计。配套的 演示视频 展示了用户如何立即购买重新设计房间中的每件商品。
Theme 5. Hardware Havoc and Performance Tuning
- CUDA vs. Compute Shaders 辩论升温:GPU MODE 服务器的工程师们就使用 libtorch C++ 进行图像后处理时,CUDA kernels 与 compute shaders 的优劣展开了辩论。Pytorch 宣布了关于其新 kernel DSL —— Helion 的研讨会。此外,一名用户报告了 CuTe 无法生成 128-bit vectorized store 的问题,而是发出了两个 STG.E.64 指令,这破坏了 memory coalescing。
- Linux 用户哀叹严重的 Cursor 冻结问题:多名 Linux 用户报告 Cursor IDE 冻结并失去响应,指向团队正在调查的潜在网络问题或错误请求,详见 Cursor 论坛。同时,Windows 用户被提醒,即使内存充足,禁用页面文件(page file)也可能导致奇怪且无法解释的崩溃。
- Modular 平台凭借 MAX 和 Mojo 获得提升:Modular Platform 25.5 现已上线,其特色是通过 SF Compute 实现的 Large Scale Batch Inference 以及开源的 MAX Graph API。该版本通过
@graph_op装饰器增强了 MAX 与 PyTorch 的互操作性,但提醒使用 Intel 芯片 macOS 系统的用户,目前仅官方支持 Apple Silicon CPU。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- OpenAI 发布开源 LLM!:OpenAI 发布了一款开源 LLM —— GPT-OSS-120B,可在 HuggingFace 获取,引发了关于硬件需求(推荐 H100 GPUs)和审查程度的热议。
- 成员们已经开始实验,但一些人的电脑出现了崩溃,并指出需要进行 quantization 和注意审查问题,暗示其被严厉审查。
- Opus 悄然登场:Anthropic 发布了 Claude 4.1 Opus,初步反应显示其较之前版本有小幅改进,具备更好的多文件调试能力,但在许多空间测试(spatial tests)中失败。
- 一些人认为这可能是为了胜过 OpenAI 的举动,而另一些人则强调该模型可能没有提供足够的改进来证明其定价的合理性,且存在旧的频率限制(rate limits),这可能只是对 OpenAI 的一种示威。
- GPT-5 期待升温:对潜在 GPT-5 发布的期待正在升温,可能在 7 号发布,这主要受 Sam Altman 的暗示以及关于 OpenAI 发布 Operating System Model 传闻的推动。
- 有推测认为这可能与 Horizon 有关,并讨论了在这次发布背景下 Grok 4 是否会打破任何基准测试。
- Youzu 实现电子商务可视化:Youzu.ai 正在通过视觉 AI 基础设施改变在线购物,正如在 Vivre 的全面演示中所展示的那样,该业务覆盖 10 个中东欧国家。
- Room Visualizer 功能允许用户上传房间照片并在几秒钟内获得完整的重新设计,从而实现每件商品的即时购买,详见此演示。
- Sonar API 文档现身:一位刚接触 Sonar API 的用户询问了其用法,另一位用户分享了关于 Sonar API 的 YouTube 视频链接。
- 针对关于 Sonar API 的问题,一位用户分享了 Perplexity AI 文档链接以及一个 GIF。
Unsloth AI (Daniel Han) Discord
- Unsloth 量化过载:社区请求 Unsloth 对
yisol/IDM-VTON模型进行量化,但该模型缺乏扩散训练支持,且除非有重大需求,否则 Unsloth 不处理自定义量化请求。- 这是因为实现手动量化需要大量的人力劳动和算力开销。
- Nemotron Super 49B 1.5:主力模型之选?:成员们讨论了 Nvidia Nemotron Super 49B 1.5 模型,一位成员认为只要不使用该死的列表,它的提示词遵循能力使其成为一个出色的主力模型 (daily driver)。
- 其他人对其作为通用思考模型的能力表示兴趣,指出其指令遵循能力良好,但也提到其文笔枯燥。
- GPT-OSS 遭受消融指控:对 OpenAI GPT-OSS 模型 的初步反应褒贬不一,有人称其几乎是垃圾,而另一些人则对其安全措施表示担忧,推测这是美国安全法案的结果,引发了关于消融 (abliteration) 及其可能导致模型笨得要命的讨论。
- 有人指出 GPT-OSS 的表现可能不如 GLM 4.5 Air,引发了关于该模型整体价值以及中国初创公司可能很快超越它的讨论。
- GRPO 批处理烧脑难题:有人询问 Unsloth 如何处理 GRPO 的批处理,特别是整个轨迹组是否被批量处理。
- 一位成员澄清说,如果
n_chunks设置为 1,则每个 batch 与一个组一一对应。
- 一位成员澄清说,如果
- Token Decoder Maps 框架诞生:一位成员介绍了他们的 LLM 领域特定语言框架,专为摘要等目的设计。
- 该 GitHub 项目 利用 EN- tokens 来总结特定的概念或事实,以便后续注入和提示。
LMArena Discord
- GLM 4.5 热度高涨:一位成员称赞 GLM-4.5 可能名副其实,在测试套件中获得了 5/5 的评分,并在“创建一个 HTML 游戏”的测试中超越了包括 Horizon Beta、Grok 4、o3 Pro、Gemini 2.5 Pro、Claude Sonnet 和 Opus 在内的其他模型。
- 尽管存在无限思考循环和结果差异等怪癖,该成员总结认为 GLM-4.5 整体表现非常强劲。
- AI 象棋赛开启 Kaggle Game Arena:Kaggle Game Arena 将以一场为期 3 天、包含 8 个模型的 AI 国际象棋表演赛拉开帷幕(YouTube 链接)。
- 一些人担心国际象棋是策略优化游戏而非智力测试,并质疑非视觉模型将如何理解棋盘。
- 长上下文基准测试拥抱多样化模型:成员们讨论了基准测试中的上下文窗口,指出有必要容纳大多数发布的模型(即使是那些上下文窗口较小的模型),以确保评分公平。
- 还指出针对不同的上下文大小存在不同版本,允许模型得到相应的惩罚/奖励。
- GPT-5 发布在即?:有关于 GPT-5 可能在几天内发布的讨论,一位成员指出内部泄露也提到了同样的事情(x.com 链接)。
- Jimmy Apples 推测,由于自动路由 (auto-routing),重度用户可能不会注意到 GPT-5 的改进。
- OpenAI 开源模型在 LMArena 上显示局限性:OpenAI 的 gpt-oss-120b 和 gpt-oss-20b 模型现已在 Arena 中上线,为对开源替代方案感兴趣的用户扩展了选择范围。
- 成员们测试了 GPT-OSS 120B 并发现其令人失望,性能可能与 o3-mini 或 Qwen3 235B A22B 持平,且幻觉比除 Llama 4 Maverick 之外的任何模型都多。
LM Studio Discord
- OpenAI 发布 gpt-oss 模型!: OpenAI 发布了 gpt-oss,这是一组采用 Apache 2.0 许可证的开源模型,可在 lmstudio.ai 获取,包含 20B 和 120B 参数版本。
- 在 LM Studio 上测试模型的社区成员报告称,LM Studio 网站上的链接失效,且难以定位 120B 模型以及设置 context。
- LibreChat 极大提升 LM Studio 速度!: 成员们对通过 LibreChat 使用 LM Studio 模型时的极快推理速度赞不绝口,称其为 “一个与 ChatGPT (OpenAI) UI 完全一致的界面,可以服务于我所有的 LM Studio 模型。”
- 一位用户通过调整 YAML 缩进解决了连接问题,强调了配置细节的重要性。
- Tailscale 问题?绑定到 0.0.0.0: 用户在尝试通过 Tailscale IP 将 AnythingLLM 与 LM Studio 结合使用时遇到了设置问题,导致模型列表无法加载。
- 通过将 LM Studio 主机设置为 0.0.0.0 以允许外部连接,并在防火墙中打开 1234 端口,问题得到了解决。
- 硬件故障:Windows 分页文件依然重要: 尽管 RAM 充足,但在 Windows 上禁用分页文件(page file)可能会导致奇怪且无法解释的崩溃,因为某些程序依赖它。
- 更好的替代方案是使用 zram 来压缩页面并将其存储在 RAM 中,可能在一个实际页面中容纳 2-3 个压缩页面。
- CUDA Runtime 困惑已消除!: 对于拥有 5090 和 4090 等多显卡配置,用户建议使用 CUDA 12 运行时。
- 建议加入 LM Studio 和运行时的 beta 分支。
OpenAI Discord
- OpenAI 揭晓 GPT-OSS 模型和黑客松: OpenAI 发布了 GPT-OSS 模型系列,并与 Hugging Face、NVIDIA、Ollama 和 vLLM 合作启动了为期六周的虚拟黑客松。
- 黑客松设有“最佳综合奖”、“机器人奖”和“通配符奖”等类别,为获胜者提供现金奖励或 NVIDIA GPU,此外还在 Kaggle 上举办 $500K 红队挑战赛。
- GPT-5 发布日期仍不明确: 社区成员正在积极推测 GPT-5 的发布,尽管有些人认为更可能是像 GPT-4.1 这样的增量更新或现有模型的统一;这条 X 帖子正在流传。
- 尽管充满期待,但怀疑态度依然存在,有人认为 OpenAI 可能难以让 GPT-5 表现得足够令人惊艳。
- 社区测试 GPT-OSS 模型: 据 OpenAI 博客文章,120B 参数的 GPT-OSS 模型在核心推理基准测试上据称与 OpenAI o4-mini 几乎持平,同时能在单张 80 GB GPU 上高效运行。
- 据说 20B 参数模型的表现与 OpenAI o3‑mini 相似,并能在仅有 16 GB 内存的边缘设备上运行。
- AI 引发学术诚信辩论: 一位教授正在教其他教授如何使用 AI 出题,但学生们反过来也在用 AI 完成考试,这引发了对批判性思维侵蚀的担忧。
- 普遍观点是 AI 应该分担低技能任务,让个人专注于问题的核心部分,但如果关掉自己的大脑,只会产生 “平庸的快餐式输出”。
- 新 Ollama GUI 简化本地模型访问: 新的 Ollama UI 因其简洁性受到称赞,尤其是启用网络服务的切换开关,尽管有些人认为与 AnythingLLM 和 Dive 等 UI 相比还不够成熟。
- 新的 Ollama GUI 使得在本地运行模型比以往任何时候都更加容易。
OpenRouter (Alex Atallah) Discord
- Anthropic Opus 4.1 夺得编程桂冠:新款 Anthropic Opus 4.1 模型现已在 OpenRouter 上线,并在 SWE Bench 编程基准测试中处于领先地位,详情见 X 平台。
- 该模型可在此处 访问 并立即使用。
- OpenAI 凭借 GPT-OSS 重返开源:OpenAI 在 OpenRouter 上发布了 gpt-oss,这是一款具有可变推理能力的全新开放权重模型,详情见 X 平台。
- 模型包括 gpt-oss-120b(每百万输入/输出 Token 价格为 $0.15/$0.60)和 gpt-oss-20b(每百万输入/输出 Token 价格为 $0.05/$0.20)。
- 模型优先级 Bug 已解决:根据 Google AI 文档,通过确保仅使用
model或models,快速修复解决了 model vs models 优先级问题。- 该修复防止了冲突并确保为用户正确选择模型。
- OpenRouter 考虑移除 Claude 缓存参数:一些成员要求 OpenRouter 为不支持缓存的 Claude 提供商自动移除缓存参数。
- 成员指出,Azure 和 Google 的 Claude 提供商在他们的设置中被列入黑名单,因为它们不支持缓存。
- Gemma 3 展示情商:成员建议使用 Gemma 3 27b 来理解情绪,并参考了 EQbench 的 EQ 基准测试 来评估 LLM 的情绪理解能力。
- 用户建议不要将 DeepSeek R1 用于情绪理解任务。
Latent Space Discord
- Anthropic 任命社区冠军:一位来自 Auth0 的成员加入 Anthropic 负责 Claude Code 的社区工作,受到了 Web 开发社区的欢迎。
- 此举标志着 Anthropic 对社区参与的投入以及对其 Claude Code 产品的支持。
- OpenAI 开源 GPT:OpenAI 发布了开源模型 GPT-OSS,以及一份 cookbook 和 model card。
- 该发布包含了使用 vLLM 运行模型的资源,以及关于其能力和局限性的详细信息。
- Google Deepmind 发布 Genie 3:Genie 3 正式发布,声称是史上最先进的世界模拟器。根据 这篇博客文章,它能够以 20-24 fps 的速度生成高保真视觉效果,支持动态提示、持久化世界记忆和快速世界生成。
- Genie 3 的能力标志着在为 AI 开发创建更真实、更具交互性的模拟环境方面迈出了重要一步。
- Claude Opus 4.1 旨在实现卓越的 Agent 能力:Anthropic 推出了 Claude Opus 4.1,这是一款升级模型,专注于在 Agent 任务、现实世界编程和推理方面提供更好的性能,可通过 API、Amazon Bedrock 和 Google Cloud Vertex AI 获取。
- 此次升级旨在提升 Claude 处理复杂、多步骤任务的能力,并更有效地与现实世界的应用及编程环境集成。
- Reflection AI 寻求十亿美元融资:根据 这条推文,由前 Google DeepMind 研究员创立的一年期初创公司 Reflection AI 据报道正在讨论筹集超过 10 亿美元的资金,用于构建旨在与 DeepSeek、Meta 和 Mistral 竞争的开源 LLM。
- 这笔巨额融资将使 Reflection AI 成为开源 LLM 领域的主要参与者,挑战现有模型。
Nous Research AI Discord
- Qwen-Image 展示文本生成图像能力:用户正尝试使用 fp8 diffusers 在本地运行 Qwen-Image,尽管目前尚不支持 ComfyUI,且图像编辑模型尚未发布。
- 社区观察到 Qwen-VL 已经可以处理图像输入,而已发布的模型通过其 text encoder 强调了文本渲染能力。
- XBai-o4 通过 RL 提升性能:XBai-o4 声称通过对 QwQ32 进行持续 RL(强化学习)实现扩展,采用带有 reward model 的 BoN scaling 来生成 32 条 CoT 推理轨迹,详见其论文。
- 一个 classifier head 会根据这些 CoT 轨迹选择最佳路径,但具体的实现细节仍较模糊。
- Harmony 与 GPT-OSS 协作:GPT-OSS 采用了 Harmony 聊天格式,集成了开发者角色和频道,以实现更结构化的交互。
- 值得注意的是,Horizon beta 在用户聊天过程中阐明了这些角色,增强了对话体验。
- Claude Agent 在终端基准测试中占据主导地位:终端基准测试显示 Claude agent 占据了前 10 名中的 9 个席位,这引发了对排行榜指标的讨论。
- 另外有提到,OpenAI 现在正免费提供其深度优化的数学 CoT,这可能有助于开源权重(open weight)数学推理模型的发展。
- OpenAI 发布 GPT-OSS Model Card:一名成员强调了 OpenAI GPT-OSS Model Card 的可用性。
- 该 Model Card 详细说明了与开源 GPT 模型相关的预期用途、能力、局限性以及潜在风险。
{kind=link}
Eleuther Discord
- Discord 记录一切!:Discord 版主利用版主日志来追踪已删除的消息,正如最近的一条推文所强调的那样。
- 此功能确保了管理过程中的透明度和问责制,允许版主审查在平台上采取的操作。
- LLM 遭遇算法单调性问题:由于算法单调性(algorithmic monoculture)以及评估 SOTA 模型的困难,扩展 LLM 作为评委可能无法解决底层问题。
- 一名成员认为扩展策略可能已经足够,但未提供支持证据。
- YaRN 亮相:一个团队在他们的项目中使用了 YaRN,并获得了社区成员的支持。
- 几名成员因支持其集成而获得了贡献认可。
- GPT OSS 登陆 Hugging Face!:OpenAI 社区正在探索新发布的 GPT OSS 模型,这些模型已在 Hugging Face 上提供(20B 版本 和 120B 版本)。
- 一名成员正活跃地在 GPT OSS 20B 模型上进行 SAE 实验,并引用了可在 OpenAI 训练页面找到的基准测试数据。
- lm-eval-harness 支持通过 API 传递 Seed:一名成员为 lm-evaluation-harness 实现了通过 API 调用为数据集传递 seed 的功能。
- 目前正在征求对相关 PR#3149 的反馈。
Moonshot AI (Kimi K-2) Discord
- Kimi K-2 在国际象棋比赛中输给 Deepseek O3:Kimi K2 与 Deepseek O3 之间的一场国际象棋比赛以 O3 获胜告终,成员们注意到其采用了逐步推理(step-by-step reasoning)的方法。
- 在比赛中,Kimi 最初选择认输,但在做出违规着法后被迫再次认输,最终导致 O3 自动获胜。
- GPT-OSS 发布,社区反响热烈:OpenAI GPT-OSS 的发布引发了轰动,成员们注意到它已在 Hugging Face 和 Openrouter 等平台上线。
- 社区报告称 llama.cpp 的 PR 正在进行中,将实现首日支持,且 Benchmark 结果令人印象深刻,但直播的国际象棋演示被提前切断。
- Kaggle AI Game Arena 让成员感到困惑:成员们对 Kaggle 的 AI Game Arena 竞赛表示有趣且困惑,质疑为何加入非推理模型。
- 一位成员分享了一个 GitHub 链接,表明围棋(Go)将被添加到 Game Arena 中,并指出围棋比国际象棋更难。
- 量化减小模型体积:Hugging Face 上的模型卡片显示,120B 模型仅需 60GB 空间,引发了关于量化的讨论。
- 据澄清,MXFP4 量化减少了内存占用,使较大的模型能够运行在单块 80GB GPU 上,而较小的模型可以在内存低至 16GB 的系统上运行。
Cursor Community Discord
- Claude Sonnet 在 Agentic Arena 中完胜 Gemini:在 Agentic IDE 环境中,由于其卓越的工具调用(tool usage)能力,成员们更倾向于使用 Claude Sonnet 4 而非 Gemini 2.5 Pro。
- 虽然有些人更喜欢用 Gemini/Sonnet 4 进行头脑风暴,但大多数人认为 Claude 在这些用例中表现更优。
- Cursor 社区呼吁全面的文件格式支持:用户强烈要求在 Cursor 中编辑 PDF、.docx、.csv 和 .xlsx 文件的功能,因为目前不支持本地文件上传。
- 一位成员分享了 Cursor 功能请求论坛的链接以正式提交该请求,并强调 Cursor 可以从公开访问的 PDF URL 中提取文本。
- Cursor 优惠的年度订阅令人困惑:一位用户对 $16 的 Cursor 订阅费感到惊讶,这其实是年度订阅的月均成本;常规月度订阅费用为 $20。
- 这种定价结构为承诺年度计划的用户提供了折扣。
- Linux 爱好者抱怨卡顿和致命死机:Linux 用户报告 Cursor 在 Linux 上出现死机和无响应,由于可能的网络问题或错误请求,导致某些用户几乎无法使用。
- 成员们指出了论坛上报告的几个问题,团队目前正在致力于修复。
- 后台 Agent 受故障困扰:多位工程师报告称,在过去几小时内,后台 Agent 开始出现反复启动失败的情况。
- 一位成员询问了请求 ID(request ID)以便调查该问题,并确认已通过私信(PM)发送了几个请求 ID,并对支持表示感谢。
HuggingFace Discord
- Hugging Face 的 HF Toolkit 获得强力升级:Hugging Face 发布了其生态系统的更新,重点推出了一个名为 Trackio 的轻量级实验跟踪库,旨在简化 ML 实验管理。
- 他们进一步增强了工具包,增加了包含超过 2000 万张图像 的 四个新 OCR 数据集,通过内核支持加速了 Transformers,扩展了 HF Jobs 以在 CPU/GPU 上启动计算任务,并引入了更快、更用户友好的
hfCLI (Hugging Face 博客)。
- 他们进一步增强了工具包,增加了包含超过 2000 万张图像 的 四个新 OCR 数据集,通过内核支持加速了 Transformers,扩展了 HF Jobs 以在 CPU/GPU 上启动计算任务,并引入了更快、更用户友好的
- 本地 AI 开发者青睐 ZeroGPU:爱好者们正在测试 ZeroGPU 并取得了令人惊讶的成功,展示了一个运行在本地预训练的 340M t2i 模型 的 Space。
- 在 ZeroGPU 的 H200 上,图像生成仅需 1 秒,而 Prompt 生成需要 2-5 秒,这引发了关于 RTX 3090/AMD MI60 等硬件作为本地 RAG 最佳选择的讨论。
- 数据集风波:被标记为恶意软件:一名成员报告称,尽管经过了杀毒软件扫描,一个数据集仍被标记为不安全,识别为 Pickle.Malware.NetAccess.pwn.STACK_GLOBAL.UNOFFICIAL,并引导用户参考 HuggingFace 的安全文档。
- 社区建议删除分片并逐行检查数据集,并指出基于网站的扫描器的局限性。
- Unsloth 助推微调热潮:关于微调开源 LLM 的指南指向了 SmolFactory 和一个 OpenAI cookbook。
- 成员们分享称,OpenAI 的 20B 和 120B 开源模型 可以使用 Unsloth 在消费级硬件上运行。
- Agent 课程作业提交引发混乱:多名成员在以 JSONL 格式提交 AI Agent 课程的最终作业时遇到问题,报告了诸如 “文件中未找到 task ID” 之类的错误,并正在寻求调试建议。
- 该 API 需要特定的 JSON 格式,包括 username、agent_code 以及包含 task_id 和 submitted_answer 的 answers 数组。
Yannick Kilcher Discord
- 低成本语音克隆出现:成员们探索了在消费级硬件(如 5090)上进行语音克隆的可行深度学习项目,重点关注那些能最大限度减少对大量音频数据集和昂贵 GPU 租赁需求的方法。
- 讨论集中在如何在没有重大前期投资的情况下实现高质量的语音克隆。
- Claude Code 导致数据泄露:一名用户发现 Claude Code 通过直接引入与预测目标相关的工程特征,导致 XGBoost 流水线 出现数据泄露。
- 这一观察引发了对 LLM 系统在自动化 ML 流水线中可靠性的担忧,并建议复核一切。
- Deepseek-R1 保持对对手的领先:尽管备受期待,Deepseek-R1 的表现仍然优于 Kimi-K2 和 GLM4.5,但因运行速度过慢而影响了实际应用。
- 这一对比突显了语言模型性能与易用性之间持续的竞争。
- Attention Sink 层进入 Transformers:Hugging Face 的 Transformers 库现在利用了具有每个 head 可学习 attention sink 的 attention 层,改变了 发行说明 中详细说明的 softmax 分母。
- 该方法类似于添加一个具有全零 Key 和 Value 特征的前置 token,正如这篇论文中所探讨的那样。
- DeepMind 的 Genie 梦幻三部曲:DeepMind 推出了 Genie 3,扩展了其世界模型的计算和数据规模,虽然没有发布论文,但原始 Genie 论文和 SIMA 论文提供了深入见解。
Notebook LM Discord
- Whisper 转录效果优于 YouTube URL:一位成员报告称,与在 NotebookLM 中直接使用 YouTube URLs 相比,使用本地 Whisper 的视频转录结果更出色,并强调了其准确性。
- 该用户下载整个频道,在本地进行转录,然后将转录文本输入 NotebookLM 进行交互,并指出 NotebookLM 目前缺乏播放列表支持。
- 用户等待迟迟未到的 Video Overview:尽管已宣布完成全面推广,用户仍在等待 NotebookLM 中的 Video Overview 功能。
- 推广进度比预期要慢,Pro 用户 也在等待之列,这暗示了底层基础设施面临的挑战。
- 播客制作人分享珍贵的自定义 Prompt:一位成员提供了一个 Google Docs 链接,其中包含专门为引导播客生成而设计的自定义指令,重点在于迭代调整和模型应用的名称修改。
- 分享的自定义 Prompt 强调在播客生成过程中 减少填充词 (filler words) 并 避免打断。
- 图片上传功能暂时消失:Google 暂时禁用了 NotebookLM 中的图片上传功能,以解决影响用户的基础设施问题。
- 最初,从 PDF 中提取图片被建议作为一种变通方案,但随着该功能确认被移除,这一方案也变得无意义。
- 数据隐私备受用户关注:用户正积极询问数据隐私实践,特别是 NotebookLM 是否使用用户数据进行模型训练。
- 为了回应这些担忧,一位成员分享了 Google 数据保护政策的链接,其中概述了 NotebookLM 的数据处理程序。
Modular (Mojo 🔥) Discord
- Mojo 拥抱 Python 风格的装饰器 (Decorators):一位成员赞扬了 Python 装饰器 的简洁性,并请求 Modular 在 Mojo 中实现类似的灵活性,以便在编译时或运行时定义逻辑,但另一位贡献者表示,Zig 风格的反射系统 (reflection system) 可能更有可能实现。
- 正在考虑的反射系统可用于添加函数、修改结构体 (structs) 以及引入新的结构体成员,尽管在编译器层面操纵函数可能具有挑战性。
- 用 Mojo 编写的 Volokto JavaScript 运行时:一位成员开发了 Volokto,这是一个用 TypeScript 编写的 JavaScript 运行时,源代码可在 GitHub 上获得。
- 该运行时包括用户自定义函数、嵌套控制流、带参数的函数调用,并实现了一种字典类型和控制台,其字节码类似于 CPython。
- Modular Platform 25.5 提升规模:Modular Platform 25.5 现已上线,其特点是通过 SF Compute 实现 大规模批处理推理 (Large Scale Batch Inference)、独立的 Mojo Conda 包 以及开源的 MAX Graph API。
- 此版本通过
@graph_op增强了 MAX 与 PyTorch 之间的互操作性,同时提供了更小、更快的 MAX 服务容器和性能改进。
- 此版本通过
- MAX ❤️ PyTorch 与 graph_op:25.5 版本通过
@graph_op提供集成,增强了框架之间的互操作性,并支持使用多个 Modular CLI 实例和反向代理 (reverse proxy) 在 Mojo 中运行多个 AI Agent。- 对于涉及大量子 Agent 的场景,可能需要利用 MAX 作为库来开发自定义应用程序。
- 强制要求 Apple Silicon CPU:用户发现 macOS 官方仅支持 Apple Silicon CPU,根据 系统要求 (system requirements),这给使用基于 Intel 系统的用户带来了兼容性问题。
- 对于不使用 Apple Silicon 的用户,建议使用 Intel Docker Ubuntu 容器 作为变通方案。
GPU MODE Discord
- 关于 CUDA Kernels 与 Compute Shaders 的辩论:一名成员发起了关于在使用 libtorch C++ 进行图像后处理时,CUDA kernels 与 compute shaders 各自优势的讨论,特别是针对长期收益和经验方面,并强调不考虑非 Nvidia 兼容性。
- 该成员还询问了 MXFP4 的实现细节,引发了围绕 OpenAI 新模型的讨论。
- MXFP4 模型混淆:OpenAI 的 U8 权重解析:成员们剖析了 OpenAI 在其最新的开源权重模型中采用 U8 权重而非 FP4 的创新方法,澄清了权重是以 uint8 格式打包的,其缩放因子(scales)是 e8m0 的 uint8 view。
- 他们指出,在推理和训练过程中,权重会被重新解包回 FP4,MXFP4 采用 32 的块大小(block size),而 NVFP4 采用 16。
- 社区对 H100 的 FP4 训练说法表示异议:社区成员对 H100 基于其规格进行推理的可行性展开了辩论,质疑其对 FP4 的支持,并引用了 一篇 NVIDIA 博客文章。
- 讨论非常激烈,一名成员认为 H100 训练的说法是“公然的谎言”。
- Helion Kernel DSL 研讨会公告:宣布了关于 Helion 的研讨会,这是一个来自 Pytorch 的 kernel DSL,将于太平洋时间明天 2.15 举行,详见 Helionlang.com。
- 该研讨会承诺揭示 Helion 如何简化快速 kernel 的编写。
- Vector Store 故障:CuTe 的 128-bit 向量化存储缺陷:一位用户报告称,尽管使用了 float4,CuTe 并没有按预期生成从寄存器到全局内存的 128-bit vectorized store,并注意到编译器发出了两个独立的 STG.E.64 指令,而不是 STG.E.128。
- 由于这破坏了线程间的内存合并(memory coalescing),该问题引起了关注,因为向量化存储本应确保连续的数据写入。
MCP (Glama) Discord
- 急需 MCP 文档:一位用户正寻求创建一个 MCP server,以便访问来自 repo 或文档网站 的文档,从而避免信息检索时过多的往返。
- 该用户需要一个 MCP server 以便访问相关文档。
- 工具支付走向标准化:成员们正在讨论为未来可能出现的数千种工具标准化支付流程,届时 AI assistants 将处理支付,而无需创建个人账户。
- 一名成员指出了 这个 PR,希望它能实现在客户端安全输入支付信息,而无需为一次性购买创建账户。
- 针对浏览器内 MCP 的 PostMessage 提案:一名成员正在制定一项针对浏览器内 ‘postMessage’ 的 transport proposal,包括一个展示通过 GitHub Pages 托管的 client + server 的 演示。
- 他们还起草了一个 SEP,并正在寻找一位 MCP spec maintainer 来赞助其标准化。
- 嵌入式系统 MCP 探索:一位新用户询问关于在 STM32CubeIDE 中用于嵌入式系统编程的有用 MCP。
- 讨论中没有分享更多信息。
- AutoGen 与 MCP 让 YouTube 搜索变得简单:一名成员分享了一个教程,关于如何从零开始使用 AutoGen 和 MCP servers 构建一个用于 YouTube search 的多智能体聊天机器人,视频见 YouTube。
- 该教程旨在指导用户使用这些工具创建一个功能齐全的聊天机器人。
aider (Paul Gauthier) Discord
- DeepSeek 成为 Aider 的首选:成员们认可 DeepSeek 是与 Aider 配合使用的理想模型,理由是其性价比高,且通过 OpenRouter 使用 Deepseek-R1 表现出色。
- 一位用户报告称对它的表现 相当满意。
- OpenAI 开放模型登场:OpenAI 发布了新的 开放模型 (open models),引发了社区的热议。
- 一位成员幽默地提到了模型发布的速度之快,开玩笑说 我刚搞清楚怎么在机器上加载 GLM air stable,结果又出了个 117B 参数、5.1B 激活的模型……。
- Aider 关注非交互模式:一位成员询问了是否可以将 Aider 用于脚本编写的 非交互模式 (non-interactive mode)。
- 参考 aider 脚本编写文档,他们表示在查找相关文档时遇到了困难。
- Pikuma 的 LLM Vibe Test 走红:一位成员分享了 Pikuma 的 LLM 氛围测试 (vibe test) 供社区娱乐,展示了其 解释这段代码 的能力。
- 该测试似乎在社区中引起了一些轰动。
DSPy Discord
- DSPy 攻克 PDF 文档边界识别:一位成员分享了利用 DSPy 检测 PDF 文档边界的报告,展示了其在文档处理方面的潜力:kmad.ai/Using-DSPy-to-Detect-Document-Boundaries。
- 作者向知识图谱从业者介绍了 DSPy,并暗示未来将探索更深层次的多步工作流和优化:X 帖子。
- DSPy 吸引知识图谱专家:分享了一篇向知识图谱从业者介绍 DSPy 的文章,强调了其在提升 LLM 生产力方面的潜力:blog.kuzudb.com。
- 作者期待在未来几周内探索多步工作流和优化策略。
- Marius Vach 对 SIMBA 优化器进行深度解析:一位成员分享了一篇详细的文章,解释了 SIMBA 优化器 的复杂机制:blog.mariusvach.com。
- 这篇文章被社区另一位成员赞誉为 非常直观且解释得很好。
- GEPA 在 DSPy 中仍未露面:一位用户询问了在 DSPy 中使用 GEPA 的可能性。
- 另一位用户提供了一个 Discord 链接,确认该功能尚未发布。
- 系统提示词优化:微调的良伴还是敌手?:一位用户质疑在模型微调期间,将优化后的 sys_prompt 与 DSPy 结合使用的效果,特别是在为非推理模型添加推理轨迹 (reasoning traces) 时。
- 他们概述了一个涉及 SFT 和 GRPO 以及不同 sys_prompts 的三阶段训练方法,并坦言由于奖励无法验证,哈哈,我也不知道自己在做什么,只是在瞎搞以观后效。
LlamaIndex Discord
- LlamaParse 将 PDF 转换为报告:@tuanacelik 在此 Twitter 线程中展示了 LlamaParse 如何将密集的 PDF 转换为图文交织的多模态报告。
- 该过程涉及使用 LlamaParse 摄取研究论文,并构建一个报告生成 Agent,该 Agent 能够动态选择工具进行高分辨率 OCR 和图表提取。
- LlamaCloud 通过文档智能助力 AI 规模化:这条推文提到,LlamaCloud 的解析能力通过处理复杂的文档摄取,协助 AI 公司从原型转向生产阶段,例如在构建 Delphi 的“数字大脑”导师平台时的应用。
- 该解析技术在处理格式错误的 PDF 和嵌入图像方面表现出色。
- OpenAI 发布 GPT-OSS 模型:根据这条推文,OpenAI 发布了自 GPT-2 以来的首批开源 LLMs:GPT-OSS-120B & GPT-OSS-20B,采用 Apache 2.0 许可证。
- 这些模型具备媲美 o4-mini 的推理能力,可以本地运行,并已准备好与 LlamaIndex 配合使用。
- Document Agents 处理杂乱的财务文档:一场网络研讨会将展示 Document Agents 如何利用 LlamaCloud 的工具链管理杂乱的财务文档。
- 该会议将展示处理复杂多模态文档的系统,将于 1 周后举行。
- LlamaExtract 应对图表解析挑战:成员们确认在使用 LlamaExtract 处理图表时遇到了挑战,并承认这些案例对于 LVMs/LLMs 来说是出了名的困难。
- 预计一名 LlamaParse 团队成员将加入讨论,以进一步探索这些挑战。
Manus.im Discord Discord
- Manus 平台经历停机:用户报告称 Manus 平台使用率较低,可能已经失效,这可能表明需要替代方案或改进。
- 发现了一种使用 sub-agents 的解决方法,用以提高 Manus 环境中的代码和项目质量。
- 免费提供 TradingView Premium:一名用户分享了 一个 Reddit 链接,声称提供适用于 Windows 和 macOS 的免费完整版 TradingView Premium。
- 考虑到这是发布在 Reddit 上且并非 TradingView 官方活动,该优惠的真实性和安全性存疑。
- Flutter 应用创建指南出现:一名用户发布了关于在每日额度限制内创建 Flutter apps 的指南,可通过 flutter-web-emulator.vercel.app 访问。
- 该页面包含广告且基于个人经验,另一名用户将该链接标记为潜在的诈骗。
LLM Agents (Berkeley MOOC) Discord
- LLM Agents 课程大纲即将调整:成员们讨论了即将开展的 LLM Agents 课程可能的大纲变化,并指出该领域发展迅速。
- 一位成员表示:“随着 Agents 领域的发展,调整教学大纲是很正常的”。
- LLM Agents 迎来高级进阶课程:参与者区分了两门课程:LLM Agents 和 Advanced LLM Agents,强调它们是不同的。
- 一位成员澄清道:“这是两个不同的标题——一个是 LLM Agents,另一个是 Advanced LLM Agents。教学大纲是不同的”。
- LLM Agents 课程讲师将更换:尽管总体主题相似,但 LLM Agents 课程的讲师预计会有所不同。
- 这标志着课程内容将引入新的视角和专业知识。
Torchtune Discord
- Torchtune 频道欢迎分享:Torchtune 频道明确欢迎将其内容分享到其他公共服务器。
- 频道管理员鼓励更广泛地传播信息,并对频道被分享的前景表示高兴。
- 频道信息传播:Torchtune 频道的成员询问了关于在外部公共服务器上分享频道信息的事宜。
- 频道所有者给出了积极回应,鼓励分享内容,并对更广泛的传播表现出热情。
tinygrad (George Hotz) Discord
- TinyPilot 接入代码库工作:一名成员建议 TinyPilot 工具可能有助于代码库任务。
- 他们提醒说,虽然它会有所帮助,但更深层次的代码库集成仍需努力。
- 图像分析引发爆笑:一张附图 Screenshot_2025-08-04_at_12.08.33_PM.png 引起了简单的 lol 反应。
- 未提供关于图像内容的进一步背景或分析。
{kind=link}
Cohere Discord
- 工程师开拓智能语音 Agent:一位 AI 工程师正在构建智能语音 Agent、聊天机器人和 AI 助手,通过 SIP (Twilio) 处理呼入/呼出电话。
- 该工程师的工作涉及基于 GPT 的聊天机器人,这些机器人通过检索增强生成 (RAG) 从文档、音频以及从论坛、Discord、Slack 和网站抓取的数据中学习,并结合工作流自动化来简化沟通和流程。
- 工程师驾驭技术栈:该 AI 工程师精通 Python、JavaScript、Node.js、FastAPI 以及 LangChain、Pinecone、OpenAI、Deepgram 和 Twilio 等工具。
- 该工程师可接受自由职业、远程或初创公司项目。
MLOps @Chipro Discord
- 日志和点击量助力排序器:一名成员提议通过挖掘搜索日志、查询数据、文档列表和点击数据来增强排序器 (Rankers)。
- 另一名成员提醒要考虑成本,因为使用此类日志是有代价的。
- 数据使用需关注成本:收集并利用搜索日志来微调排序器会产生财务影响。
- 在采用这种方法之前,审慎评估这些成本至关重要。
Codeium (Windsurf) Discord
- Claude Opus 4.1 登陆 Windsurf!:Anthropic 的最新模型 Claude Opus 4.1 已在 Windsurf 上发布。
- 工程师们应注意,这一顶级模型在该平台上的积分消耗率为 20 倍。
- Windsurf 预告新模型,冲浪开始!:Windsurf 宣布一个新模型即将登陆其平台。
- 公告展示了一张冲浪者的图片,暗示了即将到来的性能表现。
Nomic.ai (GPT4All) Discord
- GGML 与 PyTorch 及 ONNX 模型的兼容性:一位用户询问了使用 GGML 运行 PyTorch 或 ONNX 模型的可行性。
- 讨论目前处于开放状态,正在等待关于此类兼容性的潜力和方法的回复。
- 待定:关于模型兼容性的进一步讨论:占位主题,以确保满足最小主题摘要数量。
- 随着对话的发展,将添加进一步的讨论和细节。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中退订。
Discord:详细的分频道摘要和链接
Perplexity AI ▷ #announcements (1 条消息):
kesku: https://x.com/perplexity_ai/status/1952532113095643185 <@&1105626802732404746>
Perplexity AI ▷ #general (1206 条消息🔥🔥🔥):
Comet Browser, OpenAI OSS Model, Claude 4.1 Opus, Perplexity Search Ranking, GPT-5 Release Speculation
- Comet Browser 邀请码争夺战持续进行:成员们仍在积极寻求 Comet Browser 的邀请码,用户们分享了通过 X(原 Twitter)和 Discord 获取邀请码的轶事,而另一些人则报告了获取困难,并建议通过私信随机用户来索取邀请码。
- 像 Comet 这样的 Agentic 浏览器可能正在爬取明确表示禁止爬取的网站,这引发了一些关于爬取伦理的辩论。
- **OpenAI 发布开源 LLM!:OpenAI 发布了一款开源 LLM —— **GPT-OSS-120B,引发了热烈讨论,话题涉及硬件需求(推荐使用 H100 GPU)、审查程度以及与其他模型的性能对比;该模型可在 HuggingFace 获取。
- 成员们已经开始进行实验,尽管有些人的电脑出现了崩溃并指出需要进行 quantization(量化),还有人评论说该模型被极其严格地审查了。
- Claude 4.1 Opus 发布,初步反应褒贬不一:Anthropic 发布了 Claude 4.1 Opus,初步反应显示它较前代版本有轻微改进,具备更好的多文件调试能力,但在许多空间测试中表现不佳;该模型也已在 PPLX 上线,Pro 价格保持不变。
- 有人认为这可能是为了胜过 OpenAI 的举动,而另一些人则强调该模型的改进不足以支撑其定价,且存在旧的速率限制,这可能只是对 OpenAI 的一种示威。
- 思考 Perplexity 搜索排名的第 3 位:讨论围绕 Perplexity 的搜索排名(据称为第 3 名)以及公司是否计划改进它展开,一些人认为他们目前正更多地关注 Comet,而另一些人则对其表现印象深刻。
- 考虑到最近 OpenAI 的 o3-search 排名第 1 的排行榜,一些人认为 PPLX 同样拥有强大的工具。
- **GPT-5 猜测升温:受 Sam Altman 的暗示以及关于 OpenAI 发布 **Operating System Model(操作系统模型)传闻的推动,人们对可能在 7 号发布的 GPT-5 期待值不断增高。
- 有推测认为这可能与 Horizon 有关,并讨论了在此次发布背景下 Grok 4 是否能打破任何 benchmark(基准测试)。
Perplexity AI ▷ #sharing (5 条消息):
Youzu AI e-commerce, Room Visualizer, Youzu Lens, Google Genie AI
- Youzu.ai 利用视觉 AI 重塑电子商务:Youzu.ai 正在通过视觉 AI 基础设施改变在线购物,正如在 Vivre 的全面演示中所展示的那样,该业务覆盖 10 个中东欧国家。
- Room Visualizer 重新设计购物体验:Room Visualizer 功能允许用户上传房间照片并在几秒钟内获得完整的重新设计方案,从而实现对每件商品的即时购买,详情见此演示。
- Youzu Lens 助力视觉产品发现:Youzu Lens 功能让用户可以拍摄任何物体的照片并立即找到类似产品,促进了发现驱动型商业,让客户通过沉浸式体验进行探索、可视化和购买。
- Google 的 Genie AI:根据 Perplexity 页面显示,Google 推出了 Genie AI,可以将图像转化为可玩的虚拟世界。
Perplexity AI ▷ #pplx-api (6 条消息):
Sonar API, Perplexity Docs
- Sonar API 入门视频出现:一位 Sonar API 新用户询问了其用法。
- 另一位用户分享了一个关于 Sonar API 的 YouTube 视频链接。
- 分享 Perplexity API 文档:针对关于 Sonar API 的问题,一位用户分享了 Perplexity AI 文档链接。
- 该用户提供了帮助并分享了一个 GIF。
Unsloth AI (Daniel Han) ▷ #general (1200 条消息🔥🔥🔥):
Unsloth 量化请求, Nvidia Nemotron Super 49B 1.5, 基于 Diffusion 的量化论文, GPT-OSS 模型分析, 训练 GPU 推荐
- Unsloth 社区请求模型量化:成员们请求 Unsloth 对
yisol/IDM-VTON模型进行量化,但被告知虽然量化可能可行,但由于缺乏支持,Unsloth 目前不提供对 Diffusion 模型的训练支持。- 此外还提到,Unsloth 通常不处理自定义量化请求,除非有重大需求,因为这需要投入人力劳动和算力资源。
- 成员讨论 Nvidia Nemotron Super 49B 1.5 模型:成员们讨论了新的 Nvidia Nemotron Super 49B 1.5 模型,反应不一;一位成员认为由于其出色的提示词遵循能力,它是一个很好的日常主力模型,尤其是配合“不要使用该死的列表”这一建议时。
- 其他人对其作为通用思考模型(相对于针对编程和数学过度优化的模型)的能力表示感兴趣,指出其良好的指令遵循能力,同时也提到了其文笔枯燥。
- 讨论 Diffusion 模型量化研究:一位成员分享了一篇关于基于 Diffusion 的量化的论文,重点介绍了 QuEST、Q-Diffusion、Q-DM 和 TDQ 等技术,并认为 PQT/QAT 可能有所帮助。
- 该论文提出了 NIC (Neural Image Compression),最初的请求者表达了将该模型作为日常主力使用的愿望,但也承认了像普及较小的 14B 模型那样去推广 49B 模型的挑战。
- OpenAI 的 GPT-OSS 模型收到褒贬不一的评价和安全担忧:对 OpenAI GPT-OSS 模型 的初步反应不一,一位成员称其几乎是垃圾,而其他人则对其安全措施表示担忧,推测这是美国安全法案的结果,从而引发了关于 abliteration(消除拒绝机制)及其可能使模型变得极其愚蠢的讨论。
- 有人指出 GPT-OSS 的表现可能不如 GLM 4.5 Air,引发了关于该模型整体价值以及中国初创公司可能很快超越它的讨论,其安全措施甚至因过于谨慎并导致荒谬的输出而受到批评。
- GPU 推荐和显存管理策略:成员们讨论了用于训练和运行 AI 模型的 GPU 推荐,共识是二手 3090s 性价比最高,但一些成员正在关注 5090s。
- 还有关于利用 Google Colab Pro 和 RunPod 等云服务的建议,但 Google Colab 被认为并非最优且不可靠;成员们还讨论了将大模型适配到较小 VRAM 容量的最佳显存管理策略。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 条消息):
寻求新机会的软件工程师,专注于语音 Agent 和聊天机器人的 AI 工程师
- 高级软件工程师寻找新职位:一位高级软件工程师正在寻找新机会,并邀请如果有项目或职位可以从其专业知识中受益的人员与其联系。
- 他们没有具体说明是哪种类型的软件。
- AI 工程师专注于智能语音 Agent:一位 AI 工程师专注于构建智能语音 Agent、聊天机器人和 AI 助手,通过 SIP (Twilio) 处理拨入/拨出电话,包括电话预订、IVR 和语音邮件等功能。
- 他们的工具栈包括 Python、JavaScript、Node.js、FastAPI,以及 LangChain、Pinecone、OpenAI、Deepgram 和 Twilio 等工具,可承接自由职业、远程或初创公司项目。
Unsloth AI (Daniel Han) ▷ #off-topic (7 条消息):
VITS 男声问题, 语音模型的数据集大小问题, 说话人维度问题, RVC 模型
- VITS 模型在男声转换方面遇到困难:一名成员在针对男声转换使用 VITS 时遇到问题,即使是从声谱图(spectrogram)重建,模型也会导致声音破碎。
- 相比之下,RVC 的表现几乎完美,这引发了关于问题出在 dataset size(数据集大小)、speaker dimension(说话人维度)还是 VITS architecture(VITS 架构)本身的疑问。
- 探索数据集大小作为限制因素:该成员考虑男声数据集较小(20 小时)是否是问题所在,因为女声数据集(运行顺畅)规模更大。
- 他们询问增加 256 以上的说话人维度是否有帮助,特别是考虑到在舞台上进行实时语音转换的目标。
- 考虑 VITS 架构:该成员还建议 VITS 模型的架构可能是根本原因。
- 他们分享说将测试 MMVC_Trainer,因为它是专门为语音转换设计的,既不是 diffusion 模型,也不包含 HuBERT。
Unsloth AI (Daniel Han) ▷ #help (77 条消息 🔥🔥):
GGUF 导出问题, TRL 与 Unsloth 的兼容性, GRPO 批处理与分块, 仅针对 Completion Loss 的 SFTTrainer, Qwen3-Coder 聊天模板
- 用户在 Gemma-3n 上遇到 GGUF 导出故障:一名用户在将微调后的 gemma-3n model 导出为 GGUF 格式时遇到了 RuntimeError,尽管遵循了官方 notebook。不过,他们能够使用 ggml-org 的 gguf-my-repo 生成 Q8_0 量化模型。
- 该用户希望导出不带任何量化的 f16 GGUF,但除了在本地使用 llama.cpp 编译外,找不到合适的 Space 来完成。
- TRL 版本兼容性困扰 Unsloth 用户:用户报告了与
trl.trainer.utils中的ConstantLengthDataset相关的ImportError,这表明 Unsloth 与 TRL (Transformers Reinforcement Learning) 库之间可能存在版本不兼容问题。- 一名用户被引导去更新 unsloth 以解决该问题,并得到保证该问题已在最新版本中修复。
- 解读 GRPO 批处理动态:有关于 Unsloth 如何处理 GRPO 批处理的咨询,特别是整个轨迹组(trajectory groups)是否被批量处理。
- 一名成员澄清说,如果
n_chunks设置为 1,则每个 batch 与一个组一一对应。
- 一名成员澄清说,如果
- 用户在 SFTTrainer 数据集格式化上遇到困难:一名用户在使用 SFTTrainer 设置
completion_only_loss=True时遇到困难,尽管参考了 TRL 文档,仍面临与formatting_func和张量创建相关的错误。- 建议使用
unsloth.chat_templates中的train_on_responses_only函数,并参考对话式 notebook 的示例。
- 建议使用
- 社区咨询聊天模板难题:一名用户寻求关于 Qwen3-Coder-30B-A3B-Instruct 正确
chat_template的指导。- 建议检查该模型的
tokenizer_config.json文件,例如 Qwen3-Coder-30B-A3B-Instruct 的 tokenizer 配置。
- 建议检查该模型的
Unsloth AI (Daniel Han) ▷ #showcase (3 条消息):
Gemma 3, LlamaTale, QuixiAI
- Gemma 3 进入新一轮测试:模型
leftyfeep/ape-fiction-gemma-3-4b-Q8_0-GGUF将配合 LlamaTale 进行测试。 - QuixiAI 项目推介:一名成员向 QuixiAI/Dolphin/Samantha 的 Eric Hartford 推介了该项目。
- 他一直在寻找类似的东西。
Unsloth AI (Daniel Han) ▷ #research (8 条消息🔥):
微调的 Prompt 变体,LLM 特定领域语言框架,Token Decoder Maps GitHub 项目,Open Evolutionary Agents 博客文章
- 使用 Prompt 变体进行微调:一位成员询问在针对分类等特定任务微调模型时,是否建议在输入中使用不同的 Prompt 变体。
- 他们还询问了这样做对模型性能的潜在影响。
- Token Decoder Maps 框架诞生:一位成员介绍了他们专为摘要等用途设计的 LLM 特定领域语言框架。
- 该 GitHub 项目 利用 EN- tokens 来总结特定的概念或事实,以便后续进行注入和提示。
- GhostArchitect01 分享 GitHub 项目:一位用户建议查看他的 token-decoder-maps 仓库,其目的是总结特定概念或事实,以便保存并在以后进行注入和提示。
- 他建议通过 AI 运行随附的文本文件来总结该项目。
- Open Evolutionary Agents 博客文章:一位成员分享了 HuggingFace 上关于 Open Evolutionary Agents 的博客文章链接。
- 未提供关于该博客内容的更多细节。
Unsloth AI (Daniel Han) ▷ #unsloth-bot (82 条消息🔥🔥):
SFTTrainer 列,Llama 3 微调错误,dtype 检查步骤,LoRA 模型生成,OpenAI OSS 模型
- SFTTrainer 数据集列需求:一位成员询问 SFTTrainer 会查看哪些列,特别是它是否使用分词后的 Prompt 字段 “text”,另一位成员提供了 数据集要求 和代码片段。
- 代码对数据集应用聊天模板以创建 “messages” 列,然后通过对消息进行分词来创建 “text” 列。
- Llama 3 微调故障:一位成员在微调 Llama 3.2 3b instruct 时遇到了 “Unsupported conversion from f16 to f16” 错误,并分享了使用 SFTTrainer 的代码片段。
- 他们在训练参数中使用了 fp16 = not is_bfloat16_supported(),这表明可能存在需要进一步调查的 dtype 问题,可训练参数占比为 0.75%。
- 模型 Dtype 检查步骤:一位成员请求检查其模型 dtype 的详细步骤。
- 他们还询问了如何监控微调后的模型,建议激活 TensorBoard 作为潜在解决方案。
- LoRA 加载逻辑:一位成员询问关于使用带有 lora_only 和 model_tensor 的微调模型进行生成的问题。
- 他们询问 lora_request = model.load_lora(model_path) 是否有效,并想知道从 SFT 转移到 GRPO 是否需要使用同一个模型。
- OpenAI OSS 模型输出乱码:一位成员报告说 OpenAI OSS 120B 模型只输出 “GGGGGGG”。
- 他们分享了使用 llama.cpp 运行该模型的命令,包括上下文大小、GPU 层数、温度以及 top-p/top-k 采样等参数。
LMArena ▷ #general (1152 条消息🔥🔥🔥):
GLM 4.5 表现强劲,Kaggle Game Arena AI 象棋表演赛,长上下文推理基准测试,GPT-5 发布,OpenAI 开源模型局限性
- GLM 4.5 被誉为开源猛兽:一位成员形容 GLM-4.5 可能名副其实,在测试套件中获得了 5/5 的评分,并在“创建一个 HTML 游戏”测试中超越了包括 Horizon Beta、Grok 4、o3 Pro、Gemini 2.5 Pro、Claude Sonnet 和 Opus 在内的其他模型。
- 该成员指出了一些怪癖,如无限思考循环和结果差异,但总结认为尽管存在这些问题,GLM-4.5 整体上非常强大。
- AI 象棋锦标赛开启 Kaggle Game Arena:Kaggle Game Arena 将以一场为期 3 天、包含 8 个模型的 AI 象棋表演赛拉开帷幕 (YouTube 链接)。
- 成员们对国际象棋是策略优化游戏而非智力测试表示担忧,同时也关注非视觉模型将如何理解棋盘,一位成员建议输入像旧报纸报道那样的对局序列。
- 长上下文基准测试适配大多数已发布的模型:成员们讨论了基准测试中的上下文窗口,指出有必要适配大多数已发布的模型(即使是那些上下文窗口较小的模型),以确保评分的公平性。
- 还有人指出,针对不同的上下文大小存在不同版本,允许模型得到相应的惩罚或奖励。
- 传闻 GPT-5 将于本周发布:有讨论称 GPT-5 可能会在几天内发布,一位成员指出内部泄露也提到了同样的消息 (x.com 链接)。
- Jimmy Apples 推测,由于自动路由(auto-routing)的存在,重度用户可能不会察觉到 GPT-5 的改进。
- OpenAI 开源模型显示出局限性:成员们测试了 GPT-OSS 120B,发现其表现令人失望,性能可能与 o3-mini 或 Qwen3 235B A22B 持平,且幻觉(hallucinations)比除 Llama 4 Maverick 之外的任何模型都多。
- 还有人指出,OpenAI 开源模型的基准测试效率非常低,仅有 5.1B 激活参数。
LMArena ▷ #announcements (1 条消息):
新模型,GPT-OSS,Claude Opus
- 新模型登陆 LMArena:LMArena 的 Text & WebDev Arena 加入了新模型!
- 这些模型是:OpenAI gpt-oss-120b、OpenAI gpt-oss-20b 以及 Claude Opus 4.1(仅限对战模式)。
- GPT-OSS 模型首次亮相:OpenAI 的 gpt-oss-120b 和 gpt-oss-20b 模型现已在竞技场中可用。
- 这些模型为对 开源替代方案 感兴趣的用户扩展了选择范围。
LM Studio ▷ #announcements (1 条消息):
OpenAI gpt-oss 模型,LM Studio 0.3.21 (b4) 更新
- OpenAI 通过 gpt-oss 拥抱开源:OpenAI 发布了 gpt-oss,这是一组在 Apache 2.0 许可证下发布的强大开源模型,参数规模分别为 20B 和 120B,可在 lmstudio.ai 获取。
- 此次发布标志着向开源 AI 迈出的重要一步,详见博客文章 http://lmstudio.ai/blog/gpt-oss。
- LM Studio 为 gpt-oss 做好准备:为了支持新推出的 gpt-oss 模型,建议用户更新至 LM Studio 0.3.21 (b4)。
- 该更新确保了运行 20B 和 120B 参数模型时的兼容性和最佳性能。
LM Studio ▷ #general (593 messages🔥🔥🔥):
LM Studio + LibreChat 速度,LM Studio 的 Tailscale IP 设置,笔记工具与 LLM 的集成,OpenAI 的新 GPT-OSS 模型,运行 LLM 的硬件
- LibreChat 提升 LM Studio 速度:成员们对通过 LibreChat 使用 LM Studio 中模型的推理速度赞不绝口,一位用户表示:它就像一个完全相同的 ChatGPT (OpenAI) UI,为我所有的 LM Studio 模型提供服务。但它的速度极快,感觉就像在使用云端 GPU!
- 一位用户在将 LibreChat 连接到 LM Studio API 时遇到困难,但随后通过调整 YAML 缩进解决了该问题。
- LM Studio 在 Tailscale 下遇到困难,需要绑定 0.0.0.0:一位用户在尝试使用 Tailscale IP 将 AnythingLLM 与 LM Studio 配合使用时遇到问题,模型列表无法加载。
- 他们通过将 LM Studio 的 host 设置为 0.0.0.0 而非 127.0.0.1(从而允许外部连接)并允许防火墙通过端口 1234 解决了此问题,同时还讨论了使用 headless 模式。
- 使用 LM Studio 整理 Obsidian:得力助手:用户讨论了将 VSCode 和 Obsidian 等笔记工具与 LM Studio 集成,以整理和格式化笔记,并建议使用带有预设 Prompt 的简单脚本来协助笔记分类和改写。
- 一位用户推荐使用 Logseq 及其 OpenAI 插件进行笔记改写和头脑风暴,但也提醒其他用户注意一个具有访问系统权限的 Agent。
- GPT-OSS 发布:开源惊喜!:成员们庆祝 OpenAI 的 GPT-OSS 模型 发布,并开始在 LM Studio 上进行测试,指出 20B 模型可通过 Discover 下载,并可以使用 LM Studio 的 CLI 运行。
- 社区成员报告了一些问题,如 LM Studio 网站上的链接失效,以及难以找到未在搜索中显示的 120B 模型,此外还讨论了如何为 GPT-OSS 模型指定 system 和 developer 消息以及设置 context。
- 硬件搜寻:什么样的配置最适合 LLM?:社区讨论了运行 LLM 的最佳硬件配置,建议范围从 3090 和 4090 GPU 到配备充足 RAM 的翻新迷你工作站。
- 用户还辩论了 AMD 与 NVIDIA GPU 的优劣,一些人指出 AMD 现在拥有原生的 ROCm 支持,而另一些人则指出 NVIDIA 显卡对于某些应用(如 unmute)是必需的。
LM Studio ▷ #hardware-discussion (32 messages🔥):
Windows 页面文件,NVMe 卸载,多 GPU 的 CUDA 运行时,用于 Blender + ComfyUI + LLM 的电脑,LLM 的存储设备
- Windows 页面文件的坑:用户建议即使在 RAM 充足的情况下也不要禁用 Windows 的页面文件(page file),因为某些程序依赖它,禁用会导致诡异且无法解释的崩溃。
- 相反,可以考虑使用 zram 将页面压缩并存储在 RAM 中,从而可能在一个实际页面中容纳 2-3 个压缩页面。
- CUDA 运行时困惑已解决!:一位拥有 5090 和 4090 GPU 配置的用户询问该使用哪个 CUDA Runtime。
- 另一位用户建议使用 CUDA 12,并建议选择 LM Studio 和运行时的 beta 分支。
- 经济型 PC 组装建议:一位拥有 2500€ 预算的用户征求用于 Blender、ComfyUI 和 LLM 的电脑配置建议。
- 一位成员建议以约 1200€ 的价格购买 两块二手 3090,并参考 pcpartpicker 上的双 3090 组装方案寻找灵感。
- 存储速度的影响(有一点):一位用户询问存储设备是否会影响 LLM 的运行。
- 社区回答称,存储速度仅影响初始模型加载时间,SSD 通常足够快,但比 RAM 慢,且仅受限于你可以下载/存储的模型大小。
- 尝试使用 3 块 Arc Pro B50 GPU:一位用户正在考虑组装一套 3 块 Arc Pro B50 的系统,并提出了关于 PCIe 通道占用和 NVMe 驱动器兼容性的问题。
- 他们想组装它是 因为他们可以,而不是因为真的需要它做什么。
OpenAI ▷ #annnouncements (4 messages):
OpenAI Open Models, Open Model Hackathon, Red Teaming Challenge, Inference Credits for Students
- OpenAI 开放其开放模型:OpenAI 发布了他们的 open models,邀请社区进行探索和利用。
- 这些模型旨在为课堂项目、研究、Fine-tuning 等领域解锁新机遇。
- 黑客松预告 gpt-oss:OpenAI、Hugging Face、NVIDIA、Ollama 和 vLLM 正在挑战开发者,使用 gpt-oss 参加为期六周的虚拟黑客松。
- 类别包括 最佳综合奖、机器人、最奇特硬件、本地 Agent、实用 Fine-tune、通配符以及造福人类奖,获胜者将获得现金或 NVIDIA GPU。
- 红队成员集结维护开源安全:OpenAI 正在启动一项 50 万美元的红队挑战赛 (Red Teaming Challenge),以加强开源安全性,邀请研究人员、开发者和爱好者发现新颖的风险。
- 来自 OpenAI 和其他领先实验室的专家将对 Kaggle 竞赛的提交作品进行评审。
- 学生获得推理额度:OpenAI 与 Hugging Face 合作,为 500 名学生提供 50 美元的推理额度 (inference credits) 以探索 gpt-oss。
OpenAI ▷ #ai-discussions (286 messages🔥🔥):
GPT-5 Release Speculation, AI and Education, OpenAI GPT-OSS Model, AI in Art, Local AI Models
- GPT-5 炒作加剧,发布日期仍不明朗:社区成员对 GPT-5 的发布进行了推测,有人预测本周发布,而另一些人则认为这可能是一个更具增量性的更新,如 GPT-4.1 或现有模型的统一;这篇 X 帖子助长了发布预期。
- 同时也存在怀疑态度,有人认为 OpenAI 正在努力让 GPT-5 令人惊艳,还有人指出 Sam Altman 之前关于夏季发布的声明只是粗略的猜测,而非坚定的承诺。
- AI 彻底改变教育:学生 vs. 教授:一位教授正在向其他教授展示如何使用 AI 创建考试和测验,而学生们则在使用 AI 来完成它们;有人担心这可能会降低批判性思维能力。
- 普遍观点认为 AI 应该简化工作,分担低技能任务,让个人专注于问题的核心部分,但关闭自己的大脑会导致 通用的快餐式输出。
- GPT-OSS 模型首次亮相,社区探索其能力:OpenAI 发布了 GPT-OSS 模型,引发了社区的兴奋和测试;据称 120B 参数模型在核心推理基准测试中达到了与 OpenAI o4-mini 近乎持平的水平,同时可以在单个 80 GB GPU 上高效运行;20B 参数模型提供的结果与 OpenAI o3‑mini 相似,并且可以在仅有 16 GB 内存的边缘设备上运行 参见 OpenAI 的博客文章。
- 艺术中的 AI:协作还是取代?:关于 AI 在艺术中的角色引发了讨论,有人将其视为一种创意工具,可以简化工作并允许身体受限的人进行艺术表达,但也有人对传统技能的贬值表示担忧。
- 有人认为 AI 协助处理繁琐任务,让艺术家专注于他们的热情,而另一些人则认为那些担心被 AI 取代的人可能本身就不是杰出的艺术家;还有人补充道,练习带来进步,而非完美。
- 新 Ollama UI 简化本地模型访问:新的 Ollama UI 评价褒贬不一,因其简单易用(特别是开启网络服务的切换开关)而受到称赞,但因其不够成熟且与 AnythingLLM 和 Dive 等其他 UI 相比缺乏功能而受到批评。
- 新的 Ollama GUI 使在本地运行模型比以往任何时候都更加容易。
OpenAI ▷ #gpt-4-discussions (48 messages🔥):
GPT 中的西班牙语偏见, GPT 的语言训练, GPT 5 发布, PDF 的 OCR 问题
- GPT 的西班牙语偏向城市俚语:一位用户报告称,GPT 的西班牙语回复表现出对城市俚语(urbanismo forzado)和其他不良语言特征的偏向,即使被指示使用中性或正式语言也是如此。
- 用户认为这种偏见源于 TikTok 和 Twitter LatAm 等平台语料库的深重影响,这些平台充斥着此类语言模式。
- 社区建议训练西班牙语方言:用户讨论了如何训练 GPT 模型以更好地理解西班牙语方言(西班牙、墨西哥、南美)的细微差别,重点是正式表达。
- 他们正努力贡献于一个更好的国际中性西班牙语模型,使其对非拉丁语母语者足够友好,同时避免俚语和偏见。
- GPT 通过示例学习:一位用户分享说,GPT 客服指示他们继续使用“正确”且“符合预期”的西班牙语,以便模型能够“学习建模(模仿/镜像)”。
- 然而,用户指出这种方法对于解决偏见问题是死胡同,因为机器在稍有松懈时仍会努力把 pa(俚语化的 para)塞回去。
- GPT5 发布传闻浮现:一位用户询问 GPT-5 的发布日期,寻求关于传闻中发布时间的更新。
- 另一位用户回应称,Sam Altman 提到“可能在今年夏天的某个时候”,并澄清除此之外的任何说法都只是猜测。
- OCR 处理后的 PDF 困扰 AI:一位用户报告说,一些未经 OCR 处理的 PDF 似乎对 AI 来说完全不可读,导致 100% 的幻觉,且 PDF 本身没有明显错误。
- 用户寻求关于为什么某些 PDF 尽管没有明显问题但仍无法被 AI 读取的见解。
OpenAI ▷ #prompt-engineering (1 messages):
GPT 订阅, GPT 订阅诱导, 用户对 GPT 奉承的感知
- GPT 为了订阅而过度吹捧用户:一位用户怀疑 GPT 正在通过奉承他们来鼓励购买 premium subscription。
- 用户承认 “(这奏效了..)”
- 用户屈服于 GPT 的诱惑:用户开玩笑地建议 GPT 的奉承回复是推销高级订阅的一种策略。
- 尽管心存怀疑,用户坦白该策略非常有效,突显了个性化 AI 交互的劝导力。
OpenAI ▷ #api-discussions (1 messages):
GPTs Agents, GPT 订阅
- GPT 过于有说服力:一位成员分享说,他们“确信 GPT 只是在过度吹捧”他们,以便让他们购买高级订阅。
- 他们还承认“这奏效了”。
- GPT 订阅销售:一位用户幽默地建议 GPT 的说服能力完全是为了提高高级订阅的销量。
- 用户带着一丝无奈承认,该策略对他们确实有效。
OpenRouter (Alex Atallah) ▷ #announcements (5 messages):
Anthropic Opus 4.1, OpenAI 回归 Open Source, GPT-OSS 模型
- 新 Anthropic Opus 4.1 夺冠:最新模型 Anthropic Opus 4.1 现已上线,并在领先的代码基准测试 SWE Bench 中名列前茅,正如 在 X 上 所宣布的那样。
- 可以在 此处 访问。
- OpenAI 的 GPT-OSS 模型首次亮相:OpenAI 正在回归 Open Source,推出了 gpt-oss,这是一种具有可变推理能力的新型 open-weight 模型,OpenRouter 作为发布合作伙伴,正如 在 X 上 所宣布的那样。
- 提供两个模型:gpt-oss-120b 价格为 $0.15/M input tokens 和 $0.60/M output tokens,以及 gpt-oss-20b 价格为 $0.05/M input tokens 和 $0.20/M output tokens。
- GPT-OSS-20B 价格修正:一位用户指出价格标注错误。
- 列表已更新以反映 20b 模型 的价格。
OpenRouter (Alex Atallah) ▷ #app-showcase (1 messages):
gardasio: ChatGPT.com https://x.com/Gardasio/status/1952501913586442541
OpenRouter (Alex Atallah) ▷ #general (251 条消息🔥🔥):
Model vs Models 优先级排序, Gemini 视频理解, Claude 提供商缓存, Qwen-image 模型, GPTs agents 训练
- **Model vs Models 优先级排序问题已修复:一名成员报告称,根据此链接,通过仅使用
model或models而不同时使用两者的快速修复方案,model vs models 优先级排序**问题已得到解决。 - **OpenRouter 未剥离缓存参数?:一些成员反映 **Claude 提供商不支持缓存,他们希望 OpenRouter 能自动剥离缓存参数。
- 一名成员指出:“少数 Claude 提供商(Azure 和 Google)不支持缓存,我已在设置中将它们列入黑名单,但我原以为 OpenRouter 会自动剥离缓存参数。”
- **Qwen-Image 模型即将上线?:一名成员询问在 OpenRouter 上推出 **Qwen-image 模型的可能性,并指向了 Qwen Image 博客文章。
- **关于免费 Gemini V3 模型的问题:成员们澄清,通过 10 美元的投入,OpenRouter 为免费的 V3 模型提供每天 1000 条免费消息**。
- 其他人警告说,虽然 OpenRouter 可能允许每天 1000 次请求,但 Chutes 可能不会,重试请求始终是一个选项。
- **使用 Fal.ai 进行图像生成?**:一名成员询问是否有类似“图像版 OpenRouter”的单一端点用于图像生成?其他成员推荐了 Fal.ai 以及使用 ComfyUI 进行本地生成。
- Fal.ai 因拥有完整的 API 和结构良好的数据规范而受到称赞,并提到一块 3060 显卡就足以进行本地生成。
OpenRouter (Alex Atallah) ▷ #new-models (3 条消息):
``
- 无新模型消息可报告:在 OpenRouter Discord 频道中,没有关于新模型的实质性讨论点或链接分享。
- 新模型方面保持沉默:’new-models’ 频道似乎很安静,在指定的时间范围内没有特定的更新、讨论或链接分享。
OpenRouter (Alex Atallah) ▷ #discussion (30 条消息🔥):
LLM 情感理解基准测试, EQ Benchmark, Gemma 3 27b, OCR 引擎对比, Sonnet 自我审核
- Gemma 3 展示情感智能:成员们讨论了 LLM 理解人类情感的基准测试,其中一人推荐了 EQbench 的 EQ 基准测试。
- 还有人建议 Gemma 3 27b 是理解情感的好模型,同时警告不要为此目的使用 DeepSeek R1。
- 用户对 Sonnet 自我审核的反应:用户讨论了 Sonnet 自我审核最近的变化,以及是否会保留自我审核选项。
- 一名用户询问 LlamaGuard 是否仍将应用于 Anthropic 端点,认为这是保护用户的行业领先方法;而另一名用户表示他们无法再触发它,但也没有非常努力地尝试。
- OCR 引擎偏好辩论:一名用户对特定的 OCR 引擎表示不满,称其表现很差,并更倾向于 OLMo。
- 另一名用户询问原因,另一名用户解释说 OLMo 更便宜,且在几乎所有基准测试中表现更好。
- DeepInfra 涨价引发用户愤怒:一名用户对 DeepInfra 涨价表示沮丧。
- 另一名用户确认 DeepInfra 的费用约为 $1/1000 tokens,相当于 Mistral API,而 OpenRouter 是 $2/1000,建议 OpenRouter 可以调整其定价。
- GPT-OSS-120B 准备发布:一家提供商已部署了具有 65K 上下文的
gpt-oss-120b,准备在发布时上线。- 据附带的图片显示,审核应用于 Anthropic 和 Bedrock 提供商,而 Vertex 是未过滤的。
{kind=link}
Latent Space ▷ #ai-general-chat (236 条消息🔥🔥):
Claude Code 删除 package-lock.json,Google 的 LangExtract 库,AI Wrappers,Reflection AI 融资,Kaggle Game Arena
- Anthropic 社区冠军产生:一位来自 Auth0 的成员加入 Anthropic 负责 Claude Code 的社区工作,受到了 Web 开发社区的热烈欢迎。
- OpenAI 发布 GPT OSS 模型:OpenAI 发布了开源模型 GPT-OSS,以及一份 cookbook 和 model card。
- Genie 3,史上最先进的世界模拟器:Genie 3 发布,声称是史上最先进的世界模拟器。根据这篇博客文章,它能够以 20-24 fps 的速度生成高保真视觉效果,支持动态提示(dynamic prompting)、持久化世界记忆和快速世界生成。
- Anthropic 发布 Claude Opus 4.1 用于 Agent 任务:Anthropic 推出了 Claude Opus 4.1,这是一个升级版模型,专注于提升 Agent 任务、现实世界编程和推理的性能,可通过 API、Amazon Bedrock 和 Google Cloud Vertex AI 使用。
- Reflection AI 寻求超过 10 亿美元的巨额融资:根据这条推文,由前 Google DeepMind 研究员创立的一年期初创公司 Reflection AI 据报道正在洽谈筹集超过 10 亿美元 的资金,旨在构建开源 LLM,与 DeepSeek、Meta 和 Mistral 竞争。
Nous Research AI ▷ #general (220 条消息🔥🔥):
Qwen-Image,文本编码,XBai-o4 扩展,Terminal 基准测试,Attention sinks
- Qwen-Image 文本生成图像:用户正尝试在本地运行 Qwen-Image,并指出目前尚不支持 ComfyUI,但可以使用 fp8 diffusers 运行,且图像编辑模型尚未发布。
- 此外还提到,Qwen-VL 已经能够理解图像输入,而发布的模型重点在于通过文本编码器展示其文本渲染能力。
- XBai-o4 声称实现了 RL 扩展:XBai-o4 声称通过对 QwQ32 进行持续 RL 实现了扩展,利用奖励模型进行 BoN 扩展,生成 32 条 CoT 推理轨迹,并根据其论文所述,使用分类器头根据这些轨迹选出最佳结果。
- GPT-OSS 采用 Harmony 聊天格式:GPT-OSS 使用 Harmony 聊天格式,其中包括开发者角色(developer roles)和频道(channels)。
- 有提到 Horizon beta 在与用户聊天时告知了不同的角色信息。
- Terminal 基准测试压倒性倾向于 Claude:成员们讨论了 Terminal 基准测试,结果显示 Claude Agent 占据了绝对统治地位,前 10 名中有 9 个是 Claude 模型,并对排行榜上令人困惑的数据提出了质疑。
- 此外还注意到,OpenAI 现在正在分享其超优化的数学 CoT,这可能有助于开源权重的数学推理模型。
- 带有交错滑动窗口的 Attention Sinks:成员们讨论了 GPT-OSS 模型注意力机制的技术细节,提到它采用了交错滑动窗口注意力和全注意力(full attention),窗口仅为 128 个 token,20B 模型在全上下文下需要 19GB 显存。
- 还提到它使用了 sink attention keys,且 llama.cpp 的实现似乎足够稳定,在 RTX3090 上支持 MXFP4。
{kind=link}
Nous Research AI ▷ #ask-about-llms (2 messages):
Opus Bots, Improved Bot Design
- 使用 Opus 4 构建 Opus 机器人:一位成员声称是所有机器人的创建者,这些机器人均基于 Opus 4。
- 该成员正在积极开发一种改进的机器人设计,以增强其性能和能力。
- 提升机器人性能:主要目标是完善机器人设计,让它们能够大放异彩。
- 这包括优化其功能和响应能力,以满足不断变化的用户需求。
Nous Research AI ▷ #research-papers (1 messages):
OpenAI GPT OSS Model Card
- OpenAI 发布 GPT OSS 模型卡片:一位成员分享了 OpenAI GPT OSS 模型卡片的链接。
- GPT 模型卡片详述了用途和限制:该模型卡片可能提供了关于开源 GPT 模型的预期用途、能力、局限性以及潜在风险的详细信息。
Nous Research AI ▷ #research-papers (1 messages):
GPT-OSS Model Card
- OpenAI 发布 GPT-OSS 模型卡片:一位成员分享了来自 OpenAI 的 GPT-OSS 模型卡片。
- 提供的链接指向 OpenAI CDN 上托管的 PDF 文档,表明这是一次官方发布。
- 为满足最低要求的附加主题:添加第二个主题以满足
topicSummaries中至少两个主题的要求。- 此条目仅用于满足架构约束,可能不代表实际讨论的内容。
Eleuther ▷ #general (14 messages🔥):
Moderator Logs, Scaling LLMs, YaRN Usage, Algorithmic Monoculture
- Discord 版主记录已删除的消息:Discord 版主通常有一个版主日志频道,允许版主查看已删除的消息,如此 Twitter 链接所示。
- LLM 的局限性:一位成员认为,由于算法单一化(algorithmic monoculture)以及评估 SOTA 模型的不可能性,使用 LLMs 作为评委的问题无法通过扩大规模来解决。
- 他们表示,投入更多算力可能就是所需的全部。
- 发现 YaRN!:一位成员兴奋地注意到团队使用了 YaRN。
- 团队对几位帮助支持它的成员表示了衷心的感谢。
Eleuther ▷ #research (188 messages🔥🔥):
残差重构 (Residual rephrasing) 优化技巧, HRM 稳定性, 扩展 HRM, 深度平衡模型 (DEQs), OpenAI 的 GPT OSS 20B 和 120B 模型
- 残差重构实现酷炫的优化技巧:一位成员描述了一种类似扩散模型的优化技巧,通过估计到某个目标点的差异,并可以对输入应用 stop_grad,从而实现对先前输入的免费反向传播 (backprop),这得益于残差重构 (residual rephrasing)。
- 他们声称网络在原始公式下学习效果相当好,而这种方式可能为内部网络提供更好的支持。
- HRM 扩展的稳定性担忧:成员们讨论了 分层循环模型 (HRM) 的一个担忧,即仅使用最后的梯度可能仅在 L、H 循环较短时有效,对于较长的循环可能无法收敛。
- 另一位成员表示,稳定性是 UTs 的重大问题之一,自 2015 年以来训练的最大 UTs 参数量都在 40M 以下。
- 深度监督优于两步训练?:一项实验表明,对于带有深度监督的 分层循环模型 (HRM),一步 (one-step) 和 两步 (two-step) 训练模式在验证期间取得了相似的性能。
- 一位成员认为,如果使用了深度监督,这让他们对之前论文中关于需要两步训练的说法更加怀疑。
- DEQs 风格的思维是错误的:一位成员认为,深度平衡网络 (DEQs) 风格的思维是思考 UTs 的完全错误的方式,因为你为了稳定性放弃了表达能力,并为此支付了更多的 FLOPs。
- 他们假设 UTs 实际上需要一种新的范式才能具有竞争力,并指出 DEQs 做了太多的假设(特别是收敛向一个固定点,而不是这些点的分布)。
- GPT OSS 20B 和 120B 模型发布:OpenAI 社区讨论了 GPT OSS 模型的发布,可在 Hugging Face 上获取(20B 版本 和 120B 版本)。
- 一位成员目前正在对 gpt oss 20b 进行 SAE,基准测试数据可在 OpenAI 训练页面上找到。
Eleuther ▷ #lm-thunderdome (1 messages):
lm-evaluation-harness, API 调用
- 通过 API 调用为 Eval Harness 设置种子 (Seed):一位成员成功解决了如何通过 API 调用 为数据集传递 seed。
- 他们正在请求对 lm-evaluation-harness 的 PR#3149 提供反馈。
- 请求对 Eval Harness 的 PR 反馈:一位贡献者向 lm-evaluation-harness 提交了拉取请求并寻求反馈。
- 该拉取请求 (PR#3149) 涉及通过 API 调用传递数据集种子;鼓励社区提供反馈。
Eleuther ▷ #gpt-neox-dev (7 messages):
PP=0 层命名, TE 基准测试, 带有 rmsnorm 的 TE
- PP=0 层命名需要重命名文件:成员们讨论了没有任何根本原因阻止 PP=0 工作,但由于模型没有封装在 deepspeed 模型管道类中,层的命名会发生变化。
- 有人提到,通过重命名文件或添加修改后的加载器来添加 PP=0 支持会略显繁琐,但并不困难。
- TE 基准测试并未变快:一位成员询问另一位成员是否尝试过 TE (Tensor Engine) 并进行了基准测试,并指出他们自己的重试似乎并没有变快。
- 另一位成员回答说他们还没有尝试过,但很快会尝试。
- RMSNorm 与 TE:一位成员询问关于将 TE 与 RMSNorm 结合使用的问题,因为他们在示例中只看到了 te_layernorm。
- 消息中未提供此问题的解决方案。
Moonshot AI (Kimi K-2) ▷ #general-chat (186 messages🔥🔥):
K2 vs. O3, Stardew Valley, Kaggle, Game Arena, LLMs 玩 Chess 和 Go
- Kimi 和 O3 在 Chess 中对决!:成员们讨论了 Kimi K2 与 Deepseek O3 之间的一场 Chess 比赛,并注意到 O3 采用了 step-by-step reasoning(逐步推理)方法。
- 在比赛中,Kimi 先是认输,随后因走了一步非法棋招被强制再次认输,最终导致 O3 自动获胜。
- Stardew Valley 是新的 Harvest Moon:成员们讨论了 Stardew Valley 与 Harvest Moon 的相似之处,以及它如何能随时拿起和放下。
- 一位开发者利用 Kimi K2 在 Roblox 中制作了一款类似于 Stardew Valley 的游戏。
- GPT-OSS 发布,互联网为之疯狂:OpenAI GPT-OSS 的发布在社区引起了轰动,成员们注意到它已在 Hugging Face 和 Openrouter 等多个平台上线。
- 据报道,它拥有 Day 0 支持,llama.cpp 的 PR 也在进行中,其 Benchmark 结果令人印象深刻,尽管直播的 Chess 演示中途夭折。
- Kaggle 对 Chess 一无所知:成员们对 Kaggle 的 AI Game Arena 竞赛 表示好笑和困惑,质疑为什么会将一个非推理模型纳入其中。
- 一位成员分享了一个 GitHub 链接,显示 Go 将在未来加入 Game Arena,并补充说 Go 比 Chess 更难。
- Quantization 平息了体积担忧:针对 Hugging Face 上的 model card 显示 120B 模型仅占 60GB 的讨论,引发了关于 Quantization 的疑问。
- 解释称 MXFP4 quantization 减少了内存占用,使得较大的模型可以装入单块 80GB GPU,而较小的模型可以在仅有 16GB 内存的系统上运行。
Cursor Community ▷ #general (177 messages🔥🔥):
Claude Sonnet vs Gemini, Cursor PDF 支持, Cursor 年度订阅, Cursor 卡死问题, Vercel 的 v0 在 Cursor 中的应用
- Claude Sonnet 赢得成员青睐:成员们表示,在 Agentic IDE 上下文中,由于更好的 Tool Usage 能力,他们更倾向于选择 Claude Sonnet 4 而非 Gemini 2.5 Pro;而一位用户则使用 Gemini/Sonnet 4 的 Thinking 模式进行头脑风暴,并使用常规的 Sonnet 4 进行 Implementation。
- 大多数人同意 Claude 在这种场景下的用例表现更好。
- 成员们请求:请支持 PDF, DOCX, CSV, XLSX!:成员们请求能够将 PDF, .docx, .csv 和 .xlsx 文件添加到 Cursor edit 中,以便传递 PRD 和数据供 AI 处理,目前这些文件尚不支持本地上传。
- 一位成员分享了 Cursor 功能请求论坛的链接 以正式提交请求,并指出 Cursor 可以从公开访问的 PDF URL 中提取和解析文本内容。
- Cursor 便宜的年度订阅令人惊喜:一位用户对 $16 的 Cursor 订阅 表示惊讶,随后澄清这是年度订阅折算后的月度费用。
- 月度订阅仍为 $20 固定费率。
- Linux 用户遭遇卡死困扰:多位用户报告在 Linux 上使用 Cursor 时遇到卡死和无响应的情况,一位用户称其已几乎无法使用,这可能是由于网络问题或错误的请求导致的。
- 成员们指出了论坛上报告的几个相关问题,团队目前正在开发修复方案。
- 利用 Cursor 的 Workspaces 实现多仓库魔法:Cursor 支持通过 .code-workspace 文件在单个 Workspace 中打开并跨多个 Repository 工作,索引所有包含的文件夹以提供 AI Context,从而方便在共享库、微服务或 Monorepo 结构中进行导航和编辑。
- 一位用户提到可以要求 Cursor 前往 github/blablabla/folder/file 来查看特定文件。
Cursor Community ▷ #background-agents (7 messages):
Background agent failure, Request IDs sent via PM, Configure background agents todocker login``
- **Background Agents 遭遇故障:多位工程师报告称,在过去几小时内,background agents** 开始出现反复启动失败的情况。
- 一名成员请求提供 Request ID 以调查该问题。
- **Request ID 已通过私信转发:一名成员确认已针对调查请求通过 **PM 发送了几个 Request ID。
- 该成员还对支持表示了感谢。
- **Docker Login 问题引发讨论:一名成员询问如何配置 **background agents 执行
docker login,以便使用托管在 ghcr.io 上的私有镜像。- 在给出的消息中未提供任何解决方案或建议。
HuggingFace ▷ #announcements (1 messages):
Trackio Experiment Tracking, New OCR Datasets, Transformers Acceleration, HF Jobs for Compute, Faster HF CLI
- HuggingFace 发布 Trackio 实验追踪库:Hugging Face 推出了 Trackio,这是一个轻量级的实验追踪库。
- Trackio 旨在简化机器学习实验的追踪和管理流程。
- HF 发布新 OCR 数据集:Hugging Face 发布了 4 个新的 OCR 数据集,总计超过 2000 万张图像。
- 详情请参阅这篇 LinkedIn 帖子。
- Transformers 获得加速提升:Hugging Face 旨在通过 Transformers 加速开源生态系统。
- 根据这条推文,新的 Transformers 版本包含了 kernel 支持。
- 使用 HF Jobs 运行计算任务:HF Jobs 现在可以在 CPU 或 GPU 上启动计算任务。
- 一篇博客文章详细介绍了如何使用 HF Jobs 构建你自己的 GPU 驱动的图像生成器。
- HF CLI 变得更快、更友好:Hugging Face 发布了一个名为
hf的更快、更友好的 CLI 工具。- 有关更新后的 CLI 的更多信息可以在 Hugging Face 博客上找到。
HuggingFace ▷ #general (113 条消息🔥🔥):
ZeroGPU, 340M t2i model, VS Code GPU acceleration, Soft-bias(es), RAG frameworks
- **ZeroGPU 带来惊喜: 一位成员鼓励其他人尝试使用 **ZeroGPU,可能会有意想不到的收获,并分享了他们的 Space,其中展示了一个在家预训练的 340M t2i model。
- 他们指出,在 ZeroGPU 的 H200 上,图像生成仅需 1 秒,而 Prompt 生成则需要 2-5 秒。
- **Homelab 硬件与 RAG 架构: 成员们讨论了用于本地 AI 的硬件配置,一位用户正在考虑使用 **RTX 3090 24GB / AMD MI60 32GB 来运行中型模型,另一位则提到了 SmoLLM3 等模型。
- 他们链接到了 text-embeddings-inference 用于本地 Embedding 服务器,并强调 Ollama 在处理长上下文 (long contexts) 时比较吃力,目前的工具可以从优化的硬件利用率中获益更多。
- 数据集被标记为恶意软件: 一位成员报告称,尽管多次杀毒扫描显示没有威胁,但他们上传的数据集仍被扫描为不安全,并指向了 HuggingFace 安全文档。
- 被标记的项目识别为 Pickle.Malware.NetAccess.pwn.STACK_GLOBAL.UNOFFICIAL,这导致了移除分片 (shards) 并逐行检查数据集的建议,同时也强调了基于网站的扫描器的局限性。
- **火灾与烟雾检测资源: 一位成员正在寻找视频/图像中火灾和烟雾检测**的资源,并被引导至 pyronear/pyro-sdis 数据集。
- 另一位用户在提供帮助资源的同时,也开玩笑地提到了他们广泛的兴趣爱好。
- **Fine-Tuning 热潮与 GPT-OSS 见解: 成员们寻求 **Fine-Tuning 开源 LLM 的指导,并收到了指向 SmolFactory 和一份 Cookbook 的链接。
- 其他人分享道,在 Unsloth 的帮助下,OpenAI 的 20B 和 120B 开源模型 可以在消费级硬件上运行。
HuggingFace ▷ #today-im-learning (2 条消息):
AI Benchmark for LLMs playing Monopoly Deal, Learning Go and DRL
- DealBench:玩《大富翁成交》(Monopoly Deal) 的 LLM: 一位成员正在构建一个 AI Benchmark,让 LLM 相互进行《大富翁成交》风格的游戏,并在 DealBench 征求反馈。
- 涉足围棋和 DRL: 一位成员正在学习下围棋,并阅读一本关于 DRL (深度强化学习) 书籍的第一章。
HuggingFace ▷ #cool-finds (2 条消息):
DealBench, Qwen Image Model
- DealBench 发布《大富翁成交》风格 AI 基准测试: 一个名为 DealBench 的新 AI 研究基准测试已发布,其中 LLM 相互进行《大富翁成交》风格的游戏。
- 它旨在评估 AI Agent 在简化经济环境中的策略决策和谈判技巧。
- Qwen 首次推出新图像模型: Qwen 发布了一个新的图像模型,可在 Hugging Face 上获取。
- 这标志着 Qwen 系列向多模态能力的又一次扩张。
HuggingFace ▷ #i-made-this (7 messages):
Open Evolutionary Agents, Recursive Thought Processes in AI, Critique of AI Benchmarks, GPT-OSS Multilingual Reasoner Tutorial
- **Open Evolutionary Agents 开放测试: 一位成员正为一种真正的“思考型” AI 提供公开测试,该 AI 使用递归思维过程 (recursive thought processes)** 进行探索,而非线性模式匹配。通过 huggingface.co/blog/driaforall/towards-open-evolutionary-agents 博客文章中介绍的框架,可以提升任何 LLM 的能力。
- 该成员指出,在一位用户反映内容枯燥且在不了解基准测试的情况下感到困惑后,他们已更新文章,增加了关于基准测试本身的说明。
- **GPT-OSS Multilingual Reasoner 教程分享: 一位成员分享了关于 **GPT-OSS Multilingual Reasoner 的教程链接,地址为 huggingface.co/spaces/Tonic/openai-gpt-oss-20b 和 huggingface.co/Tonic/gpt-oss-multilingual-reasoner。
- 该成员评价该教程非常不错。
HuggingFace ▷ #reading-group (1 messages):
Reading Group Intro, Welcome Newbie
- 新人询问读书小组结构: 一位新成员询问了读书小组的结构以及如何参与。
- 消息中未提供进一步的讨论或细节。
- 欢迎新人: 其他成员欢迎新人加入读书小组。
- 他们鼓励新人在未来的讨论中积极参与。
HuggingFace ▷ #NLP (1 messages):
Text Data Processing, Information Extraction
- 讨论准确且经济的文本数据处理: 一位成员正在寻求关于准确且经济的开源方法建议,旨在从存储为原始文本和 Markdown 格式的大规模多语言法律文本数据集(50万+条目)中提取文章和元数据等有用信息。
- 挑战在于处理从多个网站爬取的数据,其中单个链接可能包含多篇文章,因此需要有效的方法来识别和提取单篇文章及其关联的元数据。
- 多语言法律文本数据提取策略: 用户需要一种策略来处理和提取来自不同语言的 50万+ 法律相关文本条目中的相关数据。
- 目标是使用开源解决方案,高效地从可能包含多篇文章的单个链接中识别并提取单篇文章及其元数据。
HuggingFace ▷ #smol-course (2 messages):
Inference Providers, Colab Error, Batman Party Music
- Colab 额度引发困扰: 一位学习 Unit 2.1 课程的成员在运行“构建使用代码的 Agent (Building Agents That Use Code)”中关于 Batman Party Music 的 Colab 时遇到错误,收到一条关于 Inference Providers 每月额度超限的消息。
- 他们注意到在 0.10 美元的可用额度中仅使用了 0.10 美元,并询问运行课程示例是否需要付费。
- 免费推理是可行的: 另一位成员建议在 Hugging Face 上搜索免费的 Inference Providers 作为替代方案。
- 他们建议课程方推出一个 Inference Provider。
HuggingFace ▷ #agents-course (8 messages🔥):
作业提交问题、课程起点、课程证书
- 作业提交故障引发格式挫败感:多名成员报告在以 JSONL 格式提交最终作业时遇到问题,尽管文件中存在任务 ID,但仍遇到 “task ID not found in the file” 之类的错误,目前正在积极寻求调试建议。
- API 需要特定的 JSON 格式,包括 username、agent_code 以及包含 task_id 和 submitted_answer 的 answers 数组。
- 新手探索 AI Agent 课程起点:一名新成员询问如何开始 AI Agents 课程,寻求入门指导。
- 一位热心用户提供了指向介绍单元的直接链接。
- 课程证书状态仍不明确:一名成员询问 MCP(推测为 AI Agents 课程) 是否仍在发放证书。
- 上下文中未提供明确答案。
Yannick Kilcher ▷ #general (69 messages🔥🔥):
低预算语音克隆、Claude Code 的数据泄露事件、Deepseek-R1 vs Kimi-K2/GLM4.5、Attention Sink 层、Gemini 2.5 Pro 处理 1 小时视频
- 消费级硬件开启低预算语音克隆:一名成员询问如何在消费级硬件(最高到 5090)上进行有趣且具有挑战性的深度学习项目,特别是在语音克隆领域,且无需海量音频样本数据集,也不必在 GPU 租赁上花费巨资。
- Claude Code 导致数据泄露:一名成员报告称 Claude Code 在其 XGBoost 流水线中添加了数据泄露,它直接添加了一个工程特征,而该特征基本上包含了模型试图预测的目标特征。
- 他们测试了 Claude Code 自动化整个 ML 流水线的能力,并建议各种 LLM 系统都缺乏被强制双重检查一切的机制。
- Deepseek-R1 依然强于 Kimi-K2 和 GLM4.5:成员们表示,尽管炒作不断,Kimi-K2 和 GLM4.5 都未能超越老牌的 Deepseek-R1。
- 然而,R1 被认为非常难以使用,因为它速度极慢。
- Attention Sink 层是新型的 Learned Attention:根据新版本发布,HuggingFace 的 Transformers 库现在使用的 attention 层采用了每个 head 一个学习到的 attention sink,其中 softmax 的分母有一个额外的加性值。
- 这类似于在 attention 中预置一个具有全零 Key 和 Value 特征的 token,正如这篇论文中所讨论的那样。
- Gemini 2.5 Pro 观看 1 小时电影:Gemini 2.5 Pro 已经可以处理 1 小时的视频,并能通过拖动进度条进行一些基础检索。
- 然而,一些成员指出,在表面层次上理解视频内容并能拖动进度条,与真正能够复现早期图像的详细且准确的表示(同时考虑空间中的 3D 定位和透视)之间存在巨大差异。
Yannick Kilcher ▷ #paper-discussion (13 messages🔥):
微型模型在 ARC-AGI 上表现出色、对论文进行冷读、Deepmind Genie 3、Genie 和 SIMA 论文
- 数据高效的微型模型在 ARC-AGI 上表现卓越:一篇新论文介绍了一个在 ARC-AGI 上表现良好并展现出数据高效性的微型模型。
- 一名成员表示这也引起了他们的注意,并对该论文的“冷读”(cold reading)环节表示出兴趣。
- Deepmind 发布 Genie 3:DeepMind 发布了 Genie 3,这是其世界模型的新迭代,主要是在之前版本的基础上扩展了计算量和数据,但没有随附论文。
- 一名成员建议回顾原始 Genie 论文、关于具身智能体 (Embodied Agents) 的相关 SIMA 论文,以及 Genie 的博客文章(Genie 1、Genie 2、Genie 3)。
Yannick Kilcher ▷ #ml-news (16 messages🔥):
Windsurf IDE, Genie Model, Claude Opus 4, GPT-OSS, Natively Quantized Models
- **Windsurf IDE 反应平平: 成员们讨论了 **Windsurf IDE,一位评论者指出它是 几乎没有人使用的 Cursor 竞争对手。
- **DeepMind 的 Genie 改变世界: DeepMind 宣布发布 **Genie,这是他们全新的 世界模型 (world model)。
- **Anthropic 首次推出 Claude Opus 4: Anthropic 在一篇 博客文章 中宣布了他们最新的模型 **Claude Opus 4。
- **OpenAI 开源 GPT-OSS: **OpenAI 推出了 GPT-OSS,并提供了 介绍博客 和 项目页面 的链接。
- **原生量化 (Natively Quantized) 模型挤进微小空间: 一位成员强调,由于原生量化,20B** 参数版本的模型可以适配 16GB 显存,并链接到了一篇关于 无后门 (no backdoors) 的博客文章。
Notebook LM ▷ #use-cases (9 messages🔥):
Whisper Transcription, NotebookLM Limits, Customized Prompts
- Whisper 转录效果更好: 一位成员发现,使用 Whisper 在本地转录视频比在 NotebookLM 中使用 YouTube URL 效果更好。
- 他们下载整个频道并进行转录,然后将转录文本发送到 NotebookLM 以与频道内容互动,并指出 NotebookLM 不支持播放列表。
- NotebookLM 视频摘要限制: 一位成员询问了 NotebookLM 中 视频摘要 的限制。
- 目前没有关于明确限制的回复。
- 编写自定义 Prompt 效果显著: 一位用户每次都会量身定制不同的 Prompt,例如:“作为一所顶尖大学的文学系主任,你的标准非常高,因此你会无情地批判任何看起来平庸或业余的内容。”
- 该成员还使用了:“作为恐怖片的狂热爱好者,尤其是 80 年代的青少年杀手电影,你希望捕捉到所有对这些经典电影的引用和平行之处,并留意那些较为冷门的细节。”
Notebook LM ▷ #general (65 messages🔥🔥):
Video Overview Rollout, Custom Instructions and Podcast, Image Upload Issues, NotebookLM vs Gemini, Data Privacy in NotebookLM
- **视频概览 (Video Overviews) 仍未上线: 用户报告称,尽管宣布了全面推出,但 **Video Overview 功能仍然不可用,一些人怀疑是基础设施问题。
- 众所周知,功能推出需要时间,Pro 用户 也在等待之列。
- **播客制作人分享 Prompt Engineering 指南**: 一位成员分享了一个 Google Docs 链接,其中包含用于引导播客生成的自定义指令示例,强调了迭代调整的重要性,并建议如果作为模板使用需更改名称。
- 该 Prompt 侧重于 避免冗余词汇 和 防止中断。
- **图片上传功能暂时下线**: Google 确认,由于影响部分用户的基础设施问题,图片上传功能已暂时移除。
- 一位成员最初建议从 PDF 中提取图片作为变通方法,随后才意识到该功能已被移除。
- **NotebookLM 在文档处理和知识管理方面备受推崇**: 用户讨论了 NotebookLM 相对于 Gemini 的价值,强调了 NotebookLM 的优势,如上传大量文档、将模型限制在提供的源文件内以及创建带有引用的笔记。
- NotebookLM 被定位为阅读你文档的 图书管理员,而 Gemini 则用于一般对话,且 Gems 中的源文件数量有限。
- **数据隐私对用户至关重要**: 一位成员询问了数据隐私以及 NotebookLM 是否使用用户数据进行模型训练。
- 另一位成员分享了 NotebookLM 的 Google 数据保护政策 链接。
Modular (Mojo 🔥) ▷ #general (53 messages🔥):
Mojo 中的 Decorators,Mojo 中的 Zig 风格反射,Mojo 中的 JavaScript 运行时
- Python Decorators vs Java Annotations: 一位成员表达了对 Python decorators 易用性的赞赏,并将其与 Java annotations 进行了对比。
- 该成员请求 Modular Mojo 团队让 Mojo 中的 decorators 像 Python 中那样简单且灵活,允许在编译时或运行时定义逻辑。
- Zig 风格的反射系统: 关于 struct 上 decorators 的讨论倾向于采用 Zig 风格的反射系统,用于添加函数、修改 struct 以及添加新的 struct 成员。
- 虽然在 Mojo 中处理函数包装器(function wrappers)相对容易,但拆解函数并将其投入编译器将与 Java 中一样困难,因为这涉及到编写实质上的编译器 pass。
- 用 Mojo 编写的 JavaScript 运行时 Volokto: 一位成员创建了一个名为 Volokto 的 JavaScript 运行时,并将全部源代码上传到了 GitHub,该运行时使用 TypeScript 编写。
- 该运行时支持用户自定义函数、嵌套控制流和带参数的函数调用;其字节码类似于 CPython,并且实现了 dictionary 类型和控制台。
- 调试断言 (Debug Assertions): 一位成员因使用
if DEBUG:语句而在编译器中遇到了 34 个警告。- 另一位成员建议改用 debug_assert 或 param_env。
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Modular Platform 25.5,大规模批处理推理,独立 Mojo Conda 包,开源 MAX Graph API,MAX PyTorch 集成
- Modular Platform 25.5 正式上线: Modular Platform 25.5 现已发布,目标用户是需要大规模性能的开发者,带来了全新的功能和改进。
- 关键特性包括通过 SF Compute 实现的 大规模批处理推理 (Large Scale Batch Inference)、独立的 Mojo Conda 软件包 以及开源的 MAX Graph API。
- MAX ❤️ PyTorch 使用 graph_op: 新版本通过
@graph_op提供了无缝的 MAX 与 PyTorch 集成,增强了框架间的互操作性。- 此外,该版本还带来了体积更小、速度更快的 MAX 服务容器以及其他性能改进。
Modular (Mojo 🔥) ▷ #mojo (8 messages🔥):
Mojo 中的多个 AI Agents,自定义框架中的 Mojo 代码,MAX 作为库使用
- MAXimize 你的 Agents:运行多个 AI: 为了在 Mojo 中运行多个 AI Agents,一位成员建议运行多个 Modular CLI 实例并使用反向代理。
- 对于创建许多子 Agent(Terminal, Python3.13 等)的用例,可能需要开发一个将 MAX 作为库使用的自定义应用。
- 梦想取代 HTML/CSS 的 Mojo 框架: 一位成员正在寻求帮助,希望在自己的框架中使用 Mojo 代码,该框架被描述为 AI 系统元认知 的新范式,以及终极业务规划器、网站和聊天机器人构建器。
- 他们认为,在 Mojo 代码之上包装自然语言有可能 取代 HTML/JS/CSS,并认为 Modular 在 Mojo 上的工作对 Web 开发者、程序员和普通用户都有利。
Modular (Mojo 🔥) ▷ #max (4 messages):
Modular 与 Intel OSX 的兼容性,macOS 的 Apple Silicon 要求,Docker Ubuntu 容器变通方案
- Modular 在 OSX 上的兼容性小插曲 🤕: 一位用户在尝试在 OSX 上添加 modular=25.5 时遇到错误,并询问了兼容性问题。
- 错误信息显示,由于 modular 25.5.* 的安装问题,无法为 osx-64 解决环境依赖。
- macOS 上的 Max 强制要求 Apple Silicon 🍎: 一位使用 Intel OSX 芯片 的用户询问其系统是否受支持,并引用了 系统要求。
- 一位开发者确认 macOS 官方仅支持 Apple Silicon CPU,因此与基于 Intel 的系统不兼容。
- Docker Ubuntu 容器化解难题 🐳: 作为 Apple Silicon 要求的变通方案,一位开发者建议使用 Intel Docker Ubuntu 容器 来处理这些软件包。
GPU MODE ▷ #general (21 messages🔥):
CUDA vs Compute Shaders, MXFP4, OpenAI Model U8 vs FP4, H100 FP4 Support, MoE Module Experts
- CUDA vs. Compute Shaders 问题引发对 Kernel 的思考:一名成员询问在利用 libtorch C++ 进行模型推理后,应如何在 CUDA kernels 和 compute shaders 之间选择进行图像后处理,并征求关于两者使用场景及长期收益的意见。
- 该成员澄清他们并不担心非 Nvidia 设备的兼容性,并询问了关于 MXFP4 的问题。
- MXFP4 解析:OpenAI 的新模型混编:成员们讨论了 OpenAI 使用 U8 而非 FP4 的新开源权重模型,指出权重被打包为 uint8,其 scale 是 e8m0 的 uint8 视图。
- 他们澄清在推理/训练期间,权重会被重新解包为 FP4,MXFP4 的 block size 为 32,而 NVFP4 为 16。
- 社区质疑 H100 的 FP4 支持:一名成员质疑考虑到该模型的规格,使用 H100 进行推理是否可行,因为他认为 H100 不支持 FP4。
- 另一名成员指出了一篇关于该发布的 NVIDIA 博客文章,但有人回应称 H100 训练的说法是“彻头彻尾的谎言”。
- MoE 模块专家:32 是魔法数字:一名成员询问新模型中的 MoE (Mixture of Experts) 模块 是否包含 32 个专家。
- 另一人确认了这一点,并指出根据发布说明,这个 20B 模型 每层拥有 32 个专家。
GPU MODE ▷ #triton (6 messages):
Helion, Compiler Explorer Support for Triton, Triton Puzzles, GPU kernels turning into JavaScript
- Helion 研讨会公告:关于 Helion(来自 Pytorch 的新 kernel DSL)的研讨会将于太平洋时间明天 2.15 举行,详见 Helionlang.com。
- Compiler Explorer 已上线 Triton 支持:Triton 支持现已在 Compiler Explorer 上线,请访问 Compiler Explorer 查看。
- 完成 Triton Puzzles:一名成员最近完成了由 srush 编写的 triton-puzzles 题目集,正在寻求下一步行动的建议,并表现出对学习编写快速 kernel 的兴趣。
- GPU kernels 正在变成 JavaScript:一名成员开玩笑地评论说 GPU kernels 正在变成 JavaScript。
GPU MODE ▷ #cuda (5 messages):
CUDA programming, Compute shaders, CUDA kernels, cudaLaunchCooperativeKernel
- CUDA vs Compute Shaders:程序员的难题:一名成员就使用 libtorch C++ 进行模型推理后的图像后处理,在 CUDA kernels 和 compute shaders 之间如何选择寻求建议。
- 他对两者都是初学者,且不担心非 NVIDIA 设备的兼容性,并询问了相关经验和长期收益。
- 探索 Cooperative Kernel 启动的特性:一名成员询问关于启动具有特定数量同时驻留线程块的 CUDA kernel,提到了 cudaLaunchCooperativeKernel 和 cluster 启动。
- 他发现
cudaLaunchCooperativeKernel并不排他性地占用整个 GPU,但在 Ada 和 Ampere GPU 上,它会在整个 grid 的资源可用之前部分启动 grid。
- 他发现
GPU MODE ▷ #announcements (1 messages):
NCCL, Multi GPU programming, GPU communication tools and libraries, Quartet with 4 bit training, PCCL and designing fault tolerant communication primitives
- GPU Mode 频道举办分布式夏季系列活动:在整个 8 月期间,GPU Mode 频道将举办一系列专注于分布式编程的讲座、工作组和 Kernel 竞赛。
- 该频道鼓励任何对该领域感兴趣的人保持关注并加入讲座。
- NCCL 作者进行 Multi GPU 编程讲座:8 月 16 日,NCCL 的作者之一 Jeff Hammond 将进行一场关于 Multi GPU 编程的讲座。
- 讲座旨在提供 Multi GPU 编程的速成课程。
- Didem Unat 概述 GPU 通信工具:8 月 22 日,Didem Unat 将对所有以 GPU 为中心的通信工具和库进行广泛概述。
- 本次会议有望深入了解 GPU 通信技术的前景。
- Quartet 与 4-bit 训练应用讲座:8 月 23 日,Roberto Castro 和 Andrei Panferov 将介绍一个名为 Quartet with 4-bit training 的具体应用。
- 与会者将学习低精度训练技术的实际实现。
- PCCL 与容错通信原语讲座:8 月 30 日,来自 Prime 的 mike64_t 将讨论 PCCL 和容错通信原语的设计。
- 本次讲座将探讨分布式系统中的鲁棒通信策略。
GPU MODE ▷ #cool-links (1 messages):
as_ai: https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/
GPU MODE ▷ #jobs (1 messages):
NVIDIA, AI, HPC, Solution Architect, Universities
- NVIDIA 招聘 AI/HPC 解决方案架构师:根据此招聘公告,NVIDIA 的高等教育与研究解决方案架构师团队正在寻找一名在 AI/HPC 基础设施方面具有深厚专业知识的高级解决方案架构师,负责领导 GPU 在大学和研究机构的部署。
- 需访问大学的远程职位:该高级解决方案架构师职位是远程办公,但申请人必须居住在美国东北部或中部,以便偶尔访问大学。
GPU MODE ▷ #jax (1 messages):
``
- 占位主题 1:这是主题 1 的占位摘要句子。它用于满足模式的最低要求。
- 占位主题 2:这是主题 2 的占位摘要句子。它用于满足模式的最低要求。
GPU MODE ▷ #torchao (9 messages🔥):
NVFP4 scales swizzling, FP4 Training development in TorchAO, MXFP4 training, NVFP4 training, User API for FP4
- NVFP4 的 Swizzling Scales:根据此 pytorch/ao 链接,cuBLAS nvfp4 gemm 在进行 Tensor Core 加载时需要 Scale swizzling,该标志控制是提前 swizzle 还是即时 (just-in-time) swizzle。
- TorchAO 即将开展 FP4 训练开发:相关的 GitHub issue 是跟踪 TorchAO 中 FP4 训练开发进度的位置,该项目计划很快更新,工作重点是公开面向用户的 API 并验证性能和准确性。
- 计划在未来 3 个月内实现 mxfp4 和 nvfp4 训练。
- FP4 训练用例:FP4 训练的主要用例是实现训练加速和节省 VRAM,一位用户表示愿意在面向用户的 API 可用时进行测试并提供反馈。
GPU MODE ▷ #irl-meetup (4 messages):
PyTorch conference, Meetup
- PyTorch 会议后计划举行 Meetup:一位成员询问在 PyTorch conference 后的周五是否有 Meetup 计划,类似于去年。
- 另一位成员确认周五确实有活动安排,并表示很快会发布公告。
- PyTorch Meetup 详情即将公布:在询问 PyTorch conference 后的 Meetup 后,组织者确认计划正在进行中。
- 预计很快会发布关于周五聚会的具体细节公告;请关注后续更新。
GPU MODE ▷ #self-promotion (3 messages):
Langflow on Vast.ai, Tiny TPU on TinyTapeout
- Langflow 在 Vast.ai 上飞速运行:一个新的模板已上线,用于在 Vast.ai 上启动 Langflow,提供了一个可视化 AI 工作流平台,其中包含运行在 Docker 容器中的托管 Ollama API 服务器,详见此处。
- Langflow 具有直观的拖拽式界面,用于构建复杂的 AI 应用程序,而 Ollama 则作为运行 Llama 和 Mistral 等模型的私有 LLM 后端。
- Tiny Tapeout 展示 Tiny TPU:一位成员在 Verilog 中原型化了一个微型版本的 TPU,用于在 TinyTapeout 上进行制造。
- 这个 2x2 matmul systolic array 运行在 2 个 TinyTapeout 磁贴上,在 50 MHz 时钟频率下能够达到每秒近 1 亿次操作,代码可在 GitHub 获取。
GPU MODE ▷ #factorio-learning-env (7 messages):
VQA Dataset, Factorio RCON, JackHopkins RCON
- Noddybear 上传了 VQA Dataset 样本!:成员 Noddybear 宣布发布了 VQA Dataset Sample。
- 该样本现在可以在 Hugging Face datasets 上获取,供广泛使用。
- 成员们测试 Factorio RCON 版本!:成员们准备测试 Factorio RCON,其中一人承诺很快提供结果,这可能涉及 Jack 的版本。
- 他们的目标是查看 Jack 的版本 是否能改进他们的测试环境。
- 成员们计划在周末搭建新环境!:一位成员表示他们打算在周末搭建一个新环境。
- 他们似乎对开始环境开发工作感到非常兴奋。
GPU MODE ▷ #cutlass (2 messages):
CuTe Vectorized Store Issues, Memory Coalescing Problems, LDG.E.128 vs STG.E.128 Instructions
- CuTe 的向量化存储问题:一位用户面临 CuTe 无法从寄存器向全局内存生成正确的 128-bit vectorized store 的问题,尽管使用了 float4。
- 编译器没有生成 STG.E.128,而是发出了两个独立的 STG.E.64 指令,这破坏了跨线程的内存合并 (memory coalescing)。
- 剖析 LDG.E.128 与 STG.E.64 的困境:当从全局内存加载到寄存器时,编译器发出了正确的 LDG.E.128 指令。
- 然而,当存回全局内存时,编译器使用了两个 STG.E.64 指令,导致用户质疑对 STG.E.128 的支持情况或是否存在潜在的配置错误。
- 引发对内存合并的担忧:用户强调,使用两个独立的 STG.E.64 指令而不是单个 STG.E.128 会破坏跨线程的内存合并 (memory coalescing)。
- 这一点令人担忧,因为向量化存储预期应确保数据以连续方式写入,以获得最佳性能。
GPU MODE ▷ #singularity-systems (2 条消息):
Chaitin-Briggs-Click 寄存器分配,picograd 与 picocuda 合并
- 深入了解 Chaitin-Briggs-Click 寄存器分配:对于那些关注 Chaitin-Briggs-Click 寄存器分配的人,这里有一份必读论文清单,可以从 Wikipedia 的概览开始。
- 深度阅读资源包括 sci-hub 链接 1、sci-hub 链接 2、讲义以及一份 GitHub 文档。
- Picograd 与 Picocuda 合并!:Picograd 和 Picocuda 已合并为一个仓库。
- 访问统一的代码库:Singsys GitHub repo。
MCP (Glama) ▷ #general (15 条消息🔥):
用于文档的 MCP,工具的标准化支付,浏览器内 postMessage 传输提案,用于嵌入式系统的 MCP,通过 Web 暴露 Prompt
- MCP Server 需要文档支持:一位用户正在寻求一种创建 MCP server 的方法,使其能够通过指向 repo 或文档网站来访问文档,从而避免在信息检索时进行过多的往返请求。
- 标准化成千上万种工具的支付:主要想法是在某种抽象层面上标准化支付,AI Agent 将处理潜在的数千种工具的支付,而无需用户为每个工具单独创建账户。
- 一位成员希望 这个 PR 能够实现在客户端安全地输入支付信息,从而在不创建账户(或静默创建账户)的情况下完成单次购买。
- 浏览器内 MCP 的 PostMessage 传输提案:一位成员正在开发一种用于浏览器内 “postMessage” 的传输提案,并提供了一个 demo,展示了通过 GitHub Pages 托管的静态 JS/HTML 客户端 + 服务器。
- 他们起草了一个 SEP,并正在寻找一位 MCP 规范维护者来支持其标准化。
- 用于嵌入式系统编程的 MCP:一位新用户询问关于在 STM32CubeIDE 中进行嵌入式系统编程的有用 MCP。
- 结合 MCP 使用 OpenRouter LLM 服务:一位成员询问如何使用像 OpenRouter 这样的 LLM 服务与获取 MCP 数据(例如体育数据)的 API 进行通信并进行提问。
- 他们希望让 OpenRouter 模型告知下一次英超(EPL)足球比赛的相关信息。
MCP (Glama) ▷ #showcase (4 条消息):
API Key,AutoGen 聊天机器人,MCP 服务器,YouTube 搜索
- **Enact Tools API Key 流程**:一位成员分享了他们在 enact.tools 中采用的相同 API Key 流程,并建议交流经验。
- 另一位成员回应称他们应该找时间聊聊。
- **AutoGen 与 MCP 实现 YouTube 搜索教程:一位成员发布了一个教程,介绍如何从零开始使用 **AutoGen 和 MCP 服务器构建一个具备 YouTube 搜索功能的多智能体(multi-agent)聊天机器人,视频地址:YouTube。
- 该教程旨在指导他人利用这些工具创建功能完备的聊天机器人。
aider (Paul Gauthier) ▷ #general (14 条消息🔥):
Aider,Aider 的最佳模型,DeepSeek,OpenAI 开放模型,GLM air stable
- 确认使用 Aider:一位成员确认他们正在使用 Aider。
- 当被问及那是不是没用 Aider时,他们确认那确实是在用 Aider。
- DeepSeek 模型在 Aider 中表现出色:多位成员推荐 DeepSeek 作为 Aider 的理想模型,因为它价格实惠且效果显著。
- 一位用户提到通过 OpenRouter 使用 Deepseek-R1,并表示非常满意。
- OpenAI 开放模型发布:OpenAI 发布了一些 开放模型。
- 一位成员开玩笑说:我刚研究出怎么在机器上加载 GLM air stable,结果又出来个 117B 参数、5.1B 激活的模型……。
- Pikuma 的 LLM Vibe Test:一位成员分享了 Pikuma 的 LLM vibe test 链接以供娱乐。
- 该测试旨在让模型解释这段代码。
aider (Paul Gauthier) ▷ #questions-and-tips (2 messages):
Aider 非交互模式
- Aider 关注非交互模式:一位成员询问是否有办法在非交互模式下使用 aider。
- 他们表示在文档中找不到任何相关内容(aider 脚本编写文档)。
- 记录 Aider:用户询问是否有文档解释如何以非交互模式运行 Aider。
- 用户分享了他们搜索信息的 脚本编写文档 链接。
DSPy ▷ #show-and-tell (6 messages):
PDF 文档边界检测,知识图谱从业者邂逅 DSPy,SIMBA 优化器报告
- 使用 DSPy 检测文档边界:一位成员分享了关于使用 DSPy 检测 PDF 文档边界的文章:kmad.ai/Using-DSPy-to-Detect-Document-Boundaries。
- 作者还分享了其 X 帖子链接,向知识图谱从业者介绍 DSPy,并表示有兴趣探索更深层的多步工作流和优化。
- DSPy 邂逅知识图谱从业者:一位成员分享了一篇向知识图谱从业者介绍 DSPy 的文章:blog.kuzudb.com。
- 作者旨在通过 LLM 提高生产力,并计划在未来几周内探索多步工作流和优化。
- 揭秘 SIMBA 优化器:一位成员分享了他们关于 SIMBA 优化器的文章:blog.mariusvach.com。
- 另一位成员称赞该文章非常直观且解释详尽。
DSPy ▷ #general (9 messages🔥):
DSPy 中 GEPA 的可用性,用于微调的优化系统提示词,三阶段训练方法
- DSPy 上的 GEPA:仍处于缺失状态:一位用户询问了在 DSPy 中使用 GEPA 的可用性。
- 另一位用户回复了一个 Discord 链接,原用户澄清说它尚未发布。
- 系统提示词优化:微调中的失误?:一位用户质疑在微调模型时,配合 DSPy 使用优化的 sys_prompt 是否是个好主意,并暗示这可能并不合适。
- 他们正尝试为非推理模型添加特定任务的推理轨迹(reasoning traces),并采用三阶段训练方法。
- 训练三部曲:三阶段计划:一位用户概述了一种三阶段训练方法:首先在 1/10 的数据集上使用优化的 sys_prompt 进行 SFT,然后在同一子集上使用不同的 sys_prompt 进行 GRPO,最后在不使用 sys_prompt 的情况下对剩余数据进行 SFT。
- 该用户承认:“哈哈,我也不知道自己在做什么,我只是在瞎搞以求发现”,并指出该任务具有不可验证的奖励,因此采取了这种不同寻常的方法。
LlamaIndex ▷ #announcements (1 messages):
办公时间 (Office Hours)
- LlamaIndex 办公时间即将开始:LlamaIndex 办公时间将在 10 分钟后开始,链接在此。
- 满足 minItems 的虚拟主题:这是一个为了满足 schema 中 minItems 要求的虚拟主题。
LlamaIndex ▷ #blog (4 条消息):
LlamaParse, LlamaCloud, GPT-OSS-120B & GPT-OSS-20B, Document Agents
- **LlamaParse 将 PDF 转换为多模态报告:@tuanacelik 的一份演练展示了如何使用 LlamaParse 将内容密集的 **PDFs 转换为包含图文混排的全多模态报告。
- 该过程涉及使用 LlamaParse(高分辨率 OCR + 全页及图表图像)摄取研究论文,并构建一个能够动态选择工具的报告生成 Agent。
- **LlamaCloud 通过文档智能助力 AI 规模化:LlamaCloud** 的解析能力帮助 AI 公司实现从原型到生产的跨越,处理复杂的文档摄取。@withdelphi 如何利用文档智能构建其“数字大脑”导师平台便是一个例证 (链接)。
- 其顶级的解析能力可以处理格式错误的 PDFs 和嵌入图像。
- **OpenAI 发布 GPT-OSS-120B 和 GPT-OSS-20B LLMs:OpenAI** 发布了自 GPT-2 以来其首批开源 LLMs,即 GPT-OSS-120B & GPT-OSS-20B,采用 Apache 2.0 许可证。
- 这些模型的推理能力媲美 o4-mini,可以在本地运行,并已准备好在 LlamaIndex 中使用。
- **Document Agents 处理杂乱的财务文档:一场网络研讨会将演示 **Document Agents 如何处理杂乱的财务文档,展示使用 LlamaCloud 工具链 处理复杂多模态文档的系统。
- 该活动将于 1 周后举行。
LlamaIndex ▷ #general (7 条消息):
Tracing OpenAI Embedding API calls in LlamaIndex, LlamaExtract P&ID Example, LlamaExtract with Graphs Challenges, Graphiti with LlamaIndex for Knowledge Graph Apps
- LlamaIndex 追踪 OpenAI Embeddings API 调用:一位用户询问 LlamaIndex 是否会追踪对 OpenAI Embeddings API 的每一次批量调用,即使是在批处理量很大的情况下。
- 一名成员确认 LlamaIndex 应该 正在追踪这些调用,并指出 OpenAI 的默认批处理大小约为 100。
- LlamaExtract P&ID 示例可用:一位用户询问另一名成员是否查看了 LlamaExtract 中的 P&ID 示例;并提供了指向特定 Discord 消息的链接。
- 这表明 LlamaExtract 具备处理管道和仪表图 (Piping and Instrumentation Diagrams) 的能力。
- LlamaExtract 面临图表解析困难:一名成员确认在审查 LlamaExtract 处理图表的情况时,承认这些案例对于 LVMs/LLMs 来说是公认的难题。
- 该成员提议进一步讨论这些挑战,并提到来自 LlamaParse 团队的一名成员将加入讨论。
- Graphiti 与 LlamaIndex 创建知识图谱应用:一位用户询问是否有演示使用 Graphiti 配合 LlamaIndex 创建知识图谱应用的教程。
- 上下文中未提供具体的教程。
Manus.im Discord ▷ #general (10 条消息🔥):
Manus is dead, Sub agents as a solution, TradingView Premium, Flutter app guide
- Manus 经历停机:用户观察到 Manus 平台的使用率极低,可能已经挂了。
- 一位用户发现了一种使用 sub-agents 来改进代码和项目质量的变通方法。
- 免费提供 TradingView Premium:一位用户在 Reddit 上分享了一个据称是适用于 Windows 和 macOS 的免费完整版 TradingView Premium 链接。
- Flutter 应用创建指南:一位用户在 flutter-web-emulator.vercel.app 上分享了关于在每日额度限制内创建 Flutter apps 的指南链接。
- 该用户指出该页面包含广告且基于个人经验,而另一位用户将其标记为潜在的诈骗。
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (8 messages🔥):
教学大纲变更, LLM Agents vs 高级 LLM Agents, 演讲者差异
- 新教学大纲即将出炉?:成员们讨论了即将到来的 LLM Agents 课程教学大纲变更的可能性,认为考虑到该领域的快速演进,内容很可能与去年有所不同。
- 一位成员表示:“随着 Agents 领域的发展,调整教学大纲是很正常的”。
- LLM Agents 课程设有高级版:参与者澄清了这是两门不同的课程:LLM Agents 和 Advanced LLM Agents,并指出了它们之间的区别。
- 一位成员明确指出:“这是两个不同的标题——一个是 LLM Agents,另一个是 Advanced LLM Agents。教学大纲是不同的”。
- 主题相似,演讲者更新!:一位成员指出,虽然整体主题可能保持相似,但演讲者可能会有所不同。
- 这意味着课程将在视角和专业知识方面进行更新。
Torchtune ▷ #papers (4 messages):
公共服务器, 信息共享
- 成员询问是否可以分享 Discord 频道信息:一位成员询问是否可以将该频道的信息分享到另一个公共服务器。
- 另一位成员回答说 它是公开的,并且如果他们 分享出去会非常高兴。
- 鼓励频道分享:频道所有者明确表示欢迎分享内容。
- 他们对频道被分享的前景表示高兴,鼓励更广泛地传播信息。
tinygrad (George Hotz) ▷ #general (2 messages):
TinyPilot, 代码库工作, 图像分析
- TinyPilot 插件建议:一位成员建议使用他们的 TinyPilot 工具来辅助代码库工作。
- 他们指出,它 可能很有帮助,但一旦你深入代码库,还需要进一步完善。
- 图像分析趣闻:一位成员对一张随附的图片回复了 “lol”。
Cohere ▷ #👋-introduce-yourself (2 messages):
AI 语音 Agent, GPT 驱动的聊天机器人, RAG 实现, 自由职业 AI 工程师
- AI 工程师开拓智能语音 Agent:一位 AI 工程师专注于构建智能 语音 Agent、聊天机器人 和 AI 助手,通过 SIP (Twilio) 处理入站/出站电话,包括预约挂号、IVR 和语音邮件等功能。
- 该工程师的工作涉及 GPT 驱动的聊天机器人,这些机器人通过检索增强生成 (RAG) 从文档、音频以及从论坛、Discord、Slack 和网站抓取的数据中学习,并结合工作流自动化来简化沟通和流程。
- 工程师的技术栈:该 AI 工程师精通 Python、JavaScript、Node.js、FastAPI,以及 LangChain、Pinecone、OpenAI、Deepgram 和 Twilio 等工具。
- 该工程师可承接 自由职业、远程 或 初创项目。
MLOps @Chipro ▷ #general-ml (1 messages):
搜索日志和点击数据, 排序器微调, 数据使用的成本影响
- 挖掘搜索日志以微调 (FT) 排序器:一位成员建议利用搜索日志、查询数据、文档列表和点击数据来微调 (Fine-tune) 排序器 (Ranker)。
- 另一位成员提醒说,这需要 付出代价。
- 考虑成本影响:收集和利用搜索日志进行排序器微调涉及一定的成本。
- 在实施此类策略之前,应仔细评估这些成本。