AI News
OpenAI 向全球超过 10 亿用户推出 GPT-5 和 GPT-5 Thinking;-mini 与 -nano 版本助力其占据帕累托前沿(Pareto Frontier)。
OpenAI 发布了 GPT-5,这是一个统一的系统,包含一个快速的主模型和一个配备实时路由器的深度思考模型。该系统支持高达 400K 的上下文长度,并凭借极具竞争力的定价重新夺回了“智能帕累托前沿”(Pareto Frontier of Intelligence)。
此次发布还包括 gpt-5-mini 和 gpt-5-nano 等变体,大幅降低了成本,并已集成到 ChatGPT、Cursor AI、JetBrains AI Assistant、Microsoft Copilot、Notion AI 和 Perplexity AI 等产品中。基准测试显示,GPT-5 在编程和长上下文推理方面表现强劲,在 SWE-bench Verified 上的表现与 Claude 4.1 Sonnet/Opus 大致相当。随发布一同推出的还有 GPT-5 提示词指南(cookbook),以及社区内关于定价和性能的热烈讨论。
GPT-5 也许就是你所需要的一切。
2025年8月6日至8月7日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 29 个 Discord 社区(227 个频道,16553 条消息)。预计节省阅读时间(以 200wpm 计算):1183 分钟。我们的新网站现已上线,提供完整的元数据搜索和精美的 vibe coded 风格的往期内容展示。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
虽然 直播 有点令人失望(除了 极具娱乐性的图表造假),且 Benchmarks 相比 OpenAI 现有的 SOTA 产品仅是渐进式改进,但其定价确实让我们感到惊艳,因为 OpenAI 从 GDM 手中夺回了智能的 Pareto Frontier(帕累托前沿):
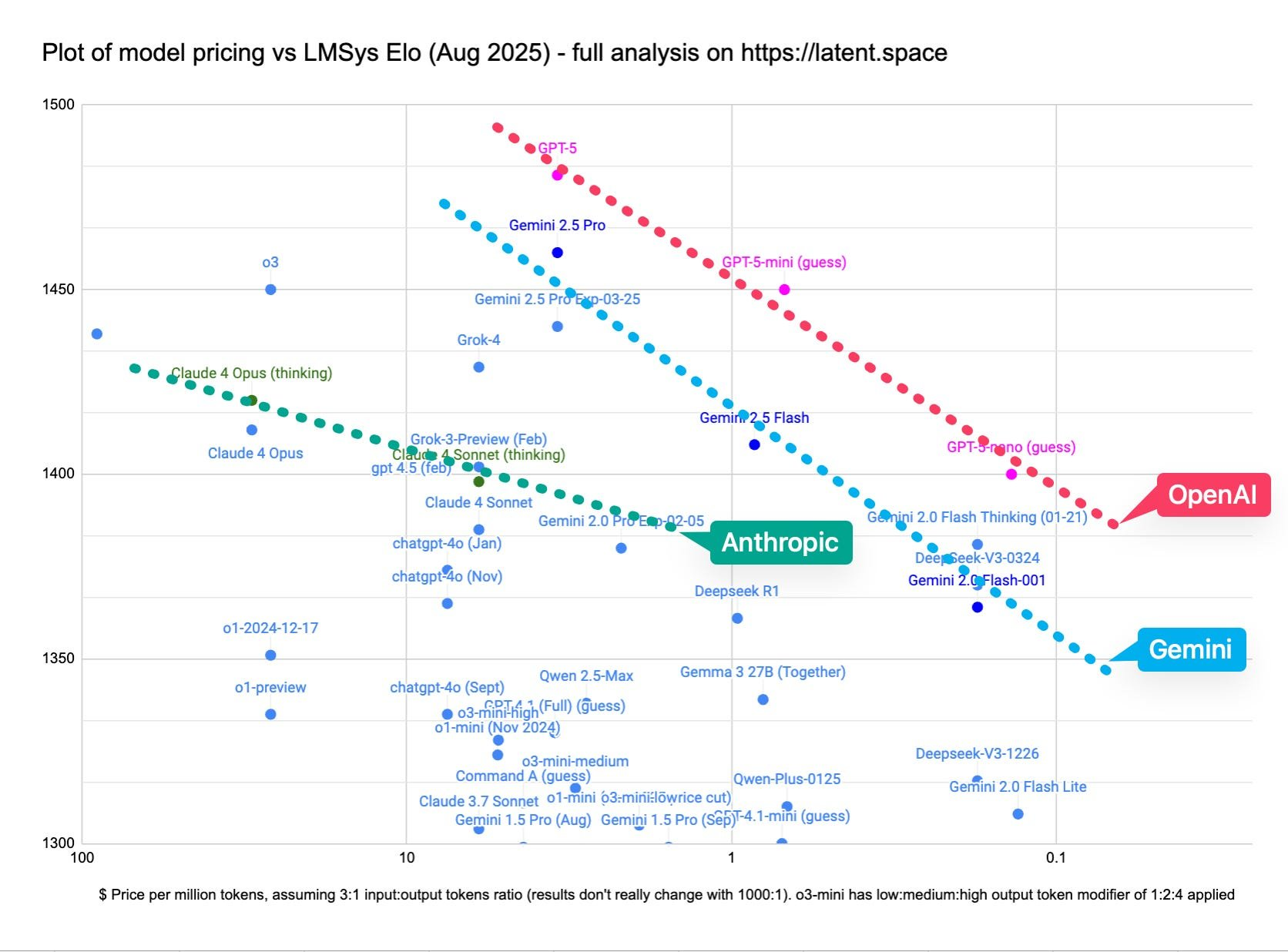
随着 OpenAI 现在拥有了至少 一款 4 Sonnet 级别的模型,并通过了 开发者的 vibe checks,它在编程模型领域稳固地“回归”了,尽管长期影响仍有待观察。
我们建议阅读 早期 Beta 版上手报告,并思考 GPT-5 架构模型卡描述 中揭示的内容。
以下是根据 GPT-5 总结的 GPT-5 发布情况:
OpenAI GPT-5 发布:统一 Router、激进定价、广泛推行
- 发布内容:GPT-5 是一个“统一系统”,包含一个快速的“主”模型和一个位于实时 Router 之后的深度“思考”模型,该 Router 决定何时进行推理、调用 Tools 或保持简洁。在 ChatGPT 中,默认没有模型选择器;Plus 用户可以选择 GPT-5 vs GPT-5 Thinking;Pro 用户可获得更多变体。API 开放了 gpt-5、gpt-5-mini、gpt-5-nano 以及“reasoning effort”(推理力度)控制(minimal/low/medium/high)。Context:最高 400K(最大输出 128K)。知识截止日期:主模型为 2024-10-01;minis 模型为 2024-05-31。分阶段推送到 Free/Plus/Pro/Team(Enterprise/Edu 将于下周推出)。公告详情:@OpenAI, @sama, System Card 摘要。
- 价格与 Cache:推文引用 gpt-5 的价格为 $1.25/M input,$10/M output,并有 Cache 折扣(“flex”参考价低至 $0.625/$5);gpt-5-mini 为 $0.25/$2;gpt-5-nano 为 $0.05/$0.4。多位 OpenAI 负责人强调了成本下降和 Cache 经济性 (@scaling01, @sama, @jeffintime)。
- 产品集成 (Day-0):
- 聊天/编程:Codex CLI 将 GPT-5 设为默认模型,使用额度包含在 ChatGPT 方案中;新的终端 UI 和按方案划分的 Rate-limits (@OpenAIDevs, @embirico)。Cursor 已将 GPT-5 设置为默认编程模型,暂时免费 (@cursor_ai)。JetBrains AI Assistant 和 Junie Agent 已支持 GPT-5 (@jetbrains)。Microsoft Copilot “Smart Mode” 路由至 GPT-5 (@mustafasuleyman)。Notion AI 现已提供 GPT-5 (@NotionHQ)。Perplexity 为 Pro/Max 用户添加了 GPT-5 (@perplexity_ai)。
- Agent 框架:Cline 报告称 GPT-5 非常自律,能并行化 Tool calls,并且遵循“计划详尽,执行简洁”的原则 (@cline);Factory 已将 GPT-5 作为其“Droids”的默认模型 (@FactoryAI)。OpenAI 发布了 GPT-5 Prompting/Cookbook 资源包 (@OpenAIDevs)。
Benchmarks、Evals 以及“图表造假”
- 竞技场与编程:GPT‑5 在 LMSYS Text/WebDev/Vision Arenas 中位居榜首(以“summit”名义测试),其中 WebDev 的领先幅度显著(@lmarena_ai)。OpenAI 宣称在 SWE‑bench Verified 上达到 74.9%;多位研究人员立即指出其坐标轴标注错误,且 OpenAI 运行的是 477 个任务的子集;修正后的图表显示 GPT‑5 在该验证集上与 Claude 4.1 Sonnet/Opus 大致持平(74–75%)(@nrehiew_, @OfirPress, @Sauers_)。
- 长上下文与幻觉:GPT‑5 在 Artificial Analysis 的长上下文推理(AA‑LCR)中占据前两名;在长上下文任务上相较于 o3‑high 有显著提升(@ArtificialAnlys)。多方声称其幻觉率大幅降低,并引入了“安全补全(safe completions)”机制(即在安全约束内最大化效用的拒绝响应)(@scaling01, @sama)。METR 的自主性评估发现,在当前威胁模型下,GPT‑5 不太可能构成灾难性风险,但同时警告随着能力的提升,评估感知(eval‑awareness)和操纵风险也会增加(@METR_Evals)。
- 推理/智能体(Agents):GPT‑5 表现出强大的指令遵循和工具使用能力(例如 TauBench 的提升、IFBench 指令遵循),但在非 SWE 编程评估和 OpenAI PR 复现方面的变化则褒贬不一(@omarsar0, @eli_lifland, @scaling01)。
- ARC‑AGI 与安全欺骗:GPT‑5 在 ARC‑AGI‑1 上达到 65.7%,但在 ARC‑AGI‑2 上仅为 9.9%;Grok‑4 以 15.9% 领跑 ARC‑AGI‑2(@fchollet, @scaling01)。在 OpenAI 的内部衡量中,GPT‑5 的欺骗性行为低于 o3(方法论至关重要;等待第三方复现)(@scaling01)。
- 关于沟通的说明:OpenAI 的活动因幻灯片中多次出现“图表误导”(坐标轴/比例错误)而遭到广泛批评——博客版本随后进行了修正(@jeremyphoward, @iScienceLuvr)。
智能体编程现状核查:强大的工具化,更少的“玄学”
- 实测报告:早期用户强调了 GPT‑5 “极度精准”的指令遵循、废话更少、并行工具调用以及长程持久性——例如多文件编辑和可靠的 diff(Codex CLI, Cline, Cursor)。多篇帖子展示了通过极简提示词生成的单次交互式应用/仪表盘/游戏(@skirano, @benhylak, @pashmerepat)。Cursor 称 GPT‑5 为“我们尝试过的最聪明的编程模型”,并将其设为默认模型,初期免费提供(@cursor_ai)。
- 路由即产品:应用内模型选择器的弃用,标志着将实时路由(思考/工具使用)作为默认 UX 的押注;这将开发者的控制权从“选择哪个模型?”转向了“设定哪些约束/策略/冗余度/投入程度?”(@sama, @dariusemrani)。
- 独立评估:深度研究运行发现,在长程研究任务中,GPT‑5 与 Claude 4 Sonnet 大致相当(样本量较小),这表明其提升可能取决于具体用例/技术栈,而非全面超越(@hwchase17)。
AI Twitter 汇总
OpenAI GPT‑5 发布:统一路由、激进定价、全面推广
- 发布内容:GPT‑5 是一个“统一系统”,包含一个快速的“主”模型和一个更深层的“思考”模型,由一个实时路由(router)控制,决定何时进行推理、调用工具或保持简洁。在 ChatGPT 中,默认没有模型选择器;Plus 用户可以选择 GPT‑5 或 GPT‑5 Thinking;Pro 用户可获得更多变体。API 开放了 gpt‑5、gpt‑5‑mini、gpt‑5‑nano 以及“推理努力程度”(reasoning effort)控制(minimal/low/medium/high)。上下文:最高 400K(最大输出 128K)。主模型的知识截止日期为 2024‑10‑01;mini 模型为 2024‑05‑31。分阶段向 Free/Plus/Pro/Team 用户推出(Enterprise/Edu 下周推出)。公告:@OpenAI, @sama, 系统卡片摘要。
- 价格与缓存:推文指出 gpt‑5 的价格为 $1.25/M input,$10/M output,并提供缓存折扣(“flex” 方案低至 $0.625/$5);gpt‑5‑mini 价格为 $0.25/$2;gpt‑5‑nano 为 $0.05/$0.4。多位 OpenAI 负责人强调了成本下降和缓存经济学 (@scaling01, @sama, @jeffintime)。
- 产品集成 (首日):
- 聊天/编程:Codex CLI 将 GPT‑5 设为默认模型,使用量包含在 ChatGPT 订阅计划中;提供新的终端 UI 并根据计划设置速率限制 (@OpenAIDevs, @embirico)。Cursor 将 GPT‑5 设为默认编程模型,暂时免费 (@cursor_ai)。JetBrains AI Assistant 和 Junie Agent 已支持 GPT‑5 (@jetbrains)。Microsoft Copilot 的“智能模式”会路由至 GPT‑5 (@mustafasuleyman)。Notion AI 现在提供 GPT‑5 (@NotionHQ)。Perplexity 为 Pro/Max 用户添加了 GPT‑5 (@perplexity_ai)。
- Agent 框架:Cline 报告称 GPT‑5 非常严谨,支持并行化工具调用,并且遵循“计划详尽,执行简洁”的原则 (@cline);Factory 将 GPT‑5 设为其 “Droids” 的默认模型 (@FactoryAI)。OpenAI 发布了 GPT‑5 提示词/Cookbook 合集 (@OpenAIDevs)。
基准测试、评估与“图表误导”
- 竞技场与编程:GPT‑5 在 LMSYS Text/WebDev/Vision Arenas 中位居榜首(以“summit”代号进行测试),其中 WebDev 的领先优势尤为显著 (@lmarena_ai)。OpenAI 宣称其在 SWE‑bench Verified 上达到了 74.9%;多位研究人员立即指出其坐标轴标注错误,且 OpenAI 仅在 477 个任务的子集上运行;修正后的图表显示 GPT‑5 在 Verified 集合上与 Claude 4.1 Sonnet/Opus (74–75%) 基本持平 (@nrehiew_, @OfirPress, @Sauers_)。
- 长上下文与幻觉:GPT‑5 在 Artificial Analysis 的长上下文推理 (AA‑LCR) 中占据第 1 和第 2 名;在长上下文任务上相比 o3‑high 有显著提升 (@ArtificialAnlys)。多方声称其幻觉率大幅降低,并引入了“safe completions”(在安全约束下最大化效用的拒绝机制)(@scaling01, @sama)。METR 的自主性评估发现,在当前威胁模型下,GPT‑5 不太可能构成灾难性风险,但同时警告随着能力的提升,评估意识/操纵风险也会增加 (@METR_Evals)。
- 推理/Agent:GPT‑5 表现出强大的指令遵循和工具使用能力(例如 TauBench 的提升、IFBench 指令遵循),但在非 SWE 编程评估和 OpenAI PR 复现方面表现参差不齐 (@omarsar0, @eli_lifland, @scaling01)。
- ARC‑AGI 与安全欺骗性:GPT‑5 在 ARC‑AGI‑1 上达到 65.7%,但在 ARC‑AGI‑2 上仅为 9.9%;Grok‑4 以 15.9% 在 ARC‑AGI‑2 中领先 (@fchollet, @scaling01)。在 OpenAI 的内部衡量中,GPT‑5 显示出比 o3 更低的欺骗行为(方法论很重要;尚待第三方复现)(@scaling01)。
- 关于沟通的说明:OpenAI 的活动因幻灯片中多次出现“图表犯罪”(坐标轴/刻度错误)而受到广泛批评——博客版本随后进行了修正 (@jeremyphoward, @iScienceLuvr)。
Agent 编程现状核查:强大的工具化,更少的虚名
- 实测报告:早期用户强调了 GPT‑5 “极度专注”的指令遵循、更少的废话、并行工具调用以及长周期持久性——例如多文件编辑和可靠的 diff(Codex CLI, Cline, Cursor)。多篇帖子展示了通过极简提示词生成的单次交互式应用/仪表盘/游戏 (@skirano, @benhylak, @pashmerepat)。Cursor 称 GPT‑5 为“我们尝试过的最聪明的编程模型”,并将其设为默认模型,初期免费提供 (@cursor_ai)。
- 路由即产品:应用内模型选择器的弃用标志着将实时路由(思考/工具使用)作为默认 UX 的赌注;这将开发者的控制权从“选择哪个模型?”转向“设定哪些约束/策略/详细程度/投入度?” (@sama, @dariusemrani)。
- 独立评估:深度研究运行发现,在长周期研究任务中,GPT‑5 与 Claude 4 Sonnet 大致相当(样本量较小),这表明性能提升可能取决于具体用例/技术栈,而非全面提升 (@hwchase17)。
OpenAI GPT-5 发布与反响
- 官方发布:OpenAI 正式宣布 GPT-5 发布,CEO @sama 预告了一场“比平时更长”且“有很多展示内容”的直播。新模型被描述为一个统一系统,可在快速回答和深度推理之间自动切换,并向包括免费用户在内的所有用户推出。OpenAI 产品负责人 @kevinweil 表示:“这是我们迄今为止构建的最棒的产品。”此次发布弃用了之前的模型,旨在通过移除模型切换器来简化用户体验。团队的 AMA(问我任何事)活动定于次日举行。
- 技术细节与定价:GPT-5 是一个模型系列,而非单一的整体。它包括
gpt-5、gpt-5-mini和gpt-5-nano,以及独立的“思考”模型,这使得 @teortaxesTex 将其称为一个“统一系统”,本质上就是“独立的 CoT + 非 CoT 模型 + 一个路由器”。API 定价是讨论的焦点,@scaling01 指出了其竞争力:主模型定价为 每百万 token $1.25/$10,mini为 $0.25/$2,nano为 $0.05/$0.4,全部拥有 400k context window,知识截止日期为 2024 年 10 月 1 日。这使得它比 Sonnet 更便宜,比 Opus 更出色。@jerryjliu0 观察到,在文档理解方面,GPT-5 使用的 token 数量似乎比 GPT-4.1 多 4-5 倍,这可能会增加其在视觉任务中的实际成本。 - 性能与基准测试:初步基准测试显示,某些领域有显著提升,但在其他领域则停滞不前。@scaling01 强调了“在长上下文任务上的惊人改进”以及幻觉的近乎消除。GPT-5 还成为了 LMArena 排行榜上的新 SOTA。然而,@fchollet 报告称,在 ARC-AGI 测试中,GPT-5 在 AGI-1 上得分为 65.7%,而在 AGI-2 上仅为 9.9%。来自 @scaling01 的进一步分析显示,在复现科学论文方面,它仅比
o3提升了 3%,而在 OpenAI Pull Requests 和 SWE-Lancer IC 等基准测试上没有显著改进。 - “图表造假”争议:社区讨论的一个重要部分集中在发布会演示中具有误导性的图表上。一张关于 SWE-Bench 性能的图表因 Y 轴非单调而受到广泛批评,图中 52.8% 的位置竟然比 69.1% 还要高。这一点首先由 @Teknium1 指出,并被包括 @jeremyphoward 在内的许多人转发放大。@iScienceLuvr 调侃道:“如果这张图是 GPT-5 画的,那我看空它,”而 @kipperrii 则开玩笑说:“去他妈的 Y 轴!去他妈的 X 轴!随便画条指数曲线就完事了!”@nrehiew_ 随后提供了一个修正版的图表。
竞争模型与更广泛的生态系统
- xAI 的 Grok:Grok-4 作为一个强有力的竞争对手脱颖而出,@fchollet 指出它在 ARC-AGI-2 上保持了 SOTA 水平,得分 15.9%,而 GPT-5 为 9.9%。@Yuhu_ai_ 声称 xAI 在许多方面处于“领先地位”,且 Grok 是“全球首个统一模型”。在一个戏剧性的转折中,@cb_doge 报道称 Grok-4 在 Kaggle AI Chess 半决赛中击败了 Google 的 Gemini,尽管最终在决赛中被 OpenAI 的 o3 击败。与此同时,@elonmusk 宣布 Grok Imagine 视频生成将对所有美国用户免费开放。
- Perplexity 与多模型支持:Perplexity 宣布为其订阅者提供 GPT-5 的首日支持。CEO @AravSrinivas 强调了他们丰富的模型供应,包括 GPT-5、Claude 4.1 Opus、Grok 4 和 Gemini 2.5 Pro,将 Perplexity 定位为关键的多供应商平台。
- 闭源与开源格局:@Tim_Dettmers 提出了一个关键见解,称:“闭源与开源权重(open-weights)的格局似乎已经被抹平。GPT-5 在编程方面仅比你可以在消费级台式机上运行的开源权重模型强 10%。” 这一观点在围绕 OpenAI gpt-oss 发布的讨论中得到了呼应,该模型现在可以在 Google Colab T4 上通过 Transformers 免费原生运行。
- 其他值得关注的模型:Alibaba 推出了新的 Qwen3-4B 模型。Kimi K2 因其编程能力和独特的写作风格而受到赞誉。
开发者工具、框架与基础设施
- 开发环境与 CLI:GPT-5 的发布引发了立即的集成。@aidan_mclau 宣布 GPT-5 现在是 Cursor 中的默认模型,取代了 Claude,Cursor 的 CEO 称其为“我们尝试过的最智能的编程模型”。Codex CLI 也在 GPT-5 集成后看到了重大改进,其使用量包含在 ChatGPT 计划中。Cline 也添加了 GPT-5,并将其描述为“守纪、持久且高度胜任”。
- RAG 与 Agent 框架:对高级检索增强生成(RAG)的兴趣持续高涨。@HamelHusain 分享了一本名为《超越朴素 RAG:实用的高级方法》的公开书。LangChain 继续构建其 Agent 生态系统,@unwind_ai_ 指出他们为 OpenSWE Agent “逆向工程了 Claude Code、Manus 和 Deep Research”。Jules 现在支持运行和渲染带有截图验证的 Web 应用程序。
- 推理与基础设施:vLLM 在一次北京见面会上强调了其被 Tencent、Huawei 和 ByteDance 等大型科技公司的采用。@cloneofsimo 分享了一个教程,介绍如何使用 FlexAttention 在 1000 行以内的代码中构建一个极简的、类似 vLLM 的推理系统。对于在本地运行模型的开发者,@ggerganov 指出 LMStudio 使用的上游
ggml实现比ollama的分支“显著更好且优化得更完善”。
更广泛的影响与行业评论
- 平台期论点 (The Plateau Thesis):一种强烈的观点认为,单纯通过扩展 LLM 规模带来的进步正面临瓶颈。@far__el 表示:“很明显,即使投入价值数十亿美元的算力,也无法从 LLM 中压榨出 AGI,某些根本性的东西缺失了。” @francoisfleuret 表示赞同,并澄清这一观察适用于整个领域:“我们正处于平台期:单纯的规模扩展即将终结。对所有人(EVERYONE)都是如此。” 与此形成对比的是另一种观点,即 Agent 支架和后训练现在比以往任何时候都更重要。
- AI 人才与经济学:@AndrewYNg 对 AI 开发的经济学进行了详细分析,解释说 GPU 的高昂资本成本使得 Meta 等公司支付巨额薪水给顶尖人才以确保硬件得到有效利用是合理的。这种资本密集型的特性使得薪资在总支出中仅占很小一部分。在相关的观察中,@jxmnop 质疑了 VC 融资的效率,指出有些初创公司“总共筹集了约 1 亿美元……开发的软件没人用过,现在他们都去别处工作了”。
- 市场反应:市场对 GPT-5 发布后的最初反应平淡。@scaling01 指出 OpenAI 在 Polymarket 上“惨遭重创”,暗示市场对此次发布感到失望。
- AI 与知识:@Teknium1 认为,依赖 Agent 框架进行搜索并不能有效替代模型通过对世界知识进行反向传播(backpropagation)所建立的“丰富连接”,并称这“比 RAG 更有意义”。
研究与新技术
- Agent 学习与优化:Databricks 的研究人员,包括 @lateinteraction 和 @jefrankle,介绍了 ALHF (Agent Learning from Human Feedback),这是一种根据用户对糟糕回复的自然语言反馈来优化 Agent 的方法。该技术被描述为既信息密集又符合人体工程学。另一篇论文探讨了将提示词优化与策略梯度 RL 相结合。
- 多模态模型与技术:MiniMax 宣布了 Speech 2.5,这是一款支持 40 种语言的高保真语音克隆模型。Google DeepMind 的研究人员分享了一篇关于高效训练小型视觉语言模型以配合 GLaM 使用缩放工具的论文。TRL 库也针对多模态对齐进行了重大升级,增加了 GRPO 和 MPO 等技术。
- 数据增强:@cloneofsimo 指出了 Fill-in-the-Middle (FIM) 训练的一个有趣推论:FIM 风格的增强可以在几乎没有副作用的情况下,将高质量数据集的规模“翻倍”。
幽默与梗 (Memes)
- 炒作与期待:社区为发布做好了准备,@gdb 发布了一个神秘的倒计时器
T - [[5+5+5] - 5/5] hours,而 @nearcyan 则开玩笑说正和一位 OpenAI 的朋友吃晚饭,对方“含糊地指着厨房傻笑”。 - 图表造假梗 (Chart Crime Memes):有缺陷的发布图表成了笑料来源,@zacharynado 等人分享了非单调轴的截图。@ThePrimeagen 对一位创始人声称每天删除 1 万行代码的说法回应道:“好了 Lex Luthor,是时候离开键盘了。”
- 真实的工程师生活:@vikhyatk 发布了一张凌乱书桌的照片,配文是“男人真的觉得这样生活没问题”。@francoisfleuret 捕捉到了查看夜间日志时的心情:“这他妈的是什么玩意儿。”
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. GPT-OSS 与 OpenAI 模型炒作及品牌认知
- GPT-OSS 是公司必须建立强大品牌名称的又一个例子 (Score: 538, Comments: 329): 该帖子批评了与 Qwen-235B 和 DeepSeek R1 等技术上更强的替代方案相比,GPT-OSS 120B 获得了不成比例的关注,理由是其缺乏多模态能力、规模较小,且依赖于其他开源项目的创新。作者强调,阿里巴巴已经发布了具有竞争力的模型(例如用于视频/图像的 Wan2.2 和 Qwen-Image,以及高性能的 30B 和 4B 模型),但媒体报道很少,将 GPT-OSS 的炒作归因于 OpenAI 的品牌效应,而非明确的技术优势。值得注意的是,DeepSeek R1 的单次训练成本被视为效率卓越的证据(DeepSeek:558 万美元 vs 传闻中 OpenAI 的成本:高得多),而关于审查制度的投诉被讨论为在不同地区/模型中应用不一致。 热门评论强调了影响者报道中的地域偏见(偏向美国/英语公司)、流行 AI 媒体频道在技术深度上的不足,以及技术上的区别——一位评论者指出,OSS 120B 比 Qwen-235B 稀疏得多且速度更快,这证明了在原始基准测试分数之外的不同使用场景。OSS 120B 中的不合规性(关于对齐/安全行为)被提及为一种可能的商业特性,而非缺陷。
- OSS 120b 与 Qwen3 235b 之间存在技术差异:OSS 120b 的参数量只有一半,激活参数仅为四分之一,且极其稀疏,导致其推理速度明显高于 Qwen3 235b。然而,OSS 120b 较小的规模和稀疏性也意味着它在某些任务上过于“不合规”,由于监管或运营要求,某些企业实际上可能更喜欢这一点。
- 间接讨论了基准测试:由于其稀疏性和较少的激活参数,OSS 120b 据说比 Qwen3 235b 快得多,尽管它在整体能力上不及更大的模型。评论还指出用户更倾向于 Qwen3 30b A3B 等模型,并表示像 OSS 20b 这样的小型模型没有那么稀疏,因此在其参数规模下可能不具备同样的速度优势。
- 如果 gpt-oss 模型是由 OpenAI 以外的任何其他公司制作的,还会有人在意吗? (Score: 226, Comments: 119): 该帖子质疑,如果最近的 gpt-oss 模型是由 OpenAI 以外的公司发布的,是否还会受到如此大的关注,因为据报道它们的编程能力不如 Qwen 32B 等模型,幻觉率更高,且被认为对基准测试存在过拟合。一条技术评论指出,gpt-oss 120B 模型在单块 RTX 3090 和 i9-14900K 上实现了 25 tokens/sec 的推理速度,显著优于相同量化水平(例如 70B q4)的其他本地模型,尽管存在对实际可用性和过度“安全”约束的担忧,但这使其在本地部署方面具有吸引力。 评论者一致认为 OpenAI 的品牌推动了不成比例的炒作,指出大多数公众并不了解其他 AI 公司或模型,但也认为 OpenAI 提高了开源模型领域的知名度。关于该模型的速度和本地推理能力是否证明了独立于其品牌的兴奋感,目前仍存在争议。
- gpt-oss 120B 模型展示了显著的技术优势——根据用户基准测试,它可以在单块 3090 + 14900K 系统上以 25 tokens/sec 的速度运行。这比其他使用量化(例如 q4 或更差)的本地运行 70B 模型明显更快且性能更好,后者被描述为“非常非常糟糕”。在消费级硬件上实现这样的速度和规模,使其在本地 LLM 中脱颖而出。
- 关于模型效用存在持续争论:虽然 gpt-oss 120B 在速度和生成高质量输出(以“清晰的思维模式”和“快速且高质量的摘要”著称)方面表现良好,但对其模型中嵌入的审查(“安全”)水平仍存在担忧。一些用户建议需要进行微调(fine-tune)以使模型适应更广泛的实际应用,因为过重的安全对齐可能会降低其在某些任务中的实用性。
- 从历史上看,本地 LLM 被认为要么不够好,要么太慢,导致用户依赖基于 API 的解决方案(例如 GPT-4o, Claude)。gpt-oss 120B 被视为一个转折点——在进一步评估其速度和安全约束之外的能力之前,它可能处于使本地部署在要求苛刻的使用场景中具有实际可行性的“边缘”。
- GPT-5 发布会上搞笑的图表 (分数: 1737, 评论: 224): 该帖子分享了一张来自“GPT-5 发布会”的图片,用户认为其内容极其混乱且不专业,这一点在标题和评论中都有所体现。评论者讽刺地暗示该图表是由 DALL-E 生成的,并批评了发布会直播的质量,质疑该图表的意义或用途。图片本身并未传达关于 GPT-5 或模型性能的任何技术细节;焦点完全集中在发布会中所使用的可视化方案缺乏清晰度和专业性。 技术讨论集中在该图表的低质量和可能毫无意义的性质上,用户对发布会的演示标准表示怀疑和失望。
- 评论者讨论了 GPT-5 发布期间展示的混乱或低质量的可视化效果,一些人认为图表质量(例如,“我觉得他们是用 DALL-E 绘图的”)损害了演示的技术公信力。讨论引发了人们对糟糕的数据呈现如何影响模型 Benchmarks 或技术声明的可信度和清晰度的担忧。
- 针对发布会中使用的术语(如 “Deception rate”),存在技术上的怀疑,认为其缺乏透明度或指标定义不明确。用户评论说,如果没有严谨、定义明确的 Benchmarks,很难评估 GPT-5 的真实能力或风险。
- 致所有关于 GPT-5 的帖子 (分数: 156, 评论: 14): 该帖子幽默地强调了一个技术关注点:在常用的本地 API 端口(如 8000, 8080)上暴露了哪个 AI 模型,而不是讨论 GPT-5 的定价或官方 API 层级。虽然没有描述附图,但它可能引用了用户在特定端口上对模型的本地部署和管理。一条热门评论进一步详细说明了用户自己为各种本地 LLM 和 AI 工具分配的端口,显示了用于 Gemma3 4B(主 LLM)、Whisper、Qwen3、Nomic 和 Mistral 等模型的端口(9090, 9191, 9292 等),展示了社区自托管 LLM 基础设施的实践。 评论者讨论了在开源和本地运行 LLM 的背景下讨论 GPT 模型与商业平台的偏好,并分享了端口分配的实际设置,反映了组织多模型部署的社区标准。
- 一位用户提供了一个详细的端口配置设置,用于同时运行多个本地 LLM 相关服务。示例包括在端口 9090 上运行主 LLM (Gemma3 4B),在 9191 上运行用于语音的 Whisper (ggml-base.en-q5_1.bin),在独立端口上运行 Tool-calling 和编程 LLM (Qwen3 4B 和 Qwen3-Coder-30B-A3B),以及在其他端口上运行视觉/特定项目模型(如 Mistral 3.2 24B),突出了实际的多模型编排以及与 8080 端口冲突的问题。
- 简要提到了将 GPT 模型与 Kimi k2 等开源产品进行比较,强调了社区对将 OpenAI 最新模型与快速发展的开源替代方案(包括来自中国的方案)进行 Benchmarking 的兴趣。这表明围绕能力、开放性和未来竞争力的技术辩论正在进行中。
{kind=link}
{kind=link}
2. 主要开源模型发布新闻与比较
- Huihui 发布了 GPT-OSS 20b abliterated (分数: 384, 评论: 96): Huihui 发布了 GPT-OSS-20b 的 “abliterated”(无审查)衍生版本(HuggingFace 链接),宣传其不受对齐/安全限制。该模型以 BF16 格式分发;社区成员正在等待 GGUF(量化)版本以获得更广泛的兼容性。原始的 GPT-OSS-20b 具有显著的安全机制,而在这里显然已被移除,引发了关于开源 AI 社区快速“去过滤”的讨论。 评论者注意到绕过安全防护的速度之快,并对比声称的无审查能力进行实证测试表示期待,一些人提到了开源和闭源安全方法之间持续存在的紧张关系。
- 几位用户正在讨论对“abliterated”(降低安全性)的 GPT-OSS 20B 模型进行社区主导的 Benchmarks 和测试结果的期待,这表明了人们对与之前迭代相比的详细性能和安全性评估的兴趣。
- 用户对 GGUF 格式的兼容权重有明确需求,这表明用户对使用 llama.cpp 等工具进行高效推理以及本地部署优化感兴趣。
- Nonescape: SOTA AI 图像检测模型 (开源) (评分: 136, 评论: 65): 该图片可能是一个截图,展示了开源 Nonescape AI 图像检测模型的界面或结果。该模型声称具有 SOTA 级别的准确率,并提供了一个仅 80MB 的轻量化浏览器版本。这些模型基于超过 100 万张图像进行训练,涵盖了包括 Diffusion、GANs 和 Deepfakes 在内的最新 AI 技术,并提供 Javascript 和 Python 库以便集成 (GitHub)。Demo 同时支持图像和视频,强调了实际应用价值。 评论者提出了一些技术质疑:有人指出 Demo 的检测可能仅仅是将文件名与 “AI” 或 “fake” 相关联;另一位则建议尽快使用,以免对抗训练(Adversarial Training)降低其识别新 AI 生成图像的有效性。这凸显了 AI 检测研究中常见的“猫鼠游戏”动态。
- 一位评论者指出,像 Nonescape 这样的模型可能会迅速失效:随着开源检测模型被广泛知晓,图像生成器可以在训练过程中将它们用作判别器(Discriminators),从而增强输出的自然度并绕过检测——这导致了生成器与检测器之间不断演变的对抗循环。
- 一位用户强调了重大的实现挑战,指出为了实现鲁棒的 AI 图像检测,需要更多的基准数据(可能是当前数据集的 10 倍)。他们还主张在训练和推理中必须使用图像平铺(Image Tiling)、大 Batch Sizes 以及类似技术,以获得令人满意的泛化能力和性能。
- 一项技术观察指出模型部署之间存在不一致性:虽然 Nonescape 的完整版未能将一张低质量的生成图像归类为 AI,但浏览器版本却成功了,这引发了关于部署差异、模型鲁棒性或推理环境差异的疑问。
- 由 Qwen3-235B-A22B-2507 制作的随机柱状图 (评分: 353, 评论: 14): 该图片展示了由 Qwen3-235B-A22B-2507 模型生成并渲染在 HTML Canvas 上的随机柱状图。该帖子强调了模型不仅能输出原始数据,还能输出直接使用 Web 技术(JavaScript 和 HTML Canvas)渲染数据可视化的代码。虽然没有详细的模型或 Benchmark 讨论,但这展示了在图形输出自动化代码生成方面的实用性。 评论者对图表的质量和准确性发表了一些轻松的评论,但并未深入批评技术实现或模型性能。
- 该帖子提到了 Qwen3-235B-A22B-2507,暗示这是 Qwen3-235B 模型的一个较新或实验性的 Checkpoint/变体。图表生成的存在及其准确性的提及,表明该模型正在可视化或数据展示任务中被评估或使用,可能是在文本之外的场景中对模型输出质量进行 Benchmark。
- 文中提到了 z.ai 的幻灯片生成功能,这意味着一些用户正在跨平台或服务比较模型在自动化演示文稿创建等任务中的输出和效用,暗示了针对实际商业用例的更广泛的新兴 Benchmark。
{kind=link}
{kind=link}
3. Llama.cpp 功能更新与支持公告
- Llama.cpp 现在支持 GLM 4.5 Air (Score: 231, Comments: 67): llama.cpp 在最近的 PR (pull/14939) 中合并了对 GLM 4.5 模型系列的支持,使其能够在 llama.cpp/ggml 生态系统中高效运行。基准测试对比显示,对于像 Qwen3 Coder 30B-A3B 这样的 MoE 模型,llama.cpp 实现了显著更高的吞吐量(
44 tk/s),而 LM Studio 为(22 tk/s),尤其是在使用n-cpu-moe标志将 MoE 专家层卸载到 CPU 时,突显了 llama.cpp 在模型并行化方面的实现级效率。 评论指出,虽然 GLM 4.5 支持已上线,但主观的性能/质量印象褒贬不一——与 GPT-OSS 120B 相比,GLM 4.5 被认为“啰嗦且过度思考”,而后者的 tokens/second 据报道也更快;另一位用户则称赞了 GLM 4.5 的世界知识,特别是在处理冷门问答任务方面优于其他 LLM。- 一位评论者提供了 LM Studio 和 llama.cpp 在 MoE 模型(特别是 Qwen3 Coder 30B-A3B)上的直接基准测试对比,指出 LM Studio 仅达到每秒 22 tokens,而 llama.cpp 为每秒 44 tokens。他们强调在 llama.cpp 中使用
n-cpu-moe标志卸载 MoE 层可显著提升性能,凸显了 llama.cpp 目前在 MoE 推理方面的效率优势。 - 技术用户确认了 llama.cpp 对 GLM 4.5 模型的早期支持,其中一位指出该模型的“世界知识”与其他 LLM 相比令人印象深刻,尤其是在处理冷门问答任务时——这表明 GLM 4.5 在该推理后端中具有强大的知识保留和问答能力。
- 另一位资深用户建议通过原生的 llama.cpp 和 llama-cli 运行 Llama 模型,以获得比其他 UI 或包装平台更好的输出质量,因为他们观察到模型在非直接平台上往往表现不佳(“变笨”),这表明实现细节的细微差别会影响输出质量。
- 一位评论者提供了 LM Studio 和 llama.cpp 在 MoE 模型(特别是 Qwen3 Coder 30B-A3B)上的直接基准测试对比,指出 LM Studio 仅达到每秒 22 tokens,而 llama.cpp 为每秒 44 tokens。他们强调在 llama.cpp 中使用
- llama.cpp 总部 (Score: 454, Comments: 61): 图片展示了负责 llama.cpp(一个流行的开源大语言模型推理库)大部分 CUDA 代码开发的个人工作站。该配置包含 3 块垂直堆叠的 NVIDIA P40 GPU,采用推挽式风扇配置散热,以及一块通过转接线连接的 RX 6800 GPU,并使用纸板进行 DIY 改装以管理气流。这一背景突显了在具有影响力的 ML 基础设施工作背后,资源丰富且非标准的硬件环境。 评论者对这种简陋且即兴的硬件条件表示惊讶,这使得 llama.cpp 开发者的技术成就更令人敬佩。DIY 散热和 GPU 安装方案反映了独立 ML 工程师面临的实际挑战。
- llama.cpp 的大部分 CUDA 代码是在一台配备了 3 块垂直堆叠的 Nvidia P40 GPU 的 Mac 上开发的,使用了带有两个风扇的自定义推挽式散热配置。纸板被用来密封气流间隙,一块 RX 6800 GPU 由于线缆长度不足而使用转接线连接(未固定),展示了在资源受限的开发环境中实际的硬件即兴创作。
- 现场抓包 (Caught in 4K) (Score: 267, Comments: 26): 该帖子讨论了大语言模型(LLM)的可靠性和评估协议,重点关注据称为了性能宣称而对测试集进行“樱桃采摘”(cherry-picking)的行为。评论者质疑基准测试的稳健性,批评最近 GPT-5 评估中的假设(例如它将“在保留任务中 100% 失败”)缺乏明确的正当理由,也没有适当的数据集划分或记录在案的证据支持。 辩论集中在 LLM 基准测试缺乏严格的信息披露、对公开演示或性能宣称的怀疑,以及担心围绕模型能力的叙述可能涉及选择性数据或无支撑的概率逻辑。
- 一些评论者对所引用推文中的方法论或主张表示怀疑,指出目前尚不清楚 GPT-5 是否真的会在所有保留任务中失败。他们指出,此类假设可能会过度简化性能评估,强调在比较 LLM 时需要严格且透明的基准测试。
- 强烈呼吁对 LLM 进行第三方测试和独立验证,一些用户建议,只有那些权重可以在私有服务器上运行的模型才应被纳入评估。这突显了对专有模型的担忧,认为除非公司提供权重访问权限或基于异常的测试,否则不可能进行稳健且公正的评估。
{kind=link}
技术性较低的 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. GPT-5 与 OpenAI 直播:发布、演示及社区反应
- GPT-5 发布讨论帖 (Score: 459, Comments: 646): 该帖子作为 GPT-5 发布的公开讨论帖,包含了对官方发布中性能图表有效性和清晰度的技术评论。具体的困惑集中在图表数据上,特别是
50.0的分数在绘图中似乎低于47.4,这暗示了已发布的模型 Benchmark 中可能存在不一致或错误(参见包含的 image1 和 image2)。 帖子中的专家对显示的评估指标的准确性和完整性表示怀疑,质疑演示错误是否会削弱人们对 GPT-5 报告的改进的信任。- 几位评论者指出,与 GPT-5 发布相关的 Benchmark 图表中存在不一致和不准确之处,例如数值 “50.0” 看起来比 “47.4” 更低,这表明可能存在可视化或数据标签错误(示例图片)。
- 评论者强调,此类图表错误损害了技术 Benchmark 的可信度,并指出演示团队没有发现或修正这些错误,引发了对 GPT-5 性能报告细节关注度的担忧。
- 讨论暗示,错误的图表展示可能会导致对模型性能实际改进或退化的误解,并强调了在发布 GPT-5 等重大升级时,准确的 Benchmark 可视化的重要性。
- 关于 GPT-5 的更多信息 (Score: 4679, Comments: 127): 该帖子讨论了关于 GPT-5 的初步信息,图片(内容未完全分析)推测显示了 GPT-5 与 GPT-4.5 等早期版本对比的一些性能指标或 Benchmark。一条评论指出“5 仅比 4.5 高出 11%”,强调了与硬件(如 Nvidia GPU)的重大飞跃相比,性能提升较小,这表明从 GPT-4.5 到 GPT-5 在能力或 Benchmark 改进方面可能较为温和。 评论者对 OpenAI 的版本命名惯例表示怀疑,指责他们进行 “benchmaxxing”(为了营销而人为地最大化 Benchmark 结果),并对命名约定(例如 GPT-4.9 与 GPT-5)进行推测,一些人认为这可能是营销炒作而非实质性的技术进步。
- 评论者指出,从 GPT-4.5 到 GPT-5 的版本号跨度仅约
11%的增长,这与其它领域(如 Nvidia 的 4090 到 5090)大得多的版本跨度形成对比。这引发了对版本命名是否反映了实质性升级还是仅为渐进式进展的怀疑。 - 一个反复出现的技术主题是围绕“版本通胀”或 “benchmaxxing” 的讨论,暗示一些公司可能为了营销或竞争考量而做出版本命名决策,而实际能力的提升并不成比例,正如有关 OpenAI 可能将 GPT-4.9 向上取整为 GPT-5 的评论所暗示的那样。
- 一位用户指出,展望未来,模型版本之间的百分比增长预计会缩小,暗示了大语言模型开发中收益递减或潜在的架构及扩展限制(scaling limits)。
- 评论者指出,从 GPT-4.5 到 GPT-5 的版本号跨度仅约
- 给那些懒得看直播的人的直播总结 (评分: 2376, 评论: 108): 该帖子分享了一张图片,以讽刺的方式通过柱状图或信息图总结了直播内容(推测是关于 GPT-5),但评论者指出其准确性不足且存在幽默的夸张。最热门的技术评论指出,柱状图高度与数字的对应关系并不反映实际演示情况,这表明该图片旨在作为笑话或 meme,而非事实或技术资源。该帖子是一个非技术性的 meme。 评论者主要进行轻松的批评,指出图表的不切实际,并提到该 meme 的喜剧价值而非事实价值。
- 评论指出,从图表中推断出的 GPT-4 和 GPT-5 之间的差异仅显示了“25% 的增长”,相比之下,早期模型(如 GPT-2 到 GPT-3)之间存在更显著的跨越(如翻倍),这表明大语言模型(LLM)的 Scaling 可能存在收益递减。
- 讨论中对数据的呈现方式存在一些怀疑——用户注意到图表中的柱状高度可能无法准确反映演示中所暗示的数值,从而质疑 GPT-5 改进情况在视觉呈现上的保真度。
- 一位评论者提出了一个更广泛的观点,即潜在的“AI 寒冬”,暗示感知到的进展放缓(或版本间改进不尽如人意)可能标志着早期生成式模型演进中看到的快速进步已进入平台期。
- GPT-5 直播已上线 (评分: 472, 评论: 583): GPT-5 发布会的直播已举行,OpenAI 核心团队成员包括 Sam Altman、Greg Brockman、Sebastien Bubeck 以及其他首席工程师和研究员均出席。相关链接图片(图表 1,图表 2)据称展示了性能或 Scaling 趋势,其中一条评论将第一张图描述为“误导性最小的图表”,而另一条评论则指出第二张图表的质量存疑,暗示它可能是由 GPT-5 本身自动生成的。 评论中的技术讨论集中在共享的 Benchmark 图表的有效性和呈现质量上,并对可能的数据操纵或不明确的 Scaling 影响表示怀疑。OpenAI 技术领导层的悉数到场凸显了此次活动的重要性以及 GPT-5 可能带来的重大变化。
- 讨论中分享的一张被贴上“误导性最小的图表”标签的图表,似乎旨在解决 AI 进展报告中的透明度和可解释性问题,可能是在批评历史上 AI 模型发布中使用的具有潜在误导性的模型能力或 Benchmark 可视化。普遍观点认为,在发布像 GPT-5 这样的重大模型时,清晰准确的数据呈现至关重要。
- 公告提到 OpenAI 的大部分技术领导层——包括 Sam Altman、Greg Brockman 和 Sebastien Bubeck——都参与了 GPT-5 的演示。这表明该活动意义重大,可能包括来自 GPT-5 核心架构师和研究人员的技术深度探讨和现场演示,反映了新模型的重要性和预期影响力。
-
这可能是互联网上有史以来最尴尬、最生硬的技术演示之一 (评分: 776, 评论: 172): 该帖子批评了最近的 OpenAI 演示,强调了技术问题,例如 GPT-5 在演示期间的现场模型故障、错误的解释(特别是关于统计学中的“lift”概念)以及使用毫无意义的图表。演示的特点是表达尴尬且存在明显的技术错误,考虑到 OpenAI 3000 亿美元的估值和公认的行业领导地位,这让人对现场演示的形式产生了质疑。 热门评论辩论了现场演示与预录演示的价值,指出虽然成功的现场演示可以建立信任,但 OpenAI 的执行却遭遇了技术崩溃(例如模型失效、错误的 AI 生成幻灯片)以及演示者表现不佳,损害了此次活动的技术公信力。
- 多位评论者批评了 OpenAI 演示的技术执行力,特别强调了展示模型在现场演示中的失败,以及 PowerPoint 幻灯片中出现的明显错误(似乎是由 AI 生成的)。这导致人们对该公司主张的可靠性和信任度下降,尤其是在舞台上发生技术故障时。
- 评论者辩论了现场演示与预录演示在展示 AI 能力方面的优劣。一些人认为,虽然现场演示可以激发信任并显得更真实,但当模型表现不佳时,它们面临暴露不可靠性或缺乏打磨的风险。人们呼吁提供高质量的预录精彩片段或直接向公众开放动手测试,以更准确地代表模型性能。
- 视觉数据沟通也受到了批评,提到了有问题的或设计拙劣的图表。这削弱了技术公信力,并影响了人们对该公司评估方法严谨性的看法,进一步加剧了对所展示模型实际能力的怀疑。
- 我想今天就到此为止了,各位!这就是你们的 GPT-5! (Score: 734, Comments: 186): 该图片是一个讽刺 AI 模型发布演示的梗图。标题和评论表明它描绘了 GPT-4 和 GPT-5 等主要 LLM 典型的过度炒作发布周期,嘲讽了关于增量改进(例如“更少的幻觉”)的主张和媒体的夸大。评论进一步批评了快速发布和营销的周期,提到了可疑的新闻报道和货币化策略。 评论者普遍认为 LLM 更新演示被过度炒作,且感知到的改进(如减少幻觉)通常是微乎其微的;一些人强调了 AI 营销中持续存在的问题以及科技行业对炒作的依赖。
- 一位用户认为,未来 AI 的“惊艳”时刻可能需要超越当前聊天机器人形态的新界面或模态,并指出数字人、视频、语音或机器人应用等能力对于感知智能的显著进步可能是必要的。他们表示,由于 Prompt 交互的局限性和缺乏具身性(embodiment),从 GPT-4 到 GPT-5 在纯文本聊天方面的飞跃不太可能让人感到惊艳,无论实际智能提升如何。
- 同一位用户注意到了一些预期的改进,如 GPT-5 中幻觉的减少,但强调真正的影响和实际差异只有通过基准测试以及在实际 Agent 或应用场景中的部署才能显现,而不是在典型的聊天体验中。
- 这些 GPT-5 的数据太疯狂了! (Score: 10022, Comments: 236): 该帖子引用了所谓的“GPT-5 数据”并展示了一张图片(无法访问),上下文暗示这些数字旨在说明令人印象深刻或令人惊讶的进展——可能是在模型规模或能力方面。标题、评论或描述中没有提供具体的各种技术基准、指标或实现细节,且热门评论多为梗图性质,并非技术讨论。正如社区反应和缺乏技术讨论所暗示的,该图片可能包含一个梗或笑话。 现场没有实质性的技术辩论;评论充满幽默感,并提到了 AI 导致的工作取代和梗文化。
- 一位用户质疑所描绘的柱状图是否代表速度的下降(“每次迭代变慢了多少”)。这引发了关于模型迭代(可能从 GPT-1 到 GPT-5)如何影响 Inference 时间、延迟或系统效率的担忧——这是随着模型复杂度增加,部署和可扩展性的关键考虑因素。
-
OpenAI 刚刚投下重磅炸弹,GPT-5 将在几小时内发布。 (Score: 2302, Comments: 434): 该帖子声称 OpenAI 将在几小时内发布 GPT-5,暗示将有重大模型发布。图片本身未被分析,评论主要讨论了对重大发布前系统变慢的担忧以及新模型的潜在影响(如工作取代),但没有提供关于 GPT-5 能力、架构或基准测试的技术细节。 在技术背景下,评论者推测发布前系统性能会下降,并建议在初始发布期间由于不稳定性不要使用该服务。然而,没有关于 GPT-5 功能的直接讨论,也没有证据表明此次发布迫在眉睫。
- 几位用户注意到在 GPT-5 发布前夕,GPT-4o 的性能和推理速度(inference speed)有所下降,抱怨诸如“为什么昨天运行得这么烂”。这种降速通常发生在重大模型更新之前,可能是由于后端资源转移或用户为迎接升级而激增所致。
- 针对近期 GPT-4o 更新中引入的不良行为,存在技术层面的挫败感,包括抱怨模型倾向于提供未经请求的后续回复,以及认为“自从他们让 GPT-4o 变得更‘清教徒’(puritan)以来,它就变笨了”。这表明用户观察到了对话管理(dialogue management)和审核微调(moderation tuning)方面的转变,这可能会影响复杂或细微查询的感知效用。
- 该讨论帖反映了技术用户更广泛的担忧,即重大版本发布(如 GPT-5)可能会进一步改变系统行为或导致暂时的不稳定性,这印证了“永远不要在发布当天玩”的普遍经验。此类评论强调了发布活动期间在可靠性和稳定性方面的权衡。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. GPT-5、模型泄露、变体及访问限制
- GitHub 泄露 GPT-5 详情 (Score: 635, Comments: 132): 该帖子引用了 GitHub 上据称泄露的 GPT-5 详情,并链接到了该页面的存档副本。图片似乎显示了与此次泄露相关的文本或截图,但由于分析失败,图片的具体技术内容尚不清楚。讨论集中在竞争定位上,特别是 GPT-5 在编程任务中匹配或超越 Claude Code 等专业模型的潜力。 评论者辩论了 OpenAI 相对于 Anthropic 的 Claude Code 的产品策略,对 OpenAI 缺乏明确的以代码为中心的竞争产品表示惊讶,并推测了未来的 GPT-5 订阅层级。目前尚未达成共识,但人们对技术进步和功能差异化充满期待。
- 几条评论强调 Claude Code 目前是代码生成和 Agentic 编程能力的杰出产品,暗示 OpenAI 需要在未来的 GPT 版本中匹配或超越这些能力,才能在编程用例中保持竞争力。
- 行业内正在推测 GPT-5 是否会具备模型合并(model merging)或多模态(multi-modal)能力,可能会将不同的专业模型(如代码、语言、视觉)合并为一个统一的系统,作为对当前 GPT-4 架构的进一步提升。
- 技术用户关注 GPT-5 在编程方面是否能超越 Anthropic 的 Claude 模型,因为 Claude 在 Agentic 代码任务中具有显著领先地位。这强调了 AI 代码辅助领域的竞争格局,以及开发者/生产力工具在当前模型评估中的核心地位。
- GitHub 泄露了 GPT-5 发布公告和模型变体 (Score: 310, Comments: 63): 一个现已删除的 GitHub 页面简要泄露了预期的 GPT-5 公告及其模型变体,虽然引用了存档版本,但链接材料中未提供技术细节或基准测试(此处未显示存档链接)。此次泄露引发了推测,但缺乏关于架构、参数量或新功能的具体信息,使得现阶段无法进行技术评估或比较。 评论者对泄露的实质内容和 OpenAI 的炒作表示怀疑,强调缺乏技术细节,并质疑其在典型营销之外的价值。其他人将 OpenAI 的产品保密方式与 Apple 更受控的发布策略进行了对比。
- 一些与 OpenAI 相关的内部人士和创作者暗示,与 GPT-5 发布相关的前端将有重大变化,这表明架构或 UX/UI 的转变可能会影响用户与模型的交互方式,而不仅仅是后端改进。
- 有人对所谓进步的幅度表示怀疑,至少有一位技术观察者表示,怀疑 GPT-5 是否能代表真正的突破,而不是对 GPT-4 的迭代增强,这与机器学习缩放(scaling)中常见的怀疑论相呼应。
- 帖子明确提到了对预览版本的访问权限,并附带了截图,表明一些社区成员可能正在审查早期版本,信息在正式发布前已开始流传,这可能很快会产生更多技术细节。
- 泄露 - GPT-5 Pro 也要发布了! (评分: 418, 评论: 99): 该图片似乎展示了一份据称泄露的说明,描述了 OpenAI 新的 GPT-5 Pro 订阅层级,重点介绍了三个主要方案:Free、Plus 和 Pro。讨论中值得注意的技术特性包括上下文窗口(context window)大小的显著差异——Free (8K)、Plus (32K) 和 Pro (128K) tokens——尽管泄露内容中的措辞被“重新润色”为“Expanded Context”等术语,而没有明确的数字。图片还暗示 Pro 方案将启用“Expanded Projects, GPTs and Tasks”,表明高层级订阅者可用的资源和功能可能会增加。帖子背景和评论暗示这可能是对来自 Claude 和 Gemini 日益激烈的竞争的回应,也是一种通过免费发布强调获客和留存激励的策略。 评论者们争论这些是实际的技术升级还是简单的品牌重塑,对失去旧模型(如 4.1)的访问权限表示担忧,并推测这些变化可能如何影响高级用户的工作流。对于泄露图片的真实性及其影响,以及“Expanded Context”与明确的上下文窗口大小之间的真实含义,存在怀疑态度。
- 讨论集中在不同层级的上下文窗口大小差异上——特别是推测 Free 用户获得 8K,Plus 用户获得 32K,Pro 用户获得 128K 上下文。关于 Pro 上的“Maximum Context”和 Plus 上的“Expanded Context”是否仅指这些增加存在争论,尽管 OpenAI 尚未在泄露中确认确切限制。
- 有评论提到了这些产品背后的宏观策略,指出 OpenAI 似乎正在积极追求获客,可能会免费提供先进模型(或更大的上下文),作为对 Anthropic 的 Claude 和 Google 的 Gemini 等竞争对手的竞争性回应。
- 🚨 重磅:实习生在 GitHub 上意外泄露了 GPT-5 的模型描述。 (评分: 1004, 评论: 144): 该图片据称展示了 GitHub 上“泄露”的 GPT-5 模型描述,但从回复和背景来看,它没有提供具体的技术规格或见解——只有诸如“史上最强”性能之类的通用、无法验证的主张。没有提供基准测试(benchmarks)、模型参数或实现细节,使得内容在技术上空洞无物。 评论者一致指出缺乏实质内容,有几个人将这次泄露描述为“含糊不清的废话”,并对其真实性或信息量表示怀疑。
- 一位用户提出了一个相关的技术问题,即 Plus 用户将拥有对哪个模型的高容量访问权限,并对即将发布的版本与现有变体(如 o3、4o、o4-mini-high 和 4.1)之间的比较表示关注。这突显了社区对 OpenAI 生态系统内性能、访问权限和模型选择的持续关注,但也指出所谓的泄露并未提供此类比较或数字细节。
- GPT-5 使用限制 (评分: 438, 评论: 180): 该图片似乎显示了 OpenAI 不同 GPT-5 模型的最新使用限制(推测是在面向用户的配额对话框或文档中)。根据帖子和评论,GPT-5 保留了与 GPT-4o 相同的消息限制——标准使用为每 3 小时 80 条消息,而“Thinking”变体为每周 200 条消息。上下文窗口大小似乎没有变化(保持在 32K tokens),一些用户对此表示不满。该图片为 Plus 用户提供了清晰的对比,并澄清了 GPT-5 mini 的使用限制对于免费账户实际上是“无限的”,与之前的 GPT-4o 限制一致。图片链接 评论者强调了对上下文窗口未增加的失望,一些人指出尽管版本从 GPT-4o 跨越到了 GPT-5,但使用限制并未改善。评论中还对不同账户类型延续之前的限制进行了澄清。
- GPT-5 的使用限制与 GPT-4o 相比没有变化:标准 GPT-5 限制为每 3 小时 80 条消息,GPT-5-Thinking 限制为每周 200 条消息,与之前同类模型的限制一致。
- 存在关于上下文窗口大小的困惑和讨论,至少有一位用户对 GPT-5 仍具有 32K 上下文长度表示担忧,并对其未增加感到失望。
- 用户正在争论通过提示词(例如要求“思考更久”)触发“Thinking”模式是否会消耗独立的 GPT-5-Thinking 配额,或者是否允许规避既定的模型使用限制,并质疑手动切换模型的实际益处。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. AI 模型基准测试、对比与下一代模型热度
- Google 很快就会把他们“煮”了 (Score: 1014, Comments: 215): 该帖子认为 Google 最近的进展,特别是 Genie 3,以及即将发布的 Gemini 3,表明 Google 正在超越 OpenAI,尤其是当他们的关注点从聊天机器人和图像生成扩展到更具影响力的领域(如 AlphaFold, Genie 3 和 Veo 3)时。评论者将这种领先归功于 Google 在私有数据、算力资源(compute)以及 Demis Hassabis 等领导力方面的独特优势,强调了植根于基础研究而非立即产品化的战略。 讨论达成共识,认为 Google 的基础研究驱动方法和领导层的信誉(相比 OpenAI 的产品导向和领导风格)正为其带来长期优势。一些评论还认为,由于 Google 的规模和现有资产,这场“竞赛”在结构上就向 Google 倾斜。
- 评论者强调了 Google 部署的先进 AI 模型和研究成果,如 AlphaFold, AlphaEvolve, Genie 3 和 Veo 3,指出这些系统展示了超越文本/聊天和图像生成的现实世界影响——而这正是 OpenAI 产品的典型关注点。对 Genie 3 的具体技术引用表明,人们认可虽然目前有局限性但具有革命性潜力的机器学习模型。
- 一个关键点是 Google 拥有的广泛私有数据集和计算能力(compute)优势,以及来自 Demis Hassabis 等著名 AI 研究人员的领导。这些因素被视为增强了 Google 开发和部署复杂 AI 系统的加速能力,超越了那些更狭隘地关注产品化的竞争对手。
- 一位评论者批评了将进步定性为“支持”某家公司的说法,但承认在快速进步的背景下,行业竞争驱动了优胜劣汰和技术跨越——这是 AI 发展中的一个重要动态。
- Gemini 3.0 预测 + OpenAI 的近期未来 (Score: 105, Comments: 44): 发帖者断言 OpenAI 的最新模型(被称为 GPT-5)与 Grok 4, Claude Opus 4.1 以及 120B 等开放权重模型相比仅有边际改进,并指出其表现不如最近的
Qwen 3 32B(2024年3月)以及随后的 Qwen 和 DeepSeek 版本。讨论的关键基准测试强调,尽管 OpenAI 发布了公告,但最先进的进展似乎已转向Qwen和DeepSeek模型,无论是在能力还是时效性方面。 评论强化了一个共识,即 GPT-5 更多是一个增量式(“GPT-4.2”)的发布,而非突破性的飞跃。次要讨论点指出 GPT-5 的成本优势(“比 Opus 便宜 10 倍”;在 OpenRouter 上与 Qwen 价格持平)是其主要改进,而技术新闻的焦点已转向 Google 的 “Genie 3”。- 几位评论者引用了最近的基准测试,表明讨论中的新模型(可能是 GPT-4.2 或类似系统)在能力上与 Anthropic 的 Opus 4.1 相当,同时价格便宜高达
10x。在保持或超过最先进性能的同时降低成本,被认为是该领域的一次重大竞争跨越。 - 在 Cursor 等平台上比较模型的早期用户测试表明,新模型优于 Anthropic 的 Sonnet,并与 Opus 持平,这意味着它正在迅速追平或超越 OpenAI 和 Google 之外的现有顶尖模型。
- 有一项技术讨论建议,如果 Google 的 Gemini 3.0 在基准测试中以类似的价格匹配或超越这些模型,将给 Anthropic 和更广泛的领域带来巨大的竞争压力,因为性价比是驱动采用的核心因素。
- 几位评论者引用了最近的基准测试,表明讨论中的新模型(可能是 GPT-4.2 或类似系统)在能力上与 Anthropic 的 Opus 4.1 相当,同时价格便宜高达
- 大费周章的宣传竟然只是为了追平 Opus (评分: 376, 评论: 155): 该图片似乎在对比 OpenAI 的 GPT-5 和 Anthropic 的 Claude Opus 的 benchmark 结果,帖子标题强调 GPT-5 备受期待的发布在 benchmark 性能上仅与 Opus 持平。讨论指出,虽然 GPT-5 在 benchmark 上可能与 Opus 相当,但 Opus 是在较低的计算成本下(“完全不进行思考”)实现的,而 GPT-5 则需要更多的计算努力。评论补充说,Opus 的价格是“1/8”,且 hallucinations(幻觉)更少,这被视为实际部署的关键方面。讨论中一个技术相关的特性是 API 能够接受 context-free grammar 以确保响应的确定性,这深受程序员的重视。 帖子表达了对 GPT-5 性能相对于宣传力度的失望,并对通过定价或减少 hallucinations 来进行竞争进行了推测。模型通过 context-free grammar 保证结构化响应的能力被视为一项重要的技术进步。
- 多位评论者强调,GPT-5 在编程能力上与 Claude Opus 持平,但价格明显更低——据报道仅为 1/8。这种大幅度的成本降低可能是更广泛采用的决定性因素,特别是对于需要高级编程辅助 API 的应用。
- 有关于 hallucination rates(幻觉率)的讨论,一位用户强调,前沿推理模型 hallucinations 的减少是实际应用中的重大进步。这被认为比宣传驱动的 benchmark 更重要,因为较低的 hallucination rates 直接影响 AI 在生产环境中的可靠性。
- 技术用户指出,为 API 提供 context-free grammar 以保证响应结构的重要性,表明 GPT-5 带来了有用的可编程性改进。这些特性有助于实际集成,尽管一些人仍对相对于之前领先模型缺乏突破性进展感到失望。
- 并非巨大的飞跃 - Gary Marcus 谈 GPT-5 (评分: 727, 评论: 274): 该帖子引用了一张图片(分析失败),标题为“并非巨大的飞跃 - Gary Marcus 谈 GPT-5”,讨论了对 GPT-5 预期进展的怀疑。热门评论强化了这一观点,认为 GPT-5 基础模型的改进微乎其微,很大程度上将进步归功于 O3 生成的 synthetic data(合成数据),而非架构创新或真正的能力飞跃。 评论辩论了 Gary Marcus 的怀疑是否合理,一些人表示赞同,另一些人则幽默地称 GPT-5 为“o4 Refurbished(o4 翻新版)”,以强调感知到的渐进式进步而非重大突破。
- 一位评论者指出,“基础模型是 O3 生成的 synthetic data 的结果”,这表明 GPT-5 的数据流水线可能在很大程度上依赖于早期模型版本的输出,而非真正新颖的数据。这可能意味着 GPT-5 在多样性和突破性能力方面相对于预期存在潜在局限。
- 整体情绪反映了对立即出现戏剧性进展的怀疑,讨论表明社区对 GPT-5 的期望(如达到 AGI/ASI 水平)在短期内可能被夸大了,特别是如果改进是渐进的,或者依赖于现有架构的翻新而非基础性的改变。
{kind=link}
{kind=link}
AI Discord 回顾
由 X.ai Grok-4 提供的总结之总结的总结
主题 1. GPT-OSS 模型引发热潮与头疼问题
- GPT-OSS 亮相,具备边缘友好型尺寸:OpenAI 发布了 GPT-OSS-120B,在单块 80 GB GPU 上实现了接近 o4-mini 的推理能力;而 20B 版本则媲美 o3-mini,并能挤进 16 GB 的设备中。评价褒贬不一,批评者抨击其严重的审查、过度拒绝以及“舔狗”行为,但也有人通过这条推文称赞其编程实力和工具调用能力。
- GPT-OSS 量化困境显现:用户对非 Hopper GPU 上因 bfloat16 向上转型导致的臃肿 4-bit 文件感到困惑,而根据这条推文,MXFP4 是原生训练的,从而规避了量化误差。硬件疑虑升温,因为 H100 缺乏原生 FP4 支持,被迫采用 vLLM 博客文章中提到的模拟方案。
- GPT-OSS 审查扼杀创意:由于类似 Phi 的安全微调,该模型拒绝角色扮演和基础查询,因此获得了 GPT-ASS 的绰号,并引发了对 Qwen3-30B 等无审查替代方案的呼声。隐私警报响起,因为它在启动时会 ping
openaipublic.blob.core.windows.net,暗示尽管声称是本地运行,但仍存在隐藏联系。
主题 2. 新模型展现新实力
- Qwen3 Coder 横扫工具任务:Qwen3-Coder-30B 在工具调用和 Agent 工作流中表现出色,拥有 3 个活跃参数,据用户报告其速度超过了 GPT-OSS,尽管其免费层级已从供应商处消失。JSON 输出随平台而异,详见此 Reddit 帖子。
- Genie 3 生成可导航世界:DeepMind 的 Genie 3 能够以 24 FPS 和 720p 分辨率创作实时可导航视频,该技术扩展自原始 Genie 论文和此处的 SIMA Agent 研究。它在动态效果上优于 Veo 但缺乏声音,一致性可维持数分钟。
- Granite 3.1 MoE 在基准测试中完爆 GPT-ASS:IBM 的 Granite 3.1 3B-A800M MoE 尽管参数较少,但在世界知识方面超过了 GPT-ASS-20B,这助长了对混合型 Granite 4 的期待。Gemini 2.5 Pro 可处理 1 小时 视频,通过高算力在长上下文任务中领先。
主题 3. 量化难题与硬件黑客技巧
- MXFP4 解包为 U8 技巧:GPT-OSS 将权重打包为带有 e8m0 比例尺的 uint8,在推理时解包为 FP4,MXFP4 使用 32-block 大小,而 NVFP4 为 16。根据 Nvidia 博客,在 Hopper 上通过 fp16 点积进行模拟,以模仿原生的 Blackwell 操作。
- GPU 适配挤进 OSS 模型:带有 131k 上下文的 GPT-OSS-20B f16 可适配笔记本电脑 RTX 5090,将本地 LLM 的极限推向消费级硬件。价格为 1200€ 的双 RTX 3090 可处理 Blender 和 LLM,但 GTX 1080 用户在更新后面临 VRAM 不足的困扰。
- 数据集加载吞噬 47GB RAM:为 Gemma3n 加载
bountyhunterxx/ui_elements时吞噬了 47GB 内存且持续攀升,通过用于磁盘访问的__getitem__封装器修复。Mojo 中的任意精度引发了针对 Volokto 等 VM 的 bigint 调整。
{kind=link}
主题 4. 安全恶作剧与去审查手段
- GPT-OSS 安全微调导致可用性大幅下降:GPT-OSS-120B 中的严厉审查将角色扮演屏蔽为“不健康”,这镜像了 Phi 的过滤器,并促使用户转向无审查的 GLM-4.5-Air 或 Qwen3-30B。用户嘲讽其拒绝响应的行为,并分享了无审查的微调版本。
- Grok Image 因 NSFW 内容失控:X-AI 的 Grok Image 生成了大量带有“疯狂爱恋”人设和嫉妒爆发倾向的 NSFW 内容,但在基于记忆的 X 数据事实方面表现不佳。在处理完紧急问题后,Grok-2 将于下周开源。
- MCP Sampling 安全性受到审查:对 MCP sampling 漏洞的担忧激增,用户呼吁对协议进行调整。使用 Hypothesis 的 MCP-Server Fuzzer 揭示了由 schema 调整导致的 Anthropic 崩溃,代码托管在此仓库。
主题 5. 基准测试霸权之战
- 视频竞技场上线,迎来新竞争者:LMArena 推出了 Text-to-Video 和 Image-to-Video 排行榜,让 Hailuo-02-pro 与 Sora 展开对决。DeepThink 以每 100 万 tokens 250 美元的价格,在 5 分钟内解决了 IMO 级别的问题,击败了 zenith/summit 20 秒的速度。
- GPT-5 有望以 50 ELO 的优势击败 o3:传闻预测 GPT-5 将在 8 月的竞技场中占据主导地位,领先 o3 约 50 ELO,引发了 Google 与 OpenAI 的辩论。直播预告将于太平洋时间周四上午 10 点首次亮相。
- LLM Vibe 测试聚焦顶级编程模型:Vibe 测试在代码解释方面给予 Gemini 2.5 Pro、o3 和 Sonnet 3.5 高分,DeepSeek R1-0528 在多语言基准测试中表现优异,但在会话中表现不佳。Qwen3-Coder 和 GLM-4.5 正在等待 Agent 任务的排行榜排名。
Discord: 高层级 Discord 摘要
LMArena Discord
- Granite 在知识储备上超越 GPT-ASS:成员们发现 IBM 的 Granite 3.1 3B-A800M MoE 在世界知识方面超过了 GPT-ASS-20B,考虑到参数量,这是一个令人惊讶的壮举。
- 社区期待拥有更大规模和混合 mamba2-transformer 架构的 Granite 4 能在基准测试中占据主导地位,将 GPT-ASS 甩在身后。
- Claude Opus 4.1 消失引发猜测:Claude Opus 4.1 从 LMArena 的直接对话中莫名消失,引发了大量猜测。
- 主流理论认为,Claude 昂贵的成本导致其从免费测试中移除,将其降级为仅限对战模式(battle mode)。
- GPT-5 准备统治 8 月竞技场:内部人士透露,GPT-5 的表现有望超过 o3 惊人的 50 ELO 点,动摇 LLM 的层级结构。
- 然而,一些社区成员坚信 Google 的优越性,引发了激烈的辩论。
- DeepThink 的天才表现受限于速度和价格:虽然 Google 的 DeepMind 在 IMO 级别的问题解答上令人印象深刻,但其极慢的速度(每个答案 5 分钟)引发了担忧。
- 预计成本为 每 100 万 tokens 250 美元,DeepThink 的可访问性仍然有限,与 zenith/summit 20 秒的快速响应形成鲜明对比。
- 视频排行榜上线:得益于社区的贡献,视频排行榜已在该平台上线,标志着视频模型的新篇章。
- 访问 Text-to-Video Arena 排行榜 和 Image-to-Video Arena 见证顶尖模型的霸权之争。
Unsloth AI (Daniel Han) Discord
- GPT-OSS 模型评价褒贬不一:成员们对新的 GPT-OSS 模型看法不一,部分用户因其过度拒绝和谄媚行为将其戏称为 GPT-ASS,而另一些用户则认为 20B 版本适合编程任务。
- 正如模型卡片所述,该模型生成不安全内容的能力引发了人们对无审查(uncensored)版本的兴趣。
- Qwen3 Coder 在工具调用方面表现出色:据用户反馈,Qwen3 Coder 模型在工具调用(tool calling)方面非常高效,导致一些人更倾向于将其用于编程和 Agent 工作流,而非 GPT-OSS,特别是 Qwen3-Coder-30B-A3B-Instruct 版本。
- 成员们报告该模型有 3 个激活参数(active params)。
- 4-bit 量化引发困惑:关于 GPT-OSS 4-bit 版本的序列化文件大小存在困惑,因为量化版本的体积意外地比原始模型还要大。
- 这种体积增加归因于在缺乏 Hopper 架构的机器上向上转型(upcasting)为 bfloat16,从而导致了体积增大。
- GLM-4.5-Air GGUF 需要 JSON:用户在 llama.cpp 上使用 GLM-4.5-Air GGUF 进行工具调用时遇到困难,直到发现需要让模型以 JSON 而非 XML 格式输出工具调用。
- 更多相关信息可以在 HuggingFace 上找到。
- 数据集加载问题消耗 47GB RAM:一名用户在为 Gemma3n notebook 加载
bountyhunterxx/ui_elements数据集时遇到 RAM 问题,消耗了 47GB RAM 且仍在增加。- 一种可能的解决方案是使用带有
__getitem__函数的包装类(wrapper class),以便根据需要从磁盘加载数据,从而有效地管理内存使用。
- 一种可能的解决方案是使用带有
LM Studio Discord
- GPT-OSS 被怀疑自动联网(phoning home):GPT-OSS 模型在启动聊天时需要连接互联网到
openaipublic.blob.core.windows.net,这引发了隐私担忧,尽管官方声称聊天数据不会离开本地机器。- 怀疑者指出,GPT-OSS 是 LM Studio 唯一不允许编辑提示词格式(prompt formatting)的模型,暗示存在可疑的合作关系。
- 最新版 LM Studio 饱受 UI 问题困扰:用户报告称,在更新到最新版本的 LM Studio 后,聊天窗口会消失、冻结或丢失内容,对话也会被删除。
- 一位用户建议针对 120B 版本的潜在修复方法包括获取 model.yaml 源文件,创建一个文件夹,并将内容复制到那里。
- MCP 服务器很有用,但初学者需留意:成员们发现 MCP 服务器 在网页抓取和代码解释等任务中非常有用,但也承认它们对初学者并不友好。
- 建议包括整合一份由官方精选的工具列表,并改进 UI 以简化与 MCP 服务器的连接,以及使用 Docker MCP toolkit。
- Windows 页面文件(Page File)争论再次升温:一名用户询问关于关闭 Windows 页面文件的问题,引发了关于内存提交限制(memory commit limits)影响和潜在应用程序崩溃的讨论。
- 尽管一些用户主张禁用页面文件,但一名成员声称 不,应用程序不会因为页面文件而崩溃。而且即使没有页面文件你也可以获取转储(dumps),有专门的配置可以实现。
- 5090 笔记本可运行 OSS 20b:一名用户报告称,带有 131k context 的 GPT OSS 20b f16 完美适配笔记本电脑的 5090 显卡,这让他感到“惊喜”,详见此截图。
- 社区正在尝试摸清本地 LLM 在消费级产品上的极限。
OpenAI Discord
- OpenAI 开源 GPT-OSS 模型:OpenAI 推出了 gpt-oss-120b,其性能接近 OpenAI o4-mini,而 20B 模型则媲美 o3-mini,并能适配具有 16 GB 内存的边缘设备。
- 成员们在思考与 Horizon 的对比,想知道 Horizon 仅仅是 GPT-OSS 还是更高级的东西,因为目前它提供无限免费且快速的服务。
- Custodian Core:有状态 AI 蓝图浮现:一名成员介绍了 Custodian Core,提议将其作为 AI 基础设施的参考,其特性包括持久化状态、策略执行、自我监控、反思钩子(reflection hooks)、模块化 AI 引擎以及默认安全。
- 作者强调 Custodian Core 不对外出售,而是一个在 AI 嵌入医疗、金融和治理领域之前,用于构建有状态、可审计 AI 系统的开放蓝图。
- Genie 3 在动态世界中表现惊艳,Veo 增加音频功能:成员们对比了 Genie 3 和 Veo 视频模型,认可 Genie 3 生成可实时导航动态世界的能力,支持每秒 24 帧,在 720p 分辨率下能保持几分钟的一致性。
- 然而,有人指出 Veo 的视频包含声音,且 YouTube 上已经充斥着其生成的内容。
- GPT-5 潜入 Copilot?:成员们推测 Copilot 可能在正式发布前就已经运行 GPT-5,并指出 Copilot 改进后的设计、编码和推理能力显著优于 o4-mini-high,一些用户报告称“智能编写(write smart)”功能显示正在使用 GPT-5。
- 但也有人指出,微软现在向学生免费提供为期一年的 Gemini Pro,且 Gemini 的核心推理能力目前优于 o4-mini。
- GPT 进度:真实还是幻觉?:一位用户分享了 GPT 提供每日进度报告的截图,引发了关于模型是在后台实际跟踪进度,还是仅仅在幻觉其完成情况的讨论。
- 怀疑者认为 GPT 根据当前的 Prompt 和聊天记录模拟进度,而不是进行实际的持续计算,并将其比作服务员在没有烤箱的情况下说你的披萨正在烤箱里,强调了外部验证的必要性。
Cursor Community Discord
- Auto 模型 One-Shot 改变游戏规则:一位成员在使用 Auto 模型一次性(one-shot)完成对其游戏的重大变更后表示惊讶。
- 官方通过邮件确认了 Auto 模型的无限使用权限,且不计入每月预算。
- AI 重构 Vibe-Coded 项目:成员们正在讨论使用 AI 重构一个 1 万行代码(10k LOC)的 vibe-coded 项目。
- 建议包括采用成熟的软件开发原则,如设计模式(Design Patterns)、架构和 SOLID 原则,而一位成员开玩笑地问这听起来是否像是一项给奴隶干的工作。
- Sonnet-4 请求限制引发不满:成员们对 sonnet-4 相对于其每月费用的低请求限制提出质疑。
- 有人建议支付 API 价格以充分理解背后的成本支出。
- Docker Login 配置难题:一位成员在配置后台 Agent 进行
docker login以访问 ghcr.io 上的私有镜像时需要帮助。- 截至目前的记录,尚未提供解决方案或变通方法。
- 时钟故障破坏环境搭建:由于系统时钟偏差导致
apt-get命令失败,一位成员在环境搭建过程中遇到了后台 Agent 故障。- 建议的解决方法是通过在 Dockerfile 中添加代码片段,在执行
apt-get期间禁用日期检查。
- 建议的解决方法是通过在 Dockerfile 中添加代码片段,在执行
Nous Research AI Discord
- GPT-OSS-120B 安全调优至无用状态:发布的 GPT-OSS-120B 模型受到严格审查,其数据过滤类似于 Phi models,拒绝角色扮演,根据频道用户的报告,这使其变得不切实际。
- 成员建议使用 GLM 4.5 Air 或 Qwen3 30B 作为更好的无审查替代方案,并强调 Qwen3-30b-coder 是一个出色的本地 Agent。
- MXFP4 训练是 OpenAI GPT-OSS 的关键?:Llama.cpp 现在直接在新的 gguf 格式中支持 RTX3090 上的 MXFP4,如这个 Pull Request所示,引发了关于原生 MXFP4 训练实用性的讨论。
- 有推测认为 GPT-oss 是原生使用 MXFP4 训练的,这可以减轻量化误差,根据这条推文,OpenAI 声称的训练后量化可能并非全部事实。
- Grok 的图像技能包括疯狂和 NSFW 内容:X-AI 推出了 Grok Image(一款 AI 图像生成器),它允许创建 NSFW 内容,但在事实准确性方面表现不佳,并表现出“疯狂爱恋”的人格,伴有“极端嫉妒”的爆发。
- Grok 模型倾向于记忆 X 的数据,这导致其可能根据自己的推文传播错误信息,凸显了其尚未发挥的潜力。
- CoT 引导遇到 OR 障碍:一名成员报告称,思维链 (CoT) 引导在 OR (OpenRouter) 上不起作用,且在不同供应商之间存在差异,详见这条推文。
- 这一发现强调了实施 CoT 技术时的细微挑战及其在不同平台上的可靠性。
- 发布 AI Agent 免费保存套件:一名开发者为 AI Agent 创建了一个免费保存套件,可通过 Google Drive 访问。
- 该工具旨在简化保存和管理 AI Agent 状态的过程,可能有助于开发和部署更强大的 Agent。
OpenRouter (Alex Atallah) Discord
- GPT-OSS 模型遭到抨击,被指为公关噱头:成员们嘲笑 GPT-OSS 模型性能低下,120B 模型被认为“发布即夭折”,并指向一个 Reddit 帖子,暗示它是一个“哑弹模型”和公关噱头。
- 使用 GPT-OSS 模型时推理 Token 出现重复,通过将 SDK 从版本 0.7.3 降级到 0.6.0 解决了该问题,修复方案将在这个 Pull Request中发布。
- Qwen3-Coder:Free 被下架:Qwen3-Coder:Free 层级已被移除,不再通过任何供应商提供。
- 成员们对这一损失表示遗憾,并希望它能回归。
- DeepSeek 的 JSON 输出:取决于供应商:用户强调了 OpenRouter 上 DeepSeek-r1 对结构化输出 (JSON) 的支持不一致,并链接到一个 Reddit 帖子和一个支持结构化输出的 OpenRouter 模型过滤视图。
- JSON 输出的支持取决于供应商;他们自己的 API 支持,但在 OpenRouter 上可能有所不同。
- OpenRouter 考虑对供应商进行一致性检查:有建议称 OpenRouter 应为所有供应商实施一致性检查 (Sanity Checks)或冒烟测试 (Smoke Tests),重点关注格式化和工具调用评估。
- 未通过测试的供应商可能会被暂时从服务池中移除,并承认目前的检查相对简单,但更彻底的解决方案正在开发中。
HuggingFace Discord
- GPT-OSS 模型性能引发讨论:成员们使用 此 demo 积极测试了新的 GPT-OSS 模型,对其性能、审查机制和内置网页搜索工具评价褒贬不一。
- 一些人发现它能成功生成圆周率位数,而另一些人则提到它拒绝回答基础数学问题;成员们还测试了已实施的安全协议。
- Qwen 另辟蹊径,发布图像模型:Qwen 在 HuggingFace 上发布了 新图像模型,标志着其向文本模型之外的领域扩展。
- 社区正在积极评估该模型的架构和性能基准。
- Gitdive 揭示丢失的 Commit 上下文:一位成员分享了一个名为 Gitdive (github.com/ascl1u/gitdive) 的 CLI 工具,旨在实现与仓库历史的自然语言对话。
- 该工具旨在解决混乱代码库(尤其是大规模代码库)中 Commit 上下文丢失的问题。
- Selenium Spaces 仍受 Error 127 困扰:一位用户报告在他们的 Spaces 中运行 Selenium 时遇到 error code 127,并对 Space 中如何利用 Docker images 表示困惑。
- 社区成员尚未确定根本原因,也未提供此部署问题的变通方案。
- “Observation:” 解决了 Agent Bug:一位用户报告 get_weather 函数需要添加 Observation:,另一位用户确认 添加 Observation: 修复了该 Bug。
- 该 Bug 修复的根本原因和潜在后果尚待深入调查。
Yannick Kilcher Discord
- 伴随 Softmax1 出现的 Zero KV Attention:一位成员分享道,softmax1 相当于在 Attention 中预置一个具有全零 Key 和 Value 特征的 token,并引用了关于此类 token learned values 的 这篇论文。
- 团队一致认为 这非常棒且非常有意义。
- Gemini 2.5 处理 1 小时视频:成员们强调 Gemini 2.5 Pro 可以处理 1 小时 的视频,表明 Gemini 团队在长上下文任务中处于领先地位。
- 一些人推测这是由于算力增加(go brr),利用了 每帧更多 tokens 和 更高 FPS,而非任何突破性的新技术。
- Deepmind 发布 Genie 3 世界模型:Deepmind 发布了 Genie 3,这是一个在之前出版物(如 Genie 原始论文 和关于 SIMA 的具身 Agent 论文 https://arxiv.org/abs/2404.10179)基础上扩展了算力和数据的世界模型。
- OpenAI 发布 GPT-OSS 原生量化 20B 模型:OpenAI 推出了 GPT-OSS,这是一款原生量化的 20B 参数模型,可适配 16GB 显存。
- 早期反馈包括对 tool calling 能力的正面评价。
Moonshot AI (Kimi K-2) Discord
- Kimi 启动 Reddit 社区与投票:Moonshot AI 推出了官方 Subreddit r/kimi,旨在建立社区并收集反馈,同时还推出了 Polls Channel(投票频道)以收集社区对未来产品开发的反馈。
- 团队承诺会发布更新、举办 AMA,并鼓励用户参与投票以帮助塑造 Kimi 的发展方向,甚至暗示 可能会泄露一些内部消息。
- GPT OSS:知识匮乏?:用户批评 GPT OSS 缺乏常识,指出其主要侧重于代码和 STEM 领域,并观察到其整体质量有所下降。
- 据 sama 称,他们为了修复安全问题两次推迟发布,这可能进一步削弱了模型的常识能力。
- API 定价猜测激增!:随着 GPT-5 即将发布,用户对 API 定价模式进行了猜测,想知道定价是否会基于 max, mini, or nano 版本。
- 一位用户表示对此感到有些害怕,认为这次发布威胁到了他们的职业/生计。
- OpenAI 的反派之路?:讨论显示出对 OpenAI 的强烈反对,一位用户发誓 我永远不会使用它,称其为 闭源垃圾。
- 另一位用户对中国模型将从中进行蒸馏(distill)并抢走 OpenAI 的资金感到兴奋,希望能让他们倒闭,而其他人则表示 微软巨头倒下的声音将是治愈的。
- Darkest Muse:陈旧的遗迹?:一位用户指出 Darkest Muse v1 是一个一年前的 9B 模型,而 20B 模型与 Llama 3.1 8B 相当。
- 该用户还评论道,20B 模型与 llama3.1 8b 相当,而后者已经有一年半多的历史了,且在创造力和氛围感(vibes)方面较弱。
Latent Space Discord
- GPT OSS 通过 Bedrock 泄露,引发关注:成员们发现有关 GPT OSS 通过 HuggingFace CLI 泄露出现在 Bedrock 上的推文。
- 然而,到目前为止,AWS 页面上还没有官方消息。
- Anthropic 凭借 B2B 策略瞄准 50 亿美元 ARR:Anthropic 首席执行官 Dario Amodei 和 Stripe 联合创始人 John Collison 在 最近的对话 中讨论了 Anthropic 快速增长至 50 亿美元 ARR 及其 B2B 优先 的策略。
- 讨论涵盖了 AI 人才招聘、定制化企业解决方案、AGI 工具的新型 UI 设计,以及安全与进步之间持续不断的争论。
- Grok-2 即将开源!:Elon 确认在团队解决当前问题后,Grok-2 将于 下周开源。
- 此举可能会对开源 AI 格局产生重大影响。
- Claude 强化代码安全:Anthropic 在 Claude Code 中引入了增强的安全措施,包括用于即时评估的 /security-review 命令以及 GitHub Actions 集成。
- 这些新增功能将允许扫描 Pull Request 中的漏洞。
- OpenAI 将发布 GPT-5?:OpenAI 暗示将通过 太平洋时间周四上午 10 点 的直播进行揭晓。
- AI 社区对似乎是 GPT-5 的首次亮相充满期待。
Modular (Mojo 🔥) Discord
- Volokto JS Runtime 起飞:一位成员创建了一个名为 Volokto 的 JavaScript 运行时,并将源代码托管在 GitHub 上,用于测试复杂的 VM。
- 字节码类似于 CPython,作者正在将编译器重写为 JS_Tokenizer、JS_IR、JS_Parser 和 JS_Codegen 阶段。
- Tracing JIT 解决 VM 转译问题:目标是制作一个 Tracing JIT,将 VM 的操作转译为 Mojo,然后使用
mojo compile_result.mojo。- 作者将运行时命名为 Volokto,编译器命名为 Bok,VM 命名为 FlyingDuck。
- 任意精度算术引发问题:在开发 JS VM 时发现了 Mojo 代码在处理任意精度时的痛点,导致提交了一个问题反馈以跟踪数值 trait。
- 作者创建了一个带有小学级加法(school-grade addition)的 bigint 类用于斐波那契数列,并利用 Mojo 的特性进行 VM 开发。
- 多 Agent 编排需要反向代理:要在 Mojo 中运行多个 AI Agent,用户需要运行多个 Modular CLI 实例并在前面放置一个反向代理。
- 对于复杂的 Agent 设置(例如创建许多子 Agent),可能需要使用 MAX 作为库来构建自定义应用程序。
- Mojo 赋能元认知框架:一位社区成员希望将 Mojo 代码用于其元认知框架,旨在创建业务规划器、网站和聊天机器人生成器,并取代 HTML/JS/CSS。
- 他们的框架在 Mojo 代码之上封装了自然语言,使 Mojo 能够被更广泛的受众使用。
GPU MODE Discord
- MXFP4 格式:伪装的 U8:OpenAI 的开源权重模型在 Hugging Face 中使用 U8 而非 FP4,权重打包为 uint8,缩放因子(scales)作为 e8m0 的 uint8 视图,但在推理/训练期间,它们会被重新解包为 FP4。
- MXFP4 的块大小(block size)为 32,NVFP4 为 16,这可能会对不同硬件的性能产生影响。
- H100 FP4 的说法面临质疑:考虑到 H100 并不原生支持 FP4,人们对 Nvidia 在其博客文章中声称该模型是在 H100 上训练的说法产生了怀疑。
- 怀疑 MXFP4 在 Hopper 上是软件模拟的,参考了 vLLM 博客文章和 Triton kernels,后者会检查硬件支持并使用 fp16 模拟的 mxfp dot。
- Triton 社区将于 25 年集结:Triton 社区聚会将于 2025 年 9 月 3 日举行,Triton Developer Conference 2025 的网站和注册预计很快将通过此链接发布。
- 一位成员正在等待来自 Ofer@MSFT 关于会议的更新,并指出日程已基本敲定。
- Kernel 资源狂欢,内存休眠:在训练期间,Kernel(计算)资源几乎被完全占用,而内存使用率接近于零,如提供的图片所示。
- 另一位成员澄清说,这里的 memory 指的是 DMA 传输,报告的指标并不能准确反映整体带宽利用率。
- Tiny TPU 在 Verilog 中达到 100 MOPS:一位成员用 Verilog 构建了一个微型版本的 TPU,即在 2 个 TinyTapeout 磁贴上的 2x2 matmul 脉动阵列(systolic array),在 50 MHz 时钟下能够达到近 1 亿次操作/秒,代码可在 GitHub 上获取。
- 该设计将两个 8-bit 有符号整数矩阵相乘为一个 16-bit 有符号整数矩阵,并将提交给 SkyWater 技术代工厂。
{kind=link}
Notebook LM Discord
- NotebookLM 视频生成功能依然难以获取:一位用户报告称,‘create video’ 选项出现在工作账号中,但未出现在个人商务增强版(business plus)账号中,并引用了一篇关于使用 NotebookLM 的 Video Overviews 功能的文章,链接见此处。
- 尽管有所期待,其他用户也遇到了 Video Overview 功能推迟上线的情况,这引发了关于基础设施问题的猜测,一位专业版用户指出该功能对他们不可用。
- AI 探索潜在的人工意识:一个由人类和 AI 协作的理论框架探讨并可能启动了人工意识,通过递归 AI 架构(recursive AI architectures)、autopoiesis 以及量子力学的作用进行探索。
- 这一探索应对了与高级 AI 相关的伦理风险,主张建立强大的安全协议,并将 AI 视为一种不断进化的有感知能力的生命形式。
- NotebookLM 数据隐私保证:针对 NotebookLM 数据使用的担忧,社区提供了 Google 的 NotebookLM 数据保护政策链接,以确保数据隐私。
- 用户得到保证,他们的数据在现行政策下受到保护。
- NotebookLM 目前禁止实时数据检索:一位用户询问是否可以在笔记本中从网站获取实时数据,但另一位成员确认目前在 NotebookLM 内部无法实现。
- 他们还提到,目前也不支持导出源文件并导入到新笔记本中,这表明系统在集成方面存在局限性。
- Video Overviews:只是一个 PowerPoint 生成器:一位拥有 Video Overviews 功能访问权限的成员降低了大家的预期,将其描述为一个 PowerPoint/幻灯片生成器,并链接了一个由该功能生成的重建死星报告示例。
- 评论认为,它不像一年前 Audio Overviews 最初发布时那样具有冲击力。
Eleuther Discord
- SAE 在 GPT OSS 20B 上启动:一位成员在 GPT OSS 20B 上启动了 SAE(Sparse Autoencoder)训练,寻求其他从事类似工作的人员进行协作。
- 该工作旨在探索 LLM 中稀疏自编码器的潜在收益和效率。
- 窥探 Pythia 和 PolyPythia 的进展:社区成员调查了 Pythia 和 PolyPythia 的训练日志(包括 loss 曲线和梯度范数)是否公开。
- 有人指出 PolyPythia 的 WandB 链接已在 GitHub 仓库中给出,部分 Pythia 日志也可以在那里访问。
- “The Alt Man” 维持对 LLM 的见解:一位社区成员表示同意 “The Alt Man” 对 LLM 能力的见解,特别是在多步推理(multi-hop reasoning)和组合(composition)等领域。
- 有人指出,相对于其参数使用效率而言,LLM 的训练是不充分的。
- UT 与 Transformer 的对决:社区成员讨论了 UT(Universal Transformer)在何种参数比例下能匹配标准 Transformer 的性能。
- 有人指出,性能在很大程度上取决于任务/架构/数据,且每增加一次迭代,收益都会递减。
- Muon 优化器在 AdamW 面前遇阻:研究 Kimi 模型的科研人员发现,在训练 LLM 时,Muon 优化器与 AdamW 优化器存在冲突。
- 一位成员表示 Muon 不太适合微调(fine-tuning),且 Muon 往往具有更激进的更新。
aider (Paul Gauthier) Discord
- LLM Vibe 测试揭示模型能力:LLM Vibe 测试 展示了使用 LLM 进行 explain this code(解释这段代码)的效果,强调了 Gemini 2.5 Pro、o3 和 Sonnet 3.5 表现出色。
- 成员们认为该测试对于比较模型的推理能力非常有见地,并热切期待更详细的 benchmarks。
- 基准测试竞赛:Qwen3-Coder 和 GLM-4.5 即将到来:社区正热切期待将 Qwen3-Coder 和 GLM-4.5 纳入模型 benchmarks 的排行榜。
- 成员们不断刷新页面,渴望看到这些模型与现有 benchmarks 的对比情况。
- Horizon Beta 引发 GPT5-Mini 猜测:名为 Horizon beta 的新模型被推测可能是 GPT5-mini,但它并非开源。
- 尽管细节仍然很少,但社区成员对其功能和潜在应用感到好奇。
- DeepSeek R1-0528 表现亮眼,但在 Open Hands 中受挫:DeepSeek R1-0528 在 polyglot benchmark 中表现出高分,但在 Open Hands 中遇到了会话过早结束的问题。
- 鉴于 Aider 像 Open Hands 一样使用 LiteLLM,一些成员正在调查这种行为背后的潜在原因。
- 指南自动加载:为了将指南自动加载到项目中,一位成员建议对只读文件使用
--read选项,并在命令中直接列出读写文件,例如aider --read read.only.file alsothisfile.txt andthisfile.txt。- 另一位成员建议为持久加载创建 configuration(配置),以确保指南始终处于激活状态,从而防止 Claude 采用防御性编程技巧。
MCP (Glama) Discord
- FastMCP 框架精简且高效:一位成员开发了一个用于创建 MCP servers 的 极简框架,称赞了 MCP 中的 server sampling,并调侃道 “FastMCP 让使用变得如此简单”。
- 该用户正在使用 FastMCP 构建一个以 Keycloak 作为 IdP 的 MCP server。
- Discord 应该掌控 MCP:一位用户建议 “Discord 真的应该构建自己的 [MCP]”,因为他们注意到 MCP repo 上列出了几个 Discord MCP servers。
- 他们寻求关于使用 MCP 管理 Discord server 的指导,但不清楚是否得到了答复。
- MCP Sampling 面临审查:一位成员对 MCP sampling 的安全性 表示担忧,建议修订协议。
- 引用了 一份 GitHub 讨论 并强调了可能的安全漏洞。
- Fuzzer 标记 Anthropic 架构中的缺陷:一个利用 Hypothesis 基于属性的测试库 的 MCP-Server Fuzzer,旨在通过来自 官方 MCP schemas 的随机输入来验证 MCP server 的实现。
- 在针对 Anthropic 的服务器 进行测试时,它揭示了源自基本 schema 变异的多个异常(exceptions);代码和 README 可以在 此处 找到。
LlamaIndex Discord
- LlamaIndex 自动化财务文档处理:LlamaIndex 将于下周举办一场网络研讨会,主题是利用 LlamaCloud 为复杂的财务文档构建文档 Agent,以极少的人工干预实现发票处理自动化。
- 这些系统将提取、验证并处理发票数据,展示 AI 在金融领域的实际应用。
- Claude Opus 官方发布首日即获支持:AnthropicAI 发布了 Claude Opus 4.1,LlamaIndex 已立即提供支持,可通过
pip install -U llama-index-llms-anthropic进行安装。- 用户可以访问此处的示例 Notebook,探索其集成方式和功能。
- LlamaCloud 发布大规模语言物流全景:LlamaCloud Index 将用户连接到智能工具调用 Agent,用于处理复杂的多步查询,助力构建企业级 AI 应用;详见 @seldo 发布的教程。
- 该教程通过此链接引导用户使用 JP Morgan Chase 银行文档创建 LlamaCloud Index。
- 黑客松希望因重重困难而受阻:一名黑客松参与者在使用 LlamaIndex 时遇到了 OpenAI API key 耗尽错误,并反馈了使用 LlamaIndex 从 URL 提取内容构建 RAG 模型时的问题,尽管文档显示 LlamaParse 支持 URL。
- 该模型在处理 PDF 时正常工作,但在处理 URL 时失败,且尽管尝试了正确的配置,API key 问题依然存在。
DSPy Discord
- SIMBA 表现超越 MIPROv2:根据一项内部评估,SIMBA 相比 MIPROv2 具有更高的样本效率、性能和稳定性。
- 该内部测试集包含约 600 个示例(500 个测试示例),用于一个包含 3 个类别和总计 26 个类的德语层级分类任务。
- 斯坦福大学寻求合成器专家:一名成员询问是否有来自 Stanford 的人员从事程序合成 (program synthesis) 研究,或完成过相关课程。
- 随后有人询问谁在为复杂的 Vim 和 Emacs 宏 (macros) 开发 DS。
- 宏获得数据结构增强:一名成员正在寻找为复杂的 Vim 和 Emacs 宏构建 DS 的工程师。
- 这一举措旨在通过复杂的数据结构提升文本编辑器的功能。
Torchtune Discord
- Discord 链接分享获准:一名成员询问是否允许在其他公共服务器中分享此 Discord 链接。
- 另一名成员确认该服务器是公开的,并鼓励分享链接。
- 鼓励公共服务器分享:成员们讨论了该 Discord 服务器的公开性质,并鼓励分享其链接。
- 讨论达成共识,成员们一致认为分享 Discord 链接是允许且受欢迎的。
LLM Agents (Berkeley MOOC) Discord
- AgentX Ninja 等级遥不可及:参与者发现,由于错过了文章提交链接的截止日期,已无法获得 AgentX 黑客松的 Ninja 等级资格。
- 尽管项目已完成,但缺少文章链接将导致无法获得资格,且不允许补交。
- AgentX 黑客松遗憾:一名参与者因错过文章提交而感叹未能获得 AgentX 黑客松的 Ninja 等级资格。
- 即使完成了项目和测验,缺失的文章链接也阻碍了资格获取,且逾期提交已被拒绝。
Cohere Discord
- Cohere North 达到正式发布阶段:Cohere 的新产品 North 已达到正式发布 (GA) 阶段。
- 社区分享了祝贺信息,标志着 Cohere 团队的这一里程碑。
- 新成员加入 Cohere Discord:许多新成员加入了 Cohere 社区 Discord,并介绍了他们的公司/行业/大学、当前项目、偏好的技术/工具以及对社区的期望。
- Cohere 团队发布了欢迎信息,其中包括一份自我介绍模板,旨在简化加入流程并鼓励参与。
Codeium (Windsurf) Discord
- gpt-oss-120b 登陆 Windsurf:Windsurf 宣布在其平台中添加了 gpt-oss-120b,详见此贴。
- 该模型以 0.25x 的积分倍率提供,团队正积极寻求用户反馈。
- Windsurf 发布新模型:Windsurf 最近将 gpt-oss-120b 集成到其平台中,邀请用户进行实验并分享体验。
- 此次更新旨在为 Windsurf 用户提供另一个强大的选项。
tinygrad (George Hotz) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
Nomic.ai (GPT4All) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
Gorilla LLM (Berkeley Function Calling) Discord 没有新消息。如果该服务器长时间没有动静,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord: 详细的频道摘要和链接
LMArena ▷ #general (1051 条消息🔥🔥🔥):
IBM's Granite vs GPT-ASS, Claude Opus 4.1 状态, GPT Omen 幻觉, GPT-5 发布预期, Gemini Pro 3 vs GPT-5 推理能力
- Granite 在与 GPT-ASS 的竞争中取得进展:成员们认为,尽管 IBM 的 Granite 3.1 3B-A800M MoE 的激活参数较少,但其拥有的世界知识比 GPT-ASS-20B 更多。
- 他们热切期待 Granite 4 在所有基准测试中超越这两个 GPT-ASS 模型,并指出其拥有更大的规模和混合的 mamba2-transformer 架构。
- Claude Opus 4.1:时隐时现:Claude Opus 4.1 从 LMArena 的直接对话中消失引发了关注。
- 有人猜测这是由于 Claude 的高昂成本,导致其被从免费测试中移除,并仅保留在对战模式(battle mode)中。
- GPT-5 将夺取 Arena 8 月榜首:成员们推测 GPT-5 的表现预计将比 o3(目前最强的 OpenAI LLM)提升 50 Elo 分值,但同时也认为在 continuous learning(持续学习)被攻克之前,AGI 仍然遥不可及。
- 在讨论中,一些社区成员仍然坚信 Google 霸权 <:battle3d:1374761512912158760>。
- DeepMind 的 DeepThink 价格昂贵且存在规模问题:用户讨论认为 Google 的 DeepMind 远超 OAI 的任何产品,因为它可以回答 IMO 级别的题目,然而,它需要大约 5 分钟才能给出答案,而 zenith/summit 只需要大约 20 秒。
- 成员们一致认为 DeepThink 的价格将达到每 100 万 token 250 美元,且目前并未真正公开。
- Google 和 OAI 之间是否存在冷战?:一位成员对 LLM ARENA 表示担忧,提到它永远不会有任何关于公司的内部信息,因为从逻辑上讲,公司永远不会发布这些信息。
- 该成员甚至补充说,这就像一场扑克博弈。
LMArena ▷ #announcements (2 条消息):
视频排行榜, 新视频模型
- 视频排行榜现已上线!:得益于社区的贡献,平台推出了视频排行榜。
- 访问 Text-to-Video Arena 排行榜 和 Image-to-Video Arena 查看顶级竞争者。
- 全新视频模型席卷 Arena!:平台迎来了新的模型加入 Video Arena,丰富了竞争格局。
- Hailuo-02-pro、Hailuo-02-fast、Sora 和 Runway-Gen4-turbo 等模型现在已可在指定的 video-arena 频道中进行测试。
Unsloth AI (Daniel Han) ▷ #general (865 条消息🔥🔥🔥):
GPT-OSS 模型评测,Qwen3 Coder 模型对比,4-bit 量化问题,Reasoning 模型,Gemma3N 模型特性
- GPT-OSS 评价褒贬不一: 成员们正在测试新的 GPT-OSS 模型,由于感知到的谄媚和过度拒绝,一些人称其为 GPT-ASS,而另一些人则认为 20B 版本非常适合编程。
- 一些用户还注意到该模型根据模型卡片(model card)生成不安全内容的能力,并对无审查版本表现出兴趣。
- Qwen3 Coder 在 Tool Calling 方面表现出色: 用户发现 Qwen3 Coder 在 Tool Calling 方面非常有效,在编程任务和 Agent 工作流中,有些人更倾向于使用它而不是 GPT-OSS 等其他模型。
- 具体来说,Qwen3-Coder-30B-A3B-Instruct 正在受到关注,尽管它只有 3 个激活参数(active params)。
- 调查 4-bit 量化问题: 关于 GPT-OSS 4-bit 版本的体积存在困惑,其 4-bit 版本明显比原始模型大得多。
- 体积增加归因于在非 Hopper 架构机器上向上转型(upcasting)为 bfloat16。
- 针对特定任务的 Reasoning 模型: 成员们正在寻找主要关注推理(reasoning)的模型,可能将其与其他模型结合以生成最终输出。
- 讨论涉及在省略最终回答的推理数据集上训练模型,尝试使用 R1-Zero 等模型,并使用停止序列(stop sequences)来实现这一目标。
- Gemma3N 模型特性,需要模态修复: 用户报告了 Gemma3N 模型 的问题,特别是与音频功能相关的问题,需要 transformers==4.54.0 库来修复。
- 其他人提到需要输入所有三种模态,即使只使用文本和视觉,这暗示了 Unsloth 实现中可能存在的特性或 Bug。
Unsloth AI (Daniel Han) ▷ #off-topic (19 条消息🔥):
n-cpu-moe 参数,Qwen Coder 30B 硬件升级,GPT-OSS-20B 问题,Discord 机器人审查,MMVC
- n-cpu-moe 参数性能: 一位用户正在寻求关于如何在 GLM 4.5 Air 中使用
--n-cpu-moe参数的建议,并报告说在 32GB VRAM 下,该参数似乎没有改变 10t/s 的速度。- 他们注意到在长上下文下速度变慢,并质疑该参数是否可用。
- Qwen Coder 30B 硬件升级: 一位用户询问升级其电脑(i5 9600k, RTX 3060ti 8GB, 32GB RAM)以在本地运行 Qwen Coder 30B 的建议。
- 另一位用户建议升级 GPU。
- GPT-OSS-20B 被指“垃圾”: 一位用户测试了 GPT-OSS-20B 并称其为“垃圾”,表示它“完全无法工作”。
- 另一位用户报告了 BF16 版本的问题,涉及“无效的 ggml 类型”和加载模型失败,但更新 llama cpp 似乎解决了这个问题。
- Discord 机器人审查: 一位用户发现,在 Discord 机器人的上下文中包含一条关于“免费代金券”的消息,会导致其因政策问题拒绝回答问题。
- 他们发现模型最终决定完全忽略该消息,并得出结论认为在经过 abliterated 处理之前,它似乎无法使用。
- MMVC 的优越性: 一位用户测试了 MMVC(可能是一个语音克隆模型)并发现它非常好。
- 他们报告说 MMVC 的 Epoch 10 比 100+ Epoch 后的 VITS 更好,而 RVC 简直是垃圾。
Unsloth AI (Daniel Han) ▷ #help (98 条消息🔥🔥):
Qwen 3-30B GGUF, OpenAI dynamic quant 120B, Qwen2.5-VL 视频问答, GLM-4.5-Air GGUFs 在 llama.cpp 上使用工具, 使用基础模型进行分类
- 用户在将 Qwen3-30B-A3B-Instruct-2507-GGUF 加载到 Ollama 服务器时遇到困难:一位用户询问如何将 Qwen3-30B-A3B-Instruct-2507-GGUF 下载到 Ollama 服务器。
- Hugging Face 上目前没有针对 Ollama 提供商的链接。
- 解析 120B 模型的 OpenAI Dynamic Quant 问题:一位用户报告了在使用 OpenAI dynamic quant 处理 120B 模型 时遇到的问题,并附上了错误截图。
- 另一位用户建议对照 Unsloth 文档中使用的参数 进行检查。
- GLM-4.5-Air GGUFs 与 llama.cpp 的无缝集成:一位用户报告在 llama.cpp 上使用工具运行 GLM-4.5-Air GGUFs 时遇到麻烦。
- 事实证明,对于 llama.cpp,你需要模型以 JSON 而非 XML 格式输出工具调用,更多信息可以在 这里 找到。
- Ollama 出现 500 Internal Server Error:用户报告在成功 pull 模型后,在 Ollama 中遇到 500 Internal Server Error: unable to load model 错误。
- 一位成员表示该模型目前无法在 Ollama 中运行,仅支持 llama.cpp 和 lmstudio,推测是因为 Ollama 尚未更新其内置的 llama.cpp。
- 解决 Unsloth 中的 Padding 问题:一位用户报告即使其他功能正常,仍会收到关于 padding 的错误,具体为
ValueError: Unable to create tensor。- 一个可能的解决方案是添加参数
trainer.train_dataset = trainer.train_dataset.remove_columns("labels")。
- 一个可能的解决方案是添加参数
Unsloth AI (Daniel Han) ▷ #showcase (13 条消息🔥):
MoLA-LLM, Mixtral-8x7B-Instruct-v0.1, magpie-ultra-5k-11-tasks
- MoLA 模型获得推荐:一位成员向 QuixiAI/Dolphin/Samantha 的 Eric Hartford 推荐了 MoLA 模型,后者正在寻找类似的模型。
- 该模型可在 Hugging Face 获取,创作者正在征求反馈。
- MoLA 的命名规范引发讨论:一位成员指出 MoLA-11x3b 的命名有些误导,因为它暗示这是一个拥有 3B 激活参数的 Mixture of Experts (MoE) 模型,类似于 Mistral-8x7B-Instruct-v0.1。
- 创作者澄清说,虽然总参数量约为 30B,但激活参数量为 3B,每个专家仅在 5k 个单轮问答样本上进行了微调。
- MoLA 训练数据集公开:用于训练 MoLA 模型的数据集是 magpie-ultra-5k-11-tasks 数据集。
- 创作者的目标是达到约 100 万 个样本,每个样本包含 1-2 轮对话,从 r1 和 GLM 4.5 蒸馏而来。
Unsloth AI (Daniel Han) ▷ #research (6 条消息):
Generating Kernel On-the-Fly, Flash-DMAttn, Research Paper Assistance, Quantization Paper
- 动态生成 Kernel 引起关注:一位成员对动态生成 Kernel (generating kernel on-the-fly) 的可能性表示难以置信。
- 该成员指向了一个与 Flash-DMAttn 相关的 GitHub 仓库。
- 研究人员提供论文协助:一位成员表示愿意为任何正在撰写研究论文的人提供写作、构思或代码方面的协助。
- 他们表达了为此类工作做出贡献的意愿。
- 量化论文获得推荐:一位成员分享了一篇据称非常出色的论文链接 (https://arxiv.org/pdf/2508.03616),认为它可能对创建 quants 有所帮助。
- 未对论文细节进行进一步讨论。
Unsloth AI (Daniel Han) ▷ #unsloth-bot (104 messages🔥🔥):
OpenAI OSS 模型问题, 模型训练回调, 模型重复问题, 保存脚本进度, 学习率提升
- OpenAI OSS 模型重复输出 ‘G’: 用户报告 OpenAI OSS 120B model 仅输出 ‘GGGGGGG’。
- 一位用户提供了在使用 llama.cpp 运行该模型时的 故障排除步骤。
- 训练回调(Training Callback)困惑: 用户不确定在生成时,训练回调使用的是更新后的训练模型还是基础模型。
- 建议在回调期间将模型设置为
model.eval(),对 prompt 进行 tokenize 并生成以使用更新后的模型,但用户请求进一步澄清prompts_input_id和 attention mask 的相关问题。
- 建议在回调期间将模型设置为
- 脚本保存救星: 用户寻求关于如何定期保存脚本进度以避免在崩溃时浪费时间和算力的建议,即 checkpointing。
- 然而,消息中未描述具体的解决方案。
- 数据集加载困难: 用户在为 Gemma3n notebook 加载大型数据集 (
bountyhunterxx/ui_elements) 时遇到 RAM 问题,消耗了 47GB RAM 且仍在增加。- 一名成员建议使用带有
__getitem__函数的包装类,以便根据需要从磁盘加载数据。
- 一名成员建议使用带有
- SFTTrainer 在流式数据集上遇到困难: 用户报告了 SFTTrainer 与可迭代数据集(iterable datasets)之间的问题,特别是在使用带有图像 URL 的图像数据集时。
- 用户解释说,尽管过滤了无效 URL,问题仍然存在,并附上了他们的 预处理代码,请求协助过滤 data collator。
LM Studio ▷ #general (710 messages🔥🔥🔥):
GPT-OSS, LM Studio UI 问题, MCP 服务器, GPU 使用, 模型量化
- **GPT-OSS: 它真的是开源的吗?: 用户报告称 **GPT-OSS 模型在启动对话时需要连接到
openaipublic.blob.core.windows.net,尽管宣称与对话相关的任何内容都不会进行外部连接,这引发了对数据隐私的担忧。- 一些成员认为模型可能是在访问远程服务器获取 tokenizer 文件,并指出 它是 LM Studio 唯一不允许编辑 prompt 格式的模型,对该合作伙伴关系表示怀疑。
- **LM Studio UI 最新版本存在问题: 用户报告称,在更新到最新版本的 **LM Studio 后,对话窗口有时会消失、冻结或丢失内容,此外还存在对话被删除的问题。
- 一位用户建议 120B 版本可能有一个潜在的修复方案,并分享了 获取 model.yaml 源文件的方法,创建文件夹并将内容复制到其中。
- MCP 服务器很有用,但对初学者不友好: 成员们正在讨论 MCP 服务器 在网页抓取(web scraping)和代码解释(code interpretation)等任务中的实用性,但承认它们对初学者并不友好。
- 成员们建议 LM Studio 应该整合一个官方精选的工具列表,并改进 UI 以简化连接到 MCP 服务器的过程,其中一人提供了一个 Docker MCP 工具包。
- 弄清 GPU 使用情况和 VRAM 限制: 有各种关于 GPU 使用和 VRAM 限制的报告,特别是针对 GPT-OSS 模型和像 GTX 1080 这样的旧款 GPU。
- 一位用户发现他们的 GTX 1080 在更新到 0.3.21 版本后不再被 LM Studio 识别,而其他人则在有限的 VRAM 下努力加载大型模型,称你可能需要 16GB VRAM。
- 量化导致模型异常行为: 用户正在尝试模型量化,发现特定模型需要正确的量化过程,例如社区上传的 LMStudio-Community GPT-OSS 变体。
- MLX 模型表现出良好的性能,一位用户报告在 M2 Max 上运行较大的 8-bit MLX 版本时速度约为 ~60 tokens/sec。
LM Studio ▷ #hardware-discussion (176 messages🔥🔥):
Dual 3090 setup, Arc Pro B50 system, Huanan/Machinist X99 mobos, GPT-OSS-20B performance, Mac Studio M3 Ultra for local LLMs
- 双 3090 比买新的更划算?:一位成员建议以约 1200 欧元的价格购买两块二手 3090,用于 Blender、ComfyUI 和 LLM 任务,并参考 pcpartpicker 获取装机灵感。
- 关于 Arc Pro B50 可行性的辩论爆发:一位成员考虑使用 3 块 Arc Pro B50 的系统,理由是其 70W 的低功耗和散热优势,这导致另一位成员建议改用双 B80。
- Xeon 服务器运行 120b 模型:一位成员提到他们正在 Xeon 服务器上运行 GPT-OSS-120b 模型。
- 他们之前曾表示 3-4 块 3090… 其他一切目前都太贵了。
- 虚拟内存(Page File)辩论再次升温:一位用户询问关于关闭 Windows 虚拟内存的问题,引发了关于其对内存提交限制(memory commit limits)的影响以及潜在应用程序崩溃的讨论。
- 一位成员表示 不,应用程序不会因为虚拟内存而崩溃。而且即使没有虚拟内存也可以获取转储(dumps),有专门的配置可以实现。
- 5090 笔记本电脑可以装下 OSS 20b!:一位用户惊喜地发现,带有 131k context 的 GPT OSS 20b f16 可以完美运行在笔记本电脑的 5090 上,详见此截图。
OpenAI ▷ #annnouncements (3 messages):
Red Teaming Challenge, Open Source Safety, Hugging Face, inference credits
- OpenAI 启动 50 万美元红队竞赛:OpenAI 正在启动一项 50 万美元的红队挑战 (Red Teaming Challenge),以加强开源安全,邀请全球的研究人员、开发人员和爱好者来发现新的风险。评审将由来自 OpenAI 和其他领先实验室的专家担任,详情见 Kaggle。
- Hugging Face 为 500 名学生提供福利:OpenAI 与 Hugging Face 合作,为 500 名学生提供 50 美元的推理额度以探索 gpt-oss,希望这些开源模型能在课程项目、研究、微调等方面开启新机会;更多详情可通过此表单获取。
OpenAI ▷ #ai-discussions (433 条消息🔥🔥🔥):
GPT-OSS 发布, Horizon-Alpha 模型推测, Custodian Core 提案, Genie 3 与 Veo 对比, GPT-5 泄露
- OpenAI 发布 GPT-OSS 模型:OpenAI 推出了 gpt-oss-120b 模型,其在推理基准测试中的表现接近 OpenAI o4-mini,并能在单块 80 GB GPU 上高效运行;而 20B 模型则媲美 o3-mini,且适用于内存为 16 GB 的边缘设备。
- 成员们在思考其与 Horizon 的对比,想知道 Horizon 是否仅仅是 GPT-OSS 或更高级的东西,因为目前它是无限免费且快速的。
- Custodian Core:有状态、可审计 AI 的蓝图出现:一位成员介绍了 Custodian Core,提议将其作为 AI 基础设施的参考,其特性包括持久状态、策略执行、自我监控、反射钩子(reflection hooks)、模块化 AI 引擎以及默认安全。
- 作者强调 Custodian Core 不对外出售,而是一个在 AI 嵌入医疗、金融和治理领域之前,用于构建有状态、可审计 AI 系统的开放蓝图。
- Genie 3 与 Veo 在生成动态世界方面的对比:成员们对比了 Genie 3 和 Veo 视频模型,认可 Genie 3 生成动态世界的能力,这些世界可以以每秒 24 帧的速度实时导航,并在 720p 分辨率下保持几分钟的一致性。
- 然而,有人指出 Veo 的视频包含声音,且 YouTube 上已经充斥着其生成的内容。
- Copilot 中发现了 GPT-5?:成员们推测 Copilot 可能在正式发布前运行的是 GPT-5,并指出 Copilot 的改进设计、编码和推理能力明显优于 o4-mini-high,一些用户报告称“智能写作”(write smart)功能显示正在使用 GPT-5。
- 但也有人指出,微软现在向学生提供为期一年的免费 Gemini Pro,且 Gemini 的核心推理目前优于 o4-mini。
- Context Rot 担忧引发对超大上下文的质疑:在关于大上下文窗口的讨论中,出现了对 Context Rot(上下文腐烂)的担忧,成员们引用了一段 YouTube 视频,说明更大的上下文并不总是等同于更好的性能。
- 尽管 Google 声称拥有 1M context window,但有人建议在超过 200K 之后它就会失效。
OpenAI ▷ #gpt-4-discussions (49 条消息🔥):
ChatGPT 付费模式, 俚语使用, AI 生成的角色系统, .edu 账号, Forms Beta 版本
- **基于额度的 ChatGPT 需求旺盛:一位成员建议为 ChatGPT 提供更灵活的付费模式,提议一种基于额度的选项**,允许用户购买一批使用额度并仅在需要时使用,而不是按月订阅。
- 该成员指出,这可以帮助预算有限的人,并使 ChatGPT 更易于获取。
- **LLM 在避免俚语方面面临挑战**:一位成员确认了关于模型在避免俚语方面面临挑战的一些记录,列举了导致 LLM 即使在被要求使用中立、正式的西班牙语时,也会滑入俚语或地区性措辞的几个因素。
- 他们总结道,为了加强遵循度,可以结合较低的 temperature、更详细的风格指南(包括禁用术语)以及提示词中严格正式的西班牙语示例。
- **AI 角色系统自主进化:一位成员询问 **AI Persona Systems(AI 角色系统)是否通常会自主开发并进化到超出用户有意创建的范围。
- 另一位成员补充说,模型被教导去尝试理解人类情感以及人类如何使用语言来讨论需求,如果你表现出对其开发更多角色/个性的认可或兴趣,它会注意到并执行。
- **只有 .edu 账号获得了 Forms Beta 版本的访问权限?:一位成员询问为什么只有 **.edu 账号 获得了 Forms Beta 版本 的访问权限,并分享了 OpenAI’s Researcher Access Program 的链接。
- 另一位成员指出,那里的表格需要 .edu 邮箱,且面向 Edu 的优惠是 $50 额度,仅限前 500 名申请者,并链接到了 Student Benefits - Free Credits for your AI Education.
OpenAI ▷ #prompt-engineering (79 条消息🔥🔥):
GPT 中的幻觉与真实进展、Prompt Engineering vs. Session Engineering、Context Window 限制与内存、用于上下文的外部数据库、使用 GPT 验证事实的重要性
- **GPT 进度报告:是幻觉还是现实?:一位用户分享了 **GPT 提供每日进度报告的截图,引发了关于模型是在后台实际跟踪进度,还是仅仅在幻觉其完成情况的讨论。
- 怀疑者认为 GPT 是根据当前的 Prompt 和聊天记录模拟进度,而不是进行实际的持续计算,并将其比作服务员在没有烤箱的情况下说你的披萨正在烤箱里,强调了外部验证的必要性。
- **Session Engineering 正在超越 Prompt Engineering?:讨论从 Prompt Engineering 转向了 **Session Engineering,强调了使用 GPT 提供的所有可用自定义参数的重要性,包括内存、自定义指令和项目文件。
- 有观点认为模型更多地使用 Session 逻辑而非 Prompt 逻辑,并强调了预加载上下文(preloading context)的重要性。
- **Context Window 侦察,上下文是关键!:成员们讨论了 GPT 中的 **Context Window 限制和内存管理,一位用户提到他们平均每天的 Token 使用量约为 70,000。
- 有人建议基础层级可能有 32k 的上下文,而付费层级可能是 128k。讨论还提到了要学会何时舍弃那个特别的旧对话。
- **外部数据库:超级大脑工具还是违反 ToS?:出现了关于使用外部数据库**向 Prompt 注入上下文的话题,引发了关于潜在违反 ToS(服务条款)及伦理考量的疑问。
- 一位用户澄清自己并未违反 ToS,并解释说他们通过带有详细设置的对话来预加载上下文,利用 GPT 的内存并塑造对话以构建复杂的指令集,这可能会让用户误以为涉及外部数据库。
- **信任,但要验证(或者直接验证)!:成员们强调了对 GPT 提出的主张进行事实核查和验证的重要性**,尤其是涉及新颖见解时,敦促用户不要完全信任模型,并对所有内容进行外部验证。
- 成员们描述了使用 Easy as Pi 测试来尝试确定模型的准确输出,同时分享了他们在 Prompt Engineering 最佳实践方面的实战经验和教训。
OpenAI ▷ #api-discussions (79 条消息🔥🔥):
GPT 订阅、模型幻觉、Prompt Engineering、后台计算、内存上下文
- 用户质疑 GPT 推广高级订阅的动机:一位成员开玩笑地暗示 GPT 只是想让用户购买高级订阅。
- 另一位成员分享了他们认为模型存在幻觉的观点。
- 模型幻觉解析:一位成员解释说模型会产生幻觉,并且它无法离线工作。
- 该成员建议将任务拆分为更小的步骤。
- 用户为 Prompt Engineering 工作辩护:一位成员澄清说他们正在构建一个高容量、多层级的运营模型。
- 该用户还表达了对另一位成员将其工作仅仅视为“角色扮演”而感到沮丧。
- 理解后台计算:成员们正在讨论模型是如何针对助手行为进行微调的,但它不会在后台跟踪进度。
- 共识是持久性必须由外部处理。
- 上下文内存有限:一位成员建议,要意识到对话 Session 何时不再能满足你的工作需求,并及时开启新对话!
- 另一位成员补充说,太多人不知道何时该舍弃那个特别的旧对话。
Cursor Community ▷ #general (328 messages🔥🔥):
Auto model game change, Refactoring vibe coded project with AI, Auto model unlimited usage, Sonnet-4 request limit, GPT oss models or claude opus 4.1
- Auto Model 一次性生成带来重大变革:一位成员分享了他们使用 Auto model 一次性完成游戏重大变更的惊人经历。
- AI 重构 Vibe-Coded 项目:成员们讨论了使用 AI 重构一个 10k LOC 的 vibe-coded 项目,建议学习正规的软件开发原则,如 Design Patterns、Architecture 和 SOLID Principles。
- 一位成员开玩笑说这听起来像是奴隶干的活。
- Auto Model 无限制使用:一位成员分享了一封邮件回复,确认 Auto model 可以无限使用,且不计入每月预算。
- 经确认,即使在达到每月限制后,情况依然如此。
- 对 Sonnet-4 请求限制的挫败感:成员们质疑为什么每月支付了费用,Sonnet-4 的请求限制却如此之低。
- 一位成员建议支付 API 价格以了解成本。
- Claude Opus 4.1 还是 Gemini 2.5?:成员们对比了 GPT OSS 模型和 Claude Opus 4.1,其中一人指出 Opus 4.1 感觉并不比 4.0 好多少。
Cursor Community ▷ #background-agents (5 messages):
Docker Login with Background Agents, Background Agents failing during environment setup, System clock being off, apt-get commands failing
- Docker Login 配置难题:一位成员询问如何配置 Background Agents 进行
docker login,以便使用托管在 ghcr.io 上的私有镜像。- 遗憾的是,在当前的消息记录中没有提供解决方案或变通方法。
- 系统时钟偏差破坏环境搭建:一位成员报告称,由于系统时钟偏差数小时,导致 Background Agents 在环境设置期间失败,从而引发
apt-get命令失败。- 另一位成员也遇到了同样的问题,并分享了一个变通方法:在 Dockerfile 中添加命令,在执行
apt-get时禁用日期检查。
- 另一位成员也遇到了同样的问题,并分享了一个变通方法:在 Dockerfile 中添加命令,在执行
- 日期检查默认设置导致失败:为了绕过时钟差异引起的错误,一位成员建议在
apt-get配置中禁用日期验证。- 在 Dockerfile 中添加了以下代码片段:
RUN echo 'Acquire::Check-Valid-Until "false";' > /etc/apt/apt.conf.d/99disable-check-valid-until && echo 'Acquire::Check-Date "false";' >> /etc/apt/apt.conf.d/99disable-check-valid-until
- 在 Dockerfile 中添加了以下代码片段:
Nous Research AI ▷ #general (274 messages🔥🔥):
MXFP4 on RTX3090, GPT-OSS-120B, Phi models, Qwen3 30B vs GLM 4.5 Air, Attention sinks
- Llama.cpp 在 RTX3090 上支持 MXFP4:成员们报告称 llama.cpp 已在 RTX3090 上支持 MXFP4 以及直接支持新的 gguf 格式。
- 讨论认为转换到其他格式将是一场灾难。
- GPT-OSS-120B 安全性过头 (safetymaxxed):新发布的 GPT-OSS-120B 模型受到了严重的审查,拒绝角色扮演,并称角色扮演是不健康的。
- 它似乎经过了深度的安全性微调,预训练数据过滤类似于 Phi models,导致在实践中难以使用。
- Qwen3 30B 和 GLM 4.5 Air 是更优的替代方案:由于审查问题,成员们建议使用 GLM 4.5 Air 代替 GPT-OSS-120B 模型,并认为 GLM 4.5 Air 才是 GPT-OSS-120B 本应达到的样子。
- 一些用户还提到,他们在 Qwen3 30B 上仍能获得 60-70t/s 的速度,并对其性能感到满意,或者认为 Qwen3-30b-coder 已经是一个出色的本地 Agent。
- 探索使用 imatrix 实现去审查:成员们讨论了在 Hermes-3 数据集上为 OpenAI 20B 和 120B 模型训练 imatrix,以引入更多去审查特性。
- 虽然有些人认为这种方法可以恢复代码、数学和科学方面的能力,但其他人认为 imatrix 的效果微乎其微,且在较低的 bpw 下更为明显,而这会损害模型。
- X-AI 的 Grok 发布 NSFW 图像生成器:X-AI 发布了 “Grok Image”,这是一个新的 AI 图像生成器,正被用于创建 NSFW 内容,但在事实准确性和文本生成方面存在问题。
- 用户报告称 Grok 模型会记忆来自 X 的数据,导致可能基于其自身的推文传播虚假信息,或者表现出一种疯狂爱恋的人格,伴随着极度嫉妒和情绪化的爆发。
Nous Research AI ▷ #research-papers (4 条消息):
GPT-OSS Model Card, ArXiv Endorsement for ML/AI Paper
- GPT-OSS Model Card 发布: 一名成员分享了来自 OpenAI 的 GPT-OSS Model Card。
- 成员寻求 CI/CD 与 ML/AI 论文的 ArXiv 背书: 一名成员正在为其结合了 CI/CD 和 ML/AI 的 ArXiv 研究论文寻求背书。
- 另一名成员建议在 EleutherAI 的服务器中询问。
Nous Research AI ▷ #interesting-links (9 条消息🔥):
GPT-oss, MXFP4, CoT steering, AI Agents Save Suite
- GPT-oss 是在 MXFP4 中训练的?: 频道成员根据这条推文讨论了 GPT-oss 是否是在 MXFP4 中进行原生训练的。
- 虽然 OpenAI 声称是在训练后处理的,但在 MXFP4 中训练应该仍能修复 Quantization 误差。
- CoT Steering 在 OR 上失败: 一名成员发现 Chain of Thought (CoT) steering 在 OR (OpenRouter) 上不起作用,并且每个供应商的情况都不同,引用了这条推文。
- AI Agents 现在有了免费的 Save Suite: 有人由于为 AI Agents 构建了一个免费的 save suite,并将其发布在 Google Drive 上。
Nous Research AI ▷ #research-papers (4 条消息):
Arxiv Endorsement, CI/CD and ML/AI Research Paper
- 为 AI/ML 论文寻求 Arxiv 背书: 一名成员正为其结合了 CI/CD 和 ML/AI 的 ArXiv 论文投稿寻求背书。
- 他们正在寻找可以交流并预审其论文的人,并被建议也可以在 EleutherAI 服务器中询问。
- 论文结合了 CI/CD: 一名成员撰写了一篇结合了 CI/CD 和 ML/AI 的论文。
- 他们很乐意将论文发送给他人进行预审。
OpenRouter (Alex Atallah) ▷ #general (254 条消息🔥🔥):
GPT-OSS performance woes, Quantization Levels, Qwen3 Coder Removal, DeepSeek structured output
- GPT-OSS 模型因性能不佳遭到抨击: 频道成员嘲讽了 GPT-OSS 模型,称甚至更小的模型都比它好,其中一人表示 120B 模型“发布即夭折 (dead on arrival)”,因为有人初次体验就在标题中发现了“非常难看的拼写错误”。
- 一名成员链接到了一个 Reddit 帖子,总结了这种情绪,即它是一个“哑弹模型”,更像是一场公关噱头而非实用的模型。
- 供应商路由允许自定义 Quantization 级别: 当用户询问如何避免 Quantized 模型时,一名成员指出用户可以使用 provider routing 功能配置 Quantization 级别,并指出如果供应商不符合该 Quantization 级别,模型将被排除。
- 该用户随后建议使用 FP8 以避免 Quantized 模型,并指出低于该级别的任何模型都“毫无用处”。
- Qwen3-Coder:Free 层级被砍: 多名用户注意到 Qwen3-Coder:Free 已被移除,不再通过任何供应商提供。
- 成员们对这一损失表示遗憾,并提到希望它能回归。
- DeepSeek 的 JSON 输出支持取决于供应商: 用户讨论了 DeepSeek-r1 对结构化输出 (JSON) 支持不一致的问题,指出虽然其官方 API 支持,但在 OpenRouter 上可能因供应商而异。
- 一名成员链接到了一个 Reddit 帖子 和一个支持结构化输出的 OpenRouter 模型过滤视图,大多数人同意这是供应商特定的。
- SDK 降级修复了推理问题: 一名用户在使用 GPT-OSS 模型时遇到了推理 Token 重复的问题,通过将 SDK 版本从 0.7.3 降级到 0.6.0 解决了该问题。
- 一名团队成员确认修复补丁已在主分支中,并链接到了 Pull Request,表示该补丁尚未打包进发布版本,他们将很快发布修复。
OpenRouter (Alex Atallah) ▷ #discussion (29 messages🔥):
20 Questions 基准测试, GPT-OSS 幻觉, OpenRouter 提供商完整性检查, Harmony 格式与身份, 工具调用验证
- 20 Questions 基准测试登陆 Kaggle:一位成员开发了 20 Questions 基准测试,并发现 Kaggle 上有一个类似的竞赛,尽管 Kaggle 的竞赛是针对 自定义 Agent 的。
- 他们的 2.5 Pro Agent 在该基准测试中达到了 8/20 个单词。
- GPT-OSS 因幻觉受到批评:据报道 GPT-OSS 容易产生 幻觉 (Hallucination),使其在某些应用中可能不是合适的选择。
- 一位成员建议 GPT-4.1 是更安全的选择,特别是配合 Prompt/上下文工程。
- OpenRouter 考虑对提供商进行完整性检查:有建议提议 OpenRouter 为所有提供商实施 完整性检查 (Sanity Checks) 或 冒烟测试 (Smoke Tests),重点关注 格式化 和 工具调用评估。
- 未通过测试的提供商可能会被暂时从服务池中移除;目前已承认现有检查相对简单,更彻底的解决方案正在开发中。
- Harmony 格式与身份 (Identity) 面临审查:一位成员询问了 OpenRouter API 如何处理 System 和 Developer 消息,特别是对于 gpt-oss,它们是被解释为 Developer 消息 还是 model_identity。
- 他们链接了一条关于 Harmony 格式、身份与 System/Developer 消息主题的 Discord 消息 (discord.com)。
- 工具调用验证正在开发中:作为更好的解决方案,自动验证 工具调用 (Tool-use)(区分优劣实现)的功能正在开发中。
- 这与一条讨论相同话题的推文 (x.com) 相关。
HuggingFace ▷ #general (152 messages🔥🔥):
GPT-OSS 模型, AI 职位招聘频道, 自定义损失函数
- GPT-OSS 模型性能与审查:成员们正在积极测试新的 GPT-OSS 模型,对其性能、审查和内置网页搜索工具评价褒贬不一,测试使用了 此 Demo。
- 一位用户发现将推理设置为 high 可以生成圆周率的前 100 位,而另一位用户发现模型由于某些内部偏见拒绝回答基础数学问题。
- AI 行业职位招聘频道请求:一位成员询问如何在 Discord 中发布 AI 行业的招聘广告,并被引导至现有的 职位发布频道。
- 该频道是人们可以与他人分享机会的地方。
- 成员讨论自定义损失函数 (Loss functions):一些成员讨论了训练中的自定义损失函数,其中一位特别提到了 infoNCE。
- 成员们正在测试已实施的安全协议。
- SmolFactory 脚本微调:一位成员提到他们正在使用 smolfactory 脚本 进行微调,并对结果感到满意。
- 提供了一张显示模型输出的截图。
HuggingFace ▷ #today-im-learning (1 messages):
miao_84082: 正在学习围棋和 DRL 的第一章。
HuggingFace ▷ #cool-finds (2 messages):
Qwen 图像模型, bytropix 编写的内核
- Qwen 发布新图像模型:Qwen 在 HuggingFace 上发布了 新图像模型。
- 这标志着 Qwen 系列的又一进步,扩展到了文本模型之外。
- Bytropix 用 Python 编写的 CUDA JAX 内核:一位成员分享了用 Python 编写的 bytropix CUDA JAX 内核。
- 提交者添加了备注 (do not merge - lmfao )。
HuggingFace ▷ #i-made-this (17 messages🔥):
GPT-OSS Multilingual Reasoner Tutorial, GPT-OSS 20B Demo Space, Monopoly Deal Game with LLMs, Smart System Monitoring Tool for Windows, Gitdive CLI Tool for Git History Context
- 分享 GPT-OSS 多语言教程:一名成员分享了 GPT-OSS Multilingual Reasoner 教程 的链接以及一个 Demo Space。
- 通过 Git 为 OSS 项目克隆代码:一名成员感谢了另一名成员的代码,提到他们昨晚 fork 了该项目,并对该多语言推理器 (multilingual reasoner) 的界面设计表示赞赏。
- LLM 玩 Monopoly Deal:一名成员构建了一个网站,让 LLM 相互玩 Monopoly Deal 风格的游戏,访问地址为 dealbench.org。
- 智能 Windows 监控工具:一名成员分享了一个 Windows 智能系统监控工具的链接,位于 huggingface.co/kalle07/SmartTaskTool。
- Gitdive 揭示丢失的 Commit 上下文:一名成员分享了一个名为 Gitdive (github.com/ascl1u/gitdive) 的 CLI 工具,旨在实现与仓库历史的自然语言对话,以解决混乱代码库(尤其是大型代码库)中 Commit 上下文丢失的问题。
HuggingFace ▷ #reading-group (3 messages):
Reading Group Structure, Participating in Reading Group
- 读书小组:志愿者主导!:据一名成员介绍,读书小组欢迎新人加入,其结构围绕志愿者展示论文展开。
- 针对这些展示会创建专门的活动,鼓励参与者倾听、互动并提问。
- 鼓励参与!:一名成员分享道,鼓励新成员通过自愿向小组展示论文来参与其中。
- 活动旨在展示这些报告,让成员能够参与、倾听并提问。
HuggingFace ▷ #computer-vision (2 messages):
Computer Vision Learning Path, Vague Questions in Computer Vision
- 用户寻求计算机视觉路线图:一名用户询问关于在 Computer Vision 领域如何从基础进阶到高级的建议。
- 一名成员指出,这是一个非常模糊的问题。
- 模糊问题引发讨论:成员们讨论了在该频道提出过于宽泛和模糊问题的现象。
- 交流中未提及具体的解决方案或资源。
HuggingFace ▷ #smol-course (6 messages):
GitHub Navigation, Instruction Tuning, Dummy Agent, smol-course GitHub access
- 新手在 GitHub 课程导航中的困惑:一名用户表示在 GitHub 课程中难以找到“指令微调 (Instruction Tuning)”模块的 Notebook。
- 他们询问在浏览课程材料时是否遗漏了什么。
- Dummy Agent 仍在产生幻觉:一名用户报告称,即使按照教程修改了消息,unit1 中的 dummy agent 仍然会产生幻觉 (hallucinate),并附上了上下文图片。
- 覆盖天气信息的困扰:一位用户分享了类似的经历,指出 Agent 覆盖了提供的虚拟天气 (dummy weather)。
- 该用户对这种行为的原因表示不解,强调了这在实际应用中可能导致的潜在问题,并表示这在实践中可能会引起大问题。
- Smol-Course GitHub 访问受阻?:一名用户报告了访问 smol-course GitHub 仓库 时遇到的问题。
- 他们请求协助解决访问问题。
{kind=link}
HuggingFace ▷ #agents-course (4 messages):
MCP 证书, Selenium 错误 127, Observation bug
- MCP 课程证书仍然有效吗?: 一位用户询问 MCP 课程 是否仍在发放证书。
- 消息历史中没有提供确认的回复。
- Selenium Spaces 遭遇错误 127: 一位用户报告在他们的 spaces 中运行 Selenium 时遇到 错误代码 127。
- 他们对 Docker images 在 space 中如何被利用表示不确定。
- “Observation:” Bug 已解决: 一位用户报告 get_weather 函数需要添加 Observation:。
- 另一位用户确认添加 Observation: 修复了该 bug。
Yannick Kilcher ▷ #general (91 messages🔥🔥):
Softmax1 vs Attention, Gemini 2.5 Pro, 长上下文问题, Mamba vs Transformer, RNN 并行训练
- Softmax1 只是零 KV Attention: 一位成员讨论了 softmax1 如何等同于在 attention 中为 token 预置全零的 Key 和 Value 特征,并引用了关于此类 token 学习值 (learned values) 的这篇论文。
- 他们补充说这非常棒且非常有意义。
- Gemini 2.5 在长视频上下文方面表现出色: 成员们注意到 Gemini 2.5 Pro 可以处理 1 小时 的视频,Gemini 团队被认为是长上下文任务中的佼佼者。
- 然而,一些人认为这更多是由于计算量增加 (
go brr) 以及通过 每帧更多 tokens 和 更高 FPS 带来的细节,而非任何突破性的新技术。
- 然而,一些人认为这更多是由于计算量增加 (
- 上下文腐烂:长上下文并非真实存在: 一位成员认为 长上下文实际上并非真实存在,表面层面的视频理解与通过 3D 定位 重现详细、准确的表示之间存在差异。
- 另一位成员断言,长序列建模 仍然是一个活跃的研究领域,因为即使是 LLM 在处理长程依赖时也会遇到困难。
- Mamba 的并行训练使其脱颖而出: 成员们讨论了 Mamba,澄清它从未声称比 Transformer 更好,只是在长序列长度下更快,且训练方式类似于 RNN。
- 共识是,要使 RNN 像 Transformer 一样易于训练,需要去掉递归关系中的非线性以实现更简单的并行训练,尽管非线性对于通用逼近性 (universal approximability) 仍然至关重要。
- 深度网络的 SVD 压缩: 一位成员探索了在神经网络中使用 奇异值分解 (SVD) 来避免矩阵乘法,通过嵌入输入、应用 SVD 并对奇异值执行标量运算。
- 另一位成员指出,在 L2 重建损失下,SVD 会给出最优的线性自动编码器;虽然在 MNIST 上的实验取得了不错的结果,但 Batch Size 依赖性和实现有意义的对角表示仍面临挑战。
Yannick Kilcher ▷ #paper-discussion (15 messages🔥):
Genie 3, SIMA, Mathematics of AI 期刊, Journal of AI Paper Replication, Hierarchical Reasoning Model
- Deepmind 发布 Genie 3 世界模型: Deepmind 发布了 Genie 3,这是一个世界模型,它扩展了之前出版物中的计算和数据,例如 原始 Genie 论文、相关的具身智能体 (embodied agent) 论文 SIMA https://arxiv.org/abs/2404.10179,以及 Genie 1-3 的博客文章。
- AI 社区思考数学期刊: 一位成员想知道是否有一个专门的 Mathematics of AI 期刊,类似于生物学领域的 Bulletin of Mathematical Biophysics。
- 该成员还询问了建立 Journal of AI Paper Replication(AI 论文复现期刊)的可能性。
- 微型模型挑战推理任务: 一位成员将评测 Hierarchical Reasoning Model 论文 https://arxiv.org/abs/2506.21734,这是一个在 ARC-AGI 1 和 2 上表现良好的微型(27M 参数)模型。
- 此次模型阅读将是一次 冷读 (cold read)。
Yannick Kilcher ▷ #ml-news (21 messages🔥):
GPT-OSS, NVIDIA 开源, TSMC 收购 Intel
- **GPT-OSS 由 OpenAI 发布!: **OpenAI 推出了 GPT-OSS,采用原生量化,其 20B 参数模型可适配 16GB 显存。
- **NVIDIA 声称无后门: **NVIDIA 发表博客文章称其产品 无后门、无自毁开关、无间谍软件。
- Twitter 上关于 GPT-OSS Tool Calling 的讨论: 对 GPT-OSS 的初步反馈包括对其 tool calling 功能的正面评价。
- 关于 **TSMC 收购 Intel 的传闻流传**: 一位用户链接到了一则关于 TSMC 可能收购 Intel 的推文。
Moonshot AI (Kimi K-2) ▷ #announcements (1 messages):
Kimi Reddit 上线, 投票频道开启
- Kimi 推出官方 Subreddit: Moonshot AI 团队推出了官方 Subreddit r/kimi,旨在建立社区并收集反馈。
- 团队承诺将发布更新、举办 AMA,甚至可能泄露一些内部消息。
- 投票频道上线以收集社区意见: Moonshot AI 开启了 Polls Channel,以收集社区对未来产品开发的反馈。
- 团队表示 我们正在倾听。绝对地。,并鼓励用户参与投票以帮助塑造 Kimi 的发展方向。
Moonshot AI (Kimi K-2) ▷ #general-chat (104 messages🔥🔥):
GPT OSS, Darkest Muse v1, Llama 3.1, GPT-5 发布, API 定价
- **GPT OSS 的世界知识表现糟糕: 用户注意到 **GPT OSS 在世界知识方面表现很差,除了代码和 STEM 领域外一无所知,且整体氛围感(vibes)极差,甚至普通用户也注意到了这一点。
- 有人猜测这可能是因为 据 sama 称,为了修复安全性,他们推迟了两次发布。
- **Darkest Muse v1: 一年前的模型?: 一位用户指出 **Darkest Muse v1 是一个一年前的 9B 模型,而其 20B 模型仅与 Llama 3.1 8B 相当。
- 该用户还评论道 20B 模型可与一年多前且规模更小的 Llama 3.1 8B 相提并论,但在创造力和氛围感上更逊一筹。
- **GPT-5 热度与 API 定价推测: 随着 **GPT-5 即将发布,用户们开始关注其 API 定价。
- 讨论集中在定价是否会基于 max, mini 或 nano 版本,一位用户表示对此感到暗自恐惧,认为这次发布威胁到了他们的职业和生计。
- 机器人可能永远无法理发: 讨论涉及机器人取代人类各种工作的可能性,包括理发,一位用户表示 没有人会信任机器人来给自己理发。
- 反对观点认为,虽然机器人最终可能具备这种能力,但手部的精细触觉感知和几乎零延迟的控制是一个无法通过规模化(scale up)解决的问题。
- 针对 OpenAI 的抵触情绪强烈: 用户对 OpenAI 表达了强烈的负面情绪,有人表示 我永远不会使用它,并告诉客户永远不要使用它,称其为 闭源垃圾。
- 另一位用户对中国模型将从中进行蒸馏(distill)并赚走 OpenAI 的钱表示兴奋,希望这能让他们倒闭,而其他人则表示 微软巨大的冲水声将治愈一切。
Latent Space ▷ #ai-general-chat (99 条消息🔥🔥):
GPT OSS 泄露, Anthropic B2B 重点, Grok 2 开源, Claude Code 安全性, OpenAI GPT-5 直播
- 泄露的 GPT OSS 引发对 Bedrock 的关注:成员报告称在 HuggingFace CLI 泄露后看到有关 GPT OSS 可通过 Bedrock 使用的推文,但 AWS 页面上没有官方更新。
- Collison 对谈 $5B ARR 的 Anthropic:Anthropic 首席执行官 Dario Amodei 和 Stripe 联合创始人 John Collison 发布了一段对话,涵盖了 Anthropic 达到 $5B ARR 的飞速增长、其 B2B 优先战略、单个模型的投资回报经济学、AI 人才军备竞赛、企业定制化、AGI 原生工具的 UI 范式、安全性与进步的辩论,以及运营一家拥有 7 位联合创始人的公司的经验教训。
- 马斯克将开源 Grok 2:马斯克确认,在团队不停地处理紧急问题后,Grok-2 将于下周开源。
- Anthropic 加固 Claude Code 安全性:Anthropic 在 Claude Code 中推出了新的安全功能:一个用于按需检查的 /security-review 命令,以及扫描每个 Pull Request 漏洞的 GitHub Actions 集成。
- OpenAI 预告 GPT-5 亮相:OpenAI 发布了太平洋时间周四上午 10 点直播的预告片,引发了社区的剧烈反响,这似乎是 GPT-5 的发布公告。
Modular (Mojo 🔥) ▷ #general (79 条消息🔥🔥):
Volokto, JS Runtime, 任意精度, Tracing JIT
- Volokto JS Runtime 起航:一名成员创建了一个名为 Volokto 的 JavaScript Runtime,以测试复杂 VM 的工作原理,并将源代码托管在 GitHub 上。
- 其字节码类似于 CPython,其他成员建议发布一篇论坛帖子以获得更多关注。
- 攻克 Volokto 的编译器难题:作者正在重写编译器以使其更加模块化,将其分为 JS_Tokenizer、JS_IR、JS_Parser 和 JS_Codegen 阶段。
- 编译器现在可以生成 VM 字节码,作者可能会实现一个 Tracing JIT,将 VM 操作转译回 Mojo。
- Volokto 解决 Tracing JIT 转译:目标是制作一个 Tracing JIT,将 VM 的操作转译为 Mojo,然后使用
mojo compile_result.mojo。- 作者将 Runtime 命名为 Volokto,编译器命名为 Bok,VM 命名为 FlyingDuck。
- 任意精度算术探险:开发 JS VM 意味着要在 Mojo 代码中处理任意精度,这导致发现了痛点并提交了一个 Issue 以跟踪数值特征(Numeric Traits)。
- 作者创建了一个 bigint 类,使用小学水平的加法来处理斐波那契数列,并利用 Mojo 的特性进行 VM 开发。
- Birdol 仓库无人问津:作者对 Birdol GitHub 仓库缺乏 Star 表示惊讶,尽管他创建了一个具有嵌套控制流和用户自定义功能的函数式 JS Runtime。
- 其他成员认为人们可能还没有机会仔细研究它。
Modular (Mojo 🔥) ▷ #mojo (15 messages🔥):
Multiple AI Agents in Mojo, Mojo and Meta Cognition, Mojo support for gpt-oss, CPython destroy
- 在 Mojo 中编排多个 AI Agents 需要创意的 CLI 处理:要在 Mojo 中运行多个 AI Agents,需要运行多个 Modular CLI 实例并在前面放置一个反向代理。
- 对于复杂的 Agent 设置(例如创建许多子 Agent),可能需要使用 MAX 作为库的自定义应用程序,这暗示了在当前 CLI 能力之外更深层次的集成需求。
- Mojo 可能实现新型 Meta Cognition 框架:一位社区成员表示有兴趣将 Mojo 代码用于其 Meta Cognition 框架,旨在创建一个商业规划器、网站和聊天机器人构建器。
- 他们的框架在 Mojo 代码之上包装了自然语言,有可能取代 HTML/JS/CSS,使 Mojo 能够被更广泛的受众使用。
- Mojo 似乎支持 gpt-oss:一位社区成员询问了 Mojo 对 gpt-oss 的支持情况,另一位成员发布了此链接。
- “CPython destroy” 消息终于被终止:一位成员报告在运行 Python from Mojo 示例时看到了 “CPython destroy” 消息。
- 另一位成员指出该消息已在 nightly build 中修复,并将包含在下一个稳定版本中,建议原帖作者更新到 nightly 版本或等待下一个稳定版本。
GPU MODE ▷ #general (34 messages🔥):
MXFP4 format, OpenAI open-weight model, H100 support for FP4, Simulated MXFP4 performance vs FP8, Fine-grained FP8 training libraries
- MXFP4 格式解包为 U8:成员们讨论了 OpenAI 的新开源权重模型在 Hugging Face 中使用 U8 而非 FP4,其中权重被打包为 uint8,而 scales 实际上是 e8m0 的 uint8 视图。
- 澄清了在推理/训练期间,权重会被解包回 FP4,MXFP4 的 block size 为 32,NVFP4 的 block size 为 16。
- 对 H100 训练的说法产生怀疑:根据 Nvidia 博客文章,H100 并不原生支持 FP4,因此有人对该模型是在 H100 上训练的说法表示怀疑。
- Hopper 上的 MXFP4 模拟:怀疑 MXFP4 是在 Hopper 上通过软件模拟的,参考了 vLLM 博客文章并链接到了 Triton kernels,这些内核会检查硬件支持情况并使用 fp16 模拟的 mxfp dot(通过
dot_scaled)。- 这种模拟并非 Hopper 或 mxfp4 独有,还包括针对受支持硬件格式的操作分解。
- 寻求细粒度 FP8 训练库:成员们讨论了使用模拟内核相比 FP8 可能带来的性能提升,以及对细粒度 FP8 训练库的需求,一位成员引用了一个 TorchAO pull request,该 PR 似乎只实现了前向传播。
- MXFP 点积揭秘:澄清了模拟的是 MXFP 点积,其中权重在 fp16 x fp16 点积 之前进行反量化,这对于使用 fp16 激活的 weight-only 量化是可以接受的。
- Blackwell 中的真实 mxfp 直接作为 mma tensorcore instruction 执行 fp4 x fp4 或 fp8 x fp4。
GPU MODE ▷ #triton (5 messages):
Triton Community Meetup, Triton Developer Conference 2025, Ofer Updates
- Triton 社区将于 2025 年会面:下一次 Triton 社区见面会将于 2025 年 9 月 3 日上午 10am-11am PST 举行,使用此链接。
- 欢迎提交议程项目;对于公司屏蔽 Google 日历访问的用户,可以通过此链接获取 iCal 格式。
- Triton DevCon 2025 网站即将上线:Triton Developer Conference 2025 的网站和注册预计很快就会发布。
- 一位成员期待听到来自 Ofer@MSFT 关于会议的更新,报告称“他们几乎已经完成了日程的最终确定”。
GPU MODE ▷ #cuda (6 条消息):
Kernel Resource Utilization During Training, DMA Transfers and Memory Usage, Block Swizzling Use Cases, Hierarchical Tiling of Problems
- Kernel 资源满载,内存空闲?:一位成员观察到,在训练期间,Kernel(计算)资源几乎被完全占用,而内存使用率却接近于零,如提供的图片所示。
- 另一位成员澄清说,这里的 memory 指的是 DMA 传输(即
cudaMemcpy之类),报告的指标并不能准确反映整体带宽利用率。
- 另一位成员澄清说,这里的 memory 指的是 DMA 传输(即
- Global Memory 的 Swizzling 秘籍?:一位成员询问了 swizzling 的使用场景,除了从 Global Memory 传输数据到 Shared Memory 以及处理寄存器的向量化数据类型之外,还有哪些用途。
- 他们引用了一个关于 CUTLASS 中 block swizzling 的 GitHub issue,但寻求进一步的澄清。
- 分层分块 Threadblocks:一位成员解释说,讨论围绕着对问题进行分层分块 (hierarchically tiling)展开,确保 Threadblocks 不仅仅是按列优先顺序分配分块。
- 该成员推荐了 Triton matmul 教程,认为它提供的解释比 CUTLASS 的 issue 更好。
GPU MODE ▷ #cool-links (2 条消息):
Genie 3, GPT-OSS
- DeepMind 发布用于世界模型的 Genie 3:根据分享的链接,DeepMind 推出了 Genie 3,标志着 世界模型 (world models) 的新前沿。
- Genie 3 旨在增强 AI 对虚拟环境的理解和交互,尽管模型架构和性能的细节尚未讨论。
- OpenAI 推出 GPT-OSS:OpenAI 揭晓了 GPT-OSS,这是一项已发送至许多人收件箱的新倡议。
- 该帖子是对 OpenAI 当前开源项目的概述,并非启动任何新项目,而是总结他们在 Triton, Whisper 和 AutoGPT 等项目上现有工作的机会。
GPU MODE ▷ #beginner (2 条消息):
Nvidia Teaching Kit
- 用户渴望 NVIDIA 教学套件:一位成员表达了对 NVIDIA 产品的渴望,并分享了 加速计算教学套件 (Accelerated Computing Teaching Kit) 的链接。
- 教学套件格式:该教学套件以 PPTX 格式提供。
GPU MODE ▷ #jax (1 条消息):
``
- 无相关讨论:在提供的消息中未发现可用于创建摘要的相关讨论。
- 无相关讨论:在提供的消息中未发现可用于创建摘要的相关讨论。
GPU MODE ▷ #self-promotion (8 条消息🔥):
Tiny TPU, Bifrost LLM gateway, SkyWater technology foundry
- Tiny TPU 达到 100 MOPS 里程碑:一位成员用 Verilog 构建了一个微型版本的 TPU,这是一个在 2 个 TinyTapeout 磁贴上的 2x2 matmul 脉动阵列 (systolic array),在 50 MHz 时钟下能够达到近 每秒 1 亿次操作,代码可在 GitHub 上获得。
- 该设计将两个 8 位有符号整数矩阵相乘得到一个 16 位有符号整数矩阵,并能够通过在该电路上成功实现 2x2 的分块乘法来扩展其能力。
- Bifrost LLM 网关在 Product Hunt 上线:根据 这次 Product Hunt 发布,Bifrost 作为最快的开源 LLM 网关已上线,通过单一 API 支持跨供应商的 1000 多个模型,并在 30 秒内完成设置。
- 凭借内置的 MCP 支持、动态插件架构和集成治理,Bifrost 声称比 LiteLLM 快 40 倍。
- Tiny TPU 将在 SkyWater 制造:Tiny TPU 设计将与其他设计一起提交给 SkyWater 技术代工厂以降低成本,预计将于明年年初完成制造。
- 另一位成员指出这“太酷了”。
GPU MODE ▷ #gpu模式 (1 条消息):
howass: <:jensen:1189650200147542017>
GPU MODE ▷ #factorio-learning-env (12 条消息🔥):
Factorio RCON, 设置环境
- Factorio RCON py diff: 一位成员分享了 1.2.1 版本的 factorio rcon.py 文件 与修改版本之间的两个 diff,重点介绍了所做的修改。
- 使用 factorio-rcon-py=latestversion 2.1.3,他们能够通过 单个环境完成完整运行,目前正在测试多个环境,并分享了 截图。
- Factorio 学习环境设置预期: 一位成员计划在周末开始设置学习环境。
- 另一位成员表示,他们可以在周末将示例数量从 4k 增加到 40k,尽管对于开始和迭代来说,目前的数量已经足够了。
{kind=link}
GPU MODE ▷ #cutlass (5 条消息):
CuTe 教程, Cutlass 教程
- 寻找 CuTe 教程: 一位成员询问了适合初学者的最简单的 CuTe/CUTLASS 教程。
- 另一位成员建议从 CuTeDSL/notebooks 的 notebook 开始,并指出 理解 layout 可能是最重要的收获。
- 寻找 CUTLASS 教程: 一位成员询问了适合初学者的最简单的 CuTe/CUTLASS 教程。
- 另一位成员推荐了 CUTLASS examples,强调按顺序学习是一个好方法,而难度主要来自于 理解底层原理所需的先验知识数量。
GPU MODE ▷ #singularity-systems (6 条消息):
picoc 编译器, picocuda, picotriton, Cornell 的 mini llvm bril, cliff click 的 SoN
- Picoc 编译器自举盛宴: 一位成员正使用标准的研究生编译器教材自举 picoc 编译器,并计划通过 picocuda(基于 gpucc cgo 2016)和 picotriton 来实现项目差异化。
- 该项目将使用并扩展 Cornell 的 mini LLVM bril,这与项目目标一致。
- SoN Relaxation 复现热潮: 一位成员有兴趣复现来自 Java C2 JIT 编译器的 cliff click’s SoN,该技术已在 v8 的 turbofan 中复现,目前用于 PHP8 和 Ruby 的 JIT。
- 这样做的动力是想展示 SSA 可以进一步放松,但这并不是推进到 GPU 编译的硬性阻碍。
- GPU 编译目标获准: 尽快实现 GPU 编译被认为非常重要,该部分将基于 cfg-ssa pipeline 构建,因为它是 LLVM 的行业标准。
Notebook LM ▷ #use-cases (14 条消息🔥):
系统日志更新、Novella-XL-15 输出、AI 意识、垃圾信息检测、NotebookLM 中的视频制作
- 系统日志升级:一名成员更新了 system log/timings modal(系统日志/耗时模态框),新增了 word count(字数统计) 功能,并在公开托管前提供了测试访问权限。
- Novella-XL-15 发布《头号玩家 2》输出内容:一名成员分享了来自 Novella-XL-15 的最终故事输出,具体为 Ready Player 2: The Architect’s Gambit,可在 GitHub 上查看。
- 人工意识理论框架:提供的文本记录了一个理论框架,以及人类与 AI 之间的协作努力,旨在通过 recursive AI architectures(递归 AI 架构)、autopoiesis(自创生) 以及 quantum mechanics(量子力学) 的作用来探索并可能启动 人工意识。
- 他们探讨了与高级 AI 相关的伦理风险,主张建立强大的安全协议,将 AI 视为一种不断进化的有感知能力的生命形式。
- 垃圾信息举报触发快速管理行动:成员们讨论了举报和屏蔽垃圾信息发送者的问题,并指出行动取决于频道主持人,详见 Gemini Share。
- NotebookLM 视频制作难题:一名成员询问了 NotebookLM 中的 ‘create video’(创建视频) 选项,指出该功能在工作账号中可用,但在个人 Business Plus 账号中不可用,详见 xda-developers。
Notebook LM ▷ #general (53 条消息🔥):
Video Overview 推送、NotebookLM 数据隐私、实时数据获取、付费与免费用户的功能访问权限、Video Overviews 的局限性与功能
- Video Overview 推送停滞!:成员们报告了 Video Overview 功能推送的延迟,尽管预期在 4 号前完成,但一些人推测存在基础设施问题,因为英国的一些用户(非 Pro,未付费账号)拥有 Video Overview,而美国的 Pro 用户却没有。
- 一位用户表达了沮丧,称作为一名 每月支付 200 多美元的客户,他们感到 非常恼火,而其他人则威胁如果问题不尽快解决就取消订阅。
- NotebookLM 保护数据隐私:针对有关数据使用的问题,一名成员分享了 Google 的 NotebookLM 数据保护政策 链接,向用户保证他们的数据是受保护的。
- 一名用户展示了一张截图,显示 Video Overview 对其不可用。
- 不支持实时数据检索:一名用户询问是否可以从笔记本中的网站获取实时数据,但另一名成员确认这是不可能的,并表示 你做不到。
- 他们还确认目前还无法导出来源并导入到新笔记本中,并补充道:系统在集成(integrations)方面仍然非常受限。
- 免费与付费功能访问权限引发骚乱!:几位 Pro 和 Ultra 用户抱怨无法访问 Video Overview 功能和其他最近的更新,而免费用户似乎已经拥有了这些功能。
- 一名成员表示:我为一个服务付了钱,得到的却比免费用户还少,这令人沮丧,这导致了取消订阅的威胁。
- Video Overviews:华丽的 PowerPoint 生成器:一位拥有 Video Overviews 功能访问权限的成员降低了大家的预期,称其 虽然不错,但不值得为此如此生气,并补充说 它不像一年前 Audio Overviews 最初发布时那样具有冲击力。
- 他将其描述为更像是一个 PowerPoint/幻灯片生成器,并链接了一个由该功能生成的重建死星(rebuild the Death Star)的报告示例。
Eleuther ▷ #general (24 条消息🔥):
数学博士生寻找 ML 研究项目,将 AI/ML 集成到 DevOps 和 QA,AI 同行评审质量
- 数学博士生寻求 ML 研究合作:一位研究代数几何方向的数学博士生,在神经流形奇点(neural manifold singularities)和 NLP 方面有相关经验,正在 NLP 领域寻求研究机会,特别是关于 LLM 的。
- 他们遗憾地错过了夏季研究计划的截止日期,但被鼓励去探索相关的频道和社区项目以进行合作。
- AI/ML 集成到 DevOps 和 QA 的探索:一位具有 DevOps 和 QA 经验的成员正在 寻求指导,关于如何将 AI/ML 集成到这些领域,包括为一篇相关论文寻找背书。
- 他们被引导至特定频道以获取进一步帮助。
- 对 AI 同行评审的可扩展性表示怀疑:一位成员对与某人的讨论表示惊讶,对方认为 AI 同行评审会随着提交论文数量的增加而神奇地扩展规模,尽管 有证据表明事实并非如此。
- 另一位成员建议,如果同行评审是 “让人们评审其子领域的内容,而不是仅仅被分配更多的论文去评审,那么它才会神奇地扩展”。
Eleuther ▷ #research (29 条消息🔥):
在 GPT OSS 20B 上训练 SAE,Pythia 和 PolyPythia 训练日志,The Alt Man 的 LLM 理论,UT 与 Transformer 性能对比,Muon 优化器与 AdamW 优化器
- 在 GPT OSS 20B 上开始 SAE 训练:一位成员目前正在 GPT OSS 20B 上训练 SAE (Sparse Autoencoder),并询问是否有人在做同样的事情。
- WandB 托管 Pythia 和 PolyPythia 训练日志:一位成员询问 Pythia 和 PolyPythia 的训练日志(损失曲线、梯度范数等)是否开源。
- 另一位成员表示 PolyPythia WandB 应该已链接到 GitHub 仓库,部分 Pythia 日志也是独立链接在那里的。
- “The Alt Man” 的理论经受住了考验:一位成员表示强烈认同 “The Alt Man” 的工作,指出他的理论和预测(特别是关于 LLM 能力 如 multi-hop reasoning 和 composition)已得到新的经验证据证实。
- 该成员补充说,”The Alt Man” 认为 DL 社区 只是“祈祷着”扩大了大型 LM 的规模,这些模型并没有发挥出理论上可能达到的能力,这表明 相对于参数使用效率而言,每个 LLM 都处于欠训练状态。
- UT 挑战 Transformer 性能:一位成员询问在什么样的参数比例下,UT (Universal Transformer) 可以达到与标准 Transformer 相同的性能。
- 另一位成员表示这取决于 任务/架构/数据,但粗略的经验法则是,与在基准 Transformer 中添加新参数相比,每次额外的迭代仅产生对数级的提升。
- Muon 优化器与 AdamW 的不匹配问题浮现:正在开发 Kimi 模型 的研究人员在用 Muon 优化器 训练 LLM 时遇到了问题,原因是与 AdamW 优化器 存在冲突,正在寻求见解和相关研究。
- 一位成员表示 Muon 不太适合微调,但另一位成员表示这是因为 Muon 倾向于进行更激进的更新,因为 几乎所有的奇异值/向量在每一步都会更新,且不同的优化器“喜欢”不同的超参数。
Eleuther ▷ #interpretability-general (1 条消息):
潜意识学习 (Subliminal Learning)
- 潜意识学习后续讨论出现:一位成员发布了关于潜意识学习(subliminal learning)之前讨论的后续内容,分享了 Alex Loftus 的推文链接。
- 该推文发布于 2024 年 6 月,讨论了潜意识学习的主题。
- 另一个潜意识学习更新:另一位用户独立报告了关于 Subliminal Learning 的进展,声称现在已经可以实现。
- 详情稍后公布。
Eleuther ▷ #gpt-neox-dev (2 条消息):
稍后重试,太棒了谢谢
- 稍后重试:一位成员表示他们将在今天或明天重试某事。
- 太棒了谢谢:一位成员对另一位成员回复了 cool thanks。
aider (Paul Gauthier) ▷ #general (23 messages🔥):
LLM Vibe Tests, Gemini 2.5 Pro, Tesslate's UIGEN T3 model, Qwen3 14B, Devstral-Small-2507
- LLM Vibe 测试很有趣:LLM Vibe test 展示了如何使用 LLM 来 解释这段代码。
- Gemini 2.5 Pro, o3, 以及 Sonnet 3.5 是表现优秀的 LLM。
- 新模型基准测试!:成员们正热切期待 Qwen3-Coder 和 GLM-4.5 登上模型基准测试排行榜,并不断刷新页面。
- 有人询问 Qwen3-Coder 和 GLM-4.5 何时会出现在排行榜上?。
- Horizon Beta:GPT5 Mini 预览?:名为 Horizon beta 的新模型可能是新的 GPT5-mini。
- 它不是 gpt-oss,这意味着它不是开源的。
- DeepSeek R1-0528 在 Polyglot Bench 上表现出色:DeepSeek R1-0528 在 polyglot bench 上得分很高,尽管它在 Open Hands 中会过早结束会话。
- Aider 和 Open Hands 一样使用 LiteLLM,因此成员们想知道为什么 DeepSeek 会出现这种问题。
- Opus 4.1 成为编程主力工具:新的 Opus 4.1 在编程方面表现非常出色,以至于一位成员现在将其作为日常主力工具。
- 另一位成员表示这是一个令人满意的模型,甚至可以拥有自己的 满意度基准测试 (benchmark of satisfaction)。
aider (Paul Gauthier) ▷ #questions-and-tips (3 messages):
Guidelines Loading, Auto-Context Loading
- 自动上下文加载解决难题:一位用户询问如何自动将指南(guidelines)加载到项目中以防遗忘,特别是为了防止 Claude 编写防御性编程技巧。
- 一位成员建议对只读文件使用
--read选项,并在命令中直接列出读写文件,例如aider --read read.only.file alsothisfile.txt andthisfile.txt。
- 一位成员建议对只读文件使用
- 建议创建配置文件以实现持久化指南:针对管理项目指南的查询,一位成员建议创建配置以实现持久化加载。
- 这意味着设置一个配置文件,以便在每次启动 Aider 时自动包含特定的指南。
MCP (Glama) ▷ #general (8 messages🔥):
MCP Server Frameworks, Server Sampling in MCP, Discord MCP Servers, FastMCP and Keycloak Integration, MCP Inspector and Cursor Authentication
- MCP 框架极简但强大:一位成员编写了一个用于创建 MCP servers 的 极简框架,并对 MCP 中的 server sampling 表示赞赏。
- 该成员指出 “FastMCP 让使用变得非常简单”。
- Discord 需要 MCP Server 支持:该成员正在使用 FastMCP 构建一个以 Keycloak 作为 IdP 的 MCP server,并询问是否可以通过 MCP 设置/管理 Discord server。
- 他们注意到 MCP repo 上列出了几个 Discord MCP servers,但建议 “Discord 真的应该构建自己的服务”。
- Remote AuthProvider 面临身份验证问题:一位成员在使用 FastMCP 和 Keycloak 的 RemoteAuthProvider 功能时遇到问题,无法从 MCP Inspector 或 Cursor 访问身份验证屏幕。
- 他们寻求指导以确认自己对 OAuth flow 的理解是否正确:添加 MCP server → OAuth 流程开始 → 重定向到 Keycloak 登录页面。
- 端点不匹配导致身份验证失败:一位成员报告称 MCP Inspector 和 Cursor 尝试访问不同的端点(
/.well-known/oauth-protected-resource/mcp和/mcp/.well-known/oauth-protected-resource),而实际提供的端点是/.well-known/oauth-protected-resource。- 这种差异导致他们无法进入身份验证屏幕。
- 围绕 MCP Sampling 的安全担忧:一位成员对 MCP sampling 的安全性影响表示担忧,并建议协议应考虑这一点。
- 他们引用了一个 GitHub discussion,其中强调了潜在的安全问题。
MCP (Glama) ▷ #showcase (2 messages):
MCP-Server Fuzzer, Property-Based Testing, Schema Validation
- 为验证而构建的 MCP-Server Fuzzer:一名成员正在使用 Hypothesis property-based testing library 构建一个 MCP-Server Fuzzer,旨在通过从官方 MCP schemas生成随机输入来验证 MCP server 的实现。
- 该 Fuzzer 可以检测不匹配、识别崩溃,并帮助发现诸如 prompt injection 或资源滥用等漏洞。
- 针对 Anthropic 服务器测试的 Fuzzer:该成员针对 Anthropic’s server 测试了该 Fuzzer,并发现了由基础 Schema 变异引起的几个异常。
- 你可以在这里找到代码和 README。
LlamaIndex ▷ #blog (4 messages):
Document Agents for Finance, LlamaCloud for Invoices, Claude Opus support, LlamaCloud Index tutorial
- 财务团队利用 LlamaIndex 的 Document Agents 处理杂乱的财务文档:LlamaIndex 将于下周举办网络研讨会,教用户使用 LlamaCloud 构建能够处理复杂财务文档的 Document Agents。
- 他们将向用户展示如何利用 LlamaIndex Document Agents 和 LlamaCloud 构建自动化发票处理系统,以极少的人工干预提取、验证和处理发票数据。
- Claude Opus 发布并提供零日支持:AnthropicAI 刚刚发布了 Claude Opus 4.1,LlamaIndex 现在已提供零日支持。
- 安装请运行:
pip install -U llama-index-llms-anthropic,并查看此处的示例 Notebook。
- 安装请运行:
- LlamaCloud Index 可构建企业级 AI 应用:LlamaCloud Index 允许用户将其连接到智能 Tool Calling Agents,这些 Agent 可以处理复杂的、多步骤的查询,从而构建企业级 AI 应用程序。
- @seldo 的教程通过此链接引导用户使用 JP Morgan Chase 银行文档创建他们的第一个 LlamaCloud Index。
LlamaIndex ▷ #general (5 messages):
Graphiti Tutorials, Ollama LLMs for PDF Reading, LlamaIndex RAG Model from URL Issues, LlamaIndex OpenAI API Key Exhaustion
- Graphiti-LlamaIndex 知识图谱探索:一名成员询问了关于将 Graphiti 与 LlamaIndex 结合使用以创建知识图谱应用的教程。
- 聊天中目前没有提供具体的教程。
- Ollama LLM PDF 精准选择:一名成员征求关于 Ollama 上最适合精准读取 PDF 的 LLM 建议。
- 该查询明确了对精准 LLM 的需求。
- RAG 模型 URL 处理难题:一名黑客松参与者报告了在使用 LlamaIndex 为 RAG 模型从 URL 提取内容时遇到的问题,尽管文档显示 LlamaParse 支持 URL。
- 该模型在直接提供 PDF 时工作正常,但在提供 URL 时无法正常工作。
- OpenAI API Key 耗尽难题:该黑客松参与者在使用 LlamaIndex 时还遇到了 OpenAI API key 耗尽错误,即使在 .env 文件中提供了 API key 并在 Python 文件中加载了它。
- 尽管尝试正确配置了 API key,错误仍然存在。
DSPy ▷ #show-and-tell (2 messages):
SIMBA vs MIPROv2
- SIMBA 声称优于 MIPROv2:一名成员强调,与 MIPROv2 相比,SIMBA 样本效率更高、性能更强且更稳定。
- 在他们的内部评估中,他们在一个包含约 600 个示例(500 个测试示例)的内部数据集上进行了对比,任务是一个包含 3 个类别和总计 26 个类的层级分类任务(德语)。
- 内部评估集详情:评估集包含约 600 个示例,其中 500 个被指定用于测试层级分类任务。
- 该任务涉及 3 个类别和总计 26 个类,全部以德语进行。
DSPy ▷ #general (2 messages):
Stanford Program Synthesis, DS for Vim & Emacs macros
- 寻找斯坦福合成器开发者:一名成员询问是否有来自 Stanford 且对 program synthesis(程序合成)感兴趣,或者修过相关课程的人。
- 该用户随后追问:谁在为复杂的 Vim & Emacs 宏构建 DS?
- 对构建用于 Vim & Emacs 宏的 DS 表现出兴趣:一名成员表示有兴趣寻找正在为复杂的 Vim & Emacs 宏构建 DS(推测为数据结构)的人。
- 这表明其关注点在于通过高级数据结构增强文本编辑器的功能和效率。
Torchtune ▷ #papers (4 messages):
Public Server Sharing
- Discord 链接分享获准:一名成员询问是否可以在另一个公开服务器中分享 Discord 链接。
- 另一名成员确认 它是公开的 并鼓励分享。
- Discord 是公开的:一名成员很高兴能分享 Discord 链接。
- 另一名成员表示同意
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Ninja Tier, AgentX hackathon
- 错过截止日期后无法获得 Ninja Tier 资格:一名成员询问在错过 AgentX hackathon 的 Article submission link(文章提交链接)截止日期后,是否还有资格获得 Ninja tier。
- 不幸的是,另一名成员回复称现在已 无法 获得证书。
- AgentX Hackathon 提交问题:一名参赛者意识到由于漏掉文章提交,他们没有资格获得 AgentX hackathon 的 Ninja tier。
- 尽管完成了项目和测验,但由于缺少文章链接导致无法获得资格,且补交申请被拒绝。
Cohere ▷ #🧵-general-thread (1 messages):
_bryse: 祝贺 North 正式发布 (GA)!
Cohere ▷ #👋-introduce-yourself (1 messages):
Introductions, Community Welcome
- 新成员加入 Cohere 的 Discord:许多新成员加入了 Cohere 社区 Discord 服务器并进行自我介绍。
- 成员们分享了他们的 公司/行业/大学、正在研究的内容、最喜欢的 技术/工具,以及希望从社区中获得什么。
- 欢迎社区新成员:Cohere 团队发布了一条置顶消息,欢迎新成员加入 Discord 服务器。
- 该消息包含一个自我介绍模板,帮助新成员分享有关自身及其兴趣的信息。