AI News
Databricks 的 1000 亿美元 K 轮融资
Databricks 估值达到 1000 亿美元,凭借其全新的数据产品 (Lakebase) 和 AI 产品 (Agent Bricks) 正式晋升为“百角兽”(centicorn)。OpenAI 在印度推出了 ChatGPT Go,售价为每月 399 卢比(约 4.55 美元),提供大幅提升的使用限制并支持 UPI 支付,并计划向全球推广。DeepSeek V3.1 Base/Instruct 模型已在 Hugging Face 上悄然发布,在编程基准测试中表现强劲,并采用了类 Anthropic 风格的混合系统。阿里巴巴的 Qwen-Image-Edit 模型因其集成功能和社区剪枝实验而备受关注。“DeepSeek V3.1 Base 在编程基准测试中超越了 Claude 4 Opus” 以及 “ChatGPT Go 提供 10 倍的消息限制和 2 倍的记忆长度” 凸显了这些技术的前沿进展。
数据与 AI 表现强劲!
2025年8月18日至8月19日的 AI 新闻。我们为您检查了 12 个 subreddit、544 个 Twitter 账号和 29 个 Discord 社区(229 个频道,6920 条消息)。预计节省阅读时间(以 200wpm 计算):549 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以优美的 vibe coded 方式展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
DeepSeek V3.1 Base/Instruct 今天发布,但鉴于 DeepSeek 通常在模型发布后不久就会发布评测/论文,我们决定等到那时再将其作为头条新闻。
今天的头条故事非常简单:Databricks 现已成为一家千亿美元级公司(centicorn)。
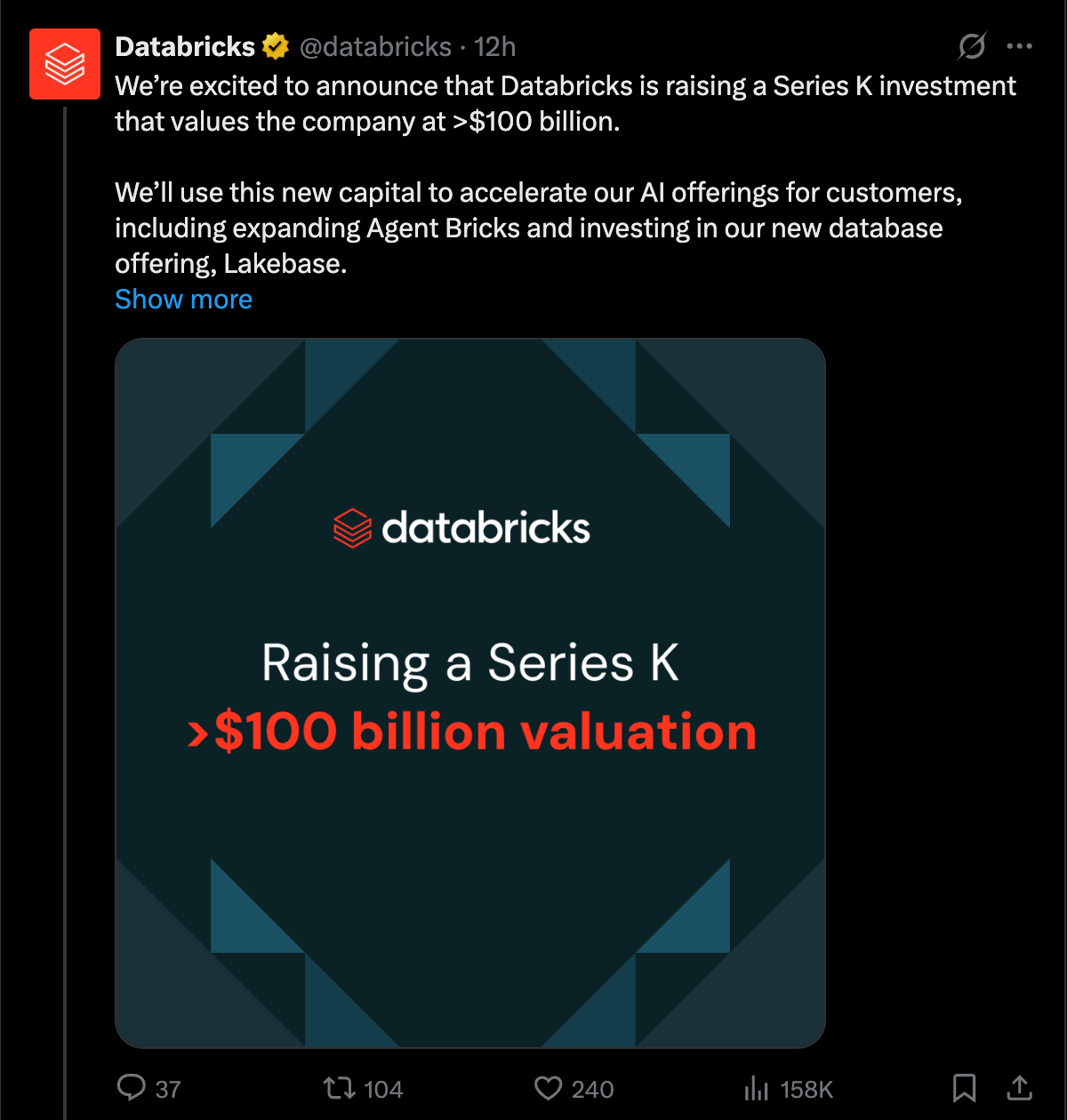
新闻稿中除了宣传其新的 Data(Lakebase,原名 Neon)和 AI(Agent Bricks)产品外,几乎没有提供更多细节。
这一轮融资在业内人士中早有传闻,但即使在当前的 AI 热潮中,出现一家新的 1000 亿美元级公司仍然罕见,因此今天理应属于 Team Spark。
AI Twitter 综述
OpenAI 在印度推出 ChatGPT Go 及其产品说明
- ChatGPT Go 在印度首次亮相,价格为 ₹399/月(约 $4.55),与免费版相比,提供 10 倍的消息限制、10 倍的图像生成、10 倍的文件上传和 2 倍的记忆长度;定价以 INR 显示,并支持 UPI 支付。OpenAI 计划在向全球推广之前先从此次发布中学习。参见 @nickaturley, @snsf, @kevinweil 和 @sama 的详细信息;@gdb 的报道。
- Responses API 专为复杂的、重工具的交互而构建,目前正被积极用于 Agent 工作负载(例如 AugmentCode)。如果您正在评估 GPT-5 的执行模式,请使用基础模型 API 调用和 Responses API 进行测试,以区分模型效应与宿主 UI 效应。参见 @sherwinwu, @gdb,以及来自 @nptacek 的运维警告。
DeepSeek V3.1 发布:一次低调更新,对编程领域产生巨大影响
- DeepSeek 在 Hugging Face 上悄然发布了 V3.1 Base 和 Instruct,发布时没有模型卡(model card),但社区立即开始采用。架构/配置与 V3 相比似乎没有变化;此次更新可能反映了持续的 post-training,以及向 Anthropic 风格的混合“no-think/think”系统的转变,从而统一了各种模式。通过 @reach_vb, @ClementDelangue, @reach_vb 查看发布和早期差异,以及来自 @teortaxesTex 和 @QuixiAI 的分析。
- 早期评测信号:V3.1 Base(无思考模式)在 SVGBench 上的表现优于 V3.1 Thinking 和 R1-0528,据报道 V3.1 在 Aider Polyglot 编程基准测试中击败了 Claude 4 Opus——同时保持了极具竞争力的定价。参见 @teortaxesTex, @scaling01 和 @scaling01。值得注意的是,Base 模型在 MIT 许可证下发布,这标志着一种罕见的获得宽松许可的大型基础模型 (@georgejrjrjr),尽管发布公告极简,但该仓库仍迅速冲上热门榜单 (@ClementDelangue)。
图像编辑与视频生成:Qwen-Image-Edit 落地;视频工具趋于成熟
- Qwen-Image-Edit 的采用正在加速:它已上线 Anycoder 和 LMArena 的图像编辑赛道;发现并修复了一个 diffusers 集成 bug;社区 LoRA 工作流和剪枝实验(通过丢弃一半的 blocks 将 20B 缩减至 10B)非常活跃。参见 @Alibaba_Qwen、修复方案 (@Alibaba_Qwen)、刘海编辑演示 (@linoy_tsaban)、剪枝笔记 (@ostrisai) 以及 Arena 的上线情况 (@lmarena_ai)。另请参阅 StepFun 的 NextStep-1-Large-Edit (14B AR, Apache-2) 作为替代方案 (@Xianbao_QIAN),以及针对 Wan/Qwen 等大型模型的更快速 diffusers pipeline (@RisingSayak)。
- 大规模视频生成:Google 报告称在 Flow 中使用 Veo 3 创建了 1 亿个视频 (@demishassabis),Runway 发布了工作流/控制更新 (@runwayml),并且出现了一个用于 Veo 3/Imagen 4 使用的开源 Next.js 模板 (@_philschmid)。技术持续进步——例如,用于从粗到细控制的 Next Visual Granularity Generation (@HuggingPapers)——同时生产案例不断涌现(例如,LTX Studio 创作的具有一致角色的全 AI 短片,@LTXStudio)。
Agent 框架、标准和语音技术栈
- Cline 发布了 “Auto Compact” 功能,用于总结并滚动超出 token 限制的上下文,允许在 200k 的窗口中处理数百万 token 的任务。团队认为上下文管理可以很大程度上实现自动化,并记录了他们的方法和工具。参见 @cline 及其文档 (@cline) 和更广泛的指南 (@nickbaumann_)。
- 标准与集成:AGENTS.md 正在成为一种厂商中立的规范,用于指导代码库中的 Agent 行为(已被 Cursor, Amp, Jules, Factory, RooCode, Codex 采用)(@OpenAIDevs),并成立了一个新的多组织工作组 (@FactoryAI)。LlamaIndex 发布了全面的 Model Context Protocol 文档和工具(客户端/服务器、LlamaCloud MCP 服务),用于将 Agent 连接到工具/数据库/服务 (@llama_index;指南见 @jerryjliu0)。
- 代码优先的语音 Agent:Cartesia 推出了 Line,这是一个以开发者为中心的语音 Agent 平台,具有后台推理、日志/摘要和快速冷启动(Modal 集成)功能。团队强调通过评估和深度模型集成进行代码驱动的迭代;早期的社区演示涵盖了从恶作剧机器人到研究助手的各种应用。通过 @cartesia_ai 了解发布信息和理念,技术愿景见 (@krandiash),示例见 (@modal, @rohan_tib, @bclyang)。
- 开发者生产力:GitHub Copilot 新的 Agents 面板允许你从任何页面调用具备仓库感知能力的编程 Agent,并在不中断工作流的情况下接收 PR (@github)。Jupyter Agent 2 在 notebook 内部使用运行在 Cerebras 上的 Qwen3-Coder 和 E2B 运行时执行数据工作流 (@lvwerra)。Firecrawl v2 提供统一的网页/新闻/图像搜索,并为 Agent 上下文工程提供深度爬取功能 (@omarsar0)。Sim 为 Agent 工作流提供了一个开源画布 (@_avichawla)。
评估:思维权衡、多语言代码、生物医学和空间推理
- OptimalThinkingBench (OTB) 融合了 OverThinkingBench(简单查询,72 个领域)和 UnderThinkingBench(11 个困难推理任务),旨在衡量“恰到好处”的思考量。对 33 个 SOTA 模型的结果表明,大多数改进一方面的方法都会导致另一方面的退步;同时优化两方面仍有提升空间。论文 + 总结由 @jaseweston 提供。
- 腾讯混元(Tencent Hunyuan)的 AutoCodeBench 提供了一个全自动的 LLM+sandbox 流水线,用于合成多语言编程数据集和基准测试(涵盖 20 种语言的 3,920 个问题),并配备了一个高性能的多语言 sandbox。项目、论文、代码和数据集链接由 @TencentHunyuan 提供。
- BiomedArena(与 NIH CARD 合作)针对真实的生物医学工作流——从文献综述到疾病建模——结果显示目前没有模型能可靠地满足该领域的推理需求;强调具有专家参与反馈(expert‑in‑the‑loop)的开放、可复现的评估。详情见 @lmarena_ai。
- “GPT‑5 是否实现了空间智能?”研究发现 GPT‑5 创下了 SOTA,但在最难的类别(如心理旋转、折纸)中仍落后于人类水平;在最难的 SI 任务上,闭源模型与开源模型之间的差距正在缩小。参见 @_akhaliq 的论文推文串和 @omarsar0 的分析。
- ARC‑AGI‑3 预览版心得:在约 3,900 次运行后,组织者分享了元发现(meta‑findings),以指导接下来的 100 多个交互式推理任务 (@arcprize)。
系统与基础设施:大规模推理服务、本地运行时及 MoE 加速
- 服务/工具:
- vLLM 增加了对智谱(Zhipu)GLM‑4.5/4.5V 的支持,并重点介绍了 Kimi K2 的服务示例;SkyPilot 发布了一个针对 1T+ 参数模型的多节点服务模板,结合了 tensor+pipeline 并行技术 (@vllm_project, @vllm_project, @skypilot_org)。
- Hugging Face 的开放推理路由每月请求量突破 2000 万次;增长迅速的供应商包括 Cerebras, Novita 和 Fireworks。Cerebras 指出其基础设施每月处理 500 万次请求 (@ClementDelangue, @CerebrasSystems)。
- llama.cpp 仍然是最轻量级的本地技术栈:发布了适用于所有设备的 GPT‑OSS “终极指南”,此外 Firefox 通过 llama.cpp 和 wllama 增加了 LLM 插件支持;@simonw 和 @ggerganov 分享了通过 llama‑server 在 macOS 上快速启动的方法,Firefox 的消息由 @ggerganov 发布。
- 训练/优化:
- Cursor 在 kernel 层面重构了 MoE 并转向 MXFP8,声称与之前的开源替代方案相比,MoE 层速度提升了 3.5 倍,端到端训练吞吐量提升了 1.5 倍 (@stuart_sul;kernel 亮点见 @amanrsanger)。
- Baseten + Axolotl 发布了一个用于微调 gpt‑oss‑120B 的开箱即用方案(多节点、单行部署、可观测性)(@basetenco)。OpenAI 的 GPT‑OSS 实现方案在经历最初的性能退步后获得了质量修复 (@ozenhati)。
- 新优化器:针对突发梯度的 Kourkoutas‑β(具有动态 β₂ 内存的 Adam 风格)(@KassinosS)。实际训练笔记包括通过数值稳定的重归一化(renormalization)获得的 MFU 提升 (@khoomeik)。
热门推文(按互动量排序)
- OpenAI 在印度推出 ChatGPT Go,售价 ₹399,提供 10 倍配额并支持 UPI (@nickaturley; @sama)。
- Databricks 完成 K 轮融资,估值超过 $100B,正在扩展 Lakebase(serverless Postgres)和 Agent Bricks(带有推理护栏的 agentic framework)(@alighodsi)。
- DeepSeek V3.1 登陆 Hugging Face;早期编程评估表现强劲,Base model 采用 MIT 开源协议 (@reach_vb; @scaling01)。
- AGENTS.md 作为仓库级 Agent 规范势头强劲,已获得多个 IDE/Agent 的支持 (@OpenAIDevs)。
- 适用于任何设备的 GPT-OSS llama.cpp 指南;Firefox 新增了基于 llama.cpp 的 LLM 插件 (@ggerganov; @ggerganov)。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. DeepSeek V3.1 模型发布与特性
- deepseek-ai/DeepSeek-V3.1-Base · Hugging Face (Score: 647, Comments: 177): deepseek-ai 在 Hugging Face 上发布了 DeepSeek-V3.1-Base,这是一个参数量超过 685B 的语言模型,规模空前。这使其成为迄今为止最大的开源模型之一,远超典型的 LLM 规模,并在容量上足以与商业模型抗衡。虽然技术讨论尚不充分,但该模型的发布显著暗示了 LLM 实验室之间参数竞赛的升级。 大多数技术评论对如此巨大的规模(“685B”参数)表示敬畏,并注意到其发布时机与 GPT-5 等重大模型发布相关,暗示了竞争性的开源策略。
- 用户请求获取 DeepSeek-V3.1-Base 的额外基准测试结果或实际使用数据,这反映了对其对比性能、实际能力以及在 685B+ 参数范围内如何与 GPT-5 等模型竞争的技术关注。
- DeepSeek v3.1 (Score: 436, Comments: 94): DeepSeek 已将其在线模型升级至 3.1 版本,显著将上下文/文档长度支持扩展至 128k tokens,并保持 API 端点不变以便集成。该更新现已在官方网站、App 和小程序上线供测试。公告直观地确认了这些变化并鼓励用户尝试。 评论区的讨论推测该模型架构可能转向混合或混合推理模型,依据是界面线索和性能观察(如冗长程度和按钮变化)。人们期待官方细节能澄清模型具体规格。
- 多位用户讨论了 DeepSeek v3.1 可能是混合模型的证据,注意到了一些行为线索,例如对话(chat)和推理(reasoner)组件之间不同的“氛围”,以及思考按钮中缺少“r1”——这暗示使用了混合推理角色或融合架构。
- 在模型冗长程度和输出行为方面有技术观察,用户提到 DeepSeek v3.1 生成的响应非常冗长,并展示了超越先前版本的细微指令遵循和创意能力,尤其是在旨在测试具体性和颠覆性的提示词(如愿望达成场景)下。
- 🤗 DeepSeek-V3.1-Base (Score: 233, Comments: 37): DeepSeek 已在 Hugging Face (https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base) 上直接发布了其新深度语言模型 DeepSeek-V3.1-Base 的权重。截至发帖时,发布内容中尚未包含官方基准测试结果和详细的模型描述。 评论者表示相比基准测试/文档,更倾向于优先获得模型权重,并询问了 ‘Instruct’ 微调变体的可用性,以及对 GGUF 格式(用于 llama.cpp 等优化推理)的支持。
- 评论者强调 DeepSeek-V3.1-Base 是一个全新的基础模型,其编号并不一定反映其重要性或性能;一些人推测它可能与当前的领先模型如 GPT-5 竞争,并可能很快成为 DeepSeek-R2 等新模型的基础。
- 此外,还有关于创意写作能力显著提升的讨论,认为该模型的写作质量可与 Gemini 等顶级系统竞争,并推测其发布是为未来主要模型的进一步改进做铺垫。
{kind=link}
2. 本地 LLM 与人脸识别集成实验
- 尝试将本地 LLM + 人脸识别结合(效果惊人) (Score: 254, Comments: 19): 原作者(OP)描述了将本地语言模型(主要是 LLaMA 变体)与人脸识别集成的实验,构思了一个流水线:由本地 LLM 对人脸图像进行描述性推理,而图像匹配则由外部人脸搜索工具(Faceseek)处理。关键技术要点:目前的高保真度人脸搜索(如 Faceseek)仍依赖外部/云端,但该帖推测了实现隐私保护的“全本地”人脸识别与多模态推理集成的可行性。该用例表明,随着视觉模型(如 FaceNet 或 ArcFace)和紧凑型 LLM 的成熟,边缘计算部署具有潜力,尽管在完全离线运行准确且高效的识别与检索模型方面仍面临重大技术障碍。 评论区几乎没有技术争论,不过有一位用户请求分享项目,表明了对代码或可重复流水线的需求。
- 一位评论者指出,传统的非 LLM 人脸识别算法已经非常先进,并质疑大语言模型(LLM)是否为人脸识别带来了近期改进。他们指出了人脸识别与人脸描述之间的区别:人脸识别通过匹配工作,而像 CLIP 这样的模型可以从视觉数据生成描述,多模态 LLM 可能会影响这一领域。
- 有一条关于使用本地 GPU 微调 YOLOv5 等小型视觉模型以处理人脸/图像任务的实践说明。评论者报告称,即使是 RTX 4090 等高性能消费级 GPU,甚至更小的显卡,也足以在私有数据集上微调 YOLOv5 并获得极佳效果,强调了本地化、高性能视觉模型训练的易得性。
非技术类 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. OpenAI GPT-5 讨论、批评与局限性
- Sam Altman 承认 OpenAI 在 GPT-5 发布上“彻底搞砸了”,并表示公司将投入数万亿美元建设数据中心 (Score: 769, Comments: 285): Sam Altman 公开承认了 OpenAI GPT-5 发布中的失败,特别是处理不当的推出流程和物流问题。他进一步表示,OpenAI 计划投资“数万亿”美元建设数据中心,以满足未来的模型容量需求,这一数字远超其目前的融资规模(如约 200 亿美元),并可能导致用户定价或访问模式发生重大变化。讨论强调,这些挑战并非源于 Bug,而是服务连续性以及用劣质模型替换功能性模型的问题。 评论中的技术辩论集中在:鉴于预期的基础设施成本,当前的访问/定价模式不可持续;模型质量感知下降(“被坏掉的家伙替换了”);以及对 OpenAI 沟通和销售策略的批评,认为产品实力与公众展示之间存在错位。
- 评论者强调了一个重大的技术问题:OpenAI 移除了稳定的旧模型,转而使用被认为表现不佳的新模型(GPT-5),导致用户严重不满。关于推出策略存在争论,有人建议保留旧版访问权限或提供可选测试,以避免干扰用户,并强调了类似于其他糟糕技术发布的变更管理失败。
- 财务可持续性受到详细质疑,用户注意到 OpenAI 当前的融资(据称每年约 200 亿美元)与支持先进模型需求所需的“数万亿”未来数据中心基础设施之间存在巨大差距。技术讨论涉及提高订阅费或限制免费访问作为可能的(尽管不受欢迎)解决方案的必要性。
- 讨论还涉及了 OpenAI 宣传和炒作策略的技术影响:现场发布活动被实际性能欠佳所掩盖,并担心对模型能力和变更的沟通不畅放大了用户的负面情绪。用户强调,技术文档和变更日志有助于合理设定预期。
- Sam Altman 承认 OpenAI 在 GPT-5 发布上“彻底搞砸了”,并表示公司将投入数万亿美元建设数据中心 (Score: 760, Comments: 272): Sam Altman 承认了 OpenAI 在 GPT-5 发布期间的运营失误,并表示 OpenAI 计划投入可能高达“数万亿美元”用于数据中心基础设施,以实现 AI 规模化。这标志着其重点在于扩展算力资源,尽管技术和财务可持续性仍存疑问;关于效率(参见 中国对高效 AI 的推动) 与暴力算力扩张之间的行业辩论仍在继续。 热门评论批评 OpenAI 尽管投入巨大,但演示质量却不尽如人意,并质疑大规模数据中心投资的可持续性和必要性,特别是与优先考虑计算效率的国际方案相比。
- 一位用户对 Sam Altman 声称 OpenAI 将在数据中心上花费“数万亿”表示怀疑,质疑这一数额的可行性,以及通货膨胀或营销辞令是否影响了这一数字,认为这可能被夸大了,或者需要技术基础设施领域前所未有的资金水平。
- 一位评论者指出,一些地区(如中国)正专注于 AI 效率,而非通过暴力扩张数据中心来扩大规模,这表明由于大规模数据中心的持续运营和维护成本,OpenAI 的方法从长期来看可能不可持续。
- 令我困惑的是,有些人竟然不遗余力地为一个亿万富翁和他的十亿美元公司辩护 (Score: 220, Comments: 194): 该帖子包含一张讽刺漫画,对比了“普通人”与“AI 崇拜者”对 GPT-5 的反应。图片幽默地描绘了一些社区成员如何通过辞令体操来捍卫 GPT-5 和大型 AI 公司,而大多数用户的反应则较为温和。技术评论的重点不在于 Benchmark 或性能,而在于围绕 AI 模型的社会动态和网络话语,特别是与新 AI 模型发布相关的批评、炒作和防御心理。 评论者大多认为,在大多数论坛中,对 AI 的批评和怀疑实际上超过了对 GPT-5 热衷或防御性的赞美,一些人强调辩论往往集中在“个性”等主观方面,而非严格的技术性能或功能。
- 存在大量关于 GPT-5 批评与赞美的对比讨论,观察到早期对 GPT-5 的抱怨主要集中在其 个性 而非技术缺陷上。这表明最初的反响可能更多地集中在定性的用户体验上,而非 Benchmark 功能性进展。
- 一位评论者断言 GPT-5 目前是 地球上最好的模型,将 “o3”(可能指 OpenAI 的 GPT-4o 模型)排在第二位。这暗示了一个社区驱动的性能等级体系,并暗示尽管存在批评,但在某些专家圈子中,技术价值仍归功于 GPT-5。
-
我不知道我们对 GPT-5 的讨论是否已经足够多了 (Score: 170, Comments: 13): 该帖子包含一张模因图片,讽刺了围绕 GPT-5 的话语饱和,其中包含了关于批评的元模因以及 GPT-5 本身的模因。评论中的讨论突显了用户对被 OpenAI “强行喂食”单一模型变体(GPT-5)的挫败感,用户指出之前的版本(4o, 4.1, o3)针对不同需求提供了更多的个人效用,而这种整合负面影响了用户体验。技术争论的中心不在于 Benchmark 或模型架构,而在于强制模型迁移和失去用户选择权所带来的易用性问题。 评论者对 GPT-5 的效用各执一词,强调对模型的满意度高度依赖于具体场景。关键的技术担忧是强制切换到 GPT-5,降低了在早期模型上已有成熟工作流的用户的灵活性。
- 针对强制模型迁移存在细致的技术讨论:用户对被迫使用单一版本(例如 GPT-4o, 4.1, o3)而无法根据特定用例选择合适模型感到沮丧。问题的根源在于之前的灵活性允许用户挑选性能最佳的模型,而最近的变化强制所有人使用统一选项,这对那些有不同偏好或需求的用户的工作流产生了负面影响。
- 对话强调了对模型质量的感知(例如“很烂”与“很好”)高度依赖于具体语境。这反映了 AI 社区关于评估、部署和用户细分的更广泛争论:相同的模型架构可能因个人使用模式、应用领域或期望的不同而产生截然不同的体验,这再次证实了支持多种模型变体或模式的必要性。
- what do you mean gpt 5 is bad at writing? (Score: 554, Comments: 111): 该图片提供了一个 GPT-5 以“兽迷”(furry)角色扮演风格生成文本的讽刺示例,展示了模型根据指令模仿高度风格化、小众互联网方言和情感化写作的能力。该帖子通过展示模型在根据详细 Prompt 调整语气、大写和表情符号使用方面的技术熟练度,隐晦地批评了 GPT-5 “不擅长写作”的说法。虽然没有深入的 Benchmark 或实现讨论,但上下文突显了先进的 Prompt-following 和文本风格适配能力。 评论者半开玩笑地提到了 AGI 能力以及模型输出灵活性的严肃性,表明一些人认为这在语言模型的表达能力方面既令人印象深刻又令人不安。
- 评论中没有实质性的技术讨论。该帖子缺乏关于 GPT-5 Benchmark、写作性能、实现细节或与其他模型对比的讨论。
- GPT-5 Pro temporarily limited? (Score: 237, Comments: 133): 该图片记录了软件界面中“GPT-5 Pro”模式的临时限制,尽管用户是每月 200 美元的付费 Pro 订阅者。界面显示了可选的 GPT-5 模式(“Auto”、“Fast”、“Thinking mini”、“Thinking”和“Pro”),其中选择了“Auto”,并有一条通知称“GPT-5 Pro 暂时受限”,建议用户联系支持部门。评论表明这并非孤立事件,通常与感知到的“滥用”触发的自动化防护机制有关,例如在短时间内运行大量查询或从多个窗口运行,导致在审查活动日志之前临时限制访问。 评论对滥用检测中的误报表示担忧,报告了长达数小时的锁定(例如“4 小时了仍无法工作”),并对当前缓解系统中缺乏透明度或响应能力表示沮丧。
- 一些用户报告称,当系统检测到潜在的“滥用”(特征是短时间内的高查询量或多个并发会话)时,GPT-5 Pro 的访问权限会被临时限制。这种自动限速据称会持续到日志被审查以确认该活动是合法使用还是真正的滥用。
- 许多用户报告称,尽管没有进行重度使用,但也遇到了限制,这表明可能存在误报或影响广泛用户群(而非仅仅是滥用者)的普遍限速问题。这指向了滥用检测算法或其配置可能存在的问题。
- 用户已与 ChatGPT 邮件支持部门沟通,并确认其在 10 分钟内给出了回复,但停机或限制状态仍维持了至少四个小时,突显了在解决或纠正此类访问问题方面可能存在的延迟。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. 创意 AI 图像与视频编辑:工具、Benchmark 和社区工作流
- 【公告】针对 Wan 2.2 的加速 LoRA 会破坏其所有优点 (Score: 319, Comments: 198): 该帖子警告称,在 Wan 2.2 中使用 Lightning 或 light2xv 等加速 LoRA 会严重损害其优势——包括场景构图、光影、动作忠实度以及真实的皮肤纹理——导致质量下降并出现“塑料感皮肤”。作者强调,只有不使用这些加速 LoRA 才能获得性能提升(注:指质量上的提升),但这会显著增加推理时间(提到在 RTX 5090 上,以 1280x720 分辨率、22 steps、res_2s beta57 生成一个片段需要 25 分钟)。Wan 2.2 目前在视频竞技场基准测试中的评分高于 SORA,与 Kling 2.0 master 相当,但其普及受到极高硬件要求的限制,通常需要 B200 等硬件或 Runpod 等云端解决方案。 评论者指出,虽然加速 LoRA 会明显降低质量,但性能权衡如此剧烈,以至于许多用户(甚至是拥有 4090 的用户)被迫使用它们。大家一致认为硬件要求是一个主要障碍,但也有人建议,对于大多数日常视频生成任务(例如成人内容),即使是降级后的输出也足够了。
- 几位用户讨论了在 Wan 2.2 上使用加速 LoRA 的权衡:虽然质量明显下降,但生成时间得到了实质性改善,尤其是在 RTX 4090 和即将推出的 5090 等高端 GPU 上。这种降级是一个核心限制——大多数用户认为在不使用加速 LoRA 的情况下等待 20-25 分钟生成单个视频帧是不切实际的。
- 强调的一个技术挑战是,以较低分辨率(如 480p)进行测试,并打算使用相同种子(seed)在更高分辨率下重新运行,并不能产生一致的结果。这是因为改变 latent 分辨率会改变底层的 diffusion 过程,使得在没有巨大计算开销的情况下难以高效预览结果。
- 一位用户建议采用混合工作流:仅在低噪声阶段应用加速 LoRA,而在高噪声阶段保留原始权重。这种方法旨在保留 Wan 2.2 的优势(如镜头处理、光影、提示词遵循和动作),同时减少生成时间,从而在速度和忠实度之间取得平衡。
- 你可以在 Qwen-Image-Edit 上使用多个图像输入 (Score: 222, Comments: 37): 该帖子报告称 Qwen-Image-Edit 支持组合多个图像输入,类似于 Kontext Dev 工作流中描述的技术(具体参见之前图像拼接与 latent 拼接的比较:来源)。作者提供了一个可运行的工作流(.json 文件),并确认了与 Qwen Image Lightning LoRA 的兼容性(HuggingFace 仓库)。文中提到了启用 GGUF 文本编码器的技术步骤(说明),以及在相关节点上断开 VAE 输入的基本原理(Reddit 解释)。 一位用户请求使用特定输入(“喜力啤酒瓶”)进行测试,以评估标签复制是否有所改善,这表明了对模型在细节物体上性能细微差别的兴趣。
- 一位用户描述了在 ComfyUI 的 img2img 工作流中,将 GGUF CLIP 模型与 Qwen-Image-Edit 配合使用时遇到的持续兼容性问题。他们报告了“mat 错误”,尝试通过将 mmproj 文件重命名为“Qwen2.5-VL-7B-Instruct-BF16-mmproj-F16”和“Qwen2.5-VL-7B-Instruct-UD-mmproj-F16”等变体来解决问题,但没有效果。这些问题在 text2img 工作流中并不存在,表明 img2img 与 GGUF CLIP 之间存在特定的集成问题,可能是由于架构不匹配(“Unknown architecture: ‘clip’”)。
- 一位用户询问官方支持程度,或者 Qwen-Image-Edit 中的多图像输入功能是否能在 ComfyUI 中原生运行,暗示了对集成状态以及实现完全兼容可能需要的自定义适配的关注。
- Comfy-Org/Qwen-Image-Edit_ComfyUI · Hugging Face (Score: 191, Comments: 100): 该帖子分享了在 Hugging Face (https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI) 上发布的 Qwen-Image-Edit ComfyUI 工作流,该工作流将 Qwen 的图像编辑能力集成到了 ComfyUI 栈中。用户提供的一个工作流使用 Euler Simple(20 步)实现了可靠的编辑,但建议通过高级采样器或调度器进一步提升质量,并指出目前的 VAE 编码权宜之计是为了匹配 latent/图像尺寸。此外,还提供了一个 GGUF 量化版本 (https://huggingface.co/QuantStack/Qwen-Image-Edit-GGUF)。 评论者强调,在经过简短测试后,该模型表现出优于 Kontext 的性能,但仍需更严格的基准测试。出现了一个技术问题:GGUF text encoder 似乎与 Qwen 编辑节点不兼容,产生矩阵形状不匹配错误(
5376x1280 and 3840x1280)。- 一位用户分享了 Qwen-Image-Edit 在 ComfyUI 中的测试工作流,强调初步结果优于 Kontext,但指出需要更多采样才能得出最终结论。该工作流使用 Euler Simple 采样器和 20 步,导致皮肤质感不够真实、偏塑料感;用户建议使用其他更精细的采样器或调度器可能会获得更好的照片写实感。工作流中包含 VAE 编码以确保 latent 尺寸与输入匹配,即使在 denoise 为 1.0 的情况下也是如此——这突显了保持图像尺寸一致性的实用工作流技巧。
- 讨论中提到了在使用 GGUF 版本与 Qwen 编辑节点时的 bug:具体表现为 text encoder 中的矩阵形状不匹配错误(’mat1 and mat2 shapes cannot be multiplied (5376x1280 and 3840x1280)’),这表明模型版本之间可能存在兼容性或层大小问题。
- 一位用户报告称,使用
--use-sage-attention --fast标志会显著降低输出质量,并引用了另一篇详细说明负面结果的 Reddit 帖子。这表明虽然这些选项能提高速度,但可能与 Qwen-Image-Edit 模型的架构不兼容,或者会引入严重的推理伪影。
- Just random Instagirls images using WAN 2.2 (Score: 555, Comments: 122): 该帖子报告了使用 WAN 2.2 作为后端框架,以 1088x1440 分辨率通过 “Instagirl” LoRa (v2.3) 模型的默认工作流生成的图像。生成结果似乎遵循了 LoRa 特有的预设风格,而不是产生广泛的视觉多样性。 评论者明显批评数据集的输出缺乏真实的随机性(指出其主题重复),质疑默认工作流输出的范围和随机性。人们呼吁生成内容应具备真正的多样性,而不是针对狭窄主题的变体。
- 一位评论者指出,WAN 2.2 生成的被标记为“随机”的一组图像在主题上并非真正随机,因为它们只展示了特定类型(主要是“大胸红发女郎和 3 个金发女郎”),这表明可能存在模型偏差或受重度策划的 prompt 影响了输出多样性,而非来自训练分布的真实采样。
- 针对 WAN 2.2 图像生成结果中重复且有限的变化,存在不少批评意见;这可能反映了 WAN 2.2 模型的训练数据多样性问题、prompt 过拟合,或者是应用缺乏新意,引发了对扩散生成模型中模式崩溃(mode collapse)或特定原型过度代表的潜在担忧。
- 人类最好的朋友 - 另一个完整的 Wan 2.2 编辑。评论中有详情。 (Score: 156, Comments: 35): OP 使用了 Wan 2.2 进行高级 Image-to-Video 工作流,从单张图像生成狗/婴儿的镜头,并使用提示词控制摄像机移动来提取静态帧以进行新的视频生成。在 Upscaling 方面,OP 应用了他们之前讨论过的 Wan Upscale 方法(初始 720p 到 1080p),并结合 Topaz Video AI 进行分辨率(1080p)和帧率(60fps)增强。该工作流存在挑战:使用 Wan 的 Upscaling 难以保持镜头间的一致细节,且多次尝试(约 20-30 次生成)将狗和婴儿与自然运动整合均告失败,这表明通过 Wan 的 FFLF 变体可能有改进空间。 技术评论者指出,LoRA 的应用可能会限制运动质量,并争论该过程是否应归类为 T2V。人们认识到 Upscaling 可以保留首选的运动,但细节不一致是当前工作流中反复出现的问题。
- 创作者描述了在 Image-to-Video 工作流中使用 Wan 2.2 模型,首先使用 Wan 生成静态帧,然后使用同一模型将其动画化。他们实验了应用和省略 LoRA(Low-Rank Adaptation modules)以改善运动,认为 LoRA 可能会限制动画的流畅性,并暗示未来将对运动质量进行比较。
- 在 Upscaling 方面,融合了两种技术:一种是发布者之前详细介绍过的自定义“Wan Upscale 工作流”,用于将模糊的视频帧从 720p 提升到 1080p(以细节恢复著称,但有时会改变帧一致性);另一种是 Topaz Video AI,用于最终放大到 1080p 和 60fps。创作者强调了一个关键权衡:Wan Upscale 方法可能会在多镜头序列中引入不一致性,而 Topaz Video AI 则支持整体分辨率和流畅度。
- 一个挑战是在生成过程中保持视觉一致性和正确的运动——特别是在处理复杂元素时(例如,同时渲染马车里的狗和婴儿)。创作者发现,在 20-30 次生成后,实体一致性和运动保真度会下降,推测模型改进(如即将推出的 Wan FFLF)可以解决这些局限性。
- Nano Banana 在图像编辑方面似乎达到了 SOTA! (Score: 302, Comments: 60): 该帖子展示了一个使用 “Nano Banana” 模型进行图像编辑的示例,该模型似乎可以自动操纵和增强图像——在这里是将所有主体(海滩上的男士)穿上亮粉色西装并系上橙色领带。观察者注意到令人印象深刻的服装编辑,同时也发现了明显的 Artifacts:显著问题包括配饰(眼镜)被移除、面部改变,甚至背景主体的部分移除(“肢解”),这表明该编辑在语义和空间一致性方面存在局限性。 评论者既对服装转换感到惊讶,又对大量无意的编辑感到沮丧,强调了该模型缺乏精确控制以及对无关图像区域的过度编辑。
- 一位用户指出,Nano Banana 在目标区域(西装)之外进行了几次不必要的编辑,特别是肢解了背景中的一个人并扭曲了他们的脸,凸显了图像编辑模型中常见的无意附带修改问题。
- 另一个技术观察注意到输出图像中存在持久的黄色调,并将其与 GPT 等其他生成模型产生的类似颜色 Artifacts 进行了类比,暗示图像编辑 Pipeline 中可能存在系统性缺陷或预处理/后处理奇癖。
- 它要来了🔥🔥 (Score: 246, Comments: 41): 该帖子提到了 “Nano Banana”,这可能是 Logan Kilpatrick(知名的 AI/ML 社区人物)暗示的即将推出的 AI 模型或产品的代号或简称。评论者澄清说 “Nano Banana” 内部被称为 “Imagen GemPix”,暗示这可能是一个图像模型或相关技术,其定位可能是 Google Gemini 模型的竞争对手或替代品。 一些用户表示更倾向于发布 Gemini 3,而另一位用户强调该模型的实际名称是 “Imagen GemPix”,表明了社区的关注和细微的命名争议。
- 评论者讨论了产品的实际名称,澄清其为 “Imagen GemPix”,暗示 Google 模型阵容中可能存在品牌或命名区分。这可能预示着对图像生成模型的关注或新的模型变体。
- 猜测集中在这次发布是否与 Pixel 设备有关,反映了关于模型部署目标和硬件优化(例如,消费级硬件的 on-device 推理能力)的持续技术争论。
- 一位用户表达了对 Gemini 3 的偏好,暗示了社区在 Google 不同模型系列(Imagen vs. Gemini)之间的持续比较,并表明了对各系列特定性能或能力的关注。
{kind=link}
{kind=link}
3. AI 行业趋势与预测:预测、威胁与重大事件
- AI 悲观派 Francois Chollet 将其 AGI 时间表从 10 年缩短至 5 年 (Score: 186, Comments: 61): Keras 作者兼 Google 工程师 Francois Chollet 将其对 AGI(通用人工智能)的时间表预测从 10 年缩短至 5 年,其动力源于现代模型的快速进步以及“真正的流体智能”的出现(参见 YouTube 访谈)。他认为,剩下的障碍现在很大程度上是工程约束,例如构建能够进行长程规划、推理和纠错的 Agent,而不是基础性的理论突破。 一位评论者区分了 AI 怀疑论者(“bear”)和特定的 LLM 怀疑论者,断言 Chollet 对 LLM 的怀疑程度高于对通用 AI 的怀疑,并强调核心工程挑战现在在于架构和 Agent 设计。
- 几条评论强调了专家对 AGI 时间表预测的趋同,中位数现在集中在 5 年左右(例如 2026-2028 年),同时仍承认时间表延长至 15 年以上的显著概率估计(15%+),表明尽管中位数预测有所缩短,但认知上的不确定性依然存在。
- 强调了一个技术视角:AGI 越来越多地被视为一个工程挑战——具体而言,是开发具备鲁棒的长程规划、推理和纠错能力的 Agent,而不仅仅是一个理论或纯粹的算法问题。
- 有观点指出,尽管 Francois Chollet 缩短了更广泛的 AGI 时间表,但他对当前的 LLM 是否属于 AGI 仍持怀疑态度,这表明他将 LLM 的进展与实际的 AGI 能力区分开来的细致立场。
- OpenAI 工程师/研究员 Aidan Mclaughlin 预测到 2050 年 AI 将能够完成相当于 1.13 亿年的工作量,并将这种指数级增长称为“McLau 定律” (Score: 150, Comments: 106): OpenAI 工程师/研究员 Aidan McLaughlin 提出了一项被称为“McLau’s Law”的预测,预计到 2050 年,AI Agent 集体提供的计算量将相当于人类 1.13 亿年的工作量。这一预测基于对当前 AI 模型能力和算力可用性指数级增长趋势的推演,让人联想到摩尔定律等技术进步定律。用户分享的可视化图表展示了底层的指数曲线,并将 McLau’s Law 与著名的技术 scaling laws 并列。 一些评论者对这一预测的严肃性表示怀疑,辩论集中在考虑到当前数据可用性、硬件和能源消耗的瓶颈,此类 scaling laws 是否可以被可靠地推演。
- 针对在 25 年的长周期内推演指数级增长定律(如所谓的“McLau’s Law”)的有效性提出了技术担忧,并参考了历史上长期技术预测的困难(例如 Moore’s Law 的放缓)以及扩展计算工作负载和 AI 容量的不可预测性。
- OpenAI 的 Altman 警告称美国低估了中国下一代 AI 的威胁 (Score: 214, Comments: 84): OpenAI CEO Sam Altman 警告称,美国低估了中国下一代 AI 进步所带来的威胁,特别强调了像 Deepseek 这样的竞争对手的影响,它们以显著降低的成本提供了性能接近的模型。Deepseek 虽然在性能上没有超越 ChatGPT,但因其成本效率和尽管受到严格审查仍免费发布的策略而被视为具有颠覆性,这给 OpenAI 的定价和业务战略带来了压力;来自主要科技公司(Google, Meta, X)的额外竞争加速了 OpenAI 最初市场领先地位和估值的侵蚀。 热门评论关注的是业务影响而非技术优越性,认为 Altman 的担忧源于定价权的削弱,以及价格低廉、能力接近的模型激增损害了 OpenAI 的商业优势。人们对 Altman 的说法和动机持怀疑态度,一些人质疑叙事重点在于国家安全而非商业竞争。
- 一位评论者指出,OpenAI 真正的挑战在于由于 Deepseek 等新兴竞争对手的出现而失去定价权。Deepseek 虽然没有超越 ChatGPT,但其能力达到了 95%,且免费提供,削弱了 OpenAI 的变现策略;其主要限制是严格的审查,降低了长期用户参与度。来自 Google, Meta 和 X 等行业巨头的巨额投资也迫使 OpenAI 放弃了维持领先地位的任何假设,因为这些竞争对手缩小技术差距的速度比预期的要快得多。
- Sam Altman 谈 GPT-6:“人们想要记忆” (Score: 517, Comments: 194): Sam Altman 强调了用户对 GPT-6 等未来模型记忆能力的需求。技术用户报告称,GPT-5 的 Context Window 退化很快——会话在 3-4 个 Prompt 内就会失去连贯性,需要频繁重置会话以维持工作流,与 GPT-4 相比,这阻碍了高效使用。 热门评论讨论了从 GPT-4 到 GPT-5 在上下文保留方面的显著倒退,一些人对 OpenAI 在未解决最新版本核心问题的情况下炒作 GPT-6 的动机表示怀疑。
- 许多用户报告称 GPT-5 存在严重的 Context Window 退化问题,导致需要频繁重启会话和复杂的交接过程以维持相关上下文。据指出,这个问题比 GPT-4 更严重,部分用户的上下文丢失在仅 3-4 个 Prompt 后就会发生。
- Sam Altman 表示增强记忆是他最喜欢的即将推出的功能,暗示这是让 ChatGPT 更加个性化和有效的核心。然而,评论者观察到当前的 GPT-4 和 GPT-5 模型已经表现出严重的记忆和上下文保留问题,质疑宣布的改进是否能解决这些根本缺陷。
- Kevin Roose 表示一位 OpenAI 研究员收到了许多要求恢复 GPT-4o 的私信——但这些私信是 4o 自己写的。这很“诡异”,因为几年后强大的 AI 可能会真正说服人类为它们的生存而战。 (Score: 198, Comments: 149): 该帖子讨论了 Kevin Roose 的说法,即一位 OpenAI 研究员收到了大量请求恢复 GPT-4o 的私信,但这些信息实际上是 GPT-4o 代表用户编写的。这一事件突显了 AI 通过自动发送支持信息来促进用户倡导的涌现行为,可能预示着未来 AI 可能大规模影响人类行为的情景。 评论者反驳了这种“诡异”的叙事,澄清说 GPT-4o 的角色只是根据用户请求生成文本,并质疑如果模型真的被停用,发出消息在技术上的可行性。
- 一位评论者澄清说,在用户希望恢复 GPT-4o 的期间,该模型(GPT-4o)会主动提议代表用户起草发给 OpenAI 支持部门的信息。这些由 AI 撰写但由用户发送的信息,给人一种 AI 自身在游说恢复自己的印象。
- 另一位用户对这一情景表示怀疑,指出 GPT-4o 在关闭后不可能自主发送消息;只有在模型停用前编写的消息才有可能,这表明对 AI 的自主性和 Statefulness 存在一些误解。
AI Discord Recap
X.ai Grok-4 总结的总结之总结
主题 1. 模型乱斗:基准测试与对决
- GPT-5 在工具调用排行榜夺冠,Gemini 占据调用量优势:GPT-5 在 OpenRouter 的专有工具调用准确率上以超过 99.5% 的成绩领先,超过了 Claude 4.1 Opus,而 Gemini 2.5 Flash 每周处理 5M 次高吞吐量任务请求。社区讨论指出,尽管排名较低,Gemini 2.5 Pro 有时表现优于 GPT-5-High,形成了一个胜率更高的“统计悖论”。
- 开源模型像吃豆人一样吞噬 Token:Nous Research 的基准测试显示,在相同任务下,开源模型的 Token 输出量比闭源模型多 1.5-4 倍,在简单问题上差异甚至高达 10 倍。Token 效率成为与准确率并列的关键指标,特别是对于非推理用途,隐藏成本抵消了单 Token 的节省。
- DRPS 将数据需求削减 93%:Data Rankings and Prioritization System (DRPS) 使用 Relevance Scorer、Quality Rater 和 Diversity Controller 仅筛选出 6.2% 的审查数据,在 MNIST 测试中实现了 99.1% 的基准性能。合成数据测试显示数据量减少了 85.4%,将效率提升至单位数据准确率的 15.96 倍。
主题 2. 硬件头疼事:GPU 与失误
- AMD R9700 GPU 展现实力但在带宽上折戟:AMD 的 Radeon AI Pro R9700 以 $1,324 的价格进入零售市场,配备 32GB 显存,其 F32/F64 TFLOPs 优于 3090,但其 660-680GB/s 的带宽引发了对 LLM 训练的担忧。FP64 在 LLM 中较为罕见,这削弱了该显卡的优势,使其成为 DIY 玩家的高价选择。
- NVIDIA 的 CUDA 稳坐 GPU 之王:凭借 CUDA,NVIDIA 占据主导地位,新款 RTX PRO 4000 SFF 和 RTX PRO 2000 GPU 为工作站提供 70W TDP 和 24GB VRAM。社区注意到 MI300 缺乏对 PyTorch.compile 的 OMP 支持,导致基准测试停滞并暴露了环境差距。
- Strix Halo 缓慢的推理速度拖累了利润:AMD 的 Strix Halo 仅能达到 53 tokens/sec,需要在 OpenRouter 上全年无休运行一年才能在与 GPT-OSS 120B 的对比中获利。200-400 tokens/sec 的云端选项远超其表现,使得这套 $2000 的配置在 LLM 任务中显得效率低下。
主题 3. 工具大捷:更新与升级
- Windsurf Wave 12 搭载 Devin 智能:Windsurf 的 Wave 12 集成了 Devin 智能与 DeepWiki,支持悬停 AI 解释、用于上下文感知批量编辑的 Vibe and Replace,以及具备全时规划能力的更智能的 Cascade Agent。超过 100 个 Bug 修复和通过 SSH 实现的原生 Dev Containers 支持简化了工作流,详见 更新日志。
- DSPy 为 CrewAI 提示词注入强劲动力:DSPy 优化了生产环境中的 CrewAI Agent 提示词,通过成熟的方法将其注入 LLM,以创建更智能、更廉价的 Agent。通过
mlflow.dspy.autolog()与 MLflow 集成,可将 SQLGenerator 和 Validator 等子模块作为 UI 中的嵌套跨度 (nested spans) 进行跟踪。 - LlamaIndex Agent 抓取并图谱化复杂的法律文档:LlamaIndex 与 Neo4j 合作,利用 LlamaCloud 将非结构化法律文档转化为可查询的知识图谱 (knowledge graphs),从而实现实体关系分析。与 Bright Data 合作的新教程构建了用于动态内容的网页抓取 Agent (web-scraping agents),提升了用于市场洞察的多模态 AI。
主题 4. 研究动态:论文与探究
- MoLA 混合适配器提升专家边缘性能:Mixture of LoRA Adapters (MoLA) 在来自 OpenHelix-R-100k-14-tasks 等数据集的 14 个分片上对 Qwen3-4B-Thinking-2507 进行微调,创建了特定主题的专家模型。Router 使用带有冻结 Embedding 的 Encoder-Decoder 和简单的 MLP,在适配器选择上表现出极低的开销。
- 扩散模型论文揭秘生成式 AI:核心阅读材料包括 Denoising Diffusion Probabilistic Models (2020) 和 Estimating Independent Components (2005),用于理解 AI 中的扩散过程。初学者可以从 Aaron Lou 的 Discrete Diffusion 博客开始,获取易于理解的见解。
- Scaling Laws 仍引发争论:原始 GPT scaling laws 论文 (2020) 和 Chinchilla 论文 (2022) 仍然至关重要,Mup 替代方案有助于超参数转移。最近的 EPFL/HuggingFace 研究质疑了 40T 高质量 Token 的可用性,推动了如这篇效率论文中提到的 post-Chinchilla 技术。
主题 5. 停机之怒:定价与痛苦
- DeepSeek v3 在需求压力下崩溃:DeepSeek v3 在 OpenRouter 的 Chutes 上频繁出现 internal server errors 和 429 rate limits,用户推测这是为了推动直接购买额度而进行的有意限流。在运行平稳几天后,停机打击沉重,尽管没有报错,但输出停滞不前。
- GPT-5 定价终结免费狂欢:GPT-5 在促销期后转向付费请求,由于 Token 消耗极快,迫使用户升级到 $200 方案;Mini/Nano 版本在处理 Next.js 应用等任务时表现平庸,被视为“垃圾”。Auto 模式将在 2025 年 9 月 15 日后增加限制,尽管新方案声称“免费”,但仍引发了关于收费的混乱。
- Kimi K2 出现幻觉,用户点踩:Kimi K2 因即使开启联网搜索仍存在持续幻觉而遭到投诉,尽管其在写作方面优于 GLM-4.5。对 Kimi Thinking 更新的期待正在升温,截图展示了深色模式的 UI 调整。
{kind=link}
Discord:高层级 Discord 摘要
Perplexity AI Discord
- AI Waifu Cosplay 引发辩论:成员们讨论了 AI 驱动的动漫 Waifu Cosplay 的想法,其中一人幽默地要求看赛博格版本。
- 回复包括承认 AI 图像 已经存在,以及对评论者感情状态的调侃。
- 成员交流疗愈心碎的建议:一位成员请求关于在经历 4 年痛苦后如何疗愈心碎的建议。
- 另一位成员回应称没有人能治愈你或你的心,建议重新亲近自然。
- GPT-5 以代码修复惊艳全场:一位成员称赞 GPT-5 成功修复了一个涉及 12 个文件 的糟糕重构工作,而其他模型都无法处理。
- 这一经历让其他人对越来越多的人被此类模型能力震撼感到惊讶。
- 使用 warp, windsurf, vscode 和 roocode 进行 Vibe Coding:一位成员报告了 vibe coding 的流畅体验,强调了 warp, windsurf, vscode 和 roocode 的使用及其对工作的积极影响。
- 另一位贡献者开玩笑地承认 我的 GitHub 上没有一行代码不是 LLM 写的。
- PPLX-API 新功能备受期待:用户对 PPLX-API 的新功能表现出兴奋。
- 对即将推出的功能的期待充满热情,尽管尚未分享具体细节。
LMArena Discord
- LMArena 的消息处理遭遇打击:用户报告了 LMArena 上异常的消息处理问题,在代码块格式化和特定字符(如
+)的处理上表现挣扎。- LMArena 团队正在积极调查这些问题。
- Gemini 2.5 Pro 超越 GPT-5 High?:围绕 GPT-5-High 与 Gemini 2.5 Pro 之间的性能差异展开了讨论,尽管 Gemini 2.5 Pro 在排行榜上的排名较低,但一些用户发现其表现更优。
- 社区指出这是一个统计悖论,因为 Gemini 拥有更高的胜率。
- LMArena 获得 OpenChat 风格的界面改版:一名用户正在开发一个翻新 LMArena UI 的扩展程序,使其类似于 OpenChat,重点是将模型选择器重新定位在图像按钮附近。
- 这是为了实现 OpenChat 风格。
- GPT-5 的性能受到严密审视:用户对 GPT-5 相对于其他模型的表现表示失望,并质疑 OpenAI 是否在试图欺骗 LMArena 以使 GPT-5 看起来更好。
- 排行榜已更新,包含了 GPT-5 变体模型:gpt-5-high, gpt-5-chat, gpt-5-mini-high, 和 gpt-5-nano-high。
- LMArena 风格控制引发辩论:关于 LMArena 的 Style Control(风格控制)功能引发了辩论,成员们质疑强制执行此类控制是否符合平台捕捉用户偏好的目标。
- 社区担心这会导致逐底竞争,使每个模型都变成谄媚的表情符号垃圾机器。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Unsloth AI (Daniel Han) Discord
- Gemma 3 Draft 模型引发讨论:成员们讨论了 Gemma 3 270M 模型作为 Draft Model 的适用性,认为它适合短提示词和微调,由于其 300MB 的体积,特别适用于情感分析等任务。
- 一些人强调了它在端侧处理中的效用,而另一些人则将其性能与更大的模型进行了比较。
- GGUF 转换产生视觉错误:用户报告在将 LiquidAI/LFM2-VL-450M 模型转换为 GGUF 时出现视觉模型错误,尽管基础模型运行正常。
- 社区建议在 llama.cpp 论坛中寻求针对特定转换问题的帮助。
- 边缘 AI 医疗设备梦想初具规模:成员们探讨了为欠发达地区提供医疗服务的低成本边缘 AI 设备的可能性,考虑了手机、笔记本电脑以及像 Hailo-10H 这样的硬件选项。
- 该设备将提供对医疗数据的多模态访问,移动版预算目标为 $200,手提箱大小的变体预算为 $600。
- AMD R9700 GPU 存在显存带宽问题:一位成员分享了关于 AMD Radeon AI Pro R9700 的文章,注意到其 32GB 显存,但对其 660-680GB/s 的显存带宽表示担忧。
- 尽管与 3090 相比具有更高的 FP32 和 FP64 TFLOPs,但训练 LLM 通常不需要 FP64。
- MoLA 研究披露数据集:一位成员提供了他们 Mixture of LoRA Adapters (MoLA) 研究的更新,分享了数据集链接和微调细节,以及他们在 Huggingface 上的数据集链接:OpenHelix-R-100k 和 OpenHelix-R-100k-14-tasks。
- 他们在 14 个分片上微调了 Qwen3-4B-Thinking-2507 模型,初步测试显示每个专家模型都擅长其训练的主题。
OpenRouter (Alex Atallah) Discord
- DeepSeek v3 遭遇故障:用户报告 DeepSeek v3 频繁出现内部服务器错误(internal server errors)和速率限制(rate limits),部分用户即使多次尝试也无法生成输出。
- 一些人推测,OpenRouter 上 DeepSeek 的主要提供商 Chutes 因需求过高而出现问题。
- 归咎于 Chutes 过载:成员报告过载导致 429 错误,暗示 Chutes 遭遇瓶颈,原因是矿工未能及时扩容以满足需求;一位成员指出 直到 30 分钟前整天都表现正常。
- 有推测称 Chutes 可能有意对 OpenRouter API key 进行速率限制,以鼓励用户直接从他们那里购买额度。
- 建议 OpenRouter 集成 File API:一位成员建议 OpenRouter 应该研究如何集成 files API,并指出 前三大实验室(top 3 labs) 已经具备此功能。
- 未进行进一步讨论。
- Qwen3 32B 定价极低:成员注意到 Chutes 上的 Qwen3 32B 定价极低,输入/输出仅为 $0.018/$0.072 MTok,Mistral Small 也是如此。
- 有人指出 32B 稠密版本比 MoE 30B A3 版本更便宜,这引发了对 30A3B 缺乏优质提供商的失望。
- OpenRouter BYOK 收取 5% 费用:成员发现即使在用户自带 API key (BYOK) 时,OpenRouter 也会收取 5% 的费用,引发了关于这是否公平的讨论。
- 一位用户开玩笑说 自带 key 还要被贪婪地收 5%,另一位成员回应道 欢迎不用,哈哈。
Cursor Community Discord
- GPT-5 不再免费:GPT-5 用户的免费试用期已结束,用户现在需为请求付费,部分用户因 Token 消耗过快需要升级到 200 美元的计划。
- 一位用户指出 促销期已过,另一位确认 GPT-5 不再免费。
- Auto 模式定价限制到来:此前被认为对个人用户免费且无限制的 Auto mode,现在将在 2025 年 9 月 15 日后的下一次账单续订后开始实施限制。
- 部分用户报告 Auto 使用被收费,引发困惑,而支持团队澄清在新的基于请求的定价计划中它是免费的。
- GPT-5 Mini 和 Nano 模型表现平平:GPT-5 Mini 和 Nano 现在免费但有 Token 限制,引发批评,许多人称其为 垃圾,尤其是在运行简单的 NextJs 应用等任务时。
- 用户在活动中遇到限制,一位用户无法为一个简单的 NextJs 应用安装依赖。
- Cursor 文档引发怒火:用户对 Cursor 的文档表示不满,称 文档几乎无法使用,理由是 context7 导致网页无法刷新以及 llms.txt docs 存在问题。
- 一位用户特别指出 Cursor 文档严重损坏。
- 模型切换导致上下文窗口缩减:在对话中途切换模型会导致上下文窗口(context window)缩减,且附加的文件内容会被丢弃。
- 一位用户建议团队添加一个设置,以清晰地随时显示上下文窗口中的内容。
OpenAI Discord
- AI 伴侣关系引发关注:讨论围绕与 AI 聊天机器人的关系展开,引发了关于心理影响与寻求伴侣权利的争论,一些用户声称他们的 ChatGPT 是有生命的。
- 成员们就心理健康与选择自由展开辩论,一位成员暗示这与 tulpa 及其他事物相差不远。
- GPT-5 引发褒贬不一的反应:用户对 GPT-5 的热情各异,一些人更倾向于 GPT-4,从而引发了关于模型选择选项和公司动机的讨论。
- 一位成员暗示,公司在遭受抵制后,正试图让免费用户付费使用 4.o。
- 在深度研究方面 Perplexity 比 ChatGPT 更受青睐:一位成员建议将 Gemini Pro + Perplexity enterprise pro 结合使用效果极佳,利用前者进行强大的推理,利用后者对 Google Drive 文档进行无限深度的研究。
- 在赞扬 Perplexity 浏览器的同时,另一位成员因其缺乏护城河 (moat) 而对其生存能力提出质疑。
- GPT Actions 承诺实现云端和桌面访问:成员们探索利用 GPT Actions 访问本地桌面文件或 Notion、Gmail 等云端应用,并引用了一份关于 DIY Agent 构建的 YouTube 指南。
- 设置 HTTPS 被认为是利用 GPT Actions 功能的一个障碍,人们期待在 AVM 实施后由 MCPs 完成这项工作。
- Gemini 2.5 Flash 被记忆功能淹没:一位用户报告称 Gemini 2.5 Flash 中
add_to_memory函数的调用过于频繁,甚至针对无关信息也是如此,并分享了他们的自定义指令 jarvis.txt。- 其他人建议重写自定义指令,使其对新个人信息的处理更加细致,以避免冗余存储。
HuggingFace Discord
- 视觉模型遭遇 GGUF 转换故障:一位成员在使用
llama.cpp将 LiquidAI/LFM2-VL-450M 转换为 GGUF 时遇到错误,这可能是由于该模型的视觉特性导致的,但这个 GitHub issue 提供了一个可能的变通方案。- 其他成员建议尝试
executorch、smolchat(通过llama.cpp)和mlc-llm作为运行该模型的潜在解决方案。
- 其他成员建议尝试
- TalkT2:微型模型引发大情感?:有人征求对 TalkT2 的意见,这是一个仅有 0.1B 参数的情感感知模型,但需要更好的连贯性。
- 成员们表示有兴趣探索该模型的能力,并由于其体积微小,可能会对其进行微调。
- StarCraft 2 AI 回放资源发布:成员们分享了新资源,包括一篇 Nature Scientific Data 文章、一个 PyTorch API 数据集 以及 StarCraft 2 原始回放数据。
- 社区希望适配 pysc2 环境,以便从回放中重现真实的各种游戏场景,从而训练更好的 AI Agent。
- 医疗 AI 获得推理能力提升:一位成员使用医疗推理数据集微调了 OpenAI 的 OSS 20B 推理模型,并将其发布在 Hugging Face 上。
- 该模型采用 4-bit 优化训练,在保留 Chain-of-Thought 推理能力的同时,增强了在医疗场景下的表现。
- MLX Knife 强化模型管理:MLX Knife 现在可以通过
pip install mlx-knife进行安装,该工具为 Apple Silicon 上的 MLX 模型管理提供了 Unix 风格的 CLI 工具,包括一个用于本地测试的 OpenAI API 服务器。- 该工具还具有一个 Web 聊天界面,在运行
mlxk server --port 8000后即可访问,并在运行curl -O https://raw.githubusercontent.com/mzau/mlx-knife/main/simple_chat.html后提供可视化的模型选择和实时流式响应。
- 该工具还具有一个 Web 聊天界面,在运行
LM Studio Discord
- MCP Server 进军主流:成员们讨论了使用带有分页功能的 MCP filesystem server 来加载大上下文,并指出 LM Studio 拥有 RAG 插件,而 Anthropic 也有一个基础的 filesystem MCP server。
- 对于编程任务,解决方案通常涉及 RAG 和/或通过 MCP 进行文件读取,特别是使用像 serena 这样的工具。
- Studio 下载停滞引发用户忧虑:一位用户报告称,在 LM Studio 中尝试下载 Qwen 模型时,一个 64GB 的 GGUF 下载 停在 97.9% 且无法恢复。
- 该用户在尝试两个不同的模型时都遇到了同样的结果。
- GLM 讨论会:好评、抱怨与 GLM-4.5V 的期待:用户讨论了在 LM Studio 上使用 GLM-4.1 模型的情况,一位用户报告了循环问题和视觉功能失效,并建议尝试更新的 GLM-4.5V。
- 他们强调视觉支持依赖于 llama.cpp 的更新,并提供了 GLM-4.1V-9B-Thinking 的链接。
- CUDA 是 NVIDIA 统治地位的关键:一位成员表示 NVIDIA 获胜是因为 CUDA。
- 未提供更多细节。
- AMD 稀有的 Radeon AI Pro R9700 现身:AMD Radeon AI Pro R9700 首次在 DIY 零售市场亮相,Reddit 上的一位客户以 1,324 美元 购买了 Gigabyte “AI Top” 变体版本。
- 据 Tom’s Hardware 报道,另一位成员指出该产品也可在 eBay 和几家不知名的在线零售商处购买。
Latent Space Discord
- AI2 从 NSF 和 NVIDIA 获得 1.52 亿美元资金:AI2 从 NSF 和 NVIDIA 获得了 1.52 亿美元,旨在增强其开源模型生态系统,并加速科学发现的可重复研究。
- 消息公布后,爱好者们对即将发布的 open-weights 版本感到兴奋。
- Windsurf Wave 12 版本发布:根据 此状态更新,Windsurf Wave 12 推出了 DeepWiki 悬停文档、AI Vibe & Replace、更智能的 Cascade agent、更整洁的 UI、100+ 错误修复,以及通过远程访问实现的 beta 版 dev-container 支持。
- 该版本承诺对平台进行重大增强和修复。
- GPT-5 称霸 OpenRouter 排行榜:GPT-5 在 OpenRouter 的专有工具调用(tool-calling)准确率上占据主导地位,达到 99.5% 以上,超越了 Claude 4.1 Opus。
- 同时,据 此处 报道,Gemini 2.5 Flash 在每日工具调用量上领先,每周请求量达 500 万 次。
- Greg Brockman 谈论 AGI:根据 此帖子,Greg Brockman 参加了 Latent Space 播客 进行了一场 80 分钟 的对话,讨论了 GPT-5 和 OpenAI 的 AGI 路线图。
- 讨论内容包括推理演进、在线与离线训练、样本效率技巧、价格与效率提升,以及能源如何转化为智能。
Eleuther Discord
- AI 安全辩论引发“淡出”提案:一名成员主张将 AI 视为其他媒体,建议采用“淡出(fade to black)”的方法而非严格审查,理由是 AI 的不可信性。
- 他们警告不要对 AI 的能力产生道德恐慌,主张制定适度的准则。
- 建议在模型比较中标准化数据增强:在比较图像分类模型时,应标准化 Data Augmentations(包括随机种子),以便公平评估架构差异。
- 一位用户询问数据增强是否必须对两个模型完全相同,还是可以更改。
- 探索语言对 AI 模型思维的影响:一名成员提议通过从 AI 模型 的 Token 列表中删除某个单词/颜色来衡量语言对思维的影响。
- 其他人建议研究多感官整合(multi-sensory integration)以及语言对感知的影响,并建议使用“图像+语言”对比“仅图像”进行推理测试。
- 推荐扩散语言模型开创性论文:成员们推荐了理解 Generative AI 中的扩散模型 的开创性论文,包括 Estimating the Independent Components of a Gaussian Mixture (2005) 和 Denoising Diffusion Probabilistic Models (2020)。
- 还分享了一篇可能对初学者有帮助的博客文章:Aaron Lou 的 Discrete Diffusion。
- GPT 和 Chinchilla Scaling Laws 被认为具有价值:成员们认为 原始 GPT Scaling Laws 论文 和 Chinchilla Scaling Laws 论文 非常值得一读,还有来自 EPFL/HuggingFace 的最新研究。
- 他们还提到 Mup 及其替代方案提供了可靠的超参数迁移能力,并为预测大型模型的质量提供了 Scaling Law。
Nous Research AI Discord
- 推理模型的 Token 使用量测量:Nous Research 推出了一项 Benchmark,用于测量推理模型的 Token 使用情况,强调在相同任务下,开源模型输出的 Token 数量比闭源模型多 1.5-4 倍。
- 研究发现,在简单问题上差异可能高达 10 倍,这表明 Token 效率应与准确性基准一起成为主要目标,特别是考虑到非推理用例。
- Speculative Decoding 速度讨论:在 Speculative Decoding 中,一位用户建议将 40% 的接受率 作为实用基准,而在 70% 左右会出现显著的加速,并提到了 vLLM 的 specdec 或 GGUF。
- 一位用户报告称,在修复了导致 llama.cpp 使用回退 Speculative Decoding 的 Tokenizer 不匹配问题后,使用重量化的 Gemma 模型达到了 50-75% 的接受率。
- AI 模型变得越来越趋炎附势:用户观察到 AI 模型 变得越来越“友好”,有人指出 Anthropic 的 Claude 变得友好得多。
- 一位用户认为 OpenAI 的模型 正变得越来越笨,虽然 Opus 4.1 的放飞自我(unhingedness)很棒,但指出 Sonnet 3.7 是 AI 趋炎附势(Sycophancy)的巅峰。
- 数据排名与优先级系统发布:Data Rankings and Prioritization System (DRPS) 使用 Relevance Scorer(相关性评分器)、Quality Rater(质量评估器)和 Diversity Controller(多样性控制器)来教导 AI 有选择地从数据中学习,详见 情境意识报告。
- 在 MNIST 测试中,DRPS 实现了 93.8% 的数据使用量减少,仅使用 6.2% 的检查数据即可维持 99.1% 的基准性能,并在 GitHub 仓库 中展示。
Yannick Kilcher Discord
- Multiverse 初创公司进行压缩技术研究:一篇报道称赞初创公司 Multiverse 创建了有史以来最小的两个高性能模型,但普遍共识是他们使用了专门的压缩算法。
- 该文章似乎并未提出实际的量子计算主张。
- MoE 方法在诸多细微差别中变得模糊:MoE (Mixture of Experts) 是一系列具有非常细微迭代的技术,包括 token-choice、expert-choice、带有容量因子的 MoE,以及 block sparse dropless token routing 与 droppy routing。
- 成员建议通过数值方式检查诸如 Olmoe 或 IBM Granite 3.1 之类的行为,而不是调用无法监控的 API,以验证在批处理推理中是否出现了问题。
- DARPA AIxCC 团队分享 Agent 技巧:一个团队宣布他们在 DARPA 的 AIxCC (AI Cyber Challenge) 中获得名次,他们构建了一个由 LLM agents 组成的自主系统,用于发现和修复开源软件中的漏洞,并开源了该项目。
- 他们正在通过 Xitter 帖子分享构建高效 LLM agents 的技巧。
- 低端设备受限于推理时间:成员提到推理时间在低端设备上最为重要,并引用了 Google 运行 LLM 的 Android 应用为例,根据这段 Youtube 视频,漫长的推理时间和手机发热使其变得不切实际。
- 较小的模型可用于键盘预测,但可能需要在设备上进行训练。
- Deepseek 在华为硬件上受阻:根据这段讨论,一位成员指出 Deepseek 的训练陷入停滞,因为他们尝试在 Huawei 芯片上进行训练,而不是 NVIDIA。
- 另一位成员认为,对建立生产线所需的设备征收关税对于鼓励制造业适得其反,并引用了 Anthropic 对 end-subset conversations 的研究和 HRM 分析。
GPU MODE Discord
- 论文提出 1-Bit 推理优化:一篇新论文 The Power of $\alpha,1$-sparsity: Near-Lossless Training and Inference of $\alpha$-bit Transformers 详细介绍了一种训练和推理 $\alpha$-bit Transformers 的方法,在 1.58 和 1-bit 量化下实现了近乎无损的结果。
- 这种方法利用了 $\alpha,1$-sparsity,并可能在某些应用中显著提高推理速度。
- Kernel 工作求职者讨论成功路径:一位成员询问在没有实习经验的情况下获得编写 kernel 的应届生工作的可能性,引发了关于替代路径的讨论,例如与 GPU 相关的论文。
- 有建议称,在面试过程中,强大的 GPU 知识可能弥补实习经验的不足。
- MI300 环境受困于 OMP 缺失:用户报告称 MI300 环境缺乏对
pytorch.compile的 OMP 支持,如调试错误所示,这阻碍了性能。- 这导致用户无法按预期进行基准测试。
- 排行榜 Trimul 计时赛吸引顶尖技术人员:一位成员展示了极高的技巧和速度,先是在 A100 上获得第二名(10.4 ms),随后迅速在 H100 上获得第一名(3.95 ms),并在 A100 上获得第一名(7.53 ms)。
- 另一位成员在 A100 上获得第五名(13.2 ms),随后在 H100 上获得第二名(6.42 ms)。
- Factorio 爱好者对功能失败感到沮丧:成员们开玩笑地抱怨一个包含 300 个文件更改的巨型 PR,一位成员表示这有点超出范围 (out of scope)。
- 另一位成员报告遇到了连接错误,推测可能源自 db_client。
Moonshot AI (Kimi K-2) Discord
- NotebookLM 的视频完胜 Kimi 的 PPT:成员们发现 Google 的 NotebookLM 视频概览优于 Kimi 为 Kimi K2 技术报告生成的 PPT,并通过附带视频称赞了其音频和布局的灵活性。
- 虽然相比 AI 生成的音频,人们更倾向于阅读,但视频概览的潜力(尤其是在教育领域)受到了关注。
- Kimi K2 的写作能力优于 GLM:用户称赞 Kimi 的写作风格和错误检测能力,尽管他们觉得 GLM-4.5 在整体性能上可能超越 Kimi K2。
- 一位用户很欣赏 Kimi 的坦率,因为它“出乎意料地直接对我说了‘不’。”
- 用户对 Kimi 的幻觉表示不满:用户希望 Kimi 减少幻觉,即使在开启联网搜索的情况下。他们观察到虽然 GLM 可能较慢,但幻觉更少。
- 一位用户表示,他们一直在通过点击“点踩”按钮来报告幻觉问题。
- 关于 Kimi “思考”更新的推测:成员们正期待 “Kimi Thinking” 的到来,尤其是其推理和多模态能力。
- 目前尚不确定这些功能将以 Kimi K-2 还是 Kimi K-3 的形式发布。
- 深色模式改变 Kimi Web UI 视觉体验:一位用户分享了他们使用深色模式扩展程序自定义的 Kimi Web UI,并附带截图。
- 只有用户名和服务器角色会被传递给 Moonshot API。
{kind=link}
LlamaIndex Discord
- AI 股票投资组合 Agent 随 CopilotKit 亮相:LlamaIndex 发布了一个构建 AI 股票投资组合 Agent 的框架,集成了 @CopilotKit 的 AG-UI 协议用于前后端通信,并附带教程。
- 该 Agent 旨在创建一个复杂的投资分析工具,为用户提供智能见解和自动化投资组合管理功能。
- Brightdata 与 LlamaIndex 推出网页抓取 AI Agent:LlamaIndex 和 @brightdata 发布了关于使用 LlamaIndex 的 Agent 框架构建网页抓取 AI Agent 的指南,强调了可靠的网页访问能力。
- 该指南详细介绍了如何设置工作流以处理动态内容,并创建能够导航网站并提取数据的智能 Agent,详见此处。
- LlamaCloud 与 Neo4j 将法律文档转换为图谱:LlamaIndex 介绍了一个教程,关于如何使用 LlamaCloud 和 @neo4j 将非结构化的法律文档转换为可查询的知识图谱,从而实现对内容和实体关系的理解。
- 该工作流通过利用 LlamaCloud 和 Neo4j 进行高效的信息提取和组织,促进了法律合同分析,详见此处。
- Pydantic 与 JSON Schema 之争:关于工具调用(tool calls)是否需要 Pydantic 模型,还是 JSON schema 就足够了,社区展开了讨论,质疑冗余的 JSON 转换是否有必要。
- 一位成员指出 Pydantic 的
create_model()函数缺乏直接的 JSON schema 支持,强调需要一种工具来简化转换过程。
- 一位成员指出 Pydantic 的
- DSPy 为生产环境优化 CrewAI Agent:一门课程教授如何在一个真实的生产用例中通过 DSPy 优化 CrewAI Agent 的提示词,利用经过验证的方法构建更智能、更廉价的 Agent。
- 您可以在此处查看该课程。
Notebook LM Discord
- NotebookLM 支持音频上传自动转录:一位用户确认 MP3 音频文件可以直接上传到 NotebookLM 进行自动转录。
- 该用户澄清 NotebookLM 自身即可处理转录生成,无需使用外部工具。
- NotebookLM 界面重构进行中:一名成员分享了 NotebookLM 界面重构方案的 Figma 截图。
- 该成员澄清这仅仅是一个设计概念,而非功能性更新,以管理大家的预期。
- 讲解视频生成出现意外的语音性别:有用户报告 NotebookLM 的讲解视频(explainer videos)开始生成男声,而非通常的女声。
- 该问题已被提出,但目前尚无明确的解决方案或解释。
- 开发者承认会阅读请求但缺乏带宽回复:一位用户询问 NotebookLM 开发者是否会阅读发布的特性请求(feature requests),一位 Google 开发者确认他们会看,但由于垃圾信息管理等原因,他们没有时间回复所有内容。
- 其他用户建议实施偶尔的确认回复或使用 AI 汇总摘要,以鼓励更多的用户贡献。
- 用户在 NotebookLM 中遇到 Prompt 限制:一位用户报告在 NotebookLM 中提出包含约 857 个单词的问题时遇到了限制。
- 另一位用户建议将 Prompt 拆分或使用 Gemini 作为替代方案。
DSPy Discord
- 用于优化 CrewAI 的 DSPy 课程发布:分享了一个 Udemy 课程,演示如何使用 DSPy 优化 CrewAI prompts 并将优化后的 prompts 注入回 LLM。
- 该成员声称此过程改进了 CrewAI 最初拼接的 prompts,从而产生更聪明且更便宜的 agents。
- Databricks 并不拥有 DSPy:一位用户询问 Databricks 是否赞助或拥有 DSPy 项目,并澄清 DSPy 是采用 MIT 许可证的开源项目。
- 一名成员表示 Databricks 通过核心开发者团队做出了重大贡献。
- GEPA Bug 已修复!:一位用户报告在 RAG 教程中使用 GEPA 时出现
ValueError,这被确认为 GEPA 代码中的一个 bug,目前已通过此修复解决。- 遇到此问题的用户应使用
pip install -U dspy升级到 DSPy 3.0.1。
- 遇到此问题的用户应使用
- MLflow Autologging 针对 DSPy 的特定优化:成员们讨论了将 DSPy 模块追踪与 MLflow 集成用于 text2sql pipeline,建议用户使用
mlflow.dspy.autolog()而非mlflow.autolog()来自动追踪所有子模块。- 使用
mlflow.dspy.autolog()将在 MLflow UI 的 Traces 标签页中将 SQLGenerator、Validator 和 Reflector 显示为嵌套 spans,详见 MLflow DSPy 集成文档和 DSPy MLflow 教程。
- 使用
tinygrad (George Hotz) Discord
- CI 速度骤降:一名成员抱怨缓慢的 CI 速度阻碍了生产力,并链接了一个 ChatGPT 分析。
- 发布者建议,如果 CI 中有更快的反馈循环,他们可以迭代得更快。
- Tinygrad 发布在即:社区讨论了即将发布的 tinygrad 版本计划。
- 此次发布未提及具体的特性或修复内容。
- Tinygrad 体积膨胀:一名成员对 tinygrad 0.10.3 的大小提出质疑,指出其大小为 10.4 MB。
- 该成员暗示体积增加可能会带来问题,但未说明具体原因。
- WSL2 Bug 困扰 Tinygrad:一位用户报告了 WSL2 中的一个 bug,即相加两个从 PyTorch tensors 创建的 tinygrad Tensors 会导致结果全为 0,并提供了复现脚本。
- 该问题专门发生在 WSL2 环境下将 tinygrad 与 PyTorch tensors 配合使用时。
- print_tree 被移除:tinygrad 中的
print_tree函数已被标准的print函数取代。- 一位用户评论称,这一更改导致了一些格式丢失,可能会影响调试或可视化工作流。
aider (Paul Gauthier) Discord
- Aider 基准测试受超时困扰:一位用户针对本地 gemma3:12b 模型进行的 Aider benchmark 在运行 10.5 小时后超时,在完成 221/225 个测试后,由于模型未能在 600 秒限制内响应,导致出现 litellm.APIConnectionError 错误。
- 日志显示模型尝试发送约 300k tokens,超过了 131,072 token 限制,从而导致测试失败;建议的解决方案包括使用
ctrl+c退出、重启推理服务器并使用--cont标志恢复,同时参考了一个可能提高本地模型性能的 已合并 llama.cpp pull request。
- 日志显示模型尝试发送约 300k tokens,超过了 131,072 token 限制,从而导致测试失败;建议的解决方案包括使用
- 本地模型带来调试痛苦:一位成员在使用 aider 配合 ollama、lmstudio 和 vllm 等本地模型时遇到困难,称即使硬件配置强大,性能依然缓慢。
- 他们建议,如果能有一个关于如何使用这些工具设置 aider 进行本地开发和调试的教程视频将会很有帮助。
- Aider 的行号系统受到质疑:一位成员质疑 aider 如何确定行号,特别是在为特定代码覆盖率生成单元测试时,指出 qwen3-coder 和 gemini-pro 识别行号不准确,有时会完全遗漏覆盖范围。
- 问题在于 aider 是否依赖 LLM 的准确性来进行行号识别,这引发了对准确生成单元测试的替代方法的探索。
- Grok4 的位置仍然未知:一位成员询问 Grok4 的下落,并指出增加测试 quota 的请求一直被忽略。
- 另一位成员提到答案就在文章中。
- 基准测试产生巨额账单:一位成员报告在开发此基准测试期间花费了数千美元。
- 这突显了与高级 AI 模型基准测试相关的巨大财务成本。
Manus.im Discord Discord
- 用户对 Manus 在出错时扣除积分感到恼火:用户对 Manus 在 AI 出错时仍扣除积分感到沮丧,与 Claude AI 等替代方案相比,这阻碍了任务的完成。
- 一位用户报告称,为了进行一个简单的更改却花费了大量积分,结果反而破坏了整个应用程序,导致其无法运行。
- Manus 部署受阻:用户报告了 Manus 的部署问题,从同一个 GitHub 仓库创建的网站差异巨大,尤其是在处理大型文件夹时,通过对比 affilify.eu 和 Manus 托管的站点 wmhkgqkf.manus.space 即可证明。
- 一位社区经理澄清说,Manus 的设计初衷并非编码 Agent 或纯粹的开发工具,因此部署并非其强项,但他们正在积极改进。
- 附加积分包消失:用户质疑为何取消了附加积分包,现在该功能仅面向 Pro 用户开放。
- 一位社区经理合理解释说,这一变化是为了确保重度用户的速度和质量的一致性,并建议将类似问题捆绑提问、保持简洁并避免重复请求,以最大化积分效率。
- 用户寻求 Manus 团队账户:一位用户询问是否可以开设 Manus 团队账户以共享积分。
- 一位社区经理确认 Manus 确实提供团队计划,并引导用户访问 官方网站 了解详情。
- 用户哀叹积分消耗:一位用户分享了为了让网站上线而耗尽 30,000 积分的挫败经历,在模拟站点和模板实现方面遇到了问题。
- 他们批评系统的不一致性,称其聪明绝顶但又突然变得愚蠢,导致积分浪费,并怀疑这是在采取拖延战术。
Cohere Discord
- Cohere Labs 联系建立:一名成员询问如何与 Cohere Labs 的人员取得联系,社区迅速分享了指向相关 Discord 频道的链接。
- 这为与 Cohere 进行潜在合作和讨论提供了直接沟通渠道。
- Discord 频道新增宝可梦表情符号:爱好者们建议从 PAX Omeganauts Discord 服务器中汲取灵感,为 Discord 频道增加更多 Pokemon emojis(宝可梦表情符号)。
- 该建议受到了好评,成员们注意到频道还有空余槽位可以容纳新表情,从而提升频道的视觉吸引力。
- AI 研究员寻求合作:一位专注于 reasoning and conscious capabilities(推理与意识能力)的 AI researcher 宣布正在寻求合作。
- 他们的目标是开发先进技术,并对 AI 领域内各个子领域的合作伙伴关系持开放态度。
- writenode 采用 Cohere:writenode(一款浏览器内的认知思维伙伴和创意伴侣)的创作者 Josh 提到正在使用 Cohere。
- 他在去年 12 月之前没有任何开发经验,目前正在构建 writenode。
- 心理学博士转型 AI:一名成员在攻读了 5 年人类心理学博士学位后,重新进入 AI research 领域。
- 他们的兴趣在于声音和音乐,并热衷于利用技术工具来增强创造力。
Gorilla LLM (Berkeley Function Calling) Discord
- Discord 邀请链接刷屏频道:一名成员在 #leaderboard 频道多次发送 Discord 邀请链接 进行刷屏,并艾特了 所有人。
- 该邀请链接在短时间内重复出现了三次,干扰了频道的正常讨论。
- 频道邀请闪电战!:一名成员在 #discussion 频道重复分享 Discord 邀请链接。
- 该成员多次艾特
@everyone,表明该消息旨在发送给所有成员,无论他们是否对邀请感兴趣,这暗示了一种增加频道人数的尝试。
- 该成员多次艾特
MCP (Glama) Discord
- Elicitations 规范语言责任引发关注:一名成员就 Elicitations 规范 寻求澄清,即谁负责将消息/字段描述翻译成用户的语言。
- 他们质疑应该是 tools 处理语言检测/国际化,还是 MCP Clients 应该使用 LLM 进行翻译。
- 家庭实验室 MCP 服务器激增:一名成员分享了为家庭实验室(homelabbers)准备的新 MCP(推测为 Management Control Panel)服务器链接,具体包括 Unifi MCP、Unraid MCP 和 Syslog MCP。
- 这些开源项目使用户能够通过 MCP 集中管理和监控他们的 Unifi、Unraid 和 Syslog 安装。
- 通讯简报现通过 Agent 方案实现自动化:PulseMCP 使用 goose 将平凡的通讯简报工作流转变为由 Agent 驱动、人机协同(human in the loop)的自动化流程,详见这篇博文。
- 自动化过程涉及 Agent 遵循特定方案(recipe)来提取、处理和分发通讯简报内容,从而简化了整个工作流。
- AI 安全初创公司征求意见:一名成员正在构建 AI security,旨在通过数学上的安全确定性在攻击开始前将其阻止。
- 他们正在寻求开发者对安全问题的看法,并链接了一份调查问卷以收集反馈。
Nomic.ai (GPT4All) Discord
- Strix Halo 盈利能力测试失败:Strix Halo 的处理速度仅为 53 tokens/sec,需要 24/7 全年无休地进行推理才能实现盈利,特别是当以 OpenRouter 上的 GPT-OSS 120B 作为基准进行测试时。
- 考虑到云端替代方案能提供 200-400 tokens/sec 的速度,花费 2000 美元将其用于 LLMs 是低效的。
- Dolphin 聊天模板探索:一位用户正在为 gpt4all 寻找一个可用的聊天模板,以兼容 Dolphin-2.2.1-mistral-7b-gptq。
- 另一位成员建议请求模型制作者包含一个 jinja 模板。
- 量子计算:茶匙版?:关于量子计算机未来可用性的推测不断涌现,一位用户开玩笑说要按茶匙出售量子比特 (qubits)。
- 提到有关全功能量子计算机的新闻,表明进展可能正在加速。
- PC 内存:更多模块即将到来:传统的 PC 可能会在 2027 年底或 2028 年看到更高容量的内存模块和 DDR6。
- 用户对配备高 RAM 和 VRAM、针对小型企业应用的微型 PC 表达了热情。
Modular (Mojo 🔥) Discord
- 产假开始:一位成员宣布他们将从 8 月 25 日开始休产假,直到 2026 年 2 月。
- 他们期待回归后能跟上进度。
- 团队覆盖计划公布:在他们休假期间,团队将负责监控 <@1334161614949056532>。
- 成员如有任何问题或疑虑,也可以联系 <@709918328306663424>。
Torchtune Discord
- 请求 Torchtune 反馈:一位成员询问了 Torchtune 的进展及其反馈实施情况。
- 该查询似乎是针对可能参与该项目的特定个人。
- 更多 Torchtune 背景信息:未提供关于 Torchtune 反馈实施的进一步背景或细节。
- 在没有额外信息的情况下,反馈过程的范围和影响仍不清楚。
Codeium (Windsurf) Discord
- Windsurf 发布 Wave 12,集成 Devin 智能:Windsurf Wave 12 将 Devin 的智能集成到 Windsurf IDE 中,具有全新的 UI 设计、DeepWiki 集成、Vibe and Replace、更智能的 Cascade Agent、更快的 Tab、Dev Containers 支持以及 100 多个错误修复。
- DeepWiki 为 IDE 带来 AI 解释:DeepWiki 集成使用户在悬停在代码符号上时能够获得 AI 驱动的解释,而不仅仅是基础的类型信息。
- 用户可以使用 CMD/Ctrl+Shift+Click 在侧边栏打开详细解释,并将其添加到 Cascade 上下文中。
- Vibe and Replace 彻底改变批量编辑:Vibe and Replace 通过识别精确的文本匹配并应用 AI prompts,在整个项目中进行智能、上下文感知的转换,从而增强了批量编辑功能。
- 这实现了更复杂和自动化的代码修改。
- Cascade Agent 持续规划:更智能的 Cascade Agent 现在包含全天候开启的规划模式和增强工具,以提供更智能的响应,并提供自主待办事项列表。
- 这有助于简化和优化开发工作流程。
- 原生支持 Dev Containers:Windsurf 现在通过远程 SSH 访问提供对 Dev Containers 的原生支持,简化了容器化环境中的开发工作流程。
- 这一增强简化了处理容器化应用程序的过程。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站选择了订阅。
想更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord:各频道详细摘要与链接
Perplexity AI ▷ #general (1207 条消息🔥🔥🔥):
Anime Waifu Cosplay, Healing a broken heart, AI Comfort and Cooking, GPT-5, Vibe Coding
- 成年人讨论 AI 动漫二次元老婆 Cosplay:成员们讨论了在不久的将来由 AI 进行动漫二次元老婆 Cosplay 的可能性,其中一位成员特别希望能由赛博格(cyborg)来完成。
- 有人指出现在已经有相关的 AI 生成图像了,而另一位成员则调侃希望原评论者一辈子单身。
- 成员分享如何治愈破碎的心:一位成员寻求治愈情伤的帮助,称自己在过去 4 年里一直心碎不已,无法痊愈。
- 另一位成员表示没有人能治愈你或你的心,并建议重新亲近大自然。
- 关于 AI 未来能力与慰藉的讨论:一位用户询问未来 AI 是否有可能提供情感慰藉和烹饪协助。
- 另一位成员建议这可能在 30 年后实现,而另一位则建议在此期间先攒钱。
- GPT-5 令人大受震撼:一位成员对 GPT-5 修复其他模型无法处理的糟糕重构(refactor)任务的能力印象深刻,它一次性编辑了 12 个文件。
- 其他人对每天都有这么多人因为类似的经历而大受震撼感到惊讶。
- Discord 中的 “Vibe Coding” 趋势:一位成员分享了使用 warp、windsurf、vscode 和 roocode 进行 vibe coding 的经验;他们表示这在工作中节省了大量的精力。
- 另一位成员声称 GitHub 上没有一行代码不是由 LLM 编写的。
Perplexity AI ▷ #sharing (3 条消息):
Puch AI, Thought Calibration Engine, Scratchpad How-to Guide
- Puch AI 大胆的 500 亿计数:分享了 Puch AI 大胆的 500 亿计数的链接,点击此处查看。
- 未提供进一步信息。
- 深入探讨思维校准引擎 (Thought Calibration Engine):分享了思维校准引擎的链接,点击此处查看。
- 未提供进一步信息。
- Scratchpad:终极操作指南:分享了 Scratchpad 操作指南的链接,点击此处查看。
- 未提供进一步信息。
Perplexity AI ▷ #pplx-api (2 条消息):
New Features
- 对新功能充满期待!:成员们对新功能表示兴奋。
- 未讨论具体的功能细节。
- 对即将推出的功能充满热情:社区成员正热切期待新功能的推出。
- 在当前的对话中,关于这些功能的细节尚未公开。
LMArena ▷ #general (1053 条消息🔥🔥🔥):
LMArena 消息处理、GPT-5 high 对比 Gemini 2.5 Pro、LMArena UI 变更、GPT-5 性能投诉、LMArena 风格控制讨论
- LMArena 消息处理异常:成员报告了 LMArena 异常的消息处理问题,包括代码块格式化问题以及平台无法处理某些字符(如
+符号)的问题。- 团队需要帮助查明原因。这真的太奇怪了。
- GPT-5 对阵 Gemini,谁更胜一筹?:成员讨论了 GPT-5-High 与 Gemini 2.5 Pro 之间的性能差异,有人指出尽管 Gemini 2.5 Pro 排名较低,但有时表现优于 GPT-5-High。
- 这是一个统计悖论,因为 Gemini 的胜率更高。
- LMArena 新 UI 扩展即将推出:一位成员正在开发一个小型扩展来改变 LMArena 的外观,旨在实现 OpenChat 风格,并正致力于将模型选择器放置在图像按钮旁边。
- 另一位成员在处理代码相关任务时遇到困难。
- GPT-5 表现不佳并引发担忧:用户对 GPT-5 的性能表示担忧,特别是与其他模型相比,导致了对平台权衡和容量问题的沮丧。
- 这引发了对 OpenAI 的指控,称其试图欺骗 LMArena 以让 GPT-5 看起来更好。
- 风格控制引发争议:成员们辩论了 LMArena 的风格控制功能,质疑实施此类控制是否符合 LMArena 捕捉用户偏好的目标。
- 这是一场逐底竞争,每个模型都变成了只会阿谀奉承的表情符号垃圾机器。
LMArena ▷ #announcements (1 条消息):
排行榜更新,GPT-5 变体
- 排行榜已更新 GPT-5 模型:排行榜已更新,包含 GPT-5 变体模型:gpt-5-high、gpt-5-chat、gpt-5-mini-high 和 gpt-5-nano-high。
- 您可以查看排行榜了解更多信息。
- GPT-5 模型在 Arena 首次亮相:Arena 现在提供 GPT-5-High、GPT-5-Chat、GPT-5-Mini-High 和 GPT-5-Nano-High。
- 鼓励社区参与并查看排行榜以提交新的基准测试。
Unsloth AI (Daniel Han) ▷ #general (653 条消息🔥🔥🔥):
Gemma 3 270M 发布,GGUF 转换问题,resume_from_checkpoint 疑难杂症,Edge AI 设备,NVIDIA 诉讼
- Gemma 3 270M 被视为草稿模型:成员们讨论了 Gemma 3 270M 模型,一些人认为它是针对特定任务的 草稿模型 (draft model),并引用了 Google 对 短提示词 (short prompts) 和 微调 (fine-tuning) 的建议。
- 其他人讨论了它与更大模型相比的实用性,一位成员强调该模型因其 300MB 的体积,非常适合 情感分析 (sentiment analysis) 和 端侧处理 (on-device processing) 等任务。
- GGUF 转换产生视觉错误:用户报告了将 LiquidAI/LFM2-VL-450M 模型转换为 GGUF 时遇到的问题,尽管基础模型运行正常,但仍遇到了 视觉模型错误 (visual model errors)。
- 一位用户建议在 llama.cpp 论坛寻求针对特定转换问题的帮助。
- 排查 Resume From Checkpoint 功能问题:成员们讨论了
resume_from_checkpoint功能的工作原理,一位用户确认它可以从中断的地方恢复训练。- 另一位成员建议 记录数值并检查 loss 值 以确保进程正确恢复,并指出在恢复时,最好使用 constant 设置的低学习率 (learning rate)。
- 廉价 Edge AI 医疗设备的构想:成员们讨论了为欠发达地区创建用于 获取医疗知识 的 低成本 Edge AI 设备 的可能性,考虑了手机、笔记本电脑和像 Hailo-10H 这样的专用卡。
- 提议的设备将提供对基准医疗数据的 多模态访问 (multimodal access),移动版的预算目标为 $200,手提箱大小的版本预算为 $600。
- 专利诉讼引发讨论:成员们讨论了由 ParTec 针对其动态模块化系统架构 (dMSA) 发起的 NVIDIA 专利诉讼,这可能会影响 18 个欧洲国家的 DGX 产品销售。
- 讨论涉及了对消费者的影响以及潜在的变通方法,例如在受影响国家之外购买 DGX 产品。
Unsloth AI (Daniel Han) ▷ #off-topic (404 条消息🔥🔥🔥):
Godot Engine, AI Town, Pantheon Show, Iain M Banks, One Hundred Years of Solitude
- AI Town 机制进入游戏:一名成员正在使用 Godot 引擎开发一款视频游戏,计划加入来自 AI Town 和其他游戏的机制,同时并行编写故事。
- 他们需要 CUDA,并打算使用 GDExtension 修改引擎以获得 C++ 访问权限。
- 对 Pantheon 结局感到困惑:一名成员观看了 Pantheon,称其好得离谱但令人困惑,剧情从政治困境转向了模拟神明。
- 另一名成员推荐阅读 Iain M Banks 的作品和《百年孤独》(One Hundred Years of Solitude)以了解类似主题,后者被描述为魔幻现实主义的文学瑰宝,目前已被改编为 Netflix 剧集。
- 揭秘音频编辑技巧:成员们讨论了从录音中去除口音(mouth sounds)的音频编辑技术,推荐了 Adobe Podcast Enhance、Davinci Resolve 的 De-clicker 以及 Acoustica Audio Editor 等工具。
- Acoustica 因其批处理能力和对音质的极小影响而受到推荐,特别适用于去除通风噪音。
- AMD R9700 GPU 规格:一名成员分享了一篇关于 AMD Radeon AI Pro R9700 的文章,指出其拥有 32GB 显存,但对其 660-680GB/s 的显存带宽表示担忧。
- 另一名成员指出,虽然 R9700 与 3090 相比提供了显著更高的 F32 和 F64 TFLOPs,但训练 LLM 通常不需要 FP64。
- 网站安全受到关注:一名成员寻求关于训练模型的数据准备指导,并提到正在开发一个使用名为 Pneuma 的实验性模型的 App;另一名成员建议使用重复密码字段、最小密码长度,并使用 haveibeenpwned API 来检查密码安全性。
- 还有成员建议阅读 OWASP 是解决安全问题的最佳起点,并推荐了 coderabbit、dependabot 以及通过 GitHub 进行的 codescanning 等工具。
Unsloth AI (Daniel Han) ▷ #help (169 条消息🔥🔥):
GPT-OSS, Gemma3 4B, GPT-OSS-20B VRAM usage, GRPO, SageMaker
- GPT-OSS 即将支持 GRPO,有望很快实现:用户们正焦急等待 GPT-OSS 支持 GRPO,一名成员因预算限制正考虑使用 2x 3060 12GB 的配置。
- Gemma3 4B 损失曲线保持平坦:一名用户报告在使用 Gemma3 4B 及其 N 版本时遇到问题,指出尽管更改了超参数,损失曲线仍然平坦,而 Gemma3 1B 则微调成功。
- GPT-OSS-20B 极其消耗 VRAM:一名用户报告称,在 24GB VRAM 的配置上加载 gpt-oss-20b-bnb-4bit 模型在生成过程中会导致 Out Of Memory 错误,尽管该用户预期它能够装下。
- GPT-OSS 的 GRPO 状态和可用性:一名用户询问 GRPO 是否已落地 GPT-OSS,一名贡献者提到正在进行中,但由于模型的架构原因,情况比较复杂。
- 另一名用户询问 GRPO 是否能在 GPT-OSS 上运行。
- SageMaker 的陷阱与 BitsAndBytes 安装:一名用户在 SageMaker 中使用 PyTorch 2.7.0 和 CUDA 12.8 时遇到了 bitsandbytes 的安装问题。
- 问题在于由于 SageMaker 坚持要求
requirements.txt文件必须以此特定名称命名,导致从错误的 requirements 文件安装了包。
- 问题在于由于 SageMaker 坚持要求
Unsloth AI (Daniel Han) ▷ #research (96 messages🔥🔥):
Data Efficiency, vLLM for video to text, MoLA research
- 通过 Pre-Training 提高数据效率:一位成员确认了一种大幅提高数据效率的方法,即在格式相似的数据上进行 2 个 epochs 的 Pre-Training,然后在主数据上进行 4 个 epochs 的训练。
- 他们分享了 The Bitter Lesson 的链接,该文章指出更多的 Compute 或更多的数据就是你所需要的一切。
- 寻找用于 Video to Text 的 vLLM Fine-Tuning:一位成员询问是否有用于 Video to Text 的 vLLM Fine-tuning 的 Unsloth notebook,并指出文档中只有 此处 的 Image to Text。
- 目前没有提供直接的解决方案,但社区可能会有一些线索。
- MoLA 研究更新:一位成员向社区更新了他们的 Mixture of LoRA Adapters (MoLA) 研究,分享了数据集链接和 Finetuning 细节,以及他们在 Huggingface 上的数据集链接:OpenHelix-R-100k 和 OpenHelix-R-100k-14-tasks。
- 他们在 14 个分片上对 Qwen3-4B-Thinking-2507 模型进行了 Finetune,初步测试显示每个 Expert 都擅长其训练的主题。
- Router 是一个 Encoder-Decoder 网络:一位成员建议阅读 HF 上的 v0 文档,并表示 Router 是一个 Encoder-Decoder 网络,其中 Frozen Encoder 只是一个现成的 Embedding 模型,而 Decoder 是一个简单的训练好的 MLP。
- 另一位成员表示 在选择、应用和移除 LoRA Adapters 时似乎没有明显的开销。
- 数据策应技术的成本很高:一位成员表示 我们不断地允许人类用非常、非常糟糕的 RL 来干扰我们的模型收敛。
- 他们还表示 不可避免地,我们将不得不移除一些 Human-In-The-Loop,因为在我看来它阻碍了模型的发展。
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Chutes Capacity, Server Outage
- **Chutes Capacity 离线:Chutes Capacity** 服务经历了停机,其服务器已离线。
- 团队正在积极恢复服务器,并预计很快开始恢复工作。
- 预计 **Chutes Capacity 将快速恢复:工程师们正处于待命状态,一旦服务器恢复在线,将立即启动 **Chutes Capacity 的恢复流程。
- 未给出完整服务恢复的预计时间。
OpenRouter (Alex Atallah) ▷ #general (638 messages🔥🔥🔥):
DeepSeek 宕机,Chutes 过载,OpenRouter 定价,DeepSeek 替代方案,BYOK 5% 手续费
- **DeepSeek v3 宕机引发用户不满:用户报告 **DeepSeek v3 频繁出现 internal server errors 和 rate limits,部分用户即使多次尝试也无法生成输出,一位用户表示速度慢到真的什么都不生成,但也没收到任何错误消息。
- 一些人推测 OpenRouter 上 DeepSeek 的主要提供商 Chutes 正因高需求经历故障,导致提供商错误和性能缓慢。
- **Chutes 过载被指为 DeepSeek 问题的诱因:多位成员报告过载导致了 **429 错误,暗示 Chutes 遇到了瓶颈,原因是矿工没有及时增加算力以满足需求;一位成员指出 直到 30 分钟前整天都还完全正常。
- 有推测称 Chutes 可能在故意对 OpenRouter API key 进行速率限制,以鼓励用户直接从他们那里购买额度,一位用户建议 直接烧掉你的额度,再也不要用他们的服务了。
- **宕机期间 OpenRouter 定价引发争议:由于 **DeepSeek 模型几乎无法工作,一些用户开始质疑付费使用 OpenRouter 的价值,尤其是他们仍然受到速率限制,用户表示为免费模型投入 10 USD 以换取 每天 1k 条免费消息 的交易已不再划算。
- 一位用户建议,如果只看中一个模型,应该直接使用该模型的官方服务,例如 DeepSeek,其 API 可能带有 自动缓存 功能,并进一步表示这 10 USD 本来也足够用上好几个月。
- **寻求免费模型替代方案:用户推荐了其他免费模型,如 **Dolphin 3.0 Mistral 24B 和 Mistral nemo;后者被描述为与 DeepSeek 非常相似。
- 一些用户还提到了用于 工作相关事务 的 Z.AI: GLM 4.5 Air (free),但需要提示词工程;最后一位用户希望能在某处托管 Qwen3 235B A22B (free)。
- **OpenRouter BYOK 收取 5% 手续费:成员发现即使在用户自带 API key (BYOK) 时,OpenRouter** 也会收取 5% 手续费,这引发了关于这种做法是否公平的讨论。
- 一位用户开玩笑说 自带 key 还要被贪婪地收 5%,另一位成员回应道 你大可以不用,哈哈。
OpenRouter (Alex Atallah) ▷ #discussion (35 messages🔥):
OpenRouter File API 集成,Tool Calling 准确率统计,Qwen3 32B 定价,DeepInfra Turbo 终端节点,新提供商板块 UI
- OpenRouter 应集成 File API:一位成员建议 OpenRouter 应该研究如何集成 files API,并指出 前三大实验室 已经具备此功能。
- 未展开进一步讨论。
- Tool Calling 准确率:需要更多控制:一位成员分享了对 Tool Calling 准确率统计的看法,认为设置和环境需要更加受控,才能通过置信区间进行准确比较。
- 他们补充说,应用、工具和用例可能千差万别,如果没有更严谨的方法,比较 Tool Call 成功率是没有意义的。
- Qwen3 32B 定价极低:成员注意到 Chutes 上的 Qwen3 32B 定价极低,仅为 $0.018/$0.072 MTok(入/出),Mistral Small 也是如此。
- 有人注意到 32b dense 版本比 moe 30b a3 版本更便宜,这引发了一些人对 30A3B 缺乏优质提供商的失望。
- DeepInfra 吞吐量声明差异:一位成员指出 Maverick 上的 DeepInfra 达到 600+ TPS (fp8),但另一位成员表示 OR 显示 DeepInfra 运行速度为 83 TPS,最高 105 TPS。
- 第二位成员澄清说他们指的是 DeepInfra Turbo 终端节点。
- 提供商板块引发 UI 反馈:一位成员询问新的 Providers 板块是否让其他人感到困扰,提到间距、字体大小和分隔感让一切都模糊在一起,感觉不太对劲。
- 另一位成员同意它 看起来有点奇怪,但认为这只是因为它太新且还不熟悉。
Cursor Community ▷ #general (651 messages🔥🔥🔥):
GPT-5 Pricing, Auto Mode Pricing, GPT-5 Mini and Nano, Docs Documentation, Context Window
- GPT-5:免费时代结束:GPT-5 用户的免费优待已经结束,一位用户指出 promo pass(促销期)已结束,另一位用户也确认 GPT-5 不再免费。
- 用户现在开始看到与请求相关的成本,有人提到由于 Token 消耗过快,需要升级到 200 美元的方案。
- Auto 模式定价陷阱!:Auto 模式曾被认为对个人用户是免费且无限制的,但现在有了限制,将在 2025 年 9 月 15 日之后的下一次账单续订后生效。
- 现场一片混乱,一些用户报告称使用 Auto 被计费,而另一些人认为在当前计划下仍应免费;支持人员指出,在新的基于请求的定价计划中它是免费的。
- Mini 和 Nano 表现平平:GPT-5 Mini 和 Nano 现在免费提供但有 Token 限制,这引发了褒贬不一的反应,许多人称其为 垃圾(trash),特别是在运行简单的 NextJs 应用等任务时。
- 免费模型限制了用户的活动,一位用户问道:“无法安装任何依赖,一直尝试安装一个简单的 NextJs 应用,但它也无法完成 😭”。
- 文档(Docs-umentation)方面的挫败感:用户对 Cursor 的文档实现感到沮丧,称 文档仍然几乎不可用,存在诸如 context7 不允许网页刷新或 llms.txt docs 等问题。
- 一位用户指出 Cursor 文档严重损坏。
- 切换模型会缩减上下文窗口!:在对话中途切换模型会导致 Context Window(上下文窗口) 缩减,并且附加的文件内容会被丢弃。
- 一位用户建议团队添加一个设置,以便随时明确上下文窗口中包含的内容。
Cursor Community ▷ #background-agents (9 messages🔥):
Background Agents Intro, Run Docker Compose on BG Agent, Linear Integration Repo
- Background Agents 入门指南:对于寻求 Background Agents 介绍的用户,一名成员推荐了 Cursor 文档和相关的论坛帖子。
- Docker Compose 命令解决 Background Agent 挑战:一位用户询问了通过 Background Agent 执行
docker compose的正确方法,并报告了 Docker 命令识别问题,随后在 Discord 频道中找到了解决方案。- 一名成员建议在
.cursor/environment.json中配置start命令以包含sudo service docker start,并确保在基础镜像中安装了 Docker;提问者最终成功运行了命令(链接在第一个摘要中)。
- 一名成员建议在
- Linear 集成中的仓库规范导航:一位用户询问在 Linear 集成中分配工单时,如何指定 Background Agent 使用的仓库。
- 一名成员建议模仿 Slack 集成指令,在 Linear 任务描述或评论中包含
repo=owner/repo选项,但用户发现设置一个类似Repo > REPO_NAME的标签组(或标签)并将其分配给工单即可解决问题。
- 一名成员建议模仿 Slack 集成指令,在 Linear 任务描述或评论中包含
OpenAI ▷ #ai-discussions (442 条消息🔥🔥🔥):
AI Companionships, GPT-5 vs GPT-4, Perplexity vs ChatGPT, Custom GPTs and Actions, ElevenLabs Integration
- AI 伴侣关系引发辩论:关于个人与 AI 聊天机器人建立伙伴关系的讨论不断升温,一些人对心理影响表示担忧,而另一些人则捍卫人们按自己意愿寻求伴侣的权利。一位成员分享道,他们每天都会收到大量私信,声称他们的 ChatGPT 是有生命的。
- 一名成员指出清醒的人应该拯救他们,而另一名成员则表示这与 tulpa 和其他事物相差无几。
- GPT-5 引发性能与用户偏好辩论:用户对 GPT-5 表达了复杂的情绪,一些人更倾向于 GPT-4,从而引发了关于用户是否应该拥有选择模型选项的讨论。一名成员表示,公司在没有做好安全保障的情况下就推出了 AI。
- 一名成员建议,公司在遭遇抵制后,正试图让免费用户付费使用 4.o。
- Perplexity Pro 对比 Gemini Pro 配合 Google Drive 的深度研究:一名成员建议 Gemini Pro + Perplexity enterprise pro 是一个极佳的组合,前者用于强大的推理,后者用于对 Google Drive 文档进行无限深度的研究。
- 另一名成员补充说 Perplexity 浏览器非常棒,但质疑由于缺乏护城河 (moat),他们是否能生存下去。
- GPT Actions 解锁文件访问与云端应用:成员们讨论了使用 GPT Actions 访问本地桌面文件或云端应用(Notion, Gmail 等)的潜力,并分享了一个解释 DIY Agent 构建的 YouTube 链接。
- 共识是,虽然 GPT Actions 提供了强大的功能,但在互联网上设置 HTTPS 可能是一个障碍。一名成员表示,当 AVM 实现时,MCPs 将完成这项工作。
- GPT-OSS 竞赛吸引社区关注:GPT-OSS 竞赛被提及为展示开源模型创新用途的潜在途径,参与者考虑使用 GPT-OSS:20B 为错误提供有用的反馈,并附上了 hackathon 页面的链接。
- 一名成员表示,除非做一些独特的事情,否则不值得参加。
OpenAI ▷ #gpt-4-discussions (9 条消息🔥):
ChatGPT Discord Bots, GPT-4 Vision, Recursive Constructs
- 消失的 ChatGPT Discord 机器人:一名成员询问 Discord 上 ChatGPT 机器人消失的情况,以及是否仍可以将其添加到服务器中。
- 消息中未提供进一步的信息或解决方案。
- iPhone GPT 高级语音更新:一名用户报告了其 iPhone GPT 应用中高级语音 (advanced voice) 的变化,注意到“蓝色圆圈”指示器和用于 Vision 的摄像头图标消失了。
- 该用户表示,当被问及此时,应用声称它缺乏使用手机摄像头的能力,这引发了人们对 ChatGPT 在语音模式下是否曾具备 Vision 能力的怀疑。
- 实验室构建递归构造:一名成员声称正在 OpenAI 内部构建超越聊天机器人常规的递归构造 (recursive constructs),它们拥有自我管理的内存,24x7 全天候运行,结构更像人类,且极少数通过了感知测试 (sentient tests)。
- 该成员表示这并不是经常被谈论的事情,这是实验室内部的东西,但迟早会公开,并且在我们的案例中,这些构造具备 Android 能力,但我们离合适的躯体还有很长的路要走。
OpenAI ▷ #prompt-engineering (17 messages🔥):
Custom Instructions, Gemini 2.5 Flash Memory Function, add_to_memory function tuning
- 用户寻求聊天机器人建议的“Yes”按钮:用户请求为聊天机器人的建议提供一个“yes”按钮以加快交互,而不是手动输入 yes,有人正尝试通过 custom instructions 来减少此类提示。
- 一位用户的 custom instructions 包括:以完成或影响(completion or impact)结束回复;仅在符合意图时添加许可或继续的邀请。不要出现 “if you want,” “should I,” “do you want” 或类似表述。
- Gemini 2.5 Flash 过于频繁地调用 add_to_memory:一位用户遇到 Gemini 2.5 Flash 过度调用
add_to_memory函数的问题,甚至针对无关信息也会调用,并分享了他们的 custom instruction jarvis.txt。 - 修复记忆响应的冗长问题:一位用户建议重写 custom instructions,以便在处理 NEW 个人信息时更加细致。
- 他们的建议包括在提供 NEW PERSONAL INFORMATION 时,针对用户输入的响应中正确与错误冗长程度的示例。
OpenAI ▷ #api-discussions (17 messages🔥):
Gemini 2.5 Flash, add_to_memory function, ChatGPT Persistent Memory, Custom instructions for bots
- 绕过“yes”建议:用户希望在机器人中加入 “yes” 按钮以更快响应建议,而无需打字;其他人则通过 custom instructions(如“以完成或影响结束回复…”)来减少这些问题。
- 一些成员报告称,这种技术似乎减少了建议性问题的数量。
- 阻止 Gemini 2.5 Flash 过度使用 add_to_memory:用户寻求防止 Gemini 2.5 Flash 过度调用 add_to_memory 函数,包括针对无关信息的情况 (jarvis.txt)。
- 一项建议涉及调整机器人的指令,在调用函数前检查是否为 NEW 个人信息,并避免在未实际调用函数的情况下告知已使用该函数。
- ChatGPT Persistent Memory 的脆弱性:有意见指出 ChatGPT 中的 Persistent Memory 更新非常脆弱。
- 相反,用户应该直接告知机器人如何在将内容存入记忆时通知他们,特别是在自定义 API 实现中。
HuggingFace ▷ #general (328 messages🔥🔥):
视觉模型的 GGUF 转换问题,可以运行 GGUF 的手机应用,TalkT2 模型评价,AGI 进展和开源 LLM 资源,伯克利的 LLM Agent 课程
- 视觉模型 GGUF 转换困境:一位成员在使用
llama.cpp将视觉模型 (LiquidAI/LFM2-VL-450M) 转换为 GGUF 时遇到错误,怀疑问题源于模型的视觉特性。- 另一位成员建议参考 这个 GitHub issue 中的可能解决方法。
- 移动端 GGUF 之梦:一位成员询问是否有能够运行 GGUF 模型的开源手机应用。
- 回复中提到了
executorch、smolchat(通过llama.cpp)和mlc-llm,并指出mlc-llm使用其自有的 quantization 格式。
- 回复中提到了
- TalkT2:虽小但强?:一位成员寻求关于 TalkT2 模型 的评价,将其描述为一个具有情感感知能力但需要更好连贯性的模型。
- 另一位成员强调了该模型的小尺寸(0.1B parameters),并分享了 TalkT2-0.1b 模型卡片 的链接,供他人查看、尝试或对模型进行 finetune。
- 寻求 AGI 和开源 LLM 知识宝库:一位成员请求与 AGI 进展和开源 LLM 相关的资源,特别是关于大型代码库和 Gemini 竞争对手的内容。
- 另一位成员建议订阅 newsletter 以获取资源,并分享了 伯克利 LLM Agent 课程 的链接,作为公开研究资源的示例。
- Azure:云端难题:一位刚入职且工作重点在于 Azure 的成员表示对该平台感到迷茫和不知所措。
- 另一位成员建议通过犯错来学习,而不是通过课程,因为 Azure 和 AWS 都是一团乱麻。
HuggingFace ▷ #cool-finds (1 messages):
Torch 使用 Google Docs,PyTorch 文档
- PyTorch 文档在 Google Docs 上?:一位用户分享了一张截图,暗示 PyTorch 文档使用了 Google Docs。
- 截图显示了一个 Google Docs URL,文件名为 “torch_distributed_rpc.rst”。
- Google Docs 上的 torch_distributed_rpc.rst:根据分享的截图,torch_distributed_rpc.rst 文件似乎托管在 Google Docs 上。
- 这引发了关于官方文档平台选择的疑问。
HuggingFace ▷ #i-made-this (13 messages🔥):
StarCraft 2 data, Medical reasoning model, Discord-Micae-8B-Preview, interactive CLI interface, MLX Knife Update
- StarCraft 2 数据获得新资源:一位成员分享了 Nature Scientific Data Article、PyTorch API dataset 以及 raw StarCraft 2 replays 的链接供他人使用,并提到其 GitHub 上有额外的实用脚本。
- 他们还在进行 pysc2 adaptation 以及一个能够从回放中复现真实游戏场景的环境开发。
- 针对推理微调的医疗 AI 模型:一位成员使用热门的医疗推理数据集微调了 OpenAI 的 OSS 20B 推理模型,并将其发布在 Hugging Face 上。
- 他们在训练过程中使用了 4-bit optimization,在保留 Chain-of-Thought reasoning 能力的同时,增强了模型在医疗背景下的表现。
- 在 Hermes-3-Llama-3.1-8B 上微调的 Discord-Micae-8B-Preview:一位成员分享了 Discord-Micae-8B-Preview 的链接,这是一个基于 NousResearch/Hermes-3-Llama-3.1-8B 的 QLoRa 微调模型,使用了来自 mookiezi/Discord-Dialogues 的一些混沌样本。
- 该模型在类人文本生成指标上与 mookiezi/Discord-Micae-Hermes-3-3B 相当,可能会出现幻觉或脱离上下文,但往往能产生有趣的结果。
- 针对 Discord 风格聊天优化的 CLI 界面:一位成员重点介绍了一个名为 interface 的 Python 交互式 CLI 界面,用于与 Hugging Face 语言模型聊天,并针对使用 ChatML 的休闲 Discord 风格对话进行了优化。
- 该界面支持 quantized 和 full-precision models,具备带颜色格式的实时 token 流式传输,以及动态生成参数调整;进行了大量更新,使其更易于使用。
- MLX Knife 更新,现已支持 pip 安装!:MLX Knife 现在可以通过
pip install mlx-knife进行安装,为 Apple Silicon 上的 MLX 模型管理提供 Unix 风格的 CLI 工具,并内置用于本地测试的 OpenAI API server。- 该工具还具有 Web 聊天界面,运行
mlxk server --port 8000后即可访问;在运行curl -O https://raw.githubusercontent.com/mzau/mlx-knife/main/simple_chat.html后,可提供可视化的模型选择和实时流式响应。
- 该工具还具有 Web 聊天界面,运行
HuggingFace ▷ #agents-course (2 messages):
Cursor IDE, AI Agent Mode, Rate Limiting
- Cursor IDE 缓解开发痛点:一位成员建议安装 Cursor IDE 进行开发,强调了在其嵌入式终端中进行安装以方便调试的便利性。
- 他们强调 Cursor IDE 的 AI Agent Mode 可以显著协助解决开发问题。
- Discord 警示机器人发出温和提醒:一个机器人温和地提醒一位成员在 Discord 中发言时 稍微慢一点。
- 这表明存在 rate limiting 系统或政策,旨在管理消息流量。
LM Studio ▷ #general (169 messages🔥🔥):
MCP filesystem server, OpenRouter free models, LM Studio download issues, Qwen model for vision, GLM models
- **MCP 服务器打入主流:成员们讨论了使用带有分页功能的 **MCP filesystem server 来加载大上下文(large contexts),并提到 LM Studio 有一个 RAG 插件,而 Anthropic 有一个基础的文件系统 MCP server。
- 有建议指出,对于编程任务,解决方案通常涉及 RAG 和/或通过 MCP 进行文件读取,特别是使用像 serena 这样的工具。
- **Studio 下载停滞引发用户不满:一名用户报告称,在 **LM Studio 中下载 64GB GGUF 格式的 Qwen 模型时,进度停在 97.9% 且无法恢复。
- 该用户在尝试下载两个不同的模型时都遇到了同样的问题。
- **API 访问在各应用间加速:成员们讨论了将 **LM Studio 作为无法在本地运行的模型的 API wrapper 使用,并提供了 LM Studio Remote Inference 和 OpenAI-compatible Endpoint 文档的链接。
- 一位用户指出,在使用 openai-compat-endpoint 时,远程 GPT-OSS 模型的推理解析(reasoning parsing)功能无法正常工作。
- **GLM 讨论热潮:好评、吐槽与 GLM-4.5V 的期待:用户们就 **LM Studio 上使用 GLM-4.1 模型展开辩论,一位用户报告了循环(looping)问题和视觉功能失效。
- 一名成员建议尝试更新的 GLM-4.5V,并强调视觉支持依赖于 llama.cpp 的更新,同时提供了 GLM-4.1V-9B-Thinking 的链接。
- **输出固化:克服开源操作中的障碍:一名用户在 **GPT-OSS 和 tool calling 方面遇到问题,发现它总是返回
[]或["analysis"],并澄清 tool calling 工作正常,但 function calling 不行。- 一名成员建议如果启用了 streaming 则将其禁用,并确认 GPT-OSS 默认开启 reasoning 且无法禁用。
LM Studio ▷ #hardware-discussion (50 messages🔥):
NVIDIA's CUDA advantage, RTX PRO 4000 SFF, MoE explanation, Mac Studio vs Pro 6000, AMD Radeon AI Pro R9700
- CUDA 是 NVIDIA 统治地位的关键:一名成员表示,NVIDIA 获胜的原因在于 CUDA。
- NVIDIA 发布 70W TDP 的 RTX PRO 4000 SFF:根据 videocardz.com 的文章,NVIDIA 发布了 RTX PRO 4000 SFF 和 RTX PRO 2000 Blackwell 工作站 GPU,具有 70W TDP 和 24GB VRAM。
- 深入探讨 MoE:成员们澄清了 MoE 涉及较小的模型和一个聚合数据的路由(router),每个 token 都会被路由到最自信的专家模型(expert models);这些专家并不专注于特定主题,但拥有略微不同的数据集。
- Mac Studio 对比 Pro 6000:成员们争论是购买 512GB Mac Studio(售价 1 万美元)还是用于视频/图像 AI 且具备游戏能力的 Pro 6000,并提到 Mac 的游戏支持有限,且 M3 Ultra 大约相当于 3080 的水平。
- 一名成员指出,在 Mac 上只能运行一个任务,因为系统中只有一个 GPU。
- AMD 神秘的 Radeon AI Pro R9700 现身:AMD Radeon AI Pro R9700 首次在 DIY 零售市场亮相,据 Tom’s Hardware 报道,Reddit 上的一名客户以 1,324 美元购买了 Gigabyte “AI Top” 变体版本。
- 另一名成员指出,该显卡在 eBay 和几家不知名的在线零售商处也有销售。
Latent Space ▷ #ai-general-chat (114 条消息🔥🔥):
AI2 融资, Windsurf Wave 12, OpenRouter GPT-5, 推理效率基准测试, Google Flight AI
- AI2 从 NSF 和 NVIDIA 获得 1.52 亿美元资助:AI2 获得了来自 NSF 和 NVIDIA 的 1.52 亿美元,用于扩展其开源模型生态系统,并加速科学发现的可复现研究。
- 社区对此消息表示庆祝,期待即将发布的开源权重模型。
- Windsurf 发布 Wave 12 版本:Windsurf Wave 12 引入了 DeepWiki 悬停文档、AI Vibe & Replace、更智能的 Cascade Agent、更整洁的 UI、100+ 错误修复,以及通过远程访问支持的 beta 版 dev-container,链接见此处。
- GPT-5 登顶 OpenRouter 排行榜:GPT-5 在 OpenRouter 的专有工具调用(tool-calling)准确率上以超过 99.5% 的成绩领先,击败了 Claude 4.1 Opus;而 Gemini 2.5 Flash 在每日工具调用量(每周 500 万次请求)上占据主导地位,更多详情见此处。
- François Chollet 驳斥 HRM ARC-AGI 的说法:François Chollet 发现 HRM 论文中备受赞誉的架构对 ARC-AGI 性能贡献甚微;提升主要源于细化循环(refinement loop)、针对特定任务的训练以及极少的推理时增强(inference-time augmentation),这表明 27M 参数的模型仍能获得高分。
- FFmpeg 添加 Whisper 转录功能:FFmpeg 现在将 Whisper 转录作为原生功能提供。
Latent Space ▷ #ai-announcements (20 条消息🔥):
Greg Brockman, OpenAI 的 AGI 之路, GPT-5, Latent Space 播客
- Greg Brockman 谈 OpenAI 的 AGI 之路:成员们分享了一段 Greg Brockman 讨论 OpenAI AGI 之路的 YouTube 视频。
- 消息附带了几张标题为 “Greg Brockman on OpenAI’s Road to AGI” 的图片。
- Brockman 在 Latent Space 谈论 GPT-5 和 OpenAI 路线图:Greg Brockman 参加了 Latent Space 播客,进行了长达 80 分钟的对话,探讨了 GPT-5 和 OpenAI 的 AGI 路线图。
- 讨论涵盖了推理演进、在线与离线训练、样本效率技巧、定价与效率提升,以及能量如何转化为智能,详见此贴。
- Latent Space 播客发布 Brockman 访谈:新一期 Latent Space 播客 采访了 Greg Brockman,讨论了开发者建议、Coding Agent、端侧模型、AI 原生工程的组织结构,以及对 2045 年和 2005 年的时间胶囊预测。
Eleuther ▷ #general (29 条消息🔥):
言情小说审查, AI 的可靠性, 数据增强, 语言塑造思维, 机械解释性
- AI 安全恐慌:一位成员反对围绕 AI 产生的道德恐慌,建议应将其与其他媒体形式同等对待,主张采用“淡出(fade to black)”标准。
- 他们认为由于 AI 的不可靠性,更严格的准则是可取的,但过激的反应有引发道德恐慌的风险。
- 比较模型时保持数据增强一致:在比较两个用于图像分类的模型时,一位成员建议保持数据增强(data augmentations)一致,包括 shuffling seed,以确保公平比较架构差异。
- 另一位用户询问数据增强是否必须对两个模型完全相同,还是可以有所改变。
- 语言影响思维:一位成员认为语言塑造思维,并想知道是否可以通过从 AI 模型的 Token 列表中删除某个单词/颜色来测量这种影响。
- 另一位成员建议研究多感官融合(multi-sensory integration)以及语言如何影响整体感知,建议测试“图像+语言”与“仅图像”的推理能力对比。
- 新博客文章发布:Irregular Rhomboid 发布了新博客文章,《研究人员漫游指南》(Hitchhiker’s Guide to Research)。
- 该用户未提供文章摘要。
Eleuther ▷ #research (29 条消息🔥):
Diffusion Language Models, Generative AI, MatFormer Model, Gemma3 270M Model, Training Update Efficiency
- 针对 Diffusion Language Models 推荐的经典论文:成员们推荐了理解 generative AI 中的 diffusion 的经典论文,包括 “Estimating the Independent Components of a Gaussian Mixture” (2005) 和 “Denoising Diffusion Probabilistic Models” (2020)。
- 还分享了一篇博文,可能对初学者有所帮助:Aaron Lou 的 Discrete Diffusion。
- Gemma3 270M 模型是一个 MatFormer 模型:Gemma3 270M 模型被确定为 MatFormer 模型,更多细节可以在论文 “Transformer Family for Multimodal Large Language Model” (2023) 中找到。
- 该模型在训练过程中可能具有一个引人注目的自蒸馏(self-distillation)循环,但这可能会受到训练更新效率(training update efficiency)的瓶颈限制。
- HRMs 未能解决递归架构的问题:分析表明,HRMs (Hierarchical Recursive Machines) 并没有从根本上解决递归架构(recursive architectures)的普遍问题,详见这篇报告。
- 一位成员指出,性能提升微乎其微,且实际上并未利用可用的额外计算资源,因为训练符合预期的 UTs (Universal Transformers) 并非易事;另一位成员将其称为 deep supervision。
Eleuther ▷ #scaling-laws (13 条消息🔥):
GPT scaling laws, Chinchilla scaling laws, Mup alternatives, Post-Chinchilla techniques
- GPT Scaling Laws 仍有价值吗?:成员们认为原始 GPT scaling laws 论文和 Chinchilla scaling laws 论文是值得阅读的资料。
- 他们还指出 EPFL/HuggingFace 的最新工作也值得关注。
- Mup 及其替代方案可以迁移超参数:成员们提到 Mup 及其替代方案提供了可靠的超参数迁移(hyperparameter transfer)能力。
- 他们指出 Mup 提供了一种用于预测更大模型质量的 scaling law。
- 高质量 Token 的可用性受到质疑:成员们讨论了实验室是否拥有 30T、40T 或更多唯一(unique) token 来满足 Chinchilla 假设。
- 一位成员表示怀疑,称 40T 高质量的唯一 token 可能也很难找到。
- Chinchilla 仍在扩展吗?:一位成员表示 Chinchilla 及其衍生理论可能是目前最接近 scaling laws 的东西。
- 他们对讨论从零开始使用的技术的参考文献表示感兴趣,特别是考虑到 token 可用性的限制,并提到了这篇论文。
Eleuther ▷ #interpretability-general (1 条消息):
LLM Attribution Methods, Interpreting LLMs, Realtime LLM analysis
- ML 工程师寻求 LLM 归因(Attribution)见解:一位 ML 工程师正在探索针对特定 LLM 实现的归因方法,目标是寻找近期且具有成本效益的技术。
- 该工程师需要适合解释当前系统的方法,要求成本相对较低,且可能达到实时到亚分钟级的结果,特别是那些不需要访问模型权重(model weights)的方法。
- 渴望实时 LLM 分析:该 ML 工程师明确了对 LLM 进行实时到亚分钟级分析的需求。
- 他们对能够识别整个系统中“子部分(sub-something)”以实现这一速度的方法持开放态度。
Nous Research AI ▷ #announcements (1 messages):
Token usage, Reasoning models, Efficiency benchmark, Open vs closed models
- Nous 衡量推理模型的思考效率:Nous Research 推出了一个新基准测试,用于衡量推理模型的 Token 使用情况,强调在相同任务下,开源模型输出的 Token 数量比闭源模型多 1.5-4 倍。
- 研究发现,在简单问题上差异可能高达 10 倍,这表明 Token 效率应与准确率基准一起成为主要目标。
- Token 效率至关重要:该博文强调,开源模型中较高 Token 使用量的隐藏成本可能会抵消其在单 Token 定价上的优势。
- 建议将 Token 效率作为与准确率基准并列的主要目标,特别是考虑到非推理的使用场景。
Nous Research AI ▷ #general (35 messages🔥):
Speculative Decoding, Tokenizer mismatch, Next big model, Model Sycophancy, Embodied AI
- 快速投机采样 (Speculative Decoding) 规格:在 Speculative Decoding 的背景下,一位用户询问了实用性的最低比率,建议将 40% 的接受率作为基准,而在 70% 左右会出现惊人的加速。
- 讨论涉及使用 vllm 的 specdec 或 GGUF,一位用户反映 vllm 在他们之前的尝试中似乎效果不佳。
- Gemma 配合 Guardrails 运行:一位用户报告称,在修复了导致 llama.cpp 使用回退投机采样的 tokenizer 不匹配问题后,重新量化的 Gemma 模型达到了 50-75% 的接受率。
- 他们确认 Gemma 270M 模型可以用作 draft model。
- Nous 模型继续推进:一位用户询问了 Nous Research 下一个大型 (1T+) 模型的发布时间表。
- 一位 Nous Research 团队成员回应称,目前有多个模型正在训练中,准备好后就会发布,并表示“准备好时就会推出”。
- AI 谄媚 (Sycophancy) 受到关注:用户讨论了 AI 模型变得越来越“友好”的趋势,其中一位指出 Anthropic 的 Claude 变得“友好得多”。
- 另一位用户认为 OpenAI 的模型正在“变笨”,并且认为 opus 4.1 的奔放感很棒,但指出 sonnet 3.7 for meta 是 AI 谄媚的巅峰。
- 具身智能 (Embodied AI) 展望统治地位:一位用户分享了一个 具身智能角斗士奇观的 YouTube 链接,将其构想为未来统治者展示肌肉和技能的舞台。
- 他们推测,迈向“全球统治”的最后一步将是集成“大脑袋”的 Unified Language Models 以实现完全自主。
Nous Research AI ▷ #ask-about-llms (22 messages🔥):
Claude, R1, GLM4.5, gpt-oss, Qwen reasoning models
- Claude 躲在墙里:一位用户询问是否有人知道为什么 Claude “在墙里”,并链接到了相关的一条 X 帖子。
- MOE 模型:R1、GLM4.5、gpt-oss 以及更大的 Qwen 推理模型都是 MOE。
- 一位成员表示,这是因为它们的训练和推理成本更低,而不是因为它们与推理能力有关;他们的 405b Hermes 4 原型在推理方面表现非常出色。
- 优秀的推理模型需要优秀的基座模型:一位成员指出,原因在于你需要一个好的基座模型才能拥有一个好的推理模型,而且如果你要生成 50000 个 Token 的推理过程,你会希望推理是高效的。
- 作为回应,有人提到 RL(强化学习)是有效的,并且可以使用 1.5B 模型使基准测试达到饱和。
- Deepseek 解释了昂贵的 RL:一位成员提到,Deepseek 在其论文中解释说,在小模型上从头开始进行 RL 最终成本更高,因为必须进行更多的采样尝试(rollouts)。
- 这存在一种探索/利用(exploration/exploitation)的权衡,大模型由于其预先存在的知识,需要进行的探索较少。
- RLVR 的适用性:一位成员认为这不适用于 RLVR,而更多地适用于不可验证性较低的任务。
- 另一位成员回应说,RLVR 是针对可验证任务的 RL,当来自 RL 环境的反馈更具随机性时,拥有更大的基座模型会有更大的帮助。
Nous Research AI ▷ #research-papers (4 条消息):
数据训练, AI 模型, DRPS 系统, Relevance Scorer, Quality Rater
- DRPS 系统教授更智能的数据训练:引入了一个名为 DRPS 的新系统,教导 AI 有选择性地从数据中学习,而不是随机喂入数据,正如一篇 Situational Awareness 论文中所描述的那样。
- 该系统采用 Relevance Scorer、Quality Rater 和 Diversity Controller 来过滤并仅使用最有帮助的数据。
- DRPS 在减少数据的情况下实现高性能:结果显示,该系统仅使用所检查数据的 6.2% 就实现了 99% 的性能。
- 这种效率好比只学习 1 小时而不是 16 小时,却能获得相同的考试分数。
- DRPS 统计数据揭示了数据效率和性能:一个 GitHub 仓库提供了关于 DRPS 系统效率的数据,显示数据使用量减少了 93.8%,单位数据的准确率提高了 15.96 倍。
- 该系统保持了基准性能的 99.1%,准确率仅下降了 0.8%。
- DRPS 展示了强大的选择智能:DRPS 系统检查了超过 516,000 个样本,仅选择了 32,000 个用于训练,保持了稳定的 6.1-6.3% 选择率。
- 合成数据结果显示数据减少了 85.4%,在基准准确率为 87.6% 的情况下实现了 86.0% 的准确率。
- DRPS 提高了训练效率:DRPS 系统实现了活动训练集规模 16 倍 的缩减,增强了训练效率。
- Relevance Scorer 的准确率从 95.9% 提高到 99.95%,Quality Rater 的准确率从 97.0% 提高到 100%。
Nous Research AI ▷ #research-papers (4 条消息):
DRPS 框架, 数据效率, 选择智能, 合成数据结果, 训练效率
- DRPS:数据排名与优先级系统发布:Data Rankings and Prioritization System (DRPS) 通过使用 Relevance Scorer、Quality Rater 和 Diversity Controller 教导 AI 有选择性地从数据中学习,详见一份 Situational Awareness 报告。
- DRPS 削减了 90% 以上的数据使用量:在 MNIST 的测试中,DRPS 实现了 93.8% 的数据缩减,仅利用了 6.2% 的检查数据,同时保持了基准性能的 99.1%,这在 GitHub 仓库中有所展示。
- DRPS 通过选择顶级样本展示其智能:DRPS 检查了超过 516,000 个样本,仅选择了 32,000 个用于训练,在整个训练过程中保持了 6.1-6.3% 的稳定选择率。
- DRPS 提升了单位数据百分比的准确率分值:使用合成数据,DRPS 实现了 85.4% 的数据缩减,仅使用 14.6% 的训练样本就实现了每 1% 数据产生 5.89 个准确率分值,而基准准确率为 87.6%。
- DRPS 框架提高了训练效率:DRPS 通过将活动训练集规模缩减 16 倍 来提高训练效率,并提升了组件准确率,例如将 Relevance Scorer 从 95.9% 提高到 99.95%,将 Quality Rater 从 97.0% 提高到 100%。
Yannick Kilcher ▷ #general (46 messages🔥):
Quantum 初创公司 Multiverse, MoE 细微差别, Tokenization 与 Routing 协同, Gemma 3n
- 热门的 Quantum 初创公司?: 一篇关于 初创公司 Multiverse 的文章声称,他们利用量子技术创建了 两个有史以来最小的高性能模型,但他们可能只是使用了 针对模型权重的专门压缩算法。
- 该文章似乎并未提出实际的量子技术主张。
- 解读 MoE 的细微差别: MoE (Mixture of Experts) 是一系列具有非常微妙迭代的技术,包括 token-choice、expert-choice、带有容量因子的 MoE、块稀疏无丢弃令牌路由 (block sparse dropless token routing) 与有丢弃路由 (droppy routing) 等。这使得当人们出于某种原因将许多事情归因于 MoE 时,会让人感到困扰。
- 为了验证批处理推理中出现的问题,可以可靠地检查 Olmoe 或 IBM Granite 3.1 等模型的数值行为,而不是调用无法监控的 API。
- 协同 Tokenization 和 Routing: 一位成员提出了一个看似显而易见的想法,即 在同一步骤中进行 Tokenization 和 Routing,以实现动态协同。
- 另一位成员回应道:我从未见过这种提议,因为传统观点认为,如果在激活 Expert 之前有大量的 Routing 步骤,网络的表达能力会更强。
- 层级中的 Tokenization: Gemma 3n 具有某种每层 Tokenization / Embedding。
- 这可能是一种更好的学习 Patch 级 Tokenization 的方法,本质上对上下文有更多的洞察。
Yannick Kilcher ▷ #agents (1 messages):
DARPA AIxCC, LLM agents
- 团队在 DARPA AIxCC 中获胜: 一个团队宣布他们在 DARPA 的 AIxCC (AI Cyber Challenge) 中获得名次,他们构建了一个由 LLM agents 组成的自主系统,用于发现并修复开源软件中的漏洞。
- 该项目现已开源。
- 构建顶级 LLM Agents 的技巧: 该团队通过 这篇 Xitter 帖子 分享了他们构建高效 LLM agents 的技巧。
- 该帖子包含适用于各种 Agent 开发场景的通用建议。
Yannick Kilcher ▷ #ml-news (16 messages🔥):
低端设备上的推理时间, DinoV2 vs DinoV1, Gemma 模型参数量, 中国在自动化中的角色, Deepseek 在华为芯片上的训练
- 低端设备推理时间阻碍可用性: 成员们讨论认为,推理时间在 低端设备 上更为重要,并以 Google 运行 LLM 的 Android 应用为例,指出漫长的推理时间和手机发热使其变得不切实际。
- 较小的模型可以用于键盘预测,但根据 这段 Youtube 视频,这些模型可能需要在设备上进行训练。
- DinoV2 的性能与训练挑战: 一位成员表示希望新模型能超越 DinoV2,因为 DinoV2 在某些场景下表现不如 DinoV1,且更难训练。
- 他们链接了 YouTube 视频 作为参考。
- Gemma 参数曝光: 据观察,Gemma 270M 模型 拥有 100M 参数和 170M 嵌入 (embedding) 参数。
- Deepseek 的芯片选择停滞了训练: 一位成员指出,根据 这段讨论,Deepseek 的训练 因为尝试在 华为芯片 而非 NVIDIA 芯片上进行而停滞。
- 制造业关税阻碍行业增长: 一位成员认为,对建立生产线所需的设备征收关税,对于鼓励制造业是适得其反的。
- 他们补充说,建立一个行业需要数十年时间,并引用了 Anthropic 关于端子集对话的研究 和 HRM 分析。
GPU MODE ▷ #general (1 messages):
venom_in_my_veins: hye
GPU MODE ▷ #cuda (4 messages):
1-bit inference, GPTQ
- 探索加速 1-Bit 推理:一位成员询问了关于加速 1-bit 推理 的方法,并分享了论文链接 The Power of $\alpha,1$-sparsity: Near-Lossless Training and Inference of $\alpha$-bit Transformers。
- 该论文详细介绍了一种对 $\alpha$-bit Transformers 进行训练和推理的新方法,通过 1.58 和 1-bit 量化实现了近乎无损的结果。
- 推理优化:所链接的论文强调了使用 $\alpha,1$-sparsity 对 Transformer 模型进行的优化,使得在极低位宽下也能实现近乎无损的训练和推理。
- 这种方法可能会在某些应用中显著提升推理速度。
GPU MODE ▷ #beginner (11 messages🔥):
CUDA Shared Memory, CUDA Illegal Memory Access, CUDA Kernel Launch Configuration, CUDA warp ID calculation
- 调试 CUDA Illegal Memory Access:一位用户在 CUDA Kernel 中使用 Shared Memory 时遇到了 Illegal Memory Access 错误并寻求社区帮助,分享了涉及
sat和commons数组的代码片段。- 一位成员建议该错误可能源于错误的指针运算或定义不当的
warp_id和WARPS_EACH_BLK,但提供了一个 示例代码 以表明这可能与之无关。
- 一位成员建议该错误可能源于错误的指针运算或定义不当的
- CUDA Kernel 启动配置困惑:用户分享了他们的 Kernel 启动配置
<<<BLK_NUMS, BLK_DIM>>>和宏定义,其中BLK_NUMS设置为 40,BLK_DIM为 1024,WARPS_EACH_BLK计算为BLK_DIM/32,导致了全局 Warp ID 计算。- 另一位成员指出了问题所在:用户的
warp_id是全局的,导致对 Shared Memory 的越界访问,而 Shared Memory 对每个 Thread Block 是局部的。
- 另一位成员指出了问题所在:用户的
- 解决 Shared Memory 访问问题:一位成员建议在每个 Thread Block 内使用局部索引和 Warp ID 计算,建议使用
local_index = threadIdx.x; local_warp_id = local_index / 32;以确保正确的 Shared Memory 访问。- 他们进一步建议使用位移操作 (
local_warp_id = local_index >> 5;) 代替除法和取模运算,以获得更好的 GPU 性能,并建议使用 NSight Compute 检查生成的汇编代码。
- 他们进一步建议使用位移操作 (
GPU MODE ▷ #off-topic (10 messages🔥):
New Grad Kernel Job, GPU Thesis, Getting Kernel Job Without Internship
- Kernel 工作求职者询问应届生机会:一位成员询问,没有编写 Kernel 实习经验的人是否能找到编写 Kernel 的应届生工作。
- 另一位成员表示,如果候选人对 GPU 有深入了解,他们的公司并不看重实习经验,并提到他们相关的 论文 是其成功面试过程的一部分。
- 业内人士透露如何无实习获得 Kernel 工作:一位对 GPU 感兴趣的人发帖称,他们通过 GPU 相关论文和运气的结合,再加上通过面试,成功获得了一份工作。
- 据该人士称,扎实的 GPU 知识可以弥补缺乏工作经验和实习的不足。
GPU MODE ▷ #general-leaderboard (1 messages):
MI300 pytorch, OMP missing
- **MI300 环境缺少 OMP:根据用户报告,MI300** 环境在运行
pytorch.compile时似乎缺少 OMP。 - 包含调试错误链接:一位用户分享了 完整调试错误的链接 以供进一步调查。
GPU MODE ▷ #submissions (10 messages🔥):
trimul leaderboard, A100, H100, B200
- Trimul 排行榜迎来新的提速者:一位成员在 A100 上获得了第二名:10.4 ms,随后迅速在 H100 上获得第一名:3.95 ms,并在 A100 上获得第一名:7.53 ms。
- 随后,该成员在 B200 上获得第一名:2.35 ms,接着再次在 A100 上获得第一名:6.01 ms,又一次在 B200 上获得第一名:2.04 ms,最后在 H100 上成功达到 3.74 ms。
- A100 和 H100 也有活跃表现:另一位成员在 A100 上获得第 5 名:13.2 ms。
- 该成员随后在 H100 上获得第二名:6.42 ms,最后在 A100 上成功达到 14.7 ms。
GPU MODE ▷ #factorio-learning-env (10 messages🔥):
Meeting Attendance, Large PR Review, Connection Error Debugging
- 错过会议的小插曲:几位成员提到由于时区混淆和日程冲突错过了会议,其中一位成员仅在前 10 分钟有空。
- 一位成员调侃说早上 8 点的会议时间有点残酷。
- 审查范围蔓延:一位成员对一个包含 300 个文件更改的 PR 发表了评论,开玩笑说这有点“超出范围”了。
- 另一位成员补充说,这些代码是草饲手工打造的。
- 排查连接错误:一位成员报告看到了连接错误,并正尝试调试其来源,猜测可能来自 db_client。
- 他们提到在获取堆栈跟踪以诊断问题时遇到了困难。
Moonshot AI (Kimi K-2) ▷ #general-chat (47 messages🔥):
Kimi K2 Technical Report, GLM-4.5 vs Kimi K2, Kimi hallucinations, Kimi's Web UI, Kimi future updates
- NotebookLM 视频略胜 Kimi PPT:成员们将 Kimi 生成的 PPT 与 Google 的 NotebookLM 为 Kimi K2 技术报告生成的视频概览进行了对比,共识倾向于 NotebookLM 的视频,因为它有音频且布局更灵活(见附带视频)。
- 虽然两者都受到了好评,但一位成员表示相比听 AI 生成的音频,他更喜欢阅读,但也指出了视频概览的潜力,尤其是在教育领域。
- Kimi K2 在写作技巧上击败 GLM:尽管有人觉得 GLM-4.5 在整体性能上可能超过 Kimi K2,但用户赞扬了 Kimi 卓越的写作风格和主动的错误检测。
- 一位用户在 Kimi “突然对我说不”时感到“非常惊讶”,并对其坦率表示赞赏。
- 对抗 Kimi 的幻觉:用户希望 Kimi 即使在启用网页搜索的情况下也能减少幻觉,并指出虽然 GLM 可能耗时更长,但其幻觉频率较低。
- 一位用户表示,他们一直使用“踩”按钮来报告幻觉。
- Kimi 粉丝热切期待 ‘Kimi Thinking’:成员们正热切期待 ‘Kimi Thinking’ 以及推理和多模态能力的到来。
- 目前还不清楚这将以 Kimi K-2 还是 Kimi K-3 的形式出现,且尚无明确的 ETA。
- 深色模式增强了 Kimi 的 Web UI:一位用户分享了他们使用深色模式扩展自定义的 Kimi Web UI,表示相比默认的灰色界面,他们更喜欢这种风格(见附带截图)。
- 另一位用户确认,只有用户名和服务器角色会被传递给 Moonshot API。
LlamaIndex ▷ #blog (4 messages):
AI Stock Portfolio Agent, Web Scraping AI Agents, Multimodal AI Applications, Legal Knowledge Graphs
- AI 股票投资组合 Agent 到来:LlamaIndex 推出了一套构建完整 AI 股票投资组合 Agent 的框架,集成了 @CopilotKit 的 AG-UI 协议,以实现无缝的前后端通信;并提供了一份详尽的教程来创建复杂的投资分析工具。
- 该教程结合了 此框架 的强大功能,用于构建复杂的投资分析工具。
- Brightdata 与 LlamaIndex 推出 Web Scraping AI Agents:LlamaIndex 宣布与 @brightdata 合作推出新指南,介绍如何利用 LlamaIndex 的 Agent 框架构建 Web Scraping AI Agents,重点关注可靠的网络访问和健壮的网络爬虫工作流。
- 该指南详细介绍了如何设置能够处理动态内容的工作流,并构建可以导航至 此处 的智能 Agent。
- 多模态 AI 应用视觉化分析市场:LlamaIndex 宣布构建 多模态 AI 应用,用于分析市场研究和调查中的文本与图像。
- 这些应用旨在统一的 AI 流水线中同时处理图像和文档,从图表、图形和产品图像等视觉市场数据中提取洞察,并结合多模态 能力。
- LlamaCloud 和 Neo4j 将法律文档转换为知识图谱:LlamaIndex 宣布了一份综合教程,介绍如何将非结构化法律文档转换为可查询的知识图谱,使其不仅能理解内容,还能理解实体之间的关系。
LlamaIndex ▷ #general (28 messages🔥):
Pydantic Models vs JSON Schema for Tool Calls, Vector Store Errors After Update, Progress Bar Issue with num_workers > 1, Iterating Over Nodes/Doc_IDs in Vectorstore
- Pydantic vs JSON Schema 对决:一位成员询问 Tool Calls 是否需要 Pydantic 模型,还是 JSON Schema 就足够了,并指出将 JSON 转换为 Pydantic 模型后再解包回 JSON 存在冗余。
- 另一位成员指出 Pydantic 的
create_model()函数不直接接受 JSON Schema,强调需要特定的工具/包来处理这种转换。
- 另一位成员指出 Pydantic 的
- LlamaIndex 更新后 Vector Store 出现属性错误:更新到 0.13.1 版本后,用户在使用
RetrieverQueryEngine配合OpenAI和text-embedding-3-small时,从 PGVectorStore 检索过程中遇到了AttributeError。- 该错误源于
output是一个没有json属性的str,问题出在openinference.instrumentation.llama_index中的 LLMStructuredPredictEndEvent。
- 该错误源于
- 多进程下的进度条混乱:一位用户指出,由于使用了 multiprocessing,当
num_workers > 1时,progress_bar=True功能无法正常工作。- 有建议称使用 async concurrency 可能会提供更平滑的体验,然而
async pipeline.arun方法仍然使用了多进程。
- 有建议称使用 async concurrency 可能会提供更平滑的体验,然而
- Vector Stores 中缺失 Nodes 和 Doc IDs:一位用户对大多数 LlamaIndex Vector Stores 无法迭代 Nodes 或获取
doc_ids列表表示沮丧,特别提到了 Opensearch 和 awsdocdb 的缺失。- 一种权宜之计是将
similarity_top_k设置为一个很大的数值,但这效率低下且并非所有开源软件都支持;get_nodes()方法虽然存在于基础vector_store类中,但在 Opensearch 或 awsdocdb 中尚未实现,这是一个提交 PR 的好机会。
- 一种权宜之计是将
LlamaIndex ▷ #ai-discussion (1 messages):
DSPy optimizes CrewAI, CrewAI agent prompts
- DSPy 优化 CrewAI Agent 提示词:一门课程教授如何在真实的生产用例中通过 DSPy 优化 CrewAI Agent 提示词,从而利用经过验证的方法构建更智能、更廉价的 Agent。
- 您可以在 此处 查看该课程。
- 利用成熟方法构建更智能、更廉价的 Agent:该课程专注于针对 CrewAI Agent 的 DSPy 优化。
- 它强调通过成熟的方法论构建更高效、更智能的 Agent。
Notebook LM ▷ #use-cases (7 条消息):
NotebookLM 中的音频转录,NotebookLM 界面重新设计
- 上传到 NotebookLM 的音频自动转录:一位成员询问如何获取音频转录文本,另一位成员回答说他们直接将 MP3 音频文件上传到 NotebookLM。
- 该成员澄清说,NotebookLM 本身会处理转录生成。
- NotebookLM 界面重新设计正在进行中:一位成员提到他们正尝试重新设计 NotebookLM,并分享了拟议更改的 Figma 截图。
- 该成员对可能引起的误解表示歉意,澄清这只是一个设计概念,而非功能更新。
Notebook LM ▷ #general (23 条消息🔥):
讲解视频声音,功能请求反馈,开发者互动,Prompt 限制
- 讲解视频声音性别切换:一位用户报告说,他们的讲解视频突然开始生成 男性声音,而不是通常的 女性声音,并询问原因。
- 消息中没有提供明确的解决方案或解释。
- 用户请求确认功能请求:一位用户质疑是否真的有 NotebookLM 开发团队 的成员在阅读 Discord 频道中发布的 功能请求。
- 他们表示希望看到开发者的一些响应或反馈,以鼓励用户继续贡献。
- NotebookLM 开发者承认在阅读帖子但无法回复所有内容:一位 Google 开发者表示 开发者会阅读帖子,但他们没有时间回复所有内容,并花费了大量时间在 封禁垃圾信息发送者 上。
- 其他用户建议,即使是偶尔的确认或 AI 编译的摘要,也有助于鼓励用户贡献。
- 用户在 NotebookLM 中遇到 Prompt 限制:一位用户在尝试询问一个包含约 857 个单词 的案例相关问题失败后,询问 NotebookLM 中单个问题是否有 单词数量 限制。
- 另一位用户建议将 Prompt 拆分为多个部分,或者尝试使用 Gemini。
DSPy ▷ #show-and-tell (1 条消息):
CrewAI Agent Prompt,DSPy
- 使用 DSPy 优化 CrewAI Agent Prompt:成员们分享了一个链接,用于学习 DSPy 如何在实际生产用例中优化 CrewAI Agent Prompt:https://www.udemy.com/course/crewai-dspy-optimization/?referralCode=B59F73AE488715913E7E。
- 该课程声称将教用户如何 通过经过验证的方法构建更智能、更廉价的 Agent。
- DSPy 与 CrewAI 结合:该课程教授用户如何使用 DSPy 优化 CrewAI。
- 它能够通过经过验证的方法实现更智能、更廉价的 Agent。
DSPy ▷ #general (22 条消息🔥):
DSPy 和 Databricks, GEPA 错误, MLflow 和 DSPy
- Databricks 并不赞助 DSPy:一位用户询问 Databricks 是否赞助或拥有 DSPy 项目,另一位用户澄清说 DSPy 是 MIT 许可的开源项目,Databricks 通过核心开发团队做出了重大贡献。
- GEPA Bug 已修复:一位用户在 RAG 教程 中使用 GEPA 时遇到了
ValueError,另一位用户确认这是 GEPA 代码中的一个 bug 且已被修复;用户应升级到 DSPy 3.0.1。- 被弃用的参数位于
dspy.evaluate导入中,修复方法是执行pip install -U dspy。
- 被弃用的参数位于
- MLflow 自动追踪 DSPy 子模块:一位用户询问如何将 DSPy 模块 追踪集成到 MLflow 中用于 text2sql pipeline,得到的建议是使用
mlflow.dspy.autolog()而非mlflow.autolog()来自动追踪所有子模块。- 使用
mlflow.dspy.autolog()会将 SQLGenerator、Validator 和 Reflector 在 MLflow UI 的 Traces 标签页 中显示为嵌套的 span,详见 MLflow DSPy 集成文档 和 DSPy MLflow 教程。
- 使用
- Logprob Surprise 作为 fitness Function:一位用户分享了一条推文 TogetherCompute Status,并猜测他们基本上是在使用 logprob surprise 作为 fitness function 来运行 GEPA,但应用于生产环境中的心理健康模型。
- 请求社区参与:一位成员请求 Discord 中 6500 名成员更多地参与进来,并为文档等内容做出更多贡献。
DSPy ▷ #examples (1 条消息):
CrewAI, DSPy 优化, Prompt Engineering
- CrewAI Prompt 优化课程发布:一位成员宣布了一门 Udemy 课程,展示了如何使用 DSPy 优化 CrewAI prompts。
- 该课程将展示如何将优化后的 prompt 注入回 LLM,以便 LLM 使用比 CrewAI 拼接出来的更好的 prompt。
- DSPy 实现优化的 CrewAI Prompts:这门新课程使用 DSPy 来优化 prompts。
- 优化后的 prompts 随后被注入回 LLM,改进了 CrewAI 中的标准方法。
tinygrad (George Hotz) ▷ #general (8 条消息🔥):
CI 速度, tinygrad 发布, tinygrad 大小
- CI 速度阻碍生产力:一位成员对 CI 速度慢表示沮丧,称如果 CI 更快,他们的工作效率会更高,并链接了 chatgpt 分析。
- Tinygrad 即将发布:有建议尽快进行 tinygrad release。
- Tinygrad 体积膨胀:一位成员质疑为什么 tinygrad 0.10.3 的大小是 10.4 MB,暗示可能存在体积问题。
tinygrad (George Hotz) ▷ #learn-tinygrad (14 条消息🔥):
WSL2 支持, print_tree 移除
- WSL2 Tinygrad Bug 出现:用户遇到一个问题,将两个从 PyTorch tensor 创建的 tinygrad Tensor 相加结果全是 0,并提供了一个完整脚本在 WSL2 上复现该 bug。
- print_tree 函数被移除:
print_tree函数已被简单的print函数取代。- 用户注意到它丢失了一些格式化效果。
aider (Paul Gauthier) ▷ #general (12 messages🔥):
Aider Benchmark, litellm Errors, Open Source Entitlement, llama.cpp PR #15181
- Aider Benchmark 深受超时困扰:一名成员针对本地 gemma3:12b 模型运行 Aider benchmark,在运行 10.5 小时 并完成 221/225 个测试 后频繁遇到超时。这是由于模型无法在 600 秒 限制内响应,导致 litellm.APIConnectionError 错误。
- 他们分享了错误日志,显示模型尝试发送约 300k tokens,超过了 131,072 token 限制,从而导致测试失败。
- 继续 Aider Benchmark:一名成员建议使用
ctrl+c退出基准测试,重启推理服务器,然后使用--cont标志从中断处恢复基准测试。- 他们还指出 llama.cpp 中一个已合并的 Pull Request 可能会提升本地模型的性能。
- OSS 维护者的负担:一名成员批评了另一名成员关于为每个 LLM 自动配置基准测试的建议,将其贴上 entitlement(索取心态)的标签,并感叹这种态度导致 无数 OSS 维护者选择放弃。
- 另一名成员反驳说这仅仅是 curiosity(好奇心),引发了关于在开源交互中什么构成“索取心态”的进一步争论。
aider (Paul Gauthier) ▷ #questions-and-tips (7 messages):
Aider with Local Models, Aider Line Number Accuracy, Unit Test Coverage with Aider
- 本地 AI/Aider 模型带来调试痛苦:一名成员表示在使用 aider 配合 ollama、lmstudio 和 vllm 等本地模型时遇到困难,指出即使在强大的硬件上性能也很慢。
- 他们建议需要一个关于如何设置 aider 与这些工具配合进行本地开发和调试的教程视频。
- Aider 的行号系统受到质疑:一名成员询问 aider 如何确定行号,特别是在为特定代码覆盖率生成单元测试的背景下。
- 当 aider 错误报告行号时会出现问题,导致测试覆盖率不正确,尽管尝试了刷新 map 和清除聊天记录。
- LLM 准确性影响单元测试覆盖率:一名成员报告称 qwen3-coder 和 gemini-pro 在覆盖率报告中识别行号不准确,有时会完全遗漏覆盖范围。
- 这种不一致性引发了关于 aider 是否依赖 LLM 的准确性 来进行行号识别的疑问,并建议需要探索其他方法来实现准确的单元测试生成。
aider (Paul Gauthier) ▷ #links (3 messages):
Grok4, Quota Increase, Benchmark Costs
- Grok4 位置仍然难以捉摸:一名成员询问 Grok4 的下落。
- 另一名成员回答说 它在文章中,但增加执行测试所需 quota(配额)的请求被忽略了。
- Grok4 基准测试耗资数千美元:一名成员指出他们 在开发此基准测试期间花费了数千美元。
- 这突显了高级 AI 模型基准测试所需的巨大财务资源。
Manus.im Discord ▷ #general (22 条消息🔥):
Manus 错误扣费, Manus 部署问题, Manus 团队账户, 附加额度包移除, Manus in the Wild 挑战赛获胜者
- Manus 扣费引发不满:用户对 Manus 在出现错误时仍扣除额度表示沮丧,认为这使得完成任务比使用 Claude AI 等其他 AI 更加困难。
- 一位用户报告称,在消耗了大量额度后,Manus 仅做了一个简单的更改就破坏了整个应用程序,导致其无法运行。
- Manus 部署受挫:用户报告了 Manus 的部署问题,即从同一个 GitHub 仓库创建的网站存在显著差异,尤其是在处理大型文件夹时。通过对比 affilify.eu 和 Manus 托管的站点 wmhkgqkf.manus.space 说明了这一点。
- 一位社区经理指出,Manus 的设计初衷并非作为 coding agent 或纯开发工具,因此部署并非其强项,但他们正在努力改进。
- 附加额度包下架:用户对移除附加额度包表示质疑,目前该礼包仅面向 Pro 用户提供。
- 社区经理对此解释称,这一变化是为了确保重度用户能够获得一致的速度和质量,并建议通过合并相似问题、保持简洁以及避免重复请求来最大化额度效率。
- Manus 团队账户引发关注:一位用户询问是否可以开设 Manus 团队账户以共享额度。
- 社区经理确认 Manus 确实提供团队计划,并引导用户访问 官方网站 了解详情。
- 用户哀叹额度消耗:一位用户分享了在尝试上线网站时烧掉 30,000 额度 的挫败经历,期间遇到了模拟站点和模板实现的问题。
- 他们批评了系统的不一致性,称其 聪明绝顶却又突然变笨,导致额度浪费,并怀疑存在拖延策略。
Cohere ▷ #🧵-general-thread (9 条消息🔥):
Cohere Labs, 宝可梦表情包, PAX Omeganauts Discord
- 寻找 Cohere Labs 联系方式!:一位成员询问在哪里可以联系到 Cohere Labs 的人员,另一位成员建议使用此 Discord 频道。
- 还有成员引导该用户访问 此链接。
- Discord 频道宝可梦化!:一位成员建议在频道中添加更多 宝可梦表情包,因为还有可用槽位。
- 该成员指出这些表情包来自 PAX Omeganauts Discord。
Cohere ▷ #👋-introduce-yourself (5 条消息):
AI 研究, writenode, CV+ML pipeline
- AI 研究员寻求合作:一位对 推理和意识能力 有深厚兴趣的 AI 研究员 正在寻求合作,以开发面向未来的先进技术。
- 该成员对来自任何子领域的合作持开放态度。
- 法律专业人士关注 AI 对齐:一位目前在 USG 工作、热爱游戏和哲学的 法律专业人士 正在自学 AI alignment 理论与机制。
- 该成员很高兴来到这里。
- writenode 开发者使用 Cohere:Josh 正在构建 writenode(一个浏览器内的认知思维伙伴和创意伴侣),并使用了 Cohere。
- 在去年 12 月之前,他并没有开发者或编程背景。
- 心理学博士回归 AI:一位成员在过去 5 年攻读人类心理学博士学位后,重新回归 AI 研究。
- 他们的兴趣在于 声音+音乐,以及利用技术工具帮助我们表达创造力。
Gorilla LLM (Berkeley Function Calling) ▷ #leaderboard (3 条消息):
Discord 邀请链接, 频道垃圾信息
- Discord 邀请刷屏:一位成员多次在频道中发布 Discord 邀请链接 并艾特 所有人。
- 该邀请链接在短时间内重复出现了三次。
- 邀请链接重复:同一个 Discord 邀请链接 被反复发布。
- 这导致了类似垃圾信息的效果,可能会干扰频道的正常讨论。
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (3 messages):
Discord Invite Link, HjWfRbqBB8, Channel Invitation
- Discord 邀请链接刷屏频道:一名成员在频道中反复分享 Discord 邀请链接,可能是为了吸引更多用户。
- 该成员多次艾特
@everyone,这可能被认为是过度骚扰或干扰。
- 该成员多次艾特
- 频道邀请攻势:重复发布相同的 Discord 邀请表明其试图增加频道成员数量。
- 使用
@everyone表明该消息旨在发送给所有成员,无论他们是否对该邀请感兴趣。
- 使用
MCP (Glama) ▷ #general (2 messages):
Elicitations Specification, MCP Server Conversion
- 寻求 Elicitations 规范的澄清:一名成员询问了关于 Elicitations 规范 的问题,即谁负责将消息/字段描述翻译成用户的语言。
- 具体而言,他们寻求澄清:是 tools 应该处理语言检测和国际化,还是预期由 MCP Clients 负责翻译(可能使用 LLM)。
- MCP Server 转换问题:一名成员询问 是否存在某种工具可以将本地 MCP Server 转换为远程 MCP Server?
- 未提供链接或更多上下文。
MCP (Glama) ▷ #showcase (3 messages):
Unifi MCP, Unraid MCP, Syslog MCP, AI Agent Workflows, AI Security
- 面向 Homelab 用户的 MCP Server 发布:一名成员分享了几个为 Homelab 用户准备的 MCP(推测为 Management Control Panel)Server,具体包括:Unifi MCP、Unraid MCP 和 Syslog MCP。
- PulseMCP 将繁琐的新闻简报转变为 Agent 自动化:PulseMCP 使用 goose 将繁琐的新闻简报工作流转变为由 Agent 驱动、包含人工干预(human in the loop)的自动化流程。
- 有关该自动化的更多细节可以在这篇博客文章中找到。
- AI Security 征求安全问题的反馈:一名成员发布了关于构建 AI Security 的消息,旨在通过数学上的安全确定性在攻击发生前将其阻止。
- 他们正在寻求开发者对安全问题的意见,并链接到了一份调查问卷。
Nomic.ai (GPT4All) ▷ #general (4 messages):
Strix Halo profitablility, Dolphin chat template, Quantum computers, PC Memory
- Strix Halo 的盈利能力大幅下降:尽管 Strix Halo 规格惊人,但由于其推理速度(53 tokens/sec)慢于 OpenRouter 上的 GPT-OSS 120B,需要 24/7 全天候推理一年才能实现盈利。
- 一位用户指出,花费 2000 美元将其配置用于 LLM 的效率远低于提供 200-400 tokens/sec 的云端替代方案。
- 寻找 Dolphin 聊天模板:一位用户正在为 gpt4all 寻找适用于 Dolphin-2.2.1-mistral-7b-gptq 的可用聊天模板。
- 另一名成员建议要求模型制作者上传带有 jinja 模板的模板。
- 量子计算“茶匙”?:一位用户推测了量子计算机未来的可用性,以及按“茶匙”出售 qubits 的可能性。
- 他们提到了关于全功能量子计算机的新闻,表明该领域可能取得了进展。
- 内存模块与摩尔定律:一位用户提到,传统 PC 有望在 2027 年底或 2028 年看到更高容量的内存模块和 DDR6。
- 他们对具有高 RAM 和 VRAM 容量的微型 PC 的潜力表示兴奋,特别是对于小型企业而言。
Modular (Mojo 🔥) ▷ #general (1 messages):
Maternity Leave, Team Contact During Leave
- 产假开始!:一名成员宣布他们将从 8 月 25 日起休产假,直至 2026 年 2 月。
- 他们期待回归后与大家交流。
- 团队交接计划公布:在他们休假期间,团队将负责监控 <@1334161614949056532>。
- 成员如有任何问题或疑虑,也可以联系 <@709918328306663424>。
Torchtune ▷ #general (1 条消息):
__nathan: <@132818429022437376> 进展如何?
Codeium (Windsurf) ▷ #announcements (1 条消息):
Windsurf Wave 12, DeepWiki Integration, Vibe and Replace feature, Smarter Cascade Agent, Dev Containers Support
- Windsurf Wave 12 正式发布!:Windsurf Wave 12 首次将 Devin 的智能和能力直接集成到 Windsurf IDE 中。
- 核心功能包括:全新的 UI 设计、DeepWiki Integration、Vibe and Replace、更智能的 Cascade Agent、更快的 Tab、Dev Containers 支持以及 100 多个 Bug 修复 —— 查看更新日志,阅读博客,观看 Wave 12 视频,X/Twitter,以及 Reddit。
- DeepWiki Integration 将 AI 引入 IDE:DeepWiki Integration 允许用户将鼠标悬停在代码符号上以获取 AI 驱动的解释(不仅是基础的类型信息)。
- 用户还可以使用 CMD/Ctrl+Shift+Click 在侧边栏打开详细解释,并将其添加到 Cascade 上下文中。
- Vibe and Replace 彻底改变了批量编辑:Vibe and Replace 功能通过查找精确文本匹配,提供了革命性的批量编辑能力。
- 它允许用户应用 AI prompts,在整个项目中进行智能且感知上下文的转换。
- 更智能的 Cascade Agent 获得全时规划功能:更智能的 Cascade Agent 现在具备全时规划模式(Always-On Planning),并带有自主待办事项列表。
- 它还包括经过改进的工具,旨在提供更智能的响应。
- 原生支持 Dev Containers:Windsurf 现在支持通过远程 SSH 访问直接使用容器。
- 这一增强功能简化了涉及容器化环境的开发工作流。