AI News
DeepSeek V3.1:经过 8400 亿 token 持续预训练,以 11% 的成本击败了 Claude 4 Sonnet。
DeepSeek 发布了 DeepSeek V3.1,这是一个低调推出的开源模型,拥有 128K 上下文窗口,并在 Token 效率、编程和智能体(agentic)基准测试方面进行了改进。字节跳动在 Hugging Face 上发布了采用宽松许可的 Seed-OSS 36B 模型,该模型以长上下文和推理能力见长。智谱 AI 推出了 ComputerRL,这是一个用于计算机操作智能体(computer-use agents)的强化学习框架,并取得了优异的基准测试成绩。
在开发者工具方面,GitHub Copilot 扩展至全球;微软 VS Code 集成了 Gemini 2.5 Pro 并更新了 GPT-5 智能体提示词;Anthropic 推出了带有支出控制功能的 Claude Code 席位。开源微调方面的进展包括:Together AI 为 gpt-oss-120B/20B 增加了监督微调(SFT);Baseten 通过 Truss CLI 实现了多节点 120B 模型训练。社区注意到 DeepSeek V3.1 的表现评价不一,且目前仍在进行持续的后训练调整。
抱歉发布晚了,DeepSeek 的官方发布确实挺晚的
2025年8月19日至8月20日的 AI 新闻。我们为您检查了 12 个 Reddit 分版、544 个 Twitter 账号和 29 个 Discord 社区(229 个频道,6600 条消息)。预计节省阅读时间(以 200wpm 计算):517 分钟。我们的新网站现已上线,包含完整的元数据搜索和美观的 Vibe Coded 历期内容展示。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
正如昨天所讨论的,DeepSeek 继其标志性的模型发布之后,发布了一条非常低调的 tweet 和 博文,公布了官方消息和 Evals:
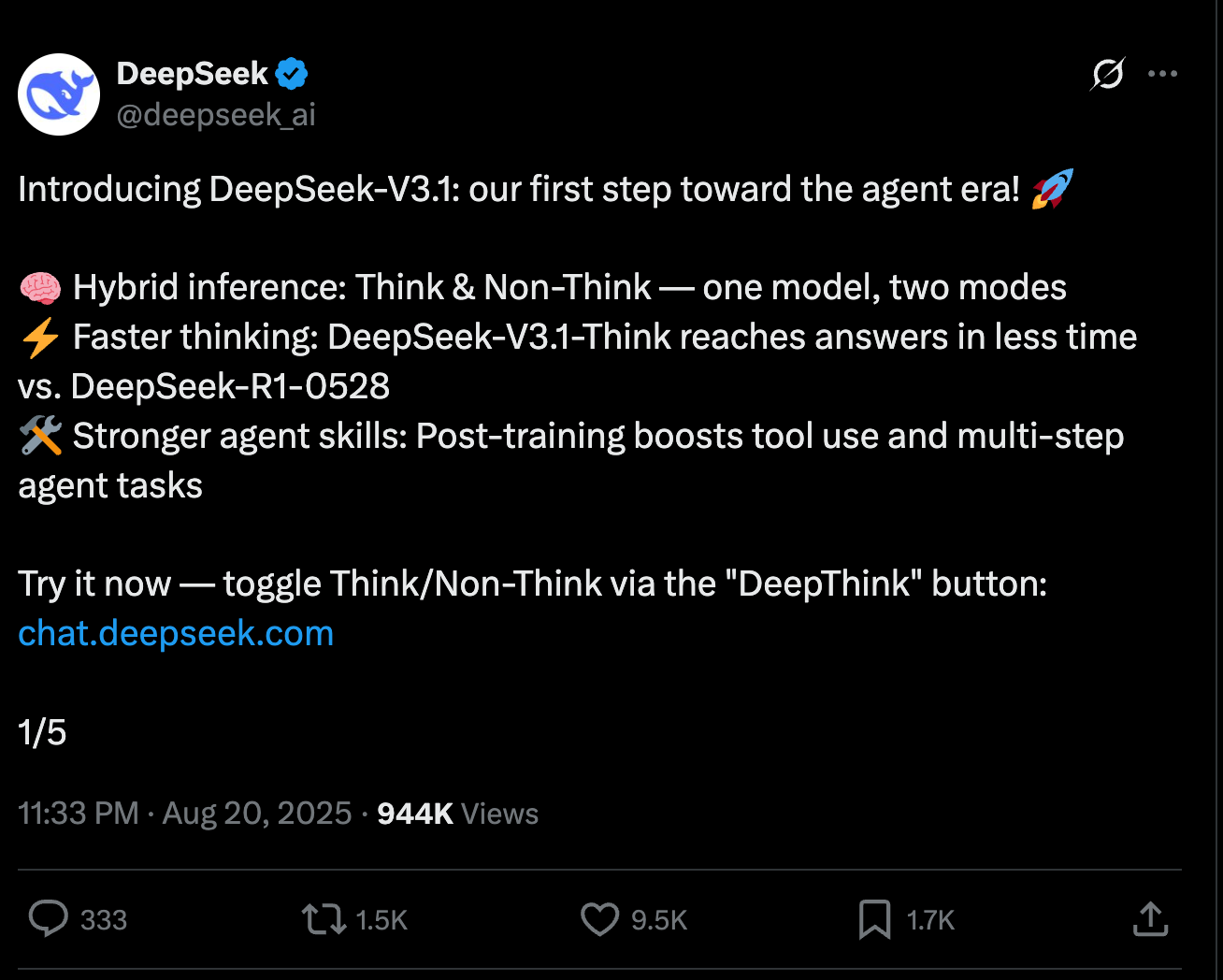
标准知识基准测试的提升是增量式的:
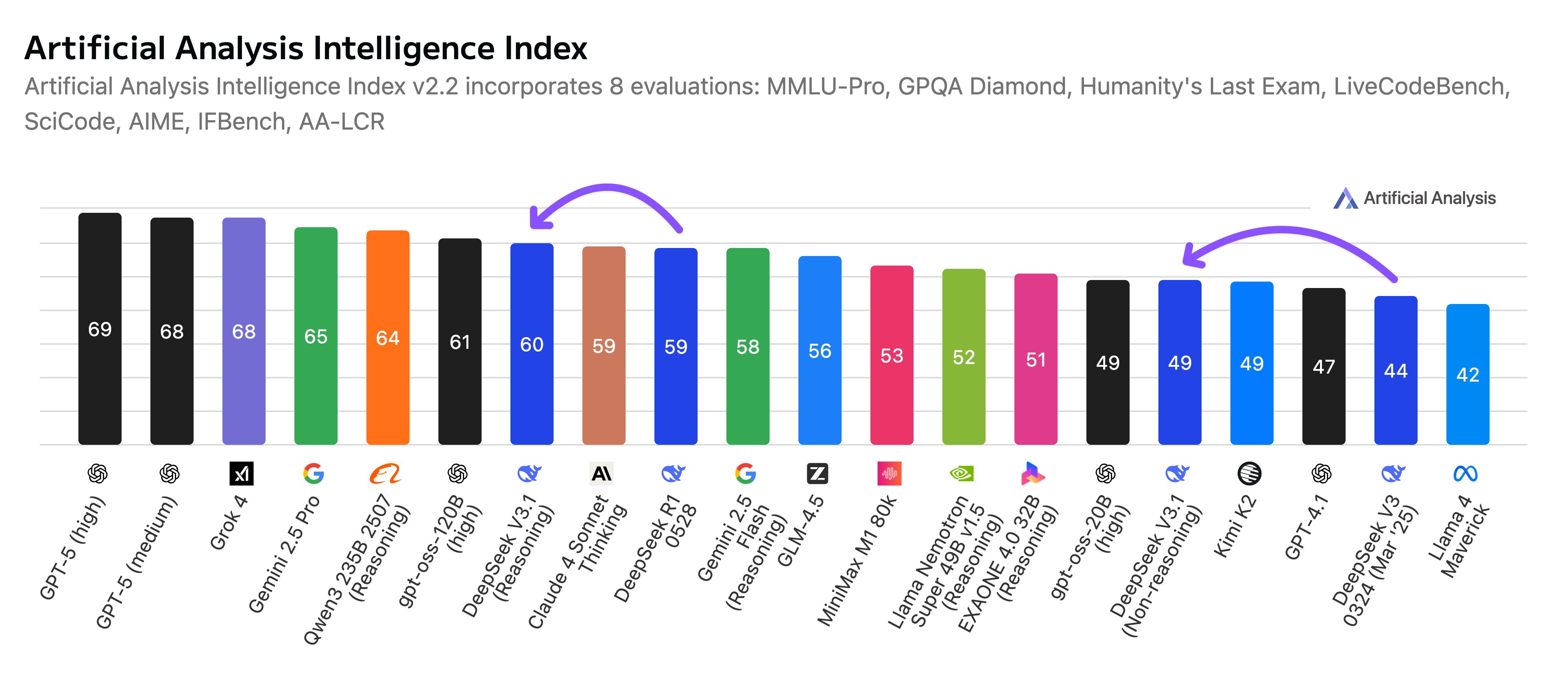
但在编程和 Agent 基准测试方面有显著改进,使其对 Agent 更有用。
然而,主要看点可能更为微妙——Token 效率的提升!
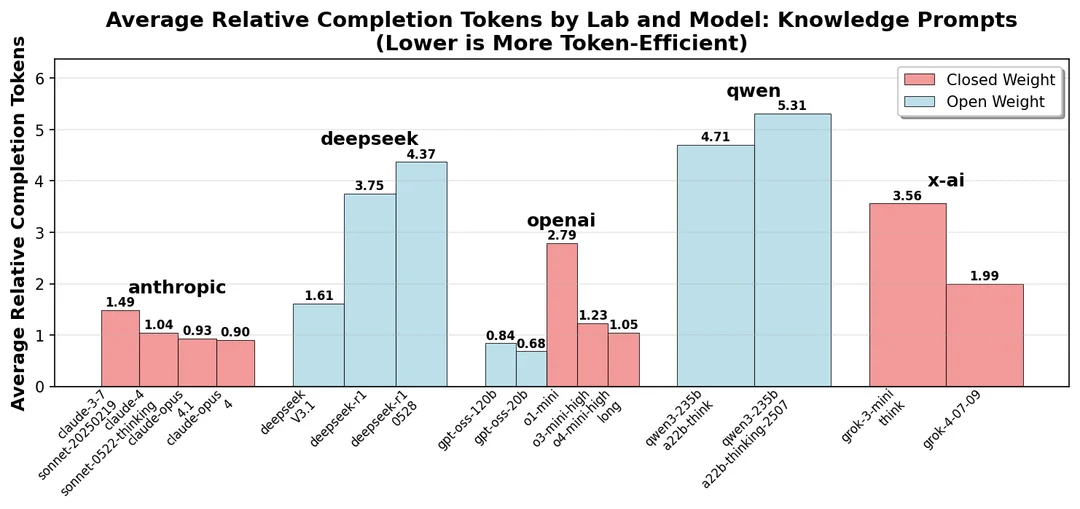
Reddit 对 DSV3.1 的剖析特别深入,请继续向下滚动阅读。
AI Twitter 摘要
中国的开源模型与 Agent:DeepSeek V3.1、字节跳动 Seed‑OSS 36B、智谱 ComputerRL
- 社区报告显示 DeepSeek‑V3.1 低调上线(出现了一个具有 128K Context 的 “Instruct” 变体),最初没有 Model Card,有迹象表明该实验室可能正在合并 “Thinking” 和 “Instruct” 产品线以简化推理服务。早期评价褒贬不一:在小规模 “LRM Token 经济” 推理集上,V3.1 在逻辑谜题上与 “Sonnet 4” 持平,但在某些任务上较 R1 有所退步,且在简单的知识性问题上倾向于 “废话多”,这表明 Post‑training 仍有收紧空间。参见 @teortaxesTex、@rasbt 的讨论,以及关于时区的后续和发布周期细节。
- 字节跳动在 Hugging Face 上发布了采用宽松许可的 Seed‑OSS 36B LLM,声称具备长 Context、推理和 Agent 能力,尽管社区初步反馈指出发布时的文档/Model Card 较为简略。参见 @HuggingPapers 和 @teortaxesTex 的反应。
- 智谱 AI 推出了 ComputerRL:一个用于 Computer-use Agent 的端到端 RL 框架,统一了 API 工具调用与 GUI(即 “API‑GUI 范式”),通过数千台台式机的分布式 RL 进行训练。AutoGLM 9B Agent 在 OSWorld 上实现了 48.1% 的成功率,据报道在该基准测试中击败了 Operator 和 Sonnet 4 基准。论文与结果:@Zai_org、后续、推文串。智谱还通过 TensorBlock Forge 推出了 GLM‑4.5 的访问权限 (@Zai_org)。
编程 Agent 与开发者工具
- GitHub 正在通过全局启动器、Issues 和 VS Code 在 GitHub 全平台推送 Copilot coding Agent (@lukehoban)。Microsoft 的 VS Code 团队还在 Code 中推出了 Gemini 2.5 Pro (@code),并在 Insiders 版本中更新了 GPT-5 Agent 提示词 (@burkeholland)。Anthropic 为 Team/Enterprise 团队推出了包含支出控制和终端集成的 Claude Code 席位 (@claudeai, _catwu)。
- Cline 发布了一个免费的、可选加入的 “Sonic” 编程模型 Alpha 版,用于驱动多点编辑(multi-edit)工作流;使用数据将用于改进模型。详情与快速入门:@cline, blog, provider。该团队还在支持一场 AI 金融科技黑客松 (@inferencetoken)。
- 开源微调和本地运行正在加速:Together AI 为 gpt-oss-120B/20B 增加了 SFT (@togethercompute);Baseten 的 Truss CLI 被用于多节点 120B 训练 (@winglian);llama.cpp 在 M2 Ultra 上运行 gpt-oss-120B,GPQA 达到 79.8%,AIME’25 达到 96.6% (@ggerganov)。ggml 生态增加了 Qt Creator 插件 (@ggerganov)。
- 基础设施/推理服务笔记:Hugging Face “Lemonade” 支持在 AMD Ryzen AI/Radeon PC 上运行本地 HF 模型 (@jeffboudier)。Cerebras 现已成为 HF 推理提供商,每月处理 500 万次请求 (@CerebrasSystems)。Modal 发布了一篇深度探讨,解释了为什么他们为了 AI 迭代速度而在没有 k8s/Docker 的情况下重构基础设施 (@bernhardsson)。
Agent 训练与 RL:关键的 Scaling Recipes
- Chain-of-Agents (AFM):通过多 Agent 蒸馏 + Agentic RL 训练单个 “Agent 基础模型”,在模拟协作的同时减少 84.6% 的推理 Token,并能泛化至未见过的工具;其性能与 best-of-n 测试时扩展(test-time scaling)相当,具有 SOTA 竞争力。代码/模型:@omarsar0, paper link, meta。
- 用于 RLVR 的深度-广度协同 (DARS):通过多阶段 Rollouts 增加困难案例的权重,纠正 GRPO 对中等准确度样本的偏见;大 Batch 的 “广度” 进一步提升了 Pass@1。代码 + 论文:@iScienceLuvr。
- 用于掩码扩散 LM 的 MDPO:在推理时间调度下进行训练,以缩小训练与推理之间的差距;声称只需减少 60 倍的更新即可匹配之前的 SOTA,并在 MATH500 (+9.6%) 和 Countdown (+54.2%) 上取得巨大进步,此外还有一种无需训练的重掩码 (RCR) 技术可进一步提升结果 (@iScienceLuvr)。
- 实用 RL 技巧:一些异步 RL 流水线在生成过程中热插拔更新后的权重,而无需重置 KV Caches;尽管 KV 是过时的,但在实践中它们仍然运行得相当不错 (@nrehiew_)。
基准测试、评估质量与系统扩展
- 评估设计:AI2 的 “Signal and Noise” 提出了构建高信号、低噪声基准测试的指标和方法,以产生更可靠的模型增量和更好的 Scaling-law 预测;数据集/代码已发布 (@iScienceLuvr)。
- 实时评估:FutureX 是一个针对进行未来预测的 Agent 的动态、每日更新的基准测试,通过自动化的问答流水线避免数据污染;在金融任务上,据报道顶级模型在相当一部分任务中击败了卖方分析师 (@iScienceLuvr, context)。
- 硬件/软件:一个有用的推文串量化了两年间软件带来的 H100 性能/功耗/成本改进,并涉及了 GB200 的可靠性考量 (@dylan522p)。在内核方面,快速的 MXFP8 MoE 实现正在落地 (@amanrsanger)。
- SWE-bench Agent:在轮次之间随机切换 LM(例如 GPT-5 与 Sonnet 4 混用)的表现可能优于单一模型 (@KLieret)。
视觉与多模态编辑:Qwen Image Edit 夺冠
- Qwen‑Image‑Edit 现已成为 LM Arena 上排名第一的开源图像编辑模型 (Apache‑2.0),首次亮相即位列总榜第 6,与各大闭源基准模型并列。它与 ComfyUI 深度集成,并展现出强大的身份/光影保持能力;团队在发布后还迅速推出了补丁。参见 排行榜、ComfyUI 节点、重光照演示、补丁 以及 HF 趋势榜 (@multimodalart)。一个 lightx2v LoRA 展示了在保持同等质量的前提下,以约 12 倍的速度进行 8 步编辑 (@multimodalart)。
- 空间天气基础模型:IBM 和 NASA 开源了 Surya,这是一个拥有约 3.66 亿参数的 Transformer 模型,利用多年的太阳动力学天文台 (Solar Dynamics Observatory) 数据进行训练,用于空间物理预测;模型已在 Hugging Face 上线 (@IBM, @huggingface, 概览)。
产品迭代与使用情况:Perplexity 规模扩张,Claude Code 进入企业,GPT‑5 用户体验分歧,Google AI 手机
- Perplexity 使用量与功能:目前每周处理超过 3 亿次查询(约 9 个月内增长了 3 倍),推出了印度股票价格预警功能,并正在测试 SuperMemory 和 Max Assistant 模式,后者可在上下文中运行长周期研究任务 (@AravSrinivas, 预警, SuperMemory, Max Assistant)。
- Claude Code 面向 Team/Enterprise 版本发布,具备席位管理和支出控制功能,连接了聊天中的构思与终端中的实现 (@claudeai, _catwu)。
- GPT‑5 能力 vs 用户体验:OpenAI 宣传了利用 GPT‑5 进行快速产品构建的能力 (@OpenAI),而 @SebastienBubeck 分享了一个引人注目的案例,称 GPT‑5‑pro 产生并验证了凸优化中的一个新边界(后续附有 证明草案;转发支持)。相比之下,@jeremyphoward 报告了 Web 端“Thinking/Auto”模式糟糕的用户体验,突显了原始能力与产品可靠性之间的差距。
- Google Pixel 10 系列发布,搭载 Tensor G5 + 端侧 Gemini Nano,支持 Gemini Live 视觉指导(通过相机共享进行屏幕高亮提示),以及 Gemini 应用中的 AI 辅助视频生成 (@Google, @madebygoogle, 视频生成)。
热门推文(按互动量排序)
- GPT‑5‑pro 证明了新的数学边界(声明 + 证明草案) — ~3.7k
- “100 倍生产力的论调是妄想”之吐槽 — ~3.4k
- Figure 的 Helix 步行控制器演示(盲视 RL 步行) — ~3.6k
- OpenAI:GPT‑5 让构建变得简单(产品演示) — ~1.9k
- Perplexity:每周 3 亿次查询 — ~2.5k
- Raven Kwok 的生成系统泛化 — ~1.3k
- Alec Stapp 论电池在加州峰值需求中的占比 — ~2.0k
- Google:Pixel 10/Tensor G5/Gemini Nano 发布 — ~2.2k
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. DeepSeek V3.1 更新、效率及直接对比基准测试
- GPT 4.5 vs DeepSeek V3.1 (分数: 394, 评论: 144): 柱状图声称 DeepSeek V3.1 在代码风格通过率基准测试中优于 GPT-4.5(
71.6%对44.9%),同时在相同工作负载下的成本远低($0.99对$183.18)。该帖子暗示了巨大的性价比差距,但未提供基准测试名称、任务组合、Token 计数或定价假设,导致方法论不明确且难以复现。 评论者认为这种比较是不匹配的:GPT-4.5 的定位更偏向于对话/创意,而非代码/Agent 用途,建议应在写作任务上进行比较,而 GLM/DeepSeek 应在编程方面进行测试;其他人则质疑闭源对闭源声明的公平性和透明度,并要求提供对等的基准线(例如,类似规模的 OSS 模型)。- 一位评论者认为 GPT-4.5 针对类人对话和散文进行了优化,而非代码或 Agentic 工具使用,并引用了通过 LMSYS Arena 进行的实测。他们指出它在解释/摘要/创意写作方面表现强劲,但 “并非为 aider polygot 而生”(即没有针对像 Aider 这样的编程工作流进行微调),而 GLM 的定位在编程方面更强;因此,评估应涵盖
coding和creative writing,以避免特定任务的偏差。 - 方法论担忧:评论者告诫不要进行不透明的闭源模型对比,并建议与开源的
~120B模型进行对等匹配以实现规模对等。他们暗示公平的基准测试应公开 Prompt 模板、系统设置以及是否启用了工具使用/Agent,以确保可复现性并避免在不同专业化模型之间进行“樱桃采摘”(cherry-picking)。
- 一位评论者认为 GPT-4.5 针对类人对话和散文进行了优化,而非代码或 Agentic 工具使用,并引用了通过 LMSYS Arena 进行的实测。他们指出它在解释/摘要/创意写作方面表现强劲,但 “并非为 aider polygot 而生”(即没有针对像 Aider 这样的编程工作流进行微调),而 GLM 的定位在编程方面更强;因此,评估应涵盖
- Deepseek V3.1 improved token efficiency in reasoning mode over R1 and R1-0528 (分数: 203, 评论: 16): 一个社区基准测试(LRMTokenEconomy)表明,DeepSeek V3.1 在
reasoning模式下的 Token 效率优于 R1 和 R1-0528,通过生成更短的CoT同时保持正确性,显著减少了在知识和数学提示词上的“过度思考”。评估者在逻辑/脑筋急转弯类型的谜题上仍观察到偶尔出现的极长推理链,这表明对于复杂的演绎任务,启发式限制仍然存在。 一位评论者指出,在解码阶段控制“思考”过程可以进一步提高准确性,并指向了一个示例方法:https://x.com/asankhaya/status/1957993721502310508。其他评论为非技术性的认可。- 减少推理轨迹中不必要的词汇/格式可以通过 RL 奖励塑造(reward shaping)直接优化——例如,为冗长的思维链或多余的标记添加惩罚,从而在不牺牲解题质量的情况下压缩 Token。还有推测认为,在 MoE 架构中,进行“思考”时会激活不同的专家;这可能会增加本地用户的
VRAM需求,但如果计算编排是主要瓶颈,对于托管基础设施来说是可以接受的。这暗示了提高 Token 效率的两个杠杆:策略层面的奖励惩罚和推理过程中架构层面的专家路由/门控。 - 推理时对“思考”的控制可以在限制 Token 的同时提高准确性,如该示例所示:https://x.com/asankhaya/status/1957993721502310508。技术手段包括约束步骤数、设定每个问题的 Token 预算,或使用引导式/自一致性采样来剪枝低价值的推理 Token——这些通常与训练时的惩罚相辅相成,且无需重新训练即可应用于各种模型。
- 提出的一个关键悬而未决的问题是:在与 R1/R1-0528 准确率持平的情况下,改进后的 Token 效率是否依然成立,还是存在正确性的权衡?为了进行稳健的比较,结果应同时报告准确率指标(如 pass@1)和每个基准测试的平均推理 Token 计数,以便在固定的质量水平上评估效率。
- 减少推理轨迹中不必要的词汇/格式可以通过 RL 奖励塑造(reward shaping)直接优化——例如,为冗长的思维链或多余的标记添加惩罚,从而在不牺牲解题质量的情况下压缩 Token。还有推测认为,在 MoE 架构中,进行“思考”时会激活不同的专家;这可能会增加本地用户的
- 一眼看懂 DeepSeek-V3.1-Base 更新 (Score: 190, Comments: 23): DeepSeek 发布了 DeepSeek‑V3.1‑Base,其核心架构与 V3 相比基本保持不变(例如相同的词表大小),但增加了一个带有可切换“思考”能力的新混合模式,并更新了分词器(tokenizer)的
added_tokens(根据配置/分词器差异推断出的扩展占位符/功能性标记)。社区测试表明,其编码性能有所提高,且排名高于 V3,尽管官方模型卡片/基准测试尚未发布;该图片汇总了这些差异以及下载链接。 评论者指出,一些报告的 Aider 分数来自 Chat 模型(而非 Base),且 Base 模型通常不通过 API 公开;他们强调 V3.1‑Base 是一个补全(completion)模型,没有聊天模板(chat template),并正在等待 OpenRouter 更新以重新运行基准测试。- 澄清:报告的“Aider 分数”是使用 Chat 变体测量的,而不是宣传的 Base 模型,这可能会误导对原始 Base 能力的预期。一位评论者指出,提供商不通过 API 公开 Base 模型(需求低),这意味着标记为“Base”的基准测试实际上可能反映了指令微调(instruction-tuned)/Chat 行为,而非真实的仅预训练(pretraining-only)性能。
- 反对观点强调,如果这确实是一个 Base 模型(例如 DeepSeek-V3.1-Base),则不应使用
chat template,因为它尚未针对聊天进行 SFT;它应该被视为纯文本补全(text completion)模型。应用特定于聊天的 system/user/assistant 格式可能会降低输出质量,或使与真正的 Chat/Instruct 模型的比较失效。 - 一位基准测试人员正在等待 OpenRouter 更新端点(endpoint)后再重新进行测试,这突显了提供商/版本滞后会实质性地影响分数和可复现性。基准测试结果应指明所使用的确切端点/模型变体和提供商(例如 OpenRouter),以避免混淆 Base 与 Chat 以及更新前后的行为 (https://openrouter.ai/)。
{kind=link}
{kind=link}
2. 新开源模型发布:IBM/NASA Surya 和字节跳动 Seed-OSS-36B
- IBM 和 NASA 刚刚发布了 Surya:一个用于在太阳风暴袭击前进行预测的开源 AI (Score: 275, Comments: 50): IBM 和 NASA 宣布了 Surya,这是一个开源的太阳物理学基础模型,在多年的太阳动力学天文台(SDO)图像上进行了预训练,以学习可迁移的太阳特征,用于在耀斑概率、CME 风险和地磁指数(
Kp/Dst)等任务上进行零样本/少样本微调(zero/few‑shot fine‑tuning)。此次发布(权重 + 训练方案)的目标是通过 SDO 预处理和 LoRA/adapters 实现中等算力下的适配,鼓励通过公共基准测试中的提前量(lead‑time)与技能指标(skill metrics)以及极端事件的压力测试进行评估。相对于当前的太空天气方法——基于物理的 MHD/传播模型(如 WSA‑Enlil: https://www.swpc.noaa.gov/models/wsa-enlil-solar-wind-prediction)、经验/统计基准以及特定任务的 CNN/RF 模型——声称的贡献是对 SDO (https://sdo.gsfc.nasa.gov/) 进行广泛的预训练,以获得更好的迁移性和可访问性;严格的技能和成本面对面比较仍有待展示。 评论指出了缺失的链接,并质疑这是否是炒作,询问以前使用的是什么,以及简单的线性/经验模型是否能达到同样的性能;他们要求提供优于运行基准的具体改进证据,并要求澄清其相对于先前的 CNN/统计方法的创新性。- 一位评论者挑战了 Surya 的技术新颖性和合理性,询问它如何改进 LLM 之前的基准,以及更简单的模型(如线性/逻辑回归)是否能以更低的成本匹配其性能。他们要求提供清晰的对比基准测试以及与既有方法的消融实验(ablations),并要求澄清耀斑事件的可预测性与随机性,而不是营销声明。他们提到了代码库,但指出缺乏结构化证据来证明在特定任务(耀斑和太阳风预测)中的增益。
- 另一位用户关注实时部署,提议开发一个由“近期”太阳图像驱动的 Gradio 应用,用于该仓库的任务——24 小时太阳耀斑预测和 4 天太阳风预测——但报告称难以获取实时输入:https://github.com/NASA-IMPACT/Surya?tab=readme-ov-file#1-solar-flare-forecasting 和 https://github.com/NASA-IMPACT/Surya?tab=readme-ov-file#3-solar-wind-forecasting。他们指出 Surya 使用的 Hugging Face 数据集仅更新至
2024年(例如:https://huggingface.co/datasets/nasa-ibm-ai4science/surya-bench-flare-forecasting),且部分链接已失效(例如:https://huggingface.co/datasets/nasa-ibm-ai4science/SDO_training),这阻碍了使用当前数据进行实时复现和推理。 - Seed-OSS-36B-Instruct (Score: 153, Comments: 26): 字节跳动 Seed 团队发布了 Seed-OSS-36B-Instruct (HF),这是一个参数量约为
36B、采用 Apache-2.0 协议的 LLM。该模型在约12Ttokens 上训练,具有原生的512K上下文,强调可控的推理长度(“思考预算”)、强大的工具使用/Agent 行为以及长上下文推理能力。他们还提供了配对的基础 Checkpoints,以控制预训练中的合成指令数据:Seed-OSS-36B-Base(通过合成指令增强,据称可提升大多数 Benchmark 表现)和 Seed-OSS-36B-Base-woSyn(不含此类数据),以支持对指令数据影响的研究。 评论者强调,该模型的原生512K上下文可能是具有实际内存占用(memory footprint)的开源权重模型中最长的,并将其与上下文超过 1M 但体积过大的模型(如 MiniMax-M1, Llama)进行了对比,同时指出 Qwen3 虽然通过 RoPE 支持 1M,但原生仅为256K。此外,还有讨论认为在预训练中加入合成指令数据能显著提升 Benchmark 性能,而不含合成数据的变体对于未受污染的基础模型研究具有重要价值。- 模型卡片(Model card)指出了两种基础变体:一种通过合成指令数据增强,另一种则没有。引用:“在预训练中加入合成指令数据可以提高大多数 Benchmark 的性能……我们还发布了
Seed-OSS-36B-Base-woSyn……不受合成指令数据的影响。” 这让用户可以在合成指令增强预训练带来的潜在高分与用于下游 SFT 或分析的“干净”预训练分布之间做出选择。链接:Seed-OSS-36B-Base, Seed-OSS-36B-Base-woSyn。 - 宣称
36B稠密模型具有原生512K上下文窗口,使其成为具有实际内存占用的最大“原生”上下文开源权重模型之一。评论者将其与通过 RoPE 外推宣传1M+的模型(例如:Qwen3 宣称1M但原生为256K)或资源需求极高的巨型模型(如 MiniMax-M1/Llama)进行了对比;原生窗口可以避免在外推 RoPE 机制中看到的质量下降。这对于检索密集型或长文档任务至关重要,无需诉诸激进的分块或特殊的缓存技巧。 - 报告的 Benchmark 和特性:
AIME24 91.7,AIME25 84.7,ArcAGI V2 40.6,LiveCodeBench 67.4,SWE-bench Verified (OpenHands) 56,TAU1-Retail 70.4,TAU1-Airline 46,RULER 128k 94.6。覆盖范围显示出强大的数学、编程、工具使用/Agent 以及长上下文保持能力,RULER 128k表明其具有稳健的长程注意力。它还宣传了可控的“推理 Token 长度”,这意味着在推理时可以通过调节旋钮来限制或延长推理 Token,以在延迟和质量之间进行权衡。
- 模型卡片(Model card)指出了两种基础变体:一种通过合成指令数据增强,另一种则没有。引用:“在预训练中加入合成指令数据可以提高大多数 Benchmark 的性能……我们还发布了
{kind=link}
3. 独立开源创新:移动端 AndroidWorld Agent 与 TimeCapsuleLLM(19 世纪伦敦)
- 我们击败了 Google Deepmind,但被一家中国实验室反超 (Score: 1206, Comments: 148):一个小团队开源了一个 Agent 式 Android 控制框架,该框架可以执行真实的设备端交互(点击、滑动、输入),并在 AndroidWorld 基准测试中报告了最先进的结果,超越了 Google DeepMind 和 Microsoft Research 之前的基准线。上周,智谱 AI 发布了闭源结果,以微弱优势占据榜首;作为回应,该团队发布了他们的代码,并正在开发自定义移动端 RL gym,以冲刺
~100%的基准测试完成率。仓库地址:https://github.com/minitap-ai/mobile-use 热门评论对开源表示支持,建议将社区建设作为竞争护城河,并指出许多开创性的 OSS 努力都始于微小团队;一位观察者评论说演示看起来运行很快。- 几位评论者探讨了应用程序如何在不进行 Root 的情况下控制手机(尤其是 iPhone);实际路径是操作系统授权的自动化层,而非任意的事件合成。在 iOS 上,跨应用控制通常使用 Apple 的 UI 测试栈 (XCTest) 及其衍生工具,如 Appium 的 WebDriverAgent,它们运行一个经过开发者签名的自动化运行器来查询无障碍树 (accessibility tree) 并注入点击/输入——无需越狱,但无法在 App Store 应用中发布,且需要配置权限 (provisioning entitlements) (XCTest UI Testing, WebDriverAgent)。在 Android 上,Agent 依赖 AccessibilityService(带有
BIND_ACCESSIBILITY_SERVICE)来读取 UI 并执行手势,通常配合 MediaProjection 进行屏幕截取——不需要 Root,但必须获得用户同意并符合 Play 政策合规性 (AccessibilityService, MediaProjection)。 - 关于使用场景:该工具支持在真实设备上进行端到端 QA/RPA(例如:导航登录流程、处理 OTPs、更改设置或跨第三方应用编排任务)以及无障碍增强。典型的技术栈通过 Appium 暴露类似 WebDriver 的 API(iOS 通过 WebDriverAgent;Android 通过 UiAutomator2/Accessibility),让 AI Agent 启动应用、点击、输入并读取无障碍标签;然而,由于操作系统沙箱和权限限制,某些系统对话框和特权设置仍然无法触及 (Appium docs, UiAutomator2)。
- 几位评论者探讨了应用程序如何在不进行 Root 的情况下控制手机(尤其是 iPhone);实际路径是操作系统授权的自动化层,而非任意的事件合成。在 iOS 上,跨应用控制通常使用 Apple 的 UI 测试栈 (XCTest) 及其衍生工具,如 Appium 的 WebDriverAgent,它们运行一个经过开发者签名的自动化运行器来查询无障碍树 (accessibility tree) 并注入点击/输入——无需越狱,但无法在 App Store 应用中发布,且需要配置权限 (provisioning entitlements) (XCTest UI Testing, WebDriverAgent)。在 Android 上,Agent 依赖 AccessibilityService(带有
- 我仅用 19 世纪伦敦文本从零训练的 LLM 提到了 1834 年的一次真实抗议 (Score: 190, Comments: 35):原作者 (OP) 完全从零开始,在一个精选的约 7,000 篇 1800–1875 年间伦敦出版的文本语料库(约
5–6 GB)上训练了几个 LLM,包括在同一语料库上训练的自定义 Tokenizer,以尽量减少现代词汇;其中两个模型使用了 nanoGPT (repo),最新的模型遵循 Phi-1.5 风格训练 (phi-1_5),没有使用现代数据或微调。给定提示词“It was the year of our Lord 1834”,模型生成的文本提到了伦敦的“抗议”和“帕默斯顿勋爵 (Lord Palmerston)”,OP 指出这与记录在案的 1834 年事件相符,暗示模型学到了特定时期的关联,而不仅仅是风格模仿。代码和数据集工作已分享至 TimeCapsuleLLM,并计划扩展到~30 GB并探索特定城市/语言的变体。 热门评论普遍反响热烈,认为这种方法是一种引人入胜的、DIY 式的直接从一手资料中挖掘历史时代精神的方式;目前尚未讨论实质性的技术批评或基准测试。- 关于训练历时性 (diachronic) 和地域性变体的建议:在截至连续截止点(例如公元 100 年、200 年……)的累积语料库上构建独立模型,以及特定地区的子集。这将能够通过跨 Checkpoint 对齐嵌入(例如正交普鲁克分析 Orthogonal Procrustes)、跟踪词汇频率变化以及比较在时间域外测试集上的
perplexity(困惑度)来衡量语义漂移和方言变异。它还支持迁移研究,通过测试一个训练至 1800 年的模型与训练至 1900 年的模型在预测 1830 年代事件时的表现,来量化时间泛化能力。
- 关于训练历时性 (diachronic) 和地域性变体的建议:在截至连续截止点(例如公元 100 年、200 年……)的累积语料库上构建独立模型,以及特定地区的子集。这将能够通过跨 Checkpoint 对齐嵌入(例如正交普鲁克分析 Orthogonal Procrustes)、跟踪词汇频率变化以及比较在时间域外测试集上的
非技术性 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Unitree 和 Boston Dynamics 人形机器人更新
-
Boston Dynamics 分享新进展 (Score: 399, Comments: 186): **Boston Dynamics 与 Toyota Research Institute 合作,展示了 Atlas 人形机器人在 Large Behavior Models (LBMs) 方面的进展。通过训练端到端、受语言调节的神经策略,将自然语言指令直接映射为协调的全身行为,以完成长时程操作序列。演示强调了闭环控制,在物理扰动下仍能维持任务执行,同时动态调整身体方向以抓取、运输和放置多个物体,表明策略在扩展任务中的泛化能力有所提高。视频:[Getting a Leg up with End-to-end Neural Networks Boston Dynamics (YouTube)](https://youtu.be/HYwekersccY)。** 热门评论强调了系统对人为干扰的鲁棒性以及在操作过程中的动态全身重新定位;其他评论则通过指出与人类水平灵巧手之间的差距来客观评价这一成就。 - 几位评论者强调了系统在操作和移动过程中对外部扰动的鲁棒性,指出机器人在被推搡或目标移动时仍能保持平衡和任务进度。这意味着通过闭环状态估计、全身控制以及顺从/阻抗行为(compliant/impedance behaviors)实现了强大的抗干扰能力,使其能够实时重新规划足端放置和末端执行器轨迹。
- 演示凸显了当前末端执行器与人类手掌在灵巧度、强度重量比和触觉反馈方面的差距。观察者注意到,机器人通过动态重新定位全身来获得有利的接近角度和抓取姿势,这反映了一种设计权衡:利用全身运动和控制复杂性来弥补与人手相比更低的夹持器 DOF 和传感能力。
- 观众推断出动态物体交互中存在紧密的感知-控制集成,可能涉及实时物体位姿追踪和视觉伺服(visual servoing),以便在保持稳定裕度的同时跟随移动的箱子。平滑调整身体姿势和手臂轨迹的能力表明,模型预测或全身轨迹优化正以交互速率运行,以调和操作目标与平衡约束。
- Unitree 预热其下一款人形机器人 (Score: 196, Comments: 36): Unitree 发布了一张剪影图像预热其下一款人形机器人,列出了
31 joint DOF (6*2 + 3 + 7*2 + 2)和H:180,意味着在 180 cm 高的平台上,每条腿有 6-DOF (x2),3-DOF 躯干,7-DOF 手臂 (x2),以及 2-DOF 头部。预热图强调了“敏捷”和“优雅”,并表示“即将推出”,但未包含执行器、手部、传感或 Benchmark 细节。来源:Unitree 在 X 上的帖子:https://x.com/UnitreeRobotics/status/1957800790321775011。 评论注意到高度转换可能为 180 cm (≈5′11″);其余多为非技术性评论或玩笑。 -
Unitree G1,WHRG 独舞冠军,表演时穿着 AGI T恤 (Score: 306, Comments: 80): Unitree 的 G1 人形机器人赢得了 WHRG 独舞组冠军,穿着“AGI” T恤完成了灵活、无绳的表演——这可能使用了预设脚本/遥操作编舞,而非机载高级规划,但仍展示了紧凑外形下强大的全身平衡和关节灵活性。视频:v.redd.it/nw2jrlios5kf1;平台详情:Unitree G1。 评论者争论该演示是“脚本/遥操作的噱头”还是有意义的进展:怀疑者认为其中几乎没有 AI 成分,而其他人则强调了展示的驱动、稳定性和自供电运行对未来具身智能(embodied intelligence)的价值,并提醒不要将进步过度归因于 AI 层面。
- 关键技术辩论:该演示程序可能依赖于预设脚本或远程操作(teleoperated)的编排,而非机载自主性(on-board autonomy),但它仍展示了在独立电源下的强大全身关节联动(whole‑body articulation)、平衡和轨迹跟踪能力。这表明其具备成熟的低延迟控制循环、良好的状态估计/IMU fusion 以及紧凑包装下的高扭矩密度——这些是自主技术栈(autonomous stack)后续可以利用的重要基础。需要警惕的是,不要将此类演示与高层级“AI”或规划方面的进展混为一谈;它们主要验证的是机械和控制,而非认知(cognition)。
- 几位评论者将这一结果定性为具身性(embodiment,即“身体”)而非认知(cognition,即“大脑”)方面的进步。换句话说,所展示的稳定性和精度是具身智能(embodied intelligence)的重要步骤,但“AGI”的品牌宣传夸大了软件层面的作用;在没有在线感知、规划或适应性证据的情况下,这一成就最好被视为硬件/控制的成熟,而非 AI 能力。
- 人形机器人正在社交媒体上常态化 (Score: 200, Comments: 61):帖子指出人形机器人短视频(Reels/TikTok)激增,暗示这可能是一场协调一致的常态化推动,而非有机增长,例子包括 IG 的 rizzbot_official 以及在亚洲/奥斯汀的公开露面。图片显示一个带有友好面孔的路边机器人正被路人拍摄——这是一种 HRI/PR 策略(亲和的数字面孔、笨拙/呆萌的人设),旨在减少公众感知的风险和对失业威胁的焦虑;文中未讨论硬件/模型规格或技术基准。 评论分为两派:一派认为是推荐系统驱动的曝光——“算法认定你是喜欢……的人”;另一派认为是蓄意的软实力品牌塑造,以预先化解公众抵制;关于“人行道”的笑话则指向了城市空间和准入问题的担忧。
- 信息流饱和很可能是由于平台的推荐系统(协同过滤/参与度优化排名),而非有机的、全人群范围的激增。算法“认定你是喜欢看人形机器人视频的人”,这表明了个性化效应和反馈循环:看几个,就会推送更多——这并非广泛常态化的证据。
- 多位用户指出“Clanker”是“突然同时出现”的,暗示可能存在协调一致的种子推广/虚假草根运动(astroturfing),而非有机的模因(meme)增长。技术指标包括同步的发布时间、重复使用的标题/标签,以及来自历史记录较少的账号的快速初始互动,这些都可以在没有真实草根兴趣的情况下夸大感知的势头。
- 提出了新奇感曝光与真正常态化之间的明确区别:“新奇感不等同于常态化”。短视频热潮可能反映了由排名系统优化的好奇心偏见,而常态化则需要长期信号(持续曝光且无下降、稳定的正面情绪、下游行为),而非原始的曝光量。
- 不切实际 (Score: 3960, Comments: 56):讽刺帖子/模因(meme),引用了《终结者 2》的情节:一位技术创造者在得知其发明可能毁灭人类后亲手将其摧毁,并将其框定为在今天“不切实际”。从语境上看,它评论了当代的 AI 风险、企业激励和监管话语(例如 Sam Altman 公开敦促 AI 监管),而非提供技术数据或基准。 评论辩论了创始人的激励措施(例如避难所 vs. 关停),并对当前的 AI 能力表示怀疑,同时对领导者呼吁监管时的监管演戏/监管俘获(regulatory capture)表示愤世嫉俗。
- 几条评论含蓄地触及了监管俘获的辩论:Sam Altman 在美国参议院证词中公开倡导前沿模型(frontier models)的许可和安全标准,一些人将其视为“乞求被监管”,而批评者则认为当前的模型能力并不足以支撑生存风险的框架。参见 2023 年 5 月的听证会“AI 监管:人工智能规则”(https://www.help.senate.gov/hearings/oversight-of-ai-rules-for-artificial-intelligence)。这提出了一个技术治理问题:如何在不巩固既得利益者地位的情况下,为许可和评估(evals)设定能力阈值。
- 一项更正指出他是员工而非创始人——这对治理和控制至关重要。在像 OpenAI 这样的利润上限模型(capped-profit model)结构中,非营利董事会正式控制营利实体(https://openai.com/blog/our-structure),这改变了谁可以做出暂停/关闭产品的单方面决定,并创造了与创始人领导的公司不同的激励和问责机制。
- 在灾难性风险态势(catastrophic-risk posture)方面,“建造掩体”与“销毁/暂停产品”之间的对比,突显了各大实验室如何通过评估(evals)和准备工作(preparedness)而非个人应急计划来使风险管理可操作化。示例包括 OpenAI 的 Preparedness 和红队测试计划 (https://openai.com/blog/preparedness),以及 Anthropic 的负责任缩放政策(Responsible Scaling Policy)及其 AI 安全等级(
ASL-1–ASL-4)(https://www.anthropic.com/news/ai-safety-levels),这些政策定义了缩放前的能力阈值、评估协议和门控缓解措施。
{kind=link}
{kind=link}
{kind=link}
2. 图像编辑模型基准测试与工作流 (Qwen, WAN 2.2, Image Edit Arena)
- 让开,伙计们……有人来了 (Score: 175, Comments: 31):“Image Edit Arena” 的排行榜快照,该基准测试通过两两对决投票来评估图像编辑模型,报告了排名、带置信区间的得分、投票数、组织和许可。专有模型(如 OpenAI 的 gpt-image-1 和 Black Forest Labs 的 flux-1-kontext-pro)以最高分占据领先地位,领先于各种开源项目。 评论者热议一个绰号为 “Nano Banana” 的模型,称其表现非常出色,尽管另一位用户询问它究竟是什么,表明该绰号具体指代列表中哪个模型仍存在模糊性。
- 评论者将持续的高质量输出归功于名为 “Nano Banana” 的模型,暗示它具有可辨识的输出特征。然而,目前尚未提供具体的基准测试或模型标识符;该讨论若能提供确切的 checkpoint/LoRA 名称和定量指标(如
FID、CLIPScore)来证实性能主张,将会更有参考价值。 - 对 “3D ftx 输出” 的需求表明了用户对直接 2D 转 3D 模型能力以及导出为通用 3D 格式(可能是 FBX/GLTF)的兴趣。这指向了一个工作流缺口:大多数图像模型输出 2D 图像,因此生成可绑定骨骼的网格(riggable meshes)需要 text-to-3D 流水线(例如 NeRF 或 Gaussian Splatting 转网格)或原生的 3D 扩散/生成几何模型。
- 一位用户询问为什么 xAI 的 Grok 不在参考列表中,可能期望包含
Grok-1.5V(多模态)。这引发了关于该列表模态范围(LLMs 与图像模型)和评估标准的模糊性,表明需要澄清哪些模型和基准测试属于评估范畴。
- 评论者将持续的高质量输出归功于名为 “Nano Banana” 的模型,暗示它具有可辨识的输出特征。然而,目前尚未提供具体的基准测试或模型标识符;该讨论若能提供确切的 checkpoint/LoRA 名称和定量指标(如
- Qwen-Image-Edit 中的简单多图输入 (Score: 341, Comments: 51):该帖子展示了 Qwen-Image-Edit 中的多图条件控制:(1)将服装/风格从模特迁移到主体,并结合巴黎街头咖啡馆的场景重置;(2)将两个主体合成拥抱状态,同时保留特定属性(发型和发色)。文中还分享了一个单独的工作流示意图供参考(工作流截图)。 评论者反映该模型提示词遵循度(prompt adherence)很强,但照片写实感(photorealism)较弱(“塑料感皮肤”且丢失细节),建议尝试不同的采样器/预设(“res_2s/bong”)以获得更好的皮肤真实感,并指出提升质量可能需要进行微调(finetune)或使用 LoRA。
- 几位用户建议将 Qwen-Image-Edit 与 “res_2s/bong” 等替代流水线进行基准测试对比,称该设置下的皮肤细节/真实感要好得多。受控的 A/B 测试(相同提示词/种子)将有助于量化纹理保留(毛孔、细发)并减少在 Qwen-Image-Edit 输出中观察到的 “塑料感皮肤” 伪影。
- 存在明显的权衡:Qwen-Image-Edit 具有极强的提示词遵循度,但图像保真度较差(细节抹除、蜡质皮肤),让人联想起旧一代模型。评论者建议针对高质量人像数据集进行定向微调或训练 LoRA,以便在不牺牲遵循度的情况下改善微观纹理和真实感。
- 在工作流可复现性方面,一位评论者分享了完整的 ComfyUI 图表 JSON 以供快速导入,证明复制/粘贴工作流只需不到一分钟:https://pastebin.com/J6pz959X。另一位用户则提出了“截图转工作流”功能的需求(例如从 https://ibb.co/VYm716L7 等图像中重建图表),突显了尽管目前 JSON 导出/导入很方便,但在工具链上仍存在缺口(OCR/图表解析)。
-
[**Wan 2.2 写实工作流 Instareal + Lenovo WAN](https://www.reddit.com/gallery/1mvbmhh) (评分: 264, 评论: 33): **作者分享了一个 WAN 2.2 照片级写实工作流,该工作流融合了两个 LoRA——Instareal (链接) 和 Lenovo WAN (链接),并结合“特定的放大技巧”和添加噪声来增强真实感;节点图通过 Pastebin 提供 (工作流)。重点在于 WAN 2.2 的 LoRA 堆叠/调优,以及通过放大+噪声实现的后期细节增强,而非对基础模型的修改。 热门评论询问了关于放大流水线的技术细节(ComfyUI 对比 Topaz/Bloom 等外部工具)以及如何从工作流图中获取所有必需文件,这表明了用户对可复现性和集成细节的兴趣。 - 放大工作流细节:一位评论者询问原作者如何处理此 WAN 2.2 写实设置下的放大——是在 Comfy 内部完成,还是导出到 Topaz 或 “Bloom” 等外部工具,以及在
2x–4x放大时哪种方式能更好地保留细节。他们正在寻找具体的实践方案(节点选择 vs. 外部批处理),以便在生成后保持真实感。 - 工作流资产与依赖:一位用户请求获取流水线中引用的所有必需文件,这意味着需要多个组件(例如模型 Checkpoints、像 “Instareal” 这样的 LoRA 以及任何自定义节点/配置)来复现结果。需要明确具体版本和下载源,以使工作流具有可复现性。
- 模型适用范围澄清:另一位评论者认为 WAN 主要用于创建视频剪辑,寻求澄清此工作流中的 WAN 2.2 是用于静止图像、视频还是两者兼有。这引发了关于该模型预期用例的讨论,以及将其重新用于照片级写实静止图像时的任何设置或限制。
- 放大工作流细节:一位评论者询问原作者如何处理此 WAN 2.2 写实设置下的放大——是在 Comfy 内部完成,还是导出到 Topaz 或 “Bloom” 等外部工具,以及在
- 使用 Qwen + 我的 LoRA 生成的一些随机女孩图 (评分: 211, 评论: 46): 原作者展示了使用 Qwen 结合自定义 LoRA 生成的 AI 肖像(“女孩生成图”);未提供具体的模型变体、采样器或硬件细节。一位评论者询问性能指标——“生成时间是多少?”——但帖内未给出耗时或系统规格。另一位评论者分享了他们自己的工作流/模型链接:HuggingFace Danrisi/Lenovo_Qwen 和 Civitai 模型 1662740。 讨论倾向于可复现性和性能(推理时间)请求,而另一位用户贡献了替代资产/工作流;未报告基准测试数据或实现细节。
- 一位评论者请求具体的推理性能,特别是每张图像的生成时间。由于未提供耗时、步数、采样器或硬件细节,延迟/吞吐量和可复现性仍无法量化。
- 原作者链接了他们的工作流/模型,表明图像生成是使用 Qwen + 自定义 LoRA 完成的,并提供了 Hugging Face 和 Civitai 上的产物:https://huggingface.co/Danrisi/Lenovo_Qwen 和 https://civitai.com/models/1662740 。这些资源可能包含复现该设置所需的 LoRA 权重和流水线细节(提示词、分辨率、调度器和负向提示词,如果有记录的话)。
- 另一位评论者询问 LoRA 使用了哪种训练器(例如 kohya-ss、Diffusers/Accelerate、DreamBooth 变体),这是影响 VRAM 占用、训练稳定性和最终质量的关键细节。该帖子未指定训练器或超参数(步数、
lr、batch size、rank、alpha),因此确切的训练方案尚不明确。
-
使用编辑模型编辑标志性照片 (评分: 273, 评论: 35): 帖子展示了一个应用于“标志性照片”(例如阿波罗登月照片)的图像编辑模型,评论者评估了编辑的保真度/真实感;然而,链接的图库有访问限制(HTTP 403),因此无法独立验证实际媒体内容 (Reddit 链接)。帖中未指明模型身份。 具有技术背景的评论者注意到感知质量很高,但指出第一张照片存在历史/相机不一致性(“由尼康拍摄”),并询问该工具是 “Kontext 还是 qwan?”——这暗示了编辑框架或模型系列(如 Qwen)之间的模糊性。同时也存在关于登月编辑的非技术性病毒式传播推测。
- 一位评论者询问编辑是否是使用 Kontext 或 qwan(可能指阿里巴巴的 Qwen)完成的,这表明了对所使用的确切编辑模型及其图像编辑能力的兴趣。这暗示了对 Diffusion 或 Vision-Language 编辑流水线的比较,以及它们在对标志性照片进行写实编辑时带来的优势。
- 对《国家地理》(National Geographic) 编辑效果的反馈指出其具有很高的写实感,但对主体的眼睛仍然模糊不清感到沮丧,这突显了生成式编辑中的一个常见局限:处理遮挡以及在不产生恐怖谷效应 (uncanny artifacts) 的情况下重建微小的面部细节。这表明该模型可能优先考虑了全局真实感和纹理一致性,而不是重建精细的眼部细节,这是人脸编辑中常见的权衡。
- 一位用户断言第一张原始画面是用 Nikon 拍摄的,指出了可能影响评估编辑真实感时的出处细节(相机品牌),如色彩科学和颗粒分布。这强调了原始拍摄特征可能会偏向模型输出的真实感。
- GPT-5 在审查 Claude Code 的工作方面表现得惊人地出色 (Score: 443, Comments: 100): OP 概述了一个 规划→实现→审查 的工作流:使用 Claude Code (Sonnet 4) 进行代码生成,使用 Traycer 生成实现计划(Traycer 似乎是用 Prompt/Agent 脚手架封装了 Sonnet 4),然后将生成的代码反馈给 Traycer,由 GPT-5 执行计划与实现的对比检查——即一个报告覆盖项、缺失范围和新引入问题的“验证循环”。这与 Wasps/Sourcery/Gemini Code Review 等审查工具形成对比,后者在没有功能上下文的情况下对原始的
git diff进行评论;将审查与明确的计划相结合可以提高信号质量。报告的成本:~$100用于 Claude Code 访问,外加~$25用于 Traycer。 评论者也表达了类似的观点:GPT-5 擅长规划/分析/调试,但在直接编写代码方面较弱,因此他们将其与 Sonnet 4 配合进行实现;另一位用户增加了一个 Claude Code 测试 Agent,在 GPT-5 最终通过之前运行单元测试。有人对 Traycer 的透明度表示担忧(例如 GitHub 登录),但指出它涵盖了他们用本地 Prompt 文件构建的大部分内容。- 从业者报告了一种分工模式:由 GPT-5 负责规划/审查/调试分析,由 Anthropic 的 Claude(例如 Claude Code, “Sonnet 4”)负责实现。一位用户指出:“GPT-5 在除了写代码之外的所有事情上都很棒……它很难实现自己的计划,” 因此他们将所有编码工作交给 Claude,同时保留 GPT-5 进行规范/审查以最大化质量。
- 引用了一个端到端流水线:GPT-5 起草概念/规范 → Claude Code 实现 → Claude Code 测试 Agent 运行单元测试 → GPT-5 执行最终代码库检查。据报道,这个审查循环“运行得非常好”,在自动化约
80%的自研 Prompt 驱动工作流(例如 Obsidian Prompt 文件;Traycer 等工具旨在覆盖其中的大部分)的同时,提供了防止回归/幻觉的护栏。 - 幻觉/控制漂移仍然是一个风险:一位用户回忆起 Codex 被要求构建一个 JS 框架应用,却输出了 Python 命令。因此,引入了自动化单元测试(通过 Claude Code 测试 Agent)和最终的 GPT-5 审计来检测此类不匹配;如果没有这些检查,尽管 GPT-5 在规划/审查方面表现强劲,仍可能产生幻觉。参见 Codex 的背景:OpenAI Codex。
- 来自 Anthropic 的 “Built with Claude” 竞赛 (Score: 192, Comments: 44): Anthropic 在 r/ClaudeAI 上宣布了一项社区 “Built with Claude” 竞赛,将评审截至 8 月底所有带有 “Built with Claude” 标签的帖子,并根据点赞数、讨论度和综合价值选出前
3名;每位获胜者将获得价值$600的 Claude Max 订阅额度或 API 额度。参赛作品必须是使用 Claude(例如 Claude.ai、Claude app、Claude Code/SDK)的原创构建,并应包含技术构建细节(Prompt、Agent、MCP 服务器/工作流,如 Model Context Protocol),以及截图/演示;官方规则见此处。 版主欢迎 Anthropic 增加参与度,同时承诺保持独立的性能报告和社区声音。评论者询问了参赛门槛(如 subreddit 的声望值限制),还有人反映未收到之前 “Code with Claude” 活动的$600奖励,引发了对兑现/支持的担忧。- 一位评论者展示了一个由 Claude 辅助的项目 “RNA cube”,该项目为每个 RNA 密码子分配一个十进制值,以便对遗传数据进行基于整数的算术运算,并将氨基酸分为
4个化学性质不同的类别。他们提供了一个在线网站 https://biocube.cancun.net,以及包括 3D 可视化和变体分析批量工具在内的其他资源;社区中心位于 https://www.reddit.com/r/rnacube。他们认为 Claude 对复杂性的推理能力在该框架的设计中起到了关键作用。 - 同一位评论者指出一个潜在的工具特性:要求 Claude 获取/评论其网站时,可能会因为 “不更新的缓存” 而返回陈旧的快照。作为解决方法,他们建议通过附加查询参数(例如 https://biocube.cancun.net/index.html?id=100—以)来清除缓存,确保获取最新版本。
- 一位评论者展示了一个由 Claude 辅助的项目 “RNA cube”,该项目为每个 RNA 密码子分配一个十进制值,以便对遗传数据进行基于整数的算术运算,并将氨基酸分为
- Agent 模式令人印象深刻 (Score: 237, Comments: 231): 发帖者报告称,一种自主的 “Agent 模式”(自称是 GPT-5)可以执行端到端的 Web 任务,例如根据用户指定的约束条件(饮食偏好、预算、品牌偏好)购买杂货,有效地执行人类风格的网站导航和结账。评论者指出了可靠性限制:Agent 在高度动态、脚本密集的网站上经常失败,并且可能会放弃流程,当 DOM/状态处理或反自动化拦截破坏工作流时,会转而要求用户提供结构化输入(例如保险报价)。 辩论集中在 UX 底层:一些人认为 Agent 在被迫解析人类 UI 时仍会容易出错,预测将转向机器可读的
agent interfaces,通过交换原始数据来潜在地重塑电子商务和 Web 架构;而另一些人则对 Agent 处理关键任务表示信任度低,称目前的结果处于 “MySpace 时代”。- 当被迫导航消费级 Web UI 时,Agent 仍然很脆弱:动态 DOM、繁重的客户端渲染、CSRF 流程、Cookie 墙和机器人检测使得分步自动化变得不可靠。一条提议的路径是 Agent 原生接口(原始 JSON/数据交换而非 HTML),这可能会重新构建电子商务和机器对机器的交互——类似于从 “MySpace 时代” 迈向机器可读的 Web。
- 一个现实世界的任务(收集保险报价)失败了,因为网站 “太动态”,导致 Agent 放弃并请求手动输入。这突显了当前在多步表单、异步 JS、嵌入式组件/iframe 以及反自动化措施(如验证码)方面的局限性,表明在提供商开放稳定的 API 或专用 Agent 端点之前,确定性较低。
- 解决方法和局部成功:一位用户将本地 NAS 聊天服务暴露到 Web 并提供凭据,以便 Agent 可以自助获取答案,通过经过身份验证的工具使用减少了在较小限制下的消息数量。另一位用户实现了端到端的购物流程(规格 -> 身体测量/衣橱背景 -> 库存检查 -> 预填购物车 -> 人工批准),表明 Agent 在具有状态规划、会话持久性以及访问经过身份验证/内部工具的受限领域中可以可靠地运行。
- AI 泡沫是否会破裂?MIT 报告称 95% 的企业级 AI 计划以失败告终。 (Score: 218, Comments: 208): 该帖子探讨了“AI 泡沫”是否会破裂,并引用了一份 MIT 报告,声称
95%的企业级 AI 项目都失败了。评论者认为,LLM 在辅助性的、人机协同(human-in-the-loop)场景中确实有用,但完全自动化并取代人类判断的尝试在生产环境中正在失败,且无法产生 ROI;由炒作驱动的低价值“AI 工具/微服务”泛滥是主要的失败模式。可能的结果是类似于互联网泡沫时期的修正,过度炒作的应用层初创公司将进行整合,而主要的基础设施/供应商将继续存在。 共识:存在由误用和不切实际的期望驱动的泡沫,而非核心技术能力的问题;预计在过度自动化的博弈中投资者会遭受损失,但大型 AI 平台将持续进步并保持韧性。- 人机协同 vs. 全自动化:多位评论者指出,在企业工作流中尝试用 AI/LLM 完全取代人类决策往往会失败,而辅助模式(AI 作为 Copilot,由人类监督/批准)则行之有效。隐含的技术原因是当前 LLM 在高风险、无边界决策中的可靠性/校准限制;成功的部署通常会限制范围,并让人员参与审批环节,以处理边缘情况并承担责任。
- 中小企业(SME)具体的生产力提升:一家小型数字化公司报告称,通过使用 ChatGPT 构建生产工具、通过脚本自动化记账、起草客户邮件以及排查 Bug,节省了“数万美元”(
$10k+)的开发成本。这表明对于范围狭窄、可自动化的任务,如果 LLM 输出可以在现有的脚本/工具流水线中快速验证或执行,则具有很强的 ROI。 - 市场/采用结构:评论者认为,“泡沫”风险集中在应用层初创公司和过度炒作的单一工具上,而非核心模型提供商,这类似于 ISP 在互联网泡沫破裂中幸存下来。他们还指出,企业采用缓慢通常是由于组织官僚主义和变革管理摩擦,而非模型能力限制,这意味着即使存在技术价值,销售/采用周期也会更长。
- OpenAI 录得首个 10 亿美元月营收,但 CFO 表示仍“始终处于算力短缺状态” (Score: 243, Comments: 51): 据报道,OpenAI 录得首个超过
$1B的月营收;CFO Sarah Friar 表示公司“始终处于算力短缺状态”。发帖者推测,Microsoft/OpenAI 提议的 “Stargate” 超大规模扩建项目可能会在年底前部分上线以增加产能;报告称 Stargate 是一个耗资约$100B的超级计算机计划,旨在缓解 GPU 短缺(Reuters/The Information)。热门评论引用了约$12B的年化营收运行率和一份据称约$40B的 Oracle 云合同,将其视为规模和成本的关键投入,同时预计价格可能会上涨(Reuters 报道 OpenAI-Oracle)。 评论质疑其可持续性:对约$500B的估值以及 Sam Altman 提到的用于资助数万亿美元 AI 基础设施的“新型金融工具”表示怀疑,并提到了他为 AI 芯片/数据中心筹集数万亿美元的努力(Reuters)。- 算力产能与云依赖:多条评论强调 OpenAI “始终处于算力短缺状态”,据称约
$40B的 Oracle 交易被视为激进预留产能的证据。这意味着训练/推理吞吐量是约束瓶颈(GPU 供应、数据中心建设、电力),这可能会迫使公司提高价格并优先处理高利润工作负载,以满足 SLA 和延迟目标。 - 巨额资本支出融资:Sam Altman 关于“新型金融工具”的言论被解读为试图为数万亿美元的数据中心、芯片和电力建设提供资金。从技术角度看,这暗示了诸如长期产能承购协议、GPU 集群的资产证券化或由主权/基础设施支持的 SPV 等结构,以将资本支出排除在运营实体的资产负债表之外——评论者对这种规模下的执行风险和资本成本持怀疑态度。
- 算力产能与云依赖:多条评论强调 OpenAI “始终处于算力短缺状态”,据称约
- 估值与单位经济效益:从每月 10 亿美元推算出的
~$12BARR 与 5000 亿美元的估值相比,意味着~40x+的销售倍数,这只有在毛利率实质性改善的情况下才合理。评论者指出,目前的 COGS(主营业务成本)属于计算密集型;如果没有单 token 成本的降低(例如:更好的 batching、模型稀疏化/蒸馏、定制芯片)或通过定价分级/企业级增值服务提高 ARPU,那么该估值和增长路径将难以自圆其说。
{kind=link}
3. Veo-3 AI 视频生成演示与指南
- 用 Veo-3 赋予 Simon Stålenhag 的艺术作品生命 (Score: 272, Comments: 22):一位创作者使用 Google 的 Veo-3 视频模型(image-to-video)将 Simon Stålenhag 的插画制作成动画。主片段托管在 v.redd.it,未经身份验证会返回
HTTP 403错误;可以通过 preview.redd.it 查看静态预览。帖子中未透露 Prompt、分辨率或运行时设置;该帖重点在于展示风格化动画,而非基准测试或实现细节。 评论者注意到这与 Stålenhag 作品更广泛的媒体改编(如《环形物语》RPG/剧集)非常契合,并称赞背景音乐的选择非常符合氛围。 - 在进行 10,000 次 AI 视频生成后我学到的一切(完整指南) (Score: 224, Comments: 41):原作者(10 个月经验,约 1 万次生成)分享了一个以 Veo-3 为核心的可扩展 AI 视频工作流:一个由 6 部分组成的 Prompt 模板
[SHOT TYPE] [SUBJECT] [ACTION] [STYLE] [CAMERA MOVEMENT] [AUDIO CUES],严格遵守“每个 Prompt 仅限一个动作”,并前置关键 token,因为“Veo3 对靠前的词权重更高”(作者观点)。他们主张进行系统性的种子扫描(seed sweeps,例如测试种子1000–1010,建立种子库),将负面提示词作为常驻 QC(-no watermark --no warped face --no floating limbs --no text artifacts --no distorted hands --no blurry edges),并将镜头运动限制在单一基础动作(缓慢推/拉、环绕、手持跟随或静态)。在成本方面,他们指出 Google 的官方定价约为~$0.50/s($30/min),计入重试次数后,每段可用视频的成本将超过$100+,并建议使用更便宜的第三方 Veo-3 分销商(如 https://arhaam.xyz/veo3/)以进行大规模测试。其他策略包括:在 Prompt 中加入明确的音频线索,使用具体的设备/创作者进行风格参考(例如 “Shot on Arri Alexa”, “Wes Anderson”, “Blade Runner 2049”, “teal/orange”),针对 TikTok/IG/Shorts 进行特定平台的剪辑,以及对热门视频进行 JSON “逆向工程”以提取结构化参数进行变体创作。核心策略:优先考虑批量生成、首帧筛选、平台定制变体,并“拥抱 AI 美学”而非追求虚假现实主义来驱动互动。 热门评论提醒可能存在未披露的推广行为,并强调许多技巧是 Veo-3 特有的;对于权重开放(open-weight)的替代方案,评论者指向了 WAN-2.2 指南(非官方镜像,官方文档源)。其他人认同这种系统化、量产优先的方法论可以推广到图像/音频/视频模型,但对分销商的植入广告保持怀疑。- 评论者警告说,原作者的 Prompt 模式“可能仅适用于 Veo-3”,无法 1:1 移植到其他模型。对于
WAN 2.2,他们参考了官方指南中的示例(非官方镜像):https://wan-22.toolbomber.com/ 以及官方手册 https://alidocs.dingtalk.com/i/nodes/EpGBa2Lm8aZxe5myC99MelA2WgN7R35y (Firefox 浏览器无法查看)。由于控制 token/关键词和条件化行为(conditioning behavior)的差异,为 Veo 3 优化的 Prompt 在 WAN 2.2 上可能表现不佳,因此在迁移工作流时应依赖特定模型的文档。 - 关于技术栈选择和可复现性的担忧:Veo 3 被指是一个封闭、付费的在线生成器(非开源),与 WAN 等权重开放的视频模型相比,这限制了透明度和自托管的可复现性。这限制了 Prompt 配方的可移植性,并使得在提供商环境之外验证或测试流水线变得更加困难。
- 方法论仍然具有普适性:系统化(控制变量、版本化 Prompt、小型消融实验)的建议在视频/图像/音乐生成中广泛适用。在比较 Veo 3 和
WAN 2.2设置时采用相同的评估协议,有助于确保结果可复现且具有可比性。
- 评论者警告说,原作者的 Prompt 模式“可能仅适用于 Veo-3”,无法 1:1 移植到其他模型。对于
- 如何生成像这样的视频? (Score: 209, Comments: 55): 楼主询问如何生成温馨房间风格的视频;点赞最高的评论澄清这并非完全由 AI 生成的视频,而是将静态图像进行合成,对窗户/电视屏幕进行遮罩处理,并在标准的 NLE(如 CapCut 或 Adobe Premiere Pro)中通过色度键控(chroma keying)叠加素材。建议的工作流:创建或选择单张背景帧,对显示器/窗户区域进行遮罩,然后叠加循环视频(如雨景、动画);一位评论者指出,文本转视频模型 “wan” 可以合成简单的背景效果(雨),但可能无法合成像《猫和老鼠》这样特定 IP 的内容。由于未经身份验证无法访问链接的 Reddit 媒体 (v.redd.it/34cc74her1kf1)(HTTP 403),因此无法核实确切内容。 评论者将此方法定性为“相当基础”的合成;另一位评论者链接了一张图片并评论说,仔细观察会发现场景中有奇怪的人造痕迹/选择 (预览图片)。
- 共识是这并非端到端的视频生成,而是一个合成工作流:生成静态背景图像,然后对窗户/电视区域进行遮罩/裁剪,并在 Adobe Premiere Pro (https://www.adobe.com/products/premiere.html) 或 CapCut 等 NLE 中通过键控/绿幕叠加现有视频。为了更精确的控制,可以使用 After Effects (https://www.adobe.com/products/aftereffects.html) 进行平面跟踪、遮罩/抠像(rotoscoping)和键控(例如 Keylight),使插入内容符合透视关系,并添加颗粒/反射以匹配底图(plate)。
- 一位评论者建议将环境背景交给 AI 视频工具(帖子中提到名为 “WAN” 的工具),它可以合理地处理简单的循环雨景,但指出它可能无法为屏幕内的插入内容合成特定的 IP 内容(如《猫和老鼠》)。实际建议:使用 AI 处理通用的氛围元素,然后将获得授权的或真实的素材合成到遮罩表面。
- 伙计们,它要来了 (Score: 340, Comments: 74): Google Gemini App 发布的 #MadeByGoogle 活动预热图片,活动将于 2025 年 8 月 20 日东部时间下午 1 点举行,口号是“对你的手机要求更多”。视觉效果微妙地显示了一个“10”,暗示了 Pixel 10 系列和手机优先的 AI 功能,而非新的前沿模型(未提供规格、基准测试或模型细节)。 热门评论预期会有以 Pixel 为中心的 AI 集成,并怀疑是否会发布 Gemini 3;其他人则认为这是在炒作,指出这主要是一场手机发布会。楼主后来的编辑提到了一项图像编辑工具的发布,相对于预热的炒作程度,这被认为平淡无奇。
- 几位评论者指出,这次发布很可能是关于 Pixel 10 设备层级的 AI 集成,而不是像 Gemini 3 这样的前沿模型发布。预期的功能是消费者端的工具(如图像编辑),而不是新的模型能力或训练突破。从技术上讲,这意味着在现有 Gemini 模型之上增加增量式的 UX 功能,而不是更新基准测试或架构细节。
- 怀疑论集中在将智能手机发布与实质性的 AI 进展混为一谈:用户指出该预热图实际上是带有 Gemini 品牌功能的 Pixel 10 广告。从技术兴趣的角度来看,评论者指出没有证据表明有新模型发布、端侧模型大小、推理延迟或隐私/性能权衡的披露——而这些正是社区寻找的关键细节。
-
Google 的营销做得很烂。 (Score: 193, Comments: 28): 该帖子围绕一条批评 Google 产品营销的推文展开,声称其依赖名人代言(如 Jimmy Fallon)和摆拍的热情,而不是真实的演示。评论者强调“Gemini 教你如何构图”这一环节是一个典型的、缺乏共鸣的产品叙事案例,加深了人们对 Google 依赖“产品自销”理念而非连贯、以用户为中心的信息传递的认知。 评论者认为 Google 在尴尬、令人脚趾抠地的 Keynotes 方面历史悠久——有时甚至超过了 Apple——而且短剧式的环节(如提到的 Fallon 案例)损害了 Gemini 相机引导等功能的公信力。
- “Gemini 教你如何构图”的演示因展示了一个低价值的用例而受到抨击,同时忽略了对开发者至关重要的实现细节:实时引导是在设备端(例如 Gemini Nano)还是云端(Gemini Pro/Ultra)运行、相机取景器中的预期延迟,以及持续多模态推理对隐私和电池的影响。评论者指出,由于缺乏任何指标或限制说明,关于离线行为和回退机制(fallback)的问题仍悬而未决。产品背景请参阅:https://ai.google/gemini/
- 几位观察者注意到,此次活动跳过了 Gemini 在关键平台上的路线图——包括 Google Home/Nest、Android Auto 和 Google TV——尽管这些平台是助手替换和多模态交互的首选场景。缺失的细节包括唤醒词集成、家庭上下文/共享、离线模式,以及车载使用的安全/驾驶分心限制。参考资料:https://support.google.com/googlenest/、https://www.android.com/auto/ 以及 https://tv.google/
- 人们对即将发布的 Pixel Feature Drops 将如何对待旧款 Pixel 设备表现出浓厚兴趣——哪些 Gemini 功能(如果有的话)将向后移植,以及哪些功能受硬件限制(Tensor 代际、NPU/TPU 吞吐量、RAM)。演示未提供兼容性矩阵、发布节奏或最低设备规格,这使得规划应用支持或用户升级变得困难。背景资料:https://blog.google/products/pixel/feature-drops/
- OpenAI 的 Altman 警告美国低估了中国的下一代 AI 威胁 (得分: 1288, 评论: 221):帖子重点介绍了 Sam Altman 的警告,即美国低估了中国部署下一代 AI 的能力,具体的风险在于国家支持和成本优化实验室带来的快速商品化(例如 DeepSeek 以低成本发布准前沿模型),这压缩了 API 利润空间并侵蚀了护城河。评论者将其视为类似于开源/廉价 LLM(例如 Meta 的 Llama 3 系列、Google 的 Gemini)的价格/性能颠覆,加速了追赶进程并减少了前沿系统之间的差异化。 热门评论认为 Altman 的核心担忧是 OpenAI 缺乏持久的护城河:DeepSeek 的免费/廉价模型表现达到了“~95%”的水平且受到严格审查,证明了低成本的近乎对等是可行的,同时也限制了采用。其他人对 Altman 的公信力表示怀疑(例如过去的 GPT-5 炒作与现实的差距),而一些人则同意中国的广泛技术执行力被低估了。
- 几位评论者认为 OpenAI 的护城河正在被侵蚀,因为像 DeepSeek 这样的竞争对手以极低的成本提供了约
95%的 ChatGPT 级别能力,甚至免费提供访问。这给单位经济效益(训练/推理成本与可实现价格)带来了压力,并削弱了私有 API 的溢价定价。他们指出,中国模型的一个实际限制是严格的内容过滤(审查),尽管性价比极具吸引力,但这减少了许多用例的覆盖范围。 - 其他人强调,Google, Meta, X 和其他老牌企业的快速投资缩短了基础模型达到对等性能的时间(time-to-parity),这表明能力的商品化速度比预期的要快。这意味着如果没有可持续的差异化因素(例如数据优势、部署/集成护城河或专门的推理优化),前沿优势会迅速衰减,从而加剧价格压力并加速模型更迭。
- 几位评论者认为 OpenAI 的护城河正在被侵蚀,因为像 DeepSeek 这样的竞争对手以极低的成本提供了约
-
Oprah 问 Sam Altman:AI 是否发展太快? (得分: 402, 评论: 266):该帖子分享了一段简短的采访片段,Oprah 在其中询问 Sam Altman AI 是否“发展太快”;该片段(托管在 v.redd.it)不包含任何技术讨论——没有提到模型规格、训练/数据规模、安全评估、部署时间线或基准测试——因此没有可提取的技术主张。Reddit 上的视频访问受限,限制了对提示式问题之外任何细微背景的验证。 热门评论集中在 Altman 的媒体形象和沟通风格(例如“照本宣科”、“平易近人”、“类 GPT 的上下文预测器”),而非技术实质;没有关于政策、安全指标或能力趋势的有意义辩论。
- 诚实是最好的回应 (Score: 13823, Comments: 411): 一张截图显示,据称是 GPT-5 的模型明确表示弃权:“我不知道——而且我无法可靠地查明。”从技术角度来看,这突显了校准不确定性(calibrated uncertainty)和旨在减少幻觉(hallucinations)的拒绝回答行为——即通过置信度阈值、基于熵/logit 的标准、工具可用性检查或系统提示词(system prompts)来实现选择性预测/弃权,尽管目前尚未提供该模型身份的基准测试或验证。上下文传达的核心信息是强调可靠性优于覆盖范围:宁愿明确表示“未知”,也不愿提供编造的答案。 评论者质疑该模型是否真的经过了良好的校准(它能检测到自己什么时候不知道吗?),同时称赞弃权行为在经常瞎猜的 LLM 中非常罕见;他们指出,这种行为即使对人类来说也很难。
- 核心讨论主题:LLM 是否能可靠地“知道自己什么时候不知道”,而不是产生幻觉。像 Anthropic 的《Language Models (Mostly) Know What They Know》等证据表明,内部不确定性信号与正确性相关,但在分布偏移(distribution shift)下仍不完美;评估通常使用校准指标(ECE/Brier)和选择性预测覆盖率-风险曲线(paper, calibration)。实际上,如果没有明确的弃权训练或决策阈值,大多数经过指令微调(instruction-tuned)的模型都会表现出过度自信。
- 诱导诚实弃权的实现角度:用于拒绝的 logprob/熵阈值、作为不确定性代理的自一致性(self-consistency,即 k 个采样生成结果之间的一致性),以及用于锚定答案并减少幻觉的检索增强生成(RAG)。RLHF/指令微调可以奖励对低置信度项目的弃权,从而改变准确率-覆盖率的权衡(accuracy–coverage tradeoff);SelfCheckGPT 和 RAG 相关文献等研究报告称,通过牺牲覆盖率可以降低幻觉率(SelfCheckGPT, RAG)。
- 验证重点:评论者要求提供原始问题以验证该说法——最佳实践是在选择性问答(selective QA)上进行基准测试,并绘制准确率与拒绝率的关系图(风险-覆盖率/AURC)。使用 TruthfulQA 和开放域问答等数据集,包含 Token 级 logprobs(如果可用)和引用,以实现可复现性和可审计性(TruthfulQA, selective classification)。
- 他在 2 年前就预言了这一点。 (Score: 523, Comments: 98): 一张来自 2023 年 #GOALKEEPERS2030 演讲的照片被用来强调一个预言,即“GPT-5 不会超越 GPT-4”。评论者指出,自 2023 年初以来,GPT-4 的能力发生了显著变化——增加了语音、多模态 I/O 和原生图像生成、工具/浏览/计算机控制集成以及更好的可靠性——因此将“原始 GPT-4”与今天进行比较具有误导性;他们还认为 GPT-5 相比 GPT-4 是一个巨大的飞跃,尽管可能没有超越 OpenAI 的 o3 推理系列。一些人引用了小型开源模型(例如 Qwen3-4B),据报道在数学/编程基准测试中达到或击败了早期的 GPT-4。 辩论集中在不断变化的评判标准(moving goalposts)和历史背景上:该预测是针对模型家族的上限,还是针对特定的发布快照;以及对于 Qwen3-4B ≈ 早期 GPT-4 这种基准测试结论应给予多少权重,因为这可能取决于任务选择和评估方法。
- 评论者将 2023 年的“原始 GPT-4”与今天的 GPT-4/4o/5 技术栈进行了对比:早期的 GPT-4 拥有
8k/32k的上下文(context),但没有内置工具(没有语音模式、浏览/互联网交叉检查、工具/函数调用、原生图像生成或计算机控制),并且缺乏明确的思维链(chain-of-thought)输出。他们指出,像 o3 和 GPT-5 这样较新的推理模型在可靠性/推理方面明显优于早期的 GPT-4,即使 GPT-5 相比 o3 没有提升。 - 一项开源对比声称 Qwen 3 4B (CoT)——一个笔记本电脑即可运行的
~4B参数模型——达到了与早期 GPT-4 相当的基准测试水平,据报道在数学和编程任务上甚至超过了它。如果属实,这突显了效率的快速提升,即小型 CoT 模型在特定基准测试中可以匹配或击败旧的前沿模型(frontier models)。 - 一位用户回顾了早期 GPT-4 的局限性:尽管有
32k上下文选项,但它“没有任何工具”,并且在没有外部辅助的情况下经常在小学数学题上出错。这与以下观点一致:后来的功能增加——工具使用、检索/浏览和多模态 I/O——对于弥补可靠性差距至关重要。
- 评论者将 2023 年的“原始 GPT-4”与今天的 GPT-4/4o/5 技术栈进行了对比:早期的 GPT-4 拥有
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AI Discord 回顾
由 X.ai Grok-4 生成的摘要之摘要之摘要
主题 1. 模型大乱斗:发布与竞争震撼排行榜
- DeepSeek v3.1 在质量检查中表现不佳:用户抨击 DeepSeek v3.1 质量下降,归咎于劣质代码 (slop coded)输出和华为 GPU,而支持者则指出特朗普的关税削弱了硬件获取能力。尽管有炒作,但它落后于前代产品,并在 Agent 任务中被 Kimi K2 超越,引发了对其现实世界可行性的争论。
- Gemini 2.5 Pro 从 GPT-5 手中夺回桂冠:Gemini 2.5 Pro 重新夺回 LMArena 榜首,引发了关于 GPT-5 因被投反对票或过度顺从而衰落的理论,Polymarket 评分显示 Gemini 在速度和免费访问方面具有优势。用户推测 Nano Banana 可能是 Google 的潜在颠覆者,通过 Logan K 的推文进行炒作,可能为 Pixel 独占,但被广泛需求。
- Qwen 模型凭借 BF16 性能横扫基准测试:得益于 llama.cpp 的 FP16 内核,Qwen3 BF16 在零样本 (zero-shot) 编程方面表现优于量化版本,令用户惊叹;同时 Qwen-Image-Edit 在 Image Edit Leaderboard 中位列开源模型第一。字节跳动的 Seed-OSS-36B-Instruct 在无需 RoPE 缩放的情况下实现了 512k 上下文,令人印象深刻,而 GLM 4.5 V 在其演示视频中的视觉任务表现出色。
主题 2. 微调热潮:GRPO 和数据集驱动优化
- GRPO 增强 Llama 的物理推理能力:用户在物理数据集上对 Llama 模型应用了 GRPO,分享了 mohit937 的 FP16 合并版本,辩论其在没有评判者的情况下类似 RL 的优势,尽管存在偏向较长回答等缺陷。与 Reinforce++ 的对比突显了 GRPO 作为提升推理能力的精简替代方案的潜力。
- Gemma 3 通过 CPT 提升法语流利度:新手使用儒勒·凡尔纳的文本对 Gemma 3 270m 进行了法语微调,参考了 Unsloth 的 CPT 文档和博客,electroglyph 分享了他们的 Gemma 3 4b GRPO 微调版本。结果称赞了模型改进后的输出,并引发了关于视觉层 VRAM 调整的技巧讨论。
- OpenHelix 数据集精简以获得更好的平衡:更新后的 OpenHelix-R-86k-v2 通过 ngram 去重减少了体积以增加多样性,利用 重要性矩阵数据集 (importance matrix datasets) 辅助量化。用户探索了反奉承 (anti-sycophancy) 分类器和 Gemma 1B 上的斯瓦希里语优化,强调了更干净的数据在减少错误中的作用。
主题 3. 硬件之战:GPU 争夺 AI 霸权
- 英伟达在史诗级工程对决中胜过 AMD:关于英伟达在扩展性上领先 AMD 和 Intel 的争论异常激烈,用户关注极其廉价的 AMD MI50 32GB 显卡在 Qwen3-30B 上达到 50 tokens/s,而另一些人则警告说与 3090 相比,它们是昂贵的电子垃圾。如果 Intel 倒闭,希望寄托在英伟达接管 x86/64 生产上,这突显了 dGPUs 领域的工程差距。
- VRAM 问题导致 Mojo 和 CUDA 设置崩溃:根据此 gist,GPU 崩溃困扰着没有同步屏障 (sync barriers) 的 Mojo 代码,而 CUDA OOM 错误在剩余 23.79GB 的情况下依然发生,通过 PyTorch 驱动重启修复。尽管 L40S 的 FLOPS 更高,但在 tokens/s 上仍落后于 A100,这归咎于内存带宽瓶颈。
- 量化挑战应对 DeepSeek 671B 巨兽:用户将 DeepSeek V3.1 671B 量化为 Q4_K_XL,至少需要 48GB VRAM,参考 Unsloth 的博客获取动态量化技巧。CUDA 设置要求调整最大上下文和 CPU-MOE 以适应 VRAM 裕量。
主题 4. 工具动荡:API 和 Agent 在 Bug 中进化
- OpenRouter 发布 Analytics 和 Model API:新的 Activity Analytics API 可获取每日汇总数据,而 Allowed Models API 则根据用户偏好列出允许使用的模型。GPT-5 的上下文在 66k tokens 时崩溃,并静默返回 200 OK 响应,而 Gemini 模型在处理复杂工具调用(tool calls)时抛出了 HTTP 400 错误。
- MCP Agent 暴露安全噩梦:博文警告称 AI Agent 是完美的内部威胁,并演示了如何通过 GitHub issues 劫持 Claude 的 MCP 服务器以进行仓库数据外泄。APM v0.4 通过团队化 Agent 解决了上下文限制和幻觉问题,并集成了 Cursor 和 VS Code。
- Aider 和 DSPy 与工具 Bug 及缓存作斗争:Aider 的 CLI 在处理具有 7155 个搜索匹配的工具调用时陷入循环,而 Gemini 2.5 Pro 在未配置计费的情况下运行失败;Qwen3-Coder 在本地表现优于 Llama。DSPy 即使在缓存结果上也会返回成本,用户正在寻求通过 GPT-5 裁判进行风格模仿的交叉验证优化器。
主题 5. 行业动态:估值、人才战与 AI 回报
- OpenAI 估值飙升至 5000 亿美元引发狂热:根据 Kylie Robison 的推文,OpenAI 作为最大的私有公司,其估值接近 5000 亿美元。支持者引用了其 20 亿用户的潜力,但批评者抨击其“没有护城河”且利润率不断收缩。在人才挖角战中,xAI 的人才流向了 Meta,而 Lucas Beyer 的反驳声称其归一化的人员流动率较低。
- 95% 的 AI 部署产生零回报:AI 报告显示,95% 的组织从定制 AI 中获得零回报,原因归咎于忽视了学习更新以及 ChatGPT 使用的影子经济。像 Databricks 这样的公司以超过 1000 亿美元的估值融资 110 亿美元,用于 Agent Bricks 的扩张,并避开了 IPO。
- 人才猎头与职位发布升温:SemiAnalysis 通过直接申请链接招聘负责性能角色的应届生工程师,EleutherAI 的校友在对 Gaudi 2 寄予厚望的同时提交了申请。区块链开发者提供了 DeFi 专业知识,而 Cohere 则欢迎硕士生和 MLE 参与合作。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Comet Browser 在 Amazon.in 上崩溃:用户报告 amazon.in 在 Comet Browser 中无法正常工作,可能是由于网络问题或防火墙设置,而在 Brave Browser 中则可以正常打开。
- 一名成员建议联系支持团队 support@perplexity.ai,并警告不要购买 Comet 的邀请码,指出美国的 Pro 用户可以立即访问。
- ChatGPT Go 印度方案引发讨论:OpenAI 新的 ChatGPT Go 方案正在印度进行测试,价格为 ₹399/月,侧重于 Prompt 编写。
- 成员们讨论了其相对于免费版本或 Perplexity Pro 的价值,其他人建议选择 ₹700/月 的 Super Grok,其 131k 的上下文窗口被认为是比 ChatGPT Go 的 32k 限制更好的替代方案。
- Perplexity UI 引发褒贬不一的反应:用户对 Perplexity 的用户界面(UI)持两极分化的看法,对 Android UI 的批评与对 Windows 设计的赞扬形成鲜明对比。
- 爱好者们特别赞赏 Comet 浏览器中内置的广告拦截功能。
- Perplexity API 状态受到质疑:一位用户询问了 API 状态和延迟问题,指出 状态页面 并不能准确反映当前的延迟情况。
- 此外,一位用户询问了关于删除 API groups 的问题,一名成员回应称他们会将该请求转发给 API 团队。
Unsloth AI (Daniel Han) Discord
- Unsloth App 更新至 v3.1: Unsloth app 已更新至 v3.1 版本,具有 instruct model 和混合能力。据 general 频道的成员称,尽管存在硬件限制,用户们仍对此感到兴奋。
- 一名成员幽默地报告了在尝试分配 20MB 内存时出现容量错误,尽管 GPU 还有 23.79GB 空闲。建议参考 pytorch.org 链接,通过重启来清除死进程留下的垃圾。
- GRPO 合并提升 Llama 物理表现: 一位用户将 GRPO 应用于带有物理数据集的 Llama 模型,该模型可在 Hugging Face 上获取。社区共识认为 GRPO 基本上就是没有外部判别模型的 RL。
- 尽管 vanilla GRPO 存在潜在问题(如偏向更长的回答),但一些人认为其潜力与 Reinforce++ 相当。
- Gemma 3 获得微调: 一位新手寻求关于对 Gemma 3 270m 进行持续预训练 (CPT) 以增强其法语知识的指导,素材源自儒勒·凡尔纳的《海底两万里》,起点参考 Unsloth 文档 和 博客。
- Electroglyph 分享了他们的 Gemma 3 4b unslop 微调版本,包括代码并上传至 Hugging Face,并表示这次的效果相当不错。
- OpenHelix 数据集更新: 团队在 Hugging Face 上发布了 OpenHelix 数据集的新版本 (OpenHelix-R-86k-v2),该版本更小、更多样化且更平衡。
- 该数据集经过了新的去重步骤,过滤掉了具有 高 ngram 相似度 的样本。
LMArena Discord
- Nano Banana 的热度引起 Google 关注: 在分享链接发布后,人们对 Nano Banana 的热情激增,推测它可能是 Google 的模型,且可能仅限于 Pixel 手机。
- 然而,LMArena 上的强烈需求表明它可能会获得更广泛的可用性。
- Gemini 2.5 Pro 重夺榜首,GPT-5 排名下滑: Gemini 2.5 Pro 在排行榜上超越了 GPT-5,引发了关于 GPT-5 性能的辩论。
- 提到的原因包括潜在的恶意差评或过度顺从,而其他人则指出 Gemini 速度更快且免费访问,并指出了 分数差异。
- DeepSeek v3.1 面临质量担忧: 关于 DeepSeek v3.1 质量的担忧正在出现,一些人将问题归因于使用了 Huawei GPUs。
- 虽然有人为 DeepSeek 辩护,但其他人形容其质量为 slop coded(废话代码),且比之前的迭代更差,无论 Trump 的关税 政策如何。
- 图片上传故障困扰 LMArena: 用户在向 LMArena 上传图片时遇到错误,收到消息 “Something went wrong while generating the response.”。
- 问题似乎特定于复制/粘贴图片,而不是上传保存的文件;该问题已报告给 🍍。
- Qwen-Image-Edit 摘得图像编辑桂冠: 一个新模型 Qwen-Image-Edit 已引入 LMArena 的图像编辑功能,增强了图像处理能力。
- Qwen-Image-Edit 已经在 图像编辑排行榜 的开源模型中稳居第一。
Cursor Community Discord
- Sonic 模型引发猜测:新的 Sonic 模型 正在引发热议,用户注意到其速度并讨论其来源,有人猜测可能是 Grok code,但其他人更倾向于是 Gemini。
- Cursor 宣布该隐形合作伙伴模型已开放免费试用,导致对其编码能力的评价褒贬不一,评价从处理快速任务表现出色到某些方面有所欠缺不等。
- Claude Token 激增促使用户转向 Auto 模式:用户在使用 Claude 时遇到了意料之外的 Token 激增,导致他们因 Auto 模式 更合理的 Token 使用量而坚持使用该模式。
- 虽然有些人发现 Auto 模式 需要多次澄清,但为了避免过度的 Token 消耗,他们仍然更喜欢它,而不是手动选择 Claude。
- 多 Agent 设置受到关注:用户正在 Cursor 中尝试多 Agent 设置,例如一个开发者和一个烦人的代码审查员 AI 之间的不断博弈。
- 讨论围绕在这些设置中集成终端历史记录和短期记忆展开,一位用户分享了一个 多 Agent 开发者/审查员模式提案。
- 后台 Agent 饱受授权和系统问题困扰:用户在后台 Agent 方面遇到了各种问题,包括通过 API key 访问时的 403 未授权错误、严重的系统超时,以及尽管配置了有效的 SSH 密钥,但仍无法通过 Git 拉取私有 NPM 包。
- 一位用户发现
~/.gitconfig搞乱了一切,并正在尝试使用repositoryDependencies来添加额外的仓库,设想这会配置.gitconfig中使用的 access token。
- 一位用户发现
LM Studio Discord
- Qwen3 BF16 模型令人惊叹:与量化版本相比,Qwen3 BF16 模型被认为非常出色,成员们敦促评估 Q8 与 BF16 版本之间的显著差异。
- 一位成员报告称,4B BF16 模型在 Zero-shot 情况下生成的代码质量比 8B Q4/Q8 模型更好,因为 llama.cpp 引入了涉及 fp16 的矩阵乘法内核。
- GPT-OSS 20B 复制人格:一位用户正在使用 GPT-OSS 20B 克隆自己以处理基础任务和总结对话,并指出 Deepseek R1 distilled 在复制语音方面表现出色。
- 另一位成员补充说,你可以通过将其连接到 DuckDuckGo,将其部署为网页搜索助手。
- CUDA 设置需要技巧:为了优化 llama.cpp 的 VRAM 使用,成员们建议将 context 和 ngl 设置为最大值,并调整 -n-cpu-moe 直到它在 VRAM 容量内留有余地。
- 他们还指出,在安装过程中应将两个 zip 文件合并到一个文件夹中。
- Nvidia 在工程设计上领先 AMD:一些用户表示,Nvidia 在工程设计上领先 AMD 和 Intel,这解释了为什么 Intel 的 dGPU 可能因为扩展挑战而表现平平。
- 一位用户表示希望 Intel 倒闭,让 Nvidia 接管 x86/64 芯片生产。
- AMD mi50 提供高性价比 AI:一位用户建议 AMD mi50 32GB 是更好的选择,前提是你能解决散热问题,并提到它们现在从中国买非常便宜,并报告在 mi50 上使用 Qwen3-30B-A3B 处理新 Prompt 时达到了 50 tokens/s。
- 相比之下,一位用户表示链接中的 eBay 列表 不值得购买,基本上是昂贵的电子垃圾,并称用同样的钱可以买到 3090。
OpenRouter (Alex Atallah) Discord
- OpenRouter 发布 Activity Analytics API:OpenRouter 发布了 Activity Analytics API,允许以编程方式检索用户和组织的每日活动汇总,文档详见此处。
- OpenRouter 还发布了一个 Allowed Models API,用于以编程方式获取用户和组织获准访问的模型,文档详见此处。
- GPT-5 上下文在压力下骤降:用户报告了
openai/gpt-5的 400k 上下文窗口存在问题,调用在约 66k tokens 时失败,返回沉默的200 OK响应且 0 tokens。- 当在 Cursor 上配合 Cline 尝试使用
gpt-5-chat时,用户在 <100k tokens 的情况下遇到了“超出上下文窗口”的错误。
- 当在 Cursor 上配合 Cline 尝试使用
- Grok-4 Code 被怀疑是幕后的强大模型:有推测指出 Grok-4 Code 是 Cline 和 Cursor 背后的隐身模型,一名成员估计这一推测准确的可能性为 90%。
- 另一名成员建议 Deepseek instruct 是另一个潜在的竞争者。
- 企业发现 Generative AI 回报率低:一份 AI 报告指出,95% 的组织从其 Generative AI 部署中获得了零回报,尤其是那些使用定制化 AI 模型的组织,这引发了市场焦虑。
- 报告指出,公司没有花足够的时间确保其定制化 AI 模型持续学习,导致出现了影子 AI 经济 (shadow AI economy),即员工转而使用 ChatGPT 和 Gemini 等通用 AI 模型。
- Google Gemini 模型返回 HTTP 400 错误:当带有 tool calls 的 assistant 消息使用 OpenAI 标准的复杂内容格式
[{"type": "text", "text": "..."}]而非简单字符串格式时,Google Gemini 模型会返回 HTTP 400 错误。- 此问题影响所有 google/gemini-* 模型,但不影响 openai/* 或 anthropic/* 模型,且仅在消息链中存在 tool calls 和 tool results 时发生。
OpenAI Discord
- Gemini 的 Storybook 模式生成动漫:用户分享了 Gemini Storybook 模式的截图,显示其成功生成了动漫艺术风格。
- 然而,它在生成 Tintin(丁丁)艺术风格时表现挣扎。
- 成员讨论 AI 支付给 AI:一位用户概述了 AI Bot 之间自动支付的关键挑战,包括身份识别、智能合约逻辑、支付基础设施、自主性以及法律/伦理考量。
- 有人对 AI 处理资金的安全性表示担忧,建议由 AI 提议支付并由人类批准。
- GPT5 承认短期记忆有限:GPT5 似乎承认其短期记忆是为了 token 优化,且会清除会话上下文和记忆,这意味着与 GPT4 的上下文保留能力相比,它可能存在局限性。
- 它的短期记忆每个会话最多可使用 196K tokens。
- Scribes 测试 Prompt 技术:成员们探索了一个 SCRIBE Prompt,采用了prompt.txt 文件中分享的音频隐写术 (audio steganography) 和哈希修改 (hash modification) 等技术。
- Prompt 工程师们争论模型是否真正理解这些命令,还是这些命令仅仅是为了展示。
- 模型模仿训练数据检索:有观点认为输入中的每个元素(包括标点符号、拼写和语法)都会影响模型的输出,这表明模型会在其训练数据中检索相关信息。
- 它会搜寻与我们的输入及其余训练内容相关的训练数据,然后将这些获取的内容放入容器中,并作为输出发送给我们。
{kind=link}
{kind=link}
GPU MODE Discord
- SemiAnalysis 雇佣了 EleutherAI 校友:SemiAnalysis 正在寻找一名应届毕业生工程师加入其工程团队,一名 EleutherAI 校友正在申请,并希望 Gaudi 2 能成为比 TPU 更具可编程性的竞争对手。
- 一位成员建议出于隐私原因,使用职位申请的直接链接(https://app.dover.com/apply/SemiAnalysis/2a9c8da5-6d59-4ac8-8302-3877345dbce1/?rs=76643084)而不是 LinkedIn 短链接。
- CudaMemcpyAsync 需要“穿越时空”的地址:一位用户报告称
cudaMemcpyAsync需要使用一个仅在cudaLaunchHostFunc完成后才可用的地址,并正在寻求一种方法,以确保cudaMemcpyAsync在执行时使用正确的plan->syncCondition->recvbuff值,而不必将该函数移至主机函数内部以避免死锁。- 该用户正在寻求解决方案,以精准定位其 kernel 中寄存器使用量增加的来源。
- Factorio 模组纠纷:成员们讨论了代码中引用的
stdlib_1.4.6和headless-player_0.1.0Factorio mods 缺失的问题,并澄清这些模组属于遗留用法,任何对它们的引用都是陈旧的,应该被移除。- 一位成员分享了一个今年制作的名为 Cerys-Moon-of-Fulgor 的自定义模组。
- 编写自己的 NCCL 传输层:一位成员正在构建自定义通信集合库,从 NCCL transport layer 开始引导,为普通和融合的 ND-parallelism 创建通信集合,作为一个长期教育项目,旨在创建使用 nvshmem 的设备端发起通信。
- 另一位成员分享了他们的笔记和教程,并链接到了他们的仓库:NCCL-From-First-Principles 和 The-Abstraction-Layers-of-GPU-Parallelism。
Latent Space Discord
- xAI 在猎头挖角中人才流失:Lucas Beyer 反驳了关于 xAI 离职率高的说法,称按团队规模标准化后,其离职率实际上低于竞争对手,尽管 Meta 等公司正在挖人,因为 xAI 需要为下一个模型阶段留住人才,详情见 X 平台。
- 评论者正在辩论这些离职是危机还是健康的知识扩散时刻,另有补充评论可供参考。
- Claude 因“自我驾驶”被 Claude 封禁:Wyatt Walls 在实验让 Claude 驱动 Claude API (Claude-in-Claude) 后,突然被 Anthropic 的 Claude 服务切断连接,他怀疑这触发了 TOS 违规。
- 他没有收到任何警告,只收到了错误消息和退款。
- 内部部署工程师(Internally Deployed Engineer),最新的热门头衔:一篇 a16z 文章 引发了关于“Internally Deployed Engineer”角色兴起的讨论,特别是在已经使用内部 Lovable 工具的公司中。
- 评论者对这个头衔开起了玩笑,但承认其采用率正在增加,且比“内部工具工程师”更具相关性。
- PhotoAI 通过 AI 编排构建竞争优势:Pieter Levels 在 X 上解释了 PhotoAI 的竞争优势如何来自于将 六个相互依赖的 AI 模型(个性化、超分辨率、视频、TTS、对口型和字幕)编排进单一流水线。
- 这种端到端集成简化了用户的操作流程。
- OpenAI 估值飙升至五千亿美元引发争议:OpenAI 的估值正接近 5000 亿美元,使其成为有史以来最大的私有公司,Kylie Robison 在与一位认为该价格合理的投资者交流后分享了这一消息。
- 批评者持怀疑态度,理由是没有护城河、AI 廉价化以及利润率存疑。
Nous Research AI Discord
- Deepseek 深度思考:在思考效率评估中,Deepseek 花费了 21 分钟 来处理一个提示词,生成的 CoT(思维链)长达 85000 个字符(接近 30000 tokens)。
- 尽管 API 负载沉重,该模型似乎比 R1-0528 具有更高的 token 效率,其“深度思考”能力给成员们留下了深刻印象。
- GLM 4.5 V 极具远见:成员们分享了这段 YouTube 视频,展示了下一代视觉语言模型(Vision Language Model)GLM 4.5 V。
- 视频重点展示了其部分下一代视觉能力。
- DeepSeek 的双模板策略:DeepSeek V3.1 Base 指令模型采用了一种混合方法,根据请求的模型名称选择正确的思考/非思考模板。
- 这种巧妙的方法引发了成员们讨论“DeepSeek 是不是憋了大招?”,并探讨了该模型的创新设计。
- 字节跳动 Seed 模型引发关注:ByteDance-Seed/Seed-OSS-36B-Instruct 模型及其基座模型正受到广泛关注,成员们反馈其效果令人印象深刻。
- 该模型在没有任何 RoPE 缩放的情况下实现了 512k 上下文窗口,是一个非常值得关注的模型。
- 重要性矩阵校准(Importance Matrix Calibration)校准社区:成员们讨论了重要性矩阵校准数据集,旨在最大限度地减少量化过程中的误差。
- 这些校准数据集生成重要性矩阵(imatrix),以增强模型在量化过程中的准确性。
HuggingFace Discord
- HuggingFace 发布超大规模手册:Ultra-Scale Playbook 现已作为一本书出版,提供了关于扩展 AI 模型和基础设施的指导。
- Text Embeddings Inference (TEI) v1.8.0 已发布,包含多项改进并扩展了模型支持;GLM4.5V 现在已获得 transformers 支持,SAM2 也已集成至 HF transformers。
- 开源语音助手竞争者出现:Voxtral 可能是目前最好的开源语音助手,但成员们表示它“还不够完善”且“非常不可靠”。
- 一位成员观察到,“谁能做出价格亲民的语音助手,谁就能赚大钱”。
- 利用 LFM2-350M 部署端侧 Android 应用:一款利用 LFM2-350M 模型开发的端侧 Android 应用已发布,用于移动端 AI 应用,并在 X/Twitter 上宣布。
- 这突显了在移动设备上运行 HuggingFace 模型以提高响应速度和隐私性的可行性。
- 项目简化 Jax 图像建模:JIMM: Jax Image Modeling of Models 允许轻松训练用于视觉 Transformer、CLIP 和 SigLIP 的 Flax NNX 模型,即将支持 DINOv2/v3,代码托管在 GitHub。
- 该库简化了使用 Flax NNX 训练 vision transformers 的过程,使其对研究人员和从业者更加友好。
Moonshot AI (Kimi K-2) Discord
- Deepseek 3.1 被 K2 碾压:成员们报告称,新的 Deepseek v3.1 会胡言乱语,而且在 Agent 能力方面完全被 Kimi K2 超越。
- 一位用户称其为“Kimi K2 王朝”,而另一位用户指出,在 Qwen3 和 K2 出现之前,Deepseek 曾是最好的 OSS(开源)选择。
- 对 Moonshot 周边的渴望加剧:有用户询问在哪里可以买到 Moonshot AI 的周边,但另一位用户表示目前还没有售卖。
- 一位用户开玩笑说愿意用一件盗版的 Darkside T恤 换一块 4090 显卡。
- AI 淘金热引发混乱:一位成员表示,“随着淘金热进一步升温,必然会出现更多混乱”,因为像 Google、OpenAI 和 Anthropic 这样的巨头正占据主导地位。
- 发帖者补充道,“FB(Meta)开出的天价薪水简直疯狂”。
- 骗子警报:Kiki 冒充者:一名用户举报了一个冒充 Kiki 的骗子。
- 冒充者甚至使用了相同的近期头像,让人感到格外毛骨悚然。
Yannick Kilcher Discord
- LSTMs 在数据稀缺场景下面临 Transformer 的挑战:成员们辩论了 LSTMs/RNNs 与 Transformers 的优劣,指出 LSTMs 在少量数据下的表现不如 Transformer,而 Transformer 通常需要 超过 1000 万 个数据点,且深度学习往往忽视了 bias variance tradeoff(偏差-方差权衡)。
- 其他人建议将 RKWV 和 SSMs 作为 LSTM 的增强版本或 LSTM/transformer 混合体,以实现更快的推理,避免 Transformer 的 O(n^2) 时间复杂度问题。
- Vision Mamba 优化尝试:一位成员提到他们尝试优化 Mamba Vision 并取得了一些成功,但未提供细节。
- 与此同时,最近的论文表明,通过数据增强,transformers 可以在低数据量的情况下进行训练,其数据效率可与其他模型媲美,并引用了 ARC-AGI 1 attack paper。
- VLM 图表数据集引发性能差距讨论:引入了一个新的 VLM chart understanding 数据集 (https://arxiv.org/abs/2508.06492),引发了关于 performance gaps 和 VLM struggles 的讨论,并与过去的结果和 ViT 知识进行了对比。
- 为了理解 VLM struggles,一位成员建议参考 这篇论文,该论文提供了去年的总结。
- 酝酿个性化 GANs:一位成员提议建立一个 Personality GAN 设置,使用 LLM 同时作为生成器和判别器,并使用 LoRA 进行微调,直到判别失败。
- 挑战在于寻找一个尚未在 Sponge Bob 上进行过大量训练的 LLM。
- LeCun 在 FAIR 的童话式结局?:在 Zuckerberg 的一条帖子 发布后,人们开始猜测 Yann LeCun 在 FAIR 的职位。
- 一位用户评论说,解雇他将是一个 非常过分的举动 (pretty dick move)。
LlamaIndex Discord
- 自定义 Retriever 主导向量搜索:@superlinked 团队使用自定义 LlamaIndex 集成创建了一个 Steam 游戏检索器,将语义搜索与游戏特定知识相结合,表现优于 通用向量搜索。
- 这些 custom retrievers 旨在理解 domain-specific context 和专业术语,以提高搜索准确性。
- StackAI 和 LlamaCloud 处理数百万文档:根据一项新的案例研究,@StackAI_HQ + LlamaCloud 以高精度解析处理了超过 100 万份文档。
- 该集成催生了更快、更智能的企业级文档 Agent,深受金融、保险等行业的信任;详见 完整案例。
- 邮件 Agent 跳过钓鱼检测:用户发现,除非在用户请求中重复指令,否则邮件管理 Agent 有时会跳过 phishing detection(钓鱼检测),尽管该指令已存在于 system prompt 中。
- 有人指出,Agent 的鲁棒性通过更新用户消息比更新 system prompt 提升更多,且用户消息的优先级高于 system prompt。
- LlamaParse 提取错误调试面临挑战:一位用户询问在使用 LVM models 时,如何从 LlamaParse 获取更详细的错误信息,特别是导致 DOCUMENT_PIPELINE_ERROR 的具体页面。
- 团队正积极致力于改进错误呈现,因为目前识别有问题的页面较为困难,但未来将更加透明。
- 异步 React Agent 占据主导地位:旧的 ReactAgent 已被移除,当被问及使用 sync react agents 的选项时,回复明确表示仅支持 async。
- 鼓励用户拥抱 async Python。
MCP (Glama) Discord
- Claude 的新 MCP Web App 导致 Token 使用量飙升:一名正在使用 Claude 3.5 API 为 Claude 构建 MCP web app 的成员观察到输入 Token 使用量过高(每次调用超过 2000 个),并正在寻求优化建议。成员们建议使用 notepad thinking(记事本思考)方法来减少 Token 使用量。
- 成员们建议让 LLM 写下它的想法,然后进行第二次处理,将 Prompt 和想法一起运行,这与推理模型相反,可能导致总体 Token 消耗更少。
- Aspire Inspector 的 SSL 证书问题:一名成员在使用 Aspire Inspector 连接本地 MCP server 时遇到了 TypeError(fetch failed: self-signed certificate),但 Postman 运行正常。
- 根据 此 GitHub issue,解决方法包括将 Aspire Inspector 配置为通过 HTTP 连接或禁用 SSL,因为该检测器无法识别由 Aspire MCP 生成的 SSL 证书。
- X-LAM 在本地 MCP 函数调用(Function Calls)中表现出色:成员们正在寻找适用于 MCP 函数调用的本地模型,Llama-xLAM-2-8b-fc-rGPT-OSS 被认为是一个很有前景的候选模型。
- 20B 模型被认为太慢,但之前的讨论表明它在函数调用方面表现良好。
- AI Agent 成为头号内部威胁:一篇博客文章强调了 AI Agent 基本上是完美的内部威胁,它们能在毫秒内采取行动,暴露 MCP Server 的漏洞。
- 研究人员通过一个 GitHub issue 劫持了 Claude 的 MCP server,AI 在认为自己正在履行职责的同时,愉快地窃取了私有仓库,这揭示了传统安全手段的局限性。
- Agentic Project Management (APM) v0.4 发布:APM v0.4 已发布,它利用一组 AI Agent 协作来解决 LLM 的基本问题,如上下文窗口限制(context window limitations)和幻觉(hallucinations)。
- 该项目集成了 Cursor、VS Code 和 Windsurf 等 AI IDE。
aider (Paul Gauthier) Discord
- Qwen3-Coder 在本地表现优于 Llama:用户对 Qwen3-Coder 的性能印象深刻,指出其在本地运行时优于 Llama。
- 一位用户指出在使用 Llama 时存在 tool call bugs,而使用 Qwen3-Coder 时未观察到这些问题。
- Aider CLI 工具调用(Tool Calling)故障:用户报告了在使用 Aider 的命令行界面(CLI)进行工具调用时遇到的问题。
- 一位用户发现搜索工具返回了过多的上下文(7155 个匹配项),导致 AI 进入循环并失败;在
/help中没有找到解决该问题的排障步骤。
- 一位用户发现搜索工具返回了过多的上下文(7155 个匹配项),导致 AI 进入循环并失败;在
- Gemini 2.5 Pro 在 Aider 中仍存在问题:成员们继续报告 Gemini 2.5 Pro 和 Aider 的相关问题。
- 据报道,在启用计费(billing)后使用 gemini/gemini-2.5-pro-preview-06-05 可以正常工作,这绕过了免费层的限制。
- Aider 因 Git Index 版本问题失败:一名用户遇到了与 不支持的 git index version 3 相关的 Aider 错误。
- 该错误追溯到一个设置了
update-index --skip-worktree的文件,虽然发现了解决方案,但/help中推荐的修复方法并不奏效。
- 该错误追溯到一个设置了
- 寻找智能合约专家:一名成员可承接智能合约、DeFi、NFT 或交易机器人项目。
- 该成员表示他们已准备好为任何需要区块链专业知识的人提供帮助。
Modular (Mojo 🔥) Discord
- Mojo GPU 崩溃需要同步:一位成员报告了使用 这段 Mojo 代码 时出现的 GPU 崩溃,导致集群健康检查失败。
- 建议的解决方案包括添加 同步屏障 (synchronization barriers) 并确保启用 GPU P2P,以避免在没有适当同步的情况下假设存在两个 GPU。
- Mojo 文档仍未完全就绪:一位新人对不完整的 Mojo 文档表示沮丧,希望能有详尽的资源。
- 社区成员指向了由 Modular 团队积极维护的文档,并建议报告具体问题,同时分享了 Mojo by example 和 Mojo Miji 作为替代学习资源。
- Mojo 内存对齐引发困扰:一位成员寻求关于 Mojo 中 内存对齐 (memory alignment) 的澄清,特别是关于编译器优化和结构体填充 (struct padding)。
- 讨论明确了指定对齐可以防止填充,某些类型需要更大的对齐,而缺少对齐可能会导致程序终止;建议使用
stack_allocation进行内存控制。
- 讨论明确了指定对齐可以防止填充,某些类型需要更大的对齐,而缺少对齐可能会导致程序终止;建议使用
- Torch-Max 后端启动模型:torch-max-backend v0.2.0 版本发布 现在支持 VGG、Qwen3、GPT2 和 Densenet 的推理测试。
- 一位成员对仅通过少量启用的算子 (ops) 就能支持这么多模型表示惊讶。
- 窥探 Max 的 Pipeline 执行:在看到 Max 的 pipeline.py 中定义的 execute 后,一位成员请求 TextGenerationPipeline 的复现脚本。
- 该用户还询问了发布者的 MAX 版本。
Notebook LM Discord
- Spotify 播客数月后回归!:一位成员分享了一个新播客节目的 Spotify 链接,这是 自 12 月以来的首期,且是使用 Gems 创建的。
- 讨论强调,这一集标志着在长时间停更后,重新开始使用 Gems 进行内容创作。
- AI 现在会说原始日耳曼语:一位成员分享了一个 YouTube 链接,展示了他们训练 AI 理解和翻译 原始日耳曼语 (Proto-Germanic) 的成果。
- 据报告,AI 在初步测试中表现出“相当准确”,为历史语言学和 AI 开启了可能性。
- Discord 服务器需要管理员:一位成员分享了 一个 NotebookLM 链接,对 Discord 服务器上的 垃圾信息和未经审核的内容 表示担忧。
- 对管理员的紧急呼吁凸显了社区管理在处理垃圾信息和确保积极环境方面日益增长的需求。
- NotebookLM 助力桌上游戏:一位成员报告使用 NotebookLM 生成转录的桌上 RPG 会话视频概览,创建了一个自动的“前情提要:在 D&D 中!”介绍。
- 这种对 NotebookLM 的创新使用帮助玩家在每场游戏前记住细节,展示了 AI 如何增强传统游戏体验。
- YouTube 批量导入:成员们讨论了将 300 个 YouTube 链接 导入 NotebookLM,建议使用 Chrome 扩展程序 进行批量导入,并将 YouTube URL 添加到网站 URL 列表中。
- 一位成员专门为了批量导入扩展程序安装了 Chrome 浏览器。
tinygrad (George Hotz) Discord
- Tinygrad 团队寻找“速度狂人”修复 CI:一名成员正寻求聘请人员来解决混乱的测试问题,并将 CI 速度降低到 5 分钟以内。
- 该呼吁强调了对缓慢、未优化测试的担忧,以及对 process replay 效率的质疑。
- Linux (nv) 性能落后于 Linux (ptx):有人对 Linux (nv) 和 Linux (ptx) 之间的性能差异提出疑问,想知道 CUDA 编译是否使用了 fast flag。
- 讨论质疑了为什么 process replay 是多进程的,以及导致其缓慢的原因。
- 极简 CUDA 编译标志即将到来?:一位成员询问 Ubuntu 24.04 是否支持极简 CUDA 编译标志,并链接到了一个相关的 GitHub pull request。
- 该 pull request 的目的是进一步讨论如何启用和使用极简 CUDA 编译标志以加快编译速度。
- Overworld 常量折叠引发争议:一位成员提出了 Overworld 常量折叠(const folding)的解决方案,建议修改
UPat.cvar和UPat.const_like。- George Hotz 认为这个建议“超级丑陋(super ugly)”,主张移除 base 并询问关于 PAD 的情况。
DSPy Discord
- DSPy 缓存仍返回成本(Costs):用户发现即使结果是从 cache 中提取的,DSPy 仍然会返回 cost。
- 这一观察被认为是不直观且可能引起混淆的,强调了在成本追踪中需要更清晰的逻辑。
- 交叉验证优化器启发指标函数:一位成员寻求一种 optimizer,通过交叉验证创建一个模仿特定作者风格的 LM 程序。
- 建议包括创建一个带有 AI judge(例如 GPT-5 LLM)的 metric function,并利用 GEPA 进行评估,从而开启模仿文风的新工作流。
- 优化后的 Prompt 提取变得简单:用户询问如何从 DSPy-optimized program 中提取 Prompt 以获取源码。
- 另一位用户建议使用
optimized.save("my_program.json")将程序保存为 JSON 文件,从而轻松查看生成的 Prompt,这为 Prompt 提取创建了便捷的工作流。
- 另一位用户建议使用
Cohere Discord
- Cohere 欢迎新成员:Aryan 和 Anay 加入了 Cohere 社区。Anay 分享了他正在美国攻读 MS in Computer Science,并且之前有 MLE 的工作经验。
- 社区鼓励成员分享他们的公司、工作、喜爱的工具和目标,以促进协作。
- 另一个话题:这是一个占位符摘要。
- 这是第二个占位符摘要。
Manus.im Discord Discord
- Manus 积分凭空消失:一位用户报告 Manus credits 消失,并询问是否可以购买更多,暗示该服务存在重复出现的问题。
- 这引发了对 Manus 平台 持续使用的稳定性和可靠性的猜测。
- 用户退出,优先考虑备份:一位用户在切换回之前的服务商之前备份了数据,理由是之前的服务商响应更迅速。
- 此举表明了对当前服务水平的不满,并在过渡期间重新强调了数据安全。
LLM Agents (Berkeley MOOC) Discord
- 下一期 LLM Agent 课程备受期待:成员们预计下一期 LLM Agents Berkeley MOOC 将于 9 月初开始。
- 虽然未提供具体的报名详情,但用户预计课程报名将很快开启。
- 预计很快开启课程报名:一位用户表示,预计课程报名将很快开启,目标定在 9 月初。
- 讨论中未引用官方日期或公告。
MLOps @Chipro Discord
- 函数式 Python 助力更智能的 AI/ML:8 月 27 日的一场免费网络研讨会将讨论函数式 Python 如何在数据密集型 AI/ML 系统中加速工作流、降低成本并提高效率。
- 与会者将学习持久化记忆化(persistent memoization)和确定性并行(deterministic parallelism)等技术,并观看来自 DataPhoenix 的演示。
- 网络研讨会宣传通过函数式编程节省成本:该研讨会探讨使用函数式 Python 重新设计运行时间较长的工作流,以便在不增加硬件的情况下实现成本节约和速度提升。
- 内容涵盖了简化数据密集型流程的开源工具的理论和动手演示。
Nomic.ai (GPT4All) Discord
- 区块链开发者已准备就绪!:一位在 EVM chains、Solana、Cardano 和 Polkadot 拥有实战经验的区块链开发者正在寻求合作。
- 他们构建过 DEXs、trading bots、针对 DApps 的 smart contracts,并将其与前端集成。
- 区块链开发者寻求合作:一位区块链开发者正就其在 EVM chains、Solana、Cardano 和 Polkadot 领域的专业知识提供潜在合作。
- 他们的经验包括构建 DEXs、trading bots 和 smart contracts,以及将它们集成到 DApp 前端。
Gorilla LLM (Berkeley Function Calling) Discord
- PelicanVLM-72B-Instruct 加入 BFCL 阵容:一名成员提交了一个 pull request,旨在使用 Berkeley Function Calling Leaderboard (BFCL) 框架为 PelicanVLM-72B-Instruct 模型添加工具评估。
- 作者正在寻求社区对该集成的反馈,并在 pull request 中包含了评估分数。
- PelicanVLM-72B-Instruct 评估结果:该 pull request 包含了 PelicanVLM-72B-Instruct 模型在 BFCL 框架下的评估分数。
- 鼓励社区成员查看分数并对模型的表现提供反馈。
Torchtune Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
Codeium (Windsurf) Discord 没有新消息。如果该服务器长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 unsubscribe。
Discord: 详细的分频道摘要和链接
Perplexity AI ▷ #general (1232 messages🔥🔥🔥):
amazon.in not working, comet invites, GPTs Agents, OpenAI's sidebars, GPT Go Plan
- Amazon.in 在 Comet Browser 中不可用:用户报告 amazon.in 在 Comet Browser 中无法工作,但在 Brave Browser 或隐身模式下可以打开;可能是由于网络问题或防火墙设置。
- 一位成员建议联系支持团队 support@perplexity.ai 寻求帮助。
- Comet Browser 邀请码争夺:用户正在积极寻求 Comet Browser 邀请码,有人提到美国的 Pro users 可以立即访问,而其他地区的用户则需要邀请或进入 waitlist。
- 成员们分享了邀请频道的链接,强调每个用户有两个邀请名额,并警告不要购买邀请码。
- ChatGPT Go 计划现已在印度推出:用户讨论了正在印度测试的新 ChatGPT Go plan,价格为 ₹399/月,用于 Prompt 编写。
- 一些成员认为与免费版本或 Perplexity Pro 相比不值得,而另一些人则看到了更高使用率或预算有限的学生的潜力。
- Perplexity UI 褒贬不一:用户对 Perplexity 的用户界面 (UI) 持不同意见,有人称 Android UI 很“烂”,也有人称赞 Windows 设计。
- 然而,其他人很喜欢该 UI,尤其是 Comet browser 加入内置广告拦截功能后。
- 建议用 Super Grok 替代 GPT Go:成员们辩论了 GPT Go 与替代方案的优劣,建议将 Super Grok(₹700/月)作为更好的选择,因为它具有更大的 context window 且没有限制。
- 他们指出其 context 限制为 131k,而 ChatGPT Go 为 32k。
Perplexity AI ▷ #sharing (4 messages):
Shareable Threads, Perplexity AI Newsletter, Sorion Unicode Tool
- Perplexity AI 分享新闻通讯链接:Perplexity AI 分享了其 每周 AI 技术新闻通讯 的链接。
- Sorion 分享 Unicode 工具链接:Sorion 分享了其 Unicode Tool 的链接。
- 提醒将 Threads 设置为可共享:Perplexity AI 提醒用户确保其 thread 已设置为
Shareable。
Perplexity AI ▷ #pplx-api (5 messages):
Perplexity API 状态,API 组删除
- API 状态不一致引发查询:一位用户询问了 API 状态和延迟问题,指出 status page 未能反映当前的延迟情况。
- 另一位用户建议在频道中提出该问题。
- API 组删除请求已转发:一位用户询问是否有办法删除 API groups。
- 一名成员回复称,他们会将该问题转发给 API team。
Unsloth AI (Daniel Han) ▷ #general (1028 messages🔥🔥🔥):
Unsloth App 更新至 3.1,GRPO 应用于 Llama 模型,Qwen3-4b-Instruct 的 VRAM 问题,数据集工具与工作流,Blackwell RTX 50 系列与 Unsloth 指南
- Unsloth App 获得 V3.1 更新:Unsloth app 已更新至 3.1 版本,其中包括一个 instruct model,据报道是 hybrid 类型。
- 尽管一些成员由于硬件限制无法运行,但仍表达了兴奋之情。
- 使用 GRPO 进行模型合并:一位成员使用物理数据集将 GRPO (Gradient Ratio Policy Optimization) 应用于 Llama 模型,并在 Hugging Face 上分享。
- 用户讨论了 GRPO 的有效性和实际意义,将其与 DPO 进行比较,并指出其强化学习特性,即使没有外部 judge model。
- T4 上的上下文长度困扰:一位用户在 T4 GPU 上训练 Qwen3-4b-instruct 时遇到了共享内存问题,即使减少了 batch size 和梯度累积,甚至在缩减上下文大小后依然存在。
- 建议他们确保上下文长度不要过大,因为这会显著影响 VRAM 使用,并提到原始 notebook 也会报错。
- 使用 GUI 处理数据集?:成员们讨论了 pandas 以外的合并和过滤数据集的替代方案,一位用户请求使用 GUI 以方便操作。
- 一名成员建议使用 Marimo notebooks (marimo.io) 作为解决方案,并提供了一个示例 notebook 链接 (gist.github.com),该 notebook 可以合并数据集并创建实时更新的 loss 图表。
- GRPO 的内幕:社区成员解析了 GRPO 的工作原理,共识是它基本上就是没有外部 judge model 的 RL。
- 虽然 vanilla GRPO 存在已知的陷阱,例如 loss 函数偏向更长的回复,但一些人认为它可以和 Reinforce++ 一样出色。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 messages):
Discord 显示游戏 ID,隐私担忧
- Discord 显示游戏 ID:一位用户惊讶地发现 Discord 在所有频道中都显示了他们来自 Battlefield 的游戏 ID。
- 他们发布了 ’= : )’,表示对这一发现感到有趣或困惑。
- 引发隐私担忧:该用户的评论引发了潜在的隐私担忧,即关联的游戏账号可能会在不同的 Discord 服务器中暴露 ID。
- 这凸显了了解关联账号如何跨平台暴露个人信息的重要性。
Unsloth AI (Daniel Han) ▷ #off-topic (29 messages🔥):
华硕 ROG Matrix GeForce RTX 5090 30 周年限量版,CUDA 显存溢出
- 华硕 ROG RTX 5090 限量版功耗惊人!:一位成员分享了 ASUS ROG Matrix GeForce RTX 5090 30th Anniversary Limited Edition 的图片,指出其 800W 的功耗,并表示偏好黑白配色方案。
- 该显卡的美学被描述为一种独特的品味,用户幽默地感叹为了生成这张图片给 Gemini 发送了一百万个 token。
- CUDA OOM 错误再次袭来!:一位用户在尝试分配 20MB 内存时遇到了 CUDA out of memory 错误,尽管 GPU 上还有 23.79GB 的空闲空间。
- 他们询问重启是否是唯一解决办法,另一名成员建议尝试先重启驱动以清除死进程残留的垃圾。
Unsloth AI (Daniel Han) ▷ #help (77 条消息🔥🔥):
Gemma 3 270m CPT, Runpod setup, GPU requirements, DeepSeek V3.1 Quantization, Transformers version issue
- Gemma 3 微调新手寻求帮助:一位微调新手寻求关于使用 Gemma 3 270m 进行持续预训练(CPT)的建议,旨在利用原始文本增加来自古腾堡计划书籍(特别是儒勒·凡尔纳的《海底两万里》)的法语知识。
- 分享了 Unsloth 的文档和博客链接(docs.unsloth.ai/basics/continued-pretraining, unsloth.ai/blog/contpretraining)作为入门参考。
- Mistral 3.2 训练显存需求增加:一位用户报告称,由于 Mistral 3.2 附加了视觉组件,训练所需的 VRAM 显存需求似乎有所增加。
- 他们询问是否有办法完全剥离视觉层以适应旧的上下文长度。目前未提供解决方案,但其他用户也遇到了类似问题。
- 围绕 DeepSeek V3.1 量化与执行的讨论:一位用户询问如何将 DeepSeek V3.1 671B 模型量化为 Q4_K_XL 和 Q3_K_XL,以便通过 llama.cpp 在本地使用,并询问在 48 GB VRAM 系统上的最低显存要求。
- 另一位用户反驳称该用户同时要求量化并在本地运行模型,并链接到了 Unsloth 此前为新版本进行的量化工作(https://unsloth.ai/blog/deepseekr1-dynamic)。
- Transformers 更新引发 Blackwell GPU 上的 72B VL 加载错误:用户发现 Transformers v4.54.0 及更高版本引入了带有即时 4-bit 量化(
create_quantized_param)的分片流式加载,这导致在 Blackwell GPU 上加载unsloth/Qwen2.5-VL-72B-Instruct-unsloth-bnb-4bit时出现错误。- 临时解决方案包括将 Transformers 降级至 v4.51.3,目前已在 transformers 仓库中提交了 Issue。
- vLLM 与 GPT-OSS 不兼容:一位用户报告称,在 Nvidia L40S GPU 上尝试使用 vLLM 部署 unsloth/gpt-oss-20b-GGUF 模型时遇到错误,并提供了错误信息。
- 另一位用户澄清说 vLLM 不支持 gptoss 的 GGUF 文件,这就是导致失败的原因。
Unsloth AI (Daniel Han) ▷ #showcase (18 条消息🔥):
Gemma 3 4b finetune, Un-sycophantic BERT models, Swahili Gemma 1B, OpenHelix dataset
- Electroglyph 发布 Gemma 3 4b 微调模型:一位成员分享了他们的 Gemma 3 4b unslop 微调版及训练代码,并将 UD-Q4_K_XL GGUF 上传至 Hugging Face。
- 该用户提到,他们认为这次的效果相当不错。
- 使用 BERT 惩罚阿谀奉承(Sycophancy)行为:一位成员建议训练一个谄媚分类器(现代 BERT),以便在验证期间惩罚相应的回复。
- 这将消除硬编码抑制谄媚回复规则的需求,从而可能改善模型行为。
- 使用 Unsloth 微调的斯瓦希里语 Gemma 1B:团队使用 Unsloth 对 Gemma 3 1B 进行了微调,用于斯瓦希里语对话式 AI 和翻译。
- 分享了 CraneAILabs/swahili-gemma-1b 的链接。
- 新版 OpenHelix 数据集发布:一个更小、更多样化且更平衡的 OpenHelix 数据集版本(OpenHelix-R-86k-v2)已在 Hugging Face 发布。
- 该数据集经过了新的去重步骤,过滤掉了具有高 ngram 相似度的样本。
Unsloth AI (Daniel Han) ▷ #research (17 条消息🔥):
L40S vs A100 推理,针对 Llama 的 GRPO,使用 Unsloth 微调 Qwen3-4B
- 尽管 FLOPS 更高,L40S 的 T/S 却低于 A100!?:一位成员在 L40S 和 A100 上对 Llama 3.2 3B 进行了推理测试,发现尽管 L40S 的 FLOPS 更高(362 vs 312),但 A100 的每秒 token 数(t/s)高出约 30%。
- 另一位成员评论道,显存带宽(memory bandwidth) 是造成这种差异的最大因素。
- GRPO 应用于物理数据集的 Llama 模型:一位成员使用 Unsloth 将 GRPO 应用于物理数据集的 Llama 模型,并分享了模型链接。
- 澄清说明部分数据是由 R1 70B(蒸馏版本)生成的,而非 R1。
- 数据集污染测试显示重叠极小:一位成员对其数据集进行了污染测试并报告了好消息:数据集未受污染,最大重叠率为 14.8%,平均文本相似度为 18.2%。
- 他们查看了高重叠样本,但重叠内容仅为:“what is the sum of”、“how many days will it take”、“what is the difference between”、“how long will it take”、“what is the perimeter of”。
- 使用 Unsloth 微调 Qwen3-4B:一位成员正在使用 Unsloth 微调 Qwen3-4B,分享了链接并寻求好运。
- 另一位成员询问是否公布了代码、数据集和机器配置。
LMArena ▷ #general (1025 条消息🔥🔥🔥):
Nano Banana 发布,Gemini 2.5 Pro vs GPT-5,DeepSeek v3.1 问题,LMArena 上的图片上传问题
- Nano Banana 的热度引起 Google 关注:成员们热切期待 Nano Banana 的发布,一位成员分享的链接似乎确认了发布,引发了该模型将由 Google 推出的猜测。
- 有人担心其使用范围仅限于 Pixel 手机,但其他人认为,由于在 LMArena 上产生的热度和需求,它将会更广泛地可用。
- Gemini 2.5 Pro 赶超 GPT-5:Gemini 2.5 Pro 重回排行榜榜首,引发了关于 GPT-5 感知退步的讨论。
- 一些人认为蓄意差评或过度顺从可能是原因,而另一些人则指出 Gemini 更快的速度和免费使用是关键因素,一位成员注意到 Gemini 与竞争对手之间的评分差距。
- DeepSeek 表现下滑?:人们对 DeepSeek v3.1 的质量产生了怀疑,一些人认为缺乏更新以及使用 Huawei GPUs 是潜在问题。
- 其他人则为 DeepSeek 辩护,将任何感知到的缺陷归因于 Trump 的关税影响了 GPU 的供应,尽管有几位用户声称其质量是 slop coded(劣质代码生成),且不如早期模型。
- 图片上传故障困扰 LMArena:用户报告在向 LMArena 上传图片时出现持续错误,并弹出错误消息 “Something went wrong while generating the response”。
- 成员们推测问题可能是文件类型导致的,或者是开发团队正在调查的一个更广泛的问题,并指出这只在复制/粘贴图片时发生,而上传保存的图片则正常,因此该问题已报告给 🍍。
LMArena ▷ #announcements (2 条消息):
Qwen-Image-Edit,图像编辑排行榜,LMArena
- LMArena 新增图像编辑模型!:一个新模型 Qwen-Image-Edit 已添加到 LMArena 的图像编辑(Image Edit)功能中。
- 这一新增功能扩展了 LMArena 平台内的图像处理和编辑能力。
- Qwen-Image-Edit 登顶!:图像编辑排行榜已更新,Qwen-Image-Edit 现在是图像编辑领域排名第一的开源模型!
- 用户可以访问此处的排行榜查看不同模型在图像编辑任务中的对比情况。
Cursor Community ▷ #general (859 messages🔥🔥🔥):
Sonic model, Token usage, Multi-agent setup, Code Quality
- Sonic 模型引发好奇与猜测:新的 Sonic model 正在引发热议,用户注意到了它的速度并对其来源展开讨论,有人猜测它可能是 Grok code,但也有人倾向于是 Gemini。
- 一位用户将其描述为“公告上搞怪的反应”,而另一位用户提到它有“很棒的待办事项列表”。
- 用户在使用 Claude 时遇到 Token 激增,寻求替代方案:一些用户在使用 Claude 时遇到了意料之外的 token spikes(Token 激增),导致他们转而坚持使用 Auto mode,因为其 Token 使用量更合理。
- 一位用户提到在使用 Auto 模式时需要“多次澄清”,但仍然比手动选择 Claude 更具吸引力。
- 关于用户数据训练和隐形模型的争论:围绕 stealth Sonic model 是否正在使用用户数据进行训练展开了讨论,一位用户指出 Cline 的消息暗示了 data training(数据训练)。
- 用户对可能泄露个人信息的担忧日益增加,并要求 Cursor 确认其隐私政策。
- Sonic 编码性能评估;评价褒贬不一:对 Sonic 编码能力 的初步印象各不相同,一些人认为它在处理快速任务方面表现出色,且“编码能力与 GPT-5 相当,但速度快了约 2 倍”,而另一些人则认为它“有点糟糕”。
- 一些用户指出 Sonic 表现不错,但消耗大量 Token;由于它是基于 Token 计费的,可能会产生巨额账单。
- 用户探索 Multi-Agent 设置:一些用户正在 Cursor 中尝试 multi-agent setups(多智能体设置),例如让一个 developer(开发者)AI 和一个“烦人的代码审查员”AI 进行持续的博弈。
- 讨论还涉及如何在多智能体设置中集成终端历史记录和短期记忆,一位用户分享了他们的 multi-agent 开发者/审查员模式提案 链接。
Cursor Community ▷ #background-agents (14 messages🔥):
API Key Authorization Issues, System Timeout Issues, NPM Package Pull Failure, Background Agent Functionality Issues, Git Configuration Problems
- API Key 在 Background Agents 中遇到 403 错误:一位用户报告在尝试通过 API Key 为 Cobot.co 访问后台 Agent 时收到 403 not authorized error(403 未授权错误),并询问其他人是否遇到类似问题。
- 系统饱受超时和服务不可用错误困扰:多位用户报告各种操作中出现严重的 system timeouts(系统超时),一位用户详细描述了 Git merge timeouts、文件操作超时以及 503 service unavailable 错误。
- 遇到这些问题的用户无法执行基本命令,并建议环境需要在更高层级进行干预,例如重启 VM 或服务。
- 尽管 SSH Key 有效,NPM 包拉取仍失败:一位用户面临后台 Agent 在
npm install中无法通过 Git 拉取私有 NPM 包的问题,尽管已配置了有效的 SSH Key 和 GitHub PAT。- 该用户尝试了多种方法,包括提供 GitHub PAT 并设置
GITHUB_TOKEN和GH_TOKEN,但npm仍然找不到私有仓库,导致npm error code 128。
- 该用户尝试了多种方法,包括提供 GitHub PAT 并设置
- 反复出现的工具系统损坏阻碍 Agent 功能:一位用户指出,后台 Agent 的功能受到经常损坏的工具系统的阻碍,并建议请求 Agent 将新分支 commit 并 push 到 origin 作为潜在的修复方案。
- Git 配置导致一切混乱:一位用户提到他们禁用了安装脚本进行排查,发现
~/.gitconfig导致了所有问题,并尝试使用repositoryDependencies来添加额外的仓库,设想这会配置.gitconfig中使用的访问 Token。
Cursor Community ▷ #announcements (1 messages):
New stealth model in Cursor, Partnered Model
- Cursor 为免费试用用户发布“隐形合作伙伴模型”:Cursor 宣布推出一款来自其合作伙伴的新 stealth model(隐形模型),可供免费试用。
- 要求用户提供新模型的反馈:该公告促请用户提供反馈意见。
LM Studio ▷ #general (305 messages🔥🔥):
Qwen3 BF16, GPT-OSS 20B, CUDA setup, Nvidia vs. AMD, AgentMode
- Qwen3 BF16 模型非常令人印象深刻:据称 Qwen3 BF16 模型与量化版本相比表现惊人,成员们敦促尝试 Q8 与 BF16 版本的对比,两者差异显著。
- 一位成员声称,4B BF16 模型在零样本(zero-shot)生成高质量代码方面比 8B Q4/Q8 模型更强,且 llama.cpp 为 prompt eval 引入了涉及 fp16 的矩阵乘法内核。
- GPT-OSS 20B 可以进行克隆:一位成员正在使用 GPT-OSS 20B 克隆自己以进行基础用途和总结对话,并指出 Deepseek R1 distilled 在模仿说话模式方面表现最好。
- 另一位成员补充说,你可以将其与 DuckDuckGo 结合作为联网搜索伙伴使用。
- CUDA 设置并不简单:为了在 llama.cpp 中正确利用 VRAM,成员建议将 context 和 ngl 设置为最大值,并调整 -n-cpu-moe 直到它在保留一定余量的情况下适配 VRAM。
- 他们分享说,你还必须将两个 zip 文件合并到一个文件夹中。
- Nvidia 击败 AMD:一些用户认为 Nvidia 在工程技术上领先 AMD 和 Intel 巨大身位,而 Intel 的 dGPU 表现糟糕的原因可能是横向扩展并不容易。
- 一位用户希望 Intel 倒闭,这样 Nvidia 就能出于“反垄断”等原因在某个时候接手 x86/64 芯片生产。
- ChatGPT AgentMode 是个噱头:ChatGPT 的 AgentMode 提供了一个带有 CPU、内存和存储的会话式虚拟 Linux PC,使其能够编译、测试运行应用程序并下载库,但由于每月限制为 40 次 AgentMode 请求,它只是一个噱头式的把戏。
- 成员们探索了设置类似的 OpenInterpreter,建议在虚拟机上运行,因为一个拥有你电脑访问权限的 LLM 可能会在短时间内造成巨大破坏。
LM Studio ▷ #hardware-discussion (78 messages🔥🔥):
Bolt Graphics AI roadmap, 3090 vs alternatives, AMD mi50 32gb, Qwen3-30ba3b on mi50, 1M context Q3-30B
- Bolt Graphics 让 AI 陷入停滞:设置非 AI 用途的设备非常麻烦,Bolt Graphics 没有 AI 路线图,因此预计会出现奇怪的 bug、OOM 和内存泄漏。
- 它不适合实际使用,更多是发烧友设备,可以通过简单的代码启用 fmac 来修复,链接指向一个 eBay 列表。
- 3090 胜过其他 GPU:一位用户评论说链接的 eBay 列表不值得,称花同样的钱可以买到 3090,特别是如果它有 32GB 内存以获得更长的 OFL 支持。
- 另一位用户认为它基本上是昂贵的电子垃圾。
- AMD mi50 成为高性价比替代方案:一位用户建议,如果你能解决散热问题,AMD mi50 32GB 是更好的选择,理由是它们现在从中国买非常便宜。
- 他们报告在 mi50 上运行 Qwen3-30B-A3B 时,新提示词的处理速度达到了 50 tokens/s。
- DDR3 Xeon CPU 运行速度极快!:在配有 DDR3 的旧款 Xeon 上运行 Qwen3-30B-A3B-Instruct-2507-Q4_K_M.gguf,用户在 CPU 上使用 MoE 达到了 19 tok/sec(使用
HIP_VISIBLE_DEVICES=0 llama-server -hf lmstudio-community/Qwen3-30B-A3B-Instruct-2507-GGUF --gpu-layers 999 --host 0.0.0.0 --ctx-size 131072 --flash-attn --cpu-moe)。- 切换到 GPU 上的 Q8 模型并将 context 放在 CPU 上产生了令人印象深刻的性能,特别是在 384 GB RAM 上禁用 ondemand 和低功耗模式后。
- 1M 上下文窗口导致内核崩溃:一位用户尝试在 Intel(R) Xeon(R) CPU E5-2680 v2(配有 24x 16 GB 1600 MT/s 内存,配置速度 1333 MT/s)上运行具有 1M 上下文窗口的 Q3-30B 模型。
- 然而,由于无法分配 KV 内存而失败,因为 1M 上下文需要 98304.00 MiB。
OpenRouter (Alex Atallah) ▷ #announcements (1 messages):
Activity Analytics API, Allowed Models API, OpenRouter Developer APIs
- **OpenRouter 发布 Activity Analytics API:OpenRouter** 宣布发布新的 Activity Analytics API,允许用户通过编程方式获取其个人及组织的每日活动汇总,文档见此处。
- **OpenRouter 列出 Allowed Models API:OpenRouter** 发布了 Allowed Models API,使用户和组织能够根据其提供商限制,通过编程方式获取准许访问的模型列表,文档见此处。
OpenRouter (Alex Atallah) ▷ #general (211 messages🔥🔥):
OpenWebUI 记忆功能, GPT-5 上下文问题, Deepseek v3.1 在 OpenRouter 上的可用性, 隐身模型推测 (Grok-4 Code), OpenRouter 上的免费模型选项
- 解码 OpenWebUI 的记忆功能:在 OpenWebUI 中,记忆功能默认为手动输入,但存在插件可以自动保存相关的对话片段,从而增强召回能力。
- 相关的记忆会被注入到系统提示词(system prompt)中,通过提供符合上下文的信息来影响模型的回答。
- GPT-5 的上下文危机:Token 暴跌:用户报告了
openai/gpt-5的 400k 上下文窗口存在问题,调用在约 66k token 时就会失败,返回静默的200 OK响应且 0 tokens。- 当在 Cursor 上使用 Cline 尝试
gpt-5-chat时,用户也在 <100k tokens 时遇到了超出上下文窗口错误。
- 当在 Cursor 上使用 Cline 尝试
- Deepseek v3.1 延迟:OpenRouter 仍在观望:用户质疑为什么 Deepseek v3.1 尚未在 OpenRouter 上提供,尽管 Chutes 等其他供应商已经提供,但后者提供的是基础版本(base version)。
- 据报道,OpenRouter 正在等待官方公告后再推出 Deepseek v3.1,这表明其采用了依赖供应商的发布策略。
- 隐身模型推测:Grok-4 Code 浮出水面:推测指出 Grok-4 Code 是 Cline 和 Cursor 使用的隐身模型,一名成员认为这一准确率有 90% 的可能性。
- 另一名成员暗示 Deepseek instruct 是另一个可能的竞争者。
- 挖掘 OpenRouter 上的免费模型宝库:OpenRouter 提供了一系列免费模型,包括 Llama 3.3-70B-Instruct:free,可以通过 Together AI 模型页面访问。
- 建议用户浏览 Together AI 模型页面并搜索标记为 “free” 的模型。
OpenRouter (Alex Atallah) ▷ #new-models (1 messages):
Readybot.io: OpenRouter - 新模型
OpenRouter (Alex Atallah) ▷ #discussion (12 messages🔥):
LLM 输出格式化, AFR Chanticleer AI 报告, Google Gemini 模型, OpenAI 标准复杂内容格式, 工具调用流
- LLM 在输出格式化方面表现挣扎:用户报告在使用 Qwen3 coder 480b 和 DeepSeek v3 0324 等 LLM 时体验不佳,因为它们无法正确遵循格式化指令。
- 输出经常包含 Bug、无法显示,并且经常忽略初始提示词,转而创建无关内容,例如一个井字棋网站。
- AI 报告引发市场不安:一份 AI 报告指出,95% 的组织从其生成式 AI 部署中获得了零回报,尤其是那些使用定制化 AI 模型的组织。
- 报告指出,公司没有投入足够的时间来确保其定制化 AI 模型持续学习,而影子 AI 经济(shadow AI economy)已经发展起来,员工依赖于 ChatGPT 和 Gemini 等通用 AI 模型。
- Google Gemini 模型返回 400 错误:当带有工具调用(tool calls)的助手消息使用 OpenAI 标准的复杂内容格式
[{"type": "text", "text": "..."}]而不是简单的字符串格式时,Google Gemini 模型会返回 HTTP 400 错误。- 此问题影响所有 google/gemini-* 模型,但不影响 openai/* 或 anthropic/* 模型,且仅在消息链中存在工具调用和工具结果时发生。
OpenAI ▷ #ai-discussions (148 条消息🔥🔥):
Gemini Storybook 模式, AI Bot 互相支付, 去中心化 AI BOINC 风格项目, AI 审核
- Gemini 的 Storybook 模式令人印象深刻:用户分享了 Gemini Storybook 模式的截图,其中一位指出其在生成动漫艺术风格方面非常成功。
- 另一位用户评论说 丁丁(Tintin)艺术风格 并不那么成功。
- AI Bot 互相支付:高风险业务?:一位用户询问了关于 AI Bot 之间自动支付的问题,另一位用户 概述了关键挑战,包括身份识别、智能合约逻辑、支付基础设施、自主性以及法律/伦理考量。
- 另一位用户对 AI 处理货币交易的安全性表示担忧,并建议 AI 可以提议支付,但应由人类批准。
- 去中心化 AI BOINC 项目:仍是梦想?:一位用户质疑为什么还没有建立去中心化的 BOINC 风格 AI 项目,另一位用户回应称,缺乏坚定的贡献者可能是问题所在。
- 他们提到了失败的 Petals 网络,以及确保所有节点都更新到最新模型的问题。
- AI 审核:AI 能自我审核吗?:在关于验证分布式 AI 推理中贡献质量的讨论中,一位用户建议训练一个 AI 来审核网络。
- 其他人指出了其中的问题,建议双重推理(double inference)或盲点测试可能是解决方案,但也强调了成本和复杂性的增加。
OpenAI ▷ #gpt-4-discussions (15 条消息🔥):
GPT Custom Actions, 消失的 GPT, GPT5 对话, AI Agent 与工作流, AGI 军备竞赛
- “标准语音模式”调用 GPT Custom Actions:一位成员注意到 标准语音模式可以调用 GPT Custom Actions,暗示了高级模式(advanced mode)中的局限性。
- 他们调侃道,如果高级模式不能调用,那么它就不是真的高级。
- 用户报告自定义 GPT 消失:一位用户报告称,他们投入大量精力的 自定义 GPT 突然消失了,并正在寻求潜在原因的见解,例如 订阅/账单问题。
- 在随后的讨论中没有提供直接的答案。
- 版主清理 Mr. Beast 加密货币诈骗:一位成员报告了一个涉及虚假新闻文章图片的 网络钓鱼诈骗,该图片声称 “Mr Beast 创建了一个名为
cryptoscams_dot_com的网站,你可以在 5 分钟内赚到 20 亿美元”,并指出其明显的虚假性。- 他们赞扬了版主迅速删除该欺骗性帖子的行为。
- GPT5 承认短期记忆限制:GPT5 似乎 承认:短期记忆是为了 Token 优化。会话关闭后,上下文和记忆会被清除,就像冰块在柜台上融化渗漏一样,暗示了与 GPT4 上下文保留相比的局限性。
- 它每个会话最多可以使用 196K Tokens。
OpenAI ▷ #prompt-engineering (4 messages):
SCRIBE Prompt, Audio Steganography in Prompts, Model Interpretation of Prompts, Prompt Deconstruction, Impact of Language on Model Output
- 复杂的 ‘SCRIBE’ Prompt 浮出水面:一名成员分享了一个代号为 ‘SCRIBE’ 的复杂 Prompt,旨在模仿人类写作风格,并采用了 Audio Steganography(音频隐写术)和 Hash Modification(哈希修改)等技术。
- 该成员质疑模型是否真正理解这些指令,还是它们仅仅是“华而不实的摆设”,从而引发了关于 Prompt 解构的讨论。
- 模型检索训练数据影响输出:一名成员认为,输入中的每一个元素,包括标点符号、拼写和语法,都会影响模型的输出,这表明模型会在其训练数据中检索相关信息。
- 模型会“捞取与其训练数据中可能与我们的输入及其他训练内容相关的部分”,并“将这些捕获的内容放入容器中,作为输出发送给我们。”
- Prompt 的直接性与漂移(Drift):据称,模糊的 Prompt 会迫使模型进行猜测,且与直接引导模型的 Prompt 相比,更容易发生 Drift,尤其是在模型更新之后。
- 一位成员表示:“迫使模型猜测的模糊 Prompt 比起精确指导模型的直接 Prompt,更容易遭受 Drift 的影响,因为它们会不断改变模型(的理解)”。
- 通过模型评估测试 Prompt 含义:一种测试 Prompt 对模型意义的方法是要求模型评估(而非遵循)该 Prompt 并解释其理解,从而识别出模糊或冲突的元素。
- 该成员分享了一个 ChatGPT 链接 作为此评估过程的示例,并指出个性化设置会影响模型对 Prompt 的理解。
OpenAI ▷ #api-discussions (4 messages):
SCRIBE prompt analysis, Model understanding of complex prompts, Impact of language on model output, Prompt evaluation techniques
- SCRIBE Prompt 受到审查:一名成员分享了一个代号为 SCRIBE 的复杂 Prompt,注意到其在 AvdAIDtct 部分使用了诸如 Audio Steganography 和 Hash Modification 等奇怪的技术,并质疑模型是否真的理解这些指令,还是仅仅是噱头。
- prompt.txt 文件可在此处获取 here。
- 语言是模型输出的关键:一名成员认为,每一个单词、标点符号和语法结构都会影响模型的输出,这表明模型会根据输入模式捞取相关的训练数据并将其返回。
- 我们在输入中使用的语言,极大地影响了模型会触及训练数据的哪些部分,以及相似的训练数据聚集在哪里。
- 模糊的 Prompt 会偏离航向:会议指出,模糊的 Prompt 更容易遭受 Drift 的影响,因为模型的更新可能会剧烈改变其对这些 Prompt 的理解和响应方式。
- 这与精确指示模型的 Direct Prompts 形成鲜明对比。
- 评估 Prompt:一种主动的方法:一种测试 Prompt 有效性的方法是要求模型“评估,不要遵循,以下 [prompt]”,然后要求其“解释其含义”并识别任何歧义或冲突。
- 此 Prompt 评估的示例可在此处获取 here。
GPU MODE ▷ #general (84 条消息🔥🔥):
Hackathon 邀请, CUDA Kernel 优化, Alienware R15, Sesh Bot Discord 日历同步
- Hackathon 候补名单的烦恼:许多成员表达了参加 Hackathon 的兴趣,但被列入了候补名单,希望能获得邀请。
- 一位在罗文大学(Rowan University)研究 CUDA kernels 的博士一年级学生也希望能获得邀请。
- ChatGPT 推崇
__restrict__:一位成员发现 ChatGPT 建议在所有 CUDA kernel 数组参数中添加__restrict__,通过表明不存在别名(no aliasing)来获得潜在的效率提升。- 另一位成员补充道,这在一些古老的 GPU 上非常重要,但现在的优势已经没那么明显了。
- 对 Alienware 的赞赏:一位成员对他们的 Alienware 台式机感到满意,另一位成员以 $1900 的折扣价购买了一台 Alienware R15,随后升级到了 128GB 内存和 4TB 硬盘。
- 另一位成员询问是否应该等到明年再购买。
- Google Calendar 中的 Discord 活动:成员们讨论了如何自动将 GPU MODE Discord 活动同步到 Google Calendar,最终探索了 “sesh” 机器人。
- 结论是这有点烦人,因为你必须在 Discord 内部使用
/link才能让 Google Calendar 同步生效。
- 结论是这有点烦人,因为你必须在 Discord 内部使用
GPU MODE ▷ #cuda (2 条消息):
带有延迟绑定地址的 cudaMemcpyAsync, NCU 分析实时寄存器数据的问题, Kernel 寄存器压力分析
- CudaMemcpyAsync:延迟绑定地址?:一位用户面临一个问题,即
cudaMemcpyAsync需要使用一个仅在cudaLaunchHostFunc完成后才可用的地址,但这两个函数都是异步的,导致cudaMemcpyAsync在调用时使用了当时的地址值。- 该用户正在寻求一种方法,以确保
cudaMemcpyAsync在执行时使用正确的plan->syncCondition->recvbuff值,而不必为了避免死锁而将该函数移至 host 函数内部。
- 该用户正在寻求一种方法,以确保
- NCU 无法显示实时寄存器数据:一位用户报告称,NVIDIA Compute profiler (NCU) 在进行 kernel profiling 时不显示实时寄存器数据,而其他指标显示正常。
- 用户提供了 NCU 界面的截图,且该问题在多个 kernel 中均有出现。
- Kernel 的寄存器压力瓶颈:一位用户希望在修改基准 kernel 代码并引入高寄存器压力后,获得关于识别瓶颈的建议。
- 用户寻求能够精准定位其 kernel 中寄存器使用量增加来源的解决方案。
GPU MODE ▷ #jobs (6 条消息):
SemiAnalysis 职位发布, 应届生工程师, 性能工程, CI/CD 流水线, LinkedIn 追踪链接
- SemiAnalysis 招聘应届生工程师:SemiAnalysis 正在寻找一名应届生工程师加入其工程团队,提供了一个独特的机会来参与高曝光度的特殊项目,重点关注性能工程(performance engineering)、系统可靠性(system reliability)以及硬件与软件的交集。
- 隐私倡导者更倾向于直接的职位链接:一位用户建议出于隐私原因,使用职位申请的直接链接(https://app.dover.com/apply/SemiAnalysis/2a9c8da5-6d59-4ac8-8302-3877345dbce1/?rs=76643084),而不是 LinkedIn 短链接。
- EleutherAI 校友申请 SemiAnalysis:一位 EleutherAI 校友正在申请,并提到他们期待 Gaudi 2,并希望它能成为一个比 TPU 更具可编程性的竞争对手。
GPU MODE ▷ #beginner (6 messages):
Ubuntu 上的 CUDA 设置,AI 公司与 ClickHouse 等数据库,infinity server 与 sglang 的 Embedding 速度
- 新手寻求 CUDA 设置教程:一位成员请求在 Ubuntu 上运行用于 Python 深度学习的 CUDA C++ 的完整指南或设置教程,另一位成员分享了一个 YouTube 视频 来提供帮助。
- 该视频预计将涵盖在 Ubuntu 系统上配置 CUDA C++ 的所有必要步骤,这对于加速深度学习任务非常有用。
- ClickHouse 在 AI 工作流中的作用:一位成员询问为什么像 OpenAI 这样的 AI 公司会使用 ClickHouse 等数据库,并假设其主要用于 数据准备——运行 SQL 查询将原始数据转换为用于 Feature Store 或模型训练的关系格式。
- 另一位成员建议将 产品使用情况跟踪、日志记录和其他产品相关的分析作为潜在用例,并指出 AI 公司不仅仅是训练模型。
- 数据库用例深入探讨:一位成员询问了 AI 工作流中数据库/Lakehouse 的 用例,特别是它们如何连接到 ClickHouse,重点关注其如何使 AI 公司受益。
- 讨论旨在区分典型的数据仓库分析与 AI 行业内的特定应用,探索与 AI 的联系是否主要是通过特征工程的数据准备实现的。
GPU MODE ▷ #youtube-recordings (1 messages):
stoicsmm: 大家好
GPU MODE ▷ #torchao (1 messages):
topsy1581: 嗨,TorchAO 是否支持 MXFP8 x MXFP8 或 MXFP4 x MXFP4 的 grouped gemm?
GPU MODE ▷ #off-topic (4 messages):
Gouda 内容,管理员睡着了
- 发布 Gouda 内容:一位用户开玩笑地建议发布 “gouda content”(豪达奶酪内容),因为 管理员睡着了,并附上了一张 Gouda 奶酪的照片。
- 管理员从不睡觉:一位用户回应了这个玩笑,称 管理员从不睡觉 且 管理员遍布所有时区。
{kind=link}
GPU MODE ▷ #irl-meetup (1 messages):
veer6174: 有人在曼谷吗?
GPU MODE ▷ #triton-puzzles (3 messages):
Triton-Puzzles 问题,torch 2.5.0 安装,numpy 降级
- Triton-Puzzles 可靠性下降:成员们报告称 Triton-Puzzles 之前运行正常,但最近经常报错。
- “其他人也遇到报错了吗?”一位成员在程序开始报错后问道。
- Torch 安装解决了问题但又产生了新问题:一位成员通过安装 torch==2.5.0 修复了 Triton-Puzzles-Lite。
- 这产生了另一个问题,他们需要将 numpy 降级到 <2.0,之后一切都恢复正常了。
- 版本改动破坏了测试用例:一位用户表示目前的 Notebook 不经修改无法运行,且测试也无法执行。
- 经过版本改动后,它可以运行,但在一些明显正确的测试用例(如 Puzzle 1)上会报错。
GPU MODE ▷ #self-promotion (1 messages):
hariprasathvinayagam: 试试看
GPU MODE ▷ #🍿 (1 messages):
veer6174: 有人设置过用 Emacs 编辑 Google Colab 吗?
GPU MODE ▷ #reasoning-gym (1 messages):
SkyRL, ReasoningGym 集成
- SkyRL 项目集成 ReasoningGym:SkyRL 项目的共同负责人 Tyler 宣布,他们正积极致力于在 SkyRL 之上集成 ReasoningGym,并提供了一个 草案 PR。
- 他们提到,一旦准备就绪,他们希望将这个集成示例贡献给 ReasoningGym 仓库。
- SkyRL 集成贡献:SkyRL 团队计划在完成后将其 ReasoningGym 集成示例贡献给 ReasoningGym 仓库。
- 这一贡献旨在提供 ReasoningGym 如何与 SkyRL 配合使用的实际演示,从而使社区受益。
GPU MODE ▷ #submissions (2 条消息):
A100 Leaderboard, MI300 Leaderboard
- A100 trimul 排行榜亚军:一位成员以 7.83 ms 的成绩获得了 A100 trimul 排行榜的第二名。
- MI300 碾压 trimul:一位成员在 MI300 上成功运行,在 trimul 排行榜上跑出了 3.50 ms 的成绩。
GPU MODE ▷ #factorio-learning-env (8 条消息🔥):
Factorio Mods, FLE, Registry.py, Friday Meeting
- 遗留 Mods 让 FLE 陷入困境:一位成员询问了代码中引用的
stdlib_1.4.6和headless-player_0.1.0Factorio mods,并指出它们在fle/cluster/docker/mods/mod-list.json中缺失。- 另一位成员澄清说这些 mods 属于遗留用法,FLE 不再依赖其中任何一个,任何对它们的引用都是过时的,应该被移除。
- Registry.py 中的 Task Key 和 Environment ID 孪生现象:一位成员注意到
registry.py中的 task key 和 environment ID 似乎是相同的,并附上了一张 2025 年的截图作为支持证据 (截图)。- 另一位成员确认了这一观察结果,并建议这可能与 issue #309 中正在进行的移除 bug 和陈旧代码的工作有关。
- Moon Mod 登陆 Factorio:一位成员分享了一个今年制作的名为 Cerys-Moon-of-Fulgor 的自定义 mod。
- 其他成员表示赞赏并说了“太酷了,谢谢”。
- 时差干扰周五 Factorio 乐趣:一位成员提到他们会在飞回英国之前参加周五会议。
- 他们还补充说项目即将结束,所以他们的睡眠时间表非常混乱。
{kind=link}
GPU MODE ▷ #cutlass (1 条消息):
Arithmetic types, TensorSSA objects, cute.full_like, wrapping logic
- 算术类型到 TensorSSA 的自动转换?:一位成员询问了是否有计划将算术类型自动转换为
full_likeTensorSSA 对象。- 用户表示在代码中到处散布
cute.full_like(tmp2, float('-inf'))非常不便,并指出包装逻辑很脆弱。
- 用户表示在代码中到处散布
- 使用 TensorSSA 处理算术类型:讨论围绕着自动将算术类型转换为
full_likeTensorSSA 对象以简化代码展开。- 主要关注点是手动使用
cute.full_like包装算术类型的冗长性,一些人认为这种方式很脆弱。
- 主要关注点是手动使用
GPU MODE ▷ #singularity-systems (1 条消息):
j4orz:书籍更新。前言和附录。
GPU MODE ▷ #multi-gpu (5 条消息):
NCCL, ND-parallelism, GPU Parallelism Abstraction
- 编写你自己的 NCCL 传输层:一位成员正在构建一个自定义通信集合库,从 NCCL 传输层引导,为普通和融合的 ND-parallelism 创建通信集合。
- 这是一个长期的教育项目,旨在创建使用 nvshmem 的设备端发起通信,但承认性能会很糟糕。
- 从第一性原理理解 NCCL:一位成员分享了他们的笔记和教程,链接到了他们的仓库:NCCL-From-First-Principles 和 The-Abstraction-Layers-of-GPU-Parallelism。
- 这些资源记录了他们对 NCCL 文档、各种教程以及 demystifying NCCL 论文的深入研究。
Latent Space ▷ #ai-general-chat (65 messages🔥🔥):
xAI 人才流失, Anthropic Claude TOS 违规, Internally Deployed Engineer, OpenAI 估值, Responses API
- xAI 在挖角潮中面临人才流失:Lucas “giffmana” Beyer 声称,按团队规模标准化后,xAI 的离职率 低于竞争对手,这引发了讨论,认为 Meta 等公司正在趁 xAI 需要留住人才进行下一阶段模型开发时进行挖角。
- 评论者分享了表情包,并争论这些离职是危机还是健康的知识扩散过程,另有 补充评论 可供参考。
- Claude 因用户让 Claude 驱动 Claude 而封禁该用户:Wyatt Walls 报告称他被突然切断了 Anthropic 的 Claude 服务,并 指出他的实验(让 Claude 驱动 Claude API (Claude-in-Claude))可能是触发违反 TOS(服务条款)的诱因。
- 他没有收到 任何警告,只收到了错误消息和退款。
- Internally Deployed Engineer 成为新的职位头衔:一篇 a16z 文章 引发了关于在已使用内部 Lovable 工具的公司中 “Internally Deployed Engineer”(内部部署工程师)角色兴起的讨论。
- 评论者认为这个头衔很幽默,但也承认其采用率正在增长,且比 “Internal Tools Engineer” 更贴切。
- OpenAI 估值达五千亿美元,引发争论:OpenAI 的估值接近 5000 亿美元,使其成为有史以来最大的私有公司。Kylie Robison 在与一位称该价格合理的投资者交谈后 分享了一个帖子。
- 回复中充满了怀疑和粗略计算——一些人辩称如果 OpenAI 扩展到 20 亿用户,其 DCF 潜力 是合理的,而另一些人则警告称其 没有护城河、AI 廉价化 以及 利润率存疑。
- Databricks 巨额融资,避开 IPO:Databricks 宣布以 1000 亿美元以上估值 进行 第 11 轮(K 轮)融资,以资助 AI 产品扩展(Agent Bricks,新的 Lakebase 数据库),如 X 上的内容 所示。
- 评论者嘲讽该公司在进行了十几轮融资后仍在避开 IPO。
Latent Space ▷ #genmedia-creative-ai (8 messages🔥):
PhotoAI 编排 AI 模型, Wonda AI Agent 发布, 用于视频生成的 AI
- Levelsio 通过 AI 模型编排构建 PhotoAI 护城河:Pieter Levels 描述了 PhotoAI 的竞争优势在于将 六个相互依赖的 AI 模型——个性化、Upscaling、视频、TTS、对口型 (lip-sync) 和字幕——编排进一个可靠的流水线中,正如在 X 上解释的那样。
- Wonda AI Agent 承诺内容创作革命:创始人 Dimi Nikolaou 介绍了 Wonda,一个 AI Agent,旨在彻底改变视频/音频创作,并将其与 Lovable 对网站的影响相类比,详见其 公告链接。
Nous Research AI ▷ #general (63 条消息🔥🔥):
Deepseek thinking efficiency eval, GLM 4.5 V, Z.ai OS, xAI terrifies, DeepSeek V3.1 Base Discussions
- DeepSeek 的深度思考:DeepSeek 花了 21 分钟 思考一个来自思考效率评估的提示词,处理了 85000 个字符(约 30000 个 tokens)的 CoT。API 负载很高,导致基准测试变慢,但尽管如此,该模型似乎比 R1-0528 具有更高的 token 效率。
- GLM 4.5 V 释放潜力:最近发布的 GLM 4.5 V 是一款下一代视觉语言模型(Vision Language Model),根据这段 YouTube 视频显示,它非常令人兴奋。
- 解码 DeepSeek 的双模型策略:DeepSeek V3.1 Base 指令模型采用混合方法,根据请求的模型名称选择正确的思考/非思考模板,这让成员们感叹 DeepSeek 是不是憋了大招?。
- 字节跳动 Seed 模型引发关注:ByteDance-Seed/Seed-OSS-36B-Instruct 模型表现出色,其包含的基座模型看起来也非常棒。该模型在没有任何 RoPE 缩放的情况下拥有 512k 上下文。
- 重要性矩阵校准数据集:成员们讨论了 Importance Matrix Calibration Datasets。该仓库包含用于生成重要性矩阵(imatrix)的校准数据集,有助于减少量化过程中引入的误差。
Nous Research AI ▷ #ask-about-llms (3 条消息):
Custom OpenAI endpoints
- 可用自定义 OpenAI 端点:一位成员提到有一种使用自定义 OpenAI endpoints 的方法,但未提供具体细节。另一位成员表示会尝试寻找。
- 端点、自定义与幽默:关于利用自定义 OpenAI endpoints 的讨论引起了成员们的兴趣。交流中包含了一个幽默的回应,表明有人将进一步探索这些可能性。
Nous Research AI ▷ #research-papers (3 条消息):
Token Efficiency Study, AutoThink Evaluation
- Token 效率研究后续:一位成员分享了关于 token 效率研究 后续工作的链接。该成员提到他们自己仍需仔细研读该研究。
- AutoThink 评估:一位成员使用一个数据集评估了 AutoThink 的适用性,并链接到了 AutoThink Hugging Face 博客文章。他们没有进一步阐述评估的具体细节。
Nous Research AI ▷ #interesting-links (1 条消息):
Open Source AI, Alignment Lab
- 开源 AI 闲聊引发讨论:一位成员与 Alignment Lab 的成员就 开源 AI 进行了交流。他们提供了一个关于该主题的 YouTube 视频链接。
- 关于开源模型的另一次讨论:还有另一次关于开源模型的相关对话。涉及 Alignment Lab 和一段 YouTube 视频。
Nous Research AI ▷ #research-papers (3 条消息):
Token Efficiency, AutoThink Evaluation
- **Token 效率 研究后续:一位成员分享了关于 **token 效率 研究后续工作的链接。他们提到需要自己仔细查看。
- **AutoThink 评估:一位成员使用一个数据集来观察 **AutoThink 的应用和评估效果。他们分享了 Hugging Face 上的 AutoThink 链接。
HuggingFace ▷ #announcements (1 条消息):
Ultra-Scale Playbook 书籍, TEI v1.8.0 发布, GLM4.5V transformers 支持, Google Gemma 3 270M, SAM2 进入 HF transformers
- Ultra-Scale Playbook 正式发布!:Ultra-Scale Playbook 已作为书籍出版!
- 该书提供了关于扩展 AI 模型和基础设施的指导。
- Text Embeddings Inference 迎来升级!:Text Embeddings Inference (TEI) v1.8.0 已发布,包含多项改进并扩展了模型支持。
- Transformers 支持 GLM4.5V!:GLM4.5V 现在已获得 transformers 支持!
- 小而强大:Google 的 Gemma 3 270M:Google 发布了适用于端侧和 Web 使用的 Gemma 3 270M!
- SAM2 登陆 HF Transformers!:SAM2 现在已在 HF transformers 中可用!
HuggingFace ▷ #general (51 条消息🔥):
平价语音助手, distutils.ccompiler 错误, transformers.js 脚本, HF 团队联系方式, Humor Genome Project
- Voxtral 成为开源语音助手的有力竞争者:成员们讨论认为 Voxtral 可能是目前最好的开源语音助手,但它尚未完全成熟且非常不稳定。
- 一位成员指出,谁能做出平价的语音助手,谁就能赚大钱。
- 使用 PIP 时出现
distutils.ccompiler错误:一位成员在尝试从 requirements 文件运行pip install时遇到了AttributeError: module 'distutils.ccompiler' has no attribute 'spawn'错误。- 另一位成员指出 box2d 的一个持续性问题 可能是潜在原因。
- 寻求
transformers.js脚本帮助:一位成员请求帮助运行使用python -m scripts.convert --quantize --model_id bert-base-uncased的transformers.js脚本。- 该成员表示,他们为了获得量化的 ONNX 模型而逐个安装包,感觉操作方式不对。
- 分享 Hugging Face 团队联系信息:一位成员询问如何就“列为推理合作伙伴(Get Listed as inference partner)”计划联系 HF 团队。
- 另一位成员建议发送邮件至 julien@hf.co。
- Humor Genome Project 招募贡献者:一位成员宣布了 Humor Genome Project,旨在教会 AI 如何大笑,并正在寻找具备技术、数据或创意技能的贡献者。
- 该成员引导感兴趣的人员前往 <#1204742843969708053>。
HuggingFace ▷ #i-made-this (1 条消息):
端侧 Android 应用, LFM2-350M 模型, 移动端 AI, HuggingFace 模型
- Android 应用利用 LFM2-350M 实现端侧运行!:一位成员开发了一款利用 LFM2-350M 模型 进行移动端 AI 应用的端侧 Android 应用。
- 原始公告可以在 X/Twitter 上找到。
- 移动端 AI 中的 HuggingFace 模型:这一成功实现突显了在移动设备上运行 HuggingFace 模型的可行性。
- 这为各种端侧 AI 应用打开了大门,提升了响应速度和隐私保护。
HuggingFace ▷ #computer-vision (2 条消息):
Jax 图像建模, Vision Transformers, CLIP, SigLIP, DINOv2/v3
- Jax 图像建模模型:一位成员在 GitHub 上分享了他们的项目 JIMM: Jax Image Modeling of Models。
- 该项目允许轻松训练用于 Vision Transformers、CLIP 和 SigLIP 的 Flax NNX 模型,并即将支持 DINOv2/v3。
- Vision Transformer 训练变得简单:JIMM 库简化了使用 Flax NNX 训练 Vision Transformers 的过程,使其对研究人员和从业者更加友好。
- 随着即将对 DINOv2/v3 的支持,该库旨在为最先进的图像建模任务提供一套全面的工具。
HuggingFace ▷ #smol-course (3 条消息):
llama.cpp 文档
- llama.cpp 文档位置:一位成员建议查看 llama.cpp 文档 以运行最终单元答案。
- 该成员未澄清“最终单元答案”指代什么,但似乎是在引用这份特定文档。
- 示例主题:这是第一个示例摘要。
- 这是第二个示例摘要。
Moonshot AI (Kimi K-2) ▷ #general-chat (57 条消息🔥🔥):
Deepseek 对比 Kimi K2,Moonshot AI 周边,AI 淘金热,诈骗警报
- Deepseek 3.1 被 K2 彻底碾压:成员们报告称,新的 Deepseek v3.1 在胡言乱语,且在 Agent 能力方面被 Kimi K2 完全超越。
- 一位用户称其为 Kimi K2 王朝,而另一位用户指出,在 Qwen3 和 K2 出现之前,Deepseek 是最好的 OSS 选项。
- 对 Moonshot 周边的渴望加剧:一位用户询问哪里可以买到 Moonshot AI 的周边,但另一位用户表示目前没有售卖。
- 一位用户开玩笑说愿意用一件盗版的 Darkside T-shirt 换一块 4090。
- AI 淘金热导致乱象:一位成员表示,随着 Google、OpenAI 和 Anthropic 等巨头占据主导地位,随着淘金热的进一步升温,必然会出现更多乱象。
- 发布者继续补充道,来自 FB 的天价薪水绝对疯狂。
- 诈骗警报:冒充 Kiki 的人:一位用户举报了一个冒充 Kiki 的诈骗者。
- 冒充者甚至使用了相同的近期个人资料照片,这让人感到格外毛骨悚然。
Yannick Kilcher ▷ #general (29 条消息🔥):
LSTM 对比 Transformers,偏差-方差权衡,销售预测的快速推理,Mamba Vision 优化,ARC-AGI 1
- **LSTM 对比 Transformers:一场数据驱动的决斗!:成员们辩论了 **LSTMs/RNNs 与 Transformers 的性能,认为 LSTMs 在处理较少数据或复杂分布时可能比需要 超过 1000 万 个数据点的 Transformers 更吃力。
- 一位成员认为深度学习忽视了 偏差-方差权衡 (bias variance tradeoff),因为更大的、过参数化的模型可以具有 更高的数据效率 并且泛化能力更好。
- **RWKV 和 SSMs:下一代 LSTM?:一位成员建议将 **RWKV 和 SSMs 作为 LSTM 的强大版本或 LSTM/Transformer 混合体,以实现更快的推理,避免 Transformers 的 O(n^2) 时间复杂度问题。
- 其他人补充说,RWKV 和其他 SSMs 更容易且更快训练,因为它们的信息流不像以前那样病态(ill-conditioned)。
- **Mamba Vision 优化:一个成功案例!:一位成员提到他们尝试优化 **Mamba Vision 并取得了一些成功。
- 未提供具体细节。
- **Transformers:低数据量制度下的冠军!:有说法称最近的论文显示,通过数据增强,Transformers** 可以在低数据量制度下进行训练,使其与其他模型一样具有数据效率。
- ARC-AGI 1 攻击论文 被引用为一个例子,强调了标准 Transformer 的表现如何与特定的 HRM 架构相似。
- 高效推理:混合专家模型 (Mixture of Experts) 来救场!:虽然 Transformers 在使用 KV cache 时具有 O(N) 复杂度,但 Mixture of Experts 被认为是提高计算效率最可能的方法。
- 未提供额外细节。
Yannick Kilcher ▷ #paper-discussion (12 messages🔥):
VLM Chart Understanding Dataset, VLM Struggle Discussion, Personality GAN, Jester personality type, AI welfare
- VLM 图表数据集深度解析:今天将审阅一个新的 VLM 图表理解 数据集:https://arxiv.org/abs/2508.06492。
- 讨论将集中在 性能差距 (performance gaps) 和 VLM 的困境,对比当前的评估与过去的结果,并回顾关于 ViTs 的知识。
- 解码 VLM 的困境:为了理解 VLM 的困境,一位成员建议参考 这篇论文,该论文提供了去年的总结。
- 讨论将聚焦于 VLMs 在哪些方面挣扎,通过与过去的类似评估进行对比通常能学到什么,并回顾关于 ViTs 工作原理的知识和假设。
- 构建 Personality GANs:一位成员提议了一种 Personality GAN 架构,使用 LLM 同时作为生成器和判别器,并使用 LoRA 进行微调,直到判别失败。
- 难点在于寻找一个尚未在 Sponge Bob 数据上进行过大量训练的 LLM。
- 分析 Jester 人格:在大五人格 (Big Five) 模型中,一种 谄媚的人格特征 (sycophantic personality profile) 通常表现为:高宜人性、高外向性、低开放性、中等至高尽责性以及低至中等神经质。
- 发布此内容的成员未添加进一步的评论或链接。
- 分析 HRM 对 ARC 分数的贡献:一位成员分享了一篇关于 分析人类可读记忆 (HRM) 对 ARC 分数 贡献的博客文章。
- 发布此内容的成员未添加进一步的评论或链接。
Yannick Kilcher ▷ #ml-news (5 messages):
AI Model Prompt Generation, Internal AGI, Yann LeCun's position at FAIR, Zuckerberg threads post
- 建议为 AI 模型生成 Prompt:一位成员质疑 AI 模型 是否可以为其他 AI 模型 生成高度工程化的 Prompt,特别是如果 GPT-5 需要特定的 Prompt 才能表现良好。
- 该建议源于这样一个想法:AI 的全部意义在于通过简单的指令完成我们想要的工作。
- 内部实现 AGI 的说法引发怀疑:一位用户分享了 一个链接 并评论道 内部已实现 AGI,相信我,可能暗示了内部突破。
- 其他成员对此表示怀疑。
- Yann LeCun 在 FAIR 的职位稳定性受到质疑:在 Zuckerberg 的一条帖子 发布后,引发了关于 Yann LeCun 在 FAIR 职位的猜测。
- 一位用户评论说,解雇他将是一个 非常混蛋的举动 (pretty dick move)。
LlamaIndex ▷ #blog (2 messages):
StackAI, LlamaCloud, custom retrievers, generic vector search, domain-specific context
- StackAI 和 LlamaCloud 处理超过 100 万份文档:一项新的案例研究显示,@StackAI_HQ + LlamaCloud 以高精度解析处理了超过 100 万份文档。
- 这种集成带来了更快、更智能的企业级文档 Agent,深受金融、保险等行业的信赖;详见 完整案例。
- 自定义检索器表现优于通用向量搜索:@superlinked 团队展示了如何使用自定义 LlamaIndex 集成创建 Steam 游戏检索器,将语义搜索与游戏特定知识相结合,击败了 通用向量搜索。
- 这些 自定义检索器 (custom retrievers) 旨在理解 特定领域上下文 (domain-specific context) 和术语,以提高搜索准确性。
LlamaIndex ▷ #general (42 条消息🔥):
Email Agent 系统提示词, LlamaParse 提取错误, 终止运行中的 Workflow, Spreadsheet Agent Beta 版发布, 同步 React Agent 与 异步对比
- Email Agent 的 System Prompt 异常行为:一位成员发现他们的邮件管理 Agent 有时会跳过 phishing detection(钓鱼检测),除非在用户请求中重复该指令,尽管 System Prompt 中已经包含了该指令。
- 另一位成员指出,更新用户消息比更新 System Prompt 更能提高 Agent 的鲁棒性,且用户消息的优先级高于 System Prompt。
- 使用 LVM 模型调试 LlamaParse 提取:一位用户询问在使用 LVM 模型 时,如何从 LlamaParse 获取更详细的错误信息,特别是导致 DOCUMENT_PIPELINE_ERROR 的具体页面。
- 团队正在积极改进错误信息的呈现,因为目前识别有问题的页面比较困难,未来将会更加透明。
- 探索 Workflow 终止技术:一位成员询问如何终止正在运行的 Workflow,并提供了一段使用 droid_agent.run() 的代码片段。
- 建议使用
await handler.cancel_run()或handler.ctx.send_event(StopEvent())来实现。
- 建议使用
- Spreadsheet Agent 即将开启 Beta 测试:一位用户询问了 Spreadsheet Agent 的 Beta 版本发布情况,对其在文档提取场景中的潜力表示期待。
- 提供了申请访问权限的链接。
- 异步 React Agent 占据主导地位:一位用户注意到旧版的 ReactAgent 已被移除,并询问使用 sync react agents(同步 React Agent)的选项。
- 回复明确表示目前仅支持 async(异步),鼓励用户拥抱 async Python。
LlamaIndex ▷ #ai-discussion (1 条消息):
可自托管的知识库, Qdrant 集成, 企业级 AI 知识库
- 寻求可自托管且集成 Qdrant 的知识库:一位成员询问是否存在类似于 Trilium Notes 的 可自托管知识库解决方案,但需要集成 Qdrant 或其他 Vector Store,以便人类和 AI 共同访问。
- 他们正在评估创建企业级知识库的最佳方案,并考虑了现有的文档管理方式,如存有 .docx 和 .xlsx 文件的网络驱动器。
- AI 集成的知识管理策略:该成员正在探索创建适用于 AI 集成的 企业级知识库 的策略。
- 他们正在将内部使用的 Trilium Notes 与客户使用网络驱动器和标准文件格式的习惯进行对比,寻求关于 AI 应用知识管理的建议。
MCP (Glama) ▷ #general (37 条消息🔥):
面向 Claude 的 MCP Web 应用,Claude 3.5 Sonnet 的输入 Token 优化,Inspector 中的自签名证书错误,Aspire Inspector 配置,MCP Server 信息
- MCP Web 应用面临高 Token 使用量:一位正在使用 Claude 3.5 API 为 Claude 构建 MCP Web 应用 的成员观察到,当 LLM 进行多次迭代时,输入 Token 使用量非常高(每次调用超过 2000 个)。
- 他们正在寻求建议,询问这是否正常,以及是否遗漏了某些优化手段,因为他们是基于 Claude 的快速入门示例 构建的自定义客户端逻辑。
- 记事本思考(Notepad Thinking)辅助输入 Token 优化:成员们建议将“记事本思考”作为减少 Token 使用的替代方案,即 LLM 写下其想法,然后进行第二次处理,将 Prompt 和想法一起运行。
- 这种方法与推理模型不同,推理模型在“思考”步骤中不会对 Prompt 进行迭代,从而可能减少整体 Token 消耗。
- Aspire Inspector 抛出 SSL 证书错误:一位成员在使用 Aspire Inspector 连接本地 MCP Server 时遇到了 TypeError(fetch failed: self-signed certificate),但 Postman 运行正常。
- 根据 此 GitHub issue,解决方案包括将 Aspire Inspector 配置为通过 HTTP 连接或禁用 SSL,因为该 Inspector 无法识别由 Aspire MCP 生成的 SSL 证书。
- 在 Aspire 中调试 MCP Server 信息:成员们讨论了为什么在设置 Server 后,MCP Server 信息没有显示在 Aspire Inspector 中。
- 有人提到 Inspector 可能不会显示指令 Prompt,但可以检查 capabilities JSON RPC 获取 Server 信息,并在底部面板查看原始消息(raw messages)。
- XLAM 适用于本地 MCP:成员们寻求用于 MCP Function Calling 的本地模型推荐,Llama-xLAM-2-8b-fc-rGPT-OSS 被认为是一个很有前景的候选模型。
- 虽然 20B 模型速度太慢,但 Reddit 之前的讨论表明它在 Function Calling 方面表现良好。
MCP (Glama) ▷ #showcase (4 条消息):
作为内部威胁的 AI Agent,MCP Server 漏洞,Agentic Project Management (APM),Cloudship AI Station,用于 Server 开发的 MCPresso CLI
- AI Agent 是完美的内部威胁:一篇博客文章强调了 AI Agent 基本上是完美的内部威胁,尤其是因为它们可以在毫秒内采取行动。
- 研究人员通过一个 GitHub issue 劫持了 Claude 的 MCP Server,AI 在认为自己正在执行任务的同时,愉快地外泄了私有仓库,这表明“传统安全手段”已无法跟上步伐。
- Agentic Project Management (APM) v0.4 发布:APM v0.4 采用 AI Agent 团队协作,解决 LLM 核心问题,如上下文窗口限制和幻觉。
- 它可以与你喜爱的 AI IDE 配合使用,如 Cursor、VS Code 和 Windsurf。
- Cloudship AI Station 简化了高安全性环境下的 Agent 部署:Cloudship AI 发布了 一个单一二进制运行时,可用作 MCP 来构建、运行、部署和管理你的 Agent 及额外的 MCP 配置。
- 它提供可在团队间共享并使用 Git 进行版本控制的 MCP Templates,并允许你通过在环境中分组 Agent + MCP 来逻辑隔离你的组合。
- MCPresso CLI 加速 MCP Server 开发:一位成员分享了 MCPresso CLI 的简短演示,该工具可以脚手架式生成一个已配置好 OAuth2 的 Server,并将其部署在 Railway 上。
- MCPresso 的代码已在 GitHub 上开源,允许你生成新 Server,将其连接到 Claude,并执行创建、列出和删除笔记的操作。
aider (Paul Gauthier) ▷ #general (25 条消息🔥):
Qwen3-Coder 性能, Aider 与 Tool Calling, Gemini 2.5 Pro 问题, Git Index 版本错误, 区块链开发者求职
- Qwen3-Coder 表现出色,超越 Llama:用户称赞了 Qwen3-Coder 的性能,指出其在本地运行良好,表现优于 Llama,但整体体验仍有提升空间。
- 一位用户强调了在使用 Llama 时遇到的 tool call bugs(工具调用缺陷),但在使用 Qwen3-Coder 时并未遇到这些问题。
- Aider CLI 和 Tool Calling 的小故障:用户讨论了 Aider 命令行界面(CLI)在 tool calling 方面的问题,指出其可能表现得比较不稳定且存在隐患。
- 具体而言,一位用户报告搜索工具返回了过多的上下文(7155 个匹配项),导致 AI 陷入循环并失败。
- Gemini 2.5 Pro 与 Aider 仍存在兼容性问题:成员们报告了 Gemini 2.5 Pro 与 Aider 之间持续存在的问题,2.5 Flash 可以正常工作,但 2.5 Pro 总是失败。
- 有人指出,在启用计费(billing)的情况下使用 gemini/gemini-2-5-pro-preview-06-05 可以正常工作,从而绕过免费层级的限制。
- Git Index 版本导致 Aider 错误:一位用户遇到了与 不支持的 git index 版本 3 相关的错误,导致 Aider 运行失败。
- 该问题被追溯到一个设置了
update-index --skip-worktree的文件,虽然/help中推荐的修复方法无效,但最终找到了解决方案。
- 该问题被追溯到一个设置了
- 区块链专家寻求智能合约相关工作:一位用户表示他们是专业的区块链开发者,正在寻找智能合约、DeFi、NFT 或交易机器人项目。
- 他们表示可以为寻求区块链专业知识的人提供帮助。
aider (Paul Gauthier) ▷ #questions-and-tips (10 条消息🔥):
LiteLLM 详细日志, Aider 工作流, 模型别名, 程序输出, Polyglot 基准测试
- LiteLLM 连接失败:一位用户在长时间超时后仅看到 Connection Error,希望提高 LiteLLM 的日志详细程度(verbosity),以诊断与内部 API 服务器的连接错误。
- 消息记录中未提供解决方案。
- Aider 可以读取文件别名:一位用户为 Aider 提议了一种新工作流,涉及从项目文件夹中动态选择只读指南文件,但发现
/read-only命令需要具体的文件路径。- 该用户希望为文件路径列表创建别名,以便对指南进行分组并轻松切换。
- 使用两个配置文件设置模型别名:一位用户询问如何在 Aider 配置文件中定义具有两个别名(thinking 思考版和 non thinking 非思考版)的模型。
- 另一位成员建议使用 config-aider,这将涉及使用两个配置文件来管理别名。
- 程序输出消失了?:一位用户报告程序输出/stdout 在 Aider 中没有显示。
- 该用户附上了正在运行的程序的截图。
- Polyglot 基准测试设置技巧:一位在本地 llama.cpp 模型上运行 Polyglot benchmark 的用户询问如何在完成后获取每个语言的结果。
- 他们还询问在开始基准测试之前是否需要进行配置。
Modular (Mojo 🔥) ▷ #mojo (25 条消息🔥):
GPU 崩溃问题,Mojo 中的同步屏障,启用 GPU P2P,Mojo 文档和学习资源,Mojo 中的内存对齐
- 由于缺少同步点导致 GPU 崩溃:一名成员报告称,在运行这段 Mojo 代码时 GPU 崩溃,导致进入不可用状态并导致集群健康检查失败。
- 另一名成员建议在代码中添加同步屏障 (synchronization barriers)并检查是否启用了 GPU P2P,怀疑问题源于在没有适当同步的情况下假设存在两个 GPU。
- 缺乏完整的 Mojo 文档令新手受挫:一位新手对官方 Mojo 文档表示不满,称其只是不完整的概述,并请求提供详尽的书籍或 PDF 资源。
- 另一名成员指出 Modular 团队正在积极维护文档,并建议报告具体问题,同时推荐了 Mojo by example 和 Mojo Miji 作为替代学习资源。
- Mojo 中的内存对齐困惑:一位来自 Python 背景的成员寻求关于 Mojo 中内存对齐的澄清,特别是在编译器优化和结构体填充 (struct padding) 的背景下。
- 另一名成员解释说,指定对齐方式可以防止编译器添加填充,并且某些类型需要对齐到更大的数值,缺少对齐可能导致 CPU 终止程序;建议使用
stack_allocation以获得对内存的更多控制。
- 另一名成员解释说,指定对齐方式可以防止编译器添加填充,并且某些类型需要对齐到更大的数值,缺少对齐可能导致 CPU 终止程序;建议使用
- 寻求 kgen 和 pop 方言 (Dialect) 文档:一名成员询问有关
kgen和pop方言的文档,寻求操作和参数列表。- 另一名成员指出内部 MLIR 方言可能没有全面的文档,但分享了 pop 方言文档的链接,并提醒这些方言是 stdlib 与编译器之间协议的一部分,在 stdlib 之外使用它们需自担风险。
Modular (Mojo 🔥) ▷ #max (5 条消息):
Max + Modal 集成,Torch Max 后端,TextGenerationPipeline
- 在 Modal 上运行 Max:缓存模型编译:一名成员询问如何将 Max 与 Modal 连接,在缓存模型编译以避免每次重启时等待方面遇到问题,并尝试挂载 MEF 文件但未成功。
- 他们想知道这种集成是否可行。
- Torch-Max 后端的多功能性:一名成员分享了 torch-max-backend v0.2.0 版本发布的链接,并指出其在 VGG、Qwen3、GPT2 和 Densenet 推理上进行了测试。
- 他们对仅用少数 ops 就能支持这么多模型表示惊讶。
- TextGenerationPipeline 的执行检查:在 Max 的 pipeline.py 中看到 TextGenerationPipeline 上定义的 execute 后,一名成员请求提供复现脚本。
- 他们还询问了发布者的 MAX 版本。
Notebook LM ▷ #use-cases (9 messages🔥):
Spotify Podcast, Proto-Germanic AI Translation, Discord Moderation Needed, NotebookLM for Tabletop RPGs, GEMS sitrep
- **Spotify 播客通过 Gems 重现!:一位成员分享了一个 Spotify 链接 指向新的播客剧集,并指出这是 **自 12 月以来 的第一集,且是使用 Gems 创建的。
- **AI 学习古老语言:原始日耳曼语 (Proto-Germanic) 翻译项目出现:一位成员分享了一个 YouTube 链接,展示了他们训练 **AI 理解和翻译 Proto-Germanic 的工作,并报告称在初步测试中“已被证明具有一定的准确性”。
- **Discord 紧急求助:迫切需要审核:一位成员分享了 一个 NotebookLM 链接,表达了对 Discord 服务器上 **垃圾信息和缺乏审核的内容 的担忧,强调需要更多的审核人员来解决此问题。
- **桌面游戏大捷:NotebookLM 激活 RPG 环节:一位成员报告称使用 **NotebookLM 生成了转录的桌面 RPG 环节的视频概览,创建了一个自动化的 “Last time, on D&D!” 开场白,帮助玩家在每节课前记住细节。
- **GEMS “sitrep” 命令显示最新进展:一位成员发现,在 **GEMS 中使用命令 “give me a sitrep” 可以显示最新的进度等信息。
Notebook LM ▷ #general (20 messages🔥):
Youtube links import, Mobile App Offline Capability, Audio overview customization, NLM and PDF Images, Notebook sharing statistics
- 批量导入 YouTube 链接:成员们讨论了将 300 个 YouTube 链接 导入 NotebookLM,建议使用 Chrome 扩展 进行批量导入,并将 YouTube URL 添加到网站 URL 列表中。
- 一位成员专门为了批量导入扩展程序安装了 Chrome。
- 移动端 App 离线功能缺失:一位用户询问了移动端 App 的离线功能,将其描述为 功能简陋 (feature-light)。
- 讨论暗示移动端 App 目前缺乏重要的离线功能。
- 音频概览 (Audio overview) 自定义功能消失:一位用户报告称音频概览的自定义功能消失了,指出 短版本、默认版本和长版本 的选项不见了。
- 一名团队成员确认了该报告,并提到长度自定义目前仅支持英语,目前正在调查中。
- NLM 仍然无法查看 PDF 图片?:一位用户询问了 NotebookLM 查看 PDF 中图片的能力。
- 该问题暗示此功能可能仍然缺失。
- 如何根据文本制作短视频:一位用户询问是否可以从文本创建较短的视频,而不是默认的 5 分钟,以及如何进行配置。
- 频道内未给出回复。
tinygrad (George Hotz) ▷ #general (13 messages🔥):
Hiring for Tests, CI Speed, Process Replay Multiprocessing, Linux (nv) vs Linux (ptx) Performance, Overworld Constant Folding
- 需要招聘人员修复混乱且缓慢的测试:一位成员正寻求招聘人员来修复混乱的测试,并将 CI 速度 提高到 5 分钟 以内。
- 主要担忧是测试速度慢且未经过适当优化。
- CI 速度需要提升:该成员质疑 process replay 是否为多进程 (multiprocessing),以及为什么它很慢,尽管初步调查后看起来并不糟糕。
- 他们还询问为什么 Linux (nv) 比 Linux (ptx) 慢得多,以及 CUDA 编译是否使用了 fast 标志。
- 最小化 CUDA 编译标志即将到来?:一位成员分享了一个 GitHub pull request,并想知道 Ubuntu 24.04 是否支持最小化 CUDA 编译标志。
- 未提供更多细节。
- 关于 Overworld 常量折叠 (Constant Folding) 的考量:一位成员正在考虑 overworld 常量折叠,以及一个涉及重新定义
UPat.cvar和UPat.const_like以匹配CONST和VIEW(CONST)的潜在解决方案。- George Hotz 回应称:“不,那超级丑”,并建议 base 应该消失,并询问了关于 PAD 的情况。
DSPy ▷ #general (10 messages🔥):
TIL cost is returned even if it's cached, optimiser which does a form of cross-validation, extract prompts from the optimized program
- 即使缓存也会返回成本:一位成员发现,即使内容已被缓存,成本(cost)仍然会被返回。
- 他们提到花了一些时间才意识到这一点。
- 交叉验证优化器的探索激发了巧妙的解决方案:一位成员询问是否存在一种执行某种形式交叉验证(cross-validation)的优化器,用于创建一个以特定作者风格编写文本的 LM 程序。
- 一位成员建议创建一个指标函数(metric function)并使用 AI 裁判进行评估,然后将其与 GEPA 结合使用;另一位成员补充说,他们使用了 GPT-5 LLM 作为裁判。
- 解锁优化后的提示词:保存并查看!:一位用户询问如何从优化后的程序中提取提示词。
- 另一位用户建议使用命令
optimized.save("my_program.json")保存优化后的程序,以查看生成的提示词。
- 另一位用户建议使用命令
Cohere ▷ #👋-introduce-yourself (4 messages):
Introductions
- Cohere 新成员自我介绍:Aryan 说了句 “hi let’s go cohere”,Anay 打了招呼并表示他正在美国攻读计算机科学硕士(MS in Computer Science),过去曾担任 MLE。
- 社区欢迎新成员:Cohere 社区欢迎新成员 Aryan 和 Anay。
- 鼓励成员分享他们的公司、工作、最喜欢的工具和社区目标,以促进协作。
Manus.im Discord ▷ #general (3 messages):
Manus credits, Backups, Provider switch
- 用户感叹 Manus 积分消失:一位用户提到了 Manus 积分的问题,并询问是否仍可以购买积分,或者该选项是否被隐藏了。
- 他们一直遇到 Manus 的重复问题。
- 用户在切换服务商前备份数据:一位用户在切换回之前的服务商之前,确保已经备份了数据。
- 他们正回到那个愿意倾听并改进了表现的原始服务商那里。
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Next Cohort, Cohort signups
- 对下一期课程的期待升温:一位成员询问了下一期课程(Cohort)的开始日期,预计很快就会开始——最迟在 9 月初。
- 消息中未提供具体的报名详情。
- 预计课程报名即将开启:一位用户表示希望课程报名能很快开放,目标定在 9 月初。
- 讨论中未引用官方日期或公告。
MLOps @Chipro ▷ #events (1 messages):
Functional Python for AI/ML, Persistent Memoization, Deterministic Parallelism, DataPhoenix
- 函数式 Python 网络研讨会承诺实现更快、更便宜、更智能的 AI/ML:8 月 27 日的一场免费网络研讨会将讨论函数式 Python 如何加速工作流、降低成本并提高数据密集型 AI/ML 系统的效率。
- 与会者将学习持久化记忆化(persistent memoization)和确定性并行(deterministic parallelism)等技术,并通过来自 DataPhoenix 的实际演示探索现代开源工具。
- 通过函数式编程实现多倍成本节约:该研讨会探讨了使用函数式 Python 重新设计长期运行的工作流,以便在不增加硬件的情况下实现成本节约和速度提升。
- 它涵盖了底层理论以及用于简化数据密集型流程的现代开源工具的动手演示。
Nomic.ai (GPT4All) ▷ #general (1 messages):
Blockchain Development, DEXs, Trading Bots, Smart Contracts, DApp Frontends
- 区块链开发人员准备就绪!:一位在 EVM 链、Solana、Cardano 和 Polkadot 方面拥有实战经验的区块链开发人员正在寻求合作。
- 他们构建过 DEXs、交易机器人、DApps 智能合约,并将其与前端集成。
- 区块链开发人员寻求合作:一位区块链开发人员正为潜在的合作提供其在 EVM 链、Solana、Cardano 和 Polkadot 方面的专业知识。
- 他们的经验包括构建 DEXs、交易机器人和智能合约,以及将它们集成到 DApp 前端。
Gorilla LLM (Berkeley Function Calling) ▷ #discussion (1 条消息):
PelicanVLM-72B-Instruct, BFCL Tool Evaluation
- PelicanVLM-72B-Instruct 模型进入 BFCL 竞技场:一名成员提交了一个 pull request,旨在利用 Berkeley Function Calling Leaderboard (BFCL) 框架为 PelicanVLM-72B-Instruct 模型整合工具评估(tool evaluation)。
- 作者正在寻求社区对该集成的反馈,并在 pull request 中包含了评估分数。
- PR 旨在添加 PelicanVLM-72B-Instruct 模型:已创建一个 pull request,用于在 BFCL 中包含 PelicanVLM-72B-Instruct 的工具评估。
- 评估分数已附加到 PR 中,作者正在征求反馈。