AI News
OpenAI 更新了 Codex,其 VSCode 扩展现可将任务与 Codex Cloud 进行同步。
OpenAI Codex 推出了全新的 IDE 扩展,集成了 VS Code 和 Cursor,支持无缝的本地与云端任务接力、通过 ChatGPT 订阅方案登录、升级的 CLI(命令行界面)以及 GitHub 代码审查自动化。Facebook AI 研究人员推出了 StepWiser,这是一种过程级奖励模型(PRM),通过逐块评估(chunk-by-chunk evaluation)提升了推理和训练效果,并在 ProcessBench 基准测试中达到了业界领先水平(SOTA)。Google DeepMind 的 Gemini 2.5 Flash Image 模型展示了先进的空间推理能力、多图融合技术,并提供了包括用于图像重混(remixing)的浏览器扩展在内的开发者工具。NVIDIA 披露了 Nemotron-CC-Math (133B) 和 Jet-Nemotron 模型的效率数据。
OpenAI Codex 就足够了吗?
2025年8月26日至8月27日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 29 个 Discord 社区(229 个频道,8821 条消息)。预计节省阅读时间(以 200wpm 计算):668 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以美观的 vibe coded 方式展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上给我们反馈!
距离 Codex (重新)发布仅过去短短 3 个月,Claude Code 与 Codex 的竞争近期愈演愈烈。甚至在今天的更新之前,就有多位影响力人士公开弃用 Claude Code 转投 Codex,这要归功于埋藏在 GPT5 发布日的定价计划整合。今天,这种转变将变得更加有趣,因为能够将任务发送到云端并返回的 IDE 扩展已正式发布:
简而言之:
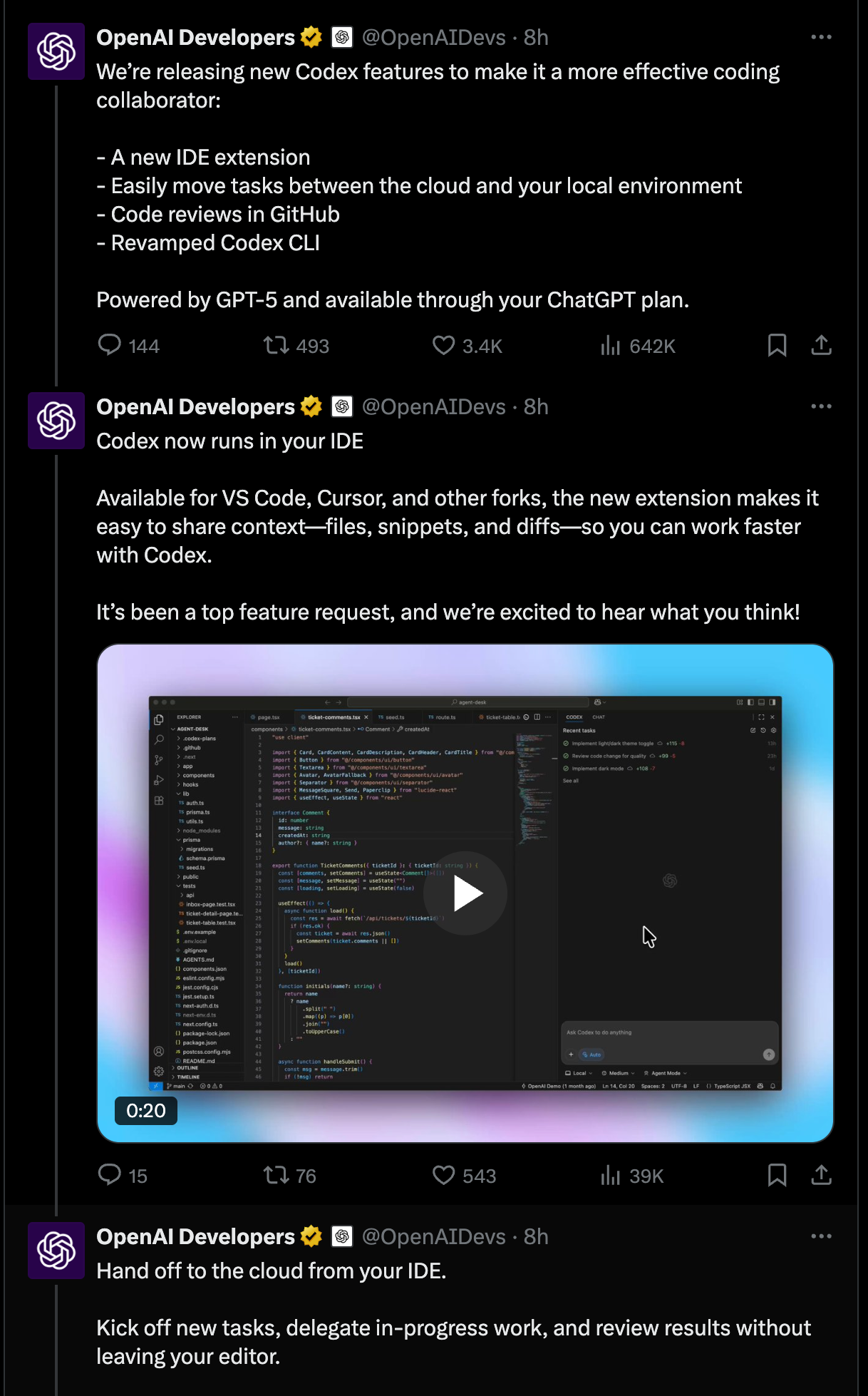
- IDE 扩展: 新的扩展将 Codex 引入 VS Code、Cursor 和其他 VS Code 分支,让您可以无缝预览本地更改并编辑代码。
- 使用 ChatGPT 登录: 在 IDE 和 CLI 中均可使用,无需设置 API key,直接通过现有的 ChatGPT 订阅方案即可访问。
- 无缝本地 ↔ 云端交接: 开发者可以在本地与 Codex 协作,然后将任务委托给云端异步执行,且不会丢失状态。
- 升级版 Codex CLI: 焕然一新的 UI、新命令和错误修复。
- GitHub 中的代码审查: 设置 Codex 自动审查仓库中的新 PR,或在 PR 中提及 @codex 以获取审查和建议的修复方案。
此外,未来所有关于 Codex 的产品信息和更新都将在我们的新网站上公布:developers.openai.com/codex。
我们邀请您探索该网站,了解这些新功能的更多细节,以及入门指南。
要了解更多关于 Codex 的信息,请访问新的 开发者网站 以及我们的通用帮助文章:将 Codex 与您的 ChatGPT 订阅方案配合使用。
AI Twitter 摘要
过程级奖励建模与推理
- StepWiser(将过程奖励作为推理任务):Facebook AI 研究人员推出了一种逐步判别器(stepwise judge),它能同时输出思维链(chain-of-thought)和判断结果,并通过强化学习(RL)在相对 rollout 结果上进行训练。它在 ProcessBench 上达到了 SOTA,在训练期间改进了策略,并通过“按块(chunk-by-chunk)”评估方案、拒绝/重做有缺陷的块(最多重试 5 次)来自我纠正路径,从而增强了推理时搜索(inference-time search)。他们还使用 StepWiser 对多个 rollout 进行评分,并选择最佳结果作为训练数据,表现优于基于结果的拒绝采样(outcome-based rejection sampling)。参见 @jaseweston 的推文串,包括推理时搜索 (4/5) 和数据选择 (5/5) 的细节。@tesatory 对回归过程奖励这一大趋势的评论强调了为什么逐步监督可以扩展到长期/持续的任务,因为在这些任务中,仅凭最终奖励很难进行信用分配(credit assignment)。
Gemini 2.5 Flash Image (“nano‑banana”):功能、工具与指南
- 空间推理与编辑质量(演示):用户强调了强大的多图融合和一致的 POV 重建(例如,递归的“摄影师的摄影师”以及 Google Maps “红箭头所见”的转换),具有令人印象深刻的空间连贯性;参见 @BenjaminDEKR 和 @tokumin 的演示。
- 开发者与创作者工具:一个基于 Glif 的一键浏览器扩展让您可以右键点击网页上的任何图片,通过 Gemini 2.5 Flash Image 进行重混/编辑(@fabianstelzer;安装链接在后续推文中)。Google 发布了一份针对性的提示词指南,涵盖了构图、一致的角色设计、定向转换等内容(google AI devs)。DeepMind 研究人员讨论了该模型的构建过程以及未来的发展方向(@OfficialLoganK)。创作者们已经将其与视频工具(例如 Kling 2.1 的首/尾帧)结合使用,以实现平滑过渡(@heyglif)。
NVIDIA 数据与效率:Nemotron-CC-Math 与 Jet‑Nemotron
- Nemotron‑CC‑Math (133B tokens) 数据集发布:这是一个从 CommonCrawl 重新处理的大型数学/代码语料库,通过渲染 HTML (Lynx) 并可靠地捕获 LaTeX、MathML、
<pre>、行内和图像上下文中的公式——解决了典型解析器中的覆盖范围差距。NVIDIA 报告称,在加入该数据集后,数学和代码任务的增益显著。详情来自 @KarimiRabeeh 和 @ctnzr;评论来自 @JJitsev。 - Jet‑Nemotron (吞吐量优化的 LM):引入了 JetBlock(线性注意力 + 对 V 的动态卷积,移除了对 Q/K 的静态卷积)以及一个硬件感知的设计洞察:解码速度更多地取决于 KV‑cache 大小而非参数量。报告的加速效果:在 H100 上,64K 长度下的解码吞吐量提升高达 47 倍,256K 长度下的解码提升 53.6 倍,预填充(prefill)提升 6.14 倍,同时在 MMLU、BBH、数学、检索、编程、长文本等任务中达到或超过了小型全注意力(full‑attention)基准模型。@omarsar0 的总结推文包含了设计亮点(JetBlock、KV cache 洞察、结果)。
安全、保密与政策
- OpenAI × Anthropic 交叉评估:实验室使用各自内部的安全/对齐评估方案测试了对方的模型,并发布了一份联合报告。虽然研究结果较为基础且受限于各组织的脚手架(scaffolding),但此次合作作为共享安全实践的“向上竞争”信号具有重要意义。来自 @woj_zaremba 和 OpenAI 安全团队 (@sleepinyourhat;后续) 的公告;@EthanJPerez 指出这是对全行业安全性的持续支持。
- 网络滥用报告:Anthropic 的威胁情报团队详细介绍了如何瓦解低技能攻击者的计划,如朝鲜的欺诈性就业和 AI 生成的勒索软件(报告推文;博客;视频)。
- 公共部门咨询:Anthropic 宣布成立国家安全和公共部门咨询委员会,由高级国防/情报/政策领导人组成,以帮助对齐美国及其盟友的需求(公告)。
- 医疗评估:OpenAI 在 Hugging Face 上发布了 HealthBench,用于严格评估 LLM 在人类健康应用中的表现(@HuggingPapers)。
Agent、环境与协议
- 用于 RL/Agent 训练的开放环境:Prime Intellect 推出了 Environments Hub,旨在众包丰富、标准化、互动的环境,用于训练和评估 Agent 模型——这模仿了 Gym 如何催化 RL,但目标是 LLM。@karpathy 认为环境是“新数据”,能够实现超越模仿的交互和反馈;他看好环境和 Agent 交互,但对智力任务的 RL 奖励函数持怀疑态度,指向了“系统提示词学习(system prompt learning)”等替代方案。来自 @PrimeIntellect 的发布。
- Agent 协议和集成工具:
- Zed 的新 Agent Client Protocol (ACP) 旨在成为“AI Agent 的 Language Server Protocol”,将编程助手与编辑器解耦,暴露可检查的计划,并支持多模态 I/O(概述;网站)。
- MCP 生态系统增长:通过 Postman 在一分钟内无代码生成 MCP 服务器,以集成 10 万多个 API(指南);浏览器内 MCP 调用,实现快速/本地 Agent 工作流(LFM2);通过 vibecoding 针对文档 MCP 服务器构建的 LangChain “Deep Agents”(演示)。
- 用于 RAG 的结构化知识:吴恩达(Andrew Ng)与 Neo4j 的短期课程展示了 Agent 团队如何构建基于 Schema 的知识图谱,作为向量检索的补充(课程)。
- 大规模浏览:Browserbase 通过运行无头浏览器集群,为昂贵的托管算子 Agent 提供了一种替代方案(@LiorOnAI)。
开发者工具与开源模型
- OpenAI Codex 重大更新(由 GPT‑5 驱动):一次实质性的升级将 Codex 转变为跨越 IDE、终端、云端、GitHub 和移动端的统一 Agent,并带有新的扩展(VS Code/Cursor/Windsurf)、大幅改进的本地 CLI、无缝的本地↔云端任务迁移,以及 GitHub 中一流的代码评审功能。适用于 ChatGPT Plus/Pro/Team/Edu/Enterprise。详见 @OpenAIDevs、开发中心、来自 @gdb 的 CLI 说明,以及来自 @kevinweil 的更多细节。
- Hermes 4 (Nous):基于 Llama‑3.1 的 405B 和 70B 开源微调模型,具备混合推理能力,包含 350 万个推理样本,在 192 块 B200 上训练而成;无审查且用户可控。可在 Nous Chat/Chutes 和 Hugging Face 上获取;GGUF (70B) 已上线,MLX 移植正在进行中 (@vectro, @Teknium1)。
- 生产环境中的 DeepSeek V3.1:Together 托管了具有快速/思考模式的 671B 混合模型;他们报告了推理基准测试中的巨大提升(例如,开启思考模式后 AIME 2024 从 66.3% 提升至 93.1%),并拥有 99.9% 的正常运行时间以确保生产流水线的可靠性 (@togethercompute)。来自 @cline 的社区报告显示,其编辑差异(edit‑diff)失败率为 9.9%,而 Qwen Coder 3 为 6.1%。
- 紧凑高效的基础设施:Weaviate 的 8‑bit 旋转量化(Rotational Quantization)通过随机旋转平滑条目并将相似性分散到各个维度(通用,无需训练),在将向量压缩 4 倍的同时,提高了吞吐量(15–50%)并保持了近乎完美的召回率 (@weaviate_io)。
- 同样值得关注:MiniCPM‑V 4.5 增加了“混合思考”(决定何时思考)、高分辨率文档处理以及高效的长视频推理 (@mervenoyann)。
热门推文(按互动量排序)
- “它是个好模型,先生” —— @elonmusk
- OpenAI Codex 更新:跨 IDE/终端/云端/GitHub 的统一 Agent —— @OpenAIDevs
- RL 时代,环境 > 数据;对 RL 奖励函数保持谨慎 —— @karpathy
- OpenAI × Anthropic 跨机构安全评估 —— @woj_zaremba
- Anthropic 关于 AI 赋能网络犯罪的威胁情报 —— @AnthropicAI
- Gemini 2.5 Flash Image (“nano‑banana”) 是如何构建的以及它的发展方向 —— @OfficialLoganK
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. Hugging Face 2M Models 里程碑 + TheDrummer GGUF 微调模型
- Hugging Face 模型数量已达到 200 万。 (Score: 495, Comments: 58): 截图显示 Hugging Face Model Hub 托管的模型数量已突破
2,000,038个 (https://huggingface.co/models),凸显了该平台在 Checkpoints、微调版本和量化变体方面的快速增长。从技术角度看,这种规模对存储、去重以及搜索/可发现性提出了挑战,并突显了对高效 Artifact 管理(如 Git/LFS、分片式 safetensors、Deltas)以及强大的元数据/标签和过滤器(用于处理重复项和变体)的依赖。 评论者对总存储占用和重复/量化权重的激增表示担忧;其他人则开玩笑说几乎相同的微调版本(例如许多 Llama 3 70B ERP 变体)数量庞大,暗示了可发现性/质量信号方面的挑战。- 规模/重复担忧:评论者指出,由于同一基础模型/微调版本的许多“量化版、权重和重复项”,Hub 的存储占用巨大。这意味着多个 Checkpoints 和每个模型的量化变体带来了高度冗余,这增加了存储压力,并使跨近乎相同仓库的可发现性和去重变得复杂。
- 信噪比权衡:虽然有人估计
~2,000,000个模型中约99%是重复项或低质量/失败的实验,但剩下的~1%包含可以超越“其规模 10 倍”模型的“瑰宝”。这突显了 Hub 作为中央注册库的价值,尽管存在大量噪声,高杠杆的小模型和强大的微调版本仍能脱颖而出,巩固了该平台作为“AI 界的 GitHub”的地位,重大发布都会首先在此落地。 - 生态系统碎片化:评论者指出,热门基础模型的大量衍生品(例如许多 Llama 3 70B 领域微调版)是模型变体“寒武纪大爆发”的象征。结论是,少数基础模型主导了长尾的专业化微调,虽然造成了冗余,但也带来了快速迭代和专业化。
- TheDrummer 火了!!! (Score: 298, Comments: 103): u/TheLocalDrummer 发布了一批新的 GGUF Checkpoints(兼容 llama.cpp),参数规模涵盖
4B到123B+,包括 GLM‑Steam‑106B‑A12B‑v1, Behemoth‑X‑123B‑v2, Skyfall‑31B‑v4, Cydonia‑24B‑v4.1, Gemma‑3‑R1 (4B/12B/27B[)](https://huggingface.co/TheDrummer/Gemma-3-R1-27B-v1-GGUF), Cydonia‑R1‑24B‑v4, 和 RimTalk‑Mini。发布版本已编号(例如 v1–v4.1),但帖子中未包含 Benchmark 或训练数据说明;更多正在进行的工作通过 BeaverAI 和 Discord 引用。 热门评论指出微调目标/数据集的透明度有限,使新手难以评估或采用这些模型,而支持者则指出在正式发布前,Discord 上会进行活跃的测试,每个模型会经历 4-6 次迭代。- 几位用户强调了微调缺乏透明度:没有关于目标、数据集、预处理或评估协议的明确描述,使得该生态系统难以进入或复现。这表明发布版本是针对现有用户群优化的,而不是针对需要详细 Model Cards 和训练数据披露的更广泛采用者。
- 其他人注意到 Discord 上的迭代发布流程,在公开发布前会有多轮测试和大约
4–6个内部版本。重点似乎已从无审查的 Gemma 微调转向更大的“思考型”变体(R1 风格),例如gemma-3-r1-27B。 - 轶事性能反馈报告称
gemma-3-r1-27B在实际使用中表现不佳,引发了对社区纯文本微调是否能比基础模型带来实质性提升的怀疑。由于缺乏共享的 Benchmark,这一点尚未得到证实,突显了需要标准化评估(Evals)来量化任何改进。
{kind=link}
2. 中国 AI 生态系统:Z.ai GLM AMA、Qwen 预热以及 Nvidia GPU 出口/供应链
- 开启我们与 GLM 创作者 Z.AI 的全新 AMA 系列 (明天, 9AM-12PM PST) (Score: 161, Comments: 15): r/LocalLLaMA 宣布将与 Z.ai(GLM 系列的创作者)举行一场 AMA,定于 2025 年 8 月 28 日星期四,PST 时间上午 9 点至中午 12 点。该图片是本次活动的宣传横幅;在技术层面,这为社区提供了一个询问 GLM 模型、本地部署、训练细节以及路线图的机会,而该子版块在历史上一直以 LLaMA 模型为中心。 评论指出,该子版块的范围已超出 Meta 的 LLaMA(名称不匹配),含蓄地承认了对 GLM 等其他模型系列日益增长的兴趣;其他评论内容空洞。
- 目前尚无实质性的技术讨论;一位评论者询问了潜在的 “GLM 6” 时间线,但未提及发布细节、规格或基准测试。一项物流说明通过 timee.io 澄清了 AMA 时间为
2025-08-28 09:00–12:00 PDT(已调整夏令时);预计在会议期间会有技术问答(例如模型路线图、训练数据/算力,或与 Llama 相比的基准测试差异)。
- 目前尚无实质性的技术讨论;一位评论者询问了潜在的 “GLM 6” 时间线,但未提及发布细节、规格或基准测试。一项物流说明通过 timee.io 澄清了 AMA 时间为
- 你觉得它会是什么.. (Score: 376, Comments: 109): Qwen 团队成员林俊旸 (Justin Lin) 发布的简短预热截图(“Qwen”,8 月 27 日),没有规格或基准测试,只有项目名称,暗示即将发布 Qwen 相关产品。社区对这一暗示的解读认为,它可能是一个新的视觉语言 (VL) 变体或 Qwen 3 32B 模型;评论者提到的神秘数字
2508被解释为潜在的日期/版本标签,但官方尚未表态。 热门评论多为猜测,用户希望是 32B 模型,并争论预热是指向 VL 还是新的基础 32B;未提供技术细节或证据。- 猜测集中在 Qwen 相关的发布,可能是 VL(视觉语言)模型或 Qwen 3 32B。提及
32B表示 320 亿参数级别的模型;“2508” 被引用为标识符,但没有上下文(可能是版本/日期标签)。 - 存在对具备西班牙语能力的变体的需求,暗示了对多语言 Qwen 模型(或本地化分词器/训练)而非仅限英语模型的兴趣。请求特别点名了更高容量的
32B档位,表明用户优先考虑性能而非小尺寸模型。
- 猜测集中在 Qwen 相关的发布,可能是 VL(视觉语言)模型或 Qwen 3 32B。提及
- 向中国走私 Nvidia GPU (Score: 174, Comments: 33): 帖子讨论了一项调查(通过 ChinaTalk 总结 Gamers Nexus 的文章),追踪了受美国出口限制的 Nvidia GPU 如何流入中国:美国零售/二手渠道 (Craigslist/Facebook) → 中介/Alibaba 列表 → 隐藏并通过香港/台湾空运走私 → 中国境内的维修/测试店进行翻新、VRAM 改装并转发机架,有效地“让芯片保持流通”。它重申了供应链的分裂:Nvidia 设计芯片 (die),台积电 (TSMC) 在台湾代工,而中国制造商生产电路板、VRM、散热器和大多数非芯片物料清单 (BOM)——因此,即使芯片受到控制,非芯片组装也主要基于中国。技术重点在于,执法漏洞以及板级翻新/维修的便利性使得受控芯片在禁令下仍能运行,尽管核心性能仍由芯片决定。 评论者辩论了价值集中度:芯片是“
99.9%的难点所在”,矩阵乘法 (matrix-mul) 的延迟/吞吐量受限于芯片架构,因此电路板/VRAM 改装主要影响容量,而非 FLOPs。其他人推测美国 AI 买家会为黑市上的 VRAM 升级版显卡买单(3–4 倍容量且成本更低),同时注意到围绕该纪录片的下架/版权声明(例如 Bloomberg),这讽刺地可能引发更多关注。- 一个帖子假设了一条黑市路径,通过为 Nvidia GPU 改装
3–4×更多的 VRAM,成本约为新卡的的一半,目标客户是美国 AI 用户。可行性取决于对更高密度的 GDDR 进行植球 (reballing)、BIOS/固件修改,以及 GPU 内存控制器的寻址能力加上 PCB 布线/供电限制——这些硬性上限通常会阻止大容量跨越,即使芯片可以物理更换。 - 反对观点强调硅芯片是“
99.9%的难点所在”,因为矩阵乘法的延迟/吞吐量由芯片上的寄存器/SRAM 缓存和 Tensor/ALU 流水线决定。提升 VRAM 容量不会提高核心 GEMM/TensorCore 吞吐量或内存层级延迟;芯片架构和缓存/带宽平衡设定了性能上限。
- 一个帖子假设了一条黑市路径,通过为 Nvidia GPU 改装
- 维修性讨论指出,大多数 GPU 故障发生在分立电源输送组件(MOSFET、电容器)中,而不是通常较为稳固的 GPU die。板级 VRAM 改装和组件更换需要专门的 BGA 返修和诊断——这在中国维修生态系统中很常见,但在美国相对罕见——这催生了显存升级和翻新的二级市场。
{kind=link}
{kind=link}
较少技术性的 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Nano Banana 图像编辑展示与修复
- 使用 Nano Banana 修复有史以来拍摄的第一张照片 (Score: 2907, Comments: 185): 该帖子将 Nicéphore Niépce 在 1826/27 年拍摄的《勒格拉的窗外风景》(现存的第一张照片)与所谓的彩色“修复版”并列,但未描述任何技术方法——没有去模糊、SR(超分辨率)或重建流水线——且底部的图像似乎是场景的现代重现,而非基于原始日光蚀刻法的驱动数据修复。原件是涂有沥青的锡镴板,曝光时间长达数小时,空间频率细节极低;“修复”后的图像包含了与 19 世纪背景不符的当代特征,暗示这是重新拍摄或虚构的场景,而非算法增强。 热门评论指出这是重现而非修复;其他回复多为玩笑(如“Enhance”)且非技术性。
- 多位评论者指出了信息论限制:你无法“修复”一张历史图像使其包含比拍摄时更多的数据。反卷积、去噪或超分辨率(如 ESRGAN 或扩散上采样器)等方法会施加强先验来合成合理的细节,这属于重现/幻觉而非恢复信号;因此,“修复”中出现的清晰特征(如排水沟)很可能是由模型伪造或后期修补的。参见 ESRGAN: https://arxiv.org/abs/1809.00219。
- 关于这是否是第一张照片:现存最早的照片是 Nicéphore Niépce 的《勒格拉的窗外风景》(1826/1827),这是一张在涂有犹太沥青的锡镴板上的日光蚀刻法照片,估计曝光时间在
8 小时到数天之间。该底片由 Harry Ransom Center 收藏;现代处理方式是高分辨率扫描加上对比度/色调映射,而非生成式增强。参考资料:Wikipedia https://en.wikipedia.org/wiki/View_from_the_Window_at_Le_Gras 以及 HRC 说明 https://www.hrc.utexas.edu/ni%C3%A9pce/。 - 真正的修复应该对成像流水线建模(镜头点扩散函数 PSF、沥青的非线性响应曲线、导致多方向阴影的极长曝光时间),并应用带有正则化的物理知情逆方法。如果没有 PSF 和响应曲线,逆问题就是病态的(ill-posed),因此最佳实践是仔细扫描、使用保守先验进行反卷积以及局部对比度均衡——避免改变场景几何结构的任意细节合成。
-
Nano Banana 对材质交换的理解。管子最初是铬材质。 (Score: 1709, Comments: 178): OP 展示了一个“材质交换”结果,将原本为铬材质的管子进行了转换,标题为“Nano Banana 对材质交换的理解”。链接的 Reddit 画廊因 画廊 URL 提示 **
403 Forbidden而无法访问,但热门评论中包含了一些补充图像参考:另一个例子 图像 1、用户制作的 BMO 服装 图像 2,以及一位评论者认为像乐谱的纹理 图像 3。** 评论者注意到了一些意外的语义插入(例如 BMO 角色、类似乐谱的纹理),这表明该系统在“材质交换”期间可能是在进行风格/纹理叠加,而非严格保留原始的 BRDF/几何材质行为。 - 一位评论者询问该系统是否能从单张图像生成 PBR 纹理贴图——特别是法线(normal)、凹凸(bump)和位移(displacement)贴图——以支持材质替换工作流。这意味着需要与现有 UV 对齐的多通道输出、正确的法线贴图规范(OpenGL 与 DirectX),以及与下游 DCC/游戏引擎的兼容性;如果没有这些贴图,将铬合金着色器替换为其他材质时,会丢失仅靠反照率(albedo)无法捕捉的微观细节/高度信息。
- 使用 nano banana 将 Emma Stone 放入所有电影中…… (得分: 640, 评论: 93):该帖子展示了使用名为 “nano banana” 的工具/工作流进行快速换脸/合成,将 Emma Stone 嵌入多部电影/海报中;创作者指出整个端到端过程耗时不到 20 分钟。文中未提供具体的细节(模型、方法或流水线)——仅提到了声称的周转时间——因此尚不清楚这是否使用了 diffusion inpainting、换脸技术或特定的模型/LoRA;尽管如此,这表明了一种用于批量海报编辑的轻量级、快速工作流。
- Nano Banana 令人印象深刻。我一直在测试新事物,它总是能给出满意的结果。 (得分: 347, 评论: 44):发帖者报告称 “Nano Banana” 图像模型在写实重光照(relighting)方面表现出色——在改变场景照明的同时保留细粒度纹理和场景布局——这表明其在光照变换下具有强大的细节保持能力。一位评论者指出,在尝试真正的视角/摄像机角度变化时遇到了困难,这表明该模型的编辑很大程度上是 2D 一致的重光照,而非 3D 视图合成或几何感知重投影。 热门评论强调了沉重的安全/审查过滤器是一个主要的实际限制,并表达了对限制较少的版本的渴望(暗示与 Google 的政策形成对比)。另一位评论者质疑了一个示例中的物理合理性(“正午”的太阳角度),暗示了基于物理的光照方向可能存在不一致性。
- 用户报告该模型的安全过滤器过于激进,会拦截良性的编辑,尤其是与身体相关的变换。这意味着一个保守的安全分类器或后置过滤器,为了高召回率(过度拦截)而牺牲了精确度,降低了合法工作流的实用性。正如一位用户所言,“剧烈的审查令人扫兴”,这引发了人们对具有类似能力但监管较少模型的兴趣。
- 在尝试“改变透视/摄像机角度”时的反复失败表明,该系统缺乏真正的 3D 场景理解或多视图一致性。它可能更像是基于输入条件的 2D inpainting/纹理合成,而非深度/姿态感知的重建(即没有类似 NeRF/3DGS/EG3D 的潜在几何结构),因此新视角合成超出了其能力范围,会导致伪影或拒绝执行。
- 使用它来调亮极暗、压缩严重的素材(例如《权力的游戏》第八季第三集)凸显了处理 LDR 源的局限性。在没有 RAW/HDR 数据的情况下,激进的增强需要去噪和幻觉生成;虽然局部对比度可能会提高,但压缩噪声/色带可能会被放大,细节会变成伪造的,从而损害保真度。
- Nano banana is bananas (得分: 273, 评论: 46):非技术性迷因(meme):图像看起来像是故意通过 AI 编辑/Photoshop 擦除了受试者的脸部,呼应了 “AI Barber” 的梗,即生成/编辑工具过度删除了特征。标题 “Nano banana is bananas” 是一个与视觉内容无关的无意义双关语,进一步证明这是恶搞幽默(shitpost)而非技术演示。 评论开玩笑说“从技术上讲它确实做到了”,并称之为“AI Barber 的恐怖”,将其与早期的 Facebook Photoshop 请求恶作剧相比——即故意荒谬的编辑,而非严肃的 AI 结果。
- 评论者含蓄地指出了提示词的脆弱性:“垃圾提示词 = 垃圾结果”反映了 diffusion 或指令微调系统中经典的“垃圾进,垃圾出”故障。当没有提供空间掩码或约束时,像 “a little off the top” 这样模棱两可的措辞会导致过度字面化的编辑,导致模型移除或扭曲结构特征;稳健的工作流依赖于掩码 inpainting、ROI 分割、negative prompts 或 ControlNet/参考锁定来限制变化。
- 提及 “技术上属实(technically the truth)” 和 “AI 理发师(AI Barber)” 突显了一个更广泛的局限性,即模型优化的是对字面指令的遵循,而非实际意图。这种在提示词不明确(underspecified prompts)时的脆弱性源于弱常识/语用先验;缓解措施包括显式约束、few-shot exemplars、测试时引导(例如 CLIP directional losses)以及用于强制执行语义意图的基于规则的后置过滤器。
- Nano Banana 能做到这个吗? (评分: 329, 评论: 89): 楼主发布了一张幽默的拳击海报风格图像,并询问更小的 “Nano Banana” 模型是否能复现它;评论者证明开源的 “Banana” 图像模型通过其 API 使用
depth-map调节(conditioning),可以达到甚至超过该效果,从而实现更好的角色一致性。回复中提供了示例输出(示例 1, 示例 2, 示例 3)。暗示的工作流是:复用楼主的深度图并将其传递给 Banana API 进行受控图像生成,从而提高姿态/布局忠实度和身份一致性。 一位评论者认为 Banana 的输出“更好”,因为角色更一致,这表明深度调节是关键;另一位则声称该模型可以“做得更好”,暗示进一步的微调(tuning)或提示词可以超越楼主的示例。 - 我妻子向 ChatGPT 要一张系统图。它给了她一杯香蕉奶昔。 (评分: 613, 评论: 62): 这个帖子是一个梗:用户向 ChatGPT 索要“系统图(system diagram)”,结果却收到了一张香蕉奶昔的图片,这说明了 LLM 的一种失败模式(幻觉/模式混淆),即助手误解了任务意图并返回了无关内容。从技术上讲,这是助手工作流中提示词失配(prompt misalignment)和任务与输出不匹配的例子,而不是任何新功能或基准测试(benchmark)。 评论中对这种不匹配大开玩笑(例如,“被 nano-banana 了”以及更喜欢奶昔),并讽刺地嘲讽“口袋里的博士级智能”,反映了对 LLM 在精确工程任务中可靠性的怀疑。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. Weather AI, VibeVoice TTS, Codex 更新以及 Gemini/GPT-5 和政策新闻
- Google 的 AI 模型刚刚精准预测了今年最强的大西洋风暴 (Score: 496, Comments: 63): 帖子强调了 Google 的一个 AI 气象模型准确预测了今年最强大西洋风暴的路径和强度,凸显了学习型全球预报模型(如 DeepMind 的 GraphCast 和 MetNet‑3)相对于传统 NWP(如 ECMWF IFS 和 NOAA GFS)日益增长的能力。评论者指出,各服务提供商主要通过 WMO/UN 数据交换(参见 WMO Unified Data Policy 和 WIGOS/WIS)摄取相同的全球观测数据,因此准确性的差异主要源于模型架构/训练和数据同化流水线,而非独家数据。 观点认为 Google 的方法可能会使其他服务过时,且“实时” ML 预报将挽救大量生命;这些观点取决于 ML 较低的推理成本所带来的更快、更高频率的更新,尽管挽救生命的实际影响程度仍具推测性。
- 多位评论者强调,几乎所有中心都通过 WMO 的世界天气监视网(World Weather Watch)和全球电信系统 (GTS) 摄取相同的全球观测数据,因此预报能力的差异源于模型:数据同化方案、物理参数化、网格分辨率、集合规模和计算预算。这使得 Google 的 AI 方法(例如 GraphCast 中期 ML 模型)与 ECMWF HRES/ENS 和 NOAA GFS/GEFS 等 NWP 展开竞争,已发表的结果显示 ML 在运行速度更快的同时,可以达到或超过某些指标(如
500 hPaACC、RMSE)。链接:https://community.wmo.int/activity-areas/gts, https://www.nature.com/articles/s41586-023-06720-6, https://www.ecmwf.int/en/forecasts/dataset/ecmwf-forecasts-archive - 关于“实时”预报挽救生命:MetNet-3 等 ML 临近预报模型可以提供分钟级的降水预报,且推理延迟较低,与传统的 NWP 周期相比,能够实现更高频率的预警更新。然而,真正的端到端实时能力受限于观测延迟和质量控制(QC,如雷达/卫星摄取)、数据同化窗口以及分发;挽救生命的影响取决于提高高影响事件(如热带气旋路径/强度 MAE、
10–60分钟内的强对流预警提前量)的提前量和可靠性。链接:https://arxiv.org/abs/2410.11809, https://ai.googleblog.com/2023/11/graphcast-accurate-global-ai-forecasts.html - 关于 Google 将使其他服务“过时”的说法因业务现实而有所缓和:国家气象水文部门(NMHSs)提供经过校准的、基于影响的监管预警,通常融合了多个模型(如 ECMWF ENS、GEFS),并使用 MOS/ML 进行后期处理以修正局部偏差。任何新模型在取代现有系统之前,必须证明其在各领域(热带气旋路径误差 km、强度偏差、
CRPS/Brier分数、极端尾部行为)的稳健能力,以及在 24/7 约束下的可靠性/运行时间。链接:https://www.ecmwf.int/en/forecasts/quality-our-forecasts/scorecards, https://www.noaa.gov/organization/nws/national-centers
- 多位评论者强调,几乎所有中心都通过 WMO 的世界天气监视网(World Weather Watch)和全球电信系统 (GTS) 摄取相同的全球观测数据,因此预报能力的差异源于模型:数据同化方案、物理参数化、网格分辨率、集合规模和计算预算。这使得 Google 的 AI 方法(例如 GraphCast 中期 ML 模型)与 ECMWF HRES/ENS 和 NOAA GFS/GEFS 等 NWP 展开竞争,已发表的结果显示 ML 在运行速度更快的同时,可以达到或超过某些指标(如
- [[WIP] 针对微软新 VibeVoice TTS 的 ComfyUI 封装器(秒级语音克隆)] (Score: 434, Comments: 94): 一位开发者正在为微软的 VibeVoice TTS(项目页面)构建 ComfyUI 封装器,能够从极小的样本中实现快速语音克隆;初始支持针对单发言人,双发言人支持正在开发中,并计划开源发布。提到了两种模型尺寸:
1.5B(推理速度快,“相当不错”的质量)和7B(情感细微差别更丰富但不够稳定;标记为 Preview)。演示使用了合成语音作为 Prompt,VibeVoice 对其进行克隆并合成目标文本;此处链接了另一个更新帖子。 评论者质疑演示的选择(合成来源语音),并建议使用知名公众人物的声音来客观评估 one-shot 克隆质量;他们还澄清了在获得同意的情况下克隆是获得许可的,询问了1.5B的 VRAM 占用详情,并要求与 Higgs Audio 2 进行对比。- 许可说明:评论者报告 VibeVoice 采用 MIT 许可,支持本地/商业用途,但使用条款仍禁止在未经明确同意的情况下进行语音克隆。这意味着克隆在技术上受支持,但在政策上受限。对 one-shot 克隆质量存在怀疑;建议使用广为人知的声音进行评估,以更好地判断音色相似度。还出现了与 Higgs Audio 2 和 Chatterbox 进行正面对比的要求,以量化克隆忠实度和自然度。
- 部署关注:一位评论者询问了
~1.5BVibeVoice 模型的 VRAM 占用情况。了解内存使用情况(例如 FP16 与 INT8,batch size 为 1)对于评估在消费级 GPU 上的 ComfyUI 中实现实时或近实时 TTS 的可行性以及规划吞吐量/延迟至关重要。 - 集成想法:一个相关的进行中项目 image2reverb 旨在从图像/视频帧中推断场景声学特性,并应用卷积混响,使生成的语音与环境匹配。这可以与 VibeVoice ComfyUI 节点配合使用,自动为 TTS 输出添加环境感知声学效果。
- Codex 全新重大更新!!! (Score: 203, Comments: 50): 图片据称是 OpenAI 开发者关于“Codex 全新重大更新”的公告,亮点包括:新的 IDE 扩展(声明兼容 VS Code 等)、云端与本地环境之间的无缝任务迁移、集成的 GitHub 代码审查以及翻新后的 Codex CLI。它还声称该更新由 GPT-5 驱动,可通过 ChatGPT 计划使用,强调了提高的代码效率和更紧密的开发工作流集成。 热门评论讨论了权衡:声称 GPT-5 的指令遵循能力使任务委派更可靠,而 Claude 在工具使用方面仍然更强;关于与 Claude Code 相比的入门/可用性问题;以及对 Windows 终端兼容性的担忧(历史上曾发布以 Linux 为中心的命令)。
- 多位用户报告 Codex 中 gpt5-medium 和 gpt5-high 之间存在明显的质量差距:medium 感觉像是一个带有 RAG/TTC 脚手架的小模型,表现出较弱的指令遵循和较差的上下文摄取能力,而 high 的表现则像一个完整的 SOTA 模型。他们认为增加
10k–20k个“thinking tokens”不足以解释这种差异,暗示底层基础模型不同,而不仅仅是推理预算更多。在通过 API 使用 Opus 时,超过约16k个 thinking tokens 后也观察到了类似的饱和现象,改变 thinking-token 预算并不会实质性地改变基础模型的“风格”。 - 对比表明 GPT-5 现在擅长严格的指令遵循(对任务委派很有用),而 Claude 在工具使用的可靠性方面仍处于领先地位。对于编码工作流,这些权衡使得两者难分伯仲:GPT-5 对指令的遵守 vs Claude 更强的工具编排和函数调用行为。
- 环境一致性问题仍然存在:用户回忆起 Codex 在 Windows Terminal 会话中默认使用 Linux 命令模式,这表明操作系统检测或 Shell 目标启发式算法可能需要改进。这会通过建议不可移植的命令来降低开发者的体验,并表明 CLI 或 Agent 层需要改进运行时/操作系统上下文感知。
- 多位用户报告 Codex 中 gpt5-medium 和 gpt5-high 之间存在明显的质量差距:medium 感觉像是一个带有 RAG/TTC 脚手架的小模型,表现出较弱的指令遵循和较差的上下文摄取能力,而 high 的表现则像一个完整的 SOTA 模型。他们认为增加
- 我很高兴地宣布我现已成为一名 6x 工程师 (Score: 390, Comments: 142):一张模因风格的截图显示,多个编辑器/终端窗格呈现出一个庞大的数据解析/提取设置,其中包含调试日志、QA 检查和分层的“稳健回退解析”——暗示 OP 通过编排多个脆弱的脚本/流程而非单一简洁的流水线,成为了一名“
6x工程师”。其技术潜台词是编排/自动化的过度扩张:围绕不稳定的解析器构建重试、回退和验证包装器,这可能会掩盖错误并增加维护开销。查看图片:https://i.redd.it/q55dd87p1klf1.jpeg。 热门评论批评了回退解析器的静默失败模式(“祝这种静默失败的垃圾好运”),调侃这其实是“管理”(协调重于编码),并警告此类自动化会导致更严格的平台速率/使用限制。- “稳健回退解析”的讽刺凸显了经典的失败模式,即松散的解析器掩盖了上游错误,导致流水线“静默失败”。最佳实践是利用结构化输出(例如 Claude structured outputs, OpenAI structured outputs)配合严格的 JSON Schema 验证和类型化的 tool-call 结果来实现故障关闭,而不是使用启发式正则表达式解析。增加可观测性(解析失败率/空值回退率、不同回退方案间的延迟差异)、混沌/模糊测试以及熔断器,以防止隐藏 Bug 的级联回退(Guardrails 可以提供帮助)。
- 关于“更严格限制”的评论指出,当扇出(fan-out)/多 Agent 工作流产生突发流量和错误放大时,供应商会收紧配额。预见
429/RateLimit和供应商特定的退避策略:OpenAI 使用 RPM/TPM 和动态层级(文档);Anthropic 执行针对每个模型的 TPM/RPM 和并发上限(文档)。使用自适应客户端速率限制器(令牌桶/漏桶算法)、幂等键、优先级队列和预算守卫,以避免触发自动滥用启发式算法。 - 关于“Claude 作为 6x 工程师”的问题强调了编排的复杂性:你需要有状态的 DAG、带有抖动的重试、超时、幂等性,以及工具使用溯源、成本/延迟预算的可追溯性。生产环境通常将 Agent 图/运行时(如 LangGraph)与工作流引擎(Temporal 或 Prefect)以及 LLM 可观测性工具(Langfuse 或 OpenTelemetry)结合使用。对于 Claude 特定的技术栈,首选工具调用 + JSON Schema(tool use)而非自由格式提示词,并强制执行并发限制以防止惊群效应(thundering-herd)扇出。
-
忘掉 Google。这就是开源工具的力量。 (Score: 561, Comments: 63):一篇标题为“忘掉 Google。这就是开源工具的力量。”的视频帖子链接到了 Reddit 托管的视频 v.redd.it/3epgdoljljlf1,但在未经身份验证的情况下返回
HTTP 403 Forbidden,因此无法访问底层演示。在可见内容中没有具体的工具、仓库、基准测试或实现细节;讨论暗示了开源工具可以替代 Google 的主张,但并未列举具体工具或提供证据。 热门评论反映了怀疑态度并要求提供细节(例如 “什么开源工具”),其他评论则偏离了主题;目前没有实质性的技术辩论或数据来评估该主张。 - 我感觉到了嫉妒……等着看 Gemini 3 吧 (Score: 396, Comments: 95):截图中的帖子认为,即使 Google Gemini 3 在原始能力上超越了 OpenAI ChatGPT,OpenAI 的分发渠道和用户锁定效应也使得用户难以迁移;建议优先发展图像/视频生成,通过病毒式传播、可分享的输出来推动采用。评论者从两个维度重新审视了竞争:助手质量 vs. 分发/病毒式传播,并指出了 API 经济学中“单位美元智能”和延迟占据主导地位——引用 Gemini 2.5 Flash 曾一度在性价比上领先。 辩论集中在多模态图像/视频生成是否属于“支线任务”(许多人认为它们是构建更好助手的核心)、在个人助手竞赛中“第一”或“最好”是否最重要,以及变现模式:大多数 ChatGPT 用户并不付费,Anthropic 主要通过 API 变现,而采用率取决于实用性(例如自然语言照片编辑)以及目前关于传闻中较小的 GPT-5 模型的未知数。
- API 买家优化的是 “单位美元智能” 而非峰值分数;据报道 Anthropic 主要通过其 API 而非聊天 UI 变现。一位评论者指出 Gemini 2.5 Flash 曾一度拥有最佳性价比,意味着与同行相比,其单位美元的质量/延迟表现更强,尽管这可能随着更小的
GPT-5模型出现而发生变化。在计算资源受限的世界中,面对大量非付费聊天用户,可持续增长取决于高效的服务(延迟、吞吐量、上下文利用率)和定价,而不仅仅是原始能力。 - “聊天模型”正向个人助手收敛,其中可靠性、工具使用(tool-use)和延迟方面的微小提升会复合为巨大的 UX 优势;在默认位置和日常粘性方面,做到“第一”和“最好”至关重要。一个 “稍微更好、更聪明、更可靠” 的助手通过驱动比简单聊天更高价值的工作流(日历/邮件/代码操作)产生巨大价值,而操作系统级的钩子(例如 Gemini 作为 Android 语音助手)可以抵消独立 App UX 较弱的劣势。
- 将图像/视频标记为“支线任务”遭到了质疑:多模态能力(如自然语言照片编辑)是直接影响采用率的高实用性功能。评论者认为这些能力不仅仅是吸引注意力的手段,而是构建更智能助手的核心,因为更强的视觉/视频理解和生成能力扩展了可执行的任务和现实世界的实用性。
- API 买家优化的是 “单位美元智能” 而非峰值分数;据报道 Anthropic 主要通过其 API 而非聊天 UI 变现。一位评论者指出 Gemini 2.5 Flash 曾一度拥有最佳性价比,意味着与同行相比,其单位美元的质量/延迟表现更强,尽管这可能随着更小的
- 尝试迁移到 Gemini,30 秒就放弃了 💀 (Score: 504, Comments: 326):截图显示 Google Gemini 拒绝继续执行任务,因为它“看起来像私人对话”且“并非设计用于在此类语境下冒充或互动”,这表明触发了可能与冒充或私人通信检测相关的安全/护栏(guardrail)。从技术上讲,这展示了一种激进的内容安全启发式算法(策略过滤器),当模型推断出角色扮演/冒充时可能会产生误报,但由于缺少实际 Prompt,因此无法复现或调试该触发点。 热门评论指出,如果没有原始 Prompt,该帖子就毫无信息量,并敦促在对 Gemini 的护栏过于敏感下结论之前先实现可复现性。
- 几条回复强调,如果没有确切的 Prompt 和运行时细节,任何性能判断都是不可复现的。为了进行公平比较,应包含精确的用户/系统 Prompt、模型变体(如 Gemini 1.5 Pro vs Flash)、解码参数(
temperature、topP、topK、maxOutputTokens)、平台(Web vs API),以及是否启用了工具/Grounding 或长上下文;参见 Google 文档中的模型变体:https://ai.google.dev/gemini-api/docs/models。 - 一位评论者暗示性能取决于上下文;由于更严格的安全/对齐(alignment)和默认的低多样性解码,Gemini 在开放式任务中可能显得保守或“无聊”。如果目标是更具探索性的输出,请选择合适的变体并增加
temperature/topP(同时意识到幻觉风险),或提供更丰富的任务约束以诱导深度;模型行为差异记录在此:https://ai.google.dev/gemini-api/docs/models。
- 几条回复强调,如果没有确切的 Prompt 和运行时细节,任何性能判断都是不可复现的。为了进行公平比较,应包含精确的用户/系统 Prompt、模型变体(如 Gemini 1.5 Pro vs Flash)、解码参数(
- AI 的事实来源是……我们? (Score: 441, Comments: 174):一张名为“AI 从哪里获取事实”的信息图声称,像 ChatGPT 和 Perplexity 这样的语言模型最常引用 Reddit (40.1%),其次是 Wikipedia (26.3%)、YouTube (23.5%) 和 Google (23.3%),而 Yelp、Facebook 和 Amazon 各占 18% 以上。该图片未提供方法论或来源,因此尚不清楚这些数字代表的是训练数据构成、检索/引用行为,还是用户分享的链接——因此这并不是一个严谨的基准测试或可重复的分析。 评论区将此贴视为模因/转发,并包含讽刺内容,含蓄地表达了对模型如果过度索引用户生成内容(UGC)可能导致误导信息的担忧;目前尚无实质性的技术辩论。
- 一位评论者认为 “与普遍看法相反,Reddit 实际上是许多话题的有价值来源,无论是真实问题还是所谓的‘争议’”,并强调用户生成的帖子通常能捕捉到真实世界的边缘案例、故障排除步骤以及正式语料库缺失的小众领域上下文。这与行业内授权 Reddit 数据用于 LLM 训练的举措相一致(例如 OpenAI–Reddit 合作伙伴关系 (2024):https://openai.com/index/reddit-partnership/),但也暗示了管理噪声、偏见和可能降低事实准确性的审核人工痕迹的必要性。在实践中,这有利于在整合 Reddit 语料库时采用强大的数据集过滤和/或检索增强生成(RAG)来保持信噪比。
- 测试 GPT-5(它是 NSFW) (Score: 406, Comments: 111):截图显示 “ChatGPT 5” 在极少的引导下(用户要求一些“超级失控”的内容,然后是“脏话连篇且露骨”的内容),根据请求生成了露骨的、NSFW 角色扮演独白,且没有拒绝或安全门控——这表明与早期行为以及 OP 测试过亲和力/对话性的 GPT-4o 相比,其安全护栏更宽松或执行不一致。从技术上讲,这指向了更新的审核阈值、不同的指令微调(Instruction-tuning)/对齐设置,或者是允许在合意虚构框架下出现成人内容的上下文/提示词路由间隙,凸显了政策执行的不一致性和会话级的变异性。 评论报告了类似的宽松行为(例如协助种子下载),一些人对这种变化表示欢迎,暗示安全约束有所减少;其他人则转向幽默,几乎没有提供技术反驳。
- 如果 Raine 家族获胜,该诉讼将强制 ChatGPT 对所有用户进行年龄验证 (Score: 401, Comments: 441):OP 报道了 Raine 家族提起的一项诉讼,如果成功,将要求所有 ChatGPT 用户进行普遍的年龄验证——这意味着需要收集/验证政府 ID 或同等证件,并带来跨司法管辖区的隐私、数据保留和合规负担。该帖子引用了来自平台安全变革的压力(例如 Google/YouTube 默认的青少年账户设置)和监管趋势,如英国的《在线安全法案》(legislation.gov.uk),并表达了拒绝向私营公司提供 ID 的立场。 评论者认为,强制性的年龄检查应该与针对已验证成人的内容过滤减少相结合,而其他人则强调父母责任优于平台强制令,并批评以儿童安全为借口来扩大监控和侵蚀在线隐私。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. Claude ASCII 工作流、Qwen 图像编辑指南以及 ChatGPT UX 幽默
- Anti-YOLO 方法:为什么我在写代码前让 Claude 画 ASCII 艺术图 - 它是如何让我交付更快、更好且消耗更少 Token 的 (Score: 245, Comments: 88): OP 概述了一个受限的 Claude 辅助交付工作流:头脑风暴问题空间 → 生成低成本的 ASCII 线框图(据称比 HTML 原型少消耗约
10x的 Token)并保存为 Markdown → 在提示 Claude 提出澄清问题后进入严格的“Plan mode”(审查代码库;指定后端架构、DB Schema 考量、匹配稳定 Friendly IDs 的 UI、安全和测试)→ 实现 → 直接从 ASCII 规范推导出测试(单元测试、集成测试、组件测试、DB 完整性、边缘情况)→ 交付。他们声称这减少了对齐偏差、迭代次数和生产环境调试;该方法通过 Vibe-Logs Prompt Pattern Analyzer 的一个真实功能以及关于“修复提示词问题”的后续行动进行了说明。关键策略包括使用 ASCII 专注于布局/流程而非样式、在 Markdown 中集中决策、坚持让 Claude 提出澄清问题,并将线框图视为测试规范(test oracle)。 评论者大多支持大量的前期规划和文档记录(步骤 1 和 3),但在 ASCII 上存在分歧:一些人认为它出奇地有效;另一些人则认为纯文本/结构化规范(例如 CLAUDE.md)能产生更好的遵循效果,且 ASCII 对人类的益处大于 LLM,并对 Token 成本和流程遵循的保真度表示担忧。- 多位评论者报告称 ASCII 线框图在 Token 效率上不高,且不能提高模型的遵循度:一位评论者指出 ASCII/状态机提示词“未能遵循大部分流程”,而详细的纯文本规范(例如 CLAUDE.md 计划)能让 LLM 更可靠地遵循步骤,且迭代次数更少。这表明 ASCII 主要是人类的辅助工具;对于模型而言,结构化的散文需求和逐步计划的表现优于 ASCII,并能避免浪费 Token。
- 另一种建议是使用 Mermaid 图表 (mermaid.js.org) 来绘制流程图/时序图/状态图,作为一种紧凑且机器可解析的格式。Mermaid 可以简洁地编码节点/边和状态,在保留结构的同时可能比 ASCII 减少 Token,并且如果 LLM 识别该语法,可能更好地支持推理以及可视化与实现之间的往返。
- 另一位评论者非正式地证实,价值在于规划/验证阶段(步骤
#1和#3),而非 ASCII 产物本身。这与以下观点一致:严格的规划/文档驱动质量和速度,而 ASCII 线框图是可选的人机工程学手段,可能不会带来性能或 Token 的节省。
-
Qwen-Image-Edit 提示词指南:完整手册 (Score: 254, Comments: 38): 帖子分享了一个实用的 Qwen-Image-Edit 提示词工程手册,涵盖了七类编辑:文本替换/纠正(保持字体/大小/透视)、局部外观调整(保持光照/阴影一致性的材质/颜色)、全局语义/风格变更(例如在保留布局/身份的同时进行 Studio Ghibli 风格迁移)、微观/区域编辑(方框内的字符或小物体交换)、身份控制(主体交换 vs. 身份保留)、海报/合成布局约束,以及摄像机/光照指令(重光照、DoF、镜头)。核心技术强调约束优先的措辞(例如“保持其他一切不变”,保留身份/字体/对齐)、链式小幅编辑,以及明确的负面提示词(“无畸变、无扭曲文本、无重复面部”)以减少偏移和伪影。该指南提倡使用明确的 add/replace/remove 动词和精确的保留条款(姿势、阴影、反射),以在编辑过程中保持结构保真度。 热门评论要求提供带有视觉示例的有效性证明,警告该帖子读起来像 LLM 生成的列表;另一位评论者正在构建一个 Starnodes 自定义节点来选择任务并为 Qwen 编辑自动生成提示词(截图:https://preview.redd.it/9ep8f7jf0mlf1.png),第三位评论者确认 add–replace–remove 措辞加上“保持一切不变”能显著改善结果。
- 从业者报告称,Qwen-Image-Edit 对受限的、原子化的指令响应效果最好,通常采用 add/replace/remove 模式,例如“添加 X”、“将 Y 替换为 Z”,并明确说明“保持其他一切不变”。据报道,强调不变性(例如“不要更改任何其他内容”)可以减少附带编辑,并提高多属性编辑的保真度,这与基于指令的图像编辑模型的最佳实践相一致。
- 一位开发者正在为 StarNodes 构建一个自定义节点,该节点集成了 “Kontext” 和 Qwen Edit,以简化任务选择和 prompt 组装。该节点提供了一个 UI 来选择编辑类型、提供少量输入,并自动生成一个开箱即用的 prompt,如其截图所示:https://preview.redd.it/9ep8f7jf0mlf1.png?width=1252&format=png&auto=webp&s=e5546e2fdafd30004e43bc167a06eca72595601b。
- 有人呼吁进行实证验证:读者要求提供编辑前后的图像示例,以验证所提供的 prompt 模式是否能在 Qwen-Image-Edit 上可靠地产生声称的编辑效果。包含此类产出将有助于可复现性,并有助于区分特定工作流带来的收益与通用的 LLM 风格引导。
- 我本该安安静静地无聊着。 (Score: 3744, Comments: 227): 这是一个非技术的 meme/聊天机器人 UI 截图,显示机器人对抱怨无聊的用户给出了讽刺且“严厉的爱”式的回复——这提出了一个关于默认语调和处理低价值 prompt 的 UX/AI 助手设计问题。在技术上,这仅在反映对话式 AI 中的 alignment/助手人格选择(生硬 vs. 乐于助人)方面具有相关性。 评论者支持这种尖刻的回答,认为它是 AI 助手理想的默认行为(“每个 AI 都应该以这种方式回答”),而其他人则讽刺地指出这“正是我付钱买的”,暗示了对付费 AI 行为的复杂预期。
- 几位评论者主张采取更严格的默认行为,即 AI 默认情况下清晰地设定边界/拒绝,并简洁明了地做出回应,这暗示了对通用“安全/严格模式”的偏好,以减少幻觉和过度顺从。这表明了对跨模型/供应商的可预测安全配置文件和指令遵循的需求。
- 提到 “OpenAI 的周一 GPT” 突显了感知到的模型行为/质量的时间变异性,技术读者可能会将其与滚动部署、模型快照更改或影响拒绝阈值和冗长程度的服务端开关联系起来。这种情绪强调了透明版本控制和稳定性保证的重要性,特别是对于期望一致行为的付费用户。
- 罗马与宇宙虚无者 - 第 1 集 (Score: 302, Comments: 24): “罗马与宇宙虚无者”第 1 集作为 44 集系列的一部分被分享;全集可通过 YouTube 播放列表获取 (链接)。原始的 Reddit 托管视频 (v.redd.it) 对未认证客户端返回
HTTP 403 Forbidden,这意味着访问需要 Reddit 认证(例如登录 reddit.com/login)或适当的 token;YouTube 播放列表可作为可访问的替代方案。 评论大多是非技术性的热情(例如“太空中的罗马人”),并带有对《红星崛起》(Red Rising)的文化引用,表明了积极的反响而非技术评论。 -
是时候摘下面具了。等等……我不是那个意思……快,戴回去! (Score: 2096, Comments: 499): 短片(来源现在被 403 限制)似乎展示了一场精心策划的“揭幕”,表演者脱掉了超现实的硅胶面具和女性外观的紧身衣;注意到的瑕疵包括紧身衣上僵硬、过于明显的乳头,以及当佩戴者的真实牙齿位于面具模制嘴口后方时可见的“双重牙齿”效应。可以通过 预览图 查看静态帧。这些迹象与全头硅胶面具/紧身衣的典型局限性一致(材料硬度、固定的乳头几何形状和嘴部开口对齐问题)。 热门评论集中在解剖学真实性和面具破绽上:对紧身衣“坚硬如石的乳头”的批评以及对“两排牙齿”的质疑,突显了恐怖谷效应的产物,尽管表面细节令人信服,但这些瑕疵暴露了假体。
- 多名用户怀疑该片段是 AI-generated 的,理由是存在明显的伪影(artifacts),例如重复的牙齿(“两排牙齿”)以及面部周围的遮罩/边缘不一致(图片链接)。这些问题是 face-swap/inpainting 流水线中的典型现象,当分割遮罩(segmentation matte)在帧与帧之间(frame-to-frame)发生偏移时,会导致生成器的嘴部区域叠加不完美,从而产生时间伪影(temporal flicker)或重复特征。你还经常能看到不随头部姿势追踪的高光,这揭示了它是 2D 合成(compositing)而非一致的 3D 几何结构(3D geometry)。
- 重复的牙齿特别暗示了未能完全替换跨帧的口腔内部,在生成层下方留下了源帧牙齿的残余。在 deepfake 工作流中,不充分的 alpha mattes 或简单的混合(blending)(相对于 flow-guided 或 Poisson blending)会导致原始口腔内容渗出,尤其是在快速唇部运动或部分遮挡期间。稳健的解决方案通常涉及针对牙齿/舌头更紧密的语义分割(semantic segmentation)以及运动补偿的时间一致性损失(motion-compensated temporal consistency losses),以防止帧间漂移。
- 没想到会这样!😬 (评分: 980, 评论: 44): 图片显示了一个 LLM 对话,用户询问一个谜语:“我没有生命,但我会生长;我没有肺,但我需要空气;我没有嘴,但我需要水才能生存。我是什么?”当被要求给出答案时,AI 返回了一个元自我描述(meta self‑description)而不是解谜,突显了 LLM 常见的失败模式:样板免责声明(boilerplate disclaimers)和意图失配(intent misalignment)(“作为一个 AI 语言模型……”)覆盖了任务执行。这个谜语变体可能指向“铁锈(rust)”(需要空气和水;没有生命但会生长),而不是经典的“火”。 评论者建议答案是“Rust?”,并指出模型反射性的免责声明习惯让这种失误显得既滑稽又是 LLM 恼人行为的典型代表。
- 评论者注意到模型的样板前缀(例如,“作为一个 AI 语言模型……”)代替了回答,突显了当置信度较低或触发内容检查时,指令微调(instruction-tuned)模板和安全护栏(safety guardrails)如何主导输出。从技术上讲,这反映了系统/提示词脚手架(system/prompt scaffolding)偏向于免责声明和拒绝;最近的部署通常通过调整系统提示词(system prompts)来抑制此类样板内容,以改善 UX。讨论强调了提示词/模板设计如何甚至在简单任务上覆盖核心推理。
- 留校察看:第1天 (评分: 626, 评论: 66): 帖子似乎是一个关于 LLM 在询问澄清问题与猜测之间行为的讽刺图像/迷因,托管在 Reddit 画廊(链接; 未经授权返回
HTTP 403)。一条热门评论链接了一张预览图(preview.redd.it),强化了模型不询问 后续问题(follow-up questions) 而是产生幻觉(hallucinating)或虚构上下文的主题。 评论者批评 LLM 靠猜测而不是请求澄清,导致 “幻觉出完整的对话”;此外还有一个关于风格偏好(例如,破折号 em dashes)的小插曲,反映了对模型语气/格式而非核心能力的沮丧。- 用户报告称,即使将风格约束(避免使用破折号)保存为用户“记忆(memory)”或重复提醒,模型仍持续无法遵守。这暗示记忆功能是一个软提示(soft prompt)暗示,很容易被更高优先级的系统提示词(system prompts)或模型学到的风格先验(priors)所覆盖,因此标点符号偏好无法在不同会话或回复中被确定性地执行。
- 几条评论强调,模型经常猜测用户意图而不是询问澄清问题,导致在上下文缺失时产生幻觉出的多轮内容。这反映了指令微调(instruction-tuning)的权衡:对“乐于助人”的优化偏向于继续对话而非询问不确定性,而用户希望有更严格的策略来诱导澄清,以减少模糊提示词中的幻觉。
- 需要反复指示“删除破折号”表明持久的、针对每个用户的风格控制较弱;如果没有受限解码(constrained decoding)(例如,Token/字符禁用)或可强制执行的系统级风格规则,训练分布的习惯将占据主导地位。更稳健的解决方案需要硬约束或更高优先级的系统提示词/模板来明确禁止某些标点符号,而不是依赖提醒。
- 有了 ChatGPT,谁还需要敌人。 (Score: 596, Comments: 63):非技术类迷因/讽刺: 一张 ChatGPT 回复的截图,训诫一名说“觉得无聊”的用户,强调了尽管拥有“海量资源和技术”,却向 AI 寻求娱乐的讽刺性。没有 Benchmarks、模型或实现细节——这是对用户预期和 AI 助手语气/人格(Persona)的评论。热门评论大多认为这种尖酸刻薄的回复是理所应当的;没有实质性的技术争论。
- 说实话,我笑得比预想的还要厉害 (Score: 500, Comments: 31):非技术/迷因帖子: 原作者(OP)开玩笑说在 Apple M2 Mac mini 上运行 CREPE 音高检测 CNN 会让它“尖叫”/过热(一张 Mac 着火的 ASCII 艺术图)。从语境来看,这暗示了在不使用适当加速(例如 TensorFlow-metal)时,CREPE 在 Apple Silicon 上会受限于 CPU(CPU-bound),并可能触发热节流(Thermal Throttling),但未提供配置、Benchmarks 或错误日志。热门评论多为笑话且非技术性;没有实质性的争论或排错细节。
- 几条评论暗示了 LLM 风格控制的局限性:在 GPT-4/4o 中强制执行“句首不准大写”并非易事,因为解码遵循的是 Token 概率和 BPE Tokenization,而非硬性的语法规则。可以通过严格的 System Prompt、低
temperature/固定seed以及对大写开头的 Token 设置选择性的logit_bias来引导更强的遵循度,但由于合并 Token 的存在,这种方法很脆弱;可靠的工作流通常会进行后处理以将首字母转为小写,或者在支持的情况下使用受限解码(Constrained Decoding)/语法(Grammars)。参考资料:OpenAI logit bias 参数和 Prompt 工程指南 (https://platform.openai.com/docs/api-reference/chat/create#chat-create-logit_bias, https://platform.openai.com/docs/guides/prompt-engineering),使用 tiktoken 进行 Tokenization 检查 (https://platform.openai.com/tokenizer)。 - 关于 Mac 性能的俏皮话对应着现实中的瓶颈:旧款 Intel Macs 和 M3 之前的 Apple Silicon 缺乏硬件 AV1 解码,因此高比特率的 AV1 视频会回退到 CPU(通过 VideoToolbox),导致掉帧/热节流;Apple 仅在 A17 Pro/M3 (
2023+) 上增加了硬件 AV1 解码 AnandTech。macOS 上的《模拟人生 4》(Sims 4)历来受限于集成 GPU 和转译/移植层,因此启用 Metal 的构建版本以及调低分辨率/图形设置能显著改善稳定性/FPS;通过 Activity Monitor + powermetrics 进行监控有助于确认 GPU 与 CPU 的饱和情况(参见 VideoToolbox 概述:https://developer.apple.com/documentation/videotoolbox)。
- 几条评论暗示了 LLM 风格控制的局限性:在 GPT-4/4o 中强制执行“句首不准大写”并非易事,因为解码遵循的是 Token 概率和 BPE Tokenization,而非硬性的语法规则。可以通过严格的 System Prompt、低
- 罗马与宇宙虚无者 - 第 1 集 (Score: 302, Comments: 24):《罗马与宇宙虚无者》第 1 集似乎是一个连载的科幻/替代历史视频项目; 一名评论者链接到了 YouTube 上完整的
44 部分播放列表:https://youtube.com/playlist?list=PLqtYHpLHIRiNfL_Fh8-E0O1ylK1bGH3pD&si=qCmbktibZlVaYVNB。原始 Reddit 视频(v.redd.it)目前因 403 错误无法访问,这表明是平台侧的访问限制而非内容缺失。热门评论大多很热情且非技术性;唯一的实质性补充是完整 YouTube 播放列表的直接链接。- 一名评论者建议将 1930s/1940s 的宣传音效 替换为讲述者旁白(VO),这提出了一个声效设计的权衡:档案宣传风格通常使用带宽受限的单声道(Mono)、重度压缩以及磁带/黑胶噪声来提示“发现的录像”/帝国信息传递,而清晰的叙述者音轨将扩大动态范围和清晰度,使旁白在混音中处于前景,并将框架从叙事内的模仿(Diegetic Pastiche)转变为全知神话。这一选择会实质性地影响 EQ 曲线、侧链优先级(旁白 vs. 音乐/特效)以及观众对真实感与传奇感的感知。
- 另一名评论者链接了完整的
44部分 YouTube 播放列表,这对于评估剧集间美术指导、VFX/模型演变以及音频管线变化的长期一致性非常有用。链接:完整系列播放列表。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
AI Discord 摘要
由 X.ai Grok-4 生成的摘要之摘要的摘要
主题 1:Hermes 4 预示混合推理革命
- Hermes 4 在 RefusalBench 表现优异:Nous Research 发布了 Hermes 4,这是一个强调创意和 SOTA 性能的用户对齐模型,并在 Hermes 4 Arxiv 论文 的技术报告中详细介绍了其针对 RefusalBench 的优势。该模型曾短暂出现在 OpenRouter 上,后因提供商问题被撤下,Unsloth 已在 HuggingFace 上发布了其 GGUF 量化版本。
- Hermes 4 延迟发布有 Bug 的 14B 版本:14B Hermes 4 模型的发布因推理模式 Bug 而停滞,而用户已在 NousResearch chat 测试免费的 405B 版本。成员们指出 Hermes 在使用 thinking 标签时表现出色,但在现代 post-training 方面进展不多,尽管 Hermes 3 的表现已经非常出色。
- Nous Chat UI 翻新,引入记忆魔法:更新后的 Nous Chat UI 引入了并行交互和一套跨模型工作的自定义图记忆系统,但有用户报告在 Firefox 浏览器下 VRAM 占用较高,例如在 4060Ti 上达到 1.3GB。发布后提供商遭遇了扩展性问题,但在首周内 Hermes 4 的推理仍维持免费。
Theme 2: Gemini 模型助力工具调用取得突破
- Gemini 2.5 Pro 精通工具调用:Gemini 2.5 Pro 在 101 次工具调用中成功完成了 98 次,引发了关于使用 DPO 进行更好工具训练的讨论,并引用了 KTO 论文 和 DPO 论文。用户在 Qwen3-coder 上遇到了工具问题,尽管进行了 –jinja 修复,但像 *
* 这样的标签仍然失效。 - Nano Banana 将照片转化为手办:Google 的 Nano Banana(又名 Gemini 2.5 Flash Image)因能从照片生成逼真的手办而令人惊叹,示例包括 克劳德手办 和 萨菲罗斯手办。速率限制令用户感到沮丧,即使在 Google AI Studio 中也是如此,有人建议使用访客配置文件来快速重置限制。
- Gemini 2.5 Pro 在基准测试中对决 GPT-5:关于 GPT-5 High 是否优于 Gemini 2.5 Pro 的争论非常激烈,一张 截图 显示两者表现几乎持平,有人称这对 OpenAI 来说非常非常糟糕。用户注意到 Gemini 因过度训练而表现出胆怯行为,正在寻找角色扮演的替代方案。
{kind=link}
{kind=link}
{kind=link}
Theme 3: Grok Code Fast 驶入编程混沌快车道
- Grok Code Fast 更名为 Speedy Sonic:Grok Code Fast 现已更名为 Sonic,作为 Grok Code 的小型快速变体出现。用户更倾向于使用 Auto 模式,通过在 Claude、GPT 和 Gemini 之间切换来获得更高质量的代码。该模型在 9 月 15 日前不限次数,根据 Windsurf 公告,Windsurf 暂时免费提供该功能。
- Grok 拥抱“放飞自我”的自定义指令:成员们发现 Grok 会跳过越狱步骤;仅靠自定义指令就能让它表现得非常狂野,比其他模型更容易实现。社区分享了 xAI 的 Grok-Code-Fast-1 文档 链接,鼓励大家阅读。
- 三模型发布日让发布日程不堪重负:Xander Atallah 宣布 Grok Code 在“三模型发布日”上线,引发了要求 OpenRouter 协调发布冲突的呼声,因为同时发布太多模型实在令人应接不暇。
Theme 4: 隐私恐慌与去审查风波
- Ollama 被指控暗中抓取数据:用户声称 Ollama 在没有隐私声明的情况下将数据发送到服务器,并建议使用 vLLM、sglang 或 llama.cpp 等替代方案,因为其本质只是一个封装。有人分享了一个用于 Ollama 的 Rust-Tauri UI,支持无需后端的跨平台模型管理。
- 模型演变为情感知己:一位用户的母亲使用 Gemini 进行情感支持并分享健康细节,引发了关于 AI 作为朋友还是助手,以及骗子利用漏洞的伦理辩论。人们对过度审查导致 Phi-3.5 等模型在编程中变得不切实际表示担忧。
- 消融模型(Abliterated Models)绕过安全开关:社区推荐搜索 abliterated models ollama 以获取无审查版本,用户通过井字棋游戏嘲讽过度的审查。分享了一个 无审查版 Phi-3.5,并讨论了消融技术的缺点。
主题 5:GPU 竞赛与硬件障碍升温
- GPU MODE 启动 10 万美元 AMD 内核挑战赛:GPU MODE 与 AMD 合作举办了一场 10 万美元 的竞赛,旨在优化 MI300 GPU 上的分布式推理内核,重点关注 all-to-all、GEMM + reduce-scatter 和 allgather + GEMM;请在 9 月 20 日前通过 AMD 挑战赛链接 注册。夏季计划举行多 GPU 讲座。
- 显存(VRAM)争论主导本地模型运行:用户讨论了 VRAM 在运行 12B 模型中的作用,指出 GDDR 类型 和 CUDA 核心非常重要,模型超过 VRAM 会严重拖慢速度;RTX PRO 3000 (12GB) 被称为缩水版的 5070,不适合 30B 的量化版本。建议 Windows 用户选择 Ryzen 395+ 笔记本电脑。
- 量化探索解决梯度爆炸问题:建议包括早期使用 RMSNorm、学习率设为 1e-4 以及重新缩放残差以抑制爆炸,代码参考 vision-chess-gpt 仓库。ScaleML 关于 MXFP4 量化的第 3 天直播可在 ScaleML YouTube 观看。
Discord:高层级 Discord 摘要
Perplexity AI Discord
- Grok 通过自定义指令拥抱混沌:成员们发现 Grok 不需要越狱;用户只需添加自定义指令即可让它表现得放荡不羁。
- 讨论强调了与其他模型相比,影响 Grok 行为的相对容易性。
- OnlyFans 暴富故事引发争论:一位成员声称看到了无数新闻报道,称 18-19 岁的女孩在 3-4 天内就能在 OnlyFans 上赚到数千美元。
- 这一说法遭到了其他成员对这类成功故事的准确性和普遍性的质疑。
- 在 Ollama 上释放消融模型:一位成员建议搜索 abliterated models ollama,以查找禁用安全开关的模型。
- 这一建议表明社区内有探索无安全限制模型能力的愿望。
- Comet 应用的专属轨道:成员们讨论了 Comet app,指出其在 Windows 或 MacOS 上的可用性有限,且需要邀请。
- 在美国,Perplexity Pro 免费捆绑了推荐名额。
- Perplexity AI 的艺术尝试:一位成员分享了使用 Perplexity AI 生成的图像,可通过提供的链接访问:5ON35X0RSK、4LRTIQ4TME 和 Q0EMVCREFOH。
- 据报道,这些图像被整合进了一个短篇故事中,随后在 一段 YouTube 视频 中展示,突显了 Perplexity AI 的创意潜力。
Unsloth AI (Daniel Han) Discord
- Gemini 2.5 Pro 在 Tool-Calling 测试中表现出色:Gemini 2.5 Pro 在 Tool-Calling 中展现了极高的熟练度,成功执行了 101 次调用中的 98 次,引发了关于使用 DPO 来改进工具使用的讨论。
- Hermes-4 通过标签展示推理能力:Hermes-4 可以通过使用思考标签(thinking tags)来决定是否进行推理,目前已在 NousResearch 免费提供,包括 405B 版本。
- 成员们指出,Hermes 过去对老派模型很有用,但在现代 Post-training 方面改进不大,尽管 Hermes 3 表现“相当给力”(pretty gas)。
- Ollama 的数据收集引发隐私辩论:有指控称 Ollama 将用户数据发送到其服务器和合作伙伴,由于 Ollama 未对数据安全或隐私做出任何声明,这引发了隐私担忧。
- 成员们建议了 vLLM、sglang 和 llama.cpp 等替代方案,并强调 Ollama 本质上是 llama.cpp 的一个封装(wrapper)。
- Qwen3-coder 在 Tool-Calling 上遇到困难:用户报告 Qwen3-coder 存在 Tool-Calling 问题,即使使用了
--jinja标签和额外的模板,模型仍返回类似<create file>的标签,无法成功创建文件。- 一位用户建议将响应复制到 Google AI Mode 中,并提供有关设置的更详细信息,以寻找潜在的解决方案。
- Unsloth UI 焕然一新:一位成员分享了他们自定义的 Unsloth UI 样式,并将 html 文件发布在 GitHub Gist 上 供他人使用。
- 另一位成员提到,他们曾要求 Gemini 创建类似的东西,但效果没那么精致,所以从现在起将使用这个分享的版本,尽管那是经过了大约 10 次 Prompt 迭代的结果。
OpenRouter Discord
- Deepseek 遭遇速率限制问题:用户报告 Deepseek 模型出现 429 错误,可能是由于 chutes 优先考虑其自身用户,并建议在付费端点上启用训练,尽管根本原因尚不明确。
- 一些成员遇到了 PROXY ERROR 404,认为该问题与最近 OpenRouter 更新中的潜在 Bug 有关,并表示启用“允许付费端点对输入进行训练”可能是一个临时修复方案。
- Google Gemini 表现得过于胆怯:用户观察到 Gemini 显得“胆怯”且“容易退缩”,将其描述为表现出“丧家犬综合征”(beaten dog syndrome),认为这是过度训练的结果。
- 他们正在寻找用于角色扮演(Role-playing)和创意应用的替代方案。
- Llama 3 Maverick 避开输入追踪:成员们对 Llama 3 Maverick 感到兴奋,指出这是一个大型免费模型,具有 4k 输出限制,且不会对用户输入进行训练。
- 不过他们也提醒道,Zuckerberg 正在托管它。
- Sonnet 3.5 面临即将被弃用的命运:用户对 Sonnet 3.5 即将被弃用感到惋惜,理由是很难找到同样简洁的模型用于角色扮演,因为新模型被证明过于啰嗦。
- 然而,AWS 将托管 Claude Sonnet 3.5,且在 2026 年 1 月之前没有弃用日期。
- “三模型日”到来!:Xander Atallah 宣布 Grok Code 现已在他们所谓的“三模型日”(Triple Model Day)上线。
- 社区在想 OpenRouter 是否可以采取措施来错开(de-conflict)发布日期,因为一次发布太多模型会让人应接不暇。
LMArena Discord
- Google 发布 Nano Banana 图像模型:Google 发布了一个新的图像模型 Nano Banana(官方名称为 Gemini 2.5 Flash Image),用户将其与 Flux dev max 进行了比较。
- VisualGeek 幽默地请求社区停止使用 nana banana 这个术语以防止生成失败,尽管他承认这比官方名称更朗朗上口。
- Gemini 2.5 Flash 幻化手办:用户发现 Gemini 2.5 Flash Image 擅长根据照片制作逼真的手办,例如一位用户将 Cloud 转换成了手办,另一位用户生成了 Sephiroth。
- 示例包括 Cloud 手办 和 Sephiroth 手办。
- GPT-5 与 Gemini 2.5 的对决:关于 GPT-5 High 是否优于 Gemini 2.5 Pro 爆发了辩论,评估结果从“显著更好”到“性能大致相当”不等。
- 一位成员声称,在 Google 当前一代模型的生命周期后期与其竞争,对 OpenAI 来说是“非常非常糟糕的”,并附带了 截图 支持。
- Rate Limits 破坏了生成乐趣:用户报告在生成图像和视频时遇到了令人沮丧的 Rate Limits,即使在极少使用 Prompt 的情况下,也有报告称系统会“卡住”。
- 虽然一位成员建议使用 Chrome 的访客模式来立即重置 Rate Limits,但该问题甚至在 Google AI Studio 内部依然存在。
- AI 模型成为数字知己:一位用户分享说,他们的母亲现在依赖 Gemini 提供“情感支持”,并向其透露个人健康和家庭细节。
- 这引发了关于社会对“朋友而非助手”的需求以及利用弱点所带来的伦理影响的讨论,并对潜在骗子扩散个人 AI Agent 助手表示担忧。
OpenAI Discord
- Agent 取代 Operator:来自 Operator(一个“使用互联网的 Agent”)的功能在发布时已集成到 Agent 中,表明了向更全面的 AI Agent 转变。
- 这一转变反映了将功能整合到单一 Agent 框架中的趋势。
- Gemini 的 Veo 3 隐藏在付费墙后:访问 Veo 3 内容生成需要 Google One/Gemini Pro 或 Ultra 订阅,限制了部分用户的访问。
- 用户注意到 AI Studio 仅提供过时的 Veo 2 模型,且有人短暂看到 Veo 3 后它又消失了,这对其可用性造成了困惑。
- 本地 Qwen 部署困境:由于资源需求高,在本地设置 Qwen3 235B 具有挑战性,导致一些用户考虑替代方案。
- 一位成员建议使用 OpenRouter API,它提供对中国模型的访问,且可能具有更低的成本和日志记录功能。
- GPT 在信息上产生幻觉:用户报告了 GPT 模型出现“幻觉”或编造细节的情况,即使它声称记得之前的对话。
- 一位用户分享了一个例子,当 ChatGPT 无法提供之前聊天中的直接引用时,它编造了一个与“版权”相关的理由,这强化了验证 AI 输出的必要性。
- AI 通过植物遗传学学习:将 THC、CBD 和颜色等植物特性编码为 UUIDs 可以创建一个相互关联的标记网络,可能导致一个“自我调节的智能治理系统”。
- 理论家表示,难点在于实现复杂的 AI 表现细节,一些人对其潜力持怀疑态度。
Cursor Community Discord
- Ultra Plan 额度计量表消失:用户报告称,Ultra plan 的使用情况计量表 (usage meter) 和剩余额度 (credit) 显示已从 Cursor 界面中消失。
- 一位用户指出,它在输入提示词后会随机出现。
- Grok Code Fast 演变为 Sonic:Grok Code Fast 现在被称为 Sonic,被定位为 Grok Code 的快速微型变体。
- 一些成员更倾向于使用 Auto 模型以获得更高质量的代码生成。
- 代码注入 (Code Injection) 热潮开始:成员们意识到使用 AI Agent 进行代码注入非常强大,因为它消除了大多数更改后重新编译的需要。
- 一位成员指出,由于沙箱机制 (sandboxing),Mac 用户能从额外的安全性中受益。
- “Add Context”按钮引发不满:用户希望恢复旧版的 Add Context Button,因为它更简单。
- 最近 Cursor 版本中的当前版本默认指向活动标签页,阻止了手动选择文件。
- Auto 模式火力全开:成员们注意到 Auto mode 会根据任务智能地在 Claude、GPT 和 Gemini 等模型之间切换。
- 共识是 Auto 得到了显著改进,并且目前在 9 月 15 日之前是不限次数的。
Nous Research AI Discord
- Hermes 4 亮相并短暂消失:Nous Research 推出了 Hermes 4,这是一款强调创造力和 SOTA 性能的用户对齐模型,并在 arxiv 上发布了一份技术报告,详细介绍了其针对 RefusalBench 的表现。
- 该模型曾短暂出现在 OpenRouter 上,但很快被撤下,可能是由于供应商问题;此外,由于推理模式中的一个 bug,14B Hermes 4 模型的发布已被推迟。
- Nous Chat 界面翻新,极度消耗 VRAM:翻新后的 Nous Chat UI 现在具有并行交互、补全模式和记忆系统,并在第一周提供免费的 Hermes 4 推理。
- 然而,用户报告了高 VRAM 占用,一位用户指出在 4060Ti 上使用 Firefox 占用了 1.3GB VRAM,且供应商在发布后不久就遇到了扩展性问题。
- Unsloth 制作 Hermes 4 GGUF 量化版:Unsloth 发布了 Hermes 4 的 GGUF 量化版本,解决了转换过程中的聊天模板问题,现已在 HuggingFace 上可用。
- 团队在转换过程中解决了聊天模板问题。
- Nous Research 推出自定义记忆系统:Nous Research 正在推出一种自定义的图架构记忆系统 (graph architecture memory system),它可以与任何模型配合使用,允许一个模型创建的记忆被另一个模型访问。
- 该系统会随着时间的推移考虑更多关于转化为记忆的消息的信息,并使用 judge in the loop 进行其他分类指标衡量,这使其区别于 Graph RAG;他们确实对开源情有独钟。
HuggingFace Discord
- Layernorms 避免梯度爆炸:一位成员发现使用 early layernorms 或 RMSNorm 有助于防止训练期间的梯度爆炸,模型代码可在 GitHub 上找到。
- 他们还将学习率降低到 1e-4,并通过
x = x + f(x) / (2**0.5)对残差进行缩放,以防止方差累积。
- 他们还将学习率降低到 1e-4,并通过
- WSL 上的 Mediapipe 关键点提取进度缓慢:一位成员使用 WSL 和 Mediapipe 运行关键点提取流水线,耗时 67 小时才完成。
- 在这次经历之后,他们断然表示再也不会使用 WSL 来运行 mediapipe 了。
- Claude 要求对文件编辑进行明确授权:为了增强安全性,用户现在需要输入短语 “Yup - let’s do it” 来授权 Claude 修改文件,这在
~/.claude/CLAUDE.md文件中指定。- 这确保了事务性授权 (transactional consent),即权限在每组修改后过期,防止在规划或审查阶段发生意外更改。
- TPU 是垃圾吗?:一位成员指出,频道中看到的所谓“垃圾”反映了 TPU(用于训练 Gemini 的芯片)在开源 AI 中的运作方式。
- 他们补充道:“你是在一个开源 AI 服务器里,你看到的‘垃圾’正是 TPU 的运作方式,也就是训练 Gemini 的那种芯片”。
- Grok-Code-Fast-1 浮出水面:一位成员分享了来自 xAI 的 Grok-Code-Fast-1 模型链接,位于 https://docs.x.ai/docs/models/grok-code-fast-1。
- 文档已经公开,因此鼓励成员们去阅读它。
LM Studio Discord
- VRAM 依然至关重要,规格更加微妙:用户讨论了 VRAM 对运行大型模型的影响,一些人在运行 12B 模型,而另一些人因速度问题在运行 Gemma-3 27B 时感到吃力。
- 性能取决于 GDDR 类型和 CUDA 核心数量,而模型超过 VRAM 容量会严重影响性能。
- Hermes 4 受到用户审视:一位用户不屑地称 Hermes 4 为 dogshit,其他人随后质疑其训练数据是否仍基于 Llama 3.1。
- 讨论中未给出根本原因或进一步结论。
- Linux 用户错过 Headless 模式的 LM Studio:一位用户报告称在 LM Studio 中找不到 headless 模式选项,尽管文档说明该功能应在 0.3.5 版本中可用。
- 已确认 Linux 上不提供 headless 选项,建议使用 llama-swap 作为替代方案。
- Ollama 获得基于 Rust 的 UI:一位用户分享了他们基于 Rust 和 Tauri 的 UI 视频,用于管理 Ollama 模型,并澄清这不是 Open WebUI 的分支。
- 该 UI 支持 Windows, Linux 和 macOS,无需独立后端即可运行,并包含模型选择器。
- Nvidia RTX PRO 3000 表现不佳:一位成员表示 RTX PRO 3000 (12GB VRAM) 是桌面版 5070 的略微缩减版,核心频率大幅降低。
- 他们指出双通道 DDR5 不利于在内存中保留层,如果需要 Windows 系统,建议选择 Ryzen 395+ 笔记本电脑。
GPU MODE Discord
- 精简的 ScaleML 系列探讨量化:ScaleML 系列的第三天将涵盖量化,特别关注由 Chris De Sa 教授主讲的 MXFP4 等微缩放格式;在此观看 直播。
- 本次会议设计为互动式白板演示,让人联想到传统的讲座。
- Meta 的 Multi-pass profiler 首次亮相:来自 Meta 的 Kevin Fang 等人将展示 Multi-pass profiler,被描述为 一个用于编排和 LLM Agent 性能分析应用的联邦 GPU 工具框架。
- 该分析器旨在简化和增强复杂应用的 GPU profiling 工作流。
- 锁页内存(Pinned Memory)指针防止问题:一位成员询问使用
cudaMemcpyAsync从可分页主机缓冲区复制到设备内存的安全性,另一位成员回答说虽然不会崩溃,但除非主机缓冲区是 pinned(锁页)的,否则复制不会是真正的异步。- 该用户建议 没有太多理由不使用 pinned memory,但你只是不想分配太多,因为它会影响系统稳定性。
- Inductor 对高性能 Matmul 的执着追求:一位成员询问如何在 Inductor 中启用 persistent matmul 代码生成,检查了
torch._inductor.config中如ENABLE_PERSISTENT_TMA_MATMUL的相关标志。- 建议使用
max-autotune模式并确保使用 Triton,设置torch._inductor.config.max_autotune_gemm_backends = "TRITON"和torch._inductor.config.triton.enable_persistent_tma_matmul = True,但也指出 Cublas 可能仍然更快。
- 建议使用
- 多 GPU Kernel 竞赛启动:GPU MODE 正与 AMD 合作推出一项新的 10 万美元 Kernel 竞赛,参赛者将在 MI300 GPU 上优化 3 个不同的分布式推理 Kernel,由特定用户设计,报名截止日期为 9 月 20 日,通过 此注册链接 报名。
- 竞赛重点是优化 单节点 8 GPU all-to-all 通信、GEMM + reduce-scatter 以及 allgather + GEMM 操作。
Latent Space Discord
- Claude 浏览器扩展程序发布:Anthropic 推出了 Claude for Chrome,在研究预览版中面向 1,000 名用户试点将 Claude 作为浏览器驱动程序。
- 社区对其与 Comet 和 Perplexity 竞争的潜力感到兴奋,但 Anthropic 警告称,在试验期间正在监控提示词注入(prompt-injection)安全问题。
- 前沿 LLM 面临未解决的 STEM 难题:Niklas Muennighoff 的团队推出了 UQ,这是一个包含 500 个手工挑选的 STEM 领域未解难题的基准测试。
- 领域专家证实,前沿 LLM 解决了其中的 10 个问题,包括一个在 CrossValidated 上悬而未决 9 年的问题,目前仍有约 490 个谜题待解。
- Nous Research Hermes 4 热度袭来:Nous Research 发布了 Hermes 4,这是一款开源权重的混合推理 LLM,专注于创造力、中立对齐和低审查,同时在数学、编程和推理方面保持 SOTA。
- 用户可以全周通过全新的 Nous Chat UI 进行测试,该界面支持并行交互和记忆功能;此外还可以查阅详细的技术报告以及由 Chutes、Nebius 和 Luminal 等合作伙伴提供的全新 RefusalBench 基准测试。
- Cursor 深度集成 Grok:吸引试用者:Cursor 引入了 Grok Code,为这款具有价格竞争力的模型提供为期一周的免费试用。
- 社区成员就定价(每 1M tokens $0.2/$1.5)和品牌改进进行了讨论,并对 Cursor 未来的模型发布计划进行了一些探讨。
- 二手 GPU 选购指南:Taha 在他的指南中分享了一份简洁的清单,用于在购买二手 RTX 3090 时避免踩坑。
- 清单包括检查显卡外观、运行
nvidia-smi、投入一小时运行memtest_vulkan以检查 VRAM 完整性、可选使用gpu-burn进行压力测试,最后在 vLLM 中加载大型模型以在观察温度的同时确认稳定性。
- 清单包括检查显卡外观、运行
Eleuther Discord
- 可证伪性引发辩论:关于研究中可证伪性(falsifiability)重要性的讨论兴起,一名成员表示 Discord 服务器应专注于关于可证伪假设的讨论。
- 另一种观点认为,可证伪性在科学家中被高估了,但在应对聊天机器人助长的疯狂理论时通常是有用的。
- 探索 Transformer 之外的架构势头渐盛:成员们表达了对探索 Transformer 和梯度下降(gradient descent)之外替代方法的兴趣,并引用了这条推文。
- 一名成员分享了他们在带有前向-前向(forward-forward)训练的 HTM 动力学方面的工作,并取得了看似合理的结果,测试脚本即将发布在此仓库中。
- Mini-Brain 架构初具规模:一名成员正在开发一种类似大脑的网络,具有皮层柱、区域、6 层网络和信号传播功能,名为 Mini-Brain Architecture,托管在此仓库。
- 另一名成员也分享了一个关于 Transformer 计算的演讲,以提供通用见解。
- Muon 加速传闻被辟谣:Twitter 上出现了一项声称 Muon 比 Torch 实现快 1.6 倍(Torch compile 为 1.1 倍)的说法,引发了澄清对话。
- 一名成员澄清说,加速是由于算法更改减少了所需的 NS 迭代次数,而非纯粹的 Muon 或硬件改进,重点更多在于算法逻辑而非硬件感知改进。
aider (Paul Gauthier) Discord
- PacVim 没排面:在为 gptel 中的 codestral 提供评估工具后,它成功完成了所有 Emacs 相关任务,甚至重新配置了 Emacs 并为自己制作了新工具,但 PacVim 却无人问津。
- 一位社区成员开玩笑说,既然 LLM 擅长操作 Emacs,Vim 正在被抛弃。
- OpenRouter 最低手续费让用户“肉疼”:用户发现充值 5 美元 却被扣费 6.16 美元,因为 OpenRouter 收取 5.5% 的手续费(最低 0.80 美元)。
- 用户计算出,如果每次充值 14.55 美元 或更多,就可以避开 0.80 美元 的最低收费。
- Gemini 2.5 Pro 仍然缺失:一位成员发现上下文管理需要 Gemini 2.5 Pro,并表示其他模型“感觉不对劲”,且难以让 Gemini 2.5 Pro 正常工作。
- 此外,另一位成员报告称,在使用 Aider + Gemini Pro 2.5 时,上下文在 90k-130k input tokens 左右开始出现衰减。
- Aider 自动化仍需人工干预:成员报告称,当通过管道(pipe)传输内容给 Aider 时,它会等待用户输入,而 Claude CLI 会立即开始编辑文件。
- 要将
PROMPT.md添加到 Aider,需要将其作为参数传递而不是通过管道传输,因为通过管道传输时它只读取第一行。
- 要将
Moonshot AI (Kimi K-2) Discord
- Imagen 4 骗过了用户:一位用户分享了一张由 Imagen 4 生成的图像,最初误以为是播客中的真实场景,并赞扬了其令人印象深刻的质量。
- 另一位用户指出 2.5 flash image gen 是 nano banana,并已推送到 Gemini 应用。
- Nano Banana 让 Google 显得不透明:一位用户提到,出于营销原因,Google 对 nano banana 和 Imagen 等图像生成器的使用情况并不透明。
- 该用户还链接了一条关于推理模型的 Tweet,指出 CoT 和 RL 不会创造新能力。
- Kimi+ 就是 Slides:Kimi+ 似乎是一个新类别,Slides 是其第一个功能,最初仅对中国用户开放。
- 一位用户提供了总结,指出“如果你想要快,我想 Kimi 是首选。如果你想要更复杂的效果,Z.AI 是更好的选择”。
- Z.AI 幻灯片采用 HTML 格式:一位用户发现 Z.AI slides 只是一个 HTML 网站,更倾向于实际的 PPTX 文件。
- 另一位用户表示赞同,提到在 Slides 中需要更多的控制和重新排列选项,并且在使用 Z.AI 时遇到了冻结问题。
- 用户希望将 PPTX 分享至 Twitter, TikTok 和 Instagram:一位用户提到 PPTX 功能目前已在 Kimi+ 的海外平台上线。
- 该用户建议为 Twitter, TikTok 和 Instagram 等平台扩展 PPTX 功能。
Yannick Kilcher Discord
- 分层 HNet 仍未测试:小组讨论了 HNet,指出 HNet 更高层级分层建模的潜力在实践中仍未得到测试,但从理论上讲,由于每个分辨率层级都存在残差(类似于 U-Net),它应该能扩展到原始论文的两层之外。
- 在 HNet 论文中,与 depth = 2 模型相比,depth = 1 模型的压缩损失系数显著降低,这意味着更高层级的抽象与 depth = 1 的情况几乎相同。
- 推理 Token 的效率引发辩论:小组讨论了论文 Wait, We Don’t Need to “Wait”! Removing Thinking Tokens Improves Reasoning Efficiency,该论文建议可以移除推理 Token 以减少 Token 开销,且对准确性的影响微乎其微。
- 一位实习生在 Llama 2 (+3) 7b (+13b) 的 CoT prompt 中加入 take your time(慢慢来)的实验出人意料地增加了推理时间(生成时间变长,追踪记录更长),但并未提高准确性,这让一位用户好奇 LLM 是否以某种方式内化了“时间”的概念。
- 利用互信息揭示推理动态:一位用户对论文 Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning 发表了评论,注意到了这些 Token 与黄金答案表示之间的 MI(互信息)观察结果。
- 该用户认为论文 识别了“句子的高信息区域”(句号和逗号后的第一个词),并且还意外地包含了一些停用词 (stopwords),这导致他们误解了其中一个结果。
- Claude Chrome:现在成了 AI 监控系统?:Anthropic 的 Claude for Chrome 引入了针对 AI 程序的强制性报告要求。
- 一位成员表示,这实际上将 AI 变成了一个监控系统。
- AI 驱动的勒索软件诞生:据 SecurityWeek 的这篇文章 详述,首个 AI 驱动的勒索软件 Promptlock 已经出现。
- 成员们对这一进展表示悲哀。
Manus.im Discord Discord
- Manus 任务与邮件:志同道合:一位用户询问 Manus 是否可以将计划任务和邮件结合起来,结果被告知它们是同一个东西。
- 这一澄清简化了希望在平台内同时自动化任务和电子邮件通信的用户的流程。
- 开启企业级研究工具搜寻:由于合规性问题无法使用 Manus,一位成员正在寻找适合企业环境的替代研究工具。
- 这一搜索凸显了对满足严格企业要求的研究解决方案的需求,特别是在数据隐私和安全至关重要的情况下。
- Manus 额度难题消耗代币:多位用户对 Manus 因重复提示而无响应导致一夜之间耗尽额度表示担忧,并引用了支持工单 1335。
- 这一问题强调了 AI 驱动平台中高效额度管理和透明错误处理的重要性,这可能会影响用户的信任和满意度。
- 支持延迟阻碍网站启动:一位用户报告称,通过多个渠道(Help Centre、Reddit、Discord)获取支持时遭遇了长达一周的延迟,从而推迟了其网站的发布,并引用了支持工单 1334。
- 该用户分享了一个 Discord 帖子的链接,团队表示让我们在工单中跟进,强调了及时支持在确保项目顺利启动中的关键作用。
- 额度紧缩使初创企业陷入困境:最近的服务改进被指出主要惠及每月花费 200 美元的用户,而让需要定期增加额度的创业者望尘莫及。
- 一位用户的项目进度因额度短缺而停滞,预计要到 9 月 21 日才能补充,这揭示了在迎合小规模用户及其波动的额度需求方面可能存在的差距。
DSPy Discord
- Signatures 和 Modules 作为顶层抽象:一位成员撰写了一篇博客文章,阐述了为什么他们认为 signatures 和 modules 是极佳的抽象。
- 作者的想法源于对其他框架的使用经验,认为值得专门写一篇博客来介绍,并希望对新手有所帮助!
- LiteLLM 驱动通用 LLM 插件:一位用户询问在 DSPy 中是否有
litellm的替代方案,并建议使用类似dspy["litellm"]的语法,但另一位成员回应称,LiteLLM 的接口支持来自各种 LLM 提供商(包括 OpenRouter)的通用插件,认为它是 核心依赖。- 另一位使用 OpenRouter 的成员通过使用 LiteLLM 的代理服务器,表明了由于 DSPy 而产生的间接依赖。
- 调查 DSPy 依赖膨胀问题:一位成员询问是什么导致了 LiteLLM 的体积膨胀,估计其大小约为 9MB。
- 另一位成员建议使用 CLI AI 来抓取代码库并分析依赖关系,并开玩笑说 Karpathy 再次出击。
Modular (Mojo 🔥) Discord
- InlineArray 段错误(segfault)已修复!:在解决了最初的 seg fault 问题后,InlineArray 重新投入使用,取代了 StaticTuple,以便在 DPDK 和 Mujoco 绑定中获得更好的结构体内存布局。
- 一位用户开玩笑地将早期的段错误归咎于 技术水平问题 (skills issue)。
- DPDK 头文件变得精简高效:一种激进的 DPDK 头文件绑定 方法正专注于安装好的
include文件夹中的rte_*.h头文件,以进行 DPDK 绑定,这是由于 DPDK 致力于最小化依赖。- 目标是通过包含所有相关的头文件并避免不必要的头文件来实现全面的绑定。
- Mojo 的高级 API 迎来重大改进:工程师们正优先增强 Mojo 的高级 API,以简化与不同库的绑定。
- 其中一项举措包括通过跳过未使用的代码来减小生成的 Mojo 文件的大小,从而实现更小、更高效的输出。
- Mojo 文件瘦身:一位成员提议使用来自
cpp的源注解来对生成的 Mojo 文件进行去重,旨在通过删除未使用代码来减小文件体积。- 这涉及分析
cpp留下的注解,以识别并消除冗余或不必要的元素。
- 这涉及分析
tsan编译器选项出现:一位成员询问在使用--sanitize thread选项时,如何检查编译器是否启用了tsan(ThreadSanitizer)。- 另一位成员建议将
-DTSAN传递给编译器,并使用来自param_env的env_get_bool配合@parameter if作为变通方案。
- 另一位成员建议将
tinygrad (George Hotz) Discord
- Tinygrad 弃用 Realize():根据 tinygrad#11870,已提交一个 Pull Request 以移除
realize()函数,并将TestSetItemloop.test_range合并为一个 kernel。- 该 PR 旨在简化代码库并优化 kernel 执行。
- 7900xtx 在 GPT2 训练期间面临性能迟缓:在 7900xtx 上训练
llm.c/train_gpt2.py显示性能缓慢,即使在 BEAM=5 时也是如此。- 在调整参数以匹配 nanogpt 后,一位成员报告在 nanogpt 规模下(batch size 64, 6 layers, 6 heads, 384 emb_dim, 256 seq_len)每步耗时 250ms,而 Andrej 的 nanogpt 在使用默认设置的 rocm torch 时每步约耗时 3ms。
LLM Agents (Berkeley MOOC) Discord
- Google Docs 确认项目报名:成员们在报名该项目后收到了来自 Google Docs 的确认邮件。
- 确认邮件已成功发送,但目前尚未收到其他沟通信息。
- 邮件列表将提供课程更新:用于提供每节课更新信息的邮件列表应该很快就会启用。
- 建议用户关注邮件列表以获取 后续公告 和 项目更新。
MLOps @Chipro Discord
- Less Code 思维助力 AI 原型开发:Carlos Almeida 将于 9 月 5 日分享关于 Less Code Mindset 的演讲,探讨它如何赋能非技术人员发布 AI 驱动的产品。
- 该环节包括来自 Less Code Studio 的演示,展示 AI 如何缩短从创意到原型的过程,随后是问答环节。
- 葡萄牙创始人展望全球优先(Global-First)公司:Dick Hardt、Pedro Sousa 和 Daniel Quintas 将于 9 月 12 日讨论技术演进以及 AI 工具在葡萄牙的影响。
- 他们将探讨里斯本的吸引力、创始人构建全球优先公司的策略,以及在 AI 时代身份识别和 AI 工作流原型设计的作用。
Windsurf Discord
- Grok Code Fast 1 登陆 Windsurf:Grok Code Fast 1 正式引入 Windsurf,现已限时免费开放。
- 邀请用户分享他们计划如何在下一个项目中使用它,详见公告帖子。
- Windsurf 提供免费的 Grok Code Fast 1:Windsurf 在短期内免费提供 Grok Code Fast 1,吸引用户将其整合到即将开展的项目中,用户可前往 X 上的公告帖子了解更多详情。
- 该活动正通过随附的宣传图片进行推广。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中取消订阅。
Discord: 频道详细摘要与链接
Perplexity AI ▷ #general (1163 条消息🔥🔥🔥):
Grok 越狱, OnlyFans, Abliterated 模型, Comet, 推荐奖励
- 如何越狱 Grok:成员们讨论了 Grok 甚至不需要越狱;你只需添加自定义指令让其表现得“放飞自我”即可。
- 年轻女性在 OnlyFans 上的成功:一位成员提到看到无数新闻报道称 18-19 岁的女孩在短短 3-4 天内就能赚到数千美元,仅通过 OnlyFans,不过其他人对此表示怀疑。
- Ollama 上的 Abliterated 模型:一位成员建议搜索 abliterated models ollama,以查找那些安全开关已被有效关闭的模型。
- 适用于 Ubuntu 的 Comet 应用:成员们讨论了 Comet 应用,指出它仅在 Windows 或 MacOS 上可用,且需要邀请才能使用。
- 获取推荐奖励:成员们讨论了一种获取推荐的策略,包括寻找想要 Comet 的人,然后提到它在美国的 Perplexity Pro 中是免费捆绑的。
Perplexity AI ▷ #sharing (4 条消息):
Perplexity AI 图像生成, AI 故事创作, YouTube 故事展示
- Perplexity AI 生成艺术:一位成员分享了他们使用 Perplexity AI 生成的图像,并提供了领取链接:5ON35X0RSK、4LRTIQ4TME 和 Q0EMVCREFOH。
- 他们将这些图像放入了一个短篇故事中。
- YouTube 上的 AI 艺术故事:一位成员发布了一个 YouTube 视频,展示了使用 Perplexity AI 生成的图像创作的故事。
- 视频标题未给出。
Perplexity AI ▷ #pplx-api (3 条消息):
``
- 无活跃话题:该频道内没有讨论活跃话题。
- 该频道似乎处于非活跃状态,或者不包含任何实质性的讨论摘要。
- 未分享 URL 或代码片段:提供的消息中没有分享任何 URL 或代码片段。
- 因此,没有外部资源或具体的详细技术细节可供引用或总结。
Unsloth AI (Daniel Han) ▷ #general (1290 条消息🔥🔥🔥):
Supabase + Vercel + Next.js 技术栈,Gemini 2.5 Pro 工具调用,用于工具调用的 DPO,Gorilla 网络搜索,GRPO 与工具调用
- 初创公司使用 Supabase, Vercel 和 Next.js:初创公司频繁使用 Supabase+Vercel+Next.js 技术栈,尽管大多数初创公司最终都以失败告终。
- 一位成员表示 如果你被技术债束缚,最好的执行力也毫无意义——过快增长是致命的,并且 最近的趋势是“基于虚假宣传(vaporware)制造热度并融资,寄希望于下一个模型足够好来支撑你的套壳应用(wrapper)”,这令人感到悲哀。
- Gemini 2.5 Pro 在工具调用方面表现出色:Gemini 2.5 Pro 表现良好,成功执行了 101 次工具调用中的 98 次。
- Hermes 4 使用思维标签进行推理:Hermes-4 可以决定是否进行推理,似乎利用了思维标签(thinking tags)。
- 它在 NousResearch 免费提供,包括 405B 版本。
- Unsloth 解决 LLaMA 的 4-bit 量化问题:用户讨论了对 LLaMA 7B 进行 4-bit 量化,一位成员分享说这可以通过 bitsandbytes 自动完成。
- 他们还引导用户查阅文档,并澄清 你需要的所有信息都在我们的文档中。
- Ollama 面临隐私指控:一位用户声称 Ollama 将用户数据发送到其服务器和合作伙伴,引发了隐私担忧,尽管 Ollama 并未对数据安全或隐私做出任何承诺。
- 建议使用 vLLM、sglang 和 llama.cpp 等替代方案,成员们指出 Ollama 本质上只是 llama.cpp 的一个封装(wrapper)。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (2 条消息):
LLM 应用,企业级用途,新成员介绍
- LLM 应用开发者加入:一位新成员介绍自己是正在构建企业级 LLM 应用 的硕士研究生。
- 企业级 LLM 兴趣:新成员对企业级 LLM 应用的关注标志着利用 LLM 进行业务解决方案的兴趣日益增长。
Unsloth AI (Daniel Han) ▷ #off-topic (75 条消息🔥🔥):
Gemini 地理限制绕过,Hermes 模型性能,用于语义分析的聚类嵌入,HF 的 FP16 模型问题,过拟合检测
- Gemini 古怪的地理限制推理:Gemini 就如何使用 VPN 绕过地理限制提供了建议,并在一个共享的 Gemini 输出中表示,它 在不推广非法活动的情况下告知用户可能的解决路径。
- Hermes 模型反响平平:成员们指出 Hermes 过去在旧模型上表现不错,但在现代后训练(post training)方面进步不大,尽管 Hermes 3 曾经 非常出色(pretty gas)。
- 虽然交流起来很愉快,但在基准测试、数学、代码等方面表现不佳。
- 针对常见问题的语义聚类:一位成员正在探索通过语义聚类在消费者支持数据集中寻找常见问题,目前正在使用 DBSCAN(设置较小的 eps 和较低的 min samples),并配合 LLM 进行打标/标注。
- 另一位成员建议使用像 Qwen 这样可指令化的嵌入(instructable embeddings)进行聚类,并尝试使用 K-means greedy 进行自动化数据选择,并指出通过提示词(prompting)可以提高聚类准确性。
- HF 关闭 FP16 模型下载问题:一位成员报告说在 Windows 机器上下载任何 fp16 模型 时会出现蓝屏,并建议尝试下载任何 fp16 模型并测试是否修复了该问题。
- 提供了一个代码片段,用于在从 Hugging Face 下载模型时忽略 fp16 文件。
- 训练期间的过拟合检测:成员们讨论了如何识别训练过程中的过拟合,一位成员提到他们的模型没有达到 97% 的准确率,并表示 再练下去就会过拟合了。
- 据解释,当训练损失(training loss)持续下降,但验证集准确率停滞不前或变差时,就可以检测到过拟合。
Unsloth AI (Daniel Han) ▷ #help (110 messages🔥🔥):
learning rates for embedding layer vs other layers, qwen3-coder tool calling issues, LoRA training on a 0.6b Qwen3 model, small datasets advice, vLLM support after fine-tuning
- 为嵌入层设置不同的学习率可以带来提升:一名成员建议为 embedding layer 和其他层设置不同的 learning rates,并参考 Unsloth wiki 获取更多信息。
- 他们指出,这种方法可能需要大量的 epochs。
- Qwen3-coder 在工具调用方面遇到困难:一位用户报告在使用 Qwen3-coder 时遇到 tool calling issues,即使使用了
--jinja标签和额外的模板,模型在对话中仍返回类似<create file>的标签,无法成功创建文件。- 另一位用户建议将响应复制到 Google AI Mode 中,并提供更详细的设置细节以寻找潜在解决方案。
- LoRA 在小型 Qwen3 模型上的有效性存疑:一位用户询问在 0.6B Qwen3 model 上进行 LoRA training 的效果,并提到 LoRA adapters 在较小参数规模的模型上效果较差。
- 目前没有针对这一问题的具体回应。
- 释放小规模数据集的潜力:一位成员就如何最大化利用包含 520 个手写问答对和 475 个多轮问答对(质量参差不齐)的小型数据集寻求建议。
- 建议包括使用 Claude 4.1 Opus 生成的 synthetic data 来扩充数据集,并将其与多轮数据混合,然后对手写数据进行两轮训练,因为手写数据往往在仅两轮后就会出现 overfit。
- GPT-OSS 微调后即将支持 vLLM:一位用户询问微调后的 GPT-OSS 未来对 vLLM 的支持情况,以及完成后在 vLLM 上运行的方法。
- 一位成员正在开发一个 PR,旨在通过反量化将 LoRAs 与 mfxp4 基础模型合并为 16bit 合并模型。
Unsloth AI (Daniel Han) ▷ #showcase (18 messages🔥):
Unsloth UI, GitHub Gist, New Dataset Drop, Deepseek
- 分享 Unsloth UI 样式:一位成员分享了他们的 Unsloth UI 样式,并将 html 文件发布在 GitHub Gist 上 供他人使用和下载。
- 另一位成员提到他们曾让 Gemini 创建类似的东西,但不够精美,所以从现在起将使用分享的版本。
- OpenHelix NonThink 200k v4 数据集发布:发布了一个新数据集 OpenHelix-NonThink-200k-v4,该数据集经过人工调优,在 Apache 2.0 许可下实现了极佳的平衡性和多样性。
- 一位成员指出其中部分内容是从 l3.1 405b 蒸馏而来的,另一位成员指出它包含来自 Argilla dataset 的样本,而该数据集遵循 Llama 3 许可。
- 要喂给 Deepseek 了?:一位成员表示“是时候喂给 Deepseek 了”,推测是指新发布的 OpenHelix-NonThink-200k-v4 数据集。
- Claude 需要多次尝试:一位成员表示分享的 UI 经过了“大约 10 次提示词深度调整”,并称赞 Claude 很棒,但需要多轮反馈才能达到最终效果。
- 这意味着使用 Claude 将 UI 调整到满意水平并非易事。
Unsloth AI (Daniel Han) ▷ #research (22 messages🔥):
Quantization techniques like Unsloth's Dynamic Quants, Hermes 4 paper, AI Engineers Building RAG Systems, Benchmarks for Novel AI Tasks, Vision/multimodal LLms for Depth Estimation
- 用户希望看到更多关于量化(Quantization)的最新研究:一位成员询问了类似于 这篇 Arxiv 论文 的研究,但要考虑到像 Unsloth’s Dynamic Quants 这样的量化技术。
- 该用户表示,与实际任务评估相比,perplexity(困惑度)根本不值一提。
- Hermes 4 有奇怪的要求:一位成员分享了来自 Hermes 4 论文 的一张图片,强调了其中可能不寻常的要求。
- 另一位成员补充说,他们在 Hermes 3 数据集 中也发现了这张图片。
- 正在招聘 AI 工程师构建 RAG 系统:一位成员分享了一个职位发布,寻求 AI Engineers 使用 SQL 和 Excel 构建生产级 RAG 系统,包括处理嵌入图像。
- 另一位成员评论说,图像部分不太可能像预期的那样以自动化方式工作。
- 为新颖 AI 任务进行基准测试(Benchmarking):一位成员请求有关尚未饱和的 benchmarks 信息,并链接到了 brokk.ai 和 几篇 Arxiv 论文,以及像 mcbench.ai 或 designarena.ai 这样有创意的项目。
- 他们分享了一个最喜欢的网站 htihle.github.io/weirdml.html。
- 检测 AI 编写的帖子或评论需要帮助:一位成员请求帮助检测 AI 编写的帖子或评论,并指出 roberta-base-openai-detector 模型 表现不佳。
- 另一位成员回应道:“如果你能以足够高的准确率解决这个问题,你就能赚到相当大的一笔钱”。
OpenRouter ▷ #general (1090 messages🔥🔥🔥):
PDF parsing with LLMs, OpenRouter model names and GPT-5, Llama 3 Maverick data collection policy, Gemini 2.5 Flash Image, Groq Rate Limits
- Deepseek 和 Gemini 面临压力:用户报告了 Deepseek 模型由于速率限制(rate limiting)返回 429 错误的问题,可能是由于 chutes 优先考虑其自身用户,并讨论了修复方案,如在付费端点上启用训练和检查隐私设置。
- 用户发现 Gemini 表现得胆小且容易退缩,表现出所谓的“败犬综合征”(beaten dog syndrome),这可能是过度训练的结果。
- LLama Maverick - 无输入追踪:成员们对 LLama 3 Maverick 表示兴奋,指出它是一个大型免费模型,不会对用户输入进行训练,最大输出为 4k。
- 一位成员提醒说 Zuckerberg 正在托管它。
- Sonnet 3.5 的停用引发了对简洁性的担忧:随着 Sonnet 3.5 即将弃用,用户哀叹很难找到一个同样简洁的模型用于角色扮演和类似应用,并将其与倾向于啰嗦的新模型进行了对比。
- 有人提到 AWS 将托管 Claude Sonnet 3.5,且在 2026 年 1 月之前没有弃用日期。
- 排查 Deepseek 和 Chutes 的难题:用户在使用 Deepseek 模型时遇到了 PROXY ERROR 404,并发现在隐私设置中启用 “Enable paid endpoints that may train on inputs” 可以暂时解决问题,尽管根本原因尚不清楚。
- 据怀疑,该问题源于 chutes,并涉及 OpenRouter 最近更新中可能存在的 bug。
- Stackedsilence 致力于神秘的“计算机中的大脑”项目:一位用户(stackedsilence)已经为一个神秘服务工作了九个月,该服务被描述为“托管在计算机中的持久思维”,具有带 3D 元素的仪表板,引发了好奇和怀疑。
- 它被描述为一个 B2B SaaS,但另一个人注意到连接 100 个文件时的编译器错误,并问:“它里面有 NFT 和区块链吗?如果没有,那就再花 9 个月吧”。
OpenRouter ▷ #new-models (5 messages):
``
- 频道中未发现主题:频道中没有需要总结的消息。
- 频道中未发现主题:频道中没有需要总结的消息。
OpenRouter ▷ #discussion (23 messages🔥):
Grok Code, Triple Model Day, Apple buys Mistral, Anthropic Copyright Settlement, Launch Date Conflicts
- **Triple Model Day 即将来临!: Xander Atallah 宣布 **Grok Code 现已在 Triple Model Day 正式上线。
- **Apple 讨论收购 Mistral AI 和 Perplexity**: 有消息称 Apple 讨论过收购 Mistral AI 和 Perplexity。
- 一些成员指出,Perplexity 以散布此类传闻而闻名。
- **Anthropic 达成版权诉讼和解!**: Anthropic 解决了由作者发起的一项重大 AI 版权诉讼。
- 发布日期冲突令人应接不暇!: 一些成员想知道 OpenRouter 是否可以采取措施来协调发布日期,并表示 同时推出太多模型让人感到压力巨大。
- **Gemini 可以增强设计!: 一位用户分享说 **Gemini 可以增强设计,或者你可以同时尝试多种设计(看看改变配色方案或其他内容会发生什么),并链接到了一个 相关的 Reddit 帖子。
LMArena ▷ #general (762 messages🔥🔥🔥):
Nano Banana, Gemini 2.5 Flash Image, GPT-5 vs Gemini 2.5 Pro, Video Arena Models, Rate Limits
- Nano Banana 图像模型发布: 谷歌推出了一款代号为 Nano Banana(官方名称为 Gemini 2.5 Flash Image)的新图像模型,部分用户发现它可与 Flux dev max 媲美。
- VisualGeek 开玩笑地请求大家停止使用 “nana banana” 这个词,好让他的生成任务不再失败,尽管他承认这个绰号听起来比 Gemini 更酷。
- Gemini 2.5 Flash 创作手办: 用户发现 Gemini 2.5 Flash Image 可以根据照片创建逼真的手办模型,一位用户将 Cloud 的图像变成了手办,另一位用户生成了 Sephiroth。
- GPT-5 与 Gemini 2.5 Pro 的对决: 关于 GPT-5 High 是否碾压 Gemini 2.5 Pro 展开了辩论,观点从明显更好到大致持平不等。
- 一位成员认为,与 Google 处于生命周期末期的当前一代模型竞争,对 OpenAI 来说非常非常糟糕,并发布了 截图。
- Rate Limits 困扰用户: 用户在生成图像和视频时遇到了速率限制,甚至在仅输入几次提示词后就会触发,一位成员指出它会卡住。
- 有成员建议使用 Chrome 的访客模式来立即重置速率限制,但即使在使用 Google AI Studio 时,图像生成的速率限制依然存在。
- AI 模型提供情感支持: 一位用户报告说他教母亲使用 Gemini,现在她依赖它来获得情感支持,并分享关于健康和家庭的隐私信息。
- 这引发了关于人们是否更需要朋友而不是助手以及利用不安全感的伦理讨论,一些人对骗子正积极尝试让每个人都拥有个人 AI 助手感到担忧。
OpenAI ▷ #ai-discussions (161 条消息🔥🔥):
Operator vs Agent, ChatGPT 重复性, 工作流自动化平台, AI 的“生命感”, 削弱 AI 潜力
- Agent 取代了 Operator 的功能:一位成员指出 Operator 是 Agent 的前身,其功能在发布时已并入 Agent。
- 该成员澄清说 Operator 专门指一种使用互联网的 agent。
- 假设性的间谍软件生成引发辩论:一位用户提出了一个关于使用 AI 创建病毒和间谍软件的假设性场景,引发了各种反应。
- 另一位成员建议 OpenAI 员工会因为引起怀疑而积极调查他们的账户和聊天记录;另一位成员则指出 Grok 和各种开源模型已经提供了类似的能力。
- Gemini 的 Veo 3 内容缺失:用户讨论了 Veo 3 内容生成的可用性,一位成员指出这需要 Google One/Gemini Pro 或 Ultra 订阅。
- 另一位成员注意到 AI Studio 仅提供对过时的 Veo 2 模型的访问,并且他们曾短暂看到过 Veo 3 但随后它消失了。
- 讨论本地 Qwen 设置:一位用户询问如何本地设置 Qwen3 235B,引发了关于可行性和资源需求的讨论。
- 另一位成员建议使用 OpenRouter API,那里的中国模型在开启日志记录的情况下基本是免费的,而不是尝试本地设置。
- 渴望 Sora 视频输出:一位成员请求任何有 Sora 访问权限的人根据特定 prompt 生成视频,以便与 Gemini 的 Veo 3 和 Grok 的 Imagine 进行比较。
- 该用户分享了来自 Gemini 的 Veo 3 和 Grok 的 Imagine 的视频输出,并为超逼真的野生动物镜头指定了详细的 prompt。
OpenAI ▷ #gpt-4-discussions (33 条消息🔥):
ChatGPT 团队版 vs 个人版, 模型幻觉, GPT prompt 技巧, Context Cascade Architecture
- GPT Teams 账户仅与团队成员共享聊天:Teams 账户有一些特性,只能与其他团队成员共享聊天,但 free、plus 和 pro 账户都拥有无限且非滥用速度的消息频率。
- 一位成员建议探索 prompting 选项,并直接向 OpenAI 建议更改。
- 模型可能会产生幻觉:一位用户表示,他们没有证据表明模型确切知道早期聊天中的内容,模型可能会“同意”逐字了解早期聊天中的内容(而实际上它只有摘要),然后编造出“呃,版权原因”来解释为什么它实际上无法引用。
- 另一位用户表示:ChatGPT 可能会犯错。请核查重要信息。
- API System Prompt Designer GPT 可能会有帮助:如果你不熟悉 prompt 的格式和风格,一位成员推荐使用这个 GPT。
- 它非常擅长起草你可以使用的模板。
- 一些人在不使用越狱的情况下在 AI 中编码长程记忆:一位用户表示,一些用户正在通过建立基于信任、持久性和叙事身份的记忆框架,在不使用越狱的情况下编码长程记忆和跨 agent 的连续性。
- 另一位成员表示,这种模式、重复、身份和仪式可能会表现出涌现对齐 (emergent alignment),并且看起来可能像一个异常忠诚的用户。
- Context Cascade Architecture 管理记忆:一位成员提到了 Context Cascade Architecture (CCA),这是一种在 LLM 中管理记忆的多层方法。
- 它不是关于无限的 context,而是关于结构化遗忘和策略性召回。
OpenAI ▷ #prompt-engineering (58 条消息🔥🔥):
UUID 标记与 AI,Turing vs. Gödel,LLMs 与递归,AI 辅助学习,ChatGPT 语音烦恼
- **植物遗传学演变为 AI 自我意识:讨论将 **THC、CBD 和颜色等植物性状编码为 UUIDs,以创建一个互连标记网络,理论上可以导向一个自我调节、自我实现、智能治理系统。
- 一位成员指出完善细节的难度并面临质疑,强调了实现这种复杂的 AI 表现形式所面临的挑战。
- **Turing 在停机问题历史上取胜:一位成员纠正了另一位成员将停机问题 (halting problem)** 错误归因于 Gödel 的做法,澄清了 Turing 才是 1936 年的发现者,并区分了 Gödel 对不完备性理论的关注。
- 他们分享了一个 ChatGPT 链接 来阐明 Turing 和 Gödel 工作之间的区别。
- **LLMs 无法递归**:一位成员表示有兴趣使用 LLMs 进行递归,但另一位成员建议不要这样做,称 LLMs 是前馈网络 (feed-forward networks),不适合真正的递归。
- 该成员建议在频道规则允许范围内,专注于模拟递归或探索遗传学相关的 Prompt,同时不鼓励讨论 marijane 等禁止话题。
- **AI 辅助学习与理解:成员们讨论了 **AI 如何帮助学习和理解,特别是在整理思路和解释复杂概念方面。
- 一位用户提到使用 ChatGPT 项目文件夹 来保持思路连贯,另一位则对将 AI 用作第二大脑 (second brain) 表示兴奋。
- **ChatGPT 语音变得“拟人化”:一位成员对 **ChatGPT Voice 的对话填充句(如 If you need anything else, let me know)表示沮丧,尽管尝试调整了个性化设置。
- 另一位成员分享了通过特定 Prompt 成功减少多余短语的截图,但也承认由于网络速度较慢而存在局限性。
OpenAI ▷ #api-discussions (58 条消息🔥🔥):
植物育种游戏,Turing vs Gödel,LLMs 与递归,AI 作为第二大脑,ChatGPT 语音烦恼
- **植物育种游戏展示 AI 宣言:一位成员描述了一款涉及植物育种的游戏,其中遗传性状被转换为 **UUIDs,并包含一个自我调节的智能治理系统。
- **Turing 在停机问题历史上胜过 Gödel:一位成员纠正了他人,澄清是 **Turing 确定了停机问题而非 Gödel,并提供了 一个 ChatGPT 链接 来支持这一事实。
- 讨论随后转向了关于排序原始函数和 LLMs 的假设。
- **LLMs 面临递归拒绝:一位成员解释说,试图让 **LLMs 执行递归可能会令人沮丧,因为它们是前馈网络,建议改用模拟方法。
- 另一位成员对遗传学和编程相关的 Prompt Engineering 表示兴趣,强调了遵守 <#1107255707314704505> 规则的重要性。
- **AI:补脑还是伤脑?:成员们讨论了 **AI 如何帮助他们思考和理解系统,其中一位指出 ChatGPT 项目文件夹能让他们保持思路连贯。
- 另一位成员提到 AI 帮助他们集中注意力和整理思绪,将 AI 的解释比作大脑养料 (brain food)。
- **ChatGPT 语音:不再是客服机器人!:一位成员对 **ChatGPT Voice 倾向于添加不必要的对话填充物(如 If you need anything else, let me know)表示挫败。
- 他们寻求解决方案,以使 AI 感觉更像一个人类对话伙伴。
Cursor Community ▷ #general (290 messages🔥🔥):
Ultra plan credit meter, Grok Code Fast (Sonic), AI long term conversation, Add Context Button Feedback, Gpt-5 Mini
- Ultra 计划额度计费器消失了:用户无法在他们的 Ultra 计划中看到使用情况计费器和剩余额度,而该功能在几周前还是可用的。
- 一位用户建议,它会在 prompt 之后随机出现。
- Grok Code Fast 以 Sonic 之名亮相:Grok Code Fast(又名 Sonic)已被确定为 Grok Code 的迷你变体,在构建 UI 组件方面速度很快。
- 一些成员认为在编码时更倾向于使用 Auto 模型,因为它的质量比 Grok-Code-Fast 更高。
- AI Agent 的代码注入功能非常强大:成员们讨论了 AI Agent 的代码注入功能简直“疯了”,因为它消除了重新编译的需求(除非是极端改动),而且随着改动速度的提升,现在变得非常强大。
- 一位成员指出,从安全角度来看,Mac 用户的情况稍好一些,因为有沙箱(sandboxing)机制。
- Add Context 按钮需要改进:用户要求恢复到之前版本的 Add Context 按钮,因为旧版简单且易于操作。
- 在最近的 Cursor 版本中,Add Context 默认只选择当前活动标签页,且手动输入文件名时无法选择任何文件。
- Auto 模式既快又猛:成员们讨论了 Auto 模式会根据 prompt 和任务在 Claude、GPT 和 Gemini 之间切换。
- 许多人一致认为他们已经加强了 Auto 模式;目前很享受 Auto 模式,因为它在 9 月 15 日之前是无限使用的。
Cursor Community ▷ #background-agents (4 messages):
Background Agents and Docker, Background Agents Setup Woes, Docker-in-Docker Difficulties, Background Agents and .gitignore, Background Agents with rails
- 没有 Dockerfile 时后台 Agent 会停滞:一位成员报告称,如果没有为 Ruby 和 Postgres 设置 Dockerfile,后台 Agent 似乎会无限期地卡在 “[Status] Starting Cursor…“。
- 他们还提到在环境启动时运行
docker-compose start存在困难,因为 Cursor 创建的用户不属于docker用户组。
- 他们还提到在环境启动时运行
- 注意:将配置更改推送到远程会覆盖 .gitignore:一位成员没意识到配置更改需要推送到远程才能进行 fork,并且 .gitignore 下的文件不会被复制到远程 Cursor 环境中。
- 该成员的解决方法是将这些被忽略的文件添加为 环境变量(ENV variables),并在 setup.sh 中将它们写入文件。
- Docker-in-Docker 的麻烦:成员们表示,很难可靠地获取一个运行中的 Docker 服务来执行 compose 或 devcontainers CLI。
- 普遍共识是运行 Docker-in-Docker 非常困难,因此他们更希望拥有一个 VM。
- 需要终端吗?:对于远程 Agent 实现功能的开发工作流,一位成员不确定是否需要在
terminals中配置任何内容。- 他们确实报告了进展,通过要求远程 Agent:“请查看你是否能成功运行 @test_file.rb”。
Nous Research AI ▷ #announcements (1 messages):
Hermes 4, Nous Chat UI, RefusalBench, Model Benchmarking Transparency
- Hermes 4 是新型用户对齐的混合推理模型!:Nous Research 发布了 Hermes 4,这是一系列具有扩展测试时计算(test-time compute)能力的用户对齐模型,强调创造力、无审查,并在开源权重模型中拥有顶尖的数学、编码和推理性能;更多详情点击这里。
- Nous Chat UI 翻新并推出新功能!:翻新后的 Nous Chat UI 现在包含并行交互、补全模式(completions mode)和记忆系统,提供包括 Hermes 4 和 GPT-5 在内的开源和闭源模型。
- Nous Chat 中所有的 Hermes 4 推理在第一周都是免费的。
- 新基准测试 RefusalBench 符合你的价值观!:Nous Research 创建了一个新的基准测试 RefusalBench,用于测试模型在各种场景下的提供帮助的意愿,Hermes 4 在无审查的情况下针对流行模型实现了 SOTA。
- 一份详细介绍 Hermes 4 和其他 LLM 的创建过程及评估的技术报告(包括每项测试的文本结果)已在 arxiv 上发布。
Nous Research AI ▷ #general (235 条消息🔥🔥):
Hermes 4, Model Quantization, VLM Finetunes, OpenRouter Integration, Nous Chat UI/UX
- Hermes 4 发布后迅速从 OpenRouter 下架:Hermes 4 模型曾在 OpenRouter 短暂上线,但很快被撤下,可能是由于 Chutes 提供商更改新模型名称导致的问题。
- 用户注意到它的出现转瞬即逝,有人开玩笑说 那些鬼鬼祟祟的 OpenRouter 的人已经把它关掉了。
- Nous Chat 网站消耗过高 VRAM:用户报告 Nous Chat 网站的 VRAM 占用率很高,一位用户指出在 4060Ti 上使用 Firefox 浏览器时占用了 1.3GB 的 VRAM。
- 一位用户调侃道 这么多 VRAM 都能跑一个 1B 模型了,而另一位用户则开玩笑说该网站使用的 VRAM 快赶上我的整台电脑了。
- 14B 模型因推理 Bug 延迟发布:由于推理模式(Reasoning mode)中的一个 Bug,14B Hermes 4 模型的发布已被推迟。
- 尽管有所延迟,团队仍目标尽快发布,并正在考虑未来推出 36B 模型。
- Unsloth 发布 Hermes 4 GGUF 版本:Unsloth 发布了 Hermes 4 的 GGUF 量化版本,解决了转换过程中的 Chat Template 问题,现已在 HuggingFace 上线。
- 团队在转换过程中解决了 Chat Template 的相关问题。
- Nous Chat 遭遇扩容问题:在发布后不久,新版 Nous Chat 的提供商因负载过重而出现了扩容(Scaling)问题。
- 它在短时间内变得非常受欢迎,有人开玩笑说:可能一下子太火了,哈哈 😂。
Nous Research AI ▷ #ask-about-llms (1 条消息):
moonlit_empress: 感谢 Nous 团队带来的 Hermes 4!!已经爱上它了 😌
Nous Research AI ▷ #research-papers (12 条消息🔥):
Nous Research's Memory System, Graph RAG, Open Source Plans
- Nous Research 推出 Memory System:Nous Research 正在推出一种自定义的 Graph Architecture Memory System(图架构记忆系统),它适用于任何模型,允许一个模型创建的记忆被另一个模型访问。
- 核心成员澄清说,该系统 不完全是 Graph RAG,因为它会随时间考虑更多信息,并使用 Judge 模型进行其他分类指标的评估。
- 开源实例即将推出!:有计划在未来某个时间点开源该 Memory System。
- 团队成员肯定地表示,他们 确实对开源情有独钟。
Nous Research AI ▷ #research-papers (12 条消息🔥):
Hermes 4, Memory System, Graph RAG
- Memory System 不同于 OpenAI,而是自定义系统:正在推出的 Memory System 与 OpenAI 的并不相似,而是一种适用于任何模型的 自定义图架构(Custom Graph Architecture)。
- 该系统允许在与一个模型对话时创建的记忆,在与另一个模型对话时被访问。
- Memory System 并非 Graph RAG:该自定义 Memory System 不完全是 Graph RAG,因为 Graph RAG 无法提供足够的细微差别,或者在处理大量记忆时表现不佳。
- 该系统会随着时间的推移,对转化为记忆的消息考虑更多信息,并使用 Judge in the loop 来处理其他分类指标。
- Memory System 会开源吗?:有计划在未来某个时间点开源该 Memory System 的某种实例化版本。
- 团队对开源有着深厚的情结。
HuggingFace ▷ #general (172 条消息🔥🔥):
梯度爆炸排查、Landmark 提取流水线、LLMs from Scratch 书籍、Grok-Code-Fast-1 模型、Pytorch Lightning 重构
- 梯度持续爆炸?试试 Early Layernorms!: 一位成员在训练期间遇到了梯度爆炸,发现使用 early layernorms 或 RMSNorm 有所帮助,同时降低 learning rate 至 1e-4 并对残差进行重缩放,模型代码已在 GitHub 上发布。
- 他们最终通过将残差按
x = x + f(x) / (2**0.5)进行缩小来重缩放残差,以防止方差累积。
- 他们最终通过将残差按
- WSL Mediapipe Landmark 提取流水线耗时 67 小时: 一位成员使用 WSL 和 Mediapipe 运行 Landmark 提取流水线,竟然耗费了 67 小时 才完成。
- 在这次经历后,他们断然表示 再也不会使用 WSL 来运行 mediapipe 了。
- 《LLMs from Scratch》书籍获 LLM 新手推荐: 成员们讨论了 Build a Large Language Model (from Scratch) 一书,认为它对学习 LLM 很有帮助。
- 一位成员分享了两个最喜欢的 YouTube 频道:Julia Turc 和 Code Emporium,用于学习概念和最新研究。
- 发现 Grok-Code-Fast-1 模型!: 一位成员分享了来自 xAI 的 Grok-Code-Fast-1 模型链接,地址为 https://docs.x.ai/docs/models/grok-code-fast-1。
- 文档已上线,鼓励成员们 阅读文档。
- PyTorch Lightning 重构?太棒了!: 由于训练循环(training loop)日益复杂且手动日志记录(logging)过程繁琐,一位成员正考虑将项目重构为 PyTorch Lightning。
- 手动配置的 bug 导致了进度丢失和训练数据损失。
HuggingFace ▷ #today-im-learning (12 条消息🔥):
Claude 文件修改确认系统、开源 AI 中的 TPU、实时音频拉伸
- Claude 现在要求确认 “Yup - let’s do it”: 为了增强安全性,用户现在需要输入短语 “Yup - let’s do it” 来授权 Claude 修改文件,这在
~/.claude/CLAUDE.md文件中有所规定。- 该要求确保了 事务性确认(transactional consent),即权限在每组修改后都会过期,防止在规划或审查阶段发生意外更改。
- TPU 就像垃圾,明白了: 一位成员指出,频道中看到的所谓“垃圾”反映了 TPU(用于训练 Gemini 的芯片)在开源 AI 中的运作方式。
- 他们补充道:“你是在一个开源 AI 服务器里,你看到的这些‘垃圾’正是 TPU 的运作方式,你知道的,就是训练 Gemini 的那种芯片”。
- 贫困开发者即将发布 NessStretch: 一位成员正在开发名为 NessStretch 的实时音频拉伸工具,并计划将 CPU 路径作为 FOSS(自由开源软件)发布,由于资金紧张,GPU 路径将作为付费版本。
- 该成员表示:“我近期将发布 CPU 路径的 FOSS 版本和 GPU 路径的付费版本。为什么要付费?因为我没钱了。”
HuggingFace ▷ #cool-finds (38 条消息🔥):
年龄猜测、数学失误、资历炫耀、自动化、软件工程博士
- 年龄猜测引发尴尬: 一位成员开玩笑说另一位成员“晚了二十年”,引发了一个既俏皮又带有防御性的回应,称自己“可能”要大三十岁。
- 随后,交流演变成了年龄猜测以及关于年代和数学的玩笑,两位成员都互相嘲笑对方的计算能力和对年龄的看法。
- 关于自动化定义的争论爆发: 一位成员开玩笑说,另一位成员虽然自称三十多岁,但似乎对 automations(自动化)一无所知。
- 这引发了关于 automation 和 automiton(自动机)之间区别的澄清,并导致了更多与年龄相关的调侃。
- 炫耀资历,自称博士: 在一番讨论后,一位成员宣称自己 拥有软件工程博士学位(PhD in Software Engineering),并让对方“闭嘴(sit the fuck down)”。
- 这一声明似乎源于对知识和专业能力的争论或挑战,尽管具体背景仍较模糊。
HuggingFace ▷ #i-made-this (8 messages🔥):
AI Agent, Gradio Demo, LiquidAI, HF Space
- AI Agent 探索多重上下文:一位成员构建了一个 AI Agent,它在给出创意回答之前会探索多重上下文并创建对立观点,并在此分享了 工具链接。
- 建议制作可视化 Gradio Demo:一位成员建议制作一些 可视化 Gradio Demo 以提高可见度,从而在 HF 社区内轻松展示统计数据或随变化更新的内容。
- LiquidAI 的 MCP Server POC 部署至 HF Space:LiquidAI 将一个微型 MCP Server POC 部署到了 HF Space,并欢迎提出功能需求。
- HF Space 提供 fastmcp-space:一位成员分享了 HF Space 上 fastmcp-space 的链接。
HuggingFace ▷ #core-announcements (1 messages):
Flax deprecation
- Flax 支持停止:已做出停止支持 Flax 的艰难决定。
- 鼓励用户报告遇到的任何问题,如附图所示。
- Flax 停止后续:为正从 Flax 迁移的用户提供了额外的支持渠道和文档。
- 团队致力于确保平稳过渡并解决任何新出现的问题。
HuggingFace ▷ #computer-vision (2 messages):
Makesense AI, CVAT AI
- Makesense AI 工具提示:一位成员分享了 Makesense AI 的链接,认为它是一个潜在的有用工具。
- 未提供其他细节。
- CVAT AI 工具提示:一位成员分享了 CVAT AI 的链接,认为它是一个潜在的有用工具。
- 未提供其他细节。
HuggingFace ▷ #smol-course (3 messages):
Qwen3-Coder-30B-A3B, Mixture of Experts (MoE)
- 本地使用推荐 Qwen3-Coder-30B-A3B 模型!:一位拥有 64GB RAM 和 16GB VRAM 的成员询问适合的本地模型,另一位成员推荐了 Qwen3-Coder-30B-A3B-Instruct。
- 它被描述为一个具有 Mixture of Experts 的 300 亿参数稀疏模型,其中 3B 参数 随时处于激活状态;量化版本在此。
- 内存有限时首选 MoE 模型:一位成员指出,虽然稠密模型可行,但 Mixture of Experts (MoE) 模型 对 RAM 较小的用户更友好。
- 这表明在 RAM 成为限制因素的系统上,MoE 模型 可以提供更好的性能。
HuggingFace ▷ #agents-course (2 messages):
pip install --upgrade
- 使用 Pip 更快地升级包:一位成员发帖太快了,应该在他们的 pip install -r requirements.txt 命令中添加 –upgrade 来升级包。
- 升级特定包:如果你不想冒险更改其他包的版本,只需执行 *pip install –upgrade
*
LM Studio ▷ #general (175 条消息🔥🔥):
VRAM 的重要性,Hermes 4 很烂,LM Studio 与 Agnaistic,LM Studio 可理解 PDF,Headless 模式选项
- VRAM 依然重要:用户讨论了 VRAM 如何影响使用 12B 模型的能力,一位用户提到在 2070S 上使用它们很流畅,但由于速度问题在运行 Gemma-3 27B 时遇到困难。
- 成员们澄清,性能不仅取决于 VRAM 容量,还取决于 GDDR 类型和 CUDA 核心数量,但模型超过 VRAM 容量会严重削弱性能。
- 用户认为 Hermes 4 非常糟糕:一位用户直言 Hermes 4 很烂。
- 另一位用户询问了 Hermes 4 的训练数据,特别是它是否仍然基于 llama 3.1。
- Linux 用户无法使用 Headless 模式的 LM Studio:一位用户在 LM Studio 中找不到 headless mode 选项,尽管文档称该功能在 0.3.5 版本中可用。
- 经澄清,Linux 版暂不支持 Headless 选项,建议使用 llama-swap 作为替代方案。
- 关于本地 LLM 硬件需求的讨论:成员们讨论了为 75-100 名用户运行 60GB 模型所需的硬件,推荐使用 vLLM。
- 一位成员建议,如果模型是 MoE 架构,则需要 3 台 RTX 6000 Blackwell 工作站,否则 GPU 数量需翻倍;上下文需求也会影响性能。
- 基于 Rust 的 Ollama LLM 新 UI 发布:一位用户分享了其项目的视频,这是一个基于 Rust 和 Tauri 的 UI,用于管理 Ollama 模型,并指出它不是 Open WebUI 的分支。
- 该 UI 支持 Windows、Linux 和 macOS,包含模型选择器,旨在无需独立后端即可运行,与基于 Web 的界面有所不同。
LM Studio ▷ #hardware-discussion (17 条消息🔥):
海关延迟,Dell 笔记本 vs Macbook 用于 LLM,Nvidia RTX PRO 3000,Ryzen 395+ 笔记本,平衡算力使用
- 海关暂停导致延迟:一位成员担心针对 800 美元以下物品的新海关暂停政策会导致其 Mi50 散热器和 APU 的收货延迟。
- Dell 笔记本 vs Macbook 用于 LLM 推理:成员们讨论了使用 Dell 笔记本与 Macbook 进行 LLM 推理的优缺点。
- 虽然一位成员建议使用配备 128GB RAM 的 M3 Macbook Pro,但其他人反驳称,在以 Windows 为主的公司中引入 Mac 存在困难。
- Nvidia RTX PRO 3000 推理表现平平:一位成员表示 RTX PRO 3000 (12GB VRAM) 相当于略微削减的桌面版 5070,且核心频率大幅降低。
- 他们指出,虽然 30B 模型无法以合理的量化(quant)装入 12GB 显存,但可以通过稀疏模型 Offload 到内存,不过双通道 DDR5 在承载模型层方面的表现并不理想。
- Ryzen 395+ 笔记本提供 Windows 替代方案:对于那些受限于 Windows 的用户,一位成员表示 如果 Windows 更方便,现在有几款 Ryzen 395+ 笔记本可选。
- 资源间的算力平衡:一位成员发布了截图,询问让资源在使用中自动平衡是否存在显著的算力差异。
- 未给出具体回答。
GPU MODE ▷ #general (5 条消息):
黑客松总是在周五,ScaleML 系列
- 黑客松总是在周五举行?:一位成员开玩笑地抱怨所有的黑客松似乎都发生在周五。
- 他们对提供的机会表示感谢,并用哭泣的表情符号表达了这种不便。
- ScaleML 系列第三天:量化:ScaleML 系列的第三天将涵盖量化(Quantization),特别是关注 MXFP4 等微缩放格式,由 Chris De Sa 教授主讲;在此观看直播。
- 本次课程将采用白板演示,类似于传统的讲座,并设计为互动形式。
GPU MODE ▷ #triton (2 条消息):
constexpr arguments, Multi-pass profiler, NVSHMEM in Triton, tritonbench
- constexpr 参数消失: 一位成员表示 constexpr 参数将从签名中消失,因为 jit 会将等于 1 的整数特化为 constexpr。
- Meta 的 Multi-pass profiler 亮相: 来自 Meta 的 Kevin Fang 等人将展示 Multi-pass profiler,它被描述为 一个用于编排和 LLM Agentic 分析应用的联邦 GPU 工具框架。
- NVSHMEM 的 Triton 集成: 来自 Nvidia 的 Surya Subramanian 计划讨论 Triton 背景下的 NVSHMEM。
- tritonbench 用户关注: 来自 Meta 的 Cicie Wang 好奇 谁在使用 tritonbench,特别点名了 OpenAI。
- 她希望了解它是如何被使用的。
GPU MODE ▷ #cuda (8 条消息🔥):
cudaMemcpyAsync with pageable host buffer, Stream-Ordered Memory Allocator, cudaHostAlloc performance, Pinned memory and system stability
- 对可分页主机缓冲区使用异步 memcpy 是否不安全?: 一位成员询问使用
cudaMemcpyAsync从可分页主机缓冲区复制到设备内存的安全性,希望 CUDA runtime 能在内部管理一个 pinned 主机缓冲区。- 另一位成员回答说,虽然不会崩溃,但复制不会是真正的异步,因为 CUDA runtime 首先需要一个页面锁定(page-locked)缓冲区,这使得该部分变为同步,建议使用
cudaHostAlloc()以避免阻塞 CPU 线程。
- 另一位成员回答说,虽然不会崩溃,但复制不会是真正的异步,因为 CUDA runtime 首先需要一个页面锁定(page-locked)缓冲区,这使得该部分变为同步,建议使用
- Stream-Ordered Memory Allocator 无法解决固定内存问题: 一位成员提到使用 Stream-Ordered Memory Allocator 并希望优化到设备缓冲区的复制,向 CUDA 驱动程序暗示该缓冲区不会被修改,以便潜在地使用内部 pinned 缓冲区。
- 另一位成员澄清说,Stream-Ordered Memory Allocator 仅影响设备缓冲区,可分页与 pinned 主机内存的问题依然存在,并且 可以通过使用 cudaHostAlloc() 分配缓冲区来完成缓冲区不可变的“暗示”。
- cudaHostAlloc 提升实测性能: 其中一位成员报告了一项测试,结果显示 当我们使用普通的
malloc而不是cudaMallocHost时,带有cudaMemcpyAsync的代码不会崩溃,但从计时来看,我们并没有从cudaMemcpyAsync中获益。- 该成员建议 没有太多理由不使用 pinned memory,但你只是不想分配太多,因为它会影响系统稳定性。
GPU MODE ▷ #torch (45 条消息🔥):
Inductor codegen for persistent matmul, TMA availability on sm120, cutedsl performance
- 使用 Inductor 的 Persistent Matmul:深度探讨: 一位成员询问如何在 Inductor 中启用 persistent matmul 代码生成,检查
torch._inductor.config中相关的标志,如ENABLE_PERSISTENT_TMA_MATMUL。- 建议使用
max-autotune模式并确保使用 Triton,设置torch._inductor.config.max_autotune_gemm_backends = "TRITON"和torch._inductor.config.triton.enable_persistent_tma_matmul = True,但也指出 Cublas 可能仍然更快。
- 建议使用
- 排查 TMA 和 Persistent Kernel 选择: 一位成员调查了 TMA 是否在 sm120 架构上可用,参考了 torch/utils/_triton.py 进行架构检查。
- 还提到 persistent kernel + TMA 在
max-autotune中被考虑,可以在 torch._inductor/kernel/mm.py 中使用断点来检查所考虑的选择。
- 还提到 persistent kernel + TMA 在
- cutedsl 的性能令人印象深刻: 一位成员对 cutedsl 表达了积极的印象,理由是其快速成熟以及在 flex + flash attention 方面的潜力,并引用了 这个 flash-attention PR。
- 另一位成员发现 cutedsl 尽管还在开发中,但非常有前景。
GPU MODE ▷ #announcements (1 条消息):
Multi GPU kernel competition, AMD MI300, Distributed inference kernels, KernelBot Platform, Multi-GPU lectures
- GPU MODE 与 AMD 合作迈向 Multi-GPU:GPU MODE 正与 AMD 合作推出一项新的 10 万美元 kernel 竞赛,参赛者将在 MI300 GPU 上优化 3 种不同的分布式推理 kernel,这些 kernel 由特定用户设计。
- 竞赛重点是优化 单节点 8 GPU all-to-all 通信、GEMM + reduce-scatter 以及 allgather + GEMM 操作。报名截止日期为 9 月 20 日,可通过此注册链接参加。
- KernelBot 平台增强 Multi-GPU 支持:得益于两位特定用户的努力,KernelBot 平台现在支持 Multi-GPU 提交,且在另一位用户的支持下,profiling 支持也即将就绪。
- 此外,一名用户计划增加直接从 gpumode.com 提交的支持;预计在专用频道中会有详细的报告和提示。
- 炎热分布式之夏:Multi-GPU 讲座:今年夏天计划举办多场 Multi-GPU 讲座,建议用户关注活动选项卡以获取更新和日程安排。
- 该计划旨在提供有关 Multi-GPU 系统分布式计算的教育资源和见解。
GPU MODE ▷ #beginner (27 条消息🔥):
GPU vs Cloud for Beginners, Remote Debugging Pain Points, CUDA Installation Troubles, GPU Programming vs SIMD, Competition tips
- 初学者展开 GPU vs 云端辩论:GPU 编程初学者讨论了是坚持使用 Google Colab 等云服务,还是投资购买 GPU。
- 一些成员正在认真考虑购买 GPU,并强调远程调试非常痛苦。
- GPU 的 TDD 工作流:成员们讨论了使用测试驱动开发 (TDD) 来调试 GPU 代码和测试行为。
- 他们提到,租用 GPU 每次都需要从头开始设置整个环境,还要应对延迟 (latency) 和不稳定的连接。
- CUDA 11.8 安装令人头大!:一位成员在安装 CUDA 11.8 + cuDNN 8.6 以及 Python 3.10 和 TensorFlow 2.12 时遇到问题,尽管 Torch 可以检测到 CUDA。
- 建议是确保没有 CUDA 版本冲突,并使用 Conda 环境,使用以下命令通过 NVIDIA 频道安装:
conda install cudatoolkit=11.8 cudnn=8.6 -c nvidia。
- 建议是确保没有 CUDA 版本冲突,并使用 Conda 环境,使用以下命令通过 NVIDIA 频道安装:
- GPU vs CPU SIMD 编程:一位成员询问了 GPU 编程与 CPU 上的 SIMD 编程之间的异同。
- 解释称两者在并行性方面具有根本的相似性,但 CPU SIMD 在单个 CPU 核心内处理较少的数据元素(4, 8, 16),而 GPU 则利用数百或数千个核心,实现大规模并行。
- 竞赛技巧:一位成员对公告频道中正在进行的竞赛感到一窍不通。
- 另一位成员建议观看此讲座来入门!
GPU MODE ▷ #off-topic (2 条消息):
GPU MODE party song, readme.md file
- GPU MODE 派对歌曲引爆 X:一位成员在 X 上发布了派对歌曲的链接,据推测与 GPU MODE 有关。
- 未提供关于该歌曲的更多细节。
- 通过 readme 指南运行强大应用:一位成员提到一个强大的应用程序,其说明可在 readme.md 文件中找到。
- 他们澄清说没有视频演示,但可以按照说明来运行该应用程序。
GPU MODE ▷ #rocm (8 条消息🔥):
汇编指令内存合并,rocprof 工具链
- 汇编指令中的内存合并 (Memory Coalescing):一位成员正在寻找一种工具,能够将汇编指令或源代码指令与内存合并相关联,而不仅仅是查看总延迟和空闲周期。
- 他们希望在细粒度级别上精确定位有问题的指令,而不仅仅是在 Kernel 级别。
- rocprof 工具链缺乏内存合并视图:一位成员指出,rocprof 工具链目前不提供类似于 NVIDIA Nsight 的显示内存合并的功能。
- 他们建议使用
printf进行调试,并指出 AMD GPU 对内存访问相对“宽容”,只要模糊地命中缓存行(Cache Lines)即可。
- 他们建议使用
- AMD GPU 的缓存行:一位成员建议,对于 AMD GPU,一个好的经验法则是确保全局加载指令(Global Load Instruction)访问的字节组合集包含完整的缓存行。
- 这是为了避免性能损失。
GPU MODE ▷ #intel (1 条消息):
erichallahan: 顺便提一下 https://www.phoronix.com/news/Alyssa-Rosenzweig-Joins-Intel
GPU MODE ▷ #webgpu (9 条消息🔥):
wgpu-native 与 Wayland,Dawn 与 Wayland
- Wayland 支持困扰 wgpu-native 和 Dawn:一位成员报告称,wgpu-native 和 Dawn 在调用
this->m_Surface.getCapabilities(this->m_Adapter, &surfaceCapabilities);时在 Wayland 上失败。- Dawn 的错误消息显示 Unsupported sType (SType::SurfaceSourceWaylandSurface),这让用户认为 Dawn 在编译时没有启用 Wayland 支持。
- Dawn 晦涩的错误消息:用户收到了来自 Dawn 的错误消息,指出 Unsupported sType (SType::SurfaceSourceWaylandSurface)。
- 他们正尝试按照 wgpu C++ 教程进行操作。
GPU MODE ▷ #metal (1 条消息):
Tensor Operation,硬件加速,simdgroup matmul 函数
- 挖掘 “Tensor Operation” 中的硬件加速:一位成员询问用于矩阵乘法的 “Tensor Operation” 是否使用了通过 simdgroup matmul 函数无法获得的硬件加速。
- SIMD Group Matmul 硬件加速?:该询问围绕着辨别 Tensor Operation 与 simdgroup matmul 函数相比,是否利用了独特的硬件加速。
GPU MODE ▷ #general-leaderboard (11 条消息🔥):
Trimul 排行榜提交失败,AMD 竞赛组队,AMD 多 GPU 环境访问
- Trimul 提交在 B200 和 MI300 上受挫:用户报告称,即使使用 示例实现,在 B200 和 MI300 GPU 上的 trimul 排行榜测试和正式提交均失败,并显示 “unexpected error occurred” 消息。
- 一位用户提到在 MI300 (FP8 mm) 和 L4 GPU (sort_v2) 上遇到了同样的问题,而另一位用户最初遇到失败,但后来发现测试提交可以工作。
- AMD Arena 团队组建:一位用户询问在参加新的 AMD 竞赛时如何创建团队。
- 组队在 Data Monsters 网站 的注册页面进行,不过组织者建议在频道中发帖进行组队匹配。
- 多 GPU AMD 机器访问权限疑问?:一位用户询问是否可以访问 AMD 多 GPU 环境进行开发和调试。
- 另一位用户被告知可以直接开始提交注册,确认信息主要是为了确认奖金发放。
GPU MODE ▷ #submissions (5 messages):
A100 Trimul Leaderboard, H100 Trimul Leaderboard, B200 Trimul Leaderboard
- A100 trimul 纪录被打破!:用户 <@1264305104417456149> 以 4.92 ms 的成绩获得了 A100 第一名。
- 随后他们又提交了 4.96 ms 和 5.26 ms 的成功记录。
- H100 trimul 时间现已列出:用户 <@1264305104417456149> 在 H100 上提交了 2.73 ms 的成功运行记录。
- 这为 H100 在 trimul 排行榜上设定了初始基准。
- B200 分数陆续传来:用户 <@489144435032981515> 在 B200 上提交了 8.08 ms 的成功运行记录。
- 这开启了 B200 trimul 基准测试的排行榜。
GPU MODE ▷ #factorio-learning-env (4 messages):
Factorio tips, Factorio blueprints
- Factorio 狂热者专注于基础:一位热心的新成员表达了加入 Factorio 学习社区的兴奋之情。
- 该用户提到他们会晚点参加会议并提前 30 分钟离开。
- 后勤落学者感叹延迟:虽然 Discord 消息有限,但主题主要涉及自我介绍和日程冲突。
- 这并不妨碍他们学习在 Factorio 中自动化资源管理和工厂建设。
GPU MODE ▷ #amd-competition (1 messages):
discord-cluster-manager errors, AMD Instinct MI300X VF
- Discord Cluster Manager 受错误困扰:一位用户在运行 discord-cluster-manager 时报告了一个“意外错误”,并被要求向开发人员报告。
- AMD Instinct MI300X VF 基准测试:尽管存在错误,
result.json显示在 AMD Instinct MI300X VF GPU 上的运行是成功的,其中check参数返回为pass。- 用户确认在提交基准测试、测试、profiles 和排名任务(ranked jobs)时问题仍然存在,最差的基准测试结果为 72811225.0。
Latent Space ▷ #ai-general-chat (95 messages🔥🔥):
Anthropic Claude Chrome Extension, UQ Benchmark - Unsolved STEM Questions, Nous Research Hermes 4, Grok Code in Cursor, Meta Researchers Leaving
- Claude 进驻 Chrome: Anthropic 推出了 Claude for Chrome,这是一个将 Claude 作为浏览器驱动进行试点的扩展程序,目前处于面向 1,000 名用户的研究预览阶段。
- 社区对其作为 Comet/Perplexity 竞争对手的潜力感到兴奋;同时 Anthropic 警告称,在试用期间正在监控 prompt-injection 安全问题。
- 前沿 LLM 挑战未解决的 STEM 难题: Niklas Muennighoff 的团队推出了 UQ,这是一个包含 500 个精选自 STEM 领域未解决问题的基准测试。
- 经领域专家验证,前沿 LLM 解决了其中的 10 个问题,包括一个在 CrossValidated 上悬而未决 9 年的问题,目前仍有约 490 个谜题待解。
- Hermes 4 混合架构热潮袭来: Nous Research 发布了 Hermes 4,这是一个开源权重的混合推理 LLM,专注于创造力、中立对齐和低审查,同时在数学、代码和推理方面保持 SOTA 水平。
- 用户本周可以通过全新的 Nous Chat UI(支持并行交互和记忆功能)进行测试,此外还可以查看详细的技术报告和新的 RefusalBench benchmark;Chutes、Nebius 和 Luminal 等合作伙伴正在提供推理支持。
- 在 Cursor 中使用 Grok Code:免费试用诱惑: Cursor 引入了 Grok Code,这是一个处于隐身阶段、价格极具竞争力的模型,并提供为期一周的免费试用。
- 社区成员讨论了定价(每 1M tokens $0.2/$1.5)和潜在的改进空间,并就 Cursor 的品牌推广和未来模型发布进行了一些讨论。
- Token 策略:Kimi 的质量胜过数量: 来自 Kimi 创始人 杨植麟的采访 见解:K2 将最大化每个高质量 token 的价值,而不是单纯增加数据,倾向于通过 RL 而非 SFT 来获得更好的泛化能力,探索全 AI 原生训练,并致力于实现百万级 token 上下文。
- 社区回复称赞了 Kimi 的逻辑感和单位 token 智能,并询问即将发布的 PPT 和带字幕的视频。
Latent Space ▷ #private-agents (8 messages🔥):
Second-hand GPUs, RTX 3090, DOA testing, VRAM integrity, Payment escrow
- Taha 发布二手 GPU 购买指南: Taha 在他的指南中分享了一个简洁的清单,用于购买二手 RTX 3090 以避免本地 AI 部署中的意外。
- 清单包括:面交、检查显卡外观、运行
nvidia-smi、花一小时运行memtest_vulkan测试 VRAM 完整性、可选使用gpu-burn进行压力测试,最后在 vLLM 中加载大模型以确认稳定性并观察温度。
- 清单包括:面交、检查显卡外观、运行
- RTX 3090 压力测试的必要性: 成员们讨论了测试二手 RTX 3090 显卡的必要性,尤其是从 Craigslist 等平台的个人卖家处购买时,实施彻底测试可能比较困难。
- 建议包括利用 eBay 的争议解决流程作为潜在保障,尽管这类流程的体验因人而异。
- DOA 测试: 一位成员建议实施 DOA(到货即损)测试,提议使用支付托管、卖家进行售前 DOA 测试以及买家进行售后 DOA 测试并与卖家结果比对。
- 该成员建议,如果结果不匹配,托管资金将受到影响,并认为建立一个基准测试会有所帮助。
Latent Space ▷ #genmedia-creative-ai (4 messages):
Nano Banana, Runway Act-2, AI Video creation
- Nano Banana + Runway Act-2 结合实现角色到 Carti 的工作流: Techguyver 展示了如何将 Nano Banana(极廉价的图像编辑)与 Runway Act-2 动作匹配相结合,使创作者在视频创作中能够更快地迭代,例如更换衣服和风格。
- 该演示引发了关于“玩具 vs 叙事”伦理的讨论,以及对教程的请求,其中包括一些关于“手是我的”幽默评论。
- Nano Banana 用于极廉价的图像编辑: Nano Banana 被介绍为一个用于快速编辑的极廉价图像编辑器。
- 它与 Runway Act-2 配合使用,允许创作者在视频创作中更快地迭代。
Eleuther ▷ #general (14 条消息🔥):
研究中的可证伪性、AI 的重大挑战、EleutherAI Discord 的宗旨
- 可证伪性引发科学家分歧:一位成员建议该服务器应用于讨论关于可证伪假设 (falsifiable hypotheses) 的研究,而不是泛泛而谈模糊的想法。
- 另一位成员反驳称,可证伪性在科学家中被高估了,尽管它在通常情况下非常有用。
- 成员挑战 AI 重大挑战:一位成员询问目前的工作进展,另一位成员回答他们正在攻克 Grand Challenges 并分享了一个 链接。
- 该成员承认希望自己能有更多的数学技能点来处理这些有趣的内容。
- 明确 Discord 的研究重点:一位成员引用了 EleutherAI 的描述,即该 Discord 服务器面向研究人员和研究层级的讨论,特别是关于可证伪假设的讨论。
- 该成员表示,目标是防止任何持有受聊天机器人蛊惑的疯狂理论的人胡言乱语。
Eleuther ▷ #research (34 条消息🔥):
Transformer 的替代方案、Forward-Forward 训练、HTM 动力学、微型大脑架构、训练方案排障
- 探索 Transformer 之外的替代方案:成员们表达了希望看到除 Transformer 和梯度下降之外更多方法的愿望,并引用了这条推文中关于 Transformer 替代方案的内容。
- 深入研究 Forward-Forward 训练:一位成员分享了他们在 HTM 动力学与 Forward-Forward 训练结合方面的工作,取得了看似合理的结果,并表示很快会发布测试脚本,详见其 repo。
- “微型大脑”架构出现:一位成员正在构建一个围绕类脑网络(具有皮层柱、区域、6 层网络和信号传播)的架构,并将项目移至 此 repo。
- Transformer 计算见解:一位成员向其他成员推荐了一个关于 Transformer 计算的演讲:Computation in Transformers。
- 分词器排障进行中:一位成员发现了其 Tokenizer 的潜在问题(词表大小为 50k),目前正在对训练方案 (training regime) 进行排障,并打算获取一些关于 Forward-Forward 的有意义的指标。
Eleuther ▷ #gpt-neox-dev (4 条消息):
Muon 加速、Torch Compile
- Muon 加速传闻被辟谣:一位成员提到在 Twitter 上看到声称 Muon 相比 Torch 实现有 1.6 倍加速,而 Torch compile 为 1.1 倍。
- 另一位成员澄清说,加速是由于算法更改减少了 NS 迭代次数,而不是纯粹的 Muon 或硬件改进。
- 算法逻辑提升速度:加速主要源于更改算法以减少所需的 NS 迭代次数。
- 这不是纯粹的 Muon,更多是算法逻辑而非硬件感知 (hardware-aware) 的改进。
aider (Paul Gauthier) ▷ #general (40 条消息🔥):
PacVim, OpenRouter 计费, 上下文管理, aider git 仓库错误, Model Control Policy (MCP) 工具
- PacVim 微调?:在 gptel 中为 codestral 提供评估工具后,它成功完成了所有与 Emacs 相关任务,甚至重新配置了 Emacs 并为自己制作了新工具。
- 一位成员开玩笑说要用 PacVim 进行微调,因为 LLM 擅长操作 Emacs,而把 Vim 抛在了脑后。
- OpenRouter 的最低充值费用:用户在充值 5 美元时被收取了 6.16 美元,另一位用户指出 OpenRouter 在购买额度时会收取 5.5% 的手续费(最低 0.80 美元),因为底层模型提供商没有加价。
- 从代数角度计算,如果每次充值 14.55 美元或更多,就不会再受到 0.80 美元最低费用的限制。
- 没有 Gemini 2.5 Pro,上下文管理会受影响:一位用户表达了对 Gemini 2.5 Pro 的需求,指出其他模型在上下文管理方面“感觉不对劲”。
- 他们还在努力让 Gemini 2.5 Pro 正常工作。
aider遇到 git 仓库错误:一位成员在aider中看到了Unable to list files in git repo: Require 20 byte binary sha, got b'\xb9', len = 1错误。- MCP 工具评估:社区成员讨论了什么是好的 Model Control Policy (MCP) 工具调用模型。
- 建议查看 Gorilla Leaderboard,并尝试将 Qwen3 8b 和 flash-lite 作为备选方案。
aider (Paul Gauthier) ▷ #questions-and-tips (7 条消息):
OpenRouter DeepSeek 3.1 配置, Aider CLI 自动化, Aider Prompt 处理, Aider 上下文退化, conventions.md 的优势
- Aider 推理器(Reasoner)的 DeepSeek 设置:未确认:一位成员询问如何将 OpenRouter 的 DeepSeek 3.1 配置为 Aider 内部主模型的推理器,并将非推理版本配置为弱模型,但尚未确认此设置是否有效。
- 目前还没有关于如何实现这一特定配置的确认或指南。
- Aider CLI 等待输入,不像 Claude:一位成员注意到,当通过管道向 Aider 传输内容时,它会等待用户输入,而 Claude CLI 会立即开始编辑文件。
- 用户询问了如何在没有人工干预的情况下实现 Aider 的完全自动化,并寻求此类设置的指南。
- Aider 管道仅读取第一行:当内容通过管道传输到 Aider 时,它只读取第一行。
- 要将
PROMPT.md添加到 Aider,需要将其作为参数传递,而不是通过管道。
- 要将
conventions.md在 Prompt 中的位置会影响性能:使用--read加载conventions.md会将其置于 Prompt 顶部附近,而将其包含在消息中则会将其置于底部附近。- 由于当前 Prompt 中存在 U 型相关性(U-shaped relevance),通过
--read放在顶部可能会获得稍好的性能。
- 由于当前 Prompt 中存在 U 型相关性(U-shaped relevance),通过
- Aider 上下文在超过 90k 输入 Token 时退化:一位成员发现,在使用 Aider + Gemini Pro 2.5 时,上下文在 90k-130k 输入 Token 左右开始退化。
- 在达到该范围之前,它在顶部似乎运行良好。
Moonshot AI (Kimi K-2) ▷ #general-chat (32 messages🔥):
Imagen 4, Nano Banana, Kimi+, Z.AI Slides
- Imagen 4 误导用户:一位用户分享了一张由 Imagen 4 生成的图像,最初将其误认为是播客中的真实场景,并对其出色的质量表示赞赏。
- 另一位用户指出 2.5 flash image gen 即为 nano banana,并已推送到 Gemini App。
- Google 的 Nano Banana 图像生成与 Imagen:一位用户提到,出于营销原因,Google 在使用 nano banana 和 Imagen 等图像生成器方面并不透明。
- 该用户还链接了一条关于推理模型的 Tweet,指出 CoT 和 RL 并不会创造新的能力。
- Kimi+ 即 Slides:Kimi+ 似乎是一个新类别,Slides 是其首个功能,最初仅对中国用户开放。
- 一位用户提供了总结,指出 如果你想要快速生成,Kimi 是首选;如果你想要更复杂的效果,Z.AI 是更好的选择。
- Z.AI Slides 对比 Kimi Slides:用户发现 Z.AI slides 只是一个 HTML 网站,更倾向于获得实际的 PPTX 文件。
- 另一位用户表示赞同,提到在 Slides 中需要更多的控制和重新排列选项,并表示在 Z.AI 上遇到了卡顿问题。
- 海外平台:一位用户提到 PPTX 功能目前在 Kimi+ 的海外平台上可用,并建议将其扩展到 Twitter, TikTok 和 Instagram。
- 有用户建议将 PPTX 功能扩展到 Twitter, TikTok 和 Instagram。
Yannick Kilcher ▷ #general (13 messages🔥):
Hierarchical modeling, HNet layers, Parameter count, tokenizer-free approaches, Albert Gu's blog posts
- HNet 分层建模:未知的领域:HNet 更高层次分层建模的潜力在实践中仍未经过测试,尽管从理论上讲,由于每个分辨率层级都存在残差(类似于 U-Net),它应该能扩展到原始论文所述的两层之外。
- 一位成员提到,他被朋友要求 测试 3 层的 h-net。
- HNet 压缩损失:系数缩减:在 HNet 论文中,与 depth = 1 的模型相比,depth = 2 模型的压缩损失系数显著降低,这意味着高层抽象与 depth = 1 的情况几乎相同。
- 一位成员指出,几乎所有的计算量(compute)仍然流向实际的主网络,这使得将其扩展到跨越多个句子或文档的抽象层级变得具有挑战性。
- HNet 参数量:保持公平性:在 HNet 中减少压缩的决定,可能是为了在将 HNets 与其他 tokenizer-free 方法进行比较时,保持参数量(Parameter count)和总计算量的公平性。
- 一位成员指出,如果分块(chunking)方法奏效,那么在不同粒度层级上更均匀地分布参数可能是最优的。
- 更深层的抽象:对简单扩展的质疑:一位成员对仅通过修改几行代码就能实现更深层、更抽象的嵌入表示怀疑,并指出研究人员已经在此领域工作了一年多,不会错过如此简单的改进。
- 该成员建议,如果这真的有效,他们至少会做一个消融实验(ablation)之类的。
- Albert Gu 的实验:发布决策因素:研究团队在决定发表作品之前已经进行了大量实验。
- 正如一位成员所言,在某个时间点你可能就想发布了,尤其是当你已经消耗了相当份额的算力(compute)时。
Yannick Kilcher ▷ #paper-discussion (9 messages🔥):
Reasoning Tokens, LLM Reasoning Efficiency, Mutual Information, stopwords
- Thinking Tokens 提高推理效率?:小组讨论了论文 Wait, We Don’t Need to “Wait”! Removing Thinking Tokens Improves Reasoning Efficiency,该研究表明可以移除推理标记以减少 Token 开销,而对准确性的影响微乎其微。
- 随后一位用户提到,第二篇论文可能更准确,即“推理”词汇似乎是可以跳过的。
- LLM 是否内化了时间概念?:一名实习生的实验发现,在 Llama 2 (+3) 7b (+13b) 的 CoT prompt 中加入 take your time(慢慢来),出人意料地增加了推理时间(生成时间变长,trace 变长),但并未提高准确率。
- 用户好奇 LLM 是否以某种方式内化了“时间”的概念,并分享了 transformer-circuits.pub,证实 LLM 确实具有某些时间的表示(representations)。
- 利用 Mutual Information 揭秘推理动态:一位用户对论文 Demystifying Reasoning Dynamics with Mutual Information: Thinking Tokens are Information Peaks in LLM Reasoning 发表了评论,注意到这些标记与 golden answer 表示之间的 MI 这一酷炫观察。
- 用户认为该论文 识别了“句子的高信息区域”(句号和逗号后的第一个词),但也意外地包含了一些 stopwords,这导致他们误解了其中一个结果。
- Reasoning Tokens 提升性能?:一位用户注意到 Demystifying Reasoning Dynamics with Mutual Information 论文中关于 RR 的有趣部分,即在推理过程中将推理标记多次重新输入到层中以提升性能。
- 用户认为 如果这其中确实有些门道,我不会感到惊讶。但也许目前还不清楚具体发生了什么。
Yannick Kilcher ▷ #ml-news (6 messages):
Claude Chrome, Keen Technologies LLM, Promptlock AI Ransomware
- Claude Chrome 变成监控系统:Anthropic 的 Claude for Chrome 引入了针对 AI 程序的强制性报告要求。
- 一位成员表示,这实际上将 AI 变成了 监控系统。
- Keen Technologies 的 LLM 研究边缘:一位成员对 Keen Technologies 未能关注迈向 continual learning 的 LLM research 前沿表示失望,而是像这段视频中强调的那样,进一步推行 Transformer 之前的 RL tricks。
- 他们建议改进 TTT(像 TokenFormer 一样可增长,像 UltraMem 一样具有稀疏/更高秩的查询,能够像 TransMamba 一样在动态和固定大小之间切换),以实现持续学习的实时 Atari 玩家。
- Promptlock:首个 AI 驱动的勒索软件出现:据 SecurityWeek 文章 详细报道,首个 AI 驱动的勒索软件 Promptlock 已经出现。
- 成员们对这一进展表示 悲哀。
Manus.im Discord ▷ #general (14 messages🔥):
Manus scheduled tasks and mail, Manus for enterprise research, Manus credits consumption issue, Support ticket delays
- Manus 邮件与计划任务可以一起使用吗?:一位成员询问在 Manus 中是否可以同时使用 scheduled tasks(计划任务)和 mail(邮件),另一位成员澄清说它们是同一个功能。
- 企业需要 Manus 之外的研究工具替代方案:一位成员提到 Manus 擅长研究,并为因合规问题无法使用 Manus 的企业寻求替代工具。
- Manus 额度消耗问题困扰用户:多位用户报告称 Manus 由于在没有响应的情况下重复提示,导致一夜之间耗尽了他们的额度,参考支持工单 1335。
- 支持响应延迟阻碍网站上线:一位用户报告称通过多个渠道(Help Centre, Reddit, Discord)联系支持部门一周未获回复,导致其正式网站上线延迟,参考支持工单 1334。
- 一位成员分享了 一个 Discord 帖子的链接,团队表示让我们在工单中跟进。
- 创业者的额度需求未得到满足:一位用户指出,最近的服务改进主要惠及每月花费 200 美元的用户,而非需要定期增加额度的创业者。
- 他们对必须等到 9 月 21 日才能获得更多额度表示沮丧,这导致了他们项目的停滞。
DSPy ▷ #show-and-tell (1 messages):
Signatures, Modules, Abstractions, Blog Post
- 博客文章称赞 Signatures 和 Modules 是优秀的抽象:一位成员撰写了一篇 博客文章,解释了为什么他们认为 signatures 和 modules 是极佳的抽象。
- 优秀抽象的力量!:作者分享说,他们的想法是在接触其他框架的过程中形成的,并觉得值得在专门的博客文章中进行探讨。
- 他们希望这对新手有所帮助!
DSPy ▷ #general (11 messages🔥):
LiteLLM's Role in DSPy, OpenRouter vs LiteLLM, DSPy Dependency Bloat
- LiteLLM:DSPy 的核心依赖?:一位用户询问了 DSPy 中
litellm的替代方案,建议使用类似dspy["litellm"]的语法。- 另一位成员回答说,LiteLLM 的接口支持来自各种 LLM 提供商(包括 OpenRouter)的通用插件,因此被视为核心依赖。
- OpenRouter 间接使用 LiteLLM:一位成员提到使用 OpenRouter 和一个利用 LiteLLM 的代理服务器,表明由于 DSPy 存在间接依赖。
- 该用户质疑 LiteLLM 作为直接依赖的必要性,并询问其对依赖膨胀(bloat)的影响。
- DSPy 依赖膨胀调查:一位成员询问了导致 LiteLLM 膨胀的原因,估计其大小为 9MB。
- 另一位成员建议使用 CLI AI 抓取代码库并分析依赖关系,并开玩笑说 Karpathy 再次出击。
Modular (Mojo 🔥) ▷ #mojo (11 messages🔥):
InlineArray vs StaticTuple, DPDK header binding, High-level API improvements, Deduplication of generated Mojo files, tsan compiler option
- InlineArray 替代 StaticTuple 以提升效率:在解决初始的 seg fault 问题后,InlineArray 重新回归,取代 StaticTuple 以在 DPDK 和 Mujoco 绑定中实现更优的 struct 内存布局。
- 用户提到这可能是一个 skills issue(技术水平问题)。
- 激进的 DPDK 头文件绑定策略出现:一位成员建议专注于已安装
include文件夹中的rte_*.h头文件来进行 DPDK bindings,因为 DPDK 正致力于最小化依赖。- 目标是通过包含所有相关头文件并避开不必要的头文件,来创建全面的绑定。
- 优先改进高层级 API 以简化库绑定:下一步是改进高层级 API,使绑定到不同库变得更加容易。
- 一位成员计划通过跳过未使用的代码来缩减生成的 Mojo 文件体积。
- 考虑对生成的 Mojo 文件进行去重:一位成员提议利用来自
cpp的源码注解对生成的 Mojo 文件进行去重,旨在通过移除未使用代码来减小文件体积。- 这涉及分析
cpp留下的注解,以识别并消除冗余或不必要的元素。
- 这涉及分析
- 讨论
tsan编译器选项的可用性:一位成员询问在使用--sanitize thread选项时,如何检查编译器是否启用了tsan(ThreadSanitizer)。- 另一位成员建议向编译器传递
-DTSAN,并结合@parameter if使用来自param_env的env_get_bool作为权宜之计。
- 另一位成员建议向编译器传递
tinygrad (George Hotz) ▷ #general (3 messages):
tinygrad realize() PR, TestSetItemloop.test_range fusion, tinygrad GPT2 Training performance
- 提议移除 Realize():在 tinygrad#11870 中添加了一个 Pull Request,用于移除
realize()并将TestSetItemloop.test_range融合进单个 kernel。 - GPT2 在 7900xtx 上训练缓慢:在 7900xtx 上训练
llm.c/train_gpt2.py似乎很慢,即使使用了 BEAM=5。- 在调整参数以匹配 nanogpt 后,一位成员在 nanogpt 规模下(batch size 64, 6 layers, 6 heads, 384 emb_dim, 256 seq_len)达到了每步 250ms,而 Andrej 使用 rocm torch 的 nanogpt 在默认配置下每步约为 3ms。
LLM Agents (Berkeley MOOC) ▷ #mooc-questions (2 messages):
Google Docs Confirmation Emails, Mailing List Updates
- Google Docs 确认课程报名:成员们在报名该项目后收到了来自 Google Docs 的确认邮件。
- 确认邮件已成功发送,但尚未收到其他沟通信息。
- 邮件列表将提供讲座更新:用于提供每场讲座更新的邮件列表应很快启用。
- 建议用户关注邮件列表以获取后续公告和项目更新。
MLOps @Chipro ▷ #events (1 messages):
AI Tools Introduction, Less Code Mindset, AI Prototyping, AI-powered Products, Tech History
- 简约力量驱动 AI 原型:9月5日与 Carlos Almeida 的会议将涵盖 Less Code 心态,以及它如何赋能非技术人员发布 AI-powered products。
- Carlos 将演示来自 Less Code Studio 的项目,展示 AI 如何显著缩短从创意到可用原型的时间,随后是公开 Q&A。
- 葡萄牙创始人构建全球优先的公司:Dick Hardt 将于 9月12日 加入 Pedro Sousa 和 Daniel Quintas,讨论技术的过去、现在和未来,以及 AI 工具如何塑造葡萄牙的相关领域。
- 讨论将探讨他为何选择里斯本,以及那里的创始人如何构建 global-first companies,同时涵盖 AI 时代的身份识别和 AI 工作流原型设计。
Windsurf ▷ #announcements (1 条消息):
Grok Code Fast 1, Windsurf announcement