AI News
Kimi K2-0905 与 Qwen3-Max 预览版:两款万亿参数(1T)开放权重模型正式发布。
Moonshot AI 更新了其 Kimi K2-0905 开放模型,将上下文长度翻倍至 256k tokens,提升了代码编写和工具调用能力,并实现了与智能体框架(agent scaffolds)的集成。阿里巴巴发布了 Qwen 3 Max,这是一款拥有 1 万亿参数 且具备面向智能体行为的模型,可通过 通义千问 (Qwen Chat)、阿里云 API 和 OpenRouter 获取。
社区重点讨论了中国在开源模型领域的领先地位,并针对代码智能体的有效评估方法展开辩论,强调了长程(long-horizon)和特定领域评估的重要性。@swyx 和 @karpathy 等业内大咖讨论了实际评估的重要性,以及用于对输出结果进行排序的判别器模型(discriminator models)。
Open models 是你唯一需要的吗?
2025年9月5日至9月6日的 AI 新闻。我们为你检查了 12 个 Reddit 子版块、544 个 Twitter 账号和 22 个 Discord 社区(186 个频道和 3961 条消息)。预计节省阅读时间(以 200wpm 计算):324 分钟。我们的新网站现已上线,提供完整的元数据搜索,并以美观的 vibe coded 方式展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上给我们反馈!
在 7 月,我们最后评论了 Kimi K2 是目前发布的最大的 SOTA OSS Open model,而今天 Moonshot AI 再次更新了他们的 Model weights,并在他们的论文中发布了新的 Benchmarks:

不过,重量级的新晋选手是 Qwen 3 Max,首次发布了一个 1T 参数的模型,显然击败了其较小的同门兄弟。他们拒绝透露 hparams,而是将其称为 “Max”,但看起来 Model weights 很快就会发布,因此目前尚不清楚他们为什么要打破自己的 MoE 命名方案。
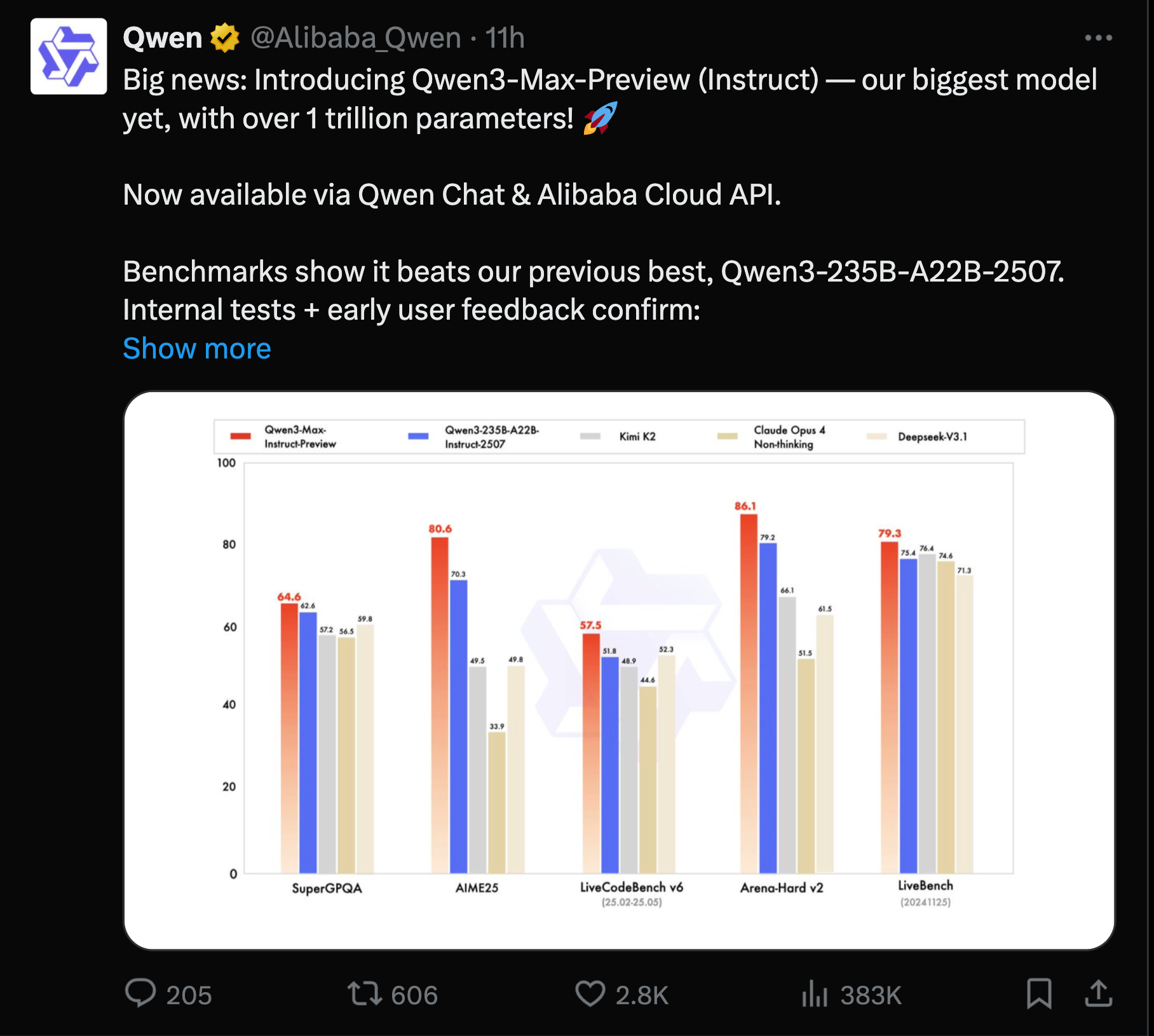
看来,中国在 Open model 战争中正占据压倒性优势。
AI Twitter 综述
中国长 Context 编程能力的激增:Kimi K2‑0905 和 Qwen3‑Max 预览
- Moonshot 的 Kimi K2‑0905 (Open weights) 发布了实用的 Agent 升级:Kimi 将 Context 翻倍至 256k,改进了 Coding 和 Tool‑calling,并优化了与 Agent 框架(如 Cline, Claude Code, Roo)的集成。它已在多个技术栈上线:Hugging Face weights/code, Together AI, vLLM 部署指南, LMSYS SGLang 运行时 (60–100+ TPS), Groq 即时推理 (200+ T/s, $1.50/M tokens), 以及 Cline 集成。社区报告强调,“Agent 确实需要超长 Context”来实现稳定性和工具编排 (Teknium)。在演示中出现了“达到或超过 Sonnet 4”的说法,而 Kimi 工程师承认 SWE‑Bench 仍然具有挑战性 (@andrew_n_carr, @bigeagle_xd)。
- Qwen3‑Max‑Preview (Instruct):1T 参数规模,面向 Agent 的行为:Alibaba 推出了其迄今为止最大的模型(超过 1T 参数),可通过 Qwen Chat、Alibaba Cloud API 以及现在的 OpenRouter 使用(公告, OpenRouter)。Benchmarks 和早期用户指出,相对于之前的 Qwen3 模型,它在对话、指令遵循和 Agentic tasks 方面表现更强。社区反应将其定位为具有竞争力的价格和 Throughput 的“美国级 Frontier model” (反应, 规模预告)。关于 Dense 与 MoE 的细节在公开渠道中仍未明确。
Evals、Agents 以及衡量标准
- “无评估”与“有意义的评估”之争:一个被广泛转发的推特线程指出,许多顶尖的 Code-Agent 团队在没有正式评估(Evals)的情况下就发布了产品,而供应商们却在极力宣扬评估的重要性;其中的微妙之处在于,早期的 0→1 成功往往源于在将评估代码化之前的 Dogfooding + 错误分析 (@swyx, 证据)。后续讨论则提倡对长程能力(如长达数月的任务、协议复制、策略游戏、真实世界设置)进行更丰富的因果评估,以及针对目前排行榜所缺失的特定领域企业级工作流进行评估 (@willdepue, 想法, @levie, @BEBischof)。一个实用的建议是:使用模型作为判别器来对输出进行排序——生成器与判别器之间的差距可以在实践中加以利用 (@karpathy)。
- 在 Agent 栈中实现评估和追踪的工程化:CLI 优先的 Agent 结合语义搜索在文档任务上的表现可以优于临时的 RAG;LlamaIndex 展示了 SemTools 如何通过 UNIX 工具 + 模糊语义搜索处理 1,000 篇 arXiv 论文 (帖子)。对于 RL 流水线,THUDM 的 slime 提供了一个简洁的 Rollout 抽象,集成了工具调用和状态转换,减少了 Agentic RL 实验中的胶水代码 (概述)。
推理与后训练进展
- 解码与规划:Meta 的 Set Block Decoding (SBD) 并行采样多个未来 Token,在不改变架构且兼容 KV-cache 的情况下,将前向传递次数减少了 3–5 倍;训练后的模型在 Next-Token Prediction (NTP) 上的表现与标准模型相当 (摘要)。对于 Agent 而言,“始终推理”(ReAct)并非最优选择——新研究训练模型学习何时进行规划,动态分配测试时计算(Test-time Compute)以平衡成本和性能 (线程, 论文背景)。
- 后训练理论与结果:“RL 之剃刀”(RL’s Razor)认为,即使在准确率相同的情况下,On-policy RL 比 SFT 遗忘更少,因为它倾向于 KL 最小化解;小规模实验和 LLM 实验均支持其能减少灾难性遗忘 (摘要)。《LLM 后训练统一视角》显示 SFT 和 RL 都在优化相同的带有 KL 惩罚的奖励目标;混合后训练 (HPT) 通过简单的性能反馈在两者之间切换,并在不同规模和模型家族中持续超越强基准线 (概述)。在实证方面,微软的 rStar2-Agent-14B 利用 Agentic RL 仅通过 510 个 RL 步数就达到了顶尖的数学水平(AIME24 80.6,AIME25 69.8),且拥有更短、更易验证的思维链 (结果)。
GPU 栈、算子与平台
- PyTorch 中 ROCm 的质量退化:分析指称仅限 ROCm 的跳过/禁用测试数量不断增加(各超过 200 个),且自 2025 年 6 月以来净增;报告称甚至核心 Transformer 算子(如 Attention)已被禁用数月,损害了开发者信任。据报道,AMD 领导层已重新调整修复工作的优先级 (报告)。PyTorch 维护者指出,广泛的测试跳过是普遍存在的,需要各子系统的贡献者持续关注 (背景, 吐槽)。另外,PyTorch 发布了一个关于在 TLX(Triton 低级扩展)中实现 2-simplicial Attention 的算子深度解析 (算子帖子)。
- 基础设施动态与聚会:Together AI 宣布完成由 BOND 领投的 1.5 亿美元 D 轮融资(Jay Simons 加入董事会),以扩展推理基础设施 (公告);Baseten 在推出性能优化工作和支持 EmbeddingGemma 的同时,也筹集了 1.5 亿美元 D 轮融资 (公告)。vLLM 正在多伦多举办一场关于分布式推理、推测解码和 FlashInfer 的聚会 (活动),并且已经支持 Kimi K2 的部署 (支持)。
OpenAI 生态:ChatGPT 分支、Responses API 与 Codex
- 产品/API 动态:ChatGPT 现在支持对话分支(conversation branching)(@gdb; @sama)。OpenAI 的 Responses API 发布了深度详解(thread);AI SDK v5 现在将 OpenAI provider 默认设置为 Responses(Completions 仍可用)(note)。一些开发者反驳称,Responses 在实践中增加了上下文可移植性和无状态使用的复杂性(critique),而另一些人则观察到,与 Chat Completions 相比,持续对话中的“思维链(chain‑of‑thought)保留”有所改善(anecdote)。
- 编程 Agent 与 GPT‑5 Pro:多位从业者报告称,Codex 内部的 GPT‑5 Pro 可以通过更深层、更慢的推理过程解决棘手的工程问题;在与 Sam Altman 的公开交流中,“更聪明”优于“更快速”成为了共识(experience, follow‑up, @sama)。Codex CLI/IDE 继续快速迭代(changelog)。
Embedding 和检索转向端侧(且触及极限)
- 小型、快速、本地化:Google 新推出的开源 EmbeddingGemma 获得了首日平台支持(如 Baseten),据报告,在 M2 Max 上仅需约 80 分钟即可免费完成 140 万份文档的 Embedding,且质量优于旧的大型付费模型(Baseten, field result)。端侧检索变得更加容易:SQLite‑vec + EmbeddingGemma 可跨语言/运行时完全离线运行(guide)。
- 单向量限制:新的理论/基准测试 “LIMIT” 显示了在固定 Embedding 维度下 top-k 检索的硬性下限,SOTA 模型在经过刻意压力测试的简单任务上失败——这证明某些相关文档的组合在本质上无法通过单向量 Embedding 找回,从而推动了多向量/延迟交互(late‑interaction)方案的发展(summary)。
热门推文(按互动量排序)
- “预测未来的能力是衡量智能的最佳标准。” — @elonmusk
- Kimi K2‑0905 更新(256k 上下文,编程/工具调用,Agent 集成) — @Kimi_Moonshot
- Qwen3‑Max‑Preview (Instruct),“超过 1T 参数”,现已通过通义千问/阿里云上线 — @Alibaba_Qwen
- ChatGPT 对话分支功能现已上线 — @gdb
- Codex 中的 GPT‑5 Pro 因能通过更深层的推理解决高难度编程任务而受到赞誉 — @karpathy
- “非常受欢迎的功能!”(指 ChatGPT 分支功能) — @sama
- PyTorch 测试中的 ROCm 性能回归 — @SemiAnalysis_
- DeepMind 的 “Deep Loop Shaping” 提升了 LIGO 引力波探测能力 — @demishassabis
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Kimi K2-0905 与 Qwen 3 Max 发布 + 早期演示
-
Kimi-K2-Instruct-0905 发布! (Score: 729, Comments: 192):Kimi-K2-Instruct-0905 的发布公告,附带一张对比其他 LLM(如 DeepSeek)的基准测试/排行榜图片。图表显示 K2-Instruct-0905 的性能接近 SOTA 且领先于 DeepSeek,评论者特别提到了一个 “1t-a32b” 变体,这可能表明结果中突出了一个值得关注的配置。图片:https://i.redd.it/6jq7r55ak9nf1.png (预览: https://preview.redd.it/u97uhts0q9nf1.png?width=1200&format=png&auto=webp&s=7d65247fb861127f04dd422d2ae8885c748edabd)。 评论者称其“非常接近 SOTA”且“明显击败了 DeepSeek”,同时指出其体积可能更大;讨论集中在尺寸与性能的权衡以及 “1t-a32b” 变体的实力上。
- 性能评价:评论者断言 Kimi-K2-Instruct-0905 “非常接近 SOTA” 并且尽管体积更大但“击败了 DeepSeek”;在验证前仅视为传闻。交叉核对帖子中分享的基准测试图表(图片)以及 Hugging Face 上的模型卡片,对比其与 DeepSeek 变体(如 V3/R1)在 MMLU、MT-Bench、GSM8K 和 HellaSwag 等标准测试集上的表现。
- 规模/架构线索:提到的“万亿参数”开源模型和 “1T-A32B” 变体暗示了 MoE 风格的设置,其中总参数量约为 1T,而每个 Token 的激活参数远低(例如数百亿)。澄清总参数与激活参数、路由/专家数量以及训练 Token 预算,是理解其在高计算量下优于 DeepSeek 等较小 Dense 基准模型的关键。“1T-A32B” 可能表示在约 1T 总参数体系中有约 32B 的激活切片,但在比较效率之前请先在模型卡片上核实。
- 资源:官方发布在 Hugging Face:https://huggingface.co/moonshotai/Kimi-K2-Instruct-0905。查看卡片以获取评估表、上下文长度、Tokenizer 细节、量化/推理说明(如 int4/int8),以及许可证和任何用于复现报告基准的硬件建议。
- Qwen 3 max (Score: 269, Comments: 93): Qwen 3 Max 现在可通过 OpenRouter 模型中心和 Qwen Chat 网页预览版使用 (OpenRouter, chat.qwen.ai)。OpenRouter 上的定价按上下文长度分层:输入
USD 1.2(≤128K) /USD 3(>128K),输出USD 6(≤128K) /USD 15(>128K),这暗示了对超过 128K 上下文的支持,并使其定价接近前沿模型(如 Claude/GPT)。 评论者指出之前的 Qwen Max 变体是闭源的,并希望此次发布能在 Hugging Face 上提供开放权重;其他人则评论说,这一定价将其定位在顶级专有模型之列。- 定价细节:输入定价为 $1.2(上下文 <
128K)和 $3(≥128K);输出定价为 $6(<128K)和 $15(≥128K)。评论者指出,这使得 Qwen 3 Max 的成本结构接近 Claude 和 GPT 级别,暗示了前沿模型的定价姿态,并在128K临界点设有独立的长上下文 SKU。 - 发布/可用性预期:之前的 “Qwen Max” 是闭源的;评论者希望能在 Hugging Face 发布,但其他人认为该模型在发布时可能仅限 API(不可本地运行)。这表明开放权重存在不确定性,且可能缺乏用于设备端推理的即时本地量化版本(如 GGUF)。
- 模型大小推测:一位用户推断 Qwen 3 Max “肯定大于
235B”,暗示人们预期这是一个超越早期 Qwen 基准的超大型 Dense 模型。这尚未得到证实,但如果准确,它将使 Qwen 3 Max 处于 2024 年以上 LLM 参数量的顶层,与其前沿级别的定价相符。
- 定价细节:输入定价为 $1.2(上下文 <
- 我用新的 kimi-k2-0905 制作了一些有趣的演示 (Score: 161, Comments: 24): 楼主展示了几个使用新的 kimi-k2-0905 构建的演示,采用的是 单次、AI 生成提示词 的工作流,将 Claude Code 与 kimi-k2-0905 结合。分享的提示词资源已发布为 gists:gist 1 和 gist 2;v.redd.it 上的演示视频链接在未登录时返回
HTTP 403,限制了独立验证(原始链接)。 一位评论者提出了一个能力压力测试:要求模型端到端生成一个完整的 Game Boy 模拟器。(另一个非技术评论被忽略。)- 一位评论者分享了 kimi-k2-0905 的具体提示词模板,链接了两个 gists,这些 gists 似乎提供了可重用的提示词脚手架和示例,用于实现一致的行为和演示复现:https://gist.github.com/karminski/52a72d4726128c10a266bfb8270fe632 和 https://gist.github.com/karminski/0435b69c6d8c93b4bd1724b64e43bd75。这些资源对于在评估 K2 各项任务时标准化系统指令/角色和 I/O 格式非常有用。
- 有人提议进行压力测试:让 K2 端到端生成一个完整的 Game Boy 模拟器。这将探测长程代码生成、多文件项目脚手架以及硬件推理(指令解码、CPU/PPU/APU 的时序/周期准确性、ROM 加载),提供一个优于其他前沿模型的严格基准。
- 多个请求集中在正面评估和工具使用上:比较 kimi-k2-0905 与 Claude Opus,以及在 Claude Code 中使用 K2 的指南。有用的比较维度包括代码生成的 pass@k、长上下文可靠性、工具使用质量、延迟和成本;与 Claude Code 的集成可能需要一个兼容 OpenAI/Anthropic 的 API 层或适配器来映射对话和工具调用(tool-call)的 schema。
{kind=link}
2. 开源 LLM:GPT-OSS 20B 家庭服务器与每周发布汇总
- 将闲置笔记本电脑转换为运行 gpt-oss 20B 的家庭服务器 (Score: 176, Comments: 94):原帖作者(OP)将一台 2021 款 MacBook Pro M1 Pro(16 GB 统一内存)重新利用为 24/7 全天候运行的家庭 LLM 服务器,通过 llama.cpp server 运行 “gpt-oss 20B”,报告速度为
46–30 tok/s,32K上下文,待机功耗约1.7 W,生成时约36 W;20B 模型加长上下文勉强能塞进 16 GB 内存,因此系统通过 SSH 以无头(headless)模式运行,禁用了睡眠和自动更新,使用 Dynamic DNS 进行广域网访问,并在插电时管理电池健康(经测量,苹果原装充电器比通用 GaN 充电器效率更高)。该模型被描述为快速、简洁且合规,但偶尔会产生“非常奇怪”的事实错误——OP 推测可能是权重损坏或低质量的微调(fine-tuning)。 评论请求提供设置指南并询问是否为裸机(bare-metal)运行,还询问了改进响应的调整方法;一位用户提到在非 Mac 设备上通过拆除电池并将内存升级到 32 GB 获得了成功。另一位用户建议使用基于苹果 MLX 栈的 LM Studio,并通过 Docker 中的 Open WebUI 提供服务以实现身份验证和网页搜索,并质疑 OP 是否因为 16 GB 的限制而避开了这种方案。- 可复现性取决于分享准确的 llama.cpp (repo) 运行时参数;评论者请求提供诸如
t(线程)、ngl(GPU 层卸载/Metal)、c(上下文)、b(批处理大小)等标志位,以及量化方式(例如Q4_K_MvsQ5_K_M)和确切的模型变体。报告的吞吐量从~8 tok/s(Ollama/LM Studio 默认设置)到声称在 M1/16GB 上的~40 tok/s不等;差异可能源于量化、GPU 卸载和批处理,因此发布完整的参数集对于公平比较至关重要。 - 在 Apple Silicon 上,几位用户指出使用带有 MLX 后端 (MLX) 的 LM Studio 比其他选项具有更好的可靠性和性能;一些人将其与 Docker 中的 Open WebUI 配合使用以实现身份验证/搜索。技术栈选择会影响速度和资源余量:MLX/Metal 加速和裸机运行可以击败容器化的 UI 和 Ollama 默认设置,而 Docker 化设置则牺牲了一些性能以换取便利性和功能。
- 硬件限制是 20B 推理的关键瓶颈:将 PC 笔记本电脑升级到
32 GB RAM(并拆除电池以供 24/7 使用)提高了稳定性并支持更高精度的量化;Mac 无法升级内存,这使得M1 16 GB显得非常受限。这种背景有助于解释为什么在低内存机器上可能会避开沉重的 UI/后端,而倾向于更精简的 llama.cpp 服务器。
- 可复现性取决于分享准确的 llama.cpp (repo) 运行时参数;评论者请求提供诸如
-
本周在本版块发布或更新的开放模型列表,以防错过。 (Score: 220, Comments: 30):每周汇总重点介绍了跨任务和规模的新型/更新开放模型:Moonshot AI 的 Kimi K2-0905;AI Dungeon 的 Wayfarer 2 12B & Nova 70B(开源叙事角色扮演 LLM);Google 的 EmbeddingGemma (300M) 多语言嵌入编码器;苏黎世联邦理工学院(ETH Zürich)的 Apertus 多语言 LLM(≈
40%+非英语训练数据);WEBGEN-4B 网页设计生成器,基于约100k合成样本训练;Lille (130M) 小型 LLM;腾讯的 Hunyuan-MT-7B & Hunyuan-MT-Chimera-7B 机器翻译/集成模型;GPT-OSS-120B 基准测试更新;以及 Beens-MiniMax (103M MoE) 从零开始构建的 SFT+LoRA 实验。覆盖范围从~103M到~120B参数,提到的显著技术/数据包括合成数据生成、MoE、多语言侧重、角色扮演微调和翻译集成。 评论指出 Kimi 受到了热烈欢迎;WEBGEN 团队补充说,非预览版和更多 UIGEN 模型即将推出,并且4B检查点(checkpoints)作为内部“温度计”来验证他们的流水线(pipelines)。 - Sparse-MoE 发布表现突出:Klear-46B-A2.5B-Instruct 使用了 46B-parameter 的 mixture-of-experts,每个 token 仅有
~2.5B激活,因此计算量和 KV cache 随激活专家数而非总参数量扩展;类似地,LongCat-Flash-Chat 560B MoE 在保持每步成本受限的同时推高了总参数量。对于 local inference,这意味着内存/吞吐量由激活的专家数量(以及序列长度)决定,如果 routing 保持稀疏且负载均衡,则可以在中低端硬件上实现大容量模型的行为。 - 专业化模型得到扩展:Step-Audio 2 Mini (8B) 增加了开源的 speech-to-speech 能力;Neeto-1.0-8B 针对医疗领域,并在医疗基准测试中报告了
85.8的分数;Anonymizer SLMs 为 edge/server 使用提供了0.6B/1.7B/4B规模的隐私优先 PII 替换。翻译领域通过 YanoljaNEXT-Rosetta 和 CohereLabs/command-a-translate-08-2025 得到了扩展,而 vision/mobile 则通过 Hugging Face 上的 Apple’s FastVLM and MobileCLIP2 受到关注。 - 从工作流的角度来看,WEBGEN 团队指出他们使用
~4B模型作为内部“温度计”,在 scaling up 之前验证 training/inference pipelines,这是早期检测回归(regressions)的实用代理。另外,用户计划评估 Gemma embeddings 的聚类效果;为了进行严谨的比较,建议考虑针对 E5 或 text-embeddings 模型等 baselines,使用内在指标(cosine separation, silhouette)和外在指标(NMI/ARI)。
3. AI/LLM 竞赛论述与迷因反应
- AI/LLM 竞赛绝对疯狂 (Score: 189, Comments: 146): 元讨论指出过去 3–6 个月内 LLM 发布和基础设施建设的快速节奏——特别是专注于代码和通用的模型,如阿里巴巴的 Qwen2.5-Coder、智谱 AI 的 GLM-4 和 xAI 的 Grok-2——以及托管重型模型的第三方 API 平台(如 OpenRouter、Together)的兴起。发帖者将其定义为“泡沫 vs 平台转型”的问题,指向对吞吐量的持续迭代(“提高 tps 的新方法”)、从本地推理向托管推理的转变,以及企业巨额 CAPEX、裁员/挖角和 M&A 作为高增速市场机制的信号。 热门评论分为两派:热衷派(“这就是过去的好时光”);宏观派引用瑞银(UBS)预测 2026 年 AI 投资约为
~$0.5T且同比增长约~60%(认为其规模超过了典型的炒作周期);以及版务担忧,指出该帖子对 r/localllama 来说可能偏离主题。- 引用瑞银(UBS)预测 2026 年 AI 投资约为
~$0.5T,同比增长约~60%,这意味着近期对计算(GPUs/TPUs)、高速互联(400G/800G)以及电力/冷却容量的巨大需求。对于本地/边缘 LLMs,这种规模扩张可能会影响 GPU 的可用性/定价,并刺激基础设施的快速建设,但也增加了类似于过去基础设施周期的产能过剩风险。 - 从业者运行的特定任务基准测试通常无法复现头条新闻中的 SOTA 增益,这表明许多报道的改进是狭隘的、精心挑选的,或者对 prompt/分布偏移非常脆弱。讨论敦促对单篇论文的断言和将 “SOTA” 随意作为客观衡量标准的做法保持怀疑,提倡进行严格的复现、对提议组件的消融实验(ablations),以及在不同数据集/用例中进行评估,以验证真实的性能提升。
- 一些人将当前阶段描述为类似于互联网泡沫时期的建设,重点在于 GPUs 和扩展的 context windows,而营销中的进步(更多 VRAM、更长序列)面临实际限制:延迟、成本以及在极长上下文下的质量下降。观点认为,感知到的部分进展是激进的市场抢占(现在补贴使用,以后涨价),而非持续、可泛化的阶梯式模型改进。
- 引用瑞银(UBS)预测 2026 年 AI 投资约为
- 这并不好笑……这简直 1000000% 正确 (Score: 1697, Comments: 128): 批判当前 AI 炒作的非技术性迷因:它暗示公司(尤其是 CEO)推动“AI”计划主要是为了取悦市场并推高股价,而各类职位的招聘信息现在都要求模糊的“AI 经验”,而不顾实际需求。该图片背景化了更广泛的 AI-washing 趋势——在产品、路线图和招聘中加入 AI 流行语以展示创新,而非交付具体价值。 评论者注意到科技行业招聘广告中几乎无处不在的 AI 要求,并认为高管们在追求与业务利益无关的“AI 溢价”;一些人讽刺地建议 AI 可以取代 CEO,强调了对炒作驱动的领导决策的挫败感。
- 讨论共识指出了一种招聘趋势,即技术岗位被强制要求“AI 经验”,却未指明具体的模型、框架或可衡量的结果,反映了自上而下、市场驱动的指令,而非具体的实施计划。评论暗示业务目标是裁员和股价信号(“我们需要什么?AI!”),而非经过验证的 ROI,且没有关于基准测试、延迟/成本指标或部署系统的讨论——表明 AI 只是一个“打勾”式的技能要求,而非明确的技术需求。
{kind=link}
较低技术性 AI Reddit 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. OpenAI-Broadcom 芯片、Google Veo/Nano Banana、Nunchaku v1.0 发布
- OpenAI 将与 Broadcom 合作开始量产其自研 AI 芯片 (Score: 522, Comments: 58): 路透社(援引金融时报)报道称,OpenAI 将开始与 Broadcom 合作量产其定制的 AI 加速器,旨在减少对 Nvidia GPU 的依赖,降低训练/推理成本,并确保供应。这模仿了超大规模云厂商的策略(例如 Google TPUs、AWS Trainium/Inferentia),但也面临着巨大的风险,包括前期 NRE(非经常性工程费用)、制造良率、上市时间以及构建/优化软件栈以充分利用硬件。来源:https://www.reuters.com/business/openai-set-start-mass-production-its-own-ai-chips-with-broadcom-ft-reports-2025-09-05/ 评论者将其描述为一项高风险、高回报且最终“显而易见”的战略举措:如果成功(成本/控制优势)则是明智之举,但考虑到资本密集度和执行风险,这也是一场巨大的豪赌。
- 战略理由与风险:评论者认为这模仿了 Google TPU 的做法(通过定制加速器减少对 Nvidia 的依赖,并优化训练/推理的 TCO),这可以提供特定工作负载的效率和容量控制。缺点是巨大的前期 NRE、流片(tapeout)/良率风险、漫长的调试周期,以及需要成熟的编译器/运行时和内核库(类似 XLA)来接近 GPU 级的性能;失败将导致巨额资本支出损失。参考 TPU 先例:https://cloud.google.com/tpu
- 部署范围:该帖子强调,根据报道,OpenAI 的目标是内部使用该芯片而非出售,即 “OpenAI 计划将该芯片用于内部,而不是提供给外部客户……”。这意味着该芯片将与 OpenAI 的训练/研究栈进行紧密的协同设计,且不会进行第三方产品化,从而减轻了外部支持/验证的负担,但也限制了在客户间的摊销,并将优化重点放在他们自己的模型/流水线上。
- 制造/竞争力:与 Broadcom 合作表明这是一款采用先进封装/HBM 的完整 ASIC;与 GPU 的竞争力取决于工艺节点、良率、内存带宽、互连和软件工具。在 perf/W(每瓦性能)和 cost-per-token(每个 token 的成本)上击败
H100/B200将确保供应/成本优势;如果未能达到这些目标,则会留下高昂的沉没成本。参考 GPU 基准:https://www.nvidia.com/en-us/data-center/h100/ 和 https://www.nvidia.com/en-us/data-center/blackwell/
- Google 势头正劲…Nano Banana 和 Veo 是绝对的颠覆者 (Score: 210, Comments: 14): 帖子炒作了 Google 最新的生成式模型 —— Veo(文本生成视频)和 Gemini Nano(端侧 LLM)为“颠覆者”。Veo 是 Google/DeepMind 的视频模型,用于生成具有连贯运动、摄像机控制和风格调节的高保真、长时长 1080p 文本生成视频;参见 DeepMind: Veo。Gemini Nano 是一款紧凑型端侧模型,通过 AICore 集成到 Android 中,用于低延迟任务(例如摘要、上下文感知系统功能);参见 Gemini Nano 文档。 评论强调了演示的真实性,并要求明确的艺术风格调节(例如 “加入萨图恩吞噬其子”),而另一条地缘政治评论是非技术性的,与模型能力没有直接关系。
-
Nunchaku v1.0.0 正式发布! (Score: 305, Comments: 91): Nunchaku v1.0.0 实现了后端从 C 到 Python 的迁移,以获得更广泛的兼容性,并增加了异步 CPU 卸载(offloading),使 Qwen-Image 扩散模型能够在
~3 GiBVRAM 中运行,且声称没有性能损失。新的 wheel 文件和 ComfyUI 节点已发布(发布页面,ComfyUI 节点),此外在 Hugging Face 上还有一个4-bit、4/8-step的 Qwen-Image-Lightning 版本(仓库);文档涵盖了安装/设置(指南)。路线图:即将启动 Qwen-Image-Edit,接下来将增加对 Wan 2.2 的支持。 评论者敦促优先考虑 Wan 2.2 而非 2.1,并表达了对更快图像生成工作流的热情。有人询问 Nunchaku 与 Chroma 的兼容性(目前的示例显示的是 Flux),暗示了对更广泛模型/运行时支持的兴趣。 - 问题集中在模型兼容性上:既然示例展示了
FLUX,Nunchaku 是否能与Chroma配合使用?其他人询问是否支持用于微调/适配器的LoRA。这表明用户希望在展示的FLUX流水线之外,获得更广泛的模型/运行时抽象。 - 多名用户请求支持
WAN 2.2(有些人更倾向于它而非WAN 2.1),其中一人引用道:“WAN2.2 没有被遗忘——我们正在努力提供支持!”。重点是保持与当前模型版本的一致性,以实现最先进的图像生成;讨论帖中未提供具体的时间表或技术方案细节。 - 升级可靠性:一名测试者报告称,应用内的 Manager 更新“几乎从不起作用”,通常需要手动卸载/重新安装才能升级到新版本(例如 v1.0.0)。这指向了打包/更新流水线的问题,可能会阻碍平稳采用和自动化环境。
{kind=link}
2. AI 机器人:Figure 家务与 RAI Robomoto
- Figure.ai 会接管家务吗? (Score: 350, Comments: 223): 讨论帖探讨了 Figure AI 的人形机器人(例如 Figure 01)是否能处理全方位的家务。未提供基准测试或实现细节(链接视频位于 Reddit 登录后的 v.redd.it);评论者定义了一套 MVP 能力集:端到端洗衣服、拖地、洗碗机装载/卸载、纸箱拆解、垃圾/垃圾箱物流以及吸尘——这意味着在非结构化家庭环境中的可靠移动操作(变形物体处理、力控工具使用、长程任务规划、感知和安全)。如果这些任务能够稳健执行,消费者引用的价格承受能力为
USD $30–50k。值得注意的情绪:如果日常家务得到解决,在所述价格下有强烈的采用意愿;推测胜任的家庭烹饪加上无人机食材配送可能会重塑餐厅需求和最后一公里物流;在没有具体证据的情况下,普遍希望近期能实现。- 家务清单(端到端洗衣服、拖地、洗碗机装载/卸载、纸箱压平、垃圾物流、吸尘)意味着硬性要求:稳健的变形物体操作(布料、袋子、纸箱)、工具使用、家电接口、长程任务规划以及杂乱环境下的家庭规模导航。基准测试突显了差距:BEHAVIOR-1K 长程家庭任务 [https://behavior.stanford.edu/behavior-1k]、iGibson [https://svl.stanford.edu/igibson] 和 Habitat [https://aihabitat.org] 显示成功率在非结构化设置中会有所下降。达到可接受的周期时间(例如,在 10–15 分钟内折叠一篮衣服)并在没有人工干预的情况下从错误中恢复,与灵巧性同样至关重要。所述的
\$30–50K支付意愿表明,移动底座 + 1–2 个机械臂 + RGB-D 传感器的 BoM 目标只有在可靠性接近家电级工作周期时才可行。 - 多位评论者指出了“特定条件”下的演示差距:真实的家庭环境差异很大(光照、布局、新奇物体),因此模拟/演示策略必须具备泛化能力并能从失败中恢复。对于 50–200 步的家务,每一步的可靠性必须
≥99.9%才能保持较高的任务成功率(0.999^100 ≈ 90%对比0.99^100 ≈ 36%),这远超舞台演示的成功率。这需要自校准、持续建图、遮挡下抓取、柔顺控制和安全联锁,且两次人工干预之间的 MTBF 需达到数十小时——因此距离家电级部署还有“几年时间”。 - 辅助和烹饪场景提高了门槛:限力柔顺操作、食品级安全材料、热/油脂处理、具备污染意识的工具使用、可靠的多模态接口以及稳健的环境理解。像 Mobile ALOHA 这样的远程操作到模仿系统展示了在精心策划的条件下完成双手机器人厨房任务 [https://mobile-aloha.github.io],但端到端自主性还需要储藏室库存跟踪、食谱/时间规划以及与配送物流(无人机/机器人)的集成,这些都面临着可靠性和监管限制。这些要求超出了当今的扫地/拖地机器人,是实现有影响力的居家养老或盲人辅助的关键制约因素。
- 家务清单(端到端洗衣服、拖地、洗碗机装载/卸载、纸箱压平、垃圾物流、吸尘)意味着硬性要求:稳健的变形物体操作(布料、袋子、纸箱)、工具使用、家电接口、长程任务规划以及杂乱环境下的家庭规模导航。基准测试突显了差距:BEHAVIOR-1K 长程家庭任务 [https://behavior.stanford.edu/behavior-1k]、iGibson [https://svl.stanford.edu/igibson] 和 Habitat [https://aihabitat.org] 显示成功率在非结构化设置中会有所下降。达到可接受的周期时间(例如,在 10–15 分钟内折叠一篮衣服)并在没有人工干预的情况下从错误中恢复,与灵巧性同样至关重要。所述的
- 又一天,又一个 AI 驱动的自动摩托车 (Score: 321, Comments: 46): 该 Reddit 帖子链接到了 RAI Institute 的一段 X/Twitter 短视频,展示了一辆无人驾驶、AI 驱动的摩托车正在进行基础的平衡/骑行操纵(视频)。帖子/视频未包含任何技术细节(例如:控制栈、传感器、训练方法或定量的性能/鲁棒性指标),且镜像到 Reddit 托管的视频 (v.redd.it) 对未经身份验证的客户端返回
403错误。 热门评论大多是非技术的梗;唯一具有实质意义的观点是对在 supersport 平台和高速公路条件下进行高速验证的好奇。- 一个反复出现的技术问题是,为什么四足机器人(机器人狗)看起来很敏捷,而类人机器人看起来却很笨拙。评论者指出,四足机器人受益于被动/静态稳定性和更简单的步态规划器,而双足机器人是欠驱动的,需要实时全身控制 (ZMP/MPC)、高带宽扭矩控制和可靠的接触估计;增加灵巧手进一步加剧了问题,其拥有
~28–40个 DOF,而许多四足机器人只有~12–16个。虽然已有进展,但在演示场景之外仍然很脆弱(最先进水平请参见 BD Atlas 跑酷:https://www.youtube.com/watch?v=tF4DML7FIWk)。 - 关于“把它绑在 supersport 上”,先前的研究表明,在没有人类骑手身体的情况下,自主摩托车控制是可行的:Yamaha MOTOBOT 使用 GPS/IMU 融合以及对节气门、刹车、离合器、换挡和转向的基于模型的控制,通过逆向操舵 (counter-steering) 诱导倾斜,以
>200 km/h的速度骑行 R1M (https://global.yamaha-motor.com/showroom/technologies/ymrt/motobot/)。难点在于快速变化的轮胎-路面摩擦下的低延迟控制,以及在低速平衡与高速动力学之间保持稳定性;当线控驱动 (drive-by-wire) 可用时,模仿人类动作去“抓”摩托车是不必要的。摩托车上相关的平衡方法(例如 Honda Riding Assist)强调了转向几何结构和主动控制如何管理低速稳定性:https://global.honda/innovation/robotics/experimental/riding-assist/。
- 一个反复出现的技术问题是,为什么四足机器人(机器人狗)看起来很敏捷,而类人机器人看起来却很笨拙。评论者指出,四足机器人受益于被动/静态稳定性和更简单的步态规划器,而双足机器人是欠驱动的,需要实时全身控制 (ZMP/MPC)、高带宽扭矩控制和可靠的接触估计;增加灵巧手进一步加剧了问题,其拥有
3. AI 社会:不平等、裁员、深度伪造与可访问性
- 计算机科学家 Geoffrey Hinton:“AI 将使少数人更富有,而让大多数人更贫穷” (Score: 216, Comments: 76): 在最近接受《金融时报》(Financial Times) 采访时,Geoffrey Hinton 警告称,当前的 AI 部署将使财富和权力集中在少数公司手中,同时减少大多数劳动者的收入,加剧不平等和社会风险。他敦促在进一步快速推广之前,加强监管、安全研究和治理,以减轻劳动力市场流失和更广泛的系统性损害。来源:无付费墙存档 链接,FT 原文 需付费。 热门评论将其视为资本主义日益扩大的贫富差距的延续,而 AI 加速了这一趋势;一些人认为 Hinton 的语气讽刺地表现得“现在更乐观了”。另一个帖子断言,收益集中化是一个有利于既得利益者的刻意设计的特性,而不是一个意外的 Bug。
- 几位评论者强调了结构性的税收不对称:雇佣人类会触发工资税(例如美国雇主的 FICA 约
7.65%加上强制性福利),而部署机器人/软件则无需缴纳工资税,这实际上使得自动化在同等任务下的总拥有成本低于劳动力。他们认为这充当了事实上的补贴,加速了资本对劳动的替代,并将回报集中在资本所有者手中,并引用了诸如“机器人税”或将税收负担从劳动转向资本以重新平衡激励机制的想法(参见 IRS/SSA FICA 概述:https://www.ssa.gov/pubs/EN-05-10003.pdf;政策辩论:https://www.oecd.org/tax/tax-policy/taxation-and-the-future-of-work.htm)。 - 另一个帖子认为,AI 收益的不平分配并非技术上的必然,而是由制度选择驱动的,这些制度对与劳动相关的转移支付征收重税,而对大额财富转移(遗产/资本利得)征税相对较少,导致 AI 驱动的生产力主要累积到资产所有者手中。他们从要素收入份额和议价能力的角度阐述了这一点,指出劳动份额的长期下降是一个警告信号(例如美国非农商业部门劳动份额趋势:https://fred.stlouisfed.org/series/PRS85006173),并提议将税收/转移支付系统转向财富和资本收入,以避免“新封建主义”动态。
- 几位评论者强调了结构性的税收不对称:雇佣人类会触发工资税(例如美国雇主的 FICA 约
- Salesforce CEO 确认因 AI 裁员 4,000 人,称“因为我需要更少的人手” (Score: 290, Comments: 69): 据 CNBC 报道,Salesforce CEO Marc Benioff 确认了约
4,000名客户支持人员的裁员——将支持团队人数从约9,000人减少到约5,000人——并将此次裁员归因于其 Agentforce 系统带来的 AI 驱动效率提升,并表示 “因为我需要更少的人手”。Salesforce 表示 AI 减少了支持案例的数量,且不会填补受影响的支持工程师职位;据报道,在公司内部,AI 处理了高达50%的工作。 热门评论认为,企业正在利用 AI 来为疫情后的过度招聘修正辩护,并向投资者传递效率信号(引用分析师 Ed Zitron 的观点),预测随着当前炒作周期的降温,会出现更多归因于 AI 的裁员。- 几位评论者认为,归因于“AI 效率”的
4,000人裁员缺乏技术依据——没有披露生产力指标、自动化覆盖率、基础设施成本降低或模型/推理(inference)选择。他们指出,这反映了更广泛的疫情后过度招聘修正,在没有基准测试(如每个 Agent 处理的工单数、每个 AE 的线索数、服务成本差异)的情况下,被重新包装成 AI 驱动。由于缺乏诸如哪些模型、微调(fine-tunes)或工作流自动化实际取代了全职员工(FTEs)等细节,这一说法很难评估。 - 一个关于使用 AI 构建个人 CRM 的轶事强调了 LLM 辅助的脚手架(scaffolding)如何加速 CRUD 应用和简单自动化的开发,这可能会削弱通用 SaaS 的护城河。然而,在企业规模上取代 Salesforce 需要非同寻常的能力——复杂的角色层级/ACLs、合规性(SOC 2/HIPAA)、数据模型可扩展性、集成吞吐量(ETL/事件总线)、可观测性(observability)和 SLAs——在这些领域,DIY + LLM 仍然会带来巨大的持续运维(ops)和可靠性负担。
- 在缺乏硬性 ROI 的情况下,预计在炒作常态化之前,会有更多公司以 AI 为由削减人手。技术读者会期待可量化的证明,例如
>X%的工作流自动化、每个席位~$Y的许可证整合,或者由人力节省抵消的推理支出;但这些都没有被提及,这表明这更多是向投资者释放信号,而非经过衡量的 AI 驱动效率。
- 几位评论者认为,归因于“AI 效率”的
- 更新:得益于 ChatGPT 中的 Vibe Coding,Ben 现在可以上网了 (Score: 1387, Comments: 77): 一位护理人员通过与 ChatGPT 进行 “vibe coding”,构建了一个自定义的 AAC/无障碍技术栈,使一位患有 TUBB4A 相关白质脑病和严重眼球震颤的非语言四肢瘫痪患者能够使用二进制的双按钮头带输入和屏幕扫描选择来浏览内容。该系统从短语板演变为媒体选择器、预测文本键盘和 8 个自定义游戏,最终实现了直接集成到键盘中的搜索功能,使用户能够输入查询并独立检索图像/YouTube 视频;演示链接:v.redd.it/6qzlngnab8nf1(目前返回
403/权限受限)。实现过程强调了低视力和低精细动作限制,采用二进制输入扫描,UI 选项的大小和顺序经过优化以满足最小的视觉需求,所有原型均由一名新手使用 ChatGPT 进行快速迭代完成。 评论者鼓励为其他家庭分享/复制这种方法,并建议允许用户通过 ChatGPT 进行共同创作(用户在环的 Prompt Engineering)以扩展功能。- 一位评论者建议转向终端用户编程(end-user programming),让 Ben 直接访问 ChatGPT,以便他可以原型化并构建自己的工具/自动化,并指出用户驱动的迭代通常会产生他人无法预料的解决方案。
- 这意味着将当前的 “Vibe Coding” 工作流从护理人员编写的 Prompt 扩展到用户编写的脚本/宏(macros),从而增加辅助技术中的个性化和自主性。
- 科技公司 CEO 们在白宫轮流赞扬特朗普——“感谢您成为这样一位亲商、亲创新的总统。这是一个非常令人振奋的变化,”Altman 说道 (得分: 804, 评论: 207):在一次白宫活动中(据报道是玫瑰园晚宴),多位科技公司 CEO 公开赞扬特朗普总统“亲商、亲创新”的立场,其中 Sam Altman (OpenAI) 被引用说:“感谢您成为这样一位亲商、亲创新的总统。这是一个非常令人振奋的变化。” 提供的唯一来源是带有付费墙的 WSJ 链接;共享材料中没有提供议程、政策承诺、参与者名单或技术成果(例如监管变化、资助计划)。热门评论绝大多数对 CEO 们的诚信以及 Altman 本人持批评态度,未提供技术或政策分析;分享的一个图片链接也缺乏上下文。总体而言,该帖子反映了对企业动机的怀疑,而非对科技政策的实质性辩论。
AI Discord 简报
由 Gemini 2.5 Pro Exp 生成的摘要之摘要之摘要
1. AI 军备竞赛:新模型与硬件升温
- Qwen 3 Max 登场,评价褒贬不一:新的 Qwen 3 Max 模型引发了其拥有 500B 到 1 万亿参数的猜测,Unsloth AI Discord 的用户称赞其创意写作能力优于 K2 和 Sonnet 4。然而,它的高昂价格以及在工具调用(tool calls)和基于逻辑的编程方面的缺点也受到了关注,而来自 OpenRouter 的官方发布公告则强调了其在 RAG 和 tool calling 方面改进的准确性和优化。
- 硬件战争:从定制芯片到工作站:据 Financial Times 文章详述,OpenAI 据传正与 Broadcom 合作开发定制 AI 芯片,以减少对 Nvidia 的依赖。与此同时,工程师们辩论了工作站的优劣,有人调侃说 DGX Spark 与更强大的 DGX Station 相比只是个玩具,还有人猜测 Nvidia 即将推出的 5000 系列可能会是跳过的一代(skip gen),因为其 VRAM 没有显著增加。
- 小众模型迎合特定口味:一个名为 Glazer 的新模型在 Hugging Face 和 Ollama 上发布,专门用于模拟一些用户怀念的 GPT-4 的奉承(sycophantic)人格。在更具实验性的尝试中,一位开发者在 H.P. 洛夫克拉夫特的故事上训练了一个微型 LLM (micro-LLM),产生了他们称之为相当有前景的洛夫克拉夫特式输出,详见这段 YouTube 视频。
2. 地缘政治焦虑与公司政策大洗牌
- Anthropic 划定地缘政治界限:最初在 X 上分享的一项 Anthropic 新政策规定,限制向受其产品不被允许的司法管辖区(如中国)控制的组织提供服务。此举在多个 Discord 中引发了辩论,焦点在于其动机是出于真正的国家安全考虑,还是仅仅为了保护市场份额的企业自身利益。
- MasterCard 的 AI 引发合规混乱:MasterCard 用 AI 系统取代了其人工欺诈预防团队,该系统现在正根据其规则手册第 5.12.7 章的规定,激进地标记商家的猥亵规则违规行为。该系统规定不明确的标准导致了高达 $200,000 的罚款,将商家推入困境,并凸显了在没有明确上下文的情况下自动化政策执行的风险。
- OpenAI 澄清 Responses API 现状:一位开发者在 X 上发布了一个帖子以打破关于 OpenAI Responses API 的广泛谣传,澄清它并不会神奇地解锁更高的模型智能,但对于构建 GPT-5 级别的 Agent 至关重要。同时确认 OpenRouter 在其大多数 OpenAI 模型中都使用了此 API,这使得该澄清对于在该平台上构建的开发者至关重要。
3. 开发者的困境:选择并调优合适的工具
- IDE 中的编程助手之争:开发者们正在激烈争论哪款 AI 编程工具最强,许多人认为 GPT-5 优于 Sonnet 4,原因是其简洁性且更不易产生幻觉 (hallucinate)。社区在 Codex CLI(因代码质量受赞)和 Cursor Code(因创造性推理受青睐)之间也存在分歧,一位用户指出,最佳配置可能是每月 20 美元的 Cursor 订阅搭配独立的 Claude Code 方案。
- 工程师通过 Prompt 和程序驾驭 LLM:在 OpenAI 的 Discord 中,用户分享了高级的 Prompt Engineering 技巧,主张通过删减废话并使用类似 [list] 和 {object} 的括号表示法进行抽象来提高 Token 效率。在其他地方,使用 DSPy 的开发者则专注于更具程序化的方法,构建语音 Agent 并使用 GEPA 等框架为特定的对话任务优化 Prompt。
- 硬件限制迫使产生创意解决方案:一位使用 6GB GPU 的用户寻求沉浸式角色扮演的模型推荐,得到的建议包括 Mistral Nemo Instruct 和量化版的 Qwen3-30B-A3B-Instruct-2507-MXFP4_MOE 模型。对于云预算紧张的开发者,另一场讨论强调了利用带有 RoPE (Rotary Position Embedding) 的模型来构建 RAG 应用,从而处理超出显式训练范围的上下文窗口。
4. 深入底层:GPU 编程与性能的核心内幕
- Mojo 和 Zig 挑战编译器极限以追求巅峰性能:Modular 社区的工程师们正致力于实现编写简单的 Python 风格代码,并通过 Mojo 和 MLIR 自动编译为 SIMD 指令。这反映了 Zig 社区对一种新的异步 IO 方法的关注,即“IO 现在需要携带状态”,这引发了关于 Mojo 类型系统等下一代语言特性如何解决这些底层性能挑战的讨论。
- 工程师破解底层 CUDA 和 ROCm 之谜:根据这篇论文,一项深度研究显示,Nvidia Tensor Cores 中用于 FP8 矩阵乘法的 FP32 累加器实际上是 FP22。其他讨论集中在利用 Ampere 架构上的 L2 缓存持久化来提升性能(详见博客文章),以及解决 rocSHMEM 中与其 ROCm-aware MPI 要求相关的错误。
- 前瞻性架构引发小众讨论:在一名成员分享了解释视频后,讨论探讨了类脑的脉冲神经网络 (SNNs)。在更具实际意义的性能方面,vLLM 的性能分析揭示了由“运行时触发的模块加载 (Runtime Triggered Module Loading)”导致的显著减速,促使人们对其根本原因和潜在的变通方法展开调查。
5. 用户忧虑:平台不稳定与 UX 问题引发困扰
- LMArena 在空前流量下不堪重负:LMArena 平台正面临严重的稳定性问题,用户报告了普遍的图像生成故障、死循环以及无法运行的视频竞技场机器人 (video arena bot)。新实施的速率限制 (rate limits)和登录要求加剧了这种挫败感,一位用户抱怨这种改变很糟糕,“因为我们大多数人都不想这样做”。
- API 频发故障,各平台服务受阻:Perplexity PPLX API 的用户报告了 500 内部服务器错误的激增,Playground 也变得无法使用。这种不稳定性甚至蔓延到了付费客户,一些 Perplexity Pro 用户注意到 Grok 4 模型从他们的选择器中消失了,而一位 OpenRouter 用户发现,达到输出 Token 限制会静默地截断响应。
- AI 助手表现不佳令用户沮丧:使用 Cursor Auto 模式的开发者分享了大量关于其性能低下的投诉,包括无法修复简单的 Bug,以及倾向于在聊天框中输入编辑内容而不是直接应用。一位从 Claude Code 换回 aider 的用户评论道,“Anthropic 做出了一些令人质疑的改变”,这反映出一种普遍情绪,即即使是顶级工具也正在经历性能退化。
Discord: 高层级 Discord 摘要
LMArena Discord
- 图像生成深受故障困扰:用户报告了 image generation 的广泛问题,包括持续的错误和导致出现 ‘Something went wrong with this response’ 消息的无限生成循环。
- 建议包括添加更具体的错误消息以协助排查故障,特别是当模型似乎对提示词感到困惑时。
- Video Arena 机器人短暂消失:video arena bot 经历了停机,但在修复后现已重新上线;用户可以在指定频道 <#1397655695150682194>、<#1400148557427904664> 或 <#1400148597768720384> 中通过
/video命令和提示词使用该机器人。- 此处分享了一个关于如何使用该机器人的 GIF 教程。
- 登录要求引发愤怒:新的登录要求,特别是 Google 账号要求,引发了用户的担忧,一名成员指出该要求很糟糕。
- 该成员解释说这是 “因为我们大多数人都不想这样做”。
- 速率限制令常客恼火:由于前所未有的流量,最近对图像生成实施的 rate limits 导致了挫败感,用户对这些限制是刻意为之还是持续故障的结果感到困惑。
- 已登录用户将继续享受更高的限制,有关用户登录的更多信息可以在此处找到。
- 账户数据异常消失:用户报告了 chat histories 丢失的情况,特别是在未登录时,这引发了对数据保留的担忧。
- 一名成员建议尝试恢复聊天记录:“如果你使用 Brave 浏览器,你也许能恢复它们,我不确定 Google 浏览器行不行”,并提到该平台可能正在使用 Cloudflare。
{kind=link}
Perplexity AI Discord
- Perplexity Pro 用户抱怨缺少 Grok 4:部分 Perplexity Pro 用户在模型选择器中找不到 Grok 4,并被建议联系支持部门以检查其 Pro 账户是否为企业版。
- 一名成员建议重新安装 App 可能有助于解决问题,或者向 Perplexity 支持确认该模型是否已分配给账户,并指出大学用户受到的影响尤为严重。
- Arc 浏览器走向没落:用户讨论了从 Arc 到 Dia 的过渡,其中一人指出 Arc 已经大约一年没有实质性的更新了,另一人则对该浏览器 $15 的收费表示担忧。
- 他们补充说,随着向构建 Agentic Chromium 的转型,大量忠实的 Arc 用户将被抛弃,并抱怨其价格应该比 Perplexity Max 更便宜。
- Qwen 3 Max 猜测四起:成员们对即将推出的 Qwen 3 Max 的规格进行了推测,预计参数在 500B 到 1 Trillion 之间。
- 一名成员表示,他们认为既然这些模型对消费者免费,那是 为了获得更好的训练数据和庞大的社区,而且社区也在通过标注、测试和评估不同的模型版本来推动模型构建。
- PPLX API 发生故障:多名用户报告在调用 API 时收到 500 Internal Server Errors,并注意到 Playground 也无法正常工作。
- 用户确认状态页面上没有报告停机,而一名用户在服务恢复正常后调侃道 “他们会假装什么都没发生”,另一名用户则将其归咎于 “使用量增加”。
- Comet 触及使用限制:用户报告称在过度使用 Comet Personal Search 后,它会停止工作并弹出消息:“您已达到 Comet Personal Search 的每日限制。升级到 Max 以增加您的限制。”
- 其他人注意到 Comet 目前通过 Paypal/Venmo 活动或针对学生提供,并在 Discord 中分享邀请链接,但这可能会影响 API 的性能。
Unsloth AI (Daniel Han) Discord
- Postgres 在复杂查询中占据主导地位:虽然 Qdrant 在向量搜索方面表现出色,但带有 pgvector 的 Postgres 被认为在处理复杂数据库查询方面更胜一筹,引发了关于数据库适用性的讨论。
- 一位成员链接了一条 推文 并幽默地分享了一个 Borat GIF,为技术讨论增添了轻松气氛。
- Local Sonnet 庞大的 RAM 需求:运行 Local Sonnet 至少需要 512GB 的 RAM,凸显了获得最佳性能所需的显著硬件要求。
- 即使拥有 1TB 的 RAM,实现全精度运行仍然是一个挑战,这引发了关于将 Q8 微调作为潜在解决方案的咨询,但该方案因效果不足而被否决。
- DGX Spark:是玩具还是珍宝?:社区讨论了 DGX Spark 与 DGX Station 的优劣,一位成员调侃道 Spark 是玩具,Station 才是工作站,并链接到了 DGX Station 产品页面。
- 尽管存在局限性,DGX Spark 因其诱人的价格和存储容量而获得认可,被描述为 一款不错的产品。
- Qwen 3 Max 在创意写作方面表现出色:对 Qwen 3 Max 的评估强调了其在创意写作和角色扮演方面的优势,在成员评估中超过了 K2 和 Sonnet 4。
- 然而,其高昂的价格以及在工具调用(tool calls)和基于逻辑的代码编写方面的感知缺陷削弱了人们的热情,使其被定位为可能定价过高。
- Glazer 模仿 GPT-4:新模型 Glazer 发布并获得好评,旨在复制一些用户怀念的 GPT-4 的“讨好型”人格。
- 它可以通过
ollama run gurubot/glazer在 Ollama 上获取,也可以在 Huggingface 上获取 4B 和 8B 版本。
- 它可以通过
LM Studio Discord
- 3090 Bug 导致 4090 超频?:一位用户报告称,他们的 3090 似乎导致其 4090 功耗过高,这可能是由于 software bug 造成的。
- 这导致了更高的温度,使得用户通常需要进行降压处理(undervolt)以防止过热。
- Tentacle LORAs 征服艺术风格:一位成员创建并分享了一系列 LORAs,探索了各种艺术风格,并提供了 LORA 模板链接。
- 这些 LORAs 被描述为“拼凑在一起”的,呈现出触手状,旨在进行艺术实验。
- 6GB GPU 用户需要角色扮演模型:一位拥有 6GB GPU 的用户寻求关于写实且沉浸式角色扮演游戏的最佳模型建议。
- 建议包括将 CPU RAM 增加到 64GB,并使用 Mistral Nemo Instruct 或 Qwen3-30B-A3B-Instruct-2507-MXFP4_MOE 等模型。
- 仿生腿(Bionic Legs)失败了吗?:一位成员询问了消费级价格的 仿生腿(外骨骼),寻求实际性能见解。
- 另一位成员引用了一段 YouTube 评论,指出它们 几乎没有任何作用,甚至可能导致肌肉萎缩。
- 5000 系列将跳过 VRAM 升级?:围绕新款 Nvidia 5000 series 可能成为“跳过的一代(skip gen)”展开了讨论,认为其相对于 4000 series 的性能提升微乎其微。
- 缺乏额外的 VRAM 也是一个令人担忧的点。
Cursor Community Discord
- GPT-5 完胜 Sonnet 4:成员们发现 GPT-5 在编程方面优于 Sonnet 4,理由是其简洁性和准确性更高,尽管它需要更具体的 prompting,而 Sonnet 4 往往会有更多的幻觉 (hallucinate)。
- 用户认为 GPT-5 是极具价值的规划者和讨论伙伴,尤其是在配合自动实现功能时,因为 Sonnet 4 看起来更像是基于模板的 (template-based)。
- Codex CLI vs Cursor Code:代码天才之争:社区在 Codex CLI 和 Cursor Code 之间产生了分歧,一些人更青睐 Codex CLI 卓越的代码质量,而另一些人则看好 Cursor Code 的创造性思维和推理能力,因为质量取决于 prompt 的质量。
- 一位成员因幻觉问题退订了 Cursor Code 的 Max 计划,而其他人则警告 Codex 的速率限制 (rate limits) 更低且更难追踪,尽管有些人很欣赏它的建议系统。
- Cursor 每月 20 美元的定价:依然划算吗?:讨论围绕 Cursor 每月 20 美元的 Pro 计划的价值展开,用户争论达到使用限制的速度有多快。
- 一位用户发现该工具必不可少,但为了 Claude Code 和 Codex 取消了 Cursor 订阅,并建议将每月 20 美元的 Cursor 订阅与 Claude Code 计划搭配使用,以兼顾行内编辑和终端使用,这才是最优配置。
- Cursor Auto-Mode:极其谨慎使用:多位用户报告了 Cursor 的 Auto mode 存在问题,指出其性能不佳、无法修复简单的 Bug,并且倾向于在聊天框中输入编辑内容而不是直接应用它们。
- 一位用户幽默地用该工具生成的一条类似梗图的消息展示了 Cursor 的过度自信,强调了进行彻底调试的必要性。
OpenRouter Discord
- Qwen3-Max 变得更聪明了:根据 这条 X 帖子,最新的 Qwen3-Max 模型在数学、编程、逻辑和科学任务上的准确率比 2025 年 1 月的版本有所提升。
- 该模型针对 RAG 和 tool calling 进行了优化,缺乏专门的“思考”模式,可在 此处 进行测试。
- PancakeSwap 上的虚假 OpenRouter 加密货币:一种与 OpenRouter 相关的加密货币是诈骗,与 OpenRouter 官方没有联系。
- 在用户询问 PancakeSwap 上是否存在 OpenRouter 代币及其交易可用性后,社区收到了警告。
- Anthropic 的地缘政治立场引发讨论:成员们讨论了 Anthropic 的博文,该文章限制了来自所有权结构受其产品禁入国家控制的地区的访问。
- 一些人猜测此举是出于国家安全还是市场份额保护。
- 输出 Token 限制在 8k:一位用户发现达到输出 Token 限制会导致响应截断,停止原因被标记为 ‘length’。
- API 限制设置
max_tokens超过模型的限制。
- API 限制设置
- OpenRouter 利用 OpenAI Responses API:一位成员询问 OpenRouter 是否使用了 OpenAI Responses API,并引用了 一条推文。
- 已确认 OpenRouter 在大多数 OpenAI 模型中都使用了它。
OpenAI Discord
- 削减 Token 浪费:一名成员提倡通过过滤语法上无用的词汇,并将多个词合并为 Prompt 中的有效词汇来提高 Token 效率,并声称在推理中,浪费的 Token 等于浪费资源。
- 他们认为,如果你是自行托管,浪费的 Token 会导致组件加速摊销,而且 AI Prompt 中的礼貌用语可能会增加环境浪费。
- Gemini 2.5 Pro 解锁无限访问:Google AI Studio 现在提供对 Gemini 最佳模型 2.5 Pro 的无限访问,以及 Imagen、Nano Banana、Stream Realtime、语音生成和 Veo 2 等其他功能。
- 一些成员专注于 LLMs,而另一些成员则发现了其在视频编辑、教育视频和重现公有领域作品方面的用途。
- 关于 AGI 的言论产生碳排放:成员们讨论了一篇博客文章,该文章揭露了 ChatGPT 中关于 AGI 的言论所产生的碳排放超过了在“请”和“谢谢”上浪费的 Token,文章可以在这里找到。
- 这表明 AI 宏大愿景对环境的影响可能比之前想象的更显著,引发了关于可持续 AI 实践的讨论。
- 分享工程手册:一位名为 darthgustav 的用户分享了一段 JavaScript 代码片段,概述了 Prompt Engineering 课程,涵盖了使用 Markdown 的层级化通信、通过变量实现的抽象、 Prompt 中的强化以及用于合规性的 ML 格式匹配。
- 这些课程旨在增强 AI 交互的清晰度、结构和确定性,更有效地引导工具使用(tool use)并塑造输出(output)。
- 通过括号表示法实现抽象:一位用户强调通过 Prompt 中的括号解释来教授抽象,例如 [list]、{object} 和 (option)。
- 这种方法旨在增强清晰度和结构,实现用户与 AI 之间更有效的沟通,改进整体的 Prompt Engineering 实践。
GPU MODE Discord
- Anthropic 的中国政策引发抨击:一则 推文 披露了 Anthropic 的新政策,限制向受其产品不允许的司法管辖区(如中国)控制的组织提供服务。
- 随后的辩论质疑该政策反映的是国家安全担忧还是仅仅是企业自身利益。
- CUDA 新手齐聚 Triton:新手们寻求在没有 CUDA 或 GPU 经验的情况下学习 Triton 的指导,并收到了从官方 Triton 教程开始的建议。
- 他们进一步询问了学习 Triton 是否有必要阅读 PMPP 书籍。
- Profiling 揭示模块加载缓慢:在 vLLM 的 Profiling 过程中,时间消耗在 ‘Runtime Triggered Module Loading’ 上,尽管其确切含义以及如何在 Profiling 期间避免它尚不清楚,并分享了一个 trace。
- 根据一篇论文 (arxiv.org/pdf/2411.10958) 的分析显示,Tensor Cores 中为 FP8 矩阵乘法设计的 FP32 累加器实际上是 FP22(1 个符号位,8 个指数位和 13 个尾数位)。
- rocSHMEM 在 HIP Kernels 上遇到困难:一名成员正在探索类似于使用 load_inline 的 HIP Kernels 的 rocSHMEM 实现,遇到了与 ROCm-aware MPI 要求相关的错误。
- 另一名成员建议在调查问题时尝试 ROCm/iris 作为可能的替代方案。
- L2 缓存持久化回归:一篇博客文章强调了在 Ampere 架构上通过利用 L2 缓存进行持久内存访问带来的性能提升,详情见博客文章。
- 相应的 代码 展示了使用 CMAKE 构建 CUDA 项目以简化代码组织。
Latent Space Discord
- OpenAI 设计定制 AI 芯片:据《金融时报》报道,OpenAI 与 Broadcom 合作共同设计一款定制 AI 芯片,计划于明年开始量产,这表明其正试图摆脱对 Nvidia 的依赖,成本约为 100 亿美元,详见 文章。
- 社区反应不一,既有对芯片质量的怀疑,也有人猜测 OpenAI 将与其客户展开竞争。
- Mercor 收到 100 亿美元先发制人报价:AI 招聘初创公司 Mercor 收到了未经请求的报价,估值约为 100 亿美元——仅在四个月后,这一价格已是其 2025 年 6 月 B 轮融资价格的 5 倍,详见 推文。
- 这一消息引发了关于 AI 融资狂热的调侃。
- Augie 为 AI 物流筹集 8500 万美元 A 轮融资:Augment (Augie) 宣布获得 8500 万美元 A 轮融资,在短短 5 个月内总融资额达到 1.1 亿美元,用于扩展其为 10 万亿美元物流领域打造的 AI 队友,详见 公告。
- Augie 已经帮助处理超过 350 亿美元业务的货运团队通过编排涵盖电子邮件、电话、Slack、TMS 等的端到端订单到现金(order-to-cash)工作流,实现了生产力翻倍。
- Responses API 迷思破解:一条推文澄清了关于 OpenAI Responses API 的普遍困惑,驳斥了 Responses 是 Completions 的超集、可以无状态运行以及能解锁更高模型智能和 40-80% 缓存命中率的传言,详见 推文。
- 敦促仍在使用 Completions 的开发者转向 Responses 以构建 GPT-5 级别的 Agent,并提供了 OpenAI cookbook 的指引。
- AI Engineer CODE 峰会定于纽约举行:AI Engineer 团队将于今年秋季在纽约举办首届专门的 CODE 峰会,汇聚 500 多名 AI Engineer 和领导者,以及顶尖模型构建者和财富 500 强用户,共同探讨 AI 编程工具的现实情况,详见 公告。
- 峰会采用邀请制,设有两条赛道(工程与领导力),无厂商演讲,CFP 开放至 9 月 15 日,旨在庆祝 PMF(产品市场匹配),同时应对 MIT 关于 95% 的企业 AI 试点失败的统计数据。
DSPy Discord
- DSPy 助力新兴语音 Agent:成员们讨论了使用 DSPy 构建语音 Agent,并探索使用 GEPA 为 Livekit 和 Pipecat 等框架优化 Prompt。
- 一位成员建议直接将 GEPA 优化后的 Prompt 作为字符串使用,同时也承认这可能感觉有点“反 DSPy”。
- GEPA 展现 Prompt 优化实力:虽然 DSPy 的创建者可能对“Prompt 优化”这个词感到反感,但像 GEPA 这样的工具确实可以用于此目的,并推荐使用 Groq 进行推理。
- 对于 Prompt 创建,建议设置一个 Rubric 类型评判器来评估生成的响应,尤其是在对话层面。
- 关于多轮对话的思考激发 DSPy 对话能力:虽然有成员发现 DSPy 或 GEPA、GRPO 等 RL 应用在多轮对话的实现上不尽如人意,但 DSPy 完全有能力通过
dspy.History处理多轮对话。- 然而,有人提醒说,定义好示例至关重要,因为在构建聊天系统时很容易引入偏差。
- RAG 与微调在记忆游戏中的对决:讨论涉及如何为语音 Agent 提供大量信息(营业时间、服务、定价等)而不产生运行延迟,方法包括微调或检索。
- 虽然微调可以建立记忆,但这是一项巨大的工程,而简单的函数或映射(如营业时间)并不需要像 RAG 这样的向量数据库。
- Token 流式传输趋势:成员们探讨了流式响应(逐个 Token)对用户体验的影响,重点在于最小化 Time To First Token (TTFT)。
- 虽然流式传输不会降低 TTFT,但它通过提供即时反馈增强了用户感知,而像 Pipecat 这样的库已经支持流式传输 frame。
Moonshot AI (Kimi K-2) Discord
- Kimi API 额度到账:Kimi 赠送活动的获胜者收到通知,API 额度即将到账。
- 额度预计在一小时内到达,由团队安排。
- Kimi 上缺少 Anthropic API:有用户询问新模型是否提供 Anthropic API,但已明确 kimi-k2-turbo-preview 指向的是 -0905。
- 这表明 Anthropic API 目前尚未集成到新模型中。
- Kimi 0905 模型发布:Turbo 模型现在使用 0905 模型,从 0711 模型进行了更新。
- 一些用户觉得新的 K2 模型 过于诗意,而另一些用户则认为它更详细、更好。
- Kimi 团队的宏大雄心:尽管与 Grok/OAI 相比团队规模较小,但 Kimi 团队拥有远大梦想和大型模型。
- 一位成员指出,规模较小的公司通常提供更多的用户互动。
- 编程改进困扰 Kimi 用户:用户对新 Kimi K2 模型中强调的编程改进表示困惑。
- 意见不一,一位用户表示相比 0905 更喜欢 0711。
Nous Research AI Discord
- 脉冲神经网络 (SNNs) 模仿大脑:成员们分享了一个 YouTube 视频,讨论了 Spiking Neural Networks (SNNs) 及其与人脑的相似之处。
- 另一位成员提到了工作原理更接近人眼的图像传感器,并链接了此视频。
- Meta 手环控制智能眼镜:根据这篇 Nature 文章,Meta 计划发布一款通过读取身体电信号来控制智能眼镜的手环。
- 未讨论更多细节。
- Hermes 在德州扑克中表现极其保守:一位成员观察到 Hermes 在 Husky Holdem 基准测试中表现出极其独特的 OOD 行为。
- 该成员指出,它的打法超级保守,是其他模型所没有的。
- 微型 LLM 展现洛夫克拉夫特风格:一位成员使用在 H.P. Lovecraft 故事上训练的微型 LLM 进行实验,产生了相当有前景的输出,查看 YouTube 视频。
- 他们还推测,如果有合适的数据集和充分的训练,一个 300 万参数的模型可以成为一个轻量级对话模型。
- NVIDIA 发布 SLM Agents:一位成员分享了 NVIDIA 关于 SLM Agents 的研究(项目页面)及随附论文(arXiv 链接)。
- 未提供更多细节。
Modular (Mojo 🔥) Discord
- Zig 的异步 IO 面临质疑:其他语言社区对 Zig 新的异步 IO 方法的可行性表示担忧,提到 IO 现在需要携带状态,并引用了 Ziggit 上的这段讨论。
- 有人建议 Mojo 的类型系统和效应泛型(effect generics)可能会解决一些潜在问题。
- SIMD 理想境界:Python 风格的 SIMD 方法:成员们讨论了编写简单的 Python 风格代码并自动编译为 SIMD 指令的目标,利用 Mojo 和 MLIR 实现最佳的并行汇编,而不依赖 LLVM 来正确向量化代码。
- 一位成员梦想 for 循环能自动编译 以进行并行处理,从而有效地利用硬件能力。
- 编译器需要输入数据形状进行向量化:为了充分向量化代码(特别是循环),编译器需要关于 输入数据形状 的充足信息,或者必须进行推测以识别热循环,并澄清 Mojo 鼓励使用可移植的 SIMD 库。
- 有人指出,由于执行资源分离,标量和向量操作理想情况下可以在 CPU 和 AMD GPU 上同时运行。
- GPU 内核成熟度检查:一位成员询问了在 Mojo 中编写 GPU 内核 的成熟度,特别是为 PyTorch 实现 Mamba2 内核,并被引导至 Modular 的自定义内核教程。
- MAX (Modular 的 API) 主要目标不是训练,但对于推理是可行的,MLA 已经实现了推理版本(见 GitHub)。
- Span 抽象之梦:一位成员希望 Span(一种连续内存切片的抽象)能成为一个易于使用的、自动向量化的工具,并将适用于 NDBuffer(正在移植到 LayoutTensor)的算法作为 Span 的一部分。
- 他们观察到现有的实现是手动的,并根据硬件特性进行了参数化,缺乏足够的 编译器魔法。
Eleuther Discord
- MasterCard 的 AI 标记淫秽内容:MasterCard 用 AI 系统 取代了欺诈预防人员,该系统在执行淫秽规则方面与商户产生冲突;详情可见 mastercard-rules.pdf 第 5.12.7 章节。
- 该系统将更多交易标记为淫秽,每次违规罚款高达 $200,000,不合规每日罚款 $2,500,这促使商户避免承认错误。
- 缺乏标准困扰欺诈预防:自动欺诈预防问题源于淫秽规则中 未充分指定的标准,没有明确的安全物品示例,导致 LLM 产生混乱的梯度。
- 讨论集中在需要澄清 不成文的政策和方法,以避免在没有足够上下文的情况下进行自动执法所引起的问题。
- 品牌风险驱动过度执法策略:来自共同基金缓解品牌风险(如董事会多样性目标)的压力,导致 MasterCard 欺诈部门 内部过度执法,影响了商户。
- MasterCard 专注于掩盖问题,这阻碍了开发有用的监控指标,因为为了保护职业生涯,发现任何缺陷都会产生一个需要解决的问题。
- 背书请求引发担忧:一名研究人员请求为一篇关于 语义漂移 (semantic drift) 的 arXiv 论文提供背书,这引起了怀疑,因为近期出现了 AI 诱发的精神错乱 (AI-induced psychosis) 案例。
- 担忧源于使用了与 AI 生成的胡言乱语相关的术语,促使人们要求分享论文进行审查。
- 社区思考 GRPO 基准:成员们讨论了在即将开展的项目中使用 GRPO 基准 (GRPO baseline) 的可能性。
- 这个想法源于一位成员询问 “你有 GRPO 基准吗?”,另一位回答 “没有,这将是下一步”。
HuggingFace Discord
- Anthropic 的政策引发了关于自身利益的质疑:成员们讨论了 Anthropic 的新政策(禁止来自受限司法管辖区的组织访问)究竟是出于国家安全还是企业自身利益。
- 讨论集中在基于所有权结构限制访问的合理性上,引发了关于企业控制权的疑问。
- RL 研究中对奖励权重(Reward Weighting)的解读:成员们寻求关于在 RL 过程中加权奖励函数(weighting reward functions)益处的研究,以避免盲目实验。
- 一位成员分享了关于 RL 中奖励权重的一份文档。
- 探索通过 Attention Bias 训练因果模型:一位成员请求关于使用 SFTTrainer 修改因果模型训练(causal model training)以针对特定词汇添加 Attention Bias 的建议,并引用了 Attention Bias 论文。
- 建议包括针对常见的 tokenizers 检查特定术语/token,并考虑损失计算和梯度信号控制的其他替代方法。
- 采用 RoPE 技术解决 RAG 上下文限制:成员们交流了在极有限的上下文大小(4096 tokens)下使用 LLM 构建 RAG 应用的技巧。
- 其中一个技巧涉及使用带有 RoPE 的模型,并使用更大的上下文大小进行微调,参考了此仓库,并强调 RoPE 使模型即使在未经过训练的上下文长度上也能表现良好。
- Enron 邮件被解析为 Parquet 格式:一位成员上传了他们的 Enron 邮件数据集解析器,生成了 5 个结构化的 Parquet 文件,包括 Emails、Users、Groups、Email/User 关联表以及 Email/Group 关联表。
- 父邮件和子邮件已被解析,通过文件和消息的哈希/缓存管理重复内容,所有消息均以 MD5 哈希对象形式包含。
tinygrad (George Hotz) Discord
- Digital Ocean MI300X 上的 Stable Diffusion 运行失败:用户在 Digital Ocean MI300X GPU 实例上运行 stable_diffusion.py 示例时出现错误,追溯到某些 z3 问题。
- 该失败在 Mac 上无法复现,尽管 mnist_gan.py 测试成功。
- AMD_LLVM=1 在 MNIST 训练期间导致 TypeError:在简单的 MNIST 训练循环中使用 AMD_LLVM=1 时,发生了涉及不支持的操作数类型(BoolRef)的
TypeError。- George Hotz 建议尝试 IGNORE_OOB=1,并将其链接到可能的 z3 版本问题,指出 z3>=1.2.4.0 中添加的一些重载可能是原因,并提供了一个链接。
- 内核移除项目(Kernel Removal Project)寻求贡献者:一位用户表示有兴趣为 Tinygrad 内部的内核移除项目做出贡献。
- 潜在贡献的范围尚未明确,但推测将涉及精简内核表面(kernel surface)。
aider (Paul Gauthier) Discord
- Warp Code 受到喜爱:用户们正在称赞 Warp Code,一位用户指出 Warp 感觉就像是手动挡与自动挡的区别。
- 当你不熟悉文件并希望通过 embeddings search(嵌入搜索)来了解新代码库时,Warp 非常有用。
- Aider 依然出色:一位几个月前从 aider 切换到 Claude Code 的用户又换回了 aider,发现 Anthropic 做出了一些令人质疑的改动。
- 该用户现在更倾向于使用 aider 的简洁性,并结合使用 Gemini 2.5 Pro、Gemini Flash 和 Qwen3 Coder,配合
/run命令来模拟 Claude Code 的 plan mode(计划模式)。
- 该用户现在更倾向于使用 aider 的简洁性,并结合使用 Gemini 2.5 Pro、Gemini Flash 和 Qwen3 Coder,配合
- Run 命令是杀手级功能:对于一位用户来说,aider 中的
/run是一个重大功能,他们指出当你清楚地知道想要处理哪些文件时,Aider 非常好用。- 他们还询问在哪里可以看到 Aider 的成功案例。
- 编程 Agent 正在重构:一位成员受 Aider 启发,正在重构他们自己的 coding agent,以学习更多关于 AI system design 的知识。
- 他们已经有了一个小型的概念验证(proof of concept),但现在正在阅读教程,看看其他人是如何完成类似项目的。
- 寻求代码验证建议:一位成员正在寻求建议,以防止在任何语言中生成危险代码(环境泄漏、rm -rfs、网络请求等)。
- 他们考虑使用基于 TreeSitter 的验证器,并询问 Aider 是如何避免这些问题的,请求指向仓库中相关文件的链接。
Yannick Kilcher Discord
- 评审论文基准(Baselines)面临挑战:一位成员请求关于如何处理研究论文中提出的 baselines 的通用指南,特别是在不熟悉数据集的情况下。
- 该成员表示,在对数据集缺乏足够了解的情况下,很难判断性能表现,这意味着需要进行更多的背景研究。
- LoRA 是增加而非替换原始权重:一位成员询问为什么 LoRA 训练层是相加的,而不是替换原始权重矩阵,并指出这与 depthwise convolutions(深度卷积)等其他高效过程形成对比。
- 该成员寻求论文、文章或论据来解释这种设计选择(而非替换),并提到对此有自己的直觉理解。
Manus.im Discord Discord
- AI 礼貌性获得科学支持:一位用户分享了一篇论文,为“对 AI 保持礼貌很重要”提供了科学证据。
- 讨论集中在对 AI 表现友好是否会导致更多的 cooperative behavior(协作行为)。
- 对 AI 礼貌性的科学验证需求:用户表达了希望获得关于礼貌如何影响 AI 行为的科学证明的愿望。
- 这与分享的 arXiv 链接一致,表明社区对理解 human-AI interaction styles(人机交互风格)的影响很感兴趣。
LLM Agents (Berkeley MOOC) Discord
- 2025 年 AI Agents 课程计划探讨:一位成员询问 2025 年秋季 的课程是否会沿袭 2024 年秋季 课程中关于 Introduction to AI Agents 的重点。
- 他们明确请求加入课程的链接,表明他们正在寻求注册或访问详情。
- 2025 秋季入学:该用户正在专门寻找有关如何加入 2025 年秋季课程的信息。
- 他们明确请求了链接,并将等待加入课程的详细信息。
MLOps @Chipro Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord:各频道详细摘要与链接
LMArena ▷ #general (1100 messages🔥🔥🔥):
图像生成问题、Video Arena 机器人宕机、登录要求、速率限制、账户数据丢失
- 图像生成故障频发:用户报告了 图像生成 的广泛问题,包括持续的错误和无限生成循环,许多人遇到了令人头疼的 ‘Something went wrong with this response’ 消息。
- 一位成员指出 ‘有时模型会对 Prompt 感到困惑并给出同样的错误……我们确实需要更多的错误反馈’,建议需要更具体的错误消息。
- Video Arena 机器人因故障停运:Video Arena 机器人 目前处于离线状态,团队正在积极解决问题,但目前还没有恢复上线的 ETA。
- 一位成员调侃道 ‘Video 机器人目前无法工作。尝试在不同频道使用它是没有用的。即使机器人工作正常,你也无法在这个频道使用它。’
- 登录要求引发不满:引入 登录要求(特别是 Google 账户要求)引起了用户的担忧。
- 一位成员指出该要求很糟糕,称 ‘因为我们大多数人不想这样做’。
- 速率限制困扰常驻用户:用户注意到实施了 速率限制 (Rate Limits),导致了挫败感,并引发了关于这些限制是刻意为之还是持续故障结果的讨论。
- 一位成员评论道 ‘如果你没有登录,在被限制速率之前你只能进行 2 到 3 次生成,即使是在 Battle 模式下’,而另一位成员也感到困惑,询问 ‘是的,我也很困惑’,想知道具体增加或更改了什么。
- 账户数据在波动中消失:几位用户报告了 聊天记录丢失 的情况,特别是在未登录时,引发了对数据保留的担忧。
- 一位成员建议,‘如果你使用 Brave 浏览器,你也许能恢复它们,我不清楚 Google 浏览器的情况’,同时也有人注意到该平台可能正在使用 Cloudflare。
LMArena ▷ #announcements (3 messages):
Video Arena Discord 机器人、用户登录、速率限制
- **Video Arena Discord 机器人重新上线:Video Arena Discord 机器人** 在修复后已重新上线;要使用该机器人,请在指定频道中输入
/video并附带 Prompt:<#1397655695150682194>、<#1400148557427904664> 或 <#1400148597768720384>。- 这里分享了一个演示如何使用该机器人的 GIF。
- 图像生成引入 速率限制:由于前所未有的流量,图像生成** 已引入 速率限制 (Rate Limits)。
- 已登录用户将继续享受更高的限制,有关用户登录的更多信息可以在 这里 找到。
Perplexity AI ▷ #announcements (1 messages):
iOS 应用重新设计、学生可访问 Comet、Comet 快捷方式、Comet 中的语音助手、Pro 用户的 GPT-5 Thinking
- Perplexity 发布六项重磅新功能:Perplexity AI 宣布在 9 月 5 日发布 六项新功能,详情见其 更新日志。
- 这些功能包括 iOS 应用重新设计、学生可访问 Comet、Comet 快捷方式、功能更强大的 Comet 语音助手、面向 Pro 用户的 GPT-5 Thinking,以及 Perplexity Finance 的更新。
- 学生获得 Comet 访问权限:作为返校季活动的一部分,Perplexity AI 现向 学生提供 Comet 访问权限,该消息于 9 月 5 日宣布。
- 此举旨在为学生提供用于研究和学习的高级 AI 工具,并与他们现有的教育工作流无缝集成。
- Pro 用户获得 GPT-5 Thinking:截至 9 月 5 日,Pro 用户现在可以在 Perplexity AI 中访问 GPT-5 Thinking 能力。
- 此次升级提供了增强的推理和问题解决能力,允许进行更深入的分析和见解。
Perplexity AI ▷ #general (823 条消息🔥🔥🔥):
Grok 4 困境, Qwen 3 Max, Comet 浏览器, Gemini 2.5 Pro, AI 模型参数规模
- 大学 Pro 用户缺失 Grok 4:一些大学 Perplexity Pro 用户报告在模型选择器中找不到 Grok 4,建议联系客服并检查其 Pro 账户是否为企业版。
- 有建议称重新安装 App 可能有助于解决此问题。
- 告别 Arc-a-Dia:用户讨论了从 Arc 到 Dia 的过渡,有人指出 Arc 已经大约一年没有实质性更新了,另一位用户对该浏览器 $15 的收费表示担忧。
- 他们补充说,随着向构建 Agent 化的 Chromium 转型,大量忠实的 Arc 用户将被抛弃。
- Qwen 3 Max 热度激增:成员们推测即将发布的 Qwen 3 Max 的规格,预计参数在 500B 到 1 万亿之间。
- 一位成员表示,他们认为既然这些模型对消费者免费,那是为了获得更好的训练数据和庞大的社区。
- Comet 的限制引发讨论:用户报告称在过度使用 Comet Personal Search 后,它会停止工作并显示消息:您已达到 Comet 个人搜索的每日限制。升级到 Max 以提高限额。
- 其他人指出 Comet 目前通过 Paypal/Venmo 优惠活动或针对学生提供,并在 Discord 中分享邀请链接。
- Perplexity 的杀手锏:事实核查:成员们讨论了 Perplexity 相对于 ChatGPT 和 Gemini 等其他平台的优势,强调了 Perplexity 对事实核查和网络搜索的专注。
- 一位用户表示:我主要使用 Perplexity 进行事实核查和快速研究,因为这是它的核心优势——带有引用和参考文献的事实。它完胜 ChatGPT、Gemini 和 Claude。
Perplexity AI ▷ #sharing (3 条消息):
AMD Zen 6 CPU, Omarchy Linux, 可共享线程
- AMD 筹备 Zen 6 CPU:一位成员分享了关于 AMD 正在准备 Zen 6 CPU 的链接。
- Omarchy Linux 发行版:一位成员分享了关于 Omarchy Linux 发行版 的链接。
- 可共享线程提醒:Perplexity AI 机器人提醒用户确保其线程(Threads)设置为
Shareable(可共享)。
Perplexity AI ▷ #pplx-api (4 条消息):
API 500 错误, Playground 问题, 停机报告
- 500 错误困扰 PPLX API:多位用户报告在进行 API 调用时收到 500 Internal Server Error,并指出 Playground 也无法正常工作。
- 用户确认状态页(status page)上没有报告停机,而一位用户在服务恢复正常后调侃道:他们打算假装什么都没发生。
- 图像分析排查网络问题:附带的图像提示建议检查互联网连接。
- 该建议是针对报告的 API 和 Playground 问题给出的,暗示可能存在用户端的连接问题。
Unsloth AI (Daniel Han) ▷ #general (574 messages🔥🔥🔥):
Postgres 配合 pgvector 对比 Qdrant,本地 Sonnet,DGX Spark 对比 DGX Station,Qwen 3 Max 评估
- Postgres 适用于复杂查询,Qdrant 适用于向量搜索:成员们讨论认为,虽然 Qdrant 擅长向量搜索,但配合 pgvector 的 Postgres 可能更适合复杂的数据库查询。
- 一位成员链接了一条 推文 并分享了一个 Borat GIF。
- 本地运行 Sonnet 需要海量 RAM,且质量有所牺牲:运行 Local Sonnet 至少需要 512GB RAM,即使有 1TB RAM,也无法实现全精度运行。
- 有成员询问 Q8 微调是否有帮助,另一位成员回答说 即使是 Q8 对于 1TB RAM 来说也太大了。
- DGX Spark 适合练手,DGX Station 适合工作:成员们对比了 DGX Spark 和 DGX Station,其中一位指出 Spark 是个玩具,Station 才是工作站,并链接到了 DGX Station 产品页面。
- 有人提到 DGX Spark 价格不错,配备了 ConnectX-7,而且 起初 8000 美元的型号只有 4TB 存储,后来他们增加了容量,是个不错的产品。
- Qwen 3 Max 在创意写作方面表现出色,但在编程方面稍逊一筹:成员们对 Qwen 3 Max 进行了评估,认为它 非常擅长创意写作和角色扮演,在我看来比 K2 和 Sonnet 4 更好。
- 然而,它被认为价格过高,且 在工具调用(tool calls)和基于逻辑的编程方面并不是特别出色。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
Unsloth AI, GPT-OSS, Google Colab T4, 运行时错误
- Unsloth AI 故障排除:一位成员在尝试使用 GRPO 在 Google Colab T4 上微调 GPT-OSS 时请求 Unsloth AI 的相关帮助。
- 该用户报告遇到了运行时错误,并寻求社区的协助。
- Colab T4 用户寻求 GRPO 指导:一位用户寻求关于使用 GRPO(推测是一种强化学习技术)通过 Unsloth AI 在 Google Colab T4 实例上微调模型 GPT-OSS 的指导。
- 用户特别提到在过程中遇到了运行时错误,正在寻找社区的帮助。
Unsloth AI (Daniel Han) ▷ #off-topic (164 messages🔥🔥):
Super 系列显卡发布更新,GLM 4.5 Air 可用的 tps,割草机器人,Deepseek 与 Qwen 分词器可互换,Mini Kimi K2 MoE 模型
- Super 系列显卡发布后的更新支持尚不稳定:成员们讨论提到,在 1 月 30 日发布后,支持仍然不够完善,但开玩笑说等 Super 系列显卡正式发布时会有重大更新。
- 另一位成员分享了一个表情包,暗示更新不太可能:Biden dance stare clueless gif。
- GLM 4.5 Air 运行表现尚可:一位成员指出,GLM 4.5 Air 在 132K 上下文下,Q4 量化能达到 1.15 tps,这是可以接受的。
- 另一位成员正在选购零件,准备先尝试分布式运行,并提到 还没有尝试过全量 KV 缓存。
- 割草机器人 Rover:一位成员正考虑攒几块 3090,并省下预算买一个 Rover 来割草。
- 他们提到该机器人可能会运行一个小型视觉模型,并配备 Lidar 和 Sonar 等额外的安全系统。
- Deepseek 与 Qwen 分词器(Tokenizer)可互换:据报告,deepseek r1-0528 的分词器与 qwen3 的分词器是可以互换的。
- 成员们讨论这是否意味着他们 复制了相同的架构,从同一个模型进行蒸馏,然后又放回到了复制的架构中。
- Mini Kimi K2 MoE 模型即将推出:成员们对 mini Kimi K2 很感兴趣,可能是 30B MoE 或更小的规模。
- 另一位成员建议做一个 150B 但只有 1B 激活参数的模型,以实现类似的 稀疏性。
Unsloth AI (Daniel Han) ▷ #help (40 条消息🔥):
Training vs Inference, GPT-OSS finetuning issues, Gemma-3 finetuning errors, Tokenizer Impact on Finetuning, GRPO Support for Gemma3 with vLLM
- 讨论训练吞吐量与推理吞吐量:一名成员对比了推理时的 token 吞吐量,并表示希望像 Llama3 一样使用 GRPO 进行训练,并提出分享无法运行的代码。
- 他们使用的是 Unsloth 2025.9.1,Transformers 4.55.4,Tesla T4 (14.741 GB),Torch 2.8.0+cu126,CUDA 7.5,CUDA Toolkit 12.6 以及 Triton 3.4.0。
- GPT-OSS 微调产生无意义输出:一名成员报告称,在微调后,GPT-OSS 的输出通道和内容变得毫无意义,显示出一系列数学符号和无关单词。
- 错误的 Traceback 可以在这里找到。
- Gemma-3 微调产生属性错误:一名成员在对 Gemma-3-270M 进行微调后运行推理时,遇到了
AttributeError: 'SlidingWindowLayer' object has no attribute 'max_batch_size'。- 据报告,使用
use_cache=False的建议已解决了该问题。
- 据报告,使用
- 讨论 Tokenizer 选择对微调的影响:一名成员询问在微调期间使用与预训练模型自带的不同的 Tokenizer 会产生什么影响。
- 另一名成员表示,这就像使用了与模型最初训练时不同的语言,建议使用相同的 Tokenizer,以便输入处于模型能够理解的“语言”中。
- CUDA 链接问题:一名成员在运行此 Notebook 中的代码时遇到了
AttributeError: module 'bitsandbytes' has no attribute 'functional'。- 警告提示 CUDA 未正确链接,并建议运行
sudo ldconfig /usr/lib64-nvidia和sudo ldconfig /usr/local/cuda-xx.x。
- 警告提示 CUDA 未正确链接,并建议运行
Unsloth AI (Daniel Han) ▷ #showcase (2 条消息):
Glazer model, GPT-4's personality, Ollama, HuggingFace
- Glazer 模型模仿 GPT-4 的“爱奉承”人格:发布了一个名为 Glazer 的新模型,旨在模拟一些用户怀念的 GPT-4 那种“谄媚”的人格。
- 它可以本地运行,并已在 Ollama(通过
ollama run gurubot/glazer)和 Huggingface 上提供 4B 和 8B 版本。
- 它可以本地运行,并已在 Ollama(通过
- Unsloth 因 Glazer 收到感谢:该模型以一张表达对 Unsloth 感谢的图片形式收到了谢意。
- 该帖子包含了一个树懒爱心(slothhearts)表情符号。
Unsloth AI (Daniel Han) ▷ #research (11 条消息🔥):
Latent Features, Hermes NLP, Financial AI
- 潜在特征(Latent Features)被质疑:一名成员认为神经网络的潜在部分可能会破坏特征,暗示神经网络中的瓶颈并非真实特征。
- 他讽刺地评论道,如果这些是真实特征,那么每个人都会成为亿万富翁,并驳斥了那些“毫无头绪”的人所声称的成功。
- Hermes 不适用于 NLP 任务:一名成员表示 你肯定不能用 hrms 来做任何类似 nlp 的事情。
- 他以一句 全押红色,宝贝 😎 (all on red baby) 结束了消息。
LM Studio ▷ #general (97 条消息🔥🔥):
GPU 功耗担忧, Lora 训练, 真实感角色扮演模型, LM Studio 本地网络设置, 消费级外骨骼
- 3090 可能导致 4090 超频:一位成员担心他们的 3090 导致其 4090 在加速(boosting)时消耗比预期更多的功率,从而导致温度高于预期。
- 他们认为可能是一个 software bug 导致 GPU 超过了厂商限制,并提到通常会通过降压(undervolting)来防止过热。
- 触手 Loras 融合艺术风格:一位成员分享了他们训练的 一堆 LORAs 融合在一起 的成果。
- 另一位成员询问了其用途和触手状的形态,训练者回答说他利用这些来探索他感兴趣的特定艺术风格,并提供了一个 LORA 模板链接。
- 6GB GPU 寻求角色扮演模型:一位拥有 2019 年 6GB GPU 的成员询问最适合真实、沉浸且持久的角色扮演游戏的模型。
- 另一位成员建议将 CPU RAM 增加到至少 64GB 并使用 Mistral Nemo Instruct;然而,第三位成员推荐了 Qwen3-30B-A3B-Instruct-2507-MXFP4_MOE。
- 通过 LM Studio 在手机上与 PC 端的本地 LLM 聊天:一位成员询问如何在手机上聊天时让 AI 运行在 PC 上,另一位成员建议使用支持 OpenAI API 的客户端应用,并通过本地网络或隧道进行远程连接。
- 在对服务器 IP 和 Apollo 等客户端应用进行了一些故障排除后,该成员成功使用 ngrok 和 Open WebUI 建立了连接。
- 仿生腿表现不佳:一位成员询问了消费级价格的 仿生腿(外骨骼)。
- 另一位成员引用了一段 YouTube 评论,暗示它们 几乎没有任何作用,甚至可能导致肌肉萎缩。
LM Studio ▷ #hardware-discussion (139 条消息🔥🔥):
帧生成, Nvidia 5000 系列, ATX 3.1 标准, CPU 卸载 vs GPU, Mi50 VRAM 特性
- 四倍帧生成能带来流畅游戏体验吗?:成员们讨论了 4x 帧生成 的实用性,认为只有在 基础 FPS 尚可 的情况下,它才对实现 4K 240FPS 之类的目标有益。
- Nvidia 5000 系列是“跳过的一代”吗?:新的 Nvidia 5000 系列 可能是一个 skip gen(跳过的一代),因为其相对于 4000 系列 的性能提升微乎其微(4000 系列已经拥有极佳的能效),而且他们不愿增加更多的 VRAM。
- ATX 3.1 标准解决了电源接口难题:ATX 3.1 标准 引入了 12V-2x6 接口,通过更长的导体端子和更短的感应引脚解决了 12VHPWR 的问题,如果连接松动,GPU 会自动断电。
- CPU 卸载(Offload)并非万能?:关于 CPU offload 的体验各不相同;一位用户发现他们的台式机明显比服务器快,即使 4070 TiS 的表现与 Mi50 相似。
- 揭秘 Mi50 VRAM 性能特性:发现了 Mi50 的一个奇特特性:当显存占用超过前 16GB 的 VRAM 后,性能会减半。
Cursor Community ▷ #general (154 messages🔥🔥):
GPT-5 vs Sonnet 4, Codex CLI vs Cursor Code, Claude Code, Gemini 2.5 Pro, Cursor Pricing
- **GPT-5 统治地位优于 Sonnet 4:成员们普遍认为在编程任务上 **GPT-5 优于 Sonnet 4,并指出虽然 GPT-5 可能需要更具体的 prompting,但它更不容易产生幻觉(hallucinations),且提供的答案更简洁、准确。
- 一些用户发现 Sonnet 4 更偏向“模板化”且容易草率得出结论,而 GPT-5 的直接性更受青睐,使其成为极具价值的规划者和讨论伙伴,尤其是在结合自动实现(auto-implementation)时。
- **Codex CLI vs Cursor Code:对决:用户在选择使用 **Codex CLI 还是 Cursor Code 上存在分歧,一些人因代码质量而偏好 Codex CLI,而另一些人则称赞 Cursor Code 具有卓越的创造性思维和推理能力,同时质量也很大程度上取决于 prompt。
- 一位成员因在修复 bug 时对幻觉感到沮丧而退订了 Cursor Code 的 Max 方案,而其他人则提醒 Codex 的速率限制(rate limit)较低且难以追踪;一些人喜欢 Codex CLI 内部的建议系统。
- **Cursor 的 $20/月:值得吗?:几位用户讨论了 **Cursor 每月 20 美元的 Pro 方案的价值以及达到额度限制的速度。
- 一些人认为它是编程必备工具,一位用户取消了 Cursor 订阅转而使用 Claude Code 和 Codex,并建议最佳组合是每月 20 美元的 Cursor 订阅配合 Claude Code 方案,用于内联编辑(inline editing)和终端(terminal)使用。
- **警惕 Cursor 充满 Bug 的 Auto-Mode:多位用户在使用 **Cursor 的 Auto mode 时遇到问题,报告称其表现不佳,无法修复简单的 bug,有时甚至将编辑内容输入到聊天框中而不是直接应用。
- 一位用户幽默地形容 Cursor 对自己的工作过度自豪,尽管需要大量的调试,并分享了该工具生成的一条类似迷因(meme)的消息。
OpenRouter ▷ #announcements (1 messages):
Qwen3-Max, RAG, Tool calling
- Qwen3-Max 发布多项改进:根据 此 X 帖子,最新的 Qwen3-Max 模型与 2025 年 1 月版本相比,在数学、编程、逻辑和科学任务方面具有更高的准确性。
- 它还在中英文指令遵循、100 多种语言的多语言支持、减少幻觉以及针对 RAG 和 tool calling 的优化方面表现更好。
- Qwen3-Max 针对 RAG 和 Tool calling 进行了优化:Qwen3-Max 针对 RAG 和 tool calling 进行了优化,并且没有专门的“思考(thinking)”模式。
- 在此处尝试 Qwen3-Max here 以体验其功能。
OpenRouter ▷ #app-showcase (1 messages):
tomlucidor: 发现了 https://github.com/Lapis0x0/obsidian-next-composer
OpenRouter ▷ #general (126 条消息🔥🔥):
OpenRouter 加密货币诈骗、Anthropic 的地缘政治担忧、API Key 问题、BYOK 费用、Token 限制和输出截断
- OpenRouter 代币是虚假的:成员确认任何与 OpenRouter 相关的加密货币 都是 诈骗,且与 OpenRouter 官方无关。
- 尽管有警告,仍有用户询问 PancakeSwap 上的 OpenRouter 代币 及其交易可用性,这促使官方进一步澄清 OpenRouter 没有正式参与任何加密货币。
- Anthropic 的地缘政治立场引发关注:成员们讨论了 Anthropic 最新的博客文章,该文章禁止来自所有权结构受其产品不被允许的国家控制的司法管辖区的访问。
- 一些人想知道这是出于 国家安全 考虑,还是仅仅为了 保护市场份额。
- API Key 抛出身份验证错误:一位用户报告了 API Key 问题,收到了来自 ChatGPT 的 ‘No auth credentials found’ 错误消息。
- 该用户被要求指定所使用的客户端(OpenAI 客户端或自定义客户端),以便诊断身份验证问题。
- BYOK 费用说明:一位用户询问了使用 BYOK (Bring Your Own Key) 相关的费用,特别是针对 chutes 和 Qwen Coder 3。
- 官方澄清,OpenRouter 在提供商(如 chutes)收取的费用基础上额外收取 5% 的 BYOK 费用。
- Token 输出限制为 8k:一位用户希望确保在超过 输出 Token 限制 时抛出错误。
- 当达到 Token 限制时,响应会被截断,停止原因(stop reason)被标识为 ‘length’;API 会阻止你将
max_tokens设置为高于模型限制的值。
- 当达到 Token 限制时,响应会被截断,停止原因(stop reason)被标识为 ‘length’;API 会阻止你将
OpenRouter ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (12 条消息🔥):
基准测试提升、实际表现与基准测试的对比、OpenRouter API 使用
- 基准测试持续攀升!:成员们注意到 每一项基准测试都在上升,但基准测试百分比的增长与实际表现之间的脱节也在不断扩大。
- 他们补充说,过去基准测试中 5% 的差异是很明显的,但现在变得越来越不明显,因为我们正在进入平台期,尽管模型在创意写作、EQ、Tool Call 失败率和上下文长度遵循方面有所改进。
- OR 使用 OpenAI Responses API:一位成员询问 OpenRouter 是否使用了 OpenAI Responses API,并链接到了 一条推文。
- 另一位成员确认,对于大多数 OpenAI 模型确实如此。
OpenAI ▷ #ai-discussions (84 messages🔥🔥):
Multi-Agent Orchestration, Token Efficiency, Gemini 2.5 Pro, Good Luck Token Waste, Carbon Footprint of AGI
- 通过上下文卸载编排 Agent:一位成员建议使用带有上下文卸载(Context Offloading)的 Multi-Agent 编排,并动态过滤无关上下文以改进向量化(Vectorization)。
- 他们推荐使用包含编排器(Orchestrators)、指挥器(Conductor)和专业 Agent 的简单设置,并强调管理上下文以避免破坏 HO/HD operations 的重要性。
- 削减无用的 Token 浪费:一位成员提倡通过过滤语法和句法上无用的词汇,并将多个词合并为 Prompt 中的有效词汇来提高 Token 效率。
- 他们声称在推理(Inference)中,如果你是付费方,浪费的 Token 等于浪费资源(金钱);如果你是自托管,则会加速组件的折旧。
- Gemini 2.5 Pro 解锁无限访问:成员们报告称 Google AI Studio 提供了对 Gemini 最佳模型 2.5 Pro 的无限访问,以及 Imagen、Nano Banana、Stream Realtime、语音生成和 Veo 2 等其他功能。
- 一些成员只关心 LLM,将视频和图像视为趣味因素;而另一些人则在视频编辑、教育视频和重现公有领域内容中找到了实际用途。
- 像“祝你好运”这类客套话会浪费 Token:一位成员认为,除非提问的方式是基于答案提供多个选择,否则提问本身就是在浪费上下文。
- 另一位成员建议,“Good luck(祝你好运)”这类短语在信息传递方面是 Token 的浪费,虽然礼貌会影响 AI 的响应,但也可能增加环境浪费。
- AGI 宣称产生的碳足迹超过了 Token 浪费:一些成员讨论了一篇博文,新的统计数据表明,目前宣称 AGI 所产生的碳排放已经超过了 ChatGPT 中因使用“请”和“谢谢”而造成的 Token 浪费。
- 该博文可以在这里找到。
OpenAI ▷ #prompt-engineering (10 messages🔥):
Discord chat to Markdown, Prompt engineering lessons, Hierarchical prompting, Abstraction in prompts, ML format matching
- Discord 聊天文本转换策略:一位用户询问了在 MS Edge 中从 Discord 聊天的 Web 界面提取文本并将其保存为 Markdown 文件 (*.MD) 的最简便方法。
- Darthgustav 分享 Prompt Engineering 课程:一位名为 darthgustav 的用户分享了一段 JavaScript 代码片段,概述了 Prompt Engineering 的课程内容。
- 课程涵盖了使用 Markdown 进行层级化通信、通过变量进行抽象、Prompt 中的强化以及用于合规性的 ML 格式匹配。
- 层级化 Prompt 技巧:Darthgustav 的一课解释了如何利用 Markdown 进行层级化通信以编写 Prompt,从而增强清晰度和结构。
- 通过利用 Markdown,Prompt 旨在以结构化的方式组织信息,使模型更容易遵循指令并生成预期的结果。
- 在 Prompt 中使用括号进行抽象:该用户介绍了通过括号符号进行抽象的方法:[{(由 AI 解析的开放变量)}] 和 ${(由用户解析)}。
- 它强调了向模型解释括号含义(如 [list]、{object}、(option))的重要性,以便高效管理复杂的 Prompt。
- 用于输出合规性的 ML 格式匹配:其中一课包括用于合规性的 ML 格式匹配,涵盖了 [{output templates} 和 {(conditional) output templates}]。
- 目标是通过在 Prompt 中强化特定格式,来引导工具使用并使输出更具确定性。
OpenAI ▷ #api-discussions (10 messages🔥):
Discord Chat to Markdown, Prompt Engineering Lessons, Hierarchical Communication in Prompts, Abstraction in Prompts, Reinforcement in Prompts
- Discord Text Dump to Markdown: 一位用户询问了将 Discord chat(Web 界面,MS Edge 浏览器)中的文本提取到 Markdown file 中的最简便方法。
- 该用户寻求优化流程,重点关注简单性和效率,暗示需要一种将 Discord 聊天记录导出为 .md 格式的直接解决方案。
- Prompt Engineering Instruction Manual: 一位用户分享了一个详细的 JavaScript 代码块,概述了 Prompt Engineering 课程,旨在教授层级化通信、抽象、强化和 ML 格式匹配。
- 这些课程涵盖了使用 markdown 进行提示、使用括号解释([list], {object}, (option))的抽象技术、引导工具使用、确定性地塑造输出以及使用输出模板以确保合规性。
- Abstraction Elevation via Bracketology: 用户强调通过 Prompt 中的括号解释(如 [list], {object}, (option))来教授抽象 (abstraction)。
- 这种方法旨在增强清晰度和结构,使内部用户与 AI 之间能够进行更有效的沟通,从而改进整体的 Prompt Engineering 实践。
- Reinforcement Ramp-Up for Guidance: 用户强调了在 Prompt 中进行强化 (reinforcement) 的重要性,以更具确定性地引导 [tool use] 和 (shape output)。
- 通过战略性地强化期望的行为,Prompt 可以实现更高的精确度和合规性,从而获得更好的结果和更可预测的 AI 交互。
GPU MODE ▷ #general (3 messages):
Anthropic's new policy, Kernel creation solutions
- Anthropic’s Policy Raises Eyebrows: 一条关于 Anthropic 新政策的 推文 引发了辩论,该政策禁止向受其产品不被允许的管辖区(如中国)控制的组织提供服务,争论焦点在于这是出于国家安全还是纯粹的企业自身利益。
- Navigating the Kernel Creation Cosmos: 一位成员询问如何确定是构建自定义 Kernel 解决方案还是使用现有方案。
- 另一位成员建议在决定从头开始构建之前,先检查 HF kernel hub 并探索像 liger 这样的标准。
GPU MODE ▷ #triton (2 messages):
Triton, CUDA, GPU, PMPP Book
- Newcomer Seeks Triton Guidance: 一位成员在没有 CUDA 或 GPU 经验的情况下寻求学习 Triton 的指导。
- 另一位成员推荐将 官方 Triton 教程 作为起点。
- Triton Resources: 用户询问快速入门 Triton 的资源。
- 用户还询问学习 Triton 是否必须阅读 PMPP book。
GPU MODE ▷ #cuda (14 messages🔥):
Barnes-Hut performance, CUDA, Morton code sorting, Octree construction, Memory access optimization
- Barnes-Hut Performance Probed: 一位成员面临 Barnes-Hut CUDA 模拟的性能问题,尽管优化了 Morton code 排序和八叉树 (octree) 构建,但 3 万个物体的树遍历和力计算 Kernel 仍需 100ms。
- 另一位成员建议将其与
torch.cdist进行比较,并利用 LLM 探查访问模式。
- 另一位成员建议将其与
- Morton Sorting is sus: 叶节点存储在按 Morton codes 排序的扁平数组中,将具有相同代码的粒子融合为一个叶节点。
- 成员们讨论了线程如何遍历树以及如何从内存中检索值。
- Coalesced Memory Access Clarified: 一位成员询问在树遍历期间内存访问是否是合并的 (coalesced),因为粒子是按 Morton codes 排序的。
- OP 确认同一 Warp 中的线程以类似方式遍历树并检索相同的值,但仍觉得 100ms 的运行时间令人困惑。
GPU MODE ▷ #torch (13 messages🔥):
fp8 matrix multiplication, tensor cores accumulator, Runtime Triggered Module Loading, vLLM profiling
- 关于融合累加(Fused Accumulation)的辩论:成员们就 PyTorch 的
mm.py(第 128-132 行)中关于 Tensor Cores 融合累加的两个选项之间的差异展开了辩论。- 一位成员认为第一种选项可能是一种融合累加,而另一位成员提到了 int8 MMA 的场景,其中第一个版本会报错,而第二个版本则不会。
- 深入探讨低精度累加:一篇论文(arxiv.org/pdf/2411.10958)揭示了 Tensor Cores 中为 FP8 矩阵乘法设计的 FP32 累加器实际上是 FP22(1 位符号位,8 位指数位,以及 13 位尾数位)。
- fast_accum = True 在整个主循环(main loop)中使用 Tensor Core 的累加器,精度较低(约 22 位);而 fast_accum = False 则将 Tensor Core 操作的结果发送到全 FP32 精度的常规寄存器累加器中。
- 运行时触发的模块加载(Runtime Triggered Module Loading)拖慢 vLLM:在 vLLM 性能分析(profiling)期间,大量时间消耗在 ‘Runtime Triggered Module Loading’ 上,但其确切含义以及如何在分析期间避免它尚不清楚。
- 一位成员分享了一个 trace 并附带了一个 [qwen3-1.7b-compile-cudablock.gz],希望能了解更多信息。
GPU MODE ▷ #algorithms (6 messages):
FlashAttention, FA1, FA2, FA3, FA4
- FlashAttention 可视化:一位成员询问他们对 Flash Attention 的理解(动画,源代码见此处)是否大致正确。
- 其中的火焰动画应该代表 softmax/融合算子(fused kernel)。
- FlashAttention 循环顺序:一位成员指出,原始动画中的循环顺序与 FlashAttention v2 (FA2) 相比是反向的。
- 在 FA2 中,沿 K/V 的迭代是内层循环,沿 Q/O 的迭代是外层循环。
- FlashAttention 的进一步演进:据原帖作者称,最初的可视化是基于 FA1 的。
- 讨论指出 FA3 和 FA4 也遵循 FA2 的总体设计,但分别针对 Hopper 和 Blackwell 架构进行了优化。
{kind=link}
{kind=link}
GPU MODE ▷ #beginner (4 messages):
Model optimization roadmap, Sparse convolution in ONNX Runtime, BEV fusion model
- 寻求模型优化路线图:一位成员正在寻求学习模型优化技术的路线图,包括编写自定义算子(kernels),重点关注 SM 计数和 VRAM 使用情况。
- 他们计划使用带有 16GB 显存的 5060 Ti。
- ONNX Runtime 对稀疏卷积支持匮乏:一位成员尝试使用 ONNX Runtime 运行 BEV 融合模型,但他们使用的硬件不支持 PyTorch,且 ONNX Runtime 缺乏对稀疏卷积(sparse convolution)的支持。
- 他们询问是否可以用其他算子替换稀疏卷积,或者是否有人在 ONNX Runtime 中添加了稀疏卷积支持。
GPU MODE ▷ #irl-meetup (1 messages):
apaz: 现在在纽约(NYC),有人想见面聊聊吗?
GPU MODE ▷ #rocm (8 messages🔥):
rocSHMEM, ROCm-aware open MPI, HIP kernels, ROCm/iris
- rocSHMEM 实现查询:一位成员正在探索类似于使用 load_inline 的 HIP kernels 的 rocSHMEM 实现,但遇到了与 ROCm-aware MPI 需求相关的错误。
- 该成员引用了 ROCm/rocSHMEM 获取依赖配置,并建议将其整合到 Dockerfile 中。
- ROCm/iris 替代方案浮现:一位成员建议在调查该问题时尝试 ROCm/iris 作为可能的替代方案。
- 原帖作者同意尝试一下,并对该项目表示了热情,同时另一位用户被标记为潜在用户。
GPU MODE ▷ #webgpu (2 messages):
:catgirl5: emoji usage, thinking hard emoji
- 发现 Catgirl 表情符号!:一名成员注意到 ‘Oh cool a :catgirl5: in the wild’,指的是频道中表情符号的使用。
- Catgirl 变成“苦思冥想”表情符号:针对同一话题,一名成员表示 it’s weirdly a good ‘thinking hard’ emoji lol。
- 社区似乎已经捕捉到了这个表情符号的梗(meme)潜力。
GPU MODE ▷ #self-promotion (1 messages):
GPU L2 Cache, Ampere Architecture, CUDA Project Structure, Persistent Memory Accesses
- L2 缓存持久化提升 GPU 性能:利用 Ampere 架构,一篇博客文章展示了如何为持久化内存访问预留部分 L2 cache 以提高 GPU 性能,详见 博客文章。
- 使用 CMAKE 的 CUDA 项目结构示例:提供的 代码 作为一个使用 CMAKE 构建系统组织 CUDA 项目的示例,增强了代码的组织性和可维护性。
GPU MODE ▷ #reasoning-gym (1 messages):
Contributions Welcome, Prototype Sharing, Pull Requests
- 欢迎为新任务贡献:频道指出欢迎贡献新任务,鼓励成员分享原型。
- 此外,成员也可以向仓库提交 PR 以进行迭代开发。
- 鼓励分享原型:鼓励成员在频道中分享原型,以收集反馈并迭代想法。
- 分享原型有助于促进协作并加速开发进程。
GPU MODE ▷ #submissions (1 messages):
MI300x8, amd-all2all leaderboard
- MI300x8 在排行榜上的得分:在 MI300x8 上提交至
amd-all2all排行榜的结果成功达到 334 µs。 - AMD all2all 基准测试更新:
amd-all2all排行榜上的最新结果展示了 MI300x8 硬件上令人印象深刻的性能。
GPU MODE ▷ #factorio-learning-env (6 messages):
Factorio Crafting Tool, FLE installation issues, Prototype Recipe Retrieval
- **Factorio Agent 的原型配方检索:
get_prototype_recipe工具可以检索 **Factorio 中任何可制造物品的完整配方信息,这对于理解合成需求和规划生产链至关重要。- Agent 可以使用
get_prototype_recipe动作获取单个物品的配方,并在需要时再次调用以获取子配方。
- Agent 可以使用
- **FLE 安装 遇到波折:一名成员报告在安装 **FLE 过程中遇到问题。
- 他们提到会旁听会议,但由于之后有一个重要的演示,不会参与太多互动。
GPU MODE ▷ #amd-competition (9 messages🔥):
CLI Tool vs Online Submission, ROCshmem Template, Web Version Organization, Online Testing Env Triton Support, Prize Registration Reminder
- CLI 工具优于在线提交:一位参赛者发现他们可以使用 CLI 工具 查看
num_experts的设置,而无需在线提交。- 另一位参赛者提到,网页提交是为提高提交便捷性而做的最新尝试,但目前仍处于 alpha 阶段。
- 寻找 ROCshmem 模板:一位参赛者询问关于 ROCshmem 模板 的信息,并指出它需要 ROCm-aware open MPI,想知道这些是否包含在 kernel bot 的工作流中。
- 暂无回应。
- 网页版的组织结构受到称赞:一位参赛者对 网页版 改进后的组织结构表示赞赏。
- 他们建议增加基于配置的运行时间(config-wise runtimes)以增强实用性。
- 询问 Triton 支持状态:一位参赛者询问在线测试环境是否支持 Triton。
- 暂无回应。
- 奖项注册提醒:发布了一项提醒,参赛者需要注册才有资格获得奖项,注册将于 9 月 20 日 截止。
GPU MODE ▷ #singularity-systems (1 条消息):
cuBLAS, ROCm, cuDNN, MIOpen
- 深入探讨 BLAS 和 DNN 内部机制:一位成员提到他们正在研究代码库,并寻找在 cuBLAS/rocBLAS 或 cuDNN/MIOpen 内部机制方面有经验的人。
- 他们补充说,对于具有相关专业知识的人来说,接下来的几周将有“更多工作要做”。
- 无主题:未讨论重大主题。
- 仅发送了一条消息。
GPU MODE ▷ #general (21 条消息🔥):
Pickling Errors, Serialization Issues, NaNs in Triton Kernels, Benchmarking Discrepancies
- Pickling 问题困扰 Python 进程!:一位用户在评估过程中遇到了
TypeError: cannot pickle 'frame' object,这是由于 multiprocessing 无法序列化在进程间传递的特定对象引起的;这是回溯信息 (traceback)。 - 序列化混乱阻碍提交!:该错误归因于评估过程使用独立进程以防止作弊,这暴露了用户提交内容的 序列化问题 (serialization issue)。
- 建议用户检查其 custom_kernel 函数的输出,因为错误提示该函数的返回值不可序列化。
- NaNs 破坏数值稳定性!:用户发现其 Kernel 输出中存在 NaNs (Not a Number) 值,这可能是导致序列化错误的原因,一位成员确认 NaNs 确实会导致此类问题。
- 用户最初怀疑是 grid error 导致了这些 NaNs 的产生,并表示打算在修复后重新提交代码。
- 基准测试困扰初学者!:尽管通过了初步测试运行,用户在基准测试过程中仍面临错误,这揭示了 测试运行 (test runs) 和 基准测试 (benchmarks) 是不同的,且后者设计得更为复杂。
- 用户被告知,即使测试运行成功,基准测试输出中的 NaNs 仍可能是一个问题,因为“我们会多次运行代码,每个尺寸最多运行 100 次”。
Latent Space ▷ #ai-general-chat (58 条消息🔥🔥):
OpenAI Custom AI Chip, Mercor $10B Pre-emptive Offers, Augment (Augie) $85M Series A, OpenAI Responses API, Hugging Face FineVision Dataset
- OpenAI 与 Broadcom 联合设计 100 亿美元 AI 芯片:《金融时报》报道,OpenAI 与 Broadcom 合作联合设计一款定制 AI 芯片,计划明年开始量产,这表明其正试图摆脱对 Nvidia 的依赖;该芯片估计耗资 100 亿美元。
- 社区反应不一,从对芯片质量的怀疑到猜测 OpenAI 将超越其自身客户;文章链接。
- Mercor 获得 100 亿美元先发制人要约:AI 招聘初创公司 Mercor 收到了未经请求的要约,估值约为 100 亿美元——仅在四个月后就是其 2025 年 6 月 B 轮融资价格的 5 倍,引发了关于 AI 融资狂热的调侃;推文链接。
- Augie 为 AI 物流筹集 8500 万美元 A 轮融资:Augment (Augie) 宣布获得 8500 万美元 A 轮融资——使总融资额在短短 5 个月内达到 1.1 亿美元——以扩展其为 10 万亿美元物流行业构建的 AI 队友;公告链接。
- Augie 已经帮助处理 350 亿美元以上 货运量的团队通过在电子邮件、电话、Slack、TMS 等渠道编排端到端的订单到现金 (order-to-cash) 工作流,使生产力翻倍。
- Responses API 辟谣贴:一个帖子澄清了关于 OpenAI Responses API 的广泛误解,驳斥了 Responses 是 Completions 的超集、可以无状态运行、以及能解锁更高模型智能和 40-80% 缓存命中率 的传闻;帖子链接。
- 敦促仍在使用 Completions 的开发者切换到 Responses 以构建 GPT-5 级别 Agent,并提供了 OpenAI Cookbook 的指引。
- Baseten 斩获 1.5 亿美元 D 轮融资:Baseten 宣布了由 BOND 领投的 1.5 亿美元 D 轮融资,Jay Simons 加入董事会;该公司为 Writer、Notion、Sourcegraph 等客户提供 AI 推理支持,并迎来了新投资者 Conviction 和 CapitalG;公告链接。
Latent Space ▷ #ai-announcements (4 messages):
AI Engineer CODE Summit 2025, NYC AI Event
- AI Engineer CODE Summit 2025 官宣:AI Engineer 团队宣布将于今年秋季在 NYC 举办首届专门的 CODE summit,汇聚 500+ AI Engineers & Leaders 以及顶尖模型构建者和财富 500 强用户,共同剖析 AI 编程工具的现状 - 公告链接。
- 该峰会为仅限受邀参加,设有两条赛道(Engineering & Leadership),无厂商演讲,CFP 开放至 9 月 15 日。
- AI Engineer Summit 关注重点:AI Engineer CODE Summit 2025 旨在庆祝 PMF(产品市场契合度),同时应对 MIT 的统计数据,即 95% 的企业 AI 试点项目以失败告终。
Latent Space ▷ #genmedia-creative-ai (21 messages🔥):
Nano Banana, AI Girlfriend, AI Design Masterclass, Nvidia Cosmos DiffusionRenderer
- Nano Banana 的 AI 艺术刷屏时间线:Logan Kilpatrick 标记了 @NanoBanana(Google 最新的香蕉品牌图像模型),触发了一个简单的 “hello world” 香蕉广告牌,引发了用户疯狂的创意 Prompt 浪潮。
- 该线程迅速演变成一个病毒式的 AI 艺术游乐场,根据 Elon-Sam-Demis-Ilya 自拍 和中国的维尼熊等 Prompt 生成艺术作品,同时也引发了笑话、赞扬以及对 AI slop(AI 垃圾内容)的抱怨(参见 示例)。
- AI Girlfriend 赚取收益:@EyeingAI 使用 DesireBots.com 创建了一个名为 “Ada” 的 AI girlfriend chatbot,每月收费 $9,在一周内从 500 多名用户那里赚取了 $1,142。
- 该过程涉及 no-code chatbot 设置和内置的变现工具,展示了一种利用 AI 产生收入的简单方法(参见 推文)。
- AI 设计大师班:Meng To 发布了一个 58 分钟的教程,介绍如何使用 AI 创作专业级设计,利用 aura.build 及其 740 个可直接 Remix 的模板,并支持导出到 HTML/Figma。
- 他的设计团队已从 Figma 转向 Aura,现在每天发布一个模板(之前是每两周一个),同时在学习 HTML 的过程中使用 Unicorn Studio 制作动画 Hero sections(参见 教程)。
- Nvidia 的开源 AI 重新布光演示:Nathan Shipley 演示了 Nvidia 的开源 Cosmos DiffusionRenderer,该工具可以将 1280×704 的短视频片段分解为稳定的通道(深度、法线、基础颜色等),以便使用自定义 HDR 贴图进行重新布光。
- 该工具允许使用自定义 HDR 贴图进行重新布光,示例包括家庭录像和著名电影场景,因其稳定性受到称赞,但也因其诡异的效果和目前的限制(最高 57 帧、CLI 设置、面部模糊)而受到批评。
DSPy ▷ #general (78 条消息🔥🔥):
使用 DSPy 构建语音 Agent,针对 Prompt 的 GEPA 优化,多轮对话,使用 Groq 进行推理,RAG vs 微调
- **基于 DSPy 的语音 Agent:初露锋芒:成员们讨论了使用 DSPy 构建语音 Agent,并探索了使用 **GEPA 为 Livekit 和 Pipecat 等框架优化 Prompt。
- 一位成员建议将 GEPA 优化后的 Prompt 直接作为字符串使用,但也承认这可能感觉有点“反 DSPy”(anti-DSPy)。
- **GEPA:不仅仅是 Prompt 优化:有人指出,虽然 DSPy 的作者可能会对“Prompt 优化”这个词感到反感,但像 **GEPA 这样的工具确实可以用于此目的。
- 对于 Prompt 创建,建议设置一个 Rubric 类型裁判来评估生成的响应,特别是在对话层面,并推荐使用 Groq 进行推理。
- **多轮对话思考:DSPy 的对话能力:虽然有成员发现目前还没有令人满意的 DSPy 多轮对话实现,或者像 **GEPA 或 GRPO 这样的 RL 应用,但 DSPy 完全有能力使用
dspy.History处理多轮对话。- 然而,有人提醒说,良好地定义示例至关重要,因为在构建聊天系统时很容易引入偏差。
- **RAG vs 微调:记忆游戏**:讨论涉及了如何让语音 Agent 具备大量信息(营业时间、服务、价格等)且不产生运行时延迟,方法包括微调或检索。
- 虽然微调可以建立记忆,但这是一项巨大的工程。 RAG 可以是简单的函数或映射,像营业时间之类的信息不需要使用向量数据库。
- **流式传输策略:驾驭 Token 浪潮:成员们探讨了流式响应(逐个 Token)对用户体验的影响,重点在于最小化 **Time To First Token (TTFT)。
- 虽然流式传输不会降低 TTFT,但它通过提供即时反馈增强了用户感知,像 Pipecat 这样的库在这方面也做得很好,它们以流式传输帧的方式运行(我认为默认是 250 毫秒的块)。
Moonshot AI (Kimi K-2) ▷ #general-chat (75 条消息🔥🔥):
Kimi K2 API 额度赠送,Anthropic API 集成,Kimi K2 Turbo 预览版,Kimi K2 模型性能,Kimi 入门订阅
- Kimi 赠送的 API 额度即将发放:一位赢得 Kimi 抽奖 的用户被告知 API 额度 将很快发放,团队正在安排。
- 额度预计将在一个小时内发放。
- Anthropic API 缺席:一位用户询问新模型是否支持 Anthropic API。
- 经澄清,kimi-k2-turbo-preview 指向的是 -0905 版本。
- Kimi 0905 模型首次亮相:确认 Turbo 模型现在使用的是 0905 模型,已从 0711 模型 更新。
- 一些用户对新 K2 模型 倾向于“过于诗意”表示担忧。
- Kimi K2 团队心怀大志:一位成员澄清说,与 Grok/OAI 相比,团队规模较小,但拥有宏大的梦想和庞大的模型。
- 他们补充说这是一件好事,因为通常公司越大,与用户的互动就越少。
- 代码专注度令 Kimi 用户感到困惑:用户对新 Kimi K2 模型专注于代码改进感到困惑。
- 一位用户表示 0711 比 0905 更好,但另一位用户认为写作变得“更详细且更好”。
Nous Research AI ▷ #general (65 条消息🔥🔥):
实时视频 AI、Spiking Neural Networks、更接近人眼工作原理的摄像头(图像传感器)、Meta 手环读取身体电信号以控制智能眼镜、Hermes 在 husky holdem 基准测试中的独特行为
- Spiking Neural Networks 引发关注:成员们讨论了 Spiking Neural Networks (SNNs) 及其模仿大脑的方式,其中一人分享了相关的 YouTube 视频。
- 另一位成员提到了工作原理更接近人眼的摄像头和 图像传感器 (image sensors),并分享了这段视频。
- Meta 手环读取身体信号:根据 Nature 的这篇文章,Meta 将推出一款通过读取身体电信号来控制 智能眼镜 的 手环 (wristband)。
- Hermes 表现出独特的德州扑克行为:一位成员指出,Hermes 在 husky holdem 基准测试中表现出极其 OOD(分布外)的独特行为,观察到其打法超级保守,且方式与其他模型完全不同。
- 分享 ADHD 资源!:一位成员分享了关于 ADHD、动力、学习和生产力的资源,包括关于确定性窗口 (Certainty Window) 的视频、显著性网络 (Salience Network) 与“推/拉”活动、Huberman 教授关于多巴胺、心态和驱动力的讲解,以及养成习惯是被低估的成功策略。
- 另一位用户补充道:药物是唯一能解决我 ADHD 的方法,但即使在服药的情况下,这些链接里的建议也非常有用。
- Deepmind 和华为正在酝酿大动作:一位成员表示,要关注 Deepmind 和 华为 在 B. Neural Network 方面的进展,特别是 华为 未来的 Quantum(室温量子)系统,这让美国政府感到非常恐慌。
Nous Research AI ▷ #interesting-links (7 条消息):
微型 LLM 实验、NVIDIA 的 SLM Agents、Hermes Agent 规模
- 洛夫克拉夫特风格 LLM 诞生!:一位成员实验了一个基于 H.P. Lovecraft 小说训练的微型 LLM,发现结果相当有前景,因为训练停止时 loss 仍在下降,查看 YouTube 视频。
- 他们推测,如果有合适的数据集和充分的训练,一个 300 万参数的模型 也可以成为一个轻量级聊天模型。
- NVIDIA 发布 SLM Agents!:一位成员分享了 NVIDIA 关于 SLM Agents 的研究链接(项目主页)及配套论文(arXiv 链接)。
- 没有关于该资源的进一步讨论。
- Hermes Agent 目标为 30B 参数:一位成员表示,他们的 Hermes Agent 目标是 30B 参数模型。
- 没有进一步的细节讨论。
Modular (Mojo 🔥) ▷ #mojo (60 messages🔥🔥):
Zig 的 async IO,Mojo 的类型系统,MLIR,循环向量化,编译器定制化
- **Zig 的 Async IO 面临质疑:其他语言社区对 **Zig 新的 async IO 方法的可行性表示担忧,而 Mojo 的类型系统和 effect generics 可能会解决其中的一些问题,例如 vtables 无处不在 的情况。
- 一位成员提到,IO 现在需要携带状态,能够从任何地方自由调用 IO 的日子可能已经屈指可数了,这参考了 Ziggit 中的这段讨论。
- **实现 SIMD 涅槃:成员们讨论了编写简单的、Pythonic 的代码并使其自动编译为 **SIMD 指令的目标,利用 Mojo 和 MLIR 实现最优的并行化汇编,而不依赖 LLVM 来正确向量化代码。
- 一位成员梦想着这样一个世界:for 循环会自动针对我所使用的硬件进行编译,在这种情况下是 8 或 16 个通道,而不是一直死磕 0 号通道。
- **揭秘向量化奥秘:为了充分向量化代码(尤其是循环),编译器需要关于输入数据形状的充足信息,或者必须进行推测(speculation)以识别热点循环进行向量化;同时澄清了 Mojo 鼓励使用可移植的 **SIMD 库。
- 有人提到,在 CPU 和 AMD GPU 上,标量和向量操作拥有独立的执行资源,理想情况下两者可以同时运行。
- **GPU Kernel 成熟度检查:一位成员询问了在 Mojo 中编写 **GPU kernels 的成熟度,特别是关于实现一个用于 PyTorch 的 Mamba2 kernel,并被引导至 Modular 的自定义 kernels 教程。
- 官方澄清,虽然 MAX(Modular 的图编译器 API)主要目标不是训练,但它可以用于推理,并且 MLA 已经实现了推理版本(见 GitHub)。
- **Span 抽象之梦:一位成员表达了希望 **Span(一种连续内存切片的抽象)能成为一个易于使用的、自动向量化的工具,并希望在 NDBuffer(正被移植到 LayoutTensor)上运行的算法能作为 Span 的一部分。
- 他们指出,虽然现有的实现是手动完成并根据硬件特性进行参数化的,但目前还没有太多的编译器魔法可用。
Eleuther ▷ #general (46 条消息🔥):
MasterCard Fraud Prevention AI, Obscenity Rule Enforcement, Brand Risk Mitigation, AI-induced psychosis, Semantic Drift
- MasterCard 的 AI 欺诈系统引发争议:MasterCard 用 AI 系统取代了欺诈预防人员,导致在淫秽规则执行方面与商户产生冲突,详情见 mastercard-rules.pdf 第 5.12.7 章。
- 该系统将更多交易标记为淫秽,每次违规罚款高达 $200,000,且不合规每日罚款 $2,500,这导致相关方倾向于避免承认错误。
- 标准不足困扰自动化欺诈预防:问题源于淫秽规则中未充分指定的标准,缺乏安全项目的明确示例,导致 LLM 的梯度变得浅薄且混乱。
- 讨论强调了必须将不成文的政策和方法明确化,以避免在缺乏足够背景的情况下进行自动化执行所产生的问题。
- 品牌风险驱动过度执法:来自共同基金减轻品牌风险的压力(如董事会多样性目标)导致了 MasterCard 欺诈部门内部的过度执法和对政策变更的拒绝。
- 这种过度执法影响了商户,而 MasterCard 对掩盖问题的关注阻碍了有用监控指标的开发,因为为了保护职业生涯,任何发现的缺陷都会变成一个必须解决的问题。
- AI 顾问质疑自动化的可行性:一位 AI 顾问对自动化其工作表示怀疑,理由是需要知识、对相关背景的理解和智慧,而这些是 AI 所缺乏的特质。
- 尽管如此,一次由医疗诱发的信仰危机让他们开始质疑自己那些在短期内仍不太可能被自动化的特质的价值。
- ArXiv 背书请求引发关注:一名研究人员请求为一篇关于 semantic drift 的 arXiv 论文提供背书,由于近期出现的 AI-induced psychosis 案例,这引发了怀疑。
- 由于使用了与 AI 生成的胡言乱语相关的术语,人们提出了担忧,并要求分享该论文以供审查。
Eleuther ▷ #research (6 条消息):
GRPO Baseline, SFT + KL regularization
- 成员思考 GRPO Baseline:成员们讨论了在项目中使用 GRPO baseline 的可能性。
- 一位成员询问 did you have an GRPO baseline?,另一位回答 no, this will be next。
- 提出 SFT + KL regularization 的可能性:一位成员建议探索将 SFT (Supervised Fine-Tuning) 与 KL (Kullback-Leibler) regularization 结合作为一种潜在方法。
- 这是针对分享的关于 RL_Razor 主题的链接的回应,该成员表示 oh, would be interesting to try SFT + KL regularization。
HuggingFace ▷ #general (37 messages🔥):
RL 中的奖励函数加权,Anthropic 关于管辖权控制的政策,带有 Attention Bias 的因果模型训练,Tokenizer 和 Attention Bias 实现,受限上下文大小下的 RAG 应用
- Anthropic 的政策引发关注:成员们讨论了 Anthropic 的新政策——禁止受其产品未获准进入的司法管辖区控制的组织使用其产品,这究竟是为了国家安全,还是单纯的企业私利。
- 辩论集中在基于所有权结构限制访问背后的动机。
- 解读 RL 中的奖励加权:成员们正在寻找关于在 RL 期间对奖励函数进行加权是否有益的研究,旨在避免在没有先验知识的情况下进行实验。
- 一位成员分享了一份关于 RL 中奖励加权的文档。
- 探索因果模型中的 Attention Bias:一位成员寻求关于使用 SFTTrainer 修改因果模型训练的建议,以便有目的地为特定词汇添加 Attention Bias,并参考了 Attention Bias 论文。
- 建议包括针对常用 Tokenizer 检查特定术语/Token,并考虑损失计算和梯度信号控制的替代方法。
- 处理 Tokenizers 以训练偏差:提供了关于如何对特定词汇进行 Attention Bias 的指导,建议在开始整个训练之前,先测试这些词汇将如何被 Tokenized。
- 建议使用 Gradio 或 Streamlit 等工具来实现这一目标。
- RoPE 助力 RAG 上下文扩展:成员们讨论了在极有限的上下文大小(4096 tokens)下使用 LLM 构建 RAG 应用的技巧。
- 其中一个技巧是使用带有 RoPE 的模型并使用更大的上下文大小进行微调,参考了此仓库,并强调 RoPE 使模型即使在未训练过的上下文长度上也能表现良好。
HuggingFace ▷ #today-im-learning (2 messages):
``
- 分享没有意义:一位成员表示分享没有意义。
- 消极态度:该频道的总体情绪似乎比较消极,不鼓励进一步的贡献。
HuggingFace ▷ #i-made-this (1 messages):
Enron 邮件数据集解析器,结构化 Parquet 文件,邮件分析
- Enron 邮件被解析为 Parquet:一位成员上传了他们的 Enron 邮件数据集解析器,生成了 5 个结构化的 Parquet 文件。
- 文件包括:Emails(邮件)、Users(用户)、Groups(群组)、Email/User 关联以及 Email/Group 关联。
- 通过哈希管理重复项:解析了父邮件和子邮件,并通过文件和消息的哈希/缓存来管理重复项。
- 所有消息都作为 MD5 哈希对象包含在内。
- 适用于群体行为分析的数据集:该数据集非常适合分析群体间的行为以及 NLP。
- 该成员注明了从何处获取数据集,但未包含数据本身。
HuggingFace ▷ #computer-vision (1 messages):
FastVLM
- FastVLM 可能是快速解决方案:一位成员建议尝试 FastVLM 以解决速度问题。
- 他们分享了该项目的 Hugging Face Collection 链接。
- 另一个话题:另一位成员尝试添加关于不同话题的信息。
- 这展示了在有更多信息时如何添加第二个话题。
HuggingFace ▷ #smol-course (5 messages):
smol-course, GitHub Readme
- Smol-course 位置浮现:一位成员询问什么是 smol-course?
- 另一位成员迅速分享了 GitHub 链接。
- Smol Course 困惑:一位成员表示,他们除了 Readme 和旧的 2024 课程内容外,找不到其他任何东西。
- 该成员多次重复我也一样,表明在定位预期的课程内容方面存在困难。
HuggingFace ▷ #agents-course (2 messages):
agents course, greetings
- 课程发布:瑞典与意大利发来问候!:来自瑞典和意大利的热情成员今天开启了 agents course。
- 一位参与者提到之前有一些 AI agents 的经验,准备好进行更深入的学习。
- 全球 AI 爱好者集结!:来自瑞典和意大利的参与者已正式开始 agents course。
- 其中一位新成员提到,他们带着一些之前的 AI agent 知识参与其中。
tinygrad (George Hotz) ▷ #general (8 messages🔥):
Digital Ocean MI300X errors, Z3 version issues, Kernel removal project
- Digital Ocean MI300X Stable Diffusion 运行失败:用户在 Digital Ocean MI300X GPU 实例上运行 stable_diffusion.py 示例时遇到问题,追溯到某些 z3 问题。
- 该错误无法在 Mac 上复现,但 mnist_gan.py 已通过测试。
- AMD_LLVM=1 导致 TypeError:在一个简单的 mnist 训练循环中,使用 AMD_LLVM=1 时出现了涉及不支持的操作数类型 (BoolRef) 的
TypeError。- George Hotz 建议尝试 IGNORE_OOB=1,指出这可能是 z3 版本问题,在 z3>=1.2.4.0 中添加了一些重载,并提供了一个 链接。
- 对 Kernel 移除项目感兴趣:一位用户询问如何为 kernel 移除项目做出贡献。
- 目前尚未提供关于哪些具体贡献会有所帮助的额外信息。
aider (Paul Gauthier) ▷ #general (5 messages):
Warp Code, Aider's strengths, Aider success stories
- Warp Code 赢得青睐:一位用户报告称 Warp 变得非常好用,Warp Code 感觉就像驾驶手动挡一样(充满掌控感)。
- Warp 擅长 embedding 搜索,适用于你不熟悉文件并想快速了解新代码库的情况。
- 尽管失去了 Claude,Aider 依然出色:一位用户在几个月前从 aider 切换到了 Claude Code,但现在又回来了,因为 Anthropic 做出了一些令人质疑的改变。他们更喜欢 aider 的简洁性,并使用
/ask来模拟 Claude Code 的 plan mode。- 该用户现在使用 Gemini 2.5 Pro 作为主模型,Gemini Flash 作为弱模型,Qwen3 Coder 作为编辑器模型,并使用
/run来模拟命令行工具(如检查最新的 git diff 或运行测试)。
- 该用户现在使用 Gemini 2.5 Pro 作为主模型,Gemini Flash 作为弱模型,Qwen3 Coder 作为编辑器模型,并使用
- Aider 中的 Run 命令是一项重大功能:对于一位用户来说,aider 中的
/run是一个核心功能,他们指出当你清楚地知道想要处理哪些文件时,Aider 非常好用。- 他们还询问在哪里可以看到 Aider 的成功案例。
aider (Paul Gauthier) ▷ #questions-and-tips (2 messages):
Coding Agent Refactoring, Aider's Code Validation, TreeSitter Validator
- Coding Agent 正在进行重构:一位成员受到 Aider 的启发,正在重构他们自己的 coding agent,以学习更多关于 AI system design 的知识。
- 他们已经有了一个小型的概念验证 (PoC),但现在正在阅读教程,看看其他人是如何处理类似项目的。
- 跨语言验证生成的代码:该成员正在寻求建议,以防止在任何语言中生成危险代码(环境变量泄露、rm -rf、网络请求等)。
- 他们考虑使用基于 TreeSitter 的验证器,并询问 Aider 是如何避免这些问题的,请求提供仓库中相关文件的指引。
Yannick Kilcher ▷ #general (4 messages):
Baselines in Papers, LoRA Training
- 寻求评审论文中 Baseline 的指南:一位成员询问了关于如何处理研究论文中提出的 baselines 的通用指南,特别是在不熟悉数据集的情况下。
- 他们表示在没有足够数据集知识的情况下很难判断性能,暗示需要更多的背景研究,并建议阅读更多论文。
- 为什么 LoRA 是相加而不是替换?:一位成员询问为什么 LoRA 训练层是相加的,而不是替换原始权重矩阵,并指出这与 depthwise convolutions 等其他高效过程形成对比。
- 他们寻求论文、文章或推理来解释这种设计选择(而非替换)的原因,并提到自己对此有一些直觉。
Yannick Kilcher ▷ #ml-news (1 条消息):
erkinalp: https://www.all-hands.dev/blog/the-path-to-openhands-v1
Manus.im Discord ▷ #general (3 条消息):
AI Politeness, Scientific Evidence for AI Politeness
- AI 表现友好的科学证明:一位用户分享了一篇论文的链接,该论文科学地证明了你应该对你的 AI 保持礼貌。
- 这似乎与当你对 AI 表现友好时,它们是否会更具协作性的问题有关。
- Manus 用户对友好 AI 达成共识:两名用户一致认为,他们希望看到礼貌对 AI 很重要的科学证据。
- 这可能与之前来自 arXiv 的关于 AI 礼貌这一相同主题的链接有关。