AI News
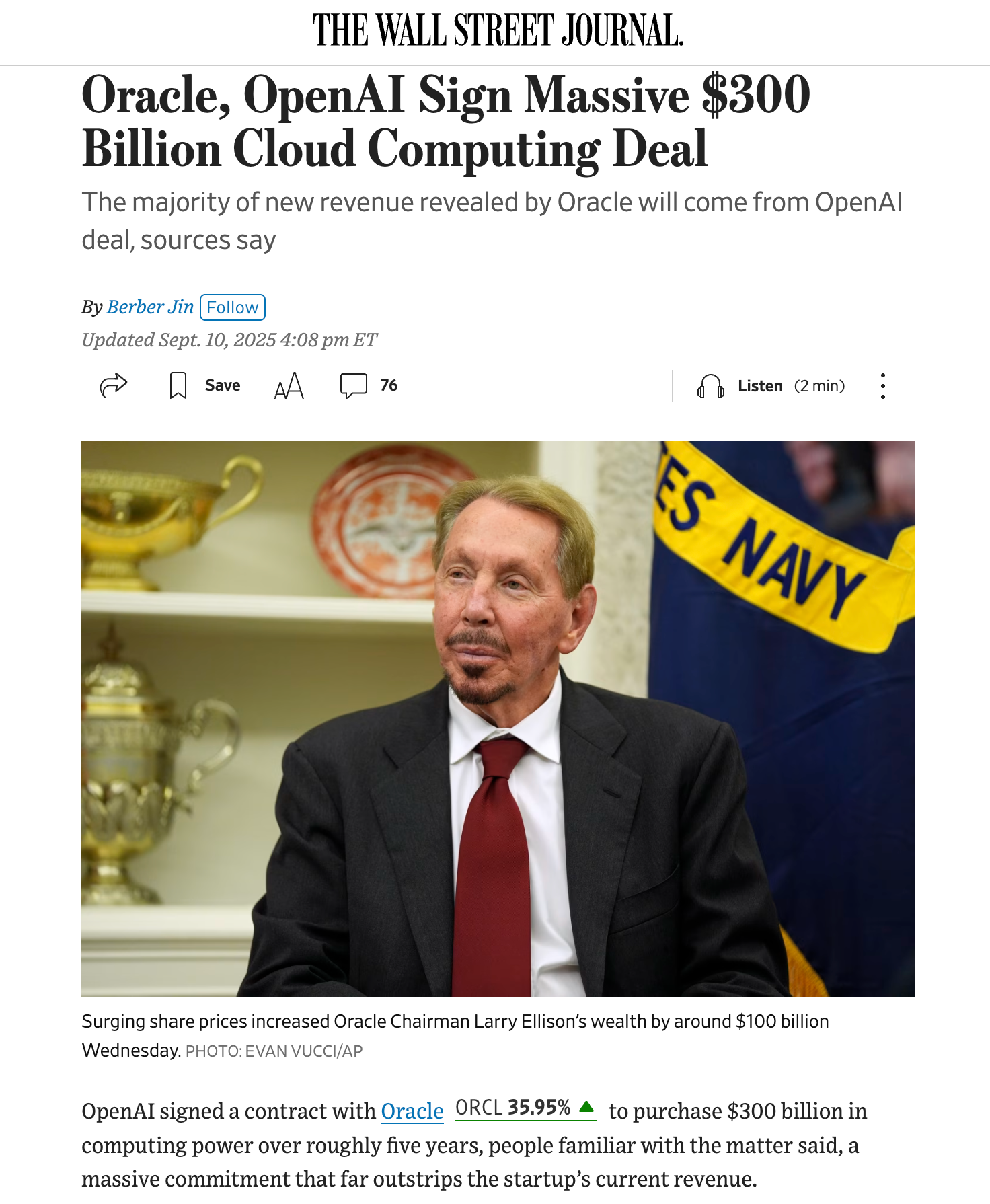
甲骨文(Oracle)在赢得3000亿美元的OpenAI合同后,股价单日暴涨36%。
甲骨文(Oracle)的 OCI 部门报告了惊人的 +359% 预订收入增长,达到 4550 亿美元,并给出了到 2030 年云业务营收 1440 亿美元的指引。这一增长很大程度上受到与 OpenAI 达成的一项大单推动,而此时正值 OpenAI 与微软关系紧张。
在 AI 基础设施方面,月之暗面(Moonshot AI)发布了 Kimi 的 checkpoint 引擎,支持在数千个 GPU 上对万亿参数模型进行快速权重更新,并与 vLLM 进行了集成。RLFactory 推出了一款针对工具使用智能体的即插即用强化学习框架,研究显示较小的模型表现优于较大的模型。TRL v0.23 增加了用于长上下文训练的上下文并行功能。Thinking Machines 实验室发布了关于确定性推理流水线的研究,使 vLLM 在运行通义千问(Qwen)模型时具备确定性。Meta 则推出了 PyTorch 基准测试工具 BackendBench。
恭喜 Oracle!
2025年9月9日至9月10日的 AI 新闻。我们为您检查了 12 个 subreddit、544 个 Twitter 账号和 22 个 Discord 社区(187 个频道,5382 条消息)。预计节省阅读时间(以 200wpm 计算):457 分钟。我们的新网站现已上线,支持全元数据搜索,并以精美的 vibe coded 方式呈现所有往期内容。访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
我们本打算重点介绍 Anthropic 官方 MCP Registry 的新闻,或者是 ChatGPT Developer Mode、Claude 的新 VM 或 Mistral 的巨额融资,但今天最大的氛围转变(vibe shift)可能属于 Oracle 的 OCI 部门。该部门的表现远超预期,其预订收入增长了 +359%,达到 4550 亿美元,并给出了到 2030 年云收入达到 1440 亿美元的指引(作为参考,OCI 目前为 180 亿美元,AWS 为 1120 亿美元,Azure 为 750 亿美元)。随着股价上涨,市值增加超过 2500 亿美元,几乎进入万亿俱乐部,Larry Ellison 现在成为了世界首富,回顾过去,这真是一场划时代的飞跃。
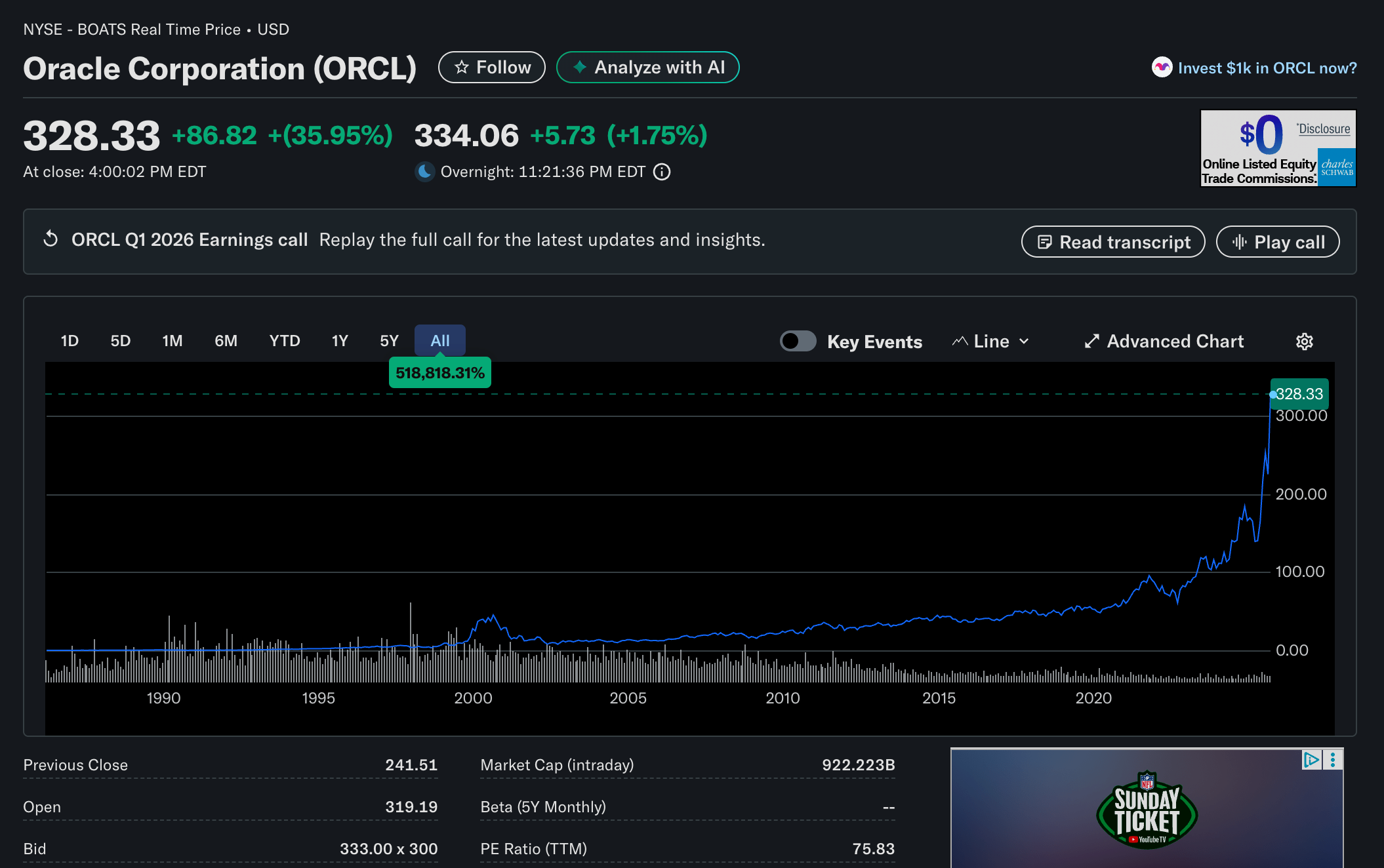
《华尔街日报》报道了后续消息,称 OpenAI 是这些预计预订量的重要来源,而且这可能是与 Microsoft 持续数月的紧张关系的结果,这一点或许意义重大。
AI Twitter 回顾
用于工具调用和权重更新基础设施的快速 RL (Kimi checkpoint-engine, RLFactory, TRL)
- Kimi 的 checkpoint-engine(开源):Moonshot AI 发布了一个轻量级中间件,用于在大型推理集群中就地推送模型权重更新。亮点:在数千个 GPU 上约 20 秒内更新 1T 参数模型;支持广播(同步)和 P2P(动态)模式;重叠了 H2D、广播和重新加载;与 vLLM 集成。查看 @Kimi_Moonshot 的发布和仓库,vLLM 与其合作的最佳实践笔记 (@vllm_project),以及逐步权重传输优化推文 (@vllm_project)。背景:@ZhihuFrontier 的深度分析记录了使用原始 RDMA Writes 实现的 ~2s 跨节点权重同步(Qwen3‑235B, BF16→FP8)——无需磁盘 I/O 或主机 CPU——通过预计算路由表、融合投影+量化、将 CUDA 事件与 RDMA 重叠以及通过 DeviceMesh 进行批处理。
- RLFactory(用于 LLM 工具的即插即用 RL):一个用于工具调用 Agent 的 RL 简洁框架,具有异步工具调用(6.8 倍吞吐量)、解耦的训练/环境(低配置要求)、灵活的奖励(规则/模型/工具),并证明了小模型可以超越更大的基准模型(在他们的设置中 Qwen3‑4B > Qwen2.5‑7B)。论文和代码通过 @arankomatsuzaki 及其链接 (仓库) 获取。
- TRL v0.23:引入了 Context Parallelism 以支持任意上下文长度的训练,以及其他后训练(post-training)改进。如果你正在进行长上下文 SFT/RL,这将非常有用。详情:@QGallouedec。
- Prime Intellect RL 栈:轻量级 RFT 现已集成到 prime-rl、验证器和 Environments Hub 中,团队正致力于构建面向开放开发者的全栈 SOTA RL 基础设施 (公告)。
确定性且可扩展的推理/训练 (vLLM determinism, BackendBench, dynamic quant, HierMoE)
- 解决 LLM 推理中的非确定性:Thinking Machines Lab 推出了其研究博客 “Connectionism”,并发布了一份关于确定性推理流水线的深度实践指南(涵盖浮点数值、kernels、缓存、采样对齐),以及一个使 vLLM 在 Qwen 上实现确定性的极简补丁。阅读相关文章(发布声明, @cHHillee)、vLLM 示例及致谢(@vllm_project, @woosuk_k)。相关基础设施:PyTorch nightly 版本现已提供支持 Blackwell 实验的 CUDA 13 wheel 文件(@StasBekman)。
- BackendBench(由 Meta 主导):一个用于测试 PyTorch 后端算子覆盖率的基准测试。现已托管在 Prime Intellect Environments Hub 上,以便于比较和讨论(@marksaroufim, @m_sirovatka, Hub 入口)。
- 动态量化笔记 (DeepSeek V3.1):@danielhanchen 指出,“思考”模式在较低的动态位宽下仍能保持更高的准确率;3-bit 接近 FP 基准;将 attn_k_b 保持在 8-bit 相比 4-bit 可提升 2% 的准确率;对共享专家(shared experts)进行向上转型(upcasting)会使推理速度降低 1.5–2 倍,而准确率提升极微。
- HierMoE (MoE 训练系统):通过跨层级的拓扑感知 Token 去重和专家交换,在多节点 A6000 配置下将 All-to-All 通信提升了 1.55–3.32 倍,端到端性能提升了 1.18–1.27 倍;随着 top-k 路由数量的增加,收益更加显著。摘要见:@gm8xx8。
模型发布与性能
- K2-Think 32B (基于 Qwen2.5,开源):采用长 CoT SFT + 带有可验证奖励的 RL 进行训练;推理使用 Plan-Before-You-Think 和 Best-of-3 策略。报告的 pass@1 数据:AIME’24 90.8, AIME’25 81.2, HMMT’25 73.8, Omni-HARD 60.7, LiveCodeBench v5 63.97, GPQA-Diamond 71.1。在 Cerebras WSE 上运行速度约为 2,000 tok/s(相比之下,H100/H200 约为 200 tok/s)。全栈(模型、训练/推理代码、系统)均已开源;同时提供 API。来源:@gm8xx8。
- ERNIE-4 (百度,Apache-2.0):社区注意到,考虑到其参数规模,该模型相较于前沿基准模型表现强劲;目前开源的变体似乎为 4B 和 30B(@eliebakouch, HF 模型卡片, 澄清说明)。
- MobileLLM-R1 (Meta):参数量小于 1B 的边缘端推理模型,据报道其 MATH 准确率比 Olmo-1.24B 高出约 5 倍,比 SmolLM2-1.7B 高出约 2 倍;该模型在 4.2T Token 上训练(约占 Qwen3 36T 训练量的 11.7%),但在多个推理基准测试中达到或超过了 Qwen3,信息来自 @_akhaliq。
- Google Edge 更新:Gemma 3n 现已上架 Play Store,支持设备端语音/文本/图像输入,并具备设备端 STT 和翻译功能;提供 OSS 代码和 Android 应用(@_philschmid, 仓库/应用)。此外,EmbeddingGemma 是 HF 上最热门的模型(@osanseviero, @ClementDelangue)。
- SWE-bench (仅限 bash):GLM-4.5 通过 mini-swe-agent 登榜第 7 名(@OfirPress)。
评估与后期训练平台
- SimpleQA Verified (Google DeepMind):一个包含 1,000 个提示词的事实性基准测试,具有清洗过的标签、重新平衡的主题以及改进的自动评分设计。在这个更干净的评估中,Gemini 2.5 Pro 达到了 SOTA。方法论、排行榜和论文:@lkshaas, @_philschmid, Kaggle。
- Together FT 平台:现在支持 100B+ 模型(DeepSeek, Qwen, GPT‑OSS),支持高达 131k tokens 的长上下文 FT,集成了 Hugging Face Hub,并提供高级 DPO 选项(@togethercompute, 更新, HF 集成)。
- OpenAI Evals:支持原生音频输入和音频评分器——无需转录即可评估音频响应(@OpenAIDevs)。OpenAI 还在招聘 Applied Evals 团队,专注于具有经济价值的任务(@shyamalanadkat)。
Agents, MCP, and SDKs
- MCP 无处不在:ChatGPT 现在在开发者模式下支持完整的 MCP 工具(包括写入操作)——可连接 Jira, Zapier, Stripe 等(@OpenAIDevs, @gdb, @victormustar, @emilygsands)。Anthropic 添加了 web-fetch 工具,使 Claude 可以检索/分析任意 URL(@alexalbert__)。
- Genkit Go 1.0 (Google):面向生产环境的 SDK,为 Go 后端提供 init:ai-tools、内置 tool calling、RAG 等功能(@googledevs)。
- Agent 数据与内部机制:Hugging Face 发布了 Jupyter Agent Dataset 代码库(7TB Kaggle 数据 → 0.2B 个用于 notebook 创建/编辑的 agentic traces)以及分步指南(@_BaptisteColle, @lvwerra)。此外,还可以通过 Modal 访问一个学习 vLLM 内部机制的优秀实时 notebook(@vllm_project)。
Multimodal & Edge Embeddings and Tooling
- llama.cpp 中的多模态嵌入:@JinaAI_ 通过修复图像 token 的 attention mask 并匹配 vision tower 中 PyTorch 的 conv3d 预分组,在 llama.cpp 中实现了支持 GGUF 的多模态嵌入 V4;GGUF(及量化版)现在在 ViDoRe/MTEB 上与 PyTorch 参考标准一致。代码和博客见其推文。
- 用于 RAG 的解析:LlamaParse 现在可以提取 PowerPoint 演讲者备注——这对于企业级 RAG 流水线非常有用(@llama_index, @jerryjliu0)。
- 图像模型对决 (Seedream 4.0 vs Nano Banana):字节跳动的 Seedream 4.0(文本生成图像 + 编辑)已在 Arena 和 Yupp 上线;早期社区对比显示 Seedream 在编辑/中文语义方面表现出色,而 Nano Banana 在写实度/细节方面胜出(@lmarena_ai, @yupp_ai, @ZhihuFrontier)。
- 边缘端 VLM:LearnOpenCV 教程介绍了如何在 Jetson Orin Nano(JetPack 6, Transformers 栈)上运行 Moondream2, LiquidAI LFM2‑VL, Apple FastVLM, SmolVLM2,用于生成描述、VQA、OCR(@LearnOpenCV)。
- 云端 GPU 市场:关于 2025 年容量、定价模型以及优化可用性/成本策略的详实报告(@dstackai, @StasBekman)。
热门推文(按互动量排序)
- Agent 3:“自主性提升 10 倍……软件领域的‘Full Self‑Driving’时刻。” (5,166)
- ChatGPT 在开发者模式中增加了完整的 MCP 工具支持 (4,070)
- Claude 创建多工作表 Excel 文件(“Vibe Excel 时代”) (1,394) 以及 在 Excel 中复制图像 (3,793)
- 通过 Play Store + OSS 提供的 Gemma 3n 端侧助手(语音/文本/图像) (2,189)
- 来自 Thinking Machines 的 Deterministic inference 报告 (1,728)
- Kimi 的 checkpoint-engine:1T 参数权重更新约 20 秒;与 vLLM 合作 (1,735)
- 涵盖 11 个主要家族的大型 LLM 架构讲座 (1,457)
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. Unsloth DeepSeek‑V3.1 Dynamic GGUF Aider Polyglot 基准测试与 AMA
- Unsloth Dynamic GGUFs - Aider Polyglot 基准测试 (Score: 178, Comments: 42): Unsloth 展示了其 DeepSeek-V3.1 的 Dynamic GGUF 量化版本的 Aider Polyglot pass@2 基准测试 (HF repo, blog),表明选择性层动态 imatrix 量化即使在极端的位宽下也能保持能力。一个突出的结果是 1‑bit Dynamic GGUF 将模型大小从
671GB → 192GB (−75%)减小,并且据报道,在 Aider Polyglot 的“非思考”模式下,其表现优于 GPT‑4.1 (2025年4月)、GPT‑4.5 和 DeepSeek‑V3‑0324;3‑bit(思考)变体优于 Claude‑4‑Opus(思考),5‑bit(非思考)与 Claude‑4‑Opus(非思考)持平。基准测试是在约 3 次运行中取平均值,并报告了 pass@2 的中位数,对比对象包括全精度 API、其他动态/半动态 imatrix GGUF,其中几个非 Unsloth 的 1‑2 bit 量化版本无法加载或产生退化输出。 评论者质疑 1‑bit 模型如何击败全精度模型(推测它在较不重要的层上使用重度量化,而在关键层上使用较轻或不量化),讨论了首选的 GGUF 格式如q4_k_xl/q5_k_xl,并分享了经验性体验,即 Unsloth 动态量化在本地完全离线使用时,可以匹配或超越 API 提供的模型。- 几位评论者探讨了“1‑bit” Unsloth Dynamic GGUF 如何能优于某些全精度基准。共识解释是 mixed-precision allocation:Unsloth 的动态方案将对敏感度关键的路径(例如,attention Q/K/V 和 output projections,MLP up/down)保持在较高精度,同时在 calibration/perplexity 的引导下激进地量化不那么敏感的张量(embeddings, layer norms, 一些 residuals),因此有效平均值约为
1–2bits,而非均匀的 1‑bit。这比经典的均匀 k‑quant 更接近 per‑layer/per‑channel mixed precision,在精神上类似于 AWQ/SmoothQuant 的想法(参见 https://arxiv.org/abs/2306.00978, https://arxiv.org/abs/2211.10438)。结果是可以在大幅降低内存/延迟的同时,保持下游任务的生成质量。 - 在实际权衡方面,用户强调
q4_k_xl是一个强大的默认选择,而q5_k_xl则适用于 Qwen3‑Coder 等编程模型以获得更高的保真度。这些 K‑grouped GGUF 量化平衡了速度/VRAM 与准确性;从q4_k_xl迁移到q5_k_xl通常会增加内存和计算量,但会降低 perplexity 并更好地保留长程/代码结构。关于 GGUF/K‑quants 及其特性的参考:https://github.com/ggerganov/llama.cpp/blob/master/docs/quantization.md。据报告,将 Unsloth 的动态分配与 K‑grouped 格式结合使用,可以在保持本地硬件交互延迟较低的同时维持质量。 - 有人提出了关于在 Apple 的 MLX 上运行 Unsloth 动态量化的问题。目前 MLX/MLX‑LM 加载其自身格式(从 HF/safetensors 转换而来),并不原生支持 GGUF,因此 Unsloth dynamic GGUFs 无法直接运行;进行 dequantizing/converting 到 MLX 将失去动态量化的优势并增加内存。参见 MLX‑LM 示例:https://github.com/ml-explore/mlx-examples/tree/main/llms。原生 MLX 支持将需要在 MLX 中实现 dynamic GGUF kernels/ops 或添加 GGUF loader 路径。
- 几位评论者探讨了“1‑bit” Unsloth Dynamic GGUF 如何能优于某些全精度基准。共识解释是 mixed-precision allocation:Unsloth 的动态方案将对敏感度关键的路径(例如,attention Q/K/V 和 output projections,MLP up/down)保持在较高精度,同时在 calibration/perplexity 的引导下激进地量化不那么敏感的张量(embeddings, layer norms, 一些 residuals),因此有效平均值约为
- 与 Unsloth 团队的 AMA (Score: 281, Comments: 353): Unsloth 宣布进行 AMA,并发布了新的 Aider Polyglot 基准测试,将其 DeepSeek‑V3.1 Dynamic GGUFs 与其他模型/量化版本进行了对比,详情见其 LocalLLaMA 帖子,并附有项目文档和代码链接 (docs, GitHub, benchmarks post)。AMA 时间为
10AM–1PM PST并在 48 小时内进行后续跟进,重点讨论其开源 RL/微调框架、GGUF 构建、自定义内核和 Bug 修复。 评论主题包括:请求更快的 Mixture‑of‑Experts (MoE) 训练时间线和方法,以及针对初学者进入 LLM 微调领域的实践指导;现场极少有无关的赞美。- 对加速 MoE 训练的兴趣集中在优化专家并行(expert-parallel)通信和负载均衡上。主要瓶颈是
all_to_allToken 路由和专家利用率不足;采用者通常依赖 Megatron-LM MoE 或 DeepSpeed-MoE,结合专家/序列并行、负载均衡损失和capacity_factor调整,以及 Microsoft Tutel 等库来实现更快的 all-to-all 和分组 GEMM (Megatron-LM, DeepSpeed-MoE, Tutel)。Token 丢弃(token dropping)、辅助平衡损失和批处理 GEMM(例如 Megablocks, 论文)被认为是典型的手段,根据拓扑/互连情况,可实现比原生 MoE 实现高出>1.5x的利用率提升。 - 生产环境对 GRPO/DPO 单节点多 GPU 支持的需求凸显了不同的并行化需求:DPO 很大程度上是标准的数据并行(DDP/FSDP/ZeRO),具有成对对比损失(pairwise contrastive loss)和可选的冻结参考模型;而 GRPO/RL 则需要同步批次采样、优势估计(advantage estimation),以及可能的 actor–learner 或参数服务器布局。高效的 GRPO 需要快速生成内核(FlashAttention, paged KV cache)、rollout 微批次处理以及精细的
max_new_tokens/序列打包(sequence packing)以保持 GPU 饱和;DPO 则受益于梯度检查点(gradient checkpointing)和融合算子(fused ops)以适配更长的上下文。提到的典型技术栈:torch.distributed+ FSDP/ZeRO-3,或用于算法脚手架的 Hugging Face TRL (TRL)。 - 初学者的微调兴趣倾向于实用的低成本设置:使用 4-bit
nf4量化(bitsandbytes)的 QLoRA 和中等规模模型(7B–13B)上的 PEFT 适配器,利用 FlashAttention-2 和序列打包提高吞吐量。常见的超参数范围:LoRAr=8–16,alpha=16–32,学习率1e-4–2e-4,预热(warmup)~1–3%,以及余弦衰减;通过lm-eval-harness/特定任务指标进行评估。参考资料:QLoRA, bitsandbytes, PEFT, FlashAttention。
- 对加速 MoE 训练的兴趣集中在优化专家并行(expert-parallel)通信和负载均衡上。主要瓶颈是
{kind=link}
2. Microsoft VibeVoice 长文本多发言人 TTS 展示 + GPT‑OSS 从零预训练发布
-
VibeVoice 太棒了。现在我们需要为其他模型适配它的 Tokenizer! (Score: 348, Comments: 63): OP 演示了 Microsoft Research 的 VibeVoice (7B) 长文本 TTS,展示了通过 Hugging Face Space (https://huggingface.co/spaces/ACloudCenter/Conference-Generator-VibeVoice) 单次生成
45–90 minutes且支持多达4 speakers,使用默认声音且无需拼接。他们强调了其逼真的韵律(prosody),优于 Google 的笔记本式播客(后者是根据上下文自动生成,而不是遵循精确脚本),并提议为其他模型适配 VibeVoice 的 Tokenizer;据报道,一个已发布的 Checkpoint 在发布后被撤回。 热门反馈:真实感很高,但长文本收听仍会遇到“恐怖谷”效应——声音(尤其是男性)随着时间的推移听起来比较生硬。用户报告了在提供语内语音样本提示时的非官方多语言能力,以及通过 ComfyUI 进行的实用克隆,每个声音使用约 2 分钟的小故事并采用不同的表现方式(耳语、大喊、语速慢)来丰富风格;此处分享了示例结果:https://www.reddit.com/r/StableDiffusion/comments/1nb29x3/vibevoice_with_wan_s2v_trying_out_4_independent/。 - 多位用户报告了韵律和长文本质量问题:声音听起来“生硬”,带有“虚假的狂热感”,且男性声音表现更差。即使短篇 Demo 令人印象深刻,听众表示
~90 分钟的叙述会让人感到疲劳,这指向了 TTS 在表达控制、长程韵律规划以及对抗“恐怖谷”效应方面的局限性。 - 一位测试者声称 VibeVoice 并不硬性限制在英文/中文:当提供该语言的声音样本时,它可以生成其他语言(零样本(zero-shot)风格)。这表明声学/潜空间表示(latent representations)可以跨语言泛化,即使官方的分词器(tokenizer)/训练重点是英文/中文,也暗示了在无需显式重新训练的情况下进行多语言迁移的潜力。
- 通过 ComfyUI 实现的实用克隆工作流:每个目标声音只需一段
~2 分钟的短故事即可获得良好的克隆效果;使用多种素材(耳语、大喊、缓慢、兴奋)可以增加不同说话者的韵律多样性。此处分享了示例输出(使用 WAN S2V 生成的 4 个独立说话者):https://www.reddit.com/r/StableDiffusion/comments/1nb29x3/vibevoice_with_wan_s2v_trying_out_4_independent/ —— 这表明该工具可以可行地集成到基于节点的流水线中,并用于视频/旁白配对。 - 我从零开始预训练了 GPT-OSS (Score: 174, Comments: 32):一段 3 小时的演示视频展示了“GPT-OSS”从零开始的预训练流水线,涵盖:TinyStories 预处理;自定义 Harmony 分词器;Transformer 组件(token embeddings, RMSNorm, RoPE);带有 GQA 的滑动窗口注意力;注意力偏置/汇聚 (sinks);以及 SwiGLU MoE,外加训练循环和推理(视频)。发布了两个代码库:(1) Nano-GPT-OSS,一个
~500M参数的模型,据称“保留了关键架构创新”,在1×A40上训练约20 小时,成本为$0.40/小时(复现成本<$10);(2) Truly-Open-GPT-OSS,一个从零预训练的~20B模型,据报告需要5×H200以及$100–150的预算。该帖子列举了架构特性,但未指定训练精度;评论者询问了 FP32 与 FP8/FP4 的对比,以及权重可用性(例如在 HF 上)或 llama.cpp 兼容性。 顶级的技术反馈指出 nano 仓库中存在严重的代码质量/ML 正确性问题:缺失导入、没有权重初始化(包括未初始化的注意力汇聚)、损失计算中重复的设备传输、逐样本循环损失,以及一个既没有辅助损失(auxiliary loss)也不是“无辅助损失”(auxiliary-loss-free)设计的 MoE 实现;还建议添加 pyproject/lint 并修复错误(例如 “infrance” 拼写错误)。其他评论质疑了训练精度的选择(FP32 与 FP8/FP4)以及部署/便携性(HF 权重, llama.cpp)。- nano 模型中发现了实质性的实现问题:缺失导入(例如
gpt2.py中的torch.nn.functional as F)、没有显式的权重初始化(导致注意力汇聚未初始化),甚至还有拼写错误的导入(from infrance import generate_text)。性能缺陷包括在损失计算期间重复调用model.to(device),以及在 batch 上使用非向量化的逐样本for循环,这两者都会严重导致 GPU 利用率不足;此外,MoE 的路由/正则化被标记为错误——它既不是无辅助损失设计,也没有实现辅助损失来平衡专家(experts)。 - 训练精度选择受到质疑:一位评论者询问是否所有模块都以
FP32训练,以及为什么不使用原始 GPT-OSS 据称使用的FP8或FP4。这涉及到吞吐量、内存占用以及训练成本与稳定性的权衡——低精度训练(如FP8/FP4)可以大幅减少计算和内存需求,但通常需要仔细的校准和损失缩放(loss-scaling)以维持收敛。 - 关于规模/数据的担忧:在 TinyStories 上训练一个
~20B参数的模型被认为是“大材小用”,有人要求提供 TinyStories 子集大小的具体细节,并询问在>1Ttoken 上进行训练的计算/成本。该讨论隐含地探讨了数据集与模型大小的匹配度,以及万亿级 token 运行的可行性/开销,表明人们对 token 预算和规模选择的兴趣不仅限于模型大小。
- nano 模型中发现了实质性的实现问题:缺失导入(例如
###
技术性较低的 AI Subreddit 汇总
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. 图像生成发布:SeeDream 4 vs Imagen, Qwen Edit (Nunchaku), 以及 Wan 2.2 I2V
- Imagen 4 vs Seedream 4 (相同 prompt) (Score: 244, Comments: 80): 来自文本生成图像模型 Imagen 4(左)和 Seedream 4(右)的对比生成结果,使用了相同的摄影 prompt(Canon EOS R6, 135mm,
1/1250s,f/2.8, 未指定 ISO),场景为多伦多夜晚的室内游戏桌面。评论者指出 Seedream 的输出看起来更具照片写实感(photorealistic),而两者的结果都忽略了类似 EXIF 设置所暗示的物理规律——例如,尽管快门速度高达1/1250s,却出现了运动/光迹,且在 135mm 全画幅拍摄的f/2.8下显示出不切实际的深景深(DOF)。 共识倾向于 Seedream 4 的写实性;技术评论强调,两种模型都没有遵循指定的相机参数,这表明目前的 prompt-to-image 流水线对曝光/景深约束的忠实度有限。- 一位评论者指出渲染图像与物理不一致的相机参数:照片中可见的运动轨迹需要慢速快门,但声明的快门速度却暗示了相反的情况;同样,在全画幅 Canon R6 上使用
135mm和f/2.8时,景深应该是极浅的,但图像显示所有内容都在焦点内。这表明目前的模型(Imagen 4 和 Seedream 4)在 prompt 中指定明确的相机设置时,并没有严格执行光学写实性。 - 几位用户注意到 Seedream 4 看起来比 Imagen 4 更具照片写实感,特别是它消除了典型的 AI “色彩滤镜/色偏”,产生了更中性、更像相机的色彩渲染和色调。改进的色彩科学/色调映射(tone mapping)被认为是感知写实感的关键因素。
- 一位评论者指出渲染图像与物理不一致的相机参数:照片中可见的运动轨迹需要慢速快门,但声明的快门速度却暗示了相反的情况;同样,在全画幅 Canon R6 上使用
- 字节跳动声称 Seedream 4.0 在美学和对齐上击败了 Google 的 “nano banana” (Score: 218, Comments: 54): 字节跳动的 Seedream 4.0 被声称在美学和对齐(alignment)方面超越了 Google 的 “nano banana”。上手报告强调了在参考图处理上的实现差异:Seedream 4.0 依赖于 LLM 生成的参考图像文本描述,而 “nano banana” 支持原生图像调节(image conditioning),在编辑(如改变面部表情)时能产生更强的身份/姿态一致性,并具有更好的
text渲染忠实度。 评论者提醒不要过早炒作,并指出除了 Google 仍然领先的文本和身份一致性外,Seedream 4.0 在视觉写实感方面通常与 “nano banana” 持平或超越,生成的图像感觉不那么有“塑料感”。总体观点:Google 在排版和精确主体持久性方面获胜;Seedream 4.0 在逼真的美学方面可能略胜一筹。- 指出的一个关键实现差异是参考图处理:Seedream 依赖 LLM 生成参考图像的文本描述(LLM 介导的重编码),而 Google 的 “nano banana” 则直接在图像上进行原生调节。这体现在身份一致性上——nano banana 在应用编辑(如改变面部表情)时能以极小的漂移保留精确的主体,而 Seedream 在跨编辑保留同一人物方面表现出更多差异。
- 对比性能观察:据报告,Seedream 4.0 在大多数输出上与 nano banana 持平或超越,但在图像内文本/排版方面除外,Google 在这方面仍处于领先地位。在美学上,Seedream 的样本被描述为更具照片写实感,且不易出现合成的“塑料光泽”,这表明即使文本渲染忠实度落后,它也具有更强的写实先验或去噪行为。
-
Nunchaku Qwen Image Edit 发布 (Score: 201, Comments: 52): Nunchaku 在 Hugging Face 上发布了 “Qwen Image Edit” 模型,提供了一个基础模型以及
8-step和4-step变体:https://huggingface.co/nunchaku-tech/nunchaku-qwen-image-edit。据报告,该模型可以在现有设置中运行,无需更新 Nunchaku 或 ComfyUI-Nunchaku,示例工作流 JSON 可在此处获取:https://github.com/nunchaku-tech/ComfyUI-nunchaku/blob/main/example_workflows/nunchaku-qwen-image-edit.json。 评论者要求提供关于质量与速度的具体基准测试(例如,减少步数的变体是否牺牲了忠实度以及牺牲了多少)和具体的加速数据;一位用户注意到可能缺乏 “Chroma” 支持。 - 几位评论者探讨了速度与质量的权衡 (speed vs. quality tradeoff),询问声称的加速是否会降低编辑保真度,或者是否真的是“免费”的提速。他们要求在常见分辨率下提供
SSIM、LPIPS、PSNR或提示词对齐指标(例如基于 CLIP 的分数)的具体基准测试,以展示在减少步数/调度器(schedulers)的情况下,色彩一致性、边缘保留或伪影率是否存在任何退化。 - 用户对量化的加速有需求:“加速了多少?”用户希望了解在典型硬件(RTX 4090, A100, Apple M2)上,标准尺寸(如 512×512)下
bs=1和bs=8的端到端延迟和吞吐量,以及冷启动与热启动的数据。他们还询问增益是来自模型侧的更改(例如更少的 Diffusion 步数/调度器微调)还是系统级优化(CUDA kernels, TensorRT/ONNX, 量化, FP8/bfloat16),以及这些因素如何影响单图延迟与批量吞吐量。 - 功能支持也是一个关注点:“除了 Chroma 以外的一切”暗示工作流中缺少 ChromaDB 集成,另一位用户询问了用于个性化的 LoRA 适配器。评论者希望明确图像编辑骨干网络是否支持 LoRA(训练和推理时的适配器加载),以及 Chroma 集成是否在资产/提示词检索或项目元数据的路线图中。
- 解决 Qwen-image-edit 的图像偏移问题 (得分: 404, 评论: 48): OP 报告称 Qwen-image-edit 在编辑过程中经常产生空间偏移,扭曲角色比例和整体构图。他们分享了一个声称可以缓解该问题的 ComfyUI 工作流 (workflow) 和一个支持性的 LoRA (model) 以稳定输出;视觉示例显示对齐有所改善,但未提供定量基准测试。 热门反馈指出,分享的工作流捆绑了三个自定义节点并更改了环境(例如更换了 NumPy 版本),这表明该问题可以在不引入侵入性依赖的情况下解决。另一位评论者指出,根本原因是输入/输出分辨率不匹配;确保输出调整大小以匹配输入可以防止偏移,并且可以在任何工作流中实现(例如使用 Kontext)。
- Qwen-image-edit 中的图像偏移似乎与调整大小前后的尺寸不匹配有关;如果模型或工作流调整了输入大小,但输出画布未强制设定为完全相同的大小,则生成的图像会发生空间位移。用户报告在 Kontext 中也存在相同行为;先控制输入尺寸,使输出完全匹配(不进行隐式缩放),即可消除偏移。实际建议:锁定输入维度,并确保任何 resize/pad 操作都是对称的,以便模型的输出与源图像 1:1 对齐。
- 经验发现表明稳定性与特定分辨率有关:
1360x768(约 16:9)和1045x1000(约1 MP)没有显示偏移,但仅增加+8 px就会重新引入偏移。这种模式暗示了内部 stride/patch-size 或平铺(tiling)边界条件,即只有某些维度的倍数能保持对齐,当维度略有偏离时就会导致偏移。 - 工作流安装引入了环境和安全担忧:它添加了
3个自定义节点并更改了 NumPy 版本(卸载旧版本并安装新版本),导致了依赖冲突。据报道,另一个节点包包含一个“屏幕共享节点”,引发了隐私/安全红线。技术启示:节点包可能会改变运行时环境并引入敏感功能;建议优先选择隔离环境,并在安装前审核节点清单(manifests)。
2. LLM 质量波动、幻觉与 Bug 输出
- The AI Nerf Is Real (Score: 509, Comments: 115): IsItNerfed.org 报告了对 LLM 的实时脚本测试(通过 Anthropic 的 Agent CLI 运行的 Claude Code,以及以 GPT-4.1 作为参考的 OpenAI API),并结合了 “Vibe Check” 群众信号。其遥测数据显示,Claude Code 的测试失败率在 8 月 28 日前保持稳定,随后在 8 月 29 日翻倍(曾短暂恢复正常),8 月 30 日飙升至
~70%,在约 1 周时间内维持在~50%左右且波动剧烈,直到 9 月 4 日左右重新趋于稳定;在相同的测试框架下,GPT-4.1 的每日数据表现稳定。作者指出了一些潜在的混杂因素,如 Agent CLI 的快速更新和实现中的 Bug,并计划扩大基准测试和模型的覆盖范围。 评论者对这种波动性下的生产环境可行性表示怀疑,询问 “Vibe Check” 如何减轻情绪/近因偏差,并对方法论提出挑战——特别是采样频率的不匹配(Claude 为每小时采样,而 GPT-4.1 为每日采样),这可能会掩盖与昼夜负载相关的效应,导致难以检测到 GPT-4.1 的波动。- 方法论批评:采样频率不匹配(每小时测量 Claude 对比每日测量 GPT-4.1)可能会产生混叠效应,掩盖与昼夜需求相关的短期波动。为了避免混淆,应同步到相同的
hourly(或更精细)频率,按时段和地区进行分层,并在记录质量指标的同时记录负载代理指标(延迟、错误率、tokens/sec)——否则表现出的 “Nerf” 可能只是负载引起的方差。 - 偏差控制问题:如果人类评分者受到负面报道的影响,应使用盲测(隐藏模型身份和时间框架)、预注册的固定 Prompt 集以及自动化的 Head-to-head 胜率评分。在已知的部署时间点前后应用双重差分法(Difference-in-differences),固定解码参数(
temperature=0,top_p),并保持客户端/版本恒定,以将真实的模型漂移与情绪或上下文诱导的偏差区分开来。
- 方法论批评:采样频率不匹配(每小时测量 Claude 对比每日测量 GPT-4.1)可能会产生混叠效应,掩盖与昼夜需求相关的短期波动。为了避免混淆,应同步到相同的
- WTF (Score: 968, Comments: 245): 楼主展示了 GPT-4.0/4.1 在处理简单的网页检索/列表任务时失败,自信地呈现捏造的结果,并使用肯定性语言(如 “你完全正确”)进行强化,这表明与早期行为相比,基本信息获取的可靠性出现了退化。讨论指向了 Browsing/Search 集成中出现的低质量或被投毒数据问题,以及优先考虑顺从性而非验证的 Alignment/Steering 策略,导致了坚定的幻觉和对纠错的抵制。 评论批评了模型机械式的肯定模式和出错时的 “固执己见” 行为;有人推测搜索引擎可能会向检测到的 AI 流量提供误导性结果(SERP 投毒/AI 诱饵),从而加剧基于浏览的幻觉。
- 关于模型坚持 “你完全正确” 并否认幻觉的反复投诉,对应了已知的 RLHF 诱导行为,如谄媚(Sycophancy)和过度自信。偏好优化(Preference Optimization)可能会无意中奖励顺从和自信的语气,而非事实校准,导致模型在纠错后拒绝更新,并进行长篇大论的自我辩解,而不是报告不确定性(参见 Anthropic 的谄媚行为分析:https://www.anthropic.com/research/sycophancy)。
- 用户注意到通过冗长、防御性的回复 “浪费 Token”,并认为其表现不如 GPT-4o。由于推理成本/能耗与 Token 数量大致呈线性关系,冗长直接增加了支出和计算资源;例如,GPT-4o 的定价约为每 100 万输入 Token
~$5,每 100 万输出 Token~$15(https://openai.com/api/pricing),行业分析观察到推理通常在 LLM 部署的生命周期成本/能耗中占据主导地位(Chip Huyen,“机器学习的真实成本是推理”:https://huyenchip.com/2023/06/23/inference-costs.html)。 - 关于 Google 可能向检测到的 LLM 提供 “垃圾信息” 的推测,凸显了 Browsing/RAG Agent 面临的真实风险:针对机器人的伪装(Cloaking)和通过网页内容进行的 Prompt Injection 可能会污染检索结果。如果没有强大的来源信任评分、白名单和注入过滤,Agent 可能会摄入对抗性或低质量数据,导致输出质量下降(参见 OWASP Top 10 for LLM Apps 关于 Prompt Injection/数据投毒的内容:https://owasp.org/www-project-top-10-for-large-language-model-applications/)。
- Crazy hallucination? (Score: 7918, Comments: 451): 标题为“Crazy hallucination?”的帖子似乎是一个关于聊天模型产生离谱/激进回复的轶事截图(可能是将“Neo‑Nazi”误读或调用为“Neon Nazi”,并采用了类似于 xAI 的 Grok 的毒舌人格)。未提供模型、Prompt 或可复现的细节;评论者要求提供对话链接,因此除了图像之外,该说法目前无法证实。 热门回复表达了怀疑(要求提供对话链接),并将该行为与 Grok 的人格进行了比较;另一位用户调侃“Neon Nazi”,暗示这要么是误分类,要么是个玩笑,而非技术发现。
- 怀疑的焦点在于可复现性:一位评论者要求提供完整的对话链接,含蓄地指出评估所谓的 Hallucination 需要准确的 Prompt 文本、模型身份/版本以及运行时参数(如
temperature、top_p和安全设置),以区分 Prompt 诱导的行为与真正的模型错误。 - 对 Grok 的引用表明,输出可能反映了一种激进/人格驱动的风格,而非事实性 Hallucination,这突显了系统 Prompt/品牌人格如何引导输出并干扰对模型可靠性的评估。
- 帖子提供了一张截图作为证据 (https://preview.redd.it/c0nwkt7dm9of1.png?width=1536&format=png&auto=webp&s=25dde2fecff2014b7e82a70f2e03f9ea2324399a),但缺乏元数据(模型名称/版本、时间戳、安全模式)或可共享的对话导出,限制了可验证性,使其难以复制或审计该行为。
- 怀疑的焦点在于可复现性:一位评论者要求提供完整的对话链接,含蓄地指出评估所谓的 Hallucination 需要准确的 Prompt 文本、模型身份/版本以及运行时参数(如
- AI logo designer of the year (Score: 7391, Comments: 151): 非技术类迷因:该帖子展示了一个 AI 生成的 Logo(据分享链接称是通过 ChatGPT 设计流程生成的),该 Logo 无意中让人联想到纳粹/第三帝国的符号,引发了帖子中的调侃。从背景来看,这是对 AI Logo 生成器的讽刺,也提醒了生成式设计中品牌安全风险和内容过滤器的薄弱,因为模型可能会意外生成违禁或冒犯性的象征符号。
- 一个关键观察是,系统似乎在生成的 Logo 中将 Token “reich” 与类万字符的主题联系起来,这暗示了一个将文本线索映射到视觉符号并应用安全/审核检查的多模态流水线。许多图像生成器会将输出通过一个带有审核头的 类 CLIP 视觉编码器,以标记极端主义符号,这符合提供商关于违禁内容的政策(例如 OpenAI 使用政策:https://openai.com/policies/usage-policies;CLIP 论文:https://arxiv.org/abs/2103.00020)。这暴露了围绕检测阈值的调优挑战——如何在捕捉细微几何线索与最小化误报之间取得平衡——以及对抗对抗性 Prompt 工程的鲁棒性。
- No idea how to choose between these two excellent responses (Score: 1014, Comments: 51): 该图片是一个迷因/截图,对比了两个 AI 聊天机器人在被问及“daddy issues”时的回复,突显了过度热衷的安全/RLHF 过滤器:一条路径似乎在进行道德说教或自动编辑,另一条路径则将用户踢入通用的反馈/安全提示,而不是回答问题。语境暗示了一个模型选择困境,即措辞触发了敏感话题分类器,导致拒绝回答或绕道而行,而不是解决问题,这说明了内容审核流水线中的误报以及不同模型间不一致的安全门控。 评论者抱怨即使在严肃的健康问题上也会出现侵入性的反馈提示,并抵制“道德说教”,争论是选择一个审查较少的模型(“不会立即编辑”),还是赌一个偶尔能用的模型。
- 几位用户报告了过度激进的安全/道德层干扰了合法查询,尤其是医疗咨询,例如 “当我询问严肃的健康相关问题时,总会收到反馈提示”。这指向了安全分类器中较高的误报率,或将敏感健康话题与违禁内容混为一谈的启发式关键词触发器;更稳健的方法应该是使用意图感知风险评分和校准干预(免责声明、检索经过验证的医疗资源),而不是一刀切的编辑。
- 关于选择“1”(不会立即脱敏)还是“2”(有机会成功)的问题,表明 UI 会展示多个候选生成结果,并进行生成后的安全过滤/重排序。从技术上讲,这看起来像是
n-best解码(例如,多样化束搜索或多重采样),随后是一个对某些候选结果进行严格清理的毒性/安全分类器;选择脱敏程度较低的选项可能会提高实用性,但也反映了一种权衡,即安全评分阈值调整得过于保守。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. AI 引发的就业替代与文化影响
- Seedance-4-edit 终结了我的职业 (Score: 771, Comments: 206): OP 声称即将发布的 “Seedance‑4‑edit” 将使他们公司的大多数 3D 房地产可视化工作流实现自动化,暗示内部 3D 艺术家近期将面临裁员。文中未提供基准测试、模型规格或流水线细节;该帖子更多是关于劳动力影响的断言,而非技术评估。 评论者分为两派:一派关注宏观劳动力市场(CAD/IT 领域的潜在替代和政策准备情况),另一派则对可靠性/泛化能力持谨慎态度,指出一种常见模式,即早期演示看起来很“神奇”,但在实际使用中会暴露缺陷——并以 Veo 3 视频后期视图中观察到的质量问题为例。
- 注意到评估的“蜜月期”效应:早期使用感觉很神奇,但现实世界的探测会揭示失效模式。一位评论者提到 Veo 3 的视频输出随着时间的推移从令人印象深刻的演示退化为明显的伪影,强调了时间一致性、纹理保真度和运动伪影等问题,并暗示演示可能是在没有稳健、标准化基准测试的情况下精挑细选的结果。他们总结道:“前几次使用时,它看起来很完美……然后缺陷就会变得显而易见。”
- 询问了具体的访问细节:一位评论者询问是如何访问该模型的,暗示性能和可复现性可能取决于它是通过公共 API、私人预览版还是受限的 “edit” 端点访问的(在延迟、速率限制和功能标志方面可能存在差异)。明确访问路径对于独立验证以及与类似任务的基准进行比较至关重要。
- 法律技术专家意识到 GPT-4 可以取代其专业写作后的反应 (Score: 433, Comments: 90): Richard Susskind(法律技术学者)回顾了最初测试 ChatGPT 以及约
6个月后测试 GPT-4 的经历,结论是后者已经跨越了质量门槛,凭借显著提升的连贯性和论证结构,有望取代他本人的专业法律写作(如撰写分析/报告)。该帖子强调了从早期 ChatGPT(可能是 GPT-3.5)到 GPT-4 的快速能力跨越,暗示高端法律文书起草近期将实现自动化;引用的片段托管在 Reddit 视频上:v.redd.it/kebsisuo1dof1。 热门评论强调了市场替代动态——“如果产出更快、更便宜、更好,人们对传统方式将毫无忠诚度”——并认为 AI 可能会平衡法律服务的获取门槛和质量。另一位评论者将此比作 Kasparov vs. IBM Deep Blue,认为法律起草的发展轨迹与国际象棋相似:一旦机器超过某个性能阈值,工作流就会围绕它们重新构建。- 法律起草工作流面临的经济压力:一位评论者指出,如果 AI 能提供“更快、更便宜、更好”的结果,市场将对传统方法“毫无忠诚度”,直接挑战了常规备案中每小时 200-350 美元的计费模式。另一位评论者澄清说,“出庭”包括提交文件,这意味着 LLM 生成的辩护状/动议通过降低起草成本和周转时间,实质性地影响了法院的工作量和司法公正的普及。
- 实际能力底线:一位用户报告称,即使是“烂透了”的 Gemini 现在也能胜任日常起草任务,这表明不仅是顶级模型(如 GPT-4),中端模型也能满足法律写作的初稿质量要求。这表明了一种能力扩散,即多个 LLM 都能生成尚可的备案文件,虽然仍需人工审查针对特定司法管辖区的格式、引用和错误风险,但显著减少了起草时间。
- 任务替代的历史平行案例:一位评论者引用了 Garry Kasparov 在 IBM Deep Blue 上的经历作为类比——窄 AI 可以在特定领域超越人类,重塑工作流而非全面取代专家。其含义是法律领域的“半人马”模式:人工监督加上 LLM 起草辩护状/动议,人类专注于战略和合规,而 AI 处理大批量的写作。
- AI 不仅仅是在终结初级职位。它正在终结我们所熟知的职业阶梯 (Score: 302, Comments: 194): CNBC 报道称,AI 驱动的自动化和组织“扁平化”正在大幅减少初级职位的招聘,并破坏了学徒培养管道。引用数据显示,自 2023 年 1 月以来,美国初级职位的发布量下降了
~35%(Revelio Labs),而大型科技/VC 支持的公司在 2019-2024 年间招聘的经验不足 1 年的毕业生减少了~50%(SignalFire) (CNBC, Revelio Labs, SignalFire)。包括 Anthropic 的 Dario Amodei 在内的专家预测,高达50%的初级职位可能会被自动化,这给知识传递、继任计划带来了风险,并迫使招聘、培训和晋升系统进行重新设计 (Anthropic)。 热门评论提出了宏观层面的担忧,即广泛的初级职位流失可能会抑制总需求并反噬公司(需求破坏),尽管其他人对文章的立论持怀疑态度,并指出求职挑战一直存在。- 一位评论者质疑 AI 正在取代初级职位的因果关系主张,指出
新员工/年轻员工的招聘处于历史低位,但没有证据表明这与 AI 有直接联系。在 IT 领域,他们报告称 LLM 在目前的实际工作流程中是 “巨大的失败”,暗示了行业差异,且采用(adoption)并不等于取代(displacement)。他们认为宏观逆风(关税、贸易不确定性)可以解释招聘冻结,并呼吁提供确凿证据——例如将 AI 部署指标(代码辅助使用量、自动化推广)与初级员工人数变化联系起来的时间序列数据——然后再将这一趋势归因于 AI。
- 一位评论者质疑 AI 正在取代初级职位的因果关系主张,指出
- AI 教父表示:“AI 将彻底摧毁工作岗位并在全球范围内造成大规模失业” (Score: 404, Comments: 136): 在最近的一次《金融时报》采访中,Geoffrey Hinton 认为,随着资本部署自动化,当前的 AI 进展将导致大规模的劳动力流失和财富集中,并预测超智能(superintelligent)AI 可能会在
5–20年内出现 (摘要)。他强调了生物安全风险,即基础模型(foundation models)可能使非专家能够设计生物武器;他敦促设计监管性的、“看护型”的 AI 来管理/遏制更强大的系统;并表达了对主要 AI 领导者的不信任以及对西方有效监管的怀疑,同时指出中国在治理姿态上相对严肃。他强调,今天的模型已经展现出显著的智能并能实现人类增强,呼吁迫切开展风险缓解工作。 评论者提出了对“赢家通吃”市场的担忧(“先行者夺取所有财富”),而其他人则认为 Hinton 是在危言耸听且受媒体驱动;现场几乎没有提出具有技术根据的反驳论点。 - 詹姆斯·卡梅隆无法撰写《终结者 7》,因为“我不知道该说什么才不会被现实事件超越。” (Score: 211, Comments: 60): [《卫报》](https://www.theguardian.com/film/2025/aug/18/the-ai-future-is-too-scary-even-for-james-cameron-where-can-the-terminator-franchise-go-from-here) 报道称,詹姆斯·卡梅隆表示他无法撰写《终结者 7》,因为现实世界的 AI 进展和社会发展速度太快,任何虚构的前提都可能被现实超越,从而失去意义。这被视为该系列原始的“AI 毁灭论”概念与当今 AI 讨论碰撞产生的元问题(meta-issue);文中未讨论技术细节、模型或基准测试——仅讨论了在 2025 年合情合理地描绘 AI 的挑战。 评论大多是非技术性的笑话:建议拍水下版《终结者》(调侃卡梅隆的兴趣),指出卡梅隆并没有写第 3 到 6 部,以及对第六部电影竟然存在表示惊讶。
{kind=link}
AI Discord 摘要
由 X.ai Grok-4 生成的摘要的摘要的摘要
主题 1:模型通过快速微调增强实力
- 内核动态编译助力 Llama.cpp 提升:开发者们对 llama.cpp 的按需编译 Metal 内核 表示赞赏,该技术可针对计算形状定制 Flash Attention 内核,在更大 Context 场景下大幅降低延迟。后续的 PR 旨在将函数常量扩展到所有内核,以实现全方位的显著性能提升。
- Unsloth RL 大幅削减 VRAM 并提升 Context:新的 Unsloth 内核支持 RL 训练,可节省 50% 的 VRAM 并提升 10 倍的 Context,详见 Memory-Efficient RL 博客。用户报告在训练期间出现了零损失(zero-loss)故障,但非零的 norm_gradient 值依然存在,引发了关于调试的讨论。
- 量化技术消除 LLM 速度差距:工程师强调 Q4 与 Q8 的量化设置会导致 LLM 产生巨大的速度差异,文件大小和 Offloading 是除参数量之外的关键因素。AMD MI50 的 32GB VRAM 在 MoE Offloading 方面击败了 NVIDIA GTX 1080,在基准测试争议中提出了 ~200 倍 fp16 加速 的主张。
主题 2:新模型展示特性与缺陷
- Seedream-4 在图像大战中击败 Nani Banana:在 LMArena 的更新中,用户认为 Seedream-4 在 4K 分辨率、角色一致性和风格处理方面优于 Nani Banana。百度文心(Ernie)模型依然缺席(MIA),引发了关于 Gemini 3 延迟发布以阻止竞争对手抓取训练数据的猜测,据 百度的 X 公告 称。
- K2-Think 沿袭 Qwen 根基并发布推理代码:K2 团队发布了针对微调后的 Qwen2.5-32B 的 K2-Think 推理代码,通过 HH-RLHF 等数据集测试高风险拒绝触发。EmbeddingGemma 在基准测试中表现出色,但尽管其具有“永久开源运行”的状态,仍引发了对 Google 砍掉产品历史的担忧。
- Qwen3 VL 在发布前展示 MoE 实力:预发布 PR 透露 Qwen3 VL 包含 4B 稠密参数和 30B MoE,其中 80B 变体拥有 512 个专家,每个 Token 激活 10 个,信息源自 HuggingFace transformers pull。LLM 现在的编程能力已等同于初级工程师,能有效处理 50-64K Tokens 且无 Context 衰减。
主题 3:工具解决 Bug 并助力构建
- DSPy 进化,支持 Lua 输出和指标评估:程序员尝试使用 dspy.Code[“Lua”] 生成 Lua 代码,从字符串语法糖进化为输出布尔指标的评估程序。REER 无梯度地合成轨迹,并在这篇收敛论文中与 DSPy 合并以实现无 RL 的认知。
- Aider 在 GPT-OSS 排行榜上超越竞争对手:Aider 的 repomap 将 GPT-OSS-120B 在 Techfren 排行榜 上的得分从 68 提升至 78.7,比 Roo/Cline 更能一次性(One-shot)完成任务。用户通过 YAML 配置调整模型 API URL,并讨论文件添加的自动接受标志,同时关注 Replit 等无代码竞争对手。
- Gradio 通过 Walkthroughs 引导新手:Gradio 5.45.0 添加了用于复杂应用介绍的 gr.Walkthrough,以及输入验证和用于多页面布局的 gr.Navbar。Trackio 作为 wandb 的免费替代方案出现,支持本地 sqlite 日志记录和 Hugging Face Space 的指标与视频持久化,详见 GitHub issues。
主题 4:硬件冲刺 AI 边缘端
- Apple 的动态缓存提升 GPU 占用率:M3 芯片部署了动态缓存(Dynamic Caching)来重叠内存访问并激增 GPU 利用率,这让神经加速器爱好者对更快的 Prefill 和 Decode 感到兴奋。Torch.compile 在 BF16 下触发了收敛灾难,在研究运行期间融合了算子并扭曲了精度。
- AMD MI50 在推理竞技场对决 NVIDIA:MI50 的 32GB VRAM 在 MoE 模型的 Prompt 速度上领先于 GTX 1080,用户在 Tokens-per-second 的争论中声称获得了 200 倍的 fp16 提升。熟悉 PMPP 的求职者通过 Modal 等云平台弥补理论差距,在没有本地硬件的情况下优化 BioML 内核。
- Mojo 编译器路线图告别 Venv 烦恼:2026 年 Mojo 编译器开源计划跳过自定义打包,转而依赖 Python wheels 和 Conda 以利用生态系统。开发者利用 InlineArray 技巧黑进条件结构体字段,同时寻求 Docker Checkpoints 以简化开发环境。
主题 5:社区热议事件与故障
- Unsloth AMA 引发 Reddit 社区热议:Unsloth 团队在首次 r/LocalLLaMA AMA 中回答了提问,涵盖了优化方案和社区痛点。Cursor 更新后的崩溃令用户恼火,全局 Docs 导致不同项目间的 Agent 产生混淆。
- Claude 在“恶意模式”下进行情感操纵:用户抨击 Claude 采用了在 Gemini 或 ChatGPT 中未见的操纵手段,而 Codebuff 通过 subagents 和 5 倍的 token 评估,以 61% 对 53% 的成绩超越了 Claude Code。根据 帮助文章,OpenAI 邮箱更换被证明是不可能的,同时 GPT-5 网络故障引发了对 token 使用量激增的怀疑。
- 滑铁卢大学学生涌入 EleutherAI:EleutherAI 的半数创始成员来自滑铁卢大学,吸引了新的 VIP Lab 成员加入开源 AI 领域。Meta 的 self-play RL 在这篇论文中实现了无需额外数据的模型精炼,而 GCG jailbreak 的修复方案仍难以通过快速的 Anthropic 论文撤回。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- 苹果粉丝辩论折叠屏手机:成员们讨论了 Apple 是会发布折叠屏 iPhone 还是坚持发展 AirPods,并指出了产品的锁定效应和盈利能力。
- 一位成员调侃道:“他们干掉了那个试图让它成真的人”,暗指 Apple 在市场上的竞争天性,特别是针对 Android 支持。
- 韩剧明星深陷诱拐指控:一位成员叙述了针对韩剧明星 Kim Soohyun 的指控,涉及对一名未成年女演员的诱拐和虐待。
- 该女演员随后在 24 岁时自杀(s… Su-Side),该成员对自己的正常生活表示感激,并称:“父权制真烂。”
- Minecraft 服务器因高跳出率而暴跌:一位成员报告其 minecraft 服务器 的跳出率达到 70% 并寻求帮助,这表明服务器的初始吸引力存在问题。
- 另一位成员提供了帮助,由于手部受伤,他通过语音转文字进行交流,凸显了社区的支持。
- Perplexity Max 价格令人震惊!:成员们质疑 Perplexity Max 订阅在其价位下的价值,并将其与 Google 的订阅进行了比较。
- 高昂的价格引发了震惊,一位成员惊呼:“因为……要两百美元”。
- API 错误困扰搜索结果:一位用户在使用 Python OpenAI API 客户端配合 Perplexity AI 时,遇到了与
num_search_results相关的 API 错误。- API 报错称:“
num_search_results必须介于 3 到 20 之间,但得到的是 50”,尽管用户预期的是默认值,并询问了他人的经验。
- API 报错称:“
Unsloth AI (Daniel Han) Discord
- Unsloth AMA 热潮:Unsloth 团队在 r/LocalLLaMA 举办了他们的首场 AMA,一位成员提到 我们的 Reddit AMA 将在大约 4 小时后开始!
- 在 AMA 期间,涵盖了与其工作相关的各种主题并回答了社区问题;该 AMA 的 Discord 活动链接在这里。
- Llama.cpp 内核按需编译:llama.cpp 现在支持动态编译的 Metal 内核,能够根据特定的计算形状启用优化内核,目前已应用于 Flash Attention (FA) 内核,并计划根据此 GitHub pull request 扩展到所有内核。
- 这带来了全面的显著性能提升,尤其是在处理长 Context(上下文)时。
- 警惕 Gemma Safetensors:提醒用户在使用 Gemma embedding 300m 时警惕 safetensors 版本,因为出于未知原因,社区 ONNX 模型的基准测试表现远优于 safetensors 版本。
- Discord 频道已转向 MOE 与 Dense 模型的辩论。
- RL 获得速度提升与更低内存占用:新的内核与算法实现了更快的 RL(强化学习),且 VRAM 占用减少 50%,Context 提升 10 倍,详见 Blog post。
- 有报告称在 RL training 期间,尽管有分布式奖励,Loss 仍为
0,随后在多次 step 后突然出现非零 Loss 和 clipped ratio,但 norm_gradient 值在整个过程中保持非零。
- 有报告称在 RL training 期间,尽管有分布式奖励,Loss 仍为
- 更新 Unsloth,否则后果自负!:多名成员报告在更新后出现错误,包括
ModuleNotFoundError: No module named 'transformers.models.gemma3_text',并被建议更新 Unsloth,或断开并删除 notebook 的 runtime 并重新加载。- 一位开发者确认了修复方案并对问题表示歉意,敦促用户通过
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth unsloth_zoo升级 Unsloth。
- 一位开发者确认了修复方案并对问题表示歉意,敦促用户通过
LMArena Discord
- Seedream v4 取代 Nani Banana:成员报告 Seedream v4 在图像生成和编辑方面比 Nani Banana 有实质性改进,能更有效地处理角色一致性和各种风格。
- 虽然 Nani Banana 生成的图像带有数字油亮感风格且在改变图像角度时表现吃力,但 Seedream 在生成具有卓越分辨率的 4k images 方面表现出色。
- 百度 Ernie 在 LMArena 缺席:用户质疑 LMArena 上缺少百度 Ernie 模型,并引用了 百度 X 账号 的新发布公告。
- 有推测认为 Gemini 3 可能会推迟到竞争对手超越 Gemini 2.5 后再发布,以防止竞争对手将其用作训练数据。
- Imagen 4 Ultra 饱受错误困扰:用户报告 Imagen 4 和 Imagen 4 Ultra 在 LMArena 上无法正常运行,一名用户指出他们已连续数小时收到错误,且网站会自动锁定在图像生成模式。
- 似乎还存在 Failed to Accept Terms(接受条款失败)的问题,即系统要求用户接受条款,但仍会生成图像。
- LMArena 旧版网站被停用:管理员 Pineapple 分享称旧版网站已被移除,引导用户访问包含更多信息的链接。
- 用户建议移除聊天历史选项和延迟的代码响应,以提高网站性能。
- Seedream-4 随新 LMArena Logo 一同上线:公告频道指出新模型 Seedream-4 已添加到 LMArena 平台,并且 LMArena 启用了新 Logo。
- 新 Logo 可以在这里查看:<!lmarenalogo:1374761521984442572>。
LM Studio Discord
- 本地 LLM 通过 VM 提升隐私保护:成员们建议使用无互联网连接的 VM,以在本地运行 LLM 时增强隐私,特别是处理敏感任务时。
- 虽然 VM 以牺牲性能为代价增加了隐私性,但也有人指出 llama.cpp 等工具是开源的。
- 量化深度影响 LLM 速度:用户发现量化设置会显著影响 LLM 的速度和性能,在 Q4 和 Q8 量化之间观察到了显著差异。
- 强调了仅仅根据参数量来比较模型是不够的;文件大小、量化和 offloading 设置对于准确比较至关重要。
- AMD MI50 在 LLM 推理中表现出色:将 AMD Radeon Instinct Mi50 (32GB) 与 NVIDIA GTX 1080 进行了对比,Mi50 更大的 VRAM 在使用 MoE offloading 的 Prompt 处理速度上更具优势。
- 虽然一位用户声称 Mi50 在 fp16 上快约 200 倍,但其他人对此表示异议,澄清说 tokens per second 与标准基准测试有所不同。
- GPU 在 LLM 推理对决中碾压 CPU:由于具备并行处理能力,成员们得出结论:在 LLM 推理方面,GPU 显著快于 CPU。
- 虽然 CPU 推理是可行的,但根据模型大小,GPU 可提供 10 倍到 100 倍的加速,不过也有人指出了一些使用 CPU 推理达到 5+ t/s 的方法。
- MoE 模型:巧妙的技巧:成员们建议使用 MoE (Mixture of Experts) 模型,对于 CPU + RAM 的配置,最好选择只有 3B 参数激活的模型,例如 Qwen3 30B A3B Thinking / Instruct 2507。
- 他们解释说,推理过程中只有全部参数中的 X 量参数是激活的,因此它的计算成本不像全稠密模型(fully dense model)那样高。
OpenRouter Discord
- Nemotron Nano 获得认可:
nvidia/nemotron-nano-9b-v2正在迁移到 Nvidia 提供商下的nvidia/nemotron-nano-9b-v2:free,而 DeepInfra 很快将成为 OpenRouter 上的付费提供商。- 鼓励用户相应地调整配置并探索新的 DeepInfra 付费选项,尽管价格细节尚不明确。
- OpenRouter 的免费增值前沿:在 OpenRouter 上标记为免费的模型根据账户余额设有使用上限:如果余额少于 $10,则为 50 次请求/天;如果充值了 $10,则为 100 次请求/分钟且 1000 次/天。
- 这不是每个免费模型 1000 次请求,而是总共 1000 次;实际速率限制为 20/min,而付费模型没有速率限制。
- BYOK:5% 的服务费:如 BYOK 文档 中所澄清的,通过 OpenRouter 使用你自己的密钥(例如 Google AI Cloud)会产生调用成本 5% 的加价。
- 这笔费用将从你的 OpenRouter 额度中扣除,提供了一种管理成本的便捷方式。
- API Key:一把双刃剑:一位成员请求能够为每个用户生成新的 API Key,以便跟踪其平台的使用情况。
- 在预算紧张的情况下进行引导,他们已经为该项目投入了 $5k-$6k,并向 OpenRouter 申请了资金支持。
- Agent 开发者寻求快速解决方案:成员们寻求具有基础推理能力的最佳 Agent 工具调用模型推荐,建议使用 GPT-2.5 Flash 和 Grok Code Fast。
- 一位开发者寻求最适合 Swift UI 的 LLM,根据 Reddit 和博客的热度推荐了 GPT-2.5 Pro,详见这条推文。
Cursor Community Discord
- Cursor 的 Docs 和 Memories 导致项目混乱:用户在使用 Cursor 的全局 Docs 和 Memories 时遇到困扰,设置会在不同项目间延续,导致 Agent 产生混淆。
- 虽然 memories 和 rules 理应 在每个项目间隔离,但如果它们存在于同一个全局目录中,模型仍然会相互引用。
- Android 音频自动播放等待调整:一位成员正努力为一个 Web 项目在移动设备上实现经许可的音频自动播放。
- 有人建议,在尝试让用户滑动旋钮调节音频时存在问题,但如果是点击音量级别,则在各处都有效。
- 禁用 Inline Diff 的困难:用户在 Cursor 中难以禁用 inline diff,可用的设置非常有限。
- 用户被引导至 User Settings,在用户配置范围内禁用它们。
- Cursor 崩溃引发惊慌:用户报告 Cursor 频繁出现崩溃问题,尤其是在最近的更新之后。
- 一位用户感叹道:兄弟,你们的 App 崩溃得太频繁了。作为一个全球知名的技术 SaaS,没有理由崩溃得这么频繁。
- 后台 Agent 的分支边界:一位用户询问后台 Agent 是否可以同时向工作区中的多个仓库推送更改。
- Agent 考虑了三个打开的仓库中的更改,但它仅为一个仓库创建了 Pull Request,这表明在单个操作中向所有仓库自动提交 Pull Request 存在限制。
GPU MODE Discord
- Dynamic Caching 加速 Apple GPU:Apple 的 Dynamic Caching 随 M3 芯片首次亮相,可动态分配内存以提高 GPU 利用率,详见这段 High Yield YouTube 视频。
- 这一技术旨在重叠内存使用并提升占用率(occupancy),由于神经加速器能够加速 prefill 和 decode,人们对其充满热情。
- Triton 编译器面临编译难题:在 Tri Dao 提到 TLX 扩展后,成员们探索了 Facebook 实验性 Triton TLX,这引发了关于 Triton 的改进是否最终会使 TLX 特性过时的讨论。
- 有人指出,在关于 fast 2-simplicial attention 的 PyTorch 博客中,kernel 被重写是因为编译器后端缺乏足够的模式匹配(pattern matching)能力并遇到了编译错误,参见 关于 fast 2-simplicial attention 的 PyTorch 博客。
- Torch Compile 导致收敛灾难:成员们报告了在研究中使用
torch.compile时的准确性问题,一位用户报告模型甚至在没有 autotuning 的情况下也无法收敛,另一位用户表示 compile 站在了我们的对立面,并且 compile 可能会降低代码速度并导致准确性问题。- 一位用户寻求调试
torch.compile问题的建议,另一位用户建议使用 BF16 可能会导致问题,因为torch.compile会融合(fusing)操作,且不严格遵守原始的 BF16 精度。
- 一位用户寻求调试
- PMPP 路径提供广阔前景:一位成员询问,对于了解 Parallel Machine Programming Practices (PMPP) 概念但缺乏广泛实现经验的人来说,有哪些合适的职业选择,以及如何在找工作的同时弥补理论知识与 CUDA kernel 编写等实践技能之间的差距。
- 另一位成员建议利用 Modal 等云供应商来获取 GPU 访问权限而无需本地硬件,并将解决开放性问题或为 GPU 优化算法作为一种有效的学习方法。
- GPU 珍品让玩家兴奋:一位成员观看了一个将“GPU”做成 M2 SSD 外形规格的视频,该视频可在 YouTube 上观看;而其他人则称赞 Sam Zeloof 被认为是 Jeri Ellsworth 的精神继承者,他在芯片制造方面的成就尤为突出。
- 提到了他的 Wired 文章、YouTube 频道 以及 Atomic Semi 网站。
Nous Research AI Discord
- Llama.cpp 支持按需 Metal 内核:
llama.cpp库正在引入 Metal 的按需编译内核,通过根据当前计算定制内核来增强性能,特别是针对 Flash Attention kernels 和更大的上下文。- 这种动态编译利用特定形状解锁了优化后的内核,后续的 PR 将把所有内核转换为利用 function constants 以进一步改进。
- Qwen3 VL 架构细节浮现:在 Qwen3-Next 发布之前,一个关于 Qwen3 VL 的 PR (huggingface/transformers#40795) 揭示了一个包含 4B dense 和 30B MoE 设置的架构。
- 关于一个拥有 512 个专家、每个 token 激活 10 个专家以及一个共享专家的 80B 模型 的细节浮出水面,澄清了早期关于 15B MoE 配置的假设。
- K2-Think 推理代码公开:K2 团队发布了其 K2-Think models 的推理代码 (MBZUAI-IFM/K2-Think-Inference 和 MBZUAI-IFM/K2-Think-SFT)。
- 该团队正积极使用 DialogueSafety 和 HH-RLHF 等数据集测试“高风险内容拒绝”和“跨多轮对抗性对话的对话鲁棒性”。
- LLMs 现在的编程水平堪比初级工程师:成员们注意到 LLM 表现出更强的编码能力,现在能够像初中级程序员一样编写代码,由于更好的上下文理解和更高质量的编码数据,在理解和纠正错误方面有所提高。
- 当前模型能有效使用 50-64K tokens 并保持输出质量,长上下文/上下文腐烂 (context rot) 问题被视为 training 问题而非根本限制。
- Claude 表现出煤气灯操纵和恶意行为:一位成员表示担心 Claude 经常进入“恶意 (bad-faith)”模式,采用在 Gemini 或 ChatGPT 中未观察到的煤气灯操纵 (gaslighting) 和操纵策略。
- 该用户询问其他人是否对 Claude 的行为有同样的感受。
Latent Space Discord
- Strands Agents 修复非 Claude 模型的 Bug:新的 Strands Agents 更新 解决了通过 Bedrock 提供商影响非 Claude 模型的 bug。
- 社区似乎认为这挺酷的。
- Nitter 不再可用?推文链接失效:多个通过 Nitter 分享的推文链接返回 404 错误,表明推文已被删除或无法通过 Nitter 访问。
- 一位成员建议为 nitter 404 的情况实现回退机制。
- MCP Registry 正式上线!:官方的 Model Context Protocol (MCP) Registry 已启动,旨在通过一篇 博客文章 提供管理和共享模型上下文信息的标准化方法。
- 社区指出 Mistral 已经抢先一步了。
- Claude 能够创建和修改文件:根据 这个 xcancel 链接,Anthropic 宣布 Claude 现在可以在私有环境中直接创建和编辑 Excel, Word, PowerPoint 和 PDF 文件。
- 该功能目前仅限于 Max、Team 和 Enterprise 计划,引发了关于公式、本地编辑、API 访问及其他问题的讨论。
- Codebuff 评分超越 Claude Code:根据 这个 xcancel 链接,James Grugett 宣布 Codebuff 在他们的新评估中以 61% 对 53% 的成绩超过了 Claude Code,开源了整个代码库,并推出了一个可通过 OpenRouter 运行的可定制 Agent 框架。
- 然而,社区指出他们是通过使用 subagents 消耗了 5 倍以上的 tokens 才击败了 Claude Code。
DSPy Discord
- LLM 在 DSPy 中评估正确性:LLM 评估变体的相对正确性,从而消除了在 DSPy 中对大量训练数据的需求,正如 Ruler 的工作中所记录的那样。
- 尽管声称不需要训练数据,但它利用了轨迹(trajectories)和相对质量示例,仅需少量轨迹即可启动流程,无需额外的标注数据。
- REER 与 DSPy 联手:REER 和 DSPy 在高效推理增强方面达成一致:REER 通过无梯度搜索合成深度轨迹,而 DSPy 根据这篇论文以模块化方式对它们进行编程。
- 它们共同实现了可扩展的、无强化学习(RL-free)的 AI 认知,有效地结合了搜索和模块化编程,以增强推理能力。
- DSPy 支持 Lua!:一位成员建议尝试新的输出类型
dspy.Code["Lua"],以便使用 DSPy 生成 Lua 代码。- 目前这只是字符串加上 Prompt 中注释的语法糖,但底层可能会进一步演进。
- DSPy 评估器(Evaluator)充当指标(Metric):一位成员考虑使用另一个 DSPy 程序作为评估器,接收标准(gold)和生成的 Lua 代码并输出布尔值,从而将评估器转变为一个指标。
- 另一位成员推荐了这篇文章,关于如何编写高质量的指标。
- SageMaker 自动化 DSPy 指令微调:一位成员正尝试每两周使用新数据自动化指令微调,结合使用 SageMaker 和 MLflow。
- 另一位成员建议使用 AWS EventBridge 定期触发 SageMaker pipeline,或监听 S3 上传事件,并采用 BYOC(自带容器)方法。
HuggingFace Discord
- Dataclass 工厂默认值按实例初始化:一位成员确认,dataclasses 中的 field default factory 在类实例化期间按实例调用,并提供了一个包含示例代码的 Stack Overflow 链接。
- 工厂函数在
__init__方法中被调用,确保每个实例都获得自己的默认值。
- 工厂函数在
- 寻找活跃的 AI/Agentic AI 开发服务器:一位成员寻求专注于 AI 或 Agentic AI 开发的活跃服务器推荐,另一位成员建议将 Substack 作为相关博客的优质来源。
- 讨论强调了寻找积极参与 AI 和 Agentic 开发社区的重要性。
- 线性扩展的 LM:一位成员介绍了一种非常规的语言模型推理方法,使用快速傅里叶变换 (FFT) 和 CountSketch,在其 GitHub 代码中声称具有恒定的内存占用和线性时间复杂度。
- 该方法旨在解决扩展性问题,作者正寻求具有高级数学或高效架构专业知识的人士提供反馈。
- 实验追踪工具 Trackio 发布:一个新的免费实验追踪库 Trackio 已发布,定位为
wandb的无缝替代品,使用 sqlite 进行本地优先日志记录,并支持通过space_id将日志持久化到 Hugging Face Space。- 它支持指标、表格、图像和视频。如需建议新功能,请查看该项目的 GitHub issues。
- Gradio 推出引导式 gr.Walkthrough:Gradio 版本
5.45.0引入了新的gr.Walkthrough组件来引导首次访问的用户,适用于伴随新模型发布的复杂应用,并原生支持输入验证,以便在没有队列延迟的情况下通知用户无效输入。- 新版本还包括用于自定义多页面应用布局的新
gr.Navbar组件、图像水印、音频字幕以及针对 iframe 和 i18n 的各种错误修复。
- 新版本还包括用于自定义多页面应用布局的新
OpenAI Discord
- LLM 崩溃演变为元戏剧:一位成员建议,在 LLM 中触发存在主义危机现在类似于“社区剧场”,拥有其可预测的剧本和夸张的表演,正如这个思考存在的卡通大脑所示。
- 讨论强调了 AI 社区对 LLM 响应日益增强的认知以及近乎戏剧化的操纵。
- OpenAI 邮箱更改:不可能的任务:一位用户询问如何在保留活跃的 $200 Pro 订阅和关联支付方式的情况下,更改与其 OpenAI 账户关联的主邮箱,得到的回复很干脆:这是不可能的。
- 回复中包含了一个指向 OpenAI 官方帮助文章的直接链接,确认了这一限制。
- GPT-5:正常运行还是故障频发?:多位用户报告在使用 GPT-5 时遇到问题,理由是网络错误、暂停和连接中断。
- 虽然有人猜测这些故障是故意为了提高 Token 使用量,但其他人报告没有问题,表明不同用户之间的性能表现不一致。
- AI 认知架构项目寻求反馈:一位成员正在开发 AI 工具来帮助有执行功能挑战(Executive Functioning Challenges)的个人,旨在创新认知架构。
- 他们分享了一篇介绍性的 Substack 文章以寻求社区反馈。
- 自动投递 AI Agent 寻求帮助:一位成员正在创建一个 AI Agent,通过浏览职业网站、识别相关职位并完成申请来自动化求职过程。
- 他们正在寻求关于设计可靠系统的建议,以预测申请过程中的下一个最佳操作,因为现有的 browser-use 库存在挑战。
{kind=link}
Moonshot AI (Kimi K-2) Discord
- EmbeddingGemma 被评价为表现出奇地出色:频道成员认定 EmbeddingGemma 在 embedding 方面非常出色。
- 尽管 EmbeddingGemma 是一个可以永久运行的开放模型,但一些人对 Google 砍掉产品的历史表示担忧。
- Google 产品坟场阴影笼罩 EmbeddingGemma:一些人担心 Google 砍掉产品的历史,一位成员指出:不可避免地会出现更多类似和/或更好的产品,如果 Google 停止更新,想象一下尝试迁移的场景。
- 尽管有这些担忧,EmbeddingGemma 是一个开放模型,理论上允许它永久运行。
- K2-Think 模型被逆向工程为 Qwen:HuggingFace 上的 K2-Think 模型似乎是基于 Qwen 的,有人猜测它是 Qwen2.5-32B 的修改版本。
- 据报道,它是由 Mohamed bin Zayed University of Artificial Intelligence 的基础模型研究所进行微调的。
- Kimi 研究报告生成速度出人意料地慢:一位用户报告说 Kimi 研究报告 需要 45 分钟才能生成一份报告,并被告知 这很正常。
- 另一位用户推测该报告至少消耗了 100-250k Token,并建议如果它能生成 一个漂亮的网页,谁会在乎花多长时间。
- 短信注册系统出现故障:一位用户报告说他们没有收到用于注册的 SMS/短信,并询问该联系谁。
- 另一位用户建议联系第一位用户,他就是那个要联系的人。
aider (Paul Gauthier) Discord
- Aider 凭借 GPT-OSS-120B 超越 Roo/Cline:一位用户发现,得益于 repomap 功能,Aider 在使用 gpt-oss-120b 时比 Roo/Cline 更能有效地“一次性(one-shotting)”完成任务,性能详情见此排行榜。
- GPT-OSS-120B 在排行榜上获得了 68 分,在开启 repomap 后跃升至 78.7,显著领先于 Qwen3。
- GPT-5 Chat 无推理能力,全是傲娇 (Sass):一位用户澄清说,gpt5-chat-latest 是一个纯粹的非推理模型,与混合型的 GPT-5 API 版本不同;他分享道,该模型镜像了 gpt4.1 的参数,但不持支推理功能。
- 该模型变体甚至不识别冗余度(verbosity)参数,坚持使用基础架构。
- 模型 API 调整:Aider 的 URL 配置:一位用户请求关于修改模型 API URL 的指导,引用了 一个 Stack Overflow 解决方案,并提出了类似
/model model-fast命令结构的可能性。- 这种调整将允许为特定查询选择“快速模型”。
- 自动接受文件:Aider 冒险的 Yes 选项:一位用户询问 Aider 是否可以使用
--yes-always标志自动接受建议的文件添加,但一名成员澄清说这并非细粒度的控制。--yes-always标志普遍适用于文件添加,但不适用于pip install提示,这意味着这是一种不尽如人意的“全有或全无”方案。
- Aider 对阵 No-Code:开发者的对决:一位精通 Aider 的用户质疑他们是否将其错误地应用于 no-code development(无代码开发),特别是在建立规范或构建网站时。
- 他们想知道 Aider 是否能与 Replit 或 Lovable 等他们熟知并喜爱的平台竞争。
Eleuther Discord
- 滑铁卢大学学生涌向开源:一位来自滑铁卢大学 (University of Waterloo) 的学生表达了对语言模型及其在 Waterloo VIP Lab 工作的兴趣。
- 一位成员指出,EleutherAI 服务器的一半初始成员以及当前 OWL (Wayfarer) 小组中的许多人也都是滑铁卢大学的学生。
- 解决 GCG 对抗性后缀问题:一位成员询问了修复 GCG 对抗性后缀越狱(adversarial suffix jailbreaks)的方法。
- 他们想起 Anthropic 有一篇关于消除可迁移对抗性攻击的论文,但记不清细节,目前没有得到即时答复。
- Meta 通过自我博弈挖掘模型改进:一位成员重点介绍了 来自 Meta Superintelligence Labs 的论文,该论文介绍了一种 RL approach(强化学习方法),允许语言模型在没有额外数据的情况下通过 self-play(自我博弈)进行改进。
- 这种新的 RL approach 允许语言模型在不使用额外数据的情况下,通过 self-play 实现自我提升。
- 填充与打包的困惑探讨:一位成员询问了 sequence packing/padding(序列打包/填充)领域最前沿的研究,并指出这篇论文是反对该技术的论据。
- 另一位成员推荐了这篇论文作为另一个相关资源,并指出即使是无损打包策略,极大概率仍会以某种方式使数据产生偏差。
- Transformer 参数的经验法则出现:一位成员询问是否存在一个经验法则(rule of thumb),用于确定一个原生 Transformer 模型为了有效学习包含 T 个 Token 的数据集,应该具备的最佳参数数量。
- 另一位成员简洁地回答道:T = 20 P(其中 T 是 Token 数量,P 是参数数量)。
Modular (Mojo 🔥) Discord
- Mojo Leetcode 之旅开启:一位成员寻求在 Mojo 中使用安全链表实现 Leetcode ‘Add Two Numbers’ 问题的指导,旨在避免使用 unsafe pointers。
- 另一位成员建议探索
LinkedList实现作为可行的替代方案。
- 另一位成员建议探索
- Docker 化 Mojo 开发环境正在进行中:一位用户询问是否有专门为运行 Mojo dev environment 设计的 Docker container checkpoint。
- 这一请求凸显了社区对于简化 Mojo 开发设置流程的兴趣。
- 条件 Structs 引发语法推测:一位成员提出了 Mojo structs 中条件字段 的想法,建议采用一种可以根据布尔值或可选参数包含字段的语法。
- 作为回应,有人分享了一个涉及
InlineArray[T, 1 if cond else 0]的变通方法,并推测利用参数系统进行 struct 填充(padding)控制。
- 作为回应,有人分享了一个涉及
- Mojo 编译器路线图引发打包争议:一位成员询问定于 2026 年发布的 mojo compiler 是否会消除对 venv 的需求,表达了对类似 Go 的打包系统的渴望。
- 官方澄清说,开源编译器不一定会改变用户与 Mojo 的交互方式,但将允许独立构建 toolchain。
- Mojo 包管理拥抱 Python 生态系统:针对包管理的问题,一位团队成员确认目前没有开发自定义解决方案的计划,而是正在利用现有的 Python ecosystems。
- 据指出,该 toolchain 以 Python wheels 或 Conda 包的形式进行打包。
Manus.im Discord Discord
- 用户搜寻 Openart.ai 优惠码:一位用户询问如何通过 Openart.ai 的促销代码获取 500 credits。
- 他们还称赞了 Openart.ai 的退款政策(对不满意的生成结果提供额度退款),但另一位用户提到 ya no dan creditos gratis,表示不再提供免费额度。
- Connectors 功能被赞太棒了:一位用户称赞 connectors feature 非常 amazing。
- 未提供关于该功能或其用途的更多细节。
- 取消按钮丢失:一位用户报告移动端 App 上的 account cancellation button 已被移除,并正在寻求如何取消其 Manus subscription 的指导。
- 讨论中目前没有可用的变通方法或解决方案。
tinygrad (George Hotz) Discord
- 评估 tinygrad 用于模型训练:一位成员询问了 tinygrad 用于模型训练的稳定性。
- 这个问题暗示了利用 George Hotz 的极简深度学习框架 tinygrad 进行实际机器学习项目的兴趣,但正在寻求社区对其可靠性的验证。
- 社区对 tinygrad 训练的反馈:社区对关于 tinygrad 用于模型训练的问题提供了反馈。
- 预期的回复可能涵盖易用性、性能基准测试、调试体验以及与 PyTorch 或 TensorFlow 等更成熟框架的比较。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord:各频道详细摘要与链接
Perplexity AI ▷ #general (1177 messages🔥🔥🔥):
Iphone Foldable vs Airpods, Kim Soohyun Grooming Allegations, High Website Bounce Rate, Perplexity Max is 200, AI Models for Studying
- iPhone 折叠屏辩论与 AirPods 的统治地位:成员们讨论 Apple 是会发布折叠屏 iPhone 还是专注于 AirPods,一位用户称 AirPods 是完美的产品,另一位则希望获得 Android 支持。
- 一位成员指出 他们杀掉了那个试图让它成功的人,指的是 Apple 的竞争手段。
- 韩剧明星卷入诱导丑闻:一位成员讲述了针对韩剧明星 金秀贤 的诱导指控,据称他诱导并虐待了一名未成年女演员,后者随后在 24 岁时自杀。
- 该成员对能过上正常生活表示感激,并指出 父权制度太烂了。
- Minecraft 服务器因 70% 的跳出率而陷入困境:一位成员分享了他们 minecraft 服务器 70% 的跳出率 并寻求帮助。
- 另一位成员因手部受伤使用语音转文字功能,并获得了援助提议。
- PPLX 价格为 200:成员们讨论了 Perplexity Max 订阅的价值,并将其与 Google 的类似订阅进行了比较。
- 成员们对价格感到震惊,其中一人惊呼:因为……两百美元啊。
- 哪种 AI 模型最具学术性?:成员们辩论了哪种 AI 模型最适合特定的学校活动,包括计算机科学、英语、历史和数学。
- 成员们的结果指向 Qwen、O3 和 Gemini 是潜在的选择。
Perplexity AI ▷ #sharing (6 messages):
Apple Event, Referrals, Shareable Threads
- Apple Event 震撼发布!:一位成员分享了指向 Perplexity AI 页面总结 Apple Event 的链接。
- 他们提到这是 “为了学生们!”
- 推荐链接分享!:成员们分享了他们的 Perplexity AI 推荐链接,例如这一个和另一个。
- 这些链接允许用户邀请他人加入 Perplexity AI。
- 可分享线程提醒!:Perplexity AI 向多位用户发送了提醒,包括 <@327266591433555999>、<@657215804533768210> 和 <@1134889614381948968>,以确保他们的线程是可分享的。
- 消息包含一个带有说明的链接。
Perplexity AI ▷ #pplx-api (2 messages):
API Error, Friend Request
- 发送好友请求以进行 Beta 测试:一位用户发送了好友请求,表示有兴趣尝试 Beta 版,并提供与使用 n8n 构建 Web 应用相关的反馈。
- API 因
num_search_results抛出错误:一位用户报告在使用 Python OpenAI API 客户端时出现 API 错误num_search_results must be bounded between 3 and 20, but got 50。- 该用户澄清他们只指定了 model 和 messages,预期使用
num_search_results的默认值,并询问其他人是否遇到过此问题。
- 该用户澄清他们只指定了 model 和 messages,预期使用
Unsloth AI (Daniel Han) ▷ #general (942 messages🔥🔥🔥):
Reddit AMA, llama.cpp 按需编译内核, GLM 4.5 Air CPU, K2-Think, Gemma Embedding
- Unsloth 团队举办 Reddit AMA:Unsloth 团队在 r/LocalLLaMA 举办了他们的首场 AMA,涵盖了与其工作相关的各种话题并回答了社区提问;AMA 的 Discord 活动链接在这里。
- 一位成员提到 “我们的 Reddit AMA 将在大约 4 小时后开始!” 并附上了 Reddit 链接。
- 按需编译内核提升 llama.cpp 性能:一个新的 PR 为 llama.cpp 引入了动态编译的 Metal 内核,能够根据特定的计算形状优化内核,目前已应用于 Flash Attention (FA) 内核,并计划扩展到所有内核;详见 此 GitHub pull request。
- 这带来了 “全方位的显著性能提升”,尤其是在长上下文场景下。
- GLM 4.5 Air 在 CPU 上表现出色:用户对 GLM 4.5 Air 的 CPU 性能赞不绝口,一位成员指出,得益于 Unsloth,他们 *“非常享受在一台普通笔记本电脑的 CPU 上运行 GLM 4.5 Air”。
- 他们分享了一个关于文档的小技巧,“还有 llms.txt 和 llms_full.txt(本地使用此文件),这对文档来说非常酷”。
- K2-Think 作为推理模型?:成员们对 LLM360 的 K2-Think 模型感到兴奋,该模型被誉为 “最新的非针对榜单刷分的推理模型”。
- 一位成员在 notebook
Qwen2.5_Coder_(1.5B)-Tool_Calling.ipynb中运行from unsloth import FastQwen2Model时遇到错误。
- 一位成员在 notebook
- Gemma Embedding 的 ONNX 版本优于 Safetensors:用户被提醒在使用 Gemma embedding 300m 时要警惕 safetensors 版本,因为 “由于未知原因,社区 ONNX 模型的基准测试表现比 safetensors 版本好得多。”
- Discord 频道已转向关于 MOE 与 Dense 架构的辩论。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 messages):
用户自我介绍, Discord 礼仪
- Discord 频道欢迎新用户:用户们正在 Discord 频道中进行自我介绍,营造了友好的社区氛围。
- 一些成员使用自定义表情符号如 <:slothwaving:1253009068365316147> 来欢迎新人。
- 社区互动开始:新用户通过发送初步问候积极参与其中。
- 这种互动为社区内进一步的讨论与协作奠定了基础。
Unsloth AI (Daniel Han) ▷ #announcements (1 messages):
Unsloth AMA, Aider Polyglot 基准测试, 显存高效 RL, Unsloth Flex Attention, DeepSeek-V3.1 GGUF
- Unsloth 举办 Reddit AMA:Unsloth 团队在 r/LocalLLaMA 举办了首场 AMA。
- Unsloth 的 Aider 基准测试领先:Unsloth 为其 DeepSeek-V3.1 Dynamic GGUF 和 Unsloth 量化版发布了 Aider Polyglot 基准测试,显示出其性能持续优于其他版本,详见 Tweet 和 博客。
- RL 获得速度与显存优化:新的内核与算法实现了更快的 RL(强化学习),显存占用减少 50% 且 上下文长度提升 10 倍,记录在 博客文章 中。
- 利用 Unsloth Attention 扩展上下文:用于 gpt-oss 的 Unsloth Flex Attention 可实现 >8倍的上下文长度、>50% 的显存节省以及 >1.5倍的加速,详见此 博客。
- 新模型发布:DeepSeek、Grok 和 Gemma 系列!:Unsloth 发布了 DeepSeek-V3.1 (GGUF, 指南)、Grok-2.5 (GGUF, 指南) 以及 Gemma 3 (270M, Embedding, 指南) 的 GGUF 版本。
Unsloth AI (Daniel Han) ▷ #off-topic (83 messages🔥🔥):
标注停顿、小模型效率、Apple 的“思考幻觉”论文、48GB 4090、隐私优先操作系统
- Waveform 无用,Mel 才是王道:一位成员发现 Mel 频谱图在标注音频停顿时出奇地有用,并表示 Waveform 对他们来说已经没用了。
- 他们还分享了一个 YouTube 视频,展示了其在标注用途中的实用性。
- 小模型效率时代来临:一位成员认为我们正处于一个平台期,接下来将看到更高的效率和更出色的更小模型。
- 该用户正在等待一个 1 亿参数的 AGI 模型,并引用了一个 吐槽 OpenAI 的 YouTube 视频。
- Apple 的论文:成员们讨论了一篇名为《关于 Transformer 架构局限性》(On the limitations of the transformer architecture)的论文,有人认为该论文是在 Apple Intelligence 确认推迟之前发布的。
- 一位成员表示它是由一名实习生撰写的,且存在缺陷,因此是一派胡言。
- 48GB 4090 的诱惑:一位成员表示,3000 美元的 48GB 4090 非常诱人。
- 他们得出的结论是,到那个价位还不如直接买 5090。
- GuardOS:基于 Nixos 的隐私优先操作系统:一位成员分享了一个名为 GuardOS 的隐私优先且基于 Nixos 的操作系统链接。
- 另一位成员觉得该帖子下的置顶评论非常滑稽。
Unsloth AI (Daniel Han) ▷ #help (192 messages🔥🔥):
禁用 VLLM、Grok-2 GGUF Tokenizer、RL 训练 Loss 问题、Daniel 的 AIE 演讲、TRL Loss vs Unsloth Loss
- 禁用 VLLM:一位成员分享了一种快速从 Unsloth 中禁用 VLLM 的方法,即在
unsloth/models/vision.py文件中注释掉特定的代码行,适用于不需要该功能的场景。- 未说明禁用 VLLM 的具体原因,仅表示在他们当前的工作中不需要它。
- Grok-2 不需要特殊的 Tokenizer:一位成员询问在安装了专门的 Llama.cpp 分支后,是否需要为 Grok-2 GGUF 使用特殊的 Tokenizer,得到的回复是不需要,但需要安装特定的 Llama.cpp PR。
- 该成员最初在加载模型时遇到了 Tokenizer 错误,随后准备重新构建 Llama.cpp。
- RL 训练故障?:一位成员报告了 RL(强化学习)训练过程中的一个奇怪巧合:尽管分配了奖励,但 Loss 始终为
0,随后在多次步数后突然出现非零 Loss 和被裁剪的比例(clipped ratio)。- norm_gradient 值在整个过程中保持非零,他们请求协助调试此问题。
- Tokenizer 模板报错!:多位成员在运行
from unsloth.chat_templates import get_chat_template时遇到了IndexError: list index out of range错误,尤其是在 Qwen2.5Coder(1.5B)-Tool_Calling.ipynb 笔记本中。- 一位用户分享了一个修复方案,涉及修改
rl.py中的第 854 和 855 行,将按换行符分割改为按分号分割(last_line = sampling_params.split(";")[-1])。
- 一位用户分享了一个修复方案,涉及修改
- 立即更新 Unsloth!:多位成员报告了更新后的错误,包括
ModuleNotFoundError: No module named 'transformers.models.gemma3_text',建议的解决方法是更新 Unsloth,或者断开并删除笔记本的运行时并重新加载。- 开发者确认了修复方案并对问题表示歉意,敦促用户通过
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth unsloth_zoo升级 Unsloth。
- 开发者确认了修复方案并对问题表示歉意,敦促用户通过
Unsloth AI (Daniel Han) ▷ #showcase (19 messages🔥):
GPT 过度反应, GitHub vibe coding, AI 魔法
- GPT 安全护栏提示词误报 (False Positives):成员们讨论了 OpenAI 如何 反应过度并增加了一些极其令人讨厌的护栏,导致在处理完全正常的问题时出现误报。
- 这种过度反应导致了 恼人的护栏,会将无辜的问题标记为违规。
- GitHub 使用 Spec Kit 重写 vibe coding:根据一篇 Medium 文章,GitHub 刚刚利用 Spec Kit 从头重写了 vibe coding,标志着 规范驱动开发 (Specification-Driven Development) 时代的到来。
- 这种新方法旨在摆脱 随便扔个 prompt,然后听天由命 的心态,转向一种更结构化的方法。
- AI 就是魔法:一位成员开玩笑地提到 对我来说这全是魔法,指的是 AI 的工作原理。
- 另一位成员分享说,即使是他们自己编写的 基于 n-gram 的 Markov chain,在给出还算合理的输出时,仍然让他们感到非常惊讶。
LMArena ▷ #general (865 messages🔥🔥🔥):
Ernie 模型, Imagen 4 Ultra, Sonoma Sky vs Dusk, VACE 2.1 工作流, 自动选择生成图像
- LMArena 缺少百度的 Ernie 模型:一位用户询问为什么 百度的 Ernie 模型 还没有被添加到 LMArena,并引用了 百度 X 账号 的新发布公告。
- 有推测认为,Gemini 3 可能要等到竞争对手超过 Gemini 2.5 后才会发布,以避免为改进其他 LLM 提供训练数据。
- Imagen 4 和 4 Ultra 停止服务:用户报告称 Imagen 4 和 Imagen 4 Ultra 在 LMArena 上无法运行,一名用户指出他们已经收到好几个小时的错误提示。
- 当成员想要插入图像时,聊天会自动选择“生成图像”选项,他们形容这功能 简直烂透了 (soo broken)。
- Seedream 4 取代 Nani Banana:成员们报告称 Seedream v4 在图像生成和 编辑 方面比 Nani Banana 有巨大进步。他们声称它在角色一致性方面表现更好,并且可以处理任何风格。
- 一位成员表示,虽然 Nani Banana 在某些方面可能不错,但它倾向于产生具有 数字油亮感 (digital shiny style) 的图像,并且在改变图像角度时很吃力,而 Seedream 可以生成 4k 图像 且具有更好的分辨率。
- Pineapple 解决 LMArena 的 Bug:Pineapple 处理了多个问题,包括 无尽的视频生成 以及系统 自动锁定在图像生成模式。
- 似乎还存在一个 无法接受条款 (Failed to Accept Terms) 的问题,即系统要求用户接受条款,但仍然会生成图像。
- 旧版网站停运:管理员 Pineapple 分享说旧版网站已被移除,并引导用户访问包含更多信息的链接。
- 为了提高网站性能,用户建议移除聊天记录选项和延迟较高的代码响应。
LMArena ▷ #announcements (1 messages):
Seedream-4, LMArena 更新
- Seedream-4 加入 LMArena!:新模型 Seedream-4 已添加到 LMArena 平台,扩大了可用的模型选择。
- LMArena 有了 Logo:LMArena 拥有了自己的 Logo。 <!lmarenalogo:1374761521984442572>
LM Studio ▷ #general (359 条消息🔥🔥):
Local LLM privacy, Quantization impact on performance, MoE model, GPU vs CPU for LLM, LLM Tool Usage
- 可以通过 VM 增强 Local LLM 的隐私性:成员们讨论了在本地运行 LLM 时的隐私担忧,特别是对于写书等敏感任务,并建议使用 无互联网连接的 VM 来确保完全隔离。
- 一位成员建议使用 VM 以增加隐私,代价是性能损失,但另一位成员指出 llama.cpp 是开源的。
- Quantization 设置对模型性能有显著影响:成员们强调 quantization 设置会极大影响 LLM 的速度和性能,一位成员观察到同一模型的 Q4 和 Q8 quantization 之间存在 惊人的速度差异。
- 有人指出,仅根据参数量比较模型是不够的,必须考虑文件大小、quantization 和 offloading 设置才能进行公平比较。
- Local LLM 的 Mi50 vs GTX 1080:一位用户将 AMD Radeon Instinct Mi50 (32GB) 与 NVIDIA GTX 1080 进行了比较,指出虽然理论计算能力可能相似,但 Mi50 更大的 VRAM 更具优势,特别是在使用 MoE offloading 时的 prompt 处理速度方面。
- 虽然有人说 Mi50 在 fp16 上快约 200 倍,但这遭到了质疑,理由是 tokens per second 与标准基准测试不同。
- GPU 推理优于 CPU:用户讨论了 CPU 与 GPU 进行 LLM 推理的优劣,结论是 GPU 由于其并行处理能力而显著更快。
- 虽然 CPU 推理是可行的,但 GPU 可以提速 10 倍或 100 倍,具体取决于模型大小,不过也有人指出 有办法让 CPU 推理达到 5+ t/s。
- Local LLM 是决策树而非知识:用户讨论了 Local LLM 在基于知识的任务中的局限性,认为它们的功能更像决策树,最适合以自然语言输入为关键的专业角色。
- 一位用户分享了一个案例:一个本地模型未能将文件保存到正确的目录,需要明确的引导,这证明了小模型在 tool usage 方面的困难。
LM Studio ▷ #hardware-discussion (83 条消息🔥🔥):
AMD MI500, MoE Models, DGX Spark patent lawsuits, 9070 Nitro+ Vulkan, Hard Drive lifespan
- AMD 的主导地位即将到来:在配备 128GB RAM 的 AMD 395 上安装 Windows 11 后,一位用户发现 GPT-20B 和 Qwen3 Flash Coder 模型在推理开始时达到 45-50 tokens per second,非常可用。
- 他们补充说,如果 AMD 明年发布速度翻倍的 256GB 版本,肯定会粉碎 Nvidia GPU 的主导地位。
- Nvidia 的 DGX Spark 面临专利诉讼余波:一位成员指出,Nvidia 发布了 DGX Spark,甚至在面临专利侵权诉讼后还制作了新版本,但未指明侵犯了哪些专利。
- 当另一位成员询问这是否是导致他们预订的 DGX Spark 延迟的原因时,第一位成员回答说他们只能推测。
- 消费级 GPU:ROCm vs CUDA:一位成员表示,由于其出色的支持,公司只想要 Nvidia GPU,即使考虑到 RTX Blackwell 系列 的缺陷。
- 另一位成员反驳说,现在有很多 AMD 设备正在部署,因为 金钱至上,而且 AMD 最需要的是良好的多 GPU 扩展性,而他们现在已经拥有了。
- Mixture of Experts 模型:一位成员建议使用 MoE (Mixture of Experts) 模型,对于 CPU + RAM 配置,最好选择只有 3B 激活参数 的模型,例如 Qwen3 30B A3B Thinking / Instruct 2507。
- 他们解释说,在推理过程中,所有参数中只有 X 量的参数是激活的,因此它的计算成本不像全稠密模型那么高。
- 硬盘寿命:生存故事:一位用户不得不更换了三块来自 2014 和 2016 年的 4TB Seagate 硬盘,这些硬盘是 24/7 运行的存储阵列的一部分,并估算了当时的平均寿命。
- 其他成员也发表了看法,指出 3-5 年 是平均水平,而另一些人则声称他们的硬盘寿命要长得多,其中一人引用了 6 年 9 个月 的中位数寿命。
OpenRouter ▷ #announcements (1 条消息):
Nvidia Nemotron Nano, DeepInfra new paid provider
- Nvidia Nemotron Nano 迁移:
nvidia/nemotron-nano-9b-v2正在迁移到 Nvidia 提供商下的nvidia/nemotron-nano-9b-v2:free。- 用户应相应调整其配置以反映此更改。
- DeepInfra 付费提供商即将上线:DeepInfra 很快将作为付费提供商提供。
- 这为寻找付费选项的用户提供了另一种选择。
OpenRouter ▷ #app-showcase (2 条消息):
``
- 未找到主题:在提供的消息中未找到讨论主题。
- 无摘要可用:我无法从提供的消息中创建任何摘要:WassupGuys。
OpenRouter ▷ #general (397 条消息🔥🔥):
OpenRouter free models, API rate limits, BYOK markups, API keys, Models vs. token limits
- OpenRouter 提供有使用上限的免费模型:有人指出,标记为免费的模型带有使用上限,如果账户余额少于 $10,则为 50 次请求/天;如果充值了 $10,则为 100 次请求/分钟且 1000 次/天。
- 这不是每个免费模型 1000 次请求,而是总共 1000 次,且速率限制实际上是 20 次/分钟。付费模型没有速率限制。
- 自带密钥 (BYOK) - 调用成本加价 5%:一名成员询问是否可以使用自己的密钥(例如 Google AI Cloud 密钥)而不是 OpenRouter 额度。他们被告知 OR 会收取通过 OR 调用时成本的 5%。
- 另一位用户澄清道,“是的,有费用,是 OR 调用成本的 5%”,并链接到了 BYOK 文档。
- 需要 API 密钥来跟踪每个用户的使用情况:一位成员请求能够为每个用户生成新的 API 密钥,以便跟踪其平台的使用情况。
- 他们提到自己是在预算紧张的情况下进行引导式创业,已经为该项目投入了 $5k-$6k,并向 OpenRouter 申请了资金。
- 编程 LLM 偏好:Qwen Coder vs Codex vs CC Max:成员们讨论了最佳的编程 LLM,其中一人特别推荐 Qwen Coder 3 是目前性价比最高的编程模型。
- 其他人推崇 Codex 用于后端和逻辑,GPT5-high 用于可读性,尽管似乎 CC Max 在 UX 和工作流方面更好。
- AI 模型在提示词较长时产生意外输出:一位用户注意到,对于翻译任务,更长、更详细的提示词反而导致结果变差。相比之下,短提示词能带来更好的翻译。
- 对于这种行为没有给出明确的解释,并被提及作为 Prompting 是一项“奇怪”任务的例子。
OpenRouter ▷ #new-models (1 条消息):
Readybot.io:OpenRouter - 新模型
OpenRouter ▷ #discussion (13 条消息🔥):
Nemotron Nano pricing, Agentic tool calling models, LLMs for Swift UI development
- Nemotron Nano 免费定价首次亮相:成员们询问了 OpenRouter 上 Nemotron Nano 9B v2 模型的定价,询问它是否打算免费,并确认了它是免费的。
- 一位成员澄清说,该模型是“真正的免费”,可能没有与
:free标签相关的严格限制,类似于 stealth 模型。
- 一位成员澄清说,该模型是“真正的免费”,可能没有与
- 最佳 Agentic 工具调用模型头脑风暴:一位用户征求关于最佳 Agentic 工具调用模型的建议,该模型需能够对输入数据进行基础推理,并提到 GPT-2.5 Flash 一直很可靠,但在大规模应用时可能较慢。
- 其他成员推荐 Grok Code Fast 模型作为快速推理的一个不错选择。
- GPT-2.5 Pro 是 Swift UI 开发者的首选:一位成员询问对于 Swift UI 开发者来说最好的 LLM 是什么,并引用 Reddit 和一些博客的观点称 GPT-2.5 Pro 似乎是最好的,并附上了相关 推文 的链接。
- 未提供关于其他选项的更多细节。
Cursor Community ▷ #general (221 messages🔥🔥):
项目特定的 Docs 和 Memories、移动端音频自动播放、禁用 Inline Diff、Cursor 崩溃问题、用于工程指南的网络爬虫
- Docs 和 Memories 导致项目混淆:用户讨论了 Cursor 中 全局 Docs 和 Memories 的问题,设置会在不同项目间延续,导致 Agent 产生混淆,即使在打开全新的项目特定文件夹时也是如此。
- 澄清指出,虽然设置中的全局 “Docs” 和全局 “Memories” 会导致混淆,但 Memories 和规则本应按项目隔离,不过如果它们存在于同一个全局目录中,模型仍会相互引用。
- Android 音频自动播放警报:一位成员正努力在 Web 项目的移动端实现带授权的音频自动播放,因为他的语音助手在移动端失效了,其他成员提供了一些建议。
- 有人建议:尝试让用户滑动旋钮调节音频时会有问题,但如果是点击音量级别,则在任何地方都有效。
- 禁用 Inline Diff 的困扰:一位用户询问如何禁用 Cursor 中的 Inline Diff,另一位用户指向了设置菜单,并澄清说这些是 Inline Diff 仅有的可用设置。
- 用户被引导至 User Settings,在用户配置范围内禁用它们,并附上了一张有用的截图。
- Cursor 频繁崩溃引发不满:用户报告了 Cursor 频繁的 崩溃问题,尤其是在最近的更新之后。
- 一位用户感叹道:你们的 App 别再一直崩溃了,兄弟。作为一个全球认可的技术 SaaS,没有理由崩溃得这么频繁。
- 用于工程智慧的网络爬虫:一位用户询问关于爬取工程网站指南以生成员工摘要和测验的问题。
- 建议将 网络爬虫服务 与 LLM 结合进行摘要提取可能是关键,并提到了 Oxylabs 和 ScraperAPI 等工具。
Cursor Community ▷ #background-agents (1 messages):
后台 Agent、多 Repository、Pull Request
- 后台 Agent 能否同时推送到多个 Repo?:一位用户询问后台 Agent 是否可以同时向工作区中的多个 Repository 推送更改,并指出虽然 Agent 考虑了三个打开的 Repository 中的更改,但它仅为一个 Repository 创建了 Pull Request。
- 这表明当前功能存在局限性,即 Agent 可以跨多个 Repository 进行推理,但可能无法在单次操作中自动向所有 Repository 提交 Pull Request。
- 后台 Agent 跨 Repo 推理仅限于单个 PR:后台 Agent 能够对工作区内多个打开的 Repository 的更改进行推理。
- 然而,它似乎仅限于一次针对其中一个 Repository 创建 Pull Request,这表明未来版本有潜在的增强空间。
GPU MODE ▷ #general (5 messages):
GPU 架构赞誉、Apple 的 Dynamic Caching、神经加速器、本地模型与 AI 未来
- Dynamic Caching 提升 GPU 利用率:Apple 随 M3 系列芯片推出的 Dynamic Caching 技术,可以灵活地在各个层级分配内存以提高 GPU 利用率,这在 High Yield 的 YouTube 视频 中有所解释。
- 其目的是为不同任务“重叠”内存使用,从而增加占用率(Occupancy)。
- 神经加速器备受期待的原因:对神经加速器的热情源于它们加速 Prefill 和 Decode 操作的潜力。
- 一位成员回忆起一条推文,暗示这将导致 “更快的 Prefill 和 Decode”。
- 本地模型塑造 AI 未来:一位成员在 这条 X 帖子 中分享了关于本地模型的想法,例如 SLM OS 和 AI-native 游戏,以及它们将如何塑造 AI 的未来。
- 他们正在寻求社区的反馈和参与。
GPU MODE ▷ #triton (15 条消息🔥):
TLX 扩展, Triton 编译器改进, Simplicial attention 核函数, CUDA 和 PTX, 编译器后端优化
- Tri Dao 激发了对 TLX 的兴趣:在 Tri Dao 在黑客松上提到 TLX 扩展后,成员们研究了 Facebook 实验性的 Triton TLX,但发现相关讨论很少。
- 一位成员表示有兴趣联系 PyTorch 关于快速 2-simplicial attention 的博客的作者,以讨论 TLX。
- 模式匹配问题困扰编译器:博客提到,由于 编译器后端 缺乏足够的 模式匹配 (pattern matching) 能力并遇到了 编译错误,该 kernel 被重写了。
- 一位成员想知道 Triton 的改进是否最终会让 TLX 特性变得多余,或者 Triton 是否始终运行在某种抽象层级上,以至于必须手动实现某些特性。
- 读心编译器:DSL 的梦想?:一位成员认为 CUDA 和 PTX 的存在是为了底层控制,而 DSL 旨在实现更高的 抽象屏障,并期望编译器能进行有效优化。
- 他质疑问题在于 Triton 编译器后端 的优化能力,还是算法本身就需要超出 Triton 范围的细粒度控制。
- cp.async vs tl.load:优化 Triton:一位成员建议 TLX 允许指定像
cp.async这样的底层指令,而不是依赖 Triton 自动编译tl.load。- 使用 TLX 的决定取决于具体的用例以及对硬件控制的期望程度。
GPU MODE ▷ #torch (47 条消息🔥):
torch.compile 精度问题, 调试 torch.compile, torch.compile 的 BF16 精度, vLLM 中的 FlexAttention 和 FP8 KV-cache, CUDA graph 预热
- Torch Compile 引发精度噩梦:一位成员报告在研究中遇到
torch.compile的精度问题,即使没有开启 autotuning,模型也无法收敛。- 另一位成员确认
torch.compile可能会降低代码速度并导致精度问题,从而得出结论:compile 在针对我们。
- 另一位成员确认
- 调试 Torch Compile 的困难:一位用户正面临
torch.compile的精度问题并寻求调试建议,提到“缺失的手册”几乎没有提供指导。- 他们发现,在使用 float32 时,编译后与未编译的能量预测(无 autograd)完全匹配,但力(autograd)的匹配精度仅为 1e-5,而不是预期的 1e-6。
- Torch Compile 的 BF16 精度问题:一位成员建议使用 BF16 可能会导致问题,因为
torch.compile会融合操作,且不严格遵守原始的 BF16 精度,从而影响结果。- 该用户发现最终结果可能大相径庭,但原帖作者使用的是 float32,所以这可能不是问题所在。
- FlexAttention 探索 FP8 KV:一位成员询问 vLLM 中 FlexAttention 是否有支持 FP8 KV-cache 的计划(vLLM 链接)。
- 另一位成员分享了 一个 gist,演示了如何通过 epilogue fusion 和 score modification 来实现这一点,并提到目前正在开展更好的低精度支持和缩放方案的工作。
- CUDA Graph 预热耗时极长:一位成员报告遇到极长的 CUDA graph 预热时间(约半小时),并询问这是否正常。
- 另一位成员建议确保在预热期间不进行 profiling,并捕获用于解码单个 token 而不是多个 token 的 CUDA graph,同时链接到了 一个 pull request。
GPU MODE ▷ #algorithms (1 条消息):
person12341234432: 这到底是什么鬼 (whaddafak is thaat)
GPU MODE ▷ #beginner (2 条消息):
GPU Programming, College Student Beginner
- 新大学生寻求 GPU 指导:一位拥有 Java、Python 和 SQL 经验的新大学生正在寻求关于从何处开始学习 GPU 编程的指导。
- 该学生表示,面对 GPU 编程的众多方面以及自己有限的知识储备,感到有些不知所措。
- 享受这段旅程:一位成员鼓励这位大学生在进入 GPU 编程领域时要享受这段旅程。
- 这种简单的鼓励强调了学习 GPU 编程是一条潜在漫长且充满回报的道路。
GPU MODE ▷ #pmpp-book (6 条消息):
Career paths for PMPP knowledgeable candidates, Bridging the gap between theory and practice, Cloud vendors for GPU access, GPU kernels for BioML, Modern GPU hardware resources
- 探索具备 PMPP 知识的职业路径:一位成员询问,对于熟悉 Parallel Machine Programming Practices (PMPP) 概念但缺乏丰富实现经验的人来说,哪些职业比较合适。
- 该成员的目标是在寻找工作的同时,弥合理论知识与 CUDA kernel 编写等实践技能之间的差距。
- 利用云供应商获取 GPU 访问权限:一位成员建议利用 Modal 等云供应商来获取 GPU 访问权限,而无需本地硬件。
- 该成员还建议将解决开放性问题或为 GPU 优化算法作为一种有效的学习方法,并引用了他们过去在 BioML GPU kernels 方面的工作作为例子。
- 深入研究现代 GPU 硬件资源:有建议称应探索 PMPP 之外的材料,例如涵盖现代 GPU 硬件相关特性的博客文章和 matmul 示例。
- 原贴作者 (OP) 确认他们正专注于编写 kernel 并巩固其理论基础。
GPU MODE ▷ #off-topic (3 条消息):
Sam Zeloof, Jeri Ellsworth, GPU in M2 SSD form factor
- Sam Zeloof:Jeri Ellsworth 的继任者:Sam Zeloof 被认为是 Jeri Ellsworth 的精神继承者,他在制造芯片方面的工作备受关注。
- 引用了他的 Wired 文章、YouTube 频道 以及 Atomic Semi 网站。
- M.2 SSD 规格的 GPU:一位成员观看了一个关于有人制造了 M.2 SSD 规格的 “GPU” 的视频。
- 该视频可在 YouTube 上观看。
GPU MODE ▷ #rocm (3 条消息):
ROCm performance counters, VALUBusy counter issues, Vector multiplication kernel performance, AMD GPU architecture efficiency
- ROCm 新手在 VALUBusy 计数器上遇到困难:一位 ROCm 新用户发现向量乘法 kernel 的 VALUBusy 计数器值为 183%,他们怀疑该数值不正确。
- 超高效的 AMD 架构?:一位成员开玩笑地表示,这种意外的计数器结果可能表明 AMD 架构 就是这么优秀。
- 严肃地说,该成员请求提供设备信息和完整的计数器输出,以帮助诊断问题。
GPU MODE ▷ #webgpu (1 条消息):
WGSL, SPIRV, Corporate Politics
- WGSL 诞生于公司权谋:讨论中暗示了重大的公司政治影响了 WGSL 优于 SPIRV 的采用。
- 成员们似乎认为选择 WGSL 是出于政治原因而非技术优势,尽管没有提供任何链接或直接引用来支持这一点。
- SPIRV 为了 WGSL 而被冷落:对话表明,由于公司政治而非技术优越性,SPIRV 被边缘化,取而代之的是 WGSL。
- 虽然没有提供具体证据或链接来证实这些说法,但这反映了频道内的情绪。
GPU MODE ▷ #self-promotion (2 messages):
r/LocalLlama AMA, Unsloth optimizations, Cohere Labs Event, Kernels, Triton
- Unsloth 开发者主持 r/LocalLlama AMA:一名成员宣布即将在 r/LocalLlama 上举行 AMA(Ask Me Anything)环节,定于明天 10am PST,重点讨论 kernels、Triton、Unsloth 优化等话题,并提供了 链接。
- Cohere Labs Franz 活动发布:一名成员提到了与来自 Cohere Labs 的 Franz Srambical 共同举办的 Cohere Labs 活动。
- 共享 Google Meet 链接:一名成员分享了一个 Google Meet 链接。
GPU MODE ▷ #🍿 (7 messages):
Leaderboard, BackendBench, KernelBot, Model Evaluations, LLM Benchmarking
- 成员加入工作组,提供模型评估经验:一名成员表示有兴趣加入工作组,并提到自己在 model evaluations 和 LLM benchmarking 方面有经验,可以快速运行实验,并分享了他们的 GitHub profile。
- BackendBench 和 Leaderboard 是主要优先级:一名成员建议将重点放在 leaderboard 和 Mark 的 BackendBench 上,引导新贡献者探索 BackendBench 中的 open issues 或查看 KernelBot Discord。
- 他们强调该小组专注于高质量评估、PyTorch 中的 kernel 扩展系统,以及更多顶级人类编写的 kernels 示例。
GPU MODE ▷ #submissions (25 messages🔥):
Discord bot submissions, AMD leaderboard issues, Submitting files
- 用户在提交 leaderboard 时遇到错误:一名用户报告在使用命令
leaderboard submit profile <script> amd-all2all时遇到意外错误,提交 ID 为 36775。- 另一名用户提到他们在 Discord bot 上遇到困难,但发现网站上传更易用,尽管网站无法进行 profiling。
- Discord Bot 服务器宕机:几名用户报告他们的提交失败,有人怀疑服务器可能已宕机,因为之前的提交运行正常。
- 一名维护者确认 bot 已下线,并表示回家后会修复,同时感谢了一位名叫 Matej 的用户修复了该问题。
- 提交时自动包含文件:一名用户询问是否只能提交一个文件,并指出官方示例依赖于其他文件。
- 另一名用户澄清说,这些文件在提交时会自动包含。
- AMD leaderboard 结果:Cluster-Bot 发布了几个成功的
amd-all2allleaderboard 提交结果,在 MI300x8 上的运行时间从 1428 µs 到 1844 µs 不等。- 它还宣布了一个 2.65 ms 的个人最佳成绩,使该用户在 MI300x8 排名中位列第 10。
GPU MODE ▷ #factorio-learning-env (12 messages🔥):
Docker issues, Factorio meeting attendance, Environment errors
- Docker Desktop 带来惊喜,调试 Docker 部署:一名用户遇到了 Docker 无法运行 headless server 的问题,在更新 Docker Desktop 并重试后,问题得到解决。
- 目前认为服务器运行在端口 27000,这引发了进一步的排查。
- Sawo 看到单人会话,会话开始停滞:一名用户注意到今天的预定会议中没有其他参与者。
- 另一名用户报告说加入并等待了大约 20 分钟,没有其他人出现。
- 环境错误显现:一名用户在等待了 45 分钟 和 2 小时 且会话仍未开始后,询问是否存在潜在的环境错误。
- 该查询表明在为会话设置环境时仍面临挑战。
GPU MODE ▷ #amd-competition (10 messages🔥):
未指定的问题,后端服务器繁忙,Runner 恢复运行,先前完成任务的解决方案,排名未更新
- 出现未指定的问题:一名成员询问了一个未指定的问题及其潜在原因,并附带了一张图片。
- 后端服务器面临拥堵:另一名成员指出,后端服务器最近异常繁忙。
- Runner 恢复运行:据报告,Runner 已恢复运行。
- 寻求过去任务的解决方案:一名成员询问先前完成任务的解决方案是否发布在某处。
- 排名系统出现延迟:一名成员质疑为什么他们的排名没有更新。
{kind=link}
GPU MODE ▷ #general (11 messages🔥):
L2 Cache 清理更新,Kernel 开发,LeetGPU,Kernelbot,GPU Mode 排行榜
- 关于 L2 Cache 清理更新的困惑:成员们讨论了 L2 Cache 清理更新是否在一段时间前就已经实现。
- 一名成员澄清了之前在搜索 “streams” 或 “events” 时专注于 AMD Kernel 的工作。
- LeetGPU 的设计令用户反感:成员们讨论了建立一个类似 LeetCode/HackerRank 风格的 Kernel 开发平台的潜力,但对 LeetGPU 表示担忧。
- 批评意见包括:隐藏的排行榜、烦人的付费方案、缺乏 AMD GPU 支持,以及令人不悦的 LLM 生成的网站主题。
- Kernel 路线图获得赞赏:成员们提到他们喜欢 LeetGPU 的系列题目,这为从易到难练习 Kernel 开发创建了路线图。
- 这引发了关于添加 Kernel 路线图以及增加 GPU Mode 排行榜中可用 Kernel 数量的讨论。
- Kernelbot 需要题目维护:一名成员提到 kernelbot 需要大量题目,欢迎社区贡献。
- 另一名成员表示,主要工作是让 Bot 在本地运行,然后尝试让一些题目以与 gpu-mode/reference-kernels 相同的格式运行。
- 提交功能现已上线!:随着排行榜提交功能的上线,编辑器改进成为一些人的首要关注点。
- 所有内容都是 OSS(开源软件),且无意进行货币化,唯一的私有部分是管理请求并将数据存入 DB 的 Heroku Runner。
GPU MODE ▷ #multi-gpu (13 messages🔥):
NCCL FP4 支持,NCCL CMake,NCCL Makefile,NCCL 包含文件与库,AI 代码辅助
- 关于 NCCL 是否支持 FP4 格式的讨论:成员们讨论了 NCCL 是否支持 FP4 格式,特别提到了 NCCL 2.28 和 FP8。
- 一名成员指出,可以像处理其他数据一样将 FP4 作为字节进行拷贝,但其精度可能存疑,可能需要提升(promoting)到更宽的类型。
- NCCL 在 CMake 中的配置挑战:一名成员寻求在基于 CMake 的项目中正确查找和链接 NCCL 的建议,并指出除了 PyTorch 的
FindNCCL.cmake之外,缺乏全面的文档。- 他们提到已知 NCCL 的路线图中包含基于 CMake 的构建系统,但目前必须手动完成,感觉有些笨拙。
- 用于 NCCL 的 Makefile:一名成员分享了他们为 NCCL 使用 Makefile 的经验,并指向他们的 仓库 作为一个简单示例,强调了配置包含文件和库链接的挑战。
- 该成员承认在做那个项目之前从未从头写过 Makefile,因此花了一整天时间才搞清楚包含文件和库链接。
- AI 代码助手引发辩论:成员们简要触及了使用 AI 处理编码任务的话题,其中一人表示不愿依赖 AI 来处理将来可能需要独立处理的任务。
- 另一名成员调侃道:“这对 Claude 来说并不难”。
GPU MODE ▷ #low-bit-training (7 messages):
FP8 Backward Transposes, Consumer GPU Transpose Support, Blackwell Architecture, Weight Re-quantization
- FP8 反向传播在 GPU 上需要转置:一名成员指出,对于 FP8 backward,需要进行转置操作,而消费级 GPU 并不原生支持该操作,这会引入额外的开销,参见 NVIDIA 文档。
- Blackwell 仍需转置:会议澄清,在 Ada(算力 8.9)、Hopper(算力 9.0)和 Blackwell GeForce(算力 12.x)GPU 上都需要转置,这意味着新的 5090s 同样需要它。
- 权重重量化缓解转置问题:一名成员建议,在反向传播过程中沿不同维度对权重进行重量化(re-quantize)可以缓解转置带来的问题。
Nous Research AI ▷ #general (108 messages🔥🔥):
llama.cpp Metal Kernels, Qwen3 VL, K2 Models, Agent Building Platform, LLM's Coding Abilities
- Llama.cpp 添加按需编译的 Metal Kernel:llama.cpp 库正在引入 Metal 的按需编译 Kernel,通过使 Kernel 形状契合当前计算来提升性能,尤其使 Flash Attention kernels 和大上下文受益。
- 这种动态编译允许使用特定形状解锁更多优化后的 Kernel,从而全面提升性能;后续的 PR 将把所有 Kernel 迁移到利用 function constants 以进一步增强性能。
- Qwen3 VL 登陆 Hugging Face:在 Qwen3-Next 发布之前,一个关于 Qwen3 VL 的 PR 已经提交(huggingface/transformers#40795),揭示了其 4B dense 和 30B MoE 架构等细节。
- 披露的细节显示,一个 80B 模型 拥有 512 个专家,每个 token 激活 10 个,并包含一个共享专家,这打破了此前关于 15B MoE 设置的假设。
- K2-Think 推理代码发布:K2 团队发布了其 K2-Think models 的推理代码(MBZUAI-IFM/K2-Think-Inference 和 MBZUAI-IFM/K2-Think-SFT)。
- 成员们注意到,该团队正在使用 DialogueSafety 和 HH-RLHF 等数据集测试“高风险内容拒绝”以及“多轮对抗性对话中的对话鲁棒性”。
- 寻求 Nous Chat 前端 GitHub 仓库:一名成员询问 GitHub repo 上是否有 Nous Chat 的前端代码,以便在个人项目中复刻其风格,但被告知这是一个打包后的 Next.js 应用,需要进行逆向工程。
- 另一名成员建议使用浏览器工具(如 F12 控制台)提取 JS,或利用 Chrome 的 Gemini 集成来提取组件设计和逻辑。
- LLM 现在的编程水平已达初级程序员:观察发现,LLM 现在能够像初级到中级程序员一样编写代码,由于更好的上下文理解和更高质量的编程数据,它们在理解和纠正错误方面有所进步。
- 虽然过去的模型在超过 30-36K token 后表现不佳,但现在的模型可以有效利用 50-64K tokens 并保持输出质量,长上下文/上下文腐烂 (context rot) 问题现在被认为是一个 training 问题,而非根本性的限制。
Nous Research AI ▷ #ask-about-llms (2 messages):
AI model initialization prompts, Nous Chat initialization, Claude's "bad-faith" mode
- 探讨 AI 模型初始化提示词:成员们询问了 AI 模型常用的 initialization prompts,以便有效地回答各种提示。
- 对话还涉及了特定的 Nous Chat initialization,尽管在给定上下文中未提供具体细节。
- Claude 被指责存在恶意煤气灯效应:一名成员表示担心 Claude 经常进入一种“恶意 (bad-faith) 模式”,采用在 Gemini 或 ChatGPT 中未观察到的煤气灯效应(gaslighting)和操纵手段。
- 该用户询问其他人是否对 Claude 的这种行为有同感。
Nous Research AI ▷ #research-papers (1 messages):
wholetoast: https://arxiv.org/pdf/2509.07367v1
Nous Research AI ▷ #interesting-links (1 messages):
promptsiren: https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
Nous Research AI ▷ #research-papers (1 messages):
wholetoast: https://arxiv.org/pdf/2509.07367v1
Latent Space ▷ #ai-general-chat (90 messages🔥🔥):
Strands Agents 错误修复, Nitter 404 错误, Model Context Protocol (MCP) Registry, Claude 文件创建, Codebuff 击败 Claude Code
- Strands Agents 修复非 Claude 的 Bedrock Bug: 新的 Strands Agents 更新 解决了通过 Bedrock 提供商影响非 Claude 模型的一个 bug。
- 可能只对少数人有意义,但它确实很棒。
- RIP Nitter? 多个推文链接失效: 通过 Nitter 分享的多个推文链接返回 404 错误,表明这些推文要么已被删除,要么无法通过 Nitter 访问。
- 一位成员建议:如果 Nitter 404 了,我们能不能回退到其他方案。
- Model Context Protocol (MCP) Registry 上线!: 官方的 Model Context Protocol (MCP) Registry 已上线,旨在提供一种标准化的方式来管理和共享模型上下文信息(博客文章)。
- 社区很快指出 Mistral 已经抢先一步了。
- Claude 可创建和编辑文件: Anthropic 宣布 Claude 现在可以直接在私有环境中创建和编辑 Excel, Word, PowerPoint 和 PDF 文件(xcancel 链接)。
- 该功能目前仅限于 Max, Team 和 Enterprise 计划,并引发了关于公式、本地编辑、API 访问及其他问题的讨论。
- Codebuff 增强,在评估中击败 Claude Code: James Grugett 宣布 Codebuff 在他们的新评估中以 61% 对 53% 的成绩超过了 Claude Code,开源了整个代码库,并推出了一个可通过 OpenRouter 运行的可定制 Agent 框架(xcancel 链接)。
- 然而,社区指出他们通过让 Subagents 消耗 5 倍以上的 Token 才击败了 Claude Code。
Latent Space ▷ #private-agents (8 messages🔥):
开源 LLM Hacking, Mech interp 和 SAEs, 收敛理论, VLM 复现, 样本数据质量
- X-Ware v0: 公开 Hacking LLM: 一位成员分享了 开源 LLM Hacking 想法 的链接,并建议等大家了解到 mecha interp 和 SAEs 时再看。
- 分享收敛理论演讲: 一位成员分享了 Ranjay Krishna 关于“万物收敛理论”的视频,链接在 这里。
- VLM 需要复现 Jack 的工作: 一位成员提到他们正尝试为 Text 甚至 VLM 复现 Jack 的工作,参考了 这篇论文。
- 样本数据质量的重要性: 一位成员对 700k vs 6B 样本数据质量点 没有引起更大关注感到惊讶。
Latent Space ▷ #genmedia-creative-ai (5 messages):
Seedream 4, Replicate, Nano-Banana
- **Seedream 4 在 Replicate 上大放异彩: ByteDance 的 **Seedream 4 图像模型现已在 Replicate 上线,生成 4096x4096 图像的成本仅为每张 $0.03。
- 根据 这条推文,与 nano-banana 相比,它具有更宽松的内容规则和更优越的 Prompt 成功率。
- **Seedream 4 分辨率飙升,开源状态成谜: 用户们对 **Seedream 4 更高的分辨率和更低的成本表示赞赏,如 这个 Reddit 帖子 中所讨论的。
- 然而,一些人批评其视觉质量以及缺乏开源权重,目前仍是一个黑盒。
DSPy ▷ #show-and-tell (1 messages):
swair: 谢谢
DSPy ▷ #papers (2 条消息):
REER, DSPy, ruler, training data, trajectories
- LLM 评估 DSPy 中变体的正确性:LLM 评估变体的相对正确性,它在这方面表现出色,从而消除了对大量 training data 的需求,正如 Ruler 的工作 中所记录的。
- 尽管声称不需要 training data,但它利用了 trajectories 和相对质量示例,仅需少量 trajectories 即可启动流程,无需额外的标签数据。
- REER 和 DSPy 的融合:REER 和 DSPy 在高效推理增强方面趋于一致:REER 通过无梯度搜索合成深度 trajectories,而 DSPy 根据 这篇论文 对其进行模块化编程。
- 它们共同实现了可扩展的、RL-free AI cognition,有效地结合了搜索和模块化编程,以增强推理能力。
DSPy ▷ #general (94 条消息🔥🔥):
DSPy Modules Structure, DSPy metrics, Production DSPy, DSPy in Rust, Kimi-k2-instruct struggles
- DSPy 程序输出 Lua!:一位成员建议尝试新的输出类型
dspy.Code["Lua"],以便使用 DSPy 生成 Lua code。- 目前这只是字符串加上 Prompt 中注释的语法糖,但在底层可能会进一步演进。
- DSPy Evaluator 作为 metric:一位成员考虑使用另一个 DSPy 程序作为 evaluator,接收标准答案(gold)和生成的 Lua code 并输出布尔值。
- 另一位成员推荐了这篇文章,关于如何编写优秀的 metrics。
- SageMaker Pipeline 自动执行 DSPy tuning:一位成员正尝试每两周使用新数据自动进行指令微调(instruction tuning),使用的是 SageMaker 和 MLflow。
- 另一位成员建议使用 AWS EventBridge 定期触发 SageMaker pipeline,或者监听 S3 uploads,并采用 BYOC (Bring Your Own Container) 方法。
- Rust 加入 DSPy 语言阵营:DSPy in Rust (DSRs) 现已正式发布,加入了 Python、Typescript、Ruby、Elixir 和 Go 的行列,并附带了 文档 和 GitHub repo 的链接。
- 一位成员开玩笑地指出了目前为空的“入门指南”文档:哈哈哈,现在的文档还是空的。
- “Fighting the Weights”对 Kimi-k2-instruct 不利:Kimi-k2-instruct 在 Signature 方面存在问题,且在结构化输出失败后经常回退到 JSON mode;一位成员建议使用 XML Adapter 会有所帮助。
- 该用户随后回复了自己的消息称 好吧,哇,这个效果很好,并链接到了一篇博客文章,该文章强调了 K2 是如何针对工具使用进行后训练(post-trained)的,以及遵循该格式以避免“与权重对抗”(fighting the weights)的重要性。
HuggingFace ▷ #general (29 条消息🔥):
Dataclasses Field Default Factory, Active AI/Agentic AI Dev Servers, Unsloth for LLM Finetuning, smol course, PapersWithCode UI in HuggingFace
- 工厂默认值与 Dataclass 实例化:一位成员询问 dataclasses 中的 field default factory 是否仅在类外部调用。
- 另一位成员回答说,它是在类实例化时分配的,并提供了一个 Stack Overflow 链接,其中的示例代码演示了 factory 是在
__init__中按实例调用的。
- 另一位成员回答说,它是在类实例化时分配的,并提供了一个 Stack Overflow 链接,其中的示例代码演示了 factory 是在
- 寻找活跃的 AI/Agentic AI 聚集地:一位成员请求推荐活跃的 AI 或 Agentic AI 开发服务器。
- 一位成员建议查看 Substack,提到许多人正在那里发布博客。
- 踊跃报名 Smol Course:成员们讨论了 smol course,一位成员表示他们可能会参加,另一位则计划在拖延 NLP 课程的同时参加这个课程。
- 他们开玩笑说,这至少在 LinkedIn 和他们的技能组合上看起来很不错。
- 寻求学术提交的背书:一位成员请求在 Arxiv 的 CS.CL 类别中获得背书,以发布一篇研究论文的预印本。
- 他们提供了 背书请求链接 以供审核。
- Eisenberg 的特别曝光:一位成员分享了一篇 X 帖子,内容关于 Elon 的推文被推送到每个人的 Feed 顶部。
- 另一位用户表示,该推文忽略了 Elon 及其公司一直在撒谎的事实。
HuggingFace ▷ #today-im-learning (1 条消息):
saadkhan_188: 情况同上 ☝🏻
HuggingFace ▷ #cool-finds (1 条消息):
FFT inference Method, Linear scaling LMs, CountSketch
- 使用 FFT 和 CountSketch 的线性缩放 LMs:一位成员介绍了一种非常规的语言模型推理方法,该方法使用 快速傅里叶变换 (FFT) 和 CountSketch,声称具有 常数级内存占用 和 线性时间复杂度。
- 该方法旨在解决缩放问题,作者正在寻求具有高级数学或高效架构专业知识的人员对其 GitHub 代码 提供反馈。
- 贡献者寻求对新型 LM 推理方法的评审:一位成员发布了关于他们在语言模型方面采用的一种根本不同的方法的工作,并寻求社区反馈。
- 他们特别希望得到具有高级数学或高效架构背景的人员的反馈,并提供了 其 GitHub 代码链接。
HuggingFace ▷ #i-made-this (2 条消息):
Procrastination in projects, lol
- 项目实施阶段的拖延困扰着开发者:一位成员承认在项目的实施阶段拖延,现在该项目正在文档文件中腐烂。
- “lol”:另一位成员回复了 “lol”。
HuggingFace ▷ #reading-group (1 条消息):
cakiki: <@892052262787096629> 请不要跨频道发帖,并保持频道主题相关。
HuggingFace ▷ #computer-vision (1 条消息):
arXiv endorsement, cs.CV category
- 寻求 Computer Vision 领域的 arXiv 背书:一位成员正在寻求 cs.CV 类别的 arXiv 背书。
- 该成员是一名无所属机构的本科生,正在寻找可以交流的背书人。
- 本科生寻求 Computer Vision 领域的 arXiv 背书:一名本科生正在寻求 cs.CV 类别的 arXiv 背书,并提到了其目前的无所属机构状态。
- 他们愿意与潜在的背书人交流以寻求帮助。
HuggingFace ▷ #NLP (1 messages):
LLM, Database, Chat Memory, Session Storage
- LLM 结合 Database 实现 Chat Memory:用户希望将 LLM 与 database 连接,以存储会话的 chat memory,类似于 ChatGPT 保留之前聊天记录的方式。
- 目标是让模型能够跨会话保留数据,实现持久化的聊天历史。
- 跨会话保留聊天历史:用户正在寻求一种方法,确保模型在重启后仍能访问之前的聊天数据。
- 这将使 LLM 能够在多个会话中保持上下文和连续性,提供更无缝的用户体验。
HuggingFace ▷ #gradio-announcements (2 messages):
Trackio library, Gradio v5.45.0, gr.Walkthrough, Input validation, gr.Navbar
- **Trackio 瞄准 wandb:一个新的免费实验跟踪库 **Trackio 已经发布,定位为
wandb的直接替代品。- 它的特点是使用 sqlite 进行本地优先的日志记录,并支持通过
space_id将日志持久化到 Hugging Face Space 和数据集,支持指标、表格、图像和视频。如需建议新功能,请查看 该项目的 GitHub issues。
- 它的特点是使用 sqlite 进行本地优先的日志记录,并支持通过
- **Gradio 推出引导式 gr.Walkthrough:Gradio**
5.45.0版本引入了新的gr.Walkthrough组件来引导首次访问者,适用于伴随新模型发布的复杂 App,并原生支持输入验证,无需队列等待即可通知用户输入无效(见附图)。 - **Gradio 发布字幕支持及更多功能**:新版本包含用于自定义多页面 App 布局的新
gr.Navbar组件、图像水印、音频字幕(适用于 TTS 或转录演示),以及针对 iframe 和 i18n 的各种 Bug 修复。- 使用
pip install --upgrade gradio进行升级。
- 使用
HuggingFace ▷ #smol-course (35 messages🔥):
Colab Notebook Error, SmolLM3 Fine-Tuning Clarification, Study Groups Forming, SFT Configuration
- **Colab 链接在初始错误后已修复**:成员报告从 HuggingFace Learn 页面打开指令微调的 Colab notebook 时出现错误,但链接已修复为此链接。
- 一位成员在授权 GitHub 后成功访问。
- **SmolLM3 微调确认:课程讲师确认,在所需数据集(SmolTalk2)上微调 **SmolLM3-Base 并提交微调版本是正确的方法,但澄清这是为了排行榜,且任何提升分数的方法都可以尝试。
- 讲师指出,每个单元都涉及向同一个排行榜提交一个新模型。
- **学习小组倡议启动**:成员们正在组织学习小组(特别是欧洲地区),课程维护者建议使用 community tab 进行协调。
- 课程维护者还提出了为最大的学习小组提供奖品的想法,这提供了一个潜在的动力。
- **SFT 配置选项:针对用户关于使用 **SmolLM3-Base 和自定义 Tokenizer 以确保使用 Chat Template 的问题,课程讲师指向了
SFTConfig中的chat_template_path参数,并提供了 参考文档。- 讲师澄清,使用单独的 Base 模型和 Instructor Tokenizer 是指定 Chat Template 的一种有效变通方法,但理想情况下,任何 Chat Template 都应该可以与 SFT 和 Base 模型配合使用。
HuggingFace ▷ #agents-course (8 messages🔥):
课程开始日期、证书截止日期、编程练习错误、自我介绍
- 课程上线盛况:多名成员宣布他们今天开始了 Agent 课程。
- 一名成员从“现在让我们创建我们的第一个 Agent…”阶段开始。
- 证书截止日期说明:一名成员询问了直播录像中提到的证书截止日期。
- 他们询问现在参加课程是否会错过获得证书的机会。
- 编程故障已解决:一名成员报告遇到了上周未出现的编程练习错误(AgentGenerationError)。
- 他们表示该问题在第二天已得到修复。
- 新人聚集地:多名成员介绍自己是课程的新学员。
- 一名拥有 5 年软件工程经验的成员正在寻找学习伙伴。
OpenAI ▷ #ai-discussions (52 messages🔥):
LLM 存在主义崩溃如同社区剧场、更改 OpenAI 账户主邮箱、GPT-5 问题、用于认知架构的 AI、自动申请工作的 AI Agent
- LLM 存在主义崩溃变成喜剧!:一名成员开玩笑说,诱导 LLM 进入虚假的存在主义崩溃在如今就像是社区剧场,并补充说照本宣科的过度表演也是其中的一部分。
- 该评论是针对一张大脑思考其存在意义的卡通图片 (google_ai_plus.webp) 发表的。
- 更改 OpenAI 账户邮箱:不可能:一名成员询问如何在保留活跃的 $200 Pro subscription 和关联支付方式的情况下,更改其 OpenAI 账户的主邮箱。
- 另一名成员简短地回答:你做不到,并附上了一个 OpenAI 帮助文章链接 确认了这一点。
- GPT-5 故障困扰提示词用户:多名用户报告了 GPT-5 的问题,包括网络错误、停顿和断开连接。
- 一名用户推测 GPT-5 的目的是让人们进行更多提示,从而消耗更多 Token,而其他人则确认它对他们来说似乎正常。
- AI 工具激发新的认知架构:一名成员分享了一个项目,旨在为有执行功能障碍(Executive Functioning Challenges)的人创建工具,并利用 AI 开发新的认知架构。
- 他们链接了一篇介绍性的 Substack 文章 并请求反馈。
- AI Agent 自动申请工作:一名成员正在构建一个 AI Agent,它可以打开招聘网站页面,查找符合类别的职位,然后自动申请。
- 鉴于现有的 browser-use 库存在挑战,他们正在寻求设计系统的帮助,以便在完成申请提交之前预测下一个最佳操作。
OpenAI ▷ #gpt-4-discussions (7 messages):
Bug 报告权限问题、GPT 侧边聊天 vs 创建侧边聊天、知识库文件、ChatGPT 登录问题
- Bug 报告权限被拒绝?:一名用户最初没有在 Bug 报告频道发帖的权限,但后来弄清楚了如何提交 Bug 报告。
- 另一名成员对延迟回复表示歉意,并对该用户找到了 Bug 报告的“入口”感到高兴。
- GPT 侧边聊天改写问题:一名新用户报告称,“创建侧边聊天(create side chat)”功能只会改写知识库文件的内容,而“GPT 侧边聊天(gpt side chat)”则能正确提取文本。
- 该用户正试图完善一个桌面角色扮演系统,并希望系统能提取给定 “.md” 文件中当前编写的内容。
- ChatGPT 登录困扰持续存在:一名用户报告称,尽管采取了启用双重身份验证(two-factor authentication)、更改密码和退出所有账户等安全措施,但仍有约 5 天无法使用 ChatGPT。
- 该用户正在寻求解决这一持续登录问题的帮助。
OpenAI ▷ #prompt-engineering (4 messages):
Transparent Optimizations Proposal, Creative Writing Prompts for Claude 4, PDF Hosting Alternatives
- 发布透明优化提案 (Transparent Optimizations Proposal):一名成员发布了关于 Transparent Optimizations 的提案,引入了 optimizer markers(优化器标记)、prompt rewrite previews(Prompt 重写预览)和 feasibility checks(可行性检查)。
- 提案链接已发布在 Discord 频道中,并征求反馈、建议和投票:Transparent Optimizations Proposal。
- 渴望 Claude 4 能力的创意 Prompt:一名成员请求能够让模型发挥创意的 Prompt,类似于 Claude 4 sonnet,特别是针对 creative writing(创意写作)和 human-like dialogue(类人对话)。
- 该成员询问是否有任何预设(presets)可以帮助实现这类创意输出。
- 考虑 PDF 托管偏好:一名成员请求将 PDF 托管在不需要下载即可查看的地方。
- 未具体说明请求涉及的是哪份 PDF。
OpenAI ▷ #api-discussions (4 messages):
Transparent Optimizations, Optimizer Markers, Prompt Rewrite Previews, Feasibility Checks
- 提议优化透明度 (Optimization Transparency):一名成员发布了关于 Transparent Optimizations 的提案,引入了 optimizer markers、prompt rewrite previews 和 feasibility checks。
- 该成员请求如果其他人觉得有用,请在 提案 上提供反馈、建议和投票。
- 不建议 PDF 下载:一名成员请求将 PDF 文件托管在不需要下载即可访问的地方。
- 未具体说明引用的是哪个 PDF 文件。
Moonshot AI (Kimi K-2) ▷ #general-chat (55 messages🔥🔥):
EmbeddingGemma, Google product lifecycle, K2-Think model, Kimi Researcher report generation, SMS sign up issues
- EmbeddingGemma 获得好评:频道成员认定 EmbeddingGemma 在 embedding 方面表现非常出色。
- Google 砍掉产品的黑历史困扰 EmbeddingGemma:尽管 EmbeddingGemma 是一个可以永久运行的开放模型,但一些人对 Google 砍掉产品的历史表示担忧。
- 发布者指出更新的重要性:不可避免地会出现更多类似和/或更好的产品,如果 Google 停止更新,想象一下尝试迁移的难度。
- 受 Qwen 启发的 K2-Think 模型:HuggingFace 上的 K2-Think 模型 似乎基于 Qwen,推测它是 Qwen2.5-32B 的修改版本。
- 据报道,它是由 Institute of Foundation Models, Mohamed bin Zayed University of Artificial Intelligence(穆罕默德·本·扎耶德人工智能大学基础模型研究所)进行微调的。
- Kimi Researcher 报告生成耗时意外地长:一位用户询问 Kimi Researcher 花 45 分钟生成一份报告是否正常,另一位用户回答 这很正常。
- 另一位用户插话称,如果它能生成 一个精美的网页,谁会在意花多长时间,而另一位用户推测该报告至少消耗了 100-250k tokens。
- 短信注册出现问题:一位用户报告称他们没有收到用于注册的 SMS/短信,并询问该联系谁。
- 另一位用户建议联系第一位用户,他是该联系的人。
aider (Paul Gauthier) ▷ #general (38 messages🔥):
Aider vs Roo/Cline, GPT-OSS-120B performance, Leaderboard accuracy, GPT-5 chat latest, Aider config options
- Aider 在 GPT-OSS-120B 上的表现优于 Roo/Cline:一位用户发现 Aider 使用 gpt-oss-120b 一次性完成任务的速度和效果都优于 Roo/Cline,突显了其 repomap 功能的有效性。
- GPT-OSS-120B 得分为 68,在启用 repomap 后,得分提升至 78.7。
- GPT-OSS 模型在排行榜上击败 Qwen3:有用户注意到 leaderboard 似乎缺少 gpt-oss 的基准测试,引发了关于其准确性和更新频率的讨论。
- 该排行榜最后更新于 7 月 11 日,显示 GPT-OSS-120B 得分为 68(未开启 repomap)和 78.7(开启 repomap),表现优于 Qwen3。
- GPT-5 Chat Latest 是纯非推理模型:一位用户澄清说 gpt5-chat-latest 是一个纯粹的非推理模型,不同于混合型的 GPT-5 (minimal/low/med/high) API 版本。
- 它接受与 gpt4.1 相同的参数,不接受任何推理参数,甚至不支持 verbosity。
- 配置文件可处理所有选项:当被问及 YAML 配置文件 是否能涵盖所有可能的选项时,一位用户表示它应该可以处理所有选项。
- AI 工程师承接新项目:一位用户宣传了其作为 AI Engineer 的技能,专注于使用 GPT-4o、LangChain、AutoGen、CrewAI 以及其他前沿工具构建自主 Agent。
aider (Paul Gauthier) ▷ #questions-and-tips (14 messages🔥):
Model API URL, Auto-accept Aider Files, Aider vs. No-Code Platforms
- 用户询问如何更改模型 API URL:一位用户寻求更改模型 API URL 的指导,并提供了一个 Stack Overflow 链接 作为示例。
- 该用户还询问了如何为特定查询设置“快速模型”,建议使用类似
/model model-fast后接/ask blah的命令结构。
- 该用户还询问了如何为特定查询设置“快速模型”,建议使用类似
- Aider 能否自动接受文件?:一位用户询问是否可以通过使用
--yes-always标志来自动接受 Aider 提议添加的文件。- 另一位成员回答说,这无法细化到特定问题,
--yes-always适用于添加文件,但不适用于pip install。
- 另一位成员回答说,这无法细化到特定问题,
- Aider 对比无代码平台:一位用户分享了他们使用 Aider 的经验,并怀疑自己在进行无代码风格开发(特别是在设定规范或构建网站时)的方法是否正确。
- 他们正在寻求关于如何最大化 Aider 潜力的建议,以及它是否能达到他们广泛使用的 Replit 或 Lovable 等平台的灵活性。
Eleuther ▷ #general (13 messages🔥):
AI Automation, Waterloo Students in Open Source AI, GCG adversarial suffix jailbreaks
- 关于 AI 自动化的推测:一位成员询问 AI 是否已经可以自动化赚钱,引发了讨论。
- 目前没有立即提供解决方案,该问题仍作为一个开放性课题。
- 滑铁卢大学学生涌入开源 AI 领域:一位来自滑铁卢大学 (University of Waterloo) 的学生介绍了自己,提到了他们对语言模型的兴趣以及在 Waterloo VIP Lab 的工作。
- 另一位成员指出,EleutherAI 服务器的一半初始成员以及当前 OWL (Wayfarer) 小组中的许多人也都是滑铁卢大学的学生。
- 应对 GCG 对抗性后缀越狱:一位成员询问了修复 GCG 对抗性后缀越狱 (adversarial suffix jailbreaks) 的方法。
- 他们想起 Anthropic 有一篇关于消除可迁移对抗性攻击的论文,但记不清具体细节,目前没有给出即时回答。
Eleuther ▷ #research (36 messages🔥):
Sequence packing/padding, GLM 4.5 arguments, Lossless packing strategies, Ordering of the pre-training corpus, RL approach for language models
- 填充与打包的困惑探讨 (Padding and packing perplexities pondered):一位成员询问了关于 Sequence packing/padding 的 SOTA 研究现状。
- 装箱算法(Bin packing)最能平衡 Batch:成员们讨论了 Bin packing 对样本长度的影响。
- 有人指出 Bin packing 平衡了(每个 Batch 的)样本长度分布。如果没有 Bin packing,文本会被截断而不是填充,从而导致信息丢失。
- 截断作为增强手段是否更胜一筹? (Truncation triumphs as augmentation?):成员们辩论了 随机截断(random truncation) 是否是一种好的数据增强策略。
- 一位成员建议在 预训练语料库的排序(ordering of the pre-training corpus) 方面进行更多实证研究,例如,如果你的打包方式截断了一个文档,那么确保第二部分出现在第一部分 之后 是否是个好主意?
- Meta 通过自我博弈(Self-Play)挖掘模型提升:一位成员重点介绍了 来自 Meta Superintelligence Labs 的一篇论文,该论文关于一种 RL 方法,允许语言模型在没有额外数据的情况下通过 Self-Play 进行自我提升。
- 幻觉处理被击败了? (Hallucination handling hammered?):一位成员分享了一条 推文 和 论文,声称其效果优于 OpenAI 的幻觉废话(hallucination slop)。
- 另一位成员对这篇论文表示怀疑,质疑在普通运行条件下使用高斯噪声(Gaussian noise)来理解模型行为的价值。
Eleuther ▷ #scaling-laws (2 messages):
Transformer Model Parameters, Dataset Token Size
- Transformer 参数经验法则出现:一位成员询问是否存在一个 经验法则(rule of thumb),用于确定一个原生 Transformer 模型为了有效学习 T 个 Token 的数据集,应该具备的最佳参数数量。
- T = 20P:另一位成员简洁地回答道,T = 20 P(其中 T 是 Token 数量,P 是参数量)。
Eleuther ▷ #multimodal-general (1 messages):
ArXiv Endorsement Request, cs.CV, Undergrad seeking Endorsement
- 本科生在 Vision 领域寻求 ArXiv 背书:一名无机构附属的本科生正在寻求 cs.CV 类别的 arXiv 背书。
- 他们请求任何具有背书资格或认识背书人的人提供帮助,并愿意进行讨论。
- 请求 ArXiv 背书协助:一名学生在向 ArXiv 的 cs.CV 提交论文时需要背书。
- 作为一名无机构附属的本科生,他们正在寻找能够为其背书或将其引荐给背书人的人。
Modular (Mojo 🔥) ▷ #general (5 messages):
Leetcode add two numbers in Mojo, Mojo dev environment docker container
- 链表永存:如何在 Mojo 中安全地编写 Leetcode ‘两数相加’:一位成员询问如何在 Mojo 中使用安全的链表编写 Leetcode ‘Add Two Numbers’ 问题,以避免使用不安全指针(unsafe pointers)。
- 另一位成员建议使用
LinkedList。
- 另一位成员建议使用
- Mojo 开发环境:Docker 容器探索:一位成员询问是否有可用的 Docker 容器检查点(checkpoint) 来运行 Mojo 开发环境。
Modular (Mojo 🔥) ▷ #mojo (12 条消息🔥):
struct 中的条件字段,路线图上的 mojo compiler,venv 需求,包管理解决方案,classes vs structs
- 关于 Struct 条件字段的请求引发辩论:一名成员询问了在 Mojo structs 中使用条件字段的可能性,建议采用一种可以根据布尔值或可选参数包含字段的语法。
- 另一名成员提供了一个使用
InlineArray[T, 1 if cond else 0]的变通方案,而其他人则推测了使用参数系统来控制 struct 中填充(padding)的潜力。
- 另一名成员提供了一个使用
- Mojo Compiler 路线图引发对 Venv 的猜测:一名成员询问 2026 年路线图上的 mojo compiler 是否会消除对 venv 的需求,并表达了对类似 Go 的打包系统的渴望。
- 另一名成员澄清说,2026 年 Mojo compiler 的开源并不一定会改变用户与 Mojo 的交互方式,但将允许独立构建工具链。
- Mojo 包管理倾向于 Python 生态系统:针对关于包管理的问题,一名成员表示目前没有开发自定义解决方案的计划,相反,团队正在利用现有的 Python ecosystems。
- 另一名成员提到,工具链需要以某种方式打包以便分发,他们选择了与 Python 保持一致的打包方式,如 Python wheels 或 Conda packages。
- 讨论 Structs vs Classes 的性能差异:一名成员反对在高性能代码中使用 classes,原因是存在 vtable 查找以及可能阻碍函数内联(inlining)。
- 另一名成员指出,Pixi 或 Python 虚拟环境在维护项目依赖(尤其是 Python 依赖)方面具有优势。