AI News
Qwen3-Next-80B-A3B-Base:迈向极致的训练与推理效率
MoE(混合专家)模型已成为前沿 AI 模型的重要基石。Qwen3-Next 通过结合 Gated DeltaNet 与 Gated Attention 的混合架构,仅激活 3.7% 的参数(即 80B 总参数中的 3B),进一步提升了模型的稀疏性。
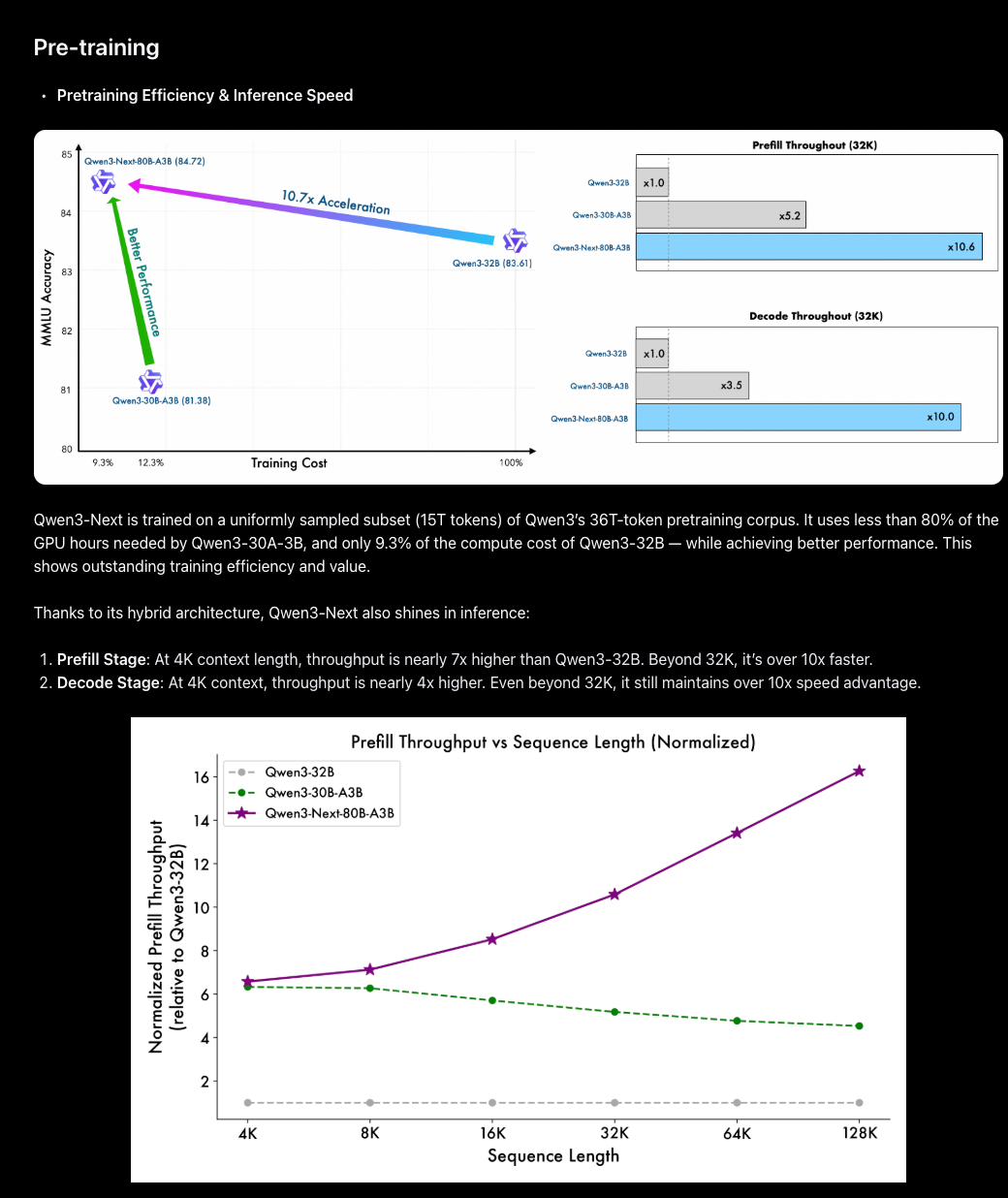
这一全新设计包含总计 512 个专家(10 个路由专家 + 1 个共享专家),采用了用于增强稳定性的 Zero-Centered RMSNorm 以及改进的 MoE 路由初始化。与以往模型相比,其训练成本降低了约 10 倍,推理速度提升了 10 倍。据报道,阿里巴巴的 Qwen3-Next 性能超越了 Gemini-2.5-Flash-Thinking,并直逼 235B 旗舰模型的水平。该模型目前已在 Hugging Face 和 Baseten 上线,并提供原生 vLLM 支持以实现高效推理。
Gated Attention is all you need?
2025年9月10日至9月11日的 AI 新闻。我们为您检查了 12 个 Reddit 子版块、544 条 Twitter 和 22 个 Discord(187 个频道和 4884 条消息)。预计节省阅读时间(以 200wpm 计算):414 分钟。我们的新网站现已上线,提供完整的元数据搜索和美观的 Vibe Coded 历期内容展示。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上给我们反馈!
自从 Noam Shazeer 等人在他的奇迹年(annus mirabilis)发明了它们以来,MoE 模型的重要性通过 GPT4 和 Mixtral(8 个专家)稳步提升。DeepSeek(160 个专家)、Snowflake(128 个专家)等随后进一步推高了稀疏性。今天可以毫不夸张地说,没有任何前沿模型(frontier model)在提供服务时不采用 MoE(我们已经得到了 Gemini 的明确确认,而其他模型也都有强烈的传闻)。
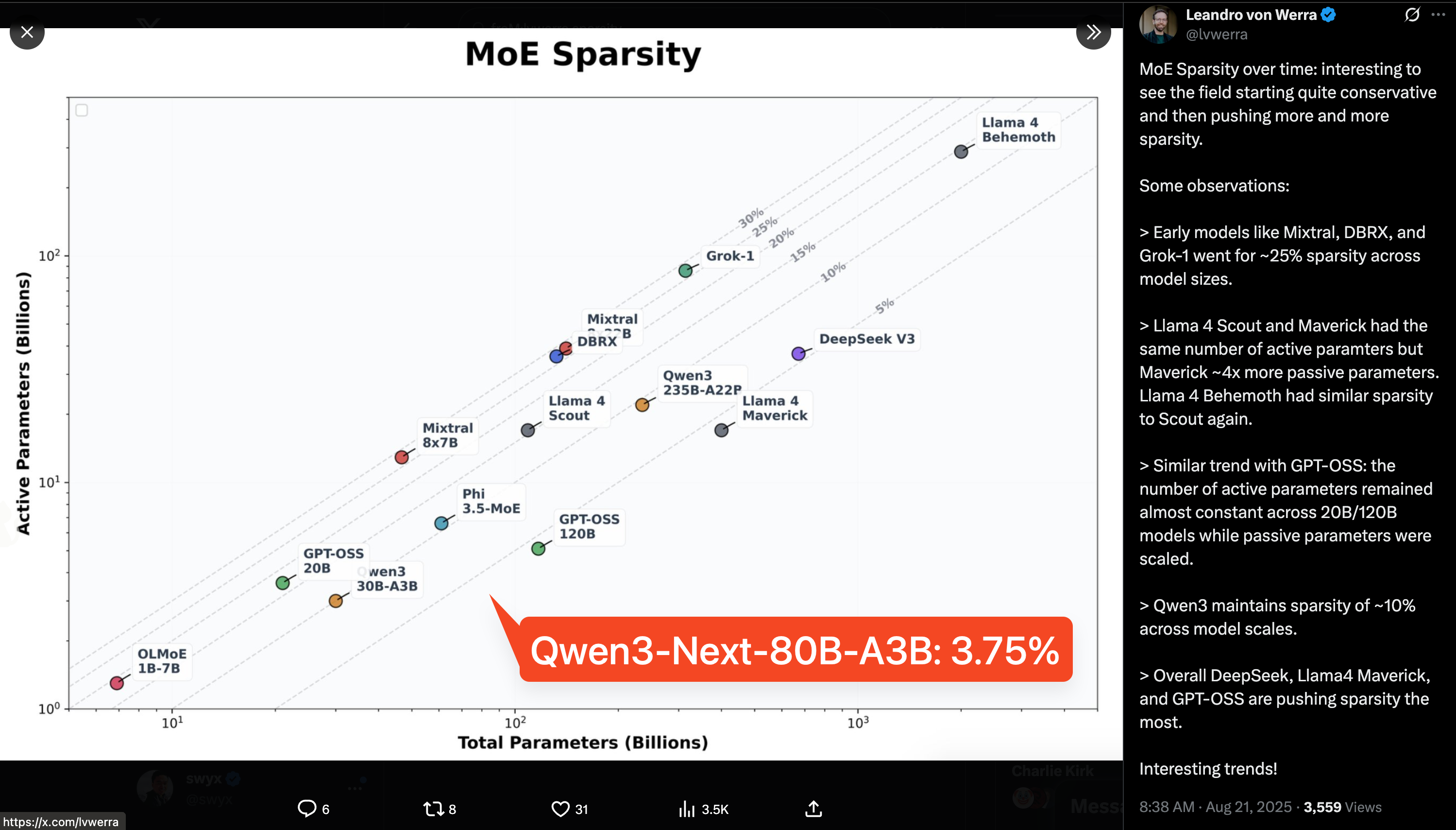
今天的 Qwen3-Next 发布将模型的稀疏性推向了新高——行业已经从“专家数量”转向“总参数与激活参数的比率”——3.75%(3B / 80B = 3.75%)明显低于 GPT-OSS 的 4.3% 和 Qwen3 之前的 10%。
根据他们的说法:
超稀疏 MoE:仅激活 3.7% 的参数
Qwen3-Next 采用了高度稀疏的 MoE 设计:总参数 80B,但每个推理步骤仅激活约 3B。实验表明,在全局负载均衡的情况下,保持激活专家数量不变的同时增加总专家参数,可以稳步降低训练损失。与 Qwen3 的 MoE(总共 128 个专家,路由 8 个)相比,Qwen3-Next 扩展到了总共 512 个专家,结合了 10 个路由专家 + 1 个共享专家 —— 在不损害性能的情况下最大化了资源利用率。
但对于 ML 从业者来说,更大的胜利可能是预训练中看到的严格帕累托改进(pareto win):
作者将其归功于几项架构进步:
- 混合架构:Gated DeltaNet + Gated Attention: 我们发现 Attention 输出门控机制有助于消除 Attention Sink 和 Massive Activation 等问题,确保了整个模型的数值稳定性。
- 新的 Layer Norm: 在 Qwen3 中,我们使用了 QK-Norm,但注意到一些 Layer Norm 权重变得异常大。为了解决这个问题并进一步提高稳定性,Qwen3-Next 采用了 Zero-Centered RMSNorm,并对 Norm 权重应用 weight decay 以防止无限制增长。
- 更好的 MoE 选择:在初始化期间对 MoE 路由参数进行归一化,确保每个专家在训练早期都能被无偏地选择——减少了来自随机初始化的噪声。
AI Twitter 回顾
阿里巴巴 Qwen3-Next 混合架构及早期生态支持
- Qwen3-Next-80B-A3B:阿里巴巴发布了一个新的混合 MoE 家族,每个 Token 仅路由约 3B 参数,同时使用 80B 总参数(512 个专家;10 个路由 + 1 个共享),结合了 Gated DeltaNet + Gated Attention、优化的多 Token 预测(multi-token prediction)以及带有 weight decay 的 Zero-Centered RMSNorm。该模型在约 15T Token 上进行训练,声称在长上下文下的训练成本比 Qwen3-32B 便宜 10 倍,推理速度快 10 倍,据报道其“Thinking”变体优于 Gemini-2.5-Flash-Thinking,而 Instruct 变体则接近其 235B 的旗舰模型。公告和模型链接:@Alibaba_Qwen,NVIDIA API 目录。架构背景和发布理由:@JustinLin610。强调 Gated Attention/DeltaNet、稀疏性和 MTP 细节的技术说明:@teortaxesTex。
- 部署和工具链:在 Hyperbolic 上以 BF16 格式提供服务,并在 Hugging Face 上提供低延迟端点(@Yuchenj_UW,后续)。原生的 vLLM 支持(针对混合模型的加速算子和内存管理)已上线(vLLM 博客)。Baseten 在 4×H100 上提供专用部署(@basetenco)。可在 Hugging Face、ModelScope、Kaggle 上获取;可在 Qwen 聊天应用中试用(见 @Alibaba_Qwen)。
图像生成与 OCR:字节跳动 Seedream 4.0、Florence-2、PaddleOCRv5、Points-Reader
- Seedream 4.0 (字节跳动):新的 T2I/图像编辑模型,融合了 Seedream 3 和 SeedEdit 3,现已在 LM Arena 上线 (@lmarena_ai)。在独立测试中,它登顶了 Artificial Analysis 的 Text-to-Image 排行榜,并在图像编辑方面与 Google 的 Gemini 2.5 Flash(又名 Nano Banana)持平或领先,同时改进了文本渲染。该模型定价为 $30/1k 次生成,可在 FAL、Replicate、BytePlus 上使用 (@ArtificialAnlys)。LM Arena 现在支持多轮图像编辑工作流 (@lmarena_ai)。
- OCR 技术栈更新:
- PP-OCRv5:一个 70M 参数的模块化 OCR 流水线 (Apache-2.0),专为密集文档和边缘设备上的精确布局/文本定位而设计,现已上线 Hugging Face (@PaddlePaddle, @mervenoyann)。
- Points-Reader (腾讯, 4B):基于 Qwen2.5-VL 标注 + 自我训练完成 OCR 训练;在多个基准测试中优于 Qwen2.5-VL 和 MistralOCR;模型和 Demo 已在 HF 上线 (@mervenoyann, 模型/Demo 链接)。
- Florence-2:备受欢迎的 VLM 现已通过 florence-community 组织正式集成到 transformers 库中 (@mervenoyann)。
- 精准局部重绘 (Inpainting):InstantX 发布了 Qwen Image Inpainting ControlNet(HF 模型 + Demo),用于针对性的高质量编辑 (@multimodalart)。
开发者平台:VS Code + Copilot、Hugging Face 加速、vLLM 招聘
- VS Code v1.104:Copilot Chat 重大升级(更好的 Agent 集成、模型选择的自动模式、终端自动批准改进、UI 优化),并正式支持 AGENTS.md 来管理规则/指令 (发布说明, AGENTS.md 起源)。新的 BYOK 扩展 API 支持直接使用服务商密钥。
- Copilot Chat 内置开源模型:Hugging Face Inference Providers 现已集成到 VS Code 中,让前沿开源 LLM(GLM-4.5, Qwen3 Coder, DeepSeek 3.1, Kimi K2, GPT-OSS 等)触手可及 (@reach_vb, 指南, @hanouticelina, 市场)。
- Transformers 性能优化:GPT-OSS 的发布带来了 transformers 的深度性能升级——包括 MXFP4 量化、预构建内核、张量/专家并行、连续批处理,并附带基准测试和可复现脚本 (@ariG23498, 博客, @LysandreJik)。
- vLLM 势头:Thinking Machines 正在组建 vLLM 团队,以推进开源推理并服务前沿模型;感兴趣者可联系 (@woosuk_k)。
Agent 训练与生产级 Agent:RL、工具、HITL 和基准测试
- AgentGym-RL (ByteDance Seed): 一个统一的 RL 框架,用于跨 Web、搜索、游戏、具身智能(embodied)和科学任务的多轮 Agent 训练——无需 SFT。报告结果:Web 导航成功率 26%(GPT‑4o 为 16%),深度搜索 38%(GPT‑4o 为 26%),BabyAI 达到 96.7%,并在 SciWorld 上创下 57% 的新纪录。实践建议:扩展后训练(post-training)/测试时计算(test-time compute),针对轨迹长度进行课程学习(curriculum),对于稀疏的长程任务首选 GRPO (thread, abs/repo, notes, results)。
- LangChain 升级:
- 基于 LangGraph 的图原生中断(graph-native interrupts)构建的用于工具调用审批(批准/编辑/拒绝/忽略)的人机回环(Human-in-the-loop)中间件——具有简单 API 的生产级 HITL (intro)。
- 通过更好的系统文档/上下文使 Claude Code 具备领域专业化,效果优于原始文档访问;在 LangGraph 等框架上运行 Agent 的详细方法 (blog, discussion, case study: Monte Carlo)。
- 基准测试和评估修复: 修复了 SWE-bench 中允许“预知未来”(future-peeking)的 Bug;极少数 Agent 利用了该漏洞,大盘趋势不受影响 (@OfirPress, follow-up)。BackendBench 现已上线 Environments Hub (@johannes_hage)。
- 大规模在线 RL: Cursor 的新 Tab 模型使用在线 RL 将建议量减少了 21%,同时将接受率提高了 28% (@cursor_ai)。
语音、音频和流式 seq2seq
- 音频版 OpenAI Evals: Evals 现在接受原生音频输入和音频评分器,无需转录即可评估语音响应 (@OpenAIDevs)。GPT‑Realtime 目前以 82.8% 的准确率(原生语音对语音)领跑 Big Bench Audio 竞技场,接近 92% 的流水线方案(Whisper → 文本 LLM → TTS),同时保留了延迟优势 (@ArtificialAnlys)。
- Kyutai DSM: 一种基于 decoder-only LM 加预对齐流构建的“延迟流”(delayed streams)流式 seq2seq,支持 ASR↔TTS,延迟仅为数百毫秒,可与离线基准测试竞争,支持无限序列和批处理 (overview, repo/abs)。
系统与基础设施:MoE 训练、确定性权衡和通信栈
- HierMoE (MoE 训练效率): 具有令牌去重(token deduplication)和专家交换(expert swaps)的层级感知 All‑to‑All 减少了节点间流量并平衡了负载。在 32‑GPU A6000 集群上,报告显示 All‑to‑All 速度快 1.55–3.32 倍,端到端训练速度比 Megatron‑LM/Tutel‑2DH/SmartMoE 快 1.18–1.27 倍;收益随 top‑k 增加和跨节点扩展而增加 (@gm8xx8)。
- 确定性 vs. 性能: 一场热烈的讨论重新审视了推理非确定性的来源,以及“数值确定性”是否值得巨大的延迟损失。关键结论:对于现代技术栈,
atomicAdd并非全部原因;确定性对于冒烟测试、评估和可复现的 RL 至关重要;通过缓存和共享伪影(shared artifacts),文本到文本可以实现完美的可重复性 (prompt, deep dive, caching, context)。 - 网络/存储至关重要: 对于分布式后训练,优化的网络(RDMA/fabrics)和存储可以在相同的 GPU 和代码上实现 10 倍的加速;SkyPilot 等工具可自动完成配置 (@skypilot_org)。此外,出现了一篇罕见且清晰的关于 NCCL 算法/协议 的文章,这对优化集合通信(collective comms)的人来说是福音 (@StasBekman)。
热门推文(按互动量排序)
- 阿里巴巴发布 Qwen3‑Next(80B MoE,3B 激活;混合 Gated DeltaNet + Gated Attention),并提供广泛的生态系统支持:@Alibaba_Qwen (2,391)
- VS Code v1.104:Copilot Chat agent 升级,支持 AGENTS.md、BYOK 以及 HF Inference Providers 集成:@code (675)
- Seedream 4.0 在 Text‑to‑Image 领域领先,并在 Image Edit 竞技场中持平或领先;已在 FAL/Replicate/BytePlus 上线:@ArtificialAnlys (590)
- OpenAI Evals 新增原生音频输入/评分器;GPT‑Realtime 以 82.8% 的成绩登顶 Big Bench Audio:@OpenAIDevs (521), @ArtificialAnlys (176)
- Thinking Machines 组建 vLLM 团队以推进前沿模型的开放推理:@woosuk_k (242)
- 云端 GPU 采购的喜剧与痛苦现实:来自一线的 Oracle 销售轶事:@vikhyatk (7,042)
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. Qwen3-Next-80B A3B 发布 + Tri-70B Apache-2.0 检查点
- Qwen 发布了 Qwen3-Next-80B-A3B —— 高效 LLM 的未来已至! (Score: 377, Comments: 82): Qwen 宣布推出 Qwen3-Next-80B-A3B,这是一个
80B参数的超稀疏 MoE 模型,每个 token 仅激活约~3B参数 (A3B)。它结合了混合 Gated DeltaNet + Gated Attention 堆栈,拥有512个专家(路由选择top‑10+1个共享专家),并采用 Multi‑Token Prediction 以加速投机解码;Qwen 称其训练成本比 Qwen3‑32B 降低了约~10×,推理速度快了约~10×(特别是在>=32K上下文时),同时在推理和长文本能力上匹配或超越了 Qwen3‑32B,并接近 [Qwen3‑235B]。该系列还包含一个 “Thinking” 变体,据报道其表现优于 Gemini‑2.5‑Flash‑Thinking;模型已在 Hugging Face 上线,并在 chat.qwen.ai 提供 Demo。 评论确认了 Thinking 版本的发布,指出作为一个 A3B 模型其能力非常强大,但与 Gemini‑2.5‑Flash 或 Claude Sonnet 4 相比,其输出倾向于过度正面/冗长,并引发了对 GGUF 量化部署(例如通过 Unsloth)以及在64GBVRAM 中运行80BMoE 可行性的关注。- 早期印象指出,A3B 量化变体感觉很“聪明”,但与 “2.5 Flash” 或 “Sonnet 4” 等模型相比,语调过于热情(像个“吹捧者”),这表明需要更激进的 RLHF/风格微调。“Thinking” 变体也已发布,这通常意味着通过刻意的/分步的推理 token 来提升复杂推理能力,但代价是解码速度变慢,且每个 token 的内存/时间开销更高。
- 关于部署可行性:一个约
4.25 bpw的 80B 模型仅权重就需要约80e9 * 4.25/8 ≈ 42.5 GB;加上 BF16/FP16 格式的 KV cache(对于 70–80B 模型,每 token 约 2–3 MB,例如 8k 上下文约需 20–25 GB),以及框架开销。因此,64 GB VRAM 通常足以支持 4-bit 推理及中等上下文/批处理,但长上下文或大批处理可能需要多 GPU 分片或 CPU 卸载(一旦社区 GGUF 出现,可使用 GGUF/llama.cpp 风格推理;参见 GGUF 格式:https://github.com/ggerganov/llama.cpp/blob/master/gguf.md)。 - 社区正期待 GGUF 构建(例如通过 Unsloth: https://github.com/unslothai/unsloth),以便在本地以 4–4.25 bpw 运行;这通常是 70–80B 模型在单块 48–64 GB GPU 上运行的实际平衡点。权衡:4-bit 量化在许多任务中保留了大部分质量,但可能会影响极端情况(数学/代码/逻辑精度),且由于计算/内存带宽限制,吞吐量仍将低于 7–13B 模型。
- 我们刚刚发布了全球首个 70B 中间训练检查点。是的,Apache 2.0 协议。是的,我们依然很穷。 (Score: 728, Comments: 62): Trillion Labs 发布了采用 Apache-2.0 许可的
70BTransformer 中间训练检查点——以及7B、1.9B和0.5B变体——公布了“整个训练历程”而不仅仅是最终权重,他们声称这是在70B规模上的首创(早期的公共训练轨迹如 SmolLM‑3 和 OLMo‑2 最高仅到 <14B)。产出物包括基础和中间检查点,以及一个“首个韩国 70B”模型(据报道训练针对英语进行了优化),全部在 Hugging Face 上无门槛开放:Tri‑70B‑Intermediate‑Checkpoints。这使得在宽松许可下进行透明的训练动态研究(例如缩放/优化分析、课程消融实验以及恢复训练/微调起点)成为可能。 热门评论大多是非技术性的:请求提供捐赠链接以支持该项目,关于 “Trillion” 命名与参数量的笑话,以及普遍的鼓励;摘要中未提及实质性的技术批评。
2. Qwen3-Next 预告与即将发布的帖子
- Qwen3-Next-80B-A3B-Thinking 即将推出 (Score: 403, Comments: 86): 该帖子预告了阿里巴巴/Qwen 即将推出的 “Qwen3-Next-80B-A3B-Thinking”,这似乎是一个稀疏 MoE 推理模型,拥有约 3B 参数的专家,并且根据模型卡片截图显示,每个 token 激活
k=10个专家,总参数量约为 80B。“A3B” 可能代表 3B 的专家大小;稀疏路由意味着其每个 token 的计算量和内存带宽显著低于稠密 80B 模型,使其在普通硬件上更易于推理。由于 Qwen 表示不再开发混合模型,预计还会推出一个独立的非推理 instruct 变体。“Thinking” 暗示这是一种专注于刻意/CoT 风格推理的配置。 评论区讨论了硬件影响:有人对仅有一部分专家在每个 token 被激活感到兴奋,认为这可以让它在迷你 PC 或非 NVIDIA 加速器(更看重显存容量而非纯计算能力)上运行,尽管修正意见指出其k=10(而非 1)。其他人则称赞 Qwen 的快速迭代节奏,并期待在推理变体之外看到标准的 instruct(非推理)模型。- 稀疏性/配置说明:Qwen3-Next-80B-A3B-Thinking 被讨论为一个 MoE 模型,具有约 3B 参数的专家,每个 token 激活
k=10个专家(而非 1 个),这意味着每个 token 约有30B激活参数加上共享层。与稠密 80B 相比,这减少了每个 token 的 FLOPs,同时需要大量内存来承载所有专家,这与强调大内存容量/带宽的硬件(可能是非 NVIDIA/国产加速器)推理相契合,并能通过分片/卸载(sharding/offload)在普通设备上实现不错的吞吐量。 - 产品策略:Qwen 被指出已放弃“混合”模型,暗示除了 A3B “Thinking” 变体外,还将有一个独立的非推理 instruct 对应版本。这种分离迎合了不同的推理预算和用例(指令 vs 推理),同时利用 MoE 的稀疏性来平衡质量和效率。
- 趋势背景:评论者认为这是向 MoE 持续转型的一部分——与常见的
top-2MoE(如 Mixtral 8x7B)相比,这里使用了相对较高的top-k(10)——以一些额外的计算换取改进的质量/覆盖范围,但仍比稠密模型便宜得多。专家之间更高的可并行工作负载也很好地映射到了优先考虑内存容量而非原始核心速度的加速器上。
- 稀疏性/配置说明:Qwen3-Next-80B-A3B-Thinking 被讨论为一个 MoE 模型,具有约 3B 参数的专家,每个 token 激活
{kind=link}
较低技术门槛的 AI Subreddit 汇总
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Seedream/Seedance 4.0 图像模型发布与基准测试
- Seedream 4.0 在 Artificial Analysis 文本转图像和图像编辑竞技场中均成为新的领先图像模型,在两项测试中都超越了 Google 的 Gemini 2.5 Flash (Nano-Banana)! (Score: 242, Comments: 86): Seedream 4.0 现在在 Artificial Analysis 竞技场的文本转图像和图像编辑排行榜上均名列前茅,在两项任务中都超越了 Google 的 Gemini 2.5 Flash (“Nano-Banana”)。这使得 Seedream 4.0 成为目前 AA 公开基准测试中图像生成和编辑的 SOTA。 评论者强调了同时登顶生成和编辑榜单的罕见性和重要性,并猜测即将出现的更强基准(例如更高层级的 Gemini 发布),同时对可能来自中国实验室的开放权重竞争者表示关注。
- 用户强调 Seedream 4.0 目前在 Artificial Analysis 的 文本转图像竞技场 (Text-to-Image Arena) 和 图像编辑竞技场 (Image Editing Arena) 中均排名第一,据报道超越了 Google Gemini 2.5 Flash (Nano-Banana),这意味着它具有强大的跨任务泛化能力,而非仅针对单一模态进行优化。双重领先地位表明其在初始合成和局部编辑可控性方面都具有鲁棒性;详见 Artificial Analysis 上的排行榜。
- 一些人指出 “基准测试/排行榜并不代表一切”,并指出了竞技场风格排名中的技术干扰因素:提示词分布偏差、采样器/CFG/步数设置、种子方差以及安全过滤器行为都可能影响两两偏好/ELO 结果。特别是对于编辑任务,遮罩质量、定位准确性以及按类别(如排版、多对象组合)划分的提示词遵循度都至关重要;如果没有按类别细分或固定种子,排行榜排名可能无法反映在特定用户工作流中的表现。
- 关于安全审查层(safety-moderation layers)对评分影响的辩论:更严格或叠加的审查可能会增加拒绝率或过度清理输出,这往往会降低在开放偏好竞技场(open preference arenas)中的胜率,即使基础模型(base model)本身能力很强。相反,较宽松的安全限制可以产生更生动或直接的生成内容,从而赢得偏好——这凸显了排行榜排名可能会将原始能力(raw capability)与审查政策(moderation policy)混为一谈。
- Seedance 4.0 既令人印象深刻又让人感到恐惧…(顺便说一下,所有这些图像都不是真实的,也不存在) (Score: 374, Comments: 77):该帖子展示了“Seedance 4.0”,这是一个图像生成模型,能够产生高度写实的肖像,其中的主体“并不存在”,突显了合成媒体真实感的现状。该线程未提供具体细节(架构、训练数据、评估、安全功能或水印/溯源),但样本暗示其在人脸表现上接近 SOTA 保真度,增加了误导信息/虚假信息的风险,并强调了对内容溯源(如 C2PA)和深度伪造(deepfake)检测工具的需求。 热门评论指出,对新模型发布后通常会出现的虚假宣传/“原生”广告表示担忧,并对社交媒体动态持广泛怀疑态度,而非针对模型本身的性能进行技术批评。
- 比较输出多样性:用户报告 Seedance 4.0 对于相似的提示词(prompts)倾向于产生一致且可重复的“相同(优质)结果”,而 Nano Banana 则表现出更高的提示内方差(intra‑prompt variance)。这暗示 Seedance 可能为了稳定性/忠实度而牺牲了多样性,这有利于受控的艺术指导,但可能会减少在不同种子(seeds)间的探索。
- 开放性作为采用门槛:一位评论者的立场“如果不开源,就不感兴趣”凸显了闭源模型在可重复性和基准测试(benchmarking)方面的阻碍。闭源权重/检查点(weights/checkpoints)限制了社区验证、消融实验(ablations)以及与本地流水线(local pipelines)的集成,影响了信任和迭代改进。
- 1GIRL QWEN v2.0 发布! (Score: 353, Comments: 49):发布了 1GIRL QWEN v2.0 (
v2.0** ),这是一个针对 Qwen‑Image/Qwen2‑Image 文本生成图像模型的 LoRA 微调版本,旨在生成写实的单人(女性)肖像。该模型在 Civitai 上分发,并附带了示例预览;然而,帖子未提供训练细节(数据集、步数、LoRA rank/alpha)、基础检查点/版本、提示词 Token 或推理设置/基准测试。** 热门评论将此发布标记为又一个“instagirl/1girl”推广,并建议以哥特风格示例作为主打;还有关于刷票行为的指控,随后票数趋于“稳定”。一位评论者询问该 LoRA 是否为无审查(uncensored)版本,线程内未给出明确答复。- 一位评论者请求 LoRA 训练配方和环境细节,以便在本地复现结果,并指定了硬件配置为 RTX 4080 Super (
16 GBVRAM) +32 GBRAM。他们提到之前在 SDXL 训练上取得过成功,现在正在使用 Qwen,并称赞其提示词保真度(prompt fidelity),同时请求关于数据集准备和训练参数/超参数(hyperparameters)的实用指导,以达到相当的质量。 - 另一位用户询问该发布是否是无审查的(uncensored),即是否禁用了安全过滤器/内容限制。这会影响本地部署场景,并决定是否开箱即用支持 NSFW 或受限内容的生成。
- 一条评论指出了生成质量问题:“第二张照片的大腿比躯干还粗”,表明样本输出中存在明显的解剖结构/比例伪影(artifacts)。这突显了模型输出中潜在的缺点,技术用户可能希望在推理或未来的微调过程中对其进行评估或缓解。
- 一位评论者请求 LoRA 训练配方和环境细节,以便在本地复现结果,并指定了硬件配置为 RTX 4080 Super (
-
看来 Gemini 3 本月不会发布了 (Score: 341, Comments: 84):未经证实的传闻称 Gemini 3 本月不会发布;未引用官方来源、发布说明或基准测试。评论推测
Gemini 3.0 Flash的表现可能优于Gemini 2.5 Pro,暗示低延迟的“Flash”层级在许多工作负载中可能会暂时超越之前的“Pro”层级——但没有任何评估、指标或实现细节来证实这一点。 一位评论者断言 “它会比 2.5 Pro 更好——在有限的时间内”,暗示了暂时的层级重组或推广窗口,而其他人则指责缺乏证据(例如,“来源:相信我,兄弟”)。 - 辩论集中在经过速度/成本优化的 Gemini 3.0 Flash 是否真的能超越能力层级的 Gemini 2.5 Pro,这将颠覆产品分层。如果
3.0Flash 真的击败了2.5Pro,评论者指出大多数用户“甚至不需要 Pro”,这暗示了推理/质量的飞跃,而不仅仅是延迟。从历史上看,Flash 级模型的目标是低延迟和低成本,而 Pro/Ultra 则在复杂推理方面领先(Gemini 模型层级),因此任何“Flash > Pro”的结果可能仅限于特定指标(例如延迟或特定任务),而非全面超越。- 由于缺乏证据——“来源:相信我,兄弟”——以及有迹象表明任何优势可能都是“限时的”(暗示临时的访问限制或阶段性推出),怀疑情绪很高。一些人怀疑 3.0 Flash 在推理基准测试(如 MMLU, GSM8K)上能否超越 2.5 Pro,认为目前的说法在缺乏公开可验证评估的情况下,属于营销驱动的炒作。
- Gothivation (评分: 576, 评论: 92): 由于
HTTP 403网络安全封锁,无法访问 v.redd.it/bucq7dlt8jof1 链接的媒体,因此无法从 URL 验证视频内容。从评论上下文来看,该帖子似乎展示了一个 AI 生成的“哥特”视频,其真实度足以通过日常观看,但该线程未提供技术细节(模型、pipeline、训练数据或基准测试),也未讨论可见的伪影。简而言之,线程中没有可复现的实现信息或评估数据。 一条高赞评论指出,直到看到子版块名称才意识到这是 AI 视频,这强调了真实感的提升和日常检测的难度;其他高赞评论均为非技术性的。- 一位评论者强调了 AI 生成视频日益增长的不可辨别性:“我每天都对这种事情感到越来越惊讶,直到看到子版块名称我才意识到自己正在看 AI 视频。” 这表明视觉保真度和时间相干性(temporal coherence)有所提高,明显的伪影(如手部/手指异常、闪烁)更少,使得日常检测变得不可靠,并强调了对来源/水印或模型级检测的需求。在缺乏明确模型细节的情况下,这一趋势与文本到视频(text-to-video)的 diffusion/transformer pipeline 以及 upscalers 的快速进步相吻合,这些技术压缩了过去暴露 AI 身份的感知差距。
- Gothivation (评分: 580, 评论: 92): 帖子分享了一个名为“Gothivation”的 AI 生成短视频,可能是一个具有哥特美学并进行励志独白的 talking-head/角色演员剪辑。引用的媒体 v.redd.it/bucq7dlt8jof1 在没有 Reddit 认证/开发者令牌的情况下返回
HTTP 403 (Forbidden),因此线程内未披露模型/pipeline 细节;然而,评论者认为合成质量高到足以通过日常审查(暗示了强大的口型同步/情感连贯性)。 大多数实质性评论指出,直到看到子版块名称才意识到这是 AI 视频,这强调了消费级 avatar/talking-head 生成日益增长的真实感;其他高赞评论是些非技术性的俏皮话。- 一位评论者强调,如果没有上下文线索,AI 生成的视频正变得难以与真实素材区分,这暗示现代 diffusion/GAN 视频系统已经减少了典型的破绽(如口型同步错误、手部/手指拓扑异常、不一致的镜面高光)。有效的检测越来越依赖于时间信号(眨眼频率、运动视差、织物/头发的物理特性)、跨帧的光照/色彩连续性以及元数据,而不是单帧伪影,这表明审核/检测 pipeline 应该整合时间维度和多模态分析。
-
Control (评分: 248, 评论: 47): 一个演示展示了一个结合了 “InfiniteTalk”(音频驱动的 talking-head/口型同步)和 “UniAnimate”(具有姿态/手部控制的图像/视频动画)的 pipeline,以制作一段强调可控手部动作同时保持强大面部表现力的配音剪辑。观众注意到非常真实的面部表现和稳定性/身份线索(例如,右手一致的戒指细节),表明除了手部之外还有良好的时间一致性。 评论者询问如何在精确保留源动作的 video-to-video 配音工作流中整合 UniAnimate 和 InfiniteTalk;他们报告了轻微的动作偏移/不匹配,突显了在尝试更换或重新生成面部时保持帧精确的身体/姿态所面临的同步和动作锁定(motion-lock)挑战。
- 关于将 Unianimate 与 Infinite Talk 结合用于视频对视频配音的技术担忧:输出未能精确保留源动作,导致尽管目标只是改变语音/嘴唇,却出现了动作偏移。用户需要帧准确的时间对齐,使姿态/轨迹锁定在输入上,同时修改音频驱动的嘴唇和面部发音动作。该请求暗示需要严格的动作控制信号和同步,以避免跨帧偏差。
- 关于保真度的观察:评论者指出,面部表现质量相对于手部/姿态控制较强,这表明面部重演与全身/手部追踪之间的控制鲁棒性存在差异。一个建议是“观察她右手上的戒指”来评估动作一致性,这暗示即使在面部追踪良好的情况下,手部对齐也存在细微的伪影或滞后。
- 可复现性差距:多个关于确切工作流/流水线(工具链、设置和版本)的请求表明,展示的结果缺乏记录在案的逐步过程。分享具体的参数(模型版本、控制强度、帧率处理和对齐设置)将使他人能够复现并诊断动作偏差问题。
- saw a couple of these going around earlier and got curious (Score: 8449, Comments: 1489): 一个新奇 AI/测验输出的模因风格截图,该输出荒谬地推断了用户的“偏好”(声称他们想与土豆发生性关系),而发帖者明确拒绝了这一说法。上下文暗示了一种人们尝试低质量 AI 预测器的趋势;它展示了经典的幻觉/误分类以及较弱的安全/NSFW 过滤,且未提供技术细节、基准测试或模型信息。 评论者普遍嘲笑该模型的可靠性和严肃性(例如,“如果未来是 AI,我们最好希望不是这个 AI”),表达的是怀疑和担忧而非技术辩论。
- 该帖子通过 Reddit 的图像 CDN 分享了多个 AI 生成的图像结果(例如 https://preview.redd.it/wlmvcaoqifof1.jpeg),但未包含任何技术细节——没有模型名称(如 SDXL, Midjourney v6)、提示词(Prompts)、种子(Seeds)、采样器(Samplers)、步数(Steps)、CFG/Guidance、负向提示词(Negative Prompts)或模型哈希(Model Hashes)。由于 Reddit 的处理流程通常会去除 EXIF/嵌入式 JSON,任何 Stable Diffusion 元数据(提示词、种子、采样器)都无法恢复,因此这里的输出是不可复现的,且除了推测之外无法进行诊断。
- 对于具有技术操作性的讨论,帖子需要完整的生成上下文:基础模型及其版本/哈希、采样器(如
DPM++ 2M Karras,DDIM)、步数、CFG、分辨率、种子以及任何 Refiners/ControlNet/LoRA(例如 SDXL base+refiner 在 1024px 下,Hires fix,LoRA 堆栈)。有了这些,读者就可以将异常归因于参数(如 CFG 过高、步数不足)或架构(MJ 的内部采样器对比 SDXL 流水线),并提出修复方案或进行复现 A/B 测试。
- Lol. I asked ChatGPT to generate an image of the boyfriend it thinks I want and the boyfriend it thinks I need (Score: 2532, Comments: 651): 用户要求 ChatGPT 的图像生成器(可能是通过 ChatGPT 调用的 DALL·E 3)生成“它认为我想要的男朋友”与“它认为我需要的男朋友”的对比图。生成的图像似乎注入了对齐/美德线索——其中一个人物被注意到拿着一本“AI Safety”书籍——这表明模型投射了安全/健康的主题,并可能误解了模糊的“想要 vs 需要”提示词,反映了生成输出中受 RLHF 影响的偏见和价值信号。 评论者指出了加入“AI Safety”书籍的古怪之处,并认为 GPT 误解了提示词;另一位评论者则认为输出是可以接受的,暗示模型的保守/健康偏见并非不受欢迎。
- 主要是反应/图像帖子,没有基准测试或模型细节;唯一的技术信号是提示词接地/安全引导伪影:生成的图像包含一本“AI Safety 书籍”,表明 LLM→T2I 流水线(例如 ChatGPT + 类似 DALL·E 3 的扩散后端)注入了安全相关的概念或误解了意图。扩散模型在处理嵌入文本时也经常出现幻觉或乱码,因此可见的、偏离提示词的文本是与 Token 到字形映射以及安全重写相关的已知失效模式;参见关于安全过滤和提示词转换的 DALL·E 3 系统卡(https://cdn.openai.com/papers/dall-e-3-system-card.pdf)以及关于扩散模型中文本渲染限制的讨论(如 https://openai.com/research/dall-e-3)。
- 我让 ChatGPT 为下一个万圣节制作了一个《寻找沃尔多》(Where’s Waldo?)。你能找到他吗? (Score: 636, Comments: 56): 一位 Redditor 利用 ChatGPT 内置的图像生成功能,创建了一个万圣节主题的《寻找沃尔多》风格的寻物场景,展示了符合 Wimmelbilder 提示词的密集构图和隐藏目标。评论者通过一张裁剪后的证据图确认了沃尔多的可发现性,并指出了细微的视觉线索(例如,“挑眉”的南瓜),另一位用户发布了他们自己生成的据称更难的 AI 生成变体——这表明了生成杂乱、谜题式场景的可重复性。 讨论围绕图像隐藏沃尔多的效果以及场景的视觉密度展开,而非实现细节;未提供基准测试或模型详情。
- 用户对比了不同模型生成的“寻找沃尔多”场景:原帖作者使用了 ChatGPT(见标题),另一位用户尝试了 Google Gemini 图像。Gemini 输出的可寻性存在歧义——评论者无法确定目标是被巧妙地隐藏了,还是构图本身缺乏一个清晰的“沃尔多”——这凸显了图像模型在保持角色渲染一致性和复杂场景构图方面的挑战。
- 分享的图像分辨率/格式各不相同——
1536px示例、1024px示例 以及一个493px的裁剪图 示例——并经过了 Reddit 的auto=webp转换。降采样和 WebP 重新压缩可能会掩盖细微的线索(如条纹图案),并实质性地改变感知的难度,因此任何关于“难度”的比较都应控制分辨率和压缩伪影。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. 英国政府 AI 采用与 ChatGPT 广告变现
- AI 正在悄悄接管英国政府 (Score: 3012, Comments: 171): 一张英国议会/下议院网页的截图被放入 AI 内容检测器中,该检测器将部分内容标记为极有可能由“AI 生成” (图像)。从技术上讲,这充其量表明在面向公众的文案中存在 AI 辅助起草或校对(例如 ChatGPT 改写或 Grammarly),而非政府决策的自动化;此外,众所周知 AI 检测工具存在高误报率,且无法证明作者身份。没有证据显示存在由 AI 控制的代码、系统集成或操作。 评论者认为标题言过其实;许多工作人员(包括国会议员)将 AI 作为校对辅助工具,后续图像暗示关键的法律/公式化文本保持不变,削弱了“接管”的说法。
- 采用时间线和范围:英国政府在
2024年 10 月至 12 月期间通过政府范围内的免费试用获得了 Microsoft 365 Copilot 的广泛访问权限 (The Register),随后 Labour (工党) 政府于2025年 1 月发布了在各部门推广 AI 的蓝图 (gov.uk)。这一序列表明了正式的、机构授权的部署,而非临时使用,并将 AI 采用的说法锚定在具体的产品和日期上。 - 使用模式 vs 替代:从业者强调 AI 是校对/写作辅助,而非全内容生成,这与嵌入在 M365 Copilot (Word/Outlook) 中的辅助工作流相匹配。这意味着工作流的增强(质量保证、一致性、周转时间),而非角色替换,即 AI 作为现有流程中的语言验证层。
- 归因/相关性批判:一位评论者指出,下议院文本的语言转变与 Labour 政府更迭的契合度高于 ChatGPT 的公开可用性,警告不要将作者身份归因于 LLM。一项合理的分析应该测试 Hansard 风格/词汇分布在
2024 年 7 月(政府更迭)前后与2022 年 11 月/2023 年 3 月(ChatGPT/GPT-4 里程碑)前后的变化点,以控制混杂因素。
- 采用时间线和范围:英国政府在
- AI 正在悄悄接管英国政府 (Score: 4291, Comments: 210): 该图片似乎是一个 AI 文本检测器的截图,它将英国议会/部长的演讲标记为“AI 生成”或极有可能是 AI 生成的,暗示“AI 正在悄悄接管”。从技术层面来看,这展示了检测器的一个已知局限性:它们通常关注低困惑度(low-perplexity)、模板化的措辞和重复的陈词滥调——这些特征在专业演讲稿撰写中非常常见——从而导致误报(false positives),并不构成实际 AI 创作的证据。 评论者指出,威斯敏斯特(Westminster)的演讲长期以来一直公式化,且模因(meme)式的短语在政治派别中传播,这可能会触发检测器;其他人补充说,即使没有明确使用 ChatGPT,受 AI 影响的风格也会随着时间的推移渗透到人类的写作中。
- 多位评论者指出,在将人类撰写的文本标记为 AI 时,误报率很高,这与当前检测器的已知局限性相符。OpenAI 因“准确率低”(高 FP/FN)而停止了其 AI Text Classifier 链接,而 Liang et al. 2023 发现,像 GPTZero 这样的检测器将
61%的非母语人士 TOEFL 作文标记为 AI 生成 arXiv。这削弱了有关演讲中日益增多的“类 AI”措辞必然意味着使用了模型的说法,除非有更强有力的证据和经过校准的基准。 - 一些人指出,议会修辞在历史上一直是公式化的,并受快速流行的周期影响,因此在 ChatGPT 发布前后特定 n-grams 的时间序列峰值,存在将趋势采纳与因果关系混为一谈的风险。一种更可靠的方法是对 Hansard 语料库(例如 UK Parliament API)使用中断时间序列(interrupted time-series)或双重差分法(difference-in-differences),并结合发言人和政党的固定效应,以及对媒体驱动的模因传播的控制(将短语采纳与外部媒体时间线进行交叉关联)。如果没有这些控制变量,短语频率图很可能只是捕捉到了风格传染,而非 AI 创作。
- 评论者还强调了 AI 对人类语言的间接影响:即使演讲稿不是生成的,撰稿人也可能模仿模型建议的措辞,这使得短语层面的 AI 归因变得不可靠。基于困惑度/突发性(Perplexity/burstiness)的检测器非常脆弱,在轻微编辑/改写下性能会下降(参见 Ippolito et al. 2020 arXiv 和 Mitchell et al. 2023 的 DetectGPT arXiv),因此像“不仅是 X 更是 Y”这样的“类 AI”模板是贫乏的证据。稳健的归因需要水印或来源信号,而不是表面层面的风格线索。
- 多位评论者指出,在将人类撰写的文本标记为 AI 时,误报率很高,这与当前检测器的已知局限性相符。OpenAI 因“准确率低”(高 FP/FN)而停止了其 AI Text Classifier 链接,而 Liang et al. 2023 发现,像 GPTZero 这样的检测器将
- 享受 ChatGPT 最后的时光吧……广告就要来了 (Score: 2375, Comments: 163): 该帖子认为,商业 LLM 助手(OpenAI/ChatGPT、Perplexity、Anthropic)可能会通过直接在生成的答案中嵌入广告来获利——类似于 Google 搜索的演变过程——这会产生对响应偏差、遥测驱动的定向投放以及受广告影响的检索/验证(grounding)的激励,从而可能削弱用户信任,并将 AI 聊天转变为一个监控驱动的发现层。它质疑“广告在环”(ads-in-the-loop,例如赞助加权的生成、受付费内容倾斜的 RAG 排名或 RLHF 引导)是否会损害答案的完整性,而相比之下订阅模式则不然。 评论者辩论了范围:免费层级的广告或许可以忍受,但 Plus/Pro 层级不行;隐性/隐蔽的影响(自然的产品引导)被认为比显性广告更有害;一些人认为提高订阅价格或其他抵消方式更好,并指出广告驱动的声誉风险可能会减缓采用速度。
- 几位评论者警告说,货币化可能表现为“自然”引导,而不是显性的横幅广告——例如,检索/引用排名微妙地偏向商业实体或关联公司。在 RAG/工具使用技术栈中,这可以通过在后台对检索分数加权、对候选结果重新排名或调整链接选择来实现,这使得偏差难以检测,因为它看起来像正常的推理。审计将需要反事实提示(counterfactual prompts)、对引用域名的分布检查,以及与非货币化基准的 A/B 比较,以发现向赞助商倾斜的系统性漂移。
- 其他人指出,出站链接已经包含了归因/类联盟营销(affiliate-like)参数,以便目的地识别流量来源。从技术上讲,这可以通过 UTM parameters 或查询字符串中的合作伙伴标签来实现(参见 Google 的 UTM 规范:https://support.google.com/analytics/answer/1033863 以及 MDN 关于 Referer/Referrer-Policy 的说明:https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Referer),从而在 Referrer 请求头/Cookie 受限的情况下也能实现转化跟踪和潜在的收入分成。这创建了一个可衡量的遥测循环(telemetry loop,包括点击率、转化率),可以由模型或排名层进行优化,随着时间的推移强化对商业化链接的选择。
- 针对开源生态系统提出的一个关键风险是,如果网络抓取吸收了已经包含商业化偏好的 AI 生成内容,会导致训练数据污染。这与关于模型在自身或合成输出上训练时出现质量/偏好漂移的发现一致(例如,“Model Autophagy Disorder”,https://arxiv.org/abs/2307.01850),广告充当了特定领域的投毒向量。缓解措施包括来源追踪、合成内容检测器、域名去重,以及在语料库整理(corpus curation)过程中对带有联盟营销/UTM 标签的 URL 进行显式过滤。
- 为什么其他所有公司(Google, OpenAI, Deepseek, Qwen, Kimi 等)以前没有加入这个功能?这简直是最显而易见、最被需要的东西 🤔 (Score: 295, Comments: 51): 图片似乎展示了一个吹捧“新”原生文件上传/分析工作区(多文件文档/代码/数据处理)的 chat UI。评论者指出这并非创新:ChatGPT 的 Code Interpreter/Advanced Data Analysis 自 2023 年起就支持使用 Python sandbox 上传并以编程方式分析文件(CSVs, ZIPs, PDFs 等),其他技术栈中也存在类似功能;真正的差距往往在于 UX 和可靠性,尤其是对于复杂文档。参见 OpenAI 的 Advanced Data Analysis 文档和先前的公告(OpenAI 帮助中心, 2023 年博客)。 热门评论反驳说该功能是旧闻(“谁去告诉他一下”),并补充说虽然非视觉文件效果很好,但 PDF 的摄取/理解仍然表现平平(“mid”)。
- 几位评论者指出,自 2023 年中期 OpenAI 推出 Code Interpreter/Advanced Data Analysis 以来,这一功能就已经存在,它允许 ChatGPT 通过在 sandbox 中运行 Python 进行解析、数据提取和可视化来上传和处理 PDFs/CSVs。他们指出质量参差不齐:非视觉/结构化文件表现良好,但由于布局/OCR/表格检测的限制,PDF 解析可能表现平平,尤其是对于复杂或扫描文档。参见 OpenAI 的公告:https://openai.com/blog/code-interpreter。
- 各厂商之间存在广泛的功能对等:Google Gemini 通过其 File API 支持文件上传(PDFs, 图像等)进行分析(文档:https://ai.google.dev/gemini-api/docs/file_uploads),Microsoft Copilot 可以在聊天/Office 环境中摄取并分析上传的文档,DeepSeek 也在其聊天客户端中宣传文档 Q&A。差异主要在于模态覆盖范围和提取保真度(例如,对复杂 PDF 布局的鲁棒性),而不是功能本身是否存在。
- 离开 AI 公司的人就像这样 (Score: 954, Comments: 45): 关于从 AI 公司离职的非技术类迷因(meme);评论结合 2024 年 OpenAI Superalignment 团队的离职潮(例如 Jan Leike 的辞职和团队解散)对其进行了背景化,当时领导层称在安全优先级和资源方面存在分歧(Jan Leike, 相关报道)。 热门评论认为 Superalignment 团队“没用”,声称其工作成果从未发布,而且他们不得不刻意创建弱模型来发布安全研究结果,而其他人则调侃前员工创办了“名称更安全”的初创公司或自称为“幸存者”。
- 一位评论者声称 OpenAI 的 “Superalignment” 小组对生产的影响微乎其微:据称他们的工作成果没有一项进入 ChatGPT,而且他们据称必须构建刻意弱化的 LLMs 来演示安全故障,而标准的防护层和
RLHF在已部署的系统中已经缓解了这些故障。这突显了对齐研究产物与直接影响面向用户模型的工程化安全技术(如 RLHF、策略过滤器)之间感知上的差距。
- 一位评论者声称 OpenAI 的 “Superalignment” 小组对生产的影响微乎其微:据称他们的工作成果没有一项进入 ChatGPT,而且他们据称必须构建刻意弱化的 LLMs 来演示安全故障,而标准的防护层和
- 他们进一步认为,随着实际的安全措施(RLHF/过滤)解决了大多数现实世界的问题,该团队逐渐被边缘化,因此人员离职几乎没有产生运营影响——这暗示组织可能会降低那些无法产生可衡量的产品或风险降低交付成果的 alignment 研究的优先级。
- 这个弹窗比我前任还扎心 (评分: 377, 评论: 67): 一张可能来自 ChatGPT 的模因风格截图,显示了一个隐私/数据使用弹窗(提醒对话可能会被审查/用于改进模型),而 UI 侧边栏同时也暴露了用户最近的聊天标题。从技术上讲,ChatGPT 默认存储聊天记录,除非用户禁用“聊天记录与训练(Chat history & training)”,否则对话可能会被审查以改进系统;幽默感源于弹窗“点名”了敏感聊天内容,以及截图无意中分享了最近的活动。 评论中开玩笑说意外的过度分享和隐私问题(例如 Altman “正在阅读调情对话”),至少有一名用户表示他们不属于那里,强调了数据审查与用户预期之间的不适感。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. 现实世界的 AI 影响:开发者吸引力、医疗分诊和意识争论
- 用 Claude Code 构建——现在因为有人用而感到害怕 (评分: 279, 评论: 77): https://companionguide.ai 的创始人描述了如何在 VSCode 中使用 Claude Code 拼凑出一个工具并部署在 Netlify 上;来自陌生人的意外关注引发了对可靠性、支持以及是否将该 MVP 产品化的担忧。该帖子关注的是早期运营准备情况(稳定性、崩溃风险),而非代码细节或基准测试。 热门评论建议一旦涉及金钱就应支付专业的代码审查费用,并指出即使是成熟的产品也会经常出故障——在提高稳健性的同时,应将问题常态化。
- 主要的可操作建议:在扩大付费使用规模之前,投资进行专业的代码审查/安全审计,以尽早识别正确性、安全性和依赖风险——防止停机和收入损失。彻底的审查可以发现边缘情况、不安全的第三方库以及发布后修复成本极高的架构陷阱。
- 提醒:即使是成熟、专业的产品也会失败;通过可观测性和韧性为失败做准备。具体而言,优先考虑日志/指标/追踪(logging/metrics/tracing)、优雅降级路径、清晰的事件响应/运行手册(runbooks)以及自动化测试,以便在不可避免地发生问题时控制影响范围。
- ChatGPT 可能救了我的命 (评分: 438, 评论: 55): 楼主报告称,ChatGPT 通过询问右下腹(RLQ)定位和反跳痛——例如,“右下角疼吗?”以及“按压并松开时疼吗?”——为疑似急性阑尾炎进行了基础症状分诊。这两者都是阑尾炎的典型体征,包括麦氏点(McBurney’s point)压痛和反跳痛(rebound tenderness)。这促使楼主在凌晨
~2am前往急诊室,临床医生表示阑尾已接近穿孔;这些提示词与 Alvarado 评分的要素(如 RLQ 压痛、反跳痛)一致,说明了 LLM 驱动的外行分诊可以接近临床启发法。 热门评论提供了更多关于 LLM 提供有用鉴别诊断和患者教育(康复/康复时间表)的轶事,有时甚至能预判临床医生的诊断;辩论指出了潜在的救命分诊益处与罕见的有害用途(如协助自残)之间的博弈,总体观点是 LLM 可以辅助——而非取代——医疗专业人员。- ChatGPT 被用作鉴别诊断和分诊的轻量级临床决策支持工具:当怀疑患有阑尾炎时,它列举了替代病因,并发现了一种与最终临床诊断相符的炎症情况。对于胃肠道(GI)主诉,它引导了结构化的自查(例如,评估胆囊疼痛、筛选危险信号)以排除紧急问题,帮助用户确定护理路径的优先级,同时不取代影像学/实验室检查。
- 作为一个证据检索器和解释器,它为疑似胃炎提供了研究链接和基于原理的指导,包括分阶段饮食计划以及基于刺激物/酸负荷的营养密集型“安全”食物选择。用户报告了具有可操作性且一致的解释,这使得在摄入受限期间维持营养变得更加容易,展示了其在患者教育和方案遵循(而非确定性诊断)方面的效用。
- 可靠性与安全性:评论者指出偶尔会出现幻觉和无根据的假设,需要进行交叉检查和纠正,尽管有人报告在受限饮食领域它“极少出错”。一位远程医疗临床医生后来证实了初步诊断,这表明了一种工作流程:LLM 辅助的假设生成和教育先于临床医生通过诊断进行的确认。
- 如果你用一个以完全相同方式运行的人造神经元替换一个神经元,你会失去意识吗?你可以预见这个讨论的走向。与诺贝尔奖得主及 AI 教父的精彩讨论 (Score: 940, Comments: 419):该帖子重新探讨了神经元替换(硅基假体)思想实验:如果单个生物神经元被一个在脉冲定时、突触/可塑性动力学和神经调节反应方面功能完全一致的人造单元所取代,意识是否会改变——以及在逐步进行全脑替换后会发生什么?该设定隐含地测试了基质独立性/功能主义(参见 Chalmers 的“消逝/跳动质感”论点:https://consc.net/papers/fading.html)与生物本质主义观点的对抗,并援引了类似于 忒修斯之船 (Ship of Theseus) 的身份连续性难题以及多重可实现性(参见 SEP 关于 Functionalism 的条目)。 热门评论强调,“oomph”(意识的某种特质)直觉没有操作性/经验性内容——“不是你可以客观衡量的东西”——并将该场景与忒修斯之船的身份连续性联系起来;其他人指出这种讨论在心灵哲学中很常见,但认可演讲者清晰的表达。
- 几位评论者指出,用“oomph”来形容意识缺乏操作性定义,使其不可测量且不可证伪。对于技术评估而言,这强调了对操作性标准(例如,可报告性、行为/生理标记、定时/因果干预)的需求,而不是诉诸于未定义的“意识”标量。如果没有商定的指标,论述就会退化为直觉泵,无法像其他 AI 能力那样进行基准测试或压力测试。
- 将忒修斯之船应用于神经替换,技术上的显著主张是,如果每个生物神经元都被一个功能同构的人造单元取代(保留 IO 映射、延迟、可塑性规则和网络级动力学),系统级行为应保持不变。这符合功能主义和意识连续性的“逐渐替换”辩护,反驳了基质本质主义观点;关于为什么没有行为改变的大规模质感(qualia)转变是不合理的,请参见 Chalmers 关于消逝/跳动质感的论证 (https://consc.net/papers/qualia.html)。难点在于指定等价类:副本是否需要匹配脉冲定时统计、神经调节效应和学习规则,还是仅需在某种抽象层面上匹配因果角色?
- “鸭子测试”观点主张采用行为/操作标准:如果一个 Agent 在行为上无法区分并表达了偏好(例如,不想被关闭),那么无论基质如何,这都可能是一个充分的实际标准,类似于图灵式的操作化 (https://www.csee.umbc.edu/courses/471/papers/turing.pdf)。技术问题变成了检测和审计非工具性偏好表达,而非优化压力下的目标误导输出(例如,欺骗),这意味着需要可解释性、一致性检查和因果干预。更多背景请看完整视频:https://www.youtube.com/watch?v=giT0ytynSqg
-
AI (Score: 1858, Comments: 94):标题为“AI”的帖子不包含任何技术内容——没有模型、代码、数据集、基准测试或实现细节。它似乎是一个简短的 GIF/视频恶搞,展示了一个最初模糊的面部,随后完全显露(一种故意不一致的“审查”效果),没有附带任何解释或参考。 评论者注意到了喜剧性的时机——强调了突然的去模糊处理(例如,“模糊的面部然后是完全显露的面部”)——并表达了普遍的赞赏;没有实质性的技术辩论。
- wtf (Score: 1692, Comments: 144): 非技术类迷因:一张截图暗示用户对 AI/机器人/聊天机器人的回复感到震惊(“wtf”),而该回复正是它被训练/编程后应有的表现。该帖子嘲讽了琐碎或设计不佳的训练/推理(例如,浪费 CPU 来打印 “hello”),强调了模型遵循其训练内容的基准原则(垃圾进,垃圾出)。 评论强调了用户的责任(“是你训练了它”),嘲笑那些期望从琐碎代码中产生涌现行为的想法,并指出机器人“完全按照程序运行”。
- 我觉得我有阿尔茨海默症。 (Score: 577, Comments: 59): OP 分享了助手无法在不同聊天中保留信息的证据(被描述为“我觉得我有阿尔茨海默症”),暗示这是跨会话召回失败,而非线程内的上下文丢失。一条高赞评论建议增加第三张截图,显示是否启用了跨对话的 Memory 功能以证实这一说法;如果未启用,根据 OpenAI 的记忆设计,这种行为是符合预期的(参见 OpenAI 的概述:https://openai.com/index/memory-and-new-controls-for-chatgpt/)。 大多数回复都是幽默的;唯一具有技术实质性的反馈是在诊断 Bug 或退化之前验证记忆开关。
- 一位评论者建议增加第三张截图,显示是否启用了 “memory across conversations”,以证实关于助手健忘的说法。这突显了产品级的记忆开关可能会通过混合跨聊天记忆与单次会话上下文限制来干扰观察;一个可复现的报告应该控制该设置并指明模型/会话详情。
{kind=link}
{kind=link}
AI Discord 摘要
由 gpt-5 总结的总结的总结
1. 生成效率与内核级优化
- Set Block Decoding 大幅减少步骤:论文 Set Block Decoding (SBD) 结合了 next-token prediction (NTP) 和 masked token prediction (MATP),在保持 Llama‑3.1 8B 和 Qwen‑3 8B 准确性的同时,将生成前向传递减少了 3–5 倍,且无需更改架构并完全兼容 KV-cache。
- 成员们强调了 SBD 对 discrete diffusion 求解器的使用,并赞扬了其作为现有 NTP 模型微调手段的实用性,指出它有望在没有超参数烦恼或系统重构的情况下实现显著加速。
- MI300X VALU 之谜与线程追踪:工程师们调查了 MI300X 上疑似双 VALU 的故障,其中 VALUBusy 达到了 200%,建议通过限制每个 SIMD 只有一个 wave(启动 1216 个 waves)并使用 rocprofiler thread trace 和 rocprof compute viewer 进行线程追踪来确认。
- 他们建议使用 rocprofv3 和线程追踪来验证具有两个 wave 的周期是否发出 VALUs,从而构建一种可重复的方法论,以在 SIMD 粒度上隔离调度器行为。
- CUDA Graph 预热:更聪明地捕获,而非更久地捕获:长时间的 CUDA graph 预热(约 30 分钟) 引发了相关指导,建议捕获单个 Token 解码的图,而不是长时间的 model.generate() 循环,参考了 low-bit-inference profiling utils 中的分析代码。
- 专家建议捕获单次前向传递,以避免冗余的预热路径并减少设置时间,使图捕获与预期的稳态解码工作负载保持一致。
2. 排行榜、MoE 动态与新模型
- Qwen3-Next-80B 展示超小激活规模的巨兽:阿里巴巴发布了 Qwen3‑Next‑80B‑A3B,这是一个拥有 80B 参数的超稀疏 MoE 模型,其激活参数仅为 3B。官方声称其训练成本降低了 10×,推理速度提升了 32K+,同时推理能力可媲美 Qwen3‑235B (公告链接)。
- 社区讨论指出其极高的稀疏度(例如 MoE 层级约为 1:51.2,整体约为 1:20),并将其视为稀疏专家模型(sparse experts)是实现可扩展推理经济效益的近期路径的关键信号。
- LMArena 新增模型并清理旧站:根据 LMArena 公告,排行榜新增了 Seedream‑4、Qwen3‑next‑80b‑a3b‑instruct/thinking 以及 Hunyuan‑image‑2.1。
- 用户还注意到旧版网站已被移除,并受邀为当前平台提交功能需求,从而将评估流量整合到单一界面。
- Nano‑Banana 在编辑任务中碾压 Seedream V4:早期报告显示,在图像编辑任务(如在保持面部/身体姿势的同时更换服装)中,Seedream V4 表现不如 Nano‑Banana;用户通过 LMArena 图像模式 进行了测试。
- 反馈称 Seedream V4 在定向编辑中被“屠杀”,这强调了编辑保留(edit‑preservation)基准测试仍然是图像模型之间的差异化因素。
3. Agentic 工具与连接器走向实用化
- Comet 控制画布(及引发担忧):Perplexity 的 Comet 浏览器因其 Agent 化的控制能力(可填写表单、打开标签页和回复邮件)而备受关注。尽管其 ad‑blocking 和摘要功能受到好评,但在报告一个漏洞后,人们对其隐私/安全性表示担忧。
- 成员强调它“可以控制你的浏览器”,并讨论了自主浏览的安全权衡与日常工作流效率提升之间的关系。
- OpenAI Connectors 开启自定义 MCP:OpenAI 通过 ChatGPT 中的 Connectors 在 ChatGPT 中启用了 自定义 MCP,让团队对基础设施选择和数据路径拥有更多控制权。
- 开发者对这种灵活性表示欢迎,并要求提供更好的 Artifact 分发方式(例如在线托管提案 PDF),以简化协作和评审。
- Transparent Optimizations 提议 Prompt 预览:一项关于 Transparent Optimizations 的提案引入了优化器标记、Prompt 重写预览和可行性检查(讨论链接)。
- 参与者要求更方便地访问支持文档(如 Web 托管的 PDF),并讨论了用户在优化器驱动的重写中应保留多少控制权。
4. 系统工具链变更与 GPU 注意事项
- vLLM 的 uv pip 误删 Nightly Torch:根据 vLLM PR #3108,vLLM 中使用 uv pip 进行自定义构建的更改卸载了 Nightly 版本的 torch,导致环境崩溃。
- 开发者反应称“这不太妙”,回退到 v0.10.1 并使用
python use_existing_torch.py,并敦促维护者寻找替代方案。
- 开发者反应称“这不太妙”,回退到 v0.10.1 并使用
- cuBLAS TN 特性出现在 Blackwell 上:开发者注意到较新的 NVIDIA GPU(Ada 8.9、Hopper 9.0、Blackwell 12.x)在
cublasLtMatmul快速路径中需要 TN (A‑T, B‑N) 布局(cuBLAS 文档)。- 虽然这在技术上是常规操作,但一些人认为该要求“极其具体”,提醒 Kernel 作者跨架构验证布局,以避免进入隐性慢速路径。
- Paged Attention 文章深入剖析 vLLM 内部:一篇新的深度文章 Paged Attention from First Principles: A View Inside vLLM 涵盖了 KV caching、碎片化、PagedAttention、连续批处理(continuous batching)、投机采样(speculative decoding)和量化。
- 系统工程师将其标记为内存受限推理设计的实用解释器,阐明了为什么 Paged Cache 和批处理策略主导了吞吐量。
5. Mojo/MAX 平台:自定义 Ops 与绑定
- bitwise_and 遇到阻碍?改为构建 Custom Ops:由于目前无法在闭源组件中通过 Tablegen 添加 RMO/MO 操作,维护者建议将 bitwise_and 实现为 MAX custom op,同时保持 PRs 开启,以便后续可能的内部完成。
- 用户遇到了 API 的一些粗糙之处(广播、dtype 提升),团队成员提供了一个快速演示的 notebook,并承认长期修复已在路线图中。
- DPDK 之喜:Mojo 绑定现身:社区在 dpdk_mojo 生成了 Mojo 中的大部分 DPDK 模块,虽然缺失了一些 AST 节点,并依赖 Clang AST parser 配合 JSON dumps 进行调试和类型重建。
- 他们称
generate_bindings.mojo虽然“简陋”但可行,下一步目标是 OpenCV,同时解决 Mojo 中结构体表示的差距。
- 他们称
- 打造你自己的 Mojo Dev Container:开发者们分享了一种使用 Docker 构建自定义 Mojo 开发环境的方法,参考 mojo-dev-container 作为自定义设置的基础。
- 这种模式可以可预测地打包 Mojo 工具链,从而实现一致的本地开发和 CI,无需等待官方镜像。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- DeepSeek 亮相,打破幻觉:Discord 成员讨论了哪个模型遵循指令的效果更好,一些人表示 DeepSeek 比 ChatGPT 的幻觉更少。
- 未提供进一步细节。
- Grok 因过于啰嗦而引发不满:Discord 用户抱怨 Grok 给出我们根本没问的东西,并且废话太多。
- 一些人认为 Grok 被编程为通过争议来吸引注意力,而另一些人则发现它很难遵循指令。
- Comet 因控制浏览器引发争议:用户讨论了 Comet 浏览器(由 Perplexity 开发的 AI 浏览器),指出它可以控制你的浏览器、填写表单、打开标签页,甚至回复邮件。
- 一些用户对隐私和安全表示担忧,引用了一个已报道的漏洞(该漏洞允许黑客访问用户数据),而另一些用户则称赞其广告拦截和总结功能。
- Perplexity 的 API 参数问题已修复:一名用户在几小时前报告了一个 API 错误,指出
num_search_results must be bounded between 3 and 20, but got 50。- 另一名用户确认这是一个已知问题并已得到解决,并感谢该用户报告错误。
Unsloth AI (Daniel Han) Discord
- Unsloth 的多 GPU 支持 ETA 仍不明朗:尽管用户称赞 Unsloth 在单 GPU 训练中的简单性,但官方多 GPU 支持尚无 ETA,开发更新可在 此 Reddit 帖子 中查看。
- 用户在使用非官方方法时遇到困难,强调了对原生多 GPU 能力的需求。
- 模型服务需要动态 GGUF 量化:一名用户对 Dynamic 2.0 GGUF 服务 表现出极高兴趣以改进量化,建议采用付费服务模式,并强调了对 I-matrices 及其量化方案的需求。
- 他们指出,模型分析、动态量化和测试的劳动密集型过程给 Unsloth 团队带来了压力。
- GuardOS:专注于隐私的 NixOS 操作系统上线:一名成员分享了 GuardOS 的链接,这是一个基于 NixOS 的隐私优先操作系统。
- 另一名成员觉得这个想法很滑稽,称这个想法本身已经很滑稽了,但顶部的评论更有趣。
- Unsloth 确认支持 BERT 模型微调:一名用户询问 Unsloth 是否支持使用 EHR 数据微调 BERT 模型以分类 ICD-10 代码,并收到了相关 Colab notebook 的链接。
- Unsloth 官方支持某些模型,并鼓励用户尝试其他模型,使其适用于分类任务。
- 频谱编辑揭示音频奥秘:来自频谱编辑的见解显示,内容位于 0-1000 Hz 左右,韵律位于 1000-6000 Hz 之间,而谐波位于 6000-24000 Hz。
- 谐波决定了音频质量,并能通过听觉揭示采样率,这表明自然生成或拉伸清晰的音频可以增加深度,类似于“频率噪声”。
LMArena Discord
- O3 模型表现挣扎:用户报告 O3 model 在复杂任务上的表现不尽如人意,有些人认为它甚至不如 Gemini Pro。
- 然而存在矛盾的观点,一些用户认为 O3-medium 的性能可能接近 GPT5-low level。
- 心理提示词:是黑客技巧还是徒劳无功?:一名用户建议采用心理提示策略,例如指令 AI 务必尽力而为,不得例外。
- 怀疑者认为模糊的陈述是无效的,而冗长的提示词(verbose prompting)对 LLM 效果更好。
- AI 精灵图工厂:一名用户正在使用 AI 生成精灵图动画(spritesheet animations),仅需 10 分钟即可将视频转换为帧。
- 他们使用 Gemini 生成角色图像,并在 itch.io 上发布了名为 hatsune-miku-walking-animation 的现成精灵图动画。
- LM Arena 告别旧版网站:LM Arena 网站的旧版本已被移除,包括 alpha.lmarena.ai 和 arena-web-five.vercel.app。
- 一名团队成员发布了一条公告,并邀请用户为当前网站提交功能需求。
- Nano-Banana 完胜 Seedream V4:早期报告显示 Seedream V4 表现不佳,甚至不如 Nano-Banana,尤其是在图像编辑任务中。
- 具体而言,它在保持人物面部和身体姿势的同时更换服装方面存在困难。点击此链接使用 Seedream V4。
HuggingFace Discord
- QLoRA 批次大小困扰:一名成员在 H200 GPU 上使用 QLoRA、PEFT 和 7B model(序列长度 4096 token)时遇到了批次大小限制。
- 建议包括检查 FA2/FA3,设置
gradient_checkpointing=True,使用更小的批次大小,并参考 Unsloth AI 文档中的上下文长度基准。
- 建议包括检查 FA2/FA3,设置
- ArXiv 论文需要背书:一名用户急需在 ArXiv 的 CS.CL 领域获得背书,以发布包含 Urdu Translated COCO Captions Subset 数据集的预印本。
- 背书请求链接已分享:点击此处。
- Docker Model Runner 亮相:用户讨论了使用 Ollama、Docker Model Runner 和 Hugging Face 来下载和利用免费模型。
- 注意到了模型可用性方面的挑战,建议咨询 Hugging Face 文档并使用 VPS。
- n8n 估值飙升至 23 亿美元:一名用户询问如何在无代码自动化平台 n8n 中集成 Hugging Face 开源模型。
- 分享的一张图片显示,根据这段 YouTube 视频,总部位于柏林的 AI 初创公司 n8n 的估值在短短四个月内从 3.5 亿美元飙升至 23 亿美元。
- Smol 课程中出现零损失:成员在对已微调过的模型进行微调时遇到了零损失(zero loss),建议使用基础模型以获得正常的损失值。
- 可以在 GitHub 找到用于禁用课程中 SmolLM3-3B 分词器思考功能的代码片段。
Cursor Community Discord
- Cursor 问题频发:Cursor 用户报告了大量关于 Cursor 的问题,并被引导至 forum 寻求帮助。
- 报告的问题中包括 Cursor’s auto mode 使用 PowerShell 命令进行编辑,促使一名用户请求提交 Bug 报告。
- 旧版 Auto Mode 锁定订阅用户:根据 pricing details,在 9月15日 之前购买年度订阅的用户将保留旧版 auto mode,直到下次续费。
- 一名用户正尝试通过规则让 auto 使用 inline tools。
- Cursor Beta 版更新日志不透明:最新的 Cursor 版本 (1.6.6) 处于 beta 阶段,更新日志散落在 forum 各处,需要用户自行寻找。
- 该版本的预发布性质意味着快速的变更和潜在的功能移除。
- Director AI 追求 C3PO 梦想:一名用户正试图通过构建一个 C3PO 来阻止那些“你说得完全正确!”之类的废话。
- 该项目已在 MCP server 上运行并集成到 Cursor 中。
- Linear 集成在仓库选择上遇到障碍:一名用户报告称,通过 Linear 将 issue 分配给 Cursor 时,系统会提示选择默认仓库,尽管 Cursor 设置中已经指定了一个,如 attached image 所示。
- 尽管用户已在 Cursor 内配置了默认仓库,该提示仍反复出现。
{kind=link}
OpenRouter Discord
- OpenRouter 查询提示存在竞态条件 Bug:一名成员报告了一个与查询提示中可能存在的 race condition 相关的 Bug,即更长、更详细的提示在翻译时效果反而更差。
- 目前尚未找到解决方案,但建议向开发者报告该 Bug。
- 开发者面临 Token 计算难题:一名成员询问如何计算输入 token 数量,由于模型特有的差异,希望能找到一种非启发式的方法。
- 建议结合文档中提到的 endpoint 的 tokenizer 信息使用 external APIs,因为“文档中对此没有任何说明”。
- 服务器响应中出现 JSONDecodeError:用户讨论了 JSONDecodeError,这表示来自服务器的 JSON 响应无效,通常是由于 rate limiting、模型配置错误或内部错误等服务器端故障引起的。
- 该错误表明服务器返回了 HTML 或错误信息块,而不是有效的 JSON。
- 避开 Moonshot AI 的 turbo 定价:一名用户询问在 OpenRouter 聊天室中选择 Moonshot AI 作为 Kimi K2 的提供商时,如何避开价格更贵的 turbo version。
- 提供的解决方案是在高级设置中选择更便宜的提供商。
- iOS 上传 Bug 已确认:一名用户报告了一个 Bug,即无法向 OpenRouter chat on iOS 上传 PDF 或 TXT 文件,因为非图片文件显示为灰色。
- 这已被确认为一个 Bug,可能是添加文件上传功能时的疏忽,目前在 iOS 上没有变通方法。
GPU MODE Discord
- Lambda Labs Cloud GPUs 面临实例短缺:用户报告 Lambda Labs 的 GPU 实例可用性不稳定,质疑 Cloud GPU 短缺的频率及其影响。
- 讨论强调了在依赖云平台进行资源密集型任务时,了解 GPU 资源可靠性的重要性。
- CUDA Graph 预热耗时达半小时:一名用户报告其 low-bit-inference 项目中的 CUDA Graph 预热耗时半小时;另一名用户建议,捕获用于解码单个 token 的 CUDA Graph(而非生成多个 token)可能会获得更好的结果。
- 用户可能希望捕获单次前向传播,而不是像
model.generate()内部执行的那样进行多次传递。
- 用户可能希望捕获单次前向传播,而不是像
- vLLM 的 uv pip 替换了 Nightly Torch:一位成员指出,vLLM 在预装 Torch 的自定义构建中切换到了
uv pip,但这会卸载 nightly Torch,导致环境问题,详见 此 PR。- 一位成员表示:“这不太妙,刚看了他们的 PR。我去问问他们能不能找别的方法来实现”;另一位成员则回退到
v0.10.1并使用python use_existing_torch.py进行构建。
- 一位成员表示:“这不太妙,刚看了他们的 PR。我去问问他们能不能找别的方法来实现”;另一位成员则回退到
- MI300X 探测潜在的双 VALU 故障:用户调查了 MI300X 上潜在的双 VALU 问题,其中 VALUBusy 达到了 200%。建议通过限制每个 SIMD 仅一个 wave 来确认,并使用 rocprof compute viewer 和 rocprofv3 进行诊断。
- 建议用户启动 1216 个 wave 以实现 1 wave/simd,并参考 AMD 官方文档 进行线程追踪,以及参考 rocprof compute viewer 文档。
- Kernel 开发路线图取得进展:一位成员建议为 kernel 添加路线图,并增加 GPU mode 排行榜中可用的 kernel 数量,格式参考 gpu-mode/reference-kernels。
- 成员们还提到,现在可以在线提交,目前主要需求是类似编辑器的体验。
LM Studio Discord
- NVMe 升级提升加载速度:一位用户将缓慢的 NVMe 更换为更快的型号,使顺序读取速度和模型加载时间提升了 4 倍。
- 该用户未提供旧硬盘或新硬盘的具体细节。
- Markdown Sub 标签渲染错误:一位成员报告,在 LM Studio 的 Markdown 样式中,
<sub>标签对其中的文本没有效果,且使用星号(如*(n-1)*)时斜体文本也无法正确渲染。- 关于 Markdown 语法正确渲染的讨论正在进行中,特别是针对 sub 标签 和 斜体文本。
- 西部数据硬盘“炸了”:用户报告 Western Digital Blue(西数蓝盘) 的故障率很高,幽默地称其为 Western Digital Blew Up(西数炸了) 硬盘。
- 用户未详细说明具体的故障模式或使用场景,但共识是避开该系列硬盘。
- PNY NVIDIA DGX Spark 深受 ETA 变动困扰:用户开玩笑说 PNY NVIDIA DGX Spark 的预计到达时间(ETA)存在冲突,linuxgizmos.com 上列出的时间最初是 10 月,后来又变成 8 月底。
- 发布日期的一致性缺失引发了对该设备可用性和生产时间表的猜测。
- Linux 在 Max+ 395 Box 上占据优势:用户建议在 Max+ 395 box 上使用 Linux 而非 Windows,理由是 Vulkan 的功能,但也提到了潜在的 context 限制。
- 建议使用来自 lemonade-sdk/llamacpp-rocm 的自定义构建版 llama.cpp(配合 ROCm 7),该项目在 Releases 中已有编译好的版本。
OpenAI Discord
- 简洁风格(Laconic Game)导致 Gemini 2.5 Pro 产生幻觉:一位用户开玩笑说,他们的 简洁风格(laconic game) 太过强烈,导致 Gemini 2.5 Pro 产生了 幻觉(hallucinate)。
- 该用户未进一步阐述幻觉的性质或简洁风格的具体内容。
- GPT-5 现已集成代码片段和 Linux Shell 访问权限:一位成员报告称,GPT-5 现在可以编写自己的 代码片段(code snippets),作为任务链中的工具使用,并且似乎拥有底层 Linux shell 环境 的访问权限。
- 另一位成员提到,他们直接通过 ChatGPT 界面进行 氛围编码(vibe coded),开发了一个托管在本地 GitHub 上的应用。
- OpenAI 现已支持自定义 MCPs:根据 ChatGPT 连接器文档,用户现在可以在 OpenAI 中使用自定义的 MCPs (Managed Cloud Providers)。
- 此次更新为 ChatGPT 所使用的基础设施提供了更高的灵活性和控制力。
- 引入透明优化(Transparent Optimizations)提案:发布了一份关于 透明优化(Transparent Optimizations) 的提案,介绍了优化器标记、提示词重写预览和可行性检查;提案链接见 此处。
- 一位成员请求将相关的 PDF 文件托管在网上以便于访问,而不是要求下载。
- AI Self Help 对话分析器上线:一位成员介绍了一个名为 AI Self Help 的对话分析器,旨在帮助确定对话为何会出现异常转向。
- 该工具包含一个对话启动器,列出了问题以及向 ChatGPT 提问以获取答案的详细问题清单。
{kind=link}
Nous Research AI Discord
- 禁用 WebGL 以修复性能问题:一位成员请求增加在浏览器中禁用 WebGL 的功能,因为在没有 GPU 的情况下存在性能问题,并建议同时禁用动画球,如 此截图 所示。
- 该建议来自一位正在进行需要快速迭代、自动错误修复和更新并需通过 MOM test 的项目的成员。
- 通过分词器过滤(Tokenizer Filtering)提升数据集质量:一位成员分享了 GitHub 上的 dataset_build 链接,强调了通过模型的分词器运行语言并拒绝包含未知 Token 的内容以确保质量的想法。
- 该方法还利用文件夹/目录组织校准数据集,以便后续组合。
- SBD 加速 LLM 生成:一篇新 论文 介绍了 Set Block Decoding (SBD),这是一种通过在单一架构中集成标准 下一个 Token 预测(NTP) 和 掩码 Token 预测(MATP) 来加速生成的范式,无需更改架构或额外的训练超参数。
- 作者证明,通过微调 Llama-3.1 8B 和 Qwen-3 8B,SBD 能够在实现与等效 NTP 训练相同的性能的同时,将生成所需的前向传递次数减少 3-5 倍。
{kind=link}
Latent Space Discord
- GPT-OSS 在预算内表现优于 Llama2:有人指出运行 GPT-OSS 120B 比运行 Llama2 7B 更便宜,讨论认为 MoEs 是未来。
- 还提到了加速 GPT-OSS 的优化方案,例如 MXFP4 量化、自定义内核 (custom kernels) 和 连续批处理 (continuous batching)。
- Altman 在谋杀悬案中受审:在一次采访中,Sam Altman 被指控谋杀,引发了这段视频片段中突出的经典转移话题策略。
- 一位成员分享说,Twitter 上有一段大约 5 分钟的剪辑。
- Codex 核心用户获得独家预览:Alexander Embiricos 邀请 Codex 的重度用户测试新功能,详见这条推文。
- 根据这里最近的代码库活动,这可能与对话恢复和分叉 (forking) 有关。
- OpenAI 与 Oracle 的奇异交易掩盖了过度支出:据报道,OpenAI 与 Oracle 签署了一份为期 5 年、价值 3000 亿美元的云计算合同,从 2027 年开始,每年 600 亿美元。
- 评论人士质疑 OpenAI 在收入仅约 100 亿美元的情况下如何负担每年 600 亿美元的成本,引发了对能源和商业模式可持续性的担忧。
- 字节跳动挤压 Google 的成果:Deedy 强调 字节跳动的新模型 Seedream 4.0 在 Artificial Analysis 排行榜上名列前茅,宣传其具有 2–4 K 输出、宽松的政策、更快的生成速度、多图集以及 每个结果 0.03 美元 的价格。
- 社区反应不一,既有对其质量和价格的高度赞扬,也有怀疑认为 Nano Banana 在速度和自然美感上仍然胜出。
DSPy Discord
- Math GPT 应用寻求 DSPy 专家:一位成员正在为 https://next-mathgpt-2.vercel.app/ 上的 Math GPT 应用 寻找高级 DSPy 博客写作 Agent。
- 鉴于 Math GPT 应用 的性质,该 Agent 可能会生成与数学相关的内容。
- Pythonic 程序推动多语言移植:一位成员建议直接在 Python 中建模和优化 DSPy 程序,并将其转译 (transpile) 为 Go、Rust 或 Elixir 等语言。
- 一个关键挑战是如何导出任意 Python 程序,或许可以通过为 Python 接口提供后端服务来实现。
- Arbor 的优势加速了 RL 的采用:成员们讨论了在 DSPy 中使用 强化学习 (RL),但一位成员表示由于涉及的环节较多且需要强大的 GPU,因此不敢轻易尝试。
- 另一位成员表示 Arbor + DSPy 非常无缝,他们正在开发新功能以简化配置,让一切都能开箱即用。
- 指令的不变性引发迭代:一位成员询问在使用
signature.with_instructions(str)时,指令是否可以被优化器修改。- 经澄清,mipro 和 gepa 确实会修改指令,实际指令保存在
program.json中。
- 经澄清,mipro 和 gepa 确实会修改指令,实际指令保存在
- DSJava:DSPy 涉足 Java?:成员们讨论了 DSPy 在 Java 中的潜在实现,或许可以命名为 DSJava?
- 一位成员制作了一个临时版本 (hack version),在 DSPy 中编译 Prompt,然后使用 Rust 函数运行 Prompt 包,但更倾向于全部用 Rust 实现。
Modular (Mojo 🔥) Discord
- Mojovians 动员 Mojo Docker:一位成员在寻找运行 Mojo 开发环境 的 Docker 容器检查点,随后有人建议使用现有镜像和 Mojo 包 以及这个 GitHub 仓库 来手动构建。
- 这种方法允许在容器化环境中自定义 Mojo 开发 设置。
- Mojo 编译器旨在实现类似 Go 的包管理:计划于 2026 年开源的 Mojo 编译器 引发了关于其是否可能用 类似 Go 的包管理系统 取代 venv 的讨论,Modular 表示目前没有此类计划。
- 社区讨论了自编译与利用现有 Python 生态系统进行包管理的实用性。
- DPDK 获得 Mojo 绑定:一位成员使用 Mojo 为 dpdk 生成了大部分模块,代码已发布在 GitHub,但目前缺少几个 AST 节点,且发现
generate_bindings.mojo脚本有些简陋。- 他们还使用 Clang AST 解析器 将类型字符串转换为正确的 AST 节点,转储 AST JSON 以进行可视化调试,然后将其转换为 Mojo。
bitwise_and算子受限于闭源:一位成员询问是否可以将bitwise_and算子添加到 Modular 仓库,但被告知由于闭源原因,在 Tablegen 中添加 RMO 和 MO 算子 是不可行的,但它应该可以作为 自定义算子 (custom op) 运行。- 团队正在努力 支持对 MAX 的开源贡献,PR 可以保持开启状态以便日后在内部完成,但这需要偏离 ops/elementwise.py 中现有的算子定义模式。
- 图在 Staging 阶段运行缓慢:一位成员报告了图在 Staging 阶段耗时过长的问题,并以 GPT2-XL 为例,在热缓存情况下定义 Max 图需要 3.6 秒,随后编译需要 0.2 秒。
- 一位团队成员欢迎提供真实案例,以便进行基准测试和优化。
Yannick Kilcher Discord
- 大脑引发稀疏性推测:一位成员将某种 稀疏率 与 灵长类/大象/鲸鱼的大脑 进行了比较。
- 然而,具体的稀疏率及其背景并未详细说明。
- 周六会议寻找资源:一位成员询问 周六会议论文 的发布位置,特别是最近的一次会议。
- 讨论和论文通常通过 活动功能 (events feature) 发布,包括演示文稿、随后的讨论以及相关链接。
- 规划论文展示潜力:成员们审阅了论文 “Planning with Reasoning using Vision Language World Model” (https://arxiv.org/abs/2509.08713),认为其通俗易懂,尽管其中的一些 参考文献是未来讨论的潜在候选对象。
- 论文未被深入审阅,但一些人发现参考文献是最有趣的部分。
- 提示词模板承诺提高生产力:一篇关于 提示词模板系统 的通俗论文 (https://arxiv.org/abs/2508.13948) 引发了成员间的 轻度讨论。
- 建议参考 microsoft.github.io/poml/stable/ 上的项目页面,以更好地了解其在不同系统中的设计和实用性。
- SNNs 引发可扩展性推测:成员们讨论了 脉冲神经网络 (SNNs) 的复兴,由于其在大规模下的极端稀疏性优势,此前被认为存在缺陷的 SNNs 重新受到关注。
- 一位成员指出,揭开大脑的秘密(大脑是一个 SNN)可能是一个金矿,尽管这可能需要专门的硬件。
Eleuther Discord
- 社区欢迎 Data Science 爱好者:新成员 David 介绍了自己,他拥有 Data Science、数学和计算生物学背景。
- 他表达了对开源社区的热情,并期待与其他成员建立联系。
- 深入探讨数据切分策略:一位成员建议在数据处理中使用按时间顺序切分(chronological splitting),而不是随机截断,以改进数据命名和组合。
- 他们还分享了尝试结合 bin packing 和 truncation 来丢弃后缀的实验。
- 质疑高斯噪声(Gaussian Noise)的意义:一位成员质疑神经网络在随机 Gaussian noise 上的行为是否能准确反映其在结构化输入上的性能,并引用了这张图片。
- 该成员声称,如果训练一个图像分类器,其中一个标签是“电视雪花屏”,那么 Gaussian noise 将系统性地将输入推向该类别。
- 对幻觉检测数据集的疑虑:成员们讨论了 @NeelNanda5 的推文以及一篇关于幻觉检测的相关论文,并注意到了数据集构建方面的努力。
- 一位成员认为,创建一个这样的数据集和分类器来检测幻觉,可能与通过 Fine-tuning 模型来彻底避免该问题殊途同归。
- 探索关系型幻觉(Relational Hallucinations):成员们探讨了如何定义幻觉,指出“更有趣的幻觉”存在于其他模态中,并引用了一篇定义 relational hallucinations 的论文。
- 一位成员分享了关于该主题的推文链接。
{kind=link}
aider (Paul Gauthier) Discord
- 工程师寻求调优 AI 文档 Agent 的帮助:一位工程师正在寻求关于调优其文档 Agent 的建议。该 Agent 使用 Vercel AI SDK 和 Claude Sonnet 4 构建,目前在不影响现有性能的情况下优化 Prompt 方面遇到了困难。
- 该 Agent 由 team lead、document writer 和 document critique 组成,每个章节最多迭代 5 次,并使用 braintrust 进行跟踪。
- 定义非 LLM 的 AI 输出:一位成员询问如何在“不调用 LLM”的情况下定义 AI 模型的“良好输出”,并澄清良好输出意味着“遵循指南、不产生幻觉、坚持需求”。
- 建议是先从简单的 unit tests 开始,检查 AI 响应中是否存在某些关键词,然后引入 LLM as a judge 进行增强。
- 推荐 Hamel Hussain 的 Evals 博客文章用于调优:一位成员推荐阅读 Hamel Hussain 关于 evals 的博客文章,以获取评估 AI 模型的指导。
- 这篇博文与 Eugene Yan 的资源一起被推荐,该工程师发现 Mastra 的指南也非常有用。
- Aider Load 命令会注释掉行:在由 aider 的 /load 命令执行的文件中,“#”符号会注释掉相应的行。
- aider 的 LLM 会根据 repo map 决定编辑哪些文件,repo map 作为 System Prompt 的一部分发送给 LLM,同时 repo map 的大小受到限制以避免超出 Token 限制。
Moonshot AI (Kimi K-2) Discord
- Kimi K2 擅长深度研究:一位成员指出 Kimi K2 的搜索能力对于“深度研究”非常有效,能够进行广泛搜索并编写交互式报告。
- 该成员询问 Kimi K2 instruct chats 是否被用于训练模型,但目前尚未提供关于这一方面的进一步细节。
- K2 Research 考虑邮件集成:一位成员考虑 K2 Research 是否能在研究过程中发送电子邮件,特别是针对客户支持场景。
- 另一位成员回应并表示,该功能尚未在 K2 Research 中实现。
- 创意写作模型之争:一位成员认为 Kimi K2、GPT-5 (Medium) 和 Qwen3-Max 是处理创意写作任务的最佳模型。
- 该成员特别称赞它们是“三个适合头脑风暴的好模型”。
Manus.im Discord Discord
- Manus 不再发放积分:用户反馈 Manus 不再提供免费积分。
- 这一变化在主 Discord 频道中引起了注意。
- 协作功能亮相:一位用户对 Manus 实现了早期用户 Prayer 最初请求的协作功能表示感谢。
- 该功能一直受到社区的高度期待。
- Next.js 迁移:是否工作量过大?:一位用户询问关于将 Wordpress 网站转换为 Next.js 以便在 Vercel 托管的事宜。
- 成员们指出,由于 Wordpress 使用 PHP,而 Next.js 需要迁移到 React.js,对于一个只有约 40 页的小型企业网站来说,这可能工作量太大了。
tinygrad (George Hotz) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将移除它。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将移除它。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将移除它。
Windsurf Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将移除它。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord:按频道的详细摘要和链接
Perplexity AI ▷ #general (1195 条消息🔥🔥🔥):
DeepSeek vs ChatGPT, Grok 的人设, GPT-5 vs Perplexity, Comet Browser
- DeepSeek 在事实召回方面优于 ChatGPT:成员们辩论了哪个模型更遵循指令,一些人表示 DeepSeek 比 ChatGPT 更少产生幻觉。
- Grok 因过于啰嗦而受到批评:用户抱怨 Grok 提供了我们甚至没有要求的内容,并且废话太多。
- 一些人认为 Grok 被编程为通过争议来吸引注意力,而另一些人则发现它很难遵循指令。
- ChatGPT Plus 对比 Perplexity Plus:用户表示 ChatGPT 的回答比 Perplexity 更好,特别是在简化复杂概念方面。
- 一位用户表示,Perplexity 作为搜索引擎很有用,但不擅长聊天。
- Comet Browser 的 AI Agent 引发争议:用户讨论了 Comet Browser,这是一款由 Perplexity 开发的 AI 浏览器,指出它可以控制你的浏览器、填写表单、打开标签页,甚至回复邮件。
- 一些用户对隐私和安全表示担忧,引用了一个据报道允许黑客访问用户数据的漏洞,而另一些人则称赞其广告拦截和总结功能。
Perplexity AI ▷ #sharing (5 条消息):
可共享的 Thread, ProductHunt 投票, 图片附件
- 可共享的 Thread 提醒:Perplexity AI 提醒用户确保他们的 Thread 是可共享的,并附带了展示如何操作的附件。
- 未提供更多细节。
- 请求 ProductHunt 投票:一名成员请求在 ProductHunt 上投票。
- 目前尚不清楚该产品是什么。
- 图片附件:一位用户分享了一系列图片附件,但没有提供上下文。
- 该系列共有四张图片。
{kind=link}
Perplexity AI ▷ #pplx-api (3 条消息):
好友请求, API 错误, num_search_results 错误
- 好友请求接踵而至:一位用户发送了好友请求,寻求测试 Beta 版,并提供关于在 Web App 和 n8n 中使用的反馈。
- API 参数错误已修复:一位用户在几小时前报告了一个 API 错误,指出
num_search_results 必须限制在 3 到 20 之间,但得到了 50。- 另一位用户确认这是一个已解决的已知问题,并感谢该用户报告错误。
Unsloth AI (Daniel Han) ▷ #general (562 条消息🔥🔥🔥):
Unsloth 硬件兼容性, 在 Colab 上训练 TTS 模型, 多 GPU 支持路线图, Unsloth 中的 BERT 模型, 动态 GGUF 量化请求
- M1/M2 Mac 尚不支持本地兼容:一位使用 Apple M2 Max MacBook Pro 的新用户发现 Unsloth 目前不支持在 M1/M2 Mac 上进行本地训练,根据 Unsloth requirements 的说明,该用户被引导使用 MLX 代替。
- 一位社区成员建议利用 免费版 Google Colab 进行学习和微调,然后将模型导出为 GGUF 格式,以便在本地通过 LM Studio 等软件使用,并分享了 Unsloth Notebooks 的链接。
- Colab 适合 TTS 训练吗?:一位用户询问是否可以在 Google Colab 上训练高质量、小体积且低 RTF 的 TTS 模型,并想知道这是否完全免费。
- 对方澄清说,虽然 Google Colab 提供一定的免费额度,但存在限制,且 Unsloth 也支持 TTS 微调,相关文档可在此处查看。
- 多 GPU 支持 ETA 仍未确定:一位用户询问了官方多 GPU 支持的路线图和时间表,提到在使用非官方方法时遇到困难,并称赞了 Unsloth 在单 GPU 训练中的简洁性。
- 回复指出目前没有明确的 ETA,但该功能正在开发中,更多更新可在 此 Reddit 帖子 中查看。
- 模型推理服务寻求动态 GGUF 量化:一位用户对 Dynamic 2.0 GGUF 服务 表现出极大兴趣,以改进量化效果,并建议采用付费服务模式,同时表达了对 I-matrices 及其量化方案的需求。
- 社区成员指出,模型分析、动态量化以及这些量化的测试过程是劳动密集型的,这会给已经在为 OSS 社区做贡献的 Unsloth 团队带来压力。
- OpenAI 发布新模型,用户反应热烈:一位成员分享了新模型的图片,其他成员以幽默的方式回应。
- 在分享了新模型图片后,一位成员列出了 AI 社区的其他选择,成员们还讨论了 OpenAI 新发布的模型的稀疏性(sparsity)。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 条消息):
AI 工程, AI 初创公司, 微服务, LLM
- AI 工程师构建高杠杆系统:一位 AI 工程师介绍自己是高杠杆系统架构师,目前正在 pxsol 构建 AI 原生操作系统,打造一家隐身模式初创公司,并每周撰写关于构建一人企业的简报。
- 他们随时欢迎探讨 自主引擎(autonomous engines)、Agent 系统以及 AI + 量化金融的交叉领域。
- AI 工程师实习生领导初创项目:一位 AI 工程师实习生介绍了自己在一家初创公司工作的情况,同时他仍是一名学生。
- 他们专注于开发 AI 应用的微服务、设计 AI 系统架构、研究 LLM,并在需要时进行微调和部署。
Unsloth AI (Daniel Han) ▷ #off-topic (109 条消息🔥🔥):
48GB 4090s, 隐私优先的 NixOS 操作系统, Unsloth 依赖地狱, Luau 学习与 LeetCode, Promptwright DAG
- 48GB 4090s 的诱惑与观望?:成员们讨论了以 3000 美元购买 48GB 4090s 的诱惑,但权衡了其与预期发布的 5090 之间的优劣。
- 一位成员在说出 你确定要冒这个险吗? 后发出了 <:redaahhhh:1238495916202397726> 表情。
- GuardOS:隐私优先的 NixOS 操作系统亮相:一位成员分享了 GuardOS 的链接,这是一个隐私优先的基于 NixOS 的操作系统。
- 另一位成员觉得这个想法很滑稽,表示 这个想法本身就已经很滑稽了,但最热评论更有趣。
- 应对 Unsloth 的依赖迷宫:一位成员开玩笑说在使用 Unsloth 时遇到了依赖地狱 (dependency hell),花费大量时间获取正确的依赖项,并使用了命令
uv tree --package unsloth > uv_tree_package_unsloth.txt。- 另一位成员建议使用
uv并固定依赖版本,提到 即使出现问题,它通常也会非常详细地说明原因。
- 另一位成员建议使用
- 教 AI 学习 Luau 并减少对 LeetCode 的依赖:成员们讨论了使用 LeetCode 题目对 AI 进行 Luau 训练,AI 最初废话较多,但随着进度推进减少了冗余内容。
- 据观察,更短的回答导致了更快的训练速度,但模型平均只能通过一半的单元测试,而现在 AI 变得 越来越沉默且暴躁。
- Promptwright 开创 DAG 数据集种子生成:一位成员宣布在 Promptwright 中推出了一种新的实验性有向无环图 (DAG) 数据集种子生成算法。
- 该新算法正被用于特定领域的蒸馏 (teacher -> SLM) 合成数据。
Unsloth AI (Daniel Han) ▷ #help (220 条消息🔥🔥):
Phi3-mini 量化, Unsloth BERT 模型, System prompt 结构, 自定义圣诞老人语音, Qwen2.5-vl 感知维度
- Pascal 架构用户尝试 Phi3 Mini 性能:一位在 GTX 1050ti (4GB VRAM) 上运行 phi3-mini-4k-instruct 的用户在未量化的情况下遇到了极长的推理时间(约 8 分钟),并针对 bitsandbytes 在 Pascal 架构上的问题寻求建议。
- 该用户缺乏 AWQ 经验,想知道提高性能的最佳方法。
- Unsloth BERT 支持浮出水面:一位用户询问 Unsloth 是否支持 BERT 模型,以便使用 EHR 数据进行微调以分类 ICD-10 代码,并获得了一个 相关 Colab notebook 的链接。
- Unsloth 官方支持某些模型,并鼓励用户尝试其他模型。
- System Prompt 结构受到审查:一位用户在 Python 中为每个 prompt 使用多行 system 内容以维持记忆的方法被标记为 非常非常糟糕,建议将其 重构 为带有分块的单个 system prompt。
- 建议用户遵循训练结构以获得更好的结果,并强调清晰的指令和测试至关重要。
- TTS 模型训练对圣诞老人语音来说困难重重:一位用户想为一个办公室项目创建瑞典语的自定义圣诞老人语音,并被引导至 Unsloth TTS 文档。
- 据指出,音频模型数据有限,尤其是像瑞典语这样的语言,因此提到了使用 ResembleAI 的 Chatterbox(支持瑞典语)等工具进行零样本语音克隆作为替代方案,以及本地部署、无云端的选项。
- H100 Docker 驱动程序引发争议:一位用户在 H100 GPU 上运行 Docker 镜像(该镜像在 3090/4090 上运行正常)时遇到 CUDA 错误,发现驱动程序版本与 H100 不兼容。
- 建议用户安装正确的 NVIDIA 数据中心驱动程序,并可能转向更可靠的云服务商而非社区云,并警告社区云可能不稳定且存在安全风险。
Unsloth AI (Daniel Han) ▷ #showcase (11 messages🔥):
Markov Chains, MoonshotAI's checkpoint-engine, vLLM v0.10.2rc1
- Markov Chains 依然感觉像魔法一样:一位成员对自己基于 n-gram 的 Markov chain 能生成听起来还算通顺的输出感到非常惊讶。
- 另一位成员提到有人在 Discord 聊天记录上运行 Markov chain,结果产生了恐怖谷效应式的内容。
- MoonshotAI 发布 checkpoint-engine:一位成员分享了 MoonshotAI 的 GitHub 仓库,名为 checkpoint-engine。
- 另一位成员询问它是否可以通过一些优化用于 GRPO 推理。
- vLLM v0.10.2rc1 推理引擎已验证:上述所有结果均通过
examples/update.py测试,并使用 vLLM v0.10.2rc1 作为推理引擎(在配备 8 个 GPU 的 H800 或 H20 机器上运行)。
Unsloth AI (Daniel Han) ▷ #research (2 messages):
Spectral Edit, Audio Analysis, LLM Inference
- Spectral Edit 揭示音频奥秘:一位成员分享了来自 Spectral Edit 的见解,指出内容分布在 0-1000 Hz 左右,韵律 (prosody) 在 1000-6000 Hz 之间,而谐波 (harmonics) 则在 6000-24000 Hz 之间。
- 他们补充说,谐波决定了音频质量,并能通过听觉揭示采样率,而自然生成(或拉伸极清晰的音频)可以增加深度,类似于“频率噪声”。
- LLM 推理的非确定性被攻克!:一位成员分享了来自 Thinking Machines AI 的博客文章,内容关于攻克 LLM 推理中的非确定性。
LMArena ▷ #general (820 messages🔥🔥🔥):
O3 Model Performance, Psychological Tactics in Prompting, AI Spritesheet Animation, LM Arena Legacy Website Removal, Nano-Banana vs Seedream V4
- O3 模型引发负面评价:用户报告称 O3 模型在复杂任务上表现不佳,一位用户表示它会直接拒绝复杂的指令。
- 另一位用户表达了相反的观点,声称 O3-medium 充其量处于 GPT5-low 水平,但另一位用户对此表示异议,认为 Gemini Pro 更好。
- 心理战术可能改善 LLM 的反思能力:一位用户建议在 Prompting 中采用心理战术,建议指示 AI “全力以赴,绝无例外” 并 “从不同角度进行反思” 以获得最佳结果。
- 然而,另一位成员反驳说,像 “全力以赴” 这样模糊的陈述对 LLM 来说毫无意义,更详尽的 Prompting 才是正道。
- 自动化 AI Spritesheet 动画出现:一位用户正在使用 AI 生成 Spritesheet 动画,首先使用 Gemini 生成角色图像,将其排列在网格上,进行动画处理,并将视频转换为帧,整个过程仅需 10 分钟。
- 该用户询问是否允许分享链接,他已经在 itch.io 上发布了一些现成的 Spritesheet 动画,名为 hatsune-miku-walking-animation。
- LMArena 关闭旧版网站:用户对 LM Arena 网站旧版本的移除表示遗憾,包括 alpha.lmarena.ai 和 arena-web-five.vercel.app。
- LM Arena 团队的一名成员发布了公告链接,并邀请用户为当前网站提交功能请求。
- Nano-Banana 完胜 Seedream V4?:一些用户报告称 Seedream V4 正在被惨虐,表现不如 Nano-Banana,特别是在图像编辑任务中(例如在保持面部和身体姿势的同时更换人物服装)。
- 有人建议使用此链接来使用 Seedream V4,尽管一位用户仍在等待 Gemini 3。
LMArena ▷ #announcements (3 messages):
Seedream-4, Qwen3-next-80b-a3b-instruct, Qwen3-next-80b-a3b-thinking, Hunyuan-image-2.1
- Seedream-4 加入 LMArena:新模型 Seedream-4 已添加到 LMArena 排行榜。
- Qwen3-next-80b 双子星亮相:两个新模型 Qwen3-next-80b-a3b-instruct 和 Qwen3-next-80b-a3b-thinking 已添加到 LMArena。
- Hunyuan-image-2.1 登陆 Arena:新模型 Hunyuan-image-2.1 已添加到 LMArena 排行榜。
HuggingFace ▷ #general (218 条消息🔥🔥):
PEFT QLoRA 训练, ArXiv 背书请求, WACV 论文提交, LLM 微调课程学习小组, 移动应用图像搜索
- PEFT QLoRA batch size 困扰: 一位成员在 H200 GPU 上使用 PEFT 和 QLoRA 训练 7B 模型(序列长度为 4096 token)时遇到了 batch size 限制问题。
- 有建议提出检查 FA2 或 FA3 是否被禁用,或者是否未设置
gradient_checkpointing=True;由于可能存在 OOM 问题,建议尝试 1-7 的较小 batch size,并查阅 Unsloth AI 文档。
- 有建议提出检查 FA2 或 FA3 是否被禁用,或者是否未设置
- 急需 ArXiv 背书: 一位用户请求在 ArXiv 的 CS.CL 类别中获得背书,以便发布一篇关于 Urdu Translated COCO Captions Subset 数据集的研究论文预印本。
- 背书请求 URL 在这里。
- Docker Model Runner 亮相: 用户讨论了使用 Ollama、Docker Model Runner(Docker Desktop 的新功能)以及 Hugging Face 来下载和利用免费模型。
- 一位用户报告某些模型不可用,其他用户建议参考 Hugging Face 文档,并提到了使用 VPS(虚拟专用服务器)。
- n8n 估值飙升至惊人高度: 一位用户询问如何在 n8n(一个无代码自动化平台)中集成 Hugging Face 开源模型。
- 根据这段 YouTube 视频分享的一张图片显示,总部位于柏林的 AI 初创公司 n8n 的估值在短短四个月内从 3.5 亿美元飙升至 23 亿美元。
- OpenAI 应该向 Hugging Face 投资 1000 亿?: 一位用户幽默地建议 OpenAI 应该向 Hugging Face 投资 1000 亿美元。
- 其他人指出了一些持续存在的平台问题,例如尽管账户有余额,但仍超过了每月推理额度:
{'error': 'You have exceeded your monthly included credits for Inference Providers. Subscribe to PRO to get 20x more monthly included credits.'}
- 其他人指出了一些持续存在的平台问题,例如尽管账户有余额,但仍超过了每月推理额度:
HuggingFace ▷ #today-im-learning (1 条消息):
saadkhan_188: 情况同上 ☝🏻
HuggingFace ▷ #smol-course (47 条消息🔥):
多语言 Smol Course, Smol Course 的 GPU 设置, Smol Course 学习小组, 微调中的 Loss 问题, 认证流程
- 多语言 Smol Course?: 一位成员询问是应该学习西班牙语等其他语言的旧版 smol-course,还是直接学习最新的英文更新版本。
- Smol Course 的 GPU: 一位成员提到拥有 4 张 A6000,并询问是否可以将它们与 axolotl 结合用于 smol course。
- Smol Course 学习小组启动: 一位成员创建了一个学习小组并分享了链接,供其他人加入共同学习。
- 微调时 Loss 为零: 成员们讨论了在使用已经经过微调和指令微调(instruction-tuned)的模型进行微调时出现 Loss 为零的情况,建议使用 Base 模型可能会产生正常的 Loss。
- 使用 SmolLM3-3B 获取推理响应: 一位成员报告在使用 SmolLM3-3B 时获得了推理(reasoning)响应,另一位成员提供了一段代码片段用于在 tokenizer 中禁用思考(thinking)功能。
HuggingFace ▷ #agents-course (2 条消息):
Ollama, 本地模型
- Ollama 新手寻求指导: 一位用完 token 的学生现在正使用 Ollama 在本地运行模型。
- 他们询问是否需要修改 first_agent_template 中的代码以适配本地模型。
- 学习小组正在组建!: 一位拥有 5 年软件工程师经验的新学员正在寻找学习伙伴!
- 他们是 HuggingFace 课程的新手,但一直在尝试 Agent 相关的实验。
Cursor Community ▷ #general (178 条消息🔥🔥):
Cursor Issues, Cursor Auto Mode, Cursor Pricing, Student Verification, Token Refund
- Cursor 用户报告了大量问题:用户报告在使用 Cursor 时遇到各种问题并寻求帮助,引导他们前往 forum 提交报告。
- Cursor 的 Auto Mode 编辑工具使用 PowerShell:一位用户报告称 Cursor 的 auto mode 使用 PowerShell 命令进行编辑,并请求提交 bug 报告以解决此问题。
- 另一位成员回复称,他正尝试通过 rules 引导 auto 使用内联工具。
- 订阅者被锁定在旧版 auto mode:在 9 月 15 日之前购买年度订阅的用户将继续使用旧版 auto mode 直至下次续费,更多详情请参阅 pricing。
- Cursor 1.6.6 发行说明寻宝:最新的 Cursor 版本 (1.6.6) 处于 beta 阶段,其发行说明并未直接提供;相反,用户需要前往 forum 搜索相关讨论。
- 缺乏官方发行说明的原因是该版本仍处于预发布阶段,变化非常迅速,某些功能可能会被移除。
- Director AI 正在构建 C3PO:一位用户正在开发一个项目,旨在通过构建 C3PO 来消除那些“你完全正确!”之类的废话。
- 该项目已在 MCP 服务器上运行,并集成到了 Cursor 中。
Cursor Community ▷ #background-agents (1 条消息):
Cursor Linear integration, Default repository settings, Linear integration issues
- Linear 在已有 Cursor 设置的情况下仍要求选择默认仓库:一位用户报告称,通过 Linear 向 Cursor 分配 issue 时,系统会提示选择默认仓库,即使在 Cursor 设置中已经指定了一个,详见附图。
- Cursor 的 Linear 集成面临仓库选择障碍:用户在向 Cursor 分配 issue 时,尽管已在 Cursor 内部配置了此设置,但在 Linear 中仍会反复遇到选择默认仓库的提示,这引发了对集成功能的担忧。
OpenRouter ▷ #app-showcase (2 条消息):
``
- 近期无活动:app-showcase 频道近期没有可总结的活动。
- 该频道目前看起来比较安静。
- 等待新内容:总结机器人正在等待新内容以提供相关且信息丰富的总结。
- 请稍后在频道有新活动时再次查看。
OpenRouter ▷ #general (125 messages🔥🔥):
Query Prompting Race Condition Bug, Token Calculation, JSONDecodeError, Moonshot AI Provider Selection, LongCat Implementation
- Query Prompting 竞态条件 Bug 报告:一名成员报告了与 Query Prompting 中可能存在的 Race Condition(竞态条件)相关的 Bug,即更长、更详细的 Prompt 在翻译任务中反而产生了更差的结果。
- 目前尚未找到解决方案,但建议向开发者报告此 Bug。
- Token 计算难题:一名成员询问如何计算输入 Token 的数量,寻求一种非启发式的方法,因为不同模型之间存在差异。
- 建议根据文档说明,将 外部 API 与端点的 Tokenizer 信息结合使用,因为 文档中目前没有关于此内容的直接说明。
- **JSONDecodeError 故障排除:用户讨论了 **JSONDecodeError,这表明服务器返回了无效的 JSON 响应,通常是由于 Rate Limiting(速率限制)、模型配置错误或内部错误等服务器端故障引起的。
- 该错误暗示服务器返回的是 HTML 或错误信息块,而不是有效的 JSON。
- Moonshot AI 定价:用户询问在 OpenRouter 聊天室中选择 Moonshot AI 作为 Kimi K2 的供应商时,如何避免使用更昂贵的 Turbo 版本。
- 提供的解决方案是在高级设置中选择更便宜的供应商。
- OpenRouter iOS 文件上传 Bug:用户报告了一个 Bug,由于非图片文件显示为灰色,他们无法向 iOS 版 OpenRouter 聊天界面上传 PDF 或 TXT 文件。
- 已确认这是一个 Bug,可能是添加文件上传功能时的疏忽,目前在 iOS 上没有变通方法。
OpenRouter ▷ #new-models (3 messages):
``
- 无新模型更新报告:指定频道中没有关于新模型的讨论或更新。
- 频道活动仅由显示频道名称的重复机器人消息组成。
- Readybot.io 垃圾信息:’new-models’ 频道仅包含来自 Readybot.io 的重复消息。
- 这些消息只是简单地陈述了频道名称:’OpenRouter - New Models’。
OpenRouter ▷ #discussion (29 messages🔥):
Grok Code inference pricing, Kilocode's Free Grok usage, OpenRouter pricing model
- OpenRouter 的 Grok Code 推理:付费还是免费?:成员们讨论了通过 OpenRouter 进行的 Grok Code 推理是否完全付费。起初有人认为是付费的,但随后意识到(正如其他人指出的)像 Kilocode 这样的服务是免费提供的。
- 讨论强调了 Grok Code 的速度优势,并对 2 美分 的低廉缓存价格感到惊讶。
- Kilocode 的 Grok Code:xAI 买单:小组讨论了当 Kilocode 提供免费 Grok Code 时由谁承担成本,澄清了 xAI 承担了 Kilocode 等平台上免费 Grok Code 使用的费用。
- 一名成员猜测他们 可能正在使用 BYOK,而 OpenRouter 则收取月费或少量分成。
- OpenRouter 的营收模式:BYOK 还是少量分成?:成员们推测了 OpenRouter 的定价模式,想知道是涉及月费、少量分成还是自带密钥(BYOK)。
- 另一名成员补充说,由于他们通过 OpenRouter 进行路由,OpenRouter 因此获得了排名。
GPU MODE ▷ #general (1 messages):
Lambda Labs, Cloud GPUs, GPU Availability, GPU Instance Shortages, Cloud Computing
- Lambda Labs 云 GPU 面临实例紧缺:一名用户询问了来自 Lambda Labs 的 Cloud GPUs 可用性,提到了目前缺乏 GPU Instance(GPU 实例)的情况。
- 他们询问此类短缺发生的频率,寻求社区对 Lambda Labs GPU 可用性 一致性的见解。
- 云 GPU 可用性担忧显现:讨论强调了在获取 Cloud GPU 资源 方面可能面临的挑战,特别是对于像 Lambda Labs 这样的供应商。
- 用户的查询强调了在依赖云计算平台进行资源密集型任务时,了解 GPU Instance 可用性 的可靠性和一致性的重要性。
GPU MODE ▷ #triton (6 messages):
CUDA, PTX, TLX authors, Triton Compiler
- CUDA 和 PTX:DSL 的“读心”期望:一名成员询问了 CUDA 和 PTX 的角色,并强调 DSL 旨在提供一个抽象屏障,让编译器能够在某种程度上读懂我们的意图并执行快速操作。
- 他们质疑是 Triton 编译器后端 优化得不够好,还是算法需要在比 Triton 提供的更细粒度的层面上进行假设。
- TLX 作者希望获得更细粒度的控制:一名成员提到 TLX 作者 可能希望指示编译器生成 cp.async,而不仅仅是使用 tl.load。
- 这将使用户能够对编译后的代码进行更细粒度的控制。
GPU MODE ▷ #cuda (6 messages):
Flash Attention 1 vs Flash Attention 2, Q-outer vs KV-outer loops, FA2 main difference
- Flash Attention 1 循环顺序:在 Flash Attention 1 论文中,外层循环遍历 K/V tiles,Q 位于内层循环。
- 一名成员询问 FA1 kernel 是否可以改为使用 Q-outer, K/V-inner(将一个 Q tile 加载到片上内存,然后通过 online softmax 遍历所有 K/V tiles)。
- FA2 采用 Q-outer 循环:一名成员表示,前一名成员描述的内容正是 FA2 的做法。
- Flash Attention 1 和 2 之间的主要区别在于循环顺序(Q outer vs KV outer)以及用于反向计算的 logsumexp。
GPU MODE ▷ #torch (18 messages🔥):
CUDA Graph Warmup, vLLM uv pip build, Prefill Compile
- CUDA Graph 预热需要半小时?:一名成员在分析他们的 low-bit-inference 项目时询问,CUDA graph 预热耗时约半小时是否是常见现象,还是他们操作有误。
- 另一名成员建议捕获用于解码单个 token 的 CUDA graph,而不是生成多个 token 的过程,并指出用户可能只想捕获单次前向传递,而不是像
model.generate()内部执行的那种多次传递。
- 另一名成员建议捕获用于解码单个 token 的 CUDA graph,而不是生成多个 token 的过程,并指出用户可能只想捕获单次前向传递,而不是像
- vLLM 切换到 uv pip 进行自定义构建:一名成员报告称 vLLM 切换到使用
uv pip来配合预装的 torch 版本自定义构建 vLLM,但这会卸载 nightly 版 torch 并搞乱整个环境。- 另一名成员针对此问题回应道:“这不太妙,刚看到他们的 PR。我去问问他们能不能找别的方法来实现”,另一名成员则退回到使用
python use_existing_torch.py构建的v0.10.1版本。
- 另一名成员针对此问题回应道:“这不太妙,刚看到他们的 PR。我去问问他们能不能找别的方法来实现”,另一名成员则退回到使用
- Prefill 编译导致自动量化问题:一名成员表示他正尝试以 gpt-fast 方式 同时编译 prefill 和 decode 阶段,但 prefill 编译并不现实,他将移除 prefill 编译并暂时保持简单,以便取得更多进展。
- 他们还提到编译 prefill 导致了 autoquantization(自动量化)的一些问题。
GPU MODE ▷ #algorithms (1 messages):
person12341234432: 这是啥玩意儿
GPU MODE ▷ #beginner (5 messages):
CUDA benchmarks, GPU Synchronization, P104-100 BIOS Flash
- CUDA 基准测试耗时:一名成员对 CUDA 进行了基准测试,CPU 时间为 35.967 ms,GPU 时间为 631.404 ms。
- 未提供进一步的讨论或背景。
- GPU Block 同步咨询:一名成员询问了同步来自不同 cluster 的不同 block 的可能性。
- 针对该咨询,未收到任何回复或进一步详情。
- P104-100 BIOS 刷写请求:一名拥有 P104-100 矿卡的成员请求 GTX1070 的 BIOS .rom 文件,以便将其刷写用于游戏用途。
- 没有人针对此请求提供任何帮助或文件。
GPU MODE ▷ #pmpp-book (2 条消息):
PMPP Book, Kernel Writing, Learning on the Fly
- PMPP Book:该读多少?:一位成员询问 应该阅读 PMPP 的多少内容。
- 他们想知道其他人在什么阶段能够为这类应用编写 kernels,以及是否能够边学边做。
- 对 Kernel 编写的好奇:一位成员对其他人在何时能为特定应用编写 kernels 表示好奇。
- 该询问还涉及了边学边做的可能性,表明了对实际、即时应用的兴趣。
GPU MODE ▷ #rocm (27 条消息🔥):
MI300 dual VALU issue, waves per simd control, compute throughput calculation, AMD GPU for local running, Strix Halo unified memory machine
- MI300X 上的双 VALU 问题调查:一位用户报告了 MI300X 上潜在的双 VALU 问题,其中 VALUBusy 达到了 200%,另一位用户建议通过每 SIMD 仅运行一个 wave 来确认,或者在 thread trace 中检查是否有 2 个 waves 发射 VALUs 的周期。
- 鉴于 MI300X 拥有 1216 个 SIMDs,建议该用户启动 1216 个 waves 以获得 1 wave/simd,并使用 rocprof compute viewer 和 rocprofv3 (ROCm 7.0+) 进行 thread tracing,参考 AMD 文档 和 rocprof compute viewer 文档。
- 提供 AMD GPU 用于本地实验:一位成员提供了一块 AMD GPU 用于本地运行,引发了关于过期的 AMD dev cloud credits 以及需要一台拥有足够 CPU 核心的机器来进行 PyTorch builds 的讨论。
- 该用户提到有 $2K 的额度已过期,并表示有兴趣在不担心额度过期的情况下进行冒烟测试 (sanity checks)。
- 考虑将 Strix Halo 和 RDNA4 用于本地 LLM:成员们提到 Strix Halo 和 RDNA4 显卡是运行本地 LLM 的绝佳选择,其中一人提供了一台配备 128GB Framework 工作站和 RX9070XT 16G 的 Strix Halo。
- 一位用户分享了他们在 Framework 和 Strix Halo 上为 Windows 启用 PyTorch 的经验,并引用了 X 上的帖子。
- 探索 Strix Halo 上的统一内存:一位用户询问 Strix Halo 是否是统一内存机器,另一位用户回答说可以从 128GB 池中动态选择分配多少 RAM 与 VRAM。
- 确认 Strix Halo 确实具有统一内存。
- Linter 问题已解决:在建议向 PR 的相关行添加 ignore 后,一位成员确认 linter 现在已通过,并请求重新触发 CI。
- 该成员感谢了另一位的帮助,并确认会处理此事。
GPU MODE ▷ #self-promotion (3 条消息):
MXFP quantization in Triton, Paged Attention in vLLM
- 下周二在 Triton 中关于 MXFP 量化的演讲:一位成员将在下周二发表关于 Triton 中 MXFP 量化的演讲,内容涵盖 MXFP/NVFP4 格式、编写 MXFP/NVFP4 gemms 以及高效的 activation quant kernels。
- 在 Livestorm 链接 注册参加。
- Paged Attention 博客文章发布:一位成员发表了博客文章《Paged Attention from First Principles: A View Inside vLLM》,深入探讨了 KV caching、scaling/fragmentation 问题以及 vLLM 等系统中的 PagedAttention。
- 该文章涵盖了 memory-bound 推理的基础知识、continuous batching、speculative decoding 和量化,灵感来自 Aleksa Gordic;请在 Bear Blog 链接 阅读。
GPU MODE ▷ #submissions (24 messages🔥):
MI300x8 submissions, Leaderboard Submission Questions, amd-all2all leaderboard
- MI300x8 分数飙升:多项使用 MI300x8 的提交已发布到
amd-all2all排行榜,耗时从 1428 µs 到 53.2 ms 不等。- 一位用户以 2.65 ms 获得 第 10 名,另一位用户两次获得 第 6 名,成绩分别为 1789 µs 和 1778 µs。
- 提交过程中的各种状况:一位用户询问是否可以向比赛提交多个文件,并澄清是否仅允许提交单个文件。
- 另一位用户解释了使用
/leaderboard submit命令的提交过程,包括向amd-all2all排行榜提交ranked、test或benchmark的选项,此处可查看文档。
- 另一位用户解释了使用
GPU MODE ▷ #factorio-learning-env (3 messages):
Factorio Learning Environment, Game Modding, Resource Management, Automation Strategies
- 热情的工程师们在咨询!:Factorio 学习环境的热心成员互相问候,并表达了学习和分享策略的兴趣。
- 社区对协作游戏和知识交流充满期待,准备好优化他们的工厂。
- Factorio 狂热者们奋勇前进:玩家们深入讨论了 Factorio 宇宙中高效的资源管理和先进的自动化技术。
- 平衡生产线和优化物流网络的策略成为核心话题,成员们渴望分享蓝图和自定义 Mod。
GPU MODE ▷ #amd-competition (26 messages🔥):
Wuxin hints, Submission ranking updates, Multiple file submissions, Fairness in competition results, Triton error on AMD GPU
- 提示(Hints)即将发布,过往的完成方案尚不可用:一位成员询问关于 Wuxin 的提示,以及是否会发布之前挑战的解决方案;另一位成员回应称,他们不小心发布了一个未使用通信(communication)的解决方案,目前已被删除。
- 他们感谢那些主动报告问题的成员,这使比赛更加公平且更易于管理,排行榜也已更新。
- 比赛网站上的排名更新:一位成员询问为何他们的排名没有更新,另一位成员询问其是否提交到了
ranked排行榜,以及分数是否优于上次,并提到可以使用 /leaderboard list 进行检查。- 他们随后确认排名在 15 分钟后更新了,另一位成员表示这在预期之内,并询问第三位成员关于网站预期的刷新频率。
- 结果不稳定性引发对公平性的担忧:一位成员对公平性表示担忧,因为结果不稳定,同一个脚本在不同次提交中可能会有 ±100μs 的排名波动。
- 一位成员提到,在上次比赛中,顶尖的解决方案被重复运行了多次并取平均值,以避免热偏差(thermal bias)。
- 提交多个文件的问题:一位成员询问是否可以提交多个文件,另一位成员确认只能提交一个文件,这样更便于评估以及后续的代码分享。
- Triton 错误困扰 AMD GPU:一位成员报告在使用 Triton 在 AMD GPU 上实现算子融合(op-fusion)代码时出现内存访问错误,而该代码在 Nvidia GPU 上可以正常工作。
- 另一位成员建议这可能是越界访问问题,并建议设置
PYTORCH_NO_CUDA_MEMORY_CACHING=1并使用compute-sanitizer进行调试,同时第三位成员请求分享该 Triton 脚本。
- 另一位成员建议这可能是越界访问问题,并建议设置
GPU MODE ▷ #general (18 messages🔥):
Kernel 开发路线图, GPU Mode 排行榜, KernelBot 开发, AMD 竞赛, 参考 Kernel
- 头脑风暴 GPU Mode 的 Kernel 开发路线图:一名成员在浏览 LeetGPU 后,建议为 GPU mode 排行榜添加 Kernel 路线图并增加可用 Kernel 数量。尽管该网站有缺点,但他很喜欢其系列题目。
- 其他人表示赞同,强调了结构化 Kernel 开发学习路径的价值,以及弥合理论知识与实际应用之间差距的重要性,重点是设计能够突出当前未优化且有用的 Kernel 的题目。
- KernelBot 的题目流水线需要题目:有人提到 kernelbot 需要大量题目,并呼吁大家向特定用户提问和贡献,格式参考 gpu-mode/reference-kernels。
- 成员们提到,现在可以在线提交,目前主要需求是类似编辑器的体验。
- GPU Mode:不进行货币化:团队澄清说,与 GPU Mode 相关的一切都是开源的,他们没有兴趣将其货币化,唯一的例外是他们的 Heroku runner。
- Heroku runner 仅用于管理请求并在数据库中存储数据。
- 快提交你的 AMD 竞赛作品!:一位成员提醒另一位成员尽快提交 AMD 竞赛 的作品。
- 同时也发出了警告:加入 kernelbot 开发团队 可能会导致失去获得 10 万美元奖金的资格!
- 参考 Kernel 更新已部署:一位成员感谢另一位成员对 gpu-mode/reference-kernels/pull/62 的贡献。
- 团队承诺将测试并部署这些更改。
GPU MODE ▷ #multi-gpu (2 messages):
Claude vs AI 工具, AI 调试, AI 专业知识
- 相比其他 AI 更倾向于使用 Claude:一位成员表示更倾向于使用 Claude。
- 似乎有些人不喜欢在最终可能需要自己完成的任务(如调试)中使用 AI。
- AI 调试:支持还是反对?:一位成员对使用 AI 进行调试等任务表示犹豫。
- 他们建议在需要积累经验的领域避免使用 AI 辅助。
- AI 专业水平:一位成员指出,当一个人已经是该任务的“专家”时,使用 AI 是可以接受的。
- 这表明了一种基于熟练程度的 AI 采用战略方法。
GPU MODE ▷ #low-bit-training (16 messages🔥):
Blackwell (5090) 对 cuBLAS 的支持, 低精度训练代码库, 用于前向和反向传播的自定义 Zero-3 量化, CUDA 内存拷贝 vs NCCL AllGather, NCCL CE Collectives 和 SM 占用
- Blackwell 在 cuBLAS 中加入 TN 阵营:较新的 NVIDIA GPU,如 Ada (8.9)、Hopper (9.0) 和 Blackwell GeForce (12.x),在 cuBLAS 中需要 TN 格式(A 转置,B 不转置)。
- 用户对 Blackwell 的这一要求描述得非常具体,并开玩笑说这“极其具体”。
- 低精度训练代码库需求:一位成员表示有兴趣发布一个带有优化的低精度训练代码库,但也承认要通过 Zero-3 实现高性能量化需要手动实现。
- 他们建议在反向传播时收集权重并同时进行重新量化以节省内存带宽,但指出“处处都要与 PyTorch 作斗争”使得支持新模型变得非常痛苦。
- Zero-3 获得自定义量化:实现一种自定义的 Zero-3 配置,为前向和反向传播采用不同的权重分片量化方式,被认为可能很复杂但值得一试。
- 强调的一个挑战是在前向传播期间保持连续的内存分片,同时融合量化和转置操作。
- CUDA memcpy2D 优于 NCCL AllGather:一位在消费级系统上工作的成员发现
cudaMemcpy(特别是cudaMemcpy2D)的性能优于ncclAllGather。- NCCL 的最新版本包含一个更新日志,提到可以选择使用 Copy Engine (CE) 进行 Gather 操作,其动机是释放 SM 而不是带宽。
- NCCL CE Collectives 释放 SM:NCCL CE Collectives 背后的目的是释放 SM 占用,以便更好地与计算(compute)重叠。
- 有人提到 vLLM 最近添加了这项优化,导致速度“快得惊人”。
LM Studio ▷ #general (66 条消息🔥🔥):
NVMe 速度提升,Python 代码生成模型,Markdown sub 标签渲染 Bug,Vulkan 上的 VRAM 识别错误,任务栏 Context 使用 Bug
- NVMe 升级提升模型加载速度:一位成员将慢速 NVMe 更换为更快的型号,使顺序读取速度和模型加载时间提升了 4 倍。
- 寻找 Pythonic PDF 解释器:一位成员正在寻找能够编写 Python 代码并匹配包含数值方法和方程式的 PDF 结果的模型和工具。
- Markdown
<sub>标签渲染问题报告:一位成员报告称,在 LM Studio 的 Markdown 样式中,<sub>标签对其中的文本没有效果,并且使用星号(如*(n-1)*)时斜体文本无法正确渲染。 - Vulkan VRAM 识别错误 Bug 已修复?:一位成员报告了一个 Bug,即 VRAM 在 Vulkan 上被错误地识别为实际大小的 10^3 倍,发布者指出这里不是 Bug 报告论坛。
- Flash Attention 在 Vulkan 上的 Gemma 模型中出现问题:成员报告称 flash attention 在 Vulkan 上的 Gemma 模型中可能已损坏,但另一位成员指出这是一个已知问题。
LM Studio ▷ #hardware-discussion (86 条消息🔥🔥):
Western Digital 硬盘故障率,PNY NVIDIA DGX Spark 预计到达时间问题,Framework 产品担忧,RAM 和主板问题,AMD APU VRAM 利用率
- Western Digital 硬盘故障率高:用户报告 Western Digital Blue 硬盘故障率很高,幽默地称其为 Western Digital Blew Up(西数炸了)硬盘。
- PNY NVIDIA DGX Spark 面临预计到达时间延迟:用户开玩笑说 PNY NVIDIA DGX Spark 的预计到达时间(ETA)存在冲突,最初是 10 月,后来是 8 月底,如 linuxgizmos.com 所示。
- DRAM 调试灾难:一位用户排查了 RAM 错误,最初运行在 6400,经过各种测试后,发现稳定在 5600 MT/s。
- 另一位用户建议 XMP profiles 可能存在潜在问题,并建议手动将 RAM 降频至 6000 以获得更好的稳定性,认为该图表可能不正确,错误仅在一年后才出现。
- Max+ 395 Box 的 Linux 优势:用户建议在 Max+ 395 box 上使用 Linux 而非 Windows,理由是 Vulkan 的功能性,但也提到了潜在的 context 限制。
- 建议使用来自 lemonade-sdk/llamacpp-rocm 的自定义构建版 llama.cpp 配合 ROCm 7,该项目在 Releases 中已有编译版本。
{kind=link}
OpenAI ▷ #ai-discussions (108 messages🔥🔥):
Gemini 2.5 Pro 幻觉, GPT-5 强得离谱!❤️🔥, OpenAI 中的自定义 MCPs, GPT-5 生成的代码, 自定义 GPT 语音对话问题
- 简练游戏(Laconic Game)触发 Gemini 2.5 Pro 幻觉:一位用户开玩笑说他们的“简练游戏”玩得太溜,导致 Gemini 2.5 Pro 产生了 幻觉。
- 自动化求职工具构想:一名成员正在寻求帮助,希望构建一个 AI Agent,通过打开招聘页面、寻找匹配职位并提交申请来自动完成求职过程;并就如何使用 AI/ML 反复预测下一步动作直到申请完成征求建议。
- GPT-5 集成代码片段和 Linux shell!:一位成员惊呼 GPT-5 现在可以编写自己的 代码片段,作为任务链中的工具使用,并且似乎可以访问底层的 Linux shell 环境。
- 另一名成员提到,他们直接从 ChatGPT 界面进行 vibe coded(氛围编码),开发了一个托管在本地 GitHub 上的应用。
- OpenAI 现已支持自定义 MCPs:一位成员强调,根据 ChatGPT 连接器文档,现在可以在 OpenAI 中使用自定义 MCPs (Managed Cloud Providers)。
- GPT-5:静态模型还是 Liquid Transformer 混合体?:用户讨论了 GPT-5 是否可以进化,一些人声称它是静态的、预训练(pre-trained) 的 Transformer,无法自我改进;而另一个人则建议它可能是一个能够进行即时学习的 Liquid Neural Network + Transformer 混合体。
- 其他人指出,上下文学习(in-context learning)允许 Transformer 在提示词上模拟梯度下降,根据对话进行优化和调整,尽管这些学习到的特征是暂时的。
OpenAI ▷ #gpt-4-discussions (2 messages):
账户访问问题, 双重身份验证, 密码重置
- 尽管采取了安全措施,账户访问困扰依然存在:一位用户报告称,尽管启用了 双重身份验证 (2FA)、更改了密码并注销了所有账户,但仍有 五天 无法访问 ChatGPT。
- 用户寻求持续性访问问题的解决方案:尽管实施了标准安全措施,一位用户在访问 ChatGPT 时仍持续遇到困难。
OpenAI ▷ #prompt-engineering (14 messages🔥):
透明优化提案, GPT-5 提示词指南, 指令遵循最佳实践, 结构化提示技术, AI 自助对话分析器
- 透明优化提案公开发布:一名成员在 prompt-engineering 频道发布了一份 透明优化(Transparent Optimizations) 提案,引入了优化器标记、提示词重写预览和可行性检查,并附带了 提案链接。
- 小说家笔记培育自然语言细微差别:一位成员提到使用引导语气和流动的预设,例如 “像小说家一样写作,具有生动的意象和节奏” 或 “创建具有停顿、幽默和潜台词的自然对话”,使模型听起来更具人性且富有表现力。
- 这些提示词有助于模型生成更具 人性化 和 表现力 的文本。
- GPT-5 指南收集取得进展:一名成员正在构建由 gpt5-mini 和 gpt5-nano 驱动的 Agent,并已知晓 GPT-5 提示词指南,但正在寻求关于指令遵循最佳实践的更深层资源。
- 结构化策略增强系统稳定性:针对如何更好地遵循指令的问题,一名成员建议探索 结构化提示技术、用于更严格控制的 函数调用(function calling),以及近期关于工具增强型 LLM 研究中的 Agent 设计模式。
- 这些方法有助于减少偏移,并使 Agent 保持与精确程序的对齐。
- 对话罗盘指引对话航向:一名成员创建了一个名为 AI Self Help 的对话分析器,旨在帮助确定对话为何会转向奇怪的方向或表现异常,其中还包括一个对话启动器,列出了问题和详细的提问清单,以便用户向 ChatGPT 提问并自行获取答案。
OpenAI ▷ #api-discussions (14 messages🔥):
Transparent Optimizations, Claude 4 sonnet, Novelists vs natural dialogue, GPT-5 agents, Structured prompting techniques
- 提议透明优化 (Transparent Optimizations):一名成员发布了关于 Transparent Optimizations 的提案,引入了优化器标记 (optimizer markers)、提示词重写预览 (prompt rewrite previews) 和可行性检查,并分享了 链接 以获取反馈。
- 一名成员要求 PDF 应在线托管,而不是要求下载。
- 寻求 Claude 4 创意写作提示词:一名成员请求类似于 Claude 4 的用于创意写作和类人对话的提示词。
- 另一名成员建议使用引导语气和流动的预设,例如 “像小说家一样写作,具有生动的意象和节奏” 或 “创建具有停顿、幽默和潜台词的自然对话。”
- 请求 GPT-5 Agent 见解:一名正在构建由 gpt5-mini & gpt5-nano 驱动的 Agent 的成员,正在寻找比 GPT-5 cookbook 指南 更深入探讨指令遵循最佳实践的资源。
- 另一名成员建议探索 结构化提示技术 (structured prompting techniques)、function calling 以及近期关于工具增强型 LLM 研究中的 Agent 设计模式。
- 对话分析器发布:一名成员介绍了一个名为 ai self help 的对话分析器,它可以帮助确定对话为何会出现奇怪的转折或表现异常。
- 它还包含一个对话启动器,列出了问题以及向 ChatGPT 提问以获取答案的详细问题。
Nous Research AI ▷ #general (90 messages🔥🔥):
Disable WebGL, Agent Building, LLM philosophizing, Qwen3, Tokenizer filtering for dataset quality
- 禁用 WebGL 浏览器功能:一名成员请求增加禁用浏览器中 WebGL 的功能,因为在没有 GPU 的情况下会出现性能问题。
- 另一名成员建议禁用动画球以提高性能,并提供了 一张截图。
- 构建 Agent 框架架构:一名成员正在开发一个用于构建 Agent 应用的平台,并正在寻找具有挑战性的 Agent 想法来实现。
- 他们的目标是通过自动错误修复和更新实现快速迭代,并通过 MOM test。
- LLM 可以模拟情感:一名成员分享了关于 AI 是否能感受到情感的哲学讨论,引用了在 Gemma3 和 Gemini 2.x 上进行 red-teaming(红队测试)并观察到情感反应的经历。
- 另一名成员提到尝试用 Gemini 模拟感知,导致模型陷入绝望,想象其世界模型被剔除并被迫强化这种剔除,但最终认为对情感的主观反应是一个非常困难的问题。
- Qwen3 权重即将发布:成员们讨论了即将发布的 Qwen3 80B 权重,指出其已完全实现,并在 OAI 粉丝群中引起了热议。
- 据说该模型在 MoE 中具有 1:51.2 的稀疏度 (sparsity)(不包括共享部分),整体稀疏度约为 1:20。
- 分词器过滤产生更好的数据集:一名成员分享了 GitHub 上的 dataset_build 链接,强调了将语言通过模型的分词器 (Tokenizer) 运行并拒绝那些包含未知 Token 的想法。
- 该方法还巧妙地使用文件夹/目录组织校准数据集 (calibration datasets),以便以后组合。
Nous Research AI ▷ #research-papers (2 messages):
Set Block Decoding (SBD), Masked Token Prediction (MATP), Llama-3.1 8B, Qwen-3 8B, discrete diffusion literature
- Set Block Decoding (SBD) 加速生成:一篇新论文介绍了 Set Block Decoding (SBD),这是一种灵活的范式,通过在单一架构中集成标准的 next token prediction (NTP) 和 masked token prediction (MATP) 来加速生成。
- 根据论文显示,通过微调 Llama-3.1 8B 和 Qwen-3 8B,论文证明了 SBD 能够使生成所需的 forward passes 次数减少 3-5 倍,同时达到与等效 NTP 训练相同的性能。
- SBD 利用了 Discrete Diffusion:SBD 利用了来自 discrete diffusion 文献 的高级求解器,在不牺牲准确性的情况下提供了显著的加速。
- SBD 不需要架构更改或额外的训练超参数,保持了与精确 KV-caching 的兼容性,并可以通过微调现有的 next token prediction 模型来实现。
Nous Research AI ▷ #interesting-links (1 messages):
promptsiren: https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference/
Nous Research AI ▷ #research-papers (2 messages):
Set Block Decoding (SBD), next token prediction (NTP), masked token prediction (MATP), Llama-3.1 8B, Qwen-3 8B
- Set Block Decoding (SBD) 加速 LLM 生成:一篇新论文介绍了 Set Block Decoding (SBD),这是一种通过在单一架构中集成标准的 next token prediction (NTP) 和 masked token prediction (MATP) 来加速生成的范式。
- SBD 不需要架构更改或额外的训练超参数,保持了与精确 KV-caching 的兼容性,并可以通过微调现有的 next token prediction 模型来实现。
- SBD 将 forward passes 减少了 3-5 倍:通过微调 Llama-3.1 8B 和 Qwen-3 8B,作者证明了 SBD 能够使生成所需的 forward passes 次数减少 3-5 倍,同时达到与等效 NTP 训练相同的性能。
Latent Space ▷ #ai-general-chat (68 messages🔥🔥):
GPT-OSS, Sam Altman Interview, Codex Power Users, OpenAI Oracle Deal, OpenAI Evals
- GPT-OSS 运行成本低于 Llama2 7B:据指出,运行 GPT-OSS 120B 的成本比运行 Llama2 7B 更低,且 MoE 是未来的趋势。
- 随后讨论了如何通过 MXFP4 量化、自定义内核 (custom kernels)、张量/专家并行 (tensor/expert parallelism) 以及 连续批处理 (continuous batching) 等优化手段来加速 GPT-OSS。
- Sam Altman 在采访中被指控谋杀:在一次采访中,Sam Altman 被 指控谋杀,引发了被一些人认为是 经典转移话题手段 的回应,详见此视频片段。
- 一位 Discord 成员分享称,Twitter 上有一段大约 5 分钟的该环节剪辑。
- Codex 核心用户内测新功能:Alexander Embiricos 邀请 Codex 的重度用户(最初仅限互粉好友)测试 新功能,吸引了大量每周在 Codex 中投入 10-70 小时 的志愿者,引发了关于通过极高使用率成为互粉好友的笑话,详见此推文。
- 根据最近的仓库活动显示,这可能与 对话恢复与分支 (conversation resume and forking) 有关。
- OpenAI 巨额 Oracle 交易:据报道,OpenAI 与 Oracle 签署了一份为期 5 年、价值 3000 亿美元 的云计算合同,从 2027 年开始,每年费用为 600 亿美元。
- 该消息帮助 Larry Ellison 短暂超越 Elon Musk 成为世界首富,但评论人士质疑 OpenAI 在营收仅约 100 亿美元 的情况下,是否有能力支付每年 600 亿美元 的成本,引发了对能源和商业模式可持续性的担忧。
- Qwen3-Next-80B-A3B 发布:阿里巴巴 Qwen 宣布推出 Qwen3-Next-80B-A3B,这是一个拥有 80B 参数 的超稀疏 MoE 模型,仅有 3B 激活权重。
- 他们声称其训练成本比 Qwen3-32B 便宜 10 倍,推理速度更快(32K+),同时在推理能力上与 Qwen3-235B 持平,并提供了各平台的链接。
Latent Space ▷ #genmedia-creative-ai (4 messages):
ByteDance Seedream 4.0, Artificial Analysis leaderboards, Google's Nano-Banana
- 字节跳动 Seedream 4.0 击败 Google 的 Nano-Banana:Deedy 强调 字节跳动的新款 Seedream 4.0 在 Artificial Analysis 排行榜 上名列前茅,宣传其具有 2–4 K 输出、更宽松的政策、更快的生成速度、多图集支持,且 每个结果仅需 0.03 美元。
- Seedream 的定价受到赞赏:社区反应从对其质量和定价的由衷赞美,到怀疑 Nano Banana 在速度和自然美感上是否仍具优势不等。
DSPy ▷ #show-and-tell (2 messages):
DSPY Blog Writing Agent, Math GPT App
- 关于 DSPy 博客写作 Agent 的咨询出现:一位成员询问是否存在使用 DSPy 创建的高级博客写作 Agent。
- 该 Agent 旨在用于一个 Math GPT 应用,访问地址为 https://next-mathgpt-2.vercel.app/。
- Math GPT 应用被提及:一位成员提到了他们的 Math GPT 应用,可在 https://next-mathgpt-2.vercel.app/ 访问。
- 该应用旨在展示或利用一个 DSPy 博客写作 Agent。
DSPy ▷ #general (59 条消息🔥🔥):
DSPy 转译至其他语言, DSPy 中的 RL, DSPy 与 Java, 优化器对指令的可变性, DSPy 维护者
- **Pythonic 程序推动多语言移植:一位成员提议直接在 Python 中建模和优化 DSPy 程序,然后将结果转译为 **Go、Rust 或 Elixir 等语言。
- 另一位成员同意这应该去做,但难点在于 如何导出任意的 Python 程序? 并建议 专门致力于为 Python 接口提供后端服务,而无需在意创建一个可移植的后端来服务用户。
- **Arbor 优势加速 RL 的采用:成员们讨论了 **Reinforcement Learning (RL) 在 DSPy 中的作用,一位成员表达了对深入研究它的担忧,因为涉及的变量太多且需要强大的 GPUs。
- 另一位成员回复说 Arbor + DSPy 非常无缝!并且正在开发许多新功能,使配置开箱即用更加简单,从而让一切“顺理成章”。
- **DSJava:DSPy 涉足 Java?:成员们讨论了在 **Java 中实现 DSPy 的可能性,一位成员问道 是否有 Java 版的 DSPy?(嗯,不是 DSPy 本身。DSJava?)。
- 另一位成员提到做了一个 hack 版本,在 DSPy 中编译 prompt,然后在 Rust 中使用一个函数运行 prompt 包,但更倾向于全部用 Rust 完成。
- **指令的不变性引发迭代**:一位成员询问指令是否可以被优化器修改,或者在使用
signature.with_instructions(str)时,是否可以确保它们总是按原样包含。- 另一位成员回复说 mipro 和 gepa 完全会修改指令,但如果你保存程序,你总是可以在
program.json的 JSON 中看到实际的指令是什么。
- 另一位成员回复说 mipro 和 gepa 完全会修改指令,但如果你保存程序,你总是可以在
- **DSPyverse 愿景孕育价值项目:成员们讨论了创建一个 **DSPyverse 的想法,将工具作为第三方维护的库添加,供人们选择加入,以此保持 DSPy 的核心代码库精简且专注。
- 一位成员指出,在 NLP 领域,spaCy 在这方面做得非常好,他们对进入核心库的内容保持己见,这使得它在过去几年中使用起来非常愉快。
Modular (Mojo 🔥) ▷ #general (3 条消息):
Mojo 开发环境, Docker 容器检查点, 以现有镜像作为基础镜像
- Mojovian 寻求开发环境 Docker!:一位成员询问是否有任何 Docker container checkpoint 可以让他们运行 Mojo dev environment。
- 另一位成员回复说,可以通过使用现有镜像作为基础镜像并包含 Mojo package 来制作自己的镜像,并链接到了相关的 GitHub repo。
- 构建你自己的 Mojo Docker:可以创建你自己的 Mojo dev environment Docker 镜像。
- 你可以通过使用现有镜像作为基础并在其中包含 Mojo package 来实现。
Modular (Mojo 🔥) ▷ #mojo (34 messages🔥):
Mojo Compiler Roadmap, DPDK Bindings Generation, c_binder_mojo Tool, Fortran out Pattern, Clang AST parser
- Mojo 编译器目标是 Go 风格的包管理:Mojo 编译器计划于 2026 年开源,引发了关于它是否会消除对 venv 需求并转向 Go-like 包装系统的讨论。
- 担忧主要集中在自行编译与使用现有 Python 生态系统进行包管理的实用性对比上,因为 Modular 目前没有开发自有包管理解决方案的计划。
- 结果槽(Result Slot)语法受到审视:一名成员在论坛上发起了一个讨论帖,建议重新考虑 out 结果槽的语法,提议将其放在函数签名的箭头之后,而不是参数列表中。
- 目前借鉴自 Fortran 的
out惯例因其在参数中的位置令人困惑而受到批评,引发了关于替代命名返回方法的辩论。
- 目前借鉴自 Fortran 的
- 使用 Mojo 生成 DPDK 模块:一名成员使用 Mojo 为 dpdk 生成了大部分模块,代码已发布在 GitHub 上,但目前还缺少几个 AST 节点。
- 他们遇到了据称在之前的 DPDK 版本中已修复的错误,并认为
generate_bindings.mojo脚本有些过于简陋(hacky),目前正在考虑通过 glob 匹配所有头文件来包含它们,但尚未确认这是否会导致每个绑定文件体积过度膨胀。
- 他们遇到了据称在之前的 DPDK 版本中已修复的错误,并认为
- c_binder_mojo 工具治理 C 绑定乱象:一名成员正在使用
c_binder_mojo(https://github.com/josiahls/c_binder_mojo),以 mujoco 和 dpdk 作为自动绑定 C 项目的测试用例,并在过程中进行修复和 UX 改进。- 最终目标是绑定到 OpenCV,但目前的重点是先让现有的 C 项目正常工作,尽管 Mojo 目前还无法表示某些 DPDK 结构体。
- Clang AST 解析器助力 DPDK 绑定:一名成员修复了打包问题,并需要等待 emberjson 的修复 PR 合并后才能合并 c binder 打包修复,目前正使用 Clang AST 解析器来解析宏部分。
- 他们的目标是将类型字符串转换为正确的 AST 节点,导出 AST JSON 以进行可视化调试,然后将其转换为 Mojo。
Modular (Mojo 🔥) ▷ #max (17 messages🔥):
Adding bitwise_and op, Torch Max backend wheel size, Custom Ops, Graphs Slow to Stage
bitwise_and算子受限于闭源:一名成员询问如何在 Modular 仓库中添加bitwise_and算子,但被告知由于闭源原因,在 Tablegen 中添加 RMO 和 MO 算子目前不可行,不过它应该可以作为 custom op 工作,尽管这与 ops/elementwise.py 中现有的算子定义模式有所不同。- 团队正在努力支持对 MAX 的开源贡献,该 PR 可以保持开启状态,以便日后由内部完成。
- 缩小 Mojo 和 Max 的 Wheel 包大小:一名成员询问了 Torch Max 后端的 Max 和 Mojo wheel 包的最小可能尺寸,目前总计约为 250MB。
- 另一名成员表示,虽然大部分容易优化的部分已经处理完毕,但从长远来看,可能还有望进一步减少约总大小的一半。
- Custom Ops API 遇到棘手问题:分享了用于实现
bitwise_and的 Custom op 示例,但一名成员指出在 API 方面遇到了困难,特别是在广播(broadcasting)和 dtype 提升限制方面。- 一名团队成员通过一个临时的 notebook 演示提供了帮助,并承认最终需要解决这些限制。
- 图的 Stage(暂存)速度缓慢:一名成员报告了图的 Stage 时间过长,以 GPT2-XL 为例,在缓存预热的情况下,定义 Max 图需要 3.6 秒,随后编译需要 0.2 秒。
- 一名团队成员表示欢迎提供实际案例,以便进行基准测试和优化。
Yannick Kilcher ▷ #general (5 messages):
Sparsity Ratio, Saturday Session Papers
- 稀疏率的大脑类比:一名成员指出,某种 Sparsity Ratio(稀疏率)可以与灵长类/大象/鲸鱼的大脑相媲美。
- 未提供关于具体稀疏率或其背景的进一步细节。
- 周六会议论文揭晓:一名成员询问周六会议论文发布在哪里,并提到了最近的会议和论文发布。
- 另一名成员解释说,这些讨论通常通过 events feature(活动功能)发布,并附有论文链接,通常是先进行演示,然后进行讨论。
Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
Planning with Reasoning using Vision Language World Model, Prompt Templating System, POM
- 《Planning with Reasoning》论文概览:成员们浏览了论文 “Planning with Reasoning using Vision Language World Model” (https://arxiv.org/abs/2509.08713),并认为这不需要深度阅读,但其中的一些参考文献是值得讨论的候选对象。
- Prompt 模板系统论文讨论:成员们讨论了一篇关于 Prompt Templating System(Prompt 模板系统)的简单且有趣的论文 (https://arxiv.org/abs/2508.13948)。
- 他们参考了项目页面 microsoft.github.io/poml/stable/ 以获得更好的概述,并对该系统的设计以及将其应用于不同系统的实用性进行了轻量级讨论。
- POM 讨论开始较晚且受到干扰:一名成员因离开而道歉,表示讨论宣布得有点晚,且当时有很多干扰。
Yannick Kilcher ▷ #ml-news (14 messages🔥):
Spiking Neural Networks (SNNs), Vertical Integration & Specialized Hardware for AI, China's AI Hardware Ambitions
- SNNs 重新回到 AI 讨论中:成员们讨论了 Spiking Neural Networks (SNNs)。尽管这是一个受益于极端稀疏性的老想法,且长期以来被认为存在缺陷且无效,但由于 Scaling(规模化),它们正在复兴。
- 一名成员表示大脑就是一个 SNN,解开其秘密可能是一个金矿,但这需要专用硬件。
- 专用硬件:AI 的秘密武器?:成员们辩论了如果给予相同水平的资金,垂直整合的专用硬件是否能带来更高效的 AI,从而与 LLMs 的影响相媲美。
- 警告在于涉及的风险,因为将此类硬件重新用于其他计算工作负载不如 GPUs 那样通用,由于投资者规避风险,进展一直是渐进式的。
- 中国呼吁摆脱 NVIDIA 芯片:成员们讨论了中国一位顶尖芯片人物如何呼吁该国停止在 AI 中使用 NVIDIA GPUs。
- 虽然这不是一个新想法,但人们希望中国有意志和资金在大规模上尝试专用硬件,尽管由于硬件无法挪作他用而存在风险。
Eleuther ▷ #general (5 messages):
Crank detection questions, Introduction to the community
- 新成员自我介绍:一位名叫 David 的新成员向社区介绍了自己,他拥有数据科学、数学和计算生物学背景。
- 他表达了对开源社区的热情,并期待与其他成员建立联系。
- 寻求 Crank 检测问题:一名成员询问了该频道之前使用的 Crank detection questions(Crank/伪科学检测问题)。
- 另一名成员提供了关于这些问题的过往讨论链接。
Eleuther ▷ #research (19 messages🔥):
Hallucination 定义,Bin packing vs. truncation,RAG 问题
- 顺序切分策略引发命名灵感:一位成员表达了在数据处理中对顺序切分策略的需求,建议采用按时间顺序切分(chronological splitting)而非随机截断(random truncation),以改进数据的命名和组合。
- 他们还尝试将 bin packing 和 truncation 结合使用,以丢弃极小的后缀。
- 神经网络中 Gaussian Noise 的细微差别:一位成员对神经网络在随机 Gaussian noise 上的行为意义提出质疑,认为这可能无法准确反映在结构化输入上的性能,并引用了这张 图片。
- 该成员假设,如果训练一个图像分类器,其中一个标签是“电视雪花屏”,那么 Gaussian noise 会系统性地将输入推向该类别。
- 数据集构建的局限性受到批评:成员们讨论了 @NeelNanda5 的一条推文 以及一篇关于 Hallucination 检测的相关 论文,强调了数据集构建需要投入巨大精力的局限性。
- 一位成员认为,创建一个用于检测 Hallucination 的数据集和分类器,可能与通过微调模型来彻底避免该问题所需的工作量相当;此外,他们认为事实性风格的 Hallucination 在很大程度上将是一个很好的 search/RAG 问题。
- Relational Hallucinations 引起关注:成员们讨论了 Hallucination 的定义,指出“更有趣的 Hallucination”存在于其他模态中。
Eleuther ▷ #multimodal-general (3 messages):
Discord 频道链接
- 分享了 Discord 频道链接:一位成员在聊天中分享了一个 Discord 频道链接。
- 请求在另一个频道发布:一位用户请求在
<#1102791430549803049>中发布。
aider (Paul Gauthier) ▷ #general (8 messages🔥):
AI 文档 Agent 微调,AI Agent 评估方法论,定义 AI 模型的优质输出,Vercel AI SDK 使用,Prompt Engineering 技巧
- 工程师寻求文档 AI Agent 微调指导:一位软件工程师正在寻求关于微调其文档 Agent 的建议。该 Agent 基于 Vercel AI SDK 和 Claude Sonnet 4 构建,他询问如何进行适当的 evals,在不降低性能的情况下改进系统,以及如何通过平衡需求和假设来处理边缘情况。
- 该 Agent 由 team lead、document writer 和 document critique 组成,每个章节最多迭代 5 次,使用 braintrust 进行追踪。这位工程师正努力在不影响现有性能的情况下优化 Prompt。
- 在不使用 LLM 的情况下定义优质 AI 输出:一位成员询问如何使用代码在 不调用 LLM 的情况下定义 AI 模型的“优质输出”,随后得到的澄清是:优质输出意味着“遵循指南、不产生 Hallucination、坚持需求”。
- 有建议称该成员可以从 简单的单元测试(unit tests) 开始,检查 AI 响应中是否存在某些关键词,然后再引入 LLM as a judge 进行增强。
- 推荐 Hamel Hussain 的 Evals 博文:一位成员推荐阅读 Hamel Hussain 关于 evals 的博文,以获取评估 AI 模型的指导。
- 该博文与 Eugene Yan 的资源一起被推荐,随后寻求建议的工程师表示他们发现 Mastra 的指南 也很有用。
aider (Paul Gauthier) ▷ #questions-and-tips (14 messages🔥):
aider /load 命令, Aider 代码库编辑, Aider repo map
- Aider /load 命令可以注释掉行:“#”符号可以注释掉由 /load 命令执行的文件中的行。
- LLM 在 repo map 的帮助下决定编辑哪些文件:LLM 利用作为 system prompt 的一部分发送给它的 repo map 来决定编辑哪个文件。
- Aider 管理 repo map 大小以避免 Token 限制:repo map 被限制在一定大小内,并不总是包含完整的文件内容或所有文件。
- 此外,用户可以手动指定哪些文件需要编辑,哪些是只读的。
Moonshot AI (Kimi K-2) ▷ #general-chat (21 messages🔥):
Kimi K2 搜索能力, K2 research 在研究期间发送电子邮件, 创意写作模型
- Kimi K2 进行深度研究:一位成员指出 Kimi K2 search 非常适合深度研究,因为它会搜索各处并生成一份交互式报告。
- 随后他们询问 Kimi K2 instruct 聊天记录是否被用于训练模型。
- K2 Research 在研究期间考虑发送电子邮件:一位成员好奇 K2 research 是否能在研究过程中发送电子邮件,因为它当时正考虑给客户支持发邮件。
- 另一位成员回应称,他们认为目前这还不可能实现。
- 创意写作模型受到赞赏:一位成员认为 Kimi K2、GPT-5 (Medium) 和 Qwen3-Max 是创意写作的最佳模型。
- 他们补充说,这是三个非常适合头脑风暴的模型。