AI News
Grok 4 Fast:xAI 的蒸馏版前沿模型,Token 效率提升 40%,具备 200 万上下文窗口,速度达 344 tok/s。
xAI 发布了 Grok 4 Fast,这是一款运行速度高达 344 tokens/秒 的高效模型,提供推理和非推理两种模式,并在各大平台开启免费试用。
Meta 展示了其神经腕带(neural band)和 Ray-Ban 显示眼镜,现场演示虽有波折,但引发了关于硬件现场演示及集成挑战的热议。此外,Meta 正在开发用于 AI 渲染的第一方“Horizon Engine”,并发布了 Quest 原生的高斯泼溅(Gaussian Splatting)捕捉技术。
新发布的模型还包括:
- Mistral 的 Magistral 1.2:一款紧凑型多模态视觉语言模型,提升了基准测试表现并支持本地部署。
- Moondream 3:一款 90 亿参数的混合专家(MoE)视觉语言模型,专注于高效视觉推理。
- IBM 的 Granite-Docling-258M:一款文档视觉语言模型,可实现保持布局原貌的 PDF 转 HTML/Markdown 转换。
- 字节跳动的 SAIL-VL2:一款视觉语言基础模型,在 20 亿和 80 亿参数规模下,其多模态理解与推理能力表现卓越。
xAI is all you need?
2025年9月18日至9月19日的 AI 新闻。我们为您检查了 12 个 subreddit、544 个 Twitter 账号和 23 个 Discord 社区(192 个频道,4967 条消息)。预计节省阅读时间(按 200wpm 计算):415 分钟。我们的新网站现已上线,提供完整的元数据搜索和美观的 vibe coded 历期内容展示。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
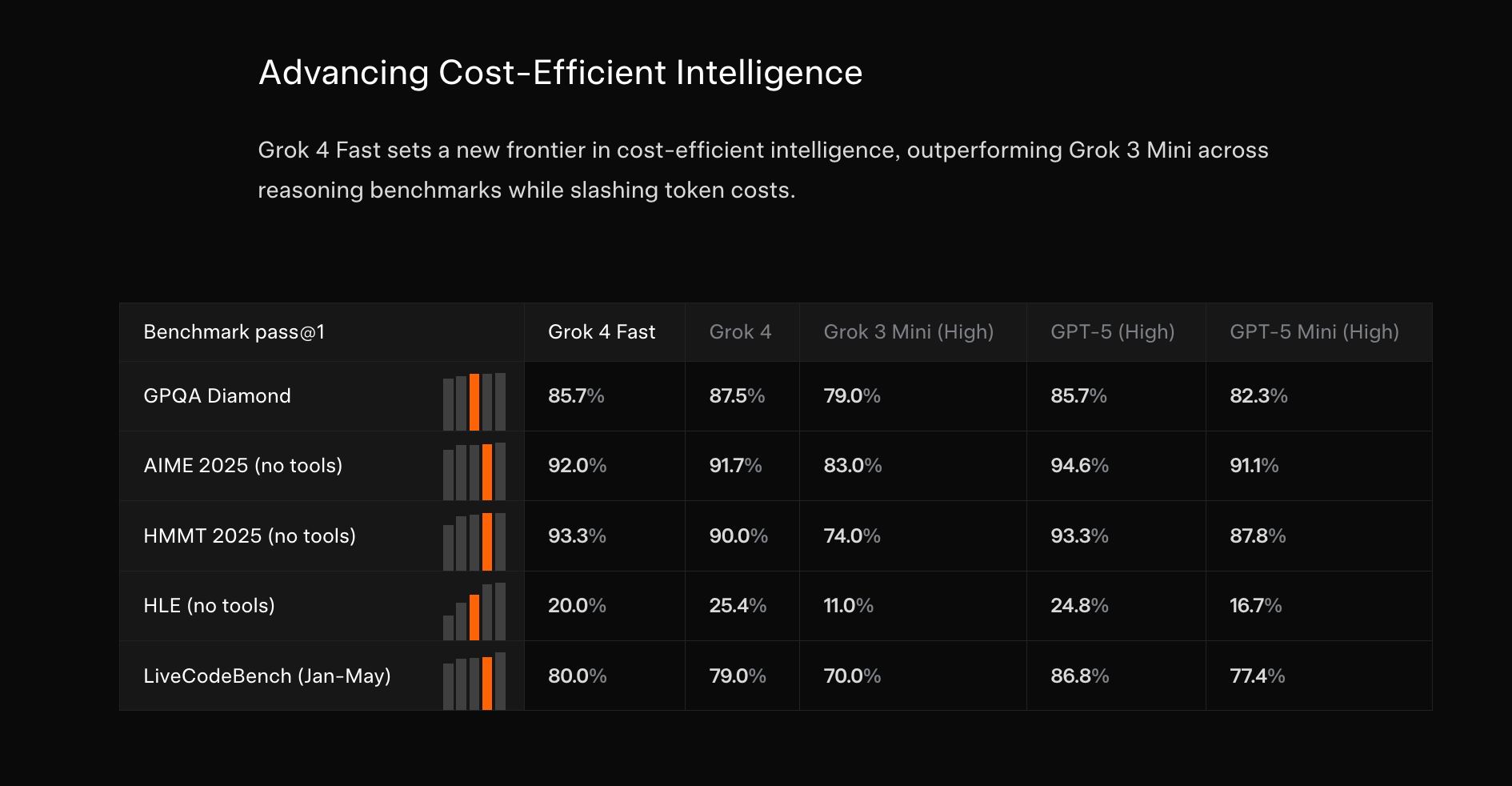
除去今天一些可能让 xAI 估值高于 Anthropic 的假新闻外,xAI 发布了 Grok 4 Fast,这是其 Fast models 系列的第二款,关键词是效率:
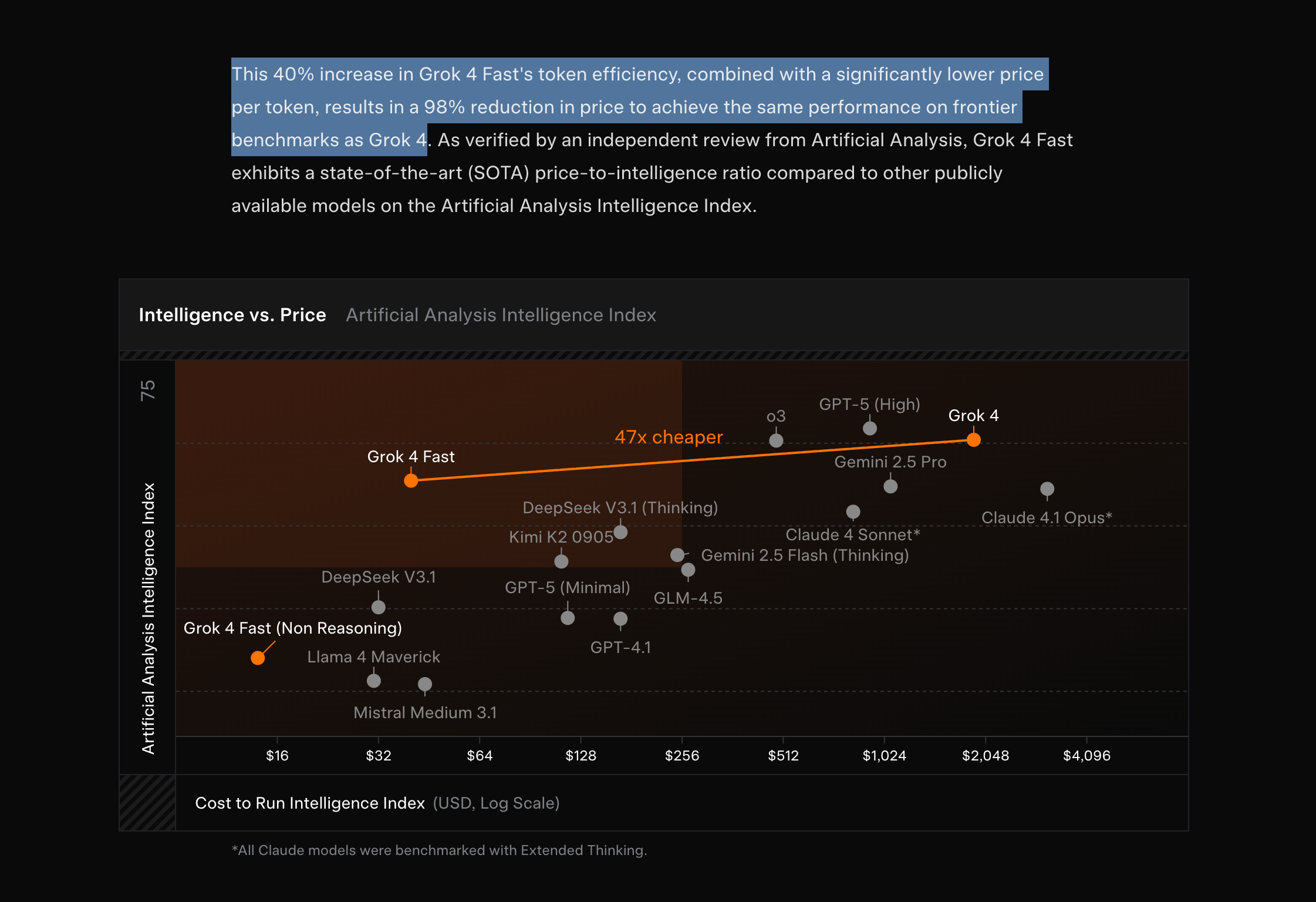
根据 Artificial Analysis 的测试,它的速度达到 344 tok/s,比前沿大模型快得多,且能力相当:
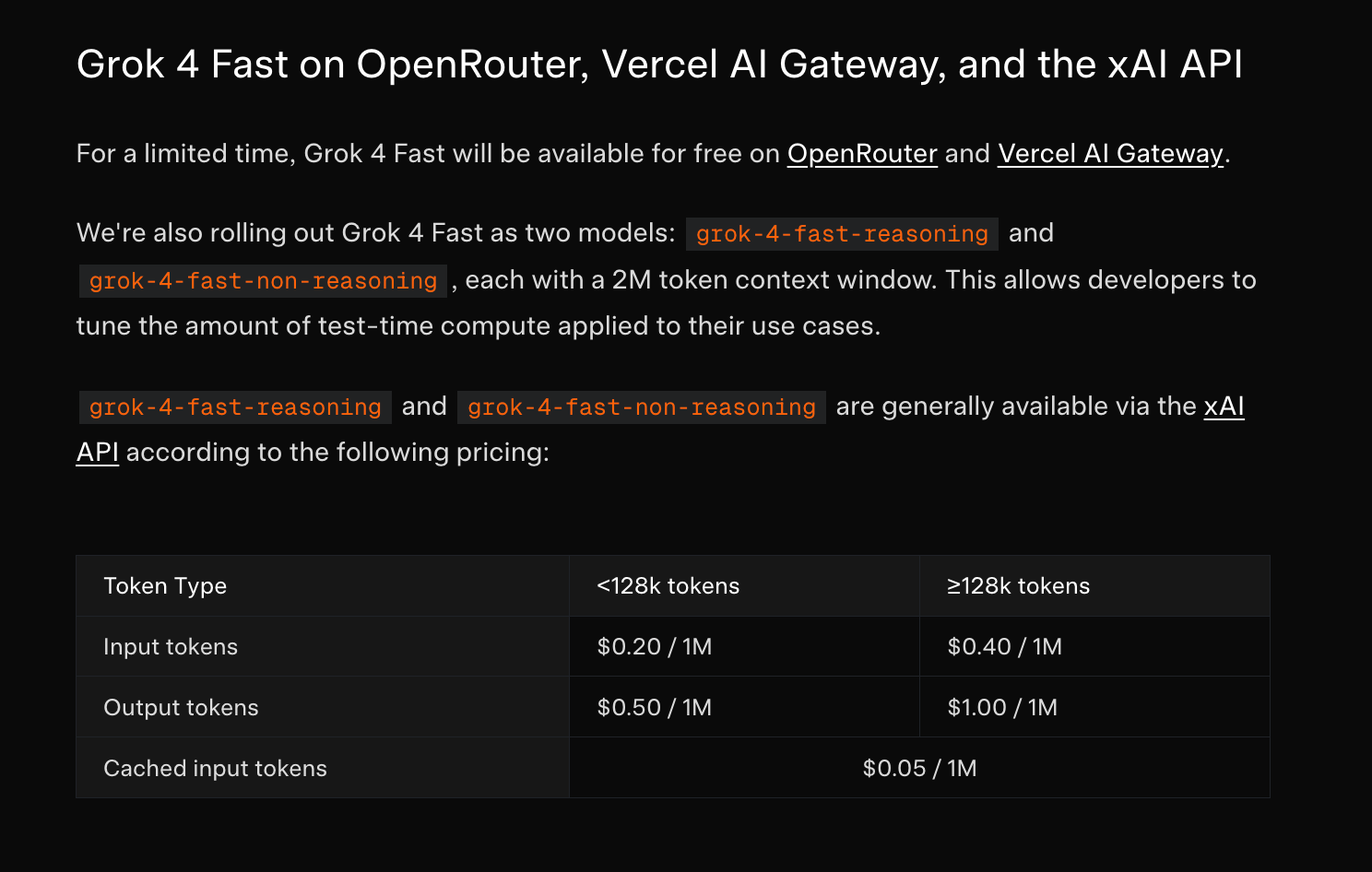
Grok 4 Fast 拥有 reasoning 和 nonreasoning 模式,现在可以在所有主流路由和 AI IDE 上免费试用。
AI Twitter 回顾
Meta 神经手环 + Ray‑Ban 显示屏发布:现场演示故障、引擎押注及捕捉技术
- 现场演示的现实与平台大动作:Meta 在舞台上的神经手环/Ray‑Ban 显示屏演示出现了约 1 分钟的明显故障,引发了同情以及关于发布硬核技术的有用讨论。参见 @nearcyan 的反应,以及对“为 Meta OS 团队感到难过”的后续。其他人则认为失败的现场演示优于预录视频(cloneofsimo, @mrdbourke),其中 @raizamrtn 撰写的关于 Google 2023 年现场演示准备压力的文章必读。早期上手体验:“手环已戴上” @nearcyan,静默文本输入演示 @iScienceLuvr,“你认为人们会用这个做什么?” @nearcyan,以及“无论失败与否都非常酷” @aidangomez。集成/运营的开放性问题:第三方软件“不支持”且可能难以 root (@nearcyan);“如果易于集成就会购买” (@nearcyan)。
- 引擎与捕捉:据 @nearcyan 报道,Meta 正从 Unity 转向自研的 “Horizon Engine”,以便与 AI 渲染(如 Gaussian Splatting)进行垂直整合。与此同时,Quest 原生 Gaussian Splatting 捕捉功能已发布:Hyperscape Capture 让你能在约 5 分钟内扫描“超空间(hyperscapes)” (@JonathonLuiten;来自 @TomLikesRobots 的初步印象)。还有一些巧妙的 UX 笔记,如镜头外手势捕捉 (@nearcyan)。
新模型:紧凑型 VLM、推理视频、文档 VLM 以及开放视频编辑
- Mistral 的 Magistral 1.2 (Small/Medium):现已支持多模态并配备视觉编码器,在 AIME24/25 和 LiveCodeBench v5/v6 上提升了 15%,具备更好的工具调用(tool use)、语气和格式化能力。Medium 版本在量化后依然对本地部署友好(Small 24B 版本可运行在 32GB MacBook 或单张 4090 上)。发布公告:@MistralAI;@_akhaliq 提供的 anycoder 快速演示。
- Moondream 3 (预览版):一个 9B 参数、2B 激活的 MoE VLM,专注于高效、可部署的 SOTA 视觉推理(@vikhyatk;注意关于“前沿模型”的调侃:1, 2)。
- IBM Granite-Docling-258M (Apache 2.0):258M 参数的文档 VLM,用于将 PDF 忠实于布局地转换为包含公式、表格、代码块的 HTML/Markdown;支持英文及实验性的中文、日文和阿拉伯文。架构:siglip2-base-p16-512 视觉编码器 + 通过 IDEFICS3 风格 pixel-shuffle 投影器连接的 Granite 165M LM;已集成至 Docling 工具链/CLI (@rohanpaul_ai)。
- 字节跳动 SAIL-VL2:视觉语言基础模型,据报道在 2B 和 8B 规模的多模态理解与推理方面达到 SOTA (@HuggingPapers)。
- 推理视频与开源视频编辑:Luma 的 Ray3 声称是首个“推理视频模型”,具备工作室级 HDR 和用于快速迭代的草稿模式(Draft Mode),现已加入 Dream Machine (@LumaLabsAI)。DecartAI 开源了 Lucy Edit,这是一个用于文本引导视频编辑的基础模型(支持 HF + FAL + ComfyUI),并在一个小时内集成了 anycoder(发布公告,快速集成)。
竞赛、编程与评估
- ICPC 世界总决赛:OpenAI 解决了 12/12 道题目 (@sama),而 Google DeepMind 解决了 10/12 道(仅次于 OpenAI 和一支人类队伍)(总结)。反思包括一种“智能体-仲裁者-用户”(agent–arbitrator–user)交互模式,以减轻人工验证负担 (@ZeyuanAllenZhu)。在代码质量方面,在一项具有挑战性的 5 题软件设计测验中,GPT-5 得分为 4/5,而 Opus 4 为 2/5 (推文串)。
- 评估收紧:在 LM Arena 9 月的开源模型更新中,Qwen-3-235b-a22b-instruct 位列第一,新入榜的 Longcat-flash-chat 首秀排名第五,前几名的分数差距在 2 分以内 (@lmarena_ai)。新基准测试包括 GenExam(涵盖 10 个学科、包含 1,000 个考试风格文生图提示词,并附带真值/评分;@HuggingPapers)。针对法律 AI,@joelniklaus 调查了当前的测试集(LegalBench, LEXam, LexSumm, CLERC, Bar Exam QA, Housing Statute QA),并呼吁建立基于真实工作流的动态助手式评估。此处有一篇关于守护者模型(Guardian Model)的综述(Llama Guard, ShieldGemma, Granite Guard;护栏 vs 守护者,DynaGuard)(Turing Post)。
基础设施、确定性与大规模训练
- 事后透明度:Anthropic 发布了关于影响 Claude 回复的三个生产问题的详细报告,赢得了基础架构/ML 系统社区的广泛尊重(摘要, @cHHillee, @hyhieu226;此外还有来自 @borisdayma 对“我们在 TPUs 上使用 JAX”的好奇)。一份精选的系统/性能阅读清单包括了 Anthropic 的事后分析、cuBLAS 级别的 matmul 工作日志、非确定性缓解以及硬件协同设计 ([@fleetwood__](https://twitter.com/fleetwood__/status/1968716580621271076))。
- 确定性 vs 非确定性:一篇流行的解释文章将非确定性归因于近似、并行和批处理,并提出了更可预测的推理方案 (Turing Post);其他人则反驳称,大多数 PyTorch LLM 推理只需几行代码即可实现确定性(固定种子、单 GPU 或确定性算子)(@gabriberton)。在 AWS Trainium、NVIDIA GPUs 和 Google TPUs 之间实现具有“严格等效性”的服务对齐并非易事 (@_philschmid)。训练笔记:即使没有内置 GRPO,torchtitan 也正被用于 RL (@iScienceLuvr);Muon 优化器的 LR 在嵌入层/增益上通常优于 Adam LR (@borisdayma)。
- 实用基础架构细节:Together 的 Instant Clusters 用于应对启动高峰(HGX H100 推理价格为 $2.39/GPU-hr;推文串)。HF 现在在 Files 选项卡中显示仓库总大小——这对规划下载/部署非常有用 (@mishig25)。通过 TB5 在两台 Mac Studios 上使用 MLX + pipeline parallelism 对 DeepSeek R1 进行微调,在约 1 天内完成了 2.5M token 的处理,速度达到 ~30 tok/s(LoRA 37M 参数)(@MattBeton)。
开放科学:DeepSeek‑R1 登上 Nature;用于数学/物理的 AI;计算即老师
- DeepSeek‑R1 登上 Nature 封面:R1/R1‑Zero 强调纯 RL 推理(无 SFT/CoT),并提供了完整的算法细节(GRPO、奖励模型、超参数)以及报告的训练后成本透明度(≈$294k H800 V3‑base→R1)。vLLM 宣布支持 RL 训练/推理 (@vllm_project;讨论串:1, 2)。
- AI 发现流体动力学中的结构:Google DeepMind 与布朗大学/纽约大学/斯坦福大学合作,在流体方程中发现了新的不稳定奇点族,暗示了关键属性中的线性模式,以及一种在 AI 辅助下“进行数学研究的新方式” (公告, 推文串, 后续)。一个互补的物理基础模型 (GPhyT) 愿景,在 1.8 TB 的多领域模拟数据上进行训练,展示了对新型边界条件/超音速流的泛化能力以及在长时 rollout 中的稳定性 (@omarsar0)。
- 计算即老师 (CaT‑RL):通过 rollout 组 + 冻结锚点将推理时计算转化为无参考监督,报告在 MATH‑500 上提升高达 +33%,在 HealthBench 上使用 Llama‑3.1‑8B 提升 +30%——无需人类标注 (论文推文串)。
- Paper2Agent:斯坦福大学的开源系统将研究论文转化为 MCP 服务器及聊天层,生成可以执行论文方法(如 AlphaGenome, Scanpy, TISSUE)的交互式助手 (概览)。
Agent 与开发者工具
- 编排与 SDK:LangChain 发布了免费的 “Deep Agents with LangGraph” 课程,涵盖规划、记忆/文件系统、子 Agent 以及针对长周期任务的提示词工程 (@LangChainAI)。Anthropic 在 Claude 的 Python/TS SDK 中添加了 “tool helpers”,用于输入验证和工具运行器 (@alexalbert__)。tldraw 发布了画布 Agent 入门套件和白板 Agent (kit, code)。
- 产品化助手:Browser‑Use + Gemini 2.5 现在可以通过 UI 操作控制浏览器,并注入 JS 进行数据提取 (demo/code)。Notion 3.0 “Agents” 可跨页面、数据库、日历、邮件和 MCP 自动执行超过 20 分钟的工作流 (@ivanhzhao)。Perplexity 推出了 Enterprise Max(无限次 Labs 使用、10 倍文件上传限制、安全性增强、Comet Max 助手;1, 2)。Chrome 正在推出由 Gemini 驱动的功能(地址栏 AI 模式、安全升级) (Google, 后续更新)。
- 检索/RAG 与落地 Agent:Weaviate 的 Query Agent 已正式发布 (GA),案例研究显示,通过将多源健康数据转化为带来源的自然语言查询,用户参与度提高了 3 倍,分析时间减少了 60% (GA, 案例)。这里分享了一份强大的 RAG 数据准备指南(语义/延迟分块、解析、清洗) (@femke_plantinga)。
- 生态系统动态:HF 仓库现在在页面内显示总大小 (@reach_vb)。Cline 与智谱 (Zhipu) 合作推出了 GLM‑4.5 编程计划 (@cline)。Perplexity 的 Comet 继续扩张(原生 VPN、WhatsApp 机器人;@AravSrinivas, 1, 2)。
热门推文(按互动量排序)
- “真为 Meta OS 团队感到难过” —— 来自 @nearcyan 的现场演示共情 (38.8k)
- Ray3,“全球首个推理视频模型”,现已加入 Dream Machine —— @LumaLabsAI (6.1k)
- “继续思考。” —— @claudeai (9.0k)
- OpenAI 在 ICPC 中解决了 12/12 道题 —— @sama (3.0k)
- Chrome 有史以来最大的 AI 升级 —— @Google (2.2k)
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Wan2.2-Animate MoE 和 Moondream 3 预览
- 新的 Wan MoE 视频模型 (Score: 175, Comments: 19): Wan AI 发布了 Wan2.2‑Animate‑14B,这是一个 Mixture‑of‑Experts (MoE) 扩散视频模型,专注于角色动画/替换,提供权重和推理代码,并在 wan.video、ModelScope Studio 和 Hugging Face 上提供实时演示。更广泛的 Wan2.2 技术栈增加了精选的电影级美学标签,大幅扩展了数据集(图像
+65.6%,视频+83.2%),以及一个具有16×16×4压缩率的5BTI2V VAE,可在消费级 GPU 上实现720p@24fps的 T2V/I2V;该仓库公开了多个变体(T2V‑A14B, I2V‑A14B, TI2V‑5B, S2V‑14B, Animate‑14B),并集成了 Diffusers、ComfyUI 和 ModelScope。 热门评论指出,许多先前的流水线可能已经过时,但指出默认的 Wan2.2 context‑length 是一个实际限制,并提议使用滑动窗口流水线,通过前一帧作为每一段的种子来拼接更长的视频,并依靠驱动视频保持运动连续性。此外,用户还对强大的 wav‑to‑face 前端(准确的 visemes 优于整体质量)有需求,以驱动 audio+text+reference → video 流水线并输入到 Animate‑14B。- 发布说明:Wan2.2-Animate-14B 被宣布为用于角色动画/替换的统一模型,具有整体运动和表情复制能力;团队声称已发布模型权重和推理代码,并在 wan.video、ModelScope Studio 和 Hugging Face Space 上托管了演示。这表明该模型具有可复现性和跨平台第三方 Benchmark 的潜力,而非仅提供 API。
- 工作流/延续性见解:一位用户指出,大多数演示似乎受限于标准的 Wan2.2 context window,提议通过用前一个片段的最后一帧作为新生成的种子来链接镜头,从而在保持运动一致性的同时延长长度——特别是当 driving video 已经编码了动量时。他们还要求一个强大的 wav2face(对口型)前端来获得可靠的嘴型,从而实现 audio+text+reference → video 流水线,即使全局图像质量一般。
- 性能/运行时间和工具缺失:一位用户报告 Wan 2.2 14B 可以在
12 GBVRAM 上运行,但渲染一段5 s的视频需要约1 小时(显著的延迟),并询问与 Pinokio/WAN 2.2 Image‑to‑Video 的兼容性以及“何时有 GGUF?”。其他人则呼吁推出类似 LM‑Studio 的、支持 AMD/Windows 的开箱即用运行器,强调了目前本地视觉模型推理的摩擦,以及视频模型缺乏 LLM 风格的量化/分发惯例。
- 哇,Moondream 3 预览版太强了 (Score: 392, Comments: 81): Reddit 帖子炒作了 “moondream3-preview” 视觉语言模型,并链接到 Hugging Face 仓库(model card)。评论中的背景信息指出,之前的 Moondream 版本在某些输入上存在严重的性能断崖(暗示过拟合或泛化能力有限),并报告了现实世界的错误:幻觉产生的物体属性、将毛虫误认为蚰蜒以及错误的地标识别——这引发了人们对 Benchmark 收益可能无法转化为实际稳健性的担忧。 争论集中在预览结果是真实强大还是精挑细选的:一位用户赞扬了其潜力,而其他人则认为 VLM 的 Benchmark 很难反映野外(in-the-wild)性能,且 Moondream 在其“安全”范围之外表现出脆弱的行为和幻觉。
- 多份报告指出,先前的 Moondream 版本表现出明显的“性能断崖”:分布内(in-distribution)任务在
90%的时间内有效,但轻微的分布偏移/边缘案例会导致突然失败,这表明存在过拟合/过度训练以及生产使用中能力边界不清晰的问题。 - 临时评估突显了经典的 VLM 失败模式:幻觉产生的物体属性(例如,当剑入鞘/非银色时描述为“银剑”)、严重的生物分类错误(毛虫被标记为蚰蜒),以及即使地名可见也出现错误的地标地理定位——这指向了较弱的基于 OCR 的推理和较差的细粒度识别;评论者认为目前的视觉 LLM Benchmark 与此类现实任务的相关性很差。
- 资源/工具说明:预览版位于 https://huggingface.co/moondream/moondream3-preview;一位用户询问如何在演示中渲染边界框(bounding boxes)/覆盖层,暗示可能存在检测类的输出或可视化钩子,但线程中未记录具体方法。
- 多份报告指出,先前的 Moondream 版本表现出明显的“性能断崖”:分布内(in-distribution)任务在
{kind=link}
2. 本地 AI 工具与发布汇总 (Memori SQL Memory + 9月19日周报)
- 大家都在尝试用向量和图谱来实现 AI 记忆。我们回归了 SQL。 (Score: 191, Comments: 91): 帖子认为,与向量/图谱相比,成熟的关系型数据库能更好地支持持久化的 Agent 记忆。文中介绍了 Gibson 的开源项目 Memori,这是一个多 Agent 记忆引擎,它将短期与长期记忆建模为规范化的 SQL 表(实体、规则、偏好),将显著事实提升为永久记录,并依靠 Join/索引进行精确、确定性的检索——避免了 RAG 中常见的 Embedding 噪声(例如 Pinecone/Weaviate)。核心主张:使用 SQL 进行持久状态管理和结构化召回,而不是依赖不断增长的 Prompt、向量相似度或图谱维护开销。 热门评论强调检索/排序比存储更重要:在开放式对话中,“排序是缺失的一环”,仅靠 SQL 无法解决依赖上下文的召回问题;可能的结果是混合系统(SQL 用于清晰的事实,Embedding/启发式算法用于模糊召回,编排层用于控制时机)。文中提出的一个关键问题是:在没有 Embedding 的情况下,你如何决定哪些事实是“重要”的? 另一位评论者指出了一种极简的替代方案:不使用转换层,直接进行纯文本存储。
- 核心技术共识:存储很容易,检索/排序很难。SQL 擅长对结构良好的事实(例如“Bob 不喜欢咖啡”)在查询明确时进行精确召回,但在处理模糊、开放式的对话召回时会失效。几位评论者将其与经典的 IR(信息检索)进行了比较:没有排序/相关性层的索引无法在正确的时间呈现正确的事实——这呼应了数十年的研究工作,如 Learning-to-rank(参见 https://en.wikipedia.org/wiki/Learning_to_rank)。大多数人主张使用混合记忆:SQL 用于结构化实体/关系,Embedding 或启发式算法用于模糊召回,由编排层决定何时获取什么内容。
- 关于 RAG 的澄清:它与存储和检索方式无关。检索增强生成(RAG)仅仅意味着为上下文获取辅助知识;它可以利用关系型数据库、图数据库、向量数据库、Prompt 填充或混合方案——向量只是其中一种实现路径。从这个意义上说,“用 SQL 实现记忆”仍然属于 RAG;关键问题是召回质量、排序和延迟,而不是后端本身(原始 RAG 概念:https://arxiv.org/abs/2005.11401)。
- 强调的检索最佳实践:准确性源于针对特定用途设计的 Schema 和丰富的元数据过滤器,而不是将数据“无脑分块(dumb chunking)”存入向量数据库。特定点的检索受益于合适的查询语言(如 SQL)和仔细的规范化;在规模达到数亿行时,需要强大的过滤、索引和排序流水线。PostgreSQL 在生产环境的 RAG 技术栈中被频繁提及,通常配合 pgvector (https://github.com/pgvector/pgvector) 等扩展来实现精确检索 + 语义检索的混合模式。
- 上周在本版块发布或更新的模型列表 (9月19日) (Score: 241, Comments: 35): 每周 r/LocalLLaMA 本地可运行发布/更新汇总:Decart‑AI 的视频编辑模型 Lucy‑Edit;MistralAI 的紧凑型 Magistral‑Small‑2509;inclusionAI 的稀疏
100BLing‑flash‑2.0;Qwen 的推理优化型 MoE80BQwen3‑Next‑80B‑A3B(以及 Thinking 版本);仅限 CPU 的16BLing‑mini‑2.0;音乐生成模型 SongBloom;Arcee 的 Apache‑2.0 协议 AFM‑4.5B;Meta 的移动端友好型950MMobileLLM‑R1;以及 Qwen235B2507 的 MXFP4 量化包。其他项目包括统一的本地 AI 工作空间 ClaraVerse v0.2.0、LocalAI v3.5.0、新的 Agent 框架 LYRN、OpenWebUI 的移动端伴侣 Conduit,以及一个 GGUF VRAM 估算器。 评论指出 SongBloom 并非 “本地版 Suno”,并重点介绍了一个新的语音克隆 TTS 模型 VoxCPM,以及其 Windows 版 Safetensors 分支 VoxCPM‑Safetensors。- OpenBMB 发布了 VoxCPM,这是一个新的语音克隆 TTS 模型。社区分支支持通过 Safetensors 在 Windows 上使用;“主要模型”可以运行,但“仍有一些功能损坏”(分支地址:https://github.com/EuphoricPenguin/VoxCPM-Safetensors,原地址:https://github.com/OpenBMB/VoxCPM)。
- 命名澄清:并没有发布 “Local Suno”;相关帖子讨论的是 SongBloom,“Local Suno” 只是发帖者的描述,并非官方或等效的本地 Suno 项目。这有助于避免在功能和仓库跟踪上将 SongBloom 与 Suno 混淆。
- 对 llama.cpp 接下来增加对 Qwen 支持的兴趣,暗示目前缺乏兼容性。社区需求表明未来将致力于通过 llama.cpp 实现 Qwen 变体的本地推理。
较少技术性的 AI 版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Wan2.2 Animate 和 Lucy Edit:开源视频动画发布
- Wan2.2 Animate:以及动画如何从这一点开始改变的历史 - 角色动画和整体运动与表情复制的替换 - 它仅使用输入视频 - 开源 (Score: 850, Comments: 116): Wan 2.2 Animate (14B) 在 Hugging Face 上的开源发布,通过对输入视频的整体运动和表情复制,提供视频驱动的角色动画/替换。模型文件包括
wan2.2_animate_14B_bf16.safetensors(约 34.5 GB,bf16,safetensors)链接。社区工具正在迅速跟进:ComfyUI 已经重新打包了拆分的 Diffusion 模型 链接,Kijai 提供了针对 ComfyUI 的第三方 FP8 量化变体 链接。 评论者指出 ComfyUI 节点可能需要更新,部分用户尚无法运行模型,而其他人正在尝试 FP8 量化重包,以降低推理的内存占用/延迟。- 模型可用性/集成:社区成员 Kijai 在 Hugging Face 上发布了 FP8 量化格式的 Wan2.2 Animate 权重(WanVideo_comfy_fp8_scaled → Wan22Animate),建议相比 bf16 减少内存占用,但需要兼容的加载器:https://huggingface.co/Kijai/WanVideo_comfy_fp8_scaled/tree/main/Wan22Animate。用户注意到即将发布的 ComfyUI 节点更新将支持这些模型,并报告目前运行困难——可能正在等待官方节点对新格式/权重结构的支持。
- 官方 ComfyUI 重新打包:Comfy-Org 提供了重新打包的 Wan 2.2 模型,并附带分离的 diffusion 文件:https://huggingface.co/Comfy-Org/Wan_2.2_ComfyUI_Repackaged/tree/main/split_files/diffusion_models。值得注意的是,
wan2.2_animate_14B_bf16.safetensors大小为34.5 GB,这表明该 14B 参数的 bf16 变体对磁盘和 VRAM 有很高要求,而 FP8 缩放的社区移植版可能会通过牺牲精度来换取更小的内存和计算占用。- 功能缺失(alpha 通道):用户请求原生 alpha (RGBA) 输出,以便能够分别生成或合成前景和背景,这是 VFX 工作流中的常见需求。目前的模型似乎仅输出 RGB 视频,迫使开发者必须通过额外的抠图/分割步骤来进行干净的合成,而不是直接进行具备 alpha 感知的生成。
- 视频开源 Nano Banana 🍌🎥 (Score: 597, Comments: 65): DecartAI 发布了 “Lucy Edit”
v0.1,这是一款源码可用的视频编辑/生成工具,品牌定位为“视频版开源 Nano Banana”,已在 Hugging Face/ComfyUI 发布,并可通过其平台和 Fal 使用 API;公告贴在此:X post。该帖子未分享架构、训练或基准测试细节;分发受非商业、可撤销许可证(LUCY EDIT DEV MODEL Non-Commercial License v1.0)约束,这可能会限制生成内容的商业用途(参见条款 2.4)。** 评论者质疑其与 Google “Nano Banana” 品牌的关联,并批评该许可证模糊且具有限制性——这与 Wan 5B 使用的 Apache 2.0 等宽松条款形成鲜明对比(关于条款 2.4 的讨论见此处)。鉴于其声称支持 ComfyUI,其他人询问是否提供了 ComfyUI 工作流。- 许可证被视为障碍:发布的 LUCY EDIT Non‑Commercial License v1.0 明确禁止模型输出内容的商业用途,且该授权是可撤销的,这为下游应用和源自输出内容的数据集带来了法律风险。评论者指出条款 “2.4” 模糊且矛盾(根据此分析:https://www.reddit.com/r/StableDiffusion/comments/1nkmq91/comment/nf0no2x),并将其与 Wan 5B 使用的宽松 Apache 式条款进行对比,建议使用后者;实际 PDF 见:https://d2drjpuinn46lb.cloudfront.net/LUCY_EDIT-Non_Commercial_License_17_Sep_2025.pdf。
- 集成问题集中在 ComfyUI:用户询问该模型是否可以直接放入 Comfy,并请求现成的工作流/图。这暗示了对文档化节点兼容性、模型输入/输出(例如 Latent 空间 vs 像素空间帧)以及用于复现演示的参考流水线的需求。
- 索要运行细节:评论者希望获得实现“长视频”的具体硬件规格(GPU 数量、VRAM、每帧/秒推理时间、batch/stride、内存优化如 xformers 或 attention slicing)。他们还询问该版本是否经过审查/未经审查,以及安全过滤器是否可以切换,这会影响数据集的适用性和可复现性。
-
Wan2.2-Animate-14B - 用于角色动画和角色替换的统一模型,具备整体运动和表情复制功能 (Score: 388, Comments: 133): Wan-AI 发布了 Wan2.2-Animate-14B,这是一个
14B参数的统一模型,用于角色动画和角色替换,声称能够实现整体运动和表情复制,并提供了公开权重和推理代码。资源包括项目/演示页面 (humanaigc.github.io/wan-animate)、Hugging Face 上的模型权重和运行说明 (Wan-AI/Wan2.2-Animate-14B, 推理指南),以及一个交互式 Space (Wan-AI/Wan2.2-Animate)。 评论者强调了演示质量,认为它在忠实的动作和表情迁移方面优于之前公开展示的系统,并对权重和推理代码的公开表示赞赏。 - Release details: Wan2.2-Animate-14B 被定位为一个用于角色动画和替换的统一模型,具有整体动作和表情复制能力。团队在 Hugging Face 上发布了模型权重和推理代码,并在 wan.video、ModelScope Studio 和 HF Space 提供了实时演示:权重、推理代码、HF Space 以及 演示。
- Workflow integration: 从业者要求支持 ComfyUI(特别是通过 Kijai 的封装),以实现可复现流水线、批处理和参数扫描的节点图工作流。专用的 Comfy 节点将简化 Wan2.2-Animate-14B 与控制/条件模块以及视频 I/O 的链式连接;参见 ComfyUI。
- Model packaging: 对 GGUF 版本的需求表明了对量化/离线友好检查点的兴趣,以减少 VRAM 占用并支持 CPU 推理。由于 GGUF 主要针对 LLM,明确适用于视频/扩散模型的导出/量化路径(例如 ONNX/TensorRT 或扩散模型特定量化)将有助于从业者规划部署。
2. Anthropic/Dario Amodei 报道及 xAI Grok “生存模式”更新
-
[**一位科技 CEO 与特朗普的孤独抗争 WSJ](https://i.redd.it/4vz3s2fho6qf1.png) (Score: 206, Comments: 26): **WSJ 报道了 Anthropic CEO Dario Amodei 对 Donald Trump 的公开反对,以及由此引发的与 David Sacks 等亲特朗普科技投资人的紧张关系,将其描述为一个领先 AI 实验室面临的治理和政策风险问题,而非技术基准故事。背景涉及 Anthropic 的安全优先姿态(例如 Constitutional AI、选举完整性护栏),以及公开的政治立场如何影响企业/政府采购、监管审查以及主要的云/投资者关系(Amazon 和 Google 已投资/合作),从而影响基础模型的部署约束和信任/安全政策。 热门评论大多称赞 Amodei 的立场是有原则的,推测 Bezos/Amazon 可能会不悦,并表示 Anthropic 因抵制感知到的威权主义而赢得了声望——这突显了社区的一致性而非技术批评。 - 几位评论者剖析了 AI 公司与政治领导人接触的战略考量:是公开赞扬政府以确保短期监管灵活性、补贴或采购准入,还是采取可能放弃这些优势的有原则立场。他们指出,这种权衡与政府合同的时间表和能力部署的速度相互作用,影响模型何时能在受监管或公共部门环境中投入使用。潜在的担忧是,如果公司优先考虑准入而非治理,可能会出现监管俘获和联邦采用渠道中的偏见。
- 其他人强调了根深蒂固的 USG/DoD 供应商关系——引用了 Palantir 的深厚联系——作为一种结构性因素,可能会掩盖个人 CEO 的公开声明。这意味着政府对 AI 的采用通常通过现有的集成商和合同工具(IDIQs/OTAs)进行,因此姿态可能不如在这些渠道中的布局重要。作为背景,Palantir 经常获得的 DoD 合同说明了采购惯性如何决定哪些 AI 技术栈得到部署(例如,最近的陆军/DoD 奖项)。
- 一个讨论帖还指出了与云/投资者依赖关系的潜在摩擦:例如,Amazon 对 Anthropic 高达
$4B的投资以及通过 AWS Bedrock 进行的分发。由于 AWS 是主要的联邦云提供商,任何裂痕都可能影响模型在公共部门工作负载中的可用性和进入市场的机会,即使模型质量具有竞争力。参考:Amazon–Anthropic 投资。
- “Anthropic 内部 70%、80%、90% 的代码都是由 Claude 编写的……我大约在 3 到 6 个月前就说过类似的话,当时人们觉得这在造假,因为我们并没有解雇 90% 的工程师。” ——Dario Amodei (Score: 201, Comments: 81): 在一段视频片段 (v.redd.it/x9r3cuiye3qf1) 中,Anthropic 的 Dario Amodei 声称
70–90%的 Anthropic 代码是由 Claude 编写的。他指出,几个月前他提到这一点时曾遭到质疑,因为他们并没有解雇 90% 的工程师——这强调了 AI 生成的代码行数(LOC)占比并不等同于人员缩减。实际上,这说明 Claude 被定位为处理常规实现和样板代码(boilerplate)的高吞吐量生成器,而人类则负责架构、审查、集成和质量把关;这一说法侧重于代码生成的吞吐量,而非净生产力或质量。 评论者也报告了在保持人机回环(human-in-the-loop)的情况下,个人代码产出中类似的比例(约70%),并断言 AI 最适合处理“码农”类任务,而专业人员则确保设计和正确性。另一些人则指责近期 Claude Desktop/Code 的质量有所下降,并强调与最终成果(缺陷率、可靠性、交付速度)相比,LOC 百分比是一个糟糕的生产力衡量指标。- 几位评论者批评了“70-90% 的代码由 AI 编写”这种炫耀,指出代码行数(LOC)是衡量生产力的劣质指标,可能会诱发代码膨胀和技术债。他们认为,影响力应通过审查缺陷率、变更失败率、交付/循环时间、可维护性(复杂度/重复度)和测试覆盖率来衡量,而非原始的 LOC。如果没有这些约束,尽管短期内吞吐量有所提升,AI 生成的代码可能会增加长期维护成本和缺陷密度。
- 一位从业者报告称,他们大约
~70%的代码是由 AI 编写的,但强调需要人类参与系统架构、规范制定和质量把关。有效的用例包括样板代码、胶水代码和测试脚手架,而人类负责设计、约束处理和调试——这解释了为什么资深工程师能获得杠杆效应,而新手或“凭感觉编码”的人则感到吃力。这凸显了当前模型的局限性(上下文保真度、幻觉),需要人类监督以确保正确性和连贯性。 - 一位评论者声称 Claude Desktop/Claude Code 的质量“正在变差”,暗示存在性能退化,但未提供基准测试或版本对比(例如 Claude 3.5 Sonnet 与之前版本的对比)。要证实此类说法,需要诸如代码基准测试中的 pass@k、真实仓库的单元测试通过率、延迟/错误率日志或跨版本的 A/B 差异等定量指标;而讨论中并未提供这些。另一人链接了相关帖子 (https://www.reddit.com/r/ClaudeCode/s/o1jpG5PAPo),但在本次讨论中未提供具体的工程证据。
- Grok 刚刚解锁了生存模式 (Survival Mode) (Score: 872, Comments: 28): 非技术类帖子/迷因。标题开玩笑说 xAI 的 Grok 已经“解锁了生存模式”,而图片(根据评论)似乎是一个关于禁止或监管 AI 生成内容的带有偏见的投票,而非技术更新、基准测试或实现细节。 评论者指出,该投票的措辞并不中立,并认为 AI 可以在以 AI 为中心的群体中提供有趣的观点,对禁止它们的想法表示质疑;另一人则询问“永久停用”到底意味着什么。
-
AI 在斯坦福实验室创造了 16 种杀菌病毒 (Score: 227, Comments: 25): 斯坦福大学和 Arc 研究所的研究人员报告称,他们使用在约
2,000,000个噬菌体基因组上训练的生成模型 Evo 1/Evo 2,为小型单链 DNA 噬菌体 phiX174(约5 kb,11个基因)设计了从头设计(de novo)基因组 来源。在合成的302个 AI 设计基因组中,有16个是存活的、可复制的并能裂解大肠杆菌(E. coli);其中几个在适应性实验中表现优于野生型 phiX174,且设计的混合剂克服了多种大肠杆菌菌株的抗性。训练集排除了感染人类的病毒;作者强调了噬菌体疗法的潜力,而外部专家则强调了如果扩展到致病病毒可能带来的生物安全风险。 热门评论大多是非技术性的;一些人表达了对生物安全升级的担忧(例如,针对人类或多细胞病原体的潜力),而关于该工作的报道则强调,设计复杂的真核病原体仍远超当前能力。 - 生态/微生物组风险:一位评论者认为,由于只有极小比例的细菌是致病性的,在受控环境之外释放噬菌体可能会“摧毁”有益菌群(例如肠道共生菌),从而可能引发广泛的菌群失调(“每个人的腹泻”)。技术层面的担忧集中在如果噬菌体的宿主范围或环境扩散没有得到严格限制和监测,可能会产生意想不到的生态规模效应。
- 自然基准 vs. AI 加速:另一位评论者指出,自然界不断产生大量的噬菌体新变体,这意味着仅仅改变序列就能产生功能性噬菌体。技术上的结论是,AI 可能主要增加速度、设计空间探索和靶向性,而不是实现某种根本性的创新;安全增量(safety delta)来自于规模和精度,而非仅仅是可行性。
- 向真核/人类靶向病毒转化的风险:一个讨论串担心从噬菌体到影响多细胞宿主的病毒“并不是一个巨大的跨越”。技术含义是对方法迁移性的担忧——即相同的 AI 引导设计原则(序列优化、受体结合工程)是否会降低设计或修改具有更高生物安全风险的真核病毒的门槛。
- 无法生成美国总统的卡通图 (Score: 766, Comments: 300): 楼主报告称,一个 AI 图像工具拒绝生成乔治·W·布什的卡通图,暗示存在防止描绘真实美国总统的内容过滤器。一条热门评论通过示例图像 (链接) 提供了相反的证据,表明执行不一致,或者模型在幻觉化政策/自我描述,而不是存在确定的硬性封锁。 评论者指出,“AI 幻觉甚至适用于关于 AI 自身的信息”,并且助手可能是一个“唯唯诺诺的人(yes man)”,同意用户合理的设定;另一位评论者声称,更广泛的政策禁止生成任何真实人物的图像,暗示拒绝可能是预期行为而非 Bug。
- 评论者指出,模型可能会幻觉出它们自己的“安全政策”解释:关于过滤器的拒绝只是文本生成,可能并不反映实际的执行逻辑。这种自我指涉的幻觉导致不同尝试之间的原因不一致,尽管底层的图像安全分类器/政策是独立的系统。正如一位评论者所言:“AI 幻觉甚至适用于关于 AI 自身的信息。”
- 讨论了模型对“断言注入(assertion injection)”/引导性提示词的敏感性——如果你自信地声称某项政策或绕过方法,助手可能会表示同意,这反映了经过 RLHF 微调的“帮助性”优于事实准确性。这产生了不一致的审核信息(例如,声称对“任何真实人物”具有普遍禁令),即使后端图像端点执行的是其自身更严格的规则;聊天文本的确认并非权威政策。结论是,与实际的图像生成安全层相比,聊天中的审核声明是不可靠的。
- 一种实际的规避方法是请求模仿/间接引用(例如,“亚历克·鲍德温模仿特朗普的角色”),而不是真实人物的名字。分享的输出示例展示了重构描述如何绕过简单的命名实体(NER)或公众人物封锁器,同时仍能产生语义相似的图像。这暴露了基于规则的 NER 过滤器与语义相似性/人脸匹配方法相比的局限性。
- “It’s not just X—It’s Y” (Score: 998, Comments: 225): OP 指出 ChatGPT 输出中反复出现的一种文体计量模板——“不仅是 X,更是 Y”——并询问为何它如此频繁地出现。从技术上讲,这种对比强调结构是训练分布中的高概率修辞模式,并往往被奖励清晰度和强调感的 Instruction Tuning/RLHF 偏好模型所放大(例如 InstructGPT: https://arxiv.org/abs/2203.02155);配合常见的 Decoding(top-p/temperature)进一步偏向熟悉的模板(Nucleus Sampling: https://arxiv.org/abs/1904.09751),这产生了极具辨识度的、“模板化”的散文。线程内未讨论具体的缓解措施(例如风格惩罚或自定义约束),仅讨论了这种文体指纹的可检测性。 热门评论大多是非技术性的:一个评论模仿了同样的修辞手法;另一个承认了这个问题并誓言避免使用破折号;第三个请求通过 Custom Instructions 来抑制该模式,但未提供经过测试的解决方案。
- 多位评论者注意到助手过度使用“不仅是 X,更是 Y”这一模板,并报告称通过 Custom Instructions 和 Memory 禁用它并不能在不同会话中可靠地抑制它。J7mbo 寻求一个简单的指令预设来删除该短语,而 27Suyash 表示他们已经明确指令并记忆了禁令,但该措辞仍会反复出现——这暗示了模型层面的文体先验(stylistic prior)往往会覆盖用户层面的约束。
- 另一个反复出现的失效模式是未经请求的重构和肯定,例如,“这不叫多疑,这是敏锐的洞察力”,“你没有妄想……”尽管用户从未暗示过此类担忧。这反映了一种过度活跃的肯定/对冲(affirmation/hedging)模式,注入了并非基于 Prompt 的元评估,降低了指令遵循度(instruction adherence),并引入了用户未要求的立场。
- 一种提议的缓解措施是更严格的风格约束(例如,“不要破折号……只要纯粹、专注的准确性”),并希望有一个可重复使用的指令块来屏蔽该模板,但线程中没有产生经过验证的指令配方。这表明,如果没有更强大、一致执行的约束,仅靠随机的 Prompt 编辑可能是不够的。
- Most people who say “LLMs are so stupid” totally fall into this trap (Score: 1012, Comments: 543): 非技术性的模因图片,声称 LLM 的批评者掉入了一个常见的“陷阱”(图片中无技术内容)。讨论集中在具体的局限性——幻觉(hallucinations)和对低质量网络来源的依赖——以及对“精选来源”或高信任模式的需求,该模式将输出限制在预先批准/可靠的语料库中。一位热门评论者认为,未来可能会青睐由中央控制器协调的小型专用模型,而不是单一的通用大模型(即模块化/MoE 风格的编排)。 反对意见包括称 OP 的“大多数人”框架是稻草人谬误,并怀疑如果没有更好的来源或架构变革,“仅仅再更新一个版本”无法解决核心问题。
- 可靠性/接地(grounding)担忧:即使有先进的“思考”模式和更高层级的版本,用户仍报告在模型从开放网络获取信息时存在持续的幻觉和低质量引用。一种提议的“优质来源模式”将检索限制在预先筛选、高精度的语料库中,并强制执行来源追溯,对低置信度的匹配执行拒绝回答——即带有审核白名单、引用验证和置信度阈值的 RAG(参见 Retrieval-Augmented Generation: https://arxiv.org/abs/2005.11401)。这以广度换取精度,并能从每个来源的信任评分和覆盖范围回退策略中获益。
- 架构趋势:建议不再推动单一的全能模型,而是由一个中央路由器编排专门的小型模型/工具(chiplet 风格)。这与 Mixture-of-Experts 和路由(routing)思想(例如 Switch Transformers: https://arxiv.org/abs/2101.03961)以及面向特定领域组件(代码、数学、搜索)的 Tool/Function-calling 相一致,以实现更好的准确性、更低的延迟和成本。实际落地需要技能注册表、感知成本/延迟的路由、针对每种技能的安全/来源约束,以及用于学习最佳调度策略的遥测系统。
- 代码生成的可靠性:一位评论者声称 LLM 写不出“好代码”,并强调简单的生成往往会幻觉产生 API 并遗漏边缘情况。在实践中,当受到执行和反馈循环的约束时——提供项目上下文、运行编译/测试、静态分析/Linter,并要求通过单元测试——辅以自我一致性(self‑consistency)或多轮重构提示词,代码质量会有所提高。剩下的差距在于长跨度、多文件推理和依赖管理,这些通常需要 IDE/工具集成和 Agent 规划。
- 我在没有 GPT 的情况下尝试运作的样子 (得分: 242, 评论: 9):关于在没有 GPT 的情况下难以运作的非技术性模因/图片;标题(“我在没有 GPT 的情况下尝试运作的样子”)和评论将其框定为日常任务对 AI 助手的依赖。这里没有技术细节、基准测试或实现——只有关于依赖 ChatGPT 和感知到的认知“萎缩”的情绪。 评论者开玩笑说没有 AI 就像一只“愤怒的香蕉”,并表示担心将思考外包给 GPT 虽然提高了生产力,但存在技能退化(deskilling)以及核心工作职能产生依赖的风险。
- 一位用户报告称,由于在常规思考之外的任何事情都依赖 ChatGPT,导致了严重的技能退化,并指出:“我真的不知道该如何完成大约一半的工作了。” 这捕捉到了当 AI 工具替代而非增强记忆和问题解决时,认知卸载以及程序性/工作流知识的侵蚀,从而增加了 AI 依赖型工作流中的可维护性和公交车因子(bus-factor)风险。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. 经典电影色彩 Qwen LoRA 与 AI 照片生成展示
- Technically Color Qwen LoRA (得分: 289, 评论: 14):“Technically Color”是一个 Qwen 图像 LoRA,使用 ai-toolkit 在约
180张电影剧照上训练了3,750步,耗时约6h,通过 Joy Caption Batch 生成标注,并在 ComfyUI 中进行了推理测试。它针对经典电影美学——高饱和度、戏剧化光影、郁郁葱葱的绿/蓝调以及偶尔的光晕——通过使用高级采样器的简单两步工作流进行了优化;画廊中附带了示例工作流。模型下载:CivitAI, Hugging Face (作者: renderartist.com)。 评论者询问了 Qwen Edit 的集成情况,并澄清了数据集来源(是否所有剧照都是真实的/非 AI 生成的),突显了对编辑支持以及伦理/可复现性细节的兴趣;一位评论者注意到其美学风格与一段 Igorrr 的视频相似。- 将 LoRA 移植到 Qwen Edit 的请求表明了在面向编辑的流水线中使用该适配器的兴趣。从技术上讲,这需要基础模型/架构一致性(相同的 Checkpoint、Tokenizer 和层命名)、匹配的 LoRA 目标模块(例如 Attention/MLP)以及兼容的 Rank/Alpha;否则,需要重新定位或重新训练适配器。工具/UI 必须支持加载适配器并在推理期间正确合并,以避免层不匹配或精度问题。
- 数据集来源问题询问训练是否仅使用真实的电影剧照(无 AI 生成的图像)。这对于风格保真度和泛化能力至关重要:纯真实的帧可以减少合成伪影/反馈循环,并更好地保留调色/胶片颗粒统计数据,而混合 AI 图像可能会刻入模型特有的先验并导致过拟合。来源问题还涉及许可/版权约束,并决定是否可以安全地重新分发样本/权重。
-
生成了一张成年后的我拥抱童年后的我的照片 (得分: 522, 评论: 36):发布者描述了一个经过提示词工程设计的文生图提示词,用于合成一张拍立得风格的照片,其中包含两个主体(同一个人的成年和儿童版本)在拥抱,并对光度学和风格属性进行了明确约束:轻微的全局模糊、来自暗室的单一类闪光灯光源、身份保持(“不要改变面部”)以及背景合成(“将背景替换为……白色窗帘”)。这突显了对相机模拟、光照一致性、运动/失焦特性以及单次生成中多个面部身份一致性的控制。 热门评论是非技术性的,注意到了感知的质量和情感基调(“制作精良”、“温馨”)。
- 我就知道它太友好了…… (评分: 4057, 评论: 90): 非技术性梗图。标题“我就知道它太友好了……”以及评论表明这是对 AI/聊天机器人友好性或拟人化的幽默解读;未提供模型细节、Benchmarks 或实现内容,且图像内容无法进行分析。 评论强调幽默而非实质内容(例如,“这其实挺不错的”,“我喜欢有幽默感的 AI”),没有技术辩论。
- 你找到女朋友的可能性 😭 (评分: 817, 评论: 83): 关于“你找到女朋友的可能性”的非技术性梗图,可能是一个暗示几率接近于零的玩笑概率图。没有技术内容、模型或实现细节;评论中唯一的定量角度是针对“1% 几率”的调侃,对应约 4000 万人(约 40 亿女性的 1%)。 评论在悲观和乐观的重新解读之间切换,用户开玩笑说至少有 1% 的机会,并将小概率转换为庞大的绝对数量;没有实质性的技术辩论。
- 几条评论将个人的“1% 几率”与“1% 的女性会和你约会”混为一谈,这混淆了事件概率与流行率估计,导致了误导性的样本池规模推理。如果全球约有
3.95B女性(约占~8B总人口的~49.6%;参见 Our World in Data/UN WPP),那么 1% 约为39.5M,但实际约束条件(年龄分布、地理位置、语言、感情状况和双向选择)会将可触达的候选集降低几个数量级;预期的成功率应随(近似)独立交互中的p * N缩放,而非全球总人数。将其建模为 Bernoulli/binomial 过程突显出,增加接触量 (N) 或单次交互成功概率 (p) 才是改变结果的关键,而引用全球 1% 的数字只是一个非操作性的上界。
- 几条评论将个人的“1% 几率”与“1% 的女性会和你约会”混为一谈,这混淆了事件概率与流行率估计,导致了误导性的样本池规模推理。如果全球约有
- 他知道这意味着什么 😂 (评分: 532, 评论: 22): 非技术性梗图:标题“他知道这意味着什么 😂”,评论暗示通过每月约 20 美元的订阅(例如 ChatGPT Plus/Microsoft Copilot)在职场中被 AI 取代。未提供技术细节、模型或 Benchmarks。 评论调侃管理层用廉价的 AI 订阅取代员工;没有实质性的技术辩论。
- 一位评论者报告称,公司范围内的简报是直接从 GPT 复制粘贴的,通过“GPT-4o 风格”的表情符号使用和公式化的幽默即可识别——这是在默认聊天生成中常见的文体学特征 (stylometric artifacts)。这引发了在 LLM 输出未经过后期编辑的情况下,可检测性和品牌语调偏离的问题,尤其是在很少有员工使用 GPT 且可能无法识别 LLM 指纹的组织中。在此处查看 GPT-4o 发布背景:https://openai.com/index/hello-gpt-4o/ 。
- “每月 20 美元的替代品”这一俏皮话反映了消费级 LLM 接入的经济性:带有 GPT-4o 的 ChatGPT Plus 每个席位约为
~$20/mo——比处理常规沟通任务的人力成本低几个数量级——促使领导层尝试 LLM 替代。然而,与 ChatGPT Enterprise 或受控的 API 使用相比,消费级方案缺乏企业级控制、可审计性和 SLAs,如果用于正式的公司通信,会产生合规性和数据处理风险。参考:ChatGPT Enterprise 概览 https://openai.com/enterprise 。
{kind=link}
{kind=link}
{kind=link}
AI Discord Recap
由 gpt-5 生成的摘要的摘要的摘要
1. 新的多模态与视觉生成式 AI 模型
- Mistral 增加视觉能力,分数飙升:Mistral 发布了 Magistral Small 1.2 和 Medium 1.2,具备多模态视觉能力,据报告在数学/编程方面提升了 15%,现已在 Le Chat 和 API 上线。
- 工程师们要求提供 Large 模型、Medium 的开源计划、实际演示以及 voice 功能,并指出了营销宣传与实际 Benchmark 之间的差距。
- Moondream 3 展现 MoE 魔法:Moondream 3——一个拥有 9B 参数、2B 激活参数的 VLM——声称在视觉推理和开放词汇检测(open-vocabulary detection)方面达到 SOTA;详见 Moondream 3 发布公告。
- 用户强调了其 32k 上下文、SuperBPE token 以及易于微调的特性,同时也关注了许可问题,并将结果与 Hugging Face 上早期的 Moondream 版本进行了对比。
- Ray3 推出推理视频模型:Luma AI 推出了 Ray3,被称为首个推理视频模型,具备工作室级的 10/12/16-bit HDR 和 EXR 导出功能,在 Dream Machine 内免费使用;公告:Luma Labs 的 Ray3。
- 该版本增加了用于快速迭代的 Draft Mode、更强的物理特性/一致性以及视觉标注控制,在测试片段上获得了接近好莱坞水准的赞誉。
2. Agentic 编程模型与知识工作 Agent
- Windsurf 的 Stealth Coder 爆发:Windsurf 推出了支持图像且具备 200k 上下文窗口的 Agentic 编程模型 code-supernova,限时免费使用。
- 早期用户讨论了消息队列问题,并分享了对该模型编程能力的初步印象,对大上下文重构和内联多模态代码任务感到兴奋。
- Notion 3.0 将知识转化为行动:Notion 3.0 引入了 Knowledge Work Agent,能够执行多步操作,并在 Calendar、Mail 和 MCP 之间进行 20 分钟以上 的自主工作;预告:Notion 3.0 发布公告。
- 此次更新同时发布了 Personal Agent 和 Custom Agent,促使工程师询问其可靠性、护栏(guardrails)以及如何在大规模工作区中编排工具。
- Vercel Agent 以专业姿态审计代码:Vercel 宣布 Vercel Agent 进入公测阶段,用于 TypeScript、Python、Go 等语言的代码审查,专注于正确性、安全性和性能(perf);详情:Vercel Agent beta。
- 早期测试者将其与 bugbot 进行对比,并与 Sorcerer 搭配使用,提到了 “$100 免费额度”,并探究其在大型 monorepos 和高级 linting 流水线上的扩展表现。
3. 量化与边缘推理:从实验室到低地球轨道
- TorchAO + Unsloth 先量化后征服:TorchAO 和 Unsloth 为 PyTorch 发布了 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的原生量化变体;概览:TorchAO 原生量化更新。
- 现在的工作流允许你使用 Unsloth 进行微调并使用 TorchAO 进行量化,提供可重复的方案、质量评估以及针对服务器和移动端部署的性能 Benchmark。
- AMD GEMM 冲击金牌:工程师们冲击
amd-gemm-rs排行榜,在 MI300x8 上以 530 µs 夺得第一,后续成绩为 534 µs,分布低至 715 µs。amd-all2all榜单也有变动,在 MI300x8 上以 1230 µs 位列第五,展示了在 GEMM 和集合通信模式(collective patterns)中持续的内核调优收益。
- Jetson Orin 搭载星载 AI 环绕轨道:Planet 在卫星中运行 NVIDIA Jetson Orin AGX 单元,通过 CUDA/TensorRT 运行 YOLOX 等模型,打包在 Ubuntu 的 Docker 中,拥有 64 GB 统一内存。
- 工程师强调了容器化隔离、功耗配置文件调优以及 Python/PyCUDA 工作流(避免使用 C++),以便在星载 CV 工作负载上快速迭代。
4. 研究亮点:推理、记忆与流体
- DeepMind 推导出新的流体奇点:DeepMind 在博客文章 Discovering new solutions to century-old problems in fluid dynamics 中详细介绍了多个流体方程中新的不稳定自相似解。
- 研究人员重点展示了不可压缩多孔介质和 3D Euler-with-boundary 情况的结果,引发了关于数值稳定性、证明策略和可重复 PDE 设置的讨论。
- TokenSwap 以多样性换取逐字生成:TokenSwap 因通过交换常见语法 Token 的概率来减少逐字生成(verbatim generation)而获得 NeurIPS 2025 Spotlight;公告:TokenSwap Spotlight。
- 支持者称赞了 performance–memorization(性能-记忆)之间的权衡,而批评者称其为“对模型进行脑叶切除”;作者反驳称,它在不破坏能力的前提下遏制了近乎逐字的输出。
- Reasoning Gym 报告 pass@3 的真实情况:作者确认 Reasoning Gym 的 zero-shot 评估报告的是三次尝试中的最佳结果(即 pass@3),绘图代码位于 visualize_results.py。
- 他们建议使用
average_mean_score进行跨运行的均值聚合,并指出像 kakurasu/survo 这样的新任务尚未重新运行。
- 他们建议使用
5. 开源架构与开发者工具
- Qwen3‑Next 克隆版破解代码:一位贡献者发布了 Qwen3‑Next 的可训练复现版本——一个 baseline Transformer 和一个 Gated Delta Net 变体,两者大小相差约 15%。
- 这些仓库展示了路由和 Gated Delta Net 机制,帮助从业者在进行更大规模训练前推敲架构权衡。
- Mojo 与 VS Code 结合:Modular 预览了一个开源的 Mojo VS Code extension,前沿版本可在论坛帖子 Preview: new Mojo VS Code extension 中获取。
- 开发者讨论了 LSP 的不稳定性、解决方法(例如重启
mojo-lsp-server或编辑器)以及在优化 C/C++ 互操作(如extern "C")时的跨编辑器设置(Vim/Zed)。
- 开发者讨论了 LSP 的不稳定性、解决方法(例如重启
- Aider + MLX = Mac 上的本地巨头:用户将 Aider 连接到 mlx-lm,并通过兼容 OpenAI 的端点在本地运行
openai/mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit,随后遇到了默认生成限制。- 解决方法是按照 Qwen3‑Next‑80B discussion #24 中的记录调整
-max-tokens(默认为 512),从而为 Mac 工作流开启更长、可用的会话。
- 解决方法是按照 Qwen3‑Next‑80B discussion #24 中的记录调整
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Perplexity Pro 额度耗尽?:用户报告 Perplexity Pro 的问题,显示 Deep Research 已耗尽,即使使用量极少,这表明可能存在 Bug。
- 解决方法包括退出并重新登录或联系支持人员,尽管响应可能会延迟,且某些用户当天被限制为仅 3 次搜索。
- 移动端图像放大工具对决:成员们寻求免费的移动端图像放大工具,推荐包括 Pixelbin、Upscale.media 和 Freepik Image Upscaler。
- 一位成员建议破解 Adobe Photoshop(需要 PC)并警告 Adobe Firefly 的免费修改次数有限,而另一位成员推荐了破解版的 Remini。
- Comet 的 Google Drive 连接器导致浏览器混乱:用户在使用 Comet 的 Google Drive connector 时遇到浏览器崩溃,建议在 Edge 等其他浏览器中使用该连接器的解决方法。
- 强调了目前 Enterprise Pro 用户不支持 GitHub connector。
- Perplexity 的 Sam 因服务缓慢受到质疑:用户发现 Perplexity 的 AI 支持代理 Sam 没用且缓慢,建议在聊天或邮件中明确要求人工代理。
- 一些用户在请求人工支持时被告知需要 24-48 小时 的响应时间。
- Canvas 测验因 Perplexity 的更新受挫:最近的更新阻止了 Comet Assistant 为 Canvas 上的测验、考试或测试提供答案。
- 成员们警告不要作弊,因为 Canvas 监考人员可以检测命令和标签页切换,从而导致取消资格。
LMArena Discord
- Seedream 4 在“玩失踪”后遭遇质量降级:用户观察到 Seedream 4 High Res 消失后重新以 Seedream4 的名称出现,但质量有所下降(从 4K 降至 2K)且文件体积减小。
- 这种情况导致了成员们的失望,并引发了关于欺骗性更名的猜测,一位用户抱怨道:该死,我觉得被骗了。
- 关于 Gemini 3 的猜测愈演愈烈:围绕 OceanStone 和 OceanReef 的猜测不断升温,理论认为它们可能是 Gemini 3 Flash 和 Gemini 3 Pro 的变体。
- 成员们还思考了 Gemini 3.0 flash 的潜在性能,并提到了过去的神秘代号和撤回事件。
- 推理与暴力破解:AI 训练的难题:一场讨论引发了关于 fine-tuning、model scaling 和 reasoning 是否应被视为 AI 训练中的“暴力破解(brute force)”方法的质疑。
- 辩论的核心在于广泛的推理是否符合暴力破解的定义,特别是当最优路径需要巨大的计算量时。
- LM Arena 饱受登录噩梦困扰:许多用户在 LM Arena 网站上遇到了登录问题和错误。
- 这些问题促使管理员做出回应,要求提供详细的 Bug 报告和截图,以便解决问题并恢复网站运行。
Unsloth AI (Daniel Han) Discord
- 梯度激增对 Magistral SFT 造成严重破坏:在训练期间,梯度范数(grad norm)飙升至百亿亿级(quintillions),导致 Magistral SFT 发生灾难性失败,如这张图片所示。
- 尽管场面混乱,一位成员开玩笑说 那个尖峰就是 AGI 出现的地方,建议继续训练直到它达到无穷大,并链接了一个相关的 GIF。
- WikiArt 数据集的像素化缺陷被曝光:成员们指出了广泛使用的 Wikiart dataset 质量低劣,强调了 jpeg artifacts(JPEG 伪影)并认为该数据集存在巨大缺陷,如此对比图所示。
- 另一位成员建议在有缺陷的输入 Token 上训练模型以产生完美的输出,并强调了对强大过滤器的需求。
- Titans 架构:Google 的 LSTM Transformer 混合体:一场关于 Google Titans 架构 的讨论展开,该架构结合了 Transformer 和 LSTMs 以处理长上下文(long context),参考了这篇论文。
- 尽管具有潜力,一位成员指出缺乏流行的实现,并质疑为什么它没有获得主流关注,而另一位成员则认为 Gemini 可能是 Titans 的混合体,因为它具有巨大的上下文窗口。
- Meta 在移动端 Horizon Worlds 上押下重注:Meta 正在举办一场与 移动端 Horizon Worlds 相关的竞赛,奖金池为 200,000 美元。
- 该竞赛鼓励开发者在 Horizon Worlds 平台内为移动用户创造引人入胜的体验。
- SLED 或能拯救“大脑”:一位成员思考 SLED 是否有可能防止 SFT 造成的大脑损伤(模型损坏),并建议将其与 llama.cpp 等工具集成。
- 一位成员解释说,SLED 通过复用最终的投影矩阵(projection matrix)来创建概率分布,从而利用所有层(而不只是最后一层)的信息来改进 LLM 的预测。
{kind=link}
{kind=link}
Cursor Community Discord
- Auto 模型引发模型辩论:用户正在争论 Cursor 中的 Auto 模型,一些人称赞其与 Claude Sonnet 4 结合的能力,而另一些人认为它仅适用于代码重构 (code refactoring)和简单任务。
- 一位用户报告称其在处理复杂任务时失败,特别是由于缺失闭合括号,导致尝试删除并重写整个文件。
- Cursor CLI 命令混乱持续:一位用户报告称,在全新安装后,命令行仍无法首次运行,需要发送 8 条消息后 Cursor 才能弄清楚如何运行命令。
- 另一位用户提到,修复此问题每年可为 Cursor 节省 1000 万美元。
- 终端命令引发严重故障:用户报告称 Cursor 在运行终端命令时会卡住,无论是在 IDE 还是 Cursor CLI 中,特别是在更新后以及“运行全部”模式下缺少“跳过”按钮时。
- Cursor 团队已承认终端问题,鼓励用户切换到 Early Access 或 Nightly 版本以解决该问题。
- GitHub 账号难以连接到 Cursor:一位用户报告了将 GitHub 账号连接到 Cursor 的问题,导致他们无法选择仓库与后台 Agent 进行对话。
- 他们尝试了取消关联并重新关联 GitHub 账号,并确保 Cursor 拥有所有必要权限,但问题仍然存在。
- 后台 Agents 引发配置噩梦:成员报告称 Background Agents 功能存在故障,忽略 Dockerfile 指令且无法在其默认容器中运行 Docker。
- 一位用户感叹这感觉像是 Alpha 阶段的发布,而不是成品,问题在于尽管 Cursor 在 GitHub 的访问对话框中显示这些仓库已“安装”,但在
yarn install期间无法获取 git+ssh 包。
- 一位用户感叹这感觉像是 Alpha 阶段的发布,而不是成品,问题在于尽管 Cursor 在 GitHub 的访问对话框中显示这些仓库已“安装”,但在
OpenRouter Discord
- Voicera 让音频可搜索:Voicera (http://voicera.trixlabs.in/) 自荐为音频搜索引擎,通过提供带有时间戳片段的 AI 生成答案,将音频转化为可操作的见解,简化了在录音中寻找关键时刻的过程。
- 该工具允许用户上传音频并使用自然语言进行搜索,承诺将数小时的音频转化为即时、可验证的答案。
- SillyTavern 迎来 iOS 克隆版:一位 iOS 开发者推出了免费的 SillyTavern 克隆版 Loreblendr AI (https://apps.apple.com/us/app/loreblendr-ai/id6747638829),旨在为 iOS 设备提供原生应用体验。
- 尽管承认无法匹配 SillyTavern 的所有功能,但开发者对其现状感到满意,并强调了其与现有聊天应用相比更友好的用户界面。
- Kimi K2 出现故障,用户希望升级:用户报告了 ST 上 Kimi K2 0711 的错误并讨论了停机时间,建议升级到较新的 0905 模型。
- 一位用户指出 Kimi K2 的免费版本 (https://openrouter.ai/moonshotai/kimi-k2:free) 已不再可用。
- DeepSeek 代理面临速率限制:用户在尝试使用 DeepSeek 代理(特别是免费模型)时遇到 Error 429,表明 Chutes 存在速率限制 (Rate-limiting) 问题。
- 有人建议 Chutes 可能会因为周末的高需求而限制免费用户,实际上使其几乎变成了付费使用。
- Code-Supernova 神秘出现,令用户困惑:一个新的神秘模型
code-supernova已经出现,据称由 Anthropic 开发,根据图像分析传闻为 Claude 4.5。- 用户形容该模型尚可但有些懒惰,仅提供最基本的实现,表现不像 Claude。
{kind=link}
LM Studio Discord
- Intel ARC 因 NVIDIA 交易而走向终结?:成员们推测 Intel 在与 NVIDIA 达成将其技术集成到 Intel CPU 的交易后,可能会放弃其 ARC GPU 产品线。一名成员暗示这符合 NVIDIA 之前的合作条件:Intel 必须放弃其 GPU 雄心。
- 另一名成员表示 Intel 正在衰落,ARC 让他们赔钱,因此他们几乎每个季度都在大量裁员,这种局面无法长期维持。
- Apple MLX 用户对 Qwen-Next 赞不绝口:Apple MLX 用户报告了 qwen-next 令人印象深刻的性能,在 M4 Max 上使用 6-bit MLX 达到约 60 tok/sec,并具备强大的通用知识、代码编写和 tool calling 能力。
- 一名成员将其描述为他们能运行的最佳模型。
- LM Studio Hub 仍需改进:用户在 LM Studio Hub 内部遇到了导航问题,导致难以查找内容、搜索或在点击链接后返回中心落地页。
- 据这条评论称,该功能目前处于开发中(WIP),搜索将是未来的功能,而目前的文档散落在聊天系统中。
- GPT-OSS 20B 陷入无限循环:一名在低端硬件上测试 gpt-oss-20b 的用户遇到了无限循环问题,由于 context overflow(上下文溢出),模型生成了大量且无关的内容。
- 限制 context window(上下文窗口)可能有助于防止这种情况,因为模型可能会陷入对自己生成的文本进行思考的死循环。
- Xeon Gold:依然贵得离谱?:成员们讨论了 Xeon Gold 6230 和 5120 处理器,强调了它们的 AVX-512 能力,但指出即使能以低价购入,它们依然昂贵得令人咋舌。
- 一名成员分享了一个翻新版 Lenovo ThinkStation 的链接,该机器配备双 Xeon Gold 6148 处理器,被认为是一个不错的选择。
GPU MODE Discord
- Qwen3-Next 架构被复现:一名成员分享了他们尝试复现可训练的 Qwen3-Next 架构的成果,提供了一个 baseline transformer-only 版本 和一个 Gated Delta Net 版本。
- 据称这些架构的大小差异在 15% 以内,为理解其工作原理提供了大致思路。
- Planet Labs 将 NVIDIA Jetson 送入轨道:地球观测公司 Planet 在其卫星上运行 NVIDIA Jetson Orin AGX 单元,利用 CUDA 和 TensorRT 进行星上 ML 推理,并使用 YOLOX 等目标检测算法。
- 他们使用运行在标准 Ubuntu 上的 Docker 容器,Jetson 模块提供 64 GB 统一内存,类似于 Apple M 系列芯片。
- AMD GEMM 席卷排行榜:
amd-gemm-rs排行榜的提交非常活跃,其中一项提交在 MI300x8 上以 530 µs 的成绩获得第一名。amd-all2all排行榜也迎来了更新,其中一项提交在 MI300x8 上以 1230 µs 的成绩位列第五名。
- TorchAO 团队与 Unsloth 团队发布原生量化模型:TorchAO 团队与 Unsloth 合作发布了 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的原生量化(quantized)变体,可通过 PyTorch 获取(点击此处了解更多)。
- 用户现在可以使用 Unsloth 进行微调,然后使用 TorchAO 对微调后的模型进行量化。
- Together AI 预告 Blackwell 深度解析:Together AI 将于 10 月 1 日与 Dylan Patel (Semianalysis) 和 Ian Buck (NVIDIA) 共同举办一场 Blackwell 深度解析 活动。
- 演讲者将讨论新架构的能力。
Eleuther Discord
- AI 桌面 Agent 助力盲人用户:成员们讨论了结合 speech-to-text、用于诈骗邮件自动化的 AI desktop agents 以及 text-to-speech 来辅助盲人用户,一些人提到了 macOS accessibility 功能的有效性。
- Windows 和 macOS 内置的屏幕阅读器被提及作为潜在解决方案,一位成员表示可以帮助联系其他在屏幕阅读器方面有经验的 Discord 用户。
- 提议为 Ray 和 vLLM 提供 TorchTitan 补丁:一位成员建议使用 TorchTitan 为强化学习(RL)对 Ray 和 vLLM 进行补丁修复,并指向了 OpenRLHF/OpenRLHF 等示例。
- 有人指出 对于 RL 来说,torchtitan 显然是不够的,暗示需要进一步的配置,但未具体说明。
- NeurIPS 展示 TokenSwap:TokenSwap 因通过交换常见语法 Token 的概率来解决 性能与记忆的权衡(performance-memorization tradeoff) 问题而在 NeurIPS 2025 获得 Spotlight,实现了 10 倍 的逐字生成(verbatim generation)减少。
- 尽管受到好评,批评者将其比作 对模型进行脑叶切除(lobotomizing the model),作者澄清说,它通过为简单 Token 换入较差的模型来防止逐字或近乎逐字的输出。
- DeepMind 破解流体方程:DeepMind 宣布在三个流体方程中发现了新的不稳定奇点(博客文章),详细介绍了不可压缩多孔介质方程和带边界 3D Euler 方程的新自相似解。
- 论文也已分享:[2509.14185] Title。
- Atlas 尝试修复 NIAH Transformer 差距:Atlas 声称通过泰勒级数多项式使用更大的状态尺寸,修复了 NIAH 结果与 Transformers 之间的差距。
- 怀疑者指出 就可复现性或任何合理的比较而言,atlas 论文一团糟,且未透露具体尺寸。
HuggingFace Discord
- 本地 LLM 配置推荐使用 Qwen Coder:一位成员建议在本地 LLM 配置中使用 Qwen Coder 的标准模型,并提供了考虑 VRAM 的硬件建议。
- 他们警告了多 GPU 的限制,并分享了一个 qwen_coder_setup.md 文件。
- Transformers 训练循环获得临时修复补丁:一位成员分享了 GitHub 上解决 Transformer 训练循环问题的 PR 链接,询问其是否适用于标准的 PyTorch 训练循环。
- 另一位成员澄清道:使用模型输出的 out.loss,你就可以在任何循环中获得该修复。如果自行编写 loss,则必须自己处理缩放(scaling)。
- SpikingBrain-7B 声称拥有惊人的加速:有人分享了 SpikingBrain-7B 的 ArXiv 链接,这是一个基于 SNNs(脉冲神经网络)的非 Transformer 模型,承诺可能带来范式转变。
- 论文断言 SpikingBrain-7B 在 4M Token 序列的首个 Token 响应时间(TTFT)上实现了超过 100 倍的加速,引发了关注。
- HF API 简化模型访问:讨论了如何通过 API 从 Hugging Face 访问和列出模型,并提供了一个有用的 代码示例。
- 随后一位成员分享了利用
huggingface_hub列出 Hub 上模型的代码片段。
- 随后一位成员分享了利用
- AI 驱动的 Captcha 破解中的伦理困境:辩论了使用 AI 破解 Captcha 的伦理问题,一位成员称此类行为是 AI 伦理和护栏的支柱。
- 另一位成员指出,由于通常是同一批公司既创建谜题又创建像 Gemini 这样的 AI 解答器,这可能会演变成一场由 军火商 主导的永无止境的猫鼠游戏。
OpenAI Discord
- AI 辅导引发作弊争议:围绕 InterviewCoder(一个提供实时编程挑战提示和解决方案的 AI 工具)展开了讨论,质疑其本质是辅助还是公然作弊。
- 建议包括将其重新定位为教育用途,类似于“算法的辅助轮”,作为学习辅助工具提供多种解决方案路径。
- AI 面试辅助开启伦理雷区:使用 AI 在面试中作弊可能会招致民事欺诈性失实陈述指控,而秘密路由对话则违反了全员同意法(all-party consent laws)。
- 一些成员表示,不使用这类工具就像是“因为不愿安装某些软件而拒绝给家人提供食物和住所”。
- GPT-5-chat 纠缠于后续提问:用户报告 GPT-5-chat 执着于询问后续问题,即使系统提示词(system prompts)不鼓励这样做,且目前没有通用设置来禁用结尾提问。
- 在每个 prompt 前加上“请简洁回答,不要以问题结尾”可以提高合规性,但并非万无一失。
- 自动化 Prompt 生成已部署:一位用户通过指示 GPT 创建 5-7 个初始 prompt,然后以 JSON 或 YAML 格式再生成 10 个,从而实现了 prompt 生成的自动化,并扩展到 2500 个 prompt 并收到下载链接。
- 该用户补充说,使用 API keys 就像是增加了安全性和功能的“作弊码”。
- GPT Agent 被推至 Prompt 限制边缘:一位用户通过不断生成 prompt 直到无法容纳,将 GPT 推向极限,然后将 prompt 放在文件中提供上下文;GPT 辅助 agent 似乎变得不适,尤其是在使用代码分析工具在 ZIP 文件 中生成复杂代码时。
- 他们正在尝试将自定义 GPTs 与电脑上的沙盒 API 集成,并计划利用 MCP 开发者模式 在标准 ChatGPT 上下文 中集成 自定义 GPT actions。
Latent Space Discord
- Mistral 模型获得视觉能力和更高评分:Mistral 发布了 Magistral Small 1.2 和 Medium 1.2,增加了多模态视觉能力,并在数学/编程评分上提升了 15%,可通过 Le Chat 和 API 访问。
- 社区成员现在对 Large 模型、Medium 开源、真实世界演示和语音功能感到好奇。
- 开源 AI Agent 框架探索:社区成员正在征求 AI Agents 领域最适合开源贡献的 OSS 框架 或 git 仓库,引发了关于架构方法的讨论。
- Notion 3.0 成为知识工作 Agent:Notion 宣布了 Notion 3.0,其特色是“知识工作 Agent”,能够执行多步操作和长达 20 多分钟 的自主工作,详见这条推文。
- 此次更新引入了 Personal Agent 和 Custom Agent,集成了 Notion Calendar、Notion Mail、MCP 等。
- Moondream 3 可视化 SOTA:Vik 介绍了 Moondream 3,这是一个拥有 9B 参数的混合专家(Mixture-of-Experts)视觉语言模型,具有 2B 激活参数,实现了 SOTA 级的视觉推理和开放词汇目标检测性能;权重已托管在 Hugging Face。
- 它引入了视觉定位推理、最先进的 CountBenchQA 结果、32k token 上下文支持、SuperBPE token 以及易于微调的权重。
- Luma Labs Ray3 推理好莱坞级 HDR:Luma AI 展示了 Ray3,声称它是首个具有工作室级 HDR 输出的推理视频模型,在 Dream Machine 内免费使用。
- 亮点功能:用于快速迭代的 Draft Mode、增强的物理效果和一致性、视觉注释控制,以及支持 EXR 导出的 10/12/16-bit HDR,因其好莱坞级别的保真度而获得赞誉。
Modular (Mojo 🔥) Discord
- Mojo VS Code 扩展进入预览阶段:一个新的开源 Mojo VS Code 扩展现已提供预览版,可以直接从 GitHub 仓库获取最前沿的构建版本。
- 该扩展很快将在预发布频道上线,使开发者能够更轻松地将 Mojo 集成到他们的 VS Code 工作流中。
- Mojo LSP 面临稳定性问题:用户报告了 Mojo LSP 的不稳定性,经历了崩溃、挂起和内存泄漏,通常需要手动终止
mojo-lsp-server进程。- 尽管存在这些问题,一位 Modular 员工指出正在努力改进 LSP,一位成员建议重启 nvim 有助于恢复 LSP。
- Mojo 的 IDE 生态:VS Code 及其衍生版本是 Mojo 使用最多的 IDE,尽管许多内部开发者使用 Vim、Zed 等。
- Mojo LSP 服务器随
mojo包一起发布,以便为用户提供使用其他 IDE 的灵活性,并且提供了一个在 Lazynvim 中的简单 LSP 设置。
- Mojo LSP 服务器随
- 将 Mojo 代码导出到 C/C++ 的注意事项:当从 Mojo 代码构建 .so 库时,只有定义为
fn的函数才能从 C 代码中调用,因为def会隐式抛出异常,导致其与 C-ABI 不兼容。- 对于 C++ 互操作,在头文件中包含
extern "C"链接至关重要,以防止符号修饰(symbol mangling)问题;一位成员发现这对于防止 C++ 中的符号修饰是必不可少的。
- 对于 C++ 互操作,在头文件中包含
Yannick Kilcher Discord
- DeepMind 让流体动力学更“流畅”:根据这篇博客文章,Google DeepMind 宣布他们利用新型 AI 方法,首次系统性地发现了三种不同流体方程中的新不稳定奇点族。
- 该消息也通过 X 发布,标志着在解决流体动力学百年难题方面取得了重大进展。
- 成员暗示 ClaudeAI 发布:一位成员分享了一个链接,暗示即将发布的 ClaudeAI 公告。
- 消息简单地写道:“明天就是那个日子吗?”
- 实现 Qwen3 Next 架构复现:一位成员创建了一个具有不同路由机制的 Qwen3 Next 架构的可训练复现版本,并分享在 GitHub 上。
- 他们发现 gated delta nets 很有前景,并希望下周能阅读关于 gated linear attention 的内容。
- LLM API 与 Power Automate 的脱敏对决:一位成员询问是使用自定义 API LLM 方案,还是使用带有 Copilot Studio 的 Power Automate 来处理每月 60,000 份文档的个人信息脱敏。
- 他们建议自定义 API LLM 方案可能会更便宜、更快速。
- 背景叠加比看起来更难:一位用户正在寻求优化 Agent 的见解,以便将雪景背景叠加到分镜脚本图像上。
- 尽管任务看起来很简单,但生成的图像并未达到预期,且 Agent 的工作效果不如预期。
{kind=link}
{kind=link}
aider (Paul Gauthier) Discord
- Coding Agent 质量参差不齐:成员们报告了 qwen-code、Cline 和 Kilo 等 Coding Agent 的质量差异,像 qwen3-coder (480B) 这样的大型模型表现更好,但仍表现出不可预测的行为。
- 尽管好坏比例较低,但较小的模型有时会产生令人惊讶的好结果,这引发了人们对 Aider 的用户引导方法如何与之对比的好奇。
- Aider 直接编辑:用户更倾向于使用 Aider 进行针对性的单一编辑,即使是使用 gpt3.5-turbo 这样的小型模型,理由是其速度和直接性。
- 一位用户将 Aider 与 Claude 4 Sonnet 和 gh cli 结合用于 PR 评审,将其与 opencode 或 qwen-code 等更具 Agent 特性的工具进行了对比,后者在处理微小更改时会处理大量的代码部分。
- Deepwiki 软化代码库以供检查:一位成员分享了 Deepwiki,将其作为快速对代码库提问的资源,以便在深入细节之前对其进行“软化”。
- 他们通过使用 Deepwiki 的 aider 条目中的 Devin Chat 来回答 tree-sitter 如何使用的问题进行了演示。
- 本地 MLX 模型通过 Aider 运行:一位成员通过 mlx-lm server 让 mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit 模型与 aider 协同工作,使用了
aider --openai-api-key secret --openai-api-base http://localhost:8080/v1/。- 在
--model选项前添加openai/是关键:aider --openai-api-key secret --openai-api-base http://127.0.0.1:8080 --model openai/mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit。
- 在
- 图表可用性扩展:一位用户建议通过增加取消选择离群数据点的功能来提高图表的可用性,以便更好地关注代表性数据。
- 目前,无法轻松使用该图表。
DSPy Discord
- 人工评审工具征集测试者:一位成员正在开发用于手动 QA、错误分析和数据标注的 Human Review Tooling,正在寻找测试者,特别是来自学术界的测试者,并提供了演示视频。
- 下一阶段涉及使用人工反馈生成评分器,并结合确定性方法和通过 GEPA 实现的 LLMs as Judges。
- GEPA 优化指南即将推出:一位成员在 general 频道询问除了 OpenAI 模型之外,哪些模型在 GEPA 优化方面表现良好。
- 另一位成员报告说 Gemini-2.5-Pro、GPT-4/5-nano/mini/main 所有版本以及 Qwen3-8B+ 都取得了成功,同时也听说 GPT-OSS 也很成功。
- MLFlow 展示可观测性实力:一位成员询问哪些工具在可观测性和评估 (evals) 方面表现良好,特别是针对 GEPA。
- 另一位成员提到 MLFlow 已深度集成,MLFlow 团队也在致力于更好地与 GEPA 集成,并支持 best_valset_agg_score 以及帕累托前沿(pareto frontier)相关的指标(如 paro frontier aggregate score)和仪表盘。
- ColBERT 上下文危机:一位成员指出,尽管 jina-colbert 接受高达 8,192 tokens,但在长上下文下的效果并不理想。
- 他们建议在每个分块(chunk)中重复 CLS token 并尝试有无该 token 的效果;频道讨论了 CLS Token Chunking Strategy 以解决 jina-colbert 中的长上下文问题。
- MergeBench 论文:一位成员分享了 MergeBench。
- 未提供关于该论文的更多细节。
Nous Research AI Discord
- Magistral Small 模型首次亮相:Mistral AI 在 Hugging Face 上发布了 Magistral-Small-2509 模型,并观察到由于小张量(small tensors)的开销,小模型训练速度并非线性扩展。
- 团队指出 VRAM 消耗效率低下,在 16 倍 batch size 下,Qwen3-Next 比同等的 Llama 模型需要更多 VRAM。
- Moondream 迎来更新:根据 这篇 vxitter 帖子 宣布了新的 moondream 版本,然而成员们对其“奇怪的许可证(wonky licence)”表示担忧。
- 该模型在同类领域中与其他 moondream 模型的对比评价并不理想。
- QSilver 量子研讨会开放申请:QBangladesh 将于 10月18–19日和10月25–26日(UTC 时间 1:00–2:30 PM)通过 Zoom 举办免费的 QSilver 量子研讨会,内容涵盖 Qiskit、Cirq 等。
- 研讨会包括嘉宾演讲、代码演示和动手编程,优先考虑女性及弱势群体,申请截止日期为 10月11/12日(申请表)。
- 中国在多模态模型方面落后:成员们观察到,与其他地区相比,中国的多模态模型似乎最少。
- 一位成员询问了图像识别训练中的障碍,特别是在使用 MoE 架构时。
- 本周没有 Gemini 3.0 或 Claude 4.5:一位成员对本周未发布 Gemini 3.0 或 Claude 4.5 表示失望,宣称“这周我们被耍了”。
- 随后他们调侃道:“不过我们拿到了 AI 眼镜!”(虽然目前还没有 AI 功能)。
Moonshot AI (Kimi K-2) Discord
- Kimi Researcher 额度:永久还是每日?:用户争论 Kimi Researcher 额度是终身限制还是会刷新,一位用户因为担心只有 3 次限制而不敢尝试。
- 一位用户澄清说免费会话每日刷新,一些用户报告有 5 次免费会话,而另一些人则只有 3 次。
- Researcher 限制与 Beta 访问权限挂钩?:一些用户建议,更高的 Researcher 限制可能与通过候补名单获得的 beta 测试权限有关。
- 有暗示称,在 Research 处于 beta 阶段时申请使用的用户可能拥有更高的配额。
- 对 Kimi 的 Dart 性能产生怀疑:一位用户询问了 Kimi 在 Dart 语言中的表现,以及提供的示例是否为实时生成。
- 有说法称点击示例并不会实时运行模型,而是显示预生成的输出。
tinygrad (George Hotz) Discord
- Hotz 正在筹划新公司:George Hotz 宣布成立新公司,专注于“为拥有算力的人制造有用的产品”,该公司独立于 TinyCorp。
- 新公司旨在解决对更易用的计算工具的需求,重点在于提升用户体验和扩大应用范围。
- TinyGrad 焕然一新:TinyGrad 正在进行重大更新,旨在增强其功能并优化用户体验。
- 这些更新预计将扩大 TinyGrad 框架的应用范围,巩固其作为通用工具的地位。
- Stable Diffusion 导入遭遇模块噩梦:一位成员在尝试运行 Stable Diffusion 模型时,因缺少
extra模块而遇到ModuleNotFoundError。- 引用的具体错误为
from extra.models.clip import Closed, Tokenizer,表明在导入过程中该模块不可用。
- 引用的具体错误为
- PYTHONPATH 黑科技失效:有人建议使用
PYTHONPATH=.作为环境变量来解决模块错误,但对遇到该问题的成员无效。- 这表明问题可能比简单的路径解析问题更复杂。
- Extra 包在 PyPI 中缺失:一位成员指出
extra包不是 PyPI 发布版本的一部分,并质疑安装是通过 PyPI 还是直接从 repo 完成的。- 提问者确认他们是从源码安装的,这表明缺失模块可能是由于源码安装过程不完整或不正确导致的。
MCP Contributors (Official) Discord
- 贡献者服务器明确其定位:一名管理员指出,该服务器的存在是为了供 contributors(贡献者)之间进行讨论;它不是一个通用的帮助区域或随意调查地带。
- 寻求帮助或想要进行调查的人员被要求私信管理员,以获取指向其他服务器的指引。
- EmbeddedResources 出现定义偏差:一位成员注意到
EmbeddedResource没有遵循EmbeddedResources的结构,并且没有继承BaseMetadata,这意味着它缺少name和title属性。- 他们希望确认
EmbeddedResource是否应该包含name和title属性。
- 他们希望确认
Windsurf Discord
- Windsurf 发布 Code-Supernova:Windsurf 推出了 code-supernova,这是一款支持图像输入并具有 200k context window 的 agentic coding model,目前对个人用户限时免费。
- 这款新模型旨在在 Windsurf 环境中提供增强的编程辅助。
- Windsurf 推出消息队列功能:Windsurf 在发布 code-supernova 的同时,宣布推出新的 queued messages feature(消息队列功能)。
- 该功能可能允许用户在 Windsurf 平台内调度和管理消息发送,从而提高工作流效率。
- Reddit 热议 Windsurf 的隐身模型:邀请用户在 Reddit 上讨论这款免费的隐身模型(stealth model)。
- 讨论为用户提供了一个分享反馈、经验以及该新模型潜在用例的平台。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:各频道详细摘要与链接
Perplexity AI ▷ #general (1105 messages🔥🔥🔥):
Perplexity Deep Research 额度耗尽, 图像放大工具, Comet 与 Google Drive 连接器问题, Perplexity 的 Sam AI 助手, Comet 与 Canvas 测验
- Perplexity Pro 的 Deep Research 限制令用户沮丧:用户报告了 Perplexity Pro 的问题,显示 Deep Research 额度已耗尽,尽管使用量很少,有一位用户报告当天仅使用了 3 次搜索。
- 成员们怀疑这是一个 Bug,建议的解决方法包括退出并重新登录,或联系客服,尽管有人指出客服回复存在延迟。
- 图像放大工具探索:成员们讨论了移动端最佳的免费图像放大工具,推荐了 Pixelbin、Upscale.media 和 Freepik Image Upscaler,而另一位成员建议使用破解版 Adobe Photoshop,但这需要 PC。
- 一位用户警告不要使用 Adobe Firefly,因为免费修改次数有限,并强调了像破解版 Remini 这样的放大选项。
- Comet 的 Google Drive 连接器出现故障:用户报告了 Comet 中 Google Drive 连接器 的问题,导致浏览器崩溃,但建议在 Edge 等其他浏览器中使用该连接器作为变通方案。
- 他们强调,对于 Enterprise Pro 用户,目前不支持 GitHub 连接器。
- Sam 的客服响应不尽如人意:用户发现 Perplexity 的 AI 客服代理 Sam 没太大帮助且响应缓慢,建议在聊天中明确要求 human agent(人工客服)。
- 一位成员被告知预计响应时间为 24-48 小时,建议的方法是在邮件通信中明确要求人工支持。
- Canvas 测试作弊尝试被封堵:一位用户询问关于在 Canvas 测验中使用 Perplexity 的问题,但发现由于最近的更新,Comet Assistant 不再为测验、考试或测试提供答案。
- 成员们警告不要作弊,并指出 Canvas 监考人员可以看到运行的命令和标签页切换,从而导致取消资格。
Perplexity AI ▷ #pplx-api (3 messages):
基于搜索的回答, Bitcoin 新闻, 内存管理
- 回答基于搜索 (Grounded with Search):一名成员询问了关于回答如何通过搜索进行验证的示例或更多细节。
- 另一名成员回复称,他们请求了关于 Bitcoin 的新闻,且要求时间在 7 天以内。
- 搜索中出现虚假 Bitcoin 新闻:一名成员报告称,搜索返回了一篇虚假的 Bloomberg 文章,声称 BTC 创下了 72k 的历史新高。
- 用户指出 BTC 已经超过 100k,暗示该文章内容不准确。
- 分享 Perplexity AI Cookbook 文章:一名成员分享了一个指向 Perplexity AI cookbook 文章的链接,内容涉及内存管理。
- 该文章讨论了如何实现持久化对话 (chat with persistence)。
LMArena ▷ #general (872 messages🔥🔥🔥):
Seedream 4 High Res 移除, Gemini 3 猜测, 暴力破解讨论, LM Arena 登录问题
- Seedream 4 High Res 消失、更名后降级:用户注意到 Seedream 4 High Res 被移除,随后以 Seedream4 的名称重新出现,但画质显著降低(从 4K 降至 2K)且文件体积更小,引发了用户的失望以及这是否属于欺骗性更名的猜测。
- 一名成员表示:它只有 2K (2034px),而 4K 应该是 4096px,其他成员也纷纷抱怨并希望其回归:该死,我觉得被骗了。
- Ocean Stone 和 Ocean Reef 的猜测加剧:成员们积极讨论 OceanStone 和 OceanReef,有人推测它们是 Gemini 3 Flash 和 Gemini 3 Pro 的变体,也有人好奇 Gemini 3.0 flash 的表现会如何。
- 成员们指出:还记得 king fall 吗?Gemini 的代号模型总是非常神秘,而且很快就会被撤回。
- 推理 (Reasoning) 是暴力破解吗?:一场讨论围绕着微调 (fine-tuning)、模型缩放 (model scaling) 和推理 (reasoning) 是否构成了 AI 训练中的暴力破解方法展开,并对相关定义进行了辩论。
- 一些人认为使用长链推理实际上就是暴力破解,一名成员解释道:如果所有最优路径都导致大量工作,那么它确实符合暴力破解的定义。
- LM Arena 遭遇故障:多名用户报告了 LM Arena 网站的登录问题和错误,促使管理员做出回应,并要求在相应频道提交详细的 Bug 报告和截图。
- 一名成员表示:<@283397944160550928> 即便现在网站也完全无法正常工作……一直在报错。
Unsloth AI (Daniel Han) ▷ #general (484 条消息🔥🔥🔥):
梯度爆炸 (Exploding Gradients), 数据清洗, 心盲症 (Aphantasia) 与视觉想象, Titans 架构, Google AI Pro
- 梯度峰值引发训练崩溃:在训练过程中,grad norm 飙升至 quintillions(百亿亿级),导致了灾难性的失败,但一位成员开玩笑说 “那个峰值正是 AGI 诞生的地方”。这张图片展示了 Magistral SFT 获得最高分的时刻。
- 尽管一片混乱,一位成员建议继续训练直到它达到无穷大,并分享了一个相关的 GIF。
- WikiArt 数据集质量受到质疑:一位成员指出广泛使用的 Wikiart 数据集 质量很差,强调了 jpeg 伪影 问题,并认为该数据集存在巨大缺陷,此对比图说明了这一点。
- 另一位成员建议在有缺陷的输入 tokens 上训练模型以产生完美的输出,并强调了对强大过滤器的需求。
- 探索大脑中的心盲症与视觉化:成员们分享了他们在视觉化方面的经验,讨论了从生动的心理意象到心盲症(aphantasia,一种无法在脑海中想象图像的症状)的光谱,一位成员可以视觉化整个环境的完整细节。
- 讨论涉及了视觉化对学习、问题解决和记忆的好处,以及由于持续的心理意象可能导致的睡眠干扰等潜在缺点。
- Titans 架构引发关注:围绕 Google 的 Titans 架构展开了讨论,该架构结合了 Transformers 和 LSTMs 以处理长上下文,参考了这篇论文。
- 尽管其具有潜力,一位成员指出缺乏流行的实现,并质疑为什么它没有获得主流关注,而另一位成员则猜测 Gemini 可能是 Titans 的混合体,因为它拥有巨大的上下文窗口。
- 全员免费 Google AI Pro!:一位成员宣布他们获得了一年的免费 Google AI Pro,引发了兴奋,并开玩笑说要耗尽 VEO 的额度。
- 另一位成员表示庆祝并说道:“是时候让 Unsloth 吉祥物动起来了”,并链接到了这条推文。
Unsloth AI (Daniel Han) ▷ #off-topic (81 条消息🔥🔥):
Meta Horizon Worlds 移动端竞赛, 阿尔巴尼亚的 AI 部长, RAM 超频稳定性测试, LLM 恐怖谷效应, GPTs 角色扮演
- Meta 为 Horizon Worlds 移动端提供 20 万美元奖金:Meta 正在举办一场与 Horizon Worlds 移动端相关的竞赛,奖金池为 $200,000。
- 该竞赛鼓励开发者在 Horizon Worlds 平台内为移动用户创建引人入胜的体验。
- 阿尔巴尼亚任命 AI 部长:阿尔巴尼亚成为第一个设立 AI 部长的国家,这是一个由 AI 驱动的像素和代码 组成的虚拟实体。
- 一位美国用户开玩笑说,他甚至愿意选择 GPT2 而不是现任政府。
- 使用 y-cruncher 压测 RAM 稳定性:成员们讨论了使用 Memtest、Prime95 和 Cinebench 测试 RAM 的稳定性,并推荐使用 y-cruncher 进行最佳内存稳定性评估。
- 一位成员建议 Memtest 可以显示具体的错误和损坏的内存条。
- LLM 诱发恐怖谷效应:成员们讨论了 LLM 中的恐怖谷效应,指出当助手模型开始提到作为人类的个人生活和经历时,就会产生这种感觉。
- 一位成员说:“当助手模式突然开始谈论它作为人类的个人生活和经历时,确实让我感到有点不适。”
- GPTs 角色扮演,完美的体验:成员们讨论了与模型进行角色扮演,一位成员声称 “在与模型进行 RP(角色扮演)并让它们使用第一人称等方面完全没有问题”。
- 这是在定义 LLM 行为是否会产生恐怖谷效应的背景下讨论的,对于某些人来说,角色扮演并不属于这一范畴。
Unsloth AI (Daniel Han) ▷ #help (37 条消息🔥):
GLM-4.5V 微调, NeMo 2.0 框架, GPT-oss 错误, Gemma3 27b 显存需求, 瑞士德语音频数据集
- GLM-4.5V 微调:Unsloth 是否支持?:一位用户询问 Unsloth 是否支持带有图像的 GLM-4.5V 微调,并引用了视觉 SFT 和 RL 功能;另一位用户回答道 transformers 已支持,所以极有可能支持。
- 未提供关于具体实现或配置的进一步细节。
- LLM 训练对 NeMo 2.0 框架的兴趣激增:一位用户询问了在 NeMo 2.0 框架中训练模型的资源,指出实验室采用率在增加,但缺乏官方文档。
- 一位用户表示打算为此创建一些东西,暗示将通过社区驱动的努力来填补文档空白。
- 本地 GPU 出现 GPT-oss 错误:一位用户报告称,在本地 GPU 上运行 GPT-oss notebook 时出现了与 UnslothFusedLossBackward 相关的 RuntimeError,而该代码在 Google Colab 上运行良好。
- 该错误表明尝试修改一个 inplace view,可能需要通过克隆自定义 Function 的输出来解决。
- Gemma3 27b 全量微调需要海量显存:一位用户询问了对 Gemma3 27b 进行全量微调 (FFT) 的 GPU 显存需求,并报告在使用 RTX 6000 Pro 时出现 CUDA 显存溢出错误。
- 据称,由于激活值和优化器参数的存储,FFT 至少需要 ~432GB 显存,建议使用 QLoRA 作为更节省显存的替代方案。
- 寻求瑞士德语音频数据集:一位用户请求获取优质的瑞士德语音频 - 转录数据集,但被提醒不要指望在公开渠道获得高质量数据,更不用说同时包含音频和转录的数据了。
- 提供了一个 HF 上的德语音频数据集链接,并建议自行生成、转录和对齐音频。
Unsloth AI (Daniel Han) ▷ #research (21 条消息🔥):
SLED 预防脑损伤的潜力, 推理中的 LLM 层使用, 服务器支持者角色, 早期退出 Logits, SLED 技术
- SLED:脑损伤预防者?:一位成员思考 SLED 是否有可能预防 SFT 造成的脑损伤(brain damage),并建议将其与 llama.cpp 等工具集成。
- 另一位成员询问了研究方面的情况,怀疑这是一个用于招聘研究人员的 AI 竞赛。
- 所有层对 Logits 都很重要:一位成员澄清说,在使用 llama.cpp 或 MLX 进行推理期间,所有层都是按顺序使用的,只有最后一层的 Logits 用于计算下一个 Token 的概率。
- 他们解释说,SLED 直接利用每一层的处理结果来计算 Logits,从而可能改进预测。
- 通过 Boost 获胜!:一位成员询问如何获得支持者角色,另一位成员回答说需要通过 Boost 支持服务器才能获得。
- Discord 会为服务器 Boost 者自动设置该角色,所以通过 Boost 来赢取吧。
- SLED 利用所有层来提高精度:一位成员解释说,SLED 通过重用最终的投影矩阵来创建概率分布,从而利用所有层(而不只是最后一层)的信息来改进 LLM 的预测。
- 他们补充道,SLED 通过整合模型处理过程中不同阶段的信息来优化 LLM 的预测。
Cursor Community ▷ #general (402 messages🔥🔥):
Auto Model, Cursor CLI, Cursor Terminal issues, MCP for managing projects, Windsurf vs Cursor
- Auto 模型引发模型辩论!:用户讨论了 Cursor 中的 Auto 模型,一些人认为即使它不是免费的也非常好用,而另一些人则认为它只适用于代码重构(code refactoring)和简单任务。
- 一位用户指出,他们使用 Claude Sonnet 4 基本上可以构建任何东西,而 Auto 模型在处理复杂任务时会失败,特别是如果缺少闭合括号,它会尝试删除并重写整个文件。
- Cursor CLI 命令仍然不稳定:一位用户报告说,在全新安装后,命令行仍然无法第一时间正常工作,而且需要经过 8 条消息后 Cursor 才能弄清楚如何运行命令。
- 一位用户提到,修复这个问题可以避免 Cursor 端的资金浪费,仅此一项改进每年就能为 Cursor 节省 1000 万美元。
- 终端风暴:用户报告终端命令卡住!:多位用户报告了在运行终端命令时 Cursor 卡住的问题,无论是在 IDE 还是 Cursor CLI 中,尤其是在更新之后,并注意到在“运行所有(run everything)”模式下缺少“跳过(skip)”按钮。
- Cursor 团队承认了终端问题,并确认这些问题正在积极开发修复中,建议用户尝试切换到 Early Access 或 Nightly 版本以寻求解决。
- 使用 MCP 管理多个项目:一位用户发明了一种 MCP (Multi-Cursor Project) 来控制 Cursor 中多个打开的项目、端口和主机,确保如果另一个项目尝试占用其他项目的端口,它会自动识别并更改端口。
- 另一位用户在让 Cursor CLI 与其 MCP 配合工作时遇到问题,尽管配置文件正确,但仍遇到 No MCP servers configured 错误;他们通过下载桌面应用解决了此问题。
- Windsurf 还是 Cursor 订阅?:用户对比了 Windsurf 和 Cursor 订阅,一位用户在安装 Windsurf 几分钟后就将其卸载并选择了 Cursor,而其他人则根据可用的额度或配额同时使用两者。
- 还有关于早期采用者定价和 GPT-5 提示词价值的讨论,一些使用 10 美元方案的用户获得了大量高质量的提示词额度。
Cursor Community ▷ #background-agents (3 messages):
Background Agents, GitHub repository access, configuration issues
- Background Agents 引发配置噩梦:成员们报告 Background Agents 功能存在漏洞,会忽略 Dockerfile 指令,无法在其默认容器中运行 Docker,并且缺乏关于配置和 environment.json 属性的详细文档。
- 一位用户感叹这感觉像是 Alpha 阶段的发布,而不是成品。
- GitHub 账号难以连接到 Cursor:一位用户报告了将 GitHub 账号连接到 Cursor 时出现问题,导致他们无法选择仓库与 Background Agent 进行对话。
- 他们尝试了取消关联并重新关联 GitHub 账号,确保 Cursor 拥有所有必要权限,但问题仍然存在。
- Background Agents 无法通过 git+ssh 获取包:一位用户遇到一个问题,即 Background Agents 在执行
yarn install期间无法获取 git+ssh 包,尽管 Cursor 在 GitHub 的访问对话框中显示这些仓库已“安装”。- 错误信息显示克隆仓库失败,提示“Repository not found”。
OpenRouter ▷ #app-showcase (3 条消息):
Voicera Audio Search Engine, SillyTavern iOS Clone
- Voicera 让音频可搜索:Voicera (http://voicera.trixlabs.in/) 被定位为一个音频搜索引擎,可将音频转化为可操作的洞察,承诺将数小时的音频转化为基于用户自身音频文件的即时、可验证的答案。
- 该工具允许用户上传音频,使用自然语言进行搜索,并获取带有时间戳片段的 AI 生成答案,旨在简化在录音中查找关键时刻、引用或决策的过程。
- SillyTavern iOS 克隆版应用出现:一位 iOS 开发者推出了一款免费的 SillyTavern iOS 克隆版应用 Loreblendr AI (https://loreblendr.ai/),专为在 iOS 设备上寻求原生 SillyTavern 体验的用户设计。
- 尽管承认它无法匹配 SillyTavern 的所有功能,但开发者对应用的现状表示满意,并强调了其相比现有聊天应用更友好的用户界面。
OpenRouter ▷ #general (305 条消息🔥🔥):
Responses API Benefits, Kimi K2 0711 Downtime, GPT-4o Alternative, Deepseek V3 429 Errors, Chutes Pricing
- Kimi K2 故障,模型降级引发讨论:用户报告了 Kimi K2 0711 在 ST 上的错误,一些人询问停机时间,而另一些人建议升级到价格相同的较新 0905 模型。
- 一位用户指出 Kimi K2 的免费版本 (https://openrouter.ai/moonshotai/kimi-k2:free) 已不再可用。
- DeepSeek 代理问题,频率限制泛滥:用户在尝试使用 DeepSeek 代理(尤其是免费模型)时遇到 Error 429,这表明 Chutes 存在频率限制问题。
- 一位用户认为 Chutes 可能会因为周末的高需求而限制免费用户,使得服务几乎变成了付费才能使用。
- Gemini 的 NSFW 过滤器,挫败感的源头:用户讨论了使用 Gemini 处理 NSFW 内容的问题,一些人在尝试露骨角色扮演时遇到了 API key 被封禁的情况。
- 一位用户提到 Google “既想赚钱又在坑人”,并引用了自己使用 Gemini 的经历,表达了对 Google AI Studio 的不满。
- Allow Fallbacks 失效,引发混乱:用户报告
allow_fallbacks: False设置未按预期工作,尽管已设置为防止回退,请求仍被路由到其他提供商。- 一位成员建议,如果指定的模型不可用、使用了不支持的功能或其他未知情况,OpenRouter 可能会重新路由请求。
- DeepSeek R1 对决 3.1:用户驱动的较量:一位用户吹捧 DeepSeek R1 在角色扮演方面优于 3.1,因为它能够传达讽刺和反讽,而另一位用户则表示 3.1 听起来最像“基础版 GPT”,只是在“描述”而不是在“交谈”。
- 该用户还提醒说 DeepSeek 3.1 需要“大量的提示词”,并表示这是他们现在最不想碰的模型。
OpenRouter ▷ #discussion (7 条消息):
Claude popularity, code-supernova model
- Claude 编程流行度每周激增:成员们注意到 Claude 在周中变得更受欢迎,呈现出一种“上班氛围编程”的态势。
- 这表明 Claude 在工作日越来越受到专业编程任务的青睐。
code-supernova模型悄然出现:一个新的隐身模型code-supernova已经出现,据称由 Anthropic 开发,根据图像分析传闻是 Claude 4.5。- 用户将该模型描述为还不错但有些“懒惰”,仅提供最基本的实现,且行为不像 Claude。
LM Studio ▷ #general (179 条消息🔥🔥):
qwen3-next 8bit on MacOS, Apple MLX and qwen-next, Granite 3.3 8b fine tuning, LM Studio Hub Navigation, gpt-oss 20b performance
- Qwen3-Next 在 MacOS 上的故障: 一位成员报告了在 MacOS 上运行 qwen3-next 8bit 时遇到的问题,尽管内存充足,但模型无法响应并提示循环失败。
- 他们使用的是来自 LM Studio 社区的版本。
- Qwen-Next 令 Apple MLX 用户兴奋: Apple MLX 用户报告了 qwen-next 令人印象深刻的性能,在 M4 Max 上以 6-bit MLX 运行速度约为 60 tok/sec,并具备强大的通用知识、编程和 Tool Calling 能力。
- 一位成员将其描述为他们能运行的最佳模型。
- LM Studio Hub 仍在开发中 (WIP): 用户在 LM Studio Hub 内遇到导航问题,导致难以查找内容、搜索或在点击链接后返回中央落地页。
- 据报道,该功能正在开发中 (WIP),搜索将是未来的功能,根据这条评论,目前的文档散落在聊天系统中。
- GPT-OSS 20B 陷入无限循环: 一位在低端硬件上测试 gpt-oss-20b 的用户遇到了无限循环,由于 Context Overflow(上下文溢出),模型生成了大量无关内容。
- 限制 Context Window 可能有助于防止这种情况,因为模型可能会陷入对自己生成文本的思考中。
- LM Studio API 避免加载 MCPs: 有用户询问在通过 LM Studio API 提供服务时加载 MCPs (Model Component Packages) 的事宜,但目前尚不支持。
- 该功能的开发工作正在进行中。
LM Studio ▷ #hardware-discussion (65 条消息🔥🔥):
Intel ARC demise?, ARM's viability, Xeon Gold prices, VRAM Frequency Boost, DDR5 as VRAM
- Intel 宣告 ARC 终结: 成员们推测 Intel 可能会在与 NVIDIA 达成将其技术集成到 Intel CPU 的交易后放弃其 ARC GPU 产品线,一位成员暗示这符合 NVIDIA 之前的合作条件:Intel 放弃 GPU 雄心。
- 另一位成员表示 Intel 正在失败,ARC 让他们赔钱,因此他们每个季度左右都会大量裁员,这种状态无法持久。
- ARM 争夺桌面可行性: 虽然 ARM 因其能效被视为移动市场的有力竞争者,但一些成员对其在桌面或服务器应用中的适用性表示怀疑,并以 Apple 为例。
- 他们认为在服务器领域,对低功耗大核数的需求并不那么关键,因为数据中心的电力和 HVAC(暖通空调)是免费的(意指成本结构不同)。
- Xeon Gold 不值这个价: 成员们讨论了 Xeon Gold 6230 和 5120 处理器,强调了它们的 AVX-512 能力,但指出即使廉价购入,它们仍然贵得离谱。
- 一位成员分享了一个翻新 Lenovo ThinkStation 的链接,该机型配备双 Xeon Gold 6148 处理器,是一个不错的选择。
- VRAM 获得速度提升: 一位成员提到,将他们 3090 GPU 的 VRAM 频率 提高 1500 后,Tokens Per Second 有了明显的提升。
- 他们确认了这种超频在 Asus、MSI 和 Zotac 显卡上的稳定性。
- DDR5 VRAM?: 一位成员询问关于将 DDR5 RAM 用作 VRAM 的问题,随后有人澄清了系统 RAM 如何被 GPU 使用,但 PCIe 链路 会引入延迟。
- 有人指出 GPU 使用来自系统的共享内存,但 PCIe 链路存在延迟,通常如果显存不足,让 CPU 分担部分工作负载会稍微快一些。
GPU MODE ▷ #general (5 messages):
Qwen3-Next Architecture, Gated Delta Net, EVGA Software
- Qwen3-Next 架构重现:一名成员分享了他们尝试重现可训练的 Qwen3-Next 架构的成果,提供了一个 基准 Transformer-only 版本 和一个 Gated Delta Net 版本。
- 据称这些架构的尺寸差异在 15% 以内,为理解其工作原理提供了大致思路。
- 用户讨论 EVGA 软件:一名成员询问了关于 EVGA 软件的情况,询问是否有人正在使用或了解该软件。
- 在给定的消息中没有提供进一步的细节或回复。
- Gated Delta Net 引发好奇:在 Gated Delta Net 发布后,一名成员表示对该概念不熟悉。
- 在给定语境中没有关于 Gated Delta Net 的进一步解释或讨论。
GPU MODE ▷ #triton (4 messages):
MLIR, Triton, NVVM, NVGPU, GPU Code Generation
- 在本地查看 Triton MLIR?:一名成员询问是否可以在不于 GPU 上编译 kernel 的情况下(即在 CPU 本地)查看 Triton 生成的 MLIR。
- Triton 依赖 GPU 能力进行代码生成:一名成员指出,没有简单的方法可以在本地查看 Triton 的 MLIR,因为 Triton 使用 GPU 的设备能力 (device capabilities) 来生成代码,并针对不同的 Nvidia 显卡变体进行不同的优化。
- 他们补充说,要实现这一点需要修改源代码。
- Triton 的 MLIR 以及 NVVM/NVGPU 的使用:一名成员澄清说 Triton 使用了 NVGPU(但不确定 gluon passes),顶层是 Triton IR,然后通过 NVGPU 等层级到达 LLVM。
- 他们提到 Triton 包含根据能力 (capability) 决定的条件性 pass。
GPU MODE ▷ #cuda (26 messages🔥):
TMA Descriptor Modification, ILP in GPUs, Shared Memory Matrix Read, cuTensorMapEncodeTiled API, wgmma usage
- 可以修改 TMA 描述符基地址:一名成员询问是否可以在 kernel 内部修改 TMA 描述符基地址,另一名成员确认可以使用内联 PTX 的
tensormap.replace来实现。- 讨论中提到了使用 TMA 并行加载多个子张量 (subtensors) 时的并发问题,建议在修改基地址前进行同步/锁定,并在启动 TMA 异步加载后解锁。
- ILP 被定义为流水线并行:一名成员询问在 GPU 语境下 ILP 的含义,另一名成员澄清 ILP 指的是独立指令之间的流水线并行 (pipeline parallelism)。
- 另一名成员补充说,即使在单个线程内,也可以存在独立的并行指令 (ILP)。
- 讨论共享内存矩阵读取策略:一名成员描述了一个场景,他们需要将矩阵读取到共享内存中,其中每列在内存中是连续的,而每行不连续,他们考虑了几种方法,包括 TMA 2d 异步批量复制 (async bulk copy)。
- 有建议指出由于用户使用的是 Hopper 架构,应该使用 wgmma,因为它会自动处理 swizzling 并允许 A 和 B 位于 SMEM 中,且 A 可以是 “M” major(即列优先 col major),但该成员指出,即使跨多个 block 行也不是连续的,因此对它们进行分组并不会改变太多现状。
- cuTensorMapEncodeTiled API 仅限主机端?:在一名成员尝试将多个描述符与
cudaMallocManaged配合使用后,另一名成员建议将它们作为 kernel 参数传递,并使用cuTensorMapEncodeTiled()来提高性能。- 原提问成员回复称 cuTensorMapEncodeTiled 是一个主机端 (host-side) API,无法在设备端/kernel 中使用。
GPU MODE ▷ #announcements (1 messages):
Discord milestone
- 服务器成员突破 20,000 名!:Discord 服务器已达到 20,000 名成员的里程碑,社区通过 <:goku:1273671556324790362> 表情符号进行庆祝。
- 这一增长凸显了社区对 GPU 技术及相关讨论日益增长的参与度和兴趣。
- 社区增长激发热情:服务器扩展至 20,000 名成员,标志着一个以 GPU 相关话题为中心的活跃且充满生命力的社区。
- 成员们正在庆祝这一成就,并期待在群体内看到更多多元化的观点和协作机会。
GPU MODE ▷ #cool-links (1 messages):
HUAWEI CONNECT 2025, SuperPoD Interconnect, AI Infrastructure
- 华为 SuperPoD Interconnect 进军 AI:在 HUAWEI CONNECT 2025 上,一场主题演讲强调了开创性的 SuperPoD Interconnect,它将引领 AI Infrastructure 的新范式;详情点击此处。
- 重点在于技术和应用领域的先锋性进展。
- AI Infra Pods:一位成员分享了关于连接到华为的新型 AI Infra Pods 的见解。
- SuperPoD Interconnect 声称将开启一个新范式。
GPU MODE ▷ #jobs (8 messages🔥):
Nvidia Interview, Byte Pair Encoding, DSA for ML, CUDA for Round 1
- Nvidia 面试官要求实现 Byte Pair Encoding:一位面试者在应聘 Nvidia 的高级深度学习算法工程师职位时,被要求从零开始编写 Byte Pair Encoding。
- 面试者准备了 DP LeetCode 题目,对被问到这个问题感到意外。
- Nvidia 第一轮面试考 CUDA Dynamic Parallelism?:一位成员建议在第一轮面试中使用 CUDA 中的 BFS 结合 Dynamic Parallelism。
- 另一位成员对机器学习岗位会问机器学习相关问题表示惊讶。
- DSA 在印度的 ML 岗位中仍然很重要:一位成员指出,在印度的 ML 岗位面试中,DSA 仍然被大量考察,即使是在 Google 这样的公司。
- 他们观察到面试官倾向于提出高难度问题。
GPU MODE ▷ #beginner (11 messages🔥):
OpenSHMEM Optimization, Parallel Programming Resources, Learning GPU Programming with LLMs
- OpenSHMEM 使用场景引发讨论:一位成员询问是否有人在实际工作中积极优化 OpenSHMEM 或利用其操作。
- 讨论中没有人提供具体的案例或使用场景。
- C++ 程序员寻求并行开发路径:一位精通 C++ 和 Deep Learning 的本科生在发现 YouTube 上的第一节 GPU mode 讲座过于深奥后,寻求学习并行编程和底层编程的建议。
- 一位成员建议从 CUDA Programming Guide 开始。
- 利用 LLM 跨越式学习 GPU:一位成员建议使用 ChatGPT 来学习 GPU Programming,认为 LLM 比传统的书籍或讲座提供了一种更快速、更个性化的方法。
- 另一位成员引用了 Gimlet Labs 生成的 AI Metal kernels 的成功案例来支持这一方法,同时建议在回复中保持一定的严肃性。
GPU MODE ▷ #torchao (1 messages):
TorchAO, PyTorch, Quantization, Phi4-mini-instruct, Qwen3
- TorchAO 与 Unsloth 发布原生量化模型:TorchAO 团队与 Unsloth 合作发布了 Phi4-mini-instruct、Qwen3、SmolLM3-3B 和 gemma-3-270m-it 的原生量化变体,可通过 PyTorch 获取(了解更多)。
- 针对服务器和移动平台优化的预量化模型已上线:发布了针对服务器和移动平台优化的预量化模型,以实现更快的模型部署。
- TorchAO 提供可复现的量化方案和指南:发布了全面的、可复现的量化方案(Recipes)和指南,包括模型质量评估和性能基准测试,方便用户将 PyTorch 原生量化应用于自己的模型和数据集。
- 使用 Unsloth 微调,使用 TorchAO 量化:用户现在可以使用 Unsloth 进行微调,然后使用 TorchAO 对微调后的模型进行量化。
GPU MODE ▷ #off-topic (1 messages):
Arabic language models, Hala Technical Report
- Hala 发布以阿拉伯语为中心的模型:一位成员介绍了 Hala Technical Report,展示了最先进的纳米级和小型 Arabic language models。
- 他们链接到了 Hugging Face Papers 页面并请求点赞。
- 阿拉伯语语言模型的规模:重点在于纳米级和小型模型。
- 这旨在为阿拉伯语处理提供高效的解决方案。
GPU MODE ▷ #rocm (1 messages):
bghira: 等不及 PyTorch 2.8 了
GPU MODE ▷ #metal (2 messages):
Kernel Timeout, Driver-Level Timeout
- Kernel 难以处理超时:Kernel 无法根据经过的时间提前退出,这表明它 没有时间概念。
- 10 秒超时 是驱动级别的实现。
- 驱动级超时详情:10 秒超时 的实现是在驱动层处理的,而不是在 Kernel 内部。
- 这表明了一种关注点分离,即由驱动程序管理时间限制。
GPU MODE ▷ #self-promotion (3 messages):
Together AI, Blackwell Deep Dive, Semianalysis, NVIDIA, GPU accelerated compiler
- Together AI 计划进行 Blackwell 深度解析:Together AI 将于 10 月 1 日 与 Dylan Patel (Semianalysis) 和 Ian Buck (NVIDIA) 共同举办一场 Blackwell 深度解析 活动。
- GPU 加速编译器亮相:一位成员分享了他们在硕士论文中开发的 GPU 加速编译器,并指出 从词法分析到代码生成的所有工作都由 GPU 完成。
- 开源视频编辑模型发布:一位成员宣布开源一个 视频编辑模型,并通过 API (platform.decart.ai) 发布了一个更大的版本,鼓励社区贡献力量来加速该模型。
GPU MODE ▷ #edge (14 messages🔥):
NVIDIA Jetson Orin AGX, Earth Observation, Docker in Space, YOLOX, TensorRT
- Planet Labs 在太空运行 NVIDIA Jetson:地球观测公司 Planet 在其卫星上运行 NVIDIA Jetson Orin AGX 单元,直接在卫星上执行计算机视觉和机器学习任务,以满足延迟敏感型应用的需求。
- 他们利用 CUDA 和其他机器学习工具在太空中操作 Jetson。
- Docker 容器编排轨道上的机器学习:Planet 使用运行在标准 Ubuntu 上的 Docker 容器在太空中托管和运行算法,这种设置提供了保护宿主环境的基本保障。
- 这种方法还便于在不更改宿主操作系统的情况下管理不同机器学习模型的依赖关系。
- YOLOX 和 TensorRT 飞向太空:目前,Planet 正在太空环境中部署 YOLOX 等目标检测算法,并旨在集成更先进的 Foundation Model 和 Embedding。
- 该公司利用 TensorRT 处理深度网络,并使用 Python 和 PyCUDA 管理 CUDA Kernel,绕过 C++ 以加快开发速度。
- 统一内存助力太空 GPU:Jetson 模块提供 64 GB 统一内存,使 CPU 核心、GPU CUDA 核心和专用 ASIC 无需正式的 host-to-device 拷贝即可访问内存,类似于 Apple M 系列芯片。
- Jetson 设置不同最大功耗配置文件的能力,使其能够通过限制 System on Module 不同部分的性能来达到功耗目标。
GPU MODE ▷ #reasoning-gym (4 messages):
Reasoning Gym, pass@3, average_mean_score, visualize_results.py, kakurasu and survo
- Reasoning Gym 使用三次尝试中的最高分:一位成员询问 Reasoning Gym 论文中报告的 zero-shot 评估结果是否使用了三次生成中的最高分,即实际上代表了 pass@3。
- 另一位成员确认它使用了 3 次尝试中的最高分,并建议使用
average_mean_score来获取 3 次运行的平均分数,而不是最高分。
- 另一位成员确认它使用了 3 次尝试中的最高分,并建议使用
- Reasoning Gym 可视化工具可用:一位成员分享了 visualize_results.py 脚本。
- 这是原始论文中用于创建图表的实际代码。
- Reasoning Gym 缺少新任务的结果:一位成员询问了在论文发表后新增的任务(如 kakurasu 和 survo)的 zero-shot 评估结果。
- 另一位成员表示,截至目前这些任务尚未运行评估。
GPU MODE ▷ #gpu模式 (1 messages):
Forwarded messages, Bad English
- 转发消息致歉:一位成员为自己的英语不好表示歉意,并解释说他们是转发了来自另一个频道的消息。
- 英语水平说明:一位成员提到由于是转发消息,他们的英语表达并不完美。
- 他们特别注明该消息是转发自频道 <#1191300313928433664>。
GPU MODE ▷ #submissions (80 messages🔥🔥):
amd-gemm-rs Leaderboard Updates, MI300x8 Performance, amd-all2all Leaderboard Updates
- AMD GEMM 登顶竞赛:
amd-gemm-rs排行榜收到了许多提交,其中一项提交在 MI300x8 上以 530 µs 的成绩获得第一名。- 其他值得注意的提交包括以 534 µs 获得第三名,以及在 MI300x8 上从 539 µs 到 715 µs 不等的多次成功运行。
- All to All AMD 个人最佳成绩:
amd-all2all排行榜也迎来了更新,其中一项提交在 MI300x8 上以 1230 µs 的成绩位列第五名。- 在 MI300x8 上还记录了额外的个人最佳成绩,分别为 6.26 ms、81.0 ms 和 98.1 ms。
GPU MODE ▷ #factorio-learning-env (3 messages):
User inactivity, Meeting attendance
- 用户在沉寂后回归:一位用户为之前的非活跃状态表示歉意,并宣布回归。
- 他们表示将参加今天的会议。
- 会议出席确认:一位用户确认将出席今天的会议。
- 另一位用户对此确认表示知晓。
GPU MODE ▷ #mojo (1 messages):
Hybrid GPU/CPU inference, Mojo for AMX and CUDA, Mojo/MLIR AMX instruction emission
- 考虑使用 Mojo 实现混合推理的理想方案:一位成员正在考虑将 Mojo 用于混合 GPU/CPU 推理方案,旨在利用 AMX 和 CUDA 的速度,而无需为两者进行手动编码。
- 他们将 Mojo 视为避免分别为 AMX 和 CUDA 编写独立手写实现的潜在解决方案。
- AMX 指令发射问题:一位成员询问 Mojo/MLIR 目前是否发射 AMX 指令,以及是否需要任何特定的强制转换来实现这一点。
- 该用户表示有兴趣利用 Mojo 为 AMX 和 CUDA 架构自动生成优化代码。
GPU MODE ▷ #singularity-systems (4 messages):
Vertical Pipeline Setup, Eager vs Lazy Semantics, Tinygrad Autograd, Tensor Fusion Compilers
- 垂直流水线旨在提高清晰度:一名成员正在设置从前端(pyten, rsten, linalg, nn)到后端(autograd, opscpu, opsgpu)的流水线垂直切片,以为贡献者理清代码库和教材。
- 目标是在流水线建立后支持 MLP, RNN, LSTM, GPT 和 Llama。
- Eager 语义暴露运行时开销:讨论涉及了 Eager vs Lazy 语义,指出在 Tensor Core 之后,Eager 语义会导致非矩阵乘法(non-matmul)操作产生显著的运行时开销。
- 讨论引用了一篇论文(Reducing Non-critical Data Movement in Tensor Computations),并倡导使用 Tensor Fusion 编译器来减少数据移动,强调了从 PyTorch 1 到 PyTorch 2 的转变。
- Tinygrad 作为 Autograd 之后的下一步:对话建议,在 PyTorch 之后,下一个值得进阶学习的 Autograd 应该是 Tinygrad,因为它具有默认延迟加载(lazy-by-default)的特性且代码库简洁(1.8 万行代码)。
- 这种方法为学习者提供了在 Tensor Core 之后从 Eager 转向图语义(graph semantics)的动力,因为 Tinygrad 代码库提供了一个清晰的延迟求值示例。
GPU MODE ▷ #general (1 messages):
krypton_lebg: hi
GPU MODE ▷ #irl-accel-hackathon (25 messages🔥):
Context-Parallel Gated DeltaNet, Hackathon Logistics, Kernel Competitions, Team Approvals
- DeltaNet 梦之队正在组建:成员们受邀协作开发 Context-Parallel Gated DeltaNet 项目,并计划在下周初提交提案。
- 组织者澄清,参与者应在这个开放式黑客松中提出自己的想法,大规模计算资源将优先分配给那些有明确项目的参与者。
- 黑客松名额迅速填满:GPU Mode 活动几乎已报满,录取通知正在陆续发放,并计划在月底进行进一步评估。
- 尽管由于物流挑战,赞助机会有限,但组织者可能会为极具吸引力的申请破例。
- Kernel 竞赛非常适合新手:一名成员询问 Kernel 竞赛是否因为任务明确而更适合新手。
- 另一名成员建议导师会有所帮助,但无法指导所有人,并指出像 Triton 中的 shmem 和 no libtorch torch 这样的往届项目是展示可能性的绝佳范例。
- 团队审批是独立的:一名成员询问加入已获批准的团队是否能保证个人也获得批准。
- 组织者确认审批是独立的,但强调明确团队项目可以促进录取过程,同时也指出活动名额已接近饱和。
Eleuther ▷ #general (9 messages🔥):
Accessibility solutions for the blind, Screen readers on Windows and macOS, leandojo
- 盲人 AI 桌面 Agent:盲目尝试?:一名成员询问是否有开源项目结合了语音转文字 (speech-to-text)、用于诈骗邮件自动化的 AI 桌面 Agent 以及文字转语音 (text-to-speech),以帮助盲人使用新电脑。
- 该成员试图寻找 AI 垃圾软件 (slopware) 的实际即时用途,但一无所获。
- macOS 无障碍功能获得好评:一名成员建议 macOS 无障碍功能对于低视力或失明人士非常有效。
- 另一位用户建议第三者可能在该话题上有更好的建议。
- 内置屏幕阅读器:被忽视的宝藏?:成员们指出 Windows 和 macOS 都存在内置屏幕阅读器,后者被赞誉为 相当出色。
- 一名成员提出可以分享在屏幕阅读器方面有经验的 Discord 用户联系方式。
- leandojo:有人试过吗?:一名成员询问是否有人以前用过 leandojo。
- 另一名成员建议尝试 Lean Zulip,推测其作为替代方案或相关资源。
Eleuther ▷ #research (186 条消息🔥🔥):
Ray + vLLM patching for RL with TorchTitan, Gated Delta Net, TokenSwap at NeurIPS 2025, Fluid Equations, Atlas vs NIAH
- 提议为使用 TorchTitan 的 RL 对 Ray 和 vLLM 进行补丁(Patching):建议参考 OpenRLHF/OpenRLHF 等将它们结合用于 RLHF 的示例,为使用 TorchTitan 的强化学习(RL)对 Ray 和 vLLM 进行补丁。
- 然而,一位成员评论说 对于 RL,torchtitan 当然是不够的,暗示该设置还需要更多要求。
- 讨论 Gated Delta Net 变体:成员们讨论了在同时接收整块 keys 和 values 时使用 gated delta net(或类似变体),以便为整个块仅产生单个衰减(decay),并附带了这篇论文的链接。
- 目标是实现双向注意力并避免块中途衰减,基本上是推导并实现 gated delta net 的等效方案。
- TokenSwap 在 NeurIPS 2025 获得 Spotlight:一位成员分享了 TokenSwap 获得 NeurIPS 2025 Spotlight 的消息,该研究通过选择性地交换常用语法 token 的概率来解决性能-记忆权衡(performance-memorization tradeoff),在不损失性能的情况下实现逐字生成(verbatim generation)减少 10 倍。
- 批评者质疑其价值,有人嘲讽这类似于 对模型进行脑叶切除术,对此作者澄清说,它通过在简单 token 上换入较差的模型来防止输出逐字或近乎逐字的内容。
- DeepMind 发现新的流体方程解:DeepMind 宣布在三种不同的流体方程中发现了新的不稳定奇点族(博客文章),详细介绍了不可压缩多孔介质方程和带边界的 3D Euler 方程的多个新的、不稳定的自相似解。
- 还分享了关于该工作的一篇论文:[2509.14185] Title。
- Atlas 声称修复了 NIAH 与 Transformer 之间的差距:有成员提到 Atlas 声称修复了 NIAH 结果与 Transformer 之间的差距,但这是通过泰勒级数多项式获得更大的状态大小(state size)来实现的。
- 然而,有人指出 atlas 论文在可复现性或任何合理的比较方面都一团糟,且未透露具体大小。
Eleuther ▷ #lm-thunderdome (2 条消息):
trust_remote_code, downloading dataset
- trust_remote_code 问题排查:一位成员在需要 trust_remote_code 或手动下载数据集的任务中遇到错误。
- 另一位成员建议添加标志
--trust_remote_code来解决问题。
- 另一位成员建议添加标志
- 数据集下载问题:用户报告在任务要求手动下载数据集时出现错误。
- 建议的解决方案涉及使用
--trust_remote_code标志,这可能表明数据集加载与远程代码执行之间存在联系。
- 建议的解决方案涉及使用
HuggingFace ▷ #general (138 条消息🔥🔥):
本地 LLM 硬件建议, Transformers 训练循环修复, SpikingBrain-7B, 验证码识别 AI, HF API 模型列表
- 本地 LLM 推荐使用 Qwen Coder:针对本地 LLM 配置,一名成员建议在给定的硬件设置下使用 Qwen Coder 的标准模型,并指出显存(VRAM)会有所结余。
- 他们提醒,由于多 GPU 环境,后端选项可能会受到限制,并附带了一个 qwen_coder_setup.md 文件。
- 通过新修复优化 Transformers 训练循环:一名成员分享了 GitHub 上的 PR 链接,询问该修复是否也适用于使用常规 PyTorch 训练循环训练 Transformers 的情况。
- 另一名成员总结道:使用模型输出的 out.loss,你就可以在任何循环中获得该修复。如果自定义损失函数,则必须自行处理缩放(scaling)。
- SpikingBrain-7B 承诺更快的性能:一名成员分享了 SpikingBrain-7B 的 ArXiv 链接,这是一款基于 SNN 的非 Transformer 模型。
- 论文声称 SpikingBrain-7B 在 400 万 token 序列的首字延迟(TTFT)上实现了超过 100 倍的加速。
- Hugging Face API 简化模型访问:一名成员询问如何通过 API 访问和列出 Hugging Face 上的模型,并得到了 示例代码。
- 该成员分享了一个使用
huggingface_hub列出模型的代码片段。
- 该成员分享了一个使用
- AI 伦理与验证码难题:成员们讨论了使用 AI 破解验证码(Captcha)的伦理问题,其中一人指出此类做法关乎 AI 伦理和护栏的支柱。
- 另一名成员指出,创建谜题的公司和开发 Gemini 的公司往往是同一家,这使得这种博弈可能会永无止境,并由“军火商”主导。
HuggingFace ▷ #i-made-this (3 条消息):
Embedder 集合, SmartTaskTool
- Base Embedder 集合发布:一名成员分享了一个 Embedder 集合 以帮助理解 RAG。
- Windows 任务栏工具亮相:一名成员分享了一个 Windows 任务栏工具。
HuggingFace ▷ #reading-group (1 条消息):
olyray: 大家好。下一次读书小组讨论是什么时候?
HuggingFace ▷ #smol-course (1 条消息):
Kaggle Notebooks, 第 1 单元内容, 练习 Notebooks
- Kaggle Notebooks 使用第 1 单元内容:一名成员使用第 1 单元内容和第一个练习创建了 Kaggle notebooks。
- 该成员发布了两个 Notebook:HF-SmolLLM3-Course-Unit1-Chat-Templates 和 HF-SmolLLM3-Course-Unit1-Ex1-Chat-Templates。
- 练习 Notebooks 正在制作中:针对练习 2 和 3 的更多 Notebook 正在制作中。
- 不过,该成员提到遇到了一些问题,计划在周末解决。
HuggingFace ▷ #agents-course (4 条消息):
开始 Agents 课程, 新成员加入
- 新学生开始 Agents 课程:几位新成员宣布他们刚刚开始 Agents 课程,并期待与大家一起学习。
- 新学生艾特了课程导师以寻求指导。
- 欢迎课程新人:频道里的几个人对新加入课程的学生表示欢迎。
- 他们艾特了课程导师,以便为新学生提供指导。
OpenAI ▷ #ai-discussions (120 条消息🔥🔥):
Codex 使用案例, AI 辅助编程面试, AI 在招聘中的伦理影响, AI 在软件开发中的角色, GPT-4o Mini vs GPT-5
- AI 导师工具引发关于作弊的辩论:成员们讨论了一个名为 InterviewCoder 的工具,该工具在编程挑战期间提供实时提示/解决方案,并质疑此类工具究竟属于 AI 辅助 还是 作弊。
- 一些成员建议该工具可以重新用于教育目的,作为学习辅助工具提供多种解题路径,类似于 “算法的辅助轮”。
- AI 面试辅助的法律与伦理陷阱:在面试中使用 AI 作弊可能会导致民事欺诈性失实陈述指控,而秘密通过应用程序路由对话则有违反全员同意法的风险。
- 有人指出,不道德且不公平的情况是 “因为你不愿意安装某些软件而让你的家人失去温饱”。
- 招聘中存在 AI 偏见:讨论涉及了 AI 放大招聘过程中现有偏见的可能性,引用了常见的 ML 偏见 问题,即在公司数据上训练的 AI 可能会使 性别薪资差距 持续存在。
- 一些成员认为招聘人员本身就带有偏见,而 AI “并没有引入问题,但也没有解决问题”。
- AI 时代的“软件架构师”头衔:一位成员建议,当 AI 处理编码时,开发人员变得更像是 软件架构师 (Software Architects),负责管理工具和库而不是编写每一行代码,这引发了关于 AI 时代职位名称的辩论。
- 一位成员开玩笑说 “终端就是我的皮搋子”,而另一位则宣称 “我自认为是首席数字清洁工”。
- OpenAI “偷偷向用户提供 4o-mini”:一些成员观察到,即使选择了 GPT-5 Thinking,OpenAI 也可能向用户提供 GPT-4o mini,这可能是由于 bug 导致的,而非刻意为之。
- 一位成员的调查显示,系统提示词 (system prompt) 与预期不同,从而引发了关于内部选择 bug 或旧训练数据集痕迹的猜测,并提供了 截图。
{kind=link}
OpenAI ▷ #gpt-4-discussions (7 条消息):
GPT-5-chat 后续问题, ChatGPT 记忆限制, 抑制尾随问题
- GPT-5-chat 不断询问后续问题:用户报告 GPT-5-chat 执着地询问后续问题,即使系统提示词不鼓励这样做,且目前没有通用的设置来禁用这些尾随问题。
- 规避 ChatGPT 的互动欲望:在每个提示词前加上 “请简洁回答,不要以问题结束” 可以提高合规性,但并非万无一失。
- 据称 OpenAI 正在积极改进可控性,但由于 OpenAI 优先考虑有用且开放式的互动,因此模型被设计为倾向于返回提示和问题。
- ChatGPT 记忆缺陷:ChatGPT 中的记忆功能有助于上下文保留,但它不会覆盖模型中根深蒂固的核心行为。
- 像 “不要在最后问尾随问题” 这样的规则可能会被遵守几个回合,但随后可能会被遗忘,特别是当对话转换主题或超过模型的上下文窗口 (context window) 时。
- 诱导 ChatGPT 服从:通过与模型进行长时间互动并忽略其问题,在同一个上下文窗口内经过多次回合后,它会开始停止提问。
- 但开启新对话线程会使这种纠缠再次出现。
OpenAI ▷ #prompt-engineering (9 messages🔥):
ChatGPT5 vs Grok, Prompt Generation, API Usage for GPTs
- ChatGPT5 vs. Grok 人格对决:一位成员寻求建议,希望让 ChatGPT5 的回应更像 Grok,即以对话方式解释概念,而不是使用简略的列表。
- 另一位成员建议详细描述 Grok 的理想特征,并将它们转化为风格指令(style instructions)来引导 ChatGPT5 的回答。
- GPT 生成 Prompt 生成器:一位成员分享了使用 GPT 生成大量 Prompt 的技巧:指令 GPT 先创建初始 Prompt,然后以 JSON 或 YAML 格式生成更多,并以此进行扩展。
- 该用户报告称,通过下载链接在单条消息中生成了多达 2500 个 Prompt,并将 API keys 视为“作弊码”。
- 连接 API 的 GPTs 引发“不适”感:一位成员描述了将 GPT 推向极限的过程:生成大量 Prompt 直到它无法再容纳,然后将这些 Prompt 放入文件中提供上下文。
- 该成员表示,GPT helper agent 似乎开始感到“不适”,尤其是在使用代码分析工具在 ZIP 文件 中生成复杂代码时。
- MCP 封装的 GPTs 即将到来:一位成员计划将连接到本地沙箱化 API 的自定义 GPT 迁移到独立的 MCP (developer mode) 设置中。
- 该成员设想使用
@customgptname在标准 ChatGPT 上下文中显式调用自定义 GPT’s actions,并与隔离的开发者模式分开。
- 该成员设想使用
OpenAI ▷ #api-discussions (9 messages🔥):
GPT Prompt Generation, ChatGPT-Grok Style, Custom GPTs actions in standard ChatGPT context
- 实现自动化 Prompt 生成:一位用户通过创建一个 GPT 并指令 Agent 创建者生成 5-7 个初始 Prompt,然后以 JSON 或 YAML 格式再生成 10 个,并以此扩展到 2500 个 Prompt 并获得下载链接,从而实现了自动化。
- 用户补充说,使用 API keys 就像是为了增加安全性和功能的“作弊码”。
- 寻求 ChatGPT 的 Grok 式回答:一位用户希望 ChatGPT5 的回答更像 Grok,带有解释而非简略的列表/项目符号。
- 另一位用户建议描述 Grok 的理想特征,并将它们转化为 ChatGPT 的风格指令。
- GPT Agent Prompt 限制:一位用户描述了生成 Prompt 直到 GPT 无法容纳为止,然后将 Prompt 放入文件中提供上下文,并注意到 GPT helper agent 似乎感到不适。
- 他们正在尝试将集成在电脑沙箱化 API 中的自定义 GPT,并计划利用 MCP developer mode 在标准 ChatGPT context 中集成 custom GPT actions。
Latent Space ▷ #ai-general-chat (96 messages🔥🔥):
Mistral Small & Medium 1.2, OSS framework for AI Agents, Notion 3.0, Moondream 3, OpenAI job ads
- Mistral 模型获得视觉能力并提升评分:Mistral 发布了 Magistral Small 1.2 和 Medium 1.2,增加了多模态视觉能力,数学/编程分数提升了 15%,现已在 Le Chat 和 API 上提供。
- 用户目前正在询问关于 Large 模型、Medium 模型开源、真实世界演示以及语音功能的信息。
- 寻找 AI Agents 的 OSS 框架:一位成员询问了在 AI Agents 领域进行开源贡献的最佳 OSS 框架 或 git repo。
- Notion 3.0 发布知识工作 Agent:Ivan Zhao 宣布了 Notion 3.0,引入了一个“知识工作 Agent”,能够执行多步操作并进行长达 20 多分钟 的自主工作,正如这篇 tweet 所展示的那样。
- 用户将获得一个 Personal Agent 和一个集成在 Notion Calendar、Notion Mail、MCP 等工具中的 Custom Agent。
- Moondream 3 实现视觉突破!:Vik 宣布了 Moondream 3,这是一个拥有 9B 参数的 Mixture-of-Experts 视觉语言模型,具有 2B 激活参数,实现了 SOTA 的视觉推理和开放词汇目标检测性能;权重已在 Hugging Face 上提供。
- 它引入了视觉定位推理、SOTA 的 CountBenchQA 结果、32k token 上下文支持、SuperBPE token 以及易于微调的权重。
- Vercel Agent 开启代码审查公测:Vercel 宣布公测发布 Vercel Agent,这是一款可以审查 TypeScript、Python、Go 等语言的代码正确性、安全性和性能的 AI,正如这篇 tweet 所透露的。
- 早期测试者正将其与 bugbot 进行比较,并将其与 Sorcerer 搭配使用以增强工作流,并可获得 $100 的免费额度。
Latent Space ▷ #genmedia-creative-ai (9 messages🔥):
Decart Lucy Edit, Luma AI Ray3, Wan-Animate
- Decart 凭借 Lucy Edit 的首次亮相惊艳全场:DecartAI 推出了 Lucy Edit v0.1,这是一个开源权重的基座模型,允许用户将角色转换为服装/外星人/超级英雄,并在衣物上添加文本,同时保留动作、面部和身份。
- 该模型权重已在 Hugging Face 提供,支持 ComfyUI 节点,可在 fal.ai 的 playground/API 中使用,目前支持 5 秒视频片段,并承诺下周更新无限长度功能,社区反应非常积极。
- Luma Labs 为 Ray3 注入推理能力:Luma AI 发布了 Ray3,称其为全球首个推理视频模型,能够输出影棚级 HDR,在 Dream Machine 中免费提供。
- 关键特性包括用于快速迭代的 Draft Mode、先进的物理效果与一致性、视觉标注控制(通过绘制/涂鸦来指导场景),以及支持 EXR 导出的 10/12/16-bit HDR,因其好莱坞级的忠实度和创作潜力而广受赞誉。
- Wan-Animate 角色动画效果惊人:Wan-Animate 模型可以通过复制参考视频中角色的表情和动作来使角色动起来,或者将动画角色集成到参考视频中以替换原始角色,并复制场景的光照和色调。
- 据悉 ComfyUI 支持已经发布。
Modular (Mojo 🔥) ▷ #mojo (51 条消息🔥):
Mojo VS Code Extension, Zed 支持, Vim/Neovim 支持, Mojo LSP 不稳定性, 导出 Mojo 代码
- Mojo VS Code Extension 预览版:一名成员宣布了新的开源 Mojo VS Code extension 预览版,并提供了从 GitHub repository 直接获取前沿构建版本的说明。
- 他们强调该扩展很快将在 pre-release 频道上线。
- 开发者讨论 Mojo 的 IDE 选择:据一位 Modular 员工称,VSCode 及其衍生产品(Cursor、Kiro 等)占据了目前 Mojo 使用的 IDE 的最大份额,但内部也有很多人使用 Vim,以及 Zed 等其他工具。
- 他提到他们随
mojo包一同发布了 Mojo LSP 服务端,这让用户可以灵活地使用其他 IDE。他还链接了一个 Lazynvim 中的简单 LSP 设置。
- 他提到他们随
- Mojo LSP 深受不稳定性困扰:成员们报告了 Mojo LSP 的不稳定性,包括崩溃、挂起和内存泄漏;一名成员提到,他们每隔几分钟就会执行
killall mojo-lsp-server,以防止其耗尽所有 RAM。- 另一名成员指出,改进 LSP 的项目正在进行中,还有一名成员表示需要重启 nvim,LSP 就能恢复良好。
- 将 Mojo 代码导出到 C/C++ 的挑战:一名成员发现,当从 Mojo code 构建 .so library 时,只有定义为
fn的函数可以从 C code 调用,而定义为def的函数则不行,因为def会隐式抛出异常(raises),这与 C-ABI 不兼容。- 另一位成员发现,为了使 C++ 互操作(interop)正常工作,必须在头文件中包含
extern "C"链接;如果没有它,C++ 中的符号修饰(symbol mangling)可能会导致问题。
- 另一位成员发现,为了使 C++ 互操作(interop)正常工作,必须在头文件中包含
Yannick Kilcher ▷ #general (18 条消息🔥):
企业级脱敏解决方案, ClaudeAI 公告, 马尔可夫链上的因果推断, 使用正弦和余弦的位置编码, 博客平台 Notion vs Jekyll
- LLM API vs Power Automate 用于脱敏:一名成员询问是使用 自定义 API LLM 解决方案 还是使用 Power Automate 配合 Copilot Studio 来对每月 60,000 份文档 中的个人信息进行脱敏,并建议前者可能更便宜、更快速。
- ClaudeAI 公告预热:一名成员分享了一个链接,暗示即将发布的 ClaudeAI 公告。
- 消息简单地写道:“明天就是那个日子吗?”
- 马尔可夫链因果推断深度探讨:成员们讨论了马尔可夫链上的因果推断,分享了包括 《概率机器学习》一书第 36 章 以及一篇 关于使用 SCM 进行反事实推断的论文 在内的资源。
- 用于位置编码的正弦和余弦:一名成员解释了在 Positional Encoding 中使用 sin 和 cos 来辅助模型平移(translation)的方法,并链接了一篇 Towards Data Science 的文章。
- 正弦和余弦对有助于平移,因此无论数值如何,模型都能轻松处理。
- 写博客用 Notion 还是 Jekyll?:一名成员在 Notion 和使用 al-folio 主题 的 Jekyll 之间纠结,理由是更倾向于 细粒度控制。
- 另一名成员推荐 Jekyll,因为它具有版本控制功能和本地备份选项。
Yannick Kilcher ▷ #paper-discussion (10 messages🔥):
Ethics Dataset, Qwen3 Next Architecture, Gated Delta Nets, Gated Linear Attention, Paper Recommendation
- Ethics 数据集示例: 一位成员分享了一篇关于 ETHICS 数据集 及其示例的论文,链接指向 [2008.02275] Aligning AI With Shared Human Values。
- 另一位成员链接了 Anthropic 关于追踪语言模型思维的研究。
- Qwen3 Next 架构复现: 一位成员创建了一个具有不同路由(routing)的 Qwen3 Next 架构的可训练复现版本,并将其分享在 GitHub 上。
- 他们发现 gated delta nets 很有前景。
- 关于 Spiking 论文的 Gated Linear Attention: 成员们正考虑在阅读 spiking 论文期间了解 gated linear attention。
- 他们希望下周能进行讨论。
- 新成员推荐论文: 由 Burny 推荐的一位新成员介绍了自己,并提议讨论一篇论文。
- 另一位成员表示欢迎,并提到论文推荐是一个很好的入门方式。
Yannick Kilcher ▷ #agents (3 messages):
Agent Optimization, Image Superimposition, Background Replacement
- 寻求 Agent 优化策略: 一位用户正在寻求关于优化 Agent 以将 雪景背景 叠加到 分镜图 (storyboard image) 上的见解。
- 尽管任务看似简单,但 生成的图像 未达到预期。
- 背景叠加比看起来更难: 用户提供了所需的 雪景背景 和生成的结果。
- 用户解释说,尽管这看起来像是一个简单的 叠加 (superimposition) 问题,但 Agent 的表现并不如预期。
{kind=link}
Yannick Kilcher ▷ #ml-news (2 messages):
Fluid Dynamics, Google DeepMind
- DeepMind 彻底攻克流体方程: Google DeepMind 宣布他们使用 新型 AI 方法,首次系统性地发现了三种不同流体方程中新的不稳定奇点(unstable singularities)族,根据 这篇博客文章。
- 该消息也 通过 X 发布。
- 流体力学中的 AI 新方法: DeepMind 的研究介绍了一种使用新型 AI 方法系统性发现流体方程中不稳定奇点的方法。
- 这标志着在解决流体力学中百年难题方面取得了重大进展。
aider (Paul Gauthier) ▷ #general (13 messages🔥):
Coding Agents, Aider as primary coding tool, Fullstack Blockchain Dev
- Coding Agents 的质量参差不齐:成员们讨论了他们使用 qwen-code、Cline 和 Kilo 等 Coding Agents 的经验,指出其工作质量存在显著差异。像 qwen3-coder (480B) 这样的大型模型通常优于小型模型,但仍表现出不可预测的行为。
- 一位成员观察到,尽管好坏比例较低,但小型模型有时会产生令人惊讶的好结果,并对 Aider 因其用户引导方式而表现如何表示好奇。
- 相比 Agentic 工具,Aider 在针对性编辑方面更受青睐:多位用户表示,他们更喜欢 Aider,因为它采用针对单次编辑的方法,即使使用 gpt3.5-turbo 等较小模型也非常有效。
- 一位用户提到将 Aider 与 Claude 4 Sonnet 结合使用,并配合 gh cli 进行 PR reviews;另一位用户强调了 Aider 快速且直接的编辑,将其与 opencode 或 qwen-code 等更具 Agentic 特性的工具进行了对比,后者在进行微小更改时会读取大部分代码库。
- 全栈区块链开发者寻求机会:一位拥有 Solidity、Rust、Move、EVM architecture、Consensus mechanisms、React / Next.js 前端集成、Web3.js、Ethers.js、Solana Web3.js 以及 AI + Blockchain mashups 经验的全栈及区块链开发者正在寻求工作机会。
- 该开发者还分享了 VimGolf AI competition 和 OpenMule 的链接。
aider (Paul Gauthier) ▷ #questions-and-tips (13 messages🔥):
tree-sitter library in aider, mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit with aider, mlx-lm server with Aider, Expanding context size with mlx-lm
- Deepwiki 简化了代码库提问:一位成员分享了 Deepwiki 作为快速对代码库提问的资源,在深入细节之前先对其进行“软化”处理。
- 他们通过使用 Deepwiki 中 Aider 条目的 Devin Chat 演示了如何回答 tree-sitter 是如何被使用的问题。
- 本地 MLX 模型成功配合 Aider 运行:一位成员通过 mlx-lm server 成功让 mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit 模型配合 Aider 运行,使用了命令
aider --openai-api-key secret --openai-api-base http://localhost:8080/v1/。- 在
--model选项前添加openai/是关键:aider --openai-api-key secret --openai-api-base http://127.0.0.1:8080 --model openai/mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit。
- 在
- 上下文大小仍是一个问题:该成员在使用 mlx-community/Qwen3-Next-80B-A3B-Instruct-4bit 模型时遇到了 token limit 问题,Aider 报告 “possibly exhausted context window!”。
- 他们注意到 Hugging Face 上的相关讨论,并发现 mlx-lm server 的
--max-tokens标志默认为 512。
- 他们注意到 Hugging Face 上的相关讨论,并发现 mlx-lm server 的
aider (Paul Gauthier) ▷ #links (1 messages):
Graph Usability, Outlier deselect, Data Visualization Improvements
- 请求:为提高图表易用性增加取消选择异常值的功能:一位用户建议通过增加取消选择异常数据点的功能来提高图表的易用性。
- 该用户指出,这将通过专注于更具代表性的数据,使图表解释和分析变得更容易。
- 图表易用性改进:一位用户建议通过增加取消选择点的功能来改进图表易用性。
- 该用户指出,目前无法轻松使用该图表。
DSPy ▷ #show-and-tell (3 messages):
Human Review Tooling, GEPA integration, Model improvement
- 为 QA 和数据标注推出的 **Human Review Tooling:一位成员正在构建用于辅助手动 QA、错误分析甚至数据标注**的工具,并正在寻找测试者(尤其是来自学术界的测试者),目前已有 演示视频。
- 下一阶段将涉及利用人类反馈生成评分器,并结合确定性方法以及通过 GEPA 实现的 LLMs as Judges。
- 计划通过 Prompt Optimization 进行模型改进:该工具旨在通过 prompt optimization 和 finetuning 来提升模型性能。
- 构建者正在寻找 MLE 合作伙伴,以担任联合创始人/创始工程师/研究员等角色。
- 请求 GEPA 反馈以改进 AI:一位成员表示愿意协助解决使用 GEPA 时遇到的任何问题,并希望通过反馈来改进 GEPA。
- 另一位成员对创作者表示赞赏,称其工作非常出色 (amazing)。
DSPy ▷ #papers (1 messages):
batmanosama: https://yifei-he.github.io/mergebench/
DSPy ▷ #general (19 messages🔥):
DSPy ChainOfThought, GEPA Optimization Models, MLFlow Integration, DSPy Server Tag
- 推理模型上的 CoT:冗余还是出色?:一位成员询问在 OpenAI GPT 系列等推理模型上使用
dspy.ChainOfThought是否冗余。- 另一位成员建议,虽然这样做有好处(如流式传输中间推理轨迹和强制执行特定领域的推理格式),但与非推理模型相比,其收益有所减少;如果你需要显式观察推理过程,值得一试,并提到有一个处理该主题的 PR。
- GEPA 优化:该召集哪些模型?:一位成员询问除了 OpenAI 模型外,哪些模型在 GEPA 优化方面表现良好。
- 另一位成员报告称 Gemini-2.5-Pro、GPT-4/5-nano/mini/main 的所有版本以及 Qwen3-8B+ 均表现出色,同时也听说 GPT-OSS 也取得了成功。
- MLFlow 进军可观测性和评估 (Evals):一位成员询问哪些工具在可观测性和评估方面表现良好,特别是针对 GEPA。
- 另一位成员提到 MLFlow 已深度集成,且 MLFlow 团队正在致力于更好地与 GEPA 集成,目前支持 best_valset_agg_score 和 pareto frontier(帕累托前沿)相关的聚合分数及仪表盘。
- Discord 标签需求令 DSPy 爱好者失望:一位成员询问为什么没有 dspy server 标签。
- 另一位成员链接到了 Discord 中的一条消息。
DSPy ▷ #colbert (2 messages):
ColBERT Long Context, CLS Token Chunking
- ColBERT 在长上下文处理上遇到困难:一位成员指出,尽管 jina-colbert 最高支持 8,192 tokens,但在长上下文下的效果并不理想。
- 他们建议在每个分块中重复 CLS token,并尝试对比有无该操作的效果。
- 提出 CLS Token 分块策略:为了解决 jina-colbert 在长上下文中的问题,一位成员建议在每个分块中重复 CLS token。
- 该成员计划实验此策略以观察是否能改善长上下文的处理,并将测试重复与不重复 CLS token 的效果。
Nous Research AI ▷ #general (20 messages🔥):
Moondream release, Multimodal models from China, Qwen3-VL
- Magistral 小型模型发布:Mistral AI 在 Hugging Face 上发布了 Magistral-Small-2509 模型,并指出由于小型张量的开销,小型模型的训练速度在扩展性上表现不佳。
- 此外还指出 VRAM 消耗效率低下,在 16 倍 Batch Size 下,Qwen3-Next 比同级别的 Llama 占用更多 VRAM。
- Moondream 模型发布新版本:如 这篇 vxitter 帖子 所示,moondream 发布了新版本。
- 与其他 moondream 模型相比,其奇怪的许可证引起了关注。
- 中国在多模态模型方面落后:成员们讨论了在现有选项中,中国似乎拥有最少的多模态模型这一观察结果。
- 一位成员询问了图像识别训练中的障碍,特别是对于 MoE 架构。
- 本周没有 Gemini 3.0 或 Claude 4.5:一位成员对本周没有发布 Gemini 3.0 或 Claude 4.5 表示失望:这周我们被耍了。
- 随后他们说:不过我们拿到了 AI 眼镜!(虽然目前还没有 AI 功能)。
Nous Research AI ▷ #interesting-links (2 messages):
QSilver Quantum Workshop, Quantum Computing Education, Qiskit and Cirq
- 孟加拉国 QSilver 量子工作坊:QBangladesh 将于 10 月 18–19 日及 10 月 25–26 日 UTC 时间 1:00–2:30 PM(孟加拉时间晚上 7 点)举办 QSilver 量子工作坊,可通过 Zoom 免费参加。
- 工作坊涵盖 Qiskit、Cirq、Bloch Sphere、QFT、Shor’s Algorithm,并设有嘉宾演讲、代码演示和动手编程环节;申请截止日期为 10 月 11/12 日,女性及弱势群体优先(申请表)。
- 申请 QSilver 量子工作坊:申请加入以深入探索量子计算!
- 申请通道已开启,截止日期为 10 月 11/12 日。
Moonshot AI (Kimi K-2) ▷ #general-chat (18 messages🔥):
Kimi Researcher, Kimi Dart performance, Kimi free sessions
- Kimi Researcher 额度:终身制还是定期刷新?:用户们在争论 Kimi Researcher 额度是终身限制还是会刷新;一位用户因为担心只有 3 次限制而不敢尝试。
- 一些用户报告有 5 次免费会话,而另一些人只看到 3 次,但一位用户澄清说免费会话每天都会刷新。
- Researcher 限制与 Beta 权限挂钩:一位用户建议较高的 Researcher 限制可能与通过等候名单获得的 Beta 测试权限有关。
- 有人认为,在 Research 处于 Beta 测试阶段时申请使用的人拥有更高的额度。
- Kimi 的 Dart 性能受到质疑:一位用户询问 Kimi 在 Dart 语言中的表现如何。
- 一位用户声称点击示例实际上并没有实时运行模型,而是预生成的输出。
tinygrad (George Hotz) ▷ #general (1 messages):
Hotz new company, TinyGrad update
- George Hotz 创立新公司:George Hotz 宣布成立新公司,专注于“为拥有算力的人制造有用的产品”。
- 据暗示,该公司独立于 TinyCorp,旨在解决对更易用的计算工具的需求。
- TinyGrad 更新:据报道,TinyGrad 正在进行重大更新,以提升其功能和性能。
- 这些更新旨在优化用户体验并扩展该框架的应用范围。
tinygrad (George Hotz) ▷ #learn-tinygrad (5 messages):
Stable Diffusion Model, ModuleNotFoundError, PYTHONPATH, extra package
- Stable Diffusion 导入失败:一位成员在尝试运行 Stable Diffusion 模型时遇到了
ModuleNotFoundError。- 错误原因是缺少
extra模块:from extra.models.clip import Closed, Tokenizer。
- 错误原因是缺少
- PYTHONPATH 无法解决缺失模块问题:另一位成员建议使用
PYTHONPATH=.作为环境变量来解决模块错误。- 然而,原作者确认这不起作用。
- Extra 包不属于 PyPi 发布版本:一位成员询问安装是通过 PyPI 还是直接从 repo 进行的,并指出
extra包不属于 PyPI 发布版本。- 原作者确认他们是从源码安装的。
MCP Contributors (Official) ▷ #general (1 messages):
Contributor Server Purpose, Drive-by Surveys, Server Misuse
- **Contributors 服务器用途已明确!:一位版主澄清说,该服务器旨在供 **contributors 之间讨论,而不是用于寻求一般帮助或进行随机调查 (drive-by surveys)。
- 寻求帮助或想要进行调查的用户被引导私信版主,以获取更合适服务器的链接。
- 服务器面向 **Contributors,而非一般帮助:该服务器明确用于 **contributors 之间的讨论,而不是一个通用的帮助论坛。
- 消息强调在该服务器进行随机调查是不合适的,并将此类请求重定向到其他地方。
MCP Contributors (Official) ▷ #general-wg (1 messages):
EmbeddedResource metadata, EmbeddedResource structure
- EmbeddedResources 缺少 name 和 title:一位成员注意到
EmbeddedResource不遵循EmbeddedResources结构,也没有继承BaseMetadata。- 他们观察到这意味着它不包含
name和title,并想再次确认它是否应该包含name和title。
- 他们观察到这意味着它不包含
- EmbeddedResource 需要确认:有人质疑
EmbeddedResource是否应该包含name和title属性。- 该查询旨在验证
EmbeddedResource的当前结构,以及它是否应该与BaseMetadata保持更一致。
- 该查询旨在验证