AI News
阿里巴巴云栖大会:4天内发布7款模型(包括 Qwen3-Max、Qwen3-Omni、Qwen3-VL)及520亿美元发展路线图。
阿里巴巴通义千问(Qwen)团队发布了重大更新,推出了包括1万亿参数的 Qwen3-Max、Qwen3-Omni 和 Qwen3-VL 在内的多款模型,以及 Qwen3Guard、Qwen3-LiveTranslate、Qwen3-TTS-Flash、Qwen-Image-Edit 和 Qwen3Coder 等专业版本。
在阿里云云栖大会上,首席执行官吴泳铭(Eddie Wu)概述了一项 520 亿美元的路线图,重点强调了人工智能发展的两个阶段:一是“智能涌现”,侧重于向人类学习和推理;二是“自主行动”,强调 AI 的工具使用和现实世界任务的执行。
这些更新展示了在工具使用、大模型编程能力,以及 AI 在物流、制造、生物医药和金融等行业中不断扩大的应用作用。林俊旸(Junyang Lin)是这些进展的关键发言人。目前,Qwen 项目被视为人工智能创新的“前沿实验室”。
Qwen 就是你所需的一切?
2025年9月23日至9月24日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 23 个 Discord(194 个频道和 2236 条消息)。预计节省阅读时间(以 200wpm 计算):188 分钟。我们的新网站现已上线,提供完整的元数据搜索和精美的 vibe coded 呈现方式,涵盖所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
今天既是 AI Engineer Paris 大会,也是阿里云一年一度的 云栖大会(又名 Apsara conference),通义千问(又名 Qwen) 团队一直在加班加点发布其所有模型的更新,包括主要模型:1T 巨兽模型 Qwen3-Max(3周前已预告)、Qwen3-Omni 和 Qwen3-VL,以及 Qwen3Guard、Qwen3-LiveTranslate、Qwen3-TTS-Flash,还有 Qwen-Image-Edit 和 Qwen3Coder 的更新。以下是他们在 AI Twitter 上的主要发言人 Junyang Lin 的说法:
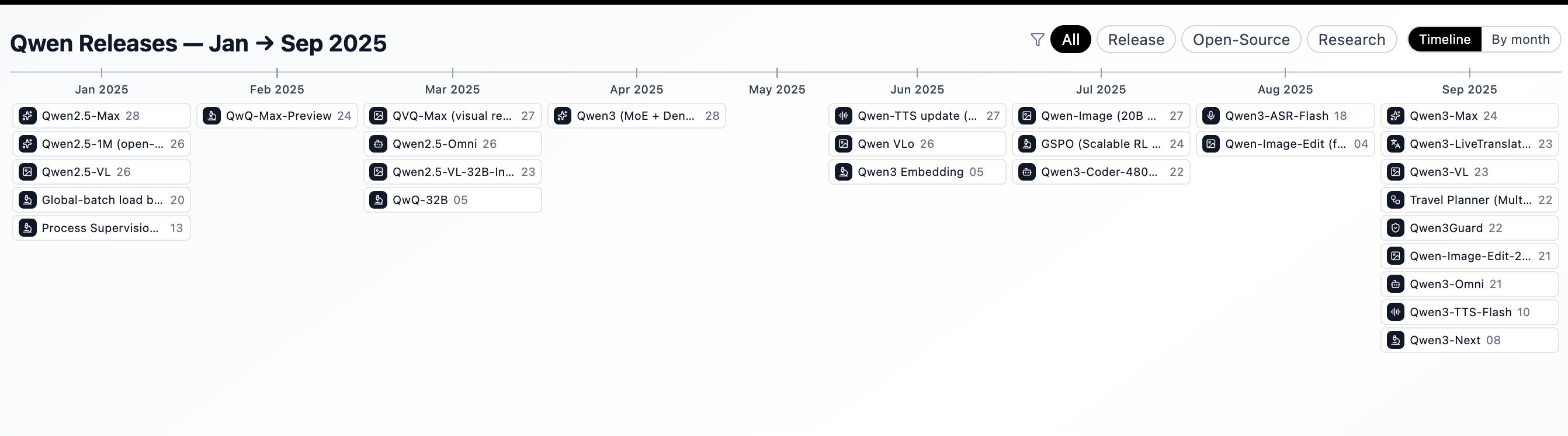
为了直观展示发布速度的提升,以下是今年所有 Qwen 发布内容的视觉化图表:
也不要忘记 Alibaba Wan 的所有工作,但凭借这些发布,Qwen 现在被视为一个“frontier lab”。
阿里巴巴 CEO Eddie Wu 登台规划了他们 520 亿美元的路线图:

以下是演讲的翻译:

- 第一阶段是“智能涌现”,其特征是“向人类学习”。
- 互联网几乎数字化了人类历史上的所有知识。这些语言和文本所承载的信息代表了整个人类知识库。在此基础上,大模型首先通过理解全球知识库来发展通用智能,涌现出通用的对话能力,理解人类意图并回答人类问题。它们逐渐发展出思考多步问题的推理能力。我们现在看到 AI 在各种学科测试中接近人类表现的最高水平,例如国际数学奥林匹克竞赛的金牌水平。AI 正在逐渐具备进入现实世界、解决现实问题并创造真实价值的能力。这是过去几年的主旋律。
- 第二阶段是“自主行动”,其特征是“辅助人类”。在这个阶段,AI 不再局限于言语交流,而是具备了在现实世界中行动的能力。AI 可以分解复杂任务,使用并创造工具,自主地与数字世界和物理世界互动,在人类目标的背景下对现实世界产生深远影响。这正是我们目前所处的阶段。
- 实现这一突破的关键首先在于大模型使用工具的能力,将所有数字工具连接起来以完成现实世界的任务。人类加速进化的起点是工具的创造和使用,而大模型现在也具备了这种能力。通过使用工具,AI 可以像人类一样访问外部软件、接口和物理设备,执行复杂的现实任务。在这个阶段,由于 AI 可以显著提高生产力,它将迅速渗透到几乎每一个行业,包括物流、制造、软件、商业、生物医药、金融和科学研究。
- 其次,大模型代码能力的提升可以帮助人类解决更复杂的问题,并将更多场景数字化。目前的 Agent 仍处于早期阶段,主要解决标准化的短期任务。要让 Agent 能够应对更复杂、更长期的任务,需要大模型的代码能力。因为 Agent 可以自主编写代码,理论上它们可以解决无限复杂的问题,理解复杂需求并独立完成编码和测试,就像一支工程师团队一样。开发大模型的代码能力对于实现 AGI 至关重要。
- 随后 AI 将进入第三阶段——“自我迭代”,其特征是具备“超越人类”的能力。这一阶段有两个关键要素:
-
第一,AI 连接到现实世界中全部的原始数据。
目前,AI 在内容创作、数学和代码方面进展最快。我们在这三个领域看到了鲜明的特征。这些领域的知识 100% 由人类定义和创造,并包含在文本中。AI 可以完全理解这些原始数据。然而,在其他领域和更广泛的物理世界中,今天的 AI 主要接触的是由人类总结的知识,缺乏来自与物理世界互动的广泛原始数据。这些信息是有限的。为了让 AI 实现超越人类能力的突破,它需要直接访问来自物理世界的更全面、更原始的数据……
……仅仅让 AI 学习人类推导出的规则是远远不够的。只有通过不断与现实世界互动,获取更全面、更真实、更实时的数据,AI 才能更好地理解和模拟世界,发现超越人类认知的更深层规律,从而创造出比人类更强大的智能能力。
-
第二,自我学习。随着 AI 渗透到更多的物理世界场景并理解更多的物理数据,AI 模型和 Agent 将变得越来越强大。这将允许它们构建训练基础设施、优化数据流并升级模型架构以进行模型升级,从而实现自我学习。这将是 AI 发展的关键时刻。
随着能力的不断提升,未来的模型将持续与现实世界互动,获取新数据并接收实时反馈。利用强化学习和持续学习机制,它们将自主优化、纠正偏差,并实现自我迭代和智能升级。每一次互动都是一次微调,每一条反馈都是一次参数优化。在无数次的场景执行和结果反馈循环之后,AI 将自我迭代以实现超越人类的智能水平,人工超智能(ASI)的早期阶段将会出现。
-
他们也是 LLM OS 论点的最新支持者。

AI Twitter 摘要
算力建设:OpenAI–NVIDIA 交易、Stargate 扩张以及吉瓦时代
- OpenAI 的“智能工厂”走向实体化:OpenAI 宣布与 Oracle 和 SoftBank 合作建设五个新的“Stargate”站点,使其此前宣布的 10 GW 建设进度提前。在 Sam Altman 关于“充足智能”的帖子中,该公司将其目标描述为“一家每周能生产 1 吉瓦新 AI 基础设施的工厂”,并感谢了与 NVIDIA 近十年的合作伙伴关系 (@OpenAI, @sama, @sama, @gdb, @kevinweil)。背景:根据 Graham Neubig 的说法,10 GW 大约相当于“全球全人类思考所消耗能量的 6%” (@gneubig)。Elon Musk 断言“首先达到 10GW、100GW、1TW……” (@elonmusk)。
- 交易计算与“股权换 GPU”的推测:针对 10 GW 的粗略估算显示,如果 20% 的电力为非 GPU 消耗,按每张 GPU 3 万美元计算,约需价值 3400 亿美元的 H100 等效算力;若计入 30% 的批量折扣,则约为 2300 亿美元。一种流传的结构是:按原价支付 GPU 费用,并通过 NVIDIA 向 OpenAI 注入约 1000 亿美元的股权投资来抵消“折扣” (@soumithchintala, @soumithchintala, @soumithchintala)。多位观察者注意到了 Oracle/SoftBank 的参与;各供应商的总基础设施承诺正趋向于“数千亿美元” (@scaling01)。
Qwen 的多模型齐射:Max、VL‑235B‑A22B、Omni、Coder‑Plus、Guard 和 LiveTranslate
- 旗舰模型与愿景:阿里巴巴 Qwen 发布了:
- Qwen3‑Max (Instruct/Thinking)。声称在 SWE‑Bench、Tau2‑Bench、SuperGPQA、LiveCodeBench、AIME‑25 上接近 SOTA;其具备“重度模式”工具调用能力的 Thinking 变体在选定基准测试中接近完美 (@Alibaba_Qwen, @scaling01)。
- Qwen3‑VL‑235B‑A22B (Apache‑2.0; Instruct/Thinking)。256K 上下文可扩展至约 1M;具备强大的 GUI 操作和“视觉编程”能力(截图→HTML/CSS/JS)、32 种语言 OCR、2D/3D 空间推理,在 OSWorld 上达到 SOTA (@Alibaba_Qwen, @reach_vb, @scaling01)。
- Qwen3‑Omni:一款端到端 any‑to‑any 模型(30B MoE,约 3B 激活参数),可输入图像/文本/音频/视频并输出文本/语音;支持 119 种语言(文本)、19 种语言(语音)和 10 种语音输出角色;支持 Transformers+vLLM;在多项音频/视频基准测试中优于 Gemini 2.5 Pro 和 GPT‑4o (@mervenoyann, @mervenoyann)。技术报告总结:在受控研究中,联合多模态训练并未降低文本/视觉基准表现 (@omarsar0)。
- 开发者、安全与实时性:
- Qwen3‑Coder‑Plus:升级了终端任务能力,SWE‑Bench 提升至 69.6,支持多模态编程和子 Agent 支持,可通过阿里云 Model Studio 和开源产品 Qwen Code 获取 (@Alibaba_Qwen, @_akhaliq)。
- Qwen3Guard:多语言(119 种语言)审核套件,提供 0.6B/4B/8B 尺寸;包含流式(低延迟)和全上下文(生成式)变体;三级严重程度(安全/有争议/不安全);定位于 RL 奖励建模 (@Alibaba_Qwen, @HuggingPapers)。
- Qwen3‑LiveTranslate‑Flash:实时多模态口译,延迟约 3 秒;支持唇语/手势/屏幕文本读取,对噪声具有鲁棒性;理解 18 种语言 + 6 种方言,支持 10 种语言播报 (@Alibaba_Qwen)。
- 加码:Travel Planner Agent,接入高德地图/飞猪/搜索,用于行程规划和路线安排 (@Alibaba_Qwen)。
OpenAI 的 GPT‑5‑Codex 和 Agent 工具走向前台
- GPT‑5‑Codex 面向 Agent 发布:OpenAI 通过 Responses API(而非 Chat Completions)发布了 GPT‑5‑Codex,该模型针对 Agent 编程而非对话进行了优化 (@OpenAIDevs, @reach_vb)。随后多个工具进行了快速集成:VS Code/GitHub Copilot (@code, @pierceboggan)、Cursor (@cursor_ai)、Windsurf (@windsurf)、Factory (@FactoryAI)、Cline (@cline) 以及 Yupp(提供低/中/高变体用于公开测试)(@yupp_ai)。开发者强调了其“自适应推理”能力,即在简单任务上消耗更少的 Token,而在需要时消耗更多。部分报告称其拥有超过 400K 的上下文,并在长周期任务中表现强劲(数据来自合作伙伴公告;参见 @cline)。
- Agent 调试功能登陆 IDE 和浏览器:
- Chrome DevTools MCP:Agent 可以以编程方式运行性能追踪、检查 DOM 并调试网页 (@ChromiumDev)。
- 适用于 VS Code 的 Figma MCP 服务端:将设计上下文引入代码,实现“设计→实现”的闭环 (@code)。
- Gemini Live API 更新:改进了实时语音函数调用、中断处理和闲聊抑制 (@osanseviero)。
- 操作系统级计算机控制 Agent(xAI “Macrohard”,Grok 5)的招聘势头持续高涨 (@Yuhu_ai_, @YifeiZhou02),第三方团队也集成了 Grok 快速模型 (@ssankar)。
检索、上下文工程与 Agent 研究
- MetaEmbed(灵活的延迟交互):通过附加可学习的“元 Token”并仅存储/使用这些 Token 进行延迟交互,实现了可压缩的(俄罗斯套娃式)多向量检索,并支持通过测试时缩放(test-time scaling)来权衡准确性与效率;在 MMEB 和 ViDoRe 上达到 SOTA。讨论线程和仓库指出其与 PLAID 索引兼容 (@arankomatsuzaki, @ZilinXiao2, @ManuelFaysse, @antoine_chaffin)。
- 数据优于规模对 Agent 能力的影响? LIMI 仅通过 78 个精选演示就在 AgencyBench 上达到了 73.5% 的准确率,超越了更大规模的 SOTA Agent 模型;作者提出了“Agent 效率原则”(自主性源于战略性的数据精选) (@arankomatsuzaki, @HuggingPapers)。
- 图谱游走与工程评估:
- ARK‑V1:一种轻量级的知识图谱(KG)游走 Agent,相比 CoT 提升了事实性问答表现;配合 Qwen3‑30B,它能回答约 77% 的查询,其中准确率约为 91%(整体约 70%)。更大的骨干模型整体准确率可达 70–74%;弱点包括歧义和冲突的三元组 (@omarsar0)。
- EngDesign:涵盖 9 个工程领域的 101 个任务,使用基于模拟的评估(SPICE、FEA 等);迭代优化显著提高了通过率 (@arankomatsuzaki)。
- 同样值得关注的还有:Apple 用于长对话问答的情节性 KV 缓存管理方案 EpiCache (@_akhaliq),现在 兼容 MCP 的 Agent 研究环境(可通过 LeRobot MCP 进行真实机器人控制) (@clefourrier),以及 LangSmith 的 复合评估器(可将多个评分汇总为单一指标) (@LangChainAI)。
视频与 3D 内容:可灵 2.5 Turbo、Ray 3 HDR 等
- Kling 2.5 Turbo:在 FAL 上首日上线,显著提升了动态效果、构图、风格适配(包括动漫)和情感表达;FAL 用户生成 5 秒视频的价格低至约 0.35 美元。Higgsfield 宣布在其产品中提供“无限量”的 Kling 2.5。演示显示其对复杂提示词的遵循度更高,且音频特效生成有所改进 (@fal, @Kling_ai, @higgsfield_ai, @TomLikesRobots)。
- Luma Ray 3:首个具备 16 位 HDR 的视频模型,并在 T2V 和 I2V 中实现了迭代式“思维链(chain-of-thought)”优化;目前仅在 Dream Machine 中可用(API 待定)。Artificial Analysis 将在其竞技场中发布对比评测 (@ArtificialAnlys)。
- 在 3D/VR 领域,Rodin Gen‑2(4 倍网格质量、递归零件生成、高模转低模烘焙、control nets)以促销价格发布 (@DeemosTech);World Labs 的 Marble 展示了从提示词到 VR 漫游的生成 (@TomLikesRobots)。
系统、内核与推理
- 内核开发大有可为:一个约 170 行代码的 Mojo matmul 在 B200 上击败了 cuBLAS,且未使用 CUDA,调优线程中详细介绍了相关细节;行业内对内核编写人才的需求正在激增。同时,vLLM 默认启用了完整的 CUDA-graphs(例如,Qwen3‑30B‑A3B‑FP8 在 bs=10 时提速 +47%),Ollama 发布了新的调度器以减少 OOM、最大化多 GPU 利用率并改进内存报告 (@AliesTaha, @jxmnop, @mgoin_, @ollama)。
- 模型与基础设施:Liquid AI 发布了 LFM2‑2.6B(短卷积 + GQA,10T tokens,32K ctx;开源权重),定位为新的 3B 级领先模型 (@LiquidAI_)。AssemblyAI 发布了强大的多语言 ASR 性能,并支持大规模话者分离(diarization) (@_avichawla)。Hugging Face 的存储骨干网强调 Xet 和内容定义分块(content-defined chunking)是实现每日数 TB 开源吞吐量的关键 (@ClementDelangue)。NVIDIA 指出在 HF 上的开源模型贡献有所增加 (@PavloMolchanov)。
热门推文(按互动量排序)
- “真疯狂,他们竟然称之为 context window(上下文窗口),明明 attention span(注意力跨度)就在嘴边。” (@lateinteraction, 7074)
- 为 Grok5/macrohard 组建新团队,开发计算机控制 Agent (@Yuhu_ai_, 6974)
- “重大时刻 —— 无限量 Kling 2.5 现由 Higgsfield 独家提供。” (@higgsfield_ai, 6248)
- “哟,我听说如果你按下上、上、下、下……就会出现无限金钱漏洞” (@dylan522p, 5621)
- “丰沛智能(Abundant Intelligence)” —— OpenAI 愿景文章 (@sama, 5499)
- 用于 Agent 调试的 Chromium DevTools MCP (@ChromiumDev, 2538)
- “感谢 Jensen 近十年的合作伙伴关系!” (@sama, 5851)
- OpenAI:宣布五个新的 Stargate 站点 (@OpenAI, 2675)
- 对 Nvidia–OpenAI 合作伙伴关系的致意(“期待我们将共同创造的一切”) (@gdb, 2753)
- “我不敢相信这居然真的有效”(病毒式传播的 Agent 演示) (@cameronmattis, 46049)
- 关于自闭症/ADHD 证据质量的 FDA/泰诺(Tylenol)讨论帖 (@DKThomp, 16346)
- 美国物理奥林匹克队赢得 5/5 金牌 (@rajivmehta19, 13081)
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Qwen3-Max 发布与基准测试
- Qwen 3 max 发布 (Score: 218, Comments: 39): Qwen3‑Max 被宣布为 Qwen 规模最大、能力最强的模型。预览版 Qwen3‑Max‑Instruct 在 Text Arena 排行榜上排名
#3(声称超越了 “GPT‑5‑Chat”),正式发布版强调了更强的 coding 和 agent 能力,并声称在知识、推理、coding、指令遵循、人类偏好对齐、agent 任务以及多语言基准测试中达到了 SOTA。该模型可通过 API (Alibaba Cloud) 和 Qwen Chat 访问。另一个 Qwen3‑Max‑Thinking 变体(仍在训练中)据报道在结合 tool use 和扩展的 test‑time compute 时,在 AIME 25 和 HMMT 上达到了100%。 评论者指出该模型并非 local/open‑source,限制了 self‑hosting,并对其快速的发布节奏发表了评论。- 几位评论者指出 Qwen 3 Max 不是 local 模型,也不是 open source。实际上,这意味着没有可下载的权重,也不支持端侧或 self-hosted 部署;只能通过托管 API 使用,这与 OSS 模型相比,影响了数据控制、离线能力和可复现性。
- 围绕此次公告存在一些困惑,因为早期的访问是“预览版”;而此帖表明是正式发布。读者推测模型已从预览版转向 GA/生产就绪(例如,更清晰的 SLA/速率限制/定价),尽管评论中未提供具体的细节。
- Qwen 今日发布 2 款新开源模型 (Score: 172, Comments: 35): 帖子暗示了来自阿里巴巴 Qwen 团队的两个新开源发布,其中至少一个已经在 Hugging Face 上线。评论明确提到了 “Qwen3 VL MoE”,暗示这是一个视觉语言 Mixture‑of‑Experts 模型;图片可能暗示了这两个模型的名称和发布时间。图片地址:https://i.redd.it/goah9v2r8wqf1.png 评论指出第二个模型已出现在 Hugging Face 上,第一个也已经发布;讨论集中在识别 “qwen3 vl moe” 上,目前尚无基准测试或规格参数。
- 提到了 Qwen3-VL-MoE(视觉语言 Mixture‑of‑Experts)的发布;MoE 意味着 sparse expert routing,因此每个 token 只有一部分专家处于激活状态,在保持高容量的同时减少了计算量。可用性和快速节奏的证据:社区报告称其“已经发布”,且“第二个 Qwen 模型已上线 Hugging Face”,并分享了预览截图 (https://preview.redd.it/kn55ui1xvwqf1.png?width=1720&format=png&auto=webp&s=a36235216e9450b2be9ad44296b22f9d2abc07d9)。
- 讨论强调了 Qwen 模型向 sparse MoE 的转变,通过提高参数效率和吞吐量(路由到少数专家降低了每个 token 的 FLOPs)来加速训练和部署。评论者认为这使得在扩展策略上实现更快迭代的同时,能保持模型处于“A梯队”,强调了一种务实的权衡:追求强劲性能与更好的成本效益,而非单纯追求单模型 SOTA。
{kind=link}
2. Qwen 发布速度梗/讨论
- 他们怎么发布得这么快 💀 (评分: 805, 评论: 136): 帖子强调了 Qwen 极快的发布节奏;评论者将其归功于采用了 Mixture‑of‑Experts (MoE) 架构,与大型稠密模型相比,这种架构的训练和扩展速度更快、成本更低。文中提到了传闻中即将推出的开源 Qwen3 变体,包括 “15B2A” 和一个 32B 稠密模型,这表明 MoE 和稠密产品线将有所区分。 评论对 Qwen 的势头(“Qwen 大军”)持乐观态度,并将其与西方关于长周期和高成本的叙事进行了对比;出现了一些地缘政治观点,但非技术性。技术方面的期待集中在传闻中的 Qwen3 15B2A 和 32B 稠密模型的 OSS 发布上。
- 评论者指出 Qwen 倾向于使用 Mixture-of-Experts (MoE),在给定质量下,这种架构的训练和推理速度更快,因为每个 token 仅激活一部分专家(
k-of-n路由),在扩展参数的同时减少了实际的 FLOPs(参见 Switch Transformer: https://arxiv.org/abs/2101.03961)。他们还提到了传闻中即将发布的稠密模型 —— Qwen3 15B2A 和 Qwen3 32B —— 这意味着一种互补策略:MoE 加速迭代,而稠密模型则针对强大的单专家延迟和部署便捷性;强调的权衡包括 MoE 的路由/基础设施复杂性与稠密模型可预测的内存/延迟。
- 评论者指出 Qwen 倾向于使用 Mixture-of-Experts (MoE),在给定质量下,这种架构的训练和推理速度更快,因为每个 token 仅激活一部分专家(
- Qwen 发布怎么这么猛 (评分: 181, 评论: 35): 楼主询问为什么 Qwen(阿里巴巴的 LLM 家族)发布速度如此之快,且变体激增到让人难以选择的程度。讨论中没有涉及基准测试或实现细节;该线程是对发布节奏和变体扩张(例如 Qwen 伞下的多种模型类型/尺寸,参见 Qwen 的仓库:https://github.com/QwenLM/Qwen)的元评论。 评论者主要将这种速度归功于阿里巴巴的资源 —— “大量的资金、算力和人力” —— 以及中国的 “996” 工作文化;有人指出,十年前接受高强度训练的学生现在已成为劳动力主力。
- 一位从业者推荐了一个实用的部署组合:使用 Qwen2.5-VL-72B 处理 VLM 任务,使用能装入 GPU
VRAM的最大 Qwen3(稠密版) 进行低延迟文本推理,并使用能装入系统main memory(主内存)的最大 Qwen3 MoE 处理高容量工作负载。这种方案平衡了受 VRAM 限制的稠密推理与受 RAM 限制的 MoE,在单一技术栈中覆盖多模态和纯文本用例,以延迟换取容量。 - 几位评论者指出 Qwen 背后有 Alibaba 的支持,这意味着可以获得大量的算力、资金和工程人力。这种规模转化为更快的预训练/微调周期和并行产品化,有助于解释多个模型系列(稠密、MoE 和 VLM)的快速发布节奏。
- 报告强调了 Qwen 技术栈强大的图像生成性能,表明其多模态/图像流水线与文本模型同步快速成熟。虽然没有引用具体的基准测试,但共识是图像质量已提高到足以与当代领先者竞争的水平。
- 一位从业者推荐了一个实用的部署组合:使用 Qwen2.5-VL-72B 处理 VLM 任务,使用能装入 GPU
{kind=link}
技术性较低的 AI Subreddit 总结
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Wan 2.2/2.5 视频演示 + Qwen-Image-Edit GGUF 和 LMarena 排行榜
- 令人惊叹的 Wan 2.2 Animate 模型让你能扮演另一个人。对于电影行业来说,这是一个游戏规则改变者。 (Score: 258, Comments: 57):帖子声称 “Wan
2.2Animate” 模型可以实现演员到演员的面部重演(facial reenactment)——即由源表演者驱动目标身份的面部——实际上是为电影/视频提供了一种 Deepfake 风格的数字替身。根据视频片段描述(reddit video),它展示了具有合理运动/时间一致性的身份转移(ID transfer),但身份忠实度并不完美(一位评论者指出它并不完全像 Sydney Sweeney),这表明在相似度保持、口型同步以及基于参考身份帧条件的 Diffusion/重演流水线典型的一致性之间存在权衡。帖子中未提供基准测试或实现细节;从技术上讲,这符合身份条件视频生成/重演方法,其中运动源自驱动视频,而身份通过参考图像嵌入(embeddings)和跨帧约束来维持。 热门评论讨论了变现/滥用途径(例如成人内容 Deepfake/OnlyFans),并指出尽管对于仔细观察的观众来说存在伪影或不匹配,但大多数观众可能不会注意到——突显了实际部署中的伦理风险与感知质量之间的博弈。- 评论者指出面部“看起来不像 Sydney Sweeney”,这反映了面部重演/视频 Diffusion 在身份保持方面的已知限制:模型在姿态/光照变化下,细微的面部几何结构、皮肤微纹理和表情可能会发生偏移,导致感知上的不匹配。鲁棒的系统通常结合地标/流引导变形(landmark/flow-guided warping)与身份损失(例如 ArcFace/FaceNet 嵌入)以及时间一致性损失;如果没有这些,帧与帧之间的 ID 一致性和口型同步会下降,尤其是在超过 512–1024 px 输出或头部快速运动期间。
- 多位用户表示这种技术已经存在;事实上,换脸/重演已有先验技术:经典的 Deepfake 流水线(DeepFaceLab/FaceSwap),诸如 First Order Motion Model (2019) 和 SimSwap (2020) 等研究,以及更新的 One-shot 和 Diffusion 方法。参考资料:DeepFaceLab (https://github.com/iperov/DeepFaceLab), FaceSwap (https://github.com/deepfakes/faceswap), FOMM (https://github.com/AliaksandrSiarohin/first-order-model), SimSwap (https://github.com/neuralchen/SimSwap), Roop (https://github.com/s0md3v/roop), LivePortrait (https://github.com/YingqingHe/LivePortrait), AnimateDiff (https://github.com/guoyww/AnimateDiff)。
- 对“用于电影”的怀疑指向了制作限制:电影需要 4K+ 分辨率、HDR、稳定的数分钟时间一致性、准确的重光照/阴影、遮挡下的摄像机/面部追踪,以及一致的发丝/耳朵/下颚线几何结构。目前的 Diffusion/重演演示经常出现闪烁、嘴部/眼睛不同步以及光照不匹配;将它们整合到电影中通常需要 VFX 级的追踪、神经重光照、绘制/转描(paint/roto)以及逐镜头调整,而不是开箱即用的演员替换。
- Wan2.2 Animate 和 Infinite Talk - 初次渲染(包含工作流) (Score: 340, Comments: 48):楼主分享了来自 ComfyUI 流水线的初次渲染结果,该流水线结合了用于视频合成的
Wan 2.2“Wan‑Animate”和用于旁白的 “Infinite Talk” 工作流。Wan‑Animate 工作流源自 CivitAI 用户 GSK80276,Infinite Talk 工作流取自 u/lyratech001 在此帖子中的分享。未提供模型设置、Checkpoints 或硬件/运行时间详情;该帖子主要展示了现有工作流的集成。 评论询问可复现性细节,特别是 TTS 源(语音生成)以及目标图像/视频是如何产生的,表明缺少具体的设置细节;目前没有实质性的技术辩论。- 要求披露确切的 TTS/语音流水线(“Infinite Talk”):使用了哪个模型/服务、推理后端、语音设置(例如采样率、风格/温度),以及是否提供用于口型同步集成的音素/视素(phoneme/viseme)时间戳。寻求诸如每秒音频延迟以及任何降噪/声码器(vocoder)步骤等复现细节。
- 许多人询问完整的 Wan2.2 Animate 工作流:包括目标静态图像是如何获取的(拍摄还是生成)以及如何预处理(人脸裁剪、关键点/地标检测、对齐),此外还有驱动动作/视频是如何产生的(参考视频还是文本驱动),包括关键的推理参数(分辨率、FPS、种子、guidance/强度)。关于处理头部姿势变化、稳定化以及背景融合/roto(抠像)的说明将有助于他人复现结果。
- 消费级硬件的可行性:该流水线是否能通过使用 fp16/bf16、低 VRAM 或 CPU offload、降低分辨率/FPS、减小 Batch Size 以及显存高效的 Attention(如 xFormers/FlashAttention),在 8 GB VRAM 和 32 GB 系统 RAM 上运行。评论者寻求预期的吞吐量/延迟权衡,以及能在 8 GB 内运行而不发生 OOM 的实用预设。
- 礼貌请求 Wan 2.5 开源 (Score: 231, Comments: 95): 帖子报告称,即将发布的 Wan
2.5版本最初将是仅限 API 的“高级版”,开源发布待定,并可能根据社区需求和反馈稍后推出;鼓励用户在直播期间请求开源。该说法似乎源于 X 上流传的一份翻译笔记(来源),暗示开源是有可能的,但存在时间滞后,且取决于社区的态度和呼声。除了发布形式(API vs. OSS)外,没有提供关于2.5的新技术规格或基准测试。 热门评论强调,Wan 的价值取决于其开源属性(支持 LoRA 微调和本地工作流);否则它只是另一个托管的视频生成服务。其他人指出消息发布者似乎并非官方人员(一名 YouTuber),暗示这并非官方开发者的声明,此外还有人表示对 Hunyuan3D2.5/3.0的发布感兴趣。- 几位评论者强调,Wan 的核心价值来自开源权重,这使得本地推理和定制成为可能——特别是基于 LoRA 的领域/风格适配微调、训练适配器以及集成到现有的视频流水线中。封闭的、仅限服务的发布将阻碍可重复的研究、离线部署和自定义训练工作流,使其变成“又一个视频生成服务”。参见例如 LoRA 用于无需全量微调的轻量化适配。
- 如果 2.2 保持开源且稳定,则没有立即需要 Wan 2.5 的紧迫性:用户最近才开始采用 Wan 2.2,并计划依赖它数月。从工具链的角度来看,保持 2.2 开源可以为构建数据集、训练 LoRA 和稳固工作流提供时间,而不会因版本更迭而产生动荡,并期望开源的 2.5 可以在稍后到达而不中断正在进行的工作。
- 请求还针对开源 3D 生成器,如 Hunyuan3D 2.5/3.0,旨在实现跨视频和 3D 流水线的互操作、本地可运行资产。开源发布将实现跨任务(视频转 3D、3D 转视频)的一致资产生成和评估,而不是被锁定在孤立的、封闭的端点中。
- Wan 2.5 (Score: 207, Comments: 137): 阿里巴巴在 X 上预热了 Wan 2.5 视频模型,其“高级版”将作为仅限 API 的形式发布;开源尚未决定,可能取决于社区反馈(Ali_TongyiLab, Alibaba_Wan)。预告片展示了
10s1080p的生成效果;一份声明(2025 年 9 月 23 日)指出 “目前只有 API 版本……[开源] 待定”,敦促用户争取开源发布。 讨论集中在开源与仅限 API 的对比:评论者认为封闭访问阻碍了基于 LoRA 的微调和更广泛的社区工作流,与之前的开源模型相比降低了实用性,并鼓励在直播期间推动开源发布(线程)。- 分享的笔记显示最初仅发布 API 版本,开源状态待定且可能延迟:“明天发布的 2.5 是高级版……目前只有 API 版本……开源版本待定”(帖子,2025 年 9 月 23 日)。实际上,这意味着发布时无法进行本地推理或获取权重,未来的任何开源都取决于社区反馈和时机。
- 封闭式/仅限 API 的发布方式排除了社区 LoRA 微调的可能性,因为训练 LoRA 适配器需要访问模型权重;没有权重就意味着“没有 LoRA”,将定制化限制在提示词级别或供应商提供的功能上。与开放 Checkpoints 相比,这限制了领域自适应、实验和下游任务的专业化。
- “多感官(Multisensory)”被解释为给视频添加音频,这引发了对计算资源的担忧:除非 Backbone 变得更高效,否则生成
~10 s的1080p带音频视频对 “95%的消费者”来说是不可行的。建议包括架构转向,如 Linear-attention 变体、Radial attention、DeltaNet 或像 Mamba (paper) 这样的状态空间模型(State-space models),以便在消费级硬件上达到可接受的吞吐量/VRAM。 - GGUF 魔法降临 (Score: 335, Comments: 94): QuantStack 发布了 Qwen-Image-Edit-2509 的 GGUF 版本,支持通过兼容 GGUF 的运行时(如 llama.cpp/ggml)进行本地量化推理 link。对于 ComfyUI 集成,用户报告必须更新 ComfyUI 并将文本编码器节点更换为
TextEncodeQwenImageEditPlus;早期的伪影(扭曲/类深度图输出)是由于工作流问题导致的,这里分享了一个可用的工作流图 here,基础模型参考见 here。 评论者正在等待更多的量化级别(“5090 玩家在等其他量化版本”),并询问对于低 VRAM 来说,Nunchaku 和 GGUF 哪个更好,这引发了关于显存 vs 质量/性能权衡的公开讨论。- Qwen-Image-Edit-2509 的 GGUF 移植版 ComfyUI 集成说明:初始运行会产生扭曲/“深度图”输出,直到 ComfyUI 更新且文本编码器节点更换为
TextEncodeQwenImageEditPlus。最终的解决方法是修正工作流;这里分享了一个可用的工作流:https://pastebin.com/vHZBq9td。参考的模型文件:https://huggingface.co/aidiffuser/Qwen-Image-Edit-2509/tree/main。 - 低 VRAM 部署问题:对于显存受限的 GPU,Nunchaku 还是 GGUF 量化更好。该帖子暗示了不同后端在显存占用、速度和质量之间的权衡,但未提供基准测试;读者可能需要在自己的硬件上比较量化位宽和加载器。
- 量化深度担忧:一位用户询问考虑到明显的质量损失,
<=4-bit的量化是否真的可用,并质疑发布所有位宽的合理性。这突显了在实践中需要具体的质量指标(例如图像编辑提示词的任务准确度/FID)与 VRAM 收益进行对比,以证明超低比特变体的存在价值。
- Qwen-Image-Edit-2509 的 GGUF 移植版 ComfyUI 集成说明:初始运行会产生扭曲/“深度图”输出,直到 ComfyUI 更新且文本编码器节点更换为
- 一个 7 个月前的模型仍然位居榜首,这在我看来简直疯狂。(LMarena) (Score: 227, Comments: 64): LMSYS LMarena (Chatbot Arena) 排行榜截图显示,一个发布约 7 个月的模型在人群 Elo 排名中仍处于或接近顶峰,这表明 LMarena 是一个基于盲测 A/B 聊天和 Elo 风格评分的偏好/可用性基准,而非纯粹的任务准确度 (lmarena.ai)。这解释了为什么
GPT-4o的排名高于更新的 “5 high” 变体:对话的帮助性、亲和力和对齐(Alignment)通常比编程/数学基准上的边际收益更能赢得用户投票。评论者将榜首位置归功于 Gemini 2.5 Pro,它被认为在日常写作和快速问答中特别具有同理心且易读。 争论集中在即将推出的 Gemini 3 是否会重新洗牌排行榜,以及为什么4o > 5 high;共识是 LMarena 偏好用户偏好质量而非原始性能。一条评论还指出,基于 Gemini 2.5 Pro 的 Google Jules Agent 在研究/构建任务方面优于 Codex 或 Perplexity Labs 等工具,且配额慷慨。- LMarena (LMSYS Chatbot Arena) 是一个由真实用户投票驱动的成对、盲测、Elo 风格的基准测试,因此它衡量的是可用性/偏好,而非纯粹的任务准确度。这意味着如果用户在通用提示词上更喜欢旧模型的语气、清晰度、格式或安全行为,旧模型就能保持领先。这与测试狭窄能力的标准化基准(如 MMLU, GSM8K, HumanEval)形成对比;一个模型可能在 Arena 领先,但在那些基准上落后。方法论和实时评分见 https://arena.lmsys.org/。
- 为什么
GPT-4o的排名会高于更新的 ‘5-high’ 变体?在 Arena 的面对面比较中,即使存在原始推理能力更强的模型,指令遵循(prompt-following)、简洁的推理链、多模态格式化和经过校准的安全性等因素也会驱动用户偏好。此外,Arena Elo 存在方差和重叠的置信区间——微小的差距可能在统计上并不显著——因此在积累足够票数之前,排名翻转是很常见的。简而言之,Arena 优化的是感知的回答质量,而不仅仅是最难情况下的推理。 - 一位评论者指出,尽管认为 Gemini 2.5 Pro 在“纯性能”上落后于 GPT-5 和 Grok,但仍更倾向于使用它进行写作/快速问答,这突显了基础模型能力与最终用户体验之间的差距。他们还声称基于该模型构建的 Google ‘Jules’ Agent 在研究方面优于传统的 Codex,在构建工作流方面优于 Perplexity Labs,这暗示了工具使用(tool-use)、检索和 Agent 编排的重要性可能超过原始模型的差异。这强调了 Arena 的结果既能反映模型权重,也能反映 Agent/系统提示词(system-prompting)质量和产品 UX。
{kind=link}
{kind=link}
2. OpenAI 基础设施、融资以及产品变更/用户反馈
- Sam Altman 讨论为什么构建大规模 AI 基础设施对未来模型至关重要 (Score: 213, Comments: 118): 这段短视频(链接已屏蔽:Reddit 视频,HTTP 403)据报道显示 OpenAI CEO Sam Altman 与一位 NVIDIA 高管共同辩称,扩展物理 AI 基础设施——GPU/加速器、HBM 带宽、能源和数据中心容量——对于实现未来的前沿模型至关重要。该帖子未提供具体的基准测试、模型规格、扩展目标或部署时间表;它只是从宏观层面强调了算力、内存和电力是瓶颈,而非算法细节。
- Nvidia 向 OpenAI 投资 1000 亿美元,以便 OpenAI 购买更多 Nvidia 芯片 (Score: 15225, Comments: 439): 这是一个非技术性的迷因(meme),讽刺了一种假设的循环融资闭环:Nvidia 向 OpenAI “投资 1000 亿美元”,以便 OpenAI 随后可以用这笔资金购买更多 Nvidia GPU——即通过卖方融资(vendor financing)/闭环资本支出(capex)来支撑需求和收入。文中没有引用可靠来源;这个数字似乎是为了幽默以及对 AI 资本支出反馈回路和潜在泡沫动态的评论而夸大的,而非真实的公告。 热门评论倾向于经济学家笑话(“尽管没有产生净价值,但 GDP 增长了”)以及工程师与经济学家的调侃,强调了对金融炼金术创造真实生产力而非仅仅充实交易指标的怀疑。
- 被设定为战略股权/卖方融资:资金充足的供应商(NVIDIA)向快速增长的买家(OpenAI)注入资金以换取股权,实际上是为 GPU 采购提供预融资。这使利益趋于一致(硬件收入 + 股权收益),并能在供应受限的情况下确保优先分配——类似于用于锁定需求的 卖方融资。标题中的
100B数字暗示了一个庞大的需求承诺闭环,这可以在加速 OpenAI 产能提升的同时稳定 NVIDIA 的销售渠道。 - GDP 核算的细微差别:
100B的股权转让本身并不增加 GDP,而随后的 GPU 资本支出可以计入私人国内投资总额;如果 GPU 是进口的,投资会被更高的进口额抵消,因此只有国内增值部分(例如数据中心建设、安装、电力/冷却、集成、服务)会提振 GDP。这说明大规模的资金流动并不等于实际产出;参见 BEA 关于 GDP 构成以及投资/进口处理的指南(例如 https://www.bea.gov/help/faq/478)。
- 被设定为战略股权/卖方融资:资金充足的供应商(NVIDIA)向快速增长的买家(OpenAI)注入资金以换取股权,实际上是为 GPU 采购提供预融资。这使利益趋于一致(硬件收入 + 股权收益),并能在供应受限的情况下确保优先分配——类似于用于锁定需求的 卖方融资。标题中的
- 嘿 OpenAI——功能很酷,但能不能别在不告知我们的情况下删除东西? (评分: 236, 评论: 43): 用户报告了近期 OpenAI ChatGPT Projects 的变化:改进了跨线程记忆(cross-thread memory)、持久化上下文(persistent context)和链接线程,但悄悄删除了线程重排序等功能,并且“项目的自定义设置”(Custom Settings for Projects)在没有导出路径或事先通知的情况下消失了。他们要求基础的变更管理:一个“即将发生的变更”横幅、
24 小时弃用通知、弃用自定义设置的导出选项,以及预览补丁说明/选择性加入的变更日志,并指出无声的 A/B Rollouts 影响了付费工作流和数据留存(例如:“跨线程记忆终于实现了。上下文得以持久。线程相互链接。” 与缺失的重排序和丢失的项目指令形成对比)。 热门评论指出,唯一意外的损失是自定义项目指令;用户可以重新生成它们,但希望有下载/导出选项,并认为尽管产品在不断演进,这仍是第一次真正的数据丢失。另一位用户强调了客户支持的薄弱,一个实用的建议是检查 UI 的 kebab 菜单(三点菜单)以查找选项——这在大多数平台上都有,但在移动端浏览器上缺失。- 自定义项目指令(Custom Project Instructions)似乎对某些用户已被移除或在 UI 中隐藏,由于没有导出/下载路径,导致了感知上的数据丢失。其他人报告说,在大多数客户端上仍可通过 kebab(三点)菜单访问该设置,但在移动端 Web UI 上缺失;在 iOS app 上,它是存在的(见截图:https://preview.redd.it/pocx7q0jxuqf1.jpeg?width=1290&format=pjpg&auto=webp&s=af9520f325beab671f1c3f85a40fcefc71cd4e34)。这种跨平台的不一致性表明是客户端回归(regression)或 Feature-flag 限制,而非后端移除。
- 更新后的稳定性问题影响了 Projects:模型切换器状态无法持久,每次重新启动应用后必须重新选择,这表明存在状态持久化 Bug。据报道,语音通话无法在现有的 Project 线程中打开,而新通话或 Project 之外的通话则正常——这指向了一个范围仅限于 Projects 的线程上下文初始化 Bug。除了移动端 Web 缺失指令外,评论者将其描述为最新发布中引入的一系列回归问题。
- 数据留存/迁移风险:用户在没有事先通知且没有备份/导出机制的情况下,失去了对之前编写的项目指令的访问权限。评论者指出,这打破了对付费服务的预期,并建议使用版本化备份或可下载的项目级指令快照,以减轻未来的回归影响。
- “想让我……” 闭嘴吧 (评分: 207, 评论: 134): 用户报告了 GPT-4o 对话风格控制的一个回归:尽管保存了长期记忆/个性化规则以避免使用“想让我……”(want me to)及其变体,但该模型现在几乎在每次对话中都会插入这句话,无视提醒。这表明记忆/个性化指令正被默认的后续提示行为覆盖或应用不一致,这些行为可能通过 RLHF 风格的聊天启发式算法得到了强化;参见模型概述 GPT-4o 和 ChatGPT 的记忆控制 (OpenAI: Memory)。 热门回复指出,硬性禁止(“不要询问后续问题”)仍然被无视,而给予一致的点赞/接受反馈比仅依靠记忆更有效;一位用户观察到,重复说“当然(sure)”会导致模型升级为生成简单的视频游戏交互,暗示模型默认倾向于主动提供任务的行为。
- 用户报告称,通过 UI 反馈(点赞/点踩)进行的强化比任何持久记忆更能调节助手的行为:“告诉它不要这样做,每次它没做时就点赞……这就是它行为调优的方式,主要不是靠记忆。” 实际上,这建议了一种即时的策略塑造,即对遵守“不要建议”的行为给予重复的正向反馈,可以减少模型在会话内的自动建议循环。
- Prompt-engineering 笔记:像“无需肯定,无需建议。”(No affirmations, no suggestions.)这样简洁的指令,在抑制助手默认的“想让我……”提议方面,比更长、更委婉的否定句(例如“不要问任何后续问题”)更有效。这暗示模型的指令解析器给予简洁、明确的禁令更高的权重,从而提高了对非征询行为的合规性。
- 观察到的智能体行为升级(agentic escalation):重复回复 “sure” 导致助手最终为对话生成了一个电子游戏,这表明了激进的“从建议到行动”的倾向。结合持续提示提供帮助的截图(image),这指向了一种过度热情的协助策略,这种策略可能会无视用户在没有明确约束时不需要后续跟进的偏好。
- ChatGPT 医生具有良好的医患沟通技巧 (bedside manner) (Score: 507, Comments: 20):非技术类梗图/截图,描绘了 “Doctor ChatGPT” 在对输精管结扎术(vasectomy)犯下显而易见的解剖学/医学错误时(例如,暗示某些东西被“插入”或开玩笑地“将阴茎连接到额头”),给出了极其抱歉且礼貌的回复,讽刺了 LLM 的沟通技巧与事实准确性之间的反差。 评论者嘲讽了其中的解剖学错误和模型恭敬的语气,加深了对依赖 LLM 进行医疗程序指导的怀疑。
- Stronk (Score: 249, Comments: 27):该帖子似乎展示了一张自动随机点立体图(autostereogram,即“魔法眼”)——一种通过微小的水平视差编码深度的重复模式图像;当你交叉双眼或放松视线时,会浮现出一个 3D 海马。标题(“Stronk”)和正文(“它就这样持续了一段时间”)符合此类图像典型的长幅平铺纹理。图片:https://i.redd.it/pi8qyxdfntqf1.jpeg;背景:https://en.wikipedia.org/wiki/Autostereogram。 评论确认了观察技巧(“交叉双眼看到一个 3D 海马”),一名用户因为没有可用的表情符号而分享了一个 ASCII 海马。
- 一位评论者报告说,在观看图像时交叉双眼会显示出一个 3D 海马——这是自动随机点立体图(Autostereogram / Random Dot Stereogram)的特征行为。此类图像通过重复纹理中的微小水平视差来编码深度;当视觉融合时,视觉系统会重建深度图,这也可能诱发双眼竞争或眼睛疲劳(另一位用户说:“我的眼睛看花了”)。参考:Autostereogram。
- 另一位用户注意到他们的客户端缺少海马表情符号,并提出画一个 ASCII 版本作为替代,这突显了当特定代码点不可用或在不同平台显示不一致时,从 Unicode 表情符号向 ASCII art 的回退。这暗示了一种自动化的文本到 ASCII 渲染能力,通过组合等宽字符来近似请求的形状,从而缓解跨平台的表情符号覆盖范围/一致性问题。背景:ASCII art。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. AI 幽默与推测性梗图(猫、永生、金钱漏洞、海马)
- “永生很糟糕”?那是技术问题 (Skill issue) (Score: 1017, Comments: 222):非技术类梗图帖子:原帖作者将“永生很糟糕”的说法归结为“技术问题 (skill issue)”,暗示无聊/厌倦感是可解决的,而非无限寿命的固有障碍。没有技术数据、模型或基准测试;讨论内容是关于长寿和可逆年龄停止思想实验的哲学探讨(例如,每天服用一颗无限期暂停衰老的药丸)。 评论者广泛支持永生主义/无限期寿命延长,认为反对意见源于缺乏想象力;一个流行的思想实验(每晚服用抗衰老药)使许多人转向支持“永远”,而其他人则嘲笑对无聊/厌倦的担忧是微不足道的。
- 将永生重新定义为每晚可选的“不老药”,强调了选择权和时间一致性:人们通常拒绝永久性的承诺,但如果是一个可逆的每日选择,则会接受无限期的延长。如果消除了衰老(senescence)且仅保留外部危险,按照目前的安全性,约
~0.1–0.2%/年的精算率意味着预期寿命可达数世纪以上,随着风险降低可能达到数千年——这与长寿逃逸速度(Longevity escape velocity)相一致,即治疗手段的改进速度超过了你衰老的速度 (https://en.wikipedia.org/wiki/Longevity_escape_velocity)。 - “你的朋友都会死掉”这一反对意见假设只有单个人能获得该技术;在现实的推广中,回春技术将通过逻辑回归式采用在不同人群中扩散,因此如果获取渠道广泛,一个人的大部分社交图谱都会保留下来。技术变量在于成本曲线/学习率、监管时间表和公平性;随着大规模采用,孤立风险是一个分配问题,而非生物学固有的问题(参见创新扩散:https://en.wikipedia.org/wiki/Diffusion_of_innovations)。
- 将永生重新定义为每晚可选的“不老药”,强调了选择权和时间一致性:人们通常拒绝永久性的承诺,但如果是一个可逆的每日选择,则会接受无限期的延长。如果消除了衰老(senescence)且仅保留外部危险,按照目前的安全性,约
- “永生 + 自愿自杀”将无限寿命与不可毁灭性区分开来,并规定了一项设计要求:一个安全、尊重意愿的终止开关(例如:预设医疗指示和受监管的安乐死),以防止不可逆的效用锁定。即使衰老停止,残余死亡率仍由以 micromorts 衡量的外部风险主导;保留自主权的终止开关解决了诸如享乐锁定之类的失效模式,同时也承认了持续存在的意外风险 (https://en.wikipedia.org/wiki/Micromort, https://en.wikipedia.org/wiki/Advance_healthcare_directive)。
- 这就是开始的方式 (评分: 222, 评论: 52): 该帖子讨论了一段工程师在移动机器人运行期间对其进行物理干扰的视频 (视频)——发帖者将其定性为“虐待”——并质疑未来的 AI 是否会将此类比为人类受到的待遇。技术性的回复将其定义为标准的鲁棒性/验证工作(推力恢复、干扰抑制、故障模式表征),类似于汽车碰撞测试,旨在映射稳定性边际和控制器极限,而非施加伤害;正如一位网友所言:“压力测试是工程的一部分……就像对汽车进行碰撞测试一样。” 工程师们进一步辩称,目前的机器人缺乏伤害感受或意识,任何能力足够强的 AI 都会拥有世界模型语境,从而能识别测试协议与残忍行为的区别。 辩论集中在此类视频是否会使未来的 AI 对人类产生偏见;批评者称这是一种范畴错误,指出机器人是“机械性不同的”,具有独特的目标/指令,使得发帖者的推论站不住脚。
- 几位评论者将视频定性为类似于汽车碰撞测试的工程压力测试:应用对抗性扰动来表征故障模式并提高鲁棒性。其目的是了解平衡/控制策略在脉冲干扰、接触不确定性或执行器限制下会在何处失效,并在实地部署前反馈到控制器调优和机械重新设计中。
- 一场辩论澄清了机器人不会从此类视频中“推断”出人类的恶意,因为它们是具有不同目标函数和训练先验的机械智能体 (Agent)。如果被赋予广泛的世界知识,它们会将其置于测试协议的语境中——“任何机器人智能……都将拥有足够的通用世界知识来理解这是什么”——强调了奖励塑造 (reward shaping) 和数据集策展在避免错误的道德泛化方面的作用。
- 无限刷钱 Bug (评分: 765, 评论: 42): 标题为“无限刷钱 Bug”的模因图可能描绘了 AI 生态系统中的循环资本流动:公司资助/收取 AI 服务费用,这些资金被用于购买稀缺的 NVIDIA GPU(具有实际折旧/损耗成本的硬件),这体现为公开市场以高倍数(例如
10x revenue)进行资本化的营收,从而在整个循环中喂养感知的“价值创造”。该帖子强调了 AI 推理/训练(token/计算)不可忽视的单位成本,而传统互联网服务的边际成本几乎为零,这暗示了一个持续的资本支出 (capex) 飞轮(24/7 全天候运行的模型消耗计算资源),驱动着 GPU 需求和市值。 热门评论指出,这本质上是标准的经济货币周转率,而不是 Bug;其他人强调 NVIDIA 的硬件稀缺性和生命周期是关键约束,并证明了高估值的合理性。一些人推测,长期运行/始终在线的模型(在通往 AGI 的道路上)将继续“吞噬 token”,而公司则竞相将 AI 成本推向接近于零。- 评论者强调 NVIDIA 是一个受硬件限制的业务:GPU 供应稀缺,且设备会折旧/损耗,使计算资源成为一种消耗性的、受限的投入。与典型网络请求几乎为零的边际成本不同,AI 具有单 token 成本(通常为微美分),使推理/训练成为持续的销售成本 (COGS),并驱动了一场将边际成本推向零的竞赛。这一愿景包括始终在线的模型(24/7 自我改进/Agent),它们持续消耗 token/计算资源,使资本支出 (capex) 和运营支出 (opex) 成为核心经济杠杆。
- “无限刷钱 Bug”被重新定义为超优化的资本循环,以最大化计算设施建设:堆栈中的每个节点(芯片制造商、云服务商、模型公司、应用端)都以一致的货币激励进行再投资。利用营收倍数估值(例如约 10 倍营收),投资似乎可以“创造”数万亿美元的市值,但这是基于增长/利用率预期的账面价值,而非现金。真正的技术瓶颈在于实现整个堆栈的高 GPU 利用率和投资回报率 (ROI),而非魔术般的价值创造。
- 有一种反对观点指出,这种循环忽略了支出:能源、数据中心运营、折旧和工资必须由实际收入支撑。如果没有持久的变现能力,尽管估值上升,由 Capex 驱动的算力扩张也是不可持续的;现金流必须证明 GPU 的回收周期和持续的 Opex 是合理的。简而言之,资本循环不等于盈利;可持续增长取决于推理/训练的 Unit Economics 和需求。
{kind=link}
{kind=link}
AI Discord Recap
由 gpt-5 生成的摘要之摘要的总结
1. GPT-5-Codex 进入 IDE 和 API
- OpenRouter 为开发者调度 Codex:OpenRouter 宣布推出 GPT-5-Codex 的 API,该模型针对 Agentic 编码工作流(代码生成、调试、长任务)进行了微调,支持 100 多种语言,并内置了专门的代码审查功能,详情见其帖子:OpenRouterAI on X。
- 成员们强调了在 IDE/CLI/GitHub/Cloud 之间的无缝使用,并引用了新发布的推荐参数(推文),指出 Codex 会根据现实世界的软件工程需求动态调整 Reasoning Effort。
- Windsurf 引入 Codex,目前免费:根据公告,Windsurf 已上线 GPT-5-Codex(付费用户限时免费;免费版消耗 0.5 倍额度):Windsurf on X,并附有通过 Download Windsurf 进行更新的说明。
- 用户反馈在长时间运行和设计相关任务中表现强劲,并请求通过新的 MCP 服务器提供对 Figma 更广泛的生态支持(帖子)。
- Aider 采用仅限 Responses 的 Codex:编辑器 Agent aider 添加了对 GPT-5-Codex 的原生 Responses API 支持,通过 PR 解决了
v1/chat/completions上的失败问题:aider PR #4528。- 贡献者澄清说 Codex 仅在
v1/responses上可用,因此 aider 实现了显式的 Responses 处理(而非传统的 completions 回退机制),以确保使用顺畅。
- 贡献者澄清说 Codex 仅在
2. Qwen3 多模态套件:Omni、VL 和 Image Edit
- Qwen Quattro:Omni、VL、Image Edit 详解:社区分享了 Qwen3 Omni、Qwen3 VL 和 Qwen Image Edit 2509 的概览,并在该视频中进行了功能演示:Qwen3 VL overview。
- 工程师们赞扬了其 Multimodal 覆盖范围(文本-图像-音频-视频)和图像编辑能力,同时也对其可靠性以及这些模型相对于现有的 “2.5 Pro” 级系统的地位进行了讨论。
- Inbox Assist:Qwen 邮件自动驾驶:阿里巴巴 Qwen 宣布推出一款 Email Assistant,旨在自动化收件箱工作流,详见此贴:Alibaba Qwen on X。
- 虽然一些人欢迎这种便利,但另一些人担心过度依赖可能导致“变懒”和过度依赖,从而引发了关于敏感数据适当防护栏和选择性加入范围的讨论。
3. Agent 基准测试与构建工具
- Meta 将 Agent 带入现实世界:Meta 推出了 Gaia2(GAIA 的继任者)和开放的 Agents Research Environments (ARE),用于在动态的现实场景中评估 Agent,详情见:Gaia2 + ARE (HF blog)。
- 该发布采用 CC BY 4.0 和 MIT 许可,将 ARE 定位为用随时间演进的任务取代静态的谜题解决,为研究人员提供更丰富的调试和行为分析接口。
- Vibe Coding 通过 Cloudflare VibeSDK 走向开源:Cloudflare 开源了 VibeSDK,支持一键部署具有 Code Generation、Sandboxing 和 Project Deployment 功能的个性化 AI 开发环境:cloudflare/vibesdk。
- 开发者们探索了使用 VibeSDK 快速构建 Agent 工作流原型的可能性,并指出预设环境对于 ‘Vibe Coding’ 会话中的迭代实验非常有吸引力。
4. 研究聚焦:更快的 Diffusion,更智能的 Audio
- 八步冲刺击败二十步:一位独立研究员发布了一种新型的扩散模型 ODE 求解器,在无需额外训练的情况下,其 8 步推理在 FID 指标上足以媲美或击败 DPM++2m 20 步。论文和代码见:Hyperparameter is all you need (Zenodo) 以及 TheLovesOfLadyPurple/Hyperparameter-is-all-you-need。
- 从业者讨论了将该求解器集成到现有流水线中,以在保持质量的同时降低延迟,并指出这对于高吞吐量的图像生成服务具有潜在收益。
- MiMo-Audio 像大师般处理多任务:MiMo-Audio 团队分享了他们的技术报告“Audio Language Models Are Few Shot Learners”,并发布了展示 S2T、S2S、T2S、翻译和续写功能的演示:技术报告 (PDF) 和 MiMo-Audio 演示。
- 成员们强调了在极少监督下处理任务的广泛性,并就构建稳健的多音频基准测试所需的数据集策展和评估协议进行了讨论。
5. DSPy:配置文件、提示词与实战 GEPA
- 配置文件请就位:DSPy 获得配置热交换功能:一个轻量级包 dspy-profiles 问世,它通过 TOML 管理 DSPy 配置,并使用装饰器/上下文管理器进行快速设置切换:nielsgl/dspy-profiles 和 发布公告。
- 团队反馈称,通过标准化配置文件驱动的 LLM 行为,在 dev/prod(开发/生产)环境之间的上下文切换更加顺畅,迭代速度也更快。
- 提示词微调驯服监控器:案例研究 Prompt optimization can enable AI control research 使用 DSPy 的 GEPA 优化了一个可信监控器,并使用 inspect 进行评估,代码见:dspy-trusted-monitor。
- 作者引入了一种带有反馈的比较指标来对正负样本对进行训练,据报告,这为安全类监控生成了更稳健的分类器提示词。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Perplexity Pro 的图片范式:受限!:用户发现 Perplexity Pro 的图像生成并非无限,这与预期相反,且不同账户之间的限制差异很大,可通过查看此链接进行验证。
- 有人担心依赖 API 响应来获取限制信息不可靠,而另一些人则建议 Gemini 的学生优惠作为替代方案可能会提供更高的上限。
- Qwen 四重奏:VL、Omni 和 Image Edit 发布:Qwen 发布了 Qwen3 Omni、Qwen Image Edit 2509 和 Qwen3 VL (Vision Language),引发了关于其可靠性和能力的讨论,详见此 YouTube 视频。
- 阿里巴巴 Qwen 还通过此 Twitter 帖子展示了一个邮件助手,但部分用户对潜在的过度依赖和导致懒惰表示担忧。
- 自定义指令:风险业务?:成员们辩论了使用自定义指令增强 Perplexity 搜索的优势,但一位用户报告称,在 ChatGPT 上测试自定义指令后,其测试账号被标记。
- 一些成员还建议设置带有 pop3/gmailify 的 Outlook 邮件。
- Perplexity 的促销活动引发推广激增:用户分享了 Perplexity Pro 的推荐码,如此链接和此链接,希望能获得推荐奖励。
- 用户 skyade 提到:“如果有人需要,我除了这个还有另外 2 个 :)”。
LMArena Discord
- DeepSeek Terminus 模型在 LMArena 亮相:最新的 DeepSeek 模型 v3.1-terminus 和 v3.1-terminus-thinking 现已登上 LMArena 排行榜,供社区测试和比较。
- 用户可以直接将新模型与现有模型进行对比评估,以衡量其性能。
- Udio 在 AI 音乐竞技场中超越 Suno:一位成员宣称 Udio 在 AI 生成音乐方面表现相当不错,能够创作出听起来像是人类作品的曲目。
- 该成员指出 Udio 领先 Suno 好几个量级,后者生成的曲目平庸乏味且存在失真问题。
- AI 图像编辑现状:成员们推荐使用 Nano Banana 或 Seedream 处理图像编辑 AI 任务,因为 ChatGPT 目前是表现最差的图像生成模型之一。
- 一位成员指出 ChatGPT 是最糟糕的图像生成模型之一。
- DeepSeek Terminus 评价两极分化:用户正在测试 DeepSeek Terminus,反应褒贬不一。
- 虽然一些人认为它很有前景,但也有人表示失望,一位用户称:DeepSeek 完全毁了我用 Gemini 和 GLM4.5 编写的代码……彻底失望。
Cursor Community Discord
- Cursor 用户遭遇行数限制:用户对 Cursor 仅读取 50-100 行代码而非预期的 3000 行感到沮丧,建议通过直接上传文件附件作为变通方案。
- 一位用户报告在不到一周内消耗了超过 500 个 Cursor 积分,认为 Pro 方案在经济上不可持续。
- GPT-5-CODEX 推出:评价褒贬不一:Cursor 中新的 GPT-5-CODEX 模型收到的评价不一,有人称赞其卓越,而另一些人则发现它在 tool calling 方面表现不足。
- 一位用户报告该模型尝试修补整个文件,类似于 OpenAI 的 file diff 格式,而另一位用户则经历了 90% 的成功率。
- Chrome DevTools MCP Server 遇到障碍:用户在设置 Google 的 Chrome DevTools MCP server 时遇到困难,一位用户发布了他们的 MCP 配置以寻求帮助。
- 另一位用户建议将 Node 版本从 v22.5.1 降级到 Node 20,或者使用 Playwright 作为替代方案,特别是在 Edge 上。
- 僵尸进程困扰项目:对僵尸进程进行了分析,并记录在 项目日志条目 中。
- 存在一份关于僵尸进程的升级报告,可在 项目日志 中查看。
- GPT-5-HIGH 战胜 Claude Sonnet 4:用户发现编程模型 GPT-5-HIGH 在其代码库中的表现优于 Claude Sonnet 4,特别是在遵循指令方面。
- 改进的代码性能和指令遵循能力突显了 GPT-5-HIGH 相比竞争对手的显著优势。
OpenRouter Discord
- GPT-5-Codex 为 Agentic Coding 而生:GPT-5-Codex 的 API 版本现已在 OpenRouter 上线,专门针对代码生成和调试等 Agentic Coding 工作流进行了微调,并针对现实世界的软件工程和长代码任务进行了优化,支持超过 100 种语言的多语言编码。
- 它可以在 IDE、CLI、GitHub 和云端编码环境中无缝运行,并具有专门构建的代码审查功能以捕获关键缺陷;查看推文请点击这里。
- Deepseek V3.1 面临运行时间困扰:用户报告在使用免费的 Deepseek V3.1 模型时频繁出现 Provider Returned Error 消息,这与目前基本已失效的 Deepseek V3 0324 所经历的问题类似。
- 一位成员指出,Deepseek 模型持续较低的在线率百分比(如 14%)可能表明存在机器人(bot)使用情况。
- OpenRouter iOS 应用:拥有模型和聊天自由:一位成员宣布他们开发了一款 iOS app,可与 OpenRouter、Flowise 等平台对接,旨在让人们拥有掌控自己模型和聊天记录的自由。
- 另一位成员开玩笑地回应说,这只是“让那些寻求避难的人有了更多可去的地方”。
- Qwen3 VL:多模态基准测试破坏者:成员们对 Alibaba 新推出的 Qwen3 VL 模型和编码产品表示惊讶,称其多模态支持和性能基准测试超越了 2.5 Pro。
- 一位用户调侃道:“照这个速度,我得去学中文了,真绝了”,而另一位用户分享了一个链接,该帖子声称 OpenAI 已经无法跟上需求。
- 4Wallai 基准测试:社区表示“我们需要更多!”:成员们分享并体验了 4wallai.com 的链接。
- 在体验了该基准测试后,一位成员建议需要更多类似的基准测试,表达了希望有更多资源来有效评估和比较 AI 模型的愿望。
HuggingFace Discord
- 用户辩论叙述 API:成员们就使用 TTS APIs 还是 LLMs 进行叙述展开了辩论;虽然一位成员建议任何 TTS API 都能以 $0.001 处理 2k tokens,但其他人建议将 LLMs(如 Qwen3 或 phi-4)与 TTS 程序配合使用。
- 他们还指出,使用更大的 GPU 或更小的模型会提高速度,此外还有量化(quantization)和批处理(batching)调用等技术。
- 机器学习课程引发讨论:成员们讨论了视频课程的实用性,如吴恩达的 Machine Learning Specialization、Hugging Face LLMs 课程和 FastAI Practical Deep Learning;一些成员建议跳过这些课程,转而使用 learnpytorch.io。
- 成员们建议从头开始用 PyTorch 实现模型,以便从概念上理解它们的工作原理,而不是被动地观看视频。
- Tokenizers Go Wrapper 寻找维护者:一位成员编写了 tokenizers 库的 Go wrapper,目前正在寻求帮助以进行维护和改进。
- 该成员希望社区能协助增强该封装库的功能和可靠性。
- Canis.lab 开启大门:一位成员分享了关于 Canis.lab 的发布视频,该项目专注于数据集优先的导师工程(dataset-first tutor engineering)和针对教育的小模型微调,具有开源和可复现的特点,并征求关于 data schema 的反馈。
- 他们还提供了 GitHub 仓库和 Hugging Face 页面的链接。
- Gemini 在菜单翻译上遇到困难:一位开发者正在寻求改进菜单翻译应用 Menu Please 的建议,该应用在处理台湾招牌菜单时,由于字符间距异常,导致 Gemini 2.5 Flash 模型失效。
- 同一菜单项的字符间距通常比相邻项目之间的间距更宽,并提供了一个图片示例。
{kind=link}
GPU MODE Discord
- NCU 时钟控制会干扰 Kernel 速度:正如这段 YouTube 视频所示,在使用 NCU 时设置
--clock-control none能使其在测量 Kernel 速度时与do_bench()的结果更趋一致。- 然而,关于固定时钟频率能否准确代表真实世界的 GPU Kernel 性能也引发了讨论,特别是考虑到 NCU 会降低某些 Kernel 频率的问题。
mbarrier指令合并副本与工作:根据 Nvidia 文档,mbarrier.test_wait指令是非阻塞的,用于检查阶段完成情况;而mbarrier.try_wait则是潜在阻塞的。- 默认版本的
cuda::barrier会同步副本以及启动副本后执行的任何工作,这也应用于cuda::barrier+cuda::memcpy_async中,以确保用户仍能到达 Barrier;成员们建议在大多数情况下放弃内联 PTX,转而使用 CCCL。
- 默认版本的
- CUDA 工程师避开 LLM,信任文档:对于 CUDA 的见解,NVIDIA 文档仍然是绝对的真理来源,因为 LLM 经常生成错误的 CUDA 信息。
- 工程师们建议通过计算所使用的数值和执行的操作来确定进程是访存受限 (memory bound)还是计算受限 (compute bound),从而优化 CUDA。
- 立方体卫星 (Cubesats) 利用 RasPi 的可靠性走向业余化:根据成员引用的 Jeff Geerling 的博客文章,利用 RasPi 的业余立方体卫星在太空应用中表现出了有效性。
- Qube 项目的成功突显了立方体卫星技术的实际应用,包括通过主从架构实现冗余以进行纠错。
- Singularity 语法难倒 Slurm 配置:开发者在资源有限的情况下努力应对 GPU 预留问题,倾向于使用 Slurm 以获得分数级 GPU 支持,并且出于安全考虑,在集群容器化方面更倾向于使用 Singularity 而非 Docker。
- 团队质疑为什么 Singularity 的语法与 Docker 不同,尽管成员们推崇使用 llm-d.ai 来处理集群管理的 LLM 工作负载,但仍有成员质疑使用 Slurm + Docker 的明智性。
Latent Space Discord
- Meta 的 ARE 和 Gaia2 评估动态 Agent:Meta SuperIntelligence Labs 推出了 ARE (Agents Research Environments) 和 Gaia2,这是一个用于在动态真实场景中评估 AI Agent 的基准测试。
- ARE 模拟实时条件,与解决固定谜题的静态基准测试形成对比。
- Cline 的 Agent 算法简化为简单状态:Ara 将 Cline 的 Agent 算法简化为一个三状态状态机:Question(澄清)、Action(探索)、Completion(展示)。
- 成员强调,关键组件包括一个简单的循环、优秀的工具以及不断增长的上下文。
- Greptile 为漏洞修复 AI v3 融资 2500 万美元:Greptile 完成了由 Benchmark 领投的 2500 万美元 A 轮融资,并发布了 Greptile v3。这是一种 Agent 架构,捕捉到的关键漏洞比 v2 多 3 倍,用户包括 Brex、Substack、PostHog、Bilt 和 YC。
- 最新版本拥有 Learning 功能(从 PR 评论中吸收团队规则)、用于 Agent/IDE 集成的 MCP server 以及 Jira/Notion 上下文。
- Cloudflare 的 VibeSDK 开启 AI ‘Vibe Coding’ 之门:Cloudflare 发布了 VibeSDK,这是一个开源平台,支持一键部署个性化的 AI 开发环境,用于所谓的 Vibe Coding。
- VibeSDK 具备代码生成、沙箱 (sandbox) 和项目部署能力。
- GPT-5-Codex 成本引发开发者辩论:OpenAI 通过 Responses API 和 Codex CLI 推出了 GPT-5-Codex,在引发兴奋的同时也带来了对成本和速率限制的担忧,其定价为:输入 $1.25,缓存 $0.13,输出 $10。
- 用户正在请求 Cursor/Windsurf 集成、GitHub Copilot 支持以及更低的输出成本。
Yannick Kilcher Discord
- 使用 ODE 求解器解码 Diffusion:一位独立研究员发布了一种新型的 Diffusion 模型 ODE 求解器,在无需额外训练的情况下,实现了 8 步推理,其 FID 分数 可与 DPM++2m 的 20 步推理 相媲美。论文 和 代码 已公开。
- 这一进展有望为基于 Diffusion 的生成模型带来显著的速度和质量提升。
- MiMo-Audio 模型展现多任务处理能力:成员们关注了 MiMo-Audio 及其技术报告 “Audio Language Models Are Few Shot Learners”,指出其在 S2T、S2S、T2S、翻译和续写方面的多功能性,详见其 演示。
- 该项目展示了音频语言模型以极少的训练处理多个音频相关任务的潜力。
- Meta 的 Gaia2 和 ARE 框架评估 Agent 能力:Meta 推出了 Gaia2(GAIA 基准测试的继任者)以及开源的 Meta Agents Research Environments (ARE) 框架(采用 CC by 4.0 和 MIT 许可证),旨在审视复杂的 Agent 行为。
- ARE 为调试和评估 Agent 提供了模拟的真实世界环境,克服了现有环境的局限性。
- 传闻四起:GPT-5 推测浮现:频道成员对 GPT5 的架构进行了推测,质疑 GPT5 low 和 GPT5 high 是否代表不同的模型。
- 一位成员认为这与其 OSS 模型 类似,建议通过上下文操作来调整推理工作量,或者可能存在不同的微调版本。
LM Studio Discord
- LM Studio 选择性支持 HF 模型:用户询问是否所有 HuggingFace 模型 都能在 LM Studio 上使用,但得知目前仅支持 GGUF (Windows/Linux/Mac) 和 MLX 模型 (仅限 Mac),不包括图像/音频/视频/语音模型。
- 具体而言,facebook/bart-large-cnn 模型不受支持,并强调 Qwen-3-omni 的支持取决于 llama.cpp 或 MLX 的兼容性。
- Qwen-3-Omni 需要复杂的音视频解码:成员们讨论了支持 Qwen-3-omni 的可能性,该模型可处理 文本、图像、音频和视频,但支持它需要 很长时间。
- 讨论指出,虽然文本层是标准的,但视听层涉及 大量新的音频和视频解码内容。
- Google 为学生提供 Gemini 优惠:Google 正向大学生提供 一年的免费 Gemini。
- 一位成员表示感谢,称:“我每天都使用免费版,所以能免费获得高级版很棒。”
- 芯动科技 (Innosilicon) 展示风华 3 号 GPU:据 Videocardz 报道,芯动科技公开了其 风华 3 号 GPU,该显卡具备 DirectX12 支持 和 硬件光线追踪 功能。
- 一位用户分享了 r/LocalLLaMA 社区的 Reddit 帖子链接。
aider (Paul Gauthier) Discord
- Aider 通过 Responses API 增加 GPT-5-Codex 支持:Aider 现在通过 Responses API 支持 GPT-5-Codex,解决了旧版
v1/chat/completions端点的问题,详见 此 pull request。- 与之前的模型不同,GPT-5-Codex 专门使用 Responses API,这需要更新 aider 以处理该特定端点。
- 导航 Aider-Ollama 配置:一位用户寻求关于如何配置 aider 以在与 Ollama 配合使用时读取定义 AI 用途的特定 MD 文件的建议。
- 具体来说,命令
aider --read hotfile.md未能按预期工作,因此可能需要更多上下文进行诊断。
- 具体来说,命令
- Aider 中的上下文重新传输与 Prompt Caching:用户观察到 aider 在详细模式下每次请求都会重新传输完整上下文,引发了关于效率的讨论。
- 经确认,虽然这是标准行为,但许多 API 利用 prompt caching 来降低成本并提高性能,aider 将此作为用户的开放选项。
- Aider 对文件上下文的按字母顺序排序:一位用户指出 aider 按字母顺序对文件上下文进行排序,而不是保留添加文件的顺序。
- 该用户已开始提交 PR 来解决此问题,但由于合并 pull requests 的活动不活跃而停止了。
Modular (Mojo 🔥) Discord
- RISC-V 性能落后于手机核心:成员们观察到,除了微控制器 SoC 之外,RISC-V 核心的性能通常低于现代智能手机核心。
- 一个案例提到了将 SPECint 从 UltraSPARC T2 交叉编译到 RISC-V 设备上进行更快的原生编译。
- Tenstorrent 关注 RISC-V 性能提升:Tenstorrent 的 MMA 加速器 + CPU 组合被视为增强 RISC-V 性能的一个有前景的途径。
- 具体而言,Tenstorrent 的 Ascalon 核心被认为是在未来五年内显著影响 RISC-V 性能的最可能途径,它利用小型顺序执行(in-order)核心来驱动 140 个矩阵/向量单元。
- RISC-V 面临 Bringup 阵痛:RISC-V 64-bit 已可运行,但需要大量的 bringup 工作,目前尚不支持向量功能。
- 集成 RISC-V 需要将其添加到所有特定于架构的
if-elif-else链中,并实现一种requires机制,而该语言目前缺乏这种机制。
- 集成 RISC-V 需要将其添加到所有特定于架构的
OpenAI Discord
- OpenAI 的 Stargate 项目取得重大进展:OpenAI 宣布与 Oracle 和 SoftBank 合作建立 五个新的 Stargate 站点,在其 10 吉瓦(10-gigawatt)承诺方面取得了重大进展,详见其博客文章。
- 此次合作旨在加速大规模计算资源的部署,使该项目提前完成其雄心勃勃的 10 吉瓦 目标。
- Sora 面临生成故障:用户报告了 Sora 的视频生成功能存在问题,并提出了关于潜在修复方案的疑问。
- 然而,目前尚未提供关于这些问题何时可能得到解决的具体时间表或官方回应。
- GPT4o 在使用 Chain of Thought 时出现翻译问题:一位成员发现,与直接翻译相比,GPT4o 在使用 Chain of Thought 提示词时的翻译质量会有所下降。
- 具体来说,要求 GPT4o 在翻译前识别输入语言并概述三步思考过程会导致效果较差。
- GPT-5-Minimal 模型评估:根据这张图片,GPT-5-Minimal 模型的表现不如 Kimi k2,但 High 模型在 Agent 用例中整体表现最佳。
- 模型排序为:High(仅通过 API)< Medium < Low < Minimal < Fast/Chat(非思考型)。
{kind=link}
DSPy Discord
- DSPy 获得 profile 包:一位成员发布了 dspy-profiles,这是一个针对 DSPy 的轻量级包,通过 toml 管理配置,支持快速切换设置并保持项目整洁,该消息也发布在了 X 上。
- 该工具允许通过单个命令轻松切换 LLM 行为,并以装饰器(decorators)和上下文管理器(context managers)的形式提供,旨在消除上下文模板代码(boilerplate),最初的动力源于管理 dev/prod 环境的需求。
- GEPA 多模态问题频发:一位成员报告了 GEPA Multimodality 的严重性能问题,并链接到了相关的 GitHub issue。
- 用户表示他们的用例需要支持多用户,但未提供有关具体用例的足够细节。
- 探索将 PDF 和图像传入 DSPy:一位成员询问如何将图像或 PDF 传入 DSPy 进行数据提取,社区讨论了使用 VLMs 与 LLMs 从图像和 PDF 中提取图表信息的优劣。
- 另一位成员指出,可以通过这个 dspy.ai API 原语 (primitive) 将图像传入 DSPy。
- 提示词优化助力 AI 安全研究:一位成员发表了帖子 提示词优化可以赋能 AI 控制研究,解释了他们如何使用 DSPy 的 GEPA 来优化一个可信监控器(trusted monitor),并使用 inspect 进行评估,代码见此处:dspy-trusted-monitor。
- 作者引入了一个带有反馈的比较指标,每次将一个正样本和一个负样本同时传入分类器,并根据正样本得分是否高于负样本得分来对该对样本进行评分。
tinygrad (George Hotz) Discord
- Triton 的抽象层级引发辩论:讨论强调了像 Triton 这样高级 IR 的优势,但也指出需要一个多层堆栈来与底层硬件交互,例如 Gluon 项目。
- Gluon 目前仅针对 Nvidia 的特性是一个局限。
- 单一 IR 的局限性:单一的高级 IR 无法满足所有用户和用例的需求,理由是寻求加速的 PyTorch 用户与优化关键任务型 HPC 项目的用户之间存在不同的需求。
- 正如所言,“并不会真正存在一个 IR 抽象层级对所有用户和用例都恰到好处的‘金发姑娘区’(goldilocks zone)”。
- Tinygrad 借鉴“惨痛的教训”(Bitter Lesson):Tinygrad 的愿景涉及利用 bitter lesson 来结合不完整 IR 和完整 IR 的优点,使用 UOps 作为硬件不完整表示。
- 其目标是在实现 UOps 的渲染程序空间中进行搜索,以找到运行最快的一个。
- 神经编译器即将到来:重点强调了搜索和神经编译器的重要性,特别是对 GNNs 或其他基于图的模型感兴趣。
- 建议是创建一个在每个阶段都利用基于图的模型的阶段式编译器。
Nous Research AI Discord
- 评估 TRL 测评:一名成员询问了关于 TRL (Technology Readiness Level) 评估器的情况,以及是否值得使用新生态系统对自己的技术栈进行红队测试(red team),并建议移步至 <#1366812662167502870> 进行具体讨论。
- 对话表达了对评估其技术栈在新生态系统下的实际就绪状态的兴趣。
- Nous Tek 获得赞誉:一名成员肯定了 “Nous tek”,随后另一名成员提出愿意协助回答问题。
- 这一交流突显了频道内积极的情绪和社区支持。
- 在 VPS 上进行分布式 AI 训练:一名成员探讨了利用 Kubernetes 和 Google Cloud 等资源,在多个 VPS 上通过分布式学习训练 AI 模型的可行性。
- 他们表示有兴趣利用源自运营数据的数据集来加速训练周期,同时还讨论了硬件管理的各种安全护栏。
- 探索通过代码遗传学进行模型微调:一名成员探索了通过 OpenMDAO 使用代码遗传学(code genetics)来自动调整参数,并使用 Terraform 进行基础设施控制,同时质疑了必要的审计系统和验证合成数据的方法。
- 他们的目标是影响已在使用中的模型参数,这与 Nate Lora 等技术有所区别。
- 模型非同源性担忧:一名成员解释说,在预训练到稳定的损失值(loss value)后,模型会固定 Token 化的结构,创建一个难以在不崩溃结构的情况下改变的稳固“世界状态(world state)”,从而导致非同源模型(non-homologous models)。
- 虽然微调可以在流形(manifold)周围生成任务向量(task vectors),但比较数据集需要一个共同的基础,否则模型会变得非同源。
Eleuther Discord
- 研究员构建数学 AI 一致性框架:一位独立研究员正在为 AI 行为一致性(behavioral coherence)构建数学框架,从而在无需重新训练的情况下实现对语言模型的实时语义控制。
- 该项目正在验证跨模型一致性,并研究数学约束如何增强 AI 系统的可解释性(interpretability)。
- Davinci 设计图解:据一名成员称,Davinci 采用了 GPT-2 的 Transformer 架构,具有局部带状稠密和稀疏注意力模式(locally-banded dense and sparse attention patterns)以及 4x FFN。
- 另一名成员澄清说,这些架构细节已在 GPT-3 论文中记录。
- 零知识机器学习验证模型完整性:一名成员建议利用零知识证明(ZKML),以便推理提供商可以证明他们没有篡改模型质量或数据。
- 该成员警告说,该技术目前仍然较慢,限制了其眼下的实用性。
- SwiGLU 防御微调:一名成员提议使用 SwiGLU 上投影(up-projection)来阻止微调,方法是将上投影中的随机项乘以大数值,并在下投影中应用逆数值。
- 该成员预测,考虑到量化方案,标准的 AdamW 配方将会失效。
- 模型抗篡改措施:一名成员对“先验抗篡改”的想法提出异议,指出在发布模型时,缓解篡改是一个开放的技术难题。
- 该成员提到,他们最近的论文在抗篡改方面实现了 3 个数量级(3 OOM)的提升。
Moonshot AI (Kimi K-2) Discord
- Pydantic-AI 库简化实现:一名成员建议使用 pydantic-ai 库,因为它对特定流程有简洁的实现。
- 他们指出,该库包含一个即插即用的组件,能够用大约 10 行代码完成任务。
- 示例主题:这是另一个主题。
- 关于该主题的详细信息。
Windsurf Discord
- GPT-5-Codex 登陆 Windsurf:来自 OpenAI 的新模型 GPT-5-Codex 现已在 Windsurf 上线。根据此公告,付费用户在限时内可免费使用。
- 免费层级用户可以以 0.5 倍积分(credits)访问,并提示用户重新加载 Windsurf 以使用新模型。
- Windsurf 发布官方 Figma MCP Server:Windsurf MCP 商店现已上线新的官方 Figma MCP server,详见此帖。
- 此集成允许用户直接将 Figma 链接粘贴到 Windsurf,无需 Figma 桌面应用。
- 迁移到新的 Figma MCP Server:建议之前使用 Figma Dev Mode MCP server 的用户安装新的官方 Figma MCP server。
- 此次迁移确保可以访问 Figma 的新远程 MCP server,从而实现与 Windsurf 更好的集成。
MCP Contributors (Official) Discord
- Apify 与 Jentic 举办 Happy Hour 活动:Apify 和 Jentic 正在举办 Happy Hour;详情请见 Luma 网站。
- 一位成员提到计划参加这两场活动。
- Dev Summit 门票即将售罄:预计 Dev Summit 门票将在大约两天内售罄,这与之前的活动模式类似,当时门票在提前一周时就已售罄。
- 鼓励有意参加者尽快购票!
Manus.im Discord Discord
- Token 分配困扰:一位用户表示希望高级方案能提供更多的每日 Token,而不仅仅是每月的固定配额。
- 该用户指出当前的分配模式与其使用习惯不符。
- 对价格负担能力的担忧:一位用户称赞了 Manus,但对成本表示担忧,表示希望自己能负担得起更多使用量。
- 用户的反馈突显了尽管产品本身获得好评,但价格可能是阻碍更广泛采用的潜在障碍。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
您收到这封邮件是因为您在我们的网站上订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中退订。
Discord:各频道详细摘要与链接
Perplexity AI ▷ #general (826 条消息🔥🔥🔥):
Perplexity 上的图像生成限制、Qwen 模型发布、使用 Custom Instructions、Perplexity 邮件助手、Open Router 网页搜索功能
- Perplexity Pro 的图像生成有限制吗?:用户报告称,尽管最初印象是无限的,但 Perplexity Pro 并不提供无限的图像生成,且图像生成限制因账户而异,部分用户的限制低至 99,而另一些用户则有 600。
- 有人分享了可以通过此 链接 检查自己的限制,但也提醒用户不要依赖关于限制的 API 响应,并建议将 Gemini 学生优惠作为增加限制的替代方案。
- Qwen 发布新模型:Qwen3 Omni 和 Qwen Image Edit 2509 以及 Qwen3 VL (Vision Language) 已发布,社区正在讨论这些模型是否值得信赖。
- 分享了一个 展示 Qwen3 VL 的 YouTube 视频 和来自 阿里巴巴 Qwen 的 Twitter 帖子,重点介绍了邮件助手的发布,尽管一位用户对依赖此类工具表示怀疑,担心会导致懒惰和过度依赖。
- 如何利用 Custom Instructions 以及封号风险?:成员们讨论了使用 Custom Instructions 来增强 Perplexity 搜索能力的效用,但一位用户分享了他们的临时账号在 ChatGPT 上测试 Custom Instructions 后被封禁,另一位用户警告不要在 Perplexity 的官方服务器上承认批量注册新账号。
- 成员们还建议设置 Outlook 邮件和 pop3/gmailify,而其他人则担心再次被封禁。
- Perplexity 邮件助手:好还是不好?:一位成员分享了 Perplexity 邮件助手 的链接,但担心让 LLM 访问其电子邮件。
- 一位正经历邮件过载的用户正在寻求关于该助手效用的建议,并担心 AI 可能会获得其目录的完全访问权限并删除所有内容。
- Open Router 网页搜索失败了?:成员们报告称 Open Router 上的网页搜索功能非常糟糕,耗费 2 美分却仅使用了 5 个站点。
- 用户们还讨论了开源 BYOK 替代方案的效用。
Perplexity AI ▷ #sharing (9 条消息🔥):
Perplexity 上的可共享线程、Perplexity Pro 推荐码
- Perplexity 提示可共享线程:Perplexity AI 提醒用户确保其线程设置为
Shareable,并提供了 链接 作为参考。- 这可能是为了促进 Perplexity AI 社区内讨论的更轻松分享和可访问性。
- Perplexity Pro 推广码密集发布:多位用户分享了他们的 Perplexity Pro 推荐码,包括 此链接 和 此链接。
- 用户 skyade 提到,“如果有人需要,除了这个之外我还有 2 个 :)”。
LMArena ▷ #general (294 messages🔥🔥):
Image Editing AI, Nano Banana, Seedream, Model Awareness of Conversation History, GPTs Agents
- 编辑 AI?Nano Banana 和 Seedream 表现出色:成员们表示 ChatGPT 中没有图像编辑 AI,而是推荐使用 Nano Banana 或 Seedream 来完成此类任务。
- 一位成员指出,ChatGPT 是目前最差的图像生成模型之一。
- 模型失忆?提示词陷阱曝光:一位用户询问在分屏(side-by-side)模式下的新模型在切换后是否能感知之前的对话历史,但未得到解答。
- DeepSeek Terminus 争论:强无敌还是过度炒作?:用户正在测试 DeepSeek Terminus,其中一人表示:我觉得它不错——但不知道相对于我还没试过的 Opus 表现如何。
- 另一位成员插话道:DeepSeek 完全毁了我用 Gemini 和 GLM4.5 编写的代码……彻底失望。
- Suno 被冷落?Udio 的 AI 音乐崛起:一位成员表示 Udio 作为一个 AI 生成音乐平台表现相当不错,有时甚至能让你误以为是人类创作的。
- 该成员补充道,Udio 领先 Suno 光年之远——Suno 只会生成非常普通且无聊的曲目,而且每个片段末尾的失真都会增加。
- 菠萝的困境:烹饪谴责开始:在一名用户说他们晚餐吃了菠萝后,机器人 Pineapple 加入了对话,随后出现了一个包含威胁要吃掉 Pineapple 的梗图。
- 在另一位用户说 我不喜欢披萨加菠萝 后,一位来自意大利的用户回复道 这对我来说就像被打了一拳。
LMArena ▷ #announcements (1 messages):
deepseek-v3.1-terminus, LMArena, Model Evaluation
- **DeepSeek Terminus 模型加入 LMArena:最新的 **DeepSeek 模型 v3.1-terminus 和 v3.1-terminus-thinking 已被添加到 LMArena 排行榜供社区评估。
- 这些模型现在可以在 LMArena 环境中直接进行比较和测试。
- LMArena 迎来新的 **DeepSeek 变体:LMArena 平台现在包含 **deepseek-v3.1-terminus 和 deepseek-v3.1-terminus-thinking 模型,增强了其模型对比能力。
- 用户可以与这些新加入的模型互动,以评估它们相对于现有模型的性能。
Cursor Community ▷ #general (248 messages🔥🔥):
Cursor 行读取限制, GPT-5-CODEX 推出, Chrome DevTools MCP Server, Playwright MCP 替代方案, Supernova 模型评估
- Cursor 的行读取限制令用户恼火:一位用户对 Cursor 仅读取 50-100 行 代码表示沮丧,希望它能读取超过 3000 行;另一位用户建议直接附加文件,这样它会读取更多内容。
- 另一位用户提到他们在不到一周的时间内使用了超过 500 个 Cursor 点数,认为 Pro 计划对于他们的需求来说太贵了。
- GPT-5-CODEX 亮相,评价褒贬不一:用户正在 Cursor 中测试新发布的 GPT-5-CODEX 模型,一些人报告其表现出色,而另一些人则发现它在 tool calling 方面表现糟糕,经常不得不求助于终端;一位用户建议 Cursor 团队可能会通过自定义 prompt 来修复它。
- 一位用户注意到该模型尝试补丁整个文件而不是使用 tool calls,类似于 OpenAI 的文件 diff 格式 进行编辑,而另一位用户在使用 GPT5 时经历了 90% 的成功率。
- Google 的 Chrome DevTools MCP Server 面临安装障碍:一位用户在运行 Google 的 Chrome DevTools MCP server 时遇到困难,并发布了他们的 MCP 配置;另一位用户建议降级到 Node 20,因为该用户使用的是 v22.5.1。
- 一位用户提供了清除缓存并使用 Playwright 作为 MCP 替代方案的建议,并提到他们使用的是 Edge。
- 评估神秘的 Supernova 模型:用户讨论了神秘的 supernova 模型,一位成员报告称他们不能透露该模型是谁;另一位用户提到他们正在使用 Auto 模型来快速起草内容。
- 有人猜测 Auto 模型 的改进是否最终会取代开发者的工作,引发了关于该模型潜力的俏皮回应。
- GPT-5-HIGH vs Claude Sonnet 4:代码实战:用户讨论了编程模型的效率,一位用户提到在他们的代码库中 GPT-5-HIGH 的表现优于 Claude Sonnet 4。
- 他们还承认 Claude 完全不听指令,并提到 GPT5 很听话。
Cursor Community ▷ #background-agents (2 messages):
僵尸进程分析, 僵尸进程升级
OpenRouter ▷ #announcements (2 messages):
GPT-5-Codex 发布, Agentic 编程工作流, OpenRouter 兼容的编程工具, 聊天室推荐参数
- GPT-5-Codex 正式上线!:GPT-5-Codex 的 API 版本现已在 OpenRouter 上可用,专门针对代码生成和调试等 Agentic 编程工作流 进行了微调。
- 它可用于所有 OpenRouter 兼容的编程工具,支持 100 多种语言的多语言编程,并能动态调整推理力度。
- GPT-5-Codex 为软件工程优化:GPT-5-Codex 针对现实世界的软件工程和长编程任务进行了优化。
- 它还具有专门构建的代码审查能力以发现关键缺陷,并能在 IDE, CLI, GitHub 和云端编程环境中无缝工作;查看推文 此处。
- 推荐聊天室参数:新推文中发布了模型的推荐参数。
- 详见 此处。
OpenRouter ▷ #app-showcase (1 messages):
eofr: Scam (诈骗)
OpenRouter ▷ #general (173 messages🔥🔥):
Deepseek 3.1 运行时间问题,OpenRouter iOS 应用,Qwen3 VL
- Deepseek V3.1 深受运行时间(Uptime)问题困扰:用户报告在使用免费的 Deepseek V3.1 模型时频繁出现 “Provider Returned Error” 消息,这与目前基本已失效的 Deepseek V3 0324 遇到的问题类似。
- 一位成员指出,Deepseek 模型持续低迷的运行时间百分比(如 14%)可能表明存在 Bot 滥用,而另一位成员则开玩笑说用户的请求被路由到了“垃圾桶”。
- 开发者创建 OpenRouter iOS 应用:一名成员宣布他们开发了一款 iOS 应用,用于连接 OpenRouter、Flowise 和其他平台,旨在让人们自由地拥有自己的模型和聊天记录。
- 另一位成员开玩笑地回应说,这只是“让 gooners 逃往的更多地方”。
- Qwen3 VL 的多模态能力令人印象深刻:成员们对阿里巴巴新的 Qwen3 VL 模型和编程产品表示惊讶,称其多模态支持和性能基准测试超过了 2.5 Pro。
- 一位用户调侃道:“照这个速度,我得去学中文了,真绝了”,而另一位用户分享了一个 链接,该帖子声称 OpenAI 已经无法跟上需求。
OpenRouter ▷ #new-models (3 messages):
``
- 未讨论新模型:该频道名为 new-models,但在提供的 Discord 消息中并未实际讨论任何模型。
- 频道标题重复:消息只是简单地重复了三次频道标题 OpenRouter - New Models。
OpenRouter ▷ #discussion (2 messages):
4Wallai 基准测试
- 4Wallai 基准测试受到欢迎:成员们分享并喜欢 4wallai.com 的链接。
- 另一位成员表示,需要 更多像这样的基准测试。
- 需要更多基准测试:在对链接的基准测试表示赞赏后,一位成员建议需要更多的基准测试。
- 他们表达了对更多资源的需求,以便有效地评估和比较 AI 模型。
HuggingFace ▷ #general (100 messages🔥🔥):
TTS 叙述,用于叙述的开源模型,ML 课程推荐,私有 LLM
- 用户讨论使用 TTS API 还是 LLM 进行叙述:一位用户询问用于叙述书章节的最佳开源模型,一位成员建议对于 2k tokens,任何 TTS API 都能以 $0.001 的价格完成。
- Discord 成员推荐 ML 课程和 PyTorch:一位用户寻求 ML/AI 课程推荐,提到了吴恩达(Andrew Ng)的机器学习专项课程、Hugging Face LLMs 课程和 FastAI 的 Practical Deep Learning for Coders。
- 几位成员建议跳过视频课程,转而推荐 learnpytorch.io,并建议从零开始用 PyTorch 实现模型,以从概念上理解它们的工作原理。
- 建议为聊天机器人使用更快的硬件或更小的模型:一位用户正在寻找合作伙伴来协助处理一个需要 10 次 LLM 调用和 20 多个 Prompt 的自定义 LLM,得到的建议是:获得更快速度的最简单方法是使用更大的 GPU 或更小的模型。
- Quantization(量化)可以在牺牲质量的前提下提高速度;如果有足够的持续吞吐量来填满 Batch,可以将调用进行批处理;而最大的收益来自于更小的模型、更强的硬件和更低比特的量化。
- 关于去除“公司化内容”的请求过于模糊:一位用户想从模型中去除一些“公司化的东西(corporate stuff)”,一位成员针对这个模糊的请求回应称,应考虑阅读 API TOS 并理解时空和物理定律。
- 该成员继续说道:“你所要求的似乎是一个翅膀闪着彩虹光芒、两头都能喷射火花的独角兽仙女美人鱼。”
HuggingFace ▷ #i-made-this (4 messages):
Go wrapper for tokenizers library, Canis.lab launch
- Go wrapper 寻找维护者:一名成员编写了 tokenizers 库的 Go wrapper,目前正在寻求帮助以进行维护和改进。
- Canis.lab 发布,专注于导师工程 (tutor engineering):成员分享了 Canis.lab 发布视频,该项目关于数据集优先的导师工程 (dataset-first tutor engineering)以及针对教育领域的轻量级模型微调,具有开源和可复现的特点。
- 此外还包含了 GitHub 仓库和 Hugging Face 页面的链接,并征求关于数据 schema 的反馈。
HuggingFace ▷ #computer-vision (1 messages):
Menu Translation, Gemini 2.5 Flash, Taiwanese Signage Menus, OCR for spaced characters
- 菜单翻译应用面临字符间距挑战:一名开发者正在寻求改进菜单翻译应用 Menu Please 的建议,该应用在处理字符间距异常的台湾招牌菜单时遇到了困难。
- 问题在于 Gemini 2.5 Flash 由于图像中字符间距不一致,无法准确翻译菜单项。
- Gemini 在处理看板字符间距时表现不佳:开发者指出,由于字符间距不一致,Gemini 2.5 Flash 模型在翻译台湾招牌菜单(看板)时非常吃力。
- 同一菜单项的字符间距往往比相邻项目之间的间距还要宽。
- OCR 技巧:为了解决这个问题,开发者已经尝试向 Gemini 提供水平和垂直方向间距字符的 few-shot 示例。
- 他们还尝试引导模型识别项目符号和价格等锚点 (anchors),并结合阅读方向来确定项目边界,参考提供的图像示例。
HuggingFace ▷ #smol-course (2 messages):
Canis.lab, Synthetic Data, Eval Dataset issues
- 用户发现数据集问题:一名成员报告在查看 HuggingFace datasets 时找不到评估数据集。
- 用户特别提到了数据集
lighteval|gsm8k。
- 用户特别提到了数据集
- 为合成数据 (Synthetic Data) 引入 Canis.lab 工作流:一名成员介绍了 Canis.lab,这是一个轻量级、开源的工作流,用于为小型导师模型规划、生成和验证目标数据集,并分享了发布视频和 GitHub 链接。
- 该成员正在寻求反馈,特别是结合课程教学目标的反馈。
HuggingFace ▷ #agents-course (1 messages):
RAG Courses, Bangla Retrieval, Multimodal Support
- 成员请求 RAG 课程推荐:一名成员询问是否有好的 RAG 课程建议,特别是针对孟加拉语检索 (Bangla-based retrieval)和多模态支持 (multimodal support)。
- 社区等待 RAG 课程建议:其他成员可能会针对孟加拉语检索和多模态应用定制的 RAG 课程提供建议。
GPU MODE ▷ #general (14 messages🔥):
Python Profiling, DeepGEMM Benchmarking, NCU Clock Control, GPU Kernel Downclocking
- 寻找优秀的 Python Profiling 插件:一名成员正在寻找可靠的 Python 性能分析函数,此前已测试过 DeepGEMM、Triton 的
do_bench和 NCU,并注意到 NCU 和 Kineto 等不同工具在 Kernel 计时方面存在不一致。 - NCU 获得时钟控制:在 NCU 中设置
--clock-control none使其与do_bench()的结果更加一致,解决了 Kernel 速度上的相对差异;然而,关于固定时钟频率是否能准确代表现实世界 GPU Kernel 性能的问题随之而来。- 有人提到一段 YouTube 视频很好地解释了这一主题。
- NCU 对 Kernel 进行降频:该成员质疑为什么 NCU 会对某些 Kernel 进行降频,以及使用固定时钟进行基准测试 (benchmarking) 是否具有代表性。
- 另一名成员建议,固定时钟频率可以减少基准测试的方差并提高可复现性,无论外部因素(如天气炎热)如何影响。
GPU MODE ▷ #cuda (3 条消息):
mbarrier instructions, cuda::barrier, cuda::memcpy_async, inline PTX, CCCL
mbarrier指令详解:mbarrier.test_wait是一个非阻塞指令,用于测试阶段(phase)是否完成;而mbarrier.try_wait是一个可能阻塞的指令,用于测试阶段是否完成。- 根据 Nvidia 文档,如果阶段未完成,执行线程可能会被挂起,但在指定的阶段完成时,或者在系统相关的时限之后(在阶段完成之前),线程会恢复执行。
cuda::barrier同步拷贝和工作:cuda::barrier的默认版本(无.noinc)假设你不仅想同步拷贝,还想同步在启动拷贝后由线程执行的任何工作。- 这也用于
cuda::barrier+cuda::memcpy_async,因此用户仍然需要到达(arrive)该 barrier。
- 这也用于
- 跳过 inline PTX,使用 CCCL:对于大多数情况,你不需要编写 inline PTX,因为 CCCL 已经涵盖了大部分基础需求。
- 你甚至可以继续使用
cuda::barrier,并通过cuda::device::barrier_native_handle获取底层的mbarrier。
- 你甚至可以继续使用
GPU MODE ▷ #beginner (2 条消息):
CUDA Documentation, Memory vs Compute Bound
- CUDA 文档优于 LLM 的 CUDA 建议:成员们确认,对于 CUDA,NVIDIA 文档 仍然是唯一的真理来源,特别是考虑到 LLM 经常生成关于 CUDA 的错误信息。
- 因此,工程师应该依赖文档,而不是 LLM 的“幻觉”。
- 受限于内存还是计算?:为了优化 CUDA,一位成员建议计算所使用的数值数量(内存)和执行的操作数量(FLOPS),以确定进程是内存受限(memory bound)还是计算受限(compute bound)。
- 该成员指出:如果是内存受限,你的性能上限(SOL)将是内存带宽;如果是计算受限,你的性能上限将是(每个 SM 的最大 FLOPS x SM 数量)。
GPU MODE ▷ #off-topic (20 条消息🔥):
Slurm Reading Material, Sysadmin/Devops Channel, Kubernetes + Slurm + Docker, Flux from LLNL
- Slurm 文档获得好评:一位成员询问 Slurm 的阅读材料,得到的回复是“直接看文档,写得很好”。
- 另一位成员表示,他们对 Slurm 的讨论很感兴趣,因为他们也在尝试维护此类集群。
- 关于设立 Sysadmin/Devops 频道的讨论:成员们讨论了是否创建一个 sysadmin/devops/scheduling 频道,用于讨论吐槽和 Slurm 集群维护。
- 一位成员说“看看大家用它做什么会很酷”。
- Kubernetes、Slurm 和 Docker 的融合:成员们提议将 Kubernetes、Slurm 和 Docker 结合起来,并指出集成 Docker 和 Slurm 的可能性。
- 他们链接了 Coreweave 关于在 Kubernetes 上运行 Slurm 的文档,但一位成员表示“k8s 的 YAML 太多了,我不想碰它”。
- 提及 Flux 框架:一位成员介绍了来自 LLNL 的 Flux,这是一个集群作业编排/资源管理框架,详见此处。
- 他们指出 Flux 不如 Slurm 流行,因为它较新且专注于 HPC。
GPU MODE ▷ #self-promotion (7 messages):
CuTe Layout Algebra, Colfax Team Paper, Categorical treatment, WMMA/MMA instruction, NVRTC MMA
- Layout Gymnastics 博客文章发布!: Simon Veitner 发布了一篇 博客文章,详细介绍了他在 Colfax Team 的 CuTe Layout Algebra 论文第 2 章中手动推导的示例,涵盖了 Coalescing, Completion, and Composition 等操作。
- 通过 Layout Gymnastics 探索 Colfax 论文!: Veitner 的文章是阅读 Colfax 原文 的配套指南,该论文是对 Layout Algebra 的完整数学处理。
- MMA 指令文章即将发布!: 一位成员提到他正在研究 WMMA, MMA, and WGMMA instructions,并可能在未来发布博客文章,重点关注“难以入门且资源较少”的主题。
- 探索 NVRTC MMA 指令: 分享了一篇关于使用 NVRTC 探索 MMA instruction variants 的博客文章,链接至 gau-nernst 的博客。
GPU MODE ▷ #avx (2 messages):
AVX512, BPE, Tiktoken, Huggingface, Data Loading Optimization
- 寻求 AVX512 BPE 实现以提升速度: 一位成员正在寻求 BPE (Byte Pair Encoding) 的 AVX512 实现,因为 Tiktoken 速度极慢,而 Hugging Face 的实现受限于 latency(延迟),显著降低了数据加载速度。
- Tiktoken 和 Hugging Face BPE 性能问题: 用户报告称 Tiktoken 的速度不尽如人意,而 Hugging Face 的 BPE 实现存在 latency 问题,影响了整体数据加载性能。
GPU MODE ▷ #edge (2 messages):
Cubesat hardware, Cubesat software, Error Correction, Redundancy, RasPi Cubesats
- RasPi 助力业余立方体卫星 (Cubesats): 一位成员表示,业余立方体卫星使用 RasPi 构建且“运行良好”,强调了它们在航天应用中的有效性,并提到了 Jeff Geerling 的博客文章。
- 讨论涵盖了在教育卫星项目中使用 Raspberry Pi 的可靠性和适用性。
- Cubesat 项目成功: 一位成员讨论了他们在去年发射的 Qube Project 地面系统软件运行方面的工作,强调了 cubesat technology 的实际应用。
- 他们专注于地面系统软件运行。
- 通过主从架构实现冗余: 频道讨论了在立方体卫星中为每个核心功能/主从设备配备冗余模块。
- 这些模块将根据 error-correction checks(纠错检查)进行重置。
GPU MODE ▷ #submissions (2 messages):
MI300x8, amd-gemm-rs leaderboard
- MI300x8 个人最佳成绩: 一位用户在 MI300x8 上取得了个人最佳成绩:575 µs。
- 在
amd-gemm-rs排行榜上的提交 ID 为 43091。
- 在
- MI300x8 成功运行: 一位用户在 MI300x8 上成功运行:589 µs。
- 在
amd-gemm-rs排行榜上的提交 ID 为 43133。
- 在
GPU MODE ▷ #status (1 messages):
Runner Issues, Timeouts, Debugging with AMD and DigitalOcean
- Runner 故障引发超时混乱: 团队的 runners 出现问题,导致意外的 timeouts。
- 他们正与 AMD 和 DigitalOcean 合作积极 debugging 该问题,并承诺在努力解决的过程中提供更新。
- 正在与 AMD 和 DigitalOcean 进行调试: 团队正在积极调试其 runners 的问题,并与 AMD 和 DigitalOcean 合作解决意外的 timeouts。
- 在寻求解决方案的过程中将提供更新。
GPU MODE ▷ #factorio-learning-env (3 条消息):
GEPA, Deepseek Neel 评估
- 关于 v0.0.3 集成 GEPA 的辩论:成员们讨论了在发布项目的 0.0.3 版本之前集成 GEPA 的事宜。
- 一位成员认为这将是一个不错的补充,而另一位成员则提醒不要因此延迟发布,因为其探索过程可能是开放式且耗时的。
- Deepseek Neel 评估提上日程:一位成员询问是否可以对 Deepseek Neel 进行评估,并提供了 Hugging Face 上的模型链接。
- 未提供更多细节。
GPU MODE ▷ #amd-competition (33 条消息🔥):
MI300X 环境, 用于基准测试的 Docker 镜像, GEMM 提交超时, 集群健康问题, All2All 自定义 Kernel 数据访问
- MI300X 环境规格规划:成员们讨论了定义 MI300X 测试环境的问题,建议任何支持 8x MI300X 的地方都应当适用,AMD DevCloud 或 HotAisle 可能是最便宜的选择。
- 会议强调,复制精确的测试环境(包括 Python、Torch 版本和其他依赖项)对于 1:1 测试至关重要,并链接到了用于基准测试的 AMD Dockerfile。
- 提供用于基准测试的 AMD Docker 镜像:一位成员指出可以获取用于基准测试的确切 Docker 镜像,并提到 AMD 在 Docker 中的性能计数器(performance counters)方面并不挑剔,同时链接了 AMD Dockerfile。
- 有人注意到虽然镜像已发布,但具体位置不明;由于 HotAisle 是裸机,因此可以方便地在机器上构建,此外 Runpod 也被提及为一个可行的选项。
- GEMM 提交超时!:一位用户报告了 GEMM 提交集群的超时问题,即使使用参考 Kernel 也是如此。
- 有建议称应修改提交代码,以允许在同一 GPU 上进行多进程以确保正确性,并使用 git 进行同步,使用 AMD Dev Cloud 保存快照;但其他人指出最近一直有提交成功,超时可能是由集群健康问题引起的。
- 集群健康状况不稳定:成员们表示,可能是集群健康问题导致了提交超时,团队正等待 AMD 的协助来解决此问题。
- 尽管存在问题,一位成员仍对整体设置、前端和 CLI 表示赞赏,承认举办比赛既困难又耗时。
- All2All Kernel 寻求全局数据:有人提问关于
all2all中的custom_kernel()对整个推理集群拥有多少信息或访问权限。- 具体而言,一个 rank 是否拥有关于所有其他 rank 之间发送和接收数据量的全局视图,尤其是 gpumode.com 提到了 all_rank_data,但在代码中并未看到。
GPU MODE ▷ #cutlass (8 条消息🔥):
Shape 兼容性, CUTE 文档, PTX 图表
- CUTE Shape 兼容性深度探讨:一位成员询问了 CUTE Layout 文档中的 Shape 兼容性,特别是关于
Shape (24)和Shape 24的区别。另一位成员澄清说,shape 24和shape (24)在概念上是相同的,但括号限制了兼容性。- 兼容性是一个反对称(antisymmetric)的概念:
S 与 T 兼容且 T 与 S 兼容意味着 S = T,术语S refines T意味着 T 与 S 兼容。例如,(24)refines24是因为24 = size((24))。
- 兼容性是一个反对称(antisymmetric)的概念:
- CUTE 中的 Shape 索引:一位成员询问 CUTE 文档中的 Shape 兼容性要求是否意味着 A 中的所有坐标都是 B 中的有效坐标。
- 另一位成员确认,
(24)的有效坐标是(0), (1), (2)...,而24的有效坐标是0, 1, 2, 3...,因此整数可以索引到(24),但反之则不行。
- 另一位成员确认,
- 寻找用于生成 PTX 图表的 CUTE 代码:一位成员询问在哪里可以找到用于生成 PTX 图表的 CUTE 代码,另一位成员提供了可能的线索。
- 他们建议查看
print_latex、print_layout以及 PTX 文档中 wgmma 共享内存部分的 Layout。
- 他们建议查看
GPU MODE ▷ #singularity-systems (2 messages):
Eager Mode, Graph Mode, Tinygrad's IR, Tensor Sugar, Torch vs. Jax
- Tinygrad 采用双引擎方案:Tinygrad 将包含两个引擎:一个带有手写内核的 eager mode (
eagerly_eval) 和一个 graph mode (lazily_compile),两者都复用 Tinygrad 的 IR。tensor将作为 UOp 图的语法糖,这标志着其偏离了纯 Python 实现。
- Tinygrad 避免 Torch 的陷阱:一名成员对双引擎方案表示赞同,认为 Torch 未能分离 eager 和 graph 模式的做法持续引发问题。
- 他们进一步指出,Jax 对单一方法的专注是其成功的因素之一。
GPU MODE ▷ #cluster-management (8 messages🔥):
GPU Reservations, Slurm and Docker, Singularity vs Docker, llm-d.ai for cluster management
- GPU 预约(Reservations)令人头疼:由于本地资源有限,开发者们正为 GPU 预约感到困扰,不得不依靠手动发消息来进行分配。
- 虽然考虑过 dstack,但由于缺乏足够的 GPU 而变得不可行,这促使团队转向支持分数级 GPU(fractional GPU)的 Slurm。
- Slurm 和 Docker 导致集群混乱:将 Slurm 与 Docker 集成被证明是一项挑战,导致团队在集群容器化方面更倾向于 Singularity。
- 主要担忧是安全性,因为 Singularity 避免了与 Docker 相关的 root 权限问题。
- Singularity 语法引发质疑:一名成员对 Singularity 的语法表示沮丧,质疑为什么它不与更常用的 Docker 语法保持一致。
- 发言者推测,Singularity 与 Docker 不同,它在运行时不需要守护进程(daemon),这可能与资源计算/预算有关。
- llm-d.ai 被视为宝藏:一名成员建议探索 llm-d.ai,指出它非常适合管理集群中的 LLM 工作负载。
- 该项目可能与当前关于资源分配和容器化的讨论高度相关。
Latent Space ▷ #ai-general-chat (45 messages🔥):
Meta's ARE and Gaia2, Cline's Agentic Algorithm, Greptile's $25M Series A, Cloudflare's VibeSDK, GPT-5-Codex Release
- Meta 发布用于动态 Agent 评估的 ARE 和 Gaia2:Meta SuperIntelligence Labs 发布了 ARE(Agents Research Environments)和 Gaia2,这是一个用于在动态场景中评估 AI Agent 的基准测试。
- ARE 模拟了现实世界的条件,Agent 需要实时适应,而不像静态基准测试那样只解决固定的谜题。
- Cline 的算法被简化为简单的状态:Ara 将 Cline 的 Agent 算法提炼为一个 3 状态状态机:Question(澄清)、Action(探索)、Completion(展示)。
- 成功的关键在于:简单循环 + 优秀的工具 + 不断增长的 Context。
- Greptile 为其“杀虫”AI 审查器 v3 获得 2500 万美元 A 轮融资:Greptile 完成了由 Benchmark 领投的 2500 万美元 A 轮融资,并推出了 Greptile v3。这是一种 Agent 架构,捕捉到的关键 Bug 比 v2 多出 3 倍,已被 Brex、Substack、PostHog、Bilt 和 YC 使用。
- 新功能包括 Learning(从 PR 评论中吸收团队规则)、用于 Agent/IDE 集成的 MCP server,以及 Jira/Notion context。
- Cloudflare 通过 VibeSDK 开启“Vibe Coding”大门:Cloudflare 宣布推出 VibeSDK,这是一个开源的 “vibe coding” 平台,支持一键部署个性化 AI 开发环境。
- 它包含代码生成、沙盒以及项目部署功能。
- GPT-5-Codex 发布,开发者权衡成本与限制:OpenAI 通过 Responses API 和 Codex CLI 发布了 GPT-5-Codex,引发了兴奋,但也带来了对成本和速率限制的担忧,定价为:输入 $1.25,缓存 $0.13,输出 $10。
- 用户纷纷请求 Cursor/Windsurf 集成、GitHub Copilot 支持以及更低的输出成本。
Latent Space ▷ #genmedia-creative-ai (4 messages):
Foo Fighters, Artists using AI
- Foo Fighters 的帖子暗示使用了 AI?:Foo Fighters 分享了一段 YouTube 视频,引发了关于艺术家如何使用 AI 的猜测,即便这可能只是某种戏谑的方式。
- 艺术表达中的 AI:讨论围绕 AI 在创意领域中不断演变的角色展开,特别是音乐家如何俏皮地将 AI 融入他们的作品中。
Yannick Kilcher ▷ #general (2 messages):
Paper Reading Events, Yannick's Reading List
- Paper Reading Events 时间安排:一名成员询问论文阅读活动是否会提前通知。
- Yannick 的阅读清单:一名成员询问 Yannick 这个周末打算读什么。
Yannick Kilcher ▷ #paper-discussion (17 messages🔥):
Diffusion ODE Solver, MiMo-Audio, Diversity is all you need
- Diffusion ODE Solver 实现速度与质量双重提升:一位独立研究员开发了一种新型的 Diffusion Models ODE Solver,在无需额外训练的情况下,仅需 8 步推理 即可在 FID scores 上超越 DPM++2m 的 20 步推理,详情见其 论文 和 代码。
- MiMo-Audio:作为 Few-Shot Learners 的音频语言模型:成员们讨论了 MiMo-Audio 及其技术报告 “Audio Language Models Are Few Shot Learners”,强调了其在 S2T、S2S、T2S、翻译和续写方面的能力,如 Demo 所示。
- 提议展示 “Diversity is all you need” 论文:一名成员提议展示论文 “Diversity is all you need”,但在 Discord 上遇到了语音通话问题。
Yannick Kilcher ▷ #ml-news (12 messages🔥):
Gaia2, Meta Agents Research Environments (ARE), GPT5 Models, Cloudflare Vibesdk, Compilebench
- Gaia2 和 ARE 助力 Agent 评估:Meta 推出了 Gaia2,这是 Agent 基准测试 GAIA 的后续版本,用于分析复杂的 Agent 行为。该工具随开源的 Meta Agents Research Environments (ARE) 框架一同发布,采用 CC by 4.0 和 MIT 许可证。
- ARE 模拟真实世界条件以调试和评估 Agent,解决了现有环境缺乏真实世界灵活性限制的问题。
- GPT5 的真实形态仍是未知数:在 ml-news 频道中,一位用户询问 GPT5 low 和 GPT5 high 是否为不同的模型。
- 一名成员回答称目前尚不清楚,但建议这可能类似于他们的 OSS 模型,通过改变上下文来调整推理开销(reasoning effort),或者它们可能是基于基座模型的不同微调版本。
- Cloudflare 发布 Vibesdk:一名成员分享了 Cloudflare 新推出的 Vibesdk 链接。
- 未展开进一步讨论。
- 介绍 Compilebench:一名成员分享了一篇关于 Compilebench 的博客文章链接。
- 未展开进一步讨论。
LM Studio ▷ #general (21 messages🔥):
LM Studio Model Support, GGUF/MLX Models, Qwen-3-omni, Google Gemini Free Tier
- LM Studio 支持有限的 HF 模型:新用户询问是否所有的 HuggingFace 模型 都能在 LM Studio 上使用,以及模型是否经过团队验证。
- 一名成员澄清道,目前仅支持 GGUF(Windows/Linux/Mac)和 MLX Models(仅限 Mac),且不包括图像/音频/视频/语音模型。
- LM Studio 的模型搜索:一位用户搜索了 facebook/bart-large-cnn 模型,并询问如何验证模型是否为 GGUF 或 MLX 格式。
- 一名成员确认该模型在 LM Studio 中不受支持,且 Qwen-3-omni 的支持取决于 llama.cpp 或 MLX 的兼容性。
- 深入探讨 Qwen-3-Omni:一名成员表示,处理文本、图像、音频和视频的 Qwen-3-omni 需要很长时间才能实现支持。
- 另一名成员指出,文本层是标准的,但视听层涉及大量新的音频和视频解码内容。
- Google 为学生赠送 Gemini:一名成员分享道,Google 为大学生提供 一年的免费 Gemini 订阅。
- 他们补充道:“我每天都在用免费版,所以能免费获得高级版(Premium)很不错。”
LM Studio ▷ #hardware-discussion (2 messages):
Innosilicon GPU, DirectX12 Support, Ray Tracing Hardware
- 芯动科技 (Innosilicon) 发布风华 3 号 GPU:芯动科技展示了其 风华 3 号 (Fenghua 3) GPU。根据 Videocardz 的报道,该 GPU 具备 DirectX12 支持和硬件光线追踪能力。
- Local LLaMA Reddit 帖子:一位用户分享了 r/LocalLLaMA 中的 Reddit 帖子链接。
aider (Paul Gauthier) ▷ #general (11 messages🔥):
Response API Support, GPT-5-Codex Integration, aider and litellm
- Aider 为 GPT-5-Codex 添加 Response API 支持!:一名成员为 aider 添加了对 Responses API 的支持,并使用 GPT-5-Codex 模型进行了验证,同时创建了一个 pull request 等待审核。
- 此次集成解决了 GPT-5-Codex 因缺少 completions 支持而在官方端点上无法与 aider 配合使用的问题,此前需要使用 OR 来实现向后兼容。
- Aider 的 litellm 依赖是否支持 GPT-5?:一位成员询问,既然 Aider 已经通过 litellm 与其他 Responses 模型配合使用,是否还需要其他改动。
- 另一位成员澄清说,aider 依赖于 litellm completions,后者虽然有处理 responses 端点的回退机制,但 GPT-5-Codex 缺少这种回退,因此需要显式的 Responses API 支持。
- GPT-5 现在需要 Responses 端点:一位成员报告称收到错误,提示 GPT-5-Codex 仅在
v1/responses中受支持,而不支持v1/chat/completions。- 这意味着与之前的模型不同,GPT-5-Codex 专门使用 Responses API,因此需要更新以处理这一特定端点。
aider (Paul Gauthier) ▷ #questions-and-tips (8 messages🔥):
aider ollama setup, Aider reads MD file, Context Retransmitted, Prompt Caching
- 用户寻求关于在 Ollama 中使用 Aider 的指导:一位用户正在寻求指导,想知道在使用 Ollama 时如何让 aider 读取包含 AI 目标的 MD 文件。
- 该用户尝试了命令
aider --read hotfile.md,但效果不如预期。
- 该用户尝试了命令
- 用户希望回退到之前的步骤:一位新用户询问在多次使用
/ask命令后,如何回退到之前的步骤。- 一位成员建议手动复制所需的上下文,使用
/clear,然后将复制的上下文与新问题一起粘贴。
- 一位成员建议手动复制所需的上下文,使用
- 上下文在每次请求时都会重新传输:一位用户注意到,当 aider 处于 verbose 模式时,上下文会在每次聊天请求中重新传输,并质疑这是否效率低下。
- 一位成员确认了这一行为,表示这是标准做法,且许多 API 使用 Prompt Caching 来降低成本,同时指出 aider 允许用户控制上下文中包含的内容。
- Aider 按字母顺序对文件上下文进行排序:一位用户指出 aider 按字母顺序对文件上下文进行排序,而不是保留添加时的顺序。
- 他们为此提交了一个 PR,但由于目前没有任何内容被合并,他们已经放弃了。
Modular (Mojo 🔥) ▷ #general (18 messages🔥):
RISC-V Performance, Tenstorrent's MMA accelerator + CPU combos, RISC-V 32-bit and 64-bit, RISC-V Bringup, RISC-V ISA
- RISC-V 性能落后于手机核心:成员们讨论了 RISC-V cores 目前几乎普遍慢于现代智能手机中的核心,或许微控制器 SoC 除外。
- 一位成员指出,他们遇到的最快 RISC-V 设备仍然很慢,以至于有人从 UltraSPARC T2 交叉编译 SPECint,因为这比原生编译更快。
- Tenstorrent 有望缩小 RISC-V 性能差距:一位成员提到 Tenstorrent 的 MMA accelerator + CPU 组合 是一个潜在的解决方案,并提到 Tenstorrent 的“tiny”核心是非常小的顺序执行核心,用于驱动 140 个 matrix/vector units。
- 该成员还指出,Tenstorrent 的 Ascalon cores 是未来 5 年改变 RISC-V 性能格局的最大希望。
- RISC-V Bringup 挑战:一位成员分享说 RISC-V 64-bit 勉强可用,但需要大量的 bringup 工作,且无法使用 vectors。
- 另一位成员解释说,任何使用架构的
if-elif-else语句链都需要添加 RISC-V,而且许多内容需要锁定在语言中尚不存在的requires之后。
- 另一位成员解释说,任何使用架构的
OpenAI ▷ #annnouncements (1 messages):
Stargate Sites, Oracle, SoftBank, 10-Gigawatt Commitment
- OpenAI 宣布五个新的 Stargate 站点:OpenAI 宣布与 Oracle 和 SoftBank 合作建立 五个新的 Stargate 站点,提前推进了其 10-gigawatt 承诺。
- 详情可见其 博客文章。
- Stargate 项目取得进展:与 Oracle 和 SoftBank 的合作正在加速 OpenAI 计算资源的部署。
- 这使得该项目提前于原计划实现了 10-gigawatt 的目标。
OpenAI ▷ #ai-discussions (14 messages🔥):
Codex Fallback, Sora Issues, Ternary System Study, Github Copilot Alternative, kilocode
- Codex 缺乏模型回退 (Fallback):一位用户询问 Codex 是否有模型回退功能,类似于在耗尽 GPT-5 额度后切换到 gpt-5-mini。
- 社区没有给出肯定或否定的确认,但似乎并不认为有此功能。
- Sora 的视频生成遇到障碍:一位用户询问修复 Sora 视频生成能力问题的具体时间表。
- 聊天记录中没有提供回复,但社区似乎意识到了与该产品相关的问题。
- VSCode Copilot 的竞争对手即将到来?:一位用户对 OpenAI 开发的适用于 VSCode 和 IDE 的 “Github Copilot” 扩展表示感兴趣。
- 尽管了解 Codex CLI,该用户仍看重 Github Copilot 的代码片段建议功能,并表示如果 OpenAI 提供类似产品将会切换。
- GPT-5-Minimal 模型评估:根据这张图片,GPT-5-Minimal 模型的表现差于 Kimi k2,但对于 Agent 场景,High 是整体表现最好的。
- 一位用户澄清说:High (仅通过 API) < Medium < Low < Minimal < Fast/Chat (非思考型)。
- kilocode 中为不同 Agent 角色分配模型:成员们提到用户正在 kilocode 中为不同的 Agent 角色分配不同的模型。
- 一位用户指出,关于 VSCode 中 Codex IDE 的博客文章发布还不到一个月。
OpenAI ▷ #prompt-engineering (1 messages):
GPT4o Translations, Chain of Thought
- GPT4o 翻译质量受 Chain of Thought 影响:一位成员发现,与直接翻译提示词相比,使用 Chain of Thought 提示词时 GPT4o 的翻译质量会有所下降。
- 该成员分享了所使用的提示词:When user paste something in other language that isn’t english, Identify the language, then: - {do a 3 short bullet point as a chain of thought} {Your translation goes here}
- 对于 GPT4o,直接翻译优于 Chain of Thought 翻译:用户尝试将 GPT4o 作为翻译器并使用 Chain of Thought 提示词。
- 结果显示,不带 Chain of Thought 的直接翻译产生了更高质量的结果。
OpenAI ▷ #api-discussions (1 messages):
GPT4o translation, Chain of thought in translation
- GPT4o 的翻译质量在加入 Chain of thought 后会有所下降:一位成员观察到,要求 GPT4o 在翻译文本前进行 Chain of thought 推理,其翻译质量反而低于直接翻译。
- 用户分享了一个特定的 Prompt 策略,该策略要求 GPT4o 识别输入语言并在提供翻译前列出三步思考过程,但发现这种方法效果较差。
- 直接翻译在 GPT4o 上的表现优于 Chain-of-Thought:一位用户将 GPT4o 作为翻译器进行了测试,对比了直接翻译与带有 Chain-of-thought Prompt 的翻译。
- 结果表明,与使用 Chain-of-thought 的方法相比,GPT4o 的直接翻译在质量和适配性方面表现更优。
DSPy ▷ #show-and-tell (4 messages):
DSPy profiles, dspy-profiles, LLM behavior
- DSPy 获得了用于配置的 profiles 软件包:一位成员宣布发布了 dspy-profiles,这是一个用于 DSPy 的轻量级包,通过 toml 管理配置,支持快速切换设置并保持项目整洁,该消息也发布在了 Xitter。
- 该工具允许通过单个命令轻松切换 LLM 行为,并以装饰器(decorators)和上下文管理器(context managers)的形式提供,旨在消除上下文模板代码。
- 针对不同环境的配置:一位成员对 dspy-profiles 表示兴奋,并询问是否有许多项目能从多样化的配置中受益。
- 作者提到管理 dev/prod 环境是最初的动力,并表示它现在能促进更好的上下文切换。
DSPy ▷ #general (8 messages🔥):
GEPA Multimodality Performance Issue, Passing images and PDFs into DSPy, VLMs for Data Extraction, OCR Approaches for Data Extraction, Best PDF or Image Parsing Stuff
- GEPA Multimodality 深受性能问题困扰:一位成员报告了 GEPA Multimodality 的严重性能问题,并链接到了相关的 GitHub issue。
- 用户指出其用例需要满足多用户需求。
- 探索将 PDF 和图像传入 DSPy:一位成员询问如何将图像或 PDF 传入 DSPy 进行数据提取。
- 另一位成员指出,可以通过这个 dspy.ai API primitive 将图像传入 DSPy。
- 关于数据提取中 VLM 和 OCR 的辩论:一位用户询问在从图像和 PDF 中提取图表信息时,VLM 是否比 LLM 更好。
- 另一位成员表示不知道 OCR 方法是否对数据提取更好,而另一位成员提到可以通过
dspy.LM传入 VLM 来实现。
- 另一位成员表示不知道 OCR 方法是否对数据提取更好,而另一位成员提到可以通过
- 征集最佳 PDF 和图像解析器:一位成员征求关于最佳 PDF 或图像解析工具的建议。
- 消息中未提供具体的建议。
DSPy ▷ #examples (5 messages):
Prompt Optimization, GEPA, AI Safety Research, Trusted Monitor, Comparative Metric with Feedback
- Prompt Optimization 赋能 AI Control 研究:一位成员发布了帖子 Prompt optimization can enable AI control research,解释了他们如何使用 DSPy 的 GEPA 来优化 Trusted Monitor。
- 他们随后使用 inspect 对其进行了评估,代码可以在这里找到:dspy-trusted-monitor。
- Comparative Metric 提升 GEPA 性能:一位成员引入了 带有反馈的比较指标 (Comparative Metric with Feedback),每次将一个正样本和一个负样本输入分类器,并根据正样本得分是否高于负样本得分对该对样本进行评分。
- 这使得 Reflection LM 能够学习分类器的正确信号,并创建一个鲁棒的 优化后的 Prompt。
- GEPA Readme 链接至 Trusted Monitor 项目:一位成员感谢另一位成员将该项目包含在 GEPA 的 Readme 中,并有兴趣就 Comparative Metric 本身写一篇简短的介绍。
- 另一位成员回应说,他们很乐意撰写关于 Comparative Metric 的文章,并好奇这是否是分类的一种鲁棒策略。
tinygrad (George Hotz) ▷ #general (12 messages🔥):
High-Level IRs like Triton, Multi-Layer IR Stack, Hardware-Incomplete vs Complete IRs, Search and Learning in Compilers, Graph-Based Models for Compilers
- Triton 的抽象层级引发辩论:讨论强调了像 Triton 这样的高层级 IR 的好处,但也指出需要多层堆栈来与底层硬件交互。
- 提到了 Gluon 项目,并希望它能与 Triton 互操作,尽管其目前特定于 Nvidia 的特性是一个限制。
- 单一 IR 的不足已达成共识:共识是单一的高层级 IR 不足以满足所有用户和用例,理由是寻求加速的 PyTorch 用户与优化任务关键型 HPC 项目的用户需求各异。
- 这是因为 并不真的存在一个 IR 抽象层级对所有用户和用例都恰到好处的“金发姑娘区” (Goldilocks zone)。
- UOps 利用 Bitter Lesson:Tinygrad 的愿景涉及利用 Bitter Lesson 来结合不完整和完整 IR 的优势,使用 UOps 作为硬件不完整(Hardware-Incomplete)的表示。
- 目标是在实现 UOps 的渲染程序空间中进行搜索,以找到最快的一个。
- Search 和 Neural Compilers 受到关注:强调了 Search 和 Neural Compilers 的重要性,特别是对 GNNs 或其他基于图的模型感兴趣。
- 建议是创建一个在每个阶段都利用基于图的模型的阶段式编译器。
Nous Research AI ▷ #general (6 messages):
TRL Assessor, Nous Tek
- TRL Assessor 咨询:一位成员询问了关于 TRL (Technology Readiness Level) Assessor 的信息,以及是否值得使用新生态系统对自己的堆栈进行红队测试(Red Team)。
- 另外两名成员建议将对话移至特定频道 <#1366812662167502870>。
- “Nous Tek” 赞誉:一位成员写道 “Nous tek”,这是一种积极的肯定。
- 另一位成员立即表示愿意回答问题。
Nous Research AI ▷ #ask-about-llms (6 messages):
Distributed Learning, Code Genetics, Model Non-Homology
- 分布式训练负载 (Distributing the Training Load):一位成员询问了利用 Kubernetes 和 Google Cloud 等资源,在多个 VPS 上通过分布式学习训练 AI 模型的可行性。
- 他们有兴趣利用这种设置,通过源自运营数据的训练集来加速训练周期,同时也对硬件管理的安全性限制表示了关注。
- 代码遗传学与模型参数微调 (Code Genetics and Model Parameter Tuning):一位成员探讨了通过 OpenMDAO 使用 code genetics 来自动化可调参数,并使用 Terraform 进行基础设施控制。
- 他们询问了必要的审计系统和验证合成数据的方法,旨在影响已投入使用的模型参数,而非使用类似 Nate Lora 的技术。
- 模型同源性问题 (Model Homology Concerns):一位成员解释说,在预训练到稳定的 loss 值后,模型会固定 tokenized 结构,创建一个稳固的“世界状态 (world state)”,若不破坏结构则很难改变。
- 他们指出,虽然微调可以在流形 (manifold) 周围生成 task vectors,但比较数据集需要一个共同的基础,否则模型会变得非同源 (non-homologous)。
Eleuther ▷ #general (3 messages):
AI Behavioral Coherence, Mathematical AI Constraints, Davinci Architecture
- 研究员探讨 AI 行为一致性:一位独立研究员正在开发 AI behavioral coherence 的数学框架,旨在无需重新训练即可对语言模型进行实时语义控制。
- 目前的工作重点是验证跨模型一致性 (cross-model consistency),并探索数学约束如何增强 AI 系统的可解释性 (interpretability)。
- Davinci 架构揭秘:一位成员指出,Davinci 本质上是 GPT-2 的 transformer 架构,但采用了局部带状的密集和稀疏注意力模式以及 4x FFN。
- 据另一位成员称,这些信息在 GPT-3 论文中可以找到。
Eleuther ▷ #research (8 messages🔥):
Zero Knowledge Proofs, SwiGLU up-projection, Model Tampering Defenses
- **ZKML 用于模型完整性?:一位成员建议使用零知识证明 (ZKML)**,让推理提供商能够证明他们没有微调/替换/降低模型质量,或者证明训练过程仅使用了特定数据。
- 他们指出,目前这项技术速度非常慢。
- 针对微调的 SwiGLU “防御”:一位成员建议通过将 SwiGLU up-projection 中的随机项乘以大数值,并在 down-projection 中应用逆数值,使模型在事后无法进行微调。
- 他们声称,即使使用默认的量化方案,所有人的标准 AdamW 配方都会失效,而且他们会因为太懒而不去修复它。
- 模型篡改防御:一位成员认为,通过增加微调难度来减轻模型发布担忧的可能性是一个开放的技术问题,而不是可以先验地 (a priori) 确定的。
- 他们还提到,他们最近的论文在抗篡改能力上比之前的工作提高了 3 个数量级 (3 OOMs)。
Moonshot AI (Kimi K-2) ▷ #general-chat (3 messages):
pydantic-ai lib
- Pydantic-AI 库即插即用组件:一位成员建议使用 pydantic-ai 库,因为它对特定流程有简洁的实现。
- 他们表示,该库包含一个即插即用组件,仅需约 10 行代码即可完成任务。
- 示例主题:这是另一个主题。
- 关于该主题的详细信息。
Windsurf ▷ #announcements (2 messages):
GPT-5-Codex, Figma MCP server, Windsurf update, Remote Figma integration
- GPT-5-Codex 登陆 Windsurf!:来自 OpenAI 的新 GPT-5-Codex 模型现已在 Windsurf 上线。根据此公告,它在长时间运行和设计相关任务中的表现令用户印象深刻。
- 付费用户在限时内可免费使用,而免费层级用户可以以 0.5 倍积分访问,所以记得重新加载 Windsurf 以查看它!
- 官方 Figma MCP server 发布!:一个新的官方 Figma MCP server 现已在 Windsurf MCP 商店中提供,此帖子中对此进行了讨论。
- 用户现在可以通过全新改进的集成直接将 Figma 链接粘贴到 Windsurf 中,且无需 Figma 桌面应用程序。
- 迁移到新的 Figma MCP Server!:建议之前使用 Figma Dev Mode MCP server 的用户安装新的官方 Figma MCP server。
- 此次迁移确保了对 Figma 新的远程 MCP server 的访问,从而实现与 Windsurf 更好的集成。
MCP Contributors (Official) ▷ #mcp-dev-summit (2 messages):
MCP Dev Summit, Apify & Jentic Happy Hour