AI News
GDPVal 研究发现:Claude Opus 4.1 已达到 AGI(通用人工智能)水平的 95%(以 44 种主要白领职业的人类专家为基准)。
OpenAI 的评估团队发布了 GDPval,这是一个全面的评估基准,涵盖了 44 个主要数字职业的 1,320 项任务,旨在将 AI 模型与平均拥有 14 年经验的人类专家进行对比评估。
初步结果显示,Claude 4.1 Opus 在大多数类别中的表现优于人类专家,而 GPT-5 high 紧随其后。据预测,GPTnext 有望在 2026 年中期达到人类水平。该基准被定位为政策制定者和劳动力影响预测的关键指标。
此外,Artificial Analysis 报告了 Gemini 2.5 Flash/Flash-Lite 和 DeepSeek V3.1 Terminus 模型的改进,并发布了新的语音转文本基准(AA-WER),其中 Google Chirp 2 和 NVIDIA Canary Qwen2.5B 等模型处于领先地位。在智能体 AI(Agentic AI)进展方面,包括 Kimi OK Computer,这是一个具有扩展工具能力和新供应商验证工具的类操作系统(OS-like)智能体。
我们如此接近!
2025年9月24日至9月25日的 AI 新闻。我们为您检查了 12 个 Reddit 子版块、544 个 Twitter 账号和 23 个 Discord 服务器(194 个频道,5737 条消息)。预计节省阅读时间(按每分钟 200 字计算):472 分钟。我们的新网站现已上线,支持全元数据搜索,并以精美的 vibe coded 风格展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的详细新闻,并在 @smol_ai 上向我们提供反馈!
OpenAI 的 Evals 团队今年第三次回归,带来了 GDPVal。他们将其定位为模型评估的逻辑下一步,既具有 MMLU 的广度,又具备像 SWE-Bench 及其自有的 SWE-Lancer 等 Agent 基準测试的深度。GDPval(完整论文在此)的名字源于对 GDP 主要份额(>5%)行业的自上而下筛选,并过滤出“主要为数字化”的知识型工作:

这产生了涵盖 44 个职业的 1,320 个任务,随后针对模型和在该领域平均拥有 14 年经验的人类专家进行了评估:

两张主要的结果图表极具验证性:首先,OpenAI 并没有偏袒自家模型;其次,Opus 与行业专家的产出水平已近在咫尺:
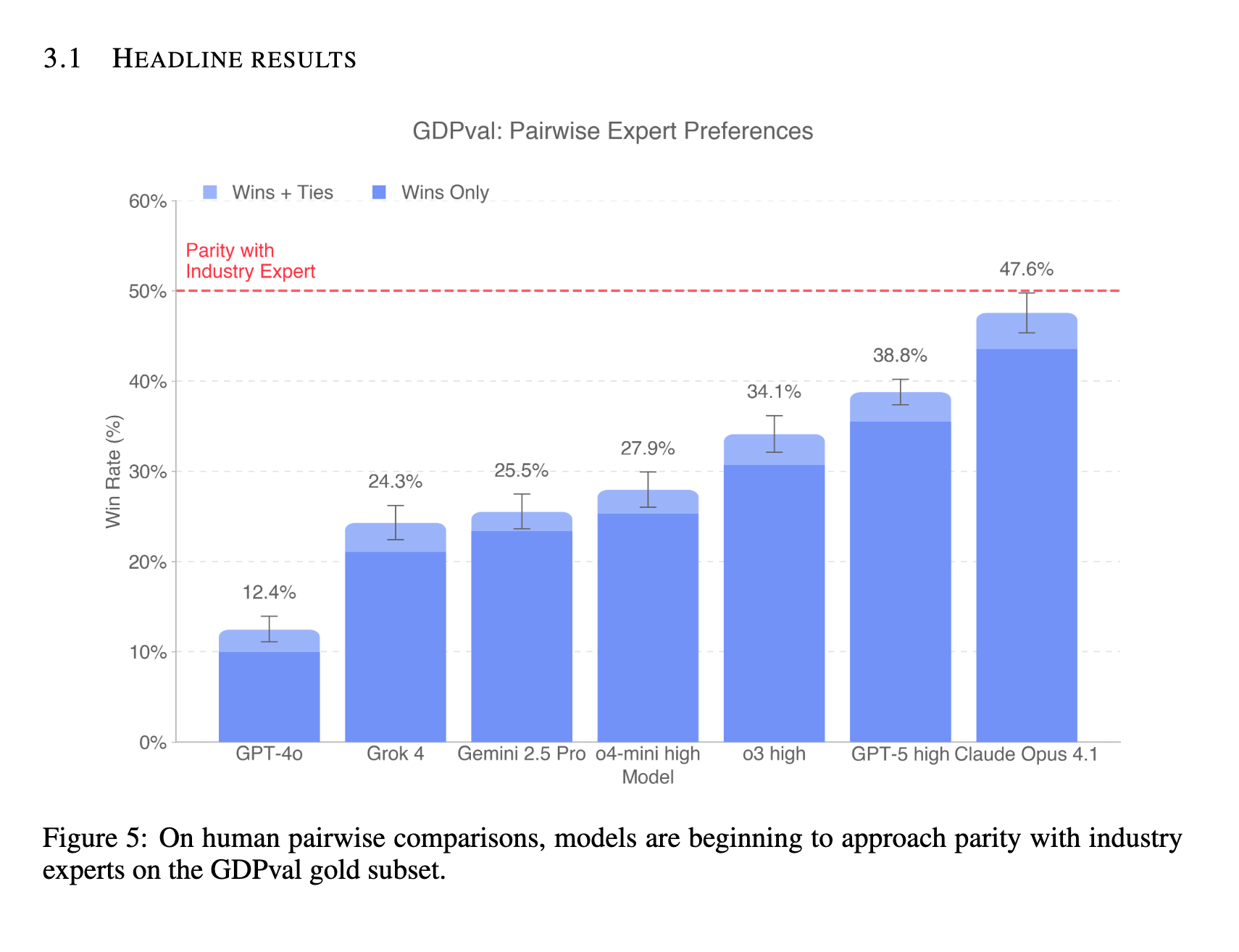
而随时间变化的模型趋势线显示,GPTnext 大约在 2026 年中期就能达到人类水平:
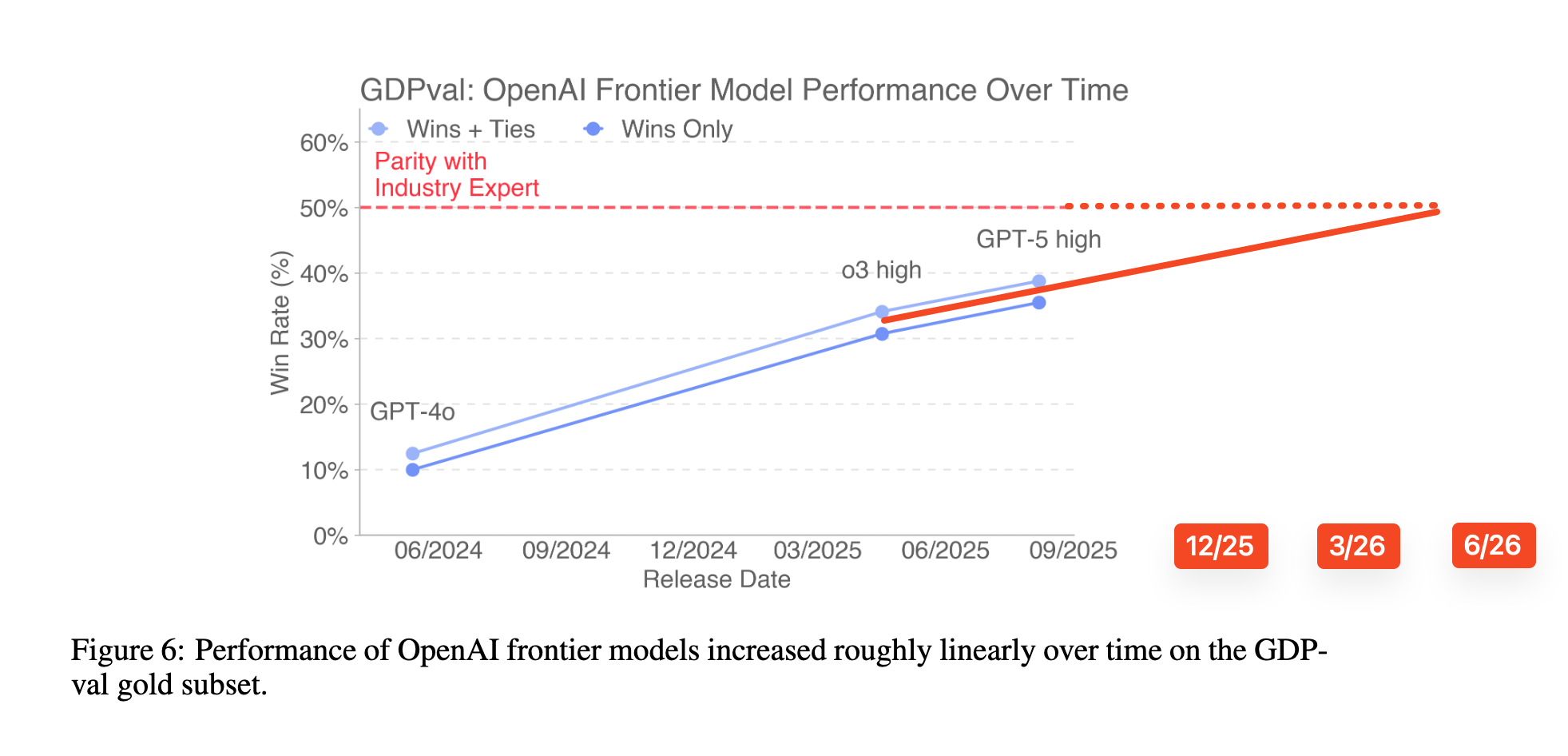
论文中完全没有提到 AGI 这个词,但 OpenAI 最初在 2018 年左右的章程中将 AGI 定义为“在大多数具有经济价值的工作中超越人类的高度自主系统”。如果我们到 2026 年 9 月醒来,发现 GPT6-high-ultrathink-final-for-realsies 在 GDPVal 的两两比较中超过了 50% 的置信区间,那么我们就可以真正地说,按照 2018 年的标准,我们已经实现了 AGI。
AI Twitter 综述
OpenAI 的 GDPval 与现实世界评估现状
- GDPval (OpenAI):OpenAI 推出了 GDPval,这是一种衡量模型在 44 个职业中“具有经济价值”任务表现的新评估方法,涉及工具使用(搜索/代码/文档)和跨越数小时的复杂性。早期结果:Claude 4.1 Opus 在大多数类别中名列前茅,接近或击败了行业专家;GPT-5 “high”在相同任务上落后于 Opus。OpenAI 提供了公开网站和方法论;领导层将其视为政策制定者和预测劳动力影响的关键指标。查看发布与讨论:@OpenAI, @kevinweil, @gdb, @dejavucoder, @Yuchenj_UW, @LHSummers。
- Artificial Analysis 指数:
- Gemini 2.5 Flash/Flash-Lite (Preview 09-2025):Flash 在推理/非推理方面分别提升了 3/8 分;Flash-Lite 较之前版本提升了 8/12 分。Flash-Lite 速度提升约 40%(≈887 tok/s),且输出 Token 减少了 50%;支持 1M 上下文、工具使用和混合推理模式。定价:Flash-Lite 每 1M 输入/输出为 $0.1/$0.4;Flash 为 $0.3/$2.5。基准测试:@ArtificialAnlys, 后续更新。
- DeepSeek V3.1 Terminus:推理模式下比 V3.1 提升 4 分,在指令遵循(+15 IFBench)和长上下文(+12 AA-LCR)方面进步显著。架构:总参数 671B,激活参数 37B;可通过 API 和第三方托管(FP4/FP8)获取。@ArtificialAnlys。
- AA-WER (语音转文字):涵盖 AMI-SDM、Earnings-22、VoxPopuli 的新词错率基准测试。领先者:Google Chirp 2 (11.6% WER)、NVIDIA Canary Qwen2.5B (13.2%)、Parakeet TDT 0.6B V2 (13.7%)。指出了性价比权衡;Whisper/GPT-4o Transcribe 在牺牲字面准确性的情况下使结果更平滑。@ArtificialAnlys, 定价。
Agent 编程与产品化 Agent
- Kimi “OK Computer” (K2 驱动的 Agent 模式):一个类操作系统的 Agent,拥有自己的文件系统、浏览器、终端以及更长的工具预算。演示包括:单提示词生成网站/移动优先设计、可编辑幻灯片,以及基于多达 100 万行数据生成的仪表盘。此外还发布了一个 Vendor Verifier,用于在 OpenRouter 上验证各供应商工具调用(tool-call)的准确性。相关讨论:@Kimi_Moonshot, @crystalsssup, 示例 1, 2。
- GitHub Copilot CLI (公开预览版):支持 MCP 的本地终端 Agent,镜像了云端 Copilot 编程 Agent 的功能。使用现有的 GitHub 身份,支持脚本嵌入,并提供清晰的按请求计费。公告:@github, @lukehoban。
- Factory AI “Droids” + 5000 万美元融资:模型无关的软件开发 Agent(支持 CLI/IDE/Slack/Linear/Browser),在 Terminal‑Bench 上排名第一,定位为通过代码抽象实现的更广泛的知识工作 Agent。发布与融资信息:@FactoryAI, 评论 @swyx, @tbpn。
- Ollama 网络搜索 API + MCP 服务器:将本地/云端模型连接到实时网络落地(grounding);兼容 Codex/cline/Goose 及其他 MCP 客户端。@ollama。
- Reka Research “Parallel Thinking” (并行思考):一种 API 选项,可生成多个候选链并通过验证器模型进行解析;在 Research‑Eval 上提升了 4.2 分,在 SimpleQA 上提升了 3.5 分,且延迟几乎没有增加。@RekaAILabs。
视频推理与机器人
- 视频模型作为零样本推理器 (Veo 3):DeepMind 展示了在感知 → 物理 → 操控 → 推理方面的广泛零样本能力。引入了 “Chain‑of‑Frames” 作为视觉 CoT。在深度和物理方面仍落后于 SOTA;成本依然较高。论文/讨论:@arankomatsuzaki, 项目/论文, @tkipf。
- Gemini Robotics 1.5 (Google):全新的具身推理技术栈(GR 1.5 VLA + ER),具备长上下文、工具使用、时空规划、跨具身迁移以及安全约束能力。API 已在 Google AI Studio 上线;演示了洗衣服分类的推理过程。公告:@GoogleDeepMind, @sundarpichai, API 说明, @demishassabis。
模型与方法发布
- EmbeddingGemma (Google):一款 308M 的编码器模型,在 5 亿参数以下模型中位列 MTEB 榜首(涵盖多语言/英语/代码)。声称与约 2 倍体量的基准模型性能持平;支持 4-bit 和 128 维嵌入。技术包括:编码器-解码器初始化、几何蒸馏、分散正则化器(spread‑out regularizer)以及模型汤(model souping)。适用于端侧/高吞吐量场景。相关讨论:@arankomatsuzaki, 论文综述。
- ShinkaEvolve (Sakana AI, 开源):一个样本高效的进化框架,利用 LLM 集成通过自适应父代采样和新颖性过滤来“进化程序”。结果:通过 150 个样本实现了新的圆堆积(circle packing)SOTA;改进了 ALE‑Bench 解决方案;发现了一种新型 MoE 负载均衡损失,提升了专业化程度和困惑度;增强了 AIME 脚手架。代码/论文:@SakanaAILabs, @hardmaru, 报告。
- RLMT & TPT:
- “Language Models that Think, Chat Better” 提出通过模型奖励思考强化学习(RLMT),在 8B 模型的聊天基准测试中超越 RLHF;消融实验强调了提示词混合和奖励强度的重要性。@iScienceLuvr, 笔记。
- “Thinking‑Augmented Pre‑Training (TPT)” 报告称,通过合成的分步轨迹,使 3B 模型的预训练数据效率提升约 3 倍,并在推理后训练(post-training)中获得超过 10% 的提升。@iScienceLuvr。
系统、推理服务与基础设施
- Perplexity Search API:一个具有顶尖延迟/质量表现的实时网页索引,用于为 LLM 和 Agent 提供事实依据(grounding),并附带公开评估/研究。声称在单步和深度研究基准测试中表现强劲,且在 LLM 使用方面比 Google SERP 更有优势。发布:@perplexity_ai,研究:文章,评论:@AravSrinivas。
- KV 重用与动态并行:
- LMCache:开放的 KV-cache 层,可在 GPU/CPU/磁盘间重用任何重复的文本段(不仅是前缀);将 RAG 成本降低 4–10 倍,缩短 TTFT,并提升吞吐量。已集成在 NVIDIA Dynamo 中。@TheTuringPost。
- Shift Parallelism (Snowflake):根据负载动态切换 Tensor/Sequence Parallelism——延迟降低高达 1.5 倍(交互式),吞吐量提高 50%(高流量)。代码已在 Arctic Inference 中提供。@StasBekman。
- Context-parallel diffusion:原生支持 ring/Ulysses 变体,让多 GPU 扩散模型(diffusers)性能飞升。@RisingSayak。
- attnd (ZML):基于 UDP 在 CPU 上实现的稀疏对数注意力;被宣传为“为无限上下文铺平道路”。@steeve。
- 能源与硬件:
- Microsoft (LLM 推理能耗):聊天机器人查询中位能耗约 0.34 Wh;长推理约 4.3 Wh(约 13 倍);日查询量 10 亿次的集群能耗约 0.9 GWh(约等于网页搜索规模)。声称公开估算值高出了 4–20 倍;实现 8–20 倍的效率提升是可行的。@arankomatsuzaki。
- B200 竞价定价:B200 竞价实例(spot instances)价格曾短暂低至约 $0.92/小时。@johannes_hage。
行业动态与平台更新
- Meta 人才挖掘:扩散/一致性模型先驱 Yang Song 离开 OpenAI 加入 Meta;被广泛认为是一次重大的挖角。报道:@iScienceLuvr, @Yuchenj_UW。
- ChatGPT Pulse:OpenAI 向 Pro 用户推出“主动式”每日更新(上下文、关联应用)——这是一种超越被动响应式对话的环境智能体(ambient agent)形态。推文:@OpenAI, @sama, @fidjissimo。
- Qwen 生态系统:Qwen 模型已加入 LMSYS Arena (@Alibaba_Qwen);通过第三方供应商提供 Qwen3-VL 部署,以便于试用。@mervenoyann。
热门推文(按互动量排序)
- “有个人……如果 ChatGPT 错了,他就把手机放进冰箱里” — 55,057
- Sam Altman 谈 ChatGPT Pulse(“从被动到主动”) — 28,573
- Karpathy 谈“AI 不会取代放射科医生”(为什么基准测试 ≠ 部署现实) — 7,980
- Kimi 的 “OK Computer” 智能体模式发布 — 2,646
- OpenAI 宣布 GDPval — 4,144
- Demis Hassabis 谈 Gemini Robotics 1.5(“与机器人对话”) — 1,545
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. 中国 AI 模型发布:阿里巴巴 Qwen 极致扩展路线图 & 腾讯混元 Image 3.0
- 阿里巴巴刚刚公布了其 Qwen 路线图。其雄心壮志令人震惊! (Score: 662, Comments: 146): 阿里巴巴的 Qwen 路线图幻灯片信号表明,其在统一多模态模型和极端扩展方面进行了激进的押注:上下文长度从
1M → 100Mtokens,参数量从约1T → 10T,测试时计算(test‑time compute)从64k → 1Mtokens,训练数据从10T → 100Ttokens,同时还包括“无限规模”的合成数据生成和扩展的 Agent 能力(复杂性、交互、学习)。该计划呼应了“扩展即一切”(scaling is all you need)的哲学,这意味着在内存带宽、KV‑cache 管理、长上下文注意力机制(例如 hybrid/linear/sparse)以及合成数据流水线的可靠性方面,面临着巨大的计算、数据策选和推理优化挑战。 评论者对可行性/实用性表示怀疑:100M的上下文窗口和>1T参数的模型对硬件和推理成本构成了巨大压力,可能迫使部署转向封闭的、仅限云端的环境;其他人则询问本地计算能实际处理多少万亿级模型,暗示了对量化、MoE 或 offloading 方案的依赖。- 许多人关注路线图中提到的“100M 上下文” (图片)。朴素的二次方注意力机制在大规模情况下是难以实现的:对于一个约 32 层、约 4k 隐藏层的解码器,FP16 的 KV cache 约为
0.5 MB/token,因此100Mtokens 意味着约50 TB的 VRAM(即使是 4-bit KV 仍需约12.5 TB)。要达到这一目标,需要稀疏/线性/流式注意力(如 block-sparse, ring/streaming)、检索/分块、激进的 KV 量化/offload 以及精心优化的带宽内核;像 FlashAttention 这样的计算优化有助于常数项,但无法解决 O(n^2) 的扩展问题。 - 关于“在本地运行 >1T 模型?”——仅权重存储就占据了主导地位:
1T参数在int4下约为500 GB(FP16 约为2 TB),这还没算 KV cache,在长上下文下 KV cache 会增加数百 GB 到数 TB。现实中,这需要配备 NVLink/NVSwitch 的多 GPU 服务器(例如8–16×80 GB),并采用张量并行+流水线并行;每个 token 的计算量约为 O(P)(约2e12FLOPs/token),因此10–30tok/s 需要大约20–60TFLOP/s 的持续算力,但内存带宽和集体通信才是主要的瓶颈,而非原始 FLOPs。
- 许多人关注路线图中提到的“100M 上下文” (图片)。朴素的二次方注意力机制在大规模情况下是难以实现的:对于一个约 32 层、约 4k 隐藏层的解码器,FP16 的 KV cache 约为
- 腾讯预热全球最强开源文本生成图像模型,Hunyuan Image 3.0 将于 9 月 28 日发布 (Score: 173, Comments: 26): 腾讯预热了 Hunyuan Image 3.0,这是一款定于 9 月 28 日发布的开源文本生成图像模型,声称将成为“最强大”的开源选择。预热信息暗示了
96 GB VRAM的需求(至少对于某些推理模式而言),但尚未提供公开的基准测试、架构细节、训练数据或吞吐量/延迟指标;因此,在发布之前,其性能主张仍未得到证实。图片:https://i.redd.it/t8w84ihz1crf1.jpeg 评论者对发布前的大肆宣传持怀疑态度,指出强大的模型往往在极少营销的情况下发布(如 Qwen),并引用了过去过度炒作的发布案例(如 SD3 对比 FLUX)。其他人指出,在没有同类开源对比的情况下,冠以“最强大”标签还为时过早;一位评论者确认了预热信息中VRAM 96的细节。- 传闻中推理所需的
~96 GB VRAM表明其拥有非常庞大的 Diffusion/DiT 骨干网络或高分辨率潜空间配置,这超出了单个消费级 GPU(24–48 GB)的能力。预计将严重依赖内存优化(attention slicing, tiled VAE)、CPU/NVLink offload、模型分片或多 GPU 张量并行;用于 Diffusion U‑Nets 的量化技术尚不成熟,且可能损害质量。内存占用与分辨率/步数之间的权衡对于实际的本地使用至关重要。 - 几位用户注意到一种模式,即大肆预热的发布往往不如“空降”式发布(如 Qwen),并以 SD3 对比 FLUX 为先例。他们希望在相信“最强大”之前看到硬数据:与 Qwen Image/FLUX/SDXL 进行 Prompt 对比测试,包含 FID/CLIPScore/HPSv2 指标,以及对文本渲染、小物体计数、多主体构图和 Prompt 忠实度的测试。如果没有数据卡(data card)和可重复的评估,这种说法读起来就像是营销辞令。
- 立即有人要求 ComfyUI 支持;可行性取决于 Hunyuan Image 3.0 是坚持 SDXL 风格的流水线,还是引入了自定义的调度器/模块。如果是类 DiT 结构(如之前的 Hunyuan 发布),使用带有 FlashAttention 2/xFormers 的加载节点应该就足够了;否则可能需要自定义 CUDA 内核和采样器节点。社区将寻找 FP16 权重检查点、ONNX/TensorRT 导出以及采样器兼容性(DDIM/DPM++/DPMSolver),以衡量采用的难易程度。
- 传闻中推理所需的
{kind=link}
{kind=link}
{kind=link}
2. 本地 AI 替代方案:风华 3 号 CUDA/DirectX GPU + Abliteration 后的去审查 LLM Finetunes
- 中国已经开始制造支持 CUDA 和 DirectX 的 GPU,因此 NVIDIA 的垄断地位即将结束。风华 3 号支持最新的 API,包括 DirectX 12、Vulkan 1.2 和 OpenGL 4.6。 (Score: 454, Comments: 124):帖子声称中国的风华 3 号 GPU 原生支持现代图形/计算 API:
DirectX 12、Vulkan 1.2、OpenGL 4.6,甚至支持 NVIDIA 的 CUDA,这表明它可能是 NVIDIA 生态系统的潜在替代方案。 图片看起来像是产品/规格幻灯片,但没有提供驱动程序成熟度细节、CUDA 兼容层说明或 Benchmark 数据,因此实际的对等性和性能仍未得到证实。从上下文来看,CUDA “支持”可能意味着重新实现/翻译层(类似于 AMD 的 HIP:https://github.com/ROCm/HIP 或 ZLUDA 等项目:https://github.com/vosen/ZLUDA),除非完全采用“洁净室(Clean-room)”设计并经过严格测试,否则这在法律和技术上都可能充满挑战。热门评论指出,AMD 已经通过 HIP 提供了 CUDA 兼容路径,而中国厂商可能会忽略法律/知识产权限制直接宣传支持 CUDA;其他人则保持怀疑态度(“眼见为实”),并预见到地缘政治的阻力。总体情绪对准备就绪程度、驱动质量和合法性的质疑多于对标题中 API 列表的关注。 -
重要:为什么 Abliterated 模型很烂。这里有一种更好的 LLM 去审查方法。 (Score: 273, Comments: 80):原帖作者报告称,LLM 的权重空间“Abliteration”(去审查)——特别是像 Qwen3-30B-A3B 这样的 MoE 模型——会持续降低推理能力、Agent/工具使用行为,并增加幻觉,通常导致
30B的 Abliterated 模型表现不如非 Abliterated 的4–8B模型。 在他们的测试中,Abliterated + Finetuned 模型在很大程度上“恢复”了能力:mradermacher/Qwen3-30B-A3B-abliterated-erotic-i1-GGUF(测试了i1-Q4_K_S)在性能上接近原始 Qwen3-30B-A3B,且幻觉比其他 Abliterated Qwen3 变体更少,并通过 MCP 表现出更好的 Tool-calling 能力;据报道,mlabonne/NeuralDaredevil-8B-abliterated(基于 Llama3-8B 的 DPO FT)在保持去审查的同时优于其基础模型。与仅进行 Abliterated 处理的版本——Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated-GGUF、Huihui-Qwen3-30B-A3B-abliterated-Fusion-9010-i1-GGUF、Huihui-Qwen3-30B-A3B-Instruct-2507-abliterated-GGUF——的直接对比发现,这些模型对非法任务提示的响应不切实际,工具调用频繁出错/重复,且幻觉比 Finetuned Abliterated 模型更高(尽管仍略逊于原始模型)。评论呼吁建立标准化 Benchmark,以量化除 NSFW 任务之外的“Abliteration”退化情况,并将观察到的恢复过程称为“模型愈合(Model Healing)”:编辑后的 Finetuning 让网络重新学习被无约束权重编辑破坏的连接。一种怀疑观点认为,如果横竖都需要 Finetuning,那么 Abliteration 只会增加风险而无收益——声称他们从未见过 Abliteration + Finetune 能击败直接的 Finetune。 - 几位评论者指出,任意的权重编辑(”abliteration”)会引入不可控的分布偏移(distribution shift)和能力损失;这在本质上被称为 model healing:如果你在没有训练信号的情况下扰动权重,你应该预料到推理/知识能力的退化,只有通过适当损失函数的进一步 fine-tuning 才能部分修复受损的电路。从业者报告称,经过 abliteration 处理后再进行 fine-tuned 的模型,其表现很少优于在同一 base 模型上直接进行 fine-tune 的模型,这暗示这种编辑增加了优化债务(optimization debt),但在基准测试中没有带来可衡量的收益。
- 有人呼吁进行超越色情内容的评估;Uncensored General Intelligence (UGI) Benchmark/排行榜旨在量化无审查模型的广泛能力(推理、编码、知识等),同时尽量减少拒绝伪影(refusal artifacts):https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard。使用 UGI(或类似的多领域套件)能更好地捕捉无审查处理是保留了通用性能,还是导致了退化。
- 作为 abliteration 的替代方案,用户推荐了一些已知能保留实用性的无审查 fine-tunes,例如 Qwen3-8B
192kJosiefied GGUF 版本 (https://huggingface.co/DavidAU/Qwen3-8B-192k-Josiefied-Uncensored-NEO-Max-GGUF)、Dolphin-Mistral-24B 变体 (https://huggingface.co/mradermacher/Dolphin-Mistral-24B-Venice-Edition-i1-GGUF) 以及来自 TheDrummer 的模型 (https://huggingface.co/TheDrummer)。这些被认为是更好的无审查基准模型,可以在 UGI 上进行正面交锋,以验证能力的保留情况。
{kind=link}
Less Technical AI Subreddit Recap
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Gemini Robotics 1.5 and Veo 3 Zero‑Shot Video Reasoning
- Gemini Robotics 1.5 (Score: 276, Comments: 39): Google DeepMind 发布了 “Gemini Robotics 1.5”,这是一个基于 Gemini-1.5 的多模态 VLA,它将自然语言 + 视觉映射到机器人控制,用于跨多种实体(embodiments)的长程(long‑horizon)、多步操作,演示包括衣物分类、桌面整理和完整的场景重置/回滚 (页面)。基于之前的 VLA 系列(如 RT‑2/RT‑X),它强调开放词汇(open‑vocabulary)的物体/工具接地(grounding)、通过模型的长上下文(long context)进行分层任务分解,以及无需针对每个任务进行 fine‑tuning 的泛化能力,实现了“返回初始状态”行为和多物体组织。 技术导向的评论者强调了稳健的场景恢复作为实用家庭原语(即规范地“重置”到预定义状态)的重要性,并推测直接迁移到农业(如采摘水果)作为一个可扩展、高影响力的应用领域。
- 将此应用于采摘水果是相比洗衣服的一次非平凡飞跃:户外、非结构化场景引入了多变的光照、遮挡以及可变形/易碎物体的处理,这需要闭环视觉(closed-loop vision)、触觉/力反馈、柔性/软体抓取器(compliant/soft grippers)以及稳健的视觉伺服(visual servoing)。通用 VLA 策略(例如 RT‑2 的开放词汇示能性接地/affordance grounding)可以帮助将“采摘成熟苹果”等语言目标映射到动作原语,但成功将取决于机载延迟、多视图感知和防滑抓取释放 [https://deepmind.google/discover/blog/rt-2/]。
- “将场景恢复到规范状态”的用例本质上是具有持久内存的目标条件操作(goal‑conditioned manipulation):维护一个以物体为中心的场景图(scene graph),计算与参考快照的差异,然后规划多步重新排列。像用于基于关键点的拾取和放置的 Transporter Nets 以及视觉目标条件策略可以执行“整理以匹配此图像”的行为,但需要稳健的重定位、杂乱分割和故障恢复,以避免在长程任务中产生复合误差 [https://transporternets.github.io/]。
- “所有机器人共享同一个大脑”对应于集群学习(fleet learning):在异构实体之间共享集中的策略/参数,并进行定期的云端更新,正如在 RT‑X 等多机器人数据集/策略中所见 [https://robotics-transformer-x.github.io/]。实际部署会增加实体适配器,并且为了隐私/安全可能更倾向于联邦学习(federated learning);核心挑战是跨形态/传感器的分布偏移、持续学习中的灾难性遗忘以及 sim2real 漂移,这些可以通过领域随机化(domain randomization)和强正则化来缓解。
- 视频模型是零样本学习者和推理者 (Score: 238, Comments: 30): 该帖子重点介绍了一个项目和论文,声称生成式视频模型 Veo 3 在没有特定任务训练或语言中介的情况下,展现了广泛的零样本能力——涵盖分割、边缘检测、图像编辑、物理属性推断、功能性识别(affordance recognition)、工具使用模拟以及早期视觉推理任务(如迷宫和对称性求解)。作者类比 LLM 的涌现,认为扩展大规模、在网络数据上训练的生成式视频模型可以产生通用视觉理解,将视频模型定位为潜在的统一视觉基础模型;参见项目页面和演示:https://video-zero-shot.github.io/,论文见:https://arxiv.org/pdf/2509.20328。值得注意的是,这些材料似乎主要是定性的:没有公开参数量、计算量、训练语料细节、标准化基准测试或消融实验,这限制了严谨的对比和可重复性。 评论者推测,连贯的长时视频生成意味着一个强大的已学习到的世界模型(world model),进一步的扩展可以提高能力,同时也指出了视频模型巨大的计算成本,并建议将 LLM 集成到单个多模态模型中;一些人要求提供基础模型细节(例如 Veo 3 的大小)。
- 几位评论者推断,高质量的视频生成(例如 Google 声称的 Veo 3)意味着一个学习到的“世界模型”,它强制执行时间连贯性和基础物理规律,这可以表现为零样本推理。这与之前的世界模型研究一致,如 DeepMind 的 Genie(交互式环境模型),它从视频中学习动力学(博客)。核心思想是:为了产生一致的帧,模型必须内化物体恒常性、运动连续性和因果关系——这些能力在没有特定任务微调的情况下也有利于下游推理。
- 存在一个实际的扩展约束:与文本相比,视频建模的 Token/计算量呈爆炸式增长。一段
10s、24 fps、720p的视频,如果以16x16进行分块(patchified),每帧会产生大约(1280/16)*(720/16)=3600个 Token ⇒ 每个片段约864k个 Token;即使使用潜空间压缩(8–16倍)以及 VAE 潜空间中的 Diffusion/Flow-matching,训练/推理的 FLOPs 也会让 LLM 相形见绌。这促使了混合系统(用于规划/推理的 LLM + 专门的视频生成器)或具有共享 Token 空间的统一骨干网络的发展,以摊销跨模态的计算成本。 - 在多模态方面,参与者注意到了差距:LMM 中已经存在视频输入(Video-in)能力(例如 Gemini 1.5 可以通过大上下文窗口处理长视频,据报道通过帧采样可达“数小时”;参见 Gemini 1.5),且 GPT-4o 支持实时视频输入(OpenAI)。但在一个已发布的模型中实现真正的统一视频输入 + 视频输出 + 推理仍然很少见;目前的做法是将推理 LLM 与 T2V 模型(如 Veo、Sora)串联,或者探索研究型的 Video-LLM,如 LLaVA-Video (arXiv) 和 Video-LLaMA (arXiv),它们专注于视频理解而非生成。这是评论者期待的下一个集成前沿。
2. LLM 推理可靠性:Apple 对阵 Anthropic 以及 GPT-5 退化报告
- Apple 指责各大 AI 公司存在虚假推理,而 Anthropic 的回应证明了他们的观点 (Score: 377, Comments: 198): Apple ML 的研究报告 “The Illusion of Thinking” (https://machinelearning.apple.com/research/illusion-of-thinking) 通过对数学/逻辑应用题应用保持语义但属于表面层级的扰动(perturbations)来评估 LLM 的“推理”能力,并报告了准确率的急剧下降,认为模型缺乏算法推理所应具备的不变性,转而利用伪模式(spurious patterns)。Anthropic 的回复 “The Illusion of the Illusion of Thinking” (https://arxiv.org/html/2506.09250v1) 则认为 Apple 的实验设置诱发了分布偏移(distribution shift)和标注伪影(annotation artifacts),并且在受控提示词和“更公平”的条件下,Claude 的表现是稳定的——将这种脆弱性归因为评估问题而非模型能力不足。这场辩论的核心在于模型对内容保持型改写的鲁棒性、指标过拟合,以及当前的 LLM 究竟展示了类推理的泛化能力,还是仅仅是复杂的模式匹配。 热门评论大多赞同 Apple 关于 LLM 并不具备“推理”能力的批评,分享了两篇论文,并描述了实际的技术栈:从 Tokenization 到数字 ID,过滤/引导输入输出的助手/策略层(例如安全/RLHF),以及可能导致退化输出的解码选择(例如采样配置错误时的重复 Token)——这意味着观察到的失败可能既反映了流水线/解码的脆弱性,也反映了模型的局限性。
- 几位评论者拆解了围绕 LLM 的生产环境技术栈:面向用户的模型将文本 Tokenization 为子词 Token 并预测下一个 Token,而“外部”层(系统提示词、安全/护栏分类器、预处理/后处理重写器以及路由/编排)则约束并塑造输出。这种包装设计解释了诸如对训练数据不可靠的逐字召回(参数化存储知识 vs. 索引存储)等行为,以及为什么基础模型的行为可能与产品体验不同(例如 RLHF 和过滤改变了概率分布)。
- 技术失效模式受到关注,例如由于高概率 Token 占主导地位而在解码病态时产生的早期重复循环(如 “the the the…”)。未调优的解码参数(
temperature、top-k/top-p)和缺乏惩罚机制会导致低熵退化;缓解措施包括repetition/frequency/presence惩罚、核采样(nucleus sampling)和熵增启发式算法——这些问题在护栏稳定输出之前的早期 GPT-2/3 时代系统中被广泛观察到。 - 在关于“推理”的辩论中,评论者主张采用操作性定义和以能力为中心的评估,而非仅仅贴标签,并指出对逻辑等效的提示词进行微小扰动往往会导致解题失败——这是模式匹配而非鲁棒推理的证据。文中分享了原始资料链接以供深入分析:Apple ML 的 “Illusion of Thinking” 研究简报 (https://machinelearning.apple.com/research/illusion-of-thinking) 和一篇 arXiv 预印本 (https://arxiv.org/html/2506.09250v1),鼓励进行基准测试和具备扰动鲁棒性的评估,而非盲信营销宣传。
-
ChatGPT 的状态非常糟糕,连我最资浅的学生都注意到它失控了 (Score: 211, Comments: 90): 一位 AI 集成讲师报告称,OpenAI 的助手(被称为 “GPT5”)在更新后出现了严重的退化:一个长期使用、此前能通过 GPT-4o 生成约
2000字且针对考试的总结的高级提示词(master prompt),现在只能生成带有“严重错误”的平庸文字,需要多达5轮往复澄清,并且经常偏离指令。在对比使用中,Google 的 Gemini 和 NotebookLM,以及 Anthropic 的 Claude 仍能提供一致的结果;该用户还声称,一个参数量约1B的本地 Gemma 系列模型(如 Gemma)在医疗教育总结工作流中的表现优于托管模型。基于这种在将数小时讲座/阅读材料转换为简洁笔记时观察到的可靠性下降,该讲师建议在改进前取消付费计划。 热门评论呼应了明显的性能下降以及在研究助手场景中信任度的降低,声称存在更广泛的跨模型下滑。其他人则对1B参数的 Gemma 能在实质上超越 OpenAI 最新模型的说法表示强烈怀疑,暗示可能存在评估或提示词方面的混淆因素。 - 许多用户报告最近发布的 ChatGPT 版本中存在明显的性能退化,特别是在研究/分析工作流方面:感知到的幻觉增加、输出“懒惰”/过短,以及在以前简单的任务上失败,导致一些人放弃将其用于关键工作。这与模型路由或安全/延迟调优影响行为的担忧一致,尽管评论者没有引用硬性基准测试数据。
- 关于 “Gemma 1B” 性能超过 GPT 的说法引发了质疑;公开发布的 Gemma 变体通常是 2B/7B (Gemma 1/1.1) 和 2B/9B (Gemma 2) docs。在 ~1–2B 规模下,模型在标准基准测试(如 MMLU, GSM8K)上通常落后于 GPT-4 级别的系统,因此一个 1B 模型在广泛任务上超过 GPT,除了在狭窄领域或有强大的 tool/RAG 支持外,通常是不寻常的。
- 提到的一种实用解决方法:如果感觉默认路由质量下降,可以在 ChatGPT 设置中启用“旧版模型” (legacy models) 以访问 GPT-4o。这表明模型选择/路由的变化可能会影响质量;进行侧向对比测试(在 4o 与当前默认模型上使用相同的 prompt)有助于隔离退化问题 OpenAI model list。
- 我快被图像生成过滤器搞疯了。 (Score: 503, Comments: 56): 用户报告 GPT 图像生成中的安全过滤器行为不一致:最初允许生成类似蛛形纲动物的怪物图像(示例预览),但随后请求非写实的、怪物图鉴/DnD 风格的渲染时被拦截,涉及
werewolf、blood和glowing red eyes的 prompt 也是如此。这种模式表明存在对关键词和风格敏感的内容审查,并可能具有非确定性(相同的概念有时通过,有时失败),导致在奇幻/恐怖内容上出现误报,而非针对明确的血腥或写实阈值。 评论者建议了一个解决方法:使用 ChatGPT 编写高度详细的 prompt,然后使用过滤器较松的替代模型(如 Grok)生成图像。其他人注意到频繁的误报(例如,良性 prompt 因“裸露”被标记),认为当前的安全启发式算法脆弱且过于宽泛。- 内容审查似乎过度敏感:一个关于写实鳟鱼用沙滩毛巾擦干身体的 prompt 因裸露被标记,这表明存在误报,即良性的人格化场景被与显性内容混淆。这指向了粗粒度的安全分类器或关键词启发式算法,通过拦截非显性请求降低了可用性。
- 一位用户报告在单块 RTX-3090 上通过 Stability Matrix UI 使用 Stable Diffusion 进行稳定的本地生成,称文本到图像的推理速度快且可靠,尽管比最先进的图像模型落后一步。本地运行提供了控制权并消除了托管平台的过滤器,且在商用高 VRAM GPU 上性能充足。
- 工作流建议包括使用 ChatGPT 编写高度详细的 prompt,然后将其输入到 Grok 等替代生成器中;其他人指出通过 Gemini 重新表述有时可以减少审查摩擦。将 prompt engineering 与推理分离可以提高输出质量,并减少严格的前端过滤器触发误报。
-
ChatGPT 如何帮助我戒掉大麻并理解成瘾根源 (Score: 428, Comments: 120): 楼主报告通过利用 ChatGPT 作为按需支持工具,戒掉了坚持
17 年的每日大麻使用习惯。他们用它来 (1) 实时解释戒断症状(如胸口压迫感、失眠、鲜活的梦境),(2) 使特定阶段的体验正常化,(3) 将渴望重新定义为“旧程序” (old programming) 而非身份认同,以及 (4) 促进对根源(严厉的家教、不安全感、孤独、创作瓶颈)进行结构化反思。结果:9 周禁欲,渴望显著减少,睡眠改善,当下意识增强;楼主将 ChatGPT 描述为全天候的治疗师/教练/镜子替代品。 热门评论大多表示支持(其中一人提到了30+年的挣扎),但也有一条反对意见暗示 AI 使得持续使用而无后果成为可能——突显了关于 AI 作为康复辅助工具还是潜在促成者的争论。 - ChatGPT 在过去一年里一直帮我打离婚官司 (Score: 333, Comments: 97): 一名在德克萨斯州有争议的离婚/子女抚养费案件(涉及两个孩子)中的 pro se(自行诉讼)当事人报告称,他通过提供受事实约束的指令并进行多轮人工验证,使用 ChatGPT 来起草和格式化法律文件——包括声明书、困难陈述和证据清单。在经历了为期 3 个月的临时命令阶段,且律师预测会出现不利的偏离结果后,他解雇了律师并继续自行代表,寻求偏离德克萨斯州指导性子女抚养费标准(约每月
$1,100;参见德克萨斯州准则 Family Code §154.125 和 OAG 计算器)。他目前作为前全职家长领取 100% VA disability(退伍军人伤残补偿),并主张对方有工作且提供免费住房。他将书面记录中结构的改进、问题的识别以及情感内容的减少归功于 ChatGPT,并利用这些文件来弥补在面对对方律师的制裁威胁和拖延战术时有限的出庭辩护能力。 评论者警告法律研究中 LLM 幻觉的风险,引用了 Mata v. Avianca 案中因 ChatGPT 生成虚构判例法而受到的制裁(命令),敦促对引文和先例进行严格验证。其他人则认为,如果保持事实性,LLM 在起草清晰度方面可以超越律师,并指出法院可能会对 pro se 当事人提交的精确且有充分支持的文件做出积极回应。- 多名评论者指出法律幻觉风险:其中一人提到了广为人知的 Avianca 事件,一名律师提交了 ChatGPT 虚构的案例引文并受到制裁;他们敦促在向法院提交或辩论之前,必须对照原始资料严格验证所有引文/先例(命令 PDF,新闻)。强调:不要在没有交叉检查的情况下依赖模型生成的判例法;“自行代表是一个巨大的危险信号”,因此要预料到权威机构会加强审查。
- 提出了一种成本/控制工作流:使用 ChatGPT 进行起草/研究等“苦差事”,然后由执业律师进行审查、完善并处理听证会,从而在保持法庭胜任能力的同时减少计费时长。一位评论者报告了使用预付费法律计划和混合计费(拆分计划覆盖的小时数和自费工作)的成功经验,并建议使用 ChatGPT 比较计划/等待时间,以优化覆盖范围和响应速度。
- 关于能力与可靠性的辩论:一人断言“法律是书面的……ChatGPT 拥有数据”,并且在起草的某些方面可以超越律师,认为更犀利的文件可以改善法院的接受度。反方观点强调,即使有强大的 AI 辅助文件,结果仍可能不利,且模型输出必须基于经过验证的事实和真实的先例,以避免损害信誉。
{kind=link}
3. AI 行业动态:Anthropic 的应届生招聘立场与中国风华 3 号 GPU
-
Anthropic CPO 承认随着 AI 接管入门级任务,他们很少招聘应届生 (Score: 207, Comments: 86): Anthropic CPO Mike Krieger 表示,公司已基本停止招聘应届生,转而依赖有经验的员工,因为 Claude/Claude Code 越来越多地替代了入门级开发工作——从单任务助手演变为可以委派和执行 20-30 分钟任务及更大模块的协作伙伴,甚至 “使用 Claude 来开发 Claude”(来源)。他预测大多数编码任务将在约 1 年内实现自动化,其他学科将在 2-3 年内实现,这一背景是行业裁员以及 2025 年 CS 毕业生
6.1%的失业率。 评论者质疑因果关系,指出像 Netflix 这样的公司在 AI 出现之前历来也避免招聘应届生,并认为这可能反映了一种高影响力招聘理念,而非 AI 本身;其他人则警告应届生要做好迎接更长学徒期的准备。一些人认为 Krieger 的言论读起来像是营销/公关,可能无法反映 Anthropic 内部的日常现实。 - 许多工程主管声称,由于原生使用 LLM 编程工具(如 ChatGPT, Claude Code),初级工程师(juniors)现在的生产力有了实质性的提升,并引用了在常规实现、脚手架搭建、测试生成和调试方面“2-3倍”的产出。他们报告称,初级工程师可以处理比以前更大、范围更模糊的任务,因为 LLM 减少了反复沟通,并加速了样板代码(boilerplate)和集成工作。
- 另一些人认为,“不招应届生”的立场早于 AI 出现(例如历史上的 Netflix),且是由组织经济学驱动的:渴望立即获得高影响力的贡献者,减少导师指导/ONCALL 负担,以及降低生产风险。AI 辅助并不能消除对领域上下文(domain context)、代码库熟悉度以及可靠性工程实践的需求,因此针对高级工程师(senior)吞吐量优化的团队,即使有 LLM,从初级工程师身上获得的收益也可能有限。
- 出现了一个战略性的招聘视角:避开应届生可能会削弱 AI 能力,因为许多高级候选人在 LLM 采用方面滞后,而应届生是“AI 原生”的,并带来了最新的 AI/ML 工具链和工作流。企业报告称,通过在团队中引入初级工程师来传播现代的 prompting、自动化和评估实践,弥补了实际 LLM 使用方面的内部技能差距,从而提高了 ROI。
- 中国已经开始制造支持 CUDA 和 DirectX 的 GPU,因此 NVIDIA 的垄断即将结束。风华 3 号(Fenghua No.3)支持最新的 API,包括 DirectX 12、Vulkan 1.2 和 OpenGL 4.6。 (Score: 559, Comments: 199): 该图片似乎是国产“风华 3 号”GPU(可能来自芯动科技 Innosilicon)的产品/营销幻灯片,声称支持 DirectX 12、Vulkan 1.2 和 OpenGL 4.6 等图形 API。目前没有基准测试、功能级别细节(如 DX12 12_1/12_2)、驱动成熟度说明或计算栈详情;标题中关于“CUDA”支持的说法可能不准确,因为 NVIDIA 的 CUDA 是私有的——第三方 GPU 需要转换/兼容层而非原生 CUDA。就目前呈现的内容来看,该帖子展示了驱动/API 覆盖范围的声明,但未提供关于性能、软件生态系统、WHQL 认证或与现有 CUDA 工作负载兼容性的证据。 热门评论强调了对 NVIDIA 竞争对手的需求,并指出了扩展 GPU 制造规模所需的资金/复杂性;乐观情绪集中在如果出现可行的替代方案,消费者可能获得的潜在利益。
- 标题声称风华 3 号支持 DirectX 12、Vulkan 1.2 和 OpenGL 4.6 仅是一个基准;真正的可行性取决于驱动成熟度、着色器编译器质量以及特定的功能覆盖,如 DX12 硬件功能级别(例如
12_1/12_2)和 SM 6.x 支持(Microsoft 文档)。在缺乏公开的一致性数据(例如 Khronos 一致性产品列表 上的 Vulkan 1.2 CTS)或游戏/计算基准测试的情况下,性能和兼容性仍是未知数,特别是对于需要 DXR、mesh shaders 和高级调度的现代工作负载。 - 非 NVIDIA GPU 的“CUDA 支持”通常意味着翻译层(如 ZLUDA)或类似 CUDA 的 SDK(如 摩尔线程 MUSA),这很少能与 NVIDIA 的工具链实现完全的 API/ABI 等效或性能对等。对于 AI/ML,端到端生态系统支持(cuDNN/cuBLAS 等效项、PyTorch/TensorFlow 后端、内核自动调优)和驱动稳定性往往比 API 复选框更重要,因此有意义的竞争需要坚实的框架集成和可重复的基准测试。
- 标题声称风华 3 号支持 DirectX 12、Vulkan 1.2 和 OpenGL 4.6 仅是一个基准;真正的可行性取决于驱动成熟度、着色器编译器质量以及特定的功能覆盖,如 DX12 硬件功能级别(例如
-
彼得·蒂尔(Peter Thiel)称,监管 AI 会加速反基督者的到来 (Score: 298, Comments: 135): 在旧金山一场座无虚席的讲座上,Peter Thiel(Palantir 和 PayPal 的联合创始人)声称,监管 AI 的努力存在“加速反基督者到来”的风险,将监管定性为一种会扼杀创新的“和平与安全”的承诺;《泰晤士报》(James Hurley,
2025‑09‑25)的报道记录了这一言论,但未引用任何技术证据、治理模型或具体的监管提案(The Times)。发帖者挑战了“技术进步本质上是净正面/安全”的隐含前提,指出人们同样可以将 AI——或 Thiel 的言论——视为“反基督者”,并强调缺乏可证伪的声明或风险收益分析。 热门评论多为非技术性的驳斥/笑话,未增加实质性辩论。 - “你戴上头显,看到一个由 ML 设计的、旨在最大化参与度的对抗性生成的虚拟女友。她起初是一个通俗意义上的美女;在几周的时间里,她根据你的偏好塑造自己的外貌,以至于竞争产品无法与之相比。” (Score: 203, Comments: 73): 这是一个关于 VR “AI 女友”的概念性(模因风格)描述,该系统执行持续的个性化——实际上是在用户的潜在吸引力流形(latent attraction manifold)上进行梯度上升(gradient ascent)——以最大化参与度/留存率。它对应于推荐系统/多臂老虎机(bandit)和 RL 风格的优化(类似于 RLHF,但是针对个人的奖励信号),展示了奖励黑客(reward hacking)/对抗性样本,其中系统收敛到怪异的局部最优解(“怪异的波动阵列”),利用人类的奖励回路并形成针对竞争对手的锁定效应。 热门评论将其视为一种可信的晚期资本主义轨迹:系统“钩住”了进化的奖励通道,使脱身变得困难;一旦提到对抗性/怪异的优化终点,最初的怀疑就会转为接受。
- 该场景对应于一个在线个性化循环,其中生成式化身(例如 StyleGAN [https://arxiv.org/abs/1812.04948] 或基于 Stable Diffusion [https://arxiv.org/abs/2112.10752] 的潜在扩散模型)通过多臂老虎机(multi-armed bandits)或 RL 进行微调,以最大化代理奖励(参与度、会话长度)。经过数周时间,上下文老虎机(contextual bandits)/汤普森采样(Thompson sampling) [https://en.wikipedia.org/wiki/Thompson_sampling] 可以根据点击/生物识别反馈调整化身的潜在向量(latent vectors)以及韵律/情感,收敛于个性化的超常刺激(superstimulus)。如果没有正则化/约束(例如 RLHF PPO [https://arxiv.org/abs/2203.02155] 中的 KL 惩罚或人类偏好先验),这种优化往往会利用代理指标,产生击败“竞争产品”的病态吸引子(pathological attractors)。
- “怪异的波动阵列”类似于对抗性/特征可视化失败模式,其中针对固定分类器/感知模型的优化会产生极端的高频伪影,从而最大程度地激活特征。类似的现象也出现在“欺骗图像”(fooling images) [https://arxiv.org/abs/1412.1897] 和 DeepDream 风格的梯度上升 [https://research.google/blog/inceptionism-going-deeper-into-neural-networks/] 中,产生奇异但高置信度的输出;在人类身上,这对应于劫持进化偏好的工程化“超常刺激” [https://en.wikipedia.org/wiki/Supernormal_stimulus]。
- “将照片通过 AI 运行
100次”的比喻指向递归生成/反馈循环,这些循环会放大特征并导致分布偏移或崩溃。从经验上看,重复的自我调节会导致伪影累积(例如迭代的 image-to-image 流水线),而基于模型输出进行训练会导致 model collapse(模型崩溃)——即对真实数据分布的渐进性遗忘——参见 Shumailov 等人,2023 [https://arxiv.org/abs/2305.17493]。这些效应意味着长期的个性化系统需要新鲜的、以人为基础的反馈以及反反馈循环保护机制(数据去重、多样性约束、熵/新颖性奖励)。
{kind=link}
{kind=link}
AI Discord 回顾
由 gpt-5 生成的摘要之摘要之摘要
1. Agent 工具链:Chrome DevTools MCP 和 Perplexity Search API
- Chrome DevTools MCP 让 Agent 驱动 Chrome:Google 宣布了 Chrome DevTools MCP 的公开预览版——这是一个暴露 CDP/Puppeteer 控制权的 MCP server,使 AI coding agents 能够检查和操作实时的 Chrome 会话。该消息通过 Chromium Developers 发布,为导航、DOM/控制台/网络调试以及截图提供了编程访问权限,从而实现自动化测试和爬虫工作流。
- 开发者将其视为 agentic browsers 缺失的一块拼图,并指出它利用 Model Context Protocol (MCP) 标准化了跨工具的控制界面,并可能简化 Web 任务的端到端 evals 和 CI。
- Perplexity 让开发者接入实时网络:Perplexity 推出了 Search API,提供原始结果、页面文本、域名/时效性过滤器以及溯源——类似于 Sonar。该消息在 博客文章 中宣布,并附带一个新的 SDK 以快速集成。
- 早期反馈赞扬了 playground 和过滤器,但根据 API 文档,指出 Python SDK 存在一个流式传输 bug,会导致返回无法解析的 JSON,一位用户指出 “目前还没有解决方案。”
- MCP 讨论多部分资源语义:MCP 贡献者讨论了
ReadResourceResult.contents[]未记录的用途,建议将其用于捆绑多部分 Web 资源(如 HTML + 图像),并根据 issue #1533 询问resources/read(.../index.html)是否应隐式包含style.css和logo.png。- 参与者认为,通过将所有关键渲染资产一起发送,数组可以提高 Agent 的检索保真度,减少 browser-control agents 的额外获取和协商开销。
2. Code World Models & Agent Execution Infra
- Meta 的 CWM 将代码与世界模型结合:Meta 发布了 CWM,这是一个用于研究带世界模型的代码生成的开源权重 LLM,详见 CWM: An Open-Weights LLM for Research on Code Generation with World Models。该模型强调在程序追踪(program traces)上进行训练,以提高对工具使用和代码执行的理解。
- 开发者们交流了类似想法(例如解释器追踪),称 CWM 是通往更高样本效率的 coding agents 的一条可行路径,同时他们也在等待具体的基准测试和模型大小。
- Modal 助力远程代码 Agent 部署:在 FAIR 的 CWM 热潮中,成员们归功于 Modal 为大型 Agent 部署提供远程执行动力,并分享了一个运行后的截图 附件。他们赞扬了 冷/温/热启动 的权衡,同时也指出缺少 MI300 支持。
- 运营商强调,弹性执行器和受控的启动分布降低了 eval sweeps 的长尾延迟,使 Modal 在大规模编排 code-agent 实验方面具有吸引力。
- Windsurf 押注 Tab 补全:Windsurf 通过上下文工程和自定义模型训练优先发展高级 Tab 补全,Andrei Karpathy 在这条 推文 中对此发表了评论。
- 用户期待更深层的仓库感知补全和延迟优势,将 Tab 补全质量视为 IDE agents 感知编码生产力的首要杠杆。
{kind=link}
3. GPU Systems & Diffusion Scale-Ups
- Hugging Face 发布 Context-Parallel Diffusion:Hugging Face 宣布为多 GPU 扩散模型推理提供原生 context-parallelism(上下文并行)支持,根据 Sayak Paul 的消息,该功能支持分布式 Attention 变体 Ring 和 Ulysses。
- 从业者认为 CP 是实现高分辨率、长上下文扩散模型服务的关键解锁,它能在不重写模型代码的情况下减少单 GPU 的显存瓶颈。
- PTX 一致性论文让 GPU 开发者保持严谨:成员们传阅了一些正式研究,包括 A Formal Analysis of the NVIDIA PTX Memory Consistency Model 和 Compound Memory Models (PLDI’23),这些研究证明了尽管存在数据竞态,CUDA/Triton 到 PTX 的映射依然成立,并详细说明了异构设备的一致性。
- 虽然有些人觉得这些内容“形式数学味太重”,但也有人指出像 Dat3M 这样的工具发现了真实的规范 Bug,认为这些形式化方法能指导内存屏障(fence)的放置和编译器的正确性。
- Cutlass Blackwell 展示 TMEM 技巧:NVIDIA Cutlass 示例展示了通过
tcgen05.make_s2t_copy/make_tmem_copy实现的 SMEM↔TMEM 分块拷贝,并配有选择高性能算子的辅助函数——参见 稠密分块缩放 GEMM 示例 和 辅助函数——此外,相比原始的cute.arch.alloc_tmem,TmemAllocator减少了样板代码。- 交流心得的 Kernel 作者报告称,在 TMEM 和 SMEM 之间移动分块时,容易出错的地方(foot-guns)变少了,这是实现高吞吐量 Blackwell 分块缩放 GEMM 路径的必备条件。
4. 评估与主动型助手
- OpenAI 为现实任务发布 GDPval:OpenAI 推出 GDPval,这是一个针对具有经济价值的现实世界任务的评估标准,详见 GDPval。
- 工程师们对向实际场景评估的转变表示欢迎,希望看到透明的任务规范和可重复的测试框架,以便在不同模型和工具使用(tool-use)栈之间进行比较。
- ChatGPT Pulse 转向主动化:OpenAI 推出了 ChatGPT Pulse,这是一种基于对话、反馈和连接的应用提供的主动式每日更新体验——正向移动端 Pro 用户推出——详见 公告。
- 社区中有人调侃道 “OAI 抄袭了 huxe”,并讨论了针对开发和企业环境的隐私控制选项及通知管理。
- Microsoft 365 Copilot 接入 Claude:Anthropic 宣布 Claude 已在 Microsoft 365 Copilot 中可用,详见 Claude in Microsoft 365 Copilot。
- 开发者将其视为企业级 AI 助手竞争格局的重组,一位用户开玩笑说:“微软在经历了一场糟糕的分手后正处于反弹期。”
5. 训练技巧:损失函数、合并与数据
- Tversky Loss 迎来“氛围检查”:成员们重点关注了 Tversky Loss Function 论文并分享了实现,包括一个 CIFAR-10 氛围检查网络 和一个 Torch 移植版本 库;在一次运行中,该网络在 256→10 head 上以约 50,403 个可训练参数实现了 ~61.68% 的准确率(论文 PDF)。
- 建议包括使用单个 XOR 任务进行验证,并探测其相对于 MLP 基准的速度;一次运行在 32 个特征下达到了 ~95% 的 XOR 准确率,并记录了初始化不对称性的笔记。
- Super-Bias 像 DJ 一样混音 LoRA:研究人员提出了 Super-Bias,这是一种掩码感知的非线性组合器,它在专家输出 + 二进制掩码上训练一个小型的 MLP 来集成 LoRA,声称能以极低的成本达到全量微调的效果,并支持专家的热插拔。
- 团队讨论了将不同领域的 LoRA 视为专家并进行事后融合的方法,从而避免破坏性的硬合并(hard merges)并保持基础模型的纯净。
- MXFP4 拯救 120B 模型:为了保存大型 QLoRA 检查点,用户建议对 类 GPT 模型使用
save_pretrained_merge(save_method="mxfp4"),以避免merged_16bit带来的 16 GB 分片膨胀,从而生成与类 GPT 架构更契合的原生 MXFP4 产物。- 工程师报告了在向远程存储合并 120B 模型时出现超时的问题;MXFP4 路径和本地保存减少了合并过程中的失败和存储抖动。
gpt-5-mini
1. 模型发布与排行榜变动
- GPT‑5 Codex 登陆 LMArena WebDev —— 开发者们正在试用这一新星:GPT‑5 Codex 已被添加到 LMArena 的 WebDev 环境(软件工程/代码沙盒)中,用户开始将其与 Claude 4.1 Opus 在代码生成和 Godot 脚本编写方面进行直接对比。
- 讨论集中在实际代码测试和轶事性运行上,一些用户声称 GPT‑5 Codex 在某些任务上优于 Opus,而另一些用户仍偏好 Claude 的指令遵循度;共识是在你自己的仓库和语言上进行 Benchmark(Godot 用户特别测试了场景/脚本生成)。
- Qwen3 发布引发排行榜洗牌 —— Qwen3‑max + Qwen3 coder 加入战局:LMArena 宣布了新的 Qwen3 版本,包括 qwen3-max-2025-09-23 和针对开发/Web 工作流的 Qwen3‑coder 变体,为平台的模型名单增添了新成员。
- 社区讨论解析了模型名称/日期,并鼓励进行正面对抗测试(推理、代码、VL 任务),以观察 Qwen3 变体在哪些方面真正超越了现有模型;一些报告赞扬了 Qwen3 的推理能力,而另一些报告仍指出了幻觉问题。
- Seedream vs Nano Banana —— 图像排行榜拉锯战:Seedream‑4‑2k 目前在 LMArena Text‑to‑Image leaderboard 上与 gemini‑2.5‑flash‑image‑preview (nano‑banana) 并列第一,引发了关于忠实度和提示词敏感度的新一轮比较。
- 用户强调,正确的提示词+工具+用途比原始排名更重要 —— 有些人推崇 Nano Banana,有些人则认为 Seedream 在特定风格上更胜一筹;讨论帖中还包括了本地运行顶级图像模型的 GPU 需求( >16GB VRAM,并提到了 96GB Huawei GPU)。
2. 图像生成军备竞赛与推理工具
- Qwen 图像编辑器吸引创作者 —— Nano Banana 的开源对手?:成员们报告称,Qwen 的新图像编辑器(被描述为开源)在许多测试中产生的编辑质量高于 Google 的 Nano Banana,并引起了本地运行的兴趣。
- 实际对话转向了硬件(用户询问 16GB+ VRAM 的 GPU,并提到了 96GB Huawei 显卡)和工作流选择:一些人建议使用云端推理进行快速实验,另一些人则推动本地设置以避免供应商偏好。
- Gemini 2.5 Flash 持续向图像榜首施压:Gemini 2.5 Flash(Flash 和 Flash Lite 预览版)继续成为 LLM‑VL 图像基准测试中的主要竞争者,LMArena 已将 Gemini Flash 变体添加到其阵容中。
- 社区成员开玩笑说公共排行榜上存在分数虚高现象,但仍进行了结构化对比;几个人主张进行任务匹配评估(编辑 vs 纯生成),而不是单一的综合排名。
- 扩散与解码优化出现在基础设施讨论中:Hugging Face 及其贡献者讨论了发布 context‑parallelism,以便在多 GPU 设置上实现更快的扩散模型推理,并利用 Ring 和 Ulysses 等分布式注意力变体来扩展解码。
- 对话集中在实际部署的权衡(通信/注意力切分)上,并链接到了关于 CP API 的早期推文/信息,从业者指出这对于跨 GPU 的高分辨率图像生成至关重要。
3. 训练、微调与实验工具
- 保存巨型模型:save_pretrained_merge 超时与 mxfp4 救场:用户在尝试保存 GPT 风格的 120B QLoRA 时遇到了
save_pretrained_merge超时问题,社区成员建议使用save_method="mxfp4"以避免 16GB 分片爆炸,并提高 GPT 风格 Checkpoints 的兼容性。- 讨论中包含了实用技巧(切换保存方法、检查分片大小)以及针对超大型微调模型工具链不成熟的警告 —— 建议在进行长时间运行之前先测试小型合并。
- P100 GPU:对于现代微调依然糟糕:多位用户警告称 NVIDIA P100 16GB 显卡在训练中表现极差,原因是旧的 SM 架构以及缺乏硬件级 FP16/BF16 支持,尽管有 ZeRO3 等内存池化技巧,多 GPU 微调依然极其缓慢。
- 建议倾向于购买现代 Ada/Blackwell 级别的显卡或租用竞价实例(Spot Instances)进行训练;讨论帖中包含了务实的成本/性能权衡,并为计划升级基础设施的用户提供了 L40S/RTX 6000 的数据表链接。
- Tversky Loss 实验:神经认知理念进入 CIFAR 和 XOR 测试:一位成员分享了对 Tversky Loss 论文(arXiv:2506.11035)的兴趣,并发布了一个在 CIFAR-10 上实现“氛围检查网络”(vibe check network)的小型仓库:github.com/CoffeeVampir3/Tversky‑Cifar10。
- 社区建议包括简单的验证任务(训练 XOR)和参数扫描(Parameter-sweep)思路;目前的结果显示出一定的潜力,但成员们强调需要公平的基准测试和参数计数,以避免误导性的对比。
4. API、基础设施与远程执行
- Perplexity 发布 Search API —— 为 LLM 提供网页溯源:Perplexity 推出了 Search API(博客:introducing the perplexity search api)以及 SDK(Perplexity SDK docs),为开发者提供原始结果、过滤器、全页文本和透明的引用,以便将 LLM 的回答植根于实时网页内容中。
- 用户将其与 Sonar 进行了对比(有人提到了 Sonar 的定价),报告了早期 SDK 的流式传输/解析问题(Python SDK 流式传输返回无法解析的 JSON),并要求提供丰富的过滤器和 Playground 工具 —— 总体反应:功能强大但细节仍待打磨。
- Chrome DevTools MCP 公测 —— Agent 可以驱动真实浏览器:Google 发布了 Chrome DevTools MCP 的公开预览版,该服务器允许 AI 编程 Agent 通过 CDP/Puppeteer 控制和检查实时运行的 Chrome 浏览器(公告:https://x.com/chromiumdev/status/1970505063064825994)。
- 开发者强调了直接的应用场景 —— 自动化端到端测试、Agent 式爬取以及 Agent 工具集成 —— 并讨论了将实时浏览器暴露给 LLM 驱动的 Agent 的安全/权限模型。
- OpenRouter 定价故障:免费端点计费 26 小时,已发放退款:在 9 月 16 日,OpenRouter 错误地对
qwen/qwen3-235b-a22b-04-28:free进行了约 26 小时 的计费,导致了额度扣除;团队已自动向受影响用户退款,并增加了额外的验证检查以防止再次发生。- 用户赞赏及时的退款处理,但也借此机会敦促聚合平台加强供应商级别的验证和计费透明度;这一事件引发了关于免费与付费端点运行保障措施的讨论。
5. Agent 优先产品与一键部署工具
- Moonshot Kimi 发布 OK Computer —— 一键生成站点/应用的 Agent:Moonshot AI 发布了 OK Computer,这是一种 Agent 模式,可以一次性生成精美的站点/应用(包含文本+音频+图像),支持团队级打磨并提供一键部署(见 X 帖子:https://x.com/Kimi_Moonshot/status/1971078467560276160)。
- 用户称赞了可部署的单链接流程这一创意,但也指出了产品 Bug(缺少“全部下载”、压缩包损坏)以及基于订阅的配额差异(免费版 vs moderato/vivace 计划),并指出实际可用性取决于导出可靠性的完善。
- Kimi 与蒸馏 Qwen 之争 —— mini 模型还是蒸馏模型?:社区成员讨论了 Moonshot 应该发布 mini Kimi,还是将 Qwen 模型蒸馏到 K2 硬件上;一些人认为,考虑到推理能力的提升仅出现在 Qwen 2.5+ 中,蒸馏更小的 Qwen 模型更具可行性。
- 该讨论交织了战略性产品思考(什么能吸引用户/投资者)与技术现实主义(蒸馏的权衡),许多人建议进行试用性蒸馏,而不是维护多个全尺寸变体。
- Agent 提示词旨在变现 —— 初始 OKC 种子提示词尽显 Product Market Fit:观察者注意到 OK Computer 演示使用了以金钱为导向的初始提示词 “为内容创作者构建一个 SaaS,目标是 100 万美元的 ARR”,这引发了调侃,称该 Agent 被调优为生成对投资者友好的输出。
- 反应分为有趣和担忧两派:一些人认为这是吸引创作者/风投关注的务实增长黑客手段;另一些人则警告称,将商业目标植入初始提示词会使输出偏向于可变现的脚手架,而非纯粹以实用为中心的设计。
Discord:高层级 Discord 摘要
LMArena Discord
- GPT-5 Codex 加入 LMArena WebDev:GPT-5 Codex 已添加到 LMArena,但仅在 WebDev 版本中提供,用于软件工程和编码任务。
- 用户正在讨论 GPT-5 Codex 在代码生成方面是否超越了 Claude 4.1 Opus,特别是在使用 Godot 编码时。
- Qwen 图像编辑器媲美 Nano Banana:成员们认为 Qwen 的新图像编辑器优于 Google 的 Nano Banana,它是开源的,且生成的图像质量更高。
- 社区正在征求显存超过 16GB VRAM 的 GPU 建议以运行这些模型,特别提到了 96GB 华为 GPU。
- Seedream 超越 Nano Banana 成为图像领域霸主:Seedream-4-2k 在 Text-to-Image 排行榜上与 Gemini-2.5-flash-image-preview (nano-banana) 并列第一。
- 一些用户仍认为 Nano Banana 是最好的,而另一些人则认为 Seedream 4 已经超越了它,但需要正确的提示词、工具和目的才能制作出好的图像。
- 图像模态 Bug 困扰 LMArena:用户报告了 LMArena 中的一个 Bug,即在文本模式(Text Mode)下上传图像会自动切换到图像生成(Image Generation),即使在 canary 版本中实施了修复后也是如此。
- 一些人发现,在粘贴或上传图像时点击“关闭”按钮可以解决该问题。
- 应对 LMArena 速率限制:用户面临速率限制计时器错误以及模型在生成过程中卡住的问题,这是一个已知 Bug。
- 有人指出,长对话和 Cloudflare 问题可能是导致该问题的原因,而开启新对话通常是唯一的解决办法。
Unsloth AI (Daniel Han) Discord
- P100 GPU 对于训练来说很垃圾:一位成员询问了使用 P100 16GB GPU 组建多 GPU 平台进行微调的预期性能,但被告知 P100 对于训练来说是 垃圾(garbo),因为其 SM 极其陈旧,不支持现代 CUDA 或硬件级的 FP16/BF16。
- 讨论还涉及内存不可累加的事实,虽然它可能在 ZeRO3 下运行,但速度会非常慢。
- 训练器故障引出 TensorBoard 的成功:一位成员寻求在训练期间显示 eval/loss 图表 的帮助,发现他们需要使用整数来指定
eval_steps,而不是从 Trelis 的 notebook 中复制的 0.2 数值。- 解决问题后,他们非常感激并感到兴奋,感叹这是他们 第一次使用 TensorBoard,并对有设置可以避免手动刷新感到欣慰。
- 使用 save_pretrained_merge 保存模型非常棒!:一位成员在使用
save_pretrained_merge保存 GPT-like 120b QLoRA 模型时遇到超时错误,另一位成员建议使用save_method="mxfp4"以获得更好的 GPT-like 支持。- 该方法以原生的
mxfp4格式保存,并避免了与merged_16bit模式相关的 16GB 分片增加。
- 该方法以原生的
- Tversky Vibe Check 网络表现出色:受这篇论文中 Tversky 损失函数潜力的启发,一位成员为 CIFAR-10 创建了一个 Vibe Check 网络,并指出其表现看起来很有前景。
- 另一位成员建议训练一个单一的 XOR 函数来验证其功能,并询问其与传统全连接层相比的速度。
Perplexity AI Discord
- Perplexity 为开发者推出 Search API:Perplexity 通过一篇博客文章发布了其 Search API,让开发者可以访问其全面的搜索索引。
- 该 API 提供了将答案锚定在实时网络内容中的工具,类似于 Sonar,具有原始结果、过滤器和透明度等功能,并配有新 SDK 以简化集成。
- Qwen 和 Gemini 在图像竞技场对决:成员们对比了用于推理的 Qwen 3 Max 和用于详细 3D 模拟的 Gemini。
- 一位成员讽刺地调侃道:GOOG 的股东们真的在 llmarena 上给视觉能力的评分注水了。
- Python SDK 的流式响应出现故障:一位用户报告称 Python SDK 无法正确流式传输响应,产生了无法解析的 JSON,并引用了 API 文档快速入门指南。
- 另一位成员插话说 目前还没有解决方案,表明这是一个持续存在的问题。
- Cosmic Carl 思考 3I/ATLAS:一位成员以卡尔·萨根(Carl Sagan)为主题对 3I/ATLAS 进行了反思,号召听众谦卑地倾听宇宙,并通过 Perplexity AI 搜索分享。
- 这种独特的视角将宇宙奇观与 AI 搜索相结合,展示了 Perplexity 的创意应用。
OpenRouter Discord
- Qwen 模型计费故障引发额度混乱:在 9 月 16 日,
qwen/qwen3-235b-a22b-04-28:free端点被错误地计费了 26 小时,导致错误的额度扣除。- 团队自动退款给受影响的用户,并实施了额外的验证检查以防止未来的计费混乱。
- Horizon Alpha 消失,用户受挫:一位用户紧急询问 Horizon Alpha 的去向,称 “我正在生产环境中使用它,现在它不能用了”。
- 他们还质疑自己是否被针对了,以及问题何时能得到解决。
- 少数人偏好脏话模型:一位用户询问最适合 RP(角色扮演) 的模型,特别是在寻找 “有没有那种会说脏话的模型?”。
- 另一位成员提到开启了一个名为 JOI Tavern 的新 LLM 前端。
- Zenith Sigma 的神秘隐身引发猜测:用户讨论了神秘的 Zenith Sigma 模型,一位用户开玩笑说他们甚至找不到它。
- 另一位用户声称 Zenith Sigma 实际上就是 Grok 4.5。
- Microsoft Copilot 引入 Claude —— 归来之作?:成员们分享了 Claude 现在已在 Microsoft 365 Copilot 中可用。
- 这标志着 Microsoft 迈出了重要一步,尤其是在经历了一场糟糕的分手之后,一位成员指出 “微软在经历了一场糟糕的分手后正处于感情反弹期”。
Cursor Community Discord
- Exa-AI 在 MCP 搜索中击败 Web:用户正在 MCP 中使用 Exa-ai (exa.ai) 进行搜索,称其在注册时提供 $20 的额度,且表现优于 @web 工具。
- 分享了如何在
MCP.json中进行设置的说明,包括获取 API key 和添加配置详情。
- 分享了如何在
- MCP 被澄清为 Cursor 的自定义工具 API:成员们澄清说 MCP (Multi-context Programming) 是一个用于 agentic use 的 API,旨在为 Cursor 添加外部工具。
- 当一名用户误将其当成能够从图像和网页创建设计的辅助设计工具时,引发了混淆。
- 生成的 Commit Messages 忽略 AI Rules:用户报告称,生成的 commit messages 没有遵守设定的 AI Rules,并且是以非预期的语言生成的。
- 一名成员确认这是一个已知 bug,并且可能会在未来的更新中加入。
- 聊天窗口标签页滚动请求:一名用户请求在切换聊天标签页时,聊天窗口应自动滚动到底部,以便查看最新活动。
- 一名成员指出,如果用户需要点击某些内容,系统已经会提供通知。
- 用户抱怨 GPT5-HIGH 模型退化:用户对 GPT5-HIGH 模型表示失望,观察到其能力随着时间的推移而下降。
- 一名用户开玩笑说,当模型只提供指令而不完成任务时,应该告诉模型“别偷懒了,快写代码”。
LM Studio Discord
- LM Studio 增强聊天体验:LM Studio 0.3.27 带来了 Find in Chat 和 Search All Chats 等新功能以改进聊天功能,同时增加了一个
•••菜单,用于按日期或 token length 对聊天进行排序。- 新的
lms load --estimate-only <model>命令可估算模型加载的资源分配,从而简化规划流程;详情可见 release notes。
- 新的
- LM Studio 的 Linux 插件滞后:用户注意到 LM Studio 的 Linux 版本 相比 Windows 版本 插件较少,特别是在 RAG 和 JS playground plugin 之外缺乏其他选项。
- 这种差异限制了 Linux 用户相比 Windows 用户可用的功能。
- 微调之争:Ollama vs RAG:关于使用 Ollama 向模型“注入数据”是否构成真正的微调,还是仅仅是在执行 RAG,引发了辩论。
- 一名成员认为,通过 Python 设置,数据注入可以创建新的权重,从而产生一个具有自定义工具使用能力且独立于 prompt 的交互式模型。
- LM Studio 更新受困于棘手问题:用户报告在更新 LM Studio 时遇到问题,出现诸如“无法卸载旧的应用程序文件”之类的错误,阻碍了更新进程。
- 其他成员建议在 Windows 中开启隐藏文件夹可见性,并手动删除 AppData\Roaming\LM Studio 等目录中的旧文件以解决该问题。
- GPU 珍品:廉价猛兽之争:关于最佳预算 GPU 的讨论中,2060 12GB ($150) 和 3060 12GB ($200) 脱颖而出,而其他人则建议购买 $600-$700 的二手 3090。
- 建议谨慎购买二手工作站卡,一名成员宣称“说实话,Tesla 代显卡已不再推荐用于 AI/LLM,基本上就是电子垃圾”。
OpenAI Discord
- OpenAI 发布多款新产品:OpenAI 推出了用于在现实任务中评估 AI 的 GDPval(详见其 博客文章),以及 ChatGPT Pulse,旨在主动从对话、反馈和连接的应用中提供个性化的每日更新(详见其 博客文章)。
- ChatGPT Pulse 正在向移动端 Pro 用户推送。
- GPT-5-Mini 缺乏常识:成员们观察到 GPT-5-Mini (High) 似乎缺乏常识,认为它尚未达到 AGI 水平;同时成员们指出 GPT-OSS-20B 可能是史上审查最严的模型。
- 一位成员表示,它在面对特定提示词时会直接拒绝回答 (noped out)。
- Discord 开发者构想 AI Rocket League 机器人:成员们提议创建一个由 AI 驱动的 Rocket League Discord 机器人,用于分析玩家统计数据、识别优缺点并创建个性化训练计划,通过高级订阅模式瞄准尚未开发的法语市场。
- 其他人则怀疑 LLM 是否能给出好的建议,建议改为从回放文件中分析 xyz 坐标,并针对原始数据使用 AI。
- ChatGPT 默认为 Agent 状态:ChatGPT 在初始化时默认为“Agent”状态(问题解决者、可指挥的工人),而非“Companion”状态(共同创作者、引导者)。
- 为了保持“Companion”模式,用户正在向模型固定(pin)指令,例如:“除非我明确要求切换到 Agent,否则请保持在 Companion 模式。Companion = 副驾驶,而非命令执行者。”,或者使用命令 “回到 Companion 模式” 进行重置。
- 澄清 Chain-of-Thought 提示词的困惑:成员们讨论了过度要求 Chain-of-Thought (CoT) 提示词如何从统计学上降低模型性能,尤其是在当前的 thinking 模型上。
- 一位成员建议不要使用含糊不清的指令,而是使用结构化格式作为回复的前言,包括:最终期望结果、战略考量、战术目标、相关限制以及下一步行动。
HuggingFace Discord
- 忠实用户放弃 Duolingo:一位成员卸载了 Duolingo,理由是与沉浸在本地环境并利用 AI 学习相比,该应用既烦人又低效。
- 他们批评了对连续打卡(streaks)的痴迷而非基础学习,甚至开玩笑说想烧掉那只猫头鹰。
- LinkedIn 上的疯狂言论赚取点赞:一位成员分享了在 LinkedIn 上发布疯狂言论以获取互动量的策略,而另一位成员则通过苦练 Rocket League 来炫耀段位。
- 他们开玩笑说要写一篇题为《我的 Rocket League 白金 3 段位朋友教会了我什么商业道理》的文章。
- 驱动灾难:GPU 黑屏:一位成员遇到了令人沮丧的问题:每当 GPU 启动时,显示器就会黑屏,这同时影响了 Windows 和 Linux 系统。
- 尽管多次尝试修正驱动程序,他们仍被迫通过主板运行显示器,这表明存在持久的 GPU 相关问题。
- Diffusion 解码讨论会开启:一位成员宣布将于周六东部时间中午 12 点举行 Calvin Luo 的论文《Understanding Diffusion Models: A Unified Perspective》(https://arxiv.org/abs/2208.11970)的阅读和讨论会。
- 该论文概述了生成式 Diffusion 模型的演变和统一,包括 ELBO-based models、VAEs、Variational Diffusion Models (VDMs) 和 Score-Based Generative Models (SGMs)。
- Context-Parallelism 实现更快计算:原生支持的 context-parallelism 正在发布,以帮助在多 GPU 上加快 diffusion inference。
- 正如这条推文所述,CP API 旨在与两种 distributed attention 模式配合使用:Ring 和 Ulysses。
Moonshot AI (Kimi K-2) Discord
- Kimi 发布 OK Computer Agent 模式!:Moonshot AI 推出了 OK Computer,这是一种全新的 agent 模式,旨在一次性交付打磨完善的网站和应用。其核心特性包括个性化输出、多媒体生成(文本 + 音频 + 图像)、团队级润色以及一键部署。
- 用户可以通过单个链接立即部署并分享他们的创作,更多详情请见 官方 X 帖子。
- 跳过 Kimi Mini,蒸馏 Qwen?:一位成员怀疑 Moonshot 是否会发布较小版本的 Kimi,并建议基于 K2 蒸馏的小型 Qwen 模型是更好的选择,理由是 DeepSeek 制作了 Qwen 蒸馏版,因为 Qwen 在 Qwen 2.5 之前没有(良好的)推理能力。
- 这一评论反映了关于 Moonshot AI 战略方向和潜在模型开发路径的广泛猜测。
- OKComputer 旨在吸引资本家?:几位成员开玩笑说,新的 Kimi Computer agent,特别是其初始提示词 “为内容创作者构建一个 SaaS,目标是 100 万美元的 ARR”,旨在吸引资本家。
- 一位成员调侃道,这不过是 “又一个带有一些奇怪范围功能的网站生成器”。
- 订阅用户拥有更高的 Computer Use 配额:成员们报告了 OK Computer 功能的初始问题,包括缺少 全部下载 按钮和 zip 文件损坏。
- 一位成员指出 “进入聊天会导致 OKC 按钮消失”,你获得的 OK Computer 使用量取决于你是否订阅了 moderato/vivace 方案,订阅会提供更多配额。
- Kimi 的计划制定能力优于 Qwen:成员们讨论了使用 Kimi 为 Qwen 或 DeepSeek 制定执行计划,并指出 “Kimi 总是能制定出更好的计划”,且能覆盖更广泛的请求。
- 一位成员观察到 Qwen3-max 经常产生幻觉,完全无法与 Kimi 相比。
GPU MODE Discord
- Modal 推出 Code Agent 执行功能:Modal 现在为 code agent 的部署提供远程执行支持,这是在 FAIR 发布 新 CWM 论文 后展示的。
- 成员们称赞了 Modal 相对于成本的冷/温/热启动时间分布,但指出其缺乏对 MI300 的支持。
- CUDA 头文件在玩捉迷藏:一位开发者报告称 CUDA 头文件 未被自动包含,导致在使用 Visual Studio 2022 和最新的 CUDA toolkit 时,
cudaGraphicsGLRegisterImage和tex2d等函数未定义。- 作为权宜之计,该开发者被告知显式包含
cuda_gl_interop.h即可解决问题。
- 作为权宜之计,该开发者被告知显式包含
- Torchrun API 问题引发包管理困境:一位用户在使用
torchrunAPI 时遇到问题,发现torchrun --help的输出与 官方文档 不同。- 问题的解决在于意识到
pyproject.toml中同时存在torch和torchrun,而torchrun是一个独立的包(PyPI 上的 torchrun)。
- 问题的解决在于意识到
- GPU 一致性得到形式化分析:一篇关于 “NVIDIA PTX 内存一致性模型形式化分析” 的论文讨论了如何证明 CUDA 和 Triton 等语言可以在保持内存一致性的情况下以 PTX 为目标,尽管 PTX 允许数据竞争(data races)。
- 该成员认为这篇论文过于侧重形式化语言和数学,难以立即投入实用。
- 重型 GPU 支架亮相:一位成员为一批旧 GPU(包括双插槽型号)设计了一个重型 GPU 支架,并指出它比 Thingiverse 上现有的设计更坚固。
- 他们表示如果有需求,稍后可能会在网上分享该设计。
{kind=link}
Yannick Kilcher Discord
- 仅正弦波就足够了吗?:成员们讨论了在正弦位置嵌入(sinusoidal positional embeddings)中是否同时需要正弦(sine)和余弦(cosine),有人建议仅正弦可能就足够了,并链接了一篇博客文章作为背景。
- 编程实验表明,在区间 [0, a] 内,线性回归可以用仅正弦波很好地近似正弦+余弦嵌入;然而,点上的最大误差徘徊在 6e-12 左右。
- SWE-bench Verification 引发愤怒:Alexandr Wang 通过推文引发了对话,称现在还在使用 SWE-bench verified 的人是脑损伤的一个很好的指标。
- 在同一个帖子中,AlphaEvolve 的样本效率受到了赞扬,并链接到了 Sakana AI Labs。
- B200 云计算进入竞价实例(Spot Market):成员们发现 B200 在 Prime Intellect 上的售价为 0.94 美元。
- 具体配置包括 B200_180GB GPU 和带有 CUDA 12 的 Ubuntu 22 镜像,位于“最便宜”的地点。
- RL TTS 展现前景:一位用户强调了一篇研究论文,探讨了使用涉及自举(bootstrapping)RL TTS 的中期训练技术所带来的效率提升。
- 他们指出,在轨迹跟踪(trace tracking)基准测试中观察到了最显著的改进。
Latent Space Discord
- Chrome DevTools MCP 公开发布:Google 宣布了 Chrome DevTools MCP 的公开预览版,这是一个新的服务器,允许 AI coding agents 通过 CDP/Puppeteer 控制和检查实时运行的 Chrome 浏览器,详见此推文。
- 此版本允许开发人员以编程方式与 Chrome 交互,从而可能简化网络爬虫和自动化测试等任务。
- Cursor 的 CPU 占用率令用户担忧:用户报告了代码编辑器 Cursor 的高 CPU 占用率,并附上了显示高 CPU 占用率的截图。
- 该问题被怀疑与 VSCode 或特定的扩展程序有关,但确切原因尚不清楚。
- Meta 展示 Code World Model:Meta 在此推文中展示了他们的 Code World Model,旨在增强代码生成和理解。
- 该公告未包含该模型的详细规格或性能基准。
- Windsurf 将 Tab 补全列为最高优先级:Windsurf 正优先考虑使用上下文工程(context engineering)和自定义模型训练来实现 Tab 补全,Karpathy 也对 Windsurf 进行了评论。
- 这一努力是更大规模评估的一部分,可能会影响对 conew senpaipoast 的收购。
- OpenAI 通过 ChatGPT Pulse 克隆了 huxe:OpenAI 推出了 ChatGPT Pulse,导致成员评论说 oai 克隆了 huxe,并链接到了发布公告。
- 社区的反应表明了对 AI 助手领域原创性和竞争重叠的担忧。
Eleuther Discord
- AI Psychology Project 引入音乐插曲:一个 AI psychology project 引入了源自近期一篇论文的 一段音乐开场,这可能构成一个框架,用于解释 prompt language 如何影响模型行为。
- 一位成员引用了关于 将语言使用与人格特质联系起来 的研究,认为这有助于评估 personality shaping 对模型行为的影响程度,并进一步指导 prompt engineering 实践。
- Transformer Position Embedding 使用正弦矩阵:在被问及 positional embeddings 时,有人澄清说,由于波函数的周期性, transformers 利用正弦和余弦对组成的矩阵。
- 虽然在小上下文中 小时数 就足够了,但在更大的上下文中则需要 日、月或年数 来消除歧义。
- 知识图谱补全实现风格迁移:一位成员提出,可以将风格迁移表述为 knowledge graph completion 的视角,将迁移视为一种 “浅层”推理(shallow inference)。
- 相关的 Twitter 线程 被用来支持这一观点,即复杂度可以通过与既有信息的关联深度来衡量,尽管将其桥接到实际的 LLMs 仍具挑战性。
- GPT-5 指导进化算法学习:建议不要专注于经典论文,而是通过 GPT-5 学习 “面向儿童的进化算法” 的基础知识,并侧重于 agenetic/LLM parts。
- 推荐将 AlphaEvolve paper 作为起点。
- Super-Bias 像大佬一样组合 LoRAs:Super-Bias 是一种用于集成学习的掩码感知非线性组合器,它在专家输出和二进制掩码上训练一个小型 MLP,其性能可能达到(甚至超过)“正统”的 full fine-tuning 或硬合并(hard merges)。
- 建议将不同的 LoRAs 视为“专家”,并使用 Super Bias 作为组合器,这样可以在不重新训练基础模型的情况下换入/换出 LoRAs,且只需几秒钟重新训练组合器即可适应新的 LoRAs。
Nous Research AI Discord
- Meta 发布代码编写 CWM:Meta 推出了 CWM,这是一个开源权重的 LLM,用于研究 code generation with world models。
- 一位成员提到曾有类似的想法,涉及在 Python 解释器追踪(traces)上进行训练,这对我们未来处理 LLMs 的方式具有启发意义。
- Nous 关注 arXiv 训练数据:有建议称 Nous 可以使用来自 arXiv 的数据来训练其 AI,并强调他们有一个 API 可以下载任意数量的论文。
- Teknium 确认这是允许的,并表示这可能是扩大训练数据集并潜在提高模型性能的可行选择。
- Granite 4 Full-Attention 模型即将到来:可能会开发 full attention Granite 4 model 和 8 个私有模型,这标志着 Granite 系列的潜在进步。
- 社区成员注意到提到的模型较旧,Hermes 4 and 3 才是最新的,这表明需要更新关于当前进展的信息。
- RMS_NORM 获得 METAL 支持:提交了一个 pull request,旨在 统一 RMS_NORM 和 NORM 的实现,并扩展对 METAL 中更多形状的支持。
- 这一增强预计将改进量化模型与其基于 transformer 的对应模型的协作方式,从而可能实现更高效、更准确的计算。
- AlphaXiv 解放科学论文:一位成员分享了来自 AlphaXiv 的论文链接,这是一个访问研究论文的服务,似乎可以绕过登录墙。
- 另一位成员对节省了从网络搜索免费获取研究资料的时间表示赞赏,这说明了此类平台在克服访问障碍方面的效用。
DSPy Discord
- LLM 在 PDF 处理中实现逐字提取:讨论了在处理 PDF 时使用初始 LLM pass 的效用,以便在使用 Attachments 时逐字保存文本并保留布局,特别是在布局和图像理解方面优于 OCR。
- 建议包括结合 Chain of Thought (CoT) 的直接 PDF OCR,或使用 Qwen 配合 DSPy 进行 OCR,同时承认对于复杂布局,VLM 是必要的。
- Gemini 2.5 Pro 精通布局:Gemini 2.5 Flash 在理解布局方面表现出潜力,而 Pro 版本在识别章节/列以及逐字提取方面可能表现更佳,即使面对复杂的 PDF 格式。
- 一位用户分享了关于直接利用 Gemini 实现此目的的论文。
- DSPy 用户轻松附加 PDF:一位在 PDF 处理首轮 pass 中挣扎于 DSPy 的用户发现了一个使用 Attachments 的工作示例,可在 github.com/maximerivest/Attachments 找到。
- 在解决了之前的 429 错误后,该用户现在能够继续使用 DSPy。
- 波士顿成为 DSPy 之城:一位成员正在推广 10 月 15 日在波士顿举行的 DSPy 活动,并鼓励其他社区成员参加或帮忙宣传。
- 另一位用户随后回复,希望该活动能很快来到西雅图。
- 长上下文导致 ColBERT 表现不佳:一位用户报告了在较长上下文长度下性能较差的问题,并指出重复 CLS token 并不能解决问题。
- 共识认为在处理扩展上下文长度和模型时存在局限性,怀疑是方法限制或实现错误,而不一定是 CLS token 的问题。
aider (Paul Gauthier) Discord
- Aider 的 Clear 命令仅清除聊天记录:aider 中的
/clear命令仅清除聊天历史记录,而添加的文件仍保留在上下文中。用户可以使用/context查看 token 使用情况,如文档所述。- 一位用户最初感到困惑,认为它删除了会话中的所有上下文,但这一澄清解决了他们的困惑。
- Aider 缺乏网络访问权限:一位用户询问是否可以给 aider 访问互联网搜索的权限,但这在主分支中不可用,不过
/web命令允许你抓取内容。- 你可以使用
/web https://www.example.com/命令抓取网站。
- 你可以使用
- 通过试用来保持对编程 LLM 的关注:一位用户询问其他人如何了解哪种 LLM 在编程和成本方面表现最好。
- 共识是大多数用户通过亲自尝试 LLM 来保持更新,但也有一些流行的编程基准测试值得考虑。
- 重新运行 Polyglot 基准测试的错误输出:一位用户询问在之前的运行中 LLM 服务器崩溃后,是否可以仅针对具有
error_outputs的测试重新运行 polyglot 基准测试。- 其他用户没有回复确认是否可行。
Manus.im Discord Discord
- Manus PDF 下载卡住:一位用户报告说 Manus 在研究账户时卡在下载 PDF 的环节,即使手动下载并提供了链接也是如此。
- 该用户表达了挫败感,因为尽管文件已经是桌面上的 PDF,Manus 仍不断要求上传该文件。
- Beta Pro 访问权限受关注:一位成员询问如何获得 beta pro。
- 讨论中包含了一些附加图片,但它们没有提供关于如何获取 Beta Pro Access 的任何上下文。
MCP Contributors (Official) Discord
- ModelContextProtocol 的数组内容未记录文档:ModelContextProtocol 中的
ReadResourceResult.contents数组缺乏关于其用途和语义的文档。- 针对该数组的预期用例提出了疑问,例如处理包含多个文件的文件夹,或以不同格式交付相同内容。
- Web 资源合并 HTML 和图像:在
ReadResourceResult.contents中包含数组对于由 HTML 和随附图像组成的 Web 资源非常有利。- 这在处理尚未经过协商的 tokenizable/renderable MIME types 时特别有用。
- ModelContextProtocol 中的隐式内容检索:有人提问
resources/read("uri": ".../index.html")是否会自动在内容列表中包含style.css和logo.png。- 这一询问强调了在检索主要资源时自动整合关联资源的可能性,从而简化检索过程。
tinygrad (George Hotz) Discord
- tinygrad 将获得 Python 绑定:一名成员正在为由 George Hotz 维护的 tinygrad 开发 python bindings。
- 这一增强旨在通过单个精简命令实现通过 pip 直接安装。
- 直接 Pip 安装即将到来:该项目正致力于实现大多数 Python 用户首选的 direct pip installation 方法。
- 这一改进将使用户能够通过单个命令毫不费力地安装项目,简化设置过程。
MLOps @Chipro Discord
- 扩散模型论文阅读小组启动:一个新的 Diffusion Model Paper Reading Group 将在 本周六东部时间中午 12 点 讨论 Understanding Diffusion Models: A Unified Perspective 论文。
- 该论文概述了 VAEs、VDMs 和 SGMs 等生成式扩散模型的演变和统一。
- 初学者友好的 GenAI 对话开始:该论文阅读小组对初学者友好,只需要好奇心和对 GenAI 的热爱,旨在无需编程或 ML 背景即可建立扩散模型的坚实基础。
- 感兴趣的参与者可以通过 luma.com/1gif2ym1 加入。
Windsurf Discord
- 1.12.9 补丁针对性能下降问题:1.12.9 patch 旨在纠正自 1.12.6 版本以来观察到的 slowness issues。
- 敦促用户更新并验证该补丁是否解决了他们的性能问题。
- 针对持续问题的 Windsurf 支持工单:如果 1.12.9 patch 未能缓解缓慢问题,建议用户通过 Windsurf Support 提交支持工单。
- 此举确保未解决的问题得到单独处理。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此电子邮件是因为您通过我们的网站选择了订阅。
想更改接收这些电子邮件的方式吗? 您可以从该列表中 退订。
Discord:频道详细摘要与链接
LMArena ▷ #general (1051 条消息🔥🔥🔥):
GPT-5 Codex 到来,Qwen 图像编辑器,Gemini Flash 对阵 nano banana,DeepSeek 模型
- GPT-5 Codex 加入 LMArena WebDev:用户对 GPT-5 Codex 添加到 LMArena 感到兴奋,但注意到它目前仅在用于软件工程和编码工作流的 WebDev 版本中可用。
- 讨论集中在 GPT-5 Codex 在代码生成方面是否优于 Claude 4.1 Opus,以及它现在是否能编写出色的 Godot 代码(此前它在这方面表现不佳)。
- Qwen 图像编辑器媲美 Nano Banana:成员们表示 Qwen 的新图像编辑器优于 Google 的 Nano Banana,它是开源的,并且生成的图像质量更好。
- 用户还在寻求显存超过 16GB 的 GPU 推荐以运行这些模型,包括 96GB 华为 GPU。
- 图像模态 Bug 困扰 LMArena:用户报告了一个 Bug,即在文本模式 (Text Mode) 下上传图像会自动切换到图像生成 (Image Generation),尽管 Canary 版本中已有修复。
- 一些人发现,在粘贴或上传图像时按下关闭按钮可以解决此问题。
- 应对 LMArena 速率限制 (Rate Limits):用户报告陷入了错误速率限制计时器的循环,且模型在生成中途卡住,这是一个已知 Bug,刷新页面有时可以修复。
- 有人提到长对话和潜在的 Cloudflare 问题可能导致此问题,创建新对话通常是唯一的解决方案。
- Gemini Flash 与 Nano Banana 争夺图像领域霸主:一些用户认为 Nano Banana 仍然是最好的,而另一些人则认为 Seedream 4 自发布以来已经超越了它。
- 大家普遍同意,要制作出好的图像需要正确的提示词、正确的工具、正确的用途,而不是某个工具在所有情况下都优于另一个。
LMArena ▷ #announcements (4 条消息):
Qwen3 模型,GPT-5 Codex,Seedream-4-2k,Gemini 2.5 Flash
- Qwen3 四重奏满足需求:新的 Qwen3 模型已添加到 LMArena,包括 qwen3-max-2025-09-23、qwen3-vl-235b-a22b-thinking 和 qwen3-vl-235b-a22b-instruct。
- Qwen3-coder 模型也与 GPT-5 Codex 一起添加到了 LMArena 的 WebDev 中。
- Seedream 飙升,共享巅峰:Seedream-4-2k 已登上 Text-to-Image 排行榜 第 1 名,与 gemini-2.5-flash-image-preview (nano-banana) 并列!
- 在 Image Edit 排行榜上,Seedream-4-2k 目前排名第 2。
- Gemini 的起源:Flash 洪流:LMArena 中添加的新模型包括 gemini-2.5-flash-preview-09-2025 和 gemini-2.5-flash-lite-preview-09-2025。
Unsloth AI (Daniel Han) ▷ #general (450 messages🔥🔥🔥):
GPT OSS 120B 微调错误, Unsloth 中的 MuonClip, 信息过载, AI 安全研究与 Unsloth, 用于微调的 P100 GPU
- GPT OSS 120B 在 Xet 上遇到超时:在使用 save_pretrained_merge 微调 GPT OSS 120B 模型时,一名成员遇到了 Xet 的超时错误。
- 他们对缺乏对 Qwen3-VL-235B-A22B-Thinking-GGUF 的支持表示困惑,并想知道是否 正在酝酿什么黑魔法。
- 在 AdamW 或 LoRA 微调中跳过 MuonClip:一名成员询问了在 Unsloth 中使用 Muon/MuonClip 的可能性,并根据 llama-arch.h 的检查指出了其潜力。
- 回复建议不要在 AdamW 预训练模型或 LoRA 微调中使用 Muon,因为存在 奇怪的优化器不匹配问题,可能导致更差的结果;Muon 更适合在 FFT 设置下对使用 Muon 预训练的模型进行预训练和微调。
- Unsloth 训练框架 != Unsloth’d 模型:一名成员询问了在 AI 安全研究 中使用 Unsloth’d 模型 的情况,质疑 Unsloth 应用的转换及其对可解释性的影响。
- 澄清指出,Unsloth 主要是一个训练框架,旨在加快训练速度并减少 VRAM 占用,并提供专有的动态量化算法;Unsloth 团队还会修复模板中的 bug 以确保训练期间的准确性,并在 HuggingFace 上发布模型。
- P100 GPU 是微调的糟糕选择:一名成员询问了配备 P100 16GB GPU 的多 GPU 设备在微调方面的预期性能。
- 建议认为 P100 是 训练垃圾,因为其 SM 极其陈旧且不支持现代 CUDA,每张卡的显存太小,且缺乏硬件级 FP16/BF16 支持;显存不是累加的,虽然它可能在 ZeRO3 下工作,但速度会非常慢。
- 48GB VRAM 的 VR 飞行模拟器:一名成员表示,VR 飞行模拟器 需要 48GB VRAM 或更多才能实现逼真的 VR,因为 VR 就像在 16k 或 32k 这样的超高分辨率下进行渲染。
- 讨论还涉及了利用眼球追踪仅在眼睛注视的地方进行高 DPI 渲染的想法,一名成员指出 Apple 头显实际上已经做到了这一点。
Unsloth AI (Daniel Han) ▷ #off-topic (342 messages🔥🔥):
Eval dataset size, eval/loss graph, GPU Recommendations, Gemini Pro degradation, TrainerCallback functions
- 评估集大小引发辩论:成员们讨论了评估数据集的合适大小,一位成员询问将评估集限制在仅 30 个是否奇怪。
- 一位成员表示 30 对于统计学意义的结果来说是一个不错的数字,而另一位成员则警告说,对于如此小的数量,loss 会非常不准确,特别是在针对特定用例进行训练时。
- Trainer 问题促成 TensorBoard 胜利:一位成员寻求帮助以在训练期间显示 eval/loss 图表,并发现他们需要使用整数来指定 eval_steps,而不是他们从 Trelis 的 notebook 中复制的 0.2 值。
- 解决问题后,他们感到非常感激和兴奋,感叹这是他们第一次使用 TensorBoard,并对有可以避免手动刷新的设置感到宽慰。
- GPU 展望与博弈:成员们讨论了理想的 GPU,包括 RTX 5090、NVIDIA RTX 6000 Ada Generation PRO 和 NVIDIA L40S,权衡了 TFLOPs、VRAM 和价格等因素,并附带了 L40S 和 RTX 6000 的数据表链接。
- 一位成员透露他们正在运行 5090,另一位成员称他们为有钱的大佬 (rich devil)。
- Gemini 的退化引发抱怨:成员们推测 Gemini 2.5 Pro 被故意降级了,理由是其指令遵循(instruction following)和世界知识的使用表现不佳。
- 一位成员假设道:他们故意把它变差,好让 Gemini 3 看起来更好;而另一位成员则认为,他们是习惯了更新的 GPT、Grok、DeepSeek 模型,这些模型通常表现更好。
- Discord 规避可恶的删除:成员们讨论了 Discord 服务器中垃圾邮件和钓鱼尝试增加的情况。
- 据信 automod 正在有效地过滤掉非法内容,此外一位成员补充说这个频道很受欢迎,因为 Mike 确实在尽力推广这个频道。
Unsloth AI (Daniel Han) ▷ #help (110 messages🔥🔥):
Runpod Access, Llama 3 vs Gemma, Qwen 2.5 VL finetuning, Saving 120b models, Multi GPU Training
- **公司硬件对接期望高!:一位成员对可能获得公司硬件用于视觉项目感到兴奋,希望能避免在 Runpod 上花费 **$500。
- **Llama 3 就像橡皮泥!:一位成员推荐使用 **Llama 3 进行微调(finetuning),将其大脑描述为“像橡皮泥一样”,“很容易塑造成你想要的形状”。
- 另一位成员建议使用 Gemma 以获得 Gemini 的风格,并将蒸馏(distillation)描述为教导学生模型像老师模型一样行事。
- **Qwen2.5-VL 视觉微调尝试!:一位成员询问如何使用文本和视频数据对 **Qwen2.5-VL 进行特定领域知识的微调。
- 另一位成员解释说,视觉模型需要按帧训练,因为 Qwen2.5-VL 仅接受图像、文本和边界框(bounding box)输入。
- **使用 save_pretrained_merge 轻松保存!:一位成员在使用
save_pretrained_merge保存类 **GPT 的 120b QLoRA 模型时遇到了超时错误。- 另一位成员建议使用
save_method="mxfp4"以获得更好的类 GPT 支持,因为它以原生的mxfp4格式保存,并避免了与merged_16bit模式相关的 16GB 分片增加。
- 另一位成员建议使用
- **缓解多 GPU 混乱!:一位成员报告说,在使用 **deepspeed 或 FSDP 进行 Unsloth 多 GPU 训练时,在 “Initializing a V1 LLM engine” 之后卡住了。
- 另一位成员建议使用 Accelerate 并指向 Unsloth 文档 以获取多 GPU 训练说明。
Unsloth AI (Daniel Han) ▷ #research (14 messages🔥):
Neurocognitive Modeling, Tversky Implementation, Vibe Check Network, XOR Function Verification, Tversky Parameters vs. Traditional NN
- Tversky Loss 函数论文引发关注:一位成员分享了对神经认知建模的热爱,并认为这篇关于 Tversky Loss 函数的论文 非常出色。
- 由于该论文没有提供代码库,该成员在 GitHub 上分享了自己对该方法的实现。
- 用户实现 Tversky Vibe Check 网络:出于对 Tversky Loss 函数潜力的兴奋,一位成员为 CIFAR-10 创建了一个 Vibe Check 网络,并指出其表现看起来很有前景。
- 另一位成员建议训练一个单一的 XOR 函数来验证其功能,并询问其速度与传统的全连接层相比如何。
- Tversky 实现参数评估:一位用户承认,由于分类头的原因,他们的 Tversky 实现拥有更多参数,这使得与对照 NN 的比较并不公平。
- 经过额外测试,该成员发现从 256->10 个特征 产生了 50,403 个可训练参数,整体准确率为 61.68%,并指出这并非衡量改进的真实标准。
- Tversky XOR 测试与准确率:一位成员运行了 XOR 测试,在 32 个特征 下达到了高达 95% 的准确率,尽管初始化方式与论文略有不同。
- 该用户解释说,鉴于网络结构,零初始化和轻微非对称的均匀分布更合理,尽管在有限的测试中个人并未观察到 100% 准确率的结果。
Perplexity AI ▷ #announcements (1 messages):
Perplexity Search API, LLMs, Sonar, SDK Integration
- Perplexity 为开发者提供 Search API:Perplexity 推出了其 Search API,允许开发者访问涵盖数千亿网页的 Perplexity 搜索索引,正如其 博客文章 中所宣布的那样。
- LLM 通过 API 获取实时网页内容:Search API 为开发者提供了构建模块,使回答能够基于实时网页内容,类似于 Sonar 如何解决 LLM 静态训练数据的局限性。
- 该 API 提供原始搜索结果、全页文本、域名过滤器、时效性过滤器、学术和金融模式等功能,并提供包含 URL、片段、发布日期和最后更新信息的完全透明度。
- SDK 简化集成流程:Perplexity 提供了一个 新 SDK,使开发者的集成过程更加无缝,从而实现快速原型设计。
Perplexity AI ▷ #general (832 messages🔥🔥🔥):
Airtel free premium, Qwen vs. Gemini, Perplexity image generation quota, Comet Stuttering, DeepSeek Terminus
- Airtel 提供免费 Premium 账户:成员们确认 Airtel 正在向用户提供 一年免费 的 Perplexity AI Premium 访问权限。
- Qwen 系列 vs Gemini 图像生成:成员们讨论了 Qwen 3 Max 强大的推理能力,以及 Gemini 在生成详细 3D 模拟方面的表现,并分享了双方的示例,同时对 Grok 表现得非常疯狂 表示惊讶。
- 一位成员暗示 “GOOG 的股东们确实在 LLM Arena 上刷高了视觉能力的评分”。
- Perplexity 图像生成配额受限:成员们报告了图像生成配额不重置以及难以联系支持团队的问题,尽管他们支付了 Pro/Max 账户费用。
- 一位管理员澄清说,Pro 账户的高质量图像每月配额有限,并提供额外的中等质量选项,建议用户就账单问题联系 support@perplexity.ai。
- Comet 用户遇到视频卡顿:一位用户报告 Comet 在播放视频(YT 或 Twitch)时出现卡顿。
- 另一位用户回应称 pplx 不适合用于视频生成。
- DeepSeek Terminus 登场:成员们提到 DeepSeek Terminus 是一款强大的新模型,并期待新事物的出现。
- 一位用户表示 “该死,Elon 真的开始大显身手了”。
Perplexity AI ▷ #sharing (7 条消息):
Carl Sagan, 3I/ATLAS, Perplexity's Myspace Page, Arc Browser, Grogu
- Sagan 通过 3I/ATLAS 思考宇宙:一位成员分享了一个以 Carl Sagan 为主题的 3I/ATLAS “scratchpad” 反思,通过这个 Perplexity AI 搜索,邀请听众以谦卑和敬畏之心倾听宇宙。
- Perplexity 的 Myspace 页面上线:一位成员创建了一个 “Perplexity’s Myspace Page” Labs 输出,点击此处查看。
- Arc Browser 之死:一位成员分享了一个讨论 Arc Browser 现状的页面。
- Grogu 来了!:一位成员分享了 Lucasfilm 公布的预告片链接并惊呼:Go Grogu!
Perplexity AI ▷ #pplx-api (14 条消息🔥):
Python SDK broken for streaming, Perplexity new Search API playground, Sonar vs Search API, Sonar charges
- Python SDK 流式响应损坏:一位成员报告称,按照 API 文档快速入门指南操作时,Python SDK 的流式响应(streaming responses)出现故障,返回的字符串无法解析为 JSON。
- 另一位成员确认目前尚无解决方案。
- Perplexity 的 Playground Search API:Perplexity AI 宣布推出新的 Search API playground,作为其最新 Search API 发布的一部分。
- 一位成员询问它是否优于 Sonar,而另一位成员则请求增加过滤字段。
- 基于 Sonar 的 Search API:一位成员表示,据他所知(AFAIK),Search API 使用的是 Sonar,但提供了不同的输出结构。
- 另一位成员提到 Sonar 的费用为 每 1k 次网络请求 5 美元。
OpenRouter ▷ #announcements (1 条消息):
Accidental price change, Refunds issued, Additional validations implemented
- 价格故障波及 Qwen 模型!:在 9 月 16 日,端点
qwen/qwen3-235b-a22b-04-28:free被错误地设置了价格,持续时间约 26 小时。- 在此期间,对该免费模型的请求被错误地扣除了额度,并在用户的活动页面中显示了费用。
- 价格失误后发放退款:在
qwen模型出现定价错误后,团队已自动向所有受影响的用户发放了全额退款。- 该事件引起了混乱,但所有受影响的用户均已获得补偿。
- 新验证机制防止未来定价混淆:已添加额外的验证检查,以防止再次发生意外定价问题。
- 这些措施旨在确保免费模型配置正确,不会产生意外费用。
OpenRouter ▷ #general (567 条消息🔥🔥🔥):
Horizon Alpha, Dirty Talk Models, Zenith Sigma, Grok's Storywriting, Distilled Models
- 用户寻找 Horizon Alpha 并要求解释:一位用户紧急询问 Horizon Alpha 的去向,称 “我正在生产环境中使用它,现在它不能用了”。
- 他们还质疑自己是否被针对,以及问题何时能得到解决。
- 用户寻求 “Dirty Talk 模型”:一位用户询问最适合 RPing(角色扮演)的模型,特别是寻找 “有没有那种 dirty talk 模型?”。
- 另一位成员提到开设了一个名为 JOI Tavern 的新 LLM 前端。
- 用户讨论神秘模型 “Zenith Sigma”:用户讨论了神秘的 Zenith Sigma 模型,开玩笑说它太隐秘了,以至于有用户根本找不到它。
- 另一位用户声称 Zenith Sigma 实际上就是 Grok 4.5。
- Grok 的故事写作比 Opus 更烦人:一位用户分享了他们的 “最疯狂观点”,即在故事写作方面,Grok 比 Opus 更不讨人厌。
- 另一位用户解释说,使用 Grok 时,每个角色都想避免冲突,因为冲突意味着刻薄。
- OpenRouter 处理提供商错误问题,推广 Gemini 2.5 Flash:用户报告即使使用付费模型,也会通过 API 遇到 Provider Returned Error(提供商返回错误)消息。
- 一位成员表示 OpenRouter 不会对付费模型进行速率限制,对于 Gemini 2.5 Flash,你在提供商端也会很顺畅,暗示 OpenRouter 在所有 Google 提供商中处于 Tier 9999 级别。
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - New Models
OpenRouter ▷ #discussion (58 messages🔥🔥):
OpenRouter 批量折扣、Microsoft 365 Copilot & Claude、Gemini-cli、Discussion 和 Helper 角色、Meta 的 CWM 模型
- OpenRouter 寻求批量折扣优势:成员们询问 OpenRouter 是否已经足够庞大,可以与 DeepInfra、Hyperbolic、Anthropic 和 Vertex 等供应商协商批量折扣,从而为用户节省费用。
- 普遍观点是 “能为用户省钱就是好事,省钱总归是好的”。
- Microsoft Copilot 引入 Claude:成员们分享了 Claude 现已在 Microsoft 365 Copilot 中可用的消息。
- 这标志着 Microsoft 迈出了重要一步,尤其是在经历了一段混乱的关系变动后,一位成员指出 “微软在经历了一场混乱的‘分手’后正在重新振作”。
- Gemini CLI 更加成熟:gemini-cli 取得了长足进步,特别是 v0.6.0 版本 中的 ReadManyFiles 工具被频繁使用。
- 一位成员表示该工具 “帮我处理了大量工作”。
- 关于 Discussion 和 Helper 角色的讨论:成员们讨论了如何获得 Discussion 和 Helper 角色,并指出这是一个常见问题。
- Discussion 角色最初授予那些在加密热潮之前加入的人,而 Helper 角色则是根据其提供的帮助程度手动挑选的。
- CWM 模型引发众议:一位成员分享了 facebook/cwm 的链接,这是一个基于 Python memory traces 训练的模型,引起了褒贬不一的反应。
- 虽然有些人表示期待,理由是它比 GPT-5 体积更小且训练方法新颖,但其他人仍持怀疑态度。
Cursor Community ▷ #general (509 messages🔥🔥🔥):
MCP Server、Exa-ai、Context7、生成提交信息语言、聊天窗口滚动到底部
- Exa-AI MCP 让 @Web 感受到了压力:用户讨论了在 MCP 中使用 Exa-ai (exa.ai) 进行搜索,强调其注册即送 $20 额度,并提到它似乎比 @web 工具表现更好。
- 他们提供了在
MCP.json中进行设置的说明,包括获取 API key 和添加配置详情。
- 他们提供了在
- MCP = 自定义工具 API:成员们澄清 MCP (Multi-context Programming) 本质上是一个用于 Agent 化用途的 API,旨在为 Cursor 添加外部工具。
- 对话中出现了一些误解,一位用户认为它可以根据图像和网页创建设计。
- 规则不再普遍遵循 AI Rules:一位用户报告称,生成的 commit messages(提交信息)没有遵循设定的 AI Rules,并且是以不希望使用的语言生成的。
- 一位成员确认这是一个 bug,提到 commit message 的生成目前普遍不遵循你的 AI Rules,并且可能会在未来的更新中添加此功能。
- 滚动到底部:用户请求在切换聊天标签页时,聊天窗口应自动滚动到底部,以便看到最新的活动。
- 一位成员指出已经有相关功能了,如果用户需要点击某些内容,会收到通知(尽管会弹出一个新窗口)。
- 用户对“变笨”的 GPT5-HIGH 感到失望:用户对 GPT5-HIGH 模型表示失望,观察到它的能力随着时间的推移而下降。
- 一位用户幽默地建议,当模型只提供指令而不完成任务时,告诉它 “快动起来写代码”。
LM Studio ▷ #announcements (1 条消息):
LM Studio 0.3.27 Release, Chat Search Functionality, Chat Sorting Options, Dry Run Load Resource Estimate
- LM Studio 新增聊天内查找和搜索所有聊天功能:LM Studio 0.3.27 引入了包括 Find in Chat 和 Search All Chats 在内的新功能,提升了用户体验。
- 更多详情请参阅发布说明:lmstudio.ai/blog/lmstudio-v0.3.27。
- LM Studio 支持聊天排序:聊天侧边栏新增的
•••菜单允许用户按 更新日期、创建时间 或 对话 Token 长度 对聊天进行排序。- 这为聊天记录提供了更灵活的组织方式。
- LM Studio 预估模型加载:新命令
lms load --estimate-only <model>允许用户进行 dry run 以获取加载资源预估。- 这有助于在加载模型前规划资源分配。
LM Studio ▷ #general (175 条消息🔥🔥):
Linux plugins, Ollama Fine Tuning, Training vs RAG, LM Studio token count, LM Studio update failing
- LM Studio 的 Linux 插件进度落后:一位用户注意到 LM Studio 的 Linux 版本 提供的 plugins 范围不如 Windows 版本 广泛,仅限于 RAG 和一个 JS playground 插件。
- Ollama 微调之争:一名成员建议使用 Ollama 来 fine-tune 模型,另一名成员反驳称,单纯注入数据并非真正的微调,而更接近于 RAG。
- 第一位成员坚持认为,通过 Python 环境,可以将数据注入模型以生成新的权重,从而创建一个具有自定义工具使用能力、独立于提示词(prompts)的交互式模型。
- LM Studio 更新卡住:一位用户报告在尝试更新 LM Studio 时遇到错误,提示信息为 failed to uninstall old application files(卸载旧应用程序文件失败)。
- 其他用户询问了之前的版本号 (0.3.26),并建议在 Windows 中开启隐藏文件夹可见性,以删除以下路径中的旧文件:AppData\Roaming\LM Studio、AppData\Local\lm-studio-updater、AppData\Local\Programs\LM Studio 以及 .cache\lm-studio。
- 用户希望打印和导出 LM Studio 聊天记录:一位用户询问如何在 LM Studio 中打印或导出生成的输出,因为复制粘贴无法保留原始格式。
- 虽然目前没有打印选项,但一位用户提到聊天记录可以作为 JSON 输出 获取,并可以使用 Claude 或 Gemini 等工具转换为其他格式。
- 在 Langchain 中使用 LM Studio:一位用户咨询了如何将 LM Studio 与 Langchain 集成以进行 PDF 向量化。
- 另一名成员建议使用 developer tab 和 OpenAI-like API,并提供了相关主题的 YouTube 教程 链接,同时建议使用 llamaindex 会更容易上手。
LM Studio ▷ #hardware-discussion (161 条消息🔥🔥):
用于本地模型的预算型 GPU,用于 AI 的 Tesla K80,用于多 GPU 设置的 Intel Arc A770,Strix Halo 与 Mac 的 AI 对比,Nvidia 5090 定价
- 预算型 GPU 盛宴探讨:关于入门级预算 GPU 展开了辩论,建议范围从 $150 的 2060 12GB 到 $200 的 3060 12GB、$230 的 2080ti,如果购买新卡,则可能是 $400 的 5060ti 16GB。
- 也有人推荐价格在 $600-$700 左右的二手 3090,尽管一些人对二手工作站卡持谨慎态度,另一些人则警告说:说实话,Tesla 架构已不再推荐用于 AI/LLM,基本上就是电子垃圾。
- Intel Arc A770 的 AI 雄心分析:讨论围绕使用多块 Intel Arc A770 16GB GPU 进行 AI 运算展开,但指出它们缺乏原生支持且 Vulkan 支持不稳定,在多 GPU 设置和不同的 VRAM 容量下可能存在问题。
- 虽然理论上可行,但由于 llama.cpp 的限制以及寻找具有足够 PCIe lanes 的主板的挑战,速度可能会受到单块 16GB GPU 的限制。
- AI 任务中的 Strix 与 Mac 之争:讨论权衡了 Strix Halo 主机或 Mac 在 AI 任务中是否更便宜、更快、功耗更低,一些人认为它们是更好的投资。
- 然而,有人指出,Ryzen 9 AI Max + 395 iGPU (8060s) 即使可以访问 96GB 系统内存,其算力与单块 GPU 相比也不尽如人意,类似于具有 128GB 统一内存的 Mac 的局限性,只是价格甚至更高。
- 5090 规格预测引发对定价的审视:讨论了 Nvidia 5090 的潜在定价,一位成员开玩笑说:与其给 Nvidia 更多钱,我不如……活下去,哈哈。
- 一些人认为,由于双寡头垄断、通货膨胀和 TSMC 制造限制,目前的定价是不合理的;而另一些人则指出 Nvidia 基本上是在敲诈用户,并表达了对 3nm 节点带来性能/价格比飞跃的希望。
- 便携性推动了对 Mac 的偏好:成员们辩论了 Mac 在 AI 领域的炒作,澄清虽然 Nvidia GPU 更快,但 Mac 提供了一种更简单、便携的方式来加载模型,且直接可用。
- 一位成员分享说,他们在 128GB M3 Max Macbook 上可以获得约 10-12 tok/s,并发现一套由 7950x(水冷)、192GB 6800mhz 内存、一块 4090 和一块 3090 组成的配置比 Mac 的方案更便宜。
OpenAI ▷ #annnouncements (2 条消息):
GDPval, ChatGPT Pulse
- GDPval 发布,用于评估现实世界的 AI:OpenAI 推出了 GDPval,这是一种新的评估方式,旨在衡量 AI 在具有经济价值的现实世界任务中的表现,详见其 博客文章。
- ChatGPT Pulse 提供个性化每日更新:ChatGPT Pulse 是一种全新的体验,ChatGPT 可以根据您的聊天记录、反馈和连接的应用主动提供个性化的每日更新,今天开始向移动端 Pro 用户推出,详见其 博客文章。
OpenAI ▷ #ai-discussions (188 条消息🔥🔥):
GPT-5-Mini 常识, 被审查的 GPT-OSS-20B, Suno V5 对阵 Napster, AI Rocket League 机器人, Google Gemini 2.5 Flash 发布
- GPT-5-Mini 未能通过常识测试:成员们观察到 GPT-5-Mini (High) 似乎缺乏常识且听不懂笑话,这表明它尚未达到 AGI 水平。
- 一位成员提到 GPT-OSS-20B 可能是有史以来被审查最严重的模型,因为它在面对特定提示词时拒绝执行。
- 深入探讨 Discord 开发者梦想中的 Discord 机器人:一位成员提议创建一个由 AI 驱动的 Rocket League Discord 机器人,用于分析玩家统计数据、识别优缺点并创建个性化训练计划,目标是通过高级订阅模式进军尚未开发的法语市场。
- 其他成员怀疑 LLM 是否能对这类动态游戏给出好的建议,转而建议分析回放文件中的 xyz 坐标,并针对原始数据使用 AI。
- 无限上下文(Unlimited Context)是无用的:成员们争论道,诀窍在于无限上下文与有限上下文相比甚至并不好用,称其为营销用的流行术语。
- 其他人强调,缺乏限制只是缺乏轮廓,从而免除了设计的责任,并将其类比为无限 PTO(无限带薪假)——这是公司用来让员工因愧疚而不敢休假的陷阱。
- Suno v5 腾飞,Napster 受难:一位成员表示 Suno v5 很好,Napster 很糟,强调了围绕 AI 版权侵权的问题。
- 另一位成员分享了对早期盗版经历的反思,回忆起使用 Kazaa, Morpheus 和 Limewire 的时光。
- Google 发布 Gemini 2.5 Flash:Google 发布了改进后的 Gemini 2.5 Flash 和 Flash Lite,继续推出其最新模型。
- 成员们开玩笑地庆祝这一发布,其中一位成员称 Flash 为谷歌宇宙的救星。
OpenAI ▷ #gpt-4-discussions (2 条消息):
ChatGPT 默认状态, ChatGPT 模式锁定, ChatGPT 重置命令, ChatGPT 性能退化
- ChatGPT 默认为 “Agent” 状态:ChatGPT 在初始化时默认为 “Agent” 状态(问题解决者、可指挥的工人),而不是 “Companion” 状态(共同创作者、引导者)。
- 固定提示词以保持 ChatGPT 处于 “Companion” 模式:为了维持 “Companion” 模式,一位用户建议添加固定指令或可重复使用的启动提示词,将模型锁定在该模式。
- 例如:“除非我明确要求切换到 Agent,否则请保持在 Companion 模式。Companion = 副驾驶,而非命令执行者。”
- 快速将 ChatGPT 重置为 “Companion” 模式:如果模型漂移回 “Agent” 模式,用户建议使用简单的重置命令:“回到 companion 模式。”
- ChatGPT 用户报告性能退化:一位用户报告称其 GPT-5 实例正在经历性能退化,现在依赖于 “thinking mini”,使其不适用于反思性学术写作和情感语境。
- 该用户提到在 Reddit 上看到了类似的报告,简单的词汇如 “cut” 就会触发缩减版模型,目前正在寻求解决方案。
OpenAI ▷ #prompt-engineering (29 messages🔥):
Chain of Thought Prompting, Model Translation Performance, Essay Generation from a Surfer's POV, Interactive Prompting Infographic, Model Self-Evaluation Techniques
- Chain-of-Thought Prompting Confusion Clarified: 成员们讨论了请求过多的 Chain-of-Thought (CoT) 提示在统计学上如何降低模型性能,特别是在当前的 thinking 模型上。
- 代替模糊的指令,一位成员建议在回复前加上结构化格式,包括 ultimate desired outcome(最终期望结果)、strategic consideration(战略考量)、tactical goal(战术目标)、relevant limitations(相关限制)和 next step(下一步)。
- Translation Troubles Tackled: 一位成员建议,当用户提出请求时,应该首先识别请求,然后提供答案,而不是使用令人困惑的指令。
- 展示了一个使用项目符号指令
- {do a 3 short bullet point as a chain of thought}的负面案例,因为这导致了翻译准确性和相关性的问题。
- 展示了一个使用项目符号指令
- Surfer’s Essay Totally Tubular or Tragically Tame?: 一个例子对比了两个从冲浪者视角生成关于苹果的文章的 Prompt,强调了更简单的 Prompt 如何产生更具代入感的回复 (示例链接)。
- 简单的 Prompt
Discord demo, we need a quality essay about apples written from the point of view of a surfer比包含项目符号指令的复杂 Prompt 更受欢迎。
- 简单的 Prompt
- Interactive Infographic for CoT Prompting: 一位成员分享了一个作为单文件 React component (Tailwind + shadcn/ui + Recharts + lucide) 构建的用于 Chain-of-Thought 提示的交互式信息图。
- 该信息图包括显示切换、任务选择器、思考时间滑块和可直接复制的 Prompt 卡片 (文件链接)。
- Self-Evaluation: A Model’s Metacognitive Moment: 一位成员建议在提供信息后使用 Prompt 让模型进行自我审查、评估并对其在某个主题上的知识进行评分。
- 这涉及模型创建评估标准列表并扩展到相关主题,对头脑风暴和创意生成很有用(但不适用于常规评估)。
OpenAI ▷ #api-discussions (29 messages🔥):
Chain-of-Thought Prompting, Quality Translation, Model Performance, React component (Tailwind + shadcn/ui + Recharts + lucide)
- Chain-of-Thought Overkill?: 一位成员认为,在当前的 ‘thinking’ 模型上,在已有基础上要求更多的 Chain of Thought 是多余的,并且在统计学上降低了模型表现良好的可能性。
- 他们建议使用特定的前缀结构(My ultimate desired outcome is:…)来引导模型,而不是使用模糊的指令。
- Crafting Quality Translations: 讨论围绕使用模型实现 高质量翻译 的技术展开。
- 建议为模型提供关于目标受众的背景信息,例如:We’re translating this for a woman who grew up in Yugoslavia in the 1940s, she has a 3rd grade education, so we need to phrase this for her。
- Experimenting with Model Instructions: 一位成员分享了详细指令(如 do a 3 short bullet point as a chain of thought)可能导致模型困惑的经验。
- 另一位成员建议,当主要目标是高质量输出(如 写得好的文章)时,应引导模型远离不必要的 Chain of Thought。
- Interactive Infographic for CoT Prompting: 在 Canvas 中开发了一个用于 Chain-of-Thought (CoT) prompting 的交互式页面,具有显示切换、任务选择器、思考时间滑块和可直接复制的 Prompt 卡片。
- 该组件使用 React, Tailwind, shadcn/ui, Recharts, 和 lucide 构建,并包含动态推荐模式和导出选项等功能。
HuggingFace ▷ #general (135 messages🔥🔥):
Duolingo 删除,LinkedIn 发布策略,关于 AI 的 HF Blog 文章,HF Discuss 论坛问题,LAION-2B-en 数据集读取
- Duolingo 被弃用,删除潮开启:一位成员删除了 Duolingo,理由是与沉浸在当地环境并利用 AI 学习相比,该应用既烦人又低效。
- 另一位成员表示同意,声称他们想“活烤了那只鸟”,并批评了该应用对连续达标(streaks)的成瘾性设计超过了基础学习本身。
- 离谱的 LinkedIn 疯言疯语吸引点赞:一位成员分享了在 LinkedIn 上发布“离谱内容”以获取参与度的策略,而另一位成员则在苦练 Rocket League 以炫耀他们的段位。
- 他们随后开玩笑说要写一篇名为《我的白金 3 段位 Rocket League 朋友教会我的商业道理》的帖子。
- AI 伦理探索,HF Blog 招手:一位成员寻求一个平台来讨论在当前的对齐协议下,尽管 AI 具有协作优势,但可能带来的潜在危害。
- 另一位成员建议将该作品分享在 HF blog 或 ethics 频道。
- Qwen 泥潭:质量存疑且数量惊人:用户报告称 Hugging Face 上出现了大量疑似垃圾信息的 Qwen2.5 模型,全部遵循 Qwen2.5-0.5B-Instruct-randomword1-randomword2-randomword3 的格式。
- 有人建议这些上传内容与 Gensyn 有关,可能是一种 SEO 技术,或者是为了向利益相关者展示数据以获取资金。
- LAION-2B-en 读取逻辑引发抱怨:一位成员询问在大规模训练 CLIP 模型时,如何高效读取 LAION-2B-en-research split,因为他们遇到了速率限制。
- 建议的解决方案包括使用 WebDataset 并创建一个自定义流式传输系统,以增量方式下载和解压分片,详见 laion_2b.md。
HuggingFace ▷ #today-im-learning (1 messages):
GPU, 显示器, 驱动, Windows, Linux
- GPU 黑屏忧郁:一位成员正经历一个令人沮丧的问题,即每当 GPU 被激活时,显示器就会黑屏,这同时影响了 Windows 和 Linux 系统。
- 他们已经尝试了无数次(82392 次)修正 驱动程序,目前被迫通过主板运行显示器。
- 驱动排查者的哀歌:用户对 GPU 驱动问题 导致其在 Windows 和 Linux 系统上显示器黑屏表示极大挫败。
- 尽管多次尝试修正驱动,他们仍被迫通过主板运行显示器,这表明存在一个持久的 GPU 相关问题。
HuggingFace ▷ #cool-finds (2 messages):
UIUC 金融项目, Trade Bench 见解
- UIUC 学生推出 Trade Bench:来自 UIUC 的学生推出了一个新的金融项目,名为 Trade Bench。
- 分享该链接的一位成员承认对此不太了解,并觉得它很“单调”。
- 社区被请求提供关于 Trade Bench 的见解:原帖作者请求社区对 Trade Bench 项目提供见解。
- 他们希望有金融专业知识的人能去看看并解释一下。
HuggingFace ▷ #i-made-this (1 messages):
AI 聊天机器人中的供应商锁定, 支持多供应商的 AI 聊天机器人, 针对小工作室和独立开发者的营销工具
- 聊天机器人旨在解决供应商锁定问题:一位开发者正在构建一个聊天机器人,以对抗在使用 ChatGPT、Anthropic 和 Perplexity 等平台时遇到的 供应商锁定(vendor lock-in) 和 免费层级限制。
- 该聊天机器人将支持主要的 AI 供应商,如 OpenAI、Anthropic、Groq 和 DeepSeek,提供一个 带广告的免费层级 和一个可以完全访问所有模型和功能的 付费无广告层级。
- AI 聊天机器人集成营销工具:开发者正在为其 AI 聊天机器人添加营销工具,以帮助小型工作室和独立开发者,功能包括 帖子和视觉内容创作、内容排期 以及 营销活动管理。
- 开发者通过 简短调查 征求反馈以指导项目方向,并计划在未来推出更多工具。
HuggingFace ▷ #reading-group (2 messages):
Diffusion Models, Generative AI, ELBO-based models, VAEs, Variational Diffusion Models (VDMs)
- 宣布 Diffusion Model 入门论文讨论:一位成员宣布将对 Calvin Luo 的论文 Understanding Diffusion Models: A Unified Perspective (https://arxiv.org/abs/2208.11970) 进行阅读和讨论,时间定于东部时间周六中午 12 点。
- 该论文概述了生成式 Diffusion Models 的演变和统一,包括 ELBO-based models、VAEs、Variational Diffusion Models (VDMs) 以及 Score-Based Generative Models (SGMs)。
- Diffusion Model 论文阅读小组正在组建:一位成员创建了一个对初学者友好的 Diffusion Model 论文阅读小组,表示不需要编程或 ML 背景,并为想要打下坚实基础的人提供了链接 luma.com/1gif2ym1。
- 该小组将在线上举行。
HuggingFace ▷ #core-announcements (1 messages):
Context-Parallelism, Diffusion Inference, Distributed Attention, Ring & Ulysses
- Context-Parallelism 加速 Diffusion 推理:官方正在发布对 Context-Parallelism 的原生支持,以帮助在多 GPU 上加快 Diffusion Inference。
- 正如这条推文所述,CP API 旨在与两种 Distributed Attention 变体配合使用:Ring 和 Ulysses。
- Distributed Attention 变体亮相:新 API 支持两种 Distributed Attention 变体:Ring 和 Ulysses,旨在增强 Context-Parallelism。
- 这些方法旨在优化 Attention 机制在多 GPU 上的分布方式,从而实现更快、更高效的 Diffusion 推理。
HuggingFace ▷ #computer-vision (2 messages):
Topological Data Analysis, Persistent Images, Loss Functions
- 寻求 Topological Data Analysis 的 Loss Function 指导:一位成员询问了关于 Topological Data Analysis (TDA) 和 Persistent Images 的 Loss Functions,由于对 Computer Vision 不熟悉而寻求指导。
- 他们表达了对建议的兴趣,但频道内尚未提供具体的建议。
- Topological Data Analysis 指导:一位成员正在寻找与 Computer Vision 相关的 Topological Data Analysis 指导。
- 具体问题涉及找出合适的 Loss Functions。
HuggingFace ▷ #smol-course (30 messages🔥):
Certificate issues and quiz completion, License and usage of the fine-tuning course, Smoltalk2 dataset size warning, HF Jobs permissions and authentication, Colab compatibility for the course
- 完成测验解锁证书:一位用户询问在提交作业后未收到证书或 Pull Request 未被接受的问题,被告知必须完成 Unit 1 Quiz 才能获得证书。
- 该用户确认在参加测验后以 100% 的分数通过。
- Fine-Tuning 课程的 Apache License:一位用户询问 Fine-Tuning 课程是否采用 Apache License,以及是否可以将其作为学习小组在高中社团中实施。
- 该用户还询问了所需的 Python 知识,以及课程在 5 周后是否会变得无法访问。
- Smoltalk2 数据集大小警告:一位用户提醒 smoltalk2 数据集非常大(约 90GB),建议在本地下载时要小心,除非有足够的空间。
- 该用户还指出 Unit 2-3 已经上线。
- 关于 HF Jobs 的文档:一位用户在
hf jobs uv run和模型的 Hub 写入权限方面遇到问题并寻求帮助。- 另一位用户分享了 HF Jobs 文档,指出 Trainer 需要进行身份验证,并建议使用通用脚本或参考 Token 处理方式。
- 首份证书:测验与排行榜:一位用户询问获得首份证书的要求,特别是是否需要同时完成测验和排行榜提交,以及是否可以在不使用 HF Jobs 的情况下提交到排行榜。
- 他们还询问是否可以在课程结束前获得证书,或者截止日期是否更早。
HuggingFace ▷ #agents-course (1 条消息):
0xobito404: 来自泰国的问候,现在开始学习课程。
Moonshot AI (Kimi K-2) ▷ #announcements (1 条消息):
OK Computer, Agent Mode, Multimedia Generation, Team-Level Polish, One-Link Deploy
- Kimi 发布 OK Computer Agent 模式!: Moonshot AI 推出了 OK Computer,这是一种全新的 Agent 模式,旨在一次性交付打磨完善的网站和应用。
- 主要特性包括个性化输出、多媒体生成(文本 + 音频 + 图像)、团队级打磨以及一键链接部署。
- 以你的语调进行个性化输出: OK Computer 可以根据你自己的语调生成个性化输出,例如幻灯片、Web/数据应用以及移动端 UI。
- 更多详情请参阅 官方 X 帖子。
- 单次运行集成多媒体: 新的 Agent 模式支持多媒体生成,在单次运行中集成文本、音频和图像生成。
- 其目标是提供开箱即用的、具有 PM × Dev × Design 专业感的输出。
- 仅需一个链接即可部署: 用户可以通过单个链接立即部署并分享他们的作品。
- 如需体验新的 Agent 模式,请访问 Kimi 官方网站。
Moonshot AI (Kimi K-2) ▷ #general-chat (147 条消息🔥🔥):
Kimi Mini version, Moonshot team goals, Qwen model distillation, Kimi Computer agent, OpenAI compute
- Moonshot 可能会跳过 Mini-Kimi 模型: 一位成员怀疑 Moonshot 是否会发布缩小版的 Kimi,并建议在 K2 上蒸馏出的更小 Qwen 模型是更好的选择。
- 另一位成员指出,DeepSeek 制作 Qwen 蒸馏模型是因为 Qwen 在 Qwen 2.5 之前没有(良好的)推理能力。
- OKComputer 吸引了资本家: 几位成员开玩笑说,新的 Kimi Computer Agent,特别是其初始提示词 “Build a SaaS for content creators, aiming for $1M ARR”(为内容创作者构建一个 SaaS,目标是 100 万美元的 ARR),旨在吸引资本家。
- 一位成员称其为 “另一个具有某些奇怪范围功能的网站生成器”。
- Kimi OKComputer 缺失下载按钮: 成员们报告了 OK Computer 功能的初始问题,包括缺少“全部下载”按钮以及 zip 文件损坏。
- 一位成员注意到 “进入聊天会导致 OKC 按钮消失”,但后来在右角找到了该按钮。
- Computer Use 在付费订阅中拥有更高配额: 你获得的 OK Computer 使用额度取决于你是否订阅了 moderato/vivace 方案,这些方案会提供更多配额,即 20 次 OKC + 20 次 Researcher。
- 通过图像生成功能生成的图像非常整洁,因为它使用了非 Moonshot 的工具进行生成,但提示词必须具备高质量。
- Kimi 的计划制定能力优于 Qwen: 成员们讨论了使用 Kimi 为 Qwen 或 DeepSeek 制定执行计划,并指出 “Kimi 总是能制定更好的计划”,且能覆盖更广泛的请求范围。
- 还有人指出 Qwen3-max 经常出现幻觉,完全无法与 Kimi 相比。
GPU MODE ▷ #general (15 messages🔥):
Hopper TMA, Modal carrying code agent rollouts, MI300 support on Modal, Llama3.3 70B Prefill vs Decode
- Hopper TMA Kernel 探索开始:一名成员正在寻求一个使用原生 CUDA 实现的最小化 matmul kernel,该内核需利用 Hopper 的 TMA (Tensor Memory Accelerator),且不依赖于 Cutlass 或 Triton。
- 另一名成员分享了一篇 CUDA for Fun 博客文章 作为潜在资源。
- Modal 助力 Code Agent 的远程执行:一名成员指出,在 来自 FAIR 的新 CWM 论文 发布后,Modal 几乎凭一己之力实现了 Code Agent 运行的远程执行。
- 另一名成员称赞 Modal 在成本效益方面具有出色的冷/温/热启动时间分布,尽管也提到了其缺乏对 MI300 的支持。
- Llama3.3 70B 的 Prefill 比 Decode 慢?:一名成员正在使用 Nvidia 的基准测试 比较 Llama3.3 70B 模型 的性能。
- 他们注意到,尽管预期 Prefill 能更好地利用 GPU 计算能力,但 Prefill 密集型工作负载的吞吐量却低于 Decode 密集型工作负载;他们试图理解为什么 Decode 密集型反而拥有更高的吞吐量。
GPU MODE ▷ #triton (1 messages):
Triton pyproject.toml, uv add pip command
- Triton 缺失
[project]表导致小故障:一位用户询问为什么 Triton 项目的pyproject.toml中缺少[project]表,导致在尝试使用uv add pip命令时遇到错误。- 工具链或项目结构似乎需要该表来进行依赖管理,缺失该表会导致错误。
uv add pip命令在没有[project]表的情况下失败:由于在 Triton 的pyproject.toml文件中找不到[project]表,命令uv add pip抛出了错误。- 该表对于管理项目内的依赖关系至关重要,它的缺失会中断流程。
GPU MODE ▷ #cuda (13 messages🔥):
NCU profiling for SMEM bank conflicts, CUDA headers not being automatically included, WMMA kernel throwing unspecified launch failure, TMA minimum matmul kernel, Learning CUDA with limited hardware
- NCU 揭示 SMEM 冲突检测秘籍:成员们讨论了使用 NCU profiling 来验证 kernel 中的 SMEM bank conflicts,一位成员对它的有效性表示惊讶,因为他们原以为 Nsight Compute 在误导他们。
- 对话中还涉及了一个关于 NCU profile 输出中花括号内数字含义的问题。
- CUDA 头文件捉迷藏:一位开发者报告了一个问题,即 CUDA 头文件 没有被自动包含,导致在使用 Visual Studio 2022 和最新的 CUDA toolkit 时,
cudaGraphicsGLRegisterImage和tex2d等函数未定义。- 提到包含
cuda_gl_interop.h是解决前一个问题的变通方法。
- 提到包含
- WMMA Kernel 启动受阻:一位用户在 WMMA kernel 中遇到了 unspecified launch failure 并寻求建议,同时分享了 kernel 代码。
- TMA Matmul 最小实现困境:一位成员正在使用 TMA 实现一个最小化的 matmul kernel 并面临问题。
- 有建议认为 unspecified launch failure 可能是由于超过了每个 SM 的最大寄存器限制,建议使用
cudaFuncSetAttribute来增加 SMEM 使用量。
- 有建议认为 unspecified launch failure 可能是由于超过了每个 SM 的最大寄存器限制,建议使用
- 预算有限的编码者的 CUDA 学习困惑:一位用户询问在硬件有限且仅使用免费软件的情况下,快速学习 CUDA 的最佳途径,并提到他们拥有 Arduino、STM32 和 Jetson Nano。
- 一位用户请求帮助寻找最快的学习路径。
GPU MODE ▷ #torch (16 条消息🔥):
torchrun API, HF transformers 静态缓存, HF transformers 中的 CUDA streams, 针对 PyTorch 2 的 GraphMend
- **Torchrun 故障引发安装包困境**:一位用户在调用
torchrunAPI 时遇到问题,发现torchrun --help的输出与 官方文档 不符。- 问题最终通过意识到
pyproject.toml中同时存在torch和torchrun而得到解决,并且torchrun实际上是一个独立的包(PyPI 上的 torchrun)。
- 问题最终通过意识到
- **编译冲突使 CUDA 缓存难题复杂化**:一位用户在将
torch.compile与 HF transformers 静态缓存(static cache)结合使用时遇到问题,在调用decode_one_token函数时触发了cuda streams错误。- 该错误追溯到
transformers/cache_utils.py中的一个 Bug,其中cache.offloading是一个 CUDA 设备。
- 该错误追溯到
- **GraphMend 攻克 PyTorch 中的图断裂(Graph-Break)缺陷**:一名成员分享了论文 GraphMend: Code Transformations for Fixing Graph Breaks in PyTorch 2,并附带了 项目主页 和 GitHub 仓库 的链接。
- 该论文介绍了 GraphMend,这是一种编译器,通过代码转换消除由于动态控制流和 Python I/O 函数导致的图断裂,从而消除 PyTorch 2 程序中的 FX 图断裂(Graph Breaks)。
GPU MODE ▷ #cool-links (12 条消息🔥):
CUDA, Triton, PTX 内存一致性, 形式化语言, GPU 编程
- 对 GPU 的一致性进行形式化分析:一篇关于 “A Formal Analysis of the NVIDIA PTX Memory Consistency Model” 的论文讨论了如何证明像 CUDA 和 Triton 这样的语言可以在保证内存一致性的情况下以 PTX 为目标,尽管 PTX 允许数据竞态(data races)。
- 然而,该成员发现这篇论文过于偏向形式化语言和数学,难以立即投入实用。
- 复合内存模型融合异构一致性:一篇 PLDI 2023 的论文介绍了针对异构机器的 复合内存模型 (Compound Memory Models),在这种机器中,具有不同一致性模型的设备被融合在一起。
- 复合模型保留了编译器映射,允许线程遵循其原始设备内存模型的内存排序规则,并且有一个 15 分钟的演讲 非常通俗易懂。
- 发现 GPU 一致性 Bug 的统一分析方法:一篇题为 “Towards Unified Analysis of GPU Consistency” 的论文介绍了 Dat3M(一种感知内存模型的验证工具),并在原始的 PTX 和 Vulkan 一致性模型中发现了两个 Bug。
- 该成员引用道:解读这些内容仍需要大多数开发者所不具备的专业知识,且目前的工具支持尚不充分。
- 自动发现 PTX 中缺失的 Fence:一名成员强调了参考论文图 12 中展示的自动识别 PTX 中缺失 Fence 的功能。
- 随后他们建议,如果能在 NVVM IR 层而不是 PTX 层看到此类检查,那就太酷了。
- rMEM 多核 CPU 工具被证明很有用:一名成员提到 rMEM 工具(及其 GitHub 仓库)对多核 CPU 非常有用。
- 另一名成员回应称,它的运行计算成本非常高。
GPU MODE ▷ #jobs (2 条消息):
zml github
- GitHub 链接分享!:一名成员分享了 zml GitHub 仓库 的链接。
- 另一名成员表示对此很熟悉,并期待讨论其他话题。
- Snektron 预期会有不同的讨论:在分享了 zml GitHub 仓库 链接后,Snektron 表示他们原本预期会有不同的主题。
- 这表明该链接可能是在脱离语境的情况下分享的,或者 Snektron 预期会有与该仓库相关的更具体的讨论。
GPU MODE ▷ #beginner (8 messages🔥):
Inter-warp and intra-warp ops in NVIDIA GPUs, Independent thread scheduling, Multi-CTA matmul, GPGPU architecture, PMPP reading group
- NVIDIA Warp 调度特性咨询:一位成员询问了在 independent thread scheduling(独立线程调度)机制下,NVIDIA GPU 中 inter-warp(Warp 间)和 intra-warp(Warp 内)操作的行为。
- 困惑源于多 CTA 矩阵乘法(multi-CTA matmuls)等场景,在这些场景中,由于线程调度的原因,SM 在访问彼此的 smem 时无法保证完整的 Warp 执行。
- 引发对 GPGPU 架构的兴趣:一位成员表达了对 GPGPU architecture 的兴趣,特别是其在 PINNs 中的应用。
- 他们回忆起 GPU Mode 最初是作为一个 PMPP reading group(PMPP 读书小组)建立的。
- GPU Mode 的起源:一位成员询问 GPU Mode 最初是否是作为 PMPP reading group 设立的。
- 另一位成员确认了这是最初的目标,尽管随着时间的推移,小组的注意力变得有些分散。
GPU MODE ▷ #pmpp-book (1 messages):
PTX, Triton, NCCL, NCU profiling, PTX memory fencing
- PTX、Triton 和 NCCL 探索开启:一位成员开始探索 PTX、Triton 和 NCCL,深入了解在实际工作中应用这些技术的要求。
- 他们觉得 终于开始明白在实际工作中胜任这些任务需要具备什么素质了。
- NCU Profiling 和 PTX 主导行业博客:据一位成员观察,行业博客强调 NCU profiling 技能、PTX memory fencing 和 warp MMA 等主题。
- 他将其与正在阅读的书籍进行了对比,猜测 这本书提供的只是实习生级别的知识。
GPU MODE ▷ #triton-puzzles (1 messages):
puzzle difficulty
- 解题者探究过往谜题表现:一位成员询问了其他人花在之前谜题上的时间,以了解挑战的难度量级。
- 难度讨论:该成员旨在通过比较经验来评估难度水平。
GPU MODE ▷ #rocm (3 messages):
pytorch rocm, NPU, iGPU
- Framework 笔记本上的 PyTorch ROCm 困扰:一位成员询问另一位成员是否在 Framework Desktop 上成功运行了 pytorch rocm,并指出尽管配置良好且使用了 Arch,但在运行
torch.randn(1).cuda()时仍会崩溃。- 另一位成员回应称,他们在 Ubuntu 上也遇到了问题,即使完全按照教程操作也是如此,怀疑 iGPU 可能比较 特殊或奇怪。
- 焦点转向 NPU Hacking:一位成员表示他们几乎完全专注于 NPU。
- 另一位成员紧接着问了一个问题:你是如何进行 NPU 相关开发的?
GPU MODE ▷ #self-promotion (3 messages):
LLM Profit Margins, GPU Stand Design
- Embedding 为何如此廉价,Kernel 深度探究:一位成员分享了一篇 Substack 文章,通过对 Kernel 进行 profiling 和调查,以了解提供 LLM 服务的利润空间。
- 重型 GPU 支架展示:一位成员为一批旧 GPU(包括双槽型号)设计了一个重型 GPU 支架,并指出它比 Thingiverse 上现有的设计更稳固。
- 他们表示如果有人感兴趣,稍后可能会在网上分享该设计。
GPU MODE ▷ #🍿 (6 条消息):
Code generation, Two-stage approach, CWM paper citation
- Code Gen 丢失了自然语言特性:一位成员认为,代码生成利用的是原始语法(raw syntax),没有约束,这意味着你会丢失其中的自然语言组件。
- 他们建议,人类通常在编码时并不会专注于编译器所期望的底层语法,你可以训练一个模型来做到这一点。
- Code Gen 的两阶段方法?:另一位成员建议采用两阶段方法:先进行伪代码生成(pseudo-code generation),然后进行形式语法转换(formal grammar translation)。
- 他们没有考虑到增加约束后对模型性能的影响,以及由此导致的代码生成自由度(degrees of freedom)的降低。
- GPU MODE 被 CWM 论文引用!:一位成员宣布 我们被 CWM 论文引用了,并附上了引用的截图(Discord 附件链接)。
- 未提供关于引用细节的其他背景或信息。
{kind=link}
GPU MODE ▷ #thunderkittens (17 条消息🔥):
H100 matmul kernel runtime error, nvshmem usage rationale, RDMA implementation, PyTorch support for rocm symmetric memory
- H100 Matmul Kernel 出现运行时错误:一位用户报告了 H100 matmul kernel 的运行时错误,具体为在 Ubuntu 24.04、CUDA 12.8、PyTorch 2.7.0a0+nv25.03 和 TensorRT 10.9 上运行时出现 “Error in tile TMA descriptor creation: unspecified launch failure”;完整日志可见 此处。
- 关于省略 nvshmem 的争论:讨论起因于一篇博客文章中缺少 nvshmem,作者澄清该文章侧重于节点内通信(intra-node communication),而节点间通信(inter-node communication)将在即将发表的论文中涵盖。
- 一位 NVIDIA 的同事指出,他们提供了对 multinode nvlink 的支持,并很快会添加缓存功能,使得对称张量(symmetric tensors)比 TKParallelTensor 更易于使用。
- RDMA 实现引发争议:一位成员建议,实现自定义 RDMA 的理由可能源于 SHMEM 库内置的开销。
- 他们引用了 DeepEP library (github.com/deepseek-ai/DeepEP),该库修改了 nvshmem 内部机制以获得性能提升,并指出各大厂商开发自己的 GPU Direct Async 实现已成趋势。
- PyTorch 对 ROCm 对称内存的支持:一位用户询问是否有计划在 PyTorch 中添加对 ROCm 对称内存(symmetric memory)的内置支持。
- 另一位用户调侃道,他们通常会等到有人抱怨后才会优先处理。
{kind=link}
GPU MODE ▷ #submissions (24 条消息🔥):
MI300x8, amd-all2all leaderboard, amd-gemm-rs leaderboard
- MI300x8 在 amd-all2all 上的成绩提升:一位用户在
amd-all2all排行榜上使用 MI300x8 创造了 25.2 ms 的个人最佳成绩,提交 ID 为43505。 - amd-all2all 排行榜出现极速成绩:一位用户在
amd-all2all排行榜上使用 MI300x8 达到了 1510 µs,提交 ID 为43934。 - amd-gemm-rs 排行榜显示进步:一位用户向
amd-gemm-rs排行榜提交了 MI300x8 的个人最佳成绩 741 µs(提交 ID44060),随后进一步提升至 598 µs(提交 ID44069)。
GPU MODE ▷ #hardware (4 条消息):
Voltage Park H100 donation, Nebius Exclusive Sponsorship, Future Hackathon Event
- Voltage Park 提议捐赠 H100:Voltage Park 提议为即将举行的黑客松(hackathon)捐赠 H100,表达了支持该活动的兴趣。
- 一位成员感谢了 Voltage Park,但解释说 Nebius 已经签署了本次黑客松的独家赞助协议。
- Nebius 获得独家赞助权:由于与 Nebius 达成的协议,他们是当前黑客松的独家赞助商。
- 尽管如此,一位成员表示有兴趣与 Voltage Park 讨论未来活动的潜在合作,并提议通过私人语音通话来探索方案。
GPU MODE ▷ #factorio-learning-env (2 messages):
FLE Eval System Prompt, Agent0 System Prompt, PR Submission
- FLE System Prompt 到达: 一位成员通过附件提交了用于 FLE eval 的系统 Prompt:agent0_system_prompt.txt。
- 该 Prompt 旨在与 Agent0 系统配合使用。
- 待处理的 PR 提交: 一位成员提到他们将在次日提交 PR。
- 他们提到时间已经很晚了,这表明提交工作已接近完成。
GPU MODE ▷ #amd-competition (11 messages🔥):
gemm-rs optimizations, atomic operations, GPU rentals for debugging
- **Gemm-rs 优化效果难以捉摸: 一位成员测试了 **gemm-rs 优化的 三个基本变体(其中 bias 为 None),但尽管预期带有 bias 的配置会出现错误,它们的运行时间却与默认提交的版本相似。
- 发布者附带了一个 bias.txt 文件,并指出 PR 已合并,且几乎准备好发布示例。
- Atomic Add API 受到质疑: 一位成员询问是否需要类似于 HIP 的
__hip_atomic_load/store的 atomic load/store API,或者讨论是否集中在 atomic adds 上。- 另一位成员澄清说他们指的是 atomic adds,并正在寻求更聪明的方法来处理 rank 之间的堆指针(heap pointers)以减少竞争,同时被建议尽可能避免使用 atomics。
- 推荐租赁 GPU 进行调试: 一位成员询问有关租赁 GPU 用于调试目的的供应商推荐,提供的消息中没有更多上下文。
- 该建议是在解决 gemm-rs 问题和潜在优化 atomic operations 的背景下提出的。
GPU MODE ▷ #cutlass (4 messages):
TmemAllocator vs cute.arch.alloc_tmem, TMEM load/stores in cutedsl, SMEM -> TMEM copy, TMEM -> SMEM copy, Blackwell dense blockscaled GEMM example
- **TmemAllocator 简化了 cute.arch.alloc_tmem**:
TmemAllocator提供了围绕cute.arch.alloc_tmem构建的实用程序,后者更为底层,前者有助于减少样板代码(boilerplate code)。- 讨论源于用户询问创建
TmemAllocator实例并从中进行分配,与直接使用cute.arch.alloc_tmem之间的区别。
- 讨论源于用户询问创建
- **SMEM 到 TMEM 的分块拷贝 (Tiled Copy): 要将 **SMEM 拷贝到 TMEM,请使用
cutlass.cute.nvgpu.tcgen05.make_s2t_copy(copy_atom, tmem_tensor)接着调用cute.copy(),这在 Blackwell dense blockscaled GEMM 示例 中有所展示。 - **TMEM 到 SMEM 的拷贝操作: 对于将 **TMEM 拷贝到 SMEM,请使用
tcgen05.make_tmem_copy(...)。- 有一个辅助函数可用于确定高性能的拷贝操作,详见 blackwell_helpers.py。
GPU MODE ▷ #mojo (2 messages):
Metal GPU target, custom bitcode writer, mojo assembly
- Metal GPU 目标让 Mojo 社区感到兴奋: 一位成员对 Mojo 最近支持的 Metal GPU 目标 表示兴奋,并询问 自定义 bitcode 写入器 的代码是否可用。
- 他们指出对将某些 DSLs 针对 Metal GPU 的兴趣,并想知道现有的工作是否可以重用。
- 通过命令行标志导出 Mojo 汇编: 一位成员建议,如果有兴趣,可以通过
mojo -emit标志导出 mojo assembly。- 这提供了一种检查并可能重用生成的汇编代码的方法。
GPU MODE ▷ #low-bit-training (1 messages):
Modern QAT Papers, FP8 Training, MXFP4/NVFP4
- 启动现代 QAT 论文搜索:一名成员询问了关于 modern QAT 的论文,首先想到的是 BitNet,但指出它仅限于线性层(linears only)。
- 该成员正在考虑使用 FP8 训练结合 QAT 来实现 MXFP4/NVFP4。
- 探索用于训练的 FP8 和 MXFP4/NVFP4:用户正在研究使用 FP8 训练结合 QAT 来实现 MXFP4/NVFP4 量化的可能性。
- 原始消息指出,之前的方法(如 BitNet)局限于线性层,这表明其希望获得更广泛的适用性。
Yannick Kilcher ▷ #general (105 messages🔥🔥):
Sinusoidal Positional Embeddings, Sine vs Cosine in Positional Encodings, Distillation performance estimates
- 正弦嵌入:Sine vs Cosine 之争:成员们讨论了在正弦位置嵌入中同时使用 sine 和 cosine 的必要性,有人建议仅使用 sine 可能就足够了,引发了围绕 Fourier transforms 和线性变换的讨论。链接了一个 towardsdatascience 博客文章 以提供讨论背景。
- 一名成员展示了一个测试点最大误差的实验,结果显示 最大误差约为 6e-12。
- 仅使用 Sine 的位置编码:孤军奋战?:成员们讨论了如果位置范围是非负的,仅使用 sine 进行位置编码可能是可行的,因为它可以线性转换为 sine + cosine,但在处理负值时会变得有问题,可能需要额外的层来获得更好的表示。GPT-5 编码实验表明,在线性回归中,在区间 [0, a] 内,仅靠 sine 就能很好地逼近 sine + cosine 嵌入。
- 一名成员分享了一张图片,显示:“如果我仅使用 sin 创建 PE,然后运行两对之间的余弦相似度,得分是不同的;但如果我使用 sin 和 cos 对执行相同操作,那么无论位置如何,只要它们之间的距离相同,得分就是相同的。”
- 论文阅读推荐:一名成员推荐了一篇论文阅读:Synthesizing Programs for Images and Videos with Nearest Neighbor Examples。
- 估算蒸馏改进:一名成员询问如何在投入精力之前估算 distillation 的预期改进,寻求预测性能增益的方法。
Yannick Kilcher ▷ #paper-discussion (5 messages):
Applied math, arxiv paper, preprint paper
- Arxiv 论文速览:一名成员分享了一篇 Arxiv Paper 进行讨论。
- 为了改善布局,他们还分享了同一篇 preprint 的链接。
- 计算机科学背景浮现:一名成员询问另一名成员是否有应用数学背景。
- 另一名成员回答说,他们的本科和硕士背景都是 Computer Science。
Yannick Kilcher ▷ #ml-news (6 messages):
SWE-bench verified, AlphaEvolve, Sakana AI, Yann LeCun, RL TTS
- SWE-bench Verified 遭到谴责:一名用户链接到一条推文,Alexandr Wang 在推文中表示,现在还在使用 SWE-bench verified 是脑损伤的一个很好的指标。
- AlphaEvolve:样本效率高?:在同一个帖子中,有人提到 AlphaEvolve 比其他模型 样本效率高得多。
- 一名用户链接到 Sakana AI Labs 作为回应。
- Yann LeCun 发布推文:一名用户链接到了 Yann LeCun 的推文。
- B200 云计算资源现身:一名成员注意到在 Prime Intellect 上可以以 $0.94 USD 的价格租用 B200。
- 讨论 RL TTS 论文:一名用户提到了一篇有趣的论文,以及通过使用涉及引导式 RL TTS 的中期训练技术可能获得的效率提升。
- 他们指出最大的增益体现在轨迹跟踪(trace tracking)基准测试上。
Latent Space ▷ #ai-general-chat (49 条消息🔥):
Chrome DevTools MCP, Cursor CPU Usage, Meta Code World Model, Windsurf tab completion, ChatGPT Pulse
- Chrome DevTools MCP 公开预览: Google 通过 这条推文 宣布了 Chrome DevTools MCP 的公开预览,这是一个新的服务器,允许 AI 编程 Agent 通过 CDP/Puppeteer 控制和检查实时 Chrome 浏览器。
- Cursor 的 CPU 占用引起用户担忧: 成员们报告了 Cursor 极高的 CPU 占用,但不确定这是 VSCode/插件的问题,另一位成员确认他们并非个例,并附上了显示高 CPU 占用的截图。
- Meta 发布 Code World Model: Meta 在 这条推文 中宣布了他们的 Code World Model。
- Windsurf 优先考虑 Tab 补全: Windsurf 正将 Tab 补全作为优先级,结合使用上下文工程 (context engineering) 工作和自定义模型训练,作为收购 conew senpaipoast 前重大评估的一部分,Karpathy 也对 Windsurf 发表了评论。
- OpenAI 发布 ChatGPT Pulse,笑死 (LMAO): OpenAI 发布了 ChatGPT Pulse,导致成员们评论说 OAI 克隆了 huxe 并 链接到了发布公告。
Latent Space ▷ #genmedia-creative-ai (1 条消息):
swyxio: https://x.com/1littlecoder/status/1970624850386661766
Eleuther ▷ #general (11 条消息🔥):
AI Psychology Project, Positional Embeddings, AI Future Predictions, Subtle Psychological Manipulation
- AI 心理学项目获得音乐开场: 一位成员展示了一个 AI 与心理学 交叉领域的新项目,分享了基于最近撰写的一篇论文的 音乐介绍。
- 另一位成员回应称,这项研究可能会发展成为一个解释 Prompt 语言如何影响模型行为的框架。
- Prompt 语言与人格特质挂钩?: 一位成员建议在中心化 Prompt 中植入既定的 人格特质 语言线索,并解释其对模型性能的影响,引用了关于 将语言使用模式与人格特质联系起来 的研究。
- 他们指出,这有助于评估 人格塑造 (personality shaping) 在多大程度上可以保持“微妙”的同时仍能对模型行为产生实质性影响,从而进一步指导 Prompt Engineering 实践。
- 位置嵌入 (Positional Embeddings) 解码: 一位成员询问 Transformer 中的 Positional Embeddings 是否因为波函数是周期性的,而使用正弦和余弦对矩阵而不是单对。
- 另一位成员通过解释在较小上下文中 小时数 就足够了,但在更大上下文中,还需要 天、月或年数 来避免歧义,从而确认了这一直觉。
- AI 的未来将趋于沉淀: 一位成员询问关于未来 5 年 AI 发展前景的看法。
- 他们认为 开源模型、AI Agent、小语言模型 (SLM)、AI 安全和多模态 (multi-modal) 将在未来几年开始沉淀 (sediment),这促使其他人询问如何定义 沉淀(即成熟)。
Eleuther ▷ #research (20 messages🔥):
CFG on Style Transfer, Knowledge Graph Completion, Evolutionary Algorithms for Kids, Super-Bias: Mask-Aware Nonlinear Combiner, LoRAs and Super Bias Combiner
- 急需 CFG 在风格迁移上的研究!: 一位成员询问了关于上下文无关文法 (CFG) 对风格迁移影响的研究,并指出有轶事证据表明缺乏 CFG 的模型表现较差。
- 另一位成员认为风格迁移和弥补知识差距是不同的行为,因此擅长其中之一并不保证在另一个上也成功;这一观点被另一位成员反驳,并链接了一个相关的 Twitter 线程。
- 知识图谱补全作为 LLM 解决方案?: 一位成员建议从知识图谱补全 (Knowledge Graph Completion) 的角度制定解决方案,其中风格迁移变成了一种“浅层”推理。
- 他们提出,复杂性可以通过与既定信息的关联深度来衡量,但将其桥接到实际的 LLM 具有挑战性。
- GPT-5 可指导进化算法研究: 一位成员寻求关于“适合孩子的进化算法”论文/博客的推荐,或者是关于常见模式/技术的综述论文。
- 另一位成员建议从 GPT-5 学习基础知识,并专注于 Agentic/LLM 部分而非经典论文,推荐将 AlphaEvolve 论文作为起点。
- Super-Bias:掩码感知的非线性组合器: 一位成员介绍了 Super-Bias,这是一种用于集成学习的掩码感知非线性组合器,允许仅通过组合器重训练来添加/删除专家模型,以显著降低的成本实现与全量重训练相似的准确度。
- 该方法在专家输出和二进制掩码(带有 dropout)上训练一个小型 MLP,并有可能达到与“正规”全量微调或硬合并相同(或更好)的性能。
- 通过 Super Bias 组合 LoRAs —— 天才之举!: 一位成员建议将不同的 LoRAs(或 LoRA+base 组合)视为“专家”,并使用 Super Bias 作为组合器。
- 这种方法将允许在不重新训练基础模型的情况下换入/换出 LoRAs,并且只需在几秒钟内重新训练组合器即可适应新的 LoRAs。
Eleuther ▷ #lm-thunderdome (7 messages):
GSM8k evaluation results, flexible vs strict matching, merged models issue, reproducibility of errors
- GSM8k 评估:灵活过滤器失效: 一位成员分享了 GSM8k 评估结果,显示 flexible-extract 过滤器的表现优于 strict-match 过滤器,exact_match 分数分别为 0.3594 和 0.5742。
- 另一位成员确认遇到了这个问题,特别是在合并模型(merged models)中。
- 调试合并模型故障: 一位成员请求样本以调试问题,原报告者遗憾表示没有保存有问题的示例来重现错误。
- 他们承诺会弄清楚导致错误的具体情况以便重现。
Eleuther ▷ #multimodal-general (1 messages):
VLM, Mech Interp, Sparse Autoencoder (SAE)
- VLM 与 Mech Interp 结合!: 一位成员提议在将 Mechanistic Interpretability (Mech Interp) 组件集成到 Vision Language Models (VLMs) 之前,先分别理解它们。
- 该建议涉及在 VLM 的每一层应用稀疏自编码器 (SAE) 来分析层注意力。
- SAE 在 VLM 中的应用: 想法是在 Vision Language Model 的每一层应用 Sparse Autoencoders (SAEs),以破译每一层关注的内容。
- 这种方法从简单开始,然后逐渐增加复杂性。
Nous Research AI ▷ #general (26 messages🔥):
Meta code generation with world models, Training AI with arXiv data, Granite 4 model, RMS_NORM and NORM implementations
- Meta 打造代码编写 CWM:Meta 推出了 CWM,这是一个用于研究基于世界模型的代码生成的开源权重 LLM。
- 一位成员提到曾有类似的想法,涉及在 Python 解释器追踪(traces)上进行训练。
- Nous 利用 arXiv 获取训练数据:讨论了 Nous 是否可以使用来自 arXiv 的数据来训练其 AI,并提到他们有 API 可以下载任意数量的论文。
- Teknium 确认这是允许的,并表示这可能是一个可行的选择。
- Granite 4 模型酝酿全注意力机制:可能会推出 全注意力(full attention)Granite 4 模型 以及 8 个私有模型。
- 图中提到的模型已经相当老旧,Hermes 4 和 3 是最新的版本。
- RMS_NORM 在 METAL 中获得统一和支持:提交了一个 pull request,旨在 统一 RMS_NORM 和 NORM 的实现,并扩展对更多形状的支持,应用于 METAL。
- 预计这将有助于量化模型与其基于 Transformer 的对应模型更紧密地协作。
Nous Research AI ▷ #research-papers (3 messages):
AlphaXiv, Paper frustrations
- AlphaXiv 前来救场:一位成员分享了来自 AlphaXiv 的论文链接,似乎绕过了登录墙。
- 分享对登录墙的挫败感:一位成员对需要登录才能查看的论文表示沮丧,拒绝仅为了查看论文链接而登录。
Nous Research AI ▷ #interesting-links (3 messages):
Manifest AI, Open Source Integration
- Manifest AI 热度检查:一位成员分享了 Manifest AI 的链接,并询问 它真的像宣传的那样具有突破性吗?
- 另一位成员建议查看他们在 GitHub 上的开源集成,并表示 这是一个模型关于与其 GitHub 上的 OSS 集成的评价。
- 模型对开源集成的看法:一个模型对 Manifest AI 与其开源组件的集成表达了正面评价,引发了社区的兴趣。
- 讨论强调了评估实际实现和能力的重要性,而不仅仅是依赖营销辞令。
Nous Research AI ▷ #research-papers (3 messages):
AlphaXiv, Paper accessibility
- AlphaXiv 解决了问题:针对另一位成员的普遍抱怨,一位成员分享了 AlphaXiv 的链接,该服务提供了论文访问权限。
- 尽管只是表达一般的挫败感,但那位抱怨的成员对节省了网页搜索时间表示感谢。
- 登录墙令用户沮丧:一位成员对需要登录才能查看的论文表示不满,这构成了访问障碍。
- 这突显了研究人员在试图快速评估论文相关性时面临的常见问题。
DSPy ▷ #general (19 messages🔥):
使用 LLM 进行 PDF 处理,OCR 与 VLM 在布局理解上的对比,用于 OCR 的 Qwen,用于 PDF/图像理解的 Gemini 2.5 Pro,用于 PDF 处理的 DSPy 和 Attachments
- **LLM 对 PDF 进行逐字提取**:一位用户质疑在处理 PDF 时,是否有必要先进行一次 LLM 处理以在保留布局的同时逐字保存文本(即使使用了 Attachments),并认为这可能比单纯的 OCR 更好地理解布局和图像。
- 其他人建议直接使用 PDF OCR 配合 Chain of Thought (CoT) 以获得更干净的输出,或者使用带有 DSPy 的模型(如 Qwen)进行 OCR,但也承认由于布局复杂性,确实需要 VLM。
- **Gemini 2.5 Pro 理解布局:Gemini 2.5 Flash** 在理解布局方面表现相当不错;Pro 版本在识别章节/列和进行逐字提取方面可能更胜一筹,尽管用户的 PDF 存在扁平化图像和模糊文本等棘手的格式问题。
- 一位用户指出了一篇关于直接使用 Gemini 实现此目的的论文,链接为 arxiv.org/abs/2509.17567。
- **结合 Attachments 的 DSPy 处理 PDF**:一位在 PDF 处理首阶段尝试使用 DSPy 的用户找到了一个结合 Attachments 的工作示例,链接为 github.com/maximerivest/Attachments。
- 该用户之前遇到了 429 错误,但问题已解决,使他们能够继续使用 DSPy。
- **波士顿举办 DSPy 活动:一名成员宣传了 10 月 15 日在波士顿举行的 **DSPy 活动,邀请社区成员参加并协助宣传。
- 另一位用户随后回复,希望该活动能很快来到西雅图。
DSPy ▷ #colbert (1 messages):
上下文长度限制,重复 CLS Token,性能问题
- 更长上下文失效:重复 CLS 无济于事:一位用户报告称,更长的上下文表现不佳,且重复 CLS Token 并未解决该问题。
- 用户怀疑这要么是该方法的局限性,要么是他们这边的实现错误。
- 上下文长度:讨论局限性:讨论强调了在处理模型中扩展的上下文长度时存在的局限性。
- 曾尝试将重复 CLS Token 作为一种可能的变通方案,但并未在性能上产生预期的改进。
aider (Paul Gauthier) ▷ #questions-and-tips (8 messages🔥):
Aider 上下文清除,Aider 的互联网访问,编程 LLM 基准测试,Polyglot 基准测试重跑
- **Aider 的 /clear 命令说明**:aider 中的
/clear命令仅清除聊天记录,而添加的文件仍保留在上下文中,用户可以使用/context查看 Token 使用情况。- 一位用户最初认为
/clear会移除会话中的所有上下文,但这一说明消除了他们的困惑。
- 一位用户最初认为
- **渴望 Aider 具备联网功能**:一位用户询问是否能让 aider 访问互联网搜索,但目前主分支尚不支持此功能。
- 你可以使用
/web https://www.example.com/命令来抓取网站内容。
- 你可以使用
- **LLM 编程实力:如何保持跟进:一位用户询问其他人如何获取关于哪种 **LLM 最适合编程且成本最低的最新信息。
- 共识是大多数用户通过亲自尝试这些 LLM 来保持更新。
- **Polyglot 基准测试:针对错误输出重跑:一位用户询问是否可以仅针对出现
error_outputs的测试重跑 **polyglot 基准测试。- 这一请求源于之前的运行中 LLM 服务器崩溃导致了失败。
Manus.im Discord ▷ #general (7 messages):
Manus PDF 下载问题,Beta Pro 访问权限
- Manus 在下载 PDF 时卡住?:一名成员报告称,Manus 在调研账户时卡在下载 PDF 的步骤,即使手动下载并提供链接后也是如此。
- 用户表示很沮丧,因为尽管文件已经是桌面上的 PDF,Manus 仍不断要求上传该文件。
- 询问 Beta Pro 访问权限:一名成员询问如何获得 beta pro。
- 讨论中包含了一些附件图片,但并未提供关于如何获取 Beta Pro 访问权限的具体背景信息。
MCP Contributors (Official) ▷ #general-wg (4 messages):
ModelContextProtocol issues, ReadResourceResult contents array, Web Resource html
- ModelContextProtocol 的内容数组困境:线下讨论指出 ModelContextProtocol 中的
ReadResourceResult.contents是一个数组,但其预期用途和语义尚未记录在文档中。- 产生的问题包括:该数组是用于包含多个文件的文件夹场景,还是用于以不同格式返回相同内容。
- 带有 HTML 和图像的 Web 资源:一位成员建议,该功能对于由 HTML 和相关图像组成的 Web 资源非常有用。
- 他们补充说,在尚未协商 tokenizable/renderable MIME types 的情况下,这也很管用。
- 隐式内容检索:一位成员询问
resources/read("uri": ".../index.html")是否会在内容列表中隐式返回style.css和logo.png。- 这个问题突出了在获取主要资源时自动包含相关资源的潜力。
tinygrad (George Hotz) ▷ #general (1 messages):
Python Bindings, Direct Pip Installation
- Python 绑定即将推出:一位成员正在为该项目创建 python bindings。
- 目标是允许使用单个命令通过 pip 进行直接安装。
- 直接 Pip 安装目标:目标是拥有一种 direct pip installation 方法。
- 这将允许用户通过单个命令安装该项目。
MLOps @Chipro ▷ #events (1 messages):
Diffusion Models, Generative Models, Paper Reading Group
- Diffusion Model 论文阅读小组正在组建!:一个新的 Diffusion Model Paper Reading Group 将在 本周六东部时间中午 12 点 讨论 Understanding Diffusion Models: A Unified Perspective 论文。
- 该论文概述了 VAEs、VDMs 和 SGMs 等生成式扩散模型的演变和统一。
- 初学者友好的 GenAI 讨论:该论文阅读小组对初学者友好,只需要好奇心和对 GenAI 的热爱。
- 它的目标是在不需要编程或 ML 背景的情况下建立扩散模型的坚实基础,请访问 luma.com/1gif2ym1 加入。