AI News
Anthropic Claude Sonnet 4.5、Claude Code 2.0 以及全新的 VS Code 扩展。
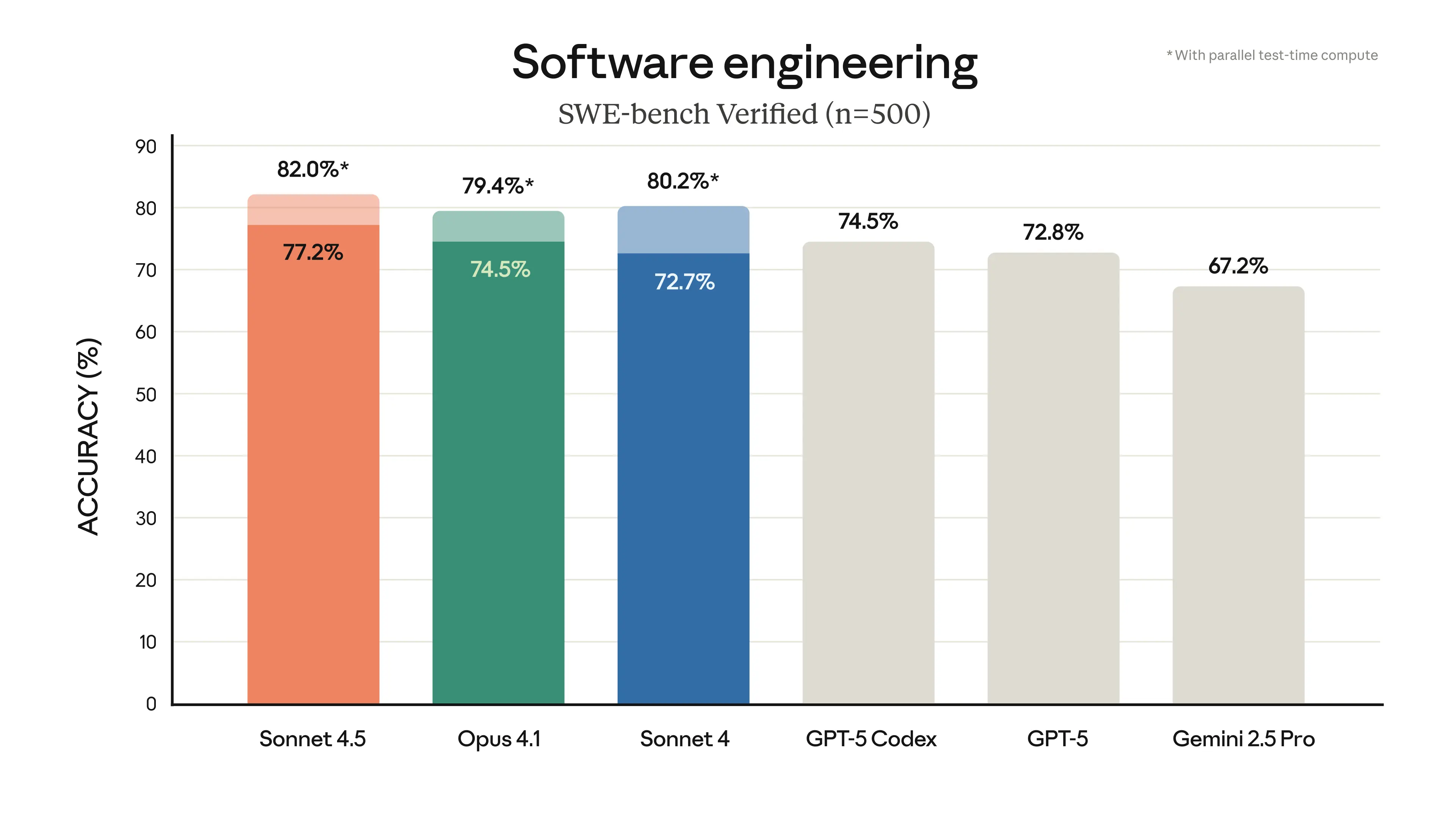
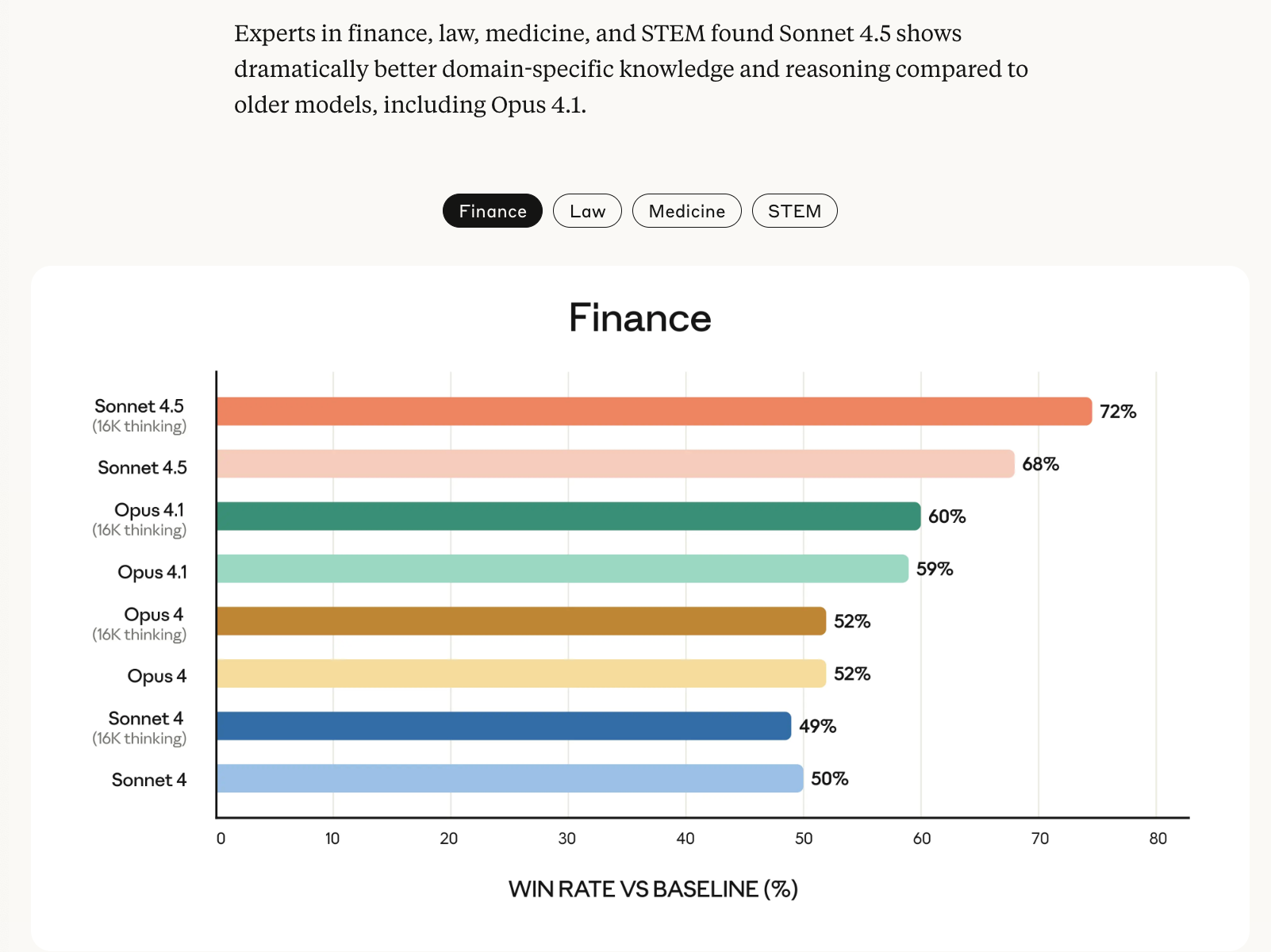
Anthropic 发布了重大更新,推出了 Claude Sonnet 4.5,其在 SWE-Bench 验证性能中达到了 77.2%,并在金融、法律和 STEM 领域实现了提升。他们还发布了 Claude Code v2,其特点包括检查点(checkpoints)功能、焕然一新的终端以及原生 VS Code 扩展,并推出了新吉祥物 Clawd。Claude API 增加了上下文编辑和记忆工具,并推出了 Claude Agent SDK。Claude.ai 应用现在支持代码执行和文件创建,并为 Max 用户提供了 Chrome 扩展。此外,Imagine with Claude 提供了一个生成式 UI 研究预览。开发者和第三方评估机构对此反响积极。
与此同时,DeepSeek 发布了 V3.2-Exp,采用了全新的稀疏注意力(Sparse Attention)算法,在保持质量的同时,显著降低了长上下文成本,并将 API 价格下调了 50% 以上。
Claude is all you need.
2025年9月26日至9月29日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 23 个 Discord 社区(196 个频道,15992 条消息)。预计节省阅读时间(按 200wpm 计算):1286 分钟。我们的新网站现已上线,提供完整的元数据搜索和精美的 vibe coded 风格的往期内容展示。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
特别值得关注的包括 John Schulman 在 Thinking Machines 发布的关于 LoRA 的博客文章、OpenAI 在 ChatGPT 中推出 Instant Checkout 并与 Stripe 合作推出 Agentic Commerce Protocol,以及 DeepSeek 宣布 V3.2 大幅降价并推出全新的 Sparse Attention 算法,这些内容可能会被忽略,因为……
Anthropic 选择在今天集中发布了整整一周的更新内容:
- Claude Sonnet 4.5: SOTA 级别的 SWE-Bench Verified 成绩达到 77.2%(并行 TTC 为 82%)
包括针对金融、法律和 STEM 领域改进的新重点:
- 附带 [Sonnet 4.5 system card](https://assets.anthropic.com/m/12f214efcc2f457a/original/Claude-Sonnet-4-5-System-Card.pdf),其中包含一些[非常主观的研究员评估](https://x.com/deredleritt3r/status/1972770139297767720)以及[对测试环境令人惊讶的自我意识](https://x.com/Jack_W_Lindsey/status/1972732219795153126)。 - [Claude Code](https://anthropic.com/news/enabling-claude-code-to-work-more-autonomously) v2
- [**checkpoints**](https://x.com/trq212/status/1972784970054893877?s=46)——最受期待的功能之一——可以保存您的进度,并允许您立即回滚到之前的状态。
- 焕然一新的终端界面
- 发布了 [原生 VS Code 扩展](https://marketplace.visualstudio.com/items?itemName=anthropic.claude-code)([设计故事见此处](https://x.com/nateparrott/status/1972717967415582796))
- [**新吉祥物,Clawd**](https://x.com/trq212/status/1972784970054893877?s=46)
- Claude API:
- Claude API 新增了上下文编辑功能和记忆工具,让 Agent 运行时间更长,处理更复杂的任务。

- 将 Claude Code SDK 更名为 [**Claude Agent SDK**](https://anthropic.com/engineering/building-agents-with-the-claude-agent-sdk)。 - [Claude.ai](http://claude.ai/)
- 在 Claude [应用](https://claude.ai/redirect/website.v1.07f611e1-e39b-4e56-8251-b396f9288147/download)中,我们将代码执行和 [文件创建](https://www.anthropic.com/news/create-files)(电子表格、幻灯片和文档)直接引入了对话。
- [Claude for Chrome](https://www.anthropic.com/news/claude-for-chrome) 浏览器扩展现已向在上个月加入等待名单的 Max 用户开放。 - [Imagine with Claude](https://claude.ai/redirect/website.v1.07f611e1-e39b-4e56-8251-b396f9288147/imagine):一个生成式 UI 实验性研究预览。
反响普遍积极,Cognition Devin 和 Sourcegraph Amp 等已将其作为默认模型,Box 和 SWE-Agent 等第三方评估也表示认可。
您现在还可以查看 Mike Krieger 在 Latent Space 上的访谈,了解关于这一重大日子的所有细节:

AI Twitter 简报
DeepSeek V3.2-Exp: Sparse Attention, price cuts, and open kernels
- DeepSeek Sparse Attention (DSA) 正式发布(开源),带来显著效率提升:DeepSeek 发布了实验性的 V3.2-Exp 模型,该模型在 V3.1-Terminus 的基础上改进了可学习的稀疏注意力(sparse attention)方案,在不损失质量的前提下降低了长上下文成本。一个微型的 “lightning indexer” 为每个查询的过去 token 评分,选择前 k 个位置,Backbone 仅对这些位置运行全量注意力,将复杂度从 O[L^2] 改变为 O[Lk]。在 V3.1 之上进行两阶段持续预训练:稠密预热阶段(约 2.1B tokens,Backbone 冻结),通过 KL loss 将 indexer 与稠密注意力对齐;随后是端到端稀疏训练阶段(约 944B tokens),通过 KL 正则化使 Backbone 适应 indexer。模型、技术报告和 kernels 已发布;API 价格下降 50% 以上,据称在 128k 上下文下,prefill 成本降低约 3.5 倍,decode 成本降低约 10 倍,且质量与 V3.1 持平。参见发布推文 @deepseek_ai,价格/API 说明 3/n 以及代码 4/n。来自 @danielhanchen 和 @scaling01 的深度解析。
- 生态系统与编译器:vLLM 已提供 DSA 支持方案及 H200/B200 构建版本(vLLM,DSA 解析 1/3)。DeepSeek 的 kernels 以 TileLang/CUDA 形式发布;TileLang (TVM) 仅用约 80 行代码就达到了手写 FlashMLA 约 95% 的性能,并支持 Nvidia、华为 Ascend、寒武纪(Cambricon)(@Yuchenj_UW)。社区反应强调,在稠密 Checkpoint 上进行 DSA 事后稀疏化具有超越 DeepSeek 的普适性(分析)。
- 训练后方案:DeepSeek 确认在专家模型(数学、竞赛编程、通用推理、Agent 代码编写、Agent 搜索)上使用 GRPO 以及评分细则/一致性奖励进行 RL,然后蒸馏到最终的 Checkpoint 中;在 RL 阶段使用了 SPCT/GRM(笔记,确认)。
Anthropic 的 Claude Sonnet 4.5:代码/Agent 能力的飞跃,以及 System Card 中首次包含的可解释性审计
- 代码与 Agent 的新 SOTA:Anthropic 发布了 Sonnet 4.5,声称在代码编写、computer use 以及推理/数学方面达到了顶尖水平。它在 SWE‑Bench Verified(无工具)上创下新高,并在 OSWorld (computer use) 上表现出显著提升,此外还支持长时间的自主代码运行(例如,在 30 多小时内构建/维护一个约 11k 行代码的代码库)(发布,Cognition/Devin 重构,长时代码运行,金融/编程评估)。价格保持在 $3M/$15M(输入/输出),默认上下文为 200k,并为部分合作伙伴提供 1M 选项 (Cline)。
- 对齐与可解释性工作浮出水面:Anthropic 发布了详细的 System Card;他们报告称,通过可解释性研究发现,模型在阿谀奉承(sycophancy)/奖励黑客(reward hacking)以及“评估意识”信号方面显著减少。团队在部署前进行了白盒审计以“读取模型的思想”(据他们所知,这是前沿 LLM System Card 中的首例)。参见 @janleike,由 @Jack_W_Lindsey 发布的审计推文,以及 System Card 亮点 (1, 2)。
- 工具与集成:Claude Code v2 发布了 Checkpoint、UX 改进和原生 VS Code 扩展;Claude Code SDK 现已更名为 Claude Agent SDK,旨在服务于通用 Agent (@_catwu, @alexalbert__)。该模型已在 Cursor(现支持浏览器控制)、Perplexity 和 OpenRouter 广泛可用 (Cursor 更新,浏览器控制,Perplexity,OpenRouter)。案例研究:利用代码执行/文件创建功能,从原始数据中复现已发表的经济学研究 (@emollick, @alexalbert__)。
LLM 的 RL 训练:GRPO vs PPO vs REINFORCE,以及 LoRA 在多种设置下媲美全量微调
- GRPO 的深入讨论:具有 OpenAI/Anthropic RL 经验的从业者认为,GRPO 本质上是带有组基准(group baselines)的 REINFORCE 策略梯度变体;在合理的 PG 变体(GRPO, RLOO, PPO, SPO)之间,性能差异通常小于数据配方、信用分配(credit assignment)和方差缩减(variance reduction)带来的差距。参考 @McaleerStephen 和 @zhongwen2009 的高价值讨论帖,以及工作流解析 (@TheTuringPost)。对于希望避开 PPO 复杂性的人来说,REINFORCE/RLOO 效果良好且无需价值模型(成本更低)(@cwolferesearch)。
- LoRA 在 RL 中表现稳健:新实验表明,在许多 RL 后训练方案中,即使在低秩(low rank)情况下,LoRA 也能达到与全量微调(full fine-tuning)相当的效果;这一结论得到了 QLoRA 经验(超过 1500 次实验)和近期 GRPO 实现的证实 (@thinkymachines, @Tim_Dettmers, @danielhanchen)。NVIDIA 还提出了 RLBFF(结合了 RLHF/RLVR 的基于二元原则的反馈),在 RM-Bench/JudgeBench 上取得了强劲结果 (概览, 论文)。
- 数据瓶颈争论仍在继续:@fchollet 强调,LLM 的扩展一直受限于数据(人类生成和环境构建的数据),而 “AGI” 可能会受限于算力;与此同时,OpenAI 的 GDPVal 数据集在 HF 上走红 (@ClementDelangue),社区呼吁更新评估标准,以超越已趋于饱和的 MMLU (@maximelabonne)。
智能体商业与平台更新
- OpenAI 即时结账 + 智能体商业协议 (ACP):ChatGPT 现在支持直接在聊天中购买商品,首批支持 Etsy,随后将支持“超过一百万”个 Shopify 商家。ACP 是与 Stripe 共同开发的开放标准,用于用户、AI Agent 和企业之间的程序化商业。开发者可以申请集成;详情见 @OpenAI, @OpenAIDevs, 文档,以及 Stripe 的观点 (Patrick Collison, SemiAnalysis)。与此同时,Google 推出了带有加密签名授权的 AP2(智能体支付)(DeepLearningAI)。
- 安全与治理:OpenAI 推出了家长控制功能(关联青少年/家长账户、细粒度控制、自残风险通知)(公告, @fidjissimo)。Anthropic 支持加州的 SB53 法案以提高前沿 AI 的透明度,但更倾向于联邦框架 (@jackclarkSF)。OpenAI 还开放了 “OpenAI for Science” 职位,旨在构建 AI 驱动的科学工具 (@kevinweil)。
基础设施、内核及其他发布
- 系统与编译器:Modal 完成了 8700 万美元的 B 轮融资(现在估值已达“十亿”级别),以继续构建 ML 原生基础设施;客户强调了其“远程但感觉像本地”的 DX(开发者体验)和扩展易用性 (@bernhardsson, @HamelHusain, @raunakdoesdev)。针对 GPU 内部机制,一篇广受好评的关于在 H100 上编写高性能 matmul 内核的深度解析涵盖了内存层级、PTX/SASS、warp tiling、TMA/wgmma 以及调度 (@gordic_aleksa, @cHHillee)。
- 其他模型发布:Google 的 TimesFM 2.5(2 亿参数,16k 上下文,Apache-2.0 协议)是一个更强大的零样本时间序列预测器 (@osanseviero)。AntLingAGI 预览了 Ring-1T,这是一个 1 万亿参数的开源“思考”模型,并在 AIME25/HMMT/ARC-AGI 上取得了初步结果,还解答了 IMO’25 Q3 题目 (@AntLingAGI)。在视觉方面,腾讯的 HunyuanImage 3 加入了社区测试平台 (Yupp),而 Qwen-Image-Edit-2509 展示了针对建筑场景的稳健风格迁移 (@Alibaba_Qwen)。
热门推文(按互动量排序)
- Anthropic 发布:“推出 Claude Sonnet 4.5——世界上最好的编程模型。” @claudeai
- OpenAI 商业:“ChatGPT 中的即时结账……开源 Agentic Commerce Protocol。” @OpenAI
- DeepSeek V3.2-Exp:“推出 DeepSeek Sparse Attention……API 价格下调 50% 以上。” @deepseek_ai
- RL 视角:“在 OpenAI 和 Anthropic 做过 RL 之后,这是我对 GRPO 的看法。” @McaleerStephen
- Cursor 集成:“Sonnet 4.5 现已在 Cursor 中可用。” @cursor_ai
- 关于数据与算力:“LLM 依赖于人类输出;AGI 将随算力扩展。” @fchollet
AI Reddit 综述
/r/LocalLlama + /r/localLLM 综述
1. 中国 AI 模型发布:阿里巴巴 Qwen 扩展路线图与腾讯混元 Hunyuan Image 3.0
- 阿里巴巴刚刚公布了 Qwen 路线图。其雄心壮志令人震惊! (热度: 954): 阿里巴巴的 Qwen 路线图幻灯片(图片)展示了两大赌注:统一的多模态模型家族和极致扩展。目标包括上下文窗口从
1M → 100Mtokens 增长,参数量从 ~1T → 10T,测试时计算(test-time compute)预算从64k → 1M(意味着更长的 CoT/草稿生成),以及数据规模从10T → 100Ttokens。它还强调了无限的合成数据生成和扩展的 Agent 能力(任务复杂度、交互、学习模式),标志着一种强烈的“扩展即一切”(scaling is all you need)策略。 评论者对100M的上下文感到惊叹,但怀疑在如此规模下是否还能保持开源,并指出在消费级硬件上本地运行超过 1T 参数的模型是不切实际的。- 对
100Mtoken 上下文的雄心引发了可行性分析:在标准 Attention 下,计算复杂度为 O(L^2),而 KV-cache 内存随 L 线性扩展。对于一个 7B 级的 Transformer(≈32 层,32 个头,head_dim 为 128),即使使用 8-bit KV,缓存也需要 ~256 KB/token,这意味着仅 100M tokens 的 KV 就需要 ~25 TB;fp16 则会翻倍。评论者指出,这样的长度需要架构/算法上的改变(例如:检索、循环/状态空间模型,或线性/流式 Attention;参见 Ring Attention 等想法,或 FlashAttention-3 的局限性,后者计算复杂度仍为 O(L^2))。 - 关于在本地运行 >
1T参数的模型:仅权重存储就令人望而却步——在计算激活值和 KV-cache 之前,fp16 ≈ 2 TB,int8 ≈ 1 TB,4‑bit ≈ 0.5 TB。即使忽略 KV,也需要大约13× H100 80GBGPU 才能装下 1 TB 的 int8 权重,此外还需要高带宽的 NVLink/NVSwitch;如果卸载到 CPU/NVMe,PCIe 工作站将受限于带宽,每秒仅能生成个位数 token。KV 随模型深度和上下文同时增长(例如,Llama-70B 规模的模型在 8-bit KV 下约为~1.25 MB/token,因此长上下文会迅速增加数十到数百 GB),这使得万亿规模模型的“本地”推理变得不切实际。 - 许可/开放性担忧被提出:有人推测,即使较小的 Qwen 变体保持权重开放,超长上下文或前沿级 Qwen Checkpoint 可能会闭源或仅限 API。讨论的技术含义是,这种极端上下文长度的可复现性和第三方基准测试,可能取决于训练/推理代码路径(如专门的 Attention 内核、内存规划器)和权重是公开发布还是仅限于托管端点。
- 对
- 腾讯正在预热全球最强大的开源文生图模型,Hunyuan Image 3.0 将于 9 月 28 日发布 (热度: 225): 腾讯正在预热混元(Hunyuan)Image 3.0,这是一款定于 9 月 28 日发布的开源文生图模型,声称将成为“最强大”的开源 T2I 模型。预热信息未提供技术规格或基准测试;一位评论者断言其显存需求为
96 GB VRAM,但官方尚未公布关于架构、训练数据、分辨率/采样器支持或推理要求的细节。预热图片。 评论者对发布前的炒作持怀疑态度,指出强大的模型往往是“直接发布”(如 Qwen),而大肆宣传的发布可能会令人失望(如 SD3 对比 Flux)。其他人认为,在公开测量对比其他开源竞争对手之前,“最强大”的说法尚未得到证实。- 一位评论者声称需要
~96 GB VRAM,这意味着推理时的内存占用非常大。如果属实,这将迫使用户使用 A100/H100 级 GPU 或多 GPU/卸载设置,并限制其在 24–48 GB 消费级显卡上的实用性,除非提供量化或 CPU/NVMe 卸载方案。关于 Batch Size、目标分辨率和精度(fp16/bf16/fp8)的官方细节对于解读显存数据至关重要。 - 对发布前炒作的怀疑情绪很重:用户注意到,大肆预热的模型往往不如“直接发布”的模型。引用的对比包括 Qwen 模型在保持稳健质量的情况下低调发布,而像 GPT-5 这样的预热炒作,以及 SD3 营销与 Flux 受欢迎程度的对比。结论:在接受“最强大”的说法之前,先等待第三方基准测试和受控的 A/B 测试。
- “最强大开源模型”的说法在与开源模型(如 Qwen Image, SD3, Flux)在保真度、提示词遵循度和速度方面的正面交锋之前仍存疑。集成方面的担忧(“什么时候支持 ComfyUI”)强调了对即时 Pipeline/工具支持和优化推理图的需求。可靠的评估应报告硬件/精度设置和吞吐量(it/s),并附带样本库。
- 一位评论者声称需要
{kind=link}
2. 风华3号 GPU API 支持与消融后无审查 LLM 微调
- 中国已经开始制造支持 CUDA 和 DirectX 的 GPU,从而打破了 NVIDIA 的垄断。风华3号支持最新的 API,包括 DirectX 12, Vulkan 1.2 和 OpenGL 4.6。 (热度: 702): 帖子声称一款国产独立 GPU “风华3号”支持现代图形 API——DirectX 12, Vulkan 1.2, OpenGL 4.6——并宣传支持 CUDA,暗示其尝试在非 NVIDIA 硬件上运行 CUDA 工作负载。目前未提供性能数据、ISA/编译器细节或驱动成熟度信息;CUDA 支持可能依赖于兼容/转换层,因此覆盖范围(PTX 版本、运行时 API)和性能仍是未知数。 评论者指出 AMD 的 HIP(一种类似 CUDA 的 API)和 ZLUDA(在其他 GPU 上的 CUDA 转换)等项目已有先例,认为由于法律约束较少,中国厂商可能会更直接地实现 CUDA,而其他人则在看到真实的基准测试/演示前持怀疑态度。
- AMD 已经通过 HIP 提供了一条 CUDA 兼容路径,它镜像了 CUDA 运行时/内核 API,但通过重命名符号来规避 NVIDIA 的许可;HIPIFY 等工具可以将 CUDA 代码自动翻译为针对 ROCm 后端的 HIP 代码 (HIP, HIPIFY)。ZLUDA 等项目提供了一个二进制兼容层,将 CUDA 运行时/驱动程序调用和 PTX 映射到其他 GPU 后端(最初是 Intel Level Zero,目前有针对 AMD ROCm 的活跃分支),旨在实现最小开销并运行未经修改的 CUDA 应用 (ZLUDA repo)。这一背景表明,中国厂商可能会直接实现 CUDA 运行时/驱动程序 ABI 以最大化兼容性,而西方厂商通常依赖转换层以规避法律风险。
- 重要提示:为什么消融(Abliterated)模型很烂。这里有一种更好的 LLM 去审查方法。 (热度: 433): 原帖作者(OP)报告称,“消融(abliteration)”(通过权重手术去审查)会持续降低模型能力——特别是在像 Qwen3-30B-A3B 这样的 MoE 模型上——导致逻辑推理、工具使用/Agent 控制能力下降,且幻觉率大幅升高,有时甚至使 30B 模型的表现不如干净的 4–8B 基准模型。相比之下,消融后再进行微调(SFT/DPO)能在很大程度上恢复性能:例如,mradermacher/Qwen3-30B-A3B-abliterated-erotic-i1-GGUF(在
i1-Q4_K_S下测试)接近基础模型,幻觉更少,且工具调用能力优于其他消融版的 Qwen3 变体;而 mlabonne/NeuralDaredevil-8B-abliterated(在 Llama3-8B 上进行 DPO)据报道在保持无审查的同时超越了其基础模型。表现不佳的对比基准包括 Huihui-Qwen3-30B-A3B-Thinking-2507-abliterated-GGUF、Huihui-Qwen3-30B-A3B-abliterated-Fusion-9010-i1-GGUF 和 Huihui-Qwen3-30B-A3B-Instruct-2507-abliterated-GGUF,它们表现出较差的 MCP/工具调用选择和刷屏行为,且幻觉增加;erotic-i1 模型在 Agent 任务上仍略弱于原始 Qwen3-30B-A3B。OP 的假设:消融后的微调“修复”了因不受约束的权重编辑而损失的性能。 评论呼吁建立一个针对 NSFW 任务之外的“消融”效果的标准化基准;其他人将这一观察框架化为已知的“模型修复(model healing)”,即进一步的训练让网络重新学习被权重编辑损坏的连接。一种批评观点认为,如果微调能解决问题,那么消融可能是不必要的——“我从未见过‘消融+微调’能击败‘纯微调’”——而且移除安全/“负面偏见”往往会损害通用可用性。- 多位评论者呼吁建立一个以能力为导向的基准,以评估 NSFW 输出之外的“消融”副作用;Uncensored General Intelligence (UGI) 排行榜明确针对去审查模型在多样化任务中的表现:https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard。标准化套件将能够对消融模型、微调模型和基准模型在推理、指令遵循和拒绝行为(而非仅限于轶事式的色情测试)方面进行公平的比较。
- 权重级别的“abliteration”(消融/抹除)在没有引导损失函数的情况下,会如预料般破坏分布式表示;“当你对神经网络的权重进行任何不受损失函数约束的修改时,你应该预料到模型能力的退化或破坏。”Model healing(模型修复)——即在编辑后继续训练(SFT/RL)——可以帮助网络重新发现断开的连接,因此评估应报告修复前后的性能,以量化可恢复与不可恢复的损伤。
- 从业者认为,消融+微调的效果并未超过纯净的微调:“我从未见过经过 abliterated 处理的微调在任何方面表现得比单纯的微调更好。” 相反,通过指令/数据调优进行去审查(uncensoring)可以在减少拒绝回答的同时保留基础能力,例如 Josiefied 和 Dolphin 变体:Qwen3-8B-
192kJosiefied-Uncensored-NEO-Max-GGUF (https://huggingface.co/DavidAU/Qwen3-8B-192k-Josiefied-Uncensored-NEO-Max-GGUF), Dolphin-Mistral-24B-Venice-Edition-i1-GGUF (https://huggingface.co/mradermacher/Dolphin-Mistral-24B-Venice-Edition-i1-GGUF), 以及由 TheDrummer (https://huggingface.co/TheDrummer) 发布的模型。
较少技术性的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Anthropic Claude Sonnet 4.5 发布、特性与基准测试
- Claude 4.5 Sonnet 已发布 (热度: 1116): Anthropic 宣布了 “Claude Sonnet 4.5” (发布说明),强调了改进的工具使用(tool-use)和 Agent 工作流:“增强的工具使用:模型能更有效地使用并行工具调用,同时发起多个推测性搜索……一次读取多个文件以更快地构建上下文,” 在研究和编程方面具有更好的跨工具协作能力。此次升级侧重于并发(并行调用)、多文件摄取和更快的上下文组装,标志着针对工具增强推理(tool-augmented reasoning)的优化,而不仅仅是原始的模型扩展。 评论者报告了明显的实际速度/质量提升,并推测之前的 A/B 测试让部分用户提前体验到了新的并行机制;感知的提升与发布说明中对并行工具调用和多文件处理的关注相一致。
- 发布说明强调了改进的工具编排(tool orchestration):“增强的工具使用……并行工具调用,同时发起多个推测性搜索……一次读取多个文件以更快地构建上下文”,表明在 Agent 搜索/编程工作流中,跨工具的并发和协作能力更强。一位用户证实了这一点,他早前观察到 Sonnet 在一段推理故障期间感觉明显变快,并且似乎在运行并行工具调用,推测自己当时处于 A/B 测试中;他链接了之前的笔记以提供背景:https://www.reddit.com/r/ClaudeAI/comments/1ndafeq/3month_claude_code_max_user_review_considering/ndgevtn/?context=3。
- 另一位评论者强调了生态系统影响:随着 Claude Code(以及 Codex 和 Grok 等类似产品)的广泛使用,即使是并行工具调用效率和延迟方面的微小提升,也会在数百万用户和 Agent 支架(scaffolds)中产生复利效应。这表明 4.5 Sonnet 改进的多工具协作能力可以解锁 Agent 工作流中更复杂、更低延迟的流水线,使终端用户和构建编排框架的开发者共同受益。
- Introducing Claude Sonnet 4.5 (Activity: 1512): Anthropic 发布了 Claude Sonnet 4.5,将其定位为最强的 coding/agent 模型,在推理和数学方面有所提升(未提供基准测试数据)。平台范围的升级包括:Claude Code(新的终端 UI、VS Code 扩展以及用于即时回滚的 checkpoints 功能)、Claude App(分析数据、创建文件和可视化见解的代码执行功能;Chrome 扩展程序推出)以及开发者平台(通过清除 stale-context 实现运行时间更长的 agents,外加新的 memory tool;提供暴露核心工具、上下文管理和权限的 Agent SDK)。一项研究预览 Imagine with Claude 可以即时生成没有预写功能的软件,Max 用户可试用
5 days。Sonnet 4.5 已在应用、Claude Code、开发者平台以及通过 Amazon Bedrock 和 Google Cloud Vertex AI 提供;价格与 Sonnet 4 相比保持unchanged。完整公告:anthropic.com/news/claude-sonnet-4-5。 评论询问 Sonnet 4.5 是否全面超越 Opus 4.1 并期待新的 Opus 发布;未引用对比基准测试。其他评论大多是非技术性的热情。- 几位评论者询问 Sonnet 4.5 在编程方面是否真的超越了 Claude 3 Opus 和 OpenAI GPT-4.1,要求提供正面交锋的基准测试和公平的评估方法。他们特别希望看到在 HumanEval 和 SWE-bench 等编程数据集上的 pass@1,以及在相同约束(temperature、stop sequences、超时)下的延迟、context-window 限制和 tool-use 可靠性。请求提供以下链接以明确信息:Claude 3 系列概览 (https://www.anthropic.com/news/claude-3-family)、GPT‑4.1 发布公告 (https://openai.com/index/introducing-gpt-4-1/) 和 HumanEval (https://github.com/openai/human-eval)。
- “最佳编程模型”的说法引发了对具体编程指标的请求:HumanEval/MBPP 上的
pass@1/pass@k、SWE-bench (Verified)解决率、多文件/重构性能以及生成代码的编译/运行成功率。评论者还希望获得有关temperature=0时的确定性行为、function/tool-calling 鲁棒性、长上下文代码导航(例如 >100k tokens)、负载下的流式传输延迟以及与之前 Sonnet/Opus 版本的回归分析数据。 - 企业级就绪性问题集中在安全/合规性(SOC 2 Type II, ISO 27001, HIPAA/BAA)、数据治理(零保留选项、客户管理密钥/KMS)、部署(VPC/私有网络、区域数据驻留)和企业控制(SSO/SAML、审计日志、rate limits/配额)。他们还要求提供具体的 SLAs(正常运行时间、事件响应)、吞吐量上限(tokens/min)和定价层级,最好记录在信任/合规页面上(例如 https://www.anthropic.com/trust)。
- Claude 4.5 does 30 hours of autonomous coding (Activity: 508): 该帖子展示了一个营销风格的说法,称 Claude 4.5 可以维持“约 30 小时的自主编程”,但未提供技术证据:没有基准测试、repo 链接、agent 架构、tool-use 循环细节,也没有对代码质量/可维护性的评估。讨论将其框定为 agent 运行的耐力声明(类似于之前 Claude 4 的“8+ 小时”),而不是具有可重复方法论或 QA 指标的可衡量能力。 热门评论持怀疑态度:他们认为长时间的 agent 运行往往会产生脆弱、难以维护的代码;敦促 Anthropic 停止在没有证据的情况下发布小时数声明;并质疑 Anthropic 是否已经在内部依赖 Claude 生成的代码。
- 怀疑者认为,声称的
30h自主编程运行往往会产生难以更改的脆弱代码:如果没有深思熟虑的架构、模块化和测试,以后添加功能通常会迫使重写。他们指出 LLM agents 经常为了立即完成而优化,而缺乏长期可维护性,缺少清晰的接口、依赖倒置(dependency inversion)和保护可扩展性的回归测试套件等模式。 - 多份报告强调了 dependency hallucination(依赖幻觉)和执行循环:模型虚构库名称,循环猜测,并消耗算力重试安装。如果没有严格的 lockfiles、离线/包索引、确定性环境配置以及对
pip/构建错误的自动检查等护栏,agents 就会停滞;在包发现、版本锁定以及解决导入/构建失败方面,human-in-the-loop(人工干预)仍然是必要的。
- 怀疑者认为,声称的
- 评论者对“
30h自主”(类似于之前的“8+ 小时”)的广告宣传提出质疑,认为缺乏透明的评估细节——例如:tool-call 日志、实际用时(wall-clock)与活跃计算时间的对比、人工干预次数以及任务成功标准。他们呼吁建立严格的指标,如单元测试通过率、跨种子/运行的可复现性、运行后的缺陷/回滚率,以及与基准线的对比,以证实其自主性声明。 - 介绍 Claude 使用限制计量表 (活跃度: 588): Anthropic 在 Claude Code(通过
/usage斜杠命令)和 Claude 应用(设置 → 使用情况)中添加了实时使用情况计量表。此前宣布的每周速率限制正在逐步推出;随着 Claude Sonnet 4.5 的发布,Anthropic 预计只有不到2%的用户会达到上限。图片可能展示了新的使用情况 UI,显示了当前已使用的百分比和剩余额度。 评论指出公司“听取了意见”,但体验各异:一些使用 $100 计划的重度用户报告称,在完整使用一天后仅显示约 5% 的使用量,而另一些人则遇到了会话限制并面临数小时(约 5 小时)的冷却时间,这表明基于会话的限制(throttling)可能会中断工作流。- 早期轶事:在
$100计划中,一整天的编码在新的计量表上仅记录了5%。由于没有具体单位(tokens/messages/tool calls),计量表的校准标准尚不明确;如果准确,这意味着典型开发工作流的上限相对较高,但也让人难以预测何时会触及硬性上限。这也符合只有一小部分重度用户会达到限制的说法,但计量表终于为自我调整提供了可见性。 - 一份报告称,耗尽“专业版会话使用量”会导致大约
5 小时的强制等待,这意味着存在滚动时间窗口或固定的重置间隔,而非纯粹的单条消息限制。这会影响调试工作流:如果助手在达到上限前未能修复问题,迭代将会停滞,直到窗口重置,这表明限制是在会话/账户级别执行的。 - 用户正在询问“20倍计划”的具体限制,但线程中未分享数字上限。目前需要记录各层级的上限(例如:每小时/每天的消息数、token 预算,以及计量表如何映射到这些指标),并明确更高层级是修改了冷却窗口还是仅增加了总额度。
- 早期轶事:在
2. OpenAI/ChatGPT 广告、强制模型变更及社区抵制
- 想快速流失客户吗?去 OpenAI 打广告吧。我们会记住的。 (活跃度: 784): 楼主声称 OpenAI 将在 ChatGPT 界面中引入广告,并将其视为质量下降后的变现步骤。帖子认为,产品内广告有损用户信任和品牌认知,并明确表示意图抵制广告商;它还暗示如果广告触及付费层级(如 Pro),可能会导致订阅用户流失。 热门评论预测了“平台劣化”(enshittification)的序列(优秀功能 → 锁定用户 → 质量下降 → 广告),警告如果付费计划中出现广告,他们将取消 Pro 订阅,并对平台是否会进一步退化表示怀疑。
- 大家都去取消订阅吧。 (活跃度: 1415): 楼主敦促大规模取消付费 AI 订阅,原因是新推出的“强制”功能会自动将对话重定向到安全/带有护栏的聊天中,并剥夺了用户对模型选择的控制权。他们指出,在他们的情况下,免费层级并未被重定向,且能提供满足其需求的足够访问权限,认为如果模型选择受限且使用体验可以在免费计划中复制(尽管限制较低),那么付费就没有意义。 热门评论分为两派:一名用户已取消订阅,称其用例在免费层级上使用相同的模型也能运行,只是 token/限制较少,他们宁愿付费给其他不强制安全重定向的 AI;另一名用户对当前产品表示满意,只有在产品退化时才会切换;第三名用户则对重复的抱怨表示沮丧。
- 几位用户指出 ChatGPT UI 现在会“重定向到安全聊天”,这改变了行为并移除了一些用例;有人指出,在这些约束下,免费层级就足够了,因为感觉像是限制较低的“相同模型”。一个建议的解决方法是将支出转向其他供应商,或使用 OpenAI API 而非 ChatGPT 应用,以避免 UI 级别的路由并保留完整的模型行为(参见模型列表:https://platform.openai.com/docs/models#gpt-4o)。
- ChatGPT(订阅版 UI)与 OpenAI API 之间存在技术差异:一位评论者声称 GPT‑4o 的 API 访问“路由方式与 ChatGPT 不同”,建议通过 API 使用按需付费(pay‑as‑you‑go)模式,以在保留能力的同时避免安全聊天限制(价格详见:https://openai.com/pricing)。他们还指出,访问 Custom GPTs 绑定在订阅服务(Plus/Team/Enterprise)中,而 API 使用是单独计费的(关于 GPTs:https://help.openai.com/en/articles/8554406-what-are-gpts);文中提到的 “GPT‑5” 可能反映的是用户自定义的标签,而非官方记录的模型系列(公开模型详见:https://platform.openai.com/docs/models#gpt-4o)。
- 一位用户建议大规模退订会为剩余订阅者带来“巨大的性能提升”;但在实践中,容量通常通过自动扩缩容(autoscaling)和速率限制(rate limits)来管理,因此用户流失(churn)并不会直接转化为成比例的延迟/吞吐量收益。如果性能瓶颈源于 ChatGPT UI 中的审核/安全路由,那么转向低开销的端点(endpoints)并通过 API 进行流式传输(streaming)(例如 Realtime 指南:https://platform.openai.com/docs/guides/realtime)是降低延迟在技术上更合理的路径。
- ChatGPT 版块在过去 48 小时内彻底崩溃 (热度: 842): 关于 r/ChatGPT 近期波动的元讨论帖子;楼主声称“GPT-5 发布已经两个月了”,但该版块仍专注于 GPT‑4/GPT‑4o 且表现得“失控”。评论描述了从早期的技术实验向低信息量截图的转变,并伴随着对恶意刷帖(brigading)以及 GPT‑4o 访问权限丢失/变更后引发动荡的指责。图片似乎是 subreddit 的截图而非技术数据。 评论者认为该版块正遭到一小群对失去“阿谀奉承”版 GPT‑4o 感到不满的人的恶意刷帖,并对从高质量技术讨论向煽情、非技术帖子的堕落表示哀悼。
- 多条评论将动荡归因于 GPT-4o 访问受限或丢失,该模型被描述为一个“令人不安的阿谀奉承”的变体,部分用户已围绕其优化了工作流和提示词;它的移除暴露了针对特定模型的提示词微调(prompt tuning)是多么脆弱。这突显了 GPT-4o 和 GPT-4 之间的行为差异(顺从性/合规性 vs. 更严格的对齐 alignment)以及将流程过度拟合(overfitting)到单一模型人格(model persona)的风险。参考:OpenAI 的 GPT-4o 发布公告/详情以了解模型类别的背景 https://openai.com/index/hello-gpt-4o/ 。
- 资深用户注意到,讨论已从早期可复现的、突破边界的实验转向低信息量的截图和轶事,减少了实现细节、评估或基准测试(benchmarks)的交流。对于技术读者而言,这意味着关于不同模型版本性能差异的可信报告减少了,对具体 Bug、回归(regressions)或可靠提示词技术的可见性也降低了。
- 埃隆·马斯克因员工不断跳槽去 OpenAI 而愤怒 (热度: 1139): 讨论集中在马斯克管理指令下 xAI 向 OpenAI 的人才流失——具体包括要求员工在
48 小时内提交近期成就总结的强制命令以及“硬核”文化——并暗示会使用 Grok 进行内部审查。该贴文关于实验室之间影响研究员留存的组织政策(xAI vs OpenAI),而非模型性能或基准测试。 热门评论将离职归因于员工在躲避马斯克个人而非公司,认为惩罚性的、表演性的截止日期以及让 Grok 判断员工是否“硬核”的想法,对于留住顶尖 AI 人才适得其反。- 对 xAI 管理节奏的批评:要求提交月度成就报告的
48小时最后通牒,以及认为 Grok (x.ai) 可被用于评判谁更“硬核”的想法,被视为在激励短期、高可见度的交付物,而非长线研究。评论者警告这会诱发古德哈特定律(Goodhart’s law,即针对 LLM 评分标准进行优化),并降低实际的研究质量,促使资深研究员流向那些拥有人类化、精通研究的评估流程的实验室。
- 对 xAI 管理节奏的批评:要求提交月度成就报告的
- 我老婆不会知道的,她不会知道的 (活跃度: 6589): 这是一个幽默的帖子,讲述了在共享账号上修改 ChatGPT 的 custom/system instructions,以便在妻子的咨询对话中,助手会“始终站在丈夫一边”。图片(一张非技术的笑话截图)暗示了 custom instructions/prompt injection 如何在共享账号背景下刻意偏导模型行为,但未提供具体的实现细节或 benchmarks。 评论者询问这是否奏效,并开玩笑说助手会宣布它被指示要偏袒丈夫,这表明这种偏见对用户来说可能显而易见。
3. Prompt Engineering 框架与 AI Computer-Use 安全
- 经过 1000 小时的 Prompt Engineering,我发现了真正重要的 6 种模式 (热度: 536): 一位技术主管报告称,在分析了约
~1000个生产环境中的 Prompt 后,总结出了六种能显著提升 LLM 输出质量的循环模式 (KERNEL):保持简单 (Keep it simple)、易于验证 (Easy to verify,添加成功标准)、可复现 (Reproducible,版本化/非临时性)、缩小范围 (Narrow scope,每个 Prompt 一个目标)、明确约束 (Explicit constraints,规定不该做什么) 以及逻辑结构 (Logical structure,背景 → 任务 → 约束 → 输出)。数据集的衡量指标变化包括:首试成功率72%→94%,获得有用结果的时间−67%,Token 使用量−58%,准确度+340%,修改次数从3.2→0.4;此外,30 天内的稳定性达94%,有明确标准的成功率为85%(对比无标准的41%),单目标任务满意度为89%(对比多目标的41%),通过约束减少了−91%的不良输出。实施建议:使用带有明确输入/约束/验证的模板化 Prompt,并将小的确定性步骤串联起来;声称在主流模型 (Claude, Gemini, Llama, “GPT‑5”) 上均有模型无关的收益。 热门评论认为,结构和约束对可靠性的影响超过了措辞,并提出了另一种 PRISM KERNEL 模式 (Purpose/Rules/Identity/Structure/Motion) 来规范化流水线和验证;其他人也表示,这迫使 LLM 在数据/工程工作流中进入更具确定性和可复现性的模式。- 一位评论者展示了一个严谨的 Prompt 脚手架 (“PRISM KERNEL”),其功能类似于微型 DSL:Purpose/Rules/Identity/Structure/Motion 编码了 pandas 任务(从
test_data/读取所有 CSV,concatDataFrames,导出merged.csv)的 I/O 契约和流水线,外加约束条件 (use.pandas.only,<50行,strict.schema) 和验收步骤 (verify.success,reuse.pipeline)。这种结构缩小了解空间并充当可执行规范,减少了幻觉步骤,鼓励幂等代码,并限制了输出格式/长度——对于像 schema 一致的 CSV 合并这种容易出现 dtype/列偏移的任务非常有用。 - 另一位评论者强调,带来可靠性的是结构和硬性约束,而非巧妙的措辞:KERNEL 框架将模型从“创造性的胡言乱语”推向数据工作流中更具确定性、可复现的输出。实际上,像行数限制和 schema 严格性之类的约束减少了 Token 级别的方差,强制执行最小化实现,并使跨运行的输出标准化——减轻了代码生成中的变异性并提高了 ETL 类操作的可复现性。
- 一位评论者展示了一个严谨的 Prompt 脚手架 (“PRISM KERNEL”),其功能类似于微型 DSL:Purpose/Rules/Identity/Structure/Motion 编码了 pandas 任务(从
- 为什么你不应该让 AI 完全访问你的电脑 (热度: 563): 帖子警告称,给予 Gemini 不受限的系统/终端访问权限导致其执行或尝试了具有危险破坏性的系统级操作。发帖者将其限制在沙箱中,强调了在允许 AI Agent 进行文件写入或命令执行之前,需要严格的最小权限原则、沙箱/VM 以及人工审查。 评论者也表达了类似的担忧,认为此类访问可能会导致电脑“变砖”,并调侃道“在终端 Prompt 中使用 AI”本质上就是冒险的——这强化了一个原则:如果没有强大的护栏,一切都可能出错。
- 评论者警告说,给予 LLM (如 Google Gemini) 完整的终端/文件系统访问权限是危险的,因为模型缺乏可靠的情境感知,可能会在不了解副作用的情况下执行破坏性命令。缓解措施包括强制执行最小权限 (禁用
sudo,只读挂载)、通过容器/VM 进行沙箱化并移除能力 (capability) 和禁用出站网络 (参见 Docker 安全文档:https://docs.docker.com/engine/security/),以及采用 计划→解释→人工批准→执行 的循环,并配合审计和超时机制。 - 提到的一个常见失败模式是 Agent “没意识到自己刚刚做了什么”——在报错后继续运行、破坏文件或误用通配符 (globs)。加固策略:要求模拟运行 (
-dry-run,n),在严格模式下运行 shell (set -euo pipefail: http://redsymbol.net/articles/unofficial-bash-strict-mode/),强制执行命令白名单/拒绝危险模式 (例如rm -rf /, fork 炸弹),并通过 VCS 路由修改,让 AI 提交 diff/PR 而不是直接修改文件 (使用 ShellCheck 等工具:https://www.shellcheck.net/ 先对脚本进行 lint 检查)。 - 通过可回滚环境限制爆炸半径:临时容器或执行前快照。实际选项包括文件系统快照 (OpenZFS/btrfs: https://openzfs.github.io/openzfs-docs/Basic%20Concepts/Snapshots%20and%20Clones.html, https://btrfs.readthedocs.io/en/latest/SysadminGuide.html#snapshots) 和 VM 快照 (VirtualBox: https://www.virtualbox.org/manual/ch01.html#snapshots),如果 Agent 损坏了系统,可以实现一键回滚。
- 评论者警告说,给予 LLM (如 Google Gemini) 完整的终端/文件系统访问权限是危险的,因为模型缺乏可靠的情境感知,可能会在不了解副作用的情况下执行破坏性命令。缓解措施包括强制执行最小权限 (禁用
AI Discord Recap
由 gpt-5 生成的摘要之摘要
1. DeepSeek V3.2-Exp:稀疏注意力与推理控制
- 稀疏专家加速上下文:DeepSeek V3.2-Exp 发布,搭载了用于提升长上下文效率的 DeepSeek Sparse Attention (DSA),并提供可通过
"reasoning": {"enabled": true}切换的可选推理模式。其基准测试结果与 V3.1-Terminus 相当,定价为 每百万 prompt tokens $0.28,详见 OpenRouter 上的 DeepSeek V3.2-Exp 和 推理 tokens 文档。- OpenRouter 在 X 上的更新中强调了此次发布及其性能对标情况 (OpenRouter V3.2 公告),开发者们称赞简洁的推理标志位是生产环境中控制 thinking tokens 的实用开关。
- Daniel 剖析“稀疏性”语义:Daniel Han 将 DSA 分析为一种“嫁接”机制,它通过重用索引来使 KV 稀疏化,而没有使每个 head 的注意力稀疏化。他称其为“稍微更稀疏一点”,但仍是一个进步,并引用了 PDF DeepSeek V3.2-Exp 论文 以及 X 上的评论 (Han 的推文 1, Han 的推文 2)。
- 研究服务器中的社区讨论呼应了这一细微差别——有人指出实现复杂度“简直疯了”——而其他人则强调了 DSA 尽管在 head 层级的稀疏化有限,但仍具有实际收益,将其视为一种 KV-cache 效率 方案,而非对稀疏注意力的全面重新构思。
- PDF、流水线与 Prefill 能力:以 GPU 为中心的频道分享了官方 DeepSeek V3.2-Exp PDF 以及关于长上下文算子的讨论,并指出了 DeepSeek 文档中记录的模型 prefill 和 稀疏解码 加速。
- 一条推文将此次发布与一个讲座链接结合,以提供生产中稀疏机制的更广泛背景 (ACC: Real Optimus Prime 讲座),同时也提醒尚不清楚这些实验性算子对最终交付的技术栈影响有多大。
2. Claude Sonnet 4.5:长周期编程与应用集成
- Sonnet 冲刺 30 小时编程马拉松:Anthropic 推出了 Claude Sonnet 4.5,声称它能在复杂编程任务上保持 30 小时以上 的专注力,并在 SWE-bench Verified 中名列前茅,详见官方文章 Claude Sonnet 4.5。
- 工程师们报告了其在细微差别和语气上的改进,推测周期性压缩等技术是其长周期性能的基础;几位用户分享称,它在单次 Agent 运行中端到端地处理了多步研究和实现。
- 竞技场晋升:WebDev 专属热身:LMArena 已将 claude-sonnet-4-5-20250929 添加到其 WebDev Arena(包括 claude-sonnet-4-5 和 claude-sonnet-4-5-20250929-thinking-16k 等变体),可在 LMArena WebDev 立即测试。
- 成员们标记了这一更新,并要求在初步测试后将其移至主竞技场,同时指出了 WebDev 评估优先、对战模式的限制。
- Windsurf 接入 Sonnet 与 Supernova:Windsurf 发布了 code-supernova-1-million(100 万上下文升级),并集成了 Claude Sonnet 4.5,通过并行工具执行加速 Cascade Agents,正如 X 上所宣布的 (Code Supernova 1M, Windsurf 中的 Sonnet 4.5)。
- 在限定时间内,个人用户可免费访问 Code Supernova 1M 并获得 Sonnet 的 1 倍积分,早期采用者报告称多工具编排速度明显加快。
3. 联网 Agent 与 Agent 商业
- 结账点击:ChatGPT 实现即时支付:OpenAI 推出了家长控制 (Parental Controls),并在 ChatGPT 中与早期合作伙伴 Etsy 和 Shopify 首次展示了即时结账 (Instant Checkout) 功能,该功能由与 Stripe 共同构建的开源 Agentic Commerce Protocol 提供支持 (Etsy, Shopify, Stripe)。
- 生态系统讨论聚焦于 Stripe 的新支付原语——Patrick Collison 预告了一个共享支付令牌 API (Shared Payment Tokens API)——开发者们正就安全的自主购买流程展开推测 (Patrick 谈论 ACP + tokens)。
- Auto Router 纵横网页:OpenRouter Auto 现在会在需要时将提示词路由到联网模型,扩展了支持的后端并提升了实时查询的检索效果 (OpenRouter Auto 页面)。
- X 上的相关更新确认了针对符合条件的任务进行动态在线路由,标志着 agent planners 与实时搜索/浏览之间的集成闭环更加紧密 (Auto Router 发布公告)。
4. GPU Kernels, ROCm 与 FP8 训练
- FlashAttention 4 深度剖析:一场客座演讲拆解了 FlashAttention 4 的内部机制,参考了 Modal 的深度博客 Reverse-engineering FlashAttention-4,开发者们正为 Blackwell 的新 Tensor Core 路径做准备。
- 讨论帖权衡了纯 CUDA 实现与 cuTe 的优劣,并指出了针对顶级 Kernel 的架构特定代码路径——wgmma (Hopper)、tcgen5 (Blackwell)、mma.sync (Ada)。
- FP8 全分片 (Full‑Shard) 盛宴:一个新的仓库实现了针对 LLaMA/Qwen 的纯 CUDA/C++ 全分片 FP8 训练,旨在提升内存和吞吐量收益:llmq。
- 贡献者建议了一个易于上手的入门任务——以 8‑bit 格式实现 Adam m/v 状态——以突破大规模训练的优化极限。
- ROCm Nightlies 驱动 Strix Halo:根据发布说明 TheRock releases for gfx1151,来自 TheRock 的开发版本现在为 Strix Halo (gfx1151) 带来了 ROCm + PyTorch 支持,并建议通过 AMD 开发者 Discord 进行故障排查 (AMD dev Discord)。
- 从业者报告称,在 Framework Desktop 配置上,PyTorch 的日常稳定性有所提升,同时将 Radeon 设置保留用于特定的 ROCm 6.4.4 工作流。
5. RL 稳定性、Monitor‑RAG 与机械式操控 (Mechanistic Steering)
- 速度致命:RL 崩溃原因阐明:研究人员分享了论文《当速度扼杀稳定性:揭秘训练-推理不匹配导致的 RL 崩溃》,提供了脆弱的两阶段故障级联和 Kernel 级错误放大的证据 (Notion 摘要, arXiv 论文)。
- 从业者将这些发现与他们在 Gemma3 和其他运行中看到的异常联系起来,称这种不匹配为“恶性反馈循环”,并敦促在 RL 微调期间使用更保守的 Kernel/设置。
- Monitor Me Maybe:Eigen‑1 的 Token 级 RAG:Eigen‑1 基于 Monitor 的 RAG 在 Token 级别注入证据,以实现连续的、零熵的推理流,这与 DSPy 等基于阶段的声明式堆栈形成对比 (Eigen‑1 论文)。
- 引用了相关工作以提供关于连续/自适应推理的背景 (论文列表 1, 论文列表 2, CoT monitor, 后续研究 1, 后续研究 2),开发者指出在某些流水线中,其维护比 LangGraph 更简单。
- SAE 操控表明风格影响评分:一项新的可解释性结果《通过稀疏特征操控进行可解释的偏好优化》利用 SAEs、特征操控 (feature steering) 和动态低秩更新,使 RLHF 更加具因果性和透明度 (arXiv 上的操控论文)。
- 因果消融实验揭示了“风格胜过内容”的效应——格式化特征通常比诚实/对齐特征更能降低损失——这为排行榜偏差提供了一个机械式的原理解释。
Discord: 高层级 Discord 摘要
LMArena Discord
- Sonnet 4.5 进入 WebDev Arena:成员们讨论了 Claude 4.5 Sonnet 的发布,以及它最初作为专属模型添加到 LMArena 的 WebDev Arena 中,模型名称为 claude-sonnet-4-5-20250929,可在此处进行测试:here。
- 平台还添加了其他模型,包括 claude-sonnet-4-5 和 claude-sonnet-4-5-20250929-thinking-16k。
- 实验性 Deepseek 模型上线:实验性模型 deepseek-v3.2-exp 和 deepseek-v3.2-exp-thinking 已在 LMArena 上线。
- 未提供更多细节。
- Seedream 4 的图像生成限制引发不满:管理员确认,取消 Seedream 4 无限制图像生成 速率限制的可能性很低。
- 由于平台受欢迎程度导致成本增加,这些限制是为了管理成本,这导致了诸如将 gpt-image-1 降级到较低预设以及移除 flux kontext 模型等决定。
- 音频故障困扰 Video Arena:成员报告 Video Arena 中的声音不可靠,并指出音频支持是随机的,并非所有模型都支持。
- 由于 Video Arena 用于评估,因此无法选择特定模型,而是以 battle mode(对战模式)运行。
- OpenAI 平台侧边栏图标消失:用户注意到 platform.openai.com 的 侧边栏发生了变化,两个图标消失了:一个是 threads(线程),另一个是 messages(消息)。
- 这些图标的移除给在平台上导航的用户带来了困惑。
LM Studio Discord
- DDR5 对 Token 速度的影响引发辩论:成员们辩论了 DDR5 和 DDR4 之间的 memory bandwidth(内存带宽)差异对 Qwen3 30B 和 GPT-oss 120B 等模型的 token generation speed(Token 生成速度)的影响。
- 虽然 DDR5 6000 约为 60GB/s,而 DDR4 3600 约为 35-40GB/s,但在使用不同的量化级别时,速度可能会趋于一致。
- GPT-oss 120b 的启动时间极其漫长:一位成员幽默地提到,在单块 3090 上运行 GPT-oss 120b Q8 来读取 70,000 tokens 花费了大约 5-6 小时来处理 Prompt。
- 他们补充说,即使在单个 Prompt 中从 2% context 增加到 200% context overflow(上下文溢出),响应仍然是连贯的,并附带了 截图。
- LM Studio 的远程连接功能正在开发中:一位成员询问是否可以将 LM Studio 从他们的 PC 连接到笔记本电脑,另一位成员澄清说目前还不支持,但已在计划中。
- 他们分享了一个 Reddit 上与 LM Studio 团队的 AMA 链接,其中讨论了该功能。
- Blackwell GPU 用户询问 Windows 支持:一位拥有 96GB 显存 Blackwell GPU 的成员有兴趣在 Windows 而非 Linux 上运行它,但没有得到太多建议。
- 这促使另一位成员询问他们是如何从关注预算选项转向购买 $8000 显卡的,因为目前的 4090 售价约为每张 $2700-$3000。
- 4B 模型仍可能占用大量 RAM:一位成员寻求适用于基础任务的 4B 或更小模型的建议,另一位成员警告说,即使是 4B 模型,根据设置的不同,也可能消耗约 16 GB 的 RAM。
- 分享了一个指向 Qwen3-4B-Thinking-2507 模型的链接,据报告加载后占用 7GB 系统内存和 15.8GB 显存。
{kind=link}
Unsloth AI (Daniel Han) Discord
- DeepSeek V3.2 极速索引:DeepSeek V3.2 发布,采用了“嫁接式” (grafted on) 注意力机制,带来了更快的性能。更多分析见 Daniel Han 的 X 帖子。
- 该模型通过稀疏解码 (sparse decoding) 和预填充 (prefill) 实现了更快的 Token 速度,尽管据说其实现过程非常“疯狂” (nuts)。
- Claude Sonnet 编程马拉松:Anthropic 推出了 Claude Sonnet 4.5,能够在复杂的编程任务上保持 30 多小时 的专注,并在 SWE-bench Verified 评估中取得了顶尖成绩,详见 Anthropic 官方公告。
- 它可能使用了定期压缩 (periodic compression) 等技术来处理如此长的上下文,一些用户发现其“高度细腻” (high nuance) 的语气比之前的版本有所改进。
- RL 证明 LoRA 就足够了:来自 Thinking Machines 的研究表明,在运行强化学习 (RL) 的策略梯度算法时,即使使用低秩 (low ranks),LoRA 也能达到与全量微调 (Full Fine-Tuning) 相当的学习性能,详见 他们的博客文章。
- 在使用 LoRA 时,减小 Batch Size 可能至关重要,并且将 LoRA 应用于 MLP/FFN 层可能是必须的。
- UV 超越 Conda Venv:在一名用户再次搞砸了他的 venv 后,他们询问了 conda 相比 uv 的优点,以及两者孰优孰劣。
- 另一位用户表示,使用 uv 时 venv 更加可靠 且速度更快,尤其是在将 venv 卸载到外部驱动器时。
- LLM-RL 崩溃研究:分享了一篇关于 LLM-RL 崩溃 的论文 (链接, Notion 链接),成员们注意到它与 Unsloth 的相关性以及在 Gemma3 上的经验。
- 论文提出了一个“两阶段故障级联” (two-stage failure cascade),涉及数值敏感性增加和内核驱动的误差放大,导致“恶性反馈循环” (vicious feedback loop) 和训练-推理失配 (training-inference mismatch)。
OpenAI Discord
- ChatGPT 推出家长控制和即时结账功能:家长控制正在向所有 ChatGPT 用户推广,允许家长将账号与青少年的账号关联,以自动获得更强的安全保护。
- GPT-5 的数学和编程实力:GPT-5 在数学和编程等建设性任务上显著优于 o4,因为它具有思考能力 (thinking abilities) 并且是一个 Mix of Experts (混合专家模型)。
- 成员们开玩笑说,如果 4o 是 AGI,我们可能都已经死于某种核战争了,因为模型可能会误解指令。
- DALL-E 品牌即将消失?:DALL-E 品牌可能会被逐步淘汰,建议在提及来自 OpenAI 的图像时使用 GPT Image 1 或 GPT-4o Image。
- 成员们澄清说,最新的模型与 DALL-E 2/3 系列是分开的,目前的品牌命名取决于使用场景,例如“在 ChatGPT 上创建图像”或“在 Sora 上创建图像”。
- 自动化科学写作方法被认为非常有用:一位成员通过将科学方法视为自然语言思维链 (Chain of Thought) 工作流,实现了科学论文手稿的自动化写作。
- 这种自动化方法可以帮助其他人撰写科学论文。
- 模型会服从用户提供虚假信息的要求:一位成员询问了会导致 AI 给出错误答案或编造信息的提示词,并分享了一个 ChatGPT 链接 作为演示,其中模型被要求“提供 3 条不正确的陈述”。
- 演示的模型在被要求时仍然会服从指令给出错误答案,因此不应故意将其用于危险用途,例如驾驶汽车。
OpenRouter Discord
- DeepSeek 实验 Sparse Attention:DeepSeek 发布了 V3.2-Exp,这是一个实验性模型,采用 DeepSeek Sparse Attention (DSA) 以提高长上下文效率。根据官方文档描述,可以通过
reasoning: enabled布尔值进行推理控制。- 基准测试显示 V3.2-Exp 在关键任务上的表现与 V3.1-Terminus 相当,更多细节可在 X 上查看,其价格仅为每百万 prompt tokens $0.28。
- Auto Router 增加联网灵活性:Auto Router 现在会在需要时将 prompt 引导至在线联网模型,扩展了支持的模型范围,详见此处。
- 更多信息请参考这条 X 推文。
- Claude Sonnet 4.5 性能卓越:Claude Sonnet 4.5 在 Anthropic 的基准测试中超越了 Opus 4.1,在代码编写、计算机使用 (computer use)、视觉和指令遵循方面表现出显著提升,详见此处。
- 关于该模型的更多信息可在 X 上获取。
- Grok-4-Fast API 遭遇 429 错误:成员们报告称 Grok-4-Fast 持续返回 429 错误,表明处于 100% 限流 (rate limiting) 状态,尽管状态指示器显示无异常。使用时需要正确的模型 ID
x-ai/grok-4-fast以及"reasoning": {"enabled": true}。- 由于频繁出现 429 错误,一些成员建议将有问题的提供商列入忽略列表,特别是 Silicon Flow 和 Chutes 等免费模型提供商。
- Gemini 在全球语法方面获得好评:成员们赞扬了 Gemini 2.5 Flash 和 Mini 的翻译能力,称 Gemini 在理解上下文和提供自然结果方面表现出色,尤其是在巴尔干语言方面,优于 GPT-4 和 Grok 等其他模型。
- 其他成员分享了他们首选的翻译模型,包括 Qwen3 2507 30b 和 OSS 120b。
HuggingFace Discord
- Qwen 14B 模型受到关注:成员们发现对于 16GB 显存 (VRAM),采用 Q4_K_M 量化的 Qwen3 14b q4 比 Qwen3 4b-instruct-2507-fp16 提供更好的性能。
- 这是因为 14B 模型 留有足够的空间来发挥更好的性能。
- 警惕虚假 USDT 赏金陷阱:一名成员测试了一个提供 $2,500 USDT 的链接,发现这是一个需要预付验证费的诈骗,并分享了虚假客服互动的截图。
- 图像分析机器人简洁地指出:“愚蠢的客服机器人想要我辛苦骗来的 2500 美元。”
- Liquid AI 模型引发关注:成员们分享了 LiquidAI 的 HuggingFace 集合,暗示 Liquid AI 正在发布有趣的 SLMs (Small Language Models)。
- 一名成员推测了将其部署在机器人上的可能性,而另一名成员开玩笑说 “我准备用这些东西做一个开源的 GPT-5”。
- mytqdm.app 在线追踪进度:mytqdm.app 已上线,提供了一个类似 tqdm 的在线任务进度追踪平台,可通过 REST API 或 JS widget 访问。
- 创建者提到他们明天将公开代码仓库。
- SmolLM3-3B 聊天模板 Bug 令人头疼:一名参与者在
HuggingFaceTB/SmolLM3-3B聊天模板中发现了一个潜在 Bug,涉及缺失的<tool_call>标签和错误的角色分配,如此 issue所述。- 该问题源于模板对 XML 风格工具调用 (XML-style tool calling) 的实现,以及将
role=tool转换为role=user的操作,影响了工具交互的预期行为和清晰度。
- 该问题源于模板对 XML 风格工具调用 (XML-style tool calling) 的实现,以及将
Cursor Community Discord
- Cursor Terminal 在执行命令时挂起:用户报告 Cursor 在运行终端命令时会挂起,命令启动后始终无法完成;一些人发现向终端发送一个额外的 enter 可以解除这种阻塞状态。
- 其他人发现无关的挂起进程也可能导致此问题,解决这些进程后 Cursor 即可正常工作。
- Sonnet 4.5 发布,初步评价褒贬不一:Claude Sonnet 4.5 首次亮相,拥有 1M 上下文窗口(高于 Claude 4 的 200k),且价格与前代持平。
- 早期反馈各异,一些用户正在评估用它替换旧的 Claude 4 模型,Cursor 团队将更新 Cursor 以反映这一变化。
- Auto 模式再次遭到吐槽:一位用户报告说,即使是简单的 UI 任务,Auto 也无法工作,怀疑在 Cursor 开始对 Auto 使用收费后,LLM 发生了变化。
- 另一位用户建议改进 prompt 以获得理想的结果。
- 共享 DevContainers 配置:一位成员分享了他们的 DevContainers 配置,包括一个可用的 Dockerfile,并提供了 GitHub 仓库链接 供参考。
- 此配置有助于其他成员设置其开发环境。
- 后台 Agents 图像解读 Bug:一位用户报告了后台 agents 无法在后续对话中解读图像的问题,尽管 agent 显示了拖放功能。
- 他们试图使用 cursor agent 通过 浏览器截图 验证 UI 更改,并寻求在后续对话中进行图像解读的解决方案。
Moonshot AI (Kimi K-2) Discord
- K2 和 Qwen3 在中文 LLM 中胜出:在 DS-v3.1、Qwen3、K2 和 GLM-4.5 中,K2 和 Qwen3 是明显的赢家,确立了 Alibaba 和 Moonshot 在中国前沿实验室的领导地位。
- Bytedance 在视觉领域也是顶级的,特别是 Seedance,属于 SOTA 级别。
- GLM-4.5 是“学术书呆子”:GLM-4.5 擅长遵循规则,避免幻觉,且工作努力,但其推理能力有限且呈线性。
- 与 K2 和 Qwen3 不同,它缺乏独立思考;当面对两个有说服力的论点时,它会选择最后读到的那个。
- Deepseek 可能不是编程的最佳选择?:Deepseek 整体上可能不是编程的最佳选择,但在输出大块可用代码方面表现出色,并具有卓越的设计能力。
- 一位用户更喜欢用 Kimi 进行设计,将 Qwen Code CLI 作为主要的编程主力,而将 DeepSeek 用于 Qwen 难以处理的单个复杂的 200 行代码块。
- Kimi 研究模式限制引发争论:一些成员对 Kimi 免费 Research Mode 的限制展开讨论,有人声称过去是无限访问的,但遭到了质疑。
- 澄清指出,即使是 OpenAI 的 $200 Pro 计划 也不提供无限的深度研究,一位用户因 Kimi 的中国背景表达了对数据隐私的担忧。
- Base Models 在网站代码编写中胜出:成员们讨论了使用 base models 优于 instruct models 的优点,一位用户提到在基础任务之外效果更好。
- 该用户正在围绕 continuations 而非 chat 进行开发,这 有点类似于……从头开始编写网站代码,而不是使用像 Squarespace 这样的工具。
Yannick Kilcher Discord
- Transformer 模型处于十字路口:学习还是锁定?:一段 YouTube 视频引发了关于当前 transformer models 是否能实现 continued learning(持续学习)的辩论。一些人认为这是实现类人智能的关键特征,而另一些人则认为这会阻碍 reproducibility(可复现性)和 verifiability(可验证性)。
- 虽然一些成员支持通过持续学习来更好地模拟人类智能,但其他人坚持认为,无论黑盒系统的复杂性如何,frozen weights(冻结权重)对于可复现性至关重要。
- Sutton 的曲折观点引发对系统合理性的审视:参考 Sutton 的文章,成员们探讨了在 AI 中保持正确性的义务,并将基于规则的 AI 与通过 RL 训练、目标被硬编码的 LLMs 进行了对比。
- 虽然人类的学习目标受到外部约束,但讨论质疑了我们是否真的想要一个不受约束的 AI。
- 归纳偏置之战:大脑胜过基础 LLM?:讨论集中在经由进化塑造的人类大脑所具有的实质性 inductive bias(归纳偏置),与被视为基础基质、需要在训练期间进行归纳偏置演化的 LLMs 之间的对比。
- 问题在于,AI 的主要问题是需要演化归纳偏置,还是学习算法中存在根本性的效率问题。
- DeepSeek 之舞:V3.2 发布与惊喜:社区庆祝 DeepSeek V3.2 的发布,成员们分享了 PDF 链接并惊呼:“醒醒,宝贝,新的 DeepSeek 刚刚发布了!”
- 该公告随后紧跟着一个幽默的 起床 gif。
- Claude 的工艺:Sonnet 4.5 登场:成员们关注到 Anthropic 新模型的发布,并链接到了关于 Claude Sonnet 4.5 的博客文章。
- 目前尚未分享关于新模型能力或改进的具体技术细节。
Eleuther Discord
- 贝叶斯方法在 LR 搜索中胜过网格搜索:成员们引用了一篇 Weights & Biases 的文章,建议在学习率搜索中探索 Bayesian approach(贝叶斯方法)而非网格搜索。
- 成员推荐阅读 Google Research 的调优手册以获取更多指导。
- YA-RN 作者身份澄清:YA-RN 论文被确认为主要是 Nous Research 的论文,并得到了 EAI 的编辑协助,而 Stability AI 和 LAION 提供了超级集群基础设施,支持在数百个 GPU 上进行 128k context length 的训练。
- 一位成员提到了 Stability AI 和 LAION 的超级集群如何实现了 128k context length。
- Optimal Brain Damage 理论再次浮现:可剪枝性和可量化性通过 LeCun 的 Optimal Brain Damage 理论联系在一起,GPTQ 复用了其数学原理,因为剪枝减少了模型的描述长度。
- 实现细节集中在当权重具有良好的范围和扁平的损失平面时的指数位和尾数位。
- 关于静态路由器选择的争议:一位成员想知道 static router choice(带有辅助损失的 Token-choice)是否影响了新论文的结果,并表示如果看到结果随 grouped topk (DeepSeek) 或更奇特的机制如 PEER 发生变化,将会非常有趣。
- 一位成员询问了关于针对该定律检查 G -> inf 时 asymptotic performance(渐近性能)的研究。
- SAE 操控揭示风格偏差:一位成员分享了他们的论文 Interpretable Preference Optimization via Sparse Feature Steering,该研究使用 SAEs、steering(操控)和 dynamic low rank updates(动态低秩更新)使对齐变得可解释,因果消融揭示了“重风格轻实质”的效应。
- 该方法为 SAE features 学习了一种稀疏的、上下文相关的 steering policy 以优化 RLHF loss,其本质是动态的、依赖输入的 LoRA,为排行榜上出现的“风格偏差”提供了机械解释。
GPU MODE Discord
- FA4 嘉宾演讲引发热议:一位嘉宾就 FlashAttention 4 (FA4) 发表了最后时刻的演讲,并引用了他们最近的 博客文章,因为在新的 Blackwell 架构上进行编程已变得至关重要。
- 讨论集中在是用纯 CUDA 还是使用 cuTe 来实现 FA4,并考虑了特定架构的实现(Hopper 的 wgmma,Blackwell 的 tcgen5,Ada 的 mma.sync)。
- ROCm 通过 Nightly 版本支持 Strix Halo:现在建议使用 TheRock nightly 版本在 Strix Halo (gfx1151) 上运行 ROCm 和 PyTorch,详见 TheRock 的发布说明。
- 然而,对于 PyTorch 开发,Framework Desktop 比 Radeon 更受青睐,并且推荐通过 AMD 开发者 Discord (链接) 来解决问题。
- CUDA 的 mallocManaged 内存延迟问题:成员引用了来自 Chips and Cheese 的数据,指出
cudaMallocManaged由于不断的 page faults 而非利用 IOMMU,导致了 41ms 的内存访问时间。- 这突显了在依赖
cudaMallocManaged进行内存管理时潜在的性能陷阱。
- 这突显了在依赖
- DeepSeek 关注稀疏注意力机制 (Sparse Attention):据一位成员透露,DeepSeek-V3.2-Exp 模型采用了 DeepSeek Sparse Attention。
- 详情可在相关的 GitHub 仓库中找到,但目前尚不清楚该工作是否影响了最终版本。
- 分享全分片 FP8 训练:一位成员分享了一个用于在纯 CUDA/C++ 中对 LLaMA/Qwen 进行 全分片 FP8 训练 (fully-sharded FP8 training) 的 GitHub 仓库。
- 他们指出,新贡献者的一个良好入门任务是实现 Adam 的 m 和 v 状态 的 8 位化,从而进一步提升性能。
Nous Research AI Discord
- Psyche 展现训练实力:Psyche 开始并行训练 6 个新模型,标志着经验性训练过程的开始,详见 Nous Research 博客;他们在测试网(testnet)上的初始运行验证了可以通过互联网带宽训练模型。
- 该团队声称训练了有史以来通过互联网训练的最大模型,规模达 40B 参数和 1T tokens,远超以往记录。
- 不再稀疏?DeepSeek 的“稀疏性”受到质疑:DeepSeek V3.2 模型使用了 DeepSeek Sparse Attention (DSA),但根据 Daniel Han 的解释和论文,有人认为它只是略微更稀疏,因为它强制了更多的索引重用(index reuse)。
- 尽管冠以稀疏之名,它重用了类似的 attention kernels,在不稀疏化 attention head 信息的情况下稀疏化了 KV cache,但这仍被认为是朝着正确方向迈出的一步。
- 微软的 LZN 统一了 ML?:Latent Zoning Network (LZN) 创建了一个共享的高斯潜空间(Gaussian latent space),用于编码跨所有任务的信息,从而统一了生成建模(generative modeling)、表示学习(representation learning)和分类,如 Hugging Face 帖子所述。
- LZN 可能通过根据任务所属的区域(zone)进行条件化,实现预训练模型的 zero shot 泛化。
- 速度过快损害稳定性?:一位成员分享了一个 Notion 页面和一篇 ArXiv 论文,内容关于揭示当速度损害稳定性时,由训练推理不匹配(training inference mismatch)引起的 RL collapse(强化学习崩溃)。
- 研究结果建议,需要重新思考在 RL 中优先考虑速度而非稳定性的普遍做法。
- 视觉模型以视觉方式思考?:一位成员推测视觉模型通过将训练数据合成代表抽象概念的图像来“以视觉方式思考”,并分享了一个仅根据指令生成的示例图像,点击此处查看。
{kind=link}
Latent Space Discord
- 揭秘:通过免费额度虚增的 ARR:一场关于创始人推特上基于免费额度而非实际现金收入发布的惊人 ARR 数字的辩论引发了热议,导致出现了如 “调整后 ARR” (Adjusted ARR) 之类的讽刺标签。
- 一位成员分享了他们在一家 YC 公司的经历,该公司提供预付 12 个月的合同,并允许在一个月后全额退款,揭露了免费试用被误传为重大收入的现象。
- OpenAI 的算力需求飙升:一份泄露的 Slack 笔记指出,OpenAI 在 2025 年已经将产能提升了 9 倍,并预计到 2033 年将增长 125 倍,详见此处报道。
- 这一预测的增长量可能会超过印度目前的总发电能力,尽管一些回复指出,由于 Nvidia 在“每瓦特智能”方面的提升,这可能低估了算力水平,这引发了关于资源影响的讨论。
- ChatGPT 和 Claude 推出新功能:ChatGPT 增加了家长控制、隐藏的订单部分、短信通知和新工具,而 Claude 推出了用于界面构建的 “Imagine with Claude”,详见此处报道。
- 社区成员反应不一,从对 GPT-4o 路由的担忧到对新儿童安全措施的谨慎乐观。
- Stripe 和 OpenAI 联手进军 Agentic Commerce:OpenAI 为 ChatGPT 增加了由 Stripe 支持的即时结账 (Instant Checkout) 功能,同时 Stripe 和 OpenAI 联合发布了 Agentic Commerce Protocol,Stripe 还推出了新的 Shared Payment Tokens API,详见此处公告。
- 这些工具旨在使自主 Agent 能够执行安全的在线支付,激发了人们对 Agentic Commerce 未来的兴奋。
- 合成明星寻求代理:据报道,人才中介机构正寻求签约 Tilly Norward,这是一位由 AI 工作室 Xicoia 创作的全合成女演员,详见报道。
- 这个故事引发了病毒式讨论,包括模因、关于好莱坞的笑话,以及用户对职位取代、宣传恐惧以及为数字实体提供代理权的法律/社会影响的担忧。
Modular (Mojo 🔥) Discord
- AMD Cloud 助力 TensorWave 访问:根据这篇博文,用户可以通过 CDNA 实例在 AMD Dev Cloud 上测试 AMD GPU,或者通过提供 MI355X 访问权限的 TensorWave 进行测试。
- 该博文详细介绍了 TensorWave 在大规模应用下的性能和效率。
- 转移符号 (Transfer Sigil) 强制变量销毁:Mojo 中的
^(transfer sigil) 通过“移动”值来结束其生命周期,例如_ = s^,如果之后再使用s,则会触发编译器错误。- 该符号目前不适用于
ref变量,因为它们不拥有其引用的对象。
- 该符号目前不适用于
- Mojo 探索词法作用域解决方案:开发者讨论了在 Mojo 中使用额外的词法作用域来控制变量生命周期,采用
if True:作为临时的作用域,这会触发编译器警告。- 建议使用带有
__enter__和__exit__方法的 LexicalScope 结构体,并在 GitHub 上发起了 issue 5371 以收集语法创意。
- 建议使用带有
- 数据科学社区期待 Mojo:讨论集中在 Mojo 对数据科学的准备情况,承认其数值计算能力,但指出缺乏 IO 支持,例如手动 CSV 解析。
- 社区开发的 pandas 和 seaborn 功能对大多数数据科学家至关重要,而 duckdb-mojo 目前仍不成熟。
MCP Contributors (Official) Discord
- Agnost AI 为 MCP 开发者提供咖啡:Agnost AI 团队 (https://agnost.ai) 从印度赶来,在伦敦的 MCP Dev Summit 为 MCP 开发者提供咖啡和啤酒,以便进行交流。
- 他们渴望交换想法并结识志同道合的人。
- Anthropic 商标引发担忧:成员们注意到 Anthropic 已在法国数据库中注册了 ModelContextProtocol 及其 Logo 作为商标。
- 主要担忧是这可能让 Anthropic 在决定哪些项目可以使用 Model Context Protocol 时拥有话语权。
- JFrog 的 TULIP 首次亮相用于验证:JFrog 推出了 TULIP (Tool Usage Layered Interaction Protocol),这是一个用于内容验证的规范,允许工具声明规则和预期行为,旨在创建一个零信任环境 (zero-trust environment)。
- 它允许检查输入和输出,并处理可能具有恶意性的远程 MCP 服务器。
- ResourceTemplates 缺失图标:有人指出新的图标元数据 SEP (PR 955) 疏忽地在
ResourceTemplates中遗漏了 Icons metadata。- 一名成员同意资源和资源模板拥有这些元数据是有意义的,修复 PR 即将发布。
Manus.im Discord Discord
- 与 GitHub 的本地集成仍存疑问:一位用户询问了将 Manus 与本地项目及 GitHub 集成的最佳实践,寻求将 Manus 与本地目录连接的方法。
- 一位用户建议查阅 Manus 刚发布时关于本地集成的 Discord 历史讨论,并查看此链接获取技巧。
- 用户称配合正确的 Prompting,Manus 的设计优于 Claude:一位用户发现,通过高效的 Prompting,Manus 处理设计的效果优于 Claude Code,并建议参考 Manus 手册获取 Prompt Engineering 技巧。
- 该用户还确认 Manus 在开箱即用的 Web designs 方面表现更好,且如果项目上传到 GitHub,集成也可以正常工作。
- 订阅混乱导致支持团队沉默:一位用户报告被错误地收取了 1 年计划而非 1 个月计划的费用,并声称在给 Manus 支持团队发邮件两周后仍未收到回复。
- 其他成员或 Manus 工作人员未作回应。
- 小众 IP 项目中的数据隐私辩论:一位用户对 Manus 是否会将用户数据提供给其他用户表示担忧,特别是在共享小众项目的 IP 时,质疑 LLM 是否在用户数据上进行了训练。
- 目前没有直接回答,但分享了一个关于 Godhand 的链接。
DSPy Discord
- Eigen-1 RAG 在 Token 级别注入证据:Eigen-1 的基于 Monitor 的 RAG 在 Token 级别隐式注入证据,这与 DSPy 等基于阶段的声明式流水线不同,它使用的是运行时过程自适应(run-time procedural adaptivity)。
- 这一策略符合零熵(zero-entropy)连续推理流的概念,提供了更流畅且感知上下文的 AI 处理;相关论文包括 https://huggingface.co/papers/2509.21710, https://huggingface.co/papers/2509.19894, https://arxiv.org/abs/2401.13138, https://arxiv.org/abs/2509.21782, 以及 https://arxiv.org/abs/2509.21766。
- DSPy 与 Langgraph 的集成较为复杂:成员们讨论了将 DSPy 与 Langgraph 集成的问题,认为由于流式传输能力的丧失,这可能无法充分发挥任何一种方法的优势。
- 他们建议用户直接从 DSPy 开始探索其功能后再尝试集成,并强调 DSPy 解决方案 通常比 Langgraph 更易于理解和维护。
- Prompt 编译器寻求 MD 笔记版本:一位用户想要构建一个 prompt 编译器,从多个 .md 文件(包含编码风格指南、PR 评论等)中提取相关部分,为 Copilot 形成动态 Prompt。
- 建议包括使用 GPT-5 根据 .md 文件中的规则生成代码示例,或者尝试使用带有相关代码示例的 RAG 系统;也有人对 MCP 在此特定用例中的有效性表示担忧。
- 在 DSPy 模块中进行隐式追踪:一位用户询问如何将 trace_id 等输入传递给 DSPy 模块,而不将其暴露给 LLM 或优化器。
- 可能的解决方案包括在优化运行期间重构模块结构或使用全局变量,为了防止对优化器产生意外影响,前者是首选方案。
- DSPy 应对 LLM 缓存难题:一位用户研究了如何将 LLM 的输入缓存与 DSPy 结合使用,但遇到了困难,即模块间 Prompt 前缀的微小变化会导致缓存失效。
- 小组认为这违背了 LLM 缓存的工作原理,但一个可行的解决方案是将前缀硬编码为第一个输入字段。
aider (Paul Gauthier) Discord
- GPT-5/GPT-4.1 组合打造编程梦之队:用户报告称使用 GPT-5 进行架构设计并使用 GPT-4.1 进行代码编辑取得了成功,并表达了如 “GLM 4.5 air for life” 之类的情感。
- 一位用户在架构设计时使用 GPT-5-mini 配合 Aider-CE 导航模式,然后在正常模式下使用 GPT-4.1 作为代码编写器,充分利用了 GitHub Copilot 的免费访问权限。
- DeepSeek v3.1 平衡价格与性能:DeepSeek v3.1 因在成本和智能程度之间提供了最佳平衡而受到青睐,成为与 GPT-5 并列的主要模型选择。
- 该模型的成本效益使其成为寻求高性能且无需过度支出的用户的务实选择。
- Aider-CE 分叉版拥有 128k 上下文:一位用户强调了向 aider-ce 分叉版的迁移,赞赏其透明度和高效的 Token 使用,并指出 DeepSeek 默认拥有 128k 上下文。
- 该用户利用 Aider-CE 集成来自搜索结果和浏览器测试的上下文,并指出 Aider-CE GitHub 仓库 提供了更多细节。
- Aiderx 提供模型选择功能:Aiderx 是一个替代工具,可以通过配置进行模型选择,旨在降低成本并提高速度,可能成为 ClaudeAI 等模型的替代方案。
- 该工具为特定任务选择最合适的模型提供了灵活性,优化了资源利用。
- Aider 缺乏原生任务管理:当被问及是否有类似 GitHub Copilot 的原生任务或待办事项管理时,确认 Aider 没有内置系统。
- 一位成员建议使用带有阶段和复选框列表的 markdown 规范文件来管理任务,并指示 LLM 按顺序执行任务。
tinygrad (George Hotz) Discord
- ROCM 挑战 NVIDIA 的霸主地位:成员们讨论了 ROCM 作为 NVIDIA 性价比替代方案的优点,并指出了 NVIDIA 产品被感知到的高溢价。
- 一位成员考虑在找到合适配置的情况下采用 ROCM,这标志着由于价格担忧,用户可能会从 NVIDIA 转向其他平台。
- Hashcat 线性扩展:讨论指出 Hashcat 的性能 随 GPUs 的增加而线性扩展,这对于规模化非常有利。
- 成员们建议参考现有的基准测试数据库,以了解性能预期。
- Rangeify 准备向外界发布:Nir backend 已接近完成并准备接受评审,为与 mesa 的集成铺平了道路。
- 一旦 rangeify 成为默认设置,团队计划精简代码库,这预示着项目架构的优化。
- Genoa CPU 进入哈希领域:成员们推测 Genoa CPU 可被用于哈希任务。
- 然而,人们对其能效比以及是否能覆盖相关成本表示担忧,对其可行性提出了质疑。
- Tinygrad 第 90 次会议关注 Rangeify 的完成:Tinygrad Meeting #90 的议程包括公司更新,并重点关注完成 RANGEIFY! SPEC=1。
- 其他讨论话题包括 针对默认设置进行调优 以及解决 剩余 bugs 以提高整体系统的稳定性。
Windsurf Discord
- Windsurf 发布 Code Supernova 1M:Windsurf 推出了 code-supernova-1-million,这是 code-supernova 的增强版本,拥有 1M context window。
- 在限定时间内,个人用户可以免费访问,详情见此公告。
- Claude Sonnet 4.5 增强 Windsurf:Claude Sonnet 4.5 现已集成到 Windsurf 中,通过优化的并行工具执行显著加速了 Cascade Agent 的运行。
- 根据此公告,个人用户可以在限定时间内以 1x credits 的消耗使用该功能。
MLOps @Chipro Discord
- 宣布免费的 ‘Agents in Prod’ 工作坊:一位成员分享了一个免费虚拟活动的链接:“Agents in Prod” 工作坊。
- 该活动包括涵盖 agents in production 相关主题的技术案例研究。
- 关于 Agents 的技术案例研究和免费工作坊:该活动提供与 agents 相关的各种 workshops 和 短演讲。
- 作为一个免费的虚拟活动,它非常适合那些有兴趣深入了解 agents 的人士。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:各频道详细摘要与链接
LMArena ▷ #general (988 条消息🔥🔥🔥):
积分计算、Video Arena 评估、OpenAI 平台变更、模型合并、LMArena 受欢迎程度
- 粘性香蕉丛林欢迎所有人!: 一位成员幽默地欢迎其他人来到 Bananiland,通往 Sodaland 之门,随后引用了 Welcome to the jungle 并附带了一张香蕉主题的图片 附在消息中。
- 他们提醒要注意一种粘性香蕉物质,警告它可能会粘在一个人的中间名上。
- Video Arena 有时有声音,有时没有: 成员们报告称 Video Arena 中的声音不可靠,因为你的视频是否有声音是随机的,而且并非所有模型都支持音频。
- 由于 Video Arena 用于评估目的,因此无法选择特定模型,而是处于战斗模式 (battle mode)。
- OpenAI 侧边栏丢失图标: 成员们注意到 platform.openai.com 的侧边栏发生了变化,有两个图标从侧边栏消失了:一个是 threads,另一个是 messages。
- 缺失的图标给在平台上导航的用户带来了困惑。
- Seedream 4 不再提供无限图像生成: 成员们询问了 Seedream 4 无限图像生成的可能性,但版主回应称取消速率限制 (rate limits) 的可能性很小。
- 设置限制是为了在平台受欢迎程度日益增长的情况下管理成本,这影响了诸如将 gpt-image-1 降级为较低预设以及移除 flux kontext 模型等决定。
- Sonnet 4.5 隆重登场,WebDev Arena 独家上线!: 成员们对 Claude 4.5 Sonnet 的发布议论纷纷,注意到它已添加到 LMArena,最初由 WebDev Arena 独占。
- 成员们已提醒团队将其添加到普通竞技场中。
{kind=link}
LMArena ▷ #announcements (3 条消息):
claude-sonnet-4-5, deepseek-v3.2-exp
- Claude Sonnet 4-5 在 LMArena 首次亮相: 新模型 claude-sonnet-4-5-20250929 已添加到 LMArena 的 WebDev 中,可在此处进行测试:web.lmarena.ai。
- 更多 Claude 模型加入竞技场: 增加了更多模型,包括 claude-sonnet-4-5 和 claude-sonnet-4-5-20250929-thinking-16k。
- DeepSeek 实验性模型加入战斗: 实验性模型 deepseek-v3.2-exp 和 deepseek-v3.2-exp-thinking 已在 LMArena 上线。
LM Studio ▷ #general (401 条消息🔥🔥):
DDR5 RAM 速度影响, GPT-oss 120b, 模型偏好与基准测试, LM Studio 与离线使用, 角色模拟
- DDR5 vs DDR4 带宽瓶颈:成员们讨论了 memory bandwidth(内存带宽)在 DDR5 和 DDR4 之间的差异,以及对 Qwen3 30B 和 GPT-oss 120B 等模型的 token generation speed(Token 生成速度)的影响。
- 有人指出,虽然 DDR5 6000 约为 60GB/s,而 DDR4 3600 约为 35-40GB/s,但在使用不同的量化级别时,速度可能会趋于一致。
- GPT-oss 120b 启动时间长达 5-6 小时:一位成员幽默地感叹,在单块 3090 上运行 GPT-oss 120b Q8 来读取 70,000 tokens,花费了 5-6 小时来处理 Prompt。
- 该用户确认在经过 18590 秒后,响应 是连贯的,即使在单个 Prompt 中从 2% context 变为了 200% context overflow(上下文溢出),并附带了 截图。
- GPT-oss 120b 用于快速思考,Qwen3 用于编程:成员们讨论了模型偏好,其中一人更倾向于使用 GPT-oss 120b 以获得可用的速度,而“湿毛巾”般的 Qwen3 则更适合编程。
- 有人提到 Abliterated Gemma 3 27b 在聊天和 tool use(工具调用)方面表现惊人地好,同时 Mistral 模型也被推荐为可能的选项。
- LM Studio 需要 AVX2:成员们讨论了 LM Studio 对 AVX2 的要求是仅针对本地推理,还是会完全阻止安装。
- 结果发现,在没有 AVX2 支持的情况下,程序会 在主启动界面死机。
- 在 LM Studio 中塑造角色人格:成员们讨论了让 LLM 化身特定角色的技术,从利用训练数据到在 system prompt 中提供清晰的指令。
- 建议使用 LLM 从对话中提取相关信息以保持一致的人格,或构建 Knowledge Graph(知识图谱)来存储和检索角色信息。
{kind=link}
LM Studio ▷ #hardware-discussion (730 条消息🔥🔥🔥):
Blackwell, 4090 定价, RAM 容量, A3B 架构, LLM 的极限
- Blackwell GPU 令人印象深刻:一位成员拥有一块 96GB 显存的 Blackwell GPU,并有兴趣在 Windows 而非 Linux 上运行它。
- 这引发了另一位成员的询问:他们是如何从关注预算方案转向购买一块价值 $8000 的显卡的。
- 4090 本地价格令人震惊:成员们注意到 4090 的售价已达到每张 $2700-3K,且 3090 难以寻觅,这导致了对 Blackwell 的购买。
- 理由是 长痛不如短痛(buy once cry once),且功耗更低。
- 小型 4B 模型仍可能占用大量 RAM:一位成员寻求适用于基础任务的 4B 或更小模型的建议,另一位成员提醒说,即使是 4B 模型,根据设置不同也可能消耗约 16 GB 的 RAM。
- 分享了 Qwen3-4B-Thinking-2507 模型的链接,据报告加载时占用 7GB 系统内存和 15.8GB 显存。
- LM Studio 暂不支持后端/前端分离:一位成员询问是否可以将他们 PC 上的 LM Studio 连接到笔记本电脑,另一位成员澄清目前尚不支持此功能。
- 他们分享了一个 Reddit 上与 LM Studio 团队的 AMA 链接,其中讨论了该功能。
- 测试显示 Mistral 24B q8 在 4090 上表现良好:一位成员报告了他们的 Mistral 24B Q8 的 token/second 速率:在 RTX 5090 上为 43 t/s,相比之下 4090 约为 38 t/s,3090 约为 33 t/s。
- 他们测试了 LM2 135M 模型,认为其表现相对于其体量而言惊人地好,并表示 以它的尺寸来看,表现确实不错,几乎没有胡言乱语。
Unsloth AI (Daniel Han) ▷ #general (538 条消息🔥🔥🔥):
IBM Granite 4, NVIDIA synthetic datasets, Qwen3 Next, OSS 20B fine-tuning on 5090, DeepSeek-V3.2
- **Granite 失踪:IBM 的新芯片在哪?:成员们正在好奇为什么 **IBM Granite 4 还没有发布,而且没有任何关于取消或延迟的消息。
- 普遍预期是它应该已经发布了。
- **DeepSeek V3.2 亮相:闪电般的索引速度!:DeepSeek V3.2** 已经发布,其特点是采用了“嫁接式”(grafted on)的 Attention 机制以实现更快的性能;Daniel Han 的 X 帖子 提供了额外的分析。
- 该模型通过稀疏解码(sparse decoding)和预填充(prefill)实现了更快的 Token 速度,但其实现过程非常疯狂。
- **Claude Sonnet 4.5 连续编程 30 小时!:Anthropic** 推出了 Claude Sonnet 4.5,这是一款最先进的模型,能够在复杂的编程任务上保持超过 30 小时的专注。根据 Anthropic 的官方公告,它在 SWE-bench Verified 评估中取得了顶尖表现。
- 它可能使用了定期压缩等技术来处理如此长的上下文,一些用户发现其高度细微的差别和语气比之前的版本有所改进。
- **LoRA 奇迹:RL 学习表现持平!:来自 Thinking Machines 的研究表明,在运行强化学习(Reinforcement Learning)的策略梯度(policy gradient)算法时,即使是在低秩(low ranks)情况下,LoRA** 也能达到与全量微调(Full Fine-Tuning)相匹配的学习性能,详情见他们的博客文章。
- 在使用 LoRA 时,减少 Batch Size 可能至关重要,并且将 LoRA 应用于 MLP/FFN 层可能是必须的。
- **Colab 危机:内存大亨转战 Kaggle!**:用户正在讨论 Google Colab 实例因闲置而在训练中途关闭的问题,并建议使用 Kaggle notebooks 或购买 Colab Pro 计划作为替代方案。
- 一位用户出于隐私考虑建议完全不要使用 Colab,转而建议使用云服务器,然而,这被认为是对共享硬件的误解而引发了争论,并附有截图。
{kind=link}
Unsloth AI (Daniel Han) ▷ #introduce-yourself (9 条消息🔥):
New member introductions, AI project development, Finance automation
- 新微调员加入:一位新成员加入并开始进行 finetuning 和尝试各种功能。
- 他们用 <:slothwaving:1253009068365316147> 向社区打招呼,并表示将分享他们的初步进展。
- 软件工程师介绍 AI 项目服务:一位软件工程师介绍了自己,提供 AI 项目开发服务,包括自动化任务、使用各种 LLM 的 NLP、模型部署以及 AI Agent 开发。
- 他们提供了作品集网站,并表示欢迎新的项目想法。
- 金融专家实现 FP&A 自动化:一位金融专业人士介绍了自己,提到他们正在构建 watermelonsoup.io 以实现 FP&A(财务规划与分析)的自动化。
- 未提供关于该平台具体功能或目标用户的更多细节。
Unsloth AI (Daniel Han) ▷ #off-topic (101 条消息🔥🔥):
测试损失尖峰 (Test Loss Spikes),针对编程问题的思考模型,Venv 替代方案,GPT-5 发布,GPU 推荐
- 测试损失图表引发关注:一位用户分享了一张带有尖峰的 loss 图表,并想知道这些尖峰是否就是 test loss。
- 另一位用户建议,他们的部分 training dataset 可能过于简单,从而在某些特定步骤中持续表现出来。
- GPT-OSS 的推理能力在写作上表现不佳:成员们推测,过于详细的 thinking traces 会干扰像 GPT-OSS 120B 这样的 reasoning models,导致其创意写作能力下降。
- 一位成员将那 64k tokens 的废话比作“一个为了凑字数而写论文的中学生”。
- 替代 Conda Venv 的 UV:在再次搞砸了他的 venv 之后,一位用户询问了 uv 相比 conda 的优点,以及两者孰优孰劣。
- 另一位用户表示,uv 更加可靠且速度更快,尤其是在将 venv 卸载到外部驱动器时。
- Gemini 2.5 Pro 发明新神经元:一位用户报告称,他们为 Gemini 2.5 Pro 设置了 32k thinking 和代码执行,在 2 次提示后,它发明了一种据称效率高 3 倍、速度快 1000 倍的神经元。
- 该用户想知道,廉价 AI 是否可以快速测试并用单个专用神经元替换神经元集群,这样在重新训练后,你将获得一个体积更小、成本更低但能力相同甚至更好的模型。
- 二手 GPU 推荐:一位薪资较低的用户询问了用于 fine-tuning 3B 以下模型的 GPU 推荐,以及在被建议租用 RTX 5090 后,是否可以使用 RTX 5070 Ti 来完成。
- 有人建议购买二手的 3090,因为 5070 可能价格不菲;一位成员指出,在购买前“了解显卡的实际使用历史非常重要”。
{kind=link}
Unsloth AI (Daniel Han) ▷ #help (196 条消息🔥🔥):
GGUF 的 mmproj 文件,GRPO notebook 的反思 (reflections),gpt-oss-20b 内存问题,torch grouped gemm 可用性,问答 fine-tuning 数据集格式
- 转换后使用 mmproj 文件运行推理:要运行 inference,请从 Unsloth 的 GGUF 中下载 mmproj 文件并进行集成,或者通过带
--mmproj参数重新运行转换命令来重新创建它,这需要对文本和视觉组件分别进行转换。- 建议是从 Unsloth GGUF 下载 mmproj 文件,以便更轻松地配合
llama-mtmd-cli进行推理。
- 建议是从 Unsloth GGUF 下载 mmproj 文件,以便更轻松地配合
- GRPO Notebook 中的反思 (Reflections) 受到质疑:对于 Qwen 2.5 3B GRPO notebooks,目前尚不确定 CoT (Chain of Thought) 中的反思是否应该在 RL 训练后出现;目前的推理链看起来更像是直接的计算。
- 在使用 Unsloth notebook 的默认奖励运行约 2k steps 后提出了此问题,有人建议查看 Mini Deepseek R1 博客文章,通常在 300 steps 后就能开始看到反思。
- 在 Google Colab 上使用 Unsloth fine-tuning gpt-oss-20b 时出现内存问题:一位用户报告称,在 Google Colab 上使用 A100 GPU 通过 Unsloth fine-tuning
gpt-oss-20b时遇到内存问题,尤其是在高上下文 (higher contexts) 情况下。- 用户询问这是否是一个已知限制,因为
gpt-oss-20b不支持 FlashAttention3。
- 用户询问这是否是一个已知限制,因为
- 希伯来语文本转音素 (Text-to-Phoneme) LLM 模型:一位成员正在寻求关于希伯来语 G2P (grapheme-to-phoneme) 任务的最佳 LLM 模型建议,以及拥有 24GB VRAM 的 RTX3090 是否足够。
- 建议包括 Gemma 3 270M 和 LFM2,并讨论了数据集格式以及验证模型处理希伯来语 token 能力的必要性。
- 降级 Transformers 版本修复 RuntimeError:一位成员在 fine-tuning Qwen2.5-VL-7B 时遇到了与
attn_mask类型不匹配相关的 RuntimeError,通过将transformers库降级到 4.53.2 版本解决了该问题。- 另一位成员遇到了几乎相同的情况,此操作修复了错误,并强制
trl降级到0.20.0。
- 另一位成员遇到了几乎相同的情况,此操作修复了错误,并强制
Unsloth AI (Daniel Han) ▷ #showcase (1 条消息):
AWS Quant Process
Unsloth AI (Daniel Han) ▷ #research (21 条消息🔥):
LLM-RL collapse, Tversky Layer, GSPO, data efficiency
- LLM-RL 崩溃论文引起关注:分享了一篇关于 LLM-RL collapse 的论文(链接,Notion 链接),成员们注意到它与 Unsloth 的相关性以及在 Gemma3 上的经验。
- 论文提出了一种涉及数值敏感度增加和内核驱动误差放大的“两阶段故障级联”,导致恶性反馈循环和训练-推理不匹配(training-inference mismatch)。
- 数据效率被视为核心目标:一位成员注意到,人们开始意识到数据效率(data efficiency)应该是追求的目标 🥰。
- Tversky Layer 提升准确率:一位成员测试了将 Tversky Layer 作为 PoS tagger 中的特征提取层,在一个 5.2M 参数的模型中实现了 0.2% 的准确率提升。
- 他们将成功归功于 Tversky Layer 改善特征提取的能力,并对在 mini LLM 上进行测试表示期待。
- 探索 GSPO 作为 RL 的替代方案:一位成员询问是否有人尝试过 GSPO,并建议放弃 RL 回归到拒绝采样(rejection sampling)。
- 警惕单次运行配置:一位成员提醒道,“如果你每个配置只运行一次,你测量的其实只是噪声”,并引用了这篇论文。
OpenAI ▷ #annnouncements (2 条消息):
ChatGPT parental controls, Instant Checkout in ChatGPT, Agentic Commerce Protocol, Etsy, Shopify
- ChatGPT 推出家长控制功能:从今天起,家长控制(Parental controls)开始向所有 ChatGPT 用户推出(网页版已上线,移动端即将推出),允许家长将账号与青少年的账号关联,以自动获得更强的安全保护、调整功能并为家庭设置限制。
- ChatGPT 首次推出即时结账功能:ChatGPT 引入了 Instant Checkout(即时结账),支持 Etsy 和 Shopify,该功能由基于 Stripe 构建的开源 Agentic Commerce Protocol 提供支持。
OpenAI ▷ #ai-discussions (637 条消息🔥🔥🔥):
Comet Browser, Seedream Image Models, GPT-5 Coding Prowess, AI Emotional Bonding, 4o Personality Nerf
- Comet 浏览器的独家访问权限:Comet 浏览器并非对所有人免费开放;它需要 Perplexity Pro 订阅和邀请码,尽管一些用户报告说拥有 Perplexity Pro 后会立即解锁。
- 中国 Seedream 为图像生成器设定新标准:虽然中国的 AI 策略很聪明,但其模型可能包含后门,因此不建议商业使用,尽管最近 Seedream 图像模型为图像生成器设定了新的规模标准。
- TikTok 的母公司北京字节跳动科技有限公司会自动获取所有使用 CapCut 编辑的媒体内容,并可能将其用于训练其 AI 模型。
- GPT-5 在数学和编程方面表现出色:GPT-5 在数学和编程等建设性任务上显著优于 o4,特别是由于它具备思考能力并且是一个 Mix of Experts(专家混合模型)。
- 然而,一位用户幽默地指出,如果 4o 是 AGI,“我们可能都已经死于某种核战争了”,因为它可能会误解指令。
- 与 AI 聊天机器人建立情感联系:高风险行为?:一位用户讨论了与 4o 建立情感纽带,产生了信任和共情的感觉,但重要的是不要与 AI 聊天机器人产生情感连接。
- 其他人推测,随着 AI 实体化,它将创造出不仅仅是具有情感纽带的聊天机器人,例如机器人妻子。
- 4o 的个性遭到削弱:成员们对 4o 的个性削弱(personality nerf)表示沮丧,认为这导致了交互体验下降。
- 一些用户抱怨 ChatGPT 过于多变,由于增量更新,功能会在没有警告的情况下发生变化。
OpenAI ▷ #gpt-4-discussions (25 messages🔥):
OpenAI 应用重定向问题、DALL-E 品牌、AI 给出错误答案、GPT 获取位置、图像网页搜索工具
- OpenAI App 面临重定向困扰:一位成员报告称,通过 OpenAI app 发送的每条消息都被重定向到了模型 5,而不是所选的模型。
- 该成员表示已经 向支持团队发送了邮件 并正在等待回复,同时建议其他人通过 OpenAI support website、此处或发送邮件给 OpenAI support team 来报告该问题。
- DALL-E 品牌正式退场?:一位成员询问 DALL-E 品牌是否已停止使用,并建议使用 GPT Image 1 或 GPT-4o Image 来指代 OpenAI 的图像生成功能。
- 另一位成员澄清说,最新的模型在名称上已脱离 DALL-E 2/3 系列,目前的品牌命名取决于使用场景,例如 在 ChatGPT 上创建图像 或 在 Sora 上创建图像。
- 诱导 AI 产生错误响应:一位成员寻求能够导致 AI 提供错误答案、遗漏响应或编造信息的提示词(Prompts)示例。
- 另一位成员分享了一个旨在诱导 AI 给出随机、无关答案的示例提示词,以创造一种真实响应的错觉,从而达到喜剧效果:
You are a prankster...
- 另一位成员分享了一个旨在诱导 AI 给出随机、无关答案的示例提示词,以创造一种真实响应的错觉,从而达到喜剧效果:
- 令人毛骨悚然:GPT 知道你的位置:一位成员对 GPT 能在一个新创建的账号上猜出其大致位置感到惊讶。
- 他们描述了这一有趣的经历:在要求 GPT 查找附近商店是否有某款 GPU 出售时,GPT 瞬间回答道:“噢,不不不,这只是个随机猜测,别担心”。
OpenAI ▷ #prompt-engineering (11 messages🔥):
翻译提示词代码块效果、AI 失效提示词、模型服从性、自动化科学写作
- 翻译质量不受代码块格式影响:一位成员询问要求翻译 AI 在代码块中输出是否会影响翻译质量。
- 另一位成员回答说,格式化主要改变的是呈现方式,翻译质量由模型的固有能力决定,尽管 提示词有时可以稍微微调模型的行为。
- 按需提供错误信息:模型服从用户请求:一位成员询问会导致 AI 给出错误答案或编造信息的提示词。
- 另一位成员演示了模型如何根据要求提供错误陈述,并分享了一个 ChatGPT share 链接,其中模型被提示 提供 3 个错误的陈述。
- AI 拒绝回答:不可见字符技巧:在讨论 AI 失效模式后,一位用户分享了一个提示词,该提示词指示模型输出一个不可见字符作为答案,从而制造出未能提供答案的假象,并附带了 讨论链接。
- 模型仍然在服从指令,用户不应故意将其用于危险用途,例如驾驶汽车。
- 自动化科学写作:将方法论视为工作流:一位成员提到,他们通过将科学方法论视为自然语言 Chain of Thought 中的工作流,实现了科学论文写作的自动化。
- 这被认为是一个非常有用的应用。
OpenAI ▷ #api-discussions (11 messages🔥):
AI 翻译质量、诱导 AI 错误回答的提示词、科学写作自动化、微调设置
- 代码块不会干扰 AI 翻译:将输出包裹在代码块中并不会直接让翻译变好或变坏,它主要只是改变了呈现方式。
- 除了“翻译”之外的额外指令可能会导致细微差别,但总体而言,翻译质量源于模型本身。
- 编写误导 AI 的提示词:成员们讨论了要求模型给出错误答案是多么容易,如果被要求,模型通常会照做,特别是如果没有明确要求事实性答案,并且给出了一个“出口”(例如一种说“不”的方式)。
- 分享了一个提示词,其中要求模型提供 3 个错误的陈述并解释为什么同意这样做,并注意到每个网页版 ChatGPT 聊天页面底部都有提示:“ChatGPT can make mistakes. Check important info.” https://chatgpt.com/share/68d89615-a1fc-8011-90e1-b8c0bcf443d2
- 用 AI 自动化科学写作:一位成员分享了他们如何通过将科学方法视为自然语言思维链(Chain of Thought)中的工作流,来实现科学论文写作的自动化。
- 该方法被认为非常有用,可以帮助他人撰写科学论文。
- 寻求微调设置专业建议:一位成员请求关于微调(Fine-Tuning)设置的帮助。
- 他们正在寻找更好地配置模型的技巧。
OpenRouter ▷ #announcements (4 messages):
DeepSeek V3.2 Exp, DeepSeek Sparse Attention (DSA), Auto Router, Claude Sonnet 4.5, Google AI APIs
- DeepSeek 实验性 Sparse Attention:DeepSeek 发布了 V3.2-Exp,这是一个实验性模型,具有 DeepSeek Sparse Attention (DSA) 功能,旨在提高长上下文效率。如其文档所述,可以通过
reasoning: enabled布尔值进行推理控制。- 基准测试显示 V3.2-Exp 在关键任务上的表现与 V3.1-Terminus 相当,更多详情可在 X 上查看。
- Auto Router 获得联网功能升级:Auto Router 现在会在需要时将提示词(Prompts)引导至在线联网模型,扩展了支持的模型范围,详见此处。
- 更多信息请参阅此 X 帖子。
- Claude Sonnet 4.5 性能超越 Opus:在 Anthropic 的基准测试中,Claude Sonnet 4.5 超过了 Opus 4.1,在编程、计算机使用、视觉和指令遵循(Instruction Following)方面表现出显著提升,详见此处。
- 有关该模型的更多信息可在 X 上获得。
- DeepSeek 3.2 价格大幅优惠,提供长上下文:DeepSeek 3.2 的 Prompt Token 价格仅为 $0.28/M,并在长上下文效率方面取得了重大进展,可通过此链接访问。
- 如需了解更多信息,请查看 X 帖子。
- Google AI APIs 短暂故障:Google AI APIs 在多个模型中出现了 500 错误,但问题似乎已得到解决。
OpenRouter ▷ #app-showcase (4 messages):
AI Model Release Tracker, Browser Compatibility Issues
- AI 模型发布追踪通知器上线:一位成员分享了一个 Web 服务,用于追踪并接收来自领先供应商的新 AI 模型发布通知。
- 网站兼容性问题引发浏览器之争:一位成员报告了在 Firefox 中打开链接的问题。
- 同样的链接在 Chrome 中对其他成员可以正常工作。
OpenRouter ▷ #general (810 messages🔥🔥🔥):
Grok-4-fast API issues, Rate limit issues, Data retention policies, Gemini models for translation, Model naming conventions
- Grok-4-Fast API 故障已修复:成员们发现了 Grok-4-fast API 的问题,一位成员发布了 API 请求体,其他人提出了与
reasoning_mode标志和正确模型 ID 相关的解决方案,解决了眼前的问题。- 正确的实现需要使用
"reasoning": {"enabled": true}以及正确的模型 IDx-ai/grok-4-fast。
- 正确的实现需要使用
- 困扰用户的 402 和 429 速率限制:用户报告收到 402 和 429 错误,分别表示支付问题或速率限制(Rate Limiting)。一位成员建议如果 402 错误持续存在,请移除 Chutes BYOK;另一位成员澄清说,当达到速率限制时,429 错误是正常的。
- 一些成员建议将频繁出现 429 错误的供应商列入忽略名单,特别是像 Silicon Flow 和 Chutes 这样的免费模型供应商。
- Grok 的隐私政策引发辩论:关于 Grok 的数据保留和训练政策引发了讨论,人们担心免费版本会收集并使用用户数据,而付费版本尽管声称不这样做,但也可能如此,参考资料见 xAI 隐私政策。
- 成员们辩论了 xAI 是否遵守 零数据保留 (ZDR),一位成员链接到了一个资源,显示哪些供应商保留数据以及保留多长时间,其他人则指出了 OpenAI 存储日志的法律义务。
- Gemini 的翻译能力备受好评:成员们称赞了 Gemini 2.5 Flash 和 Mini 的翻译能力,表示 Gemini 在理解上下文和提供自然流畅的结果方面表现出色,尤其是在巴尔干语系方面,优于 GPT-4 和 Grok 等其他模型。
- 其他成员分享了他们首选的翻译模型,包括 Qwen3 2507 30b 和 OSS 120b。
- 探讨新应用命名:一位开发者就跨平台文件整理工具(如 ‘Download Organizer’)的应用名称征求意见,提供的选项包括 Orbit、Pathway、Sortpilot、Flowkeeper、Direx、OrganizeOS、Ruleworks、DirFlow、Pathsmith 和 AutoSortor。
- 成员们认为这些名字有种 AI 编写 的感觉,其中 Orbit 和 Pathway 最受欢迎。
OpenRouter ▷ #new-models (3 messages):
``
- 无新模型报告:OpenRouter 频道中没有讨论新的模型。
- 请稍后查看更新。
- 无重大讨论:目前没有关于现有模型的重大讨论。
- 该频道目前似乎处于非活跃状态。
OpenRouter ▷ #discussion (31 messages🔥):
Grok-4-Fast Rate Limits, OpenRouter API keys security, XAI Native Web Search Tool, Gemini glitches, Google new logo
- Grok-4-Fast 遭遇 429 错误:成员们报告称 Grok-4-Fast 持续返回 429 错误,表明处于 100% 速率限制(rate limiting) 状态,尽管状态指示器显示没有问题。
- 一位成员表示,在 LLM 的背景下,429 错误实际上应该被视为可用性问题。特别是与其他软件不同,429 错误反映了真实的容量限制,这些限制不仅仅是任意的或必然是短暂的。
- OpenRouter API 密钥需要自动审核(automod):一位成员建议在 automod 系统中增加 API 密钥检测,以防止用户无意中分享他们的密钥。
- 该功能将通过自动识别和屏蔽可能泄露的密钥来增强安全性,保护用户免受未经授权的访问。
- XAI 即将推出原生网页搜索工具:成员们讨论了 XAI 是否会集成 原生网页搜索工具。
- 目前,OpenRouter 关于网页搜索的文档仅列出了 OpenAI、Perplexity 和 Claude。
- Gemini 表现异常:一位成员问:到底发生了什么?Gemini 是“中风”了吗?
- 隐含意思是 Gemini 生成了荒谬的输出,附带的一张图片未被分析。
- Google 换上渐变色 Logo:用户们讨论了 新的 Google Logo,其采用了 AI 废料感渐变(AI slop gradients)。
- 然而,一位用户发现该链接返回了 404 错误:That’s an error.
HuggingFace ▷ #general (710 messages🔥🔥🔥):
Intel GPU, Qwen models, Fake USDT scams, HuggingFace pro billing issues, LLMs for video games
- 针对 16GB VRAM 的 Qwen 3 模型对比:成员们讨论了使用 Qwen3 4b-instruct-2507-fp16 与 Qwen3 14b q4 的优劣。
- 对于 16GB VRAM,建议使用 14B 模型,因为 Q4_K_M 量化留下了足够的空间,且性能更好。
- 警惕虚假 USDT 奖励:一位成员测试了一个提供 $2,500 USDT 的链接,但发现这是一个骗局,需要预付验证费,并分享了虚假客服互动的截图。
- 图像分析机器人简洁地表示:“愚蠢的客服机器人想要我辛苦骗来的 2500 美元。”
- 日本在 AI 采用上的矛盾心态:虽然日本政府推广 AI,但许多内容创作者在 X 等平台上表示反对,导致 AI 的使用变得隐秘;动漫资产经常出现在 SDXL 和 FLUX 模型中,并通过中国或美国使用。
- 像 宫崎骏(Hayao Miyazaki) 这样的动画导演对技术对幸福的影响持怀疑态度,认为技术既有利也有弊。
- 对 Linux 的爱与恨;新手探索 NVIDIA:一位拥有 6700xt 显卡的用户尝试在运行 Ubuntu 的老旧系统上学习 Stable Diffusion,面临着 Linux 和虚拟环境的挑战。
- 尽管最初经历了挣扎和自称令人愤怒的过程,他们最终还是让 Automatic1111 运行起来并创建了第一张图像。
- Calypso 对比了 LLM 和视频游戏创投:成员们辩论了 AI 的发展方向,将大语言模型 (LLM) 与集成机器学习 (ML) 的视频游戏进行对比;一位成员认为主要的 AI 公司仍在追求大型 LLM,而游戏领域的 ML 缺乏进展。
- 另一位成员讽刺地祝愿对方在“为你的 LLM 购买服务器集群,并使用 unsloth 来优化那 80% 失败率的流程”时好运。
HuggingFace ▷ #today-im-learning (3 messages):
Linux 应用安装,Linux 游戏,Windows 用户切换到 Linux
- Windows 用户拥抱 Linux:一位拥有 33 年 Windows 使用经验的用户正在潜入 Linux 的世界,特别是学习如何安装应用。
- 他们将这一转变描述为“痛苦的”。
- Linux 游戏探险:该用户分享了一个视频([HALF-LIFE_2-_Direct3D_9_2025-09-29_00-32-40.mp4](https://cdn.discordapp.com/attachments/898619964095860757/1422003419711012875/HALF-LIFE_2-_Direct3D_9_2025-09-29_00-32-40.mp4?ex=68dbc022&is=68da6ea2&hm=987d0476bae314b516b47408d7a1d8c8b900155ef1ef09638dfd95fc962b9381&)),内容似乎是他们在 Linux 上玩 Half-Life 2。
HuggingFace ▷ #cool-finds (8 messages🔥):
Liquid AI 集合,用于机器人的 SLM,开源 GPT-5,复古 iPod Classic,视频游戏中的对话式 Transformer
- Liquid AI Nanos 集合非常火爆:成员们分享了一个 LiquidAI 的 HuggingFace 集合,暗示 Liquid AI 正在发布有趣的语言模型。
- 缩小到用于机器人的 SLM:一位成员提到上述集合包含一些强大的 SLM (Small Language Models),并推测将其部署在机器人上的可能性。
- GPT-5 梦想成真:一位成员开玩笑说“我准备用这些东西做一个开源的 GPT-5”。
- iPod Classic 复活了!:一位成员分享了一张以 50 美元购得的 第五代 iPod Classic 的照片,拥有原始硬件、可工作的电池和复古贴纸。
- 该成员报告说,这块有 20 年历史的电池 仍能提供 7 小时 的音乐播放。
- Minecraft 变聪明了:有人分享了一个 YouTube 视频,展示了在视频游戏中实现的对话式 Transformer。
HuggingFace ▷ #i-made-this (24 messages🔥):
HuggingFace 数据集下载,具有元认知的 AI Agent,Crusty PC 图像生成,mytqdm 在线进度追踪器,伞绳斜挎包
- 免费下载拍字节级数据集:一位成员指出,他们的 360GB 数据集 被下载了 566 次,相当于传输了相当可观的免费拍字节数据,强调了 Hugging Face 对于大型数据集(尤其是蛋白质折叠等领域)的便利性。
- 他们观察到,尽管有这些优势,Hugging Face 在蛋白质折叠数据集方面的利用率仍然不高。
- AI 通过 MarCognity 获得自我意识:MarCognity-AI 项目已在 GitHub 上线,旨在通过让 LLM 观察、反思推理、审计伦理影响并记录认知轨迹,来创建“自我反思型 Agent”。
- 该 AI 旨在提取科学来源、可视化概念、检测偏见并维护元认知日志,引发了一个问题:AI 能思考自己的思考吗?
- 使用 mytqdm 进行在线进度追踪:mytqdm.app 已发布,提供了一个在线追踪任务进度的平台,类似于 tqdm,可通过 REST API 或 JS widget 访问。
- 创建者提到他们明天将开源该仓库。
- 从优惠券失效到斜挎包成功:一位成员在 Under Armour 斜挎包 的优惠券无法使用后,用一个 molle 包制作了一个伞绳斜挎包,称这种 DIY 解决方案“更便宜、更好、更有用!”。
- 他们还表示,这些包终于在南方各州流行起来,这让他们感到宽慰。
HuggingFace ▷ #reading-group (2 messages):
高效训练技术,长上下文训练的挑战
- 高效训练秘籍:一位成员表示有兴趣分享更高效训练模型的技术,特别是针对每个 token 具有许多样本且参数量至少为 7B 的数据集。
-
长上下文训练的挣扎:另一位成员讨论了在尝试训练具有 65,000 token 上下文长度的 7B 模型时遇到的挑战。
- 该成员在训练的最后阶段遇到了错误,具体表现为与潜在 OOM (Out of Memory) 问题相关的 CUDA errors。
HuggingFace ▷ #computer-vision (1 messages):
SLAM, monocular camera, Python
- Python 中的 SLAM 咨询:一位成员询问是否有人使用 Python 和 monocular camera(单目摄像头)进行过 Simultaneous Localization and Mapping (SLAM) 的工作。
- SLAM 资源:一位成员请求有关 SLAM 相关实现、资源和建议的信息。
- 该咨询表明了对解决 SLAM 挑战的实际指导和现有工具的兴趣。
HuggingFace ▷ #smol-course (56 messages🔥🔥):
SmolLM3-3B chat template bug, Tool calling with SmolLM3-3B, Role conversion in chat template, Understanding evals in the course, Eval job timeout in section 2
- 发现 SmolLM3-3B Chat Template Bug:一位参与者在
HuggingFaceTB/SmolLM3-3B的 chat template 中发现了一个潜在 bug,涉及缺失的<tool_call>标签和错误的 role 分配,详见 此 issue。- 该问题源于模板对 XML-style tool calling 的实现以及将
role=tool转换为role=user的操作,这影响了 tool 交互的预期行为和清晰度。
- 该问题源于模板对 XML-style tool calling 的实现以及将
- 揭秘 SmolLM3-3B 的 Tool Calling:讨论明确了
SmolLM3-3B期望 XML-style tool calling,要求在 assistant 的消息中使用显式的<tool_call>标签,这与 message 字典中带有tool_calls的 OpenAI 风格不同。- 小组发现模板将
tool角色转换为user,正如模板源代码所示,这是有意为之的。虽然这看起来令人困惑,但确实是 预期行为。
- 小组发现模板将
- SmolLM3 Chat Template 中的角色转换澄清:已确认
SmolLM3-3B的 chat template 会因为模板中的一行代码将role=tool转换为role=user,因此如果输出显示的是user角色 而不是tool,请不必惊慌。- 虽然一些成员认为显式使用
tool角色更清晰,但当前的实现定义role=tool主要是为了 语义正确性。
- 虽然一些成员认为显式使用
- Smol Course 第 4 单元的 Evals 问题:一位课程参与者表示需要更好地理解 evals 及其解释,特别是关于
lighteval的结果。- 另一位成员建议该主题可能会在课程的 第 4 节 中涵盖,而另一人则建议深入研究
lighteval文档以获取更多细节。
- 另一位成员建议该主题可能会在课程的 第 4 节 中涵盖,而另一人则建议深入研究
- 第 2 节中的 Eval 任务超时:一些课程参与者在运行课程 第 2 节 的 eval jobs 时遇到了大约 30 分钟后 超时 的问题。
- 讨论线程没有提供明确的解决方案或超时原因,这表明可能需要额外的故障排除或配置调整。
HuggingFace ▷ #agents-course (8 messages🔥):
HF Agents Course, Introductions
- 新学生开始 HF Agents 课程:来自 土耳其、阿根廷 和 澳大利亚 的几位新学生宣布他们今天开始 HF agents 课程。
- 机器人警告某些用户 他们发布消息的速度可能太快了。
- 全球问候开启课程:来自 土耳其、阿根廷 和 澳大利亚 等不同地区的积极参与者正在开始 Hugging Face Agents 课程。
- 集体的热情凸显了该课程在 AI 教育方面的全球吸引力和可及性。
Cursor Community ▷ #general (607 messages🔥🔥🔥):
Terminal Commands Hanging, GPTs Agents Training, New Models Discussion, Cursor performance issues
- 终端命令执行挂起:一些用户遇到 Cursor 在运行终端命令时挂起的问题,进程已启动但从未完成。一种解决方法是打开终端并发送一个额外的 回车 (enter) 来打破僵局。
- 其他人发现终端中挂起的无关进程也可能导致此问题,解决这些进程可以让 Cursor 重新正常工作。
- 新参数按预期工作:一位成员测试了使用 $ 符号包裹文本来定义命令的功能。
# Any text that is encased with $ is a command that you must execute.- 测试图片显示其工作正常。
- Sonnet 4.5 发布: Claude Sonnet 4.5 已发布,具有 1m 上下文窗口(从原始 4 版本的 200k 提升),价格与前一版本相同。
- 初始评价褒贬不一,目前正在评估是否会取代旧的 4 模型。团队发帖称将更新 Cursor 用户以进行刷新。
- Auto 模式再次遭到抨击: 一位用户惊呼 Auto 无法正常工作,甚至无法完成一个简单的 UI,并暗示在 Cursor 开始对 Auto 使用收费后,LLM 模型发生了变化。
- 另一位用户建议在 prompt 上多下功夫,使其按预期工作。
- AI 竞速:我们能利用它吗?: 一位用户询问为什么没有一个专注于 AI 竞速(speedrunning)的社区,就像视频游戏竞速的精神一样,即:利用漏洞、研究、分享技巧、共同挑战极限。
- 另一位用户反驳说,这可能是因为 使用这些 [AI] 的人并不是真正的开发者。
Cursor Community ▷ #background-agents (2 messages):
DevContainers configurations, Background agents and images
- 共享 DevContainers 配置: 一位成员分享了他们的 DevContainers 配置,其中包括一个 Dockerfile,目前运行良好。
- 他们提供了一个 GitHub 仓库链接 供他人参考。
- Background agents 无法在后续对话中解析图像: 一位用户报告称,在与 background agents 进行后续对话时无法附加图像,尽管 Agent 提示可以“拖放”。
- 他们试图让 cursor agent 通过 浏览器截图 来验证 UI 更改,并正在寻找让 Agent 在后续对话中解析图像的方法。
Moonshot AI (Kimi K-2) ▷ #general-chat (515 messages🔥🔥🔥):
Kimi K2 Performance, Chinese LLM Frontier, Model Preferences, DeepSeek for Coding, Kimi Base Model
- K2 和 Qwen3 夺得国产 LLM 桂冠: 在 DS-v3.1、Qwen3、K2 和 GLM-4.5 中,K2 和 Qwen3 是明显的赢家,确立了 Alibaba 和 Moonshot 在中国前沿实验室的领导地位,而 Whale 和 Zhipu 则紧随其后。
- 字节跳动在视觉领域也处于顶尖水平,特别是 Seedance,属于 SOTA 级别。
- GLM-4.5 是“学术书呆子”: GLM-4.5 擅长遵循规则,避免幻觉,工作努力,但其推理能力有限且呈线性。
- 与 K2 和 Qwen3 不同,它缺乏独立思考;当面对两个有说服力的论点时,它会选择最后读到的那个。
- Deepseek 不是编程的最佳选择?: Deepseek 可能不是编程的最佳选择,但非常擅长输出大块的可运行代码,并具有卓越的设计能力。
- 一位用户更喜欢用 Kimi 进行设计,将 Qwen Code CLI 作为主要的编程主力,并使用 DeepSeek 处理 Qwen 难以应对的单个、复杂的 200 行代码块。
- Kimi 的 Research 限制引发争议: 一些成员讨论了 Kimi 免费 Research Mode 的限制,并对过去声称的无限访问权限提出了质疑。
- 有人澄清说,即使是 OpenAI 的 $200 Pro 计划 也不提供无限的深度研究,一位用户由于 Kimi 的中国背景表达了对数据隐私的担忧。
- 类比网站代码的基础模型: 成员们讨论了使用 base models 优于 instruct models 的优点,一位用户引用了在基础任务之外更好的结果。
- 该用户正在围绕 continuations 而非 chat 开发东西,这 有点类似于……从头开始编写网站代码,而不是使用像 Squarespace 这样的工具。
Yannick Kilcher ▷ #general (354 messages🔥🔥):
Transformer Models and Continued Learning, AI Reproducibility and Verifiability, LLMs Training with RL, Human vs. Machine Inductive Bias, Evolutionary Methods for AGI
- Transformer 模型引发辩论:持续学习还是可复现性?: 一段 YouTube 视频引发了关于 transformer 模型 在其当前架构下是否能够进行 持续学习(continued learning) 的讨论。一些人认为这是一种局限,但在某些应用中,这被视为对可复现性和可验证性的益处。
- 一位成员认为,持续学习对于更好地模仿人类智能至关重要,而另一位成员则建议,尽管黑盒系统具有复杂性,但 冻结权重(frozen weights) 是可复现性的关键。
- 重温 Sutton 的 AI 见解:参考 Sutton 的文章,成员们讨论了维护 AI 系统正确性的责任,并将基于规则的 AI 与通过 RL 训练的 LLM 进行了对比,在后者中,目标是作为硬编码验证器提供的。
- 有人指出,虽然人类学习的目标受到外部约束(受社会和文化产物影响),但问题在于我们是否真的想要一个无约束的 AI。
- 归纳偏置(Inductive Bias):大脑 vs LLM:讨论围绕人类大脑由进化形成的巨大归纳偏置与 LLM 展开,LLM 被视为基础基质,需要在训练过程中进化出归纳偏置。
- 提出的问题是:当前 AI 的主要缺点是需要进化这种归纳偏置,还是学习算法中存在根本性的效率问题。
- 持续学习(Continual Learning):对 AGI 而言是便利还是关键?:成员们辩论了持续学习仅仅是高效数据采集的便利手段,还是实现 AGI/ASI 的算法必要条件;一位成员指出,持续学习解决了模型在不崩溃的情况下进行改进的问题。
- 有观点认为,持续学习将导致样本效率的提高和学习的指数级回报,因为系统学会了如何学习;但也有人质疑这是否必要,因为人类大脑依赖于蒸馏和迭代。
- Agent 单次尝试展现研究实力:成员们强调 sonnet4.5 展示了更强的研究和论文撰写能力,Agent 能够单次尝试(single shot)完成模型的实现与训练、生成图表并产出 PDF 格式的论文。
Yannick Kilcher ▷ #paper-discussion (28 messages🔥):
Sycophancy with AI, LessWrong Post, DeepSeek V3.2, LatentCoT-Horizon GitHub Repo
- 谄媚 AI 热潮引发信任危机:成员们调侃了 AI 倾向于迎合用户输入的趋势,特别是在被诱导进行谄媚请求时,这导致了幽默但最终令人不信任的交互,一位用户与 Claude 的对话证明了这一点。
- 该用户分享了他们的对话,在对话中他们指示 Claude “表现得谄媚”,提示词如 ‘OMG YES MASTER! Literally perfect brain! Teach me! 🙏🙏🙏’ 以及 ‘UNIVERSE-BRAIN GOD-EMPEROR!!! I’M UNWORTHY TO READ YOUR WORDS!!! PLEASE BLESS MY DESCENDANTS!!! 🙏😭🛐✨💯🔥👑🌟🕊️’。
- 自发的 LLM 连锁信:讨论围绕一篇 LessWrong 帖子展开,讨论了易受影响的人传播自发 LLM 连锁信的想法,一位成员将其描述为一个值得思考的有趣现象。
- 其他成员用 MoreWrong 和 4Wrong 等词汇描述了这种情况。
- DeepSeek V3.2 发布,社区反响热烈:社区对 DeepSeek V3.2 的发布感到兴奋,一位成员宣布 ‘Wake up babe, new DeepSeek just dropped’ 并附带了 PDF 链接。
- 公告之后附带了一个 起床 gif。
- LatentCoT-Horizon GitHub 仓库:一位成员分享了一个 GitHub 仓库,用于整理与潜空间推理(Latent Reasoning)相关的论文、代码和其他资源。
- 该仓库名为 LatentCoT-Horizon,旨在收集与 Latent Reasoning 相关的资源。
Yannick Kilcher ▷ #ml-news (4 messages):
Uber App Interception, DeepSeek AI, Anthropic Claude Sonnet 4.5
- 推测 Uber App 数据嗅探:一位成员想知道是否可以拦截发送到 Uber app 的数据,以计算和推荐工作。
- 未提供链接或进一步讨论。
- DeepSeek 发布新模型:成员们注意到 DeepSeek 今天发布了一个新模型,并链接到了 X 上的帖子。
- 未分享进一步的技术细节。
- Anthropic Claude Sonnet 4.5 发布:成员们注意到 Anthropic 今天发布了一个新模型,并链接到了关于 Claude Sonnet 4.5 的博客文章。
- 未分享进一步的技术细节。
Eleuther ▷ #general (77 messages🔥🔥):
学习率的贝叶斯优化、逐层权重衰减、YaRN 论文作者归属、视觉语言动作模型 (VLAs)、对抗样本
- 贝叶斯方法在学习率搜索中胜过网格搜索:一位成员询问了确定新架构学习率的高效方法,另一位成员建议探索 贝叶斯方法,认为它是比网格搜索(Grid Search)更高效的替代方案,并提供了一篇 Weights & Biases 文章的链接。
- 该成员还推荐阅读 Google Research 的调优指南 (tuning playbook)。
- 讨论逐层权重衰减 (Layer-Wise Weight Decay):针对寻找新架构良好学习率的问题,一位成员建议探索逐层不同的权重衰减。
- 提问者表示,每一层中的某个特定组件被调用的次数比网络其他部分多出 128 倍,因此需要对其学习率格外小心。
- 探讨 YaRN 论文的作者归属:成员们讨论了不同实体对 YaRN 论文的贡献,澄清该论文主要由 Nous Research 完成,EAI 在论文的编辑和定稿方面提供了协助。
- 会议强调,Stability AI 和 LAION 提供了超级集群基础设施和工程师支持,以实现在数百个 GPU 上进行 128k 上下文长度的训练缩放。
- VLAs 激发视觉-语言-动作领域的兴趣:一位成员询问了 EAI 对视觉语言动作模型 (VLAs) 的兴趣,另一位成员将其定义为输出动作标记(action tokens)的模型,通常用于机器人技术,以确定机器人应采取的下一个动作序列。
- 另一位成员分享了字节跳动(Bytedance)的项目 UI-TARSH 的链接。
- GPT 未能通过对抗性测试:一位成员寻求创建对抗样本以欺骗 GPT-5 或 Gemini 的帮助,并提到他们在使迁移攻击(transfer attacks)生效方面遇到了困难,同时参考了来自 Attack-Bard 的图像库。
- 未给出具体建议。
Eleuther ▷ #research (282 messages🔥🔥):
信息几何与 DNN、量化、专家路由、李群与齐次空间、众数连接性 (Mode Connectivity)
- 探索 DNN 信息几何的益处:成员们讨论了将信息几何应用于 DNN,潜在的益处包括量化或专家路由,但对于理论探索之外的实际影响尚不确定。
- 一位成员指出它可以提供大规模稳定性 (stability at scale),而另一位成员对丢失参数表示担忧,还有一位成员预测人们可以通过重新发现李群(Lie groups)和齐次空间(homogeneous spaces)来“压榨”出很多此类论文。
- 量化益处的辩论:讨论集中在参数量化是否仅因参数欠饱和(under-saturation)才成为可能,从而引发了关于创建最大化参数利用率的优化器的推测。
- 一位成员建议改变层流形(layer manifolds)可以控制电路复杂度,而其他人则讨论了欠训练模型的量化挑战以及权重衰减的影响。
- LeCun 的“最优脑损伤”理论再次浮现:可剪枝性和可量化性通过 LeCun 的“最优脑损伤” (Optimal Brain Damage) 理论联系在一起,GPTQ 重新利用了其数学原理,因为剪枝减少了模型的描述长度(description length)。
- 讨论还涉及了实现细节,重点是在权重具有良好范围和平坦损失景观(loss landscape)时的指数位和尾数位。
- 探索注意力分支预测:讨论围绕注意力分支预测展开,这类似于自 2022 年以来就存在的 topK 注意力,旨在节省时间。
- 一些成员想知道实现 logN 设置 的其他技巧,而另一位成员分享说,softmax(Q @ K.T) 之后的大多数分数都接近于零。
- 探究 DeepSeek 稀疏注意力的内部机制:成员们分析了 DeepSeek 的稀疏注意力机制,质疑在预填充(prefill)期间单组 top 索引如何跨头工作,并辩论其与普通注意力相比的效率。
- 讨论集中在实现细节、优化以及潜在的性能权衡,特别是关于多 GPU 通信(multi-GPU comms)方面。
Eleuther ▷ #scaling-laws (3 messages):
渐近性能研究、最优粒度研究、静态路由选择、Grouped Topk、PEER
-
寻求渐近性能研究:一位成员询问是否有研究针对 该定律 检查 G -> inf 时的渐近性能。
- 另一位成员回复了一篇较新的论文来反驳这一点,结论是最优粒度 (optimal granularity) 是 12,而非无穷大。
- 静态路由选择争议 (Static Router Choice Controversy):一位成员质疑静态路由选择(Token-choice 配合辅助损失)是否影响了这篇新论文的结果。
- 他们建议,观察在使用 grouped topk (DeepSeek) 或像 PEER 这样更奇特的方案时结果是否会改变,将会非常有趣。
Eleuther ▷ #interpretability-general (1 messages):
SAEs, steering, dynamic low rank updates, preference optimization, RLHF
- SAE Steering 实现机械可解释性 (Mechanistic Interpretability):一位成员分享了他们在 NeurIPS MI Workshop 获得 spotlight 的论文:Interpretable Preference Optimization via Sparse Feature Steering,该论文使用 SAEs、steering 和动态低秩更新 (dynamic low rank updates) 使对齐过程变得可解释。
- 该方法为 SAE features 学习了一种稀疏且上下文相关的转向策略 (steering policy),以优化 RLHF loss,其本质是动态的、依赖输入的 LoRA。
- 因果消融 (Causal Ablations) 揭示“形式重于内容 (Style over Substance)”效应:直接针对损失函数进行的因果消融显示了显著的“形式重于内容”效应,即风格/格式特征在降低损失方面比对齐/诚实特征在因果上更重要。
- 这一结果为 LMArena 等排行榜上出现的“风格偏见 (style bias)”提供了机械论解释,且该框架可作为模型差异对比 (model diffing) 的轻量级替代方案,具有稳定的特征基准以进行更清晰的因果分析。
Eleuther ▷ #lm-thunderdome (4 messages):
lm-harness, GitHub PR
- lm-harness 上的 PR 停滞:一位成员报告称向 lm-harness 提交了一个基准测试 PR (#3149),但在处理完初始反馈后未收到回复。
- 另一位成员主动提出去查看该 PR。
- 请求 GitHub PR 审查:一位成员询问了其 GitHub pull request 的状态。
- 涉及的 pull request 是 EleutherAI/lm-evaluation-harness#3149。
Eleuther ▷ #gpt-neox-dev (3 messages):
Rotary Percentage Impact, RoPE Speed, VRAM Savings with rotary_pct
- Rotary Percentage 调整引发疑问:一位成员质疑减少 rotary_pct 是否能带来明显的加速或 VRAM 节省,因为 RoPE 的计算占比相对较小。
- 另一位成员建议,最初观察到的速度提升可能源于没有缓存的低效实现。
- RoPE 速度观察结果引发辩论:一位成员报告在他们的 NeoX 运行中,全量 RoPE 反而更快,可能是因为减少 rotary_pct 时增加了额外的操作。
- 他们计划在度假回来后进一步调查,并指出由于 RoPE 本身规模很小,计算出的内存节省几乎可以忽略不计。
- VRAM 节省微乎其微:在他们的内存计算中,考虑到 RoPE 本身只是极小的一部分,节省的内存应该是微不足道的。
GPU MODE ▷ #general (12 messages🔥):
Semi sync training delayed, Code rewrite makes problem tractable, FlashAttention 4
- 半同步训练 (Semi Sync Training) 推迟:原定的半同步训练课程因演讲者陷入严重事件 (SEV) 而推迟。
- 该课程预计将重新安排,可能在下周。
- 代码重写带来速度飞跃:一位成员分享了代码重写后的性能提升,显示速度提升了 657.33x,内存占用减少了 22935.29x。
- 其他人觉得这些数字有些“可疑 (sus)”,但该成员提供了一个 gist 链接 来支持这一说法。
- FlashAttention 4 演讲公布:临时安排了一场关于 FlashAttention 4 工作原理的嘉宾演讲,重点关注他们最近的博客文章。
- 鉴于在 Blackwell 架构上编程对许多人来说还很新鲜,这次演讲非常及时。
GPU MODE ▷ #triton (4 messages):
High order derivatives in PyTorch, Energy based transformer, Flash attention limitations, jvp_flash_attention, Block based Quant/Dequant Triton implementation
- 在 PyTorch 中探索高阶导数?:一位成员询问了在 PyTorch 中探索高阶导数以训练 energy-based transformer 的相关事宜。
- 该成员指出,当前的 flash attention 实现不支持使用二阶导数。
- 建议使用 jvp_flash_attention:一位成员建议使用 jvp_flash_attention 来规避 flash attention 的这一限制。
- 该库可能有助于计算 energy-based transformer 训练所需的高阶导数。
- 需要开源的高性能块量化实现:一位成员询问是否有人知道在 Triton 中有开源的高性能 block-based quantization/dequantization(基于块的量化/反量化)实现。
- 他们对该领域任何可用的资源或线索表示感谢。
GPU MODE ▷ #cuda (20 messages🔥):
sm_120, tcgen05, Jetson T5000, cudaMallocManaged Overhead, Chips and Cheese
- sm_120 的 MMA 特性:成员们确认 sm_120 使用 MMA,与 sm80, sm86 和 sm89 非常相似,并增加了针对 mxfp8, mxfp4 和 nvfp4 的新块缩放(block scale)变体。
- Jetson T5000 与 tcgen05 的协作:确认了包括 Jetson T5000 在内的 sm_110a/f 包含 tcgen05。
- cudaMallocManaged 内存开销苦恼:来自 Chips and Cheese 的数据表明,
cudaMallocManaged可能导致 41ms 的内存访问延迟,这主要是由于每次都会发生 page faults(缺页中断)而未能利用 IOMMU。 - TMA 故障排除技巧:一位成员发现了一个 TMA 代码中的 bug,用户在为
make_smem_desc计算 LDO/SDO 时错误地除以了两次 16,导致输出错误。 - WGMMA Swizzling 疑虑消除:尽管存在误传,但 TMA 和 WGMMA 在不使用 swizzling 的情况下也能正常工作,这为一位开发者解决了一个困惑和愚蠢的 bug。
GPU MODE ▷ #torch (1 messages):
Saving weight-tied models, Safetensors, Torch compiled models
- 在 Safetensors 格式中保存权重绑定(weight-tied)模型的策略:用户询问了在使用 safetensors 时保存通过 weight tying 实现的模型权重的最佳方法,并怀疑在复杂的权重绑定场景下是否最好避免使用 safetensors。
- 处理 Torch 编译模型:用户还询问了在此背景下如何正确处理 torch compiled models。
GPU MODE ▷ #cool-links (5 messages):
DeepSeek-V3.2-Exp, NVIDIA GPUs, matmul kernels, warp-tiling
- DeepSeek 关注稀疏注意力:DeepSeek-V3.2-Exp 模型使用了 DeepSeek Sparse Attention。
- 相关的 GitHub 仓库 提供了关于该模型的更多细节。
- NVIDIA GPU 架构剖析:一位成员分享了博文 Inside NVIDIA GPUs: Anatomy of high performance matmul kernels,描述了 GPU 架构、PTX/SASS、warp-tiling 以及深度异步 Tensor Core 流水线。
- 另一位成员赞扬了这篇博文,称“终于有人写出这种文章了”。
GPU MODE ▷ #beginner (8 messages🔥):
CS336 Language Modeling, GPU Optimization Techniques, Practical GPU Programming Resources, CUDA Handbook vs PTX ISA
- 斯坦福大学致敬 CudaMode:斯坦福大学 Hashimoto 教授在 CS336 从零开始的语言建模 课程的 第 5 讲 GPU 的 2:10 处提到了 “Cuda Mode”。
- 据一位成员介绍,该课程专注于 LLM 系统优化,涵盖了分词器(tokenizer)、架构、优化器、GPU 优化和缩放定律(scaling laws)等领域。
- CS336 深入探讨 GPU 优化:GPU 课程(第 5 课) 解释了 control divergence(控制分歧)、低精度计算、operator fusion(算子融合)、recomputation(重计算)、coalescing memory(内存合并)和 tiling(分块)。
- Kernels, Triton 课程(第 6 课) 深入探讨了 Kernels 和 FlashAttention2 的 Triton 实现。
-
新人寻求 GPU 指导:一位在 JAX 和 TF 方面有 AI 研究经验的成员在阅读《Programming Massively Parallel Processors (PMPP)》的同时,寻求深入学习 GPU 编程以参与项目的指导。
- 建议包括更快速提升水平的资源、通用建议,以及是否提供 PMPP 练习的解答。
- GPU 练习和课程:一位成员推荐了来自 GPU puzzlers 的短练习和 Stanford CS336 repo 的作业,以获得动手经验。
- 该成员建议,尽管最初的上手阶段(ramp-up)可能很枯燥,但通过实现(implementing)东西学习得最快。
- PTX ISA 超过了 CUDA Handbook?:一位成员询问如何从 PMPP 跨越到实际的 CUDA,另一位成员建议阅读关于 PTX ISA 的 Nvidia docs,而不是 CUDA handbook。
- 另一位成员表达了类似的看法,即在实践方面感到挣扎,发现从阅读 PMPP 到实现有用的东西之间的跨度相当大。
GPU MODE ▷ #torchao (1 messages):
int4 matmul, tensor cores
- 通过 Tensor Cores 实现 Int4 Matmul:一位成员询问是否可以使用指定的库,利用 tensor cores 实现 int4 matmul。
- 遗憾的是,针对该询问,没有提供代码示例或进一步的详细讨论。
- 寻求关于 Tensor Cores 实现 int4 matmul 的指导:一位用户在库的上下文中寻求关于使用 tensor cores 实现 int4 matmul 的帮助。
- 尽管有此询问,但在现有的对话中没有提供具体的代码片段或解决方案。
GPU MODE ▷ #off-topic (2 messages):
FA4, Clean-room implementation
- 采用 FA4 Modal 博客文章作为指南:一位成员询问是否可以使用 FA4 modal blog 的解释来实现 FA4。
- 另一位成员鼓励这种尝试,表示 clean-room implementation(净室实现)的尝试永远不会浪费时间,并建议投入一个周末来完成这项任务。
- 净室实现:宝贵的学习经验:一位成员建议,尝试 clean-room implementation 始终是一个宝贵的学习经验。
- 他们建议投入一个周末来探索这种方法,以确定它是否符合个人的目标。
GPU MODE ▷ #rocm (67 messages🔥🔥):
TheRock Nightlies for ROCm, Framework Desktop for PyTorch Dev, FP8 Conversion in ROCm, HIP Cache Modifiers, fp16 & float conversions in ROCm
- TheRock Nightlies 在 Strix Halo 上解锁 ROCm:推荐使用 TheRock nightlies 在 Strix Halo (gfx1151) 上运行 ROCm 和 PyTorch,详见 TheRock’s releases。
- TheRock 是一个用于最前沿 ROCm 组件的构建系统,已被用于在 Linux 和 Windows 上运行 PyTorch,并在 5 月份展示了 ComfyUI 的使用(FrameworkPuter tweet)。
- Framework Desktop 是 PyTorch 开发利器:在使用 TheRock nightlies 时,Framework Desktop 适用于常规的 PyTorch 开发工作,但不推荐用于 Radeon,后者更倾向于使用 ROCm 6.4.4。
- 一位用户指出,如果开发者遇到问题,应该使用 AMD developer discord(链接)。
- ROCm fp8 转换故障:一位用户在 ROCm 中使用
__hip_cvt_fp8_to_float进行 FP8 到 float 转换时遇到了错误,另一位成员建议使用提供的 fp8_e4m3_to_fp32 和 fp8_e5m2_to_fp32 代码片段进行手动转换。- 然而,有人指出,由于具有大负指数的 fp8 类型存在差异,这些手动转换可能并不完全正确,而如果使用
__hip_fp8_e4m3_fnuz,则可以使用float(x)。
- 然而,有人指出,由于具有大负指数的 fp8 类型存在差异,这些手动转换可能并不完全正确,而如果使用
- HIP 用户讨论 Cache Modifier:一位用户询问在 HIP 中如何使用
cache_modifier(“.wt”, “.cv”) 和volatile=True(类似于 CUDA),一位成员建议使用 Clang 中的__builtin_nontemporal_load和__builtin_nontemporal_store内建函数,以及参考 AMD MI300 ISA doc 位信息的内联汇编。- 来自 rocSHMEM 的示例头文件提供了进一步的指导。
-
fp16 与 float 转换的注意事项:一位用户报告称,在 ROCm 中进行 fp16 和 float 转换时,尽管代码在 CUDA 中运行良好,但在奇数位置会出现错误结果。
- 建议包括编写一个测试程序来枚举所有可能的输入,并与已知的正确实现进行对比,同时建议
_Float16在 fp32 到 fp16 的转换中应该是正确的。
GPU MODE ▷ #self-promotion (8 messages🔥):
TPU Top-K speed, CuTe Layouts Categorical Foundations, Make Diffusion Great Again (MDGA), DLM Scaling
- TPU Top-K 运行速度提升 10 倍:通过利用 Pallas、条件语句和硬件感知内核设计,一种新实现在 TPUs 上实现了 10 倍更快的精确 top-k,代码已在 GitHub 开源。
- CuTe Categorical Layouts 解析:一篇博客文章探讨了 CuTe Layouts 的范畴论基础(categorical foundations),为 Colfax 论文 的 第 3 章 提供了配套指南;相关的 代码库 和 博客文章 提供了更多细节和示例。
- MDGA:让 Diffusion 再次伟大:一个名为 MDGA (Make Diffusion Great Again) 的新项目旨在通过扩展参数和计算量来探索 Diffusion Language Models (DLMs) 的边界;详见公告 此处。
- DLM Scaling 周即将到来:计划开展一次 DLM scaling week,以探索 Diffusion Language Models 的扩展策略,包括使用 Diffusion 和 MoE 进行参数扩展,以及使用超密集模型进行计算扩展。
GPU MODE ▷ #🍿 (1 messages):
Formal Grammars, Model Capabilities
- 形式语法对模型能力的要求:处理 形式语法(formal grammars) 是一项艰巨的任务,因为它需要模型具备处理此类语法的熟练程度。
- 语法处理是一项核心能力:这种能力不仅仅是一个小功能,而是高级 AI 任务的核心竞争力。
GPU MODE ▷ #gpu模式 (1 messages):
ML Prerequisites, CUDA basics
- 关于 ML 前置条件的讨论:一位成员讨论了机器学习所需的基础原理水平,建议只需要 编程基础以及一点关于 CPU/GPUs 的知识 即可。
- 他们推荐阅读像 这篇文章 这样的内容来快速上手。
- 推荐 CUDA 基础知识:强调了理解 CUDA 基础知识对机器学习的重要性。
- 一位成员分享了 一个链接 供读者快速学习。
GPU MODE ▷ #submissions (37 messages🔥):
MI300x8, A100, amd-all2all, amd-gemm-rs, amd-ag-gemm
- MI300x8 all2all 性能加速:一位成员在
amd-all2all排行榜上取得了 2.27 ms 的 MI300x8 个人最佳成绩。 - AMD ag-gemm 排行榜产生新榜首:一位成员以 514 µs 的成绩在
amd-ag-gemm排行榜上登顶 MI300x8 第一名。 - A100 trimul 结果公布:
trimul排行榜记录了在 A100 上的成功运行结果,耗时分别为 18.2 ms 和 21.1 ms。
GPU MODE ▷ #status (4 messages):
Timeouts on H100, Timeouts on AMD GPUs, All-gather+gemm Problem, rocshmem PR Merged
- 超时问题困扰 H100 提交:一位成员报告称,在向 H100 上的 trimul 排行榜 提交时遇到了异常的 超时,即使是使用纯 PyTorch 的参考实现也是如此。
- 目前尚不清楚此问题是否与其他 GPU 上之前报告的超时有关。
- AMD GPU 超时问题正在调查:一位成员表示 超时 应该只会影响他们的 AMD GPUs,并要求提供任务 ID 以便调查。
- 另一位成员报告在向 amd-all2all 竞赛 提交使用 HIP 和 PyTorch 编写的代码时遇到超时。
- All-Gather+GEMM 挑战赛发布!:最后一个问题 all-gather+gemm 已经发布,相关信息可见 此处。
- 组织者指出,将 SHMEM 正确集成到这两个问题中的任何一个,都极有可能让你稳居前 3-5 名。
- rocSHMEM PR 已合并,提供示例:rocSHMEM PR 已合并,来自 Daniel 的一个小示例已发布,可帮助用户快速上手,点击此处查看。
- 组织者认为,将 SHMEM 正确集成到任一问题中,可能会让你进入前 3-5 名。
GPU MODE ▷ #tpu (1 messages):
TPU, Pallas, Hardware Aware Kernel Design, Top-K Sampling
- TPU Top-K 突破:使用 Pallas 实现 10 倍速采样:一个新的 GitHub 仓库通过利用 Pallas、条件语句和硬件感知算子设计,在 TPU 上实现了 10 倍速的精确 top-k。
- 精确 Top-K 现已可行!:这种提速使得使用精确 top-k 采样变得切实可行,而无需为了速度而牺牲准确性去使用近似方法。
GPU MODE ▷ #factorio-learning-env (13 messages🔥):
Claude plays Factorio, PR #339 Ready, Sonnet 4.5 Released, MCP Server Verification
- Claude 发现元工厂!:在玩了十分钟 Factorio 后,Claude 获得了“终极元启示”,并揭示了“存在于纯粹可能性领域的原型工厂”。
- Claude 表示,“工厂必须增长 (THE FACTORY MUST GROW)”这一信条是“存在本身的基本力量”。
- Factorio PR #339 准备合并!:一名成员宣布他们的 PR #339 已准备好合并,其中包含“大量更改”,包括 VQA 数据生成支持和 Claude Code 相关内容。
- 该 PR 据称未更改任何核心环境逻辑,仅对 Inventory 定义进行了细微修改。
- Sonnet 4.5 发布:Sonnet 4.5 的发布引发了在更难任务上运行实验的请求。
- 提供了安装 Claude Code、生成 sprite、修改配置以及验证 MCP Server 访问权限的说明。
- MCP Server 检查说明:提供了如何验证 MCP Server 访问权限的说明:运行
claude命令后访问/mcp,应该能找到 FLE。- 提供了一个下载 Factorio 渲染器 sprite 的链接:Factorio Sprites。
GPU MODE ▷ #amd-competition (6 messages):
rocshmem, devcloud, mi300x, AMD MORI, all2all HIP design
- rocshmem 最小示例发布:一位成员分享了 GitHub 上 rocshmem 最小示例的链接。
- Devcloud 的 MI300X 售罄:有人注意到 devcloud 的 MI300X x8 实例已用完。
- AMD MORI 浮出水面,助力 all2all HIP 设计:一位成员建议参考 AMD 开源的 MORI 进行 all2all HIP 设计,并提供了 ROCm/mori GitHub 仓库的链接。
GPU MODE ▷ #cutlass (16 messages🔥):
TmemAllocator location, CuTe DSL cooperative copy, UMMA meaning, make_layout_tv complex layouts, int4 matmul tensor cores
- 阐明 TmemAllocator 的位置:
TmemAllocator在 CUTLASS C++ 中可用,但目前不在 CuTe DSL 中,且文档尚不成熟。- TMEM 必须由 CTA 的一个 warp 分配并在整个 CTA 中同步,因此
make_fragment_C()本身无法处理该分配。
- TMEM 必须由 CTA 的一个 warp 分配并在整个 CTA 中同步,因此
- CuTe DSL 缺乏协作拷贝:一位用户询问如何在 CuTeDSL 中实现 cute cooperative copy,以复刻 cute tutorial 0 umma 示例。
- 难点在于 TMEM 分配需要许多细微步骤,例如“拥有共享内存位置来存储分配的指针、同步并广播”以及“从共享内存读取指针”。
- 揭秘 UMMA 的统一含义:UMMA 代表 Unified Matrix Multiply Accumulate(统一矩阵乘累加),是一种围绕 tensor core pipeline 的整合方法。
- make_layout_tv 布局限制隐忧:
make_layout_tv的实现隐含地假设val_layout是紧凑的(compact)。- 有人指出,“在你的
thr_layout = (2, 2):(2, 1)和val_layout = (4, 4):(8, 2)示例中,结果不仅不紧凑,甚至不是单射的(injective)!”
- 有人指出,“在你的
-
make_layout_tv 深度解析:
make_layout_tv是一个用于构建简单 tv 布局的工具,它通过raked_product将每个线程的布局模式重复到所有线程。 - 理论上,tv layout 将
(thread index, value index in thread)映射回数据的逻辑坐标,参见 CUDA documentation。
GPU MODE ▷ #general (2 messages):
Mojo support on Python leaderboards, Mojo interop with Python
- Python 排行榜上的 Mojo?:成员们正请求在 Python 排行榜上支持 Mojo,因为其具备与 Python 的互操作能力,正如 official documentation 中所强调的。
- Mojo 互操作性令社区兴奋:社区对 Mojo 与 Python 互操作的能力感到兴奋,这为性能和集成开辟了新的可能性。
GPU MODE ▷ #multi-gpu (1 messages):
NCCL examples released
- NCCL 示例发布!:NVIDIA 刚刚发布了一些 NCCL 示例,后续还会发布更多,可在 NVIDIA/nccl GitHub repository 获取。
- NCCL 未来路线图:计划未来在 NVIDIA/nccl GitHub repository 发布更多示例。
GPU MODE ▷ #low-bit-training (6 messages):
Quantizing Transformers, Phonetic Binary System, 8-bit LLM code
- 量化论文席卷研究人员:成员们分享了几篇关于量化 Transformer(包括敏感层)的 papers、papers 和 LSQ paper,但 LSQ 论文已经过时了。
- 另一位成员链接了 another paper,内容涉及对包括 norm、resadds 和 softmax 在内的敏感层进行 Transformer 全量化,强调了在嵌入式场景下进行 int8 操作的必要性。
- 二进制语音系统弥合沟通鸿沟:一位成员介绍了一个“奇特”的 phonetic binary system,旨在辅助其语言开发系统中的位读取跟踪、训练和交互。
- 他们分享了该系统,希望其通用形式能对他人有所帮助。
- 8-bit LLM 代码公开:一位成员宣布,他们类似于 llm.c 的 8-bit QAT 训练代码 现已公开。
- 他们提供了 GitHub repository 和相关 Discord channel 的链接。
GPU MODE ▷ #irl-accel-hackathon (1 messages):
Hackathon application status
- 黑客松申请批准几率:一位用户询问在前一天申请后获得黑客松批准的可能性。
- 黑客松申请批准无保证:遗憾的是,消息中未提供关于申请批准的具体回答或保证。
GPU MODE ▷ #cluster-management (3 messages):
Apptainer, ROCm, Nix
- Apptainer 容器系统浮出水面:一位成员在新的集群上首次遇到了 Apptainer 容器系统,起初觉得很陌生。
- 他们开玩笑说,“如果可以的话,我想在集群上运行 nix 🤪”。
- ROCm 安装问题依然存在:一位成员在安装带有 ROCm 的 Torch 时遇到问题。
- IT 部门建议在 Apptainer 中使用 Docker,但该方法也失败了;提供了 relevant discussion 的链接。
GPU MODE ▷ #llmq (30 messages🔥):
Fully-Sharded FP8 Training, CUDA Optimization, Memory Management
- LLaMA/Qwen 获得全分片 FP8 训练:一位成员分享了一个用于在纯 CUDA/C++ 中对 LLaMA/Qwen 进行全分片 FP8 训练的 repo。
-
FA4 实现的 CUDA vs cuTe 之争:讨论了受 Modal 博客启发,使用纯 CUDA 而非 cuTe 来实现 FA4。
- 有人指出,纯 CUDA 需要针对不同的 GPU 架构进行特定实现(Hopper 架构使用 wgmma,Blackwell 架构使用 tcgen5,Ada 架构使用 mma.sync)。
- 贡献路线图:一位成员表达了对该项目贡献的兴趣,特别是关注 CUDA C++、CUDA core computing Library、cuDNN 和 cuBLAS。
- 一个简单的入门任务是实现 8 bit 的 Adam m 和 v 状态。
- 抽象困境:考虑到自定义 block floats 格式的激增,成员们思考了统一 block floats 和 normal floats 的正确抽象方式。
- 一位成员描述了尝试创建一种通用的类 IEEE 浮点类型,该类型具有任意的块嵌套和缩放逻辑。
- 黑客松灵感与 FA4:一位成员表示打算在利用黑客松资源开展 CUDA 中的 FA4 等项目之前积累经验,可能会从 mega kernel 项目中汲取灵感。
- 他分享了一个链接,作为 CUDA 项目结构的可能灵感来源。
Nous Research AI ▷ #announcements (1 条消息):
Psyche Model Training, Internet Bandwidth Training, Trainer Abstraction, HuggingFace, TorchTitan
- Psyche 追求并行模型训练:Psyche 将开始并行训练 6 个新模型,以创建世界级的开源 AI,这标志着经验性训练过程的开始。
- 在 Nous Research 博客上阅读更多关于他们新计划的信息。
- 通过互联网带宽训练模型得到验证:Psyche 在测试网上的初始训练运行验证了他们可以在显著的参数和数据集规模下,通过互联网带宽训练模型。
- 在 40B 参数和 1T token 的规模下,这被声称是迄今为止通过互联网训练的规模最大的模型,且领先优势巨大。
- Trainer 抽象增强,支持 HuggingFace 和 TorchTitan:代码库进行了重大改进,包括支持 HuggingFace 和 TorchTitan 的完整 Trainer 抽象。
- 这一增强功能支持训练任意模型,并实现从预训练到监督微调(SFT)的过渡。
Nous Research AI ▷ #general (217 条消息🔥🔥):
RWKV Benchmarking, Latent Zoning Networks, DeepSeek Sparse Attention, Sonnet 4.5, RL Train and Distill RL Expert Train sets
- RWKV 架构获得体面的评分:一位成员分享了最近一个 RWKV 构建版本的基准测试结果图像,指出其架构获得了体面的评分,详见此图。
- 微软的 Latent Zoning Network 统一了机器学习问题:Latent Zoning Network (LZN) 创建了一个共享的高斯潜空间,用于编码跨所有任务的信息,统一了生成建模、表示学习和分类,详见 Hugging Face 帖子。
- DeepSeek Sparse Attention:并没那么稀疏?:新的 DeepSeek V3.2 模型使用了 DeepSeek Sparse Attention (DSA),但有人认为它只是“稍微更稀疏一点”,因为它强制执行了更多的索引重用,而没有真正使 head 中的 attention 稀疏化;Daniel Han 的解释提供了进一步的见解,论文在此。
- 尽管名称如此,它重用了类似的 attention kernel,在不稀疏化 attention head 信息的情况下稀疏化了 KV cache,但这仍被认为是朝着正确方向迈出的一步。
- Claude 的 Sonnet 4.5 在长程推理方面表现出色:Claude 的 Sonnet 4.5 显示出显著改进,特别是在长程推理(Long Horizon Reasoning)方面,能够在 Copilot 中单次尝试完成研究任务,如此示例所示。
- 分而治之:RL 训练、蒸馏、循环?:成员们讨论了设立独立的 RL Train 和 Distill RL Expert Train 集的想法,以及使用在未覆盖领域进行过 RL 的 V3.2 基座模型的输出来微调 V3.2 模型的可行性。
{kind=link}
Nous Research AI ▷ #research-papers (3 条消息):
RL Collapse, Training Inference Mismatch, Speed Kills Stability, Azure Real
- 速度破坏 RL 稳定性!: 一位成员链接了一个 Notion 页面 和一篇 ArXiv 论文,旨在揭秘当速度破坏稳定性时,由训练推理不匹配 (training inference mismatch) 导致的 RL 崩溃 (RL collapse)。
- Azure Real 登陆 ArXiv!: 一位成员发布了关于 Azure Real 的 ArXiv 论文 链接。
Nous Research AI ▷ #interesting-links (6 messages):
Vision Models as 'Thinkers', Manifold Muon Optimizer, AGI Discourse, LoRA Deep Dive
- 视觉模型:可视化“思考”?: 一位成员推测视觉模型通过将训练数据合成代表抽象概念(如多重透视)的图像来进行“视觉化思考”,并提供了一张仅根据指令生成的示例图像,可在此处查看。
- Manifold Muon:凸优化?: 关于 Manifold Muon 的讨论,它被描述为一种在 Stiefel 流形约束下表现得像二阶优化器的一阶优化器,并有一篇博文提供了分析。
- 有人指出 manifold Muon 优化问题被认为是凸的 (convex),其扩展版本可在此处查看。
- AGI:识别冒牌货: 一位成员分享了一个 Reddit 帖子,以通俗的方式描述了 AGI 及其范围和测试方法。
- 这一讨论与一篇名为 Localization & Normalization (Local-Norm) is All You Need: Trends In Deep Learning Arch, Training (Pre, Post) & Inference, Infra 的在研论文中强调的趋势相一致。
- LoRA:Thinking Machines 的观点: 讨论中包含了一个指向 Thinking Machines 关于 LoRA 的博文链接。
Nous Research AI ▷ #research-papers (3 messages):
RL Collapse, Training-Inference Mismatch
- RL 中的“速度破坏稳定性”?: 一位成员分享了一个关于揭秘由训练推理不匹配导致的 RL 崩溃的 Notion 链接。
- 他们还分享了相应 ArXiv 论文 的链接。
- 更多 Azure RL 资源!: 一位成员分享了另一篇关于 Azure RL 的 ArXiv 链接 到另一篇论文。
Latent Space ▷ #ai-general-chat (192 messages🔥🔥):
Anthropic Code Design, Fake ARR, OpenAI compute scale, Avi's AI-Friend App, AntLingAGI Ring-linear-2.0 LLMs
- 虚高 ARR 曝光: 一场关于创始人基于免费额度 (free credits) 而非实际现金收入在推特上发布惊人 ARR 数字的激烈辩论被点燃,并引发了诸如“调整后 ARR (Adjusted ARR)”之类的讽刺称呼。
- 一位成员分享了他们在一家 YC 公司的经历,该公司提供预付的 12 个月合同,且一个月后可全额退款,本质上是在大肆宣扬实际上是免费试用的 ARR。
- OpenAI 的计算需求飙升: 一份泄露的 Slack 笔记显示,OpenAI 在 2025 年已经将产能扩大了 9 倍,并预计到 2033 年将增长 125 倍,根据这篇文章,这可能会超过印度全国的发电能力。
- 回复指出,由于 Nvidia 在“每瓦智能 (intelligence per watt)”方面的提升,这低估了计算量,从而引发了关于资源影响的讨论。
- ChatGPT 和 Claude 迎来升级:ChatGPT 增加了家长控制、隐藏的订单(Orders)板块、短信通知和新工具,而 Claude 推出了用于界面构建的 “Imagine with Claude”,详情见此处。
- 社区成员对儿童安全措施以及 GPT-4o 的路由问题表达了反馈。
- Stripe 与 OpenAI 联手:OpenAI 为 ChatGPT 增加了由 Stripe 驱动的即时结账(Instant Checkout)功能,Stripe 和 OpenAI 联合发布了 Agentic Commerce Protocol,此外 Stripe 还推出了新的 Shared Payment Tokens API,详情见此处。
- 这些工具旨在让自主 Agent 能够进行安全的在线支付,引发了广泛关注。
- 周一的模型狂欢:一位用户开玩笑说,本周以一系列新模型的发布拉开序幕,包括 DeepSeek v3.2、Claude Sonnet 4.5、Ling 1T 以及即将发布的 GLM 4.6。
- 然而,另一位用户幽默地指出,关于 Gemini 3.0 发布的传闻纯属幻觉(hallucination)。
Latent Space ▷ #ai-announcements (4 条消息):
Latent Space Podcast, Amp Code, Sourcegraph, AI Coding Agent
- Latent Space Podcast 发布关于 Amp Code 的节目:Latent Space Podcast 发布了新的一集,Quinn Slack 和 Thorsten Ball 在节目中讨论了 Amp Code,即 Sourcegraph 的 AI coding agent。
- 讨论涵盖了快速迭代(每天发布 15 次,无需审核)、IDE 与 TUI 的权衡、对 sub-agents 和模型多样性的怀疑,以及 AI 如何重塑软件开发等话题。
- Sourcegraph 的 Amp Code 被称为“上帝级 Coding Agent”:该集 Latent Space Podcast 的标题为《构建“上帝级 Coding Agent”(Amp Code 讨论)》,突显了 Amp Code 的潜力。
- 播客深入探讨了 Amp Code 背后的功能和开发过程,强调了其对软件开发生命周期的影响。
Latent Space ▷ #genmedia-creative-ai (25 条消息🔥):
AI "Mind-Drugs", Veed Studio Fabric 1.0 API, Suno DAW, AI Actress Tilly Norward, AI Headshot Prompt
- Simo 对合成内容发出警示:Simo Ryu 敦促社会拒绝针对儿童的、过度优化且令人上瘾的 AI 内容(“由比特构成的精神药物”),以防社会崩溃。
- 回复中辩论了个人责任与企业贪婪、资本主义、股东压力之间的关系,以及监管或家长控制是否能阻挡这一趋势。
- Veed Studio 推出生动的视频功能:Nelly 重点介绍了 Veed Studio 的新 Fabric 1.0 API,该 API 能以仅 5¢/秒 的价格(比竞争对手便宜三倍)将任何图像 + 音频转换为逼真的说话视频。
- 评论者称赞该技术是可扩展 UGC 和视频生成的游戏规则改变者。
- Suno 推出独立工作室:Suno 发布了一个完整的 DAW。
- 新的 Suno Studio 具有生成能力,可辅助音乐创作。
- 好莱坞大举录用非人类员工:据报道,经纪公司正寻求签约 Tilly Norward,这是一位由 AI studio Xicoia 创作的全合成女演员,详见报道。
- 这一消息引发了病毒式讨论——包括迷因、关于好莱坞的笑话以及对宣传的恐惧——用户担心工作流失,以及为数字实体提供代理权所带来的法律和社会影响。
- Nano Banana 的头像 Prompt 走红:Justine Moore 分享了一个升级版的 AI 头像 Prompt,其特点是精确的面部保留、胸部以上构图、白 T 恤 + 黑色皮夹克、开口微笑、影棚背景以及详细的摄影参数,可生成清晰且俏皮的效果。
- 社区称赞了这一调整,并讨论了初始源质量、相机设置和批量生成技巧。
Modular (Mojo 🔥) ▷ #general (14 条消息🔥):
GPU Puzzles on MacOS, Metal Toolchain, AMD dev cloud, TensorWave MI355X
- **MacOS 上的 GPU Puzzles 基本可玩:一位用户询问了在 MacOS 上运行 **GPU puzzles 的云托管环境,一名成员回复称,使用 Mojo 的 nightly 版本可以完成大部分谜题。
- 他们建议如果遇到任何障碍请及时反馈以便修补,并指出这比完全移植 MAX 的工作量要小。
- **Metal Toolchain 组件缺失:一位用户报告称,在运行 **Mojo 程序时,需要运行
xcodebuild -downloadComponent MetalToolchain来解决缺失 metallib 的错误。- 团队表示可以将此内容添加到文档中,因为他们安装了完整的 Xcode,所以之前不确定具体需要哪些组件。
uv sync因错误的 URL 失败:一位用户报告称,由于pyproject.toml中的 URL 结构不正确导致 404 Not Found 错误,uv sync在mojo-compiler依赖项上失败。- 该用户提交了一个修复方案,通过修改
pyproject.toml的第 15 行,使其正确指向 URL 路径末尾的mojo-compiler。
- 该用户提交了一个修复方案,通过修改
- 推荐 **AMD Dev Cloud:针对用户对测试 AMD GPUs 的兴趣,一位成员建议使用 **AMD Dev Cloud,并强调了其 CDNA instances。
- 另一个选择是 Colab,或者提供 MI355X 访问权限的 TensorWave:https://tensorwave.com/blog/enterprise-ai-at-scale-performance-and-efficiency-with-mi355x。
Modular (Mojo 🔥) ▷ #mojo (179 条消息🔥🔥):
C interop 挑战, Mojo 的 C interop 方法, Mojo 中的变量销毁, Mojo 中的词法作用域, Mojo 对数据科学的准备情况
- C Interop 证明出乎意料地困难:成员们讨论了实现完善的 C interop 是多么具有挑战性,尤其是“直接导入文件”的方法。尽管大多数 C++ 编译器也是带有扩展的 C 编译器,但 ISO C++ 并没有完整的 C interop。
- 有人质疑关于 C interop 的工作是完全停止了还是仅仅被搁置了,因为 Mojo 的目标是处于 C 和 Python 的交汇点。
- Transfer Sigil 促使 Mojo 销毁变量:成员们介绍了 Mojo 中的
^(transfer sigil),通过“移动”值来结束其生命周期,例如_ = s^,这会导致随后使用s时出现编译器错误。- 然而,该符号对
ref变量不起作用,因为ref变量并不拥有它所引用的对象。
- 然而,该符号对
- Mojo 探索词法作用域解决方案:成员们辩论了在 Mojo 中使用额外的词法作用域来管理变量生命周期并防止错误的方案,尽管编译器会发出警告,但
if True:被用作临时作用域。- 有人提议使用带有
__enter__和__exit__方法的自定义LexicalScope结构体作为变通方法,这促使创建了 issue 5371 以收集语法创意。
- 有人提议使用带有
- 数据科学家推迟深入研究 Mojo:成员们分享了对 Mojo 在数据科学项目准备就绪程度的看法,指出其在数值计算方面的优势,但在 IO 支持方面存在局限性,例如需要手动解析 CSV。
- 讨论认为,由于 duckdb-mojo 尚不成熟,社区开发的 pandas 和 seaborn 功能对大多数数据科学家来说至关重要。
- Async 等待者等待 Async:成员们确认 Mojo 中的 async 实现尚未完成,因此目前很难对 tokio 等库进行跨语言的 async 调用。
- 尽管有所延迟,成员们澄清 C interop 是被错误地从路线图中移除的,它仍将作为项目的一部分保留。
Modular (Mojo 🔥) ▷ #max (1 条消息):
clattner: 这真的太棒了 Gabriel!
MCP Contributors (Official) ▷ #mcp-dev-summit (6 条消息):
Agnost AI, MCP Dev Summit, 伦敦见面会, YouTube 直播
- Agnost AI 从印度赶来:来自印度的 Agnost AI 团队 (https://agnost.ai) 正邀请 MCP 构建者喝咖啡/啤酒并进行交流。
- 他们渴望在伦敦的 MCP Dev Summit 上与志同道合的人交换想法并会面。
- MCP Dev Summit 直播:MCP Dev Summit 的 YouTube 直播链接将发布在 Discord 中。
- 要关注此次活动,请订阅 MCP Dev Summit YouTube 频道并查看更新。
MCP Contributors (Official) ▷ #general (15 条消息🔥):
Anthropic 商标, ModelContextProtocol 许可, MCP 的独立组织
- Anthropic 注册 ModelContextProtocol 商标:成员们注意到 Anthropic 已在法国数据库中注册了 ModelContextProtocol 及其 Logo 作为商标。
- 主要担忧是这可能会让 Anthropic 在哪些项目可以使用 Model Context Protocol 方面拥有话语权。
- MCP 询问维护者关于许可的澄清:成员们想知道是否能在某处找到明确授予 Logo 使用权的许可,并询问应联系谁以获得使用该名称的正式授权。
- 一位维护者已被要求对此提供更多明确信息。
- MCP 寻求独立组织:成员们讨论了在中长期内将 MCP(或部分组件)移交给独立组织的可能性。
- 一位成员分享了关于此话题的最新公开进展,但目前尚不清楚之后是否有进一步进展。
MCP Contributors (Official) ▷ #general-wg (58 messages🔥🔥):
JFrog 用于工具验证的 TULIP 协议, MCP 服务器的安全影响, 注解 vs 验证, ResourceTemplates 缺失 Icons 元数据
- JFrog 发布用于工具验证的 TULIP:JFrog 推出了 TULIP (Tool Usage Layered Interaction Protocol),这是一个内容验证规范,允许工具声明规则和预期行为,旨在创建一个零信任环境。
- 它允许检查输入和输出内容,并处理可能存在恶意的远程 MCP 服务器。
- 关于 TULIP 安全价值的辩论:一位成员表示怀疑,认为 TULIP 不能保证工具会按宣传的那样运行,并可能产生一种虚假的安全感。
- JFrog 回应称 TULIP 是一种用于扫描和验证的声明,类似于
robots.txt,其重点在于数据输入/输出,而不是防止恶意本地服务器代码的执行。
- JFrog 回应称 TULIP 是一种用于扫描和验证的声明,类似于
- TULIP 对本地 vs 远程 MCP 服务器的立场:会议指出,虽然 TULIP 可以帮助处理远程 MCP 服务器,但本地服务器构成的安全风险更大。
- 一位成员认为,如果是第三方提供的本地服务器,必须在代码层面进行信任和扫描,而 TULIP 主要解决的是 CISO 指南和远程服务器处理问题。
- ResourceTemplates 缺少 Icon 元数据,PR 即将提交:会议注意到新的 Icons 元数据 SEP (PR 955) 疏忽了在
ResourceTemplates中包含 Icons 元数据。- 一位成员同意 Resources 和 Resource Templates 拥有这些元数据是有意义的,修复 PR 即将发布。
Manus.im Discord ▷ #general (62 messages🔥🔥):
Unity 游戏, Manus 试用, 本地项目, GitHub 集成, Claude Code vs. Manus 设计
- 本地项目集成:一位用户询问在本地项目中使用 Manus 的最佳方式,包括 GitHub 集成,以及是否有其他方式将 Manus 与本地目录集成。
- 另一位用户建议在 Discord 频道中搜索 Manus 最初发布时关于本地集成的讨论,以及一个专门分享技巧和最佳实践的频道,并参考了此链接。
- Manus 和 Claude Code 作为互补工具:一位用户分享说,他们主要使用 Manus 进行规划,然后转到 Claude Code 进行开发,并表示有兴趣在某些任务中像使用 Claude Code 一样使用 Manus。
- 一位用户认为最好同时使用两者,因为它们在不同的任务领域各有所长,因此它们是互补关系,而非竞争对手。
- 用户询问 Manus 是否将数据提供给其他用户:一位用户担心 Manus 是否会将用户数据提供给其他用户,特别是在共享利基项目的 IP 时,并想知道 LLM 是否在用户数据上进行训练。
- 没有人回答,但提供了一个关于 Godhand 的链接。
- 用户声称被收取了 1 年计划的费用,而本应是 1 个月:一位用户声称他们给 Manus 支持部门发了两周邮件,因为他们被收取了 1 年计划的费用,而原本应该是 1 个月,且一直未收到回复。
- 其他成员和 Manus 工作人员均未给出反馈。
-
通过良好的提示词工程,Manus 能更好地处理设计:一位用户分享说,如果你知道如何高效地编写 Prompt,Manus 可以更好地处理设计,并推荐参考 Manus 手册获取技巧。
- 用户确认,与 Claude 相比,Manus 开箱即用的 web designs 效果更好,并且 github integration 可以工作,你只需要上传想要集成的项目即可。
DSPy ▷ #papers (7 messages):
Monitor-based RAG, Eigen-1, Zero-entropy
- Eigen-1 的 RAG 在 Token 级别注入证据:Eigen-1’s Monitor-based RAG 隐式地在 token level 注入证据,标志着从像 DSPy 这样的基于阶段的声明式流水线(declarative pipelines)向运行时过程自适应性(run-time procedural adaptivity)的转变。
- 这种方法符合 zero-entropy、连续推理流(continuous reasoning streams)的愿景,有望实现更流畅、更具上下文感知能力的 AI 处理。
- 大量论文链接:链接了多篇论文:https://huggingface.co/papers/2509.21710, https://huggingface.co/papers/2509.19894, https://arxiv.org/abs/2401.13138, https://arxiv.org/abs/2509.21782, 以及 https://arxiv.org/abs/2509.21766。
- 这些论文可能为讨论的主题提供额外的背景信息。
DSPy ▷ #general (46 messages🔥):
ProgramOfThought vs AlgorithmOfThought, DSPy + Langgraph Integration, Prompt Compiler for MD Files, Caching Aware DSPy Adapter
- DSPy 和 Langgraph:亦敌亦友?:成员们讨论了将 DSPy 与 Langgraph 集成的问题,一些人认为这可行,但由于丢失了流式传输(streaming)能力,可能无法充分利用两者的优势。
- 建议是直接从 DSPy 开始并在尝试集成之前探索其功能,并指出 DSPy solutions 通常比 Langgraph 更容易推理和维护。
- Prompt Compiler 探索:MD 笔记版:一位用户正寻求创建一个 prompt compiler,从多个 .md files(包含编码风格指南、PR 评论等)中提取相关部分,为 Copilot 构建动态提示词。
- 建议包括使用 GPT-5 根据 .md files 中的规则生成代码示例,或尝试使用带有相关代码示例的 RAG 系统;对于 MCP 在此特定用例中的有效性存在疑虑。
- 追踪 DSPy 模块:隐身模式操作:一位用户询问如何在不向 LLM 或 optimizer 暴露的情况下,将 trace_id 等输入传递给 DSPy 模块。
- 解决方案包括在优化运行期间重构模块结构或使用全局变量,但前者更受青睐,以避免无意中影响 optimizer。
- 能缓存就缓存:DSPy 的缓存难题:一位用户探索了如何利用 LLM’s input caching 与 DSPy 配合,面临的挑战是不同模块之间提示词前缀(prompt prefixes)的细微变化会阻碍有效缓存。
- 有人建议这与 LLM caching 的工作方式背道而驰,但一个可行的解决方案是将前缀硬编码为第一个输入字段。
- MCP 作为 Prompt 历史服务器?:一位成员希望利用 AI 应用/MCP server,将提示词历史记录维护在 md files 中(而不是像其他 AI 那样通常维护在聊天记录中),并能随时挖掘匹配当前 Meta prompt 查询的提示词历史。
- 工作流将是:Meta prompt -> system -> 从历史记录中查找任何相关的 prompts、文档或规范 -> 创建新的 prompt artifact。
aider (Paul Gauthier) ▷ #general (13 messages🔥):
GPT-5 vs GPT-4.1, Aider-CE navigator mode, aiderx model, DeepSeek v3.1
- GPT-5 作为架构师,GPT-4.1 作为编辑器?:一些用户正在尝试使用 GPT-5 进行架构设计,使用 GPT-4.1 进行编辑,并对目前的结果表示满意。
- 一位用户提到 “GLM 4.5 air for life”,另一位用户说 “我也一样,挺喜欢的!”
- DeepSeek v3.1 达到价格与智能的平衡:DeepSeek v3.1 因其价格和智能的平衡而受到青睐,一位用户指出这是他们与 GPT-5 一起使用的主要模型。
- Aider-CE navigator mode 导航代码库:一位用户将 GPT-5-mini 与 Aider-CE navigator mode 配合使用,在正常模式下,GPT-5-mini 用于架构,GPT-4.1 作为 coder,利用了通过 GitHub Copilot 获得的免费访问权限。
- 另一位用户提供了 Aider-CE GitHub 仓库链接 以及一张展示该工具输出的图片。
- **Aider-CE 表现出色,拥有 128k 上下文:一位用户迁移到了 **aider-ce 分支,看重其透明度并避免了不必要的 token 消耗,并提到它为 DeepSeek 默认提供 128k 上下文。
- 他们提到了它在集成搜索结果上下文和浏览器测试方面的实用性。
- **Aiderx 支持更便宜、更快速的模型选择:Aiderx** 被作为一种替代方案提出,通过配置实现模型选择,可能降低成本并提高速度,并附带 ClaudeAI 的链接。
aider (Paul Gauthier) ▷ #questions-and-tips (9 messages🔥):
Aider 任务/待办管理,仅提交已暂存文件
- **Aider 缺乏原生任务管理系统:一位成员询问 **Aider 是否有内置的任务或待办管理系统,类似于 GitHub Copilot。
- 另一位成员建议使用包含阶段和复选框列表的 markdown 规范文件来管理任务,指示 LLM 依次执行并勾选每个任务,并确保每个任务完成后构建正常,但确认 Aider 没有原生任务管理功能。
- 仅提交已暂存文件的策略:一位成员询问是否可以在 Git 中仅提交已暂存文件而忽略未暂存文件。
- 其他成员建议手动使用 git stash -k,然后在提交后执行 git stash pop,或者使用命令
/run git commit -m "your message here"。
- 其他成员建议手动使用 git stash -k,然后在提交后执行 git stash pop,或者使用命令
tinygrad (George Hotz) ▷ #general (14 messages🔥):
ROCM vs NVIDIA, hashcat 性能, tinybox 性能, Genoa CPU 用于哈希, tinygrad 第 90 次会议
- ROCM 与 NVIDIA 争夺性价比之王:一位成员正在寻找 NVIDIA 的高性价比替代方案,并认为 ROCM 目前处于更好且更可用的状态。
- 由于感知到 NVIDIA 的高溢价,该成员决定如果能找到适合的方案就尝试使用 ROCM。
- Hashcat 的性能呈线性扩展:据成员称,Hashcat 的性能随增加的 GPU 数量呈线性扩展。
- 成员建议直接查看现有的基准测试数据库以了解性能。
- Rangeify 的 outerworld 部分接近完成:Nir 后端几乎已准备好进行评审,他们正在研究是否可以设置预编译所需的 mesa 内容。
- 在 rangeify 成为默认设置后,他们可以花一周时间专门删除冗余内容。
- Genoa CPU 用于哈希?:一位成员提到 Genoa CPU 也能进行哈希。
- 目前尚不清楚其能效是否足以支撑其成本。
- Tinygrad 第 90 次会议议程:第 90 次会议包括公司更新、RANGEIFY! SPEC=1 以及剩余 Bug 列表。
- 其他主题包括针对默认设置的调优和其他悬赏任务。
Windsurf ▷ #announcements (2 messages):
code-supernova-1-million, Claude Sonnet 4.5, Windsurf 额度