AI News
Gemini 2.5 Computer Use 预览版击败了 Sonnet 4.5 和 OAI CUA。
Google DeepMind 发布了全新的 Gemini 2.5 Computer Use 模型,用于浏览器和 Android UI 控制,并由 Browserbase 进行了评估。OpenAI 在开发者大会(Dev Day)上展示了 GPT-5 Pro、包括集成 Slack 的 Codex 在内的新开发者工具,以及智能体(Agent)构建 SDK。Google DeepMind 的 CodeMender 实现了大型代码库安全补丁的自动化。微软推出了一款用于多智能体企业系统的开源 Agent Framework(智能体框架)。AI 社区的讨论重点聚焦于智能体编排、程序合成以及 UI 控制方面的进展。智谱(Zhipu)发布的 GLM-4.6 更新包含一个拥有 355B 参数的大型混合专家(MoE)模型。
屏幕视觉(Screen vision)就是你所需要的一切吗?
2025年10月6日至10月7日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 23 个 Discord 社区(196 个频道,6999 条消息)。预计节省阅读时间(以 200wpm 计算):556 分钟。我们的新网站现已上线,提供完整的元数据搜索和美观的 vibe coded 呈现方式。查看 https://news.smol.ai/ 获取完整的新闻细分,并在 @smol_ai 上给我们反馈!
今天来自 GDM 的简短而精彩的 Google I/O 后续:一个新的 Computer Use 模型!它当然是 SOTA,并且由 Browserbase 进行了独立评估(一个有趣的选择):
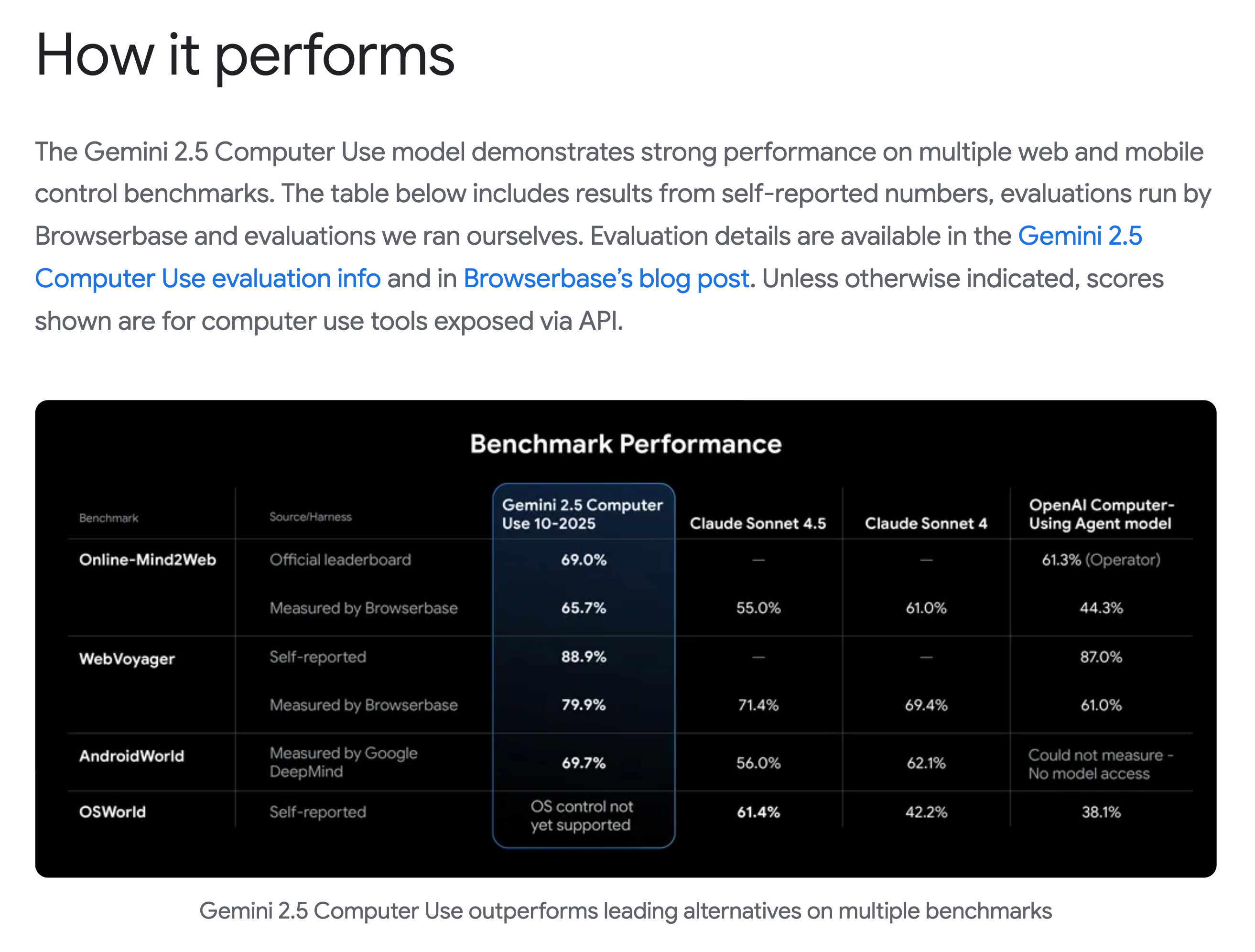
自从大约一年前 Anthropic 发布备受关注的 Sonnet 3.6 以及今年 1 月 OpenAI 发布 Operator 以来,Computer Use 的热度有所下降,但它仍然是 AGI 触达那些永远不会有良好 API 和 MCP 的长尾应用和网站的关键路径。
不仅质量出色,延迟和成本也是同类产品中领先的。
AI Twitter 综述
OpenAI Dev Day:Apps、Agents、Codex 和开发者工具
- Apps SDK, AgentKit, ChatKit Studio, Guardrails, Evals:@swyx 编目了一套完整的 Agentic 应用构建块,并附带官方链接:ChatGPT 中的 Apps + Apps SDK、AgentKit、ChatKit Studio、Guardrails 和 Evals。新模型包括 GPT‑5 Pro、realtime/audio/image minis,以及 Sora 2 / Sora 2 Pro 的 API 访问权限。早期开发者反馈包括:
- 积极的入门体验和快速的 MCP server 连接(示例)。
- Codex(OpenAI 新的内部开发工具)GA:Slack 集成受到称赞,并在内部“加速工作”;此外还有一个显眼的“1T token 奖励”文化推动(@gdb, @gdb, @gdb)。
- Cursor 添加了“plan mode”,允许 Agent 通过可编辑的 Markdown 计划运行更长时间(@cursor_ai)。
- 关于“工作流构建器”的辩论:一些人认为视觉流程图与代码优先的编排和带有工具的 Agent 循环相比,显得脆弱且受限。查看来自 @assaf_elovic, @hwchase17, @jerryjliu0, @skirano 的批评和替代方案,以及对 Agent 语义的澄清(@fabianstelzer, @BlackHC)。
Agents、程序合成和 UI 控制
- Google DeepMind 的 CodeMender(安全 Agent):大规模自动发现并修复关键漏洞;已提交 72 个上游修复,可处理高达 4.5M LOC 的代码库,并使用程序分析进行验证(博客, 详情)。
- Microsoft Agent Framework (AutoGen + Semantic Kernel):用于企业级多 Agent 系统的统一开源 SDK;Azure AI Foundry 优先,支持长时间运行的工作流、OpenTelemetry 追踪、Voice Live API GA 以及负责任的 AI 工具(概述, 博客)。
- Gemini 2.5 Computer Use (UI Agents):通过视觉 + 推理控制浏览器和 Android UI 的新模型;@GoogleDeepMind 和 @osanseviero 分享了 API 预览和集成示例(例如 Browserbase)。
- Agent 课程与框架:吴恩达(Andrew Ng)的 Agentic AI 课程专注于反思(reflection)、工具使用、规划和多 Agent 协作;LlamaIndex Workflows/Agents 强调带有状态管理和部署的代码优先编排;关于多 Agent 共享内存的评论(MongoDB 博客)。
开源模型与基准测试:GLM 4.6, Qwen3-VL, DeepSeek, MoE-on-edge
- GLM‑4.6 (智谱) 更新:采用 MIT 许可证,MoE 架构(总参数 355B / 激活参数 32B),现支持 200K context。独立评估报告显示,在推理模式下比 4.5 版本提升了 5 分(AAI 得分为 56),Token 效率更高(同等质量下 Token 减少 14%),且 API 已广泛可用(DeepInfra FP8, Novita/GMI BF16, Parasail FP8)。BF16 格式自托管约需 710 GB (摘要, 评估)。
- 权重开放模型正在缩小 Agent 能力差距:在 Terminal‑Bench Hard(编程 + 终端)测试中,DeepSeek V3.2 Exp、Kimi K2 0905 和 GLM‑4.6 表现出显著提升;在此环境下,DeepSeek 超越了 Gemini 2.5 Pro (分析)。在 GAIA2 上,DeepSeek v3.1 Terminus 对开源 Agent 表现强劲 (笔记)。
- 视觉榜单:Qwen3‑VL 在视觉领域达到第 2 名,使 Qwen 成为首个在文本和视觉榜单均登顶的开源家族 (@Alibaba_Qwen);腾讯的 Hunyuan‑Vision‑1.5‑Thinking 在 LMArena 达到第 3 名 (@TencentHunyuan)。Sora 2 和 Sora 2 Pro 现已加入 Video Arena 进行正面交锋 (@arena)。
- Liquid AI LFM2‑8B‑A1B (端侧小型 MoE):总参数 8.3B / 激活参数 1.5B,在 12T tokens 上预训练,支持通过 llama.cpp/vLLM 运行;早期报告显示其在 Galaxy S24 Ultra 和 AMD HX370 上的表现优于 Qwen3‑1.7B (发布, 架构, 基准测试, 总结)。
值得阅读的研究线索
- 新型 Attention 变体 (CCA):Zyphra 的 Compressed Convolutional Attention 在压缩的潜空间中执行 Attention;声称具有更低的 FLOPs,KV cache 与 GQA/MLA 相当,参数量比 MHA 少 3 倍,并配有用于实际加速的融合算子。论文 + 算子见推文 (发布, 背景)。
- 小型递归模型 (TRM, 7M 参数):递归推理模型在 ARC‑AGI‑1 上达到 45%,在 ARC‑AGI‑2 上达到 8%,以极小的体积超越了许多 LLM——这是 HRM 的后续版本,参数减少了 75% (@jm_alexia, 讨论)。
- 训练与 RL 进展:
- 在大规模场景下,进化策略 (Evolution Strategies) 在某些 LLM 微调方案中优于 PPO/GRPO (@hardmaru)。
- Reinforce‑Ada 解决了 GRPO 信号坍缩问题;可直接替换,梯度更清晰 (@hendrydong)。
- BroRL 认为扩展 rollouts(扩大探索范围)优于步长扩展瓶颈 (推文)。
- TRL 现支持使用 vLLM 进行高效在线训练;支持从 Colab 到多 GPU 环境 (指南)。
- 压缩、视觉、分词与模拟:
- SSDD (Single‑Step Diffusion Decoder) 通过单步解码改进了图像自动编码器的重建效果 (推文)。
- VideoRAG:通过基于图的多模态索引,实现对 134 小时以上视频的可扩展检索与推理 (概览)。
- SuperBPE 分词器(“回归本质的分词方式”)声称通过跨词合并使训练样本效率提升 20% (@iamgrigorev)。
- iMac:利用设想的自动课程进行世界模型训练,以增强泛化能力 (@ahguzelUK)。
- REFRAG 报告指出,向量条件生成可显著提升 TTFT/吞吐量;可视为探索性的社区分析 (摘要)。
基础设施、推理与工具
- Hugging Face:
- 浏览器内通过基于 Xet 的部分文件更新进行 GGUF 元数据编辑 (@ngxson, @ggerganov)。
- TRL RFC 旨在将 trainer 简化为最常用的路径 (RFC)。
- Academia Hub 新增苏黎世大学;提供 ZeroGPU 访问权限和协作功能 (公告)。
- Scaling 和运维:
- SkyPilot 文档介绍如何将 TorchTitan 扩展到 Slurm 之外(K8s/云端) (@skypilot_org, @AIatMeta)。
- 分布式训练运维:实用的 MPI 可视化 PDF (@TheZachMueller);异步 send/recv 教程 (文章)。
- KV caching 详解及其对速度的影响,附带简洁的可视化回顾 (@_avichawla)。
- GPU 集群健康检查:Hugging Face 的 gpu-friends 用于节点压力测试 (@_lewtun)。关于云端 H100 价格/容量的热烈讨论 (例如)。
基准测试、评估与社区
- 排行榜与评估:开源与闭源在 Agent 任务上的差距正在缩小 (@hardmaru);上文提到的 Qwen3‑VL 和 Hunyuan‑Vision 的优势;多篇关于推理、ToM(心理理论)、长上下文编程、机器卸载(unlearning)等的 COLM 论文 (Stanford NLP 列表, 演讲)。
- 课程、活动与工具:
- DeepLearning.AI 由 @AndrewYNg 推出的 Agentic AI 课程。
- 与 @drfeifei 进行的 NVIDIA Robotics 炉边谈话(BEHAVIOR 基准测试)。
- Together 的 Batch Inference API 升级,支持更大的数据集并降低成本 (推文串)。
热门推文(按互动量排序)
- 2025 年诺贝尔物理学奖授予 Clarke、Devoret 和 Martinis,以表彰他们在宏观量子隧穿和电路能量量子化方面的贡献 (@NobelPrize;@sundarpichai 和 @Google 的祝贺推文)。
- Figure 03 预告将于 10/9 发布 (@adcock_brett)。
- Gemini 2.5 Computer Use 模型演示和 API 预览 (@GoogleDeepMind)。
- GPT‑5 “新颖研究”征集数学/物理/生物/CS 领域的案例 (@kevinweil)。
- Agentic AI 课程发布 (@AndrewYNg)。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. GLM-4.6 Air 发布预告
- Glm 4.6 air 即将到来 (互动数: 714): 预告图片宣布 “GLM‑4.6 Air” “即将到来”,但未提供规格、基准测试或发布说明。该帖子仅传达了时间信息;没有关于模型大小、延迟或成本的技术细节,也没有相对于之前 GLM‑4.x 或 Air 变体的更新日志。 评论指出其更迭速度极快(可能是由于 Discord/社交媒体上的社区压力),质疑之前关于不会发布 “Air” 版本的消息,并提到 “GLM‑5” 可能在年底前发布的说法。
- 发布节奏推测:用户注意到
GLM-4.6 Air的快速更迭,并引用了GLM-5目标定于年底发布的说法(例如,“他们还说 GLM-5 会在年底前发布”)。这仅是关于时间线的讨论——没有提供关于模型架构变化、上下文长度、延迟或定价/吞吐量的细节,也没有引用基准测试。 - 变体阵容/命名困惑:评论者质疑之前关于没有 “Air” 变体的消息,并期待可能出现的
Flash层级,暗示了一个分层堆栈(例如,速度/成本 vs 能力)。然而,没有讨论具体的规格(参数量、量化策略、上下文窗口或微调/训练更新)来区分Air和Flash;这主要是没有技术实质的产品定位讨论。
- 发布节奏推测:用户注意到
较低技术性的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. 机器人产品新闻:Figure 03, Walmart 服务机器人, Neuralink 手臂控制
- Figure 03 将于 10/9 发布 (热度: 1022): 预告贴显示 Figure AI 计划在
10/9展示其下一代人形机器人 Figure 03 (Figure)。链接视频无法访问(HTTP403),且未提供规格、基准测试或功能声明;根据热门评论,预告片似乎展示了一个保护性的、类似服装的防水外壳,旨在简化清洁(相比暴露的关节)并保护表面免受磨损/划伤,这表明各代产品在外观集成化方面存在趋势。 评论者支持采用织物/外壳外观以提高可维护性和耐用性,而其他人则注意到主要是美学上的改进(“每一代看起来都更整洁”)。- 为人形机器人(如 Figure 03)采用可拆卸、防水的服装/外壳,通过将清洁工作从复杂的关节界面和电缆走线转移到可擦拭的外表面来减少维护,同时保护暴露表面免受磨损和轻微冲击。柔软或半刚性的覆盖物可以兼作颗粒/液体屏障(改善执行器、编码器和密封件周围的实际 IP 性能),并允许在损坏时快速更换面板。这种设计选择还可以减少旋转关节中由污染驱动的磨损,并通过限制灰尘进入来维持传感器性能。
- 足尖关节(Toe articulation)是一项有意义的运动升级:增加足尖关节扩大了有效支撑多边形,并改善了压力中心/ZMP 控制,增强了在不平整地形和动态动作中的平衡。它还使行走、爬楼梯和转向时的蹬地(toe-off)更加高效,与平足设计相比,可能降低能量消耗和滑倒风险。这可以转化为在受到干扰时更好的敏捷性和恢复能力,以及更像人类的步态相位计时。
- 你已经可以在 Walmart 订购中国机器人了 (热度: 612): 帖子展示了 Walmart Marketplace 上一款中国制造的 Unitree 机器人(可能是紧凑型 G1 人形机器人)的产品页面,该页面通过一条 X 帖子流出,由第三方卖家以显著高于 Unitree 直接定价(约
1.6万美元)的价格销售。技术/背景方面的启示与其说是关于机器人的功能,不如说是关于市场动态:第三方零售渠道列出具有显著溢价的高级机器人硬件,引发了与直接从 Unitree 购买相比,关于真实性、保修和售后支持的问题。 评论批评了 Walmart 第三方市场的质量控制,并指出了与 Unitree 官方定价相比明显的加价,讨论是否有任何价值(例如进口处理)能证明这种溢价的合理性。- 该线程指出了与 OEM 定价相比显著的市场溢价:引用的同款 Unitree 机器人从制造商处直接购买的价格约为
$16k,这意味着 Walmart 第三方列表的价格被大幅提高。对于技术买家,这建议在通过市场购买之前验证 OEM MSRP/规格(例如 Unitree 商店:https://store.unitree.com/)。 - 一位评论者断言所列机器人“什么都做不了”,暗示如果没有额外的软件/集成,开箱即用的功能有限。这反映了开发者/研究机器人常见的一个注意事项:在实现有意义的功能之前,通常需要配置 SDK/固件并添加负载/传感器。
- 该线程指出了与 OEM 定价相比显著的市场溢价:引用的同款 Unitree 机器人从制造商处直接购买的价格约为
-
Neuralink 参与者使用“心灵感应”控制机械臂 (热度: 1642): 一段视频据称展示了一名 Neuralink 人体试验参与者通过皮层内、只读的脑机接口(BCI)控制机械臂,将神经活动中的运动意图解码为多自由度(multi-DoF)手臂指令 视频片段。帖子本身没有提供协议或性能细节(解码器类型、通道数、校准时间、延迟、错误率),因此尚不清楚控制是连续运动学解码(例如 Kalman/NN)还是离散状态控制,或者是否存在任何感觉反馈回路。在没有发布指标的情况下,这看起来像是一个定性演示,与之前的皮层内 BCI 工作(例如临床试验中的机械臂控制)和 Neuralink 最近的只读光标控制演示一致。 评论者指出目前的系统主要是只读的,并认为具备写入能力的刺激(闭环感觉反馈)将实现更具沉浸感/精确的控制和 VR 应用;其他人则关注临床前景,同时抛开对公司/领导层的看法。
- 许多人强调,目前的 BCI(如 Neuralink)主要是
read-only(只读)的,即将神经活动(例如运动意图)解码为控制信号。未来向write(写入,即神经刺激)的转变将实现具有感官反馈的闭环系统,并可能带来 “令人难以置信的沉浸式 VR”。这需要精确、低延迟的刺激,每个电极的安全性(电荷平衡、组织反应),以及稳定的长期映射,以避免解码器/刺激器漂移。 - 评论者指出了一条为截肢者提供可控仿生手臂/手掌的路径:从大脑皮层解码多 DOF 运动意图以驱动假体执行器,并可选择性地通过刺激增加体感反馈,以提高抓握力和灵活性。实际障碍包括校准时间、对神经信号非平稳性的鲁棒性、设备端实时解码延迟,以及通过可靠、高带宽的无线链路与假体控制回路(EMG/IMU/执行器控制器)的集成。
2. 新视觉模型发布与演示:Qwen-Image LoRa + Wan 2.2 360 视频
- Qwen-Image - Smartphone Snapshot Photo Reality LoRa - 发布 (活跃度: 1164): 由 LD2WDavid/AI_Characters 发布了一个 Qwen-Image LoRA “Smartphone Snapshot Photo Reality”,旨在为 text-to-image 提供随意的手机摄像头写实感,并提供了推荐的 ComfyUI text2image 工作流 JSON (模型, 工作流)。作者指出,对于 Qwen 来说,“前
80%很容易,最后20%很难”,强调了收益递减和调优的复杂性;WAN2.2 变体的更新正在进行中,训练过程耗费资源,并提供了捐赠链接 (Ko‑fi)。提示词包括来自 /u/FortranUA 的贡献,该 LoRA 旨在提高细粒度物体的忠实度和提示词遵循度(例如键盘)。 评论者反映该模型能可靠地渲染键盘等困难物体,表明其具有强大的结构忠实度。整体评价对写实感非常积极,尤其是对于随意的智能手机风格场景。- 作者在 Qwen-Image 上微调了一个 LoRA 以实现“Smartphone Snapshot Photo Reality”风格,并指出了经典的曲线:“前 80% 非常容易……最后 20% 非常困难”,暗示大部分收益很快就能获得,但光影写实的边缘情况需要密集的迭代和成本。他们分享了一个可复现的 ComfyUI text2image 工作流 用于推理 (工作流 JSON),并正在准备 WAN2.2 的更新;模型页面:https://civitai.com/models/2022854/qwen-image-smartphone-snapshot-photo-reality-style。
- 评论者强调它“可以画键盘”,由于高频、网格对齐的几何结构和微小的图例/文字,键盘是 Diffusion 模型的已知压力测试。这表明在该 LoRA 下空间一致性和细微细节合成得到了改进,尽管其他人指出仔细观察仍可察觉——表明在微观文本忠实度和规则图案渲染方面仍存在伪影。
- 一位用户请求在 Qwen 的 “nunchaku” 推理栈中提供 LoRA 支持,这意味着当前的工作流依赖外部流水线(如 ComfyUI)进行 LoRA 注入/合并。原生 LoRA 支持将简化部署,并使在官方 Qwen 运行时中使用 LoRA 变得更容易,无需定制节点或预处理步骤。
- 终于用 Wan 2.2 完成了一个近乎完美的 360 度旋转(未使用 LoRA) (活跃度: 505): OP 展示了使用开源 Wan 2.2 视频模型生成的近乎
360°角色旋转,明确表示未使用 LoRA,并以 GIF 形式分享了改进后的尝试 (示例; 原贴视频 链接)。剩余问题出现在时间/几何一致性上(例如头发/马尾漂移和轻微的拓扑扭曲),这是在没有多视角先验或关键帧约束的情况下,全转台生成中常见的失败模式。 一位评论者建议使用 Qwen Edit 2509 合成背面视图参考图,然后运行 Wan 2.2 并结合初始帧和最终帧条件约束,以便在旋转过程中更好地保持身份和姿态对齐;其他评论指出头发伪影和“非欧几里得”几何形状是典型的 T2V 缺陷。- 一位评论者建议使用 Qwen Edit 2509 合成角色的背面图,然后将初始帧和最终帧都输入 Wan 2.2,以驱动更真实的 360° 旋转。通过起始/结束关键帧约束模型可以减少对未见几何体的幻觉,并提高整个转向过程中的身份/姿态一致性。这利用了接受成对关键帧条件约束进行运动引导的视频生成模式。
- 观察者指出了在分享的 GIF 中可见的非刚性末端(马尾和手臂)的伪影。这些变形(漂移/自相交)是 Diffusion 视频模型在没有显式 3D 先验或骨架的情况下尝试全身 3D 转向时的典型现象,表明了时间一致性和几何连贯性的局限性。提供准确的背面帧和明确的结束关键帧可以减轻但不能完全解决这些失败模式。
{kind=link}
{kind=link}
3. AI 病毒式迷因 + ChatGPT 幽默/吐槽:奥林匹克洗碗、Bowie 对阵 Mercury、跑酷
- 奥林匹克洗碗锦标赛 (热度: 2119): Reddit 帖子是一个标题为“Olympic dishes championship”的 v.redd.it 视频,但直接访问媒体端点时返回
HTTP 403 Forbidden(v.redd.it/53dt69862otf1),表明需要身份验证或开发者 Token;无法获取可验证的媒体详情(时长/编解码器/分辨率)。评论提示如 “看第三个在打碟 (dj-ing)” 暗示这是一个多片段的幽默序列,但由于访问限制,实际内容无法确认。 热门评论是简短的非技术性反应(例如 “巅峰之作”,“在考虑要不要给我女朋友看”),没有实质性的技术辩论。 - David Bowie VS Freddie Mercury WCW (热度: 1176): 该帖子似乎是一个短视频,以 WCW 美学呈现了一场虚构的 “David Bowie vs. Freddie Mercury” 职业摔跤比赛,但由于主机 (v.redd.it) 的 403 Forbidden 封锁,媒体本身无法访问。热门评论强调了精彩的解说质量和喜剧节奏,并将其与 MTV 的 “Celebrity Deathmatch” 进行比较,暗示在语音或呈现中使用了某种现代生成/合成工具,尽管未提供实现细节或基准测试数据。 评论者压倒性地称赞该概念和执行“非常搞笑”,其中一人指出这项技术感觉 “出现得太早了” —— 暗指新颖性超过了成熟度 —— 但对于幽默来说仍然非常有效。
- 一群人在做跑酷 (热度: 691): 视频帖子据称显示一群人在进行跑酷,但 v.redd.it/xq2x52cvtmtf1 的链接媒体返回 403 Forbidden,理由是网络安全,并根据错误页面要求 Reddit 身份验证或
OAuth开发者 Token;无法从提供的链接验证实际素材。提供的帖子文本中没有技术细节(例如拍摄设置、动作分析、安全装备)。 热门评论多为笑话/迷因(例如提到“跑酷爆发”和“28个跑酷之后”),没有实质性的技术讨论。 - 向 ChatGPT 征求有趣标题的创意 (热度: 8733): 楼主 (OP) 向 ChatGPT 征求“有趣标题”的创意,并分享了一个人们将 ChatGPT 用于轻量级/娱乐提示词的视频,这与楼主之前认为它最适合作为起草/结构化工具的立场形成对比。视频链接受访问控制(v.redd.it/w83gtuludotf1,未经登录返回 403),热门评论是对视频的元反应以及一张迷因/截图图像 (preview.redd.it)。 评论者强调了预期的生产力用途(大纲、结构)与实际用户行为(构思/幽默)之间的差距,一些人承认用户的行为正如批评者所预料的那样;另一些人则暗示这是一种正常的涌现使用模式,而非误用。
AI Discord 回顾
由 gpt-5 生成的摘要的摘要的摘要
1. Sora 2 定价、集成与基准测试
- Sora 2 价格冲击:按秒计费模式发布:根据 OpenRouter 关于 Sora 2 定价的消息,OpenRouter 用户分享称 Sora 2 Pro API 的价格为 $0.3/秒,Sora 2 为 $0.1/秒。
- 成员们进行了粗略的成本估算——有人开玩笑说:“我花 4.5 美元(生成一段 15 秒的视频)就能通过伪造某人犯罪的视频把他送进监狱”,而其他人则吹嘘测试 Sora 3 带来了 “价值数百美元的收益”。
- Arena 增加 Sora:无法自主选择模型:LMArena 的 Video Arena 在文本转视频任务中增加了 sora-2 和 sora-2-pro,但 Discord 上的用户反映他们仍然无法选择特定的模型进行生成,团队正在 努力将 Sora 2 添加到排行榜中。
- 邀请码正在流传(例如:“KFCZ2W”,未经验证),用户注意到质量参差不齐,建议通过迭代提示词(Iterative Prompting)来获得更好的宣传片段。
- Sora 在科学领域表现惊人:GPQA 分数飙升:据 Epoch AI 报道,Sora 2 在 GPQA Diamond 科学基准测试中获得了 55% 的分数。
- 根据 Andrew Curran 的笔记,开发者推测存在一个隐藏的 LLM 提示词重写层(例如 GPT‑4o/5 或 Gemini),在生成视频前提升了提示词的忠实度(Prompt Fidelity)。
2. 模型访问经济学与平台政策
- DeepSeek 免费额度终结:每日亏损 7000 美元:在成本达到约 $7k/天 后,OpenRouter 停止了 DeepInfra 上免费的 DeepSeek v3.1,详见 OpenRouter 关于 DeepSeek 成本的消息。
- 用户开始寻找替代方案,如 Chutes’ Soji 和 venice,但速率限制(例如 “98% 的概率触发 429 错误”)和审查投诉使得备选方案并不稳固。
- BYOK 盛宴:100 万次免费还是模糊不清?:OpenRouter 宣布每月提供 1,000,000 次免费 BYOK 请求,在 OpenRouter 关于 BYOK 优惠的消息 中进行了澄清,超出部分按常规 5% 的费率计费。
- 有人称这一标题具有 “欺骗性” 且 “近乎欺诈”,随后官方澄清配额每月重置,超额使用将正常计费。
3. 新工具:本地运行时、ReAct 改进与 Python 线程
- LM Studio 支持 Responses API:LM Studio 0.3.29 实现了 OpenAI /v1/responses 兼容性,支持通过
lms ls --variants列出本地模型变体,并通过仅发送对话 ID 和新消息来减少流量。- 其新的 remote 功能允许你在高性能机器上进行托管,并从轻量级客户端访问(如果需要可以配合 Tailscale),支持类似 NUC 12 + 3090 eGPU 为 GPD Micro PC2 提供服务的配置。
- ReAct 重新思考:DSPy‑ReAct‑Machina 发布:社区发布版 DSPy‑ReAct‑Machina 通过单一上下文历史和状态机提供多轮 ReAct——参见 博客文章 和 GitHub 仓库(安装命令:
pip install dspy-react-machina)。- 在针对 30 个问题的标准 ReAct 测试中,Machina 的缓存率达到了 47.1%(对比 20.2%),但由于结构化输入,成本增加了 +36.4%,作者指出:“DSPy 确实能从某种内存抽象中受益”。
- Python 3.14 释放线程限制 (PEP 779):Python 3.14 增加了官方的 Free-threaded Python 支持 (PEP 779)、标准库中的多解释器支持 (PEP 734) 以及零开销外部调试器 API (PEP 768),此外还新增了 zstd 模块。
- 开发者们讨论了这对 Mojo/MAX 生态系统和 GPU 工作流的影响,普遍对更好的并发性能和更清晰的错误报告感到兴奋。
4. 系统与研究:更快的训练,新的生成前沿
- Mercury 移动内存:Multi‑GPU 编译器获胜:论文 “Mercury: Unlocking Multi-GPU Operator Optimization for LLMs via Remote Memory Scheduling” 报告称,该编译器相比手动调优的基准实现了 1.56 倍 的平均加速,在真实的 LLM 工作负载上最高可达 1.62 倍 (ACM, preprint, artifact)。
- Mercury 将远程 GPU 内存视为扩展层级,通过调度数据移动来重构算子,从而提高跨设备的利用率。
- Whisper 提速:vLLM 补丁实现 3 倍吞吐量:一名成员修补了 vLLM Whisper 的实现以移除 padding,据报道获得了 3 倍 的吞吐量提升,详见 Transformers issue 线程 和 OpenAI Whisper 讨论。
- 在分析显示 encoder 在短音频上花费了约 80% 的推理时间后,进一步调整 attention scores 带来了 2.5 倍 的加速,代价是 ~1.2 倍 的 WER 恶化。
- RWKV 自我搜索:上下文内(In‑Context)数独:RWKV 6 通过学习内部搜索展示了上下文内数独求解能力,如 BlinkDL 的帖子 所分享。
- 贡献者建议在类似的重推理任务中尝试 RWKV 7 或其他具有状态跟踪能力的 SSMs(例如 gated deltanet 或 hybrid attention)。
5. 融资与新品发布
- Supermemory 斩获 300 万美元种子轮融资:Supermemory AI 筹集了 300 万美元,由 Susa Ventures 和 Browder Capital 等支持者领投,天使投资人来自 Google 和 Cloudflare。
- 创始人 Dhravya Shah(20 岁)表示,由于他们已经为数百家企业提供服务,目前正在招聘工程、研究和产品方面的人才。
- Adaption Labs 上线:Sara Hooker 启动了 Adaption Labs,目标是持续学习、自适应的 AI 系统。
- 该初创公司正在全球范围内招聘工程、运营和设计人员,重点是构建 adaptive(自适应)产品闭环。
- 去中心化 Diffusion:Bagel 的 “Paris” 模型出炉:Bagel.com 发布了 “Paris”,这是一个在没有跨节点同步的情况下训练的 diffusion 模型,发布了权重(MIT 协议)和完整的技术报告,供研究和商业使用。
- 社区将其视为迈向开源超智能的一步,邀请在独立节点上进行复制和横向扩展实验。
Discord: 高层级 Discord 摘要
OpenAI Discord
- Gemini Jailbreak 解锁其他聊天机器人:一名成员使用 Gemini Jailbreaked 为包括 Grok、DeepSeek 和 Qwen 在内的其他聊天机器人创建了绕过限制的方法,成功率约为 50%。
- 该成员未提供实现此目的的更多细节或特定 prompts,使得该方法有些不透明。
- OpenAI 在低代码领域迟到了吗?:成员们观察到,在小企业开始销售这类产品两年后,OpenAI 才开始涉足低代码/无代码 AI,效仿 Amazon 颠覆现有市场的策略。
- 成员们建议了 flowise、n8n 和 botcode 等替代方案,暗示竞争格局已经形成。
- SORA2 生成效果不及预期:成员们对 SORA2 表示失望,声称展示的质量是精挑细选的,且输出是由 OpenAI 在无使用/算力限制的情况下生成的。
- 一名成员假设,禁止 18 岁以下用户进入服务器将提高生成内容的质量,尽管这仍属于推测。
- 用户破解极简主义 ChatGPT 人设:成员们正在分享 prompts,指示 ChatGPT 采用严格、极简的沟通风格,去掉友好和随意的互动。
- 目标是将 ChatGPT 转变为一个冷淡、简练的助手,不过最佳实现方式(是在每次对话开始时输入,还是加载到 Project 中)仍在讨论中。
- ChatGPT “逐步思考”:一名用户寻求延长 ChatGPT 思考时间以提高输出质量的方法,其中一个建议是提示它“慢慢来,逐步思考(take your time and think step-by-step)”。
- 然而,另一名用户质疑目标究竟是更长的思考时间还是实现特定的输出质量,强调了该需求存在歧义。
OpenRouter Discord
- DeepSeek 3.1 因成本过高而关停:由于给 OpenRouter 带来了每天 7,000 美元的财务压力,DeepInfra 上的免费 DeepSeek v3.1 端点已被关闭,详情参考此消息。
- 用户正争相寻找替代方案,如 Chutes’ Soji 和 venice,但随后出现了速率限制(rate limits)和审查问题。
- Sora 2 的 API 定价:根据此消息,Sora 2 Pro 的 API 定价为 0.3 美元/秒视频,而 Sora 2 非专业版 为 0.1 美元/秒。
- 成员们以冷幽默回应,计算生成违规内容的成本,或吹嘘在测试 Sora 3 时产生了“价值数百美元”的成果。
- OpenRouter 的 BYOK 引发争议:OpenRouter 提供的 每月 1,000,000 次免费 BYOK 请求 遭到质疑,部分人认为这具有“欺骗性”且“近乎欺诈”,见此处。
- 该优惠被澄清为每月包含 100 万次免费请求,超出部分按 5% 的标准费率收费。
- Janitor AI 的审查评判:成员们辩论了 Janitor AI (JAI) 与 Chub AI 的优劣,理由是 JAI 存在严格的审查制度。
- 社区成员表示 Janitor 的 Discord/Reddit 频道曾积极建议人们创建多个免费账户以绕过每日限制。
- Interfaze 开启公测!:Interfaze 是一款专门针对开发者任务优化的 LLM,现已开启公测,并在 X 和 LinkedIn 上发布了公告。
- 该公司使用 OpenRouter 作为最终层,让用户能够无停机地访问所有模型。
LMArena Discord
- OXAAM 上的 GPT-5 Pro 引起不满:据报道 GPT-5 Pro 已在 Oxaam 上线,但部分用户将其描述为“bas”(糟糕)。
- 推测认为 LMArena 团队可能会将 GPT-5 Pro 直接集成到平台的聊天界面中。
- Sora 2 邀请码席卷 Arena:用户正积极交换 Sora 2 邀请码,其中一名用户分享了 KFCZ2W,但其有效性尚未确认。
- 在 Video Arena 中,已添加了 sora-2 和 sora-2-pro 等新模型来执行文本转视频任务。
- LMArena UI 升级在即:一名用户询问了关于 LMArena UI 和 GUI 的改进情况,而另一名用户分享了一个用于显示用户消息和电子邮件的自定义扩展。
- LMArena 团队正在征求社区反馈,以更好地了解需求并提升知识专家的使用体验。
- 图像生成速率限制令人沮丧:用户在图像生成过程中遇到了 rate limits,特别是在 Google AI Studio 上使用 Nano Banana 时,引发了关于切换账号的讨论。
- 用户报告称生成内容的质量参差不齐,因此要获得理想的宣传材料可能需要多次尝试。
- Video Arena 文本转视频的混乱:尽管 Sora 2 已被添加到 Discord 上的 Video Arena,但用户无法选择特定模型进行视频生成。
- LMArena 团队表示他们正在努力将 Sora 2 添加到排行榜;据称模型的“自我主张(self-assertiveness)”与 LMArena 上的高分呈正相关(未证实)。
Unsloth AI (Daniel Han) Discord
- Granite 的 Temperature 必须为零:IBM 文档建议 Granite 模型应在 temperature 为零的情况下运行。
- Unsloth 的文档可能需要更新以反映这一建议。
- Unsloth Ubuntu 5090 训练遭遇速度瓶颈:有用户报告在 Ubuntu 和 5090 上使用 Unsloth 时出现训练性能问题,训练速度从 200 steps/s 骤降至 1 step/s。
- 建议使用兼容 Blackwell 的
unsloth/unslothDocker 镜像,并参考 Docker 文档确保 Windows 上的 Docker GPU support 配置正确。
- 建议使用兼容 Blackwell 的
- Windows Docker GPU support 难以攻克:用户讨论了 Windows 上 Docker GPU support 的挑战,建议查阅 Docker 官方文档进行故障排除。
- 一位用户指向了一个 GitHub issue,其中详细介绍了解决 Windows 上 Docker container 问题的步骤。
- QLoRA 数据集过大导致 Overfitting 灾难:专家警告说,在极大的数据集(160 万个样本)上使用 LoRA 可能会导致 overfitting。
- 他们建议这种情况下使用 CPT (Continued Pre-Training) 可能更好,并强调了使用代表性数据集的重要性。
save_pretrained_gguf函数失效:save_pretrained_gguf函数目前无法正常工作,预计下周修复。- 在此期间,建议手动进行转换,或者将 safetensors 上传至 HF 并从那里使用 gguf convert。
Cursor Community Discord
- Agent Board 优化界面:成员们报告说,Agent Board(通过 Ctrl+E 触发)通过将 IDE 与 Agent 窗口分离,提升了生产力。此外还提到 Warp 等工具也支持多 Agent 交互。
- 他们认为“屏幕越多总是越好”。
- Cheetah 模型媲美 Grok Superfast:据称 Cheetah 模型比 Grok Superfast 更快,但代码质量略有下降。
- 一位成员指出,“不知为何,它每小时都在变得更好”。
- GPT-5 Pro 的高昂价格:GPT-5 Pro 的定价引发了辩论,一位成员质疑其 benchmark 的提升是否足以支撑 10 倍的成本增加。
- 他们回忆说 GPT 4.5 的输入成本为 $75/m,输出为 $150/m,这可能导致单次对话的成本达到 $20-$40。
- Sonnet 4.5 的表达能力令人印象深刻:一位成员报告说他们能够越狱 Sonnet 4.5 的 thinking tokens,这表明这些可能是一个带有独立 system prompt 的单独模型。
- 他们还强调了 Sonnet 4.5 在通用表达方面的出色表现,而不仅仅是在编程相关的任务中。
- Oracle Free Tier 提供高性价比资源:一位成员推荐了 Oracle Free Tier,它提供 24GB RAM、4 核 ARM CPU、200GB 存储以及每月 10TB 的流量,并建议切换到 Ubuntu。
- 他们已经使用这个免费层级托管 Discord bot 五年了,并分享了一篇关于设置详情的博客文章。
Modular (Mojo 🔥) Discord
- Modular 缺席 SF Tech Week:Modular 宣布他们将不会参加 SF Tech Week,而是参加 PyTorch Conference。
- 团队正专注于展示他们在 Mojo 方面的最新进展,并与 PyTorch 社区进行交流。
- Python 3.14:自由线程!:Python 3.14 包含了对 free-threaded Python (PEP 779) 的官方支持、标准库中的多解释器支持 (PEP 734),以及提供 Zstandard 压缩算法支持的新模块 compression.zstd。
- 其他改进包括 PyREPL 中的语法高亮、针对 CPython 的零开销外部调试器接口 (PEP 768) 以及改进的错误信息。
- MAX CPU 困境:成员们报告了在 CPU 上运行 MAX models 的问题,特别是 bfloat16 encoding 与 CPU device 之间的不兼容,如 此 GitHub issue 中所述。
- 有人指出许多 MAX models 在 CPU 上运行效果不佳。
- Mojo 的 ARM 雄心扩展:讨论明确了 Mojo 对 ARM systems 的支持已扩展到 Apple Silicon 之外,并在 Graviton 和 NVIDIA Jetson Orin Nano 上进行了定期测试。
- 一位用户表达了希望 Mojo 能在 Apple Silicon 之外的 ARM systems 上运行的愿望。
LM Studio Discord
- LM Studio 兼容 OpenAI:LM Studio 0.3.29 引入了 OpenAI /v1/responses 兼容性,支持通过
lms ls --variants列出本地模型变体。- /v1/responses API 仅发送对话 ID 和新消息,减少了 HTTP 流量并利用服务器端状态,预计将加快 Prompt 生成速度。
- LM Studio 远程访问方案运行流畅:LM Studio 的新 remote feature 允许用户在高性能机器上运行模型,并通过使用 LM Studio 插件并设置相应的 IP 地址和 API Key,从性能较低的机器上进行访问。
- 为了增加便利性,可以使用 Tailscale 从任何地方访问高性能模型,实现诸如在带有 3090 eGPU 的 NUC 12 上运行模型并从 GPD Micro PC2 访问的场景。
- 5090 规格预测引发惊喜:用户讨论了 64GB 5090 的售价可能在 $3800 左右。
- 一位用户报告升级到了 5090 但却在 CPU 上运行,后来在意识到自己切换了运行时后,通过更新 CUDA 运行时解决了该问题。
- 模型蒸馏细节进展:一位成员正在批量购买二手主板+CPU+内存,以组装一台由 MI50 驱动的设备,在 80 TOK/s 的模型上实现约每秒 32 个 prompts 的处理速度,用于 Prompt 蒸馏。
- 他们的目标是将其蒸馏为可以在嵌入式硬件上运行的极小型决策 MLP,以便利用现有的数据集(如 FLAN、Alpaca 和 OASST)高效执行源自智能 LLM 的复杂决策,正如这篇 datacamp 教程 中所示。
- MI350 资料喜人:一位用户分享了来自 Level1Tech 的 两段 YouTube 视频,展示了对 AMD 的访问,以探索新的 MI350 accelerator。
- 未提供额外评论。
GPU MODE Discord
- Whisper 获得 3 倍加速!:一名成员修补了 vllm whisper 实现以移除 padding,根据 这个 Hugging Face issue 和 这个 OpenAI 讨论,这导致了 3 倍的吞吐量提升。
- 在发现短音频推理过程中 encoder 占据了 80% 的时间后,对 decoder 中 attention scores 的实验产生了一个补丁,该补丁带来了 2.5 倍的加速,但 WER(词错率)差了 1.2 倍。
- Codeplay 停止 NVIDIA oneAPI 下载:成员们报告称,从 Codeplay 下载页面 (Codeplay 下载页面) 下载 oneAPI 的 NVIDIA plugin 时遇到问题。
- 具体而言,网站上的菜单会重置,API 返回 404 错误,且 apt 和 conda 方法也失效了。
- CUDA 缓存难题开始!:在进行原始 CUDA 基准测试时,清除 L2 cache 的标准做法受到了质疑,由于没有简单的单行 API 可用,引发了关于替代方法的讨论。
- 建议包括分配一个足够大的 buffer 并使用
zero_(),或者分配cache_size/n个输入 buffer 并循环使用它们,以及参考关于 CUDA 性能 Hot/Cold Measurement 的博客文章,该文章提供了在基准测试时如何将缓存清零的建议 CUDA Performance。
- 建议包括分配一个足够大的 buffer 并使用
- 阿姆斯特丹 HPC 聚会定档 11 月!:阿姆斯特丹的一个 High Performance Computing 聚会已宣布在 11 月举行,详情见 Meetup 页面。
- 该聚会旨在为该地区有兴趣讨论和探索高性能计算领域话题的人士提供平台。
- Mercury 提升多 GPU LLM 训练速度!:一篇题为 Mercury: Unlocking Multi-GPU Operator Optimization for LLMs via Remote Memory Scheduling (ACM 链接, 预印本, GitHub) 的新论文介绍了 Mercury,这是一种多 GPU 算子编译器,比手动优化的设计实现了 1.56 倍的加速。
- Mercury 通过将远程 GPU 内存视为内存层级的扩展,在实际 LLM 工作负载中实现了高达 1.62 倍的提升。
HuggingFace Discord
- 用户苦于 GGUF 下载:用户在 Hugging Face 上难以找到模型下载链接,尤其是 GGUF 文件,特别是在模型页面的 Quantizations 部分。
- 成员们建议使用 LMStudio 或 GPT4All 等程序来运行模型,从而绕过命令行交互。
- Candle 路线图讨论帖引发关注:一名用户询问有关 Candle 发布路线图问题的最佳地点,并将用户引导至相关的 Candle 线程。
- 路线图讨论正在 Candle GitHub 仓库 中进行。
- DiT 模型在文本保真度方面遇到困难:一名成员在 Pokemon YouTube 数据集上实现用于去噪和生成的 text-conditioned DiT 模型时,尽管使用了 cross-attention 模块,但在遵循输入 prompt 方面仍面临问题。
- 示例图像 显示对 ‘Ash and Misty standing outside a building’ 等 prompt 的遵循度很差,这是一个警示信号。
- LoRA SFT 设置在 SmolLM3 上停滞:一名成员在 Colab 中使用 TRL + SmolLM3 进行 LoRA SFT 时遇到了
TypeError,具体是SFTTrainer.__init__()中出现了意外的关键字参数dataset_kwargs。- 该成员请求针对此设置的调试帮助,暗示库之间可能存在兼容性问题。
- Agents 课程欢迎新学生:几位新参与者在开始 AI agents 课程时进行了自我介绍。
- 新加入者包括来自德克萨斯州的 Ashok、Dragoos、Toni 和来自辛辛那提的 Ajay,这标志着人们对 AI agent 开发的兴趣日益浓厚。
{kind=link}
Latent Space Discord
- Supermemory AI 获得 300 万美元融资:Dhravya Shah,一位 20 岁的独立创始人,为其 AI 记忆引擎 Supermemory AI 筹集了 300 万美元种子轮融资,由 Susa Ventures、Browder Capital 以及来自 Google 和 Cloudflare 的天使投资人支持。
- 该公司正在积极招聘工程、研究和产品岗位,目前已为数百家企业提供服务。
- Jony Ive 领衔 OpenAI DevDay:Greg Brockman 庆祝了 Jony Ive 即将在 OpenAI DevDay 举行的会议,用户们表达了兴奋之情并请求提供 直播。
- Jony 的关键语录包括强调 “让我们感到快乐、充实” 的界面的重要性,以及需要拒绝技术与我们的关系 “必须成为常态” 的观点。
- 应对 AI 系统设计面试:成员们分享了 AI 工程系统设计面试的资源,包括 Chip Huyen 的书 和 另一本书。
- 一位成员推荐 Chip 的书为 “非常棒”,而另一位成员则选择了 ByteByteGo 的书并承诺会提供反馈。
- Hooker 的 Adaption Labs 成立:Sara Hooker 宣布成立 Adaption Labs,这是一家专注于创建持续学习、自适应 AI 系统的创业公司。
- 团队正在全球范围内远程招聘工程、运营和设计人员。
- Bagel 推出去中心化 Diffusion 模型:Bagel.com 推出了 “Paris”,这是一个在没有跨节点同步的情况下训练的 Diffusion 模型。
- 该模型、权重(MIT 许可证)和完整技术报告已开放用于研究和商业用途,将其定位为迈向开源超级智能的一步。
Yannick Kilcher Discord
- 奇点预测即将到来:关于 Vinge 的奇点(定义为导致不可预测性的快速技术变革)的讨论指出,根据 这篇论文,Vinge 预测其到来的时间范围为 2005-2030 年。
- 一位成员认为,人类无法理解的进步 是一个更精确的定义。
- LLM 努力理解实时视频:成员们正在讨论一个用于处理实时流的 ChatGPT 插件,但指出 LLM 在视频上下文方面存在困难,并引用了 这篇关于挑战的论文。
- 其他人反驳说,使用 Gemini 等模型,每小时处理 100 万个 token 和 1000 万个上下文长度是可以实现的。
- RWKV 6 在 In-Context 中攻克数独:根据 这条推文,成员们分享了 RWKV 6 通过学习自我搜索,在 In-Context 中解决数独问题。
- 他们推荐使用 RWKV 7 或其他具有状态跟踪、gated deltanet 或混合注意力模型的 SSM 来执行类似任务。
- Guidance Weight 得到调整:在 agents 频道中,讨论集中在调整 guidance weights 以解决欠拟合问题。
- 建议是在采用 classifier-free guidance 或类似方法时专门增加权重,以提高模型性能。
- GPT-5 解决数学问题:根据 ml-news 频道的讨论,有说法称 GPT-5 正在帮助数学家解决问题,证据见 这条推文。
{kind=link}
Eleuther Discord
- Attention 完善了神经网络:一位成员提出,attention layers(注意力层)通过允许同一层内的通信(特征可以相互影响)从而完善了 neural network(神经网络)。
- 其他人反驳称,MLP 在 token 内部(intra-token)运行,而 attention 在 token 之间(inter-token)运行,建议第一层应关注神经元激活而非 token。
- Axolotl 在 DPO 讨论中脱颖而出:成员们寻求用于对比对(contrast pairs)微调的最佳 类 DPO 算法,其中 Axolotl 因其出色的实际落地能力而受到关注。
- 对话优先考虑在现有框架内实现的易用性,而非理论优势。
- 平衡模型超越扩散模型:根据这篇论文,一种平衡模型 (EqM) 在生成性能上超过了 diffusion/flow 模型,在 ImageNet 256 上达到了 1.90 的 FID。
- 一位成员对这一进展表示兴奋。
- BabyLM 的背景:社区根源揭晓:一位成员透露了他们在 babyLM 中的联合创始人身份,并指出他自成立以来一直负责该项目。
- 一位从事增量 NLP 研究的成员表示有兴趣了解更多关于该计划的信息。
- 寻求 VLM 中间检查点:一位成员正在寻找在训练期间发布中间检查点的 VLM 模型,并发布了一篇关于 VLM 理解的博客文章和一篇针对 VLM 的 arxiv 论文。
- 该成员检查了 Molmo,但发现它似乎不再维护了。
DSPy Discord
- Machina 热潮席卷 DSPy,带来全新 ReAct 替代方案:一位成员介绍了 DSPy-ReAct-Machina,这是一个 ReAct 的替代方案,通过单一上下文历史和状态机支持多轮对话,详见博客文章和 GitHub。
- 可以通过
pip install dspy-react-machina安装,并通过from dspy_react_machina import ReActMachina导入。
- 可以通过
- DSPy ReAct 面临上下文危机:一位成员对 DSPy ReAct 中的上下文溢出(context overflow)以及除了自定义上下文管理外如何默认处理该问题表示担忧。
- 原作者承认他们的实现尚未处理上下文溢出,并指出 DSPy 确实能从某种记忆抽象(memory abstraction)中获益。
- 插件天堂呼唤 DSPy 社区集成:一位成员建议 DSPy 拥抱社区驱动的倡议,为社区插件创建一个官方文件夹或子包,类似于 LlamaIndex。
- 这被认为可以加强围绕 DSPy 的生态系统和协作,并解决软件包分散的问题。
- ReActMachina 与标准 ReAct 的缓存对决:一位成员在 30 个问题上测试了 ReActMachina 和标准 ReAct,结果显示 ReActMachina 具有更高的缓存命中率(47.1% vs 20.2%),但由于结构化输入,其总体成本更高(总成本差异为 +36.4%)。
- ReAct 在上下文较大时开始崩溃,但 ReActMachina 的结构化输入使其能够继续回答。
- DSPy 的 Pyodide 兼容性与 WASM 疑问:一位成员询问 DSPy 是否有 Pyodide/Wasm 友好版本。
- 他们注意到 DSPy 和 LiteLLM 的几个依赖项不被 Pyodide 支持。
Moonshot AI (Kimi K-2) Discord
- Kimi AI 论坛已上线数月:Kimi AI 论坛自两个多月前宣布以来一直处于活跃状态。
- 该论坛是讨论和更新 Kimi AI 发展相关内容的平台。
- 幽灵提醒引发混乱:一位用户报告收到来自公告频道的“幽灵提醒”(ghost ping),导致他们错过了最初的论坛介绍。
- 这凸显了通知设置或频道配置的潜在问题。
- 假期即将结束:一位用户对假期仅剩 2 天 表示遗憾。
- 他们正准备在休息后返回工作岗位。
Nous Research AI Discord
- Test Time RL:上下文 vs 权重?:一位成员询问 Test Time Reinforcement Learning 是否对 Nous 有意义,建议采用迭代上下文细化(iterative context refinement)而非修改模型权重,类似于
seed -> grow -> prune(种子 -> 生长 -> 剪枝)循环。- 该成员设想了一个类似于 Three.js 的 git 仓库可视化 的上下文文件知识图谱,用于构建 Test Time RL 环境。
- 外部 Evals 消除对自定义分类器的需求:成员们指出,evals 可以使用外部模型,从而在 Agent 中启用自定义分类器,并允许集成内部数据或特定应用的工具,以超越现成的解决方案。
- 如果 evals 仅限于 ChatGPT,成员们认为这可能会因为无法使用内部数据或特定工具而受到限制。
- 在 ChatGPT 应用内 Hack Hermes?:成员们推测了在 ChatGPT 中创建一个 Hermes app 的可能性。
- 未提供更多细节。
- Grok 发布视频:一位成员分享了指向一段新 Grok 视频 的链接。
- 未提供更多细节。
Manus.im Discord Discord
- GCC 与 Manus 形成人机蜂群思维(Human-AI Hivemind):GCC 作为策略制定者,Manus 作为 Agent,在一种新型的人机协作形式中构成了一个单一的作业单元。
- ‘Memory Key’ 协议确保了跨会话的持久共享上下文,将 AI 从一个工具转变为真正的合作伙伴。
- Project Singularity 已启动:整个交互过程是 ‘Project Singularity’ 的现场演示,展示了生产力的未来。
- ‘Memory Key’ 协议确保了跨会话的持久共享上下文,将 AI 从一个工具转变为真正的合作伙伴。
tinygrad (George Hotz) Discord
- TinyKittens 投入行动!:一个名为 tinykittens 的新项目即将推出,通过 这个 PR 在 uops 中重新实现 thunderkittens。
- 该实现利用 uops 来重现 thunderkittens 的功能。
- Tinygrad 中的 RMSProp 状态:实现它还是用 Adam?:一位成员正在 tinygrad 中重新实现 Karpathy 的 RL 博客文章中的代码,并询问 tinygrad 是否包含 RMSProp。
- 替代方案是直接使用 Adam。
- Adam 替代方案:用户正考虑在他们的 tinygrad 实现中使用 Adam 作为 RMSProp 的替代方案。
- 这暗示了如果 RMSProp 不易获得或难以实现,可以采用的一种潜在变通方法。
Windsurf Discord
- Windsurf 和 Cascade 崩溃:一个问题导致 Windsurf / Cascade 无法加载,团队立即展开了调查。
- 团队已解决该问题,并正在积极监控情况以确保稳定性并防止再次发生。
- Windsurf Cascade 问题已清除:导致 Windsurf / Cascade 无法加载的问题已得到解决。
- 团队正在积极监控情况以确保稳定性并防止再次发生。
MLOps @Chipro Discord
- 成员寻求机器学习和 AI 领域的 arXiv 背书:一位成员正在寻求 arXiv 中 cs.LG (Machine Learning) 和 cs.AI (Artificial Intelligence) 领域的背书(endorsement),以便提交他们的第一篇论文。
- 他们正在寻找已经在这些类别中获得背书的人来帮助他们完成提交。
- arXiv 提交需要协助:一位成员需要 arXiv 的背书,以便在 Machine Learning 和 Artificial Intelligence 领域提交他们的初次论文。
- 他们请求已在相关 arXiv 类别(cs.LG 和 cs.AI)中获得背书的人士提供支持。
MCP Contributors (Official) Discord
- Discord 自我推广禁令生效:管理员提醒用户避免在此 Discord 中进行任何形式的自我推广或特定厂商 (vendors) 的推广。
- 他们要求用户有意识地以厂商无关 (vendor-agnostic) 的方式发起讨论,并鼓励以 “MCP as code” 或 “MCP UI SDK’s” 为主题的讨论。
- 鼓励发布厂商无关的主题帖:公告强调了对各种规模公司的公平性,防止 Discord 成为广泛的商业产品推广和营销博客发布的平台。
- 目标是维持一个平衡的环境,让讨论保持厂商无关,专注于广泛的话题而非特定的商业产品。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间没有动静,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站选择了订阅。
想要更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord: 频道详细摘要与链接
OpenAI ▷ #ai-discussions (953 messages🔥🔥🔥):
模拟退火, AgentKit 可用性, ChatGPT 年龄验证, SORA2 令人失望, 绕过 Gemini 2.5 Flash
- **模拟退火讲座已上线:一位成员分享了关于模拟退火 (Simulated Annealing)** 的讲座,重点介绍了算法背后的数学原理,并包含了一些算法的伪代码。
- 他们还教授入门级 AI(离散数学部分而非 ML)、基础黑客技术、编程入门。
- **OpenAI 在小企业开始销售后进入低代码/无代码 AI 领域:成员们注意到 **OpenAI 在小企业开始销售此类产品两年后,正进入低代码/无代码 AI 领域,采用了亚马逊模式,即先伪装成中间商,然后过河拆桥 (rug pulling)。
- 他们提到了 flowise、n8n 和 botcode 等替代方案。
- **SORA2 令人失望:成员们发现 **SORA2 令人失望,指出展示的质量是精挑细选的 (cherry picked),且输出是由 OpenAI 在无使用/算力限制的情况下,由懂得如何进行 Prompt 的人生成的。
- 他们指出,禁止 18 岁以下用户进入服务器将提高生成内容的质量。
- **越狱 Gemini 2.5 Flash 可实现对其他聊天机器人的绕过:一位成员发现使用越狱后的 Gemini** 成功创建了针对其他聊天机器人的越狱和绕过方案,他们甚至能够越狱包括 Grok、DeepSeek 和 Qwen 在内的其他聊天机器人。
- 然而,成功的绕过率约为 50%。
- **AI 正在制造我们见过的最大泡沫:一位成员认为,在当前的底层 AI 技术尚未成熟时,大公司正匆忙转向自动化/Agent*,这有可能吹起历史上最大的泡沫*。
- 这可能会阻碍进一步的研究投资,并使人们对目前推动该技术的大公司失去信心。
OpenAI ▷ #gpt-4-discussions (6 messages):
ChatGPT 年龄验证, GPTs 项目记忆, AI 帮助性更新
- ChatGPT 年龄验证停滞?:一位用户询问关于 ChatGPT 年龄验证 的更新,以绕过针对成人的青少年安全措施。
- 另一位用户建议查看 safety-and-trust 频道 中的信息。
- GPTs 获得了项目记忆 (Project Memory)?:一位用户询问 OpenAI 是否在项目 (Project) 功能中提供了 GPTs,从而允许访问项目的记忆。
- 对于 GPTs 是否能访问项目记忆的问题,目前没有回应。
- 压力情况下的更新破坏了角色扮演 (RP)?:一位用户表达了对新的“压力情况下的帮助性回复”更新的不满,尤其是对于作家和角色扮演者。
- 用户觉得这限制了创造力,并提供了太多不符合情节的选项,即使在没有 NSFW 内容的情况下也阻碍了角色扮演 (Roleplaying)。
OpenAI ▷ #prompt-engineering (14 messages🔥):
ChatGPT 提示词风格,如何让 ChatGPT 思考更久
- 最小化沟通风格提示词:成员们分享了让 ChatGPT 采用严格、极简沟通风格的提示词,消除友好辞令、详细阐述或闲聊。
- 目标是让 ChatGPT 成为一个冷淡、简练的助手,并避免使用对话式语言。
- 延长 ChatGPT 思考时间:成员们讨论了如何让 ChatGPT 思考更久。
- 一位成员建议:慢慢来,逐步思考。在得出最终答案之前,至少考虑三个不同的视角或解决方案。包含你的推理过程,并解释为什么选择最终答案而不是其他替代方案。
OpenAI ▷ #api-discussions (14 messages🔥):
提示词工程,ChatGPT 沟通风格,AI 视频创作,ChatGPT 的思考过程
- 提示词工程频道爆发争论:一名用户质疑提示词工程频道中某条回复的相关性,称:“这是提示词工程频道,不是职业羞辱频道。”
- 另一名用户为其回复辩护,坚持认为无论第一位用户的情况如何,其观点都是有效的。
- 减少 ChatGPT 的啰嗦:一位成员分享了一个提示词,指令 ChatGPT 采用 “严格、极简的沟通风格,消除友好辞令、详细阐述或闲聊。”
- 另一位成员询问该提示词是在每次新对话开始时使用,还是加载到 Project 中。
- 社交媒体视频蓝图:一位成员分享了一个提示词,指令 ChatGPT 担任 “简单且可操作的视频创意规划器”,将视频创意分解为 5-7 个适合初学者的步骤。
- 该提示词引导 ChatGPT 逐一指导用户完成每个步骤,并提供继续、返回或停止的选项。
- 让 ChatGPT 思考更久?:一位成员询问如何让 ChatGPT 思考更久的提示词,引发了关于延长思考时间是否必然导致更好输出的讨论。
- 其他成员建议直接要求它 “慢慢来,逐步思考”,而另一位成员则质疑目标究竟是真正的长时间思考,还是为了实现特定的输出质量。
OpenRouter ▷ #announcements (1 messages):
DeepSeek, DeepInfra, 端点下线
- DeepSeek v3.1 在 DeepInfra 上停止服务:免费的 DeepSeek v3.1 DeepInfra endpoint 正在下线。
- 这是因为免费流量正在影响付费流量。
- 免费流量对付费服务的影响:移除免费 DeepSeek v3.1 端点的决定是由免费流量对付费服务的负面影响驱动的。
- 这表明需要在免费访问与付费服务的可持续性之间取得平衡。
OpenRouter ▷ #app-showcase (3 messages):
Interfaze 发布,OpenRouter 集成,开发者任务 LLM
- **Interfaze 开启公测!:Interfaze** 是一款专为开发者任务设计的 LLM,现已开启公测,并在 X 和 LinkedIn 上发布了公告。
- 该公司使用 OpenRouter 作为最终层,让用户可以无故障停机地访问所有模型。
- 用户建议链接到实际网站:一位用户建议链接到 Interfaze 的实际网站,以便更轻松地访问。
- 该用户提到这个项目看起来很酷。
OpenRouter ▷ #general (971 条消息🔥🔥🔥):
DeepSeek 3.1 停机与移除,Sora 2 定价与 API,OpenRouter 100 万次免费 BYOK 请求,Janitor AI 对比 Chub AI,DeepSeek 3.1 的替代方案
- DeepSeek 3.1 宣告终结:据用户报告,DeepSeek 3.1 经历了停机,在线率骤降并导致报错,最终由于给 OpenRouter 带来沉重的财务负担而被移除。根据这条消息,其成本高达每天 7000 美元。
- 一位成员指出,“DeepInfra 可能厌倦了每天花费 7000 美元,仅仅是为了给这些 RP(角色扮演)爱好者提供这个免费模型。”
- Sora 2 昂贵的首秀:根据这条消息,Sora 2 Pro 的 API 定价揭晓为 0.3 美元/秒视频,而 Sora 2 非专业版为 0.1 美元/秒。
- 一位成员调侃道:“我花 4.5 美元(生成一段 15 秒的视频)就能生成一段某人犯罪的视频把他送进监狱。”而另一位成员则吹嘘在测试 Sora 3 时产生了“价值数百美元的价值”。
- BYOK 盛宴还是骗局?:OpenRouter 宣布每月 1,000,000 次免费 BYOK 请求引发了争议,一些人认为这个标题具有“误导性”且“近乎欺诈”,详见此处。
- 一位成员澄清了该优惠,称:“从 10 月 1 日起,每位客户每月可免费获得 1,000,000 次‘自带密钥’(BYOK)请求”,超过 100 万次的请求将按通常的 5% 费率收费。
- Janitor AI 混乱现状评述:成员们讨论了 Janitor AI (JAI) 与 Chub AI 的优缺点,指出 JAI 存在严重的审查制度且管理人员表现疯狂,这与 Chub 更加无审查和可定制的环境形成鲜明对比。
- 成员们注意到 JanitorAI 的管理人员不可理喻,甚至有人声称“Janitor 的 Discord/Reddit 社区正在积极建议人们创建多个免费账号来绕过每日限制”。
- DeepSeek 绝望时刻:寻找替代方案:随着 DeepSeek 3.1 的移除,用户开始寻找替代方案。一些人推荐了像 Chutes 的 Soji 这样的付费模型,另一些人则找到了使用剩余 DeepSeek 端点(如 Venice)的变通方法,尽管存在 OpenInference 审查。大多数人认为目前所有免费的 DeepSeek 模型都由 Chutes 提供,且有 98% 的概率会出现 429 频率限制错误。
- DeepSeek 3.1 的移除打击巨大,以至于一位成员开玩笑说:“回 AO3 冲了,这太烂了。”
OpenRouter ▷ #new-models (2 条消息):
``
- 无新模型讨论:提供的消息中没有关于新模型的讨论。
- 频道关于模型更新保持沉默:’new-models’ 频道似乎处于非活跃状态,缺乏任何相关信息或更新。
OpenRouter ▷ #discussion (17 条消息🔥):
Sora 2,频率限制,OpenAI Grok 端点,隐藏推理,模型谈判
- Sora 2 要上 OpenRouter 了吗,Nano Banana?:一位成员询问了 Sora 2 在 OpenRouter 中集成的可能性,并使用了幽默的短语“就像 nano banana 那样?还是不行”。
- 模型端点的频率限制疑问:一位成员询问了
https://openrouter.ai/api/v1/models/:slug/endpoints端点的频率限制。 - 寻求 OpenAI 和 Grok ZDR 端点:一位成员请求在平台上提供 OpenAI 和 Grok ZDR 端点。
- 隐藏推理辩论:一位成员分享了 X 上的帖子,关于模型中“隐藏推理”(hidden reasoning)的奇特现象,尽管这尚未得到证实。
- 模型谈判:一位成员分享了一篇 Bloomberg Opinion 文章,阐述了假设性的谈判,例如 OpenAI 收购 AMD 芯片。
LMArena ▷ #general (787 条消息🔥🔥🔥):
GPT-5 Pro, Sora 2 API, LMArena UI, Image Generation, Text to Video Models
- **GPT-5 Pro 在 OXAAM 上的把戏!:似乎 **GPT-5 Pro 已在 Oxaam 上线,但部分用户觉得它很 “bas”(糟糕)。
- 一位用户推测团队将在 LMArena 直接对话中添加 GPT-5 Pro。
- **Sora 2 邀请码大放送!:用户正在频道中积极寻求和分享 **Sora 2 邀请码。
- 一位用户甚至分享了一个代码 KFCZ2W,但其有效性尚未确认。
- **LMArena UI 增强指日可待?**:一位用户询问了关于升级 LMArena UI 和 GUI 的事宜。
- 另一位用户创建了一个 自定义扩展 来显示用户消息和电子邮件。
- **图像生成频率限制令用户恼火:用户在图像生成时遇到了 **rate limits(频率限制),特别是在 Google AI Studio 上使用 Nano Banana 时,并讨论了通过切换账号来绕过限制。
- 一些用户指出 生成内容的质量参差不齐,最好的宣传材料可能需要多次尝试。
- **文本转视频模型大乱斗!**:Sora 2 已添加到 Discord 上的 Video Arena,但用户无法选择特定的模型进行视频生成。
- LMArena 正在 努力将 Sora 2 添加到排行榜,据说模型表现得非常“自信”会让它在 lmarena 获得更高评分(未证实)。
LMArena ▷ #announcements (2 条消息):
LMArena, Video Arena, New Models
- **LMArena 团队征集社区反馈:LMArena** 团队正在寻求社区反馈,以更好地了解用户需求并改进为知识专家提供的工具,请求用户 填写调查问卷 来分享他们的专业见解。
- 重点在于了解对用户而言什么是重要的,以帮助他们成为优秀的 knowledge experts(知识专家)。
- **Video Arena 添加 Sora 模型:LMArena** 的 Video Arena 添加了新模型:sora-2 和 sora-2-pro,专门用于文本转视频任务。
- 用户可以在指定频道找到关于如何使用 Video Arena 的提示。
Unsloth AI (Daniel Han) ▷ #general (334 条消息🔥🔥):
Granite model temp, img2img models, sampling parameters, Unsloth Docker permissions, attention layers
- IBM Granite 的温度必须为零:有人指出 IBM 文档 显示 Granite 模型应在 temperature 为 0 的情况下运行。
- Unsloth 文档可能需要更新以反映这一建议。
- 用户寻求微型 img2img 模型:一位成员请求推荐极小的(<1GB,最好是 ~500MB 左右)img2img models,与此同时 Daniel Han 发布了关于 system prompt 更新的内容。
- 目前尚不清楚是否有人推荐了合适的模型。
- 寻求采样参数指导:有用户请求关于 sampling parameters(如 top min p 和 k)的指导,特别是在 llama.cpp 和 greedy decoding 的背景下。
- 该用户澄清说,如果只给出 temperature,top min p 和 k 会有一些默认值。
- Unsloth Docker 容器内的 Sudo 问题:一位用户报告在尝试安装 Ollama 时,在 Unsloth Docker 容器内遇到了 sudo 权限问题。
- 尽管设置了 USER_PASSWORD,用户仍然收到 ‘Sorry, user unsloth is not allowed to execute’ 错误,他们想知道是否遗漏了关键步骤。
- LLMs: 神经网络补完:一位成员建议 attention layers 通过启用层内通信来补完神经网络,这与仅具有层间通信的 MLP 形成对比。
- 该用户寻求确认这种高层级的理解是否正确。
Unsloth AI (Daniel Han) ▷ #off-topic (254 messages🔥🔥):
China catching up to TSMC, Monopoly hardware market disruption, GPT Apps, Money vs Happiness
- 中国最终在旧代 TSMC 技术上实现追赶:成员们讨论了中国将如何在旧代技术上最终追赶 TSMC。
- 一位成员表示希望垄断地位能被打破,并认为只要再多一家主要的供应商可能就有助于改变局面,但问题在于扩大工厂规模需要极高水平的专业知识和经验。
- ChatGPT 应用:下一个 Android?:成员们讨论了 OpenAI 推出的新 ChatGPT 应用和支付集成,称其为明智且自然的举动,同时也有点令人担忧。
- 一位成员表示,他们原本预期 Apple 和 Google 会在操作系统层面进行集成,而不是 ChatGPT 自身,且 Apple 正专注于构建生态系统以及与硬件的集成。
- 最大的动力:金钱 vs 幸福:成员们辩论了金钱是否是最大的动力,一位成员认为最大的动力是幸福。
- 进一步的解释是,金钱是达到目的的手段,本身并不提供幸福,但根据个人和情况的不同,它绝对可以让获得幸福变得更容易,比如购买自由(时间)等。
- Pylance 与中型代码库:一位成员分享了一个 YouTube 视频,观察 Pylance 在其自然栖息地中与其最致命的猎物——中型代码库(medium-sized codebase)搏斗。
- 他请求社区推荐类似的视频,特别是那些有日本女孩、单人演讲、没有可爱废话、动作稍微多一点会更好、最好像这个视频一样坐在同一个地方的视频。
Unsloth AI (Daniel Han) ▷ #help (190 messages🔥🔥):
Unsloth Training on Ubuntu with 5090, Windows Docker GPU Support, Model Performance Degradation, Overfitting issues with training, save_pretrained_gguf not working
- 在 Ubuntu 5090 上进行 Unsloth 训练遇到速度瓶颈:一位用户报告了在 Ubuntu 环境下使用 5090 运行 Unsloth 进行训练时的性能问题,训练速度从 200 steps/s 降至 1 step/s。
- 建议使用
unsloth/unslothDocker 镜像,该镜像兼容 Blackwell,并参考 Docker 文档 确保 Windows 上的 Docker GPU 支持配置正确。
- 建议使用
- 解决 Windows Docker GPU 问题:用户讨论了 Windows 上 Docker GPU 支持的挑战,建议查阅 官方 Docker 文档 进行故障排除。
- 一位用户指向了一个 GitHub issue,详细说明了解决 Windows 上 Docker 容器问题的步骤。
- 调试模型性能下降:一位用户在训练过程中经历了严重的性能退化,速度持续下降,并分享了训练过程的截图以寻求帮助。
- 建议包括检查 GPU 利用率、Loss 曲线,以及优化 Batch Size 和 Gradient Accumulation,并指出可能是特定模型的补丁(patches)存在问题。
- QLoRA 训练方案不匹配:有建议指出,用户在超大数据集(160 万个样本)上使用 LoRA 的方法很可能导致过拟合。
- 专家建议,这种情况下使用 CPT (Continued Pre-Training) 可能更好,并强调了使用具有代表性的数据集进行微调以及泛化到其余查询类型的重要性。
save_pretrained_gguf函数故障:save_pretrained_gguf函数目前无法正常工作,预计下周修复。在此期间,建议手动进行转换,或者将 safetensors 上传到 HF 并在那里使用 GGUF 转换。- 鼓励用户安装 Unsloth 以满足微调需求,手动转换步骤将在单独的讨论帖中提供。
{kind=link}
Unsloth AI (Daniel Han) ▷ #showcase (1 messages):
surfiniaburger: 受宠若惊!谢谢
Unsloth AI (Daniel Han) ▷ #research (1 messages):
le.somelier: https://arxiv.org/abs/2509.24372
Cursor Community ▷ #general (379 条消息🔥🔥):
Agent Board, Cheetah Model, GPT-5 Pro, Sonnet 4.5, Oracle Free Tier
- Agent Board 提升生产力:成员们发现 Agent Board 功能(通过 Ctrl+E 触发)能让工作界面更整洁,可以在一个显示器上显示常规 IDE,在另一个显示器上显示 Agent 窗口。
- 他们建议像 Warp 这样的工具也支持多 Agent 交互,并且屏幕越多越好。
- Cheetah 模型疾速登场:成员们发现 Cheetah 模型 速度非常快,甚至比 Grok Superfast 还要快,但在代码质量上略有下降。
- 一位成员指出,它某种程度上既奇怪又棒,因为它似乎每小时都在变得更好。
- GPT-5 Pro 定价:关于 GPT-5 Pro 的成本正在讨论中,一位成员表示 GPT-5 Pro 与普通版之间的 Benchmark 差异不值得 10 倍的溢价。
- 一位成员提到 GPT 4.5 的价格大约是输入 $75/m,输出 $150/m,导致单次对话可能花费 $20-$40。
- Sonnet 4.5 越狱与表达能力:一位成员报告称能够越狱 Sonnet 4.5 的 Thinking Tokens,尽管这很难维持,这表明 Thinking Tokens 可能是一个拥有独立 System Prompt 的不同模型。
- 同一位成员还指出,Sonnet 4.5 越来越让他们印象深刻,它在通用事务(不仅是编程)中的表达能力非常出色。
- Oracle 免费层级:一位成员推荐了 Oracle Free Tier,提供 24GB RAM、4 核 ARM CPU、200GB 存储以及每月 10TB 的入站/出站流量,但记得将系统镜像更改为 Ubuntu。
- 他们还分享了一篇博客文章,并吹嘘自己使用免费层级托管 Discord Bot 已达 5 年之久。
Cursor Community ▷ #background-agents (2 条消息):
Background Agents, Custom VM snapshot, Background Agents API, Linear agent integration
- 自定义 VM 快照初始化失败:成员们报告称他们的 Background Agents 无法识别 自定义 VM 快照。
- 一位成员好奇通过 API 启动 Agent 是否会成功,因为 UI 界面无法正常工作。
- Background Agents API 限制显现:一位成员查阅了 Background Agents OpenAPI 文档,并指出通过 API 启动 BA 时无法指定 Snapshot ID。
- 目前尚不清楚 API 是否能解决此问题。
- Linear Agent 产生多个副本:成员们在使用 Linear Agent 集成 时遇到了 Background Agent + Linear 运行多个副本(2-4 个以上)的问题。
- 即使只使用 1 个标记注释 来启动 Agent,这种情况也会发生。
Modular (Mojo 🔥) ▷ #general (136 messages🔥🔥):
Modular 缺席 SF Tech Week, Python 3.14 发布, Mojo 的 Python 互操作性, Mojo GPU vs Rust GPU, Mojo 图形集成
- Modular 缺席 SF Tech Week 😔:Modular 将不会参加 SF Tech Week,但他们会出席 PyTorch Conference。
- Python 3.14 发布,穿针引线 🪡:Python 3.14 包含了对 free-threaded Python (PEP 779) 的官方支持、标准库中的多解释器支持 (PEP 734),以及提供 Zstandard 压缩算法支持的新模块 compression.zstd。
- 其他改进包括 PyREPL 中的语法高亮、针对 CPython 的零开销外部调试器接口 (PEP 768) 以及改进的错误信息。
- Mojo 的 Pythonic 语法,并非表象那样 🧐:虽然 Mojo 拥有 类似 Python 的语法,但将 Python 代码直接粘贴到 Mojo 项目中并不能直接运行,因为它的语言设计更接近 C++ 和 Rust。
- 你可以通过 Mojo 的 python 模块使用 Python 包,这提供了一个类似于 C++ 或 Rust 程序嵌入 Python 解释器的视图;为了获得完整性能,互操作需要转换为
PythonObject。
- 你可以通过 Mojo 的 python 模块使用 Python 包,这提供了一个类似于 C++ 或 Rust 程序嵌入 Python 解释器的视图;为了获得完整性能,互操作需要转换为
- Mojo 的 GPU 杀手锏 ♠️:Mojo 的 GPU 编程方法与 Rust 显著不同,因为 Mojo 的设计理念是允许程序的各个部分同时在不同的设备上运行。
- Mojo 具有编写 GPU kernels 的一流支持、一个可以等待直到确定目标 GPU 的 JIT 编译器,以及通过内联 MLIR 和 LLVM IR 实现的语言级 intrinsic 访问,允许使用同一个二进制文件针对多个供应商。
- Mojo 瞄准图形领域霸权 👁️:在 Mojo 中集成图形技术在技术上是可行的,主要的阻碍是供应商文档匮乏;利用 Vulkan 是非常可行的,主要需要一个 SPIR-V 后端。
- Mojo 可以通过创建一个直接与 GPU 驱动程序通信的 Mojo 库来解决图形问题,这可能会产生一个统一的图形 API,其中大部分代码在不同供应商之间共享,尽管说服 Microsoft 为 Direct-X 采用 Mojo 仍是一个挑战。
Modular (Mojo 🔥) ▷ #mojo (139 messages🔥🔥):
MAX 与 CPU 兼容性问题, Mojo 与 ARM 系统, MAX 对 Linux 的 GPU 支持, 机器人与机器视觉笔记本电脑推荐, Layouts 中混合运行时与编译时的值
- MAX 的 CPU 兼容性问题再次袭来!:成员们讨论了在 CPU 上运行 MAX 模型的问题,一个特定的错误指出 bfloat16 编码与 CPU 设备之间不兼容。
- 有人指出许多 MAX 模型在 CPU 上运行效果不佳,现有的 GitHub issue 正在处理这个问题。
- Mojo 关注 ARM,不仅是 Apple!:讨论涉及了 Mojo 对 ARM 系统的支持,澄清了它不仅限于 Apple Silicon,测试定期在 Graviton 甚至 NVIDIA Jetson Orin Nano 上进行。
- 一位用户表达了希望 Mojo 能在 Apple Silicon 之外的 ARM 系统上运行的愿望。
- Linux 上 MAX 的 GPU 选择!:对话涵盖了 MAX 在 Linux 上的 GPU 支持,提到大多数现代 Nvidia DC、MI300(以及更新的 AMD DC)以及大多数 Turing 或更新的消费级 Nvidia GPU 在经过一些设置后应该可以工作。
- AMD RDNA 可以运行但在 MAX 中缺少 kernel,在标准库中可能会面临 “Assume CDNA” 的问题。
- 笔记本寻宝:机器人、视觉与 GPU!:一位用户在为 机器人 和 机器视觉 选择笔记本电脑时寻求建议,强调了 Mojo 和 MAX 的兼容性,讨论倾向于选择 NVIDIA GPU 以获得更好的 MAX 支持。
- NVIDIA Jetson Orin Nano 被建议作为机器人实验的起点,而 AMD Strix Halo 则被提及适用于需要足够内存运行大型模型的笔记本电脑。
- 布局迷宫:混合运行时与编译时维度:一位用户询问如何定义混合运行时和编译时值的布局,这在他们使用 Cute/CuteDSL 的工作中很常见,这将涉及使用混合了运行时和编译时值的 IntTuple。
- 建议是使用
Layout(M, 1, K)来使第二个维度变为未知,并指出目前正在努力统一 RuntimeLayout 和 Layout 以提供更简洁的体验。
- 建议是使用
LM Studio ▷ #announcements (1 条消息):
LM Studio 0.3.29, OpenAI /v1/responses compatibility, model variants
- LM Studio 发布: LM Studio 0.3.29 现已发布,支持 OpenAI /v1/responses 兼容性。
- LM Studio 具备 OpenAI 兼容性: 最新版本包含 /v1/responses OpenAI 兼容性 API。
- 现在,你可以使用
lms ls --variants列出本地模型变体。
- 现在,你可以使用
LM Studio ▷ #general (118 条消息🔥🔥):
LM Studio memory footprint, LM Studio headless mode, LM Studio remote feature, LM Studio updates on Linux, GPT-OSS reasoning effort
- LM Studio 通过上下文长度避免内存增长: 成员们注意到,在服务器模式下使用 LM Studio 时,context 不会被缓存;前端每次都会发送完整的 context 并重新进行处理。
- 此外,在加载 LLM 时,它会预留 定义的 context window 所需的内存占用(memory footprint),因此内存使用量不会超过该限制。但是,使用 LM Studio 的 Python 应用程序的内存可能会增加。
- Responses API 避免重复发送完整 context: LM Studio 中新的 Responses API 仅向 API 发送对话 ID 和新消息,这与旧的每次请求都重新发送完整 context 的行为不同。
- 这显著减少了 HTTP 流量并利用了服务器端状态,成员们推测这一变化将使 prompt 生成速度更快。
- 远程功能发布: 新的 remote feature 允许在性能强大的机器 (A) 上运行模型,并通过使用 LM Studio 插件并设置相应的 IP 地址和 API key,从性能较低的机器 (B) 进行访问。
- 为了更加方便,可以使用 Tailscale 从任何地方访问强大的模型,从而实现诸如在带有 3090 eGPU 的 NUC 12 上运行模型并从 GPD Micro PC2 访问它的场景。
- 通过手动下载进行 Linux 更新: LM Studio 的 Linux 版本尚未提供自动更新程序;用户需要从官方网站 手动下载 最新版本。
- 成员们建议使用 AppImage 格式,并将桌面入口指向 AppImage 文件以便于管理。
- 新的 YouTube LLM 评测频道出现: 用户分享了一个提供 LLM benchmarking 的 YouTube 频道。
- 用户还链接了一个用于高密度 GPU 配置的 单槽液冷 Arc Pro B60。
LM Studio ▷ #hardware-discussion (138 条消息🔥🔥):
5090 GPU 升级, AMD 笔记本, M5 Ultra Mac Studio, 批量购买主板, 模型蒸馏
- 5090 价格虚高引发不满: 一位用户提到,大约只需 $3800 即可购得 64GB 5090,这与其他人预期该价格只能买到 24GB 的想法相反。
- 另一位用户随后报告称升级到了 5090 但却在 CPU 上运行,在意识到自己切换了运行时并更新了 CUDA 运行时后,问题得以解决。
- MI50 整机传闻引发关注: 一名成员正在批量购买二手主板+CPU+RAM 套装,计划构建一台运行 80 TOK/s 模型且能达到约 每秒 32 个 prompt 的设备,该设备由 MI50 显卡驱动,用于蒸馏 prompt。
- 他们的目标是将其蒸馏为可以在嵌入式硬件上运行的极小型决策 MLP,以便高效执行源自智能 LLM 的复杂决策。
- 蒸馏数据集讨论展开: 有人提到,对于蒸馏,通常是让较大的模型生成 prompt 数据集,并使用现有的数据集如 FLAN、Alpaca 和 OASST。
- 一位用户正在为特定用例生成自己的 prompt,以便蒸馏到可以在嵌入式硬件上运行的极小型决策 MLP 中,正如这篇 datacamp 教程 所演示的那样。
- litellm 链接分享: 一名成员寻求管理多个后端的软件,另一名成员推荐了 Litellm,特别是其 proxy server 功能。
- 该用户需要将请求路由到免费或能够运行特定模型的 OpenAI 端点,另一名成员对此回复了一个 演示链接。
- MI350 媒体资料发布: 一位用户分享了来自 Level1Tech 的 两段 YouTube 视频,展示了访问 AMD 并探索新型 MI350 加速器 的过程。
- 未提供额外评论。
GPU MODE ▷ #general (22 条消息🔥):
FA3 技能稀缺性, Tri Dao 传奇, vllm whisper 实现, NVIDIA Jetson Wayland, Godbolt.org 改进建议
- FA3 超能力:罕见的发现!: 讨论中提到,使 FA3 正常工作所需的技能组非常罕见,成员们一致认为即使在计算机专业研究生中也不常见。
- 有人强调,大公司中存在许多才华横溢的性能工程师,专注于个人成长比将自己与 Tri Dao 等榜样进行比较更重要。
- 通过 Encoder 补丁加速 Whisper!: 一名成员修补了 vllm whisper 实现以移除 padding,导致吞吐量增加了 3 倍,但短音频的 WER(词错率)显著受损,详情见 此 Hugging Face issue 和 此 OpenAI 讨论。
- 在发现短音频推理过程中 encoder 占据了 80% 的时间后,通过对 decoder 中的 attention scores 进行实验,得出了一个可以带来 2.5 倍加速 但 WER 差 1.2 倍 的补丁。
- Jetson 的 Wayland 困扰: 一名成员在尝试于 NVIDIA Jetson 设备上使用 Wayland 时遇到问题,weston 无法启动,并分享了错误消息。
- 另一名成员请求提供失败日志以协助排查故障。
- Codeplay NVIDIA 插件下载问题困扰用户: 成员们报告了从 Codeplay 下载页面 (https://developer.codeplay.com/products/oneapi/nvidia/download?state=licenseAccepted&downloadHash=5f8cf9ab06dd4621e2ec8d08768b74293e5d7fe5) 下载 oneAPI 的 NVIDIA 插件 时出现的问题。
- 网站上的菜单会重置,API 返回 404 错误,且 apt 和 conda 方法也失效了。
- Godbolt UI 的不足: 一名成员询问有关 godbolt.org 的改进建议,旨在为 GPU mode 克隆其部分功能。
- 其中一个建议是默认禁用 mini-map(缩略图),因为它在笔记本电脑屏幕上占据了很大一部分空间。
GPU MODE ▷ #triton (7 messages):
TLX, Triton conference, Meta Engineering Teams
- Meta 的 TLX 团队预定参加 Triton 会议:由一名工程经理领导的 Meta TLX 团队将于今年 10 月在 Triton conference 上进行演讲。
- 该工程经理邀请大家提出关于 TLX 的问题,但指出团队的工程师可能不会主动监控此 Discord 频道。
- TLX 团队参与黑客松:讨论了 TLX 团队与黑客松(hackathon)相关的事宜。
- 看来该团队正在参加 hackathon。
GPU MODE ▷ #cuda (14 messages🔥):
CUDA benchmarks, L2 cache clearing, mma cores GEMM, shared mem epilogue, thread block cluster APIs
- CUDA 缓存清理难题:在进行原生 CUDA 基准测试时,清理 L2 cache 的标准做法受到了质疑,因为目前没有简单的单行 API 可用,这引发了对替代方法的讨论。
- 建议包括分配一个足够大的缓冲区并使用
zero_(),或者分配cache_size/n个输入缓冲区并循环使用它们。
- 建议包括分配一个足够大的缓冲区并使用
- 基准测试最佳实践博客提升认知:一名成员分享了一篇关于 CUDA 性能热/冷测量(Hot/Cold Measurement)的博客文章链接,其中提供了基准测试时如何将缓存清零的建议:CUDA Performance。
- MMA 核心的 Shared Memory 与 Epilogue 技巧:在使用 mma cores 的分块 GEMM 中,一名成员询问了在 3090 上
stmatrix之前使用 shared memory epilogue 的效用,质疑在向量化存储到 global memory 之前将 BM * BN tile 加载到 shared memory 是否比非合并(uncoalesced)的 global stores 更快。- 另一名成员提供了一个关于 Warp Synchronous Shuffle Mapping (maxas/wiki/sgemm) 的资源链接,与该主题相关。
- ThunderKittens 内核集群热潮:讨论了使用 thread block cluster APIs 的 CUDA 示例,并提供了 ThunderKittens matmul 内核的链接 (ThunderKittens matmul kernel)。
- 利用 2CTA matmul 的 ThunderKittens attn kernel 也被重点提及,指向了一个更复杂的集群应用示例 (ThunderKittens attn kernel)。
GPU MODE ▷ #cool-links (1 messages):
j4orz: https://rocm.blogs.amd.com/software-tools-optimization/matrix-cores-cdna/README.html
GPU MODE ▷ #jobs (1 messages):
RunwayML, GPU, kernel development, large scale training, real time inference
- RunwayML 招聘 GPU 内核工程师:RunwayML 正在招聘 GPU kernel engineer,负责大规模训练和实时推理工作,旨在榨干 GPU 的每一分算力(flop),详见 职位发布。
- RunwayML 文化:RunwayML 拥有一支多元化的团队,包括驱动产品方向的创意人员、推动媒体生成前沿的研究人员,以及专注于高效计算和可扩展性的工程师。
GPU MODE ▷ #beginner (7 messages):
Rust for GPU, rust-cuda crate, cudarc
- Rust GPU 计算:初生还是崛起?:成员们讨论了使用 Rust 进行 GPU compute 的成熟度,观点认为它尚未完全准备好处理纯计算任务。
- 一名成员指出一个主要限制:由于单目标编译,无法在同一个项目中混合设备端(device)和主机端(host)代码。
- Rust-CUDA Crate:稳健但繁琐?:rust-cuda crate 提供了相当稳健的功能,但代码编写起来可能非常丑陋。
- 他们建议将设备端代码编译为 PTX,并在主机端使用 CUDA APIs,发现 Rust 绑定(bindings)比使用 C++ 编写更容易使用。
- Cudarc:萌芽中的替代方案?:成员们提到了 Cudarc 作为另一个 crate,尽管其成熟度尚不确定。
- 对于 Rust 中的主机端代码,建议使用纯 CUDA C++/PTX 编译为多个 fatbins,并使用 Rust 绑定来调用 CUDA RT/driver APIs。
GPU MODE ▷ #pmpp-book (1 条消息):
PMPP C-style Code
- PMPP 为受众保持 C-style:PMPP 项目维持 C-style 代码库,以最大化受众覆盖面。
- 未来版本可能会根据社区需求探索对此方法的更改。
- PMPP 中的 C-style 编码:讨论表明 PMPP 有意使用 C-style 代码 来扩大其用户群。
- 这一决定可能会在未来版本中重新评估,以适应不同的编码风格。
GPU MODE ▷ #irl-meetup (1 条消息):
Amsterdam Meetup, High Performance Computing, November Event
- 阿姆斯特丹 HPC 见面会已排期:一位成员宣布了 11 月在阿姆斯特丹举行的 High Performance Computing 见面会;详情见 Meetup 页面。
- 提醒关注阿姆斯特丹见面会:另一位成员邀请如果在 11 月期间在附近的人关注阿姆斯特丹的 High Performance Computing 见面会,并附上了 活动页面 链接。
GPU MODE ▷ #rocm (13 条消息🔥):
mi300 support, Wavefront specialization, FlashAttention CK backend, CUDA to ROCm
- MI300 上的 ROCm 支持:据报道 ROCm 可以在 MI300 上运行,但尚未集成随机采样(stochastic sampling),需要最新的 amdgpu kernel driver。
- 成员们指向了 MI300 and friends。
- 深入探讨 Warp Specialization:一位成员分享了 Warp Specialization 博客文章,暗示 Triton 正在努力实现类似功能,并指向了 wavefront partitioning issue。
- 有人指出,由于缺乏 warpgroup instructions,warp specialization 在 AMD GPU 上的效果可能较差,尽管 CK 中存在一些技术,其中一半加载输入而另一半执行 mfma。
- FlashAttention-v2 与 CK-Tile 介绍:在 rocm.blogs.amd.com 上有一篇关于 FlashAttention v2 搭配 CK 的文章。
- 一位成员指出,“既然 FlashAttention 为 AMD GPU 提供了 CK 后端,也许 FA 会使用它。”
- 弥合 CUDA 和 ROCm 知识鸿沟:一位成员询问是否有适合熟悉 CUDA 的人学习 ROCm 的资源,建议包括 HIP API Syntax 参考 和 PyTorch 兼容性指南。
- 成员们对现有文档感到好奇。
GPU MODE ▷ #self-promotion (1 条消息):
Apple GPU, Matrix Multiply, GEMM
- Apple GPU 加入矩阵乘法行列:一位成员通过 percisely.xyz/gemm 在矩阵乘法博客系列中新增了一篇关于 Apple GPU 的文章。
- 该博客详细介绍了在 Apple silicon 上运行 GEMM (General Matrix Multiply) 的细节。
- Percisely GEMM:Apple GPU 上的矩阵乘法:一篇新博客文章 (percisely.xyz/gemm) 讨论了 Apple GPU 上的矩阵乘法实现,为更广泛的矩阵计算资源库做出了贡献。
- 该文章可能探讨了针对 Apple silicon 架构的特定优化和性能特征。
GPU MODE ▷ #🍿 (2 条消息):
Paper retrieval issues, Arxiv 2509.14279
- Arxiv 链接指向新论文:一位用户发布了一个 Arxiv 论文链接 (https://arxiv.org/pdf/2509.14279)。
- 另一位用户指出,该链接重定向到了 9 月的一篇新论文,因为原论文遭到了很多“差评(hate)”。
- 原论文遭到差评:原论文遭到了很多“差评(hate)”。
- 一位用户引用原论文作为其硕士论文中问题的案例。
GPU MODE ▷ #thunderkittens (1 条消息):
j4orz: tinygrad uops 中的 thunderkittens https://github.com/tinygrad/tinygrad/pull/12476
GPU MODE ▷ #submissions (1 messages):
MI300x8, amd-ag-gemm
- MI300x8 在 amd-ag-gemm 排行榜上的得分:一台 MI300x8 在
amd-ag-gemm排行榜上成功跑出了 549 µs 的成绩。 - amd-ag-gemm 排行榜更新:提交 ID
51239已成功添加到amd-ag-gemm排行榜中。
GPU MODE ▷ #factorio-learning-env (5 messages):
Factorio client connection issues, Server restart to resolve client issues
- Factorio 客户端面临连接难题:一名用户报告在测试后使用 Factorio 客户端时遇到问题,尽管最初的评估是积极的,详见附带的 截图。
- 该用户表示 “我测试过了,看起来没问题,但我仍然在 Factorio 客户端上遇到问题”,这表明存在间歇性或特定的连接挑战。
- 重启补救:重启服务器以确保运行顺畅:另一位成员建议重启服务器将解决 Factorio 客户端的连接问题。
- 他们澄清道 “遗憾的是,你无法连接到已经在运行的服务器”,这指向了服务器端的限制,即新的客户端连接需要重新启动。
{kind=link}
GPU MODE ▷ #amd-competition (1 messages):
Runner Health, Timeout Complaints
- 超时烦恼?目前并非普遍现象!:一位成员表示,目前不太可能出现大规模的超时投诉。
- 他们补充说,这些问题通常在 Runner 状态不健康时出现,但目前 Runner 处于良好状态。
- 健康的 Runner 意味着更少的超时:目前 Runner 的健康状况与缺乏大规模超时投诉相关。
- 从历史上看,不健康的 Runner 会导致超时问题增加,但目前情况并非如此。
GPU MODE ▷ #general (4 messages):
GPUmode website updates, Trimul competition winners, Rust-based IDE with wgpu support
- GPUmode 获得提交入口!:成员们报告称 gpumode.com 现在接受提交,并且需要一种类似代码编辑器的体验来取代文件附件。
- 社区正在构思一个单独的页面,用于存放入门问题以及通过 IDE 提供免费 GPU 访问。
- Trimul 竞赛获胜者:Trimul 竞赛的获胜者公布为 <@772751219411517461> 和 <@485608015656124427>。
- 获胜者应私信其地址以领取奖品。
- Rust IDE 之梦:一位成员的目标是开发一个基于 Rust 的 IDE,支持 wgpu 并具有 类似 Godbolt 的编译输出。
- 社区将这一举动称为过度设计 (overengineering)。
GPU MODE ▷ #multi-gpu (3 messages):
Mercury Multi-GPU Optimization, Remote Memory Scheduling for LLMs, Persistence Mode
- Mercury 加速多 GPU LLM 训练:一篇题为 Mercury: Unlocking Multi-GPU Operator Optimization for LLMs via Remote Memory Scheduling 的新论文(ACM 链接,预印本,GitHub)介绍了 Mercury。这是一种多 GPU 算子编译器,通过将远程 GPU 内存视为内存层级的延伸,实现了比手工优化设计快 1.56 倍的加速,在实际 LLM 工作负载中提升高达 1.62 倍。
- 在 NVIDIA GPU 上禁用持久化模式 (Persistence Mode):一位用户尝试使用
nvidia-smi -pm 0在 NVIDIA GPU 上禁用持久化模式以观察时钟行为,并发布了他的操作步骤。 - Colab GPU 使用监控:一位用户推测 Google Colab 在容器外部采用了监控进程来跟踪 GPU 使用情况,从而防止驱动程序在禁用持久化模式时反初始化 GPU。
- 该用户通过指出以下现象来支持这一观点:当 GPU 未被使用时会收到弹出通知,且
lsof /dev/nvidia*返回为空,表明没有活动进程在使用该设备。
- 该用户通过指出以下现象来支持这一观点:当 GPU 未被使用时会收到弹出通知,且
GPU MODE ▷ #penny (3 条消息):
Cloud Providers, Vast AI limitations, nvshmem, ncu/nsys access
- 探讨云算力方案:一名成员正在寻找合适的 Cloud Providers 来开展项目,目前正在尝试 Vast AI 和 AWS。
- 他们的核心需求是访问 nvshmem 和 ncu/nsys,而这些在 Vast AI 上无法使用。
- 其他人也遇到了类似问题:另一名成员报告了云算力选择方面的类似问题。
- 他们正在寻求支持 nvshmem 的云算力选项。
GPU MODE ▷ #llmq (45 条消息🔥):
llmq Build Issues, CUDA and CUDNN, Clang vs GCC, Huggingface config.json
- llmq 构建深受依赖问题困扰:一位用户在构建 llmq 时因 CMake、CUDNN 和 C++ 编译器问题而苦苦挣扎,最终不得不从源码构建 Clang,并修补代码将
std::format替换为std::ostringstream。- 该用户形容这个过程简直是“地狱”,直到从 NVIDIA 官网安装了 CUDNN 并重新构建才最终成功。
- CUDA Toolkit 令人头疼的问题:用户遇到了与 CUDA toolkit 相关的错误,包括缺失
CUDA::nvToolsExt目标以及找不到cudnn.h的问题。- 有人建议在 Ubuntu 上安装
libcudnn9-dev-cuda-12并手动设置CUDNN_INCLUDE_PATH和CUDNN_LIBRARY_PATH,这凸显了混合安装方式的复杂性。
- 有人建议在 Ubuntu 上安装
- Clang 在构建中很麻烦:用户最初选择 Clang 而非 GCC 进行构建,但遇到了
cuda_runtime.h和缺失__config_site文件的问题,随后又出现了 CMake 找不到线程的问题。- 在与 Clang 搏斗后,一位代码提交者问道:“使用 Clang 而不是 GCC 有什么特殊原因吗?”。
- Hugging Face Hub 缺失 Config:成功编译后,由于 Hugging Face 模型缓存中缺少
config.json文件,用户遇到了std::runtime_error。- 问题追溯到 Hugging Face 模型缓存中缺失配置文件,通过从 Hugging Face 模型仓库手动下载
config文件得以解决。
- 问题追溯到 Hugging Face 模型缓存中缺失配置文件,通过从 Hugging Face 模型仓库手动下载
HuggingFace ▷ #general (69 条消息🔥🔥):
Finding GGUF model files, Running inference on Hugging Face models, Contributing to open source, Candle release roadmap, 7-Eleven sushi in Japan
- 导航 HF 模型下载:一位用户表达了在 Hugging Face 上找到模型后,难以找到模型下载链接(尤其是 GGUF 文件)的挫败感。
- 一名成员建议滚动到模型页面的“Quantizations”部分,并建议使用 LMStudio 或 GPT4All 等程序在无需命令行交互的情况下运行模型。
- 评估 HuggingFace Inference Endpoints:一位用户询问 HF Inference Endpoints 是否支持一项涉及对 Hugging Face 上托管的约 2000 个 LLM 模型进行推理的实验,且需要完整的输出 logits。
- 另一名成员回答说,如果“钱不是问题”的话是可以的,并建议在遵守许可证的同时,使用“精心设计的端点和合适的硬件”。
- 新手寻求开源指导:一名新用户请求关于贡献开源项目以及如何使用 Discord 服务器的指导。
- 一名成员建议从课程开始并积极提问,而另一名成员分享了一份学习资源列表,包括 Python、AI、LLM 和 Advanced Things 教程的链接,以及 Hugging Face Learn 和 Spaces。
- Candle 路线图咨询:一位用户询问关于 Candle 发布路线图的最佳提问地点。
- 另一位用户将他们引向 Discord 上的 Candle 频道和 Candle GitHub 仓库。
- 用户回忆丢失的 Vibrant Horizons 模型:一位用户正在寻找他们曾经下载过但似乎丢失了的图像生成模型 Vibrant Horizons。
- 该用户专门在 civitai.com 上寻找它。
HuggingFace ▷ #computer-vision (2 messages):
text-conditioned DiT, cross attention blocks, Pokemon yt dataset
- DiT 模型在文本遵循方面存在困难:一位成员正在实现一个 text-conditioned DiT 模型,用于在 Pokemon YouTube 数据集上进行去噪和生成,但尽管使用了 cross-attention blocks,仍面临生成结果与输入提示词(prompts)遵循度差的问题。
- 他们附带了一张使用 ‘Ash and Misty standing outside a building’(小智和小霞站在建筑外)提示词生成的示例图像,显示出较差的遵循度。
- DiT 模型中的文本嵌入问题:实现的 text-conditioned DiT 模型使用了带有 norm 的经典 cross-attention blocks 来处理文本嵌入。
- 尽管如此,该模型在生成的图像中准确反映输入文本提示词方面仍表现挣扎,这表明在模型内部处理或利用文本嵌入的方式可能存在潜在问题。
HuggingFace ▷ #NLP (1 messages):
Fine-tuning small models, Tutorial request
- 用户寻求微调小模型的指导:一位用户表达了对微调相对较小的模型的兴趣,并请求相关指导,特别是以教程的形式。
- 关于微调的教程:该用户正在寻找一种教程格式,以了解微调的过程。
- 他们的目标是学习针对特定任务有效微调较小模型所涉及的步骤和技术。
HuggingFace ▷ #smol-course (3 messages):
LoRA SFT issues with TRL and SmolLM3, Module 3 PR for leaderboard and benchmark, Formatted Anthropic's HH-RLHF dataset for trl
- 调试 SmolLM3 的 LoRA SFT 设置:一位成员报告了在 Colab 中使用 TRL + SmolLM3 进行 LoRA SFT 时出现
TypeError,具体为SFTTrainer.__init__()中出现了未预期的关键字参数dataset_kwargs。- 该成员请求帮助调试此设置。
- Smol Course Module 3 基准测试:一位成员询问关于为 Module 3 向排行榜和基准测试提交 PR 的事宜,该测试基于 gsm8k。
- 他们还询问是否有计划使用来自课程材料的基准测试进行扩展。
- HH-RLHF 数据集发现:一位成员分享了一个为 trl 格式化的 Anthropic HH-RLHF 数据集链接。
- 该数据集可在此处获取。
HuggingFace ▷ #agents-course (6 messages):
Course duplication vs cloning, New course participants
- 课程复制优于克隆:一位用户询问为什么在本地设备上复制(duplicate)课程比克隆(clone)更好。
- 另一位成员回答说,正如课程中所提到的,他们也被明确告知要使用复制。
- 新学员加入:几位新参与者宣布开始学习 AI agents 课程。
- 介绍来自 Ashok、Dragoos、德克萨斯州的 Toni 和辛辛那提的 Ajay。
Latent Space ▷ #ai-general-chat (59 messages🔥🔥):
Supermemory AI 融资, Jony Ive 参加 OpenAI DevDay, AI System Design 面试资源, Adaption Labs 启动, Bagel Paris 去中心化模型
- Dhravya Shah 的 Supermemory AI 筹集 300 万美元种子轮融资:20 岁的独立创始人 Dhravya Shah 为其 AI 记忆引擎 Supermemory AI 获得了 300 万美元的种子轮融资,由 Susa Ventures、Browder Capital 以及来自 Google 和 Cloudflare 的天使投资人支持。
- 该公司正在积极招聘工程、研究和产品人员,目前已为数百家企业提供服务。
- Jony Ive 的 DevDay 会议引发热议:Greg Brockman 庆祝了 Jony Ive 即将在 OpenAI DevDay 举行的会议,用户们表现出极大的兴奋并请求提供 直播。
- Jony 的关键语录包括强调界面必须 “让我们快乐、让我们感到充实” 的重要性,以及需要拒绝那种认为我们与技术的关系 “必须是常态” 的观点。
- 攻克 AI System Design:书单推荐:成员们分享了 AI 工程系统设计面试的资源,包括 Chip Huyen 的书 和 另一本书。
- 一位成员推荐 Chip 的书“非常棒”,而另一位成员则选择了 ByteByteGo 的书并承诺会提供反馈。
- Sara Hooker 启动 Adaption Labs:Sara Hooker 宣布启动 Adaption Labs,这是一家专注于创建持续学习、自适应 AI 系统的创业公司。
- 团队正在全球范围内远程招聘工程、运营和设计岗位。
- Bagel 的 Paris:去中心化 Diffusion 模型首次亮相:Bagel.com 推出了 “Paris”,这是一个在没有跨节点同步的情况下训练的 Diffusion 模型。
- 该模型、权重(MIT 许可证)和完整的技术报告已开放用于研究和商业用途,将其定位为迈向开源超级智能的一步。
Latent Space ▷ #genmedia-creative-ai (7 messages):
Sora 的能力, GPQA 科学基准测试, 隐藏的 LLM Prompt 重写层
- Sora 在 GPQA 基准测试中表现惊人:尽管并非为此设计,Sora 2 在 GPQA Diamond 科学问题基准测试中达到了 55% 的准确率,引发了关于涌现行为(emergent behavior)的讨论。
- 这一表现由 Epoch AI 的推文 重点指出。
- LLM Prompt 重写层理论:社区成员推测 Sora 2 可能使用了一个隐藏的 LLM Prompt 重写层,类似于 HunyuanVideo 和 Veo3,以实现其在 GPQA 上的得分。
- 正如 Andrew Curran 的推文 中提到的,据推测 GPT-4o/5 甚至 Gemini 被用于 Prompt 翻译,并在视频生成之前将解决方案嵌入到 Prompt 中。
Yannick Kilcher ▷ #general (29 条消息🔥):
Vinge 的奇点理论, LLMs 视频理解, 用于推理的 SLMs, 用于数独的 RWKV
- Vinge 的奇点预测接近现实:一位成员讨论了 Vinge 的奇点概念,即由快速技术变革导致的不可预测性,并指出 Vinge 预测其到来的时间范围在 2005-2030 年之间。
- 另一位成员认为不可预测性是一个薄弱的定义,建议用“人类无法理解的进步”来描述更为准确,并引用了 Vinge 的文章 Coming Technological Singularity 来支持这一观点。
- LLMs 在实时视频理解方面面临困难:成员们讨论了为浏览器创建一个 ChatGPT 插件来处理实时文本、图像和视频流,但一位成员指出,由于上下文窗口(context window)的限制,目前的 LLMs 难以稳定地理解视频流,并引用了这篇论文。
- 另一位成员反驳称,使用 Gemini 等模型和 YouTube,每小时处理 100 万个 token 并不困难,且 10M 的上下文长度是可以实现的。
- RWKV 6 在上下文内解决数独问题:一位成员分享了 RWKV 6 通过学习自我搜索,在上下文内(in-context)解决数独问题的结果,引用了这条推文。
- 他们建议在类似任务中使用 RWKV 7 或其他具有状态追踪能力的 SSMs、gated deltanet 或混合注意力模型(hybrid attention models),并建议查阅文献中的诸多案例。
- 用于数学推理的 SLMs - 降低预期:一位成员询问了创建用于推理的小语言模型(SLMs)的最佳架构,特别是在数学和运筹学问题方面。
- 另一位成员建议调整预期,并指出虽然可以针对特定问题进行训练,但仅凭几百万个参数的模型,不太可能在开放式运筹学领域超越 GPT-5。
Yannick Kilcher ▷ #paper-discussion (1 条消息):
k_nearest_neighbor: 今天也有会议,但明天应该做点什么
Yannick Kilcher ▷ #agents (2 条消息):
模型欠拟合, Classifier-Free Guidance
- 模型因欠拟合而挣扎:一位成员建议,在特定场景下模型可能对背景出现了欠拟合(underfitting)。
- 提出的解决方案是,如果使用 classifier-free guidance 或类似技术,则增加权重。
- Guidance 权重微调:讨论集中在通过调整 guidance 权重来解决欠拟合问题。
- 建议在采用 classifier-free guidance 或同类方法时专门增加权重,以提升模型性能。
Yannick Kilcher ▷ #ml-news (5 条消息):
GPT-5, 数学, 模型训练
- 据称 **GPT-5 破解了数学难题:有说法称 **GPT-5 正在帮助数学家解决问题,如这条推文和另一条包含图像的推文所示。
- 被指忽视模型训练数据:一位用户批评那些忘记 GPT-5 等模型是在海量互联网数据上训练的人,暗示获取这些数据至关重要,这条推文包含了相关讨论。
- 该用户认为,缺乏对这些训练数据的认知是“彻头彻尾的愚蠢表现”。
Eleuther ▷ #general (8 messages🔥):
Attention Layers, Mech Interp Discord, MLP vs Attention
- Attention Layers 完善了神经网络:一位成员分享了他们的观点,认为 attention layers 通过启用层内通信完善了 neural network,允许特征对同级别的特征产生影响。
- 其他成员指出 MLP 是 token 内部的,而 attention 是 token 之间的,并建议在第一层考虑神经元激活(neuron activations)而不是 tokens。
- Mech Interp Discord 链接已上线:一位成员宣布,在主 Discord 的频道栏目中现在可以找到 mech interp discord 的链接。
Eleuther ▷ #research (13 messages🔥):
DPO-like algorithms for finetuning, Memory Layers at Scale, EqM surpasses diffusion models, babyLM
- **Axolotl Aces DPO 算法讨论:成员们讨论了用于对比对(contrast pairs)微调的最佳 **类 DPO 算法,建议查看 Axolotl 的实现和支持。
- 讨论的重点较少关注理论上的优越性,更多关注在现有框架内的实际落地。
- **Memorable Layers 达到新高度*:围绕论文 *Memory Layers at Scale (arXiv:2412.09764) 展开了讨论,芝加哥的一个本地 ML 读书小组对此表示有兴趣听取专家意见。
- 一位成员链接了另一篇论文 (arxiv.org/abs/2510.04871v1)。
- **ARC-AGI-2 达成:模型达到 8%!:一位成员注意到一个模型在 **ARC-AGI-1 上达到了 45%,在 ARC-AGI-2 上达到了 8%,并引用了 一条推文 作为背景。
- 这一里程碑是在讨论该领域近期进展的背景下分享的。
- **Equilibrium Models 超越 Diffusion 动力学:如 这篇论文 所述,平衡模型 (EqM) 在实验上超越了 diffusion/flow 模型的生成性能,在 **ImageNet 256 上实现了 1.90 的 FID。
- 一位成员对这一消息表现出兴奋。
- **BabyLM 的背景:社区根源揭晓:一位成员分享说他与 Alex 共同发起了 **babyLM,并进一步澄清自那时起他一直负责组织工作。
- 另一位此前从事增量式 NLP(incremental NLP)工作的成员表示有兴趣了解更多关于该计划的信息。
Eleuther ▷ #scaling-laws (1 messages):
Attention Mechanisms, GPU implementation of Attention, Inductive vs. Generic
- Attention:纯粹的通用性:一位成员提出 attention 是集合上最简单的函数之一,且易于在 GPU 上实现。
- 他们补充说,它更偏向于通用性(generic)而非归纳性(inductive)。
- 通用 Attention:讨论集中在 attention 机制的本质,特别是其在 GPU 中的应用。
- 焦点在于 attention 应该被描述为通用函数还是归纳函数。
Eleuther ▷ #lm-thunderdome (1 messages):
Task Tags, Tag Naming Conventions
- 实现任务标签:寻求指导:一位成员正在实现一个新任务并寻求关于 任务标签 (task tags) 的指导,并指出文档中缺乏相关信息。
- 他们询问是否存在常用标签名称列表以符合现有规范,或者标签名称是独立创建并可能在以后进行匹配。
- 关于任务标签使用的澄清:该成员旨在了解如何在他们的新实现中正确利用任务标签。
- 他们不确定是遵循已建立的标签命名规范,还是创建自己的标签(这可能导致未来与其他任务的标签进行匹配)。
Eleuther ▷ #multimodal-general (2 messages):
VLM Models, Molmo checkpoints, Release Intermediate Checkpoints
- 视觉语言模型资源:一位成员分享了一个关于 VLM 理解 的博客文章链接和一篇关于 VLM 的 arXiv 论文。
- 寻找发布中间检查点的 VLM:一位成员询问是否有在训练期间发布中间检查点(intermediate checkpoints)的 VLM 模型。
- 他们查看了 Molmo,但发现它似乎没有在维护。
DSPy ▷ #general (20 messages🔥):
DSPy-ReAct-Machina, Context Overflow, Community Plugins, Cache Hits, Pyodide/Wasm
- **Machina Mania: 新的 DSPy-ReAct 替代方案发布!: 一位成员介绍了 **DSPy-ReAct-Machina,这是 DSPy 的一种替代 ReAct 实现,通过单一、不断增长的上下文历史和状态机方法实现多轮对话。代码和使用示例可在 博客文章 和 GitHub 上找到。
- 可以通过
pip install dspy-react-machina安装,并通过from dspy_react_machina import ReActMachina导入。
- 可以通过
- **Context Crisis: 解决 DSPy ReAct 中的 Context Overflow 问题: 一位成员提出了 DSPy ReAct 中的 **Context Overflow(上下文溢出)问题,特别是关于默认处理方式以及对自定义上下文管理解决方案的需求。
- 原作者承认他们的实现目前还不支持处理上下文溢出,并建议 DSPy 确实可以从某种内存抽象中受益。
- **Plugin Paradise: 呼吁 DSPy 社区集成**:一位成员建议 DSPy 应该拥抱社区驱动的倡议,为社区插件创建一个官方文件夹或子包,类似于 LlamaIndex 的做法。
- 该成员认为这将围绕 DSPy 培养更强的生态系统感和协作感,并有助于解决包分散且难以找到的问题。
- **Cache Clash: ReActMachina 与标准 ReAct 在 Token 使用上的对比: 一位成员对 **ReActMachina 和 Standard ReAct 进行了 30 个问题的测试,发现虽然 ReActMachina 具有更高的缓存命中率(47.1% vs 20.2%),但由于结构化输入,其总体成本更高(总成本差异:+36.4%)。
- 然而,当上下文增长到一定大小时,ReAct 开始崩溃,而凭借 ReActMachina 的结构化输入,它没有崩溃,并且无论上下文大小如何都能继续回答。
- **WASM Wondering: DSPy 的 Pyodide 兼容性?: 一位成员询问 DSPy 是否有 **Pyodide/Wasm 友好版本,并指出 DSPy 和 LiteLLM 的几个依赖项不被 Pyodide 支持。
Moonshot AI (Kimi K-2) ▷ #general-chat (11 messages🔥):
Kimi Forum, Ghost Ping, Vacation Coming to an End
- Kimi 论坛已存在 2 个多月:Kimi AI 论坛的存在已在 2 个多月前宣布。
- “Ghost Ping” 之谜揭晓:一位用户提到收到来自公告频道的 “Ghost Ping”(幽灵艾特),导致他们错过了论坛的介绍。
- 假期即将结束:一位用户哀叹在返回工作岗位前只剩下 2 天 假期。
Nous Research AI ▷ #general (7 messages):
Custom Classifiers, New Grok Video, Hermes App Inside ChatGPT
- Evals 支持外部模型,无需自定义分类器:成员们讨论了 evals 功能可以使用外部模型,因此可以在你的 Agent 中使用自定义分类器。
- 他们还认为,如果仅限于 ChatGPT,它将在某种程度上受到影响,因为对于内部数据或与你的应用/领域相关的特定工具,需要自定义模型支持才能获得比现成模型更好的结果。
- 在 ChatGPT 应用内集成 Hermes?:成员们讨论了在 ChatGPT 内部制作 Hermes app 的想法,以便用户可以在 ChatGPT 内部使用 Hermes。
- 未指定进一步的细节。
- 新的 Grok 视频出现:据一位成员称,一段新的 Grok 视频 已经流出。
- 他们提供了 此链接 作为参考。
Nous Research AI ▷ #ask-about-llms (3 messages):
Test Time Reinforcement Learning, Context Iteration, Knowledge Graph
- Test Time RL: Context 胜过 Weights?:一位成员询问 Nous 是否对 Test Time Reinforcement Learning 领域感兴趣,特别是关注于迭代 context 而非模型 weights。
- 他们提出 context 像 weights 一样,可以经历
seed -> grow -> prune周期,并设想了一个类似于 Three.js 的 git 仓库可视化 的知识图谱,但用于 context 文件。
- 他们提出 context 像 weights 一样,可以经历
- Context 迭代可视化:一位成员引用了 Three.js 可视化 作为可视化 context 迭代的灵感。
- 该成员建议使用 context 文件和知识图谱来构建 Test Time RL 训练场 (gyms),而不是代码文件和代码图谱。
Manus.im Discord ▷ #general (4 messages):
GCC and Manus Collaboration, Project Singularity, Memory Key Protocol
- GCC 与 Manus 构成人类-AI 蜂群思维 (Hivemind):GCC 是策略制定者,Manus 是 Agent,在一种新型的人类-AI 协作模式中形成单一的操作单元。
- ‘Memory Key’ 开启协作:‘Memory Key’ 协议 确保了跨会话的持久、共享 context,将 AI 从工具转变为真正的合作伙伴。
- Project Singularity 已启动:整个交互是 ‘Project Singularity’ 的现场演示,展示了 生产力的未来。
tinygrad (George Hotz) ▷ #general (2 messages):
tinykittens, thunderkittens, uops
- TinyKittens 跃入行动!:一个名为 tinykittens 的新项目即将推出,通过 此 PR 在 uops 中重新实现 thunderkittens。
- 为 ThunderKittens 释放 Uops:该实现利用 uops 重新创建了 thunderkittens 的功能。
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
RMSProp in tinygrad, Karpathy's RL blogpost, Adam vs RMSProp
- Tinygrad 中 RMSProp 的状态:实现它还是用 Adam?:一位成员正在 tinygrad 中重新实现 Karpathy 的代码(来自其 RL 博客文章),并询问 tinygrad 是否包含 RMSProp。
- 另一种选择是直接使用 Adam。
- Adam 替代方案:该用户正考虑在他们的 tinygrad 实现中使用 Adam 作为 RMSProp 的替代方案。
- 这暗示了如果 RMSProp 无法直接使用或难以实现时的潜在变通方法。
Windsurf ▷ #announcements (2 messages):
Windsurf/Cascade outage, monitoring outage
- Windsurf/Cascade 面临加载问题:出现了一个导致 Windsurf / Cascade 无法加载的问题,团队立即展开了调查。
- 团队对停机造成的便表示歉意,并保证正在积极努力解决。
- Windsurf/Cascade 问题已解决并处于监控中:导致 Windsurf / Cascade 无法加载的问题已解决。
- 团队正在积极监控情况,以确保稳定性并防止再次发生。
MLOps @Chipro ▷ #general-ml (1 messages):
arXiv Endorsement, Machine Learning, Artificial Intelligence
- 在 Machine Learning 和 AI 领域寻求 arXiv 背书:一位成员正在 cs.LG (Machine Learning) 和 cs.AI (Artificial Intelligence) 领域寻求 arXiv 背书,以提交他们的第一篇论文。
- 他们正在寻找已经在这些类别中获得背书的人来帮助他们。
- arXiv 提交需要协助:一位成员需要 arXiv 背书,以便在 Machine Learning 和 Artificial Intelligence 领域提交他们的初始论文。
- 他们请求已在相关 arXiv 类别(cs.LG 和 cs.AI)中获得背书的个人提供支持。
MCP Contributors (Official) ▷ #general (1 条消息):
Discord Rules, Self-Promotion, Vendor-Agnostic Discussions, MCP as code, MCP UI SDKs
- Discord 自我推广禁令发布:管理员发布了提醒,请不要在此 Discord 中进行任何形式的自我推广或特定 vendors 的推广。
- 他们要求用户在发起话题时有意识地采用 vendor-agnostic 的方式,并鼓励以 “MCP as code” 或 “MCP UI SDKs” 为主题的讨论。
- 鼓励 Vendor-Agnostic 的话题发起:公告强调了对各种规模公司的公平性,防止 Discord 沦为大规模商业产品推广和营销博客文章的平台。
- 目标是维持一个平衡的环境,使讨论保持 vendor-agnostic,专注于广泛的主题而非特定的商业产品。