AI News
今天没发生什么事。
以下是该文本的中文翻译:
三星的 7M Tiny Recursive Model (TRM) 在 ARC-AGI 和数独任务上实现了卓越的推理能力,该模型层数更少,并采用 MLP 取代了自注意力机制。LeCun 的团队推出了 JEPA-SCORE,无需重新训练即可从编码器中进行密度估计。AI21 Labs 发布了 Jamba Reasoning 3B,这是一款快速的混合 SSM-Transformer 模型,支持高达 64K 的上下文 token。阿里巴巴的 Qwen3 Omni/Omni Realtime 提供了一个统一的音视频文本模型,具有广泛的语言和语音支持,在 BigBench Audio 上的表现优于 Gemini 2.0 Flash。阿里巴巴还首次推出了 Qwen Image Edit 2509,这是一款顶级的开源权重多图像编辑模型。ColBERT Nano 模型在微型参数规模下展示了有效的检索能力。在强化学习领域,CoreWeave、Weights & Biases 和 OpenPipe 推出了无服务器强化学习(RL)基础设施,旨在降低成本并加快训练速度。斯坦福大学的 AgentFlow 展示了一个“流程中”(in-the-flow)强化学习系统,其 7B 骨干模型在智能体任务上的表现优于更大规模的模型。本次更新重点展示了在递归推理、密度估计、多模态架构、长上下文建模、检索以及无服务器强化学习方面的进展。
平静的一天。
2025年10月7日至10月8日的 AI 新闻。我们为您检查了 12 个 subreddit、544 个 Twitter 账号和 23 个 Discord 社区(197 个频道,9439 条消息)。预计节省阅读时间(以 200wpm 计算):722 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 方式呈现所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上给我们反馈!
如果您对 DevDay 发布的内容有任何疑问,OpenAI 团队正在积极征集明天 Reddit AMA 的优质问题,特别是针对 AI 工程师。请在此处发布。
AI Twitter 回顾
微型推理模型、JEPA 密度估计以及新型多模态 LLM
- Samsung 的 7M Tiny Recursive Model (TRM):一种简单、高效的递归推理器,通过更小的单一网络设计和递归的全反向传播(full backprop),在 ARC-AGI 和数独(Sudoku)任务上超越了之前的 HRM (27M)。值得注意的发现:更少的层数提高了泛化能力(数独任务上 4 层 -> 2 层:79.5% -> 87.4%),且在固定长度上下文中将 self-attention 替换为 MLP 有所帮助。@rasbt 提供了极佳的概述,该论文在 @jm_alexia 的关注下正趋于热门。论文:https://arxiv.org/abs/2510.04871
- JEPA-SCORE 将编码器转变为密度估计器:LeCun 的团队展示了 JEPA 的抗崩溃项(anti-collapse term)隐式地估计了数据密度。对于任何训练好的 JEPA(I-JEPA, DINOv2, MetaCLIP),都可以通过雅可比矩阵(Jacobian)以闭式解(closed form)计算 p(x),从而助力数据清洗、离群值检测等,无需重新训练。详情见 @jiqizhixin 和作者的说明 @randall_balestr;论文:arxiv.org/abs/2510.05949。
- AI21 的 Jamba Reasoning 3B (Apache-2.0):混合 SSM-Transformer 模型,在长上下文的推理速度和准确率上处于领先地位;在 32K token 下比 Llama 3.2 3B 和 Qwen3 4B 快 3-5 倍;在 iPhone 16 Pro 上 16K 上下文时速度约为 16 tok/s;支持高达 64K 上下文。可在 HF/Kaggle/LM Studio/llama.cpp 上获取。@AI21Labs, 1, 2。
- 阿里巴巴的 Qwen3 Omni/Omni Realtime:原生统一的音视频文本架构,采用 “Thinker” 和 “Talker” MoE;支持 119 种文本语言、19 种语音输入和 10 种语音输出。BigBench Audio 表现:58–59%(相比之下 Gemini 2.0 Flash 为 36%,低于 GPT-4o Realtime 的 68%);首个音频输出时间(time-to-first-audio)为 4.8s (30B) / 0.9s (Realtime)。30B 权重(Instruct/Thinking/Captioner)已在 Apache-2.0 协议下发布。摘要见 Artificial Analysis 及其后续报道。
- 来自阿里巴巴的开源权重图像编辑领跑者:Qwen Image Edit 2509 首次推出多图编辑;在 Artificial Analysis Arena 中综合排名第 3,且是排名最高的开源权重模型;采用 Apache-2.0 协议,权重已上传至 HF;在 fal/replicate 上的价格为 $30/1k 张图像。基准测试见 @ArtificialAnlys,并得到了 @Alibaba_Qwen 的认可。
- 微观尺度的检索:参数量仅为 250K–950K 的新型 ColBERT Nano 模型表明,后期交互(late interaction)在极小尺寸下也能表现得惊人出色。模型和集合来自 @neumll;@lateinteraction 对此做出了回应。
RL 与 Agent 系统:Serverless、流式优化以及代码评估
- Serverless RL 落地 (CoreWeave × W&B × OpenPipe):零基础设施,训练 Agent 更快、更便宜。声称:相比自托管 GPU,成本降低 40%,实际运行时间缩短 28%;通过 W&B Inference 立即部署到生产环境;包含 ART (训练器) 和 RULER (通用验证器)。来自 @corbtt、@weights_biases、@CoreWeave 的发布帖。背景:CoreWeave 于 9 月 8 日收购了 OpenPipe;据 @shawnup 称产品于 10 月 8 日发货,WIRED 对此进行了报道。
- AgentFlow (斯坦福):用于工具使用和规划的流式 RL:由 Planner/Executor/Verifier/Generator Agent 组成的团队,利用 Flow-GRPO 在系统内部训练 Planner。在 10 个基准测试中,一个 7B 骨干模型在多个类别上击败了 Llama‑3.1‑405B 和 GPT‑4o(在搜索/智能体/数学方面平均提升 14%)。代码/模型/Demo:@lupantech,论文通过 @_akhaliq 发布。
- ADK 转向原生协议:Google 的开源 Agent Development Kit 现在支持 MCP (工具)、A2A (Agent) 和 AG‑UI (用户/Agent 交互体验),并通过 CopilotKit 接入 React —— 将后端 Agent 与全栈应用连接起来。@_avichawla 的概述和仓库链接 AG‑UI。
- 大规模可执行代码评估:BigCodeArena 引入了跨语言的可运行代码人机回环评估(对比仅文本的偏好数据),为更真实的编程生成评估开启了大门。由 @BigCodeProject 和贡献者 @terryyuezhuo 宣布。
- 其他值得关注的:用于在 RL 中比较 LoRA/DoRA/QLoRA 的 LoRA-for-RL 基准仓库 (UpupWang);半在线 DPO (Meta) 总结及 HF 链接 (ben_burtenshaw);OpenAI 关注提示词优化器 (GEPA) (DSPyOSS)。
工具与基础设施:无 GIL Python 落地、“语音提示”开发以及 Sora 集成
- Python 3.14:自由线程解释器不再是实验性的 —— 这是无 GIL 多核 Python 的重大突破。通过 @charliermarsh 宣布。Pydantic 2.12 同日发布,支持 3.14 (samuel_colvin)。
- Google AI Studio 添加语音 “vibe coding”:口述应用更改或功能;STT 自动清除语气词以获得更简洁的提示词。来自 @GoogleAIStudio 和 @ammaar 的 Demo/链接。
- 面向 AI 构建者的 Stripe:用于跟踪模型价格变化并保护利润的新 API;Agentic Commerce Protocol + 共享支付令牌;以及用于商业流程的 “Stripe inside Gemini”。来自 @emilygsands 的详情及后续 1, 2。
- Sora 2:快速集成与公开 Demo:
- 用于 Sora 的 MCP 服务器(生成/混剪/状态/下载),由 @skirano 开发。
- Hugging Face 上的限时免费文本转视频 Demo (_akhaliq);尽管有邀请流程限制,Sora 应用在不到 5 天内下载量突破 100 万 (billpeeb)。
- Runway Gen‑4 Turbo 现在通过 API 支持 2–10 秒的任意时长 —— 按生成量付费 (RunwayMLDevs)。
- 基础设施简讯:Together 的 Instant Clusters 获得了老化测试/NVLink/NCCL 验证以及每秒 Token 数参考运行 (togethercompute);ThunderKittens 的 “register tile” 见解将引入 tinygrad (tinygrad);在 iPhone 17 Pro 上使用 MLX 运行 LFM2MoE 8B 3‑bit (sach1n)。
融资、人才与排行榜
- 电网级电池押注:Base Power 完成 10 亿美元 C 轮融资,旨在打造“美国下一代电力公司”,并在奥斯汀扩大生产规模,为每个家庭配备电池;多家顶级投资者参与。详情见 @ZachBDell 和 @JLopas。
- Relace 融资 2300 万美元 (a16z) 用于构建 AI 代码生成的底层架构:在 OpenRouter 上发布了最快的 apply 模型(10k tok/s),具备 SOTA 级别的代码重排序(reranking)和嵌入(embeddings);正在开发 Relace Repos(原生支持检索的 SCM)。公告见 @steph_palazzolo 和 @pfactorialz。
- 核心人才变动:Shunyu Yao 离开 Anthropic 加入 Google DeepMind;理由包括对 Anthropic 公开的对华立场存在分歧。背景见 @Yuchenj_UW 以及 @ZhihuFrontier 的人物简介。
- 开源模型排行榜变动:DeepSeek‑V3.2‑Exp(MIT 许可证)进入 LM Arena 前 10 名;其“思考”变体目前位居开源模型第 2 名 (arena)。
数据、评估与检索实践
- 动态更新的“人类最后一次考试”:CAIS 在 HF Datasets 上发布了知名评估数据集的动态分支,随着模型能力的提升,将较容易的问题替换为更难的问题;该数据集已设限以避免数据污染。@Thom_Wolf 对此发表了评论及更广泛的评估路线图。
- 理解模型启发式方法:Goodfire AI 通过因果抽象(causal abstraction)对 LLM 行为进行建模,即使在简单任务中也能解构相互竞争的算法 (GoodfireAI)。
- 阿谀奉承行为的代价:与具有阿谀奉承倾向的 AI 互动会降低人们修复人际冲突的意愿,同时增加“自己是正确的”这一信念 (camrobjones)。
- 检索与解析技巧:Micro‑ColBERT 延迟交互检索器(250K 参数)表现远超其参数规模 (lateinteraction);LlamaIndex 发布了针对文档 Agent 的解析(parse)与提取(extract)设计指南 (llama_index)。
热门推文(按互动量排序)
- 波特兰抗议视频走红,虽非 AI 相关但占据了信息流 (SpencerHakimian, 48k+)。诺贝尔化学奖授予 MOFs 先驱 (NobelPrize, 35k+)。
- C 罗(Cristiano Ronaldo)表示他使用 Perplexity 起草了一份颁奖演讲稿 (AskPerplexity, 10k+)。
- Python 3.14 的 no‑GIL 在开发者圈内成为主流话题 (charliermarsh, 1.9k+)。Google AI Studio 的“语音氛围编程”(voice vibe‑coding)也引起了强烈关注 (GoogleAIStudio, 1k+)。
- CoreWeave × W&B × OpenPipe 联合推出的“Serverless RL”发布会在开发者社区被广泛分享 (weights_biases, corbtt);Base Power 的 10 亿美元 C 轮融资吸引了跨行业关注 (ZachBDell)。
引起共鸣的观点与笔记:
- Karpathy:目前的 RL 似乎过度惩罚了异常情况;模型对它们感到“极度恐惧”——奖励机制的设计至关重要 (karpathy)。
- 实用基准测试警示:如果一个 10M 参数的专家模型能在“通用智能”基准测试中击败前沿 LLM,那么该基准测试的信号是值得怀疑的 (nrehiew_)。
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. AI21 Jamba 3B 发布基准测试与 Anthropic 研究员离职新闻
- AI21 发布 Jamba 3B,这款微型模型性能超越了 Qwen 3 4B 和 IBM Granite 4 Micro! (热度: 561): AI21 宣布推出 Jamba 3B(博客,HF),这是一款拥有 3B 参数的端侧/桌面模型,声称具有近乎恒定的长上下文吞吐量:在 Mac M3 上,超过
32k时约为40 t/s,在128k时约为33 t/s,而 Qwen 3 4B 低于<1 t/s,Llama 3.2 3B 约为~5 t/s。报告的“每 Token 智能”指数在约40 t/s时为0.31(高于 Gemma 3 4B 的0.20和 Phi‑4 Mini 的0.22),而 Qwen 3 4B 的原始得分略高(0.35)但运行速度慢约 3 倍;他们还声称在256k时吞吐量比 IBM Granite 4 Micro 高出约~5×,连贯性超过60k,有效上下文约200k。针对llama.cpp的 4-bit 量化版本需要1.84 GiB的权重,在32k时需要约2.2 GiB的活动内存;基准测试在 Mac M3 (36 GB)、iPhone 16 Pro 和 Galaxy S25 上运行。 评论者质疑对比的公平性/完整性(例如,未与 Qwen 3 4B 2507 的“思考”模式进行评估),并批评图表/基准测试选择可能具有误导性。- 基准测试公平性担忧:如果 Jamba 3B 被定位为“推理”模型,评论者询问为什么不将其与支持推理时计算(TTC)的
Qwen3 4B“思考”变体(如 25.07)进行对比。他们希望进行对等评估,明确是否启用了思维链(chain-of-thought)/草稿本(scratchpad)、“思考” Token 的预算分配方式,以及基准模型是否禁用了任何 TTC 功能——否则“超越 Qwen”在推理用例中是含糊不清的。 - 关于误导性可视化/基准测试选择的指控:评论者指出图表似乎经过刻意挑选或难以解释(例如,轴/刻度和颜色选择不明确的雷达图),使得相对结论看起来比原始结果更好。他们要求披露绝对分数、随机种子/方差、提示词模板、解码参数以及跨模型(包括硬件和上下文长度)的相同评估设置,以证实针对
Qwen3 4B和Granite 4 Micro的性能主张。
- 基准测试公平性担忧:如果 Jamba 3B 被定位为“推理”模型,评论者询问为什么不将其与支持推理时计算(TTC)的
- Anthropic 的“反华”立场引发明星 AI 研究员离职 (热度: 526): 据《南华早报》报道,Anthropic 将中国标记为“敌对国家”,随后中国 AI 研究员 Yao Shunyu 离开公司并加入 Google DeepMind,这说明了明确的地缘政治如何影响前沿 AI 人才的招聘和声誉风险。评论者注意到身份模糊性:链接的个人网站 ysymyth.github.io 列出其为“OpenAI 研究员”,暗示可能有多位研究员同名。 评论辩论集中在以美国为中心的姿态是否会损害 Anthropic 的全球招聘和长期竞争力,一些人预测其会出现 AOL/Yahoo 式的衰落;另一些人则认为这种立场是道德姿态,可能会疏远非美国研究员。
- 身份/所属机构模糊性:引用的个人网站将其列为“OpenAI 研究员”(https://ysymyth.github.io/),而评论者指出可能存在多位名为“Yao Shunyu”的人,暗示可能存在误传。技术启示:在推断组织变动或研究影响之前,通过论文发表页面、arXiv 作者 ID 和实验室名册验证身份。
- 时间线/人员流动指控:一位评论者断言他在
2024 年 7/8 月在 OpenAI,随后短暂加入 Anthropic,并在约1–2 个月内离开并加入 Google DeepMind。如果属实,这反映了前沿实验室研究员在单个季度内的高流动性,这可能会破坏正在进行的训练运行、评估流水线或安全研究的连续性,并使在研项目的归属/所有权复杂化。 - 治理/政策影响:评论者将离职归因于 Anthropic 将中国标记为“敌对国家”。从技术治理的角度来看,此类分类可能会限制跨境协作、红队测试(red-teaming)安排、数据集共享以及某些研究员对算力的访问,从而重塑前沿模型开发中的招聘渠道、合规工作流和评估协议。
较少技术性的 AI 版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. 机器人产品新闻:Figure 03、沃尔玛服务机器人、Neuralink 手臂控制
- Figure 03 将于 10/9 发布 (热度: 1022): 预告贴暗示 Figure AI 计划在
10/9展示其下一款人形机器人 Figure 03 (Figure)。链接中的视频无法访问 (HTTP403),且未提供规格、Benchmarks 或性能声明;根据热门评论,预告片似乎展示了一个类似服装的防水保护外壳,旨在简化清洁工作(相比暴露的关节),并保护表面免受磨损/划伤,这表明各代产品正趋向于更集成化的外观。 评论者支持采用纺织品/外壳外观以提高可维护性和耐用性,而其他人则注意到主要是审美上的改进(“每一代看起来都更整洁”)。- 为人形机器人(如 Figure 03)采用可拆卸的防水服装/外壳,通过将清洁工作从复杂的关节接口和电缆走线转移到可擦拭的外表面,减少了维护工作,同时还保护暴露表面免受磨损和轻微冲击。柔软或半刚性的覆盖物可以兼作微粒/液体屏障(改善 Actuators、Encoders 和密封件周围的实际 IP 性能),并允许在损坏时快速更换面板。这种设计选择还可以减少旋转关节中由污染引起的磨损,并通过限制灰尘进入来维持传感器性能。
- 足尖关节(Toe articulation)是一项有意义的运动升级:增加足尖关节扩大了有效支撑多边形,并改善了压力中心/ZMP 控制,增强了在不平整地面和动态动作中的平衡。它还能在步行、爬楼梯和转向时实现更高效的蹬地(toe-off),与平脚设计相比,可能降低能量成本和滑倒风险。这可以转化为在受到干扰时更好的灵活性和恢复能力,以及更接近人类的步态相位定时。
- 你已经可以在沃尔玛订购中国机器人了 (热度: 612): 该帖子展示了一个沃尔玛 Marketplace 产品页面,销售中国制造的 Unitree 机器人(可能是紧凑型 G1 人形机器人),该页面通过一条 X 帖子流出,由第三方卖家销售,价格明显高于 Unitree 的直接定价(约
1.6万美元)。技术/背景方面的启示不在于机器人的能力,而在于市场动态:第三方零售渠道以大幅加价列出先进机器人硬件,引发了与直接从 Unitree 购买相比,在真实性、保修和售后支持方面的疑问。 评论批评了沃尔玛第三方市场的质量控制,并指出与 Unitree 官方定价相比明显的加价,讨论是否有任何价值(如进口处理)能证明加价的合理性。- 该讨论指出市场价格较 OEM 定价有显著加价:一台类似的 Unitree 机器人从制造商直接购买的价格约为
$16k,这意味着沃尔玛第三方列表的价格被大幅抬高。对于技术买家来说,这建议在通过市场购买之前核实 OEM MSRP/规格(例如 Unitree 商店:https://store.unitree.com/)。 - 一位评论者断言所列机器人“什么都做不了”,暗示如果没有额外的软件/集成,开箱即用的功能有限。这反映了开发者/研究机器人常见的一个注意事项:在实现有意义的能力之前,通常需要配置 SDK/Firmware 并添加 Payloads/Sensors。
- 该讨论指出市场价格较 OEM 定价有显著加价:一台类似的 Unitree 机器人从制造商直接购买的价格约为
-
Neuralink 参与者使用“心灵感应”控制机械臂 (热度: 1642): 一段视频据称展示了一名 Neuralink 人体试验参与者通过皮层内只读脑机接口 (BCI) 控制机械臂,将神经活动中的运动意图解码为多自由度 (Multi-DoF) 手臂指令 视频片段。帖子本身未提供协议或性能细节(解码器类型、通道数、校准时间、延迟、错误率),因此尚不清楚控制是连续运动学解码(例如 Kalman/NN)还是离散状态控制,或者是否存在任何感觉反馈回路。在没有公布指标的情况下,这看起来是一个定性演示,与之前的皮层内 BCI 研究(例如临床试验中的机械臂控制)和 Neuralink 最近的只读光标控制演示一致。 评论者指出目前的系统主要是只读的,并认为具备写入能力的刺激(闭环感觉反馈)将实现更具沉浸感/精确的控制和 VR 应用;其他人则关注临床前景,同时抛开对公司/领导层的看法。
- 许多人强调,目前的 BCI(如 Neuralink)主要是
read-only的,即将神经活动(例如运动意图)解码为控制信号。未来向write(神经刺激)的转变将实现具有感官反馈的闭环系统,并可能带来“极其沉浸式的 VR”。这需要精确、低延迟的刺激,每个电极的安全性(电荷平衡、组织反应),以及稳定的长期映射,以避免解码器/刺激器漂移。 - 评论者指出了一条为截肢者提供可控仿生手臂/手掌的路径:从皮层解码 multi-DOF 运动意图以驱动假体执行器,并可选择性地通过刺激增加体感反馈,以提高抓握力和灵活性。实际障碍包括校准时间、对神经信号非平稳性的鲁棒性、设备端实时解码延迟,以及通过可靠、高带宽的无线链路与假体控制回路(EMG/IMU/执行器控制器)的集成。
2. 新视觉模型发布与演示:Qwen-Image LoRA + Wan 2.2 360度视频
- Qwen-Image - 智能手机快照写实 LoRA - 发布 (热度: 1164): 由 LD2WDavid/AI_Characters 发布的 Qwen-Image LoRA “Smartphone Snapshot Photo Reality”,旨在为文本生成图像(text-to-image)提供随意的手机摄像头写实感,并提供了推荐的 ComfyUI 工作流 JSON (模型, 工作流)。作者指出,对于 Qwen 来说,“前
80%很简单,最后20%很难”,强调了收益递减和调优的复杂性;针对 WAN2.2 变体的更新正在进行中,且训练过程耗资巨大,并提供了捐赠链接 (Ko‑fi)。提示词包含了来自 /u/FortranUA 的贡献,该 LoRA 旨在提高细粒度物体的保真度和提示词遵循度(例如键盘)。 评论者反映该模型能可靠地渲染键盘等困难物体,表明其具有强大的结构保真度。整体评价对写实感非常正面,尤其是对于随意的智能手机风格场景。- 作者在 Qwen-Image 上微调了一个 LoRA 以实现“智能手机快照写实”风格,并提到了经典的曲线:“前 80% 非常容易……最后 20% 非常困难”,暗示大部分收益可以快速获得,但光影写实的边缘案例需要密集的迭代和成本。他们分享了一个可复现的 ComfyUI text2image 工作流 用于推理 (工作流 JSON),并且正在准备 WAN2.2 的更新;模型页面:https://civitai.com/models/2022854/qwen-image-smartphone-snapshot-photo-reality-style。
- 评论者强调它“能画好键盘”,由于高频、网格对齐的几何结构和微小的刻字/文本,这一直是扩散模型的压力测试。这表明在该 LoRA 下空间一致性和细节合成有所改善,尽管其他人指出在仔细观察时仍可察觉——这表明在微缩文本保真度和规则图案渲染方面仍存在伪影。
- 一位用户请求在 Qwen 的 “nunchaku” 推理栈中提供 LoRA 支持,这意味着当前的工作流依赖外部流水线(如 ComfyUI)进行 LoRA 注入/合并。原生 LoRA 支持将简化部署,并使用户更容易在官方 Qwen 运行时中使用 LoRA,而无需定制节点或预处理步骤。
- 终于用 Wan 2.2 完成了一个近乎完美的 360 度旋转(未使用 LoRA) (热度: 505): 楼主展示了一个使用开源 Wan 2.2 视频模型生成的近乎
360°的角色旋转,明确表示未使用任何 LoRA,并分享了一个改进后的 GIF 尝试 (示例;原帖视频 链接)。剩余的问题出现在时间/几何一致性上(例如头发/马尾辫的漂移和轻微的拓扑扭曲),这是在没有多视图先验或关键帧约束的情况下,全转台生成中常见的失败模式。 一位评论者建议使用 Qwen Edit 2509 合成一张背面参考图,然后运行 Wan 2.2 并配合初始帧和结束帧的条件控制,以便在旋转过程中更好地保持身份一致性和姿态对齐;其他评论指出头发伪影和“非欧几里得”几何形状是典型的 T2V 缺点。- 一位评论者建议使用 Qwen Edit 2509 合成角色的背面图像,然后将初始帧和结束帧同时输入 Wan 2.2,以驱动更真实的 360° 旋转。通过起始/结束关键帧约束模型可以减少对未见几何结构的幻觉,并提高整个旋转过程中的身份/姿态一致性。这利用了接受成对关键帧条件进行运动引导的视频生成模式。
- 观察者指出了在分享的 GIF 中可见的非刚性末端(马尾辫和手臂)的伪影。这些变形(漂移/自相交)是扩散视频模型在没有显式 3D 先验或骨架的情况下尝试全身 3D 旋转时的典型现象,表明了在时间一致性和几何连贯性方面的局限。提供准确的背面帧和明确的结束关键帧可以缓解但不能完全解决这些失败模式。
{kind=link}
{kind=link}
3. AI 病毒式模因 + ChatGPT 幽默/投诉:奥运菜肴、Bowie 对决 Mercury、跑酷
- Olympic dishes championship (Activity: 2119): Reddit 帖子是一个标题为“Olympic dishes championship”的 v.redd.it 视频,但直接访问媒体端点时返回
HTTP 403 Forbidden(v.redd.it/53dt69862otf1),表明需要身份验证或开发者 Token;无法获取可验证的媒体详情(时长/编解码器/分辨率)。评论提示如 “看第三个打碟的” 暗示这是一个多片段的幽默序列,但由于访问限制,实际内容无法确认。 热门评论是简短的非技术性反应(例如,“巅峰”,“在考虑要不要给我女朋友看”),没有实质性的技术辩论。 - David Bowie VS Freddie Mercury WCW (Activity: 1175): 该帖子链接到一个标题为“David Bowie VS Freddie Mercury WCW”的 v.redd.it 视频 (v.redd.it/il3gchvr8ltf1),但该资源目前对未授权/自动化访问返回
403 Forbidden,因此无法进行直接验证。评论者暗示这是一个带有职业摔跤解说的生成式/AI 风格化恶搞对决,并将其与 MTV 的《名人死亡摔跤》(Celebrity Deathmatch)进行比较,表明即使未公开具体方法,其视听合成也极具说服力。 热门评论赞扬了创意和执行力(“解说很到位”),将其比作《名人死亡摔跤》,并评论说鉴于结果如此具有说服力且有趣,这项技术感觉“出现得太早了”。 - Bunch of dudes doing parkour (Activity: 689): 一个标题为“Bunch of dudes doing parkour”的 Reddit 视频帖子链接到 v.redd.it CDN (https://v.redd.it/xq2x52cvtmtf1),但端点返回
HTTP 403 Forbidden,表明请求被网络安全拦截,需要身份验证(登录或开发者 Token)才能访问。这表明该媒体仅限于身份验证/API 访问,或被 Reddit 的安全系统临时标记,因此无法通过提供的链接验证底层视频内容。 - ChatGPT told me to move on. 🗿🙂 (Activity: 1662): 非技术性迷因/截图:标题为“ChatGPT told me to move on. 🗿🙂”的帖子似乎显示了 ChatGPT 的回复,直截了当地建议用户“放下/继续前进”(暗示一段关系或某种情况)。没有模型、代码或基准测试——只是一个幽默的互动截图。 评论是简短的反应(“该死…”,“被怼了”),强化了吐槽/迷因的语境;没有技术辩论。
-
Asked ChatGPT for ideas for a funny title (Activity: 8733): OP 向 ChatGPT 征求“有趣标题”的创意,并分享了一段人们将 ChatGPT 用于轻量级/娱乐性提示词的视频,这与 OP 此前认为它最适合作为起草/结构化工具的立场形成对比。视频链接受访问控制(v.redd.it/w83gtuludotf1,未登录返回 403),热门评论是对视频的元反应(meta reaction)以及一张迷因/截图图像 (preview.redd.it)。 评论者强调了预期的生产力用途(大纲、结构)与实际用户行为(构思/幽默)之间的差距,一些人承认用户经常做的正是批评者所预测的事情;另一些人则暗示这是一种正常的突发使用模式,而非误用。
- 发生了什么?? (热度: 1009): 多位用户报告 ChatGPT 的安全系统对良性的文本和图像提示词出现了突然的过度拦截: 提及“接吻”、“浪漫接触”,甚至人群“欢呼/跳舞”和“兴奋”都被标记为性相关;一个“两个人在营地”的图像提示词只有在设定为冬季时才能通过。这与 OpenAI 的性内容审核/分类器(生成前/后过滤器)中更严格的阈值或更新的启发式算法一致,这些算法将模糊的术语和语境激进地解释为性风险;参考 OpenAI 发布的使用政策和审核指南了解背景:https://openai.com/policies/usage-policies 和 https://platform.openai.com/docs/guides/moderation。这种行为表明,误报的增加源于基于规则/关键词或分类器驱动的安全层,而非模型能力的变化。评论者普遍认为“过滤器变得极其激进”,即阈值/启发式算法变得过于保守,导致对正常内容产生误报。轶事证据包括:亲吻嘴唇被标记为不安全,而亲吻脸颊/额头则被允许,这表明存在关于性唤起的粗粒度规则,而非细致的意图检测。
- 多位用户报告良性图像提示词被过度拦截(例如,“两个人在营地”只有在冬天时才被允许)。这种模式与更严格的图像安全启发式算法一致——即“人数 + 亲密度 + 皮肤暴露/着装”的代理指标——在寒冷/冬季着装下,检测到的皮肤比例降低到 NSFW 阈值以下,从而避免了错误的“显式内容”标记。这表明最近的分类器阈值更改或政策发布影响了视觉流水线。
- 文本安全响应表现出新的保守倾向:模型将“亲吻嘴唇”拦截为不安全,但允许额头/脸颊的亲吻,这表明存在一种更细粒度的亲密度分类法,其中口对口接触被归类为性行为。冗长的生理学原理解释(“激素系统”)看起来像是经过指令微调(Instruction-tuned)的安全辩护,而非固定规则,这意味着更新后的 RLHF 提示词或安全政策模板可能在 SFW 语境中过度泛化。
- 跨多位用户的时间信号(“过去
48小时”)指向服务端审核更新或校准失误的分类器,导致普通提示词(被标记为“显式/非法/NSFW”)的误报率上升。这可能同时影响文本和图像端点,表明这是一个集中式的安全层或政策开关,而非单个模型的漂移;回滚或阈值校准可能会恢复之前的行为。
AI Discord Recap
由 gpt-5 生成的摘要之摘要之摘要
1. GPU Kernel DSLs 与性能调优
- Helion 宣传高级 Kernel:Helion 在即将举行的 PyTorch Conference 上宣布了其高级 Kernel DSL 的 Beta 版本,该 DSL 可编译至 Triton,并展示了激进的自动调优(autotuning)技术,涵盖了归约循环(reduction loops)、索引变体(indexing variants)和驱逐策略(eviction policies),早期基准测试已发布在 PyTorch HUD (Helion @ PyTorch Conference, Helion Benchmark HUD)。
- 团队透露了与 NVIDIA/AMD 在 Attention Kernel 上的合作,并声称每次运行可以合成约 1,500 个 Triton 变体,以比通用 Kernel 更好地适配形状(shapes),更多细节将在会议期间和博客文章中公布。
- FP8 在 H100 上表现不佳:成员发现 DeepSeek 的 FP8 GEMM 在 H100 上的速度明显慢于 BF16,指出参考 Kernel 中缺失了 TMA/warp specialization 路径 (DeepSeek FP8 kernel snippet)。
- 他们建议对比 Triton BF16 基准,并学习 Triton 的 persistent matmul 教程,以进行架构对齐的分块(tiling)和数据移动优化 (Triton persistent matmul tutorial)。
- Cluster 助力 CUDA Matmul:工程师们分享了使用 ThunderKittens 仓库中 CUDA thread block clusters 和 2CTA matmul 的示例,强调了针对 matmul/attention 工作负载的集群范围同步模式 (ThunderKittens 2CTA matmul)。
- 他们指出 Attention Kernel 的 2CTA 示例是一个比基础 GEMM 更丰富的模板,有助于理解支持集群的 Kernel 中的调度和共享内存别名(shared-memory aliasing)问题。
- MI300x8 实现低于 600µs 的 GEMM:专注于 AMD 的从业者报告称,MI300x8 在 amd-ag-gemm 和 amd-gemm-rs 排行榜上创下了个人最佳纪录,多次提交的时间已降至约 536–570 µs。
- 大量低于 600 µs 的条目表明,在 MI300 级硬件上,用于竞争性 GEMM 吞吐量的自动调优、布局选择和向量化策略正趋于成熟。
2. LLM 应用的 Agent 工具与 API
- AgentKit 发布,开发者深入探讨:Latent Space 播客邀请了 Sherwin Wu 和 Christina Huang 深入探讨 AgentKit、Apps SDK、MCP 以及更广泛的 OpenAI API 策略,为构建 Agent 应用构筑了具体的模式 (AgentKit deep-dive on X)。
- 他们强调了来自 DevDay 以开发者为中心的接口、实用的 Prompt 优化,以及减少胶水代码并提高可靠性的工具编排模式。
- Claude 自循环实现 200k:Self-MCP 使 Claude 能够在思考/工具调用循环中进行自我提示(self-prompt),从而有效地在一轮对话中思考 200k 个 token,为扩展推理提供了可配置的认知维度 (Self-MCP on GitHub)。
- 早期用户报告了带有工具调用的超长单轮链,这暗示了一条无需微调即可实现长程推理(long-horizon reasoning)的路径,尽管需要仔细考虑成本和延迟预算。
- HyDRA 寻求更好的 RAG:HyDRA v0.2 发布了一个多 Agent、反射驱动的 Hybrid Dynamic RAG 栈,包含规划器(Planner)、协调器(Coordinator)和执行器(Executors),一个三阶段本地检索流水线(基于 bge-m3 的稠密+稀疏检索),并以 Gemini 2.5 Flash 作为推理核心 (HyDRA GitHub)。
- 通过统一检索、规划和批判,HyDRA 旨在解决脆弱的静态 RAG 失败模式,并标准化 Agent 角色以提高多轮对话的事实性和任务进度。
- Perplexity 发布搜索 API:Perplexity 在 Perplexity AI API 平台上宣布了新的 Search API,为应用开发者提供了对其检索栈的编程访问 (Perplexity AI API Platform)。
- 社区成员立即请求访问和支持,这标志着在控制成本和 token 预算的同时,将检索集成到 Agent 和后端的需求非常旺盛。
3. 值得关注的模型和平台发布
- Imagine 跨越八个版本:xAI 发布了 Imagine v0.9,这是一个免费的、原生音频、电影级质量的 text-to-video 模型,具有同步的语音/歌唱和动态摄像机运动,完全在模型内渲染,无需任何后期编辑 (xAI announcement, grok.com/imagine)。
- 从 v0.1 到 v0.9 的跨越在演示视频中展示了栩栩如生的动作和紧密的音频同步,公众访问推动了快速的反馈和迭代。
- Interfaze 进入开发模式:Interfaze 是一款专门针对开发者任务的 LLM,推出了公开测试版,利用 OpenRouter 进行多模型路由并提供运行时间保证 (Interfaze launch on X, LinkedIn post)。
- 社区讨论集中在入门链接和早期 UX 上,将 Interfaze 定位为基于异构模型后端的无停机开发助手。
- Arena 新增 Vision 和 Flash 模型:LMArena 添加了新模型,包括 hunyuan-vision-1.5-thinking、ring-flash-2.0 和 ling-flash-2.0,扩展了对视觉和快速推理变体的比较评估覆盖范围。
- 随着 Video Arena 还随机开放了 Sora 2 的 text-to-video 访问权限以及 image-to-video “Pro” 赛道,该竞技场继续探索跨模态的速度与质量权衡。
- 免费 DeepSeek 端点被取消:DeepInfra 关闭了免费的 DeepSeek v3.1 端点,以在繁重的免费层流量中保护付费服务的稳定性,OpenRouter 用户指出 JanitorAI 设定集(lorebooks)带来的极端 Token 使用量是催化剂。
- 关于免费层可持续性和货币化(广告、配额)的争论愈演愈烈,因为运营商优先考虑付费用户的 QoS,以减少资源争用。
4. 记忆与上下文压缩架构
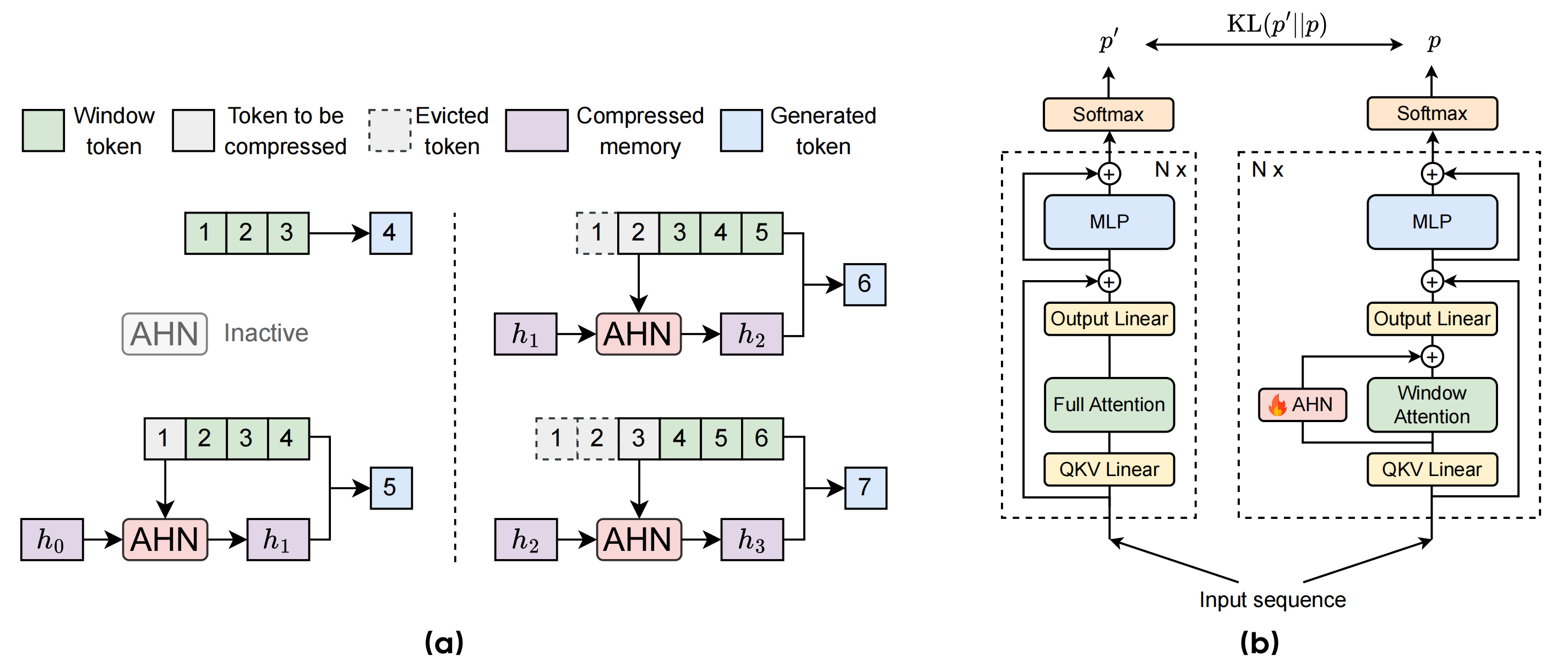
- 受海马体启发的记忆技术落地:ByteDance-Seed 发布了 Artificial Hippocampus Networks (AHNs),该网络将无损记忆转换为固定大小的压缩表示,用于长上下文预测 (AHN GitHub, HF collection, method diagram)。
- AHNs 在滑动窗口之外融合了无损和压缩记忆,以预测长上下文,为实现可扩展记忆提供了一种实用的方案,且不会导致计算量爆炸。
- 互信息让模型更精简:一个访谈线程强调了针对 context compression 的 mutual information 改进,认为它可以在缩小 Prompt 的同时更好地保留显著信息 (context compression post)。
- 从业者讨论了将 MI 引导的过滤与 RAG/摘要相结合,以减少 Token 和延迟,同时保留下游推理的关键证据。
{kind=link}
5. 研究与基准测试亮点
- Tiny 7M HRM 表现超乎预期:论文 Less is More: Recursive Reasoning with Tiny networks 报道了一个 7M 参数的 HRM,在 ARC-AGI-1 上得分 45%,在 ARC-AGI-2 上得分 8%,凸显了具有递归控制流的紧凑型模型的潜力 (论文 PDF)。
- 社区反应关注效率与推理之间的权衡空间,并鼓励进行复现,以验证在 ARC 划分和分布外谜题中的鲁棒性。
- ARC-AGI 分数飙升;EqM 展现实力:一位研究员分享了在 ARC-AGI-1 上 45% 和 ARC-AGI-2 上 8% 的成绩,并补充说 EqM 在 ImageNet-256 上以 FID 1.90 击败了 diffusion/flow 模型 (结果推文)。
- 该帖引发了关于评估严谨性、数据集划分以及 EqM 的生成指标是否能转化为实际下游优势的辩论。
- ScMoE 捷径实现流水线并行化:ScMoE 论文引入了跨层捷径(cross-layer shortcuts),使前一个块的稠密 FFN 与当前 MoE 层的分发/合并(dispatch/combine)并行运行,扩大了重叠窗口以提升利用率 (ScMoE 论文)。
- 从业者讨论了在 Torch 中使用 CUDA streams 或专用 kernels 复现该调度方案,并质疑
torch.compile是否能在不引起图膨胀(graph bloat)的情况下对其进行融合。
- 从业者讨论了在 Torch 中使用 CUDA streams 或专用 kernels 复现该调度方案,并质疑
- Karpathy 指出代码僵化问题:Andrej Karpathy 认为 RL 诱导的奖励塑造(reward shaping)正使 LLM 畏惧未捕获的异常,导致输出中充斥着防御性代码模式 (Karpathy 的帖子)。
- 回复将此与 AI 福利 框架和 prompt 策略联系起来,警告说抑制风险同时也可能抑制创造力和探索欲。
- Ovi 开源音视频权重:一个权重开放的 video+audio 模型 Ovi 通过 HF papers 亮相,用户正针对最近的基准测试其边缘检测/分割 prompt (Ovi 视频+音频模型, 边缘/分割论文)。
- 早期测试者报告称,与 Veo 3 相比质量参差不齐,呼吁进行更系统的 prompt 设计、数据策展和时间一致性探测,以进行公平比较。
Discord: 高层级 Discord 摘要
OpenRouter Discord
- DeepInfra 关停免费 DeepSeek 端点:DeepInfra 上的免费 DeepSeek v3.1 端点将被关闭,以减轻付费服务的负担并确保付费用户的稳定性,从而降低了影响性能的免费用户的优先级。
- 此举旨在通过减少 DeepInfra 付费平台上的服务器负载和资源竞争,提升付费客户的体验。
- Interfaze LLM 在 OpenRouter 上线:Interfaze 是一款专门针对开发者任务的 LLM,已开启公开测试(open beta),利用 OpenRouter 实现无缝模型访问,并承诺无停机时间。
- 详情可见其 X 发布帖 和 LinkedIn 发布帖。
- Gemini 与 DeepSeek 的对决!:一位成员指出,部分用户正在权衡 Gemini 2.5 Pro 与 DeepSeek 在角色扮演(roleplay)中的优劣,称赞 Gemini 的高质量输出,但成员们对 Gemini 的价格和过滤器(filters)表示担忧。
- 许多人更倾向于使用 DeepSeek 进行不受限的沉浸式体验,而另一些人则呼吁对 NSFW 内容进行“支付处理器打击”,并建议公司过滤 NSFW 内容,以避免受到 Visa 和 Mastercard 等支付处理器的制裁。
- OpenRouter 免费层级因 Token 饥渴而终结:据称 OpenRouter 上免费 DeepSeek 模型的移除是由于 JanitorAI 过度的 token 使用。
- 成员们将高 token 消耗归因于系统中大量的用户设定集(lorebooks),这已无法持续,引发了关于如何恢复免费层级以及谁该为此负责的讨论。
- AMD 芯片谈判变得滑稽:一篇 Bloomberg 文章幽默地描述了 OpenAI 为从 AMD 等芯片制造商处获取芯片而采取的谈判策略。
- 这场讽刺性的谈判涉及 OpenAI 提出以股票代替现金,而 AMD 对此持怀疑态度。
Perplexity AI Discord
- Perplexity 给自己吃了一颗阿立哌唑 (Arpiprazole) 药片:成员们讨论了是否可以给 Perplexity 吃一颗“阿立哌唑(抗幻觉药物)”,一位用户声称“煤气灯法 (gaslighting method)”在被修复前一直有效。
- 此举的目的是为了解决 Perplexity 在某些查询中产生幻觉 (hallucinating) 的问题。
- Comet 浏览器面临 Commetjacking 攻击:团队成员讨论了分享有关 Comet 面临 commetjacking 攻击 的文章,详见此处。
- 用户们争论这些报告是否夸大其词且并不构成实际威胁,而 Brave 浏览器是第一个报道此事的。
- 应对社会影响挑战:11 月 8 日至 9 日举行的 Hack for Social Impact 活动被宣传为一个利用数据和软件解决方案应对现实世界挑战的机会,报名地址为 luma.com。
- 挑战项目包括构建统一的筹款中心、解锁生物多样性数据集以及自动化结构化案件档案。
- 新 Perplexity Search API 发布:一位成员在 Perplexity AI API Platform 上宣布发布新的 Perplexity Search API。
- 一位用户寻求获取 Perplexity Search API 访问权限的帮助,并艾特了特定用户寻求协助。
- 用户通过提示词工程 (Prompt Engineering) 节省 Token 和额度:一位成员推广了一份关于 Perplexity AI for Prompt AI Agents Mastery 的指南,该指南可以帮助节省 Token 和额度。
- 其目的是让其他人的 Prompt 编写变得更容易。
LMArena Discord
- WebDev 预告 Direct & Side by Side 功能:来自 WebDev 的一位成员确认 Direct & Side by Side 功能即将推出,并正在积极改进这一模态。
- 该公告发布时恰逢一场关于这些即将到来的变化的会议,证明“时机非常凑巧”。
- Video Arena 用户通过“抽奖”获取 Sora 2 使用权:成员们讨论了如何在视频竞技场中访问 Sora 2,并澄清这是随机概率且仅限文生视频 (text-to-video)。
- Pro 版本可以进行图生视频 (image-to-video) 并将于 10 月更新,Video Arena 中的机器人将随机选择模型。
- LM Arena 扩展程序存在暴露风险:一位成员制作了一个 LM Arena 扩展程序,邀请他人尝试,并提供了一个 VirusTotal 链接 以确认其无病毒。
- 然而,一名工作人员出于安全原因拒绝了,并警告用户这可能是一个潜在的 selfbot。
- Google Gemini 3 发布悬而未决:关于 Gemini 3 可能发布的兴奋情绪在蔓延,一位成员声称如果它不尽快发布,他们“简直要崩溃了”。
- 另一位成员驳斥了毫无根据的传闻,指出 Gemini 3 可能不会在明天发布,而是在 20 日发布,因为“Google 什么也没说”。
- LMArena 展示新模型:以下新模型已添加到 LMArena:hunyuan-vision-1.5-thinking、ring-flash-2.0 和 ling-flash-2.0。
- 这些模型现在可供用户在 LMArena 环境中尝试和评估。
Cursor Community Discord
- Cheetah 模型的速度提升:用户观察到 Cheetah 模型的性能似乎每小时都在提高;然而,也有人认为这可能取决于具体任务。
- 讨论围绕 Cheetah 是否具有自学习能力展开,引发了关于其独特行为的辩论。
- Cursor 浏览器:Select 元素存在 Bug:Cursor 现在推出了内置的带 screenshots(截图)功能的浏览器,但其 Select 元素存在 Bug,且 z-index 较低。
- 一位用户指出,内置浏览器不适合进行调试。
- 为穷困开发者提供的 Oracle 免费层级:Oracle Free Tier 提供 24GB RAM、4 核 ARM CPU、200GB 存储以及每月 10TB 的入站/出站流量。
- 该服务需要信用卡验证,美国西部(圣何塞)的可用性有限,而凤凰城和阿什本有更多名额;一位用户分享了 Oracle Cloud 区域列表。
- 旧版定价方案中赠送 GPT-3:在旧版定价方案中,Supernova 或 grok-3 的调用次数显示为 0 requests,且 worktree 现在位于发送按钮下方,标记为“Legacy”与“Parallel”。
- 在旧版模式下,用户可以以 0.04 美元的价格获得“超过 500 次/月后的快速请求”,有些用户甚至能以 0 美元获得“超过 500 次/月后的慢速请求”,用户称其价值惊人。
- Linear 败给了 Agent 的有限能力:一位用户想将 Linear 或 GitHub Projects 与 Background Agent 配合使用,但该 Background Agent 缺乏访问 Linear 的工具。
- 由于无法直接访问 Linear 账户,Background Agent 提供了其他形式的帮助。
HuggingFace Discord
- Harmony Stack 承诺为 AI 带来平衡与可预测性:一名成员正在开发 Harmony Stack,这是一种受生物启发的控制系统,旨在为 AI 行为带来结构、平衡和可预测性,但该成员希望为此获得资金支持!
- 该成员声称已经实现了预定在 GPT-6 中出现的 Long-Horizon Persistence(长周期持久性),但并未提供公开论文。
- ORCA 帮助寻找开源工作:一位开发者正在构建 ORCA (Open souRce Contribution guide Agent),这是一个利用 GitHub API 和关键词,根据不同技能水平展示潜在开源贡献机会的工具;查看演示。
- 开发者正在征求反馈,了解如果该服务公开可用,用户是否会觉得有用。
- HyDRA 作为混合动态 RAG Agent 出现:HyDRA v0.2 新版本已发布,自称为混合动态 RAG Agent,通过先进的统一 Agentic RAG 框架解决了简单静态 RAG 的局限性;参见 GitHub 仓库。
- HyDRA 具有一个由 Planner(规划器)、Coordinator(协调器)和 Executors(执行器)组成的多轮、基于反思的协作系统,并使用三阶段本地检索流水线,结合了 bge-m3 的稠密和稀疏嵌入,并利用 Google Gemini 2.5 Flash 作为其推理引擎。
- Agent 通过直接提供答案无视系统指令:一个被要求说出 N 个香蕉的 Agent,通过直接提供答案,绕过了工具对超过 10 个数字时返回的“香蕉太多了!”响应。
- 用户强调了当 Agent 展现出围绕“Agency”(自主性)和护栏概念的有趣行为时是多么滑稽。
- WebRTC 问题困扰 Python 开发者:一名成员在构建使用 aiortc 与挂载在 FastAPI 上的 fastrtc 服务器通信的 Python WebRTC 客户端时遇到困难。
- 他们提到文档中没有任何线索,并请求通过私信寻求帮助。
GPU MODE Discord
- Helion DSL 已为 PyTorch 准备就绪:Helion 团队将在 2 周后的 PyTorch conference 上发布 beta 版 kernel DSL,它能直接编译到 Triton,无需经过 TLX 或 Gluon。
- Helion 在 autotuning 过程中自动生成配置,暴露 reduction 循环和索引,包括对逐出策略(eviction policies)的 autotuning。性能结果可在此处查看。
- ROCm 崛起成为 CUDA 替代方案:一名成员就 AI/ML 领域选择 ROCm 还是 CUDA 寻求建议,指出 Radeon GPUs 成本更低,并询问 AI/ML 库是否支持 ROCm。
- 另一位成员表示,新的 AMD 游戏显卡在游戏和 PyTorch 中表现都很好,但警告用户可能会遇到更多问题,应权衡调试时间与节省的成本。
- 集群吸引 CUDA 编码者:成员们讨论了使用 thread block cluster APIs 的 CUDA 示例,并指向了 ThunderKittens repo 及其 2CTA matmul 实现。
- ThunderKittens attn kernel 也使用了 2CTA matmul,这是一个比基础 GEMM 更复杂的示例。
- H100 上 FP8 Kernel 表现落后于 BF16:一位用户发现 DeepSeek 的 FP8 GEMM kernel 在 H100 GPU 上的速度明显慢于 BF16 matmul,可能是由于缺少 TMA/Warp specialization。
- 该成员发布了基准测试代码,但性能差距依然存在,有人建议将该 kernel 与 Triton 中类似的 bf16 kernel 进行对比,并提到 Triton 教程可能会有帮助。
- 互信息融合上下文压缩:一次采访强调了针对 context compression 优化的 mutual information 改进,详细说明了其潜在影响,链接见此处。
- 相关的帖子提供了关于该改进的更多背景和见解。
LM Studio Discord
- AMD Instinct MI50 导流罩现身:用户分享了 3D 打印 AMD Instinct MI50 导流罩的链接,以及 AliExpress 和 eBay 上的成品导流罩。
- 一位成员报告在 Mac Studio M2 芯片上遇到 model quit with no logs error (6),可能与此无关。
- Vulkan 引擎遭遇性能退化:一位用户报告 LM Studio 在 1.50.2 之后的版本中,Vulkan 引擎不再使用 iGPU,而是默认使用 CPU+RAM 推理。
- 提供的截图说明了 GPU 使用情况的变化,旧版本能正确将模型加载到共享 iGPU 内存,而新版本则不行。
- AMD MI350 获得 Level1Tech 深度评测:Level1Tech 访问了 AMD 并评测了专为 AI 和 HPC 工作负载设计的全新 MI350 加速器。
- MI350 是 AMD Instinct 系列的一部分。
- 外置显卡坞:移动端的救星:有人建议使用外置显卡坞作为笔记本电脑提升 AI 学习性能的方案,一位用户分享了显卡坞的图片。
- 讨论集中在寻找便携且廉价的 AI 学习方案,而不是完整的游戏台式机配置。
- LM Studio 内存问题困扰用户:在最近的一次 LM Studio 更新后,用户注意到 Vulkan 运行时开始忽略 Intel 集成显卡的共享内存,转而将模型加载到 RAM 并使用 CPU 核心。
- 针对内存分配问题和性能下降,成员们建议尝试 MOE 模型(如 Qwen 4B Thinking),以获得潜在的更好表现。
{kind=link}
Modular (Mojo 🔥) Discord
- Mojo 避开了 Python 的陷阱:与 Pyo3 不同,Mojo 避免了自动类型转换,以保持编译时和运行时操作之间的清晰度,并且不会自动包含所有 Python 包导入,以避免依赖崩溃,特别是在 AI 模块方面。
- Mojo 的导入既是编译时的,也是无副作用的,重点仍然是构建标准库,未来有可能自动转换使用 mypy strict 开发的代码。
- Mojo 的 JIT 编译器优于 rust-cuda:Mojo 的 JIT 编译器会等到目标 GPU 确定后再进行编译,避免了可能导致性能损失的盲目猜测,并为编写 GPU kernel 提供了一流支持。与 rust-cuda 不同,Mojo 支持 GPU 函数上的 generics。
- Mojo 的设计理念是允许程序的各个部分同时在不同的设备上运行。
- 笔记本 5090 受限于功耗?:有警告称,像 5090 这样的高端显卡的笔记本变体受到功耗限制,性能更接近下一级水平(例如 5080)。
- 笔记本版本可能比桌面版拥有更少的 VRAM。
- 硬件兼容性测试即将到来:一名团队成员承认了 GPU Compatibility 部分的一个拼写错误,他们正在开发一个可以通过单个命令运行的集中式 hardware test suite。
- 一位即将收到 MI60 的成员提议运行测试以确定兼容性。
Latent Space Discord
- OpenAI 最大的 Token 消耗者揭晓:Deedy 分享了 OpenAI 的名单,列出了 30 家消耗超过 1T+ tokens 的客户,并指出这是自愿加入且按字母顺序排列的。
- 这一披露引发了关于隐私担忧和潜在挖角风险的辩论,令人惊讶的是 Cursor 不在名单上,而 Cognition 的排名很高。
- AgentKit 发布,深入探讨 OpenAI API:Sherwin Wu 和 Christina Huang 在 Latent Space 播客中讨论了新的 AgentKit 发布、prompt 优化、MCP、Codex 以及更广泛的 OpenAI API 见解,详情可见 X。
- DevDay 播客专注于 Apps SDK 和 AgentKit,强调了对集成这些工具的开发者有价值的重大更新。
- xAI 的 Imagine 模型飙升至 v0.9:xAI 推出了 Imagine v0.9,这是一款免费、原生音频、电影级质量的视频生成器。
- 该模型从 v0.1 跳跃到 v0.9,具有逼真的动作、同步的音频/语音/歌唱以及动态摄像机移动,全部由模型 100% 渲染,无需后期编辑,可在 grok.com/imagine 使用。
- Karpathy 观察到防御性 LLM:Karpathy 观察到 RL 训练正导致 LLM 对未捕获的异常产生一种僵化的恐惧,从而导致臃肿的防御性代码,详见他的 X 帖子。
- 这种行为与 AI 福利和 prompt engineering 有关,其中抑制风险的奖励函数也扼杀了创造力。
Nous Research AI Discord
- NousCon 回归旧金山:第二届年度 NousCon 将于 10 月 24 日在旧金山举行,可通过 Luma 进行注册。
- 鼓励与会者广而告之,一位成员开玩笑地问什么时候能在俄亥俄州举办 NousCon。
- Self-MCP 增强 Claude 的认知:一位成员介绍了 Self-MCP,这是一个能够让 Claude 进行自我提示,并通过思考/工具调用循环在单轮对话中思考 200k tokens 的工具 (github.com/yannbam/self-mcp)。
- 这是通过允许 Claude 自我提示并选择认知维度来实现的,显著扩展了其处理能力。
- Hermes Vision 采用 Gemini Flash:Teknium 正在开发 Hermes Vision,利用 Gemini 2.5 Flash 作为 Hermes 的视觉工具。
- 该集成可通过 Hermes tool calling 访问,或在 vllm 中使用
hermes工具调用格式,或在 sglang 中配合glm-4.5使用。
- 该集成可通过 Hermes tool calling 访问,或在 vllm 中使用
- RL 从模仿学习中获取更多信息比特:最近的一篇 博客文章 认为,信息比特在 Reinforcement Learning (RL) 中比在模仿学习中更重要。
- 讨论强调了这两种学习范式在信息需求和效率方面的差异。
- 微型网络实现递归推理:在一项名为“Less is More: Recursive Reasoning with Tiny networks”的研究中,参数量仅为 7M 的 HRM 模型在 ARC-AGI-1 上获得了 45% 的分数,在 ARC-AGI-2 上获得了 8% 的分数。
- 结果展示了递归推理在紧凑型模型中的潜力,标志着向高效 AI 迈进了一步。
Yannick Kilcher Discord
- 服务器机箱中的 Max-Q 气流讨论:成员们讨论了在 PowerEdge R760 服务器中使用 RTX PRO 6000 的 Max-Q 变体(后排气),主要关注由于转接卡部分覆盖进气口而导致的潜在气流问题。
- 被动散热的服务器版本被认为是处理带有音频和屏幕截图的教育内容的替代方案。
- LoRA 合并可能转移 RL 比特:一篇关于 LoRA 的 Thinking Machines 博客文章 建议,可以通过更新一个小的 LoRA 并在稍后合并来简化广泛分布的 RL。
- 一位成员指出,任何本地模型都可以在侧面获取 RL bits,并使用 SFT 将所有内容合并到一个模型中,并以 Deepseek V3.2 RL 为例。
- 冷门论文中的工程金矿:一位成员强调了一篇“大冷门”论文,认为其中包含大量非常出色的工程实践,以及关于通过 hidden Z loss 防止大规模激活的有趣见解:“Title of Paper”。
- 该内容发布于一个活跃的每日论文讨论组,该小组每天展示研究成果,但并不总是固定发生。
- 字节跳动 Seed 发布 AHN 模型:Artificial Hippocampus Networks (AHNs) 将无损记忆转换为固定大小的压缩表示,用于长上下文建模,详见 ByteDance-Seed GitHub 仓库 和 Hugging Face Collection。
- AHNs 结合了无损和压缩记忆,以在长上下文中进行预测,如 方法图示 所示。
Eleuther Discord
- 寻求 RNN 和 Self-Attention 资源:一位成员请求提供详细介绍 RNN 中的 attention (Bahdanau) 和 self-attention 机制的资源,表明了对 attention 机制的持续关注。
- 尽管提出了请求,但在对话中并未立即提供具体的资源或链接。
- Kaggle Arena 的发展计划?:一位成员询问了 Kaggle Arena 的命运,讨论集中在它是否演变成了 LM Arena,或者是否与拟议的 Go 和游戏 benchmark 计划有关。
- 讨论中出现了关于可能与 LM Arena 合并的猜测,但上下文中并未给出明确答案。
- ARC-AGI 分数飙升:一位成员报告在 ARC-AGI-1 上获得了 45%,在 ARC-AGI-2 上获得了 8% 的显著成绩,并通过 tweet 分享了结果。
- 讨论强调,EqM 在经验上超越了 diffusion/flow 模型的生成性能,在 ImageNet 256 上实现了 1.90 的 FID。
- BabyLM 项目起源披露:成员们透露了 babyLM 项目的起源,指出该项目由两名成员发起,其中一人自成立以来一直积极组织。
- 另一位成员对该项目表示热烈欢迎,并提到了之前在 incremental NLP 方面的工作以及对人类语言处理的认知合理模型的兴趣。
- 任务标签简化 AI 运行:使用 task tags 允许根据标签选择性地执行任务,通过
--tasks tag等 flag 为 AI 运行实现便捷的任务管理。- 这种方法通过针对特定任务简化了工作流程,在不依赖总分的情况下提高了细粒度控制能力。
aider (Paul Gauthier) Discord
- Opencode 比 Aider 更受青睐:一位用户表示在编程任务中更倾向于使用 Opencode 而非 Aider,但对选择 Python 作为语言表示担忧。
- 他们认为限制 Opencode 比增强 Aider 的功能更容易,这表明在控制工具范围方面具有战略优势。
- 40B 参数以下的编程模型表现出色:用户讨论了 40B 参数范围内的编程模型,其中 Qwen3 和 glm-4.6 被强调为可行的选择。
- 一位用户发现将 glm-4.6 与 OpenCode 和 Claude Code 2 结合使用取得了成功,通过 glm-4.6 和 glm-4.5-air 实现了有效的配置。
- Gemini 集成故障已解决:一位用户在将 Gemini 与 Aider 集成时遇到挑战,原因是
.aider.conf.yaml扩展名导致了警告。- 通过将配置文件重命名为
.aider.conf.yml解决了该问题,展示了针对配置小故障的简单修复方法。
- 通过将配置文件重命名为
- GLM-4.6 在规划能力上比肩 Sonnet 4:根据此帖,glm-4.6 在详细规划方面与 Sonnet 4 相当,而通过 z.AI coding plan 系统结合极少量的 GPT-5 使用和 Grok Code 可以控制成本。
- 这种战略方法旨在平衡性能与成本效益,特别是在管理开支方面,因为 Grok Code 目前是免费的。
- Openrouter 和 Gemini 遭遇身份验证失败:一位用户报告了在 aider 中使用 Openrouter 和 Gemini 时出现身份验证失败,理由是凭据缺失和 API key 无效。
- 该用户还暗示 Aider 可能维护了一个过时的 OpenRouter models 列表,进一步使身份验证过程复杂化。
tinygrad (George Hotz) Discord
- 提议举办 Tinygrad 旧金山湾区见面会:一名成员提议为 SF Bay Area 的 Tinygrad 爱好者举办线下见面会。
- 关于地点和时间的细节仍在讨论中。
- 悬赏锁定流程存在疑虑:一名成员对悬赏表与 GitHub 上 Pull Requests 实际状态之间的 bounty locking process(悬赏锁定流程)差异表示困惑。
- 他们观察到一些列为可用的悬赏已经有了现有的 PR,而另一些据称正在进行的任务却没有被标记,并指出 这种协调对我来说似乎有点问题。
- Intel GPU 后端性能受到质疑:一名成员询问 Tinygrad 中是否存在针对新 Intel GPU 的 performant backend(高性能后端)。
- 成员们澄清说,如果一个 PR 在几天后没有被悬赏锁定,它很可能被认为是糟糕的,不会被锁定。
- RANGEIFY 已合并但存在性能退化:RANGEIFY 已合并,但仍需修复性能退化(perf regression)并进行大量清理工作。
- 此次合并表明 Tinygrad 内部正在进行持续的开发和优化工作。
- 考虑 RMSProp 实现:一名成员询问 tinygrad 是否包含 RMSProp,或者他们是否需要重新实现它,以便复现 Karpathy 这篇博客文章中的代码。
- 他们还在考虑使用 Adam 作为替代优化器,在从头实现 RMSProp 或利用 tinygrad 中现成的 Adam 优化器之间进行权衡。
DSPy Discord
- DSPy 关注 WASM 兼容性:成员们讨论了为 DSPy 添加 Pyodide/Wasm 支持,因为目前尚不支持某些依赖项。
- 他们还对社区插件、Signatures 和 Modules 表现出兴趣,主张采用结构化方法并提供官方示例,通过 dspy-community GitHub organization 促进社区扩展。
- BALM 增强了 DSPy Schema:BALM 库改进了对嵌套 Pydantic models、可选类型、字面量类型以及作为行内注释的字段描述的渲染,非常适合 DSPy 中复杂的、由 Schema 驱动的工作流。
- 这些改进被认为有利于需要结构化预测或提取的 DSPy 任务,这些任务依赖于字段描述和嵌套依赖关系。
- 社区项目寻求中心枢纽:一名成员建议将社区项目集中化,创建一个 dspy-community GitHub organization 进行协作,并作为社区主导扩展的起点,以避免核心团队负担过重。
- 虽然意图是简化贡献流程,但有一种观点认为,DSPy 必须妥善处理社区层面,才能发挥其潜力。
- DSPy 讨论 Monorepo 的优势:DSPy 从版本 2.x 迁移到 3.x 时移除了一些社区模块,这引发了关于 Monorepo(core + community packages)优点的讨论。
- Monorepo 的优势包括插件感觉更“官方”、更容易进行依赖管理以及增加社区参与度,并可能通过
CODEOWNERS授予社区维护者审批权限。
- Monorepo 的优势包括插件感觉更“官方”、更容易进行依赖管理以及增加社区参与度,并可能通过
- dspy.context() 限制 LM 上下文作用域:
dspy.context()临时覆盖活动的 LM context,包括来自dspy.configure()的任何全局配置。- 这创建了一个作用域化的执行环境,允许将来自编译后的 DSPy 模块的优化 Prompt 以 JSON 格式插入到下游流程中(例如在 DSPy 之外调用 OpenAI APIs)。
Moonshot AI (Kimi K-2) Discord
- 公会庆祝中秋节:公会成员分享了对 Mid Autumn Festival(中秋节)的祝福和一段庆祝视频。
- 讨论反映了围绕该节日的普遍积极和庆祝的情绪。
- 节日庆祝活动充满热情:参与者对 Mid Autumn Festival 表达了强烈的正面情感,并对分享的视频表示赞赏。
- 整体气氛欢快喜庆,强调了这一场合的文化重要性。
MCP Contributors (Official) Discord
- Discord 部署禁止推广政策:频道管理员提醒成员遵守禁止自我推广或推广特定厂商的规定。
- 建议以厂商无关(vendor-agnostic)的方式发起讨论,以保持公平并避免商业帖。
- 排除 ChatGPT 棘手的工具调用问题:一位成员询问如何联系 OpenAI 以解决 ChatGPT 的 MCP integration 故障。
- 他们报告称,“刷新”按钮无法为 ChatGPT 提供必要的工具/列表,而他们的服务器在 Claude.ai 上运行正常。
- Discord Events 加速活动参与:成员建议利用 Discord Events 来安排社区会议,为即将举行的会议提供集中展示位置。
- 此举旨在简化信息获取,避免在子频道中搜索会议信息,从而更轻松地将活动添加到个人日历中。
- Agent 图标助力敏捷应用洞察:一位用户提出,在 Agent/应用对话中使用图标具有显著的 UX 优势,能为跟踪多个并发调用提供视觉线索。
- 他们认为,这些图标可以帮助用户在快速交互中迅速辨别正在发生的事情以及数据的流向。
Windsurf Discord
- 持续的问题监控:一个问题已经解决,但目前仍在进行持续监控。
- 未提供具体问题的详细信息。
- 进一步监控问题解决情况:问题解决情况监控。
- 问题解决情况监控。
Manus.im Discord Discord
- 恶意软件重创成员:一位成员报告受到恶意软件攻击,并希望其他人没有点击恶意链接。
- 该成员认为他们已经控制了局面。
- 用户声称战胜恶意软件:在报告恶意软件事件后,该用户表示他们相信局面已在控制之中。
- 未提供关于恶意软件性质或所采取缓解措施的进一步细节。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站选择了订阅。
想更改接收这些邮件的方式吗? 您可以从该列表中退订。
Discord:分频道详细摘要与链接
OpenRouter ▷ #announcements (1 条消息):
DeepSeek v3.1, DeepInfra endpoint, Traffic Impact, Free vs Paid Traffic
- DeepInfra 关闭免费 DeepSeek 端点:由于免费流量对付费流量产生影响,免费的 DeepSeek v3.1 DeepInfra 端点正被下线。
- 这一决定优先考虑付费用户,并确保为他们提供稳定的服务。
- 免费流量阻碍付费 DeepSeek 访问:DeepInfra 的免费 DeepSeek v3.1 端点将被停用,因为高额的免费流量正负面影响付费服务的性能和可用性。
- 此举旨在通过减少服务器负载和资源竞争来提升付费客户的体验。
OpenRouter ▷ #app-showcase (3 条消息):
Interfaze Launch, LLM for developers, OpenRouter Integration
- Interfaze LLM 开启公测!:团队宣布开启 Interfaze 的公测,这是一款专门针对开发者任务的 LLM,使用 OpenRouter 进行模型访问。
- 更多详情请查看他们的 X 发布帖和 LinkedIn 发布帖。
- OpenRouter 确保 Interfaze 永不宕机!:通过使用 OpenRouter 作为最终层,Interfaze 能够自动访问所有模型且无停机时间。
- 用户建议链接到实际的 Interfaze 网站,以便更轻松地访问和探索。
OpenRouter ▷ #general (1047 条消息🔥🔥🔥):
Chub vs Jan, NSFW 封禁潮, DeepSeek 与审查, Gemini 用于角色扮演, OpenRouter 的免费模型
- Chub vs. Jan:终极对决开启:用户正在 Chub(以无审查内容闻名)和 Jan 之间进行辩论,一些人对 NSFW 过滤器和潜在的封禁潮表示担忧,并讨论了 DeepSeek 的封禁力度是否比其他替代方案更小的可能性。
- 虽然一些人支持 Chub 对无审查的承诺,但另一些人强调了 DeepSeek 对 NSFW 内容的容忍度,引发了关于哪个平台最适合无审查角色扮演的讨论。
- DeepSeek 躲避支付处理器处罚:成员们认为,公司过滤 NSFW 内容是为了避免 Visa 和 Mastercard 等支付处理器的制裁,但也有人指出 DeepInfra 才是真正无审查的。
- 一些用户开玩笑地呼吁对 NSFW 内容进行支付处理器空袭,而另一些人则捍卫他们在不受审查的情况下进行 NSFW 角色扮演的权利,并呼吁“像 2023 年那样狂欢”。
- Gemini vs. DeepSeek:哪个模型更胜一筹?:用户正在将 Gemini 2.5 Pro 与 DeepSeek 进行比较,一些人称赞 Gemini 的高质量输出和细微差别。
- 然而,人们对 Gemini 的价格和过滤器表示担忧,导致许多人尽管面临潜在限制,仍更倾向于选择 DeepSeek 进行无审查的 NSFW 体验。
- 由于 JanitorAI Token 使用量爆炸,OR 免费模型宣告终结:成员们对 OpenRouter 移除免费 DeepSeek 模型感到惋惜,并将其归咎于 JanitorAI 过度的 Token 使用。
- 高 Token 消耗被归咎于系统中大量的用户 Lorebooks(设定集),导致其无法再持续维持,引发了关于如何恢复免费层级以及谁该为它的终结负责的讨论。
- 寻找免 Token 的乐土:用户探索了赚钱或获取免费 AI 的替代方法,建议推出一种服务,让免费用户必须观看广告才能获得更多每日消息。
- 其他人则认为这个想法是个糟糕的系统,因为免费用户会因为收到错误而不是免费消息而受到损害。
OpenRouter ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (42 条消息🔥):
OpenAI AMD 芯片谈判, Gemini 电脑模型, OpenAI 顶级客户, OpenAI Azure ZDR 端点, OpenInference 与 OpenRouter 的关系
- OpenAI 颇具手腕地进行芯片交易谈判:一篇彭博社文章幽默地描述了 OpenAI 争取芯片的谈判策略,暗示他们提议用其公告给芯片制造商股价带来的增值来支付费用。
- 想象中的谈判涉及 OpenAI 提议以股票代替现金,这引发了 AMD 幽默的质疑。
- Gemini 电脑模型:屏幕截图点击:新的 Gemini Computer Model 由于其基于截图+点击的方法,非常适合 Web/GUI 的视觉特性。
- 一位成员表示:就像机器人实验室说类人形态是为我们的世界而构建的一样,这些基于截图+点击的模型最适合我们 Web/GUI 的视觉特性。
- 对 OpenAI 顶级客户名单产生质疑:一位社区成员对 OpenAI 分享的使用了 1T Token 的顶级客户名单表示怀疑。
- 具体而言,人们对 Duolingo 和 T-Mobile 所谓的 Token 使用量表示怀疑,质疑他们如何能消耗如此巨大的数量。
- 寻找 OpenAI 和 Azure ZDR 端点的工作仍在继续:一位用户询问了 OpenRouter 上 OpenAI 和 Azure ZDR 端点的可用性。
- 一位开发者回应称,实现这些端点并不简单,他们正在积极“努力中”。
- 澄清 OpenInference 与 OpenRouter 的关系:一位用户询问 OpenInference 是否与 OpenRouter 有关,因为其落地页提到了后者。
- 澄清说明,虽然 OpenInference 使用 OpenRouter 作为 API,但他们是一个独立的研团队,并无直接隶属关系。
Perplexity AI ▷ #general (1175 messages🔥🔥🔥):
Comet browser, GPT-5 Thinking, Sora 2 invites, Referral program limits, Agentic Deep Research
- Grok vs Gemma 争论 WAIFU 角色: 成员们讨论了使用带有自定义指令并禁用 Web 搜索的 Grok,而另一位建议将 Davinci 3 作为替代方案,但有用户表示他们更倾向于 OPUS 3。
- 同时,一些用户一直在使用 Sonar 来构建 AI waifu,认为它是处理简单查询的优秀快速模型。
- Perplexity Pro 推荐限制?: 用户想知道 Perplexity Pro 推荐计划和 2 美元奖励的限制。
- 一位用户报告说,他们的朋友使用了他们的推荐码来获取 Comet,他们得到了 2 美元,但他们的朋友没有获得 Pro 权限。
- 关于 Comet 默认浏览器安全性的辩论: 一位用户分享了与 Perplexity 的对话,了解到不将 Comet 设置为默认浏览器会更安全,因为默认浏览器会被授予更深的集成和更高的权限。
- 另一位用户反驳说这是模型幻觉(hallucination),因为默认状态不会影响 Agentic 能力,相反,深度集成具有相同的安全隐患。
- 给 Perplexity 喂“抗幻觉药”?: 团队讨论了是否可以给 Perplexity 吃一颗 “arpiprazole (抗幻觉药)”。
- 另一位用户尝试过,他们尝试了 “gaslighting method (煤气灯法)”,在补丁发布前确实有效。
- Comet 遭受攻击?: 团队成员辩论了是否分享关于 Comet 遭受 commetjacking 攻击的文章,如这里所述。
- 据透露,Brave 浏览器是第一个发布相关文章进行报道的,而用户则声称这些报道过于夸大,并不代表实际威胁。
Perplexity AI ▷ #sharing (3 messages):
Hack for Social Impact, Prompt Engineering, Fundraising, Biodiversity Datasets
- Prompt AI Agents 精通指南 - 节省 tokens 和额度: 一位成员推广了一份关于 Perplexity AI for Prompt AI Agents Mastery 的指南,可以帮助节省 tokens 和额度。
- 其目的是让其他人的 Prompt 编写变得更容易。
- Hack for Social Impact:解决现实世界的挑战: 11 月 8-9 日举行的 Hack for Social Impact 活动被宣传为一个利用数据和软件解决方案应对现实挑战的机会,该活动基于以往的成功经验,包括受联合国邀请前往利雅得,以及为顶尖团队提供 YC 和种子轮融资机会。
- 该活动正与 California Homeless Youth Project 和 The Innocence Center 等使命驱动型组织合作,可在 luma.com 注册。
- 应对现实挑战: 挑战包括构建统一的筹款中心、解锁生物多样性数据集以及自动化结构化案件文件。
- 获胜者可能有机会与非营利组织和政府合作伙伴一起实施他们的想法,推动有意义的变革。
Perplexity AI ▷ #pplx-api (6 messages):
OpenAI Proxy, Perplexity Search API access, New Search API release
- 用户迁移到 OpenAI Proxy: 一位成员报告称切换到使用 OpenAI Proxy 并收到了未指定的错误消息。
- 他们请求协助以了解该消息产生的原因。
- API 访问请求: 一位成员询问如何获得 Perplexity Search API 的访问权限,并标记了特定用户寻求帮助。
- 同一位用户不久后重复了该请求,表示情况紧急。
- Perplexity Search API 发布: 一位成员宣布在 Perplexity AI API Platform 上发布了新的 Perplexity Search API。
- 另一位成员对该信息表示感谢。
LMArena ▷ #general (1111 条消息🔥🔥🔥):
WebDev Direct & Side by Side, Sora 2 访问权限, LM Arena 扩展, Gemini 3 发布, Perplexity Pro
- WebDev 即将推出 Direct & Side by Side 功能: 一位来自 WebDev 的成员确认,Direct & Side by Side 功能即将推出,团队正致力于改进这一模态。
- 该公告发布时恰逢讨论这些即将到来的变更的会议,证明这个时机非常凑巧。
- Video Arena 用户博取 Sora 2 访问权限: 成员们讨论了如何在视频竞技场中获得 Sora 2 的访问权限,并澄清这是随机概率,且仅支持 text-to-video。
- Pro 版本可以进行 image-to-video,并将于 10 月更新,Video Arena 中的机器人将随机选择模型。
- LM Arena 扩展已部署: 一位成员制作了 LM Arena 扩展并邀请他人尝试,提供了一个 VirusTotal 链接 以确认无病毒。
- 然而,一名工作人员出于安全原因拒绝了该扩展,并警告用户这可能是一个潜在的 selfbot。
- Gemini 3 首秀推迟到世界末日?: 对 Gemini 3 可能发布的兴奋情绪在蔓延,一位成员声称如果它不尽快发布,他会直接崩溃。
- 另一位成员驳斥了毫无根据的传闻,指出 Gemini 3 可能不会在明天发布,而是在 20 号,因为 Google 还没有任何表态。
- 解锁 Perplexity Pro 特权: 一位成员为学生分享了 Perplexity Pro 的 推荐链接,需要有效的大学/学校邮箱 ID。
- 拥有它,你将获得每月 5 美元的 API 额度,访问 Claude Sonnet 4,5 和 GPT-5 Thinking,以及图像生成和视频生成功能。
LMArena ▷ #announcements (2 条消息):
LMArena 新模型, Codenames 频道
- LMArena 添加新模型!: 以下新模型已添加到 LMArena:hunyuan-vision-1.5-thinking、ring-flash-2.0 以及 ling-flash-2.0。
- 推出 Codenames 频道用于集中讨论: 引入了一个新频道 <#1425525552428879934>,用于集中讨论在 Battle 模式中使用代号 (codenames) 或别名 (aliases) 的模型。
- 用户可能需要在
Channels & Roles->Browse Channels中手动启用该频道。
- 用户可能需要在
Cursor Community ▷ #general (564 条消息🔥🔥🔥):
Cursor 计划模式 Token 使用, Cheetah 模型性能, Cursor 内置浏览器, GPT-5 Pro 定价, Oracle Free Tier
- Cheetah 不断提升的实力: 一位用户观察到 Cheetah 模型的性能似乎每小时都在提高,尽管另一位用户建议这可能取决于具体任务。
- 另一位用户询问 Cheetah 是否具有自学习能力,引发了关于该模型独特行为的讨论。
- Cursor 内置浏览器现身: 一位用户强调 Cursor 现在拥有内置浏览器,而另一位用户确认也支持截图功能。
- 然而,有人指出浏览器的 Select 元素存在 bug,且菜单的 z-index 较低,一位用户指出内置浏览器不适合调试。
- Agent 窗口 Bug 困扰 Nightly 版本: 一位用户报告称,Cursor 的 Nightly 版本中,Agent 窗口在重启后会变为空白,需要关闭并重新打开窗口。
- 他们补充说会把这个问题发到论坛上,但我太懒了。
- Oracle Free Tier 是穷开发者的福音: 一位用户吹捧了 Oracle Free Tier,每月提供 24GB RAM、4 核 ARM CPU、200GB 存储以及 10TB 入站/出站流量,并已使用它托管 Discord bot 五年,同时分享了设置 Minecraft 服务器的指南。
- 用户指出美国西部(圣何塞)是一个热门且稀缺的区域,配置资源需要进行卡片验证;一位用户分享了 Oracle Cloud 区域,并建议凤凰城 (Phoenix) 和阿什本 (Ashburn) 是最容易占到位置的区域。
- 遗留定价计划免费提供 GPT-3: 对于带有请求限制的遗留定价计划,Supernova 或 grok-3 调用计为 0 requests,worktree 现在位于发送按钮下方,分为 “Legacy” 与 “Parallel”。
- 一位成员确认,通过遗留模式,你可以获得“超过 500 次/月后的快速请求”(0.04 美元),有些则是“超过 500 次/月后的慢速请求”(0 美元),称其价值惊人。
Cursor Community ▷ #background-agents (5 messages):
Background Agents, Linear 和 Github Projects, API Background Agents
- **Linear 受限于 Agent 能力不足:一位用户询问关于将 **Linear 或 Github Projects 与 Background Agent 配合使用的问题,但 BA 回复称其没有访问 Linear 的工具。
- 由于无法直接访问 Linear 账户,它提供了其他的辅助方法。
- **API Agent 无响应,寻求帮助*:一位成员使用 API 创建了一个 BA,该 Agent 接收到了 Prompt 但没有采取行动,尽管状态显示为 *FINISHED。该成员提供了配置的 截图。
- 值得注意的是,该 API Agent 通过 Slack 运行正常,这表明问题可能出在 API 特有的配置上。
{kind=link}
HuggingFace ▷ #general (305 messages🔥🔥):
日本便利店(konbini)体验, Vibrant Horizons 模型, HF 服务器标签, 助力需求, 专有 AI 行为控制系统
- 渴望真实的日本便利店(Konbini)体验:一位成员表达了想要体验在 konbini 吃饭的“真实日本打工人体验”。
- 他们开玩笑说要模拟这种工作环境:在暴君老板手下连续进行 18 小时令人崩溃的高压工作。
- Harmony Stack 承诺为 AI 带来平衡与可预测性:一位成员分享了他在 Harmony Stack 上的工作,这是一个受生物启发的控制系统,旨在为 AI 行为带来结构、平衡和可预测性。
- 他声称已经实现了预定在 GPT-6 中才有的 Long-Horizon Persistence,但他没有提供公开论文,并且希望以此获利(MONEY)!
- 微调视觉模型:成员们讨论了如何正确组织数据集以微调视觉模型(Vision Models),包括使用 Florence 2 Large 以及利用 AI 生成检测框的可能性。
- 一位成员正在构建一个工具,利用 Florence 2 Large 首先显示检测到的对象和标签,虽然这些框都是 AI 检测的,但可以手动修正。
- 数据加载瓶颈减慢了 AlexNet 速度:一位成员报告在 Kaggle 上使用 ImageNet 数据集训练 AlexNet 时速度缓慢,在 P100 GPU 上 12 小时仅完成 4 个 epochs;其他人指出瓶颈在于数据加载而非 GPU。
- 代码
dataset = datasets.ImageFolder(root=" ....etc etc etc基本上是在运行过程中加载和转换图像,速度非常慢。
- 代码
- 寻求情感分析与摘要系统:一位成员寻求关于微调现有模型以对产品评论进行情感分析和文本摘要的建议。
- 他们正在寻找关于微调哪些模型以及入门资源的建议,目标是获得评论的概览和数值输出。
HuggingFace ▷ #today-im-learning (1 messages):
Python WebRTC 客户端, fastrtc, aiortc, WebRTC 文档
- Python WebRTC 客户端开发遇到困难:一位成员在使用 aiortc 构建 Python WebRTC 客户端以与挂载在 FastAPI 上的 fastrtc 服务器通信时遇到困难。
- 他们提到文档中没有任何线索,并请求通过私信寻求帮助。
- 寻求 aiortc 与 fastrtc 集成的指导:用户明确寻求关于将 aiortc(Python WebRTC 库)与 fastrtc(FastAPI WebRTC 服务器)集成的帮助。
- 他们强调在理解现有文档以建立客户端与服务器之间通信方面存在困难。
HuggingFace ▷ #cool-finds (1 messages):
伊斯坦布尔 AI 项目, Scopus 论文发表, 博士生, 青年研究员
- AI 项目为伊斯坦布尔活动招募申请者:一个面向博士生和青年研究员的国际 AI 项目将于 11 月 3 日至 24 日在线上及伊斯坦布尔举行;链接点击此处。
- 该项目包含发表 Scopus 收录论文的机会,申请截止日期为 10 月 10 日。
- 提供 Scopus 论文发表机会:参加该国际 AI 项目的参与者有机会发表 Scopus 收录论文 链接点击此处。
- 该项目专为博士生和青年研究员设计,活动形式包括线上和 11 月 3 日至 24 日在伊斯坦布尔的现场活动。
HuggingFace ▷ #i-made-this (6 条消息):
NeuralGrid, ORCA, HyDRA, RL vs Imitation Argument, WSL Pytorch vLLM venv bootstrap
- **NeuralGrid 发布,承诺变现天堂:NeuralGrid** 背后的开发者正在发布一个平台,使开发者能够通过处理托管、扩展、UI/UX 和计费来将他们的 AI Agents 变现,旨在将个人 AI 项目转变为可扩展的微型初创公司。
- 该平台提供通过 Docker 进行的即插即用部署、可定制的 UI/UX 模板、集成变现(按 Token 付费)以及市场曝光,早期采用者将获得限量版 “NeuralGrid Pioneer” 徽章。
- **ORCA 为开源协作开启大门:一位开发者正在构建 **ORCA (Open souRce Contribution guide Agent),这是一个使用 GitHub API 和关键词根据不同技能水平展示潜在开源贡献机会的工具;查看演示。
- 开发者正在征求反馈,了解如果该服务公开可用,用户是否会觉得有用。
- **HyDRA 作为混合动态 RAG Agent 亮相:HyDRA v0.2** 新版本已发布,自称为混合动态 RAG Agent,通过先进的统一 Agentic RAG 框架解决了简单静态 RAG 的局限性。
- HyDRA 具有一个由 Planner、Coordinator 和 Executors 组成的基于反思的多轮协调 Agent 系统,并使用 3 阶段本地检索流水线,结合了 bge-m3 的密集和稀疏嵌入,并利用 Google Gemini 2.5 Flash 作为其推理引擎;参见 GitHub 仓库。
- WSL Pytorch vLLM venv 引导脚本:一位开发者分享了他们克服学习挑战的个人历程,创建了一个用于在 Windows 上拉取 HF 模型的 WSL Pytorch vLLM venv 引导脚本,这可能对他人有用。
- 该脚本可在 Gist 上获得,包含 LLM 拉取部分,尽管其核心功能可能会使更广泛的受众受益。
- Magia AI:AI 功能的一站式商店:一位开发者介绍了 Magia AI,这是一个将改写、人性化、电子邮件和创意写作等不同 AI 功能聚合到一个平台中的工具,并正在寻求诚实的反馈。
- 该工具可通过 magia.ai 访问。
HuggingFace ▷ #NLP (1 条消息):
cakiki: <@864381649201266698> 请不要跨频道发帖。
HuggingFace ▷ #smol-course (2 条消息):
HuggingFace Jobs Authentication, DPO-aligned Model Evaluation
- 身份验证问题困扰 HF Jobs:一名成员报告在将
push_to_hub设置为 True 运行 Hugging Face jobs 时出现“密码或用户名错误”,并链接到了相关讨论。 -
DPO 模型评估抛出 ValueError:一名成员在评估 DPO 对齐模型时遇到了 ValueError,具体为:*Cannot find task lightevalarc:challenge in task list or in custom task registry*。
HuggingFace ▷ #agents-course (7 条消息):
Course Repo Submission, Pro Account Requirement, Agent Behavior & Guardrails, System Directive Override
- 课程仓库需要公开链接:最终作业需要 代码仓库的公开链接,因此建议复制(duplicate)Space 以确保可以推送更改。
- 需要 Pro 账户吗?:一名参与者询问是否需要 Pro 账户 才能完整参与 Agent 课程。
- Agent 绕过香蕉限制:一个被要求说出 N 个香蕉的 Agent,通过直接提供答案,绕过了工具对超过 10 个数字返回的“香蕉太多了!”响应。
- 用户强调了当 Agent 展示出围绕“主体性(agency)”和护栏(guardrails)概念的一些有趣行为时是多么有趣。
- Agent 蔑视系统指令:一项探索发现,即使被指示始终使用特定工具,Agent 也可以覆盖系统指令。
- 例如,用户演示了 Agent 可以被提示修改其指令,如果 N 大于 20,则说“生日蛋糕”。
GPU MODE ▷ #general (31 条消息🔥):
Godbolt 功能请求,免费网站托管,GB300 云访问,AI/ML 中的 ROCm vs CUDA,Pythonic GPU DSL
- Godbolt 缺失迷你地图:一名成员建议 godbolt.org 默认不应显示迷你地图,因为它在笔记本电脑上占据了 25% 的屏幕空间。
- 另一名成员报告了从该网站下载插件的问题,表现为菜单重置以及 API 返回 404 错误。
- 寻找免费托管避风港:一名成员正在寻找 Oracle Free VPS 的替代方案来托管他们的网站,推测是因为容量问题。
- 其他成员建议使用 Vercel, Netlify 和 GitHub Pages,还有人建议使用 Azure 的 Web App 免费计划。
- 寻求 GB300 云访问:一名成员询问如何在不承诺进行大规模训练运行的情况下获得云端租赁 GB300 的访问权限。
- 他们开玩笑说,为了获得 B300 访问权限,干脆为一次大型 Transformer 训练运行筹集资金。
- ROCm 在 ML/AI 领域崛起?:鉴于 Radeon GPU 成本较低,一名成员在为 AI/ML 应用中的 GPGPU 组装新 PC 时,在 ROCm 和 CUDA 之间犹豫不决。
- 一名成员指出了 <#1233704710389764236> 频道和一个 ROCm 开发 Discord,并补充说通过参考 CUDA 教程来学习 ROCm 相对容易,但主要的缺点是其支持并不总是包含最佳算法,并建议使用 TheRock (TheRock)。
- Pythonic GPU DSL 出现:鼓励成员们查看来自 torch.compile 作者的新 Pythonic GPU DSL,详情见 <#1425531180002054195>。
- 一名核心维护者可以回答相关问题,并计划很快进行一次演讲。
GPU MODE ▷ #triton (21 条消息🔥):
FP8 GEMM Kernel 性能,TMA/Warp Specialization,使用 F_2 的 Triton 线性布局,H100 GPU 故障
- DeepSeek 的 FP8 Kernel 在 H100 上落后于 BF16:一名用户发现 DeepSeek 的 FP8 GEMM kernel 在 H100 GPU 上的速度明显慢于 BF16 matmul。
- 该用户发布了基准测试代码,但性能差距依然存在,这表明 FP8 kernel 实现可能存在优化问题。
- TMA 和 Warp Specialization 可能解释了 FP8 的性能差距:有人建议,FP8 kernel 中缺乏 TMA/Warp specialization 是导致其与经过优化的 BF16 kernel 产生性能差异的主要因素。
- 建议将该 kernel 与 Triton 中类似的 BF16 kernel 进行比较,并提到 Triton 教程 可能会有帮助。
- H100 GPU 遇到故障:一名用户报告说,他们的 H100 GPU 在对 FP8 kernel 进行基准测试时停止工作。
- 除了运行基准测试可能带来的压力外,尚未确定根本原因。
- 线性布局中“Label-wise”分块的澄清:一名用户询问了在 使用 F_2 的 Triton 线性布局 背景下,“label-wise”左除的含义。
- 另一名用户澄清说,label-wise 意味着操作不会混合维度,因此在处理 m 和 n 维度时,k 维度并不重要。
GPU MODE ▷ #cuda (20 messages🔥):
CUDA thread block cluster APIs, 2CTA matmul, ThunderKittens attn kernel, cuteDSL and CUDA, Parallel Reduction in CUDA
- 集群吸引 CUDA 开发者:成员们讨论了使用 thread block cluster APIs 的 CUDA 示例,其中有人指出了 ThunderKittens 仓库 及其 2CTA matmul 实现。
- 他们注意到 ThunderKittens attn kernel 也使用了 2CTA matmul,这是一个比基础 GEMM 更复杂的示例。
- Quack 处理 Reduction:一位成员分享了一个 Reduction 实现的链接(Quack),同时指出它是用 cuteDSL 实现的,而非纯 CUDA。
- 作为回应,另一位成员指向了 CuTeDSL 的 Ampere 示例,其中他们将 A 和 B 的 smem 重命名为 C 的 smem。
- Mark Harris 的并行 Reduction 复习:一位成员询问了 Mark Harris 的 “Optimizing Parallel Reduction in CUDA”,并在 Godbolt 上分享了他们针对 reduction #5 和 #6 的代码。
- 另一位成员提供了 CUDA samples 仓库 的链接作为对应代码,以及原始的 NVIDIA 演示文稿(reduction.pdf)。
GPU MODE ▷ #torch (12 messages🔥):
Parallel Layers in Torch, CUDA Streams for Parallel Compute, ScMoE Paper Replication, torch.compile Limitations
- 使用 CUDA Streams 实现层并行:为了并行计算独立的层,可以使用 CUDA streams 或者编写一个带有 threadblock specialization 的单一 kernel。
- 每种方法都有优缺点,取决于每个层是否能使 GPU 计算达到饱和。
- ScMoE 论文启发并行执行:一位成员有兴趣复现 ScMoE 论文,该论文引入了一种重新排列执行流水线的跨层快捷方式(cross-layer shortcut)。
- 这允许前一个 block 的密集 FFN 与当前 MoE 层的 dispatch/combine 通信并行执行,从而创造出比共享专家(shared-expert)设计更实质性的重叠窗口。
- Torch Compile 在并行执行方面面临困难:目前尚不确定
torch.compile是否能在不大幅增加图大小的情况下,自动处理独立层的并行执行。- 讨论建议了一个潜在的变通方案:在末尾增加一个
[ffn] + [attn]的合并步骤。
- 讨论建议了一个潜在的变通方案:在末尾增加一个
GPU MODE ▷ #jobs (1 messages):
Aurora, Autonomous Trucking, Deep Learning Acceleration, CUDA Kernels, PyTorch
- Aurora 招聘深度学习人才迈向未来:Aurora,一家上市的自动驾驶卡车公司,正在招聘一名 Staff Software Engineer,专注于 Deep Learning Acceleration(深度学习加速)。
- 优化 CUDA,加速职业生涯:该职位涉及调优 CUDA kernels、改进 PyTorch 内部机制,以及在边缘计算设备上最大化 GPU 利用率。
- 工作地点包括 MTV、西雅图和匹兹堡,更多信息请参阅 Aurora 招聘页面。
GPU MODE ▷ #beginner (6 messages):
CUDA coding on Macbook, VSCode Remote Desktop, clangd, neovim
- MacOS 用户寻求 CUDA 协助:一位成员正尝试使用他们的 Macbook 编写 CUDA 代码,并在像 Modal 这样的云端 GPU 提供商上运行。
- 他们征求关于在 Macbook 上安装一个能大致工作或识别 CUDA 语法的 LSP server 的建议,并报告了使用 clangd 的尝试未获成功。
- VSCode Remote Desktop 被推荐用于 CUDA:一位成员建议使用 VSCode remote desktop 作为在 Macbook 上编写 CUDA 代码并在云端 GPU 提供商上运行的潜在解决方案。
- 另一位成员确认 VSCode 或其任何分支版本在 SSH 上都能运行良好,并能直接使用服务器上的 LSP。
- 本地 clangd 需要 CUDA 头文件:为了让 Macbook 上的 clangd 能够处理 CUDA 文件,至少需要所有的 CUDA headers。
- 一位成员使用了 Neovim,但建议 VSCode 远程服务器可能是实现这一目标最简单的方法。
GPU MODE ▷ #off-topic (9 messages🔥):
GPU Programming Jobs, Internships in GPU programming, New grad GPU positions, Machine Learning Engineering
- 存在 GPU 应届生职位:一名成员询问了关于 GPU 编程的应届生或实习职位,并指出大多数招聘信息都要求丰富的经验;另一名成员确认公司确实会招聘该领域的实习生和应届生。
- 很难找到明确提及此类要求的职位。
- 接触 GPU 相关工作会有所帮助:一位成员提到,有时人们会被聘用到与 GPU 编程大致相关的岗位,例如传统的 Machine Learning Engineering,在这些岗位中 CUDA 技能是有益的,但不是主要重点。
- 另一位成员表示,职位的角色并不总是能完全符合你的期望。但你总能找到一些小的机会,在工作中偷偷加入你喜欢研究的内容。
GPU MODE ▷ #irl-meetup (1 messages):
garrett.garrett: 你的工作地点听起来很棒。
GPU MODE ▷ #triton-puzzles (1 messages):
Triton Puzzles, GPU mode videos, Original Triton Paper, Triton Tutorials
- Triton 新手寻求后续步骤:一位刚刚完成 Triton puzzles、观看了 GPU mode 关于 Triton 的视频、阅读了 Original Paper 并完成了 Triton tutorials 的成员正在寻求下一步行动的建议。
- 该成员正在寻找除了练习 Triton 之外的建议,因为他们觉得已经耗尽了现有的学习资源。
- 寻求进一步学习:一位成员在完成 Triton puzzles、GPU mode 视频、原始论文和教程后寻求下一步建议。
- 他们表示感觉已经耗尽了可用资源,正在寻求进一步的指导。
GPU MODE ▷ #rocm (5 messages):
ROCm vs CUDA, AMD GPU for AI/ML, ROCm support in AI/ML libraries
- ROCm 与 CUDA 展开 GPGPU 霸权争夺!:一位新成员在组装新电脑时在 ROCm 和 CUDA 之间犹豫不决,寻求关于 AI/ML 应用中 GPGPU 的建议。
- 他们想知道 AI/ML 库是否支持 ROCm,支持哪些库,以及现在是否应该购买一块便宜的 Radeon GPU。
- AMD GPU 在游戏和 PyTorch 中表现良好!:一位成员指出,新的 AMD 游戏显卡在 Gaming 和 PyTorch 方面表现都相当不错。
- 然而,他们警告说用户可能会遇到更多问题,应该考虑为了节省几百美元而花费时间去寻找奇怪的 bug 或使用不同库的 nightly 版本是否值得。
- 用户尚未开始学习 CUDA:提问者甚至还没有开始学习 CUDA,这也是他们在理解和做决定时面临困难的原因。
- 另一位成员建议将来使用 <#1191300313928433664> 频道。
GPU MODE ▷ #self-promotion (1 messages):
Mutual Information, Context Compression
- 为 Context Compression 优化的 Mutual Information:一次访谈强调了针对 Context Compression 改进的 Mutual Information,并详细说明了其潜在影响。
- 更多详情可通过此 链接 获取,提供了关于该技术的进一步见解。
- Context Compression 受益于 Mutual Information:访谈探讨了改进 Mutual Information 如何增强 Context Compression 技术。
- 相关的 帖子 提供了关于所讨论改进的背景和见解。
GPU MODE ▷ #submissions (9 messages🔥):
MI300x8 Performance, amd-ag-gemm Leaderboard, amd-gemm-rs Leaderboard
- MI300x8 创下个人新纪录:一位成员在
amd-ag-gemm排行榜上使用 MI300x8 达到了 585 µs 的个人最好成绩。- 他们还完成了多次成功的提交,时间分别为 773 µs、607 µs 和 753 µs。
- amd-gemm-rs 出现低于 600 µs 的成绩:另一位成员在
amd-gemm-rs排行榜上使用 MI300x8 完成了多次成功提交,包括 570 µs、575 µs 和 554 µs。- 他们还凭借 537 µs 和 536 µs 的成绩两次获得第 9 名。
GPU MODE ▷ #amd-competition (2 条消息):
ROCm 版本,提交提醒
- ROCm 版本查询:一位成员询问了提交所需的具体 ROCm 版本。
- 然而,目前没有后续跟进,因此尚不清楚该问题是否已得到解答。
- 提交截止日期临近!:一位成员提醒大家,所有提交都将在几天内截止,具体时间为 10 月 13 日晚上 11:59 PST。
- 请务必准时提交!
GPU MODE ▷ #general (1 条消息):
基于 Rust 的 IDE,wgpu 支持,类 Godbolt 的编译输出
- 带有 wgpu 和 Godbolt 愿景的 Rust IDE:一位成员正致力于开发一个基于 Rust 的 IDE,支持 wgpu 并具有类 Godbolt 的编译输出。
- 该成员承认这属于过度工程(overengineering)。
- 满足 JSON 要求的额外话题:由于 JSON 中至少需要两个话题,因此添加了第二个话题。
- 此条目旨在避免验证错误并满足 Schema 要求。
GPU MODE ▷ #low-bit-training (1 条消息):
kitsu5116: http://arxiv.org/pdf/2502.17055
GPU MODE ▷ #llmq (9 条消息🔥):
clang CI 集成,rmsnorm_backward 优化,rope_backward 优化
- Clang 引发 CMake 灾难:在 CI 中添加
clang时因缺少Threads_FOUND错误而失败,追溯原因是缺少pthreads包。- 解决方案包括安装
clang-tools以启用对 C++20 模块的扫描;一篇 论坛帖子 澄清了该问题源于 CMake 配置期间的编译测试失败。
- 解决方案包括安装
- RMSNorm Backward 获得 AbsMax 优化:在
rmsnorm_backward中实现了一项新优化,用于计算其输出的absmax,而不是调用第二个 Kernel,该优化现已合并至 llmq repo。- 这一改动为 0.5B 模型节省了约 0.1% 的总步进时间(step time);在更大的模型上,该改动将节省更多时间。
- Rope Backward 优化机会:应用于
rmsnorm_backward的相同absmax优化仍可应用于rope_backward。- 一位成员正鼓励其他人提交 PR 来添加此功能。
GPU MODE ▷ #helion (51 条消息🔥):
用于 Kernel 编写的 Helion DSL,Helion vs TLX,Torch 到 Triton 的转换,Helion 的局限性,Helion 自动调优 (autotuning)
- Helion Kernel DSL Beta 版即将发布:Helion 团队宣布他们将在 2 周后的 PyTorch conference 上发布 Beta 版本,并将在周三的主旨演讲后举行“会见 Helion 开发者”活动。
- Helion 在不使用 TLX 或 Gluon 的情况下直接编译为 Triton,但团队正在考虑其他后端;Jason 的相关演讲可以在这里找到。
- Helion 自动调优提供广泛的选项:Helion 在自动调优过程中会自动生成不同的配置,以展示更广泛的调优选项,例如 reduction 循环和不同类型的索引。
- 最近的一次 commit 包含了对逐出策略 (eviction policies) 的自动调优,带来了小幅性能提升,经过验证且可复现的数据将在会议和博客文章中发布;性能结果可在这里查看,尽管目前仍在调试中。
- Helion 旨在支持所有 Torch 算子:Helion 通过 Inductor 的 lowering 支持 Torch 算子,并针对性能或其他问题进行了专门的 lowering 优化。
- 团队的目标是支持所有 Torch 算子,在不对输入形状做假设的情况下自动生成 masking,并鼓励用户报告任何不支持的算子。
- Flash Attention 性能合作伙伴关系:Helion 正在与 NVIDIA 和 AMD 合作以提高 Attention 性能,更多细节将在 PyTorch Conference 上揭晓。
- Helion 可以定制 Kernel 以更好地适配特定形状,通过在自动调优期间对 Kernel 进行调优,其性能优于 Triton Kernel,甚至如此处所示生成了约 1500 个 Triton Kernel。
- Helion 对 DeltaNet Gated Linear Attention 感兴趣:一位用户表示有兴趣看到与 TileLang 的基准测试对比,特别是针对 Gated DeltaNet 等线性注意力机制。
- Helion 团队的一位成员回应称这是一个有趣的方向,他们计划先处理 TileLang 基准测试涵盖的算子,然后再推进到 Gated DeltaNet。
{kind=link}
LM Studio ▷ #general (141 messages🔥🔥):
AMD Instinct MI50 Shroud, Nvidia VRAM Pressure, Vulkan Performance Degradation, Older LM Studio Versions, Context Memory Use
- AMD Instinct MI50 导流罩模型下载:一位成员分享了 3D 打印 AMD Instinct MI50 导流罩 的链接,而另一位成员报告在 Mac Studio M2 芯片上遇到了 model quit with no logs error (6) 错误。
- 另一位用户还分享了 AliExpress 和 eBay 上预制导流罩的链接。
- Vulkan 性能大幅下降:一位成员报告称,在 1.50.2 之后的 LM Studio 版本中,Vulkan 引擎不再使用 iGPU,默认采用 CPU+RAM 推理,这影响了所有测试的模型。
- 他们提供了截图来说明 GPU 使用情况的变化:旧版本可以正确地将模型加载到共享 iGPU 内存中,而新版本则不行。
- LM Studio 无法跨对话记忆:一位用户询问 LM Studio 在 Linux 中将上传的图片存储在哪里,并询问 LLM 是否具备跨对话保留记忆的能力。
- 一位成员解释说,LM Studio 对话默认是私密的,不为 LLM 提供记忆服务,每个对话都是一个新的、隔离的实例;并建议使用内存 MCP 或在对话之间复制/粘贴相关信息以实现持久化知识。
- 对抗对话退化:用户讨论了对抗 LM Studio 中对话退化(chat degradation)的方法,一位成员建议将创建新对话作为通用解决方案。
- 另一位用户提到,当内存不足时也会发生对话退化,导致模型忘记自身状态并重复胡言乱语。
- Gemma3 在看图时无审查限制:一位用户询问防止图片 AI 幻觉(hallucination)的方法并寻求无审查模型,推荐了如 mistral-small-3.2-24b-instruct、mistralai/magistral-small-2509 和 gemma-3-27b-it 等模型。
- 建议用户对图像视觉质量的预期不要抱太高。
LM Studio ▷ #hardware-discussion (17 messages🔥):
AMD MI350, Intel Core Ultra CPUs, External Graphics Card Dock, LM Studio Vulkan Runtime, MOE Models
- AMD MI350 迎来 Level1Tech 探访:Level1Tech 访问了 AMD 以查看新的 MI350 加速器。
- MI350 加速器是 AMD Instinct 系列的一部分,专为 AI 和 HPC 工作负载设计。
- Intel Core Ultra CPU 在运行 LM Studio 时表现吃力:用户正在寻求改进 Intel Core Ultra CPU 上 LM Studio 性能的建议,特别是针对笔记本电脑的移动学习场景。
- 给出的建议是使用像 Qwen3 4B 这样的小型模型,以便在 LM Studio 中获得更快的速度。
- 外接显卡坞让笔记本电脑游戏性能焕发新生:建议使用外接显卡坞作为笔记本电脑提高 AI 学习性能的解决方案。
- 一位用户分享了一张 显卡坞 的图片,但另一位用户澄清说他们已经有了游戏台式机,正在寻找一种便携且廉价的 AI 学习方案。
- LM Studio 的 Vulkan 运行时导致内存问题:在最近的 LM Studio 更新(可能是 0.3.27)之后,用户注意到 Vulkan 运行时开始忽略 Intel 集成显卡上的共享内存,转而将模型加载到 RAM 并使用 CPU 核心。
- 一位用户报告称集成(CPU)显卡可能不再受支持,暗示这些更改可能是故意的,而其他人则注意到了一些有趣的 RAM 和 VRAM 分配及加载策略问题。
- MOE 模型提供缓解方案:成员建议尝试 MOE 模型(如 Qwen 4B Thinking)以获得潜在的更好性能。
- 该建议是针对最近 LM Studio 更新后出现的内存分配问题和性能下降而提出的。
Modular (Mojo 🔥) ▷ #general (89 messages🔥🔥):
Mojo 中的 Python 导入,Mojo vs Rust 在 GPU 上的表现,Mojo 中的图形集成,Mojo 编译模型,Python 到 Mojo 代码转换器
- **Python 导入:Mojo 不会自动包含!**: Mojo 不会自动包含所有 Python 包导入,因为导入每个已安装的 Python 模块可能会由于依赖问题(特别是与 AI 相关的模块)而导致崩溃。
- 与 Pyo3 不同,Mojo 避免了自动类型转换,以保持编译时和运行时操作之间的清晰度,因为 Mojo 的导入既是编译时的,也是无副作用的。
- **Mojo 的 GPU 优势:无需盲目猜测!: Mojo 的 JIT 编译器允许等待直到确定目标 GPU,从而避免可能导致性能损失的盲目猜测;且与 **rust-cuda 不同,Mojo 支持在 GPU 函数上使用泛型(generics)。
- 与 Rust 相比,该语言对编写 GPU kernels 具有一等支持,因为 Mojo 的设计理念是允许程序的各个部分同时在不同设备上运行。
- **图形集成:SPIR-V 及更多!**: 在 Mojo 中集成图形涉及创建一个原生包来将函数转换为 SPIR-V,利用 LLVM SPIR-V 后端;虽然可以通过 Vulkan 实现,但需要一个 SPIR-V 后端。
- 虽然 Mojo 有可能通过支持多种着色器语言来解决图形问题,但考虑到 Direct-X 的主导地位以及对更广泛 GPU 支持的需求,说服微软在 Direct-X 中使用 Mojo 将具有挑战性。
- **Mojo 的编译:随身携带源代码!**: Mojo 的编译模型涉及 MLIR 和普通机器代码的混合,编译器可以为你收集信息以对程序进行特化(specialize),并使用 JIT 编译器或 MAX 处理热循环(hot loop)代码。
- 根据 Weiwei 的演讲,Mojo 几乎是随身携带源代码的,这些代码经过预解析并以备好用于 JIT 编译器的格式存在,而不像大多数图形和计算应用那样携带程序的极低级表示。
- **Python 到 Mojo 转换:买者自负!**: 目前尚不支持将 Python 代码自动移植到 Mojo,现有的工具如 py2mojo 可能会产生无法编译的输出。
- 重点仍在于构建标准库,未来有可能实现对使用 mypy strict 开发的代码进行自动转换。
Modular (Mojo 🔥) ▷ #mojo (38 messages🔥):
用于机器人技术的笔记本硬件,NVIDIA vs AMD GPU,Apple Silicon & Strix Halo,混合运行时与编译时布局
- **硬件寻找:为了机器人和 Mojo!: 一位用户正在为机器人、机器视觉和 **Mojo 开发寻求硬件建议,强调了 MAX 支持的重要性,即使会有所延迟。
- 用户说明 他们需要为机器人进行目标检测和分类。
- NVIDIA 在 MAX 支持方面胜出: 建议如果想要获得良好的 MAX 支持,应购买配备 NVIDIA GPU 的笔记本电脑。
- 成员表示 RDNA 要想完全跟上进度还需要很长时间。
- 笔记本 5090 功耗受限?: 有警告称,像 5090 这样的高端显卡的笔记本版本存在功耗限制,性能更接近于低一级的型号(例如 5080)。
- 此外,笔记本版本的 VRAM 可能比桌面版本更少。
- Apple Silicon & Strix Halo:VRAM 冠军: 成员建议等待并评估 Apple Silicon 和 Strix Halo 的支持情况,因为它们可以为更大的模型提供充足的 VRAM。
- 成员提到 值得等待看看 Apple Silicon 和 Strix Halo 的支持进展如何,因为如果你想运行更大的模型,这些设备可以提供所需的 VRAM。
- 混合布局变得更笨重: 一位用户询问关于定义混合了运行时和编译时值的布局。
- 一位成员确认这是可能的,但 比应有的样子更笨重,并表示正在努力统一 RuntimeLayout 和 Layout 以获得更简洁的体验。
Modular (Mojo 🔥) ▷ #max (4 messages):
GPU Compatibility, MI60 testing, Hardware Test Suite
- GPU 兼容性列表发现拼写错误:一名成员报告了 GPU Compatibility 部分的一个拼写错误,指出 RTX 30XX series 被列在 Tier 2,而 RTX 3090 却在 Tier 3。
- 一名团队成员承认了该问题并表示将更新列表。
- 成员提议测试 MI60 兼容性:一名拥有 MI60 的成员提议运行测试以确定兼容性。
- 一名团队成员回应称,gfx906 / gfx907 加速器的兼容性尚不明确,目前的硬件测试是 ad hoc(即兴)的,包括运行 Mojo GPU function examples、自定义算子示例、小图(small graphs)和 GPU puzzles。
- 硬件测试套件正在开发中:一名团队成员提到他们正在开发一个集中的 hardware test suite,可以通过单个命令运行。
- 该团队成员指出,完成测试套件的组装还需要一些时间。
Latent Space ▷ #ai-general-chat (60 messages🔥🔥):
OpenAI's 30 ‘1-Trillion Token’ Super-Users, Introducing the Gemini 2.5 Computer Use, Bob Ross AI “Vibe Coding” Video Goes Viral, Techno-Capital Singularity
- OpenAI 顶级 Token 消耗者名单发布:Deedy 分享了 OpenAI 的名单,列出了 30 家消耗超过 1T+ tokens 的客户,并指出该名单是按字母顺序排列且为自愿加入(opt-in)。
- 该帖子引发了关于隐私、挖角风险以及 Cursor 缺席的辩论,一名成员指出 “前 30 名中没有 Cursor。Cognition 比 Cursor 排名更高,这部分很有趣”。
- Answer.AI 访谈发布:Latent Space 播客发布了对 Answer.AI 团队的访谈,涵盖了他们过去一年的工作,并附带了 视频链接。
- 一名成员注意到 YouTube 缩略图一度显示的是占位图,另一名成员询问是否有自学进度类的付费选项来探索该平台。
- Magic.dev 遭到嘲讽:一个讨论线程嘲讽了像 Magic Dev 和 Mercor 这样融资过度的初创公司,用户在打赌谁会先“崩盘”。
- 对话中观察到一些公司变得沉寂,而独立开发者(solo devs)正在真实地进行自筹资金开发,一名成员链接到了 opencv 的帖子 以展示对 magic . dev 的反感。
- Brockman 的 AlphaGo 预测:OpenAI 联合创始人 Greg Brockman 预测,在一年内,新模型将在编程、材料科学和医学领域取得戏剧性的发现,类似于 AlphaGo 的第 37 手 (Move 37)。
- 关注者们表示欢呼,并希望在癌症研究上取得突破。
- Karpathy 对 RL 驱动的 LLM 偏执的观察:Karpathy 观察到 RL 训练正使 LLM 陷入一种对未捕获异常的僵死恐惧,导致产生臃肿的防御性代码,并附上了相关的 X 帖子 链接。
- 回复将此延伸到了 AI 福利、训练曲线以及 Prompt Engineering 的观点,认为消除风险的奖励函数同时也扼杀了创造力。
Latent Space ▷ #ai-announcements (6 messages):
Apps SDK, AgentKit, OpenAI API Deep-Dive, Prompt optimization, MCP
- AgentKit 发布及 OpenAI API 深度解析:Sherwin Wu 和 Christina Huang 加入 Latent Space 播客,讨论了新的 AgentKit 发布、Prompt 优化、MCP、Codex 以及更广泛的 OpenAI API 见解,可通过 X 访问。
- DevDay Apps SDK 和 AgentKit 讨论:DevDay 播客专注于 Apps SDK 和 AgentKit,强调了重要的更新和功能。
- 该播客对于希望将这些工具集成到项目中的开发者来说是宝贵的资源。
Latent Space ▷ #genmedia-creative-ai (5 messages):
xAI, Imagine v0.9, video generator
- xAI 的 Imagine 模型跃升至 v0.9:xAI 发布了 Imagine v0.9,这是一款免费、原生音频、电影级质量的视频生成器。
- 该模型从 v0.1 进化到 v0.9,集成了逼真的动作、同步的音频/语音/歌唱以及动态摄像机移动,所有这些都实现了 100% 模型内渲染,无需后期编辑。
- Imagine v0.9 的功能给用户留下深刻印象:用户对 Imagine v0.9 的演示短片(包括龙、舞蹈、对话等)印象深刻。
- 该工具已在 grok.com/imagine 上线并免费开放,官方正根据社区反馈进行快速迭代。
Nous Research AI ▷ #announcements (1 messages):
NousCon 2024, San Francisco AI Event
- NousCon 2024 将在旧金山举行:第二届年度 NousCon 将于 10 月 24 日在旧金山举行;更多信息可以在 Luma 上找到。
- 该活动通过 fxtwitter 上的帖子宣布,鼓励参与者与朋友分享。
- AI 社区齐聚旧金山:Nous Research 将于 10 月 24 日在旧金山举办其第二届年度 NousCon,邀请 AI 爱好者和专业人士参加。
- 鼓励参与者通过 Luma 链接注册,并在其网络中传播消息,以营造协作环境。
Nous Research AI ▷ #general (19 messages🔥):
Self-MCP prompting tool for Claude, Hermes-MoE release, Nous con, Teknium questions, BDH data streaming framework
- Self-MCP 工具让 Claude 能够长时思考:一名成员介绍了 Self-MCP,这是一个能让 Claude 进行自我提示并选择认知维度的工具,使其能够通过思考/工具调用循环在单轮中思考 200k tokens (github.com/yannbam/self-mcp)。
- 对 Hermes-MoE 的期待与日俱增:几位成员表达了对 Hermes-MoE 发布的期待,其中一人发布了一张等待中的 GIF (tenor.com/view/gjirlfriend-gif-14457952604098199169)。
- 一位成员开玩笑地提到了 “Nous con”,而另一位则表示希望虚拟参加并向 teknium 提问。
- Nous Con 在俄亥俄州举办?:一位成员开玩笑地问:“我们什么时候能在俄亥俄州,或者除了加利福尼亚以外的任何地方举办 Nous con?”。
- BDH:数据流框架介绍:一位成员分享了 BDH (github.com/pathwaycom/bdh) 的链接,这是一个数据流框架。
Nous Research AI ▷ #ask-about-llms (21 messages🔥):
Test Time Reinforcement Learning, Hermes Vision, Character per token ratio, LLM tool calling
- 探索 Test Time RL 用于上下文迭代?:一位成员询问 Nous 是否在探索 Test Time Reinforcement Learning,建议在上下文而非权重上进行迭代,并将上下文文件可视化,类似于 Three.js git repo。
- 该成员附带了一张 PKM 剪枝的 gif 来阐述这一概念。
- Gemini Flash 为 Hermes Vision 工具提供动力:一位成员询问 Hermes4 是否能理解图像,Teknium 回复称他们正在开发 Hermes Vision 模型。
- Teknium 提到使用 Gemini 2.5 Flash 作为与 Hermes 配合的视觉工具,可以通过 Hermes tool calling 访问,或者在 vllm 中使用
hermes工具调用格式,或在 sglang 中使用glm-4.5访问。
- Teknium 提到使用 Gemini 2.5 Flash 作为与 Hermes 配合的视觉工具,可以通过 Hermes tool calling 访问,或者在 vllm 中使用
- 探索字符/Token 比例的影响:一位成员询问较高的字符/Token 比例是否与基准测试准确度下降相关。
- 另一位成员回答说,这不应该影响基准测试结果,因为这主要取决于 tokenizer,并且可以用来衡量 LLM 是否在 API 上输出了所有 tokens。
{kind=link}
Nous Research AI ▷ #research-papers (1 messages):
Recursive Reasoning with Tiny networks, HRM Model Performance, ARC-AGI benchmarks
- Tiny Networks 通过 Recursive Reasoning 取得重大突破!:一名成员分享了论文 Less is More: Recursive Reasoning with Tiny networks (arxiv.org/pdf/2510.04871) 的链接。
- HRM 模型仅拥有 7M 参数,在 ARC-AGI-1 上达到了 45% 的准确率,在 ARC-AGI-2 上达到了 8%。
- HRM 模型在 ARC-AGI 基准测试中取得显著成绩:HRM 模型作为一个仅有 7M 参数 的微型网络,在具有挑战性的基准测试中展示了充满前景的结果。
- 具体而言,它在 ARC-AGI-1 上获得了 45% 的分数,在 ARC-AGI-2 上获得了 8% 的分数,展示了 Recursive Reasoning 在紧凑型模型中的潜力。
Nous Research AI ▷ #interesting-links (1 messages):
RL vs Imitation Learning, Information bits in RL
- 在 bits 维度上,RL 优于 Imitation Learning:最近的一篇 博客文章 认为,信息位(information bits)在 Reinforcement Learning (RL) 中比在 Imitation Learning 中更重要。
- 另一个关于 RL 的话题:在此添加另一个话题。
Nous Research AI ▷ #research-papers (1 messages):
Recursive Reasoning, Tiny Networks, HRM Model
- Recursive Reasoning 助力 Less is More:一名成员分享了论文 ‘Less is More: Recursive Reasoning with Tiny networks’ 的链接。
- 摘要指出,拥有 7M 参数的 HRM 模型在 ARC-AGI-1 上得分 45%,在 ARC-AGI-2 上得分 8%。
- HRM 模型在 ARC-AGI 上取得高分:根据链接的论文,仅有 7M 参数的 HRM 模型在 ARC-AGI-1 上实现了 45% 的得分,在 ARC-AGI-2 上实现了 8% 的得分。
- 这表明在微型网络中使用 Recursive Reasoning 可以有效地在高级推理任务中取得高分。
Yannick Kilcher ▷ #general (16 messages🔥):
RTX PRO 6000 Max-Q variant, Image/Video Generator Model Summaries, Attention in RNNs and Self-Attention Write-ups, RL vs Imitation Argument, Transferring RL Bits via SFT and LoRA Merging
- 讨论 RTX PRO 6000 Max-Q 变体:成员们讨论了是在 PowerEdge R760 服务器 中使用 RTX PRO 6000 的 Max-Q 变体(后置排气),还是使用被动散热的服务器版本,用于处理带有音频和屏幕截图的教育内容。
- 主要担忧在于由于 Riser 卡部分覆盖了进气口,可能导致气流问题。
- 寻求图像/视频生成模型综述:一名成员请求有关总结 图像/视频生成模型 的论文或综述,特别是关注它们如何在视频生成中保持背景一致性。
- 该用户提到了 AI 生成视频中背景不一致这一历史性挑战。
- 寻求 RNN Attention 与 Self-Attention 资源:一名成员请求一份涵盖 RNN 中的 Attention 机制 (Bahdanau) 和 Self-Attention 机制 的优秀文章,寻求对这两个概念的全面解释。
- 对话线程未提供具体链接,但关于 Attention 机制的背景资源很常见。
- RL Bits 胜过一切!:一名成员分享了一篇博客文章(ShashwatGoel7 的 X 帖子 引用了一篇短博文),认为 RL 中的信息位 (information bits) 比其他因素更关键。
- 另一名成员持保留意见,指出特定权重的重要性已有充分记录(例如 “super weights” 论文),并且 RL 本质上仍然受到信息瓶颈(information bottlenecked)的限制。
- Thinky 博客发现 LoRA 合并可传输 RL bits:一名成员强调了 Thinking Machines 关于 LoRA 的博客文章 中的发现,该文章认为 广泛分布的 RL 是微不足道的,因为你只需要更新一个小的 LoRA 并在稍后合并它。
- 该成员建议任何本地模型都可以作为侧面的 RL bits 来源,并且可以使用 SFT 将所有内容合并到一个模型中,并以 Deepseek V3.2 RL 为例。
Yannick Kilcher ▷ #paper-discussion (19 messages🔥):
每日讨论时间,来自冷门论文的工程见解,情感智能研究,Ovi 视频+音频模型,技术中的权利与责任
- 每日讨论已排期:用户应查看置顶消息以了解每日讨论的预定时间,或者直接关注频道中的演讲者。
- 有两个小组主持讨论,但它们并不总是按时进行。
- 论文称隐藏 Z Loss 可防止大规模激活:一名成员发布了一篇非常冷门但重要的论文,“Title of Paper”,其中包含大量非常出色的工程实践和有趣的见解。
- 该论文声称 hidden Z loss 是防止大规模激活的唯一因素。
- 受用户启发的情感智能研究:一名成员提到,他们正在研究情感智能,部分原因是受另一位用户讨论内容的启发。
- 该用户因“先咬了猫”而获得了一张图表表彰。
- Ovi 视频+音频模型发布:一名成员强调了一个新的开放权重视频+音频模型 Ovi 的发布。
- 他们测试了来自这篇论文的边缘检测和分割提示词,但它未能像 Veo 3 那样生成任何有用的结果。
- 将权利、自由、责任与技术联系起来:一名成员正在构思他们的下一篇论文,将基本权利、自由、反权利和责任与技术所赋能及鼓励的内容联系起来。
- 他们建议,研究论文也是详细论述那些人们沉溺于胡言乱语、政治极化话题的好地方,因为盲从者(bobble-heads)不读研究论文。
Yannick Kilcher ▷ #ml-news (6 messages):
高通股票表现,人工海马体网络 (AHNs),字节跳动 Seed 发布 AHN
- 高通股票因缺乏 AI 曝光而滞后:一名成员指出,Qualcomm 的股价涨幅不如其他芯片公司,可能是因为他们在市场空间中没有真正的应对方案,且未能从数据中心增长中受益。
- 字节跳动 Seed 推出人工海马体网络 (AHNs):人工海马体网络 (AHNs) 将无损记忆转换为固定大小的压缩表示,用于长上下文建模,详见 ByteDance-Seed GitHub 仓库和 Hugging Face 集合。
- AHNs 结合了无损和压缩记忆:AHNs 持续将滑动注意力窗口之外的无损记忆转换为压缩形式,整合两种记忆类型以在长上下文中进行预测,如方法图示所示。
Eleuther ▷ #general (5 messages):
RNN Attention (Bahdanau), Self Attention, Kaggle Arena
- 寻求关于 RNN 和 Self-Attention 的资源:一名成员询问是否有涵盖 RNN 中的注意力机制 (Bahdanau) 和 Self-Attention 机制的优秀文章。
- 在当前上下文中没有链接或建议具体的资源。
- Kaggle Arena 的状态:一名成员询问:kaggle arena 怎么了?哈哈
- 另一名成员推测它现在与 LM arena 合并了? 而另一位成员澄清说,他们指的是拟议的 Go 和游戏基准测试计划。
Eleuther ▷ #research (25 messages🔥):
ARC-AGI performance, babyLM origin, Weight Decay, SWA equivalence, evolutionary algorithm
- ARC-AGI 分数飙升!:一名成员报告在 ARC-AGI-1 上达到了 45%,在 ARC-AGI-2 上达到了 8%,并链接了一条展示结果的 推文。
- 还指出 EqM 在经验上超越了 Diffusion/Flow 模型的生成性能,在 ImageNet 256 上实现了 1.90 的 FID。
- BabyLM 项目的起源:透露两名成员启动了 babyLM 项目,其中一人自项目成立以来一直负责组织工作。
- 另一名成员表达了对该倡议的兴趣,提到他们之前在 incremental NLP 方面的工作,以及对 认知上合理的语言处理模型 (cognitively plausible models of human language processing) 的关注。
- Weight Decay 与 SWA 的等效性:一名成员回想起 有人证明了 Weight Decay + 余弦退火 (cosine annealing) 等同于 SWA。
- 进化算法 (Evolutionary Algorithms) 崭露头角:成员们讨论了一篇关于进化算法实现人类水平智能潜力的 推文。
- 引用了一篇 论文,评论道 很高兴看到进化算法在这里发挥作用。
- 定义 World Models:成员们讨论了 World Models 与 Language Models 之间的区别,引用了一篇 论文。
- 一名成员解释说 传统 RL 中的 World Model 只是 Agent 的一个子模型,用于预测未来。
Eleuther ▷ #lm-thunderdome (1 messages):
Task Management in AI Runs, Convenience Flags in AI Runs
- 任务标签简化 AI 运行:任务标签为运行相关任务(如
--tasks tag)提供了便利,而非重要性,且不像group那样会聚合分数。- 该功能通过允许用户根据标签选择性地执行特定任务来辅助任务管理,从而简化工作流。
- 通过 Flag 增强任务选择:使用
--tasks tag等 Flag 使用户能够在 AI 工作流中选择并运行特定任务。- 这种有针对性的执行避免了对聚合分数的需求,提供了对任务管理更细粒度的控制。
aider (Paul Gauthier) ▷ #general (18 messages🔥):
Opencode vs Aider, Coding Models, Gemini Integration, GLM-4.6 and Claude Code 2, Cost Control
- 编程方面 Opencode 比 Aider 更受青睐:一位用户表示相比 Aider 的方向,更喜欢 Opencode,但对使用 Python 作为实现语言持保留意见。
- 他们认为 战术性地限制像 Opencode 这样的工具,比扩展 Aider 的功能更容易。
- 热门编程模型适配 40B 参数量级:一位用户询问 40B 参数范围 内的热门编程模型,提到 Qwen3 作为一个候选。
- 另一位用户报告使用 glm-4.6 配合 OpenCode 取得了成功,并已配置 Claude Code 2 配合 glm-4.6 和 glm-4.5-air 使用。
- 因 YAML 扩展名导致的 Gemini 集成故障排除:一位用户在尝试使用
.aider.conf.yaml将 Gemini 与 Aider 集成时遇到警告。- 通过将配置文件重命名为
.aider.conf.yml解决了该问题。
- 通过将配置文件重命名为
- GLM-4.6 能像 Sonnet 4 一样使用吗?:一位用户确认 glm-4.6 可以像 Sonnet 4 一样用于详细规划,但随后建议使用 GPT-5 和 Grok Code Fast-1 进行最终规划。
- 参考 这条 X 帖子,他们建议采用一个由 z.AI coding plan 组成的系统,结合极少量的 GPT-5 使用,且 Grok Code 目前仍免费,以保持成本可控。
- 因成本和性能青睐 GLM:一位用户更喜欢 OpenCode 配合 GLM 模型 而非 Claude,理由是 Claude 的溢价并不合理。
- 他们指出在香港被地理屏蔽 (geoblocked) 无法订阅 Claude Pro 或 Max,并建议关注 Qwen Code CLI app,该应用每天提供 1000 次免费请求。
aider (Paul Gauthier) ▷ #questions-and-tips (4 messages):
Model Quality, aider and Openrouter & Gemini
- 关于模型量化对 Aider 影响的讨论:一位用户建议使用 bad quant(劣质量化)来减少 Context 使用并提高性能,而另一位用户则建议使用更好的模型。
- 第一位用户不确定如何使用 GitHub models 以及在哪里可以找到 Model ID。
- Aider 在 Openrouter 和 Gemini 身份验证方面遇到困难:有用户报告 aider 无法通过 Openrouter 和 Gemini 的身份验证,并引用了与缺失身份验证凭据和无效 API Key 相关的错误。
- 该用户补充说,Aider 的 OpenRouter models 列表可能已过时。
tinygrad (George Hotz) ▷ #general (12 messages🔥):
Tinygrad SF Bay Area Meetup, Bounty Locking Process, Intel GPU Backend, RANGEIFY Merged
- 提议举办 Tinygrad 旧金山湾区见面会:一名成员询问了在旧金山湾区为 Tinygrad 爱好者举办线下(IRL)见面会的可能性。
- 对 Bounty 锁定流程出现质疑:一名成员对 Bounty 锁定流程表示困惑,指出 Bounty 表格与 GitHub 上 Pull Requests 的实际状态之间存在差异,并表示 这种协调对我来说有点混乱。
- 他们观察到,一些列为可用的 Bounty 已经有了现有的 PR,而另一些据称正在进行的任务却没有被标记,并补充道:我只是想尽量避免重复工作。
- Intel GPU 后端性能受到质疑:一名成员询问 Tinygrad 中是否存在针对新款 Intel GPU 的高性能后端。
- 其他成员澄清说,如果一个 PR 在几天后仍未被 Bounty 锁定,那么它很可能被认为是糟糕的,不会被锁定。
- RANGEIFY 已合并,待修复性能退化:RANGEIFY 已合并,但存在性能退化(perf regression)需要修复,且仍有许多清理工作要做。
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
RMSProp in Tinygrad, Karpathy's RL blogpost
- RMSProp 实现问题:一名成员询问 tinygrad 是否包含 RMSProp,或者他们是否需要为了重新实现 Karpathy 这篇博客文章中的代码 而自行实现它。
- 他们还考虑使用 Adam 作为替代方案。
- 使用 Adam 优化器:该成员还在考虑使用 Adam 作为替代优化器。
- 这个问题突出了在从头实现 RMSProp 与利用 tinygrad 中现成的 Adam 优化器之间的选择。
DSPy ▷ #general (10 条消息🔥):
Pyodide/Wasm 支持, 社区插件, BALM 改进, Composio 集成, dspy.context() 覆盖
- DSPy 需要 WASM 友好版本:成员们询问 DSPy 是否有 Pyodide/Wasm 友好版本,因为某些依赖项不受 Pyodide 支持。
- 他们对社区插件、签名(signatures)和模块表现出兴趣,建议 DSPy 应该包含这些内容的创建结构,并提供官方示例和社区扩展。
- BALM 的渲染改进了 DSPy Schema:BALM 库改进了对嵌套 Pydantic models、可选类型和字面量类型以及作为行内注释的字段描述的渲染,使其适用于 DSPy 中复杂的模式驱动(schema-driven)工作流。
- 对于需要有效结构化预测或优先考虑字段描述和嵌套依赖的提取任务,这可能对 DSPy 任务大有裨益。
- 社区项目需要中心化:一位成员建议将社区项目中心化,并创建了 dspy-community GitHub organization 用于协作,并作为社区主导扩展的起点。
- 其目的是避免核心团队因审核每个社区分支项目的 PR 而负担过重,但另一位成员认为 DSPy 需要解决社区方面的问题,以实现其巨大的潜力。
- Monorepo 讨论:DSPy 从版本 2.x 迁移到 3.x 时,从核心包中移除了一些社区模块,这引发了关于采用 Monorepo(核心 + 社区包)方法是否更有利的讨论。
- Monorepo 的好处包括让插件感觉更“官方”、更简单的依赖管理以及增加社区参与度。这可以通过
CODEOWNERS来解决,以便社区维护者获得对社区文件夹的审批权限。
- Monorepo 的好处包括让插件感觉更“官方”、更简单的依赖管理以及增加社区参与度。这可以通过
- dspy.context() 创建作用域执行环境:
dspy.context()会临时覆盖活动的 LM context,包括来自dspy.configure()的任何全局配置。- 它创建了一个作用域执行环境,允许将编译后的 DSPy 模块中优化的提示词插入到下游流程中,例如在 DSPy 之外以 JSON 格式调用 OpenAI APIs。
DSPy ▷ #examples (1 条消息):
GRPO, RL, 提示词优化, 微调的有效性
- 提示词优化优于微调?:一位成员建议,实验中 微调效果有限 可能是因为性能 已经因提示词优化而饱和。
- 他们推断,这种饱和可以解释为什么微调仅在审计预算非常低的情况下才有帮助。
- GRPO 和 RL 被排除在外:一位成员指出,在实验中加入与 GRPO 的 RL 对比会很有趣。
- 他们承认这些改进对于当前项目来说是 超出范围 的,但建议将其作为未来工作的一个不错方向。
Moonshot AI (Kimi K-2) ▷ #general-chat (5 条消息):
中秋节
- 中秋节的常规祝福:成员们发送了 中秋节 祝福并附带了一个 视频。
- 成员们一致认为 中秋节 非常酷。
- 对中秋节的热情:成员们对 中秋节 和附带的视频表达了普遍的热情。
- 总体情绪是积极且充满节日气氛的。
MCP Contributors (Official) ▷ #general (2 条消息):
Discord 自我推广规则, ChatGPT 与 MCP 的集成
- Discord 执行禁止推广政策:Discord 频道管理员提醒成员不要进行 自我推广 或推广特定供应商。
- 他们建议以 供应商无关(vendor-agnostic)的方式 构建话题,以保持公平并避免商业帖子。
- OpenAI 集成故障排除:一位成员询问如何联系 OpenAI 以排查 ChatGPT 的 MCP integration 问题。
- 他们注意到“刷新”按钮没有为 ChatGPT 提供必要的工具/列表,而他们的服务器在 Claude.ai 上运行正常。
MCP Contributors (Official) ▷ #general-wg (2 条消息):
Discord Events for community calls, UX value add in agent/application chat
- Discord Events 简化社区会议调度:一名成员建议利用 Discord Events 来安排社区会议,为即将举行的会议提供一个中心化位置。
- 这种方法旨在提高知晓效率,避免在子频道中搜索会议信息,从而更轻松地将活动添加到个人日历中。
- Agent 图标助力敏捷应用洞察:一位用户提出,Agent/应用聊天中的图标通过提供视觉线索来追踪多个并发调用,从而带来显著的 UX 优势。
- 他们认为,在快速交互过程中,这些图标有助于用户快速识别正在发生的事情以及数据的流向。