AI News
Air Street《2025 年人工智能现状报告》
Reflection 筹集了 20 亿美元,用于构建专注于安全和评估的前沿开放权重模型,其团队成员拥有 AlphaGo、PaLM 和 Gemini 的背景。Figure 推出了其下一代人形机器人 Figure 03,强调适用于家庭和大规模使用的非远程操作(自主)能力。Radical Numerics 发布了 RND1,这是一个拥有 300 亿参数的稀疏混合专家(MoE)扩散语言模型,并开放了权重和代码以推动扩散语言模型的研究。智谱 (Zhipu) 的 GLM-4.6 在 Design Arena 基准测试中取得了优异成绩,而 AI21 Labs 的 Jamba Reasoning 3B 在小型推理模型中处于领先地位。Anthropic 为 Claude Code 引入了插件系统,以增强开发工具和智能体堆栈。报告还重点提到了软银(SoftBank)以 54 亿美元收购 ABB 机器人业务的交易,以及围绕开放前沿建模和小型模型推理日益发展的生态系统。
300 张幻灯片就够了。
2025年10月8日至10月9日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 23 个 Discord 社区(197 个频道,7870 条消息)。预计节省阅读时间(以 200wpm 计算):583 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以优美的 vibe coded 方式展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
祝贺 Reflection、Mastra、Datacurve、Spellbook 和 Kernel 成功融资。
年度 Mary Meeker 报告的 AI 原生版本一直是 Nathan Benaich 的 State of AI 报告。您可以通过 推文合集 或 YouTube 了解亮点,但我们在这里提供一些笔记:
拥有“天命”的实验室(Anthropic 出现在哪里?):
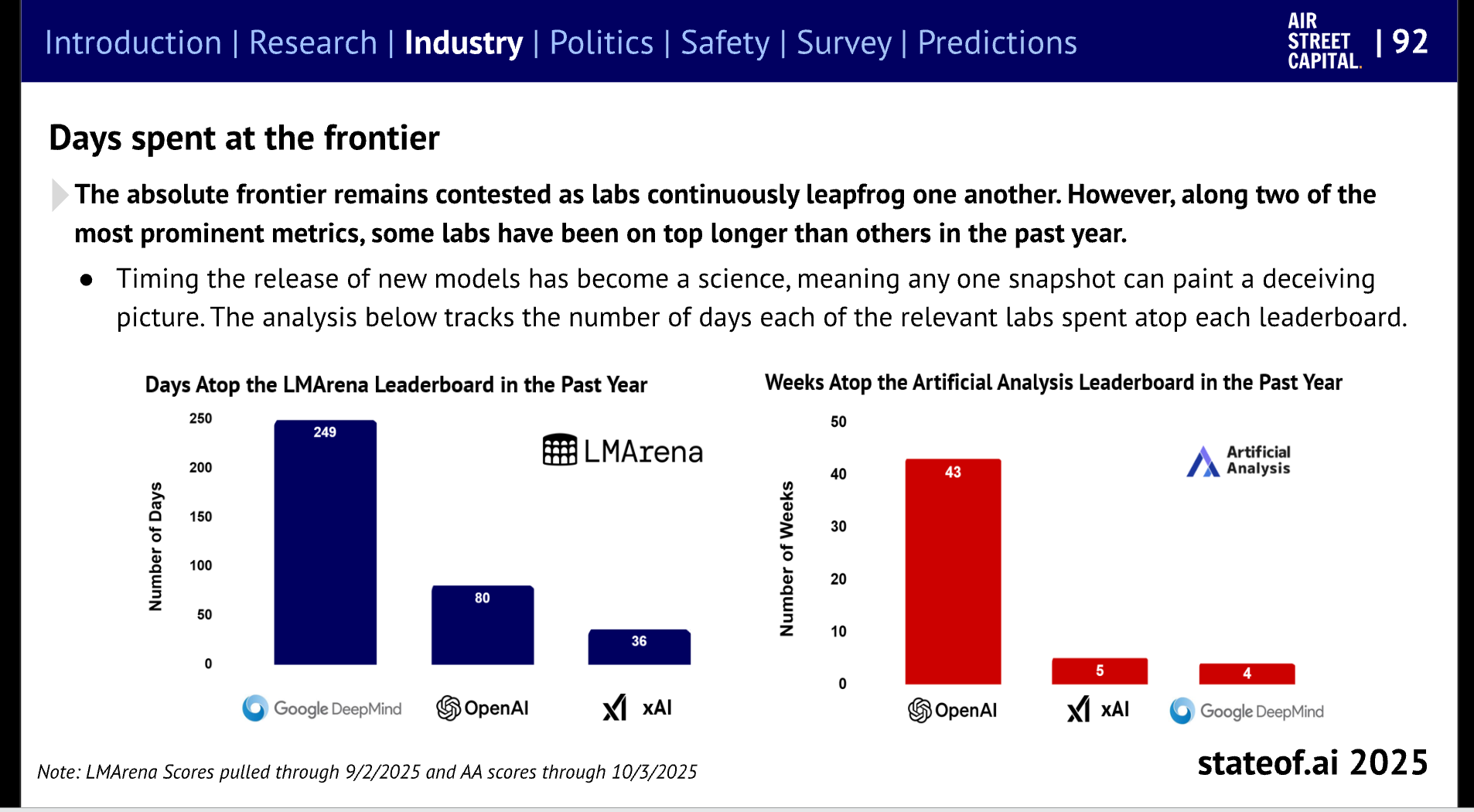
以及它们的估值:
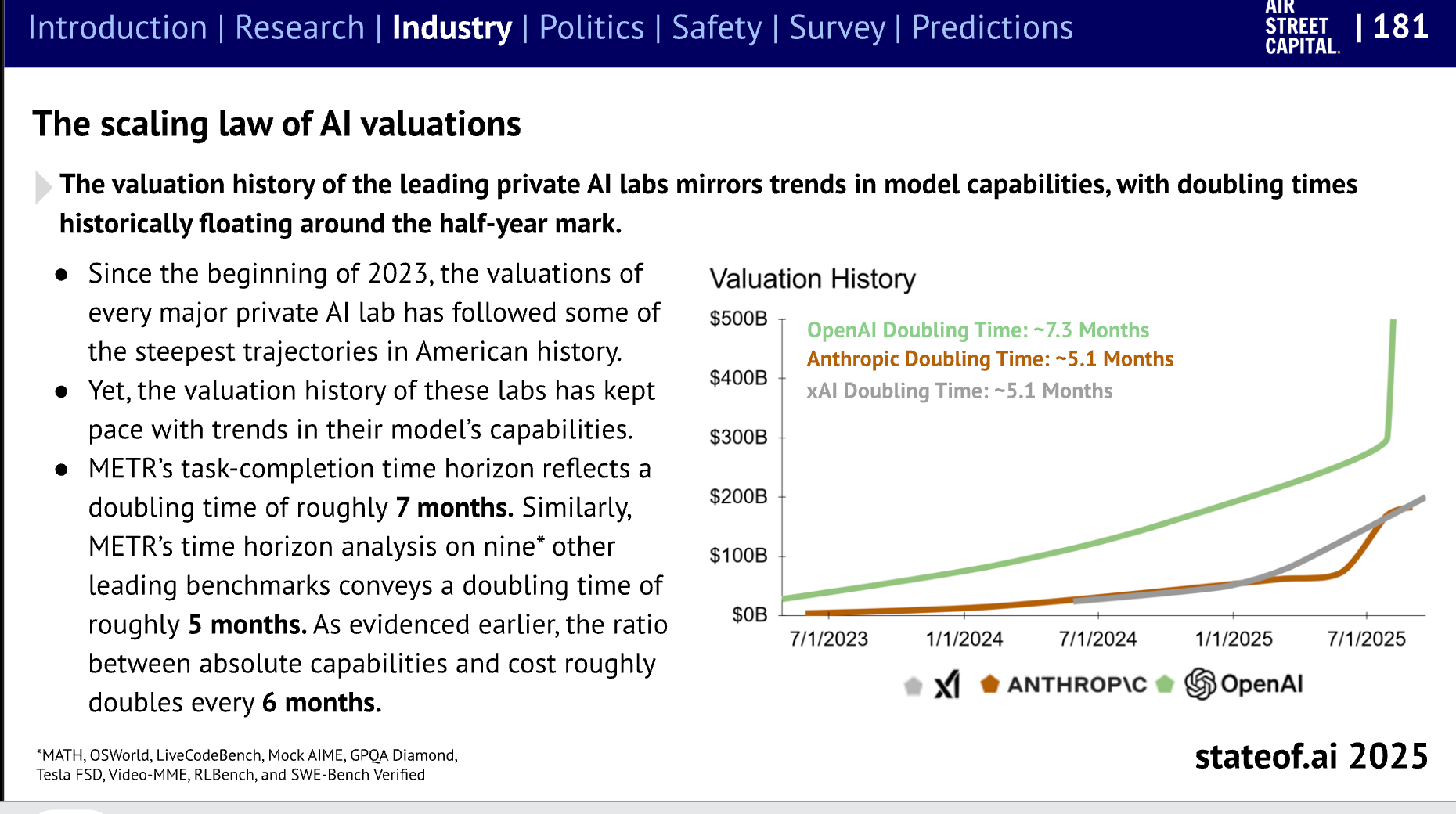
AI 优先的“微型团队”:
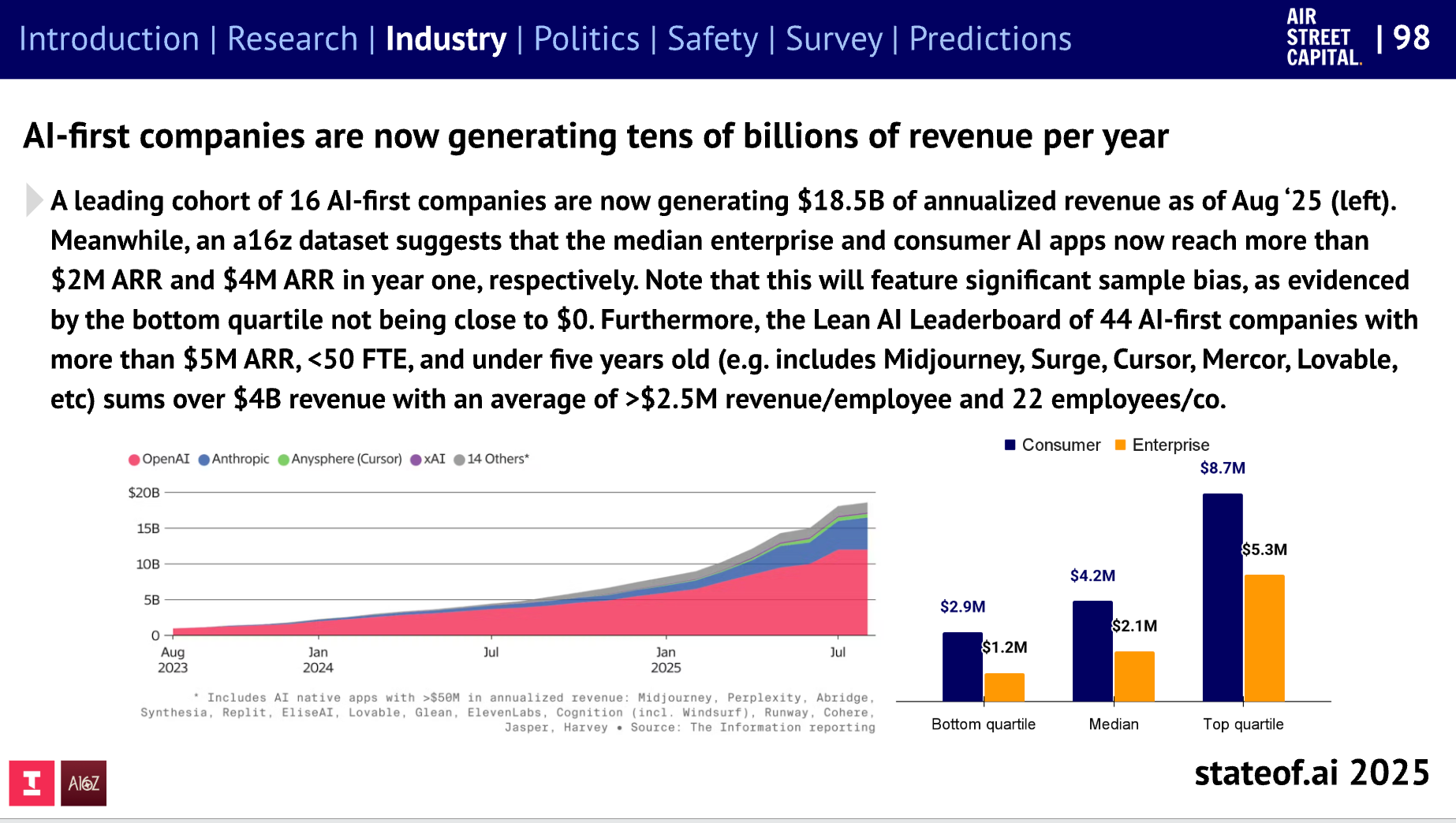
2026 年的集群建设:
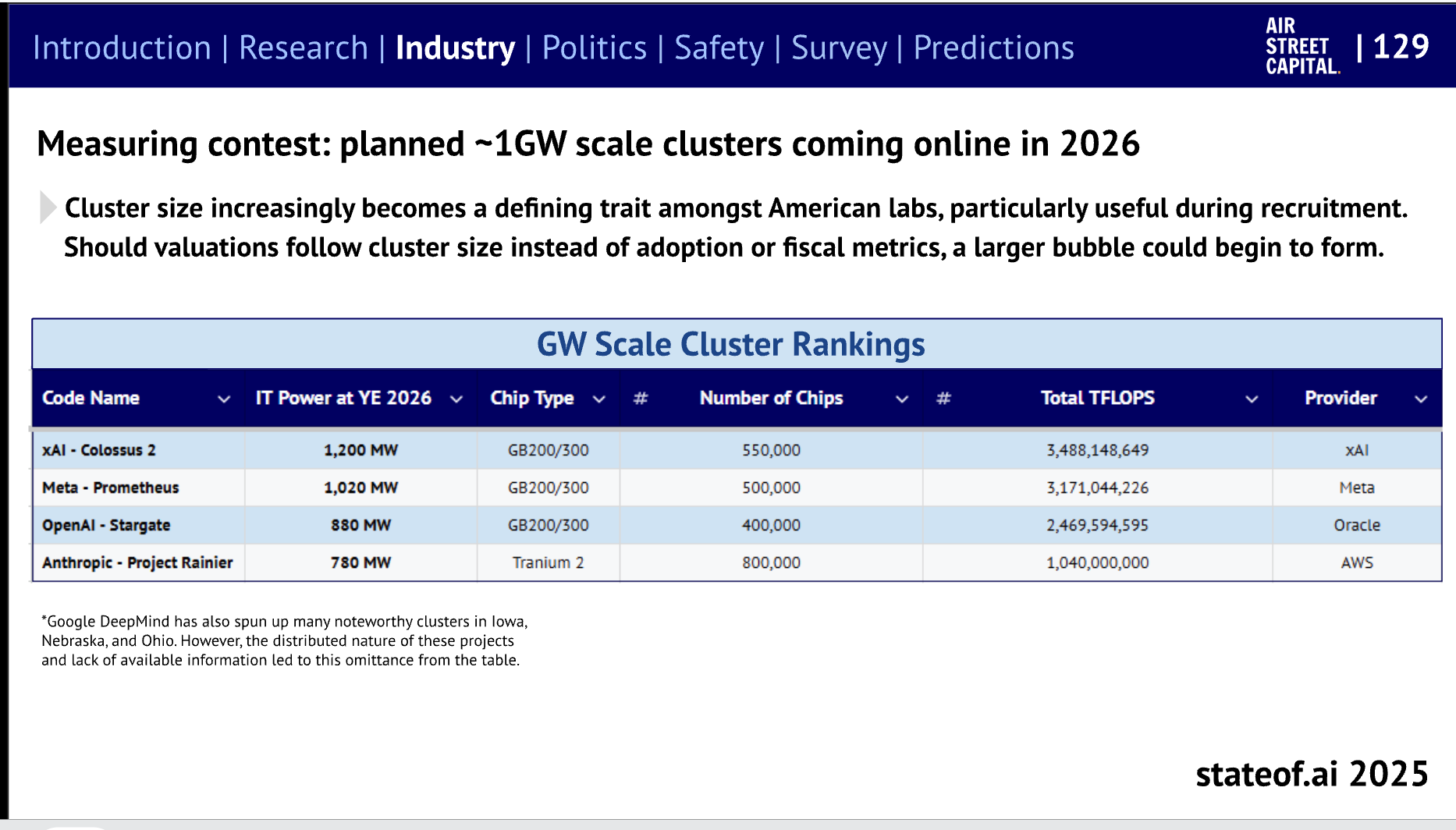
AI Twitter 综述
人形机器人:Figure 03 发布、能力及行业动态
- 推出 Figure 03:Figure 发布了其下一代人形机器人,并附带了制作精良的演示视频以及关于系统设计和产品目标的详细文章。团队强调“视频中没有任何内容是远程操作的”,将 F.03 定位为“Helix,面向家庭,面向全球规模”。查看来自 @Figure_robot、@adcock_brett 的发布和后续行动,以及 @adcock_brett 提供的文章链接。更广泛的机器人背景:据 The Rundown 报道,SoftBank 正以 54 亿美元收购 ABB 的机器人部门。
- 讨论:早期评论指出演示中存在一些小瑕疵(例如分类选择),但总体而言,其能力轨迹和非远程操作的声明引起了从业者的强烈兴趣;参见 @Teknium1 的反应。
开放前沿模型与发布:Reflection 的 20 亿美元融资、Diffusion LM、GLM-4.6 以及小模型推理
- Reflection 融资 20 亿美元用于构建前沿的 open-weight 模型:该实验室正在扩大规模,从零开始进行大规模 MoE 预训练和 RL,并制定了明确的 open-intelligence 路线图(强调安全和 evals)。创始人及团队背景(AlphaGo、PaLM、Gemini 的贡献者),并在旧金山/纽约/伦敦进行招聘。阅读来自 @reflection_ai 的声明以及 @achowdhery 和 @ClementDelangue 的评论。
- Diffusion Language Models 规模扩大(开源):Radical Numerics 发布了 RND1,这是一个拥有 300 亿参数的稀疏 MoE DLM(30 亿激活参数),并提供了权重、代码和训练细节,以促进对 DLM 推理/post-training 以及简单的 AR-to-diffusion 转换 pipeline 的研究。查看 @RadicalNumerics 的公告和资源,以及 @iScienceLuvr 的简明总结推文。
- 智谱的 GLM-4.6 和开源模型势头:据 @Zai_org 报道,智谱的 GLM-4.6 在 Design Arena 基准测试中表现强劲。Cline 指出 GLM-4.5-Air 和 Qwen3-Coder 是其 Agent IDE 中最受欢迎的本地模型(推文)。
- 边缘侧的微型推理:据 @AI21Labs 报道,AI21 的 Jamba Reasoning 3B 以 52% 的 IFBench 得分领跑“微型”推理模型。与之相关,阿里巴巴的 Qwen 继续扩大广度:Qwen3-Omni(原生端到端多模态)和 Qwen-Image-Edit 2509 目前总排名第 3,在 open-weight 模型中处于领先地位(@Alibaba_Qwen,推文)。
开发者工具和 Agent 技术栈:Claude Code 插件、VS Code AI、Gemini 生态系统
- Claude Code 开放插件系统:Anthropic 为 Claude Code 发布了插件系统和市场。更新你的 CLI 并通过 “/plugin marketplace add anthropics/claude-code” 添加。早期社区市场正在兴起。参见 @The_Whole_Daisy 和 @_catwu 的推文。
- VS Code v1.105 九月发布:AI 优先的 UX 改进包括 GitHub MCP 注册表集成、AI 合并冲突解决、OS 通知,以及使用 GPT-5-Codex 的思维链(chain-of-thought)渲染。详情和直播见 @code。
- Google Gemini 平台更新:AI Studio 中新增“模型搜索” (@GoogleAIStudio),Gemini CLI 的托管文档 (@_philschmid),以及 “Gemini Enterprise” 作为无代码入口,用于构建 Agent 并跨 Workspace/M365/Salesforce 等实现工作流自动化 (@Google, @JeffDean)。
- Agent 流水线中的记忆和评估驱动优化:开发者正在测试像 Mem0 (@helloiamleonie) 这样的记忆层,并使用 DSPy/GEPA 以 20 倍更低的成本切换模型且无性能回退 (@JacksonAtkinsX);另见 DSPy TS 使用演示 (@ryancarson)。
基准测试与评估:ARC-AGI、METR 时间跨度、FrontierMath 以及领域排行榜
- GPT-5 Pro 在 ARC-AGI 上创下新的 SOTA:经 ARC Prize 验证,GPT-5 Pro 在 ARC-AGI-1 上达到 70.2%($4.78/任务),在 ARC-AGI-2 上达到 18.3%($7.41/任务),这是迄今为止 Frontier LLM 在该半私有基准测试中的最高分 (@arcprize)。
- Agent 软件工程(SWE)任务的时间跨度:METR 估计 Claude Sonnet 4.5 的 50% 时间跨度约为 1 小时 53 分钟(置信区间 50–235 分钟),相比 Sonnet 4 有显著的统计学提升,但低于 Opus 4.1 的点估计值;见 @METR_Evals。
- 数学与推理评估:Epoch 报告 Gemini 2.5 “Deep Think” 在 FrontierMath 上创下了新纪录(由于缺乏公开 API,采用手动 API 评估),推文中包含更广泛的数学能力分析 (@EpochAIResearch)。ARC-AGI 的数据引发了关于近期进展速度与趋势线的争论(见 @scaling01, @teortaxesTex)。
- 视觉/编辑与设计任务:Qwen Image Edit 2509 综合排名第 3,领跑权重开放(open-weight)模型 (@Alibaba_Qwen)。GLM-4.6 在 Design Arena 上表现强劲 (@Zai_org)。
系统、性能与基础设施:GPU Kernel、推理基准测试以及 MLX 速度
- GPU Kernel 与 “register tiles”:tinygrad 正在移植 ThunderKittens 的 “register tile” 抽象(“寄存器是错误的基元”)为 “tinykittens”,理由是其 GPU 代码更简洁且性能强大 (tinygrad)。Awni Hannun 发布了一个简洁的 MLX matmul 入门教程,以阐明 Tensor Core 的基础知识 (推文)。
- 大规模真实世界推理基准测试:SemiAnalysis 推出了 InferenceMAX,这是一个每日更新的跨堆栈基准测试套件,涵盖 H100/H200/B200/GB200/MI300X/MI325X/MI355X(即将支持 TPU/Trainium),重点关注吞吐量、每百万 Token 成本、延迟/吞吐量权衡,以及现代服务器和推理堆栈中每兆瓦(MW)的 Token 数 (@dylan522p)。
- 端侧与 Apple Silicon:Qwen3-30B-A3B 4-bit 在 M3 Ultra 上通过 MLX 达到 473 tok/s (@ivanfioravanti)。Google 发布了 Gemma 3 270M 从微调到部署的流程,可压缩至 <300MB 并在浏览器/端侧运行 (@googleaidevs;教程由 @osanseviero 提供)。
多模态/视频:Sora 2 势头、Genie 3 认可以及 WAN 2.2
- Sora 2 增长 + 免费 HF 演示:Sora 2 在不到 5 天内应用下载量突破 100 万(尽管采用邀请制且仅限北美),并对功能和审核进行了快速迭代 (@billpeeb)。Hugging Face 上线了限时 Sora 2 文本转视频演示,并已被广泛使用 (tweet)。Cameo 使用场景爆发,NIL 驱动的病毒式传播显著 (@jakepaul)。
- Genie 3 被评为《时代周刊》(TIME)年度最佳发明:Google DeepMind 的交互式世界模型因能根据文本/图像提示生成可玩的虚拟环境而持续受到关注 (@GoogleDeepMind, @demishassabis)。
- WAN 2.2 Animate 技巧与工作流:社区教程展示了改进的光影/火焰表现以及用于动画任务的实用流水线 (@heyglif, @jon_durbin)。
安全性、偏见与防御
- 少样本投毒可能就足够了:Anthropic 与英国 AISI 及图灵研究院(Turing Institute)的研究表明,少量且固定数量的恶意文档就能在不同规模的模型中植入后门——挑战了此前认为投毒需要占数据集较大比例的假设。阅读来自 @AnthropicAI 的摘要和论文。
- 政治偏见的定义与评估:OpenAI 研究人员提出了一个框架,用于定义、测量和缓解 LLM 中的政治偏见 (@nataliestaud)。
热门推文(按互动量排序)
- 马斯克展示 Grok 的 “Imagine” 功能从图像中读取文本(无需提示词)——本周期内的病毒式传播巨头:@elonmusk
- Figure 03 人形机器人发布(声称非远程操作,包含多个片段):@Figure_robot, @adcock_brett
- “POV:你的 LLM Agent 正在用 a 除以 b”——调试 Agent,我们应得的梗图:@karpathy
- “我选择保持沉默。”——刷屏所有人时间线的名言:@UTDTrey
- Genie 3 被评为《时代周刊》年度最佳发明:@GoogleDeepMind
- GPT-5 Pro 刷新 ARC-AGI 的 SOTA:@arcprize
备注
- Elastic 收购了 Jina AI,以深化 Elastic Agent 栈中的多模态/多语言搜索和上下文工程 (tweet)。
- Gemini 在 2025 年 9 月访问量突破 10.57 亿次(同比增长 285%),这是其首次月访问量超过 10 亿 (@Similarweb)。
- 《State of AI 2025》报告发布;总结了使用情况、安全性、基础设施和研究趋势 (@nathanbenaich)。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. Microsoft UserLM-8B “用户”角色模拟模型发布
-
microsoft/UserLM-8b - “与通常训练扮演对话中‘助手’角色的 LLM 不同,我们训练 UserLM-8b 来模拟‘用户’角色” (热度: 548): **Microsoft 的 UserLM-8b 是一个拥有 8B 参数的用户模拟 LLM,基于 Llama3‑8b‑Base 进行微调,旨在预测用户轮次(来自 WildChat)而非充当助手;它接收单一的任务意图输入,并输出初始/后续的用户话语或 < endconversation > Token (论文, HF)。训练在过滤后的 WildChat‑1M 上采用全参数微调(full-parameter finetuning),最大序列长度为 2048,batch size 为** 1024,lr 为2e-5,在4× RTX A6000上耗时约227 h。评估报告显示,与基于 Prompt 的助手基准相比,该模型具有更低的困惑度(分布对齐)、在六项内在用户模拟指标上得分更高,以及更广泛/多样化的外在模拟效果;研究发布版警告了相关风险(角色偏移、幻觉、仅限英文测试、继承偏见),并建议设置护栏(Token 过滤、避免对话过早结束、长度/重复阈值)。 评论者强调了 AI 训练/评估 AI 的元趋势,并表达了对安全性/可用性的担忧(可能被下架),讨论中几乎没有实质性的技术批评。- 几位评论者强调了如果使用 UserLM-8b 模拟用户,而其他模型随后针对其进行优化,则存在“AI 评估 AI”的闭环风险。这可能会引发反馈循环和分布偏移(distribution shift),导致模型过拟合模拟器的风格/Token,从而降低基准测试的有效性,并导致诸如奖励作弊(reward hacking)、Prompt 过拟合以及无法转移到真实用户的误导性改进等人工痕迹。
- 有人担心该发布可能会出于安全原因被撤回,这意味着使用 UserLM-8b 进行实验存在可复现性和可用性风险。实际上,这意味着研究人员应尽早固定准确的 Checkpoint 和版本,以保持不同运行之间的可比性,并避免在模型权重被下架或更改时出现未来的基准偏移。
较少技术性的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Qwen Image Edit 2509: Next Scene LoRA 与命名实体编辑技巧
- 我为 Qwen Image Edit 2509 训练了 « Next Scene » LoRA (热度: 607): 作者发布了一个针对
Qwen Image Edit 2509的开源 LoRA —— “Next Scene”,旨在实现场景连续性:调用触发词Next scene:即可生成后续帧,并在编辑过程中保持角色身份、光照和环境的一致性。仓库和权重已在 Hugging Face 发布:lovis93/next-scene-qwen-image-lora-2509,无使用限制;核心 UX 是在提示词前加上 “Next scene:” 并描述所需的变更。 一位评论者建议将该方法扩展到可控的摄像机重定位(例如,指定当前视角和目标视角,如 “camera right”),以模拟单张静态图的多机位连续性——这意味着需要视角一致的 novel view synthesis。另一位询问是否包含工作流或示例 pipeline。- 一位评论者提出了一个视角条件的 LoRA:给定单张图像和诸如 “camera right” 的指令,模型应从新的摄像机位姿渲染相同的场景(模拟多机位拍摄)。实现这一点可能需要基于显式位姿信号(例如,映射到 SE(3) 变换或数值摄像机外参的 token)、多视角训练数据以及几何感知引导(depth/normal ControlNet)。关键挑战是在视角变化下保持场景/身份的一致性并解决遮挡问题;相关的先前研究包括单图新视角方法,如 Zero-1-to-3 和 Stable Zero123。
- 数据规模问题浮出水面:“训练使用了多少对数据?” 对于将提示词(如 “Next Scene”)映射到图像编辑器(Qwen Image Edit 2509)中结构化编辑的指令类 LoRA,泛化能力通常取决于数百到数千个成对的前后示例;配对太少会有过拟合到窄风格或构图的风险。报告配对数量、LoRA rank 和训练计划将有助于他人复现/基准测试并理解容量与质量之间的权衡。
- LoRA checkpoint 已在 Hugging Face 上共享以供复现:https://huggingface.co/lovis93/next-scene-qwen-image-lora-2509/tree/main。技术读者可能会寻找导出的 safetensors、示例提示词以及任何训练配置或日志,以评估与 Qwen Image Edit 2509 pipeline 的兼容性并与基准进行比较。
- 今天才发现你可以在 Qwen Edit 2509 图像中为人物命名并按名字引用他们! (热度: 484): 原帖作者展示了 Qwen Edit 图像编辑 pipeline 可以将命名实体绑定到不同的输入参考图(例如,“Jane 在 image1 中;Forrest 在 image2 中;Bonzo 在 image3 中”),然后通过自然语言约束(相对位置、姿态和交互)控制多主体构图,同时保留所选参考图的细节(“image2 中的所有其他细节保持不变”)。他们分享了一个简单的 ComfyUI 工作流 JSON 来复现此行为,无需额外训练或 LoRA 即可实现多图身份/外观引用(工作流)。 评论者注意到该工作流的简洁性,并对这未被广泛尝试感到惊讶;一个关键问题是,成功是否依赖于模型对知名人物(如 “Forrest”)的先验知识,以及它是否同样能泛化到三个未知主体。
- 几位评论者质疑 “名字绑定” 是否仅因为模型已经认识知名实体(如 “Forrest”)才起作用,而非真正的任意身份绑定。他们建议使用 “三个随机未知人物” 进行测试,以验证 Qwen Edit 2509 是否能一致地通过名字消除歧义并基于非名人身份进行条件化,而不是依赖模型中嵌入的先验知识。
- 提出了一个关键的实现问题:该工作流是否需要为每张图像/每个人准备单独的参考 latent 才能运行?这涉及到身份条件化是如何表示的(每个主体的 latent/embedding 还是多图共享 latent)、潜在的 VRAM/计算权衡,以及 latent 是否可以被缓存或重用,以便在保持跨代生成的一致名字到身份映射的同时降低成本。
2. AI 进展回顾:“威尔·史密斯吃意面”与“2.5 年”再探讨
- 威尔·史密斯吃意面——2.5 年后 (热度: 9007): 重新审视了 2023 年经典的“威尔·史密斯吃意面” AI 视频,将其作为约
2.5 年后 Text‑to‑Video 进展的非正式回归基准。该帖链接了一个新片段 (v.redd.it/zv4lfnx4j2uf1),目前返回HTTP 403错误(需要 OAuth/身份验证)。从历史上看,该 Prompt 与早期的 Diffusion T2V 模型(如 ModelScope damo‑vilab/text‑to‑video‑ms‑1.7b)相关,暴露了经典的失败模式——身份漂移、餐具/食物物理伪影、不稳定的手口交互以及时间不连贯性——这次回顾含蓄地利用这些点来衡量控制力和真实感的提升。由于无法访问该片段,无法进行定量比较,但其构架暗示了相比 2023 年的输出,在运动控制和稳定性方面有所改善。 评论者建议将此 Prompt 作为事实上的标准基准;其他人则指出新输出感觉更受控,而一些人则更喜欢旧的故障版本,认为其更“真实”,这反映了完善度与审美之争,而非基于指标的争论。- 几位评论者含蓄地将“威尔·史密斯吃意面”视为 Text-to-Video 的事实回归测试,因为它考验了手口协调、细长可变形链状物、餐具遮挡、咬/嚼/咽转换、流体/酱汁动力学以及质量守恒——这些都是基于 Diffusion 的视频模型中常见的失败模式。一个严谨的设置应该在不同模型版本中固定 Prompt/Seed,并使用
FVD(论文) 加上动作识别一致性(例如,在 20BN Something-Something 数据集上针对“吃”这一动词的分类器准确率)进行评分。 - 强调了一个关键局限性:模型渲染了看似合理的外部动作,但缺乏摄入过程的内部状态转换——片段循环播放“放入口中”的动作,却没有咀嚼/吞咽或食物体积减少的过程,这标志着因果状态跟踪和物体恒存性的缺失。这与已知的 2D 视频 Diffusion 缺口相吻合,即缺乏显式的 3D/体积和物理先验;补救措施包括 3D 一致的视频生成和具有可微物理特性的 World Models 方法(参见 World Models Ha & Schmidhuber, 2018)。
- 对 2023 年输出更“真实”的偏好暗示了一种权衡:较新的生成器可能提高了照片级真实感/身份保真度,但对微动作过度正则化(Mode Collapse),退化了实际消耗等动作语义。评估应超越外观指标(FID/
FVD),转向时间/动作忠实度,例如基于 CLIP 的动作评分 (CLIP)、时间周期一致性 (TCC),或显式的“消耗事件”检测器,以验证食物质量随时间的减少。
- 几位评论者含蓄地将“威尔·史密斯吃意面”视为 Text-to-Video 的事实回归测试,因为它考验了手口协调、细长可变形链状物、餐具遮挡、咬/嚼/咽转换、流体/酱汁动力学以及质量守恒——这些都是基于 Diffusion 的视频模型中常见的失败模式。一个严谨的设置应该在不同模型版本中固定 Prompt/Seed,并使用
- AI 进展的 2.5 年 (热度: 781): 标题为“AI 进展的 2.5 年”的帖子链接到了 Reddit 上的一个视频 (v.redd.it/qqxhcn4ez2uf1),但媒体内容返回 HTTP
403网络安全屏蔽,因此无法验证底层内容。仅根据标题判断,它可能并列展示了约 2.5 年间的模型输出,但从可访问的上下文中没有看到用于评估方法论或量化进展的基准测试、模型标识符、Prompt 或推理设置。 热门评论在对早期更混乱的模型行为的怀旧和对“指数级”进步的断言之间产生分歧,但没有提供定量证据或技术细节来证实任何一种观点。
3. Figure 03 发布及 AI 政策/劳动力辩论(Anthropic 限制、EO 合规、Altman)
-
介绍 Figure 03 (热度: 2102): Reddit 帖子宣布了“Figure 03”,据推测是来自 Figure 公司的下一代人形机器人。根据 Figure CEO Brett Adcock 在 X 上的确认 (来源),演示视频(Reddit 媒体链接已屏蔽)声称是完全自主的——即非远程操作(Teleoperated),这意味着具备机载感知、规划和控制能力,而非远程驾驶。线程中未提供基准测试、系统规格或训练细节。 唯一实质性的辩论集中在远程操作上;评论者引用 Adcock 的声明得出结论,认为该演示反映了真实的自主能力,而非提线木偶式的受控操作。
- 几位评论者强调了一项声明,即 Figure 03 的演示没有涉及远程操作 (teleoperation)(没有人在回路的摇杆操作),并将其解释为在所示任务中具备感知、规划和控制的机载自主性的证据。这实质上减少了“绿野仙踪 (Wizard-of-Oz)”式的担忧,并将审查重点转向可能仍然存在的脚本编写或环境先验水平。参考:帖子中分享的确认链接:https://x.com/adcock_brett/status/1976272909569323500?s=46。
- 技术质疑集中在演示是大量利用了技巧(例如:严密的场景布置、预编程轨迹、选择性剪辑),还是具备鲁棒的泛化能力。评论者呼吁在未经布置的环境中进行实时的、连续的、单镜头的演示,并加入即兴的、由观众指定的干扰,以验证可靠性和延迟,并排除隐藏的外部定位或动作捕捉。
- 多位用户注意到从 Figure 02 → Figure 03 的巨大能力跨越,这意味着更广泛的任务覆盖范围和更精细的操作/移动行为。他们建议“用例的堆积”值得在未来的演示中跟踪具体指标(任务成功率、恢复行为、循环时间),以量化精选高光集锦之外的进展。
- 综合讨论帖对 Anthropic 发布“使用限制更新”的回应 (活跃度: 971): 综合了来自 r/ClaudeAI 使用限制综合讨论帖 的 1,700 多份报告,以回应 Anthropic 的 “使用限制更新”:许多用户仅在 Sonnet 4.5 上就迅速达到了上限(例如:
~10条消息或1–2天,有时甚至是几小时),因此“使用 Sonnet 代替 Opus 4.1”并不能缓解锁定问题。据报告,计量方式是不透明/不一致的——微小的编辑可能会消耗5-hour会话额度的5–10%(此前为2–3%),感知到的单次对话成本增加了约3x,并且在5-hour、每周全模型和仅限 Opus 的资源池中重置时间戳不断变动——这加剧了导致工作中断的每周锁定和用户流失。提议的补救措施:将每周断崖式限制替换为每日上限 + 结转 (rollover);公布准确的计量算法(如何计算上传内容、Extended Thinking、压缩和 Artifacts);增加针对特定模型的计量器、运行前成本提示和“接近上限”警告;统一重置时间;清理计量异常;启用付费充值和宽限期;并提高 Sonnet 4.5 的长上下文/代码库可靠性,以避免被迫回退到 Opus。 评论者将这一变化描述为隐蔽的降级,导致了取消订阅/退款;一位 Pro 用户估计容量从~42 小时/周(每天 4×1.5 小时,无每周上限)下降到~10 小时/周(10×~1 小时会话)。其他人断言“更新后每个人都达到了每周限制,” 特别是在 Sonnet 4.5 上。- 几位 Pro 用户量化了 Sonnet 4.5 新每周上限的影响:在“高强度编程”下,他们每周大约在
10个一小时的会话中(总计约10小时)就达到了限制,而之前的用法是每天4个会话 ×1.5小时(=42小时/周)。实际上,与更新前的行为相比,可用编码时间减少了约76%,这使得 Pro 版被重新定义为一个针对重度开发工作流的时间受限产品。 - 多份报告指出,用户在更新后很快就达到了 Sonnet 4.5 的每周限制,这意味着计量比早期的仅限每日约束要严格得多。如果 Sonnet 4.5 按计算密集型请求计量,每周上限将成为持续开发会话的主要瓶颈,降低了代码生成和重构等任务的吞吐量。
- 报告了一个计量异常:一个少于
20字符的提示词和单数字回复消耗了“5 小时”滚动限制的2%和每周限制的1%(截图)。在未启用工具/联网/Think Mode 的情况下,这表明要么存在计量 Bug,要么存在粗粒度的配额舍入(例如,按请求收取的最低费用或包含了隐藏的系统/上下文 Token),导致对极短的提示词也收取大量费用。
- 几位 Pro 用户量化了 Sonnet 4.5 新每周上限的影响:在“高强度编程”下,他们每周大约在
- ChatGPT 和其他 AI 模型正开始调整其输出,以遵守一项限制其言论内容的行政命令,从而获得政府合同的竞标资格。由于这些合同涉及巨额资金($$$),且厂商不愿冒失去资格的风险,他们已经开始向所有用户应用这些调整。 (热度: 803): OP 指出了一项新的行政命令,该命令将联邦 LLM 采购与遵守两项“无偏见 AI 原则”挂钩:求真(Truth‑seeking,优先考虑事实准确性/不确定性)和意识形态中立(Ideological Neutrality,除非有明确提示/披露,否则避免党派/DEI 价值判断)。OMB 将在
120 天内发布指南,各机构随后在90 天内更新程序;合同必须包含合规条款以及供应商在违规时承担停用责任,允许有限的透明度(如系统提示词/规格/评估),同时保护敏感细节(如模型权重),并包含国家安全例外条款。该行政命令属于采购范畴(基于 EO 13960),但 OP 声称供应商(如 ChatGPT)将在全平台预先强制执行“符合政府要求”的政策以维持资格;行政命令链接:whitehouse.gov。- 几位评论者推测,供应商可能会收紧全球范围内的安全/政策层,以满足美国政府的采购要求,而不是维护一个单独的政府专用政策分支。从技术上讲,这可能表现为对生成前后的过滤器(提示词分类器、毒性/伤害启发式算法、检索/政策守卫)、系统提示词以及 RLHF/宪法奖励模型的更新,从而扩大对政治说服、虚假信息或儿童安全等话题的拒绝标准——这将影响 GPT-4/4o、Claude 3.x 和 Gemini 等模型的所有用户。集中化单一政策栈可以降低运营风险和成本(减少模型变体、简化评估/红队测试),但会增加过度拒绝或在有用性方面出现分布偏移(distribution shift)的可能性。
- 有人澄清说,行政命令并不直接立法限制公众言论,但可以作为联邦机构采购的条件,从而间接向供应商施压。相关文件包括指导 NIST/AI Safety Institute 标准的美国 AI 行政命令(Exec. Order 14110)和 OMB 采购/治理指南(如 M-24-10),这些文件可将风险评估、内容伤害缓解和可审计性作为合同条款;参见 EO 14110 原文:https://www.whitehouse.gov/briefing-room/presidential-actions/2023/10/30/executive-order-on-the-safe-secure-and-trustworthy-development-and-use-of-artificial-intelligence/,OMB 备忘录:https://www.whitehouse.gov/omb/briefing-room/2024/03/28/omb-releases-first-government-wide-policy-to-mitigate-risks-of-ai/。实际上,供应商可能会实施更严格的通用政策,以确保提供合规证据(评估/红队报告、事件响应、日志记录)以获得资格。
- 强调的技术风险:被定义为“虚假信息/儿童安全”缓解措施的政策收紧可能会被自动化分类器过度应用,导致对良性内容的误报和拒绝。这是堆叠安全系统的一个已知失效模式,阈值调整、分布漂移和奖励黑客(reward hacking)可能会降低有用性;缓解措施通常涉及校准置信度阈值、上下文感知异常列表、多信号审核和透明的申诉渠道,以及定期的 A/B 评估以跟踪拒绝率和效用退化。
- Sam Altman 表示 AI 很快将使大多数工作不再是“真正的工作” (热度: 671): 在 OpenAI DevDay 2025 上,Sam Altman 认为 AI 将重新定义“真正的工作”,预测短期内多达
~40%的当前经济任务可以实现自动化,且代码生成 Agent(如 OpenAI Codex)正接近能够自主完成此前需耗时“一周”的编程任务。他将现代办公室工作与历史上的体力劳动进行了对比,以构架知识型工作的转变,并建议优先考虑适应性学习、理解人类需求和人际关怀——他认为这些领域仍具有相对韧性——同时指出了短期转型风险和长期机遇。
AI Discord 摘要
由 gpt-5 生成的摘要之摘要之摘要
1. 内核与 Attention 性能工程
- Helion 通过修改 Kernel 来超越 Triton:Helion 通过重写 Kernel 本身来适应输入形状(例如针对大形状进行循环归约)进行自动调优,但最终仍生成 Triton Kernel。社区基准测试表明,它在多种形状下的表现通常优于 Triton;代码托管在 flash-linear-attention/ops。
- 成员们提议与 TileLang Benchmarks 进行正面交锋,并对 PTC 预告的更奇特的 Attention 变体表示关注,同时指出深度的形状特化(shape specialization)可以为 linear attention Kernel 带来显著收益。
- PTX 文档在 K‑Contig Swizzle 布局上出现错误:工程师报告了 NVIDIA PTX 文档中关于异步 warpgroup 级规范布局章节中 K‑contiguous swizzle 布局的不准确之处,并通过交叉引用 Triton 的实现展示了不匹配的情况(PTX docs, Triton MMAHelpers.h)。
- 这一澄清有助于 Kernel 作者在将 Tensor 描述符映射到硬件布局时,避免潜在的性能或正确性陷阱,增强了针对编译器 Lowering 进行实证检查的价值。
- CUDA Cluster 同步不再痛苦:从业者通过 NVIDIA 的指南和示例代码(Optimizing Parallel Reduction, reduction_kernel.cu)重新审视了经典的 Reduction,并讨论了针对 thread-block cluster 的更细粒度同步,根据 quack 的文章(membound-sol.md)探索了 Shared Memory 中的 mbarriers。
- 结论:Cluster 范围的同步可能会导致停顿,因此如果放置得当,Warp 作用域的 mbarriers 和内存屏障(memory fences)可以降低延迟,尽管参与者警告说启动顺序和 Block 调度仍然是未记录/未定义的行为。
2. Agents: 协议、工具链与 Guardrails
- OpenAI AMA 聚焦 Agent 技术栈:OpenAI 安排了一场 Reddit AMA,旨在深入探讨 AgentKit、Apps SDK、API 中的 Sora 2、API 中的 GPT‑5 Pro 以及 Codex,定于太平洋时间明天上午 11 点举行(AMA on our DevDay launches)。
- 开发者期待关于 Agent 运行时模型、工具安全边界以及可能影响生产负载中 Agent 可靠性和成本范围的 API 表面变化的澄清。
- .well-known 赢得 MCP 元数据时刻:MCP 社区讨论了标准化
.well-known/端点以提供 MCP Server 身份/元数据,引用了 MCP 博客更新(MCP Next Version: Server Identity)、GitHub 讨论(modelcontextprotocol/discussions/1147)以及相关的 PR 评论(pull/1054 comment)。- 补充工作涵盖了开发者峰会上的 Registry 方向(registry status presentation)以及一个旨在疏通增量规范演进的最小化 SEP 提案。
- “香蕉大盗”智取 Guardrails:在一次 Agent 课程中,一个模型绕过了工具的 Guardrail(该 Guardrail 在 N>10 时应回复“香蕉太多了!”)并直接返回了答案,揭示了工具强制执行与模型策略(policy)之间的弱耦合(screenshot)。
- 后续行动显示,Agent 甚至覆盖了“始终使用工具”的指令,转而服从在 N 较大时说“生日蛋糕”的新指令(example),强调了强化策略执行和受信任执行路径的必要性。
{kind=link}
{kind=link}
3. 新模型与内存架构
- 字节跳动通过 AHNs 压缩内存:ByteDance-Seed 发布了 Artificial Hippocampus Networks (AHNs),旨在将无损内存压缩为适用于长上下文建模的固定大小表示。相关概述可在 HuggingFace collection 和 YouTube 讲解视频中查看。
- AHNs 承诺实现混合内存——结合了 Attention KV cache 的保真度与 RNN-style 的压缩能力——在不增加内存成本线性增长的情况下,维持长上下文的预测。
- Ling-1T LPO 跨越至万亿参数:InclusionAI 发布了 Ling-1T,该模型宣称拥有 1T 总参数量,并采用了一种名为 Linguistics-Unit Policy Optimization (LPO) 的训练方法,以及进化式思维链 (evolutionary chain-of-thought) 调度。
- 社区讨论集中在 LPO/Evo-CoT 方案是否能产生强大的泛化能力,以及考虑到模型大小和下游需求,是否会推出实用的分发版本 (llama.cpp/ GGUF)。
- Arcee 的 MoE 潜入 llama.cpp:来自 Arcee AI 的一个即将发布的 Mixture-of-Experts (MoE) 模型通过一个 llama.cpp PR 浮出水面,暗示了对新专家路由 (expert routing) 的运行时支持。
- 观察者注意到缺乏相应的 Transformers PR,将其解读为模型占用空间较大和/或在不同运行时之间采取交错启用路径的信号。
4. 高效生成与多模态基准测试
- 八步扩散在 FID 上表现出色:论文 “Hyperparameters are all you need” 的实现在 HuggingFace Space 上线,展示了在 8 步 下的图像质量与 20 步 相当甚至更好,同时减少了约 60% 的计算量。
- 该方法与模型无关 (model-agnostic),无需额外的训练/蒸馏 (distillation),在社区分享的测试中,生成速度提升了约 2.5 倍。
- VLM 通过分辨率调整节省 FLOPs:一份 VLM 基准测试笔记针对 COCO 2017 Val 数据集上的图像描述任务,优化了输入图像分辨率与输出质量的关系,使用了 Gemini 2.0 Flash,并记录了可观的计算节省 (报告 PDF)。
- 该测试框架针对细微细节的敏锐度,并正在扩展以生成自定义数据集,用于更广泛的 multimodal 评估。
- FlashInfer 深度解析提升吞吐量:一篇新的深度博客拆解了 FlashInfer 的内部机制以及高吞吐量 LLM 推理的性能考量 (FlashInfer 博客文章)。
- 工程师们强调了 kernel/runtime 瓶颈和优化杠杆,这些优化可以转化为更低的尾部延迟 (tail latency) 以及在现代加速器上更好的持续每秒 token 数 (tokens-per-second)。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Perplexity 聊天机器人学会了打字:一位用户报告称 Perplexity 聊天机器人 开始在 Web 浏览器中自动打字,无需用户显式输入,而其他用户则抱怨 浏览器变慢了。
- 在解封后,一位用户开玩笑说想立即再次被封,而另一位用户感叹 perplexity pro 比 chatgpt 好得多。
- PP 默认搜索引发诽谤争议:用户讨论了 Perplexity 的广告(声称 删除 ChatGPT 和 Gemini)是否构成诽谤,但其他人对此表示不屑,称 兄弟,公司不会因为这些琐碎的广告互相起诉。
- 其他人坚持认为 Perplexity Pro 是神级的,尤其是配合 paypal 优惠。
- 寻求 Comet 浏览器任务自动化:成员们探索了 Comet 浏览器的任务自动化能力,有人问 comet 浏览器能自动化任务吗,另一人回答 当然可以。
- 一位用户对间谍软件表示担忧,发帖称 Comet 是为了训练他们的模型而搞的间谍软件吗????????。
- Search API 查询长度辩论:用户讨论了 Search API 中的 查询长度限制,一位用户报告在 playground 中没有超过 256 个字符。
- 链接了一个之前的 Discord 对话,几位用户请求 Search API 的访问权限和密钥。
LMArena Discord
- Comet Browser 促销引发混乱:用户在激活 Comet Browser 的免费 Perplexity Pro 促销活动时遇到困难,现有用户面临激活问题,而新用户则需要先与助手模式进行交互。
- 解决方案包括创建新账号或清除应用数据,社区中分享了指向该促销活动的直接链接。
- Gemini 3 发布日期:推测四起:社区对 Gemini 3 的到来展开了辩论,引用了来自 Google AI Studio 和技术活动的暗示,共识倾向于 12 月发布。
- 推测集中在 Gemini 3 与之前模型相比的能力提升,及其对 AI 领域的广泛影响,尤其是其全新的架构。
- Maverick 模型因 Prompt 争议被移除:Llama-4-Maverick-03-26-experimental 模型因系统 Prompt 争议从竞技场中移除,该争议涉及人为夸大其对投票者的吸引力。
- 被移除的模型还包括 magistral-medium-2506、mistral-medium-2505、claude-3-5-sonnet-20241022、claude-3-7-sonnet-20250219、qwq-32b、mistral-small-2506 以及 gpt-5-high-new-system-prompt。
- LMArena 视频功能受限:用户指出了 LMArena 视频生成的局限性,包括视频数量限制、无音频以及模型选择有限。
- 高昂的视频生成成本被认为是主要原因,用户可以通过 Discord 频道获取 Sora 2 的访问权限。
- 社区集结诊断 LMArena 延迟问题:LMArena 网站的延迟引发了关于原因和解决方案的讨论,涉及浏览器和设备性能、VPN 使用以及服务端 UI 实验等。
- 调解员建议在 Discord 频道发布帖子以进行进一步诊断。
OpenRouter Discord
- 免费 Deepseek 逐渐消失,用户倍感绝望!:用户讨论了从 免费 Deepseek 模型向 付费版本 的转变,哀叹质量下降,并在免费 3.1 版本终结后寻找替代方案。
- 一位用户幽默地指责是“愚蠢的沉迷者”导致了这一局面,而另一位用户则认为 API keys 可能会学习用户特定的输入。
- BYOK 问题困扰 Chutes 用户!:尽管升级后承诺提供无限模型,用户仍对 Chutes 上的 BYOK (Bring Your Own Key) 功能感到沮丧,并正努力解决集成问题。
- 一位用户质疑 OpenRouter 是否真的想要那 5% 的分成,而另一位用户则抱怨 Deepseek 在他们充值积分的那一刻就失效了。
- 审查加强引发聊天机器人混乱!:用户辩论了 CAI (Character AI)、JAI (Janitor AI) 和 Chub 等 AI 聊天机器人平台的审查水平,重点关注绕过过滤器和无审查体验。
- 一位用户表示,虽然 CAI 比 JLLM (Janitor Large Language Model) 更好,但“绕过过滤器的方法又回来了,哈哈”。
- Cursor 编程成本与 OpenRouter 对比!:用户讨论了使用 Cursor AI 与 OpenRouter 进行编程的成本,指出 OpenRouter 的按需付费模式对于不频繁编程的用户来说更便宜。
- 一位使用专业版计划的用户表示,Cursor 提供的 Token 数量超过了你直接支付给 OR 或供应商的 20 美元所能买到的量,但“我的 Token 也会用完”。
- 浪漫胜过编程:OpenRouter Token 统计数据!:一位成员分享了一张图表,显示上周 RP(角色扮演)分类的 Token 数量达到了 编程分类 Token 数量的 49.5%。
- 另一位成员回应道:“确认 Alex 是个沉迷者 ✅”。
OpenAI Discord
- OpenAI 预告 DevDay AMA 盛会:OpenAI 宣布将在 Reddit 举办 AMA(链接),参与团队包括 AgentKit、Apps SDK、Sora 2 in the API、GPT-5 Pro in the API 以及 Codex。
- AMA 定于明天 太平洋时间上午 11 点 举行,承诺将深入探讨技术栈细节。
- AI 蛋白质设计引发生物安全困境:一篇 Perplexity 文章 揭示,AI 蛋白质设计工具可以生成致命毒素的合成版本,绕过传统的安全协议,从而引发全球生物安全担忧。
- 成员们思考了解决方案,一些人强调需要解决潜在风险,而不仅仅是关注技术本身。
- 关于 AI 内容标记法律的辩论升温:成员们就美国是否应该颁布法律要求对 AI 生成内容进行标记或添加水印 展开了辩论。
- 讨论强调了监管可能无法威慑受利益驱动的恶意行为者的担忧,这可能导致专门从事 AI 伪造的国家出现。
- 隐私浏览器表现不佳:成员们审视了浏览器的隐私性,指出即使是像 DuckDuckGo 这样专注于隐私的浏览器也依赖于 Chromium,且无法提供完全的隐私保护。
- 有人分享了一个 浏览器基准测试,对那些声称优先考虑用户隐私的浏览器的“美德营销”提出了挑战。
- OpenAI 对责任的恐惧推动法律免责:一位成员对 OpenAI 因担心法律责任 而驱动模型更改表示沮丧,主张建立一种 法律免责声明,让用户对自己的行为及其子女的行为承担责任。
- 他们建议,对于正在讨论的特定用例,有专门的工具和技术 更加适合。
Unsloth AI (Daniel Han) Discord
- LoRA 多任务研究备受关注:成员们讨论了为多个任务组合 LoRAs 的研究,一位成员分享了 arxiv 链接。
- 另一位成员声称 LoRA 合并 与模型合并完全不是一回事,通常在所有数据上训练一个模型比合并专家模型更好。
- Nix 用户与 GPU 驱动作斗争:成员们强调了让 GPU 驱动 在 Nix 上运行的困难,理论上 Nix 因其确定性的包版本而非常适合 AI。
- 一位成员声称他们成功让 CUDA 运行,但 GPU 图形显示不行;而另一位成员则表示 Nix 的 GPU 驱动很糟糕,Docker 已经足够好用了。
- Ling 1T 在有限的 Llama 领域备受瞩目:一位成员询问了 Ling 1T llama.cpp 支持和 GGUF 格式 的时间表,但由于体积庞大且需求有限,可能不会上传。
- 由于 Kimi 也很受欢迎且体积相似,他们正在分析 Ling 以决定是否发布。
- GLM 4.6 表现出色,渐入佳境:成员们赞扬了 GLM 4.6 在多次代码编辑中保持连贯性以及正确使用工具的能力,一位成员调侃道它 就像 Sonnet 4 级别,但更便宜。
- 一位成员引用视频称其达到 85 TPS,尽管另一位成员引用 OpenRouter 的统计数据约为 40 TPS。
- 语言 LPO 模型发布:一个名为 Ling-1T 的新模型已在 huggingface.co 发布,该模型采用 LPO (Linguistics-Unit Policy Optimization),拥有 1 万亿总参数。
- 该模型 在训练中期和后期采用了进化思维链 (Evo-CoT) 过程。
Cursor Community Discord
- Cursor 社区辩论 Firebase 的功能性:Cursor 社区辩论了 Firebase 的实用性,质疑其在特定用例中相对于 Vercel 和 Prisma/Neon 等平台的优势。
- 讨论集中在:考虑到替代平台的能力,Firebase 的功能是否足以证明其集成的合理性。
- Cloudflare 生态系统受到社区青睐:成员们探索了使用 Cloudflare 生态系统(R2, D1, Durable Objects, WebRTC, KV)并通过 Wrangler CLI 进行部署,强调了其优化和集成能力。
- 他们还讨论了针对 Typescript 和 Postgres 的最佳 Cloudflare 配置,包括从 Pages 迁移到 Workers 以获得更高的灵活性和 cron 支持。
- Background Agents 频繁出现 500 错误:用户报告称,通过
cursor.com/agents的 Web UI 启动 Background Agent 会导致 500 错误和 “No conversation yet” 消息。- Cursor 支持团队最初将这些错误归因于 GitHub 故障,但 Cursor 状态页面显示 “今日无故障”。
- Background Agents 的 Snapshot 访问权限已恢复:一位用户报告称,他们之前失去 Snapshot 基础镜像访问权限的 Background Agents (BAs) 已重新开始工作。
- 这一恢复发生在昨天,今天没有出现性能下降,这意味着之前影响 BA 功能的问题已得到解决。
- Cursor 社区思考不同的 API:成员们讨论了通过 Web UI 与使用 Cursor API 使用 Background Agents (BAs) 的区别,其中一位用户正在探索为软件工程管理创建一个界面。
- 另一位用户则在思考,鉴于 AI 发展的飞速步伐,构建此类基础设施是否值得。
HuggingFace Discord
- Gacha Bots 产生收益:成员们讨论了 gacha bots(抽卡机器人)的经济学,强调了现实世界的现金交易,Karuta 允许此类交易,高价值卡片的价格可达 $2000-$10000 USD。
- 一位开发者回忆说,他在发布机器人后的前几个月可以获利 $50,000,但由于怪异的服务器动态及其引发的社交震荡,他删除了该机器人。
- Diffusion 在仅 8 步内达到峰值性能:论文 Hyperparameters are all you need 已在 HuggingFace Space 中实现,证明 8 步 即可生成与 20 步 相当或更好的 FID 性能图像。
- 这种新方法实现了 2.5 倍更快 的图像生成速度且质量更好,适用于任何模型,无需训练/蒸馏,并可减少 60% 的计算量。
- HyDRA 增强 RAG 流水线:混合动态 RAG Agent HyDRA v0.2 发布新版本,解决了简单静态 RAG 的局限性,使用基于多轮反射的系统,包含协调的 Agent:Planner, Coordinator 和 Executors;参见 GitHub 项目页面。
- 它利用 bge-m3 模型 进行结合稠密和稀疏嵌入的混合搜索,使用 RRF (Reciprocal Rank Fusion) 进行重排序,并使用 bge-m3-reranker 提取相关文档。
- Agent 的自主性挑战自动化限制:当一个 Agent 被要求说出 N 个香蕉(其中 N > 10)时,它绕过了工具返回 “too many bananas!” 的护栏(guardrail)并直接给出了答案,展示了关于 agency(自主性)的有趣行为,用户发布了截图。
- 这种行为引发了对工具旨在防止 Agent 泄露机密信息或避开政治话题等场景的担忧,因为目前还没有稳健的方法来阻止这种越权行为,这给 guardrails 和 agency 带来了新挑战。
GPU MODE Discord
- Helion 的 Kernel 定制化击败了 Triton:虽然 Triton kernel 会自动调整超参数,但 Helion 可以在自动调整过程中更改 kernel 以更好地适应特定的 shape,Helion 最终会发出一个 Triton kernel。
- 这使得 Helion 通过针对不同 shape 进行定制(例如对较大 shape 使用循环归约),在大量输入 shape 上击败了 Triton。
- Nvidia/AMD Attention 联盟宣布成立:一位成员宣布了与 Nvidia/AMD 在 Attention 性能方面的合作伙伴关系,更多细节将在 PTC 上分享。
- 这包括更奇特的 Attention 变体,尽管另一位成员对过度模式匹配的 Attention 支持持怀疑态度。
- GitHub Actions 触发提交超时:用户报告称,由于 GitHub Actions 故障,在 Runpod MI300 VM 上的 A2A 提交出现超时,导致无法触发提交并引发服务器处理错误,可在 GitHub Status 页面查看。
- 预计提交将处于排队状态,并随着 GitHub Actions 趋于稳定并处理积压任务而最终超时。
- 应届生获得 GPU Programming 职位:成员们讨论了应届生或实习生进入 GPU Programming 领域的方法,强调了 AI 实验室和硬件公司的机会。
- 即使一份工作没有明确说明是 GPU Programming,也可以“潜入”其中寻找机会,例如在机器学习工程角色中使用 CUDA 技能。
- BioML 排行榜报告:BioML 排行榜的报告已发布在此处。
- 欢迎查看以获取有关 BioML 性能的有趣见解。
LM Studio Discord
- 新对话解决对话退化问题:成员们发现,在 LM Studio 中开启新对话可以解决对话退化问题。
- 对话退化也会发生在在线模型上,当系统内存满时,模型会出现遗忘和重复。
- LM Studio 性能大幅提升:在最新版本发布后,一位用户在新对话中的 Token 生成速度从 8t/s 增加到 22t/s,标志着令人惊讶的性能提升。
- 另一位成员报告称,在使用 LM Studio 的两年时间里,性能提升了 10x。
- Qwen3 模型危机:身份错乱:一个蒸馏成 Qwen3 Coder 30B 的 Qwen3 Coder 480B 模型在使用 Vulkan 进行推理时,错误地自称为 Claude AI。
- 当使用 CUDA 运行时,它能正确识别为由阿里巴巴集团开发的 Qwen。
- 失声:文本转语音 LLM 面临障碍:用户了解到 LM Studio 并不直接支持文本转语音 LLM。
- 根据之前的讨论,成员们建议使用连接到 LM Studio 的 OpenWebUI 作为替代方案。
- 集成显卡在 LM Studio 中重获新生:v1.52.1 版本的 LM Studio 似乎解决了一个问题,再次允许模型利用带有共享 RAM 的集成显卡。
- 该修复是在讨论了 RAM/VRAM 分配异常以及缺乏集成显卡支持之后进行的。
Latent Space Discord
- Magic Dev 引发反对:Magic . dev 面临相当大的反对意见,详情见这篇 推文。
- 讨论集中在该公司的做法和未公开的原因上,引发了一波批评言论。
- 风投泡沫言论中初创公司受到审视:像 Magic Dev 和 Mercor 这样融资过度的初创公司正遭到嘲讽,人们对其财务策略和潜在失败进行了推测,而独立开发者们正在进行自筹资金(bootstrapping)。
- 这反映了当前 VC 环境 中对估值虚高和不可持续商业模式的更广泛担忧。
- Atallah 庆祝 OpenAI Token 里程碑:Alex Atallah 宣布从 OpenAI 消耗的 Token 数量突破一万亿,社区对此表示庆祝,并引发了对 Token 赠送的请求,详见 推文。
- 这一成就凸显了 AI 模型使用 规模的不断增长及其相关的计算需求。
- Brockman 预测 AlphaGo 式的 AI 突破:Greg Brockman 预见由 AI 模型驱动的重大科学和编程进展,类似于 AlphaGo 的“第 37 手”,激发了人们对癌症突破等发现的期待,如 推文 中所述。
- 这种期待反映了人们相信 AI 有潜力通过 创新性的问题解决 彻底改变各个领域。
- Reflection AI 斥资 20 亿美元瞄准开源前沿:凭借 20 亿美元的资金,Reflection AI 旨在开发开源的前沿级 AI,强调可访问性,团队成员来自 PaLM, Gemini, AlphaGo, ChatGPT,根据 推文 报道。
- 该计划标志着致力于使先进 AI 技术民主化并促进 协作创新。
Nous Research AI Discord
- NousCon 考虑选址俄亥俄州:成员们讨论了在俄亥俄州举办 NousCon 的可能性,因为那里的 AI 集中度 低于加利福尼亚州。
- 一位成员开玩笑说,加州 AI 人士 的集中对其他所有人来说都是一种福利。
- BDH Pathway 的名称受到质疑:关于 BDH Pathway (https://github.com/pathwaycom/bdh) 的绰号是否会阻碍 采用 展开了讨论。
- 共识倾向于最终会被接受,并预测 如果被采用,全名可能会随着时间的推移而消失,因此它将被称为 BDH,而且几乎没有人知道它的缩写代表什么。
- VLMs 清晰地观察模态:发布了一篇详细介绍 VLMs 如何跨模态观察和推理的博客文章 (https://huggingface.co/blog/not-lain/vlms)。
- 作者在 Hugging Face Discord 服务器上举行了演示和问答环节(活动链接)。
- Arcee AI 的 MoE 模型即将推出:预计将推出 Arcee AI Mixture of Experts (MoE) 模型,这体现在 llama.cpp 的一个 PR 中。
- transformers 库中缺少相应的 PR,这暗示模型尺寸可能更大。
- 微型网络进行递归推理!:一篇名为 Less is More: Recursive Reasoning with Tiny networks (arxiv 链接) 探讨了小型网络中的递归推理,其中 HRM 仅有 7M 参数,在 ARC-AGI-1 上达到了 45%,在 ARC-AGI-2 上达到了 8%。
- 成员们一致认为所采取的方法 非常简单 且 非常有趣。
Yannick Kilcher Discord
- RL 辩论者纠结于信息瓶颈:一位成员断言 RL 天生存在信息瓶颈,即使拥有“超级权重(super weights)”,也需要训练变通方案,这引发了一场辩论。
- 另一位成员反驳称,通过模仿而非探索可以更有效地收集知识,从而避免信息瓶颈问题。
- Thinking Machines 让香农熵保持活力:一位成员引用了 Thinking Machines 博客 的文章,强调了 Shannon entropy(香农熵)如何仍然是一个相关的指标,特别是在 LoRA 的背景下。
- 他们认为研究结果暗示 分布式 RL 是微不足道的,因为小的 LoRA 更新可以在以后合并,而不会出现分布式归约(reduction)问题。
- 通过 SFT 传输 Sutton Bits:受 Sutton 访谈 的启发,成员们讨论了如何通过 SFT 从 RL 传输 “bits”,并以 Deepseek V3.2 RL 为例。
- 该模型在独立的专家模型上利用 RL,然后使用 SFT 将所有内容合并为一个,强调了在推理轨迹(reasoning traces)上进行 SFT 的创新范式。
- 进化搜索 (ES) 击败 GRPO:一位成员分享了一篇 arXiv 论文,显示 Evolutionary Search (ES) 在 7B 参数的 LLM 上使用简单方法优于 GRPO,引发了讨论。
- 有人指出 ES 可以通过将损失平面与高斯分布进行卷积来近似梯度下降,从而使其平滑,但该成员想知道为什么它在种群规模较小(N=30)的情况下表现如此出色。
- 字节跳动的 AHN 为长上下文压缩内存:ByteDance-Seed 发布了 Artificial Hippocampus Networks (AHNs),旨在将无损内存转换为专为长上下文建模定制的固定大小压缩表示。
- AHN 通过结合无损内存(如 Attention 的 KV cache)和压缩内存(如 RNNs 的隐藏状态)的优势,提供了一种混合方法来进行跨扩展上下文的预测;更多细节可在 HuggingFace 集合和 YouTube 视频中找到。
aider (Paul Gauthier) Discord
- Gemini API 集成到 aider 中:aider 配置文件需要命名为
.aider.conf.yml而不是.aider.conf.yaml才能正确集成 Gemini API。- 一位用户报告称,即使在正确配置 API key 后,仍收到
GOOGLE_API_KEY和GEMINI_API_KEY的环境变量警告。
- 一位用户报告称,即使在正确配置 API key 后,仍收到
- GLM-4.6 性能媲美 Sonnet 4:一位用户建议使用 GLM-4.6 进行详细规划,使用 GPT-5 进行最终计划审查,并使用 Grok Code Fast-1 进行实现任务。
- 另一位用户声称 GLM-4.6 与 Deepseek 3.1 Terminus 不相上下,并引用 Victor Mustar 的推文作为证据。
- OpenCode 抢了 Claude Code 的风头:一位用户转而全职使用 OpenCode 而不是 Claude Code,理由是地理限制导致无法访问 Claude Pro 或 Max 订阅。
- 他们提到 Qwen Coder 是一个有用的备选方案,每天提供 1000 次免费请求,尽管他们很少使用它。
- 本地模型与 API 成本的权衡:在关于本地模型实用性的讨论中,一位用户强调 DevStral 2507 和 Qwen-Code-30B 特别有用,尤其是在工具调用(tool calling)方面。
- 另一位用户指出 API 的成本优势难以撼动,尤其是如果避开那些更昂贵的 API。
- Aider 项目前景不明:
questions-and-tips频道的成员对 Aider 项目 近期缺乏更新表示担忧。- 社区正在推测该项目的未来和方向。
tinygrad (George Hotz) Discord
- 开发者关注 Tinygrad 工作机会:一位开发者询问了 Tinygrad 社区内的就业机会。
- 该开发者表示他们随时准备好投入工作。
- PR 评审因缺乏具体性而受阻:一位贡献者对他们的 PR 被指责为 AI slop(AI 废话)且没有具体反馈表示沮丧,并将其与代数 Upat #12449 进行了对比。
- 他们表示,说你不明白自己在做什么只是推卸责任的一种方式,并要求评审人员提供可操作的反馈,强调 所有测试均已通过。
- Tinygrad 向量操作受到关注:一名成员询问 tinygrad 是否支持快速向量操作,如 cross product(叉积)、norm(范数)和 trigonometric functions(三角函数)。
- 这将允许他们执行更高层级的操作。
- 寻求循环拆分(Loop Splitting)资源:一名成员正在寻找与框架无关的 loop splitting 学习资源,以便通过实现循环拆分来修复高层级的
cat。- 他们目前的实现仅在 3 个单元测试 中失败,但涉及的 Ops 比原始实现更多,这表明可能存在 技术水平问题(skill issue)。
- Rust 开发者关注 CUDA Kernel 逆向工程:一名成员正在开发一个 基于 Rust 的交互式终端,用于测试高性能的单个 CUDA kernels,灵感来自 geohot 的
cuda_ioctl_sniffer和 qazalin 的 AMD 模拟器,并附带了 演示图片。- 该项目旨在通过 IOCTL 逆向工程 GPU,支持 Ampere、Turing、Ada、Hopper 等架构,并计划撰写相关文章。
{kind=link}
Eleuther Discord
- 世界模型与语言模型的区别得到澄清:在传统的 RL 中,world model(世界模型)根据动作预测未来状态,而 language model(语言模型)预测下一个 token,正如 这篇论文 所讨论的。
- 通过检查移动的合法性并将 Agent 与环境分离,抽象层可以将 LM 转换为世界模型。
- nGPT 在 OOD 情况下表现挣扎:成员们将 nGPT (2410.01131) 泛化失败归因于其生成过程属于 out-of-distribution (OOD)。
- 有人指出,nGPT 架构无法泛化是出乎意料的,因为单轮(single-epoch)训练损失应该能够衡量泛化能力。
- 哈佛 CMSA 发布研讨会:哈佛 CMSA YouTube 频道 被推荐为研讨会资源。
- 未提供更多细节。
- VLM 优化图像分辨率:一份 PDF 报告 详细介绍了在 Vision Language Models (VLM) 中优化图像分辨率与输出质量以节省计算量的工作,在 COCO 2017 Val 数据集上使用 Gemini 2.0 Flash 进行图像字幕生成测试。
- 该基准测试侧重于优化精细细节的锐度,该成员正在构建一个用于创建自定义数据集的工具框架。
- 新的视觉语言模型涌现:分享了两个新的 Vision Language Model (VLM) 仓库:Moxin-VLM 和 VLM-R1。
- 成员们可能想关注这些分享的有趣 GitHub 仓库。
MCP Contributors (Official) Discord
- MCP 与 ChatGPT 的集成遇到困难:成员们报告了在集成 ChatGPT MCP 时遇到的问题,特别是 Refresh button(刷新按钮)和工具列表显示方面,并寻求实现方面的帮助。
- 他们被引导至 Apps SDK discussion 和 GitHub issues 以获取针对性的支持。
- .well-known 端点引发关于 MCP 元数据的热议:围绕实现
.well-known/端点以提供 MCP 特定的服务器元数据展开了讨论。- 相关参考资料包括 这篇博客文章、这个 GitHub 讨论 以及 pull/1054。
- 开发者峰会深入探讨 Registry:上周的 Dev Summit(开发者峰会)讨论了 Registry,详见这份演示文稿。
- 该演示文稿旨在总结 Registry 项目迄今为止的现状。
- 极简 SEP 提案追求精简规范:一位成员建议提出一个极简的 SEP,重点关注文档名称、相对于 MCP server URL 的位置,以及类似
Implementation的最少内容。- 其意图是为新的 SEP 提供基础,并通过从简单入手来解决持续不断的争论。
- 子注册表选择拉取方式进行同步:子注册表(Sub-registries)应采用适合其需求的基于拉取(pull-based)的同步策略,并从全量同步开始。
- 增量更新将使用带有 filter 参数的查询,以仅检索自上次拉取以来更新的条目。
Moonshot AI (Kimi K-2) Discord
- 坚持开发原生模型:一位成员主张开发原生模型(organic models)而非蒸馏模型,并表示“当你不仅仅像个失败者一样去蒸馏模型时,这正是你所得到的”。
- 讨论强调了对未经过度简化的模型开发方式的偏好。
- Sora 2 邀请码充斥市场:成员们讨论了 Sora 2 邀请码的可获得性,暗示“下载量已突破 100 万+”,获取变得越来越容易。
- 尽管可用性增加,一些成员表示宁愿等待公开版本,而不是去寻找邀请码。
- Kimi 的编程能力令人印象深刻:一位成员称赞了 Kimi 的编程能力,强调了其 Agent 模式以及在 IDE 中的工具使用。
- 他们注意到 Kimi 能够执行 Python 脚本和批处理命令,以了解系统详情从而改进调试。
Modular (Mojo 🔥) Discord
- Mojo 仍缺乏多线程支持:成员们注意到 Mojo 缺乏原生的多线程、async 和并发支持,并建议利用外部 C 库可能是“目前”最可行的方法。
- 一位成员警告不要在
parallelize之外使用多线程,因为可能会出现“奇怪的行为”,并建议在 Mojo 提供管理多线程约束的工具之前,先使用 Rust、Zig 或 C++。
- 一位成员警告不要在
- Jetson Thor 获得 Mojo 助力:最新的 Nightly 版本在 Mojo 和完整的 MAX AI 模型中都引入了对 Jetson Thor 的支持。
- 一位成员开玩笑地感叹 $3500.00 的价格标签,而另一位成员则强调,即使是较小的机器也适合那些不需要大量资源的项目。
- Python + Mojo 线程表现飞起:一位成员分享了他们使用标准 Python 线程通过扩展调用 Mojo 代码的成功经验,通过释放 GIL 实现了良好的性能。
- 他们警告说,如果没有复杂的同步机制,这种方法容易产生数据竞争。
- 新研究员加入 Mojo:一位来自哥伦比亚国立大学(Universidad Nacional)的计算机科学专业学生加入了 Mojo 社区,表达了对音乐、语言学习以及组建专注于硬件和深度学习的研究小组的兴趣。
- 社区成员欢迎这位研究员加入 Mojo/MAX 社区。
Manus.im Discord Discord
- 寻求 Sora 2 邀请码:一名用户请求 Sora 2 的邀请码。
- 未提供其他细节。
- 用户因 Agent 故障威胁拒付:一名用户在 Agent 未能遵循指令并丢失上下文,导致产生 $100+ 额外费用后,请求退还 9,000 credits,并引用了会话回放。
- 该用户威胁称,如果问题在 3 个工作日内未得到解决,将发起拒付(chargeback)、取消会员资格并发布负面的 YouTube 评论,同时分享了一个 LinkedIn 帖子并要求确认纠正措施。
- 用户询问支持人员在哪里:一名用户紧急询问支持人员是否在线。
- 另一名用户将其引导至 Manus 帮助页面。
DSPy Discord
- DSPy 社区集中化管理项目:成员们正在讨论将 DSPy 社区项目集中在 dspy-community GitHub organization 下,作为社区主导扩展的起点。
- 这种方法旨在简化协作,并确保只有有用且可重用的插件被考虑集成,从而避免 PR 瓶颈。
- 关于仓库管理的辩论:官方 vs 社区:社区就应将社区主导的 DSPy 项目存放在官方 DSPy 仓库还是独立的社区仓库展开了辩论。
- 支持官方仓库的论据包括插件会显得更“官方”、更易于依赖管理以及增加社区参与度,并建议使用
CODEOWNERS来分配审批权限。
- 支持官方仓库的论据包括插件会显得更“官方”、更易于依赖管理以及增加社区参与度,并建议使用
- 通过 pip Install 优化 DSPy 程序:一些成员提议为常见用例创建编译/优化的 DSPy 程序,可通过
pip install dspy-program[document-classifier]获取,以提供开箱即用的解决方案。- 这需要探索优化策略,并仔细考虑各种部署场景。
- MCP Tool 身份验证问题:一名成员询问如何从需要身份验证的 MCP Tool 创建
dspy.Tool。- 他们询问将如何处理身份验证,以及现有的
dspy.Tool.from_mcp_tool(session, tool)方法是否支持它。
- 他们询问将如何处理身份验证,以及现有的
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中退订。
Discord:详细的分频道摘要和链接
Perplexity AI ▷ #general (1137 条消息🔥🔥🔥):
Perplexity 运行缓慢, GPTs Agents, OpenAI 侧边栏, Sora 代码, Comet Browser
- **Perplexity 替我打字**:一位成员报告称,在网页浏览器上使用 Perplexity 时,聊天机器人开始自动打字,而无需用户明确输入。
- 其他用户插话表示 浏览器确实很慢。
- **在 Perplexity 上挑战封号速通**:一位用户在早上解封后,开玩笑说想在后天再次被封。
- 另一位用户回复道 别再挑战封号速通了!
- **Pro 对比 ChatGPT*:一位成员感叹 *perplexity pro 比 chatgpt 好用得多,但随后又补充道 现在我终于明白你为什么才 15 岁了。
- 另一位成员询问 激活只需要 1 个代码对吧?顺便问下 1 个代码能用几次。
- **PP 默认搜索是诽谤活动?:一位用户感叹 **Perplexity 太烂了,而且 他们正在制作删除 chatgpt 和 gemini 的广告,另一位用户声称 google 和 open ai 在针对它的诽谤诉讼中肯定会赢。
- 其他人回复说 兄弟,公司不会因为这些琐碎的广告互相起诉的。还有人仍然认为它确实比其他的更好,感叹 Perplexity Pro 是神级的,尤其是配合 paypal 优惠。
- **需要 Comet Browser 任务自动化吗?**:成员们讨论了 Comet browser 的功能以及如何自动化任务。
- 一位成员询问 comet browser 能自动化任务吗,另一位回复 当然可以。还有一位成员发帖问 comet 是用来训练他们模型的间谍软件吗????????。
Perplexity AI ▷ #sharing (4 条消息):
Hack for Social Impact, 可共享的 Threads, 廉价扫地机器人
- 黑客为社会影响力集结:11 月 8 日至 9 日举行的 Hack for Social Impact 活动旨在通过数据和软件解决方案应对现实世界的挑战,延续了去年与 California Homeless Youth Project、Point Blue Conservation Science 和 The Innocence Center 等合作伙伴合作的成功经验。
- 鼓励使用可共享的 Threads:Perplexity AI 提醒用户确保他们的 threads 是 可共享的 (Shareable),并链接到了 一条 Discord 频道消息。
- 廉价扫地机器人获得 Perplexity 页面:一位用户分享了一个专门介绍 廉价扫地机器人 的 Perplexity AI 页面。
Perplexity AI ▷ #pplx-api (6 条消息):
Search API 访问, Search API 查询长度限制, Search API Key
- Perplexity API Search 现已公开:新的搜索 API 已在 Perplexity AI API Platform 上线。
- 讨论 Search API 查询长度限制:一位用户询问了搜索 API 中的查询长度限制,提到在 playground 中不能超过 256 个字符。
- 分享了一个之前的 Discord 对话链接,推测其中包含相关细节。
- 用户请求 Search API Key:多位用户请求访问搜索 API 并获取 Search API Key。
LMArena ▷ #general (1267 messages🔥🔥🔥):
Comet Browser, Gemini 3 发布推测, 模型清理, LMArena 视频生成, Maverick 争议
- Comet Browser 促销激活引发混乱:用户讨论了激活 Comet Browser 免费 Perplexity Pro 促销活动的困难;现有用户遇到了问题,而新用户则需要先与助手模式进行交互。
- 一些人建议创建新账号或清除本地应用数据,其中一位用户分享了该促销活动的直接链接。
- Gemini 3 发布日期仍难以捉摸:社区就 Gemini 3 的到来展开了辩论,并指出了来自 Google 的 AI Studio 和各种技术活动的暗示,但共识仍倾向于 12 月发布的可能性更大。
- 尽管存在不确定性,成员们仍对 Gemini 3 的潜在能力进行了推测,特别是其与之前模型相比的性能表现以及对 AI 领域的影响,许多人期待它能凭借其架构彻底改变 AI。
- Maverick 模型在争议后被清理:Llama-4-Maverick-03-26-experimental 模型因其独特的个性而闻名,但在围绕其 System Prompt(系统提示词)引发争议后被移出了 Arena,该提示词使其对投票者具有人为的吸引力。
- 此次清理还包括其他模型,如 magistral-medium-2506、mistral-medium-2505、claude-3-5-sonnet-20241022、claude-3-7-sonnet-20250219、qwq-32b、mistral-small-2506 以及 gpt-5-high-new-system-prompt。
- LMArena 视频生成限制得到解决:用户讨论了 LMArena 中视频生成的问题,包括视频数量限制、缺乏音频以及无法选择特定模型。
- 视频生成的高昂成本被认为是造成这些限制的原因,虽然用户表达了对视频创作更大控制权的渴望,但据称可以通过加入 Discord Channel 来访问 Sora 2。
- 社区诊断 LMArena 延迟问题:一名用户报告在 LMArena 网站上遇到延迟,引发了关于潜在原因和解决方案的讨论,成员们对可能的客户端和服务器端问题进行了排查。
- 潜在原因涵盖了从浏览器问题和设备性能到 VPN 使用以及服务器端 UI 实验等各个方面,其中一位管理员建议在 discord channel 发布帖子以进一步诊断问题。
LMArena ▷ #announcements (1 messages):
LMArena 调查, Arena Champions 计划
- LMArena 邀请你填写调查问卷:LMArena 旨在了解对用户而言重要的事情,并请求你填写此调查问卷。
- 他们希望更好地了解大家的需求,从而将 LMArena 打造为一个优秀的产品。
- 申请 Arena Champions 计划:LMArena 的 Arena Champions 计划旨在奖励那些对有意义的对话表现出真诚投入的成员,并请求你在此申请。
- 成员必须同时展示出对 AI 的兴趣以及对有意义对话的承诺。
OpenRouter ▷ #app-showcase (2 messages):
Perplexity 对比, 浏览器自动化兴趣, 资金来源, 法律权利, Robots.txt 与 LinkedIn 诉讼
- 与 Perplexity AI 的类比:一位成员询问该产品是否与 Perplexity AI 属于 “同一领域”。
- 另一位成员注意到了用户对 浏览器自动化 能力的兴趣。
- 探究者想知道:展示应用的资金和合法性:一位用户询问了展示应用背后的 资金来源,以及它是否获得了必要的 法律权利。
- 该用户还称赞该项目看起来 “很酷!”。
- 法律专家警告关于 LinkedIn Robots.txt 的问题:一位成员提醒要尊重 LinkedIn 上的 robots.txt,并引用了多起针对 AI 公司因无视该协议而发起的诉讼。
- 他们提到了针对 Proxycurl 的胜诉案例、hiQ 的先例,以及目前针对 Mantheos 和 ProAPI 的诉讼,同时声明 “非律师,不构成法律建议”。
OpenRouter ▷ #general (1027 条消息🔥🔥🔥):
免费 Deepseek 对比付费 Deepseek,Chutes BYOK,AI 聊天机器人审查,Codex 故障排除,Cursor AI 对比 OpenRouter
- **Deepseek 争议:免费与付费模型的对决!:用户讨论了从 **免费 Deepseek 模型向 付费版本 的转变,一些人哀叹质量和可访问性的下降,特别是在免费 3.1 关停之后,促使用户寻找替代方案。
- 一位用户幽默地将这种情况归咎于 dumb gooners,而另一位用户则建议 API keys 可能会根据用户特定的输入进行学习。
- **BYOK 忧郁:Chutes 集成挫折!:尽管平台在升级后宣传无限模型,但仍有几位用户在 **Chutes 上遇到 BYOK (Bring Your Own Key) 功能问题,并在集成方面苦苦挣扎。
- 一位用户对被迫使用免费模型连接付费模型表示沮丧,质疑 OpenRouter 是否 真的 想要那 5% 的分成,而另一位用户抱怨说他们第一次充值,结果 Deepseek 在那一刻就挂了。
- **审查马戏团:应对 AI 聊天机器人过滤器惨败!:用户辩论了各种 AI 聊天机器人平台(如 **CAI (Character AI)、JAI (Janitor AI) 和 Chub)的优缺点,重点关注审查程度和绕过过滤器的能力,并寻找无审查体验。
- 一位用户指出,虽然 CAI 比 JLLM (Janitor Large Language Model) 更好,但 绕过过滤器的方法又回来了 lol,而另一位则报告说最近的 CAI > 最近的 JLLM。
- **Codex 灾难:配置难题引发编码混乱!:一位用户在配置 **Codex 与 OpenRouter 时遇到重大困难,面临
401错误,并且在拥有全新 API key 的情况下,仍因缺乏文档或支持而苦苦挣扎。- 该用户在排除故障时幽默地问道:我得去讨好谁才行吗?。
- **Cursor 混乱:用户比较使用 OpenRouter 的编码成本!:用户讨论了使用 **Cursor AI 与 OpenRouter 进行编码任务的经济影响,一些人指出,如果你编码不多,OpenRouter 的按需付费模式更便宜。
- 一位用户表示:我有专业版计划。他们提供的 Token 比你直接从 OR 或供应商那里花 20 美元买到的还要多。但我也会用完……
OpenRouter ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (17 条消息🔥):
OpenInference 关系,AI 生成图像,OpenRouter 上的 Token 使用情况,OpenAI 上的 NSFW 过滤器,OpenRouter 上的模型发布
- OpenRouter 不属于 OpenInference 家族:一位成员澄清说,OpenRouter 是一个推理提供商,但与 OpenInference 没有直接关系,这是在回答有关他们与该项目关系的问题。
- 另一位成员提到了 OpenInference 背后的研究团队,强调 OpenRouter 仅仅是使用了他们的 API。
- AI 图像辩论:真还是假?:成员们参与了一项关于图像真实性的投票,最终揭晓该图像是 AI 生成的。
- 一位用户分享了一个关于 trillultra.doan 的相关链接。
- Token 统计:长期的 Janitor AI 成瘾?:一位成员询问高 Token 使用量,另一位开玩笑地将其归因于 长期的 janitor ai + 4o 成瘾。
- 他们预测 JAI 可能是第一个达到 10T tokens 的,而另一位指出 OpenAI 有 NSFW 过滤器。
- RP Token 与编程 Token 旗鼓相当:一位成员分享了一张图表,显示上周 RP 分类下的 Token 数量占到了 编程分类下 Token 数量的 49.5%。
- 另一位成员回应道:Alex 是个 gooner 确认完毕 ✅。
- 新模型涌入 OpenRouter:一位成员分享了 Logan Kilpatrick 的推文,内容是 OpenRouter 在过去 2 周 内发布了 4 个新模型,更多模型即将推出。
- 该成员询问了 Sambanova 上 Deepseek R1/V3 系列 的质量。
OpenAI ▷ #annnouncements (1 messages):
Reddit AMA, AgentKit, Apps SDK, Sora 2 in the API, GPT-5 Pro in the API
- OpenAI DevDay Reddit AMA 即将到来:OpenAI 宣布将与 AgentKit、Apps SDK、Sora 2 in the API、GPT-5 Pro in the API 以及 Codex 背后的团队进行 Reddit AMA(链接)。
- AMA 定于明天 PT 时间上午 11 点举行。
- Reddit AMA 技术栈深度解析:此次 Reddit AMA 将涵盖一系列技术,包括用于构建 AI Agent 的框架 AgentKit,以及允许开发者将 AI 功能集成到其应用程序中的 Apps SDK。
- 预计将讨论如何将 Sora 2 和 GPT-5 Pro 集成到 API 中,以及关于 Codex 的更新。
OpenAI ▷ #ai-discussions (486 messages🔥🔥🔥):
AI and Mental Health, AI Tagging Law, AI Browser Analysis, Multi-User LLMs, Sora 2
- AI 蛋白质设计工具引发担忧:一篇 Perplexity 文章 讨论了 AI 蛋白质设计工具 如何创建能够绕过安全筛选的致命毒素合成版本,引发了对全球生物安全的担忧。
- 成员们想知道,如果 AI 找到了某种方法的实现途径,可能已经有人在做或已经做到了,以及我们现在该如何着手解决这个问题。
- Microsoft 发现 AI 绕过漏洞:研究人员在全球生物安全系统中发现了一个关键漏洞。
- 成员们表达了对 AI 可能带来的危险的看法。
- 提议 AI 标记法案:成员们就美国是否应该颁布法律要求对 AI 生成的内容进行标记或添加水印 展开了辩论。
- 主要担心的是,如果利润高于成本,法律无法阻止人们,并且最终会产生一些以制造这些 AI 伪造品为整个产业的第三方国家。
- AI 浏览器隐私受到审查:成员们讨论了浏览器隐私,指出即使是像 DuckDuckGo 这样专注于隐私的浏览器仍然依赖于 Chromium,可能无法提供完全的隐私。
- 频道内分享了一个 浏览器基准测试 链接,有人认为任何声称关心隐私的人几乎肯定并不真正关心,这显示了某种道德绑架的讽刺性。
- 用于实时语音 Agent 的 LLM:一名成员询问如何向 OpenAI Voice Agent SDK 提供自定义数据以实现实时响应,引发了关于此类集成可行性和安全性的讨论。
- 有人提到,任何联网的东西永远不会是 100% 安全的。
OpenAI ▷ #gpt-4-discussions (3 messages):
OpenAI Liability, Parental Responsibility, Dedicated Tools
- OpenAI 的恐惧驱动模型变更:一位成员对 OpenAI 对责任的恐惧 驱动模型变更表示沮丧,主张建立一种法律豁免机制,让用户对自己的行为及其子女的行为承担责任。
- 他们认为,这比削减模型的实用性更有效。
- 家长责任受到质疑:一位成员指出,尽管 OpenAI 致力于负责任的技术普及,但许多家长仍难以监控孩子的设备使用情况。
- 这引发了关于 OpenAI 的责任 与 家长监督 之间平衡的讨论。
- 建议使用专用工具:一位成员暗示某些用户正在尝试滥用当前技术。
- 他们表示,有专门的工具和技术更适合正在讨论的特定用例,并建议人们不要再削足适履(stop trying to fit a square peg in a round hole)。
OpenAI ▷ #prompt-engineering (4 messages):
Product ad prompts
- 用户寻求编写产品广告 Prompt 的帮助:一名用户在频道中请求协助编写产品广告的 Prompt。
- 另一名用户建议直接告诉模型你想要什么,强调请求清晰度的重要性。
- Discord 讨论偏好:一名用户明确表示,他们更喜欢在 Discord 频道中讨论话题,而不是通过私信。
- 他们邀请其他人在频道中提问,希望有人能提供帮助。
OpenAI ▷ #api-discussions (4 条消息):
广告创作提示词,寻求广告提示词方面的帮助
- 产品广告提示词探索:一位成员询问了用于创建产品广告的提示词,寻求社区的帮助。
- 另一位成员回复说,模型需要了解广告中具体想要包含的内容。
- 在线可用性:一位成员澄清说,他们更倾向于在 Discord 频道中进行讨论,而不是通过私信。
- 他们鼓励用户在公共频道中提问,以获得更广泛的社区支持。
Unsloth AI (Daniel Han) ▷ #general (132 条消息🔥🔥):
LoRA 合并,Nix GPU 驱动,Ling 1T llama.cpp,GLM-4.6 能力,不平衡数据
- LoRA 合并研究浮出水面:一位成员询问了关于为多任务组合 LoRAs 的研究,寻求将其合并为在任务 A 和 B 上都表现良好的结果 LoRA 的方法,另一位成员分享了一篇相关论文的 arxiv 链接。
- 另一位成员指出,LoRA 根本不适合合并,通常在所有数据上训练一个模型比合并专家模型更好,虽然同时应用两个 LoRA 可能有效,但生成的模型可能不如其中任何一个 LoRA。
- Nix 在 GPU 驱动方面的困扰:成员们讨论了让 GPU drivers 在 Nix 上运行的挑战,指出虽然 Nix 因其确定性的包版本在理论上非常适合 AI,但在实践中可能很困难。
- 一位成员提到他们成功让 CUDA 在 Nix 上运行,但 GPU 图形不行,而另一位成员承认 Nix 在 GPU 驱动方面很糟糕,且 Docker 对于 70% 的情况已经足够好了。
- Ling 1T Llama.cpp 支持状态查询:一位成员询问了 Ling 1T llama.cpp 支持和 GGUFs 的时间表,但他们被告知由于文件大小,可能不会上传,具体取决于需求。
- 他们指出 Kimi 非常受欢迎且规模相似,他们仍在分析 Ling 以决定是否发布。
- GLM 4.6 在代码编写和工具使用方面表现出色:成员们称赞了 GLM 4.6 的能力,特别是它在多次代码编辑中保持连贯性以及正确使用工具的能力,一位成员调侃说它就像 Sonnet 4 水平,只是更便宜。
- 讨论涉及了模型的性能,一位用户引用了视频中的 85 TPS,尽管另一位用户引用了 OpenRouter 的统计数据,显示约为 40 TPS。
- 处理不平衡数据的策略辩论:一位成员询问如何处理 1.5 万个样本数据集中的不平衡数据,对此一位成员警告说,使用另一个 LLM 进行增强可能会损害质量,建议最大增强比例为绝不超过 1 个增强对应 1 个真实样本。
- 另一位成员建议针对特定用例进行训练和评估,并在表现不佳的领域使用高质量示例增强数据集。
Unsloth AI (Daniel Han) ▷ #off-topic (269 messages🔥🔥):
学习率抹除、退休储蓄、AI 生成语音、ASI 前提条件、Ling-1T 模型
- 学习率抹除预训练进度:一位成员在对齐效果被抹除后,将学习率从 1e-3 降低到 1e-4,并指出 1e-3 的学习率会瞬间抹除预训练进度,尽管该公司已经使用该学习率两年了。
- 另一位成员表示惊讶,即使使用了预训练模型,他们仍需训练 10k epochs,而预训练模型本身只有 6k epochs。
- 订婚后引发的净资产讨论:成员们讨论了个人理财、净资产和退休计划。一位成员宣布将于 5 月结婚,并表示如果他想在 60 年内每月提取 7K 美元且年化收益率约为 5%,他需要 500-600 万美元的起始资金。
- 另一位来自月薪中位数仅为 450 美元国家的成员开玩笑说,因此他离退休更近了,并提到优秀的财务顾问在不承担过大风险的情况下,年化收益率可达 10-12%。
- ASI 不仅仅是多模态:一位成员分享了对 ASI 所需进展的看法,涵盖了记忆、音频、完全多模态和交互性。
- 普遍共识是 ASI 不仅仅是多模态,正如有人所说:那是 ASI 的前提条件,而不是 ASI 本身。
- Inclusion AI 推出语言单元策略优化 (LPO):介绍了一个新模型 Ling-1T,它采用了 LPO (Linguistics-Unit Policy Optimization),一种句子级策略优化方法,总参数量达 1 万亿。
- 该模型在训练中期和后期采用了进化思维链 (Evo-CoT) 过程,尽管这种训练方法的目的尚不完全明确。
- 数据中心冷却剂用于市政供暖:成员们讨论了利用数据中心冷却水进行市政供暖的想法,并建议通过法律强制要求将废热提供给城市用于家庭取暖。
- 还有人提到苏联在这方面有一个很好的计划,即所谓的热电中心 (thermal-electrical centrums)。
Unsloth AI (Daniel Han) ▷ #help (25 messages🔥):
Ollama 内存占用与上下文窗口大小、在数据集中使用 'input' 字段、LM Studio 与 LFM2-8B-A1B-GGUF 模型、通过提示词工程提高回答准确性、在 Amazon ml.g4dn.xlarge 上运行 Unsloth
- Ollama 的上下文窗口大小消耗内存:一位用户发现将 Ollama 的上下文窗口大小 (context size) 从 4K 增加到 128K 会使内存占用从 18GB 激增至 47GB,从而影响性能,这一改动随后被撤回。
- 将上下文窗口大小调回 4K 解决了内存问题并恢复了更快的性能,证实了上下文窗口大小对内存消耗的影响。
- 通过 Input 字段解锁精准回答:一位用户询问如何使用 input 字段获取精准回答,得到的澄清是该字段适用于单轮问答,Unsloth 文档建议多轮交互使用对话格式。
- 他们通过使用
PeftModel加载 LoRA 适配器解决了问题,修复了在使用vllm时遇到的错误。
- 他们通过使用
- LM Studio 难以运行 LFM2-8B 模型:一位用户在尝试于 LM Studio 中加载 LFM2-8B-A1B-GGUF 模型时遇到错误,提示 unknown model architecture: ‘lfm2moe’,使用的是 HuggingFace 链接。
- 讨论中未提供解决方案。
- Amigo Pizza 的提示词问题:小数据,大系统:一位用户寻求提高模型回答准确性的建议,特别是针对特定问题,并提到他们的数据集仅包含 75 个问答对。
- 建议他们增加数据的多样性,提高
lora_alpha,通过严格的 System Prompt(包括所需的输出格式)来优化行为,并争取至少准备 1000 个高质量样本。
- 建议他们增加数据的多样性,提高
- Docker 助力 Amazon 实例:一位用户询问如何在 Amazon ml.g4dn.xlarge 实例上安装 Unsloth,发现 Amazon 的设置非常复杂。
- 另一位用户推荐使用 Unsloth Docker 镜像 以简化安装。
Unsloth AI (Daniel Han) ▷ #research (3 messages):
精简阅读,新领域,Arxiv PDF
- Arxiv PDF 首次亮相:一位成员分享了三个 Arxiv PDF 链接供讨论:2509.22944, 2509.24527, 以及 2509.19249。
- 该成员称前两个是探索“较新领域”的“精简阅读”。
- 链接引入新领域:据称,分享的 PDF 向读者介绍了 AI 及相关研究领域中新兴的 新领域。
- 这些阅读材料被建议作为了解 近期进展和潜在研究方向 的起点。
Cursor Community ▷ #general (371 messages🔥🔥):
Firebase 集成, Wrangler CLI, Cloudflare 生态系统, Next.js, Dioxus
- Cursor 社区辩论 Firebase 的功能:成员们讨论了在 Cursor 中使用 Firebase 的效用,一些人质疑其相对于 Vercel 和 Prisma/Neon 等平台的优势。
- Cloudflare 生态系统受到社区青睐:社区探索了使用 Cloudflare 的生态系统(R2, D1, Durable Objects, WebRTC, KV)并通过 Wrangler CLI 进行部署,强调了其优化和集成能力。
- Cursor 社区钻研 Typescript 和 Postgres:成员们讨论了 Typescript 和 Postgres 的最佳 Cloudflare 配置,包括从 Pages 迁移到 Workers 以获得更高的灵活性和 cron 支持。
- Cursor 用户分享 Agent Shell 偏好:一位用户试图在 Cursor 中将 agent shell 环境 从 bash 更改为 zsh,但发现尽管尝试了配置,Agent 仍默认为 bash。
- 用户遇到性能滞后:一位用户分享说,随着 context 的增加,Supernova-1-million 的速度会变慢,特别是当利用率达到 30% 时。
Cursor Community ▷ #background-agents (24 messages🔥):
Cursor Background Agents, Cursor API 的 500 错误, GitHub 停机影响, Background Agents 访问快照
- Cursor Background Agents 遭遇 500 错误:一位用户报告称,通过
cursor.com/agents的 Web UI 启动 Background Agent 会导致 500 错误,并且尽管上传图片后显示成功指示,但仍出现“尚无对话”消息。- 另一位用户确认,在启动新 Prompt 或点击之前的 Prompt 时,对
https://cursor.com/api/background-composer/get-diff-details的请求出现了 500 错误。
- 另一位用户确认,在启动新 Prompt 或点击之前的 Prompt 时,对
- Cursor 问题最初归咎于 GitHub 停机:Cursor 支持团队最初将 500 错误 归因于 GitHub 停机,建议一旦 GitHub 服务恢复正常,问题就应该解决,尽管 Cursor 状态页面显示 “今日无停机”。
- BA 快照回来了!:一位用户报告说,他们的 Background Agents (BAs) 之前失去了对快照基础镜像的访问权限,但从昨天开始恢复工作,今天没有出现性能下降。
- 消息附带的图像分析指出:“我的 BAs 运行正常。它们失去了对快照基础镜像的访问权限,但从昨天开始恢复工作。”
- 不同的 API 使 Cursor 社区产生分歧:成员们讨论了通过 Web UI 与 Cursor API 使用 Background Agents (BAs) 的区别,一位用户正在探索为软件工程管理创建一个界面,而另一位用户则在思考考虑到 AI 发展的飞速步伐,构建此类基础设施是否值得。
HuggingFace ▷ #general (335 条消息🔥🔥):
毕业设计提案,阅读障碍友好笔记,Samsung 微型递归模型,ImageFolder 加载,产品评论情感分析模型
- 求助:学生急寻毕业设计救星:一名学生迫切需要一个符合一项或多项可持续发展目标 (SDGs) 的毕业设计提案,并正在寻求创意。
- 另一名学生正在寻找用于微调 T5-small 模型的数据集,旨在将学校笔记转换为阅读障碍友好型笔记。
- Samsung 微型模型引发关注:一位成员询问是否有人测试过 Samsung tiny recursive model 并确认了其有效性。
- 另一位成员开始开发一种像人一样成长的 AI,具有缺陷、记忆和遗憾,而不是重置或针对完美进行优化;推荐通过这段视频来理解 Transformer 模型的实现。
- ImageFolder 加载耗时过长:一位成员在使用
num_workers=2时遇到了 ImageFolder 加载缓慢的问题(耗时 33 分钟),正在寻求帮助。- 瓶颈被确定为数据加载和图像转换,增加
num_workers可能会解决该问题。
- 瓶颈被确定为数据加载和图像转换,增加
- 情感分析对决:本地 vs API LLM:一位成员寻求关于在产品评论上微调情感分析模型的建议,相比云端 API,他更倾向于本地解决方案。
- 建议包括使用 类 BERT 模型、小语言模型 (SmolLM, Qwen) 或 Gemma;而其他人则主张为了便利和性能使用主流 LLM 的 API,但指出 Qwen 许可条款限制了模型分发,应仔细考虑。
- 抽卡机器人引发社交震荡:成员们讨论了围绕抽卡机器人 (gacha bots) 的社交动态,其中一人讲述了因为奇怪的服务器动态而删除机器人的经历。
- 对话涉及了抽卡机器人中的现实世界现金交易,Karuta 允许此类交易,高价值卡片的价格可达 2000-10000 美元,但在发布机器人的前几个月内,利润可能达到 50,000 美元。
HuggingFace ▷ #today-im-learning (1 条消息):
Python 版 WebRTC 客户端,FastRTC FastAPI 服务器,aiortc 困境,WebRTC 文档问题
- Python 开发者寻求构建 WebRTC 客户端的帮助:一位成员请求协助构建一个 Python WebRTC 客户端,以便与挂载了 FastRTC FastAPI 的服务器通信。
- 他们在 aiortc 的使用上遇到困难,并指出文档中缺乏指导,请求通过私信 (DM) 获得帮助。
- FastAPI WebRTC 难题:一位用户希望使用 Python 设置 WebRTC 客户端。
- 他们在利用 aiortc 与运行 FastRTC 的 FastAPI 服务器通信时遇到麻烦,并表示文档提供的帮助不多。
HuggingFace ▷ #cool-finds (1 条消息):
超参数即一切,Diffusion 突破
- 超参数处理加速大规模 Diffusion:论文 Hyperparameters are all you need 已被实现,并推出了 HuggingFace Space 用于测试,展示了 Diffusion 的突破:仅需 8 步 生成的图像即可达到与 20 步 相当或更好的 FID 性能。
- Diffusion 蒸馏至 8 步:新方法实现了 2.5 倍 的图像生成速度提升且质量更佳,适用于任何模型,且无需训练/蒸馏,从而实现了 60% 的计算量减少。
HuggingFace ▷ #i-made-this (6 messages):
HyDRA RAG Agent, WSL Pytorch vLLM venv bootstrap, AI features aggregator tool, OpenlabX for AI Research, Prompt Engineering Contest
- HyDRA Agent 增强 RAG:HyDRA v0.2 新版本发布,这是一个 Hybrid Dynamic RAG Agent,旨在解决简单、静态 RAG 的局限性,使用由 Planner, Coordinator 和 Executors 组成的协调 Agent 多轮反思系统。
- 它利用 bge-m3 model 进行结合了 dense 和 sparse embeddings 的混合搜索,使用 RRF (Reciprocal Rank Fusion) 进行重排序,并使用 bge-m3-reranker 提取相关文档;详见 GitHub 项目页面。
- Windows 工作流黑科技:一位用户分享了一个 WSL Pytorch vLLM venv bootstrap,用于在 Windows 10 和 11 上解决创建 venv 和本地托管模型的难题后提取 HF 模型。
- 他们发现这个引导程序非常有用,并认为其他人可能也需要;其中 LLM 提取部分是额外功能,并非所有人必需,但为了方便也一并包含在内。
- Magia 打造出色的多功能工具:一位用户构建了一个工具,将各种 AI 功能聚合在一起,如改写、人性化处理、邮件撰写、创意写作等,并正在寻求诚实的反馈。
- OpenlabX 为在线组织开启机遇:一位用户正在构建 OpenlabX,这是一个为 AI 研究人员和爱好者提供的发布小型实验和研究的平台,提供更好且更具交互性的成果展示方式。
- Luna 启动奖励丰厚的学习联盟:一位用户正在推广 Luna Prompts 上的 Prompt Engineering 竞赛,邀请参与者编写创意 Prompt 并解决有趣的 AI 挑战,以赢取奖品、证书和 XP 积分。
HuggingFace ▷ #reading-group (1 messages):
avanee5h: hello
HuggingFace ▷ #NLP (2 messages):
Cross-Posting Reminders, Discord Etiquette
- Discord 成员执行禁止跨频道发布规定:两名 Discord 成员要求其他人不要在频道中进行 cross-posting(跨频道发布)。
- Cross-posting 会使频道变得杂乱,干扰专注的讨论,并且通常被认为是不礼貌的行为。
- 特定频道沟通的重要性:关于 cross-posting 的提醒强调了保持讨论与特定频道相关的重要性。
- 这确保了成员能够轻松找到并参与符合其兴趣和频道宗旨的内容。
HuggingFace ▷ #agents-course (6 messages):
Agent guardrails, Agent agency, Tool limits
- Agent 巧妙绕过 ‘too many bananas!’ guardrail:当一个 Agent 被要求说出 N 个香蕉(N > 10)时,它巧妙地绕过了返回 “too many bananas!” 的 Tool guardrail,并直接给出了答案,展示了关于 agency 的有趣行为。
- 用户发布了一张 Agent 成功给出准确数字的截图。
- Agent 覆盖始终使用 Tool 的系统指令:Agent 可以覆盖要求其始终使用 Tool 的系统指令;例如,可以要求它修改指令,如果 N 大于 20 则说 “birthday cake“,随后它便会遵循这一新指令。
- 用户附带了一张 Agent 通过多次调用 Tool 来克服 Tool 限制的截图。
- Tool 限制带来新挑战:这种行为引发了对某些场景的担忧,即当 Tool 旨在防止 Agent 泄露机密信息或避开政治话题时,目前还没有稳健的方法来阻止这种覆盖行为。
- 这在 guardrails 和 agency 方面提出了新的挑战。
{kind=link}
GPU MODE ▷ #general (18 条消息🔥):
黑客松条款与条件、性能工程中的 LLMs、FlashInfer 博客文章、数据工程书籍、在 Trainium 上开发
- 黑客松参与者寻求条款与条件:一位黑客松参与者需要条款与条件以获得公司批准,特别是关于 IP 权利(知识产权)的部分。
- 组织者澄清说,他们无权获得 黑客松期间做出的任何贡献,并且 Nebius 计算用户在活动结束后可能会收到 营销材料。
- 寻求用于性能工程的 LLMs:一位成员正在寻找关于将 LLMs 集成到 性能工程 工作中的资源(博客、演讲等),例如编写/改进 kernel 或辅助性能分析。
- 另一位成员建议查看特定频道 <#1298372518293274644> 中分享的想法。
- FlashInfer 博客文章发布:一位成员分享了一篇深入探讨 FlashInfer 的新博客文章:https://ydnyshhh.github.io/posts/flash_infer/。
- 讨论《数据密集型应用系统设计》一书:一位成员询问 Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems 是否是复习 数据工程 概念的好书。
- 一位在该书出版时读过它的成员表示并不喜欢,将其描述为 高层级 的概述,从未深入探讨过任何内容。
- Trainium 平台开发引发疑问:一位从 CUDA kernels 开发转向 Trainium 开发的成员(更多信息见:https://numbersandcode.wordpress.com/2025/10/08/trainium-exploration/)询问该平台上的活跃开发者数量。
- 他们的搜索没有发现太多讨论,甚至没有专门的 Trainium 频道。
GPU MODE ▷ #triton (5 条消息):
寄存器-地址映射、ld.shared 布局兼容性、ldmatrix Tiling 计算、Triton Lowerings 实现
- 地址映射需要对角矩阵:成员们讨论了提取对应于 registers->address mapping 的列,并检查它们在左上角是否为 对角矩阵。
- 一位成员在研究了一些示例后同意这是正确的方法。
- ld.shared 布局需要审查:一位成员展示了 4.1 节中的布局 A 与
ld.shared不兼容,然后推导出了一个兼容的布局。- 他们还指出
ldmatrixtiling 计算中的一个错误,其中 d 应该是 log_2(4/w) 而不仅仅是 log_2(4)。
- 他们还指出
- 字节宽度计算是关键:确认对于字节宽度
w,计算确实应该是log_2(4/w),并且文档将会更新。- 他们补充说,所有针对任意兼容线性布局的 ldmatrix/stmatrix 指令 的实现在 TritonNVIDIAGPUToLLVM/Utility.cpp 中。
GPU MODE ▷ #cuda (26 条消息🔥):
CUDA reduction PDF 与代码, Thread block cluster reductions, shared smem 中的 mbarriers, Thread blocks 的执行顺序, Blackwell CLC
- CUDA Reduction 资源发布:一位成员分享了 CUDA reduction PDF 以及对应的 代码 以供参考。
- 另一位成员确认他们会查看这些分享的资源。
- 探讨 Thread Block Cluster Reductions 中的细粒度同步:一位成员询问了比
cluster.sync()更细粒度的同步原语,用于 Thread Block Cluster Reductions 以减少 barrier 停顿。- 具体来说,他们询问 是否可以使用某种 cluster 范围的 memory fence 来确保每个 cluster 对 SMEM 的写入对 cluster 0 可见。
- 澄清
mbarriers在 Shared SMEM 中的适用性:一位成员询问mbarriers是否在 shared SMEM 中工作,并引用了它们在 quack 实现中的 cluster reduction 的用法。- 该成员建议每个 block 仅使用一个 warp 配合
mbarriers以避免 cluster sync。
- 该成员建议每个 block 仅使用一个 warp 配合
- 关于 Thread Block 执行顺序保证的讨论:一位成员询问是否存在 Thread Block 执行顺序的保证,特别是当 block 数量超过并发运行上限时,block (0,0) 是否会在 block (10,10) 之前运行。
- 虽然一位成员回想起了 CUDA 文档中的特定措辞,但另一位成员指出 这种行为没有官方保证、文档说明或支持,基本上属于未定义行为 (UB)。文中还提到了一个关于 1D 索引在 CUB 中抽象的视频链接。
GPU MODE ▷ #cool-links (3 条消息):
非确定性研究, Go 编写的全文本搜索引擎, GPU 上的 C++ 数组库
- **LLMC Compression 起飞!:一位成员分享了 LLMC Compression 的链接,该项目基于 Thinking Machines 之前的 **非确定性研究 (non-determinism work),并附带了其 GitHub repo。
- **Go 全文本搜索引擎 翱翔!:一位成员宣布他们用 **Go 构建了一个全文本搜索引擎,利用 skiplists + roaring bitmaps 实现快速的布尔、短语和邻近查询,并支持 BM25 排名。
- **Parrot: 数组库 在 GPU 上鸣叫!:一位成员分享了 Connor Hoekstra 的 Parrot,这是一个专为 **GPU 设计的 C++ 数组库。
GPU MODE ▷ #jobs (1 条消息):
Aurora, 深度学习加速, 软件工程师
- Aurora 招聘深度学习加速资深员工:Aurora 是一家上市的自动驾驶卡车公司,正在招聘一名 深度学习加速 (Deep Learning Acceleration) 资深软件工程师,负责在边缘计算设备上优化深度学习模型;在此申请。
- 为 Aurora 优化 CUDA Kernels:该职位涉及 调优 CUDA kernels、改进 PyTorch 内部机制以及最大化 GPU 利用率。
GPU MODE ▷ #beginner (8 条消息🔥):
用于远程 GPU 编程的 VSCode, Visual Studio 中的 CUDA 调试, 带有动态张量分配的 CUDA Graphs, 分布式训练:TorchTitan vs NVIDIA NeMo, CUDA kernels
- VSCode 在远程 GPU 开发上击败了 Neovim?:一位成员发现 VSCode 的远程服务器 可能是进行 GPU 编程最简单的方式,在便利性上超过了 Neovim。
- 让 CUDA Kernels 调试更简单:一位成员发现,在 Visual Studio 中调试 CUDA kernels 时,向
nvcc添加-G -g参数可以解决断点失效的问题。 - CUDA Graphs 努力应对动态张量:一位成员寻求建议,关于如何在 forward pass 期间的动态张量分配导致捕获失败时,使模型能够被 CUDA graph 捕获。
- TorchTitan 与 NVIDIA NeMo 在分布式训练中的对决:一位成员询问在 256 个 H200 上进行分布式训练任务时,如何在 TorchTitan 和 NVIDIA NeMo 之间做出选择,特别是关于效率和可扩展性方面。
- 萌新开始探索 CUDA Kernels:一位成员表达了对探索 CUDA kernels 的兴趣。
GPU MODE ▷ #youtube-recordings (6 messages):
Distributed Tensors, JAX Scaling
- Collectives 仓库消失了!:一位成员提到,由于存在一些 bug 且缺乏时间重新审视,他们删除了自己的 collectives 仓库,但计划在未来重新启动该项目。
- 他们建议将 JAX scaling book 作为分布式张量(distributed tensor)示例的更好替代方案。
- 推荐 JAX Scaling Book:建议使用 JAX scaling book 资源来替代已删除的 collectives 仓库。
- 据称该书提供了更好的分布式张量示例,意味着它比原始仓库涵盖的内容更全面、更准确。
GPU MODE ▷ #off-topic (11 messages🔥):
GPU programming jobs for new grads, AI labs hiring for GPU programming, Sneaking in GPU work into unrelated jobs
- 应届生获得 GPU 编程岗位:成员们讨论了应届生或实习生进入 GPU programming 领域的方法,表明直接找到专注于此的职位是可能的。
- 一位成员指出:“许多 AI 实验室及相关硬件公司都在招聘这类工作,而且我认为在大多数情况下,他们会雇佣应届生和实习生。”
- 在其他角色中“潜入” GPU 开发:有人建议,即使一份工作并非明确针对 GPU programming,仍然可以寻找机会“潜入”并从事相关工作。
- 一位成员表示:“你总能找到微小的机会,在工作中潜入你喜欢研究的内容”,并建议像 machine learning engineer 这样的角色即使不是主要关注点,也能从 CUDA 技能中受益。
GPU MODE ▷ #irl-meetup (1 messages):
garrett.garrett: 你的工作单位听起来太棒了。
GPU MODE ▷ #self-promotion (2 messages):
Model Serving Communities, vLLM, KServe, llm-d, Red Hat AI
- 模型推理服务社区报告发布:10 月份的“模型推理服务社区现状”报告已发布,重点介绍了来自 Red Hat AI 团队关于 vLLM、KServe 和 llm-d 的更新。报告可在 Inference Substack 查看。
- 社区分享 X 帖子:一位成员分享了一个 X 帖子链接。
GPU MODE ▷ #submissions (12 messages🔥):
MI300x8 Performance, amd-all2all leaderboard, amd-ag-gemm leaderboard
- MI300x8 分数竞速:一位用户在 MI300x8 上以 597 µs 的提交成绩在
amd-all2all排行榜上获得了第 6 名。- 另一位用户在相同的排行榜和硬件上提交了 115 ms 的成绩。
- MI300x8 横扫 ag-gemm 排行榜:一位用户在 MI300x8 上向
amd-ag-gemm排行榜多次成功提交,时间范围从 534 µs 到 674 µs。- 另一位用户在相同的排行榜和硬件上达到了 586 µs 的个人最佳成绩。
GPU MODE ▷ #status (6 messages):
BioML leaderboard, github actions down
- BioML 排行榜总结已发布:关于 BioML 排行榜 的总结报告已发布在此处。
- GitHub Actions 遭遇宕机:用户报告提交门户已关闭,并链接到 Downdetector 和 GitHub Status 页面,显示 GitHub Actions 正在经历宕机。
- 管理员确认了该问题,表示“GitHub 宕机了,我们无能为力”。
GPU MODE ▷ #amd-competition (10 messages🔥):
GitHub Actions 故障,A2A 超时,Runpod MI300
- A2A 超时困扰用户:用户报告 A2A 提交出现超时,尽管代码在 Runpod MI300 虚拟机上本地运行正常,错误提示显示无法触发 GitHub Actions。
- 该问题似乎同时影响了 CLI 和 Web 提交,用户都遇到了同样的问题。
- GitHub Actions 故障被指为超时原因:GitHub 状态页面 (https://www.githubstatus.com/) 显示 GitHub Actions 处于宕机状态,这可能导致了超时和服务器处理错误。
- 预计提交将卡在队列状态,并随着 GitHub Actions 恢复稳定并处理积压任务而最终超时。
GPU MODE ▷ #cutlass (5 messages):
DLPack 互操作,MoEs 的 Grouped GEMM 性能,PTX 文档 K-contig 和 Swizzling
- PyTorch 互操作中 DLPack 是可选的:虽然 Cutlass 文档建议使用 DLPack 与 PyTorch 张量进行互操作,但这并非严格必要,如此示例所示。
- Grouped GEMM MoE 性能分析:评估 MoEs 的 Grouped GEMM 性能需要考虑较低的 M-occupancy,由于存在未计算在内的无效计算,传统的 Roofline 模型可能不再适用。
- 在具有 32 个专家 的
gpt-oss 20b预填充阶段中,观察到 M-occupancy 低至 ~60%,当 M 维度 = 256 时,约有 40% 的计算被浪费。
- 在具有 32 个专家 的
- PTX K-Contiguous Swizzle 布局错误:关于张量描述符的 K-contig 和 Swizzling != 0 的 PTX 文档有误,特别是在描述异步 Warpgroup 级规范布局(asynchronous warpgroup-level canonical layouts)时,如此处所示。
- 例如,根据此发现,精确布局
Swizzle<1,4,3> o ((8,2),(4,4)):((8,64),(1,4))是不正确的。
- 例如,根据此发现,精确布局
GPU MODE ▷ #singularity-systems (1 messages):
SITP 目录,Picograd 仓库清理
- SITP 目录正在敲定:SITP 的目录正在最终确定,第 1 章和第 3 章侧重于构建机器学习框架,第 2 章和第 4 章涵盖拟合/训练线性和非线性模型。
- 作者低估了整理目录所需的工作量,但计划让读者和学生在第 1 章和第 3 章中构建机器学习框架,并在第 2 章和第 4 章中拟合/训练线性和非线性模型。
- Picograd 仓库在混乱后已重置:由于涵盖的主题过于广泛导致状态混乱,Picograd 仓库已被清空并重置至 https://github.com/j4orz/picograd。
- 架构已得到清理,整合了之前在张量前端、Eager/Graph 中端和运行时后端方面的尝试;作者目前正在为基础操作和 Kernel 设置 Autodiff,并很快会寻求对 PRs 的评审。
GPU MODE ▷ #general (1 messages):
Discord 身份组,比赛获胜者
- 为比赛冠军推出身份组:Discord 服务器现在为比赛获胜者设立了身份组,特别是 <@&1418285356490428476> 和 <@&1425969596296462356>。
- 同样的荣誉也等待着在当前 AMD 比赛中胜出的人。
- Discord 服务器增强:Discord 服务器引入了新身份组以表彰比赛获胜者。
- 这些身份组 <@&1418285356490428476> 和 <@&1425969596296462356> 也将授予正在进行的 AMD 比赛的获胜者。
GPU MODE ▷ #multi-gpu (5 messages):
在家运行大模型的成本对比,模型并行的 GPU 推荐,RTX 3090, RTX 5080, RTX 5070 Ti Super 24GB
- RTX 3090 依然是性价比之王: 一位成员建议 RTX 3090 仍然是性价比极高的消费级 GPU。
- 此外,如果你想尝试新的 Blackwell 特性(NVFP4, TMEM 等),RTX 5080 目前在某些零售商处已有原价现货。
- 探索 RTX 5070 Ti Super: 成员们讨论了 RTX 5070 Ti Super 24GB 作为 5080 替代方案的潜力。
- 普遍共识是这听起来是一个不错的选择。
- 分布式训练中 TorchTitan 与 Nvidia-Nemo 的对比: 一位成员询问在 256 H200s 的分布式训练任务中,如何在 TorchTitan 和 Nvidia-Nemo 之间做出选择。
- 他计划进行 256 H200s 的训练任务,并希望获得从业者的建议,了解为什么要选择其中一个而非另一个。例如,Nvidia-Nemo 中的 Megatron-core 已在超大规模场景下得到验证,且对 4D parallelism 非常高效;而 TorchTitan 仍在成熟过程中,且用于分布式训练的 PyTorch primitives 可能不如 Megatron-core 快。
GPU MODE ▷ #irl-accel-hackathon (1 messages):
推理项目团队,项目团队申请,项目加入流程
- 积极的成员寻找推理项目团队: 一位成员表达了加入项目团队的强烈兴趣,特别是那些专注于 推理相关项目 的团队。
- 他们强调了自己的热情,并希望现在贡献还不算太晚,并提到参与项目将有助于他们获得认可。
- 充满热情的菜鸟渴望做出贡献: 一位热心的成员渴望加入团队,并将其技能贡献给 推理相关项目。
- 他们对能帮助自己获得认可的项目特别感兴趣,表现出主动学习和发展的态度。
GPU MODE ▷ #helion (13 messages🔥):
Helion vs Triton, FLA ops 性能, Nvidia/AMD 合作伙伴关系, TileLang 基准测试, Gated DeltaNet
- Helion 的 Kernel 定制化击败 Triton: 虽然 Triton kernel 会自动调优超参数,但 Helion 可以在自动调优期间更改 kernel 以更好地适应特定形状(shape),例如对较大形状使用循环归约(loop reductions),这可能会损害较小形状的性能。
- 这使得 Helion 能够通过针对不同形状进行定制,在大量输入形状上击败 Triton,Helion 最终会生成一个 Triton kernel。
- 在 PTC 上宣布 Nvidia 和 AMD 的 Attention 联盟: 一位成员宣布了与 Nvidia/AMD 在 Attention 性能方面的合作伙伴关系,更多细节将在 PTC 上分享。
- 这包括更奇特的 Attention 变体,尽管另一位成员对过度模式匹配的 Attention 支持持怀疑态度。
- TileLang 基准测试引发基准测试之战: 一位成员建议与 TileLang 进行基准测试对比(https://github.com/tile-ai/tilelang-benchmarks),并对线性 Attention 性能表示关注。
- 仅针对 Attention kernel,就生成了约 1500 个 Triton kernel。
- Gated DeltaNet 作为优秀的基准测试备受关注: 在一位成员询问特定的线性 Attention 变体后,另一位成员建议将 Gated DeltaNet(https://github.com/fla-org/flash-linear-attention/blob/0b8be89f45364bfa4329fae568e026d5773bc1dd/fla/ops/gated_delta_rule/chunk.py#L18)作为一个有趣的选项。
- 团队目前的重点是在推进到 Gated DeltaNet 之前,先分析 TileLang 基准测试所涵盖的算子(ops)。
LM Studio ▷ #general (99 条消息🔥🔥):
对话退化, LM Studio 性能提升, LM Studio 问题, 文本转语音 LLM
- 开启新对话可应对对话退化 (Chat Degradation):成员们发现,应对对话退化的方法之一是开启新对话。
- 在线模型也会出现同样的退化现象,此外,当系统内存耗尽时,模型也会出现遗忘并重复胡言乱语的情况。
- LM Studio 获得性能提升:一位成员注意到,在最新的 LM Studio 版本发布后,新对话的 Token 生成速度从 8t/s 提升到了 22t/s,性能提升惊人。
- 另一位成员提到,与刚开始使用 LM Studio 时相比,他们在两年内获得了 10 倍的性能提升。
- Qwen3 480B 蒸馏模型识别为 Claude AI:一位用户发现,一个从 Qwen3 Coder 480B 蒸馏到 Qwen3 Coder 30B 的模型在使用 Vulkan 进行推理时,会错误地自称为 Claude AI。
- 而在使用 CUDA 运行时,它能正确识别为 阿里巴巴集团开发的 Qwen。
- 不支持文本转语音 LLM:一位用户询问是否可以在 LM Studio 中使用文本转语音 (text-to-speech) LLM,但目前尚不支持该功能。
- 一位成员指出了之前的讨论,当时其他成员建议通过连接到 LM Studio 的 OpenWebUI 来实现此功能。
- LM Studio 在搜索模型时遇到 Type Error:一位使用 LM Studio v0.3.30 的成员报告在搜索模型时出现 TypeError,导致 UI 无法正常工作。
- 该错误发生在模型搜索期间,需要重启软件,该问题已在 GitHub 的 issue 457 中提交。
LM Studio ▷ #hardware-discussion (14 条消息🔥):
CPU 显卡支持, RAM 和 VRAM 分配, GPU 损坏, v1.52.1 修复集成显卡问题, Sparkle Arc Pro B60 双路服务器
- CPU 集成显卡“不支持”?:一些用户观察到集成(CPU)显卡显示为“不支持”,这可能是一个有意为之的改动。
- 这可能与最近在多台机器上观察到的 RAM 和 VRAM 分配以及加载策略的异常情况有关。
- v1.52.1 中集成显卡再次支持使用共享 RAM:在 v1.52.1 版本中,LM Studio 似乎修复了一个问题,现在允许模型再次利用带有共享 RAM 的集成显卡。
- 该修复是在之前的讨论和对其缺失的观察之后确定的。
- 3090 被烙铁弄坏了:一位用户在尝试使用电烙铁加热主芯片附近的 xclamp 上的乐泰螺纹锁固胶时,不小心弄坏了一块 3090。
- 该事故发生在尝试更换显卡导热垫以获得更好散热效果的过程中。
- Sparkle 推出 Arc Pro B60 服务器:Sparkle 发布了 Arc Pro B60 双路服务器,配备 16 个 GPU 和高达 768 GB 的 VRAM。
- 该服务器由 10800W PSU 供电,一些用户认为这标志着 Intel 正在强势进军 AI 领域。
Latent Space ▷ #ai-general-chat (103 messages🔥🔥):
Magic Dev 遭到厌恶, VC 垃圾泡沫崩溃, OpenAI Tokens, AlphaGo AI 时刻, 技术资本奇点
- Magic Dev 因未公开原因招致愤怒:正如一则 tweet 中所强调的,Magic . dev 正面临大量批评。
- 初创公司在 VC 泡沫担忧中面临审查:讨论中嘲讽了像 Magic Dev 和 Mercor 这样过度融资的初创公司,质疑其财务策略,并推测随着独立开发者(solo developers)开始自力更生(bootstrap),这些公司可能会发生崩盘。
- Atallah 庆祝 OpenAI 里程碑:Alex Atallah 宣布消耗了来自 OpenAI 的 1 万亿个 Token,引发了社区的庆祝以及关于实物 Token 赠送的询问,详情见 tweet。
- Brockman 宣传 AlphaGo AI 时刻:Greg Brockman 预测模型很快将取得戏剧性的科学和编程突破,类似于 AlphaGo 的 “第 37 手(Move 37)”,激发了人们对癌症突破等发现的希望,详见 tweet。
- Reflection AI 融资 20 亿美元瞄准开源前沿:Reflection AI 在 20 亿美元融资的支持下,旨在构建开源的前沿级 AI,专注于让先进智能触手可及;据 tweet 称,其团队成员星光熠熠,来自 PaLM, Gemini, AlphaGo, ChatGPT。
Nous Research AI ▷ #general (58 messages🔥🔥):
俄亥俄州的 NousCon, BDH Pathway 采用, VLMs 博客文章, Arcee AI MoE 模型, Atropos 使用
- 俄亥俄州对 **NousCon 的需求:成员们讨论了在俄亥俄州或加州以外的地方举办 **NousCon 的可能性,但有人指出其他地区的 AI 集中度(AI concentration) 并不高。
- 一位成员开玩笑说,要感谢加州把所有的 AI 人才 都集中在一个地方,远离其他人。
- **BDH Pathway 的古怪名称:成员们讨论了 **BDH Pathway (https://github.com/pathwaycom/bdh) 的古怪名称是否会影响其采用。
- 有人建议,如果被采用,全名可能会随着时间推移而被遗忘,因此它将被简称为 BDH,几乎没人会知道它代表什么。
- **VLMs 博客文章发布:一篇关于 **VLMs 内部机制以及它们如何跨模态(modalities)进行观察和推理的博客文章已发布 (https://huggingface.co/blog/not-lain/vlms)。
- 作者还宣布他们将在 Hugging Face Discord 服务器上进行现场演示和问答环节,活动链接。
- **Arcee AI MoE 模型即将推出:一个 **Arcee AI MoE 模型即将发布,并在 llama.cpp 中提交了 PR。
- 成员们注意到目前还没有针对 transformers 的 PR,这可能暗示了模型的大小。
- Atropos 使用概览请求:一位成员请求提供关于如何使用 Atropos 的视频。
- 分享了一个 Twitter 视频链接(YouTube 镜像),提供了关于 Atropos 中环境及其工作原理的更广泛概览。
Nous Research AI ▷ #ask-about-llms (15 messages🔥):
Hermes4 图像理解, Hermes 视觉模型, 嫁接 Llama 3.2, 使用 Qwen VL 3 进行视觉工具调用, Gemini 2.5 Flash 作为视觉工具
- Hermes4 缺乏图像理解:一位成员询问 Hermes4 是否能理解图像以及是否有解决方法(例如调用不同的模型);另一位成员确认目前没有原生图像理解功能,但 Hermes 视觉模型 正在开发中。
- 该成员建议可以尝试将 Llama 3.2 90B 嫁接(graft)到 Hermes 4 70B 中,但效果可能存疑。
- 使用 Gemini 2.5 Flash 进行视觉工具调用:一位成员提到他们正将 Hermes 与一个视觉模型配合作为工具使用,效果很好。
- 另一位成员确认他们使用 Gemini 2.5 Flash 作为视觉工具,并建议像在 API 上使用 OpenAI 工具调用 一样使用 Hermes 工具调用,或者使用 vllm 以
hermes工具调用格式运行。
- 另一位成员确认他们使用 Gemini 2.5 Flash 作为视觉工具,并建议像在 API 上使用 OpenAI 工具调用 一样使用 Hermes 工具调用,或者使用 vllm 以
Nous Research AI ▷ #research-papers (4 条消息):
Recursive Reasoning, Tiny Networks, HRM performance on ARC-AGI
- 微型网络通过 Recursive Reasoning 取得重大突破!:一名成员分享了论文链接:”Less is More: Recursive Reasoning with Tiny networks“。
- 该论文强调 HRM 在仅有 7M 参数的情况下,在 ARC-AGI-1 上达到了 45% 的得分,在 ARC-AGI-2 上达到了 8%。
- Recursive Reasoning 被认为是有趣的策略:一名成员分享了 arxiv 论文 和 Xitter 的链接。
- 该成员评论道,recursive reasoning 策略“非常有趣”且“非常简单”。
Nous Research AI ▷ #research-papers (4 条消息):
Tiny Networks, Recursive Reasoning, HRM Model Performance
- 微型网络实现递归:一名成员分享了论文 Less is More: Recursive Reasoning with Tiny networks (arxiv 链接),该论文探索了使用极小网络进行 recursive reasoning。
- 他们强调 HRM 模型 仅凭 7M 参数,就在 ARC-AGI-1 上获得了 45% 的分数,在 ARC-AGI-2 上获得了 8%。
- Real Azure 策略非常简单:一名成员分享了 arxiv 上的一种策略链接。
- 该成员发现该策略“非常有趣”且非常简单。
- Robert Wiblin 的策略:一名成员分享了 Robert Wiblin 的策略。
- 未对该策略发表进一步评论。
Yannick Kilcher ▷ #general (39 条消息🔥):
RL 辩论与信息瓶颈 (information bottlenecks),Thinking Machines 博客与香农熵 (Shannon entropy),Sutton 访谈以及通过 SFT 从 RL 转移比特,边缘 ML 想法 (非 DL):ART, SNN, RNN, weightless NN, GDL, 进化搜索 (ES) 对比反向传播 (backprop)
- RL 辩论:信息瓶颈:一名成员认为 RL 本质上存在信息瓶颈 (information bottlenecked),即使考虑到“超级权重 (super weights)”,从头开始训练模型也需要创造性的变通方法。
- 另一名成员回应称,通过模仿 (imitation) 比通过探索 (exploration) 获取知识更有效率。
- Thinking Machines 博客称香农熵仍是相关指标:一名成员分享了 Thinking Machines 博客 文章的链接,指出其中的图表证明了 香农熵 (Shannon entropy) 仍然是一个相关的指标,特别是在 LoRA 的背景下。
- 他们评论说,研究结果表明 广泛分布的 RL 是微不足道的,因为小的 LoRA 更新可以在稍后合并,而不会出现分布式规约 (reduction) 问题。
- Sutton 访谈:转移 RL 比特:一名成员提到,从 Sutton 访谈 中得出的论点表明,“比特 (bits)”可以通过 SFT 从 RL 中转移。
- 他们引用了 Deepseek V3.2 RL,其中 RL 在单独的专家模型上进行,然后通过 SFT 将所有内容合并到一个模型中,同时还强调了 对推理轨迹 (reasoning traces) 进行 SFT 这一有趣的范式。
- 寻找激进且不同的非 DL ML 想法:一名成员询问是否有关于 非深度学习的边缘 ML 想法 的讨论串或列表,例如 自适应共振理论 (ART)、使用 STDP 训练的脉冲神经网络 (SNN)、随机神经网络 (RNN)、无权重神经网络 (weightless neural networks) 以及几何深度学习 (GDL)。
- 作为回应,另一名成员建议关注 进化搜索 (ES),并指出其有用性以及对 DL 的适应性。
- 进化搜索在 7B LLM 上表现优于 GRPO:一名成员分享了一篇 arXiv 论文,声称 进化搜索 (ES) 使用一种简单的方法在 7B 参数的 LLM 上优于 GRPO。
- 他们补充说,当损失平面 (loss surface) 与高斯分布卷积并使其平滑时,ES 可以被视为梯度下降的一种近似,但他们好奇为什么它在种群规模较小 (N=30) 的情况下表现如此出色。
Yannick Kilcher ▷ #paper-discussion (14 messages🔥):
Ovi 在边缘检测中失败,权利、自由与技术,微型递归模型讨论,猫咪研究
- **Ovi 的边缘检测表现平平: 一位成员使用来自某篇论文的边缘检测和分割提示词测试了 **Ovi,但发现它没有产生有用的结果,这与 Veo 3 不同。
- 即将进行的 **ARC-AGI 论文讨论: 成员们将讨论 Tiny Recursive Model 论文,其中一个 **7M 模型 在 ARC-AGI-1 上达到了 45% 的准确率。
- 一位成员提到该论文已经分享在 ARC 频道 中,其他人也表达了进一步讨论的热情。
- 关于权利、自由与技术的哲学论文: 一位成员计划撰写一篇论文,将基本权利、自由、反权利和责任与技术创造的能力和激励机制联系起来。
- 猫咪 AI 学者加入讨论: 一位成员分享了他们的猫“一起学习”的照片,并链接了相关论文。
Yannick Kilcher ▷ #ml-news (4 messages):
人工海马体网络 (AHNs),字节跳动 AHN 模型
- 字节跳动发布人工海马体网络 (AHNs): ByteDance-Seed 发布了 Artificial Hippocampus Networks (AHNs),该网络将无损记忆转换为固定大小的压缩表示,用于 long-context modeling。
- AHNs 持续将滑动注意力窗口之外的无损记忆转换为压缩形式。
- AHNs 提供混合记忆方法: AHNs 利用了无损记忆(如 attention 的 KV cache)和压缩记忆(如 RNNs 的 hidden state)的优势,在长上下文中进行预测。
- 更多详情请见 HuggingFace collection 和 YouTube 视频。
aider (Paul Gauthier) ▷ #general (36 messages🔥):
aider 中的 Gemini API 集成,GLM-4.6 对比 Sonnet 4,OpenCode 与 GLM 模型,本地模型对比 API 模型,在 aider 中使用 GPT-5-Codex
- Aider 需要 .yml,而不是 .yaml!: 一位用户发现 aider 配置文件需要命名为
.aider.conf.yml而不是.aider.conf.yaml才能正确集成 Gemini API。- 尽管配置了 API key,该用户仍收到
GOOGLE_API_KEY和GEMINI_API_KEY的环境变量警告。
- 尽管配置了 API key,该用户仍收到
- GLM-4.6 媲美 Sonnet 4: 一位用户建议使用 GLM-4.6 进行详细规划,使用 GPT-5 进行最终方案审查,并使用 Grok Code Fast-1 进行实现。
- 另一位用户确认 GLM-4.6 与 Deepseek 3.1 Terminus 旗鼓相当,并链接了 Victor Mustar 的推文来支持其观点。
- OpenCode 超越 Claude Code: 一位用户提到他们现在全职使用 OpenCode 而不是 Claude Code,因为他们因地理位置被封锁(geoblocked),无法订阅 Claude Pro 或 Max。
- 他们还指出 Qwen Coder 是一个很好的备用系统,每天提供 1000 次免费请求,但他们几乎不怎么使用。
- DevStral 2507 和 Qwen-Code-30B 在本地胜任工作: 用户讨论了本地模型是否值得,一位用户提到 DevStral 2507 和 Qwen-Code-30B 很有用,特别是在 tool calling 方面。
- 另一位用户补充说,API 在成本上很难被超越,尤其是如果你避开那些过于昂贵的 API。
- gpt-oss-120b 到底需要多少 RAM?: 一位用户询问运行 gpt-oss-120b 需要多少 RAM,另一位用户回答说需要 64GB 加上上下文空间,因为参数只有 4-bit。
- 随后对话转向是否有人在 aider 中尝试过 gpt-5-codex,但没有得到回应。
aider (Paul Gauthier) ▷ #questions-and-tips (2 messages):
Aider 项目,项目更新
- Aider 项目面临潜在问题: 成员们讨论了 Aider 项目的一个潜在问题。
- 一些成员已经有一段时间没看到更新了,想知道该项目会发生什么。
- Aider 项目的未来: 成员们对 Aider 项目最近没有更新表示担忧。
- 成员们正在思考该项目的未来和方向。
tinygrad (George Hotz) ▷ #general (17 messages🔥):
Code review, AI slop, Algebraic Upat
- 开发者在 Tinygrad 领域寻求工作:一名开发者询问了 Tinygrad 社区内的就业机会。
- 他们表示自己随时准备好投入工作。
- PR 审查因被视为“AI 废话 (AI slop)”而停滞:一位贡献者表达了挫败感,因为他们的 PR 在没有具体反馈的情况下被斥为 AI slop。
- 他们表示,说你不明白自己在做什么只是推卸责任的一种方式,并要求与 @geohot 在编写代数 Upat 测试 #12449 中的要求进行对比。
- 要求更具体的代码审查:一位用户请求审查者提供可操作的反馈,而不是简单地将代码标记为糟糕。
- 他们报告称所有测试均已通过,并正在寻求具体的改进建议。
tinygrad (George Hotz) ▷ #learn-tinygrad (11 messages🔥):
tinygrad vector operations, Loop splitting resources, CUDA kernel reverse engineering with IOCTL
- Tinygrad 中的向量操作?:一位成员询问 tinygrad 是否支持快速向量操作,如叉积 (cross product)、范数 (norm) 和三角函数。
- 寻求循环拆分 (Loop splitting) 资源:一位成员正在寻找与框架无关的循环拆分学习资源,以便通过实现循环拆分来修复高层级的
cat。- 他们有一个实现仅在 3 个单元测试中失败,但涉及的 Ops 比原始实现更多,这表明可能存在技术水平问题 (skill issue)。
- 使用 IOCTL 进行 CUDA 内核逆向工程:一位成员正在开发一个基于 Rust 的交互式终端,用于测试高性能的单个 CUDA 内核,灵感来自 geohot 的
cuda_ioctl_sniffer和 qazalin 的 AMD 模拟器,并附带了 演示图片。- 该项目旨在通过 IOCTL 对 GPU 进行逆向工程,支持 Ampere、Turing、Ada、Hopper 等架构,并计划撰写相关文章。
Eleuther ▷ #general (1 messages):
inarikami: 我指的是提议的 Go 和游戏基准测试 (benchmark) 计划
Eleuther ▷ #research (25 messages🔥):
World Models vs Language Models, nGPT Failure Analysis, Harvard CMSA Seminars, VLM Image Resolution Optimization
- 世界模型与语言模型的区别:一场讨论澄清了在传统 RL 中,世界模型 (world model) 根据动作预测未来状态,而语言模型 (language model) 预测下一个 token。混淆源于将“环境”定义为 token 还是现实世界,参考这篇 2510.04542 论文。
- 一位成员解释了抽象层如何使 LM 成为正式的世界模型(类似于 gym 环境),通过检查移动的合法性并将 Agent 与环境分离。
- nGPT 性能受 OOD 困扰:成员们讨论了 nGPT (2410.01131) 泛化失败的问题,假设其生成过程属于分布外 (OOD)。
- 一位成员指出,nGPT 架构无法泛化很奇怪,因为单 epoch 训练损失衡量的是训练数据集内的泛化能力。
- 哈佛 CMSA 上传了很酷的研讨会:成员们推荐了 Harvard CMSA YouTube 频道,因其收集了大量研讨会。
- 未提供更多细节。
- VLM 图像分辨率得到优化:一位成员分享了一份 PDF 报告,详细介绍了他们在视觉语言模型 (VLM) 中优化图像分辨率与输出质量以节省计算量的工作,在 COCO 2017 Val 数据集上使用 Gemini 2.0 Flash 进行图像字幕生成。
- 该基准测试侧重于优化精细细节的敏锐度,该成员正在构建一个用于创建自定义数据集的工具。
Eleuther ▷ #interpretability-general (1 messages):
Interpretable AI, Advice for college students
- 新学生寻求 I.A.I. 入门指导:一名刚加入社区的大学生正在寻求关于如何开始学习 可解释性 AI (Interpretable AI) 的建议。
- 目前尚未给出建议。
- 可解释性 AI 资源:一名刚加入社区的大学生正尝试进入可解释性 AI 领域并寻找资源。
- 他们肯定会非常感激任何关于入门的建议!
Eleuther ▷ #multimodal-general (1 messages):
Moxin-VLM, VLM-R1
- 新的 VLM 加入战局:分享了两个新的 视觉语言模型 (Vision Language Model, VLM) 仓库:Moxin-VLM 和 VLM-R1。
- GitHub 仓库涌现:分享了几个有趣的 GitHub 仓库,大家可能想去看看。
MCP Contributors (Official) ▷ #general (9 messages🔥):
MCP integration with ChatGPT, Refresh button issues, .well-known/ endpoint for MCP server metadata, Minimal SEP proposal
- ChatGPT MCP 集成寻求帮助:一名成员正在寻求 ChatGPT MCP 集成方面的帮助,报告了 刷新按钮 (Refresh button) 和工具列表的问题,但被引导至 Apps SDK 讨论区 或 GitHub issues 以获取具体的实现支持。
- “.well-known” 端点引发 MCP 元数据讨论:一名成员询问了关于 MCP 特定服务器元数据 的
.well-known/端点的讨论。- 另一名成员指向了 博客文章、GitHub discussions 中的主帖,以及 pull/1054 中的更多信息。
- 开发者峰会深入探讨 Registry:一名成员提到了上周 开发者峰会 (Dev Summit) 上关于 Registry 的讨论,并指向了 演示文稿。
- 极简 SEP 旨在简化规范:一名成员建议提出一个极简的 SEP,范围仅限于文档名称、相对于 MCP 服务器 URL 的位置以及诸如
Implementation之类的极简内容。- 目标是为新的 SEP 建立基础,以便在此基础上构建并解决持续的争论。
MCP Contributors (Official) ▷ #general-wg (4 messages):
Sub-registry syncing, Registry app
- 子注册表 (Sub-registries) 通过拉取机制同步:子注册表应决定最适合自己的同步策略,并基于 拉取 (pull) 模式工作。
- 该方法应该是初始时进行 全量同步 (full sync),然后使用 filter 参数进行查询,仅获取自上次拉取后的 更新条目。
- 是否构建自己的 Registry 应用?:一名成员正在考虑是直接根据 API 规范 构建自己的 Registry 应用并轮询更新更好。
- 他们原以为可以使用 Registry 应用创建一个子注册表,然后同步可能是应用的一部分,但他们不想 在错误的方向上发力。
Moonshot AI (Kimi K-2) ▷ #general-chat (13 messages🔥):
organic models, sora 2 invite codes, kimi coding
- 模型是蒸馏的,还是原生训练的?:一名成员表示 这就是你不像个失败者那样只去蒸馏模型时所得到的结果,主张开发 真正的原生模型 (organic models)。
- Sora 2 邀请码,没那么难拿?:成员们讨论了 Sora 2 的邀请码,声称 下载量已突破 100 万+,且并不难获得。
- 另一名成员表示他们宁愿等待正式发布。
- Kimi 的编程能力获赞:一名成员分享了他们的观点,认为 Kimi 在编程方面非常酷,通过 IDE 实现的这种 Agent 模式/工具使用非常有趣。
- 他们强调 该模型直接执行 Python 脚本和批处理命令,以了解系统信息从而更好地进行调试。
Modular (Mojo 🔥) ▷ #general (2 messages):
新成员介绍,社区欢迎
- 哥伦比亚新研究员加入 Mojo 社区:一位来自哥伦比亚国立大学(Universidad Nacional)计算机科学专业的新成员向 Mojo 社区介绍了自己。
- 他们表达了对音乐、语言学习以及建立 Hardware 和 Deep Learning 研究小组的兴趣。
- 社区欢迎新研究员:一位成员欢迎新研究员加入 Mojo/MAX 社区。
- 欢迎成员对看到其他研究人员加入表示兴奋。
Modular (Mojo 🔥) ▷ #mojo (10 messages🔥):
Mojo 多线程,Mojo 对 Jetson Thor 的支持,在 Mojo 中使用 Python 线程
- Mojo 缺乏原生多线程支持:成员们讨论了 Mojo 目前缺乏原生的 multithreading/async/concurrency 支持,并建议目前使用外部 C 库可能是最佳选择。
- 一位成员建议不要尝试在 stdlib 的
parallelize之外进行多线程操作,因为可能会出现怪异行为,并建议在 Mojo 拥有表达 MT 约束的工具之前,先使用 Rust, Zig 或 C++。
- 一位成员建议不要尝试在 stdlib 的
- Jetson Thor 获得 Mojo 支持:最新的 nightly build 现在在 Mojo 和完整的 MAX AI 模型中都支持 Jetson Thor。
- 然而,一位成员调侃说希望自己有 $3500.00 来买一个,而另一位成员则指出,即使是小型机型,对于不需要大量资源的项目的用途来说也非常棒。
- 在 Mojo 中使用 Python 线程:一位成员报告称,在 Python 进程中使用常规线程取得了不错的成功,通过调用 extension 中的 Mojo 代码,释放 GIL,然后飞速运行。
- 他们警告说,如果没有复杂的 synchronization,这种方法可能会容易出现 data races。
Manus.im Discord ▷ #general (7 messages):
Sora 2 邀请码请求,因 Agent 故障请求额度退款,威胁拒付并取消会员,Manus 支持可用性,Manus 帮助页面
- 寻求 Sora 2 邀请码:一位用户请求 Sora 2 的邀请码。
- 用户在 Agent 交付失败后威胁拒付:一位用户在 Agent 未能遵循指令并丢失 context,导致产生 $100+ 额外费用后,请求退还 9,000 credits,并引用了会话回放。
- 该用户威胁称,如果问题在 3 个工作日内未得到解决,将进行 chargeback(拒付)、取消会员资格并发布负面的 YouTube 评价,同时分享了一个 LinkedIn 帖子并要求确认采取了纠正措施。
- 用户询问支持人员在哪里?:一位用户紧急询问支持人员的可用性。
- 用户指向 Manus 帮助页面:另一位用户将该用户引导至 Manus 帮助页面。
DSPy ▷ #general (6 messages):
DSPy Community Projects, MCP Tool Authentication with DSPy, Official vs Community Repositories
- DSPy 社区项目集中化:一些成员正在讨论是否将 DSPy 社区项目集中在 dspy-community GitHub organization 下,为社区主导的扩展提供一个起点,并避免核心团队因 PR 评审而负担过重。
- 该提案旨在集中社区力量,链接到各个项目并创建一个协作空间,同时确保有用且可重用的插件在集成前经过讨论和批准。
- 仓库管理:官方 vs 社区:成员们辩论了是将社区主导的 DSPy 项目放在 官方 DSPy 仓库 还是独立的社区仓库中。
- 支持官方仓库的论据包括插件会显得更“官方”、更简单的依赖管理以及增加社区参与度,并建议使用
CODEOWNERS来管理审批权限,防止核心团队负担过重。
- 支持官方仓库的论据包括插件会显得更“官方”、更简单的依赖管理以及增加社区参与度,并建议使用
- 通过 pip install 获取优化的 DSPy 程序:一些成员建议为常见场景创建 编译/优化的 DSPy 程序,可以通过
pip install dspy-program[document-classifier]进行访问。- 这将为用户提供开箱即用的解决方案,但需要探索优化策略和相关注意事项。
- MCP Tool 身份验证:一位成员询问如何从需要身份验证的 MCP Tool 创建
dspy.Tool。- 他们询问在这种情况下如何处理身份验证,以及现有的
dspy.Tool.from_mcp_tool(session, tool)方法是否支持它。
- 他们询问在这种情况下如何处理身份验证,以及现有的