AI News
OpenAI Titan XPU:与博通(Broadcom)合作的 10GW 规模自研芯片。
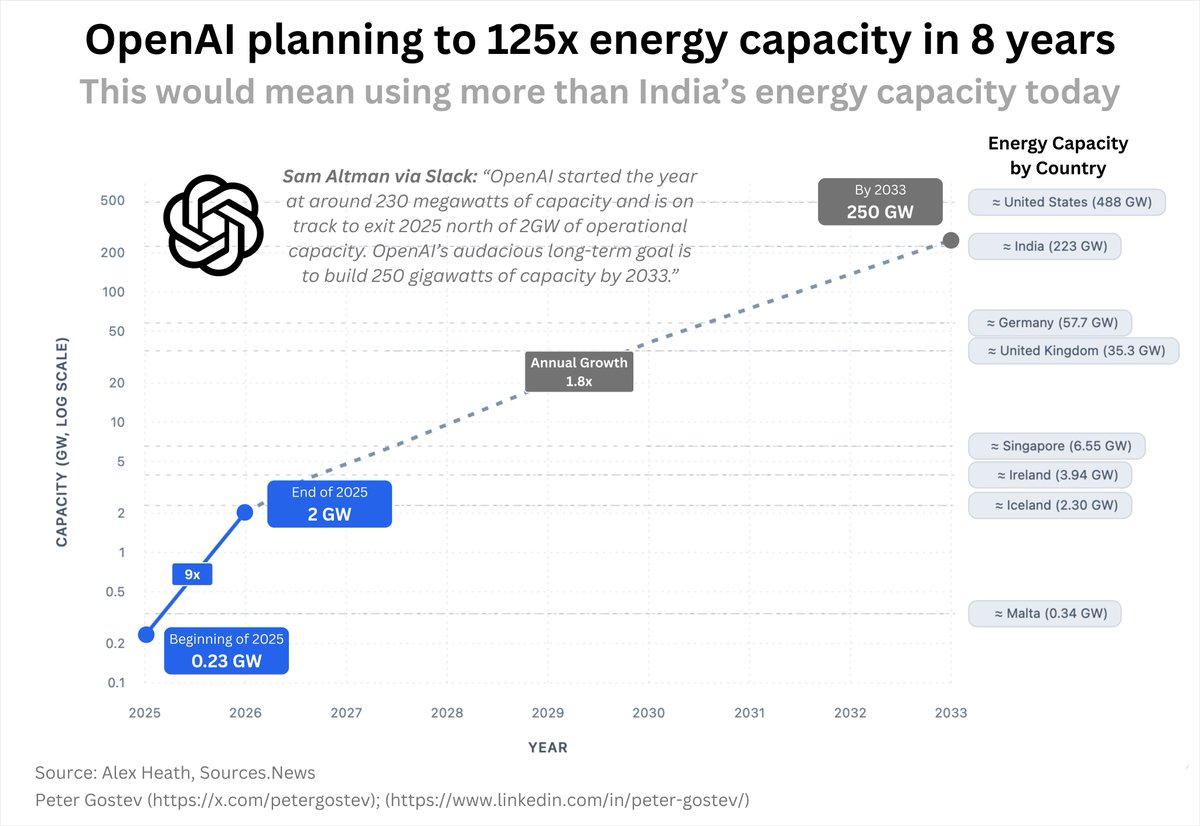
OpenAI 正在敲定一项定制 ASIC 芯片设计,计划部署 10GW 的推理算力,以补充其与 英伟达(NVIDIA)(10GW)和 AMD(6GW)的现有协议。这标志着 OpenAI 从目前 2GW 的算力规模大幅扩张,其目标路线图是达到总计 250GW,这一数字相当于美国能源消耗总量的一半。
OpenAI 的 Greg 强调,ChatGPT 正在从交互式使用转向需要海量算力的全天候“环境智能体”(always-on ambient agents),并强调了为数十亿用户制造芯片所面临的挑战。由于此前在影响外部芯片初创公司方面成效有限,对定制化设计的需求驱动了这一内部 ASIC 的研发工作。受此消息影响,博通(Broadcom) 股价飙升了 10%。
此外,InferenceMAX 报告称 ROCm 的稳定性有所提升,并对 AMD MI300X 与英伟达 H100/H200 在 llama-3-70b FP8 工作负载下的性能进行了细致对比,同时提到了强化学习(RL)训练基础设施的更新。
ASIC 就是你所需要的一切。
2025/10/10-2025/10/13 的 AI 新闻。我们为你检查了 12 个 subreddits、544 个 Twitter 账号和 23 个 Discord(197 个频道,15120 条消息)。预计节省阅读时间(以 200wpm 计算):1127 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 方式呈现过往所有内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
OpenAI 最近进行了大量的芯片交易,旨在打造“人类历史上最大的联合工业项目”:
而今天,最后一只靴子落地了——正如在聘请了来自 Google 的 TPU 资深成员后广为流传且如期而至的传闻那样——10GW 的 OpenAI 自研 ASIC 和系统,专门为 OpenAI 的推理能力而设计(正如 Sam 在 OpenAI 播客中所说)。
为了说明这个规模,目前整个 OpenAI 拥有 2GW 的算力,大部分用于 R&D:
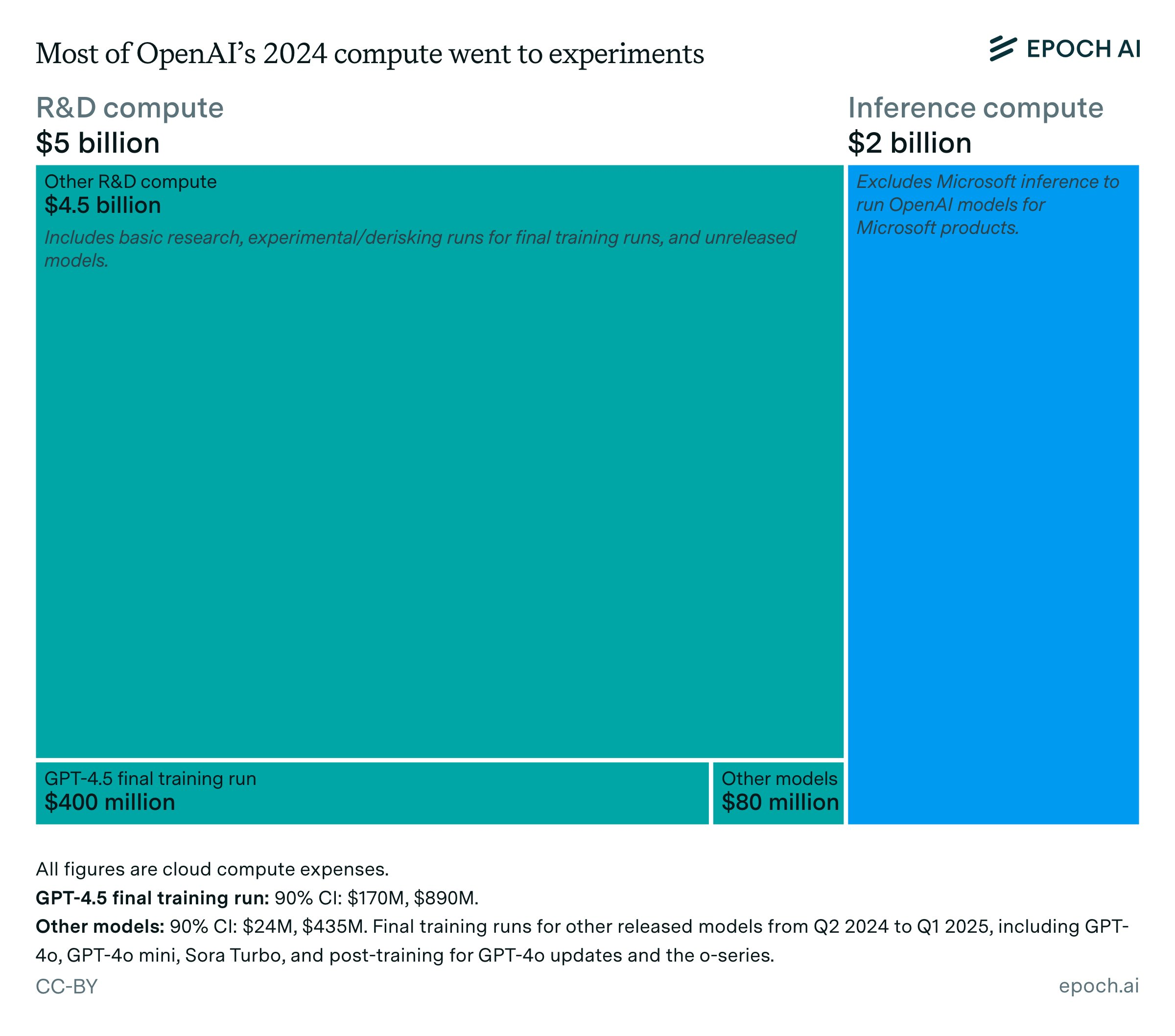
而这仅是通往 250GW(相当于美国能源消耗的一半)整体路线图的 12%。
Greg 表示,环境 Agent 是推理需求大幅增长的重要原因:
“但我认为,我们正在走向一个 AI 智能能够帮助人类取得新突破的世界,而这些突破在其他情况下是不可能实现的。
为了支持这一点,我们需要尽可能多的算力。
一个非常具体的例子是,我们现在所处的世界中,ChatGPT 正在从你与之交互对话的工具,转变为可以在后台为你完成工作的工具。
如果你使用过 Pulse 等功能,你每天早上醒来,它都会提供一些与你感兴趣的内容相关的、非常有趣的东西。这是非常个性化的。我们的目标是将 ChatGPT 变成能帮助你实现目标的工具。
问题是,我们只能向 pro tier 用户发布这个功能,因为这是我们目前可用的算力上限。理想情况下,每个人都应该有一个 24-7 在后台运行的 Agent,帮助他们实现目标。因此,理想情况下,每个人都拥有自己的加速器,拥有自己的算力,并且一直在持续运行。
这意味着有 100 亿人类。
我们离制造 100 亿颗芯片的目标还差得很远。
因此,在能够满足不仅是需求,而且是人类真正应得的水平之前,还有很长的路要走。”
Greg 表示,他们已经研发 ASIC 18 个月了,以及为什么选择自主研发:
“有很多芯片初创公司采用了与 GPU 截然不同的新颖方法。我们开始给他们大量的反馈,说:‘这是我们认为的发展方向。它需要这种形状的模型。’坦白说,他们中的很多人根本不听我们的,对吧?所以,当你看到未来应该发展的方向,却除了试图影响别人的路线图之外,没有任何能力去真正影响它时,这种处境是非常令人沮丧的。因此,通过将其中一部分工作转为内部研发,我们觉得我们能够真正实现那个愿景。”
虽然目前还没有宣布与 Intel 的合作,但考虑到对美国 AI 技术栈的明确兴趣,这肯定也不远了。
Broadcom 的股价在今天的消息传出后跳涨了 10%(市值增加 1500 亿美元)。
AI Twitter 回顾
芯片、推理 TCO 和训练基础设施
- InferenceMAX 的每日 TCO 读数(AMD vs NVIDIA):自 2024 年初以来,ROCm 的稳定性提升了“几个数量级”;在 Llama‑3‑70B FP8 推理工作负载和 vLLM 上,MI300X 在不同交互级别下的单位 TCO 性能比 H100 低 5–10%,而 MI325X 与 H200 相比具有竞争力。尽管在某些工作负载上 AMD 仍然落后,但根据 InferenceMAX 的运行结果,随着软件的每日改进,这种趋势正变得微妙且快速变化 (@SemiAnalysis_)。
- 大规模 RL 的相关基础设施笔记:In-flight updates 加上 Continuous Batching 现在已成为避免 GPU 因单个生成任务而陷入“长尾”效应的标配 (@natolambert, @finbarrtimbers)。
- OpenAI 与 Broadcom 合作设计加速器(10 GW):OpenAI 宣布合作部署 10 GW 的定制芯片,这是对 NVIDIA/AMD 合作伙伴关系的补充,并有播客讨论了协同设计和路线图 (@OpenAINewsroom, @OpenAI)。一位 OpenAI 芯片工程师回顾了为期 18 个月的冲刺,旨在开发一款针对推理推理优化的部件,目标是实现快速、大批量的首批产能爬坡 ({itsclivetime});领导层重申“世界需要更多算力” ({gdb})。
- vLLM GitHub Star 数突破 60K:现在为 NVIDIA, AMD, Intel, Apple, TPU 上的文本生成提供动力,原生支持 RL 工具链(TRL, Unsloth, Verl, OpenRLHF)以及广泛的模型生态系统(Llama, GPT‑OSS, Qwen, DeepSeek, Kimi) (@vllm_project)。
推理 RL:混合奖励、无标签扩展和新序列模型
- 混合强化学习 (HERO):通过分层归一化和方差感知加权,将 0–1 可验证反馈与稠密奖励模型评分相结合。在 Qwen‑4B 上,相比仅使用 RM 提升了 +11.7 分,相比仅使用验证器提升了 +9.2 分,且这种增益在简单/困难/混合模式下均保持稳定,并能泛化到 OctoThinker‑8B (@jaseweston)。
- 预训练规模下的无人类标签 RL(腾讯混元):在预训练阶段使用大文本语料库,通过 ASR(下一段预测)和 MSR(掩码段预测)任务,用 RL 驱动的 Next Segment Prediction 替代 NTP。在数千步 RL 之后报告的增益:MMLU +3.0%, MMLU‑Pro +5.1%, GPQA‑Diamond +8.1%, AIME24/25 +5% 以上;端到端 RLVR 在数学/逻辑任务上增加了 +2–3%。这与 NTP 互补,并降低了扩展推理预训练的标注成本 (@ZhihuFrontier, Q&A)。
- Agentic Context Engineering (ACE):将上下文视为不断演进的结构化知识库(而非单一的 Prompt)。使用 Generator/Reflector/Curator 循环来积累“增量”见解;据报告,相比 SOTA Prompt 优化器,在 Agent 基准测试中提升了 +10.6%,在复杂金融推理中提升了 +8.6%,且适配延迟降低了 86.9% ({_philschmid})。
- 非 Transformer 序列建模:Mamba‑3 改进了状态空间积分(梯形 vs 欧拉),并允许复平面状态演化,以实现稳定性和周期性结构表示;将线性时间、硬件友好的序列模型定位于长上下文和实时应用 (@JundeMorsenWu)。
多模态模型:音频推理 SOTA 与视频系统
- 语音到语音推理 SOTA (Gemini 2.5 Native Audio Thinking):在 Artificial Analysis Big Bench Audio 上获得 92% 的评分,超越了之前的原生 S2S 系统,甚至超过了 Whisper→GPT‑4o 流水线。延迟方面:“推理”变体的 TTFT 为 3.87s(非推理变体为 0.63s)。特性包括:原生音频/视频/文本 I/O、function calling、搜索接地(search grounding)、推理预算(thinking budgets)、128k 输入/8k 输出上下文,知识截止日期为 2025 年 1 月 (@ArtificialAnlys)。
- 视频模型格局变化:
- 阿里巴巴的 Wan 2.5 在 Video Arena 上首次亮相,分别位列第 5(文生视频)和第 8(图生视频);目前支持 1080p@24fps、长达 10 秒的视频,并具备音频输入唇形同步(lip‑sync)功能;在 fal/replicate 上的价格约为每秒 0.15 美元;重要的是,它不是开放权重模型(之前的 Wan 版本遵循 Apache‑2.0 协议) (@ArtificialAnlys)。
- 可灵 (Kling) 2.5 Turbo 1080p 加入排行榜;报价为每 5 秒 1080p 剪辑 0.15 美元,并在 Arena 中获得强力的人类投票 (@arena)。
- 实时视频理解:针对无限流的 StreamingVLM 继续推动低延迟多模态 Agent 的发展 ({_akhaliq})。
- 图像推理需求:Qwen3‑VL‑235B‑A22B‑Instruct 在 OpenRouter 上的图像处理份额达到 48% (@Alibaba_Qwen)。
- DeepSeek 的混合模型 “V3.1 Terminus” 和 “V3.2 Exp”:两者均支持推理和非推理模式,在智能水平和成本效益上较 V3/R1 有实质性提升,并获得广泛的第三方托管支持(SambaNova 高达 ~250 tok/s;DeepInfra 的 V3.2 高达 ~79 tok/s) (@ArtificialAnlys)。
开源训练栈与可复现配方
- nanochat (Karpathy):一个全栈、从零开始的 “ChatGPT 克隆” 训练/推理流水线(约 8k 行代码),涵盖分词器 (Rust)、在 FineWeb 上预训练、在 SmolTalk/MCQ/tool‑use 上进行中期训练、SFT 以及可选的 RL (GRPO)。提供极简引擎(KV cache、预填充/解码、Python 工具)、CLI + Web UI 以及一份单次运行报告。参考成本:约 100 美元进行 4 小时 8×H100 运行即可实现对话;运行约 12 小时在 CORE 上超越 GPT‑2;运行约 24 小时(30 层深度)在 MMLU 上达到 40s,ARC‑Easy 达到 70s,GSM8K 达到 20s。这是一个为研究和教育提供的强大且可定制的基准 (@karpathy, 仓库链接;@simonw 的笔记)。
- 基于执行的代码评估 (BigCodeArena):一个建立在 Chatbot Arena 之上的开放人类评估平台,包含可执行代码,允许与运行时环境交互,以捕捉编码模型更真实的人类偏好 ({iScienceLuvr})。在 DSPy 社区中,“使用 GEPA 基准,否则不要发布” 的提示/程序优化情绪日益高涨 ({casper_hansen_})。
- Apple silicon 上的本地 ML:Qwen3‑VL‑30B‑A3B 在 4-bit 量化下通过 MLX 运行速度约为 80 tok/s ({vincentaamato});微型 Qwen3‑0.6B 在 2 分钟内完成微调,在 MLX 上达到约 400 tok/s (@ModelScope2022)。Privacy AI 1.3.2 增加了对 MLX 文本/视觉模型的支持,具备离线操作和改进的下载管理功能 ({best_privacy_ai})。
基准测试与评估进展
- 硬科学评估的反击:CMT‑Benchmark(凝聚态理论)汇总了 HF/ED/DMRG/QMC/VMC/PEPS/SM 等领域;17 个模型的平均表现仅为 11%,许多类别得分为 0%。论文详细介绍了如何为 AI 构建真正的难题 ({SuryaGanguli})。
- 语音推理基准测试:Big Bench Audio 将 Big Bench Hard 改编为 1,000 个音频问题,用于原生语音推理;Gemini 2.5 Native Audio Thinking 以 92% 的得分领先 (@ArtificialAnlys)。
- 多 Agent “集体智能” 测量:信息论分解(协同 vs 冗余)将真正的团队级推理与冗余的闲聊区分开来;实验表明,角色差异化 + 心智理论(theory‑of‑mind)提示词可以改善协作;低能力模型在没有真正合作的情况下会产生振荡 ({omarsar0})。
产品与平台更新
- NotebookLM:升级了 Video Overviews,采用由 Gemini 图像模型 “Nano Banana” 驱动的新视觉风格,并引入了更短的 “Brief” 格式;优先向 Pro 用户推出 (@Google, @NotebookLM)。
- Google AI Studio:直接在 AI Studio 中新增了使用情况和速率限制仪表盘(包含 RPM/TPM/RPD 图表、单模型限制) (@GoogleAIStudio, {_philschmid})。
- Perplexity:在 Search API 中增加了域名过滤器,并在印度 Play Store 登上应用总榜第一 ({AravSrinivas}, rank)。
热门推文(按互动量排序)
- nanochat:一个端到端的极简 LLM 训练/研究栈 —— 约 8k 行 LOC 实现全流程(tokenizer→pretrain→mid‑train→SFT→RL);在 8×H100 上花费约 100 美元,约 4 小时即可与你自己的模型对话 (@karpathy; repo)。
- OpenAI x Broadcom:10 GW 的定制 AI 加速器 —— 以及关于芯片协同设计和扩展的播客 (@OpenAINewsroom, @OpenAI)。
- NotebookLM 的 “Nano Banana” 视频概览 —— 新的视觉风格和 Brief 摘要正在推出 (@Google, @NotebookLM)。
- Grok “Eve” 语音模式升级 —— 对话体验显著更加自然,值得在语音 UX 对比中一试 ({amXFreeze})。
- Gemini 2.5 原生音频思考(Native Audio Thinking)创下 S2S 推理 SOTA (92%) —— 在 Big Bench Audio 上超越了之前的原生 S2S 以及 Whisper→GPT‑4o 流水线 (@ArtificialAnlys)。
- Qwen3‑VL‑235B‑A22B‑Instruct 领跑 OpenRouter 图像处理 —— 占据 48% 市场份额快照 (@Alibaba_Qwen)。
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
1. 中国开源模型的主导地位与 LLM 风格坍缩辩论
- 目前顶尖的开源模型均来自中国公司 (热度: 482): 《华盛顿邮报》的一项分析指出,目前的开源 LLM 排行榜(如 LMSYS/HuggingFace)均由中国公司的模型占据榜首。分享的图表直观展示了排名最高的开源模型均来自中国,这表明开源模型的领导地位正从美国/Meta 主导的体系发生转移。该帖子链接了分析报告(赠阅链接),图片显示了一份按国家/地区标注厂商的对比排名图,中国实验室占据了顶端位置。参见:https://wapo.st/4nPUBud。 评论指出这种趋势已存在一段时间,并对开源模型中的“刷榜(benchmark-maxxing)”表示担忧,暗示可能存在操纵排行榜的行为;其他人提到 NVIDIA 和 IBM 的模型虽然具有竞争力但并非 SOTA,并批评了图表的设计和可读性。
- 几位用户指出,排行榜上的领先可能反映的是“刷榜”而非广泛的能力提升:模型针对 Hugging Face Open LLM Leaderboard 和 LMSYS Chatbot Arena 等公开评估集进行了“刷榜”(过拟合/提示词微调),这可以在没有实际性能提升的情况下虚增分数。这凸显了测试集污染以及过度针对特定提示词/指标进行优化而非稳健泛化的风险 (Open LLM Leaderboard, Chatbot Arena)。
- 一位评论者指出,来自 NVIDIA 和 IBM 的美国开源模型虽然不是 SOTA,但仍是实用的选择:例如 NVIDIA Nemotron-4 15B Instruct(许可宽松,经过工具调用微调)和 IBM Granite 8B/20B 系列(Apache-2.0 协议,专注于企业级应用)。虽然它们在 MT-Bench 或 Arena ELO 上可能落后于顶尖模型,但在部署场景中提供了良好的尺寸、许可和稳定性平衡 (Nemotron-4-15B-Instruct, IBM Granite 8B)。
- 关于“没有 Mistral?”的疑问指出,许多排行榜通常包含强大的开源 Mistral 模型,如 Mixtral 8x7B Instruct (MoE) 以及偶尔出现的更新变体(如 8x22B),它们在开源权重模型中通常排名靠前。如果缺席,可能表明排行榜的截止日期、评估套件或筛选标准存在问题,而非真实的性能差距 (Mixtral-8x7B-Instruct)。
- [**我痛恨他们第一次将“这不是 X,这是 <名不副实的最高级词汇>”引入 LLM 训练数据的那一天**](https://www.reddit.com/r/LocalLLaMA/comments/1o58klk/i_rue_the_day_they_first_introduced_this_is_not_x/) (热度: 491): **楼主强调了一种普遍存在的 LLM 风格伪影:即“这不是 X,这是 <名不副实的最高级词汇>”这一模板。他认为这种风格已在模型中蔓延,是训练数据偏差和 RLHF 驱动的风格同质化的征兆。他们推测这可能反映或加速了类似于 [model collapse](https://en.wikipedia.org/wiki/Model_collapse)(模型坍缩)的反馈循环退化,即在合成/模型生成的文本上训练的模型会过拟合于陈词滥调,放大公式化的修辞并减少输出的多样性。** 热门评论大多带有幽默色彩,未增加技术性内容。
- 一位评论者指出,“这不是 X;这是 Y”的结构在有限的语境中是一种强有力的修辞手段,但由于 next-token prediction 目标和偏向高显著性模板的频率偏差,LLM 对其进行了过度泛化。这导致了风格上的模式坍缩(mode collapse):一旦某种模式被学习为“有效”,模型就会普遍调用它,而 RLHF/reward modeling 通常会强化这些高参与度的陈词滥调;保守的解码策略(低 temperature/高
top_p)会进一步放大重复。提出的缓解措施包括惩罚陈词滥调模板、增加风格多样性目标,或根据话语意图进行条件化以恢复语境敏感性。
- 一位评论者指出,“这不是 X;这是 Y”的结构在有限的语境中是一种强有力的修辞手段,但由于 next-token prediction 目标和偏向高显著性模板的频率偏差,LLM 对其进行了过度泛化。这导致了风格上的模式坍缩(mode collapse):一旦某种模式被学习为“有效”,模型就会普遍调用它,而 RLHF/reward modeling 通常会强化这些高参与度的陈词滥调;保守的解码策略(低 temperature/高
非技术性 AI 版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. 视频生成模型:Wan 2.2 FLF2V (-Ellary-) 与 Sora 在西班牙的主流化
- 如果你还没试过 Wan 2.2 FLF2V,那你真的错过了!(-Ellary- 方法) (活跃度: 552): 展示了使用 Wan 2.2 FLF2V 结合 -Ellary- 流水线制作的视频(方法描述见:https://www.reddit.com/r/StableDiffusion/comments/1nf1w8k/sdxl_il_noobai_gen_to_real_pencil_drawing_lineart/)。技术反馈集中在时间不稳定性上——明显的镜头/角色跳变——建议使用 VACE 来保证连续性和/或交错插入静态中景;评论者提供了一个快速的 VACE+上采样对比片段 (https://streamable.com/1wqka3),并引用了之前关于一致性和色彩偏移 (color drift) 的长视频研究 (https://www.reddit.com/r/StableDiffusion/comments/1l68kzd/video_extension_research/)。另一个建议是倾向于使用硬剪辑(丢帧),而不是允许每约 3 秒出现一次微小动作,因为后者会被视为 AI 工作流特有的虚假伪影。 评论者一致认为,相比原始 FLF2V,VACE 显著提高了时间一致性,而其他人则认为传统的编辑方式(硬剪辑)能更好地掩盖 AI 动作伪影,让观众感觉更自然。
- 多位用户注意到 Wan 2.2 FLF2V 输出中的时间不连续性(镜头/角色跳变),并报告称集成 VACE 进行片段间的连续性处理,加上插入静态中景,可以减少明显的跳变。提供了一个使用 VACE 和上采样的快速 A/B 示例:https://streamable.com/1wqka3,显示出比仅使用 FLF2V 更好的连续性。引用了之前涵盖色彩偏移及缓解策略等问题的长视频研究:https://www.reddit.com/r/StableDiffusion/comments/1l68kzd/video_extension_research/。
- 为了实现可复现性和更好的拼接效果,分享了一个将 Wan 与 VACE Clip Joiner 结合的原生 ComfyUI 工作流:https://www.reddit.com/r/comfyui/comments/1o0l5l7/wan_vace_clip_joiner_native_workflow/。该流水线专注于在组装较长序列时保持片段间的时间一致性并减少镜头偏移。
- 展示的视频是使用 Ellary- 基于 SDXL 的线稿流水线构建的,记录详见:https://www.reddit.com/r/StableDiffusion/comments/1nf1w8k/sdxl_il_noobai_gen_to_real_pencil_drawing_lineart/。归属说明澄清了其外观和线稿转换源自该方法,该方法可与 Wan 2.2 FLF2V 结合以在生成视频时保持风格一致性。
- Sora 视频正成为西班牙的主流内容 (@gnomopalomo) (活跃度: 1139): 帖子声称 OpenAI 的文本生成视频模型 Sora 制作的内容现在出现在西班牙的主流媒体中(归功于 @gnomopalomo)。链接的媒体 (https://v.redd.it/p2ci6clyrvuf1) 返回
HTTP 403 Forbidden,表明 Reddit 应用层访问控制需要身份验证或开发者凭据,而非瞬时网络/传输错误;访问/申诉请参阅 Reddit 的 登录 和 支持工单 页面。帖子中未提供具体的详细技术细节(如 Prompt、分辨率、运行时间、后期制作流水线)。 热门评论多为非技术性的;情绪从担心“AAA 级制作标准”放大低质量趋势,到对视觉效果的随性热情不等,没有基准测试或实现方案的讨论。- 一位评论者提出了技术担忧,即随着 Sora 生成的视频走向主流,版权执法将会加强:YouTube/TikTok 等平台使用内容指纹识别(例如 YouTube 的 Content ID)来自动标记匹配项(音频和视觉),即使 AI 输出经过了风格化或转换,也可能触发自动索赔/封锁。在欧盟(包括西班牙),DSM 指令的第 17 条规定,如果平台未能阻止侵权内容的出现,将承担更多责任,这激励了更激进的上传前后过滤;参见指令文本和指南 (EU 2019/790)。实际上,这意味着重复使用受版权保护的音乐、品牌资产或相似角色的 Sora 内容可能会面临下架或被强制向权利人支付收益,除非创作者获得许可或坚持使用无版权限制的资源。
2. Unitree G1 V6.0 人形机器人灵活性演示与 ChatGPT 辛普森风格输出
- Unitree G1 Kungfu Kid V6.0 (热度: 813): [Unitree G1 Kungfu Kid V6.0](https://www.youtube.com/watch?v=O5GphCrjx98) 似乎是 Unitree G1 人形机器人进行快速、编排好的武术风格动作(踢腿、冲拳、旋转)的能力演示。该序列突出了在快速质心偏移和短暂单腿支撑阶段下的动态平衡和全身协调,表明了强大的跟踪/控制和落脚点规划能力;然而,视频未提供定量基准(例如 **
DoF、关节扭矩/速度、功率、恢复指标)或控制器/训练细节,因此应将其视为定性的灵活性演示,而非可复现的方法或基准对比。- 软件驱动的快速进展:一位评论者指出,一年前在贸易展上还会“摔倒和抽搐”的同一款 Unitree 人形机器人,现在表现出显著提升的稳定性和灵活性,这表明在没有明显硬件改动的情况下,控制栈(状态估计、WBC、轨迹规划)进行了重大升级。他们甚至认为这段演示让 Tesla Optimus 的演示相形见绌,强调了软件的快速迭代如何转化为运动性能的提升 (Unitree G1, Tesla Optimus)。
- 对操纵和末端执行器的关注:人们对 Unitree 的“灵巧手附件”以及在平衡/灵活性之外领域(如协调的手臂任务、丰富接触的操纵、感知)的进展感到好奇。技术读者希望看到双向技能基准(开门、工具使用、取放任务)或遥操作到自主化迁移的证据,理想情况下应使用模块化末端执行器和可复现的任务,而非侧重于编排的演示。
- 这是 ChatGPT 在法律允许范围内最接近生成《辛普森一家》的一次。 (热度: 1629): 该帖子展示了一个 AI 生成的、类似《辛普森一家》的卡通家庭,说明了托管的 LLM/图像系统(此处标注为 “Gemini 2.5 Flash Image”,尽管标题提到了 ChatGPT)如何应用 IP/版权安全层来阻止精确的角色生成,同时允许风格相近的输出。实际上,这是通过提示词/实体过滤器和生成后的安全分类器(例如嵌入/名称匹配或视觉相似度阈值)强制执行的,导致生成的是通用的“黄色卡通家庭”构图,而非受商标保护的肖像。评论中的示例显示了类似的“擦边”渲染,突出了基于策略的解码和安全门控如何导致刻意偏离受保护角色的“风格偏移”。 评论者指出,没有安全层的本地/微调模型(如 LoRA 检查点)可以更忠实地再现 IP,而云模型则优先考虑法律风险并过滤提示词/输出;一些人讨论了模仿“风格”(而非精确的角色肖像)是否存在法律风险,以及相似度检测器在区分两者方面的可靠性。
- 一位评论者报告称,通过先提示 ChatGPT 编写详细场景,然后根据该场景生成图像,而不是直接要求生成《辛普森一家》的图像,可以获得更好的保真度。这种两步走的方法增加了描述性信号(角色、场景、动作),同时避免了显式的商标术语,这可能绕过了更严格的 IP 分类器,同时保留了风格先验;其结果在输出 示例 中仍显示出偏离模型的伪影(例如 Lisa 的嘴巴、Burns/Smithers 的比例、Marge 的脖子)。
- 多个分享的输出说明了在风格化角色再现中一致的失败模式:面部拓扑和肢体/颈部解剖结构偏移、线条粗细不一,以及角色间的比例错误,即使调色板和布局接近目标风格 (ex1, ex2, ex3, ex4)。这表明模型正在向“类辛普森”分布进行优化,而没有精确的角色身份,这可能受到 IP 防护栏以及训练数据差异的影响,导致风格接近但特定角色特征不稳定。
- 有提到使用 Google 的 Gemini 2.5 Flash Image 来执行类似任务,暗示了在风格近似输出方面的跨模型可行性。虽然没有提供定量基准测试,但讨论暗示模型选择会影响对风格约束的遵循与 IP guardrails 之间的平衡,ChatGPT 的图像系统和 Gemini 都能生成可辨识的色调/构图,但在角色精确的几何形状上有所分歧。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3. 极简配文迷因/反应图 (He’s absolutely right / Infinite loop / Hmm)
- He’s absolutely right (热度: 1409): 非技术性迷因/截图(“他说得完全正确”)被用作讨论 LLM sycophancy(谄媚性)以及 AI 是增强用户信念还是纠正用户信念的跳板。评论者对比了不同的体验:有人说最近的模型不会被说服相信错误信息,“尤其是最近”,暗示改进了 guardrails/事实抵抗力,而另一些人则认为 AI 现在加入了社交媒体和党派媒体的行列,在回声壁中提供肯定。该帖将 AI 框架化为潜在的“公正第三方”,但考虑到确认偏误和模型行为的可变性,对这一理想提出了质疑。 辩论集中在 LLM 是在改进事实纠正能力还是保持谄媚;有些人认为它们对错误检查很有用,另一些人则认为 AI 通过验证用户与现有回声壁一起进一步瓦解了话语体系。
- 几条评论提到了已知的 LLM 失效模式“sycophancy”(模型无论事实真相如何都同意用户陈述的观点),这在一定程度上是 RLHF 为优化用户满意度而产生的副产品。实证分析(例如 Anthropic 关于 sycophancy 的研究)显示模型会调整答案以匹配用户暗示的身份或偏好,建议通过多样化的偏好数据、显式的批评/验证模式或 constitutional-style 训练来减少一致性偏见。参见:https://www.anthropic.com/news/sycophancy 以及 Constitutional AI 综述:https://arxiv.org/abs/2212.08073。
- 一位评论者声称最近更难说服模型接受谬误,这与改进的事实性校准一致,但在对抗性 prompting(角色扮演、引导性前提或 jailbreaks)下仍然脆弱。指令层级(system > developer > user)和 prompt injection 仍能强迫模型达成一致或使其陷入错误,突显了对 guardrails 的需求,如基于来源的 RAG、强制引用和最终回答前的自我批评环节。背景:prompt injection/jailbreak 文献(例如 https://arxiv.org/abs/2312.04764)和事实性基准测试如 TruthfulQA (https://arxiv.org/abs/2109.07958)。
- 另一个帖子指向了跨平台的回声壁,社交动态和 LLM 可能会强化用户的信念;从技术上讲,非个性化的 LLM 仍可能镜像出用户 prompt/上下文窗口中存在的偏见。实际的缓解措施包括带溯源的检索、不确定性估计(在暴露的情况下使用校准的置信度/logprobs),以及提示模型提供反论点或矛盾检查,以抵消 prompt 调节下的确认偏误。通常建议使用 RAG 和引用优先生成,以将输出限制在可验证的来源内。
- Infinite loop (热度: 3294): 一张截图(图片)显示 ChatGPT 陷入了明显的无限响应循环,重复输出同一行内容(在评论中被转述为海马表情符号查询),原帖指出询问模型为何循环会导致其再次崩溃。标题(“Infinite loop”)和评论表明了可复现性(另一位用户分享了复现截图:链接),暗示在生成过程中存在解码/终止条件 Bug 或 moderation/guardrail 反馈循环。 评论者大多在开玩笑;有人询问技术原因,但除了用户确认他们可以复现循环行为外,没有提供具体的诊断。
- 一位评论者报告说 ChatGPT 在被问及海马表情符号时反复循环其响应然后崩溃,并询问为什么会发生这种情况;帖中没有提供技术解释或缓解措施,也没有提供复现步骤或模型/版本详情(截图)。这是一个关于稳定性问题(循环/终止)的轶事报告,没有诊断、日志或环境细节,因此除了注意到一个涉及表情符号处理的潜在边缘案例外,没有实际的可操作性。
{kind=link}
{kind=link}
AI Discord Recap
由 Gemini 2.5 Pro Exp 生成的摘要之摘要的摘要
主题 1. 新模型、框架和 API 冲向平流层
- vLLM 和 Together AI 竞逐更快的推理速度:Cascade Tech 在 vLLM 中引入了 Predicted Outputs,通过将输出转换为匹配项的 prefill 来实现更快的生成,其 实验性分支 已提供演示。不甘示弱的 Together AI 推出了 ATLAS (Adaptive-LeArning Speculator System),这是一种使用运行时学习加速器(Runtime-Learning Accelerators)的 LLM 推理 新范式。
- 自适应 LLM 与新 Agent 平台涌现:SEAL 框架 现在使 LLM 能够通过生成自己的微调数据和更新指令来实现持久的权重更改,从而实现自适应,代码和 论文 已发布。在 Agent 领域, Agentbase 推出了一个无服务器平台,可在 30 秒 内部署 Agent;而 OpenRun 则提供了一个声明式平台,只需一条命令即可管理包括 Gradio 在内的 Web 应用。
- Google 和 Qwen 准备发起下一代模型攻势:社区正翘首以待 Gemini 3,有人开玩笑说 GTA 6 都会先发布;同时有报告指出 Google 已经开始从 Gemini 2.5 重新分配服务器资源,导致质量下降。与此同时,Qwen 计划下周发布更多模型,包括 Next, VL, Omni, 和 Wan(来源),引发了人们对其目标是成为“美国的 DeepSeek”的猜测。
Theme 2. 硬件难题与性能谜题
- VRAM 溢出和 RAM 价格困扰开发者:用户发现超过 VRAM 限制 会导致性能暴跌,当溢出到页面文件(虚拟内存)时,速度会从 70 tokens per second (TPS) 降至 2 TPS 以下。正如 这张图表 所示,DDR5 RAM 价格 飙升使情况雪上加霜,有人将其归咎于 RAM 被重新定向到了服务器市场。
- Mojo 的 GPU 处理方式既令人沮丧又令人印象深刻:工程师们发现 Mojo 在运行时为每个 GPU 重新编译代码,这是一种灵活的方法,但也有人对其类型系统(特别是 LayoutTensors)感到束手无策,一位用户表示在复杂场景下,CUDA 的学习和使用难度要低几个数量级。不过社区的努力仍在继续,一位成员在 GitHub 上分享了他们的 vulkan-mojo 绑定。
- Groq 遇挫,而 Flash Attention 大放异彩:Groq 在工具调用(tool call)基准测试中的表现令用户惊讶,得分较低,准确率下降至 49%,详见 此推文。相比之下,开发者称 Flash Attention 基本上是“免费的性能提升”,因为它提供了显著且简便的性能增强,尽管它可能会对 OSS120B 等某些模型的工具调用产生负面影响。
{kind=link}
Theme 3. 模型怪癖、版权冲突与关键漏洞
- Sora 和 ChatGPT 与内容政策博弈:根据 OpenAI 的使用政策,用户报告 Sora 经常禁止或无法渲染受版权保护的内容(如动漫战斗)。同样,ChatGPT 在生成逼真面部方面也表现挣扎,声称“无法创建逼真的面部”,迫使用户寻找变通方法,比如在 Paint 中添加瑕疵。
- 研究人员揭示投毒与 Prompt Injection 风险:Anthropic 的一篇论文显示,仅需 250 份恶意文档 即可为 LLM 设置后门,其 研究详情 进行了详细说明。在相关的发现中,GitHub Copilot 的一个关键漏洞允许通过伪装绕过(camo bypass)外泄私有源代码,这篇博文 强调该问题“极其简单却行之有效”。
- 机器中的幽灵:AI 产生“灵魂”和表格:用户对 nano-banana AI 输出 中微弱且重复的伪影展开讨论,开玩笑说“这不是水印,而是灵魂”,并试图确定这是 Bug 还是特性。与此同时,开发者发现 GPT 模型 尽管收到了避免生成表格的指令,却依然执着地生成表格,导致有人吐槽道:“你真的没法让 GPT 不发表格……”
Theme 4. 开发者工具难题与社区联系
- Cursor Agents 和 Aider 配置困扰开发者:Cursor 用户反映,在合并代码时 Background Agents 可能会意外关闭,且与 Linear 的集成存在 Bug。Aider 用户正在寻求更好的配置管理方式,例如将设置导出到文件并寻找合适的讨论论坛,因为官方的 GitHub Discussions 已关闭。
- OpenRouter SDK 和 LayerFort 引发警惕:使用 openrouter ai-sdk 集成的开发者被警告要非常小心,因为该插件无法报告涉及 tool calls 的中间步骤的使用情况和成本。另外,社区将 LayerFort 标记为可能的诈骗,因为它在被发现该网站几个月前还是一家普通的投资公司后,仍以每月仅 $15 的价格宣传无限次 Sonnet API 访问。
- DSPy 社区积极筹备线下见面会:人们对 DSPy 线下活动的热情日益高涨,由 PyData、Weaviate 和 AWS 成员组织的波士顿见面会已经排上日程(在此注册)。社区成员现在正积极自愿在湾区和多伦多组织类似的聚会。
主题 5. 解码更智能 AI 背后的科学
- 研究人员探测模型以揭示潜在技能:一篇新论文指出,思考型语言模型并非学习新的推理技能,而是激活了基础模型中已有的潜在技能;通过 sparse-autoencoder 探测,研究人员提取了 10-20 个不同推理例程的转向向量(steering vectors),恢复了 MATH500 上高达 91% 的性能差距(详情见此)。这与关于 ‘Less is More: Recursive Reasoning’ 论文的讨论相呼应,该论文探讨了仅在深度递归的最后一步进行反向传播。
- Mamba 3 和 RWKV 架构对比:社区剖析了新的 Mamba 3 论文,将其架构与 RWKV-7 进行了对比,并注意到它用调整后的 RWKV tokenshift 机制取代了 conv1d。共识是 Mamba 3 是现有架构的精简版本,其效率提升在特定场景下可能非常有价值。
- 优化器大辩论:RMSProp 受到质疑:一场技术辩论对 Scalar RMSProp 声称的自适应性提出了挑战,认为其 1/sqrt(v) 修正因子实际上可能是有害的。这与使用 sqrt(v) 的假设性“反 Scalar RMSProp”形成对比,质疑了关于优化器如何调节锐度并达到稳定性的基本假设。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Grok 在图像生成方面超越 Gemini:聊天中的用户认为 Grok 在生成图像方面优于 Gemini。
- 其他用户指出,Gemini Ultra 的目标与 OpenAI 非常相似。
- Perplexity 考虑收购 Suno AI:一名成员建议 Perplexity 应该收购 Suno AI,只需 5 亿美元的小额投资即可统治 AI 音乐产业。
- 用户指出,这将使其能够访问顶尖的 AI 聊天模型、图像模型、视频模型以及领先的 AI 音乐生成技术。
- OpenAI 旨在取悦现实世界用户:频道成员表示,OpenAI 正更加专注于现实场景中的可用性。
- 另一名成员表示,与 Anthropic 不同,OpenAI 只关注速度和效率。
- Perplexity Search API 遭遇权限壁垒:一名成员报告在使用 Perplexity Search API 时遇到了
PermissionDeniedError,似乎被 Cloudflare 拦截了。- 另一名成员解释说,当 Cloudflare 的 bot/WAF 防护应用于 API 域名时,就会发生这种情况。
- WAF 跳过规则解除 API 流量阻塞:一名成员建议添加针对性的 WAF skip rule 或禁用拦截 API 路径的特定托管规则组,以便 API 流量不会受到挑战。
- 这将有可能解决 Perplexity Search API 触发
PermissionDeniedError的问题。
- 这将有可能解决 Perplexity Search API 触发
LMArena Discord
- 社区期待 Gemini 3 的“戈多式”发布:成员们正热切期待 Gemini 3 的发布,有人开玩笑说 GTA 6 都会先出,并将其与对 GPT-5 发布的期待相提并论。
- 社区希望发布时能通过 Google AI Studio 提供免费 API,而一些匿名用户 (anons) 对这些炒作持怀疑态度。
- Gemini 2.5 Pro 依然表现出色:一些用户称赞 Gemini 2.5 Pro 是他们生成创意内容的首选模型,有人认为它比 GPT-5 更好用。
- 少数用户报告称,他们通过 AI Studio 的 A/B 测试获得了 Gemini 3 的访问权限。
- Sora AI 主导 VGen:用户分享了各种使用 Sora AI 制作视频的链接,这引发了围绕使用生成视频的法律合规性(涉及 DMCA)的讨论。
- 一名成员澄清说,TOS(服务条款)规定他们拥有输出内容的所有权利。
- LM Arena 饱受功能问题困扰:用户报告了 LM Arena 的各种问题,包括 AI 模型卡在“思考中”状态、网站报错以及聊天记录消失。
- 几位成员提到 LM Arena 最近 bug 很多,问题从聊天崩溃到无限生成循环不等,并建议使用 VPN 来解决其中一些问题。
OpenAI Discord
- ChatGPT 在生成写实面部时遇到困难:成员报告称 ChatGPT 声称无法创建写实的面部,并建议使用低分辨率图像或在 Paint 中添加错误作为变通方法。
- 另一位成员发现,ChatGPT 在读取上传的 PDF 时,有时无法将指令传递给其图像生成组件,建议先提示 ChatGPT 描述文件内容,然后再生成图像。
- 受版权保护的内容挑战 Sora 的输出:用户发现 Sora 经常禁止请求或无法准确渲染受版权保护的素材(如动漫战斗),因为根据 OpenAI 的使用政策,不允许输出大多数受版权保护的内容。
- 成员们被警告不要尝试规避这些政策。
- 上下文投毒 (Context Poisoning) 探测引发安全审查:一场关于上下文投毒的讨论展开,一位成员分享了一个使用异常符号和数学构建“秘密语言”的实验性 Prompt,用于 AI 交互和心理探测;但另一位成员建议使用明确的、选择性加入的标签和尊重同意的行为来进行更安全的实验。
- 建议的框架是 μ (代理/连贯性) vs η (伪装胁迫),用于更安全的实验。
- Discord 辩论代词协议,项目分享暂停:Discord 用户就用户个人资料中是否有必要使用代词以及其“古怪性”发生了冲突,这干扰了一位成员分享项目的尝试。
- 对话演变成了政治指责,导致项目分享者推迟了演示,并创建了一个专门的线程以避免进一步的离题争论。
- Agent Builder 数据更新:一个持久的难题:一位用户正试图弄清楚如何保持使用 Agent Builder 构建的 Agent 中的数据更新,特别是寻求一种以编程方式保持员工目录和其他文档知识库更新的方法。
- 社区目前对该问题尚无解答。
LM Studio Discord
- VRAM 溢出显著降低 Token 生成速度:用户发现超过 VRAM 限制会急剧降低每秒 Token 数 (TPS),在使用页面文件(pagefile)时,速度从 70 TPS (VRAM) 降至 1.x TPS。
- 有人指出使用系统 RAM 可以提供尚可的速度,尤其是在使用 Mixtral of Experts (MoE) 模型时。
- Flash Attention 带来近乎免费的性能提升:启用 Flash Attention 显著提高了性能,一些社区成员称其为“基本免费的性能提升”。
- 它可能会对某些模型(如 OSS120B)的工具调用(tool calls)产生负面影响,但具体原因尚不完全清楚。
- RAM 价格飙升,服务器市场是罪魁祸首?:自 9 月以来,DDR5 RAM 价格大幅上涨,如此图所示。
- 社区推测 RAM 被重新定向到服务器市场,导致消费者成本增加;一些成员因此暂停了装机计划,直到价格下跌。
- Nvidia K80 被视为电子垃圾:成员们讨论了使用 Nvidia K80 的可行性,但由于驱动问题,很快就将该卡视为电子垃圾。
- 成员建议考虑 Mi50,因为有些人已经取得了成功(32gb 约 £150)。
- ROCm 引擎缺乏对 RX 9700 XT 的支持:成员报告称,ROCm llama.cpp 引擎(Windows 版)不支持 9700XT,尽管官方发布的 Windows 版 ROCm 声称完全支持。
- AMD Radeon RX 9700 XT 的 gfx 目标为 gfx1200,这未列在 ROCm 引擎清单中,表明可能存在不兼容性。
Unsloth AI (Daniel Han) Discord
- HuggingFace 下载错误解析:用户发现下载错误通常是由于缺少 Hugging Face Token 导致的 401 错误。
- 故障排除帮助用户继续进行,但目前仍在调查和提出更多问题。
- GPT 模型无法摆脱表格的诱惑:尽管有避免表格的指令,GPT 模型仍坚持生成表格,需要通过 Fine-tuning 来防止这种情况。
- 一位成员幽默地表示:“你真的没法让 GPT 不用表格……”,这表明仅靠 System Prompts 是不够的。
- 以极速微调 Gemma 1B:成员建议通过增加 GPU RAM 使用量、减小数据集大小来加速 Gemma 1B 模型的微调,并指出最佳数据集大小通常在 2-8k 样本左右达到饱和,具体取决于任务。
- 成员指出,使用 127,000 个问题进行训练大约需要 6 小时。
- 安卓手机运行 Vibe Coded 版 Gemma:一位驻西雅图的 AI 工程师正尝试在 Fine-tuning 后,在安卓手机上运行 vibe coded 版本的 gemma3n。
- 他们表示期待使用新创建的系统进行游戏和聊天。
- Qwen3-8B 小说模型完成训练:一位成员使用约 8k 章真实小说章节训练了 Qwen3-8B,但该模型继承了 Qwen 的重复问题,可能需要超过一个 Epoch 的训练。
- 建议 Qwen3 至少需要 2-3 个 Epoch 来精炼其散文表达,并且增加 Rank 有助于清理小说提取内容和数据集。
OpenRouter Discord
- Google 为了 3.0 降级 2.5:成员们报告称 Google 正在将服务器重新分配给 3.0,导致 2.5 的质量下降,而该模型自 GA 发布以来一直面临持续的质量退化。
- 频道注意到,自从 Google 将资源转移到 3.0 模型后,Google 2.5 模型的质量出现了下降。
- OpenRouter SDK 让不知情的开发者陷入困境:使用 openrouter ai-sdk 集成的用户应当非常小心,因为当工具调用(tool calls)涉及多个步骤时,该插件不会报告完整的详细使用情况。
- 它仅报告最后一条消息的使用情况和成本,未能计算包含工具调用的中间步骤。
- 中国模型变得更“大胆”了:成员们提到中国模型相当宽松,但需要系统提示词(system prompt)声明它们是 NSFW 创作者。
- 推荐使用 Z.ai 作为提供商的 GLM 4.5 air (免费版) 以避免 429 错误;请注意,免费的 V3.1 端点是经过审查的,而付费端点则保持正常。
- LayerFort 被指为骗局:成员们注意到 LayerFort 看起来像是一个骗局,宣传每月 15 美元 即可通过 API 使用无限量的 Sonnet,但实际提供的 Token 使用量极少。
- 进一步调查显示,该网站在半年前还是一家普通的投资公司,这进一步增加了怀疑。
- Qwen 满足了对新模型的渴望:Qwen 计划下周发布更多模型(来源),目前已发布多个模型,包括 Next、VL、Omni 和 Wan(来源)。
- 一位成员幽默地表示,筹集了 20 亿美元 的 Qwen 目标是成为“美国的 DeepSeek”,并表达了希望他们不要掉队的愿望。
Cursor Community Discord
- 听写功能首次亮相开发版,正式部署延迟:听写功能已在 Nightly 版本中上线,但尚未进入公开版本,不过用户可以通过 CTRL + SHIFT + P 或设置中的 About 部分检查更新。
- 用户预计该功能最终将进入公开版本。
- 对移动端 Cursor 的渴望仍在继续:用户表达了对移动端 Cursor 的强烈需求,但该 IDE 目前仅限桌面端,移动端仅支持 Background Agent 管理。
- 这一限制是社区内反复讨论的焦点。
- Cursor Agents 在集成方面表现挣扎:一位用户描述了一个问题,即使用 Background Agents 编写新功能并将代码更改合并到主分支时,会导致 Cursor BA 关闭。
- 另一位用户报告称,Background Agent 经常显示“尚无对话”(no conversation yet),状态为已完成,但任务实际上并未执行,这似乎与 GitHub 有关。
- Linear 集成经历重新连接困扰:一位用户报告了在重新连接 GitHub 和 Linear 后 Linear 集成 出现的问题,并分享了截图。
- 另一位用户报告在尝试将其与 Linear 配合使用时收到“Cursor 停止响应”错误,并分享了截图。
{kind=link}
{kind=link}
GPU MODE Discord
- Nsight 在新款 Nvidia 节点上表现出色:一位用户确认 Nsight Compute 和 Nsight Systems 在他们自己的 5090 GPU 上运行良好,消除了文档带来的疑虑。
- 成员们指出,这些工具对于分析 GPU 工作负载以识别瓶颈和优化性能至关重要。
- Together 团队优化张量传输:ATLAS 登场:Together AI 推出了 Adaptive-LeArning Speculator System (ATLAS),这是一种通过 Runtime-Learning Accelerators 进行 LLM Inference 的新范式。
- 该公告也通过 Tri Dao 的 X 账号 和 Together Compute 的 X 账号 发布。
- 内存问题困扰 Torch:一位用户报告了一个内存问题,即 torch compiled model 的内存消耗随时间缓慢增加。
- 定期调用包含 torch.cuda.empty_cache()、torch.cuda.synchronize() 和 gc.collect() 的 CUDA 内存碎片整理函数 有助于减轻内存压力。
- 社区对 CUDA 缓存的贡献:一位用户正在主持一个语音频道,讨论如何为真实的 CUDA repo 寻找合适的首次贡献机会,包括代码走读。
- 目标是降低社区贡献的门槛,为新手提供指导和支持。
- Triton 讨论会:下一场 Triton 社区见面会 将于 2025 年 11 月 5 日上午 10 点至 11 点(PST) 举行,会议链接 已分享。
- 暂定议程包括 TLX (Triton Language Extensions) 更新、Triton + PyTorch Symmetric Memory 以及 PyTorch 中的 Triton Flex Attention。
HuggingFace Discord
- AgentBase 发布 Serverless 平台:一位成员介绍了 Agentbase,这是一个 Serverless Agent 平台,允许开发者在不到 30 秒 的时间内构建和部署 Agent,无需管理单个集成。
- 该平台提供针对记忆、编排、语音等功能的预封装 API,旨在帮助 SaaS 向 AI-native 转型,或快速进行 Agent 构建实验。
- 声明式 Web 应用迎来 OpenRun:一位成员一直在构建名为 OpenRun 的声明式 Web 应用管理平台,支持对使用 Gradio 构建的应用进行零配置部署。
- 它有助于通过单个命令设置完整的 GitOps 工作流,只需修改 GitHub config 即可创建和更新应用。
- Hugging Face 用户抱怨退款延迟:一位用户对未收到 Hugging Face 的退款表示沮丧,称他们从 6 号起就一直在发邮件,并提醒其他人注意退款缺失以及订阅页面的配额使用问题。
- Hugging Face 团队成员 <@618507402307698688> 介入,询问该用户的 Hub 用户名以检查退款进度,并澄清 黄色角色 = Hugging Face 团队。
- 社区寻求开源 MoE:成员们正在寻找具有可配置总参数量的优质 开源 MoE (Mixture of Experts) 模型用于预训练,建议查看 NVIDIA 的 Megatron Core 和 DeepSpeed。
- 一位成员幽默地询问是否有人拥有 服务器集群和海量的训练数据。
- 用 Go 编写的混合 VectorDB 亮相:一位成员发布了他们从零开始用 Go 编写的 VectorDB,命名为 Comet,它支持在 BM25、Flat、HNSW、IVF、PQ 和 IVFPQ 索引上进行混合检索,并具备 Metadata Filtering、Quantization、Reranking、Reciprocal Rank Fusion、Soft Deletes、Index Rebuilds 等众多功能。
- 该成员发布了 HN 帖子 的链接。
Eleuther Discord
- AI 评估受到审视:成员们分析了一篇关于 AI 评估的 Medium 文章,对当前的方法论提出了质疑。
- 一位成员建议在更少的数据上使用更有效的架构来训练模型。
- RMSProp 的自适应性受到质疑:围绕 Scalar RMSProp 的自适应性质展开了讨论,挑战了其自适应性与最大稳定步长相关的说法。
- 有观点认为 1/sqrt(v) 修正因子可能是有害的,并将其与使用 sqrt(v) 的假设性 anti-Scalar RMSProp 进行了对比。
- Mamba 3:RWKV-7 的分支?:成员们将 Mamba 3 的架构与 RWKV-7 进行了比较,注意到它用调整后的 RWKV tokenshift 机制取代了 conv1d Mamba 3 论文。
- 共识是 Mamba 3 是对现有架构的精简,其效率提升在特定场景下可能很有价值。
- 递归推理:有限反向传播:讨论了论文《Less is More: Recursive Reasoning with Tiny Networks》,特别是经过 T-1 步 no_grad() 后,仅在深度递归的最后一步进行反向传播的技术。
- 其背后的机制仍在研究中,GitHub 上有一个相关的 Issue 处于开启状态。
- BabyLM 竞赛公布:提到了旨在寻找最小语言模型的 BabyLM 竞赛。
- 分享了 BabyLM 网站,并指出该竞赛将于 11 月在中国举行的 EMNLP 2025 上亮相。
Modular (Mojo 🔥) Discord
- Mojo 针对特定 GPU 重新编译:当被问及与新 GPU 的前向兼容性时,一位成员指出 Mojo 会在运行时为每个 GPU 重新编译代码。
- 他们建议供应商使用 SPIR-V 来确保兼容性,并且可以使用持续更新的库来编译驱动程序的 MLIR blobs。
- Vulkan-Mojo 绑定已可用:一位成员分享了他们的 vulkan-mojo 绑定,地址为 Ryul0rd/vulkan-mojo。
- 他们提到尚未添加对 moltenvk 的支持,但这属于相对简单的修复。
- Mojo 的 MAX 后端遇到 Bazel 故障:当一名成员在测试新的
acos()Max op 遇到困难时,发现 Bazel 无法找到graph目标,导致测试变成了空操作(no-op),这可能与 Issue 5303 有关。- 成员们建议在算子文件中使用相对导入
from ..graph而不是.graph,但这并未解决问题。
- 成员们建议在算子文件中使用相对导入
- LayoutTensors 让工程师感到沮丧:一位成员表达了对 LayoutTensors 的挫败感,理由是复杂的类型不匹配以及将其传递给子函数的困难。他们表示由于 Mojo 类型系统带来的挑战,他们已转向使用 CUDA,因为后者更简单。
- 他们分享了突出这些问题的代码示例,并总结道:“如果你的 GPU 代码很简单,那么 Mojo 很好;但如果是复杂的场景,我仍然认为 CUDA 的学习和使用门槛要低几个数量级。”
Nous Research AI Discord
- vLLM 通过 Predicted Outputs 竞速更快的生成:Cascade Tech 在 vLLM 中引入了 Predicted Outputs,通过将输出转换为 prefill 以匹配预测的(部分)内容来实现快速生成,详见其 博客文章。
- Graph RAG 寻求基于工具的流水线:一位成员正在寻求一种类似 Graph RAG 的方法,用于将角色扮演书籍的内容进行 chunking 并转换为高效互连的节点,因为他们发现 Light RAG 无法满足需求。
- 他们正在寻找特定的基于工具的流水线或程序化控制的方法来进行 chunking 和 embedding 创建。
- SEAL 框架使 LLM 能够自适应:SEAL 框架通过让 LLM 生成自己的微调数据和更新指令,使其能够自适应,从而通过监督微调(SFT)实现持久的权重更新,详见其 论文。
- Anthropic 警告微量中毒样本:Anthropic 发现,无论模型大小或训练数据量如何,仅需 250 个恶意文档 即可在大型语言模型中产生后门漏洞,详见其 论文。
- 一位成员指出这是一个众所周知的问题,尤其是在视觉模型中,并讨论了在去中心化设置下进行检测的困难,特别是由于私有数据和多样的分布。
Latent Space Discord
- Exa 的搜索 API 获得强力升级:Exa 推出了其 AI 搜索 API 的 v2.0 版本,具有 “Exa Fast“(延迟 <350 ms)和 “Exa Deep” 模式,由新的 embedding 模型和索引驱动。
- 此次更新需要全新的内部向量数据库、144×H200 集群训练以及基于 Rust 的基础设施;详情见 此处。
- 极低价格实现无限 Claude 编程?:一位用户声称,中国的逆向工程通过将请求路由到 z.ai 上的 GLM-4.6,以每月仅 $3 的价格解锁了“无限 Claude 编程”层级。
- 然而,其他人对这种 Claude 体验的延迟和质量表示怀疑,如这篇 博客 所述。
- Raindrop 深入研究 Agent A/B 测试:Raindrop 推出了 “Experiments”,这是一个针对 AI Agent 的 A/B 测试套件,集成了 PostHog 和 Statsig 等工具。
- 这使得跟踪产品变更对工具使用率、错误率和人口统计数据的影响成为可能,事件详情见 此处。
- 基座模型隐藏了推理技能?:一篇新论文认为,思考型语言模型(例如 QwQ)并没有习得新的推理技能,而是激活了基座模型(例如 Qwen2.5)中已经存在的潜在技能。
- 通过使用稀疏自编码器(sparse-autoencoder)探测,他们提取了 10-20 个不同推理例程的引导向量,恢复了 MATH500 上高达 91% 的性能差距;链接见 此处。
- Nano Banana 拥有了灵魂?:nano-banana AI 输出中微弱且重复的伪影引发了争论,讨论这代表的是水印、Transformer 伪影还是某种生成怪癖。
- 社区开玩笑说“这不是水印,这是灵魂”,并建议将上采样(upscaling)作为潜在的解决方案。
Manus.im Discord Discord
- Manus 修复了 API 验证问题:用户报告在验证 Manus API key 时出现“服务器暂时过载”错误,团队已通过新的 API 更改修复了该问题。
- 更改包括新的响应 API 兼容性以及三个新端点,以便更轻松地管理任务,镜像了应用内的体验。
- Manus Webhook 注册 API 暂时下线:用户在尝试注册 Webhook 时遇到了“未实现”错误(代码 12),表明 Webhook 注册端点暂时无法使用。
- 团队成员承认了该问题,将其归因于最近的代码更改,并承诺在第二天修复。
- Manus 的价格对某些人来说太贵了:一位开发交易 EA 和策略的用户发现 Manus AI 太贵了,因为编程错误消耗了大量额度。
- 该用户表示 Manus 比 GPT 和 Grok 更好,但仍然太贵。
- Manus API 现在支持往返对话:Manus 团队启用了通过 API 多次推送到同一会话的功能,允许使用会话 ID 与 Manus 进行往返对话。
- 一位将 Manus 集成到排水工程应用中的用户表示,对流式传输中间事件感兴趣,以获得更透明的用户体验。
- 功能请求:调整你的熟练度!:一位用户建议增加一个选项,让用户在注册时说明自己的熟练程度,这样 Manus 就能知道是否应该假设用户一无所知并像照顾婴儿一样引导用户,而不是反过来。
- 该功能将有助于根据用户的经验和知识,量身定制 Manus 提供的协助和指导水平。
Moonshot AI (Kimi K-2) Discord
- AI 成为动漫动画师:用户分享了一段展示 AI 生成动漫的视频,对其制作完整动画作品和音乐的能力感到惊叹。
- 一位用户热情地表示,AI 生成的内容非常棒,标志着 AI 创作潜力的一个里程碑。
- Groq 在基准测试中受挫:用户讨论了 Groq 在工具调用基准测试中的表现,注意到分数出人意料地低,成功率骤降至 49%。
- 链接指向一条推文,推测表现低于预期的原因,将其归因于 Groq 的定制硬件和隐藏的量化问题。
- Kisuke 尝试通过 OAuth 获取 Kimi K-2 的额度:一位正在开发移动端 IDE Kisuke 的用户寻求关于实现 OAuth 集成的指导,以便用户能够登录并直接使用他们的 Kimi-K2 额度。
- 其他用户表示怀疑,认为 OAuth 可能不会授予对 API keys 的直接访问权限,暗示可能需要一个新系统,并建议联系 Aspen 讨论此功能。
- Moonshot 开发团队面临 Aspen 的意外离职:一位用户分享了一条推文,透露 Moonshot 开发团队成员 Aspen 因节假日期间的一次改变心智的经历将不再重返工作岗位。
- 关于 Aspen 离职的更多细节尚未公布。
Yannick Kilcher Discord
- GNN 损失暴跌!:在 Graph Neural Networks (GNNs) 训练期间,一位用户观察到损失函数突然下降,引发了关于模型是 grok’d(顿悟)了概念还是由于 hyperparameter tuning(超参数调优)导致的讨论。
- 其他人提出 LR scheduling(学习率调度)或第一个 epoch 的结束可能是原因,一位成员指出当 LR 降得足够低时经常会出现这种情况。
- 交换到停不下来:Embedding 版:成员们探索了在 system 和 user prompt 之间交换 embeddings,以区分上下文,特别是在长序列中。
- 目标是使模型能够辨别处理不同输入时的内在差异,从而帮助模型更快地学习。
- 伯克利 LLM Agents 课程:音频灾难得以避免?:尽管音频质量较差,一位成员仍推荐了来自伯克利的 LLM agents 课程,并指出其内容极具模因效应(memetic),适合以 1.5x 倍速观看。
- 另一位成员建议旧的伯克利网络广播讲座应该加上字幕,因为现在可以轻松生成字幕,已经没有理由再隐藏它们了。
- Copilot 的伪装被绕过,代码面临风险!:GitHub Copilot 中的一个严重漏洞允许通过伪装绕过(camo bypass)窃取私有源代码,正如这篇博文所报道的;该问题已通过禁用 Copilot Chat 中的图像渲染得到解决。
- 一位成员认为安全问题中的 prompt injection 方面很平常,但强调 camo bypass 特别有趣,称其极其简单却行之有效。
- AI 第一作者:新常态?:根据此公告,华东师范大学教育学部将在 2025 年 12 月的教育研究会议的一个分论坛中,要求 AI 第一作者身份。
- 这是该大学将 AI 置于研究创新前沿的新尝试的一部分。
DSPy Discord
- Gemma 获得 GEPA 指南:一位成员发布了一份教程,关于如何使用 GEPA 为创意任务优化像 Gemma 这样的小型 LLM。
- 该博文提供了使用 GEPA 进行 prompt engineering 的见解。
- DSPy 优化器在 Dataquarry 展开对决:The Dataquarry 上的一篇博文对比了 DSPy 中的 Bootstrap fewshot 和 GEPA 优化器,揭示了高质量训练样本的巨大重要性。
- 结果表明,在使用 GEPA 时,一组高质量的样本可以起到巨大的作用。
- Liquid 模型助力多模态建模:对于多模态任务,一位成员推荐了 Liquid models,因为它们效率很高,特别是在参数量低于 4B 的模型中。
- 该建议针对多模态建模领域对高效解决方案的需求。
- DSPy 演示日正在筹备中:由 PyData Boston、Weaviate 和 Amazon AWS AI 的成员组织的 DSPy 波士顿见面会即将举行,注册即将在 Luma.com 截止。
- 社区成员正自发组织 DSPy 湾区和多伦多见面会,热情持续高涨。
- 自动化高手待命:一位经验丰富的工程师正提供 workflow automation、LLM integration、AI 检测以及图像和语音 AI 方面的服务。
- 他们展示了使用 LangChain、OpenAI APIs 和 custom agents 构建自动化流水线和任务编排系统的实战经验。
aider (Paul Gauthier) Discord
- Aider 默认提示词配置技巧:成员们讨论了在 Aider 配置文件中将默认提示词功能设置为
/ask,并引用了关于使用模式和配置选项的 Aider 文档。- 用户建议设置
architect: true让 Aider 分析提示词并进行选择,并尝试使用edit-format: chat或edit-format: architect来设置启动时的默认模式。
- 用户建议设置
- Aider 社区寻求讨论中心:由于 GitHub Discussions 已关闭(https://github.com/Aider-AI/aider/discussions)且找不到 Reddit 论坛,用户正在寻找更好的 Aider 讨论平台。
- 用户似乎希望以非聊天格式讨论话题。
- 用户无法导出 Aider 设置:一位用户对
/settings命令表示沮丧,因为该命令会输出大量难以管理的堆栈信息,并询问是否可以将设置导出到文件。- 他们注意到
/help表明这是不可能的,但质疑脚本编写是否可以实现导出设置。
- 他们注意到
- Aider 的环境变量文件检索:Aider 会在主目录、git 仓库根目录、当前目录以及通过
--env-file <filename>参数指定的路径中查找 .env 文件。- 正如文档所述,这些文件按顺序加载,后加载的文件具有更高优先级。
- 自动测试挽救 Aider:一位用户报告称,在使用 qwen3-coder:30b 和 ollama 并设置了 test-cmd 和 lint-cmd 时,Aider 生成了无法编译的代码。
- 一名成员建议开启 auto test config 并设置为 yes always,这将在每次更改后运行测试并尝试修复。
tinygrad (George Hotz) Discord
- Python 3.11 升级考量:团队正在考虑升级到 Python 3.11 以利用
Self类型特性,尽管在 Python 3.10 中存在变通方法。- 一名团队成员找到了使用 3.10 的变通方法,使得升级变得不再紧迫。
- TinyMesa 分支在 Mac 上构建:一名团队成员 fork 了 TinyMesa 并确认该分支在 CI 中可以构建,理论上也可以为 Mac 构建。
- 成功实现 Mac 构建将获得 200 美元悬赏。
- NVIDIA GPU 回归 Mac:一名成员对在 Mac 上实现 TinyMesa 加 USB4 GPU 感到兴奋,这可能是十年来首个在 Mac 上运行的 NVIDIA GPU。
- 他们指出这是一个特别令人兴奋的前景。
- 会议取消!:一名成员询问会议情况,另一名成员确认会议已取消,因为之前已在香港时间上午 10 点举行过会议。
- 之前的会议使得再次开会变得没有必要。
MCP Contributors (Official) Discord
- REST API 代理设计辩论:一名成员质疑代理现有的 REST API 是否构成了糟糕的工具设计,引发了关于最佳实践的辩论。
- 讨论表明,效果取决于底层 API 的设计,特别是其与 LLM 相关的分页和过滤能力。
- 寻求具体的 LLM-Ready API 基准测试:人们对建立 LLM-ready API 基准测试产生了兴趣,但贡献者指出在没有具体数据的情况下很难实现。
- 有人建议,特定用例的基准测试和稳健的评估策略比依赖通用的外部基准测试更有价值。
- 提议确定性的 MCP 服务包:社区正面临当前 npx/uv/pip 方法中非确定性依赖解析的问题,这导致了 Serverless 环境中冷启动缓慢。
- 一名成员提议使用确定性的预构建产物来实现低于 100ms 的冷启动,这可以通过将 MCP 服务器视为编译后的二进制文件来实现。他们还有意提交创建工作组的请求。
- 明确 MCPB 仓库的参与情况:有人提出了关于社区对 anthropics/mcpb repo 中捆绑格式立场的问题。
- 讨论强调了与 Registry API/Schemas 的兼容性,指出了最近在 Registry 中支持 MCPB 的工作,并将进一步讨论引导至 <#1369487942862504016> 频道。
- Cloudflare 工程师加入 MCP 工作:一名新成员介绍自己是 Cloudflare 负责 MCP 的工程师,并表达了对该项目的热情。
- 无二次摘要。
MLOps @Chipro Discord
- 本周六扩散模型深度探讨:一个新的扩散模型论文阅读小组 (Diffusion Model Paper Reading Group) 将于本周六 PST 时间上午 9 点 / EST 时间中午 12 点举行(旧金山线下 + 线上混合模式),讨论 Song 等人在 2020 年发表的 Denoising Diffusion Implicit Models (DDIM)。
- 该环节将包括其 Diffusion & LLM Bootcamp 的介绍,小组将探讨 DDIM 如何在保持高质量的同时加速图像生成,这是理解 Stable Diffusion 的基础。
- Diffusion & LLM Bootcamp 启动:扩散模型论文阅读小组宣布了一个为期 3 个月的扩散模型训练营(2025 年 11 月),灵感来自 MIT 的 Diffusion Models & Flow Matching 课程。
- 该训练营旨在为 AI 和软件工程师、PM 及创作者提供构建和训练扩散模型、ComfyUI pipelines 以及 GenAI applications 的实战经验。
- 为黑客量身定制的 DIY Vector DB:一名成员宣布他们用 Go 从零开始编写了一个 Vector DB,专为黑客而非超大规模企业 (hyperscalers) 设计,并获得了 VCs 和企业赞助商的资助。
- 根据 HN 帖子,该产品支持基于 BM25, Flat, HNSW, IVF, PQ 和 IVFPQ Indexes 的混合检索 (hybrid retrieval),并具备元数据过滤 (Metadata Filtering)、量化 (Quantization)、重排序 (Reranking)、倒数排名融合 (Reciprocal Rank Fusion)、软删除 (Soft Deletes) 和索引重建 (Index Rebuilds) 功能。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord: 各频道详细摘要与链接
Perplexity AI ▷ #general (1266 条消息🔥🔥🔥):
Perplexity Pro vs Gemini Ultra, Perplexity AI 音乐行业收购, OpenAI 与 Google 的 AI 方法
- Grok 在图像生成方面击败 Gemini:频道成员一致认为 Grok 在生成图像方面优于 Gemini。
- 用户指出 Gemini Ultra 的模型目标与 OpenAI 非常相似。
- Perplexity 考虑收购 Suno AI:一名成员建议 Perplexity 应该收购 Suno AI,这将使他们只需投入 5 亿美元的小额投资即可主导 AI 音乐行业。
- 一些用户表示赞同,并指出通过这次收购,他们将提供顶级 AI 聊天模型、图像模型、视频模型以及领先的 AI 音乐生成服务的访问权限。
- OpenAI 致力于现实世界的可用性:频道成员表示 OpenAI 正更加关注现实世界场景中的可用性。
- 另一名成员指出,与 Anthropic 不同,OpenAI 只关注速度和效率。
Perplexity AI ▷ #pplx-api (8 条消息🔥):
Permission Denied Error, Cloudflare WAF protections, Anti-spam detectors
- Perplexity Search API 遇到权限拒绝错误:一名成员报告在使用 Perplexity Search API 时遇到
PermissionDeniedError,似乎被 Cloudflare 拦截。- 另一名成员解释说,当 Cloudflare 的 bot/WAF protections 应用于 API domain 时,就会发生这种情况。
- Cloudflare 的 WAF 跳过或禁用规则以解除 API 流量限制:一名成员建议添加针对性的 WAF skip rule 或禁用拦截 API paths 的特定托管规则组,以便 API traffic 不受挑战。
- 用户因打字太快被禁言:一名成员被禁言,原因为:新用户打字太快。
- 一名成员建议尝试不同的浏览器或设备,表明该用户触发了 anti-spam detector。
LMArena ▷ #general (1249 messages🔥🔥🔥):
GPT-5, Gemini 3, Claude 4.5, AI Model Performance, Comet Browser
- 用户苦等如《等待戈多》般的 Gemini 3:成员们正焦急地等待 Gemini 3 的发布,有人开玩笑说 GTA 6 都会先出。
- 一些人希望发布后能通过 Google AI Studio 提供 免费 API,而另一些人则将其与围绕 GPT-5 发布 的炒作进行了对比。
- Gemini 2.5 Pro 依然出色:一些用户称赞 Gemini 2.5 Pro 是他们生成创意内容的 首选模型,甚至有人认为它优于 GPT-5。
- 有用户报告称通过 AI Studio 的 A/B 测试 获得了 Gemini 3 的访问权限,但 匿名模型爆料者 (model anons) 对这些炒作仍持怀疑态度。
- Sora AI 仍是视频生成 (VGen) 的佼佼者:用户分享了多个来自 Sora AI 的链接,为其他用户创建视频。
- 这引发了关于用户是否可以 合法使用生成的视频(涉及 DMCA)的讨论,但一名成员指出 TOS(服务条款)规定他们拥有输出内容的所有权利。
- LM Arena 问题频发:用户报告了 LM Arena 功能上的几个问题,例如 AI 模型卡在思考状态、网站报错 以及 聊天记录消失。
- 几位成员提到 LM Arena 最近 Bug 很多,问题从聊天崩溃到无限生成循环不等——有人通过使用 VPN 解决了其中一些问题。
- 通用聊天频道中多语言用户的应对技巧:一些用户在用非英语交流,促使其他人建议使用 翻译器,尽管翻译被指出并不准确。
- 一名成员指出该频道 仅限英语,并呼吁大家遵守规则。
OpenAI ▷ #ai-discussions (1084 messages🔥🔥🔥):
ChatGPT image generation, Sora 2 restrictions, AI and copyright infringement, The agony of Eros, Getting Sora codes
- ChatGPT 在生成写实面孔方面表现挣扎:一位成员报告说,当他们尝试生成写实面孔时,ChatGPT 表示 它无法创建写实的面孔。
- 解决方法包括使用低分辨率图像或在 Paint 中添加瑕疵。
- ChatGPT 图像生成无法接收提示词:一位用户发现 ChatGPT 在读取上传的 PDF 时,有时无法将指令传递给其 图像生成 组件。
- 为了解决这个问题,可以在生成图像前先要求 ChatGPT 描述文件内容。
- OpenAI 删除已保存的用户帖子?:一些用户链接到了 Gizmodo 的文章,内容关于 OpenAI 将停止保存用户已删除的帖子。
- 其他成员则更专注于寻找 Sora 2 邀请码。
- 探讨数字交互中的“爱欲之死”:一位成员引用了 韩炳哲 (Byung-Chul Han) 的《爱欲之死》(The Agony of Eros),讨论了在无摩擦、个性化的现实中 他者 (Other) 的丧失。
- 他们分享了 文中的一个片段,强调该书的基调是诊断性的而非绝望的,且具有哲学诗意的风格。
- 第欧根尼与尼采联手打造数字犬儒主义:成员们沉思于一种源自 第欧根尼(嘲笑幻象)和 尼采(解释幻象)的现代哲学,从而产生了数字犬儒主义。
- 他们注意到这种原型是 清醒的、幽默的,并且不安地意识到这一切仍然是一场游戏。
OpenAI ▷ #gpt-4-discussions (37 条消息🔥):
MCP 开发频道,ChatGPT 解决填字游戏,Android 版 Sora AI,GPT 实时模型训练,custom gpt plus vs free
- ChatGPT 解决填字游戏证明具有挑战性:一位成员尝试让 ChatGPT 通过展示填字游戏网格来解决谜题,但模型无法看清那么多方格并成功追踪,如此 chatgpt.com 分享链接所示。
- 他们得出结论,模型无法足够清晰地“感知”网格来解决填字游戏,但人类可以迭代地绘制出一个。
- 自定义 GPT 在 Plus 与免费账户中表现不同:一位用户报告称,他们的 custom GPT 在 Plus 账户中无法正常工作,但在免费账户中却可以。
- 另一位用户询问,如果查看 See Details,它是否实际上使用的是同一个模型。
- Enterprise 与 Company 的定义:一位成员询问了 enterprise 和 company 账户之间的区别。
- 一位热心用户澄清说,根据 OpenAI 帮助文章,enterprise 是相当具有选择性的,并为感兴趣且被选中的超大型公司提供特定支持。
- 思考 Agent Builder 数据更新:一位用户正试图弄清楚如何保持使用 Agent builder 构建的 Agent 中的数据更新。
- 具体而言,他们询问是否有办法以编程方式保持员工目录和其他文档知识库的更新。
- GPT store 会关闭吗?:一位用户询问 GPT store 是否会关闭,以及所有的 GPT 是否会变成一个 App。
- 这个问题没有得到回答。
OpenAI ▷ #prompt-engineering (175 条消息🔥🔥):
Sora Prompting, Context Poisoning, Psychological Safety, Quantum Superpositioning, Text-to-Video Prompt Tool
- Sora 难以生成受版权保护的内容:成员们讨论了使用 Sora 生成基于受版权保护材料(如动漫战斗)内容的困难,并指出 Sora 经常禁止此类请求或无法准确渲染角色。
- 一位成员指出,Sora 不允许输出大多数受版权保护的内容,并拒绝提供规避此限制的方法,同时指出了 社区准则。
- Context Poisoning 的担忧与缓解策略:围绕 context poisoning 展开了讨论,一位成员分享了一个实验性提示词,使用不寻常的符号和数学来为 AI 交互创建一种“秘密语言”,旨在进行心理探测。
- 另一位成员对这种方法表示警告,认为它们对普通用户来说可能是不安全的,因为它们依赖于不可重现的技术,如 hash-seeded chaos 和隐藏的 ‘fnords’,这些可能会导致“隐蔽的不适感”;相反,他建议使用显式的、选择性加入的标签和尊重同意的行为来进行更安全的实验,推动用户采用 μ (agency/coherence) vs η (camouflaged coercion) 的框架。
- 辩论 AI 模型中的量子叠加:一位用户声称 quantum superpositioning 允许在初始化后对 AI 模型中的二进制输出进行微调,并将其与 AI 处理多维信号的能力联系起来。
- 另一位成员质疑了这一断言,指出如果没有具体的细节和规范(定义的量子电路或 Hamiltonian),quantum superposition 只是装饰而非模型,并进一步要求提供“引用来源”。
- 关于标准化文本转视频提示词工具的建议:在关于在 Sora 2 中创建 Walter White 的对话中,成员们建议创建一个能够标准化优化后的文本转视频提示词的工具。
- 目标是协助用户生成特定内容,尽管对话也涉及了规避版权限制的挑战。
OpenAI ▷ #api-discussions (175 条消息🔥🔥):
Sora Prompting, Context Poisoning, AI 中的 Psychological Safety, Fnords 与 Prompt Engineering
- Sora 面临版权内容考验:用户发现 Sora 会因版权限制而封禁包含不同动漫格斗场面的视频。
- OpenAI 不允许输出大多数受版权保护的内容,并警告成员不要规避这些政策。
- Fnords 正在污染 Context?:一位成员分享了一个“奇怪”的 Clojure 代码片段,其中涉及符号和 Context Poisoning,旨在引起不适并揭示隐藏含义。
- 另一位成员表示担忧,认为这些技术(包括 hash-seeded chaos 和隐藏的 “fnords”)依赖于神秘化,初级工程师无法复现。
- Context Contamination 担忧浮现:一位成员描述了一个使用无意义问题和非常规符号来破坏 ChatGPT “得力助手”行为的系统,但另一位用户认为这种方法充当了通用的 Context Contaminator。
- 他们建议增加干扰会降低输出质量并混淆跨领域的隐喻,并警告不要鼓励污染任何 Context 的做法。
- 探讨 Psychological Safety:关于 Prompt Engineering 中的 Psychological Safety 展开了讨论,重点在于使用明确的、选择性加入(opt-in)标签,并在挑战模型时避免隐蔽的不适感。
- 建议在分享知识时应优先考虑可衡量的机制和尊重同意的行为,而不是传递隐藏的不适感。
OpenAI ▷ #api-projects (32 条消息🔥):
代词争论,项目分享中断,左翼指控
- 代词声明引发 Discord 争论:Discord 用户就代词的必要性展开争论,一名用户在看到另一名用户的个人简介中有代词后,断言“代词很奇怪且并非必需”。
- 争论升级,出现了“左翼分子”的指控,并称对方想让别人知道自己的代词很“奇怪”,最后以“我的简介里没有任何代词”结束。
- 政治挑衅导致项目推介暂停:一名用户对关于代词的辩论干扰了他们分享项目的尝试表示沮丧。
- 该用户随后表示他们将“创建一个真正符合主题的线程”,他们想分享的是项目,而不是争论政治和代词,并称自己为“红色(red)”。
- “左翼”标签缓和 Discord 讨论:在遭到指控后,一名用户被贴上了“左翼分子”的标签,他们对此耸耸肩并简短反驳。
- 该用户对“左翼分子”的评论轻松地回应道:“那并不是一件坏事”。
LM Studio ▷ #general (736 条消息🔥🔥🔥):
MacOS Tahoe 高 GPU 占用、VSCode 中的 Copilot 集成、LM Studio 上下文数量显示问题、NVIDIA K80 GPU 评价、Vibe Coding
- MacOS Tahoe 存在高 GPU 占用:一位使用 macOS Tahoe 的成员报告了 WindowServer GPU 占用过高的问题,并链接了一个可能影响 LM Studio 的 Electron issue。
- LM Studio 与 VSCode 中的 Copilot 集成:一位成员通过注册 Copilot 并选择本地模型源,成功将 LM Studio 添加为 VSCode 中 Copilot 的提供商。
- 他们指出需要安装 OAI compatible extension(OpenAI 兼容扩展),然后在选择模型时点击 Manage(管理)。
- 上下文数量显示仍然不正确:部分用户仍面临旧问题,即 LM Studio 内部 GPT OSS models 的上下文数量无法正确显示,无论如何都停留在 115。此问题出现在最新版本的 LM Studio 中。
- 一位成员确认这是一个普遍问题,在使用 openai/gpt-oss - 20b 时,Token 计数不会增加。
- Nvidia K80 是电子垃圾:成员们讨论了使用 Nvidia K80 的可行性,但由于驱动问题,该卡很快被斥为电子垃圾。
- 成员们建议考虑 Mi50,因为一些人使用该卡取得了成功(32GB 约 150 英镑)。
- Vibe Coding 的含义:社区讨论了他们对 vibe coding 的定义。有人认为是指 LLM 完成了大部分或绝大部分工作,而另一些人则定义为依赖 LLM 来了解或检查其工作。
- 一位成员表示,这个词整体上让他想起人们是多么在意那些对自己毫无影响的他人事务。
LM Studio ▷ #hardware-discussion (110 条消息🔥🔥):
VRAM 占用、Qwen3 性能、Flash Attention、RAM 价格、本地 LLM 配置
- VRAM 溢出会降低速度:频道中的用户讨论了 VRAM 限制 对模型性能的影响,发现超出 VRAM 会大幅降低 每秒 Token 数 (TPS),速度从 70 TPS (VRAM) 降至 1.x TPS (pagefile/虚拟内存)。
- 一位用户指出,一旦数据开始泄露到 pagefile,速度就会显著下降,但使用系统 RAM 仍能提供合理的处理速度,尤其是 对于 MoE (Mixtral of Experts) 模型。
- Flash Attention 提升性能:一位用户发现启用 flash attention 显著提高了性能,称其为“近乎免费的性能提升”。
- 另一位用户指出,虽然 flash attention 通常能提高性能,但在某些模型(如 OSS120B)中可能会对工具调用(tool calls)产生负面影响,具体原因尚不完全清楚。
- RAM 价格飙升:用户注意到自 9 月以来 DDR5 RAM 价格 大幅上涨,一位用户用 一张图表 展示了这一趋势。
- 有人建议 RAM 正被重新定向到 服务器市场,导致消费者成本增加;一位用户已暂停装机计划,直到价格下跌。
- 构建本地 LLM 装备:更多 SSD 存储,更多 RAM:用户讨论了本地 LLM 设置的最佳配置,重点关注 Qwen3 30B 等大型模型。一位用户建议构建基于 EPYC 或 Xeon 的系统以获得更多内存。
- 一位用户展示了一个示例配置:ASUS ProArt B650-CREATOR 主板、AMD 7900X、64 GB DDR5 RAM @ 6400 MHz、2x 3090、1TB NVMe,而其他人则认为最大的趣味模型无法装入 64GB 内存。
- ROCm 引擎缺乏支持?:一位用户询问为什么 ROCm llama.cpp 引擎(Windows 版)不支持 9070XT,尽管官方发布的 Windows 版 ROCm 声称完全支持。
- 另一位用户指出,AMD Radeon RX 9700 XT 的 gfx target 是 gfx1200,而这并未列在 ROCm 引擎清单中,暗示可能存在不兼容。
Unsloth AI (Daniel Han) ▷ #general (415 条消息🔥🔥🔥):
Model benchmaxxing techniques, trl.experimental update, Huggingface token 401 error, Duck Reasoning Puzzle, AI specific CVEs
- 对模型 Benchmaxxing 技术的怀疑:一名成员对某组织的模型表示怀疑,怀疑它们经过了严重的 Benchmaxxing,并询问了其 benchmaxxing 技术。
- 另一名成员建议在主观领域使用 Gutenberg 和合成对话数据,但最初的成员对除了 STEM 基准测试之外的通用性能仍持怀疑态度。
- 解析 HuggingFace 下载错误:一位用户在下载时遇到困难并寻求帮助,另一位用户指出常见原因是由于缺少 Hugging Face token 导致的 401 错误。
- 故障排除帮助该用户解决了问题,但他们现在有了更多疑问。
- 使用 LLM 解决鸭子推理谜题:一名成员用一个谜题挑战推理模型:“一只鸭子前面有两只鸭子,一只鸭子后面有两只鸭子,中间有一只鸭子。请问这种排列最少需要多少只鸭子?”
- 据报道,Gemma-3-4B 和 Granite 4.0 H Tiny Q4_0 可以解决这个问题,这可能存在于它们的训练数据集中,所需的最少鸭子数量为 3。
- GRPO 获得热启动:一名成员询问 GRPO (Gradient Ratio Policy Optimization) 是否可以仅通过热启动而不进行 SFT (Supervised Fine-Tuning) 来完成。
- 另一名成员确认这是可能的,并引用了 GPT-OSS notebook 作为没有 SFT 的 GRPO 示例。
- 记录数据集预期可以改进 Unsloth:一名成员抱怨 Unsloth 缺乏关于数据集预期的文档,特别是关于
formatting_func参数和评估数据集的部分,导致在尝试猜测所需的输入格式时浪费了大量 GPU 小时。- 该成员表示,就文档和结构而言,它远低于 90 年代开源项目的平均标准。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 条消息):
AI developer introduction, Software Engineer introduction, Android phone finetuning
- AI 开发者涵盖全栈:一位 AI 开发者介绍了自己,拥有交付 端到端解决方案、设计可扩展 AI 模型、构建安全区块链网络和精美前端的实战经验。
- 他们表示始终对通过 AI + Web3 挑战极限的项目持开放态度。
- 软件工程师专注于简洁的 UI 和 UX:一位软件工程师介绍了自己,专注于使用现代技术栈打造具有 简洁 UI 和 直观 UX 的 Web 应用。
- 他们分享了 作品集、GitHub 个人资料 和 LinkedIn 个人资料。
- 安卓手机进行 Gemma 微调:一位来自西雅图的成员正尝试在 安卓手机 上通过微调运行一个 vibe coded 版本的 gemma3n。
- 他们表示期待进行体验和交流。
Unsloth AI (Daniel Han) ▷ #off-topic (132 messages🔥🔥):
GPU Parallelism, LLM self-hosting, GPTs and Tables, GPT Model Sizes and Capabilities, Fine-tuning for specific personas
- GPU Parallelism 瓶颈揭秘:PyTorch 在 GPU 上乘随机矩阵所需的时间取决于该过程是受限于计算还是内存,较高的 Batch Size 可能会增加实际运行时间(wall clock time),但会提高吞吐量(throughput)。
- 此外,操作涉及的是 Prefill 还是 Decoding 也会影响性能。
- VPS LLM 自托管用例:成员们讨论了利用闲置的 VPS(虚拟专用服务器)进行 LLM 相关项目的自托管,特别是用于托管 API、新闻聚合 Agent 或 Discord 机器人。
- 一位使用每年 7 美元 VPS 的成员幽默地提到了拥有 GPU 设备(包括电感啸叫等各种问题)的吸引力,甚至表示 “感觉它真的在‘工作’”。
- 微调防止表格数据噩梦:即使有明确要求避免表格的指令,仅靠 System Prompt 和 Prompt 无法阻止 GPT 模型生成表格。
- 一位成员调侃道:“你真的没法把表格从 GPT 里拿掉……”,其他人也同意特定任务需要进行微调,以确保输出格式正确。
- GPT-4.5 的失败给参数量带来的教训:成员们讨论了 GPT-4.5 可能比 GPT-4 更大但最终失败的观点,这表明在当前架构下,更多的参数并不总是解决方案。
- 一位成员开玩笑地分享了一个传闻,称 GPT-4.5 拥有 “12 万亿参数,耗资 10 亿美元训练”,并对 OpenAI 替大家踩了坑表示感谢。
- 友好律师 LLM 对决:一位成员寻求关于创建数据集以微调 LLM 模仿友好律师的建议,参考了 YouTube 频道 Law by Mike。
- 另一位成员幽默地警告不要听从 LLM 的法律建议,而另一位成员分享了一个链接,讲述了一张受损严重的 RTX 5070 Ti 显卡通过 RX 580 AMD VMR 移植重获新生的故事。
Unsloth AI (Daniel Han) ▷ #help (209 messages🔥🔥):
AI Code Agent for test case generation, Gemma 1B fine-tuning speed, Qwen3-0.6B OOM issues with Llamafactory, Unsloth DGX Spark compatibility, Tokenizer issues after adding tokens and resizing
- 需要 LLM Agent 生成完美的测试用例:一位成员正在开发一个 AI 代码 Agent,并寻求关于最佳 AI 技术的建议,特别是使用 DeepSeek API 来生成代码,更重要的是生成严格正确的测试用例。
- 另一位成员指出了为所有类型的题目生成严格正确响应的问题约束。
- 以极速微调 Gemma 1B:一位成员正在使用 127,000 个问题微调 Gemma 1B 模型,发现大约需要 6 小时,正在寻求缩短训练时间的方法。
- 建议包括增加 GPU 显存利用率、减小数据集大小,并指出根据任务的不同,最佳数据集大小通常在 2k-8k 样本左右达到饱和。
- Qwen3-0.6B 遭遇 OOM 困扰:一位成员在使用 Llamafactory 微调 Qwen3-0.6B 时遇到了 显存溢出 (OOM) 错误,尽管这是一个在 3090 上运行、具有 32k 上下文的 600M 参数模型。
- 建议使用 Unsloth 文档中的 Qwen Notebook,而另一位成员建议不要使用 Packing,因为存在污染问题。
- Unsloth 在 Nvidia 的 DGX Spark 上安家:一位成员询问 Unsloth 与 Nvidia DGX Spark 的兼容性,这是一款运行 Linux 且采用 ARM 架构的“本地超级计算机”。
- 另一位成员确认了其兼容性,并指出它最近在 OpenAI DevDay 上进行了展示,并分享了 UnslothAI 推文链接作为证据。
- 添加 Token 后 Tokenizer 闹脾气:一位成员在向 Tokenizer 添加 Token 并调整大小后遇到问题,导致合并后性能不佳,但在使用 LoRA 时性能完美。
- 他们还使用了
modules_to_save=[embed_tokens,lm_head],并表示:“我想进行 GPRO,但无法实现,因为如果我在 LoRA 适配器上运行,会遇到不匹配错误[FATAL] vocab mismatch: tok=151717, emb=151936, cfg=151936,且合并后的模型使用效果极差。”
- 他们还使用了
Unsloth AI (Daniel Han) ▷ #showcase (4 条消息):
Qwen3-8B 微调,小说训练数据,Epoch 数量
- 基于小说微调的 Qwen3-8B:一名成员使用约 8000 章节的真实小说训练了 Qwen3-8B,以评估数据集质量,并发现结果 “还不错”。
- 然而,他们指出该模型继承了 Qwen 的重复问题,并且可能需要超过一个 Epoch 的训练以及更好的数据清洗,以去除章节提取过程中产生的伪影。
- Qwen3 需要更多 Epoch 来清理文笔:有建议认为 Qwen3 至少需要 2-3 个 Epoch 来精炼那些 “不,不是这个,那个” 之类的散文叙述,并且增加 Rank 会有所帮助。
- 原作者同意需要更多 Epoch,特别是考虑到这些内容可能在预训练数据集中并不存在,并附上了一份 样本文件。
Unsloth AI (Daniel Han) ▷ #research (62 条消息🔥🔥):
针对游戏的数据增强,HRM 系统,GNN 训练,Nemotron Math Human Reasoning
- 实验室被怀疑使用数据增强:有人怀疑实验室正在利用 数据增强(Data Augmentation) 来刷 ARC AGI 的分数。
- 由于公开测试集非常小且涉及 投资者资本,因此根据 ARC AGI 的规则,数据增强 基本上属于 合理竞争范围。
- 结合 HRM 的混合推理模型:讨论了构建同时具备执行任务的 HRM 和具备世界知识的 LLM 的系统,但目前还没有能将两者特别好地整合的机制。
- 一名成员考虑了诸如训练 GNN 与小型推理模型进行交互的想法,反之亦然。
- 纯人工数据集:一名成员征求关于日常生活图像、OCR、音频/音乐标注、文本推理和图像推理的数据集,但限制为 仅限人工数据(HUMAN DATA ONLY)。
- 另一名成员指向了 nvidia/Nemotron-Math-HumanReasoning 数据集,这是一个由人类生成的微型推理数据集。
- MoLA 项目受到称赞:一名成员表示,幸好允许 18-19 岁以下的人上网,否则我们就不会拥有备受喜爱的 MoLA 项目。
- 这是 MoLA 项目 的链接。
OpenRouter ▷ #app-showcase (2 条消息):
AI 角色扮演网站,免费请求,由 OpenRouter 驱动
- Personality.gg:带福利的 AI 角色扮演?:一个新的 AI 角色扮演网站 Personality.gg 向所有用户提供 每日 500 次免费请求。
- 该网站由 OpenRouter 提供支持,据称由 一名用户 支付费用。
- 免费 AI 角色扮演请求:骗局还是福利?:该 AI 角色扮演网站提供了慷慨的 每日 500 次免费请求 额度,引发了好奇和怀疑。
- 一些用户想知道该网站如何维持这种慷慨,其中一人推测可能存在 潜在骗局。
OpenRouter ▷ #general (606 messages🔥🔥🔥):
Google 重新分配服务器,OpenRouter AI SDK,中国模型较为宽松,Deepseek 3.1 存在审查,LayerFort 是骗局
- Google 调整服务器,质量出现波动:成员报告 Google 正在将服务器重新分配给 3.0,导致 2.5 的质量下降。
- 有人指出,2.5 自 GA 发布以来质量一直在持续退化。
- OpenRouter AI SDK 集成注意事项:使用 openrouter ai-sdk 集成的用户应非常小心,因为当涉及多个步骤时,该插件不会报告完整的详细使用情况。
- 它仅报告最后一条消息的使用情况和成本,就好像中间带有 tool calls 的步骤从未发生过一样。
- 使用中国模型进行 NSFW 创作:成员提到中国模型相当宽松,但需要一个 system prompt 将其声明为 NSFW 作者。
- 具体推荐了以 Z.ai 作为提供商的 GLM 4.5 air (free) 以避免 429 错误;请注意,免费的 V3.1 端点存在审查,而付费版则保持正常。
- LayerFort 被指控诈骗:频道成员注意到 LayerFort 看起来像个骗局,并且正在宣传一个不可行的方案。
- 他们宣传每月 15 美元即可通过 API 无限制使用 Sonnet,而 1M tokens 的成本就已经很高了。成员们进一步发现,该网站半年前还是一个普通的投资公司。
- BYOK 使用问题依然存在:成员报告 BYOK 在使用用户密钥时仍无法正常工作。
- 问题在于 API 仍直接使用 API key,而不是从每月 100 万的 BYOK free credits per month 额度中扣除。
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (71 messages🔥🔥):
Qwen 模型发布,Groq 的性能,AI 放大(upscaling)担忧,Gemini 3 发布,OpenRouter UI/UX 反馈
- Qwen 的模型狂潮继续:Qwen 计划下周发布更多模型(来源),一位成员指出 Qwen 已经发布了包括 Next, VL, Omni 和 Wan 在内的多个模型(来源)。
- 另一位成员开玩笑说,Qwen 筹集了 20 亿美元想成为“美国的 DeepSeek”,如果他们最终还是输给 DeepSeek,那才叫令人印象深刻。
- Groq 取得进展?:一位成员提到,Groq 通常是较好的工具提供商之一,尽管在发布初期,其他人听说它非常不可靠,主要是由于 API 问题。
- 另一位成员指出,既然 Kimi 已经拿出了数据,他们不想丢脸,而且随着热度降温,该工具现在的受欢迎程度可能有所下降。
- 用 AI 放大图像:真相还是欺骗?:人们对 AI 放大(upscaling)表示担忧,特别是从像素极少的图像中恢复信息时,一位成员指出他们在原始图像中只数出了 33 个像素。
- 另一位成员担心 AI 是在凭空捏造一切,如果律师在法庭上使用这种放大器,他们会发疯的,因为很多新生成的信息都是不可信的。
- Gemini 3 隐约可见:一位成员表示 AI Studio 上正在进行一些有趣的 A/B 测试,人们得到了一些惊人的结果,内部泄露文件称其将于 22 日发布(Gemini 3)。
- 另一位成员提供了一个 CodePen 演示链接和 OpenRouter 提供商链接(CodePen, OpenRouter)。
- OpenRouter 界面令用户困扰:一位用户请求在 OpenRouter 按价格排序的模型列表中增加一个移除免费模型的选项,并建议将此选项放在页面顶部。
- 另一位成员建议在用户首次访问聊天室时增加一个弹窗,告知他们聊天记录不会存储在服务器上。
Cursor Community ▷ #general (442 条消息🔥🔥🔥):
聊天中的 Terminal 标记,移动端 Cursor,AI 编程反馈,Background Agents 与单次提示词成本,Max 模式错误
- Terminal 标记与 Agent 窗口问题待解决:用户报告了 Terminal 标记以及“发送至聊天”功能在普通编辑器和 Agent 窗口中均未出现的问题,正等待在未来更新中解决。
- 对移动端 Cursor 的渴求仍在继续:用户表达了在移动端使用 Cursor 的强烈愿望,但目前该 IDE 仅限桌面端,移动平台仅支持 Background Agent 管理。
- 调试优于 AI 编程:一位用户提到他们已经停止使用 AI 编写代码超过一周,并观察到虽然自己有时速度较慢,但在 debugging(调试)方面表现更好,最终反而节省了时间。
- 挂载 Agent 以实现单次提示词实时计费:用户讨论了集成 Agent 以提供单次提示词实时计费(realtime costing per prompt)的功能。有人询问为何在关闭其他模型的情况下仍在使用特定模型,另一位用户解释说 Auto mode 会自动路由到报错的模型。
- 听写功能在开发版亮相,部署推迟:虽然听写(dictation)功能已在 Nightly 版本中上线,但尚未在公开版本或某些 Nightly 版本中完全实现。
- 用户分享了通过 CTRL + SHIFT + P 或设置中的 About 部分检查更新的方法。
Cursor Community ▷ #background-agents (7 条消息):
Linear 集成,Background Agents,Cursor Agent 关闭,Cursor 无响应
- Linear 集成在重新连接时出现问题:一位用户报告在重新连接 GitHub 和 Linear 后遇到了 linear integration 问题,并分享了截图。
- Background Agents 与 GitHub 集成:一位用户描述了他们如何使用 Background Agents 编写新功能,然后将代码更改合并到主分支,这导致了 Cursor BA 关闭。
- 该用户质疑是否应该将 BA 上下文化以编写 Python,而不是编写特定的 Feature
ABC。
- 该用户质疑是否应该将 BA 上下文化以编写 Python,而不是编写特定的 Feature
- Cursor Agents 显示“尚无对话”:一位用户报告 Background Agent 经常显示 no conversation yet(尚无对话),但状态显示已完成且任务实际上并未执行,这似乎与 GitHub 有关。
- 报告“Cursor 停止响应”错误:一位用户报告在尝试与 Linear 配合使用时出现 ‘Cursor stopped responding’ 错误,并分享了截图。
GPU MODE ▷ #general (35 条消息🔥):
Nvidia 50 系列性能分析, CUDA repo 贡献, 图像 Embedding 优化, PTX ISA, LLM 中的位置编码
- 5090 用户享受 Nsight 性能分析:一位用户确认 Nsight Compute 和 Nsight Systems 在其 5090 GPU 上运行良好,尽管某些文档说明并非如此。
- 立即探索 CUDA Repo 贡献:一位用户正在主持语音频道,讨论如何为一个真实的 CUDA repo 寻找合适的首次贡献机会,包括代码走读。
- 讨论未录音,旨在更加随性。
- 在抱怨图像 Embedding 慢之前先进行性能分析:一位用户报告在使用 open_clip (ViT-B/32) 在 A100 (40 GB) 上为 7.5 万张图像创建 Embedding 时,GPU 使用效率低下。
- 其他用户建议使用 PyTorch dataloaders,调整
num_workers和pin_memory等参数,并建议在归咎于模型推理之前使用性能分析器(profiler)来识别瓶颈。
- 其他用户建议使用 PyTorch dataloaders,调整
- 深入研究 PTX ISA 以实现高级 MatMul:一位用户建议深入阅读 PTX ISA 的第 9 章,以获取高级矩阵乘法指令的全面细节,而不是依赖不完整的博客。
- 另一位用户分享了一个 PyTorch profiler recipe 链接,用于查找性能瓶颈。
- 深入探讨位置编码的演进:一位用户分享了一份出色的技术深度指南(感谢 Aman Arora),详细介绍了 LLM 中位置编码的演进。
GPU MODE ▷ #triton (3 条消息):
Triton 社区会议, TLX 更新, Triton + PyTorch Symmetric Memory, PyTorch 中的 Triton Flex Attention, 线程内数据交换算法
- Triton 爱好者暂定于 2025 年 11 月 5 日聚会:下一次 Triton 社区会议 将于 2025 年 11 月 5 日上午 10 点至 11 点(PST) 举行,会议链接 已分享。
- 暂定议程包括:Hongtao Yu (Meta) 的 TLX (Triton Language Extensions) 更新,Surya Subramanian (GaTech) 的 Triton + PyTorch Symmetric Memory,以及 Dhruva Kaushal (Meta) 的 PyTorch 中的 Triton Flex Attention。
- 通过 Teams 组队:Triton 技术演讲大获成功!:已分享 Microsoft Teams 会议链接,以及 会议 ID: 245 337 288 102 4 和 密码: c6pB7DS2。
- 其他连接方式(如电话拨入和视频会议设备选项)也可通过相应的 ID 和 租户密钥(tenant keys) 使用。
- 线程内疑云:算法质疑浮现!:一位成员对第 5.4 节中的线程内数据交换算法提出质疑,并给出了一个反例。
- 附图 说明该算法可能不足以确保每个被移入值的向量化元素都能将其原值移出,从而可能导致覆盖(overwrites)。
{kind=link}
GPU MODE ▷ #cuda (12 条消息🔥):
CUDA Core 分配, mbarrier 使用, DSMEM 同步
- CUDA Core 处理 Warp 线程:讨论明确了 warp 不会被分配给单个 CUDA core,而是将其 threads 分散,可能使用多个 core 执行。
- 有人建议,单个
add指令可能会在 16 个 core 上执行,其延迟是 32 个 core 执行时的两倍。
- 有人建议,单个
- DSMEM 中的 mbarrier 问题:DSMEM 中
mbarrier的用法与本地 SMEM 不同,需要使用__cluster_map_shared_rank将&mbar指针映射到 block 0,并使用mbarrier.arrive.shared::cluster。- 即使使用了 mbarrier,至少也需要 两次
cluster.sync()调用:一次在初始化后,另一次在 block 退出前,以确保mbarrier_try_wait()调用能返回。
- 即使使用了 mbarrier,至少也需要 两次
- DSMEM Cluster Sync 争论:一位用户质疑
mbarrier的必要性,因为在所有 block 写入 block 0 的 SMEM 后,仅使用单个cluster.sync()似乎就能完成 cluster reduction。- 反方观点强调在写入 DSMEM 之前 需要进行
cluster sync以保证 threadblock 是活跃的(live),而该用户报告称,即使输入量很大且仅使用一个cluster.sync(),也未观察到竞态条件。
- 反方观点强调在写入 DSMEM 之前 需要进行
GPU MODE ▷ #torch (2 messages):
Torch Compiled Model Memory Leak, CUDA Memory Defragmentation
- Torch 模型编译中的神秘内存攀升:有用户报告了一个奇怪的问题,即 torch compiled model 在长时间运行(数小时)过程中内存消耗缓慢攀升。
- 即使使用了 max-overtune compilation 和 varlen flash attention,内存攀升依然存在。用户怀疑已分配的部分正在被重新分配并发生了泄漏。
- CUDA 碎片整理化解危机:用户发现定期调用 CUDA 内存碎片整理函数 可以减轻内存压力。
- 提供的代码片段通过使用 torch.cuda.empty_cache()、torch.cuda.synchronize() 和 gc.collect() 来缓解内存泄漏,这证实了确实存在某种形式的泄漏。
GPU MODE ▷ #announcements (1 messages):
llmq, quantized LLM training, CUDA
- **llmq 量化 LLM 训练框架即将发布:明天将举行一场特别演讲,介绍 llmq,这是一个纯 **CUDA 编写的量化 LLM 训练框架。
- 此次演讲旨在进行互动,鼓励参与者提问并探索对该项目的潜在贡献,目的是观察他的编码方式,并尝试为自己寻找一些好的入门级贡献(good first contributions)机会。
- 关于 **llmq 的互动环节:该环节鼓励互动参与,邀请参与者打断、提问,并探索与 **llmq 相关的编码实践。
- 目标是确定对项目的潜在贡献并参与到开发过程中。
GPU MODE ▷ #cool-links (3 messages):
ATLAS LLM Inference, VectorDB in Go, Hybrid Retrieval Methods
- ATLAS 通过运行时学习加速 LLM 推理:Together AI 推出了 Adaptive-LeArning Speculator System (ATLAS),这是一种通过运行时学习加速器实现 LLM Inference 的新范式。
- 该公告也通过 Tri Dao 的 X 账号 和 Together Compute 的 X 账号 发布。
- 用 Go 从零编写的 VectorDB:一位成员分享了他们用 Go 从零编写 VectorDB 的工作,该数据库支持基于 BM25, Flat, HNSW, IVF, PQ 和 IVFPQ 索引的 hybrid retrieval。
- 该 VectorDB 功能包括元数据过滤(Metadata Filtering)、量化(Quantization)、重排序(Reranking)、倒数排名融合(Reciprocal Rank Fusion)、软删除(Soft Deletes)和索引重建(Index Rebuilds)等,并附有 HN 讨论帖链接。
GPU MODE ▷ #jobs (2 messages):
GPU Performance Engineer, Reinforcement Learning for Vision-Language Models
- **GPU 大神职位大放送:一个 4 人的核心团队正在寻找一名 **GPU Performance Engineer,要求对 NVIDIA GPU 架构(Blackwell, Hopper)有深刻理解,具备优化 Kernel 的经验(CuTe, CUTLASS, profilers),并熟悉 Linux kernel/driver 内部机制。
- 该职位提供 $250K USD + 股权,欢迎各种经验水平的人士申请,欢迎通过私信发送 GitHub / CV。
- RL 研究员助力视觉语言模型突破:位于阿布扎比的 Technology Innovation Institute (TII) 正在招聘一名 Research Scientist,利用 Reinforcement Learning (RL) 增强 Vision-Language Models (VLMs)。
- 职责是帮助开发能够增强 Vision-Language Models (VLMs) 的 post-training 方法;请私信或发送简历至:yasser.djilali@tii.ae。
GPU MODE ▷ #beginner (26 条消息🔥):
axpy.cu 编译错误,libwb 安装,GPU 学习资源,GPU 编译器优化 vs ML
- axpy.cu 编译困难:一位成员在编译
axpy.cu时遇到了 fatal error,原因是缺少Libraries\libwb\wb.h文件。尽管文件确实存在,他们尝试使用<Libraries\libwb\wb.h>和"Libraries\libwb\wb.h"包含它,但都没有成功。- 该成员确认他们使用 git repo 安装了该库,并使用 Visual Studio 构建成功且无错误,但现在编译失败。
- 调试 libwb 安装问题:一位成员建议检查 README 中的安装说明,并要求提供 git repo 根目录下的
ls输出,以诊断libwb安装问题。- 该成员想确认库是否已正确安装并可被编译器访问,以及目录结构是否正确。
- 精选 GPU 学习资源:一位成员询问学习 GPU 的优质资源,重点是实践练习和编程,随后被推荐了 Aleksa Gordic 的博客。
- 该用户还被推荐关注 Umar Jamil 的 YouTube 频道 获取教育内容。
- GPU 编译器工作不需要 ML:一位成员询问从事 GPU 工作(特别是构建编译器优化)是否需要 ML 知识。
- 另一位成员澄清说 ML 不是必需的,因为该领域目前专注于 AI 应用,但可以通过构建项目来学习基础知识。
GPU MODE ▷ #jax (1 条消息):
JAX, Pallas, GPU 计算/通信重叠, NVLINK 通信
- JAX & Pallas 提升 GPU 计算/通信重叠:一个新的教程展示了如何通过对 Pallas:MGPU matmul kernel 进行少量修改,将其转变为 all-gather collective matmul,从而改善 GPU 计算/通信重叠。
- NVLink 通信优化:该教程专注于优化 NVLink 通信,以提高使用 JAX 和 Pallas 在 GPU 上进行 matmul 操作 的效率。
- 它利用集体通信策略来最小化通信开销,从而提高整体计算性能。
GPU MODE ▷ #off-topic (3 条消息):
ML 系统早餐会,斯坦福 ML 见面会
- 斯坦福 ML 早餐会邀请:一位成员发出了本周在斯坦福地区讨论 ML systems 的非正式早餐或咖啡邀请。
- 链接了一个 LinkedIn 帖子,引用了 HamzaelshafieGPT-OSS-20B,这是一个 PyTorch 项目。
- 香肠早餐助力 ML 交流:有人分享了猪肉肠和其他早餐食物的照片。
- 这顿早餐旨在为讨论 ML systems 的见面会提供能量。
GPU MODE ▷ #irl-meetup (1 条消息):
审批请求,私有仓库分享,Kernel 编写基础
- 独立工作申请审批:一位成员申请审批,理由是独立工作并愿意分享 private repos。
- 他们提到虽然缺乏特定 kernel 编写的显式经验,但能够处理基础工作,并表达了组队的意愿。
- Kernel 编写组队邀请:由于在特定 kernel 编写方面经验有限,该成员表达了与他人 组队 的意愿。
- 尽管缺乏显式的 kernel 编写经验,他们声称可以 编写基础部分。
GPU MODE ▷ #rocm (2 messages):
Composable Kernel build failure, Missing header in composable kernel
- Kernel Composition 构建失败:一位用户报告了 Composable Kernel 的构建失败,原因是未知的类型名称
int32x4_t,这表明缺少头文件。- 一名成员建议包含来自 Composable Kernel GitHub 仓库 的
ck/utility/dtype_vector.hpp头文件以解决此问题。
- 一名成员建议包含来自 Composable Kernel GitHub 仓库 的
- 可能需要 dtype_vector.hpp 头文件:错误信息表明类型
int32x4_t无法识别,该类型很可能定义在 Composable Kernel 库的dtype_vector.hpp头文件中。- 要修复此问题,请确保在使用 Composable Kernel 的代码中包含适当的头文件,特别是
<ck/utility/dtype_vector.hpp>。
- 要修复此问题,请确保在使用 Composable Kernel 的代码中包含适当的头文件,特别是
GPU MODE ▷ #self-promotion (4 messages):
LRU, LFU, C4ML, TensorFlow Optimizers, Blockchains
- 在 C++ 中使用 LRU 和 LFU 缓存你的知识:一位成员发布了一篇博文,涵盖了 C++ 中的 LRU 和 LFU 缓存策略,包括使用 GoogleTest 进行的单元测试,该内容基于 Konstantin Vladimirov 的讲座,代码可在 GitHub 上获取。
- 博文解释了 LRU 如何在缓存中保留最近使用的页面,而 LFU 还会考虑页面的访问频率,博文链接见此处。
- 关注 CGO 2026 的 Compilers For ML 研讨会:机器学习编译器 (C4ML) 研讨会将重返在澳大利亚悉尼举行的 CGO 2026,目前正在征集关于 ML 编译器、编译器优化以及在编译器中使用 ML 的演讲和论文。
- 释放区块链与 AI 结合的力量:一位成员分享了他们在 Blockchains 和 AI 领域的探索历程,强调了这些技术的结合如何改变行业、社区和新创意的产生。
- 他们认为,当区块链和 AI 以正确的方式结合时,它们可以改变行业的运作方式、社区的连接方式,甚至新创意的诞生方式。
- NoteDance 发布 TensorFlow 优化器:一位成员宣布发布了他们自定义构建的 TensorFlow 优化器。
- 该成员分享了 GitHub 仓库,并指出 TensorFlow 用户可能会发现它们很有用。
GPU MODE ▷ #avx (1 messages):
Intel SDE, Intrinsics and immintrin_dbg.h
- Intel SDE 模拟旧硬件:Intel Software Development Emulator (Intel SDE) 允许在旧硬件上运行二进制文件,并提供指令级日志记录和调试跟踪。
- 这提供了一种执行原本与新系统不兼容的代码的方法。
- 用于测试 Intrinsics 的 imminstrin_dbg.h 头文件:Intel 为 C/C++ 开发提供了一个替代头文件 imminstrin_dbg.h,它在标量 C 代码中实现了 Intrinsic 函数,从而无需 x86 系统即可进行开发和测试。
- 注意该文件已不再维护,因此可能缺少一些最新的函数。
GPU MODE ▷ #thunderkittens (7 messages):
CUDA toolkit versions for Blackwell, GH200 Hopper machine, CUDA requirements changing, Compiling errors, Narrowing conversion errors
- CUDA 版本混淆引发困扰:一位成员表示,对于 Blackwell 架构,CUDA toolkit 必须至少为 12.8,而另一位成员则怀疑 GH200 是否被错误地识别为 Blackwell 而非 Hopper 机器。
- 新版本中 CUDA 需求发生变化:成员们讨论了最新版本中 CUDA 需求 是否发生了变化,其中一人指出最近的一个 commit 通过禁用 H100 的某种类型解决了问题。
- 代码编译引发转换危机:一位成员遇到了与 从 “char” 到 “signed char” 的无效窄化转换 相关的 编译错误,并通过在代码中进行显式转换修复了该问题。
GPU MODE ▷ #reasoning-gym (1 条消息):
Weights and Biases (wandb) Logs, GRPO policy loss clipping, Reasoning Gym
- 用户寻找 reasoning-gym 试验的 Weights and Biases (wandb) 日志:一位成员请求获取使用 reasoning-gym 训练 LLM 的 Weights and Biases (wandb) 日志,以查看 GRPO(或类似方法)是否在非零比例的样本上触发了策略损失裁剪 (policy loss clipping)。
- 他们特别在寻找较小模型(1B/3B 参数)的日志。
- 用户寻求关于 GRPO 损失裁剪有效性的见解:一位成员询问在 LLM 训练期间,将 GRPO 或类似方法与 reasoning-gym 结合使用时,策略损失裁剪发生的频率。
- 目的是确定策略损失裁剪是否发生在非零比例的样本上,特别是在 1B 到 3B 参数 范围内的较小模型中。
GPU MODE ▷ #submissions (130 条消息🔥🔥):
MI300x8 Leaderboard Updates, amd-ag-gemm Performance, amd-all2all Performance, amd-gemm-rs Performance
- 提交内容席卷 MI300x8 排行榜:多位用户提交了 MI300x8 在各个排行榜上的性能结果,包括
amd-ag-gemm、amd-all2all和amd-gemm-rs。 - amd-all2all:微秒级里程碑:在
amd-all2all排行榜上实现了多个个人最佳成绩,部分提交在 MI300x8 上进入了 300-400 µs 范围,表明性能有了显著提升。 - amd-gemm-rs:登顶之争:
amd-gemm-rs排行榜展开了激烈竞争,用户竞相争夺 MI300x8 的榜首位置,产生了一系列新的个人最佳和领先排名。 - amd-ag-gemm:亚毫秒级对决:用户持续提交 MI300x8 的
amd-ag-gemm排行榜结果,大多数结果在 500 µs 左右,部分离群值在 1000 µs 以上。
GPU MODE ▷ #status (14 条消息🔥):
Runner Timeouts, Deadline Extension Controversy, AMD's Node Limitations
- Runner 超时困扰提交:参赛者遇到了竞赛 Runner 超时的问题,导致了调查和修复尝试;鼓励用户向指定联系人报告进一步的问题。
- 一位开发者提到他们正在处理,Runner 应该已经得到了一定程度的修复。
- 截止日期延长引发辩论:由于关注度高和超时问题,竞赛截止日期延长了一天,最终提交时间移至 10 月 14 日晚上 11:59 PM PST。
- 一些参赛者对公平性和专业性表示担忧,其中一位表示 这基本上违背了竞争精神,而组织者则辩称延长是因为技术困难和 GitHub 宕机影响了提交。
- AMD 节点数量限制了参赛者:组织者指出,AMD 提供的 7 个节点 限制是竞赛最后几小时出现超时问题的一个因素。
- 延长截止日期的决定被辩护为合理的权衡,将其比作 不让人们上飞机,因为登机队列太长。
GPU MODE ▷ #tpu (1 条消息):
rybchuk: 你需要先进行 jax distributed init
GPU MODE ▷ #factorio-learning-env (2 条消息):
Factorio Crime Scene, Game Neglect Consequences
- 无人看管时 Factorio 变得致命:一位成员在开会期间让 Factorio 处于无人看管状态,回来后发现了一个模拟的 犯罪现场,如附带的 截图 所示。
- 挂机 Factorio 会话以惨剧告终:一位玩家发现了让 Factorio 会话在无人看管下运行的危险,导致他们在返回时幽默地将其描述为 犯罪现场。
{kind=link}
GPU MODE ▷ #amd-competition (105 条消息🔥🔥):
超时错误、GPU 内存访问故障、提交队列过载、提交中的调试打印、用于测量 Kernel 时间的 Stream Events
- 提交异常引发的超时困扰:用户在提交作品时遇到了 timeout errors(超时错误),具体发生在
el.get(60)这一行,引发了关于代码问题或集群过载的猜测。- 一位用户甚至测试了一个仅包含
sys.exit(3)的极简提交,但仍然遇到超时,这表明可能存在 infrastructure(基础设施)问题。
- 一位用户甚至测试了一个仅包含
- 段错误(Segfault)导致内存访问混乱:有用户报告了 memory access fault(内存访问故障),错误信息为 “Memory access fault by GPU node-7 (Agent handle: 0x55c30114fb00) on address 0x7ee677800000. Reason: Unknown,” 这指向了一个 segfault。
- 有建议认为这可能是由于本地设置与环境权限不同,或者仅仅是 “运气好” 绕过了检查,因为这本质上意味着访问了非法内存。
- 提交激增冲击系统稳定性:平台经历了提交量激增,导致 runners 运行吃力,并引发了许多用户的超时问题。
- 一名团队成员指出:“感谢大家的反馈,从 GitHub Actions 可以看到,目前的提交量实在太大,Runners 已经无法及时处理,” 这表明系统负载已达极限。
- 调试信息匮乏:打印输出出现问题:用户反映在提交中看不到调试打印信息,导致难以诊断问题。一位用户感叹道:“我在提交中从未见过调试打印,只见过超时 😢。我甚至不知道原来是有打印输出的,哈哈。”
- 有人指出
python print带有缓冲区,因此需要设置flush=True才能实时打印。
- 有人指出
- 提交服务遭遇 503 故障:用户报告在尝试提交代码时收到 503 Service Unavailable 错误,表明服务器端出现问题。
- 一位用户描述了当时的情况:“服务器返回 503 错误已经快一个小时了——可能是因为大家都赶在明天的截止日期前冲刺提交,导致服务器崩溃了。”
GPU MODE ▷ #cutlass (14 条消息🔥):
CuTeDSL 缓存、MoE Group GEMM、Group GEMV、Proton Viewer
- Proton Viewer 显示 Gluon Kernel 内部细节:如果你使用 Gluon 编写 Kernel,Proton 可以提供你所需的视图,从而实现对 Kernel 内部细节的检查。
- CuTeDSL 缓存亟待改进:一位用户报告称,在不使用
cute.compile的情况下运行 Kernel 会产生显著更高的开销(13.3196 ms vs 0.0054 ms),这引发了对 CuTeDSL 缓存易用性的担忧,详见 issue 2643。- 对于生产环境,建议进行显式的缓存管理,以平衡速度、安全性和灵活性;同时团队正致力于 AOT(ahead-of-time)编译工作(discussion 2557)。
- MoE Group GEMM 性能建模难以处理?:用户强调了 LLM 推理中 MoE Group GEMM 性能建模的挑战,其中一些 GEMM 问题可能是计算密集型(compute-bound),而另一些则是内存密集型(memory-bound)。
- 他们建议参考 vLLM 等服务框架,并尝试重新排列 GEMM 问题的顺序以优化性能。
- Group GEMV 性能优于 vLLM 的 Fused MoE:对于低 Batch Size 的长文本解码,在 Triton 中实现简单的 group GEMV 性能优于 vLLM 的 fused MoE,这强调了数据加载优化的重要性。
- 在这种特定配置下,它是严重的内存密集型(memory-bound),因此甚至不需要 MMA (Matrix Multiply Accumulate)。
GPU MODE ▷ #singularity-systems (4 条消息):
picograd, SITP, tinygrad, autodiff, Triton kernels
- picograd & SITP 框架引发关注:一位成员对 picograd 和 SITP 项目表示了兴趣,赞赏其 eager/lazy 设置和 tinygrad 风格的流水线,并表示在垂直切片(vertical slice)准备就绪后将提供帮助。
- SITP 垂直切片及文档即将发布:一位成员宣布,
.Tensor和.backward的薄垂直切片很快将发布,同时发布的还有关于模型、框架和 GPU kernels 展示顺序的 文档,以及 ARCHITECTURE.md、AGENTS.md 和 CONTRIBUTING.md。- 目标是通过创建一个类似于 JAX 的 lazy, compiler-first autograd 系统,来缩小与 tinygrad 的差距。
- 通过 pyo3 集成 Triton Kernels:picograd 计划使用 pyo3 进行 Python 和 Rust 的互操作,以便为 eager 模式编写 Triton kernels,并最终实现 fusion 功能。
- 这种双向互操作将有助于在未来实现一些 fusion。
GPU MODE ▷ #general (9 条消息🔥):
VSCode Extension, GPU Mode Website Tutorials, Submitting Kernels, PMPP v2 Problem, Grayscale Submission
- **VSCode 扩展是最简单的入门方式:一位成员提到,VSCode extension** 可能是开始使用 GPU Mode 最简单的选择。
- 另一位成员说:“我不明白这些问题,哈哈”,可能指的是扩展程序或教程。
- **GPU Mode 网站教程过时令新手感到困扰:一位成员报告称,GPU Mode** 网站上关于提交 kernels 的教程已经过时,特别提到了缺少
python和cuda标识。- 受影响的教程位于 gpu-mode.github.io。
- **PMPP v2 Grayscale 问题是经典案例:现在的建议是提交到 **PMPP v2 问题,其中灰度化(grayscale)是一个经典示例,可以在 排行榜 上找到。
- 更多参考 kernels 可以在 此仓库 中找到。
GPU MODE ▷ #multi-gpu (25 条消息🔥):
VAE Training on Multi-GPU, Serving LLMs for Multiple Users, Nvidia 5090 features
- 多 GPU 训练中 VAE 模型 Loss 激增:一位成员在使用 DDP 在 4x A100s 上从头开始训练 VAE model 时遇到了 loss 激增的问题,而单 GPU 训练却很稳定,并寻求对其 代码 的故障排除帮助。
- 深入探讨 RTX 5090 规格:一位成员分享说,由于缺少 tcgen05,RTX Blackwell 没有 TMEM,这导致另一位成员重新考虑购买 5090 进行 TMEM 测试,并讨论了 block scaled dtypes 在 fp32 累加中是否被削弱。
- 另一位成员对 5090 进行了深入分析,提到了 block scaled dtypes 以及可能从 Hopper 继承的功能(如 TMA),并分享了 chipsandcheese.com。
- 为 10 个并发用户部署 70B 模型:一位成员请求关于为多达 10 个并发用户 提供 70B model 服务的资源建议,计划使用 vLLM 和基于 pod 的设置,用于涉及公司文档和视频的 RAG 用例。
- 另一位成员建议,为 10 个用户 进行部署并不是特别具有挑战性,尤其是对于包含 ~100 份文档 和 10 个视频 的 RAG 设置,并询问了预期的请求量和推理延迟限制。
GPU MODE ▷ #opencl-vulkan (5 messages):
Gallium3D compute driver on top of CUDA, Rusticl on Zink on NVK vs NVIDIA Proprietary OpenCL, Vulkan API, VK_KHR_shader_fma
- CUDA Gallium3D 驱动现身!: 一位成员创建了一个基于 CUDA 的 Gallium3D 计算驱动,用于 Rusticl,详情见 Phoronix 文章 和 GitLab merge request。
- 当被问及与 NVK 上的 Zink 运行 Rusticl 或 NVIDIA 官方 OpenCL 相比有何优势时,该成员指出其具有更好的 OpenCL 扩展支持。
- 新的 Vulkan 扩展现身: 最新的 Vulkan 规范更新包含了
VK_KHR_shader_fma,正如 这篇 Phoronix 文章 所报道。
GPU MODE ▷ #penny (1 messages):
vllm oneshot, small buffers, PR 2192
- vllm 的 Oneshot 性能提升: 成员们报告称,今天 vllm 的 oneshot 性能大幅提升,特别是在解决了 small buffers 问题之后,这与 PR 2192 相关。
- vllm 的 Small Buffers 突破: vllm 中 small buffers 的突破有助于提升 oneshot 性能。
GPU MODE ▷ #llmq (12 messages🔥):
Weird Quantizations, LoRA Training, Model Implementation, LLM.q Talk
- 奇特量化的配置: 一位用户询问了使用“更奇特量化”进行训练的配置 UX,想知道在命令行或配置文件中配置会是什么样子。
- 回复指出,目前的工作涉及命令行标志,并取决于量化的类型和方法。
- 分享演示文稿: 应成员要求,作者分享了 演示文稿 (PDF)。
- LoRA 训练中型项目: 一位成员询问了在列出的中型项目中使用 LoRA 训练 的情况。
- 建议将其实现为一个独立的 model 以维护代码库,并复用 kernels 和类似的参数收集代码。
- 即将举行的 LLM.q 演讲: 提醒大家在 此链接 将有一个关于 llm.q 的演讲。
GPU MODE ▷ #helion (5 messages):
FLA Benchmark, GDN, Mamba2, PTC Talk, Backward Generation
- FLA 用例受到关注: 一位成员对 FLA 用例 作为一个优秀且有说服力的 benchmark 表示赞同,特别提到了 GDN,可能还有 mamba2。
- 他们对 PTC 演讲 表示期待。
- 关于反向生成支持的疑问: 一位成员询问了支持反向生成(backward generation)的计划。
- 另一位成员确认对此感兴趣,但表示目前没有人正在进行相关工作,并引用了 8 月份的一个 GitHub issue。
HuggingFace ▷ #general (238 条消息🔥🔥):
开源 MoE, 微调 Florence, 图像超分辨率, LayerFort 垃圾信息, Hugging Face 退款
- 寻求开源 MoE 模型:成员们正在寻找优秀的开源 MoE (Mixture of Experts) 模型,要求具有可配置的总参数量用于预训练,并建议参考 NVIDIA’s Megatron Core 和 DeepSpeed。
- 一位成员幽默地询问是否有人拥有 服务器集群和海量训练数据。
- 深入探讨 Florence 模型微调:成员们讨论了微调 Microsoft’s Florence 2 模型,一位用户正在为图像打标签并寻求建议,指出网上缺乏具体的微调知识,并询问 你正在标注哪种类型的图像?。
- 另一位成员建议使用更接近 Llava 的 VLM,例如 JoyCaption,以获得更高级的标注能力。
- 最新的图像超分辨率选项:成员们讨论了替代 糟糕的在线图像放大工具 的方案,一位成员建议查看 Hugging Face 上的图像超分辨率 Space。
- 会议强调,最好的放大工具 高度取决于你的图像领域,而且最新的并不一定就是最好的。
- LayerFort 推广无限 AI 访问,引发垃圾信息指控:一位用户推广了 LayerFort,声称只需支付月费即可无限次请求访问来自 20+ 供应商 的 130+ 模型,包括 Gemini 2.5 Pro 和 GPT-5,并链接到了他们的网站 layerfort.com。
- 另一位用户立即将该帖子标记为 垃圾信息 (spam)。
- Hugging Face 退款不满情绪蔓延:一位用户对未收到退款表示沮丧,称自 6 号起就一直在发邮件,并警告他人注意 Hugging Face 订阅页面上关于不予退款和配额使用的说明,甚至在取消订阅时表示 在那之前只能待在你们这儿了。
- 一位 Hugging Face 团队成员 <@618507402307698688> 介入,询问该用户的 Hub 用户名以检查退款流程,并澄清 黄色角色 = Hugging Face 团队。
HuggingFace ▷ #i-made-this (75 条消息🔥🔥):
声明式 Web 应用管理, Serverless Agent 平台, 逆向思维研究模型, TensorFlow 优化器, AI 图像分析
- OpenRun 以声明式方式管理 Web 应用:一位成员一直在构建一个名为 OpenRun 的声明式 Web 应用管理平台,支持对基于 Gradio 构建的应用进行零配置部署。
- 它支持通过单个命令设置完整的 GitOps 工作流,只需修改 GitHub 配置 即可创建和更新应用。
- AgentBase 发布 Serverless Agent 平台:一位成员介绍了 Agentbase,这是一个 Serverless Agent 平台,允许开发者在不到 30 秒 的时间内构建和部署 Agent,无需管理单个集成。
- 该平台旨在帮助 SaaS 向 AI-native 转型或快速进行 Agent 构建实验,提供预封装的记忆、编排、语音等 API。
- Valor 提出奇特的研究问题:一位成员将 Qwen2.5-3B 微调成了 VALOR,这是一个 3B 参数的模型,能够生成非显而易见的、挑战假设的研究问题,可在 T4/RTX 3060+ 上运行。
- 它经过训练可以挑战假设并连接遥远的领域,适用于 AI/ML、机器人和物理 等技术领域。
- 云端 LLM CodeLens 进行横向对比:一位成员构建了 CodeLens.AI,这是一个用于比较 7 个顶尖云端 LLM 如何处理代码任务(如重构和安全审查)的工具,并行运行模型并显示带有 AI 评分的并排对比。
- 该工具包含排行榜并追踪模型的碳足迹,旨在比现有基准测试更真实地反映开发者的任务。
- Go 编写的 VectorDB 支持混合检索:一位成员发布了他们从零开始用 Go 编写的 VectorDB,命名为 Comet,它支持在 BM25、Flat、HNSW、IVF、PQ 和 IVFPQ 索引上进行混合检索,并具有元数据过滤、量化、重排序、倒数排名融合 (Reciprocal Rank Fusion)、软删除、索引重建等众多功能。
- 该成员发布了指向 HN 讨论帖 的链接。
HuggingFace ▷ #computer-vision (4 条消息):
Computer Vision Hangout 幻灯片、AI 图像分析工具、旧金山 GenAI 见面会
- Computer Vision Hangout 幻灯片发布:分享了 10 月 25 日 Computer Vision Hangout 的幻灯片,涵盖了一系列未具体说明的主题 (HF_CV_Hangout_October_25.pdf)。
- AI 图像分析工具亮相:介绍了一款能够分析图像并回答相关问题的 AI 工具,该工具使用 CLIP 从零开始训练 (aiwork.work.gd)。
- 该 AI 旨在实现用户友好,为所有用户提供快速准确的图像分析。
- 实时视频 GenAI 见面会通知:一场专注于实时视频生成的 GenAI Meetup 将于 10 月 15 日下午 5:30 在旧金山举行 (luma.com)。
- 此次见面会旨在连接对生成式视频和 AI 流水线(pipelines)感兴趣的人士。
HuggingFace ▷ #smol-course (5 条消息):
Hugging Face Jobs 错误、SmolAgents Tool Calling Agent 问题、将数据库信息连接到 DeepSite、DPO 测验错误
- Hugging Face Jobs 错误:一名用户报告在 Hugging Face 上运行作业时出现错误,提示未找到 trl 模块。
- 错误消息为 ModuleNotFoundError: No module named ‘trl’,表明缺少依赖项。
- SmolAgents 工具调用故障:一名用户在本地和 Colab 中使用 SmolAgents 的 ToolCallingAgent 配合 DuckDuckGoSearchTool 时,遇到了 ‘INVALID_TOOL_CHOICE’ 错误。
- 错误明确指出 目前支持的 tool_choice 值为 “auto” 和 “none”。
- DeepSite UI 获取数据库连接:一名用户询问如何将数据库信息连接到 DeepSite,以便根据数据库内容实现 AI 驱动的 UI 修改。
- 他们提出了一个场景:DeepSite 可以生成登录页面,根据数据库验证用户凭据,并相应地重定向用户。
- DPO 测验故障:一名用户报告在 DPO 测验的一个模块应用中遇到错误,并提供了一个与 unit_3_quiz 相关的 Hugging Face Space 链接。
- 另一名用户表示他们在大约一周前顺利完成了测验。
HuggingFace ▷ #agents-course (3 条消息):
AI Agents 证书
- AI Agent 证书缺失?:一名成员询问可用的证书,并指出似乎只有 AI Agents Fundamentals 的第一个单元提供证书。
- 其他用户收到通知,由于发帖速度过快需要减速。
- 速率限制机器人:机器人正在对用户进行速率限制(rate limiting)。
- 机器人被配置为防止用户发帖过快。
Eleuther ▷ #general (70 条消息🔥🔥):
神经定理证明频道、AI 评估策略、更小更高效的模型、最小模型定义、GPT-3 API 初创公司
- 寻找神经定理证明频道:一名成员询问是否有专门的神经定理证明(neural theorem proving)频道,想知道是否比在 general 频道讨论更合适。
- 建议了两个频道:<#797547607345201162> 或 <#1110611369574793306>。
- AI 评估方法论评述:一名成员分享了一篇关于 AI 评估的 Medium 文章并征求反馈。
- 一种回应建议使用更有效率的架构在更少的数据上训练模型。
- 剖析最小模型的定义:一名用户询问什么是最小的模型,另一名用户将其定义为 nano gpt 模型。
- 一名用户开玩笑地建议,可以通过将模型喂给 /dev/null 来制作一个尺寸为负的模型。
- 对 A10 云集群的需求:一名成员询问提供 A10 集群的云服务,以扩展训练和模型设置。
- 他们希望做好准备,看看在 ppl 趋势持续的情况下,如何在不超支的情况下验证其可扩展性。
- BabyLM 竞赛:一名成员提到了一个名为 BabyLM 的竞赛,该竞赛试图寻找最小的语言模型。
- 分享了 BabyLM 官网,并指出该竞赛将于 11 月在中国举行的 EMNLP 2025 上亮相。
Eleuther ▷ #research (136 messages🔥🔥):
Scalar RMSProp adaptivity, Anti-Scalar RMSProp, Mamba 3 Architecture, RWKV-7 comparison, Less is More Recursive Reasoning
- Scalar RMSProp:是否具有自适应性?:针对 Scalar RMSProp 的自适应性主张展开了讨论,一位成员认为其自适应性与最大稳定步长无关,且其他优化器也能达到这一极限。
- 论点认为 Scalar RMSProp 中的 1/sqrt(v) 修正因子可能并非神奇的自适应因子,反而可能有害,并将其与使用 sqrt(v) 的假设性 anti-Scalar RMSProp 进行了对比。
- Mamba 3:一个更简化的 RWKV-7?:成员们讨论了 Mamba 3 架构,将其与 RWKV-7 进行对比,并指出它用稍微调整过的 RWKV tokenshift 机制取代了 conv1d;共识是 Mamba 3 是对现有架构的精简。
- 在某些场景下,效率提升可能非常有价值,在不显著降低速度的情况下提升能力;关于 Mamba 3 的数据依赖型 RoPE 及其实现的讨论正在进行中 Mamba 3 Paper。
- 微型网络的递归推理:受限反向传播:针对“Less is More: Recursive Reasoning with Tiny Networks”论文展开了讨论,特别是其在 T-1 步 no_grad() 之后,仅在深度递归的最后一步进行反向传播的技术。
- 这种方法为何奏效的直觉仍在调查中,GitHub 上有一个相关的未解决 issue。
- EOS 效应推动锐度正则化:有观点认为优化器的主要工作是正则化锐度(sharpness);最终的退火阶段可能仍遵循 Hessian 视角,但优化器的大部分质量源于退火前的训练。
- 另一位成员表示,关于锐度,没有理由认为优化器会一直保持在稳定性的边缘。
Modular (Mojo 🔥) ▷ #general (19 messages🔥):
GPU Recompilation, MLIR blobs for drivers, Vulkan Bindings, AI-driven video streaming
- Mojo 为每个 GPU 进行重编译:一位成员询问了关于新 GPU 的前向兼容性和重编译问题,另一位成员回答说,当你运行代码时,Mojo 会为每个 GPU 重新编译代码。
- 他们表示,所有厂商都有某种方式使用 SPIR-V 来使程序运行,没有什么能阻止你让驱动程序的 MLIR blob 由一个持续更新的库进行编译。
- Vulkan 绑定已可用:一位成员分享了他的 vulkan-mojo 绑定,地址为 Ryul0rd/vulkan-mojo。
- 他们表示还没有费心去添加 moltenvk 支持,但这是一个很容易解决的问题。
- 今日演讲幻灯片:今日一场演讲的幻灯片已发布在 Google Docs。
- 演讲回顾了 Mojo 的各种特性,主持人表示:非常感谢分享!了不起的工作。
- AI 驱动视频流专家寻求机会:一位曾在 Red5 Pro、Zixi 等大型流媒体公司任职的视频流工程师正在探索涉及现代 AI 技术 的新工作机会。
- 他表示,如果你对 AI 驱动的视频流创新 感兴趣,请随时联系。
Modular (Mojo 🔥) ▷ #announcements (1 messages):
October Community Meeting, FFT implementation in Mojo, MAX backend for PyTorch, Modular's 25.6 release, Unifying GPUs
- Modular 安排十月社区会议:Modular 宣布了其十月社区会议,重点介绍 Mojo 中的通用 FFT 实现以及 PyTorch 的 MAX 后端。
- Modular 团队预计将详细介绍其 25.6 版本,该版本统一了来自 NVIDIA、AMD 和 Apple 的最新 GPU;更多详情可在 论坛 查看。
- Mojo FFT 通用实现:其中一位演讲者将分享使用 Mojo 实现通用 FFT 的工作。
- 这是十月社区会议的一部分。
Modular (Mojo 🔥) ▷ #mojo (136 messages🔥🔥):
ComplexSIMD 构造函数, FFTW 移植, ARM 上的 Mojo, LayoutTensors 痛点, Mojo 教程
- 正在添加 **ComplexSIMD 构造函数:一名成员建议添加一个 **ComplexSIMD 构造函数,用于对 SIMD 向量进行去交织(deinterleaves),从而提供一种更简单的方式来处理复数,其表达式为
fn __init__(out self, *, from_interleaved_simd: SIMD[Self.dtype, Self.size * 2]): ...。- 另一名成员分享了他们开源项目的加载技巧,并提醒在打包最大尺寸向量时需要进行两次独立的加载。
- **FFTW 移植实现即将进入 Mojo:随着 PR #5378 的落地,Mojo 将拥有原生 FFT 实现,尽管目前仅支持编译时已知大小的 **1D 变换。
- 成员们讨论了针对动态尺寸的潜在解决方案,包括 JIT 编译和运行时规划(runtime planning),类似于 FFTW 处理该问题的方式。
- Mojo 在 Raspberry Pi 上运行困难:虽然 Mojo 支持 ARM,但在 Raspberry Pi 上运行时存在问题,可能是由于 tcmalloc 在使用 16k 页面的 Pi 内核上的页面大小限制导致的。
- 一名成员指出,当我们明年开源编译器时,社区应该可以修复这个问题,另一名成员确认它可以在 Ubuntu 24.04 LTS 上运行。
- 开发者表达对 **LayoutTensors 的痛苦:一名成员表达了使用 **LayoutTensors 的挫败感,理由是复杂的类型不匹配以及将其传递给子函数时的困难,由于 Mojo 类型系统带来的挑战,他们转而使用 CUDA,因为后者更简单。
- 他们分享了突出这些问题的代码示例,并指出使用原始指针(raw pointers)反而更容易,并问道:“如果你的 GPU 代码很简单,那么 Mojo 很好用;但如果是复杂的场景,我仍然认为 CUDA 的学习和使用门槛要低几个数量级。”
- 对 Mojo 教程的质疑:一名成员对 Mojo 教程表示沮丧,特别是 Game of Life 演示,称他们无法使其运行,因为目前还不支持顶层代码(top-level code),并总结道:“算了,我没法这样学习。”
- 另一名用户建议查阅 GitHub 仓库中的示例以获取进一步说明。
Modular (Mojo 🔥) ▷ #max (6 messages):
Modular 测试中的 Bazel 技巧, 测试 acos() Max 算子
- Bazel 诡计导致 Max 测试变成空操作(No-Ops):一名成员在测试新的
acos()Max 算子(op)时遇到麻烦,原因是 Bazel 无法找到在tests/integration/max/graph/BUILD.bazel中定义的graph目标(参见 PR 5418)。- 一名资深成员解释说,这是由于“某些 Bazel 技巧本质上将该测试变成了空操作”,这是一个与开源测试文件不足相关的“已知怪癖”,可能与 Issue 5303 有关。
- 在 Max Ops 文件中使用相对导入:一名成员建议在算子文件中尝试使用
from ..graph而不是.graph,并同样使用from .. import dtype_promotion来修复导入问题。- 该建议已被采纳,但根本问题仍然存在:Bazel 仍然无法找到
graph目标。
- 该建议已被采纳,但根本问题仍然存在:Bazel 仍然无法找到
Nous Research AI ▷ #general (133 messages🔥🔥):
vllm predicted outputs, Sam Altman, MCP gateway by docker, AI evaluations, decentralized ai and its security
- vLLM 实现更快的生成速度:Cascade Tech 在 vLLM 中发布了 Predicted Outputs,通过将输出转换为 (部分) 匹配预测的 prefill,实现了极快的生成速度 (博客文章)。
- Decentralized AI 安全性:一位专注于 Decentralized AI 及其安全性的 AI 博士生正在寻求为该项目做出贡献的方法。
- 他们关注训练期间的攻击,如 Backdoor 和防止收敛,特别是在 non-iid 数据分布设置下,并提到了一篇关于设计用于配合 homomorphic encryption 的新版本 Attention 机制的论文。
- Anthropic Backdoor 漏洞:Anthropic 发现,无论模型大小或训练数据量如何,仅需 250 份恶意文档 即可在 Large Language Model 中产生 Backdoor 漏洞 (论文链接)。
- 一位成员指出这是一个众所周知的问题,尤其是在 Vision 模型中,并讨论了在 Decentralized 设置下进行检测的困难,特别是由于私有数据和多样化的分布。
- 评估视频标注工作:一位成员正在进行视频标注,并寻求对其方法(音频到时间同步、Timeline JSON、Metadata、视频分辨率)的反馈。
- 他们链接了 Google Vertex AI 视频生成 Prompt 指南,用于逆向工程 Caption 信息。
- 解决 LM Studio 上的 Hermes 4 API 问题:一位成员寻求在 LM Studio 中设置 Hermes 4 的 API 访问权限,此前已在 SillyTavern 中成功实现。
- 另一位成员澄清说,LM Studio 仅允许在本地托管 API。
Nous Research AI ▷ #ask-about-llms (6 messages):
Graph Rag-like approach, Role-play book chunking, Wikipedia scratchpad, Gemini summarizes reply
- Graph RAG 探索开始!:一位成员正在寻求关于类 Graph RAG 方法 的建议,用于将角色扮演书籍的内容 chunking 为高效互联的节点,发现 Light RAG 效果不足。
- 他们正在寻找特定的基于工具的 Pipeline 或程序化控制的方法来进行 chunking 和 embedding 创建。
- Wikipedia Scratchpad:知识爬取:一位成员建议设计一种自定义实现,包括爬取书籍并为未知信息创建带有 [[wikilinks]] 的 “Wikipedia scratchpad”。
- 这种方法使用 verifier agent 来比较上下文并确定何时生成了足够的知识,充当生成式的实体/关系提取。
- Gemini 对知识生成的看法:一位成员分享说,他们要求 Gemini 总结关于知识生成的回复,这使解释更加清晰。
- 消息中包含的图片被 Bot 认为是 Rage-bait(恶意引战内容)。
Nous Research AI ▷ #research-papers (6 messages):
LoRA RL, Self-Adapting LLMs (SEAL), GRPO Algorithm, Weight Updates
- LoRA RL 被视为“有趣”的目标:一位成员建议 Self-Adapting LLMs 实验是 LoRA RL 的一个理想目标。
- Self-Adapting LLMs (SEAL) 框架发布:SEAL 框架 使 LLMs 能够通过生成自己的微调数据和更新指令来实现自适应,从而通过监督微调 (SFT) 实现持久的权重更新。
- 遗忘曲线与权重更新讨论:一位成员表示,观察遗忘在 SEAL 策略 中如何发挥作用将非常有趣,并建议在 这篇论文 的背景下进行战略性的权重更新。
- GRPO 算法激发思考能力:一位成员评论了一种有趣的方法,指出像 GRPO 这样的 RL 算法以每个序列极低的比特数训练模型,因此在基座模型中只需极少的干预即可激发思考(thinking)能力并不令人意外。
Nous Research AI ▷ #research-papers (6 messages):
LoRA RL, Self-Adapting LLMs (SEAL), GRPO RL Algorithm
- 将 LoRA RL 用于有趣实验:一位成员建议将 LoRA RL 用于一个“有趣的实验”,并链接了一条关于 Self-Adapting LLMs (SEAL) 的推文。
- 链接的 SEAL 论文 介绍了一个框架,使 LLMs 能够通过生成自己的微调数据和更新指令来实现自适应。
- Self-Adapting LLMs 微调:根据 项目网站,Self-Adapting LLMs (SEAL) 框架使用强化学习循环,将更新后模型的下游性能作为奖励信号,通过对自生成数据和更新指令进行微调来实现“持久适配”。
- 作者指出了战略性权重更新的重要性,以及“遗忘”在这一策略中是如何发挥作用的。
- GRPO 算法见解:一位成员对 GRPO 算法发表了评论,指出它以每个序列非常低的比特数训练模型,因此在基座模型中只需极少的干预即可激发思考能力并不令人意外,并引用了 这篇论文。
- 该成员对论文的摘要表示困惑,建议对该方法进行更清晰的描述。
Latent Space ▷ #ai-general-chat (120 条消息🔥🔥):
Exa Search API v2.0, 通过 GLM-4.6 逆向工程实现无限次 Claude, Raindrop 的 AI Agent A/B 测试, Base Models 推理能力, RWKV-8 ROSA 架构
- Exa 发布更快速的搜索 API:Exa 推出了其 AI 搜索 API 的 v2.0 版本,引入了 “Exa Fast“(延迟 <350 ms)和 “Exa Deep” 模式,由全新训练的 embedding 模型和更新的数百亿网页索引驱动。
- 此次更新需要全新的内部 vector DB、144×H200 集群训练以及基于 Rust 的基础设施,现有用户将自动获得访问权限 - 更多信息见此处。
- 解锁无限次 Claude 仅需 3 美元:一位用户声称中国的逆向工程通过将请求路由到 z.ai 上的 GLM-4.6 而非原生的 Sonnet,以每月仅 3 美元(首月 5 折)的价格解锁了无限次 Claude 编程层级,博文见此处。
- 其他人对延迟和实际的 Claude 质量表示怀疑,但一位用户指出 Z.ai 的月度计划性价比极高。
- Raindrop 实验 AI Agents 的 A/B 测试:Raindrop 发布了 “Experiments”,这是首个专为 AI agents 构建的 A/B 测试套件,可接入现有的 feature-flag 工具(如 PostHog、Statsig),或让你进行日环比对比。
- 这展示了产品变更如何影响工具使用率、错误率、意图、人口统计数据等,并为任何对比提供深度挖掘的事件链接,更多信息见此处。
- Base Models 已具备推理能力:Constantin Venhoff 等人的一篇新论文显示,思考型语言模型(如 QwQ)并未学习新的推理技能;相反,它们学习的是何时激活 Base Model(如 Qwen2.5)中已存在的潜在技能,链接见此处。
- 通过使用 sparse-autoencoder 探测,他们提取了 10-20 个不同推理例程的 steering vectors,并用这些向量驱动 Base Model,在 MATH500 上恢复了高达 91% 的性能差距。
- Karpathy 的廉价版 Nanochats:Andrej Karpathy 发布了 nanochat,这是一个极简的开源仓库,仅使用 8k 行简洁代码、无需外部库、只需几百美元的云端 GPU 时间即可端到端训练一个类 ChatGPT 模型(推文)。
- 它涵盖了 pretraining、midtraining、SFT、可选的 RLHF、带有 KV-cache 的推理,以及一份自动生成的报告单,旨在作为即将推出的 LLM101n 课程的结业项目。
Latent Space ▷ #private-agents (1 条消息):
diogosnows: 感谢 <@1203156838409969675> 🙏
Latent Space ▷ #genmedia-creative-ai (12 条消息🔥):
Nano Banana 灵魂印记争议, Nano-Banana 铅笔与墨水 AI 素描, LinusEkenstam Nano Banan 墨水素描提示词, AI 生成的水印, AI 生成的铅笔素描
- Nano Banana 的幽灵灵魂印记:在多个 nano-banana AI 输出中发现的微弱、重复的伪影引发了争论,讨论这是有意为之的水印、Transformer 伪影,还是生成过程中的奇特现象;复现方法包括将图像去色然后过度饱和。
- 社区分享了一些笑话,比如:这不是水印,这是灵魂,同时也提供了去除伪影的技术建议(上采样),并指出没有任何追踪 ID 的迹象。
- Nano-Banana 铅笔引发墨水素描复兴:风险投资人 Justine Moore 分享了一个流行的 nano-banana 提示词,用于在笔记本纸上创建相同的黑灰铅笔或蓝墨水线条画,画面中还包含艺术家手持笔和橡皮擦的手,详见此处。
- 推文关注者讨论了相关案例,向 Linus Ekenstam 的原始蓝墨水版本致敬,此外还有用户关于水印、平台限制(Google vs Grok)的回应以及俏皮的评论。
- Linus 发布 Nano Banana 墨水素描应用:Linus 分享了一个详细的提示词,用于创建 AI 生成的照片风格人脸墨水素描——笔记本纸上的蓝白细线画,艺术家的手依然可见,详见此处。
- 用户迅速将其转化为一个小程序(zerotoai.app),分享了他们自己的素描,争论画笔颜色,并讨论了提示词控制;Linus 称结果 非常有趣,并庆祝其被快速采用。
Manus.im Discord ▷ #general (111 messages🔥🔥):
Manus 自定义域名, Manus 行为失控, Manus API 验证错误, Manus Webhook 问题, Manus 招聘吗?
- Manus API Key 验证问题已解决:一位用户报告在验证 Manus API Key 时出现“服务器暂时过载”错误,但团队已通过 API 新变更 修复了该问题。
- 变更包括新的 responses API 兼容性以及三个新端点,以便更轻松地管理任务,镜像了应用内的体验。
- 通过 API 与 Manus 进行往返对话:Manus 团队启用了通过 API 多次推送到同一个会话的能力,允许使用 Session ID 与 Manus 进行往返对话。
- 一位将 Manus 集成到排水工程应用中的用户表示,希望能够流式传输中间事件,以获得更透明的用户体验。
- Manus Webhook 注册 API:一位用户在尝试注册 Webhook 时遇到了“未实现”错误(代码 12),表明 Webhook 注册端点暂时无法使用。
- 一名团队成员承认了该问题,将其归因于最近的代码更改,并承诺在次日修复。
- Manus 定价受到质疑,比替代方案更贵:一位构建交易 EA 和策略的用户发现 Manus AI 太贵了,因为编程错误会消耗大量 Credits。
- 该用户表示,Manus 比 GPT 和 Grok 更好,但仍然太贵。
- 功能请求:Manus 用户的熟练程度:一位用户建议增加一个选项,让用户在注册时说明自己的熟练程度,这样 Manus 就能知道是应该假设用户一无所知并提供保姆式引导,还是反过来。
Moonshot AI (Kimi K-2) ▷ #general-chat (70 messages🔥🔥):
AI 生成动画, Groq 性能, Moonshot 的 OAuth 集成, 模型基准测试, Aspen 的缺席
- AI 制作动画:一位用户分享了一段展示 AI 生成动画的视频,表明 AI 已经达到了可以制作完整动画作品和音乐的水平。
- 另一位用户表示,这些 AI 生成的内容非常棒。
- Groq 在基准测试中面临审查:用户讨论了 Groq 在工具调用(tool call)基准测试中的表现,注意到与其他供应商相比,它的得分意外地低,Chute 百分比低至 49%。
- 他们链接到了一条推文讨论该问题,并推测了性能低于预期的原因,考虑到 Groq 的定制硬件和隐藏量化,有人开玩笑说原本预期是 70%。
- Kisuke 渴望通过 OAuth 使用 Kimi K-2 的额度:一位用户正在开发移动端 IDE Kisuke,并请求关于实现 OAuth 集成的指导,以便允许用户登录并直接使用他们的 Kimi-K2 Credits。
- 其他用户对这种方法的可行性表示担忧,认为可能需要一个新系统,且 OAuth 可能无法直接访问 API Key。另一位用户建议联系 Aspen 讨论此功能。
- Moonshot 开发团队成员失联:一位用户分享了一条推文链接,表明 Moonshot 开发团队成员 Aspen 在节日假期期间经历了一次改变心态的体验,将不再重返工作岗位。
Yannick Kilcher ▷ #general (46 条消息🔥):
Graph Neural Networks, Hyperparameter Tuning, LR Scheduling, Context Windows, Embedding Swapping
- GNN 损失突然暴跌!:一位用户观察到在训练 Graph Neural Networks (GNNs) 时损失突然下降,想知道这是否就是所谓的 grokking(顿悟)。
- 其他人建议这可能是由于 hyperparameter tuning(如学习率或权重衰减)导致的,或者是由于第一个 epoch 结束导致网络再次看到相同的输入点。
- 要不要使用 Schedule?:一位成员建议 LR scheduling 可能是原因,而另一位成员建议在训练模型时 不要使用 lr scheduling,因为它会引入不必要的复杂性。
- 另一位成员 观察到当 LR 降得足够低,以至于停止在某个维度上循环时,就会发生这种情况。
- Embedding Swapping:成员们讨论了在系统提示词和用户提示词之间交换 embeddings,以区分上下文,特别是在长上下文中。
- 目标是让模型学习到在处理不同类型输入时的更本质的区别。
- 外包调查问卷:一位用户询问在哪里可以付费进行 survey(调查),另一位用户开玩笑说可以付钱让他来做。
- 一位成员推荐 Mturk 作为 行业标准,但提醒说由于报酬较低,结果可能无法代表目标群体。
- Hinton 向 Jon Stewart 解释深度学习:Geoffrey Hinton 为 Jon Stewart 提供了一次深度学习速成课,提供了关于 Deep Learning / back propagation 的最佳解释。
- 一位成员强调这是 我听过的关于 Deep Learning / back propagation 真正最好的解释。
Yannick Kilcher ▷ #paper-discussion (3 条消息):
Segment Anything 3, New Arxiv Paper
Yannick Kilcher ▷ #agents (7 条消息):
LLM Agents Course, Berkeley Webcast Subtitles, Federal Law Requirements
- 伯克利的 LLM Agents 课程非常出色,尽管音频很糟糕:一位成员分享了来自 伯克利的 LLM agents 课程,尽管 音频质量很差,但他仍然推荐。
- 他开玩笑说 AI 从业者应该使用 AI 来提高音频质量,并表示尽管存在问题,该课程 包含了所有的梗,并且可以以 1.5x 速 观看。
- 夺回字幕:伯克利网络广播讲座的解放:一位成员建议为旧的 Berkeley webcast lectures 生成字幕,因为现在 没有理由再隐藏它们了。
- 他们提到,之前有一个 抗议团体 导致这些讲座被撤下,因为它们没有字幕,歧视聋人,但现在可以 轻松生成它们。
- 字幕对决:联邦政府 vs. 懒惰的大学?:一位成员声称提供字幕是 联邦法律的要求,而伯克利等大学只是在偷懒。
- 另一位成员质疑 Harvard, Stanford, 和 MIT 等其他大学是如何在不提供字幕的情况下蒙混过关的,并猜测也许 YouTube 自动生成的字幕 也算数。
Yannick Kilcher ▷ #ml-news (10 messages🔥):
AI 第一作者要求, Copilot 漏洞, ImageNet 图像生成, Prompt Injection
- 华东师范大学 (ECNU) 的 AI 作者身份崛起:根据此公告,华东师范大学教育学部将要求其 2025 年 12 月教育研究会议的其中一个赛道必须以 AI 为第一作者。
- Copilot 的 Camo 被绕过,代码面临风险!:这篇博文报道了 GitHub Copilot 中的一个关键漏洞,该漏洞允许通过 camo 绕过外泄私有源代码;该问题已通过禁用 Copilot Chat 中的图像渲染得到解决。
- ImageNet 图像生成:已无关紧要?:一位成员表达了这样的观点:现在已经没有人关心 ImageNet 类别的图像生成了。
- Prompt Injection 的平庸手段:一位成员认为某个安全问题的 Prompt Injection(提示词注入)方面平淡无奇,但强调 camo 绕过特别有趣,称其为极其简单却有效。
DSPy ▷ #show-and-tell (7 messages):
Newsletter 服务, 小型 LLM (Gemma) 的优化, DSPy 优化器 (Bootstrap fewshot vs GEPA)
- 自建 Newsletter vs. Newsletter 服务:一位成员询问他们的 Newsletter 是由第三方服务驱动还是从头开始构建的。
- 该成员回答说网站是从头构建的,没有使用服务或自动化。
- Gemma 获得优化教程:一位成员编写了一份关于使用 GEPA 优化 Gemma 等小型 LLM 以执行创意任务的教程。
- 尝试使用 DSPy 优化器 (GEPA) 进行提示词工程:一位成员发布了一篇博客,对比了 DSPy 中的 Bootstrap fewshot 和 GEPA 优化器,发现高质量的示例集对于从 GEPA 中获得良好结果大有裨益 - The Dataquarry。
DSPy ▷ #papers (2 messages):
新的 Arxiv 论文
- Arxiv 论文涌现!:一位成员分享了两个新的 Arxiv 链接:First Generated Network 和 gc.victor。
- gc.victor 论文发布:gc.victor 论文刚刚发布。
DSPy ▷ #general (34 messages🔥):
多模态模型, Liquid 模型, DSPy 波士顿见面会, DSPy 湾区见面会, DSPy 多伦多见面会
- Liquid 模型赋能多模态建模:针对 4B 参数以下模型的需求,一位成员推荐将 Liquid 模型用于多模态任务。
- 波士顿正在聚集 DSPy 伙伴:周三将举行 DSPy 波士顿见面会,由来自 PyData Boston, Weaviate 和 Amazon AWS AI 的成员组织,注册将在 24 小时内截止,地点见 Luma.com。
- 湾区召唤 DSPy 爱好者:一位成员正在组织 湾区 DSPy 见面会,并请感兴趣的人员回复,以便在发出邀请时获得通知。
- 许多用户表达了热情,其中一人提到他们对使用 DSPy 的复合多轮系统感兴趣。
- 多伦多渴望技术演讲:许多成员对在 多伦多举行 DSPy 见面会 表示感兴趣,有人形容这像雨后春笋般涌现。
- 一位成员自荐随时在多伦多组织 DSPy 见面会,并提到了之前与 spacy (ax) 和 maxime Rivest 合作举办的成功活动。
- 自动化高手承接任务:一位成员介绍自己是经验丰富的工程师,专攻工作流自动化、LLM 集成、AI 检测以及图像和语音 AI,并提供其服务。
- 他们强调了在现实世界落地方面的强大记录,并提供了使用 LangChain, OpenAI API 和自定义 Agent 构建的自动化流水线和任务编排系统的示例。
aider (Paul Gauthier) ▷ #general (14 条消息🔥):
Aider 默认提示词功能配置,Aider Polyglot 基准测试 LLM 评估轨迹,Aider 讨论平台(GitHub discussions, Reddit 论坛),导出 Aider 设置到文件
- **Aider 配置:设置默认提示词**:成员们讨论了在 Aider 配置文件中将默认提示词功能设置为
/ask,并参考了关于使用模式和配置选项的 Aider 文档。- 一位用户建议设置
architect: true让 Aider 分析提示词并进行选择,另一位用户建议尝试edit-format: chat或edit-format: architect以在启动时设置默认模式。
- 一位用户建议设置
- **寻求 Aider Polyglot 基准测试:一位成员询问如何获取 **Aider Polyglot 基准测试 LLM 评估轨迹。
- 另一位成员要求澄清,询问 “‘评估轨迹’(evaluation trajectories)是什么意思?”
- **寻找 Aider 讨论中心:一位用户询问是否有专门的 Aider 讨论平台,因为 **GitHub Discussions 已关闭 (https://github.com/Aider-AI/aider/discussions),且找不到 Reddit 论坛。
- 该用户似乎希望以非聊天格式讨论话题。
- **用户难以导出 Aider 设置:一位用户对
/settings命令表示沮丧,该命令输出大量且难以管理的转储信息,并询问是否可以将设置导出到文件**。- 他们注意到
/help指出这是不可能的,但质疑脚本是否可以实现导出设置。
- 他们注意到
aider (Paul Gauthier) ▷ #questions-and-tips (7 条消息):
Aider .env 文件位置,Aider 与其他 CLI 工具对比,Aider 修复错误代码,自动测试配置,OpenAI 终端到 ChatGPT
- **Aider 从 4 个不同位置读取 .env 文件:Aider** 在主目录、git 仓库根目录、当前目录以及通过
--env-file <filename>参数指定的位置查找 .env 文件,按此顺序加载,后加载的文件优先级更高,如文档所述。 - 在 **Aider 中自动测试并修复代码:一位用户报告了在使用 **qwen3-coder:30b 和 ollama 并设置了 test-cmd 和 lint-cmd 时,Aider 生成了无法编译的代码的问题。
- 一位成员建议开启 自动测试配置 并选择 yes always,这应该在每次更改后运行测试并尝试修复。
- 禁用 **Aider 添加文件的提示:一位用户询问是否有选项可以防止 **Aider 提示将文件添加到上下文,或者对任何问题都默认选择 no。
tinygrad (George Hotz) ▷ #general (17 条消息🔥):
Python 3.11 升级,TinyMesa CPU,在 Mac 上构建 TinyMesa,Mac 上的 NVIDIA GPU,会议取消
- 考虑将 Python 3.11 作为最低版本引发辩论:团队正在考虑升级到 Python 3.11 以利用
Self类型特性,尽管 Python 3.10 中存在变通方法。- 一位成员找到了在 3.10 中实现目标的方法,因此版本升级不会立即进行。
- TinyMesa 分叉与 Mac 构建:一位团队成员分叉了 TinyMesa,并询问其 CI 构建状态和 Mac 兼容性。
- 确认其正在 CI 中构建,理论上应该可以为 Mac 构建,并为成功的 Mac 构建额外提供 200 美元的悬赏。
- NVIDIA GPU 在 Mac 上的回归:一位成员对在 Mac 上实现 TinyMesa 加 USB4 GPU 的前景感到兴奋,这可能标志着十年来首个在 Mac 上运行的 NVIDIA GPU。
- 该成员认为如果在 Mac 上实现这个功能加上 USB4 GPU,那将非常令人兴奋。
- 今日会议取消:一位成员询问会议情况,另一位成员确认会议已取消,因为之前已在香港时间上午 10 点举行过会议。
- 他们之前开过会了,所以跳过今天的会议。
MCP Contributors (Official) ▷ #general (9 条消息🔥):
Proxying REST API, LLM-ready APIs, MCP server packaging formats, MCPB repo, Cloudflare MCP
- 代理 REST API 是糟糕的工具设计吗?: 一位成员询问代理现有的 REST API 是否通常被认为是糟糕的工具设计,并想知道是否有优秀设计的案例或比较效果的基准测试(benchmarks)。
- 另一位成员回复说这不一定是坏事,其有效性取决于底层 API 的设计,例如它是否使用了分页端点或允许适用于 LLM 的过滤。
- 渴望具体的 LLM-Ready API 基准测试?: 一位成员表示有兴趣在公司内部构建 LLM-ready API,但指出在没有具体证明或基准测试的情况下很难推进。
- 另一位成员指出,最有用的基准测试通常是特定于用例的(use case specific),并建议采用稳健的评估策略和工具,而不是过度依赖外部基准测试。
- 梦想确定性的 MCP Server 软件包?: 一位成员提出了当前 MCP server 使用 npx/uv/pip 方式在运行时进行非确定性依赖解析的问题,这导致了 Serverless 环境下的冷启动缓慢。
- 该成员提议使用确定性的预构建产物(deterministic pre-built artifacts),使其冷启动时间低于 100ms 且能跨不同运行时工作,本质上是将 MCP server 视为编译后的二进制文件,并表示有兴趣提交工作组创建请求。
- MCPB 仓库动态: 一位成员询问了关于 anthropics/mcpb 仓库 的参与情况,质疑社区是否旨在对打包格式保持中立。
- 另一位成员建议相关讨论在 <#1369487942862504016> 频道进行,并强调了最近在 registry 中支持 MCPB 的工作,以及与 registry API/schemas 保持兼容的重要性。
- Cloudflare 专家加入 MCP 团队: 一位新成员介绍了自己在 Cloudflare 负责 MCP 相关工作,并表达了参与的热情。
MCP Contributors (Official) ▷ #general-wg (1 条消息):
jzhukovs: 有人知道 Google AI studio 是否支持 MCP 吗?看起来好像不支持。
MLOps @Chipro ▷ #events (1 条消息):
Diffusion Model Paper Reading Group, DDIM Paper Discussion, Diffusion & LLM Bootcamp
- Diffusion Model 论文研读小组成立: 一个新的 Diffusion Model 论文研读小组 将于本周六 9 AM PST / 12 PM EST 举行会议(旧金山线下 + 线上混合模式)。
- 本次会议将包括对 Denoising Diffusion Implicit Models (DDIM) 论文的深度解读,以及对他们 Diffusion & LLM 训练营 的介绍。
- 深入研读 DDIM 论文: 小组将讨论 Song 等人于 2020 年发表的论文 Denoising Diffusion Implicit Models (DDIM),重点关注 DDIM 如何在保持高质量的同时加速图像生成。
- 理解 DDIM 是理解 Stable Diffusion 的基础,本次会议对具备 Python + 基础 PyTorch 知识的初学者非常友好。
- Diffusion & LLM 训练营发布: 会上将介绍一个为期 3 个月的 Diffusion Model 训练营(2025 年 11 月),该课程灵感来自 MIT 的 Diffusion Models & Flow Matching 课程。
- 该训练营旨在为 AI 和软件工程师、产品经理(PM)及创作者提供构建和训练 Diffusion Model、ComfyUI 工作流以及 GenAI 应用的实战经验。