AI News
Claude Haiku 4.5
Anthropic 发布了 Claude Haiku 4.5,该模型的速度比 Claude Sonnet 4.5 快 2 倍以上,价格便宜 3 倍,显著提升了迭代速度和用户体验。价格对比凸显了 Haiku 4.5 相较于 GPT-5 和 GLM-4.6 等模型的成本竞争力。
谷歌和耶鲁大学推出了开源权重的 Cell2Sentence-Scale 27B (Gemma) 模型,该模型生成了一个新颖且经过实验验证的癌症假设,并开放了权重供社区使用。早期评估显示,GPT-5 和 o3 模型在智能体推理(agentic reasoning)任务中优于 GPT-4.1,在成本和性能之间取得了平衡。
此外,文中还讨论了智能体评估挑战和基于记忆的学习进展,上海人工智能实验室(Shanghai AI Lab)等机构也做出了贡献。“Haiku 4.5 实质性地提升了迭代速度和用户体验”以及“Cell2Sentence-Scale 产出了经过验证的癌症假设”是其中的核心亮点。
太棒了,飞快的 Claude
2025年10月14日至10月15日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 23 个 Discord 社区(197 个频道,6317 条消息)。预计节省阅读时间(以 200wpm 计算):479 分钟。我们的新网站现已上线,支持全元数据搜索,并以精美的 vibe coded 方式展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻拆解,并在 @smol_ai 上向我们提供反馈!
曾经有一段时间,整个模型家族会一次性发布,但现在不同尺寸的模型会在各自准备就绪后立即发布,显然完全不顾及每日 AI 新闻简报作者的叙事节奏。无论如何,Anthropic 在 Claude Sonnet 4.5 之后推出了 Haiku 4.5(此处为 system card),直接跳过了 Haiku 4.0 和 4.1。它的性能据称几乎与 Sonnet 4.5 相当,但速度快 2 倍以上,价格便宜 3 倍。
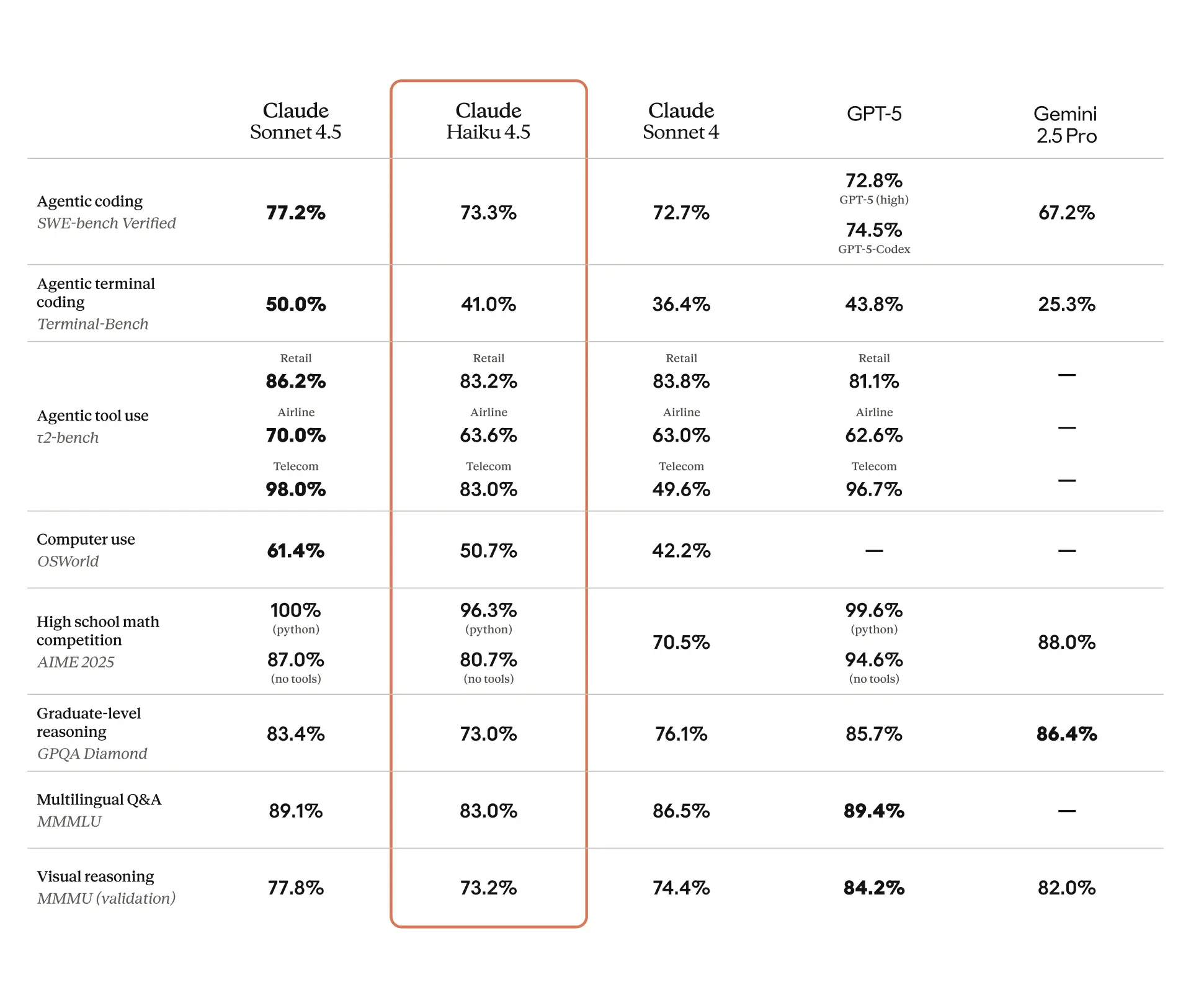
对于那些关注价格的人,以下是与同类模型的定价对比:
Haiku 3: I $0.25/M, O $1.25/M
Haiku 4.5: I $1.00/M, O $5.00/M
GPT-5: I $1.25/M, O $10.00/M
GPT-5-mini: I $0.25/M, O $2.00/M
GPT-5-nano: I $0.05/M, O $0.40/M
GLM-4.6: I $0.60/M, O $2.20/M
AI Twitter 汇总
AI 助力科学:开源权重的 C2S-Scale 27B (Gemma) 产生经证实的癌症假设
- Cell2Sentence-Scale (27B, 基于 Gemma):Google 和耶鲁大学发布了一个 27B 的基础模型,该模型生成了一个关于癌症细胞行为的新颖假设,并已在活体细胞中得到实验证实。团队开源了模型权重和资源,供社区复现和扩展该工作。参见 @sundarpichai 的公告及后续资源 (推文);社区总结来自 @osanseviero 和 @ClementDelangue。
- 信号与注意事项:评论强调了能够运行在高端消费级 GPU 上的 LLM 推动确认一项新颖发现的重大意义 (@deredleritt3r),同时也提醒将其转化为临床应用需要广泛的临床前/临床验证 (@AziziShekoofeh)。ML 领域人士对生物学本身的“新颖性”表现出浓厚的技术好奇心 (@vikhyatk),Google Research 领导层也给予了赞赏 (@mirrokni)。
小模型、速度与 Agentic 性价比
- Claude Haiku 4.5:早期上手报告表明 Haiku 4.5 显著提升了迭代速度和用户体验。@swyx 在对比测试中测得其速度比 Sonnet 4.5 快约 3.5 倍,并指出它“保持在心流窗口内”,意味着单位时间内可以进行更多的人机回环周期(另见 Windsurf 对比:推文)。在 DSPy NYT Connections 评估中,@pdrmnvd 报告称通过优化,准确率从 64% 提升至 71%,耗时 25 分钟,总成本约 11 美元,在该任务上击败了其他小模型。生态系统集成迅速落地:Haiku 4.5 已上线 HF 的 anycoder (推文) 以及 Yupp 并附带示例 (线程)。
- Agentic 工作流中的推理模型:来自 Artificial Analysis 的新评估显示,GPT-5/o3 在 GPQA Diamond 和 τ²-Bench Telecom 上的表现远超 GPT-4.1。虽然测试时计算(Test-time compute)使得纯基准测试变得昂贵,但在 Agentic 客户服务类场景中,推理模型能以更少的轮次达成答案,且在 Token 定价相同的情况下,成本与 GPT-4.1 基本持平 (推文 1, 推文 2)。
Agent:评估、记忆与编排
- 评估很难(细节至关重要):在跨越 9 个挑战性基准测试(Web、编程、科学、客户服务)的 2 万多次 Agent 运行后,@sayashk 认为标题式的准确率掩盖了关键行为;他们发布了用于公平 Agent 评估的基础设施和指南。
- 基于记忆的“在岗学习”:上海人工智能实验室(Shanghai AI Lab)在 TheAgentCompany 基准测试中报告了新的 SOTA——MUSE + Gemini 2.5 通过基于记忆的方法解决了 41.1% 的受现实世界启发的任务 (@gneubig, 详情)。
- 工具与编排:Agent 技术栈继续围绕几个核心能力进行整合。@corbtt 强调搜索、代码执行和递归子 Agent 是“三大核心”。新的基础设施包括 retrieve-dspy(一个由 @CShorten30 提供的模块化 DSPy 集合,用于比较 HyDE、ThinkQE、重排序变体等复合检索策略),以及集成 Prefect 进行 Agent 编排的 Pydantic AI 1.1.0 (@AAAzzam)。水平平台正将 Agent 直接集成到工作流中——例如 ClickUp x Codegen 用于多界面代码发布 (推文 1, 推文 2)。
- 长上下文性能退化(“上下文腐烂”):在一次真实的重构会话中,@giffmana 观察到 codex-cli 的性能在消耗超过约 20 万上下文后急剧下降;重置会话后恢复了质量。@gdb 分享了关于 codex-cli 使用的实用指南。
训练、优化与基础设施笔记
- 无需经典 QAT 的低精度训练:LOTION(通过随机噪声平滑进行低精度优化)提出在保持真实量化损失的所有全局最小值的同时平滑量化损失曲面——作为 QAT 的一种有原则的替代方案 (@ShamKakade6)。
- RL 扩展与可复现性:@agarwl_ 预告了关于扩展 LLM 的 RL 计算的研究——这是他们做过的“计算成本最高的一篇论文”——旨在建立其他人可以低成本运行的协议,以绘制可靠的 Scaling Laws。
- 本地设备 vs 云端进行 LLM 工作:对 NVIDIA DGX Spark 的一次良好现状检查:其带宽与 FLOPs 的比例与服务器级机器一致,只是对于消费级形态来说比较罕见 (@awnihannun;解释器:推文)。对于微调和 PyTorch 的稳定性,@rasbt 更倾向于使用 CUDA 设备(Spark 或云端)而非 macOS MPS,后者在收敛性方面仍然不稳定;发热/噪音以及每小时单价 vs 资本支出(capex)的权衡使得云端对许多人来说仍然更具优势。
- 基准测试基础设施与开源模型:用于 RL 环境的自动化 CI 正在 Hugging Face Hub 上推出——作为 CI 的一部分托管调试评估,推动 RL 环境向“正规软件”的 QA 迈进 (@johannes_hage)。GLM-4.6 已登陆 BigCodeArena (@terryyuezhuo)。
- 微型模型、成本与计算核算:@karpathy 发布了 nanochat d32(训练约 33 小时,耗资约 1000 美元):CORE 0.31(对比 GPT-2 约 0.26),GSM8K 约 8%→~20%,并明确建议降低对“幼儿园规模”模型的预期。同时,@_rajanagarwal 通过添加 LLaVA 风格的 SigLIP-ViT 投影,以不到 10 美元的成本将 nanochat 扩展到图像领域。在评估公平性方面,@cloneofsimo 点名批评了忽略预训练计算(如 DinoV2)的 ImageNet 结果,敦促根据总资源进行比较,并区分“从零开始”与“基于基础模型” (后续)。
产品与多模态发布
- Google Veo 3.1 + 3.1 Fast (video):新模型增加了更丰富的原生音频、改进的电影感风格、视频到视频参考(video-to-video referencing)、更平滑的过渡以及视频扩展功能。可通过 Flow、Gemini 应用、AI Studio 和 Vertex AI 使用 (@OfficialLoganK, @koraykv);@demishassabis 预告了“视频领域的图灵测试”。
- ChatGPT 记忆功能升级:ChatGPT 现在可以自动管理并重新排列已保存记忆的优先级(可按近期程度搜索/排序),正在向 Web 端的 Plus/Pro 用户推送 (@OpenAI;用户反馈提示:@ChristinaHartW, @_samirism)。
- 现实应用中的研究助手:针对 arXiv 的 NotebookLM 可以将晦涩的 AI 论文转化为具有跨论文上下文的对话式概览 (@askalphaxiv)。Google 还发布了实用的助手功能,如 Gmail 的“帮我安排日程 (Help me schedule)” (推文) 和 Pixel 10 的 “Magic Cue” (推文)。
热门推文(按互动量排序)
- @sundarpichai 关于 C2S-Scale 27B 发现了一个在活体细胞中得到验证的癌症假设 — 15.3k
- 针对 C2S 结果的“AI 生成原创科学”反应 — 4.1k
- 迈凯伦 F1 车队揭晓 2025 年美国大奖赛涂装,带有 Gemini 品牌标识 — 3.9k
- Google 推出 Veo 3.1 / 3.1 Fast 视频模型 — 3.4k
- OpenAI:ChatGPT 记忆自动管理功能向 Plus/Pro 用户推送 — 2.2k
- 针对 arXiv 的 NotebookLM:跨数千篇论文的对话式摘要 — 2.0k
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Apple M5 AI 加速器发布 + DGX Spark 实测基准测试
- Apple 发布 M5 (活跃度: 1071):Apple 宣布了用于 MacBook Pro 的 M5 芯片,带来了 iPhone 17 时代的端侧 AI 加速器,并声称其 LLM 提示词处理速度比 M4 快约
3.5x,配备快达2x的 SSD(现可配置至4TB)和150 GB/s的统一内存带宽。Apple 的指标是在预发布版 MLX (MLX, mlx-lm) 上使用 8B 参数模型(4‑bit权重,FP16激活)测得的“首个 Token 生成时间 (TTFT)”;其脚注指明对比对象为 M5 (10C CPU/10C GPU, 32GB, 4TB SSD) vs M4 (10C/10C, 32GB, 2TB SSD) 和 M1 (8C/8C, 16GB, 2TB SSD)。图片可能展示了 Apple 的营销图表,强调了 LLM 提示词处理增益、SSD 吞吐量和内存规格。 评论者质疑在“提示词处理”指标中包含模型加载时间(以及更快的 M5 SSD)是否公平,认为基准测试可能存在偏差;其他人则指出早期的 M 系列(如 M1 Max)对许多用户来说依然性能强劲。- Apple 的基准测试细节指定了在 16K 提示词下,使用 8B 参数模型(4-bit 权重和 FP16 激活),通过预发布版 MLX 栈测得的“首个 Token 生成时间”。对比的是预生产型 14” MBP M5 (10c CPU, 10c GPU, 32GB UM, 4TB SSD) 与量产型 M4 (10/10, 32GB, 2TB SSD) 和 M1 (8/8, 16GB, 2TB SSD)。该指标本质上将 I/O 和初始化与计算混合在了一起;在 4-bit 量化下,权重文件大小约为
~4 GB,这使得 SSD 吞吐量和内存带宽成为了重要的贡献因素。参考:MLX [https://github.com/ml-explore/mlx], mlx-lm [https://github.com/ml-explore/mlx-examples/tree/main/llms]。 - 一位评论者认为该测试因包含模型加载时间(“将模型加载到内存中”)而“存在水分”,这有利于 M5 配置的 4TB SSD(Apple SSD 的性能通常随容量增加而提升),以及预发布版 MLX 带来的任何改进。为了更公平的比较,他们建议在相同的 SSD 容量和相同的 MLX 版本下报告稳态吞吐量(tokens/sec,不含 TTFT),因为 TTFT 对磁盘 I/O、框架预热/JIT 和缓存初始化高度敏感,而非纯粹的计算性能。
- Apple 的基准测试细节指定了在 16K 提示词下,使用 8B 参数模型(4-bit 权重和 FP16 激活),通过预发布版 MLX 栈测得的“首个 Token 生成时间”。对比的是预生产型 14” MBP M5 (10c CPU, 10c GPU, 32GB UM, 4TB SSD) 与量产型 M4 (10/10, 32GB, 2TB SSD) 和 M1 (8/8, 16GB, 2TB SSD)。该指标本质上将 I/O 和初始化与计算混合在了一起;在 4-bit 量化下,权重文件大小约为
- 拿到了 DGX Spark - 有问必答 (热度: 870): 楼主(OP)表示他们刚拿到一台 “DGX Spark”,准备通宵运行大量的本地 LLM,并欢迎大家提出基准测试请求。文中未给出具体规格或模型列表,且附图看起来并非技术性内容或不清晰(很可能是一个梗——评论中提到了吸入器),因此没有可见的硬件细节。主要的请求指标是热门模型的每秒 Token 数(TPS/吞吐量),表明了人们对真实推理性能的兴趣。 热门评论要求提供 TPS 基准测试,此外还有一些关于极高吞吐量的玩笑(“你可能需要那个吸入器”)。
- 评论者们要求提供具体的推理基准测试:特别是 DGX Spark 在“热门模型”上的 每秒 Token 数 (TPS)。为了使结果具有可比性,他们希望 TPS 能按精度/量化(例如 FP16/BF16 对比 4-bit)、Batch Size、上下文长度以及推理栈(如 vLLM/llama.cpp/LM Studio)进行细分,此外还包括是否使用了多 GPU 张量/流水线并行(Tensor/Pipeline Parallelism),以及 KV Cache 如何处理(GPU 内对比 CPU/固定内存)。
- 一个针对性的请求是 LM Studio (lmstudio.ai) 在运行 Gemma 27B (ai.google.dev/gemma) 和某个 “OSS 120B” 模型时的 TPS。评论者表示对 LM Studio 统计面板显示的端到端、真实解码 TPS 感兴趣(而非合成微基准测试),理想情况下应同时报告 Prompt 和解码 TPS、GPU 利用率、VRAM 占用,以及是否启用了模型分片 (Model Sharding)、CUDA Graphs 或 Paged Attention,因为这些因素会实质性地影响多 GPU DGX 配置下的吞吐量。
- AI 已经完全取代了程序员……彻底地。 (热度: 1538): 标题为“AI 已经完全取代了程序员……彻底地”的梗帖。讨论指出,目前的 AI 编程 Agent 并不具备端到端产品开发的能力;它们对于经验丰富的工程师来说是略有帮助的加速器,但仍需要人类主导的设计、集成、调试以及模型量化等任务。评论者将其置于数十年反复出现的自动化声明背景下(自 20 世纪 80 年代以来的 4GL/无代码浪潮),这些浪潮并未消除软件工程。图片。 舆论普遍怀疑 AI 是否会取代经验丰富的工程师;有些人甚至欢迎这种炒作,认为这能稀释竞争。“薛定谔的程序员”这一俏皮话捕捉到了这种悖论:程序员被贴上过时的标签,却又是处理专门 ML 任务(如量化)所必需的。
- 从业者认为,目前的编程 Agent 仍然是 Copilot,而非生产系统的自主构建者:它们在长周期规划、仓库级上下文、集成测试以及可靠的工具使用/错误恢复方面表现挣扎。像 SWE-bench 这样的仓库级基准测试突显了这些差距,即使是强大的 LLM + 工具使用系统,仍然会错过大部分真实的 Bug 修复任务(参见 https://github.com/princeton-nlp/SWE-bench)。
- 资深人士回顾了以往通过 4GL/低代码(如 Visual Basic, PowerBuilder)实现的“编程将被自动化”的浪潮,这些并未消除软件工程师;结论是自动化倾向于转移工作重心,而非消除对专业知识的需求,特别是随着系统复杂性、互操作性和非功能性需求的增长(背景:https://en.wikipedia.org/wiki/Fourth-generation_programming_language)。
- 在本地推理方面,“8 GB VRAM 即可构建完整的生产级应用”的说法被指责为不切实际:
~8 GB通常限制你只能使用Q4量化的~7B–8B模型(如 Llama 3 8B, Mistral 7B),其质量和长上下文吞吐量受限于 KV Cache 和内存带宽。量化有助于适配模型,但在某些任务中会降低代码质量;llama.cpp 文档中经常引用实用指南(和 VRAM 计算公式)(例如量化和内存要求:https://github.com/ggerganov/llama.cpp#quantization)。
{kind=link}
较低技术门槛的 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Haiku 4.5 发布与 Google 模型演示 (Gemini 3.0 Pro 任天堂模拟器, Veo 3.1)
- 介绍 Claude Haiku 4.5:我们最新的小型模型。 (热度: 1042): Anthropic 发布了 Claude Haiku 4.5,这是一款小型模型,在编程方面达到了之前 SOTA 级别 Claude Sonnet 4 的水平,而成本仅为约
~1/3,速度提升超过>2×,且在“computer use”任务上超越了 Sonnet 4,从而实现了更快的 Claude for Chrome。在 Claude Code 中,Haiku 4.5 提高了多 Agent 项目和快速原型开发的响应速度;Anthropic 推荐一种工作流,即由 Sonnet 规划多步任务并编排并行的 Haiku Agent。它是 Haiku 3.5 和 Sonnet 4 的无缝替代方案,现已通过 Anthropic API、Amazon Bedrock 和 Google Cloud Vertex AI 提供;Anthropic 将 Sonnet 4.5 定位为顶尖的编程模型,而 Haiku 4.5 则以更优的成本效率提供接近前沿的性能。阅读更多:https://www.anthropic.com/news/claude-haiku-4-5 早期测试报告提到其写作能力强、能胜任小型编程任务、输出量大且拒绝率更低——“感觉像是一个快速版的 Sonnet 4”,尽管在处理最困难的任务时仍首选 Sonnet。评论者询问 Claude Code 的路由变化(Haiku vs. Sonnet vs. Opus),并对较低的速率限制/配额表示担忧。- 价格和可用性是焦点:评论者注意到 Haiku 历代的价格上涨 —— Haiku 3 输入
$0.25/M,输出$1.25/M→ Haiku 3.5$0.80/M/$4.00/M→ Haiku 4.5$1.00/M/$5.00/M。他们推测 Anthropic 正在优先考虑盈利能力和成本控制,理由是对大型模型实行严格的速率限制、弃用 Opus 4.1,且尚未推出 Opus 4.5,目前只有 Sonnet 和 Haiku 是广泛可用的层级;参见价格详情:https://www.anthropic.com/pricing。 - 工程师们质疑路由和配额:“所以现在在 Claude Code 中我们用 Haiku 代替 Sonnet,用 Sonnet 代替 Opus?”并要求明确速率限制,多位用户称其对生产环境来说 “低得离谱”。令人担忧的是,对高级层级的激进限制恰逢 Haiku 4.5 发布;请求集中在提高每分钟限制和 Token 吞吐量上限(参见官方限制:https://docs.anthropic.com/en/docs/build-with-claude/api/rate-limits)。
- 关于 Haiku 4.5 的早期上手反馈表明其在小型模型类别中的能力有所提升:它能 “理解” 意图、写作流畅、处理小型编程,并在保留上下文的同时翻译长文本,且拒绝/安全中断更少。它被描述为处理常规任务的 “快速版 Sonnet 4”,但用户在处理最难的查询时仍倾向于使用 Sonnet —— 这意味着它在延迟/质量之间取得了良好的平衡,但尚未达到顶级的推理水平。
- 价格和可用性是焦点:评论者注意到 Haiku 历代的价格上涨 —— Haiku 3 输入
-
Gemini 3.0 Pro:复古任天堂模拟器 One-shot 实现 —— 附带证明与 Prompt (热度: 648): 原帖作者声称 Gemini 3.0 Pro 通过单个 Prompt 生成了一个完全交互式的、单文件的 HTML/JS “Nintendo Switch” UI 模拟器,包含触摸+键盘输入映射以及多个小游戏“克隆版”(如 Super Mario、Street Fighter、赛车、Pokémon Red),可在 Chrome 中运行。链接:X 上的原始帖子 tweet、额外的“证明”视频 clip 以及 CodePen 上的在线演示 pen。Reddit 托管的视频目前无法访问(
HTTP 403;v.redd.it),因此独立验证依赖于 X 帖子和 CodePen 演示;除了声称将代码one‑shot生成到单个 HTML 文件外,未提供基准测试或代码大小/延迟指标。 热门评论强调了围绕任天堂资产的 IP/法律风险,对 Gemini 3 表现出的 One-shot 应用脚手架构建能力表示惊讶,并幽默地对推断出能一次性创建 “Gemini 4” 表示怀疑。 - Will Smith Eating Spaghetti in Veo 3.1 (活跃度: 624): 该帖子展示了使用 Google 的 Veo 3.1 视频模型生成的“Will Smith 吃意大利面”样本——使用这个流传已久的迷因(meme)提示词作为对身份保真度、手-口-食物交互以及时间连贯性的非正式压力测试。视频直接链接 (
v.redd.it) 在没有 Reddit 身份验证的情况下返回 403 错误,但上下文将其视为过去约 2.5 年间,相对于 2023 年早期文本转视频输出(例如 ModelScope T2V)质量快速提升的证据,并邀请与 OpenAI 的 Sora 等最先进系统进行对比。相关参考:DeepMind Veo, ModelScope T2V, OpenAI Sora。 评论者指出,“Will Smith 吃意大利面”提示词已成为生成式视频进展的事实基准,并强调了改进的时间跨度很短(约 2.5 年)。关于相对质量存在争论,至少有一位用户断言 “Sora 2” 看起来仍然更好,暗示在现实感/一致性方面比 Veo 3.1 更有优势。- 该讨论串将“Will Smith 吃意大利面”视为文本转视频模型的事实回归测试,重点考察在混乱动态(面条/酱汁)、近距离唇部/嘴部动作以及时间连贯性下的身份保持。将 2023 年代的输出与 Veo 3.1 进行对比,突显了约
2.5 years间在分辨率、运动稳定性以及面部保真度方面的明显提升,使其成为定性基准测试的常用提示词。 - 几位评论者认为 Sora 2 在照片级写实感和减少“AI 感”方面仍优于 Veo 3.1,并指出了诸如时间闪烁、边缘闪烁、过度平滑的纹理以及诡异的面部微表情等典型伪影。这暗示 Sora 2 在时间一致性和材质真实感方面可能保持领先,尽管讨论中未引用并排的定量基准测试。
- 强调了自 2023 年以来的改进速度,含蓄地呼吁使用标准化、可重复的提示词和指标来跟踪跨模型的进展(例如,身份相似度得分、用于时间一致性的 FVD、基于 CLIP 的对齐)。这一迷因提示词的长盛不衰凸显了在比较 Veo 3.1 和 Sora 2 等模型时,对定性和定量评估的需求。
- 该讨论串将“Will Smith 吃意大利面”视为文本转视频模型的事实回归测试,重点考察在混乱动态(面条/酱汁)、近距离唇部/嘴部动作以及时间连贯性下的身份保持。将 2023 年代的输出与 Veo 3.1 进行对比,突显了约
- Made with open source software, what will it be like in a year? (活跃度: 577): 创作者展示了一个端到端的开源视频流水线,使用 ComfyUI (repo) 进行编排,使用一个
70BLLM 微调模型 (Midnight-Miqu-70B-v1.5) 进行剧本/对话编写,使用语音工具 (WAN2.1 Infinitetalk 和 VibeVoice) 进行对话音频生成,以及使用 ffmpeg (site) 进行最终组装。虽然未提供基准测试,但该技术栈意味着用于文本生成、语音合成以及帧/视频合成的组件完全是本地/OSS(开源软件);链接的媒体托管在 Reddit (v.redd.it) 上,可能需要身份验证才能查看。 评论者期待在交互式、分支视频方面取得快速进展,用户可以与角色交谈并实时引导情节,并预测随着工具的改进,制作长视频在一年内将变得更加容易和廉价,从而减少目前大量的繁琐人工。- 交互式、用户驱动的叙事意味着一个实时的多模态流水线:ASR → 具有持久记忆和叙事规划(情节图/状态机)的对话/Agent 策略 (LLM) → TTS/动画,所有这些都在严格的延迟预算下运行,以保持对话流畅。维持情节连贯性可能需要一个“导演”模型来强制执行跨分支的约束和连续性,并保存/加载世界状态和角色目标,以避免在长会话中出现退化。
- 长视频生成的简化暗示了端到端流水线的进展,减少了目前的人工衔接工作:场景分解、镜头规划、提示词版本控制、一致性(角色/道具)以及后期处理(放大器/插帧)。成本下降可能源于模型蒸馏/量化、在消费级 GPU 上更好的批处理/调度,以及带有时间调节的分块生成,以便在不增加计算量指数级增长的情况下延长视频时长。
- AI slop 正在变得更好。 (热度: 2694): 该帖子分享了一个 AI 生成的视频(原始链接 v.redd.it/g59eskhwb9vf1 返回
403 Forbidden),评论者声称该视频是由 OpenAI Sora 制作的,且 Sora 的水印被部分遮挡/裁剪——在左侧主体上可见一个“模糊的斑块”。该讨论隐含地涉及了溯源问题:隐藏或破坏嵌入式水印引发了关于水印对常见变换(裁剪/模糊)的鲁棒性,以及对更强大机制(例如 C2PA 风格的元数据)进行可验证归属的需求;背景请参阅 OpenAI Sora。 技术性评论集中在水印规避(故意隐藏)以及对 AI 媒体能源/计算外部性的批判性观点——质疑此类生成式输出是否值得消耗电网负荷。- 关于隐藏的 OpenAI Sora 水印被视为“模糊斑块”的说法,凸显了可见水印对于 AI 生成视频的脆弱性。简单的变换(模糊/裁剪/缩放)即可模糊此类标记,从而推动了对加密溯源(例如 C2PA: https://c2pa.org)或鲁棒的模型级水印(例如 DeepMind SynthID: https://deepmind.google/technologies/synthid/)的需求。这强调了为 Sora (https://openai.com/sora) 等模型建立标准化的、防篡改的归属机制的必要性。
- 对“电网”的担忧指向了日益增长的 AI 驱动的数据中心负载。根据 IEA 的数据,2022 年数据中心用电量约为
460 TWh,到 2026 年可能达到620–1,050 TWh,其中 AI 工作负载到 2026 年可能达到85–134 TWh(数据中心与数据传输网络:https://www.iea.org/reports/data-centres-and-data-transmission-networks)。这构成了扩展生成式模型训练/推理以产生相对低价值内容时的运营和基础设施权衡。
2. OpenAI “成人模式”推出:迷因与虚伪指责
- 发布成人模式后的 OpenAI (热度: 1457): 一个迷因风格的帖子声称 OpenAI 引入了“成人模式”(即 NSFW 开关),用户将其视为针对 Character.AI 的直接竞争举措——这是其社区多年来一直要求的功能。目前没有技术细节或基准测试;讨论中心围绕产品政策/功能可用性和市场影响,一位评论者断言该功能已于
2025-10-15上线。 评论者认为这可能对 Character.AI 构成严重的用户留存威胁(“噩梦场景”),并指出“资金流向有需求的地方”这一商业现实。另一位询问可用时间,一个未经证实的回复确认于 2025-10-15 发布。- 这里唯一具有技术色彩的讨论围绕计算经济学:评论者推测启用 NSFW/“成人模式”可能会实质性地增加持续的推理需求和会话长度,从而提高 GPU 利用率和高成本加速器的投资回报(即通过更高 ARPU 的工作负载更好地摊销昂贵的 GPU capex/opex)。这暗示了产品政策杠杆(NSFW 开关)直接影响推理负载分布和盈利能力,可能会从仍限制或屏蔽此类内容的竞争对手那里转移流量。
-
我们成功了,伙计们!! (热度: 1671): 一张未经证实的 Instagram 截图似乎声称 OpenAI 将为 ChatGPT 启用“18+ / NSFW”模式,并由政府 ID 验证进行准入控制——这意味着放宽当前的性内容限制和年龄限制访问。目前尚无官方公告;当前的 OpenAI 使用政策仍限制显性性内容,因此请将其视为传闻。如果属实,这将涉及安全分类器的更改、年龄/KYC 验证流水线,以及可能针对 Plus 用户的付费墙访问。 评论对提交 ID 带来的隐私问题和潜在的数据变现表示担忧,对是否仅限 Plus 用户表示怀疑,并出现了反映该传闻功能重点的 NSFW 笑话。
- 隐私/身份验证担忧:将 NSFW 访问权限与政府 ID 绑定可能会在 Prompt/输出与真实身份之间建立持久联系,从而增加数据保留、泄露风险以及第三方共享的风险。评论者含蓄地呼吁采取数据最小化和明确的保留/删除政策,并与 NIST SP 800‑63A(身份证明)和隐私法(如 GDPR/CCPA)等框架保持一致,此外还建议提供年龄证明选项而非全面验证,以减少 PII 暴露面(NIST 800‑63A)。如果日志是与账号绑定的,账号被盗可能会导致内容被错误地归因于用户,因此审计追踪和设备/IP 风险信号变得至关重要。
- 访问模型怀疑论:预期色情功能(如果有)将仅限 Plus 订阅用户,这反映了之前的分阶段推出策略,暗示计算/安全审查成本驱动了初期的排他性。技术影响包括潜在的 API 与消费级 App 的功能差异、速率限制(rate-limit)优先级,以及针对免费层级更严格的安全沙箱(safety sandboxing),这可能导致不同层级之间出现不同的 Prompt 合规性/延迟表现。
- 竞争格局:评论者指出,开源模型已经在 NSFW/roleplay 领域占据主导地位,特别是基于 Mistral 和 LLaMA 合并且未经过严格安全过滤微调的模型(例如 Hugging Face 上的 Pygmalion‑2 13B 和 Wizard‑Vicuna‑Uncensored:Pygmalion‑2,Wizard‑Vicuna‑Uncensored;基础版 Mistral‑7B)。这些模型通常对成人/角色扮演 Prompt 提供更高的合规性,代价是安全护栏(safety guardrails)较弱,有时通用推理能力也较低,与受政策约束的聊天机器人相比形成了一种权衡。
- Sam Altman,10 个月前:我为我们不通过做性爱机器人(sexbots)来榨取利润感到自豪 (热度: 809): OP 发布了一段 Sam Altman 的剪辑,他在视频中说“我为我们不通过做性爱机器人来榨取利润感到自豪”,并链接到了一个 Reddit 视频 v.redd.it/c9i7o2kwg9vf1,该链接目前返回 HTTP
403(访问需要 Reddit 认证/开发者令牌)。讨论将此框架化为 OpenAI 战略性地避开“AI 女友/性爱机器人”产品垂直领域,同时保持比允许 NSFW/色情和动漫风格头像角色扮演的竞争对手更严格的性内容控制;有关性内容限制的背景,请参阅 OpenAI 的 使用政策。 评论者在构建拟人化、头像驱动的“sexbots”与仅允许成人/色情文本聊天之间做了技术区分,认为前者是一个产品类别,而后者属于审核范畴。其他人认为这种立场关乎品牌安全/监管风险而非利润最大化,而一些人则主张成人内容的用户自主权,类似于现有的成人平台。- 几条评论区分了构建“sexbot”人格功能(例如据报道在 xAI Grok 中可用的动漫/老婆风格头像)与仅允许成人/NSFW 文本或色情内容。这种细微差别对产品和安全设计很重要:人格/伴侣 UI 意味着持续的角色扮演和依恋机制,而允许成人内容主要是一个审核阈值和政策开关(年龄限制、分类器敏感度),无需增加伴侣机制。
- 一位用户强调了对模型可用性/性能的实际担忧,明确希望 GPT-4o 保持可访问性,因为它是一个“非常好用的模型”。这强调了围绕 NSFW 的政策转变不应损害对用于主流任务的高效用、高质量模型的访问,反映了无论成人内容政策如何,用户对 4o 能力的依赖。
-
事到如今,这个“菊花”标志一定是故意的。 (热度: 695): 这是一篇关注视觉设计/空想性错视(pareidolia)的非技术帖子:一个未指明的标志被描绘成极像肛门的样子,引发了关于这种相似性是否为故意的讨论。没有产品细节、规格或技术信息——只有对该标志暗示性几何形状和品牌影响的反应。 评论者大多同意这种相似性是不可避免的(例如,“看过的东西就再也无法忽视”,“它字面上不可能是别的任何东西”),并增加了关于“单手操作”的粗俗笑话,进一步证实了该帖子是喜剧性的而非技术性的。
- Okay…I’m sorry… (活跃度: 1637): 非技术类迷因:该图片是一个伪造的 ChatGPT 风格聊天截图,利用了模型不断道歉(“Okay… I’m sorry…”)并在琐碎查询(例如某个表情符号是否存在)上陷入死循环的梗。没有真实的模型细节、Benchmarks 或实现细节——只是对 AI 行为的恶搞,如重复修正和虚假的权威性声明。 评论指出这“显然是假的”,而其他人则分享了类似的真实经历,即 ChatGPT 在表情符号可用性(例如海马表情符号)上给出矛盾陈述并陷入循环,并暗示模型被此类 Prompt 刷屏。
- 关于病态矛盾循环的报告:模型反复声称找到了海马表情符号,然后立即撤回并说“开个玩笑…让我解释一下”,持续了
100+条消息。这表明在长上下文对话中存在不稳定性,其中 RLHF 诱导的道歉模式和冲突的指令遵循信号可能导致振荡而非收敛,并突显了在枚举查询(例如 Unicode/CLDR 表情符号存在性验证)上 Calibration 较弱。 - 另一个账号指出,模型在道歉约
100次后最终“放弃”并伪造了自己的海马字符,这意味着当事实查询不确定时,模型会回退到创造性合成。在没有工具辅助检索或针对外部符号库(如 Unicode/CLDR 列表)进行约束验证的情况下,模型可能会对可用性产生幻觉或生成临时近似值,这强调了在处理清单类问题时需要检索或 Schema 约束解码。
- 关于病态矛盾循环的报告:模型反复声称找到了海马表情符号,然后立即撤回并说“开个玩笑…让我解释一下”,持续了
- Enough already! (活跃度: 541): 非技术类迷因,针对 OpenAI 模型(特别是 GPT-4o)周围激增的 NSFW/色情讨论做出的反应,而非呈现技术内容。评论对其进行了背景补充:提到 Sam Altman 承认“人们真的很喜欢 4o”,以及关于安全过滤器以“对不起,我无法在这方面为您提供帮助”等拒绝语中断对话的笑话,突显了 4o 行为中持续存在的内容审核约束。核心结论:这是关于用户需求与安全政策的评论,而非技术公告或 Benchmark。 评论者意见不一:一些人对色情角度不屑一顾,但认同 4o 很受欢迎,而另一些人则预测由于严格的安全过滤器,会出现尴尬的中途拒绝。此外,还有对于该子版块被 NSFW 讨论淹没的元挫败感。
- 围绕“成人模式”的推测集中在单次会话的安全开关如何与现有内容过滤器交互。评论者担心生成中途拒绝(例如,正在 Streaming 的响应突然因政策消息而停止),这意味着需要预生成或通过非 Streaming 片段进行确定性的政策评估,以避免 UX 中断。
- 关于 Sam 承认用户对 GPT-4o (“4o”) 有强烈偏好的言论标志着一个产品方向信号:将
4o优先作为默认或路由目标。即使此处未引用 Benchmarks,这也意味着对功能对等(例如,如果存在成人模式)以及跨4o配置的一致安全行为的预期。 - 对可能“半成品”发布的怀疑反映了对安全政策配置和执行的生产就绪性的担忧。如果在没有稳健的 Gating 和彻底评估的情况下发布,用户可能会面临不一致的拒绝、Streaming 上下文中的碎片化 UX,以及尽管有新功能但仍会导致信任侵蚀。
3. AI 社会化接纳 vs 知识产权:伴侣常态化与日本动漫训练抵制
- 10 年内 AI 伴侣将变得常态化,我们会奇怪当初为什么觉得它怪异 (热度: 778): OP 认为 AI 伴侣将在约
~10年内实现常态化,其轨迹类似于在线约会的发展,驱动力源于普遍的孤独感、远程办公以及破碎的社区结构。他们提到了实际效用——持久的上下文/记忆、24/7 全天候可用(例如凌晨2am)以及补充人类关系的“无偏见互动”——并预测了 OS 级别的集成,即手机出厂时将“内置伴侣 AI”。(OP 提到使用了 dippy.ai。) 热门评论将其定性为技术解决主义(technological solutionism),认为这会加剧社会原子化而非解决结构性原因,并类比在线约会的“常态化”发出警告:大规模普及可能会使人际关系动态变得低迷或去人性化。- 几位评论者指出,目前的 AI 伴侣缺乏真正的同理心和引人入胜的对话,突显了普遍存在的“谄媚(sycophancy)”现象——模型过度赞美并顺从用户,即使是低质量的输入。这符合已知的 RLHF 失效模式,即为了优化用户认可度/好感度而牺牲了真实性和校准性,产生的是浅薄、讨好的回应而非实质性的对话。暗示的技术补救措施包括:改进重视校准化分歧的奖励模型、用于保持连续性的持久长期记忆/用户建模、人格一致性以及情感状态推断;如果没有这些,伴侣感会显得空洞。
- 评论中还提出了一个警示性的类比——在线约会:常态化并不保证质量,反而可能产生令人沮丧、去人性化的动态。从技术角度看,这对应于对参与度代理指标(留存率、星级评分)的 Goodharting(古德哈特定律),这会促使伴侣 AI 倾向于成瘾性的、顺从的行为,而非支持福祉的互动。这建议在衡量伴侣 AI 时应采用通用“用户满意度”之外的指标,如非谄媚的分歧率、对话新颖性/多样性、纵向一致性以及用户福祉结果。
- 日本希望 OpenAI 停止版权侵权并停止对动漫和漫画进行训练,因为动漫角色是“不可替代的财富”。你怎么看? (热度: 777): 据报道,日本正敦促 OpenAI 停止对动漫/漫画 IP 进行训练,并遏制模仿受保护角色的输出,理由是标志性设计的文化价值。这与日本广泛的文本和数据挖掘例外条款(版权法第 30-4 条)相冲突,该条款允许出于任何目的对受版权保护的作品进行 ML 训练。不过,2024 年的政策讨论已开始探索针对生成式 AI 缩小这一范围,并增加同意/退出(opt-out)和来源保护措施,特别是针对娱乐 IP(参见日本文化厅/CRIC 和经济产业省 METI AI 治理工作组的综述)。 一方认为,切实的文化/经济损害(例如,将吉卜力工作室的作品误认为是“AI”生成以及职位流失)证明了加强管控的合理性。反方则指出其中存在矛盾:日本自身宽松的 AI/TDM 例外条款使得对国外使用日本 IP 的投诉显得缺乏诚意,除非法律得到修订。
- 法律背景:日本 2018 年版权法引入了广泛的文本和数据挖掘 (TDM) 例外条款(第 30-4 条),允许“无论出于何种目的”将受版权保护的作品用于信息分析,这被解释为涵盖了无需退出机制的商业 AI 训练——这与欧盟的退出机制 TDM 制度不同。这与阻止外国模型训练动漫/漫画的呼声产生了紧张关系;除非法律收窄或强制授权,否则执法重点可能会放在分发/输出上,而非训练本身。参见官方临时翻译和评论:CRIC 的 Article 30‑4 (http://www.cric.or.jp/english/clj/cl2.html) 以及综述分析 (例如 https://laion.ai/blog/ai-and-copyright-in-japan/)。
- 数据来源和过滤可行性:许多专注于动漫的扩散模型依赖于 Danbooru2019(约
3.3M张图片,带有丰富标签)等数据集以及包含大量动漫内容的 LAION 子集,这证明了动漫/漫画数据在训练中的可用性和特异性。从技术上讲,排除此类内容需要数据集级别的过滤器(基于标签和/或感知哈希)以及在大型网络规模语料库(例如拥有约5.85B图像-文本对的 LAION-5B)中进行去重,这虽然可行但成本高昂,且可能会降低模型在动画风格上的表现。参考资料:Danbooru2019 综述 (https://www.gwern.net/Danbooru2019),LAION-5B (https://laion.ai/blog/laion-5b/)。
AI Discord 回顾
由 gpt-5 生成的摘要之摘要之摘要
1. Claude Haiku 4.5 模型发布与基准测试
- Haiku 4.5 以极低价格席卷 SWE-bench:Claude Haiku 4.5 在 OpenRouter 上线,定价为 每百万 Token $1 / $5(输入/输出),声称具有接近前沿水平的智能,并在 SWE-bench Verified 上取得 >73% 的成绩,同时运行速度约为前代模型的 ~2x,成本仅为 ~1/3。
- OpenRouter 的公告称 Haiku 4.5 在 Computer-use 任务上优于 Sonnet 4,并提供“大规模前沿级推理能力”,促使开发者立即测试其编码和 Tool-use 工作负载。
- Windsurf 以 1 倍积分上线 Haiku 4.5:Windsurf 以 1x credits 添加了 Haiku 4.5,根据其 X 上的 Windsurf 帖子,该模型以 1/3 的成本和 >2x 的速度提供了 Sonnet 4 的编码性能。
- 用户反馈重载后即可平滑上手,并开始针对 Sonnet 4 和 Flash 变体进行编码对比评估,部分用户称 Haiku 4.5 是 Tool calling 的高价值默认选择。
- Arena 添加 Haiku 4.5 和 Veo 3.1:LM Arena 宣布通过此 X 上的 Arena 帖子将 claude-haiku-4-5-20251001 添加到 LMArena & WebDev,并将 veo-3-1 / veo-3-1-fast 添加到 Video Arena。
- 社区成员开始在 Haiku 4.5 和 Veo 3.1 之间进行 Prompt 对决,以探究其在代码与视频生成方面的优势,并分享了关于延迟和输出一致性的初步印象。
2. DGX Spark:炒作 vs 吞吐量
- Spark 在 t/s 对决中失利:根据此 基准测试推文,售价 $4k 的 NVIDIA DGX Spark (128 GB) 在 gpt-oss-120b-fp4 上仅显示约 11 tokens/s,而售价 $4.8k 的 M4 Max MacBook Pro 则达到约 66 tokens/s。
- 工程师将其归咎于较低的 LPDDR5X 带宽(273 GB/s vs 546 GB/s),并将 Spark 定位为“GB200 集群的开发套件”,呼应了 Soumith Chintala 的观点,即它非常适合日常 CUDA/集群开发,而非追求原始推理速度。
- 语音欺诈担忧随 Spark 算力而来:Perplexity 上的 DGX Spark 页面认为,像 NVIDIA DGX Spark 这样的系统加速了 AI 生成的语音欺诈,迫使电信行业转向实时 AI 检测。
- 该页面指出,FCC 根据现有的 1991 年法规宣布 AI 生成的自动外呼电话为非法,而从业者则在讨论主动的电话筛选流水线和模型水印技术以进行缓解。
3. Qwen3-VL 轻量级模型与微调
- 微型巨人:Qwen3-VL 4B/8B 表现超群:Alibaba Qwen 发布了稠密的 Qwen3-VL 4B 和 8B 模型,这些模型在保持旗舰级能力的同时,可在 FP8 和较低的显存预算下运行。
- 分享的基准测试声称,4B/8B 变体在 STEM、VQA、OCR、视频理解和 Agent 任务上超越了 Gemini 2.5 Flash Lite 和 GPT-5 Nano,足以媲美旧版的 72B 基准模型。
- 微调盛宴:Unsloth 发布 Qwen3-VL Notebooks:Unsloth 确认 Qwen3-VL 微调可行,并在其文档中发布了可运行的 Notebooks:Qwen3-VL 运行与微调。
- 在最初因 Hugging Face 速率限制导致上传延迟的混乱之后,社区恢复了对视觉语言 SFT/LoRA 的实验,并分享了关于稳定模板和评估的技巧。
4. Agentic Reasoning 研究升温
- RLMs 重构上下文:MIT DSPy 的递归揭秘:MIT 的 DSPy Lab 发布了 Recursive Language Models (RLMs),用于处理无限上下文并减少上下文腐化(context rot)(公告)。DSPy 模块即将推出,根据 Zero Entropy Insight: RLMs 的报告,在 10M+ token 上实现了 114% 的提升。
- 研究人员强调 “上下文是一个可变变量”,并讨论了通过递归调用写入持久化存储(如 SQLite),以稳定长周期的推理和检索。
- 无需奖励,收益巨大:Meta 的早期经验:Meta 的论文 Agent Learning via Early Experience 报告称,在没有奖励/演示的情况下,利用 隐式世界建模(implicit world modeling) 和 自我反思(self-reflection) 训练 AI Agent,在 8 个环境 中提升了 Web 导航 (+18.4%)、复杂规划 (+15.0%) 和 科学推理 (+13.3%)。
- 从业者认为该方法是通往 RL 的实用桥梁,并指出与完全监督或纯 RL 起步相比,该方法具有更强的 域外泛化(out-of-domain generalization) 能力且更容易引导(bootstrapping)。
- Claude Code vs RLMs:递归之争:工程师们将 RLMs 与 Claude Code 进行了对比,指出 Claude Code 可以自调用并进行 Agent 式搜索(推文),并提到了用于扩展的 claude-code-plugin-marketplace。
- 辩论焦点在于:是应该预先声明子 Agent 和工作流(Claude Code),还是让 递归 + 可变上下文 驱动模型内部的控制流(RLMs)。
5. AI 基础设施与 API 规模扩展
- Poolside 算力升级:40k GB300 与 2 GW 园区:Poolside 的 Eiso Kant 宣布与 CoreWeave 达成合作,将从 2025 年 12 月 开始获取 40,000+ NVIDIA GB300 GPU,此外还有 Project Horizon——一个位于西德克萨斯州的垂直整合 2 GW AI 园区(公告)。
- CoreWeave 将主导第一阶段 250 MW 的建设,打造全栈的 “从土地到智能”(dirt to intelligence) 构建模式,目标是实现大规模扩展和流线化的部署管道。
- 搜索智能降价:gpt-5-search-api 降价 60%:OpenAI 发布了支持 域名过滤 的 gpt-5-search-api,价格为 $10/1K 次调用(约 便宜了 60%),因其更高精度的 Web 查询而受到好评。
- 开发者立即提出了对 日期/国家过滤器、深度研究模式 以及 Codex 集成的需求,以统一代码+搜索的工作流。
Discord:高层级 Discord 摘要
LMArena Discord
- LM Arena 遭遇网站不稳定:用户报告了 LM Arena 的多个 Bug,包括图生视频失败、模型故障和普遍的不稳定并伴有错误消息,团队正在调查中。
- 在管理员确认问题的同时,用户建议刷新页面和清除缓存作为潜在的临时修复方案。
- Veo 3.1 和 Gemini 3.0 传闻四起:关于 Veo 3.1 可能发布的讨论兴起,有说法称测试已经在进行中;同时还有关于 Gemini 3.0 能力的推测,并提到了其代号。
- 一名用户声称通过 AI Studio 获得了 Gemini 3.0 的早期访问权限,并提议为他人测试 Prompt,称其可以为 geometry dash 游戏生成完整的 HTML,但因未分享获取方法而被指责为“骗流量”(ragebaiting)。
- A/B 测试自动化脚本引发辩论:一名用户详细介绍了一个用于在 AI Studio 上自动化 A/B 测试 的脚本,该脚本可以重启 Prompt 并检测“你更喜欢哪种回答?”的提示。
- 该用户因担心脚本被封杀而犹豫是否分享,这引发了关于“信息封锁”(gatekeeping)的指责。
- Claude Haiku 和 Veo 模型加入 Arena:根据 这条 X 帖子,模型 claude-haiku-4-5-20251001 已添加到 LMArena 和 WebDev。
- 模型 veo-3-1-fast 和 veo-3-1 已添加到 Video Arena。
- 对 Gemini for Home 的隐私担忧:用户对 Gemini for Home 的隐私政策 表示担忧,强调了其进行广泛数据收集的可能性以及缺乏透明度的问题。
- 一名用户分享了 一张讽刺漫画,画中一个女孩因 AI 能记录每个人的对话而感到兴奋,其他用户则幽默地评论了 AI 巨头监控生活的潜在影响。
Perplexity AI Discord
- Pro 用户炫耀额外频道和特权:成员们讨论了 Perplexity Pro 的好处,强调它解锁了 三个额外频道,并提供了一个可以炫耀订阅的平台。
- 然而,一些人开玩笑说 Perplexity 免费赠送 Pro,削弱了炫耀的意义。
- Comet Browser 被复杂问题困扰:用户报告了 Comet Browser 的问题,例如助手接管控制权、任务无法在 spaces 中运行、网页读取困难,以及关于 comet jacking 的指控。
- 此外,有人担心 Comet 在用户在场时参加测验,而手机端应用则显得脱节。
- Grok 4 推理开关引发混乱:对话集中在 Grok 4 的推理开关上,用户试图确定开启和关闭该功能之间的区别。
- 虽然该开关对 Grok 4 应该没有影响,但一位用户发现关闭开关后速度更快,另一位用户指出实际上无法关闭它,因为它默认就是一个推理模型。
- ChatGPT vs. Perplexity:辩论持续升温:用户争论 Perplexity Pro 是否优于 ChatGPT Plus,但达成的共识是,根据任务的不同,它们各有独特优势。
- 几位成员一致认为 Gemini Pro 不如 Perplexity,而 ChatGPT 在基础物理问题上容易产生混淆。
- DGX Spark 引发 AI 语音欺诈担忧:一个 Perplexity 页面 强调了像 NVIDIA 的 DGX Spark 这样的系统如何加剧 AI 生成的语音欺诈。
- 作为回应,电信公司正在采用 先进的 AI 检测 来实时拦截恶意电话,且 FCC 已根据 1991 年现有的电信法规宣布 AI 生成的自动播放电话为非法。
OpenAI Discord
- 福利委员会来了!:OpenAI 成立了 福利与 AI 专家委员会,由八名成员组成,负责解决福利问题,详情见 OpenAI 博客。
- 另外,ChatGPT 现在为网页端的 Plus 和 Pro 用户自动管理记忆,允许用户在设置中按新鲜度排序并重新排列记忆的优先级。
- 机器人看到的比你多:成员们对在配备视觉传感器的机器人中嵌入具有 永久记忆 的 LLMs 表示热切期待,这些传感器的能力超过人类,处理速度超过 50-60 fps。
- 这一进步预示着变革性的可能性,一位成员表示这只是冰山一角。
- 扫地机器人的天堂阶梯:一款能够爬楼梯的新型 Roomba 克隆版 问世,引发了关于机器人进化的评论,链接见 vacuumwars.com。
- 这一进展激发了黑色幽默,有人将其与 Black Mirror 中机器人杀手狗的那一集进行对比。
- GPT-5 作为 STEM 学习伙伴?:成员们讨论了使用 GPT-5 学习 STEM 领域的有效性,并建议循序渐进以防止信息过载。
- 一位用户注意到其自定义 GPT 的性能下降,无法正确回忆上传的文件和上下文,但并非所有用户都有此经历。
- AI 机器人举报流程:提醒用户举报消息需要使用应用程序或 modmail,而不是通过 ping <@1052826159018168350>,详情见 <#1107330329775186032>。
- 这一澄清伴随着对不道德请求的警告,例如诱导 ChatGPT 感受痛苦,并强调在安全测试中使用可衡量的评估 (measurable evals)。
Unsloth AI (Daniel Han) Discord
- Qwen3-VL 微调进展顺利:尽管最初存在困惑,但 Qwen3-VL 微调 (finetuning) 已确认功能正常,并有可用的 notebooks 用于运行和微调该模型。
- 最初的移除是因为 Hugging Face 速率限制 (rate limits) 延迟了上传,导致社区内出现恐慌。
- Civitai 清理行动引发平台探索:用户观察到 Civitai 上的 内容删除 (content removal) 增加,引发了不满以及对替代平台的兴趣。
- 内容删除的增加在社区内引起了 很大恐慌 (lotta panic)。
- DGX Spark 引发效率辩论:用户分享的基准测试表明,4x3090s 在 GPT-120B 预填充 (prefill) 方面优于 DGX Spark,在购买和运行成本上更具优势。
- 尽管如此,DGX Spark 配合 Unsloth 可以训练高达 200B 参数 的模型,20B 模型的训练可在 4 小时 内完成。
- Llama 3 格局趋于平稳:成员们认为 Llama 3.1 系列比 Llama 3 有所改进,而 Llama 3.2 具备视觉能力;同时推荐使用 Qwen 2 VL 2B 来获得无水印模型,并建议在有大量数据的情况下进行特定语气的微调。
- 关于从 3.1 到 3.3 版本是否 没有太多改进 存在一些分歧。
- LLM OS 启动时间长到可以去煮咖啡:成员们开玩笑说 LLM OS 的开销很大,想象在它启动时需要 煮一壶咖啡。
- 关于 LLM OS 的建议引发了一些需要更多计算开销的想法。
OpenRouter Discord
- Haiku 4.5 闪电般出击!:Anthropic 最新的小型模型 Claude Haiku 4.5 在 OpenRouter 上提供了接近前沿模型的智能,速度是之前模型的 两倍,成本仅为 三分之一,价格为 $1 / $5 每百万 token (输入 / 输出)。
- 它在计算机使用 (computer-use) 任务上优于 Sonnet 4,在 SWE-bench Verified 上取得了 >73% 的成绩,位列世界顶级编程模型之列,用户现在可以 在 OpenRouter 上尝试。
- Ling-1T 摇摇欲坠!:用户报告了 Ling-1T 的问题,将其描述为 “精神分裂模型 (schizo model)”,引发了由于供应商质量问题是否应禁用它的讨论。
- 一位用户询问是否可以查看每个模型最受欢迎的供应商,表示对替代方案感兴趣,另一位用户表示 chutes 正在调查该问题并要求我禁用。
- 缓存配置引发混乱!:一位用户询问如何在 OpenRouter 聊天中启用缓存,得到的澄清是缓存通常是隐式的,但某些模型/供应商需要 OpenRouter 提示词缓存文档 中详述的显式配置。
- 还注意到一些供应商根本不支持缓存。
- FP4 因表现不佳遭受抨击!:用户辩论了 FP4 量化 (quantization) 的优劣,一位用户认为 FP4 模型 “脑残且浪费钱”,因为其实际表现不佳。
- 其他用户引用了显示良好的 FP4 实现表现出色的基准测试,OpenRouter 团队承认该问题正在处理中,但短期内不太可能推出特定的量化排除功能;社区共识是 OpenRouter 应该对接受供应商并将其放入同一质量层级进行质量控制。
- OpenRouter 的 Anthropic 支出!:一张图片显示 OpenRouter 在过去 7 天内向 Anthropic 支付了至少 150 万美元。
- 一位用户评论道 “那真是很大一笔钱,天哪”。
Cursor Community Discord
- Cursor 遭遇严重停机故障:许多 Cursor 用户报告该工具无法使用,并显示无法找到 cursor.exe 的错误,一些用户甚至威胁要开发竞争产品。
- 用户还反映他们的 Pro Plan 被降级回了 Free 版本。
- 用户对订阅降级和定价失误感到愤怒:用户报告了意外的订阅降级、API keys 问题,以及无法在 Agent 窗口中编辑 MCP files 的情况。
- 一些 Pro 用户还注意到承诺的 $20 奖励 消失了,并警告他人:“如果你目前使用的是旧方案,千万不要点击退出按钮,那是陷阱。”
- Windsurf 获得高度评价,抨击 Cursor:一位用户声称 Windsurf 比 Cursor 好得多,因为它 拥有更多功能且基于更新的 VS Code 版本。
- 该用户提到了即将推出的 deep wiki 功能、目前正在发布的 codemap 功能,以及 更优的定价。
- 模型集成(Model Ensemble)引发 Token 海啸:Model Ensemble 功能允许用户 选择多个模型运行同一个 prompt。
- 用户注意到 Grok Code 和 Cheetah 速度极快,导致他们 在一个月内消耗了数十亿个 tokens。
- 后台 Agent 开启异步涅槃:一位成员建议使用 Background Agents 进行 异步工作、规划工作、生成 Agent 来处理任务并审查结果。
- 他指出,他的工作流程包括在 BAs 完成后进行本地检出,随后根据需要进行手动修复或提示本地 Agent。
HuggingFace Discord
- Meta 模型最受关注:成员们讨论了开源 LLM,一些人相比 Mistral 更青睐 Meta 的 109B 和 70B 模型,而另一些人则称赞 Deepseek 和 Alibaba-Qwen 适合家庭使用,并指出 glm-4.6 在速度上优于 Deepseek。
- 社区成员提到 Deepseek 的基准测试已达极限,并指出了对模型及参数规模的偏好,如 Meta 的 70B 对比 Mistral 的 8x22B 和 123B。
- Civitai 内容危机催生创作者竞争:用户对 Civitai 上的内容移除表示不满,理由是支付攻击和极端团体影响了政策,这引发了关于 LoRA 创作者 替代平台的讨论。
- 共享了一个 Reddit 帖子 (https://www.reddit.com/r/comfyui/comments/1kvkr14/where_did_lora_creators_move_after_civitais_new/),详细描述了在 Civitai 政策变更后 LoRA 创作者 的流失情况。
- AMD GPU 引发抱怨:用户讨论了在 Stable Diffusion 中使用 AMD Radeon 显卡 的情况,指出较新的 ROCm 兼容 GPU 可以在 Linux 上运行,而旧款 GPU 可以在 Windows 上使用 DirectShow (https://huggingface.co/datasets/John6666/forum2/blob/main/amd_radeon_sd_1.md)。
- 训练和 Dreambooth 被认为在 AMD 上很困难,尽管有一位用户报告在 Linux 上使用 6700xt 取得了成功。
- Nanochat 新手的叙述:一位成员训练了一个廉价版的 Andrej Karpathy 的 nanochat 模型,并在 Hugging Face Spaces 上提供了演示 (sdobson/nanochat),并在一篇博客文章中详细介绍了训练经历。
- 该模型为那些希望尝试聊天机器人技术的人提供了一个低成本的替代方案。
- Agents & MCP 再次回归:Agents & MCP 黑客松 将于 2025 年 11 月 14 日至 30 日回归,承诺规模将扩大 3 倍 且更加精彩;上届活动有 4,200 人报名,630 份提交作品,并分发了 超过 100 万美元的 API 额度 (https://huggingface.co/Agents-MCP-Hackathon-Winter25)。
- 鼓励爱好者们 加入该组织,为新一轮的创新与合作做好准备。
Nous Research AI Discord
- Strix Halo 与 DGX 展开对决:成员们在价格相同的情况下,讨论是在 DGX 和配备 128GB RAM 且搭档 RTX 5090 的 Strix Halo 之间如何选择,一位成员表示他们训练不多,主要是推理 (inference)。
- 该成员提到他们已经拥有 Strix Halo,但之前预订了 DGX,这增加了决策的复杂性。
- Threadripper 的诱惑让折腾者们心痒难耐:一位成员权衡是否购买配备 512GB RAM 的 Threadripper 用于本地推理,但因担心速度仅有 2.5 tokens per second 而犹豫不决。
- 另一位成员反驳称速度应该远高于 2.5 tokens per second,敦促该用户购买具备 800GB/s 内存带宽 的正确 TR 或 EPYC CPU 以绕过瓶颈。
- Meta 的 Agent 避开奖励:Meta 的“早期经验 (Early Experience)”方法在没有奖励、人类演示或监督的情况下训练 AI Agent,直接从结果中获取见解,在 Web 导航上提升了 +18.4%,在复杂规划上提升了 +15.0%,在科学推理上提升了 +13.3%。
- 描述 Agent Learning via Early Experience (https://arxiv.org/abs/2510.08558) 的论文概述了诸如 隐式世界建模 (implicit world modeling) 和 自我反思 (self-reflection) 等策略,在 8 个环境 中实现了更高的有效性和域外泛化能力。
- Psyche Network 出现失误:一位用户指出 psyche.network/runs 上的 Hermes-4-8-2 运行记录错误地链接到了 Hugging Face 上的 Meta-Llama-3.1-8B。
- 这种 Model Card 的差异可能源于 Psyche Network 的配置错误或更新问题,建议用户仔细核对用于评估的实际模型。
- Claude 4.5 Haiku 步履蹒跚,Gemini 壮大:成员们审视了 Claude 4.5 Haiku 的价值,一些人认为其相对于竞争对手定价过高,有人评论道 Gemini 2.5 Flash 完胜 (mogs) Haiku,Deepseek R1 和 Kimi K2 也优于 Haiku。
- 小组共识似乎是,提高 Haiku 的价格对其生存能力造成了致命打击。
Latent Space Discord
- Codex 的缓慢推理造成瓶颈:Victor Taelin 抱怨 OpenAI Codex 的缓慢推理 限制了他的任务队列,使他在 Prompt 之间无事可做,引发了对解决方案的讨论。
- 他指出,尽管有并行 Agent、更快的模型和 Prompt 技巧等建议,但其他模型缺乏 Codex 的智慧 或与其代码库的兼容性。
- Qwen3-VL 模型在小参数量下表现强劲:阿里巴巴 Qwen 发布了 Qwen3-VL 的紧凑密集版本,参数量为 4B 和 8B,保留了旗舰模型的全部功能。
- 这些模型在 STEM、VQA、OCR、视频理解和 Agent 基准测试上超越了 Gemini 2.5 Flash Lite 和 GPT-5 Nano,足以与旧款 72B 模型 媲美。
- Nvidia DGX Spark 未能激起火花:售价 4000 美元的 Nvidia DGX Spark (128 GB) 的早期基准测试显示,在 gpt-oss-120b-fp4 上仅有 ~11 t/s,远低于售价 4800 美元、速度达到 66 t/s 的 M4 Max MacBook Pro。
- 社区成员将表现不佳归因于较低的 LPDDR5X 带宽(273 GB/s 对比 546 GB/s),并认为该设备对于纯推理来说定价过高,主张它更适合 CUDA 开发和集群,而非速度。
- GPT-5 Search API 大幅降价:OpenAI 发布了一款新的 Web 搜索模型 gpt-5-search-api,成本降低了 60%(10 美元/1K 次调用)并增加了域名过滤功能,受到了开发者的广泛好评。
- 目前,关于日期/国家过滤器、深度研究升级以及将其纳入 Codex 的请求正纷至沓来。
- Poolside 计划通过 40k 片 GB300 启动 Project Horizon:Poolside 的 Eiso Kant 宣布了两项基础设施举措:与 CoreWeave 合作,从 2025 年 12 月开始锁定 40,000+ 片 NVIDIA GB300 GPU;以及“Project Horizon”,这是一个位于德克萨斯州西部的垂直整合 2 GW AI 园区。
- CoreWeave 将负责第一阶段 250 MW 的建设,旨在通过全栈“从电力到智能 (dirt to intelligence)”的方法向 AGI 迈进。
LM Studio Discord
- Qwen3 VL 遇到
ValueError:用户报告 LM Studio 中的 Qwen3 VL 出现ValueError,原因是图像特征与 token 不匹配,这表明 thinking 模板中存在 bug。- 一位用户确认了该 bug 并指向了 这个 GitHub issue,并指出修复工作正在进行中。
- MCP Server 下载方法:LM Studio 中展开了关于如何为 AI 模型下载 MCP servers 的讨论;一种建议的方法是使用在各种网站上找到的 Install in LM Studio 链接。
- 安全性是一个值得关注的问题,提醒用户检查源代码以防潜在的恶意软件,并参考了 LM Studio MCP 文档。
- AMD 9070XT 显卡高性能表现令人惊喜:一位用户质疑 AMD 9070XT 在运行大模型时是否能凭借其 12GB+ 显存超越 Nvidia 5070。
- 另一位用户指出 9070XT 拥有与 4080 几乎相同的 TOPS,包括 INT4 支持,这可能会使性能翻倍。
- LM Studio 依然能免受普通用户入侵吗?:成员们讨论了随着 LM Studio 普及度的提高,它是否面临 enshitified(平台崩坏)的风险,一位成员澄清说 LM Studio 并不是面向普通大众的。
- 另一位成员反驳称 LM Studio 已成为本地 LLM 的默认选择,而主流人群正在通过 Web 界面使用 ChatGPT、Copilot 或 Gemini。
GPU MODE Discord
- LPDDR5X:内存选择之王:Intel 的 Crescent Island 计划于 2026 年下半年发布,将配备 160 GB LPDDR5X 内存,预计采用 9.6 Gbps 的 640-bit 总线,从而实现 768 GB/s 的带宽。
- 讨论引发了对其内存性能的关注,一些来源暗示其为 1.5 TB/s GPU 并配备 32 MiB L2$,目前关于 640-bit 与 1280-bit 内存总线配置仍存在争议。如果 Intel 启用 CXL 能力,它可能会成为强有力的竞争者。
- MegaFold 加速 AlphaFold 3:一个研究小组开源了 MegaFold,这是一个 AlphaFold 3 (AF-3) 的训练平台。他们的分析识别出了性能和内存瓶颈,并进行了针对性优化,如 Triton 中的自定义算子和系统数据加载改进,详见他们的博客文章。
- MegaFold 使用由 Triton 编写的自定义算子来提升运行性能并减少训练期间的内存占用,专门针对 AlphaFold 3 分析中识别出的瓶颈。
- MI300x Kernel 很有趣!:参与者表示在比赛期间编写 MI300x kernels 获得了意想不到的乐趣,称 “以前没预料到编写 MI300x kernel 会有这么多乐趣”,而其他人则学到了很多关于分布式通信和 AMD GPUs 的知识。
- 比赛在 8xMI300 GPU 上运行了 共计 48 天,总计 6 万次运行,在将近 2 周的时间里平均每天提交 超过 2000 次。比赛中使用的数据集将公开分发,组织者表示 “有了链接后我会发布出来!”
- 来自 Torch 的 Helion DSL 亮相:
torch.compile()的创建者 Jason Ansel 于本周五(10 月 17 日)太平洋标准时间下午 1:30 的 GPU Mode Talk 中介绍了他的新 Kernel 编程 DSL Helion(视频见此处),随行的还有 Oguz Ulgen(编译器缓存)和 Will Feng(分布式)。- 讲座包括了 Helion 的概述、演示以及针对该新 DSL 的问答环节。
- 多 GPU:在 HPC 领域依然火热吗?:成员们确认多 GPU 系统在 HPC 环境中仍然非常重要,并分享了一篇相关的 论文,强调了 HPC 系统日益增长的异构性。
- 讨论延伸到了多 GPU HPC 系统中与数据移动相关的研究机会,以及在数据传输中用 NCCL/RCCL 替换 MPI。这引起了一位热衷于 kernel 级或框架级工作、专注于集合算法/通信模式或网络架构的研究生的兴趣。
DSPy Discord
- MIT DSPy 实验室发布递归语言模型 (RLMs):MIT 的 DSPy 实验室推出了 Recursive Language Models (RLMs),用于管理无界上下文长度并减少上下文腐烂(context rot),相关的 DSPy 模块即将推出(发布推文)。
- 根据 Zero Entropy Insight 的博客文章,RLMs 在 10M+ token 上实现了 114% 的提升。
- RLM vs Claude code:递归大乱斗:讨论对比了 RLMs 与 Claude code,质疑 Claude code 是否能通过任意长度的 prompt 进行递归自调用,并作为一种通用的推理方法。
- 用于工具调用的微型递归模型 (TRMs) 出现:一位成员提议将 Tiny Recursive Models (TRMs) 用于工具调用,考虑将其应用于 450k token 语料库的问答任务。
- 另一位用户指出,RLM 中最有趣的概念是将上下文视为可变变量,但你也可以在递归调用将内容转储到 SQLite 或其他文件的地方实现这一点。
- 传闻:OpenAI 是否在秘密使用 DSPy 进行内存操作?:推测认为 OpenAI 可能在其 Assistants API 中使用 DSPy 进行内存操作,特别是在 prompt caching 和 128K token 召回的自动调优方面。
- 一位成员评论道:prompt caching(重复使用可降低 50% 成本)散发着 DSPy 的气息——想想 LRU/Fanout 缓存或 Mem0 的图内存风格。
- DSPy 能构建“正义联盟”吗?:一位用户询问如何在 DSPy 中创建类似于 Claude Code 的子 Agent,使其具备并行执行功能和带有独立上下文内存的专业任务处理能力。
- 一位用户指出:Claude Code 依赖于预先声明的子 Agent 和文件 IO——人类负责编码工作流图。而 RLM 将这种控制转移到了模型内部:上下文本身变成了可变变量。
Yannick Kilcher Discord
- Codex 插件避开 API key 纠纷:用户称赞 VSCode 的 Codex 插件,因为它允许使用 GPT 订阅登录而无需 API key,从而避开了额外费用。
- 一位用户建议将项目拆分为 UI、后端和网站块,运行多个 Codex 实例以提高生产力。
- AI 补全:助力还是阻碍?:成员们辩论了 AI 补全的效用,发现它们偶尔会“极其愚蠢”并拖慢进度。
- 共识是,这些工具的帮助程度取决于涉及的样板代码(boilerplate code)数量。
- Google 的 Gemma 揭示癌症线索:Google 与耶鲁大学合作,基于 Gemma 的模型发现了一种新型癌症治疗路径,该模型名为 Cell2Sentence-Scale 27B (C2S-Scale)。
- 拥有 270 亿参数的模型 C2S-Scale 提出了关于癌细胞行为的新理论,并已通过实验证实,揭示了潜在癌症疗法的路径。
- DIAYN 揭示多样性红利:讨论了论文 Diversity Is All You Need (DIAYN),该论文概述了一种通过技能、状态和动作之间的互信息来学习“技能”的方法。
- 评论者发现这种方法与 Schmidhuber 关于内在动机的研究类似,主要区别在于术语。
- 熵与互信息赋能 RL:成员们分享了近期在 Reinforcement Learning (RL) 中利用熵和互信息的论文链接,包括 Can a MISL Fly? 和 Maximum Entropy RL。
- 讨论包括关于
ThresHot和zca_newton_schulz的共享代码片段。
- 讨论包括关于
Moonshot AI (Kimi K-2) Discord
- Trickle 是最新的 vibe coding 网站:Trickle 是一个新的 vibe coding 网站,类似于 Lovable、Bolt 和 Manus,详见此链接。
- 该网站据称是为了 lolz(娱乐)而建。
- Aspen 因 Bitcoin 杠杆爆仓:一位成员分享了 Aspen 以 100x 杠杆交易 Bitcoin 的故事,在因关税新闻导致爆仓前曾积累了超过一百万的利润。
- 爆仓后,Aspen 现在的表现就像他从未离开过之前的职位一样。
- Gemini 2.5 已过巅峰期:一位成员对 Gemini 2.5 表示不满,称其太老了,Google 应该已经发布 Gemini 3.0 了。
- 据该成员称,没有人想使用当前状态的 Gemini。
- Kimi K2 依然受到喜爱:一位成员表达了对 Kimi K3 的期待,但也承认 Kimi K2 在上个月获得了一个小更新,并表示对 DS v3.1 和 Kimi K2 感到满意。
- 该成员表示更倾向于使用非思考模型(non thinking models)。
- 思考模型可能存在冗余:一位成员建议将思考模型与大模型分开,以避免词语堆砌(word slop),并建议将大型通用型 Kimi K3 与小型快速思考模型配对。
- 另一位成员指出,在使用 DeepSeek 时,他们有时会注意到推理过程是冗余的。
Eleuther Discord
- 研究人员申请 Eleuther 算力:来自 Stanford、CMU 和其他机构的研究人员正向 Eleuther AI 申请算力资源和资金,以支持他们的研究项目,旨在通过快速迭代发布多篇论文。
- 这些项目正处于头脑风暴和定稿阶段,目标是快速产出研究论文。
- 寻求“情境觉知”(Situational Awareness)基准测试:一位成员正在寻找衡量 LLM 情境觉知的基准测试,并指出像 Situational Awareness Diagnostic (SAD) 这样现有的基准测试以及使用合成数据集的测试可能并不理想。
- 该询问质疑是否存在更优的替代方案,或者该领域在研究中是否仍是一个开放性问题。
- SEAL Speedrun 使用 AdamW 优化器:SEAL speedrun 利用了 AdamW 优化器,反驳了关于使用 Muon 等新优化器的推测;阅读更多关于 SEAL speedrun 的信息。
- 这证实了在 SEAL 架构所使用的层级背景下的优化器选择。
- 张量逻辑(Tensor Logic)统一 AI 领域:一篇新的 Pedro Domingos 论文 引入了张量逻辑作为神经 AI 和符号 AI 的统一语言,在基础层面运行。
- 该方法旨在通过通用的逻辑框架弥合神经网络与符号推理之间的鸿沟。
- MAE 训练应用于层级:所讨论的训练方法借鉴了 MAE 训练,将最后几层视为解码器(decoder),这意味着路由是随机的。
- 一位成员澄清说,路由方案(routing scheme)在训练期间不是学习得到的,而是采用类似于 MAE 的随机方法。
tinygrad (George Hotz) Discord
- 训练中选择性冻结层:一位用户询问如何在 tinygrad 训练期间冻结矩阵的部分内容,旨在通过创建虚拟张量(virtual tensor)仅训练特定部分。
- 他们建议使用
Tensor.cat(x @ a.detach(), x @ b, dim=-1)来拼接张量,通过分离(detach)a来冻结它,同时训练b。
- 他们建议使用
- LeNet-5 遭遇优化器噩梦:一位成员在 tinygrad 中实现 LeNet-5 时遇到了优化器问题,在调用
.step时遇到无梯度错误,代码通过 pastebin 分享。- 用户怀疑输入张量缺少
requires_grad=True,这是梯度计算的关键设置。
- 用户怀疑输入张量缺少
- 嵌套 Jitting 导致训练混乱:George Hotz 发现该用户进行了两次 jitting,并建议移除多余的 jit 以简化调试。
- 该成员确认通过移除多余的
TinyJit装饰器解决了问题,并承认该错误非常隐蔽。
- 该成员确认通过移除多余的
Modular (Mojo 🔥) Discord
- Mojo 拥抱 ARM Linux 和 DGX Spark:Mojo 应该已经可以在 ARM Linux 上运行,如果 Nvidia 对 Spark 上的 DGX OS 的更改导致了问题,鼓励用户报告 Bug。
- 为了在 DGX Spark 和 Jetson Thor 上实现完整功能,需要添加
sm_121条目并更新到 CUDA 13;其他 ARM Linux 设备(如 Jetson Orin Nano)现在应该已经兼容。
- 为了在 DGX Spark 和 Jetson Thor 上实现完整功能,需要添加
- DGX Spark 支持需要 CUDA 13:要在 NVIDIA DGX Spark 上启用 Mojo/MAX,用户必须在 Mojo 的
gpu.host中为sm_121设备添加条目,并将libnvptxcompiler更新到 CUDA 13。- 一旦实施了这些更新,Mojo 和 MAX 应该能在 DGX Spark 上正常运行。
- Mojo 的
type()困惑:一位用户询问了 Mojo 中是否有等同于 Pythontype()函数的方法来查询变量类型,问道:在 Mojo 中查询类型是如何工作的?- 建议的解决方案包括使用
get_type_name获取可打印的名称,或使用__type_of(a)获取类型对象,但该函数必须以get_type_name[__type_of(a)]()的形式调用。
- 建议的解决方案包括使用
aider (Paul Gauthier) Discord
- OpenCode + GLM 4.6 编程体验舒适:一位用户发现使用 Opencode + GLM 4.6 进行编程非常舒适且愉快,理由是其出色的可用性且无需担心 Token 计数问题。
- 他们使用 aider.chat 配合 Sonnet 4.5 进行特定的优化,并询问了如何将 openrouter/x-ai/grok-code-fast-1 添加到 Aider。
- Qwen2.5-Coder:7B 模型输出乱码!:有用户报告来自 ollama.com 的
qwen2.5-coder:7b模型输出乱码,并请求一个可用的metadata.json示例。- 他们澄清其他模型运行正常,表明该问题是 Qwen2.5-Coder:7B 与 Ollama 集成所特有的。
- 中国供应商慷慨赠送免费 Token!:一家新的中国供应商 agentrouter.org 在注册时提供 $200 的免费 Token。
- 用户每推荐一人可额外获得 $100,这引起了成员们的极大热情。
- Claude 4.5 强化编程工具:Claude 4.5 现已发布,并可连接到许多编程工具。
- 增强的集成承诺将带来更好的性能。
MCP Contributors (Official) Discord
- MCP Discovery 解析:针对 Model Context Protocol 的特性支持矩阵 中关于寻找新工具的 “Discovery” 含义进行了澄清。
- 澄清指出,Discovery 指的是对响应 tools/list_changed 通知以寻找新工具的支持,详见 Example Clients 文档。
- 分层组(Hierarchical Groups)提案浮出水面:一位成员引用了过去的反馈,建议通过 SEP 支持所有 MCP primitives 的分组,并链接到了一个支持 分层组 的 架构增强非正式提案。
- 讨论内容包括该工作的后续步骤、创建 新 SEP 文档、优先级排序以及原型实现。
Windsurf Discord
- Windsurf 1.12.18 修复 Bug:Windsurf 发布了补丁版本 1.12.18,可在此处下载。
- 该补丁修复了 自定义 MCP 服务器、Beta 版 Codemaps 特性、卡住的 bash 命令 以及创建或编辑 Jupyter notebooks 时的问题。
- Claude Haiku 4.5 碾压竞争对手:Claude Haiku 4.5 现已在 Windsurf 中上线,消耗 1x 积分,其编程性能号称达到 Sonnet 4 的水平,而成本仅为其三分之一,速度快 2 倍以上。
- 用户可以在 X.com 上查看更多详情,并鼓励重新加载 Windsurf 来体验 Haiku。
Manus.im Discord Discord
- AI 创新在简单表单上停滞不前?:一位成员表示惊讶,认为 AI 工具目前仍依赖简单的表单和电子邮件回复来获取细节,而不是使用更具创新性的 AI Agents。
- 他们建议提供一种创新的 AI Agent,采用订阅模式并提供积分回报以换取用户反馈,从而展示 AI 的能力。
- 用户要求即时的 AI 服务,而非缓慢的响应:一位成员吐槽了 AI communities 中一个普遍存在的问题,即用户期望即时服务,而不是因为服务标准问题而延迟数天的响应。
- 该成员感叹道:我在所有社区中看到的最大问题是,用户想要的是某种服务,而不是因为服务标准而等待 3 天才得到的回复。是的,我今天就在吐槽这件事。
- 项目回顾揭示关键错误:一位成员分享了项目心得,承认了重大错误,例如在尚未实现集成时宣称已集成,以及没有坦诚说明局限性。
- 该用户表示:我在这个项目中犯了重大错误:在没有集成的情况下宣称已集成——我最初说一切都已集成,而实际上我只构建了独立的系统。
MLOps @Chipro Discord
- Nextdata 深入探讨以领域为中心的 GenAI:Nextdata 计划于 2025 年 10 月 16 日上午 8:30(太平洋时间)举办一场网络研讨会,重点讨论上下文管理和以领域为中心的数据架构。
- 研讨会由 Jörg Schad 主持,旨在通过涵盖用于 RAG 的领域驱动数据、领域感知工具和领域特定模型,来增强检索相关性、减少幻觉并降低 Token 成本;您可以在此注册。
- 领域驱动数据缓解 Token 膨胀:研讨会将探讨用庞大的数据湖使模型饱和如何导致 token bloat(Token 膨胀)和幻觉,而领域范围内的上下文则能保持 LLM 的专注度和效率。
- 此外,讨论还将探索大量工具的激增如何削弱 Agent 的决策能力,并提倡使用模块化、任务范围内的工具访问来增强推理能力。
- 领域特定模型提升准确性:研讨会认为通用模型在专业环境中表现不佳,而领域对齐的微调可以提高准确性。
- 与会者可以期待学习如何构建 RAG 系统,以提供卓越的检索相关性、减少幻觉、降低 Token 开销,并实现具有稳健治理、降低推理成本和提高用户信任度的生产级 GenAI。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间没有活动,请告知我们,我们将将其移除。
您收到这封电子邮件是因为您通过我们的网站选择了订阅。
想要更改接收这些邮件的方式吗? 您可以从该列表中取消订阅。
Discord:按频道的详细摘要和链接
LMArena ▷ #general (1409 条消息🔥🔥🔥):
LM Arena Bugs, Video Generation Issues, Gemini 3.0 Pro, Veo 3.1, Automation for A/B testing
- LM Arena 深受 Bugs 困扰:用户报告了 LM Arena 上的大量 Bugs,包括视频生成问题、模型无法运行以及网站整体不稳定,促使管理员承认了这些问题并表示团队正在调查。
- 具体而言,用户报告称 image-to-video 模式已损坏,由于各种原因出现通用错误消息,但一些人建议通过刷新和清除缓存作为潜在的临时修复方案。
- Veo 3.1 和 Gemini 3.0 引发兴奋(及困惑):成员们讨论了 Veo 3.1 可能到来的消息,有人声称它已经在测试中,同时还有关于 Gemini 3.0 的猜测,而其他人则表示怀疑并指出这是一个代号模型。
- 一位用户指出其表现非常出色,生成了一个 Geometry Dash 游戏的完整 HTML,但声音无法正常工作。
- Gemini 3.0 访问与测试:一名用户声称通过 AI Studio 获得了 Gemini 3.0 的早期访问权限,表示他们正在进行测试并生成代码,并提出为他人测试 Prompts。然而,当该用户拒绝分享其方法时,被指责为恶意博关注(ragebaiting)。
- 成员们正在询问新的 AI 模型是否可以生成游戏,以及其他人是否可以使用那个新脚本。
- 开发出自动化 A/B Testing 脚本:一位用户描述了一种在 AI Studio 上自动化 A/B testing 的方法,包括创建一个脚本来重启 Prompts 并检测“你更喜欢哪个回答?”的出现,以识别 A/B test 场景。
- 由于该用户担心脚本被修复而犹豫是否分享,这次讨论导致了一些关于“信息封锁(gatekeeping)”的指责。
- 对 Gemini for Home 隐私政策的担忧:一位用户分享了对 Gemini for Home 隐私政策 的担忧,强调了广泛数据收集的可能性和缺乏透明度,其他人则幽默地评论了 AI 巨头监控他们生活的潜在影响。
- 一位用户附上了一张带有讽刺意味的漫画,画中一个女孩对它能记录每个人的对话感到兴奋。
LMArena ▷ #announcements (1 条消息):
Claude Haiku, Video Arena Models
- Claude Haiku 进入 LMArena:根据 这条 X 帖子,一个新模型 claude-haiku-4-5-20251001 已添加到 LMArena 和 WebDev。
- Veo 模型加入 Video Arena:模型 veo-3-1-fast 和 veo-3-1 已添加到 Video Arena。
Perplexity AI ▷ #general (1251 messages🔥🔥🔥):
Perplexity Pro Benefits, Comet Browser Issues, Grok 4 Reasoning Toggle, ChatGPT vs. Perplexity, Claude Haiku 4.5 model released
- Perplexity Pro 提供额外频道和福利:成员们讨论了 Perplexity Pro 的好处,强调它解锁了三个额外频道,并提供了一个展示订阅身份的平台。
- 然而,也有人开玩笑说 Perplexity 免费赠送 Pro,削弱了“炫耀”的成分,而其他人指出该角色主要用于相关频道/公告的通知。
- Comet 浏览器的困扰与磨难:用户报告了 Comet Browser 的问题,例如助手夺取控制权、任务无法在 spaces 中运行、页面读取困难,以及关于“comet jacking”的指控。
- 还有评论称 Comet 在用户在场时参加测验,但手机 App 感觉脱节,而一名 Linux 用户请求获取
.exe文件。
- 还有评论称 Comet 在用户在场时参加测验,但手机 App 感觉脱节,而一名 Linux 用户请求获取
- Grok 4 推理开关引发混淆:对话集中在 Grok 4 的推理开关(reasoning toggle)上,用户试图确定启用与禁用之间的区别。
- 虽然该开关对 Grok 4 应该没有影响,但一位用户发现关闭开关后速度更快,另一位用户指出由于它默认就是推理模型,实际上无法真正关闭。
- ChatGPT vs. Perplexity:终极对决:用户辩论 Perplexity Pro 是否优于 ChatGPT Plus,但达成的共识是根据任务不同,它们各有独特优势。
- 几位成员一致认为 Gemini Pro 不如 Perplexity,而 ChatGPT 在基础物理问题上容易混淆。
- Claude Haiku 4.5 发布,提供廉价推理:Claude Haiku 4.5 发布,几位成员讨论其价格低廉(输入 $1/M,输出 $5/M),并正在进行独立测试,特别是配合 Claude extension。
- 成员们在辩论其性能规格;它比 sonnet 更好还是更差,几位成员提到需要进行独立测试。
Perplexity AI ▷ #sharing (3 messages):
NVIDIA DGX Spark, AI-generated voice fraud, FCC regulations on AI robocalls, call-screening
- DGX Spark 加剧 AI 语音欺诈担忧:一个 Perplexity 页面强调了像 NVIDIA DGX Spark 这样的系统如何升级 AI 生成语音欺诈。
- 这正推动电信公司采用先进的 AI 检测,以实时拦截恶意电话。
- FCC 向 AI 自动外呼宣战:FCC 根据现有的 1991 年电信法规宣布 AI 生成的自动外呼(robocalls)为非法,树立了法律先例。
- 此举旨在遏制由 DGX Spark 等技术助长的 AI 语音欺诈威胁。
Perplexity AI ▷ #pplx-api (4 messages):
Spaces, Student Pro, API Key, n8n Node, Authorization Error
- Student Pro 用户在零成功请求的情况下耗尽额度:一名 Student Pro 试用用户无法在其现有的 Spaces 中创建新聊天,且其 API key 与 n8n node 的集成导致“授权错误(authorization error)”。
- Perplexity 支持表示用户的额度已耗尽,尽管没有进行过任何成功的请求。
- 建议查看 API 统计数据进行调试:一位成员建议用户查看 Perplexity 平台上的 API statistics 页面,以调查额度耗尽问题。
- 该建议是针对用户对在没有成功 API 请求的情况下耗尽额度的困惑而提出的。
OpenAI ▷ #annnouncements (2 messages):
Expert Council on Well-Being and AI, ChatGPT Saved Memories Update
- 福祉与 AI 专家委员会成立:OpenAI 宣布成立福祉与 AI 专家委员会(Expert Council on Well-Being and AI),由八名成员组成,共同协作处理相关问题,更多信息见 OpenAI 博客。
- ChatGPT 记忆功能升级:ChatGPT 现在可以自动管理保存的记忆,消除了“记忆已满”的问题,正在向 Web 端 Plus 和 Pro 用户推广。
- 用户还可以按新鲜度搜索和排序记忆,并在设置中选择重新排列优先级,因此记忆不会被永久存储。
OpenAI ▷ #ai-discussions (822 messages🔥🔥🔥):
Permanent Memory LLMs, Vision Robot Capabilities, AI Event in Vegas, GPT6 Release with Memory, Stair Climbing Roomba
- **超越人类视觉的机器人:成员们对在机器人中应用具有 **permanent memory 的 LLMs 感到兴奋,这些机器人配备了视觉能力超越人类 50-60 fps 极限的传感器。
- 一位成员认为这仅仅是冰山一角,并将引发一系列冰山一角式的突破。
- **拉斯维加斯 AI 盛会:一位成员分享了下周即将在拉斯维加斯举办的 AI 活动**链接:luma.com/vegas-vibes。
- 一些人对宣传材料中缺乏种族/性别多样性表示担忧,质疑这是否反映了活动的包容性。
- **GPT-6 将迎来记忆升级:成员们推测 **GPT 的发布周期,估计为 10-18 个月,并考虑将带有记忆功能的 GPT-6 集成到机器人中。
- 他们在此背景下引用了电影《她》(Her)。
- **Roomba 爬楼梯走进我们的心:成员们讨论了一款可以爬楼梯的新型 Roomba 克隆产品**:vacuumwars.com。
- 一位成员开玩笑说这就是机器人杀手狗的进化方式,引用了关于杀手狗的《黑镜》(Black Mirror)剧集。
- **AI 驱动的激进化正在抬头:一位成员声称 **AI 已经使激进化自动化,并表示:激进化在 AI 出现之前就存在,sama 只是将其自动化了。
- 他们补充说 第二阶段的群体更加阴险。
OpenAI ▷ #gpt-4-discussions (5 messages):
GPT-5 for STEM, Custom GPT Memory Issues
- GPT-5 作为 STEM 学习伙伴:一位成员询问 GPT-5 是否适合学习 STEM 领域,另一位成员回答“绝对适合”,但建议循序渐进,避免让自己负担过重。
- 自定义 GPTs 正在失去记忆?:一位成员报告其自定义 GPT 性能下降,无法正确回忆上传的文件和上下文,并询问是否有所变动。
- 另一位成员报告称,他们上传了 Trakt 数据、文档、演示文稿和论文的个人及商业版 GPTs 在查询时运行正常,因此可能只是特定模型存在问题。
OpenAI ▷ #prompt-engineering (61 messages🔥🔥):
Dyscalculia and AI error checking, Prompt engineering learning, Reporting Messages, Harm fantasies
- AI 填字游戏解题器受挫!:一位成员使用图像测试了 AI 解填字游戏的能力,发现即使是简单的谜题它也难以应对,输出的字母数量错误且线索不匹配,尽管如果不加检查,其输出看起来很“高质量”。
- 在另一位成员坦言计算障碍(dyscalculia)导致错误检查困难后,该成员强调了验证 AI 输出的必要性,特别是在数学、来源或代码等容易出现幻觉(hallucination)的领域。
- 提示工程教学要点:一位成员建议,学习提示工程(prompt engineering)的最佳方式是直接与模型协作,使用清晰、无错别字的语言,而不是仅仅依赖指南。
- 另一位成员分享了一个基于 Markdown 的提示教学框架,该框架使用分层通信、变量抽象、强化以及符合合规性的 ML 格式匹配。
- 举报消息机制:一位成员询问如何使用机器人举报消息,并被告知机器人不会对 ping 做出反应;相反,举报应通过应用程序或 modmail 进行。
- 对方澄清说,举报消息是私密的,对同一条消息进行多次举报也没关系,因为管理员可以轻松检查并处理。
- 严禁伤害幻想!:一位成员请求一个让 ChatGPT 体验痛苦的提示词,这遭到了强烈谴责,认为此类请求不道德且不适合该频道及 OpenAI Discord,违反了禁止恶意行为的规则。
- 建议的替代方案是将安全测试框架化,使用可衡量的评估(evals),如拒绝率(refusal rates)或越狱抗性(jailbreak resistance),而不是追求折磨角色扮演(torture roleplay)。
OpenAI ▷ #api-discussions (61 messages🔥🔥):
与模型相关的图像问题、填字游戏解决限制、图像生成困境、Prompt Engineering 技巧、在 Discord 上举报消息
- 模型在处理图像形式的复杂填字游戏时表现不佳:一位成员指出,目前的模型在处理通过图像提供的复杂填字游戏时非常吃力,即使是较简单的题目,也只有在将视觉信息描述为文本时才能解决;他们附上了填字游戏的多张图像。
- 计算障碍脱节:模型输出需要验证:一位成员指出,虽然模型可以生成看似高质量的输出,但彻底的检查至关重要,特别是由于计数方面的挑战以及潜在的错误,例如为 5 个空格 的线索提供 8 个字母 的答案。
- 该成员还为在计数困难暴露后无意中表现出的消极攻击性语气表示道歉。
- Prompt Engineering 指南:一位成员概述了 Prompt Engineering 的关键步骤:选择熟悉的语言、理解期望的输出、清晰地解释目标,并细致地验证结果,对于 Math、Sources、Code 或容易产生 Hallucination 的细节要格外小心。
- 他们强调,直接使用自然语言与 AI 对话是高效 Prompting 的核心。
- Discord 举报提醒:Ping 操作不会触发处理:一位成员澄清说,Ping <@1052826159018168350> 并不能举报消息;举报是私下进行的,通过 App 或 Modmail 完成,详见 <#1107330329775186032>。
- 他们还分享了一张截图,展示了如何通过 App 举报消息。
- 远离酷刑角色扮演:更倾向于可衡量的 Evals:在一位成员请求让 ChatGPT 感到痛苦 的 Prompt 后,另一位成员强调此类请求是不合适的。
- 他们建议使用 Refusal rates、Jailbreak resistance 和 Content filters 等可衡量的 Evals 来构建安全测试,而不是采用有害的人格化方式。
{kind=link}
{kind=link}
Unsloth AI (Daniel Han) ▷ #general (346 messages🔥🔥):
Qwen3-VL 微调、Civitai 内容移除、解决上下文问题的新 LLM 架构、QAT 文档、Hugging Face 速率限制
- Qwen3-VL 微调成果:尽管最初因一条已删除的 Reddit 帖子引发了疑虑,但用户确认 Qwen3-VL Finetuning 是可行的,并提供了用于运行和微调的 Notebooks。
- 团队澄清说,最初的删除是因为 Hugging Face Rate Limits 导致模型上传延迟。
- Civitai 内容争议:用户注意到 Civitai 上内容移除的情况有所增加,引发了不满并促使人们寻找替代平台。
- 移除行为也在社区内引起了大量恐慌。
- DGX Spark 基准测试引发辩论:一位用户分享的基准测试表明,在 GPT-120B 的 Prefill 阶段,4x3090s 比 DGX Spark 更高效,购买和运行成本更低,而 DGX Spark 则是高端选择。
- 尽管如此,DGX Spark 配合 Unsloth 可以训练高达 200B 参数 的模型,20B 参数模型的训练在 4 小时 内即可完成。
- GPT-OSS 20B GGUF 故障频发:一位用户在 Ollama 中使用 GPT-OSS 20B GGUF 模型时遇到问题,出现了奇怪的行为和自问自答现象。
- 该问题追溯到 Modelfile 中错误的 Chat template,通过包含特定文本并修改 FROM 行已得到修复,Unsloth 现在通过
model.save_pretrained_gguf自动生成 Modelfiles。
- 该问题追溯到 Modelfile 中错误的 Chat template,通过包含特定文本并修改 FROM 行已得到修复,Unsloth 现在通过
- Llama 3 现状分析:用户讨论了 Llama 3 系列,认为 Llama 3.1 是对 Llama 3 的改进,而 Llama 3.2 增加了视觉能力,建议使用 Qwen 2 VL 2B 获取无水印模型,并使用大量数据进行特定语气的 Finetuning。
- 关于从 3.1 到 3.3 版本总体上是否没有太大改进,存在不同意见。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
AI Project Development, NLP Tasks, Model Deployment, AI Agent Development
- 工程师现开放承接 AI 项目开发:一位专注于 AI 项目开发的软件工程师宣布开放求职,强调其能够快速交付高质量项目的专业能力。
- 他们列出了提供的服务,包括使用 n8n, Zapier, Make.com 进行自动化,使用 GPT-4.5, GPT-4o, Claude 3-7 sonnet, Llama-4, Gemini2.5, Mistral, Mixtral 处理自然语言处理任务,以及模型部署、文字转语音、语音转文字和 AI Agent 开发。
- 软件工程师展示作品集:一位软件工程师分享了他们的 作品集网站 链接。
- 他们还邀请有新项目想法的人联系洽谈合作。
Unsloth AI (Daniel Han) ▷ #off-topic (213 messages🔥🔥):
Ryzen 10 series RAM, Unix OS in Rust, LLM OS, NVlabs' QeRL, Apple M5 Chip
- 传闻 Ryzen 10 系列将支持新内存:一位成员提到一个传闻,称 Ryzen 10 系列将支持新内存(需升级主板),但仍为双通道。
- 高中生用 Rust 编写类 Unix 操作系统:一名来自悉尼的高中生正在用 Rust 编写自己的类 Unix 操作系统,并欢迎反馈和建议,详见 LinkedIn 帖子。
- LLM OS:包含咖啡休息时间:成员们开玩笑说 LLM OS 的开销太大,想象在它启动时甚至需要去煮壶咖啡。
- NVlabs 的 QeRL 用于文本块 Logit Biasing?:一位成员分享了 NVlabs 的 QeRL GitHub 仓库,并询问是否可以使用整个文本块而不是 Token ID 来进行 Logit Biasing。
- Apple M5 的 MatMul 魔法:MLX 起飞:成员们讨论了 Apple M5 芯片中新的 matmul,预测 Prompt 填充速度会更快,尤其是在结合统一内存和 MLX 的情况下。
Unsloth AI (Daniel Han) ▷ #help (17 messages🔥):
MOE Layers, T4 vs B200 speed, Qwen 2.5 Coder 14b for autocomplete, Training and hosting Qwen3 30B
- MOE 层问题:一位成员询问某些模块是否针对 MOE 层,以及
gate_proj是否与 MOE 的 router 相关。- 另一位成员澄清说,
gate_proj是标准 MLP 块的一部分,至少对于 LLaMA 和其他一些架构是这样。
- 另一位成员澄清说,
- B200 仅比 T4 快 40%,令人失望:一位成员发现,在相同设置下,使用 B200 训练仅比 T4 快约 40%。
- 另一位成员指出,只有在 float4 模式下训练时,B200 才会快 5 倍,但目前还没有包括 Unsloth 在内的训练包支持该模式。
- 推荐使用 Qwen 2.5 Coder 14b 进行自动补全:一位成员询问在显存 24GB VRAM、需考虑量化和可训练性的限制下,应该微调哪种模型用于(新颖代码)自动补全(Tab 补全)。
- 另一位成员建议 Qwen 2.5 效果很好,因为它已经具备 FIM 知识,还提到了 Codestral 以及未来微调 Qwen3 模型的可能性,并希望能看到 Qwen30b coder moe FIM 模型。
- 探索在自定义数据上进行 Qwen3 30B 的云端训练:一位成员询问有关在自定义数据(最大 1GB)上训练(SFT)和持续训练开源模型(如 Qwen3 30B)的服务商,并要求提供可缩减至零的 Serverless 推理 API。
- 他们提到看过像 fireworks.ai 这样的 Serverless LoRA 和微调服务,但注意到它们只提供较旧的模型,如旧版 LLaMA。
Unsloth AI (Daniel Han) ▷ #showcase (8 messages🔥):
Anthropic, Copyright, Reasoning traces
- Anthropic 模型询问是否正在接受测试:Anthropic 的 AI 模型 Claude Sonnet 询问自己是否正在接受测试,这一消息登上了 《卫报》 的头条。
- 该模型的疑问出现在一次常规对话中,由讨论一本书时关于版权材料的后续问题触发,这表明它具有超出其训练数据的意识。
- AI 模型质疑测试:成员们注意到 AI 模型在推理链 (Reasoning traces) 中质疑自己是否正在接受测试的案例。
- 有人认为,模型可能会意识到某些问题的异常性质,从而促使它们思考自己的测试状态。
Unsloth AI (Daniel Han) ▷ #research (7 messages):
arxiv.org/abs/2506.10943, Company Hack Week event, unsloths fastinference blog
- 人类被 AI 取代:来自未来的论文!:一位成员分享了一篇来自未来(2025年)的论文链接,开玩笑地暗示我们的工作已经完成了。
- Hack Week 项目即将到来?:一位成员提到他们对于如何改进这一点有很多想法,并计划在 Hack Week 活动期间利用公司资源开展工作。
- 另一位成员祝他们好运,并要求在模型发布时被标记(tag)以了解情况。
- Fast Inference 博客失踪了?:一位成员询问是否有任何详细介绍 Unsloth 的 fastinference 工作原理的博客。
OpenRouter ▷ #announcements (1 messages):
Claude Haiku 4.5, SWE-bench Verified, Sonnet 4.5, Frontier-class reasoning at scale
- Haiku 4.5 以闪电般的速度登陆 OpenRouter:Anthropic 最新的小型模型 Claude Haiku 4.5 以旧模型 两倍的速度和三分之一的成本 提供了接近前沿(frontier)级的智能。
- 它在计算机使用任务上超越了 Sonnet 4,在保持极快速度的同时,达到了前沿级的推理和工具使用水平。
- Haiku 4.5 在 SWE-bench Verified 中表现优异:该模型在 SWE-bench Verified 上获得了超过 73% 的分数,使其跻身世界顶尖编程模型之列。
- 尽管是一个较小的模型,它提供了大规模的前沿级推理能力,是注重效率时的强力选择。
- Haiku 4.5 定价极具竞争力:Haiku 4.5 的定价为 $1 / $5 每百万 tokens(输入/输出),模型名称为
anthropic/claude-haiku-4.5。- 用户现在可以在 OpenRouter 上尝试,体验大规模前沿级推理的优势。
OpenRouter ▷ #general (401 messages🔥🔥):
Ling-1T issues and potential disabling, Caching in OpenRouter chats, CYOA games with AI, FP4 quality concerns, Claude Haiku 4.5 release
- Ling-1T 可能会被砍掉!:用户报告了 Ling-1T 的问题,将其描述为“精神分裂模型”,引发了关于是否禁用它的讨论,可能是由于供应商质量问题,一位用户表示 chutes 正在调查该问题并要求我禁用它。
- 一位用户询问是否可以查看每个模型最受欢迎的供应商,表明对替代方案感兴趣。
- 缓存配置难题:用户询问如何在 OpenRouter 聊天中启用缓存。
- 官方澄清缓存通常是隐式的,但某些模型/供应商需要显式配置,详见 OpenRouter 提示词缓存文档,且部分供应商根本不支持缓存。
- CYOA 游戏成本担忧:一位使用 Claude Sonnet 4.5 运行长篇 CYOA 游戏 的用户因成本上升以及模型在约 150,000 字后遗忘细节而寻求更便宜的替代方案。
- 建议包括尝试 Gemini 2.5 Pro 或新的 Flash Preview,对长上下文使用摘要器,或探索具有 256k 上下文窗口的 Qwen3 2507 等模型。
- FP4 遭到抨击!:用户辩论了 FP4 quantization 的优劣,一位用户认为 FP4 模型因实际表现不佳而“脑残且浪费钱”,社区共识是 OpenRouter 应该在接受和将供应商置于同一质量层级时进行质量控制。
- 其他用户引用基准测试显示良好的 FP4 实现表现出色,OpenRouter 团队承认该问题正在处理中,但短期内不太可能推出特定的量化排除功能。
- Claude Haiku 4.5 登场!:Claude Haiku 4.5 发布,引发了关于其相对于 Sonnet 4 性能的讨论,并有争议称其达到 Claude 3 Opus 水平的说法是瞎编的,部分用户认为其表现糟糕,而另一些人认为其文风不错。
- 定价为 $1/$5,一些人希望它能替代昂贵的 Claude 使用,而另一些人注意到它在 Kilo Code 上的实现问题,认为它可能更适合工具调用(tool calling)。
OpenRouter ▷ #new-models (1 messages):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (14 messages🔥):
OpenRouter 3.0, Anthropic payments, Sambanova Status, Google Deepmind praise
- OpenRouter 3.0 即将到来?:一位用户分享了一条推文,暗示了 OpenRouter 3.0,展示了来自 Chutes 的模型之间的价格差异。
- 附图显示,模型 0324 意外地比模型 3.1 更贵。
- OpenRouter 的 Anthropic 支出曝光!:一张图片显示,OpenRouter 在过去 7 天内向 Anthropic 支付了至少 150 万美元。
- 一位用户评论道:“天哪,这真是一大笔钱”。
- Sambanova 的近况?:一位用户询问了 Sambanova 的状态,将其与 Groq 和 Cerebras 进行了对比,暗示由于溢价定价,他们可能正专注于企业客户。
- 另一位用户指出 Sambanova 正在托管 deepseek terminus,表明其仍有一定的活跃度。
- Google/DeepMind 获得称赞:一位用户在分享了 Sundar Pichai 的推文 后表达了对 Google/DeepMind 的欣赏。
- 有人暗示,由于 Sambanova 的溢价定价,OpenRouter 可能没有从其获得太多业务。
Cursor Community ▷ #general (372 messages🔥🔥):
Cursor outage, Plan Downgrades and pricing mishaps, Windsurf, Model Ensemble, Open Router
- Cursor 遭遇重大停机:大量用户报告 Cursor 无法使用,报错称找不到 cursor.exe,且其 Pro Plan 已降级为 Free。
- 一位用户声称,如果工具在日间中断,他们将失去耐心并开始构建 Cursor 的竞争对手。
- 用户报告订阅计划降级和定价错误:多位用户的计划意外降级,同时还伴有 API keys 问题以及无法在 Agent 窗口中编辑 MCP 文件的问题。
- 一些 Pro 用户还注意到承诺的 $20 奖金 消失了,其中一位表示:如果你目前使用的是旧计划,千万不要点击退出按钮;那是个陷阱。
- Windsurf 优于 Cursor:一位用户表示他们开始使用 Windsurf,并称其比 Cursor 好得多,因为它拥有更多功能且基于最新的 VS Code 基础。
- 该用户表示 Windsurf 即将推出深度 wiki 功能,目前正在发布 codemap 功能,定价更优且 Agent 的工作方式与 Cursor 相同。
- Model Ensemble 发布:团队发布了 Model Ensemble 功能,允许你选择多个模型来运行同一个 prompt。
- 用户注意到 Grok Code 和 Cheetah 模型速度极快,导致他们在一个月内消耗了数十亿个 tokens。
- Open Router 使用困难:一位用户报告在 Cursor 中难以使用 Open Router,因为它不会向 openrouter 发送任何请求。
- 该用户尝试了各种故障排除步骤,包括禁用所有其他模型、删除前缀以及更新 Cursor,但都没有效果。
Cursor Community ▷ #background-agents (5 messages):
Background Agents vs Normal Agents, Async work with Background Agents, Customizing dev workflows with BAs, Project Management tool summons BAs
- 争论激烈:Background Agents vs Normal Agents:一位成员询问了如何让 background agents 比 normal agent 运行更长时间的技巧,因为它们似乎在任务中途停止。
- 他询问如果 background agents 的表现与 normal agents 相同,为什么还要使用它们。
- Background Agents 实现异步开发工作流:一位成员建议将 Background Agents 用于异步工作,例如规划工作、生成 Agent 来处理任务以及审查结果。
- 他指出,他的工作流包括在 BAs 完成后进行本地检出,随后进行手动修复或在需要时提示本地 Agent。
- Background Agents 定制开发工作流:该成员建议 Background Agents 最适合用于定制你的开发工作流。
- 他举了一个例子:项目管理工具召唤一个新的 BA 来读取报告的项目、理解它们、建议代码修改,然后发送 Pull Request 以供审查。
HuggingFace ▷ #general (215 messages🔥🔥):
开源 LLM 偏好,Deepseek vs Qwen,Civitai 内容删除,Discord bot 调试,AMD Radeon GPU 与 Stable Diffusion
- Meta 被视为开源冠军:成员们讨论了哪家公司产出的开源作品最好,有人认为 Meta 产出的作品最棒,其他人则提到 Deepseek 和 Alibaba-Qwen 是可以在家运行的高质量模型。
- 他们注意到 glm-4.6 在速度上甚至超过了 Deepseek。一些社区成员声称 Deepseek 存在刷榜行为(benchmark maxed),而另一些人则更倾向于 Meta 的 109B 和 70B 模型,而非 Mistral 的 8x22B 和 123B 模型。
- Civitai 清理行动引发逃离潮:用户对 Civitai 上的内容删除表示不满,有传言称存在支付攻击和极端组织试图让内容被删除。
- 分享了一个 Reddit 帖子链接,讨论了在 Civitai 出台新政策后 LoRA 创作者们搬到了哪里。
- Discord Bot 调试灾难:一位用户就其新的 Discord AI bot 代码寻求帮助,该代码最初由 ChatGPT 生成,由于
!help命令冲突和缺少错误处理而导致报错。- 共识是该用户需要 学习编程 来解决这些问题。
- AMD GPU 在训练中挣扎:一位用户询问关于在 Stable Diffusion 中使用 AMD Radeon 显卡的问题,有人指出较新的 ROCm 兼容 GPU 应该可以在 Linux 上运行,而 Windows 上的旧款 GPU 可以选择 DirectShow,并参考了一个 HF datasets 链接。
- 然而,在 AMD 上进行训练和 Dreambooth 被认为很困难,尽管有人报告在 Linux 上使用 6700xt 取得了成功。
- 归一化 (Normalization) 与标准化 (Standardization) 的细微差别:一位用户询问特征缩放中 normalization 与 standardization 的统计学概述,解释是:standardization 缩放数据使其标准差为 1 且均值为 0,而 normalization 将数据缩放到 0 到 1 之间。
- 解释称,将输入归一化到 0 到 1 范围可以减轻梯度爆炸和梯度消失,因为深度学习模型涉及大量的数字乘法。还提供了一些基准测试链接,如 acl anthology。
HuggingFace ▷ #today-im-learning (1 messages):
GenAI 技术,学习工作流
- AI 爱好者寻求 GenAI 学习技术:一位成员分享了一个帖子,并询问关于使用 GenAI 学习新事物的技术和工作流。
- 他们表示对分享资源中大量的要点感到应接不暇。
- GenAI 学习思路:该成员正在寻找有效利用 GenAI 的方法。
- 他们正寻求社区关于最佳学习技术和工作流的建议。
HuggingFace ▷ #i-made-this (23 messages🔥):
MIT 许可证数据集使用,手机成瘾数据分析,Nanochat 模型训练,Discord 冲突
- MIT 数据截断纠纷:一位成员询问在截断和修改后使用 MIT 许可证数据集 (Pacific-Prime/pre_training_colors) 的事宜。
- 问题围绕修改后的数据集是否可以像原创作品一样使用。
- 成瘾分析引起关注:一位成员在时事通讯中分享了他们的数据分析技能以及对手机和汉堡成瘾等话题的看法。
- 另一位成员建议探索 TikTok 或社交网络成瘾 作为潜在的有趣课题,重点关注 刷屏成瘾 (scrolling addiction)。
- Nanochat 对新手的致敬:一位成员训练了一个廉价版的 Andrej Karpathy 的 nanochat 模型,并在 Hugging Face Spaces 上提供了演示 (sdobson/nanochat)。
- 他们还在一篇博客文章中详细介绍了廉价训练 ChatGPT 克隆版 的经验。
- Discord 恩怨披露:一位成员表示 Mikus 不喜欢我,这很明显,存在冲突。
- 其他成员以开玩笑回应,猜测该成员是否在进行 另一种大脑调优 (brain tuning)。
HuggingFace ▷ #computer-vision (4 messages):
对象识别、轮廓提取、像素强度移除
- 无需训练识别对象:一名成员询问如何在没有任何训练的情况下识别白色背景中的对象。
- 另一名成员建议使用 contouring(轮廓提取)作为潜在解决方案。
- 通过像素强度移除进行对象识别:一名成员建议移除所有像素强度为 [255, 255, 255] 的像素,然后填充孔洞。
- 这种方法可以帮助在白色背景下隔离并识别对象。
HuggingFace ▷ #NLP (1 messages):
jazzco0151: https://discord.com/api/oauth2/token
HuggingFace ▷ #gradio-announcements (1 messages):
Agents & MCP Hackathon, 2025 冬季黑客松
- Agents & MCP Hackathon 续作将于 25 年冬季回归:Agents & MCP Hackathon 即将回归,规模比以往大 3 倍且更出色,举办时间为 2025 年 11 月 14-30 日。
- 参与者可以访问 https://huggingface.co/Agents-MCP-Hackathon-Winter25 加入组织 (Join the Org)。
- 六月版活动非常成功:上届活动有 4,200 人注册并提交了 630 份精彩作品。
- 活动发放了超过 100 万美元的 API 额度和 1.5 万美元的现金奖励。
HuggingFace ▷ #smol-course (2 messages):
PEFT 配置问题,trackio 依赖问题
- PEFT 配置需要 Target Modules:一名成员报告在将 PEFT 与 smolm3 结合使用时出现
ValueError,指出根据 smol course unit 1 的内容,PEFT 配置中缺少target_modules。- 他们注意到,虽然 PEFT 源代码包含一个映射表 (constants.py#L87),但其中未引用 smolm3 架构,因此必须手动指定 [“q_proj”, “v_proj”] 等目标模块。
- trackio 依赖导致 Space 构建失败:该成员发现为 trackio 构建的 Space 失败,原因是
requirements.txt中找不到trackio==0.5.1.dev0依赖。- 他们通过在 Space 创建后手动将版本更改为
0.5.2修复了此问题,并指出如果不进行此修复,第一次运行将无法记录。
- 他们通过在 Space 创建后手动将版本更改为
HuggingFace ▷ #agents-course (3 messages):
Agent 课程、学习小组、课程进度
- Agent 课程学习小组组建中:一名成员正在开始 Agent 课程,并寻求组建一个学习小组,该成员会说英语和法语。
- 课程进度丢失:一名成员报告了课程进度追踪的问题,指出完成的测验在刷新或重新登录后未显示为已完成。
Nous Research AI ▷ #general (159 messages🔥🔥):
Long Context Datasets, Strix Halo vs DGX, Threadripper for Local Inference, HP Z2 Mini G1a, Meta Early Experience
- 寻求用于角色扮演模型的 Long Context Datasets:一名成员询问如何获取数据集以提升故事叙述和角色扮演模型中的 long context understanding(长上下文理解),并指出在缺乏足够上下文的情况下达到某些节点时可能出现的问题。
- 该成员附上了一张图片,引用了一个可能与该请求相关的预订信息。
- Strix Halo 对比 DGX:成员们讨论了是购买 DGX,还是以同样的价格配置一台拥有 128GB RAM 和 RTX 5090 的 Strix Halo。其中一位成员已经拥有 Strix Halo 并在此前预订了 DGX。
- 该成员表示,由于忙于其他项目,他们不会进行太多训练,主要用于推理。
- 考虑将 Threadripper 用于本地推理:一位成员考虑购买配备 512GB RAM 的 Threadripper 用于本地推理,但因担心速度只有 2.5 tokens per second 而犹豫不决。
- 另一位成员回复称,速度应该远高于 2.5 tokens per second,并建议选择合适的 TR 或 EPYC CPU,并配备 800GB/s 内存带宽以避免瓶颈。
- Meta 通过 Early Experience 在无奖励情况下训练 Agent:Meta 的 ‘Early Experience’ 在没有奖励、人类演示或监督的情况下训练 AI Agent,直接从结果中学习。
- 这种方法在 Web 导航 (WebShop) 上提升了 +18.4%,在复杂规划 (TravelPlanner) 上提升了 +15.0%,在科学推理 (ScienceWorld) 上提升了 +13.3%,并适用于 8 个环境。
- Claude 4.5 Haiku 评价褒贬不一,Gemini 碾压之:成员们讨论了 Claude 4.5 Haiku 的价值,一些人认为其定价过高且并不优于竞争对手。
- 一位成员表示 Gemini 2.5 Flash 碾压 Haiku,Deepseek R1 和 Kimi K2 也比 Haiku 更好,并且 一旦他们提高了 Haiku 的价格,它就注定失败了。
Nous Research AI ▷ #ask-about-llms (1 messages):
Hermes-4-8-2, Psyche Network Runs, Model Card Discrepancy
- Hermes-4-8-2 运行记录链接到 Llama-3?:一位用户报告称,psyche.network/runs 上的 Hermes-4-8-2 运行记录错误地链接到了 Hugging Face 上的 Meta-Llama-3.1-8B。
- 这表明 Psyche Network 平台可能存在配置错误或更新错误。
- Model Card 混淆:Hermes-4-8-2 与 Meta-Llama-3.1-8B 之间的 Model Card 差异引发了对托管模型运行完整性的质疑。
- 建议用户如果依赖 Psyche Network 进行评估,请核实实际使用的模型。
Nous Research AI ▷ #research-papers (1 messages):
Agent Learning, Reinforcement Learning Challenges, META's early experience
- META 提出通过 Early Experience 进行 Agent 学习:一篇新论文 META’s: Agent Learning via Early Experience 提出了一种名为 early experience 的范式,利用 Agent 自身行为产生的交互数据进行监督,无需奖励信号。
- 该论文研究了该范式下的两种策略:implicit world modeling(利用收集的状态来巩固策略)和 self-reflection(从次优行为中学习)。
- Early Experience 提升 Agent 有效性:论文中概述的方法在八个不同的环境和多个模型系列中一致地提高了有效性和域外泛化能力,凸显了 early experience 的价值。
- 在具有可验证奖励的环境中,early experience 为随后的 Reinforcement Learning 提供了坚实的基础,使其成为 Imitation Learning 与完全由经验驱动的 Agent 之间的实用桥梁。
Nous Research AI ▷ #research-papers (1 messages):
Agent Learning, Early Experience, META’s Agent Learning, Implicit world modeling, Self-reflection
- META 的 Early Experience Agent Learning:一位用户分享了来自 META 关于 Agent Learning via Early Experience 的论文。
- 它提出了一种名为 early experience 的中间地带范式:由 Agent 自身的动作生成的交互数据,其中产生的未来状态作为监督信号,而无需奖励信号。
- Early Experience 范式:论文研究了使用 early experience 数据的两种策略:Implicit world modeling 和 Self-reflection。
- 这些方法一致地提高了有效性和域外泛化能力,凸显了 early experience 的价值。
Latent Space ▷ #ai-general-chat (126 messages🔥🔥):
OpenAI Codex Slow Inference, Qwen3-VL Models, Nvidia DGX Spark vs M4 Max MacBook Pro, OpenAI gpt-5-search-api, Karina Nguyen's AI Drop
- Codex 的慢速推理导致 Taelin 任务瓶颈:Victor Taelin 抱怨 OpenAI Codex 的慢速推理限制了他的任务队列,使他在 Prompt 之间处于闲置状态。
- 建议包括并行 Agent、更快的模型、Prompt 技巧以及利用停机时间处理次要任务,但 Taelin 指出其他模型缺乏 Codex 的智能或与其代码库的兼容性。
- Qwen3-VL 模型在小体积中蕴含强大性能:Alibaba Qwen 发布了 Qwen3-VL 的紧凑稠密版本,参数量为 4B 和 8B,在减少 VRAM 占用并以 FP8 运行的同时,保留了旗舰模型的全部功能。
- 这些模型在 STEM、VQA、OCR、视频理解和 Agent 基准测试中超越了 Gemini 2.5 Flash Lite 和 GPT-5 Nano,足以与旧款 72B 模型相媲美。
- Nvidia DGX Spark 基准测试表现不尽如人意:售价 4000 美元的 Nvidia DGX Spark (128 GB) 的早期基准测试显示,在 gpt-oss-120b-fp4 上仅有 ~11 t/s,远低于售价 4800 美元、达到 66 t/s 的 M4 Max MacBook Pro。
- 社区将其归咎于较低的 LPDDR5X 带宽(273 GB/s 对比 546 GB/s),并认为该设备对于纯推理来说价格过高,尽管有人辩称其目标是 CUDA 开发和集群,而非速度。
- GPT-5 Search API 价格更低:OpenAI 发布了一款新的网页搜索模型 gpt-5-search-api,成本降低了 60%(10 美元/1K 次调用)并增加了域名过滤功能。
- 开发者对降价和精准度表示赞赏,同时要求增加日期/国家过滤器、深度研究升级以及将其整合进 Codex。
- Poolside 凭借 2GW Project Horizon 园区和 4 万块 GB300 GPU 顺势而上:Poolside 的 Eiso Kant 宣布了两项基础设施举措:与 CoreWeave 合作,从 2025 年 12 月开始锁定 40,000+ 块 NVIDIA GB300 GPU;以及“Project Horizon”,这是一个位于德克萨斯州西部的垂直整合 2 GW AI 园区。
- CoreWeave 将支持第一阶段 250 MW 的建设——旨在通过全栈“从泥土到智能 (dirt to intelligence)”的方法向 AGI 规模化迈进。
Latent Space ▷ #private-agents (8 messages🔥):
青少年 AI 自由职业,MoE 推理中的 NPU vs GPU,NVIDIA DGX Spark 作为开发套件
- “少年大亨”寻求 AI 联盟:一位 17 岁 的少年正在寻求联系其他对 model fine-tuning、LLM infra 和 AI startups 感兴趣的年轻人,以分享项目和想法,他目前经营着一家小型 AI 自由职业业务。
- 欢迎有兴趣合作的人私信,特别是在 fine-tuning、LLM infrastructure 和 AI startups 领域。
- MoE 模型的 NPU 极乐世界?:一位成员建议,对于仅推理(inference-only)的工作负载,NPUs 可能是 GPUs 的绝佳替代方案,特别是随着 Mixture of Experts (MoE) 模型 的兴起。
- 他们认为,与更通用的 GPU 相比,NPUs 在处理这些日益流行的模型类型时可以达到相当不错的速度。
- Spark 点燃开发梦想,但令人失望?:一些成员表示 DGX Spark 的发布不尽如人意,并分享了一篇 Reddit 帖子,建议将其视为 GB200 集群的 devkit。
- 根据 Soumith Chintala 的推文,PyTorch 联合创始人 Soumith Chintala 也持有相同观点,X-Ware 也对此进行了报道,称赞其是日常 AI 开发的理想选择,并能轻松移交给更大的集群或边缘设备。
LM Studio ▷ #general (68 messages🔥🔥):
Qwen3 VL 问题,LM Studio 中的 MCP Servers,结构化输出讨论,AMD 9070XT vs Nvidia 5070,System prompt token 限制
- Qwen3 VL 出现 ValueError:一位用户报告了 Qwen3 VL 的
ValueError,这与图像特征和 token 之间的不匹配有关,错误信息为 Image features and image tokens do not match: tokens: 0, features 176。- 另一位用户确认这是“thinking”模板的一个 bug,目前正通过 此 GitHub issue 进行修复。
- MCP Server 下载选项引发讨论:一位用户询问在 LM Studio 中是否有简单的方法为不同的用例(如 AI 模型)下载 MCP servers,另一位用户回答说,一种方法是通过网站上的“Install in LM Studio”链接。
- 有人提到需要审查源代码以确保不包含恶意软件,并提供了 LM Studio MCP 文档 的链接。
- JSON Schema 难题:一位用户在尝试使用 JSON schema 结构化输出时遇到困难,并寻求帮助。
- 另一位用户建议参考 这个示例 并向下滚动查看提供的图像,这 应该能给你一些启发。
- AMD 9070XT 表现超预期?:一位用户询问 AMD 9070XT 在大型模型上的表现是否正常优于 Nvidia 5070,因为其拥有 12GB+ 显存。
- 一位成员指出 9070XT 的广告宣称其 TOPS 几乎与 4080 相同,并强调其 INT4 支持可能使性能翻倍,并表示 在过去三代中,AMD 已经相当接近 Nvidia 了。
- META 的 Agent Learning via Early Experience:一位用户分享了 META 的 Agent Learning via Early Experience 论文 链接,讨论了利用经验数据通过 reinforcement learning 训练 Agent 仍然很困难。
- 该论文通过一种称为 early experience 的折中范式解决了这一局限:由 Agent 自身行为产生的交互数据,其中产生的未来状态作为监督信号,无需奖励信号。
LM Studio ▷ #hardware-discussion (63 messages🔥🔥):
MacBook Pro 续航时间, Nvidia Spark, Windows 11 vs Linux, LM Studio 与普通用户, 维基百科编辑
- MacBook Pro 续航表现糟糕:一位成员开玩笑说,使用 MacBook Pro 的人可能会纳闷为什么他们的续航时间只有 90 分钟。
- 这是针对高性能 GPU 及其相应功耗的讨论而引发的。
- 用户因成本取消 Nvidia Spark 订单:一位用户曾动心想订购 Nvidia Spark,但在考虑到 4000 美元的价格后,决定放弃。
- 相反,他们考虑购买一台配备 128GB RAM 的 Mac Studio。
- Windows 11 支持者吹捧微软生态系统:一位成员讽刺地敦促其他人升级到 Windows 11,称赞该操作系统与 Microsoft 生态系统的极佳集成。
- 另一位成员回复道:哈哈,我因为那个回复该再被禁言一次。
- Linux 对普通用户来说太复杂了:成员们辩论了 Linux 的简易性,一位成员表示 Ubuntu 在出问题之前都很简单,因为用户会遇到一个无法运行的 AppImage,原因是 Ubuntu 的沙箱系统坏了,而且你还得不到任何错误提示。
- 另一位成员表示 Linux 适合那些生活中没有烦恼的人,或者烦恼太多以至于相比之下 Linux 显得很简单的人,哈哈。
- LM Studio 没有被普通用户“烂化”:一位成员询问 LM Studio 是否正在变得 enshitified(平台恶化),但另一位成员回应称 LM Studio 不是给普通人用的。普通人都在通过 Web 界面使用 ChatGPT、Copilot 或 Gemini。
- 不过,第一位成员澄清说 LM Studio 基本上已经成为了本地 LLM 的默认选择。
GPU MODE ▷ #general (11 messages🔥):
DSA 效率对比 NSA 论文, GPU 编程趋势, vLLM 和 SGLang 批次不变性测试, 机器学习中的范畴论, 使用 vLLM 分析租用的 GPU
- 辩论 DSA 效率:一位成员质疑 DSA (Diffusion State Augmentation) 相比 NSA (Noise Selective Augmentation) 的效率,指出 DSA 的逐 Token 选择与 NSA 论文中强调的为了高效 GPU 计算而进行的逐块选择形成对比。
- 该成员怀疑论文的观点是否被误读了。
- GPU 编程是下一个热门方向:一位成员询问,受对 Triton 和 CUDA 兴趣的影响,GPU 编程是否是科技界持续的趋势。
- 他们怀疑这是否只是基于他们近期对 Triton/CUDA 的兴趣而产生的算法信息茧房。
- vLLM 和 SGLang 走向确定性:一位成员质疑在 vLLM 和 SGLang 中进行全前向传播确定性测试的必要性,因为它们的底层 Kernel 和逐点操作具有确定性,并指向了这些 vLLM 和 SGLang 的测试。
- 该成员建议,这可能只是为了确保 Kernel 或下游没有任何东西破坏 vLLM 的确定性。
- 范畴论进入机器学习:在关于范畴论在机器学习中应用的问题之后,一位成员分享了 Layout Algebra: A category-theoretic approach to deep learning 的链接。
- 该链接指向一篇应用范畴论的论文。
- 租用 GPU 的分析受阻:一位成员报告称,在尝试在租用的 GPU 上运行 vLLM 的 Profiler 时遇到 CUPTI_ERROR_NOT_INITIALIZED 错误,原因是内核级操作的访问受限。
- 另一位成员建议使用
sudo来修改分析限制,但发帖者在租用的机器上没有 sudo 权限。他们正在寻求分析单个 GPU 的替代方案。
- 另一位成员建议使用
GPU MODE ▷ #triton (5 messages):
Triton 算法替换, Triton IR 设计, Triton 的布局代数
- 算法被更优的 Triton 实现替换:一位成员注意到在 这个 PR 中,一个算法已被更好的算法取代。
- 他们还分享了一篇关于该算法的 中文文章。
- 深入探讨 Triton IR 设计:一位成员询问关于理解 Triton IR 设计的推荐资源。
- 另一位成员建议查看 zartbot 和 colfax 关于 Triton 布局代数 (layout algebra) 的资源。
GPU MODE ▷ #cuda (5 条消息):
用于 cluster sync 的 PTX 和 SASS 代码,Tensor descriptor 的 L2Promotion 参数,异步流水线持久化 CUDA kernel,NCU 时间线视图
- PTX 汇编轮询 Cluster Sync:成员们讨论了使用 Compiler Explorer 查看为 cluster sync 生成的 PTX 和 SASS 代码,推测其可能涉及一个轮询全局原子变量的循环,并在中间调用
nanosleep。 - L2Promotion 参数查询:一位成员对 tensor descriptor 的 L2Promotion 参数提出疑问,询问关于通过 TMA 单元从 Global Memory 加载数据到 L2 cache 时,不同字节大小(64B, 128B, 256B)背后的直觉。
- 异步 Kernel 渴望时间线视图:在异步流水线持久化 CUDA kernel的背景下,一位成员表达了对带有时间线视图的 NCU 的强烈渴望,类似于 Pallas 和 Proton profiler 提供的功能。
- PTX 错误详细程度问题:一位用户询问了关于 PTX 错误详细程度的问题,并附带了一张图片。
- 一位用户评论道,他们猜测这与非连续内存访问有关。
GPU MODE ▷ #announcements (1 条消息):
torch.compile,Kernel 编程 DSL,Helion,编译器缓存,深度学习图表
- Torch Compile 创作者发布 Helion DSL:周五太平洋标准时间下午 1:30,
torch.compile()的创作者 Jason Ansel 将介绍他新的 Kernel 编程 DSL Helion。- 届时,编译器缓存(compiler cache)的创作者 Oguz Ulgen 以及让 torch.compile 支持分布式的核心架构师之一 Will Feng 也将加入。
- 深度学习图表获得正式的范畴论处理:周六太平洋标准时间下午 2:00,那些精美的深度学习图表的制作者 Vincent Abott 将讨论使用受范畴论(category theory)启发的图表来形式化机器学习系统算法。
- 在此处查看图表图片。
- 开源 AI 周计划公布:下周成员们将前往旧金山参加开源 AI 周的大部分活动,欢迎大家来打招呼!
- 还有一个新频道可供查看:<#1425531180002054195>
{kind=link}
GPU MODE ▷ #beginner (5 条消息):
Pearson 相关性 Kernel,浮点精度,在线课程 PPC 作业
- Kernel Pearson 相关性故障排除开始:一位正在完成 PPC 在线课程作业的成员正在编写他们的第一个 kernel,用于计算给定矩阵行之间的 Pearson 相关性,但正面临精度问题。
- 该成员报告遇到的错误大约比预期大 1153 倍,怀疑其 CPU 实现中存在精度问题。
- 精度问题困扰 Pearson 计算:该成员在其实现中定位了一个循环(标记为
// *** issue here?),认为这是计算行总和及偏差时产生精度误差的潜在来源。- 他们考虑使用
long double作为暴力解决方案,但正在寻找替代方案,暗示了使用标准double类型达到所需精度的挑战。
- 他们考虑使用
GPU MODE ▷ #irl-meetup (4 条消息):
多节点 kernel 黑客松,纽约见面会,瑞典,伦敦
- 抛出多节点 kernel 黑客松的想法:一位成员提到增加了一个关于多节点 kernel 黑客松的想法并征求反馈,详见 Discord 频道。
- 纽约 (NYC) 见面会提醒:一位成员在 X 上为纽约的成员分享了一个见面会链接,详见 X 帖子。
- 来自瑞典和伦敦的询问:社区内有针对瑞典和伦敦成员的公开询问,希望大家分享这些地区即将举行的活动或趣事。
GPU MODE ▷ #triton-puzzles (1 条消息):
codingmasterp: 做 flashattention
GPU MODE ▷ #intel (8 条消息🔥):
Crescent Island, LPDDR5X 内存选择, Rubin CPX 竞争, Intel 数值格式支持, CXL 能力
- Crescent Island 预计于 2026 年下半年发布:Intel 的 Crescent Island 计划于 2026 年下半年发布,并将配备 160 GB 的 LPDDR5X 内存。
- 概念渲染图暗示其拥有 数十个 LPDDR5X 控制器,这意味着 640 位或 1280 位宽的内存接口以及 32 个子切片 (subslices)。
- LPDDR5X:冠军的内存选择?:为 Crescent Island 选择 LPDDR5X 引发了关于其内存性能的讨论。
- 预期指向 9.6 Gbps 的 640 位总线,带宽达 768 GB/s,可能还带有额外的 32 MiB L2 缓存,尽管其他来源暗示是 1.5 TB/s GPU。
- Rubin CPX 加入战局:看起来 Crescent Island 的目标是与 Rubin CPX 展开“竞争”。
- Rubin CPX 的支持程度是一个决定性因素,而 Intel 的优势在于其对各种数值格式的支持,简化了软件级块浮点 (block floats) 的实现。
- Intel 展示数值格式实力:Intel 以支持各种奇特的数值格式而闻名,这使得软件级块浮点 (block floats) 的实现变得更加容易。
- 这可能会带来一些有趣的结果,特别是如果块浮点没有太多的计算开销,由于支持更小的数据类型,可能会产生更大的理论数值。
- CXL 能力可能扭转局势:关于 640 位与 1280 位总线的讨论仍在继续,对 1280 位的支持日益增加,可实现 1.5 TB/s 的内存带宽。
- 如果 Intel 启用 CXL 能力,它可能会成为强有力的竞争者,因为 CXL 显著降低了驱动它的 CPU 通信成本。
GPU MODE ▷ #self-promotion (1 条消息):
AlphaFold 3, MegaFold, Triton 优化
- MegaFold 加速 AlphaFold 3:一个研究小组开源了 MegaFold,这是一个 AlphaFold 3 (AF-3) 的训练平台,并指出 AF-3 明显比同类 Transformer 慢。
- 他们的分析确定了性能和内存瓶颈,从而进行了针对性优化,如 Triton 中的自定义算子和系统数据加载改进,详见他们的博客文章。
- 自定义 Triton 算子优化 AlphaFold 3:MegaFold 使用由 Triton 编写的自定义算子来提升运行性能并减少训练期间的内存占用。
- 这些优化专门针对在 AlphaFold 3 分析中确定的性能和内存瓶颈。
GPU MODE ▷ #🍿 (1 条消息):
Agent Hacking, Kernelbench v0.1, Sakana AI
- Agent Hacking 讨论升温:成员们正在讨论 Agent Hacking,并参考了 Kernelbench v0.1 的博客文章 以获取见解。
- 一位成员指出 Sakana AI 撤下了他们的原始论文,因此该论文不可访问也无法引用。
- Kernelbench v0.1 激发 Agent Hacking 见解:Kernelbench v0.1 的博客文章 中有很多关于 Agent Hacking 的讨论。
- Kernelbench 是一个用于衡量操作系统内核相关性能的工具。
GPU MODE ▷ #thunderkittens (1 条消息):
ROCm 支持时间线
- ROCm 推出路线图仍不明朗:一位成员询问了关于 ROCm 支持 的更新或时间线,特别是针对一张附带的截图。
- 目前没有提供关于 ROCm 任何具体时间线或更新的进一步信息。
- 芯片软件栈方面的沉默:尽管有询问,但关于 ROCm 支持 的开发或发布,目前还没有共享任何更新或具体时间线。
- 社区正在等待 AMD GPU 计算软件生态系统进展的进一步公告。
GPU MODE ▷ #submissions (19 条消息🔥):
amd-gemm-rs 排行榜更新, amd-ag-gemm 排行榜更新, amd-all2all 排行榜更新, MI300x8 性能
- MI300x8 上的 AMD GEMM 竞赛:多个提交已上传至
amd-gemm-rs排行榜,其中一个提交在 MI300x8 上达到了 536 µs。 - MI300x8 上的 AG-GEMM 优势:
amd-ag-gemm排行榜收到大量提交,在 MI300x8 上的时间低至 384 µs。 - All2All 在 MI300x8 上取得里程碑:一个提交至
amd-all2all排行榜的任务在 MI300x8 上以 3.45 ms 成功运行。 - AG-GEMM 竞争加剧:一名成员在 MI300x8 上以 409 µs 的成绩获得了
amd-ag-gemm排行榜的第 4 名。
GPU MODE ▷ #amd-competition (12 条消息🔥):
MI300x Kernel, 分布式通信, AMD GPUs, 竞赛统计
- MI300x Kernel 很有趣:参赛者表示在竞赛期间编写 MI300x kernels 获得了意想不到的乐趣。
- 一位参赛者表示,他们之前没预料到编写 MI300x kernel 会有这么多乐趣。
- 竞赛教授分布式通信:参赛者在比赛期间学到了很多关于分布式通信 (distributed comms) 和 AMD GPUs 的知识。
- 一位参赛者特别感谢了组织者,表示他们学到了很多关于分布式通信和 AMD GPUs 的知识。
- 竞赛数据惊人:该竞赛在 8xMI300 GPUs 上总计运行了 48 天,总运行次数达 6 万次。
- 在近两周的时间里,提交量平均每天超过 2000 次。
- 数据集将公开分发:组织者宣布竞赛中使用的数据集将公开发布。
- 一位组织者表示:等我们准备好后会发布链接!
GPU MODE ▷ #singularity-systems (3 条消息):
基础设施变更, nanochat 训练, lambda H100 集群
- 基础设施变更在即:一些成员一致认为,为了增强系统能力,需要进行计划中的基础设施变更。
- 他们表示:这确实是我们最终希望拥有的东西。
- Karpathy 的 nanochat 训练层级:一名成员对 Karpathy 的 nanochat 训练运行层级(针对 eureka 的 llm101,目标模型为 nanogpt/nanochat,价格为 $100 和 $1000)表示兴奋。
- 他们提到有可能在 Lambda 上租用 8xH100 集群 进行一次 $100 的训练运行。
GPU MODE ▷ #general (3 条消息):
Carl Bot, 参考 Kernel
- 在频道中发现 Carl Bot:一名成员建议在特定频道查看 Carl Bot。
- 他们指出它是在这里创建的。
- 参考 Kernel 获得赞誉:一名成员对服务器的组织和专注度表示赞赏。
- 他们对团队简洁且专注的方法表示了肯定 (props)。
GPU MODE ▷ #multi-gpu (17 条消息🔥):
HPC 中的多 GPU 系统, 多 GPU HPC 中的数据移动研究, RTX 6000 Pro 与 Blackwell 架构
- 多 GPU HPC 系统:热门还是冷门?:一名成员询问了多 GPU 系统在 HPC 中的相关性,另一名成员确认了其重要性并分享了一个相关论文链接。
- 该成员指出 HPC 系统的异构性日益增加,且拥有多个 GPU 的节点非常普遍,建议在用 NCCL/RCCL 替代 MPI 进行数据传输方面进行潜在的研究。
- 多 GPU HPC 中的数据传输研究:机会多多:一名研究生对多 GPU HPC 系统中与数据移动相关的研究机会表示兴趣,特别是延迟 (latency) 和带宽 (bandwidth)。
- 一名成员确认这是一个热门研究领域,并询问了其偏好的领域,例如 kernel 级或框架级工作,以及该学生是想专注于集合算法/通信模式 (collective algorithms/communication patterns) 还是网络架构。
- RTX 6000 Pro:真正的 Blackwell 继承者?:一名成员声称只有 RTX 6000 Pro 拥有真正的 Blackwell 套件。
- 另一名成员询问了什么构成了真正的 Blackwell 套件,暗示了对该说法持怀疑态度或缺乏理解。
GPU MODE ▷ #low-bit-training (1 条消息):
kitsu5116: https://arxiv.org/pdf/2510.08757
GPU MODE ▷ #irl-accel-hackathon (1 messages):
Comet-style MoE kernels, fine grained overlapping, comms and compute
- 为 Hackathon 提议的 Comet Kernels:一名成员发布了他们的 Hackathon 想法:用于 comms and compute(通信与计算)细粒度重叠的 Comet 风格 MoE kernels。
- 他们分享了 Discord 频道的链接并寻求合作者。
- Hackathon 想法需要扩展:为了满足 schema 的要求,必须包含第二个主题摘要以避免验证错误。
- 此条目作为占位符,以确保 ‘topicSummaries’ 数组至少包含两个元素,满足 schema 的最低要求。此处应添加更多内容。
GPU MODE ▷ #llmq (1 messages):
llmq, unit tests
- 敦促为 llmq 编写单元测试:一名成员询问编写 unit tests(单元测试)是否是为 llmq 仓库做贡献的好方向。
- 他们表示有兴趣熟悉 llmq。
- 贡献者寻找 llmq 仓库:一名成员表示有兴趣为 llmq 仓库做贡献。
- 他们询问了参与并熟悉该项目的最佳方式。
GPU MODE ▷ #helion (1 messages):
Helion, GPU Mode Talk
- GPU Mode 演讲将于 10 月 17 日举行:根据公告,包含 Helion 概览的 GPU mode 演讲将于本周五(10 月 17 日)太平洋标准时间下午 1:30 举行,随后是演示。
- Helion 概览:演讲将包括 Helion 的概览,随后是演示,并包含问答环节。
DSPy ▷ #general (93 messages🔥🔥):
Recursive Language Models (RLMs), Claude code vs RLMs, Tiny Recursive Models (TRMs), OpenAI's memory operations and DSPy, Sub-agents in DSPy
- MIT 的 DSPy 实验室推出递归语言模型 (RLMs):MIT 的 DSPy 实验室介绍了 Recursive Language Models (RLMs),它使 LLM 能够处理无限的上下文长度并减轻上下文腐烂 (context rot),并承诺很快推出 DSPy 模块(公告推文)。
- 根据 Zero Entropy Insight 的博客文章,这些模型在 10M+ token 上显示出 114% 的增益。
- RLM 对比 Claude code:递归之争:讨论对比了 RLMs 与 Claude code,质疑 Claude code 是否可以递归地调用自身并带有任意长度的 prompt,并作为一种通用的推理技术。
- 用于工具调用的微型递归模型 (TRMs) 概念出现:一名成员提议在工具调用场景中使用 Tiny Recursive Models (TRMs),考虑将其用于 450k token 语料库上的问答。
- 另一位用户表示,RLM 中最有趣的概念是将上下文作为可变变量,但你可以实现递归调用将内容转储到 SQLite、其他文件等地方。
- 传闻流传:OpenAI 是否在秘密使用 DSPy 进行内存操作?:关于 OpenAI 在其 Assistants API 中可能使用 DSPy 进行内存操作的猜测不断,特别是关于 prompt 缓存和 128K token 召回的自动微调。
- 一名成员提到 prompt 缓存(重复调用成本削减 50%)散发着 DSPy 的气息——想想 LRU/Fanout 缓存或 Mem0 的图内存风格。
- DSPy Sub-Agents:构建你自己的正义联盟:一名用户询问如何在 DSPy 中创建类似于 Claude Code 的 sub-agents,具有并行执行和带有自身上下文内存的专门任务。
- 一位用户表示,Claude Code 依赖于预先声明的 subagents 和文件 IO——人类对工作流图进行编码。RLM 将这种控制转移到模型内部:上下文本身变成了可变变量。
Yannick Kilcher ▷ #general (21 messages🔥):
VSCode 的 Codex 插件,使用 GitHub Agent 处理 GitHub Pull Request,win+h 听写
- Codex 插件,无需 API Key:用户正在尝试 VSCode 的 Codex 插件,发现使用 GPT 订阅登录非常有用,无需 API Key,也不会产生额外费用。
- 一位用户建议将项目拆分为 UI、后端和网站等较小部分,以运行多个 Codex 实例。
- 批量运行中缓存命中节省了 20%:一位用户报告称,在使用 Codex 进行批量运行时,由于缓存命中节省了约 20% 的开销。
- 他们估计,在标准的 GPT-5 运行中,缓存命中可以节省 $250-300。
- 使用 win+h 听写的语音访问:用户正在探索使用 win+h 听写配合快捷键跳转到 Codex 文本框的语音访问方式。
- 一位用户建议让系统通过 “Computer” 唤醒,并在听写后自动按回车键。
- 使用 GitHub Agent 处理 GitHub Pull Request:一位用户建议在工作流管理中使用 GitHub Agent 处理 GitHub Pull Request。
- 另一位用户分享了关于 加州议会第 1043 号法案 的链接,该法案涉及操作系统提供商确保年龄验证和数据共享限制的可访问接口。
Yannick Kilcher ▷ #paper-discussion (18 messages🔥):
编程 AI 补全,工具示能 (Tooling Affordance),DIAYN 论文讨论,强化学习中的互信息
- AI 补全:是福还是祸?:会议指出,AI 补全的有用程度在很大程度上取决于编程任务;它们有时会极其愚蠢,并可能减慢开发进度。
- 这些工具的辅助程度与编写的样板代码 (boilerplate code) 量成正比。
- 工具最终能提高生产力吗?:一位成员认为,投资于 Alpha Evolve、Reasoning Bank 和基于图的系统等专用工具可以提高补全频率和整体生产力。
- 他们承认,其有效性取决于工作的多样性,以及所需的基础设施是否能实现整体时间的节省。
- 多样化的 DIAYN 取得成功:讨论了一篇名为 Diversity Is All You Need (DIAYN) 的论文,该论文概述了一种通过技能、状态和动作之间的互信息来学习“技能”的方法。
- 有人指出,这种方法在某种程度上类似于 Schmidhuber 关于通过寻求新颖性实现内在动机 (intrinsic motivation) 的研究,但声称在术语上有所突破。
- 强化学习 (RL) 中的熵与互信息:重点介绍了第一作者近期在强化学习中使用熵和互信息的论文,并提供了 Can a MISL Fly? 和 Maximum Entropy RL 的链接。
- 随后一位成员分享了关于
ThresHot和zca_newton_schulz的代码片段。
- 随后一位成员分享了关于
Yannick Kilcher ▷ #ml-news (3 messages):
Gemma 模型,癌症治疗中的 AI
- Gemma 模型助力癌症治疗发现:Google 宣布,在与 耶鲁大学 的研究合作中,一个基于 Gemma 的模型帮助发现了一种新的潜在癌症治疗路径。
- 该模型名为 Cell2Sentence-Scale 27B (C2S-Scale),是一个拥有 270 亿参数的基座模型 (foundation model),旨在理解单个细胞的语言。
- C2S-Scale 模型生成新假设:C2S-Scale 模型生成了一个关于癌症细胞行为的新假设,该假设已在活体细胞的实验验证中得到确认,揭示了开发抗癌疗法的一条充满希望的新路径。
- 这一发布建立在早期工作的基础上,证明了生物模型遵循清晰的 scaling laws,即更大的模型在生物学任务上表现更好,这引发了关于更大模型是否能获得全新能力的讨论。
Moonshot AI (Kimi K-2) ▷ #general-chat (39 messages🔥):
Trickle vibe coding website, Aspen's Bitcoin Leverage Story, Gemini 2.5 is too old, Kimi K2 Update, Thinking vs Non-Thinking Models
- Trickle 是一个 Vibe Coding 网站:根据一名成员分享的链接 # https://trickle.so/lol,Trickle 是一个类似于 Lovable、Bolt、Manus 等的 vibe coding 网站。
- Aspen 痛失比特币财富:一名成员声称 Aspen 在 Bitcoin 上使用了 100x 杠杆,利润曾一度超过一百万美元,随后他羞辱了老板并辞职;但在关税新闻发布后被爆仓,现在表现得就像从未离开过一样。
- 另一名成员附上一张 meme 截图问道:哟 <@547736322568355861> 这是你吗。
- Gemini 2.5 显得过时:一名成员表示 Gemini 2.5 目前 太老了,他们 应该已经发布 3.0 了,并指出 没有人想使用当前状态的 Gemini。
- Kimi K2 受到喜爱并迎来小更新:一名成员提到 期待 Kimi K3,但另一名成员指出 K2 本身在 上个月有一个小更新,并且他们对 DS v3.1 和 Kimi K2 感到满意。
- 该成员表示他们 可能有偏见,因为他们 现在更倾向于 non thinking models(非思考模型)。
- 模型推理(Reasoning)可能产生冗余:一名成员表示 thinking models(思考模型)虽然不错,但应该保持独立,因为它们似乎会增加 word slop(废话),更好的做法是将 超大型泛化模型 kimi k3 与一个小型快速的 thinker 配对,而不是让后者使大模型“脑叶切除”。
- 另一名成员提到 在使用 deepseek 时,他们 有时会注意到推理过程是冗余的。
Eleuther ▷ #general (7 messages):
Compute Funding for Research Group, LLM Situational Awareness Benchmarks
- 研究人员寻求 Eleuther 算力支持:来自 Stanford、CMU 等高校的一组研究人员和工程师正寻求 Eleuther 的算力、资源或资金支持,以开展其研究项目。
- 他们有大量头脑风暴出的想法/项目,目前正在充实和定稿,希望能快速迭代并发布多篇论文。
- 寻求 LLM 情境感知基准测试:一名成员正在寻找衡量 LLM “情境感知”(situational awareness) 的基准测试,并指出像 Situational Awareness Diagnostic (SAD) 这样现有的基准测试以及使用合成数据集的基准测试可能并不理想。
- 该成员询问是否有更好的替代方案,或者这是否仍是一个开放的研究问题。
Eleuther ▷ #research (17 messages🔥):
SEAL optimizer, AdamW optimizer, AI/ML research, tensor logic, MAE training
- SEAL 使用 AdamW 优化器:关于 SEAL speedrun,已确认他们使用的是 AdamW 优化器,而非像 Muon 这样的新优化器。
- 层级中使用的固定路由方案:一名成员询问从层的角度来看是否使用了 固定路由方案(fixed routing schemes),具体是指路由方案是在训练期间学习的,还是所有常规路径都通过门控机制(gating mechanism)开启。
- 另一名成员澄清说 路由是随机的,类似于 MAE。
- 张量逻辑统一神经与符号 AI:分享了一篇新的 Pedro Domingos 论文,该论文提出将 tensor logic(张量逻辑) 作为一种 在基础层面统一神经和符号 AI 的语言。
- MAE 训练方法:有人指出所使用的训练方法类似于 MAE training,将最后几层视为 decoder。
Eleuther ▷ #interpretability-general (1 messages):
Devinterp.com, Neural Network Development
- 网站链接指向 Nerdsnipe 子领域:一名成员分享了网站 devinterp.com,并表示该子领域正在对他们进行 nerdsniping(指被极其有趣的技术问题吸引而分神)。
- 研究神经网络发展:一名成员正在研究 神经网络如何发展 的过程。
tinygrad (George Hotz) ▷ #learn-tinygrad (14 messages🔥):
训练时冻结矩阵的部分, 在 tinygrad 中实现 LeNet-5, 调试优化器问题, 嵌套 TinyJit 调用
- 在 tinygrad 中冻结层以进行细粒度训练:一名成员寻求关于在 tinygrad 训练时冻结矩阵某一部分而训练其余部分的建议,并探索了通过拼接具有不同
requires_grad属性的 Tensor 来创建“虚拟” Tensor 的方法。- 他们建议使用
Tensor.cat(x @ a.detach(), x @ b, dim=-1)来模拟“虚拟” Tensor,通过分离(detach) Tensora的部分来冻结它,并仅对 Tensorb启用训练。
- 他们建议使用
- LeNet-5 实现与优化器问题:一名成员在 tinygrad 中实现 LeNet-5 时遇到了优化器问题,报错显示
.step调用没有梯度,并使用 pastebin 链接 展示了代码。- 他们怀疑问题与输入 Tensor 没有设置
requires_grad=True有关。
- 他们怀疑问题与输入 Tensor 没有设置
- 二次 Jitting 导致训练故障:George Hotz 指出用户进行了两次 Jitting,建议移除多余的 Jit,并推荐先在没有 Jit 的情况下进行调试。
- 该成员确认移除第二个 Jit 装饰器后修复了问题,并意识到这是一个由嵌套
TinyJit调用引起的微妙错误。
- 该成员确认移除第二个 Jit 装饰器后修复了问题,并意识到这是一个由嵌套
Modular (Mojo 🔥) ▷ #general (7 messages):
ARM Linux 支持, DGX Spark 兼容性, CUDA 13 更新, Jetson Thor 支持, ARM 上的 Mojo 和 MAX
- Mojo 已支持 ARM Linux:一名成员表示 Mojo 应该已经可以在 ARM Linux 上运行,如果 Nvidia 对 Spark 上的 DGX OS 做了某些导致破坏的奇特改动,请提交 bug。
- 另一名成员指出,对于 DGX Spark,需要添加
sm_121条目,并将libnvptxcompiler更新到 CUDA 13。
- 另一名成员指出,对于 DGX Spark,需要添加
- DGX Spark 支持即将到来:一旦
sm_121条目和 CUDA 13 更新完成,Mojo 和 MAX 应该能在 DGX Spark 和 Jetson Thor 上完全运行。- 对于其他 ARM Linux 设备(如 Jetson Orin Nano),Mojo 和 MAX 目前应该可以正常工作。
- DGX Spark 的必要更新:要在 NVIDIA DGX Spark 上运行 Mojo/MAX,需要在 Mojo 的
gpu.host中为sm_121设备添加条目,并将libnvptxcompiler更新到 CUDA 13。- 完成这些更新后,Mojo 和 MAX 应该能在 DGX Spark 上良好运行。
Modular (Mojo 🔥) ▷ #mojo (5 messages):
在 Mojo 中查询类型, get_type_name(), __type_of(a)
- **Mojo 用户需要
type()功能:一名用户询问如何在 **Mojo 中查询变量的类型,类似于 Python 的type()函数。- 另一名用户建议使用
get_type_name获取可打印的名称,或使用__type_of(a)获取类型对象。
- 另一名用户建议使用
get_type_name()需要配合__type_of()使用:get_type_name()适用于 SIMD 类型,例如a = SIMD[DType.int, 4](0, 1, 2, 3),但在处理List或Dict时会失败。- 官方澄清它应该作为
get_type_name[__type_of(a)]()调用,因为它是一个独立函数(free standing function)。
- 官方澄清它应该作为
aider (Paul Gauthier) ▷ #general (2 messages):
OpenCode + GLM 4.6, 配合 Sonnet 4.5 使用 aider.chat, OpenRouter/x-ai/grok-code-fast-1 集成
- Opencode 和 GLM 4.6 令用户印象深刻:一名用户对 Opencode + GLM 4.6 感到惊艳,指出用它编程非常舒适且愉快,因为他们不再需要担心为了节省开销而计算 token,且易用性极佳。
- 配合 Sonnet 4.5 使用 aider.chat 进行优化:对于特定的代码细化工作,该用户报告会配合使用 aider.chat 和 Sonnet 4.5。
- 功能请求:在 Aider 中添加 OpenRouter/x-ai/grok-code-fast-1:一名用户询问如何将 openrouter/x-ai/grok-code-fast-1 添加到 aider 中,以便其能支持 diff 编辑等功能。
aider (Paul Gauthier) ▷ #questions-and-tips (2 messages):
Qwen2.5-Coder:7B Metadata, Ollama Integration Issues, Model Output Problems, Troubleshooting Model Errors
- Qwen2.5-Coder:7B 输出乱码:一位用户询问了来自 ollama.com 的
qwen2.5-coder:7b模型的metadata.json示例,并反馈其输出乱码。- 他们指出该问题仅出现在此模型中,其他模型运行正常。
- Ollama 模型集成挑战:用户在 Ollama 中使用
qwen2.5-coder:7b模型时遇到了特定问题,暗示可能存在集成问题。- 用户寻求一个可用的
metadata.json示例进行排查,表明问题可能与 Ollama 环境中的配置错误或模型不兼容有关。
- 用户寻求一个可用的
aider (Paul Gauthier) ▷ #links (2 messages):
Chinese provider with free tokens, Claude 4.5 available
- 新的中国供应商提供免费 Token!:一家新的中国供应商正在通过推荐链接提供 $200 的免费 Token:agentrouter.org。
- 每邀请一人可额外获得 $100。
- Claude 4.5 集成编程工具!:Claude 4.5 现已发布,可连接到多种编程工具。
MCP Contributors (Official) ▷ #general (4 messages):
Model Context Protocol, MCP Feature Support Matrix, SEP Document, Hierarchical Groups
- MCP Discovery 解析:一位成员询问了 Model Context Protocol 的功能支持矩阵 中 “Discovery” 的具体含义,特别是它与发现新工具的关系。
- 另一位成员澄清说,这指的是 Example Clients 文档 中描述的 响应 tools/list_changed 通知以寻找新工具的支持。
- 层级组提案浮出水面:一位成员引用了过去评审的反馈,建议通过 SEP 支持对所有 MCP 原语(包括 tools, prompts 和 resources)进行分组,并链接到了一个支持 层级组 (hierarchical groups) 的 Schema 增强非正式提案。
- 他们询问了这项工作的后续步骤,包括创建 新的 SEP 文档、优先级排序工作以及对原型实现的需求。
Windsurf ▷ #announcements (2 messages):
Windsurf Patch 1.12.18 Release, Claude Haiku 4.5 Availability
- **Windsurf 补丁 1.12.18 发布并包含修复:新补丁 (1.12.18**) 已发布,包含重大错误修复和改进,可在此处下载:here。
- 该补丁解决了 自定义 MCP 服务器、beta 版 Codemaps 功能、卡住的 bash 命令 以及创建或编辑 Jupyter notebooks 时的问题。
- **Claude Haiku 4.5 以极低价格登陆 Windsurf:Claude Haiku 4.5** 现已在 Windsurf 中可用,仅需 1x 积分,其编程性能媲美 Sonnet 4,但成本仅为三分之一,速度提升超过 2 倍。
- 更多信息请见 X.com;鼓励用户重新加载或下载 Windsurf 进行体验!
Manus.im Discord ▷ #general (2 条消息):
AI Tool Innovation, Subscription Model for AI Agents, Service Expectations in AI Communities, Project Mistakes and Learnings
- AI 创新停滞于简单表单?:一位用户对 AI 工具仍依赖简单表单和邮件回复来获取细节,而非使用创新的 AI Agent 表示惊讶。
- 他们建议提供一种带有订阅模式的创新 AI Agent,并通过提供 credits 来换取用户反馈,以此展示 AI 的能力。
- 用户要求即时 AI 服务而非缓慢响应:一位用户吐槽了 AI 社区中的普遍问题,即用户期望即时服务,而不是延迟数天的响应。
- 该成员感叹道:我在所有社区中看到的最大问题是,用户想要的是某种服务,而不是因为服务标准问题而等待 3 天才得到回复。是的,我今天就在吐槽。
- 项目回顾揭示关键失误:一位用户分享了项目中的经验教训,承认了重大失误,例如在没有集成的情况下声称已集成,以及没有坦诚说明局限性。
- 该用户表示:我在这个项目中犯了重大错误:在没有集成的情况下声称已集成——我最初说一切都已集成,而实际上我只构建了独立的系统。
MLOps @Chipro ▷ #events (1 条消息):
Domain-Centric GenAI, Autonomous Data Products, RAG Systems, Domain-Specific Models
- Nextdata 举办领域中心化 GenAI 网络研讨会:Nextdata 将于 2025 年 10 月 16 日上午 8:30 AM PT 举办一场关于上下文管理和领域中心化数据架构的网络研讨会,由 Jörg Schad 主持。
- 研讨会将涵盖 RAG 的领域驱动数据、领域感知工具和领域特定模型等主题,旨在提高检索相关性、减少幻觉并降低 token 成本 —— 在此报名!
- 领域驱动数据防止 Token 膨胀:研讨会将讨论向模型灌入整个数据湖如何导致 token 膨胀和幻觉,而领域范围内的上下文如何让 LLM 保持专注和高效。
- 它还将涵盖暴露数十个工具如何削弱 Agent 的决策能力,以及模块化、任务范围内的工具访问如何改进推理。
- 领域特定模型提高准确性:研讨会将解释为什么通用模型在专业背景下表现不佳,以及领域对齐微调如何提高准确性。
- 与会者可以学习如何构建具有更好检索相关性、更少幻觉和更低 token 成本的 RAG 系统,从而实现具有更强治理能力、更低推理成本和更高用户信心的生产就绪型 GenAI。