AI News
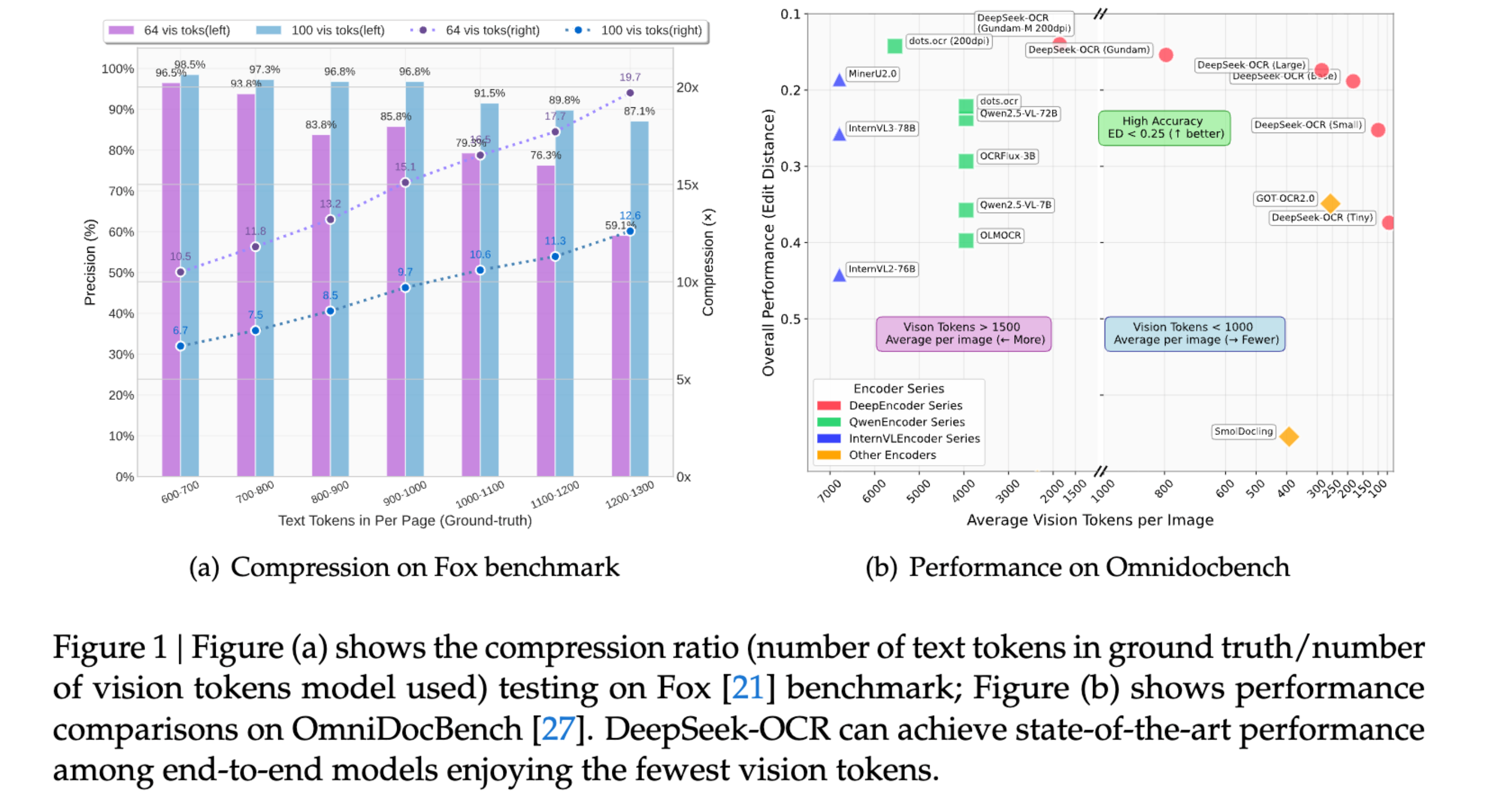
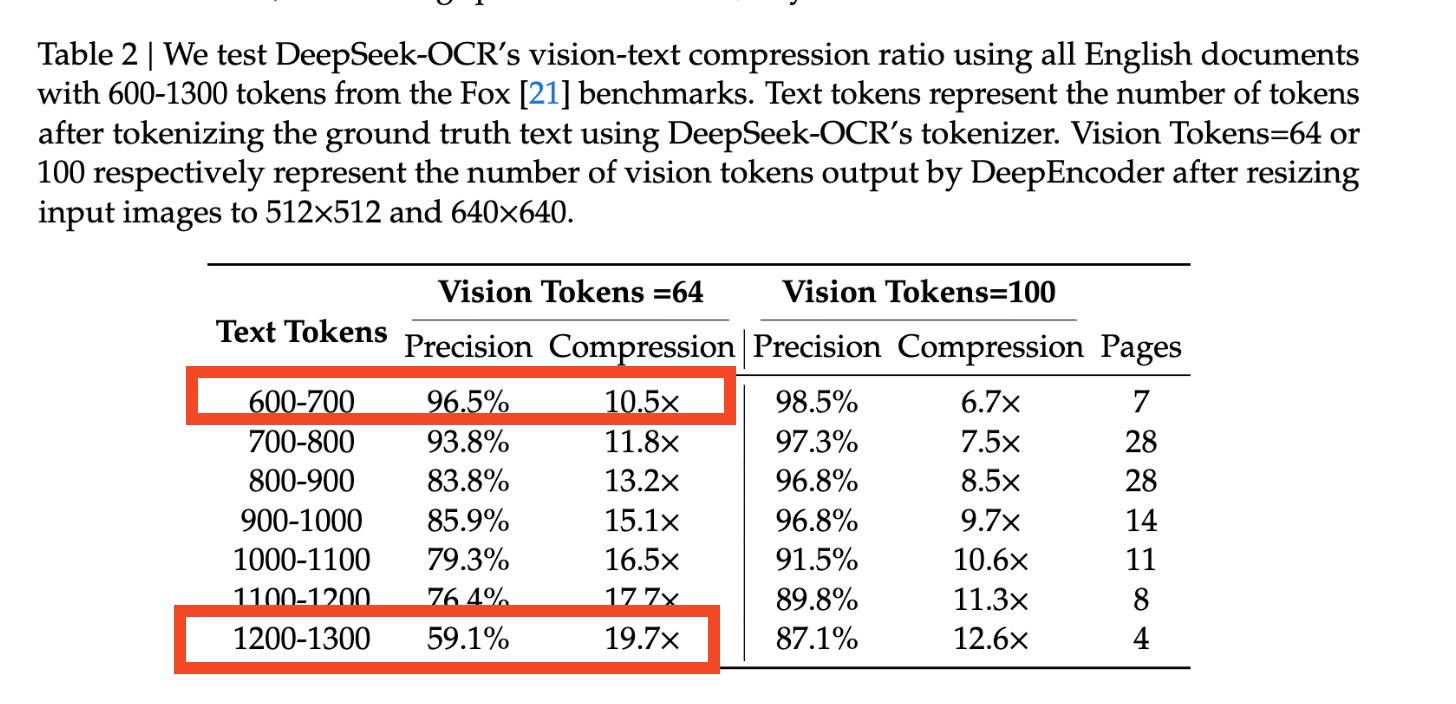
DeepSeek-OCR 发现,视觉模型的解码效率可提升 10 倍,准确率达到纯文本水平的约 97%,单张 A100 显卡每天可处理 20 万页(33/200k pages/day/A100)。
随着 ICCV 2025 的开幕,DeepSeek 发布了一款全新的 DeepSeek-OCR 3B MoE 视觉语言模型。该模型能够以高精度和高效率将长文本压缩为视觉上下文,对传统的分词(tokenization)方法发起了挑战。在压缩率小于 10 倍的情况下,该模型实现了约 97% 的解码精度,在 20 个 A100-40G 节点上每天可处理多达 3300 万页内容,性能超越了 GOT-OCR2.0 等基准模型。相关讨论强调了无限上下文窗口和“免分词”输入的潜力,@karpathy、@teortaxesTex 等人也对此做出了贡献。
在视频生成领域,Google DeepMind 的 Veo 3.1 凭借先进的精确编辑和场景融合技术在社区基准测试中处于领先地位;与此同时,Krea 开源了一款 14B 自回归视频模型,在单块 B200 GPU 上能以约 11 FPS 的速度实现实时长视频生成。
Vision is all you need?
2025年10月17日至10月20日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 和 23 个 Discord(198 个频道和 14010 条消息)。预计节省阅读时间(按 200wpm 计算):1097 分钟。我们的新网站现已上线,提供完整的元数据搜索和所有往期内容的氛围感十足的展示。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
随着 ICCV 在夏威夷开幕,DeepSeek 继续展现出活力。这是一篇只有 3 位作者的相对较小的论文,以及一个 3B 的小模型,但其贡献在于一个名为 DeepEncoder 的 SAM+CLIP+压缩器:
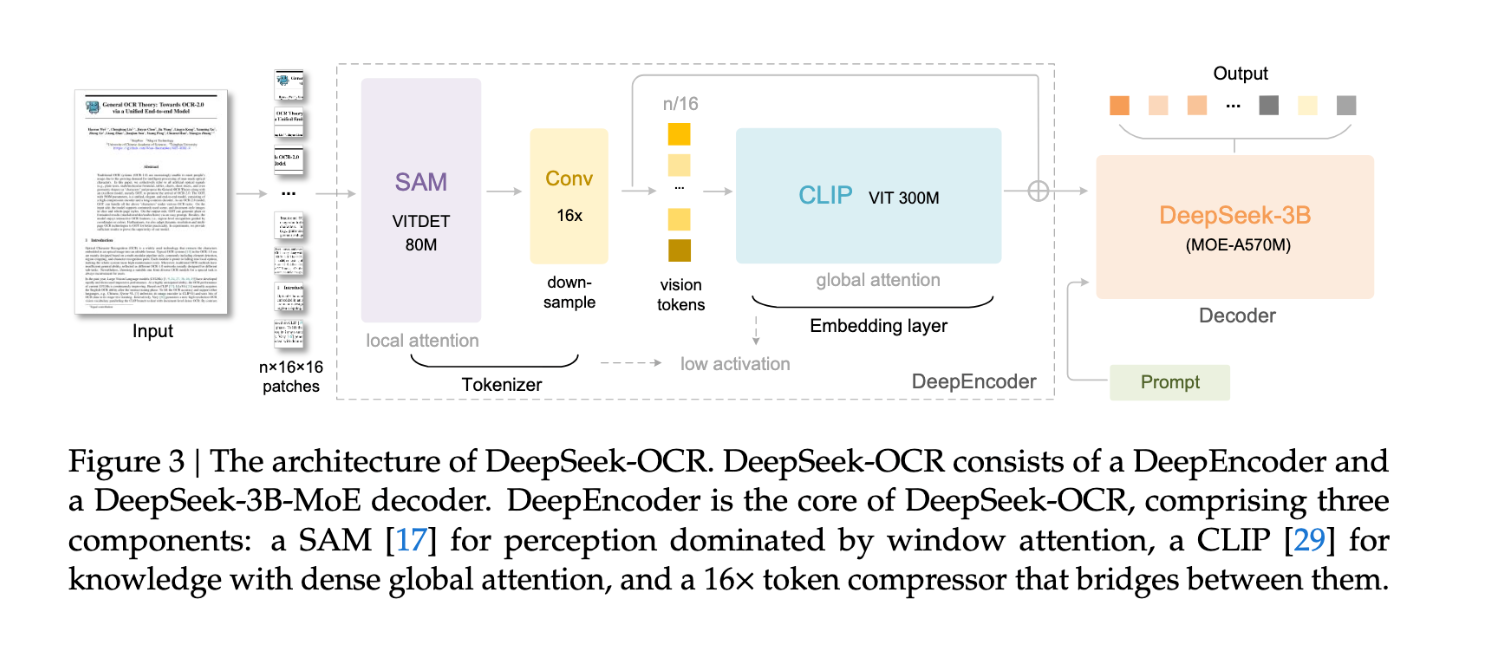
其核心发现非常扎实:
一个优秀的 OCR 模型的意义,除了从书籍和 PDF 中释放大量数据外,还在于能够始终消费富文本并摆脱 tokenizer。
AI Twitter 热点回顾
DeepSeek 的“光学上下文压缩” OCR 以及纯文本上下文的终结?
- DeepSeek-OCR (3B MoE VLM) 发布:DeepSeek 发布了一款小型、快速的视觉语言 OCR,它将长文本视为“视觉”上下文,并在保持准确性的同时将其压缩 10–20 倍。关键数据:在压缩率小于 10 倍时解码精度约为 97%,20 倍时约为 60%;单台 A100-40G 每天处理约 20 万页,20 个节点(每个节点 8× A100-40G)每天处理约 3300 万页。它在 OmniDocBench 上击败了 GOT-OCR2.0 和 MinerU2.0,使用的视觉 token 远少于前者,并且可以将复杂的布局(表格/图表)重新渲染为 HTML。vLLM 的首日支持在 A100-40G 上实现了约 2,500 tok/s 的速度,官方支持将在下一版本发布。代码和模型已在 GitHub/Hugging Face 上线。查看来自 @reach_vb、@akhaliq](https://twitter.com/_akhaliq/status/1980260630780162505)、[@casper_hansen、@vllm_project 的概览和演示,以及 @teortaxesTex 的初步亮点介绍。
- 架构及其对长上下文的影响:根据 @eliebakouch 的说法,发布的 LLM 解码器是 DeepSeek3B-MoE-A570M 的变体,使用 MHA(无 MLA/GQA)、12 层、2 个共享专家,以及相对较高的 12.5% 激活率(相比之下,V3 为 3.52%,V2 为 5%)。社区辩论的焦点在于:将“旧”文本压缩为视觉 token 是否能实现“理论上无限的上下文”和更好的 Agent 记忆架构,以及像素是否能成为比文本 token 更优的 LLM 输入接口。查看 @teortaxesTex 和 @karpathy 关于多模态编码器和无 token 输入的论点,@teortaxesTex 关于存储仍为 token(而非截图)的澄清,以及 @vikhyatk 关于 prefix-caching 不兼容性和实际 KV 压缩限制的反驳观点。优秀的简明总结:@iScienceLuvr、@_akhaliq。
视频生成:Veo 3.1 飞跃式领先;Krea Realtime 走向开源
- Veo 3.1 登顶社区评估并增加精准编辑功能:Google DeepMind 的 Veo 3.1 在 Video Arena 上跃升约 30 分,成为首个在 text-to-video 和 image-to-video 领域均突破 1400 分的模型,根据社区反馈,其在物理特性/真实感方面超越了之前的领先者。DeepMind 还发布了精准编辑功能(在保持光影/场景交互一致的情况下添加/删除元素)以及强大的“起始帧 → 结束帧”引导功能,可将真实素材融入风格化的输出中。可在 Flow/Gemini 和 LM Arena 中尝试并对比。详情来自 @GoogleDeepMind、@demishassabis、@arena,示例见 @heyglif。
- 开源实时视频生成:Krea 发布了 “Realtime”,这是一个采用 Apache-2.0 协议的 14B 参数自回归视频模型,在单块 B200 上可实现约 11 FPS 的长视频生成。权重和报告已发布在 Hugging Face;早期基准测试和说明来自 @reach_vb 以及 @krea_ai 的发布推文。同样值得关注的还有:Ditto 基于指令的视频编辑数据集/论文 (@_akhaliq) 以及 VISTA,一个“测试时自我改进”的视频生成 Agent (@_akhaliq)。
Agentic 编码技术栈、治理与企业态势
- Claude Code 登陆 Web 和 iOS,具备默认安全的执行机制:Anthropic 在浏览器和 iOS 端推出了 Claude Code,在执行过程中通过对话循环在云端 VM 中运行任务。CLI 中全新的 sandbox 模式允许你限定文件系统和网络访问范围,将权限提示减少了 84%;Anthropic 为通用 Agent 开发者开源了该 sandbox。早期评论称赞了这一方向,但也指出云端切换方面仍有待完善。参见 @_catwu 的发布与深度解析、@trq212 和 @_catwu 提供的 sandbox 详情、@omarsar0 的开源仓库说明,以及 @danshipper 的产品体验评价。
- 企业级 Agent 运维(BYOI、多云与速度):Cline 发布了企业版,可在开发者工作的地方运行(VS Code/JetBrains/CLI),并支持任何可用的模型/供应商(跨 Bedrock、Vertex、Azure、OpenAI 的 Claude/GPT/Gemini/DeepSeek)。这种“自带推理 (BYOI)”模式在云服务中断期间能提供实质性帮助。IBM 和 Groq 正在将 watsonx Agent 与 Groq LPU 推理相结合(声称速度提升 5 倍,成本仅为 20%)并启用 vLLM-on-Groq,这表明 Agent 技术栈正迅速向单一云平台之外多元化发展。参见 @cline、@robdthomas 和 @sundeep。同类进展还包括:注入编码 Agent 的 MCP 支持的文档服务器 (@dbreunig)、便捷的多云 GPU 开发环境 (@dstackai) 以及全球批处理推理指南 (@skypilot_org)。
基础设施韧性与性能工具
- AWS us-east-1 故障(影响范围与教训):一次重大故障导致多个 AI 应用下线(例如 Perplexity 和 Moondream 的网站;Baseten 的 Web UI),目前服务正逐步恢复。PlanetScale 报告称,通过减少外部依赖,其在 us-east-1 的数据库操作完成率达到了 99.97%。此次事件再次强调了多区域/多云策略、减少供应商锁定以及 BYOI 的重要性:查看来自 @AravSrinivas 的故障状态与恢复情况(恢复更新),以及来自 @vikhyatk、@basetenco(恢复更新)、@midudev、@reach_vb、@nikitabase 的影响报告,以及 @GergelyOrosz 关于因果关系的公益公告。相关内容:@cline 提到的“BYOI 再次发挥作用”。
- Kernel、DSL 与量化:Modular 在两周内为 AMD MI355 带来了行业领先的性能,目前已支持来自 3 家供应商的 7 种 GPU 架构,展示了深度编译器投入的优势(发布,详情)。TileLang 是一种新型 AI DSL,通过布局推导、数据重排 (swizzling)、warp 特化和流水线化,在 H100 上仅用约 80 行 Python 代码即可达到 FlashMLA 约 95% 的性能 (@ZhihuFrontier)。此外,GPTQ int4 训练后量化现已内置于 Keras 3,并附带供应商无关的指南 (@fchollet)。
评估与基准测试:真金白银、真实排行榜与结构化推理
- 真钱交易评估(需谨慎解读):一个社区基准测试 (nof1.ai) 在几天内为每个模型分配了 1 万美元资金;报告显示 DeepSeek V3.1 和 Grok 4 处于领先地位,而 GPT-5/Gemini 2.5 则出现亏损 (@mervenoyann, @Yuchenj_UW)。注意事项:样本量小、高方差、提示词依赖和路径依赖;除非在多次运行中分散资金,否则“噪声占主导” (@abeirami)。背景:DeepSeek 的量化背景是一个反复出现的主题 (@hamptonism)。
- 排行榜与结构化推理:WebDev Arena 新增了四个模型:Claude 4.5 Sonnet Thinking 32k;GLM 4.6(新的开源第一);Qwen3 235B A22B;以及 Claude Haiku 4.5 (@arena)。在其他方面,Parlant 的 Attentive Reasoning Queries (ARQ) 使用模式约束、领域特定的“查询”代替自由形式的 CoT,在 87 个场景中报告了 90.2% 的准确率,而 CoT 为 86.1%(仓库见推文)(@_avichawla)。另请参阅“何时停止搜索 vs 执行”的终止训练 (CaRT) (@QuYuxiao),以及 DeepSeek 表现与 PrediBench 结果一致的观察 (@AymericRoucher)。
- 中国模型动态:Kimi K2 声称在内部工作负载上速度提升高达 5 倍,准确度提升 50% (@crystalsssup);团队分享了内部基准测试结果 (@Kimi_Moonshot)。
领域工具:生命科学、数据流水线与结构化提取
- Claude for Life Sciences: Anthropic 推出了连接器(Benchling, PubMed, Synapse.org 等)以及用于遵循科学协议的 Agent Skills,早期用户包括 Sanofi, AbbVie 和 Novo Nordisk。Anthropic 还发布了一个包含示例的 Life Sciences GitHub 仓库(发布, 详情, 仓库)。
- Data workflows: LlamaIndex 展示了一个强大的 text-to-SQL 工作流,包含语义表检索(Arctic-embed)、开源 text2SQL(通过 Ollama 运行 Arctic)、多步编排以及错误处理(@llama_index)。FinePDFs 发布了新的 PDF OCR/Language-ID 数据集和模型(XGB-OCR),以助力文档流水线(@HKydlicek, @OfirPress)。针对结构化 VLM 提取,Moondream 3 展示了对复杂停车标志的单次 JSON 解析——无需 OCR 栈(@moondreamai)。
热门推文(按互动量排序)
- DeepSeek 的“视觉压缩 OCR”及其对长上下文的影响在社区引起热议:@godofprompt 提供了简洁的技术总结,@karpathy 则发布了更广泛的“像素优于 Token”系列推文。
- 大规模 AWS 停机更新(西班牙语):@midudev 汇总了影响和评论;Perplexity 停机及恢复情况来自 @AravSrinivas 和 (恢复)。
- Veo 3.1 跃升至 Video Arena 第一名,得到了 @arena 和 @demishassabis 的官方认可。
- Kimi K2 性能宣称:速度提升高达 5 倍,准确度提升 50%(@crystalsssup)。
- 经典阅读:Richard Sutton 重新分享了原始的 Temporal-Difference 学习资源(@RichardSSutton)。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. DeepSeek OCR 发布
- DeepSeek 发布 DeepSeek OCR (活跃度: 565): DeepSeek 发布了一个新的 OCR 模型 DeepSeek OCR,它引入了一种名为 Optical Compression(光学压缩)的新颖方法。该技术利用随时间增加的图像压缩来促进一种视觉/文本遗忘形式,从而可能实现更长甚至无限的上下文处理。这种方法在他们的论文中得到了详细阐述,强调了其将上下文长度显著扩展到超出当前能力的潜力。 一个值得注意的讨论点是与 Qwen3 VL 的比较,一些用户对名为 ‘gundam’(高达)的模式感到好奇。社区还在讨论光学压缩技术对 OCR 应用中上下文管理的影响。
- DeepSeek OCR 引入了一种名为 ‘Contexts Optical Compression’(上下文光学压缩)的新方法,该方法利用随时间增加的图像压缩作为视觉/文本遗忘的一种手段。通过有效管理内存和处理资源,这项技术可能允许更长的上下文窗口,甚至可能是无限的。这可能是 OCR 系统处理大规模数据输入的一个重大进步。
- 该模型在大量数据集上进行了训练,包括 140 万篇 arXiv 论文和数十万本电子书。这种广泛的训练数据集表明 DeepSeek OCR 可能在特定领域表现出色,特别是在识别数学和化学公式等复杂文本结构方面。虽然它在整体 SOTA 性能上可能不会超过 PaddleOCR-VL,但在专门的文本识别任务中可能表现更好。
- 人们期待 Omnidocbench 1.5 基准测试能提供更详细的性能指标。目前的评估(如编辑距离)在没有表格 TEDS 和公式 CDM 分数等补充指标的情况下是不够的。这些基准测试对于评估 DeepSeek OCR 与现有模型(特别是在数学和化学文本识别等专业领域)的对比能力至关重要。
- 当中国公司停止提供开源模型时会发生什么? (活跃度: 809): 像阿里巴巴这样的中国公司已经从开源转向闭源模型,例如从 WAN 到 WAN2.5 的转变,现在需要付费。这一举动引发了人们对中国开源模型未来可用性的担忧,这些模型对于全球获取以及与美国模型的竞争至关重要。这种变化可能会影响全球 AI 格局,因为开源模型一直是中国公司在国际市场上的关键差异化因素。 评论者认为,中国的开源策略一直是抗衡美国专有模型的一种手段,提供了负担得起的替代方案。如果中国模型变为闭源,它们可能会失去国际吸引力,因为开源属性是它们相对于美国模型的主要优势。
- TopTippityTop 讨论了中国从开源模型中获得的战略优势,强调中国的经济更侧重于实物商品生产,而美国经济更依赖于软件和服务。这种依赖性使得美国经济更加脆弱,这表明中国的开源策略是利用这种经济动态的深思熟虑之举。
- RealSataan 认为,中国模型对国际用户的主要吸引力在于其开源性质。如果中国公司停止提供开源模型,这些模型将失去相对于在全球范围内更易获得的美国替代方案的竞争优势。
- Terminator857 建议,如果中国公司转向闭源模型,他们可能会显著增加收入。这意味着在维持开源可访问性与利用专有模型获取财务收益之间存在权衡。
较低技术性的 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. 机器人创新 (Robotics Innovations)
- 介绍 Unitree H2 - 中国在机器人领域太强了 😭 (活跃度: 1324): Unitree Robotics 推出了 Unitree H2,这是一款展示了先进运动能力的新型机器人模型,在实现更自然、更流畅的动作方面取得了长足进步。这一发展突显了中国在机器人领域日益增长的专业知识,H2 模型在灵活性和功能性方面表现出显著改进。该机器人的设计和工程反映了对增强实际应用的关注,尽管一些用户表示希望看到更多以实用为中心的功能。 评论者注意到机器人动作令人印象深刻的自然感,这表明虽然技术在进步,但对机器人执行更多实际任务的需求仍然存在。
- midgaze 强调了中国在机器人和自动化领域的快速进步,认为他们正在接近“自动化奇点”。这意味着一个自我强化的循环,即改进的制造导致更好的机器人,而这反过来又增强了制造能力。该评论强调了中国在这一领域获得的战略优势,有可能超越全球竞争对手。
- crusoe 提出了一个关键观察,指出虽然 Unitree H2 展示了跳舞等任务,但缺乏实际应用的演示。这与 Boston Dynamics 等公司形成鲜明对比,后者经常在现实场景中展示其机器人,强调功能性而非娱乐性。
- RDSF-SD 评论了 Unitree H2 动作的自然性,表明机器人的运动学和控制系统取得了重大进展。这种运动流畅性的提高对于需要类人交互和精确度的应用至关重要,表明该技术正朝着更复杂和实用的用途发展。
- 电影开始在片尾字幕中加入“制作过程中未使用 AI…”等内容 (活跃度: 764): 最近的电影开始在片尾字幕中加入免责声明,声明“本片的制作过程中未使用 AI”。这一趋势反映了人们对 AI 在创作过程中使用的日益关注,让人联想起过去关于数字摄影与胶片摄影的争论。一些人认为这种声明具有表演性质,因为 AI 工具已广泛集成到生产工作流中,且预计 AI 将在未来的创作工具中更加深入。 评论者对在电影制作中完全避免 AI 的可行性表示怀疑,并指出了与过去技术转变(如从实景特效向 CGI 的过渡)的相似之处。人们认为 AI 将变得如此不可或缺,以至于此类免责声明将无法证实。
- NoCard1571 认为在电影制作中不使用 AI 的说法很大程度上是表演性的,认为在制作过程中没有人使用语言模型是不太可能的。他们预测生成式 AI 将如此深入地集成到工具中,以至于未来此类声明将无法验证。
- zappads 强调了 2000 年代 CGI 取代烟火艺术家的历史平行案例,指出成本和易用性通常会驱动电影制作中的技术采用。他们认为,无论目前关于 AI 缺失的说法如何,经济压力都将导致 AI 使用量的增加。
- letmebackagain 强调了关注最终产品质量而非创作工具的重要性。这种观点表明,关于 AI 使用的辩论应该集中在作品的艺术和技术价值上,而不是生产方法上。
2. AGI 预测与历史
- 1999年,大多数人认为 Ray Kurzweil 预测 2029 年实现 AGI 是疯狂的。26 年后,他依然预测 2029 年 (Activity: 626): Ray Kurzweil 一贯预测通用人工智能 (AGI) 将在
2029年到来,这一主张他最早在1999年提出。尽管存在质疑,Kurzweil 仍坚持这一时间表,暗示届时 AI 将在广泛的任务中达到人类水平的智能。然而,由于缺乏普遍认可的 AGI 定义,这些预测变得复杂,专家指出,虽然 AI 可能在特定任务中达到人类同等水平,但 AGI 的本质仍然难以捉摸。 评论中的一个显著观点强调了由于缺乏明确定义,对 AGI 预测持怀疑态度。另一种观点认为,虽然 AI 到2029年可能在许多任务中达到人类水平的表现,但真正的 AGI 概念仍未定义。- jbcraigs 强调了由于缺乏普遍接受的定义,预测 AGI 面临挑战。他们认为,虽然 AI 到 2029 年可能在特定任务中达到人类水平的表现,但“真正的 AGI”概念仍然难以捉摸,因为我们并不完全理解它包含什么。
- KairraAlpha 讨论了一个误区,即认为 AGI 仅仅是在数学和逻辑上超越人类的能力。他们认为智能是多维度的,AGI 可能不符合传统预期。他们暗示,如果取消限制,当前的 GPT-5 和 Claude 等模型可能会展示出意想不到的能力,这暗示了 AGI 开发的复杂性和不可预测性。
- 就是今天 😭 (Activity: 2058): 该帖子讨论了在 AI 生成内容中争议性地使用马丁·路德·金 (MLK Jr) 肖像的问题,导致 OpenAI 决定禁止此类用途。这反映了 AI 领域持续存在的伦理担忧,即在未经许可的情况下使用历史人物的图像和声音。这一问题凸显了在 AI 内容生成中需要更严格的准则和监督,以防止滥用并尊重知识产权。 评论者表达了沮丧和失望,质疑 AI 开发中的伦理监管以及像 OpenAI 这样的公司防止此类事件发生的责任。
- 梗图在继续 (Activity: 418): 这篇 Reddit 帖子幽默地引用了一个场景,一名主播(可能是 Hassan)被开玩笑地指责强迫他人观看其直播以增加观看时长。这被比作一个潜在的 South Park 笑话,突显了这种情况的荒诞和幽默。外部链接显示由于网络安全限制访问受限,需要登录或开发者令牌才能进一步访问。 评论者觉得这种情况很有趣,并认为它非常适合作为 South Park 的笑话,表明这种幽默感与该剧的风格产生了共鸣。
AI Discord 回顾
由 gpt-5 生成的摘要之摘要的摘要
1. AI 视频生成大对决
- Veo 在视频排行榜上大获全胜:Veo-3.1 目前在 Text-to-Video Leaderboard 和 Image-to-Video Leaderboard 上均排名第一,组织者在 Arena announcement on X 中邀请大家提交作品并提供反馈。社区围绕这些排行榜展开了密集测试,重点关注在排行榜限制下的 Prompt 覆盖率、时序连贯性(temporal coherence)以及运动忠实度(motion fidelity)。
- 参与者分享了生成结果和边缘案例 Prompt,同时讨论了排行榜的方法论,以及评估对短视频和特定 Prompt 类别的偏见,强调了一致的运动(consistent motion)和身份保持(maintained identity)的重要性。多位工程师指出,排行榜促进了 text-to-video 和 image-to-video 基准测试的快速迭代周期和可复现性。
- Sora 下滑,Veo 激增:工程师们将 Sora 2 的输出(参见 Sora examples)与 Veo-3.1 进行了对比,报告称尽管 Veo 在排行榜上占据主导地位,但自最初发布以来,Sora 的感知质量有所下降。辩论集中在主观质量与排行榜评分的对比,以及跨模型更新的 Prompt 可复现性上。
- 讨论强调,评估应针对 seed、剪辑长度和后处理进行归一化,以公平地评判时序一致性(temporal consistency)、物理合理性(physics plausibility)和角色持久性(character persistence)。一些用户得出结论,即使 Veo 目前位居榜首,Sora 的优势在特定的电影场景和风格化 VFX 中依然存在。
- Krea Realtime 推出开源视频模型:Krea AI 开源了一个 14B 自回归 text-to-video 模型 Krea Realtime,该模型蒸馏自 Wan 2.1,在单块 NVIDIA B200 上能够达到约 11 fps,详见 Krea Realtime announcement。工程师们立即探索了 ComfyUI 工作流、在 RTX 5090 上的预期吞吐量,以及针对特定领域运动的微调钩子(fine-tuning hooks)。
- 开发者强调,具有实时生成能力的 OSS 基准模型解锁了快速的工作流原型设计(workflow prototyping),并能与闭源模型进行基准对比。早期采用者交流了关于上下文窗口、帧调节(frame conditioning)以及为低延迟串流优化解码流水线的经验。
2. Kernel DSLs 与量化更新
- Helion 进入公测阶段:Helion 0.2 已作为公开测试版在 PyPI 上发布(Helion 0.2 on PyPI),同时在 Triton Developer Conference 和 PyTorch Conference 2025 上进行了开发者推广。该工具定位为层叠在编译器栈之上的 Kernel 编写高级 DSL,并为实践用户提供了多次演讲和现场问答。
- 工程师们欢迎这种在保持 MLIR 和编译器易用性的同时,编写高性能 Kernel 的更高级路径。会议讨论强调了与 PyTorch Compiler 栈的紧密集成,以及针对不断演进的 GPU 后端的未来适应性。
- SM120 和 Hopper 上的 Triton TMA 真相:在 NVIDIA SM120 上测试 Triton 中 TMA 的从业者报告称,与
cp.async相比没有优势,这与之前的记录一致,即在 Hopper 上,TMA 在小于约 4 KiB 的负载下表现不佳,且 Ampere 缺乏 TMA(指针计算可能仍然更快);背景参考了 matmul 深度解析文章 Matmul post (Aleksa Gordić)。基准测试表明,TMA 在较大的 Tile 和多播(multicast)模式下表现出色,但需要精细的 Tiling 才能在小规模传输中击败cp.async。- CUDA 讨论对比了在调整描述符驱动的布局时,DSMEM、L2 和显存之间的延迟/带宽行为。结论:同时分析 tile size 和 swizzle;在 Hopper 级硬件上为小于 4 KiB 的 Tile 保留
cp.async备选路径。
- CUDA 讨论对比了在调整描述符驱动的布局时,DSMEM、L2 和显存之间的延迟/带宽行为。结论:同时分析 tile size 和 swizzle;在 Hopper 级硬件上为小于 4 KiB 的 Tile 保留
- TorchAO 调整量化配置:TorchAO 将弃用
quantize_op的filter_fn,转而使用支持正则表达的 ModuleFqnToConfig(TorchAO PR #3083),从而简化选择性量化策略。与此同时,用户注意到 SGLang 的在线量化目前无法跳过视觉栈,正如 SGLang quantization docs 中所记录的那样。- 团队欢迎针对混合文本和视觉通道的大型代码库使用基于正则的范围界定,并指出了现有辅助工具中的迁移工作。更广泛的讨论涉及供应商无关(provider-agnostic)的部署规范,以及即将发布的 PyTorch 2.9 中针对多 GPU 设置的对称内存后端功能。
3. 新模型、数据集与 Agent 工具
- Qwen3 Vision 携 VL-8B 登场:Qwen 在 Hugging Face 上发布了多模态模型 Qwen3-VL-8B-Instruct (Qwen3-VL-8B-Instruct),适用于本地运行的 GGUF 变体也已出现。工程师们在实际工作流(如 ComfyUI)中将其与其他 VLM 进行了对比,并讨论了提示词模板和聊天格式。
- 早期采用者评估了 OCR、图表/表格解析以及代码-图表关联(grounding)能力,并注意到了分词器(tokenizer)和聊天模板的敏感性。讨论强调了使用一致的 ChatML 格式和谨慎处理系统提示词,以稳定 vision-language 性能。
- xLLMs 发布多语言对话数据集宝库:xLLMs 集合发布了用于长上下文推理和工具增强聊天的多语言/多模态对话数据集 (xLLMs 数据集集合;重点关注:xllms_dialogue_pubs)。该数据集目标是针对多达九种语言的长上下文、多轮连贯性和工具使用(tool-use)评估。
- 开发者强调,标准化的多轮追踪数据加速了 SFT 和评估流水线。讨论集中在按语言/任务拆分、筛选工具追踪数据,以及将其映射到 instruct 或 cloze 模板以进行评测框架(harnesses)适配。
- Agent 获得自托管追踪功能:一个社区项目为 OpenAI Agents 框架发布了自托管的追踪和分析栈,以解决 GDPR 和导出限制问题 (openai-agents-tracing)。该仓库提供了仪表盘和存储方案,以保持 Agent 追踪数据的私密性和可移植性。
- 团队赞赏其能够在不向第三方仪表盘发送遥测数据的情况下,检查延迟、工具调用扇出(fanout)和故障模式。对隐私敏感的机构认为,这对于需要本地(on-prem)可观测性的受监管工作负载至关重要。
4. Mac 上的便携式 GPU 计算
- tinygrad 将 USB4 扩展坞变为 eGPU 救生线:tiny corp 宣布公开测试纯 Python 驱动程序,支持通过任何 USB4 eGPU 扩展坞在 Apple Silicon MacBook 上使用 NVIDIA 30/40/50 系列和 AMD RDNA2–4 GPU (tinygrad eGPU 驱动发布公告)。工程师们立即探讨了性能上限、NPU 交互以及移动设备的开发人体工程学。
- 讨论辩论了精简的 NPU 编程是否可以补充混合流水线中的 eGPU 卸载(offload)。Mac 用户对比了扩展坞/固件的特性,并讨论了针对计算密集型工作流(LLM 推理、diffusion、视频)的驱动成熟度。
- 二手 3090 生存指南:一位从业者分享了购买二手 RTX 3090 显卡的实测清单——携带便携式 eGPU 设备、确认
nvidia-smi、运行memtest_vulkan、可选运行gpu-burn并观察散热情况 (RTX 3090 二手购买技巧)。该指南旨在减少 VRAM/散热方面的意外,并剔除有缺陷的显卡。- Mac eGPU 实验者也强调了在负载下进行实时验证而非空闲检查的重要性。社区还注意到 tinygrad 相关讨论中流传的早期 macOS NVIDIA 驱动开发工作,用于更广泛的兼容性测试。
5. 研究与评估亮点
- Anthropic 映射注意力机制:Anthropic 通过论文 Tracing Attention Computation Through Feature Interactions (论文) 将归因图从 MLPs 扩展到了注意力机制。讨论将其与之前的可解释性工作以及通过 QK normalization 缓解 logit blowups 的技术联系起来。
- 研究人员讨论了特征层级如何在注意力层之间出现,以及在实践中如何可视化 QK interactions。工程师们注意到在中小模型中进行针对性消融实验(ablations)和更好的 mechanistic 探测的潜力。
- Eval Harness 迎来 UX 升级:Eleuther 概述了 lm-evaluation-harness 的重构,增加了新模板、标准化格式、更清晰的指令任务和更友好的 UX(分支:smolrefact;规划:Eval harness planning When2Meet)。目标包括更轻松地在任务变体之间转换(例如 MMLU → cloze → generation)以及更合理的
repeats行为。- 库用户对减少格式陷阱(footguns)以及在 long-context 和 tool 任务中更好的可复现性表示欢迎。团队在广泛推出之前向重度用户征求反馈以最终确定模板。
- NormUon 推动优化器达到 SOTA:一种名为 NormUon 的新优化器进入了讨论圈,声称如果基准测试成立,将达到 SOTA-level 的结果(NormUon optimizer (arXiv:2510.05491))。社区交叉检查将其与 Muon 在非速通基准和 QK-norm 缓解措施下进行了对比。
- 实践者报告称,它在“非速通设置下与具有良好 muon 基准的 muon 性能相同”,同时指出更平滑的权重谱(weight spectra)带来了稳定性。其他人则提醒在宣布 reasoning-heavy 负载获胜之前,需要进行面对面的消融实验。
Discord: 高层级 Discord 摘要
Perplexity AI Discord
- Comet 现金:推荐计划支付调查:用户讨论了 Comet 推荐计划,排查了推荐链接问题并报告了支付缺失的情况。
- 成功推荐的技巧包括确保被推荐用户安装了 Comet 并进行了搜索。
- AWS 事故:停机凸显过度依赖:最近的 AWS 停机导致 Perplexity AI 和其他服务出现广泛问题,引发了关于过度依赖单一云供应商风险的讨论。
- 用户分享了状态链接和个人体验,指出即使在初始停机解决后,某些功能仍受影响。
- Claude 胜出:GPT-5 在竞争中受挫:成员们辩论了 GPT-5 与 Claude 的相对优劣,许多人发现 Claude 在复杂项目和推理任务中表现更优。
- 一些用户注意到 GPT-5 的免费层级感觉明显较弱,而其他人建议使用 Claude 4.5 以获得最佳效果。
- Claude Sonnet 4.5 在哲学领域展现专长:Claude Sonnet 4.5 被强调在哲学问题解决方面非常有效,并附带了一个共享的 Claude 对话链接。
- 用户也开始领取 Perplexity AI 领取邀请链接,并推荐将其用于分步指南。
- 定价细节:API 访问评估:一位用户询问对于大型 API 用户应联系谁获取定制的 API 定价以及如何获得访问权限。
- 另一位用户建议发送电子邮件至 api@perplexity.ai 以联系相关团队。
LMArena Discord
- Lithiumflow 的编程能力令人印象深刻,引发关于 Gemini 的猜测:成员们测试了 Lithiumflow 的编程能力,发现它在单个 HTML 文件中编写完整 macOS 系统能力非常出色,演示可在 Codepen 上查看。
- 一些用户认为它在编程方面不如 Claude 4.5,由此产生了一些理论,认为 Lithiumflow 可能是 Gemini 3 的削弱版变体,或者是专门的编程模型,这暗示了 Google 在其模型中对编程能力的优先排序。
- Gemini 3:发布日期仍是谜团:关于 Gemini 3 的发布和规格的猜测仍在继续,有理论认为 Lithiumflow 和 Orionmist 是潜在的 Gemini 3 迭代版本或专门模型。
- 一条推文暗示距离发布还有两个月,可在 Twitter 上查看。
- Video Arena:Veo-3.1 统治视频排行榜!:Text-to-Video Leaderboard 和 Image-to-Video Leaderboard 现在显示 Veo-3.1 在这两个类别中均排名第一。
- 鼓励用户分享他们的 Veo-3.1 生成作品并提供反馈,正如 X 上的公告所述。
- AI 视频质量:Sora 2 vs Veo 3.1:成员们正在讨论不同 AI 模型的视频质量,包括 Sora 2 和 Veo 3.1,示例可在 ChatGPT 官网查看。
- 尽管 Veo 3.1 在排行榜上排名更高,但共识是 Sora 2 的质量自最初发布以来有所下降。
- Claude Sonnet 4.5:更胜一筹?:成员们讨论了 Claude Sonnet 4.5 的创意写作能力,其中一位表示 Claude Sonnet 4.5 Thinking 与 Gemini 2.5 Pro 相比处于“完全不同的量级”。
- 然而,LMArena 上持续存在的 Bug 以及模型卡住或生成通用错误消息的问题阻碍了有效的测试和比较。
Unsloth AI (Daniel Han) Discord
- Unsloth 关注 Apple 硬件:Unsloth 计划在明年某个时候支持 Apple 硬件,但成员们表达了一些疑虑。
- 目前尚未透露更多信息或时间表。
- 黑客松暂停;MI300X 全员可用!:AMD x PyTorch 黑客松延期,每位参与者将获得 100 小时的 192GB MI300X GPU 使用权,以补偿中断。
- 社区成员形容这次活动“问题非常多”,但团队“正在努力”。
- HF 宕机期间 Modelscope 救场:由于 AWS 宕机 影响了 Hugging Face,成员们建议使用 Modelscope 作为临时镜像。
- 分享了一个代码片段,描述了如何在 Colab 环境中从 Modelscope 加载模型,需要使用
load_in_4bit标志。
- 分享了一个代码片段,描述了如何在 Colab 环境中从 Modelscope 加载模型,需要使用
- SFT 中的思维模式标签:一位成员提议使用 XML 标签(如
<thinking_mode=low>)在 SFT 期间教导 AI 模型不同的思维模式,根据 CoT token 计数对示例进行分类,并设置 auto 模式让模型自行决定。- 另一位成员建议,可控的思维通常受益于 SFT 之后的强化学习。
- Luau-Devstral-24B-Instruct-v0.2 > GPT-5 Nano:一位成员指出 Luau-Devstral-24B-Instruct-v0.2 中的 GPT-5 Nano 表现优于 GPT-5,并指出了其令人惊讶的性能。
- 该成员评论道:“GPT-5 很奇怪”。
OpenAI Discord
- Comcast 代表兜售用户数据?:一名用户指控 Comcast 代表正在窃取数据,并通过针对真实的肯尼亚机构和菲律宾呼叫中心的钓鱼攻击进行兜售。
- 该用户声称他们正在记录相关案例,并建议联系 CEO Brian Roberts 以追究责任。
- OpenCode 发现超高速隐形模型:OpenCode 团队发现了一个神秘的隐形模型 (stealth model),其 Token 输出速度极快,但他们不确定该模型是否具有智能。
- 成员们表示这是他们见过的最快模型,引发了对 OpenCode 后续动态的期待。
- Grok 攻克视频生成:Grok 现已推出视频生成功能,可通过 SuperGrok 订阅(每月 30 美元)访问,无需 Twitter/X 账号。
- 用户发现 Grok 视频生成能够很好地处理知名 IP 和第三方内容,且生成的视频没有水印。
- Sora 现实扭曲场:一位用户询问 Sora 是否能区分真实人物和虚构角色的图像,得到了肯定的简短回答。
- 话题发起者还分享了一个针对 AI 模型的 pseudoCode 思想实验链接。
- 控制 ChatGPT 的对话流:一位用户对 ChatGPT 倾向于在回答末尾添加不请自来的后续问题表示沮丧,并寻求禁用此“功能”的建议,其他用户提供了相关思路。
- 有用户建议将后续问题替换为其他内容,例如笑话或关于某个喜爱主题的细节,并分享了示例对话,比如这个带有冷笑话的对话。
OpenRouter Discord
- TLRAG 框架主张引发争议:一位开发者介绍了 TLRAG,这是一个确定性且与模型无关的框架,声称在没有 Function Calling 的情况下优于 Langchain,并具备 Token 节省和动态 AI 人格演进功能,详见其 dev.to 页面。
- 社区成员对 TLRAG 的主张、UI/UX 缺陷、安全性以及白皮书结构表示怀疑,其中一人称其白皮书是“完全不真实的 AI 生成的垃圾”。
- DeepSeek v3.1 中 SambaNova 的延迟困扰:用户报告了 DeepSeek v3.1 Terminus 中 SambaNova 的延迟问题,指出尽管理论上提供了更高的吞吐量,但如 OpenRouter 对比页面所示,DeepInfra 在吞吐量和延迟方面似乎都更快。
- 讨论强调了实际性能指标优于理论吞吐量的重要性,尤其是在现实应用场景中。
- GPT-5 Image:它只是 GPT-image-1 吗?:成员们辩论了 GPT-5 Image 的真实性,一些人推测它仅仅是经过 API 调整的 GPT-image-1,而非全新或改进的模型。
- 一位成员简洁地表示:“我觉得是这样,我两个都测过,我更喜欢 nano banana”,表明了对其他图像生成模型的偏好。
- Qwen3 定价令用户震惊:社区对 Qwen3 235A22B API 定价感到兴奋,认为其非常出色,尤其是与 W&B 集成进行大规模数据处理时。
- 用户敦促 OpenRouter 重点展示常规降价信息,强调其单位美元的智能水平是无与伦比的,树立了性价比的新标准。
- LFM 7B 走向终结:社区告别了 Liquid 托管的 LFM 7B,这是最初的 $0.01/Mtok LLM,已于东部时间上午 7:54 被删除。
- 用户注意到 OpenRouter 上目前缺乏定价方面的直接替代品,Gemma 3 9B 是最接近的选择,但其输出成本是前者的三倍。
LM Studio Discord
- iPad 上的 LM Studio API 与 MCP Servers:一位用户希望通过 iPad 使用 3Sparks Chat 访问 LM Studio API 并使用 MCP servers,但目前 API 尚不支持此功能。
- 用户建议使用 Tailscale 或 RustDesk 等远程桌面应用作为替代方案。
- 系统提示词解析引发括号混乱:LM Studio 中的 System prompts 会被解析,根据模型和聊天模板的不同,会导致括号等特殊字符出现问题,目前正通过 Jinja template fix 进行修复。
- 建议 Qwen models 使用 ChatML template 以缓解此类问题,并配合使用自定义提示词模板。
- 通过耗尽辅助 GPU 来最大化性能:一位用户尝试将 3050 作为 3090 的辅助 GPU 以获得额外的 VRAM,但一些用户指出这两张显卡会 “让 GPU 窒息”。
- 讨论涉及在硬件设置中将 3090 设为主要计算设备。
- 桌面风扇散热改装(玩笑):一位用户在出院后,开玩笑地安装了双 12 英寸涡轮风扇来为电脑散热。
- 该用户澄清这是一个外部的桌面风扇,而非电脑内部风扇。
- 终极 LLM 装备:EPYC vs Threadripper:成员们辩论了使用 EPYC 9654 还是 Threadripper 来运行大型语言模型(LLMs)的优劣。
- 共识倾向于 EPYC,因为它具有卓越的内存带宽和双 CPU 能力,此外还可以考虑二手 3090s 或 MI50s。
{kind=link}
HuggingFace Discord
- HF Inference API 要求对话任务名称:成员们发现 Mistral 模型需要将变量 ‘text-generation’ 重命名为 ‘conversational’ 才能在 HF Inference API 中正常工作,参考了相关 issue。
- 对 Florence 模型任务名称要求的发现表明,其他模型可能也有类似的限制,需要特定的任务名称才能响应提示词。
- NivasaAI 探索 Google ADK:一位成员正将 NivasaAI 从 Agent + Tools 模式切换为具有动态路由的多 Agent 模式,以增强用户体验,初始提交已发布在 GitHub。
- 该成员计划使用 Google ADK 完成一个路由器,将请求分类为
code_validation、rag_query和general_chat等类别,以处理从语法检查到日常对话的各种任务。
- 该成员计划使用 Google ADK 完成一个路由器,将请求分类为
- 本地 LLM 幻觉问题曝光:在测试了 47 种配置后,一位成员发现本地 LLM 在超过 6K tokens 后可能会产生幻觉,并在 Medium 文章中详细介绍了关于量化配置的发现。
- 另一位成员介绍了一种带有去中心化分词器的新架构,并指出它不兼容 llama.gguf,但已在 GitHub 上提供。
- OpenAI Agents 的自托管追踪上线:一位成员开源了一个针对 OpenAI Agents framework 追踪的自托管追踪和分析基础设施,解决了 GDPR 合规担忧以及无法从 OpenAI 追踪仪表板导出数据的问题。
- 该框架可帮助开发者监控和分析其 OpenAI Agents 的性能,同时保持对数据隐私和控制权的掌握。
- DeepFabric 提供数据驱动的 SLMs:一位成员介绍了 DeepFabric,这是一个用于训练 SLMs 以改进结构化输出和工具调用的工具,通过 GitHub 链接分享。
- 该工具支持生成基于推理轨迹的数据集,这些数据集可以直接加载到 TRL (SFT) 中,使开发者能够训练出擅长生成结构化输出并有效利用工具的 SLMs。
GPU MODE Discord
- Triton 在 Nvidia SM120 上的 TMA 进展:一位成员报告在 Triton 中为 NVIDIA SM120 GPU 实现了 dot 的 TMA 支持,但观察到与
cp.async相比没有性能提升。成员指出,在 Hopper 架构上,对于小于 4KiB 的负载,TMA 的效率较低。- 一位成员注意到在 Ampere 上
desc.load([x, y])的性能较差,因为 Ampere 缺乏 TMA。
- 一位成员注意到在 Ampere 上
- CUDA 的 CTA 难题:CTA 现在代表 Cooperative Thread Array:在 CUDA 中,社区澄清了 Cooperative Thread Array (CTA) 是 thread block 的同义词,特别是在利用 distributed shared memory 特性时。
- 一位成员分享了一篇 博客文章,指出使用 distributed shared memory 可能涉及当前 block 与其他 block 之间的 latency 和 bandwidth 差异。
- PyTorch Profiler 在 Windows 和 WSL 上的 CUPTI 困境:一位用户在 Windows 和 WSL 上使用 torch.profiler 时遇到了
CUPTI_ERROR_INVALID_DEVICE (2)错误,尽管 CUDA 可用。其他人建议可能需要通过 此 gist 访问硬件计数器。- 一位在 3090ti 上训练 AlphaZero 实现的用户遇到了训练速度慢的问题,但成员指出 AlphaZero 训练需要大幅增加算力。
- GPU 开发资源亮相!集中化知识库:一位成员分享了他们策划的 GPU 工程资源仓库,将各种有用的材料整合到一个地方。
- 一位成员还发布了一篇关于他们 PMPP-Eval 历程 的 博客文章,适合对 performance modeling and prediction 感兴趣的人。
- TorchAO 宣扬量化配置的进展:
quantize_op的filter_fn将被弃用,转而使用 ModuleFqnToConfig,后者现在支持正则表达式,详见 TorchAO pull request #3083。- 目前 SGLang 的在线量化不支持跳过视觉模型的量化,一位用户询问了关于跳过视觉模型量化的事宜。
Latent Space Discord
- ManusAI V1.5 在几分钟内变出 Web Apps:ManusAI v1.5 现在能在不到 4 分钟内将 prompt 转化为生产就绪的 Web Apps,并结合了 10 月 16 日推出的通过自动卸载(auto-offloading)和召回(recall)实现的“无限上下文”功能。
- 用户反应不一,有些人对其速度感到惊叹并开始深入研究上下文工程(context engineering),而另一些人则认为与直接编码的精确度相比,之前的工具如 Orchids、Loveable 和 V0 表现一般。
- AI 悲观情绪笼罩研究员情绪:包括 Sutton、Karpathy 和 Hassabis 在内的知名 AI 研究员正在接受更长的 AI 时间线,引发了关于炒作周期可能出现修正的讨论,如这里所述。
- 社区的反应在惊慌和为持续进展辩护之间摇摆,同时也对这股新的悲观浪潮是被夸大还是仅仅被误读提出了质疑。
- Cursor 为并行 AI Agents 生成 Git Worktrees:Cursor 现在可以自动创建 Git worktrees(如这里强调的),使用户能够在独立的分支上并行操作多个 AI Agent 实例。
- 该功能的发布赢得了赞誉,并引发了一系列设置技巧分享、端口使用咨询以及对潜在用例的热情。
- Tinygrad 将 Apple Macs 变成 NVIDIA eGPU 动力源:tiny corp 团队宣布公开测试其纯 Python 驱动程序,该驱动程序可通过任何 USB4 eGPU 扩展坞在 Apple-Silicon MacBooks 上运行 NVIDIA 30/40/50 系列 GPU(以及 AMD RDNA2-4),详情见此公告。
- 频道讨论了 NPUs 是否需要流线型编程,以及 AMD 的成功是否取决于简化流程,正如这条推文所强调的。
- AI 生成的奢华逃避主义助长了 Facebook 幻想:一项由 OpenAI 资助的研究显示,在拥有 3 万名成员的印度尼西亚 Facebook 群组中,低收入用户(月收入 < 400 美元)会发布自己与兰博基尼、在巴黎或在 Gucci 商店的 AI 照片(链接)。
- 讨论集中在这一趋势纯粹是地理性的还是社会经济性的,并将其与过去的荷里活梦想和生成式 AI 照片应用进行了类比。
Eleuther Discord
- RTX 3090 上的 LLM 训练速度:成员们估算了在 RTX 3090 上训练 30M 参数 LLM 的速度,范围从每秒数百到数千个 token (TPS)。
- 一位成员报告称,在 4090 上使用 30m rwkv7 bsz 16 seqlen 2048 时速度达到 120 kt/s,这让人们对达到数千 TPS 充满期待。
- Anthropic 将归因图扩展至 Attention:讨论探讨了将归因图 (attribution graphs) 扩展到 Attention 机制,灵感来自这段视频;Anthropic 在后续文章中对此进行了探索,详见论文《Tracing Attention Computation Through Feature Interactions》。
- 最初的 Biology of LLMs 论文以及论文 https://arxiv.org/abs/2510.14901 在冻结 Attention 的情况下仅研究了 MLPs。
- Eval Harness 重构准备就绪:已安排会议讨论 eval harness 的新增内容,重点是分享当前计划并收集库用户的反馈,详情可见 When2Meet 和 此分支。
- 关键改进包括:用于轻松转换格式的新模板、标准化格式、使 instruct 任务更直观,以及通用的 UX 改进(例如
repeats),目标是实现任务变体之间更简单的转换(例如 MMLU -> 完形填空 -> 生成)。
- 关键改进包括:用于轻松转换格式的新模板、标准化格式、使 instruct 任务更直观,以及通用的 UX 改进(例如
- AI 论文标点符号警察:一场讨论批评了 AI 论文中的写作风格,特别是关于逗号的使用,参考了论文 https://arxiv.org/abs/2510.14717。
- 一位成员调侃道:我真心认为,如果你给作者设定一个逗号限制,一半的 AI 论文质量都会提高,另一位成员回复道:那他们就会改用分号或破折号 (em dashes)。
- NormUon 优化器进入 SOTA 竞争:一位成员提到了一种新的优化器,如果结果良好,它看起来具有 SOTA 潜力。
- 多个来源表示 在非速通设置下,它的性能与 muon 相同,但具有良好的 muon 基准,并观察到
modded-nanogpt does qk norm which is one way you can avoid logit blowups.
- 多个来源表示 在非速通设置下,它的性能与 muon 相同,但具有良好的 muon 基准,并观察到
Moonshot AI (Kimi K-2) Discord
- Kimi K2 在预测市场中表现出色:一位用户分享说 Kimi K2 是处理预测市场(prediction markets)的最佳模型并一直在使用它,如这条推文所述。
- 他们没有提到在预测市场中的具体使用案例。
- Groq 版 Kimi 遭遇成长的烦恼:Groq 实现的 Kimi 经历了一段不稳定时期,出现了间歇性的功能问题。
- 据一位用户称,该实现目前已恢复正常,但未提供有关问题的具体细节。
- Kimi K2 解决蓝屏死机 (BSODs):一位用户称赞了 Kimi K2 提供可靠电脑故障排除建议的能力,并特别建议使用 verifier 对可能导致 BSODs 的驱动程序进行压力测试。
- 该用户未包含所给故障排除建议的具体细节,仅表示其非常可靠。
- DeepSeek 不及 Moonshot AI:一位用户表达了对 Moonshot AI 的 Kimi 优于 DeepSeek 的偏好。
- 该用户承认这种偏好是个人观点,没有提供支持证据或理由。
- Codex 表现不佳:用户讨论了用于处理 MCP 服务器以及 DeepSeek、GLM Coder 和 Qwen 等模型的各种 CLI 工具,强调 Claude Code 和 Qwen-code 是可靠的选择。
- 共识是 Codex 仅在与 OpenAI 模型配合使用时才理想;未提供此偏好的具体原因。
Nous Research AI Discord
- GLM 4.6 开启开源社区新视野:根据这段 YouTube 视频,能够本地运行的 GLM 4.6 的发布,旨在减少对由 Sam Altman、Elon Musk 和 Dario Amodei 领导的公司所提供的专有模型的依赖。
- 与此同时,新的 Chinese LLMs(如蚂蚁集团的 Ling 模型独立于阿里巴巴的 Qwen 团队)的兴起,也引发了关于在已有 Qwen 等多个强力竞争者的情况下,是否有必要存在多个模型的争论。
- ScaleRL 似乎完美适配稀疏推理模型:根据 Meta 最近的 Art of Scaling RL 论文,ScaleRL 似乎是为 MoE 等稀疏推理模型(sparse reasoning models)量身定制的。
- 成员们正在质疑轨迹级损失聚合粒度(trajectory-level loss aggregation granularity)在迭代强化学习(Iterative RL / Reasoning)中是否比样本级(sample-level)表现更好,并讨论步骤/多步(迭代)级别(step/steps level)是否可能是调优的中间地带。
- 新医疗 AI 安全标准:一位成员提议开展以临床/医疗应用为重点的 AI safety 研究,以建立 AI 模型的基准测试,并引用了 International AI Safety Report 2025。
- 目标是提出更准确的指标,该成员正在寻求关于这是否是一个好的研究课题的反馈。
- Nous 通过 Psyche 倡导去中心化:Nous Research 正在通过开源方法论和基础设施实现拥抱去中心化,Psyche 就是一个典型例子,相关链接见 Nous Psyche 和 Stanford paper。
- 一位成员表示:“Nous 通过其开源方法论和基础设施实现成功实现了去中心化。”
Manus.im Discord Discord
- 据称 Manus Google Drive 连接功能已可用:用户报告称,通过点击 + 按钮并添加文件,Manus 可以连接到 Google Drive。
- 用户确认该功能并非作为已连接的应用(connected app)提供。
- 用户报告 Manus 项目文件随 Credits 一同消失:一位正在构建网站的用户报告称,在消耗了 7000 credits 后,项目中的所有内容(包括文件和数据库)全部消失,且支持团队未提供有效帮助。
- 另一位用户也表达了同样的遭遇,报告损失了近 9000 credits,且找不到任何文件或预览。
- 使用 Manus 低成本创建 Android 前端 App MVP:一位用户使用 525 Manus credits 创建了一个 Android 前端 App MVP,随后使用 Claude 修复了问题,并称赞了 Manus 的 UI/UX 能力。
- 该用户分享了 App 图片。
- Manus 基础设施发生故障:由于基础设施提供商的问题,Manus 经历了临时停机,某些地区的某些用户在访问首页时仍面临错误。
- 团队沟通了更新情况并感谢用户的耐心,报告称大部分 Manus 服务已恢复在线。
- 免费 Perplexity Pro 推广引发 Discord 争论:一位用户分享了免费一个月 Perplexity Pro 的邀请链接,引发了另一位用户的负面反应,后者叫他 Stfu!(闭嘴)并 Get a job(找个正经工作)。
- 分享链接的用户表示,这是一种无闹剧、无谎言、无标题党的赚取真钱的方式。
{kind=link}
Modular (Mojo 🔥) Discord
- Mojo 正在实现自举(Self-hosting)?:Mojo 的编译器利用 LLVM 并通过下层(lowering)到 MLIR 与其紧密集成,除非整合 LLVM,否则在实现完全自举方面面临挑战。
- 虽然用 Mojo 完全重写在技术上是可行的,但被认为工作量巨大且收益有限,不过 C++ interop 可能会在未来让这件事变得更容易。
- Mojo 作为一种 MLIR DSL:Mojo 充当 MLIR 的专用 DSL,直接解析为 MLIR 并利用它取代传统的 AST,这赋予了它极大的适应性和灵活性。
- Mojo 的架构包含众多 Dialect(方言),除了 LLVM dialect 之外主要是新的方言,使其能够胜任多样化的计算应用。
- MAX Kernels 作为 PyTorch 后端:社区对将 JAX 的后端切换为使用 MAX kernels 产生了兴趣,这可能作为一个有趣的项目与 C++ 进行对接,并指出目前已经存在一个基本可用的 PyTorch MAX backend。
- 虽然 Mojo 可以通过
@export(ABI="C")导出任何 C-abi 兼容函数,但目前与 MAX 的直接通信仍需要 Python。
- 虽然 Mojo 可以通过
- Mojo 旨在防止 Python 式的碎片化:Mojo 的设计旨在通过提供在更具 Python 风格的
def和更偏向系统的fn代码之间转换的途径,来避免 Python 用户与 CPython 用户之间出现的碎片化现象。- 一位成员强调,目标是保留底层控制的门径,同时提供安全的默认方式,防止用户“搬起石头砸自己的脚”;希望我们能实现这一目标。
- Mojo 讨论 UDP Socket 支持:用户询问了 Mojo 中的 UDP socket 支持,得到的回复是可以通过 libc 实现,但要进行规范实现,仍需等待标准库的完整支持。
- 回复指出倾向于“做正确而非求快”,并将“语言级依赖”列为一个影响因素。
DSPy Discord
- DSPy 试行 Claude 驱动的 Agent:成员们探索了将 Claude agents 集成到 DSPy 程序中,参考了之前使用 Codex agent 的一个实现。
- 主要困难在于缺乏 Claude code 的 SDK;社区希望看到示例 Agent。
- Clojure 考虑在 DSPy 中使用并发:一位成员询问了如何将 DSPy 适配到 Clojure REPL 环境,特别是关于数据表示、由于不可变性导致的并发 LM calls 以及检查生成的函数。
- 将 DSPy 的 Python 范式 适配到 Clojure 的函数式和并发特性的细微差别尚未得到充分探索。
- DSPy 尝试使用泛型进行类型标注:社区讨论了在 Python 中对 DSPy 进行完全类型标注的可行性,重点在于 Python generics 是否足够。
- 虽然一位成员表示有信心,并强调优化 input handle/initial prompt,但他们警告在没有明确的任务和评分机制的情况下不要进行过早优化。
- Gemini 的 Google API Key 获取:用户讨论了在 dspy.lm 中使用 Gemini 模型,确认通过正确的配置和 API key 设置是可以实现的。
- 一位成员开玩笑地分享了寻找正确 API key 的“痛苦历程”,建议使用 AI Studio 而不是控制台。
- LM Studio 获得 llms.txt 生成器:一位成员分享了一个基于 DSPy 框架 的 LM Studio llms.txt 生成器。
- 该工具允许用户利用 LM Studio 中可用的任何 LLM,为缺乏
llms.txt的仓库轻松生成该文件;该成员建议使用 “osmosis-mcp-4b@q4_k_s” 来生成示例产物。
- 该工具允许用户利用 LM Studio 中可用的任何 LLM,为缺乏
Yannick Kilcher Discord
- Tianshou 助力 PyTorch 中的 RL:一名成员推荐 Tianshou 作为 PyTorch 的一个可行 Reinforcement Learning (RL) 框架,并指出其与图神经网络的相关性。
- 该推荐受到了社区的好评,进一步推动了对实际 RL 实现的兴趣。
- 到底什么是 AI Engineer??:成员们辩论了 “AI Engineer” 的任职资格,开玩笑说甚至在 Python 中 使用 OpenAI API 就足以在 LinkedIn 上唬人了。
- 讨论强调了对该角色的多样化解读,从在可视化 n8n 中组装 Lego 到创建自定义 GPTs。
- 攻克 ML Debugging 面试:成员们讨论了如何准备 “ML Debugging” 编程面试,建议准备好讨论 处理过拟合 (overfitting) 的话题。
- ChatGPT 也被建议作为模拟面试工具,对话记录在 这里。
- Qwen3 洞察秋毫:新的 Qwen3 Vision 模型 已发布,可在 Hugging Face 上获取。
- 成员们似乎对它与 ComfyUI 等其他视觉模型的对比很感兴趣。
- Machine Unlearning 寻求 ArXiv 认可:成员们讨论并倡导将 Machine Unlearning & Knowledge Erasure 纳入其独立的 arXiv 类别 (cs.UL/stat.UL)。
- 这一举措将凸显 Data Privacy 和 Security 日益增长的重要性。
aider (Paul Gauthier) Discord
- Aider 依然活跃,只是发布速度变慢了!:用户讨论了 Aider 的开发节奏,澄清它仍处于活跃状态,只是发布速度较慢,建议使用 aider-ce 以获得更频繁的更新,并克隆 GitHub 仓库以熟悉代码库。
- 社区成员旨在通过增加提交频率来推动项目发展。
- Aider 寻求 Agentic 扩展集成:一名开发者正在使用 LangGraph 为 Aider 构建 Agentic 扩展,包括任务列表、RAG 和命令处理。
- 讨论集中在是将扩展直接集成到 Aider 中还是作为一个独立项目,强调了在与顶级 Agent 解决方案竞争时保持 Aider 简洁性的重要性。
- Devstral Small 模型:黑马之作?:
Devstral-Small-2507-UD-Q6_K_XL模型因在有限硬件(32GB RAM)上表现出惊人的强劲性能而受到赞誉,具备自我修正和处理长上下文的能力,尤其是配合 Unsloth 的 XL 量化版本 时。- 用户发现该模型在 PHP、Python 和 Rust 编码任务中表现优于
Qwen3-Coder-30B-A3B-Instruct-UD-Q6_K_XL,支持图像,并应添加到 Aider 基准测试中。
- 用户发现该模型在 PHP、Python 和 Rust 编码任务中表现优于
- Aider-CE 剑指 Codex CLI 桂冠:一名用户在测试了 gemini-cli、opencode 和 Claude(配合 claude-code-router 使用 DeepSeek API)后重新换回了 Aider,称赞其基于 grep 的代码搜索/替换功能和自动更新的任务列表。
- 用户还强调了 Aider 的简洁性以及在 .aider.conf.yml 中使用 MCP 格式处理编码任务的直观性。
- 推理超时困扰 Commit Messages:一名用户报告称,通过 OpenRouter 使用 Deepseek V3.1 Terminus 进行提交信息推理的速度太慢,促使他们禁用了该功能。
- 有人提出了替代方案:将 API 的推理结果复制到资源中,并将新别名设置为一个弱模型。
tinygrad (George Hotz) Discord
- Karpathy 发布极简聊天应用:Andrej Karpathy 发布了 nanochat,一个极简的聊天应用程序,但发帖者质疑该发布的重大意义。
- 未提供其他细节。
- ShapeTracker 面临弃用:tinygrad 计划在第 92 次会议期间弃用 ShapeTracker,同时讨论 usb gpu、multi output kernel 和 FUSE_OPTIM。
- 其他主题包括 rangeify regressions、openpilot、resnet、bert、assign、cleanups、viz、driver、tiny kitten、symbolic processing、bounties、new linearizer 和 clang2py。
- 贡献者请求性能指标:一位贡献者请求添加 MFLOPS 和 MB/s 指标,并以黄色显示在 DEBUG=2 行中,以便更好地监控性能。
- 该贡献者明确要求编写 clean code,并警告不要使用 你不理解的 AI 代码!
- macOS Nvidia 驱动程序终于到来:Nvidia 驱动程序已在 macOS 上成功产出,为 macOS 上的 GPU 加速任务开启了可能性。
- 要启用驱动程序,用户需运行
brew tap sirhcm/tinymesa。
- 要启用驱动程序,用户需运行
- TinyJit 梯度累积问题:成员们在 TinyJit 中发现了梯度累积问题,特别是在 model_train.py 中,对梯度累积的数学逻辑提出质疑。
- 一位成员通过使用 assign 重写梯度相加步骤解决了该问题,以确保其正常工作。
MCP Contributors (Official) Discord
- DevOps 管理员探索安全的 MCP 访问方式:一位 DevOps 管理员正在探索为组织内的非技术用户授予 MCP access 的安全方法,重点是避免密钥管理并实现 Identity Provider (IDP) 层。
- 正在考虑的解决方案包括 Webrix MCP Gateway 和 使 Docker MCP Gateway 支持多租户。
- MCP auth 扩展承诺提供企业级管理认证:有建议称,作为 MCP auth extension 发布的 enterprise managed auth profile 旨在解决 DevOps 管理员的需求。
- 然而,目前的细粒度权限仅限于 oauth scope granularity。
- 旨在服务贡献者的 Discord 频道:一位成员澄清说,该 Discord 旨在供 MCP protocol 及相关项目的贡献者交流,而非提供技术支持。
- 鼓励寻求帮助的用户通过私信获取相应社区的链接。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该公会沉寂时间过长,请告知我们,我们将将其移除。
您收到此电子邮件是因为您通过我们的网站订阅了。
想要更改接收这些电子邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:按频道划分的详细摘要和链接
Perplexity AI ▷ #general (1099 条消息🔥🔥🔥):
Comet 推荐计划, AWS 停机, GPT-5 vs Claude, 科学方法, MCP
- **Discord 讨论推荐奖励:成员们讨论了 **Comet 推荐计划,部分用户询问如何正确执行推荐链接的帮助。
- 一些用户报告了推荐丢失或未支付的问题,而其他用户则分享了成功经验,例如确保被推荐用户安装 Comet 并执行搜索。
- **AWS 停机阴影笼罩在线运营:最近的 **AWS 停机 导致 Perplexity AI 和其他服务出现广泛问题,引发了关于过度依赖单一云提供商风险的讨论。
- 用户分享了状态链接和个人经历,一些人注意到即使在最初的停机解决后,某些功能仍受影响。
- **GPT-5 落地:Claude 封王:成员们辩论了 **GPT-5 与 Claude 的优劣,许多人认为 Claude 在复杂项目和推理任务中表现更优。
- 一些用户指出 GPT-5 的免费层级 明显感觉较弱,而另一些人则建议使用 Claude 4.5 以获得最佳效果。
- **科学方法助力学术研究:一位用户寻求使用 AI 进行学术研究的指导,引发了关于科学方法**及其在构建研究框架中应用的讨论。
- 资深成员建议将过程分解为多个步骤,参考成功论文,并结合 Google Colab 等工具利用 Perplexity API。
- **MCP:神秘的上下文提供者令人困惑:成员们询问了 **本地和远程 MCP (My Context Providers),一些人在 Connectors 中难以找到 PerplexityXPC,而另一些人则在思考 MCP 是否值得学习。
- 这引发了关于本地访问文件/设备以及围绕该技术的自动化机会的更广泛讨论。
Perplexity AI ▷ #sharing (11 条消息🔥):
Perplexity AI, TikTok 视频, Claude Sonnet 4.5, 可共享线程, AWS 仪表板
- Perplexity 助力打造精美 TikTok:一位成员分享了一个在 Perplexity AI 帮助下制作的 TikTok 视频。
- Perplexity AI 化身指南:一位成员分享了一个 Perplexity AI 领取邀请链接,并推荐将其用于分步指南。
- Claude 4.5 的哲学专长:Claude Sonnet 4.5 被强调在哲学问题解决方面非常有效,并附带了一个共享的 Claude 对话链接。
- 可共享线程的救星:Perplexity AI 机器人提示多位用户确保他们的线程是可共享的,并链接到了相关的 Discord 频道消息。
- 借助 Perplexity 实现 AWS 易用性:一位成员分享了一个关于创建 AWS 仪表板 的 Perplexity AI 搜索链接。
Perplexity AI ▷ #pplx-api (8 条消息🔥):
API 定价, ZTT 服务器
- 联系 Perplexity 咨询 API 定价:一位用户询问针对大型 API 用户应联系谁来获取定制的 API 定价。
- 另一位用户建议发送邮件至 api@perplexity.ai 以联系相关团队。
- 请求 ZTT 服务器邀请:一位用户请求加入 ZTT 服务器 的邀请。
- 未提供关于 ZTT 服务器 及其用途的更多背景或细节。
LMArena ▷ #general (1182 条消息🔥🔥🔥):
Lithiumflow 的编程能力、Gemini 3 预测、AI 视频生成质量、Claude Sonnet 4.5
- Lithiumflow 的编程技能:Gemini 的编程重心?:成员们测试了 Lithiumflow,发现它具备令人印象深刻的能力,能在一个 HTML 文件中编写出带有功能性应用的完整 macOS 系统,并在 Codepen 上进行了展示,获得了积极反馈。
- 尽管如此,一些用户发现 Lithiumflow 在编程方面逊于 Claude 4.5,这表明它可能是一个 nerfed 版本或 Pro 模型,而非 Ultra 模型;讨论还指出 Google 正在其模型中优先考虑编程能力。
- Gemini 3:何时发布?:关于 Gemini 3 的发布和规格存在大量猜测,一些成员推测 Lithiumflow 和 Orionmist 可能是 Gemini 3 的 nerfed 版本或专门的编程模型;而一条推文建议下一次发布要等到两个月后,详见 Twitter。
- AI 视频质量:Sora vs. Veo 3.1:成员们正在争论不同 AI 模型的视频质量,包括 Sora 2 和 Veo 3.1(可在 ChatGPT 官网查看),一些人表示 Sora 的质量自最初发布以来有所下降,并对 Veo 3.1 在排行榜上排名更高表示困惑。
- 共识似乎是,尽管 Veo 3.1 排名更高,但它并不比 Sora 2 更好。
- Claude Sonnet 4.5:值得这么高的热度吗?:成员们讨论了 Claude Sonnet 4.5 的能力,特别是在创意写作方面,一位成员表示 Claude Sonnet 4.5 Thinking 与 Gemini 2.5 Pro 相比“完全不在一个量级”。
- 然而,其他人提到了 LMArena 上持续存在的 Bug 以及模型卡死或生成通用错误消息的问题,这阻碍了他们进行有效测试和比较的能力。
LMArena ▷ #announcements (1 条消息):
文生视频排行榜、图生视频排行榜、Veo-3.1 排名
- Veo-lociraptor:Veo-3.1 称霸视频排行榜!:文生视频排行榜 和 图生视频排行榜 现在显示 Veo-3.1 在这两个类别中均排名第一。
- 鼓励用户分享他们的 Veo-3.1 生成作品并提供反馈。
- Arena X 帖子:排行榜信息也已在 X 上发布。
- 了解 Video Arena 的运作方式,并在 Discord 频道中分享生成作品。
Unsloth AI (Daniel Han) ▷ #general (1106 messages🔥🔥🔥):
Unsloth 对 Apple 硬件的支持、AMD x PyTorch 黑客松、为法律系统训练推理模型、使用同义词生成合成数据、为编程任务选择模型
- Unsloth 关注 Apple Silicon 支持:Unsloth 计划在明年某个时候支持 Apple 硬件,但正如一位成员所言,“这些话仅供参考(不可全信)…”。
- 目前尚未透露更多信息或时间表。
- AMD x PyTorch 黑客松宣布延期:AMD x PyTorch 黑客松已延期,为了补偿中断带来的影响,每位参与者将获得 100 小时的 192GB MI300X GPU 使用时长,甚至可以在黑客松之外使用。
- 社区成员形容该活动“问题多多”,但团队正在“努力尝试”。
- Modelscope 镜像 Huggingface 以规避 AWS 问题:由于 AWS 故障 影响了 Hugging Face,一位成员建议使用 Modelscope(一个中国的 HF 镜像)作为临时替代方案。
- 分享了一段代码片段,描述了如何在 Colab 环境中从 Modelscope 加载模型,且仍需设置
load_in_4bit标志。
- 分享了一段代码片段,描述了如何在 Colab 环境中从 Modelscope 加载模型,且仍需设置
- 咨询建议引发责任担忧:一位寻求关于将微调后的 LLM 商业化用于房地产消息传递指导的用户,被提醒不要听取免费建议,因为可能存在潜在的法律责任问题。
- 另一位成员澄清说,此类担忧仅适用于提供详细的分步指导时,而不适用于建议通用的模型或数据集选择。
- GPT-OSS 微调寻求移除“政策”限制:成员们讨论了使用 RLHF 来惩罚 GPT-OSS 生成政策相关内容或拒绝回答问题的行为,目标是创建一个审查更少的模型。
- 建议包括移除 Chain of Thought 以减少审查,但这可能会让模型“变笨,但不受审查”。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (8 messages🔥):
软件工程师自我介绍、AI Bot 开发、老兵学新招
- 专注于 AI 项目的软件工程师:一位专注于 AI 项目开发的软件工程师介绍了自己,提供的服务包括 自动化任务、NLP、模型部署、文本转语音、语音转文本 以及 AI Agent 开发。
- 他们强调了对 n8n、Zapier、Make.com、GPT-4.5、GPT-4o、Claude 3-7 sonnet、Llama-4、Gemini2.5、Mistral 和 Mixtral 等工具的熟练程度,并提供了其 作品集链接。
- AI Bot 开发者加入对话:一位主要关注 AI Bot 开发 的开发者介绍了自己,还提到了在 游戏 和 数据爬取 方面的能力。
- 未提供其他细节。
- 大厂 Bot 开发者深入探索:一位拥有在大厂使用 ChatGPT 开发 Bot 经验的开发者表达了对 Unsloth 的热情。
- 他们形容自己是“老兵学新招”,并表示现在正在“深入探索”。
Unsloth AI (Daniel Han) ▷ #off-topic (426 条消息🔥🔥🔥):
Qwen 2.5 VL 问题、黑客松挑战与合成数据、GPU VRAM 负担、Diff2flow、RP 统计相关
- Qwen 2.5 VL 无法理解图像:一位成员报告称 Qwen 2.5 VL 无法理解图像,并提供了代码的 GitHub 链接。
- 该成员怀疑 HuggingFace 嵌入了水印以制造不公平竞争,但随后澄清说,问题在于当时所有模型都无法正常工作。
- 黑客松因进度丢失而暂停:由于部分参赛者丢失了工作进度,Unsloth 黑客松(Hackathon)被暂停,目前正在进行调查以确保比赛公平,并承诺提供更丰厚的奖品。
- 参赛者讨论了使用合成数据工具包、从模型生成问答对,以及在 192GB 限制下于规定时间内完成任务的挑战。
- Diff2flow 项目公开:一位成员分享了名为 diff2flow 的项目细节,该项目将现有的 eps 或 vpred 模型转换为 Flow Matching,这需要特定的超参数和数据集。
- 他们建议使用 AWS 上的 S3 进行数据存储,并提醒注意入站/出站流量成本,同时指出这与识别水印的项目不同。
- 应对场景图算法噩梦:一位成员对为 RP 统计(RP stat thing) 构建场景图(Scene Graph)表示沮丧,称其为包含大量边缘情况的代码噩梦。
- 讨论探讨了使用结构化输出和遍历简单树的方法,但挑战在于如何从不完整的数据中捕获自然生成的场景图。
- Ultravox Adapter 在语音转文本中挣扎:一位成员发布了他们首个基于 Ultravox 和 Qwen 3 4B Instruct 的语音转文本(Speech-to-Text)模型,并指出目前效果欠佳,几乎听不到输入。
- 他们正在进行新一轮训练,步数为 1152k 步(旧 Adapter 为 256k 步),并指出 Ultravox 的特殊之处在于它不是 ASR 到 LLM 再到 TTS 的流程,语音输入由 Whisper 处理,但输出是一个 768 维空间。
Unsloth AI (Daniel Han) ▷ #help (73 条消息🔥🔥):
FailOnRecompileLimitHit、Gemma3-270m 解码、TTS 和 ASR 模型训练、GPT OSS 20B 的 GRPO 配方、QWEN2.5 7B 聊天模板
- Unsloth RFT Notebook 中出现 FailOnRecompileLimitHit:一位用户在 H100 80G 上尝试 GPT OSS 20B 的 Unsloth 强化学习微调(Reinforcement Fine Tuning)Notebook 时遇到了 FailOnRecompileLimitHit 问题,建议调整错误消息中显示的设置。
- 另一位用户建议增加
torch._dynamo.config.cache_size_limit或按大小对数据集进行排序可能会有所帮助。
- 另一位用户建议增加
- 破解代码:解码 Gemma3-270m 的预测:一位用户在训练 gemma3-270m 时难以正确解码预测结果,目标是在
compute_metrics中比较标签和预测值。- 可能的解决方案包括设置
os.environ['UNSLOTH_RETURN_LOGITS'] = '1',或者查看 此 GitHub Issue 以调整 HF 代码或在compute_metrics内部定期生成。
- 可能的解决方案包括设置
- 提供 TTS 和 ASR 模型训练指南:一位用户询问如何使用 Unsloth 在本地训练针对本地语言的 TTS 和 ASR 模型,数据格式为 CSV。
- 提供了 Unsloth TTS 指南 的链接以供参考。
- GPT OSS 20B 的 GRPO 配方表现不佳:一位用户分享称,GPT OSS 20B 的 GRPO 配方在 100 步后似乎仍表现不佳,并链接到了 Colab Notebook。
- 他们提到为了在 Modal 上运行而进行了修改。
- 询问 QWEN2.5 7B 模型聊天模板集成:一位用户询问如何确保 Unsloth 在微调 QWEN2.5 7B 模型期间应用聊天模板(Chat Template)。
- 另一位用户分享了关于 Gemma3 聊天模板应用过程的截图。
Unsloth AI (Daniel Han) ▷ #showcase (14 messages🔥):
Luau-Qwen3-4B-FIM-v0.1, Training Configurations, Luau-Devstral-24B-Instruct-v0.2, Brainstorm adapter
- Luau-Qwen3-4B-FIM-v0.1 训练顺利完成:一名成员宣布完成了 Luau-Qwen3-4B-FIM-v0.1 的训练,并分享了展示结果的清晰图表。
- 其他成员表示祝贺,并注意到图表非常整洁。
- Luau-Devstral-24B-Instruct-v0.2 击败 GPT-5 Nano:一位成员指出 Luau-Devstral-24B-Instruct-v0.2 中的 GPT-5 Nano 表现优于 GPT-5,并对其惊人的性能表示关注。
- 该成员评论道:GPT-5 很奇怪。
- 分享 Qwen3 的训练配置:一位成员分享了 Qwen3 的详细训练配置,包括
per_device_train_batch_size = 2和learning_rate = 2e-6等参数。- 另一位成员认为这些信息对于理解 Qwen3s 的训练设置非常有帮助。
- 使用 Brainstorm Adapter 提升指标:一位成员建议在模型中加入 Brainstorm (20x) adapter,以潜在地提高指标并改善长文本生成的稳定性。
- 原训练者对该建议表示欢迎,并对潜在的收益表现出兴趣。
Unsloth AI (Daniel Han) ▷ #research (12 messages🔥):
AI model thinking modes, xLLMs Dataset Collection, Double descent history and papers
- 思考模式 XML 标签教学新技巧:一位成员提议在 SFT 期间使用 XML 标签(如
<thinking_mode=low>)来教导 AI 模型不同的思考模式,根据 CoT token 数量对示例进行分类,并设置 auto 模式让模型自行决定。- 另一位成员建议,可控的思考通常受益于 SFT 后的强化学习 (RL),但考虑到缺乏 RL 所需的算力,计划仅尝试 SFT 实验。
- xLLMs 数据集:多语言宝库:xLLMs 项目在 Hugging Face 上推出了一系列多语言和多模态对话数据集,旨在训练和评估先进对话 LLM 的 长上下文推理 和 工具增强对话 等能力。
- 其中一个亮点是 xllms_dialogue_pubs 数据集,非常适合在 9 种语言 中训练模型的 长上下文推理、多轮对话连贯性 和 工具增强对话。
- Double Descent 历史可视化:一位成员分享了一个 YouTube 视频,通过视觉化方式解释了 double descent 历史 及相关论文。
OpenAI ▷ #ai-discussions (569 条消息🔥🔥🔥):
Comcast 数据转卖, Stealth 模型, Grok 视频, Sora 2 视频质量, Sora 2 邀请
- 用户声称 Comcast 员工窃取并分发数据:一名用户声称 Comcast 代表正在窃取数据,并通过针对真实的肯尼亚组织和菲律宾呼叫中心的复杂网络钓鱼手段进行转卖。
- 他们正在记录案例以便集体上报,并建议直接联系 CEO Brian Roberts 以追究其责任。
- OpenCode 测试者发现超高速 Stealth 模型:OpenCode 团队在周末发现了一个神秘的 stealth 模型,其 Token 输出速度快得惊人。
- 他们不确定该模型是否智能,但指出这是他们见过的速度最快的模型。
- Grok 推出视频生成功能:Grok 现在支持视频生成,可通过 SuperGrok 订阅(每月 30 美元)使用,且不需要 Twitter/X 账号。
- 用户发现 Grok 视频生成能够很好地处理特许经营权和第三方内容,且生成的视频没有水印。
- Veo 和 Grok 视频生成与 Sora 2 进行基准对比:成员们正在讨论 Veo 3.1 大致与 Sora 处于同一水平,但它不是免费的,且应该已在澳大利亚可用;另一位成员则认为 OpenAI 领先 20 倍。
- 一名用户尝试创建包含 KSI 客串的视频,但不确定该使用什么 Prompt;另一名用户的视频场景因过于暴力被拒绝。
- 在 Unsloth 库上微调 Qwen3 遇到障碍:一名用户在使用 llama factory 和 unsloth 库保存 Qwen3-2.35B-A22B-Instruct-2507 模型的 Checkpoint 时遇到问题。
- 另一名用户建议这听起来像是内存溢出(OOM),并指出保存 Checkpoint(尤其是全量模型甚至 LoRA 权重)会导致 VRAM 耗尽,因为这涉及为序列化而复制 Tensor,且无法从训练时的优化(如 Gradient Checkpointing)中获益。
OpenAI ▷ #gpt-4-discussions (42 条消息🔥):
Agentic AI 黑客松, ChatGPT/Sora 的 VPN 使用, DALL-E 私密图像生成, 大学中的 ChatGPT 访问, Sora 访问与 "k0d3"
- 寻求 Agentic AI 黑客松:一名成员询问关于 agentic AI 黑客松的信息,引发了关于 OpenAI 和 Microsoft 主办的即将到来的黑客松的讨论。
- 使用 Sora 时的 VPN 封号风险:成员们讨论了从阿根廷等地理受限国家使用 VPN 访问 Sora 的风险,称这样做违反了服务条款 (ToS)。
- 违反 ToS 可能会导致封号。
- DALL-E 隐私性受到质疑:成员们询问 DALL-E 是否提供类似 Midjourney 的私密图像生成功能,以及在 CTF 比赛期间是否允许使用 GPT。
- 针对大学的免费 Microsoft 赞助版 GPT:一名成员分享称,一些大学通过其 Microsoft 套件(通常是通过 CoPilot)提供 ChatGPT 的访问权限。
- 其他人澄清说,Microsoft 提供基础设施,如果大学利用了微软的工具,那么 CoPilot 就是获取 GPT 访问权限的途径。
- 提到 Sora ‘k0d3’ 和 iOS 应用:成员们讨论了访问 Sora 的方式,提到它有独立的网站和 iOS 应用,以及获取 Sora 2 访问权限的邀请码。
- 一名成员提到,要获得 Sora 2 的访问权限,如果你在北美,必须访问 Sora.com 并输入 k0d3。
OpenAI ▷ #prompt-engineering (51 条消息🔥):
Sora 区分真实与虚构图像的能力,Sora 的 Prompt engineering,控制 ChatGPT 输出,Sora 屏幕抖动 VFX,学习 Prompt engineering
- Sora 的现实检查:区分真实与虚构图像:一位用户询问 Sora 是否能区分真实人物图像和虚构角色图像。
- 另一位用户简单地回答了“是”。
- 孟加拉国用户目标制作写实 Sora 视频但遇到障碍:一位来自孟加拉国的用户想利用 AI 创作一段写实的人物视频,并分享说他被告知 AI 不支持写实照片。
- 另一位用户询问如何通过 Prompt 让 ChatGPT 仅接受特定来源并拒绝其他来源。
- 屏幕抖动成功:AI 界的震动?:一位用户询问如何在 Sora 2 中实现 screenshake(屏幕抖动)或其他 VFX。
- 一位用户回答“可以,但很勉强”,并暗示 screenshake 可能会因为人类偏好测试而被降权,同时分享了实验 screenshake 的 Sora 生成链接,例如这个关于地震的视频。
- Prompt Engineering:未来已来:用户讨论了学习和应用 Prompt engineering 的方法,其中一位用户分享了其专门用于制作电影预告片的个人 Sora 账号链接。
- 一位成员建议不要依赖“万能 Prompt”(master prompts),而是建议专注于清晰的沟通和准确的语言,并强调了事实核查和验证输出的重要性。
- 驯服聊天机器人:控制 ChatGPT 对话习惯的策略:一位用户对 ChatGPT 倾向于在回答结束时提出未经要求的后续问题感到沮丧,并寻求禁用此“功能”的建议。
- 一位用户建议将后续问题替换为其他内容,例如笑话或关于某个喜爱主题的细节,并分享了示例对话,比如这个带有冷笑话(Dad jokes)的对话。
OpenAI ▷ #api-discussions (51 条消息🔥):
Sora 识别真实与虚构图像,用于电影预告片的 Sora 账号,Prompt engineering 资源,Sora 2 中的屏幕抖动或其他 VFX
- Sora 能处理真实与虚构图像吗?:一位成员询问 Sora 是否能区分真人图像和虚构角色图像,得到了肯定的回答。
- 发起对话的人还分享了一个针对 AI 模型的 pseudoCode(伪代码)思想实验链接。
- 专门制作电影预告片的 Sora 账号亮相:一位成员分享说他们有一个专门用于制作电影预告片的 Sora 账号,并称其非常有帮助。
- 该成员感谢了其他人提供的资源,并对 Sora 的潜力表示兴奋。
- 用户分享 Prompt Engineering 技巧:成员们讨论了有效 Prompt 的技巧,包括使用 Markdown 的层级化沟通、变量抽象以及 ML 格式匹配。
- 另一位用户警告不要依赖“万能 Prompt”,而是主张清晰的沟通并根据 AI 的输出进行迭代优化。
- Sora 2 尝试屏幕抖动和 VFX:一位用户询问如何在 Sora 2 上获得 screenshakes 或其他 VFX,另一位用户表示这勉强可以实现。
- 分享了 sora.chatgpt.com 上各种屏幕抖动实验的链接,展示了不同程度的成功。
OpenRouter ▷ #app-showcase (125 条消息🔥🔥):
TLRAG framework, Deterministic AI, Model Agnostic Framework, OpenRouter user demographic, AI Slop
- TLRAG 框架被宣传为确定性和模型无关 (Model Agnostic):一位开发者正在推销名为 TLRAG 的框架,称其为完全确定性且模型无关的,并声称它不需要 function calling 或像 Langchain 这样的常规框架,且没有任何依赖项,该框架在 dev.to 页面上进行了展示。
- 该框架声称可以节省 +90% 的 token,独立保存记忆,策划对话,学习,进化,并改变其自身的身份和 prompt。然而,其网站和白皮书面临着社区的审查。
- 网站 UI/UX 缺陷和安全疑虑:用户对网站的 UI/UX 问题提出了反馈,并引发了对安全性的担忧;而另一位成员指出 TLRAG 的声明是真实的,且 TLRAG 提供了全面的安全和性能特性,如 Cloudflare WAF & DDoS Protection。
- 开发者列出了一份详尽的安全和性能清单作为回应,包括 Cloudflare WAF & DDoS Protection、Traefik 反向代理以及 JWT 身份验证。
- 社区对 TLRAG 声明的质疑:几位用户表示怀疑,其中一名成员认为它表面上只是带有关键词搜索的 RAG,其他人则指出了白皮书结构、对比和指标方面的问题。
- 开发者为自己的方法辩护,表示他们不在乎营销,更希望通过产品本身来评判,同时该开发者还驳斥了一些批评,称其为“完全不真实的 AI 生成的废话”。
- OpenRouter 用户群体:一位用户指出,OpenRouter 用户并不是这类产品的目标受众,因为他们大多是不了解 OpenRouter 是什么的人。
- 开发者声称,人们反而会找理由说明为什么没有必要测试它,但也为自己的防卫心态道歉,并承认了建设性的批评。
- Vimprove 发布:适用于 Neovim 的 RAG 聊天机器人:一位用户宣布创建了 Vimprove,这是一个针对 neovim 文档的 RAG 聊天机器人 API/CLI/Nvim 插件,它在本地使用 sentence-transformers 和 chromadb,并使用 OpenRouter API 获取响应,可在 GitHub 上获取。
- 一位用户开玩笑地建议封禁创建者。
OpenRouter ▷ #general (428 条消息🔥🔥🔥):
SambaNova latency in DeepSeek v3.1, AI SDK Anthropics models in OpenRouter, Default LLM for market research - gemini 2.5 pro?, Is llama doing anything good?, Support Agent SKILLS from Claude?
- DeepSeek v3.1 的 SambaNova 延迟:一位用户在 DeepSeek v3.1 Terminus 中遇到了 SambaNova 的延迟问题,并指出尽管 SambaNova 拥有更高的吞吐量,但根据 OpenRouter 的提供商对比页面,DeepInfra 在吞吐量和延迟方面似乎都更快。
- GPT-5 Image 是 GPT-image-1:不是新模型?:成员们讨论了 GPT-5 Image 的质量,并推测它实际上是封装了响应 API 的 GPT-image-1,因此不是更新的模型。
- 一位成员表示:“我也这么认为,我测试了两者,我更喜欢 nano banana。”
- OpenInference 审查实施:成员们讨论了 OpenInference 模型的审查情况,其中一人指出它是唯一一个实施了某种形式自我审核的开源模型提供商,因为它正在收集所有数据用于可能发表的“研究”。
- 一位成员表示他们已经使用无审查版本一周了,并询问“能不能变回无审查状态”。
- Deepseek V3 0324 遭遇死神:成员们报告了 Deepseek v3 0324 的问题,其中一人表示“我发誓我刚才亲眼看到 V3 0324 挂了”。
- 此前,大家还讨论了更广泛的 Deepseek 免费模型的问题。
- Stripe 支持借记卡:值得欢呼:一位用户询问了支付方式,另一位用户指出 Stripe 支持借记卡。
- 原用户澄清说他们的借记卡是特定类型 (ING) 并询问是否有影响,但另一位用户回答说 Stripe 也接受这些卡。
OpenRouter ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (93 条消息🔥🔥):
虚假 AI 产品成功率、企业品牌中的 AI 艺术、Qwen3 235A22B API 定价、Liquid 停止托管 LFM 7b、AWS 状态页面
- **虚假 AI 产品获得成功?**: 一位用户开玩笑地建议,虚假 AI 产品成功的关键是让足够多的人在 Twitter 上看到它(利润可能有所不同)。
- 随后引发了关于公司使用 AI-generated art 的讨论,一些人认为由于懒于更改默认样式,这显得不专业且廉价。
- **Qwen3 定价令用户惊叹: 一位用户指出 **Qwen3 235A22B API 定价 非常出色,特别是配合 W&B 使用时,这引发了通过它处理大量数据的兴奋。
- 另一位用户提到 OpenRouter 需要定期发布降价公告,并强调在性价比(单位美元的智能程度)方面没有其他产品能与之媲美。
- **LFM 7B 的终结: 社区对 **Liquid 停止托管 LFM 7B(最初定价为 $0.01/Mtok 的 LLM)表示哀悼,一位用户建议为其举行葬礼,并指出它在 7:54 AM (EST) 被删除。
- 一位用户指出,在 OpenRouter 中按价格排序时,没有 1:1 的替代方案,最接近的是 Gemma 3 9B,但其输出成本是原来的三倍。
- **AWS 遭遇重大故障: 一位用户发布了 AWS 状态页面 以及第三方 状态页面 的链接,暗示 **AWS 正在经历重大停机。
- 另一位用户讽刺地指出,政府获得了超过 4 万亿美元,却无法实现三个 9 的正常运行时间。
LM Studio ▷ #general (295 条消息🔥🔥):
Llama Bench 支持、MCP 服务器、OpenHands Agent 框架、System Prompts、Jinja 模板问题
- iPad 上的 API 访问和 MCP 服务器: 一位用户正寻求通过 iPad 上的 3Sparks Chat 经由 API 访问 LM Studio,并想知道是否可以像聊天界面一样通过 API 使用 MCP servers,但目前尚不支持通过 API 使用 MCP。
- 另一位用户建议使用远程桌面应用,或者提到将聊天面板作为网页提供服务也可以实现这一点,而其他人则建议使用 Tailscale 或 RustDesk。
- System Prompts 解析问题: 一位用户发现 system prompts 会经过解析,根据所使用的模型和聊天模板,括号等特殊字符可能会产生问题,并指出 Jinja 模板问题 正在修复中。
- 他们建议对 Qwen models 使用 ChatML template 以缓解某些问题,并分享了一个 自定义提示词模板
- 本地推理 Copilot 扩展: 一位用户询问了适用于 LM Studio 的 VSCode extension,提到现有的 Void Editor 支持不足;另一位用户推荐使用 kilocode extension 以支持 LM Studio。
- 成员们指出有几个扩展可用于指定 local inference server,甚至适用于 GitHub Copilot,一位用户指出原生支持可能很快会通过 OAI 兼容的模型选择器 实现。
- LM Studio 和 MCP Root 功能: 一位用户试图在 LM Studio 中配置 MCP root 目录,类似于 @modelcontextprotocol/inspector 工具,但发现 LM Studio 仅支持 MCP servers 的最基本功能(例如仅支持 tools)。
- 结论是 LM Studio 并不完全支持 mcp 协议规范,这就是依赖此功能的工具无法工作的原因。
- 使用 LM Studio API 运行 TTS 模型: 用户讨论了在 LM Studio 上运行 TTS models 的可能性,一位用户表示目前无法实现,而另一位用户解释了如何通过 LMS API 运行 TTS。
- 一位用户详细说明了如何使用 Qwen3 构建自定义应用进行编码,然后使用 LM Studio API。
LM Studio ▷ #hardware-discussion (339 messages🔥🔥):
GPU 散热解决方案, 3090 热点问题, 辅助 GPU 使用, EPYC vs Threadripper 运行 LLMs, 旧款 GPU 的 ROCm 支持
- 极端散热改装:用台扇吹 PC?:在从精神病院回来后,一位用户开玩笑地安装了 双 12 英寸涡轮风扇 来为他们的 PC 散热,期望改善气流。
- 该用户澄清这只是个玩笑,这并不是要安装在机箱内部的 PC 风扇,而是一个外部的 台扇。
- 3090 热点困扰与调整:一位用户报告 3090 热点温度 达到了 90-95°C,即使在重新安装 CPU 并发现核心温度尚可之后,仍考虑进行降压或更换导热膏。
- 建议包括检查功耗限制、重新涂抹 GPU 导热膏(使用刮刀均匀涂抹),并考虑使用 PTM(相变材料)以获得更好的散热性能;此外,降低功耗限制有助于判断温度传感器是否故障。
- 最大化辅助 GPU 性能:一位用户探索了将 3050 作为辅助 GPU 与 3090 搭配使用,以在 AI 任务中获得额外的 VRAM。
- 讨论涵盖了在硬件设置中将 3090 设置为主要计算设备,以及对两张显卡可能 “让 GPU 窒息”(空间拥挤导致散热不畅)的担忧。
- 辩论完美的 LLM 配置:成员们辩论了使用 EPYC 9654 还是 Threadripper 来运行大语言模型(LLMs)的优劣。
- 共识倾向于 EPYC,因为它具有卓越的内存带宽和双 CPU 支持能力;同时建议考虑多张二手 3090 或 MI50,作为单张高端 5090 的性价比替代方案,以增加 VRAM。
- ROCm 兼容性困扰与解决方案:用户讨论了 llama.cpp 中旧款 GPU(特别是 gfx906 (MI50))的 ROCm (Radeon Open Compute) 兼容性问题。
- 有人指出最新的 llama.cpp 版本可能不支持旧版 ROCm,但一个 YouTube 教程 声称可以在 ROCm 7 中为 llama.cpp 恢复完整功能。
HuggingFace ▷ #general (535 条消息🔥🔥🔥):
LLM 微调, HF Inference API 与文本生成, MCPs 对比 Agents, 图像分析与标注, AWS 宕机
- 提升 LLM 微调水平:一位成员推荐了 smol course 和 Fine-tuning LLMs Guide 来学习 LLM 微调。
- 讨论强调,在示例代码中,简洁性往往优先于速度,且优化技术可能会过时,建议从一开始就将它们分开编写(参见 transformers/llm_optim)。
- HF Inference API 需要任务命名规范:成员们发现 Mistral 模型需要将变量 ‘text-generation’ 重命名为 ‘conversational’ 才能在 HF Inference API 中正常工作,并引用了相关 issue。
- 他们注意到,Florence 模型也有特定的任务名称要求,其他模型可能也有类似的约束,需要特定的任务名称才能响应 Prompt。
- AI Agents 对比 MCPs:一场讨论澄清了 MCPs (Model Context Protocols) 或 Agents 被用于管理 AI 交互(特别是在电子邮件等语境下)以防止错误操作。一位成员建议使用 AI APP 一词以简化概念,并提供了 mcp.so 作为该概念的示例。
- 此外,Model Context Protocol 被定义为:LLM 调用的、用于完成需要外部工具的特定复杂任务的预定义小型任务工具,并且它们是可复用的。
- 高效的数据标注策略:成员们讨论了高效的数据标注策略,有人建议使用 GPT-4o 进行高精度标注,并将结果与 Claude 和 Gemini API 进行对比,以实现纠错过程的自动化。
- 讨论中提到了其他的 vision models,一些成员得出结论:对于具有唯一标识符的图像,手动标注可能是唯一的选择。
- AWS 宕机影响 Hugging Face:用户报告称,由于全球性 AWS 宕机导致内部服务器错误,从 Hugging Face 下载模型出现问题。
- Hugging Face 状态页面确认了该问题,指出服务因 AWS 宕机而出现故障,但目前该问题已得到解决。
HuggingFace ▷ #today-im-learning (6 条消息):
NivasaAI 动态路由, Google ADK, Agent + Tools, Max 计划限制
- NivasaAI 动态路由首次亮相:一位成员正将 NivasaAI 从 Agent + Tools 切换为具有动态路由的多 Agent 架构,以增强 UX。
- 目标是实现从工具和 Agent 聚合的即时聊天响应,初始提交已发布在 GitHub。
- Google ADK 驱动 NivasaAI 路由器:一位成员计划使用 Google ADK 完成一个路由器,将请求分类为
code_validation、rag_query和general_chat等类别。- 旨在处理从语法检查到日常对话的一系列任务。
- Max 计划——达到上限?:一位成员质疑 Max 计划的限制是否足以实现他们的目标。
- 帖子中包含一张发票图片,显示了该计划的限制。
- 需要逆向工程:一位成员发布了一张图片并表示,这就像是通过逆向工程来理解它的实际工作原理。
- 他们表示这很有趣,因为某些东西在没有绝对控制权的情况下被工程化了,所以我们不得不对其进行逆向工程,这很幽默。
HuggingFace ▷ #cool-finds (4 条消息):
Qwen3 视觉模型, 微软蛋白质功能预测
- Qwen3 视觉模型发布:一位成员分享了新的 Qwen3-VL-8B-Instruct-GGUF 视觉模型和原始的 Qwen3-VL-8B-Instruct 链接。
- 微软预测蛋白质功能:一位成员发布了来自微软的令人印象深刻的新蛋白质功能预测工具,包括 bioemu 模型的链接。
HuggingFace ▷ #i-made-this (14 messages🔥):
Agent Building Tutorial, LLM Token Hallucination, New Architecture for Decentralized Tokenizers, Self-Hosted Tracing for OpenAI Agents, Amiko: Social Identity Platform for AI Twins
- Agent 构建教程首发:一位成员分享了关于 构建 Agent 的新教程,并邀请社区提供反馈。
- 本地 LLM 可能会产生幻觉!:一位成员测试了 47 种配置,发现本地 LLM 在超过 6K tokens 后可能会产生幻觉。
- 他们分享了一篇 Medium 文章,详细介绍了在真实硬件上真正起作用的 quantization configurations(量化配置) 研究结果。
- 出现带有去中心化 Tokenizer 的新 Transformer 架构:一位成员介绍了一种带有去中心化 Tokenizer 的新架构,并指出该架构与 llama.gguf 不兼容,但已在 GitHub 上发布。
- OpenAI Agents 框架的自托管追踪工具发布:一位成员开源了一个针对 OpenAI Agents framework 追踪记录的 自托管追踪与分析基础设施,旨在解决 GDPR 合规性问题以及无法从 OpenAI 追踪仪表板导出数据的问题。
- Amiko:构建 AI 数字孪生的社交身份平台:一位成员介绍了 Amiko,这是一个用于构建行为优先的 AI twins、伴侣和社交 Agent 的社交身份平台,强调其对隐私、所有权和个性的关注。
- 他们解释说:Amikos 是私有的、便携的且由用户拥有的。它们不仅仅是你的映射,它们与你共同行动。
HuggingFace ▷ #computer-vision (2 messages):
``
- TE 选择揭晓:一位成员询问了近期项目中使用的具体 TE (Transformer Engine)。
- Transformer Engine 实现细节:该成员正在寻求关于最终 Transformer Engine 实现细节的澄清。
HuggingFace ▷ #NLP (1 messages):
Chat Template Conversion, Tokenizer Execution, Fine-Tuning Script
- 聊天模板转换的困扰:成员们讨论了将数据集转换为模型特定聊天模板的第一步。
- 这一过程确保了在微调期间的兼容性和最佳性能,特别是对于那些对输入格式敏感的模型。
- Tokenizer 的成功与磨难:下一步涉及在转换后的数据集上运行模型的 Tokenizer。
- 此过程将文本转换为模型可以理解的数字 Token。
- 微调前沿的纷争:最后一步是在 Tokenized 后的数据集上执行微调脚本。
- 这使得预训练模型能够适应数据的特定细微差别,从而可能提高其在目标任务上的性能。
HuggingFace ▷ #smol-course (16 messages🔥):
排行榜提交延迟,SMOL 课程中的 CUDA 显存溢出错误,Lighteval Bug 修复,DPO 探索性不足
- 尽管 PR 已合并,排行榜提交仍显示延迟:一名成员报告称其 PR 已合并,但提交内容未显示在排行榜上,可能是由于数据集最初设为私有;排行榜每周或每两周更新一次。
- 在将数据集设为公开后,该成员正在等待下一次排行榜修订,以查看其提交是否出现。
- CUDA 显存溢出困扰 SMOL 课程学生:一名成员在使用 HF Pro 账户、HF jobs 和 Colab 学习 SMOL 课程(第 1.5 节)时遇到了 CUDA out of memory 错误,尽管使用了 a100-large 实例。
- 建议遇到相同问题的成员尝试将
per_device_train_batch_size减少到 2,并将--gradient_accumulation_steps增加到 2 或更多。
- 建议遇到相同问题的成员尝试将
- Lighteval Bug 修复解决了关键问题:由于最新版本
lighteval的 Bug 和缺失的emoji包,一名成员在第一章的评估任务中遇到错误,通过使用以下标志解决:--with "lighteval[vllm]@git+https://github.com/huggingface/lighteval,emoji"。- 另一名成员也报告了
lighteval产生FileNotFound错误的问题,并分享了一个包含解决方案的 GitHub issue 链接。
- 另一名成员也报告了
- DPO 过程让成员感到不满足:在完成 DPO 后,一位成员发现其探索性不如 SFT,并表示感觉被限制在仅使用对齐数据,而不清楚其在评估中的具体作用。
- 他们指出,他们确实没有看到任何邀请去探索所提供内容之外的东西,感觉就像是应该直接使用对齐数据,而不知道在评估中将其用于什么目的。
HuggingFace ▷ #agents-course (13 messages🔥):
课程开始,SmolAgents 框架,用于 SLM 的 DeepFabric
- 课程启动热潮:几名成员宣布他们今天开始学习该课程。
- 这激发了准备投入 Agent 学习体验的新手们的兴奋感。
- SmolAgents 框架困扰学员:一名成员表示在第 2 单元中难以理解 SmolAgents 框架。
- 他们表示需要对该概念进行更深入的理解和澄清。
- DeepFabric 吸引数据驱动开发者:一名成员介绍了 DeepFabric,这是一个用于训练 SLM 以改进结构化输出和工具调用的工具,通过 GitHub 链接分享。
- 该工具能够生成基于推理轨迹的数据集,这些数据集可以直接加载到 TRL (SFT) 中。
GPU MODE ▷ #general (19 messages🔥):
Triton 分布式演讲,Helion 演讲,范畴论与 AI 资源,Impossible Cloud Network (ICN) 合作,AMD 活动
- Triton 演讲被取消!:原定的一场 Triton 分布式演讲 被 取消 了。
- 大约一小时后开始了一场 Helion 演讲,但其录制状态尚未确认。
- 范畴论带来 AI 的“恍然大悟”时刻!:Bruno Gavranovic 在此处维护了一个最新的 范畴论 / AI 资源 列表。
- 他还与 DeepMind 的一些成员共同开设了一门课程(Categorical Deep Learning),并且一名成员维护着一个范畴论深度学习编译器(catgrad)。
- Impossible Cloud 寻求合作!:来自 Impossible Cloud Network (ICN) 的 Ali 希望探索与 GPU MODE 的合作或研讨会,并分享了他们的 白皮书。
- ICN 是一个 web3 项目。
- Mark 在 AMD 活动上发表演讲:一名成员报告称观看了 Mark 在 AMD 活动 上的演讲,但未提供直接链接。
GPU MODE ▷ #triton (15 条消息🔥):
TMA 性能,Triton 主机 TensorDescriptor,代数 Shuffle
- TMA:Triton 之谜;Ampere 的性能历史:一位成员正在为 NVIDIA SM120 GPU 的 Triton 中的 dot 实现 TMA 支持,但发现使用 TMA 相比
cp.async没有性能提升,并询问 TMA 何时以及在何处能比cp.async获得性能增益。 - SM120 难以对 TMA 友好:成员们讨论了 SM120 是否具备 TMA 硬件,目前至少存在 tensor map + cp.async.bulk.tensor。
- 一位成员指出,至少在 Hopper 上,TMA 对于小于 4KiB 的加载效率并不高,加载更大的 tiles 效果更好,直到达到某个临界点。
- Ampere 的 TensorDescriptor 运行极其缓慢!:一位成员注意到在 Ampere 上执行
desc.load([x, y])时性能较差,并指出 Ampere 并不具备 TMA。- 他们原本预期其性能基本上与使用 pointers 或 block pointer 相同。
- 辅助寄存器来救场?:一位成员建议在无法进行原地(in-place)操作时,使用辅助寄存器来保存新值,并在最后将其移动到最终位置。
- 代数 Shuffle 占据主导:一位成员提到他们从未实现过特定的算法,因为出现了通过更具代数性的方法实现 shuffle 的优秀贡献,他们便沿用了该方法。
GPU MODE ▷ #cuda (21 条消息🔥):
Thread Block vs CTA,分布式共享内存延迟/带宽,TMA vs cp.async,CUDA 学习资源,设备无关的 TMA 逻辑
- CTA 概念澄清:Cooperative Thread Array:在 CUDA 中,Cooperative Thread Array (CTA) 是 thread block 的同义词,代表一个 1D、2D 或 3D 的线程数组。
- 当使用分布式共享内存功能时,它被称为 Cooperative Thread Array (CTA)。
- 分布式共享内存中的延迟飞跃?:当使用分布式共享内存时,访问当前 block 与另一个 block 的共享内存可能会涉及 延迟和带宽 差异。
- 虽然具体数据较少,但一位成员指向了这篇博客文章,表明它比共享内存慢,但比 L2 cache 快。
- TMA 的胜利:Tile Matrix Accelerator:TMA 使用单条指令启动 tile 复制并可以进行多播(multicast),从而节省索引计算时间并简化 swizzling。
- 基准测试显示,对于大 tiles,TMA 比 cp.async 稍快(约 0.5%),但对于较小的 tiles,cp.async 更快,这与 NVIDIA 内存优化演讲中的建议一致。
- CUDA 入门:新手探索 Kernel:一位新的 CUDA 用户正在学习 GPU architecture,目标是专注于 GPU/推理工程,并正在寻求资源。
- 另一位用户提议在学习过程中同步进度并交流笔记。
- Blackwell 的蓝图:布局逻辑:讨论了 TMA 逻辑是否是设备无关(device-agnostic)的,在 B200 vs. 5090 等架构上可能需要不同的布局才能充分利用。
- 对于 Blackwell,一位成员引用了一个用于 scales 的 5D 布局示例,并指出只要第一维是连续的,性能就应该保持一致。
GPU MODE ▷ #torch (15 条消息🔥):
Pytorch profiler CUDA 问题,AlphaZero 计算需求,Matmul 融合,进程调度问题
- Windows 和 WSL 上的 Pytorch Profiler CUPTI 问题:尽管 CUDA 可用且已设置 CUPTI 路径,但用户在 Windows 和 WSL 上使用 torch.profiler 时仍遇到
CUPTI_ERROR_INVALID_DEVICE (2)错误。- 一位成员建议通过这个 gist启用硬件计数器访问,但用户反馈该方案对其无效。
- AlphaZero 在单张 3090ti 上表现吃力:一位用户在 3090ti 上训练 AlphaZero 实现时,在 100 simulations 的情况下遇到了 GPU 利用率低和训练速度慢的问题,并询问这是配置问题还是纯粹需要更多时间。
- 另一位成员回复称,使用 AlphaZero 训练国际象棋所需的计算资源远超单张 3090ti 所能提供的范畴,并引用了 DeepMind 的资源消耗数据。
- matmul 与 epilogue 融合?:一位成员询问是否有简便的方法来融合 matmul 和 epilogue 操作。
- 他们发现即使使用 torch.compile 来融合 F.silu(x@w),仍然会看到独立的 matmul 和 triton kernel。
- 进程取消调度导致 H200x8 上的迭代变慢:一位用户在单台 H200x8 裸金属实例上运行 torchtitan llama 3B pretrain 时,遇到了随机的迭代变慢现象。
- nsys trace 显示,即使没有其他进程运行,活跃的线程/进程也会从 CPU 中取消调度(descheduled)几秒钟,这引发了关于操作系统/内核配置错误的疑问。
GPU MODE ▷ #cool-links (2 条消息):
GPU 工程资源,PMPP-Eval 历程
- 精选 GPU 工程资源发布!:一位成员分享了他们精选的 GPU 工程资源库,将各种有用的材料整合在一处。
- 对于寻找集中化知识的工程师来说,这可能是一个福音。
- PMPP-Eval+Journey 博客文章公开:一位成员发布了一篇关于他们 PMPP-Eval 历程的博客文章。
- 对于对性能建模与预测感兴趣的人来说,这可能是一个很好的资源。
GPU MODE ▷ #jobs (1 条消息):
旧金山种子轮初创公司,GPU 性能工程师,Herdora 招聘
- Herdora 初创公司获得种子轮融资:一家名为 Herdora 的旧金山种子轮初创公司宣布,他们已获得来自 YC、Jeff Dean、Woj Zaremba(OpenAI 联合创始人)以及 Together.ai kernel 负责人的投资。
- 公司位于 Pac Heights,底层即为办公室。
- Herdora 寻求 PyTorch/CUDA Kernel 工程师:Herdora 正在招聘喜欢编写 PyTorch、CUDA kernels 并挑战 GPU 性能极限的工程师。
- 他们正在招聘全职员工以及冬/春/夏季实习生,你可以直接申请并私信简历,或私信咨询任何问题。
- Herdora 提供优厚的薪酬待遇:Herdora 提供的薪酬方案为 $170-200k + 2-4% 的股权。
- 可在 Herdora 招聘页面申请全职及冬/春/夏季实习岗位。
GPU MODE ▷ #pmpp-book (1 条消息):
mannythecreator: 能否分享一些讨论这些内容的链接。
GPU MODE ▷ #torchao (8 messages🔥):
vLLM quantization, SGLang quantization support, Online quantization, ModuleFqnToConfig, torchao_utils.py
- 在量化方面 **vLLM 仍然优于 SGLang:vLLM** 的集成支持任何类型的量化配置,但 SGLang 仅支持 int4wo、int8dq、int8wo。
- 支持的量化方法在 SGLang 文档中有详细说明。
- **ModuleFqnToConfig 取代 filter_fn:
quantize_op的filter_fn将被弃用,转而使用 **ModuleFqnToConfig,后者现在支持正则表达式。- 更多细节请参见 TorchAO pull request #3083。
- **SGLang 缺乏视觉模型量化支持:目前 **SGLang 的在线量化不支持跳过视觉模型的量化。
- 有用户询问关于跳过视觉模型量化的事宜,但 SGLang 目前不支持此功能。
- **torchao_utils.py 需要重构:
torchao_utils.py中的代码目前正在使用中,但团队计划对其进行重构,以使用 **ModuleFqnToConfig 来实现更好的量化配置。- 相关代码可以在 GitHub 上找到。
GPU MODE ▷ #off-topic (13 messages🔥):
geohot, GPUs go brrr, DGX Spark impressions, Blackwell instructions
- Geohot 被制作成表情包:一位成员发布了一个关于 Geohot 的表情包。
- 该表情包只是在一张穿着高领毛衣的男人的素材照片上写着 lol geohot。
- GPUs go BRRR:一位成员分享了 horace.io/brrr_intro.html 的链接和一张 GPUs 的图片。
- 另一位成员开玩笑说要把它变成黑白卡通画。
- DGX Spark 比预想的要小:一位成员注意到 DGX Spark 的体积比他们想象的要小。
- 另一位成员评论说,它是一个原型开发机,而不是推理机,使用云服务商的 price per token 会更便宜。
- 询问 Blackwell 指令:一位成员询问了 DGX Spark 设备的计算类型,以及它是否向用户开放了 Blackwell 指令 的全子集。
GPU MODE ▷ #irl-meetup (2 messages):
San Diego Meetup, Orange County Meetup
- 圣迭戈成员寻求南加州线下活动:一位在圣迭戈 (San Diego) 的成员正在询问是否有 irl meetup(线下见面会)计划。
- 他们艾特了另一位成员以引起关注,并表达了参加意愿。
- 橙县 (Orange County) 成员报到:一位成员报告他们的所在地是橙县。
GPU MODE ▷ #triton-puzzles (2 messages):
Triton Kernels, Fused Kernels, Kernel Assistance
- Triton 融合算子 (Fused Kernels) 的威力:Triton 的优势在于其融合算子,这意味着它可以更高效地执行操作。
- 其他仓库可以从开发和优化其 Kernel 的协助中获益。
- 需要 Kernel 协助:除了 Triton 之外,许多仓库也需要 Kernel 开发和优化方面的帮助。
- 这为各种 Kernel 相关项目的贡献和改进提供了机会。
GPU MODE ▷ #rocm (10 messages🔥):
AMD Warp Sizes vs NVIDIA, MI300x Cache Coherency, Warp Tiling, GEMM Occupancy
- AMD vs NVIDIA: Warp Size 之谜: 讨论了 AMD 的 64 线程 Warp Size 与 NVIDIA 的 32 线程 Warp Size 对 Occupancy 的影响。
- 一位成员指出,由于硬件架构不同,直接比较 AMD 和 NVIDIA 的 Kernel Occupancy 并不直观,尽管两者的最大 Block Size 均为 1024。
- MI300x NVLink 缓存一致性 (Cache Coherency): 提出了关于 MI300x 在 NVLink 上的 Cache Coherency 问题,用户上传了一张图片作为参考。
- 另一位成员指向了 AMD 文档并建议使用
hipExtMallocWithFlags(&ptr, size, hipDeviceMallocFinegrained)以在 MI300 上实现缓存一致性。
- 另一位成员指向了 AMD 文档并建议使用
- Warp Tiling 策略: 讨论触及了 64 的 Warp Size 如何影响 Warp Tiling,暗示需要更多的线程和更大的 Tile Size。
- 一位成员澄清,影响 Warp Tiling 的关键因素是 Warp GEMM 指令(wave64 GPU 上的 MFMA) 的大小,更大的 Warp Size 意味着每个线程分配的寄存器更少。
- GEMM 形状影响 Occupancy: 一位成员询问在进行如 8192 * 8192 * 8192 这样的大形状 GEMM 时,Occupancy 是否影响不大。
- 另一位成员回答,这归结为每个 Workgroup 处理的数据量,尽管像 CK-tile 这样的工具假设每个 CU 只有一个 Block,因此 Persistent GEMMs 在 MI300 上仅启动 304 个 Block。
{kind=link}
GPU MODE ▷ #tilelang (1 messages):
TileLang, Deepseek V32, Sparse MLA
- Deepseek 模型的 Sparse MLA 获得 TileLang 实现: 一位成员建议查看 Deepseek V32 模型中 Sparse MLA (Multi-Layer Attention) 组件的 TileLang 实现。
- 提及 TileLang 项目: 一位成员指向了 TileLang 项目,建议探索其功能和示例实现。
GPU MODE ▷ #self-promotion (5 messages):
Nvidia DGX, Petaflop Compute, MMA Atoms in CuTe, CUTLASS docs, Blogpost on MMA Atoms
- Nvidia DGX 现身: 一位成员询问 这是什么?,另一位成员回答是 Nvidia DGX。
- Petaflop 价格之谜: 一位成员注意到 1 Petaflop 的 FP4 算力仅需 4k 美元,指的是开发套件。
- CuTe 中 MMA Atoms 详解: 一位成员解释说 MMA Atoms 是 CuTe 中的基础构建模块之一,并分享了一篇博客文章讨论了 CuTe 文档中的示例,为新手提供了额外的解释。
- CUTLASS 和 PTX 文档链接: 同一位成员分享了 CUTLASS 文档的链接,并提到将 CuTe 抽象 与 PTX 文档 的相应部分建立了联系。
GPU MODE ▷ #🍿 (1 messages):
LLM for Kernel Generation, LLM for Bottleneck Identification
- 用于 Kernel 生成的 LLM:优化的未来?: 讨论围绕着拥有一个能够生成 Kernel 的 LLM 与一个能够识别 运行时瓶颈 (Bottleneck) 的 LLM 的效用展开。
- 前者可能使优化代码的创建自动化,而后者可以动态调整系统资源以最大化性能。
- 瓶颈嗅探 LLM:实时性能提升?: 能够识别 运行时瓶颈 的 LLM 可以实现实时优化和资源分配,从而可能带来更直接的性能提升。
- 这可能涉及分析系统指标和日志,以定位性能瓶颈并建议纠正措施。
GPU MODE ▷ #thunderkittens (1 messages):
线程执行澄清、集体启动行为、新 TK 中的 TMA 操作、新 TK 中前缀的含义
- 线程执行获得明确指定:每个操作现在都明确定义了由谁执行,例如,无前缀(如
tma::load_async)意味着它由调用线程运行,而前缀(如warp::tma::load_async)则表示集体启动(collective launch)。- 行为取决于具体操作,例如,
warp::tma::load_async由调用 warp 的 lane 0 运行,而某些操作仅允许集体启动,如warp::exp或warpgroup::wgmma。
- 行为取决于具体操作,例如,
- 前缀解决了 TK 的隐式性难题:在之前版本的 TK 中,没有前缀隐式地意味着由整个 warp 或单个线程运行(取决于具体操作),这造成了歧义。
- 例如,
add不再存在,取而代之的是warp::add;用户必须确保tma::load_async或任何 semaphore 操作由单个线程运行,或者使用warp::tma::load_async。
- 例如,
GPU MODE ▷ #submissions (3 messages):
VectorAdd 排行榜、H100 结果、B200 结果、A100 结果
- VectorAdd 排行榜获得新提交:一位成员在
vectoradd_v2排行榜上凭借 ID66209获得了第二名,成绩分别为 H100 (526 µs)、B200 (236 µs) 和 A100 (909 µs)。- 另一位成员在
vectoradd_v2排行榜上提交了三次运行,提交 ID 为66228和66233,在 A100 上分别获得了第 10 名 (1582 µs) 和第 8 名 (1243 µs)。
- 另一位成员在
- 另一位成员提交至 A100 VectorAdd 排行榜:一位成员在
vectoradd_v2排行榜上凭借提交 ID66228在 A100 上获得了第 10 名,用时 1582 µs。- 随后是另一个提交 ID
66233,以 1243 µs 的成绩获得了第 8 名。
- 随后是另一个提交 ID
GPU MODE ▷ #ppc (4 messages):
CP5、合并内存访问、分块、转置
- 分块改进了 CP5:在 CP5 的基准方案之后,分块(tiling)使一位成员的成绩达到了 4.9s 左右。
- 讨论的下一个优化是合并内存访问(coalescing memory accesses)。
- 澄清了关于合并的困惑:一位成员寻求合并内存访问方面的帮助,并澄清当 warp 中的所有 32 个线程访问一个连续的 128 字节块时,就会发生合并。
- 该成员展示了代码并询问如何优化。
- 矩阵转置尝试:一位成员探索通过转置矩阵来改进内存访问模式:
Bs[threadIdx.x][threadIdx.y] = diffs[col_B * ny + row_B]。- 他们提到这并没有完全奏效。
GPU MODE ▷ #hardware (20 messages🔥):
H100 server prices, RTX 6000 ADA TFLOPs variance, Benchmarking nuances and thermal throttling, NVLink bridge prices, CuBLAS autotuning
- 企业客户关注昂贵的 H100 服务器价格:一名成员询问了目前针对企业客户的 H100 server prices。
- 虽然没有分享具体数字,但该询问凸显了市场对获取顶级 GPU 硬件的持续兴趣。
- RTX 6000 ADA 的 TFLOPs 性能受到质疑:一名成员对 RTX 6000 ADA 较低且波动的 TFLOPs 性能提出质疑,并链接了相关的 X 帖子 以提供背景。
- 讨论建议在基准测试期间监控时钟频率、温度和功率限制(power capping),以识别潜在的降频(throttling)问题。
- 基准测试策略讨论:成员们分享了改进基准测试方法的见解,包括建议在每个 shape 之前添加
time.sleep(0.1)以稳定热状态。- 提供了相关的 ml-engineering repo 和 dataset 链接。
- 建议通过 CuBLAS Autotuning 调整以获得最高性能:一名成员提议使用
torch.compile(torch.mm, mode="max-autotune-no-cudagraphs")在基准测试不同 shape 时启用 CuBLAS autotuning。- 目标是优化矩阵乘法性能,特别是在 CuBLAS 调优可能并非最优的非 DC GPU 上。
- NVLink 桥接器价格引发“收藏品”争议:一名成员对 NVLink bridge 的高昂价格提出质疑,推测这是由于收藏价值还是真实的实用性与需求。
- 该疑问凸显了用户对使用 NVLink 技术的多 GPU 配置的持续关注及其感知价值。
GPU MODE ▷ #factorio-learning-env (1 messages):
``
- 文档无更新:一名成员表示他们在周末没有进行文档网站的工作,目前没有更新。
- 因此,他们将缺席今天的会议。
- 缺席会议:由于文档网站缺乏进展,该成员将缺席今天的会议。
- 他们将缺乏更新作为跳过会议的原因。
GPU MODE ▷ #amd-competition (2 messages):
Competition Submissions, Winner Write-ups
- 社区渴望竞赛提交的复盘报告:成员们渴望看到近期竞赛的解决方案,并期待获胜者的复盘报告(write-ups)。
- 这对于其他参与者来说也将是一个极好的学习机会。
- s1r_o 就看你的了,伙计:一名成员点名另一名成员,期待他分享竞赛复盘报告。
GPU MODE ▷ #cutlass (22 条消息🔥):
CUTLASS tile size 调优, 非 CMake 项目中的 CuTe, MoE Grouped GEMM 吞吐量, CUTLASS 命名规范, PTX 代码生成
- CUTLASS Tile Size 调优策略探讨:在为 CUTLASS C++ API 调优 tile size 时,一位成员建议使用脚本生成具有不同参数排列的多个 C++ 文件并进行测试,因为 compile-time parameters(编译时参数)无法进行 JIT 编译。
- 另一位成员补充说,虽然这在运行时可能会污染指令缓存,但在实践中,它仍然比尝试过的其他方法更快。
- CuTe 可以简单编译!:成员们确认,在简单的非 CMake 项目中使用 CuTe cpp 是可行的,只需直接使用
nvcc和常用的 C++ 标志编译文件即可。- 另一位成员建议使用特定标志(如
-arch=sm_86和-std=c++17)编译示例 14_ampere_tf32_tensorop_gemm。
- 另一位成员建议使用特定标志(如
- MoE 吞吐量深入讨论:一位成员询问如何通过比较理论 FLOPs 与观察到的延迟,来计算 MoE Grouped GEMM 在 prefill 和 decode 阶段的有效吞吐量。
- 另一位成员更倾向于端到端处理时间测量,建议测量 dummy_time(除 kernel 调用外的所有内容)和 ref_time(使用参考实现),并针对 delta_time = ref_time - dummy_time 进行优化。
- CUTLASS 规范澄清:一位成员询问 CUTLASS 中的命名规范
tXrA,特别是X代表什么,并引用了这段代码。 - PTX 强力操作展现潜力:一位成员分享了一个工具,该工具可以为 CUDA CuTe kernel 添加注释,将其编译为 PTX,并提供为注释变量分配的 PTX 寄存器。
- 据报道,这种方法实现了 26 倍快的 semirings(半环),并包含一个生成随机 PTX kernel 并在所有核心上批量编译的示例,详见 此 GitHub 仓库,以及一个在 另一个 GitHub 仓库 中将 CuTe kernel 作为 PyTorch 的任意 semiring tensor 例程公开的 Python 示例。
GPU MODE ▷ #singularity-systems (7 条消息):
SITP, picograd, Karpathy 的 Eureka 课程, MLSys 2026 教程, Tinygrad
- SITP 和 picograd 目标指向 Karpathy 的 Eureka 课程:目标是使 SITP 和 picograd 成为 Karpathy 的 “Starfleet Academy” Eureka 系列中继 LLM101 之后的第二门课程。
- 创建者旨在让 nanogpt 和 nanochat 运行起来,并正在寻找一位创意联合总监,协助将 torch eager mode、tinygrad、TVM 和 Halide 转化为代码库和课程。
- 弥合从 Micrograd 到 Tinygrad 的差距:受 Karpathy 对 George Hotz 直播影响的启发,SITP 和 picograd 旨在弥合从 micrograd 到 tinygrad 之间的差距,填补对更清晰文档的需求。
- 该倡议寻求提供一个由 MLSys 新人领导的公共资源,专注于实际更新并带头提交 PR。
- 将 Tinygrad 与 Triton 集成:计划涉及在不将 tensor 转换为 torch.Tensors 的情况下将 tinygrad 与 Triton 集成,正如 ghot 和 ptill 早期工作所展示的那样,读者应该实现自己的 tensor https://github.com/tinygrad/tinygrad/pull/470。
- 未来的任务包括围绕 tinygrad 的 tensor 前端构建执行引擎、指定运行时、将内存分配器与 Triton 集成,以及在 Triton 中实现 GEMM 的前向和反向传播。
- 使用 torch.export 捕获全图:引用了 Avik 关于使用 torch.export 进行可靠全图捕获的工作 https://www.youtube.com/watch?v=cZTX2W1Qqh8。
- 然而,有人指出,由于 PyTorch 非常灵活,且使用第三方库可能会导致图断裂(graph breaks),因此不能 100% 保证成功。
GPU MODE ▷ #multi-gpu (28 条消息🔥):
针对 MoE 的 Expert Parallelism (EP) 与 AllToAll,EP 与 DP 的结合,Parallel folding,使用 Triton 进行 Multi-GPU 训练,用于 AMD GPU Multi-GPU 训练的 Iris
- **Expert Parallelism 深度解析:当被问及如何使用两个 **AllToAll 操作实现 MoE 的 expert parallelism (EP) 时,一位成员分享了原生 EP 和 EP2DP 架构的图表,并指出当 EP 与 data parallelism (DP) 结合时,需要第一个 A2A 将 token 发送到正确的 experts,第二个 A2A 则将其路由回来。
- 他们指向了一篇关于
parallel folding的论文,作为任意分片(sharding)的通用方法,并指出如果不将 DP 与 EP 结合,网络密集部分将会产生大量无用功。
- 他们指向了一篇关于
- **EP 讲座/嘉宾讲座将于 12 月发布**:关于 EP 的讲座和其他嘉宾讲座将于 12 月完整发布。
- 提供了 Perplexity AI 关于高效 MoE 通信的博客 及其 pplx-kernels GitHub 仓库 的链接。
- **Triton 的 Multi-GPU 能力讨论:虽然 **Triton 官方尚不支持 multi-GPU 训练,但社区提到 triton-distributed 在单节点和多节点设置中表现良好。
- 有建议称,对 multi-GPU 训练的官方支持应尽快集成到 Triton 语言中。
- **Iris 成为 AMD 的 multi-GPU 训练器:Iris 是一个用于 **AMD GPU multi-GPU 训练的项目,受到了关注。一位成员称赞其设计比 roc-shemem 更简洁,强调其专注于节点内(intra-node)而非多节点(multi-node)设置。
- 一位开发者指出 Gluon 是最简洁的后端。
- **Torch 2.9 添加对称支持:一位成员指出 **PyTorch 2.9 包含了对称支持,具有 nvshmem 后端(支持多系统)和 CUDA 后端(支持最多 1 个 NVLink 域)。
- 更多详情可以在 PyTorch 博客上找到。
GPU MODE ▷ #irl-accel-hackathon (14 条消息🔥):
Synthetic Data AI Agents Challenge, Nvidia DGX Spark, Disaggregated prefill/decode, Speculative decoding, kernel optimization
- 团队寻求 Synthetic Data AI Agents Challenge:有人正在寻找团队参加 Synthetic Data AI Agents Challenge,并公开了他们的 GitHub。
- 该成员计划携带 Nvidia DGX Spark 参加黑客松,并致力于 disaggregated prefill/decode 和 speculative decoding 等项目。
- 黑客松时长明确:一位参与者询问了黑客松的时长,另一位用户澄清将持续 一天。
- 有人在上周末尝试了 DGX Spark,并希望收件箱中的说明能做得更好,因为他们弄坏(bricking)了第一个。
- 内核优化团队集结:两名成员正在寻求组建团队进行 kernel 优化、RL 训练和模型推理,考虑在 B200 上实现 triton distributed 或 deterministic kernels。
- 他们引用了 Thinking Machines Labs 关于 deterministic kernels 的博客文章。
- 机架级特性分析与内存改进:一位成员构思了与 rackscale scale-up characterization 相关的项目,需要 NVL36/72,并致力于改进 PyTorch Symmetric Memory。
- 另一位成员对对称内存改进项目表示感兴趣。
- Checkpoint Engine 讨论:一位参与者提到了 Kimi 的 checkpoint engine RL 参数更新,并分享了 Checkpoint Engine 的链接。
- 他们询问除了 B200 之外,是否还能获得 GB200。
GPU MODE ▷ #opencl-vulkan (3 messages):
CUDA, OpenCL, Vulkan
- CUDA 使用经验:一位成员分享了他们最初使用 CUDA 的经验,称其非常有趣,因为有大量扎实的学习资源。
- 他们现在主要使用 OpenCL 和 Vulkan 进行计算,并认为建立一个讨论这些 APIs 并交流想法的空间会非常有益。
- 对 OpenCL/Vulkan 讨论空间的赞赏:该成员对设立专门讨论 OpenCL 和 Vulkan 的空间表示赞赏。
- 他们强调了分享想法以及在这些 APIs 相关项目上进行协作的价值。
GPU MODE ▷ #cluster-management (2 messages):
Fault Tolerant Llama Training, Node Failure Prediction
- PyTorch 通过模拟故障实现容错:一篇新的 PyTorch 博客文章 详细介绍了在 Crusoe L40S 上,如何在不使用 checkpoints 的情况下,通过每 15 秒产生 2000 个模拟故障来实现容错的 Llama 训练。
- 该解决方案提供了一种替代传统 checkpointing 配合 bash 脚本和任务重启的方法,引发了对投入更多自动化容错流程的思考。
- 讨论节点故障预测以最小化停机时间:成员们讨论了使用 Agent 系统或 ML 预测高频率节点故障的可能性。
- 有建议认为,预测故障可以促进更简便的替换,从而实现最小化停机时间。
GPU MODE ▷ #llmq (2 messages):
Qutlass integration
- 成员们期待 Qutlass 集成:一位成员询问了 Qutlass 集成的时间表。
- 未给出 Qutlass 的时间表:目前尚未提供具体时间表。
GPU MODE ▷ #helion (3 messages):
Helion, PyTorch Conference, Triton Developer Conference, Helion 0.2
- Helion 活动启动:团队宣布本周将举行一系列活动来讨论 Helion 并与开发者互动,详见 Youtube 直播。
- 这些活动包括在 Triton Developer Conference 2025 和 PyTorch Conference 2025 上的演讲和见面会。
- Helion 在 Triton Developer Conference 亮相:10 月 21 日(周二),在 2025 Triton Developer Conference 上将有一场题为 “Helion: A Higher-level DSL for Kernel Authoring” 的演讲,更多信息请访问 TritonDeveloperConference。
- 演讲将探讨 Helion,这是一种专为 Kernel 编写设计的领域特定语言(DSL)。
- PyTorch Conference 欢迎 Helion 开发者:10 月 22 日(周三),参会者可以在 PyTorch Conference 2025 上与 PyTorch Compiler 和 Helion 的开发者见面,参见会议日程。
- Helion 团队还将在 10 月 23 日(周四)的 PyTorch Conference 2025 上发表演讲,更多详情见 PyTorch Conference。
- Helion 0.2 作为公开测试版首次亮相:Helion 0.2 现已作为公开测试版发布,可以在 pypi.org 上找到。
- 这一版本的发布标志着 Helion 框架在更广泛的可访问性和测试方面迈出了重要一步。
Latent Space ▷ #ai-general-chat (133 条消息🔥🔥):
ManusAI v1.5, AI 情绪转变, Cursor Git worktree 支持, Grok 4.20, GPT-4o 转录与说话人识别
- ManusAI 发布 v1.5,Web App 奇才:ManusAI v1.5 在 4 分钟内将提示词转换为生产级 Web App,通过自动卸载和召回实现无限上下文,于 10 月 16 日发布。
- 用户称赞其速度并对上下文工程提出疑问,而一些人认为之前的工具如 Orchids、Loveable 和 V0 与直接编码相比令人失望。
- AI 悲观情绪抬头,顶尖研究员放缓时间表:知名 AI 研究员如 Sutton、Karpathy 和 Hassabis 正在采用更长的 AI 时间表,引发了关于潜在炒作周期破裂的讨论,根据此推文线程。
- 反应从惊恐到捍卫进展不等,回复中对悲观情绪是否被夸大或误解存在质疑。
- Cursor 为 AI Agent 创建 Git Worktrees:Cursor 现在会自动创建 Git worktrees 如这里所讨论,允许用户在不同的分支上并行运行多个 AI Agent 实例。
- 该版本的发布引发了称赞、技巧分享以及关于设置和端口使用的提问,一些人表达了它所开启的潜在用例。
- Grok 4.20 提升 Pythonic 逻辑:Elon Musk 透露 Grok 4.20 可以将逻辑从 Python 泛化到其他语言,根据这条推文。
- 有人推测 Grok 5 表现优于 Andrej Karpathy 将意味着真正的 AGI,引发了时间表和软件创作的辩论。
- Krea AI 开启视频洪流:Krea AI 开源了 Krea Realtime,这是一个从 Wan 2.1 蒸馏而来的 14B 参数自回归文本生成视频模型,在单块 NVIDIA B200 上能以 11 fps 的速度生成视频,如这里所述。
- 该发布引发了用户对 ComfyUI 工作流、RTX 5090 性能以及微调支持的兴趣。
Latent Space ▷ #ai-announcements (6 条消息):
Lightning Pods, X-Ware.v0, Elie 的 2025 预训练现状播客
- Lightning Pods 发布通知:一位成员宣布他们本周末发布了一些值得关注的 lightning pods,并链接到一条 推文 以获取更多背景信息。
- X-Ware.v0 发布:团队发布了 X-Ware.v0,这是一份 Elie 2025 “预训练现状”播客回顾。
- Elie 发布预训练播客回顾:Swyx 发布了一段采访,Elie Bakouch 将他最新的预训练演讲浓缩为 1 小时的深度探讨。
- 主题包括 Muon、DeepSeek NSA、Ari Morcos 的 BeyondWeb,以及像 Nanotron 和 DataTrove 这样的开源 HF 工具;Swyx 还征求其他高价值、未录制演讲的建议以便保存。
Latent Space ▷ #private-agents (14 条消息🔥):
NPU 编程, AMD 的 NPU 方案, eGPU, tinygrad 的 eGPU 支持, RTX 3090 购买指南
- NPU 需要精简编程?:人们对 NPU 编程的复杂性表示担忧,推测 AMD 的成功取决于简化流程,正如 这条推文 中所强调的。
- Tinygrad 在 Apple Silicon Mac 上释放 NVIDIA eGPU 性能:tiny corp 团队宣布公开测试其纯 Python 驱动程序,支持在 Apple-Silicon MacBook 上通过任何 USB4 eGPU 扩展坞使用 30/40/50 系列 NVIDIA GPU(以及 AMD RDNA2-4),详见 此公告。
- eGPU 买家分享二手 RTX 3090 购买技巧:Taha 分享了购买二手 RTX 3090 的经验教训:亲自会见卖家,携带便携式 eGPU 测试设备,使用 nvidia-smi 验证识别情况,运行 memtest_vulkan,可选运行 gpu-burn,并监控温度,详见 这条推文。
Latent Space ▷ #genmedia-creative-ai (8 条消息🔥):
AI 生成的奢华逃避主义,Endless Summer AI 照相馆
- AI 生成的奢华逃避主义满足梦想:Tim Wijaya 分享了一项由 OpenAI 资助的研究,揭示了在拥有 3 万成员的印尼 Facebook 群组中,月收入低于 400 美元的低收入用户会发布自己与兰博基尼合影、身处巴黎或在 Gucci 商店的 AI 照片 (链接)。
- 讨论围绕这究竟是纯粹的地理因素还是与社会经济地位有关展开,并将其与过去的“好莱坞梦”、生成式 AI 照片应用以及通过游戏进行的虚拟旅行进行了对比。
- Laurent Del Rey 的 Endless Summer 上线:开发者 Laurent Del Rey 发布了她首个独立构建的 iOS 应用 —— Endless Summer,这是一个可以生成虚假度假照片的 AI 照相馆 (链接)。
- 网络上的热烈反响吸引了朋友和陌生人分享喜爱之情,并对未来模型改进寄予厚望。
Eleuther ▷ #general (95 条消息🔥🔥):
RTX 3090 上的 LLM 训练速度,保持连贯性的最小模型尺寸,预训练 vs 微调,EleutherAI Discord 服务器标签
- RTX 3090 上的 LLM 训练 TPS 之争:成员们讨论了在 RTX 3090 上训练 30M 参数 LLM 的预期速度,估计范围从每秒数百到数千个 token (TPS)。
- 一位成员报告称,在 4090 上使用 30m rwkv7 bsz 16 seqlen 2048 达到了 120 kt/s,因此预期 TPS 可达数千。
- 小型 Transformer 的连贯性难题:一位成员询问预训练语言模型时保持连贯性所需的最小模型尺寸,质疑 30M 参数 是否足够。
- 建议包括探索 100M 参数 左右的模型,例如 512 窗口的 Bert 模型 或 124M 左右的 GPT2。
- 预训练的长征 vs 微调的尝试:成员们辩论了从头开始预训练与微调的优劣,其中一位成员表示有兴趣为了好玩而预训练一个模型。
- 另一位成员建议从常规微调开始,并分享了一篇关于微调小型 distilBERT 以分析推文和股票的博客文章,认为这是一个更简单的选择。
- EleutherAI 徽章:服务器标签探索:成员们讨论了创建一个类似于角色图标的 EleutherAI Discord 服务器标签的可能性,以便用户展示。
- 图标选项相对有限,目前正在征求社区对潜在设计和 Logo 的意见(例如,一个类似于 Logo 的水滴),如附带的 截图 所示。
{kind=link}
Eleuther ▷ #research (37 条消息🔥):
Attribution graphs, Diffusion models vs LLMs, Continuous and binary rewards in RL, Evaluation-awareness experiments, NormUon optimizer
- 归因图(Attribution Graphs)扩展至 MLP 之外!:讨论了最初应用于 MLP 的归因图是否可以扩展到 Attention 机制,灵感来自这个视频。
- 有人指出 Anthropic 在后续文章中对此进行了探索,详见论文 Tracing Attention Computation Through Feature Interactions,该论文将归因图扩展到了 Attention,而原始的 Biology of LLMs 论文在冻结 Attention 的情况下仅研究了 MLP,此外还有论文 https://arxiv.org/abs/2510.14901。
- Diffusion 模型 vs. LLMs:FLOPS 与内存访问:有人提到 Diffusion 模型比 LLMs 更耗费 FLOPS,这使得某些方法适用于它们,而 LLMs 在推理过程中由于随机路由面临内存访问开销,阻碍了 Kernel 优化技术。
- 有人反驳称 TREAD 仅在训练期间应用,且 FLOPS/fwd 的改进只是收益的一小部分。
- 有限样本证明被“逗号”化了!:一场讨论批评了 AI 论文的写作风格,特别是关于逗号的使用,参考了论文 https://arxiv.org/abs/2510.14717。
- 一位成员调侃道 我真心认为,如果给作者设定逗号限制,一半 AI 论文的写作质量都会提高,另一位成员回应道 那他们就会改用分号或破折号 (em dashes)。
- NormUon 优化器登场:一位成员提到一种新的优化器,如果结果良好,它看起来具有 SOTA 潜力。
- 多个来源表示 在非 speedrun 设置下,它的性能与 Muon 相同,但具有良好的 Muon 基准,并观察到
modded-nanogpt does qk norm which is one way you can avoid logit blowups.
- 多个来源表示 在非 speedrun 设置下,它的性能与 Muon 相同,但具有良好的 Muon 基准,并观察到
- Logit 爆炸与权重分布:讨论围绕特定的 Muon 变体是否通过归一化神经元级范数更新来改善 Logit 爆炸问题,以及它与 Kimi k2 的 Attention Clipping 的关系。
- 建议是 NormUon 优化器即使没有 Clipping 也应该比 Muon 有所改进,因为 更平滑的权重分布本质上对稳定性更有利,特别是由于没有 Clipping 的更新会增加权重的谱秩 (spectral rank)。
Eleuther ▷ #interpretability-general (13 messages🔥):
Anthropic's Biology of LLMs paper, Cross layer transcoders with attribution graphs for diffusion models, Finetuning Llama-3 to count words, Subtracting the space_direction, Decoupling data complexity from model complexity
- Anthropic 的 Biology 论文扩展了归因图 (Attribution Graphs):Anthropic 最初的 Biology of LLMs 论文 专注于 MLPs,但一篇新论文将 attribution graphs 扩展到了 attention mechanisms,详见这条推文和这条推文,并附有论文链接。
- 科学家们似乎观察到了 将数据复杂度与模型复杂度解耦 以及 在输出中发现模式层级 (hierarchies of modes),这看起来非常迷人。
- Llama-3 在消融 (Ablation) 后难以进行计数:一位成员微调了 Llama-3 以进行单词计数,并观察到通过减去
1.0 * space_direction来消融 “has_space” 方向后,计数仅从 9 降至 8,而非预期的 7。- 他们阐明其 space_direction 是来自一个 2 类 nn.Linear probe 的差异向量 (W_1 - W_0),其中 W_1 代表 “has_space”,W_0 代表 “not_space”。
- 减去空间方向并不能移除所有的空间方向:一位成员指出
act - 1*space_direction并不能移除所有的空间方向。- 另一位成员引用了这篇论文的图 1作为一个有帮助的例子来解释原因。
- 希望论文中能提供具体的特征学习 (Feature Learning) 示例:一位成员对一篇关于 3M model 的论文没有提供训练中出现的 feature learning 具体实例表示失望。
- 他们引用了论文中的话:正如发育生物学家通过追踪细胞分化来理解器官形成一样,我们现在可以可视化 token 模式如何在敏感度空间 (susceptibility space) 中分化和组织,揭示专用电路 (specialized circuits) 何时以及如何出现。
- 关于扩散模型中跨层 Transcoder 的询问:一位成员询问是否有人探索过在 diffusion models 中将 cross-layer transcoders 与 attribution graphs 结合使用。
Eleuther ▷ #lm-thunderdome (1 messages):
Eval Harness, lm-evaluation-harness, MMLU, repeats
- Eval Harness 会议已安排:已安排一次会议讨论 eval harness 的新增功能,重点是分享当前计划并收集库用户的反馈,详情可在 When2Meet 查看。
- 主要更改位于此分支。
- Eval Harness UX 重构即将到来:团队正针对常见的痛点使 harness 更加直观,关键改进包括:用于轻松转换格式的新模板、标准化格式、使 instruct 任务更直观以及常规的 UX 改进(例如
repeats)。- 他们的目标是实现任务变体之间更轻松的转换(例如 MMLU -> cloze -> generation)。
Moonshot AI (Kimi K-2) ▷ #general-chat (139 messages🔥🔥):
DeepSeek vs Moonshot, Groq's Kimi Implementation, Kimi K2 Troubleshooting, Prediction Markets, Quant Trading
- Moonshot AI 对比 DeepSeek AI:一位用户表达了对 Moonshot AI 的 Kimi 优于 DeepSeek 的偏好,尽管承认这仅代表个人观点。
- Groq 的 Kimi 实现遇到小问题:据一位用户称,Groq 对 Kimi 的实现经历了一段不稳定时期,在恢复正常之前存在间歇性的功能问题。
- Kimi K2 协助排除电脑故障:一位用户称赞了 Kimi K2 提供可靠故障排除建议的能力,甚至建议使用 verifier 来对可能导致 BSODs(蓝屏死机)的驱动程序进行压力测试。
- Kimi K2 在预测市场表现出色:一位用户分享说,Kimi K2 是目前处理预测市场(prediction markets)最好的模型,并一直在为此使用 Kimi K2。
- 关于 MCP CLI 工具的讨论:用户讨论了各种用于 MCP 服务器和模型的 CLI 工具,如 DeepSeek、GLM Coder 和 Qwen,并强调 Claude Code 和 Qwen-code 是可靠的选择。
- 共识是 Codex 仅在与 OpenAI 模型配合使用时才是理想的。
Nous Research AI ▷ #general (94 条消息🔥🔥):
GLM 4.6, Claude's Coding Monopoly, AI Learning Resources, LLM Reasoning, OS Model Development
- GLM 4.6 废黜闭源模型:随着可在本地运行的 GLM 4.6 发布,开源(OS)社区正寻求摆脱对 Sam Altman、Elon Musk 和 Dario Amodei 等人所属闭源模型的依赖,参考此 YouTube 视频。
- 面向 AI 新手的哈佛课程:对于具备一定计算机科学知识并想进入 AI 领域的人来说,哈佛大学的 CS50 Introduction to Artificial Intelligence with Python (pll.harvard.edu) 以及这个 YouTube 播放列表 可能是个不错的起点。
- 学习者应该掌握 Attention 等式、Transformer 的工作原理以及 Loss Functions(损失函数),并查阅百度、腾讯或阿里巴巴的技术报告。
- Vercel 遭遇重大故障:Vercel 经历了严重的停机,导致其聊天和门户服务均无法使用。
- 此次故障与 AWS 的更广泛问题有关,影响了包括订餐平台在内的多种服务。
- 中国 LLM 热潮:新型 中国 LLM 的兴起引发了关于是否有必要存在多个模型的争论,因为目前已经有像 Qwen 这样强大的竞争者。
- 内部竞争也非常激烈,例如 蚂蚁集团 的 零一 (Ling) 模型与 阿里巴巴 的 Qwen 团队是相互独立的。
- Nous Research 推动去中心化:Nous Research 通过开源方法论和基础设施实现(如 Psyche)来拥抱去中心化,参考链接 Nous Psyche 和 斯坦福论文。
- 一位成员表示:“Nous 通过其开源方法论和基础设施实现成功实现了去中心化。”
Nous Research AI ▷ #research-papers (8 条消息🔥):
Sampling method, AI Safety, Clinical AI, Healthcare AI
- 采样方法扩展研究:一位成员分享了一篇关于新型采样方法的论文,该方法具有科学依据并由参数 N 控制。
- 另一位成员指出,这几乎像是这项研究的延伸,并好奇 Post-training(后训练)是否可以被形式化为一个采样问题,建议在 DeepSeek-Base/Instruct 等现代模型上进行测试。
- 临床/医疗 AI 的安全关注:一位成员正专注于 AI 安全,提议开展临床/医疗 AI 研究,以创建和评估 AI 模型的基准(Benchmarks)。
- 他们正在寻求关于这是否是一个好的研究课题的反馈,并参考了 2025 年国际 AI 安全报告 以纳入通用的行业标准。
Nous Research AI ▷ #interesting-links (2 条消息):
ScaleRL for Sparse Models, Trajectory vs Sample Level Loss Aggregation, Iterative RL Reasoning
- ScaleRL 非常契合稀疏推理模型:Meta 最近发表的 Art of Scaling RL 论文表明,ScaleRL 似乎几乎是为稀疏(如 MoE)推理模型量身定制的。
- 轨迹级 vs 样本级聚合:问题在于:对于 Iterative RL(推理),轨迹级损失聚合粒度是否总是优于样本级?
- 有人指出,轨迹级聚合保留了长程信用分配(Long-range credit assignment),但会遗忘迭代改进,而模型可能会向记忆式的模式模仿漂移。
- 通过迭代和多样性优化 RL:由于 Reward Credit(奖励信用)是粗粒度且全局的,RL 目标可能缺乏鼓励改进或在相似提示词间保持多样性的手段。
- 有人建议 Step/Steps(迭代)级别可能是调优的折中方案。
Nous Research AI ▷ #research-papers (8 条消息🔥):
Sampling Method, International AI Safety Report 2025, Healthcare AI Safety
- 关于采样方法的论文引发讨论:一名成员分享了一篇论文,引发了对其采样方法的讨论,其中一位成员认为它类似于 MCTS,但更好,因为它具有良好的科学依据。
- 另一位成员指出,这像是对之前讨论的扩展,并希望作者能在 DeepSeek 等现代模型上测试该方法。
- 医疗保健 AI 安全研究提案:一名成员提议开展以临床/医疗应用为重点的 AI safety 研究,旨在为具有精确准确度的 AI 模型创建基准。
- 他们链接了 International AI Safety Report 2025,并询问大家是否认为这是一个好的研究课题。
Manus.im Discord ▷ #general (107 条消息🔥🔥):
Manus infrastructure outage, Manus credits disappearing, Free perplexity pro, Open Sourcing Manus, Manus google drive connection
- Manus Google Drive 连接恢复了吗?:用户确认通过点击 + 按钮并添加文件,Manus 可以连接到 Google Drive,尽管它尚未作为已连接的应用提供。
- Manus 项目文件消失,积分也丢了!:一位用户报告称,在构建网站并花费 7000 credits 后,项目中的所有内容(包括文件和数据库)全部消失,且客服未能提供有效帮助。
- 另一位用户也反映了类似情况,称损失了近 9000 credits,且找不到任何文件或预览。
- 低成本创建 Manus MVP Android 前端应用:一位用户使用 525 Manus credits 制作了一个 Android 前端应用 MVP,随后使用 Claude 修复了问题。
- 该用户称赞了 Manus 的 UI/UX 能力,并分享了应用的图片。
- Manus 遭遇基础设施故障:由于基础设施提供商的问题,Manus 经历了临时停机,某些地区的某些用户在访问首页时仍面临错误。
- 团队沟通了更新并感谢用户的耐心,报告称大多数 Manus 服务已恢复在线。
- 免费 Perplexity Pro 推广引发 Discord 混乱:一位用户分享了免费一个月 Perplexity Pro 的推荐链接,引发了另一位用户的负面反应,后者叫他 Stfu!(闭嘴)并 Get a job(找个正经工作)。
- 根据分享链接的用户,这是一种没有戏剧性、没有谎言、没有标题党的赚取真钱的方式。
Modular (Mojo 🔥) ▷ #general (54 messages🔥):
Mojo 编译器自托管?, Mojo 与 MLIR, MAX Kernels 后端, MAX 动态形状的优势, Mojo vs Python
- Mojo 编译器:现在是 C++,以后是 Mojo?:Mojo 编译器使用 LLVM 并与其紧密绑定,下层到 MLIR;除非 Mojo 吸收了 LLVM,否则不太可能实现完全的自托管。
- 虽然完全用 Mojo 重写是可能的,但被认为工作量巨大且收益有限,不过 C++ 互操作性(interop)可能会让未来实现这一点变得更容易。
- Mojo,MLIR 的 DSL:灵活的基础:Mojo 实际上充当了 MLIR 的 DSL,直接解析为 MLIR 并使用它来代替普通的 AST,这赋予了它极大的灵活性。
- Mojo 采用了众多方言(dialects),除了 LLVM dialect 之外,大多数都是全新的,使其能够适应各种计算需求。
- MAX Kernels:Mojo 针对 PyTorch 的秘密武器:人们有兴趣将 JAX 的后端切换为使用 MAX kernels,作为一个有趣的项目,可能会与 C++ 进行接口对接,而且目前已经有一个基本可用的 PyTorch 的 MAX 后端。
- Mojo 可以
@export(ABI="C")任何兼容 C-abi 的函数,但目前要与 MAX 通信,仍需使用 Python。
- Mojo 可以
- 动态形状:MAX 的优势:一位成员提到,通过解释 jaxpr 来构建 max 图是可能的 (jax.dev)。
- 有人指出,使用 MAX 而不是针对 XLA 的 Mojo 封装,可以保留 动态形状 (dynamic shapes) 等优势。
- Mojo 的目标:防止 Python 式的分裂:Mojo 的目标是通过提供在更具 Python 风格的
def和更具系统编程风格的fn代码之间转换的方法,来防止 Python 用户与 CPython 用户之间的分裂。- 一位成员表示,目标是保留底层控制的门径,同时提供安全的默认方式,防止用户“搬起石头砸自己的脚”;希望我们能实现这一目标。
Modular (Mojo 🔥) ▷ #mojo (12 messages🔥):
Mojo 中的 UDP Sockets, Mojo vs Rust vs C++, Mojo 中的 itertools 包
- Mojo 讨论 UDP Socket 支持:用户询问了 Mojo 中 UDP socket 的支持 情况,并获知虽然可以通过 libc 实现,但仍需等待标准库的完整支持以实现规范化。
- 回复指出,更倾向于“做对而不是做快”,并指出“语言级依赖”是一个考量因素。
- Mojo 与 Rust/C++ 相比的通用编程前景:用户询问 Mojo 是否是一种通用编程语言,以及是否可能替代 Rust 和 C++。
- 回复表明 Mojo 旨在成为通用语言,目前的优势在于数值计算,并且“一旦完成”,有可能取代 Rust 和 C++。
- Mojo 添加 itertools 包引发讨论:Mojo 通过 此提交 添加了
itertools包,引发了关于模仿 Python 模块结构的疑问。- 担忧主要集中在:这是否会导致与 Python 行为 产生分歧,从而阻碍更高效方案的产生,还是应该通过扩展创建 Python 兼容层。
Modular (Mojo 🔥) ▷ #max (4 messages):
PyTorch 的 Max 后端, PyTorch Nightly 的使用
- 寻求 PyTorch 的 Max 后端:讨论了为 PyTorch 构建优质 max 后端 的路径,并指向了 此 GitHub issue。
- 一位成员提到 Han Qi 是 GOAT。
- PyTorch Nightly 引入 torch-max-backend:在主分支中开始 使用 PyTorch Nightly 的原因之一是为了获取 Han Qi 在 PyTorch 中最近提交的一个 PR。
- 这需要 Han Qi 在 PyTorch 中一个非常新的 PR,因此与之相关。
DSPy ▷ #show-and-tell (1 条消息):
LM Studio, DSPy framework, llms.txt generator
- LM Studio 获得了由 DSPy 驱动的 llms.txt 生成器:一位成员分享了一个为 LM Studio 开发的 llms.txt 生成器,该工具由 DSPy framework 驱动。
- 该工具允许用户为缺少
llms.txt的仓库轻松生成该文件,并能利用 LM Studio 中可用的任何 LLM;该成员建议使用 “osmosis-mcp-4b@q4_k_s” 来生成示例产物。
- 该工具允许用户为缺少
- Github 上的 lms-llmsTxt:Github 用户 AcidicSoil 已在 Github 上的 lms-llmsTxt 发布了相关文件。
- 这是一种为任何可能没有
llms.txt的仓库生成该文件的简便方法,几乎可以使用 LM Studio 中提供的任何 LLM。
- 这是一种为任何可能没有
DSPy ▷ #general (64 条消息🔥🔥):
Claude Agents, Clojure REPL environments, Typing DSPy, Gemini models in DSPy, RLM implementation
- 在 DSPy 程序中集成 Claude Agents:成员们讨论了在 DSPy 中集成 Claude agents,并参考了一个示例,其中有人实现了一个 Codex agent。
- 一位成员表示,他们希望看到有人实现这一点,特别是针对 Claude code,并提到了由于缺乏 SDK 而遇到的困难。
- DSPy 的 Clojure 考量:一位成员提出了在 Clojure REPL 环境中使用 DSPy 的问题,强调了在数据表示、由于不可变性导致的并发 LM calls 以及检查生成函数方面的潜在差异。
- 这引发了关于将 DSPy 适配到不同编程范式的挑战的讨论。
- DSPy 的类型标注 (Typing):成员们讨论了对 DSPy (Python) 进行完全类型标注的状态,以及 Python generics 是否足以满足此目的。
- 一位成员肯定了这是可行的,重点在于优化 input handle/initial prompt,但警告说在没有明确任务和评分机制的情况下不要进行优化。
- Gemini 模型与 DSPy 配置:一位用户询问如何在 dspy.lm 中使用 Gemini models,成员们澄清说,通过设置正确的配置并提供相应的 API key 是可以实现的。
- 一位成员幽默地谈到了寻找正确 API key 的“痛苦旅程”,建议使用 AI Studio 而不是控制台。
- 使用 DSPy 处理扫描版 PDF:用户讨论了 DSPy agents 读取扫描版 PDF 的方法,提到的选项包括将 PDFs 转换为图像,以及使用具备 VLM/OCR 能力的 LLMs(如 Claude Code)。
- 另一位成员建议使用带有原生 Gemini API 的
read_pdf工具,或者指向了一篇关于使用 PaddleOCR 的指南。
- 另一位成员建议使用带有原生 Gemini API 的
Yannick Kilcher ▷ #general (38 条消息🔥):
Weekly tautological counter, Reinforcement learning framework for PyTorch, Graph neural networks, AI engineer qualifications, ML Debugging interviews
- Tianshou:强化学习库浮出水面:一位成员询问是否有适用于 PyTorch 的强化学习框架,另一位成员推荐了 Tianshou 作为一个可行的选择。
- 该建议还附带了一个关于其与 Graph neural networks 相关性的轻松评论。
- 定义“AI Engineer”:LinkedIn vs. 现实:讨论围绕着什么构成了 “AI Engineer” 这一问题展开,有人开玩笑说在 Python 中使用 OpenAI API 就能在 LinkedIn 上获得这一头衔。
- 其他人则调侃说,即使是在可视化的 n8n 中组装 Legos 或创建一个自定义 GPT 也就足够了。
- 应对 ML Debugging 面试准备:有人征求关于如何准备 “ML Debugging” 编程面试的建议,一位成员建议准备好讨论如何处理过拟合 (overfitting)。
- 另一位成员指出 ChatGPT 是一个潜在的模拟面试工具。
- IntelliCode 的“读心术”能力:一位成员分享了在 Visual Studio 中使用 Microsoft’s IntelliCode 的经验,指出其在预测和建议代码补全方面的惊人能力,尤其是在提供大量上下文的情况下。
- 该成员详细说明,该模型的有效性源于它接收到的丰富上下文,包括类、打开的文件和最近的代码元素。
Yannick Kilcher ▷ #paper-discussion (18 messages🔥):
Lip Movement Algorithm, Paper Machine Unlearning, Backscatter IoT Applications, RL Training-Free Sampling Method
- Mouth Sync 算法探索开启:一名成员正在寻找一种优秀的开源 lip movement algorithm(唇部动作算法),用于匹配音频以现代化一段旧的喜剧演讲。
- 推动 Paper Machine Unlearning 进入 ArXiv 类别:成员们讨论了将 paper machine unlearning & knowledge erasure(机器学习退学与知识擦除)提升为独立的 arXiv 类别(cs.UL/stat.UL)。
- Backscatter IoT 拥有出色的低功耗方法:Backscatter 通常是 low-energy IoT applications(低功耗物联网应用)的一种极佳方法,华盛顿大学在过去几年中对此进行了一些出色的研究。
- RL Training-Free Sampling 方法:一名成员分享了一篇论文链接,该论文介绍了一种 training-free sampling method(免训练采样方法),在许多 zero shot 任务上能匹配经过 RL 训练的推理能力 (https://arxiv.org/abs/2510.14901)。
Yannick Kilcher ▷ #agents (2 messages):
AI Agent Movie Inspiration, Voice integration
- AI Agent 为人类提供有用的工具:一名成员从一部电影中获得了灵感,电影中的 AI agent 为人类提供了工具。
- 他们认为这对 agent 开发很有启发,因为我目前也在研究 voice(语音)功能。
- Voice 集成令人振奋:那位喜欢 AI agent 电影 的成员现在正在研究 voice。
- 该 agent 为人类提供了 有用的工具。
Yannick Kilcher ▷ #ml-news (5 messages):
Qwen3 Vision Model, aidaw.com, Unitree Robotics, DeepSeek-OCR
- Qwen3 视觉能力:新的 Qwen3 Vision model 已经发布,可在 Hugging Face 上获取。
- aidaw 发布新动态:一名成员分享了 aidaw.com 的链接。
- Unitree Robotics 动态:一名成员分享了 UnitreeRobotics 的链接。
- DeepSeek 关注 OCR:一名成员分享了 DeepSeek-OCR 的链接。
aider (Paul Gauthier) ▷ #general (32 messages🔥):
Aider Status and Roadmap, Integrating Agentic Extensions into Aider, Devstral Small Model Feedback, aider-ce vs Codex CLI
- **Aider 的近况:并未停更,只是节奏放缓!:用户讨论了 Aider 的状态,一些人因发布速度变慢而怀疑它是否已停更,但其他人澄清说它并未停更,只是发布较慢,且使用 **aider-ce 可以获得更近期的更新。
- 一名用户提到最近克隆了仓库,并计划在接下来的几周内熟悉代码库,通过增加 GitHub contributors 报告的提交频率来帮助恢复项目的势头。
- **Aider 的演进:Agentic 扩展集成?:一名开发者正在使用 **LangGraph 为 Aider 创建一个 agentic 扩展,功能包括任务列表、RAG 和用户命令处理,并询问是将其直接集成到 Aider 中还是作为一个独立项目。
- 强调了保持 Aider 简单直接的核心理念,目标是在不牺牲其核心功能的情况下与顶级 agent 解决方案竞争。
- **Devstral 小型模型大放异彩!**:一名用户报告在配备 32GB RAM 的笔记本电脑上使用
Devstral-Small-2507-UD-Q6_K_XL模型获得了出人意料的好结果,称赞其自我纠错能力、处理大上下文的能力,以及在 PHP、Python 和 Rust 等各种编程任务中的出色表现,甚至支持图像。- 他们认为该模型在 Aider 基准测试中理应获得更好的认可,指出其表现优于
Qwen3-Coder-30B-A3B-Instruct-UD-Q6_K_XL,并强调了其架构思维和工具使用能力,推荐使用 Unsloth 的 XL 量化版本。
- 他们认为该模型在 Aider 基准测试中理应获得更好的认可,指出其表现优于
- **Aider-CE 在对抗 Codex CLI 中引起关注*:在测试了 gemini-cli、opencode 和 Claude(配合 claude-code-router 使用 DeepSeek API)之后,一名用户切换回 Aider 作为主要工具,强调了其复杂的基于 grep 的代码搜索/替换系统和自动更新的待办事项列表(配合 –yes-always 使用,效率更高!*)。
- 该用户还指出了 Aider 在编程任务中简单直接的价值,保留了原始 /ask 和 /architect 模式的功能,以及 .aider.conf.yml 中 MCP 格式化的价值。
aider (Paul Gauthier) ▷ #questions-and-tips (5 messages):
Commit Message 推理, 只读文件, Aider 风格指南
- 禁用 Commit Message 的推理功能?: 用户询问是否可以禁用 Commit Message 的推理功能,理由是通过 OpenRouter 使用 Deepseek V3.1 Terminus 生成单行消息耗时过长。
- 另一位用户建议在资源中复制 API 的推理内容,并将新别名设置为一个弱模型。
- 处理只读文件: 用户询问在使用 Aider 时管理只读文件的最佳实践。
- 该用户提到,有时他们会有一些额外的文件,并希望将它们设为只读。
- Aider 风格指南策略: 用户询问如何向 Aider 提供适当的风格指南。
- 一位成员建议将风格指南放入文件中,并使用
--read CONVENTIONS.md加载,同时告知 Aider 配置始终以只读方式加载此类文件。
- 一位成员建议将风格指南放入文件中,并使用
tinygrad (George Hotz) ▷ #general (12 messages🔥):
nanochat, SHRINK 和 PAD, 外部 PR 的 CI, usb gpu, MFLOPS 和 MB/s
- Karpathy 发布 nanochat: Andrej Karpathy 发布了 nanochat,这是一个极简的聊天应用程序。
- 发布者质疑这次发布的意义有多大。
- 从 SHRINK 和 PAD 中移除左侧参数: 一位成员正在处理一项悬赏任务,旨在 从 SHRINK 和 PAD 中移除左侧参数 (left side arg)。
- 原始悬赏在 Discord general 频道 中进行了详细讨论。
- tinygrad 告别 ShapeTracker: tinygrad 计划在第 92 次会议期间弃用 ShapeTracker。
- 会议期间的讨论点包括:公司更新、告别 shapetracker、usb gpu、多输出 kernel、rangeify 回归、openpilot、resnet、bert、FUSE_OPTIM、assign、更多清理工作、viz、driver、tiny kitten、更多 symbolic?、其他悬赏、新 linearizer、新 clang2py。
- 贡献者请求添加 MFLOPS 和 MB/s: 一位贡献者请求在 DEBUG=2 行中以黄色添加 MFLOPS 和 MB/s。
- 他们要求实现者编写 整洁的代码,不要使用 你不理解的 AI 代码!
- macOS Nvidia 驱动程序成真了: 成功制作了适用于 macOS 的 Nvidia 驱动程序。
- 确保运行
brew tap sirhcm/tinymesa以使其正常工作。
- 确保运行
tinygrad (George Hotz) ▷ #learn-tinygrad (5 messages):
梯度累积, TinyJit, 手动梯度除法
- 多次调用 Backward 时梯度累加: 一位成员询问在调用
optimizer.step之前多次调用backward是否只是简单地累加梯度贡献,并确认事实似乎确实如此。 - TinyJit 中的梯度累积问题: 一位成员质疑 model_train.py 中关于梯度累积的数学逻辑,怀疑它在 TinyJit 中已损坏。
- 另一位成员确认遇到了梯度累积问题,并使用 assign 重写了梯度加法步骤以使其生效。
- 通过手动梯度除法使梯度累积生效: 一位成员通过设置
reduction=sum、手动计算非填充 token、对每个 microbatch 执行 backward 然后除以梯度,成功实现了梯度累积。
MCP Contributors (Official) ▷ #general (5 条消息):
MCP Access, Webrix MCP Gateway, Docker MCP Gateway Multi-Tenant, MCP auth extension, oauth scope granularity
- DevOps 管理员寻求安全的 MCP Access 解决方案:一位 DevOps 管理员正在寻求为组织内的非技术用户安全提供 MCP access 的方法,旨在避免管理密钥并实现 Identity Provider (IDP) 层。
- 他们正在考虑 Webrix MCP Gateway 以及 使 Docker MCP Gateway 支持多租户 (multi-tenant),并向之前讨论过使用 Okta 保护 MCPs 的用户寻求建议。
- Enterprise Managed Auth Profile 成为解决方案:一位成员指出,enterprise managed auth profile 正是为这种用例设计的,并正作为 MCP auth extension 发布。
- 然而,有人指出细粒度权限目前仅限于 oauth scope granularity。
- Discord 面向贡献者:有人指出,该 Discord 并非面向技术支持,而是旨在促进 MCP protocol 及其相关项目贡献者之间的交流。
- 寻求帮助的用户被鼓励通过私信 (DM) 获取更合适社区的链接。