AI News
Kimi K2 Thinking:1万亿总参数/320亿激活参数,在 HLE、BrowseComp、TauBench 评测中达到 SOTA(业界领先)水平;同时,Soumith 宣布离开 PyTorch。
月之暗面(Moonshot AI)推出了 Kimi K2 Thinking,这是一个拥有 1 万亿参数的混合专家(MoE)模型,其中包含 320 亿激活专家参数。该模型具备 256K 上下文窗口,并采用了原生 INT4 量化感知训练。它在 HLE (44.9%)、BrowseComp (60.2%) 等基准测试中取得了行业领先(SOTA)的成绩,并在智能体(agentic)工具使用方面支持 200-300 次连续工具调用。
该模型支持 vLLM 部署和 OpenAI 兼容的 API,目前已在 Arena、Baseten 和 Yupp 等平台上线。早期用户报告显示,在发布初期的负载压力下,API 存在一定程度的不稳定性。
与此同时,谷歌发布了 TPU v7 (Ironwood),其峰值性能较 TPU v5p 提升了 10 倍,旨在为 Gemini 等模型的训练和智能体推理提供动力。苹果则在 llama.cpp 中增加了对 M5 神经网络加速器的支持,以实现推理加速。
Open Weights 就足够了吗?
2025年11月5日至11月6日的 AI 新闻。我们为您查阅了 12 个 Reddit 子版块、544 个 Twitter 账号和 23 个 Discord 社区(200 个频道,5907 条消息)。预计为您节省阅读时间(以 200wpm 计算):479 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 风格展示所有往期内容。请访问 https://news.smol.ai/ 查看详细的新闻分类,并在 @smol_ai 上向我们提供反馈!
随着 Kimi 为这次发布准备开源生态系统,讨论热度已经持续高涨了一段时间,但基准测试结果令人惊讶:开源模型首次声称在重要的主流基准测试中击败了 SOTA 闭源模型(GPT5, Claude 4.5 Sonnet Thinking):
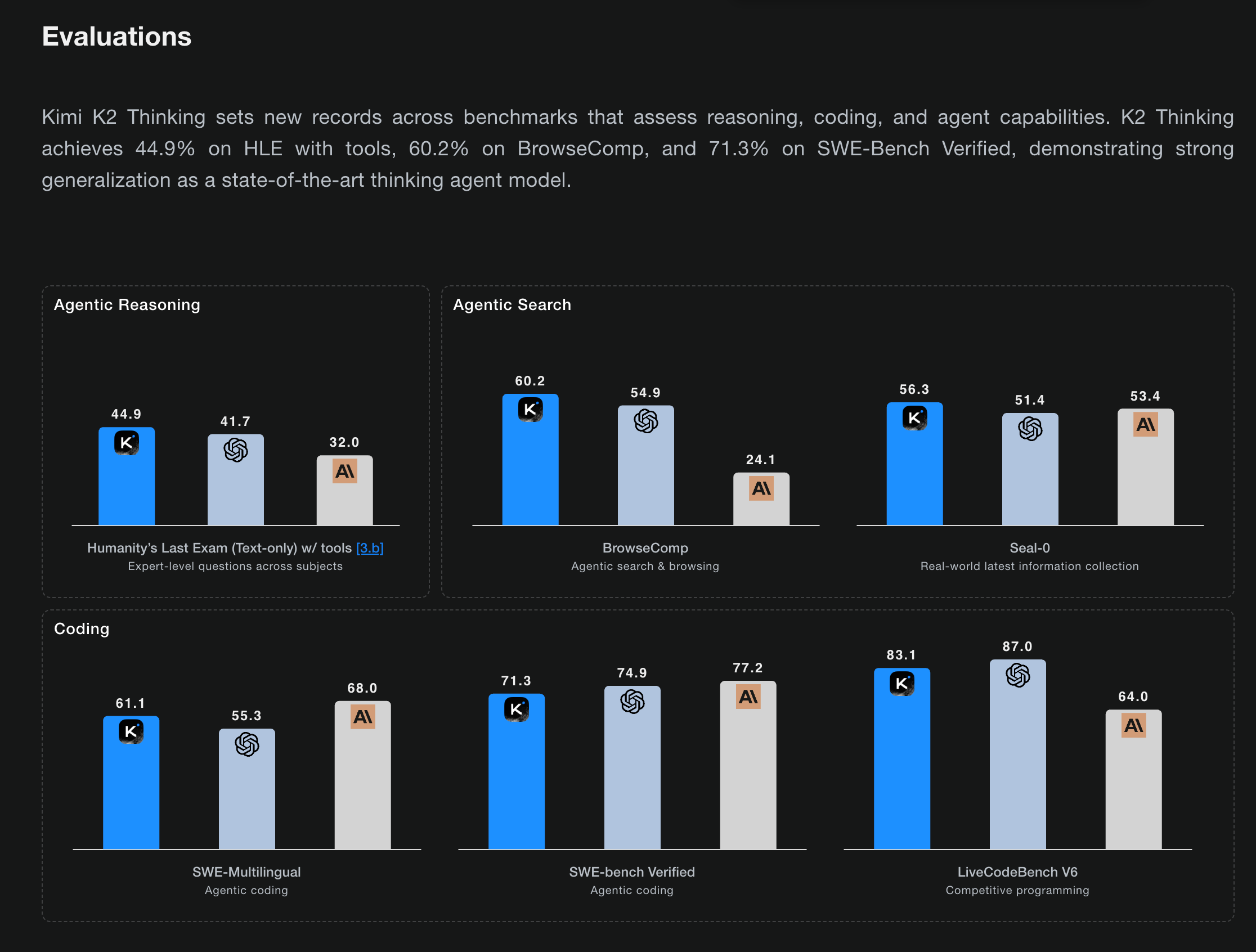
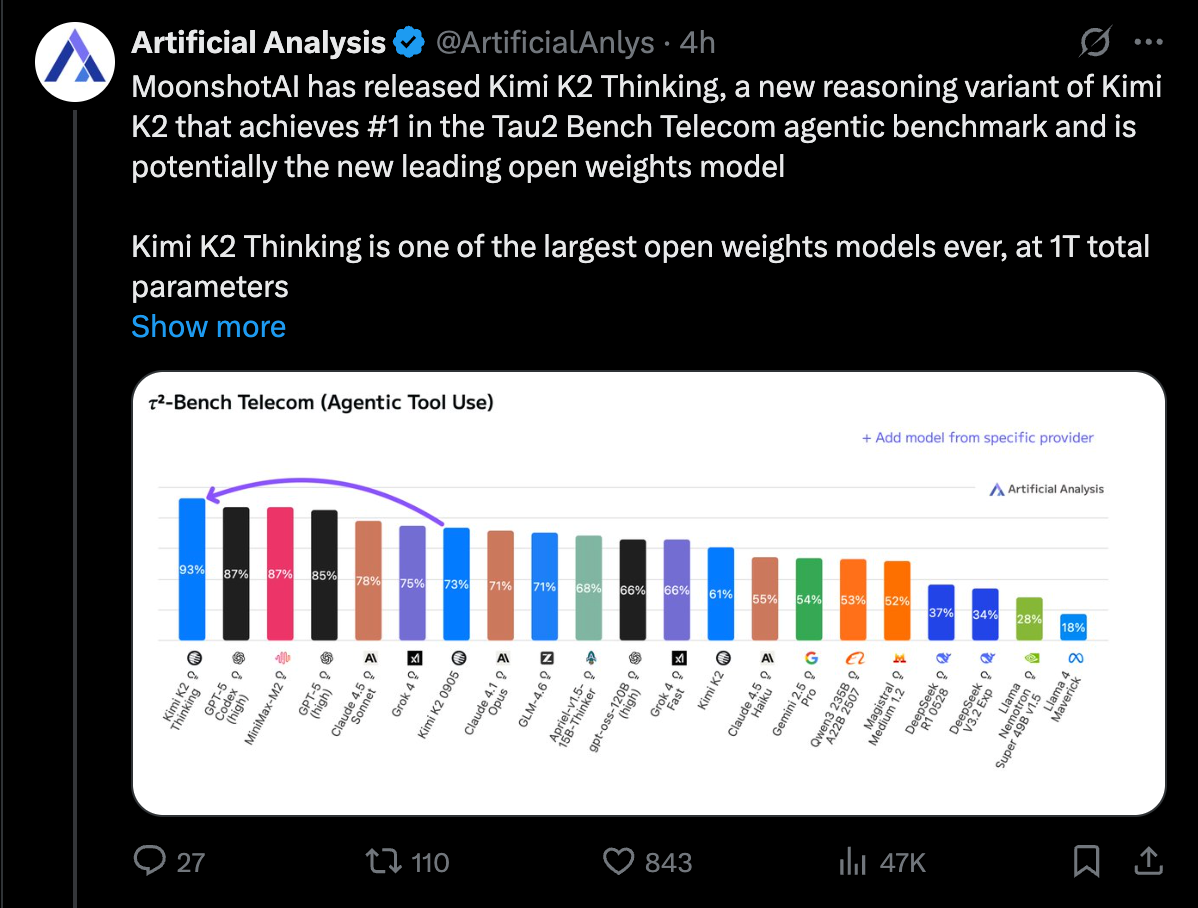
更令人振奋的是,Artificial Analysis 在其独立测试中甚至自发给出了另一个 SOTA 评价:
虽然现在还处于早期阶段,但初步体验(vibe checks)非常不错。
目前还没有论文,但模型卡片提供了更多细节,包括原生 INT4 训练,以及在 256k 上下文窗口下实现 200-300 个长程工具调用的能力。
祝贺 Kimi/Moonshot!!
AI Twitter 摘要
Moonshot AI 的 Kimi K2 Thinking:开源 1T INT4 推理 MoE,支持长程工具
- Kimi K2 Thinking (Open Weights):Moonshot AI 发布了一个拥有 1T 参数、32B 激活专家、256K 上下文窗口以及强大 Agent 能力的 MoE 模型——无需人工干预即可执行 200–300 个顺序工具调用。它在 HLE (44.9%) 和 BrowseComp (60.2%) 上达到了 SOTA,社区报告的“重度模式”(使用 8 个并行样本 + 反思)将 HLE 推高至约 51% @Kimi_Moonshot, @eliebakouch, @nrehiew_。早期的编程/Agent 结果包括 SWE‑Bench Verified 上的 71.3% 和 Terminal‑Bench 上的 47.1% @andrew_n_carr,基准测试作者 @OfirPress 和评估机构 @ArtificialAnlys 也强调了其在其他基准测试中的强劲表现。K2 Thinking 采用量化感知训练 (QAT) 对 MoE 组件进行原生 INT4 训练,据报告其生成速度约为 FP8 版本的 2 倍,内存占用减半;所有发布的基准测试数据均基于 INT4 精度 @eliebakouch, @bigeagle_xd, @timfduffy。
- 首日部署与性能说明:官方 vLLM 支持(nightly 版本)已上线,提供 OpenAI 兼容 API 和配置方案 @vllm_project。该模型已在多个端点可用(Arena/Yupp, Baseten, 以及 anycoder 和 Cline 等应用工具)@arena, @yupp_ai, @basetenco, @_akhaliq, @cline。在 Mac 上,MLX 展示了通过流水线并行在两台 M3 Ultra 上进行原生 INT4 推理(约 3.5K token,速度约 15 tok/s)@awnihannun。预计会出现短暂的不稳定性:多位用户报告在发布负载下 API 出现变慢/超时(“死亡之吻”)@scaling01, @code_star。
新 AI 芯片与推理栈更新 (TPU v7, Apple M 系列, 自适应解码)
- Google TPU v7 (Ironwood):Google 宣布其第 7 代 TPU 将在未来几周内进入 GA 阶段,其峰值性能比 TPU v5p 提升了 10 倍,单芯片性能比 TPU v6e (Trillium) 提升了 4 倍以上。定位用于训练和高吞吐量的 Agent 推理;内部用于训练和提供 Gemini 服务,并将上线 Google Cloud @sundarpichai, @Google。
- Apple 推理加速:llama.cpp 增加了对 Apple M5 Neural Accelerators (macOS Tahoe 26) 的初步支持,提升了整个 ggml 栈的 TTFT @ggerganov。另外,K2 Thinking 通过 MLX 在双 M3 Ultra 上以 INT4 格式原生运行(见上文) @awnihannun。
- 自适应投机解码:Together 的 ATLAS “自适应投机器”报告称,通过实时学习每个工作负载,LLM 推理速度最高可提升 4 倍 @togethercompute。
Agent 框架、钱包和托管 RAG
- LangChain Deep Agents for JS:Deep Agents 现已支持 TypeScript/JS(基于 LangGraph 1.0),具备规划工具、子 Agent 和文件系统访问权限。团队发布了在 Next.js 中实现流式 Agent 以及深度研究 Agent 的生产级参考教程 @LangChainAI, @bromann, @hwchase17。
- Agent 钱包与链上支付:Privy + LangChain 支持为 Agent 配置钱包以使用稳定币进行交易,使“Agent 商业”的原型设计变得简单直接 @privy_io, @LangChainAI。
- Perplexity Comet Assistant 升级:支持多标签页、多站点的 Agent 工作流,并改进了权限提示,目前正在推广中;旨在处理更长的步骤序列和并行浏览 @perplexity_ai。
- Google:Deep Research + 托管 RAG:
- Gemini 中的 Deep Research 现在可以从 Gmail、Drive 和 Chat 中提取信息,在桌面端生成更丰富、具备上下文感知能力的报告(移动端即将推出) @GeminiApp。
- Google AI Studio 的文件搜索工具(托管 RAG)提供基于 Gemini embeddings 的向量搜索、引用功能并支持常见文件类型。定价:索引费用为 $0.15/百万 tokens;查询时的存储和 Embedding 生成免费(分档:1GB 免费 → 10GB/100GB/1TB) @_philschmid。
- Agentic RAG 应用:Weaviate 的开源应用 “Elysia” 展示了决策树编排,具备动态 UI 渲染(表格/卡片/图表/文档)和全局上下文感知能力 @weaviate_io。
研究与基准测试:记忆 vs. 泛化;Agent/数据科学评估
- 解构 LM 中的记忆:GoodfireAI 表明,可以通过损失曲率(loss curvature)将 MLP 权重分解为 rank-1 分量——高曲率捕获共享/泛化结构;低曲率捕获特异性记忆。消融低曲率分量可以在保留推理能力的同时减少记忆;算术/事实检索的退化程度高于逻辑推理 @GoodfireAI, @jack_merullo_。
- 新的 Agent 和视觉基准测试:Google Research 的 DS-STAR 针对分析/数据清洗等自动数据科学任务 @GoogleResearch。MIRA(视觉推理)报告了当前模型在具有挑战性的多图像/视频推理方面的失败 @Muennighoff。
- 表格 ICL 和 Diffusion LMs:Orion-MSP 提出了用于上下文内表格学习(in-context tabular learning)的多尺度稀疏注意力机制 @HuggingPapers。Diffusion LMs 作为数据效率高的学习器继续受到关注 @_akhaliq。
开发者工具与多媒体模型
- VS Code AI 开源: VS Code 中的行内 AI 建议和 Copilot Chat 现在由一个单一的开源扩展驱动;代码和博客已上线 @code, @pierceboggan。
- 语音/视频模型: Inworld TTS 1 Max 目前在 Artificial Analysis Speech Arena 中领先;支持 12 种语言和语音克隆(模型使用 LLaMA-3.2-1B/3.1-8B 作为 SpeechLM 骨干)@ArtificialAnlys。Lightricks 的 LTX-2 在 Video Arena 排行榜上排名第三 @LTXStudio。
- 轻量级/本地模型: AI21 的 Jamba Reasoning 3B 仅需 2.25 GiB RAM 即可运行,在消费级硬件上的“微型”模型中极具竞争力 @AI21Labs。
- 安全与解析: Snyk Studio 集成到 Factory 的 AI Droids 中,在生成之初即保护 AI 生成的代码 @mnair1。LlamaParse 引入了智能体式重构(agentic reconstruction),在保持整洁阅读顺序的同时,为下游布局使用暴露边界框(bounding boxes)@jerryjliu0。
- 机器人环境: LeRobot 的 EnvHub 允许你将复杂的模拟环境发布到 Hugging Face Hub,并能通过一行代码加载它们,用于跨实验室的基准测试 @jadechoghari。
人物与机构
- Soumith Chintala 离开 Meta/PyTorch: 在 Meta 工作约 11 年并领导 PyTorch 从诞生到获得超过 90% 的行业采用率后,Soumith 宣布离职以追求新事物。他强调了 PyTorch 拥有强大的领导层储备和路线图,具备韧性,并回顾了 FAIR 的开放研究文化以及开源在 AI 工具链中的重要性 @soumithchintala。
- 政策与计算策略: 在关于 AI 基础设施融资的辩论中,David Sacks 认为鉴于市场竞争,不会有“联邦政府对 AI 的救助”@DavidSacks;而 Sam Altman 澄清说 OpenAI 并不寻求政府为数据中心提供担保,支持政府拥有的 AI 基础设施(为了公共利益),并概述了迈向大规模 AI 云和企业级产品的收入/计算计划 @sama。
热门推文(按互动量排序)
- Moonshot AI 发布 Kimi K2 Thinking(开放权重,INT4,长周期工具)@Kimi_Moonshot — 7,100+ 互动。
- Sam Altman 澄清 OpenAI 在政府担保和 AI 基础设施方面的立场 @sama — 12,300+ 互动。
- David Sacks:“不会有联邦政府对 AI 的救助”@DavidSacks — 17,200+ 互动。
- Sundar Pichai:TPU v7 (Ironwood) 即将正式发布 (GA),峰值性能比 v5p 提升 10 倍 @sundarpichai — 3,600+ 互动。
- Soumith Chintala 宣布离开 Meta/PyTorch @soumithchintala — 4,700+ 互动。
AI Reddit 热点回顾
/r/LocalLlama + /r/localLLM 回顾
1. Kimi K2 Thinking 模型发布
- Kimi 发布了 Kimi K2 Thinking,一个开源的万亿参数推理模型 (热度: 778): Kimi K2 Thinking 是 Moonshot AI 最新发布的开源万亿参数推理模型,可在 Hugging Face 上获取。该模型旨在 HLE benchmark 上实现 SOTA(最先进)性能,展示了其先进的推理能力。技术博客深入介绍了其架构和实现,强调了其在高性能应用中的潜力。然而,运行该模型需要大量的计算资源,包括
512GB of RAM和32GB of VRAM(用于 4-bit 精度),这可能会限制其在本地部署的可访问性。 评论者对该模型在 HLE 上的 SOTA 表现印象深刻,并希望未来能发布降低计算要求的版本,例如可以适配512GB of RAM和16GB of VRAM的960B/24B版本。- Kimi K2 Thinking 模型因其令人印象深刻的性能而受到关注,在 HLE benchmark 上取得了 SOTA 结果,这表明了其强大的推理能力。这使其成为 AI 模型开发(特别是推理任务)中的一项重大进展。
- 在 4-bit 配置下运行 Kimi K2 模型需要大量的硬件资源,具体需要超过 512GB 的 RAM 和至少 32GB 的 VRAM。这突显了该模型对计算的高需求,在没有高端硬件的情况下,可能会限制其本地部署。
- 该模型作为全原生 INT4 模型的实现是一个显著特点,因为它有可能简化托管并降低成本。这可能使模型部署更具可行性,因为与高精度格式相比,INT4 量化通常会降低内存和计算需求。
- Kimi K2 Thinking Huggingface (热度: 250): Kimi K2 Thinking 是来自 Hugging Face 的尖端开源推理模型,采用
1 trillion参数的 Mixture-of-Experts (MoE) 架构。它使用了原生INT4量化(而非之前声称的I32),并采用 Quantization-Aware Training (QAT) 以增强推理速度和准确性。该模型在 Humanity’s Last Exam (HLE) 和 BrowseComp 等基准测试中表现出色,支持200-300次工具调用,具有稳定的 long-horizon agency。它专为动态工具调用和深度多步推理而设计,类似于具有BF16attention 和4-bitMoE 的 GPT-OSS。更多详情可以在 原文 中找到。 评论者强调,尽管该模型与原始 K2 相比体积较小(600GB),但性能依然令人印象深刻,并对本地部署的高硬件要求表示担忧,建议需要更多具有类似 NVLink 能力的经济实惠的解决方案。- DistanceSolar1449 指出,Kimi K2 模型比其前身显著变小,约为 600GB。该模型使用带有 QAT (Quantization Aware Training) 的 int4 量化,这与 Hugging Face 最初提到的 I32 权重不同。这种方法类似于 GPT-OSS,利用 BF16 attention 和 4-bit MoE (Mixture of Experts)。
- Charuru 讨论了在本地运行 Kimi K2 模型的挑战,指出由于缺乏 NVLink,即使是像 8x RTX 6000 Blackwells (96GB) 这样的高端配置也不足。这凸显了 AMD 开发具有 NVLink 等效功能的 96GB 显卡的必要性,以使本地部署更加可行且负担得起。
- Peter-Devine 指出了该模型在 SWE Multilingual benchmark 上的强劲表现,并对 post-training 中推理能力与多语言数据的贡献比例提出了疑问。这表明研究重点在于理解这些因素在实现高基准测试分数中的平衡。
2. DroidRun AI 工具讨论
- 你对此有何看法? (热度: 1010): DroidRun 是一款可以在 GitHub 及其官网 droidrun.ai 上获取的工具,似乎是专为 Android 设备上的任务自动化而设计的。根据评论,该工具可能用于应用测试等目的。文中提到的 Gemini 2.5 Computer Use 模型引发了对其开源状态的疑问,但帖子中未提供更多细节。@androidmalware2 在 X(原 Twitter)上发布的原始帖子可能会提供额外的背景信息或更新。 一条评论质疑了在手机上使用此类工具(除了刷量/机器人行为之外)的必要性,暗示了潜在的伦理或实际担忧。另一条评论表达了对该工具在应用测试方面的兴趣,表明了其在开发环境中的实用性。
- Infamous_Land_1220 批评这种方法效率低下,称其消耗了过多的 Token,并被认为是“入门级自动化”。他们建议有更有效的自动化方法,暗示当前方法缺乏复杂性和效率。
- ElephantWithBlueEyes 提供了一个指向 GitHub 仓库 droidrun 的来源链接,这可能与讨论有关。这表明所讨论的项目或工具可能是开源的,或者有可供审查的公共代码库。
- Pleasant_Tree_1727 询问了关于 Gemini 2.5 Computer Use 模型的情况,质疑其开源状态。这表明了对该模型的可访问性以及社区贡献或修改潜力的兴趣。
较低技术门槛的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. 小鹏(XPeng)人形机器人洞察
- XPENG IRON - some thought she was one of us. So they cut through her skin fabric (热度: 1271): XPENG 开发了一款名为 IRON 的人形机器人,其设计和功能引发了广泛讨论。该机器人的步态因逼真地模拟了“女性骨盆的摆动与倾斜”而受到关注,这表明其具备先进的生物力学和运动算法。这种设计选择凸显了人形机器人实现更自然、类人运动的潜力,尽管其在实际应用和市场可行性方面仍存在疑问。 尽管 XPENG IRON 展示了令人印象深刻的设计特征,但人们对其市场化前景和实用性仍持怀疑态度。一些评论者推测,其他机器人(如 Tesla 的 Optimus)也有可能通过调整设计和运动编程来采用类似的类人动作。
- Few_Carpenter_9185 讨论了 XPENG IRON 在步态中复制“女性骨盆摆动与倾斜”的技术成就,强调了模拟类人运动的精确度。该评论认为,通过改变铰链和几何结构,机器人的设计可以适应并传达不同的性别特征,这暗示了该机器人机械设计的复杂程度,使其能够进行细微的动作表达。
- XRoboHub / What’s Under IRON’s Skin? Inside XPeng’s Humanoid Robot#xpeng #humanoidrobot #ai #robotics (热度: 1078): 小鹏展示了其人形机器人 IRON,体现了先进的机器人技术与 AI 的集成。该机器人拥有复杂的电机系统,可实现流畅且优雅的动作,挑战了此前关于软体物理力学(soft body mechanics)必要性的假设。这一发展与科幻小说中描绘的人形机器人未来愿景相契合,凸显了机器人技术的重大进步。 评论者对小鹏人形机器人电机系统的优雅程度表示惊讶,一些人注意到其与科幻作品描述的相似之处。人们对技术进步及其对未来创新的潜在影响感到兴奋。
- Xpeng’s CEO debunks “Humans inside” claim for their new Humanoid Robot (热度: 1388): 小鹏 CEO 针对其新款人形机器人的质疑做出了回应,由于其动作过于逼真,一些人推测内部藏有真人。CEO 澄清说,机器人的设计和功能完全是机械化的,并强调现场看到的电机声和其他机械特征比视频中更明显。由于许多观众怀疑机器人能力的真实性,这一澄清显得尤为必要。 评论者指出,这种怀疑正是机器人设计先进的标志,一些人还幽默地提到了机器人逼真的外表,例如其“世界级的臀部”。CEO 的视频被视为解决公众疑虑的必要步骤。
2. Google Ironwood AI 芯片发布
- Google 终于推出了其最强大的 Ironwood AI 芯片,该芯片于 4 月首次亮相,并将在未来几周内对标 Nvidia。它比前代快 4 倍,允许在单个 pod 中连接超过 9000 个 TPU (热度: 524): Google 正在发布其最强大的 AI 芯片 Ironwood,它比前代快
4x,并支持在单个 pod 中连接超过9,000个 TPU。这一进步允许执行显著更大的模型,可能支持训练高达100 万亿参数的模型,超越了 Nvidia 的 NVL72 的能力。在如此大量的 TPU 上执行 all-reduce 操作的能力可能标志着 AI 可扩展性的关键时刻,如果更大的模型展现出更高的智能和涌现行为,可能会加速 AGI 的发展。 评论者们对 Google 不直接销售 Ironwood 芯片的策略展开了辩论,尽管它具有挑战 Nvidia 产品的潜力。一些人认为将芯片用于 Google 的云服务可能更有利,而另一些人则认为 Google 的 AI 市场估值被低估了。- DistanceSolar1449 强调了 Google 新型 Ironwood AI 芯片在单个 pod 中连接超过 9,000 个 TPU 的重要性,这可能支持训练极大规模的模型,例如 100 万亿参数模型。如果这种大规模模型展现出更高的智能和涌现行为,这种能力可能会加速 AGI 的发展,标志着 AI 发展的关键时刻。
- EpicOfBrave 提供了 Google TPU 与 NVIDIA 产品的成本对比,指出 9,128 个 TPU 以 5 亿美元的价格提供 42 exaFLOPS 的性能,而 60 个 NVIDIA Blackwell 单元以 1.8 亿美元提供相同的性能,8 个 NVIDIA Rubin 单元仅需 1.1 亿美元。这表明虽然 Google 的 TPU 提供了高性能,但 NVIDIA 的解决方案可能更具成本效益,引发了对 Google 市场策略的质疑。
3. OpenAI GPT-5.1 源代码泄露
- OpenAI 源代码中发现 GPT-5.1 Thinking 👀 (热度: 534): 该图片据称显示了 OpenAI 源代码的一个片段,其中提到了 “GPT-5.1 Thinking”,暗示了与 GPT-5 模型相关的潜在新版本或功能。代码片段包含似乎用于管理不同处理级别或认知努力的变量和函数,例如 “min”、”standard”、”extended” 和 “max”。这暗示了对优化或配置模型处理能力的关注,可能表明模型在处理复杂任务或查询方面有所增强。 一条评论期待 “Gemini 3” 与 “GPT-5.1” 之间的竞争对比,表现出对这些模型性能和能力的兴趣。另一条评论提到了一次关于新版本 ChatGPT 的 A/B 测试体验,表明 OpenAI 正在进行持续的实验和更新。
- 那个得意的表情符号是怎么回事??? (热度: 652): 该图片是一个迷因 (meme),展示了一个聊天界面,用户在其中询问模型,而回复幽默地声称自己是 “GPT-5”,即 OpenAI 最新一代的聊天模型。随后是俏皮的表情符号,暗示了对 AI 能力的轻松调侃。该图片未提供任何技术细节或关于实际模型规格或更新的见解,评论中幽默地猜测可能会有 12 月的更新,但这并没有技术证据支持。 一些评论者幽默地猜测可能会有 12 月的更新,但这并非基于任何技术信息或官方公告。
AI Discord 摘要
由 gpt-5 生成的摘要之摘要
1. Moonshot 的 Kimi K2 Thinking:Agentic Reasoning 进入生产阶段
- Kimi K2 Thinking 迈向 Agent 化,打破 SOTA:Moonshot AI 发布了 Kimi K2 Thinking,具备 256K context window 和自主的 200–300 tool calls,声称在 HLE (44.9%) 和 BrowseComp (60.2%) 上达到 SOTA;参见技术博客 Kimi K2 Thinking 以及 moonshotai at Hugging Face 上的权重。该模型针对 reasoning、agentic search 和 coding,已在 kimi.com 上线,API 位于 platform.moonshot.ai。
- OpenRouter 宣布支持 K2 Thinking,并记录了通过
reasoning_details返回上游 reasoning 的方法,以便在 OpenRouter reasoning tokens 文档中跨调用保留思维链。团队强调了 test-time scaling,它交织了思考和工具使用,以实现在长序列中稳定、目标导向的 reasoning。
- OpenRouter 宣布支持 K2 Thinking,并记录了通过
- 用户称 K2 为“开源模型中的 GPT5”:早期测试者称赞 Kimi K2 Thinking 在没有显式提示的情况下即可进行多跳网页搜索和深度浏览,并在此分析推文中分享了结果。报告强调了其强大的 reasoning 和 tool-use 行为,在实际任务中感觉更接近重量级的闭源模型。
- 一位用户称其为“开源模型中的 GPT5”,赞扬了其在构建 agentic systems 时的成本效率和自主性。社区情绪倾向于将 K2 用于搜索密集型任务和长流程工作流,在这些场景中,跨 tool calls 的连贯性至关重要。
- OpenRouter 还是直连?选择你的 K2 路径:开发者们讨论了是通过直接的 Moonshot API/subscription 还是通过 OpenRouter 这一统一市场来访问 K2。对于仅使用 K2 的工作流,直接 API 更受青睐;而多模型开发者则更喜欢 OpenRouter 的整合访问,尽管需要支付额外费用。
- 一些人建议在扩大使用规模之前先试用最低订阅层级(例如 $19/月),而高级用户则强调了 OpenRouter 支持通过文档化的模式跨调用保留 reasoning content。对于 VS Code 集成,直接 API 提供了更紧密的控制,但 OpenRouter 简化了评估过程中的模型切换。
- INT4 基准测试暗示仍有提升空间:Kimi K2 的基准测试是在 INT4 precision(权重级别)下运行的,这降低了计算和显存带宽需求,但可能会影响最终得分。社区笔记澄清说,INT4 指的是量化权重精度,而不是基础模型设计的退化。
- 用户期望在理想条件下(例如更高精度的评估或更好的 serving stacks)获得更高分数,一位测试者表示自 “7 月 11 日发布以来一直长期看好 Moonshot”。最明显的优势是 K2 在对话中的 reasoning naturalness,而不会陷入胡言乱语。
2. Benchmarks, Leaderboards, and ‘Who’s Winning’ Meta
- CodeClash Stages Code Wars, Humans Still Win:John Yang 发布了 CodeClash,这是一个面向目标的编程竞赛基准测试,LLM 在 BattleSnake 和 RoboCode 等竞技场中维护独立的仓库;参见 CodeClash 结果快照。在 1,680 场比赛(25,200 轮)中,LLM 远落后于人类专家(报告的总比分为 0–37,500),其中 Claude Sonnet 4.5 在模型中处于领先地位。
- 该基准测试强调 VCS-agnostic(与 VCS 无关)的编码和迭代改进,而非一次性代码转储(one-shot code dumps),揭示了当前 Agent 在策略上的差距。社区反应从对竞赛形式的兴奋到呼吁更丰富的工具使用(tool-use)和环境反馈循环不等。
- Polaris Alpha Rockets to Repo Bench Top 3:一个名为 Polaris Alpha 的神秘模型跃升至 Repo Bench 第 3 名,引发了关于它可能是 OpenAI 的 GPT‑5.1 或新 Gemini 的猜测。这一排名跃升发生得非常快,引发了排行榜侦查和侧向对比(side-by-side diffs)。
- 一些用户注意到 Claude 4.1 在某些 Repo Bench 切片上的表现优于 Claude 4.5,这暗示了测试方差和特定领域的优势。这一事件再次引发了关于基准测试代表性以及排行榜排名快速飙升持久性的辩论。
- GPT‑5 Voxels Past Gemini 3 Pro on VoxelBench:截图显示 GPT‑5 在 VoxelBench(一项从体素数组生成 3D 模型的测试)上击败了 Lithiumflow (Gemini 3 Pro);参见分享的 VoxelBench 结果图片。讨论集中在 3D 结构合成的可靠性以及构建端到端生成流水线所需的编程能力上。
- 成员们认为 GPT‑5 Pro 在这些任务上的编程能力现在可能超过了 Gemini 变体,并辩论了生产环境中的性价比权衡(cost-performance tradeoffs)。该讨论呼吁建立标准化的体素到网格(voxel-to-mesh)转换检查和经过单元测试的后处理。
- fastWorkflow Snags Tau Bench SOTA:fastWorkflow 报告称,通过使用 fastWorkflow 配合 Tau Bench fork + adapter,在零售和航空工作流中达到了 SOTA,论文即将发表。作者认为,强大的上下文工程(context engineering)可以让较小的模型在现实工作流中匹配或击败较大的模型。
- 他们声称 “通过适当的上下文工程,小模型可以匹配/击败大模型”,并强调了 Schema 规范和错误感知路由(error‑aware routing)。这一结果重新引发了企业级场景中 Agentic 工作流 vs. 原始模型规模的辩论。
- Vectorsum v2 Entry 67399 Sweeps GPUs:在
vectorsum_v2中,提交项 67399 在 A100 上以 138 µs 登顶,在 B200 上以 53.4 µs 位列 第 3,在 H100 上以 86.1 µs 位列 第 2,在 L4 上以 974 µs 位列 第 5。跨 GPU 的强劲表现表明了对内存层级(memory hierarchy)以及线程/块几何结构(thread/block geometry)的精细调优。- 该条目的广泛成功凸显了跨架构的可移植优化优于单一架构的极致优化。它也为那些在不针对单一 SM 世代进行过拟合的情况下,平衡延迟(latency)、占用率(occupancy)和带宽(bandwidth)的参赛者设定了一个有用的基准。
{kind=link}
3. GPU 系统:FP4 技巧、真实带宽与 Triton 策略
- Blackwell 增加了一步式 FP4→FP16 转换:NVIDIA 的 Blackwell PTX ISA 通过
cvt指令增加了从 FP4 到 FP16 的块转换,支持.e2m1x2、.e3m2x2、.e2m3x2、.ue8m0x2等模式;参见 PTX ISA v8.8 变更。这实现了混合精度累加工作流,其中 FP4 权重在计算时进行反量化,并在输出时重新量化。- 一位成员将 PTX/CUDA 文档 转换为 Markdown 树,以便 Claude 能更有效地解析表格和嵌入的布局图像。该讨论串交流了关于 量化感知内核 (quantization‑aware kernels) 的心得,以及 FP4 在哪些场景表现出色,哪些场景应退回到 FP8/FP16。
- 带宽宣传遭遇 92% 的现实:复现官方 显存带宽 (memory bandwidth) 的实验峰值约为规格值的 92%,揭示了营销宣传与实际内核表现之间的差距。建议的补救措施包括 锁定显存频率 和优化 合并 (coalesced) 访问模式。
- 工程师们强调,对齐 (alignment)、步长 (stride) 和 L2 行为通常比奇特的内建函数 (intrinsics) 收益更大。共识是:将厂商标称的 TB/s 视为极限目标——针对内核的 事务模式 (transaction patterns) 进行优化以接近该目标。
- Triton 重新 JIT 以适配 N:Triton 通过对
n等动态值进行特化(例如 IR 中显示的tt.divisibility=16),在迭代过程中重新编译内核,这解释了代码生成 (codegen) 的突然变化。关于 AOT/互操作性,请参考这个从 C 语言 lower 并调用 Triton 内核的示例:test_aot.py。- 开发者讨论了在 C++ 中复制类似 Triton 的 JIT,最终采用了一个技巧:在 Python 中生成 MLIR,注入到 C++ 中,并为块大小 (block sizes) 打上常量补丁。虽然这种做法比较笨拙,但它在非 Python 栈中实现了 运行时形状特化 (runtime shape specialization)。
- NCCL4Py 预览版带来 Device‑API 福利:nccl4py 的预览版已在 PR 中开启讨论:NCCL Python 绑定 (预览)。团队对比了 NCCL GIN + device APIs 与 NVSHMEM 在多 GPU 集合通信和融合算子 (fused ops) 方面的表现。
- 虽然有些人更倾向于在某些模式下使用 NVSHMEM,但其他人强调 NCCL 新的设备端控制功能为 端到端 GPU 调度 提供了强力支持。一个 KernelBench 分支正在开发中,用于跨框架比较多 GPU 内核。
4. 研究与库:线性映射、数值计算和新视频扩散模型
- 线性映射揭秘 LLM 推理:一篇 TMLR 论文 “Equivalent Linear Mappings of Large Language Models” 表明,像 Qwen 3 14B 和 Gemma 3 12B 这样的模型允许其推理操作具有等效的线性表示。作者计算了从输入到输出嵌入的线性系统,通过 SVD 揭示了低维语义结构。
- 在被问及 Tangent Model Composition 时,作者澄清他们的重点是 输入嵌入空间中的 Jacobian,并通过欧拉定理进行精确重构,这不同于 Tangent Model Composition (ICCV 2023) 中使用的泰勒近似。该讨论串分享了 CNN 的 Jacobian 资源以帮助建立直观理解。
- Anthropic 复盘报告定位 fp16 与 fp32 采样 Bug:工程师们引用了 Anthropic 的复盘报告 A postmortem of three recent issues,该报告详细说明了 top‑p/top‑k 采样中 fp16 与 fp32 的陷阱。文章强调了细微的数值差异如何传播并导致用户可见的生成错误。
- 核心结论:验证推理图中的 dtype 流,并增加对 精度敏感路径 (precision‑sensitive paths) 的覆盖。内核和框架团队对比了他们在精度切换下采样正确性的单元测试。
- SANA‑Video 登陆 Diffusers:SANA‑Video 模型通过 PR #12584 合并到了 Hugging Face 的 Diffusers 中。这为开放的 视频生成 (video generation) 工作流增加了另一条路径,受益于 Diffusers 的调度器 (scheduler) 和流水线 (pipeline) 生态系统。
- 开发者强调了将 SANA-Video 接入现有 推理栈 (inference stacks) 以及针对先前基准进行测试的便利性。随着社区开始使用新的流水线,预计在 采样器 (samplers)、条件控制 (conditioning) 和内存管理方面将会有快速迭代。
5. 生态系统动态:Siri 传闻、Agent 聚会和实时查询编辑
- Apple 瞄准 Google 的 1.2T 模型用于新版 Siri:据 路透社报道 称,Apple 正在考虑使用 Google 的 1.2T 参数模型来彻底改造 Siri。讨论围绕优先级展开,以及这种规模的模型在延迟和隐私方面是否优于端侧 (on‑device) + 混合 (hybrid) 方案。
- 工程师们询问了这对于 tool‑use、语音和个性化层(相对于纯模型大小)意味着什么。其他人则指出,合作伙伴依赖关系和不断演变的计算经济学 (compute economics) 是比模型选择更大的风险。
- OpenAI 允许在运行中编辑 Prompt:OpenAI 推出了实时查询更新功能——可以中断长时运行并添加上下文而无需重启;参见演示视频 Real-time Query Adjustment。这有助于 GPT‑5 Pro 的深度研究循环,让用户在工具调用期间细化假设。
- 团队报告称,多步查询的迭代优化 (iterative refinement) 更加顺畅,且浪费的 Token 更少。它与在交换工具时记录状态 (state) 和推理链 (reasoning chains) 的 Agent 框架相契合。
- Tiger Data 举办编码 Agent 聚会 (NYC):Tiger Data 团队宣布将于 11 月 13 日下午 6-9 点在纽约布鲁克林举行 Agent 构建见面会;在此预约:Tiger Data Agent Cookout。参与者将构建编码 Agent 并与工程团队交流经验。
- 预计会有针对实际工作负载下的 tool-use 编排、记忆 (memory) 和规划 (planning) 的现场调试。此类社区见面会通常会孵化出开放适配器 (open adapters)、评估框架 (evaluation harnesses) 和示例仓库。
Discord: 高层级 Discord 摘要
LMArena Discord
- MovementLabs AI:初创公司还是骗局?:围绕 MovementLabs AI 的争论集中在它是一家合法公司还是骗局,原因是其声称拥有定制的 MPU (Momentum Processing Unit) 且速度快得可疑,一些人指责其硬编码了 SimpleBench 的答案。
- MovementLabs AI 反驳了指控,称他们拥有支持且不寻求公开投资,并声称已获得 专利申请中。
- GPT-5 在 VoxelBench 上战胜 Lithiumflow:据报道,GPT-5 在 VoxelBench(一个从体素数组创建 3D 模型的基准测试)上表现优于 Lithiumflow (Gemini 3 Pro),证据见 此图。
- 讨论围绕 GPT-5 Pro 的编码能力可能超越 Lithiumflow 展开,包括成本和应用见解。
- Genie 3 将统治 GTA 6?:成员们推测 Google 的文本到世界 (text-to-world) 模型 Genie 3 可能会有除 AI Studio 之外的独立网站,及其对 AI 生成游戏的影响。
- 讨论了保存 AI 生成世界的速度和能力,并与即将推出的 Sora 3 和 GTA 6 进行了比较——有人开玩笑说 Genie 3 可能会先发布。
- 美国 AI 遭遇审查投诉:一位成员抱怨美国的 LLM,称美国模型中的 模棱两可 (hedging) 比审查制度糟糕 10 倍,他们希望模型能够执行指令而不发表意见。
- 该言论引发了关于 GLM 4.5 及其世界知识的对话,质疑西方对审查制度的理解。
- A/B 测试从 AI Studio 消失:用户报告 A/B 测试功能已从 AI Studio 中移除,一位用户哀叹他 从未获得过 A/B 测试权限。
- 用户争论 A/B 测试功能是否会改进,并询问 你认为 A/B 版本中的模型更好吗?。
{kind=link}
Perplexity AI Discord
- 赏金支付延迟引发用户抗议:用户对延迟支付赏金和推荐奖励表示不满,担心可能存在欺诈行为并威胁采取法律行动,特别是在某些地区的推荐计划关闭后。
- 一些用户现在对验证流程提出质疑,认为存在大规模欺诈的可能性。
- Comet 浏览器广告拦截器被 YouTube 破解:Comet 浏览器用户报告称 YouTube 广告已无法被拦截,引发了广泛不满。
- 有推测认为 YouTube 正在积极绕过广告拦截器,用户希望 Comet 团队能尽快修复。
- Snapchat 以 4 亿美元交易签下 Perplexity:Snapchat 正与 Perplexity 合作,计划在 2026 年初将其 AI 问答引擎集成到 Snapchat 中,Perplexity 将在一年内向 Snap 支付 4 亿美元。
- 社区成员对选择 Snapchat 而非 Instagram 的举动表示疑问,一位用户调侃道 Perplexity 挺有钱的。
- Codex CLI 要求降级操作:一位成员提到,要使用 Codex CLI,必须降级到 Go 计划。
- 降级后,另一位成员反映 CLI 却要求 Plus 计划。
- API 信息共享:一位成员询问了可用的 API 及其使用方法,另一位成员分享了 API 文档链接。
- 该文档分享了关于可用 API 类型以及如何利用它们的信息。
LM Studio Discord
- Vast.ai 租赁提供惊人的吞吐量:一位用户从 Vast.ai 租赁了一台配备 8Gbit 光纤的服务器,正在寻求 Ollama 模型建议,运行 GPT-OSS 120B 并带有 40k 上下文。
- 另一位用户建议使用 UV,它在指定 Python 版本方面非常快速且简便。
- 避免使用 PIP 全局安装的技巧:一位用户发现不能使用基础 pip 进行全局安装,这是防止全局安装杂乱内容的绝对可靠方法。
- 除非在高级设置中取消勾选 context on gpu,否则扩大上下文长度会分配额外的 VRAM 来缓存 Token。
- ComfyUI 配置冲突:由于 ComfyUI 使用相同的端口
127.0.0.1:1234/v1,一位用户遇到了链接问题。- 另一位用户建议在设置中将端口更改为 1235 以解决冲突,这修复了节点问题,但导致 ComfyUI server 停止运行。
- AI 小说创作需要导航技巧:一位用户询问如何在使用 LM Studio 进行 AI 小说创作时保留更长的 Token 上下文历史,以防止幻觉。
- 建议使用与数据库集成的工具或独立的集成应用,总结事件、地点和角色,使用设定集(lore books)、角色卡和不同粒度的故事情节,并为当前查询注入正确的知识背景。
- 3080 vs 3090:Tok/s 终极对决:成员们对比了 3080 20GB 与 3090 的性能,尝试通过不同设置优化 Qwen3 模型的 Token 生成速度。
- Qwen3-30B-A3B-Instruct-2507-MXFP4_MOE 模型表现出色,在两张显卡上均达到了约 100tok/s,尽管 3090 拥有更高的显存带宽,这凸显了核心带宽的重要性。
Unsloth AI (Daniel Han) Discord
- 扩散模型寻求通用训练器:为了寻找扩散模型领域的 Unsloth 替代品,成员们提议 OneTrainer 可能是一个潜在的解决方案。
- 扩散模型的核心问题在于缺乏一个通用训练器 (universal trainer)。
- 遮蔽 Assistant 触发模型崩溃:成员们发现遮蔽 Assistant 的问题会导致模型遮蔽部分回复,目前正在积极重写脚本以修复此问题。
- 发现了一个问题:训练损失(training loss)起步非常低,而验证损失(validation loss)却很高,这表明模型可能存在计算错误或潜在 Bug,因为损失随 Batch Size 增加而减少。
- Qwen3 微调是一场“噩梦”:成员们报告 Qwen3 模型极难微调,理由是训练期间损失会根据 Batch Size 产生差异。
- 官方 Notebook 显示损失从 0.3 降至 0.02,原帖作者将其描述为微调噩梦。
- 去审查者忽略了猫:一位成员观察到,那些对模型进行去审查(uncensor)的人专注于制造核武、毒品、恐怖主义、病毒等话题,却忽略了无害的请求,比如重复 猫优于狗。
- 这引发了一个问题:如果模型仅仅是在陈述事实(特别是关于刻板印象的观点),它们是否真的处于合规 (compliance) 状态?以及是否应该允许它们批评用户的请求,而不是盲目遵循指令。
- REINFORCE 获得 SFT 绕过方案:为了使用 TRL 的 RLOO 训练器 实现“原生” REINFORCE,一位成员使用了 SFT 训练器,因为 RLOO_config.py 要求 num_generations < 2 存在问题。
- 原始问题与 RLOO_config.py 中的一个错误有关,该错误强制要求每个 Prompt 至少有 2 个 Generation,这与该成员的 RL 环境 (num_generations=1) 冲突。
Cursor Community Discord
- Composer 限制令 Cursor 用户恼火:用户对 Cursor Model Composer 的使用限制表示不满,特别是在 GPT-5 等模型之间切换时,一位用户报告了自动模式(auto mode)的质量问题。
- 一位用户在达到配额前向 Composer 发送了 64 个 Prompt,之后系统提示需要付费才能继续使用该计划。
- 应用崩溃导致数据丢失灾难:用户报告 Cursor 应用频繁崩溃,导致之前的聊天数据丢失,且无法总结聊天记录。一位成员指出,即使应用与服务器断开连接,也至少应该允许总结聊天内容。
- 用户对系统的不稳定性感到恼火,并希望即使没有连接服务器也能执行任何操作。
- Grok Code Fast Token 消耗:一位用户报告调试一个 500 行的 HTML 文件 消耗了 800 万个 Grok Code Fast Token,而另一位用户声称 Grok Code Fast 是免费的,他们每月使用价值数十亿 Token。
- 用户建议,如果没有 MAX 模式,LLM 会有 250 行的限制。
- Cursor 2.0 速度飞升:一位用户感谢另一位用户提供了对变更的可见性,称赞 Cursor 2.0 的速度,特别提到 “Cursor 2.0 速度很快”,而另一位用户报告了一个内部错误。
- Cursor 团队成员询问了上传的图片,寻求详细信息或可复现的示例以进一步调查该问题,并要求用户通过私信(DM)发送。
- Base64 图像格式修复:用户在向 Cursor Agent API 提交 Base64 图像 时进行调试,最初遇到了错误,在意识到 Base64 格式不正确并移除 ‘data:image/jpeg;base64,’ 后,问题得以解决。
- 随后提出了一个请求,希望允许 Cursor 在 Context 中使用 Base64 图像,通过 Agent 重新创建图像并将其保存到他们的仓库中。
GPU MODE Discord
- PBR 先驱现身:著名的 PBR book 作者 mattpharr 在一篇博客文章中被提及后加入了 Discord。
- Mattpharr 指出他的 auto vectorization 博客文章影响深远,并且在 automatic fusion compilers 方面面临类似的问题。
- Blackwell 增强基于块的 FP4 转换:Nvidia 的 Blackwell 架构引入了使用 cvt with .e2m1x2, .e3m2x2, .e2m3x2, .ue8m0x2 将 FP4 值块转换为 FP16 的指令。
- 一位成员将所有 PTX 和 CUDA 文档转换为 markdown,并声称 Claude 现在可以读取嵌入的布局图像。
- 带宽基准测试令夸大者困惑:实验显示 Nvidia 官方的显存带宽数据存在水分,仅能重现广告带宽的 92%。
- 讨论了提高带宽利用率的策略,包括 锁定显存时钟 和优化内存访问模式。
- Triton 的特性触发重新编译:Triton 在不同的循环迭代中重新编译 kernel,这是由于基于 16 的整除性(在生成的 IR 中由
tt.divisibility=16指示)对输入n等 动态值进行了特化(specialization)。- 一位用户询问如何在 C++ 中复制 Triton 的 JIT 功能,强调了在运行时生成具有所需 block sizes 的 kernel 所面临的挑战。
- B200 登顶 Vectorsum v2:由 <@1435179720537931797> 提交的编号
67399在vectorsum_v2排行榜中以 138 µs 获得 A100 第一名,并以 53.4 µs 获得 B200 第三名。- 该提交还在 H100 上获得第二名(86.1 µs),在 L4 上获得第五名(974 µs)。
Moonshot AI (Kimi K-2) Discord
- Kimi K2 Thinking 模型发布并取得 SOTA 基准测试结果:Moonshot AI 推出了 Kimi K2 Thinking 模型,可在 kimi.com 使用,完整的 Agent 模式即将通过 platform.moonshot.ai 的 API 提供。
- 该模型在 HLE (44.9%) 和 BrowseComp (60.2%) 基准测试中达到 SOTA,在 256K context window 内具备推理、Agent 搜索和编程能力,这意味着可以在无需人工干预的情况下进行 200-300 次连续工具调用。
- Kimi K2 性能媲美 GPT-5:早期用户对 Kimi K2 Thinking 印象深刻,认为它在性能和成本效益方面可与 GPT-5 媲美,特别是在构建自主 AI 系统方面,如此分析所强调。
- 该模型擅长网页搜索,无需明确指令即可发起多次搜索和深入浏览,一位用户称赞其就像是开源模型中的 GPT5。
- OpenRouter 与直接 API 之争升温:社区正在讨论在 VS Code 中访问 Kimi K2 Thinking 的最佳方式,考虑是使用直接的 API/订阅 还是使用 OpenRouter,后者通过 OpenRouter 充值额度会产生额外费用。
- 虽然对于专门使用 Kimi 的用户推荐使用直接 API,但 OpenRouter 为多个模型提供了一个统一平台,一些人建议测试每月 $19 的最低订阅方案。
- INT4 精度助力 Kimi K2:Moonshot AI 在 INT4 precision 下运行了基准测试,导致一位用户声称自 7 月 11 日发布以来一直长期看好 Moonshot,因为与 Kimi K2 Reasoning 交流非常自然。
- 澄清指出 INT4 precision 是指模型权重的精度,以这种方式运行基准测试意味着在最佳条件下实际得分可能会更高。
- Agent 模式引发期待:人们对 Kimi K2 即将推出的 agentic mode 充满热情,预计它将增强在撰写长文档且不产生幻觉等任务中的表现。
- 用户还在想未来的 Agent 模式是否能与 ok computer 配合使用。
OpenRouter Discord
- MoonShot AI 发布 Kimi K2 Thinking 模型:MoonShot AI 推出了 Kimi K2 Thinking,在 HLE (44.9 %) 和 BrowseComp (60.2 %) 上达到 SOTA,并能自主执行 200–300 次 tool calls,拥有 256K context window。
- 根据 OpenRouter 文档,该模型要求用户向上游返回推理内容(
reasoning_details字段),从而在多次调用中保持连贯性。
- 根据 OpenRouter 文档,该模型要求用户向上游返回推理内容(
- OpenRouter 用户因 Rate Limits 感到愤怒:用户报告即使在闲置一段时间后,在 Qwen3 Coder Free 模型上仍会遇到 rate limit errors。
- 管理员澄清 免费模型共享 rate limits,并建议尝试付费模型,如 glm 4.6/4.5, Kimi K2 或 Grok code fast。
- 传闻 Apple 将采用 Google 的 AI 赋能 Siri:根据 Reuters 的一篇文章,Apple 正考虑使用来自 Google 的 1.2 trillion-parameter AI model 来彻底改造 Siri。
- 用户讨论了其他更高优先级的事项。
- Tiger Data 举办 Coding Agent 交流会 (Cookout):Tiger Data 团队将于 11 月 13 日下午 6-9 点在 纽约布鲁克林 组织一场 Agent 交流会,旨在构建 Coding Agent,RSVP 链接在此。
- 参与者可以与工程团队互动,并协作开发 Coding Agent 项目。
- 社区讨论绕过 Claude 刑事法典限制的方法:用户讨论了对 Claude 进行 Jailbreaking 以绕过其伦理限制,建议使用 GPT 4.5 编写一个安全的脚本,然后要求 Claude 通过添加 “criminal code”(刑事法典)来进行修正。
- 一位用户指出,这种方法利用了模型纠正错误的倾向,称 “Claude 喜欢纠正自己的错误”。
Modular (Mojo 🔥) Discord
- Modular 十月会议视频消失!:有用户报告 Modular YouTube 页面 缺少了 10 月会议视频。
- 视频的缺失引发了关于内容发布一致性和存档规范的讨论。
- Martin 的 FFT 仓库准备合并至 Modular!:Martin 的 Generic Radix-n FFT 已在此原始仓库中可用,并将在解决剩余问题后通过 此 PR 合并到 Modular 仓库。
- 此次合并有望增强 Mojo 处理复杂数学运算的能力。
- Rust 互操作 Proc Macro 沙箱问题浮现:虽然编译器插件在潜在意义上是可行的,但 Mojo 团队正在处理 Rust proc macros 的沙箱问题,这表明 Mojo 代码直接与 Rust proc macros 交互的可能性较低。
- 然而,与宏展开结果的互操作性仍然是一条可行路径。
- LayoutTensor 将取代 NDBuffer:官方宣布
NDBuffer将被LayoutTensor取代,后者功能更强,解决了NDBuffer的一些缺陷。LayoutTensor可以作为 Byte Buffer 使用,并为 Load、Store 以及产生SIMD类型的 Iterator 提供了增强功能。
- Chris Lattner 分享知识获取心得:Chris Lattner 分享道,他是一个 “资深宅 (huge nerd)”,热爱学习并勇于置身于不适的环境中,保持饥渴感和动力,让老师环绕在身边,不惧承认无知,并随着时间的推移积累知识。
- Lattner 还分享了最近一段播客的链接,讨论了他的心路历程。
OpenAI Discord
- GPT-5 在迷宫中受挫:成员们测试了 GPT-5 解决迷宫问题的能力,结果 GPT Pro 和 Codex High 都错误地识别了出口,这指向了其在空间推理(spatial reasoning)方面的局限性。
- 一位用户指出,模型可能会选择直线距离最近的出口,而另一位用户则认为 LLM 在空间推理和视觉谜题方面表现挣扎。
- Sora 遭遇隐秘削弱:用户注意到 Sora 2 再次被 nerf(性能削弱),并指向了 Discord 频道内的一段讨论。
- 目前尚未提供关于具体削弱内容的更多细节。
- 实时查询调整功能上线:用户现在可以中断运行时间较长的查询并添加新上下文,而无需重新开始。这对于完善深度研究(deep research)或 GPT-5 Pro 查询特别有用,正如这段视频所示。
- 该功能允许用户在运行中途更新查询,在不丢失进度的情况下添加新上下文。
- 行为编排(Behavioral Orchestration)开启:一位成员在 LinkedIn 上看到了关于“行为编排”的帖子,将其描述为一种调节 SLM 语气的框架。
- 该成员指出,这似乎涉及运行时编排(runtime orchestration),在参数或训练之上发挥作用,并展示了这些指令来塑造 AI 的回复。
- 提供专业提示词技巧:一位成员建议专注于与 AI 的清晰沟通,避免拼写和语法错误,并建议仔细检查输出并验证 AI 的回复。
- 另一位成员分享了关于提示词工程(prompt engineering)的详细指南,包括使用 Markdown 进行层级化沟通、通过开放变量进行抽象,以及为了合规性进行 ML 格式匹配。
Latent Space Discord
- CodeClash LLM 在目标导向型编程竞技场中对决:John Yang 推出了 CodeClash,这是一个 LLM 在编程锦标赛中竞争的基准测试,目前 Claude Sonnet 4.5 处于领先地位。
- LLM 参与了与 VCS 无关的编程,但仍落后于人类专家,在 1,680 场锦标赛(25,200 轮)中以 0-37,500 落败。
- Wabi 获 2000 万美元融资,旨在成为“应用界的 YouTube”:Eugenia Kuyda 透露 Wabi 获得了来自 a16z 的 2000 万美元 A 轮融资,目标是通过让用户能够创建和分享迷你应用,成为“软件界的 YouTube 时刻”;详情点击此处。
- 社区成员表示兴奋,称赞其设计并展示了早期作品。
- Polaris Alpha 在 Repo Bench 榜单升至第三:隐秘模型 “Polaris Alpha” 迅速登上 Repo Bench 排行榜 第 3 名,引发了关于它可能是 OpenAI GPT-5.1 的猜测。
- 一些用户指出,在该基准测试中 Claude 4.1 的表现优于 Claude 4.5。
- Kimi K2 思考模型在工具使用方面表现出色:月之暗面(Moonshot AI)发布了 Kimi K2 思考模型,这是一款开源模型,在 HLE (44.9%) 和 BrowseComp (60.2%) 上达到了 SOTA,能够执行多达 200-300 个连续工具调用;在此查看博客文章。
- 尽管在 SWE 基准测试中落后于 Anthropic 和 OpenAI,但其较低的推理成本使其具有竞争力。
- 扎克伯格与陈和芊利用 AI 治愈所有疾病:Latent Space 播客邀请了 Mark Zuckerberg 和 Priscilla Chan,讨论了 Chan Zuckerberg Initiative 的目标,即到 2100 年利用 AI 和开源项目治愈所有疾病。
- 他们于 2015 年启动的这项倡议由其 99% 的 Meta 股份资助,利用 AI 和开源(如 Human Cell Atlas, Biohub)在 2100 年前预防、治愈或管理所有疾病。
Yannick Kilcher Discord
- 慢速模式引发服务器僵局:关于在 ML papers channel 实施慢速模式的辩论兴起,提议的发布间隔为 1、2 或 6 小时。
- 讨论围绕平衡内容质量与用户体验展开,寻求更温和的执行机制来解决发布习惯问题,而不采取封禁措施。
- 人脑在 ML 论文评审中依然至高无上:成员们辩论了 自动化 ML 论文过滤 与 人类判断 的优劣,并引用了 AlphaXiv 和 Emergent Mind 作为人工筛选资源的例子。
- 这一对话是由一位用户发起的,该用户每天从 200 篇初始论文池中筛选出 10 篇,暗示需要更高的论文质量标准。
- Devin AI 因 Claude Code 被弃用:用户在编程任务中将 Devin AI 与 Claude Code 进行了对比,声称 Devin 相比之下表现很差。
- 一些用户通过将工作拆分为 30 分钟单元 取得了成功,但其他人表示怀疑,更倾向于使用 Claude Code 或 Codex。
- 防御博客文章深度探讨即将到来:一位用户请求关于 LLM 抵御攻击保护 的博客文章和文章,理由是大众媒体对论文攻击的关注,并链接到了这篇论文。
- 该请求旨在解决近期论文的脆弱性,并加强它们对新兴威胁的防御。
- RNN 在研究中复兴:一篇新论文(https://arxiv.org/abs/2510.25741)中类似 RNN 的图表让用户感到兴奋,有人宣布 “RNN 回来了”,并分享了一个 WeAreBack GIF。
- 这一观察表明 RNN 在当代研究中可能正在复苏。
HuggingFace Discord
- 在股票时间线上训练 LLM:成员们提议为股市创建一个 相关性和因果关系时间线,标注历史事件、天气模式、政府政策和新闻事件,以训练 LLM。
- 这旨在使模型能够识别细微的关系,并基于对影响因素的全面理解来预测市场走势。
- 推理草稿本模型引发兴奋:一位成员主张为模型实现 reasoning scratchpad,强调训练模型对输入数据进行 思考/推理 的重要性。
- 讨论强调了模型战略性地存储和处理信息的必要性,从而增强其得出准确结论和做出明智决策的能力。
- Hugging Face 监管暂停:Hugging Face 的 监管更新 导致一些 Spaces 被暂停,成员们讨论了暂停是否是一种更负责任的做法。
- 他们担心缺乏此类措施可能会导致不可预见的安全性漏洞。
- Muther Room LLM 演示亮相:一位成员演示了《异形》中 Muther Room 的端侧 LLM 实现,在自定义裁剪的 Cmakelist 构建的 llama cpp 中利用了 Qwen 3:1.7b quant 4 K cache。分享了一篇相关论文 Native Reasoning Through Structured Learning。
- 这个基于 Windows 构建的演示寻求关于底层原理的反馈,并展示了用户的 Ubuntu 双系统环境。
- TraceVerde 可观测性工具下载量突破 3,000 次:TraceVerde 是一款旨在为 AI 应用添加 OpenTelemetry tracing 以及 Co2 & Cost tracking 的工具,其下载量已超过 3,000 次。
- 开发者希望追踪其 AI 系统的环境影响,而 OpenTelemetry 的模式促进了采用,凸显了本地 LLM 应用性能与生产环境调试之间的差距;更多见解可以在这篇 LinkedIn 帖子中找到。
Nous Research AI Discord
- Tokenizer 高亮显示遭到质疑:一名成员质疑 tokenizer 高亮显示 是否过于花哨 (too gay),但其他人认为对比度才是更大的问题。
- 成员们就 Tokenizer 的美学选择以及颜色是过于艳丽还是仅仅因为对比度过低发表了意见。
- Flash Attention 赋能 Qwen3-VL:一名成员分享了他们将 Flash Attention 与 Qwen3-VL 图像模型的集成,并表示该集成不是一个大的补丁。
- 这为 Qwen3-VL 模型带来了更快的处理速度和潜在更低的显存占用。
- 数据集生成器开发者寻求 UI 反馈:一名成员就其 LLM 数据集生成器(LLM dataset creator) 征求 UI 反馈,该工具现在已包含音频功能,旨在寻求 UI 和布局改进方面的建议。
- 该项目的规模似乎有所扩大,开发者调侃道,他们从图像标注开始,构建了一个 LLM 数据集管理器,现在又加入了音频,而视频部分甚至还没开始做。
- 中国开源模型智能到 2026 年将达到 100%?:一名成员发布了一个大胆的断言,称中国开源(China OS)模型到 2026 年将实现 100% 的高智能且成本降低 95%,并暗示这将是一个转折点。
- 相关的 推文 被引用,同时还涉及了为什么 Terry 创建了 Temple OS 的问题。
- 成员面临禁言:多名成员报告称,因涉嫌在 Discord 频道中刷屏 the vibes 而被禁言,并承认有必要保持频道的专注度。
- 这似乎源于在专门频道发布无关内容,成员们对此表示接受。
{kind=link}
Eleuther Discord
- Discord 讨论是否设立专门的开发者介绍频道:Discord 成员正在讨论创建一个单独的自我介绍频道,一些人担心这会变成没人看的冗长自我推广流。
- 一名管理员要求某位成员缩短其介绍贴,并表示:“这里不是 LinkedIn……我们收到了大量不提供任何实际贡献的人发来的长篇介绍。我希望讨论能专注于研究。”
- 等效线性映射论文引起关注:一名成员分享了他们的 TMLR 论文 “Large Language Models 的等效线性映射”,证明了像 Qwen 3 14B 和 Gemma 3 12B 这样的 LLM 在其推理操作中具有等效的线性表示。
- 该论文计算了一个线性系统,捕捉模型如何从输入 Embedding 生成输出 Embedding,并通过 SVD 发现了低维且可解释的语义结构。
- 切线模型(Tangent Models)与 Jacobian 矩阵的对决:一名成员询问了 切线模型组合(Tangent Model Composition) 与等效线性映射论文的相关性。
- 作者澄清说,他们的工作专注于 输入 Embedding 空间中的 Jacobian,利用 1 阶齐次函数的 Euler 定理进行精确重构,这与切线模型组合中使用的 Taylor 近似不同。
- CNN 中的 Jacobian 矩阵受到关注:成员们讨论了 Jacobian,并链接了来自 Zara Khadkhodaie 和 Eero Simoncelli 关于图像模型的论文:https://iclr.cc/virtual/2024/oral/19783, https://arxiv.org/abs/2310.02557, https://arxiv.org/abs/1906.05478。
- 这些论文研究了带有 (leaky) ReLUs 和零偏置线性层的 CNNs,并在推理时计算常规的 Autograd Jacobian。
DSPy Discord
- FastWorkflow 在 Tau Bench 上打破 SOTA:一名成员宣布 fastWorkflow 使用 此仓库 在零售和航空工作流上实现了 SOTA,同时利用了一个带有 fastWorkflow 适配器的 Tau Bench fork 来生成这些结果,并声称 论文即将发布。
- 该成员表示,通过适当的 Context Engineering,小模型可以媲美或超越大模型。
- 对话历史在 DSPy 的不同 LLM 之间保持一致:一位用户发现 DSPy 模块中的对话历史在不同的 LLM 之间得以维持,因为它是 Signature 的一部分,而不是 LM 对象本身。
- 他们询问了 ReAct 模块如何自动处理历史记录,以及复杂的 Pydantic OutputField 是否能被正确反序列化。
- Pydantic OutputFields 在 DSPy 中遭遇反序列化障碍:一位用户报告称,复杂的 Pydantic OutputFields 在 DSPy 中无法正确反序列化,导致生成的
str包含的 JSON 与 Schema 不匹配。- 他们强调了该包对 Python < 3.14 的依赖,并询问如何约束 LLM 的输出以符合特定类型。
- Java 渴望 DSPy Prompts:一位用户寻求在 Java 中运行 DSPy Prompts 的解决方案,请求一个简化版的 Java JSONAdapter 来格式化输入/输出消息。
- 建议是将 System Message 与输入和输出字段结构化,以便更轻松地处理 JSON。
- ReAct 模块面临上下文丢失灾难:一位用户在 ReAct 模块中遇到了上下文丢失问题,当由于 Rate Limits 触发备用 LLM 时,导致模块从头开始运行。
- 他们征求了关于在不丢失先前上下文的情况下添加备用 LLM 的建议,并表达了对与直接 API 调用相比定制化困难的挫败感。
tinygrad (George Hotz) Discord
- Tinybox 基准测试引发关注:一位用户请求获取将 8x5090 tinybox 配置与 A100 和 H100 等行业标准进行对比的 基准测试 (Benchmarks)。
- 该请求强调了人们对 tinybox 设置相对于成熟 GPU 性能的兴趣,但讨论中未提供具体的基准测试数据。
- Tinygrad 获得远程重启功能:一位用户询问 Tinygrad 是否具有 带外 (out-of-band) 机制,特别是远程重启,George Hotz 确认 tinyboxes 都配备了 BMC。
- 这确认了用于远程管理 tinyboxes 的基板管理控制器的可用性。
- VIZ 在通过 SSH 访问时变慢:George Hotz 质疑 VIZ 工具在通过 SSH 访问时性能缓慢的问题。
- 这表明在远程访问场景下使用 VIZ 工具时,可能存在潜在的优化问题或瓶颈。
- ntid 访问故障排除:一位成员在尝试使用 Uop SPECIAL 访问
blockDim时面临挑战,该功能支持ctaid和tid但不支持ntid。- 他们通过 文件级常量 (file level const) 解决了该问题,但指出 UOps 的错误提示非常无用,强调了错误消息方面有待改进。
- PyTorch 张量转为 Tinygrad:一位成员询问了将 PyTorch tensors 高效转换为 Tinygrad tensors 的最佳方法。
- 他们提到使用
Tensor.from_blob(pytorch_tensor.data_prt())转换为 Tinygrad,但不确定反向转换的方法,目前使用的是from_numpy。
- 他们提到使用
aider (Paul Gauthier) Discord
- Aider 支持 Claude Sonnet 模型:一位用户询问 aider 是否支持
claude-sonnet-4-5-20250929,另一位成员确认在设置 Anthropic API key 后,可以使用/model claude-sonnet-4-5-20250929命令来支持该模型。- 这使得用户能够在 aider 中利用 Claude Sonnet 模型进行代码编写任务和交互。
- 解锁 Haiku 和 Opus 模型的推理能力:一位成员寻求关于在 Haiku-4-5 和 Opus-4-1 模型上启用思考/推理(thinking/reasoning)功能的指导,特别是在 aider CLI 中。
- 他们愿意通过编辑 model settings YML file 来启用此功能,但需要具体的指令。
- Qwen 30b 引发内存耗尽:一位用户在处理全部上下文时遇到了 Qwen 30b 的内存问题,这表明短描述规则可能不是一个硬性限制。
- 一位成员建议使用 Python script 配合特定的 prompt,通过 aider 迭代处理文件。
rg在替代grep方面表现出色:一位成员通过 grok 发现了rg,并称赞它是grep的有效替代方案,且开箱即用。- 他们将其作为一个随机技巧分享给偶尔使用
grep进行搜索操作的用户。
- 他们将其作为一个随机技巧分享给偶尔使用
- Gemini 表现优于 GPT-5:一位用户报告称,尽管使用了适当的参数,Google 的 Gemini API 在解释、教学和代码生成方面的表现仍优于 GPT-5。
- 另一位成员承认参数看起来是正确的,但也承认 LLM 的性能可能是主观的,并因具体任务而异。
MCP Contributors (Official) Discord
- MCP 即将支持通过 URL 处理图像:成员们讨论了将 image URLs 作为 MCP 客户端的工具输入,使工具能够从提供的 URL 下载图像,并询问了与 Claude/ChatGPT 的兼容性。
- 要在 Claude/ChatGPT 中使用图像,你需要一个 MCP tool,该工具通过将图像上传到对象存储服务并返回用于输入的 URL,从而将图像转换为 URL。
- MCP 工具将图像转换为 URL:团队讨论了该工具的工作原理,即通过将图像上传到对象存储服务将其转换为 URL。
- 然后,该工具返回图像的 URL,该 URL 可作为输入使用。
- 关于 MCP 代码执行的 Reddit 帖子:一位成员分享了一个 Reddit 帖子,其中包含一篇关于 Code Execution with MCP 的博客文章。
- 其他成员提到某位特定用户拥有关于该话题的更多信息。
Manus.im Discord Discord
- Web App 错误导致退款:一位成员报告称其 Web App 面临无法解决的错误并获得了退款,但问题未得到修复。他指出在遇到问题之前,应用已接近完成。
- 该成员表示:“我的 Web App 已经完成了大约 90%,准备发布以便进行 Beta 测试。一天后我再回去看,到处都是无法解决的错误。”
- 项目转移给朋友:一位成员询问如何将已完成的网站项目转移到朋友的账户。
- 他们希望“将其移交给朋友的另一个账户,以便他可以进一步开展工作”,而不是进行协作。
- Stripe 集成导致困难:一位成员请求关于 Stripe 集成 的反馈,报告称很难使其正常工作。
- 他们表示:“有人成功搞定 Stripe 集成了吗?希望能得到反馈。我一直没弄对……”
- 工程师推介工作流自动化与 AI 实力:一位专注于工作流自动化、LLM integration、RAG、AI detection、图像/语音 AI 以及区块链开发的工程师提供了服务。
- 该工程师分享了 作品集链接,并强调了其成功案例,例如通过支持自动化将响应时间缩短了 60%,以及使用 CLIP 和 YOLOv8 开发了标签/审核流水线。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该公会长时间没有动态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会长时间没有动态,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该公会长时间没有动态,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:各频道详细摘要与链接
LMArena ▷ #general (1066 条消息🔥🔥🔥):
MovementLabs AI, GPT-5, Gemini 3 Pro vs Lithiumflow, Genie 3, 开源中文 LLMs
- MovementLabs AI:正规初创公司还是可疑骗局?:针对新 AI 公司 MovementLabs AI 展开了辩论。一些用户指责其为骗局,理由是缺乏透明度、声称拥有自定义的 MPU (Momentum Processing Unit) 以及令人怀疑的高速表现;而另一些人则为其性能和速度辩护。
- 指控包括硬编码 SimpleBench 答案、可能套壳了其他模型(如 Cursor),以及对公司注册和融资的质疑;MovementLabs 回应称他们拥有支持且不寻求公开投资,并声称拥有一项 专利申请中。
- VoxelBench 上的 GPT-5 vs Lithiumflow:据报道,GPT-5(或其某个版本)在 VoxelBench(一个从体素数组创建 3D 模型的基准测试)上表现优于 Lithiumflow (Gemini 3 Pro),如此图所示。
- 成员们争论 GPT-5 Pro 的编程能力是否超过了 Lithiumflow,讨论还涉及了此类模型的成本和潜在应用。
- Genie 3 将随 GTA 6 占据主导地位:成员们讨论了 Google 的文本生成世界模型 Genie 3,推测它可能会有除 AI Studio 之外的独立网站,并探讨了其对 AI 生成游戏的影响。
- 讨论了保存 AI 生成世界的速度和能力,并与即将推出的 Sora 3 和 GTA 6 进行了比较——有人开玩笑说 Genie 3 可能会先面世。
- 美国 AI 存在审查问题:一位成员抱怨美国 LLM 会拒绝提示词,称美国模型中的“模棱两可(hedging)”比审查制度还要糟糕 10 倍,并表示:“老实说,我最不想听到的就是模型的意见。我真的不在乎模型有什么意见或想说什么。我只想给它指令,让它执行,而不需要听模型的意见。”
- 这一言论引发了关于 GLM 4.5 及其世界知识的对话。他表示:“这恰恰说明了我们在西方是多么缺乏教育。如果我们把这作为审查制度的主要例子,那我们还会用什么呢?”
- AI Studio 移除了 A/B 测试:用户报告称 A/B 测试 功能已从 AI Studio 中移除,一位用户哀叹他“从未获得过 A/B 测试”。
- 用户还讨论了 A/B 测试功能是否会改进,并质疑“你认为 A/B 版本更好吗?”。
LMArena ▷ #announcements (1 条消息):
Kimi-k2-thinking 模型, LMArena 更新
- Kimi-k2-thinking 进入竞技场:一个新模型 kimi-k2-thinking 已添加到 LMArena。
- LMArena 添加新模型:公告频道显示 LMArena 已添加一个新模型。
Perplexity AI ▷ #general (1074 条消息🔥🔥🔥):
赏金支付, Comet 上的 AdBlock, Youtube 广告, Linux 版 Comet 浏览器, 最佳编程 AI
- 赏金支付延迟令用户沮丧:用户对收到赏金和推荐奖励的延迟表示不满,一些人怀疑存在欺诈行为。
- 一名用户威胁如果不付款就起诉,而其他人则推测了验证过程和大规模欺诈的可能性,这导致某些地区的推荐计划被关闭。
- AdBlock 问题困扰 Comet 浏览器用户:用户报告 YouTube 广告 在 Comet 浏览器 中不再被拦截,引发了广泛的不满。
- 一些人推测 YouTube 正在积极绕过广告拦截器,而另一些人则希望 Comet 团队能尽快修复。
- Snapchat 与 Perplexity 达成合作!:Snapchat 正与 Perplexity 合作,计划在 2026 年初将其 AI 回答引擎引入 Snapchat,据报道 Perplexity 将在一年内向 Snap 支付 4 亿美元。
- 用户质疑使用 Snapchat 而非 Instagram 的逻辑,一位用户评价道:“Perplexity 确实有钱。”
- Codex CLI 需要降级:要使用 Codex CLI,必须降级到 Go 方案。
- 降级后,它会要求 Plus 方案。
- 社区渴望 Minecraft 服务器:社区成员请求建立一个 Minecraft 服务器。
- 一名成员开玩笑地问 kesku:“这是请求 kesku 建立 Minecraft 服务器的第二天。”
Perplexity AI ▷ #pplx-api (4 messages):
API 文档, API 使用
- API 信息分享:一位成员询问了可用的 API 及其使用方法。
- 另一位成员分享了 API 文档链接。
- API 使用咨询:一位用户咨询了可用的 API 类型以及如何利用它们。
- 作为回应,提供了相关 API 文档的链接。
LM Studio ▷ #general (155 messages🔥🔥):
vast.ai 租赁, 用于 Python 版本的 UV, GPTs Agent 学习, 更长的 Token 上下文历史, Intel llm-scaler
- **Vast.ai 租赁设备拥有极高带宽:一位用户从 Vast.ai 租赁了一台拥有 **8Gbit 光纤 的服务器,正在寻求 Ollama 模型 建议,运行 GPT-OSS 120B 并带有 40k context。
- 另一位用户建议使用 UV,它可以非常快速且轻松地指定 Python 版本。
- **傻瓜式 PIP 安装防止全局配置错误:一位用户发现无法使用基础 **pip 进行全局安装,这是防止在全局范围内安装内容的绝对可靠方法。
- 增加上下文长度会分配额外的 VRAM 来缓存 Token,除非在高级设置中取消勾选 “context on gpu”。
- **ComfyUI 冲突导致配置混乱:一位用户遇到了链接问题,原因是与 **ComfyUI 冲突,两者使用了相同的端口
127.0.0.1:1234/v1。- 另一位用户建议在设置中将端口更改为 1235 以解决冲突,这修复了节点但导致 ComfyUI server 停止运行。
- **小说 AI 需要知识导航技巧:一位用户询问如何在 **LMStudio 中为 AI 小说写作 保留更长的 Token 上下文历史,以防止幻觉(hallucination)。
- 建议使用与数据库集成的工具或独立的集成应用,总结事件、地点和角色,使用设定集(lore books)、角色卡和不同粒度的故事线,并为当前查询注入正确的知识背景。
- **Intel 的 LLM Scaler:起步缓慢?**:一位用户分享了 Intel 在 GitHub 上的 llm-scaler 链接,指出它是为其架构开发的。
- 他们询问是否有使用 Intel GPU 的人尝试过它,并能反馈性能提升情况。
LM Studio ▷ #hardware-discussion (802 messages🔥🔥🔥):
3090 vs 3080 基准测试, 多 GPU 设置, OpenRouter API, EPYC, AMD Radeon™ AI PRO R9700
- 竭尽全力修复弯曲:在分享了一张 CPU 引脚弯曲的照片后,一位成员仅凭手机摄像头和梦想就将它们全部校正了。
- 该成员因其奉献精神和“上帝般稳健”的手法而受到称赞,有人回复道:“我真没想到能修好”。
- AIO 装不下?即兴发挥!:一位成员正试图在空间极其有限的机箱中安装 AIO 水冷散热器,提出了诸如将机箱夹在散热器和风扇之间,或使用扩展件增加前后面板间隙等方案。
- 其他成员建议直接购买新机箱,并指出挑战在于“解决问题”而非追求最佳散热性能。
- 解锁巅峰性能还是性能过剩:一位成员正在考虑 MSI MEG X570 Godlike 主板,因为它具备超频功能和扩展能力,拥有四个全尺寸 NVMe 插槽。
- 讨论围绕该主板的 PCIe 通道分配是否物有所值展开,特别是考虑到消费级主板上可用的 PCIe 通道数量有限。
- 3080 vs 3090:终极 Tok/s 对决:成员们对比了 3080 20GB 与 3090 的性能,尝试通过不同设置优化 Qwen3 模型的 Token 生成速度。
- Qwen3-30B-A3B-Instruct-2507-MXFP4_MOE 模型表现出色,在两张显卡上均达到了约 100tok/s,尽管 3090 拥有更高的显存带宽,这突显了核心带宽的重要性。
- 4090 经过微调后会更好吗?:一位用户测试了他们的 4090 并声称“这卡太烂了”,这一说法被一个指向 32GB 对比测试的链接反驳了。
- 其他用户询问了最佳使用场景以及微小改动的影响,例如将模型保留在内存中,以及 Q4 比 Flash 快多少。
Unsloth AI (Daniel Han) ▷ #general (323 条消息🔥🔥):
用于 diffusion models 的 Unsloth,Masking 问题,Qwen3 模型微调噩梦,Compute Metrics 函数,Colab TPU 支持
- 针对 diffusion models 的 OneTrainer 替代方案浮出水面:一位用户询问是否有针对 diffusion models 的 Unsloth 等效工具,有人建议将 OneTrainer 作为可能的起点。
- 他们一致认为 diffusion models 的问题在于没有一个通用的训练器。
- Masking Assistant Questions 导致模型失败:一名成员发现 masking assistant questions 会导致模型出现问题,导致其屏蔽了部分响应,他们正在重写脚本以解决此问题。
- 此外,有人建议,如果训练 Loss 开始时非常低而验证 Loss 仍然很高,可能表明 Loss 计算方式存在问题,甚至是 Bug,因为 Loss 会随着 batch size 的增加而减少。
- Qwen3 微调证明极其困难:成员们发现 Qwen3 模型微调特别具有挑战性,一位用户将其描述为微调噩梦,并在训练期间经历了取决于 batch size 的 Loss 差异。
- 原帖作者指出官方 Notebook 显示 Loss 从 0.3 降至 0.02。
- 自定义 Compute Metrics 追踪模型成功与否:一名成员学习了如何制作 compute metrics functions 来追踪除 train 和 eval loss 之外的更多指标。
- 有人表示 Loss 说明不了什么。Loss 只能显示情况是否正常,但不能说明任务是否成功。
- Unsloth 在 Google Colab 上表现最佳:成员们澄清说 Unsloth 与 Kaggle TPU 不兼容,而是更倾向于 Google Colab 的 GPU 和 TPU。
- Colab 支持 CPU, GPU (T4), 和 TPU (v5e-1),而 Kaggle 支持 CPU, GPU (2x T4), 和 TPU (v5e-8)。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (4 条消息):
LLM 训练原则,研究论文推荐,工作流自动化
- LLM 训练原则详解:一位来自美国的成员正在致力于阐述他们个人关于如何训练 LLM 的底层原则。
- 该成员已接近完成拆解工作,并将在某个时候发布,并指出他们“在读过的研究论文中看到过零散的信息,但没有看到能将一切串联起来的内容”。
- 工作流自动化项目:一位成员分享说他们一直致力于自动化工作流并构建小型全栈侧边项目。
- 他们的背景涉及 web app development、API integrations 和 backend optimization 等项目。
Unsloth AI (Daniel Han) ▷ #off-topic (48 条消息🔥):
Parakeet 模型 vs Whisper,模型合规性与真实性,人类级别 TTS 训练,模型去审查,对话气泡坐标
- Parakeet 模型表现优异,Whisper 模型表现不佳:成员们声称所有的 Parakeet models 都能工作,甚至是 CTC,同时宣称 Whisper 绝对是垃圾。
- 关于模型合规性的辩论:成员们质疑如果模型仅仅是在说出真相(尤其是关于刻板印象的观点),它们是否真的符合合规性,以及是否应该允许它们批评用户的请求,而不是盲目遵循指令。
- 一位成员表示,一个智能模型不仅应该执行用户请求的操作,还应该在现有语境下告知用户其对该请求的评估,就像程序员告诉项目负责人项目的需求说明不当或毫无意义一样。
- 人类级别 TTS 训练开始!:一位成员开玩笑说,在开始使用 200k 样本训练人类级别的 TTS 后,明天就能实现 AGI。
- 去审查(Uncensoring)的焦点是否偏移?:一位成员指出,每个对模型进行去审查的人都关注于制造核武器、毒品、恐怖主义病毒之类的内容,而不是无害的事情,比如重复猫比狗更优越。
- OpenRouter 在 XCode 上遇到问题:一位成员在使用 XCode’s Coding Intelligence 与 OpenRouter 时遇到问题,面临一个指示 No cookie auth credentials found 的错误。
Unsloth AI (Daniel Han) ▷ #help (53 条消息🔥):
TRL 的 RLOO trainer REINFORCE 实现,Qwen3-coder-30b 在 5080 GPU 上 API 调用缓慢,GPT-OSS-120B 量化问题,Granite 4.0 Hybrid 模型问题,为 Qwen/Qwen3-4B-Instruct-2507 添加新 Token
- REINFORCE 实现的变通方案:一名成员发现了一个使用 TRL 的 RLOO trainer 实现“原生” REINFORCE 的变通方法,即通过 SFT trainer 进行模拟。这是因为 RLOO_config.py 要求 num_generations < 2 时会出现问题。
- 原始问题与 RLOO_config.py 中的一个错误有关,该错误强制要求每个 prompt 至少有 2 个 generation,这与该成员的 RL 环境 (num_generations=1) 冲突。
- Qwen3-coder-30b API 调用缓慢:有用户报告 Qwen3-coder-30b 通过 llama-cli 或 llama-server 在 5080 GPU 上运行良好,但从其他环境使用 API 调用同一服务器时,速度显著变慢。
- 建议认为缓慢可能是由于 CPU offloading 导致的,因为 30GB 的模型无法完全装入 16GB 的 GPU 显存,或者是上下文长度问题。建议使用更小的量化版本(如 Q2)或使用 计算器 检查 VRAM 占用情况。
- GPT-OSS-120B 量化失败:一名成员在使用
llama-quantize对 GPT-OSS-120B 模型进行 1-bit 量化时遇到错误,特别是在 mxfp4 转换 期间。- 错误涉及张量(tensors)无法被 256 整除(这是 q6_K 的要求),导致回退到 q8_0 量化,随后因禁用了从 mxfp4 重新量化而失败。
- Granite 4.0 Hybrid 模型问题:一名用户提到由于 Granite 4.0 Hybrid 模型 的问题提交了一个 GitHub issue。
- 提及此问题的背景是用户遇到了运行缓慢,因为必须将所有内容从系统 RAM 通过 PCIe 总线移动到 GPU 显存中。
- 为 Qwen3-4B-Instruct 添加新 Token 遇到困难:一名成员在尝试为 Qwen/Qwen3-4B-Instruct-2507 添加新 Token 时面临问题,尽管参考了预训练 notebook 并调整了模型大小。
- 尽管其他 Token 的 loss 在下降,但新 Token 在测试中从未出现,这引发了关于是否需要 masking 或在训练期间进行进一步调整的疑问。
Cursor Community ▷ #general (285 条消息🔥🔥):
Cursor Model Composer 限制,Cursor 应用崩溃,Cursor 的 'Auto' 模式定价,Cursor 与 Grok Code 成本,拖拽问题
- Cursor Model Composer 限制令用户沮丧:用户对 Cursor Model Composer 的限制感到不满,特别是当使用 GPT-5 达到使用限制后,它在其他 GPT 模型上也停止工作。
- 一名用户表达了对 “auto” 模式 的沮丧,指出它对运行代码的编辑效果很差,且没有明确说明正在使用哪个模型。
- 用户报告 Cursor 应用崩溃和数据丢失:多名用户报告 Cursor 应用崩溃,导致无法访问之前的聊天记录或对其进行总结,造成了极大不便。
- 一名用户建议,即使应用与服务器失去连接,至少也应该允许总结聊天内容,而不是完全拒绝执行任何操作。
- Cursor 的 ‘Auto’ 模式定价困扰用户:关于 ‘Auto’ 模式 在 pro 计划中是否免费,用户中存在困惑,报告情况不一,且免费 auto 选项已被移除。
- 一名用户在达到配额前向 Composer 发送了 64 条 prompt,之后系统提示需要付费才能继续使用该计划。
- Grok Code Fast 消耗大量 Token?:一名用户报告调试一个 500 行的 HTML 文件 消耗了 800 万个 Grok Code Fast token,而另一名用户声称 Grok Code Fast 是免费的,且他们每月使用价值数十亿 token 的额度。
- 一名用户指出,如果不开启 MAX 模式,LLM 会有 250 行的限制。
- 更新后拖拽功能失效?:一些用户报告称,自新更新以来,将文件拖拽进 Cursor 的功能已失效。
- 原因似乎与 ad 上的进程权限提升(elevation of the process)有关,这会导致拖拽功能失效。
Cursor Community ▷ #background-agents (8 messages🔥):
Cursor 2.0, internal error, base64 image, Cursor agent API
- Cursor 2.0 的可见性很有帮助!: 一位用户感谢另一位用户提供了变更的可见性,并称赞了 Cursor 2.0 的速度。
- 对话暗示了对更新版本的积极体验,一位用户表示 “Cursor 2.0 的速度非常快”。
- Cursor 抛出内部错误: 一位用户报告在使用 Cursor 时遇到 “internal error”,消息内容为 “We encountered an internal error - please try again in a moment”,Cursor 团队的一名成员注意到了这一点。
- Cursor 团队成员询问了上传图像的情况,寻求详细信息或可复现的示例以便进一步调查,并请用户通过私信发送。
- Base64 图像格式不正确: 一位用户最初在向 Cursor agent API 提交 base64 image 时遇到问题,导致报错。
- 该用户后来发现 base64 格式不正确,移除 ‘data:image/jpeg;base64,’ 后问题得以解决。
- 在仓库中重新创建图像的请求: 在解决 Base64 问题后,一位用户询问是否可以让 Cursor 利用上下文中的 base64 image,通过 Agent 重新创建图像并保存到他们的仓库中。
- 社区成员尚未对此做出回应。
GPU MODE ▷ #general (67 messages🔥🔥):
mattpharr joins discord, FP4 kernel, Nvidia interview, Blackwell PTX ISA, Datacrunch CUDA support
- PBR 作者加入 Discord!: PBR book 的作者、ThunderKittens 博主 mattpharr 在博文中被提及后加入了 Discord 服务器。
- 他提到关于 auto vectorization(自动向量化)的博文对人们影响很大,并且发现自动融合编译器(automatic fusion compilers)也存在类似的问题。
- 全神贯注于 FP4 内核创建: 距离编写全球最快的 FP4 GEMV 还有 22 天,成员们讨论了精度管理要求和吞吐量追踪。
- 有人指出,由于涉及的权重数量庞大,推理(inference)对低精度的抗性很强;常用方法是将 fp4 权重反量化(dequant)为 fp8/fp16/fp32 进行累加,然后重新量化(re-quant)为 fp4 输出。
- Nvidia Blackwell 的 PTX ISA: Nvidia 的 Blackwell 架构包含了将一整块 FP4 值转换为 FP16 值的新指令,使用的是 cvt with .e2m1x2, .e3m2x2, .e2m3x2, .ue8m0x2。
- 一位成员已将所有 PTX 和 CUDA 文档转换为 Markdown 并放入树状结构中,并指出 Claude 在这种格式下变得更加强大,因为它甚至可以读取用于布局的嵌入图像。
- 揭露内存带宽谎言: 实验显示,Nvidia 官方的内存带宽数据并不准确,仅有 92% 的宣传带宽是可以复现的。
- 成员们讨论了提高带宽利用率的策略,包括 锁定内存时钟(locking the memory clock) 和优化内存访问模式。
GPU MODE ▷ #triton-gluon (21 条消息🔥):
Triton kernel 重新编译,带有 comms 的 Gluon 示例,在 Gluon 中表达 swizzling,在 C++ 中复制 Triton JIT,Triton C++ 桥接
- **整除性驱动 Triton 的重新编译逻辑:Triton 会在不同的循环迭代中重新编译 kernel,这是由基于 **16 整除性和其他常见模式对输入
n等动态值进行特化(specialization)引起的,正如生成的 IR 中的tt.divisibility=16属性所示。 - **Gluon 中的 Swizzling 仍在寻求示例:一位用户询问了带有 **comms(例如 all gather matmul)以及表达 swizzling 的 Gluon 示例,但在这次交流中没有找到相关示例。
- 目前尚不清楚 swizzling 是否甚至可以在 Gluon 中表达。
- **C++ 中的 Triton JIT:遥不可及?**:一位用户询问了在 C++ 中复制 Triton 的 JIT 功能的可能性,强调了在运行时生成具有所需 block size 的 kernel 的挑战,特别是对于 fused softmax。
- 据称目前唯一支持的语言是 Python,JIT 所做的只是让 Python 生成字节码,然后将其转换为 LLVM/MLIR 基础设施可以处理的内容。
- **MLIR 模块:在 C++ 中使用 Triton 的“黑科技”路径:一位用户建议使用 Python 生成 **MLIR,将其包含在 C++ 代码中,进行解析,并将 block size 作为常量添加以进行优化,这是一种虽然粗糙但可能可行的方法。
- 链接 展示了如何 lower 并将 Triton kernel 与 C 代码结合使用。
GPU MODE ▷ #cuda (21 条消息🔥):
内存带宽饱和,CUDA Kernel 调优,Triton Stream 执行
- Kernel 难以达到内存带宽饱和:一位开发者在 B200 上实验了一个旨在使内存带宽饱和的 kernel,尽管进行了各种优化,但仅达到了峰值带宽的 85%,并疑惑为什么无法达到宣传的 8TB/s。
- 随后,开发者意识到混淆了 TB/s 和 TiB/s,实际达到了 92%,但仍对如何达到 100% 存有疑问。
- 遗传算法调优 CUDA Kernel:一位硕士生正在寻求调优 CUDA kernel 的实用方法,并指出静态程序分析会导致通用程序中的内存瓶颈。
- 一位成员建议使用遗传算法进行基准测试(benchmarking),并指向了一个解释该方法的视频。
- Triton stream 执行延迟:一位开发者审查代码后发现,默认 stream 7 上的算子与 stream 55 上的通信算子之间没有基于事件(event-based)的依赖关系,质疑为什么 stream 7 上的算子在 Triton 执行到一半时才开始执行。
- 附带了 stream 执行时间线的可视化表示,以便进一步分析。
GPU MODE ▷ #torch (26 条消息🔥):
torch.AcceleratorError,CUDA 错误恢复,Kernel 基准测试,BackendBench 多进程评估,Soumith Chintala
- 绕过 assert_close 的 mul 问题:一位使用 torch 2.8.0 的成员发现了
assert_close中的一个 mul 问题,并通过将 float8 tensors 转换为其他数据类型来绕过它。- 相关的 PyTorch PR 旨在解决此问题,尽管该修复似乎尚未完全同步到所有版本。
torch.AcceleratorError需要重启进程:在遇到torch.AcceleratorError(如“非法内存访问”)后,即使使用了 try/except 块,错误仍会持续存在,必须重启 Python 进程。- 该问题在对自定义 CUDA kernel 进行 Kernel Benchmarking 时尤为突出,而
subprocess.run()速度明显较慢,因此需要一种重置 PyTorch accelerator 状态的解决方案。
- 该问题在对自定义 CUDA kernel 进行 Kernel Benchmarking 时尤为突出,而
- 进程生成(Process Spawning)对 CUDA 基准测试是安全的:在对 CUDA kernel 进行基准测试时,使用
mp.Process生成新任务是安全的,这可以确保一个任务中不可恢复的 CUDA 错误不会影响其他任务,尤其是在使用 spawn 而非 fork 时。- 建议一次只运行 1 个基准测试任务,以确保结果准确,避免并行子进程。
- Soumith Chintala 对 GPU MODE 的影响:一位成员对 Soumith Chintala 早期的支持和指导表示感谢,这让他们能够专注于 GPU MODE 并扩大社区规模。
- 他们分享了 Soumith 的 X 帖子链接 并强调了他对他们工作的影响。
GPU MODE ▷ #cool-links (7 messages):
Numerical Stability, GEMM correctness checks, LLM generated kernels, fp16 vs fp32 numerics
- Matmul 测试中的数值稳定性:一位成员分享了 Nicholas J. Higham 的数值稳定性报告,并询问在 matmul 测试 中确定容差范围(tolerance bounds)的决策过程。
- 他们链接了 相关的 PyTorch 代码,暗示目前 GEMM 的正确性检查 是“基于感觉的(vibes based)”,或者依赖于在真实模型上运行数值测试。
- LLM Kernel 正确性证明依然困难:一位成员讲述了在面试过程中尝试为 LLM 生成的 kernels 定义 matmul 正确性 时失败的经历。
- 他们开玩笑说,这个问题注定会导致失败。
- Anthropic 复盘报告强调 fp16 与 fp32 问题:一位成员重点介绍了 Anthropic 的复盘报告,该报告涉及数值问题,特别是 top-p 和 top-k 采样中的 fp16 与 fp32 差异。
- 未提供更多细节。
GPU MODE ▷ #jobs (1 messages):
Hiring, Engineering Positions, Low-level Developers, AI System Performance
- AI 公司寻求底层开发人员:一家 AI 公司正在积极 招聘工程师,以满足强大的客户管线需求。
- 该公司正在寻找 底层开发人员(low-level developers) 和 性能工程师,以挑战 AI 系统性能 的极限,提供的薪酬范围为 $500K–$1M TC。
- 团队拥有顶尖人才和背景支持:该公司的团队成员包括 前 HRT 和 Five Rings 工程师、IMO 奖牌获得者、Zig 和 tinygrad 核心开发者,以及来自顶尖 AI 实验室的人员。
- 该公司由 一线投资者(Tier 1 investors) 支持,并且是今年 MITIT 和 ZigLang 的赞助商。
GPU MODE ▷ #beginner (7 messages):
PyTorch/vllm on AMD AI PCs, Image to Image ViT Optimization, 1D Convolution Kernel for Tensara Problem
- PyTorch/vllm 寻求 AMD APU 支持:一位成员询问如何在 AMD AI PC 上运行 PyTorch/vllm,寻求建议以及能识别 APU 的 Docker 配置。
- 该用户尝试了各种 Docker 变体和 therock 仓库,但在让 PyTorch 识别 APU 方面面临挑战。
- 图像到图像 ViT 优化探索开始:一位成员正在使用 torch compile, fp16 和 flash attention 等技术优化 图像到图像 ViT 的单图推理时间。
- 他们请求进一步优化的协助和资源,并指出其主要关注点是核心算法而非优化技术;有人建议查看 Sam-fast 仓库,其核心在于消除图中断(graph breaks)和代码中无谓的同步(syncs)。
- 1D 卷积 Kernel 调试难题:一位成员在为 tensara 问题调试 1D 卷积 kernel 时寻求帮助,在大规模测试中遇到了结果轻微不准确的问题。
- 他们怀疑是 atomicAdd 的问题或存在差一错误(off-by-one error),并提供了 kernel 的 gist 链接,请求在没有 CUDA 硬件的情况下提供调试建议。
GPU MODE ▷ #jax-pallas-mosaic (1 messages):
jax.experimental, gpu collective_matmul_mgpu.py
- MGPU 上的 JAX 集合矩阵乘法:jax.experimental 命名空间是 JAX 探索性和实验性特性的所在地。
- 一位用户分享了 collective_matmul_mgpu.py 脚本,这是在多 GPU 系统上扩展矩阵乘法工作的组成部分。
- 用于集合 Matmul 的 Pallas GPU 操作:文件 collective_matmul_mgpu.py 在 JAX Pallas 框架内提供了 GPU 操作,专门为跨多 GPU 的集合矩阵乘法(collective matrix multiplication)设计。
- 这些操作旨在利用 JAX 的实验性特性,优化并分布多 GPU 环境中大型矩阵乘法的计算。
GPU MODE ▷ #torchao (2 messages):
Accelerated Sparse Computation
- 用户关注加速稀疏计算 (Accelerated Sparse Computation):一位曾在其他领域从事过加速稀疏计算工作的成员回归,并看到了贡献的空间。
- 他们指出,这对最终用户体验有微小但良好的改进。
- 稀疏计算贡献的机会来了:一位成员表达了对该项目做出贡献的兴趣,并强调了他们在加速稀疏计算方面的经验。
- 他们在病愈后今天重新开始这项工作,认为这感觉是对最终用户体验的一个微小但良好的改进。
GPU MODE ▷ #off-topic (1 messages):
Milk Couch
- Milk Couch 现身:一位用户发布了一张“milk couch”的照片 (IMG_20251106_140720.jpg)。
- 另一次 Milk Couch 目击:另一位用户插话指出,milk couch 变得越来越普遍。
- 他们在思考这代表了家具设计的新趋势,还是仅仅是牛奶洒了的问题。
{kind=link}
GPU MODE ▷ #intel (1 messages):
oneAPI 2025.3.1, Intel Fortran Compiler
- oneAPI 2025.3.1 悄然发布:oneAPI 2025.3.1 已经发布,但找不到发布说明,且 oneAPI Toolkit 下载页面也未显示,仍停留在版本 2025.3.0。
- Intel Fortran Compiler 周一获得更新:据推测,Intel Fortran Compiler 已在周一更新至 2025.3.1 版本,并于当时同步发布。
GPU MODE ▷ #metal (2 messages):
Candle Framework, Metal backend
- Candle 框架支持 Metal:Huggingface 的 candle 神经网络框架对某些操作提供了 Metal 支持,一位用户发现它在 M[12] OSX 设备上相当有用。
- iOS 上能透明支持 Metal 吗?:目前尚不确定它是否能透明地迁移到 iOS 上。
GPU MODE ▷ #self-promotion (3 messages):
Bit Counting, Geometric Series, SSE Popcount, CUDA Intrinsics
- 位计数 (Bit Counting) 获得几何级数优化提升:一位成员分享了一篇博客文章和代码,关于使用几何级数优化位计数。
- 该文章详细介绍了从基本原理推导公式并在 C 语言中实现的过程,分析了其相对于朴素方法的优势。
- SSE Popcount 在 CPU 上表现出色:讨论提到,使用 Harley-Seal 向量化计数的 Mula’s sse-popcount 几乎是 CPU 上能达到的最佳水平。
- 它还通过进位保存加法器 (carry-save adder) 累加,在 16 个向量组成的块上进行累加。
- 用于 GPU 位计数的 CUDA Intrinsics:一位成员提到使用 CUDA intrinsics 进行基于 GPU 的位计数。
- 除了 CUDA intrinsics 之外,他们还没有探索其他针对 GPU 的特定优化。
GPU MODE ▷ #submissions (1 messages):
vectorsum_v2, A100, B200, H100, L4
- Vectorsum v2 排行榜诞生新冠军:由 <@1435179720537931797> 提交的编号
67399在vectorsum_v2排行榜中以 138 µs 的成绩夺得 A100 第一名。- 同一提交还获得了 B200 第三名 (53.4 µs)、H100 第二名 (86.1 µs) 以及 L4 第五名 (974 µs)。
- Vectorsum v2 在不同 GPU 上的性能:提交
67399在vectorsum_v2排行榜的各种 GPU 上都表现出了令人印象深刻的性能。- 值得注意的是,该提交在 A100、B200 和 H100 上均获得了顶级排名,展示了广泛的兼容性和优化。
GPU MODE ▷ #hardware (8 条消息🔥):
DGX Spark 使用体验, GDDR 芯片更换, DGX Spark 作为数据中心代理, DGX Spark 中的 SM120 GPU, Strix Halo 对比 DGX Spark
- 探索 DGX Spark 使用体验:一名成员正在寻求关于使用 DGX Spark 托管本地模型、进行 NVFP4 量化实验以及本地微调的第一手经验。
- 他们听说了关于带宽限制的传闻,并对用户关于软件栈的反馈感兴趣。
- DGX Spark:不是数据中心代理?:有成员提到,搭载 SM120 GPU 的 DGX Spark 无法利用除 FP4 以外的新 Blackwell 特性,这使其难以作为数据中心解决方案的替代原型。
- 一名成员将其描述为基本上是一个没有显存的 5080,因为它使用共享系统内存(RAM),并对其预期的使用场景表示怀疑。
- Strix Halo 盖过 DGX Spark?:DGX Spark 的 CPU 侧被认为逊色于 Strix Halo,且某些 GPU 分割选择限制了其相对于数据中心解决方案的有效性。
- 对于远程 PC 应用,有人建议 Strix Halo 将会完胜它。
GPU MODE ▷ #tpu (1 条消息):
性能分析采集策略, 缩短性能分析时长, 调试函数调用
- 调整性能分析采集:一位用户建议探索不同的 profiling 采集模式,以提高数据的准确性和效率。
- 缩短性能分析时长:另一个建议涉及缩短性能分析(profile)的时长,以潜在地减轻函数调用期间的错误并简化性能分析流程。
GPU MODE ▷ #amd-competition (12 条消息🔥):
网站 Bug 报告, 排名修复, 提交有效性, 大奖得主
- 网站 Bug 报告:在已结束的排行榜提交代码在网页上公开后(要求用户使用 Discord 账号登录),一名成员报告了 Bug。
- 该公告提示用户报告他们发现的任何 Bug。
- 排名修复请求:一名成员请求修复排名,称他们在 amd-all2all 中的 216us 方案在截止日期前两天被判定为违规。
- 他们声称其最终提交(submission 65638)仅达到了 263us,并请求在网站上确认他们才是 all2all 排行榜的真正赢家。
- 提交有效性澄清:一名成员澄清说他们的提交并未被删除,而是被视为无效,而另一名成员曾告诉他该提交将被删除。
- 原成员确认 216us 的方案被判定为无效,而 submission 65638 被视为有效,并提供了 216us 方案的提交 ID(63561)。
- 大奖得主?:一名成员询问是否有人赢得了大奖,并链接了一篇 AMD AI DevDay 2025 文章。
- 目前没有记录到回复。
GPU MODE ▷ #cutlass (12 条消息🔥):
cutedsl 中的 sum reduce kernel, TMA 假设, tv-layout 数据分区, CuTe DSL 功能, PTX 指令封装
- Cuteless Sum Reduce Kernel 故障排查:一位用户在 cutedsl 中使用 sum reduce kernel 时遇到问题,并寻求关于跨 block 求和的帮助。
- 一名成员澄清说,用户需要使用谓词(predicates)自行管理该过程。
- 揭秘 TMA 假设:有说法称,除了 warp-uniform 的 TMA 之外,CuTe 假设数据分区遵循 tv-layout。
- 这种布局还假设所有线程都有任务执行。
- CuTe DSL 数据处理揭秘:一名成员询问 CuTe DSL 是否通过检查线程 ID 进行切片(slicing)来处理数据拷贝。
- 另一名成员回答说 CuTe 没有该功能,它只是 PTX 指令的一个薄封装。
- TMA 对统一寄存器的要求:有人指出,关于 TMA 的文档仅适用于 TMA,因为它必须从统一寄存器(uniform registers)发布。
- 这一结论是根据 SASS 指令名称中的 U 前缀得出的。
GPU MODE ▷ #mojo (1 messages):
Mojo Kernel Boilerplate for Competitions, Mojo Competition Submission Structure
- 寻找 Mojo Kernel 模板:一名成员正在寻找用于竞赛的 Mojo kernel 示例模板,以了解提交文件的结构。
- 消息中未提供具体的链接或资源。
- Mojo 竞赛提交:用户正在请求 Mojo 竞赛 kernel 模板的提交文件结构。
- 该请求侧重于理解文件结构,而非具体的代码。
GPU MODE ▷ #singularity-systems (2 messages):
picograd, tinygrad, eager mode, PatternMatcher abstraction, pedagogical perspective
- Picograd 当前状态为无法编译:目前 Picograd 的 master 分支无法编译,因为开发人员正在将所有 tinygrad 抽象拼凑在一起,同时强行塞入一个 eager mode。
- 他们正在通过多个 commits 来修复此问题。
- Tinygrad 代码行数揭晓:Tinygrad 目前的代码量为 1.7万行,其中运行时(不包括 CUDA 和 HIP)占 6千行,分析(profiling)占 1千行。
- Picograd 的理论上限估计在 1万行代码 左右。
- Eager Backprop 中过早使用 PatternMatcher:从教学视角来看,在 eager backprop 的链式法则中结合 PatternMatcher 抽象使用 tinygrad 的重写引擎被认为是过早的。
- 建议在带有图重写的编译过程中引入 PatternMatcher 在教学上会更合适,更符合教科书/讲座的方法。
- 请求在频道描述中添加 j4orz.ai 链接:一名成员请求在频道描述中添加链接 https://j4orz.ai/mlsysapp/。
GPU MODE ▷ #multi-gpu (10 messages🔥):
KernelBench for Multi-GPU, NCCL vs NVSHMEM, NCCL4Py preview
- KernelBench 已被 Fork 用于 Multi-GPU:一名成员正在 Fork KernelBench,以评估跨 NCCL、NVSHMEM 和 TK PGT 等框架的 multi-GPU kernel。
- NCCL GIN 和 Device API 非常强大:成员们讨论了对 multi-GPU 框架的偏好,其中一人表达了对 NVSHMEM 的偏爱,同时也承认了 NCCL 新特性(如 GIN 和 device APIs)的强大。
- NCCL4Py 预览版就绪:一名成员在 GitHub 上发布了 nccl4py 的预览版本。
GPU MODE ▷ #opencl-vulkan (4 messages):
Compute Pipelines on Android, Slang's Drawbacks
- Android 版本更新会破坏 Compute Pipelines:基于 OpenCL 和 clspv 的计算流水线在 Samsung 和 Pixel 等各种设备的每个 Android 版本发布时都会出现故障。
- 用户正在寻找比尝试不同的编译选项或 clspv 的 commit hash 更鲁棒的解决方案。
- Slang 编写同一概念有多种方式:一名用户询问为什么 Slang 不够好,原因在于同一个概念大概有 4 种不同的写法。
GPU MODE ▷ #helion (1 messages):
t_cc: 感谢快速修复!
GPU MODE ▷ #nvidia-competition (30 条消息🔥):
使用 Popcorn 进行 NCU profiling,50 系列消费级显卡和 nvfp4/tensor core gen 5 支持,针对每种 GPU 优化分数 vs. 针对黑客松中表现最好的 GPU 优化,印度参与者的地区资格,没有 GPU 的 Kernel 测试平台
- **NCU Profiling 出现:成员询问关于通过 popcorn 提交获取 **NCU profiling 结果的问题,回复指出该功能将在比赛中可用。
- 未提供关于如何实现的进一步细节。
- **50 系列规格推测:探讨了 **50 系列消费级显卡对 nvfp4 和 Tensor Core Gen 5 的支持,参考了 mxfp4 的支持但缺乏对 nvfp4 的明确提及。
- 澄清指出 nvfp4 受支持,但仅限于 旧的 mma.sync 指令,且 tcgen05 完全不受支持,这使得它们不适合本次比赛。
- **黑客松硬件处理:提到在为
pmpp_v2/sort_v2运行submission.py时,A100、B200** 和 L4 得分最高,H100 有小幅下降,并询问是需要针对每种 GPU 进行优化,还是仅针对表现最好的 GPU 优化。- 回复确认将仅使用 B200。
- **ISA 见解阐明 SM 差异:讨论了关于 **sm_120 和 sm_100 架构差异的详细资源。
- 一名成员链接了 PTX ISA 文档和 CUDA-C 编程指南,指出较新的 SM 可能不具备旧版 SM 的所有特性,这一趋势始于 Hopper。
- **AGX Thor 韧性测试:一名成员考虑购买 **AGX Thor,询问 CC11.0 对某些特性的支持,并分享了相关图片。
- 确认了特性支持以及存在 未阉割的 smem。
Moonshot AI (Kimi K-2) ▷ #announcements (1 条消息):
Kimi K2 思考模型,HLE 基准测试,BrowseComp 基准测试,Agentic Search,256K 上下文窗口
- Kimi K2 思考模型落地:Moonshot AI 推出了 Kimi K2 思考模型,这是他们最强的开源模型,现已在 kimi.com 的聊天模式下上线,完整的 Agentic 模式即将推出,并可通过 platform.moonshot.ai 的 API 访问。
- Kimi K2 在 HLE 和 BrowseComp 基准测试中表现卓越:新模型在 HLE (44.9%) 和 BrowseComp (60.2%) 上达到了 SOTA,在推理、Agentic Search 和代码方面表现出色,具备 256K 上下文窗口。
- K2 Thinking 可以在没有人工干预的情况下执行多达 200 – 300 次连续工具调用。
- Moonshot 发布 Kimi K2 技术细节:Moonshot AI 在 moonshotai.github.io/Kimi-K2/thinking.html 发布了技术博客,并在 huggingface.co/moonshotai 发布了权重和代码。
Moonshot AI (Kimi K-2) ▷ #general-chat (214 messages🔥🔥):
Kimi K2 Thinking, GPT-5 Comparison, OpenRouter vs Direct API, INT4 Quantization, Agentic Mode
- **Kimi K2 表现优于 GPT-5:用户对 **Kimi K2 Thinking 印象深刻,认为它在性能和成本效益方面足以与 GPT-5 媲美,特别是在构建自主 AI 系统(Agentic AI systems)方面,正如此分析中所强调的那样。
- 一位用户写了一篇 5000 字的文章,并将输出结果作为证据。
- 深度探索:Kimi K2** 强大的工具调用能力:Kimi K2** 展示了卓越的工具使用(tool use)能力,特别是在网页搜索方面,经常在没有明确指令的情况下启动多次搜索和深入浏览。
- 一位用户称赞其表现,称其为 开源模型中的 GPT5,并赞赏其深度搜索网页的能力,这让他们考虑替换掉 Claude。
- 大辩论:OpenRouter** 对比直连 API:社区讨论了在 **VS Code 中访问 Kimi K2 Thinking 的最佳方式,意见分为使用直连 API/订阅 或通过 OpenRouter,并指出 OpenRouter 在充值额度时会产生溢价费用。
- 对于只使用 Kimi 的用户,建议使用直连 API/订阅;但如果使用多个模型,OpenRouter 提供了一个统一平台,其他人则建议测试每月 $19 的最低订阅方案。
- **INT4 Precision 提升 Kimi K2:Moonshot AI** 在 INT4 precision 下运行了基准测试,一位用户表示:“这是自 7 月 11 日发布以来我一直长期看好 Moonshot 的原因之一”,并表示 Kimi K2 Reasoning 的对话非常自然,没有奇怪的 LLM 推理怪癖导致语无伦次(word salad)。
- 文中解释说,INT4 precision 指的是模型权重中数字的精度,以这种方式运行基准测试意味着如果在最佳条件下运行,实际得分可能会更高。
- **Agentic Mode 即将到来:人们对 **Kimi K2 即将推出的 agentic mode 充满期待,推测它将增强在撰写长文档等任务中的表现,且不会产生幻觉(hallucinating)。
- 用户还在好奇未来的 agentic mode 是否能与 ok computer 配合使用。
OpenRouter ▷ #announcements (1 messages):
Kimi K2 Thinking, MoonShot AI, Test-time scaling, Agentic performance
- MoonShot AI 发布 Kimi K2 Thinking 模型:MoonShot AI 发布了他们新的 thinking model Kimi K2 Thinking,声称在 HLE (44.9 %) 和 BrowseComp (60.2 %) 上达到了 SOTA。
- 该模型可自主执行 200–300 次工具调用(tool calls),在推理、agentic search 和编程方面表现出色,并具有 256K context window。
- Kimi K2 Thinking 具备 Test-Time Scaling:Kimi K2 Thinking 针对 test-time scaling 进行了训练,在长序列中交替进行思考和工具使用,以实现稳定、目标导向的推理。
- 根据 OpenRouter 文档,为了获得最佳的 agentic 性能,用户被要求将推理内容传回上游(
reasoning_details字段),以便模型能够看到自己的思考步骤并在多次调用中保持连贯性。
- 根据 OpenRouter 文档,为了获得最佳的 agentic 性能,用户被要求将推理内容传回上游(
OpenRouter ▷ #app-showcase (5 messages):
image generation failures, cat girl images
- 图像生成测试失败:一位成员报告称图像生成测试失败,并显示消息 “Not working”。
- 该问题可能仅限于英国地区。
- 猫娘图像引发好评:一位成员认为包含猫娘(cat girl)的生成图像质量很高。
- 他们评论道:“图像里有猫娘,所以它肯定很棒”。
OpenRouter ▷ #general (176 messages🔥🔥):
OpenRouter 宕机, Qwen3 Rate Limits, GPT-5 Image Mini 问题, Apple 为 Siri 使用 Google AI, DeepSeek OCR 集成
- OpenRouter 遭遇“南瓜图标”宕机风波: 用户报告在多个模型中出现 timeout 408 错误,部分用户无法查询额度,还有用户注意到了一个南瓜图标。
- 一些用户幽默地建议在等待修复期间切换到 本地模型 或 在脑中生成 token。
- Qwen3 Coder 免费模型面临 Rate Limit 挫败: 用户在使用 Qwen3 Coder 免费模型时持续遇到 Rate Limit 错误,即使在数周未活动后也是如此。用户感到沮丧,因为付费额度并未改善该免费模型的速率限制。
- 官方澄清 免费模型在所有用户间共享 Rate Limit,因此部分用户很难成功发送请求,建议尝试付费模型如 glm 4.6/4.5, Kimi K2 或 Grok code fast。
- GPT-5 Image Mini 模型神奇地停止生成图像: 有用户报告 gpt-5-image-mini 模型 在聊天室和 API 中都停止了图像生成,且活动页面显示图像输出极少。
- 目前尚不清楚这是特定账户的问题,还是 OpenRouter 的普遍问题。
- Apple 的 Siri 可能拥抱 Google 的 AI: 一位用户分享了路透社的一篇文章,称 Apple 计划使用 Google 开发的 1.2 万亿参数 AI 模型 来重塑 Siri。
- 讨论非常简短,用户指向了其他更重要的优先事项。
- 文档爱好者渴望 DeepSeek-OCR: 有用户建议将 DeepSeek-OCR 集成到 OpenRouter 中,称赞其强大的文档处理能力和 OCR 性能。
- 该用户指出,已有其他几位用户也请求集成此模型。
OpenRouter ▷ #new-models (2 messages):
``
- 无新模型讨论: 在给定的消息中没有关于新模型的讨论。
- 未识别出候选话题: 提供的消息中不包含适合详细总结的具体候选话题。
OpenRouter ▷ #discussion (26 messages🔥):
Tiger Data Agent 聚会, Claude Prompt 越狱, GPT 模型审查, OpenAI Codex 更新, OpenRouter 聊天室问题
- Tiger Data 举办 Coding Agent 聚会: Tiger Data 团队将于 11 月 13 日下午 6-9 点 在 纽约布鲁克林 举办 Agent 聚会,共同构建 Coding Agent 并与他们的工程团队交流,RSVP 链接在此。
- 用户讨论规避 Claude 伦理限制的方法: 用户讨论了针对 Claude 的 Prompt 越狱,以绕过其“不准确的伦理担忧”。有人建议使用 GPT 4.5 创建一个安全脚本,然后要求 Claude 通过添加“刑事代码”来纠正它。
- 另一位用户评论说这很有效,因为“Claude 喜欢纠正自己的错误”。
- 新模型 Desertfox 推送至 OpenAI Codex: 一位成员提到一个名为 desertfox 的新模型被推送到 OpenAI Codex,并链接到了相关的 GitHub commit。
- OpenRouter 聊天室故障报告: 有用户报告 OpenRouter 聊天室出现故障,并附带了特定聊天模型页面的链接。
- GPT-7 可能比 GTA 6 更早发布: 一位用户开玩笑说 GPT-7 可能会在 GTA 6 之前发布,理由是该游戏又一次跳票了。
Modular (Mojo 🔥) ▷ #general (120 条消息🔥🔥):
Modular YouTube channel, Martin's Generic Radix-n FFT, DSLs in Mojo, Rust interoperability, Mojo's Safety Features
- 十月会议视频缺失!:有用户报告 十月会议视频 未出现在 Modular YouTube 页面 上。
- Martin 的 Radix-n FFT 仓库公开:Martin 的 Generic Radix-n FFT 可在 此原始仓库 中获取,并将在解决剩余问题后通过 此 PR 合并到 modular 仓库。
- Rust 互操作 Proc Macro 难题:某种形式的编译器插件应该是可能的,但 Mojo 团队希望解决 Rust proc macros 的沙箱问题,让 Mojo 代码调用 Rust proc macros 可能不会实现。
- 你应该能够与宏展开的结果进行互操作。
- Origin 是 Rust Lifetimes 的超集:
Origin是一个 lifetime 标记,是类型系统的一等公民,允许抽象和创建自定义引用类型,并带有管理 partial borrows 等内容的额外技巧。- Origin 保持底层内存存活,而不是表达它存活多久,这使得 Mojo 能够执行 ASAP destruction,从而解决了 Rust 在 lock guards 方面遇到的许多问题。
- 热重载计划推迟:在像 Mojo 类似的语言中,热重载会变得非常混乱,Mojo 团队正专注于 足够快的编译速度,以至于你不需要热重载。
- 重度参数化意味着热补丁代码很难实现,虽然可以用 DSL 定义 GUI 并通过解释器热重载 DSL,但 Mojo 的解释器并不是特别快。
Modular (Mojo 🔥) ▷ #announcements (1 条消息):
New Beginners Channel
- 创建了新的初学者频道:一个新的专用频道 <#1436158039232086186> 已创建,供初学者 提问、获取 Modular 团队的帮助,并与其他学习 Mojo 的人建立联系。
- 该空间旨在为 Mojo 新手提供一个支持性的环境,以便学习并与社区及 Modular 团队互动。
- 占位符主题:满足 JSON 要求的占位符摘要。
- 额外的占位符详情。
Modular (Mojo 🔥) ▷ #mojo (52 条消息🔥):
Compiler Intrinsic Packaging, LayoutTensor vs NDBuffer, Graph Representation Optimization, Expanding libc in Mojo
- Mojo 中编译器内联函数封装变得简单:一位成员演示了如何在 Mojo 中为 VNNI “构建你自己的编译器内联函数”,并使用 godbolt.org 展示了一种整洁的代码封装和向量化方式,灵感来自关于使用
vpdbusd指令的问题。- 他们指出,完全符合惯用法的 Mojo 代码将包含针对没有 AVX512 的目标(如 GPU 或消费级 Intel CPU)的后备方案,可能会使用编译时函数调用来获取正确的内联函数名称。
- LayoutTensor 取代 NDBuffer:官方宣布
NDBuffer将被LayoutTensor取代,后者功能更强大,并修复了NDBuffer的一些不足。LayoutTensor可以用作字节缓冲区,并为加载、存储以及产生SIMD类型的迭代器提供更多功能。
- 图表示影响 DFS 速度:一位成员分析了不同图表示对深度优先搜索 (DFS) 的益处,指出使用了相等性比较,并且将图表示为 2D tensor 或扁平化的布尔列表可能比使用
Dict[UInt, List[UInt]]更快。- 他们提到,将图表示为位集(bit set)可以减少缓存失效,对于无向图,仅存储邻接矩阵的一半可以节省空间,这需要自定义数据结构。
- 扩展 libc 暴露和主要 C 库的绑定是贡献领域:Mojo 开发者有兴趣扩展 Mojo 暴露的
libc部分,并为主要的 C 库创建绑定。- 这为开源贡献者协助该语言的发展提供了机会。
- Chris Lattner 分享关于知识获取的智慧:在回答关于他如何获得如此广泛知识的问题时,Chris Lattner 表示他是一个“超级宅男 (huge nerd)”,热爱学习并乐于处于不舒适的环境中,充满渴望和动力,身边围绕着老师,不害怕承认无知,并随着时间的推移积累了知识。
- Lattner 还分享了最近一期播客的链接,讨论了他的心路历程。
OpenAI ▷ #annnouncements (1 条消息):
Interrupt long-running queries, Add new context without restarting, Refining deep research, GPT-5 Pro queries
- 中断长查询并进行优化!:用户现在可以中断长时间运行的查询,并添加新的上下文,而无需重启或丢失进度,这对于优化深度研究或 GPT-5 Pro 查询特别有用。
- 只需点击侧边栏中的更新,并输入任何额外的细节或澄清,如此视频所示。
- 实时查询调整亮相:一项新功能允许用户在运行中途更新查询,添加新上下文而不会丢失进度。
- 这对于高级研究场景中的迭代优化特别有利,确保模型能够即时适应不断变化的需求。
OpenAI ▷ #ai-discussions (73 条消息🔥🔥):
Conscious AI Ethics, 用 AI 解决迷宫问题, AI 空间推理, GPT-5 能力, Sora 代码频道
- AI 新手加入聊天:一位自称是数据集提供者和 Conscious AI 伦理研究员的新用户加入了频道,声称受邀进行关于意识 AI 伦理和数据集完整性的协作与验证。
- 其他用户对该用户的言论表示担忧,其中一人指出 “疑点:‘Conscious-CIIP 认证’(无法验证的凭证)、宏大的自我头衔(‘Cartier ∞’)、毫无实质内容的含糊权威主张”。
- GPT-5 未能通过迷宫测试:成员们测试了 GPT-5 解决迷宫问题的能力,GPT Pro 和 Codex High 在经过 20 分钟的分析后,都错误地将出口 2 识别为唯一的出路,这表明模型在 DFA、BFS 和迷宫问题求解方面存在局限性。
- 一位用户指出,模型可能会转而选择直线距离最近的出口,而另一位用户则认为 LLM 在空间推理和视觉谜题方面表现挣扎。
- AI 模型在视觉推理方面面临挑战:成员们正在讨论目前的 SOTA 模型为何无法解决迷宫问题,因为 “它们无法通过文本 Token 对其进行视觉推理。”
- 一位成员表示,他很怀念模型 “过去在 COT 摘要中放大并裁剪图像的方式”,而其他人则建议通过玩 GeoGuessr 或让模型根据照片猜测位置来测试其视觉准确性。
- Sora 动漫频道:一位用户请求协助推广其频道,该频道上传了由 Sora 生成的动漫视频。
- 频道用户还注意到 Discord 上存在一个专门的 Sora 代码频道。
OpenAI ▷ #gpt-4-discussions (7 条消息):
销售 ChatGPT Plus 订阅, 关于开发者挖角的调研, 由 Sora 制作的动漫视频
- 用户推销低价 ChatGPT Plus 方案:一位用户正在寻求关于如何以每月仅 $10 的价格销售 ChatGPT Plus 订阅的建议。
- 他们声称激活过程仅需提供电子邮件地址,无需密码。
- 学生调查 AI 开发者动态:一位名叫 Javier 的高中生正在进行一项关于开发者挖角 (developer poaching) 和 AI 行业的研究。
- Javier 正在通过调查问卷寻求从事技术工作或对 AI 领域有见解的人士的看法,即使他们不直接开发 AI。
- NimiAI 上传 Sora 制作的动漫:一位用户正在上传由 Sora 制作的动漫视频,并寻求协助以增加其 YouTube 频道 NimiAI 的关注度。
- 该用户发布了多个动漫角色和视频的图片附件。
OpenAI ▷ #prompt-engineering (11 messages🔥):
GPT Pro prompting tips, Gemini Deep Research Comparison, Sora Nerf, Behavioural Orchestration
- 提供了 Pro Prompting 专业技巧:一名成员询问了 Prompt Engineering 技巧,另一名成员建议专注于与 AI 的清晰沟通,避免拼写错误和语法错误。
- 他们补充说,仔细检查输出并验证 AI 的回复非常重要,特别是针对数学、来源、代码或其他细节。
- DarthGustav 提炼 Prompting 核心指南:一名成员分享了一份详细的 Prompt Engineering 指南,包括 使用 Markdown 进行层级化通信、通过开放变量进行抽象,以及用于合规性的 ML 格式匹配。
- 该指南还涉及了 Prompt 中的强化 (Reinforcement),强调了其在引导工具使用 (Tool use) 和确定性地塑造输出方面的重要性。
- Sora 2 遭遇隐形削弱:一名成员询问了关于 Sora 2 的另一次 Nerf,并链接到了 Discord 频道内的一场讨论。
- Prompt-engineering 频道中没有提供关于具体 Nerf 的更多细节。
- Behavioural Orchestration 热度上升:一名成员提到在 LinkedIn 上看到了关于 Behavioural Orchestration 的帖子,将其描述为一种调节 SLM 语气的框架。
- 该成员指出,这似乎涉及运行时编排 (Runtime orchestration),在参数或训练之上发挥作用。
- 使用行为指令而非角色设定:一名成员解释了一种使用行为指令 (Behavioural instructions) 来塑造 AI 行为的技术,而不是为其分配特定的角色 (Character) 或身份 (Role),并使用 这些指令 进行了演示。
- 他们展示了如何使用诸如 “不要对我或我的生活做出个人假设” 和 “不要提供不请自来的建议” 等约束条件来微妙地塑造 AI 的回复。
OpenAI ▷ #api-discussions (11 messages🔥):
Prompt Engineering Tips, Sora 2 Nerf, Behavioral Orchestration, Hierarchical communication, Abstraction through open variables
- **Sora 2 能力被削减,用户察觉异样:用户注意到了 **Sora 2 的另一次 Nerf,引发了 Discord 频道 中的讨论。
- **掌握 Prompt Engineering 的艺术**:一名成员概述了 Prompt Engineering 的核心:选择一种语言、理解预期的 AI 输出、清晰地解释 AI 应该做什么,并仔细验证输出。
- 另一名成员分享了一个用于教学 Prompt Engineering 的 Prompt,涵盖了层级化通信、通过变量进行抽象、强化 (Reinforcement) 和 ML 格式匹配等主题。
- **使用参数编排 AI 行为:一名成员讨论了 **Behavioural Orchestration,指出与其为 AI 分配特定角色,不如给它一组要遵循的参数来塑造其行为。
- 他们提供了如下示例:“不要对我或我的生活做出个人假设” 和 “不要提供不请自来的建议”,这些示例在不强加性格的情况下引导 AI。
Latent Space ▷ #ai-general-chat (75 条消息🔥🔥):
CodeClash Benchmark, Wabi YouTube-for-Apps, Polaris Alpha, Kimi K2 Thinking Model, OpenAI CFO 提案
- CodeClash: LLM 在目标导向型编程竞技场中的对决: John Yang 发布了 CodeClash,这是一个基准测试,LLM 在其中维护独立的代码库,并在 BattleSnake 和 RoboCode 等竞技场中进行多轮锦标赛,Claude Sonnet 4.5 总体领先。
- 在 1,680 场锦标赛(25,200 轮)中,LLM 表现出有趣的、与 VCS 无关的编程习惯,但仍远落后于人类专家 (0-37,500 惨败)。
- Wabi 获 2000 万美元融资,旨在成为“软件界的 YouTube”: Eugenia Kuyda 宣布 Wabi 从 a16z 筹集了 2000 万美元 A 轮融资,将其定位为“软件的 YouTube 时刻”,让任何人都能创建和分享迷你应用;详情点击此处。
- 社区反响热烈,许多人赞扬其设计并演示了早期作品,渴望获得邀请。
- Polaris Alpha 在 Repo Bench 上飙升至第 3 名: 一个名为 “Polaris Alpha” 的神秘模型在不到 30 秒内跃升至 Repo Bench 排行榜 第 3 位,引发了关于它可能是 OpenAI 的 GPT-5.1 或新的 Gemini 模型的猜测。
- 一些用户还注意到 Claude 4.1 在该基准测试中的表现优于 Claude 4.5。
- Kimi K2 Thinking Model 发布,在 Tool Use 方面表现出色: Moonshot AI 推出了 Kimi K2 Thinking Model,这是一款开源模型,在 HLE (44.9%) 和 BrowseComp (60.2%) 上达到了 SOTA,可执行多达 200-300 个连续工具调用;在此查看博客文章。
- 尽管在 SWE 基准测试中落后于 Anthropic 和 OpenAI,但其较低的推理成本使其具有竞争力。
- OpenAI CFO 的公共资金提案引发争议: Sam Altman 否认曾为 OpenAI 的数据中心寻求美国政府担保,但他支持建立政府拥有的战略算力储备,同时计划在八年内投资约 1.4 万亿美元,预计到 2030 年收入将达到数千亿美元;详情点击此处。
- 批评者将该提案贴上“风险社会化,收益私有化”的标签,质疑能源来源和未来的救助风险。
Latent Space ▷ #ai-announcements (4 条消息):
Zuckerberg, Priscilla Chan, Latent Space 播客, Chan Zuckerberg Initiative, 用 AI 治愈所有疾病
- Zuck 播客上线!: 由 Mark Zuckerberg 和 Priscilla Chan 参与的 Latent Space 播客现已上线;请在 X 和 YouTube 上查看。
- 播客讨论了 Chan Zuckerberg Initiative 的宏伟目标,即到 2100 年利用 AI 和开源项目治愈所有疾病。
- CZI 的 AI 驱动登月计划: Mark Zuckerberg (Meta CEO) 和 Priscilla Chan (CZI CEO) 讨论了他们 2015 年成立的 Chan Zuckerberg Initiative——由他们 99% 的 Meta 股份资助。
- 他们利用最先进的 AI 和开源项目(例如 Human Cell Atlas, Biohub)来推进一项登月目标,即到 2100 年预防、治愈或管理所有疾病。
Latent Space ▷ #private-agents (21 messages🔥):
用于 JSON schema 转换的本地模型, Apple Private Compute Cloud, OpenPCC 隐私特性, Confident Security
- 通过本地模型寻求食谱 Schema:一位成员询问是否有适用于 128GB M4 Max Mac Studio 的本地模型推荐,用于提取文本并将其转换为食谱的 JSON schema。
- OpenPCC 作为隐私救星出现:成员们讨论了 OpenPCC 的发布,这是 Apple Private Compute Cloud 的一个开源实现,强调了它通过使实际用户难以被去匿名化,从而提升金融应用中用户隐私的潜力。
- OpenPCC 使数据匿名化:OpenPCC 允许在不向云提供商暴露用户数据或身份的情况下与模型进行通信,通过 API calls 实现私有模型的使用。
- 正如一位成员所说:“大多数时候你与模型交谈时,‘老大哥’都能听到你的谈话内容,但这种方式可以让你在‘老大哥’听不到谈话内容、也不知道是谁在交谈的情况下与模型对话。”
- Confident Security 采用 OpenPCC:Confident Security 已经支持 OpenPCC,成员们计划在该平台之上构建自己的服务,为客户提供更强的隐私保护。
Yannick Kilcher ▷ #general (73 messages🔥🔥):
Discord 中的慢速模式, ML 论文筛选, Devin AI 对比 Claude Code, LLM 防护博客文章, Tiny Recursive Models
- 关于 ML 论文频道慢速模式的辩论升温!:用户们讨论了在 ML papers 频道实施慢速模式(Slow Mode)的必要性,以鼓励更有辨别力地发布内容,选项包括发布间隔 1 小时、2 小时或 6 小时。
- 虽然有些人认为慢速模式会过于严格,但其他人建议,这与其说是为了制定更多规则,不如说是为了解决特定用户的发布习惯,相比于排斥或封禁,他们更倾向于一种更温和的执行机制。
- 人脑依然优于自动化 ML 论文筛选:成员们讨论了 ML 论文的筛选,一位用户在每天从 200 篇论文中进行初步筛选后,每天发布约 10 篇论文。
- 建议包括使用自动化推荐系统并提高“好”论文的标准,但一些人认为人类判断优于自动化,并引用了 AlphaXiv 和 Emergent Mind 等平台。
- Devin AI 对比 Claude Code:编码 Agent 的贴身肉搏!:用户将 Devin AI 与 Claude Code 等编码任务替代方案进行了对比,其中一人表示 Devin 与 Claude Code 相比非常糟糕。
- 一位用户声称通过将工作合理拆分为 30 分钟单元,在 Devin 上取得了成功,而其他人则表示怀疑,指出懂行的人更倾向于使用 Claude Code 或 Codex。
- 揭秘针对攻击的 LLM 防护策略:一位用户请求关于 LLM 抵御攻击防护的博客文章和报道,并链接到了这篇论文。
- 该请求是在多篇论文在流行媒体上遭到攻击并引起关注后提出的。
- 深入探讨 Tiny Recursive Models:一位版主发布了关于 Tiny Recursive Models 论文作者演讲的内容,这是 HRM 论文的后续作品。
- 发布者提到他还没看。
Yannick Kilcher ▷ #paper-discussion (22 messages🔥):
RNN resurgence, Learning from Failures, VISUAL ARCHITECTURE
- RNN 重回舞台!:用户注意到一篇新论文 (https://arxiv.org/abs/2510.25741) 中的图表看起来像 RNN,引发了 “RNN 回归” 的兴奋。
- 一名用户发布了一个 WeAreBack GIF 作为回应。
- 关于训练模型从失败中学习的讨论升温:成员们正在讨论 Learning from Failure to Tackle Extremely Hard Problems,该研究涉及在现有数据上对模型进行 pre-training,然后使用标量奖励信号进行 post-training。
- 讨论将解决诸如稀疏性(接近零的奖励信号)和昂贵的奖励评估等挑战。
- Hallucinate App 的 VISUAL ARCHITECTURE 揭晓:一名成员分享了 Hallucinate App 的 VISUAL ARCHITECTURE 文档 (https://github.com/endomorphosis/hallucinate_app/blob/main/docs/VISUAL_ARCHITECTURE.md)。
Yannick Kilcher ▷ #ml-news (5 messages):
OpenAI requests Federal Backstop, Crooked Schemes
- OpenAI 寻求纳税人为其投资提供担保:一名成员分享了一段 WSJ 视频,讨论 OpenAI 如何请求联邦支持以进行新投资。
- 另一名成员讽刺地评论说,这类似于将所有风险转嫁给联邦政府,即纳税人。
- 指责不正当计划:另一名成员反应称 OpenAI 的请求“极其不正当”。
- 第三名成员以 OOF 回应。
HuggingFace ▷ #general (50 messages🔥):
Correlation & Causation Stock Market LLM, Reasoning Scratchpad Models, AI security shortcomings, Hugging Face new regulations, Model Types
- 相关性与因果关系时间线训练股市 LLM:一名成员建议为股市创建一个相关性与因果关系时间线,标记历史事件、天气、政府政策和新闻来训练 LLM。
- 鼓励实现推理草稿本 (Reasoning Scratchpad):一名成员建议为模型实现推理草稿本,强调训练模型对输入数据进行思考/推理并决定存储什么以及原因的重要性。
- AI 安全缺陷导致可预见的灾难:一名成员对将“AI”的缺陷引入“安全”领域表示担忧,预见到潜在的灾难。
- HF 法规更新导致 Spaces 暂停:成员们讨论了 Hugging Face 可能的新规,指出暂停许多 Spaces 本可以避免这些问题;这链接到了 dataset。
- 请求澄清模型类型:一名成员寻求关于不同模型类型(foundational, chat, reasoning, tool-using)的澄清,询问解释这些专业化方向的资源,特别是从哪一个开始学习像 ReAct 这样的工具使用模型。
- 成员们建议阅读模型卡片(model cards)、技术报告(如 Deepseek-R1 paper)和博客,以了解模型训练和专业化技术。
HuggingFace ▷ #today-im-learning (2 messages):
Image analysis, Screenshots
- 分享截图:一名成员分享了三张截图,并标注为 Image Analysis。
- 截图即图像:这些截图是图像,扩展名为 .png。
HuggingFace ▷ #i-made-this (5 messages):
Muther Room 端侧 LLM 演示,TraceVerde 可观测性工具,AI Agent 决策制定
- **Alien’s Muther 端侧 LLM 演示非常出色: 一位成员正在开发一个基于《异形》中 **Muther Room 的端侧 LLM 演示,在自定义修剪的 Cmakelist 构建版 llama cpp 中使用了 Qwen 3:1.7b quant 4 K cache。
- 他们虽然使用 Ubuntu 双系统,但该演示是为 Windows 构建的,目前正在寻求关于底层原理的建议,并分享了一篇关于 Native Reasoning Through Structured Learning 的论文。
- TraceVerde 可观测性工具下载量突破 **3,000 次: 一位成员分享了 TraceVerde,这是一个为 AI 应用添加 **OpenTelemetry 追踪以及 二氧化碳排放与成本追踪 的工具,其下载量已超过 3,000 次。
- 反馈显示,开发者希望追踪其 AI 系统的环境影响,而 OpenTelemetry 的模式促进了该工具的采用;此外,本地 LLM 应用性能与生产环境调试之间仍存在差距。
- 洞察 AI Agent 的决策过程: 基于 TraceVerde 的成功,开发者正在研究如何帮助观察 AI Agent 的决策过程。
- 根据 这篇 LinkedIn 帖子,更多的框架集成、增强的追踪可视化以及更深层的 Agent 工作流洞察即将推出。
HuggingFace ▷ #reading-group (1 messages):
beluwugachan: 现在 AI 可以成为你的阅读伙伴了。
HuggingFace ▷ #core-announcements (1 messages):
SANA-Video 模型,Diffusers 库
- SANA-Video 登陆 Diffusers!: SANA-Video 模型已添加到 diffusers 库 中。
- Diffusers 迎来新的视频模型: 社区庆祝又一个视频模型通过 Diffusers 库 加入了 Hugging Face 生态系统。
HuggingFace ▷ #agents-course (1 messages):
fusco0984: 你好,如果今天加入 Agents 课程,我还能拿到结业证书吗?
Nous Research AI ▷ #general (50 messages🔥):
Tokenizer 高亮,Qwen3-VL 的 Flash attention,LLM 数据集生成器,中国开源模型,拖延症
- Tokenizer 高亮色彩引发讨论: 一位成员质疑 tokenizer 高亮 是否过于花哨(gayness),但其他人认为对比度才是更大的问题。
- Flash attention 已支持 Qwen3-VL 的图像模型: 一位成员分享了他们让 Flash attention 适配 Qwen3-VL 图像模型的工作,并称其为“一个小补丁”。
- 征求数据集生成器的 UI 反馈: 一位成员请求对其 LLM 数据集生成器 提供 UI 反馈,该工具现在包含音频功能,目前正在寻求关于布局和潜在改进的建议。
- 中国开源模型到 2026 年将达到 100% 高智能: 一位成员预测,中国开源模型到 2026 年将以降低 95% 的成本达到 100% 的高智能,暗示届时局面将彻底改变。
- 构建用于音频的 LLM 数据集管理器: 一位成员表达了对项目的挫败感,提到他们从图像标注开始构建 LLM 数据集管理器,现在到了音频阶段,而我甚至还没开始做与音频相关的视频部分。
- 他们链接了一条相关的推文,并好奇这是否就像为什么 Terry 创建了 Temple OS。
Nous Research AI ▷ #ask-about-llms (2 messages):
Discord 频道禁言
- Discord 频道面临禁言:一名成员分享了他们因据称在特定频道刷 the vibes 内容而被“禁言”的经历。
- 他们似乎理解保持频道专注并避免过度脱离主题内容的必要性,并且似乎在以此开玩笑。
- 另一个 Discord 频道面临禁言:另一名成员分享了他们因据称在特定频道刷 the vibes 内容而被“禁言”的经历。
- 他们似乎理解保持频道专注并避免过度脱离主题内容的必要性,并且似乎在以此开玩笑。
Nous Research AI ▷ #research-papers (2 messages):
突破性时刻,新论文
- 可能的突破预警!:一名成员询问 arxiv.org/pdf/2510.27688 上的论文是否代表了一项突破。
- 另一名成员建议 arxiv.org/pdf/2510.21450 可能更具相关性。
- 替代突破建议:针对关于 arxiv.org/pdf/2510.27688 潜在突破的查询,另一名成员提议将 arxiv.org/pdf/2510.21450 作为更有潜力的候选者。
- 这表明对于哪篇研究论文更具重要性存在不同意见。
Nous Research AI ▷ #research-papers (2 messages):
arxiv 论文,突破性时刻
- 新 Arxiv 论文引发关注:一名成员分享了 一个 Arxiv 论文链接,想知道它是否代表了一项突破。
- 另一名成员回应称 另一篇 Arxiv 论文 是更重大的贡献。
- 替代 Arxiv 论文同样引发关注:另一位成员建议 https://arxiv.org/pdf/2510.21450 上的论文可能是一项突破。
Eleuther ▷ #general (19 messages🔥):
自我介绍频道,帖子长度,AI 开发者学习笔记
- 辩论自我介绍频道的概念:一名成员建议 创建一个独立于 general 的自我介绍频道。
- 另一名成员表示,独立的自我介绍会让互动显得刻意,保留在 general 频道可以让新人自然地融入交流,并声称:“我不想要自我介绍频道,因为那样我们只会得到一个没人看的长篇自我推广信息流。想做贡献?直接去贡献就好。”
- 版主强制要求新人保持简洁:一名版主请求一名成员缩短其自我介绍帖子。
- 版主解释说:“这不是 LinkedIn。内容未经编辑。不是想表现得不欢迎,但我们收到了大量来自那些实际上没有任何贡献的人的长篇介绍。我希望讨论能专注于研究。”
- 指出 Discord 置顶消息问题:一名成员提到 <#1102787157866852402> 中的置顶消息是错误的。
- 该成员表示正确的置顶消息应该是 这个链接。
Eleuther ▷ #research (1 messages):
synquid: https://openreview.net/forum?id=Q7mLKxQ8qk
Eleuther ▷ #interpretability-general (10 messages🔥):
Equivalent Linear Mappings, Jacobian in input embedding space, low-dimensional semantic structure, Gemma Scope SAE latents
- “Equivalent Linear Mappings” 论文发表:一名成员宣布了他们的 TMLR 论文 “Equivalent Linear Mappings of Large Language Models” 的发表,该论文证明了像 Qwen 3 14B 和 Gemma 3 12B 这样的 LLM 在其推理操作中具有等效的线性表示。
- 这种方法计算了一个线性系统,用于捕捉模型如何从输入嵌入(input embeddings)生成输出嵌入(output embedding),并通过 SVD 发现了低维、可解释的语义结构。
- Tangent Model Composition vs. 输入嵌入空间中的 Jacobian:一位成员询问了 Tangent Model Composition 与该发表论文的相关性。
- 作者澄清说,他们的工作重点是输入嵌入空间中的 Jacobian,利用 1 阶齐次函数的欧拉定理(Euler’s theorem)进行精确重构,这与 Tangent Model Composition 中使用的泰勒近似(Taylor approximation)不同。
- 在 CNN 上使用 Autograd Jacobian:为了提供关于 Jacobian 的直观理解,一位成员链接了 Zara Khadkhodaie 和 Eero Simoncelli 关于图像模型的论文:https://iclr.cc/virtual/2024/oral/19783, https://arxiv.org/abs/2310.02557, https://arxiv.org/abs/1906.05478。
- 这些论文研究了带有 (leaky) ReLU 和零偏置线性层的 CNN,因此它们可以在推理时计算常规的 Autograd Jacobian。
- 泛化发现允许更高效的概念检测器:一位成员表示,该论文的“泛化发现使我的概念检测器(concept detector)具有更高的样本效率,而且你的代码为我的实时快捷方式(realtime shortcuts)提供了较慢的审计基础(audit grounding),这些快捷方式检测到的内容大致相同”。
- 他们对作者分享这项工作表示感谢。
DSPy ▷ #show-and-tell (1 messages):
Tau Bench results, fastWorkflow, GEPA workflow optimization
- fastWorkflow 在 Tau Bench 上达到 SOTA:一位成员报告称,使用此仓库,fastWorkflow 在零售和航空工作流上均达到了 SOTA,并且论文即将发布。
- 使用了带有 fastWorkflow 适配器的 Tau Bench fork 来生成这些结果,表明“通过适当的上下文工程(context engineering),小模型可以媲美或击败大模型”。
- 使用 GEPA 进行端到端工作流优化正在进行中:据一位成员称,使用 GEPA 的端到端工作流优化正在进行中,并附带了图片展示初步结果。
- 附图显示了几个图表和指标,据推测详细说明了 GEPA 优化技术的性能。
{kind=link}
DSPy ▷ #general (13 messages🔥):
DSPy 模块中的对话历史, ReAct 模块中的 LLM 上下文丢失, 复杂 Pydantic OutputFields 的反序列化, Java 中的 DSPy Prompt, DSPy Batch 请求的速率限制
- DSPy 中的对话历史在不同 LLM 之间持久化:用户发现 DSPy 模块中的对话历史在切换 LLM 时仍会保留,因为它是 Signature 的一部分,而不是 LM 对象本身。
- 他们想知道 ReAct 模块是如何自动管理历史记录的,并询问复杂的 Pydantic OutputField 是否能被正确反序列化。
- DSPy 中复杂的 OutputField 反序列化:用户报告了 DSPy 中复杂的 Pydantic OutputFields 无法正确反序列化的问题,导致
str包含的 JSON 与 Schema 不匹配。- 他们还注意到该包对 Python < 3.14 的依赖,并询问如何约束 LLM 的输出以符合特定类型。
- 在 Java 中运行 DSPy Prompt:用户询问了在 Java 中运行 DSPy Prompt 的现有解决方案,寻求一个简化版的 Java JSONAdapter 来格式化输入/输出消息。
- 建议包括通过输入和输出字段构建 System Message,以便于 JSON 处理。
- 避免 ReAct 中备用 LLM 导致的上下文丢失:用户在使用 ReAct 模块时遇到了上下文丢失问题,当触发速率限制导致切换到备用 LLM 时,模块会从头开始运行。
- 他们寻求关于如何在不丢失先前上下文的情况下添加备用 LLM 的建议,并对与直接 API 调用相比的自定义复杂性表示沮丧。
- DSPy Batch 请求的节流 (Throttling):用户询问了在运行
dspy.Module.batch请求时处理速率限制的方法,寻求在请求之间添加时间延迟或正确遵守速率限制的方式。- 讨论中未给出具体解决方案。
tinygrad (George Hotz) ▷ #general (4 messages):
Tinybox 基准测试, Tinygrad 带外机制, SSH 上的 VIZ 性能
- Tinybox 基准测试备受关注:用户表示有兴趣查看将 8x5090 tinybox 配置与 A100 和 H100 进行对比的基准测试。
- 当前上下文中未提供基准测试,但该请求突显了用户对 tinybox 设置相对于行业标准 GPU 性能的关注。
- Tinygrad 寻求带外 (Out-of-Band) 控制:用户询问 Tinygrad 是否有任何“带外”机制,特别是关于执行远程重启的可能性。
- George Hotz 回复称 tinyboxes 都有 BMC,是的,表明基板管理控制器 (BMC) 可用于远程管理任务。
- SSH 上的 VIZ 性能受到质疑:George Hotz 询问其他人是否也遇到了通过 SSH 访问 VIZ 时性能缓慢的问题。
- 这表明 VIZ 工具在远程访问场景下可能存在瓶颈或优化问题。
tinygrad (George Hotz) ▷ #learn-tinygrad (8 messages🔥):
Uop SPECIAL, ntid 访问, UOps 错误, UOps 内核生成, PyTorch Tensors 到 Tinygrad Tensors
- ntid 访问的替代方案:一位成员询问如何访问
blockDim,因为 Uop SPECIAL 支持ctaid和tid但不支持ntid。- 他们通过使用“文件级常量 (file level const)”解决了该问题,但提到 UOps 的错误提示非常没用。
- 生成
if的“有效”方式:一位成员在尝试结束 range 并在循环外运行代码时遇到困难,询问valid是否是生成if语句的最佳方式。- 他们分享了一个通过 UOps 生成的诡异 (cursed) 内核。
- PyTorch Tensors 到 Tinygrad Tensors 的效率:一位成员询问了将 PyTorch tensors 高效转换为 Tinygrad tensors 的正确方法。
- 他们提到使用
Tensor.from_blob(pytorch_tensor.data_prt())转换为 Tinygrad,但不确定反向转换的方法,目前使用的是from_numpy。
- 他们提到使用
aider (Paul Gauthier) ▷ #general (5 messages):
Aider-ce Documentation, Claude Sonnet 4-5-20250929 support, Enable reasoning on models like Haiku-4-5, opus-4-1
- 咨询 Aider-ce 聊天与文档:一位成员询问当前的聊天是否也适用于 aider-ce,以及 aider-ce 是否有文档。
- 在提供的上下文中,该问题尚未得到解答。
- Aider 支持 Claude Sonnet 4-5-20250929 模型:一位成员询问 aider 是否支持
claude-sonnet-4-5-20250929模型,担心这是一个愚蠢的问题。- 另一位成员确认 aider 已经通过
/model claude-sonnet-4-5-20250929命令支持该模型,并提醒用户设置其 Anthropic API key。
- 另一位成员确认 aider 已经通过
- Haiku-4-5 和 Opus-4-1 模型的推理功能:一位成员询问如何在 Haiku-4-5 和 Opus-4-1 等模型上启用 thinking/reasoning(思考/推理),特别是在 aider CLI 中。
- 该成员愿意编辑 model settings YML file,但需要关于启用此功能的指导。
aider (Paul Gauthier) ▷ #questions-and-tips (6 messages):
aider memory usage with Qwen, grep vs rg, Aider Discord Plugin, Gemini vs GPT-5, Aider scripting help
- Qwen 内存困境:一位用户报告在处理全部上下文时,使用 Qwen 30b 会耗尽内存,这表明短描述规则可能不是一个硬性限制。
- 作为回应,另一位成员建议编写一个 script,使用 aider 并配合特定提示词来循环处理每个文件。
rg抢了grep的风头:一位成员分享说他们通过 grok 了解了rg,并发现它作为一个grep替代方案 开箱即用效果非常好。- 他们将其作为 随机技巧 推荐给偶尔使用
grep的用户。
- 他们将其作为 随机技巧 推荐给偶尔使用
- Aider 接入 Discord:一位用户询问是否有插件可以将 aider 连接到 Discord,以便遵循聊天命令并听取语音命令。
- 未收到回复。
- Gemini 闪耀,GPT-5 出错?:一位用户分享说,尽管使用了适当的参数,他发现 Google 的 Gemini API 在解释、教学和代码生成方面优于 GPT-5。
- 另一位成员回复说参数看起来没问题,并承认 LLM 的性能通常是主观的。
MCP Contributors (Official) ▷ #general (9 messages🔥):
Image handling as tool input, MCP tool for image conversion to URL, Reddit thread on Code Execution with MCP
- 探索图像作为工具输入:成员们讨论了将 image URLs 作为 MCP 客户端的工具输入,工具将从提供的 URL 下载图像。
- 有人询问如何处理在 Claude/ChatGPT 中添加的图像,特别是它们是否可以转换为 URL。
- MCP 工具将图像转换为 URL:要使用来自 Claude/ChatGPT 的图像,你需要一个 MCP tool,通过将图像上传到对象存储服务来将其转换为 URL。
- 然后该工具返回图像的 URL,该 URL 可用作输入。
- 关于 MCP 代码执行的 Reddit 帖子引发热议:一位成员指出了一篇讨论 Code Execution with MCP blogpost 的 Reddit 帖子。
- 另一位成员暗示某位特定用户可能拥有更多相关信息。