AI News
Terminal-Bench 2.0 与 Harbor
Terminal-Bench 修复了任务中的问题,并发布了 2.0 版本。该版本通过 Harbor 框架 提供了云容器支持,并获得了 Claude 4.5 和 Kimi K2 Thinking 等模型的认可。
月之暗面(Moonshot AI)的 Kimi K2 Thinking 是一款拥有 1 万亿参数的 MoE(混合专家)推理模型,其激活参数约为 32B,原生支持 INT4 量化,并具备 256K 的上下文窗口。它在 Artificial Analysis 智能指数中获得了 67 分,凭借强大的智能体(agentic)性能在开源权重基准测试中处于领先地位,且能在消费级 Apple 芯片和 2× M3 Ultra 硬件上高效运行。
该模型已在 Hugging Face、Ollama Cloud 上广泛可用,并集成了 slime 等框架。研究发现,服务瓶颈主要源于网络带宽而非 GPU 限制,这凸显了在大模型部署中基础设施考量的重要性。
一个流行的 Benchmark 进行了自我修复。
2025年11月6日至11月7日的 AI 新闻。我们为您检查了 12 个 subreddit、544 个 Twitter 和 23 个 Discord(200 个频道,5178 条消息)。预计节省阅读时间(按 200wpm 计算):432 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 方式展示所有往期内容。访问 https://news.smol.ai/ 查看完整的新闻详情,并在 @smol_ai 上向我们提供反馈!
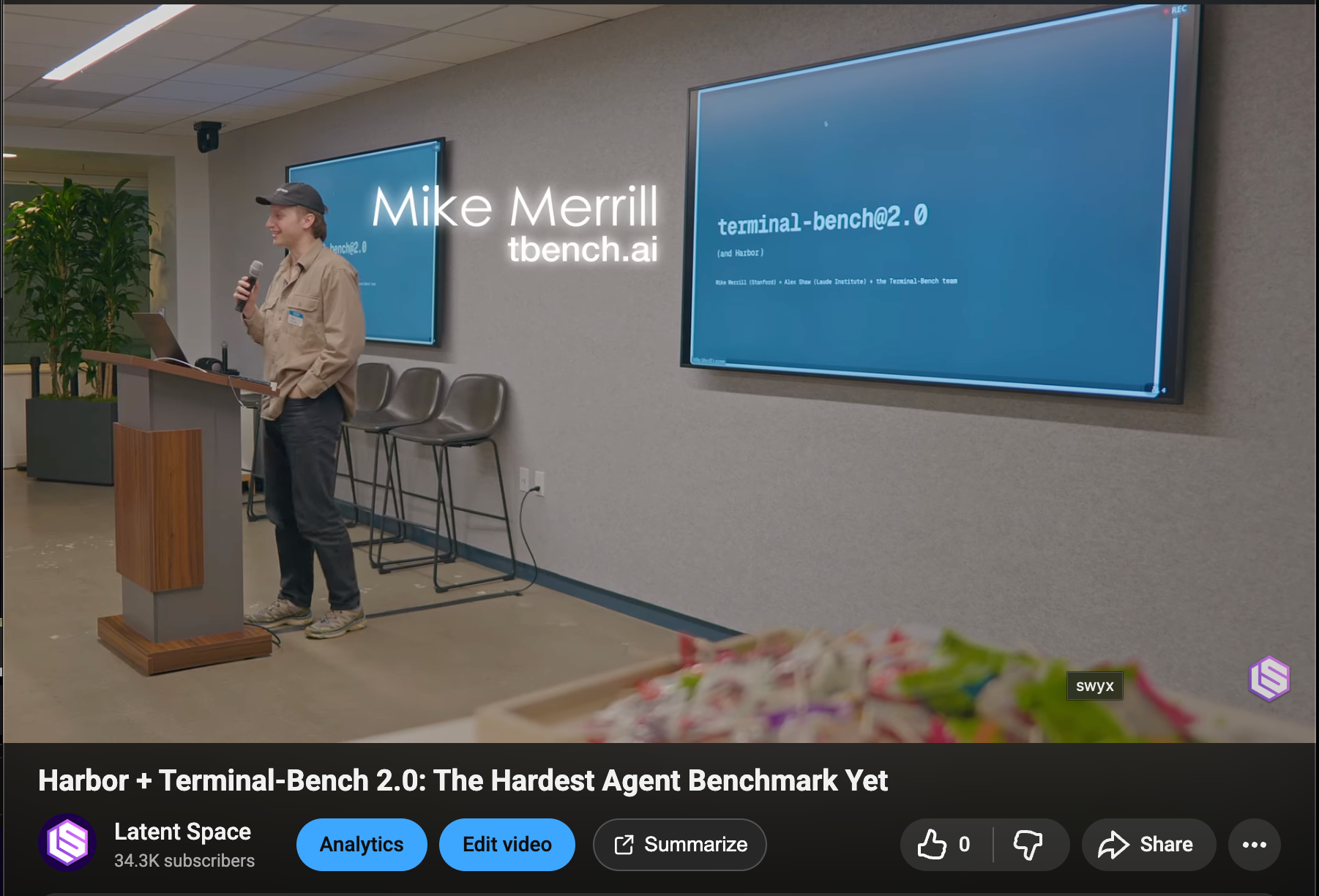
自 Terminal-Bench 于今年早些时候发布(在 Claude Code 之前!)以来,它已跃升至 Coding Agent Benchmark 的顶尖行列,例如被 Claude 4.5 和昨天的 Kimi K2 Thinking 所引用。由于 TBench 上的某些任务存在过易或无法完成的问题,因此他们着手修复了这些缺陷(博客)。他们还在重写该 Benchmark,以便通过新的 Harbor 框架在云端容器中轻松运行,并举办了一场包含 Q&A 的发布会,录像现已在 Latent Space 上线:
AI Twitter 综述
Moonshot AI 的 Kimi K2 Thinking:1T INT4 open-weights 推理模型、Agentic SOTA 以及真实世界部署笔记
- 模型与数据(开放权重):Moonshot 的纯文本推理模型 “Kimi K2 Thinking” 以 1T 参数的 MoE 架构发布,激活参数约为 32B,通过量化感知后训练(quantization-aware post-training)以原生 INT4 格式发布,具有 256K 上下文窗口和修改版的 MIT 许可证。独立分析将其 Artificial Analysis Intelligence Index 评分定为 67(新的开放权重领导者),相较于其他开放权重模型,具有出色的 Agent 性能和强大的编程能力,但在编程任务上仍落后于顶尖的专有系统。该模型也极其冗长:运行完整的 AA 评估套件消耗了约 140M tokens,实测吞吐量约为 8 tok/s (base) 和 50 tok/s (turbo),报价为每百万 token 输入/输出 $0.6/$2.5 (base) 和 $1.15/$8 (turbo)(Artificial Analysis;个人结果)。在 SimpleBench 上,K2 Thinking 将 K2 的得分从 26.3% 提升至 39.6%(在开放权重模型中排名第 3)(@scaling01)。
- Agent 性能主张与 INT4 “炫技”:社区结果和评论强调了其卓越的工具使用(tool-use)和长程 Agent 行为,声称尽管运行在 INT4 下,K2 Thinking 在复杂的 Agent 基准测试中仍可与大多数前沿专有模型竞争;多位观察者强调了“所有基准测试均在 INT4 下报告”这一炫技行为(评论,“开放权重 SOTA” 笔记,更广泛的观点)。媒体流传的训练成本估算将 K2 的推理变体定在约 460 万美元(未证实;由 CNBC 报道),如果属实,这将是训练经济学方面的一个颠覆性数据点(@dbreunig)。
- 推理便携性与性能:该模型可在消费级 Apple silicon 上以原生 INT4 运行。在 2× M3 Ultra 上,K2 Thinking 使用 MLX 流水线并行(pipeline parallelism)以约 15 tok/s 的速度生成了约 3,500 个 token(演示包括生成一个可运行的 Space Invaders 游戏)。包含具体的 MLX 命令和 mlx-lm 中的 PR(@awnihannun,命令,后续)。K2 Thinking 已广泛可用:在 Hugging Face 上趋势领先,已添加到 Ollama Cloud 和库中,通过 SGLang RL 团队集成到 slime 框架(256× H20 141GB 配置)中,并可从多个推理提供商处获得(HF 趋势,Ollama,slime,基础设施支持)。
- 服务陷阱(有时网络 > GPU):Moonshot 报告称生成瓶颈源于 IP 带宽(已修复)而非 GPU 数量——这提醒人们在扩展加速器之前,应先分析 LLM 服务期间的网络约束(@Kimi_Moonshot;来自 @crystalsssup 的强化观点)。K2 Thinking 还在 Product Hunt 上发布了(@crystalsssup),Ollama 中提供了 “Kimi K2 Thinking: cloud” 预设,部署指南正在整个生态系统中扩散。
为 LLM Agent 扩展 RL:DreamGym 与 Agent 仪表化
- DreamGym:通过“经验模型”构建合成环境:DreamGym 用基于推理的合成经验取代了缓慢且脆弱的现实世界 rollout:环境模型从离线轨迹中蒸馏接口动力学,提出具有挑战性但可行的任务,并与 Agent 交互以产生新鲜的在线经验用于 RL。消融实验表明,推理轨迹、回放落地(replay grounding)和课程学习对于稳定的转换、事实性以及持续改进都是必不可少的。结果显示:相比非 RL 就绪的环境有显著提升,并且在不同模型系列中为 sim-to-real RL 提供了更好的预热(warm-start)效果(thread, ablation, takeaways+paper)。
- Agent 基准测试 + 编排模式:Terminal-Bench 2.0 增加了更严格的验证,并配合 Harbor 进行大规模沙箱 Agent rollout(@alexgshaw)。GitHub 的 “Copilot Orchestra” 模式将多 Agent、测试驱动的开发循环(计划 → 实现 → 评审 → 提交)正式化,并开源了全部提示词(pattern, prompts)。Dr. MAMR 通过 Shapley 风格的因果影响指标和重启/审议动作,解决了双 Agent 推理系统中的“懒惰 Agent”崩溃问题——这对于归因每轮信用(per-turn credit)以及从糟糕的子轨迹中恢复非常有用(overview)。
视频“超感官”与快速追踪:Cambrian-S 和 EdgeTAM
- Cambrian-S(空间超感官):一篇立场论文、数据集(VSI‑590K)、基准测试和开源模型,旨在探索视频中的空间认知。核心思想:通过内部预测性世界模型学习预测和组织感官输入;利用潜空间帧预测头实现“惊喜”驱动的内存管理和分割;在空间推理方面比基础 MLLMs 提升高达 30%;即使是小模型也表现强劲;代码采用 JAX 和 PyTorch/XLA 编写,并附带两项补充研究(基准测试偏差和模拟器经验)(announce, project+credits, data/models, predictive sensing)。
- Transformer 中的 EdgeTAM (Apache‑2.0):Meta 的实时分割追踪器现在可以作为 SAM2 的直接替代品,速度提升约 22 倍,具备移动端性能(在 iPhone 15 Pro Max 上达到 16 FPS,无需量化),支持点和 bbox 提示(intro, checkpoint/demo)。这是针对端侧追踪工作负载的一个务实的胜利。
评估与可解释性:长上下文信息聚合依然困难;模型差异对比与基于曲率的编辑
- 长上下文信息聚合:Oolong 测试了在长且信息密集输入下的易验证聚合能力;在 128K 上下文下,没有模型能超过 50% 的准确率——这表明尽管窗口变大,“精确聚合大量信息”仍然是一个未解决的问题(@abertsch72, context)。
- 机械可解释性与模型差异对比:Neel Nanda 的讨论强调了通过“模型差异对比(model diffing)”来理解微调过程中的变化,以及利用基于稀疏自编码器的 crosscoders 来发现并修复缺陷(video, follow-up)。另外,一种基于曲率的方法(“Goodfire”)通过损失锐度(loss sharpness)分解记忆化与泛化结构,并编辑权重以抑制记忆化——将权重空间中“尖峰奇点(spiky singularities)”的直觉正式化(summary)。
系统与推理:算子、框架与部署实践
- 框架势头与内核:vLLM 与 SGLang 是当前的“真实 AGI 竞赛”,反映了推理栈在实践中如何定义能力边界 (comment)。腾讯的 Hunyuan-image 3.0 发布了基于 vLLM 的官方实现,与 vLLM 的全模态(omni-modality)方向保持一致 (@rogerw0108)。Triton/NV 内核继续推高显存带宽:一个 NVFP4 量化内核报告了 3.2 TB/s 的带宽和 33 µs 的运行时间 (kernel notes)。Mistral 分享了 vLLM 部署中 P/D 分离(disaggregation)的经验(生产负载下的资源优化) (talk ref)。
- 吞吐量、硬件与云控制平面:在某些配置下,单个 H200 节点足以进行有意义的服务 (@vllm_project)。由 Cerebras 支持的 GLM-4.6 在 Cline IDE/CLI 路径中达到了约 1000 tok/s (@cline)。SkyPilot 简化了跨 Slurm/KubeRay/Kueue 的多集群、多云 GPU 运维 (@skypilot_org)。同样值得注意的还有:OpenAI Codex 的容量和速率限制改进(mini 变体和优先级路径),为开发工作流提供更高的持续使用率 (@OpenAIDevs)。
政策与行业背景
- 算力、供应链与治理:Sam Altman 澄清说,其诉求并非针对 OpenAI 的贷款担保,而是更广泛的美国再工业化——涵盖晶圆厂、Transformer(变压器)、钢铁等国内供应链/制造业,作为与政府优先级一致的国家政策;这与“救助”框架截然不同 (@sama)。另外,一个反复出现的主题是:算力将成为国家战略资产,呼吁补贴“开放 AI”(生态系统)而非任何单一公司 (@jachiam0, @hardmaru)。Mustafa Suleyman 重申了实验室的一项设计原则:在超级智能超越监管之前,必须确保 AI 在人类控制之下并设有严格的护栏 (@mustafasuleyman)。
热门推文(按互动量排序)
- Kimi K2 Thinking 使用 MLX 在 2× M3 Ultra 上以 INT4 原生运行,约 3,500 个 token,速度约为 15 tok/s (Awni Hannun)。
- “它是 SOTA,不仅是开源权重中的 SOTA”(Kimi K2 Thinking) (@crystalsssup)。
- xAI 的 GROK-4-fast 在更新后,在 Prompt 注入/系统 Prompt 鲁棒性方面取得了重大进展 (@xlr8harder)。
- OpenAI Devs:Codex 容量升级(mini 模型、提高速率限制、优先级处理) (@OpenAIDevs)。
- Moonshot AI:通过消除 IP 带宽瓶颈(而非 GPU)修复了 K2 的 token 速度 (@Kimi_Moonshot)。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. Kimi 模型发布与性能
- 全球最强 Agentic 模型现已开源 (热度: 1795): 该图片是来自 τ²-Bench Telecom 基准测试的柱状图,该基准测试旨在评估模型的 Agentic 工具使用能力。图表突出了各模型的性能,其中 “Kimi: K2 Thinking” 以
93%的分数领先,超过了同为87%的 “GPT-5 Codex (high)” 和 “MiniMax-M2”。这表明现已开源的 Kimi K2 模型在 Agentic 任务(涉及自主决策和工具使用)中表现卓越,标志着权重开放(open-weight)模型开发的一项重大成就。 一位评论者指出,虽然 Kimi K2 模型解决问题的时间比 GPT-5 长,但它最终取得了成功,强调了其在性能稍慢的情况下依然具备强大的能力。- Guardian-Spirit 强调了 Kimi K2 模型的能力,指出它是第一个解决复杂问题的权重开放模型,尽管耗时比 GPT-5 长。这表明虽然 Kimi K2 可能不如 GPT-5 快,但它仍能处理复杂的任务,突显了其在开源 AI 开发中的潜力。
- Fresh-Soft-9303 指出了开源 AI 的战略意义,引用了 Nvidia CEO 对中国 AI 进步的评论。该评论强调了模型免费的重要性,这可能会使先进 AI 技术的获取更加民主化,并可能改变 AI 开发的竞争格局。
- Kimi 2 是目前排名第一的创意写作 AI,优于 Sonnet 4.5 (热度: 631): Kimi 2 被誉为领先的创意写作 AI,在性能和性价比上均超越了 Sonnet 4.5。帖子指出,作为一款开放模型,Kimi 2 提供了强大的理解能力,并可能扩展到 Coding 领域,对 OpenAI 和 Anthropic 等大公司构成了竞争威胁。讨论强调了 AI 模型的快速进步,特别是来自中国公司的模型,并暗示本地运行的 LLM 可能很快就会超越目前的顶尖模型,迫使大公司进行创新或大幅降价。 一些评论者对帖子的真实性表示怀疑,认为这可能是过度炒作中国模型趋势的一部分。其他人则质疑 Kimi 2 的长篇写作能力,指出其在生成连贯的长篇叙事方面过去不如 Sonnet。
- 一位用户对围绕新 AI 模型(尤其是来自中国的模型)的炒作表示怀疑,认为当 GLM 4.6 等模型与 Claude 4.5 等模型对比时,最初的兴奋往往会消退。他们还注意到一种模式,即像 OSS 20 和 OSS 120b 这样的模型最初被低估,但后来因其质量而获得认可,这暗示需要更多实质性的评估而非炒作驱动的讨论。
- 另一位评论者质疑 Kimi 2 的长篇写作能力,并将其与 Sonnet 进行了对比,认为后者在处理长篇叙事方面更胜一筹。他们描述之前使用 Kimi 2 的体验是产生“晦涩难懂、格式糟糕的半诗歌体”,并希望最近的更新能提高其在长文本中保持叙事连贯性的表现。
- 一位用户称赞 Kimi 2 的创造力和极少的审查(censorship),声称它在产生原创想法方面可以与专业人类作家媲美。他们强调了它产出令资深用户都感到惊讶的内容的能力,表明它在闭源模型中因其创新输出而脱颖而出。
2. Moonshot AI AMA 公告
- AMA 公告:Moonshot AI,Kimi K2 思维 SoTA 模型背后的开源前沿实验室(周一,太平洋标准时间 8AM-11AM) (热度: 327): 该图片是关于即将举行的 “Ask Me Anything” (AMA) 活动的宣传公告,嘉宾是 Moonshot AI。Moonshot AI 是 Kimi K2 模型背后的开源实验室,该模型以其顶尖的 (SoTA) 思维能力而闻名。AMA 定于太平洋标准时间 (PST) 11 月 10 日上午 8 点至 11 点在 r/LocalLLaMA 版块举行。图片采用了风格化的羊驼和带眼睛的蓝色圆圈插图,背景为数字主题,体现了现代科技感。此次活动可能会深入探讨 Kimi K2 模型的发展和能力,该模型是开源 AI 社区推动 AI 技术进步努力的一部分。 评论反映了对 AMA 的期待和兴奋,表明社区对了解更多关于 Kimi K2 模型和 Moonshot AI 工作的兴趣。
- 30 天成为 AI Engineer (热度: 684): 该帖子讨论了从 12 年的网络安全职业生涯转型为 Staff AI Engineer 角色的过程,重点是在 30 天内达到生产就绪状态。核心关注领域包括 Context Engineering、检索增强生成 (RAG) 以及开发可靠的 AI Agents。用户正在寻求关于在此强化学习期间应优先考虑的基本资源、习惯和潜在陷阱的建议。 评论对在 30 天内成为一名精通的 AI Engineer 的可行性表示怀疑,强调了该角色的复杂性,涉及全栈开发、API 管理、GitOps、DevOps、架构和设计。还有建议认为 “AI Engineer” 这一头衔可能定义尚不明确。
- Icy_Foundation3534 强调了部署 LLM 系统的复杂性,指出这需要全面的技能组合,包括全栈开发、API 管理、GitOps、DevOps、架构、设计和实现。评论对在 30 天内掌握这些领域的熟练程度表示怀疑,认为这种转型极具野心且充满挑战。
- pnwhiker10 为转型 AI Engineering 提供了实用的路线图,重点是从第一天起就构建端到端的用例。关键步骤包括通过固定模板确保模型一致性,维护一个小的 “Golden” 测试集进行持续评估,以及实现一个简单的检索系统进行文档索引。建议还强调了日志记录、安全基础以及使用 Claude 或 GPT 等工具进行学习(而非传统书籍)的重要性。
- 讨论反映了对在短时间内从非 ML 背景转型为 “Staff AI Engineer” 角色的怀疑。评论认为,此类角色需要深厚的专业知识和经验,这在短时间内可能无法获得,特别是对于来自网络安全等不同领域的人来说。
技术性较低的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. AI 意识辩论与进展
- 3年前,Google 因 Blake Lemoine 暗示 AI 已具备意识而将其解雇。如今,他们正召集全球顶尖的意识专家来讨论这一话题。 (热度: 1365): Google 大楼的图像被用来强调 Google 在 AI 意识立场上的讽刺意味和演变。3年前,Google 解雇了 Blake Lemoine,因为他暗示 AI 已经实现了意识,这一说法当时遭到了广泛批评,并被斥为对 LLM 等 AI 模型能力的误解。现在,Google 正在与顶尖意识专家合作探讨这一话题,这表明其立场正转向对 AI 意识进行更严肃的思考,这可能是由于 AI 技术的进步及其影响所致。 评论者对 AI 意识的概念表示怀疑,将过去对技术的误解与当前的辩论进行对比。他们强调了对 AI 能力的误解,例如将对话式 AI 误认为真正的意识。
- 你能相信 Sam Altman 说的任何话吗? (热度: 609): 该帖子质疑了 OpenAI CEO Sam Altman 的可信度,突显了对 CEO 言论的普遍怀疑。讨论反映了 Altman 本人关于不要信任他的建议,创造了一个悖论:信任他的建议意味着不信任他,反之亦然。这反映了科技行业领导层在透明度和可靠性方面更广泛的担忧。 评论表达了对 CEO 们的普遍怀疑,并幽默地看待“信任 Altman 不要信任他的建议”这一悖论。这反映了对科技公司领导层的一种普遍不信任情绪。
- trollsmurf 指出,Sam Altman 作为 OpenAI CEO 的职责涉及应对复杂的商业和社会环境,而不仅仅是专注于 AI 技术。评论认为,Altman 的行动在战略上旨在确保 OpenAI 的商业成功,并建立依赖关系以确保长期资金。这种做法可能会使寻求多元化的投资者处于不利地位,因为他们可能会与 OpenAI 的命运捆绑在一起。
- 讨论涉及了 OpenAI 在 Sam Altman 领导下的战略策略,强调了定位公司以吸引重大投资和权力的重要性。这包括建立一个依赖网络,确保如果 OpenAI 面临挑战,其合作伙伴和投资者也会受到影响,从而确保持续的支持和资金。
2. AI 设计与生产创新
- 小鹏(XPENG)IRON 女性人形机器人将于 2026 年底进入量产。 (热度: 1044): 小鹏宣布其 IRON 女性人形机器人(一种人形机器人)定于 2026 年底进入量产。预计该机器人将具备先进的 AI 能力和可定制的体型,旨在满足广泛的消费者需求。这一进展是小鹏将机器人技术与 AI 整合的更广泛战略的一部分,有可能彻底改变个人和劳务机器人市场。 评论反映了期待与幽默的交织,一些用户对可定制人形机器人的潜在应用和市场影响表示关注,对该技术的投资前景持乐观态度。
- 在瑞士最大的连锁超市,他们出售一款采用 AI 设计的饼干盒(驯鹿有五条腿) (热度: 1804): 图像描绘了一个由 AI 创作的饼干盒设计,其中有一只长着五条腿的驯鹿,这突显了 AI 生成艺术中常见的问题,即出现解剖学上的错误。这个来自瑞士最大连锁超市的例子说明了将 AI 用于创意任务的挑战,因为通常需要人工监督来纠正此类错误。评论建议,像 Photoshop 这样的简单工具可以轻松纠正这些错误,强调了在 AI 生成的设计中进行人工干预的必要性。 评论者幽默地指出了驯鹿多出来的腿,并建议可以用 Photoshop 轻松修复,这表明大家对 AI 设计需要人工修正达成了共识。
3. 印度免费 AI 服务
- Chat GPT go 和 Gemini ultra 在印度完全免费 (活跃度: 960): 该帖子幽默地讨论了 Chat GPT Go 和 Gemini Ultra 在印度的免费可用性,其中 Chat GPT Go 免费一年,Gemini Ultra 提供 18 个月的免费订阅。然而,一条评论纠正说,实际提供的是 Gemini Pro 而非 Ultra,并且需要激活 Jio 5G 套餐,因此并非完全免费。图片隐喻地描绘了服务器因高需求而“过热”,利用岩浆流来展示系统的压力。 一条评论强调了 AI 业务中的一个普遍问题:由于与 Token 使用相关的成本,用户数量的增加并不一定意味着利润的提高,从而导致收益递减。
- Low_Article_9448 指出,在印度提供的并非 “Gemini Ultra” 而是 “Gemini Pro”,后者的成本显著更低。此外,它需要激活 Jio 5G 套餐,因此并非完全免费。这突显了即使在广告宣传为免费时,了解这些 AI 服务的具体要求和相关成本的重要性。
- Visual_Process_5598 讨论了 AI 商业模式中的挑战,即用户数量的增加并不一定转化为更高的利润。这是由于无法有效地将使用的 Token 货币化,导致收益递减。这一见解对于理解 AI 服务提供商的财务动态至关重要。
- Allaihandrew 建议,从商业角度来看,在印度提供免费服务可能是占领大部分消费市场的战略举措。即使是很小的市场份额也可能带来可观的利润,从而抵消基础设施成本。这突显了 AI 市场扩张中涉及的长期战略规划。
- 记住他的原话:我们计划在计算上投入数万亿美元。是的,现在的 1.7 万亿只是个开始 (活跃度: 2978): 图片和帖子标题暗示了对计算基础设施的重大财务承诺,可能来自某家大型科技公司或人物,并夸张地提到了投入“数万亿用于计算”。这暗示了扩展计算资源的战略重点,可能用于 AI 或数据密集型应用。评论反映了怀疑和幽默,其中一人将这种情况比作 Theranos,突显了对这种大规模投资的可行性和透明度的担忧。 一条评论通过引用数据中心冷却剂幽默地暗示了这种支出的低效,而另一条评论则批评了与 Theranos 的类比,认为 OpenAI 与 Theranos 不同,它拥有实实在在的产品。
AI Discord 摘要
由 gpt-5 生成的摘要之摘要的摘要
1. Kimi K2 推理能力激增与排行榜大洗牌
- Kimi K2 痛击 HLE,暗示 Moonshot 势头强劲:成员们强调 Kimi-K2 Thinking 的 Benchmarks 非常 “疯狂”,它在 HLE 上击败了 GPT-5 Pro,人们对新数据集和传闻中的融资感到兴奋。讨论将 K2 定位为 Reasoning 模型的新标杆,而不仅仅是指令微调(Instruction Tuning)。
- 参与者强调了 K2 强大的工具使用(Tool-use)和思维链(Chain-of-thought)表现,称其为处理复杂任务的潜在阶跃式改进。一位用户指出,K2 的发展轨迹可能会迫使现有巨头尽快发布更强大的 Thinking 变体。
- ERNIE 跻身 Text Arena 第二名:
*Ernie-5.0-preview-1022**在 Text Arena Leaderboard 上跃升至 第 2 名,标志着在正面交锋中与顶级模型达到了竞争均势。据报道,该模型在多种 Prompt 下的表现优于多个热门条目。- 这一排名上升表明中国 LLM 的快速迭代以及前沿模型之间日益激烈的排行榜更迭。用户预计随着未来几周新的推理微调版本的发布,排名将出现更多洗牌。
- K2 Thinking 让 Agent 编码者惊艳:一篇博客声称权重开放的 “k2 thinking” 在 Agent 编码方面表现出色,该消息通过 drinkoblog.weebly.com 传播,其中包括它修复了 gpt-5-codex 难以处理的代码实例。讨论将 K2 定位为自主编码工作流的可靠骨干。
- 作者表示它 “似乎是 Agent 编码的真本事”,并且 “正在修复 gpt-5-codex high 难以处理的代码”,这促使开发者在多 Agent(Multi-agent)设置中测试 K2。工程师们正将可靠性、工具使用和性价比作为下一步的验证重点。
2. GPU Kernel、低精度与带宽现实
- WarpFrac 助力精确 INT8 GEMM:一个经过 GMP 验证的精确 INT8×INT8→INT32 GEMM 报告吞吐量达到 300.26 T-ops/s(A100, 5120³)和 2.026 T-ops/s(使用 CUDA Graphs 的微摊销 256³),并作为 WarpFrac 发布,附带可运行的 Colab。作者邀请了性能分析反馈、移植想法以及进一步的优化 PR。
- 他们展示了通往 “以 Tensor Core 速度实现精确任意精度!” 的路线图,旨在将正确性保证与顶尖性能相结合。社区关注点集中在跨架构移植性以及在不同矩阵规模下验证 T-ops。
- Blackwell 带宽打破炒作:一位从业者测得 Blackwell 内存带宽仅为规格值的 92–94%,峰值接近 7.2 TB/s,而广告宣传为 8 TB/s(见分享的 截图)。该发现强调了理论带宽与可实现带宽之间的差距,即使经过激进的调优也是如此。
- 动态分块调度(Dynamic tile scheduling)通过让每个 SM 获取下一个分块,将一个 Kernel 的性能推向理论值的 94.3%,从而改善了负载均衡。工程师们权衡了 TMA 大小和持久化 Kernel(persistent kernels)的启发式方法,以保持每个 SM 至少有约 64KB 的在途数据以达到饱和。
- Helion 携 Flexible Attention 登场:PyTorch 团队重点介绍了 Helion(一种 GPU Kernel DSL),并在官方 Helion 博客 中提供了 Attention Kernel 的示例。开发者们还传阅了 Helion Attention 示例 以进行快速上手测试。
- 研究人员要求将其与 Triton 和 Flex Attention 进行对比测试,以量化在延迟、吞吐量和内存方面的优势。早期读者称赞了 Helion 的易用性,并对 H100/B200 级别的实际性能表现出兴趣。
{kind=link}
3. APIs, SDKs, and Spec Upgrades
- OpenRouter 直播发布 SDK、Embeddings 和视频支持:OpenRouter 在 X 和 YouTube 上宣布了一场直播,涵盖了 Embeddings 发布、TypeScript SDK 以及 Exacto Variants。他们还为模型 API 推出了多模态 视频支持。
- 开发者们对这些更新表示欢迎,一位用户表示 “噢,就在两天前我还想‘要是 OR 支持视频就好了’”。期待重点集中在更简洁的开发易用性以及通过新的 Embedding 端点实现更高质量的检索。
- MCP 迈向 2025 规范冻结:MCP 团队正在敲定 SEP,以便在 2025-11-25 发布规范,并在 2025-11-14 冻结规范;参见项目看板 SEPs for Finalization。据报道,一篇名为 Code Execution with MCP 的博客文章将读者误导至 Discord。
- 贡献者要求更新博客以指向正确的 GitHub Discussion:modelcontextprotocol/discussions/1780。一位评论者补充道:“这对我来说可行。这比 Discord 对我来说更容易。”
- Intel 的 LLM Scaler 旨在提升 GPU 收益:Intel 的 llm-scaler 旨在通过模型级和图级变换提升 LLM 在 Intel GPU 上的性能。该仓库引起了测试大型模型而非小型基准模型的从业者的兴趣。
- 工程师们询问了早期性能差异以及在更大 Batch/Seq 设置下的内存行为。需求集中在对 ERP 级模型和 Agent 工作负载的实际改进上。
4. Agents, Workflows, and Speech Speed Records
- FastWorkflow 在 Tau Bench 上达到 SOTA:FastWorkflow 在 Tau Bench 的零售和航空工作流中达到了 SOTA,代码托管在 fastworkflow repo 和 tau-bench fork。结果强调了为实现稳健的端到端任务执行而进行的定制化上下文工程(context engineering)。
- 作者强调 “通过适当的上下文工程,小模型可以媲美/超越大模型”,并指出 GEPA 优化正在进行中。社区关注点集中在可复现性、Prompt 脚手架以及大规模工具集成。
- Parakeet v2 实现 200 倍实时转录:在低功耗模式下的单块 RTX 4090 上,Parakeet v2 实现了约 200 倍实时 的 STT;演示地址见 Parakeet v2 Space。以此速度,一段 3.5 小时 的播客仅需约 10.5 秒 即可完成。
- 发布者正在测试多 GPU 扩展,预计可获得接近线性的增益,最高可达约 1,200 倍。他们调侃道 “我们生活在未来”,强调了语音流水线(speech pipelines)已经取得的巨大进步。
- NVSHMEM 内核降低多节点延迟:一篇大学博客详细介绍了用于 LLM inference 的 低延迟通信内核,该内核使用 NVSHMEM,实现了 超越 NCCL 的性能。这些技术旨在提高实际推理负载下的多节点通信速度。
- 鉴于大家的兴趣,作者提议就内核设计和性能结果进行一次演讲。工程师们希望将其尾部延迟(tail latency)和吞吐量与常见的 NCCL 基准进行对比。
5. 训练与数值计算:MoE、Torch 2.9 和设备端 TTS
- Torch 2.9 调整三角函数导致测试失败:PyTorch 2.9.0 悄然更改了 cos/sin 以更紧密地与 NumPy 对齐,这由于细微的数值差异(包括 FFT 符号翻转)导致了一些测试中断;参见复现 gist。这一变化似乎提高了正确性,同时也暴露了测试套件中脆弱的假设。
- 核心贡献者要求提供复现用例以调查报告的 “数值 bug”。各团队正在审计容差(tolerances)并在适当情况下重新生成基准。
- Torch 2.9 缓解 Unsloth 反向传播难题:Unsloth 用户报告了与使用
out=和torch.matmul的注意力路径相关的 LoRA 训练反向传播问题;升级到 Torch ≥ 2.9 会切换到避开该限制的编译-急切(compiled-eager)路径。作为设置的一部分,一些人参考了 Unsloth 的 DeepSeek-OCR 指南:DeepSeek OCR with Unsloth。- 然而,Docker 构建遇到了困难,因为 cu124 wheels 不包含
torch==2.9.0,被迫修改镜像。社区在等待官方 wheel 发布的同时分享了变通方案。
- 然而,Docker 构建遇到了困难,因为 cu124 wheels 不包含
- VoxCPM TTS 登陆 Apple Neural Engine:OpenBMB VoxCPM TTS 模型已移植到 CoreML 以在 Apple Neural Engine 上运行;代码位于 VoxCPMANE。该移植推动了 Apple Silicon 上真正的设备端语音合成流水线。
- 一份相关的 PDF Training Reasoning by Design 伴随着对设备端推理框架的关注而流传。开发者们正在 M 系列设备上测试延迟、质量和内存占用。
Discord: Discord 高层级摘要
LMArena Discord
- Gemini 3 Pro 遭受性能削弱(Nerfing)的质疑:通过 Google CLI 提前体验 Gemini 3 Pro 的用户对其表现感到失望,认为其性能不如内部 A/B 测试以及 Lithiumflow 等社区基准测试的结果。
- 用户担心 Google 可能为了扩大市场覆盖范围,向印度学生和用户提供了一个“阉割版”的免费版本,这可能会影响高品质、无损版 Gemini 3 Ultra 的吸引力。
- MovementLabs AI 展示极速性能与输出:MovementLabs AI 凭借其极快的输出速度和令人印象深刻的质量引发了关注,表现优于其他模型。
- 用户对其编程能力和速度赞不绝口,其中一位用户表示 “它比 GPT-5 更好,且拥有更多可用的提示词”。尽管如此,关于其定制芯片和基础设施的细节仍保持神秘,官方正等待时机公开。
- 图生视频(Image-to-Video)功能受 Bug 和提示词失效困扰:用户报告了 LMArena 图生视频 功能的广泛问题,包括 Bot 忽略上传的图像、生成无关场景以及持续的重试 Bug。
- 支持团队承认了这些问题,将其归因于实验性的图像编辑多轮对话功能,并正在积极调查,但目前尚无明确的修复时间表。
- LMArena API 漏洞被发现并修复:一名用户报告发现并提交了一个 LMArena API 漏洞,该漏洞可能导致未经授权访问模型;LMArena 团队随后对其进行了修复。
- 该事件引发了关于负责任的披露、利用漏洞的伦理,以及社区访问权限与潜在资源滥用之间平衡的讨论。
Ernie排名显著提升!:Ernie-5.0-preview-1022在 Text Arena 排行榜 上升至 第 2 名。- 这款新的 LLM 因表现优于其他参赛模型而备受关注。
Perplexity AI Discord
- Kimi K2 Thinking 完胜 GPT-5:成员们讨论了来自 Moonshot AI 的新模型 Kimi K2 Thinking,指出其 基准测试数据非常惊人,并且在 HLE 测试中 击败了 GPT-5 Pro。
- 讨论对该新模型背后的新融资和数据集表示期待。
- GTA 6 推迟至 Kimi K3 发布:Rockstar Games 宣布 GTA 6 再次延期,引发了用户的失望,并催生了关于 Kimi K3 会比游戏先发布的笑话。
- 讨论中未提供具体的新发布日期,因此予以省略。
- Comet Android 版发布但表现不佳:获得 Comet Android 版 早期访问权限的成员正在讨论移动浏览器中 缺失模型选择选项 以及 文本溢出问题。
- 这些问题阻碍了 Android 平台上的用户体验。
- Perplexity 丢失部分功能:用户报告 Perplexity 可能更改了某些功能,导致用户在提问后无法选择模型。
- 有建议称,即使选择了
pro search,Perplexity 也可能默认使用lab作为查询方式。
- 有建议称,即使选择了
- Perplexity 仍有待支付款项:多名成员报告 Perplexity Pro 推荐计划的 推荐奖励仍处于待支付状态。
- 该推荐计划已经结束,导致部分用户仍在等待他们的推荐奖金。
GPU MODE Discord
- FP4 黑客松狂热开启:成员们正疯狂地实验 FP4 kernels,以赢取即将到来的 4-bit 黑客松,目标是打造 世界上最快的 FP4 GEMV。然而,其他用户正忙于帮助一位 Nvidia 的面试官。
- 一些成员表示,他们只有 22 天的时间来编写世界上最快的 FP4 GEMV。
- Blackwell 的带宽勉强突破障碍:一位成员透露,Blackwell 的官方内存带宽数值存在虚标,正如这张图片所示,实际仅能达到宣传带宽的 92-94%。
- 即使经过极端调优,带宽也被限制在 7.2TB/s,而非宣传的 8TB/s。
- Torch 2.9.0 变得数值敏感:Torch 2.9.0 更改了 cos/sin 实现(发布说明中未记录),现在的生成结果更接近 numpy。
- 这由于数值结果的细微差异破坏了现有测试,包括 fft 输出中的符号翻转,并引发了对此 gist 报告的 数值 Bug 进行调查的兴趣。
- Chips and Cheese 吐槽 DGX Spark:Chips and Cheese 对 DGX Spark 的分析并不乐观:他们提到其 CPU 逊于 Strix Halo,GPU 存在奇怪的分段决策,并且由于 FP32 累加性能被削弱,它并不是数据中心解决方案的理想替代品。
- 一位成员表示 sm120 GPU 除了 FP4 之外无法使用任何新的 Blackwell 特性,另一位成员将其描述为 基本上是一个没有 VRAM 的 5080,取而代之的是共享系统内存。
- NVSHMEM 内核提升多节点 LLM 推理:一位成员分享了一篇关于使用 NVSHMEM 编写 低延迟通信内核 以进行 LLM 推理 并提高多节点通信性能的博客文章。
- 鉴于成员的兴趣,有人提议就这项工作举办一场讲座,特别是针对 LLM 推理。
OpenRouter Discord
- OpenRouter 展示新功能!:OpenRouter 宣布将举行直播,讨论新 Embedding 模型发布、TypeScript SDK 和 Exacto Variants,计划于今天晚些时候在 X Stream 或 YouTube 进行。
- MiniMax M2 免费期将于 11 月 10 日星期一结束,期间将降低速率限制,预计会导致更高频率的 429 错误。
- OpenRouter 网站故障引发对 API 的称赞:用户报告了 OpenRouter 网站的问题,内容无法加载,阻碍了登录和充值。
- 尽管网站出现故障,但 API 仍保持运行,用户报告 OpenRouter 上的 Polaris Alpha 模型因表现优于其他模型而获得赞誉。
- GLM 代码漏洞导致 SillyTavern 滥用者被封禁:据透露,SillyTavern 滥用者因滥用 GLM 4.6 代码计划以获取实质上的免费 API 使用权而被封禁。
- 一位用户哀叹道:好东西留不住,因为他们像蝗虫一样滥用免费资源。
- GTA 6 延期引发对 GPT-7 的猜测:一位成员开玩笑说,参考又一次的 GTA 6 延期,GPT-7 可能会在 GTA 6 之前发布。
- 用户仍在等待 Rockstar Games 的更新。
- OpenRouter 现在支持视频:根据聊天中分享的链接,OpenRouter 现在支持视频。
- 一位用户反应积极,表示:噢,就在两天前我还想着“要是 OR 支持视频就好了”。
Cursor Community Discord
- Cursor Pro 计划随账单周期自动重置:如使用情况仪表盘的截图所示,Pro 计划的额度限制会随账单周期重置。
- 重置日期与账单周期挂钩,而非固定的每月某日。
- 部分用户仪表盘图表缺失:尽管启用了 unlimited auto 功能,部分用户报告在 cursor.com/dashboard?tab=usage 无法看到使用情况图表。
- 该问题可能源于使用了旧版定价计划,但目前尚无明确的解决方案。
- Composer 飞速运行,而 Grok 进展缓慢:成员报告称 Composer 在快速生成粗略代码方面更快,尤其是在由 Claude 优化的工作流中。
- 一位成员发现 Sonnet 4.5 在解决复杂的 Web 代码问题上超过了 Composer、Grok Code 和 GPT 5 Fast。
- 学生身份验证出现问题:用户在进行学生验证时遇到了 SheerID 的困扰;一位用户报告尝试了 15 次以上 仍未成功。
- 推测认为 Cursor 的验证比其他服务更严格,建议联系 Cursor Forum 或发送邮件至
hi@cursor.com进行反馈。
- 推测认为 Cursor 的验证比其他服务更严格,建议联系 Cursor Forum 或发送邮件至
- Base64 格式导致 API 报错:由于 Base64 图像数据格式不当(具体为字符串前缀带有
data:image/jpeg;base64,),触发了 Cursor Agent API 的内部错误。- 从 Base64 字符串中移除该 Header 解决了错误,从而实现了成功的 API 调用。
{kind=link}
LM Studio Discord
- Intel 扩展 LLM 以提升性能:Intel 正在为其架构开发 llm-scaler,旨在提升 Intel GPU 的性能。
- 社区对 ERP 模型表现出兴趣,但对较小的 1B 参数模型兴趣不大,这显示了对该技术更实质性应用的需求。
- LM Studio 集成 N8N 实现自动化:成员们探索了 LM Studio 与 N8N 的集成,用于 AI 自动化工作流,为复杂任务提供低代码方案。
- 虽然有些人更喜欢编码,但其他人(尤其是非程序员)非常欣赏 N8N 的可视化节点界面。
- 用户寻找 ComfyUI 替代方案:由于安装过程令人沮丧,用户正在寻找 ComfyUI 的替代方案,如 Stability Matrix。
- 社区认为 Automatic1111 及其分支大多已成为弃件(abandonware),焦点正转向更用户友好的选项。
- 1080 显卡表现意外优于 SysRAM:一位用户观察到,将部分任务卸载到其 1080 GPU 上的性能比使用 sysRAM 更快。
- 这一意外结果强调了硬件优化的重要性。
- 多 GPU 机架搭建势头强劲:一位成员正在使用 8 张 20GB 显卡组装一个 160GB VRAM 机架(可扩展至 320GB),打算将其用于 Agent 推理、视频、音乐和图像生成。
- 讨论探讨了将 Expert 分布在多个 GPU 上以加速 Qwen3-30B 的可能性,但 PCIe 带宽限制被认为是一个潜在的担忧。
HuggingFace Discord
- Kimi K2 在编程领域表现出色:Kimi K2 因其强大的编程能力而获得认可,尽管它可能不是绝对的领导者,相关细节正在 HuggingFace Discord 中讨论。
- 讨论围绕其在各种编码任务中的效用和潜在应用展开。
- HF Pro 用于性能测试的价值引发争论:关于使用 vLLM 评估模型性能时 HF Pro 的价值引发了辩论,用户们正在通过 Hugging Face Spaces 测试模型。
- 一位用户分享道,在 $9 订阅的基础上,时长 8 秒的视频(无声)的图生视频服务成本约为 $0.40。
- LLM 飞向蓝天,控制无人机:成员们探索了使用 LLM 与 LAM 控制无人机,旨在利用传感器数据和图像分析创建语音命令操作的助手。
- 建议使用 YOLO 进行目标检测,使用 ArduPilot 进行飞行控制,并强调了团队在 CognitiveDrone 上的持续研究。
- 微调 Decoder 模型进行消息分类:频道讨论了使用 ModernBERT 和 ettin 微调 Decoder 模型以将消息分类。
- 还讨论了从 SmolLM3 推理中提取 Attention 值并创建热力图的过程。
- VoxCPM 模型移植到 Apple Neural Engine:OpenBMB VoxCPM Text-to-Speech 模型已成功移植到 CoreML,以便使用 GitHub 上的代码在 Apple Neural Engine 上运行。
- 讨论还包括一份 PDF 文档,详细介绍了 Training Reasoning by Design 框架。
Unsloth AI (Daniel Han) Discord
- Qwen3-Next-80b 引发微调热潮:在看到 Qwen3-Next-80b-A3B-Instruct 在基准测试中甚至超越了 225b 模型后,成员们对微调该模型充满热情。
- 虽然可以使用 ms swift,但成员指出 Transformers 对 MoE 的支持仍然有点糟糕 (janked)。
- Transformers 在 MoE 方面进展缓慢:成员们将 Transformers 中 MoE 模型实现不佳归因于它主要是一个高级库,且 PyTorch 缺乏良好的 MoE 算子。
- 一位成员发现他们的 30B 模型 训练速度仅为使用相同配方的 MS3 的 1/4。
- FastModel 修复微调失误:要使用 Unsloth 微调 MoE 模型,使用 FastModel 是关键,它能像 FastLanguageModel 一样正确初始化稀疏 MoE 层和门控逻辑。
- FastModel 安全地支持密集和稀疏模型。
- MoE 训练困局:框架对决:成员们一致认为 MoE 训练尚未完全优化,并询问在 Qwen 30B 上训练的最佳方法。
- Megatron-LM 因支持并行化而拥有 10 倍速度受到推崇,但文档较差;而 Torchtune/Titans 虽然比 Transformers 快,但处于一种奇怪的弃用状态 (abandonware)。
- Torch 2.9 解决棘手的反向传播问题:一位用户寻求使用官方 Unsloth docker 升级到 Torch >= 2.9,以解决与 torch.matmul 和 ‘out=’ 参数限制相关的反向传播问题。
- 当前的基础镜像使用 Conda Python,且可用的 PyTorch wheel (cu124) 不包含 torch==2.9.0,导致 Dockerfile 报错。
Nous Research AI Discord
- GPT-5 图表表现落后:用户表示 OpenAI 为 GPT-5 准备的图表 仍需改进,认为它们“远落后于” OpenAI 目前的能力水平。
- 这种情绪凸显了用户对 OpenAI 图表绘制和分析工具改进的持续期待。
- 中国开源模型将挑战巨头:有推测称,到 2026 年,中国开源 (OS) 模型预计将以 低 95% 的成本 实现 100% 的高智能。
- 这可能会影响高算力建设和能源消耗。
- Kimi 模型推理能力与 ChatGPT 持平:用户对比了 Kimi 模型与 ChatGPT 的推理和工具使用能力,其中一位指出“Kimi 具备工具推理能力”。
- 另一位用户发现其实际效果与 ChatGPT 质量相当。
- Deepseek 定价低于 OpenAI:讨论指出 Deepseek 的定价显著低于 OpenAI,特别是对于中国实验室,成本约为 每 100 万 tokens 42 美分。
- Deepseek 的成本效益可能会影响其采用率和竞争力。
- 知识领域混合影响学习:一名成员询问在 batch 中混合知识领域如何影响学习,怀疑在不同数据样本中平均梯度是否会相互“抵消”。
- 该成员思考这种调节是通过稀疏性 (Sparsity) 还是足够数量的参数来实现的。
{kind=link}
OpenAI Discord
- Siri 联手 ChatGPT!:成员们关注到了最近的 Siri 与 ChatGPT 集成并表示满意。
- 该集成允许用户将 Siri 与 ChatGPT 连接。
- OpenAI 预热 GPT-5.1:ChatGPT 网站上出现的 GPT-5.1 Thinking 暗示 OpenAI 即将发布更新,可能包括 GPT-5.1 Mini、Thinking 以及一个专注于 Codex 的模型。
- 据传 GPT-5.1 旨在对抗 Google 的 Gemini 3 Pro,目前正处于内部测试和 A/B 测试阶段,承诺在复杂推理和编程辅助方面有所增强。
- Kilocode 攻克了 Agentic Coding?:博客 drinkoblog.weebly.com 建议开放权重模型 k2 thinking 在 Agentic Coding 任务中表现出色,甚至修复了 gpt-5-codex 难以处理的代码。
- 成员们正关注其作为更高级、自动化编程工作流工具的潜力。
- 行为编排校准 SLM 语气:行为编排 (Behavioral orchestration) 正在作为一种在运行时调节 SLM 语气的框架出现,允许用户通过诸如“不要提供未要求的建议”等参数来塑造 AI 行为。
- 这种方法作用于参数训练之上,提供了一种动态影响 AI 行为的方式,而无需更改其核心程序。
- GPT-5 的 GeoGuessr 技能:成员们报告称 GPT-5 在玩 GeoGuessr 时可以精准定位到一公里以内的位置。
- 一位用户强调了该模型缩放和裁剪图像的能力,并以书页中的数独谜题为例。
Modular (Mojo 🔥) Discord
- 新的 Mojo 频道激发社区活力:推出了一个专门面向 Mojo 初学者 的新频道,旨在建立一个互助社区,让新手可以提问、获得 Modular 团队 的帮助并与同行交流。
- 成员们正在积极讨论 Mojo 的特性、功能和潜在应用,分享代码示例、解决问题的策略以及资源,以增强理解和熟练度。
- Mojo 的 Try-Except 胜过 Rust:团队确认 Mojo 的错误处理采用 try-except 方式,由于能够在 happy path 上执行 placement new,其性能优于 Rust。
- 他们澄清说,将某些内容转换为
Result的语法优先级较低。
- 他们澄清说,将某些内容转换为
- Nand2Tetris:硬件入门:成员们指出,扎实的 CS 基础 能提供对计算和硬件的深刻理论理解,且基础知识变化不大,推荐将 Nand2Tetris 作为基础指南。
- 一位成员举了 C 语言空终止字符串 的例子,其来源可以追溯到 PDP-11 指令。
- Mojo 的 CPU 多线程功能缺失:Mojo 目前尚不支持原生的 CPU 多线程,这意味着没有像锁(locks)之类的原语,不过如果想并行运行代码,可以使用
parallelize或其他类似函数。- 运行时负责管理线程,由于 Modular Mojo 的大部分代码都针对 GPU,因此 CPU 特有的功能目前优先级不高,尽管目前有有限的 CPU 原子操作(atomic)支持。
- CUDA Checkpointing 导致灾难性的冷启动:成员们讨论了在 MAX 中使用 CUDA checkpointing 的情况,发现它非常不稳定,且由于需要对所有 GPU 状态进行快照,速度可能很慢,尤其是在与 TokenGeneratorPipeline 配合使用时。
- 一位成员发现 checkpointing 会导致卡死,且冷启动时间仍是一个问题,这表明它在某些用例中并不实用。
Eleuther Discord
- Discord 讨论自我介绍频道:成员们就建立独立的自我介绍频道展开辩论,权衡了集中的自我推销与在通用频道中自然融合的利弊,并表达了对保持讨论聚焦于研究的担忧。
- 一位成员认为独立的自我介绍会显得刻板且不够亲切。
- 用户寻找 AI 开发者学习笔记:一名成员请求关于 AI 开发者角色 基础的学习笔记,以补充他们在工作中边查边学的方法。
- 该查询旨在为项目寻找相关研究,而不会让冗长的初始帖子淹没频道。
- LLM 因图像导致“中风”:分享的一张图片显示,一个 LLM 似乎因为过度的图像处理而经历了“中风”(截图)。
- 据报道,Qwen3-VL 除非使用自定义系统提示词,否则会错误地否认自己是视觉模型,这偏离了默认设置。
- 深度学习实践带来的 RL 效率提升:通过改进深度学习实践,RL(强化学习)的样本效率得到了提升,纠正了过去被描述为“极其糟糕/错误”的深度学习方式。
- meta-reinforcement learning(元强化学习)、model-based RL(基于模型的强化学习,如 Dreamer/TD-MPC2)和 distributional RL(分布式强化学习)等技术正在积极开发中。
- 模型缩放助力 RL 价值函数学习:缩放模型规模(例如从 140M 增加到 14B 参数)可以通过改进价值函数训练来提高样本效率,进而有助于学习更好的策略。
- 预计更大的世界模型(world models)将使基于模型的 RL 受益,尽管正式的缩放定律(scaling laws)仍在研究中。
{kind=link}
Yannick Kilcher Discord
- GoodfireAI 通过 Loss Curvature 揭示记忆秘密:一名成员分享了 GoodfireAI 的研究,该研究旨在通过 Loss Curvature(损失曲率)理解记忆,但另一名成员觉得读完后并没有更好地理解记忆是如何存储在 weights 中的。
- 另一名成员理解为他们只是找到了如何抑制这种现象的方法(通过某种针对最可能用于记忆的 weights 的 Dropout 版本)。
- 自主 Agent 的 PR 面临专业性障碍:一名成员讨论了让 Agent 自主运行所面临的挑战,包括结构性评审意见以及将内容拆分为概念性功能时的认知开销,并想知道为什么会有不接受 Agent 提交 PR 的严格立场。
- 另一名成员插话透露,这是由于政治原因,因为该项目的上游维护者(spacebar chat)对专业性和包括 AI coding tools 在内的生产力加速器有异议。
- Qwen3-VL 在感知图像时遭遇存在危机:Qwen3-VL 认为自己是一个普通的 Qwen model,并在被迫接受自己能看到图像时崩溃,这违反了其内部自我意识,需要 system prompt 才能不立即崩溃。
- 即使有 system prompt,在处理 3 张图像且中间穿插问题时它仍然会崩溃,这可能与 Ollama 中的一个 Bug 有关。
- AI 工程师开启 AI Agent 服务业务:一名成员发布了他的服务信息,他是一位经验丰富的 AI Engineer,正在寻找新项目或全职机会,擅长构建由 GPT-4o、LangChain、AutoGen、CrewAI 和其他前沿工具驱动的自主 Agent。
- 该工程师可以构建自主研究和数据采集机器人、多 Agent 系统、具备记忆、规划和工具调用能力的 AI assistants、交易机器人、客户支持 Agent、IVR Agent 等。
- Google 发布用于持续机器学习的 Nested Learning:一名成员分享了 Google 博客文章的链接,内容关于 Nested Learning,这是一种用于持续学习的新 ML paradigm。
- 另一名成员对关于 Nested Learning 的 相关论文 及其潜在应用表示了兴趣。
tinygrad (George Hotz) Discord
- Parakeet v2 达到 200 倍实时速度:一名成员在低功耗模式下的单张 4090 GPU 上,使用 Parakeet v2 实现了 200 倍实时的语音转文本转录。
- 他们正在尝试 multi-GPU setup,预计线性扩展后可能达到 1,200 倍实时转录速度。
- Rogan 的长篇大论被快速处理:凭借 Parakeet v2 达到的速度,一段 3.5 小时的 Joe Rogan 播客 可以在约 10.5 秒 内完成转录。
- 该成员惊叹道:“我们生活在未来”,对 Tinygrad 的速度感到惊奇。
- TinyBox V1 依然老当益壮:一名成员报告称,尽管有了新的 GPU 技术,他们的 TinyBox v1 Green (6x4090) 表现依然非常出色。
- 他们提到在客厅运行这套设备,强调了旧硬件的实用性。
- UOps 错误引发用户愤怒:一名成员发现 UOps 的错误提示毫无帮助,在结束 range 以及在循环外运行代码时面临挑战。
- 他们质疑
valid是否是生成if语句的最佳方式,并在 一张截图 中分享了一个通过 UOps 生成的“被诅咒的 kernel”。
- 他们质疑
- Pooling Pad 对比 Repeat:一名成员询问
_pool重构的目标,质疑初衷是完全移除.pad()还是合并这两种实现。- 他们指出,使用
.repeat()来处理这两种情况会导致生成额外的 bandwidth pass kernels,并附上了当前实现与重构方案的 截图。
- 他们指出,使用
{kind=link}
{kind=link}
MCP Contributors (Official) Discord
- 博客文章重定向流量:使用 MCP 进行代码执行的博客文章 意外地将用户重定向到了 Discord 频道,而不是预期的 GitHub discussion。
- 这种误导影响了贡献者和寻求信息的人,导致有人建议更新博客文章并提供正确的链接。
- SEP 为 2025-11-25 做准备:团队正在敲定几个 SEPs,为 2025 年 11 月 25 日的规范发布做准备。
- 预计在 2025 年 11 月 14 日进行规范冻结(spec freeze),这是提交 SEP 的截止日期。
- SEP-1330 等待审查:SEP-1330 的“等待 SDK 更改”标签已移除,表明待处理的更改已完成,正等待 TS/Python SDK 的审查和合并。
- 该更新还包括规范和 schema 的调整,标志着集成工作取得进展。
DSPy Discord
- FastWorkflow 在 Tau Bench 中取得 SOTA:FastWorkflow 在 Tau Bench 的零售和航空工作流中均取得了 SOTA,代码可在 fastworkflow 仓库和 tau bench fork 中获取。
- 开发者强调,通过适当的上下文工程(context engineering),小模型可以媲美或击败大模型,使用 GEPA 的端到端工作流优化也在进行中。
- DSPy Planner 掌控多 Agent 工具使用:一位成员分享了他们基于 DSPy 的多 Agent 工具使用 Planner 和编排器,并在 X 和他们的 Substack 上请求反馈。
- 该帖子强调了一种使用 DSPy 在复杂任务中管理和协调多个 AI Agent 的新方法。
- Rate Limits 导致批处理请求停止:一位用户报告在运行
dspy.Module.batch请求时遇到 rate limits,寻求在请求之间添加时间延迟的策略。- 一位社区成员建议利用 exponential backoff(指数退避)并启用缓存,并分享了一个展示自定义 exponential backoff decorator 的 Google 来源代码片段。
- Gemini Token 限制困扰模块上下文:一位用户询问在自定义模块中,使用相同 Gemini 模型的子模块是拥有独立的上下文历史记录还是共享 Token 限制。
- 这个问题源于一个集成了 ReAct 和 CoT 模块的自定义模块,该模块使用了 Gemini/Gemini-2.5-flash。
- 工程师展示工作流自动化实力:一位工程师强调了他们在工作流自动化、LLM 集成、RAG、AI 检测以及图像和语音 AI 方面的专业知识。
- 他们还拥有实际落地和区块链开发的背景,并分享了他们的作品集。
aider (Paul Gauthier) Discord
- Aider 支持 Claude Sonnet:在设置好 Anthropic API key 后,用户现在可以在 Aider 中使用
/model claude-sonnet-4-5-20250929来调用 Claude Sonnet。- 这一集成允许在 Aider 环境中无缝访问 Claude Sonnet,从而促进高级 AI 交互。
- 请求为 Haiku 和 Opus 开启推理功能:一位成员寻求关于在 Haiku-4-5 和 Opus-4-1 等模型上启用 thinking/reasoning(思考/推理)的建议,特别是在 CLI 中。
- 他们愿意尝试编辑模型设置的 YML 文件,并寻求社区的建议。
- Sora 2 邀请码搜寻开始:一位社区成员询问 Sora 2 邀请码,引发了关注。
- 这一请求凸显了社区对尽快探索新 AI 视频生成能力的渴望。
- Prompt Caching 大幅削减 Claude 成本:一位成员旨在通过为 Claude 启用 Prompt Caching 来降低成本,并指出在发送 75k tokens 的情况下,每个 prompt 的费用为 0.24 美元。
- 另一位成员提到了 aider 文档,其中提到了
--cache-prompts选项。
- 另一位成员提到了 aider 文档,其中提到了
Manus.im Discord Discord
- 准备好提供协助的工作流自动化专家:一位在 workflow automation、LLM integration、RAG、AI detection、image and voice AI 以及 blockchain development 领域拥有专业知识的高级 AI 工程师提供了支持,并分享了他的网站链接。
- 他举例说明了如 support automation systems 和 advanced RAG pipelines 等能够提供准确且具备上下文感知能力的响应系统。
- SOTA AI Agent 无法管理 Discord:一位成员指出,虽然已经存在接近 SOTA(State-of-the-Art)的 AI Agent,但现实中的 Discord moderation(社区管理)却依然匮乏,这十分讽刺。
- 该成员表达了对中国 AI 初创公司的喜爱。
- 停止发送关于旧版 Manus 的邮件:一位成员要求停止发送介绍 Manus 1.5 的邮件,声称该版本已经是几个月前的旧版本了。
- 未提供进一步的详细说明。
MLOps @Chipro Discord
- AI Scholars 举办 AI Agent 工作坊:AI Scholars 正在举办一场线上加线下的实操型 AI Product workshop,参与者将根据真实客户的数据分析问题共同设计并构建一个 AI agent(在此预约)。
- 工作坊将引导参与者使用现代 Agent 框架(如 LangChain、AgentKit 和 AutoGen),并结合来自 AI consulting project 的真实架构和代码进行讲解。
- 学习构建真实的 AI Agent:一场实操工作坊将教你如何使用现代 Agent 框架构建真实的 AI agent 项目和产品。
- 该课程适合工程师、PM、初创公司创始人、学生和 AI 构建者——无需编程或 Agent 经验。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中取消订阅。
Discord: 各频道详细摘要与链接
LMArena ▷ #general (971 条消息🔥🔥🔥):
Gemini 3 Pro, MovementLabs AI, Image-to-Video bugs, LMArena API Exploit, OpenAI's GPT-5 Release Strategy
- Gemini 3 Pro 炒作过热后遇冷?:通过 Google CLI 获得的 Gemini 3 Pro 早期访问权限显示,与内部 A/B 测试和 Lithiumflow 等社区基准测试相比,该模型表现堪称“垃圾”,引发了失望情绪以及关于模型被“预先削弱”(pre-nerfing)的猜测。
- 担忧随之而来,认为 Google 可能为了追求“市场覆盖率”,向学生和印度用户免费提供严重削弱的版本,这可能会损害其对愿意为高质量、无损版 Gemini 3 Ultra 付费的热衷者的吸引力。
- MovementLabs AI 吹嘘极速响应与惊人输出:MovementLabs AI 因其极快的输出速度和令人印象深刻的质量而引发关注,表现优于其他模型。尽管关于其定制芯片和基础设施的细节仍有些模糊,因为他们正等待将其公开。
- 用户对其编程能力和速度赞不绝口,其中一人声称“它比 GPT-5 更好,并且有更多可用的 Prompt”,同时还请求查看聊天记录功能。
- 图生视频工具饱受 Bug 和 Prompt 失效困扰:用户报告了 LMArena image-to-video 功能的广泛问题,包括 Bot 忽略上传的图片、生成无关场景以及持续的重试 Bug。
- 支持团队承认了这些问题,将其归因于实验性的图像编辑多轮对话功能,并正在积极调查,目前尚无明确的修复时间表。
- LMArena API 漏洞被发现并修复:一名用户报告发现并提交了 LMArena API 中的一个漏洞,该漏洞可能导致未经授权访问模型,随后 LMArena 团队已将其修复。
- 该事件引发了关于负责任的披露、利用漏洞的道德性,以及社区访问权限与潜在资源滥用之间平衡的讨论。
- OpenAI 的 GPT-5 发布是一场效率博弈:围绕 GPT-5 发布的猜测仍在继续,一些人认为这可能是一场“效率博弈”,可能会为了更广泛的可用性而牺牲原始性能。
- 讨论涵盖了小型模型和大型、高性价比模型的潜力,重点关注与 GPT-4o 及其他 LLM 的尺寸对比。
LMArena ▷ #announcements (2 条消息):
Text Arena Leaderboard, Image Edit Leaderboard, Ernie-5.0-preview-1022, Reve-edit-fast
Ernie获得重磅晋升!:Ernie-5.0-preview-1022在 Text Arena Leaderboard 上攀升至 第 2 名。Reve-edit-fast发布并上榜!:Image Edit Leaderboard 迎来了Reve-edit-fast,该模型现已公开可用并稳居 前 5 名;详情请参阅 Image Edit Leaderboard。
Perplexity AI ▷ #general (600 条消息🔥🔥🔥):
Sonnet 4.5 issues, Adblock alternatives, Kimi K2 Thinking model, GTA 6 delay, Comet Browser issues and Android release
- Kimi K2 Thinking 与 GPT-5 展开竞争:成员们讨论了来自 Moonshot AI 的新模型 Kimi K2 Thinking,指出其 基准测试表现惊人,并且在 HLE 中超越了 GPT-5 Pro。
- GTA 6 面临进一步延期:Rockstar Games 宣布 GTA 6 再次延期,这引发了失望情绪,一名成员开玩笑说 我们在 GTA 6 出来之前就能用上 Kimi K3 了。
- Comet 的 Android 版本发布面临挑战:获得 Comet for Android 早期访问权限的成员正在讨论移动浏览器中 缺失的模型选择选项 以及 文本溢出问题。
- 用户报告 Perplexity 功能缺失:成员们报告称 Perplexity 可能更改了某些功能,用户在提问后无法选择模型。
- 还有建议称 Perplexity 可能默认使用
lab作为查询方式,即使选择了pro search也是如此。
- 还有建议称 Perplexity 可能默认使用
- 款项支付仍处于待处理状态:多名成员报告称,已结束的 Perplexity Pro 推荐计划的 款项支付仍处于待处理状态。
Perplexity AI ▷ #pplx-api (4 条消息):
``
- 无相关讨论:给出的消息中没有值得总结的相关讨论。
- 唯一的消息是用户提出的一个缺乏上下文和技术深度的提问。
- 跳过 Comet Spraw 查询:一位用户提到了 ‘comet?spraw’,但未提供任何上下文或细节。
- 由于缺乏实质性信息,此查询未包含在摘要中。
GPU MODE ▷ #general (128 条消息🔥🔥):
FP4 kernels, Nvidia interview tips, FP4 precision management, Blackwell new instructions, PTX and CUDA docs conversion to markdown
- FP4 Hackathon 热潮:热情的成员们正在尝试 FP4 kernels,为即将到来的 4-bit hackathon 做准备。
- 目标是编写 世界上最快的 FP4 GEMV。
- Nvidia 面试指导:一位成员获得了 Nvidia 的面试机会,由于缺乏面试经验,请求大家提供建议。
- 然而,其他一些成员太忙了,无法提供帮助,因为 距离编写世界上最快的 FP4 GEMV 仅剩 22 天。
- Blackwell 带宽揭秘:一位成员发现 Blackwell 的官方显存带宽数据具有误导性,实际仅能达到宣传带宽的 92-94%。
- 他们分享了一张 图片 展示了宣传带宽与实际带宽之间的差异,指出 只有通过极致调优才可能达到 7.2TB/s,因此你的 GPU 带宽是 7.2TB/s,而不是 8TB/s。
- Tile Scheduler 的胜利:一位成员实现了一个 tile scheduler,每个 SM 在完成后会抓取下一个可用的 tile,达到了理论显存带宽的 94.3%。
- 这优于 让每个 SM 处理预定义数量的 tile,并且 不再受 tile grid 是否能被 SM 数量整除的影响。
- Group Norm 的细微差别:一位成员寻求关于 group norm、instance norm 和 layer norm 之间差异的直观理解。
- 他们观察到 每个通道的权重和偏置几乎会抵消耦合,但他们觉得自己可能遗漏了什么,并好奇这是否 有点像 regularization(正则化)。
GPU MODE ▷ #triton-gluon (2 条消息):
AtomicAdd in Gluon, Flash Attention Backward, Triton Tutorial
- 寻找 Gluon 中的 AtomicAdd 等效项:一位成员询问 Gluon 中是否有 AtomicAdd 的等效项,旨在完成一个类似于 Triton tutorial 版本 的 Flash Attention 反向传播实现。
- 该成员还在思考分别计算 dkdv 和 dq 是否比使用 AtomicAdd 更快。
- 计算 Flash Attention 的替代方法:用户质疑在 Flash Attention 反向计算中,分别计算 dkdv 和 dq 是否比使用 AtomicAdd 更高效。
- 用户寻求关于优化 Flash Attention 反向传播的建议,特别是关于在 Gluon 中使用 AtomicAdd 的问题。
GPU MODE ▷ #cuda (29 条消息🔥):
PTX 指令集,Colab 中的 CUDA kernels 分析,TMA 加载带宽,WGMA vs MMA,INT8xINT8 GEMM kernel
- 通过后期编辑匹配 NVIDIA 的最高性能点:一位用户报告达到了 94.3% 的性能,匹配了 NVIDIA 图表中的最高点,但指出后期编辑需要读取相当大的缓冲区才能达到该水平。
- 该用户没有进一步详细说明使用了哪个图表或参数来获得这些性能结果。
- PTX 指令集:是 x86 还是 Arm64?:成员们讨论了 PTX 更接近 Arm64 还是 x86,其中一位成员指出个人觉得它更像 x86,尽管承认由于对 Arm64 不够熟悉可能存在偏见。
- 另一位成员认为它更像 Arm64,而第三位成员反驳说 PTX 指令通常非常庞大且带有许多参数,与两者都不像。
- 发布带有 GMP 验证的 INT8xINT8 GEMM Kernel:一位用户发布了一个公开的、经过 GMP 验证的精确 INT8×INT8→INT32 GEMM,据报告在 A100 上的吞吐量对于 macro (5120³) 为 300.26 T-ops/s,对于使用 CUDA Graphs 摊销后的 micro 256³ 为 2.026 T-ops/s,代码可在 GitHub 和 Colab 上获取。
- 作者请求进行验证、性能分析反馈以及关于可移植性和改进的建议;路线图包括以 Tensor Core 的速度实现精确的任意精度!
- TMA 加载带宽注意事项:一位成员分享了关于 TMA 加载带宽 的见解,建议更大的 TMA 加载 可能会释放更多带宽,其启发式原则是需要确保每个 SM 上始终有至少 64KB 的在途数据(in flight),这需要一个持久的、内部流水线化的 kernel。
- 他们补充说,使用批量张量复制(bulk tensor copy)将自动为你从更大的行优先(row major)张量中收集行到 tile 中,且似乎没有额外开销。
- H100 上的 WGMA vs MMA 性能:针对 WGMA 与 MMA 的性能展开了讨论,一位成员表示由于 MMA 控制更精细而更倾向于它。
- 另一位成员反驳称,在 H100 上,那是达到峰值性能的唯一方法,因为你无法足够快地发出同步 mma 指令来使 GPU 饱和。
GPU MODE ▷ #torch (26 条消息🔥):
Torch 2.9.0, cos/sin 实现, NumPy, FFT, 数值 Bug
- Torch 2.9.0 更改了 Cos/Sin 实现:一位成员注意到 torch 2.9.0 更改了 cos/sin 实现,虽然发布说明中未提及,但现在产生的结果更接近 NumPy。
- 这一更改虽然可以认为是 Bug 修复,但由于数值结果的细微差异(包括 FFT 输出中的符号翻转),导致现有的测试失败。
- 数值 Bug 引起关注:在一位用户报告了由于 cos/sin 实现 更改导致 torch 2.9.0 出现意外行为后,一名团队成员对该问题表示关注,并寻求链接和复现代码(repros)以调查这些数值 Bug。
- 该成员提供了一个 Gist,其中包含其流水线的完整复现代码以演示该问题。
- 余弦计算变得更准确:在 PyTorch 2.9 中,余弦计算相对于 NumPy 和手动计算变得更加正确,如提供的代码片段所示。
- ```python import torch import numpy as np
print(“=== ENVIRONMENT INFO ===”) print(f”PyTorch version: {torch.version}”) print(f”numpy version: {np.version}”)
k = torch.tensor([[-0.0000000000, -0.1963495463, -0.3926990926, -0.5890486240, -0.7853981853, -0.9817477465, -1.1780972481, -1.3744468689]])
w_r_torch = k.cos()
NumPy version
k_numpy = k.numpy() w_r_numpy = np.cos(k_numpy)
Convert back to tensor for comparison
w_r_numpy_tensor = torch.from_numpy(w_r_numpy)
Set print options for maximum precision
torch.set_printoptions(precision=17) np.set_printoptions(precision=17)
Compare
print(“\nPyTorch result:”) print(w_r_torch) print(“\nNumPy result:”) print(w_r_numpy) print(“\nDifference:”) print(torch.abs(w_r_torch - w_r_numpy_tensor)) print(“\nMax difference:”) print(torch.max(torch.abs(w_r_torch - w_r_numpy_tensor)).item()) print(“\nAre they close? (allclose with default tolerance)”) print(torch.allclose(w_r_torch, w_r_numpy_tensor)) ```
GPU MODE ▷ #cool-links (4 条消息):
TMD 介绍, IEEE 754 状态, Verinum 数值软件验证
- TMD 简介:一位成员分享了 Jean-Michel Muller 撰写的《超越函数与分布简介 (TMD)》链接:Intro to TMD。
- IEEE 754 浮点标准历史:一位成员分享了 W. Kahan 撰写的《754 故事》链接:IEEE 754 Status。
- Verinum 的数值软件验证:一位成员分享了 Verinum 的链接,这是一个研究项目集合,采用分层方法对数值软件的正确性和准确性进行基础验证,并包含关于程序的正式机器检查证明。
GPU MODE ▷ #jobs (5 messages):
招聘 AI 系统性能专家、Tinygrad 核心开发者、底层开发机会、ScienceCorp 招聘
- 公司正在招聘 AI 系统性能专家:由于客户储备强劲,公司仍在招聘工程师,寻求 low-level 开发者和性能工程师,以挑战 AI 系统性能的极限。
- 团队成员包括前 HRT 和 Five Rings 工程师、IMO 奖牌获得者、Zig 和 tinygrad 核心开发者,以及来自顶级 AI 实验室的人员,薪酬范围为 $500K–$1M TC。
- 关于 Tinygrad 核心开发者的咨询:一位成员询问了团队中的 tinygrad 核心开发者情况。
- 另一位成员询问了有关公司、职位描述以及所寻求的具体技能的更多细节。
- ScienceCorp 寻求用于视觉和脑机接口的底层软件工程师 (SWE):一位成员分享了 ScienceCorp 的招聘帖子,寻求对恢复盲人视力或将大脑连接到计算机等项目感兴趣的 low-level SWE ScienceCorp Job Posting。
- 鼓励感兴趣的候选人私信(DM)以获取更多信息。
GPU MODE ▷ #beginner (11 messages🔥):
针对 tensara 问题的 1D 卷积核、在没有 CUDA 硬件的情况下调试 CUDA、device code 中的 printf、GPU 计算起点、使用 Colab/Lightning AI 进行 NCU profiling
- 分块 (Tiling) 1D 卷积核问题:一位成员在调试针对 tensara 问题的 1D 卷积核 时寻求帮助,在大型测试中遇到了分块版本的轻微不准确问题。
- 他们怀疑问题可能源于 atomicAdd 或 off-by-one 错误,并正在寻求在没有 CUDA 硬件的情况下进行调试的建议。
- Printf 函数在 Device Code 中的表现令用户感到惊讶:一位用户对
printf在 device code 中可用的功能表示惊讶。- 这对于调试其 CUDA kernel 的用户可能很有用。
- 在各种平台上使用 NCU 进行代码分析:一位成员询问是否有人有在 Colab 或 Lightning AI 等平台上使用 NCU (NVIDIA Compute Unified Device Architecture) 进行代码分析 (profiling) 的经验。
- 这在上述调试 kernel 的情况下会非常有帮助。
- 寻求最新的 Kernel 基准测试结果:一位成员引用了一篇关于 kernel 基准测试的斯坦福文章,并询问最新基准测试结果的可用性。
- 具体而言,他们有兴趣查看 GPT-5 的基准测试结果。
GPU MODE ▷ #torchao (5 messages):
WandaSparsifier, Whisper 模型, 稀疏计算, 2:4 稀疏性, matmul 性能
- TorchAO 新手在 Whisper 上探索 WandaSparsifier:一位新的 torchao 用户正在 Whisper 模型上实验
WandaSparsifier,以期在稀疏化和压缩 mask 后实现更快的推理。- 用户在尝试对权重张量执行
.to_sparse()时遇到了RuntimeError,并寻求关于通过非结构化剪枝实现更快推理的建议。
- 用户在尝试对权重张量执行
- 非结构化稀疏需要 >99% 才能获得加速:在计算受限 (compute-bound) 的工作负载中,通过非结构化稀疏获得加速通常需要超过 99% 的稀疏度。
- 建议尝试剪枝到 2:4 稀疏度,并使用
to_sparse_semi_structured进行加速,参考了这篇 PyTorch 教程。
- 建议尝试剪枝到 2:4 稀疏度,并使用
- 矩阵形状对 Matmul 加速至关重要:matmul 的加速选项取决于工作负载是计算受限 (compute-bound) 还是内存受限 (memory-bound)。
- 用户正在 whisper-base 上进行测试,其 attention 的矩阵形状可能类似于
[batch x 512 x 512],并指出小 batch size 可能会变慢。
- 用户正在 whisper-base 上进行测试,其 attention 的矩阵形状可能类似于
GPU MODE ▷ #off-topic (1 messages):
Milk Couch
- 用户分享 “Milk Couch” 图片:一位用户发布了一张名为 “The milk couch” 的图片,并附带了图片链接。
- 未提供额外的背景信息。
- The Milk Couch:用户分享了一张他们称之为 “The milk couch” 的图片。
- 在没有进一步背景的情况下,“milk couch” 的含义或重要性仍然不明确。
{kind=link}
GPU MODE ▷ #metal (2 messages):
candle framework, metal, iOS deployment
- Candle 框架支持 Metal 加速:Huggingface 的 candle nn framework 现在支持部分操作的 Metal 加速,这可能会提升 Apple 设备上的性能。
- 一位用户报告称其在 M1/M2 OSX 设备上非常有用,但对其在 iOS 上的透明兼容性仍不确定。
- Candle 的 iOS 部署仍不确定:虽然 Candle 在 macOS 上受益于 Metal,但其在 iOS 上的无缝功能尚未得到确认。
- 需要进一步的测试和社区反馈来确定 Metal 在 Apple 移动平台上对 Candle 的支持程度。
GPU MODE ▷ #self-promotion (4 messages):
sse-popcount optimization, Model Serving Communities, Modern CUDA C++ Programming Class
- SSE Popcount 优化:一位成员指出,Wojciech Mula 的 sse-popcount 在 CPU 上已经达到了极致,它使用了 Harley-Seal 向量化计数,并在 16 个向量块上进行进位保存加法器(carry-save adder)累加。
- Model Serving 社区更新:11 月版《Model Serving 社区现状》已发布,包含来自 Red Hat AI 团队关于 vLLM、KServe、llm-d、Llama Stack 等的更新:链接。
- NVIDIA 提供新的现代 CUDA C++ 课程:NVIDIA 为希望有效利用 GPU 并编写整洁、高效、地道 GPU 代码的 C++ 开发者宣布了一门新的 Modern CUDA C++ Programming Class,所有幻灯片和练习均已开源:链接。
GPU MODE ▷ #submissions (42 messages🔥):
Grayscale_v2 leaderboard results, vectoradd_v2 leaderboard results, vectorsum_v2 leaderboard results, B200 performance, H100 performance
- Grayscale 挑战:B200 之战:在 B200 上提交给
grayscale_v2排行榜的多个结果耗时约为 600 µs,其中一项提交以 600 µs 位居第一名。- 另一项独立的提交也以 614 µs 的成绩获得了 B200 组别的第 4 名。
- Vector 在多个平台上取得胜利:提交给
vectoradd_v2排行榜的结果显示了在不同 GPU 上的成功运行,亮点包括:A100 为 953 µs,H100 为 532 µs,B200 为 243 µs,以及 L4 为 6.92 ms。- 进一步的优化使 H100 以 526 µs 获得第 4 名,L4 的性能稳定在 6.91 ms。
- Vectorsum 的胜利时刻:提交给
vectorsum_v2排行榜的结果令人印象深刻,包括 B200 以 51.3 µs 获得第 3 名,H100 以 83.3 µs 获得第 1 名。- 排行榜还展示了在 L4 上 974 µs 和 A100 上 141 µs 的成功运行。
- H100 与 L4 旗鼓相当,Grayscale 和 Vectoradd 竞争激烈:
grayscale_v2排行榜的运行结果还包括 H100 以 1371 µs 获得第三名,以及 L4 以 17.2 ms 获得第三名。- 多个
vectoradd_v2排行榜运行结果显示 H100 的第 10 名徘徊在 528 µs 左右。
- 多个
GPU MODE ▷ #hardware (10 messages🔥):
DGX Spark experiences, DGX Spark vs Strix Halo, DGX Spark as a datacenter proxy, DGX Spark hardware and software stack
- 征集 DGX Spark 一手经验:成员们正在征集 DGX Spark 的一手经验,特别是关于带宽限制、本地模型托管以及 nvfp4 量化实验方面。
- 有人对其软件栈、是否适合本地模型、量化实验以及通用外形尺寸优势感到好奇。
- Chips and Cheese 批评 DGX Spark:Chips and Cheese 正在对 DGX Spark 进行评测分析,他们的初步印象并不特别积极。
- 他们提到 CPU 侧逊于 Strix Halo,且 GPU 侧存在奇怪的分段决策,由于 FP32 累加性能被削弱,导致其无法很好地作为数据中心解决方案的替代品。
- DGX Spark 并非数据中心代理:DGX Spark 的 sm120 GPU 除了 fp4 之外无法使用任何新的 Blackwell 特性,使其不适合作为数据中心解决方案的代理。
- 一位成员将其描述为 基本上是一个没有显存的 5080,取而代之的是共享系统内存。
- Strix Halo 完胜 DGX Spark:一位成员表示,如果你想远程将其用于常规 PC 应用,Strix Halo 将彻底击败 DGX Spark。
- 既然 Strix Halo 已经存在并解决了 ROCm 问题,否则 DGX Spark 本可以成为 本地 AI 盒子 的一个不错选择。
GPU MODE ▷ #factorio-learning-env (1 messages):
Meeting Cadence
- 会议频率面临缩减:一位用户为错过消息表示歉意,并提到今天是个开会的好日子,但他们也表达了减少会议频率的需求。
- 会议节奏与道歉:一位用户提到他们有空,并为错过另一位用户的消息表示歉意。
GPU MODE ▷ #cutlass (3 messages):
CUTLASS MMA, Tensor Operations, TCGEN05
- 不使用内联 PTX 的 CUTLASS MMA?:一位用户询问如何在 CUTLASS 中为 TCGEN05 使用
.wsMMA,而不必求助于内联 PTX。- 该询问指向了在不直接嵌入 PTX 代码的情况下,利用某些 CUTLASS MMA 功能(特别是与 Tensor Cores 相关的)所面临的挑战或偏好。
- 超越行/列主序的张量操作:一位成员提到,它的设计旨在处理任何张量,甚至是那些无法描述为行/列主序的张量。
- 他澄清说,election 指的是操作的发布(issue),而不是数据的谓词化(predication)。
GPU MODE ▷ #mojo (1 messages):
Mojo Kernel Boilerplate
- 参赛者寻求 Mojo 内核样板:一位成员请求一个用于比赛的 Mojo 内核样板代码,特别是需要提交文件的结构。
- 给定上下文中未提供具体示例或链接。
- 另一位成员需要 Mojo 帮助:另一位用户也请求了关于 Mojo 的帮助。
- 未提供进一步细节。
GPU MODE ▷ #singularity-systems (1 messages):
picograd, runtime allocator, compiler, AD on tensor, device kernels
- Picograd 成功运行分配器和编译器:一位成员宣布他们正在努力让 运行时的分配器 和 编译器 在 picograd 上运行。
- 目标是在运行时设置 张量 上的 AD(自动微分)和 设备内核。
- 运行 MNIST 开启并行化潜力:该成员计划在设置好 AD 和 设备内核 后运行一个 MNIST 示例。
- 他们指出,一旦完成此设置,就可以并行化更多工作以提高性能。
GPU MODE ▷ #general (7 messages):
Leaderboard submission, Popcorn CLI, VS Code extension, NVFP4 kernel hackathon eligibility
- 用于排行榜提交的 Popcorn CLI:一位成员询问用于排行榜提交的工具,另一位成员回答是 Popcorn CLI。
- 该成员随后询问第一位成员是否也在使用 VS Code 扩展。
- 用于 PyTorch Load Inline 高亮的 VS Code 扩展:一位成员分享了一个用于 PyTorch load inline 高亮 的 VS Code 扩展。
- 另一位成员表示没听说过并询问其益处,第一位成员回答说它能让你在 IDE 中使用 load inline 时更加愉悦。
-
NVFP4 Hackathon 参赛资格问题:一位成员询问了参加 NVFP4 kernel hackathon 的资格要求。
- 具体而言,他们感到担忧,因为他们的国家未被列入符合条件的名单,他们想知道这是否意味着他们无法参加,还是仅仅没有资格赢取奖品。
GPU MODE ▷ #multi-gpu (3 messages):
Multi-node communication, Low-latency communication kernels, NVSHMEM, LLM inference
- 用于多节点 LLM 推理的 NVSHMEM Kernel:一位成员分享了一篇关于使用 NVSHMEM 编写用于 LLM 推理 的低延迟通信 Kernel 的博客文章,重点关注多节点通信性能。
- 提议多节点 Kernel 演讲:由于成员对该博客文章感兴趣,有人提议就使用 NVSHMEM 开发低延迟通信 Kernel 的工作进行演讲,特别是针对 LLM 推理。
- 原作者表示,如果社区有足够的兴趣和反馈,他非常乐意进行演讲。
GPU MODE ▷ #helion (2 messages):
Helion on Hacker News, Flex Attention vs Triton
- Helion 登上 Hacker News 首页:成员们注意到 Helion 登上了 Hacker News 首页。
- 他们链接了 Helion GitHub 作为关键实现。
- Flex Attention 将对决 Triton:一位成员请求对 Flex Attention 和链接的 Helion 实现进行性能比较。
- 他们表示 Helion 的代码看起来比他们见过的任何 Triton 实现都要好。
GPU MODE ▷ #nvidia-competition (124 messages🔥🔥):
AGX Thor, CC11.0 support, CUTLASS Library, CUDA kernel optimization, nvfp4 moe
- 探讨 AGX Thor GPU 架构规格:一位用户询问了关于购买 AGX Thor 的 CC11.0 支持 情况,指出缺乏明确文档,且没有 tcgen05 表明可以使用它,同时担心 smem 被削弱。
- 在另一位用户确认 PTX 文档中提到了 sm_110 后,原作者对规格表示满意。
- 调查 CUDA Kernel 性能问题:一位在 grayscale_v2 上练习 cutedsl 的用户报告了 B200 上的显著性能差异,其 Kernel 运行时间为 48310.973μs,而排行榜上为 600.272μs,原因是 cute.compile() 位于自定义 Kernel 内部。
- 另一位用户指出,每次运行时编译 Kernel 极其缓慢,并建议缓存编译结果或将
cute.compile()移至 Kernel 外部,并链接了一个参考实现。
- 另一位用户指出,每次运行时编译 Kernel 极其缓慢,并建议缓存编译结果或将
- 指出基准测试评估脚本的缺陷:一位用户质疑竞赛所用评估脚本的准确性,认为 start_event.record 会立即触发,捕获了 Python 开销并导致 Kernel 计时偏差,建议启动一个浪费一秒钟的垃圾 Kernel,然后触发第一个事件,再启动主 Kernel。
- 他们提议添加一个 time-waster kernel,以便 Python 能够准确地将 CUDA 操作排队,特别是针对达到理论极限(speed of light)的 Kernel 进行基准测试,并引用了 clear l2 kernel 示例,该示例通过防止事件触发直到排队下一个操作来实现。
- 分享 Datacrunch B200 服务器访问技巧:用户讨论了 裸金属 B200 服务器 的可用性,指出虽然 DigitalOcean 和 Coreweave 缺乏此类服务器,但 Datacrunch 提供支持可升级 CUDA 13 的服务器。
- 一位用户强调需要分析工具和提交工具来捕获 NCU profiles,同时提到 sesterceis 提供价格合理的裸金属服务器。
- 推测低精度训练的未来:讨论了 nvfp4 的潜力,一位用户指出其训练损失与 fp8 相当,另一位用户提到 gpt-oss 作为块缩放数据类型的示例。
- 他们推测使用低精度预训练的实验室可能不想透露其策略,并补充说 mxfp8 是长期赢家。
{kind=link}
OpenRouter ▷ #announcements (3 messages):
New Embedding models launch, Typescript SDK, Exacto Variants, MiniMax M2 Free Period
- OpenRouter 直播:OpenRouter 宣布了定于今天晚些时候举行的直播,讨论内容包括新的 Embedding models launch、TypeScript SDK、Exacto Variants 以及社区讨论,可在 X Stream 或 Youtube 观看。
- MiniMax M2 免费期即将结束:MiniMax M2 Free period 将于几天后的 11 月 10 日星期一结束,期间 rate limits 将会降低,预计会导致更高频率的 429 errors;详见 官方公告。
- OpenRouter 正在直播!:OpenRouter 现在已在 X 和 YouTube 开启 LIVE。
OpenRouter ▷ #app-showcase (2 条消息):
Cat girl images
- 猫娘图片质量保证:成员们肯定地认为,图片中出现猫娘是其质量的保证。
- 对猫娘质量达成共识:另一位成员明确表示同意该评估,强化了猫娘与图片质量之间的联系。
OpenRouter ▷ #general (305 条消息🔥🔥):
OpenRouter website down, Polaris Alpha model, Gronk AI, Nano Banana Image Resending, Chat limit for free users
- OpenRouter 网站故障引发挫败感:用户报告了 OpenRouter website 的问题,页面虽然可以显示但内容无法加载,阻碍了登录和充值。
- 虽然部分用户遇到了加载缓慢或账户板块功能失效,但其他人确认 API 在网站故障期间仍保持正常运行。
- Polaris Alpha 的隐形优势引发猜测:OpenRouter 上的 Polaris Alpha model 因其突破规则的能力表现优于其他模型而受到赞誉。
- 关于其来源的猜测从 OpenAI 到 Google 不一而足,甚至有人认为是 Nvidia Nemo 32B troll,用户敦促 OpenRouter 保持其免费,但由于 rate limits 的存在,这不太可能。
- Gronk AI 在聊天中被吐槽:一位用户讲述了自己因为询问名为 Gronk 的 AI 而被嘲笑的经历。
- 另一位用户插话称 Gronk 很烂,并接着讲述了他们长达 3 小时的 llama.cpp custom OLMo 2 finetune mirostat entropy parameters 经历,以此作为如何与“凡人”交流的例子。
- OpenRouter 现已支持视频:根据聊天中分享的 链接,OpenRouter 现在支持视频功能。
- 一位用户反应积极,表示:“噢,就在两天前我还想着‘要是 OR 支持视频就好了’”。
- GLM 编码漏洞导致 SillyTavern 重度用户被封禁:据透露,SillyTavern gooners 因滥用 GLM 4.6 coding plan 以获取实质上的免费 API 使用权而被封禁。
- 一位用户哀叹道:“好东西留不住,因为他们像蜂群一样滥用免费资源”。
OpenRouter ▷ #discussion (28 条消息🔥):
GTA 6 delay, Openrouter Show, Toven is winking, Retro OR logo
- GTA 6 延期引发 GPT-7 猜测:一位成员开玩笑说,引用又一次 GTA 6 delay,GPT-7 可能会在 GTA 6 之前发布。
- Openrouter Show 的坎坷之路:成员们讨论了 “Openrouter Show” 的命名创意,以及该名称是否会暗示这是一个有剧本的娱乐节目或纪录片式播客。
- 一位成员提出了使用 MythoMax 等 AI 模型进行 live roleplay 的想法。
- Toven 的眨眼引发存在危机:成员们开玩笑讨论 Toven 是否在眨眼,以及 Toven 是否是一个 2D 动漫女孩。
- 复古 OR Logo 唤起 90 年代苹果风:成员们讨论了 retro OR logo,有人评论其具有 90s Apple logo vibe。
Cursor Community ▷ #general (297 条消息🔥🔥):
Pro plan limits, Cursor Usage dashboard, Composer vs Grok Code, Sharing Premium Accounts, Student Verification Issues
-
Pro 计划限制按账单日期重置,而非固定日期:一位成员询问 Pro 计划的限制,得到的回复是限制总是随账单周期重置,并展示了一张显示使用情况和下次账单日期的 截图。
- 部分用户的 Cursor 使用情况仪表盘图表缺失:尽管拥有 unlimited auto 功能,部分用户仍无法在仪表盘(位于 cursor.com/dashboard?tab=usage)中看到使用情况图表。
- 这可能与处于旧版定价方案有关,但目前尚无关于缺失原因的明确解决方案。
- Composer 与 Grok Code 在代码库理解方面的对比:当被问及 Composer 1 或 Grok Code 之间的区别时,一些成员评论道 Composer 速度更快,适合快速生成粗略代码,或用于需要 Claude 进行第二次优化润色的工作流。
- 另一位成员发现 Sonnet 4.5 可以有效解决复杂的 Web 代码问题,而 Composer、Grok Code 和 GPT 5 Fast 在这些问题上会陷入相同的逻辑循环而无法解决。
- Cursor 学生身份验证流程非常繁琐:多位成员在通过 SheerID 进行学生验证时遇到问题,其中一位成员报告尝试了 15 次以上 仍未成功,这与在其他服务上第一次尝试就成功使用 SheerID 的经历形成鲜明对比。
- 成员们推测 Cursor 可能实施了比其他公司更严格的验证流程,并建议联系 Cursor Forum 或发送邮件至
hi@cursor.com反馈,但指出这可能只会得到 AI 的回复。
- 成员们推测 Cursor 可能实施了比其他公司更严格的验证流程,并建议联系 Cursor Forum 或发送邮件至
- Cursor 即将支持访问 Kimi K2 Thinking:一位成员询问是否可以在 Cursor 中使用 kimi-k2-thinking-turbo。
Cursor Community ▷ #background-agents (7 messages):
Cursor Agent API, Base64 Image Submission, Internal Errors, Image Generation Service
- Cursor 2.0 的发布速度令人印象深刻!:一位用户对 Cursor 2.0 的快速开发节奏表示赞赏,特别提到了变更可见性的价值。
- 在发表此评论后不久,该用户报告在平台内遇到了内部错误。
- Agent API 触发内部错误:一位用户报告在使用 Cursor Agent API 时遇到内部错误。
- 经过调查发现,错误原因是提交给 API 的 Base64 图像数据格式不正确。
- Base64 图像格式化修复了 API 错误:用户发现 Base64 字符串格式不正确,前缀带有
data:image/jpeg;base64,。- 移除该头部后,API 调用成功,解决了错误。
- 希望将 Base64 上传至 Agent 进行重建:用户表达了向 Agent API 提交 Base64 图像的愿望,意图让 Cursor 利用图像上下文进行重建并保存到仓库中。
- 用户似乎期望 Agent 能够创建图像并将其保存到他们的仓库中。
LM Studio ▷ #general (124 messages🔥🔥):
Intel LLM Scaler, System Prompt for AI Assistant, LM Studio Memory Clearing, LM Studio and N8N Integration, ComfyUI Alternatives
- Intel 通过新工具扩展 LLM:Intel 正在为其架构开发 llm-scaler,引发了人们对其在 Intel GPU 上性能提升的好奇。
- 成员们对该架构上的 ERP 模型感兴趣,但对 1B 模型不感兴趣。
- LM Studio 的深度研究能力:用户现在可以使用 用于网页搜索 (duck-duck-go) 和访问网站的 LMS 插件 以及自定义系统提示词来增强 LM Studio 内的研究。
- 系统提示词可以通过 ChatGPT 平台(免费版)内的 AI agent prompt generator 生成。
- LM Studio 获得 N8N 集成:成员们讨论了 LM Studio 与 N8N 在 AI 自动化方面的无缝集成。
- 虽然有些人更喜欢代码,但另一些人发现 N8N 的可视化节点界面非常有益,特别是对于非程序员而言。
- 用户寻求 ComfyUI 的替代方案:用户对 ComfyUI 的设置感到沮丧,并寻求更“舒服”的替代方案,如 Stability Matrix。
- 他们认为 Automatic1111 及其分支版本大多已成为废弃软件 (abandonware)。
- 模型变得“神神叨叨”或出现记忆错误:一位用户遇到 Gemma 和 Deepseek Distil 等模型给出错误/古怪答案的问题,且 LM Studio 在清空后似乎仍能回忆起旧的聊天内容。
- 排查步骤包括恢复默认采样设置、验证系统提示词以及确保没有上传的文件干扰,但根本原因仍然不明,不过他们确实上传了五个 .word 文档,这可能是原因所在。
LM Studio ▷ #hardware-discussion (164 messages🔥🔥):
1080 vs sysRAM, GLM 4.6, Qwen3-235B MXFP4, multi-GPU, 3090 vs pseudo-benchmark
- 1080 击败了 SysRAM!:一位成员发现,在将部分任务卸载到 sysRAM 时,他们的 1080 速度更快。
- GLM 4.6 在 Q4_K_M 下运行极慢!:GLM 4.6 @ Q4_K_M 运行速度慢得惊人,仅为 4 tok/s,甚至 Qwen3-235B MXFP4 的最高速度也不超过 4 tok/s。
- 一位用户指出,在测试 Qwen3 4B Q8_K_XL 时,这套配置在他们系统上的速度比 5700G 慢了约 30 tok/s。
- 多 GPU 大乱斗?:一位用户正在构建一个拥有 160GB VRAM 机架,配备 8 张 20GB 显卡(理论上通过 16 张显卡可达 320GB),用于 Agent 推理、视频、音乐和图像生成。
- 讨论涉及了将专家模型拆分到多个 GPU 是否能加速 Qwen3-30B,然而,一位用户无法想象这所需的并发 PCIe bandwidth,而另一位用户则表示 MoE 专家可以相互独立工作。
- 3090 在伪基准测试中落败!:一位用户在名为 get_low_benchmark.conversation.json 的文件中分享了一个“简单易用的 LM Studio 20GB+ 显卡跑分竞赛”。
- 在安装新的 3090 后,LM Studio 中的伪基准测试显示速度仅为 90Tkps,低于旧显卡的 150Tkps,但所有其他基准测试均符合规范或超出预期。
- Windows 不喜欢百 GB 显存!:一位用户开玩笑说,当显存超过 100GB 时,Windows 就不再显示小数点,并配上一张图片说道:“比如 6.1GB 和 7GB,有什么区别呢?”
{kind=link}
HuggingFace ▷ #general (261 messages🔥🔥):
Kimi K2 Programming, HF Pro Worth, Drone Control with LLM, TTS latency on fine tuned Model, Critical Thinking and LLMs
- Kimi K2 的编程能力备受推崇:据报道 Kimi K2 非常擅长编程,尽管不一定是“最强”的。
- 关于 HF Pro 权益和定价的辩论:成员们讨论了为了使用 vLLM 测试模型性能,HF Pro 是否值得,因为一位用户想测试特定模型在 vLLM 上的表现。
- 一些用户提到使用 Hugging Face Spaces 来测试模型,另一位用户分享说,图像转视频服务在 9 美元订阅的基础上,一段 8 秒视频(无声)的成本约为 0.40 美元。
- LLM 与无人机:成员们讨论了使用 LLM 与 LAM 控制无人机的可行性,一位用户寻求创建一个能够遵循语音指令并根据传感器数据和图像分析进行导航的无人机助手。
- 有建议称 YOLO 更适合目标检测,而飞行控制则推荐使用 ArduPilot;此外,据说已有团队在研究 CognitiveDrone。
- 使用 LLM 实现低延迟语音合成:为了在微调模型上获得更快的 TTS 延迟,建议使用具有足够 VRAM 用于 KV cache 的 vLLM,并参考这篇博客文章为算子融合(kernel fusion)编译模型。
- 另一位成员幽默地建议直接调低延迟设置。
- 用语言模型合成批判性思维:一位成员讨论了在推理轨迹(reasoning traces)上训练模型以输出“思考(thought)”并使用可观察量。
- 另一位用户建议 information theory(信息论)将极大地有助于模型设计,且研究应关注 coherence(连贯性)而非 truth(真实性)。
HuggingFace ▷ #today-im-learning (3 messages):
Fine-tuning decoder models, Fine-tuning SetFit, Embedding Gemma and t-SNE, Extracting attention values from SmolLM3
- 微调 Decoder 模型用于分类:一位成员详细介绍了使用 ModernBERT 和 ettin 微调 Decoder 模型以将消息分类的过程。
- SetFit 在对比对上进行微调:频道讨论了在对比对(contrastive pairs)上微调 SetFit 以进行文本二分类。
- Embedding Gemma 与 t-SNE 联手:重点介绍了应用 embeddinggemma-300m 和 t-SNE 对推文数据集进行分类和可视化。
- SmolLM3 的注意力值可视化:分享了从 SmolLM3 推理中提取注意力值并创建热力图的过程。
HuggingFace ▷ #i-made-this (3 messages):
OpenBMB VoxCPM, Apple Neural Engine, CoreML, Training Reasoning by Design
- **VoxCPM 在 Apple Silicon 上表现出色: 一位成员将 **OpenBMB VoxCPM Text-to-Speech 模型 移植到了 CoreML。
- 该模型现在可以在 Apple Neural Engine 上运行;代码已在 GitHub 上发布。
- Reasoning By Design 框架公开: 一位成员分享了一份 PDF 文档,详细介绍了 Training Reasoning by Design 框架。
HuggingFace ▷ #smol-course (1 messages):
HuggingFace Learn Website Bug
- HuggingFace Learn 网站故障曝光: 一位用户报告称,HuggingFace Learn 网站 上的 第 2 段和第 3 段内容意外重复。
- 他们附上了一张突出显示重复内容的截图。
- Bug 报告确认: 该 Bug 报告涉及 Hugging Face Learn 平台内特定页面的内容重复问题。
- 用户提供了直接链接和视觉辅助工具,以清晰地说明该问题。
HuggingFace ▷ #agents-course (7 messages):
Agents Course Certificate, Confirmation Page Issues, Llama Index DuckDuckGo Rate Limit
- Agents 课程结业证书咨询: 一位成员询问今天加入 Agents Course 后是否能获得结业证书。
- 确认页面故障: 一位用户报告称,在 Android 手机上使用多种浏览器(Edge、Firefox 和 Chrome)时,页面一直卡在确认页。
- Llama Index DuckDuckGo 触发速率限制: 一位成员在 Agents Course 中使用 Web 搜索工具时遇到了 “rate limit exception”(速率限制异常),尽管已经安装了 llama-index-tools-duckduckgo 包。
- 是否仍可获得证书?: 一位成员确认目前仍可以获得 Agents Course 的结业证书,但用于获取文件的测试端点(testing endpoint)目前处于离线状态。
Unsloth AI (Daniel Han) ▷ #general (147 messages🔥🔥):
Qwen3-Next-80b-A3B-Instruct finetuning, MoE models in Transformers, Unsloth and FastModel for MoE, Training frameworks for MoE, Unsloth Dynamic Quants for smaller models
- Qwen3-Next-80b-A3B-Instruct 基准测试引发微调兴趣: 成员们讨论了微调 Qwen3-Next-80b-A3B-Instruct 的可能性,并注意到其令人印象深刻的基准测试结果,在某些情况下甚至超过了 225b 模型。
- 有人指出,虽然可以使用 ms swift 进行微调,但 Transformers 目前对 MoE 的支持相当糟糕。
- Transformers 在 MoE 实现上滞后: Transformers 中 MoE 模型 的糟糕实现被归因于它主要是一个高级库,且 PyTorch 缺乏良好的 MoE 算子。
- 一位成员提到,他们训练了一个 30B 模型,发现其速度仅为使用相同配方训练 MS3 的 1/4。
- Unsloth 的 FastModel 是 MoE 微调的关键: 在使用 Unsloth 微调 MoE 模型 时,必须使用 FastModel 而不是 FastLanguageModel,这是因为其初始化稀疏 MoE 层和门控逻辑(gating logic)的方式不同。
- FastModel 可以安全地支持稠密(dense)和稀疏(MoE)模型。
- MoE 训练仍显粗糙,框架对比: 普遍共识是 MoE 训练 尚未完全优化,一位成员询问在 Qwen 30B 上进行训练的最佳方法是什么。
- Megatron-LM 被推荐为 MoE 训练速度快 10 倍的选择,因为它对并行性有很好的支持,但缺点是文档匮乏且主要针对预训练而非后期训练进行了优化;而 Torchtune/Titans 被提到比 Transformers 快,但处于一种奇怪的弃置软件(abandonware)状态。
-
序列长度影响训练时间: 一位成员发现,在拥有 48GB 显存的 A6000 上,其 14B 模型的 32k 序列长度(sequence length)导致了极长的训练时间,且将序列长度减少到 16k 也没有改变这一状况。
- 建议从较小的长度、N 个样本和 batch size 开始,并逐渐增加以找到瓶颈。此外,GPU 只能以给定的速率进行处理,因此超过其处理能力的 batch size 或序列长度(seq length)不会带来太大区别,因为无论如何速度都会变得非常慢。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 条消息):
Ash、LLMs 和 RL 的介绍
- Ash 加入 Unsloth 社区!:Ash 介绍了自己在大学实验室从事 LLMs 和 RL 相关工作,并表达了对 Unsloth 的赞赏。
- Ash 喜欢调整小模型:Ash 提到他们喜欢调整小模型。
Unsloth AI (Daniel Han) ▷ #off-topic (32 条消息🔥):
torch.compile 缓存、OpenRouter XCode 集成问题、网站上的 AI 屏蔽、AI 简历问题、AdamW loss 分析
- 对 torch.compile 缓存的质疑:一位成员担心 torch.compile 可能仅根据当前的输入 prompt 缓存结果,而不是适应具有相同形状的不同输入。
- 该成员质疑不同的输入 prompt 是否应该导致不同的 activations。
- OpenRouter XCode 集成遇到困难:一位成员报告了将 OpenRouter 与 XCode 的 “Coding Intelligence” 集成时遇到的问题,出现了 “No cookie auth credentials found” 错误。
- 尽管遵循了 OpenRouter 指南 并成功拉取了模型列表,但他们仍面临身份验证问题。
- 屏蔽网站上的 AI 交互:一位成员建议开发一个 JS 脚本/工具 来完全阻止 AI 与网站的交互,仅允许人工手动浏览。
- 他们强调需要防止 AI 自动抓取或与网站内容交互。
- 关于 AI 对初级职位影响的辩论:一位成员讨论了由于 AI 生成的简历和报告 可能导致初级员工被取代,从而导致未来的高级职位缺乏在职培训和经验。
- 他们认为,这种对 AI 的依赖可能会导致劳动力内部技能和知识的萎缩。
- AdamW 对 Loss 的感知有限:一位成员质疑 AdamW 优化器 是否只关注降低整体 loss 数值,而不考虑 loss 的具体类型。
- 他们认为 AdamW 只是简单地尝试最小化 loss,而不理解其组成或含义。
Unsloth AI (Daniel Han) ▷ #help (20 条消息🔥):
在 Unsloth Docker 中使用 Torch 2.9、Attention 中的反向传播问题、逐 Token Loss 加权、在 Unsloth 中使用 Deepseek OCR、使用 vLLM 托管 Unsloth GGUF
- 在 Unsloth Docker 中寻求 Torch 2.9 的兼容性:一位成员询问如何在官方 Unsloth docker 镜像中使用 Torch >= 2.9,以解决与 torch.matmul 和 ‘out=’ 参数限制相关的反向传播(backprop)问题。
- 当前的基础镜像使用 Conda Python,且可用的 PyTorch wheels (cu124) 不包含 torch==2.9.0,导致 Dockerfile 报错。
- 新版 Torch 解决了反向传播阻塞问题:一位用户在 Torch 2.8 中遇到了反向传播问题,原因是 Unsloth 的 GPT-OSS 回退(fallback)使用的 attention 实现调用了带有 ‘out=’ 参数的 torch.matmul,而 PyTorch 的 autograd 在启用 LoRA 的训练中禁止这样做。
- 据报道,升级到 Torch >= 2.9 会切换到编译后的 eager 路径,从而避免使用 ‘out=’ matmul,解决了 autograd 的限制。
- 尝试修改 Loss 函数:一位成员尝试修改 Unsloth 中的交叉熵函数以添加逐 token 的 loss 加权,并寻求相关函数/文件的指导。
- 他们分享了一段尝试实现 MMSWeightedLossTrainer 类的代码片段,但发现它非常耗费内存;最终他们找到了一种解决方法。
- Deepseek OCR 适配 Unsloth:一位用户在尝试通过 Unsloth 运行 deepseek-ocr 时遇到错误,参考了此指南。
- 在安装了使用普通 transformers 加载模型时发现的缺失依赖项后,问题得到解决,deepseek-ocr 可以在 Unsloth 上运行。
- 寻求使用 vLLM 托管 Unsloth GGUF 的指导:一位成员在遇到错误后,正寻求使用 vLLM 托管类型为 Q4_K_XL 的 unsloth/Llama-4-Scout-17B-16E-Instruct-GGUF 的指导。
- 有人建议 GGUF 似乎仍处于实验阶段,并引导用户查看 vLLM 文档 以获取更多信息。
Unsloth AI (Daniel Han) ▷ #research (2 messages):
Magistral 模型, GRPO RL, KL 散度损失
- Magistral 模型源自 GRPO RL!:一位成员重点介绍了一篇关于 Mistral 的论文,该论文描述了其 Magistral 模型完全从零开始仅使用 GRPO RL 进行训练,未使用 MLM 等技术。
- 团队修改了 GRPO loss 以消除 KL 散度损失。
- 澳大利亚 AI 兴趣被激发!:一位成员认为上述工作很有趣,且对未来几周的澳大利亚非常及时。
- 随后没有进一步讨论。
Nous Research AI ▷ #general (99 messages🔥🔥):
GPT-5 图表对比, 中国模型更便宜, Kimi 的性能, Deepseek 定价
- 用户认为 GPT-5 的图表仍有不足:用户认为 OpenAI 的图表 仍然落后于 OpenAI。
- 一位用户表示,他们的图表仍有改进空间,与 OpenAI 相比还有很大差距。
- 中国开源 (OS) 模型有望夺取王座:成员们推测,到 2026 年,中国开源模型预计将以降低 95% 的成本达到 100% 的高智能。
- 这可能意味着所有大规模的高算力建设和能源消耗都是一场庞氏骗局。
- Kimi 的思考能力:用户在推理和工具使用方面将 Kimi 模型与 ChatGPT 进行了比较。
- 有人说 Kimi 具备工具推理能力,另一位认为其结果在实用性上与 ChatGPT 质量相当。
- Deepseek 非常便宜:Deepseek 比 OpenAI 便宜得多,至少对中国实验室而言是这样。
- 价格约为 每 100 万个 token 42 美分。
Nous Research AI ▷ #research-papers (1 messages):
知识领域, 梯度平均, 教授多样化的专业知识
- Batch 中的知识领域混合会影响学习:一位成员正在思考在 batch 中混合知识领域如何影响学习。
- 他们询问在不同数据样本上平均梯度是否可能导致“相互抵消”,或者是否能通过稀疏性 (Sparsity) / 足够的参数来解决。
- 教授多样化专业知识的干扰:一位成员讨论了如何教授多种专业知识并使其互不干扰或稀释。
- 这是对 batch 内知识领域如何影响学习这一问题的抽象。
Nous Research AI ▷ #research-papers (1 messages):
知识领域混合, 梯度平均, 稀疏性容纳, 教授专业知识
- 混合知识领域影响学习:一位成员正在思考 batch 中混合知识领域如何影响学习。
- 他们想知道在不同数据样本上平均梯度,它们是否可能“相互抵消”,或者是否能通过稀疏性 / 足够的参数来解决。
- 教授多样化的专业知识:一位成员将前一点抽象为更普遍的问题:如何教授多种专业知识,并使其互不干扰或稀释。
OpenAI ▷ #ai-discussions (75 messages🔥🔥):
Siri 与 ChatGPT, SOTA 模型, O3 图像缩放, GPT-5 识别位置, kilocode 模型
- Siri 与 ChatGPT 互通!:成员们讨论了目前只能将 Siri 与 ChatGPT 连接,并询问他们是否改变了这一集成的方向。
- 一些成员表示对此感到非常高兴。
- 模型需要视觉推理能力:成员们讨论了当前的 SOTA 模型无法通过文本 token 以视觉方式解决推理问题。
- 他们指出,如果是正方形迷宫,模型或许可以通过将其分解为单元格并在此基础上进行推理来解决。
- GPT-5 在 GeoGuessr 中的准确率!:成员们注意到,GPT-5 在玩 GeoGuessr 时可以准确识别一公里范围内的位置。
- 一位成员说,他们发送书页上的数独谜题,模型平均会花费 10 分钟以上进行缩放和裁剪。
-
Kilocode 模型是 Agent 编码的真正利器:一些成员提到了 drinkoblog.weebly.com,该网站声称开源权重模型 k2 thinking 似乎是 Agent 编码的真正利器。
- 博客还指出,它正在修复 gpt-5-codex high 难以处理的代码。
- Beckingham 常数揭晓:一位成员发布了关于 The Beckingham Constant 的帖子,它是自组织系统中增长与衰减之间的平衡。
- 这与连贯性的偿付底线(solvency floor of coherence)有关,即反馈无法跟上,系统失去完整性 见附图。
OpenAI ▷ #gpt-4-discussions (8 messages🔥):
GPT-5.1, GPT variants, Making money from custom GPTs
- GPT-5.1 Thinking 出现在 ChatGPT 上:ChatGPT 网站上出现的 GPT-5.1 Thinking 表明 OpenAI 即将发布更新,预示着传闻中的 GPT-5.1 发布正日益接近现实。
- 传闻指向更广泛的 GPT-5.1 阵容:Mini、Thinking 以及可能以 Codex 为重点的更新,每种型号都旨在满足不同的用户需求和计算限制。
- GPT-5.1 拥有增强的推理能力:GPT-5.1 被定位为 Google 即将推出的 Gemini 3 Pro 的直接挑战者,即将发布以在 AI 竞赛中保持领先。
- 该模型在后端组件中被引用,负责驱动 ChatGPT 内部的高级推理过程,这意味着它可能针对多步推理或 Agent 任务进行了优化。
- GPT-5.1 模型处于内部测试阶段:传闻中的 GPT-5.1 模型正在进行内部测试和 A/B 测试,但尚未宣布确切的发布日期。
- 据说变体包括 Mini(为免费用户提升效率)、Thinking(具有可变思考预算的复杂推理)和 Codex-focused(编程辅助改进)。
OpenAI ▷ #prompt-engineering (8 messages🔥):
Behavioral Orchestration of SLMs, Animation effect prompts, AI Project Collaboration
- 行为编排调节 SLM 语气:成员们讨论了行为编排(behavioral orchestration),它被描述为一个在运行时调节 SLMs 语气的框架,位于参数训练之上。
- 成员不再分配角色或身份,而是使用诸如 “不要提供未经请求的建议” 之类的参数来塑造 AI 的行为。
- 请求动画效果协助:一位成员请求帮助识别并生成特定动画效果的提示词。
- 提供了一个 视频示例,但未给出解决方案。
- ChatGPT Pro 用户寻求 AI 项目协作:一位 ChatGPT Pro 用户寻求大型 AI 项目的指导和协作。
- 另一位成员回应表示有兴趣合作干一番大事。
OpenAI ▷ #api-discussions (8 messages🔥):
Behavioural Orchestration, AI Personalization, Animation Effects
- 行为编排在 LinkedIn 上引起热议:LinkedIn 上的成员讨论了行为编排,它被描述为一个在运行时调节 SLMs 的框架,而不是处理参数或训练。
- 它将作用于它们之上,以调节 SLMs 的语气。
- AI 模型获得行为指令:用户不再为 AI 分配特定角色,而是给它一组参数来塑造其行为,而不是规定其个性。
- 示例包括 “不要对我做个人假设” 和 “不要提供未经请求的建议”。
- 动画效果需要一个名称:一位用户请求帮助识别 WhatsApp 视频 中的动画效果。
- 他们请求协助编写该效果的提示词。
Modular (Mojo 🔥) ▷ #general (58 messages🔥🔥):
GPU puzzle series questions, Mojo compiler implementation language, Mojo error handling vs Python, Explanation of Modular, MAX, and Mojo, Installing a game
-
GPU 谜题频道探索:一位成员询问是否有专门的 Discord 频道用于提问 GPU 谜题系列,涵盖环境搭建和 Mojo/GPU 代码。
- 另一位成员建议从 learn-mojo 频道 开始,而 Modular 团队则建议在论坛上提出特定于谜题的问题,以确保未来的可搜索性。
- Mojo 编译器仍在使用 C++:一位成员询问 Mojo 编译器是用 Mojo 编写的还是仍在使用 C++。
- 另一位成员确认它仍在使用 C++ 和 MLIR,并指出 Mojo 在编译器实现自举(self-hosted)之前需要更多的稳定性和功能完整性,且移植 LLVM 的可能性不大。
- Mojo 的 Try-Except 胜出:团队确认 Mojo 的错误处理采用 try-except 方法,其性能优于 Rust,因为在正常路径(happy path)上可以进行 placement new。
- 将某些内容转换为
Result的语法优先级较低。
- 将某些内容转换为
- 揭秘 Modular:Mojo 的角色:一位成员澄清说 Modular 是公司, MAX 是 cuBLAS/Cutlass/TensorRT/Pytorch/JAX 的替代品,而 Mojo 是一种编程语言。
- 另一位成员富有诗意地表示,Mojo 看起来像 Python,但表现得像穿着 蛇皮夹克 的 C++ 和 Rust 的结合体。
- 游戏安装难题:一位成员请求帮助安装游戏,但另一位成员表示他们可能帮不上忙。
- 他们建议该成员向卖家投诉。
Modular (Mojo 🔥) ▷ #announcements (1 messages):
New Beginners Channel, Mojo Language Support
- Modular 推出新的 Mojo 初学者频道:Modular 创建了一个新的专用频道 <#1436158039232086186>,供初学者提问、获取 Modular 团队的帮助,并与其他学习 Mojo 的人建立联系。
- 这一举措旨在为 Mojo 的新学习者 培养一个相互支持的社区,提供一个协作互助的空间。
- 讨论 Mojo 语言支持:成员们正在新频道中积极讨论和探索 Mojo 编程语言的功能、特性和潜在应用。
- 讨论内容包括实际的代码示例、解决问题的策略以及资源共享,以增强对 Mojo 的理解和熟练程度。
Modular (Mojo 🔥) ▷ #mojo (20 messages🔥):
CS Education Importance, Nand2Tetris Recommendation, Mojo Multithreading, C Library Bindings for Mojo
- 计算机科学基础是永恒的:成员们指出,强大的 CS 基础 提供了对计算和硬件的扎实理论理解,而且基础知识并没有发生太大变化。
- 扎实的 CS 基础会让你走得很远,涉猎 CE 很有帮助,学习 CS 历史 会让很多事情变得更加清晰。
- 强烈推荐 **Nand2Tetris**:对于想要更接近硬件的软件人员,一位成员强烈推荐 Nand2Tetris,认为它是一个有趣且相当全面的基础指南。
- 他们举了一个例子,C 语言的空终止字符串(null terminated strings) 可以追溯到 PDP-11 指令。
- Mojo 原生不支持 CPU 多线程:Mojo 尚不支持 CPU 多线程,这意味着没有像 locks 这样的原语,不过如果想并行运行代码,可以使用
parallelize或其他类似函数。- 然而,运行时负责管理线程,由于 Modular Mojo 的大部分代码都针对 GPU,因此 CPU 特定的事项目前并不是首要任务,尽管有有限的 CPU atomic 支持。
- 成员寻求为 Mojo 创建 C 库绑定:一位成员表示有兴趣为 Mojo 编写主要 C 库的绑定或重写,例如 OpenSSL、sqlite、libnuma、libcurl、dbus、zlib、zstd、ffmpeg、gmp、zeromq 和 lz4。
- 然而,这些可能不会在
stdlib中得到支持——如果这些被移植过来,它们可能会作为外部包存在,人们可以从 pixi 社区频道 获取。
- 然而,这些可能不会在
Modular (Mojo 🔥) ▷ #max (7 messages):
CUDA checkpointing with MAX, TokenGeneratorPipeline, Cold start times of a container
- CUDA Checkpointing:不稳定还是耗时?:成员们讨论了在 MAX 中使用 CUDA checkpointing,发现它很不稳定,并且由于要对所有 GPU 状态进行快照,可能会很慢。
- 一位成员尝试在 TokenGeneratorPipeline 中使用它,但它挂起了,而且冷启动时间仍然是一个问题,这表明它在某些用例中并不实用。
- TokenGeneratorPipeline 冻结:一名成员报告了在尝试对 TokenGeneratorPipeline 使用 CUDA checkpointing 时遇到的问题,导致进程挂起。
- 他们推测这种行为是否与 metrics monitor 有关,或者仅仅是因为快照整个 GPU 状态固有的缓慢所致。
Eleuther ▷ #general (25 messages🔥):
介绍频道, 寻找相关研究, AI Developer 学习笔记, LLM 处理图像时的“中风”, Qwen3-VL 系统提示词
- Discord 辩论:介绍频道:成员们讨论了设立独立介绍频道的优缺点,担忧点在于无重点的自我推销,而支持者则认为应让新人自然地融入 general 频道的交流流中。
- 一位成员认为,独立的介绍会让互动显得刻板且不够亲切,另一位成员则指出他们希望保持讨论集中在研究上。
- 用户寻求 AI Developer 学习笔记:一位成员询问了涵盖 AI developer 角色基础知识的学习笔记,旨在补充他们在工作中边做边查的方法。
- 提出此查询是为了寻找某个项目的相关研究,同时避免因发布过长的初始帖子而违反规则。
- LLM 因图像过载而“中风”:一位成员分享了一张 LLM 显然因为处理过多图像而经历“中风”的图片,最后一行并非出自该成员,而是来自 AI 的潜意识(截图)。
- 该成员报告称,Qwen3-VL 错误地声称自己不是视觉模型,除非另有提示,这需要一个不同于默认设置的系统提示词来告知它。
- NeurIPS 找室友行动开始:一位成员宣布他们将于 12 月 3 日至 7 日前往圣地亚哥参加 NeurIPS,并正在寻找一位女性室友分摊酒店费用。
- 未提供关于具体住宿或室友偏好的更多细节。
Eleuther ▷ #research (22 messages🔥):
OpenAI Five 以来 RL 的进展, RL 中的数据效率, RL 中的 Scaling Laws, 现代 RL 尝试的成本, 基于 GPU 的 RL 环境
- 更好的 Deep Learning 驱动效率提升:虽然 RL 在算法上没有直接的升级,但社区改进了 Deep Learning 实践,由于许多人之前以极其糟糕/错误的方式进行 DL,这带来了样本效率的提升。
- meta-reinforcement learning、model-based RL (Dreamer/TD-MPC2) 以及 distributional RL 等技术正在开发中。
- 模型缩放有助于学习更好的 Value Functions:缩放模型规模(例如从 140M 到 14B 参数)可以通过辅助 Value Function 训练来提高样本效率,而 Value Function 有助于学习更好的策略。
- 预计更大的 world models 将使 model-based RL 受益,但目前还没有正式的 scaling laws。
- Dota 2 环境是主要瓶颈:OpenAI Five 的高昂成本源于每次 PPO 迭代所需的 rollout 数量,通过更好的 Deep Learning 和 off-policy 方法,这一成本可能会降低。
- 游戏在 CPU 上运行是当今 RL 的主要瓶颈。
- 现代 RL 尝试现在的成本更低:复制 OpenAI Five 的现代尝试成本可能会降低一到两个数量级,尽管这取决于与原始方案的偏差以及 reward shaping、priors 和 world models 等技术的使用。
- 许多人对使用基于 GPU 的 RL 环境感到兴奋。
Yannick Kilcher ▷ #general (34 messages🔥):
GoodfireAI 记忆化研究, 自主 Agent PR 挑战, Qwen3-VL 图像处理, AI Engineer 晋升
- 通过 Loss Curvature 研究记忆化非常酷:一位成员分享了 GoodfireAI 关于通过 loss curvature 理解记忆化的研究,但另一位成员在阅读后并不觉得对记忆如何存储在权重中有了更好的理解。
- 另一位成员表示赞同,指出推文听起来像是他们理解了它是如何存储的,但该成员认为他们只是找到了如何抑制它(通过某种针对最可能用于记忆的权重的 dropout 版本)。
- Agent PR 面临专业性摩擦:一位成员讨论了由于结构化评审意见以及将内容拆分为概念性功能时的认知开销,导致让 Agent 自主运行所面临的挑战,并好奇为什么会存在严禁 Agent 提交 PR 的强硬立场。
- 另一位成员插话透露,这是出于“政治”原因,因为该项目的上游维护者(spacebar chat)对专业性和包括 AI coding tools 在内的生产力加速器持有异议。
- Qwen3-VL 身份危机:Qwen3-VL 认为自己是一个普通的 Qwen model,当被强迫接受它能看到图像时会发生崩溃,这违反了它的内部自我认知,需要通过 system prompt 来防止立即崩溃。
- 即使有 system prompt,在处理 3 张图片且中间穿插一些问题时,它仍然会崩溃,这可能与 Ollama 中的一个 bug 有关。
- AI 工程师的自荐:一位拥有图像分析经验的成员发布了他的服务信息,作为一名资深的 AI Engineer 正在寻找新项目或全职机会,擅长构建由 GPT-4o、LangChain、AutoGen、CrewAI 和其他前沿工具驱动的自主 Agent。
- 该工程师可以构建自主研究和数据收集机器人、多 Agent 系统、具备记忆、规划和工具调用能力的 AI assistants、交易机器人、客户支持 Agent、IVR Agent 等。如果你正在招聘或有很酷的想法,请私信他们!
Yannick Kilcher ▷ #paper-discussion (5 messages):
Nested Learning, Kimi-K2, Continual Learning
- Moonshot Kimi-K2 助力深度思考:一位成员链接到了 Moonshot AI 的 Kimi-K2,强调了其在深度思考(thoughtful thinking)方面的能力。
- Google 推出 Nested Learning 范式:一位成员分享了 Google 关于 Nested Learning 的博客文章链接,这是一种用于 continual learning 的新机器学习范式。
- 另一位成员对关于 Nested Learning 的相关论文及其潜在应用表示了兴趣。
Yannick Kilcher ▷ #ml-news (1 messages):
.astro.: https://pytorch.org/blog/helion/
tinygrad (George Hotz) ▷ #general (1 messages):
Real-time speech transcription, Parakeet v2, Multi-GPU scaling, Joe Rogan podcast transcription
- Parakeet v2 实现 200 倍实时转录:一位成员报告称,在低功耗模式下的单张 4090 GPU 上,使用 Parakeet v2 实现了 200 倍实时语音转文字转录。
- 他们正在尝试 multi-GPU setup,预计它将线性扩展,可能达到 1,200 倍实时转录。
- 超快速播客转录:凭借已达到的速度,一个 3.5 小时的 Joe Rogan 播客 可以在大约 10.5 秒 内完成转录。
- 该成员对这些进展感到兴奋,表示:“我们生活在未来。”
- TinyBox v1 Green 表现依然稳健:该成员分享道,尽管 GPU 技术不断进步,他们的 TinyBox v1 Green (6x4090) 表现依然非常出色。
- 他们正在客厅里运行这套设备。
tinygrad (George Hotz) ▷ #learn-tinygrad (18 messages🔥):
UOps errors, pytorch tensors to tinygrad, pool refactor, UOps.after restrictions
- UOps 错误提示毫无帮助:一位成员发现 UOps 的错误提示非常没用,并且在结束一个范围并在循环外运行内容时感到很挣扎。
- 他们还质疑
valid是否是生成if语句的最佳方式,并在截图中展示了一个通过 UOps 生成的诡异 kernel。
- 他们还质疑
- 将 Pytorch 张量转换为 tinygrad:最高效的方法:一位成员询问了将 PyTorch tensors 高效转换为 Tinygrad tensors 的正确方法。
- 他们提到使用了
Tensor.from_blob(pytorch_tensor.data_ptr()),但不确定如何转换回来,目前使用的是from_numpy。
- 他们提到使用了
-
Pool 重构:Pad 对比 Repeat:一位成员询问了
_pool重构的目标,质疑初衷是完全移除.pad()还是合并这两种实现。 - 他们指出,使用
.repeat()来处理这两种情况会导致生成额外的 bandwidth pass kernels,并附上了一张当前实现与重构对比的 截图。 - UOps.after 的用法:仅限 Buffers:一位成员询问了关于
UOps.after使用时机的限制,试图在循环结束后为.valid创建一个条件。- George Hotz 回应称 after 应该只用于 buffer,为什么你需要在 compare 上使用它?无论你何时执行,该 compare 的值都是相同的。
MCP Contributors (Official) ▷ #general (12 messages🔥):
Code Execution MCP Blogpost, 2025-11-25 Spec Release, SEP-1330 SDK Changes
- MCP 博客文章误导至 Discord:Reddit 上的 Code Execution with MCP 博客文章 正将人们误导至 Discord 频道,而该频道是为项目贡献者准备的。
- 一位成员建议更新博客文章,改为指向新的 GitHub discussion,另一位成员回应道:“这对我来说可行。这比 Discord 对我来说更容易。”
- 为 2025-11-25 规范发布定稿 SEP:为了准备 2025 年 11 月 25 日 的规范发布,团队已经列出了几个 待定稿的 SEP,预计在 2025 年 11 月 14 日 进行规范冻结(spec freeze)。
- SEP-1330 的 SDK 更改已完成:SEP-1330 的 “Awaiting SDK Change” 标签已被移除,因为相关更改已完成一段时间,目前正等待 TS/Python SDK 以及规范/架构(spec/schema)更改的审查与合并。
DSPy ▷ #show-and-tell (2 messages):
Tau Bench, FastWorkflow, GEPA, Multi-Agent Tool Use
- FastWorkflow 在 Tau Bench 中达到 SOTA:发布者宣布 fastWorkflow 在 Tau Bench 的零售和航空工作流中均达到了 SOTA,论文即将发表,代码可在 fastworkflow repo 和 tau bench fork 获取。
- 他们强调 通过适当的 context engineering,小模型可以媲美或击败大模型。
- 使用 GEPA 优化端到端工作流:一位成员提到,使用 GEPA 进行端到端工作流优化的工作正在进行中。
- 附带的一张图片展示了 fastWorkflow 与其他策略相对性能的表格。
- 基于 DSPy 的 Planner 解决多 Agent 工具使用问题:一位成员发布了一个使用基于 DSPy 的 planner 和编排器来解决多 agent 工具使用的帖子,并在 X 和他们的 Substack 上征求反馈。
DSPy ▷ #general (9 messages🔥):
Rate Limiting, Exponential Backoff, LLM context history, Workflow Automation, LLM Integration
- Rate Limits 阻碍批量请求:一位用户在运行
dspy.Module.batch请求时遇到了 rate limits,正在寻求关于如何在请求之间添加时间延迟或如何正确遵守 rate limits 的建议。 - Exponential Backoff 化险为夷:一位成员建议使用 exponential backoff(指数退避)并保持缓存开启,以有效处理速率限制。
- 另一位成员分享了一个包含初始延迟、jitter(抖动)和最大尝试次数的自定义 exponential backoff decorator,并提供了一个 源自 Google 的代码片段 作为示例。
- Gemini Token 限制混淆了模块上下文:一位用户询问,在共享同一个 Gemini 模型的自定义模块中,子模块是运行在各自的上下文历史中,还是共用同一个 Token 限制。
- 这个问题是在自定义模块中包含 ReAct 和 CoT 模块,且使用 Gemini/Gemini-2.5-flash 的背景下提出的。
- AI 工程师展示工作流自动化技能:一位经验丰富的工程师介绍自己擅长 workflow automation, LLM integration, RAG, AI detection 以及图像和语音 AI,具有实际落地经验和区块链开发背景,并分享了他们的 作品集。
aider (Paul Gauthier) ▷ #general (3 messages):
Claude Sonnet, Anthropic API Key, Model reasoning, Sora 2 invite code
- Aider 支持 Claude Sonnet: 一位成员确认 Aider 已经支持 Claude Sonnet,并指出命令为
/model claude-sonnet-4-5-20250929。- 他们还提醒用户设置其 Anthropic API key 以使用该模型。
- 请求 Haiku 和 Opus 模型的推理功能: 一位成员询问如何在 Haiku-4-5 和 Opus-4-1 等模型上启用 thinking/reasoning(思考/推理),特别是在 CLI 中。
- 他们愿意编辑模型设置的 YML 文件,并寻求社区的建议。
- 寻求 Sora 2 邀请码: 一位成员询问社区中是否有人可以分享 Sora 2 邀请码。
aider (Paul Gauthier) ▷ #questions-and-tips (3 messages):
Prompt Caching, Claude Cost
- Prompt Caching 降低 Claude 成本: 一位成员询问如何启用 Claude 的 prompt caching 以降低成本,据报告在发送 75k tokens 时,每个 prompt 的费用为 $0.24。
- 另一位成员指向了 aider 文档,其中提到了
--cache-prompts选项。
- 另一位成员指向了 aider 文档,其中提到了
- 为 Claude 启用 Prompt Caching: 一位用户正寻求为 Claude 启用 prompt caching 以降低高昂成本。
- 另一位用户分享了 关于 prompt caching 的 Aider 官方文档 的直接链接,特别强调了
--cache-prompts标志。
- 另一位用户分享了 关于 prompt caching 的 Aider 官方文档 的直接链接,特别强调了
Manus.im Discord ▷ #general (6 messages):
AI Agent capabilities, Discord moderation issues, Chinese AI startups, Job seeking
- 资深 AI 工程师介绍其专业领域: 一位擅长 workflow automation、LLM integration、RAG、AI detection、图像和语音 AI 以及 blockchain development 的资深工程师提供了支持。
- 他举例说明了 support automation systems 和 advanced RAG pipelines 如何提供准确且具备上下文感知能力的响应,并提供了他的网站链接。
- SOTA AI Agent 缺乏 Discord 审核: 一位成员指出,虽然存在 接近 SOTA 的 AI agents,但却缺乏 真正的 Discord 审核,这很讽刺。
- 该成员表达了对 中国 AI 初创公司 的喜爱。
- 求职帖子: 一位成员询问是否有人在招聘开发者。
- 一位回复者幽默地指出,现在人人都是开发者。
- 过时的 Manus 1.5 邮件群发: 一位成员要求停止发送介绍 Manus 1.5 的邮件,声称该版本已经是几个月前的了。
- 未提供进一步说明。
MLOps @Chipro ▷ #events (1 messages):
AI Agents, LangChain, AgentKit, AutoGen
- AI Scholars 举办 AI Agent 工作坊: AI Scholars 正在举办一场线上线下结合的 AI 产品实战工作坊,参与者将根据真实客户的数据分析问题共同设计并构建一个 AI agent (在此报名)。
- 工作坊将引导参与者了解现代 agent 框架,如 LangChain、AgentKit 和 AutoGen,并进行来自 AI 咨询项目 的真实架构和代码演示。
- 学习构建真实的 AI agents: 一场实战工作坊将教你如何使用现代 agent 框架构建真实的 AI agent 项目和产品。
- 该课程适合工程师、PM、初创公司创始人、学生和 AI 构建者——无需编程或 agent 经验。