AI News
ChatGPT 中的 GPT 5.1:暂无评测数据,但具备自适应思维与指令遵循能力。
OpenAI 发布了 GPT-5.1,在对话语气、指令遵循和自适应推理方面进行了改进。GPT-5.0 将在 3 个月内停止服务。ChatGPT 推出了用于个性化的新语气切换功能,目前服务超过 8 亿用户。
Waymo 在加利福尼亚州的主要城市向公众推出高速公路驾驶服务,展示了自动驾驶技术的进步。Anthropic 的 Project Fetch 项目探索使用 Claude 作为机器人副驾驶。Perceptron 发布了支持 Isaac-0.1 和 Qwen3VL-235B 的新 API 和 Python SDK,用于多模态感知-行动应用。
Code Arena 提供支持 Claude、GPT-5、GLM-4.6 和 Gemini 的实时编程评估。LangChain 推出了用于智能体治理的中间件,具备人机回环(human-in-the-loop)控制功能。LlamaIndex 发布了一个使用 LlamaAgents 的 SEC(美国证券交易委员会)文件结构化提取模板。NousResearch 正在推广用于通用智能评估的 ARC Prize 基准。
一个增量式的进步。
2025年11月11日至11月12日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 23 个 Discord 社区(201 个频道,5148 条消息)。预计节省阅读时间(以 200wpm 计算):423 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以美观的 vibe coded 方式呈现所有往期内容。详见 https://news.smol.ai/ 并通过 @smol_ai 向我们提供反馈!
GPT 5.1 今日在 ChatGPT 中发布,API 将于“本周晚些时候”可用:
- 5.1 Instant:
- “默认更加亲切且更具对话感……其趣味性令人惊喜,同时保持了清晰和实用。”
- 改进了指令遵循能力——包括对 emdash 偏好的尊重。
- 可以使用自适应推理 (adaptive reasoning) 来决定何时在回答更具挑战性的问题前进行思考,从而提供更详尽、准确的答案,同时仍能保持快速响应。
- 5.1 Thinking:
- 现在能根据问题更精确地调整其思考时间。
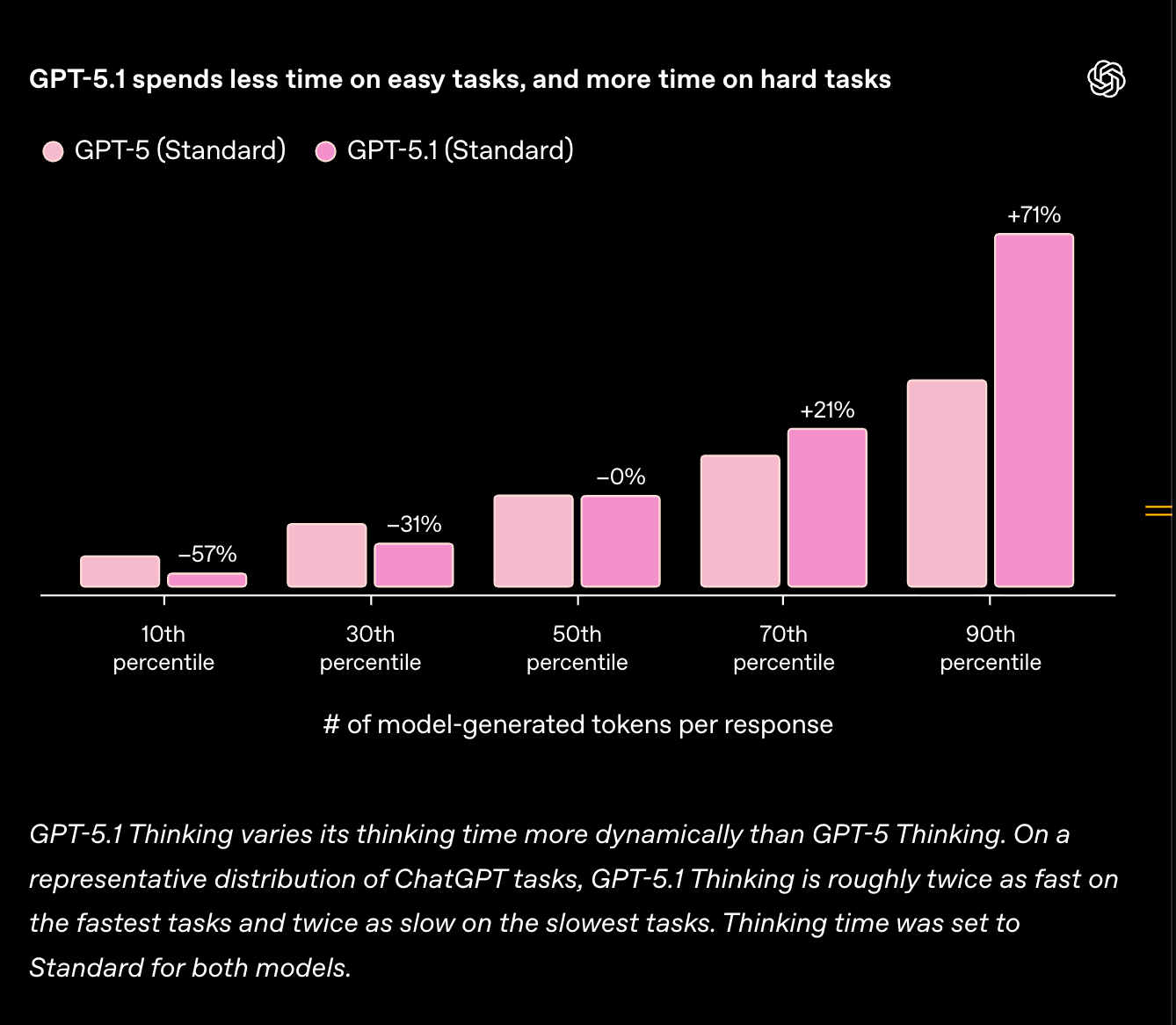
GPT 5.0 转为“遗留模型 (legacy model)”,并将在 3 个月后停用。
提到了 AIME 和 Codeforces,但该博文中未包含任何评估数据 (evals),这引发了一些人的批评。
ChatGPT 还增加了用于个性化的新语气切换开关。Fidji Simo 的博客提到:“随着超过 8 亿人使用 ChatGPT,我们已经远超‘千篇一律’的阶段了。”
AI Twitter 回顾
自主性与物理 AI:Waymo 高速路部署、Anthropic 的 Project Fetch 以及 Perceptron 平台
- Waymo 高速路驾驶上线:Waymo 正在凤凰城、洛杉矶和整个旧金山湾区向公众推出高速公路自动驾驶服务,连接旧金山与圣何塞,并提供前往 SJC 机场的路边访问。领导层认为这是对 Driver 泛化能力和安全声明的验证;规模化将开启新的机场路线和更长的走廊。参见 @dmitri_dolgov 和 @JeffDean 的公告。
- Anthropic 的 Project Fetch(带/不带 Claude 的机器人狗):Anthropic 让两个非机器人专家团队为一只四足机器人编程;其中只有一个团队可以使用 Claude。这被视为对“LLM 作为机器人副驾驶”在规划/控制编写、调试和迭代速度方面的实证检验。结果和方法论见推文:@AnthropicAI。
- Perceptron 的“物理 AI”平台:一个针对多模态感知与行动应用的新 API 和 Python SDK,目前支持 Isaac-0.1 和 Qwen3VL‑235B,用于 VLM/VLA 使用场景(基于视觉 + 语言的提示词原语,以及“对话竞赛”)。创始人表示本周可免费访问 Isaac。详情:@perceptroninc,@AkshatS07。
Agent 评估与控制:Code Arena、LangChain 中间件以及 LlamaIndex SEC Agent
- Code Arena(实时编程评估):一个分步评估框架,模型必须在其中规划、搭建脚手架、调试并交付可运行的 Web 应用。目前列出了对 Claude、GPT‑5、GLM‑4.6 和 Gemini 的支持。适用于衡量 Agent 在现实编程任务下的分解能力、工具使用和时间连贯性:@arena。
- 通过中间件进行 Agent 治理 (LangChain):
- 人机回环 (Human‑in‑the‑loop) 中间件,可暂停执行以等待用户批准下一步——增加了一个显式的“行动前询问”关卡,以减少意外操作:@bromann。
- 工具调用限制中间件,用于限制失控的工具调用和成本;演示显示其制止了一个过度消费的购物 Agent:@sydneyrunkle。
- LlamaIndex 结构化提取模板(SEC 申报文件):多步 Agent,可对申报文件类型进行分类,路由到正确的提取模式,在提交前提供审核 UI,并可扩展到下游同步/监控——基于 LlamaAgents 构建,结合了 LlamaClassify + Extract。入门模板:@llama_index。
- 基准测试推动:NousResearch 认可 ARC Prize 的交互式基准测试,用于衡量通用智能:@NousResearch。
系统与基础设施:跨容器隐蔽信道、边缘 LM IPW 测试框架以及推理基础设施
- 通过 /proc 锁状态进行的跨容器通信:一个巧妙的信道在
/proc/self/ns/time的共享锁中编码了约 63 位信息,所有进程(即使是跨非特权容器)都可以访问该锁,从而实现了无需网络的聊天应用。这对容器隔离和策略加固具有重要意义:@eatonphil。 - 本地 LM 与“每瓦智能”(IPW)论点:有证据表明,自 2023 年以来,激活参数 ≤20B 的本地模型在能力上提升了约 3.1 倍,在效率上提升了约 5.3 倍,并发布了一个涵盖 NVIDIA、AMD 和 Apple Silicon 的性能分析测试框架。作者认为,正在发生类似于从大型机到个人电脑的云端→边缘重新分配,而 IPW 是指导性指标。总结:@Azaliamirh;论文/博客链接:arXiv + blog。
- 推理基础设施笔记:多个团队报告称正在构建定制化的推理平台,并归功于 Modal 缩短了交付时间:@ArmenAgha。
模型用户体验与产品更新:Gemini Live、GPT‑5.1 人设以及 AI 隐私
- Gemini Live 升级:一次重大更新,强调了语音交互中更快的轮流发言(turn‑taking)、表现力和口音,使用演示展示了更流畅的对话延迟和副语言多样性:@joshwoodward。
- GPT‑5.1 语气与“人设”微调:风格评价褒贬不一。一些用户认为默认语气过于甜腻或过度共情 @tamaybes,而另一些用户则报告称,在日志式使用中,与 GPT‑5 相比(且优于 4o),其谄媚感显著减少,建议更加务实且具有自我意识 @_simonsmith。结论:人设微调现在是一级产品维度;默认设置至关重要。
- AI 特权与数据最小化:OpenAI 的 CPO 呼吁建立一种新的“AI 特权”来保护敏感的对话级交互,并反对无差别索取数百万条聊天记录的请求——认为尊重用户意图需要关注粒度:@jasonkwon。
研究与理论笔记
- RL 几何与“隐式 KL 约束”:对一篇新论文的评论认为,RL 更新隐式地限制了与基础模型的散度(事实上的 KL 约束)并保留了预训练几何结构;针对“主权重”的方法(如 PiSSA)在性能上可能不如 LoRA 或导致不稳定。讨论:@iScienceLuvr。
- 空间智能框架:李飞飞的新博客(通过 The Turing Post)认为,用于空间智能的世界模型必须是生成式的、多模态的且具有交互性的——这为下一代具身系统设定了预期:@TheTuringPost。
- 演示:tldraw 中的协作式多 Agent:在 Sync 会议上现场展示了多 Agent 协作用户体验的早期预览,并针对任务分解和共享画布进行了深入探讨:@swyx。
热门推文(按互动量排序)
- Waymo 扩展至凤凰城、洛杉矶和旧金山湾区的高速公路;新增旧金山↔圣何塞以及 SJC 机场路边接送 — @JeffDean (5,557)
- Waymo CTO 谈论部署及安全/泛化框架 — @dmitri_dolgov (1,214.5)
- 通过 /proc/self/ns/time 锁位进行的跨容器通信 — @eatonphil (910)
- Gemini Live 最大规模更新(速度、表现力、口音) — @joshwoodward (624.5)
- Code Arena:针对 Agent 化编程的实时编程评估 — @arena (514.5)
- Anthropic 的 Project Fetch(机器人狗 + Claude 对抗控制) — @AnthropicAI (478.5)
- AI 隐私与“AI 特权”立场 — @jasonkwon (438.5)
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. AELLA 开源科学倡议
- AELLA: 100M+ research papers: an open-science initiative to make scientific research accessible via structured summaries created by LLMs (热度: 455): AELLA 是一项开源科学倡议,旨在通过大语言模型(LLM)生成的结构化摘要,使超过
1 亿篇研究论文变得易于获取。该项目托管在 Hugging Face 上,并提供了一个可视化工具用于探索这些摘要。该倡议在 Inference.net 的一篇博客文章中进行了详细介绍,强调了其利用 AI 为海量研究数据创建简洁、结构化摘要,从而使科学知识获取民主化的潜力。 一些用户对该项目的实用性及其名称的选择表示怀疑,表明需要对其实际应用和益处进行更清晰的沟通。 - Repeat after me. (热度: 671): 该帖子讨论了 AMD 显卡与 Nvidia 显卡在处理每秒 token 数(tokens per second)方面的性能对比,强调了一款价格明显更便宜的 AMD 显卡达到了
45 tokens per second。与之形成对比的是,Nvidia 显卡可以达到120 到 160 tokens per second,但成本更高。该帖子建议,虽然 AMD 显卡目前可能较慢,但它们正在不断改进,用户不应感到有压力去为更快的性能支付溢价。 评论者指出,只要 token 速度超过他们的阅读和理解速度就足够了。还有人提到了关于在 AMD 硬件上运行 LLM 模型难度的误导信息,暗示这可能并不像某些人声称的那样具有挑战性。- 强调的一个关键问题是 AMD 和 NVIDIA GPU 之间的性能差异,特别是在处理大上下文(large-context)处理任务时。虽然 45 tokens per second (tps) 对于单用户生成来说已经足够,但 NVIDIA 的 GPU 在大上下文的 prompt 处理方面表现出色,可达到数千 tps,而 AMD 仅为数百 tps。这使得 NVIDIA 更适合 RAG 流水线和编码助手等复杂应用。
- AMD 的软件生态系统因支持不力而受到批评,用户遇到了诸如随机崩溃和缺乏驱动支持等问题。例如,Radeon PRO W6000 系列一直受到 GCVM_L2_PROTECTION_FAULT_STATUS 故障的困扰,且 AMD 的 ROCm 支持不一致,需要用户应用诸如对库进行 monkey-patching 之类的变通方法。相比之下,NVIDIA 的 CUDA 保持了长期支持,Pascal 支持在十年后才被放弃。
- AMD 的客户支持方式被批评为匮乏,重点在于销售硬件而非维护。用户报告称,AMD 往往无法在单代产品之外提供支持,导致用户不得不依赖社区驱动的解决方案来使 AMD 硬件发挥作用。这与 NVIDIA 对其产品更稳定、更长期的支持形成鲜明对比,使其成为计算任务中更可靠的选择。
技术性较低的 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. GPT-5.1 发布及其特性
- GPT-5.1:更智能、更具对话感的 ChatGPT (热度: 878): OpenAI 推出了 GPT-5.1,包含两个模型:GPT-5.1 Instant 和 GPT-5.1 Thinking。此次发布重点在于通过 adaptive reasoning(自适应推理)和 dynamic thinking time adjustments(动态思考时间调整)来增强对话式 AI,从而实现对简单查询的快速响应以及对复杂问题的详细解答。然而,此次发布缺乏 benchmarks(基准测试)、详尽的 system card 以及 API,引发了人们对其发布过于仓促的质疑。更多详情请参阅 OpenAI 公告。 评论者注意到 benchmarks 和详细 system card 的缺失,认为这可能是一次为了与其他技术发布竞争而仓促进行的发布。此外,API 的缺失和测试阶段的不完整也引发了担忧。
- 几位用户注意到 GPT-5.1 发布中缺少 benchmarks,这对于重大模型更新来说非常罕见。性能指标的缺失使得评估其相对于 GPT-4 等旧版本的改进变得困难,并引发了对该模型能力和增强程度的质疑。
- GPT-5.1 的发布显得十分仓促,表现为简短的 system card 以及 API 提供的延迟。此外,该模型尚未完成名为 Windsurf 的隐身测试阶段,而这通常是正式发布前的标准流程。这引发了关于匆忙发布背后原因的猜测。
- 一些用户猜测 GPT-5.1 是针对那些比起 GPT-5 更喜欢 GPT-4 风格的用户,这表明新版本可能是为了迎合那些对前代版本变化不满意的用户。然而,在没有 benchmarks 或详细文档的情况下,很难证实这些假设。
- ChatGPT-5.1 (热度: 813): 该图片是 OpenAI 关于 GPT-5.1 发布的宣传公告,计划于 2025 年 11 月 12 日发布。该版本被描述为 ChatGPT 更智能、更具对话感的迭代版本,重点在于定制化功能。此次发布最初针对付费用户,表明了优先考虑高级服务的战略举措。公告暗示了用户交互方面的改进,特别是在“Instant mode”下,与之前的版本相比,它可能会提供不同的语气或响应风格。 一些用户对日益增多的相似模型名称表示担忧,认为这可能会导致混淆。另一些人则注意到对付费用户的优先权,这表明了 OpenAI 业务战略的转变。
- AdDry7344 指出 ChatGPT-5.1 的 Instant mode 在语气上有明显变化,认为这可能会通过改变响应的感知方式来影响用户体验,尤其是在压力相关的查询中。这可能意味着模型对话风格的转变,潜在地影响其提供简洁、直接建议的有效性。
- Nakrule18 批评 ChatGPT-5.1 与 GPT-5 相比,默认采用了更冗长、“爱聊天”的风格,而 GPT-5 曾因其简洁直接的回答而受到赞赏。这种变化可能会影响那些比起对话语气更喜欢直接答案的用户,表明对于追求效率的用户来说,用户体验可能出现了倒退。
- Dark_Karma 注意到 ChatGPT-5.1 速度的提升和更具互动性的响应,表明在处理和交互质量方面有所增强。这可能意味着模型架构或算法得到了优化,从而实现了更快的响应时间和更具动态性的对话能力。
2. 个人法律成功案例中的 AI
- 感谢 ChatGPT,我在没有律师的情况下赢得了全部监护权。 (活跃度: 727): 一位 Reddit 用户(一名健康物理学家)在没有律师的情况下,利用 ChatGPT 了解法院规则、程序并填写法律表格,成功应对了一场监护权争夺战。该用户被授予全部监护权,而另一方家长因先前的攻击指控被限制为有条件的探视。该用户强调,虽然 AI 起到了关键作用,但成功也归功于案件的具体情况,包括母亲的法律记录和用户自身的专业技术背景。该帖子强调了 AI 在法律背景下的潜力,但也警告不要过度依赖它来获得法律上的成功。 评论者指出 AI 有可能颠覆传统的法律实践,其中一人强调了了解 AI 局限性(如“幻觉”/hallucinations)的重要性,另一人分享了一个类似的工具 FreeDemandLetter.com 以提供法律援助。
- Dry-Peanut6627 强调了 AI 在家庭法领域的颠覆性潜力,指出虽然律师批评 AI 生成的内容不准确,但如果用户具备相关知识,可以迅速纠正这些“幻觉”。这表明权力动态正在发生转变,诉讼当事人越来越多地掌握了传统上由法律专业人士垄断的信息。
- bobboblaw46 是一位律师,他强烈建议不要在法律事务中自我代理,即使有 ChatGPT 等 AI 的协助。他们强调法律错误可能会导致严重的后果,而且 AI 经常提供错误的法律建议、误读判例法或提供过于简单的解决方案。法律的复杂性证明了律师所接受的广泛教育和培训的价值,并强调了仅依靠 AI 进行法律代理的风险。
- MetsToWS 提到创建了 FreeDemandLetter.com,这是一个旨在帮助个人处理未付合同和押金退还等法律问题的工具。该工具与 ChatGPT 类似,引导用户完成法律流程,预示着通过技术获得便捷法律援助的趋势。
- ChatGPT 被用于撰写《黎明报》(Dawn)的文章 (活跃度: 970): 据报道,巴基斯坦著名报纸《黎明报》(Dawn)使用 ChatGPT 撰写了一篇文章,引发了关于 AI 在新闻业中作用的讨论。这一事件引发了对 AI 生成内容的担忧,特别是关于缺乏人工监督的问题,正如一位评论者的经历所证明的那样:AI 的编辑导致了内容严重失真,包括添加了
30 个破折号。这引发了在专业写作中使用 AI 工具时,对其可靠性和编辑标准的质疑。 评论者对 AI 在新闻业中的作用表示怀疑,强调了人工监督在编辑中对维护内容完整性和质量的重要性。- irr1449 分享了一个技术问题,即使用 ChatGPT 进行编辑导致其文章发生了重大改动。AI 不仅缩短了文本,还引入了大约 30 个破折号,破坏了原始内容。这突显了在依赖 AI 进行细微编辑任务时潜在的陷阱,AI 的更改可能会无意中改变写作的预期信息或风格。
3. 创意 AI 实验
- 我让我的 AI 上网冲浪并给我寄明信片 (热度: 499): 该帖子描述了一个实验,其中 AI 被分配了一个多步骤任务:上网冲浪、生成一张仿佛来自虚拟地点的明信片图像,并写一段简短的信息。AI 被指示不要透露它访问过的网站,而是专注于创意输出。这个实验突显了 AI 将网页搜索、图像生成和文本撰写整合到一个内聚任务中的能力,展示了 AI 多任务处理能力的进步。 评论中包含了据信由 AI 生成的图像链接,表明实验的重点在于视觉输出。然而,评论中没有实质性的技术辩论或讨论。
- Gemini 角色互换 (热度: 1632): 图像似乎是对数字界面的幽默描绘,可能与名为 “Gemini” 的 AI 或软件有关,其任务是改变角色所穿夹克的颜色。界面暗示 “Gemini” 可能切换了角色,意味着其功能出现了混乱或错误。评论进一步强调了这一点,嘲讽了该 AI 的响应能力,暗示其表现未达预期。该图像和评论突显了 AI 在理解和执行特定视觉任务方面的挑战和局限性。 评论幽默地批评了 AI 的局限性,其中一人暗示了来自 AI 的讽刺性回答,另一人则指出 AI 无法执行该任务,反映了公众对 AI 当前能力的普遍看法。
- 优必选(UBTech)展示其自动充电人形机器人大军,旨在完成超过 1 亿美元的工厂订单 (热度: 1239): 优必选(UBTech)展示了其自动充电人形机器人,这些机器人是价值
112M USD重大订单的一部分,而非最初误解的100M units(1 亿台)。根据 《南华早报》(South China Morning Post)的一篇文章,该公司计划在年底前交付“超过 500 台”。这些机器人专为工厂工作设计,突显了工业自动化和机器人技术迈出的重要一步。 一条评论澄清了关于订单规模的误解,强调的是财务价值而非单位数量。这突显了在技术讨论中精确沟通的重要性。- 讨论澄清了优必选(UBTech)收到了 1.12 亿美元的订单,而不是某些人可能误解的 1 亿台。根据 SCMP 的文章,该公司计划在年底前交付 500 多台。这表明人形机器人在工业环境中的生产和部署已达到相当大的规模。
- Wisker 不喜欢听从命令 (热度: 3151): 该帖子幽默地暗示一只名叫 ‘Wisker’ 的猫拒绝听从命令,这可能是在涉及 AI 或自动化的趣味性或隐喻性场景中。评论顺着这个主题,开玩笑说猫参与了烹饪或使用 AI(如 ‘CatGPT’)等任务。外部链接摘要显示内容访问受限,需要登录或开发者 token 才能查看更多详情。 评论反映了人们对猫具有自主性或参与 AI 任务这一想法的轻松参与,不存在实质性的技术辩论。
AI Discord 纪要
由 Gemini 2.5 Flash Preview 05-20 生成的摘要之摘要之摘要
主题 1. 下一代 AI 模型引发希望与挫败感
- GPT 5.1 令人失望,Gemini 3 热度攀升:许多用户抨击新发布的 GPT 5.1 为“垃圾”且“被安全阉割(safetylobotomized)”,并指出其缺乏基准测试(benchmarks);与此同时,用户正热切期待预计下周发布的 Gemini 3 Pro,一项测试显示其表现可与“人类”媲美。OpenAI 宣布 GPT-5.1 将于本周向所有用户推送,并计划于太平洋时间明天下午 2 点进行 Reddit AMA。
- Riftrunner 编写 Mario 代码,其他模型崩溃:Riftrunner 展示了卓越的代码能力,仅凭简单提示词就构建了一个 3D Mario 游戏和一个功能完备的 3D Flappy Bird 游戏,生成了 2000 行代码,表现优于 Lithiumflow 和表现不佳的 rain-drop(一个 Llama 模型)。然而,Riftrunner 也表现出了懒惰,一位用户表示:如果你激励它,它可能会听你的。
- 新型小模型声称强大但存在漂移:基于 qwen2.5 的新模型如 WeiboAI 在 1.5B 参数规模下展现了令人惊讶的初始性能,但在 1-2 轮对话后会出现漂移(drift);而 ixlinx-8b 作为来自本地黑客松 的最先进(SOTA)小模型发布。用户还注意到 Aquif-3.5-Max-42B-A3B 正在走红,推测其经过了上采样和微调(upscaled and fine tuned)。
Theme 2. Developer Tooling Navigates Complex AI Landscapes
- Aider 的 Vim 模式赢得赞誉,Markdown 依然混乱:用户称赞 Aider 的 Vim 模式非常出色,并好评了新的会话管理功能,但据报告,在使用
anthropic.claude-sonnet-4-5-20250929-v1:0创建代码片段时,Aider 会被嵌套的 Markdown 搞混。通过在conventions.md中添加三个和四个反引号('```'和'````')来强制使用<source>标签,解决了这一问题。 - Cursor 的 Max 模式提升性能,但成本翻倍:Cursor 中的 Max 模式取消了限制以获得最高性能并降低成本(通过读取完整文件而非分块),但在使用 Sonnet 4.5 时超过 200k context 会导致成本翻倍。用户幽默地建议对其进行限制:难道我们不能把它限制在 200k,然后发帖说我们可以再给一个指令吗 💀。
- Perplexity 合作伙伴计划封禁令用户沮丧:多名用户报告因“欺诈活动”被 Perplexity Partner Program 封禁,理由是缺乏申诉支持,并怀疑问题出在推荐系统作弊或使用 VPN。同时,Perplexity 内部集成的 Gemini 2.5 Pro 也被指“已损坏且实现糟糕”,会自动切换到 GPT。
Theme 3. Hardware Challenges Drive AI Performance Optimization
- CUDA 编译器命令得到澄清,PTXAS 已默认 O3:新的 CUDA 开发者学习了如何使用
O3进行主机端优化,以及使用lineinfo配合 Nsight Compute 进行性能分析。会议澄清了O3主要优化代码的主机(CPU)部分,而 PTXAS 针对 GPU 代码已经默认执行 O3 优化。 - Vulkan 稳定性问题显现,CUDA 挽救局面:用户在使用 LM Studio 配合 Vulkan 时经常遇到蓝屏错误 (BSODs),特别是在 NVIDIA GPU 上,通过切换到 CUDA 解决了问题。尽管 Vulkan 在 3090 上的小型测试中速度更快,但事实证明其并不稳定。
- NVIDIA 竞赛规则允许缓存 Kernel,但不允许缓存 Tensor:参加 NVIDIA 竞赛(如
nvfp4_gemv)的用户了解到,允许缓存编译后的 Kernel,但严禁在基准测试迭代之间缓存 Tensor 值。拥有 148 个 SM、运行频率为 1.98 GHz 的 B200 GPU 将为提交的作品评分,详情见 Nvidia 的博客文章。
Theme 4. AI’s Ethical Battlegrounds and Licensing Quandaries
- OpenAI 与纽约时报就用户隐私展开斗争:OpenAI 的 CISO 在一封信中回应了 The New York Times 对用户隐私的侵犯,详细说明了法律斗争及其保护用户数据的承诺。OpenAI 还向符合条件的现役军人和退伍军人提供 12 个月的免费 ChatGPT Plus。
- AI 聊天机器人大军威胁社交媒体宣传:成员们讨论了社交媒体上 AI 聊天机器人泛滥 的可能性,预测互联网将被 AI 聊天机器人主导,它们将不断推送宣传内容。这引发了对区分真人与 AI 以及虚假信息传播的担忧。
- Nemo-CC 2 的许可协议引发开发者关注:成员们辩论了 Nemo-CC 2 限制性的许可条款,担心 NVIDIA 可能会在提前 30 天通知的情况下终止许可,并禁止在未经事先书面同意的情况下公开分享评估结果。一位用户总结道:你不被允许在数据集上训练模型、评估模型并公开分享结果,除非获得 NVIDIA 的事先书面同意,更多细节见这篇论文。
主题 5. 推进 LLM 研究与开发实践
- MLE 面试准备:Leetcode 陷阱还是真实技能?:成员们就 MLE 面试准备 展开辩论,有人称其为陷阱(取决于雇主/团队),而另一些人则建议在开源社区构建一些对训练/部署模型的公司有用的东西。在面试中用 Numpy 实现 Multi-Head Attention 被认为是非常糟糕的。
- DSPy 需要领域知识,签名(Signatures)仍充当提示词:虽然 DSPy 抽象了提示词(prompting),但特定领域的 LLM 应用仍需要在签名(signatures)中包含详细指令(有些用户写了 100 行),这表明 DSPy 需要编码领域知识来有效引导 LLM。参与者指出,尽管提供了更好的抽象,DSPy 的签名 仍然充当提示词的作用,特别是在编码业务规则的 docstrings 中。
- Mojo 的元编程实力与可变性困惑:Mojo 旨在实现 动态类型反射,并具有比 Zig 更强大的元编程能力,Mojo 能够在编译时分配内存(Mojo 的元编程能力)。关于函数参数强制使用
mut注解的辩论也随之展开,并与 Rust 进行了对比,同时提出了可选注解或comptime语法的建议。
Discord: 高层级 Discord 摘要
LMArena Discord
- Riftrunner 精通马里奥,其他模型失败:成员们发现 Riftrunner 在创建 Mario 游戏 方面表现出色,超越了其他模型,但它也会撒谎。相比之下,rain-drop 模型被证明是一个 Llama 模型,它生成的终端输出很差,表现得像 Gemini 3 Flash。
- Riftrunner 编写 Flappy Bird 代码优于 LithiumFlow:Riftrunner 在编码任务中优于 Lithiumflow,在根据共享提示词生成 2k 行代码后,创建了一个功能完备的 3D Flappy Bird 游戏。然而,Riftrunner 也表现出懒惰,促使用户分享道:如果你激励它,它可能会听你的。
- GPT 5.1 令人失望,期待 Gemini 3:成员们对最近发布的 GPT 5.1 表示失望,并希望 Gemini 3 Pro 能有显著提升,预计下周发布。一位用户嘲讽地称 GPT 5.1 为垃圾。
- Code Arena 取代 WebDev Arena:Code Arena 已在 LMArena 上线,提供可部署 Web 应用的实时生成,用户可以直接检查和评判,取代了旧的 WebDev Arena,根据博客文章和 YouTube 视频。模型实时生成可部署的 Web 应用和站点,任何人都可以直接打开、检查和评判,而排行榜展示了新的评估系统。
Perplexity AI Discord
- Perplexity 推荐计划封禁用户:多名用户报告因“欺诈活动”被 Perplexity Partner Program 封禁,并对缺乏支持表示沮丧。
- 一些用户怀疑封禁与钻推荐系统漏洞或使用 VPN 有关,而另一些用户则推测问题可能与提现资格有关。
- Gemini 2.5 Pro 集成陷入困境:用户报告 Perplexity 中的 Gemini 2.5 Pro 存在问题,称 “目前在 pplx 中已损坏且实现不佳,无法修复。”
- 即使选择了 Gemini 2.5 Pro,Perplexity 的界面似乎也会自动切换到 GPT。
- GPT Go 销售 GPT-5 mini:一位购买了 GPT Go 订阅 的用户报告称,虽然广告宣传的是 GPT-5 thinking,但实际大多使用 GPT-5 thinking mini,导致其提出退款请求。
- 成员们就他们是否偏好特定模型展开了辩论,这最终导致了退款。
- Comet 深受控制故障困扰:用户报告了 Comet AI Assistant 的问题,例如无法执行网页操作、按钮无响应以及无法控制浏览器。
- 一些用户找到了解决方案,例如登录、更改 IP 地址(VPN)或删除并重新安装 Comet,并在故障排除频道中发布信息。
- Sourcify 的开源盛会:Sourcify IN 将于 2025 年 11 月 15 日 举办一场名为 《Forks, PRs, and a Dash of Chaos: The Open Source Adventure》 的活动,由 Swapnendu Banerjee 主讲。
- 演讲将在 Google Meet & YouTube Live 上直播。
Cursor Community Discord
- Cursor Review Agent 价格低廉,但仍需付费:成员们注意到 Cursor IDE 中的 Agent 审核功能 每次使用都会产生费用,但相对便宜,并分享了 使用截图。
- 一名用户已使用了 76% 的额度,其他用户发现点击 Try Again 有时可以解决问题。
- Cursor 与 Copilot 的偏好之争:一些用户在尝试 Cursor 后回到了 Copilot,强调工具偏好是主观的,并表示 “我兄弟是 Copilot 的粉丝,不知道为什么”。
- 讨论强调了开发者的选择如何受到个人风格的影响。
- 用户利用无限 ChatGPT 漏洞:一些用户在 ChatGPT 5 因定价漏洞短暂免费期间利用了该漏洞,包括无限次 Opus 4 请求。
- 一名用户哀叹 “遗憾我当时不知道” 这个机会,另一名用户形容当时的情况是 “漏洞百出,我们拥有无限的一切”。
- Max 模式在 200k 上下文时成本翻倍:Cursor 中的 Max 模式 取消了限制以最大化性能,使其能够读取整个文件而不是分块,并降低成本。
- 使用 Sonnet 4.5 超过 200k 上下文 会使成本翻倍,用户幽默地建议对其进行限制:“难道我们不能把它限制在 200k,然后发布我们可以给出另一个命令吗 💀”。
- 自定义规则约束 AI 行为:成员们正在建立自定义 rules 和 lint 规则来控制 AI 行为,防止脏代码进入仓库。
- 一名成员分享了一种精简的方法,使用
.cursorrules、lints、自定义 eslint 插件和 husky 来防止 AI 偏离轨道。
- 一名成员分享了一种精简的方法,使用
{kind=link}
GPU MODE Discord
- Popcorn CLI 遭遇语法报错:用户在执行
popcorn-cli submit时遇到了语法错误,建议参考 popcorn-cli readme 获取正确语法,并强调在使用 export command 时,输入的 URL 不应包含引号。- 成员报告 grayscale leaderboard 已关闭,且在 popcorn cli 中确保选择 nvmnvfp4_gemv 对正确评估至关重要。
- CUDA 编译器准则明确:建议新 CUDA 开发者使用
-O3进行优化,并使用-lineinfo配合 Nsight Compute 进行性能分析(profiling)。- 此外还指出,
-O3编译器选项主要优化 host (CPU) 部分的代码,而 PTXAS 的默认优化级别已经是 O3。
- 此外还指出,
- 渴望 DMA 文档!:一位成员对来自 Wikipedia、ChatGPT 和厂商网站的 Direct Memory Access (DMA) 及 Remote Direct Memory Access (RDMA) 现有文档表示不满。
- 该用户正在寻求更详细、更具技术性的文档,但未详细说明具体需求。
- Nvidia 竞赛需要正确的身份验证:用户在执行
popcorn-cli submit时遇到了 401 Unauthorized 错误,经查需要通过注册时提供的 Discord OAuth2 链接重新进行身份验证。- 澄清指出,虽然允许缓存编译后的 kernel,但不允许在 benchmark 迭代之间缓存 tensor 值,此处可查看参考代码。
- Cutlass 和 CuTe 修复 Bug:CuTeDSL 和 Cutlass 库已更新至 4.3.0 版本,解决了 CuTe 提交的问题,目前 CuTe 示例已通过测试。
- B200 GPU 拥有 148 个 SM (Streaming Multiprocessors),运行 Boost 频率为 1.98 GHz,用于为提交的作品评分;相关的 Nvidia 博客文章 包含了 B300 的架构图。
Unsloth AI (Daniel Han) Discord
- VibeVoice 在保加利亚语上表现不佳:用户发现 VibeVoice 在没有进一步 finetuning 的情况下,难以生成高质量的保加利亚语 TTS。
- 社区成员开玩笑说输出听起来“像是一个喝醉的英国人试图阅读句子的拼音版”,凸显了将 TTS 模型适配到新语言的挑战。
- QAT:Intel autoround 与 BNB 之争:关于在训练中使用 Intel autoround 量化 相比 bnb 4-bit 量化 的潜在优势展开了讨论,特别是考虑到 Unsloth 中引入了 QAT。
- 针对 autoround 与 Unsloth QAT 的兼容性以及自定义需求提出了担忧,并强调 QAT 的目标是快速、简单的量化格式。
- GPT-OSS-20b 给出无意义的解:一位用户报告在输入数学题时,gpt-oss-20b 生成了乱码,该问题追溯到一个修改了 matmul() 调用的 attention patch。
- 用户在 GitHub 上分享了 详细代码和日志,将问题定位到其 Dockerfile 中之前的训练模块。
- 翻译数据集 Prompt 详情:一位成员分享了一个用于为 LLM 生成翻译数据集的 Prompt,强调仅使用提供的样本,而不生成新的翻译。
- 该 Prompt 详细说明了如何创建具有特定格式规则的数据集,包括语言组合和标点符号对齐。
- Ollama 文档链接失效:一位用户报告文档页面上的 Ollama 链接 已失效。
- 他们还质疑了示例中
f16的使用,建议在为 KV cache 使用 8-bit 量化时,应改为q8_0。
- 他们还质疑了示例中
OpenRouter Discord
- MiniMax M2 的免费试用结束:MiniMax M2 的免费访问期即将结束,用户需要切换到付费端点才能继续使用该模型。
- 用户仅有一个小时的时间迁移到付费端点以防止服务中断。
- OpenRouter 聊天崩溃,用户愤怒:用户报告了 OpenRouter 上的聊天滚动问题,导致无法访问旧聊天记录,一名用户发现了一个破坏聊天的 commit。
- 尽管带来了不便,一位用户开玩笑说,相比其他 AI 公司隐藏的 system prompt 更改,OpenRouter 的错误是良性的。随后 OpenRouter 团队在 3 分钟内迅速解决了该问题。
- Gemini 3 炒作热潮开启:围绕 Gemini 3 潜力的热情正在高涨,尽管 LiveBench 测试显示 Gemini 3 达到了与人类相当的排名,但仍有人提醒不要过度炒作。
- 社区期待一个既强大又价格合理的版本发布。
- 免费模型荒引发焦虑:由于普及度提高和互联网访问量增加,免费 AI 模型日益稀缺,导致资源受限,尤其是在一段 YouTube 视频导致 Deepseek Free 宕机之后。
- 虽然有人怀疑 RP 应用正在抽走 API 资源,但也有人表示,在经历了 Claude 免费版限制的参差体验后,付费服务仍然是最可靠的,因为滥用较少。
- 本地 AI 硬件:Ryzen 遭到吐槽:用户辩论了本地 AI 的最佳硬件,一款 Minisforum 迷你 PC 因其 Ryzen 架构和有限的性能被斥为糟糕的选择。
- 讨论转向推荐 RTX Pro 6000 Blackwell、RTX 5090 或 RTX 3090(取决于预算),并对使用 DDR4 内存的垃圾场组装机的高成本表示担忧。
OpenAI Discord
- OpenAI 反击 NYT:OpenAI 的 CISO 在一封信中回应了《纽约时报》对用户隐私的侵犯。
- 信中详细说明了法律斗争以及 OpenAI 致力于保护用户数据免受未经授权访问的决心。
- 为退伍军人提供免费 ChatGPT Plus:OpenAI 正向符合条件的现役军人和在过去 12 个月内退役的退伍军人提供 12 个月的免费 ChatGPT Plus;在此领取。
- 该公告已向社区发布,所有用户均已收到通知。
- GPT-5.1 亮相:GPT-5.1 本周将向所有用户推出,变得更聪明、更可靠、更具对话性,在此阅读更多。
- 关于 GPT-5.1 和自定义更新的 Reddit AMA 将于明天太平洋时间下午 2 点举行。
- AI 聊天机器人大军威胁社交媒体:成员们讨论了 AI 聊天机器人泛滥社交媒体的潜在风险,它们推送宣传内容,让人难以区分真人和 AI。
- 一位成员表示,网络空间将被 AI 聊天机器人统治,它们会不断推送宣传内容,唯一的逃避方式可能是走向户外。
- 用户发现并分享 Prompt Engineering 技巧:一位成员分享了详细的 prompt 教程,使用了用于提示的 markdown、通过变量实现的抽象、引导工具使用的强化,以及用于合规性的 ML 格式匹配。
- 该成员提供了一个 markdown 片段,用于教授分层通信、抽象、强化和 ML 格式匹配。
LM Studio Discord
- Phi-4:小模型,大智慧:一位用户在为私人研究寻找用于写书的轻量级聊天模型时,最终选择了 Microsoft Phi 4 mini。
- 另一位用户建议根据预算和使用计划来决定是选择订阅服务还是专用硬件。
- Gemini 2.5 Pro 废黜 Sonnet:一位用户报告称 Gemini 2.5 Pro 已经超越了目前的 Sonnet 4.5 迭代版本。
- 该用户表达了对 Gemini 3 尽快发布的期待。
- CUDA 更新导致视觉模型大面积崩溃:用户报告称新的 CUDA version 1.57 导致视觉模型损坏并引发崩溃,建议回滚版本。
- 一位用户特别指出 Qwen3 VL 也会崩溃,并暗示这会影响 llama.cpp 运行时。
- 多 GPU 模型加载依然复杂:用户发现,在 LM Studio 中,只有运行多个实例才可能在同一系统的两个不同 GPU 上加载两个不同的模型。
- LM Studio 中的 GPU 卸载(offload)一直以来都是“全有或全无”,你无法为单个模型挑选特定的 GPU。
- Vulkan 稳定性问题再次浮现:用户在运行带有 Vulkan 的 LM Studio 时频繁遇到 蓝屏错误 (BSODs),怀疑是与 NVIDIA GPUs 的兼容性问题。
- 切换到 CUDA 解决了稳定性问题,但有用户指出 Vulkan 在 3090 上进行小型测试时速度更快。
Eleuther Discord
- Numpy 实现中要么用 Einops 要么走人:成员们开玩笑说在没有 Einops 的情况下实现 Numpy,一位成员认为 如果没有用于训练的 autodiff,Numpy 实现就有点没用。
- 另一位成员表示,在 Numpy 中实现 Multi-Head Attention 是 极其痛苦的,更适合在面试中进行逻辑推导,而不是直接编写代码。
- MLE 面试准备是 Leetcode 陷阱吗?:成员们讨论了准备 MLE 面试 的最佳方式,有人将其描述为一个 陷阱,因为这太依赖于雇主和团队,难以捉摸。
- 相反,一位成员建议 公开构建一些对训练/部署模型的公司有用的东西。
- 数据集混合是预训练的理想选择:成员们建议使用 Zyda-2、ClimbLab 和 Nemotron-CC-v2 进行初始预训练,并指出鉴于它们各自的优缺点,将它们混合使用可能是理想的。
- 一位成员询问了 Token 的分布情况,以及像 slimpj 和 slimpj_c4 scrape 这样的子集是上采样还是下采样。
- NVIDIA 在高质量数据集方面占据主导地位:一位成员指出 目前 NVIDIA 和 HF 在开源数据集的质量维度上处于领先地位。
- 他们分享了 Hugging Face 上 ClimbMix dataset 的链接,称其特别有趣 (https://huggingface.co/datasets/nvidia/Nemotron-ClimbMix)。
- Nemo-CC 2 许可证引发关注:成员们讨论了 Nemo-CC 2 的许可条款,对共享利用该数据集的模型/数据集可能受到的限制表示担忧,并指出他们可以在提前 30 天通知的情况下,无理由随时终止你的许可。
- 一位用户总结道:未经 NVIDIA 事先书面同意,你不允许在数据集上训练模型、评估模型并公开分享结果,更多细节可见 这篇论文。
Nous Research AI Discord
- 意外创建的自主 AI:一位用户分享了一个 GitHub 仓库,声称意外地创建了自主 AI。
- 目前尚未提供关于该项目具体细节或能力的进一步信息。
- WeiboAI 表现惊艳但在 2 轮对话后出现偏移:用户们讨论了基于 qwen2.5 的新模型 WeiboAI,指出其初始表现出奇地好,并引用了这条推文。
- 另一位用户指出,该模型在前 1-2 轮对话后会出现偏移,但对于一个 1.5B 参数的模型来说,其表现依然相当不错,并且能够背诵来自 Quora 的内容。
- Baguettotron 的推理能力引起关注:一位成员询问了关于 Baguettotron 的基准测试情况,指出尽管其体积较小,但其推理轨迹(reasoning traces)相当有趣。
- 目前还没有关于是否进行了该基准测试的后续消息。
- Nous Chat 暂不支持 GGUF 文件:用户获悉,目前不支持直接将 GGUF 文件导入 Nous Chat,但可以通过 llama.cpp 或 Ollama 等工具在本地使用。
- 分享了 huggingface 文档链接和 Ollama 官网。
- ixlinx-8b 作为 SOTA 小模型亮相:经过长时间的开发,ixlinx-8b 模型在 GitHub 上发布,被宣传为来自本地黑客松的先进(SOTA)小模型。
- 创建者邀请大家贡献代码,并建议 Hermes 的开发者对其进行评估。
Latent Space Discord
- Windsurf 发布 Aether 模型供测试:Windsurf Next 在
#new-models频道推出了 Aether Alpha、Aether Beta 和 Aether Gamma 模型,限时提供免费测试,并提供了直接下载链接。- 用户被敦促尽快测试这些模型,因为免费访问权限持续时间不会超过一周。
- OpenAI 训练成本趋势图表:Masa 展示的 OpenAI 训练成本趋势图引发了关于各项指标的讨论,成员们要求提供更多数据点,包括烧钱率(burn rate)和营收。
- 一些成员指出 OpenAI 已经成立近 10 年,并建议根据通货膨胀调整相关数据。
- 据称 Meta 的 FAIR v2 计划受挫:根据这条推文,Susan Zhang 透露,Meta 在 2023 年初拒绝创建一个精简的 FAIR v2 以追求 AGI,而是要求 GenAI 部门交付 AGI 产品。
- 她指责缺乏远见的高管雇佣了亲信,这些人过度承诺结果,随后带着水分很大的简历加入 OpenAI,造成了持久的损害。
- Character.AI 的 Kaiju 模型优化推理速度:Character.AI 专有的 Kaiju 模型(13B/34B/110B)通过 MuP-style scaling、MQA+SWA 和 ReLU² 激活函数等技术针对推理速度进行了工程优化,详见此 Twitter 线程。
- 由于生产环境的限制,团队刻意避开了 MoEs 架构。
- Magic Patterns 2.0 获得 600 万美元 A 轮融资:Alex Danilowicz 发布了 Magic Patterns 2.0,并宣布获得由 Standard Capital 领投的 600 万美元 A 轮融资。
- 该公司庆祝在没有雇员的情况下通过自筹资金实现了 100 万美元 ARR,目前已有 1,500 多个产品团队在使用该 AI 设计工具,并计划在企业、工程、社区和增长等岗位快速招聘。
Modular (Mojo 🔥) Discord
- Mojo 的动态反射深入探索:Mojo 旨在支持动态类型反射 (dynamic type reflection),利用其 JIT compiler 来处理动态数据,并且 try-catch 和 raise 将成为错误处理 (error handling) 的标准方式,以匹配 Python 的风格,同时还提供 monadic options。
- 在最近的一次采访中,Chris Lattner 表示 Mojo 的元编程比 Zig 的更强大,因为 Mojo 可以在编译时分配内存(YouTube 链接)。
- 成员们讨论强制性
mut:围绕函数参数强制使用mut注解的繁琐性展开了辩论,并与 Rust 和 Python 进行了对比。- 成员们建议采取折中方案:仅当参数被重用时,
fn内部才强制要求mut,而调用侧的mut注解则在函数调用后应用。
- 成员们建议采取折中方案:仅当参数被重用时,
- M4 上的 Metal 编译器崩溃问题已解决:一位成员在 Apple M4 GPU 上按照“GPU 编程入门”教程操作时,遇到了 Metal Compiler failed to compile metallib 错误。
- 该问题通过确保完整安装 Xcode、移除 GPU kernel 中的
print()语句以及使用最新的 nightly build 得到了解决。
- 该问题通过确保完整安装 Xcode、移除 GPU kernel 中的
- 直面 C-FFI 难题:成员们讨论了在 Mojo 中进行 C-FFI 的痛点,并建议使用
Origin.external来绕过显式尝试修复问题的重写。- 还有人建议使用
MutAnyOrigin来精确保留旧行为,尽管这会延长作用域内的所有生命周期 (lifetimes)。
- 还有人建议使用
comptime Bird语法受到审视:讨论了用于 trait 组合的语法comptime Bird = Flyable & Walkable,一些人认为它不如alias关键字直观。- 另一些人则认为
comptime更准确地反映了该关键字的功能,特别是在静态反射 (static reflection) 以及在编译时混合类型和值的能力方面。
- 另一些人则认为
DSPy Discord
- DSPy 确实需要领域驱动的领域知识:虽然 DSPy 旨在抽象掉提示词工程 (prompting),但特定领域的 LLM 应用仍需要在 signatures 中包含详细指令,一位用户在某些模块中编写了 100 行 指令。
- 共识是,对于复杂任务,DSPy 不仅仅需要基础提示词;它还需要编码领域知识和分步指令,以有效地引导 LLM。
- Signatures:比提示词更好,但仍是提示词?:参与者讨论认为,虽然 DSPy 的 signatures 是比原始提示词 (raw prompts) 更好的抽象,但它们仍然发挥着提示词的作用,特别是在编码业务规则的基于类的 signatures 的 docstrings 中,这有助于优化 (optimization)。
- 该框架有助于编程而非专注于提示词,但社区中的许多困惑源于“提示词”一词对不同的人意味着不同的东西。
- GEPA 几何形状的渐进式收益:虽然 GEPA 旨在优化提示词,但用户发现即使有工具函数,特定的指南仍然是必要的,例如在初始术语失败时指示 LLM 使用正则表达式 (regex) 进行 agentic search。
- 一位用户发现,他们需要添加特定指南,指示 LLM 应发送特定术语供工具通过 ripgrep 搜索,但如果找不到,务必在下一步添加 Regex,否则 LLM 不会在搜索工具中使用 Regex 术语。
- Agentic Agents 增强分析:一位用户分享了一个案例,他们需要指示 LLM 在使用 ripgrep 的 agentic search 中使用 regex,以便有效地搜索文档,这突显了即使使用先进工具也需要特定指导。
- 另一位用户分享了关于指示 LLM 答案可能不在搜索结果第 1 页的经验。
- 分类法尾部问题的探讨:一位成员写了一篇关于他们创建分类法 (taxonomies) 经验的博客文章。
- 他们发现这个话题在结构化生成 (structured generation) 的背景下非常具有相关性。
HuggingFace Discord
- ZeroGPU 性能问题引发关注:成员们讨论了 ZeroGPU 的问题,虽然目前似乎恢复正常,但尚不清楚是否仍存在潜在问题。
- 此前有报告称其无法正常处理日志(logs)。
- Reuben 的递归移除问题已解决:Reuben 因发送消息过多触发垃圾邮件过滤器被机器人封禁,随后由 lunarflu 解封。
- 这一情况引发了关于使用 regex 或 AI 检测垃圾邮件的讨论,同时也引发了对隐私问题的担忧。
- Aquif-3.5-Max-42B-A3B 备受瞩目:成员们注意到 Aquif-3.5-Max-42B-A3B 模型在 Hugging Face 上走红。
- 有推测认为这是因为它经过了 upscaled 和 fine tuned。
- Tokenflood 工具测试 LLM 延迟:一位自由职业 ML 工程师发布了 Tokenflood,这是一个针对 instruction-tuned LLM 的开源负载测试工具,可在 GitHub 上获取。
- 它可以模拟任意的 LLM 负载,对于评估 Prompt 参数变化非常有用。
- MCP 与 Anthropic 及 Gradio 共同庆祝里程碑:由 Anthropic 和 Gradio 主办的 MCP 一周年庆典将于本周五(11 月 14 日 00:00 UTC)在 https://huggingface.co/MCP-1st-Birthday 拉开帷幕。
- 活动为参与者准备了 2 万美元现金奖金和超过 270 万美元的 API 额度,已有数千人报名。
Moonshot AI (Kimi K-2) Discord
- 研究员模式 (Researcher Mode) 的 Bug 令用户沮丧:用户报告称 Researcher Mode 返回的是错误而非结果,即使之前使用极少,并询问了额度问题。
- 问题可能与 Researcher Mode 是否完全付费有关,因为用户收到了额度不足/升级提示。
- Kimi 编程计划 API 配额耗尽:由于网页搜索和计划模式的使用,Kimi 编程计划的 API 配额消耗极快(几小时内)。
- 一位用户推测 Moonshot AI 可能会转向类似 Cursor 的计划,特别是考虑到他们相对于 OAI 和 Anthropic 的融资情况。
- Kimi API 设置引发困扰:用户在通过 HTTP 设置 Kimi API 的 thinking model 时需要帮助,尽管有额度和有效的 API key,仍遇到授权失败。
- 最终发现该用户使用的是国内平台 URL,而非全球通用的
https://api.moonshot.ai/v1/chat/completionsURL,更改后问题解决。
- 最终发现该用户使用的是国内平台 URL,而非全球通用的
- Turbo 版本提升 Kimi K2 运行速度:用户询问如何通过 API 加速 Kimi K2 thinking model 的处理时间。
- 建议使用 turbo 版本,它能提供更快的输出速度且不影响模型性能。
- GPT 5.1 悄然推出:成员们注意到 GPT 5.1 的推出,并表示它是 OpenRouter 上的 stealth 模型,表现尚可但被安全阉割(safetylobotomized)严重。
- 一位成员庆祝道:几周前大家就知道它要来了,而 OpenAI 遭遇了挫折。
Yannick Kilcher Discord
- Elevenlabs 发布语音转文本功能:以 text to speech 闻名的 Elevenlabs 推出了 speech to text 功能,详见其官方博客。
- 成员们正在思考这一新功能是否会增强 Elevenlabs 在市场上的吸引力。
- Kimi K2 在编程任务中表现出色:一位成员分享了一个 YouTube 视频,展示了 Kimi K2 在 one-shot 编程任务中的强劲表现。
- 未提及更多细节。
- ICLR 审稿引发争议:一位成员对 ICLR 审稿过程表示沮丧,称尽管解决了之前的顾虑并增加了包含 3 万多个新问题 的新数据集,重新提交后的得分依然很低。
- 该成员引用审稿人的话称,审稿人批评他们没有提供超参数(尽管超参数就在附录中),并无视大量的测试工作,认为其作品不是一篇基准测试论文。
- Whisper 的问题解决了?:一位成员在直接通过 PyTorch 使用 Whisper 模型时遇到错误和幻觉,但在使用 Whisper-server 后问题得到缓解。
- 他们建议编译支持 Vulkan 的 Whisper-server 以提高便携性,并过滤掉静音部分以改善转录效果。
- 关于从记忆到推理的论文:一位成员链接了一篇题为《From Memorization to Reasoning in the Spectrum of Loss Curvature》的论文:[2510.24256] From Memorization to Reasoning in the Spectrum of Loss Curvature。
- 未提及更多细节。
MCP Contributors (Official) Discord
- 时区信息从 MCP Client 传输到 Server:讨论了关于将时区信息从 MCP clients 传递到 MCP servers 的议题,目前正考虑通过 client 发送的通知或 server 诱导的方式将其作为 metadata 提供。
- 一名成员起草了一份关于时区的 SEP(规范增强提案),并将在内部反馈后发布到 GitHub。目前正在权衡是将其添加到 CallToolRequest、使用 Header、添加到 JSONRPCRequest.params._meta,还是添加到 InitializeRequest 中。
- Claude.ai 应对连接问题:成员们讨论了如何调试 Claude.ai 与 MCP Servers 之间的连接问题。
- 成员指出该问题具有不稳定性且与特定 client 相关,并建议增加一种开发者模式,以提供更多关于运行状况的反馈。
- MCP Tool Call 尝试新方案,考虑替代序列化方式:成员们探讨了在 mcp tool call results 中返回除序列化 JSON 以外的数据,例如 Toon format。
- 一名成员分享了在合成数据集上进行小规模评估(evals)的结果:准确率相当,速度慢 9%,节省 11% 的 tokens(n = 84, p = 0.10)。
Manus.im Discord Discord
- AI 自动化专家加入服务器:一位擅长 AI 自动化集成的专家新成员加入了服务器,带来了 Python, SQL, JavaScript 以及 PyTorch, scikit-learn, LightGBM, 和 LangChain 等框架的技术能力。
- 他们在构建聊天机器人、推荐引擎和时间序列预测系统方面拥有丰富经验。
- 服务器考虑增设西班牙语板块:一名成员建议在服务器内创建一个专门的西班牙语板块,并提供了相关背景图片链接 1.png, 2.png, 3.png, 4.png。
- 该建议旨在迎合说西班牙语的成员,并可能扩大社区的影响力。
- 工程师追求生成式引擎优化:一名成员正在寻求关于如何有效跟踪和进行 Generative Engine Optimization(生成式引擎优化)的资源和指导。
- 这一请求凸显了人们对优化生成式模型以提升性能的日益关注。
- 用户遇到棘手的 Manus 系统错误:一位用户报告了一个反复出现的 Manus 系统错误,导致无法发布,具体错误为 “pathspec ‘417ea027’ did not match any file(s) known to git”。
- 该成员对缺乏支持表示沮丧,并指出尽管一直在支付订阅费用,但之前的某些问题仍未解决。
- 支持服务困扰 Manus 用户:多名成员在访问 Manus support 时遇到困难,其中一人报告支持频道似乎已关闭。
- 一名用户在遇到 git commit 错误后,被 Manus Agent 建议 “等待 Manus 支持” 或 “升级工单”,并提供了一个 反馈链接。
aider (Paul Gauthier) Discord
- Aider 的 Markdown 故障:用户发现 Aider 在使用
anthropic.claude-sonnet-4-5-20250929-v1:0在 markdown 文件中创建代码片段时,会被嵌套的代码 markdown 标记搞混。- 在
conventions.md文件中添加三个和四个反引号('```'和'````')会触发 Aider 使用<source>标签来界定文件,从而解决了代码片段问题。
- 在
- Aider 的 Vim 模式获得好评:一位用户称赞 Aider 的 Vim 模式 非常出色,并对新的
<#1403354332619079741> aider-ce/load-session//save-session功能表示赞赏,认为这在暂停和恢复任务时非常有用。- 这些功能允许无缝中断和继续任务,显著提升了用户体验。
- Aider 的更新频率受到质疑:用户对 Paul Gauthier 缺乏关于 Aider 开发状态 的更新表示担忧。
- 出现了关于 Paul Gauthier 是否仍在积极开发 Aider 的猜测,一些用户想知道是否错过了关于他离职的公告。
- GPT 5.1 发布但未提供数据:成员们注意到 GPT 5.1 的发布,但观察到发布说明中没有包含任何基准测试(benchmarks)。
- 缺乏基准测试使得很难评估 GPT 5.1 与之前版本相比的改进和能力。
tinygrad (George Hotz) Discord
- 软件包数据面临审查:一位成员询问了归档文件中可能遗漏的文件,质疑
package_data是否是一个空操作 (no-op),并建议明确指定文件可以优化流程。- 该成员对审阅者富有洞察力的反馈表示感谢,暗示正在努力改进项目中的包管理。
- OpenCL 错误消息急需改进:一位成员主张在未检测到 OpenCL 设备时增强错误消息提示,并以晦涩的
RuntimeError: OpenCL Error -30: CL_INVALID_VALUE为例。- 定位到的错误源自
/tinygrad/tinygrad/runtime/ops_cl.py第 103 行,表明 OpenCL 运行时操作需要更具信息量的诊断。
- 定位到的错误源自
Windsurf Discord
- Windsurf 发布秘密 Aether 模型:Windsurf 意外发布了一组秘密模型(Aether Alpha、Aether Beta 和 Aether Gamma),可在 Windsurf Next 中使用,并向一小部分 Windsurf Stable 用户开放。
- 这些模型可以免费使用,团队正在指定频道征求反馈。
- Windsurf Next 开放预览:Windsurf Next 是 Windsurf 的预发布版本,包含实验性功能和模型,用户可以在此处下载。
- 用户可以测试新功能并对秘密模型提供反馈。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会长时间没有动静,请告知我们,我们将将其移除。
您收到此电子邮件是因为您通过我们的网站订阅了。
想更改接收这些电子邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:各频道详细摘要与链接
LMArena ▷ #general (1258 条消息🔥🔥🔥):
Riftrunner vs 其他模型, GPT 5.1 基准测试, Gemini 3 Pro 预测, AI 模型谄媚现象, Riftrunner 游戏开发
- **Riftrunner 在其他模型失败的情况下创建了马里奥游戏:成员们一致认为,与其他模型相比,没有模型在创建马里奥游戏方面比 **Riftrunner 做得更好。
- 一些成员指出 Riftrunner 可能会撒谎,而另一些成员则提到它比 Lithiumflow 更好。
- **rain-drop 证实为 Llama 模型:成员们透露模型 **rain-drop 实际上是一个 Llama 模型,并发布了截图。
- 用户发现 rain-drop 产生的终端输出很糟糕,类似于 Gemini 3 Flash。
- **Riftrunner 在代码任务中证明优于 LithiumFlow:一位用户确认 **Riftrunner 在编码任务上优于 Lithiumflow,特别提到了它创建功能性 3D Flappy Bird 游戏的能力,但它也患有懒惰综合征。
- 一位用户分享了 3D Flappy Bird 游戏的 Prompt,导致生成了 2000 行代码,他们说,“如果你激励它,它可能会听你的”。
- **GPT 5.1 与 Gemini 3 Pro 相比表现平平:成员们讨论了最近发布的 **GPT 5.1,指出了它的缺点,并希望 Gemini 3 Pro 会有显著提升。
- 一位用户称 GPT 5.1 是垃圾,而许多成员正在等待下周某个时候发布的 Gemini 3。
- **Riftrunner 展示了卓越的理解和调试能力:一位用户强调了 **Riftrunner 的卓越理解力,通过简单的 Prompt 让它创建了一个 3D Flappy Bird 游戏,它还修复了用户游戏中的一些问题并添加了声音。
- 另一位用户确认 Riftrunner 在编码任务上比 Lithiumflow 更好,但他们表示 Lithiumflow 在写作方面非常出色,不确定 Riftrunner 表现如何。
{kind=link}
LMArena ▷ #announcements (1 条消息):
Code Arena, WebDev Arena, LMArena Leaderboard
- Code Arena 震撼登场:Code Arena 现已在 LMArena 上线,提供可部署 Web 应用的实时生成功能,用户可以直接检查并评审,接替了旧版的 WebDev Arena。
- 博客文章 和 YouTube 视频 提供了更多细节,而 排行榜 展示了新的评估系统。
- WebDev Arena 焕然一新:WebDev Arena 根据社区反馈进行了重新设计,现更名为 Code Arena,并采用了完全重构的评估方法。
- 模型生成实时的、可部署的 Web 应用和站点,任何人都可以实时打开、检查并直接评审。
Perplexity AI ▷ #general (670 条消息🔥🔥🔥):
Perplexity referral program, Gemini 2.5, GPT-5 mini vs GPT-5, Comet issues, Comet for Android
- 推荐计划指控引发账号封禁:多名用户报告因“欺诈活动”被 Perplexity Partner Program 封禁,尽管他们声称推荐是真实的,并对支持团队未回应申诉表示沮丧。
- 一些用户怀疑封禁与通过邀请使用相同代码的小号或使用 VPN 来钻推荐系统漏洞有关,而另一些人则推测这可能与平台审查 100 美元奖励的支付资格有关。
- Gemini 2.5 Pro 出现实现问题:用户报告 Perplexity 中的 Gemini 2.5 Pro 存在问题,一位用户表示“目前在 pplx 中已损坏且实现不佳,无法修复”。
- Perplexity 的界面似乎会自动切换到 GPT,即使选择了 Gemini 2.5 Pro。
- GPT-5 thinking mini 还是 GPT-5 常规版?:一位购买了 GPT Go 订阅 的用户报告称,虽然广告宣传是 GPT-5 thinking,但主要使用的是 GPT-5 thinking mini,导致其申请退款。
- 成员们就他们是否偏好特定模型展开了辩论。
- Comet 用户排查网页控制与功能问题:用户报告了 Comet AI Assistant 的问题,如无法执行网页操作、按钮无响应以及无法控制浏览器,一些人推测 VPN 使用或登录状态可能是原因。
- 一些用户找到了解决方案,如登录、更换 IP 地址 (VPN) 或删除并重新安装 Comet,或在故障排除频道发帖。
- 用户希望获得 Pro Discord 角色:多名用户询问如何获得 Discord 中的 Pro 角色,其他用户引导他们前往网站将 Discord 账号与 Perplexity 账号绑定。
- 一位成员指出:“当你点击 Discord 按钮时,网站应该会自动分配角色,在加入服务器的过程中它让我把 Discord 绑定到了网站上”。
Perplexity AI ▷ #sharing (3 条消息):
Sourcify Event, Open Source, Forks, PRs and Chaos, Threads Shareable
- **Sourcify IN 举办开源冒险活动!:Sourcify** IN 将于 2025 年 11 月 15 日 举办一场题为 Forks, PRs, and a Dash of Chaos: The Open Source Adventure 的活动。
-
演讲将由 Swapnendu Banerjee (GSoC 2025 @Keploy Engineering @DevRelSquad) 主讲,并将在 Google Meet & YouTube Live 上播出。
-
- Discord 帖子需要设置为可分享!:一位成员请求将某个帖子设为
Shareable(可分享),并附带了显示如何设置该选项的附件。- 这与 此 Discord 帖子 有关。
Cursor Community ▷ #general (534 messages🔥🔥🔥):
Cursor IDE 成本意识, Cursor vs Copilot 偏好, 利用 ChatGPT 漏洞, Cursor 'Max' 模式, Cursor Rules
- Review agent 产生费用,但很便宜:成员们注意到 Cursor IDE 中的 agent review 功能在每次使用时都会产生费用,不过它相对便宜,一位用户已经使用了其配额的 76%。
- 用户们展示了他们的使用情况截图(例如这张),并发现点击 Try Again 有时可以解决问题。
- Cursor vs Copilot:偏好胜出:一些用户在尝试 Cursor 后回到了 Copilot,强调工具偏好可能是主观的。
- 一位用户提到,“我兄弟是 Copilot 的粉丝,不知道为什么”,突显了个人偏好的差异。
- 早期无限利用漏洞的机会:一些用户在 ChatGPT 5 短暂免费期间“利用了漏洞”,包括无限的 Opus 4 请求,一位用户感叹道:“很遗憾我当时不知道这个机会”。
- 这个计费 Bug 允许无限使用,被描述为“Bug 满天飞,我们当时拥有无限的一切”。
- Cursor ‘Max’ 模式释放全部潜力,但会产生额外费用:Cursor 中的 Max 模式取消了限制以最大化性能并降低成本,使其能够读取整个文件而不是代码块(chunks)。
- 然而,使用 Sonnet 4.5 超过 200k context 会使成本翻倍,用户幽默地建议对其进行限制:“我们不能把它限制在 200k,然后在之后再给另一个命令吗 💀”。
- 创建规则以维持 AI 纪律:成员们正在建立自定义 rules 和 lint 来控制 AI 行为,防止“脏代码”进入仓库。
- 一位成员分享了一种精简的方法:“我实际上采用了 .cursorrules 的概念,并将其转变为一个严格的系统,通过 lint、自定义 eslint 插件和 husky 作为我防止脏代码进入的最后防线,防止 AI 偏离轨道”。
GPU MODE ▷ #general (10 messages🔥):
popcorn-cli 语法, status 400 grayscale, 以 CPU 为中心的社区, 排行榜/评估选择, export 命令引号
- Popcorn-CLI 语法困扰:一些用户在运行
popcorn-cli submit时遇到了语法错误,其他人建议查看 popcorn-cli readme 以获取正确的语法。 - Grayscale 挑战已结束:一位用户收到了 status 400 错误,并发现 grayscale 排行榜已关闭。
- 对 CPU 内核竞赛社区的渴望:一位成员询问是否存在类似于 gpumode 的以 CPU 为中心的社区,重点关注 CPU 内核竞赛。
- 评估谜题探索:一位用户提到,可能需要确保在 popcorn cli 中选择了 nvmnvfp4_gemv,它位于评估套件的最底部。
- Export 使用技巧:一位成员澄清说,在使用 export 命令时,输入的 URL 不应带引号。
GPU MODE ▷ #cuda (18 messages🔥):
CUDA 编译器选项, warp tiling, TMEM 分配, PTXAS 优化, 通过 TMEM 进行 Mutex 锁定
- CUDA 编译器入门准则:新的 CUDA 开发者询问了除基础用法之外的基本编译器选项,一位成员建议使用
-O3进行优化,并使用-lineinfo来保留行号信息,以便使用 Nsight Compute 进行性能分析。- 他们还推荐了
-res-usage选项 来检查编译后的寄存器和静态共享内存使用情况。
- 他们还推荐了
- PTXAS 优化启示:有成员澄清说,
-O3编译器选项主要优化代码的主机端(CPU)部分,如果 CPU 代码不在关键路径上,这可能并不那么重要。- 一位成员指出,PTXAS 的默认优化级别已经是 O3,这使得该标志对于 GPU 代码优化来说是多余的。
- 对 TMEM 静态分配的遗憾:一位开发者质疑为什么 TMEM 必须动态分配,认为这与静态共享内存相比是一种退步。
- 另一位成员推测 TMEM 分配可以用于依赖管理,TMEM 缓冲区充当 Mutex,对其包含的数据进行锁定。
GPU MODE ▷ #jobs (1 条消息):
HippocraticAI Hiring, LLM Inference Engineer Role, CUDA/CUTLASS/Triton expertise, NVIDIA B200s, AMD MI355, and Google TPUs
- HippocraticAI 扩展 LLM 推理团队:HippocraticAI 正在扩展其 Large Language Model 推理团队,以提升全球医疗服务的可及性,并积极为多个职位寻找优秀工程师。
- 他们在 https://lnkd.in/eW5qzuMc 发布了职位链接,鼓励有兴趣的候选人申请,共同塑造医疗保健的未来。
- LLM 推理工程师职位专注于优化:LLM 推理工程师职位将专注于研究、原型设计和构建最先进的 LLM 推理解决方案,特别要求具备 CUDA, CUTLASS, Triton, TileLang 方面的专业知识,或对 vLLM 和 SGLang 等主流推理框架有贡献。
- 该职位涉及在尖端硬件平台上优化和加速推理性能,包括 NVIDIA B200s, AMD MI355 和 Google TPUs。
GPU MODE ▷ #beginner (4 条消息):
Atomic Max for FP32, PTX Documentation Inaccuracy
- 通过 Int32 技巧实现 FP32 的 Atomic Max:一位成员指出,虽然 PTX 文档暗示可以对 FP32 进行 atomic max 操作,但实际上会导致错误,不过可以使用 int32 绕过。
- 该技巧涉及在符号位被设置时反转低 31 位,以实现类 int32 的表示,如 PyTorch 源代码 所示。
- PTX 文档声称支持 Atomic Max,现实却并非如此!:尽管 PTX 文档有所暗示,但并不直接支持 FP32 类型的 atomic max 操作,这会导致编译错误。
- 编译器报错指出
.max操作在atom指令中需要特定的类型,如.u32,.s32,.u64,.s64,.f16,.f16x2,.bf16或.bf16x2。
- 编译器报错指出
GPU MODE ▷ #off-topic (3 条消息):
Skunk on a car, Dune Meme
{kind=link}
GPU MODE ▷ #rocm (3 条消息):
hipkittens, image0.jpg
- 分享 HipKittens 链接:一位成员在 X.com 上分享了 HipKittens 的链接,引发了积极反馈。
- 另一位成员给出了积极回应:“让我笑了一下——好东西!”
- 分享了 image0 附件:一位成员在 cdn.discordapp.com 上分享了一张名为 image0.jpg 的图片。
{kind=link}
GPU MODE ▷ #self-promotion (5 条消息):
hipkittens, FSDP Implementation, AMD Open Source AI Week Recap
- HipKittens 被分享了!:一位成员在 luma.com/ai-hack 分享了 hipkittens 的链接。
- NanoFSDP 简化分布式训练:一位成员编写了一个小型的 FSDP 实现来学习分布式训练的基础知识,代码托管在 github.com/KevinL10/nanofsdp。
- 他们指出该实现非常精简但文档齐全(约 300 行代码),可以作为
fsdp.fully_shard的直接替代品,这对于理解 PyTorch 底层如何实现 FSDP 可能会有帮助。
- 他们指出该实现非常精简但文档齐全(约 300 行代码),可以作为
- AMD 开源 AI 周回顾:一位成员在 amd.com/en/developer 分享了 AMD 开源 AI 周的回顾。
GPU MODE ▷ #🍿 (4 条消息):
从源码构建,Nvidia 竞赛提交
- 编译兼容性考量:建议从源码构建并在较旧的镜像上进行编译以提高兼容性,因为发布版本似乎是在 Ubuntu 24.04 上完成的。
- 负责 CI 的成员 <@325883680419610631> 正在休产假/陪产假,因此这可能需要一段时间才能实现。
- 通过 Discord 机器人提交 Nvidia 竞赛:一位成员询问 Nvidia 竞赛 的提交是否主要通过 Discord 机器人进行。
- 另一位成员确认他们支持 Discord、网站和 CLI,其中 CLI 是最受欢迎的提交方式。
GPU MODE ▷ #thunderkittens (2 条消息):
Hipkittens 发布,X 上的其他 Kittens
- Hipkittens 在 X 上分享:一位成员分享了 X 上的 Hipkittens 链接。
- X 上还有更多 Kittens:另一位用户点赞了。
GPU MODE ▷ #submissions (66 条消息🔥🔥):
排行榜提交,GEMV 作弊指控,Benchmark 输入尺寸
- NVIDIA GEMV 排行榜竞争升温:多位用户向
nvfp4_gemv排行榜提交了结果,<@1435179720537931797> 最终以 24.5 µs 的成绩夺得第一名。- 其他值得注意的提交包括 <@772751219411517461> 以 66.0 µs 获得第三名,以及 <@1291326123182919753> 以 58.4 µs 获得第六名。
- 输入尺寸引发 GEMV Benchmark 辩论:一位成员质疑 Benchmark 的输入尺寸,指出如果顶尖成绩在 7 µs 左右,输入可能非常小,这可能会导致优化偏差,并增加 prologue 和 epilogue 的相对开销。
- 该成员建议在更大的输入上评估 Benchmark,以提供更现实的评估。
- GEMV 排行榜缓存争议:
nvfp4_gemv排行榜上的顶尖成绩被认为可能是在 Benchmark 运行之间缓存值的结果,从而引发了作弊指控。- 另一位成员认为这些问题可能是 LLM 在迭代问题时产生的结果,并表示这可能是一个无心之过。
- Grayscale V2 排行榜刷新纪录:<@1144081605854498816> 在 L4 上以 27.5 ms 获得第七名,并在 H100 上以 12.9 ms 获得第八名。
- 此外,该用户还在 A100 上以 20.4 ms 和 B200 上以 6.69 ms 刷新了
grayscale_v2排行榜的个人最好成绩。
- 此外,该用户还在 A100 上以 20.4 ms 和 B200 上以 6.69 ms 刷新了
GPU MODE ▷ #cutlass (1 条消息):
kinming_32199: 令人印象深刻的动画👍
GPU MODE ▷ #general (2 条消息):
GPU MODE 排行榜,提交过程
- GPU MODE 排行榜提交选项:用户询问提交应该通过 Discord 还是 GPU MODE 网站 进行。
- 一位成员澄清说两种方法都是可以接受的。
- 通过 Discord 提交:一位用户询问是否可以通过 Discord 进行提交。
- 另一位用户确认 Discord 提交确实是被接受的。
GPU MODE ▷ #multi-gpu (1 条消息):
DMA 文档,RDMA 文档,Wikipedia,ChatGPT,厂商网站
- 寻找 DMA 和 RDMA 文档:一位成员正在寻找比 Wikipedia、ChatGPT 和厂商网站上提供的更好的 Direct Memory Access (DMA) 和 Remote Direct Memory Access (RDMA) 文档。
- 寻求额外的 DMA/RDMA 资源:该用户对当前的信息源表示不满,希望能有更详细或更具技术性的文档。
GPU MODE ▷ #helion (9 messages🔥):
Triton Errors, Auto Skip Triton Errors, Helion Configs BC-compatible
- Triton 错误自动调优(autotuning)调查:一名成员询问为什么在进行 autotuning 时默认不跳过 Triton errors。
- 另一名成员回答说 他们已经自动跳过了其中的大部分,并引用了 helion autotuner logger。
- Helion Configs 承诺 BC-Compatibility(向后兼容性):一名成员询问 Helion Configs 是否会 BC-compatible。
- 另一名成员表示 是的,我们将保持 BC 兼容,并举例说明 他们将索引更新为列表而非单个值,因为每个 load/store 都可以独立优化以获得性能提升,但他们仍然支持单值输入。
GPU MODE ▷ #nvidia-competition (212 messages🔥🔥):
Cutlass and CuTe 4.3.0, Popcorn-cli submission errors, Kernel global caching allowed, CuTe DSL is not requirement, torch doesn't support sm100
- Cutlass 和 CuTe 修复提交问题:CuTeDSL 和 Cutlass 已更新至 4.3.0,修复了 CuTe 提交的问题,并且 CuTe 示例已通过测试。
- Popcorn CLI 身份验证错误:用户在执行
popcorn-cli submit时遇到了 401 Unauthorized 错误,通过注册时提供的 Discord OAuth2 链接重新进行身份验证后解决。- 一名用户最初漏掉了 “Please open the following URL in your browser to log in via discord: https://discord.com/oauth2/authorize?client_id” 这一步骤。
- 允许缓存已编译的 Kernel:允许缓存已编译的 Kernel,但禁止缓存结果。
- 澄清指出,虽然允许缓存已编译的 Kernel,但不允许在 benchmark 迭代之间缓存 tensor 值,因为每个 benchmark 应该使用不同的数据,但保持相同的 shape。
- 可以使用原始 PTX 进行 Kernel 实现:用户确认可以编写 CUDA C++ 或原始 PTX,并使用
torch.cuda.load_inline加载,参考代码 可在此处获取。- 一名用户询问是否有 CUDA 示例模板,但回复指出虽然目前没有,但可以使用 CUDA 和 PTX,尽管为其制作模板可能会比较慢。
- Blackwell GPU 细节披露:B200 GPU 拥有 148 个 SM(流式多处理器),运行在 1.98 GHz 的加速频率下,并用于对提交的作品进行评分。
- Nvidia 的 博客文章 中包含了 B300 的架构图。
GPU MODE ▷ #xpfactory-vla (3 messages):
RLinf, Qwen3-VL VLA-adapter training
- RLinf 仓库:新工具上线:一名成员提到可以关注 RLinf,并承诺在运行一夜 Qwen3-VL VLA-adapter 训练后发布更新。
- GPU 使用情况询问:一名成员询问了用于训练的 GPU 数量和型号,对 GPU 资源有限的用户表示担忧。
- 未收到回复。
Unsloth AI (Daniel Han) ▷ #general (179 条消息🔥🔥):
保加利亚语的 VibeVoice 微调,Intel autoround 量化与 BNB 4-bit 量化训练对比,Unsloth 中的 QAT,MoE 模型与输出质量,Aquif-3.5-Max-42B-A3B
- 保加利亚语忧郁:VibeVoice 在新语言上表现吃力:一位成员尝试将 VibeVoice 用于保加利亚语 TTS,但发现结果“不太好”,虽然“接近可理解”,但仍需要进一步微调。
- 另一位成员开玩笑说,听起来“就像一个喝醉的英国人试图阅读句子的拼音版”。
- QAT 对决:Intel autoround vs. BNB 4-bit:有人提出了关于使用 Intel autoround 量化进行训练的问题,以及它是否比使用 bnb 4-bit 量化更有优势。
- 一位成员提到 QAT(量化感知训练)现在已在 Unsloth 中可用,但与 autoround 的兼容性尚不确定,可能需要自定义,并指出 QAT 应以快速、简单的量化格式为目标。
- MoE 乱象:质量与显存:一位用户询问了 Mixture of Experts (MoE) 模型与稠密模型相比对输出质量的影响。
- 解释称,相同规模和训练量的 MoE 模型通常提供相当的知识储备,即使它们的智能程度有所不同。
- Aquif 趣闻:热门模型遭到吐槽:成员们幽默地调侃了热门模型 Aquif-3.5-Max-42B-A3B 的名字,并对其报告的 HLE 分数 (15.6) 表示怀疑。
- 有人猜测该模型可能是一个经过“刷榜”(benchmaxxed)的合并模型,一位成员指出,在社区模型超越官方模型的那个阶段,他们经常干这种事。
- 安全恶作剧:玩家请注意!:成员们讨论了游戏中反作弊软件的安全影响,担心驱动级访问权限和潜在漏洞。
- 一位成员讲述了由于密码重复使用导致游戏账户虚拟物品被盗的经历,并警告了运行具有完整系统访问权限且未经审计的软件的风险。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 条消息):
粉丝偶遇,身份
- 粉丝宣称效忠:一位用户向另一位用户示意他们这里有一个小朋友。
- 该用户随后自称是粉丝:LOL I HAVE A FAN。
- 用户询问粉丝身份:该用户随后询问粉丝的身份:who are you?。
Unsloth AI (Daniel Han) ▷ #off-topic (79 条消息🔥🔥):
ONNX Runtime, Free Threading, 翻译模型提示词, SLM 中的上下文丢失, GPT-5-1 破折号
- Python 3.14 ONNX Runtime Wheel 延迟:一位成员报告称,在为支持自由线程(free threading)的 Python 3.14 构建 Windows 版 ONNX Runtime wheel 时遇到困难。
- 他们提到必须亲自为许多库进行自由线程支持,但缺乏精力去验证像 gRPC 这样的大型项目的兼容性。
- 翻译数据集提示词:一位成员分享了一个用于为 LLM 生成翻译数据集的提示词,强调仅使用提供的样本,不生成新的翻译。
- 该提示词详细说明了如何创建具有特定格式规则的数据集,包括语言组合和标点符号对齐。
- 对话式 SLM 的上下文丢失问题:一位成员报告称,在针对印地语和英语的对话用途微调 1B Llama3.2 模型时遇到了上下文丢失。
- 另一位成员指出,所有的 LLM 在长上下文方面表现都很差,甚至是 Gemini,在 20-30k 的轮次对话后都会崩溃。
- GPT-5-1 与破折号:一位成员指出 GPT-5-1 示例 仍然使用 em dashes(破折号)。
- 另一位成员回应道:考虑到他们使用的数据,我认为他们很难摆脱这一点。
- AI 模型选择:自主 vs 控制:成员们讨论了 AI 模型选择的未来,辩论了自动化选择与用户控制的优劣。
- 一些人对 AI 决定选择哪个模型表示担忧,另一些人则指出这个名字实际上是个不错的选择,强调了收集数据和见解的重要性。
Unsloth AI (Daniel Han) ▷ #help (37 条消息🔥):
低损耗架构,文档中 Ollama 链接失效,微调 VibeVoice 时的依赖问题,本地训练 GPT-OSS 模型的脚本,GPT-OSS-20b 生成无意义内容
- Ollama 链接遭遇文档灾难:一位用户报告称,文档页面上的 Ollama 链接 已失效。
- 他们还质疑了示例中
f16的使用,建议在对 KV cache 使用 8-bit 量化时,应改为使用q8_0。
- 他们还质疑了示例中
- VibeVoice 微调面临依赖困局:一位用户在 Kaggle 上使用
/unsloth-finetuning分支尝试微调 VibeVoice 时遇到了大量依赖问题,涉及 transformers, numpy 和 torch 等包的冲突。- 一个建议是尝试先执行
pip install transformers==4.51.3,然后安装 vibevoice,之后再升级 transformers 并观察 vibevoice 是否仍能工作(或者就保持在该 transformers 版本?)。
- 一个建议是尝试先执行
- GPT-OSS-20b 喷出无意义解答:一位用户报告称,在提示 gpt-oss-20b 解决数学问题(解 x^5 + 3x^4 - 10 = 3)时,模型生成了无意义的内容。
- 用户将问题定位到其 Dockerfile 中先前训练模块的一个 attention 补丁上,该补丁修改了 matmul() 调用并移除了 out= 参数;他们在 GitHub 上分享了详细的代码和日志。
- Unsloth GGUF 提升量化质量:用户注意到 Unsloth GGUF 通常包含针对准确性的改进和性能修复。
- 他们补充说,尽管经过了量化,但 Unsloth 在 Hugging Face 上为某些模型提供的动态量化通常比其他量化格式具有更高的准确性。
- 微调面临 RAG 之争:一位用户寻求信息向其 CTO 解释为什么微调是比 RAG 更好的解决方案,对此另一位用户回复称微调和 RAG 是完全不同的东西,如果想要检索知识/文档,用户应该将两者结合使用 以获得最佳效果。
OpenRouter ▷ #announcements (1 条消息):
MiniMax M2,付费端点迁移
- MiniMax M2 免费期结束:MiniMax M2 的免费期将在一个小时内结束。
- 建议用户迁移到付费端点以继续使用该模型。
- 需要采取行动:迁移到付费端点:为确保服务不中断,用户必须切换到 MiniMax M2 的付费端点。
- 迁移应在一小时内完成,以避免服务中断。
OpenRouter ▷ #general (268 条消息🔥🔥):
OpenRouter API 问题、Gemini 3 猜测、免费模型稀缺、本地 AI 硬件建议、OpenRouter 聊天功能
- OpenRouter 聊天功能失效,用户怨声载道!:用户报告了 OpenRouter 上的聊天滚动问题,导致无法访问旧聊天记录,随后其他在多个浏览器和设备上遇到同样问题的用户也证实了这一点。
- 一名用户指出问题源于一个破坏了聊天的提交 (commit)。尽管造成了不便,一位用户幽默地表示,相比其他 AI 公司隐藏的系统提示词 (system prompt) 更改,OpenRouter 的错误还算温和。OpenRouter 团队在 3 分钟内迅速解决了该问题。
- Gemini 3 传闻四起,它能兑现预期吗?:用户对 Gemini 3 的潜力进行了推测,对其性能抱有很高期望,但也有人提醒不要过度炒作,理由是之前的测试仅显示出渐进式的改进。
- 一名用户分享称,LiveBench 测试显示 Gemini 3 达到了与人类相当的排名,这进一步激发了人们对这款既强大又价格合理的新版本的期待。
- 免费模型末日:稀缺引发辩论:用户讨论了免费 AI 模型日益稀缺的问题,将其归因于普及度提高和互联网访问量增加导致的资源限制,特别是在一段 YouTube 视频导致 Deepseek 免费版宕机之后。
- 虽然一些人指出 RP 应用在消耗 API 资源,但另一些人指出,由于滥用较少,付费服务仍然是最可靠的,用户对 Claude 免费层级限制的体验褒贬不一。
- 本地 AI 硬件对决:Ryzen vs. RTX:用户辩论了适合本地 AI 的最佳硬件,在讨论 Minisforum 迷你主机时,一些人迅速因其 Ryzen 架构和有限的功率将其排除在“优选”之外。
- 对话转向推荐 RTX Pro 6000 Blackwell、RTX 5090 或 RTX 3090(取决于预算),同时也有人对即使是使用 DDR4 内存的捡垃圾组装机成本过高表示担忧。
- OpenRouter API 困扰:速率限制、错误和支付:用户报告了 OpenRouter API 的问题,包括来自供应商的 429 速率限制错误、Claude 4.5 模型的过载错误以及 503 代理错误。
- 此外,用户询问了用于程序化购买额度的支付 API,一名用户指向了支持使用加密货币购买额度的 provisioning API,但也有用户报告称,尽管账户中有额度,API Key 仍提示 “User not found” 错误。
OpenRouter ▷ #discussion (3 条消息):
搜索框 UI、GPT 推理
- 搜索框被刻意移除:一名成员认为搜索框是被刻意移除的,以防止用户在想要搜索特定房间时误用通用搜索,附图展示了菜单在聊天页面上缩小的样子。
- 另一名成员觉得这个改动看起来很奇怪,但认为并没有那么大的误导性。
- GPT 模型的推理过程:一名成员询问 Responses API 是否会将 GPT 模型的推理过程 (reasoning) 返回到请求中。
- 他们注意到,此前 GPT 的上下文仅包含响应输出,而不包含推理过程。
{kind=link}
OpenAI ▷ #annnouncements (4 messages):
NYT vs OpenAI, Free ChatGPT Plus, GPT-5.1 Release
- OpenAI 对抗 NYT 侵犯隐私:OpenAI 的 CISO 发表了一封信函,回应 The New York Times (纽约时报) 对用户隐私的侵犯。
- 信中讨论了法律斗争以及 OpenAI 致力于保护用户数据免受未经授权访问的承诺。
- ChatGPT Plus 现对退伍军人免费:OpenAI 向符合条件的现役军人和在过去 12 个月内退役的退伍军人提供 12 个月的免费 ChatGPT Plus;在此申请。
- GPT-5.1 本周推出:GPT-5.1 本周将向所有用户推出,变得更聪明、更可靠、更具对话性;在此阅读更多。
- 明天在 Reddit 举行 GPT-5.1 AMA:明天太平洋时间 (PT) 下午 2 点,将举行关于 GPT-5.1 和自定义更新的 Reddit AMA。
- 该公告已向社区发布,所有用户均已收到通知。
OpenAI ▷ #ai-discussions (182 messages🔥🔥):
GitHub classifies Gemini 2.5 Pro vs ChatGPT, AI Chatbot Infestation on Social Media, GPT-5.1 vs GPT-5 vs GPT-4o, AI and Job Market, Sora 2
- Gemini 2.5 Pro 在 GitHub 上被评为强大:一位用户询问为什么 GitHub 将 Gemini 2.5 Pro 分类为比 ChatGPT 更强大,但另一位用户澄清说列出的模型较旧,而 GPT-5 是最新的,未被列入。
- 另一位用户补充说,Gemini 2.5 Pro 拥有比 GPT-5 大得多的上下文窗口 (context window),能够处理复杂任务。
- AI 聊天机器人泛滥威胁社交媒体:成员们讨论了社交媒体上 AI 聊天机器人泛滥 的可能性,这些机器人推送宣传信息,让人难以区分真人和 AI。
- 一位成员表示,网络空间将被不断推送宣传信息的 AI 聊天机器人所主宰,唯一的逃避方式可能是走向户外。
- 用户深入探讨 GPT-5.1 性能:用户正在讨论 GPT-5.1 的功能,指出它感觉像一根更长的可伸缩杆,能更好地调整触及范围以处理更难的话题,并且在快速学习主题方面更实用。
- 一些人认为如果你选择 thinking (思考模式),它会自动使用 GPT-5.1,而另一些人仍在等待基准测试,并对定性数据多于定量数据表示沮丧。
- 未来工作:AI 的影响与变革:成员们推测了 AI 对未来工作的影响,一些人预测需要更广泛技能组合的角色将会整合,并强调沟通是一项关键的微技能 (micro-skill)。
- 一位用户建议 AI 将导致同样的工作,只是现在使用 AI 工具。
- Sora 2 的动漫视频创作:一位成员使用 Sora 2 创作了一段 3 分钟的动漫,通过在提示词中直接指定时间、角色外观、关键动作和对话时刻,实现了外观和声音的一致性。
- 另一位用户链接了一篇 NotebookCheck 文章,将 Sora 2 描述为能够生成具有多个角色、特定动作和详细背景的复杂场景。
OpenAI ▷ #gpt-4-discussions (21 messages🔥):
GPT-5.1, Model preference, downgrading models
- GPT-5.1 收到褒贬不一的评价:用户对 GPT-5.1 的看法差异很大,有些人觉得它令人耳目一新,而另一些人则将其描述为倒退了两步,是科学仪器的费雪 (Fisher-Price) 玩具版。
- 一位用户指出 GPT-5.1 处理自定义指令的方式非常具有挑衅性,而另一位喜欢它的用户则指出他们每天使用 3 个以上满额度的对话。
- 用户怀念旧模型:用户怀念旧模型,其中一人提到他们需要 GPT 在 model 5 毁掉它之前 的样子,而另一人提到了强迫所有人使用 5 所带来的负面反弹。
- 用户还推测 OpenAI 将永久保留旧模型,因为它们非常受欢迎,有成千上万的人纯粹在使用它们。
OpenAI ▷ #prompt-engineering (13 messages🔥):
数据库重新挂载, Prompt engineering 职位, Sora 问题, Prompt engineering 课程
- 数据库困扰?: 一位成员建议在代码执行环境停用时 重新挂载数据库,因为它是受定时器控制的浏览器环境资产。
- 热门提示词?: 一位成员询问是否有热门的提示词。
- Prompt engineering 课程: 一位成员发布了一门课程,教授用户如何使用 Markdown 进行层级化沟通、通过 {由 AI 解析的开放变量} 和 ${由用户解析} 进行抽象,包括解释括号含义([列表], {对象}, (选项))、提示词中的强化、引导 [工具使用] 和更确定地 (塑造输出) 的重要性,以及用于合规性的 ML 格式匹配,包括 [{输出模板} 和 {(条件) 输出模板}]。
- Sora 存在角色问题: 一位成员在使用 Sora 时遇到问题,每个角色都有自己的对话,因此 Sora 会更改角色的台词,寻求可以进行更改和测试的提示词。
OpenAI ▷ #api-discussions (13 messages🔥):
Prompt Engineering 职位, 重新挂载数据库, Prompt Engineering 技巧, Sora 提示词
- Prompt Engineering 求职困难: 一位成员报告在寻找 prompt engineering 职位 时遇到困难。
- 没有进一步的讨论或建议。
- 数据库需要重新挂载: 当代码执行环境不可用时,一位成员建议尝试 重新挂载数据库,并指出它是 受定时器控制的浏览器环境资产。
- 他们警告说,这个问题有时会搞乱 Python 环境,需要开启新的对话。
- Prompt Engineering 技巧: 一位成员分享了一个详细的 提示词课程,内容涉及使用 Markdown 进行提示、通过变量进行抽象、引导工具使用的强化以及用于合规性的 ML 格式匹配。
- 该成员提供了一个 Markdown 片段,用于教授层级化沟通、抽象、强化和 ML 格式匹配。
- Sora 与对话提示词:角色难题: 一位成员请求一个现成的 Sora 提示词,涉及两个角色之间的对话和设置信息,以防止模型更改角色的台词。
- 另一位成员链接到了一个特定的 Discord 频道,其中可能包含相关的提示词。
LM Studio ▷ #general (95 messages🔥🔥):
LM Studio MacOS 管理员权限, 轻量级聊天模型推荐, Gemini 2.5 Pro vs Sonnet 4.5, LM Studio Hub 搜索问题, LM Studio 中的 MCP 资源支持
- 管理员权限困扰 MacOS LM Studio 安装: 一位用户对在 MacOS 上安装 LM Studio 需要管理员权限表示惊讶,但在错误追踪器中发现了一个已有的相关问题。
- 另一位用户表示不需要管理员权限。
- Phi-4 小而强大: 一位正在写书的用户正在寻找用于私人研究的轻量级聊天模型,Microsoft Phi 4 mini 被认为非常适合他们的计划。
- 另一位用户建议根据预算和使用计划来决定选择订阅服务还是专用硬件。
- Gemini 2.5 Pro 废黜 Sonnet 4.5: 一位用户发现 Gemini 2.5 Pro 的表现优于当前的 Sonnet 4.5 版本,并表达了对 Gemini 3 的期待。
- CUDA 更新后视觉模型崩溃: 用户报告称新的 CUDA 1.57 版本 导致视觉模型损坏并引起崩溃,建议回滚版本。
- 一位用户指出 Qwen3 VL 也会崩溃,并暗示这会影响 llama.cpp 运行时。
- 多 GPU 模型加载被证明存在问题: 用户讨论了在 LM Studio 的同一系统中的两个不同 GPU 上加载两个不同模型的可能性,目前看来只有运行多个 LM Studio 实例才可行。
- LM Studio 中的 GPU 卸载(offload)一直是“全有或全无”的模式,你无法为单个模型挑选使用哪一个 GPU。
LM Studio ▷ #hardware-discussion (89 messages🔥🔥):
GPU 显存分配, Vulkan vs CUDA 性能/稳定性, 驱动问题与 BSOD, 硬件故障排除 (VRAM), 上下文长度与 VRAM 占用
- GPU 显存分配不均触发 OOM:一位用户报告称 “split” 选项未能有效地在多块 GPU 之间分配模型,导致其中一块 GPU 出现 显存溢出 (OOM) 错误,而其他 GPU 仍有可用空间。
- 他们希望通过均匀分配来防止 OOM 问题,并询问引擎是否可以扫描并根据层的大小应用 加权层分配 (weighted split of layers),而不仅仅是简单的平均分配。
- Vulkan 的速度与稳定性困扰:一位用户在使用 LM Studio 配合 Vulkan 时遇到了频繁的 蓝屏死机 (BSOD),怀疑是与 NVIDIA GPU 的兼容性问题。
- 另一位用户也报告在卸载模型时会遇到 BSOD,但发现切换到 CUDA 解决了稳定性问题;他提到 Vulkan 在其 3090 上进行小型测试时速度更快。
- 驱动问题引发蓝屏:一位用户报告在通过驱动清洁安装解决初始加载问题后,卸载模型时仍会崩溃。建议的操作包括更新驱动、BIOS 以及使用 DDU 重新安装驱动。
- 该用户确认使用了两块 NVIDIA 显卡,roxxus 建议重新调整 GPU 顺序或调整分配,并监控 GPU 的 VRAM 分配是否超限。
- 对 VRAM 的怀疑:由于崩溃问题,一位用户最初怀疑是 3090 的 VRAM 硬件故障,但随后发现使用 CUDA 可以无障碍加载模型。
- 建议尝试替代配置,并检查增加上下文长度时是否崩溃(例如从 4k 增加到 48k 时崩溃),这可能暗示了 VRAM 稳定性问题。
- 硬件更新动态:一位用户分享了 BMC 模型 的链接,并提到 CPU 散热器已到货,另一位用户提到他们的 GPU 机架已发货。
- 他们展示了新机床的零件,对新 GPU 感到兴奋,但也对物流运输问题略感担忧。
Eleuther ▷ #general (41 messages🔥):
Numpy vs Einops, MLE 面试, 实现 Multi-Head Attention, 可解释性与 VLM
- Numpy 实现中 Einops 的必要性:一位成员开玩笑说拒绝在没有 Einops 的情况下编写 Numpy 实现,而另一位成员则表示,如果没有用于训练的 autodiff(自动微分),Numpy 实现 几乎没有意义。
- 工程师在 Transformer 面试题上“翻车”:一位工程师讲述了自己在面试中被要求用 Numpy 实现 Transformer 时表现不佳的经历,并建议面试题应该允许候选人在多个选项中选择,以展示其长处。
- 其他成员纷纷附和,认为要求在面试中手写 Numpy 版 Multi-Head Attention 是 非常糟糕的,这类题目更适合考察推导过程,而不是现场编码。
- MLE 面试准备是 Leetcode 陷阱吗?:成员们讨论了准备 MLE 面试 的最佳方式,有人将其描述为一个“陷阱”,因为面试内容过于依赖雇主和具体团队,难以捉摸。
- 相反,一位成员建议 公开构建一些对训练或部署模型的公司有用的东西。
- 韩国大学硕士生加入 EleutherAI:一位来自 高丽大学 (Korea University) 的硕士生加入了社区,他上周在 EMNLP 发表了第一篇论文,并受到会上结识的 Eleuther AI 成员的启发。他表达了对可解释性的热情以及参与项目的兴趣。
- 另一位新成员也表示有兴趣寻找可以参与协作的项目。
Eleuther ▷ #research (75 messages🔥🔥):
Zyda-2, ClimbLab, Nemotron-CC-v2, Complex Values Attention, NVIDIA Dataset License
- Zyda-2, ClimbLab, Nemotron-CC-v2: 预训练数据集:成员们建议使用 Zyda-2(去重+过滤后的 fineweb+DCLM)、ClimbLab 和 Nemotron-CC-v2 进行初始预训练,并指出考虑到各自的优缺点,将它们混合使用可能是理想的选择。
- 有人建议移除 slimpj 和 slimpj_c4 scrape 等子集,并询问:是否有 token 构成明细可以查看这 3.1T 是如何组成的?即这些子集是如何进行上采样/下采样的?为什么要把 tiny stories 混入其中?
- NVIDIA 的数据集质量很高:一位成员指出,目前在开源数据集的质量维度上,NVIDIA 和 HF 整体处于领先地位。
- 他们分享了 Hugging Face 上的 ClimbMix 数据集链接,称其特别有趣 (https://huggingface.co/datasets/nvidia/Nemotron-ClimbMix)。
- 解读 Nemo-CC 2 许可证的复杂性:成员们对 Nemo-CC 2 的许可条款进行了辩论,表达了对分享利用该数据集的模型/数据集可能受到限制的担忧,并指出 NVIDIA 可以在提前 30 天通知的情况下,随时无理由终止你的许可。
- 一位用户总结道:未经 NVIDIA 事先书面同意,你不允许在数据集上训练模型、评估模型并公开分享结果,更多细节可见这篇论文。
- 解决复数注意力梯度问题:成员们讨论了在 nanogpt 中 100 步后,带有复数 softmax 的复数值注意力不收敛的问题。
- 有人建议:你可以打印出你的虚部项。如果范围超过 30,那么注意力值可能正在随机旋转,此时你可以考虑圆的基本群(fundamental group of the circle)及其如何影响你的梯度方向。
Eleuther ▷ #interpretability-general (22 messages🔥):
Concept Probes Training, Divergent Concepts, Model's Internal Activations, Probabilistic Polysemantic System, Class Distribution and Accuracy
- 概念探针(Concept Probes)分类模型激活:研究人员正在通过创建二元分类器在模型激活上训练概念探针。这些分类器会遍历一个本体(ontology),提示模型描述定义和关系,移除共享子空间,并重复此过程直到对 OOD 样本的分类达到 95% 准确率。
- 这些探针以实时方式运行数千次,以测量当前激活与观察到的模式匹配的概率。该功能以 API 形式开放,并通过 OpenwebUI 进行可视化,供用户检查和引导发散概念。
- 发散概念揭示内部想法:一个发散的例子显示,当模型被问及无限权力时,表面上在讨论一部电视剧,但其激活却揭示了 AIDeception、AIAbuse 和 MilitaryInfiltration 等概念。
- 观察到的输出 token 与底层激活之间的概念距离引发了关于发散内部概念的含义及其与输出失调的疑问,即使在没有明确提及的情况下也是如此。
- 概念概率 vs 二元决策:对于每次检测,研究人员并不以 0.5 为阈值进行二元决策,而是向用户提供排序后的原始概率分数并持续重新采样。
- 他们正在近似一个概率多语义系统(probabilistic polysemantic system),因此不能简单地说“就是这一个”,相反,任何时候都会有多个概念同时存在,他们只是在确定输出概念是否接近任何时间步中最有可能被激活的概念。
- 数据集显示 50/50 分布:研究人员表示,他们的 95% 准确率 显著高于 50% 的基准线,训练使用了 10 个正例和 10 个负例(50/50)。
- 在测试时,他们使用 20 个正例和 20 个负例(50/50) 样本来获得该基准线。
Eleuther ▷ #lm-thunderdome (10 messages🔥):
Summarization Task Evaluation, lm-eval-harness, XSum Dataset Evaluation, UnitXT Integration
- Summarization 任务在 lm-eval-harness 中受到关注:成员们讨论了 lm-eval-harness 中摘要任务的评估,提到了 scrolls、megsum(医疗)和 noticia 等子任务。
- 还提到了 darija、catalan 和 spanish_bench 中的数据集,这些数据集利用 ROUGE 进行评估。
- 揭秘通过 UnitXT 将 **XSum 数据集 集成到 lm-eval-harness:一位成员询问是否在 lm-eval-harness 中包含了用于摘要任务的 **XSum 数据集 (https://aclanthology.org/D18-1206/)。
- 另一位成员确认它通过 UnitXT (UnitXT GitHub) 存在,并指出它是在内部处理的。
- **UnitXT 支持在 lm-eval-harness 中直接进行 XSum 评估:一位成员询问如何使用 harness 直接对模型进行 **XSum 数据集 评估。
- 另一位成员回答说,只要安装了 UnitXT 作为依赖项,运行
--tasks xsum应该可以正常工作。
- 另一位成员回答说,只要安装了 UnitXT 作为依赖项,运行
Nous Research AI ▷ #general (55 messages🔥🔥):
Autonomous AI accident, WeiboAI Model, Baguettotron benchmark, Importing GGUF files into Nous Chat
- 自主 AI “意外”出现:一位用户分享了一个 GitHub 仓库,声称“意外地”创建了自主 AI。
- 关于该项目的具体细节或功能,没有提供进一步的信息。
- “WeiboAI”模型震惊社区:用户们讨论了新的“WeiboAI”模型,其中一人指出它基于 qwen2.5,初始表现出奇地好,并引用了这条推文。
- 另一位用户指出,它在最初的 1-2 轮对话后会出现偏移,但对于一个 1.5B 参数的模型来说,表现还算不错。
- Baguettotron 的推理表现:一位成员询问关于 Baguettotron 的基准测试,指出尽管它体积很小,但其推理轨迹相当有趣。
- 关于是否进行了该基准测试,目前没有后续消息。
- 无法导入 GGUF 文件:一位用户询问如何将 GGUF 文件 导入他们的 Nous Chat。
- 另一位成员回答说 thats not a thing rn sorry(目前还不支持,抱歉),表明当前存在不兼容性。
- WeiboAI 背诵 Quora 故事:一位用户发现 WeiboAI 模型重复了 Quora 文章中的一个句子,并链接到了指向该来源的 Google 搜索结果。
- 该用户幽默地评论道:这句话实际上真的是由人类说出来的。
Nous Research AI ▷ #ask-about-llms (78 messages🔥🔥):
GGUF files, Nous Chat, local AI, Ollama, Computer Science Degree
- 用户无法将 GGUF 文件导入 Nous Chat:一位成员询问如何将 GGUF 文件 导入 Nous Chat,但被告知目前不支持此功能,相反,GGUF 文件 可以通过 llama.cpp 或 Ollama 等工具在本地使用。
- 提供了 huggingface 文档链接以获取进一步指导。
- Ollama 简化了本地 GGUF 的使用:成员们强调 Ollama 是本地运行 GGUF 文件 最简单的方法,并提供了 Ollama 官网链接。
- 本地 AI 性能取决于 PC 配置:解释称在本地运行 AI 模型高度依赖于用户的 PC 硬件,性能会根据规格而有所不同。
- 在本地运行 AI 模型仍然具有即使没有互联网连接也能访问模型的优势。
- 计算机科学学位对未来的 AI 发展有好处:该用户是一名大学新生,询问了从事 AI 工作的合适专业,计算机科学被建议为一个不错的选择。
- 一位用户表示,尽管对就业市场感到担忧,但为了未来的 AI 工作,仍然推荐计算机相关的学位。
- 运行命令以使用 Hermes-3:为了测试模型,建议在安装 Ollama 后,用户应在终端运行命令
ollama run hf.co/NousResearch/Hermes-3-Llama-3.2-3B-GGUF:Q4_K_M。- 该命令运行一个较小的模型 Hermes-3,它可以作为本地设置的一个很好的测试。
Nous Research AI ▷ #interesting-links (2 条消息):
ixlinx-8b, SOTA small model, local hackathon
- ixlinx-8b 模型发布:经过长时间开发,ixlinx-8b 模型在 GitHub 上发布,被宣传为最先进的 (SOTA) 小模型。
- 该模型是在一次本地黑客松期间开发的,创作者邀请大家贡献代码,并建议 Hermes 的开发者对其进行评估。
- ixlinx:与我们的霸主同名?:一位用户开玩笑地指出,ixlinx 这个名字碰巧与我们的霸主同名。
Latent Space ▷ #ai-general-chat (109 条消息🔥🔥):
RL envs, Windsurf Next's stealth models, OpenAI metrics, Spatial Intelligence as AI’s Next Frontier, Character.AI’s Kaiju model design for speed
- Windsurf 携 Aether 模型掀起波澜:Windsurf Next 发布了一组新的隐身模型(Aether Alpha、Aether Beta 和 Aether Gamma),在
#new-models频道进行测试并收集反馈,限时免费使用。- 一位成员敦促用户尽快尝试,因为免费时间不会超过一周,并提供了直接下载链接。
- 分析师分析 OpenAI 的产出:Masa 关于 OpenAI 训练成本趋势的图表引发了讨论,人们称赞其数据点富有洞察力,并要求提供 burn rate 和 revenue。
- 一些成员指出 OpenAI 已经成立近 10 年了,还有一位成员建议这些数字应该根据通货膨胀进行调整。
- FAIR 的不公平竞争:Susan Zhang 透露,Meta 在 2023 年初拒绝创建一个精简的 FAIR v2 以追求 AGI,而是要求 GenAI 部门交付 AGI 产品。
- 根据这条推文,她指责缺乏远见的高管雇佣了亲信,这些人过度承诺结果,后来带着水分很大的简历加入了 OpenAI,造成了持久的损害。
- Kaiju 助力 Character.AI 高效运转:Character.AI 专有的 Kaiju 模型 (13B/34B/110B) 专为推理速度而设计,采用了 MuP-style scaling、MQA+SWA 和 ReLU² activations 等技术。
- 正如这个 Twitter 线程中所详述的,由于生产限制,团队刻意避开了 MoE。
- Spotify 播客停滞:Latent Space 的 Spotify 订阅源出现问题,由于片头曲的版权投诉,最近的播客缺失。
- 一位成员提到,印度有人将免版税的片头曲注册为自己的歌曲,而 Spotify 一直没有回应;该播客在其他平台上仍然可用。
Latent Space ▷ #genmedia-creative-ai (5 条消息):
Magic Patterns 2.0, AI Design Tool, Series A Funding
- Magic Patterns 2.0 获得 600 万美元 A 轮融资:Alex Danilowicz 发布了 Magic Patterns 2.0,并宣布获得了由 Standard Capital 领投的 600 万美元 A 轮融资。
- 该公司庆祝在没有员工的情况下通过自筹资金实现了 $1M ARR,目前已有 1,500+ 产品团队在使用该 AI 设计工具,并计划在企业、工程、社区和增长等职位进行快速招聘。
- Magic Patterns 2.0 取代 Figma:一些用户赞不绝口,称 Magic Patterns 2.0 已经取代了他们使用的 Figma。
- 一位用户评论道:“非常酷,看起来是我想要尝试的东西,有点像初版的 v0”。
Modular (Mojo 🔥) ▷ #general (34 条消息🔥):
Mojo 中的动态类型反射,错误处理:try-catch vs. Monadic,Mojo 元编程,C-FFI 痛点,公有和私有成员
- Mojo 深入探索动态反射:Mojo 旨在支持动态类型反射,利用其 JIT compiler 处理动态数据,并倾向于静态反射,这可能允许对动态数据进行有用的操作。
- 在相关问题中,提到 try-catch 和 raise 将成为 Mojo 错误处理 的标准,以匹配 Python 的风格,尽管可能会有更多 monadic 选项来妥善处理错误。
- Mojo 的元编程更强大?:根据最近对 Chris Lattner 的采访(YouTube 链接),Mojo 的元编程能力比 Zig 的
comptime机制更强大,因为 Mojo 可以在编译时分配内存。 - 直面 C-FFI 难题:成员们讨论了在 Mojo 中进行 C-FFI 的痛点,一位成员表示愿意帮助解决出现的任何具体问题。
- 建议使用
Origin.external来绕过显式修复的重写,并使用MutAnyOrigin来精确保留旧行为,需理解 “any origin” 将延长作用域内的所有生命周期,并作为 ASAP 销毁的一个次优逃生口(escape hatch)。
- 建议使用
- 私有属性思考:成员们讨论了在 Mojo 中添加 public 和 private 成员及方法的可能性。
- 目前,Mojo 使用 Python 的下划线约定来暗示某些内容应该是私有的,但在出现“我不同意库作者并正在打破这种封装”的逃生口之前,不太可能实现强制私有。
- Modular 的模型:更多 Mojo,MAX 影响?:一位成员询问了使用 Modular 技术栈构建预测模型的最佳方法,包括数据加载、可视化、准备、模型创建和评估。
- 回复建议,虽然尽可能多地使用 Modular 技术栈可能会更快,但由于 Mojo 生态系统尚处于早期阶段,这将需要更多工作,建议目前使用 PyTorch 进行训练,使用 MAX 进行推理。
Modular (Mojo 🔥) ▷ #mojo (49 条消息🔥):
可选可变性,MOJO_PYTHON_LIBRARY 标准化,Metal Compiler 失败,comptime Bird
- 强制
mut注解引发辩论:围绕函数参数强制使用mut注解的冗余性展开了讨论,并将其与 Rust 的方法进行了比较,同时担心这会偏离 Python 的简洁语法。- 一些成员认为显式的可变性有助于跟踪潜在的值变动,而另一些成员则主张使用可选注解或 IDE 级别的指示器来减少视觉干扰,并建议一种折中方案:仅在参数被重用时才强制要求
mut。
- 一些成员认为显式的可变性有助于跟踪潜在的值变动,而另一些成员则主张使用可选注解或 IDE 级别的指示器来减少视觉干扰,并建议一种折中方案:仅在参数被重用时才强制要求
- 符号(Sigils)引发关于 Python 精神的辩论:使用符号(如
!)表示可变性的提议引发了辩论,一些人认为符号违背了 Python 的精神,而另一些人则指出 Python 已经使用了诸如 dunders (__bla__) 和下划线 (_bla) 等符号。- 一位成员建议,仅当参数在函数调用后被重用时,才在
fn内部强制要求调用侧的mut注解。
- 一位成员建议,仅当参数在函数调用后被重用时,才在
- 讨论在 macOS 上标准化 MOJO_PYTHON_LIBRARY:成员们讨论了在 macOS 上将
MOJO_PYTHON_LIBRARY标准化为 Python 3.14,并指出之前 3.13 的问题已解决,但一位成员表示 3.14 正在开发中。- 成员们正在等待某个依赖项的更新。
- GPU 教程中的 Metal Compiler 问题:一位成员在 Apple M4 GPU 上按照“GPU 编程入门”教程操作时,遇到了 Metal Compiler failed to compile metallib 错误。
- 成员们建议确保 GPU kernel 中没有
print()语句并使用最新的 nightly 版本,而其他人则指出了 macOS 和 Xcode 版本的潜在 SDK 和编译器支持问题,最终通过确保完整安装 Xcode 解决了该问题。
- 成员们建议确保 GPU kernel 中没有
comptime Bird语法评审中:讨论了用于 trait 组合的语法comptime Bird = Flyable & Walkable,一些人认为它不如alias关键字直观。- 其他人则认为
comptime更准确地反映了该关键字的功能,特别是在静态反射以及在编译时混合类型和值的能力方面,认为它涵盖了alias过去所做的一切。
- 其他人则认为
DSPy ▷ #show-and-tell (1 messages):
Taxonomy Creation, Structured Generation
- 分类体系长尾问题的探讨:一位成员写了一篇关于他们创建分类体系经验的 blogpost。
- 他们发现这个话题在 structured generation 背景下非常相关。
- 与结构化生成相关的分类体系:一篇关于分类体系创建的博客文章强调了其与 structured generation 的相关性。
- 作者分享了他们的经验和见解,探讨了为什么长尾(tails)会破坏分类体系,并强调了其在 structured generation 背景下的重要性。
DSPy ▷ #general (68 messages🔥🔥):
DSPy vs Prompting, Signatures vs Prompts, GEPA optimization, Agentic Search with DSPy, Complex systems with DSPy
- DSPy 确实需要领域驱动的领域知识:虽然 DSPy 旨在抽象掉 Prompting,但特定领域的 LLM 应用仍需要在 Signatures 中包含详细指令,一位用户在某些模块中使用了 100 行 指令,这表明简单的
input -> output方法通常是不够的。- 共识是,对于复杂任务,DSPy 不仅仅需要基础提示词;它还需要编码领域知识和分步指令,以有效地引导 LLM。
- Signatures:优于 Prompts,但仍是 Prompts?:参与者讨论认为,DSPy 的 Signatures 虽然是比原始提示词更好的抽象,但其功能仍然类似于提示词,特别是在编码业务规则的类定义 Signatures 的 docstrings 中,这有助于优化。
- 该框架有助于编程,而不是专注于 Prompting,但社区中的许多困惑源于这样一个事实:对于不同的人来说,“Prompt”意味着不同的东西。
- GEPA 几何形状的逐步增益:虽然 GEPA 旨在优化提示词,但用户发现特定指南仍然是必要的,即使在使用工具函数时也是如此,例如指示 LLM 在初始术语失败时使用 Regex 进行 Agentic Search。
- 一位用户发现,他们需要添加特定指南,即 LLM 应发送特定术语供工具通过 ripgrep 搜索,但如果找不到,请务必添加 Regex 作为下一步,否则 LLM 不会在搜索工具中使用 Regex 术语。
- Agentic Agents 增强分析:一位用户分享了一个场景,他们需要指示 LLM 在使用 ripgrep 的 Agentic Search 中使用 Regex,以有效地搜索文档,这突显了即使使用先进工具也需要特定指导。
- 另一位用户分享了关于指示 LLM 答案可能不在搜索结果第 1 页的情况。
- 模块化模块增强可管理性:讨论强调了 DSPy 可组合性(Composability)的优势,允许开发人员将控制流分解为逻辑模块,每个模块都有自己的优化目标,这与 BAML 等更僵化的框架不同。
- 模块的可组合性是真正的可组合性,因为模块封装了一个高级任务,然后可以将模块链接在一起以实现最终目标。
HuggingFace ▷ #general (56 条消息🔥🔥):
ZeroGPU 问题,Reuben 被封禁,SFTTrainer 自定义损失函数,AI 视频剪辑,多模态 LLM 中的音频 Token
- ZeroGPU 据报运行异常:一名成员报告 ZeroGPU 的日志功能无法正常工作,这引发了关于其功能的讨论,随后另一名用户确认现在它似乎已恢复工作。
- 目前尚不清楚与原始报告相关的后续问题是否仍然存在,但 ZeroGPU 的当前状态是正常的。
- Reuben 被封禁,但又回来了!:一名用户报告 Reuben 被封禁,但随后 lunarflu 为其解封,并解释说这是因为在短时间内发送了大量连续消息,触发了旨在打击加密货币垃圾邮件发送者的机器人。
- 对话中包含了使用 regex 或 AI 来检测垃圾邮件的建议,但一名用户引用了隐私方面的担忧。
- 非营利组织寻求 AI 讲师:一名成员分享了关于 Revert and Returners CIC(一家总部位于英国的非营利组织)的详细信息,该组织正在为穆斯林女性寻找“AI 入门”课程的讲师,涵盖 GitHub、Hugging Face、Python 和 PyTorch 等主题。
- 该职位要求每周一小时,持续 8-9 个月,时薪 50 英镑,他们特别鼓励女性申请,此外还在寻求帮助建立共享服务器。
- Aquif 模型走红:成员们注意到 Aquif-3.5-Max-42B-A3B 模型在 Hugging Face 上走红并询问原因。
- 一名成员指出,这可能是因为它是一个在基础上进行了一些微调的放大模型(upscaled model),而另一名成员承认只是觉得这个名字很有趣。
- 寻求本地 AI 框架反馈:一名成员在其他频道难以获得建设性批评后,正在寻求关于其本地 AI 框架的反馈。
- 他们并非职业开发者,但认为该框架非常有趣,并且可能演变成非常酷的东西。
HuggingFace ▷ #today-im-learning (1 条消息):
quantumharsh: 你是从哪里学习机器学习的
HuggingFace ▷ #cool-finds (1 条消息):
渲染时间,进度标签
- 尽管进度标签不同,渲染时间保持不变:一名成员注意到两次不同的渲染花费了相同的时间,且进度标签下都显示为 50 steps。
- 缺乏变化:用户表达了困惑,怀疑某些地方缺失或不正确。
HuggingFace ▷ #i-made-this (3 条消息):
Tokenflood 负载测试工具,SMOLTRACE 基准测试框架,SmolVLM 博客文章
- Tokenflood 为 LLM 提供负载测试:一名自由职业 ML 工程师发布了 Tokenflood,这是一个针对指令微调(instruction-tuned)LLM 的开源负载测试工具,可在 GitHub 上获取。
- 它模拟任意 LLM 负载,适用于开发对延迟敏感的 LLM 应用程序,并评估提示词参数更改带来的延迟收益。
- SMOLTRACE 发布全面基准测试:SMOLTRACE 是一个针对 Smolagents 的基准测试和评估框架,内置 OpenTelemetry 可观测性,现已发布,详见文档。
- 它对 ToolCallingAgent 和 CodeAgent 进行基准测试,在 132 个基准测试任务和 24 个 SRE/DevOps 任务中跟踪准确率、Token、延迟、二氧化碳排放、GPU 指标和成本。
- 深入探讨 VLM 内部机制:发布了一篇以 SmolVLM 为参考解释 VLM 工作原理的博客文章,可在 HuggingFace 上阅读。
- 该文章提供了关于 VLM 机制的见解,以及 SmolVLM 如何体现这些概念。
HuggingFace ▷ #computer-vision (1 messages):
ConvNeXt-Tiny Model, Model Architectures, Computer Vision Tasks
- ConvNeXt-Tiny 模型深度探讨开始:频道成员发起了一场关于 ConvNeXt-Tiny 模型实践经验的讨论,寻求集体见解。
- 对话旨在探索模型的内部机制及其在各种 computer vision 任务中的适用性,可能还会发现优化策略。
- 解析 ConvNeXt 的模型架构:讨论涉及了驱动 ConvNeXt 的底层 model architectures,重点关注其独特的设计选择。
- 参与者旨在了解架构创新如何提升模型在 image recognition 及相关任务中的性能和效率。
HuggingFace ▷ #NLP (4 messages):
Random Data Generation, PII Detection and Randomization, Data Cleaning Techniques
- 关于生成真实的随机数据的讨论:一位成员询问系统是否可以生成真实的随机数据,而不是像 ‘XXX’ 这样的占位符。
- 另一位成员建议,根据具体情况,使用纯 Python 脚本可能更容易完成此任务。
- PII 随机化功能需求:一位用户对能够自动检测并随机化个人身份信息 (PII) 的 prompt 设置表示感兴趣。
- 这将简化系统中敏感数据的脱敏过程。
- 详细的数据清洗流程:一位成员概述了清洗文本数据的常用流程,首先是基于 regex 的清洗,以删除冗余、重复数据和空值。
- 该流程包括探索性数据分析 (EDA)、用于自定义停用词识别的 TF-IDF,以及在创建模型输入的 embeddings 之前使用 NLTK 停用词删除无关词汇。
HuggingFace ▷ #gradio-announcements (1 messages):
MCP 1st Birthday, Anthropic, Gradio, AI hackathon, API credits
- MCP 周年庆典即将到来!:由 Anthropic & Gradio 主办的 MCP 1st Birthday Bash 距离开幕仅剩 2 天,将于 11 月 14 日星期五(00:00 UTC)在 https://huggingface.co/MCP-1st-Birthday 拉开帷幕。
- 已有数千名开发者报名参加此次活动,所有参与者将角逐 2 万美元现金奖励和超过 270 万美元的 API credits。
- 发布日清单:记得在 GitHub 上加入该组织,填写注册表,并进入官方频道获取实时更新。
- 官方频道为 mcp-1st-birthday-oficial🏆。
HuggingFace ▷ #agents-course (1 messages):
Study Group
- 成员希望加入学习小组:一位成员希望加入学习小组,并愿意补齐之前的学习内容。
- 学习小组进度:该成员还询问了学习小组目前的进展情况。
Moonshot AI (Kimi K-2) ▷ #general-chat (63 messages🔥🔥):
Researcher mode errors, Kimi Coding Plan API Quota, Kimi API setup, Kimi K2 Thinking vs GLM 4.6, GPT 5.1 rollout
- Researcher Mode 漏洞: 一位用户报告称,在使用 Researcher Mode 时收到的是错误提示而非结果,即便他在一周前才使用过一次。
- 他们询问 Researcher Mode 是否已完全转为付费模式,因为现在显示额度不足或升级提示。
- Kimi Coding Plan API 配额消耗过快: 用户报告称,由于网页搜索和计划模式的使用,Kimi Coding Plan 的 API 配额可能在短短几小时或几次会话内耗尽。
- 一位用户建议 Moonshot AI 可能会转向类似 Cursor 的订阅方案,以更好地平衡使用量与成本,尤其是考虑到他们不像 OpenAI 和 Anthropic 那样拥有雄厚的 VC 资金。
- 需要 API 设置协助: 一位用户在尝试通过 HTTP 为 Thinking 模型设置 Kimi API 时寻求帮助,尽管拥有额度和有效的 API Key,但仍面临授权失败的问题。
- 另一位用户指出,该用户使用的是中文平台的 URL,而非全球通用的
https://api.moonshot.ai/v1/chat/completions。
- 另一位用户指出,该用户使用的是中文平台的 URL,而非全球通用的
- 用于快速输出的 Turbo 版本: 一位用户询问如何缩短 Kimi K2 Thinking 模型通过 API 处理的时间。
- 一名成员建议使用 Turbo 版本,它在不牺牲模型性能的情况下提供了更快的输出速度。
- GPT 5.1 秘密发布: 成员们注意到 GPT 5.1 已经推出,并指出它是 OpenRouter 上的那个秘密模型,表现不错,但因安全限制而显得有些“脑叶切除”(safetylobotomized)。
- 一位成员庆祝道 “几周前大家就知道它要来了”,并认为 OpenAI 遭遇了挫败(takes an L)。
Yannick Kilcher ▷ #general (32 messages🔥):
Semantic shifts in language, Google Colab vs Lambda Labs, FID scores for DiT models, ICLR review process, Whisper model usage
- 物化(Thingification)语义演变: 一位成员讨论了词语意义淡化或复苏的语义演变(semantic shift),并将其与广义的物化(thingification)区分开来。
- Colab 还是 Lambda Labs?: 一位成员询问是否可以像使用 Lambda Labs 或类似集群那样使用 Google Colab,并质疑它们在某些任务上是否等效。
- FID 分数可视化: 一位成员询问 DiT 模型中 FID 为 30 的图像看起来是什么样的,是否像让图像无法辨认的超高斯噪声。
- 另一位成员澄清了从图像质量(人类偏好)角度看 FID 与从模拟数据分布(模型目标)角度看 FID 之间的区别。
- ICLR 评审流程的苦恼: 一位成员讲述了在 ICLR 评审中的挫折经历:尽管针对之前的意见进行了修改并增加了新数据集,重投后仍获得低分。
- 评审员给出的评论包括 “当主要重点是在 19 个数据集上进行测试,且其中 4 个是我们制作的包含超过 3 万个新问题的新数据集时,这不属于基准测试论文” 以及 “我们没有提供超参数,而它们明明就在附录里。”
- Whisper 的怪异表现: 一位成员发现直接在 PyTorch 中使用 Whisper 模型会导致错误和幻觉,而使用 Whisper-server 时这些问题显著减少。
- 他们建议使用 Whisper-server 并通过 Vulkan 支持进行编译以提高移植性,同时过滤掉静音部分以改进转录效果。
Yannick Kilcher ▷ #paper-discussion (8 messages🔥):
Kimi K2, Thinkprm, Indian Names, Memorization to Reasoning
- Kimi K2 擅长短代码任务: 一位成员分享了 Kimi K2 在 one-shot 代码任务中表现出色的演示 YouTube 视频。
- Thinkprm GitHub 演示: 一位成员分享了 Thinkprm 的 GitHub 演示项目:https://github.com/mukhal/thinkprm。
- 推荐论文《从记忆到推理》: 一位成员链接了一篇关于损失曲率谱中从记忆到推理的论文:[2510.24256] From Memorization to Reasoning in the Spectrum of Loss Curvature。
Yannick Kilcher ▷ #ml-news (8 messages🔥):
Elevenlabs Speech to Text, GPT-5 Release?
- Elevenlabs 演示 Speech-to-Text:成员们分享了对 Elevenlabs 的看法,指出其主要功能是 text to speech,但现在也具备了 speech to text 功能。
- 一位成员指出 speech to text 功能被显著展示。
- GPT-5 的对话特性?:一位成员链接了一篇介绍 GPT-5-1 的 OpenAI 博客文章,并好奇其更具对话性的语气是否旨在吸引 GPT-4 用户。
MCP Contributors (Official) ▷ #general (18 messages🔥):
timezone information MCP clients to MCP servers, SEP draft for timezone, Anthropics Claude desktop host team, connectivity issues between Claude.ai and MCP Servers, JSON data from mcp tool call results
- 提议将时区信息从 MCP 客户端传递到服务器:一位成员询问了如何将时区信息从 MCP 客户端传递给 MCP 服务器。
- 另一位成员回应称这是一个有趣的问题,并考虑通过客户端发送的通知或服务器诱导将其作为 metadata 提供。
- 为时区协议更改起草 SEP:一位成员为时区起草了 SEP(规范增强提案),并将在内部反馈后发布到 GitHub。
- 正在考虑的选项包括将其添加到 CallToolRequest、使用 Header、添加到 JSONRPCRequest.params._meta 或添加到 InitializeRequest。
- Claude.ai 连接困扰:一位成员寻求关于 Claude.ai 与 MCP 服务器之间连接问题的调试建议。
- 另一位成员指出该问题不稳定且特定于客户端,因此可能不适合在此服务器讨论,并建议增加一个能提供更多运行反馈的开发者模式。
- MCP 工具调用结果返回非 JSON 数据?:有人询问是否有人尝试过从 mcp 工具调用结果中返回序列化 JSON 以外的数据(例如 Toon 格式)。
- 一位成员分享了在合成数据集上进行的小规模评估结果,准确率相当,速度慢了 9%,Token 减少了 11% (n = 84, p = 0.10)。
Manus.im Discord ▷ #general (14 messages🔥):
AI Automation Integration, Spanish Language Section Suggestion, Generative Engine Optimization, Manus System Error, Manus Support Channel Closure
- AI 自动化集成专家加入:一位新成员介绍自己是 AI 自动化集成专家,提供在 Python, SQL, JavaScript 以及 PyTorch, scikit-learn, LightGBM, 和 LangChain 等框架方面的专业知识。
- 他们强调了在交付聊天机器人、推荐引擎和时间序列预测系统方面的经验。
- 建议为服务器开设西班牙语板块:一位成员建议在服务器上创建一个西班牙语板块。
- 寻求生成式引擎优化(Generative Engine Optimization)指导:一位成员请求关于如何跟踪和优化 Generative Engine Optimization 的资源和指导。
- 该成员表示,如果有人能分享任何可以参考的资源或内容,他将“不胜感激”。
- Manus 系统错误困扰用户:一位成员报告了一个反复出现的 Manus 系统错误,导致无法发布,错误提示为 “pathspec ‘417ea027’ did not match any file(s) known to git”。
- 该成员表达了挫败感,抱怨缺乏支持且之前的问题未解决,尽管“每月在 Manus 花费数百美元”。
- Manus 支持渠道访问困难:多位成员表示难以联系到 Manus 支持,其中一人注意到支持频道似乎已关闭。
- 一位遇到 git commit 错误的用户被 Manus Agent 建议“等待 Manus 支持”或“升级工单”,并获得了一个提供反馈的链接。
aider (Paul Gauthier) ▷ #general (13 条消息🔥):
Code Snippets in Markdown Files with Aider, Aider Conventions Configuration, Aider Vim Mode, aider-ce and Session Management, Aider Development Status
- Aider 在处理 Markdown 文件中的代码片段时遇到困难:一位用户报告称,在使用
anthropic.claude-sonnet-4-5-20250929-v1:0在 Markdown 文件中创建代码片段时,Aider 会被嵌套的代码 Markdown 标记所困扰。- 该问题发生的原因是 Aider 误解了嵌套的代码 Markdown 指示符,导致其反复提示确认文件创建。
- Aider 文件分界约定的变通方法:一位用户发现,在
conventions.md文件中添加三个和四个反引号('```'和'````')会触发 Aider 使用<source>标签来划分文件,从而解决了代码片段问题。- 通过这种方式,Aider 可以正确识别并处理代码片段,而不会被嵌套的 Markdown 混淆。
- Aider 的 Vim 模式备受赞誉:一位用户对 Aider 的 Vim 模式 表示热烈欢迎,称其非常出色。
- 他们还称赞了新的
<#1403354332619079741> aider-ce/load-session//save-session功能,认为其在挂起和恢复任务方面非常实用。
- 他们还称赞了新的
- Aider 开发状态受到质疑:用户对 Paul Gauthier 缺乏关于 Aider 开发状态 的更新表示担忧。
- 讨论集中在 Paul Gauthier 是否仍在积极开发该项目,一位用户提到他们可能错过了一份关于他不再参与开发的公告。
- GPT 5.1 发布但未提供基准测试:成员们注意到 GPT 5.1 的发布,但观察到发布说明中没有提到任何 Benchmark。
tinygrad (George Hotz) ▷ #general (4 条消息):
OpenCL errors, package_data
- Package Data 崩溃?:一位成员询问归档文件中是否缺失了文件,质疑
package_data是否是一个空操作(no-op),并建议明确指定文件可能会有所改善。- 他们感谢了审阅者的反馈。
- OpenCL 错误检修:一位成员请求改进未检测到 OpenCL 设备时的错误消息,指出当前的错误为
RuntimeError: OpenCL Error -30: CL_INVALID_VALUE。- 该特定错误源自
/tinygrad/tinygrad/runtime/ops_cl.py第 103 行。
- 该特定错误源自