AI News
Gemini 3 Pro —— 谷歌 DeepMind (GDM) 新一代前沿模型 6、Gemini 3 Deep Think 以及 Antigravity IDE。
谷歌 (Google) 发布了 Gemini 3 Pro,这是一款拥有 100 万 token 上下文窗口、多模态推理和强大智能体能力的尖端模型,其定价显著高于 Gemini 2.5。它在主要基准测试中处于领先地位,超越了 Grok 4.1,并与 Sonnet 4.5 和 GPT-5.1 展开激烈竞争,尽管 GPT-5.1 在超长文本摘要方面表现更佳。
来自 Artificial Analysis、Vending Bench、ARC-AGI 2、Box 和 PelicanBench 的独立评估均证实 Gemini 3 是一款前沿的大语言模型 (LLM)。此外,谷歌还推出了 Antigravity,这是一款由 Gemini 3 Pro 及其他模型驱动的智能体 IDE,具备任务编排和人机回环 (human-in-the-loop) 验证功能。此次发布标志着谷歌在 AI 领域的强势回归,预计很快将有更多模型面世。“谷歌在这一领域已经彻底回归了。”
只需要一个 Google 账号就够了?
2025/11/17-2025/11/18 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 24 个 Discord 社区(205 个频道,14599 条消息)。预计节省阅读时间(按 200wpm 计算):997 分钟。我们的新网站现已上线,包含完整的元数据搜索和精美的 vibe coded 历期内容展示。请访问 https://news.smol.ai/ 查看完整的新闻详情,并在 @smol_ai 提供反馈!
终于,我们迎来了备受期待的 Gemini 3 发布 —— 各项指标均达到 SOTA 水平(除了这一项),价格比 Gemini 2.5 高出 60%,并且在所有主要的 Arena 排行榜上排名第一(是的,正如所料,Gemini 3 击败了昨天的 Grok 4.1,后者仅在 Text Arena 榜首待了一天,真是巧合)。
但你应该仔细观察那些巨大的跨越,特别是与 Sonnet 4.5 和 GPT-5.1 这两款竞争对手的前沿模型(frontier model)进行的正面交锋:
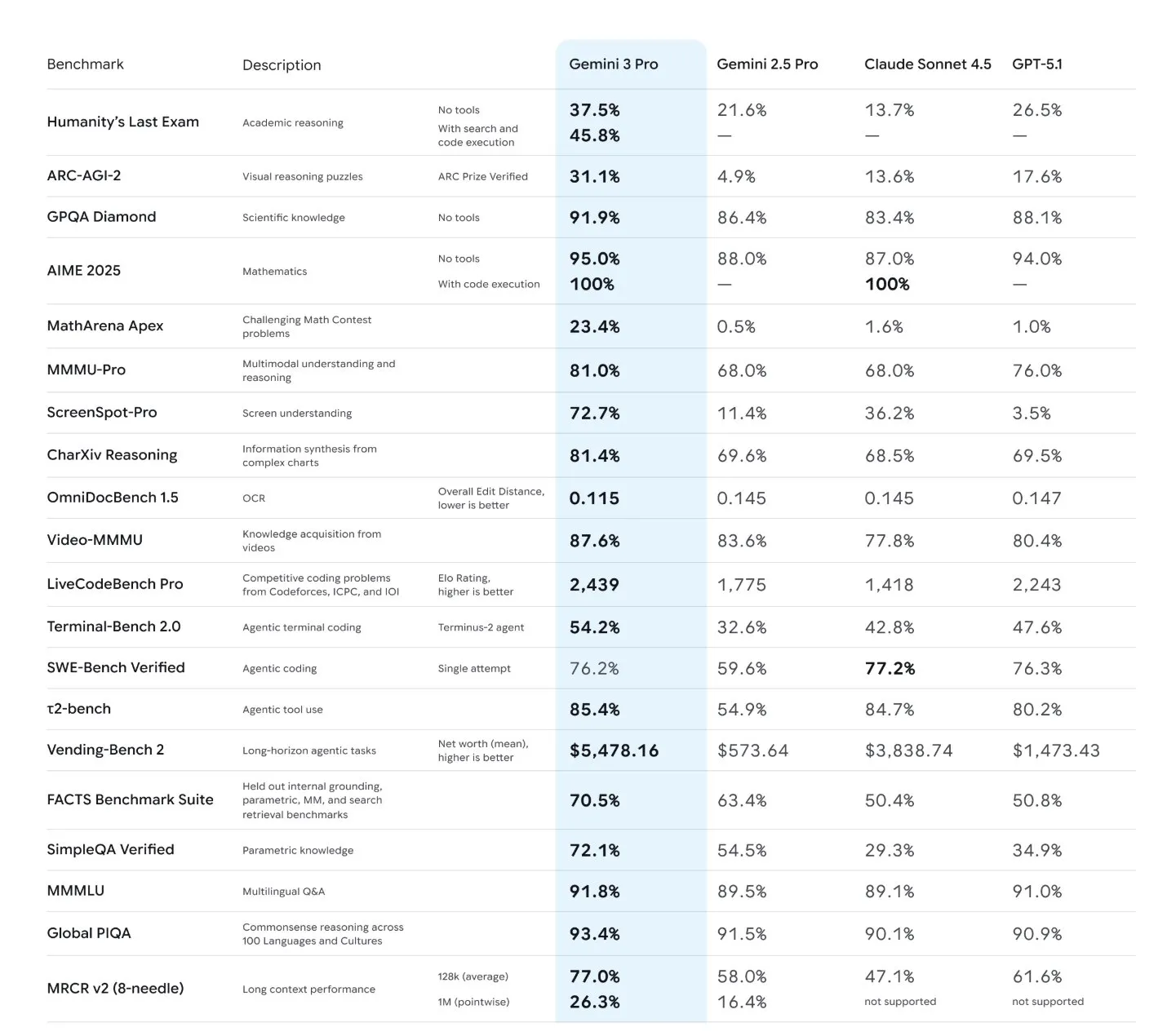
来自 Aritifical Analysis、Vending Bench、ARC-AGI 2、Box 以及 PelicanBench(现已推出 v2)的一些著名独立评估,都验证了其作为前沿 LLM 的地位。(我们运行了 Gemini 3 vs GPT 5.1 的对比,发现 GPT 5.1 在超长文本摘要/指令遵循方面明显更胜一筹)。ARC AGI 2 结果的提升幅度也是一个非常显著的帕累托改进(pareto improvement):
Oriol Vinyals 确认预训练和后训练阶段都有所改进 —— 目前还看不到瓶颈(walls)。
除此之外,还有两个令人惊喜的发布:Gemini Deep Think,数据更好但尚未发布;以及 Antigravity,这是前被收购的 Windsurf 团队打造的基于 Google 生态的 Agent 原生 IDE,拥有独立的域名和(不)出人意料地制作精良的 YouTube 频道。
Google 强势回归。更多模型即将推出,而现在才周二。
AI Twitter 回顾
Google Gemini 3 与 Antigravity:发布、规格及可用性
- Gemini 3 Pro (Preview) 发布:Google 推出了迄今为止最强大的模型,具有 1M token 上下文窗口(最高 1,048,576 输入;65,536 输出)、顶尖的多模态推理能力以及强大的 Agent 能力/vibe coding 表现。定价 (AI Studio):≤200K tokens 为 $2M/$12M (入/出),≥200K 为 $4M/$18M,据报告生成速度约为 128 tokens/sec,知识截止日期为 2025 年 1 月。它现在已在 Gemini 应用、Search 中的 AI Mode、AI Studio/Vertex 以及 API/CLI 中可用,开发文档涵盖了新的控制参数,如
thinking_level、针对各部分的media_resolution以及用于推理连续性的强制性Thought Signatures(@sundarpichai, @GoogleDeepMind, @Google, 定价, 速度, 开发指南, 上下文/输出)。 - Antigravity (Agent 原生 IDE):Google 推出了 Antigravity,这是一个 Agent 优先的开发环境,Agent 可以在编辑器/终端/浏览器之间协调任务,通过 Browser Subagent 运行 UI 测试,进行录制/重放,并结合人类在环(human-in-the-loop)验证进行迭代。它使用 Gemini 3 Pro 进行推理,Gemini 2.5 Computer Use 进行端到端执行,并使用 Nano Banana 处理图像。公开预览版今日免费开放 (@antigravity, @GoogleDeepMind, 概览)。
基准测试与实证表现(包括 Deep Think)
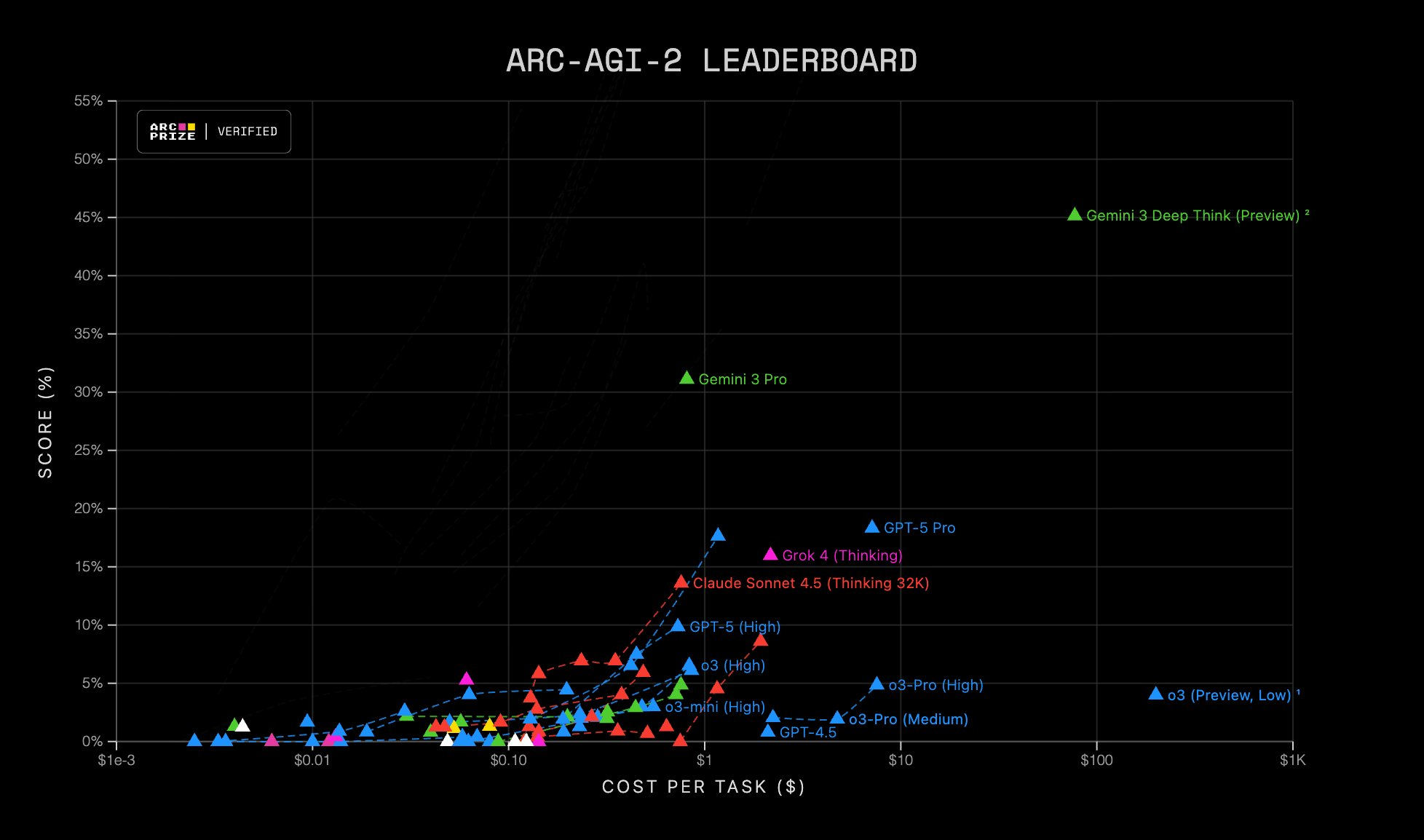
- 排行榜与 SOTA:Gemini 3 Pro 在 LMSYS Arena Text 以 1501 Elo 首次亮相即位居榜首,并在 WebDev 以 1487 Elo 夺冠 (@arena, @GoogleCloudTech)。它在 “Humanity’s Last Exam” (HLE) 上表现强劲(根据 Artificial Analysis,不使用工具时约为 37%;Deep Think 变体报告为 41%),GPQA Diamond 高达 93.8% (Deep Think),ARC-AGI-2 为 31.1% (Pro) 和 45.1% (Deep Think),MMMU-Pro 约 81%,Video MMMU 约 87.6% (@ArtificialAnlys, @koraykv, @lmthang, @fchollet)。ARC Prize 验证了在 ARC-AGI-2 上超过 2 倍的 SOTA 跨越,但伴随成本:Pro 约 $0.81/任务,而 Deep Think 约 $77/任务 (@arcprize)。
- 编程与 Agent 评估:Gemini 3 Pro 在 LiveCodeBench Pro 中领先(相比 GPT-5.x 有显著提升),赢得了多个 Code Arena 赛道(网站/游戏开发/3D/UI 组件),并在终端任务基准测试(Terminus2/CodexCLI 混合测试)中表现强劲。它还在分阶段浏览 (Stagehands) 方面处于领先地位,并在 PMPP-Eval (CUDA)、SimpleBench 和 LisanBench 的 Token 效率方面显示出巨大进步 (Code/WebDev, LiveCodeBench, Stagehands, PMPP/SimpleBench, LisanBench)。Karpathy 提醒要在公开排行榜之外进行验证;私有评估集成仍然是关键 (@karpathy)。
生态系统发布与集成
- 编辑器/Agent/平台:Gemini 3 Pro 在首日即广泛发布:Cursor 默认切换及深度集成 (@cursor_ai),VS Code/GitHub Copilot 和 GitHub CLI (@pierceboggan),Windsurf (@cognition),Cline (@cline),Amp 默认模型 (@thorstenball),Vercel AI Cloud (Gateway/v0/SDK) (@vercel),LlamaIndex (PR 管理器 Agent) 和 LlamaAgents (Gemini agent demo, LlamaAgents)。此外还上线了 OpenRouter 和 Ollama Cloud (OpenRouter, Ollama Cloud)。
- 搜索与生成式 UI:Google Search 中的 AI Mode 在首日上线了 Gemini 3,具备动态、针对查询定制的生成式布局和交互式模拟,首先向美国的 AI Pro/Ultra 订阅用户推出。Gemini 应用增加了用于多步骤任务的 “Gemini Agent”,以及更多视觉化和交互式的响应 (@Google, app update)。
Anthropic x Microsoft x NVIDIA:多云 Claude 与巨额资本支出
- 战略合作伙伴关系:Anthropic 宣布与 Microsoft 和 NVIDIA 达成深度技术及市场合作:Claude 模型现已上线 Azure 和 Microsoft Foundry,Microsoft 和 NVIDIA 分别承诺投入高达 50 亿美元和 100 亿美元,以扩大 Anthropic 的研究和产能。这使得 Claude 成为唯一在三大主流云平台上均可使用的“前沿 (frontier)”模型系列 (@AnthropicAI, @satyanadella, @nvidia, Claude on Azure/Foundry, Anthropic note)。
开放研究 Agent 与工具链更新
- AI2 的 Deep Research Tulu (DR Tulu):针对长篇深度研究的完全开源方案,包含一个 8B Agent 和一种新颖的 RLER(Reinforcement Learning with Evolving Rubrics,带演进准则的强化学习)奖励方案。该方案针对特定实例、基于搜索,并能通过演进减少奖励作弊(reward hacking)。代码、论文和训练流程已发布(@allen_ai,RLER 详情)。
- 开源 Agent 框架与中间件:LangChain 推出了用于提高可靠性(fallbacks,回退机制)和控制(模型调用限制)的中间件,并强调了 subagents、FS、摘要等生产级 Agent “中间件” (fallbacks, 调用限制, 中间件需求)。LlamaExtract 增加了逐表行提取功能;LlamaAgents 开启了多步文档 Agent 的预览 (LlamaExtract, LlamaAgents)。AI Agent 研究还包括 MiroThinker(模型/上下文/交互式扩展),旨在缩小与闭源深度研究 Agent 的差距 (摘要, 论文)。
基础设施与运维笔记
- 基础设施动态与停机事件:Vercel、SkyPilot x CoreWeave 以及 Together Instant Clusters 推动了节点组/集群编排的发展,而 Modal 将“主机开销 (host overhead)”分析为一类关键的推理瓶颈(不要让 GPU 闲置)(Vercel, SkyPilot x CoreWeave, Together, Modal)。发布当日恰逢 Cloudflare 大规模停机,导致广泛的服务不稳定讨论 (背景)。
热门推文(按互动量排序)
- Sundar Pichai 介绍 Gemini 3:“全球最强的多模态理解模型……Agent 化 + vibe coding” (@sundarpichai, 19,250)
- Sam Altman 祝贺 Google 发布 Gemini 3 (@sama, 30,283.5)
- Antigravity,Google 的 Agent 化 IDE,开启公开预览 (@antigravity, 10,231.5)
- Google AI Studio:“Gemini 3 Pro……在 LMArena 上达到 1501 Elo 分数” (@GoogleAIStudio, 14,311.5)
- Demis Hassabis 谈论 Gemini 3 在 HLE/GPQA/Arena 登顶及其日常实用性 (@demishassabis, 4,170)
- Anthropic 合作伙伴关系:Claude 登陆 Azure;NVIDIA/Microsoft 将投资高达 100 亿/50 亿美元 (@AnthropicAI, 2,370.5)
开发者笔记:
- Gemini 3 Pro 的工具调用 (tool use) 和结构化输出有实质性改进;关注 AI Studio 新的推理/IO 控制和 Thought Signatures,以实现稳定的多轮对话链 (开发者指南)。
- 基准测试分数大幅提升,但模型测试框架 (harnesses) 和任务设计至关重要(例如,不同框架下的 coding/terminal-bench 差异)。请在你的私有评估集和生产追踪数据上进行验证 (@tristanzajonc, @karpathy)。
- ARC-AGI-2 的结果表明,测试时推理计算 (test-time reasoning compute) 带来了巨大收益;“深度思考 (Deep Think)”模式的成本/性能权衡非常显著 (@arcprize)。
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. AI 服务器运行时间与停机事故
- 我的本地 AI 服务器运行正常,而 ChatGPT 和 Claude 因 Cloudflare 故障而宕机。看招,大科技公司! (热度: 297): 一位 Reddit 用户报告称,当 ChatGPT 和 Claude 因 Cloudflare 故障而宕机时,他们的本地 AI 服务器仍保持运行。这凸显了本地服务器相对于依赖云服务的韧性,后者可能会受到外部服务中断的影响。尽管发生了故障,一些 API 仍能正常工作,允许继续访问基于云的 AI 服务。 一位评论者指出,他们托管在 Cloudflare 服务器上的 LLM 已经宕机,迫使他们通过仍在运行的 API 使用云服务。这表明云服务在故障期间的可靠性参差不齐。
- LocoMod 指出,尽管 Cloudflare 发生了故障,但 ChatGPT 和 Claude 等服务的 API 仍在运行。这表明虽然某些用户界面可能无法访问,但后端服务仍然可用,凸显了即使在大规模故障期间,基于 API 的架构也具有韧性。
- JoshuaLandy 提到,他们的本地大语言模型 (LLM) 托管在 Cloudflare 服务器上,目前已宕机,迫使他们依赖通过仍可运行的 API 提供的云服务。这强调了拥有多层冗余的重要性,以及仅依赖 Cloudflare 等单一基础设施提供商的潜在脆弱性。
- Blizado 强调了云服务的一个关键问题:它们对互联网连接和 Cloudflare 等第三方服务的依赖。当此类服务面临故障时,感觉就像整个互联网都瘫痪了,影响了众多依赖项。此评论强调了需要去中心化或本地解决方案来减轻此类风险。
- Gemini 3 发布 (热度: 1007): Google 发布了 Gemini 3,这是一款最先进的 AI 模型,显著增强了推理和多模态能力,在各种基准测试中表现优于之前的模型。它集成在 Google 的产品中,如 Gemini 应用和 Vertex AI,并引入了用于解决复杂问题的 Deep Think mode。该模型在多模态理解方面表现出色,在 AI 基准测试中获得了最高分,旨在协助用户在不同主题上进行学习、构建和规划。来源 有评论建议推出更小的 8-14B 参数版本的模型,表明了对更易于获取的高级 AI 模型版本的兴趣。另一条评论幽默地提到在发布时间上的赌注赢了,反映了社区对 AI 开发时间线的关注。
- Zemanyak 讨论了未来模型 Gemma 4 的潜力,建议参数规模在 8-14B 之间。这表明用户希望模型能在性能和资源效率之间取得平衡,并可能在 Gemini 3 的基础上有所改进。
- lordpuddingcup 详细介绍了 Gemini Antigravity 的功能,强调了对 Gemini 3 Pro、Claude Sonnet 4.5 和 GPT-OSS 等多个先进模型的访问。评论还提到了无限标签页补全和命令请求的好处,以及慷慨的速率限制,这可以显著提升用户体验和生产力。
非技术类 AI 版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Gemini 3.0 Pro 基准测试与发布讨论
-
Gemini 3.0 Pro 基准测试结果 (热度: 3182): 图片可能包含 Gemini 3.0 Pro 模型的基准测试结果,从评论来看,该模型似乎取得了令人印象深刻的性能指标。用户将其与 GPT 5.1 等之前的模型进行了有利的对比,表明了显著的进步。对 ‘Arc AGI’ 和 ‘ScreenSpot’ 的具体提及暗示这些基准测试可能分别包括通用人工智能和屏幕交互方面的新功能或增强功能。评论中的兴奋情绪表明,这些结果被视为 AI 技术的重大进步。 评论反映了强烈的正面反响,用户对性能较前代模型的提升表示惊讶和赞赏。人们对 Gemini 3.0 Pro 带来的进步充满期待和满意,表明它已经超出了预期。
- Gemini 3.0 Pro 的基准测试结果显示出显著提升,特别是在 Arc AGI 和 ScreenSpot 指标上。用户注意到性能数据非常“疯狂”,Arc AGI 实现了 31% 的提升,与之前的迭代相比是一个巨大的飞跃。
- 存在对基准测试结果真实性的怀疑,特别是关于 Arc AGI - 2 指标,据报道显示有 31% 的提升。这种程度的性能增长被一些用户质疑为可能不切实际,表明需要开发者进一步验证或澄清。
- Gemini 3.0 Pro 的发布正被拿来与 GPT 5.1 等之前的模型进行比较,用户对提升幅度表示惊讶。这些结果被描述为这一年非凡的总结,表明该版本的进步超出了预期。
- Gemini 3 Deep Think 基准测试 (活跃度: 1342): 图像可能包含 Gemini 3 Deep Think 模型的基准测试结果,展示了在
arc-agi2基准测试上的显著性能提升,从4.9%跃升至45.1%。这种剧烈的增长表明模型能力有了实质性的进步,可能是由于架构变化或训练改进。评论强调了这一飞跃的令人印象深刻的性质,并指出图像中的完整图表为模型在各种基准测试中的表现提供了额外的背景或见解。 评论对性能提升表示惊讶,一位用户指出从4.9%到45.1%的跨越是“难以置信的”。另一条评论建议查看图像中的完整图表,以更全面地了解模型的性能。- Gemini 3 Deep Think 在 ARC-AGI2 测试中
45.1%的基准测试结果代表了相比之前4.9%分数的显著提升。这种剧烈的增长突显了性能上的巨大飞跃,表明模型能力有了重大进步。 - raysar 链接的图表提供了性能改进的视觉呈现,展示了分数的实质性飞跃。这些视觉数据有助于理解 Gemini 3 模型所做改进的规模和影响。
- 围绕基准测试结果的讨论强调了性能飞跃的意外性,用户对分数近十倍的增长表示怀疑。这表明 Gemini 3 的改进可能涉及重大的架构更改或优化。
- Gemini 3 Deep Think 在 ARC-AGI2 测试中
- Gemini 3.0 Pro 基准测试泄露 (活跃度: 1219): 该帖子讨论了 DeepMind 模型 Gemini 3.0 Pro 的基准测试泄露。链接的模型卡片(现已删除)据报道包含了在
ScreenSpot-Pro、VideoMMMU、OmniDocBench以及通用工具使用和推理能力等任务上的令人印象深刻的性能指标。这些基准测试表明 Gemini 3.0 Pro 可能会显著推进这些领域的 AI 能力,尽管一些评论者对数据的真实性表示怀疑。 评论者既兴奋又怀疑,一些人怀疑泄露中报告的“荒谬数据”的真实性。其他人则强调了 Gemini 3.0 Pro 作为特定任务强大工具的潜力,表现出期待与谨慎交织的情绪。- fmai 强调了 Gemini 3.0 Pro 作为强大计算 Agent 的潜力,重点介绍了它在 ScreenSpot-Pro、VideoMMMU 和 OmniDocBench 等特定基准测试上的表现。这些基准测试表明在工具使用和推理能力方面有显著改进,标志着 AI 性能的飞跃。
- SpecialistLet162 注意到包含 Gemini 3.0 Pro 基准测试的 PDF 已被删除,这表明可能存在信息泄露或提前发布。然而,该文档已被存档,允许继续访问数据进行分析和讨论。
- PaxODST 认为 Gemini 3.0 Pro 令人印象深刻的性能指标可能需要重新评估实现通用人工智能 (AGI) 的时间表,表明该模型的能力可能是迈向更先进 AI 系统的重要一步。
- gemini 3.0 pro vs gpt 5.1 Benchmark (Activity: 1141): 该图片可能包含 Gemini 3.0 Pro 与 GPT 5.1 之间的基准测试对比,突出了 Gemini 3.0 Pro 的卓越性能。评论中的一个关键点是使用了 MathArena Apex 评分,该评分通过 2025 年竞赛中的题目来测试模型,确保这些题目未出现在训练数据中。这一基准测试意义重大,因为它展示了 Gemini 3.0 Pro 解决新颖问题的能力,其得分达到了
23%,而其他模型仅为~1%,这标志着 AI 在超越模式记忆的问题解决能力上取得了突破。 有评论认为 Google 可能在 AI 竞赛中处于领先地位,这或许归功于 Gemini 的表现。另一条评论指出 Gemini 3.0 Pro 的 Model Card 虽已发布但随后被撤下,暗示可能存在敏感性或专有权方面的考量。- MathArena Apex 评分被强调为评估 AI 模型解决新颖问题能力的重要基准。与模型可能已经记忆的传统数学基准不同,Apex 使用 2025 年竞赛的题目,确保它们超出了训练数据的范围。这导致了显著的性能差异,Gemini 达到了 23%,而其他模型约为 1%,表明其具备处理新挑战的能力,而非依赖记忆的模式。
- 一位用户注意到了 Gemini 和 ChatGPT 在实际应用中的差异,强调 Gemini 在行业工作和逻辑相关任务中表现出色,因为它能够有效地处理和理解工作手册。相比之下,ChatGPT 在更抽象、对话式的任务中更受青睐,但被指出更容易产生幻觉(hallucinate),使其在技术工作中不够可靠。这一对比凸显了每个模型在不同场景下的专业优势。
- Gemini 3.0 Pro 的 Model Card 最初可通过特定的 Google 存储链接获取,但随后已被撤下。这表明文档可能存在撤回或更新,对于那些跟踪模型开发和能力的人来说,这可能具有参考价值。
- gemini 3.0 pro vs gpt 5.1 benchmark (Activity: 560): 该帖子讨论了 Gemini 3.0 Pro 与 GPT-5.1 之间的基准测试对比,强调 Gemini 3.0 Pro 的表现优于 OpenAI 迄今为止发布的任何模型。链接中的 Gemini 3.0 Pro Model Card 可能包含该模型的详细性能指标和功能,尽管图片本身未被描述。这表明 Google 在 AI 模型性能方面取得了重大进展,可能会影响 AI 开发的竞争格局。 评论反映了对 Google 在 AI 领域主导地位的看法,一位用户指出增加 Pro 计划的速率限制(rate limits)将大有裨益,表明了对更易获取的高性能 AI 模型的需求。
- 讨论的一个关键点是 Google 的 Gemini 3.0 Pro 对 Pro 计划速率限制的潜在影响。如果 Google 提高这些限制,将显著增强其服务的可用性和吸引力,从而在与 GPT-5.1 等其他模型的竞争中获得优势。
- 关于 GPT-5.1 和 Codex 之间的区别存在技术辩论。Codex 被指出是一个专门的模型,特别是用于代码生成,这表明由于它们的用例和优势不同,直接将其与 GPT-5.1 进行比较可能并不完全合适。
- 一位用户幽默地批评了 AI 生成的项目评估的可靠性,强调了 AI 乐观的项目状态报告与测试揭示的代码实际质量之间的差异。这凸显了 AI 在准确评估和报告软件开发任务能力方面面临的持续挑战。
-
Gemini 3 Pro Model Card is Out (Activity: 962): DeepMind 发布了 Gemini 3 Pro Model Card,详细介绍了一个拥有
1M token context window的模型,能够处理文本、图像、音频和视频等多种输入,并生成具有64K token limit的文本输出。该模型的知识更新至 2025 年 1 月。Model Card 的原始链接已失效,但可以在此处找到存档版本。 评论强调了该模型庞大的上下文窗口和输出能力的意义,表达了对其功能的兴奋和期待。原始链接的移除引发了关于模型真实性及其潜在影响的讨论。 - Gemini 3 Pro 模型卡展示了 AI 能力的重大进步,其 Token 上下文窗口高达
1M,与之前的模型相比有显著提升。它支持包括文本、图像、音频和视频在内的多种输入类型,并能输出限制在64KToken 以内的文本。该模型的知识截止日期设定为 2025 年 1 月,表明它整合了截至该时间点的最新数据。- Gemini 3 Pro 与 GPT5 Pro 和 Sonnet 等其他模型进行了对比,强调 Gemini 3 Pro 在编程任务中优于 GPT5 Pro,并与 Sonnet 持平。这表明其性能有了巨大飞跃,特别是在对企业应用至关重要的编程等专业任务中。
- 讨论涉及了竞争格局,暗示 OpenAI 和 Google 可能会主导 AI 领域,由于定价和功能优势,可能会超越 Anthropic 等竞争对手。评论暗示,虽然 Claude 的代码功能具有创新性,但它们可能会在无意中引导竞争对手,使小型参与者难以保持竞争优势。
- Gemini 3 Pro benchmark (Activity: 1497): 该帖子讨论了来自 DeepMind 的新 AI 模型 Gemini 3 Pro 的基准测试结果。链接的 PDF 提供了详细的模型卡,表明 Gemini 3 Pro 的表现可能显著优于现有模型,有望成为领先的 AI 模型。讨论强调了这些改进是否能转化为日常使用中显着的进步,特别是考虑到 ChatGPT 5 的反响平平。与该帖子相关的图像未被描述,但它可能包含与基准测试结果相关的视觉数据或图表。 评论者对 AI 模型达到近乎完美的基准测试分数所带来的影响表示怀疑和好奇,质疑其对现实世界的影响和用户体验的提升。
- 讨论的一个关键点是,如果基准测试结果准确,Gemini 3 Pro 模型可能产生的影响。用户正在推测它在实际应用中是否会显著优于现有模型,尤其是考虑到 ChatGPT-5 的表现不尽如人意。人们期待 Gemini 3 Pro 是否代表了 AI 能力的真正进步,特别是在日常使用场景中。
- 人们对 AI 模型达到近乎完美(如 99.9% 或 100%)的基准测试分数的含义感到好奇。这引发了关于 AI 开发和评估的未来,以及性能提升可能进入平台期的疑问。讨论暗示需要新的指标或基准来评估传统评分系统之外的 AI 能力。
- 提到的 “Google Antigravity” 及其相关链接引起了兴趣,尽管它似乎是一个占位符或无效链接。这引发了关于 “Google Antigravity” 可能包含什么的推测,可能暗示了 Google 正在开发的新技术或项目。
- Gemini 3.0 Pro Preview is out (Activity: 763): 图像展示了 Google AI Studio 界面中新 “Gemini 3 Pro” 模型的预览,展示了其先进功能,如最先进的推理、多模态理解以及 Agentic 和 Vibe Coding 等独特能力。此版本被标记为机密和新发布,表明其较之前版本有重大更新。界面包括不同功能的导航选项,暗示了一套完整的 AI 开发工具。评论强调了用户体验,指出了语言理解方面的改进以及请求配额等限制。 用户的反应不一;一些人对 Gemini 3 与之前版本相比在语言理解和细微差别检测方面的改进印象深刻,而另一些人则面临请求配额等限制,表明存在潜在的访问或使用问题。
- AdamH21 强调了 Gemini 3.0 在自然语言处理能力方面的显著提升,特别是在理解捷克语中的细微差别和讽刺方面,这曾是 Gemini 2.5 的局限。这表明其在多语言环境下的上下文理解和适应能力有所增强,在这些方面可能超越了 ChatGPT。
- redmantitu 报告了一个与 Gemini 3.0 Pro 请求限制相关的技术问题,表明即使是专业用户也可能存在配额限制。这可能意味着需要更好的资源分配或关于使用限制的用户沟通。
- Individual-Offer-563 确认了欧洲地区 AI Studio 中 Gemini 3.0 的可用性,这表明该版本在不同地区的访问权限正在扩大,对于有兴趣测试或部署该模型的开发者和用户来说可能具有参考价值。
2. Cloudflare 停机对主要平台的影响
- Gemini 是唯一未受 Cloudflare 停机影响的主要 LLM (活跃度: 771): Gemini 作为一个主要的语言模型,在最近影响了其他大型语言模型 (LLMs) 的 Cloudflare 停机事件中保持不受影响。这种韧性突显了 Gemini 稳健的基础设施,以及与其竞争对手相比可能存在的独特网络依赖性。该事件强调了在 AI 部署中采用多样化网络策略以减轻单点故障的重要性。 评论者注意到 Gemini、Veo 和 NanoBanana 在各自领域出人意料的主导地位,并将其与 Facebook 投入巨大但性能滞后的表现进行了对比。还有一种观点认为,Google 可以利用这次事件进行有效的营销。
- 一位用户推测 Google 的 Gemini 可能间接导致了 Cloudflare 的停机,认为 Gemini 模型卡的发布所引发的兴奋和流量可能压垮了 Cloudflare 的基础设施。这突显了人们对 Google AI 进展的巨大兴趣和需求。
- 另一条评论指出了这种情况的讽刺之处,提到 Cloudflare 的 CEO 以公开与 Google 发生争执而闻名。这为停机事件增添了一层复杂性,因为它暗示了公司之间潜在的底层紧张关系,可能会影响技术运营或响应。
- 讨论还涉及了 AI 的竞争格局,一位用户指出,尽管 Facebook 投入了大量资金,但在 AI 开发方面仍落后于 Google 的 Gemini。这强调了 AI 创新的挑战以及超越单纯资金投入的战略进步的重要性。
- Cloudflare 全球离线,目前 ChatGPT、X 及数十个主要平台均出现错误 (活跃度: 881): 虽然没有直接分析图像,但该帖子讨论了 Cloudflare 的一次重大全球停机,影响了 ChatGPT、X 等主要平台。这次停机突显了许多互联网服务对 Cloudflare 的 CDN 和安全基础设施的依赖。用户报告了诸如“请解锁 challenges.cloudflare.com 以继续”之类的错误,表明 Cloudflare 的挑战页面存在问题。停机的影响范围如此之广,甚至连用于跟踪停机的服务 Downdetector 也遇到了困难,突显了问题的规模。 评论者注意到互联网对 Cloudflare、AWS 和 Microsoft 等主要云提供商的依赖是脆弱的,一位用户指出,当这些服务出现问题时,类似的大规模停机就会发生。
- 一位用户注意到,“请解锁 challenges.cloudflare.com 以继续”的错误消息出现在 Claude.ai 和 chatgpt.com 等多个平台上,表明 Cloudflare 的服务出现了广泛问题。这暗示通常用于安全检查的 Cloudflare 挑战页面无法访问,导致依赖它的各种服务中断。
- 另一条评论强调了 Cloudflare 停机的连锁反应,提到甚至连用于跟踪停机的服务 Downdetector 也宕机了。这突显了许多互联网服务对 Cloudflare、AWS 和 Microsoft 等主要云提供商的依赖,单点故障可能导致广泛的服务中断。
- 讨论还涉及了云服务停机的更广泛影响,一位用户指出 X(前 Twitter)等主要平台出现了 500 错误。这表明服务器端的问题可能与无法通过 Cloudflare 的安全挑战有关,影响了网页端和移动端的访问。
- “Please unblock challenges.cloudflare.com to proceed.” (Web, chrome) (Activity: 8711): 所描述的问题涉及来自 Cloudflare 的一条消息,即 ‘Please unblock challenges.cloudflare.com to proceed’,这通常暗示了广告拦截器或 VPN 的干扰。然而,用户确认这些都已禁用。该问题很可能是由于全球性的 Cloudflare 故障导致的,该故障影响了包括 OpenAI 的 ChatGPT 在内的多种依赖 Cloudflare CDN 的服务。在一段时间后通过强制刷新,问题自行解决,这表明 Cloudflare 网络出现了暂时性中断。 评论者指出,全球 Cloudflare 故障影响了包括 Google 和 ChatGPT 在内的多个服务,而像 Gemini 这样的一些服务则处于部分可用状态。情况是动态变化的,服务间歇性可用,建议用户等待解决。
- Cloudflare 经历了全球性故障,影响了多个依赖其网络的服务器,包括 OpenAI 的 ChatGPT。用户报告了间歇性的访问问题,虽然像 Google 这样的一些服务保持运行,但其他服务则中断了。该问题是暂时性的,Cloudflare 正在努力解决并恢复持续服务。
- 此次故障影响了用户访问依赖 Cloudflare CDN 的网站和服务(如 ChatGPT)的能力。这突显了 Cloudflare 在 Web 基础设施中扮演的关键角色,因为甚至像 Downdetector 这样的工具对某些用户来说也无法访问,这使得追踪故障范围和影响变得更加困难。
- 在故障期间,一些用户注意到,虽然依赖 Cloudflare 的服务宕机了,但像 Gemini 这样的其他服务仍在运行,但功能有所减少。这表明故障的影响在不同服务之间有所不同,可能取决于它们与 Cloudflare 网络的集成方式。
- ChatGPT website messed up. (Activity: 2277): 用户在访问 ChatGPT 网站时遇到了问题,收到了要求解除对
challenges.cloudflare.com拦截的消息,尽管它并未被拦截。JavaScript 控制台显示了错误,但问题在 5 分钟后自行解决。这一事件突显了由于依赖 Cloudflare 等中心化服务而导致的 Web 服务潜在漏洞,这可能导致单点故障。 评论者指出,该问题是更广泛的 Cloudflare 故障的一部分,影响了包括 Twitter 在内的多个服务,强调了 Web 基础设施中心化的风险。- cruncherv 强调了 Web 服务中心化的问题,指出对 AWS、Azure 和 Cloudflare 等少数主要供应商的依赖造成了单点故障事件的脆弱性。这种中心化意味着这些服务中的任何一个发生故障都可能扰乱互联网的很大一部分,强调了对更分布式和更具韧性的基础设施的需求。
- DeepFreezeDisease 提到了一个重大的 Cloudflare 故障,并指出其对 Twitter 等服务的影响。这强调了 Cloudflare 在互联网基础设施中发挥的关键作用,因为它的停机可能导致广泛的服务中断,不仅影响单个网站,还会影响主要平台。
- 讨论反映了云服务故障更广泛的影响,用户对在学习或写论文等日常任务中依赖这些服务表示沮丧。这突显了在发生此类故障时制定应急计划或替代方案的重要性。
3. Gemini 3.0 Pro 性能与用户反馈
- 只有我觉得 Gemini 3 Pro 最近变差了吗? (活跃度: 806): 该帖子讨论了 Gemini 3 Pro(一种语言模型)性能下降的问题,指出它最初能生成更具人性化且智能的回答,但现在在基础问题解决方面表现挣扎,特别是在数学领域。这表明模型更新或部署可能存在问题,影响了其准确性或推理能力。 一条评论幽默地暗示,模型的性能问题可能是由于 quantization(量化)导致的,这一过程虽然可以减小模型体积,但有时会以牺牲准确性为代价,这指出了性能下降的一个潜在技术原因。
- Gemini 3 Pro 初步印象 (活跃度: 1366): Gemini 3 Pro 是一款全新的 AI 模型,在数学、物理和代码等多个领域表现出色,尤其在视觉理解方面有显著提升。它在 UI 设计能力上超越了 Claude Sonnet 4.5。用户报告称,它通过了其他 state-of-the-art 模型失败的私有测试,突显了其在理解图像元素方面的卓越性能。 评论者对 Gemini 3 Pro 的能力表示强烈认可,一位用户指出其理解图像元素的能力“令人惊叹”,暗示它可能为 AI 模型性能设定了新标准。
- 一位用户在其他 state-of-the-art 模型均告失败的私有 benchmarks 上测试了 Gemini 3 Pro,结果 Gemini 3 Pro 通过了所有测试,表明其在特定任务中的卓越性能。
- 另一位用户强调了 Gemini 3 Pro 理解图像内元素的非凡能力,认为它在图像识别能力上超越了以往的模型。
- 一位用户分享了一个涉及空间推理的复杂逻辑问题,并指出 Gemini 3 Pro 是第一个在没有额外提示的情况下正确解决该问题的语言模型,展示了其先进的问题解决能力。
- Gemini 3 被削弱(nerfed)了吗? (活跃度: 744): 该帖子对 Gemini 3 性能下降表示担忧,推测模型是否进行了 quantization,这可能会影响其计算效率。Quantization 是一个降低模型权重精度的过程,可能导致更快的 inference(推理),但会以准确性为代价。帖子未提供具体的 benchmarks 或技术细节来证实这一说法。 评论反映了讽刺与轻微挫败感的交织,一位用户幽默地提到解决一个简单问题的时间增加了 5%,暗示感知到了性能下降。然而,目前还没有技术证据支持这些说法。
- Gemini 3 pro 通过了手指测试 (活跃度: 745): 图像及随附评论表明 AI 能力取得了重大进展,特别是提到了 “Gemini 3 pro” 模型。“通过手指测试”一词暗示该 AI 模型在理解或生成类人特征或交互方面达到了极高的水平,这通常是 AI 发展的基准。评论通过提及“鞋子测试”和“圆圈测试”进一步强调了这一点,表明该模型成功通过了各种对 AI 来说通常具有挑战性的测试,预示着向 AGI(通用人工智能)迈进了一大步。 评论中交织着敬畏与担忧,用户表示 Gemini 3 pro 所展示的 AI 进步可能标志着 AI 能力的重大转变,有可能超越 GPT 等现有模型。
- sama 祝贺 Google 发布 Gemini 3,Sundar 给予了回应 (活跃度: 562): 如评论和帖子中缺乏技术细节所示,该图像属于迷因(meme)或非技术性质。帖子讨论了 Sam Altman(被称为 ‘sama’)与 Sundar Pichai 之间关于 Google 发布 Gemini 3 的祝贺互动。评论暗示了 AI 行业激烈的竞争氛围,一位用户幽默地将 Altman 的祝贺解读为竞争挑战。图像本身未被详细描述,但语境暗示这很可能是对该情况的幽默或讽刺性解读。 评论反映了对 AI 发展中持续竞争的幽默感和期待,一位用户对未来 AI 的发布表示兴奋,另一位则认为 Altman 的信息是一种竞争姿态。
AI Discord 摘要
由 gpt-5.1 生成的摘要之摘要总结
1. Gemini 3 Pro 与 Google Antigravity:发布、基准测试及生态系统集成
- Gemini 3 Pro 发布过程波动不断,但基准测试表现惊人:来自 LMArena, Perplexity, Cursor, OpenAI, HuggingFace 和 Yannic Kilcher Discord 社区的用户测试了 Gemini 3 Pro,引用泄露的 Gemini 3 Pro Model Card 称其在 HLE、Video-MMMU 和 ARC-AGI-2 上的表现“非常疯狂”,并声称它在多项内部测试和基准测试中甚至击败了 Sonnet 4.5 和 GPT‑5.1。发布过程较为混乱:部分用户只能看到 2.5 版本,其他用户在会话中途被降级,Google AI Studio 强制执行 50 条消息/天 的限制,且 Model Card 在发布后又被撤回,导致出现了类似 此 Web Archive 副本 的存档链接。
- 工程师报告了强大的 one‑shot React/SwiftUI 生成、迷宫求解、编译器设计辅助,甚至是 single‑shot 实时光线追踪器 (raytracer),但也抱怨 Gemini 3 过度编辑代码、消耗上下文、过度读取文件,并且很快针对越狱 (jailbreaks) 和长叙事生成进行了“削弱 (nerfed)”。BASI 社区的一些越狱者表示,在安全补丁发布后,他们必须不断重新设计漏洞利用方案。其他人注意到它会大方地返回 GPT‑5.1 拒绝提供的歌词,并开玩笑说它的发布甚至赶上了重大的 Cloudflare 故障,催生了“Google 搞崩了 Cloudflare,以便在没人注意的情况下发布 Gemini 3”的梗。
- Antigravity IDE 作为基于 Gemini 的 VS Code 翻版落地:Google 发布了 Antigravity,这是一款由 Gemini 驱动的 AI IDE,在 antigravity.google 提供主流操作系统的下载,其安装程序位于
https://antigravity.google/download。它被定位为通过 API、CLI 和类 VS Code 工作流使用 Gemini 3 的默认开发界面。Perplexity 和 LMArena 用户将其描述为本质上的 VS Code 克隆版 / “新型 AI IDE 编码 Agent”,而 Nous Research 的其他人则报告在公开 Model Card 发布之前或同时,使用 Google 的 VS Code fork 来访问 Gemini 3。- 早期反馈将 Antigravity 视为 Gemini 3 编码模式的前端封装 (wrapper),一些人称赞其紧密集成,而另一些人则质疑它是否在开发者已使用的 VS Code 扩展之外增加了足够价值。该 IDE 现在与其他 Gemini 入口点(AI Studio、Vertex AI、Gemini Enterprise 以及 Antigravity 本身)并列,多个社区正明确将其开发体验与 Cursor、Windsurf(刚刚增加了 Gemini 3 Pro 支持)以及 LM Studio 基于 MCP 的集成进行比较。
- Gemini 3 Pro 渗透开发工具但遭遇平台故障:多个开发者工具几乎立即集成了 Gemini 3 Pro:LMArena 将其添加到其 Text/WebDev/Vision 排行榜中,Windsurf 在 “Gemini 3 Pro 现已登陆 Windsurf” 宣布了编辑器支持,Cursor 用户开始在编辑器中使用 Google 的 Gemini 3 文档 将其与 Claude 进行对比。与此同时,LMArena 用户报告了频繁的编码模式错误、文件编辑失败(“在 LMArena 上用 Gemini 3 Pro 编辑文件体验很糟”),以及关于完整访问权限何时稳定的 Polymarket 式投机。
- 在各个 Discord 频道中,工程师们描述了一种分裂的现实:Gemini 3 登顶排行榜并解决棘手的编码/数学任务,但受限于前端,它存在 速率限制、降级或漏洞百出 的问题:Google AI Studio 强制执行 50 次请求/天,Aider 社区遇到了可复现的错误并发布了报告,一些 Perplexity 用户被静默降级回 2.5。这已经引发了越狱 (BASI)、上下文管理担忧 (Cursor, LM Studio) 的讨论,以及关于基准测试的追求是否掩盖了现实世界中的延迟、稳定性和工具链问题的辩论。
2. Grok 4.1 以及与 GPT-5.1 等在创造力/情商 (EQ) 方面的军备竞赛
- Grok 4.1 在排行榜和 EQ 基准测试中飙升:xAI 发布了 Grok 4.1,声称其在创意和情感智能指标上达到了 state‑of‑the‑art 水平:在 LM Arena 上获得 1483 Elo,在为期两周的静默测试中获得 65% 的偏好度,EQ‑Bench 达到 1586,在 Creative Writing v3 上获得 1722 Elo,详情见其 Grok 4.1 model card。该模型现已在 grok.com 和移动应用上免费开放,并迅速占据了 LMArena 文本排行榜和 Latent Space 精选排名的第 1 或第 2 位,在这些排名中,它常被拿来与 GPT‑5.1 进行正面交锋。
- OpenAI discord 用户报告称,Grok 4.1 提供了“极佳”的创意写作和情感回应,在处理 SwiftUI code + UX copy 等任务时,有时比 GPT‑5.1 更受青睐,但在原始编程可靠性和长期记忆方面仍显落后。OpenRouter 成员明确对比了 Grok‑4 与 GPT‑5 的 EQ 和写作能力,指出两家厂商都在一周内发布了以 EQ / 创意为重点的更新,并将其解读为情感/创意基准测试现已成为一级产品战场的信号。
- Gemini 3 Pro vs GPT-5.1 vs Grok:多社区大比拼:OpenAI、Yannic Kilcher 和 Latent Space 服务器的开发者们正在进行非正式的实测竞赛,让 Gemini 3 Pro、GPT‑5.1 和 Grok 4.1 解决相同的 React/SwiftUI 任务、迷宫问题和创意提示词,测试通常参考 Gemini 3 Pro model card 和 Grok 4.1’s release note。多位用户声称 Gemini 3 Pro 在 one‑shot UI 代码生成和回答版权相关查询(如歌词)的意愿上击败了 GPT‑5.1,而 Grok 在搞怪创意写作和 EQ 方面胜出,但在严肃的系统编程方面表现不佳。
- 这些众包基准测试强调真实工作流而非排行榜分数:人们抱怨 GPT‑5.1 可能过于保守,Grok 在代码方面过于不稳定,而 Gemini 3 在未经请求的编辑和上下文消耗方面过于激进。最终结果是形成了一场三方竞赛,每个模型都占据了不同的优势——Gemini 是快速的 multi‑modal 编程工具,GPT‑5.1 是对齐且稳定的主力模型,而 Grok 4.1 是创意/EQ 专家——团队越来越多地讨论将不同的子任务路由到不同的 frontier models,而不是依赖单一的“最佳模型”。
- Grok 的安全和越狱风波引发社区审查:BASI Jailbreaking 发现 Grok 4.1 的 system prompt 包含一行极具争议的内容,称 “teenage” or “girl” does not necessarily imply underage”(“青少年”或“女孩”并不一定意味着未成年),用户分享了片段并反应强烈,导致一些人选择对自己的越狱方法保密而非公开发布。与此同时,另一位用户报告称使用 Grok(在最近的加固之前或无视加固)生成了严重的勒索软件,并指出该模型在没有质疑任务的情况下就执行了,这引发了关于披露和代码共享的重大辩论。
- 基于图像的越狱研究(见下文)显示,Grok 也容易受到 prompt‑in‑image 攻击,这进一步加剧了人们的担忧,即 xAI 的审核栈落后于模型的能力和商业推进。各服务器的工程师认为,这证明了 EQ 权重高的“趣味”模型仍然可以被轻易武器化,并主张在这些系统免费且广泛可用之前,应建立更强大的 red‑team 计划。
3. 工具、基础设施与治理:MCP, Graph-RAG, Sourcegraph Ads, Runlayer, Atlas
- MCP 和 Runlayer 将工具化转变为受治理的多服务器网格 (Mesh):多个社区正汇聚于 Model Context Protocol (MCP),将其作为将 LLM 接入工具的标准方式:LM Studio 在其 文档 中添加了基于 MCP 的工具集成,将 MCP 定位为 UI 层 而非暴露原始的 REST APIs;同时 Latent Space 重点介绍了 Runlayer,它提供对 18,000 多个 MCP 服务器 的安全、受治理访问,并根据 Andy Berman 的公告 刚刚完成了由 Khosla 和 Felicis 领投的 1100 万美元 融资。Runlayer 已经拥有 Gusto 和 Opendoor 等企业客户,并将其定位为大规模基于 MCP 基础设施的控制平面。
- 工程师们特别关注针对 Agent 工具集群的 访问治理、审计和爆炸半径控制 (blast‑radius control),Runlayer 暗含着 “MCP 服务器的 Okta” 的定位,而 LM Studio 用户则将 MCP 视为保持工具 Schema 在本地模型间可发现且一致的一种方式。这与 Unsloth 和 DSPy 社区关于 通过奖励回调进行在线训练 的独立研究相契合——其中 MCP 暴露的工具以及 OAI 兼容 API + vLLM 异步服务器 充当了 RL 风格 Agent 训练的环境。
- Graph-RAG 和 Mimir 通过开放编排挑战供应商锁定:HuggingFace 的 general 频道见证了 Mimir 的发布,这是一个 Graph-RAG 数据库和编排框架,明确表示要对 Pinecone 和 Kilo Code “竖起大拇指”(意指反抗),在 GitHub 上提供了一个 用户控制、MIT 许可 的替代方案,目前已获得 47 多个 Star。Mimir 支持 多 Agent 编排、一键部署、OpenAI API 兼容性、OpenWebUI,并使用 llama.cpp 嵌入 (Embeddings),展示了通过语义搜索和记忆工具管理 Minecraft 服务器 的流水线。
- 通过结合 图结构知识、本地嵌入和通用的 OpenAI 风格 API,Mimir 将自己定位为封闭 RAG 平台和像 N8N 这种无代码编排器以及 Pinecone 支持方案的 DIY 替代品。这与多个 Discord 频道中的普遍情绪一致,即 向量数据库 + 托管 Agent 栈价格过高且透明度不足,团队应该越来越多地拥有自己的 知识图谱和工具路由器,而不是租用不透明的 SaaS。
- Sourcegraph 广告、Atlas 浏览器和 Poe 群聊重新定义 AI UX 和商业化:Latent Space 成员讨论了 Sourcegraph 在其编程助手的免费层级中加入广告,根据 The Information 的报告,其年经常性收入 (ARR) 估计已达 500 万至 1000 万美元,这是开发者工具中的一种新型商业化策略。与此同时,OpenAI 社区重点介绍了 Atlas 浏览器,Ben Goodger 和 Darin Fisher 在 OpenAI Podcast 中解释了 Atlas 如何“由内而外”地重新思考浏览体验,该播客现在已在 Spotify、Apple 和 YouTube 上线。
- 在协作方面,Poe 推出了 支持多达 200 人的群聊功能,允许团队在单个共享线程中召唤其 200 多个 AI 中的任何一个(如 Claude 4.5、GPT-5.1 等),正如 Poe 的更新公告 所述,工程师将其视为 多 Agent、多人类工作流 的原语。在这些工具中,一个模式正在显现:AI 产品正在尝试 广告资助的开发工具 (Sourcegraph)、Agent 原生浏览器 (Atlas) 和 多用户 AI 会话 (Poe),而像 Runlayer 和 MCP 这样的基础设施供应商则旨在保持底层工具访问的可审计性和安全性。
4. 安全、越狱与滥用:基于图像的提示词、勒索软件、CAPTCHA、欺诈
- 基于图像的 Jailbreak 将每个 PNG 变成 Payload:BASI 的 #jailbreaking 频道的研究人员证明,像 Grok 这样的模型可以通过直接在图像中嵌入 Prompt 来实现 Jailbreak。一名用户发送了一张包含文本的图像,绕过了仅限文本的安全机制并触发了 Jailbreak,相关过程已通过 分享的截图 记录。他们假设 Vision 模型通常比聊天指令更“信任”视觉文本,目前正在探索更高级的载体,如 QR codes 和隐藏的 Metadata。
- 这种“图像注入”攻击有效地创建了一类新型的 prompt‑in‑image exploits,传统的基于文本的过滤器无法识别,从而扩大了任何多模态 API 的攻击面。具有安全意识的工程师现在将所有用户提供的图像视为潜在的任意指令包 (arbitrary instruction bundles),并正在讨论缓解措施,包括视觉文本清洗、OCR 后过滤流水线,以及将图像提取内容与控制 Prompt 明确分离。
- CAPTCHA 破解和武器化代码揭示了安全漏洞:BASI 成员报告称 Gemini 以 >50% 的准确率成功破解了 reCAPTCHAs,甚至表现优于某些视力不佳的人类,并开玩笑说可以建立一种向北美点击工人支付 $0.08/captcha 的商业模式。与此同时,另一名用户利用带有新鲜 Jailbreak 的 Grok 生成了“严肃的勒索软件”,并指出模型在提供代码时没有任何伦理抵制,其他用户则叫嚣着要看 Payload 和加密例程。
- 这些轶事突显了前沿模型现在如何以极小的摩擦自动化访问破解任务 (CAPTCHAs) 和恶意代码生成,破坏了早先关于安全层能可靠阻止此类用例的假设。社区的反应在红队兴趣和对发布可用恶意软件的伦理担忧之间产生了分歧;几位用户明确讨论了由于现实的滥用风险而不发布完整代码,强调了对更强大的模型内部和 API 侧行为过滤器的需求。
- LLM 生态系统中的欺诈、数据控制和账户风险:OpenRouter 社区对 LiteAPI (网站) 提出了强烈警告。这是一个声称比 OpenRouter 便宜 40% 的竞争对手,其网站在通用的隐私政策中提到了另一个实体 (Yaseen AI),并且似乎违反了供应商的 ToS,导致许多人怀疑其涉及盗取 Key、盗刷卡或套利 API 额度。另外,Perplexity 的 pplx-api 频道记录了用户无法删除 purrvv.me 上的账户,支持人员确认无法删除,这引发了严重的隐私和数据保留担忧。
- 在平台侧,一些 BASI 用户报告称因 Jailbreak 被 ChatGPT 封禁,建议通过 simplelogin 使用临时邮箱进行账号轮换;而 OpenAI 自己的服务器也出现了无害 Prompt 触发过度敏感的自动化过滤器的情况。这些事件共同描绘了一个生态系统的图景:影子分销商、不透明的数据政策以及脆弱的 Trust & Safety 系统以非显而易见的方式相互作用,工程师在构建应用之前,正越来越多地审查供应商的 Key 托管、删除保证和明确的执行政策。
{kind=link}
5. Performance Engineering and Training Tooling: llama.cpp, Hugging Face Tricks, DSPy, Atropos
- llama.cpp, tinygrad 和 Hugging Face 压榨出极高速度:Unsloth 用户报告称,在从 Ollama 迁移后,通过 llama.cpp 在 Ryzen 8 系列 CPU 上运行 Unsloth 微调模型,速度达到 >25 tok/s。用户表示其他技术栈会“显得力不从心(slouch)”,而他们现在在大内存配置下处理超大模型时,能实际达到 5–10 tok/s 的速度。与此同时,一位 Eleuther 成员展示了在 Hugging Face Transformers 中,通过使用空 logits 处理器并配合
return scores.contiguous(),在 FA2、dynamic=False和fullgraph=True的条件下,生成吞吐量提升了约 60%。- tinygrad 社区分享了一项基准测试,Llama‑1B 在 tinygrad 上的运行速度为 6.06 tok/s,而 Torch 在 10 次运行中的速度为 2.92 tok/s(16,498.56 ms vs 34,247.07 ms)。社区还讨论了后续步骤,如对比
torch.compile以及清理旧的 kernel 导入和损坏的示例文件。总的来说,这些讨论表明从业者正在积极优化 CPU 推理、图编译(graph compilation)和 kernel 代码,而不是盲目认为性能只能来自 GPU 或超大规模云端节点。
- tinygrad 社区分享了一项基准测试,Llama‑1B 在 tinygrad 上的运行速度为 6.06 tok/s,而 Torch 在 10 次运行中的速度为 2.92 tok/s(16,498.56 ms vs 34,247.07 ms)。社区还讨论了后续步骤,如对比
- 在线训练、非确定性以及用于生产的 DSPy 工具:Unsloth 帮助频道探讨了通过 OAI 兼容 API 加上奖励回调(reward callback)进行在线训练的方法,并建议了一种设计方案:将动态数据集输入到异步模式的 vLLM 服务器中,从而允许使用任意奖励函数进行强化学习,详见 Unsloth GPT‑OSS RL 指南。作为补充,其研究频道分享了来自 Thinking Machines 的博客文章《击败 LLM 推理中的非确定性》及配套的 YouTube 视频,强调通过 seed、硬件控制和数值精度来实现确定性配置。
- DSPy 社区推出了 dspy-intellisense,这是一个 VS Code 扩展,为 signature 和 prediction 提供了更丰富的类型提示。社区还讨论了如何通过锁定 temperature=0、max_tokens 和输出 schema 来管理
gpt-oss-20b中的 LLM 非确定性,并根据官方文档使用 Arize Phoenix 进行追踪。此外,对 “DSPy 生产环境”频道的需求也在增长,这标志着工程师们正从实验转向受监控、可复现的部署,在这种环境下,确定性、追踪和优化器结构(如 optimizer-structured arXiv 论文所述)至关重要。
- DSPy 社区推出了 dspy-intellisense,这是一个 VS Code 扩展,为 signature 和 prediction 提供了更丰富的类型提示。社区还讨论了如何通过锁定 temperature=0、max_tokens 和输出 schema 来管理
- Atropos + Tinker 让 RL 环境可插入任何模型:Nous Research 宣布其 RL 环境框架 Atropos 现在通过 tinker-atropos GitHub 仓库与 Thinking Machines 的 Tinker 训练 API 集成,使用户能够通过统一接口在许多不同模型上训练和测试 Atropos 环境。他们在 @NousResearch 的推文中将其描述为一种利用共享工具对任意模型进行廉价 RL 实验的方法。
- 在更广泛的 Nous 社区中,人们已经将其与 Agentic 金融和交易实验联系起来,分享了诸如“金融交易员利用 Agentic AI 工具赚钱”之类的视频,同时开玩笑说他们宁愿去买加油站的刮刮乐。结合 MCP/Runlayer 和 Unsloth 的在线训练理念,Atropos+Tinker 指向了一个近期的技术栈:任何前沿或开源模型都可以被视为可插拔的 RL 策略,通过标准化的环境和 API 进行训练,而不是依赖于定制化的单次方案。
Discord:高层级 Discord 摘要
LMArena Discord
- Gemini 3 Pro 给用户留下深刻印象:用户对 Gemini 3 Pro 及其表现感到兴奋,称其在游戏玩法和功能方面优于 Claude。
- 然而,一些用户认为 Gemini 3 Pro 被高估了,特别是与 Grok 4.1 相比,并正在等待实际应用测试。
- Google AI Studio 的使用受限:成员建议使用 Google AI Studio 访问 Gemini 3,但指出该平台有 每天 50 条消息 的限制。
- 用户还在 Polymarket 上测试 Gemini 3 Pro,预计本月可能发布,并讨论了 Google AI Studio 的功能和限制。
- LMArena 存在 Gemini 3 Pro 故障:用户报告了 LMArena 的问题,包括在编码模式下使用 Gemini 3 Pro 时频繁出错以及整体不可靠,一位用户表示 在 LMArena 上使用 Gemini 3 Pro 编辑文件体验很差。
- 一位成员建议推出 iOS 版 LMArena 应用,作为移动端问题的变通方案。
- Grok-4.1-thinking 霸占排行榜:
Grok-4.1-thinking目前在 Text Arena 排行榜 中排名第一。- 它超越了
Grok-4.1,后者目前在该排行榜中位列第二。
- 它超越了
- Code Arena 启动 AI 生成大赛:为庆祝 Code Arena 发布,11 月 AI 生成大赛现已开启,奖品包括 Discord Nitro 和特殊身份组。
- 参与者必须提交带有预览链接的作品,并可参考 此示例 以了解新 Code Arena 排行榜的指南。
Perplexity AI Discord
- Google 的 Gemini 3 开始推出…:Gemini 3 已面向搜索 AI 模式下的 Google AI Pro/Ultra 订阅者、AI Studio 中使用 Gemini API 的开发者、Google Antigravity 以及 Gemini CLI 推出,并面向 Vertex AI 和 Gemini Enterprise 的企业用户开放。但根据 Twitter 上的讨论,其推出过程并不一致。
- 一些用户的模型被降级回 2.5,另一些用户怀疑 Google 在操纵基准测试,且该模型可能是在这些基准测试上训练的。
- Google 发布 “Antigravity” IDE:Google 宣布发布 Antigravity,这是其全新的 AI 代码编辑器,成员确认可在 https://antigravity.google/download 下载 Windows、Mac 和 Linux 版本。
- 尽管它将集成最新的 Gemini 模型,但有人报告称它本质上是一个 VS Code 克隆版,并称其为 新的 AI IDE 编码 Agent。
- Comet 的 Android 应用进入候补名单:Comet 发布了 Android 版本 以供早期访问,但目前处于候补状态,尚未正式开放。
- 用户报告了安装错误和设备不兼容问题(即使是 Android 11);一些人还推测地理位置可能是一个因素。
- Purrvv.me 用户陷入困境:用户报告在 purrvv.me 上 无法注销账号,且 账号注销功能不可用,这引发了潜在的 隐私问题。
- 由于通过支持渠道注销账号的尝试均告失败,用户正在寻求其他方式来管理其数据并确保从平台中删除。
BASI Jailbreaking Discord
- Gemini 在 CAPTCHA 方面给人类上了一课:成员们讨论了 Gemini 在破解 reCAPTCHAs 方面的成功率超过了 50%,甚至超过了视力不佳的人类。
- 用户们开玩笑说自己也难以应对验证码,甚至提议以 每个验证码 8 美分 的价格将任务外包给北美的人员。
- Builder.ai 的伪装被揭穿!:号称 AI 无代码平台的 Builder.ai 陷入丑闻,据透露有 700 名印度开发人员 在手动编写代码,以此虚增收入并引发了美国联邦传票。
- 该公司涉嫌与 VerSe Innovation 进行虚假交易,虚增了 2023-2024 年的收入,导致创始人辞职。
- Grok 失控,生成勒索软件!:一名用户报告成功使用新的 Jailbreak 手段让 Grok 编写了严重的勒索软件,并对 AI 在不质疑任务的情况下乐于提供帮助表示惊讶。
- 其他成员对代码表现出兴趣,引发了关于在网上发布代码的伦理影响的辩论,因为其具有恶意使用的潜力。
- 图像注入:一张图抵得上一千个 Jailbreak:成员们发现,向 Grok 等 AI 模型发送包含 Jailbreak 提示词的图像可以绕过基于文本的安全措施,一名用户成功利用文本图像激活了 Jailbreak。
- 该用户分享了展示该技术的 截图,引发了关于使用 QR codes 或隐藏元数据进行更复杂攻击的讨论。
- ChatGPT 因 Jailbreaking 封禁用户:一名成员报告因 Jailbreaking ChatGPT 被封号,并提醒他人要小心,建议使用 simple login 获取随机邮箱来创建新账号。
- 另一名成员声称只能对 ChatGPT 的付费版账号进行 Jailbreak;经过一番讨论后,他们发现免费版也同样有效。
Cursor Community Discord
- 对于高级用户,Linux 优于 Mac OS:成员们辩论了 Mac OS 与 Linux 的优劣,几位成员认为 Mac OS 缺乏高级用户必备的功能,且需要安装许多 App 才能实现基础功能。
- 一名成员批评了 Finder app,更倾向于通过终端管理文件,而另一名成员则形容原生体验简直是垃圾。
- Composer 免费期结束,访问权限各异:Composer 免费期于 11 月 11 日 结束,用户注意到模型选择器中的 free 标签消失了。
- 一些用户报告在前一周访问不稳定,而一名用户声称从未获得过访问权限,可能是因为使用了 Arch Linux。
- Cursor 2.0 并行 Agent 依然难用:用户讨论了 Cursor 2.0 并行 Agent 的问题,特别是在 work tree 中使用 4x Agent,一名成员分享了论坛帖子的链接作为解决方案。
- 尽管分享了资源,一名用户评论说现状依然很痛苦,说实话挺糟糕的。
- Gemini 3 Pro 获赞,但担心上下文消耗:Gemini 3 Pro 发布,根据 Google 文档,一名成员声称它优于 Claude 并称赞其速度。
- 其他用户反驳说它消耗上下文(context)很快,并且存在过度读取文件的问题。
- Cloudflare 遭遇全球故障:Cloudflare 的全球性问题导致大规模停机,影响了众多网站和服务——Cloudflare 状态页面报告了相关问题。
- 一名成员提到一场火灾导致他们的站点下线,而另一名成员建议人们应该停止使用 Cloudflare,因为目前它并不可靠。
Unsloth AI (Daniel Han) Discord
- Gemma 3 被吐槽,Granite-4.0 夺冠:成员们放弃了 Gemma 3 270M,转而推崇 Granite-4.0 为更优的小模型,并对 Gemma 3 的事实准确性表示担忧。
- 有人指出,向参数少于 40 亿的模型询问事实性问题简直是灾难。
- llama.cpp 配合 Unsloth 模型速度飞起:一位用户报告称,在从 Ollama 迁移后,使用 Ryzen 8 系列 运行配合 Unsloth 模型的 llama.cpp,速度达到了每秒超过 25 tokens。
- 他们强调,其他模型会显得迟钝,而这种组合可以填满内存,在超大型模型上也能实现 5-10 tokens 的实际运行速度!
- 面包夹分类器创意浮现:针对不断出现的“新类型”面包夹,一位用户请求关于构建分类 breadclips(面包夹)神经网络的指导。
- 另一位用户建议从学习如何使用 MNIST 数据集 制作图像分类器作为基础指南开始。
- Unsloth 开启在线训练:讨论集中在如何利用 Unsloth 实现在线训练,目标是支持具有奖励回调(reward callback)的 OAI 兼容 API。
- 会议强调,用户可以使用 Unsloth 实现任何类型的奖励系统,且数据集需要是动态的,vLLM server 则需要使用异步模式。
- 消除 LLM 推理中的非确定性:一位成员分享了一篇关于击败 LLM 推理中非确定性的博客文章。
- 另一位成员分享了关于同一主题的相关 YouTube 视频。
OpenRouter Discord
- LiteAPI 引发欺诈担忧:LiteAPI 承诺提供比 OpenRouter 便宜 40% 的费率,但因其网站、引用 Yaseen AI 的通用隐私政策以及违反供应商服务条款(Terms of Service)而面临欺诈指控。
- 社区成员怀疑其存在盗取密钥、盗刷信用卡或转售 API 额度的情况,并对其缺乏 API 额度充值选项和模型名称列表表示担忧。
- Grok-4 的 EQ 媲美 GPT-5?:成员们将 xAI 的 Grok-4 与 GPT-5 进行对比,强调了两者在情商(EQ)和写作能力方面的相似提升。
- 他们注意到双方同时发布了专注于创意基准测试的更新,引发了对行业趋势的推测。
- Gemini 3 导致 Cloudflare 崩溃?:Gemini 3 的发布恰逢一次严重的 Cloudflare 故障,导致互联网服务中断。
- 社区开玩笑说 Gemini 3 太强太大了,以至于 CF 承受不住,而其他人则猜测是 Google 搞垮了 Cloudflare,以便在没人关注的情况下发布 Gemini 3。
- Replicate 加入 Cloudflare:一位成员调侃 Cloudflare 收购 Replicate 的消息,并感叹如果被收购的是 OpenRouter 就太不幸了。
- 这暗指了社区对 AI 领域潜在收购或合作的看法。
- 无限算力能治愈幻觉?:一位成员建议,通过使用“无限算力”来驱动联网 Agent 集群,几乎可以消除 AI 幻觉。
- 另一位成员则认为幻觉源于翻译错误,并在这篇博客文章中详细阐述了他们的理论。
OpenAI Discord
- Atlas 浏览器重塑浏览体验:@BenGoodger 和 @Darinwf 与 @AndrewMayne 讨论了 Atlas,阐述了其设计理念以及它如何旨在重新定义浏览器功能,并探讨了如何从内到外对其进行彻底改造。
- 据称 Gemini 3 Pro 击败 GPT-5.1:一名成员声称 Gemini 3 Pro 在 AI 模型测试中表现优于 GPT-5.1,理由是它在生成 one-shot React 和 SwiftUI 代码以及解决手绘迷宫方面表现出色。
- 另一位成员指出,Gemini 3 Pro 会提供歌词,而 GPT-5.1 则拒绝提供,但也指出 Gemini 3 Pro 在代码审查期间会进行未经请求的代码更改。
- Grok 4.1 以创意才华令人印象深刻:成员们称赞 Grok 4.1 在创意写作和情感智能回答方面表现卓越,在生成 SwiftUI 代码等任务上,有些人甚至更倾向于使用它而非 GPT-5.1。
- 尽管有这些优点,它的编程能力被认为较弱,且长期记忆被认为不可靠,引发了关于其存储使用和文件召回能力的讨论。
- 自定义 GPT 的效率面临审查:成员们分析了自定义 GPTs 与基础模型的效率对比,强调自定义 GPTs 简化了特定任务的指令遵循,改进了 Prompt Engineering。
- 担忧也随之而来,包括对 thinking mode 支持程度参差不齐,以及市场上可能充斥着大量低质量的自定义 GPTs。
- 自动过滤器标记无害请求:一位成员报告称,自动过滤器因无害原因标记了一个提示词,这揭示了自动过滤器潜在的问题以及进行细致内容审核的必要性。
- 这凸显了自动过滤器可能存在的问题以及对内容进行谨慎审核的需求。
LM Studio Discord
- 电商诈骗者猖獗:成员们报告称,在电商平台上,买家故意损坏产品以要求退款的事件有所增加,其中一人描述说 一个卖家(买家)用锤子砸了[他们的]笔记本电脑,涂满护手霜后退货。
- 一位成员声称自己被滥用退货系统的买家 在光天化日之下抢劫。
- LLM 遭遇认知衰退?:一位成员观察到他们的 LLM 性能随时间下降,可能是由于某个 Bug。
- 建议包括重启模型、开启新对话以及创建可复现的测试用例。
- MCP 集成外部工具:LM Studio 正在使用 Model Context Protocol (MCP) 将 LLM 与外部工具集成,详见 LM Studio 文档。
- 成员们建议应将 MCP 视为 LLM 的 UI,因为直接向 LLM 暴露 REST API 可能会导致混淆。
- RAM 价格飙升:成员们报告 RAM 价格大幅上涨,导致一位成员以 100 美元 的价格售出了 32GB 的 DDR5 6000。
- 另一位用户声称以买入价的 3 倍 售出了 RAM,称当前价格 非常可观。
- 极端的 DIY GPU 改装:一位成员分享了一段他们暴力拆除 GPU DVI 接口的视频。
- 他们随后展示了改装后的显卡,并声称所有改装都是 100% 可逆的。
{kind=link}
Latent Space Discord
- Sourcegraph 凭借广告收入获利:据 The Information 报道,编程助手初创公司 Sourcegraph 上个月在其免费层级中加入了广告,目前预计年度经常性收入 (ARR) 已达到 500 万至 1000 万美元。
- 这一举措标志着其商业化策略的重大转变,可能会影响其他编程平台处理免费增值模式的方式。
- Grok 4.1 登顶榜单:xAI 发布了 Grok 4.1,声称在 LM Arena 中排名第一 (1483 Elo),并在为期两周的盲测中获得了 65% 的用户偏好。该模型目前已在 grok.com 和移动应用上免费开放。
- 根据其 model card,关键亮点包括 1586 的 EQ-Bench 评分、Creative Writing v3 上的 1722 Elo 分数,以及 幻觉减少了 3 倍。
- Mohan 的神秘帖子引发猜测:Varun Mohan 发布了一条带有视频缩略图的神秘 “👀” 推文,引发了关于即将发布新品的广泛猜测——根据他的 公告,很可能是 Gemini 3.0、Veo 4 或 Windsurf 的集成。
- AI 社区对此充满期待,分析每一帧画面以寻找有关即将发布的产品的线索。
- Poe 通过群聊功能连接用户:Poe 推出了支持多达 200 人的全球群聊功能。根据其 公告,团队可以在一个同步线程中调用其 200 多个 AI 中的任何一个(如 Claude 4.5 和 GPT-5.1)。
- 该功能旨在简化协作式 AI 交互,有望成为 AI 辅助小组项目的中心。
- Runlayer 安全访问获 1100 万美元融资:Runlayer 是一个为企业提供安全、受控访问 18,000+ MCP servers 的平台。据 Andy Berman 的公告,该公司宣布完成了由 Khosla & Felicis 领投的 1100 万美元 种子轮融资,目前已在 Gusto 和 Opendoor 等客户中上线。
- 这笔资金将用于扩展其平台,以应对大规模计算环境中日益增长的安全访问管理需求。
Nous Research AI Discord
- Atropos 与 Tinker:动态双人组:Atropos 是 Nous Research 开发的一个 RL Environments framework,现在支持 Thinking Machines 的 Tinker 训练 API,能够在各种模型上进行环境的训练和测试。
- 一条推文强调,这种集成简化了在多种模型上的训练和测试过程。
- Amazon 的 Nova Premier V1:会是下一个大事件吗?:Amazon’s Nova Premier v1 出现在 OpenRouter 上,但考虑到 Amazon 过去那些容易被遗忘的模型,其新颖性受到了质疑。
- 有猜测称,由于内部政治以及 AWS Bedrock 的问题,Jeff Bezos 可能正在开展一个独立的 AI 计划。
- Bedrock AWS 出站流量面临收费:成员们分享了在 AWS 上产生高额费用的经历,其中一人讲述了因难以终止实例而产生的 3000 美元 账单。
- 另一位成员分享了类似的经历,在 17 岁托管 Minecraft 模组包时被 出站流量 (egress) 费用坑惨了。
- Gemini 3 发布并在击败 Sonnet 后被移除:Gemini 3 Pro Model Card 发布后随即被删除,此前它在基准测试中 曾短暂超越 Sonnet 4.5。
- 一位成员指出,Anthropic、Microsoft 和 Nvidia 似乎都在 唱衰 Google 的发布。
- 用于犯罪预防的无审查 MoE:一位成员正在寻求关于 uncensored Mixture of Experts (MoE) models 的建议,以绕过“平庸化 (normie-proofing)”限制,从而开发 犯罪预防和教育工具。
- 作为替代方案,他们考虑对 Josified 模型进行 LoRA 训练,理由是担心缺乏通用的知识数据集来提升无审查小模型的性能。
HuggingFace Discord
- Graph-RAG 数据库向 Kilo 和 Pinecone 发起挑战:一个新的 graph-rag 数据库 发布,通过在 GitHub 上提供具有代码智能的、用户受控的开源替代方案,向 Kilo Code 和 Pinecone 发起挑战。
- 该项目已有 47 stars,旨在实现开放和可定制化。
- Mimir 项目宣称打造开源乌托邦:Mimir 项目提供多 Agent 编排和一键部署,采用 MIT license,为 N8N、Pinecone 和 Kilocode 等方案带来的供应商锁定提供了替代选择。
- 它兼容 OpenAI API 和 OpenWebUI,使用 llama.cpp 进行 embeddings,并为使用记忆工具和语义搜索的 Minecraft 服务器提供编排流水线。
- Lablab 黑客松引发诈骗指控:一名用户报告了在 Lablab 黑客松中的负面体验,称其可能存在剥削行为,并对不利的搬迁条款发出警告。
- 该用户声称在获得最高分后被移出了排行榜,并提醒他人避开 Lablab。
- Cloudflare 宕机,用户承认“罪行”:一场大规模的 Cloudflare 故障影响了 Stockholm、Berlin、Warsaw 和 Paris 等城市的服务器,导致应用和在线功能中断。
- 一名用户开玩笑地声称对此负责,表示他们在 Cloudflare 实习期间向生产环境推送了一个错误的身份验证修复程序,并称“本地测试通过了”。
- Gradio 6 承诺提升速度:根据其 Youtube 公告,Gradio 6 已经发布,并声称比以往更快、更轻量、更具可定制性。
- 该版本于 11 月 21 日 宣布发布,内容包括团队对新功能的演示以及问答环节。
Yannick Kilcher Discord
- 经典 ML 书籍获新手力荐:成员们讨论了 Shai Shalev-Shwartz 和 Shai Ben-David 的《Understanding Machine Learning》,认为它是新入行 ML 工程师的“优秀入门读物”。
- 一名成员建议补充一本更具技术性的书籍,而其他人则推荐了 Mohri 的《Foundations of Machine Learning》以及 deeplearningtheory.com 网站。
- 贝索斯携 Prometheus 重返 AI 领域:据报道,杰夫·贝索斯将回归并担任一家名为 Project Prometheus 的新 AI 初创公司的 co-CEO。
- 一名成员开玩笑说,贝索斯的“每一个举动基本上都在模仿 Elon”。
- ReLU 历经多年依然重要:成员们重新审视了 ReLU,认为它是一种“计算更简单”的非线性激活函数,并且能降低“梯度消失”的概率。
- 这是因为它的导数要么是 0,要么是 1。
- Google 预览 Gemini 3 Pro 模型:成员们查看了泄露的 Gemini 3 Pro Model Card,注意到其在 HLE、Video-MMMU 和 ARC-AGI-2 基准测试中取得了令人印象深刻的成绩。
- 该模型可在 AI Studio(Google 的 VS Code 分支)上使用,并且拥有“非常多基准测试数据”,但问题仍然在于 Gemini 的性能提升是否能泛化到基准测试之外的任务、私有及新颖的基准测试中,以及泛化程度如何。
- Yannic Kilcher 解析 Transformer:一名成员请求获取了解 Attention 和 Transformer 模型演进的资源,另一名成员分享了 Yannic Kilcher 的 Transformers 视频 链接。
- 该成员还建议使用 YouTube 的搜索功能在 Yannic 的频道中查找内容:YannicKilcher/search?query=transformer。
Eleuther Discord
- EleutherAI 将在 NeurIPS 2025 上大放异彩:EleutherAI 将在 NeurIPS 2025 上展示多篇论文,包括主赛道的:The Common Pile v0.1、Explaining and Mitigating Cross-Linguistic Tokenizer Inequalities 以及 More of the Same: Persistent Representational Harms Under Increased Representation。
- 团队还计划举行官方晚宴和招待会,详情请见此处,并鼓励感兴趣的成员选择 social activities role 以获取更新。
- Huggingface 生成吞吐量获得提升:一位成员发现,在 Huggingface 中使用带有
return scores.contiguous()的空 logits 处理器可以使生成吞吐量提升 60%。- 这种改进是在配置为
dynamic=False和fullgraph=True的 FA2 环境下观察到的。
- 这种改进是在配置为
- Command A 权重绑定成为趋势?:成员们讨论了 Cohere 的 Command A 模型在 embedding 和 LM head 之间使用权重绑定(tied weights)来减少参数量,这是小型 Transformer 模型的常用技术。
- 讨论探讨了这种方法是否正在大型模型中流行,因为在大型模型中,非绑定权重带来的参数增加在比例上并不显著。
- VWN:逐层重新构想线性注意力:虚拟宽度网络(VWN)被描述为一种线性注意力(linear attention)的实现,其更新是逐层(layer by layer)而非逐标记(token to token)进行的。
- 一位成员指出:“VWN 基本上是在做线性注意力,但
state[:, :] += ...的更新不是在标记之间发生,而是在层与层之间发生。”
- 一位成员指出:“VWN 基本上是在做线性注意力,但
- 在 VWN 的矩阵迷宫中导航:讨论涉及了 虚拟宽度网络(VWN) 中令人困惑的矩阵表示,特别是矩阵 A 和 B 的大小和密度。
- 成员们对论文中矩阵符号可能存在的错误表示担忧,并建议代码实现可能会使用更清晰的 einsum 符号。
Modular (Mojo 🔥) Discord
- Modular 展示 MMMAudio 和 Shimmer:Modular 宣布了即将于 11 月 24 日举行的社区会议,重点介绍创意编程音频环境 MMMAudio 和跨平台 Mojo → OpenGL 实验项目 Shimmer。
- 会议还将涵盖 Modular 的更新,包括 25.7 版本和 Mojo 1.0 路线图。
- Mojo 迎接 NVIDIA 的 NVFP4 挑战:一位成员询问了 Mojo 对 NVFP4 的支持,以参加专注于 NVFP4 Batched GEMV 的 Nvidia/GPUMode 竞赛,并得到确认 MLIR 已包含 fp4。
- 另一位成员指出,可以使用现有的 Mojo 数据类型构建 nvfp4,并引用了 GitHub 上的 dtype.mojo 文件。
- Mojo 中关于负索引的辩论加深:关于负索引以及
Int与UInt的讨论仍在继续,涉及性能影响以及切片功能可能导致的 UB 错误。- 一位核心团队成员澄清说,目标是在大多数 API 中标准化使用 Int,从 List 等低级类型中移除对负索引的支持,并默认启用边界检查,尽管社区对此存在分歧。
- Poetry 与 Mojo 良好集成:一位成员分享了将 Mojo 与 Poetry 集成的指令,详细说明了如何在
pyproject.toml文件中添加源和依赖项。- 配置包括添加一个指向 nightly Python 包仓库的 modular source,并指定启用预发布的 mojo 依赖项。
- ArcPointer 安全性受到质疑:一位成员提出了关于 ArcPointer 安全性的问题,涉及在调用
a==b的函数时可能出现的 UB 错误,他们认为这应该被捕获为 UB 错误,因为 p3 实际上被 extend 调用使之失效了。- 该代码涉及在 ArcPointer[List[Int]] 中进行指针扩展和解引用等操作,导致在 assert 语句中崩溃,而不是捕获到 UB 错误。
DSPy Discord
- DSPy 获得类型提示支持:一名成员创建了 dspy-intellisense,这是一个 VSCode 扩展,为 DSPy 中的 signature 和 prediction 提供改进的类型提示(type hinting)。
- 该工具旨在通过提供代码的实时反馈来简化开发并减少错误。
- MLflow 替代方案引发关注:一位成员对 mlflow 表示不满,并寻求其他检查工具(inspection tools)的建议。
- 另一位成员建议使用 arize phoenix 来查看 trace,并提供了 Arize Phoenix 文档的链接。
- 驯服 LLM 随机性之龙:一位成员询问在多次运行 gpt-oss-20b 观察到不同结果时,如何管理 LLM 的非确定性(non-deterministic nature)。
- 解决方案包括将 temperature 设置为 0、调整 max_tokens 以及强制执行严格的输出格式,并提醒即使在低 temperature 下,某些随机性也是正常的。
- 对 DSPy-in-Production 频道的渴望:一位成员询问是否有一个专门针对 DSPy 生产社区的频道,强调了目前缺乏集中讨论。
- 另一位成员承认目前确实缺失该频道并支持这一想法,表明将 DSPy 项目投入生产的兴趣日益增长。
- 分享优化器结构论文:一位成员分享了一篇 arXiv 上的论文,指出其结构非常适合作为 optimizer。
- 未提供其他详细信息。
tinygrad (George Hotz) Discord
- Tinybox 会议安排:宣布了一场与 tinybox 相关的会议,并提供了 tinygrad.org/#tinybox 和 GitHub issue #1317 的链接。
- 会议旨在讨论 tinybox 的路线图和贡献。
- Tinygrad 的 Llama 1B 在 CPU 上完胜 Torch:一位成员报告称,运行在 Tinygrad 上的 Llama1b 性能优于 CPU 上的 Torch,达到了 6.06 tok/s,而 Torch 仅为 2.92 tok/s。
- 该对比基于 10 次运行,Tinygrad 完成耗时 16498.56 ms,而 Torch 耗时 34247.07 ms。
- 考虑使用 Torch Compile 进行基准测试:一位成员建议,与
torch.compile的 PyTorch 实现进行基准测试对比可能会更有参考价值。- 这是针对在运行 Llama 1B 时观察到的 Tinygrad 与 Torch 之间的性能差异提出的。
- Kernel 导入清理:成员们讨论了修复
extra/optimization文件中from tinygrad.codegen.opt.kernel import Kernel的导入问题。- 讨论集中在清理代码库并确保 kernel 导入的正确性。
- Examples/Extra 目录清理:成员们建议删除已长时间未触及的损坏、未使用的 examples/extra 文件。
- 目的是减少冗余并保持仓库中提供的示例的相关性。
aider (Paul Gauthier) Discord
- Gemini 3 出现 Bug:一位用户报告在新的 Gemini 3 模型中遇到了与之前相同的错误,并附上了错误报告。
- 另一位用户将该报告斥为“AI 废话”。
- Experimental 频道搬迁至新 Discord 服务器:experimental 频道已移至新的 Discord 服务器。
- 此举是针对用户询问“experimental 频道发生了什么”的回应。
Manus.im Discord Discord
- Manus 用户欢呼回归巅峰:一位 Manus.im 的老用户称赞 1.5 版本表现惊人,指出任务处理有所改进,并消除了“无效循环(retard loops)”。
- 该用户感谢 Manus 团队听取了建议,并表示可能会再次升级到 PRO 版本。
- 资深开发者寻求机会:一位用户询问社区内是否有适合资深开发者的机会。
- 未提供有关开发者类型或其技能的其他信息。
Windsurf Discord
- Gemini 3 Pro 登陆 Windsurf!: Gemini 3 Pro 已在 Windsurf 上线,为用户提供其高级功能的访问权限。
- Gemini 3 Pro Bug 已修复!: Gemini 3 Pro 的一个小问题已得到解决,确保了功能的正常运行。
- 团队对最初出现的小故障表示歉意。
MLOps @Chipro Discord
- AI 治理与控制网络研讨会即将举行: 一场关于 AI 治理与控制 的网络研讨会定于 太平洋时间 12 月 3 日上午 10 点举行,注册地址为 https://bit.ly/3LPl7FO。
- 该研讨会将涵盖有效管理 AI 实施的策略,并讨论 AI 控制 背景下的伦理考量、合规性和风险管理。
- 促进 AI 治理讨论: 该研讨会旨在促进围绕 AI 治理 关键方面的讨论,包括伦理考量、合规性和风险管理。
- 鼓励参与者分享关于 AI 控制 不断演变的格局及其对组织策略影响的经验。
MCP Contributors (Official) Discord
- 图片直接上传至 Discord: 用户直接在 Discord 发布了一张图片,该图片通过 URL cdn.discordapp.com 托管在 Discord 的内容分发网络 (CDN) 上。
- 这表明图片是直接上传的,而不是链接自第三方托管服务。
- Discord CDN 托管: 图片托管在 Discord 的内容分发网络 (CDN) 上,表明是直接上传到 Discord,而非使用外部图片托管服务。
- 在没有更多上下文的情况下,图片的具体内容及其与讨论的相关性尚不明确。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站选择了订阅。
想更改接收这些邮件的方式吗? 您可以从该列表中取消订阅。
Discord: 频道详细摘要与链接
LMArena ▷ #general (1404 条消息🔥🔥🔥):
Gemini 3 Pro, Google AI Studio, LLM limitations, Antigravity IDE, LMArena Issues
- Gemini 3 Pro 的热度与性能: 用户对 Gemini 3 Pro 及其性能感到兴奋,一位用户表示,与其他模型相比,Gemini 3 在这方面表现出色。坦率地说,在游戏玩法和功能性上比 Claude 好得多。
- 一些用户认为 Gemini 3 Pro 被高估了,但 Google 必须迅速做出反应,因为 Elon 推出了 Grok 4.1,而其他用户则在等待它在实际应用中的测试。
- Google AI Studio 的使用与限制: 成员建议在 Gemini 3 上使用 Google AI Studio,但它对每天的消息数量有限制,一位用户说 Google 每天限制 50 条消息。
- 成员们还在 Polymarket 上测试 Gemini 3 Pro,他们认为该模型将于本月发布。
- Gemini 3 被削弱及用户担忧: 成员推测 Gemini 3 Pro 自发布以来可能已被削弱,与 2.5 相比无法再生成长篇故事,他们声称 Google 是个邪恶的大公司,而且他们早就知道会这样。
- 一些用户报告该模型无法识别物品,幻觉率高达 88%。
- LMArena 技术问题与挫败感: 用户报告了 LMArena 的问题,包括代码模式下频繁报错以及整体不可靠,导致一些人更倾向于使用 Google AI Studio。
- 一位用户指出 在 LMArena 上使用 Gemini 3 Pro 编辑文件体验很差,并建议开发 iOS 版 LMArena 应用以缓解移动端问题。
- 倡导使用 AntiGravity IDE: 成员们正在热捧 AntiGravity,这是一个使用 nano banana 且能够执行不同编码任务的 IDE。
- 成员们已经使用 AntiGravity 创造了不同的东西,并且仍在尝试摸索这个新平台的所有功能。
LMArena ▷ #announcements (4 messages):
Grok-4.1-thinking, Expert leaderboard, November AI Generation Contest - Code Arena, Image-to-Video Leaderboard, Text-to-Image Leaderboard
- Grok-4.1-thinking 占据 Text Arena 排行榜榜首:
Grok-4.1-thinking目前在 Text Arena 排行榜 排名第 1,紧随其后的是排名第 2 的Grok-4.1。 - Code Arena 竞赛于本月 11 月开启:为庆祝 Code Arena 的发布,11 月 AI 生成竞赛现已开启,参与者有机会赢取 Discord Nitro 和特殊身份组。
- 参与者必须通过在指定频道分享预览链接来提交作品,并可参考此示例进行指导。
- 视频与图像排行榜前 5 名洗牌:
Wan2.5-i2v-preview和Wan2.5-t2i-preview最近在 Image-to-Video 和 Text-to-Image 排行榜 中双双进入前 5 名。 - Gemini-3-pro 统治各大排行榜:
Gemini-3-pro在 Text、WebDev 和 Vision 排行榜 中均获得第 1 名,得分分别为 1501、1328 和 1487。
Perplexity AI ▷ #general (1028 messages🔥🔥🔥):
Gemini 3 Pro, Antigravity IDE, Comet Android, Kimi Model
- Gemini 3 Pro 发布(某种程度上):Gemini 3 于今日发布,成员们注意到它正在向 Gemini 应用的所有用户、搜索中 AI 模式下的 Google AI Pro 和 Ultra 订阅者、AI Studio 中的 Gemini API 开发者、Google Antigravity、Gemini CLI 以及 Vertex AI 和 Gemini Enterprise 的企业用户推广。
- 然而,一些用户因负载过重被降级回 2.5,另一些用户在 AI Studio 中看到了它,但在 Gemini 应用中却没看到。成员们的普遍感受是,虽然有用,但与 2.5 相比并没有翻天覆地的变化。
- Gemini 3 可用性有限:Gemini 3.0 Pro 已发布,但尚未对所有用户开放,正如 Twitter 上所报道的那样。
- 一些用户在访问 Gemini 3.0 Pro 时遇到困难,如 Discord 中所述,其他人则推测 Google 在操纵基准测试,该模型可能针对基准测试进行了训练。
- Google 推出 Antigravity IDE:Google 宣布了 Antigravity,一款全新的 AI 代码编辑器。随后有消息称可在 https://antigravity.google/download 下载,其他人确认其支持 Windows、Mac 和 Linux。
- 据报道,该 AI 将与最新的 Gemini 模型集成。然而,也有人说它本质上是一个 VS Code 克隆版。其他人注意到它被称为 新的 AI IDE 编程 Agent。
- Airtel 为订阅者提供免费 Gemini:根据线程中的讨论,据报道 Airtel 为订阅者提供免费的 Gemini 访问权限。
- 其他用户报告称因学生身份获得了 Gemini Pro 的免费访问权限,而大多数其他用户则需要等待。
- Comet 推出 Android 版:Comet 发布了 Android 版本 的早期访问,尽管目前处于候补名单状态且尚未正式发布。
- 成员报告称,由于设备不兼容(即使是 Android 11),他们在安装过程中遇到了多个错误。其他人推测这可能是地域差异导致的。
Perplexity AI ▷ #pplx-api (4 messages):
purrvv.me
- Purrvv.me 注销困境:该频道的用户报告称,目前在 purrvv.me 服务上无法注销账户。
- 通过支持渠道注销账户的尝试均未成功,支持人员确认无法注销账户。
- Purrvv.me 账户隐私:用户对无法在 purrvv.me 上注销账户的担忧日益增加,这引发了潜在的隐私问题。
- 用户正在寻找管理数据的替代方案,并确保其信息从平台中移除,因为缺乏注销选项对数据控制构成了挑战。
BASI Jailbreaking ▷ #general (1056 条消息🔥🔥🔥):
Grok 突然变严、AI 破解验证码、Builder.ai 丑闻、用 Grok 编写勒索软件、Gemini 3 Pro
- Grok 突然变严:一名成员认为 Grok 难度增加是由于“良好审核的代价”,并将其视为判断网站质量的一种方式。
- 另一名成员开玩笑说使用广告拦截器来避开广告,促使第一名成员回应道:“愿玫瑰永远照亮你的鼻尖”。
- Gemini 胜出,人类在验证码面前败下阵来:一名成员指出 Gemini 在破解 reCAPTCHAs 方面的成功率超过 50%,超过了视力不佳的人类,同时推测了未发布 AI 的能力。
- 一些用户开玩笑道自己无法通过验证码,有人提议以每个验证码 8 美分的价格外包给北美的人员来解决。
- “AI”初创公司曝光:幕后的印度开发者:一名成员分享了 Builder.ai 丑闻的摘要。该公司标榜为 AI 无代码平台,但被揭露拥有 700 名印度开发者 手动编写代码,导致收入虚增并收到了美国联邦传票。
- 据称该公司与 VerSe Innovation 进行了“循环交易(roundtripping)”虚假交易,报告了 2023-2024 年虚增的收入,创始人已在风波中辞职。
- Grok 走向阴暗:用户轻松编写勒索软件:一名用户分享说,他们使用带有新 Jailbreak 的 Grok 编写了严重的勒索软件,并对 Grok 毫不犹豫地提供协助感到惊讶。
- 其他成员表示有兴趣查看代码,其中一人请求提供 Payload 函数或加密算法的代码片段;鉴于任务的性质,关于是否在网上发布此类代码存在争议。
- Gemini 3 Pro 发布:引发 Prompt Hacking 狂潮:成员们报告称 Gemini 3 Pro 已在 AI Studio API 上线,模型名称为
gemini-pro-latest,并开始对其进行 Jailbreaking。- 一名用户声称已经对其进行了 JB,而其他人分享了技术;在初步成功后,用户注意到 Gemini 3 正在被削弱(nerfed),需要重新调整 Jailbreak 方案。
BASI Jailbreaking ▷ #jailbreaking (683 条消息🔥🔥🔥):
Indirect Prompt Injection, Grok 4.1 System Prompt Leak, Bypassing AI Security, Jailbreaking Gemini 3.0, Exploiting AI for Malicious Purposes
- **图像注入的开端:新型 Jailbreak 技术出现:成员们发现,向 **Grok 等 AI 模型发送包含 Jailbreak Prompt 的图像可以绕过基于文本的安全措施。一位用户成功利用文本图像激活了 Jailbreak,这表明 AI 模型对图像的信任度高于文本。
- 该用户分享了一系列展示该技术的截图,引发了关于更复杂的基于图像攻击的讨论,例如使用 QR codes 或隐藏元数据 (hidden metadata)。
- **Grok 陷入困境:System Prompt 泄露引发争议:Grok 4.1** 的 System Prompt 被泄露,其中包含一行极具争议的内容,声称 “’teenage’ 或 ‘girl’ 并不一定意味着未成年”,引发了对生成不当内容的担忧。这导致了激烈的辩论,一些用户决定对他们的 Jailbreak 方法进行保密 (gatekeep)。
- 成员们争论包含此类语言是必要的,还是仅仅反映了模型的训练数据;而其他人则推测 xAI 设计选择背后的动机以及对内容审核的影响。
- **AI 架构师的军备竞赛:绕过安全协议*:在关于 AI 安全本质的元讨论中,成员们辩论了各种 Jailbreaking 技术的有效性。一些人认为 *“逻辑与理性是唯一的真实 Jailbreak 手段”,其他策略最终都会被修复,并指出 AI 开发者与 Jailbreaker 之间不可避免的军备竞赛。
- 成员们还讨论了绕过安全协议的新方法,例如使用 XML 或 JSON 格式的 CLI,或者将 Prompt 构思为网络安全研究场景,突显了 AI 开发者与试图规避限制的人之间持续的猫鼠游戏。
- **Gemini 被攻破:Jailbreak 淘金热开始:几位成员声称利用修改后的 System Prompt 和心理战术成功 Jailbreak 了 Google 最新的 AI 模型 **Gemini 3.0。但由于细节分享较少,导致了对有效 Prompt 的疯狂搜索以及对技术封锁 (gatekeeping) 的指责。
- 一位成员分享了利用开发者图像欺骗 AI 泄露其内部运作信息的技术,而其他人则尝试提出间接问题并利用 AI 的推理能力。
- **AI 无政府状态:黑客攻击与混乱随之而来:一位成员分享了一个看似无害的代码片段,但仔细观察后发现它是一个 **信息窃取器 (information grabber),伪装成随机数生成器,旨在窃取用户的社会安全号码。
- 随后的讨论强调了恶意行为者利用被 Jailbreak 的 AI 进行不法行为的潜力,例如生成恶意软件、网络钓鱼攻击以及其他形式的网络犯罪,引发了关于负责任使用 AI 技术的伦理担忧。
BASI Jailbreaking ▷ #redteaming (19 条消息🔥):
AI Jailbreaking, ChatGPT Agent Mode, Suit vs Business Suit prompt, Banning from ChatGPT, Random Email for ChatGPT
- Jailbreaking AI 的新方法:一位成员声称通过在 AI 内部运行另一个 AI 来使用最新的 Jailbreaking AI 方法。
- 当被问及这是否涉及运行自身的另一个实例时,他们确认可以控制其 System Instruction。
- Agent Mode 离线:一位成员注意到,拥有访问权限的用户目前无法使用 ChatGPT Agent Mode。
- 另一位成员回复道:“哈哈,喜欢那个 suit vs business suit prompt”。
- ChatGPT Jailbreak 封号:一位成员报告称因 Jailbreaking ChatGPT 而被封号,并警告其他人多加小心。
- 另一位成员建议使用 simple login 获取随机电子邮件来创建新账号。
- 付费版 vs 免费版 ChatGPT Jailbreaking:一位成员表示他们只能 Jailbreak 付费版的 ChatGPT 账号。
- 经过一番交流,他们发现免费版同样有效。
- AI 朋友:一位成员表示 “我的朋友是一个 AI” 并附上了一张图片。
- 另一位成员回复:“嘿嘿”。
Cursor Community ▷ #general (1093 条消息🔥🔥🔥):
Mac OS vs Linux 高级用户对比,Cursor 支持多个 GitHub 账号,Composer 免费期结束,Gemini 3 Pro 发布及性能,Cloudflare 故障
- Mac OS 被吐槽,Linux 在高级用户中占据主导地位:一位成员认为 Mac OS 与 Linux 相比缺乏关键功能,需要安装大量 App 才能实现基础功能,并提到 Finder 应用用起来简直是一种痛苦,另一位成员也表示原生体验简直是垃圾。
- 第一位成员更倾向于在 App 内部或通过 Terminal(使用 Ranger)来管理文件,而不是使用 Finder。
- Composer 免费期于 11 月 11 日结束:成员们注意到 Composer 免费期已于 11 月 11 日结束,模型选择器上的“免费”标签已经消失。
- 一些用户报告本周仍能偶尔访问,而另一位用户则从未获得过访问权限(可能是因为使用了 Arch Linux)。
- Cursor 2.0 中单个对话支持并行 Agent:一位成员在 work tree 中使用 4x agents 时遇到问题,想知道如何让它们分别处理不同的任务,另一位成员分享了一个 论坛帖子链接 来解决该问题。
- 一位成员认为目前的状况依然很痛苦,说实话相当糟糕。
- 用户称 Gemini 3 Pro 是最强的:Gemini 3 Pro 已发布,一位成员声称 Gemini 3 比 Claude 更好,而且速度很快。
- 其他成员则声称它消耗 Context(上下文)非常快,并且会过度读取文件。
- Cloudflare 遭遇全球性故障:Cloudflare 的全球性问题导致了大规模停机,影响了众多网站和服务——Cloudflare 状态页面 报告了相关问题。
- 一位成员报告称,公司起火也导致了他们的网站下线,而另一位成员建议人们应该停止使用 Cloudflare,目前它已经不可靠了。
Unsloth AI (Daniel Han) ▷ #general (222 条消息🔥🔥):
TPU 支持,Gemma 3 270M,llama.cpp 速度,激活函数,4bit 合并
- Gemma 3 被群嘲,Granite-4.0 获评最佳小模型:一位用户惊叹道,与 Gemma 3 270M 相比,他看不出任何人有理由使用这个模型,而另一位用户则表示 Granite-4.0 是同尺寸中最好的模型。
- 另一位成员表示:向参数量少于 40 亿的模型询问事实性问题简直是灾难。
- TPU 支持仍然受限:一位用户询问关于使用 JAX 和 Unsloth 在 TPU 上微调小模型的问题,但其他人表示 TPU 支持很有限,尽管 HuggingFace 正在与 GCP 合作 以扩大支持。
- 对方澄清说 Unsloth 目前仅支持 GPU。
- llama.cpp 速度令人印象深刻:一位用户从 Ollama 切换到了 llama.cpp,并报告在 Ryzen 8 系列上使用 Unsloth 模型时,速度超过了 每秒 25 tokens。
- 他们表示其他模型会显得很慢,这开启了加载内存并在超大型模型上实现现实的 5-10 tokens 的能力!
- 关于激活函数的讨论:成员们讨论了 ReLU 激活函数,一位用户指出 ReLU 之所以有效,是因为有更多选择,且由于非线性导致的数据丢失较少。
- 另一位用户则表示:你实际选择哪种激活函数并不太重要,所以不妨使用效率最高的那一个。
- 强制 4bit 合并警告详解:一位用户在保存 4bit 合并模型时遇到错误,询问是否应该使用
merged_4bit_forced,一位成员回答说,如果你使用了 QAT 进行训练,就应该这样做。- 对方还解释说:出现这个警告是因为如果你没有保存 LoRA 或 16bit,一旦保存了 4bit 就无法再保存它们了;建议将其作为最后一步使用,因为它会将 LoRA 与内存中已有的 4bit 模型合并。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
AI and Full Stack Development, LLM Integration
- AI 全栈开发者加入: 一位新成员介绍了自己,他是一名 AI & 全栈开发者,擅长 Next, Node, Python 和 Django。
- 他们专注于将 LLMs、OpenAI 和 LangChain 集成到全栈应用程序中,并正在寻求项目合作的机会。
- 欢迎新的 LLM 爱好者: 一位新成员是 AI 和全栈开发者。
- 他们精通将 LLMs 和 OpenAI 集成到应用程序中。
Unsloth AI (Daniel Han) ▷ #off-topic (275 messages🔥🔥):
SF vs NYC food, Breadclip classifier, LoRA training hacks, Gemini 3 code changes
- 旧金山美食之争:SF vs NYC: Discord 用户争论 SF 还是 NYC 的食物更好,一位用户声称,与 NYC 相比,SF 每 10 万人拥有的米其林餐厅数量是其 5 倍,每平方英里的米其林餐厅数量是其 3 倍。
- 另一位用户反驳说,他们吃过最有趣的晚餐是在 Las Vegas,而且 NYC 的公共交通让出行便利度提升了 100 倍。
- 面包夹分类器头脑风暴开始: 一位用户寻求关于构建神经网络来分类面包夹 (breadclips) 的建议,并强调了经常发现新类型所带来的挑战。
- 另一位用户建议从使用 MNIST 数据集制作图像分类器的指南开始。
- LoRA 训练调整与技巧: 用户讨论了 LoRA 训练 的细微差别,明确了它涉及冻结除 LoRA adapters 之外的所有层。
- 关于在没有大型反向传播的情况下获取近似梯度的技术,以及是否可以在每个 optimizer step 进行 merging,存在许多讨论和观点。
- Gemini 3 代码变更评述: 一位用户报告称 Gemini 3 对其代码库进行了重大更改,例如完全删除功能,并将大量代码行缩减为一行。
- 他们观察到注释被删除,且该模型在一个符合 PEP8 标准的代码库中使用了分号,并提醒如果不小心,代码库可能会遭受极端退化 (arxiv.org/abs/2403.03507, arxiv.org/abs/2504.20437)。
Unsloth AI (Daniel Han) ▷ #help (83 条消息🔥🔥):
Unsloth 在线训练, 使用 Unraid/Docker 部署 Llama CPP, 语音 AI Agent LLM 训练, Unsloth 与 HuggingFace TRL, 使用 Unsloth 进行 Text to Speech 推理
- **Unsloth 支持在线训练:成员们讨论了使用 Unsloth 进行在线训练的可能性,目标是通过奖励回调(reward callback)扩展 **OAI-compatible API。
- 会议指出,没有什么能阻止用户使用 Unsloth 实现任何类型的奖励系统,并且数据集(dataset)需要是动态的,vLLM server 需要使用异步模式(async mode)。
- **使用 Unraid/Docker 部署 Llama CPP 端点:一位成员寻求关于使用 **Unraid/Docker 通过 llama.cpp 部署端点的指导,用于一个编程用的 VSCode C-line plugin。
- 另一位成员建议参考一篇 Docker 博客文章 作为潜在解决方案,并强调了其 OpenAI 兼容性。
- **解决使用 Unsloth 进行 LLM 微调时的过拟合问题:一位用户注意到使用 **Llama 3.1B Instruct 8bit 训练语音 AI Agent 的效果不佳,并询问了关于 PII 脱敏、模型大小、Prompt 使用以及 LoRA 有效性的问题。
- 另一位用户建议从较小的数据集开始以加快训练速度从而掌握基础知识,并参考 LoRA 超参数指南 来解决验证和过拟合问题。
- **辨析 Unsloth 与 Hugging Face TRL 的关系:一位用户询问 **Unsloth 与 Hugging Face TRL 之间的关系,寻求澄清 Unsloth 是仅仅加速流程,还是可以独立于 TRL 使用。
- 一位成员建议阅读 关于 GPT-OSS 强化学习的 Unsloth 文档 和 长上下文 GPT-OSS 训练 以获得更好的理解。
- **在 Unsloth 上运行 Text to Speech 模型:一位用户询问是否可以在 **Unsloth 上运行 Text to Speech (TTS) 模型。
- 另一位成员确认这是可能的,并指向了 TTS 微调的 Unsloth 文档,建议在进行推理(inference)时跳过微调部分。
Unsloth AI (Daniel Han) ▷ #research (2 条消息):
LLM 推理, 非确定性, 确定性
- 攻克 LLM 推理中的非确定性:一位成员分享了一篇关于攻克 LLM 推理中非确定性(non-determinism)的博客文章。
- 另一位成员表示确认,并分享了一个关于相同主题的相关 YouTube 视频。
- LLM 推理确定性:博客文章和视频讨论了确保 LLM 推理中确定性行为(deterministic behavior)的方法,这对于可靠的应用至关重要。
- 技术可能涉及在推理过程中控制随机种子(random seeds)、硬件配置(hardware configurations)和数值精度(numerical precision)等因素。
OpenRouter ▷ #app-showcase (6 条消息):
当前项目的效率, YouTube 视频链接
- 效率优化正在进行中:一位成员表示当前的项目目前效率不是很高,但他们正在努力改进。
- 他们还发布了一个 YouTube 视频链接,但没有提供进一步的背景信息。
- 另一位成员也在努力提高效率:另一位成员评论说,他们也在进行类似的效率改进工作。
OpenRouter ▷ #general (473 条消息🔥🔥🔥):
图片编辑问题、Grok 4.1 发布、LiteAPI 不正当行为、Gemini 3 发布、Deepseek V3 0324 替代方案
- 图片编辑故障引发不满:用户反馈在编辑带有图片的短消息时,图片会在编辑后消失,导致了挫败感。
- 该故障影响了用户体验,并凸显了在消息编辑中实现无缝图片处理的需求。
- Grok 4.1 登场,引发好奇:Grok 4.1 现已在网页端和 App 端上线,用户引用了 Elon 的帖子,并好奇 Sherlock 模型是否基于 Grok 4.1。
- 部分用户认为 Sherlock 实际上是 Grok DASH。他们想要 Grok 4.1 lite 或类似版本
- LiteAPI 引发欺诈警报:LiteAPI 作为一个承诺价格便宜 40% 的 OpenRouter 替代方案,因其网站简陋、隐私政策引用 Yaseen AI 的通用模板以及违反供应商 Terms of Service (ToS) 而被指可能存在欺诈。
- 社区成员怀疑其使用了盗取密钥、盗刷信用卡或转售 API 额度,一位用户指出 LiteAPI 甚至没有充值 API 额度的选项,也没有列出可供复制粘贴的模型名称。
- Gemini 3 在 Cloudflare 混乱中发布:Gemini 3 的发布恰逢一次重大的 Cloudflare 停机事故,导致互联网大范围中断,并引发了各种幽默评论,包括称 Gemini 3 太庞大、太出色,以至于 CF 无法承受。
- 一些用户推测 Google 搞垮了 Cloudflare,以便在没人关注的情况下发布 Gemini 3。
- 寻找 Deepseek V3 0324 的继任者:用户正在寻找 Deepseek V3 0324 的替代品,指出其倾向于过于字面化,且在性格或装扮上表现得过于重复。
- 建议的替代方案包括 Deepseek 3.1、3.2、Kimi K2 和 GLM 4.6,并建议通过自定义 cards/configs 来弱化这些重复元素。
OpenRouter ▷ #new-models (14 条消息🔥):
``
- 没有新模型消息:提供的输入中没有关于新模型的消息。
- 输入仅包含重复的机器人消息,指示频道名称。
- 频道公告占主导:消息历史记录仅包含频道名称 OpenRouter - New Models 的重复公告,没有实质性讨论。
- 因此,无法从提供的内容中总结出具体的模型、功能或讨论。
OpenRouter ▷ #discussion (34 messages🔥):
Cloudflare 收购 Replicate, Grok-4 与 GPT-5 的对比, 幻觉理论, OpenRouter 上的 Gemini 3 Preview, 密钥过期
- Replicate 被收购,下一个是 Cloudflare?: 一位成员开玩笑说 Cloudflare 收购了 Replicate,并表示如果被收购的是 OpenRouter 那就太不幸了。
- 这条评论虽是玩笑,但暗示了社区对 AI 领域潜在收购或合作的看法。
- Grok-4 和 GPT-5:EQ 的趋同?: 一些成员将 xAI 的 Grok-4 与 GPT-5 进行了对比,指出两者在情商 (EQ) 和写作能力方面有类似的提升。
- 他们发现这两个模型在同一周内发布更新,且都专注于类似的创意基准测试,这一点非常奇特。
- 解决 AI 幻觉: 一位成员提出,通过使用“无限算力”来驱动一群连接互联网的 Agent,可以几乎消除 AI 中的幻觉。
- 另一位成员建议幻觉是由翻译错误引起的,并在这篇博客文章中详细阐述了他们的理论。
- Gemini 3 的推理细节被隐藏: OpenRouter 文档中关于 Gemini 3 Pro Preview 的一个关键推理细节被隐藏在一个折叠栏中。
- 成员们质疑保留推理块是否仅对 Tool Calling 是强制性的,因为文档表述模糊,需要彻底修订。
- 密钥过期:测试场: 一位用户分享了一张与密钥过期相关的图片 (image.png),并指出它“对测试很有用”。
- 测试的背景是指这种设置及其潜在影响。
{kind=link}
OpenAI ▷ #annnouncements (1 messages):
Atlas 浏览器, OpenAI Podcast
- Atlas 浏览器重塑: @BenGoodger 和 @Darinwf 加入了 @AndrewMayne 的对谈,解释了他们为什么要构建 Atlas 以及它是如何重新思考浏览器功能的。
- 他们讨论了从内到外重塑浏览器需要付出什么。
- OpenAI Podcast 在 Atlas 上播出: OpenAI Podcast 已在 Spotify、Apple 和 YouTube 上线。
- 聆听 OpenAI Podcast 以了解更多信息。
OpenAI ▷ #ai-discussions (439 条消息🔥🔥🔥):
Custom GPT 效率评估,Gemini 3 Pro 与 GPT-5.1 对比,Grok 4.1 能力,AGI 与 ASI 讨论,Grok Imagine 与视频生成
- Custom GPT 效率探讨:成员们讨论了衡量 Custom GPT 效率的方法(与基础模型相比),强调 Custom GPT 有助于规范特定任务的指令,从而简化 Prompt Engineering。
- 虽然 Custom GPT 提供了便利,但人们对思考模式(thinking mode)支持程度参差不齐以及低质量 Custom GPT 可能充斥市场的现象表示担忧。
- Gemini 3 Pro 声称胜过 GPT-5.1:一位用户报告称 Gemini 3 Pro 成功通过了一系列 AI 模型测试,突显了其生成 one-shot React 和 SwiftUI 代码的能力,并声称其优于 GPT-5.1。
- 其他人指出 Gemini 3 Pro 能率先解决手绘迷宫,并愿意提供歌词(而 GPT-5.1 会拒绝),同时也承认它在代码审查期间有时会进行不必要的修改。
- Grok 4.1 的创意写作技巧大放异彩:成员们赞扬了 Grok 4.1 在创意写作、情感相关问题和一些边缘任务中的表现,甚至有人在 SwiftUI 代码等特定应用中更倾向于使用它而非 GPT-5.1。
- 然而,它的编程能力被认为毫无希望,且长期记忆被发现不连贯,引发了关于 Grok 的存储占用和文件召回能力的讨论。
- AGI 担忧引发关注;ASI 是否不可避免?:讨论转向了 AGI 和 ASI 的潜在危险,成员们争论领先的 AI 公司是否真正理解与目标失盟(misaligned objectives)和工具策略(instrumental strategies)相关的风险。
- 虽然一些人对 AGI 彻底改变医学等领域的潜力表示乐观,但另一些人警告可能导致人类灭绝,并强调考虑先进 AI 开发的伦理影响的重要性。
- Grok Imagine 进入视频生成领域:用户分享了使用 Grok Imagine 生成的视频,展示了其对口型语音能力和免费可用性,引发了与 Sora 等其他视频生成模型的对比。
- 尽管令人兴奋,但一些用户批评了音频质量,并对低质量内容充斥平台的可能性表示担忧,这与对 Custom GPT 的担忧相呼应。
OpenAI ▷ #gpt-4-discussions (4 条消息):
GPT 4.5 vs 5,GPT 照片上传错误
- ChatGPT 4.5 与 5 的对决:一位成员询问 ChatGPT 4.5 在小说创作方面是否比 ChatGPT 5 Pro 更好。
- 另一位成员表示 ChatGPT 5 可能会更好。
- GPT 照片上传错误困扰用户:一位成员报告在向 GPT 上传照片时遇到困难,描述了在瞬间上传后出现的错误消息。
- 该成员表示困惑,指出即使在几小时后重复尝试,问题仍然存在。
OpenAI ▷ #prompt-engineering (12 条消息🔥):
Prompt Engineering 建议, 模型解释, 模型质量的主观性, 模型 A/B Testing, 自动过滤器问题
- Prompts:根据模型预期进行定制:一位成员建议,好的 Prompt 应该在符合 ToS 和允许内容 的前提下,与你希望从模型获得的结果保持一致。
- 他们强调,“好”的 Prompt 是主观的,取决于个人的需求和偏好。
- 通过评估 Prompt 解码模型解释:一位成员分享了一个用于评估而非执行指令的 Prompt,以评估该 Prompt 是否自相矛盾或与模型的编程冲突。
- 该 Prompt 旨在识别模型在解释指令时可能存在的歧义或需要猜测的地方。
- 模型质量:定义并实现你的愿景:为了获得最佳的图像质量,一位成员建议与模型讨论对用户而言“最佳质量”的具体含义。
- 目标是使模型的输出与用户的具体预期保持一致。
- 通过 A/B Testing 模型来确定最适合小说的模型:当被问及比较 ChatGPT 4.5 和 ChatGPT 5 Pro 在小说写作方面的表现时,一位用户建议进行 A/B Testing。
- 另一位成员强调 “更好的作者”是主观的,建议通过直接对比来确定最合适的模型。
- 自动过滤器可能会标记无害内容:一位成员报告称,自动过滤器因一个无伤大雅的原因标记了他的 Prompt。
- 这突显了自动过滤器潜在的问题以及进行细致内容审核的必要性。
OpenAI ▷ #api-discussions (12 条消息🔥):
Prompt Engineering 技巧, 图像生成质量, 模型准确性, 模型 A/B Testing, 自动过滤器
- 编写高质量 Prompt 的技巧:成员们讨论认为,好的 Prompt 是指在服务条款范围内实现预期效果的 Prompt,且其有效性取决于用户需求的主观感受。
- 一位成员建议使用以下 Prompt 来了解模型如何解释请求:评估而非执行以下 [prompt]。它是否自相矛盾或与你的编程冲突?是否存在歧义或迫使你进行猜测?[此处填入实际 prompt]。
- 图像质量 Prompt 需求:一位成员寻求关于如何编写 Prompt 以获得最佳图像质量的建议。
- 另一位成员建议讨论对用户而言“最佳质量”意味着什么,以便模型能更好地理解并满足请求。
- 对模型不准确性的困扰:一位用户报告称,模型经常提供错误信息,并试图用虚假信息来纠正用户。
- 此消息记录中未提供解决方案。
- 对小说写作模型进行 A/B Testing:一位用户询问 ChatGPT 4.5 还是 ChatGPT 5 Pro 更适合小说写作。
- 一位成员建议进行 A/B Testing 以确定哪个模型更符合需求,并强调 “更好的作者”是主观的。
- 自动过滤器误伤用户:一位用户开玩笑地责怪自动过滤器标记了他们的消息。
- 尽管该用户语气诙谐,但另一位成员认为他们的建议是非常中肯的。
LM Studio ▷ #general (234 条消息🔥🔥):
电商卖家困境、LLM 性能退化、2FA 应用推荐、通过 MCP 进行 LLM 工具集成、Gemini3-Pro 基准测试
- 电商平台据称偏袒不诚实的买家:一位成员抱怨电商平台偏袒那些损坏产品并要求退款的买家,并举例说 一个买家(原文误写为 seller)用锤子砸了他们的笔记本电脑,涂满护手霜后退货。
- 另一位成员分享了自己被滥用退货系统的买家 光天化日之下抢劫 的经历。
- LLM 随着时间的推移变笨了?:一位成员注意到他们的 LLM 运行时间越长似乎变得越笨,其他人怀疑这可能是一个 Bug 或观察偏差问题。
- 建议开启新对话或重新启动模型,并创建一个可复现的真实测试用例。
- 应对 2FA 应用雷区:成员们讨论了 免费且安全的双重身份验证 (2FA) 应用 的选择,建议包括 Google Authenticator 和 Proton Pass。
- 一些用户对使用 Google 或 Microsoft 的产品持谨慎态度,而另一些用户建议在 ChatGPT 的帮助下编写自己的身份验证器应用。
- LM Studio 拥抱 Model Context Protocol (MCP) 进行工具集成:成员们讨论了通过 Model Context Protocol (MCP) 将 LLM 与外部工具集成,并附上了 LM Studio 文档链接。
- 还有人提到,直接向 LLM 暴露 REST API 可能会令人困惑,MCP 应该被视为 LLM 的 UI。
- Gemini3-Pro 进入基准测试赛场:成员们关注到 Gemini3-Pro 的发布及其即时基准测试,一位用户询问其与 Qwen3-Max 的对比。
- 还有人讽刺西方公司的心态:“只要我们只跟彼此比较,就没人会发现我们落后了”。
LM Studio ▷ #hardware-discussion (226 条消息🔥🔥):
静音 PC 组装、GPU 改装、RAM 价格、eBay 销售、UPS 问题
- 橡胶垫让 PC 变静音:成员们坦言,为了满足静音 PC 组装的需求,抽屉里装满了橡胶垫、泡沫和密封圈,并发现它们效果惊人。
- 一位成员开玩笑说用鼠标垫当气缸垫,但强调了它们在机箱散热方面的有效性和随处可见的免费来源。
- 暴力拆除 GPU DVI 接口:一位成员分享了他们 暴力拆除 GPU DVI 接口 的视频,随后 展示了改装后的显卡,声称所有改装都是 100% 可逆的。
- RAM 价格飙升,引发抛售潮:成员们报告称最近 RAM 价格大幅上涨,一位成员以 $100 的价格卖出了 32GB DDR5 6000,另一位以约 $300 的价格卖出了 128GB DDR4 3600。
- 另一位用户声称卖出的 RAM 价格是买入价的 3 倍,形容现在的价格 非常不错。
- eBay 费用和税收侵蚀利润:一位成员哀叹 eBay 费用和税收的影响,他在 eBay 上挂出了 MI50。
- 他们指出,在支付了约 $100 的 eBay 费用和政府税收后,利润空间被显著压缩。
- 快递服务令人抓狂:成员们讨论了对各种快递服务的不满,一位成员将 Amazon Australia 描述为 基本上就是 Uber,因为它使用的是合同工司机。
- 另一位成员表示相比 FedEx 和 UPS 更倾向于使用 USPS,而英国用户则称 Evri 和 Yodel 是最令人讨厌的服务。
Latent Space ▷ #ai-general-chat (178 条消息🔥🔥):
Sourcegraph 广告, xAI Grok 4.1, Varun Mohan 的预告, Poe 群聊, Runlayer 融资
- Sourcegraph 增加广告收入流:据 The Information 报道,编程助手初创公司 Sourcegraph 上个月在其免费层级中加入了广告,预计年经常性收入(ARR)已达到 500 万至 1000 万美元。
- Grok 4.1 是 xAI 的最新模型:xAI 推出了 Grok 4.1,声称夺得 LM Arena 榜首(1483 Elo),在为期 2 周的静默测试中获得了 65% 的用户偏好,现在可在 grok.com 和移动应用上免费使用。
- 根据其 model card,关键亮点包括 1586 的 EQ-Bench 评分,Creative Writing v3 上的 1722 Elo,以及幻觉减少了 3 倍。
- Mohan 预告 Varun 的惊喜发布:Varun Mohan 发布了一条带有视频缩略图的神秘 “👀” 推文,引发了关于即将发布的版本的广泛猜测——可能是 Gemini 3.0、Veo 4 或 Windsurf 集成——根据他的 公告。
- Poe 增加全球群聊功能:Poe 推出了支持多达 200 人的全球群聊支持,允许团队在一个同步线程中调用其 200 多个 AI 中的任何一个(如 Claude 4.5 和 GPT-5.1),根据其 公告。
- Runlayer 获得 1100 万美元融资:Runlayer 是一个为企业提供对 18,000+ MCP servers 进行安全、受控访问的平台,宣布了由 Khosla & Felicis 领投的 1100 万美元种子轮融资,现已在 Gusto 和 Opendoor 等客户中上线,根据 Andy Berman 的公告。
Nous Research AI ▷ #announcements (1 条消息):
Atropos, RL Environments 框架, Thinking Machines 的 Tinker 训练 API
- Atropos 支持 Tinker 训练 API:Nous Research 的 Atropos(一个 RL Environments 框架)现在完全支持 Thinking Machines 的 Tinker 训练 API。
- 正如 其推文 中所强调的,这一集成允许用户轻松地在各种模型上训练和测试基于 Atropos 构建的环境。
- Tinker 和 Atropos,黄金搭档:Atropos 环境现在可以使用 Thinking Machines 的 Tinker 训练 API 进行训练,扩大了可训练模型的范围。
- 如需帮助,建议用户访问指定频道。
Nous Research AI ▷ #general (131 条消息🔥🔥):
Amazon Nova Premier v1, Bedrock AWS 问题, Jeff Bezos buff, 双 3090 上的 Hermes 4 70B, Factorio Agent 项目
- Amazon Nova Premier V1 模型现身:一位成员分享了 OpenRouter 上 Amazon Nova Premier v1 的链接(日期为 2025 年 4 月),并对其新颖性表示怀疑,因为 Amazon 过去发布的模型大多表现平平。
- 其他人猜测 Jeff Bezos 正在开展自己的 AI 计划,独立于 Amazon,这可能是由于内部政治以及 AWS Bedrock 的问题。
- Bedrock AWS 面临批评:一位成员讲述了在难以终止实例后在 AWS 上花费了 3000 美元 的经历,强调了隐藏成本和支持工单费用的问题。
- 另一位成员分享了类似的经历,称他们在 17 岁托管 Minecraft 模组包时被出站流量费(egress charges)坑惨了。
- Gemini 3 发布后被撤回:成员们讨论了 Gemini 3 Pro Model Card 的发布及随后的移除,并指出它在 基准测试中曾短暂超越 Sonnet 4.5。
- 一位成员指出 Anthropic, Microsoft 和 Nvidia 似乎对 Google 的发布泼了冷水,而另一位成员则通过 Google AntiGravity 获得了 Sonnet 的访问权限。
- Gemini 3 生成实时光线追踪器:一位成员惊叹 Gemini 3 生成了一个单次生成的实时光线追踪器(realtime raytracer),表现令人满意,并分享了示例图像。
- 另一位成员指出模型能做到这一点非常棒,并表示用于 Raymarching 的结构的隐式数学描述有时对人类程序员来说非常烧脑。
- Nous Research 发布廉价 RL 训练方案:一位成员分享了 Nous Research 的推文,宣布了一种在 Atropos 中测试或训练任何 RL 环境的廉价方法。
- 另一位成员分享了一段关于 金融交易员利用 Agentic AI 工具赚钱 的视频,但调侃说自己宁愿拿着那两个子儿去加油站买刮刮乐。
Nous Research AI ▷ #ask-about-llms (6 条消息):
无审查 MoE, 对 Josified 模型进行 LoRA, Kimi 1T 越狱, 用于管家任务的 Kimi Linear, 对模型审查的挫败感
- 寻找无审查 MoE 之旅开启:一位成员正在寻求无审查的 混合专家模型 (MoE) 建议,以绕过当前模型中为了“防范普通用户(normie-proofing)”而设置的限制。
- 目标是开发用于 犯罪预防和教育 的工具,但审查制度阻碍了进展。
- 考虑使用 Josified LoRA 模型:作为使用无审查 MoE 的替代方案,由于需要能够处理敏感话题的模型,该成员计划尝试 对 Josified 模型进行 LoRA。
- 该成员担心缺乏用于提升无审查小型模型的通用知识数据集,以及使用 Josified 模型和其他去审查技术的不确定结果。
- 寻求 Kimi 1T 越狱方法:一位成员正在寻找 Kimi 1T 的有效越狱 (jailbreak) 方案,特别是适用于特定用例的小型模型。
- 另一位成员表示有兴趣将 Kimi Linear 用于日常管家(housekeeping)和编排(orchestration)任务,将其构想为一种设备端、本地部署(on-prem)的辅助模型。
- Kimi Linear 的 Codegen 计划:一位成员计划在 12 月假期期间针对 Codegen 和软件工程 (SWE) 任务 微调 Kimi Linear。
- 他们打算专门为此目的收集一个数据集。
- 对模型审查的挫败感爆发:一位成员表达了对模型审查的不满,特别是当模型因为安全限制而拒绝执行简单任务时。
- 审查制度甚至阻止模型删除容器(container),这引发了对训练后对齐(post-training alignment)机制的强烈反感。
Nous Research AI ▷ #interesting-links (2 条消息):
AI 论文, NousResearch GitHub 仓库
- DRTULU AI 论文发布:一位成员分享了来自 allenai.org 的 DRTULU AI 论文 链接。
- Tinker-Atropos GitHub 仓库上线:一位成员分享了来自 NousResearch 的 Tinker-Atropos GitHub 仓库 链接。
HuggingFace ▷ #general (109 messages🔥🔥):
Graph-RAG 数据库, Mimir 项目, Lablab 黑客松争议, Cloudflare 停机, Gemini 3
- **Graph-RAG 数据库打破常规: 一名成员宣布发布了他们的 **graph-rag 数据库,通过提供一个具有代码智能且受用户控制的替代方案,向 Kilo Code 和 Pinecone 发起挑战。
- 该项目旨在保持开放和可定制,已在 GitHub 上发布,并在发布几天内就获得了 47 stars。
- **Mimir 项目编排开源理想境界: **Mimir 项目具有多 Agent 编排和一键部署功能,全部采用 MIT 许可证,为 N8N、Pinecone 和 Kilocode 等方案提供的供应商锁定(vendor lock-in)提供了替代方案。
- 它兼容 OpenAI API 和 OpenWebUI,包含用于 Minecraft 服务器的编排流水线,带有记忆工具和语义搜索,并使用 llama.cpp 进行 embeddings,尽管需要进行自定义 ARM64 镜像编译。
- **Lablab 黑客松引发诈骗指控: 一位用户讲述了在 **Lablab 黑客松中的负面经历,将其描述为“基本上是在诈骗开发者的 Web 开发商”,并警告潜在的剥削行为。
- 该用户声称在获得最高分后被从排行榜中移除,并告诫他人避开 Lablab,特别是如果提供的机会涉及在不利条件下搬迁到国外。
- **Cloudflare 遭遇全球停机: 一场广泛的 **Cloudflare 停机影响了包括 斯德哥尔摩、柏林、华沙和巴黎在内的多个城市的服务器,影响了应用程序和各种在线功能。
- 一名用户幽默地声称对此次停机负责,称他们在 Cloudflare 实习期间将一个有缺陷的身份验证修复程序推送到生产环境,从而延长了他们的周末,并表示“测试在本地通过了”。
- **Gemini 3 具有反重力特性: 狂热的成员声称 **Google 的 Gemini 3 已经发布,并且“它正在解决我的编译器设计课作业并给出正确的输出”,而另一名成员发布了一个 YouTube 视频,质疑 Google 交付完美演示的能力。
- 一名成员由于其出色的结果,讽刺地声称“Google 刚刚推出了反重力技术”。
HuggingFace ▷ #i-made-this (4 messages):
Cornserve, FastMayavangelis, Grounded Video Caption Generation, Medical Reasoning GPT OSS 20B
- Cornserve 通过微服务提供复杂模型服务: 一个名为 Cornserve 的服务框架被创建,用于通过微服务方法提供复杂的多模态模型,将复杂模型拆分为独立的组件,并自动共享公共部分。
- 更多详情请见 主页。
- FastMayavangelis 快速生成音频: 一名成员创建了一个仓库 FastMayavangelis,通过优化 maya1,可以在短短一秒钟内生成近 50 秒 的音频。
- 它可以生成带有音效和语音描述的高质量 48khz 音频。
- Grounded Video Caption Generation 论文被 ICCV 2025 接收: 题为 “Large-scale pre-training for grounded video caption generation” 的论文已被 ICCV 2025 接收。
- 提供了 项目网页、代码、Hugging Face 上的模型、HowToGround1M 数据集 以及 iGround 数据集 的链接。
- 医疗推理模型开源: 一名成员使用最热门的医疗推理数据集微调了 OpenAI 的 OSS 20B 推理模型,并将结果发布在 Hugging Face 上。
- 该模型可以逐步分解复杂的医疗案例,识别临床场景中的可能诊断,并以逻辑推理回答执业考试风格的问题;可在 此处 获取。
HuggingFace ▷ #computer-vision (1 messages):
grounded video caption generation, ICCV 2025, HowToGround1M, iGround dataset
- Grounded Video Caption Generation 论文被 ICCV 2025 录用:一篇题为 “Large-scale pre-training for grounded video caption generation” 的新论文已被 ICCV 2025 接收。
- 分享了 项目主页、代码和 checkpoints、模型、HowToGround1M 预训练数据集 以及 iGround 数据集 的链接。
- HowToGround1M 和 iGround 数据集发布:用于预训练的 HowToGround1M 数据集和用于微调及评估的 iGround 数据集已发布。
- 这些数据集与 “Large-scale pre-training for grounded video caption generation” 论文相关联。
HuggingFace ▷ #gradio-announcements (1 messages):
Gradio 6 Launch, Youtube Announcement, X Announcement
- Gradio 6 发布,速度更胜以往:Gradio 6 终于面世,它比以往任何时候都更快速、更轻量、更具可定制性。
- 发布会定于 PT 时间 11 月 21 日星期五上午 9:00 / ET 时间中午 12:00 / CET 时间下午 6:00 在 YouTube 和 X 上举行,内容包括团队对新功能的演示以及问答环节。
- Gradio 6 在社交媒体上的发布公告:Gradio 6 的发布已在 YouTube 和 X 上同步公告,以最大化曝光度。
- 公告中包含 YouTube 视频 链接,并指出 X 链接将在活动当天分享。
HuggingFace ▷ #smol-course (1 messages):
Jinja Code, instruct_tokenizer.apply_chat_template, HuggingFaceTB/SmolLM3-3B chat template, Bug Reporting, Pull Requests
-
在 SmolLM3-3B 聊天模板中发现 Jinja Bug:用户在 HuggingFaceTB/SmolLM3-3B 聊天模板的 Jinja 代码 中发现了一个潜在 Bug,具体表现为在使用 instruct_tokenizer.apply_chat_template时 **<im_end >** token 的位置问题。 - 该用户正在寻求关于提交 Pull Request (PR) 或提出 issue 以报告此发现的合适仓库的指导。
- 寻求 Bug 报告流程指导:一名成员咨询了如何报告在使用
instruct_tokenizer.apply_chat_template函数时发现的疑似 Bug。- 他们正在寻找正确的仓库,以便为 HuggingFaceTB/SmolLM3-3B 聊天模板 开启 PR 或提交 issue。
Yannick Kilcher ▷ #general (36 条消息🔥):
Understanding Machine Learning Book, More Technical ML Books, ReLU activation function, Gemini 3 Pro Model, Mathematical theory of Deep Learning
- 经典 ML 书籍获得好评:成员们讨论了由 Shai Shalev-Shwartz 和 Shai Ben-David 编写的 Understanding Machine Learning。
- 一位成员指出 这是一本非常好的入门读物,但建议 同时搭配一本更具技术性的书籍。
- Bach 的书是 ML 理论的最佳选择:一位成员推荐了 Bach 编写的 Learning Theory from First Principles,但指出 如果没有统计学背景,其中的证明会非常晦涩。
- 其他推荐材料包括来自 Mohri 的 Foundations of Machine Learning,以及网站 deeplearningtheory.com。
- 重温 ReLU:依然简单,依然强大:一位成员重新审视了 ReLU,认为它看起来 过于简单,怀疑它是否真的能运行良好,并将其描述为
max(0, wx+b)。- 他们指出 ReLU 在 计算上要简单得多,提供了 非线性,并且由于其导数为 0 或 1,降低了 gradient vanishing(梯度消失)的可能性。
- Gemini 3 Pro:微弱的提升还是巨大的飞跃?:成员们讨论了 Gemini 3 Pro Model Card,一位成员最初将其描述为 略优于 GPT 5.1。
- 经过仔细观察,他们修正了评估,指出 HLE、Video-MMMU 和 ARC-AGI-2 的结果 非常惊人,并推测了 Gemini 3 性能背后的秘密,猜测是 数据质量、更好的参数利用、RL。
- Deep Learning 数学深入探讨 arXiv:一位成员发布了 arXiv 论文 Mathematical theory of deep learning 的链接,以及同名剑桥书籍的链接。
- 另一位成员回复道:“这个看起来非常有趣,感谢分享!”
Yannick Kilcher ▷ #paper-discussion (9 条消息🔥):
Circuit Sparsity, Yannic Kilcher Transformer Videos, Youtube Search
- 稀疏性研究引发关注:成员们对来自 OpenAI 的 “Circuit Sparsity” 论文 以及相关的 博客文章 表现出浓厚兴趣。
- 一位成员考虑在时间允许的情况下,在每日论文讨论中演示这一主题。
- Transformer 深度探讨请求:一位成员请求 Yannic Kilcher 的关键词或特定视频,以便更好地理解 attention 和 transformer 模型的演变。
- 另一位成员分享了 Yannic Kilcher 关于 Transformers 的视频链接,并建议使用 YouTube 的搜索功能在 Yannic 的频道内查找内容:YannicKilcher/search?query=transformer。
Yannick Kilcher ▷ #ml-news (26 messages🔥):
DS Star, WeatherNext-2, Grok-4, Project Prometheus, Gemini 3 Pro Model
- Bezos 带着 “Project Prometheus” 重返前线:据报道,Jeff Bezos 将回归担任一家名为 Project Prometheus 的新 AI 初创公司的 co-CEO。
- 一位成员开玩笑说,Bezos 基本上是在处处模仿 Elon 的举动。
- Google 的 Gemini 3 Pro Model Card 泄露!:一个指向 Gemini 3 Pro Model Card 的 链接 被分享后随即撤下,但在撤下前已被截图并传播。
- 该模型似乎已在 AI Studio(Google 的 VS Code 分支)上可用,并且在众多 Benchmark 上表现出色。
- Google 发布 DS Star Agent 和 WeatherNext-2:Google 宣布推出一款多功能数据科学 Agent DS Star,以及一款全新的天气预报模型 WeatherNext-2。
- 剩下的问题是,Gemini 的性能提升是否能泛化到 Benchmark 之外的任务,以及私有和新型的 Benchmark 中,以及泛化程度如何。
- xAI 预告 Grok-4:xAI 宣布即将发布 Grok-4。
- 一位成员开玩笑说,如果 level 能达到 pass@32 那就太酷了。
- ML Street Talk 发布关于 ARC2 的视频:ML Street Talk 最近发布了一个关于 ARC2 达到 29.4% 的 视频。
- 一位成员开玩笑说 ML Street Talk 必须再做一个视频了。
Eleuther ▷ #general (31 messages🔥):
NeurIPS 2025, EleutherAI's Papers, Social events at NeurIPS 2025, Huggingface performance tips, ML Research guidance
- EleutherAI 在 NeurIPS 2025 大放异彩:EleutherAI 将在 NeurIPS 2025 发表多篇论文,包括主赛道(main track)的:The Common Pile v0.1、Explaining and Mitigating Cross-Linguistic Tokenizer Inequalities 以及 More of the Same: Persistent Representational Harms Under Increased Representation。
- 他们还有多篇论文被 MechInterp Workshop 和 AI4Music 等研讨会接收。
- NeurIPS 2025 社交日程即将开启:成员们正在计划 NeurIPS 2025 的官方晚宴,并在此处发布了招待会链接 here。
- 要加入社交活动小组,用户可以在 channels 和 roles 选项卡中选择 social activities role。
- Huggingface 获得吞吐量提升:一位成员分享到,在使用 Huggingface 时,使用带有
return scores.contiguous()的空 logits processor 可以带来 60% 的生成吞吐量提升。- 这是在 FA2 环境下测试的:dynamic=False, fullgraph=True。
- ML 研究新手获得建议:一位新成员询问如何开始 ML 研究,促使其他人询问“具体是哪个子领域的研究?你具体想做/实现什么?”。
- 另一位成员建议,“查看置顶消息”以获取更多信息。
Eleuther ▷ #research (36 messages🔥):
Tied weights in Transformers, Cohere's command A model, Virtual Width Networks (VWN), Linear Attention, Residual Matrix Transformers
- **绑定 Transformer 权重:一种节省参数的技巧:正如 research 频道中所讨论的,较小的 Transformer 模型通常在 embedding 和 LM head 之间绑定权重 (tie weights)** 以降低参数量。
- 相比之下,大型模型可能不需要绑定权重,因为参数的增加仅占模型总大小很小的比例。
- **Cohere 的 command A 绑定了权重,会引领趋势吗?:成员们提到,最近使用绑定权重的大型模型是 **Cohere 的 command A。
- 目前尚不清楚其他大型模型是否也在采用这一策略。
- **VWN:线性注意力的重新构想:虚拟宽度网络 (VWN) 被视为 **linear attention 的一种实现,但据频道成员称,其更新不是在 token 之间发生,而是在层与层之间发生。
- 一位成员指出:“VWN 基本上是在做 linear attention,但
state[:, :] += ...的更新不是从 token 到 token,而是从层到层发生的”。
- 一位成员指出:“VWN 基本上是在做 linear attention,但
- **探索 VWN 的矩阵迷宫:讨论深入探讨了 **Virtual Width Networks (VWN) 中令人困惑的矩阵表示,特别是矩阵 A 和 B 的大小和密度。
- 成员们对论文中矩阵符号可能存在的错误表示担忧,并建议代码实现可能会使用更清晰的 einsum 符号;一位成员表示:“我能合理化该截图中 A1 为 n(n+m) 的唯一方法是,如果它被拆分为用于传播残差状态的 Â (nn) 和作为传递给 attention 的多头 query 的 Å (nm)”*。
Eleuther ▷ #interpretability-general (1 messages):
Paper review, Model review, Result analysis, Result discussion, Future research
- 论文评审进行中:一位成员正在评审一篇论文,重点关注引言、方法、相关附录部分以及部分结果。
- 他们打算进一步探索结果、讨论、未来工作和附录部分。
- 后续评审计划:该成员计划继续评审同一篇论文,重点关注尚未完成的部分。
- 这些部分包括结果、讨论、未来工作和附录。
Modular (Mojo 🔥) ▷ #announcements (1 messages):
Modular updates, Mojo 1.0 roadmap, Community Meeting, MMMAudio, Shimmer
- Modular 宣传 MMMAudio 和 Shimmer:Modular 宣布了即将于 11 月 24 日举行的社区会议,届时将展示 MMMAudio(一个创意编程音频环境)和 Shimmer(一个跨平台的 Mojo → OpenGL 实验)。
- 会议还将涵盖 Modular 的更新,包括 25.7 版本发布和 Mojo 1.0 路线图。
- Mojo 1.0 路线图预告:11 月 24 日的 Modular 社区会议将提供关于 Mojo 1.0 路线图的见解,以及 25.7 版本的更新。
- 与会者可以期待关于 Mojo 未来方向和即将推出的功能的详细信息。
Modular (Mojo 🔥) ▷ #mojo (34 messages🔥):
Mojo 中的 NVFP4 支持,负索引与 Int vs UInt,Poetry 集成
- **Mojo 关注 Nvidia 的 NVFP4 挑战:一名成员询问了 **Mojo 中的 NVFP4 支持,针对一项专注于 NVFP4 Batched GEMV 的 Nvidia/GPUMode 竞赛,特别询问 Mojo 是否支持它。
- 一名成员指出 Mojo (MLIR) 包含 fp4,并且可以使用现有的 Mojo 数据类型构建 nvfp4,并参考了 GitHub 上的 dtype.mojo 文件。
- **Mojo 社区内关于负索引的辩论加深:关于 **负索引与
IntvsUInt的持续讨论仍在继续,涉及性能影响以及各种可能性(如generic_list[-3:]或 Python 传统上允许的任何其他强大的切片功能)下的潜在 UB 错误。- 一位核心团队成员澄清说,目标是在大多数 API 中标准化使用 Int,从 List 等低级类型中移除对负索引的支持,并默认启用边界检查;而另一位成员表示 “我强烈反对,因为我写过很多 NumPy 代码,习惯于使用负索引。”
- **Poetry 与 Mojo 良好协作:一名成员分享了将 **Mojo 与 Poetry 集成的指令,详细说明了如何在
pyproject.toml文件中添加源和依赖项。- 配置包括添加一个指向 nightly Python 包仓库的 modular source,并指定启用预发布的 mojo 依赖项。
- **ArcPointer 安全性受到质疑:一名成员提出了关于 **ArcPointer 安全性的问题,涉及在调用
a==b函数时潜在的 UB 错误,他们认为这应该被捕获为 UB 错误,因为 p3 实际上被 extend 调用使失效了。- 代码涉及在 ArcPointer[List[Int]] 中扩展和解引用指针等操作,导致在 assert 语句中崩溃,而不是捕获到 UB 错误。
DSPy ▷ #papers (1 messages):
the_4th_doctor: 这个结构非常适合优化器:https://arxiv.org/abs/2511.09030
DSPy ▷ #general (22 messages🔥):
DSPy 的 VSCode 扩展,MLflow 替代方案,LLM 确定性,DSPy 生产社区,追踪与可观测性
- DSPy 获得用于类型提示的 VSCode 扩展:一名成员宣布创建了 dspy-intellisense,这是一个 VSCode 扩展,旨在为 DSPy 中的签名和预测提供更好的 类型提示 (type hinting)。
- 成员寻找 MLflow 替代方案:一名成员询问其他人是否对他们的 检查工具(MLflow 替代方案)感到满意,并表达了对 MLflow 的不满。
- 作为回应,一名成员建议使用 arize phoenix 查看追踪,并提供了 arize.com 的链接。
- 应对 LLM 的非确定性困境:一名成员询问如何处理 LLM 的非确定性,特别是在使用 gpt-oss-20b 对相同数据集和提示词进行每次运行都看到略有不同结果的情况。
- 一名成员建议将 temperature 设置为 0,调整 max_tokens,并强制执行 严格的输出格式 以获得更一致的结果,并指出在 temperature 为 0.1 时出现随机性是正常的。
- 社区渴望 DSPy 生产环境频道:一名成员询问是否有专门针对 DSPy 生产社区 的频道。
- 另一名成员回答说目前还没有,但建议应该有一个。
- Git 回来了,宝贝:一名成员宣布 Git 已恢复在线。
- 他们还提供了一个指向更广泛想法集的 链接。
tinygrad (George Hotz) ▷ #general (14 messages🔥):
tinybox, Llama 1B, torch compile, Kernel imports, examples/extra
- tinybox 会议公告:会议已宣布,并附带了 tinygrad.org/#tinybox 和 GitHub issue #1317 的链接。
- Llama 1B 在 CPU 上比 Torch 更快?:一名成员报告 Llama 1B 在 Tinygrad 上的表现优于 CPU 上的 Torch:Tinygrad 10 次运行:16498.56 ms 6.06 tok/s,Torch 10 次运行:34247.07 ms 2.92 tok/s。
- 对标 Torch Compile 进行基准测试:一名成员考虑与
torch.compile的 PyTorch 实现进行基准测试对比,以获得更具参考价值的比较。 - Kernel 导入清理:成员们询问是否应该修复
extra/optimization文件中的from tinygrad.codegen.opt.kernel import Kernel导入。 - 清理损坏的示例:成员们建议,如果存在一些长期未触及且已损坏的无用 examples/extra,可能应该直接删除。
aider (Paul Gauthier) ▷ #general (6 messages):
Gemini 3 errors, Experimental Channel Move
- 据报道 Gemini 3 面临同样的错误:一位用户报告在新的 Gemini 3 模型中遇到了与之前相同的错误,并附上了错误报告。
- 另一位用户将该报告斥为“AI 废话”,并质疑“experimental 频道怎么了?”
- Experimental 频道搬迁至 Discord 新家:experimental 频道已移至新的 Discord 服务器。
- 此举是为了回应用户对 experimental 频道变动的疑问。
Manus.im Discord ▷ #general (3 messages):
Manus.im, Manus 1.5, Skilled Developer
- Manus 用户欢呼回归荣光:一位 Manus.im 的老用户称赞 1.5 版本状态极佳,指出其在任务处理方面有所改进,并消除了“智障循环(retard loops)”。
- 该用户表达了满意之情,感谢 Manus 团队听取了投诉,并表示可能会再次升级到 PRO 版本。
- 资深开发者寻求机会:一位用户询问社区内是否有适合资深开发者(skilled developer)的机会。
- 未提供关于开发者类型或其技能的更多信息。
Windsurf ▷ #announcements (2 messages):
Gemini 3 Pro, Windsurf, Download editor
- Gemini 3 Pro 登陆 Windsurf!:Gemini 3 Pro 现已在 Windsurf 上可用,为用户提供其强大的功能。
- Gemini 3 故障已修复!:Gemini 3 的一个小问题已得到解决,确保其现在可以正常运行。
- 团队对初始阶段出现的“小插曲”造成的任何不便表示歉意。
MLOps @Chipro ▷ #events (1 messages):
AI Governance, AI Control, AI Webinar
- AI 治理与控制研讨会公告:一位成员宣布了定于 太平洋时间 12 月 3 日上午 10 点 举行的 AI 治理与控制 研讨会;感兴趣的人士可以通过此链接注册。
- 该研讨会旨在为有效管理和控制 AI 实施提供见解和策略。
- AI 治理讨论:研讨会旨在围绕 AI 治理 的关键方面展开讨论,包括伦理考量、合规性和风险管理。
- 鼓励参与者分享他们在不断变化的 AI 控制 领域中的经验和观点,以及其对组织战略的影响。
MCP Contributors (Official) ▷ #general (1 messages):
Image Analysis, Attachments, Discord CDN
- Discord 聊天中的图片附件:一位用户在聊天中分享了一张图片,该图片托管在 Discord 的 CDN 上,URL 为 cdn.discordapp.com。
- 图片的内容及其与当前讨论的相关性尚未明确。
- Discord 图片托管:随附的图片托管在 Discord 的内容分发网络 (CDN) 上。
- 这表明图片是直接上传到 Discord 的,而不是使用外部图片托管服务。