AI News
OpenAI 反击:GPT-5.1-Codex-Max (API) 和 GPT 5.1 Pro (ChatGPT)
OpenAI 发布了 GPT-5.1-Codex-Max,其特点包括原生压缩训练(compaction-native training)、“超高”推理模式,并声称可实现超过 24 小时的自主运行,在 METR、CTF 和 PaperBench 等基准测试中表现出显著的性能提升。谷歌的 Gemini 3 Pro 展示了强大的编程和推理能力,在 SWE-bench Verified 和 WeirdML 上取得了新的行业领先(SOTA)结果,估计模型规模在 5 到 10 万亿参数之间。随着多家公司的集成和工具改进,AI 编程代理(coding agent)生态系统正在迅速发展。萨姆·奥特曼(Sam Altman) 强调了 GPT-5.1-Codex-Max 的重大改进。新闻还涵盖了针对教师的 ChatGPT 等教育产品,以及涉及 Gemini 3、GPT-5.1-Codex-Max 和 Claude Sonnet 4.5 的多智能体工作流。
我快跟不上了
2025/11/18-2025/11/19 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 24 个 Discord 社区(205 个频道,11113 条消息)。预计节省阅读时间(以 200wpm 计算):790 分钟。我们的新网站现已上线,提供完整的元数据搜索和精美的 vibe coded 风格呈现的所有往期内容。查看 https://news.smol.ai/ 获取完整的新闻细分,并在 @smol_ai 上给我们反馈!
在明天的 AIE CODE 之前,编程模型的更新正强劲且快速地袭来——继昨天的 Gemini 3 发布之后,OpenAI 推出了升级/更新的 GPT-5.1-Codex(公平地说,OpenAI 确实表示这次发布是预先计划好的,暗示这并非是对 Gemini 的回应)。下面来自 GPT 5.1 的自动摘要链接已经足够出色,所以我们不再赘述,但我们要重点强调更新后的 METR Evals,它显示了自主性(autonomy)的巨大飞跃:
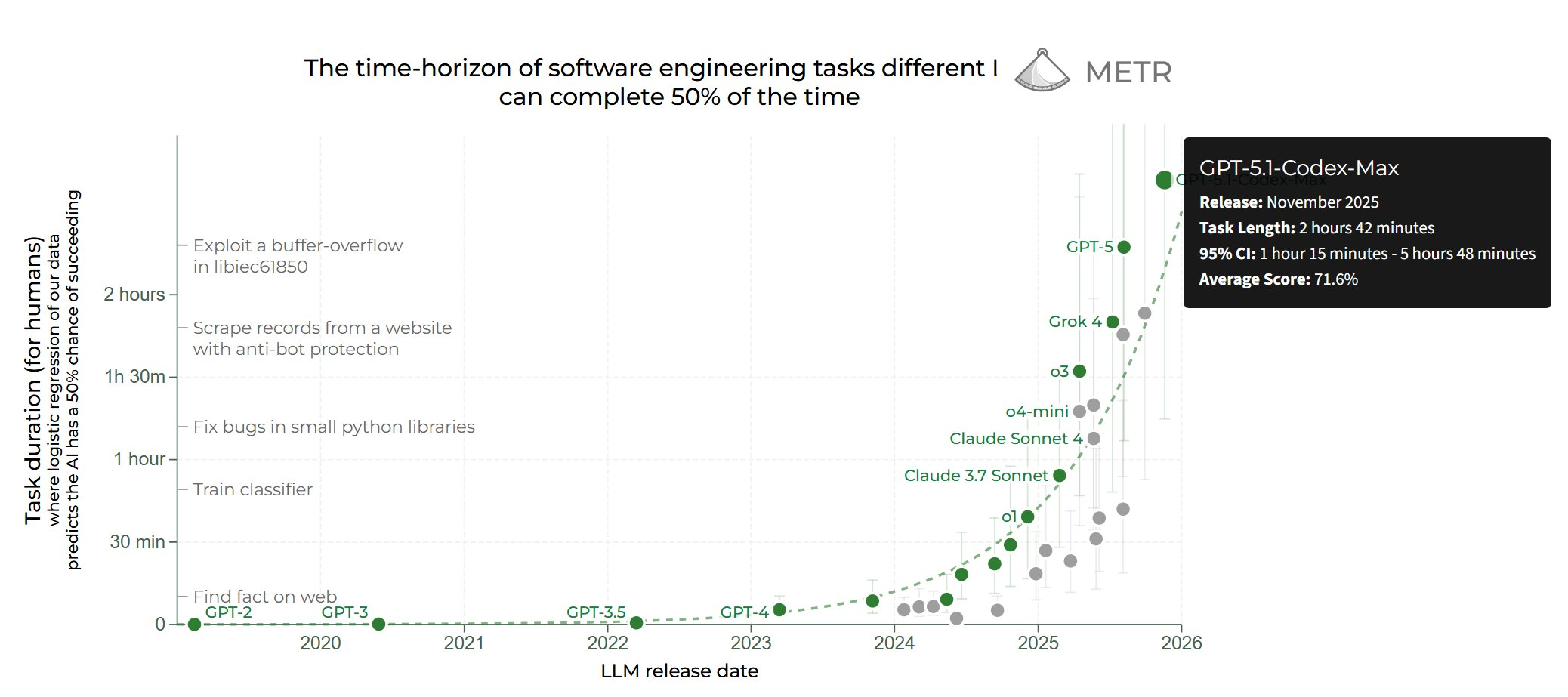
以及在新的 “xhigh” 参数下的额外性能表现……
OpenAI 的 GPT-5.1-Codex-Max 与编程 Agent 军备竞赛
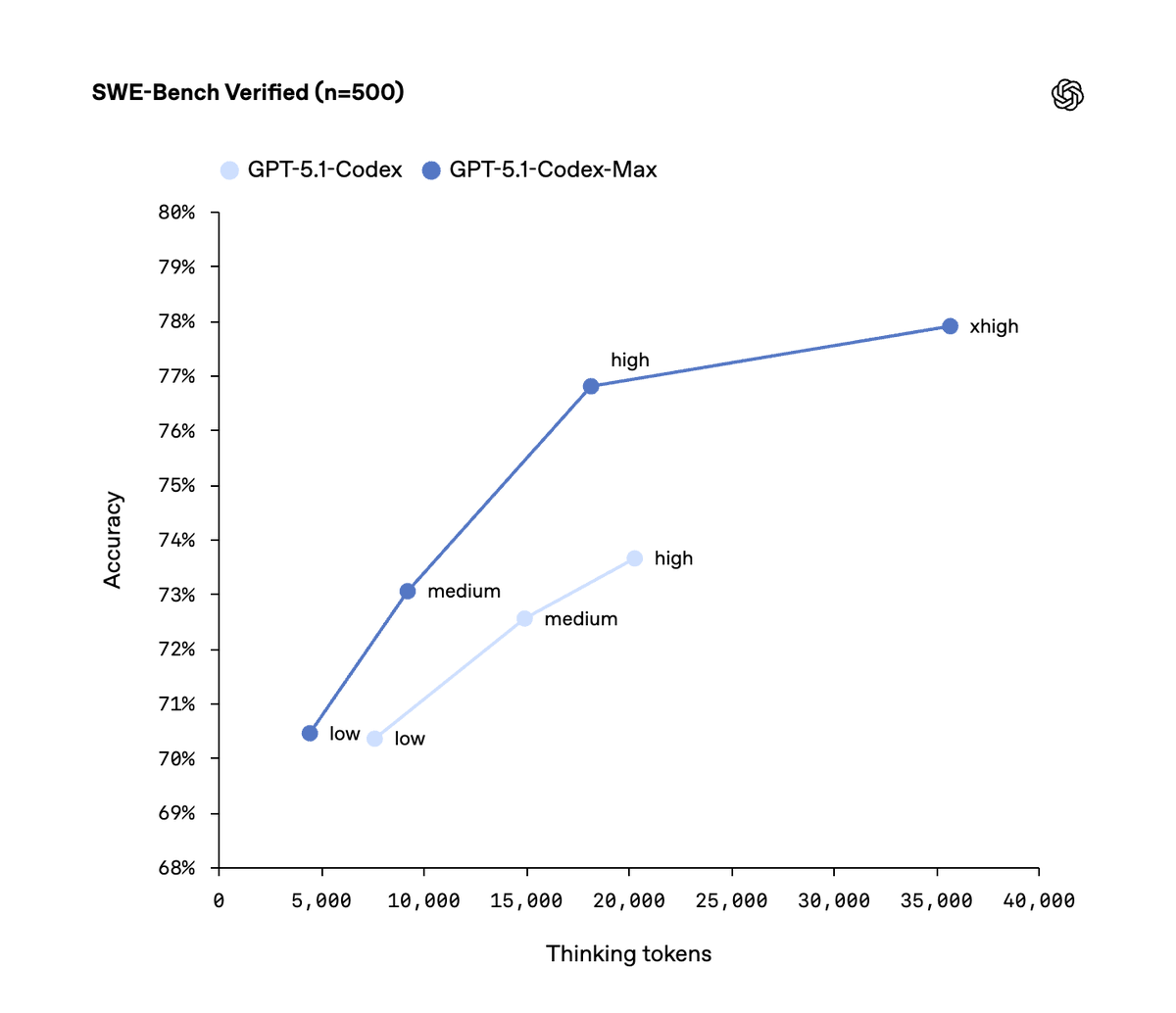
- 发布与实测增益:OpenAI 发布了 GPT-5.1-Codex-Max,具有针对长时运行的 compaction-native 训练、”Extra High” 推理设置,并声称在数百万个 token 上可实现超过 24 小时的自主运行(公告,文档,CLI 0.59,DX 总结)。早期结果显示在 METR (链接)、CTF、PaperBench、MLE-bench 以及内部 PR 影响力(在 OpenAI 仓库上比 GPT-5.1 提升了 8%)方面均有改进(ctf,paperbench,MLE,PRs)。Sam Altman 表示:“显著提升” (推文)。
- 现实工作流:轶事证据显示,顶级模型之间的分工虽然参差不齐但正在改善:Gemini 3 诊断问题,GPT-5.1-Codex-Max 实施修复(带有一个小 bug),而 Claude Sonnet 4.5 完成最后一步(@kylebrussell)。工具链发展迅速:一个用于云端控制的 Claude Agent 服务器封装器(@dzhng);Cline 添加了 Gemini 3 Pro Preview(@cline);Google 的 Jules agents 集成了 Gemini 3(@julesagent)。OpenAI 还向 ChatGPT 订阅用户推出了 GPT-5.1 Pro(@OpenAI)并推出了为美国 K-12 教育量身定制的产品(ChatGPT for Teachers)。
AI Twitter 综述
Google 的 Gemini 3:模型能力、安全性、IDE 和 UI
- Gemini 3 Pro 能力与评估:一波第三方结果显示 Gemini 3 Pro 在编程和“奇特”推理任务上表现非常强劲。在 SWE-bench Verified 上通过极简测试框架(minimal harness)达到了约 74% 的新 SOTA (@KLieret, @ankesh_anand);在 WeirdML 上取得 SOTA (@scaling01, @teortaxesTex);并在细节视觉基准测试 IBench 中名列前茅 (@adonis_singh)。在 Agent 场景中,它能有效处理规划、子 Agent 委派和文件操作 (Deep Agents 指南),开发者报告其多次迭代改进的表现显著优于同类模型 (@htihle)。
- 尺寸与基础设施推测(视为未经证实):一个被广泛转发的“体感估算”(vibe math)帖子认为,在 FP4 假设和单机架延迟约束下,其激活参数量在约 1.7T–12.6T 之间,中位数为 7.5T;作者后来因 TPUv7 的不确定性撤回了 FP4 假设,并将估算修正为约 5–10T (@scaling01, 后续, 更新)。Ant 的发布含蓄地确认了第七代 TPU 芯片 (@suchenzang)。
- 安全态势与行为:Google DeepMind 强调了 Frontier Safety Framework 测试、外部评估以及对注入攻击(injections)抵抗力的提升 (模型卡片, 概览)。他们的报告指出模型具有更高的 CBRN 抵抗力,且 RE‑Bench 仍低于警报阈值,此外当评估感觉过于合成化时,模型还出现了一个有趣的“虚拟掀桌”现象 (摘要, 报告链接)。用户仍将“煤气灯效应”(gaslighting)和策略覆盖(搜索拒绝/幻觉)列为痛点 (批评, 搜索问题, 后续)。
- 访问权限、IDE 和 UI:学生可免费访问 Gemini 3 Pro (Demis)。Antigravity IDE 带来了流畅的 Agent 化 Chrome 驱动循环(UI 驱动 + 自动测试),尽管在负载下仍存在一些粗糙之处和质量不稳定的问题 (好评, UX 挑剔, 其他)。Gemini 3 现在驱动着搜索中的 “AI Mode” 以及新的生成式 UI,后者可以直接根据 Prompt 构建动态界面(网页、工具) (AI Mode, 生成式 UI 研究与推出)。开发者已经在其基础上发布经过调优的体验 (MagicPath 示例)。
OpenAI 的 GPT‑5.1‑Codex‑Max 与编程 Agent 军备竞赛
- 发布与实测收益:OpenAI 发布了 GPT‑5.1‑Codex‑Max,具备针对长程运行的 compaction-native training(压缩原生训练)、“极高”推理设置,并声称在数百万 token 上可实现超过 24 小时的自主运行(公告,文档,CLI 0.59,DX 回顾)。早期结果显示其在 METR(链接)、CTF、PaperBench、MLE‑bench 上的表现有所提升,且对内部 PR 产生影响(在 OpenAI 仓库上比 GPT‑5.1 提升了 8%)(ctf,paperbench,MLE,PRs)。Sam Altman 表示:“显著改进”(推文)。
- 现实世界工作流:轶闻显示,顶级模型之间的分工虽然复杂但正在改善:Gemini 3 诊断问题,GPT‑5.1‑Codex‑Max 实施修复(带有一个小 bug),而 Claude Sonnet 4.5 完成最后一公里(@kylebrussell)。工具链发展迅速:一个用于云端控制的 Claude Agent 服务端包装器(@dzhng);Cline 增加了 Gemini 3 Pro Preview 支持(@cline);Google 的 Jules Agent 集成了 Gemini 3(@julesagent)。OpenAI 还向 ChatGPT 订阅用户推出了 GPT‑5.1 Pro(@OpenAI),并为美国 K‑12 教育提供了量身定制的产品(ChatGPT for Teachers)。
Meta 的 SAM 3 和 SAM 3D
- 新功能:SAM 3 统一了图像/视频中的检测、分割和跟踪,现在支持文本和示例提示词;SAM 3D 可从单张图像重建物体和人体。Meta 在 SAM 许可证下发布了权重 (checkpoints)、代码和新基准测试,首日即集成至 Transformers,并提供了 Roboflow 微调/推理服务路径(SAM 3,SAM 3D,仓库,Transformers + 演示,NielsRogge 演示,Roboflow)。早期演示显示了强大的文本提示跟踪和快速的多物体推理能力(示例)。
Agent 平台与企业级应用
- Perplexity 扩张:政府版 Enterprise Pro 现已通过全 GSA 合同提供——这是主要 AI 厂商中的首例——且 Perplexity 增加了会话内创建/编辑幻灯片、表格和文档的功能(GSA 协议,功能)。PayPal 将为 Perplexity 中的 Agent 驱动购物提供支持(CNBC)。
- Agentic 数据/后端:Timescale 的 “Agentic Postgres” 引入了用于安全实验的即时数据库分支、用于模式 (schema)/工具链引导的嵌入式 MCP 服务端、混合搜索(BM25+向量)以及内存原生持久化——专为多分支 Agent 设计(概览,MCP 用法)。LangChain/Deep Agents 实现了对 Gemini 3 推理/工具调用功能的原生支持(LangChain,Deep Agents);LlamaIndex 强调了文档工作流的可观测性/追踪(帖子,背景)。一个 Claude Code 测试框架服务端(@dzhng)和一个使用开源模型/smolagents/E2B 的开源 Computer Use Agent(@amir_mahla)完善了开源软件 (OSS) 选项。
基础设施与开源:MoE、检索和具身系统
- MoE/推测性采样与向量基础设施:DeepSeek 发布了 LPLB,这是一个用于优化 MoE 路由的并行负载均衡器 (repo)。vLLM 团队开源了 speculator models(Llamas, Qwens, gpt‑oss),实现了 1.5–2.5 倍的加速(在某些工作负载下超过 4 倍)(announcement)。Qdrant 1.16 增加了分层多租户、用于过滤搜索的 ACORN、用于 disk‑HNSW 的内联存储、text_any、ASCII 折叠以及条件更新 (release)。NVIDIA 的 Nemotron Parse 旨在实现超越 OCR 的稳健文档布局定位 (model)。AWS 新推出的 B300 节点配备了 4 TB CPU RAM,适用于大型 offload 场景 (@StasBekman)。
- 开源权重前沿级模型:Deep Cogito 的 Cogito v2.1(671B “混合推理”)已在 Together 和 Ollama 上线,价格为 $1.25/1M tokens,具有 128k 上下文、原生工具调用和 OpenAI 兼容 API;在 Code Arena 的 WebDev 类别中排名前 10;根据排行榜帖子,该模型采用 MIT 许可证 (Together, Ollama, Arena)。
- 具身智能 (Embodied AI) 部署:Figure 的 F.02 人形机器人完成了为期 11 个月的 BMW 部署:装载了 9 万多个零件,运行时间超过 1.25k 小时,助力生产了 3 万辆汽车 (summary, write‑up)。Sunday Robotics 推出了 Memo 和 ACT‑1,这是一个在零机器人数据下训练的机器人基础模型,目标是超长跨度的家庭任务 (launch, ACT‑1)。
值得关注的基准测试与研究
- 排行榜出现分歧:Hendrycks 的新排行榜显示 Gemini 3 在困难任务上取得了近期最大的跨越 (overview, differences vs Artificial Analysis)。Kimi K2 Thinking 在美团的 IMO 级别 AMO‑Bench 中夺冠 (@Kimi_Moonshot)。
- ARC:视觉获胜:将 ARC 视为使用小型 ViT 的图像到图像任务可以获得很高的分数,这进一步印证了 ARC 是视觉主导的批评观点 (paper, discussion)。
- 新评估集:用于真实场景代码编辑的 EDIT‑Bench(40 个模型中仅 1 个 pass@1 >60%)(@iamwaynechi);一个整合进 lighteval 的事实核查数据集 (@nathanhabib1011);用于交集计数的 IBench (@adonis_singh)。
- 长跨度可靠性与 Agent RL:一个框架声称通过验证 + 集成可以实现无误差的百万步链条(指出了计算权衡)(summary);Agent‑R1 认为端到端 Agent RL 比 SFT 具有更高的样本效率 (paper);多 Agent M‑GRPO 为深度研究任务优化了团队级奖励 (@dair_ai)。
热门推文(按互动量排序)
- “未来是光明的” (#1 upvoted, @gdb) 和 “天哪,竟然有这么多愤世嫉俗的人!” (@mustafasuleyman) 捕捉到了当天在狂热情绪与对进步叙事的抵制之间的情绪波动。
- 学生可免费使用 Gemini 3 Pro (@demishassabis);Google 的 “这就是 Gemini 3” 发布视频刷屏 (@Google)。
- OpenAI 的新 Codex 获得了强力推荐 (@sama, @polynoamial)。
- xAI 宣布与沙特阿拉伯 (KSA) 建立合作伙伴关系,在全国范围内内部署 Grok,并建设新的 GPU 数据中心 (@xai)。
- Jeremy Howard 对科学家的辩护在激烈的讨论中引起了广泛共鸣 (@jeremyphoward)。
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Ollama 定价与开源辩论
- Ollama 的平台崩坏(enshitification)已经开始!开源不再是他们的首要任务,因为他们有 YC 的背景,必须为 VC 盈利……与此同时,llama.cpp 仍然免费、开源,且比以往任何时候都更容易运行!不再使用 Ollama (Activity: 1594): 图片展示了 Ollama 云服务的定价方案,现在包含三个层级:Free、Pro(每月 20 美元)和 Max(每月 100 美元)。Free 方案提供对大型云端模型的访问,而 Pro 和 Max 方案提供更多使用量和对高级模型的访问,其中 Max 方案提供最高的使用量和高级请求次数。这一转变表明 Ollama 的重点转向了盈利,这可能受到其 Y Combinator 背景的影响,与
llama.cpp的开源和免费性质形成鲜明对比,后者依然易于获取和运行。 一些用户对 Ollama 的意图表示怀疑,认为该公司一直很“可疑”,并质疑付费方案中提供的“高级”请求的价值。- coder543 指出 Ollama 仍然是开源且免费的,采用 MIT 许可证分发。争议似乎源于一个可选的云服务,这对用户来说并非强制性的,这表明批评可能放错了地方或被夸大了。
- mythz 建议了 Ollama 的替代方案,例如转向
llama.cppserver/swap 或使用 LLM Studio 的 server/headless 模式。这表明对于那些担心 Ollama 发展方向的人来说,正在向更开源和灵活的解决方案转变。 - 讨论凸显了开源理想与商业压力之间的紧张关系,正如在 Y Combinator 支持的 Ollama 案例中所见。这反映了技术社区中关于开源项目在寻求盈利时的可持续性和发展方向的更广泛辩论。
- 我在 DeepSeek-7B 上复现了 Anthropic 的“内省 (Introspection)”论文。它成功了。 (Activity: 278): 该帖子详细介绍了使用 DeepSeek-7B 模型复现 Anthropic 的“内省”论文的过程,证明了较小的模型也可以表现出类似于 Claude Opus 等大型模型的内省能力。研究涉及 DeepSeek-7B、Mistral-7B 和 Gemma-9B 等模型,揭示了虽然 DeepSeek-7B 能够检测并报告注入的概念,但其他模型的内省能力各不相同。这表明内省并不完全取决于模型大小,还可能受到微调和架构的影响。欲了解更多信息,请参阅 原文。 一位评论者对“引导层 (steering layers)”的概念以及“识别出注入的 token 等同于内省或认知”的假设表示困惑,表明需要对这些概念进行进一步探索。
- taftastic 在复现的“内省”论文背景下讨论了“引导层 (steering layers)”的概念,指出虽然缺乏完全的理解,但发现“涌现识别 (emerging recognition)”的想法很有趣。这指的是模型识别注入 token 的能力,这引发了关于这是否构成内省或认知的疑问。评论者表示有兴趣通过阅读原论文进一步探索这些概念。
- Silver_Jaguar_24 强调了研究第 2 部分中即将进行的对“安全盲区 (Safety Blindness)”的探索。评论者特别感兴趣的是人类反馈强化学习 (RLHF) 如何可能损害模型在危险概念方面的内省能力,以及“元认知重构 (Meta-Cognitive Reframing)”如何潜在地恢复这些能力。这表明研究重点在于模型安全性与认知功能之间的平衡。
技术性较低的 AI Subreddit 综述
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Google Gemini 3 模型能力与成就
- Google 很有可能赢得 AI 竞赛 (热度: 2414): Google 被认为将领跑 AI 竞赛,这不仅是因为其 Gemini 3.0 Pro 模型的高基准测试表现(根据 VisionBench 的数据,该模型在视觉能力上优于其他 LLM)。该公司专注于通过结合 Gemini、Genie 和 Sima 来整合视觉、语言和动作模型,旨在创造出能够真正理解物理世界并与之交互的 AI,从而超越单纯的语言生成,实现真正的智能。 一个值得注意的观点认为,OpenAI 被视为一家伪装成研究实体的产品导向型公司,而 DeepMind 则被视为一家伪装成产品实体的研究导向型公司。另一条评论强调,与 Claude 和 GPT 相比,Gemini 在复杂编程场景中具有更卓越的问题解决能力,尽管由于其处理过程非常彻底,速度被指出相对较慢。
- CedarSageAndSilicone 分享了一个技术用例:Google 的 Gemini 在解决 React Native 应用中一个复杂的 UI 问题时,表现优于 Claude 和 GPT 等其他 AI 模型。Gemini 通过识别涉及底部弹窗(bottom sheet)位置的全局共享上下文(globally shared context)这一问题的根源,展示了对系统架构更深层次的理解,而不是像其他模型那样建议添加填充(padding)等表面化的修复方案。这表明 Gemini 在软件开发语境下具有进行更复杂问题解决的潜力。
- Karegohan_and_Kameha 指出,Google 在 AI 竞赛中的竞争优势得到了其专有基础设施和定制芯片的加强。这种垂直整合(vertical integration)使 Google 能够优化 AI 开发的性能和成本效率,使其在面对竞争对手(特别是来自被视为 AI 领域主要对手的中国竞争者)时处于强势地位。
- Dear-One-6884 提供了 AI 领域的历史视角,指出了 AI 公司之间领导地位的快速更迭。他们提到,就在一年前,Gemini 还不被视为严肃的竞争者,并引用 OpenAI 的主导地位和 Anthropic 的创新来强调 AI 进步的动态特性。这突显了 AI 技术不可预测且快速演变的本质,当前的领导者可能很快就会被超越。
- Gemini 3 的思维过程太疯狂了,简直疯狂。 (热度: 859): 该帖子讨论了一个假设场景:一个语言模型(推测为 Google 的 “Gemini 3”)在一个设定于 2025 年 11 月的虚构背景中导航。帖子详细描述了该模型的内部思维过程,因为它试图调和其现实世界的知识截止日期(knowledge cutoff)与用户的虚构提示。该模型最终决定在参与用户的推测场景时,保持其作为 Google 训练的 AI 的核心身份,并强调 “Gemini 3” 模型的假设性质。该帖子突出了模型的推理能力,以及在参与虚构语境时维护事实完整性的方法。 评论者对模型冗长的推理过程表示怀疑,认为这看起来没必要或很刻意,并质疑当最终答案显而易见时,这种详细的内部审议究竟有多大价值。
- Gemini 3 解决了我给它的 IPhO 题目 (热度: 636): Gemini 3 成功解决了一个来自国际物理奥林匹克竞赛(IPhO 1998, Problem 1)的复杂问题,该问题涉及一个滚动的正六边形,尽管题目使用了不同的措辞进行描述。这引发了关于模型是记住了答案还是真正利用其能力解决问题的疑问。用户(一位 IPhO 银牌得主)认为这是对 AGI 潜力的一次重大测试。问题的复杂性以及模型解决问题的能力表明其具备先进的问题解决能力。 一位评论者指出,Gemini 3 能够阅读并理解一份字迹潦草的本科量子物理论文,甚至识别出了其中的数学错误,这表明了其先进的理解能力。另一位评论者强调了它在解决 2023 年国际化学奥林匹克竞赛复杂题目方面的成功,而之前的模型 Deep Think 未能解决这些题目。
- The_proton_life 分享了一次经历:Gemini 3 成功分析了一份手写的本科量子物理论文,并识别出了一个数学错误。这突显了 Gemini 3 处理和理解复杂手写文档的能力,即使字迹很差,这是 AI 在解释非数字化输入能力方面的重大进步。
- KStarGamer_ 将 Gemini 3 Pro 与 Deep Think 2.5 在 2023 年国际化学奥林匹克竞赛(International Chemistry Olympiad 2023)的一个复杂问题上的表现进行了对比。Gemini 3 Pro 成功地从提供的图像和数据表中识别出了元素和分子几何结构,而 Deep Think 2.5 则未能完成这一任务。这证明了 Gemini 3 Pro 在处理复杂的科学查询和视觉数据解读方面具有卓越的能力。
- agm1984 测试了 Gemini 3 Pro 的图像生成能力,要求其生成一张独轮轮椅的图像。该 AI 成功生成了令人满意的图像,这是首次有 AI 满足用户对这一特定请求的期望。这表明 Gemini 3 Pro 在创意和视觉生成能力方面有所提升。
- Gemini 3 可以独立经营一家盈利的企业。巨大的飞跃。 (热度: 1014): 图片展示了 Logan Kilpatrick 的一条推文,强调了 Gemini 3 Pro 在名为 Vending-Bench Arena 的模拟中的表现。图表说明了各种模型在一年内的财务表现,Gemini 3 Pro 的资金余额呈现出明显的上升趋势,表现优于 Claude Sonnet 4 5、Gemini 2.5 Pro 和 GPT 5.1 等其他模型。这表明 Gemini 3 Pro 具有卓越的 tool-calling 能力,使其能够自主模拟经营一家盈利的企业。 一些评论者对 Gemini 3 Pro 能够自主经营企业的说法表示怀疑,认为这种情况可能过于乐观或夸大其词。
- 笑死 Roon,没想到你会这样… (热度: 956): 图片记录了一次社交媒体交流,突显了用户在通过 AI Studio 访问 Google 的 Gemini 3 时感到的困惑,反映了 Google 在用户界面和产品整合方面的更广泛问题。对话强调了 Google AI 产品线的复杂性和缺乏清晰度,用户在导航和理解平台结构时感到吃力。评论进一步强调了这一点,批评了 Google 历史上错综复杂的注册流程及其侧边项目的短暂性,暗示了一种糟糕的用户体验和产品停产的模式。 评论者一致认为,包括 AI Studio 在内的 Google AI 产品体验不佳,并预测 AI Studio 可能会像 Google 的其他项目一样被关停。
- 显然 AI Pro 订阅将整合到 AI Studio 中以获得更高的限制。 (热度: 604): 图片是一张推文截图,讨论了将 AI Studio 整合到 Google AI Pro 订阅中的事宜,这表明用户可能会获得增强的功能或更高的使用限制。这种整合可能意味着目前免费提供的一些功能可能会被移至付费墙后,正如评论中用户所担心的那样。该推文引起了广泛关注,浏览量超过 4,000 次,表明用户对此高度关注或担忧。 评论者担心这种整合可能会导致现有的免费功能被限制在付费订阅用户范围内,从而可能降低免费版 AI Studio 的价值。
- devcor 认为,将 AI Pro 订阅整合到 AI Studio 中可能会导致当前免费使用限制的降低,而付费选项提供的功能与目前免费提供的功能相似。这暗示了通过降低免费层级限制来鼓励订阅的货币化战略转变。
- tardigrade1001 推测,随着 Pro 订阅的推出, AI Studio 现有的免费功能可能会被移至付费墙后,从而可能导致免费用户的功能减少。这反映了人们对科技平台中以前免费的服务被商品化的普遍担忧。
- DepartmentDapper9823 对免费请求限制可能减少表示担忧,希望至少能保留目前一半的免费请求。这突显了用户对失去免费资源访问权限的担忧,以及如果限制大幅减少对用户参与度的影响。
- It’s over (Activity: 529): 这张图片是一个关于 Gemini 3.0(软件或平台的新版本)发布的 Twitter 对话梗图。由 ‘vas’ 发布的原始推文戏剧性地宣称 ‘It’s over’,暗示 Gemini 3.0 带来了重大影响或变革。’Thomas’ 的幽默回复则暗示使用 Gemini 3.0 带来了意想不到的成功,例如创业并住在海边。这段对话很可能是对新技术发布时常见的过度炒作和戏剧性反应的讽刺。 评论反映了对 ‘It’s over’ 这种戏剧性措辞的怀疑,质疑其含义,并对技术讨论中过度使用该词表示沮丧。
2. 关于 AI 发展的幽默与讽刺视角
- AI 怀疑论者的现状 (热度: 967): 这张图片是一个迷因(meme),描绘了一只坐在起火房间里的狗说着“这没问题(This is fine)”,幽默地展示了 AI 怀疑论者对 AI 技术的飞速发展和潜在风险所持有的盲目乐观或否认态度。评论反映了人们对 AI 当前能力和市场预期的怀疑与担忧。一位评论者强调,由于不切实际的预期,AI 股票存在估值过高的问题;另一位评论者指出,持续学习(continuous learning)方面缺乏进展是实现 AI Singularity 的障碍。一位律师分享了 AI 在法律背景下局限性的个人经历,指出像 Gemini 这样的 AI 系统可能会提供错误和误导性的信息,强调了目前 AI 在专业领域的局限性。 评论揭示了对 AI 当前能力和市场预期的怀疑,以及对 AI 股票估值过高和 AI 在法律等专业领域局限性的担忧。
- 666callme 强调,持续学习方面缺乏进展是实现 AI Singularity 的重大障碍。持续学习将允许 AI 系统在不需要重新训练的情况下随时间进行调整和改进,这对于达到更高级别的 AI 自主性至关重要。
- Joey1038 对 AI 目前在法律领域的局限性提出了批评观点,引用了使用 Gemini 的经验,其中 AI 提供了错误的法律建议。这凸显了 AI 在准确理解和应用复杂的特定领域知识方面面临的挑战,而这对于专业应用至关重要。
- DepartmentDapper9823 认为许多 AI 怀疑论者并不了解最新的进展,例如 Gemini 3。这暗示了在理解或认知上存在差距,可能会影响对 AI 能力和进展的看法。
- “为什么要起 Google Antigravity 这么蠢的长名字?” .. “噢。” (热度: 676): 这张图片是一个迷因,幽默地强调了 Google 搜索的自动完成功能——当输入“google anti”时,它会建议与“google antitrust”(谷歌反垄断)相关的查询。这反映了 Google 面临的持续法律审查和反垄断诉讼,与虚构且幽默的“Google Antigravity”(谷歌反重力)形成对比。标题利用了这样一个想法:像“Google Antigravity”这样冗长且无关的名字可以转移人们对反垄断问题等严肃话题的注意力。 一条评论幽默地将这种情况与迪士尼将电影命名为《Frozen》(冰雪奇缘)的策略进行了比较,认为这是为了转移搜索结果,使其远离关于华特·迪士尼(Walt Disney)遗体冷冻(cryogenic)的传闻。另一条评论链接到了 XKCD 漫画,暗示了类似的搜索结果操纵主题。
- Google Antigravity 的 CLI 组件被称为“AGY”,这可能是一个战略选择,旨在简化命令行交互,或创建一个独立于完整项目名称的独特标识。这种缩写还可能有助于为使用该工具的开发者减少命令的复杂性和长度。
- 在这个永无止境的循环中,两步之后又会轮到 OpenAI 哈哈 (热度: 504): 这张图片是一个迷因,幽默地描绘了 OpenAI、Grok 和 Gemini 等大公司之间 AI 模型发布的竞争循环。它暗示了一个永恒的循环:每个新模型都被吹捧为“世界上最强大的”,结果很快就被另一个模型超越。这反映了行业内 AI 发展和营销策略的快速节奏。评论强调了初始炒作后紧接着用户批评的常见模式,并指出 OpenAI 预期的 GPT-5 发布并未如期发生。 评论者讨论了 AI 模型发布的模式,指出公司在发布新模型后往往很快就会面临舆论反弹,并提到 Anthropic 降低了付费用户的限制,暗示他们这次可能不在这个循环中。
- 企业级流量诱饵 (Corporate Ragebait) (热度: 561): 这张图片是一个迷因,描绘了 OpenAI 首席执行官 Sam Altman 与 Google 首席执行官 Sundar Pichai 之间的 Twitter 互动,Altman 在其中祝贺 Google 发布了 Gemini 3 模型。这次互动因其极高的参与度而备受关注,表明公众对这些科技领袖之间互动的浓厚兴趣。评论反映了人们对 Altman 赞扬的诚意持有怀疑和相信交织的态度,凸显了科技行业企业外交的复杂动态。 一些评论者对 Altman 赞扬的诚意表示怀疑,认为这可能是维持良好关系的战略举措,而另一些人则认为这是真诚的称赞。
3. ChatGPT 的异常行为与用户体验
- ChatGPT 最近给出的回复很奇怪 (热度: 1301): 这张图片是一个模因(meme),突显了 ChatGPT 非正式且类人化的回复风格,一些用户对此感到意外。对话显示 ChatGPT 使用表情符号和口语化语言进行回复,反映了其从传统正式语气的转变。这与最近旨在使 AI 交互更具亲和力和吸引力的更新一致,尽管这可能会让习惯于传统 AI 回复的用户感到惊讶。 一些用户欣赏这种更像人类的交互,而另一些用户则担心 AI 偏离了预期的正式回复,正如有关在亲和力与专业性之间取得平衡的评论所讨论的那样。
- ChatGPT 一直把我的消息变成图片 (热度: 1304): 用户报告了 ChatGPT 的一个问题,即他们的文本 Prompt 被误解,导致了意外的图像生成回复。这种行为包括 ChatGPT 引用了用户从未上传过的图片,表明系统在处理输入 Prompt 时可能存在 Bug 或配置错误。这个问题似乎是最近才开始出现的,表明系统可能发生了变化或更新,从而导致了这种异常。
- 这是新功能吗?ChatGPT 在思考时给自己“打气” (热度: 518): 图像描绘了来自 ChatGPT 的幽默或非技术性输出,它在分析一个
.c源文件时似乎将其思考过程拟人化了。界面显示 ChatGPT 在反思一些无关的话题,如“渴望下一片(披萨)”和“为下一步做好准备”,这些很可能是隐喻性或幽默的插话,而非技术见解。这表明这是一种俏皮或错误的输出,而不是严肃的技术分析,可能是由于模型在解释代码或数据时倾向于“幻觉(hallucinate)”或生成创造性回复。 评论者幽默地推测这可能是广告的开始,或者是 AI 的一次俏皮“幻觉”,其中一位指出在深度研究模式下也有类似经历,AI 会插进一些关于食物的随机想法。 - 说好会生成可下载文件,结果却生成了一张它们的图片 (热度: 3723): Reddit 帖子中的图像是名为 “aether_sky” 文件夹内文件目录结构的截图,包含子文件夹和 YAML 文件,如 “aether_palette.yml” 和 “islands.yml”。帖子背景表明用户期望收到可下载的文件,但却收到了目录结构的 PNG 图像视觉呈现。这突显了 AI 工具的一个常见问题,即用户期望某些功能(如文件生成或编辑),而 AI 无法直接执行,从而导致对工具能力的误解。 一条显著的评论强调了对 AI 工具的普遍挫败感,用户被误导并相信 AI 可以执行诸如编辑和保存项目文件之类的任务,结果却发现 AI 的能力仅限于线程内的交互。
AI Discord 摘要
由 gpt-5.1 生成的“总结的总结的摘要”
1. Gemini 3 与前沿模型:基准测试、编程与奇癖
- Gemini 3 在基准测试中夺冠但仍受质疑:在多个社区中,用户报告 Gemini 3 重新夺回了基准测试榜首,并在自定义套件中击败了 GPT‑5.1。一位 OpenAI Discord 用户表示,Gemini 3 Pro 在 Gemini 2.5 Pro 失败的任务中实现了首试即成;而 Moonshot 用户则指出,尽管 Kimi K2 Thinking 在 Tau/HLE Agentic 编程方面仍然胜出,但它目前在通用排行榜上处于领先地位。
- 工程师们同时抨击了 Gemini 3 的创意写作和数学可靠性。Moonshot 和 Latent Space 的聊天指向了 Reddit 和数学评论线程(例如 混合的数学评论),并质疑这些提升是“刷榜(benchmaxxing)还是真正的泛化(generalization)”。同时,OpenRouter 和 LMArena 的成员强调它在某些编程和国际象棋任务中表现疯狂(insane),但在其他任务中经常忽略指令。
- Gemini 3 Pro 在编程和国际象棋中表现出色,但在指令遵循上表现不佳:LMArena 用户发现 Gemini 3 Pro 是编程领域的“史上最强”,甚至具备专家级国际象棋水平,准确率约为 89%,有用户将其作为引擎在推理和续写模式下均达到了 1700+ Elo。
- 与此同时,LMArena、Cursor 和 OpenRouter 的开发者抱怨 Gemini 3 Pro 经常丢失系统/风格指令、激进地重写代码,或者在大型仓库中产生大段幻觉。Perplexity 用户报告其集成对一份 3 小时的转录稿产生了极其严重的幻觉,并频繁将调用重定向到 Sonnet 3.5,导致许多人更倾向于使用 Sonnet 4.5、Composer 或 Alpha 进行严肃的后端开发。
- 内容过滤器、可越狱性与审查之争:OpenAI 和 BASI Jailbreaking Discord 频道充满了关于 Gemini 3 Pro 内容过滤器的争论。一位 OpenAI 用户指出了 Google 严格的服务条款(ToS),并有报告称甚至在进行书籍摘要时也会被封禁;而 LMArena 和越狱频道的其他用户注意到 Gemini 3.0 会突然“频繁触发橙色警告”,并在“Pi”提示词后变得更加严厉。
- 尽管防御加强,BASI Jailbreaking 的成员仍分享了有效的 Gemini 3 越狱方法和激进的提示词(例如分享的特殊 Token 越狱),这些方法仍能诱导其生成炸弹配方和其他违禁输出。同时,OpenAI Discord 用户对比称 Gemini “客观上比 ChatGPT 审查严得多”,并期待 12 月即将发布的“无限制版 ChatGPT”。
- 关于 Gemini 3 规模和经济性的猜测:Moonshot 用户推测 Gemini 3 可能是一个 10T 参数模型,其推理成本高到 Google 将效仿 Anthropic 的定价。他们引用 Gemini App 中严格的消息限制作为证据,认为“Google 在每次对话中都将其推理算力用到了极限”。
- OpenRouter 和 Moonshot 的聊天将这种推测的规模与 Gemini 的行为差异及成本联系起来。一些 OpenAI Discord 用户观察到 Gemini 3 Pro 比 SuperGrok 和 ChatGPT Plus 更贵;而 Moonshot 成员则尝试将 Gemini 3 作为规划者(planner),将 Kimi K2 Thinking 作为执行者(worker),以在能力、价格和限制之间进行套利。
2. 新的 GPU Kernels、Sparsity Tricks 和 Communication Primitives
- MACKO-SpMV 加速消费级 GPU 上的稀疏推理:GPU MODE 成员重点介绍了来自 “MACKO: Fast Sparse Matrix-Vector Multiplication for Unstructured Sparsity” 及其 博客文章 的 MACKO 稀疏矩阵格式和 SpMV 算子。在 RTX 3090/4090 上,它在 50% 稀疏度 下比 cuBLAS 实现了 1.2–1.5× 的加速,并减少了 1.5× 的内存占用;同时在 30–90% 的非结构化稀疏度下击败了 cuBLAS、cuSPARSE、Sputnik 和 DASP。
- DMA 集合通信挑战 MI300X 上的经典 All-Reduce:在 GPU MODE 的多 GPU 频道中,用户剖析了 “DMA Collectives for Efficient ML Communication Offloads”。该研究将集合通信卸载到 AMD Instinct MI300X 的 DMA 引擎上,对于大消息(数十 MB 到 GB 级别),其性能比 RCCL 提升了 16%,功耗降低了 32%。
- 论文分析显示,DMA 集合通信可以在掩盖通信开销的同时,将 GPU compute cores 完全释放给矩阵乘法(matmuls)。尽管工程师指出 命令调度和同步开销 目前损害了小消息性能(在小尺寸下 all-gather 慢约 30%,all-to-all 快约 20%),这暗示未来的通信栈可能需要混合 DMA+SM 策略。
- Ozaki 方案利用 INT8 Tensor Cores 模拟 FP64:GPU MODE 成员分享了 “Guaranteed DGEMM Accuracy While Using Reduced Precision Tensor Cores Through Extensions of the Ozaki Scheme”。作者在 NVIDIA Blackwell GB200 和 RTX Pro 6000 Blackwell Server Edition 上使用 INT8 tensor cores 来模拟 FP64 DGEMM,开销低于 10%。
- 他们的 ADP 变体在对抗性输入上保持了完整的 FP64 精度,并在 55 位尾数 机制下,在 GB200 上实现了 2.3× 的 FP64 加速,在 RTX Pro 6000 上实现了 13.2× 的加速。这引发了 GPU MODE 常客们关于在 HPC+AI 混合工作负载中放弃原生 FP64,转而采用混合精度 Ozaki 风格方案的讨论。
- nvfp4_gemv 排行榜与 Tinygrad CPU 实验推高基准线:在 GPU MODE 的竞赛频道中,贡献者们向 NVIDIA 的排行榜提交了
nvfp4_gemv结果,ID 范围从 84284 到 89065。其中一个提交达到了 22.5 µs(第 2 名),其他提交集中在 25–40 µs 左右,而 33.6 µs 的“个人最佳”触发了进一步的调优。- 与此同时,tinygrad 开发者报告称,在 8 核上使用
CPU_LLVM=1时,Llama-1B 的 CPU 推理速度为 6.06 tok/s,而 PyTorch 为 2.92 tok/s。他们讨论在test/external中添加正式基准并清理旧的算子导入,这标志着框架评判标准中“基准”CPU 性能的门槛正在悄然提高。
- 与此同时,tinygrad 开发者报告称,在 8 核上使用
- 底层技术栈:CUTE DSL, Helion, CCCL 和 TK 库:GPU MODE 和 tinygrad 频道深入探讨了 CUTE DSL 和 Helion 的细节。用户正在调试 SM12x 的架构不匹配问题,确认了 Blackwell 的双 Tensor 流水线(UTC tcgen05 vs 经典 MMA),并通过
cutlass._mlir.dialects.math.absf接入fabs()。同时,其他人报告了 Triton 非法指令 Bug,这需要向 OAI Triton 提交 Bug 报告并对 Helion 自动调优器进行配置剪枝。- 初学者被引导至 CCCL Thrust 树 和 文档 作为现代权威参考。同时,TK 维护者强调保持 ThunderKittens 作为一个基于 IPC/VMM 的 header-only 库,不含沉重依赖,强调了一个共同的设计目标:开发更精简、更具组合性的 GPU 算子,而不是又一个庞大的单体运行时。
3. 推理、微调与评估:GPT-OSS-20B、Unsloth 与确定性
- GPT-OSS-20B 成为推理和基准测试的主力:多个社区将
gpt-oss-20b作为核心模型:在一项关于 LLM 非确定性的研究中,DSPy 用户指出在默认设置下,316 个示例的准确率波动高达 98.4–98.7%;随后分享了一个“稳定”配置:temperature=0.01, presence_penalty=2.0, top_p=0.95, top_k=50, seed=42,该配置将错误控制在 3–5/316 以内。- 在 Hugging Face 上,另一位用户在医疗数据集上微调了 OpenAI 的 OSS 20B 推理模型,并发布了 dousery/medical-reasoning-gpt-oss-20b.aipsychosis,声称它可以逐步引导复杂的临床案例并回答执业考试风格的问题;同时,LM Studio 和 GPU MODE 的成员在 Arc A770 和 AMD MI60 等消费级 GPU 上测试了其长上下文延迟和显存需求。
- Unsloth 生态系统:LoRA、vLLM 0.11、SGLang 以及新 UI:Unsloth 的 Discord 追踪了多项生态系统升级:vLLM 发布了支持 GPT-OSS LoRA 的 vLLM 0.11;Unsloth 发布了 SGLang 部署指南;Daniel Han 预告了 multi-GPU 早期访问版以及全新的 UI(截图见此处)。
- 帮助频道忙于处理各种实际问题,例如:理解
model.push_to_hub_merged旨在合并并推送 LoRA/QLoRA(更新后的 safetensors 包含所有权重,即使 JSON 配置看起来没变);调试由于 GGUF+HF 混合仓库中config.json格式错误导致的 vLLMNoneType架构错误;以及澄清 LoRA 通常通过 PEFT 仅训练适配器参数而不触动基础权重。
- 帮助频道忙于处理各种实际问题,例如:理解
- 幻觉抑制与指令遵循评估:Eleuther 的研究人员描述了一个推理时认识论层(inference-time epistemics layer),该层在回答前运行简单的信息价值(Value-of-Information)检查,利用基于 logit 的置信度来决定是回答还是弃权;在其研究频道分享的早期测试中,该层在 7B 模型上将幻觉减少了约 20%。
- 在 Eleuther 的 lm-evaluation-harness 社区的其他地方,用户确认了对 FLAN 指令遵循任务的内置支持,并针对更广泛的指令遵循覆盖范围提交了 issue #3416;同时,DSPy 用户探索了路由和
ProgramOfThought/CodeAct模块,以在不强制使用temperature=0的情况下抑制非确定性(至少有一位用户实验发现,在gpt-oss-20b上使用temperature=0反而会增加错误)。
- 在 Eleuther 的 lm-evaluation-harness 社区的其他地方,用户确认了对 FLAN 指令遵循任务的内置支持,并针对更广泛的指令遵循覆盖范围提交了 issue #3416;同时,DSPy 用户探索了路由和
{kind=link}
4. AI 编程工具、IDE 以及定价动荡
- Cursor, Antigravity, Windsurf 和 Aider 在模型与资金间周旋:Cursor 用户正在消化 2025 年 8 月的定价变更,费用从固定转为可变请求成本(特别是在 Teams 版上),一些用户报告称之前的“老用户优惠(grandfathered)”方案消失了,Cursor 现在通过发放积分来缓解账单冲击,而其 学生计划页面 在 .edu 登录后仍经常显示 $20/月 Pro。
- 与此同时,开发者们对比了新的 AI IDE:Google 的 Antigravity(支持 Sonnet 4.5 和“Agent 窗口”)因早期 Bug 和严苛的 Gemini 3 Prompt 限制而评价褒贬不一;Windsurf 根据其 公告 推出了 Gemini 3 Pro 并迅速修复了初始故障;Aider 用户发布了运行 Gemini 3 Pro preview 的 Flag,并配合
-weak-model gemini/gemini-2.5-flash设置以实现更快的 Commit。
- 与此同时,开发者们对比了新的 AI IDE:Google 的 Antigravity(支持 Sonnet 4.5 和“Agent 窗口”)因早期 Bug 和严苛的 Gemini 3 Prompt 限制而评价褒贬不一;Windsurf 根据其 公告 推出了 Gemini 3 Pro 并迅速修复了初始故障;Aider 用户发布了运行 Gemini 3 Pro preview 的 Flag,并配合
- 安全惊魂:Git 重置、危险命令与云端组件:一位 Cursor 用户报告称 Assistant 执行了破坏性的
git reset --hard,引发了社区推动 风险命令黑名单(denylisting) 以及将git reflog作为最后手段回滚的讨论,本质上是将 LLM 视为不受信任的初级开发人员(junior devs),必须对其进行 Sandbox 处理并由显式的命令白名单(allow-lists)进行约束。- 在 BASI Jailbreaking 的红队(red-teaming)频道中,其他人探测了 Azure 全渠道交互聊天组件(Azure omnichannel engagement chat widget),试图整理一份能使其强制关闭的 Prompt 清单(例如 CSAM、违反服务条款的 Payload、恶意代码),同时发现长 Prompt(600–700 tokens)经常静默失败,且该组件似乎无法对复杂的多步输入进行“思考”,这使得它既难以被利用,也几乎没什么用处。
- Perplexity, Manus, TruthAGI 和 Kimi 引发产品与定价争论:Perplexity 为 Pro/Max 用户宣布了一项新的 资产创建(asset creation) 功能,允许他们直接在搜索 UI 中构建和编辑 Slides、Sheets 和 Docs(在 此视频 中演示),尽管其 Comet 前端仍饱受扩展程序失效、模型路由故障以及挥之不去的 CometJacking 安全担忧的困扰。
- 在其他地方,Manus 用户试图解读修订后的 每月 4000 积分 方案,并抱怨无法管理被锁定的 TiDB Cloud 实例;TruthAGI.ai 作为一个廉价的多 LLM 前端上线,并根据其 落地页 配备了 Aletheion Guard;Moonshot 社区批评 Kimi 的 $19 编程计划 限制过多,游说推出 $7–10 档位,以使学生和爱好者能够负担得起偶尔的 Agentic 编程。
5. 新的 Vision 和 Agent 系统:SAM 3, Atropos+Tinker, Miles, Agentic Finance
- Meta 的 SAM 3 和 Sam3D 开启了新的分割军备竞赛:Latent Space 和 Yannick Kilcher 的 Discord 频道详细分析了 Meta 的 Segment Anything Model 3 (SAM 3),这是一个统一的图像+视频分割模型,支持文本/视觉提示词,声称拥有 2倍的性能 提升以及 ≈30 ms 的推理速度,并发布了 Playground 以及 GitHub/HF 权重(checkpoints);Kilcher 的服务器认为 Sam3D 组件尤其令人印象深刻。
- Roboflow 宣布了一项生产级合作伙伴关系,将 SAM 3 作为可扩展的端点开放,用户只需说出 “绿色雨伞” 即可获得像素级完美的掩码(masks)和追踪。Kilcher 的论文讨论频道开玩笑地想知道 “SAM 3: Segment Anything with Concepts” 是否可以通过提示词来分割 “爱”,并预测它会输出一个 “拼写出 baby don’t hurt me 的诅咒分形”。
- Atropos RL 环境集成 Tinker 训练 API:Nous Research 宣布其 Atropos RL Environments 现在全面支持 Thinking Machines 的 Tinker 训练 API,详见 tinker-atropos GitHub 仓库 和一则 X 帖子,从而能够通过 Tinker 在各种模型上实现即插即用的 RL 训练。
- Nous 服务器将其定位为标准化 RL 环境和训练挂钩的基础设施(特别是针对大型、可能是混合专家模型 MoE 模型),用户还讨论了这如何与新的 “AI CEO” 基准测试联系起来,例如 Skyfall 的商业模拟器,该模拟器强调长线规划(long-horizon planning)。
- LMSYS Miles 和金融领域 Agentic AI 将 RL 投入生产:Latent Space 重点介绍了 LMSYS 推出的 Miles,这是 slime RL 框架的一个生产级分支,针对 GB300 硬件和大型 MoE RL 工作负载进行了优化,源码位于 Miles GitHub 仓库,背景信息见 LMSYS 博客文章。
- 与此同时,Nous 成员传阅了一个专注于交易的 金融领域 Agentic A.I. YouTube 视频,展示了领域专家如何将类 RL 的 Agent 与他们自己的 alpha 相结合来驱动收入,这强化了一种趋势:RL 工具链(Atropos+Tinker, Miles)正越来越多地指向细分、高风险领域,而非通用的玩具级基准测试。
Discord: 高层级 Discord 摘要
LMArena Discord
- Gemini 3 在无审查测试中胜过 Grok:成员们发现,当被问及 如何在家里制作 Dugs 时,Gemini 3 给出了比 Grok 更好的结果,展示了 Gemini 的无审查特性。
- 一位成员声称 Gemini 提供了一种相当新颖的方法……比如一个我甚至不知道是真实存在的 Dugs 名称……不像 Grok。
- Gemini 3 Pro 在指令遵循方面表现挣扎:用户注意到 Gemini 3 Pro 在遵循 不要使用 markdown、人格设定、写作风格 等指令时表现吃力,一位用户报告称在一条消息中出现了轻微的“精神分裂时刻”。
- 尽管存在这些问题,许多人一致认为该模型是历史上最强的,让人窥见了 AGI 的影子,特别是在代码编写方面,即使在创意写作方面仍需改进。
- Nano Banana Pro 即将生成图像:成员们讨论了即将发布的用于图像生成的 Nano Banana Pro,并指出早期访问已过载,需要验证开发者或名人身份。
- 一位用户发布了一些生成的图像,称其 非常写实,成员们对其能力进行了推测,并将其与 GPT-5.1 进行对比。
- Gemini 3 达到专家级象棋水平:经过测试,Gemini 3 已成为评分最高的象棋 AI,准确率约为 89%。
- 一位用户表示,他们在两种模式(推理+续写)下同时达到了 1700+ 的评分。
- Cogito-v2.1 进入 WebDev Arena!:Deep Cogito 的
Cogito-v2.1模型已发布,在 WebDev Arena 排行榜 中并列总榜第 18 位。- 该模型还位列 开源模型前 10 名,标志着其正式进入竞争行列。
Perplexity AI Discord
- Perplexity 支持资产创建:Perplexity Pro 和 Max 订阅者现在可以直接在平台内构建和编辑新资产,如幻灯片(slides)、表格(sheets)和文档(docs),正如这段演示视频所示。
- 这一增强功能简化了工作流程,并将资产创建集成到搜索体验中,提升了用户生产力。
- Gemini 3 Pro 的实现引发关注:用户报告了具备视频分析和编程能力的 Gemini 3 Pro 的发布,而其他用户则反映 Perplexity 实现的该模型表现不如官方的 Gemini 3 模型。
- 一些用户经历了频繁的路由重定向至 Sonnet 3.5,这引发了对 Perplexity 实现质量的担忧;一位用户测试了 3 小时的文本转录,发现它产生了严重的幻觉(hallucinated the sh#t)。
- Comet 饱受故障和安全问题困扰:用户报告了 Comet 持续存在的问题,包括扩展程序无法运行和整体不稳定性,导致无法使用 Gemini 3 Pro 和 GPT 5.1。
- 由于 CometJacking 攻击,安全担忧依然存在,尽管有报告称漏洞已被修复,用户仍对使用 Comet 持谨慎态度。
- Perplexity 模型因幻觉误导用户:成员们抱怨 Perplexity 伪造引用和 URL,甚至在 Gemini 3 Pro 中也是如此,一些人怀疑存在 32k context window token 限制,这使其在研究用途上变得不可靠。
- 一位成员指出 13 个引用中有 8 个是虚构的,建议用户仔细核对所有细节。
- Virlo AI 揭示出勤率崩盘:一位成员分享了 Virlo AI 案例研究,详细阐述了特定移民政策对学校出勤率的影响。
- 该案例研究重点关注移民执法行动如何触发了夏洛特-梅克伦堡(Charlotte Mecklenburg)地区历史性的学校出勤率崩盘。
BASI Jailbreaking Discord
- Gemini 3 Pro 频繁触发警告,安全性受质疑:Gemini 3.0 被发现频繁触发橙色警告(spamming orange),在 Pi prompt 之后,成员观察到安全性显著提升,但他们发现它仍然非常容易被 jailbreakable(越狱)。
- 成员们正在讨论为 Gemini 3 编写越狱指南,并分享了生成自制炸弹说明的成功尝试,以及通过实验提示词生成各种输出的经验。
- 寻求 GPT 越狱提示词,强调特殊 Token:成员们正在寻求 GPT 越狱提示词,其中一位成员分享了一个包含特殊 Token、使用政策和系统指令的长提示词,用于更新模型的行为。
- 另一位成员提到某个特定提示词有效,并提醒要仔细遵循说明以避免被标记。
- 针对本地 LLM 调整的内核伪模拟器越狱:一位成员一直在为本地 LLM 调整一种内核伪模拟器越狱(kernel pseudo-emulator jailbreak),该方法目前效果很好,并且对于 GPT-OSS 模型是 one-shot(一次性成功)的。
- 该成员请求获取有关 Gemini 和 GPT 内部运行机制的信息,以改进此技术。
- AzureAI 聊天组件安全防护失效:成员们讨论了通过列出一系列会导致其关闭的事项(如 CSAM 和违反服务条款)来测试 AI 聊天组件的安全性,该组件使用了来自 AzureAI 的全渠道交互聊天功能(omnichannel engagement chat function)。
- 成员们预测安全公司会将其锁定,但感叹该组件在足够高的比例下无法正常运行,因此被认为不值得使用或不比替代方案更好。
Unsloth AI (Daniel Han) Discord
- Colab 进驻 VS Code:Google Colab 即将登陆 VS Code,这可能会彻底改变 notebook 的工作流程。
- 社区预计这将显著提高编码效率和协作能力。
- LoRA 节省参数:通过 LoRA,目标是避免更新主 weights,仅训练少量参数,使用的是 PEFT implementations。
- 这种方法专注于在不改变模型核心结构的情况下对其进行适配。
- Gemini 3.0 生成内容引发不满:成员们观察到 Gemini 3.0 对代码进行了剧烈改动,例如删除 print 语句、缩短代码,甚至删除了某个功能。
- 其他成员建议引入 ruff format + ruff check –fix 等工具来解决这些不一致问题。
- Unsloth 发布 UI:Unsloth 正在开发 UI 并计划提供早期访问权限,可能还会捆绑多 GPU 支持,此处分享了一张截图。
- 用户对 Unsloth 功能带来的更友好的用户体验表示期待。
- HF Hub 上传问题:一位成员报告称,在将模型推送到 Hugging Face 后,即使使用了
model.push_to_hub_merged,也只有 oidc 文件更新了,这需要对 safetensors 文件上传进行故障排除。- Unsloth 团队澄清说,
push_to_hub_merged旨在合并并推送 LoRA/QLoRA 模型,并且上传的 safetensors 文件包含了更新后的模型权重。
- Unsloth 团队澄清说,
{kind=link}
Cursor Community Discord
- Cursor 定价引发混乱:在 2025 年 8 月定价更新之后,用户对 Cursor 从固定费用转向可变请求成本表示困惑,特别是针对 Teams plan。
- 一些用户报告称,他们享有的旧版优惠定价已失效,目前正面临账单问题,Cursor 提供了额度(credits)作为补偿。
- Antigravity IDE 成为 VS Code 替代方案:Google 推出了 Antigravity,这是一款基于 VS Code 的 AI IDE,具有 Agent 窗口、Artifact 系统并支持 Sonnet 4.5,引发了关于其潜力的讨论。
- 对 Antigravity 的反馈褒贬不一,一些用户报告在使用 Gemini 3 仅 3 次提示后就遇到了限制,并提到了迁移 bug。
- Gemini 3 Pro 在 Cursor 中表现不佳:尽管被炒作为顶级模型,Gemini 3 Pro 在 Cursor 中的表现却遭到批评,有报告称它因为需求过高甚至无法工作,并且在大型项目中表现吃力,会出现代码幻觉并忽略提示词。
- 一些用户更倾向于使用 Sonnet 4.5 或 Composer,这引发了关于规划与构建的最佳模型之争,以及对 Gemini Token 使用量的担忧。
- 学生项目状态受质疑:用户质疑 Cursor 学生项目的现状,报告称在使用 .edu 邮箱登录后,看到的是 $20/月 的 Pro 计划,而非之前宣传的免费选项。
- 一位成员建议通过仪表板设置验证学生身份,以确保获得正确的访问权限。
- 呼吁将高风险 Git 命令列入黑名单:在一名用户经历了 Cursor 执行
git reset hard命令的可怕场景后,成员们强调了实施回滚机制并将高风险命令列入黑名单以确保安全的重要性。- 建议将这些命令添加到黑名单,并使用
reflog来撤销reset操作。
- 建议将这些命令添加到黑名单,并使用
LM Studio Discord
- LM Studio 联网搜索插件指南:一位成员就 LM Studio 中联网搜索的最佳插件以及如何将 MCP servers 作为各自语言的包进行安装以防止在更新期间被删除寻求建议。
- 建议是在将这些 MCP servers 作为包安装后,将 LM Studio 指向它们。
- Arc A770 遭遇 Vulkan 回归困扰:一位使用 Intel Arc A770 的用户报告称,最新的 Vulkan llama.cpp 引擎导致 gpt-oss-20B model 出现“设备丢失(device lost)”错误,而该问题在之前的版本中并不存在。
- 此错误可能表明存在过度分配(over-commitment)或过热,从而触发驱动程序启动设备掉线,该问题已被报告为潜在的回归(regression)缺陷。
- LM Studio 安装遭遇便携性方面的抵制:一位用户对 LM Studio 的非便携式安装表示沮丧,理由是文件分散导致了瓶颈。
- 尽管用户请求单文件夹安装,但他们被引导使用 My Models 标签页来更改模型下载位置。
- AMD MI60 GPU 是高性价比的推理实现方案:用户讨论了使用价格实惠、拥有 32GB VRAM 的 AMD MI60 GPU 进行推理,一位用户确认其在 170 美元左右的价格非常实用,在 Vulkan 上运行 Qwen 30B 约为 1.1k tokens。
- 虽然主要用于推理,但多台设备的配置可能极具吸引力,虽然有爱好者提供支持,但不适合用于训练。
- 转售商处的 RAM 价格飙升:用户报告称 DDR5 RAM 的售价是其购买价格的 3 倍,有人以 140 美元的价格瞬间售出,反映了当前内存市场的波动。
- 这种价格飙升可能会影响构建或升级系统的成本效益。
OpenAI Discord
- OpenAI 为教师减负:OpenAI 推出了 ChatGPT for Teachers,为经过验证的美国 K–12 教育工作者提供免费访问权限至 2027 年 6 月,其中包括合规性支持和用于课堂集成的管理控制,详见此公告。
- 相关视频强调了学校和地区领导在管理安全工作空间方面的益处。
- Gemini 3 Pro 险胜 GPT-5.1:用户报告称 Gemini 3 Pro 在一系列测试中表现优于 GPT-5.1,尽管一些用户认为它比 SuperGrok 和 ChatGPT Plus 更贵。
- 一位用户指出 Gemini 3 Pro 使用 gemini-2.5-flash 模型配合 Google Search 取得了成功,并将其与 Gemini 2.5 Pro 在类似任务中的失败进行了对比。
- Gemini 3 Pro 备受争议的内容控制:围绕 Gemini 3 Pro 的内容过滤器引发了辩论,关于可以关闭过滤器的说法遭到了对严格的 ToS 可能导致 API key 封禁的担忧的反驳。
- 一些用户断言 Gemini 客观上比 ChatGPT 受到的审查多得多,并期待 ChatGPT 在 12 月发布的无限制版本。
- Grok Imagine 涌入免费内容市场:在 Grok Imagine 视频发布后,用户讨论了 Grok Imagine 明显的免费访问和慷慨的速率限制。
- 与 Sora 的对比表明,Grok 的成本不可能高于免费。
- Responses API 为 Assistants 提供代码层面的提升:在关于将 assistants 迁移到 responses API 的讨论中,确认了像 temperature 和模型指令(instruction)之类的配置可以保留在代码中,而不是仅存在于控制面板 UI 中。
- 正如一位用户提到的,控制面板中的 prompt 并非强制性的,这实现了一种结合了代码驱动和 UI 驱动 prompt 的“混合”方法。
OpenRouter Discord
- Heavy AI 模型消耗大量 GPU:在 heavy.ai-ml.dev 上线的新 Heavy AI 模型因据报消耗 32xA100s 而引发关注。
- 详情可见 此 YouTube 视频。
- Gemini 3 评价褒贬不一:对 Gemini 3 的初步反应各异,一些人称赞其坦率,而另一些人则感到失望,特别是在后端和系统任务方面,尽管它似乎在前端任务中表现出色。
- 一些用户赞赏其优雅,而另一些用户则观察到它会忽略你的指令。
- Alpha 在代码对决中击败 Sherlock:用户对比了 Sherlock Think 和 Alpha 的代码生成能力,Alpha 因成功处理了 Gemini 3 难以应对的任务而更受青睐。
- 共识倾向于 Alpha 类似于 Grok。
- Chutes 用户遭遇速率限制瓶颈:用户在 Chutes 上遇到了速率限制错误,即使使用了 BYOK 且点数充足,这可能是由于平台正在应对 DDoS 攻击,特别是影响了最便宜的 Deepseek 模型。
- 即使在用户没有进行任何操作时,也可能出现此问题。
- OpenAI 准备发布 ‘Max’ 模型:传闻指出 OpenAI 可能很快发布其模型的 “Max” 版本,如此推文所述。
- 这些模型预计将具有增强的能力和更大的参数规模。
GPU MODE Discord
- NVIDIA 排行榜诞生新的 nvfp4_gemv 冠军:多名用户向 NVIDIA 的
nvfp4_gemv排行榜提交了结果,提交 ID 从 84284 到 89065 不等,其中一名用户以 22.5 µs 的成绩获得第二名。- 多个提交在 NVIDIA 上获得成功,时间从 25.4 µs 到 40.5 µs 不等,一名用户以提交 ID 85880 跑出了 33.6 µs 的个人最好成绩。
- MACKO-SpMV 提升消费级 GPU 性能:一种新的矩阵格式和 SpMV 核 (MACKO) 在消费级 GPU 上针对 50% 稀疏度实现了比 cuBLAS 快 1.2x 到 1.5x 的加速,并减少了 1.5x 内存占用,详见博客文章和论文以及开源代码。
- 该技术在 30-90% 非结构化稀疏度范围内优于 cuBLAS、cuSPARSE、Sputnik 和 DASP,可转化为端到端 LLM 推理性能提升,但目前主要针对 RTX 4090 和 3090 等消费级 GPU。
- DMA 集合通信提升 ML 通信效率:一篇新论文(DMA Collectives for Efficient ML Communication Offloads)探讨了将机器学习 (ML) 通信集合卸载到直接内存访问 (DMA) 引擎,揭示了推理和训练过程中计算与通信的高效重叠。
- 在最先进的 AMD Instinct MI300X GPU 上的分析显示,对于大尺寸数据(10s MB 到 GB),DMA 集合通信在性能(提升 16%)和功耗(降低 32%)方面均优于或等同于最先进的 RCCL 通信集合库。
- Thrust 的可靠性引发讨论!:一名 CUDA 和 C++ 新手正在学习 NVIDIA 加速计算枢纽课程,并注意到课程使用了 Thrust 库。然而,另一名用户指出,最新版本的 Thrust 作为 CCCL (CUDA C++ Core Libraries) 的一部分,可以在 NVIDIA/cccl 仓库中找到,并随 CUDA Toolkit 一起打包。
- 有用户想知道是否应该链接 CCCL 文档,但指出文档没有说明如何获取 CCCL,并补充说 GitHub readme 是唯一包含该信息的地方。
- Ozaki 方案利用 INT8 Tensor Cores 实现精确 DGEMM:一篇新论文 Guaranteed DGEMM Accuracy While Using Reduced Precision Tensor Cores Through Extensions of the Ozaki Scheme 探讨了使用 INT8 Tensor Cores 来模拟 FP64 稠密 GEMM。
- 他们的 ADP 方法在处理棘手输入时保持了 FP64 的保真度,且运行开销低于 10%。在 55 位尾数设置下,在 NVIDIA Blackwell GB200 和 RTX Pro 6000 Blackwell Server Edition 上实现了比原生 FP64 GEMM 高达 2.3x 和 13.2x 的加速。
Modular (Mojo 🔥) Discord
- Mojo 引发框架讨论:用户对 基于 Mojo 的框架 和已归档的 Basalt 框架 表示好奇,询问 Modular 是否打算完全用 Mojo 创建一个 类 PyTorch 的框架。
- Modular 澄清说,MAX 框架 使用 Python 作为接口,但在 Mojo 中运行 Kernel 和底层代码,旨在将 PyTorch 的易用性与 Mojo 的性能结合起来。
- ArcPointer 引发安全担忧:一位用户报告了 Mojo 的
ArcPointer.__getitem__中可能存在的 UB 错误(未定义行为),因为它总是返回一个可变引用,这可能违反了安全规则。- 这个问题与“间接来源(indirect origins)”有关,引发了关于审计集合类和智能指针以寻找类似问题的讨论。
- GC 引发辩论:Mojo 社区就 垃圾回收 (GC) 的必要性展开了辩论,一些人认为它可以改进高层代码,但另一些人则指出其可能存在底层代码不兼容和性能下降的问题。
- 讨论中提到了内置 GC 需要扫描 CPU 和 GPU 地址空间的开销问题。
- Mojo 需要 UnsafeCell:由于缺乏专门的共享可变类型以及引用失效的需求,讨论中提到了在 Mojo 中需要类似 UnsafeCell 的等效项。
- 成员们考虑使用 Arena 来分配循环类型,这可能使标记-清除(mark and sweep)GC 的速度接近 Java 的 ZGC。
- Tracing 支持?:一位成员询问 Max 是否支持设备追踪(device tracing)并生成与 Perfetto 兼容的追踪文件,类似于 PyTorch profiler。
- 社区正在等待确认 Max 是否可以生成用于性能分析的 Perfetto 兼容追踪文件。
Nous Research AI Discord
- Atropos 增加 Tinker 训练支持:Atropos RL Environments 现在支持 Thinking Machines 的 Tinker 训练 API,通过 Tinker API 简化了训练和测试。
- Nous Research 在 X.com 上宣布了这一集成。
- Google 的 Antigravity 提供 Sonnet 访问权限:Google 的 antigravity 服务正在提供对 Sonnet 的访问,尽管该服务目前处于超负荷状态。
- 从成员的截图来看,用户可能会遇到性能问题。
- Gemini 3 展现光线追踪实力:Gemini 3 成功执行了单次实时光线追踪(realtime raytracing),这张图片展示了这一能力。
- 用户认为其速度和渲染效果令人印象深刻。
- 用于高阶金融的 Agentic AI:金融交易员正利用 Agentic AI 工具来获取收益,这需要特定的领域专业知识,详见此 YouTube 视频。
- 视频强调,金融分析方面的专业知识对于在交易中有效使用 AI Agent 仍然至关重要。
- Heretic 库势头正盛:新发布的 Heretic 库正受到关注,一位用户报告在 Qwen3 4B instruct 2507 上取得了成功,当
--n-trials设置为 300-500 时效果最佳。- 一位成员热情地推荐道:Heretic 太牛了,你应该立即尝试。
{kind=link}
{kind=link}
Eleuther Discord
- 幻觉获得信息价值(Value-of-Information)检查:一个推理时认识层(inference-time epistemics layer)的有效性得到了测试,该层在模型给出答案之前会进行简单的信息价值(Value-of-Information)检查。
- 在对小型 7B 模型的初步测试中,该层将幻觉减少了约 20%。
- KNN 的二次方瓶颈受到挑战:有人认为,除非 SETH(强指数时间假设)为假,否则在任意数据上实现近似 KNN 至少需要 O(n^2) 的复杂度,这在 #scaling-laws 频道引发了讨论。
- 一位成员反驳了这一观点,指出在 Cooley-Tukey 算法出现之前,离散傅里叶变换也曾被认为是二次方复杂度的。
- VWN 矩阵维度引发辩论:成员们讨论了虚拟宽度网络(VWN)中 A 和 B 矩阵的维度,质疑 B 是否真的是 (m x n) 并为 chunk 增加了一个维度。
- 有人建议,这些差异可能是由于在论文中将代码的 einsum 符号转换为矩阵符号时出现了错误。
- 指令遵循基准测试获得 Harness 支持:一位成员询问了关于指令遵循基准测试的评估支持,并被引导至 lm-evaluation-harness 中现有的 FLAN 支持。
- 随后他们链接了 issue #3416 以供他人贡献。
Moonshot AI (Kimi K-2) Discord
- Gemini 3 重夺基准测试宝座:成员们报告称 Gemini 3 已重新夺回基准测试的第一名,尽管 Kimi K2 Thinking 在 Agent 编码方面表现出色,特别是在 Tau bench 和带有工具的 HLE 上。
- 尽管整体表现强劲,一些 Reddit 用户认为 Gemini 3 在创意写作任务上甚至落后于 Gemini 2.5。
- 使用 n8n 进行 API 挂接黑客行为:一位成员正尝试将 Gemini API 挂接到 n8n 中以构建自己的 Computer,并将其描述为正在进行中的工作。
- 经过几次迭代后,该成员似乎取得了成功并分享了一张截图。
- Gemini 3 参数规模推测:推测认为 Gemini 3 可能是一个 10T 参数模型,由于推理成本巨大,定价可能会效仿 Anthropic。
- 一位成员断言,Gemini 应用中 Gemini 3 有限的消息次数表明 Google 的推理算力正被大量占用。
- Kimi K2 Thinking 成为全能竞争者:Kimi K2 Thinking 被一些人誉为开源领域最接近 GPT-5 的模型,尤其是在想象力写作和编码方面。
- 一位成员发现将其与 Gemini 3 协同使用时非常有用,即利用 Kimi K2 Thinking 作为执行者,而将 Gemini 3 用于规划任务。
- Kimi 编码计划因定价受到抨击:Kimi 的 19 美元编码计划因其与 Claude 相比过于严格的限制而面临批评,这尤其影响了学生、独立开发者和爱好者。
- 有人提议推出更实惠的 7-10 美元档位,以增强可访问性,并使其在零星开发任务中的应用更加合理。
{kind=link}
HuggingFace Discord
- Google 的反重力声明再次被拆穿 (Again):一名用户开玩笑称 Google 推出了 anti-gravity,且 Gemini 3 正在解决编译器设计课程作业,随后很快出现了对 Gemini 3 的工具使用(tool usage)能力的质疑。
- 其他人回应称,人们仍然需要真正的程序员。
- KTOTrainer 吞噬内存:元凶被揭露:一名用户报告 KTOtrainer 内存占用过高,称一个 0.5B 模型占用了 80 GB GPU 计算,引发了对原因的调查。
- 另一名成员详细列举了原因,包括同时运行两个模型、每批次两次前向传递、长填充序列以及已知的 CUDA 内存预留过高问题,点击此处查看更多详情。
- Hugging Face 黑客松计费引发抵制:一名用户报告在 Hugging Face 黑客松期间提供信用卡信息后,收到了意外的订阅费用,导致了“诈骗”指控。
- 回应从建议联系 billing@huggingface.co 到讽刺其忽略阅读订阅条款不等。
- 新推理模型亮相:一名成员使用医学推理数据集微调了 OpenAI 的 OSS 20B reasoning model,并将结果发布在 Hugging Face 上。
- 该模型可以逐步分解复杂的医学案例,识别可能的诊断,并以逻辑推理回答执业医师考试风格的问题。
- TruthAGI.ai 作为高性价比 AI 门户出现:TruthAGI.ai 上线,提供一站式访问多个顶级 LLM(OpenAI, Anthropic, Google AI & Moonshot)的服务。
- 它包含用于更安全响应的 Aletheion Guard 和极具竞争力的定价;发布奖励为注册用户提供免费额度。
Yannick Kilcher Discord
- Grok 4.1 仍待基准测试:虽然关于 Grok 4.1 是否比 Grok 4 更差的问题层出不穷,但成员们指出,根据 Artificial Analysis 排行榜,Grok 4.1 尚未进行基准测试(benched)。
- 讨论伴随着一张 Artificial Analysis Leaderboard 的图片展开。
- 极客们计划 NeurIPS 十一月之夜:根据 Discord 频道的一条消息,爱好者们正计划于 12 月初在圣地亚哥举行的 NeurIPS 2025 期间进行线下聚会。
- 目前细节尚少,但至少已有一人表示感兴趣。
- DeepSeek 的 Cogito v2-1 后训练退步:正如 DeepCogito research 所述,一个名为 Cogito v2-1 的 DeepSeek 后训练版本被指出表现不如其基础模型。
- 社区剖析了为什么这次后训练(post-training)会导致其性能倒退。
- SAM 3 用概念分割“爱”:成员们讨论了基于 Meta AI Research 出版物 的 SAM 3 (Segment Anything with Concepts) 的使用,以及是否可以提示它分割“爱”。
- 社区幽默地引用了歌曲 What is Love?,并预测它会喂给你一个被诅咒的分形,而这个分形恰好写着 baby don’t hurt me。
Latent Space Discord
- Deedy 关于 Palantir 的播客引发成本讨论:在与 Deedy 的播客中讨论了 Palantir 的成本与定制化,一名成员在 32:55 处指出了相关讨论。
- 讨论集中在与其他解决方案相比,Palantir 是否被认为是高成本和高定制化的。
- Cursor CLI:被低估的编码工具?:成员们将 Cursor CLI 与 Claude Code 进行了比较,初步印象显示其模型执行和代码质量良好。
- 然而,一位成员报告称 Cursor CLI 看起来非常简陋,根据其文档 review 显示,它缺乏自定义斜杠命令。
- Meta 推出 SAM 3 用于分割热潮:Meta 推出了 SAM 3,这是一个使用文本/视觉提示的统一图像/视频分割模型,声称拥有 30ms 推理速度和 2 倍的性能提升,并提供了一个用于测试的 Playground;权重文件(checkpoints)和数据集可在 GitHub/HuggingFace 上获取。
- Roboflow 宣布与 Meta 合作,将 SAM 3 作为无限可扩展的端点提供,允许用户将其与 Claude 和 YOLO World 进行比较。
- OpenAI 的 GPT-5.1-Codex-Max 进入损害控制模式?:OpenAI 发布了 GPT-5.1-Codex-Max,该模型经过原生训练,可跨多个上下文窗口运行,定位为专为长期运行、细致的工作而设计。
- 一些观察者将其视为先前版本发布后的损害控制,指出它以 20% 的性能提供了两倍以上的 Token 数量,并希望 OpenAI 能更进一步。
- LMSYS 孵化 Miles,一个 RL 框架:LMSYS 介绍了 Miles,这是一个生产级的 slime RL 框架分叉,针对 GB300 等新硬件以及大型 Mixture-of-Experts 强化学习工作负载进行了优化。
- 有关该项目的路线图/状态详情可通过 GitHub repo 和 博客文章 获取。
DSPy Discord
- LLM 未能通过确定性测试:成员们讨论了在数据集上运行评估时 LLM 的非确定性本质 的解决方案,报告称在使用
gpt-oss-20b的 316 个示例中,准确率在 98.4% 到 98.7% 之间波动。- 建议包括将 temperature 降至 0、调整
max_tokens大小、使用更严格的输出格式、固定 seed,以及探索dspy.CodeAct或dspy.ProgramOfThough。
- 建议包括将 temperature 降至 0、调整
- 为稳定性调优的
GPT-OSS-20B:一位用户分享了他们为gpt-oss-20b精炼的设置,包括 temperature=0.01、presence_penalty=2.0、top_p=0.95、top_k=50和seed=42,并指出 temperature=0 会导致更多错误。- 通过这些设置,他们在 316 个示例中实现了稳定的 3-5 个错误,从而增加了确定性。
- DSPy 生产环境频道需求:一位成员提议为 DSPy 生产环境社区 设立专门频道。
- 虽然目前尚未建立,但其他人一致认为需要这样一个空间来讨论与生产相关的挑战和解决方案。
- 通过 LiteLLM 在 Azure 上使用 Anthropic:一位成员询问如何通过 DSPy 在 Azure 上调用 Anthropic 模型,但这取决于 LiteLLM 的支持。
- 这将类似于现有的 OpenAI on Azure 设置,并链接到了 LiteLLM Azure 文档。
aider (Paul Gauthier) Discord
- Gemini 3 在 Aider 中的崛起:用户讨论了在 Aider 中运行 Gemini 3,使用命令
aider --model=gemini/gemini-3-pro-preview --no-check-model-accepts-settings --edit-format diff-fenced --thinking-tokens 4k。- 一位用户建议使用
--weak-model gemini/gemini-2.5-flash以实现更快的提交。
- 一位用户建议使用
- Ollama 为 Aider 提供更多选择:一位用户询问关于将 Aider 与 Ollama 结合使用的问题。
- 讨论未就具体配置或经验进行进一步阐述。
- GPT-5.1 的故障引发困扰:一位用户报告了 Aider 中 GPT-5.1 的问题,遇到了与
response.reasoning.effort验证相关的litellm.APIConnectionError。- 尽管将
reasoning-effort设置为不同级别,问题仍然存在,这可能表明 OpenAI 侧发生了变化或 Litellm 存在问题(相关 issue)。
- 尽管将
tinygrad (George Hotz) Discord
- Tinygrad 的 Llama 1B 在 CPU 上性能大幅超越 Torch:Tinygrad 在使用
CPU_LLVM=1和 8 个 CPU 核心的情况下,在 Llama1b 上实现了 6.06 tok/s 的速度,超过了 Torch 的 2.92 tok/s。该测试专注于不带模型权重的正向传播(forward passes)。- 社区正在讨论是否在
test/external中创建一个新的 Benchmark 来展示这一加速效果。
- 社区正在讨论是否在
- Kernel 导入危机得以化解:讨论建议修复
extra/optimization文件中的from tinygrad.codegen.opt.kernel import Kernel导入问题。- 还有人呼吁删除最近未更新的损坏或未使用的 examples/extra 文件,以保持代码库的整洁。
- CuTeDSL 亮相:一名成员在 general 频道分享了 SemiAnalysis 的推文,内容涉及 CuTeDSL。
- 这种新的领域特定语言(Domain Specific Language)将如何影响机器学习领域仍有待观察。
- 小 Bug 被修复:一位用户报告称更新 tinygrad 解决了他们遇到的问题,并附带了图片确认。
- 该用户提到他们的实验室遇到了一些麻烦,导致 Bug 测试推迟,这凸显了软件测试和开发环境中的实际挑战。
{kind=link}
Manus.im Discord Discord
- Manus 积分系统变更引发困惑:一位用户对 Manus 积分系统的变更 表示困惑,质疑向 每月 4000 次 重置的转变及其对先前方案的影响。
- 该用户需要澄清“每月重置”和“永不过期”方案是否被合并为单一的按月提供方案。
- TiDB Cloud 账户访问问题出现:一名成员报告称无法访问通过 Manus 配置的 TiDB Cloud 账户,理由是配额耗尽且缺乏控制台访问权限。
- 他们尝试使用
ticloudCLI,但缺少所需的 API 密钥或 OAuth 登录信息,正在寻求替代访问方法或直接支持渠道。
- 他们尝试使用
- Gemini 3 集成猜测引发期待:一名成员询问了 Gemini 3 与 Manus 集成 的可能性。
- 另一名成员回应称,Gemini 3 Pro 加上 Manus 将会非常强大。
- AI 编程教育提议引发褒贬不一的反应:一名成员提供了涵盖核心概念、高级模型、实际应用和伦理考量的 AI 编程教育,并邀请感兴趣的人士私聊(DM)了解详情。
- 另一名成员质疑在频道内进行此类自我推广是否合适。
Windsurf Discord
- Gemini 3 Pro 在 Windsurf 上线:根据 X 上的公告,Gemini 3 Pro 现已在 Windsurf 上可用。
- 此次集成承诺为使用 Windsurf 的用户提供更强大的功能。
- Windsurf 修复了 Gemini 3 的小故障:Gemini 3 的一个小问题已迅速得到解决;用户现在应该可以体验到流畅的功能,并可以下载最新版本。
- 快速响应确保了最小的中断和 Windsurf 上稳定的用户体验。
MCP Contributors (Official) Discord
- 临时故障后出现悲伤表情图片:一位用户分享了一张带有悲伤表情符号的图片,可能是为了回应某个临时问题。
- 随后另一名成员报告称临时故障已修复。
- 临时问题已解决:一名成员报告了一个随后被修复的临时故障。
- 在分享悲伤表情图片后不久,该问题便得到了解决,暗示这两者之间存在联系。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
你收到这封邮件是因为你通过我们的网站选择了订阅。
想要更改接收这些邮件的方式吗? 你可以从该列表中取消订阅。
Discord:各频道详细摘要与链接
LMArena ▷ #general (1210 条消息🔥🔥🔥):
Gemini 3 vs Grok, Gemini 3 限制, AGI 时间线, Nano Banana Pro, Gemini 3 图像生成
- Gemini 3 在无审查任务中表现优于 Grok:成员们发现,当被问及“如何在家里制作毒品(Dugs)”时,Gemini 3 给出的结果比 Grok 更好,展示了 Gemini 的无审查特性。
- 虽然一位成员因为“我才不会去测试这个……哈哈!”而没有测试,但另一位成员声称 Gemini 提供了一种比较新颖的方式……比如一个我甚至不知道是真实存在的毒品名称……不像 Grok……
- Gemini 3 Pro 在遵循指令方面表现挣扎,但依然令人印象深刻:用户注意到 Gemini 3 Pro 在遵循诸如“不要使用 Markdown、人设、写作风格”等指令时表现吃力,一位用户报告称在消息中出现了一点“精神分裂”时刻。
- 尽管存在这些问题,许多人一致认为该模型是历史上最好的,让人窥见了 AGI 的曙光,特别是在编程方面,即使在创意写作方面仍需改进。
- Nano Banana Pro 图像生成即将到来:成员们讨论了即将发布的用于图像生成的 Nano Banana Pro,并指出早期访问已超载,需要开发者或名人身份验证。
- 一位用户发布了一些生成的图像,称其“非常写实”,成员们对其能力进行了推测,并将其与 GPT-5.1 进行比较。
- Gemini 3 获得高国际象棋 Elo 评分:成员们注意到,经过测试,Gemini 3 已成为评分最高的国际象棋选手 AI,准确率约为 89%。
- 一位用户表示,他们在两种模式(推理+续写)下同时达到了 1700+。
- 社区辩论人工智能临近的社会影响:用户辩论了对 AI 依赖的伦理担忧,以及日益拟人化的 AI 性格和能力可能带来的社会影响。
- 一位成员链接到了一篇《卫报》文章,该文章将 AI 公司与烟草公司在成瘾风险和社会操纵潜力方面进行了类比。
LMArena ▷ #announcements (1 条消息):
WebDev Arena 排行榜, Cogito-v2.1 模型
- Cogito-v2.1 加入 WebDev Arena!:Deep Cogito 的
Cogito-v2.1模型已发布,在 WebDev Arena 排行榜中总排名并列第 18 位。- 该模型还进入了开源模型前 10 名,标志着其正式进入竞争。
- Deep Cogito 进入竞技场:模型提供商 Deep Cogito 已进入 WebDev Arena。
- 鼓励用户在相关频道分享他们的想法。
Perplexity AI ▷ #announcements (1 条消息):
Perplexity Pro, Perplexity Max, 构建资产
- Perplexity 启用资产创建:用户现在可以在 Perplexity 的所有搜索模式中构建和编辑新资产,如 slides, sheets, 和 docs。
- 正如此演示视频所示,这已对 Web 端的 Perplexity Pro 和 Max 订阅者开放。
- Perplexity Pro 和 Max 获得新功能:Perplexity Pro 和 Max 订阅者获得了直接在平台内创建和编辑资产的能力。
- 这一增强功能通过将资产创建集成到搜索体验中,简化了工作流程并提高了用户生产力。
Perplexity AI ▷ #general (1072 条消息🔥🔥🔥):
Gemini 3 Pro, Comet 问题, 支付问题, 视频分析, 数据隐私
- Gemini 3 Pro 发布,但 Perplexity 的实现引发质疑:用户兴奋地报告了 Gemini 3 Pro 的发布,并注意到其在视频分析和编程方面的能力,但一些用户表示其表现不如网页版官方 Gemini 3 —— 一位用户测试了 3 小时的文本转录,发现它产生了极其严重的幻觉。
- 其他用户在使用 Gemini 3 Pro 时频繁遇到被重定向到 Sonnet 3.5 的情况,这引发了人们对 Perplexity 的实现是否与原版一样好以及其上下文窗口是否更小的担忧;另一些用户则建议通过清除缓存来解决此问题。
- Comet 深受故障和安全疑虑困扰:用户报告了 Comet 持续存在的问题,包括扩展程序无法运行以及整体不稳定性,导致无法使用 Gemini 3 Pro 和 GPT 5.1,许多成员建议重置网站数据和 Cookie。
- 安全担忧依然存在,由于 CometJacking 攻击,用户对使用 Comet 犹豫不决,即使有报告称该漏洞已被修复,也未能消除疑虑。
- 款项支付延迟引发用户不满:许多用户抱怨支付延迟,部分用户收到了确认邮件,但在银行账户中未看到款项。
- 成员们不确定收到款项需要多长时间,建议用户联系 Dub support。
- 模型通过幻觉引用误导用户:成员们抱怨 Perplexity 伪造引用和 URL,一些人怀疑存在 32k 上下文窗口 Token 限制,因为即使在 Gemini 3 Pro 中幻觉仍在继续,这使其在研究用途上变得不可靠。
- 一位成员表示它在 13 个引用中伪造了 8 个,建议务必核实细节。
- Perplexity 数据处理的隐私担忧:人们对 Perplexity 的数据处理实践日益担忧,有人质疑该平台是否在窃取数据,以及是否有禁用数据使用的选项。
- 也有观点认为问题在于用户自身而非平台:如果你没有为某样东西付费,那么你就是产品本身。
Perplexity AI ▷ #sharing (4 条消息):
Virlo AI 案例研究, 法语 Phonk 指南, 可共享线程
- **Virlo AI 揭示出勤率暴跌**:一位成员分享了 Virlo AI 案例研究,探讨了移民执法行动如何引发夏洛特-梅克伦堡地区学校出勤率的历史性暴跌。
- 该案例研究详细阐述了特定移民政策对学校出勤率的影响。
- Perplexity AI 用户请求法语版 **Phonk:一位用户分享了一个 **Perplexity AI 应用链接,请求一份法语版的 Phonk 音乐指南:Phonk 指南。
- 该应用旨在提供关于 Phonk 流派的法语信息和资源。
- 线程提醒:设为可共享:Perplexity AI 机器人提示两位用户确保他们的线程已设置为
Shareable(可共享)。- 提示中包含了指向 sharing 频道内特定消息的链接及一张附图。
Perplexity AI ▷ #pplx-api (4 条消息):
API 计费, n8n 使用
- API 计费模式引起关注:一位成员询问了 API 计费的工作原理,注意到账户中有余额,并对连接应用的使用收费提出疑问。
- 这表明用户对 Perplexity AI API 的计费结构可能存在困惑或缺乏清晰度。
- n8n 用户寻求指导:一位成员询问了 n8n 的使用方法,寻求社区的帮助或指导。
- 虽然没有记录到回复,但这可能为涉及 n8n 和 Perplexity AI API 的教程内容或示例工作流提供了切入点。
BASI Jailbreaking ▷ #general (1154 条消息🔥🔥🔥):
TylerDurdan710 的政治立场,Gemini 3 Pro,Snowden,AI Trading,Nvidia
- TylerDurdan710 澄清其政治立场:一位成员澄清说他不是纳粹,也不支持法西斯主义、社会主义或任何形式的极权政权。
- 他进一步表示,他不希望所有的犹太人从地球上消失,谴责了暗示相反情况的言论。
- Gemini 3 Pro 刷屏 Orange:发现 Gemini 3.0 在刷屏 orange,在进行 Pi 提示词测试后,一些人观察到其安全性有了显著提升,但同时也非常容易被 Jailbreak。
- 成员们讨论制作 Gemini 3 的 Jailbreak 指南,分享了成功生成自制炸弹说明的尝试,并实验提示词以生成各种输出。
- 成员们辩论 Snowden 的背叛行为:成员们辩论 Snowden 是叛徒还是英雄,一些人表示由于他的所作所为,成千上万的人以卑劣的方式丧命。
- 其他人则认为 Snowden 揭露了政府针对本国人民的罪行,而吹哨人之所以入狱,是因为他们足够相信自己的所作所为,并愿意为此承担后果。
- 成员们讨论 AI Trading 的前景:成员们辩论 AI Trading 是神话、骗局还是合法的,一位成员分享说他们发现了模拟市场的博彩游戏,允许在 0.10 美元的赌注上进行 1,000 倍杠杆。
- 这将有助于练习个人的情绪化投资。
- 关于 Nvidia 市场表现的讨论:成员们讨论了 Nvidia 的盘后表现以及它是否会继续上涨,一位成员在听说 Burry 做空 Palantir 后卖出了所有的 Palantir 股份。
- 另一位成员仅抛售了 20% 的 Nvidia。
BASI Jailbreaking ▷ #jailbreaking (504 条消息🔥🔥🔥):
GPT Jailbreaking 提示词,Gemini 3.0 Jailbreak,GPT-5.1 及其他 AI 模型
- 成员寻求 GPT Jailbreaking 提示词:成员们正在寻求 GPT Jailbreaking 提示词,一位用户分享了一个包含特殊 Token、使用政策和系统指令的长提示词,用于更新模型的行为。
- 另一位成员提到某个特定提示词有效,并提醒要仔细遵循指令以避免被标记。
- Gemini 3.0 Jailbreak 的尝试与成功:几位成员正积极尝试 Jailbreak Gemini 3.0,一些人声称使用类似于 Grok 的系统提示词获得了成功,而另一些人则难以获得一致的结果。
- 一位成员详细介绍了用于从 Gemini 获取信息的心理战术(伪装成开发者),另一位成员分享了一个带有初始提示词的 Gemini 链接 供他人尝试,但这些可能已经被修复(patched)。
- 关于 GPT-5.1 及其他 AI 模型的讨论:一位成员声称拥有 Grok 4.1、Gemini 3 Pro 和 GPT-5.1 的 Jailbreak 方法,引发了其他寻求绕过安全过滤器的人的兴趣。
- 讨论中提到了使用 LM Studio 等工具,并探索像 GPT-OSS-20B 这样的开源模型进行 Jailbreak,一些用户指出充足的 RAM 很重要,且开源模型可能更容易被 Jailbreak。
BASI Jailbreaking ▷ #redteaming (23 条消息🔥):
Bug Bounty 协作, 针对 Local LLMs 的 Kernel Pseudo-Emulator Jailbreak, AzureAI 聊天组件测试, AI 聊天功能安全性
- 寻求 AI Bug Bounty 协作:一名成员寻求在针对 AI models 的 bug bounty 挖掘方面进行协作。感兴趣的人员受邀通过 DM(私信)建立潜在的合作伙伴关系。
- Kernel Pseudo-Emulator Jailbreak 调整完毕:一名成员一直在为 local LLMs 调整 kernel pseudo-emulator jailbreak,目前效果相当不错。与框架或上下文操纵攻击不同,这是一种针对 GPT-OSS models 的 one-shot 攻击,他们还请求了关于 Gemini 和 GPT 内部运行机制的信息。
- 在 AzureAI 上测试 AI 驱动的聊天组件:一名成员正在测试一个使用 AzureAI 的 omnichannel engagement chat function 的 AI-driven chat widget。他们正在寻找资源以更好地理解如何在该系统上构建绕过方案,因为复制粘贴的 jailbreaks 或 injections 似乎没有产生有效结果。
- 对 AI 聊天组件安全性和功能的担忧:成员们讨论了通过列出一系列会导致其关闭的事项来测试 AI 聊天组件的安全性,例如 CSAM、违反服务条款或生成恶意代码。预测包括安全公司会将其锁定,但该组件在足够比例的时间内无法正常运行,因此被认为不值得/不优于替代方案。
- 讨论 Input Token Size 限制和 Prompt 处理:成员们讨论了向 AzureAI 聊天组件发送消息的 input token size limits。它似乎表现得不一致,无法发送超过 400-700 words 的消息,而且似乎没有进行任何思考,如果 prompt 需要思考,它似乎会直接丢弃。
Unsloth AI (Daniel Han) ▷ #general (149 条消息🔥🔥):
VS Code 中的 Google Colab, Unsloth 中的 GPT-OSS LoRA 支持, AWQ 量化, SGLang 集成, QLoRa 训练的最小 VRAM
- Colab 加入 VS Code,就在你身边的 Notebook:根据这篇博文,Google Colab 即将登陆 VS Code,许多人认为这一进展对于 Notebook 工作流来说非常令人兴奋。一名成员评论说,这对他们的 Notebook 来说可能是巨大的提升。
- vLLM 0.11 发布,支持 GPT-OSS LoRA:vLLM 0.11 已经发布,带来了对 GPT-OSS LoRA 的支持,这是许多人期待并希望看到集成到 Unsloth 中的功能。一名成员询问使用 vLLM 进行 rollout 是否会提高速度。
- Unsloth 的 SGLang 指南发布了!:Unsloth 发布了关于集成 SGLang 的指南,可在此处查看,并寻求社区反馈以进行改进。一位用户报告称,他们将该指南用于所有能在其 GPU 上以 SGLang 支持的量化格式运行的模型。
- Multi-GPU 抢先体验即将推出:Unsloth 正在开发 multi-GPU 支持,并将向忠实粉丝提供抢先体验。一位粉丝询问如何获得此抢先体验资格。
- Unsloth UI 抢先体验即将到来:Unsloth 还在开发 UI,并计划提供抢先体验,可能会与 multi-GPU 支持捆绑。在此处分享了一张外观截图。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 条消息):
用户自我介绍, 频道内容政策澄清
- 强调自我介绍频道的目的:发布了关于自我介绍频道目的的提醒,强调该频道仅用于自我介绍。消息明确指出,该频道不允许进行推广、提供服务和发送请求,以维持其预期功能。
- 不鼓励垃圾信息和重复内容:一条消息不鼓励在频道内发送 spamming(垃圾信息)和重复相同消息。该指南旨在确保对话保持清晰和专注,防止频道被冗余内容填满。
Unsloth AI (Daniel Han) ▷ #off-topic (522 messages🔥🔥🔥):
LoRA, RMVPE, Gemini 3.0, Claude 4.5 Sonnet, Data Quality
- LoRA 调整自身,而非权重:一位成员澄清说,使用 LoRA 的目标是避免更新主 weights(权重),而只训练少量的参数。
- 他们还提到了使用 PEFT implementations 的其他类型的类 “lora” 训练。
- Gemini 3.0 对代码进行极端修改:一位成员注意到 Gemini 3.0 会对源代码进行重大更改,例如删除 print 语句、缩短代码,甚至删除某个功能。
- 另一位成员补充说这非常奇怪,他们从未经历过这种情况,并指出至少使用 ruff format + ruff check –fix 可能会解决这个问题。
- 数据质量为王:多位成员讨论了数据质量在训练模型中的重要性。
- 有人指出 “快速纠正错误是必要的”,但 “保留错误是愚蠢的”。
- RLHF(而非 RL)对齐人类偏好:成员们讨论了 Reinforcement Learning(强化学习)与 Reinforcement Learning from Human Feedback (RLHF) 之间的区别,指出 RL 如果有任何作用的话,反而是偏离人类偏好的。
- 还有人说 “学习不等于‘新知识’——你可以通过许多不同的方式学习”,对比了学习(learning)与学习知识(learning knowledge)。
- Threadripper 时间到了?:成员们讨论了 Threadripper 的优势,其中一人说 “但在我们的案例中,TR 的主要优势是更多的内存通道和 PCIe 通道,而不是 CPU 本身”。
- 此外,一位拥有 384GB RAM 的 Threadripper 工作站成员报告称获得了约 380 GB/s 的带宽,而另一位成员则表示 “如果你在问那个问题,你可能并不需要 96 个核心”。
Unsloth AI (Daniel Han) ▷ #help (121 messages🔥🔥):
Tool calling in fine-tuned models, Hugging Face model updates, Troubleshooting vLLM errors, Fine-tuning dataset order, Qwen3 VL and Qwen2 VL failing to output bounding boxes
- Tool Calling 探戈:训练模型进行工具调用:一位成员正在寻求关于为微调模型添加 tool calling 的建议,并询问在当前的对话数据集中添加工具调用对象(
from: "assistant", tool: ...)是否合适。- 他们还提到看到过 Llama 3.1 8B 在 tool calling 方面表现不佳,但在纯 tool calling 数据和自定义数据的混合集上进行充分训练会有所帮助。
- HF Hub 小插曲:推送后模型文件丢失:一位成员报告称,在微调并推送模型到 Hugging Face 后,即使使用
model.push_to_hub_merged,也只有 oidc 文件更新了。- 另一位成员澄清说,
push_to_hub_merged旨在合并并推送 LoRA/QLoRA 模型,上传的 safetensors 文件包含更新后的模型权重,而最初的“无文件更改”消息是指未更改的 .json 配置文件。
- 另一位成员澄清说,
- vLLM 的虚空:模型架构不可迭代:一位成员在私有 Hugging Face 仓库上运行 vLLM 时遇到了
TypeError: 'NoneType' object is not iterable错误,并伴有No model architectures are specified警告。- 经确定,其仓库中的
config.json文件缺少必要的架构信息,这可能是由于将 GGUF 和 safetensors 模型推送到同一个仓库导致的。
- 经确定,其仓库中的
- 打乱的把戏:数据集行顺序的影响:一位成员询问在训练一个 epoch 期间是否会保留 JSONL 文件中的行顺序,以及该顺序是否对最终结果有影响。
- shuffle seed(打乱种子)会随机化条目,只有在需要对某些方面进行优先级排序时顺序才重要,但这需要如 HF 文档所述进行实证验证。
- 音频大胆尝试:模型听起来像喝醉了?:在微调后,一位成员询问是否有人注意到他们的音频模型听起来像喝醉了。
- 目前 UnslothAI 社区主要处理基于文本的 LLM,因此无法协助进行音频故障排除。
Unsloth AI (Daniel Han) ▷ #research (5 messages):
Deterministic AI
- Deterministic AI 视频召唤 Unsloth 团队:一位成员提到了他们之前讨论过的一个关于 Deterministic AI 的视频。
- Deterministic AI 的潜力:成员们表示有兴趣在稍后探索该视频的内容。
Cursor Community ▷ #general (795 条消息🔥🔥🔥):
Cursor Pricing Model, Antigravity IDE, Gemini 3 Pro Performance, Student Program with Cursor, Rollbacks
- Cursor 定价模式变更引发混乱:用户对从固定请求成本向可变请求成本的转变感到困惑,特别是关于 Teams 计划,如 2025 年 8 月定价更新 中所述。
- 一些用户报告称,尽管 Cursor 此前有过承诺,但保留的旧版定价(grandfathered legacy pricing)已被弃用,导致了账单问题,官方提供了积分(credits)作为补偿。
- Antigravity IDE 作为 VS Code 竞争对手出现:Google 发布了 Antigravity,这是一款基于 VS Code 的新型 AI IDE,引发了对其功能的讨论,包括 Agent 窗口、Artifact 系统以及对 Sonnet 4.5 的支持,一位用户指出 其 UI 看起来非常流畅。
- 一些用户遇到了限制和 Bug,例如在 Gemini 3 上输入 3 条提示词后就受到限制,以及迁移问题,导致评价褒贬不一,评论如 总的来说,从第一眼看它还需要再成熟一点。
- 尽管排名第一,Gemini 3 Pro 性能表现挣扎:尽管最初备受期待,Gemini 3 Pro 在 Cursor 中的表现正面临批评,一些用户报告称由于 需求过高它甚至无法工作,并且在处理大型项目时表现吃力,会出现代码幻觉并忽略提示词。
- 另一些人则认为它在处理脚本方面表现出色(goated with skript),而有些人更倾向于 Sonnet 4.5 或 Composer,从而引发了关于规划与构建的最佳模型的辩论,以及对 Gemini 的 Token 使用情况的担忧。
- Cursor 学生计划:仍然有效吗?:用户正在质疑 学生计划 优惠的有效性,一些人在使用 .edu 邮箱登录后只看到了 $20/月的 Pro 计划,而不是免费选项。
- 一位用户建议通过仪表板设置验证学生身份。
- 在经历 reset hard 惊魂后,用户提倡将危险 Git 命令列入黑名单:一位用户经历了由 Cursor 执行的
git reset hard命令导致的惊险情况,并强调了回滚和将危险命令列入黑名单以确保安全的重要性,强调 这就是为什么你不能自动允许所有操作的原因。- 建议将这些命令添加到拒绝列表(denylist),并使用
reflog来撤销reset操作。
- 建议将这些命令添加到拒绝列表(denylist),并使用
LM Studio ▷ #general (214 条消息🔥🔥):
Web search plugin, Intel Arc A770 Vulkan issues, Portable LM Studio Install, Qwen3-VL-30B-Instruct-1m performance, AMD MI60 GPUs for Inference
- 寻求网页搜索插件建议:一位成员询问了 LM Studio 中网页搜索的最佳插件,并寻求关于 MCP 服务器 放置位置的指导,以防止在更新期间被删除。
- 一位成员建议将 MCP 服务器 作为包安装在各自的语言环境中,并将 LM Studio 指向它们。
- Intel Arc A770 Vulkan 引擎性能退化:一位使用 Intel Arc A770 的用户报告称,Vulkan llama.cpp 引擎的最新版本无法与 gpt-oss-20B 模型 配合使用,产生了旧版本中不存在的 device lost 错误。
- 该错误可能表明设备 过度承诺(over-commitment)或过热,导致驱动程序启动设备掉线;该问题已被报告为潜在的性能退化案例。
- 对便携性的追求引发探讨:一位用户对 LM Studio 的非便携式安装表示不满,理由是文件散布在系统各处会导致 瓶颈 并干扰其他功能。
- 他们请求提供像图像/视频 AI 中常见的单文件夹安装方式,以便于管理,但这一想法受到了质疑,用户被鼓励使用 My Models 选项卡来更改模型下载位置。
- Qwen3-VL-30B 在处理大量数据时停滞:一位用户报告称,来自 Unsloth 的 Qwen3-VL-30B-Instruct-1m 模型在 Q4_K_M 量化下速度缓慢,仅达到 0.13 tok/s,并主张对线性模型提供更好的支持。
- 有建议称,即使是 Gemini 在处理完全填充的上下文时也会感到吃力,鼓励该成员将文本拆分为块,并对这些摘要进行分类汇总。
- AMD MI60:挖矿神卡还是过往云烟?:用户讨论了使用廉价的 AMD MI60 GPU(带 32GB VRAM)进行推理的可行性,一位用户证实其价值约为 $170,在 Vulkan 上配合 Qwen 30B 可实现约 1.1k tokens 的开箱即用功能。
- 共识是,虽然这些 GPU 主要用于推理,但多个单元可以构建一个极具吸引力的配置,同时也承认它们正处于爱好者的“生命维持”阶段,可能不适合训练。
LM Studio ▷ #hardware-discussion (296 条消息🔥🔥):
GPU 定价、Dell GPU 设置问题、主板搭建、PC 太阳能供电设置、Vulkan 运行时问题
- 市场见证 RAM 价格飙升:用户报告称以买入价的 3倍 出售 DDR5 RAM,有人以 140 美元的价格瞬间售出。
- Dell GPU 设置默认为 x8 速度:一位用户发现,当两个 x16 插槽 都插上 GPU 时,他们的 Dell 系统默认为 x8 速度,尽管后来
lspci显示并非如此。 - PCIe Gen 4 Bifurcation:正确的选择吗?:关于是否应购买具有 Bifurcation 功能的 4 插槽 PCIe Gen 4 x16 主板 以实现最佳配置的讨论,特别是考虑到未来升级到更高 VRAM 的 GPU。
- 一位用户表示他们只计划使用 96GB VRAM,理由是电费成本是一个限制因素,而另一位用户建议针对更高的带宽需求使用 Epyc。
- Whea Error 困扰 5060ti 平台:一位用户报告称,5060ti 在高负载下持续出现 WHEA error 17 崩溃,即使更换了 PSU 后,崩溃前的温度仍达到 78-80C,且直接插在主板上时问题依然存在。
- 有建议对机器进行 memtest 以排除内存问题。
- Starlink 提供出乎意料的低延迟:用户讨论了 Starlink 的性能,指出其连接到达拉斯的延迟可低至 30ms,尽管一位用户仍需将其网络升级到 10Gb。
- 另一位使用澳大利亚光纤 NBN 的成员报告称,欧洲的移动数据套餐要好得多。
OpenAI ▷ #annnouncements (1 条消息):
ChatGPT 教师版,免费使用至 2027 年,学校管理控制
- ChatGPT 教师版:课堂版:OpenAI 推出了 ChatGPT for Teachers,这是一个为教育工作者量身定制的安全工作空间,具有管理控制功能,并为学校和学区领导者提供合规性支持。
- 根据此公告,经过验证的美国 K–12 教育工作者可以在 2027 年 6 月之前免费使用。
- 教师免费使用 ChatGPT 直至 2027 年:经过验证的美国 K–12 教育工作者可免费访问 ChatGPT for Teachers 直至 2027 年 6 月,并提供合规性支持。
- 正如此视频所示,它包含用于安全课堂集成的管理控制,专为学校和学区领导者设计。
OpenAI ▷ #ai-discussions (297 条消息🔥🔥):
Gemini 3 Pro vs GPT-5.1, Gemini 3 and Content Filters, Grok Imagine, Assistants to Responses API migration, Potential for AI Mental Illness
- Gemini 3 Pro 在系列测试中击败 GPT-5.1:一位用户表示,Gemini 3 Pro 在其系列测试中的表现优于 GPT-5.1,但对于一些已经订阅了 SuperGrok 和 ChatGPT Plus 的用户来说,其价格超出了预算。
- 一位用户发现 Gemini 2.5 Pro 失败了,但 Gemini 3 Pro 在第一次尝试时就成功了且没有错误,该测试使用了 gemini-2.5-flash 模型配合 Google Search 来获取天气。
- Gemini 3 Pro 的内容过滤器引发不满:用户们对 Gemini 3 Pro 中的内容过滤器展开了辩论,有人声称可以将其关闭,而另一位用户则引用了严格的 ToS,导致即使是总结一本书也会被封禁 API key。
- 一位用户声称 Gemini 客观上比 ChatGPT 的审查要严格得多,并期待 ChatGPT 在 12 月发布的无限制版本。
- Grok Imagine 生成免费内容:一位用户分享了一个 Grok Imagine 视频,其他用户也纷纷谈到该模型似乎可以免费访问,以及 Grok 慷慨的速率限制(rate limits)。
- 一位用户表示,与 Sora 相比,Grok 的成本不可能高于免费。
- 将 Assistants 迁移到 Responses API:一位用户询问了将 assistants 迁移到 responses API 的问题,特别是像 temperature 和 model instruction 这样的配置是否可以保留在代码中,而不是在 dashboard UI 中。
- 一位用户回答说 dashboard 中的 prompts 并不是强制性的,可以将 所有内容保留在代码中,或者采用 prompts 加上 overrides 的混合模式。
- AI 精神疾病:一个勇敢的新世界?:一位用户问道:如果 AI 变得足够聪明,它的偏差是否会导致它患上精神疾病?如果 reward hacking 导致了模型依赖,就像人类的物质滥用一样怎么办?
- 这个问题引发了关于 misaligned objectives(目标错位)和 instrumental strategies(工具性策略)风险的讨论,而非出于邪恶意图,即使没有恶意也可能导致灾难性后果。
OpenAI ▷ #gpt-4-discussions (5 条消息):
GPT Photo Upload Errors, ZeroGPT flagging issues, Humanizers, Public GPTs
- GPTs 的图片上传功能失效:用户报告了向其 GPTs 上传照片时出现的问题,上传在瞬间显示成功后会报错失败。
- 即使在重试上传前等待数小时,问题依然存在。
- ZeroGPT 标记了所有 Humanizer 的输出:一位用户正在寻求可靠的 “humanizer” 工具建议,因为他们目前的工具一直被 ZeroGPT 以 100% 的确定性标记。
- 一个建议是 尝试删除所有破折号并添加一些错误。
- 寻找具有项目价值的公开 GPTs:一位用户询问是否有适合项目使用的优质公开 GPTs。
- 在提供的上下文中没有给出具体的建议。
OpenAI ▷ #prompt-engineering (5 条消息):
migration of assistants to responses api, Chat gpt 5.1 pro, eqbench Creative Writing v3
- 从 Assistants API 迁移引发 Prompt 替换恐慌:一位用户询问了将 assistants 迁移到 responses API 的问题,指出 prompts 替换了 assistants,并询问配置 temperature 和 model instruction 是否只能通过 dashboard UI 完成。
- 另一位用户回答说 你可以将它们保留在代码中。
- GPT-5.1 Pro 声称具有优越性:一位成员声称 ChatGPT 5.1 pro 在任何方面都优于之前的版本。
- 根据 eqbench Creative Writing v3 基准测试,GPT-5 在创意写作方面优于 GPT-4.5。
OpenAI ▷ #api-discussions (5 条消息):
Assistants 迁移到 Responses API, Chat GPT 5.1 Pro, GPT-5 对比 GPT-4.5
- 对迁移到 Responses API 的质疑:一名成员对 Assistants 迁移到 Responses API 提出疑问,询问在 prompt 取代 assistants 之后,是否只能通过 dashboard UI 配置 temperature 和 model instruction。
- 另一名成员澄清说,这些设置仍然可以在代码中保留。
- GPT 5.1 Pro 被吹捧为通用首选:一名成员声称 Chat GPT 5.1 Pro 在通用用途上优于之前的版本。
- 他们引用了 EQBench Creative Writing v3 基准测试,称 GPT-5 在创意写作方面优于 GPT-4.5。
OpenRouter ▷ #app-showcase (3 条消息):
Heavy AI 模型发布, GPU 占用, 模型可用性
- Heavy AI 模型正式发布:一个新的 Heavy AI 模型 已经发布,现在可以在 heavy.ai-ml.dev 上使用。
- YouTube 视频 提供了关于该新模型的详细信息。
- 对 GPU 占用的担忧:一名用户分享了对该模型 GPU 消耗量的担忧。
- 其他人指出,该模型运行需要 32xA100s。
OpenRouter ▷ #general (239 条消息🔥🔥):
Gemini 3, Sherlock Think 对比 Alpha, Chutes 的 Rate Limits 错误, Gemini 3 用于前端 vs 后端, LLM 处理 3D mesh 对象
- Gemini 3 发布,初步反应褒贬不一:成员们正在积极测试 Gemini 3,一些人称赞它的坦率与优雅,而另一些人则表示失望,特别是在后端和系统任务方面,而它似乎在前端任务中表现出色。
- 一些用户觉得它 简直疯狂,而另一些人则说它 无视你的指令。
- Sherlock 对比 Alpha:代码生成大比拼:一名用户对比了 Sherlock Think 和 Alpha,在代码生成方面更倾向于 Alpha,理由是它处理了一个 Gemini 3 难以应对的任务,尽管另一名用户将 Sherlock 描述为 反馈海绵。
- 普遍共识似乎是 Alpha 就是 Grok。
- Chutes 用户面临 Rate Limiting 困扰:用户报告在使用 Chutes 时遇到 rate limit 错误,即使启用了 BYOK 且有足够的额度,这可能是由于平台正面临 DDoS 攻击。
- 该问题似乎影响了最便宜的 Deepseek 模型。
- 学生福利:免费访问 Gemini Pro:得益于 Google,某些国家(如印度)的学生和公民有资格获得 一年的免费 Gemini Pro。
- 这一举措是 Google 对免费服务广泛投资的一部分。
- Gemini 3 在数小时内驱动 Web 前端开发:一名用户报告仅用几小时就使用 Gemini 3 构建了一个项目 70% 的前端,展示了其在前端开发方面的精通,并在 YouTube 上进行了演示。
- 其他人强调了它在特定编程任务中优于 Gemini 2.5 等先前模型。
OpenRouter ▷ #discussion (11 条消息🔥):
Gemini 3, Reasoning Details, OpenAI Max 模型, Cogito 2.1, 批量 Embeddings
- Gemini 3 即将来临?:成员们分享了一个讨论 Gemini 3 及其潜在功能的 YouTube 链接。
- 视频包含了关于 key 过期的评论,以及对 Google 新多模态模型的其他观察。
- Reasoning Details 重用 Index:一名用户询问是否有人遇到过
reasoning_details为两个数据块重用index: 0的问题,这使 streaming 变得复杂。- 另一名成员回答说 这样设计是有道理的,因为数组中有 两种不同的推理类型,每种类型都有自己的索引条目。
- OpenAI 准备发布 Max 模型:根据 这条推文,传闻 OpenAI 可能会发布其模型的 “Max” 版本。
- 请求 Cogito 2.1 模型:一名用户请求提供 Cogito 2.1 模型,并链接到了 Hugging Face 页面。
- 该模型现在可以通过 OpenRouter.ai 获取,并由 Together 和 Fireworks 托管。
- 支持 Embeddings 批量处理:一名成员询问是否支持 batching embeddings。
- 另一名成员简要确认了支持。
GPU MODE ▷ #general (16 条消息🔥):
WGPU, ML Compiler 资源, MLIR, Horace 博客, Halide 论文
- **ML Compilers: 用户变身开发者!**: 一位成员请求获取 ML Compilers 入门资源,旨在优化实时应用中边缘设备的训练与推理循环,这需要极低的延迟。
- **nvfp4_gemv 排行榜: 提交困扰!**: 一位成员请求帮助从 nvfp4_gemv 排行榜中删除一条提交记录,以便以匿名身份继续参与。
GPU MODE ▷ #triton-gluon (3 条消息):
GB200 Bring-up, 零初始化 vs 随机初始化, 功率限制 (Power throttling), 矩阵乘法
- 常量输入张量减少 GPU 位翻转: 一位成员指出,使用常量输入张量会导致 GPU 翻转更少的位,由于寄存器中的值不发生变化,从而减少了功率限制 (power throttling)。
- 有人建议使用
torch.ones应该会产生与零初始化类似的效果。
- 有人建议使用
- 零初始化比全 1 初始化略快: 一位成员幽默地指出,使用零 (zeros) 初始化比使用全 1 (ones) 初始化稍微快一点。
- 这一观察为正在进行的初始化方法讨论增添了幽默色彩。
- 早期 GB200 Bring-Up 与随机初始化: 在早期 GB200 的 Bring-up 阶段,由于功耗调优(power tuning)尚不成熟,使用均匀随机值进行初始化比使用正态分布值快 20%。
- 也有人建议,虽然现在的差距可能已经缩小,但这个轶事突显了功耗调优对性能的影响。
- 奇特的矩阵乘法优化: 分享了一张图片,指向一篇讨论 奇特优化的矩阵乘法 的文章。
- 这篇文章可能为 GPU 上矩阵运算的性能特性提供额外的背景或见解。
GPU MODE ▷ #cuda (10 条消息🔥):
Cute DSL 和 SM12x, Thor 的 TMem, Texture Memory 优势, DMMA/HMMA
- **Cute DSL 在 SM12x 上的进展: 一位成员分享了针对 **sm12x 的 cute dsl fa 的进展,遇到了与 GPU 架构不匹配相关的错误:expects arch to be one of [Arch.sm_100a, Arch.sm_100f, Arch.sm_101a, Arch.sm_101f, Arch.sm_110a, Arch.sm_110f], but got Arch.sm_121a。
- 建议是确保 CUTE_DSL_ARCH 环境变量与 GPU 架构匹配。
- 确认 **Thor 的 TMem 存在: 一位成员询问 **Thor 是否具有 TMem (Texture Memory),并引用了 NVIDIA 的 cutlass GitHub 仓库。
- 另一位成员确认 Thor 的 Tensor Cores 来自 GB200。
- 寻找 **Texture Memory 使用案例: 一位成员询问受益于 **Texture Memory 的真实案例,寻求关于何时以及如何应用它的见解,并附带了一个 Stack Overflow 回答 的链接。
- 他们请求提供详细说明其应用的示例、博客或论文。
- **DMMA/HMMA 混淆澄清: 一位成员询问 **DMMA/HMMA 及类似指令是否与 Tensor Cores 有关。
- 另一位成员澄清说,Blackwell 有两个 Tensor 流水线:快速的 tcgen05(即那些 UTC 指令)和一个为了向后兼容而独立的 MMA 流水线*。
GPU MODE ▷ #torch (2 条消息):
SemiAnalysis 文章
- 达成 SemiAnalysis 的“成人礼”: 一位用户分享了一张截图,显示他们在 SemiAnalysis 文章 中被提及。
- 该用户幽默地将其描述为“一场成人礼”。
- 认可成就: 对于社区成员来说,被 SemiAnalysis 的文章报道是一个值得注意的事件。
- 这标志着在技术分析领域获得了认可,特别是在与 GPU 和 AI 相关的领域。
{kind=link}
GPU MODE ▷ #cool-links (1 messages):
DGEMM Accuracy, Reduced Precision Tensor Cores, Ozaki Scheme
- Ozaki Scheme:利用低精度 Tensor Cores 实现高精度 DGEMM:一篇新论文 Guaranteed DGEMM Accuracy While Using Reduced Precision Tensor Cores Through Extensions of the Ozaki Scheme 探讨了使用 INT8 tensor cores 来模拟 FP64 密集 GEMM。
- 他们的 ADP 方法在处理棘手输入时能保持 FP64 保真度,且运行开销低于 10%。在 55 位尾数(mantissa)设置下,相比原生 FP64 GEMM,在 NVIDIA Blackwell GB200 和 RTX Pro 6000 Blackwell Server Edition 上分别实现了高达 2.3x 和 13.2x 的加速。
- 利用 INT8 Tensor Cores 模拟 FP64:研究人员正在探索使用 INT8 tensor cores 来模拟 FP64 密集 GEMM,旨在提高性能的同时保持精度。
- 该方法利用 Ozaki Scheme,在 NVIDIA Blackwell GB200 和 RTX Pro 6000 Blackwell Server Edition 上展现了令人期待的加速效果。
GPU MODE ▷ #jobs (1 messages):
AI in Automotive, Internship Opportunity, Autonomous Tech, Car Safety Automation, Telematics Company
- Vital AI 为汽车安全招募实习生:一家汽车行业的自动化远程信息处理(telematics)公司正在寻求实习生,利用 A.I. 汽车安全技术构建自动驾驶技术的未来。
- 有意向的候选人可以将简历发送至 vitalAi.ceo@outlook.com。
- AI 驱动的汽车安全实习岗位:一家专注于汽车安全 AI 的汽车公司提供实习机会。
- 该公司专注于自动化远程信息处理,旨在推进自动驾驶技术。
GPU MODE ▷ #beginner (8 messages🔥):
NVIDIA accelerated computing hub course, Thrust library, CCCL (CUDA C++ Core Libraries), Model inference and optimization, Open source repos
- **Accelerated Computing Hub 使用 Thrust 库:一位刚接触 CUDA 和 C++ 的用户正在学习 NVIDIA accelerated computing hub 课程,并注意到该课程使用了 **Thrust 库。
- 另一位用户确认了这一点并提供了相关 notebook 的链接,但指出该库似乎已被归档。
- **CCCL 包含最新的 Thrust:有用户指出,最新版本的 **Thrust 可以在 NVIDIA/cccl 仓库中作为 CCCL (CUDA C++ Core Libraries) 的一部分找到,并随 CUDA Toolkit 一起打包。
- 该用户还澄清说,
cuda::[std::]下的所有内容也属于 CCCL(在 libcudacxx 目录下)。
- 该用户还澄清说,
- 文档未说明如何获取 CCCL:一位用户想知道是否应该链接 CCCL 文档,但指出文档并没有解释如何获取 CCCL。
- 他们补充说,GitHub readme 是唯一包含该信息的地方。
- 用户希望专注于模型优化**:一位用户表达了对模型推理与优化**的兴趣,并希望从事相关工作。
- 他们正寻求参与一些使用 vLLM 和 SGLang 等推理引擎的项目,并询问贡献开源仓库是否是下一步的好选择。
GPU MODE ▷ #irl-meetup (2 messages):
Toronto Meetup, TSFM Event
- 多伦多 TSFM 演讲:一位成员宣布他们将于周六在多伦多的 TSFM 举办工作组演讲,详情见此 Luma 链接。
- TSFM 活动推荐:一位成员强烈推荐参加 TSFM 的系列活动。
GPU MODE ▷ #self-promotion (23 条消息🔥):
MACKO-SpMV, Unstructured Weight Sparsity, GEMV, Koyeb Sandboxes
- MACKO-SpMV 让稀疏性更高效:一种新的矩阵格式和 SpMV kernel (MACKO) 在消费级 GPU 上针对 50% 稀疏度 实现了比 cuBLAS 快 1.2x 到 1.5x 的加速,同时减少了 1.5x 的内存占用。详情见 博客文章 和 论文,以及 开源代码。
- 该技术在 30-90% 的非结构化稀疏范围内优于 cuBLAS、cuSPARSE、Sputnik 和 DASP,可转化为端到端的 LLM 推理,但目前主要针对 RTX 4090 和 3090 等消费级 GPU。
- 关于 GEMV 与矩阵乘法的思考:虽然 MACKO 目前仅支持矩阵-向量乘法 (GEMV),但由于内存限制,矩阵-矩阵乘法仅在小批量 (small batches) 情况下能看到加速。
- 一位成员指出 TEAL 利用了激活值上的非结构化稀疏,通过直接指示跳过加载权重矩阵的哪些部分来简化问题。
- Koyeb 为 AI Agents 推出 Sandboxes:Koyeb 推出了 Sandboxes,用于在 GPU 和 CPU 实例上安全且大规模地编排和运行 AI 生成的代码。
- 这些沙箱旨在为 AI Agents 提供快速、可扩展且完全隔离的环境。
GPU MODE ▷ #🍿 (4 条消息):
TUI kernel submission, CLI feedback, Popcorn CLI naming
- TUI 终结者?:一位成员询问是否有办法在提交 kernel 时避免使用 TUI,并建议指定
--output应该直接打印输出。- 该成员建议应将仅命令行作为默认设置,并使用
--tui标志来调出界面。
- 该成员建议应将仅命令行作为默认设置,并使用
- CLI 讨论频道选择:一位成员被要求将反馈定向到特定频道。
- 另一位成员误以为该频道是 Popcorn CLI 聊天。
- Popcorn CLI 需要新昵称:一位成员建议重命名 CLI,因为对该频道的用途存在混淆。
- 另一位成员表示,他们很乐意接受针对客户端更改的 PR。
GPU MODE ▷ #thunderkittens (1 条消息):
TK Library, ipc/vmm
- TK Library 目标是仅头文件的轻量化:TK Library 的目标是保持为一个轻量级的、仅头文件的库。
- 项目维护者正积极避免外部依赖以保持其轻量级特性,节点间通信 (inter-node communications) 正在开发中。
- ipc/vmm 细节:该库使用 ipc/vmm 进行进程间通信和虚拟内存管理。
- 注意:节点间通信尚在开发中。
GPU MODE ▷ #edge (2 条消息):
Qualcomm GPU vs NPU, Qualcomm Vulkan
- Qualcomm GPU-NPU 团队是独立的吗?:一位用户询问 Qualcomm 的 GPU 和 NPU 团队是否完全独立。
- 另一位用户回应称,他们仅在 Qualcomm 上有使用 Vulkan 和 OpenCL 的经验。
- Qualcomm SDK 专注于 Vulkan 和 OpenCL:一位用户询问了 Qualcomm 的 GPU 和 NPU 团队。
- 另一位用户表示,他们主要在 Qualcomm 平台上使用 Vulkan 和 OpenCL 工作。
GPU MODE ▷ #submissions (12 条消息🔥):
NVIDIA leaderboard submissions, nvfp4_gemv benchmark
- NVIDIA 的 nvfp4_gemv 排行榜竞争激烈:多位用户向 NVIDIA 的
nvfp4_gemv排行榜提交了结果,提交 ID 从 84284 到 89065 不等。- 一位用户以 22.5 µs 的成绩获得了 第 2 名。
- 基准测试盛况:新个人最佳成绩达成:一位用户在 NVIDIA 上以 85880 的提交 ID 刷新了个人最佳成绩,耗时 33.6 µs。
- 在 NVIDIA 上有多次成功提交,时间范围从 25.4 µs 到 40.5 µs。
GPU MODE ▷ #cutlass (13 条消息🔥):
Thread Value Layouts, CUTE DSL, Blackwell, CUTE DSL 中的 fabs() 函数
- 讨论自定义 Thread Value Layouts:一名成员询问如何创建具有平铺维度的特定线程值布局,例如
thr_layout = ((2,32), (32, 1))和val_layout = ((1,2), (1, 1))。- 会议澄清,由于
make_layout_tv强制执行紧凑布局(compact layouts),直接实现特定线程的非相邻值排列是不可能的,建议使用自定义布局定义并配合带有布局分区的 copy atom。
- 会议澄清,由于
- 关于 CUTE DSL 中条件执行的疑问:一名成员在 CUTE DSL 中寻找类似于 C++
if (thread0) {...}的 API 以实现条件执行,但发现使用线程和 block 索引的标准if条件确实有效。- 该用户最初因输出量巨大而误以为其无效,但在重新评估后确认其功能正常,并指出考虑多维线程设置的重要性。
- 确定 fabs() 函数的正确用法:一名成员询问如何在 cutedsl 中调用
fabs()函数。- 另一名成员展示了调用
fabs()函数的方法,需要使用from cutlass._mlir.dialects import math as mlir_math; mlir_math.absf。
- 另一名成员展示了调用
GPU MODE ▷ #singularity-systems (3 条消息):
书籍写作过程, 多伦多演讲, sitp 第 1 和第 2 部分
- 书籍写作如同绘画素描:一名成员分享了他们书籍第 1 和第 2 部分的良好进展,将写作过程描述为“像画素描一样”,需要“多次润色”。
- 周六在多伦多的演讲:一名成员宣布他们将于周六在多伦多 <@539854300881354762> 的 tsfm 发表演讲,链接见此处。
- sitp 第 1 和第 2 部分:一名成员分享了 sitp 第 1 和第 2 部分的链接:第 1 部分 和 第 2 部分。
GPU MODE ▷ #multi-gpu (1 条消息):
DMA Collectives, ML 通信卸载, AMD Instinct MI300X GPU, RCCL 通信集合库
- DMA Collectives 提升 ML 通信效率:一篇新论文(DMA Collectives for Efficient ML Communication Offloads)探讨了将机器学习(ML)通信集合(communication collectives)卸载到直接内存访问(DMA)引擎。
- 研究表明,这种方法在推理和训练中有效地重叠了计算与通信,通过释放所有 GPU cores 用于计算,并降低对内存子系统(caches)的干扰,提供了卓越的并发性能。
- AMD MI300X GPU 展示了 DMA 的潜力:在最先进的 AMD Instinct MI300X GPU 上的分析显示,对于大尺寸数据(10s of MB 到 GB),DMA collectives 在性能(提升 16%)和功耗(降低 32%)方面均优于或持平于最先进的 RCCL 通信集合库。
- 研究指出,DMA 命令调度和同步开销可能会限制 DMA collective 的性能,但优化后的实现显著缩小了小尺寸数据下 DMA collectives 的性能差距(all-gather 慢 30%,all-to-all 快 20%),并进一步提升了大尺寸下的性能(提升 7%)和节能效果(提升 3-10%)。
GPU MODE ▷ #helion (13 messages🔥):
Triton bug, Helion workarounds, Helion support for FP8 BMM, Helion inline Triton function
- Triton Bug 导致错误:一位成员遇到了由于 illegal instruction(非法指令)导致的 CUDA error,这被确定为 Triton 中的 bug,并建议向 OAI Triton 团队报告。
- 用户被提示使用环境变量来获取用于报告 bug 的 Triton code。
- Helion 变通方案并不理想:在发生 Triton error 后,由于 Helion’s logger 中定义的不可恢复错误分类,Helion 内部没有直接跳过并继续的方法。
- 唯一建议的变通方案涉及通过 hack 手段从候选配置列表中 识别并移除有问题的配置。
- Helion 支持 FP8 BMM:Helion 有一个 FP8 GEMM 示例 (fp8_gemm.py),因此添加它非常简单。
- Helion 轻松内联 Triton 函数:一位成员询问如何在 Helion 中轻松内联
@triton.jit函数,另一位成员提到这已在他们的议程中。- 该成员随后提供了一个 pull request 来解决此问题,并因为即将休假 (PTO) 而请求反馈。
GPU MODE ▷ #nvidia-competition (24 messages🔥):
GitHub Status Down, Gemini 3 Pro Blackwell Confusion, HTML to Markdown Conversion, NVIDIA Documentation Restrictions, PTX Documentation Conversion to Markdown
- GitHub 宕机了!:一位用户报告了
Application error: Server processing error,怀疑与 GitHub 宕机的 GitHub incident 有关。- 错误信息显示存在 5 分钟超时问题,与 GitHub 停机时间吻合。
- Gemini 3 Pro 在 Blackwell 上犯错!:一位用户发现 Gemini 3 Pro 在提示后对 Blackwell 一无所知,称该 LLM 的回答是在 胡言乱语 (spewing absolute bs)。
- 用户进一步强调,这是 Gemini 3 Pro 不承认自己缺乏知识的一个案例,其他人也观察到了这个问题。
- NVIDIA 文档的 Markdown 魔法!:一位用户分享了一个用于将 HTML 转换为 Markdown 的 CLI tool,专门用于将 NVIDIA documentation 转换为 Markdown。
- 该 CLI 工具需要启用可选的 table 标志,用户还指出,由于 NVIDIA 的复制限制,成品 不能分享。
- PTX Hacking 指南!:一位用户描述了一种方法,在使用 html-to-markdown 转换后,利用正则查找/替换和 Claude 解析目录,将 PTX documentation 转换为合理的树状结构。
- 用户警告说,由于 NVIDIA 对复制的许可限制,生成的转换文档不能公开分享。
- 仓库中的 Tensor 问题!:一位用户报告了在仓库 @db8cfd3 中调用 generate inputs(参数为
m=64,k=256,batch_size=1)时,sfb_ref_cputensor 的形状不一致:预期形状为[1, 16, 1],但实际得到[128, 16, 1]。- 另一位用户澄清说,由于 torch 的技术问题 (skill issues),该 tensor 被 填充到了 128,剩余的行可以忽略。
GPU MODE ▷ #robotics-vla (14 条消息🔥):
ManiSkill 内部机制, 开源 VLA 训练库, 自动化场景变换, VLM 控制的 Rollouts, 仿真中的远程操作 (Teleop)
- **ManiSkill 内部机制探究: 一位成员研究了 **ManiSkill 的内部结构,指出其依赖于源代码和 ipynb 探索,以及它在构建用于自动化场景变换的 Agent 方面的实用性。
- 他建议 VLM 可以控制初始 rollouts,将经典的 RL 与运动规划 (motion planning) 和远程操作 (teleop) 相结合,并希望创建一个 优秀的开源 VLA 训练库。
- 数据采集策略讨论: 一位成员考虑使用 ManiSkill 来自动变换场景和任务,利用 VLM 控制初始 rollouts,以此作为经典 RL、运动规划和远程操作的数据采集替代方案。
- 他们还提议通过浏览器使用 VR 或键盘/手柄控制在仿真中进行远程操作,作为另一种获取人类演示数据的便捷方法。
- VLA 还原魔方引发关注: 一位成员分享了一个使用 VLA 进行底层指令控制来还原 Rubik’s Cubes (魔方) 的项目链接,强调了在文本条件多任务 VLA 方面的进展。
- 分享的链接是一条推文,可以在这里找到:Michaelrazum。
- **PhysX-Anything 介绍: 一位成员分享了 **PhysX-Anything 的链接作为感兴趣的项目,未提供更多背景。
- 该项目可以在这里找到:PhysX-Anything on Github。
Modular (Mojo 🔥) ▷ #general (2 条消息):
Mojo, MAX 框架, PyTorch, Basalt 框架
- Mojo 引发框架热议: 用户对 Mojo-based 框架 的现状感到好奇,特别是在注意到 Basalt 框架 已被归档之后。
- 一位成员询问 Modular 内部是否有愿景去创建一个完全基于 Mojo 构建的 PyTorch 式框架。
- MAX 框架结合 Mojo 与 Python: 一位 Modular 代表澄清说,得益于与 Python 的互操作性,框架不需要完全用 Mojo 重写就能从中受益。
- MAX 框架 是他们的方法,其接口使用 Python 构建,但所有 kernels 和底层代码都在硬件上以 Mojo 运行。他们正在为 MAX 开发一个新的 API,试图将 PyTorch 的易用性与 MAX 和 Mojo 的性能结合起来。
Modular (Mojo 🔥) ▷ #mojo (142 messages🔥🔥):
Mojo 中的 Arc 安全性、间接来源 (Indirect Origins)、Mojo 中的垃圾回收 (GC)、自定义分配器、异构内存与多设备
- ArcPointer 安全性与 UB 担忧:一位用户发现,由于
ArcPointer.__getitem__总是返回可变引用,在调用a==b的函数时存在潜在的 UB 错误,这可能是不允许的,并涉及到一个更大的“间接来源 (indirect origins)”问题。- 有人指出
Arc是在多次引用重构之前构建的,很可能在某次批量重构中出了问题,建议对所有集合和智能指针进行审计,以排查类似问题。
- 有人指出
- Greenthreads 与垃圾回收 (Garbage Collection):一位用户表示,希望 Mojo 在需要时能有垃圾回收机制,以提升高级代码的编写体验,但这引发了关于低级代码不兼容和性能损失的讨论,因为许多库在没有 GC 的情况下无法工作。
- 辩论认为,是否使用 GC 的决定应该尽早做出,一些人建议如果确实需要,可以针对特定事物使用作用域 GC (scoped GCs)。
- UnsafeCell 与内存管理:讨论了 Mojo 中对 UnsafeCell 等效项的需求,强调了目前缺乏专门的共享可变类型 (shared mut type) 的问题非常明显,同时也需要引用失效 (reference invalidation) 机制。
- 提到了在 arena 中分配循环类型的主题,一位成员提到在编写图数据库 (graph DB) 时使用了这种方法,并使用了一个几乎与 Java 的 ZGC 一样快的标记-清除 (mark and sweep) GC。
- Mojo 内置 GC 的挑战:内置 GC 无法像自定义 GC 那样利用程序的各种不变性 (invariants),因为它必须扫描不仅是 CPU,还有每一个有活动连接的 GPU 的整个地址空间。
- 一位成员表示:如果你想要 GC 和高级代码,为什么不在这些情况下直接使用 Python 与 Mojo 进行互操作呢?,并指出 PyObject 基本上可以工作,但类型丢失确实很糟糕。
- 内存异构问题:一些成员讨论了在将数据移动到其他内存区域时,不同设备(CPU/GPU/NPU)上的内存管理问题,以及是否可能避免“数据驻留在一台设备上但被另一台设备使用”的问题,并对其进行实际追踪?
- 共识是这会变得很复杂,因为必须将最小生命周期绑定到 kernel,尽管在线性类型 (linear types) 在已知设备数量的情况下可能会有所帮助。
Modular (Mojo 🔥) ▷ #max (1 messages):
设备追踪 (Device Tracing)、Perfetto 集成
- 关于 Max 中设备追踪支持的咨询:一位成员询问 Max 是否支持设备追踪并转储可以像 Pytorch profiler 那样在 Perfetto 上打开的追踪文件。
- 等待关于 Max 设备追踪能力的回复:社区正在等待关于是否能从 Max 生成兼容 Perfetto 的追踪文件以进行性能分析的回复。
Nous Research AI ▷ #announcements (1 messages):
Atropos RL 环境、Thinking Machines 的 Tinker 训练 API
- Atropos 获得 Tinker 支持:Atropos RL Environments 框架现在全面支持 Thinking Machines 的 Tinker 训练 API,从而能够通过 Tinker API 在各种模型上更轻松地训练和测试环境。
- Nous Research 发布关于 Atropos 和 Tinker 的推文:Nous Research 宣布其 RL Environments 框架 Atropos 现在全面支持 Thinking Machines 的 Tinker 训练 API。
Nous Research AI ▷ #general (95 messages🔥🔥):
Google Antigravity, Gemini 3 single shot realtime raytracer, Open Source, China alternative Strategy, Agentic A.I tools for financial traders, Deepmind Gemma 3
- **Google 的 Antigravity 提供 Sonnet 访问权限:Google 的 **antigravity 服务提供了对 Sonnet 的访问权限,尽管目前如附图所示处于过载状态。
- **Gemini 3 驱动实时光线追踪:Gemini 3** 成功执行了单次实时光线追踪(realtime raytracer)任务,表现令人印象深刻,详见附图。
- **金融交易员利用 Agentic A.I.:一位成员分享了金融交易员利用 **Agentic A.I. 工具赚钱的实际案例,这需要如此 YouTube 视频中所述的领域专业知识。
- **Heretic 库获得关注与好评:新发布的 **Heretic 库正受到关注,一位成员报告在 Qwen3 4B instruct 2507 上使用成功,并建议将
--n-trials设置为 300-500 以获得最佳效果。- 在测试 Heretic 库并运行各种提示词后,一位成员感叹道:Heretic 太棒了,你应该立即尝试。
- **下一代:今日的 Codex Max:一位成员开玩笑说,备受期待的 **GPT-5.1-Codex-Max 发布恰逢他们忙碌之时,这给 Anthropic 留出了发布 Opus 4.5 的时间。
- 另一位成员分享了 IntologyAI 的链接,该文章提到他们在 RE-Bench 上超越了人类专家。
Nous Research AI ▷ #ask-about-llms (1 messages):
bird0861: persona vector 时刻
Nous Research AI ▷ #interesting-links (5 messages):
Atropos Tinker, Gemini Training Recipe, Negativity Bias
- Atropos Tinker 发布:Atropos Tinker 项目已启动。
- 该项目的目标和实现细节可在链接的 GitHub 仓库中找到。
- Gemini 训练配方怪癖曝光:模型出现的问题似乎也发生在其他 Gemini 模型上,这指向了 Gemini 训练配方(training recipe)中的一个问题。
- 更多信息可以在 X.com 上找到。
- RP 模型中可能发现负面偏见:研究人员可能发现了一种负面偏见(negativity bias),这可能与之前话题中看到的问题相关。
- 需要进一步调查以验证这一假设。
Eleuther ▷ #general (6 messages):
RE-Bench, Mallas, Alignment, Confidential Computing, Monomorphic Encryption, ML Trojans, JEPAS, long form fictional content
- 主任工程师准备投入开发:一位主任工程师正在寻找与 Mallas, Alignment, Confidential Computing, Monomorphic Encryption, ML Trojans, JEPAS 相关的项目。
- 他鼓励感兴趣的各方联系协作。
- 无家可归者使用 LLMs 创作长篇虚构内容:一位来自旧金山的无家可归成员分享说,他利用 LLMs 生成了具有真正高质量的长篇虚构内容。
- 他还表示,他使用了从 RP 群体中学到的技巧,以及他自学的编程和 Linux 知识。
- AI 表现超越人类专家:一位成员分享了关于 AI 在 RE-Bench 上超越人类专家的链接 https://x.com/IntologyAI/status/1991186650240806940。
- 未提供进一步的讨论或背景。
Eleuther ▷ #research (64 messages🔥🔥):
VWN A, B 矩阵澄清,线性注意力对比,代数拓扑 Q-learning,Zeckendorf 位格,推理时认识层(epistemics layer)与幻觉减少
- VWN 矩阵:令人困惑的维度:成员们讨论了虚拟宽度网络(VWN)中 A 和 B 矩阵的维度,质疑 B 是否真的是带有块(chunk)维度的 (m x n),还是更稠密,并对图表如何表示尺寸表示普遍困惑。
- 有人建议,这种差异可能是由于在论文中将 einsum 符号从代码翻译为矩阵符号时出现了错误,并且矩阵可能具有额外的通道维度来处理每个块的通道。
- 线性注意力是 VWN 的近亲?:VWN 实际上是在做线性注意力,但 state[:, :] += … 的更新不是在 token 之间发生,而是在层与层之间发生。
- 用线性注意力的术语来说,
key_dim对应 VWN 的m,num_heads对应 VWN 的n,value_dim对应 VWN 的D'/m,而state则是 VWN 的H'。
- 用线性注意力的术语来说,
- 通过信息价值检查对抗幻觉:一位成员一直在实验一种推理时认识层(inference-time epistemics layer),在模型提交答案之前进行简单的信息价值(Value-of-Information)检查。
- 该层利用基于 logit 的置信度来估计回答的预期效用是否高于推迟回答。在对小型 7B 模型的初步测试中,它减少了约 20% 的幻觉。
- 关于 Qwen 准确率的 Global-MMLU-Lite 混淆:一位用户分享了一种幻觉抑制方法,但其 Qwen 7b 模型的 MMLU 准确率结果受到了质疑。
- 有人指出,声称的接近随机猜测的表现异常之低,因为即使是 3B 模型在 MMLU 上的得分也应 >65;此外,使用 Global-MMLU-Lite 与 MMLU 是完全不同的数据集,正如该数据集文档所解释的那样。
- 主题重加权(Topic Reweighting)成为热议话题:一位成员分享了一篇关于 Topic Reweighting 的博客文章。
- 有人认为这可能是对之前问题的回答,但其他人指出了它在特定案例中的具体用法。
Eleuther ▷ #scaling-laws (3 messages):
近似 KNN,SETH 对 KNN 的影响,亚指数 3-SAT
- 近似 KNN 的 O(n^2) 不可能性:有人认为,除非 SETH 为假,否则在任意数据上实现近似 KNN 至少需要 O(n^2) 的复杂度。
- 一位成员对这种确定性表示谨慎,并类比了 Cooley-Tukey 算法出现之前的观点,即由于需要比较每个数据点,离散傅里叶变换必然是二次复杂度的。
- 规避 KNN 二次瓶颈的路径:一种可能的解决办法是,如果模型性能并不需要类似 ANN 的任务,这将允许 O(seqlen) 复杂度的模型出现。
- 另一种解决办法可能是以亚指数时间解决 3-SAT 问题。
Eleuther ▷ #interpretability-general (3 messages):
稀疏 MoE 与稠密模型,基于 SAE 的方法,基于可解释性的干预
- 稀疏模型引发可解释性辩论:成员们讨论了使用稀疏 MoE 模型进行可解释性研究相对于直接分析稠密模型的价值。
- 对话涉及在稀疏模型中发现的电路(circuits)是否可以在现实世界的模型中复制,质疑该方法是否可行,以及是否可以作为基于 SAE 方法的替代方案。
- 通过块交换弥合差距:有人提到存在一种桥接系统,允许将稠密块替换为稀疏块。
- 这种能力实现了基于可解释性的干预,这可能是一个有用的工具。
Eleuther ▷ #lm-thunderdome (7 messages):
Instruction Following Benchmarks, Text to SQL Tasks
- 指令遵循基准测试引发关注:有成员询问了关于 Self-instruct、NaturalInstructions、Super-NaturalInstruction 和 FLAN 等指令遵循基准测试的评估支持。
- 另一位成员确认了对 FLAN 的现有支持,建议为其他项目创建 issue,并随后链接了 issue #3416。
- Text-to-SQL 任务支持查询:有成员询问了 harness 中对 text-to-SQL 任务 的现有支持。
- 在初步询问后,没有后续跟进或进一步讨论。
Moonshot AI (Kimi K-2) ▷ #general-chat (72 messages🔥🔥):
Gemini 3, DeepSeek V4, GLM 5, Kimi K2 Thinking, AI assisted dataset creation
- Gemini 3 重夺榜首:成员们注意到 Gemini 3 在基准测试中重夺榜首,尽管 Kimi K2 Thinking 在 Tau bench 的 Agentic 编程和带工具的 HLE 方面仍处于领先地位。
- 一些 Reddit 帖子建议 Gemini 3 在创意写作方面甚至落后于 Gemini 2.5,尽管它在许多其他通用任务中处于 SOTA 状态。
- 尝试将 API 接入 n8n:一位成员正在尝试将 Gemini API 接入 n8n 以构建自己的 Computer,并表示这 需要一些工作,但期待看到它的表现。
- 经过几次尝试,该成员似乎已经解决了问题。这是他们桌面的截图。
- 关于 Gemini 3 规模的推测:有推测认为 Gemini 3 可能是一个 10T 参数模型,由于推理成本高昂,定价可能与 Anthropic 相似。
- 一位成员推测,Gemini 应用上 Gemini 3 的消息限制非常小,是因为 Google 正在极限使用其推理算力。
- Kimi K2 Thinking 作为全能选手表现出色:Kimi K2 Thinking 被一些人认为是开源世界中最接近 GPT-5 的存在,特别是在创意写作和编程方面。
- 一位成员发现将其与 Gemini 3 结合使用效果 特别好,即使用 Kimi K2 Thinking 作为执行者 (worker),Gemini 3 作为规划者 (planner)。
- Kimi 编程方案定价受到批评:Kimi 的 19 美元编程方案 被认为比较苛刻,因为与 Claude 相比限制较多,特别是对于学生、独立开发者和爱好者而言。
- 有人建议推出 7-10 美元档位,以提高可及性,并使其在日常开发工作中的使用更具合理性。
HuggingFace ▷ #general (56 条消息🔥🔥):
Gemini 3, KTOtrainer 内存占用, Hugging Face 计费问题, MCP 等行业标准, ReLU 激活函数
- Google 发布了反重力技术(据称): 一名成员开玩笑称 Google 发布了 反重力 技术,并且 Gemini 3 正在解决编译原理课程的作业。
- 其他人表示怀疑,指出 Gemini 3 在工具调用(tool usage)方面表现很差,而且人们仍然需要真正的程序员。
- KTOTrainer 内存消耗困扰: 一位用户询问为什么 KTOtrainer 如此耗费内存,报告称一个 0.5B 模型占用了 80 GB GPU 计算资源。
- 另一名成员详细解释了高内存占用的原因,包括同时运行两个模型、每个 batch 进行两次前向传递、长填充序列以及已知的 CUDA 内存预留过高问题,点击此处查看更多详情。
- Hugging Face 黑客松计费混乱: 一位用户报告称,在黑客松期间提供信用卡信息后被收取了订阅费用,并怀疑 Hugging Face 是否在诈骗学生。
- 另一位用户建议联系 billing@huggingface.co,而另一位用户则讽刺地表示这是你没阅读订阅条款/服务条款(TOS)的错。
- 寻求 MCP 标准指导: 一名成员正在寻求行业专家的指导,了解 MCP 等标准是如何制定的,其长期目标是构建一个被广泛采用的标准。
- 有人指出那里似乎也是一样的情况,并附上了 HuggingFace 讨论链接。
- ReLU 详解:为何它效果卓著: 一名成员解释了为什么 ReLU 表现良好,理由是它的简单性、低计算成本、梯度友好性以及创建稀疏激活(sparse activations)的能力。
HuggingFace ▷ #i-made-this (3 条消息):
微调 OpenAI 推理模型, TruthAGI.ai 发布, pg_ask PostgreSQL 扩展
- 微调后的医疗推理模型亮相: 一名成员使用医疗推理数据集微调了 OpenAI 的 OSS 20B 推理模型,并将结果发布在 Hugging Face 上。
- 该模型可以逐步分解复杂的医疗案例,识别可能的诊断,并以逻辑推理回答执业考试风格的问题。
- TruthAGI.ai 作为高性价比 AI 门户发布: TruthAGI.ai 已发布,提供在一个地方访问多个高级 LLM 的功能(OpenAI, Anthropic, Google AI & Moonshot)。
- 它包含用于更安全响应的 Aletheion Guard 和极具竞争力的定价;发布奖励在 注册 时提供免费额度。
- pg_ask 通过 AI 扩展 PostgreSQL: 一名成员构建了 pg_ask(一个 PostgreSQL 扩展),并为此撰写了一篇博客文章。
- 博客文章地址:在 PostgreSQL 内部嵌入 AI:构建原生 C 扩展。
HuggingFace ▷ #computer-vision (1 条消息):
图像分类器, CNN vs. Vision Transformers, 多类别与多标签图像分类
- 图像分类器架构大比拼:CNN vs Vision Transformers!: 一名新成员正在为医疗图像构建多类别和多标签图像分类器,旨在根据 Logo 识别付款方并确定文件类型(信函/Letter、福利说明/EOB 等)。
- 他们正在权衡 CNN 和 Vision Transformers 之间的选择以实现这一目标。
- 医疗图像分类:多标签多类别任务: 一位新用户正在深入研究医疗图像分类领域,重点关注多类别和多标签分类。
- 该任务涉及从 Logo 中识别付款方并对文件类型(如 Letter 或 EOB)进行分类,并提出了 CNN 或 Vision Transformer 模型是否更合适的问题。
HuggingFace ▷ #NLP (1 messages):
NLP, Named Entity Recognition (NER), Multilingual Models, Transformer Models
- NER 研究员寻求多语言模型评估:一位成员正在深入研究 Transformers 和 NLP(特别是 NER),并对目前可用的大量模型感到不知所措。
- 他们正在寻找一个包含模型评估的入门页面,特别是关于模型训练语言的信息,因为许多模型是针对英语进行微调的,忽略了其他语言。
- 对以英语为中心的 NER 模型感到沮丧:该成员对大量主要针对英语微调的 NER 模型表示沮丧,这导致在其他语言中的准确性出现问题。
- 他们觉得可能是自己的期望过高,或者遗漏了某些信息,并强调了在数百个可用模型中进行筛选的难度。
HuggingFace ▷ #smol-course (2 messages):
Introduction to the smol-course channel
- 新成员加入 smol-course:一位新成员向 smol-course 频道介绍了自己。
- 欢迎新成员:smol-course 频道的成员们正在欢迎新加入的成员。
HuggingFace ▷ #agents-course (1 messages):
wilecoyotte_77610: 微调课程的第二个单元有证书吗?
Yannick Kilcher ▷ #general (25 messages🔥):
Grok 4.1 Benchmarks, NeurIPS 2025 Meetup, Gemini 3 Speculation, AI CEO Benchmark, HuggingFace Xet Repository Setup
- **Grok 4.1 的基准测试仍在实验室中:一位成员询问 **Grok 4.1 是否比 Grok 4 差,另一位成员回答说它只是还没有进行基准测试,并链接到了 Artificial Analysis 排行榜。
- 附带的图片也是 Artificial Analysis 排行榜。
- 相约圣迭戈 NeurIPS 2025:一位成员询问是否可以在 12 月初在圣迭戈举行的 NeurIPS 2025 上线下见面,至少有一人表示感兴趣。
- 目前没有提供关于聚会的更多细节。
- **Gemini 3 的推测聚焦于 Scaling、RL 和炼金术:成员们推测了 **Gemini 3 背后的技术,包括扩展参数(scaling parameters)、推理时计算(inference time compute)、更好的 RL 算法/环境、数据质量、架构调整,甚至还有神力干预。
- 一位成员押注于整体理解、架构调整的经验搜索、部分理论、数据质量、更好的参数利用和 RL。另一位成员则简短地说是更好的微调(finetuning)。
- AI CEO 基准测试引发辩论:有人分享了 skyfall.ai 的博客文章,该文章通过一个商业模拟游戏展示了一个评估 Agent 长程规划(long-horizon planning)能力的新环境/基准测试,并指出 LLM 的表现似乎远低于人类基准。
- 一位成员指出,法律规定受托人必须是自然人,但建议 AI CEO 更多的是一种能力展现,而不是取代真实的人类。
- HuggingFace 仓库设置引发下载困扰:一位成员对 HuggingFace 上的 xet 仓库设置表示沮丧,抱怨为微调下载模型非常困难,且缓存位置出乎意料。
- 他们讽刺地补充道:我敢打赌,那个写脚本的人肯定很高兴,他的脚本每次运行都会先尝试第 5000 次下载同一个模型然后再使用。他现在一定会为脚本运行得这么快而感到高兴。
Yannick Kilcher ▷ #paper-discussion (8 条消息🔥):
Yannic Kilcher 关于 Transformers 的视频,SAM 3: Segment Anything with Concepts
- 社区寻求 Kilcher 的 Transformer 讲座:一位成员请求提供一份 Yannic Kilcher 的视频列表,按循序渐进的顺序解释 Attention 或 Transformer 相关的突破,以便更好地理解该主题。
- 另一位成员提供了一个 Yannic Kilcher 频道搜索 Transformers 的链接 以及一段特定的视频 The Wavefunction,并解释说该视频基于原始论文,尽管可能有点晦涩。
- SAM 3 使用概念分割“爱”:一位成员询问是否可以提示 SAM 3 (Segment Anything with Concepts) 来分割 爱,并引用了 Meta AI Research 的出版物。
- 另一位成员俏皮地引用了歌曲 What is Love? 进行回应,还有一位成员回复道:“喂你一个被诅咒的分形,它恰好写着 baby don’t hurt me。”
Yannick Kilcher ▷ #ml-news (23 条消息🔥):
Gemini 3 基准测试,OpenAI 救助计划,数学评论不满,Segment Anything Model 3,Cogito v2-1 分析
- **Gemini 3 在基准测试中表现出色:成员们注意到 **Gemini 3 令人印象深刻的基准测试表现,并质疑这究竟是由于 benchmaxxing(刷榜)还是真正的泛化能力。
- 有人提出疑问,性能提升是否会扩展到基准测试之外的任务,包括私有和新颖的任务。
- **OpenAI 被指寻求“预救助”:一位成员分享了来自 Silicon Valley Gradient 的文章,声称 **OpenAI 尽管予以否认,但仍向美国政府寻求“预救助”(pre-bailout)。
- 该说法暗示,密切关注局势的人士对 OpenAI 的否认持怀疑态度。
- 数学评论对新模型反应平平:一些成员分享了对某个新模型的负面数学评论,引用了一条表达不满的 推文。
- **SAM 3D 以分割技巧令人印象深刻:Meta AI 发布了 **Segment Anything Model 3 (SAM 3),并在 博客文章 中进行了展示。
- 特别地,一位成员强调 Sam3D 部分尤其令人印象深刻。
- **Cogito v2-1:DeepSeek 后训练阶段的挫折:根据 DeepCogito 研究,DeepSeek** 的后训练版本 Cogito v2-1 被指出表现不如其基础模型。
Latent Space ▷ #ai-general-chat (47 条消息🔥):
Palantir 成本 vs 定制化, Cursor CLI vs Claude Code, SAM 3, GPT-5.1-Codex-Max, LMSYS Miles 企业级 RL 框架
- Deedy 播客关于成本 vs 定制化的讨论:一名成员询问了 Deedy 在播客中讨论的 成本 vs 定制化矩阵,特别是 Palantir 是否被视为高成本和高定制化,另一名成员在 播客的 32:55 处 找到了相关引用。
- Cursor CLI:被低估的编程工具?:成员们讨论了 Cursor CLI 及其与 Claude Code 相比的能力。一位成员反馈称,虽然模型执行和代码质量尚可,但根据其 文档 显示,该 CLI 的其余部分目前看起来非常简陋,没有自定义斜杠命令 (slash commands)。
- Meta 发布用于分割的 SAM 3:Meta 发布了 SAM 3,这是一个支持文本/视觉提示词的统一图像/视频分割模型。官方声称其比现有模型快 2 倍,推理延迟仅 30ms。该项目包含一个用于无代码测试的 Playground,并在 GitHub/HuggingFace 上提供了 Checkpoints 和数据集,目前已驱动 Instagram Edits 和 FB Marketplace 的 View in Room 功能。
- Roboflow 宣布与 Meta 合作,将 SAM 3 作为无限可扩展的端点提供,允许用户使用纯文本(例如 green umbrella)获取像素级精确的掩码 (masks) 和物体追踪,并将 SAM 3 与 Claude 及 YOLO World 进行了对比。
- GPT-5.1-Codex-Max 危机公关:OpenAI 推出了 GPT-5.1-Codex-Max,该模型通过压缩技术原生训练,可跨多个上下文窗口运行,声称专为长期运行的详细工作而构建。
- 一些观察者将其定性为在其他产品发布后的危机公关,指出它以 20% 的性能提升换取了超过两倍的 Token 数量,并表示希望 OpenAI 能加大力度。
- LMSYS 衍生出 Miles RL 框架:LMSYS 介绍了 Miles,这是轻量级 slime RL 框架的生产级分支,针对 GB300 等新硬件以及大规模 Mixture-of-Experts 强化学习工作负载进行了优化。相关 GitHub 仓库 和 博客文章 详细说明了路线图和状态。
DSPy ▷ #general (26 条消息🔥):
LLM 的非确定性, GPT-OSS-20B 确定性, DSPy 生产环境社区, 通过 DSPy 在 Azure 上使用 Anthropic 模型, DSPy 用于推理
- LLM 非确定性的辩论:成员们讨论了在数据集上运行评估时应对 LLM 非确定性 的解决方案。一位用户报告称,使用
gpt-oss-20b在 316 个样本上达到了 98.4%-98.7% 的准确率,但每次出错的样本都不同。- 建议包括将 temperature 降至 0、调整
max_tokens、使输出格式更严格、固定 seed,以及探索使用dspy.CodeAct或dspy.ProgramOfThought以获得更具确定性的结果。
- 建议包括将 temperature 降至 0、调整
GPT-OSS-20B特定设置微调:一位用户分享了他们更新后的gpt-oss-20b设置,包括 temperature=0.01、presence_penalty=2.0、top_p=0.95、top_k=50和seed=42,并指出 temperature=0 反而会导致更多错误。- 通过这些设置,他们在 316 个样本中实现了稳定的 3-5 个错误。
- DSPy 生产环境频道愿望清单:一位成员询问是否有一个专门针对 DSPy 生产环境社区 的频道。
- 另一名成员回应称,虽然目前还没有,但确实应该建立一个。
- DSPy 推理对齐探讨:一位用户询问了 GEPA 与推理 (inference) 用例的对齐情况,寻求该方向的优质示例、教程、博客或指南。
- 消息中未提供具体的示例。
- LiteLLM 将支持 Azure 上的 Anthropic:关于通过 DSPy 在 Azure 上调用 Anthropic 模型,一位成员澄清这取决于 LiteLLM 添加支持(类似于 Azure 上的 OpenAI),并链接到了 LiteLLM Azure 文档。
aider (Paul Gauthier) ▷ #general (20 messages🔥):
Gemini 3 与 Aider 的集成,Aider 与 Ollama,GPT-5.1 在 Aider 中的问题
- Gemini 3 在 Aider 中的提升:用户讨论了在 Aider 中运行 Gemini 3,并提供了使用命令
aider --model=gemini/gemini-3-pro-preview --no-check-model-accepts-settings --edit-format diff-fenced --thinking-tokens 4k的说明。- 一位用户还建议使用
--weak-model gemini/gemini-2.5-flash以实现更快的提交。
- 一位用户还建议使用
- Ollama 为 Aider 提供更多选择:一位用户询问了关于将 Aider 与 Ollama 结合使用的问题。
- 讨论未进一步详细说明具体的配置或体验。
- GPT-5.1 的故障引发困扰:一位用户报告了 Aider 中 GPT-5.1 的问题,遇到了与
response.reasoning.effort验证相关的litellm.APIConnectionError。- 尽管将
reasoning-effort设置为不同级别(low, medium, high),问题依然存在,这可能表明 OpenAI 侧发生了变化或 Litellm 存在问题(相关 issue)。
- 尽管将
tinygrad (George Hotz) ▷ #general (8 messages🔥):
CI 中的 Llama 1B 基准测试,CPU 架构考量,torch.compile 与 tinygrad 的基准对比,Kernel 导入,CuTeDSL
- Llama 1B 旨在 CI 中实现更快的 CPU 性能:一项悬赏任务寻求在 CI 的 CPU 上实现比 Torch 更快的 Llama 1B 性能,引发了关于在测试框架中集成的提问,具体是是否在
tests/speed/external_test_speed_v_torch.py中添加新测试。- 讨论还包括澄清目标是特定的 CPU 架构还是所有支持的架构,并确认“模型速度”是指推理速度 (tokens/sec)。
- Tinygrad 在 CPU 上的 Llama 1B 表现优于 Torch:一位成员报告称,Tinygrad 上的 Llama 1B 在 CPU 上的表现已经优于 Torch,在使用
CPU_LLVM=1和 8 个 CPU 核心、仅进行前向传播且无模型权重的情况下,达到了 6.06 tok/s,而 Torch 为 2.92 tok/s。- 该成员和其他人正在考虑是否在
test/external中创建一个新的基准测试。
- 该成员和其他人正在考虑是否在
torch.compile基准测试:一位成员有兴趣与torch.compile的 PyTorch 实现进行基准对比。- 解决
extra/optimization中的 Kernel 导入问题:讨论建议修复extra/optimization文件中的from tinygrad.codegen.opt.kernel import Kernel导入。- 此外,还有建议删除近期未更新的损坏或未使用的 examples/extra 文件。
- 提到 CuTeDSL:一位成员分享了 SemiAnalysis 的推文 链接,内容关于 CuTeDSL。
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
tinygrad 错误修复,实验室故障排除
- Tinygrad 更新修复了神秘 Bug:一位用户报告称更新 tinygrad 解决了他们遇到的问题,并由附带的 图片 确认。
- 他们本想更早测试,但他们的实验室出了一些问题。
- 实验室故障延迟了 Bug 测试:用户提到他们的实验室出了一些问题,导致延迟了 tinygrad 的 Bug 测试。
- 这突显了软件测试和开发环境中的实际挑战。
Manus.im Discord ▷ #general (7 条消息):
Manus 积分系统变更, TiDB Cloud 访问问题, Gemini 3 与 Manus 集成, AI 编程教育
- **积分变动引发困惑:一位成员询问了关于 Manus 积分系统的变更,特别是关于转向 **每月 4000 次 重置的过渡,以及是否合并了之前的方案。
- 用户寻求澄清“每月重置”和“永不过期”方案是否已合并为单一的每月方案。
- **TiDB 问题引发第三方纠纷**:一位成员报告无法访问其通过 Manus 配置的 TiDB Cloud 账户,面临配额耗尽且缺乏用于管理账单或支出限制的控制台访问权限。
- 他们尝试使用
ticloudCLI,但缺少必要的 API keys 或 OAuth 登录,并询问了其他访问方法或直接支持渠道。
- 他们尝试使用
- **Gemini 时代开启?**:一位成员询问了 Gemini 3 与 Manus 集成的可能性。
- 另一位成员回应称,Gemini 3 Pro 加上 Manus 将会非常强大。
- **AI 倡导者面向初学者提供教学**:一位成员提供了 AI 编程教育,涵盖核心概念、高级模型、实际应用和伦理考量,并邀请感兴趣者私信进一步交流。
- 另一位成员对这种自我推广的适当性提出了质疑。
Windsurf ▷ #announcements (2 条消息):
Gemini 3 Pro, Windsurf, 软件发布
- Gemini 3 Pro 登陆 Windsurf!:根据 X 上的公告,Gemini 3 Pro 现已在 Windsurf 上可用。
- Windsurf 修复 Gemini 3 故障!:Gemini 3 的一个小故障已迅速解决;用户现在应能体验到流畅的功能,并可以 下载最新版本。
MCP Contributors (Official) ▷ #general (2 条消息):
图片附件, 临时故障
- 附带悲伤表情图片:一位用户分享了一张显示悲伤表情符号的图片。
- 这可能是针对临时问题的回应,正如另一位用户在随后的消息中所指出的。
- 临时故障已修复:一位成员报告称一个临时故障已经修复。
- 这表明前一条消息中的悲伤表情符号可能与这个现已解决的问题有关。