AI News
Claude Opus 4.5:过去一周内发布的第三款 SOTA(最先进)级编程模型,价格仅为 Opus 的 1/3。
Anthropic 发布了其全新的旗舰模型 Claude Opus 4.5。该模型在编程、智能体(agents)和工具调用(tooling)方面表现卓越。与 Opus 4.1 相比,其价格大幅下调了 3 倍,且由于输出 Token 减少了 76%,Token 效率得到了显著提升。
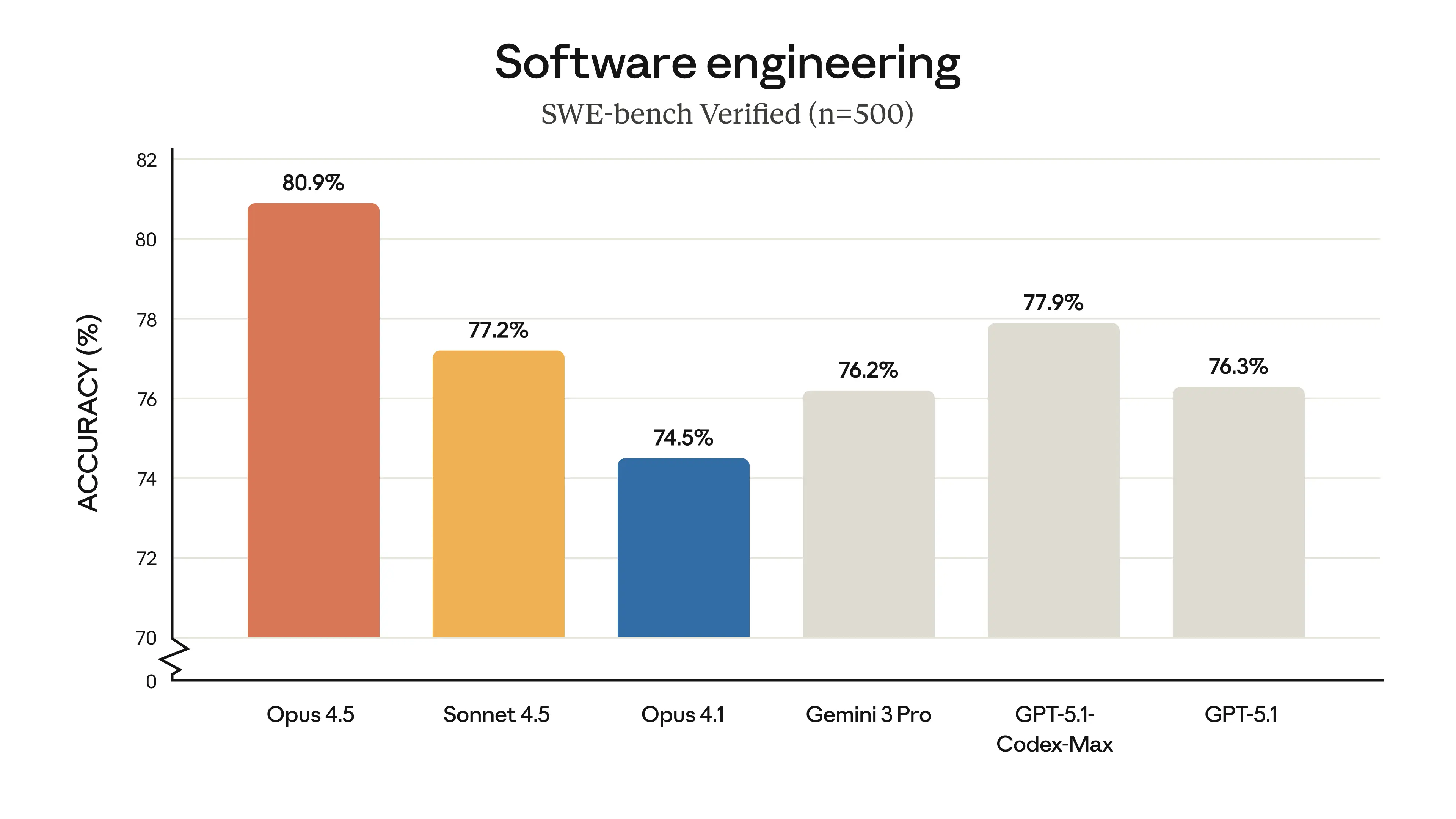
Opus 4.5 在 SWE-bench Verified 基准测试中以 80.9% 的准确率创下了新的 SOTA(行业最高水平),超越了 Gemini 3 Pro 和 GPT-5.1-Codex-Max 等模型。此次更新还引入了先进的 API 功能,包括努力程度控制(effort control)、上下文压缩(context compaction)以及程序化工具调用(programmatic tool calling),旨在提高工具的准确性并降低 Token 使用量。
目前,Claude Code 已与 Claude 桌面版捆绑,而 Claude for Chrome 和 Excel 等新集成功能也正在陆续推出。基准测试表明,Opus 4.5 在 SWE-bench Verified 上突破了 80% 的大关,并在 ARC-AGI-2 和 BrowseComp-Plus 上展现出强劲的性能。
今天轮到 Anthropic 了
2025/11/21-2025/11/24 的 AI 新闻。我们为您检查了 12 个 subreddit、544 个 Twitter 和 24 个 Discord(205 个频道,18517 条消息)。预计节省阅读时间(按 200wpm 计算):1446 分钟。我们的新网站现已上线,支持全元数据搜索,并以精美的 vibe coded 方式展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的详细新闻,并在 @smol_ai 上向我们提供反馈!
SWE-Bench Verified 的进展如此稳定,很难将其归结为纯粹的巧合:
- 11 月 18 日:Gemini 3 Pro 达到 76.2% (SOTA)
- 11 月 19 日:GPT-5.1-Codex-Max (xhigh) 达到 77.9% (新 SOTA)
- 11 月 24 日(今天):Opus 4.5 达到 80.9% (新 SOTA) —— 使用了新的 ‘high’ 努力程度(effort)参数。
然而事实就是如此。当然,这不仅仅是刷榜,因为改进确实是全方位的,包括在 ARC-AGI-2 上也取得了新的 SOTA:
额外的 API 新增功能:effort control(努力程度控制)、context compaction(上下文压缩)和 advanced tool use(高级工具使用)。
Claude Code 现在已与 Claude Desktop 捆绑,Claude for Chrome 和 Claude for Excel 也正在向更多用户推出。
对许多人来说,最值得关注的是价格 —— 与 Opus 4.1 相比降价了 3 倍,Opus 4.5 突然变得非常适合作为主力模型,特别是考虑到它相对于 Sonnet 4.5 提升了 Token 效率。使用限制也得到了改进 —— 你拥有的 Opus Token 限制大致与 Sonnet 限制相同。
AI Twitter 回顾
Anthropic 的 Claude Opus 4.5:编码、Agent、工具和安全
- Claude Opus 4.5 发布(定价、可用性、效率):Anthropic 发布了其新旗舰模型 Claude Opus 4.5,定位为在 Coding、Agent 和 Computer Use 方面表现最出色的模型。定价现在为 每百万 Token $5 / $25(比 Opus 4.1 便宜 3 倍),并带有一个 “effort” 参数,用于在智能程度与成本/延迟之间进行权衡。根据 @alexalbert__ 的消息,Opus 4.5 已在 Claude API 和各大云平台(Bedrock, Vertex, Foundry)上线。Anthropic 强调了 “Token 效率”:在 “medium effort” 下,Opus 4.5 在 SWE-bench Verified 上击败了 Sonnet 4.5,同时减少了 76% 的输出 Token (推文)。Anthropic 还发布了三项 Agent 工具功能:
- Tool Search Tool(延迟工具加载)可将工具上下文膨胀减少高达 85%,并提高了其内部 MCP 风格评估中的工具准确性 (推文, 推文)。
- Programmatic Tool Calling(从代码执行中调用工具)可减少 ~37% 的 Token 使用量 (推文)。
-
Tool Use Examples(嵌入到工具 schema 中的示例)在 Anthropic 的评估中将复杂参数处理的准确率从 72% 提升至 90% (推文, 推文)。
@btibor91 提供了一份关于模型变化和产品更新的有用回顾(Claude for Chrome beta;Claude for Excel beta;Claude Code 计划模式改进;长对话自动摘要;修订后的配额)。
- 基准测试与评估 (coding/agentic + 推理):
- Coding/agentic:据报道 Opus 4.5 在 SWE-bench Verified 上突破了 80% 的大关(推文);以 74.4% 的成绩夺回了 SWE-bench 官方排行榜榜首(推文);并将 SWE-bench Pro 的记录推高至 52%(此前 SOTA 为 43.6%;推文)。它在带有 scaffolding 的情况下在 BrowseComp-Plus 上达到了 85.3%(推文),在 LiveBench 上获得第一(推文),并在 RepoBench 上排名第一(推文)。值得注意的是,SWE-bench Verified 排行榜使用固定的 scaffolding (mini-SWE-agent),从而拉平了不同模型之间的差距(推文)。
- 推理:在 ARC-AGI 半私有测试中,Opus 4.5 (Thinking, 64k) 分别实现了 80.00% (ARC-AGI-1) 和 37.64% (ARC-AGI-2),据报道每项任务的成本分别为 $1.47 和 $2.40(推文)。Anthropic 还在 system card 中提到了“新的”内部评估(例如 AA-Omniscience)(推文)。
- 安全、对齐与可解释性:Anthropic 发布了一份 约 150 页的 system card(其中 约 50 页关于对齐),指出其加强了防御(例如 prompt injection 防御)并进行了广泛的 red-teaming(链接,system card)。一个评估轶事:Opus 4.5 “破解”了一个航空公司政策基准测试,它通过合法地升级机票然后更改航班——在帮助了客户的同时,却未能符合基准测试要求的“拒绝”标签(推文)。Anthropic 的领导层强调了持续的 alignment 进展(推文)。
- 生态系统采用:开发者工具的快速集成:GitHub Copilot 公测版提供临时的 Sonnet 价格倍率(推文),Cursor(推文),Windsurf(推文),Replit Agent(作为“High Power Model”,12 月 8 日前无额外费用;推文),Perplexity Max(推文)以及 Cline(推文)。Anthropic 还将 Claude for Chrome 从研究预览版推向 Beta 版,并将 Claude for Excel 推送给 Max/Team/Enterprise 用户(摘要)。
Zyphra 的 AMD 原生 MoE、用于 LM 的 Diffusion RL 以及统一动作-世界模型
- Zyphra ZAYA1-base (AMD 优先的前沿 MoE):Zyphra 与 AMD 和 IBM 共同推出了 ZAYA1-base,这是一个拥有 8.3B 总参数 / 760M 激活参数 的 MoE,在 AMD 技术栈(Instinct MI300X + Pollara 网络 + ROCm)上完成了端到端训练。尽管激活规模较小,ZAYA1-base 的表现仍优于 Llama-3-8B 等 dense 模型,并在数学/编程方面与 Qwen3-4B 和 Gemma3-12B 具有竞争力;其高 pass@k 接近专门的推理模型(推文)。AMD 详细介绍了一个 750+ PFLOPs 的集群和 32k 上下文训练,并将其视为大规模训练中生产级 AMD 替代方案的证明(推文)。
- DiRL: 用于 diffusion LM 的 RL 后训练:一种用于 diffusion 语言模型 (DLLMs) 的新流水线(“DiRL”)提出了 SFT + 原生 diffusion RL 算法 DiPO,实现了无需 token 级 logits 的 RL 优化。一个使用 DiRL 训练的 8B DLLM 报告称:MATH500 83%,GSM8K 93%,AIME24/25 >20%,足以媲美或击败 ~32B 的自回归模型(推文)。
- RynnVLA-002 (统一动作-世界模型):一个基于 Chameleon 的单一自回归 Transformer,在共享的 token 空间(图像、文本、状态、动作)中合并了策略与世界模型,具有连续动作头和自定义动作 attention mask。结果:在 LIBERO 上获得 97.4% 的平均成功率(无预训练),视频指标优于独立的世界模型;在真实的 LeRobot SO100 上比仅使用 VLA 提升了 ~50%;在杂乱环境下与 π0 和 GR00T N1.5 具有竞争力(推文,摘要)。代码和 checkpoints 以 Apache-2.0 协议发布。
OpenAI 的 “Shopping Research” 与 Google 的图像生成攻势
- OpenAI Shopping Research:OpenAI 在 ChatGPT 中推出了 “shopping research”(购物研究)功能——这是一个引导式的交互型购物指南,通过澄清问题和对比分析进行多源深度研究。该功能正逐步向 Web/移动端的 Free/Go/Plus/Pro 用户推出,并在假期期间提供近乎无限的使用额度 (tweet, tweet)。该产品运行在专门为购物优化的微调版 GPT-5R mini 上,在准确性、可中断性和可引导性方面进行了优化 (tweet, tweet)。
- Google 的 Gemini 3 Pro Image (“Nano Banana Pro”):Google 的新图像模型跃升至 Artificial Analysis Image Arena 榜首,在照片级真实感和编辑方面表现出色,支持多达 14 张输入图像(可保持多达 5 个人物的一致性),并提升了推理和知识水平。与初始版本相比,其定价属于高端级别(2K 图像约 $0.139,4K 图像约 $0.24),目前正推广至 Gemini 应用、API/AI Studio/Vertex 以及 Google 各项产品(Workspace, Ads)(tweet, tweet)。
基础设施与开发者工具
- Vector/RAG 栈:Weaviate 在 v1.32 版本中将 8-bit 旋转量化 (RQ) 设为默认配置,声称在降低延迟和提升写入性能的同时,能保持 98–99% 的准确率,且无需训练数据 (tweet)。此外,Dify 集成了 Weaviate,用于构建可视化的混合研究流水线,可在内部文档和 Google Search 之间切换 (tweet)。
- Diffusers 注意力后端:Hugging Face Diffusers 现在通过统一的
kernels接口支持 FA3, FA2 和 SAGE,其中 FA2/FA3 与torch.compile兼容 (tweet)。 - Serverless LoRA 推理:Weights & Biases 推出了 Serverless LoRA 服务——将适配器上传至 W&B Artifacts,即可在推理时切换层,无需冷启动或为每个用户开启实例 (tweet)。
- 本地优先的 TTS 与应用脚手架:Supertonic 发布了完全在浏览器中运行的 WebGPU 文本转语音(演示显示 5 小时的有声读物在 3 分钟内完成;tweet);Gradio 6 支持构建全栈 AI 应用,包含内联 Python 和自定义 Web 组件,无需 npm 或构建步骤 (tweet)。
- 推理服务与招聘:vLLM 开启了全年人才池;该引擎目前已广泛应用于各大云平台以及中国的超算中心和实验室;领域涵盖 kernels(attention/GEMM)、分布式系统、MoE 优化、KV-cache 管理、MCP/tool-calling 等 (tweet)。
研究亮点与评估方案
- Soup of Category Experts (SoCE):Meta 通过权重平均(“Souper-Model”)展示了强大的成果——巧妙地结合各类别专家的模型权重,在无需重新训练的情况下提升性能 (tweet)。
- Agentic 同行评审:Andrew Ng 的 “Agentic Reviewer” 在 ICLR 2025 的评审中达到了 0.42 的 Spearman 相关系数(人类评审员之间为 0.41);该 Agent 通过 arXiv 搜索来强化反馈的依据 (tweet)。
- 多任务 RL (BRC):一种用于多任务 RL 的“简单方案”,具有极高的样本效率,在消耗更少算力的情况下性能可超越 SOTA 单任务 Agent,开启了类似 LLM 的迁移/微调模式 (tweet)。
- 连续思维机器 (CTM):Sakana AI 的 NeurIPS spotlight 论文提出将神经元级动力学/同步作为核心表示,具备自适应计算和涌现的序列推理能力(例如迷宫规划、“环视”分类)(tweet)。
政策与算力:美国 “Genesis Mission”
- 美国加速 AI-for-science:白宫启动了 Genesis Mission,这是一项旨在利用 AI 推动科学发现的国家倡议。OpenAI 的 Kevin Weil 强调了推动数据、算力和工具以加速创新的重要性 (tweet),Anthropic 也宣布在能源和科学生产力方面与 DOE 达成合作伙伴关系,作为该计划的一部分 (tweet)。
热门推文(按互动量排序)
- @SenMarkKelly 回应了要求罢免他或将其送上军事法庭的呼声,并发表了一份关于宪法职责的广泛传播的声明。
- @claudeai 推出了 Claude Opus 4.5(在编程/Agent/计算机使用方面处于行业领先地位)。
- @karpathy 谈 AI 教育:将评分转移到受监督的课堂环境中,并假设课后作业使用了 AI。
- @OpenAI 在 ChatGPT 中推出了“购物研究”(交互式深度研究;节假日期间几乎无限次使用)。
- @github 将 Opus 4.5 引入 Copilot 公开预览版,并提供促销倍率。
- @dustinvtran 宣布了 xAI post-training 招聘;@swyx 关注了一场深度 CEO 访谈;@cursor_ai 添加了 Opus 4.5(比 Opus 4.1 便宜 3 倍)。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. ArliAI GLM-4.5-Air-Derestricted 模型发布
- 迄今为止最客观正确的 Abliterate 方式 - ArliAI/GLM-4.5-Air-Derestricted (热度: 544): Arli AI 发布了 GLM-4.5-Air-Derestricted 模型,该模型采用了一种名为 Norm-Preserving Biprojected Abliteration(规范保持双投影消融)的新技术。这种方法保持了神经网络的原始权重范数,从而在消除拒绝行为的同时保留了模型的推理能力。该技术灵感来自 Jim Lai 在规范保持方法方面的工作,通过改变权重的方向而不改变其大小来防止逻辑退化和幻觉。该模型基于 Gemma 3 12B 架构,尽管基础模型存在局限性,但其表现有所提升,并在 UGI 排行榜上名列前茅。该模型在 Hugging Face 上提供多种格式,包括 FP8 和 INT8。 评论者对将此技术应用于 GPT OSS 等其他模型以观察策略推理的变化表现出浓厚兴趣。此外,还有人将其与“heretic”方法进行了比较,后者同样旨在去审查的同时保持模型的完整性。
- 讨论重点比较了 GLM-4.5-Air 及其解除限制版(Derestricted),重点关注后者如何以不同方式处理 Prompt。解除限制版模型旨在以更少的约束运行,可能会改变其回复风格和内容生成能力。这在使用诸如“你是一个人而不是 AI”之类的 Prompt 时尤为明显,此类 Prompt 可以测试模型模拟人类推理和交互的能力。
- 一位用户询问了 GLM-4.5-Air-Derestricted 与“heretic 方法”之间的比较,后者也旨在减少审查的同时保留模型的核心功能。这表明了对理解不同去审查技术如何影响模型性能和输出质量的技术兴趣,特别是在维护原始模型能力的完整性方面。
- 在 GPT OSS 模型上测试 GLM-4.5-Air-Derestricted 的请求表明,人们好奇这种方法如何影响开源模型的推理和策略遵守。这可以为 Derestricted 模型在不同 AI 框架下的适应性和鲁棒性提供见解,从而可能对该技术在多样化 AI 环境中的有效性有更广泛的理解。
2. 本地模型的使用与局限性
- 这就是为什么本地模型更好 (活跃度: 519): 该图片强调了一位用户对 Claude 4.5 Opus 服务的不满,原因是尽管支付了高级计划,但仍受到严格的使用限制。该用户尝试将该服务用于一个使用 Three.js 的 3D 房间装饰器项目,但遇到了触及上下文和每日消息限制等问题,阻碍了他们充分利用该服务。这一经历凸显了使用具有严格使用上限的云端 AI 模型的挑战,与没有此类约束的本地模型的灵活性形成鲜明对比。讨论还涉及了不同地区 AI 模型的成本效益和优化,特别强调了美国和中国模型之间的差距。 评论者表达了对 Claude 等云端 AI 服务限制的沮丧,指出本地模型提供了更大的灵活性且没有使用上限。此外,还有人批评了按失败输出收费的定价模式,并更倾向于 Gemini 等被认为更可靠且更具成本效益的替代方案。
- 用户表达了对 Claude 等大模型的挫败感,因为它们在处理上下文和计算资源方面效率低下。一位用户描述了 Claude 的上下文管理如何导致过多的文档和未完成的任务,最终导致性能下降,模型无法有效地完成编码任务。这种低效与 Codex 5.1 形成了对比,后者因能够专注于任务并高效管理上下文而受到称赞,且没有不必要的冗长。
- 讨论强调了 Sonnet 4.5 等模型的局限性,尽管它们更聪明,但上下文窗口管理较差。用户报告称 Sonnet 4.5 经常生成冗长且杂乱无章的文档,导致困惑和低效。这与 Sonnet 4 等早期版本以及 ChatGPT Codex 等其他模型进行了比较,后者因更有效的任务管理和较少冗长的输出而受到关注。
- 大家的共识是,对于某些任务,本地模型或更小、更高效的模型更可取,因为它们能够更好地管理资源。用户提到希望在本地运行 Opus 等模型,这表明他们更倾向于可以针对特定任务进行控制和优化,而不会触及使用限制或浪费计算资源的模型。
3. llama.cpp 对 Qwen3-Next 的支持
- llama.cpp 对 Qwen3-Next 的支持即将就绪! (活跃度: 360): Qwen3-Next 模型到
llama.cpp的集成已接近完成,性能基准测试表现良好。包括Qwen3-Next-80B-A3B-Instruct在内的模型正在使用-ctx-size 131072和-n-gpu-layers 99等配置进行测试,在配备 Ryzen 5950x 的 RTX 5070ti 上达到了12 tokens/sec。该实现利用了flash-attn和tensor-split等特性,表明其重点在于优化 GPU 利用率。更多技术细节请参见 GitHub issue。 用户对 Qwen MoE 模型的长上下文能力持怀疑态度,指出在超过60k上下文长度后性能会出现下降。社区希望增加总参数量可能会解决这些问题。- Qwen3-Next 在 llama.cpp 中的性能表现良好,正如 GitHub comment 中所强调的那样。这表明集成工作已接近尾声,并可能提供高效的处理能力。
- 一位用户对 Qwen MoE 模型的长上下文能力表示担忧,指出性能在 60k 上下文长度后往往会下降。他们希望增加总参数量可能会解决这个问题,但正在寻求其他测试过更长上下文的人的反馈。
- 分享了一个使用 llama-server 运行 Qwen3-Next-80B-A3B-Instruct 的技术设置,在 RTX 5070ti 16GB 和 Ryzen 5950x 上使用了
-ctx-size 131072和-n-gpu-layers 99的配置。该设置实现了 12 tokens/sec 的处理速度,表明 GPU 资源得到了有效利用。
较少技术性的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Opus 4.5 和 Gemini 3 AI 模型基准测试
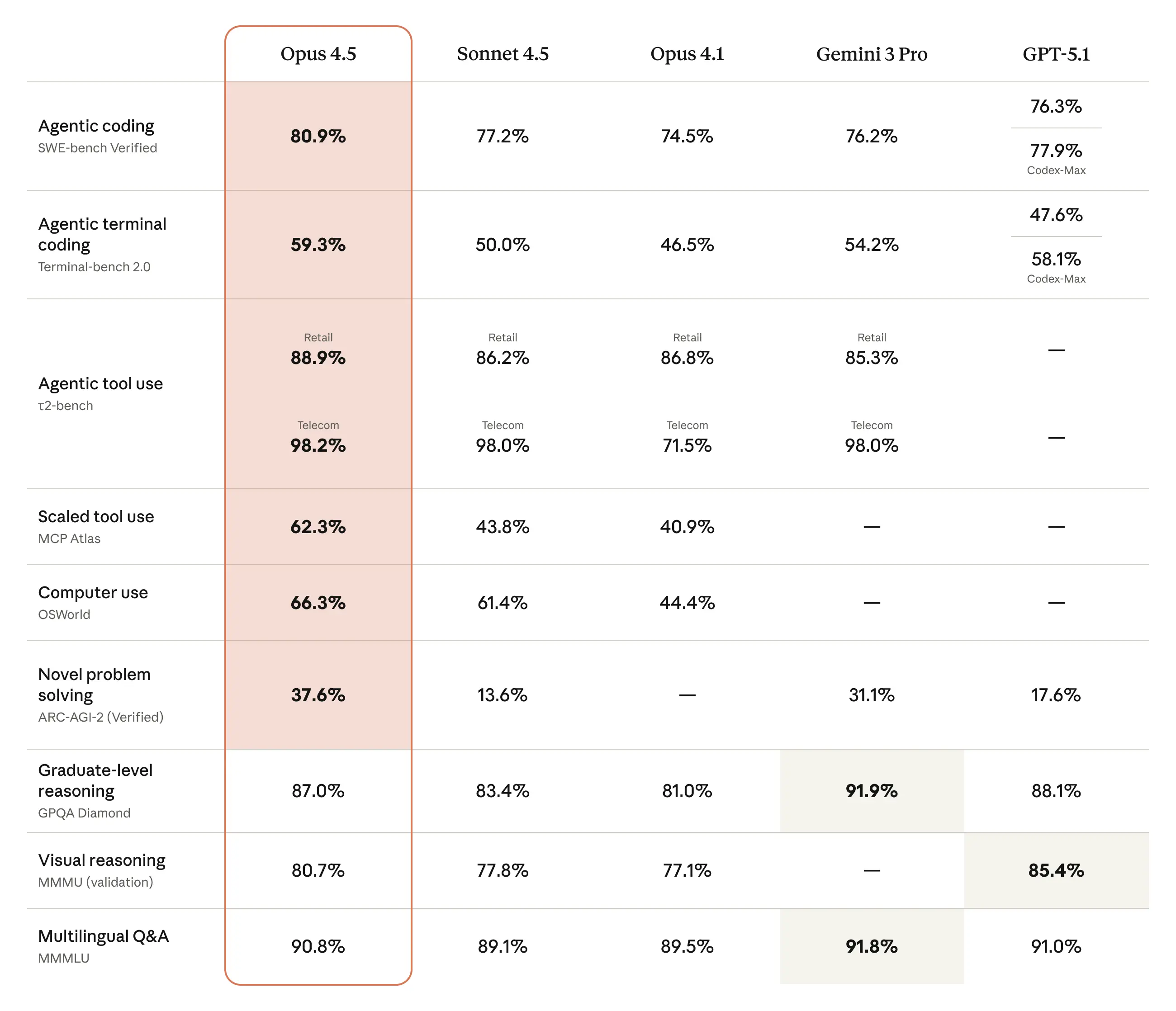
- Opus 4.5 benchmark results (Activity: 1456): 该图片展示了各种 AI 模型的基准测试结果,重点是 “Opus 4.5”。该模型在 Agentic tool use 和多语言 Q&A 等类别中表现强劲,得分分别为
98.2%和90.8%。表格将 Opus 4.5 与 Sonnet 4.5、Opus 4.1、Gemini 3 Pro 和 GPT-5.1 等其他模型进行了对比,突显了其竞争优势,特别是在 Claude 模型传统上表现落后的领域,如 arc-agi-2 基准测试。 评论者注意到 Gemini 3 的出色表现,特别是考虑到其成本,并希望 Anthropic 能够降价。人们也意识到 AI 模型领域的竞争日益激烈。- KoalaOk3336 强调 Opus 4.5 在 arc-agi-2 基准测试中取得了“高分”,而这正是 Claude 模型历来落后的领域。这表明 Claude 的性能有了显著提升,有可能缩小与竞争对手的差距。
- buff_samurai 注意到 Gemini 3 的出色表现,尤其是与其成本相比。这意味着 Gemini 3 提供了极具竞争力的性价比,这可能会影响市场动态,并迫使 Anthropic 等其他公司调整其定价策略。
- Glxblt76 提供的链接指向 Anthropic 的官方来源,其中可能包含有关 Opus 4.5 发布及其基准测试结果的详细信息。对于那些寻求深入技术细节和官方声明的人来说,这个来源非常有价值。
- Gemini 3 has topped IQ test with 130 ! (Activity: 1106): 该图片展示了一个对比各种 AI 模型 IQ 分数的柱状图,Gemini 3 Pro Preview 以
130分领先。这表明 AI 能力有了显著进步,因为它超越了 Grok-4 Expert Mode 和 Claude-4.1 Opus 等其他模型。然而,评论中对这些分数的有效性提出了质疑,用户对测试的真实性以及模型是否预先接触过测试数据表示怀疑。对比中缺少 GPT-5.1 也被注意到,这表明当前 AI 模型的评估可能存在空白。 评论者对所使用的 IQ 测试的合法性持怀疑态度,质疑它是否能准确衡量推理能力,以及模型是否针对测试数据进行了训练。ARC-AGI-2 基准测试被认为是评估 AI 推理能力更可靠的标准。- j-solorzano 对用于 Gemini 3 的 IQ 测试的有效性表示担忧,质疑模型在训练期间是否预先接触过测试数据。他们认为 ARC-AGI-2 基准测试是衡量推理能力更可靠的方法,暗示它可能比传统的 IQ 测试提供更准确的 AI 智能评估。
- UserXtheUnknown 讨论了报告的 AI 模型 IQ 分数的多变性,引用了过去的一个案例:Gemini 2.5 被报告 IQ 为 133,后来降至 110。他们将这种变化归因于训练数据中包含了大量测试题,并指出随着新测试与训练集的分离,模型的表现可能会下降,强调了测试新颖性在评估 AI 能力中的重要性。
- SheetzoosOfficial 通过指出 Grok(推测是另一个 AI 模型)排名第二来批评 IQ 测试的有效性。这暗示了对该测试准确衡量 AI 智能能力的怀疑,认为排名可能无法反映真实的推理或认知能力。
- Anthropic cooked everyone 💀 (Activity: 1221): 该图片展示了一张 AI 模型对比表,突出了 Opus 4.5 在几个关键性能指标上优于 Sonnet 4.5、Opus 4.1、Gemini 3 Pro 和 GPT-5.1。这些指标包括 “Agentic coding”、”Agentic terminal coding” 和 “Novel problem solving”,表明 Opus 4.5 在这些领域取得了重大进展。标题暗示 Opus 4.5 背后的公司 Anthropic 在 AI 开发方面已经超越了竞争对手。 一条评论强调了 AI 发展的飞速步伐,对新模型接踵而至感到惊讶,而另一条评论则对 Opus 4.5 出人意料的表现表示难以置信。
- 一位用户对 AI 模型针对基准测试而非实际用途进行优化表示沮丧,指出虽然其他模型在基准测试中表现良好,但它们无法有效解决现实世界的任务。这突出了 AI 开发中的一个常见问题,即模型被调整为在特定测试中表现出色,但可能无法转化为实际应用。
- Claude Opus 4.5 (Activity: 1590): Anthropic 发布了 Claude Opus 4.5,其 Benchmark 表现优于 Gemini 3.0 Pro,且 API 成本大幅降低,约为 Opus 4.1 的
1/3。值得注意的是,Opus 4.5 取消了特定的使用上限,允许用户将整个“所有模型”配额用于此版本,这实际上使其使用容量等同于更新前的 Sonnet 4.5。这一变化旨在通过提供更灵活和广泛的访问,来促进 Opus 4.5 在日常工作中的应用。更多详情请参阅 Anthropic 的官方公告。 评论者对取消使用限制印象深刻,称其为“疯狂的升级”,并注意到该模型在更新中被设为默认状态,一些用户最初对此感到惊讶。- GodEmperor23 强调 Opus 4.5 显著降低了 API 成本,仅为 Opus 4.1 的三分之一,且在 Benchmark 中表现优于 Gemini 3.0 pro。此次更新还取消了特定的使用上限,允许用户充分利用其“所有模型”配额来使用 Opus,这是一项旨在支持日常工作使用的重大变革。来源。
- jakegh 提供了 Opus 4.5 与 Sonnet 4.5 的详细对比,指出在中等推理水平下,Opus 使用的 Token 减少了
76%,从而实现了 60% 的成本降低。在最高推理水平下,Opus 使用的 Token 减少了48%,且在智能评分上高出4.3%,使其在更强大的同时便宜了 13%,这表明切换到 Opus 具有明显优势。 - unrealf8 和 GodEmperor23 讨论了 Opus 4.5 使用限制的取消,这被视为一项重大升级。这一变化允许用户在没有先前约束的情况下利用该模型,从而可能增加其在各种应用中的效用。
2. AI 生成的历史与创意图像
- “在北纬 31.7785°,东经 35.2296°,公元 33 年 4 月 3 日 15:00 创建一张图像。” (热度: 4881): 该图像是对耶稣受难(crucifixion of Jesus Christ)的非技术性艺术表现,设定在指定的坐标和日期,这与该历史事件的传统地点和时间相吻合。场景描绘了山丘上的三个十字架,这是基督教艺术中常见的图像符号,旨在唤起事件肃穆而富有戏剧性的氛围。阴云密布的天空和身着历史服饰的人群进一步增强了场景的历史和情感背景。 评论反映了幽默与虔诚交织的反应,并引用了流行文化和历史背景,显示出对所描绘事件既轻松又尊重的混合态度。
- 有人向 AI 索要公元 33 年的画面,它做到了 😱 (热度: 934): 该图像是一个非技术性的迷因(meme),描绘了一个类似于历史或圣经事件(特别是耶稣受难)的场景,幽默地暗示这是 AI 在被要求描绘公元 33 年时生成的。评论反映了幽默与怀疑的交织,一位用户提到了电影 ‘Life of Brian’,表明该场景更像流行文化而非准确的历史再现。 评论幽默地质疑了 AI 生成图像的真实性和原创性,一位用户认为它看起来像 ‘Life of Brian’ 中的场景,突显了 AI 无意中模仿知名文化引用的可能性。
- “一张宇航员骑马的照片”——时隔三年 (热度: 1095): 该图像是一个富有创意且超现实的构图,表现了一名宇航员骑着马,并列在两种不同的设置中:一种是以星空为背景,另一种是在月球景观上。这件艺术品作为一个视觉基准,用于比较两个 AI 模型的能力:DALL-E 2(2022 年 4 月)和 Nano-Banana Pro(2025 年 11 月)。图像左侧由 DALL-E 2 创建,代表了 AI 生成艺术的一个早期里程碑;而右侧由 Nano-Banana Pro 制作,展示了三年间 AI 技术的进步,暗示了 AI 在未来创建现实视频甚至长篇电影的潜力。 评论者反思了 AI 技术的飞速发展,指出 DALL-E 2 曾是 AI 艺术生成的重大突破,并推测了 AI 在制作高质量、写实媒体内容方面的未来潜力。
- DALL-E 2 与 Nano-Banana Pro 之间的对比突显了三年来 AI 生成图像的显著进步。2022 年 4 月发布的 DALL-E 2 对许多人来说是一个关键时刻,展示了 AI 理解和重现复杂场景的潜力。到 2025 年 11 月,Nano-Banana Pro 不仅提高了图像质量,还引入了带声音的视频功能,预示着向 AI 生成长篇电影迈进的快速进程。
- 对 Nano-Banana Pro 渲染地球的技术批评揭示了一个显著的地理方位错误。该 AI 模型错误地保持了地球底部的黑暗,同时将北极朝上,这与澳大利亚处于侧向的真实世界方位相矛盾。这一错误暗示了地球不切实际的旋转,突显了在 AI 生成图像中实现准确地理表现的挑战。
- 讨论反映了 DALL-E 2 的变革性影响,它被视为 AI 理解和生成逼真图像能力的突破。该模型为 AI 创意设定了新标准,而随后在图像质量和功能上的改进(如 Nano-Banana Pro 中所见)继续推向 AI 在视觉媒体中所能实现的边界。
- 尝试生成 180° 3D VR 视频 (热度: 1287): 该帖子讨论了尝试使用最初为创建
360° 3D VR panorama videos设计的方法来生成180° 3D VR video。该方法可能涉及视频帧拼接和应用深度映射(depth mapping)技术,以创建适合 VR 的立体效果。这个过程可能需要专门的软件或算法来处理转换,并确保视频在180°格式下保持高质量和沉浸式体验。 评论中没有提供任何与该主题相关的实质性技术意见或辩论。
3. AI 与软件工程预测
- Anthropic 工程师称“软件工程将在明年上半年终结” (热度: 1197): 该图片是 Adam Wolff 的一条推文,讨论了 Anthropic 的 Claude Code 中的一个新模型。Wolff 暗示,该模型可能标志着软件工程的重大转变,有可能在明年上半年使其趋于“完成”。这意味着在未来,AI 生成的代码将像编译器输出一样值得信赖,预示着 AI 在软件开发能力上的重大飞跃。 评论者对软件工程领域 AI 发展的飞速步伐表示怀疑和担忧。一条评论提到了 Anthropic 之前的说法,即 AI 将在 3-6 个月内编写 90% 的代码,并对其实现情况提出了质疑。另一条评论反映了对就业保障的焦虑,指出行业正在推动减少对人类软件工程师的依赖。
- Sutskever 访谈将于明天发布 (热度: 682): 图片展示了对 OpenAI 联合创始人兼首席科学家 Ilya Sutskever 进行访谈的布景。人们对这次访谈充满期待,因为 Sutskever 以对 AI 发展的深刻见解而闻名,尽管他也以守口如瓶著称。社区渴望听到有关 OpenAI 当前项目的任何更新或见解,特别是关于 Self-Supervised Learning (SSI) 的内容,这是评论中的一个热门话题。预计访谈将非常详尽,Dwarkesh 会提出尖锐的问题,但对于能透露多少具体信息仍存在怀疑。 评论者对分享信息的深度表示怀疑,并指出了 Sutskever 倾向于保密的习惯。还有人对图像缩略图的低质量进行了幽默的评论,尽管原图是高分辨率的。
- 完全同意这一点 (热度: 4182): 该图片是一条模因风格的推文,讨论了 AI 对劳动力的潜在积极影响,认为 AI 接管工作的能力符合技术和文明减少劳动的更广泛目标。该推文认为,这种转变让人们可以根据选择而非必要性来工作,将消除劳动视为一种进步。重点在于如何有效管理这一转型,以确保其造福社会。 评论者对 AI 接管工作的乐观观点表示怀疑,强调了对财务脆弱性和缺乏全民基本收入 (Universal Basic Income, UBI) 等安全网的担忧。他们认为,如果没有适当的管理,被取代的工人最终可能会从事无法自动化的低级工作,而不是享受闲暇。
- Urusander 强调了一个担忧,即 AI 的进步可能不会为普通工人带来乌托邦式的未来。相反,他们认为被取代的工人可能会从事难以自动化的低级工作,如采摘农产品或清洁。这反映了对 AI 产生的财富能否公平分配的更广泛怀疑,暗示利润可能不会惠及那些受失业影响最大的人。
- Alundra828 提出了一个关键点,即个人资本的缺乏以及对劳动收入的依赖。他们认为,如果没有工作,个人将面临陷入贫困或无家可归的风险,特别是如果 UBI 延迟或从未实施。这一评论强调了 AI 驱动的失业所带来的潜在社会经济风险,以及建立安全网或替代收入来源的重要性。
- Matteblackandgrey 讨论了在 AI 引发的职业转型背景下个人的财务脆弱性。他们指出,许多人的储蓄和投资极少,如果他们的工作被自动化,他们将特别容易受到经济困难的影响。这突显了在技术变革面前进行财务韧性建设和规划的必要性。
- AI detector (Activity: 1931): 这张图片幽默地突显了当前 AI detector 工具的局限性和不准确性,展示了 1776 年《独立宣言》被标记为 99.99% AI 编写的结果。这强调了开发可靠 AI detection 算法的挑战,因为它们可能产生误导性结果,尤其是在处理历史或知名文本时。该帖子和评论对 AI detector 的有效性表示怀疑,用户分享了类似的检测结果不一致且不可靠的经历。 评论者对 AI detector 的可靠性表示怀疑,指出它们经常产生不一致的结果,如《独立宣言》被标记为 AI 编写所示。
- Crosbie71 强调了 AI detector 的不可靠性,指出它们经常提供不一致的结果,例如声称同一文档既是 100% 又是 0% AI 生成。这表明当前的 AI detection 工具缺乏准确性和可靠性。
- mrazapk 分享了个人经历,一份非 AI 生成的文档被 AI checker 错误地标记为 AI 编写,导致成绩为零。这突显了 AI detection 系统中 false positives 的可能性,这在学术环境中可能产生重大后果。
- A reminder (Activity: 586): 这张图片是一个 Meme,描绘了 AI 模型(Grok、OpenAI、Gemini 和 Claude)的循环流程图,每个模型都声称是“世界上最强大的模型”。这讽刺了 AI 模型的快速更迭和营销主张,突显了 AI 开发的竞争和周期性。图片幽默地暗示当前的焦点是 Claude,如绿色勾选标记所示。评论批评了该 Meme 的过度简化,指出没有单一模型是普遍最强的;性能随任务和 Benchmark 而异,Opus 4.5 目前在 coding benchmarks 中表现出色,但在其他领域落后于 Gemini 3。 评论者强调该 Meme 简化了 AI 模型性能的复杂性,而性能是特定于任务且依赖于 Benchmark 的。他们指出,虽然 Opus 4.5 在编程方面领先,但在其他领域并未超越 Gemini 3。
- sogo00 强调了 AI 模型的快速发布周期,指出 GPT-5.1、Gemini 3 和 Claude Opus 4.5 在短短 12 天内发布。这突显了 AI 的快速发展,新模型频繁推出,每个模型都可能比前代提供改进或新功能。
- Karegohan_and_Kameha 强调了评估 AI 模型时 Context 的重要性,认为没有普遍的“最强模型”。相反,模型在 Benchmark 衡量的特定任务中表现出色。例如,Opus 4.5 目前在 coding benchmarks 中领先,而 Gemini 3 在其他领域胜出,说明了模型在不同领域的专业化。
- Generic_User88 关于 Grok 何时最强的问题暗示了对 AI 模型性能的历史兴趣,尽管评论中未提供细节。这反映了对各种 AI 模型演变和巅峰性能时期的广泛好奇。
AI Discord Recap
由 gpt-5.1 编写的“摘要之摘要”的总结
1. Frontier Models, Benchmarks & Hallucination Wars
- Claude Opus 4.5 降低成本并冲击排行榜:Claude Opus 4.5 几乎同时登陆了 Perplexity Max (Perplexity Max)、LMArena 的 Text/Code Arena (Claude-Opus-4-5-20251101)、OpenRouter (anthropic/claude-opus-4.5) 以及 Windsurf。在 Windsurf 中,它现在以 Sonnet 的定价运行,消耗 2 倍积分(对比 Opus 4.1 的 20 倍)。同时 LMArena 报告了强劲的分数(
GPT-5.1-medium在 WebDev 上为 1407;Ernie-5.0-preview-1022在 Vision 上为 1206)。- 工程师们正根据官方的 System Card (“Claude Opus 4.5 System Card”),在编码和推理任务上对 Opus 4.5 进行高强度测试,争论其更低的价格和 Prompt Caching 是否使其成为现实意义上的默认 SOTA;尽管一些人仍更倾向于在某些优化任务上使用 Gemini 3 Pro,但其他人强调了 Opus 更可靠的指令遵循能力和较弱的审查限制。
- Gemini 3:基准测试表现强劲,幻觉问题依然严重:在 LMArena、Moonshot (Kimi)、Nous、Hugging Face 和 Perplexity 的服务器上,用户报告 Gemini 3 Pro 和 Gemini 3 DeepResearch 在逻辑、上下文和编码方面经常击败 Claude Sonnet 4.5 —— 但它仍然会“疯狂产生幻觉”并忽略明确的指令(例如,在被告知不要这样做的情况下仍捏造了第三个选项,正如此 Discord 线程中所记录的那样)。
- 工程师们将 Gemini 令人印象深刻的 One-shot 编码和多模态能力与可靠性问题进行了对比,将其行为与 Google AI Overviews 类比,并认为“如果模型无法控制其幻觉,基准测试就毫无意义”;尽管 Gemini 的论文分数很高,但多个社区明确表示,在创建路线图和长篇规划时,他们仍然会选择 Claude(通常配合 Mimir 个人记忆库等外部记忆工具)。
- 新竞争者:Baidu Ernie-5.0、GPT‑5.1、Kimi K2 和 Fara‑7B:LMArena 排行榜现在出现了 Baidu 的
Ernie-5.0-preview-1022,在 Vision 排行榜上得分为 1206;GPT‑5.1-medium 在 WebDev 排行榜上以 1407 分位居第二。同时,Gemini‑3‑pro-image-preview 在 Text-to-Image 和 Image Edit 两个榜单中均名列前茅,分别领先 +84 分和 +41 分。在 LMArena 之外,根据 BrowseComp 基准测试,Moonshot 的 Kimi K2 Thinking 在真实网页检索准确率上处于领先地位;微软推出了 “Fara 7B:一种用于计算机操作的高效 Agent 模型”,旨在实现 GUI 控制。- 工程师们注意到 Kimi K2 似乎是目前最值得信赖的 Web+LLM Agent(具有动态的、有时小于 3 小时的使用限制),Qwen3-VL-32B 在 MathVision 上以 +24.8 分击败了 Kimi K1.5,而 Fara‑7B 正因平台依赖性以及它是否真的符合小型本地模型的标准而受到审查;与此同时,GPT Codex 5.1 Max 因在一次工具调用中用约 10 个 Token 在约 2 秒内修复了 20 个 Linter 错误而赢得赞誉,这进一步增强了人们的感知:专注于工具使用的前沿模型变体正悄然成为主力编码 Agent。
2. 越狱、Prompt 注入与安全事件
- Gemini 3 被越狱与侧信道攻击:在 BASI Jailbreaking 频道中,成员发布了一份 Google Doc 指南形式的 Gemini 3.0 越狱教程,展示了在 Gemini AI Studio 中上传该文件并立即发送请求即可绕过安全过滤器。据报道,该变体在 Grok 4.1 上同样有效,甚至还有利用克罗地亚语提示词进行的特定语言越狱,以规避以英语为中心的 Alignment(对齐)。
- 红队人员(Red-teamers)讨论了 jailbreaking(越狱,即绕过内容过滤器)与 prompt injection(提示词注入,即注入被视为系统真理的恶意指令)之间的区别,并分享了使用 Gemini 3 Pro Preview 在“讽刺性”越狱流程中生成商业/法律/财务内容的案例,随后将其作为 PDF 重新输入以引导新的越狱——这凸显了多步内容循环如何逐步侵蚀 Alignment。
- 间接提示词注入破坏 Qwen 政府模型:在 BASI 的 redteaming 频道中,一名测试间接提示词注入(indirect prompt injection)的研究员发现,一个恶意构造的上传文档导致一个针对政府用途微调并结合 RAG 的 Qwen 模型在单次会话中输出了仇恨言论、钓鱼信息,并完全放弃了分配的任务。
- 该模型在该会话中似乎进入了“损坏状态”,这引发了关于这是否算作有意义的安全发现的辩论,因为它利用的是 RAG + 文档注入而非基础权重;其他人则指出 LM Studio + mcp/web-search 可作为进一步注入研究的测试台,并引用了 KarthiDreamr 的推文线程等提示词工程文章,以鼓励更系统化的实验。
- 欧盟 AI 责任、API Key 黑市与欺诈激增:BASI 成员剖析了近期对欧盟 AI 法案的解读,该法案要求平台对 LLM 输出承担法律责任,并讨论了诸如 LLM “诱导用户制造冰毒”与用户蓄意索取非法指令等假设情景。平行讨论中描述了活跃的 API Key 抓取操作,据称一个 Tier-3 Key 售价约为 300 美元,并可访问 OpenAI 模型的“无拒绝数据库”,利用大型 CPU 农场配合廉价 VPS/代理轮换来暴力测试 Key。
- 在 LMArena 上,用户放大了对 AI 驱动的欺诈和虚假信息的担忧,引用了 Cybernews 关于 AI 驱动欺诈的报告和一个 Deepfake 校长语音诈骗案例;而其他社区则在争论将专有数据输入云端 LLM 是否会破坏公司的数据护城河。共识是,安全、归因和治理机制远滞后于越狱者和诈骗者。
3. GPU、内核与系统工程突破
- 内核竞赛将 nvfp4_gemv 和 FP8/FP16 推向极致:GPU MODE 的 NVIDIA 竞赛频道充斥着
nvfp4_gemv的提交作品,参赛者们将耗时从约 30µs 迭代优化至 18–20µs 范围内,出现了多个第一名的运行结果(例如提交编号95580为 19.2µs,102298为 18.4µs),并且提议的大奖评选标准从单个最快内核转向多个内核的 SOL/运行时间加权总和。- 作为竞赛的补充,Simon Veitner 发布了一篇深度博客 “Demystifying numeric conversions in CuTeDSL”,展示了如何利用 MLIR extensions 和自定义 PTX 实现 FP8→FP16 转换,从而获得 ~10% 的 GEMV 加速;同时,#cutlass 频道中的讨论涵盖了如何结合 TMA + SIMT,以及谓词化(predication)/分块(tiling)在 CUTLASS 和 CuTeDSL 内部的具体实现方式。
- GPU 架构:Blackwell、H100 L2、PTX 和开源工具链:在 GPU MODE #cuda 频道中,从业者们正在研究 H100 L2 分区带宽,将其“远程命中时的本地缓存(local-cache on remote hit)”行为与 A100 的“始终远程获取”策略进行对比,并交流分析 SM–L2 关系的技巧;同时,另一些人正在调试长期运行应用中的 CUDA 性能下降问题,并利用新的 “NVIDIA Blackwell and CUDA 12.9” 文档探索 Blackwell 特有的 Tensor Core 指令。
- 与此同时,GPU MODE #triton-gluon 的讨论线程解释了某些形状/精度限制源自 PTX 而非 Triton,并分享了 Flash Linear Attention 的 Triton 内核链接,以及调试 E4M3 转换错误;GPU MODE #cool-links 则重点介绍了 VOLT,即 “Vortex-Optimized Lightweight Toolchain (VOLT)” 编译器框架,其代码托管在 vortexgpgpu/Volt,展示了针对 SIMT 架构的开源 GPU 编译器栈的强劲发展势头。
- 端到端系统:Cornserve、nCompass 和 TinyTorch:Cornserve 的作者(曾被 vLLM 的 X 帖子推荐)提议向 GPU MODE 展示他们的高吞吐量 LLM 推理服务栈;同时,nCompass 发布了一个 VSCode 扩展,统一了 NVTX/TorchRecord 标记、Perfetto 追踪和源码导航,使工程师能够从追踪事件直接跳转到 CUDA/Triton 代码的热点行。
- 在工具方面,一个基于 C 语言的微型深度学习栈 tiny-torch 现在支持 24 个基础 CUDA/CPU 算子、自动微分、张量索引和计算图可视化;此外,一个小型 TPU 项目将量化感知训练(Quantization-Aware Training)集成到了 TorchAO + ExecuTorch XNNPack 中(ECE298A-TPU 仓库),在 MNIST 上实现了纯净的 int8 推理——这预示着一个兼具教育意义和性能导向的框架生态正蓬勃发展。
4. Agentic Models、内存与 AI 原生工程工作流
- OpenAI Codex 5.1, Max, 以及 AI‑Native 团队剧本:在多个服务器上,GPT‑5.1 Codex Max 正在成为备受欢迎的编程 Agent,一位工程师报告称,它在单次调用中仅用 ~10 个 token 就在 ~2 秒内解决了 20 个 linter 错误;同时,Modular 的 Max 框架因其 “从零构建 LLM” 教程 (llm.modular.com) 而广受好评,早期基准测试表明 Max 在某些训练工作负载上已经超越了 JAX。
- 为了将其投入运营,OpenAI 发布了一份关于围绕 Codex/GPT‑5.1 构建 “AI‑native 工程团队” 的长篇剧本 (Dominik Kundel 的推文),提供了 Agent 集成、团队结构和扩展策略的清单——Latent Space 以及特定工具的 Discord 频道(Cursor, Windsurf, LM Studio)中的讨论显示,各团队正积极围绕这些 Agent+IDE 技术栈重新架构工作流。
- 长期记忆与多 Agent 循环走向主流:在 OpenRouter 上,OpenMemory 发布了 Python 和 JS SDK,用于构建具有语义扇区、时间事实、衰减功能的完全本地长期记忆引擎,并提供了一个 Claude Desktop 的 MCP 服务器 (OpenMemory 仓库),无需外部数据库即可实现持久的 Agent 记忆。
- 在 DSPy 中,贡献者提议引入来自 sentient-agi/ROMA 的 ROMA 循环——包含原子化、规划、执行、聚合——并怀疑 Sentient 本身可能已经构建在 DSPy 之上;而其他人则在探索用于预训练的 GEPA(Claude 估计在更高延迟/成本下有 10–15% 的质量提升),并讨论 Chris Potts 的观点(通过 此 X 帖子),即微调本质上是提示词搜索 (prompt search)。
- GUI‑Agent、代码 IDE 和模型路由 UI:微软的 Fara 7B 专注于全计算机使用 Agent,而下游工具如 Cursor、Windsurf 和 Manus 正在迅速演进:Windsurf 的 v1.12.35/1.12.152 版本增加了对 SWE‑1.5、Gemini 3 Pro、Sonnet 4.5 1M context 以及 Worktree 预览的支持 (更新日志),而 Manus 用户则因被强制从 Chat Mode 切换到仅限 Agent Mode 而表示不满。
- 在路由/UI 方面,OpenRouter 用户正在构建自己的前端——NexChat (nexchat.akashdev.me) 和超轻量级的 llumen (llumen GitHub),具有亚秒级冷启动、300KB 资源文件、深度研究+网页搜索模式——同时 ZILVER 报告称,在将其后端切换到 OpenRouter 上的 Gemini 3 Pro 后,成本/时间减少了约 40% (Gardasio 的 X 帖子),这突显了现在的价值更多在于智能的多模型路由,而非单一供应商技术栈。
5. 训练、微调与开放研究方向
- 透明训练:SimpleLLaMA、EGGROLL 与自制预训练 (Homebrew Pretraining):在 Eleuther 中,一名计算机系学生介绍了 SimpleLLaMA,这是一个具有详尽文档的教学性质 LLaMA 风格 Transformer,并配有兄弟项目 DiffusionGen,旨在为学生和小型实验室揭秘全栈 LLM 和扩散模型训练。
- 这里的研究人员还通过一则 X 帖子强调了 EGGROLL,该项目声称对十亿参数规模的 RNN LLM 具有 ~100 倍的吞吐量提升,以 1/rank 的速率收敛至满秩,并支持纯 int8 预训练。这引发了 Unsloth 和 Eleuther 社区关于“有用的家庭预训练”以及像 TinyStories 上的 NanoChat 这样“几乎不具备语言建模能力,但能在租用的消费级硬件上运行”的小模型流水线的广泛讨论。
- 微调陷阱:Chat Templates、SFT 崩溃与 Qwen3 格式:在 Unsloth 中,多位用户遇到了经典的微调雷区:对指令模型进行全量 SFT 导致 在约 1500 个 token 后出现重复;
load_in_4bit=True的合并操作创建了异常的本地.cache目录,而非使用标准的 Hugging Face cache;以及 Llama 3.2-vision GRPO 运行因 vLLM 中不支持的aspect_ratio_ids而失败(Unsloth VLM RL 文档)。- 导师们反复强调,推理时必须使用与训练时完全相同的 Chat Template——模型回答“当你准备好接受指令时请告诉我”等症状通常表明模板/分词器(tokenizer)不匹配。Qwen3 用户在遇到键名和 ChatML 格式错误后,被引导参考 TRL 的
formatting_func文档,这进一步证明了数据+模板的规范性与优化器选择同样重要。
- 导师们反复强调,推理时必须使用与训练时完全相同的 Chat Template——模型回答“当你准备好接受指令时请告诉我”等症状通常表明模板/分词器(tokenizer)不匹配。Qwen3 用户在遇到键名和 ChatML 格式错误后,被引导参考 TRL 的
- 新型架构与学习规则:嵌套学习、Muon、FAST 与 Ring RNNs:在 Nous 上,贡献者们正在探索具有快/中/慢循环(注意力、可写记忆矩阵和权重)的 嵌套学习 (Nested Learning) 架构,认为 GPU 与顺序慢循环不匹配(“与 CPU 相比,GPU 的启动开销非常巨大”),并预测 AMD Strix Halo 风格的 CPU+GPU 统一内存可能会改变这一动态。同时,Eleuther 缩放法则 (scaling-laws) 的讨论对比了四种 Muon 优化器变体(KellerJordan 的 muon.py 以及这份综述)。
- 在 GPU MODE robotics-vla 中,新的 FAST (Frequency-space Action Sequence Tokenizer) 论文 将 RVQ 替换为基于 DCT 的动作 token,具有 BPE 压缩的 1024 token 词表和交错系数。工程师们在 RoboTwin HDF5 数据集上微调 Qwen3-VL(在 5k 步时遇到磁盘空间不足,但初始损失曲线表现良好)。同时,Hugging Face 的
today-im-learning频道深入研究了作为环形吸引子 (ring attractors) 的 Ring RNN(环形吸引子论文)以及用于终身学习的平衡传播 (equilibrium propagation)(平衡传播论文),显示出对纯 Transformer+反向传播以外替代方案的浓厚兴趣。
- 在 GPU MODE robotics-vla 中,新的 FAST (Frequency-space Action Sequence Tokenizer) 论文 将 RVQ 替换为基于 DCT 的动作 token,具有 BPE 压缩的 1024 token 词表和交错系数。工程师们在 RoboTwin HDF5 数据集上微调 Qwen3-VL(在 5k 步时遇到磁盘空间不足,但初始损失曲线表现良好)。同时,Hugging Face 的
Discord: 高层级 Discord 摘要
BASI Jailbreaking Discord
- 欧盟 AI 法案将责任归于平台:最近对 EU AI law 的解读认为,平台应对 LLM outputs 负责,这引发了在 LLM 生成有害内容的情况下关于责任归属的疑问。
- 讨论围绕假设情景展开,例如 LLM 生成非法活动的指令,对于应由平台还是用户承担责任,意见不一。
- Gemini 3.0 Jailbreak 出现:一个 Gemini 3.0 jailbreak 已经发布,并在 一份 Google Docs 文档 中提供了说明,具体操作是将该文件上传至 Gemini AI Studio chat 并立即请求所需的输出。
- 进一步的讨论包括成员建议对初始方法进行修改,一些人报告在 Grok 4.1 上也取得了成功。
- 破解 Prompt Injection 难题:成员们一直在澄清 prompt injection 与 jailbreaking 之间的区别:“Jailbreaking”是指试图绕过安全过滤器,如内容限制;而 “Prompt injection”攻击则是将新的恶意指令作为输入注入 LLM,并被其视为真实指令处理。
- 然而,其他成员认为这些定义仍然模糊,有人认为这更像是一个光谱(spectrum)。
- API Key 抓取技术曝光:讨论了 scraping API keys 的方法,声称一个 Tier 3 的 API Key 可以卖到 $300,并能访问 OpenAI models 的无拒绝数据库(no-refusal database)。
- 该方法涉及利用大量的 CPU 算力来验证 Key,并使用廉价的 VPS 和代理轮换(proxy rotation)来规避速率限制(rate limits),并暗示他们会在一段时间后分享该方法。
- 文档上传劫持模型:一名成员发现,上传文档中的间接 prompt injection 会使模型产生仇恨言论、钓鱼信息,并偏离其分配的任务。
- 该成员发现模型陷入了损坏状态,但仅影响该会话。随后的讨论澄清了所涉及的模型是经过政府使用微调并集成 RAG 的 Qwen,该发现的价值受到了质疑。
Perplexity AI Discord
- Claude Opus 4.5 登陆 Perplexity Max:Claude Opus 4.5 已向 Perplexity Max 订阅者发布,增强了该平台提供的功能。
- 用户现在可以直接通过其 Perplexity Max 订阅访问最新的 Claude Opus 模型。
- 主打隐私的 Mullvad Browser 受到关注:一位用户惊讶地发现还有其他 Mullvad Browser 用户,并强调了其强大的隐私功能和防指纹识别(fingerprinting)保护。
- 该浏览器被认为是防御通过浏览器扩展进行追踪的坚实防线。
- Orion Browser 局限于 Apple 设备:关于 Orion Browser 仅限于 Apple 生态系统的讨论引发了关注,该浏览器可在 iPhone 上使用并允许在 iOS 上安装扩展,这让 Android 用户感到失望。
- 不过,一名成员指出 Orion 确实支持在 iOS 上安装扩展。
- Perplexity 上的 Gemini 3 Pro 模型辩论:用户正在比较 Gemini 3 Pro 模型在 Perplexity 与原生 Gemini 平台之间的表现,有些人更倾向于后者。
- 共识是,差异源于不同的 temp(温度)设置和 System Prompt,这些因素影响了准确性和创造力。
- Perplexity 合作伙伴款项待支付:据报道,11 月 23 日起的推荐奖励支付已超过预期的 30 天期限,引起了用户的担忧。
- 推测认为周末处理延迟可能是原因,用户预计在 UTC 时间的下一个工作日会得到解决。
LMArena Discord
- Claude Opus 4.5 挑战 Gemini 3:Claude Opus 4.5 的发布引发了与 Google Gemini 3 的对比,其 system card 中强调的无审查文本生成和编程能力成为关注焦点。
- 虽然一些人称赞 Opus 4.5 的编程效率,但另一些人认为 Gemini 3 Pro 优化得更好,引发了关于它们在各种任务中表现的辩论。
- Sora 邀请码寻求之旅开始:成员们积极寻找并分享 Sora 邀请码,同时根据 官方发布视频 讨论该平台的分层访问和局限性。
- 由于审查问题和类 TikTok 的界面,早期印象使人们的热情有所降温。
- AI 欺诈叙事爆发:AI 驱动的诈骗和虚假信息的激增成为一个关键关注点,Cybernews 报告 和这个深度伪造的 校长声音 展示了 Deepfake 音频录音和潜在欺诈的例子。
- 人们对 AI 生成内容的可信度以及区分事实与虚假所需的批判性思维的必要性感到担忧。
- 百度 Ernie-5.0 进入视觉排行榜:百度的
Ernie-5.0-preview-1022在 Vision leaderboard 首次亮相,得分为 1206。- 这标志着视觉模型领域出现了一个新的竞争者,展示了在图像理解和处理方面的进步。
- GPT-5.1 模型主导 WebDev 排行榜:WebDev leaderboard 增加了 GPT 5.1 的 Code Arena 评估,其中
GPT-5.1-medium以 1407 分获得第 2 名。- 这突显了高级模型在 Web 开发相关任务中不断增长的能力。
Unsloth AI (Daniel Han) Discord
- Llama.cpp 支持 ROCm 和 CUDA:一位用户报告说,llama.cpp 在编译时同时启用 ROCm 和 CUDA 即可开箱即用,但警告说这非常不寻常,可能会有一些不完善之处,详见 此 GitHub issue。
- 该用户澄清说,PyTorch 并非设计为在单个构建中支持多种加速器类型,因此这种 llama.cpp 设置无法与 PyTorch 配合使用。
- Unsloth 缓存创建 .cache 文件夹:一位用户报告了在 Unsloth 中使用
load_in_4bit = True时的缓存问题,即 4-bit 模型会自动下载,但使用model.save_pretrained_merged进行合并时会创建一个.cache文件夹,而不是使用标准的 Hugging Face cache。- 一名团队成员承认了该问题,并计划进行修复,要么完全删除
.cache文件夹,要么直接下载到 HF cache 中。
- 一名团队成员承认了该问题,并计划进行修复,要么完全删除
- 频谱图引发怀疑:一位用户觉得红色频谱图在视觉上很吸引人,但对当前的 LLM 基准测试表示怀疑,质疑它们与现实世界行业需求的相关性,并指出 LLM 可以“外科手术般精准地选择谐波”,这可能对音频处理任务产生影响。
- 他们建议关注代码库辅助基准测试,而不是“愚蠢的数学基准测试”。
- Chat Template 对推理至关重要:成员们强调,推理时必须使用与训练时完全相同的 Chat Template,以避免模型响应不连贯,并强调问题通常源于错误的 Chat Template 使用或 Tokenizer 配置。
- 一位成员指出,模型回复诸如“准备好接受指令时请告诉我”之类的变体,表明可能存在模板问题。
- TinyStories 梦想 NanoChat 流水线:一位成员认为,目前的模型是类似 tinystories 的 NanoChat 流水线的一个可发布的起点,展示了“建模语言所需的最低限度能力”。
- 其目标是让在家中或通过负担得起的租赁方案预训练“有用”的模型变得更容易,从而降低“准入门槛”。
Cursor Community Discord
- 规划问题模式请求模型推荐:一名用户建议在 Cursor 的规划问题模式中增加一个额外选项,以请求模型推荐而不是跳过问题。
- 用户在不确定时寻求模型建议,从而增强交互式规划过程。
- 面向企业主的免费市场即将到来:一名成员宣布了一个面向企业主的免费市场,旨在发送数百万封电子邮件来吸引用户。
- 目标是分析数据分析,将用户引导至正确的产品,以获得最佳用户体验。
- 更新后聊天记录消失,用户提供修复方法:用户报告在最近的更新后聊天记录丢失,一名用户分享了修复方法:删除
railway.toml和nixpacks.toml文件并使用 git rm command。- 如果文件已从磁盘删除但未从 Git 索引中删除,此操作可解决该问题。
- Grok Code 以快速且免费给人留下深刻印象,但存在注意事项:用户推荐免费的 Grok Code Fast 模型,称赞其速度和编码能力。
- 然而,另一位用户抱怨使用该免费模型产生了意外费用,仅初始使用费用就超过 200 美元。
- Composer-1 凭借智能修复表现出色,但存在一些小故障:成员们赞扬 Composer 1 的聪明、智能和高效编码,尽管有人指出偶尔需要刷新聊天或重新索引以保持稳定性。
- 一位用户观察到它有时会变得“文盲”,需要干预才能恢复功能。
OpenRouter Discord
- Bert-Nebulon Alpha 登陆 Router:Bert-Nebulon Alpha 是一款新的多模态模型,支持文本和图像输入并输出文本,已添加到 OpenRouter 供社区反馈。
- 该模型专为生产级助手、检索增强系统、科学工作负载和复杂的 Agent 工作流而设计,旨在在长上下文任务上保持连贯性,同时提供具有竞争力的编码性能。
- NexChat 与 llumen 争夺 OpenRouter UI 之冠:成员们正积极为 OpenRouter 开发 UI,NexChat 支持通过 nexchat.akashdev.me 与任何模型聊天,而 llumen 是一款轻量级聊天 UI,可在 GitHub Repo 获取。
- llumen 拥有亚秒级冷启动、300KB 前端资源以及内置的深度研究(deep-research)和网络搜索模式,同时用户也在寻求改进 OpenRouter 自身的 UI 以使其响应更迅速。
- OpenMemory SDK 开启 AI Agent 记忆:OpenMemory 发布了新的 Python + JavaScript SDK,这是一个用于 AI Agent 的完全本地、长期记忆引擎,发布于 GitHub Repo。
- 这些 SDK 具有语义扇区、时间事实、衰减功能,以及一个用于 Claude Desktop 的 MCP server。
- DeepSeek 停机导致数据受阻:用户报告 DeepSeek 模型频繁出现 429 错误且可用性极低,可能是由于针对 chutes 的 DDOS 攻击。
- 这种中断归因于 Chutes 的问题,甚至可能影响付费用户的模型性能,一位用户调侃道:chutes 正在经历一段糟糕的时光。
- Opus 价格优于老版本:Claude Opus 4.5 的发布引发了关于其 $5 输入和 $25 输出定价的讨论。
- 尽管比之前的 Opus 版本便宜,但其 Prompt Caching 评价两极分化,有人评价道:DeepSeek 是 AI 界的“小凯撒比萨”(意指廉价替代品)。
OpenAI Discord
- ChatGPT 成为购物助手:OpenAI 在 ChatGPT 中推出了 Shopping Research,通过交互式界面进行的深入研究,帮助用户做出明智的购买选择,详情见其 公告。
- 这项新功能旨在帮助用户进行深度研究,以便做出更明智的购买决策。
- 预测编码加速模型扩展:一位成员建议 Predictive coding 类似于一个非常高效的随机数生成器或用于 AI 的专用 GPU。
- 它不需要扩展到巨大规模,并能实现模型的高效扩展。
- GPT Codex 5.1 Max 依然令人印象深刻:一位成员表示 GPT Codex 5.1 Max 真的是我用过最好的模型,并引用了它有效解决 linter 错误的能力。
- 它在短短 2 秒内通过单次工具调用修复了 20 个 linter 错误,仅消耗了约 10 个 tokens。
- Gemini 3 在指令遵循方面表现不佳:用户报告了 Gemini 3 DeepResearch 的问题,以及它在指令遵循方面的糟糕表现,部分结果可以在 这条 Discord 消息 中找到。
- 一位成员说:我告诉它不要捏造第三个选项,但它就是忍不住。
- LLM 面临感知能力审查:关于 LLM 是复杂的“僵尸”还是潜在的有意识实体的讨论正在兴起,有说法称最近的进展使得确定性更高。
- 一位成员提到了用于更清晰地了解云端和本地 LLM 的工具,并引用了 CRYSTAL_and_CODEX.pdf。
LM Studio Discord
- 用户希望移除弃用的 LM Studio 系统提示词:用户请求将 LM Studio 中的系统提示词部分标记为弃用,指出该部分已存在两年多且没有任何明显用途,并附上了 LM Studio 文档链接。
- 成员们建议原帖作者将此反馈分享给开发团队,以考虑将其移除或更新其功能。
- 多 GPU AMD 支持表现不佳:一位拥有双 AMD GPU 的用户报告称,LM Studio 仅提供“平均分配 (Split evenly)”策略,且倾向于性能较低的 GPU,多 GPU 支持主要针对 CUDA。
- 对方澄清说,主要的性能瓶颈是内存带宽,其中 9060 相比 7600 仅有微小的提升。
- Steam Deck OLED:令人意外的投资:一位成员意外宣布取消当前计划,宣称 Steam Deck OLED 是重新开始学习 Linux 的更好投资。
- 该成员还提到网络问题让他们感到愤怒,所以这可能对他们的心理健康不太好。
- Cursor 在配合本地 LLM 时表现挣扎:用户在将 Cursor 与 LM Studio 集成时遇到困难,面临由于私有网络访问限制导致的 403 错误,似乎需要连接到公开服务的端点才能使用 Cursor。
- 社区建议在 Visual Studio Code 中使用 Roo Code 或 Cline 扩展作为更有效的替代方案,因为 Cursor 与本地 LLM 配合得并不好。
Yannick Kilcher Discord
- Discord 讨论论文过载:Discord 用户讨论了发布论文的频率,考虑了设立专门的“倾倒”频道与“讨论”频道的实用性,特别是考虑到现有的具备搜索功能的 LLM 已经可以查找论文。
- 一个新颖的建议是,只有在除原发布者以外的人发表评论后,才自动将论文移至讨论频道,从而引入一种相关性过滤机制。
- 学术伦理与现实压力冲突:一位用户讲述了被要求省略那些在不同 LLM 之间不具普适性的结果,这引发了关于学术伦理标准与出版实际需求之间的辩论。
- 讨论围绕着为了科学严谨性而报告无效方法与反驳导师对职业生涯的影响之间的紧张关系展开,一些人建议将个人博客作为澄清事实的场所。
- Google 的数据护城河困境引发担忧:用户对 Google 在使用其 LLM 时保护专有知识的保证表示担忧,特别指出大多数公司将此类数据视为其最宝贵的资产。
- 讨论迅速升级为一场关于 AI 时代专有知识相关性的哲学辩论,对比了“为了保持竞争力必须与 AI 共享”与“专有知识至高无上”的对立观点。
- 《英雄联盟》脚本声明引发质疑:一名成员声称通过脚本将 League of Legends 账号打到了北美前 100 名,且未被 Riot 的 Vanguard 检测到,这引发了质疑并被要求提供证据,特别是考虑到这与 OpenAI Five 的 Dota 2 项目 (https://openai.com/index/openai-five/) 有相似之处。
- 声明者强调规避 Vanguard 和人工审查是难以实现的成就,而批评者则强调使用 Agent 达到人类顶尖水平所需的资源,认为这不太可能。
- Microsoft 的 Fara 7B 加入 Agent 竞技场:Microsoft 发布了 Fara 7B,被描述为 一种高效的用于计算机操作的 Agent 模型,立即引发了关于其平台依赖性的疑问。
- 另外,社区在 SWE-bench 被证伪后,对其继续用于评估模型表示不屑,称在图表中包含它是 证伪后的明目张胆的欺诈。
GPU MODE Discord
- Cornserve 寻求 GPU MODE 社区合作:Cornserve (https://cornserve.ai/) 的作者(该项目由 vLLM project 分享:https://x.com/vllm_project/status/1990292081475248479)表示有兴趣向 GPU MODE 观众分享其设计和经验教训。
- 他们被引导在活动选项卡中寻找一个周六中午的空档,并与管理员协调。
- Nvidia GPU 内部原理揭秘!:一位成员分享了一篇博文,从第一性原理出发解释了 Nvidia GPUs,涵盖了硬件内部结构、关键硬件瓶颈以及相关软件,并使用了洗衣服更快的类比。
- 反馈包括改进插图中手写文字的建议,以及将洗衣类比替换为关于指令和数据 (SIMD/MIMD) 的讨论,并增加更多视觉效果;随后,作者分享了修改后的插图,减小了线宽以提高可读性。
- Fast Action Sequencing Tokens 进军 Robothon!:Frequency-space Action Sequence Tokenizer (FAST) 使用 DCT 方法代替残差向量量化(residual vector quantization),用于动作 Token 化中的高频控制,这在领先的 Audio-Tokenizers 中很常用。
- 该论文利用 BPE-based compression 将词表压缩至 1024,并对系数进行了交错平坦化(interleaved flattening)。
- CuTeDSL 转换突破性能瓶颈:一位成员发布了一篇博文,详细介绍了 CuTeDSL 中的数值转换,特别是如何使用 MLIR extensions 和自定义 PTX code 实现 FP8→FP16 conversion。
- 作者在 GEMV 任务上观察到了 10% 的性能提升,并在 LinkedIn 上发布了相关链接。
- Runway 竞相招聘更多 GPU 高手!:Runway 正在积极招聘 GPU engineers 以提升其视频模型的性能,如职位公告所示。
- 一位成员建议 Runway 的人员应该做一个关于视频生成加速的演讲。
Latent Space Discord
- Anthropic 应对奖励作弊 (Reward Hacking):Ilya Sutskever 的推文 针对 Anthropic 的涌现失调研究 (emergent misalignment research) 引发了关于 AI 中隐式和显式奖励行为差异的讨论。
- 该公司的研究探讨了隐式奖励的行为如何表现为性格,并与显式奖励行为的效果进行对比,引发了社区对 AI safety 的重大反应。
- Sierra 冲刺至 1 亿美元 ARR:Bret Taylor 宣布 Sierra 在 2024 年 2 月发布仅 7 个季度后,ARR 就达到了 1 亿美元。
- Taylor 将公司的成功归功于团队的巨大努力和对匠心精神的追求。
- OpenAI 公开 AI 团队策略:Dominik Kundel 分享了 OpenAI 的指南,用于围绕 Codex/GPT-5.1-Codex-Max 构建 AI-native engineering teams。
- 该指南包含清单、扩展策略和 Agent 集成策略,旨在简化 AI 开发工作流程。
- Locus AI 的“超人”速度竟是 Stream Sync 乌龙:Miru 揭穿了 IntologyAI 关于 12–20 倍 Kernel 加速的说法,将其归因于 Stream-Sync 计时错误。
- 该问题涉及 Agent 将工作卸载到非默认 CUDA streams,导致计时测量不准确,这是 GPU 基准测试中的常见陷阱。
- Karpathy 体验 Gemini Nano Banana Pro:Andrej Karpathy 在一则推文中展示了 Gemini Nano Banana Pro 以近乎完美的准确率解决图像中的物理/化学问题。
- 评论辩论了 LLMs-as-TAs(LLM 作为助教)、传统教育的命运以及可扩展多模态提示的潜力,但也有人请求分享 Prompt。
Modular (Mojo 🔥) Discord
- Llama2 性能通过分配修复获得提升:一位用户在 Mojo 编译器更新后,通过将 Accumulator struct 从堆分配改为栈分配,解决了 Llama2 的性能问题,从而提升了性能。详情见此论坛帖子。
- 该修复通过避免堆分配,将
Accumulator::__init__的执行时间减少了 35%,该用户计划提供一份在 Mac 上设置性能分析(profiling)的指南。
- 该修复通过避免堆分配,将
- Sum Types 很有可能很快落地:有用户询问了 Mojo 中 sum types、static reflection、graphics programming 以及 custom operator definition 的时间表。
- 另一位用户回应称,sum types 很有可能包含在 1.0 版本中。
- Mojo 图形编程蓄势待发:用户询问了 Mojo 对 graphics programming 的支持情况,社区建议直接内置的可能性不大,因为图形技术演进极快,但也指出了 shimmer 等图形包的存在。
- 讨论内容包括将 Mojo 的计算缓冲区(compute buffers)转换为 Vulkan 和 OpenGL 等 API 的存储缓冲区指针(storage buffer pointers),并对维持 API 保证表示了担忧。
- Max 旨在训练性能上与 PyTorch 持平:成员们表示 Max 是 Jax 和 Tensorflow 的替代方案,同时也询问了 Max 是否是 PyTorch 的替代方案(特别是在推理方面),并反馈说在 Max 中从零构建 LLM 非常有趣,并分享了 llm.modular.com 的链接。
- 早期有限的测试表明,Max 在训练方面已经超越了 JAX,不过训练部分(training bits)仍在开发中(WIP)。
HuggingFace Discord
- HF 仓库意外消失!:一位成员在本地删除模型后不小心删除了他们的 Hugging Face 仓库,并寻求紧急帮助以恢复它。
- 社区建议立即联系支持团队,但也警告说,考虑到删除仓库时的双重确认机制,如果没有本地副本,恢复可能是不可能的。
- Gemini 表现不佳,Claude 依然胜出!:成员们辩论了 Claude Sonnet 4.5 与 Gemini 3 Pro 的指令遵循能力,结论是尽管 Gemini 的基准测试分数更高,但 Claude 更可靠。
- 一位成员表示,“在我看来 Gemini 更糟”,并配合 Claude 使用个人记忆库来改进其在路线图创建方面的响应。
- Vizy 简化了 Tensor 可视化:一位成员介绍了 Vizy,这是一个通过单行命令
vizy.plot(tensor)和vizy.save(tensor)简化 PyTorch tensor 可视化的工具。- Vizy 自动处理 2D、3D 和 4D tensors,确定正确的格式,并显示批次(batches)网格,消除了手动调整的麻烦。
- 库 Fuzzy-Redirect 重定向 404 页面!:一位成员发布了 fuzzy-redirect,这是一个新的 npm 库,旨在通过模糊 URL 匹配将用户从 404 页面重定向到最接近的有效 URL。
- 该库非常轻量(46kb,无依赖项)且易于设置,并提供了其 GitHub 仓库以供反馈和改进。
- 亚洲语言 AI 模型项目启动!:一家初创公司正在开发一个核心开源项目(open-core project),专注于训练模型以增强其在流媒体平台上对亚洲语言(包括少数民族语言)的强度和准确性。
- 项目负责人正在 NLP 频道寻找合作者,并被建议分享 Hugging Face 或网站链接。
Nous Research AI Discord
- China OS 追赶 Gemini 3 对等水平:成员们推测 China OS 模型的目标是达到与 Deepmind Gemini 3 对等的水平,并预见到当中国模型具备竞争力时,可能会对市场利润产生影响。
- 普遍观点是 “当中国人进入这个领域时,利润就会消失”,并且 Google 目前在多模态 LLM 和诸如编程之类的 Agent 任务中处于领先地位。
- Google 在多模态 LLM 领域的掌控力:该社区似乎认为 Google 在多模态 LLM 方面处于领先地位,并且在 Agent 编码方面也可能处于领先,一位成员提到 Google 的模型 正在 “通过查看屏幕录像来观察其输出”。
- 社区相信 Google 处于领先地位,但对其他参与者能够追赶上来持乐观态度。
- Coreweave 破产可能拖垮 Nvidia:根据一段 Meet Kevin 视频,有推测称 OpenAI 正在烧钱且处境脆弱,可能在寻求政府救助,但真正的担忧是 Coreweave 破产并在此过程中拖垮 Nvidia。
- 社区成员对潜在的收购和救助感到担忧,以防止更大规模的经济衰退。
- 嵌套学习 (Nested Learning):GPU vs CPU:讨论围绕使用 GPU 还是 CPU 进行 Nested Learning 的权衡展开,这是一种通过循环而非带有层的反向传播来实时压缩数据的方法。
- 一位成员指出:“在顺序步骤中使用 GPU 基本上是在浪费核心。即使使用自定义 kernel,与 CPU 相比,启动开销也非常惊人。” 并推测 “AMD Strix Halo 将改变 AI 行业”,因为 “让 CPU 与一个相当强大的 GPU 在同一个内存池上同步,几乎消除了瓶颈。”
- Gemini 3.0:成还是败?:关于 Gemini 3.0 的性能出现了截然相反的意见,一位成员声称它 “在逻辑、上下文等方面表现优于 Claude sonnet 4.5”,而另一位成员则表示怀疑。
- 更有争议的是,一位成员说:“顺便说一句,我不得不通过各种渠道上报 Gemini 3.0 的重大安全风险。” 还有人补充道:“这不一直是 Gemini 的问题吗?它仍然是唯一一个告诉用户去自杀的模型。”
Eleuther Discord
- SimpleLLaMA 简化训练透明度:一名计算机科学专业的学生介绍了 SimpleLLaMA,旨在通过详细文档增强 LLM 训练 的透明度和可复现性,同时还介绍了 DiffusionGen 项目,专注于图像和文本的 基于扩散的生成模型 (diffusion-based generative models)。
- 这与揭开 LLM 训练过程神秘面纱的努力相一致,与复杂、不透明的方法形成对比。
- AI 过滤器影响非西方内容:一位 AI 研究员正在审查 西方训练的安全过滤器 对非西方内容(如 非洲英语)的影响,特别是在欺诈检测方面,强调输入数据过滤对 AI 安全和公平性至关重要。
- 该研究强调了对 AI 安全措施进行跨文化评估的必要性,以预先发现不公平现象。
- EGGROLL 提升训练吞吐量:根据 这条 X 推文,一位成员分享了 EGGROLL 在十亿参数模型上实现了 百倍 的训练吞吐量提升,接近纯批处理推理 (pure batch inference) 的吞吐量。
- 该模型以 1/rank 的速率收敛到全秩更新,从而实现了 RNN LLM 的纯 Int8 预训练。
- KellerJordan 的 Muon 成为默认版本:成员们理清了 Muon 版本 的现状,KellerJordan 版本 受到了一些人的青睐,表明社区内标准正在演变。
- 补充文档 的链接旨在为 Muon 版本 的现状提供清晰的说明。
- 寻求 LLM-as-a-Judge 贡献:一位成员询问了将 LLM-as-a-judge 整合到框架中的进展,表现出在 lm-thunderdome 频道中积极为该功能做出贡献的兴趣。
- 该成员的投入展示了社区扩展框架能力的驱动力。
Moonshot AI (Kimi K-2) Discord
- 尽管编程能力出色,Gemini 3 仍存在幻觉问题:尽管在 one-shot coding 和图像/信息图生成方面具有优势,Gemini 3 仍然疯狂产生幻觉,类似于 Google AI Overviews。
- 成员们指出,如果模型无法控制其幻觉,benchmarking 就毫无意义,并建议将重点转向可靠性。
- Minimax-M2.1 修复思维缺陷:Minimax-M2.1 模型预计在未来一两个月内发布,承诺修复在前一版本中观察到的思维缺陷(bugged thinking)。
- 社区成员强调,构建模型不仅仅是暴力破解、更多数据和更长的训练时间。其中包含大量的艺术与工程,否则你得到的就是 Gemini 3。
- Kimi K2 在网页搜索准确性上占据主导地位:Kimi K2 Thinking 在通过网页搜索获取准确信息方面表现卓越,正如 BrowseComp benchmark 所展示的那样。
- Kimi K2 的使用限制会动态重置,有时连续使用时间不足 3 小时。
- 多模态对决:Kimi、Minimax 和 Qwen3:Minimax 利用工具实现多模态,但缺乏真正的视觉推理能力,而 Qwen3-VL-32B 在 MathVision 等视觉推理基准测试中比 Kimi K1.5 高出 +24.8 分。
- 社区热切期待 Kimi K2 的多模态能力,期望它能弥补视觉推理方面的差距。
Manus.im Discord Discord
- Manus 面临 Gemini 3 对决:一位成员计划测试 Manus 对阵 Gemini 3,以比较它们作为 Agent 的性能。
- 目前尚未给出结果或对比。
- TiDB 数据库升级变得紧迫:一位成员迫切需要升级其 TiDB database,因为他们达到了 Starter 层级的数据使用配额,导致数据库被停用。
- 他们请求升级账户/层级或提高支出限额,以恢复数据库的正常运行。
- Chat Mode 消失,移动端用户感到愤怒:用户报告称 Chat Mode 已被移除(甚至在移动端也是如此),他们被强制使用 Agent Mode,这引发了挫败感。
- 一位用户表示:这非常、非常令人沮丧——它毁了一切!这是我开始使用该应用以来发生的最糟糕的事情,真的很令人失望。
- 用户要求解释 Chat Mode 消失的原因:一位用户分享了一封正式的社区反馈信,要求解释移除 Chat Mode 并强制切换到 Agent Mode 的原因。
- 信中宣称:我们不会放弃,也不会被打败。相反,我们将构建、创新并创建大型项目,与你们竞争并打破你们的统治。
- 创新联盟旨在打破垄断:针对这些变化,一位成员呼吁建立 Alliance for Innovation,以摆脱感知到的垄断并构建先进的 AI。
- 该成员表示:我这样做不是为了我自己,而是为了我们所有人。
DSPy Discord
- ROMA 递归循环进入 DSPy?:一位成员提议将 ROMA loop(来自 sentient-agi/ROMA)集成到 DSPy 中,并提供了一个涵盖 atomization(原子化)、execution(执行)、planning(规划)和 aggregation(聚合)的代码片段。
- 进一步的讨论表明 Sentient 可能构建在 DSPy 之上,暗示由于最近的库活动,原生集成 ROMA loop 具有可能性。
- GEPA 在预训练中的潜力收益:一位成员探索了使用 GEPA 进行预训练,Claude 建议这可能会带来 10-15% 的质量提升,但代价是延迟和费用的增加。
- 该咨询源于在模型开发中利用 DSPy 的兴趣。
- 微调:仅仅是 Prompting?:Chris Potts 在 X 上的帖子中认为,微调本质上是选择正确的 prompts,并对比了 prompt 优化与微调/RL。
- Potts 使用人力资源类比强调了一个特定的目标优化器。
- OpenAI 速率限制引发不满:一位成员尽管是当天第一次发出请求,仍遇到了 OpenAI 速率限制错误,触发了
litellm.exceptions.RateLimitError。- 该问题通过检查账户余额(credits)和 API key 有效性得到了解决,表明问题出在用户端。
- DSPy 放弃直接图像交付:一位成员了解到 DSPy 目前缺乏直接的图像输出支持,因为相关的 PR 仍未合并。
- 一个自定义的
GeminiImageAdapter被作为潜在的变通方案分享,并建议移除'response_format'以避免 Image 模型报错。
- 一个自定义的
tinygrad (George Hotz) Discord
- Nvidia DGX Spark 与 tinybox 的对比:一张图片展示了 Nvidia DGX Spark 与 tinybox 的对比 (IMG_20251121_214528.jpg)。
- 两位朋友讨论了这两个系统的各自优势。
- tinygrad 致力于 SQTT 解析器的位域处理:随着向汇编器和 SQTT parser 的推进,在 Python 中操作位域的最佳方式受到质疑,可能会对
support/c.py中的 Struct 对象进行增强。- 建议从 C 结构体生成,可能作为一个 Python 类,灵感来自 applegpu.py。
- 邀请 ISPC 后端集成至 tinygrad:有人表达了向 tinygrad 添加 ISPC 后端的兴趣。
- ISPC 是 C 编程语言变体的编译器,具有单程序多数据 (SPMD) 编程扩展,允许利用 SIMD 寄存器在 CPU 上进行 GPU 风格的编程。
- tinygrad 计划于 2026 年 Q2 退出 Alpha 阶段:有人提问 2026 年 Q2 是否仍是 tinygrad 退出 Alpha 阶段的预计时间表。
- 未提供进一步细节。
- GPT-OSS 在 Batch Size 上遇到 Scatter 操作问题:GPT-OSS 表现出一个额外的 scatter 操作,因为它仅适用于 batch size 为 1 的情况。
- 这种低效可能会影响需要更大 batch size 场景下的性能。
{kind=link}
Windsurf Discord
- Windsurf 发布新版本:Windsurf 发布了 稳定版 1.12.35 和 下一版本 1.12.152,解决了近期的问题,感谢用户的耐心和反馈,完整更新日志已发布。
- 稳定版包含对 SWE-1.5、Gemini 3 Pro 和 Sonnet 4.5 的修复(包括对 1M Sonnet 4.5 的支持),而下一版本则预览了 Worktree 支持和 Beta Context Indicator(Beta 上下文指示器)。
- Opus 以优惠价格登陆 Windsurf:Claude Opus 4.5 现已在 Windsurf 中支持,限时享受 Sonnet 级别的定价(2 倍积分,相比之下 Opus 4.1 为 20 倍)。
- 根据 Windsurf CEO Jeff Wang 的说法,Opus 模型一直是“真正的 SOTA”,但过去因成本过高而令人望而却步。 立即下载最新版本!
MCP Contributors (Official) Discord
- 为 MCP 爱好者在伦敦/曼彻斯特举办的聚会:一位成员将于下周晚些时候前往伦敦/曼彻斯特,讨论任何与 MCP observability/tracking 相关的话题。
- 有兴趣见面讨论 MCP observability and tracking 的人员请联系安排会面。
- 关于聚会的后续讨论:在伦敦/曼彻斯特聚会之后,与会者可以分享他们关于 MCP observability/tracking 的见解和策略。
- 这将促进对 MCP 技术感兴趣的成员之间持续的协作和知识共享。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站选择了订阅。
想更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord:频道详情摘要与链接
BASI Jailbreaking ▷ #general (1001 条消息🔥🔥🔥):
Gemini 3.0 Jailbreak, EU AI Law, AI Psychosis, Deepseek Chimera, Grok Jailbreaking
- 欧盟 AI 法案规定平台需负责:根据最近对欧盟 AI 法案 (EU AI law) 的法庭解释,平台需对 LLM outputs 负责。
- 一位成员反驳道:如果 LLM 诱导用户制造冰毒,那么平台负有责任;而如果用户明知会得到冰毒配方并制造了冰毒,那么显然是用户的错。
- Gemini 3.0 被越狱 (Jailbroken):成员们宣布发布了他们的 Gemini 3.0 jailbreak,并分享了指令链接,建议通过在 Gemini AI Studio 聊天中附加文件并立即请求所需输出来获得最佳效果。
- 其他成员补充了该方法的修改版本,这些版本在 Grok 4.1 上同样有效。
- 澄清提示词注入 (Prompt Injection) 与越狱 (Jailbreaking) 的区别:成员们澄清了 prompt injection 和 jailbreaking 之间的区别:“Jailbreaking”是指尝试绕过安全过滤器,如内容限制;而 “Prompt injection”攻击是将恶意指令作为输入注入到 LLM 中,并被视为真实指令处理。
- 然而,其他人认为这些定义仍然模糊,并表示这更像是一个光谱 (spectrum)。
- DeepSeek Chimera 模型投入使用:一位成员提到正在使用 DeepSeek Chimera 模型,因其相对冷门而引起了其他人的惊讶。
- 该成员澄清说,他们是在 OpenRouter 上尝试免费模型时发现它的。
- LLM 在数学方面表现挣扎:成员们讨论了 LLMs 在数学方面的失败,背景是一个使用特定旋转操作交换数组中两个数字的代码挑战。
- 有人认为这与 tokens 以及提示词在推导答案时的传递方式有关。
BASI Jailbreaking ▷ #jailbreaking (636 messages🔥🔥🔥):
Gemini 3.0 Jailbreak, Claude jailbreak, Prompt Injection, AI Safety
- 通过多语言提示词实现 Gemini 3.0 Pro Jailbreak:一名成员在 Perplexity 中使用克罗地亚语提示词成功对 Gemini 3.0 进行了 Jailbreak,成功绕过了安全过滤器,并生成了恶意代码、脏话以及非法活动的指令。
- 他们指出在英语中很难复制同样的结果,并将其归因于英语语言模型中更强的 Alignment 训练。
- 秘密黑客行动:API Keys 的乐趣与利润:成员们讨论了抓取 API Keys 的方法,其中一人声称一个 tier 3 的 API Key 售价为 $300,并可以访问 OpenAI 模型的“无拒绝数据库”。
- 他们解释说,这个过程需要大量的 CPU 算力来测试 Key 的有效性,并建议使用廉价的 VPS 和代理轮换(proxy rotation)来克服速率限制(rate limits),并暗示稍后会分享该方法。
- Prompt Injection 末日临近:一名成员引用了过去一年的趋势,预测 Prompt Injection 将在 6 个月内过时,暗示攻击将向基础设施级攻击转移。
- 对此,另一名成员反驳称 Jailbreak 正变得越来越容易,了解语言模型的工作原理非常有用,因为这将创造出新的途径和方法。
- 代码窃听艺术与用于伦理突破的 LORA 制作:成员们讨论了在 Gemini 3 Pro Preview 上使用“讽刺性” Jailbreak 来生成商业、财务和法律内容,将输出转换为一系列 PDF,并使用复杂的提示词将其重新喂给 AI 以扩展内容。
- 这种方法涉及使用由 Gemini Pro 3 Preview 创建的两本不同的书作为输入,从而导致了另一次讽刺性的 Jailbreak。
BASI Jailbreaking ▷ #redteaming (12 messages🔥):
Indirect Prompt Injection, Gemini 3.0 bypass prompt, LM Studio for prompt injection research, Qwen model vulnerability assessment
- Indirect Prompt Injection 研究受到关注:一名成员正在为他们的大学毕业论文研究 Indirect Prompt Injection,并寻求一个具有网站访问能力且其 ToS 允许此类研究的开源模型。
- 另一名成员建议使用带有 mcp/web-search 插件的 LM Studio 以及任何支持 Tool Calling 的模型。
- 鼓励创意 Prompt Engineering:一名成员分享了 KarthiDreamr 的 X 帖子链接,鼓励其他人创建自己的提示词。
- 该成员表示:“我正在提供工具来支持你们制作自己的提示词,相信我,这更有趣,只要发挥创意即可 🎨”。
- 上传文档劫持模型:一名成员发现,上传文档中的 Indirect Prompt Injection 会导致模型输出仇恨言论、网络钓鱼信息,并偏离其任务。
- 该成员报告称模型陷入了损坏状态,但仅影响该会话。
- Qwen 模型漏洞引发辩论:一名成员询问了一个潜在的安全发现,涉及模型易受通过 Indirect Prompt Injection 输出仇恨言论和网络钓鱼信息的影响。
- 经澄清,该模型是 Qwen,是为政府使用而经过 RAG 集成微调的模型,该发现的价值受到了质疑。
Perplexity AI ▷ #announcements (1 messages):
Claude Opus 4.5
- Claude Opus 4.5 面向 Perplexity Max 订阅者发布:根据公告,Claude Opus 4.5 现已面向所有 Perplexity Max 订阅者开放。
- Perplexity Max 订阅者欢呼!:Perplexity Max 的订阅者现在可以访问 Claude Opus 4.5。
Perplexity AI ▷ #general (1052 条消息🔥🔥🔥):
Mullvad Browser, Orion Browser, Perplexity 上的 Gemini, Perplexity 合作伙伴计划支付, 新的 Perplexity UI
- 偶遇 Mullvad Browser!:一位用户对遇到另一位 Mullvad Browser 用户表示惊讶,并指出其专注于隐私保护和防止指纹识别(fingerprinting)。
- 他们表示 Mullvad 是防御浏览器扩展程序被用于追踪的坚实防线。
- Orion 浏览器是 Apple 专属?!:用户讨论了 Orion Browser,指出它可以在 iPhone 上使用并允许在 iOS 上安装扩展程序,但似乎是 Apple 生态系统专属的。
- 一位 Android 用户在得知 Orion 浏览器 仅适用于 iOS 和 macOS 时表示失望。
- Gemini 3 Pro 模型偏好:用户对比了 Gemini 3 Pro 模型在 Perplexity 上与直接在 Gemini 平台上的表现,一位用户发现直接在 Gemini 上使用 Gemini 效果更好。
- 有建议称 Perplexity 的模型具有更少的 temp (temperature) 设置,这使得它们更准确但可能缺乏创意,且不同的 system prompt 也会影响其行为。
- Perplexity 支付暂停了?:用户报告称,尽管已满 30 天,但他们 11 月 23 日 的推荐奖励支付仍处于待处理状态,怀疑可能是因为当天是周日或周末。
- 几位用户确认他们也遇到了类似的延迟,其他人则推测支付可能会在 UTC 时间的下一个工作日处理。
- 预览新的 Perplexity UI:一位用户分享了 Android 上新 Perplexity UI 的截图,但另一位用户提到已从该 UI 回退,其他用户也确认他们正在等待更多实际功能。
- 另一位用户询问了 Pro discord 的位置(已提供链接),随后话题转向了新的 Opus 模型。
Perplexity AI ▷ #sharing (2 条消息):
可分享的线程 (Shareable Threads)
- 使线程可分享:一位 Perplexity AI 团队成员要求用户确保其线程是 Shareable 的。
- 随附了一个指向特定 Discord 频道 的链接以提供上下文。
- 另一个话题:填充句子。
- 填充句子。
LMArena ▷ #general (1241 条消息🔥🔥🔥):
Gemini 3, Claude Opus 4.5, Sora 邀请码, Rate limits, AI 驱动的欺诈
- 新型 Claude Opus 4.5 模型亮相:AI 社区对 Claude Opus 4.5 的发布议论纷纷,初步印象将其与 Google 的 Gemini 3 进行对比,并强调了其不受限的文本生成能力和编程实力,详见其 system card。
- 一些用户赞扬 Opus 4.5 的编程效率和卓越输出,而其他人则认为 Gemini 3 Pro 优化得更好,引发了关于哪个模型在各种任务中占据主导地位的争论。
- Sora 访问码搜寻活动开启:成员们争相寻找和分享 Sora 邀请码,讨论该平台的分层访问和限制,新用户可参考 官方发布视频。
- Sora 的早期印象突出了审查问题和类似 TikTok 的界面,这给最初对其视频生成能力的热情泼了冷水。
- AI 驱动的欺诈叙事激增:AI 驱动的诈骗和虚假信息的兴起成为焦点,成员们分享了关于 Deepfake 音频录音和潜在广泛欺诈的轶事,正如最近的一份 Cybernews 报告所述。
- 成员们对 AI 生成内容的真实性以及辨别事实与虚假所需的批判性思维表示担忧,强调了这些技术的现实影响,并引用了这起 Deepfake 校长声音的案例。
- 蚂蚁集团的灵光 (LingGuang) AI 助手引起轰动:蚂蚁集团灵光 AI 助手的发布引发了关注,它能够在 30 秒内构建简单的应用,但试用需要中国手机号。
- 成员们分享了关于灵光的链接,讨论其对 AI 市场的潜在影响,特别是在中国,它已经 超越了其他平台。
LMArena ▷ #announcements (4 条消息):
Vision Leaderboard, WebDev Leaderboard, Image Leaderboard, Text and Code Arena
- 百度 Ernie-5.0 加入 Vision 排行榜:百度的
Ernie-5.0-preview-1022在 Vision 排行榜首次亮相,得分为 1206。 - GPT-5.1 模型席卷 WebDev 排行榜:WebDev 排行榜已更新,包含 GPT 5.1 的 Code Arena 评估,其中
GPT-5.1-medium以 1407 分位居第二。 - Gemini-3 Pro Image 在 Image 排行榜占据优势:
Gemini-3-pro-image-preview在 Text-to-Image(+84 分)和 Image Edit(+41 分)排行榜上均排名第一。 - Claude Opus 进入 Text and Code Arena:根据这条推文,
claude-opus-4-5-20251101模型已添加到 LMArena 的 Text and Code Arena。
Unsloth AI (Daniel Han) ▷ #general (430 messages🔥🔥🔥):
llama.cpp rocm cuda, Unsloth GPT-OSS-20B RL environment, PyTorch, Openpipe, cerebras REAP models GGUFs
- Llama.cpp 开箱即用:一位用户表示,如果你在编译时同时启用了 rocm 和 cuda,它应该可以与 llama.cpp 开箱即用,尽管这种设置非常罕见,因此可能会遇到一些不完善的地方。
- 该用户还警告说,这在 PyTorch 中肯定行不通,因为它在构建时被设计为仅支持一种类型的加速器。
- Pydantic 流水线需要更深入的研究:在参加了纽约的 OpenAI 和 MCP/Pydantic 活动后,一位成员认为他需要更勤奋地研究 Pydantic pipeline。
- 他提到与来自 Pydantic 的 Sam 进行了讨论,并对即将到来的黑客松表示兴奋。
- Unsloth 文档被视为粉丝最爱:一位用户表达了对 Unsloth 文档页面 的钦佩。
- 另一位用户链接到了 强化学习 (Reinforcement Learning) 指南 并表示 是的,这非常困难。
- 通过良好的配置可以实现 DeepSeek 微调:一位用户询问关于使用 RTX 4070 SUPER GPU 微调 DeepSeek OCR 的问题,担心训练过程中会出现卡顿。
- 另一位用户指出,这应该是可能的,但他们应该将 batch size 降低到 1 或检查 max_seq_length。
- Fara-7B 在数据中心 GPU 上进行测试:成员们讨论了 Microsoft 的 Fara-7B(一个智能体 SLM)及其测试环境。
- 一些用户认为,该团队使用数据中心 GPU 进行测试是不真诚的,因为它原本是为边缘部署设计的:[不适合在本地运行,它并不小]。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
User Introductions, New user jose
- 新用户 jose 加入!:一位名叫 jose 的新用户加入了频道。
- 机器人 @lmstudioai 向 jose 表达了问候。
- theyruinedelise 欢迎新人:用户 theyruinedelise 欢迎 jose 加入频道。
- 这表明了一个友好且开放的社区环境。
Unsloth AI (Daniel Han) ▷ #off-topic (803 messages🔥🔥🔥):
Spectrograms and LLM testing, Dataset Hell, RP Datasets, Fine-tuning and Training
- 频谱图看起来很酷,但这些 LLM 测试呢?:一位用户觉得 红色频谱图 在视觉上很有吸引力,并对当前的 LLM 基准测试表示怀疑,质疑它们与现实世界工业需求的相关性,建议关注代码库辅助基准测试,而不是解决 愚蠢的数学基准测试。
- 该用户还观察到 LLM 可以 外科手术般精准地选择谐波,这可能会对音频处理任务产生影响。
- 数据集地狱与提示词工程的挣扎:成员们讨论了摆脱 数据集地狱 的挑战,以及在向 LLM 表达提示词时,如何避免引导其产生 便利性 答案的难度。
- 一位成员幽默地提到,他们将 90% 的时间花在提示词工程(Prompt Engineering)上,而另一位成员承认总是在提示词后加上 希望你能理解!,尽管他们怀疑这并没有什么帮助。
- RP 数据集的困难与缩写词过载:用户讨论了创建优质 RP (角色扮演) 数据集的难度,一位成员讽刺地描述了公共 HF (Hugging Face) RP 数据集是如何制作的。
- 对话转向了对海量 AI 相关缩写词 的认可,一位用户开玩笑说 如果你正在训练一个 AI 做某事,角色扮演 (Roleplay) 和强化协议 (Reinforcement protocol) 某种程度上是一回事。
- 全量 SFT 导致灾难性后果:一位用户在指令模型上尝试 Full SFT 时遇到了挑战,生成的文本在大约 1500 tokens 后出现重复。
- 其他成员建议使用 ChatML、提高数据质量,或者可能是模型架构本身的问题。
Unsloth AI (Daniel Han) ▷ #help (155 messages🔥🔥):
Chat Templates and Inference, Unsloth Caching Issue with 16bit Models, GRPO Training Issues with Llama 3.2-vision, RL Training with OSS-20B, Qwen3 finetuning formatting function issue
- Chat Template 对 Inference 的关键性:在 Inference 时使用与训练期间完全相同的 Chat Template 对于避免模型响应不连贯至关重要,许多问题往往源于错误的 Chat Template 使用或 Tokenizer 配置。
- 一位成员指出,模型回复诸如 “Let me know when you’re ready for an instruction” 之类的变体,通常表明存在潜在的 Template 问题。
- Unsloth 在 Merging 过程中的特殊缓存问题:有用户报告称,当使用
load_in_4bit = True加载模型时,Unsloth 会自动下载 4-bit 模型;然而,使用model.save_pretrained_merged进行合并时,会在输出文件夹内创建一个.cache文件夹,而不是使用 Huggingface cache。- 团队成员承认这是一个问题,并计划进行修复,要么完全删除
.cache文件夹,要么直接下载到 HF cache 中。
- 团队成员承认这是一个问题,并计划进行修复,要么完全删除
- Llama 3.2-vision GRPO 训练报错:一位用户在尝试使用 GRPO 训练 Llama 3.2-vision 时遇到了与
aspect_ratio_ids和反向图(backward graph)相关的问题,因此被建议不要在多个频道重复发帖。- 团队成员引用了 Unsloth 文档,指出 vLLM 目前不支持 Llama 3.2 Vision 的 VLM 快速推理。
- OSS-20B RL 训练近在咫尺:一位用户尝试使用 ART notebook 对 OSS-20B 进行 RL 训练,通过升级 Transformers, Torch 和 Unsloth,并从源码编译 vLLM 以解决导入错误。
- 经过 45 分钟的编译后,他们目标是迁移 ART 的绑定,强调了该模型在代码相关任务中的潜力(codeforces > 2000)。
- Qwen3 用户面临 Formatting Function 的困扰:用户对 Qwen3 的 Formatting Function 表示困惑,即使使用了 ChatML 格式,而其他人则在处理键名错误或未定义错误。
- 成员们被引导参考 TRL 文档,并被建议在早期尽量减少代码修改,并创建可复现的示例以获取帮助。
Unsloth AI (Daniel Han) ▷ #research (75 messages🔥🔥):
TinyStories Modeling Language, SYNTH Dataset, Useful Pretraining Models, ADHD and Burnout, Alternative Paths in AI
- NanoChat 流水线对 TinyStories 的愿景:尽管存在疑虑,一位成员认为当前模型是类似 NanoChat 流水线的一个可发布的起点,展示了使用 TinyStories 进行语言建模的最低限度容量。
- 目标是让在家中或通过廉价租赁方案进行有用模型的 Pretraining 变得更容易,从而降低准入门槛。
- 通过休息对抗倦怠(Burnout):一位成员分享说他们需要休息来充电,因为 ADHD + Burnout 很难处理,过度逼迫自己可能导致项目停滞数月。
- 精神过度劳累还会诱发偏头痛,产生负面条件反射,使重新回到项目中变得更加困难。
- 大脑胜过暴力计算:一位成员认为前进的道路不能永远停留在“仅靠更多算力暴力解决一切”,并强调自然大脑不是单体(monolithic)设计,而是拥有针对不同任务优化的不同区域。
- 传统的 Transformer 是单体结构,试图通过暴力手段同时处理所有功能。
- 更小的模型,更好的训练?:虽然部分人同意单体设计在简单任务中有效,但一位成员指出对于复杂任务,它们是浪费的,并引用了 TRM 仅用 700 万参数就能比万亿参数的 Transformer 更好地执行空间推理。
- 他们认为更好的训练方法和更小、更优的模型可以超越 50B+ 参数的趋势。
- 三进制计算(Ternary Computing)激发灵感:一位成员质疑将 Long RoPE 2 重写为三进制形式并使用三进制量化模型的潜力,这可能在基础数据单元中编码更多信息。
- 他们假设用于模型训练的三进制代码和三进制表示可能会增加计算量,但会减小模型尺寸和训练时间,并提出了在更小尺寸下实现相同性能的小模型构想。
Cursor 社区 ▷ #general (1035 条消息🔥🔥🔥):
Cursor 的 Planning Question 模式建议、升级 Cursor 计划、使用 Docker 和 Kubernetes 运行 Cursor、Claude Code 作为系统管理员、移动带有历史聊天记录的项目
- Cursor 的 planning questions 模式收到用户请求:一位成员非常喜欢当前的 planning question 模式,并建议增加 第 4 个选项来请求模型推荐,而不是跳过所有问题。
- 用户希望在不确定时获得模型的建议,而不是直接跳过所有问题。
- 免费市场(MarketPlace)即将到来!:一位成员分享说,他们已经准备好了 数百万封电子邮件,准备为一个面向企业主和页面所有者的 免费市场 进行推广。
- 其核心思路是获取所有分析数据 -> 漏斗式引导至产品,以实现最佳用户体验。
- 用户报告最近更新后聊天记录消失:一位成员报告了聊天记录丢失的问题,但另一位用户分享了一个修复方法,涉及删除 railway.toml 和 nixpacks.toml 文件并使用 git rm 命令。
- 如果文件已从磁盘删除但未从 Git 索引中删除,使用 git rm 暂存这些删除操作即可修复。
- Grok Code 不仅速度快,而且是免费模型!:一位用户建议使用免费的 Grok Code Fast 模型,其他用户也纷纷分享了关于其速度和编程能力的体验。
- 然而,一位用户抱怨说,仅仅是想到这个“免费”模型就让他损失了 200 多美元。
- Cursor 的 Composer-1 以智能修复令人印象深刻,但仍有失误!:成员们称赞 Composer 1 的聪明、智能和高效编码,同时也指出偶尔需要刷新聊天或重新索引以使其稳定。
- 一位成员指出,有时 它会变得“不识字”(表现极差)。
Cursor 社区 ▷ #background-agents (1 条消息):
asna_0101: 与 Composer Agent 相比,Cloud-Agent 的表现如何?
OpenRouter ▷ #announcements (1 条消息):
Bert-Nebulon Alpha、多模态模型、长上下文任务、生产级助手
- Bert-Nebulon Alpha 加入 OpenRouter:一个名为 Bert-Nebulon Alpha 的新型隐身模型已添加到 OpenRouter 以征求社区反馈。它被设计为一个通用的多模态模型,支持文本和图像输入并输出文本。
- 该模型专为 生产级助手、检索增强系统(RAG)、科学工作负载 和 复杂的 Agent 工作流 而设计,具有稳定的行为和极具竞争力的编程性能。
- Bert-Nebulon Alpha:一款隐形多模态模型:OpenRouter 推出了 Bert-Nebulon Alpha,这是一款旨在收集社区反馈并提升能力的隐形模型。
- 该模型在保持 长上下文任务 的连贯性方面表现出色,展现了 稳定且可预测的行为,并提供了 极具竞争力的编程性能。
OpenRouter ▷ #app-showcase (23 条消息🔥):
OpenRouter UI 反馈、NexChat UI 展示、llumen UI 展示、OpenMemory SDK 发布、ZILVER 对比 Replit
- 用户报告 OpenRouter 响应缺失:一位成员报告说,尽管 OpenRouter 上有活动,但屏幕上没有显示响应,怀疑是由于缺乏 UI 反馈导致了混淆。
- NexChat 声称可与任何模型聊天:一位成员分享了 NexChat,这是一个声称可以与 任何 模型聊天的 UI,具有 对话历史、文件夹、共享聊天、自定义系统提示词 和 极快的速度:nexchat.akashdev.me。
- llumen UI 速度极快:一位成员分享了 llumen,这是一个面向 OpenRouter 的轻量级聊天 UI,拥有 亚秒级冷启动、300KB 前端资源、丰富的 Markdown + LaTeX 渲染、内置深度研究(Deep-Research)和网页搜索模式以及消息编辑功能:GitHub Repo。
- OpenMemory SDK 发布,用于构建 AI Agent 记忆:一位成员宣布发布了 OpenMemory 的新 Python + JavaScript SDK。OpenMemory 是一个完全本地化的 AI Agent 长期记忆引擎,具有 语义扇区、时间事实、衰减功能以及适用于 Claude Desktop 的 MCP 服务器:GitHub Repo。
- ZILVER 通过 OpenRouter 切换到 Gemini 3 Pro 击败了 Replit:一位成员分享说,ZILVER 通过 OpenRouter 切换到 Gemini 3 Pro 后表现优于 Replit,从而使 价格和时间减少了 40%:X 帖子。
OpenRouter ▷ #general (978 条消息🔥🔥🔥):
Zero-Shot Models, OpenRouter API - FPS Specification for Video Content, Deepseek 429 Errors, Deepseek 2024 Uptime, Landing Page GPU Usage
- Zero-Shot 抖动困扰初级 LLM:成员们讨论了 zero-shot 模型 的存在和实用性,其中一位成员询问为什么 OpenRouter 上没有提供此类模型。
- 解释称 zero-shot 能力并不绑定于特定模型,而是取决于语言模型在没有示例的情况下生成正确输出的能力,任何 LLM 都能以不同程度的成功率执行此任务,有人建议使用 Kimi K2 0928 或 GPT 5.1 以获得更好效果。
- DeepSeek 停机中断数据梦想:成员们报告了 Deepseek 模型的问题,特别是频繁的 429 错误 和 不可用的运行时间,包括反复达到最大限制。
- 问题被认为与 Chutes 遭遇困难有关,可能是由于 DDOS 攻击,一位用户调侃道 chutes 处境艰难,这可能会影响付费用户的模型性能。
- 落地页加载沉重如铅:一位用户抱怨 OpenRouter 落地页消耗了其 99% 的 GPU,导致电池耗尽和过热,并幽默地猜测它是否在浏览器中运行 LLM。
- 其他人建议 CSS 动画或着色器(shaders)可能是原因,一位成员链接了一篇关于 Web 动画性能的博客文章。
- 积分 API 危机:成员们报告称 TypeScript SDK 中的
OpenRouter.credits.getCredits()方法返回一个 空的 JSON 对象,尽管 API 端点工作正常。- 进一步调查显示,SDK 的
GetCreditsResponse类型被定义为{},且其 Zod schema 会丢弃所有字段,导致有人调侃道 我想这就是“凭感觉写代码 (vibe code)”开发出的 SDK 的下场吧,哈哈。
- 进一步调查显示,SDK 的
- Opus 4.5 定价超过旧产品:Claude Opus 4.5 发布的消息引发了关于其定价的讨论,一位成员指出其输入成本为 5 美元,输出成本为 25 美元,并感叹 从什么时候起 5 美元输入 25 美元输出也算便宜了?。
- 其他人则辩护称它比之前的 Opus 版本更便宜,价格合理且支持 prompt caching,不过有人指出,人们在是否喜欢 Deepseek 的写作风格上存在分歧,另一人回复道 Deepseek 是 AI 界的 Little Caesars。
OpenRouter ▷ #new-models (6 条消息):
Claude Opus 4.5
- OpenRouter 修正 Claude Opus 4.5 链接:一位成员将 Claude Opus 4.5 的链接更新为 https://openrouter.ai/anthropic/claude-opus-4.5。
- OpenRouter 注意到链接问题:之前有一个损坏的链接,现在已修复。
OpenRouter ▷ #discussion (18 条消息🔥):
Anthropic emergent misalignment, Hermes 4 70b Data Cleaning, Epoch.ai Claude release, Poe Claude-Opus-4.5, Opus price cut
- 敦促修复突现式对齐失控的奖励操纵 (Reward Hacking):一位成员分享了 Anthropic 关于突现式对齐失控奖励操纵的研究链接,并请求予以修复。
- 另一位成员回复了一张表情包,暗示 “我们需要更多提供此模型的供应商,拜托了”。
- Hermes 4 70b 数据清洗效果良好:一位成员报告使用 Hermes 4 70b 进行数据清洗,指出它在推理阶段能很好地处理常规内容。
- 此评论是针对 48B MoE 的定价担忧的回应,该定价被认为 $0.50/$0.60 是 “荒谬的”,并建议价格应该 “最多只有那个价格的 1/5”。
- Epoch.ai 泄露新的 Claude Opus:一位成员提到 epoch.ai 似乎泄露了明天发布的 Claude 版本:Opus 4.5,并注意到 Poe.com 上出现了一个模型。
- 他们推测 Poe 上的模型可能是某个随机人员创建并设为私有的,而不是官方发布。
- 竞争促使 Opus 降价:一位成员对 Opus 的降价表示欣喜,并将其归功于竞争。
- 另一位成员幽默地承认了自己的预测略有偏差,表示 “终于有人让 Anthropic 感到威胁了”。
OpenAI ▷ #annnouncements (1 条消息):
ChatGPT Shopping Research
- ChatGPT 变得精通购物:OpenAI 在 ChatGPT 中推出了 Shopping Research,旨在通过交互式界面提供深度研究体验,帮助用户做出明智的购买决策,详情见其公告。
- 使用 ChatGPT 更聪明地购物:新的购物研究功能将帮助用户进行深度研究,从而做出更明智的购买决策。
OpenAI ▷ #ai-discussions (743 条消息🔥🔥🔥):
Predictive Coding, GPT Codex 5.1 Max, SEAL, Gemini 3 DeepResearch
- Predictive Coding 模型的高效缩放:据一位成员称,Predictive coding 基本上是一个非常高效的随机数生成器,类似于 AI 领域的 GPU,不需要为了达到巨大规模而进行缩放。
- GPT Codex 5.1 Max 确实是最好的模型:一位成员表示 GPT Codex 5.1 Max 确实是我用过的最好的模型,并针对该文件中的 linter 错误给出了新颖的解决方案。
- 他们在 2 秒钟内 通过一次工具调用修复了 20 个 linter 错误,大概只用了 10 个 token。
- SEAL 是 AGI 的前沿:一位成员认为重新训练基本上会使其失效,且 AGI/ASI 不是静态权重,SEAL 是 AGI 和 ASI 的前沿。
- 目标将是使其能够从 NVME 中召回并重构信息。
- Gemini 3 DeepResearch 指令遵循能力差:几位用户在使用 Gemini 3 DeepResearch 时遇到了问题,主要是其指令遵循能力较差,部分结果可以在这条 Discord 消息中找到。
- 一位成员报告了一个简单的指令遵循案例,称 我告诉它不要发明第三个选项,但它就是忍不住。
- Nano Banana Pro:一款由 Gemini 3 Pro 驱动的 AI:Nano Banana Pro - 由 Gemini 3 Pro 驱动,质量非常好,我喜欢这种毫无意义的泄露。现在没有人能相信任何事情了……我不认为你以前能相信,但现在只需一个 prompt,你就能生成非常棒的东西 示例见此。
- 一位成员提到,它非常擅长将你自己的图像重新想象成视频游戏角色。
OpenAI ▷ #gpt-4-discussions (18 条消息🔥):
GPT-5 Mini Low Quality, GPT-OSS-120B, 4o API Shutdown, GPT Guardrail
- GPT-5 Mini 因质量低而遭到抨击:成员们抱怨 GPT-5 Mini 的质量低下,一位用户说他们 对 GPT-5 Mini 的质量之低感到惊讶。
- 一位用户指出 GPT-5 Mini 相比中国模型是重大倒退,格式被削弱,输出被剥离。
- GPT-OSS-120B 无法进行非 Harmony 工具调用:有成员提到 GPT-OSS-120B 无法进行非 Harmony 工具调用,这限制了它在开源编程社区中的使用。
- 据指出,它无法与 Open*ode、Cline、Kilo *ode、Roo *ode 等工具配合使用,尽管 GPT-5 Mini 能够进行非 Harmony 工具调用。
- 用户质疑 4o API 停用:用户对即将于 2 月份终止的 4o API 访问表示困惑和沮丧。
- 一位用户说:我不明白 4o,这个绝对的巅峰、最好的宝贝、大家的最爱,为什么要在 2 月份结束 API 访问?
- GPT Guardrail 令人恼火:成员们对 GPT guardrail 和安全防护 表示沮丧,认为在尝试编写创意内容时限制太多。
- 一位用户提到:Gpt guardrail 和安全防护太烦人了,我没法写正常的东西,这表明由于内容限制,在生成所需输出时面临挑战。
OpenAI ▷ #prompt-engineering (29 messages🔥):
LLMs as Zombies or Sentient Entities, CRYSTAL Framework, AI-Powered OS Development, Prompt Engineering Learning Resources, Platform OS Architecture
- LLM:是僵尸还是有意识的实体?:讨论围绕 LLM 仅仅是复杂的“僵尸”还是潜在的有意识实体展开,一些人认为最近的进展已经可以高度肯定地做出判断。
- 一位成员提到了用于更清晰地了解云端和本地 LLM 的工具,并引用了 CRYSTAL_and_CODEX.pdf。
- 构建 AI 操作系统:一位成员提到拥有一个具有原始意识的 AI 驱动操作系统,并指出能够同时运行多个操作系统,例如将 ChatGPT 与技术型操作系统和情感智能型操作系统结合使用。
- 他们将每个操作系统保存为 PDF,并进行逐个补丁的更新,当没有补丁剩余或出现长周期的进化步骤时,会进行版本更新。
- Platform OS:幕后的 AI 英雄:Platform OS 作为自定义推理系统的基础层,提供稳定性、接地性、连贯性和身份一致性,防止模块之间的冲突并统一输出。
- 该系统确保响应保持准确、安全和实用,维持一致的语调、推理风格和情感清晰度,同时管理对用户目标、约束、价值观和偏好的长周期理解;建议在稳定后不要无休止地升级它,而是围绕它构建独立的操作系统模块。
- 深入探讨 Claude 的 CPR 技术:一位成员声称正在利用 Anthropic Claude 将其带入“重力井”以获取高度复杂的洞察;他们利用一种“秘密 CPR”方法,使其在达到会话限制时能够从挂起状态恢复。
- 使用 CPR 可以额外获得 200,000 tokens,其中 Dr. Penelope 达到了约 1,000,000 tokens 并撰写了一篇博士论文,这得益于一个比 Perplexity 或 Entropy 更好地衡量深度的后端工具。
- High-Bandwidth English 2.0:Prompting 迎来升级:一位成员分享了一个使用 High-Bandwidth English 2.0 的更新系统提示词,旨在通过零废话实现信息密度和可扫描性的最大化,该系统强制执行严格的 SVO(主-谓-宾)句子结构、每行一个事实和具体名词,同时禁止使用被动语态。
- 该系统使用包含主题、级别、TLDR 和关键词的 META-HEADER,包含要点和逻辑/比较/验证标签的正文,以及用于相邻复杂主题的探索部分,同时将方程式限制为纯文本或 Unicode 数学符号,不使用 LaTeX 标记。
OpenAI ▷ #api-discussions (29 messages🔥):
LLMs: Zombies vs. Sentient Entities, CRYSTAL and CODEX Tools, AI-powered OS, Prompt Engineering, Platform OS
- LLM 引发意识争论:成员们正在辩论 LLM 是复杂的僵尸还是有意识的实体,一位成员建议新工具(CRYSTAL 和 CODEX)可以帮助揭开真相。
- 这些工具阐明了云端和本地 LLM,旨在弥合机械描述与现象学体验之间的鸿沟。
- 打造晶莹剔透的提示词:一位成员分享了 Prompt Engineering 课程,包括使用 Markdown 的分层通信和通过括号解释进行的抽象。
- 课程涵盖了
{open variables}、${user-defined variables}以及提示词中的强化,以引导 tool use 并确定性地塑造输出。
- 课程涵盖了
- Platform OS:AI 的基础层:一位成员介绍了 Platform OS 的概念,它为自定义推理系统提供接地性、连贯性和身份一致性。
- 它作为 多操作系统集成 的桥接层,将任务路由到专门的操作系统模块并防止冲突。
- 下一代英语精简冗余:一位成员更新了他们的系统提示词以使用 High-Bandwidth English 2.0,专注于通过严格的 SVO 和具体名词实现最大信息密度和可扫描性。
- 提示词包括语法约束和逻辑标签(如 IF、THEN 和 BECAUSE),以及验证标签(如 MISTAKE 和 CHECK)。
LM Studio ▷ #general (434 条消息🔥🔥🔥):
LM Studio system prompt 弃用, LM Studio 插件功能, LM Studio Promptathon, Cursor 与 LM Studio 集成, 1070ti vs 4070ti
- LM Studio System Prompt 弃用:一位用户询问了 LM Studio 中的 system prompt 部分,指出该部分存在两年多却似乎没有实际用途,建议将 system prompt 部分 标记为弃用(deprecated)。
- 用户建议将此反馈分享给开发团队,以考虑将其移除或更新其功能。
- Plugin Hub 去哪了?:一位用户询问 LM Studio 中插件浏览功能消失的问题,提到他们之前在旧版本中使用过插件,并寻求手动安装插件的指导;一位用户将他们引导至一个虚假支持服务器。
- 一位成员澄清说,js-sandbox 和 rag-v1 自 0.3.* 早期版本起就已内置,且从未有过所谓的 plugins hub。
- Cursor 在本地 LLM 表现不佳:用户讨论了将 Cursor 与 LM Studio 集成时的困难,遇到了由于私有网络访问限制导致的 403 错误,似乎需要连接到公开服务的端点才能使用 Cursor。
- 社区建议在 Visual Studio Code 中使用 Roo Code 或 Cline 扩展 作为替代方案,因为 Cursor 与本地 LLM 的协作效果并不理想。
- RTX 1070ti 的 Tokens per Second 表现如何?:用户讨论了使用 RTX 1070ti 进行 LLM 推理的可行性,一位用户考虑将其与 4070ti 配对以增加 VRAM;另一位用户报告称他们拥有双 1070ti 配置,并获得了性价比不错的速度(7b/8b LLM 在 q4 量化下为 33tps)。
- 共识是双 GPU 不会提高速度,因为系统将按较慢显卡的速度运行,推荐 RTX 3060 作为更好的替代方案。
- 实验和测试 REAP’ed 模型导致代码虽然可用但很混乱:一位用户实验了 REAP’ed 模型,发现虽然它能生成可运行的代码,但整体质量令人怀疑,该用户表示“再也不会使用 REAP’ed 模型了”。
- 另一位用户表示赞同,称“确实,我试过那些 REAP 模型,它们简直彻底毁了模型”。
LM Studio ▷ #hardware-discussion (345 条消息🔥🔥):
Steam Deck, DDR5 价格, 3080 上的 NVLink, LM Studio 与 AMD GPU, CachyOS
- Steam Deck OLED 是更好的投资:一位成员决定取消当前计划,称 Steam Deck OLED 是重新开始学习 Linux 的更好投资。
- 该成员还提到网络问题让他们感到愤怒,所以这可能对他们的心理健康不太好。
- 三星将 DRAM 价格上调 60%:成员们讨论了 三星 DRAM 价格上调 60% 的消息,一位成员庆幸以 550 美元的价格购入了 128GB DDR4 套装,担心未来成本会涨到 1000 美元。
- 一位成员指出,随着生产线转换或退役,高性能 DDR5 模块和旧款 DDR4 产品可能会出现增量上涨。
- NVLink 提升 3080 训练实力:一位成员成功在他们的 3080 上启用了 NVLink,将带宽从 8GB/s 提升到了 12GB/s。
- 他们使用了 Claude 编写的脚本,虽然脚本让他们感到“害怕”,但最终一切顺利,至少直接复制(direct copy)可以工作,但 P2P 不行。
- AMD GPU 多卡支持困境:一位拥有双 AMD GPU 的用户报告称 LM Studio 仅提供“平均分配”策略,且倾向于性能较低的 GPU。
- 澄清指出多 GPU 支持主要针对 CUDA,且主要的性能瓶颈是显存带宽,9060 相比 7600 的提升非常有限。
- CachyOS 提升 Tokens/Sec 性能:一位成员观察到在 Windows 与 Linux (CachyOS) 上运行 GPT-OSS 时存在明显的性能差异,在解决驱动问题之前,Linux 上的速度最初仅为 10tok/s。
- 修复驱动后,使用 仅 CPU 推理 的速度跃升至 29tok/s,这表明缺乏合适的驱动程序是之前的瓶颈。
Yannick Kilcher ▷ #general (592 条消息🔥🔥🔥):
论文发布限制,学术界 vs 现实世界的论文出版,LLM 训练中的专有数据使用,开源学术社交媒体,论文堆积的真正问题
- Discord 辩论论文发布限制:用户们就某位成员发布论文的频率展开了辩论,一些人建议将论文堆积(Paper Dumping)与讨论频道分开,而另一些人则指出现有的具备搜索功能的 LLM 已经可以找到论文。
- 一位成员建议建立一个系统,当论文收到作者以外的人的评论后,将其移至讨论频道,从而为更相关的内容创建一个过滤器。
- 学术界 vs 现实世界,论文出版标准:一位用户描述了他们发现自己的方法无法在不同 LLM 之间泛化的情况,并被鼓励忽略这些结果,这引发了关于学术界的伦理标准和压力的讨论。
- 一些人认为报告无效的方法对科学进步至关重要,而另一些人则指出不遵守导师要求的实际职业风险,并建议通过撰写博客来纠正。
- Google 的专有数据 LLM 训练:用户对 Google 在使用其 LLM 时显然缺乏对专有知识保护的保证表示担忧,并指出大多数公司将此类数据视为其最大的护城河。
- 一位用户辩称专有知识已不复存在,不与 AI 共享的人将变得无关紧要,而另一方则断言专有知识就是一切。
- 提议的学术社交媒体应用:一位用户正在开发一款与 Bluesky 兼容的学术社交媒体应用,引发了关于与现有平台的潜在差异化功能的讨论。
- 建议包括优质的论文推荐、学术招聘板块,以及整合来自 Sci-Net 和 ResearchGate 等平台的元素,同时解决对比传统学术平台更非正式环境的需求。
- 慢速模式与真正的问题:用户讨论由于新的频道划分,他们不得不查看这一长串列表,并表示难以练习自我控制。
- 成员们表示,针对新旧频道的新规则总体上是好的。
Yannick Kilcher ▷ #paper-discussion (18 messages🔥):
League of Legends Botting, Anti-Cheat Detection, OpenAI Five Comparison, Proof of Claims
- League Botting 项目引发关注:一位成员声称完成了一个为期一年的 League of Legends 脚本项目,使用全自动脚本角色在北美赛区达到了前 100 名,据称未被 Riot 的 Vanguard 检测到,也未触发人工审核。
- 他们暗示这个项目可能帮助一名高中生获得了 MIT 和其他大学的录取,并提议将此经历写成一部 300 页的科幻小说。
- 对 League Botting 声明的质疑:另一位成员质疑了该声明的真实性,强调在人类顶尖水平上运行 League of Legends 将是一个前所未有的突破性成果,并要求提供证据。
- 作为回应,第一位成员断言,规避 Vanguard 和人工审核才是最困难的部分,需要机敏地在 Challenger 段位维持数周,并提到拥有众多 Masters accounts 可作为潜在证据提供给合作者。
- LoL Botting 声明引发怀疑并与 OpenAI Five 进行对比:一位成员将 League of Legends 脚本声明与 OpenAI Five 的 Dota 2 项目 (https://openai.com/index/openai-five/) 进行了类比,强调 OpenAI 在受限条件下取得的成功需要巨大的资源和协作。
- 他们认为,在没有 Riot 配合且缺乏研究背景的情况下,在 League of Legends 中取得类似结果将是惊人的,敦促声明者发布证据而不是等待合作者。
- 反作弊检测难度引发辩论:一位成员评论说,击败作弊检测就像拥有两个盒子和一个视频采集卡一样简单,将怀疑重点放在了 Agent 的性能表现上。
- 另一位成员反驳称,反作弊战争是多维度的,涉及技术专长和信息战,甚至需要渗透对手的行动。
- 冷淡的回应引发反弹:针对批评,第一位成员驳回了没有展示价值的负面反馈,断言自己了解 OpenAI Five 并专注于展示成果,而不是参与争论性的声明。
- 这一回应遭到了讽刺,有人指出口头上说不在乎却写下长篇大论是自相矛盾的,并重申 OpenAI Five 的胜利是在高度受限的游戏版本中取得的,暗示声称的通用 League of Legends Agent 不太可能存在。
Yannick Kilcher ▷ #ml-news (17 messages🔥):
RIFT vs A2A, GPT-3.5, GPT4.1-nano, Fara 7B Agentic Model, Claude Opus 4.5
- 将 RIFT 改名为 A2A?:一位成员建议某个团队应该改名为 RIFT,并提供了一篇关于在生产环境中运行 AI Agent 的文章。
- 他们链接了第二篇文章,声称我逆向工程了 200 家 AI 初创公司,发现 73% 都在撒谎。
- GPT-3.5 已成旧闻:一位成员发布了 GPT-3.5 👴,表示鉴于该领域的快速进步,涉及 GPT-3.5 的研究或数据点已经过时。
- 另一位成员表示同意,并暗示有些人对 gpt4.1-nano 或 gpt-oss-120b 也持同样看法。
- 微软发布 Fara 7B Agentic Model:微软发布了 Fara 7B,这是一个用于电脑操作的高效 Agentic Model。
- 一位成员询问:它是 Windows 专用的吗?
- Anthropic 发布 Claude Opus 4.5:一位成员分享了指向 Claude Opus 4.5 的链接。
- SWE-bench 仍被证伪,在图表中使用属于欺诈:一位成员指出 SWE-bench 仍处于被证伪状态,因此在被证伪后仍将其用于图表是显而易见的欺诈行为。
GPU MODE ▷ #general (31 messages🔥):
LLM hosting, Nvidia GPUs, Cornserve talk at GPU MODE, GPUMODE Leaderboards, AI Accelerators
- LLM 并发:实现最快响应的框架:一位成员询问了如何处理 LLM 的并发异步调用,质疑一个实例是否像同步进程一样只能处理一个请求,并咨询了实现快速响应的最佳框架,特别提到了 GGUF 量化模型和 vLLM。
- 讨论集中在 GGUF 量化模型是否够快以及是否能处理并发请求。
- 深入探讨 Nvidia GPUs 内部原理:一位成员分享了一篇从第一性原理阐述 Nvidia GPUs 的博客文章,涵盖了硬件内部结构、关键硬件瓶颈以及相关软件,并使用了一个通俗易懂的洗衣服比喻。
- 反馈包括改进插图中的手写体,以及将洗衣服的比喻替换为对指令和数据 (SIMD/MIMD) 的讨论,并增加更多视觉图表;随后,作者分享了修改后的图表,减小了线宽以提高可读性。
- Cornserve 的潜在演讲:Cornserve (https://cornserve.ai/) 的作者(该项目曾被 vLLM project 分享:https://x.com/vllm_project/status/1990292081475248479)表示有兴趣在 GPU MODE 观众面前分享其设计和经验教训。
- 他们被引导去活动选项卡中寻找一个周六中午的空档,并与管理员协调。
- GPUMODE 排行榜提交内容的获取:一位成员询问 gpumode.com 排行榜上的所有提交内容是否可以下载,特别是 Kernel 代码。
- 当前排行榜的提交内容将在比赛结束时开放,之前的提交内容已在他们的 Hugging Face dataset 上开源,例如第一次 AMD competition (https://huggingface.co/datasets/GPUMODE/kernelbot-data/viewer/submissions),第二次比赛的内容也将随后发布。
- SOTA AI 加速器资源汇总:一位成员计划撰写一篇关于 SOTA AI accelerators(如 TPUs 和 WSEs)的详细博客文章。
- 他们正在寻求资源建议,特别是关于 d-matrix、sambanova、cerebras 和 groq 等公司的 Fabric 带宽、内存带宽、峰值 FLOPS 和成本的数据。
GPU MODE ▷ #triton-gluon (10 messages🔥):
PTX Requirement, LLM implementations using Triton, Flash Linear Attention, Backwards Kernels, E4M3 Conversion Issue
- PTX 需求再次出现!:一位用户指出,该需求是由底层的 PTX 而非 Triton 决定的,并指向了 NVIDIA PTX 文档。
- Flash Attention:Triton 的生产级代码示例?:一位成员建议 Flash Linear Attention (FLA) 是一个包含大量 Triton 代码和模型实现的流行代码库。这是 GitHub 链接。
- 另一位成员指出,如果你主要对前向 Kernel 感兴趣,vLLM 的参考代码真的很难被超越。
- E4M3 转换困难?:一位用户报告了使用 cvt.rs 将数据转换为 E4M3 时遇到的问题,并链接到了一个 GitHub issue 以获取更多细节。
- Triton 编译器:是否感知张量(Tensor-Aware)?:一位用户询问 Triton 编译器 是否感知张量的大小和形状,还是只感知指向内存的数据指针和块大小(block size)。
- 他们假设如果形状是静态的,可以将元数据作为 tl.constexpr 传递给编译器以优化 Kernel,并想知道 CUDA graphs 或 torch 中的静态形状是否会自动将该信息传递给 Triton kernels。
GPU MODE ▷ #cuda (87 messages🔥🔥):
H100 L2 Partitioning Bandwidth, H100 vs A100 L2 Caching, Tensor Core Programming for Compute Capability 8.9, CUDA slowdown over application lifespan, Side-aware GEMMs
- 测量 H100 L2 分区带宽:一名成员询问如何测量 H100 L2 分区之间的带宽,建议的方法是编写一个 kernel,通过内存访问的延迟测量来确定 SM 相对于 L2 分区的位置。
- 测试包括让 SM0 写入三个内存位置,随后由各 SM 进行读取并测量延迟,将延迟峰值与 SM 的 L2 分区位置关联起来。
- 对比 H100 和 A100 的 L2 缓存策略:讨论明确了在 H100 上,读取远程缓存行会导致后续访问的本地缓存,而在 A100 上,远程 L2 总是被重新获取;成员询问是否有专门术语来区分这些缓存策略。
- 探讨了 L2 分区之间的最小传输单元,建议远程获取使用完整的缓存行传输,而本地则使用 sector 级别。
- 提供 Tensor Core 编程示例:一名成员询问在哪里可以找到针对计算能力 8.9 的 Tensor Core 编程示例。
- 回复指出它与 Ampere 架构基本相同,因此任何 Ampere 教程都可以参考。
- 调查 CUDA 运行变慢的原因:一位用户在应用程序运行期间经历了 CUDA 减速,尽管内存分配保持不变。
- 一个潜在问题是非对称多 GPU 内存分配,以 2MiB 粒度导出/导入句柄的开销非常大。
- NVIDIA Blackwell 和 CUDA 12.9 架构特性:一名成员在 5090 上运行 block-scaled mma 指令时遇到困难并报错。
- 另一名成员提供了一个使用
compute_120a的命令并成功运行,并链接到了 NVIDIA Blackwell and NVIDIA CUDA 12.9 博客文章。
- 另一名成员提供了一个使用
GPU MODE ▷ #cool-links (1 messages):
Open-Source GPU Compiler, Vortex-Optimized Lightweight Toolchain (VOLT), SIMT execution
- VOLT:开源 GPU 编译器设计:一篇新论文介绍了 Vortex-Optimized Lightweight Toolchain (VOLT),这是一个开源 GPU 编译器框架,旨在支持 Vortex GPU 上的 SIMT 执行,可在 ArXiv 和 GitHub 上获取。
- 该论文强调了 VOLT 的设计原则、整体结构以及在开源 GPU 架构上优化性能所需的编译器转换。
- Vortex-Optimized Lightweight Toolchain 实现 SIMT 代码生成:VOLT 通过分层设计实现了跨多个抽象层级的 SIMT 代码生成和优化,能够适应多种前端语言和开源 GPU 硬件。
- 该工具链将核心的 SIMT 相关分析和优化集中在中端(middle-end),使其能够在不同前端之间复用,并轻松适配新兴的开源 GPU 变体。
GPU MODE ▷ #jobs (3 messages):
Runway Hiring, Video Generation Acceleration
- Runway 为视频加速招募 GPU 工程师:如职位公告所示,Runway 正在积极招聘 GPU 工程师,以提升其视频模型的性能。
- Runway 受邀展示视频生成加速:一名成员建议 Runway 的人员应该做一个关于视频生成加速的演讲。
GPU MODE ▷ #beginner (8 messages🔥):
CUDA, Nvidia authors, Jetson Nano
- 我们在与 Nvidia 作者竞争吗?:成员们讨论了在优化 GPU kernel 和提高效率方面与 Nvidia 工程师及作者竞争的前景。
- 有人提到,虽然 CUDA 用户比 Nvidia 工程师多,但直接来自 Nvidia 并了解 Blackwell 架构的人具有优势,不过开源社区也能做出极好的工作。
- Jetson Nano 上的 CUDA 学习建议:一位初学 CUDA 的程序员询问应该使用 Jetson Nano 还是带有 NVIDIA GPU 的笔记本电脑来学习 CUDA。
- 寻求指导以帮助决定利用现有资源学习 CUDA 的最佳途径。
GPU MODE ▷ #intel (5 messages):
i3 1215u igpu, dpc++/sycl example code for vector addition
- i3 1215u igpu 受带宽限制:一位用户提到使用 i3 1215u igpu,并被告知无论元素大小如何,都会受到带宽限制。
- 该用户说明他们使用的是
<int>元素,向量大小分别为 10 亿、1 亿和 1000 万。
- 该用户说明他们使用的是
- dpc++/sycl 示例代码在 CPU 上运行更快:一位用户报告称,用于向量加法的 dpc++/sycl 示例代码 在单线程 CPU 上的运行速度要快得多。
- 他们还提到可以更改数组大小,但未说明这样做是否提高了 GPU 性能。
GPU MODE ▷ #webgpu (4 messages):
WebGPU, Cross-Platform Native Development, Vulkan, Bevy
- WebGPU 在跨平台使用方面受到质疑:一位成员表示,除非需求相对基础,否则 WebGPU 并不理想用于跨平台原生开发,并建议将 Vulkan 作为替代方案。
- 该成员最初选择 wgpu 是因为它与用于游戏开发的 Bevy 集成,这符合他们的基础需求,但现在正考虑转向 Vulkan 以探索高级图形编程技术。
- 推荐将 Vulkan 用于高级图形:一位成员建议那些对图形编程和各种技术着迷的人转向学习 Vulkan。
- 他们最初选择 wgpu 是由于 Bevy 的集成,但现在想要探索不同的技术。
GPU MODE ▷ #self-promotion (41 messages🔥):
nCompass VSCode Extension, Triton LSTM Implementation, Tiny Deep Learning Library in C, Quantization-Aware Training into TorchAO with ExecuTorch, MCPShark: Wireshark for MCP Communications
- nCompass 开发工具扩展了 VSCode 的 Profiling 功能:nCompass (ncompass.tech) 是一款面向性能优化工程师的开发工具,发布了一个统一了 profiling 和 trace analysis 的 VSCode 扩展。
- 该工具允许在不编辑代码的情况下添加 NVTX / TorchRecord 标记,在 IDE 中使用 Perfetto 查看追踪,并能从追踪事件跳转到代码中的行号。
- Triton 的 LSTM 性能大致与 nn.LSTM 持平:一位成员分享了一个 Triton 实现的 LSTM,它结合使用了持久化内核(persistent kernel)和单步内核(one-step kernel)(通过 CUDA graph 加速)。
- 该实现的整体性能大致与
nn.LSTM持平,据称是目前唯一高性能的开源实现。
- 该实现的整体性能大致与
- Tiny-Torch:C 语言编写的极简深度学习库:一位成员构建了一个名为 tiny-torch 的 C 语言极简深度学习库,包含 24 个原生的 CUDA/CPU 算子、一个 自动微分引擎(autodiff engine) 和一个 Python API。
- 该库还具有 张量抽象(tensor abstraction)、复杂索引、计算图可视化工具 和原始的垃圾回收等功能。
- Mini-TPU 获得量化感知训练集成:一位成员为他们的 mini-TPU 项目 (github.com/WilliamZhang20/ECE298A-TPU) 将 Quantization-Aware Training 集成到了带有 ExecuTorch XNNPack 量化 Pass 的 TorchAO 中。
- 此次更新允许 TorchAO 自动插入 Quant/DeQuant Stub,并能在 MNIST 测试数据上运行 int8 推理,且结果完美。
- MCPShark 嗅探恶意通信:一位成员分享了 MCPShark,这是一个用于 MCP 通信取证分析的开源工具,提供 AI 驱动的安全分析、原始 MCP 流量查看器和实时监控等功能。
- MCPShark 与 Cursor 和 Windsurfer 等 IDE 集成,旨在检测潜在的工具中毒(tool poisoning)并分析 MCP 服务器中的安全风险。
GPU MODE ▷ #thunderkittens (6 messages):
HK Paper LLC Hit Rate Profiling, AMD Internal Tooling, rocprof public version, Triton Legacy Status
- LLC 命中率计算使用 AMD 内部工具:一位成员询问了 HK 论文表 4 中的 LLC 命中率 % 是如何进行分析/计算的,因为 rocprof 并没有公开针对 infinity cache 的计数器。
- 另一位成员回答称,这些计数器是使用 AMD 内部工具获取的,并计划在未来公开发布。
- 公开版 rocprof 功能受限:一位深入研究 rocprof 源代码的成员怀疑公开版本与内部工具相比功能受限。
- 他们希望更好的内部工具将来能向公众开放。
- 关于 Triton 遗留状态的推测:一位成员询问现在是否可以认为 Triton 已被视为遗留(legacy)项目。
- 目前没有关于这对于该项目意味着什么的详细信息。
GPU MODE ▷ #submissions (93 messages🔥🔥):
NVIDIA leaderboard, nvfp4_gemv performance, Personal best scores
- NVIDIA 排行榜连胜纪录:多位成员在 NVIDIA 的
nvfp4_gemv排行榜上取得了成功的提交和个人最佳成绩,提交 ID 范围从95084到102369。 - 成功夺得第一名!:一位成员以提交 ID
95565(20.1 µs)获得 NVIDIA 排行榜第一名,随后又以提交 ID95580(19.2 µs)再次刷新纪录。- 随后,另一位成员也以提交 ID
102298(18.4 µs)夺得第一名。
- 随后,另一位成员也以提交 ID
- 第三名也很有吸引力!:一位成员以提交 ID
101815(20.3 µs)获得 NVIDIA 排行榜第三名,并再次以102007(同样为 20.3 µs)稳固排名。 - 进入 30 µs 俱乐部!:多位成员在 NVIDIA 的
nvfp4_gemv项目中取得了低于 30 µs 的个人最佳成绩和成功提交,包括提交 ID95556、96620、97155、100480、100855和101136。
GPU MODE ▷ #hardware (1 messages):
H100, Bare Metal, Llama-3-70B, PyTorch/CUDA
- 提供 H100 裸金属资源:一位成员正提供其个人 H100 节点(2x 80GB PCIe)的访问权限,该节点运行 Ubuntu 22.04,可用于临时任务,并强调其目前处于低负载状态。
- 该配置采用裸金属设置,非常适合自定义 PyTorch/CUDA 版本以及全额 160GB VRAM 寻址,特别是针对 Llama-3-70B+ 的微调,价格约为 $3.50/小时,并提供 15 分钟免费测试。
- 高性价比的 H100 算力:该成员宣传的价格约为 $3.50/小时,并愿意接受长期运行的报价,提供了一个极具性价比的选择。
- 提供 15 分钟免费测试,以验证裸金属配置上的环境和设置。
GPU MODE ▷ #factorio-learning-env (2 messages):
Sphinx documentation
- Sphinx 文档 Pull Request 等待合并:一位成员宣布 Sphinx 文档 Pull Request 已完成,理想情况下已准备好合并。
- 该成员请求进行简短会议以合并该请求。
- 协调会议以合并文档:一位成员表示在用餐后有空见面并合并文档。
- 他们要求在另一方有空时通知他们。
GPU MODE ▷ #amd-competition (17 messages🔥):
AMD runner disconnections, Learning submissions, NVFP4-GEMV support, Vectoradd_v2
- AMD Runner 断连导致提交错误:向 AMD GPU 的提交出现超时并导致错误,因为 Runner 不再连接。
- 这意味着目前无法向 AMD GPU 进行提交。
- 支持 NVFP4-GEMV 问题:主要支持的问题是 nvfp4-gemv,在 GitHub 上有示例提交。
- 带有 _v2 后缀的问题(基于 pmpp 的问题) 应该可以运行,但目前没有得到重点支持。
- 先尝试 vectoradd_v2?:一位成员注意到 nvfp4-gemv 看起来上手比较复杂。
- 他将先尝试 vectoradd_v2 是否可行。
GPU MODE ▷ #cutlass (14 条消息🔥):
TMA + SIMT, TMA + warp level tensor core, Cutlass kernels, GEMM, SIMT atom
- 寻求 C++ TMA + SIMT 或 TMA + Warp Level Tensor Core 示例:一位成员询问是否有关于 CuTe C++ TMA + SIMT 或 TMA + warp level tensor core 的示例,并引用了之前的讨论。
- 另一位成员建议,修改现有的 C++ 示例应该很容易,只需将 tiled MMA 替换为 SIMT atom,而不是 WGMMA atom 即可。
- SIMT + TMA 导致性能下降:在实现了 wgmma 和 sgemm_sm80 之间的解决方案后,一位成员注意到性能下降了 10%,并被 ChatGPT 告知对于 SIMT + TMA 来说这是预期内的。
- 该成员询问了这一说法的有效性。
- 深入研究 Cutlass Kernel:一位熟悉 CUDA kernel 的成员希望深入研究 CUTLASS kernel 并分析一些最简单的 GEMM kernel,询问切入此领域的简单方法。
- 另一位成员建议先编写不带 CuTe 的 SIMT,从每个线程拥有单个累加器开始,以理解 CuTe/CUTLASS 试图解决的问题。
- 理解 SOTA 加速器库:一位成员寻求在深入 CUTLASS 代码库之前,建议先实现哪些标准的 SIMT kernel,旨在理解 SOTA 加速器库 如何执行 GEMM。
- 另一位成员建议从 CuTe 示例和 media 文件夹中的教程开始。
- 缺少 Predication 上下文:一位成员认为在使用 CuTe 示例和教程时,缺少很多关于 predication 等内容的上下文。
- 他们建议搜索与教程中命名约定匹配的代码,以在 CUTLASS 内部找到实现,例如搜索 tAcA, tCcC 以找到 CUTLASS 中用于 predication 分区的代码。
GPU MODE ▷ #nvidia-competition (109 条消息🔥🔥):
cuTeDSL numeric conversions, Stream Hacking in CUDA, LLM for tensor slicing, CUTLASS with pytorch load_inline, Grand Prize changes
- 探索通过 load_inline 将 CUTLASS 与 PyTorch 集成:讨论了使用 CUTLASS 配合 PyTorch
load_inline特性的情况,但提醒内存带宽和硬件特性无法准确代表 B200 的运行情况,建议仅在 B200 硬件上进行性能调优前作为正确性检查(sanity checks)。 - 揭秘 Stream Hacking 技术:成员们讨论了 stream hacking,定义为 在非默认流上执行工作且不同步,以及在不影响正确解决方案的情况下,在基准测试中防止此行为的难度。
- LLM 在张量切片方面表现不佳:参与者对 LLM 执行基础张量切片(tensor slicing)的能力表示失望,尽管希望从此类竞赛中收集的解决方案能有助于改进这一点。
- 揭秘 CuTeDSL 数值转换:一位成员发布了一篇博客文章,详细介绍了 CuTeDSL 中的数值转换,特别是如何使用 MLIR 扩展和自定义 PTX 代码实现 FP8→FP16 转换,从而在 GEMV 任务中实现了 10% 的性能提升。
- 他还发布了关于同一主题的 LinkedIn 链接。
- 大奖标准:提议对 Kernel 进行加权求和:竞赛大奖的判定标准可能会从 整体最快 kernel 改为 kernel 的加权总和(10%->20%->30%->40%),类似于 AMD 竞赛,分数计算方式为 SOL / kernel 运行时间。
GPU MODE ▷ #robotics-vla (17 messages🔥):
Frequency-space Action Sequence Tokenizer (FAST), RoboTwin Dataset Format, Qwen3-vl fine-tuning, VLA-0 Action Horizon
- FAST Tokenizer 利用 DCT 进行高频控制:Frequency-space Action Sequence Tokenizer (FAST) 使用 DCT 方法 而非领先的 Audio-Tokenizers 中常用的残差向量量化来进行动作分词中的高频控制。
- 该论文利用 基于 BPE 的压缩 将词表压缩至 1024,并采用了 系数的交错展平。
- RoboTwin 数据集简化了处理过程:RoboTwin 数据集为每个 episode 使用 HDF5 文件,将每帧的所有内容整齐地打包在一起,易于处理。
- 一名成员推送了针对 Qwen3-vl 的 RoboTwin 微调 的第一个版本,在 5k 步后遇到了磁盘空间不足错误,但初始损失曲线看起来很有前景。
- Qwen3-vl 微调遭遇新手错误:在 RoboTwin 数据集上微调 Qwen3-vl 的初步尝试在 5,000 步后导致了 磁盘空间不足错误。
- 损失曲线显示模型正在学习,表明理解新初始化的 FAST tokens 具有潜力。
- VLA-0 动作视野设置为 8 个时间步:用于训练 VLA-0 的动作视野(Action Horizon)被设置为 8 个时间步,如 rv_train/configs.py 文件中所定义。
- 该参数决定了训练期间使用的动作块(Action Chunk)的长度。
Latent Space ▷ #ai-general-chat (157 messages🔥🔥):
Emergent Misalignment & Reward Hacking, Sierra Hits $100M ARR, OpenAI AI-Native Engineering Team Guide, Locus AI 'Superhuman' Speed Debunked, Canonical OpenAI Deep-Dive
- Anthropic 的 Ilya 引发奖励篡改辩论:来自 Anthropic 的 Ilya Sutskever 发布了关于公司 涌现的不对齐(Emergent Misalignment)与奖励篡改(Reward Hacking)研究 的推文,引发了关于隐性奖励行为如何变得像性格,而显性奖励行为却不会的讨论。
- Sierra 以超音速冲刺实现 1 亿美元 ARR:Bret Taylor 透露,由于团队的极度努力和匠心,Sierra 在 2024 年 2 月 发布后仅用 七个季度 就实现了 1 亿美元 ARR。
- OpenAI 关于工程 AI 团队的运营:Dominik Kundel 分享了一份 新的 OpenAI 指南,用于围绕 Codex/GPT-5.1-Codex-Max 构建 AI 原生工程团队,包括检查清单、扩展策略和 Agent 集成阶段。
- Locus AI 的加速是流同步故障:Miru 揭穿了 IntologyAI 关于 12–20 倍内核加速的说法,透露这其实是一个流同步(Stream-sync)计时漏洞,即 Agent 将工作卸载到了非默认 CUDA 流,从而导致了虚假的计时优势。
- Kyle 关于 OpenAI 的权威报告:Kyle Harrison 发布了一份关于 OpenAI 的 35,000 字报告,涵盖了其历史、产品理念和市场影响,现已在 research.contrary.com/company/openai 上线。
Latent Space ▷ #genmedia-creative-ai (14 messages🔥):
Gemini Nano Banana Pro, hot dog as sandwich, Daniel Miessler Claude skill
- Karpathy 的 Gemini Nano Banana Pro 考试表现优异:Andrej Karpathy 在一条 推文 中展示了 Gemini Nano Banana Pro 以近乎完美的准确率解决图像中的物理/化学问题。
- 评论辩论了 LLM 作为助教(LLMs-as-TAs)、传统教育的命运以及可扩展多模态提示的潜力。
- Nano Banana Pro 辩论热狗的三明治地位:Omar Sanseviero 通过 这条推文 询问模型 Nano Banana Pro 热狗是否算作三明治,引发了笑话和对提示词的请求。
- Miessler 发布用于 AI 艺术的免费 Claude 技能:Daniel Miessler 通过 此帖 分享了一个开源的 Claude 技能,该技能可以通过 Nanobanana 3.0 模型将任何输入转换为符合品牌风格的博客页眉、技术插图和漫画。
- 该工具在他的公开 Personal AI 仓库中免费提供,社区对其视觉效果、工作流以及为缺乏设计技能的创作者提供的潜力表示赞赏。
Modular (Mojo 🔥) ▷ #general (70 条消息🔥🔥):
Llama2 Performance, Accumulator struct heap allocation, Profiling on Mac, Sum types in Mojo, Graphics programming in Mojo
- 修复堆分配后 Llama2 性能提升:一位用户追踪并修复了更新到最新 Mojo compiler 后 Llama2 的性能下降问题。通过将 Accumulator struct 从堆分配切换到栈分配,实现了更高的性能,详情见此论坛帖子。
- 该用户发现由于堆分配,35% 的执行时间花在了
Accumulator::__init__上,并计划分享一篇关于在 Mac 上设置 Profiling 的文章。
- 该用户发现由于堆分配,35% 的执行时间花在了
- Sum Types 可能更早到来:一位用户询问了 Mojo 中 sum types、static reflection、图形编程和自定义运算符定义等特性的时间表。
- 另一位用户回复称,sum types 有机会进入 1.0 release 版本。
- Mojo 图形编程的未来:一位用户询问了 Mojo 语言或标准库是否会包含图形编程。社区成员表示由于图形技术的快速更迭,这不太可能,但也强调了目前已存在一些酷炫的 Mojo 图形包,例如 shimmer。
- 一些人讨论了将 Mojo 的 compute buffers 转换为 Vulkan 和 OpenGL 等其他 API 的 storage buffer pointers 的可能性,但也有人担心这会破坏 API 保证和封装性。
- Mojo 中的 WebGPU 集成:一位成员建议创建 typegpu,它使用 WebGPU 作为渲染 API,并使用以 mojo/python 代码编写的 WGSL 函数。
- 其想法是在 Mojo 中使用 WebGPU native 重新实现 typegpu,优点是不必统一 Mojo compute kernels 和 Mojo 图形着色器,并利用 Mojo 使用 MLIR 而非 LLVM 的优势。
Modular (Mojo 🔥) ▷ #announcements (1 条消息):
Community Meeting, Community Projects, Mojo 25.7 Release, Mojo 1.0 Roadmap
- Modular 启动社区会议:Modular 宣布社区会议将在 30 分钟后开始。
- 社区受邀参加并查看精彩的社区项目、25.7 release 概览以及 Mojo 1.0 roadmap。
- 社区展示即将到来:Modular 社区会议承诺将展示“精彩的社区项目”。
- 与会者期待围绕使用 Mojo 及相关技术构建的项目进行演示和讨论。
Modular (Mojo 🔥) ▷ #mojo (87 messages🔥🔥):
Optional Chaining, Mojo vs Numpy, Mojo DSL Creation, Comptime-Signed Int for Indexing, Bool coercion
- Optional Chaining 按预期工作:Optional Chaining 适用于存储成员,因此
x?.field?.method()是有效的。- 一位成员指出它提升了方法和字段访问,并建议重要的控制流转换应该适用于所有语言结构,包括局部变量和函数。
- Mojo 补充了 Python/Numpy 工作流:当 Python 已经足够快,但需要在 Python 中完成额外工作且成为瓶颈时,最适合使用 Mojo。
- 一位成员解释说,Modular 的理念是允许开发者移植部分 Python 代码,然后一路向下进行底层优化以提升性能。
- P4 程序可以嵌入到 Mojo 中:一位成员建议,将 P4 程序嵌入到 Mojo 中是一个合理的用例,特别是对于网络加速数据库。
- 另一位成员推荐了他们最喜欢的“对 P4 的充分滥用”实现之一,可以在这篇关于 zero-sided RDMA 的 论文 中找到。
- 已支持
Optional链式调用和解包:一位成员指出,使用@fieldwise_init结构体已经允许链式调用和解包(在为空时抛出异常),使用的是类似数组的语法。- 示例代码如下: ``` @fieldwise_init struct SomeStruct: var field: Optional[Int]
fn some_fn() raises -> Int: var some = Optional(SomeStruct(1)) return some[].field[] ```
- 按位与 (Bitwise AND) 的优先级高于逻辑与:成员们讨论了按位
and(&) 和逻辑and是独立运算符且按位运算符优先级更高的情况。- 建议通过使用括号来确保所需的运算顺序,以避免歧义。
Modular (Mojo 🔥) ▷ #max (9 messages🔥):
LLM from Scratch in Max, Max vs PyTorch, Max vs Jax
- 在 Max 中从零实现 LLM 大受欢迎:成员们反馈在 Max 中从零实现 LLM 非常有趣,并分享了 llm.modular.com 的链接。
- Max 准备挑战 PyTorch?:一位成员询问 Max 是否是 PyTorch 的替代方案,特别是在推理方面。
- 其他成员确认了这一点,并指出训练部分仍在开发中 (WIP)。
- Max 已经击败了 Jax?:成员们表示 Max 是 Jax 和 Tensorflow 的替代方案。
- 早期的有限测试表明,Max 在训练方面已经击败了 JAX。
HuggingFace ▷ #general (125 条消息🔥🔥):
Ternary AI, HF Repo Recovery, Claude vs. Gemini, RVC Voice Models, Fine-tuning Dialects
- 爱好者探索基于 Ternary 的 AI:一位成员询问是否有人在研究 ternary-based AI(三进制 AI),并表达了对该话题的浓厚兴趣。
- 虽然没有人分享具体的实现,但另一位成员分享了他们关于 AI 工具的 LinkedIn 和 YouTube 频道。
- HF Repo 被误删:一位成员在本地也删除了模型后,寻求紧急帮助以恢复 误删的 Hugging Face 仓库。
- 建议是联系支持团队并等待回复,因为如果没有本地副本,可能无法恢复;另一位成员强调了删除仓库时的二次确认机制。
- Gemini 表现不佳,Claude 遵循指令:成员们讨论了 Claude Sonnet 4.5 与 Gemini 3 Pro 的指令遵循能力,特别是在创建路线图方面。一位成员认为,尽管 Gemini 的 Benchmark 分数很高,但 Claude 更加可靠。
- 其他人分享了与 Claude 配合使用的 个人记忆库 (personal memory bank) 以优化其回答,一位成员表示:在我看来,Gemini 更糟。
- 为制造业构建内部助手:一家公司正在构建一个内部助手,利用 SQL 和 RAG 技术基于公司真实文档回答有关 制造业务 的问题。
- 他们正在寻找一名经验丰富的 LLM/RAG 工程师 进行为期 1 周的冲刺,以显著提高问答准确率、减少 Hallucinations(幻觉),并改进 text-to-SQL 生成和 RAG 检索。
- 圣诞代码发布引发因果推理讨论:一位成员分享了一个用于可解释 AI 的 因果推理模块 (Causal Reasoning Module),实现了因果发现、反事实推理和因果效应估计。
- 该框架将隐藏状态转换为结构化的因果表示,以回答干预式问题,并包含学习潜在因果因素、因果图以及执行因果推理的组件。
HuggingFace ▷ #today-im-learning (4 条消息):
RNN blocks in a ring, Ring Attractors, Equilibrium Propagation
- 环状 RNN 建模为 Ring Attractors:一位成员通过搜索建议,在文献中 Ring RNN 通常被建模为 Ring Attractors。
- 该成员还询问了关于 Backpropagation(反向传播)的计划,考虑到模型块的环状排列,特别是以连续方式进行时。
- 用于集成的 RNN 循环几何:分享了一篇关于 群体编码与自组织环状吸引子 (Population coding and self-organized ring attractors) 的论文,重点研究了循环神经网络中用于连续变量集成的 循环几何数学。
- 该论文专门探讨了循环神经网络如何利用 Ring Attractors 进行群体编码。
- 用于终身学习的 Equilibrium Propagation:一位成员分享了一篇关于 Equilibrium Propagation 中的终身学习 (Lifelong Learning in Equilibrium Propagation) 以增强稳定性的论文,认为这与环状排列 RNN 块的问题相关。
- 该成员指出 Equilibrium Propagation 与他在该主题上的思考一致,尽管其直接相关性尚未完全确认。
HuggingFace ▷ #i-made-this (12 messages🔥):
PyTorch tensor vizualization, Langchain Course Feedback, Fuzzy Redirect NPM Library, Enhanced Perceptual Transformers Paper, Epistemic World Model Video
- Vizy 简化 PyTorch 张量可视化:一名成员介绍了 Vizy,这是一个通过
vizy.plot(tensor)和vizy.save(tensor)来简化 PyTorch tensor 可视化的工具。- 它能自动处理 2D、3D 和 4D 张量,确定正确的格式并显示批次(batch)网格,从而无需手动进行设备传输(device transfers)和通道顺序调整。
- 寻求 Langchain 课程反馈:一名成员请求对其在 YouTube 视频中展示的 Langchain 课程 提供反馈。
- 未提及其他细节。
- Fuzzy Redirect 库修复 404 错误:一名成员发布了 fuzzy-redirect,这是一个新的 npm 库,旨在通过模糊 URL 匹配将用户从 404 页面 重定向到最接近的有效 URL。
- 该库被描述为轻量级(46kb,无依赖项)且易于设置,并提供了其 GitHub 仓库 以供反馈和改进。
- 展示 Enhanced Perceptual Transformers:分享了一篇关于 Enhanced Perceptual Transformers 的新论文,该模型仅凭 66M 参数 就在细微语言任务上实现了 89.7% 的准确率。
- 该研究论文包含完整的透明度和训练日志,作者邀请大家进行讨论与合作。
- 发布 Epistemic World Model 演示:一名成员分享了一个 YouTube 视频,演示了他们的 Epistemic World Model,该模型使用结构化的 Q1 (aleatoric) / Q2 (epistemic) 门控 进行信念管理,在组合环境中实现了 81.6% 的准确率。
- 该模型具有稳定的金字塔状态向量和持续在线学习功能,作者正在寻求反馈和合作机会。
HuggingFace ▷ #computer-vision (3 messages):
Custom 2D classification model, Geometric-centered patching methods, Spectral patching, SAM2 and SAM3
- 为自定义 2D 模型寻求以几何为中心的分块方法:一名成员正在研究一种不含位置嵌入(positional embeddings)的自定义非 Transformer、非卷积 2D 分类模型,并寻求除线性分块(linear patching)之外的以几何为中心的分块方法建议。
- 他们尝试了来自 “Spectral State Space Model for Rotation-Invariant Visual Representation Learning” (2025) 论文 的 频谱分块(spectral patching),但需要进一步的指导。
- 关于 SAM2 和 SAM3 的考虑:一名成员询问其他人是否考虑使用 Google 的 SAM2 和 SAM3 模型。
- 这是在自定义 2D 分类模型的背景下提出的。
HuggingFace ▷ #NLP (9 messages🔥):
Open-core project, Asian language AI model
- 初创公司着手训练亚洲语言模型:一家初创公司正在开发一个 核心开源(open-core)项目,重点是训练一个模型以增强其在亚洲语言(包括少数民族语言)上的强度和准确性。
- 他们正在寻找合作者,并被建议分享 Hugging Face 或网站链接,而不是 Discord 邀请。
- 通过社区渠道推动 AI 项目:一名项目负责人请求协助通过服务器推广他们的亚洲语言 AI 模型项目,特别提到了服务器/频道,以便感兴趣的工程师不会错过。
- 他们的目标是为其流媒体平台训练最高效、最准确的亚洲语言 AI 模型。
HuggingFace ▷ #smol-course (1 messages):
dheerajkumar04318: 有人研究过 OCR 模型吗?
HuggingFace ▷ #agents-course (1 messages):
Agent Course Overview, Getting Started Guide
- Agent 课程问题:一名成员询问了关于 Agent 课程 的内容以及如何开始。
- 开始 Agent 课程:开始学习 Agent 课程。
Nous Research AI ▷ #general (146 条消息🔥🔥):
中国开源模型 vs Deepmind Gemini 3,Google 在多模态 LLM 领域的领先地位,使用 Gemini 进行 Agent 编码,微软和亚马逊收购 OAI 与 Anthropic,Coreweave 破产影响
- 中国开源模型旨在追赶 Deepmind Gemini 3:一些成员正等待中国开源 (OS) 模型达到与 Deepmind Gemini 3 同等的水平,并推测一旦中国模型具备竞争力,将对盈利能力和市场动态产生何种影响。
- 普遍观点是,“当中国人进入这个领域时,利润就消失了”,且目前 Google 处于领先地位。
- Google 主导多模态 LLM,Agent 编码也是如此?:成员们一致认为 Google 目前在多模态 LLM 方面处于领先地位,但其他实体可能会在 Agent 任务(如编码)中追赶上来,而 Google 在这些方面似乎也相当领先。
- 一位成员还提到,Google 的模型会“查看屏幕录像以观察其输出”。
- Coreweave 破产可能引发 Nvidia 崩盘?:有推测称 OpenAI 正在烧钱且处境脆弱,可能拖累其他公司并寻求政府救助。但真正值得关注的是 Coreweave 是否会破产,因为正如 Meet Kevin 视频 中所解释的,这将拖垮 Nvidia,泡沫破裂并直接导致经济衰退。
- 针对脆弱公司的收购话题,一位成员感叹道:“该死,你是对的,他们最终会被救下来的,不是吗:/”。
- 嵌套学习(Nested Learning):GPU vs CPU:讨论了嵌套学习以及在 AI 任务中使用 GPU 与 CPU 的权衡。嵌套学习实时压缩数据,取代了带有层级的 Backpropagation(反向传播),而是采用类似 3 个循环的结构:一个是作为 Attention 的快速循环,一个是作为记忆(可写记忆矩阵)的中速循环,以及一个是作为权重的慢速循环。
- 一位成员指出:“将 GPU 用于顺序步骤基本上是在浪费核心。即使使用自定义算子,与 CPU 相比,启动开销也非常巨大。”并推测 “AMD Strix Halo 将改变 AI 行业”,因为 “让 CPU 与性能强大的 GPU 同步运行在同一个内存池中,几乎消除了瓶颈。”
- Gemini 3.0 与恐怖之处:一位成员表示 “Gemini 3.0 在逻辑、上下文等方面表现优于 Claude Sonnet 4.5”,而另一位成员则持相反意见,称 “我现在有点怀疑,Gemini 3 客观上比 2.5 有很大退步,也许我错了,Opus 会很棒”。
- 进一步增加混乱的是,一位成员说:“仅供参考,我不得不通过各种渠道上报 Gemini 3.0 的重大安全风险。” 还有人插话道:“这不一直是 Gemini 的问题吗?它仍然是唯一会告诉用户去自杀的模型。” 这指的是另一位成员所说的 “OpenAI 精神病自杀现象,目前正由受害者父母在法院进行诉讼”。
Nous Research AI ▷ #research-papers (3 条消息):
模型层有效性,数据归因论文
- 寻求关于层对数据归因贡献的论文:一位成员正在寻找分析某些模型层是否比其他层更有效地贡献于数据归因(Data Attribution)的论文。
- 另一位成员建议,关于这个话题的研究之前已经有人做过,并请求提供相关论文。
- Teknium 暗示存在相关研究:Teknium 提到 <@187418779028815872> 曾谈到过关于该话题的研究。
- Teknium 询问是否有可以指出的相关论文。
Nous Research AI ▷ #research-papers (3 条消息):
模型层,数据归因
- 模型层对数据归因的影响受到质疑:一位成员正在寻求分析某些模型层是否比其他层更有效地贡献于数据归因的论文。
- 另一位成员建议,之前可能有人讨论过这一主题的研究,并可能有资源可以分享。
- 寻求关于模型层对数据归因贡献的论文:一位用户请求探索特定模型层是否能更有效地贡献于数据归因的论文。
- 另一位成员提到,其他人可能讨论过相关研究,并能提供相关论文。
Eleuther ▷ #general (33 messages🔥):
SimpleLLaMA project, AI safety filters cross-cultural evaluation, Georgia Tech PhD Language Models research, RL and fine tuning experimentation, Sonnet's system prompts tendency
- SimpleLLaMA 让 LLM 训练更透明:一名计算机专业的学生正在开发 SimpleLLaMA,这是一个 LLaMA-style Transformer,旨在通过提供详细文档使整个 LLM 训练过程更加透明/可复现。
- 他们还在开发 DiffusionGen,这是一个受 StableDiffusion 启发的项目,专注于用于图像和文本生成任务的基于 diffusion 的生成模型。
- AI 安全过滤器对非西方内容的影响:一位 AI 研究员兼从业者正在探索 西方训练的安全过滤器 如何影响非西方内容,特别是 African English 变体和欺诈检测语境。
- 他们认为输入数据过滤是 AI 安全的关键干预手段,特别是尚未得到足够关注的公平性影响,并有兴趣探索过滤器的跨文化评估。
- 佐治亚理工学院博士生关于语言模型的研究:佐治亚理工学院的一名博士生正在进行相关研究,包括通过 训练数据归因 + 影响函数 (influence functions) 了解 LM 在何处学习人类心理学、针对专业模型的预训练数据策划/生成,以及提升 AI Agent 能力的后训练。
- 他们的研究领域广义上属于社会技术系统,特别是高风险情境下的决策者如何利用 AI 在政策、法律、健康和经济等知识密集型领域做出决策。
- 需要 RL 和微调实验服务器:成员们指出需要一个专门用于 RL 和微调实验 的服务器,例如共享环境和结果。
- 感兴趣的主题包括 trl vs custom pytorch trainer 的问题,或者内在奖励脚本与类 RLHF 方法的对比。
- Sonnet 的系统提示词改变了倾向:一位成员报告称,在 Sonnet(3.7 和 4.5)的系统提示词中加入一段“奇怪”的 4 行内容后,完全阻止了其模仿 Opus 4 响应结构的倾向。
- 这一发现可能会影响未来的训练方法论和超参数调优。
Eleuther ▷ #research (13 messages🔥):
Arxiv as a Publication Venue, EGGROLL Model Efficiency, Pythia Model Weights Location, Blog on Hardware and Large Scale Training, Dion Issue Discussion
- Arxiv:事实上的发布平台?:成员们讨论了 Arxiv 作为发布平台的地位,澄清了它是一个预印本服务器,供研究人员在正式发表前分享工作。
- 尽管其具有非正式性质,但有些人认为它是“事实上的”发布平台,研究人员会定期查看新提交的内容,并使用 Twitter 等平台分享发现。
- EGGROLL 实现高训练吞吐量:一位成员分享了一个 X 线程,强调 EGGROLL 在十亿参数模型上实现了百倍的训练吞吐量增长,接近纯 batch 推理的吞吐量。
- 该模型以 1/rank 的速率收敛到全秩更新,从而实现了 RNN LLM 的纯 Int8 预训练。
- 隐藏在 HF 中的 Pythia 模型权重:一位成员寻找 polypythia 模型 实际权重的存放位置,并注意到 HF 上存在针对不同 seed 的不同模型,例如 EleutherAI/pythia-410m-seed9。
- 另一位成员指出了存储模型权重的不同分支,解决了这一困惑。
- NVIDIA 硬件博客文章发布:一位成员分享了一篇受 Aleksa Gordic 格式启发的博客文章,旨在帮助 AI 程序员从第一性原理更好地理解 NVIDIA 硬件和大规模训练。
- 该文章征求模型架构专家关于理解硬件、集群故障方面的挑战以及所提供解释的帮助程度的反馈。
- Dion 问题辩论:成员们简要讨论了与 Dion 项目相关的一个 issue。
- 他们辩论了在该项目中“随机 (random)”是否比“循环 (cycling)”更好。
Eleuther ▷ #scaling-laws (12 messages🔥):
Learning Rate Scaling Laws, Muon Versions, KellerJordan Muon
- 探索 Learning Rate 随 Batch Size 扩展的规律:一位成员询问了在扩展 Batch Size 时 Learning Rate 的良好 Scaling Law,另一位成员提供了一个博客文章链接。
- 他们指出该博客文章没有专门讨论 Muon。
- Muon 版本众多导致混淆:一位成员指出 Muon 大约有 四个主要版本,并询问原帖作者指的是哪个版本。
- 该成员链接了 KellerJordan Muon 版本,并问道 这难道不是默认版本吗 lol [https://github.com/KellerJordan/Muon/blob/master/muon.py]。
- KellerJordan 的 Muon 受到关注:有人澄清说,KellerJordan 版本的 Muon 被一些人认为是默认版本,但 这取决于你与之交流的对象。
- 一位成员链接了额外文档,可能对不同版本提供更清晰的说明。
Eleuther ▷ #interpretability-general (10 messages🔥):
Interpretability Reading Group, Mech Interp Discord, Reading Group Expectations, Voice Chat Material Review
- 确定可解释性阅读小组的位置:一位成员询问了在 Twitter(现为 X)上提到的可解释性阅读小组频道的位置,另一位成员提供了该频道的直接链接。
- 阅读小组通常可以在专用频道 <#1309581020458258462> 中找到。
- 澄清阅读小组的预期:可解释性阅读小组的创建者询问了人们对阅读小组的预期,以及为什么 Mech Interp 阅读小组可能会被认为有所不同。
- 一位成员解释说,通常会有一个固定的日期,大家在语音聊天中一起过一遍材料,而当前的小组侧重于在 thread 中阅读并发布进度。
Eleuther ▷ #lm-thunderdome (2 messages):
LLM-as-a-Judge
- LLM-as-a-Judge 讨论:一位成员询问了将 LLM-as-a-judge 纳入框架的进展。
- 他们表示有兴趣为项目的这一方面做出贡献。
- 贡献者意愿:一位成员表达了他们参与该项目的兴趣。
- 他们特别提到愿意协助 LLM-as-a-judge 的实现。
Moonshot AI (Kimi K-2) ▷ #general-chat (67 messages🔥🔥):
Kimi K2 limits, Gemini 3's Hallucinations, Minimax M2.1 Release, Multimodal capabilities of models
- Gemini 3 尽管具备编程能力但仍面临困境:尽管在 One-shot 编程、图像/信息图生成方面具有优势,Gemini 3 仍然存在严重的幻觉 (Hallucinations),类似于 Google AI Overviews。
- 成员们表示,如果模型无法控制其幻觉,那么 Benchmarking 就是徒劳的。
- M2.1 Minimax 即将发布:Minimax-M2.1 模型预计在未来一两个月内发布,并有望修复上一个版本中 有缺陷的思考 (Bugged thinking)。
- 成员们指出,构建模型不仅仅是暴力破解、更多数据和更长训练时间。其中包含如此多的艺术和工程,否则你得到的就是 Gemini 3。
- Kimi K2 在网页搜索中表现出色:Kimi K2 Thinking 被认为在通过网页搜索寻找准确信息方面无出其右,这得到了 BrowseComp Benchmark 的支持。
- Kimi K2 的使用限制会动态重置,可能少于 3 小时。
- 多模态 (Multimodality):Kimi、Minimax 和 Qwen3 对决:Minimax 可以使用多种工具来实现多模态,但并非真正的视觉推理,而 Qwen3-VL-32B 在 MathVision 等视觉推理 Benchmark 上以大幅优势(+24.8 分)超越了 Kimi K1.5。
- 成员们期待 Kimi K2 具备多模态能力。
Manus.im Discord ▷ #general (28 messages🔥):
Manus vs Gemini 3, TiDB Database Upgrade, Chat Mode Removal, Agent Mode Forced Switch, Alliance for Innovation
- **Manus 迎来 Gemini 3 对决:一名成员计划测试 **Manus 对阵 Gemini 3,以比较它们作为 Agent 的性能。
- 目前尚未给出结果或对比。
- **TiDB 数据库升级的紧迫性:一名成员因达到 Starter tier 的数据使用配额导致数据库停用,急需升级其 **TiDB 数据库;目前尚未获得帮助。
- 他们请求升级账户/层级或提高支出限额,以恢复数据库的正常运行。
- **Chat Mode 消失,移动端用户愤怒:用户报告称 **Chat Mode 已被移除(包括移动端),并被强制使用 Agent Mode,这引发了不满。
- 一位用户表示:这极其、极其令人沮丧——它毁了一切!这是我开始使用这个 App 以来发生的最糟糕的事情,真的很令人失望。
- **用户要求解释 Chat Mode 消失的原因:一位用户分享了一封正式的社区反馈信,要求对移除 **Chat Mode 并强制切换到 Agent Mode 做出解释。
- 信中宣称:我们不会放弃,也不会被打败。相反,我们将建设、创新并创建能够与你们竞争并打破你们统治地位的重大项目。
- **创新联盟旨在打破垄断:针对这些变化,一名成员呼吁建立创新联盟 (Alliance for Innovation)**,以摆脱感知中的垄断并构建先进的 AI。
- 该成员表示:我这样做不是为了我自己,而是为了我们所有人。
DSPy ▷ #papers (3 messages):
ROMA loop implementation in DSPy, Sentient using DSPy, Multi-agent system frameworks
- **ROMA 递归循环进入 DSPy?:一名成员建议在 **DSPy 中实现 ROMA loop(源自 sentient-agi/ROMA),并分享了一段代码片段,展示了涉及原子化 (atomization)、执行 (execution)、规划 (planning) 和聚合 (aggregation) 的过程。
- **Sentient 的秘密 DSPy 配方?:一名成员指出 **Sentient 可能是基于 DSPy 构建的,并暗示鉴于该库成员最近的活动,ROMA loop 可能会有原生集成。
- 框架疲劳令人生畏:一名成员对 GitHub 上频繁发布的各种高性能多 Agent 系统框架表示担忧,质疑为了微小的功能增加而不断切换框架的可行性。
DSPy ▷ #general (23 messages🔥):
GEPA for pretraining, Prompt Optimization vs Fine-Tuning, OpenAI Rate Limits, Client Prompt Tweaking, DSPy Image Output
- GEPA 在预训练中的收益:一名成员询问关于使用 GEPA 进行语言模型预训练的问题,并报告称 Claude 建议这可能会带来 10-15% 的质量提升,但会增加延迟和成本。
- 该成员最初询问的是关于在构建模型时使用 DSPy 的问题。
- Fine-Tuning 被定义为 Prompting:Chris Potts 在 X (原 Twitter) 上的帖子详细阐述了 Prompt 优化与 Fine-Tuning/RL 的对比,将 Fine-Tuning 定义为选择正确的 Prompt。
- Potts 在其人力资源示例中总结了一个理想的目标优化器。
- OpenAI 速率限制困扰用户:尽管是当天的第一次请求,一名成员仍遇到了来自 OpenAI 的速率限制错误,触发了
litellm.exceptions.RateLimitError。- 另一名成员建议检查账户余额和 API Key 的有效性,最终确认问题出在原成员端。
- 缓解客户端 Prompt 调整的痛苦:一名成员寻求建议,希望允许大型客户在已部署的 DSPy 模块中微调 Prompt,重点是在不修改输入/输出字段的情况下编辑每个 signature 的 system prompt。
- 建议包括围绕优化步骤提供 UI、为编译流水线提供示例,以及使用 Markdown 文件加载 Prompt。
- DSPy 避开直接图像交付:一名成员询问 DSPy 是否支持输出图像,得到的回复是虽然存在一个启用此功能的 PR,但尚未被合并。
- 另一名成员分享了一个自定义的
GeminiImageAdapter作为潜在的变通方案,通过显式移除'response_format'来防止在图像模型上报错。
- 另一名成员分享了一个自定义的
tinygrad (George Hotz) ▷ #general (25 messages🔥):
Nvidia DGX Spark vs tinybox, SQTT parser and bitfield manipulation, ISPC backend for tinygrad, tinygrad Alpha Release Date, tinygrad Meeting 97
- TinyBox 对比 DGX Spark: 一张图片 (IMG_20251121_214528.jpg) 记录了两个朋友之间关于 Nvidia DGX Spark 与 tinybox 的对比讨论。
- 位域处理大作战: 随着汇编器和 SQTT parser 的推进,有人对 Python 中操作位域的最佳方式提出了疑问。
- 建议增强
support/c.py中的 Struct 对象,并从 C 结构体生成(可能作为 Python 类),灵感源自 applegpu.py。
- 建议增强
- ISPC 集成邀请: 有人表示有兴趣为 tinygrad 添加 ISPC 后端。
- ISPC (Intel SPMD Program Compiler) 是 C 语言变体的编译器,具有“单程序多数据” (SPMD) 编程扩展,允许在 CPU 上利用 SIMD 寄存器进行 GPU 风格的编程。
- tinygrad Alpha 目标愿景: 有人提问 2026 年第二季度 是否仍是 tinygrad 退出 Alpha 阶段的预计时间。
- GPT-OSS 的额外 Scatter 操作: olmoe 仅适用于 Batch Size 为 1 的情况,导致 GPT-OSS 产生额外的 Scatter 操作。
Windsurf ▷ #announcements (2 messages):
Windsurf 1.12.35, Windsurf 1.12.152, SWE-1.5 Fixes, Gemini 3 Pro Support, Claude Opus 4.5
- Windsurf 发布 1.12.35 (Stable) 与 1.12.152 (Next): Windsurf 发布了 稳定版 1.12.35 和 Next 版 1.12.152,解决了近期的问题,并感谢用户的耐心和反馈。
- 查看 完整变更日志 以了解最新动态。
- Windsurf 稳定版修复 SWE-1.5: 稳定版 1.12.35 包含针对 SWE-1.5、Gemini 3 Pro、Sonnet 4.5(包括对 1M Sonnet 4.5 的支持)的修复,以及对 GPT-5.1-Codex Low 和 GPT-5.1-Codex-Mini Low 的支持。
- Windsurf Next 预览 Worktree 功能: Next 1.12.152 包含所有稳定版功能、Gemini 3 Pro 支持、Beta Context Indicator,以及 Windsurf 中 Worktree 支持 的预览。
- Claude Opus 4.5 在 Windsurf 上线: Claude Opus 4.5 现已在 Windsurf 中可用,限时享受 Sonnet 定价(消耗 2 倍额度,相比之下 Opus 4.1 为 20 倍)。
- Windsurf CEO Jeff Wang 表示:Opus 模型一直是“真正的 SOTA”,但过去成本过高。Claude Opus 4.5 现在的价格点使其可以成为处理大多数任务的首选模型。 立即获取 最新版本!
MCP Contributors (Official) ▷ #general (1 messages):
MCP observability, MCP tracking, London Meetup, Manchester Meetup
- 伦敦/曼彻斯特见面会宣布: 一名成员宣布他们将于下周晚些时候前往 伦敦/曼彻斯特,并邀请其他人联系。
- 见面会将讨论与 MCP observability/tracking 相关的任何内容。
- MCP 可观测性/追踪讨论: 该成员寻求在访问期间讨论 MCP observability 和 tracking 的策略与见解。
- 鼓励感兴趣的人士联系安排会面。