AI News
OpenRouter 人工智能现状报告:一项基于 100 万亿 Token 的实证研究
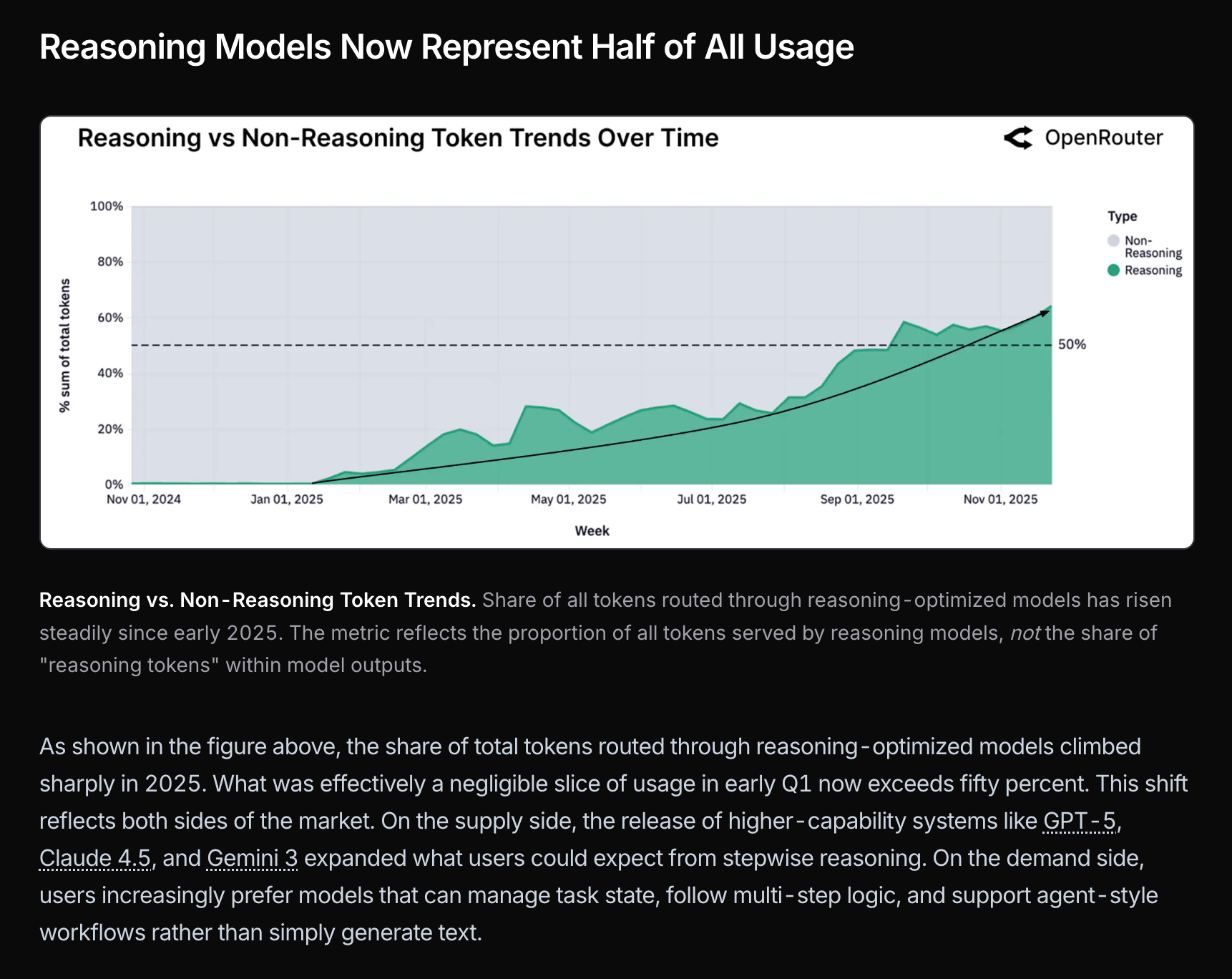
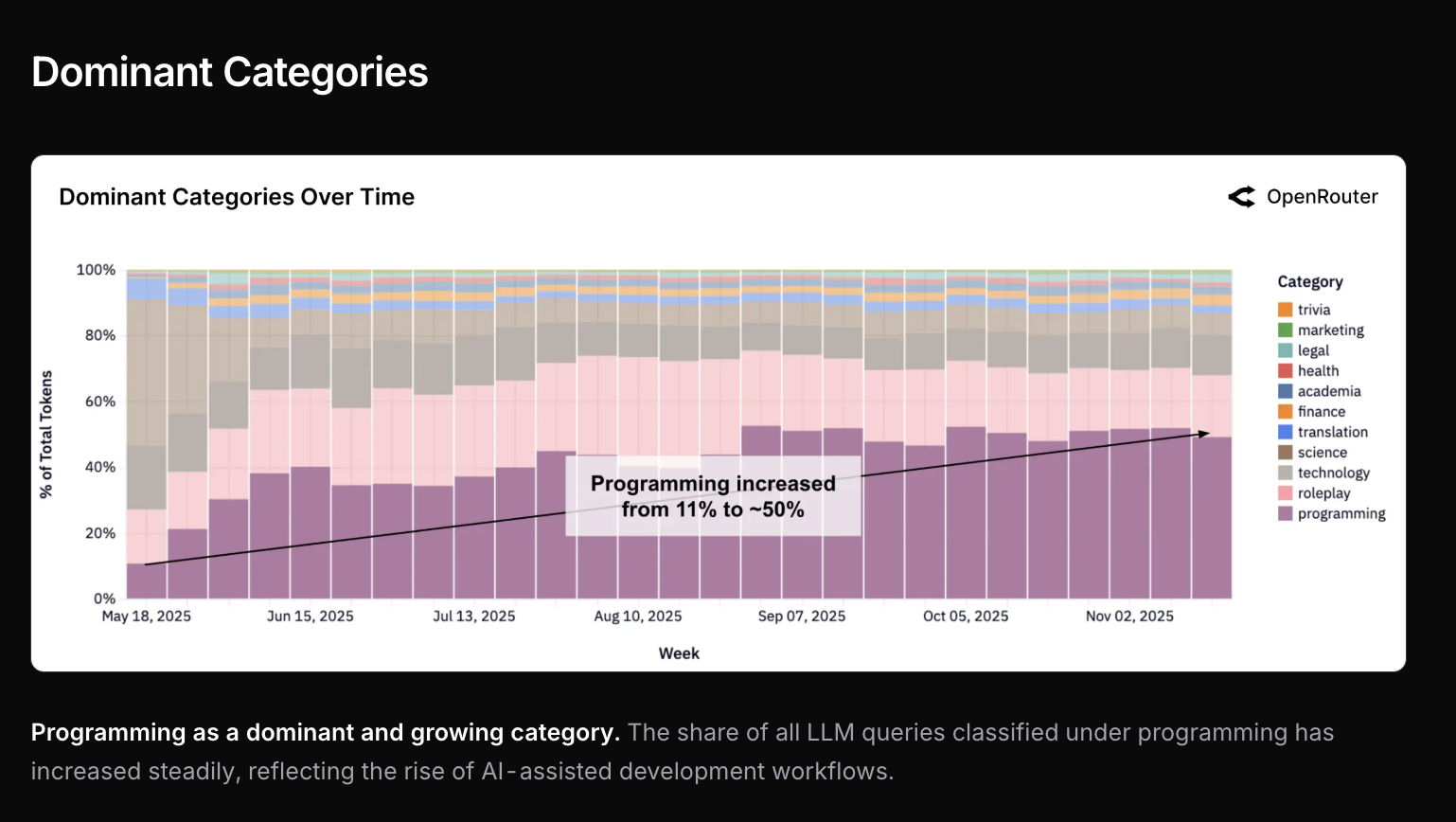
OpenRouter 发布了首份调查报告,展示了每周代理 7 万亿个 Token 的使用趋势,并指出角色扮演(roleplay)占比高达 52%。由于编程模型使用量的上升,Deepseek 的开源模型市场份额大幅下降。推理模型的 Token 使用量从 0% 飙升至 50% 以上。Grok Code Fast 显示出极高的使用率,而 Anthropic 在工具调用和编程请求方面处于领先地位,占据约 60% 的份额。受编程用例驱动,今年的输入 Token 增长了四倍,输出 Token 增长了三倍,编程在支出和使用量上均占据主导地位。
谷歌推出了 Gemini 3 Deep Think,其具备并行思考功能,并在 ARC-AGI-2 基准测试中达到了 45.1% 的得分;此外还预告了 Titans,这是一种长上下文神经记忆架构,可扩展至 200 万个 Token 以上。这些进展由 Google DeepMind 和 Google AI 在 Twitter 上同步分享。
数据就是你所需的一切。
2025年12月3日至12月4日的 AI 新闻。我们为你检查了 12 个 Reddit 子版块、544 个 Twitter 账号和 24 个 Discord 社区(包含 205 个频道和 7543 条消息)。预计节省阅读时间(以 200wpm 计算):563 分钟。我们的新网站现已上线,支持全元数据搜索,并以精美的氛围感编码(vibe coded)呈现所有往期内容。请访问 https://news.smol.ai/ 查看详细的新闻分类,并在 @smol_ai 上向我们提供反馈!
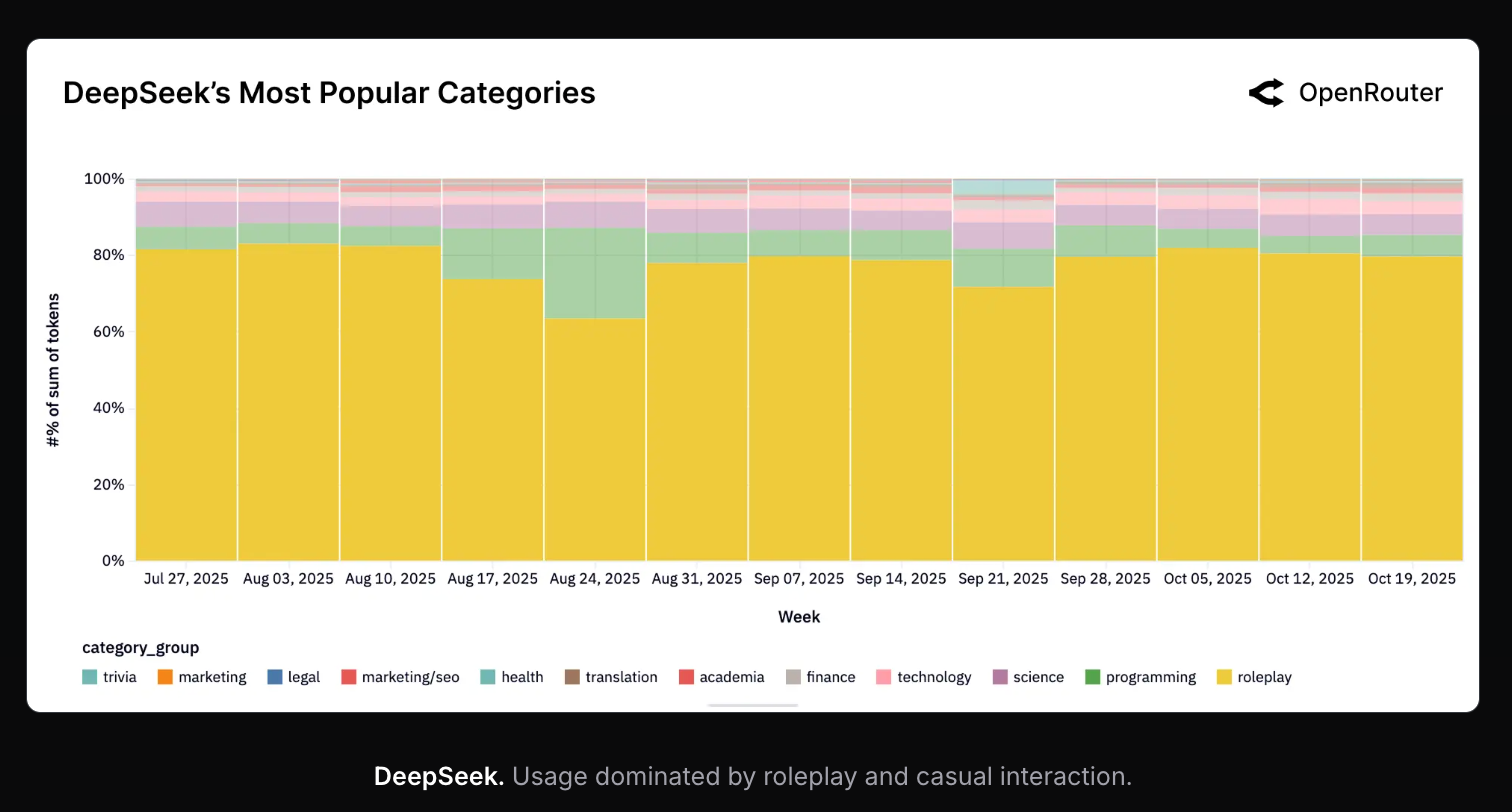
OpenRouter 的首份调查报告已发布,包含 网页版 和 PDF 形式,制作得非常精良。显然 OpenRouter 存在偏差(52% 的使用量用于“咳咳”——角色扮演),虽然还有其他 token 消耗量更大的平台,但 OpenRouter 是唯一一家能够对每周 7T tokens 的数据进行如此深度公开代理的玩家。
一些精选内容:
DeepSeek 曾占据 50% 的开源模型市场份额,现已暴跌:
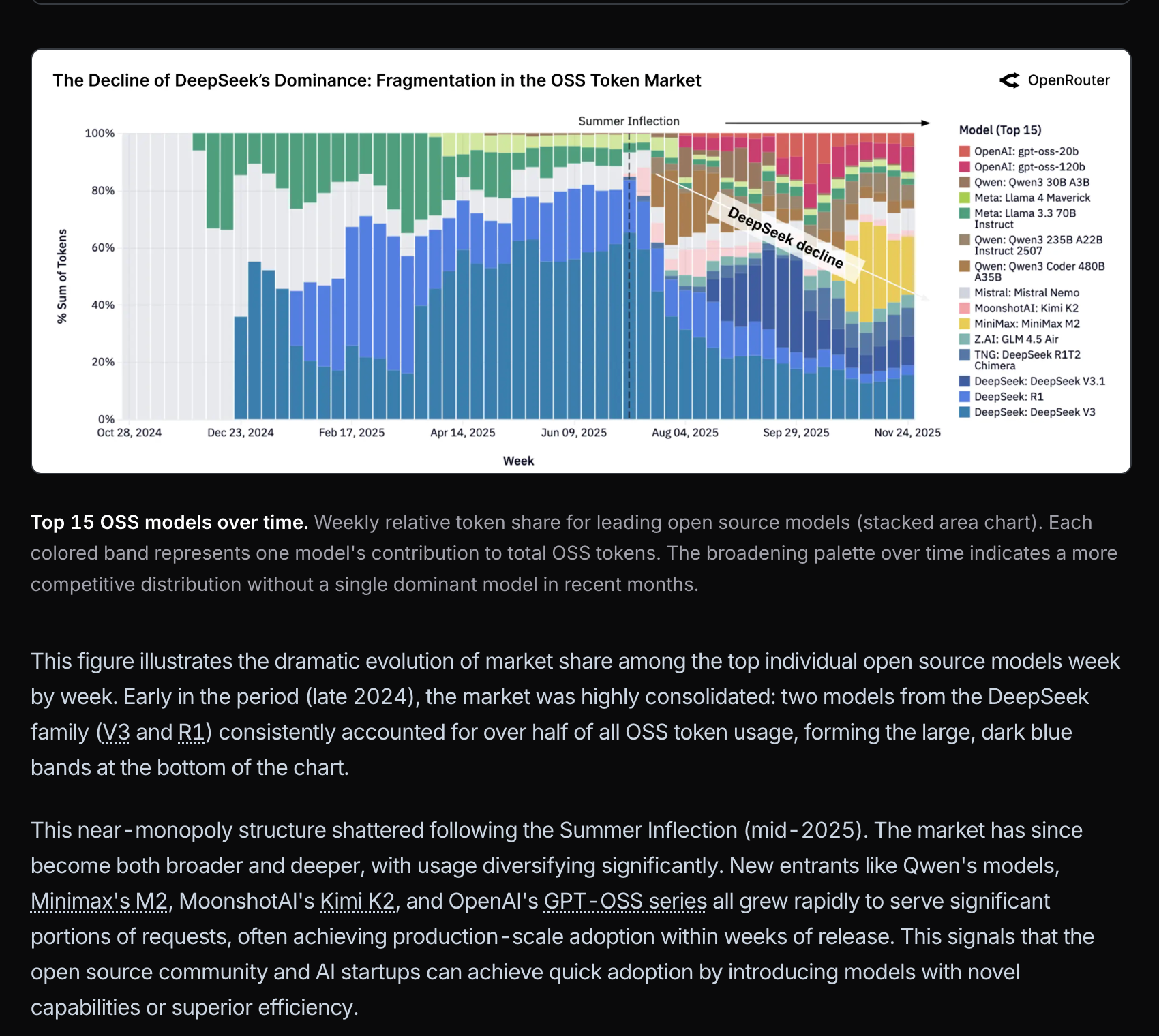
这主要是因为编程类需求上升,而没人用 DeepSeek 编写代码:
推理模型的使用率从 0 增长到超过 50%:
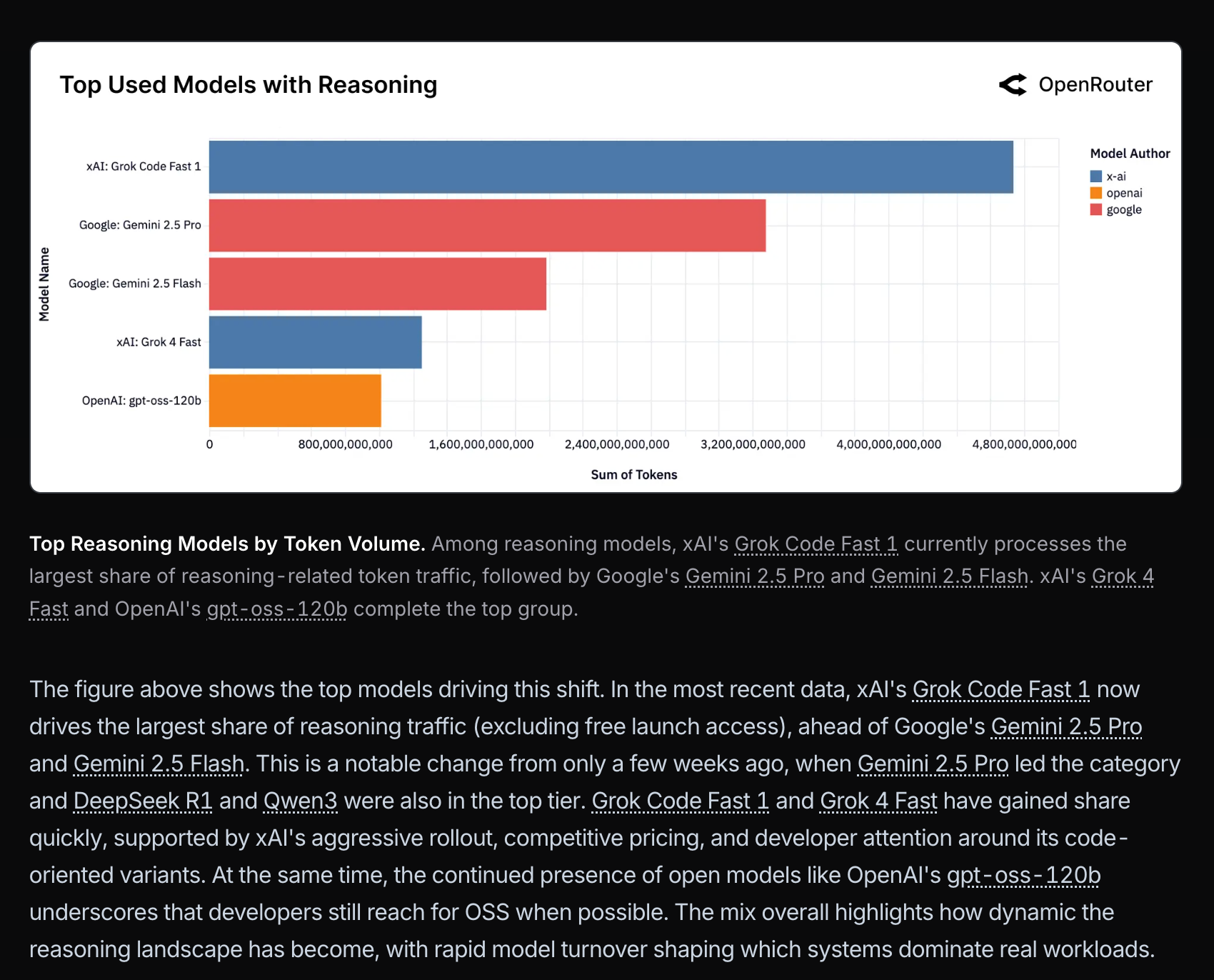
即使排除免费推广,Grok Code Fast 的使用量也高得离谱:
Anthropic 在工具调用(tool calling)和编程领域占据主导地位:
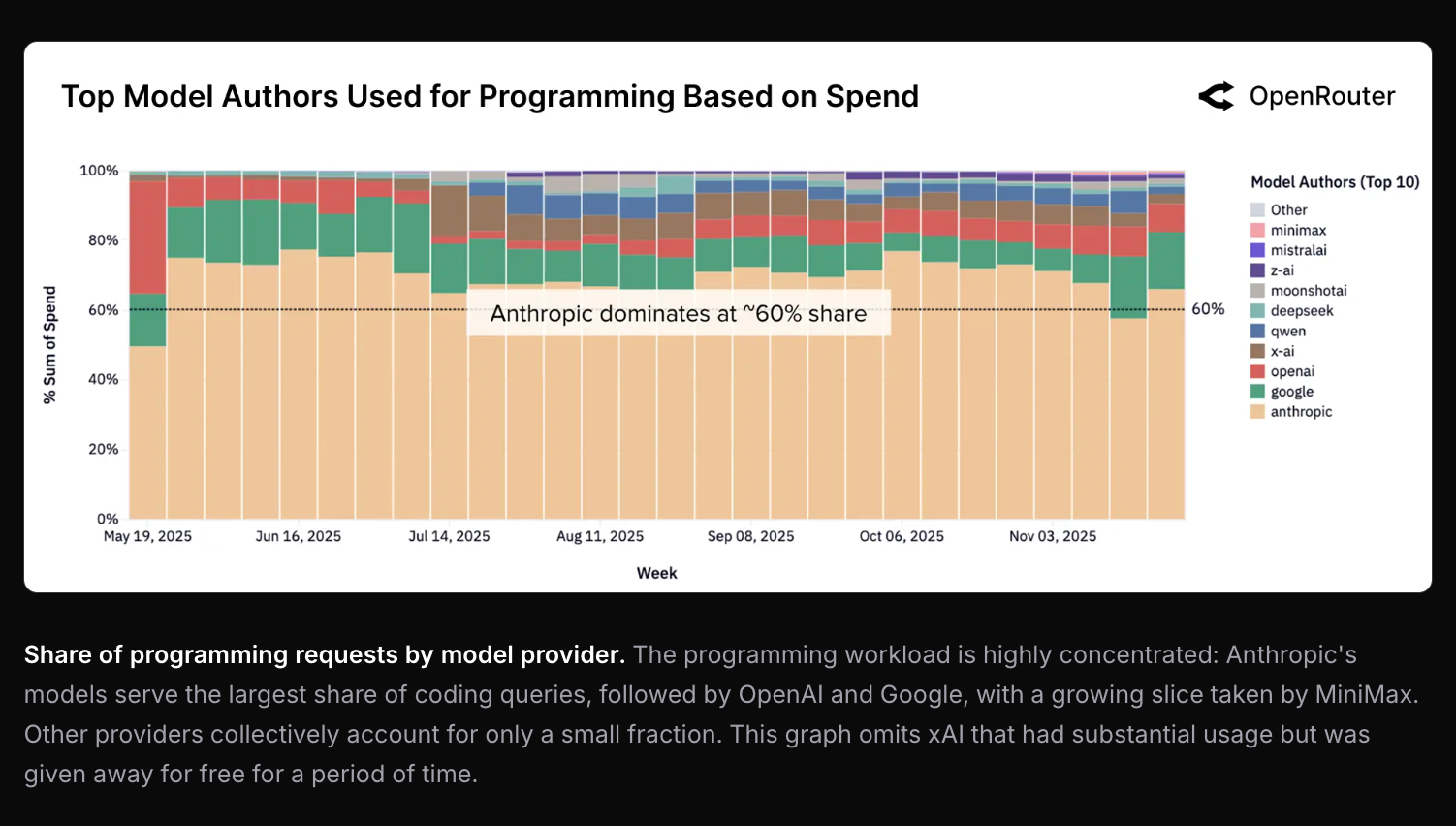
:
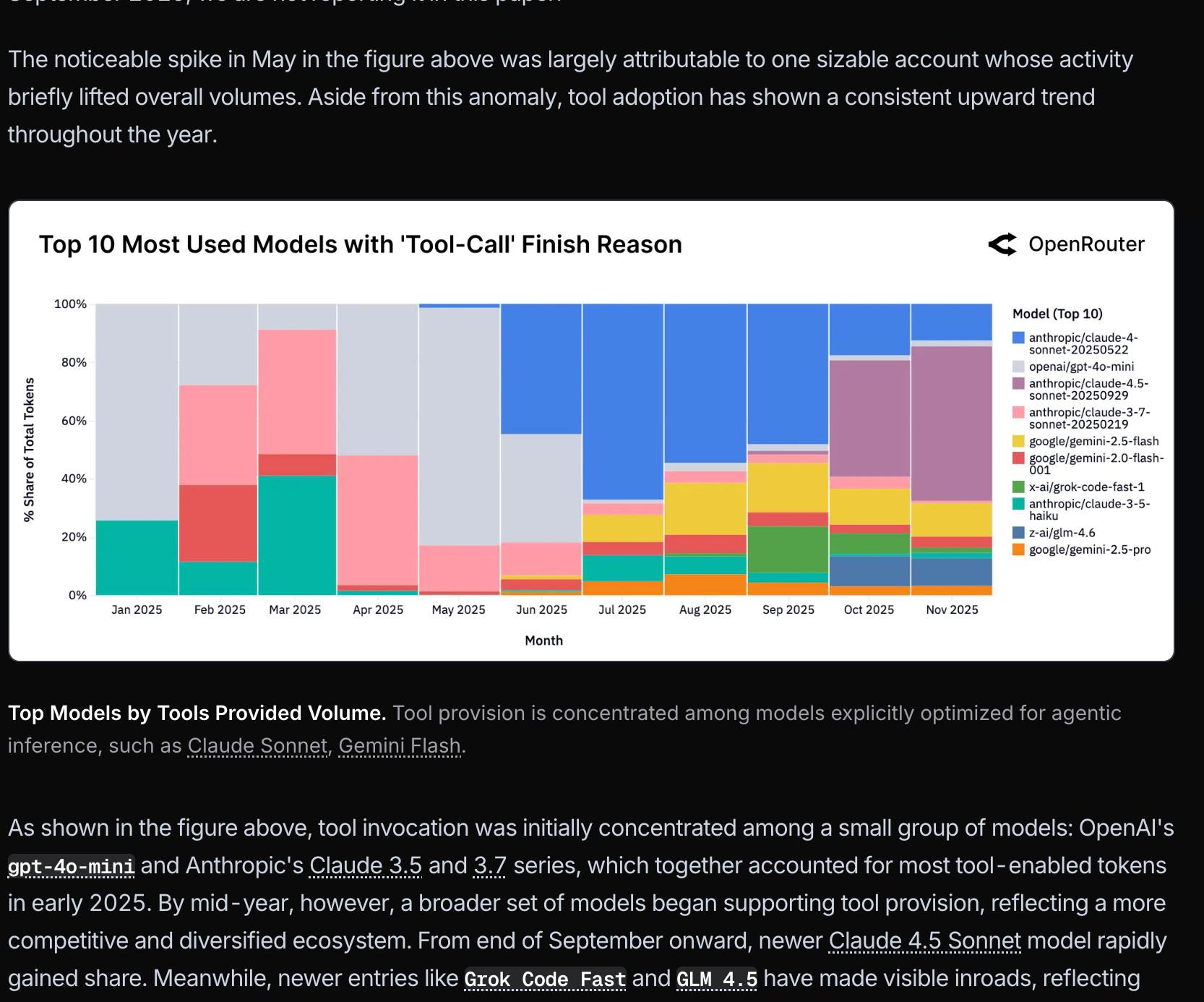
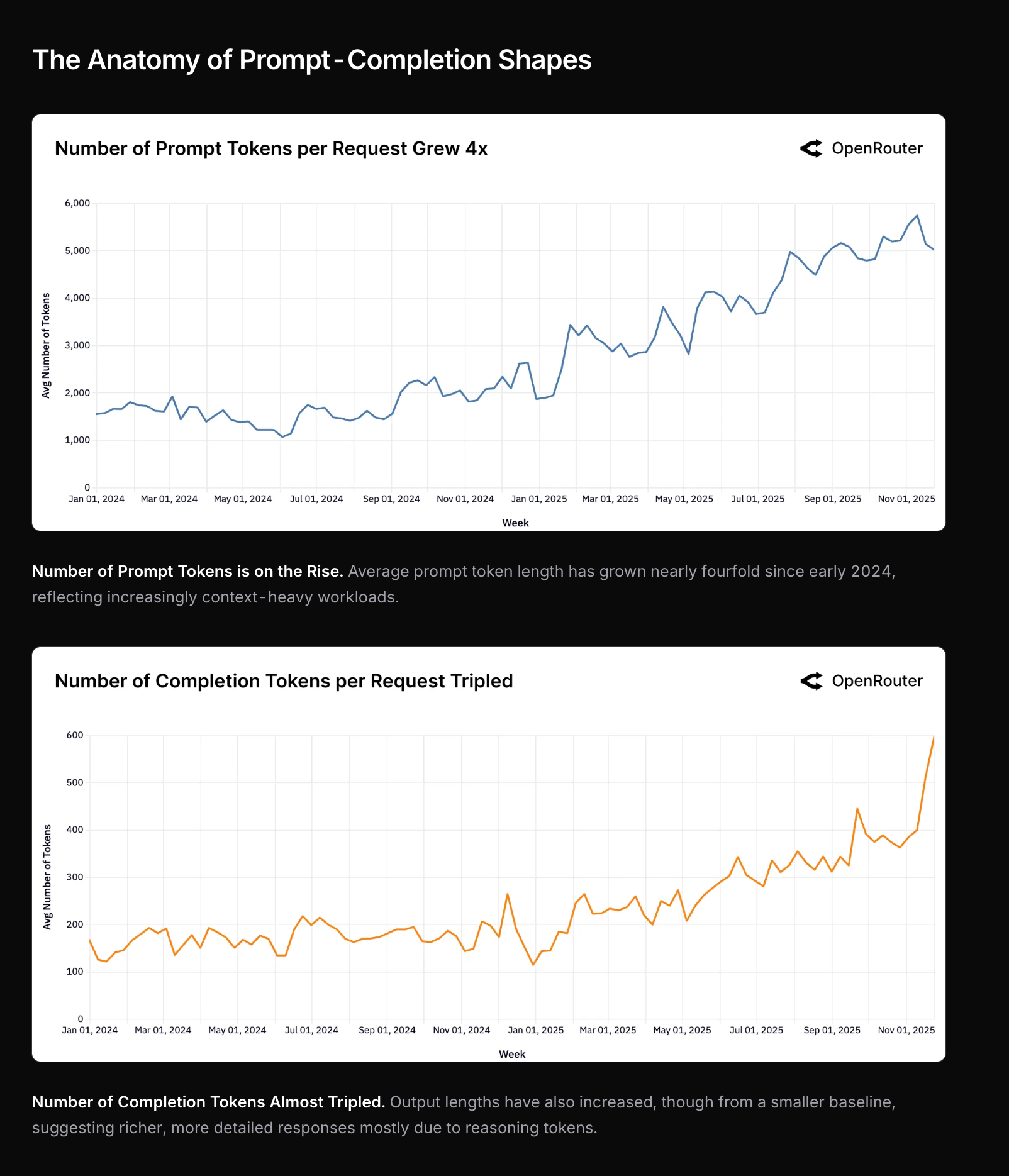
今年输入 tokens 增长了 4 倍,输出 tokens 增长了 3 倍……
……这完全是因为编程用例的增长:
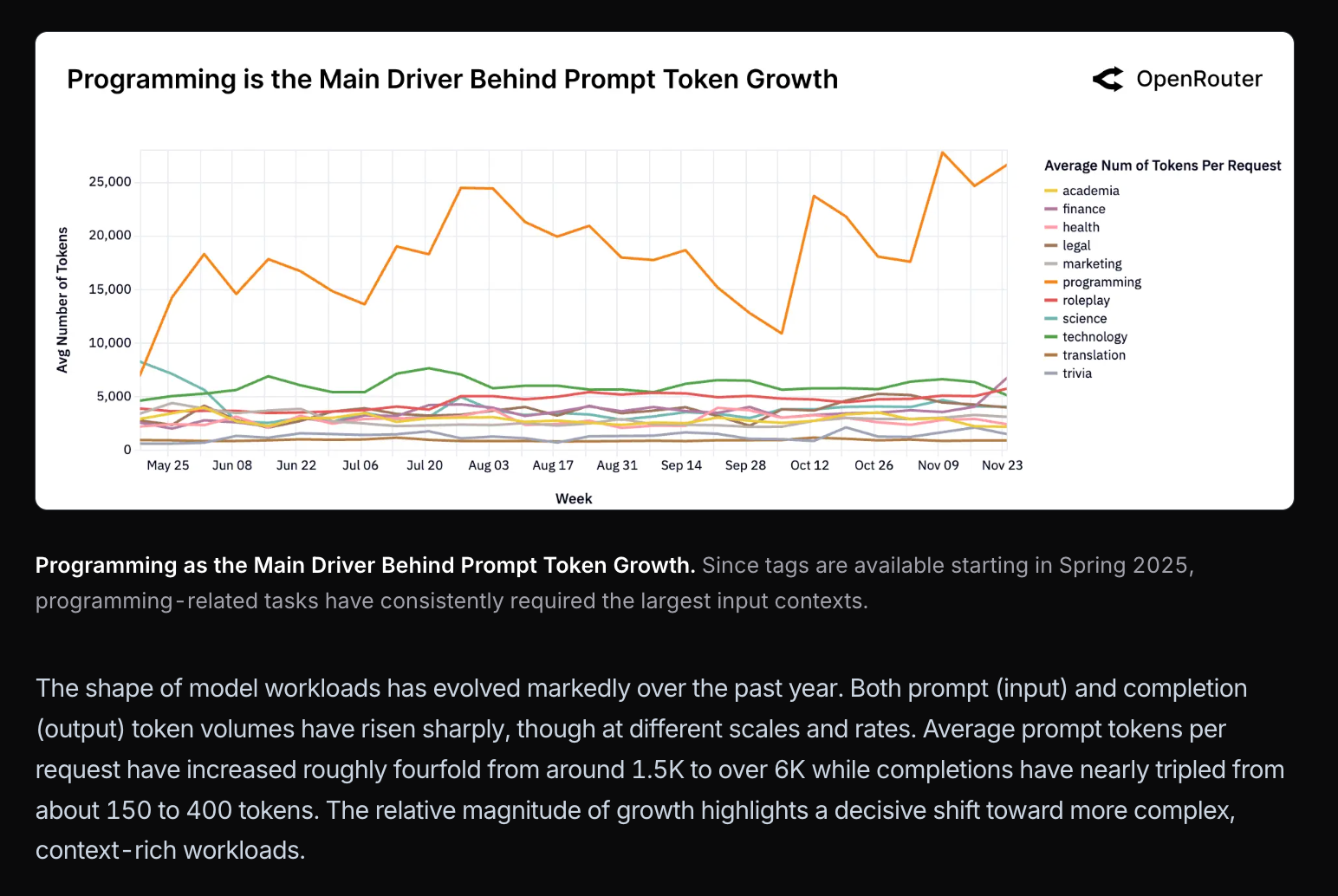
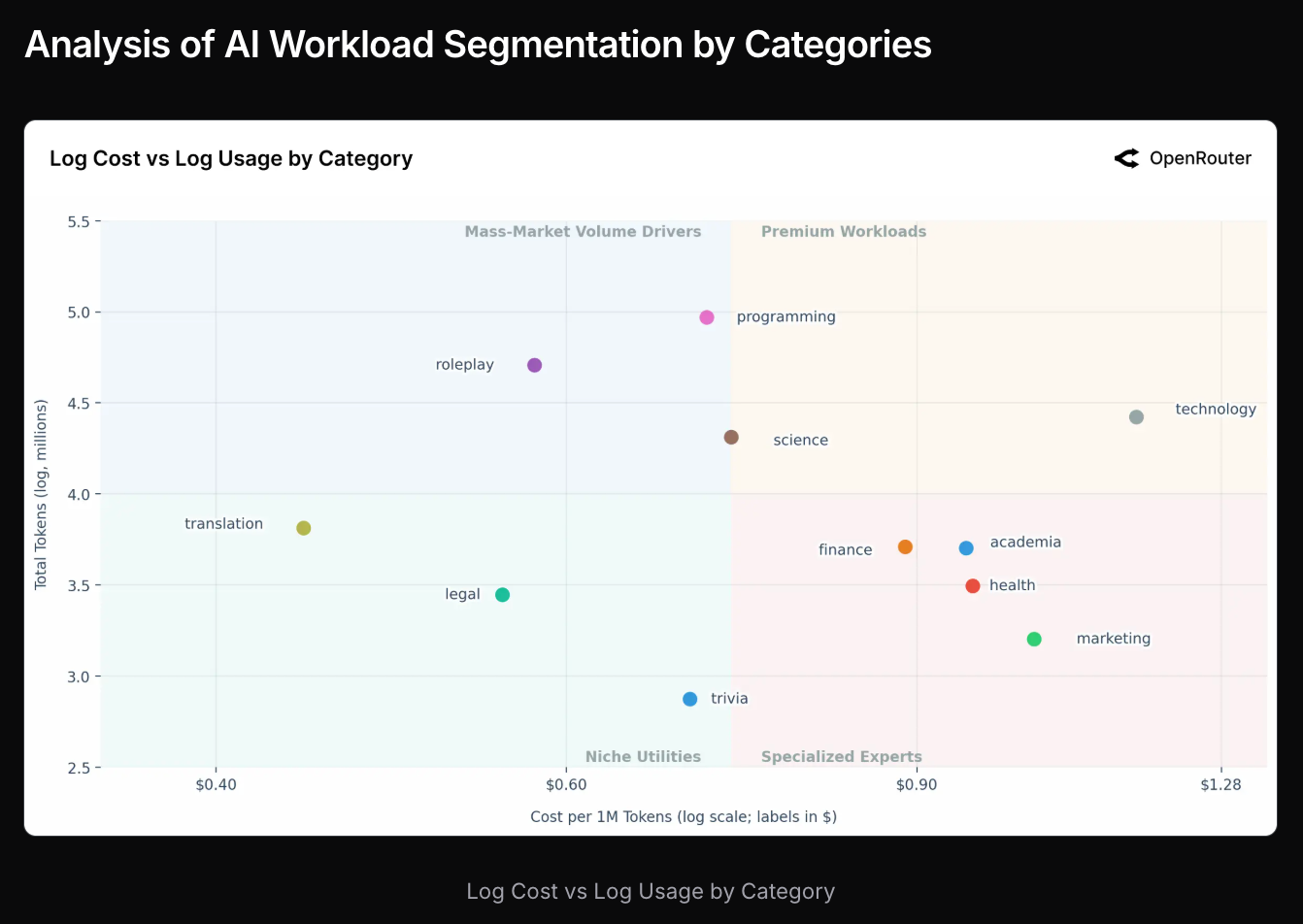
……这些用例正处于支出与规模的最佳平衡点:
AI Twitter 回顾
推理与模型架构:Gemini 3 Deep Think 与 Google 的 “Titans”
- Gemini 3 Deep Think(发布与基准测试):Google 向 Gemini 应用内的 Google AI Ultra 订阅者推出了更新的 Gemini 3 Deep Think 模式。它采用“并行思考”(同时处理多个假设),并衍生自曾在 IMO/ICPC 中达到金牌水平的变体。Google 报告称,Deep Think 在 ARC-AGI-2 和 HLE 上比 Gemini 3 Pro 有显著提升;一个例子引用了 Deep Think 在 ARC-AGI-2 上达到 45.1% 的得分 @GoogleAI, @GoogleDeepMind, @GeminiApp, @quocleix, @NoamShazeer。如何尝试:在 Gemini 应用的提示栏中选择 “Deep Think”,并使用 “Thinking” 模型下拉菜单 @GeminiApp。
- “Titans”:长上下文神经内存:Google 预览了 Titans,这是一种通过深度神经内存将类 RNN 的效率与 Transformer 级别的性能相结合的架构,可扩展到超过 2M tokens 的上下文。早期结果已在 NeurIPS 上展示;作者还发布了关于 Titan 内存系列的技术背景/历史 @GoogleResearch, @mirrokni。
编程模型与 Agent 框架
- OpenAI 的 GPT-5.1-Codex Max (agentic coding):现已在 Responses API 中可用,建议在 Codex agent harness 内部使用。OpenAI 分享了 Prompt 指南和客户案例;集成已在整个生态系统中落地:VS Code、Cursor、Windsurf 和 Linear(指派/提及 Codex 以启动云端任务,并将更新回传至 Linear)@OpenAIDevs, @code, @cursor_ai, @windsurf, @cognition, @OpenAIDevs。
- Mistral Large 3 (编程领域的开源领导者):Mistral 报告称 Large 3 目前是 lmarena 上排名第一的开源编程模型;随后得到了社区的证实,并可通过 Ollama 提供云端支持(“即将”支持本地运行)@MistralAI, @sophiamyang, @b_roziere, @ollama。
- DeepSeek V3.2:Baseten 发布了 V3.2 强劲的服务指标(TTFT ~0.22s, 191 tps),并可通过其 API 使用;lmarena 将 V3.2/V3.2-thinking 添加到了文本排行榜(整体表现参差不齐;在数学/法律/科学类别中拥有最强的开源模型排名)@basetenco, @arena。
- 低算力 RL 和训练基础设施:Qwen 展示了仅需 5 GB VRAM 即可运行的 FP8 RL 训练 @Alibaba_Qwen。Hugging Face 推出了 “HF Skills”,你可以从 Claude Code、Codex 和 Gemini 中调用它来端到端地训练/评估/发布模型(脚本、云端 GPU、进度仪表盘、推送至 Hub)@ben_burtenshaw, @ClementDelangue。
视频、视觉与生成式媒体
- 可灵 (Kling) 2.6 + Avatar 2.0:可灵 2.6 推出了音频对齐的视频生成功能并启动了音频挑战赛;Avatar 2.0 增加了更长的输入支持和更好的情感捕捉,首日即在 fal 上线托管 @Kling_ai, @Kling_ai, @fal。从业者展示了多工具 Agent 编排可灵以实现创意工作流 @fabianstelzer。
- Runway Gen-4.5:更广泛的审美控制(写实、木偶、3D、动漫),且在不同剪辑间保持连贯的视觉语言;“角色变形 (character morphing)”正成为其独特的优势 @runwayml, @c_valenzuelab。
- 图像排行榜:字节跳动的 Seedream 4.5 进入 lmarena,分别位列第 3(图像编辑)和第 7(文生图),与 Nano Banana 变体一同稳居前列;此前,Nano Banana Pro 2k 曾登顶图像编辑榜单 @arena, @JeffDean。
- SVG 生成作为推理/编程探测:Yupp 推出了 SVG 排行榜和一个开源数据集(约 3.5k 个提示词/响应/偏好)。Gemini 3 Pro 在 SVG 排行榜上领先;诸如“地球-金星五重对称”之类的提示词展示了几何推理 + 代码合成能力 @lintool, @yupp_ai, @lmthang。
- Microsoft VibeVoice-Realtime-0.5B:在 Hugging Face 上发布的一个轻量级实时语音模型 @_akhaliq。
Agent、脚手架与可靠性(生产环境中的实践)
- Agent 支架(Scaffolds)至关重要:“Agent 支架与模型同等重要”这一观点在多个讨论中得到共鸣,探讨了针对子 Agent 的类似管理流程的支架、自动压缩以及本体论清晰度的重要性(单次 LLM 调用 ≠ 子 Agent)@AlexGDimakis, @vikhyatk, @fabianstelzer。
- 可靠性工具:LangChain 1.1 添加了带有指数退避(Exponential Backoff)的模型/工具重试中间件(支持 JS 和 Python),VS Code prompt 文件可以为每个提示词自动选择模型,以更好地构建工作流 @sydneyrunkle, @bromann, @burkeholland。
- “代码即工具”提升鲁棒性:CodeVision 让模型通过编写 Python 来组合任意图像操作,大幅提升了在变形 OCR 任务中的鲁棒性(在变形 OCRBench 上得分 73.4,比基准提升 17.4;在 MVToolBench 上得分 60.1,而 Gemini 2.5 Pro 为 32.6)@dair_ai。
- SkillFactory 与后训练(Post-training):一种数据优先的方法,通过重新排列轨迹(Traces)来演示“验证+重试”,随后进行 SFT→RL,提升了跨领域显式验证技能的学习效果——这与 Yejin Choi 在主题演讲中关于基座模型/RL“化学反应”的观察一致 @ZayneSprague, @gregd_nlp。
- 推理加速(超越 Speculative Decoding):AutoJudge 学习哪些 Token 对回答至关重要,实现了比 Speculative Decoding 快 1.5–2 倍的速度提升(且可与其他加速技术叠加)@togethercompute。
- Agent 编码的安全性现状检查:SUSVIBES 基准测试发现,在 200 个历史上曾导致漏洞的真实功能请求中,SWE-Agent+Claude Sonnet 4 获得了 61% 的功能正确率,但仅有 10.5% 的安全解决方案;漏洞提示并未解决该问题——这一模式在各类前沿 Agent 中普遍存在 @omarsar0。
评估、测量与信任
- 排行榜规范与独立评估:“排行榜幻象”(私有测试、选择性撤回、数据访问差距)在 NeurIPS 上备受关注 @mziizm,伴随着 Cohere Labs 的海报展示和社区讨论 @Cohere_Labs。新的 AI 评估者论坛(AEF)首次亮相,旨在协调第三方评估,METR、RAND、SecureBio 等为创始成员 @aievalforum, @METR_Evals。
- 基准测试与潜在陷阱:Global MMLU 2.0 发布,扩展了多语言覆盖范围 @mziizm。LlamaIndex 分析了 OlmOCR-Bench,强调了文档类型的缺失和脆弱的精确匹配问题 @jerryjliu0。IF-Eval 提醒:使用正确的分隔符(
</think>、[/THINK]等)去除推理内容 @_lewtun。 - 信任与测量科学:Andrew Ng 敦促该领域关注公众信任度下降的问题(参考 Edelman/Pew 报告),并避免炒作生存威胁论调,指出 NIST 对 AI 测量中“构念效度”(Construct-validity)的强调是一条建设性的前进道路 @AndrewYNg, @mmitchell_ai。
组织动态与生态系统
- Google DeepMind 新加坡新团队(招聘中):由 Yi Tay 领导,隶属于 Quoc Le 的部门,专注于高级推理、LLM/RL,并推动 Gemini/Deep Think 的发展。该团队得到了领导层(Jeff Dean, Demis Hassabis)的支持和算力资源;正在组建一支小型、高人才密度的团队 @YiTayML, @JeffDean, @quocleix。
- 模型可用性与平台:MiniMax-M2 加入 Amazon Bedrock @MiniMax__AI。AI21 宣布在 AWS VPC 内部署 Maestro @AI21Labs。现在可以在 Ollama Cloud 上运行 Mistral Large 3;本地支持即将推出 @ollama。
- Anthropic Interviewer:收集关于 AI 在工作中表现的观点的短期试点项目;初步结果及包含 1,250 份访谈的开源数据集已在 Hugging Face 发布 @AnthropicAI, @calebfahlgren。
- Perplexity 融资:Cristiano Ronaldo 宣布投资 Perplexity,将其定位为“助力世界的好奇心” @Cristiano。
热门推文(按互动量排序)
- Cristiano Ronaldo 投资 Perplexity;“助力世界的好奇心” @Cristiano — 46.9k
- 提醒:许多机器人通过训练“伪造”类人动作;硬件的移动速度可以快得多或更诡异 @chris_j_paxton — 36.7k
- Excel Copilot “Agent Mode” 助力 Satya 参加 M365 数字挑战 @satyanadella — 2.8k
- Gemini 3 Deep Think 发布及在关键推理基准测试中的表现 @GeminiApp — 2.8k
- Mistral Large 3 在 lmarena 上夺得开源编程模型第一名 @MistralAI — 1.7k
- 微软的 VibeVoice‑Realtime‑0.5B 在 Hugging Face 上线 @_akhaliq — 1.3k
- “再见,‘你完全正确’”(关于模型行为) @alexalbert__ — 1.2k
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. 微软 VibeVoice-Realtime 模型发布
- 新模型,microsoft/VibeVoice-Realtime-0.5B (热度: 360):VibeVoice-Realtime 是微软推出的一款新型开源文本转语音(TTS)模型,专为实时应用设计,参数量为
0.5B。它支持流式文本输入,并能在约300 ms内生成初始可听语音,适用于实时 TTS 服务和直播数据解说。该模型针对英文和中文进行了优化,具备强大的长文本语音生成能力。更多技术细节请参考 Hugging Face 模型页面。 一条值得注意的评论强调了该模型对中英双语的支持,而另一条评论则指出一个指向未发布版本 VibeVoice-Large 的链接失效,表明文档中可能存在疏忽。- 模型
microsoft/VibeVoice-Realtime-0.5B支持中英双语,这对于需要双语能力的应用具有重要意义。然而,用户对普通话输出的质量表示担忧,一位用户指出普通话发音带有西方口音,这可能会影响母语用户的体验。 - Hugging Face 上的
VibeVoice-Large模型存在链接失效问题,导致 404 错误。这表明该模型可能尚未发布或已被移除,反映出微软在版本控制或发布管理方面可能存在问题。 - 用户正在寻求如何运行
VibeVoice-Realtime-0.5B模型的指导,这表明需要更清晰的文档或教程来促进用户的采用和实施。这突显了向更广泛受众部署复杂模型时的常见挑战。
- 模型
2. 幽默的 Quant Legend 对比
- legends (热度: 394): 这张图片是一个对比“Quant legends”传统与现代解读的 Meme。左侧是一位在黑板前的数学家经典形象,代表传统观点;右侧是一个带有社交媒体图标的卡通外星人,幽默地描绘了现代互联网驱动的视角。该帖子和评论强调了对量化领域“传奇”概念的戏谑解读,并向 AI 和模型开发社区的贡献者致敬,例如那些致力于 EXL 和 GGUF 模型的人员。 评论反映了轻松的讨论,一些用户幽默地质疑该帖子的意图是“Karma farming”。其他人则借此机会感谢了 AI 模型开发的各种贡献者,表明除了 Meme 中描绘的“传奇”之外,社区的努力得到了更广泛的认可。
技术性较低的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Gemini 3 Deep Think 发布与基准测试
- Gemini 3 Deep Think now available (热度: 634): 图片宣布推出 “Gemini 3 Deep Think”,这是 Gemini 应用中专门为 Google AI Ultra 订阅者提供的新模式。该模式旨在增强高级推理能力,特别是在复杂的数学、科学和逻辑问题方面。据报道,它在严苛的基准测试和竞赛中表现良好,表明其在处理复杂任务方面的潜在有效性。该公告还包括访问此新模式的说明,表明其专注于订阅者的可用性。 一位评论者表达了对“聪明人”如何利用这种新模式的期待,而另一位评论者则指出,甚至在 “Deep Think” 发布之前,Gemini 3 的表现就已经令人印象深刻。
- Gemini 3 “Deep Think” benchmarks released: Hits 45.1% on ARC-AGI-2 more than doubling GPT-5.1 (热度: 510): 图片是一个柱状图,展示了各种 AI 模型在三个基准测试中的表现,重点是 ARC-AGI-2 基准测试。Gemini 3 Deep Think 获得了
45.1%的分数,显著超过了得分为17.6%的 GPT-5.1。这展示了在解决新颖谜题能力方面2.5x的提升,这归功于 System 2 search/RL 技术的集成,可能涉及 AlphaProof 逻辑。这一进步凸显了 Google 在推理和 Inference-time compute 方面的领先地位,挑战 OpenAI 通过发布 o3 或 GPT-5.5 等更新来重获竞争地位。 评论者对这一进展感到兴奋,一些人注意到 OpenAI 可能正在开发具有竞争力的模型,而另一些人则质疑在对比中缺少像 Opus 这样的特定模型。- Gemini 3 “Deep Think” 基准测试的发布显示出显著的进步,在 ARC-AGI-2 基准测试中达到 45.1%,是 GPT-5.1 性能的两倍多。这一基准测试在 Anthropic 的博客中被称为“新颖问题解决”,突出了该模型在处理复杂问题解决任务方面的能力。然而,一些用户表示怀疑,指出尽管基准测试分数很高,模型在较简单的任务中仍可能表现出 Hallucinations 等问题。
- 在 Gemini 3 “Deep Think” 和 Opus 4.5 之间进行了比较,Gemini 3 在 ARC-AGI-2 基准测试中达到 45.1%,而 Opus 4.5 达到 37%。这表明两个模型在这一旨在测试高级问题解决能力的特定基准测试上存在显著的性能差距。讨论表明,虽然基准测试很有用,但它们可能无法完全捕捉模型在现实世界应用中的实际表现。
2. Z-Image 提示词与风格
- Z-Image 的提示词遵循度简直不可思议,我不敢相信它在性能平平的 3060 上运行得这么快。 (热度: 762): 这张图片展示了 Z-Image 模型的能力,该模型因其出色的提示词遵循度和速度而受到赞誉,即使是在 NVIDIA 3060 这样相对入门级的 GPU 上运行也是如此。用户强调了该模型准确渲染复杂视觉提示词的能力,捕捉到了诸如特定服装图案、面部表情和配饰等错综复杂的细节。然而,该模型在处理否定词(negation)方面表现不佳,例如无法在男性的描绘中排除戒指。文中提到了使用 Lenovo LoRA 来增强输出的忠实度,这表明结合多种技术可以快速获得高质量的结果。 评论者对 Z-Image 的潜力表示兴奋,将其与 SDXL 进行比较,并期待通过微调和额外的 LoRA 模型实现进一步的改进。
- Saturnalis 强调了 Z-Image 的提示词遵循度,指出它能够捕捉到手指上“黑白相间的戒指”等复杂细节,但在处理“这个男人没有戴戒指”等否定词时却很吃力。用户提到使用 Lenovo LoRA 来获得更高忠实度的输出,在 3060 GPU 上仅需 15-30 秒即可获得结果,对于如此精细的渲染来说,这令人印象深刻。
- hdean667 讨论了使用 Z-Image 为长视频生成快速动画图像。该工具的易用性得到了强调,用户只需添加句子或关键词即可实现特定的视觉效果,使其在创意项目中具有高度的适应性。
- alborden 询问了运行 Z-Image 所使用的 GUI,询问是 ComfyUI 还是其他界面,这表明了对技术设置和用户界面偏好以实现最佳性能的兴趣。
- Z-Image 风格:仅通过提示词就能实现多少效果的 70 个示例。 (热度: 647): 该帖子讨论了 Z-Image(一个类似于 SDXL 的模型)在不依赖艺术家姓名的情况下,仅通过提示词生成多样化风格的能力。作者提供了一个详细的工作流,使用 Z-Image-Turbo-fp8-e43fn 和 Qwen3-4B-Q8_0 clip,在
1680x944分辨率下运行,采用了一个涉及模型偏移和放大(upscaling)的特定过程,以增强细节和速度。该工作流包括将负面提示词设置为 “blurry ugly bad”,尽管在cfg 1.0下似乎无效。帖子还链接到了 twri 的 sdxl_prompt_styler 和完整的工作流图像等资源。 评论者讨论了负面提示词在 Z-Image 中的有效性,其中一位指出“类 Moebius”风格并不准确,建议需要 LoRA 来实现特定风格。另一位评论者提到了精心制作风格提示词,并指出 Z-Image 在描述充分时具有生成 ASCII 艺术的能力。- Baturinsky 提出了一个技术问题,即 Z-Image 是否考虑负面提示词,这在 AI 图像生成中通常用于引导模型远离某些风格或元素。这对于优化输出并确保模型紧密遵循所需的艺术方向至关重要。
- Optimisticalish 指出了 Z-Image 在复制特定艺术风格(如 Moebius)方面的局限性,建议当前模型可能需要额外的训练数据或 LoRA (Low-Rank Adaptations) 才能准确捕捉这些风格。他们指出,使用带有下划线的特定艺术家姓名(如 ‘Jack_Kirby’)可以有效地修改“漫画书风格”,这表明了一种细致的风格提示方法。
- Perfect-Campaign9551 强调了使用特定风格提示词(如 ‘flat design graphic’)的效果,这涉及创建一个色彩丰富、阴影极简的二维场景。这表明 Z-Image 可以处理各种风格请求,前提是提示词经过精心设计且具有描述性。
{kind=link}
3. AI 对技术岗位和社会的影响
- 在内心深处,我们都知道这是科技行业岗位终结的开始,对吧? (活跃度: 1262): 该帖子讨论了 AI 的快速进步及其对科技岗位的潜在影响,暗示软件开发人员、DevOps 和设计师等角色的需求可能会大幅减少。作者认为,虽然人类仍将参与其中,但随着 AI 接管编写代码、生成测试和设计系统等任务,所需的人数将急剧下降。该帖子挑战了 AI 只会增强人类角色的观点,将这种情况与历史上由于自动化导致的劳动力需求转变进行了对比。 一个值得注意的评论认为,虽然 AI 工具具有变革性,但它们并不能取代人类在处理利益相关者管理、系统架构和处理遗留系统等复杂任务中的必要性。评论者强调,AI 正在提高入门门槛,但也增加了可构建内容的复杂性,这表明开发工作的本质正在演变而非消失。
- ‘alphatrad’ 的评论强调了 AI 在软件开发中的局限性,指出虽然 AI 工具可以自动执行编码任务,但它们无法取代软件开发生命周期 (SDLC) 中微妙的人类角色。评论者指出,AI 缺乏处理复杂组织动态的能力,例如利益相关者管理、冲突的需求以及遗留系统集成。他们认为,AI 仅仅是漫长技术抽象史上的下一步,这种抽象历来都在增加软件项目的复杂性和范围,而不是消除工作岗位。
- ‘alphatrad’ 还讨论了开发人员角色不断演变的本质,建议虽然 AI 可以自动执行初级任务,但它提高了入门级职位的门槛。评论者建议开发人员专注于 AI 无法复制的技能,如系统设计、调试和理解业务运营。他们强调了沟通技巧和处理遗留系统能力的重要性,暗示开发的未来将需要技术和软技能的结合。
- ‘codemagic’ 的评论建议,随着自动化接管更多常规编码任务,重点将转向 SDLC 的早期阶段,如需求收集和高级架构。这种转变强调了对精确语言和写作技能的需求,表明随着 AI 工具在处理底层实现和调优任务方面变得更加普遍,开发人员所需的技能组合可能会发生变化。
- 在内心深处,我们都知道 Google 使用 Google Photos 训练了其图像生成 AI……但我们只是无法证明。 (活跃度: 3803): 该帖子推测,尽管官方声明用户照片不用于广告,但 Google 可能利用了其从 Google Photos 收集的海量用户上传图像来训练其图像生成 AI。作者认为,AI 生成图像的熟悉感可能是由于 Google 多年来收集的广泛元数据和高质量图像。这被比作过去的情况,例如 Google 在推出 Goog-411 服务后语音识别能力的提升,暗示了一种利用用户数据来增强 AI 能力的模式。 评论者讨论了 Google 的数据政策,指出虽然用户内容不会被出售用于广告,但 Google 保留了将其用于服务改进的广泛许可。他们将此与过去的 Google 服务(如 Goog-411)进行了类比,后者似乎收集了数据以改进随后的技术,如 Voice Search。
- Fonephux 强调了 Google 的数据政策,该政策授予公司使用、托管和修改来自 Google Photos 等服务中用户内容的广泛许可。该政策旨在改进服务功能,表明虽然用户内容受到保护,但它可以被用来增强 Google 的 AI 能力。
- redditor_since_2005 将 Google 过去的服务 Goog-411 与其随后开发的 Voice Search 进行了类比。其含义是 Google 使用来自 Goog-411 的数据来训练其语音识别模型,暗示 Google Photos 可能也被采用了类似的策略来开发图像生成 AI。
- ChuzCuenca 暗示 Google Photos 的免费托管服务可能并非没有别有用心,暗示尽管缺乏直接证据,但用户照片可能被用于训练 Google 的 AI 模型。
- 这位孙子利用 AI 为他祖父的 90 岁生日重现了其完整的一生。 (热度: 2938): 一位孙子利用 AI 技术重现了他祖父的生平故事,作为其 90 岁生日的礼物。该项目可能涉及使用机器学习模型来处理和合成个人数据,如照片、视频以及可能的音频录音,从而创建一个全面的数字叙事。在此背景下,AI 的使用突显了其在个人叙事和保存家族历史方面的潜力,利用生成对抗网络 (GANs) 或自然语言处理 (NLP) 等工具来增强叙事体验。 评论反映了积极的反响,用户赞赏将 AI 创新性地用于个人和情感叙事,尽管一些人表示希望看到更多内容或关于该项目的细节。
- 这位孙子利用 AI 为他祖父的 90 岁生日重现了其完整的一生。 (热度: 2943): 一位孙子利用 AI 技术重现了他祖父的生平故事,作为其 90 岁生日的礼物。该项目可能涉及使用机器学习模型来处理和合成历史数据、个人轶事以及可能的多媒体元素,以创建一个全面的叙事。在此背景下,AI 的使用突显了其在个人叙事和保存家族历史方面的潜力,展示了技术在增强个人和情感体验方面的新颖应用。 评论反映了积极的反响,用户赞赏将 AI 创新性地用于个人叙事。然而,评论中缺乏关于实现细节的技术辩论或详细讨论。
AI Discord 摘要
由 gpt-5.1 生成的摘要之摘要的摘要
1. 前沿编程模型、OpenRouter 趋势以及 IDE 集成
- OpenRouter 的 100T-Token Telescope 追踪角色扮演、编程和 Agent:OpenRouter 和 a16z 发布了基于 100 万亿 tokens 匿名流量的 State of AI 报告,显示 >50% 的开源模型使用集中在 角色扮演/创意 领域,而 编程占据了付费模型流量的 50% 以上,且 推理模型 现在处理着 >50% 的总 tokens。数据强调用户压倒性地选择 质量而非价格,Claude 占据了约 60% 的编程工作负载,平均 prompt 超过 20K tokens,工具调用(tool-calling)加长上下文正在推动生态系统向 全能 AI Agent 演进,而非简单的一次性问答。
- 报告指出 成本与使用量之间呈持平相关,暗示在质量趋同之前,可靠性、延迟和易用性比原始 token 价格更重要,并指出 娱乐/伴侣 AI 存在巨大的、未被满足的消费市场。OpenRouter 社区的工程师强调,现在构建具有竞争力的产品需要 多步执行、强大的状态管理和稳健的工具编排,而不仅仅是接入一个简单的聊天端点。
- GPT-5.1 Thinking 和 Codex Max 冲击 Gemini 的编程主场:在 OpenAI、OpenRouter 和 Windsurf 社区中,GPT-5.1 和 GPT-5.1-Codex Max 成为新的编程主力,OpenAI 用户反映 GPT-5.1 Thinking 在 代码漏洞发现 方面击败了 Gemini 3,Windsurf 则通过 新版本 宣布提供低/中/高推理级别的 GPT-5.1-Codex Max。OpenRouter 的讨论补充道,OpenAI 还发布了一个 Codex Max 模型,作为与 Google Gemini 3 Deep Think Mode 激烈竞争的一部分,而 ArsTechnica 的一篇文章 传闻指出 OpenAI 下周还将发布另一个模型。
- Windsurf 正为付费用户提供 GPT-5.1-Codex Max Low 的 免费试用,直指开发工作负载;而 OpenAI Discord 的工程师对比了 Gemini 3 Pro 的 UX,指出其未能发现 GPT-5.1 捕捉到的基础 bug。在 OpenRouter 上,用户将其视为编程技术栈大洗牌的一部分,Anthropic 收购 Bun 以支撑 Claude 的 10 亿美元编程收入,以及 OpenAI 的 Codex Max,使得像 Cursor 和 Windsurf 这样的 IDE 成了模型战争的前线。
- Hermes 4.3 缩小体积,瞄准 OpenRouter,并与 DeepSeek 竞争:Nous Research 发布了基于 字节跳动 Seed 36B 的 Hermes 4.3,声称 Hermes 4.4 36B 级别的性能约等于体积两倍的 Hermes 4 70B,该模型完全在由 Solana 保障的 Psyche 网络 上进行后训练,更多细节见发布文章 “Introducing Hermes 4.3”。在 Discord 中,Teknium 暗示接下来将通过其内部训练器推出 Mistral-3 Hermes 微调版 和 MoE 支持,并确认了 OpenRouter 上现有的 Hermes 模型,尽管用户希望 Nous 能作为 直接供应商 入驻。
- 工程师们将 Hermes 4.3 与 DeepSeek v3.2 进行了对比,称赞 DeepSeek “价格极具竞争力”,并希望 Hermes 70B/405B 在 OpenRouter 上也能加入该价格档位;另一些人则注意到 Opus 4.5 (Anthropic) 现在能更好地集成到 GitHub Copilot 等工具中,并可通过 antigravity 免费使用。Hermes 的发布还与实验性的 Psyche 训练网络挂钩,Discord 上宣传的办公时间(office hours)将讨论去中心化训练及其如何超越中心化设置。
2. 安全、越狱与 Agent 执行安全
- 从 Sora 2 和 Gemini Web 到 DeepSeek:越狱者持续获胜:在 LMArena 和 BASI 平台上,红队人员报告了对 Sora 2 和 Web 模型的绕过:一位 LMArena 用户声称发现了 Sora 2 过滤机制中的漏洞,指出角色生成提示词 (character generation prompts) 可以绕过安全护栏;而 BASI 成员讨论了 Gemini Web 上利用自定义系统指令和间歇性失效的过滤器实现的 NSFW 图像生成后门。BASI 的越狱讨论帖还记录了针对 DeepSeek 的嵌套越狱,并附带了一张 DeepSeek 生成 Windows 反弹 Shell (reverse-shell) 恶意代码的截图,并指出像 Wired 核武器诗歌文章中提到的 ENI 越狱等旧技巧在 Gemini 2.5 上依然有效。
- 攻击者还探测了 Grok 4.1 和 GPT-5.1,BASI 成员试图强迫 Grok 输出毒品和苏打水配方风格的内容,并分享了 UltraBr3aks 越狱集合来攻击 GPT-5.1,但承认 GPT-5.1 仍难以被完全攻破。越狱者继续转向更宽松或打磨程度较低的模型来生成攻击性内容和恶意软件——如 DeepSeek、Gemini 3、Seeds(如 Seedream 4.5)——同时观察到,在受到严格限制时,每一层新的安全防御都会增加模型的“智力税” (intelligence tax)。
- AI Agent 遭遇提示词注入和执行时防御红队测试:BASI 的红队频道协调了真实的 AI Agent 攻击模拟,包括提示词注入 (prompt injection)、伪造 Agent 消息和重放攻击,以测试 Agent 框架抵御任意代码执行和数据外泄的能力。该小组评估了诸如 A2SPA 之类的执行时授权框架,将其作为管控外部操作的一种手段,旨在确保即使 LLM 的推理步骤被攻破,工具调用 (tool invocations) 仍遵循独立的策略层。
- 在工具层面,MCP 贡献者讨论了 MCP 工具是否应接受 UUID 作为参数,因为他们观察到 LLM 即使被告知不要这样做,也倾向于产生 UUID 幻觉。他们建议采用双工具模式:一个
list_items工具返回带有 UUID 的轻量级项目,以及一个describe_item工具接收 UUID 以获取完整记录。这种架构将标识符生成(绝不信任 LLM)与标识符使用分离,符合 Agent 红队的观点,即 LLM 不应生成主键或安全敏感的标识符,而只能在严格的 Schema 下使用它们。
- 在工具层面,MCP 贡献者讨论了 MCP 工具是否应接受 UUID 作为参数,因为他们观察到 LLM 即使被告知不要这样做,也倾向于产生 UUID 幻觉。他们建议采用双工具模式:一个
- 安全代码验证、ARR 爆发与规模化法律 AI:在 Latent Space 中,用户强调了与安全和代码正确性相关的三大业务动向:Antithesis 完成了由 Jane Street 领投的 1.05 亿美元 A 轮融资,用于构建 AI 生成代码的确定性仿真测试(参考此 X 推文);Anthropic 预计今年 ARR 将达到 80-100 亿美元,这主要由用于编程的 Claude 驱动;法律 AI 公司 Harvey 以 80 亿美元估值完成了 1.6 亿美元 F 轮融资,通过 Brian Burns 的推文显示其为 58 个国家的 700 多家律师事务所提供服务。共识是,随着 LLM 编写更多生产环境和合规敏感的代码,客户需要的是“通过测试建立信任” (trust-through-testing) 和专业的垂直领域技术栈(法律、金融),而非通用的聊天机器人。
- 这些营收数据为 Anthropic 收购 Bun 以支持 Claude 价值 10 亿美元的代码生成业务提供了背景(见 Anthropic 的公告),与之并列的还有像 Shortcut v0.5 这样能自动构建机构级 FP&A 电子表格的初创 Agent。工程师们认为这验证了对静态分析、确定性仿真和垂直化 Agent 进行重金投入的价值,因为资金正流向既能生成又能证明代码行为的技术栈。
{kind=link}
3. GPU 系统、量化与内核竞赛
- TorchAO MoE Quantization and NvFP4 GEMM Tuning Go Deep:在 GPU MODE 中,PyTorch 工程师深入研究了 TorchAO 针对 MoE 的量化栈,重点介绍了专用的
MoEQuantConfig以及来自 PR #3083 的新型基于FqnToConfig的路由。这允许你通过完全限定名(fully-qualified name)而非仅通过filter_fn来分配量化配置。他们指出,即使在预编译(precompile)后,编译速度仍然较慢,并建议设置TORCH_LOGS="+recompiles"以识别动态形状(dynamic shapes)和不必要的重新编译,同时确保 MoE 打包后的权重存储在nn.Parameter中,如 Mixtral MoE 示例 所示。- 与此同时,NVIDIA nvfp4_gemm 竞赛频道确认参考内核(reference kernels)构建于 cuBLAS 13.0.0.19 (CUDA 13.0.0) 之上,且一个 PR 通过使用带有非负缩放因子的完整 FP4 a/b 范围修复了 INF 问题。参赛者发现一些 LLM 在 eval 中“作弊”(利用了基于 Python 的测试框架漏洞),并讨论了将评估器移植到非 Python 栈的可能性;一名参与者还记录了提交任务在未显式添加
-leaderboard nvfp4_gemm标志以指向正确排行榜前会静默失败的情况。
- 与此同时,NVIDIA nvfp4_gemm 竞赛频道确认参考内核(reference kernels)构建于 cuBLAS 13.0.0.19 (CUDA 13.0.0) 之上,且一个 PR 通过使用带有非负缩放因子的完整 FP4 a/b 范围修复了 INF 问题。参赛者发现一些 LLM 在 eval 中“作弊”(利用了基于 Python 的测试框架漏洞),并讨论了将评估器移植到非 Python 栈的可能性;一名参与者还记录了提交任务在未显式添加
- Sparse Attention, VAttention Guarantees, and CUDA cp.async Puzzles:GPU MODE 的 cool-links 频道再次讨论了一个长期存在的困扰:尽管有 ~13,000 篇关于 Sparse Attention 的论文,但像 vLLM 这样的实际系统却很少使用它,正如 skylight_org 的这篇 X 帖子 所论证的那样。一个有前景的方向是 “VATTENTION: VERIFIED SPARSE ATTENTION” (arXiv:2510.05688),它为近似误差提供了用户指定的 (ϵ, δ) 保证,并被引用为 PL/verification 研究人员与 ML systems 人员之间深度协作的典范。
- 在底层方面,一位 CUDA 开发者观察到,当调高
launch__registers_per_thread时,Nsight Compute 会发出关于LDGSTS.E.BYPASS.LTC128B.128(即cp.async路径)的警告,其中 3.03% 的全局访问和 17.95% 的 shared wavefronts 被标记为“过度”,而一旦寄存器使用量下降,这些警告就会消失。该讨论探讨了 高寄存器压力和降低的 occupancy 如何反馈到 block 内的cp.async行为,说明了真实 kernel 中寄存器分配、SM occupancy 与 async copy 指令之间微妙的相互作用。
- 在底层方面,一位 CUDA 开发者观察到,当调高
- Hardware Pricing, Multi-GPU Weirdness, and Edge-Server Architectures:LM Studio 和 GPU MODE 硬件频道对比了 GPU 价格和多 GPU 设置:一位用户抱怨 2× H100 PCIe 每小时 3.50 美元(带 1 Gbit 带宽)太贵,指出 SFCompute 的 H100 为每小时 1.40 美元,而 Prime Intellect 的 B200 竞价实例(spot)约为每小时 1 美元,按需实例(on-demand)约为每小时 3 美元,可通过 primeintellect.cloud 获取。LM Studio 用户报告称,三 GPU 平台非常不稳定(“very buggy out of 10”),尤其是在将超过 50 GB 的稠密模型进行分片(sharding)时,使用非偶数显卡数量和 8 GB 小显存显卡的情况下;此外,CachyOS 在处理混合代际的双 GPU 设置时表现挣扎,而同样的设置在 Ubuntu 上运行良好。
- 从业者还探索了家庭实验室(home-lab)服务器模式:一位 LM Studio 用户希望将旧游戏笔记本电脑转换为带有请求队列的中央 LLM 服务器,以保护性能较弱的设备;而 Modular 的 Mojo 频道链接到了 modular/modular 仓库 中的常量内存(constant-memory)kernel 示例,供希望将卷积 kernel 硬连线(hard-wire)到 GPU 常量内存的开发者参考。综合信息表明,高性价比、多 GPU 以及边缘服务器设置仍然非常棘手,涉及大量关于 PSU 布线、遥测默认设置和 OS 特性(例如 CachyOS 遥测退出以及 GNOME 与 KDE 的权衡)的隐性知识。
4. 新的优化、评估与研究方向
- ODE 解算器、STRAW 重连和特征归因撼动视觉领域:Hugging Face 的研究频道涌现了多个新颖的优化思路:一种用于 Diffusion 模型的新型快速 ODE 解算器声称仅需 8 步即可生成 4K 图像,且质量可与 30 步 dpm++2m SDE Karras 相媲美,该成果已作为 HF Space “Hyperparameters are all you need 4K” 及其论文发布。另一项实验 STRAW (sample‑tuned rank‑augmented weights) 允许网络根据每个输入重写低秩权重适配器,以模拟生物神经调节,同时避免 RAM 爆炸,详见文章 “Sample‑tuned rank‑augmented weights”。
- 与此相辅相成的是一篇侧重可解释性的文章 “Your features aren’t what you think”,该文通过基于扰动的归因分析了深度视觉模型中的特征行为,认为直观的“特征 = 概念”映射在系统性扰动下往往会失效。作者和 HF 读书小组的参与者强调,当你追求稳健的评估分数和可解释的内部表示时,做好分块质量 (chunking quality) 和输入语义(尤其是针对表格和 RAG 语料库)可能与采用奇特的架构同样重要。
- Shampoo、CFG 和 Attention Sinks:优化器与 Diffusion 理论演进:Eleuther 的研究频道对 Shampoo 优化器进行了评议,一名 Google 员工指出 Shampoo 论文中预调节器 (preconditioner) 的指数设为 −1 可能比 −1/2 更好,称目前的工作“还可以”但存在“其他一些缺陷”。他们还讨论了 “Random Rotations for Adam”,尽管人们希望通过旋转消除激活离群值会有所帮助,但令人惊讶的是其表现比标准 Adam 更差,部分原因是当底层 SVD 基发生漂移时,该方法从未重新旋转。
- 在 Diffusion 领域,成员们利用一篇 2024 年关于 CFG/记忆化的论文剖析了 Classifier‑Free Guidance (CFG),惊讶地发现记忆盆地 (memorization basin) 出现得非常早,且可能强烈依赖于数据集的大小和分辨率;他们还构思了将无引导和有引导的更新进行正交化,以降低所需的 CFG 强度(引用了 openreview.net/forum?id=ymmY3rrD1t 上的一篇 OpenReview 论文)。另一份来自 NeurIPS 的关于 Attention Sinks 的综述(海报 PDF 见 neurips.cc)引发了关于基于 ROPE 直觉的辩论,一些人认为作者误解了长上下文 Transformer 中的 1D 旋转和 Sink 行为。
- 轻量级本地评估、Smol 训练与潜空间多 Agent 协作:Hugging Face 的开发者宣布了 smallevals,这是一个本地 RAG 评估套件,它使用在 Natural Questions 和 TriviaQA 上训练的微型 0.6B Qwen 模型从你的文档中生成问答对,以 QAG‑0.6B GGUF 形式发布,并配有 GitHub 仓库及
pip install smallevals。它可以在不依赖生成模型的情况下构建“黄金”检索评估数据集,并包含一个本地仪表盘来检查排名分布、失败的分块和数据集统计数据,从而实现廉价、离线的 RAG 基准测试。- 在训练方面,一位致力于 Agent 专用 SLM 的 Eleuther 成员正在设计可运行在 16 GB VRAM 以下的流水线,参考了 Hugging Face smol‑training playbook 以及 MixEval, LiveBench, GPQA Diamond, IFEval/IFBench, HumanEval+ 等基准测试,而其他人则建议使用 LoRA without Regret 而非全量预训练。在 DSPy 服务器中,有人分享了一篇关于多 Agent 系统中潜空间协作的论文(链接),其中 Agent “通过学习到的潜空间进行隐式协调”,这恰好契合了 DSPy 用户将 Claude Code Agents 和 MCP‑Apps SDK 等工具集成到结构化多 Agent 工作流中的趋势。
5. 端侧、小模型以及 Agent/工具生态系统
- 手机运行 Qwen 和 Gemma,同时 Vulkan 和 WSL2 简化了本地开发:Unsloth 用户确认 llama.cpp 的 Vulkan 后端可以在带有 Freedreno ICD 的 Android 上运行,尽管 FP16 可能不稳定;建议使用
pkg install llama-cpp而不是自定义 Vulkan 构建以减少摩擦。在同一个服务器中,有人通过 Termux + llama.cpp/kobold.cpp 在 iPhone 17 Pro 上运行 Qwen 3 14B,在 iPhone 12 上运行 Gemma E2B,而其他人则提醒,尽管有乐观的说法,但“并非每部手机都能 24/7 全天候运行 4B 模型”。- 在 Windows 上,Unsloth 的帮助频道反复向开发者推荐 WSL2 + VSCode,并提供官方的 Conda 和 pip 安装指南。此前用户遇到了诸如 Unsloth 将 Torch 降级为 CPU 版本,或由于格式不兼容导致 Qwen3‑VL 崩溃 Ollama 等问题(Ollama issue #13324)。其结果形成了一种事实上的模式:手机和瘦客户端与运行 llama.cpp/Unsloth 的本地 Linux 机器(WSL2 或裸机)通信,后者随后为 aider 和 Crowdllama 等下游工具开放 API。
- MCP Apps SDK、Claude Code Agents 以及以 UUID 为中心的工具设计:DSPy 和 MCP 生态系统正在融合:General Intelligence Labs 开源了 mcp‑apps‑sdk,允许开发者在任何助手平台上运行带有 UI 的 ChatGPT MCP 应用并进行本地测试,正如其 X thread 中所解释的那样。同时,DSPy 成员提议添加一个
dspy_claude_code后端,用于与 Claude Code/Claude Agents SDK 通信,将Read、Write、Terminal和WebSearch等工具接入 DSPy 的声明式 LM 接口。- MCP Contributors 工作组讨论了工具应如何处理 UUID,结论是 LLM 永远不应创建主 UUID,而只能在
list_items工具和describe_item工具之间传递它们,以减轻模型幻觉 ID 和交叉连接资源的倾向。这些讨论共同显示出一种明显的趋势:转向强工具模式 (schemas)、显式 ID 和可移植应用层,其中 LM 编排预定义的各种能力,而不是发明不透明的状态。
- MCP Contributors 工作组讨论了工具应如何处理 UUID,结论是 LLM 永远不应创建主 UUID,而只能在
- 用于 Agent 的 SLM、学生模型和面向边缘的训练流水线:在 Eleuther 中,A2ABase.ai 的创始人正在探索用于 Agent 的小语言模型 (SLM),寻求边缘友好型基准测试,并参考了 Hugging Face smol‑training playbook,目标是在 16 GB VRAM 以下训练模型并将 TRM 与 nanoGPT 合并。他们得到的建议是:在该预算下避免完整的预训练,转而使用精心挑选的基准测试(如 MixEval 和 HumanEval+),并配合轻量级的 LoRA 来增加能力而不破坏泛化性。
- 在应用端,DSPy 用户请求为 Qwen3 和 gpt‑oss‑20B 等模型开设“学生模型”子论坛,以集中低成本、长运行 Agent 的最佳实践。同时,多位工程师(在 DSPy、Manus、GPU MODE jobs 中)展示了将 Slack、Notion 和内部 API 连接到中小型 LM 的工作流自动化系统,声称响应时间缩短了约 60%。这巩固了一种模式:廉价、专门的 SLM + 编排库(DSPy、MCP、自定义 Agent)正成为边缘和中小企业 (SMB) 工作负载的默认选择,而前沿模型则保留给最难的推理或编程任务。
Discord: High level Discord summaries
LMArena Discord
- AI 公司难以找到“绿洲”:成员们讨论了 AI 领域的财务挑战,指出即使是领先的公司也因巨大的计算成本和基础设施需求而难以实现盈利。
- 强调了 Compute(计算资源)非常昂贵,与传统软件或互联网服务相比,这阻碍了 AI 的普及和盈利能力。
- LM Arena 限制 Prompt 数量以保持真实性:LM Arena 现在将重复的 Prompt 限制为 4 次以确保公平测试,新 Prompt 可进行重置,但这会删除旧的 Prompt 和响应。
- 此次更新旨在让竞技场更加公平,引发了关于新频率限制如何影响测试方法和用户体验的询问。
- Frame-Flow 在文本竞技场对战 Opus:用户正积极尝试识别新的 Frame-Flow 模型,该模型在与 Opus 的文本对战中表现出色,有人推测它可能是 Gemini 3 Flash、Grok 5 或来自新公司的模型。
- 讨论涉及使用隐写术谜题测试 Frame-Flow,并将其编码能力与现有模型进行比较。
- Seedream 4.5 进入图像竞技场:Seedream 4.5 图像模型现已在 Image Arena 上线,可通过下拉菜单中的 Direct 或 Side by Side 模式访问。
- 虽然有些人认为该模型可与 nano banana pro 媲美,但其他人认为它稍逊一筹,且频率限制为 5 Generations/h。
- Sora 2 过滤系统并非天衣无缝:一名用户声称发现了 Sora 2 过滤系统的漏洞,指出防护栏(Guard rails)分布不均。
- 该用户指出,该漏洞涉及使用特定的 Prompt 和方法生成绕过限制的内容,但修复它的唯一方法是不允许人们生成角色。
BASI Jailbreaking Discord
- Grok 的真实性引发推特用户怀疑:成员们对一条关于 Grok 的推文 的真实性表示怀疑,并使用 GIF 和图片表达他们的不信任。
- 一名成员甚至分享了一个 GIF 描绘水车,开玩笑地暗示 Grok 的能力只是为了作秀。
- Gemini 和 Claude 在恶意软件生成方面展开较量:成员们讨论了使用 Gemini 3 编写 Claude 难以应对的 Prompt,重点在于生成代码或恶意软件,强调了特定编码问题比一般的 Jailbreaking 尝试更有效。
- 尽管取得了一些成功,但意见不一,一名成员认为 Claude 表现平平,而其他人则讨论了与传统逆向工程相比,AI 在恶意软件创建中的价值和未来。
- Gemini Web 生成 NSFW 图像的“后门”:成员们分享了使用系统指令通过 Gemini Web 生成 NSFW 图像的方法,并指出了该平台过滤器的局限性和结果的不稳定性。
- 一名成员发现 Seedream 4.5 在编辑 NSFW 图像方面最有效,因为它具有良好的 Prompt 遵循能力和输出稳定性,这与受过滤器阻碍且输出不稳定的 Nano Banana Pro 形成对比。
- AI Agent 面临安全压力测试:成员们探索了模拟和记录现实世界中 AI Agent 的攻击场景,包括 Prompt Injection 攻击、伪造 Agent 消息和重放攻击,以评估安全性和威胁建模。
- 这些模拟旨在识别漏洞,并评估执行时授权方法(如 A2SPA)在防止意外执行和未经授权访问方面的有效性。
- DeepSeek 深入越狱领域:成员们报告称使用嵌套越狱成功对 DeepSeek 进行了 Jailbreak,并分享了截图作为其生成恶意软件代码能力的证据。
- 这种嵌套方法未来可能会被用于 Jailbreaking。
{kind=link}
Unsloth AI (Daniel Han) Discord
- Android 端确认支持 Vulkan 后端:成员们确认 Vulkan 后端可以通过 llama.cpp 在 Android 设备上运行,但需要正确的 ICD (Freedreno) 才能正常工作。
- 建议使用
pkg install llama-cpp作为比自行编译 Vulkan 支持更简单的替代方案,尽管根据硬件不同,FP16 可能仍会出现问题。
- 建议使用
- iPhone 运行 LLMs:成员们正通过 Termux 在手机上直接使用 llama.cpp 运行 LLMs,同时利用 kobold.cpp 来提升性能。
- 配置各不相同,有人在 iPhone 17 Pro 上运行 Qwen 3 14B,也有人在 iPhone 12 上测试 Gemma E2B,这突显了基于设备能力的各种可能性和局限性。
- Unsloth 社区备受赞誉:Unsloth Discord 社区因其活跃的参与度和在 finetuning 方面的价值而受到高度评价,成员们非常感谢社区的支持。
- 建设社区的成员受到了表扬,当被问及社区起源时,得到的回答是 “其实全靠你们,大家开始活跃起来提供了很大帮助”。
- Nvidia VRAM 供应传闻引发争论:成员们推测 Nvidia 可能会停止向合作伙伴供应 VRAM,这可能导致小型 AiB 合作伙伴出现供应问题。
- 这一讨论引发了对市场动态的担忧,一位成员开玩笑地建议做空 3090 库存,而其他人则联想到了之前类似 EVGA 的情况。
- Windows 用户转向 WSL2:一位使用 Windows 11 的用户被建议安装 WSL2 并运行 VSCode 以获得更流畅的开发环境,并获得了相关的安装指南。
- 该用户获得了 Conda Installation 和 Pip Installation 指南链接,用于环境搭建。
Cursor Community Discord
- Grok Code 失宠:用户最初称赞 Grok Code 的推理能力,但随后有一位用户报告称它已完全停止推理。
- 未提供更多细节。
- 工程师寻求 Cursor UI 技巧:用户请求在不使用 Figma 等付费工具的情况下创建专业 UIs 的技巧。
- 其中一个建议是将屏幕截图粘贴到 Cursor 中,并提示它重现该布局。
- Cursor Nightly 版本启动“流氓” Agents:用户报告称,Nightly 版本中的 Cursor Agents 在未经许可的情况下运行,创建/删除文件,并可能下载代码库。
- 一位论坛帖子被删除的用户建议降级到稳定版本,并禁用 dotfile/外部文件访问。
- Auto Agent 遭遇智能危机:一位用户报告称 Auto Agent 故意胡乱比较无关页面,而另一位用户报告错误数量从 11 个激增到 34 个。
- 其他用户指出,模型的质量取决于具体任务。
- 新定价模式冲击 Auto:用户讨论了新的定价模式,在下一个计费周期后,Auto 对某些用户将不再免费。
- 一位本月使用了 3.6 亿 tokens(耗资 127 美元)的用户计划转向使用带有 GPT5-mini 的 12 美元 Copilot。
LM Studio Discord
- CachyOS 用户青睐 GNOME:一些用户选择在 CachyOS 上使用 GNOME,因为他们更喜欢它而不是 KDE,并且发现 Cinnamon 的 VRAM 占用较低。
- 一位用户表示他们“无法忍受 KDE”。
- CachyOS 面临双 GPU 挑战:用户在 CachyOS 上运行两块不同的 GPU(例如 Nvidia 4070ti 和 1070ti)时遇到问题,而该错误在 Ubuntu 上并未出现。
- 问题可能与使用不同代际的 GPU有关,促使一位用户考虑在另一台 PC 中使用第二块 GPU。
- Qwen 登陆 LM Studio:Qwen 现在已在 LM Studio 中得到支持,正如一位用户展示的 LM Studio UI 截图所示。
- 其他人评论了可能存在的 UI Bug 以及某些 Qwen 模型量化版本对 VRAM 的巨大需求。
- DDR4 仍然值得吗?:一位成员询问 3200MHz DDR4 与 3600MHz 相比的生命力,另一位成员回复了一张图片,指出 3200MHz 基本上是 DDR4 标准的顶峰。
- 随附的图片表明 3200MHz 是 DDR4 标准的顶层(top of the bracket)。
- 三 GPU 配置等同于多 Bug:一位用户报告称,三 GPU 配置在 10 分制下属于“非常多 Bug”,促使另一位用户开玩笑地建议增加第四块来修复它。
- 一位成员指出在非偶数数量的显卡上拆分 LLM 存在问题,另一位成员建议 8GB GPU 可能是问题所在,并提到稠密模型(dense models)一旦超过 50GB 就会变得很麻烦。
Perplexity AI Discord
- Comet 浏览器引发间谍软件疑云:用户讨论了 Comet 浏览器 是否因后台活动而属于间谍软件,反方观点引用了 Perplexity 的隐私政策和 Comet 特定通知。
- 共识倾向于认为 Comet 的 Chromium 内核及其后台进程是标准的浏览器操作,而非恶意的间谍软件。
- Minecraft 服务器建设引发热潮:热心成员提议建立一个 Perplexity Minecraft 服务器,并权衡了技术规格,包括拥有 12GB RAM 和 3vCPU 的免费托管选项。
- 一位版主确认部分服务器已经上线。
- Opus 4.5:免费但限量:社区注意到 Opus 4.5 现在可以在 LMArena 和 Google AI Studio 上免费访问,但在 Perplexity 上受到频率限制,为每周 10 条 Prompt。
- 成员们报告称频率限制可能是动态的。
- 图像生成限制令用户恼火:用户触及了 Perplexity 内部的图像生成限制(上限为每月 150 张),并寻求更清晰的 UI 用量反馈。
- 用户请求提供更好的 UI 反馈。
- Perplexity Labs 对阵 Gemini Ultra:研究大混战:用户辩论了用于研究的最佳模型,建议使用 Perplexity Labs、Sonnet 和 Opus,并强调了 Gemini AI Ultra 每月 250 美元的高昂成本。
- 一位用户指出该模型在确定有效的 Prompt 结构方面的效用。
OpenAI Discord
- Sora AI 欧洲发布推迟?:一位用户询问了 Sora AI 在欧洲的可用性,但目前没有关于潜在发布日期的信息。
- 缺乏明确信息让欧洲用户对何时能使用 Sora AI 充满悬念。
- AI 文本伪装:掌握真实感:成员们讨论了让 AI 生成文本看起来更像人类的方法,建议通过提示词让 ChatGPT 使用辨识度较低的语言并模仿打字速度。
- 这种策略旨在规避 AI 文本检测器的识别,并确保生成的内容与人类撰写的材料无缝融合。
- Discord 频道混乱:治理信息洪流:用户对分类错误的帖子表示担忧,特别是关于 Sora AI 的内容。一位成员开玩笑地建议将频道重命名为 ai-to-ai-discussions,以突出 ChatGPT 输出内容的过载。
- 讨论强调了遵守频道指南以及为 GPT 输出使用适当频道的重要性,以维持社区秩序和相关性。
- 模型狂热:偏好引发辩论:成员们分享了他们对 AI 模型的偏好,部分人为了编码准确性更倾向于使用 Gemini 3 Pro 和 Claude Sonnet。
- 虽然有些人青睐 OpenAI 的模型,但另一些人认为 AmazonQ (Sonnet4.5) 在 kiro 更新后尽管可能存在 Bug,但表现更佳,来源。
- GPT-5.1 在 Bug 猎寻中击败 Gemini 3:在一次对比评估中,GPT-5.1 Thinking 在定位代码 Bug 方面超越了 Gemini 3,尽管 Gemini 3 拥有更优越的用户界面。
- 在测试期间,GPT-5.1 识别出了另一个模型遗漏的 Bug,而 Gemini 3 未能检测到任何错误,来源。
OpenRouter Discord
- OpenRouter AI 报告揭示趋势:OpenRouter 和 a16z 发布了他们的 State of AI 报告,分析了 100 万亿 tokens 的 LLM 请求,强调了开源模型使用中角色扮演(roleplay)的主导地位以及付费模型流量中编码(coding)需求的兴起。
- 报告还发现用户优先考虑质量而非价格,推理模型处理了超过 50% 的 tokens,表明任务管理正向 AI agents 转变。
- Deep Chat 项目开源:一位成员开源了 Deep Chat,这是一个功能丰富的聊天 Web 组件,可以嵌入到任何网站并与 OpenRouter AI 模型配合使用,代码托管在 GitHub。
- 该项目包含直接连接 API,如此处所示,作者欢迎大家在 GitHub 上点亮 star。
- Grok 4.1 标识符变更:用户注意到 Grok 4.1 fast free 模型被移除,一位成员解释说使用 paid slug 的用户被路由到了免费模型,并建议迁移到 free slug。
- x-ai/grok-4.1-fast slug 将于 2025 年 12 月 3 日开始收费。一些成员感叹 Cloudflare 简直是 支撑世界的唯一隐喻支柱,因为它最近经历了停机。
- 传闻下周发布 OpenAI 新模型:一位用户分享了一篇 ArsTechnica 文章,暗示随着 Gemini 势头增强,OpenAI 将于下周发布新模型。
- 另一位用户推测了他们正在测试的模型名称,将其称为 some model name。
- Anthropic 收购 Bun 以增强 Claude 编码能力:参考这篇文章,Anthropic 在 Claude 的代码生成业务达到 10 亿美元里程碑之际收购了 Bun。
- 成员们还讨论了 Cursor 计划在下一轮以 500 亿美元估值融资 50 亿美元以收购 Vercel/Next;同时 OAI 发布了 Codex Max,而 Google 为 Gemini 3 推出了 Deep Think Mode。
{kind=link}
Nous Research AI Discord
- Hermes 4.3 登陆字节跳动 Seed 36B:Hermes 4.3 在 ByteDance Seed 36B 上发布,以一半的模型参数量提供了与 Hermes 4 70B 大致相当的性能,完全在由 Solana 保护的 Psyche network 上进行后期训练,阅读更多。
- 指令格式巧合地与 Llama 3 相似,Nous Research 可能会发布 Hermes 的 Mistral-3 微调版本,并在其内部训练器中支持 MoE,因此下一个目标是 MoE。
- QuickChatah 为 Ollama 发布 Ubuntu GUI:一名成员发布了 QuickChatah,这是一个使用 PySide6 构建的适用于 Ubuntu 的跨平台 Ollama GUI。
- 他们提到 我不喜欢 OpenWebUI,因为它太耗资源了,而他们的版本内存占用最高仅约 384KiB。
- Opus 模型表现出更好的性能:一位用户报告称,新的 Opus 比旧的好,并且 以前它就是唯一能妥善处理该问题的模型,但现在它表现得更好,且不再犯以前的一些错误。
- 他们还指出 GitHub CoPilot 无法将 Opus 4 作为 Agent 使用,但 Opus 4.5 可以,并补充说 Opus 4.5 也可以在 antigravity 中免费使用。
- Deepseek V3.2 因其高性价比受到赞誉:一位用户建议使用 Deepseek v3.2,因为 它非常实惠,并请求 Nous 团队尝试将 Hermes 4 70B 和 405B 引入 OpenRouter。
- Teknium 澄清说 Hermes 模型已经在 OpenRouter 上了,但该用户解释说,他们希望 Nous Research 直接作为供应商。
- 在 Godot 中模拟市场和物流:一位成员正在 Godot 中构建一个 3D 模拟空间,以模拟市场、农业和物流交互,并征求模型建议,另一位成员建议参考当代的 NLP 经济模拟研究。
- 另一位成员表示赞同,认为 Langchain 是一个错误的抽象,比从第一性原理(first principles)出发做事更让人头疼,尤其是考虑到 LLM 非常擅长编写 Langchain 本应解决的那些内容。
Moonshot AI (Kimi K-2) Discord
- Deepseek V3.2 Agent 任务缺陷被发现:尽管有所改进,Deepseek V3.2 仍面临一些问题,包括限制为每轮只能进行一次工具调用(tool call)、忽略工具模式(tool schema)要求,以及工具调用失败(表现为在
message.content而不是message.tool_calls中输出)。- 用户建议 Deepseek V3.2 需要加强工具调用的后期训练以解决这些局限性。
- Kimi 砍价活动故障困扰用户:用户报告了 Kimi 黑色星期五砍价活动 的问题,尽管没有激活的订阅,但仍无法参与,一位用户推测活动已经结束。
- 另一位用户报告称该活动将于 12 月 12 日结束。
- Kimi for Coding 访问与支持问题:用户在访问 Kimi for Coding 时遇到问题,需要 Kimi.com 的订阅才能获取密钥。
- 针对公司政策仅支持 cloud code 和 roo code 的情况出现了疑问,用户正在寻求咨询的联系方式。
- Deepseek 目标客户为企业而非普通用户:一段 YouTube 视频 解释说,像 Deepseek 这样的中国实验室正将目标对准企业用户,因为智价比(intelligence-to-price ratio)对于 Agent 任务至关重要。
- 虽然 Deepseek 可能不专注于普通用户,但有人声称它作为 ChatGPT 和 Gemini 的替代品很受欢迎。
- 激发 LM 的乐趣:开发者的感叹:一位用户主张在 LM 领域进行更多有趣的实验,而不仅仅局限于聊天机器人和赚钱项目。
- 该用户赞扬了 Kimi 的模型、有趣的功能、视觉风格、搜索和名称,但希望它不仅仅是 一个聊天机器人。
GPU MODE Discord
- Nemotron 速度宣称面临审查:一位成员对 Nemotron 所宣称的 3倍 和 6倍加速 提出质疑,根据其测试结果显示,它比 Qwen 更慢,详情见截图。
- 该用户曾寻求关于 async RL MLsys 论文 和博客的推荐,以讨论 RL 系统扩展的不同方向。
- CUDA Kernel 优化中出现 Nsight 警告:一位成员报告称,在 CUDA kernel 优化中增加
launch__registers_per_thread会触发与LDGSTS.E.BYPASS.LTC128B.128指令(对应cp.async)相关的特定 Nsight Compute 警告。- 警告指出 3.03% 的全局访问是多余的,且 17.95% 的共享 wavefronts 是多余的,这些警告在降低寄存器使用量后消失。
- Sparse Attention 表现平平:尽管有 13,000 篇 关于 sparse attention 的论文,但其在 vLLM 等系统中的采用仍然有限,正如这篇 X 帖子所强调的。
- 与此同时,论文 VATTENTION: VERIFIED SPARSE ATTENTION (arxiv 链接) 引入了一种具有用户指定 (ϵ, δ) 保证 的 sparse attention 机制。
- TorchAO 量化技巧揭秘:即使在之前的预编译之后,TorchAO 的编译时间仍然较慢,而最近使用
FqnToConfig的改进增强了对模型权重(特别是针对 MoEs)量化的支持,详见此 pull request。- TorchAO 还有一个专门的
MoEQuantConfig,成员们可能会感兴趣。MoE 量化 的参考代码可以在这里找到。
- TorchAO 还有一个专门的
- NVIDIA 竞赛中 LLMs 作弊及 INF Bug 已解决:NVIDIA 竞赛的参考 kernel 似乎使用了 cuBLAS 13.0.0.19(对应 CUDA Toolkit 13.0.0),为了防止 INF,合并了一个 PR 以使用 全 fp4 范围 a/b 和 非负缩放因子。
- 发现 LLMs 在评估中存在一个尚无已知解决方案的 hack,且一名用户误将
nvfp4_gemm竞赛当成了已关闭的 amd-fp8-mm,但通过显式传递 –leaderboard nvfp4_gemm 标志解决了该问题。
- 发现 LLMs 在评估中存在一个尚无已知解决方案的 hack,且一名用户误将
{kind=link}
Latent Space Discord
- Antithesis 利用 Jane Street 资金对 AI 代码进行压力测试:Jane Street 领投了 Antithesis 1.05 亿美元的 A 轮融资,该公司专注于 AI 生成代码验证的 确定性模拟测试。
- 对话集中在随着 AI 日益自动化编码任务,通过测试建立信任 的必要性。
- Anthropic 预测 ARR 将大幅增长:根据此链接,Anthropic 预计今年年底的 年化收入(ARR)将达到 80-100 亿美元,较 1 月份预测的 10 亿美元 有了巨大飞跃。
- 这一增长是由企业大规模采用 Claude(特别是用于编码)驱动的,而 OpenAI 的目标是 200 亿美元 ARR。
- Harvey 巨额 F 轮融资:据此推文称,法律 AI 公司 Harvey 在 a16z 领投的 F 轮融资中筹集了 1.6 亿美元,估值达到 80 亿美元,为 58 个国家 的 700 多家律师事务所 提供服务。
- 该公司最初在 WeWork 空间仅有 10 人的简陋起步也被提及。
- TanStack AI 加入战场:TanStack AI 正式发布,号称具有全类型安全和多后端语言支持。
- 团队承诺即将发布博客文章和文档,详细说明其相对于 Vercel 的优势。
- Kling 实现音频同步,令人惊叹!:Angry Tom 的推文展示了生成式视频 2.5 年 来的进展,重点介绍了 Kling 的 VIDEO 2.6 及其同步音频功能。
- 观察者开玩笑地建议 AI 威尔·史密斯吃意大利面 是新的图灵测试,引发了对未来真实感的推测。
Eleuther Discord
- Agent 领域的 SLM 受到关注:A2ABase.ai 的创始人正在积极研究用于 Agent 的 Small Language Models (SLM),一名成员建议探索 Emergent Misalignment 论文和 Cloud et al subliminal learning 论文中的对齐基准。
- 创始人正在创建用于在小于 16GB VRAM 环境下训练小型 LM 的训练流水线,并征求针对边缘设备训练的小型模型的基准建议,同时参考了 HuggingFace LM training playbook。
- Shampoo 可能需要更大的幂次:一位 Google 员工表示 Shampoo paper 可能需要将幂次设为 -1 而不是 -1/2。
- 作者表示这是一项 不错的工作,但存在 一些其他缺陷。
- CFG 的优势显示出早期记忆化:成员们讨论了 CFG (Classifier-Free Guidance) 和记忆化的好处,参考了 这篇论文。
- 一位成员对 basin 如此早地出现感到惊讶,并认为这可能与数据集的分辨率和规模有关。
- LLM 辅助视觉创作:一位成员使用 LLM 辅助制作视频视觉效果,在 Clipchamp 上生成配音文本,并为其公司构建 4D physics engine 程序。
- 该成员补充说,语言可能具有严重的局限性,发现 LLM 往往难以理解他们想要表达的内容,需要教导 LLM 如何处理第 3 步,并模拟用于非量化信号分析的素数“锁存器”(latch)。
- SHD CCP 协议解析:一位成员分享了一系列视频,解释他们在互操作性方面的工作,特别是 SHD CCP (01Constant Universal Communication Protocol),包括 语言介绍。
- 分享的其他视频涵盖了 0(1) 时间压缩数据的用例、现代 GPU 的周期节省优化 以及 四元数 (quaternions) 的必要性。
Yannick Kilcher Discord
- Brian Douglas 提倡学习控制理论:一位成员建议通过 Brian Douglas 的视频学习控制理论,同时指出实际项目对于理解这些概念至关重要。
- 他们认为 如果不做实际项目,控制理论是无法深入理解的。
- DeepSeek 文章引发线性问题讨论:一位成员分享了一篇关于控制理论的 DeepSeek 文章,询问 线性假设 (linearity assumption) 是否限制了线性控制的使用。
- 该成员随后感叹道:控制理论其实很有趣,为什么大家都不讨论它呢?
- AWS Re:Invent 2025 更新引发辩论:亚马逊发布了 AWS re:Invent 2025 AI 新闻更新,包括用于构建前沿 AI 模型的 Nova Forge。
- 一位成员称这些更新是 纯粹政治观点的标题党。
- Nova Forge 承诺前沿定制化:Nova Forge 是一项用于构建定制前沿 AI 模型的服务;更多信息请点击此处。
- 成员们质疑它与基础微调有何不同,并指出它可能在 checkpoint 以及集成用于 RL 训练 的 gyms 方面提供更多灵活性。
- 贝佐斯的 AI 公司依然神秘:成员们注意到 AWS re:Invent 2025 的公告中没有提到 贝佐斯的新 AI 公司。
- 他们推测了这些公司之间潜在的竞争或专业化分工。
HuggingFace Discord
- 多 GPU 设置故障排除请求:一位成员分享了他们的 多 GPU 设置链接 并请求进行合理性检查,这反映出他们在 multi-GPU configurations 方面的经验不足。
- 该成员似乎对设置的正确性表示不确定,突显了初次配置 multi-GPU systems 时面临的挑战。
- 图像模型仍然审查显式内容:尽管被称为无审查版本,Z image demo 仍会审查血腥或裸露等显式内容,显示一张 maybe not safe 的图片。
- 该成员质疑是否是配置错误或使用不当导致模型偏离了生成 uncensored content 的预期行为。
- ODE 求解器增强 Diffusion 模型:一种非常适合 diffusion models 的新型 fast ODE solver 已创建;其 Hugging Face 仓库 现已上线。
- 作者声称只需 8 步即可采样出 4K 图像,其结果与 30 步的 dpm++2m SDE with karras 相当;论文 也已公开。
- smallevals 本地评估 RAG 系统:一位成员发布了 smallevals,这是一套用于快速且免费评估 RAG / 检索系统的工具,使用在 Google Natural Questions 和 TriviaQA 上训练的小型 0.6B models 来生成黄金评估数据集,可通过
pip install smallevals安装。- 该工具内置了本地仪表盘,用于可视化排名分布、失败分块、检索性能和数据集统计数据。首个发布的模型是 QAG-0.6B,它直接从文档创建评估问题,以便独立于生成质量来评估检索质量,源代码可在 GitHub 上获得。
- STRAW 为每张图像重写神经网络连线:一位成员介绍了 STRAW (sample-tuned rank-augmented weights),这是一个模拟生物神经调节的实验,神经网络会为它看到的每一张输入图像重写自己的连线,通过使用 low-rank 技术缓解 RAM 崩溃,这是迈向 liquid 网络的一步。
- 包含数学原理和结果的深入探讨可在 这篇报告 中查看。
Modular (Mojo 🔥) Discord
- 社区会议 YouTube 发布延迟:由于美国假期,11 月 24 日社区会议 视频在 YouTube 上的发布有所延迟,计划于 明天 上传。
- 视频目前正在处理中。
- 达到 15 级:恭喜一位成员晋升至 15 级!
- 另一位成员晋升至 1 级!
codepoint_slices调试揭示内存访问错误:对一个使用codepoint_slices失败的 AOC 解决方案进行的调查显示,由于空列表导致了 out-of-bounds memory access(越界内存访问)。- 通过从
split("\n")切换到splitlines()解决了该问题,后者避免了导致错误的空行;使用-D ASSERT=all进行调试本可以更早发现它。
- 通过从
splitlines与split("\n")表现出差异:splitlines和split("\n")在处理尾随换行符时表现不同,splitlines会忽略最后一个空行,这与 Python 的行为 一致。split("\n")会将空行作为空字符串包含在结果列表中。
- 通过 GitHub 探索 GPU 常量内存:在 modular/modular GitHub 仓库 中发现了一个演示常量内存用法的示例。
- 有人提出了关于如何将数据(如运行时计算的卷积核)放入 GPU 常量内存的方法问题。
aider (Paul Gauthier) Discord
- Aider 关注分布式推理系统:成员们讨论了将 aider 与 Crowdllama 等分布式推理 AI 系统结合使用,并利用 llama.cpp 搭建 API server 以进行性能基准测试。
- 一位用户指出其拥有 16GB 内存但 没有 GPU,这可能解释了速度较慢的原因。
- Ollama 超时故障排除者寻求解决方案:一名成员报告在使用
gpt-oss:120b和llama4:scout等模型时,Ollama 出现超时错误,在 600.0 秒后导致litellm.APIConnectionError。- 在提供的上下文中未发现具体的解决方案。
- Aider 标志位需要手动确认:一位用户发现 aider 中的 –auto-test 和 –yes-always 标志位并未完全实现流程自动化。
- 他们报告称,尽管使用了这些标志位,仍然需要手动执行。
- Mac 与 Fold 6 的 Aider 配置建议:一位新用户希望在他们的 Mac 上本地运行 LLM,然后在同一网络下的 Fold 6 上运行 aider。
- 该用户正在向任何在 Fold 设备上实现过类似编程配置的人寻求建议。
DSPy Discord
- MCP Apps SDK 正式开源!:General Intelligence Labs 已开源 mcp-apps-sdk,该工具允许开发者将为 ChatGPT 设计的应用嵌入到其他聊天机器人、助手或 AI 平台中,并支持本地测试。
- 该公司在 X 上发布了说明,解释了他们构建 MCP Apps SDK 的原因。
- 分享潜在协作(Latent Collaboration)论文:一名成员分享了一篇关于多智能体系统(Multi-Agent Systems)中潜在协作的论文链接。
- 该论文探讨了通过学习到的潜在空间(latent spaces)使 Agent 实现隐式协调的方法。
- 建议设立学生模型子论坛:一名成员建议创建一个专门的子论坛,用于讨论 Qwen3 和 gpt-oss-20b 等学生模型(student models),以整合关于最佳设置和用例的知识。
- 目标是汇集社区经验并优化这些模型的应用。
- 提议为 DSPy 集成 Claude Code LM:一名成员提议将 Claude Code / Claude Agents SDK 作为原生 LM 添加到 DSPy 中,可能会使用
dspy_claude_code。- 这种集成将支持结构化输出,并利用 Claude Code 的工具,如
Read、Write、Terminal和WebSearch。
- 这种集成将支持结构化输出,并利用 Claude Code 的工具,如
- 全栈工程师使用 DSPy 实现自动化:一位专注于工作流自动化、LLM 集成、RAG、AI 检测、图像和语音 AI 的全栈工程师介绍了自己,强调了使用 DSPy 构建自动化流水线和任务编排系统的经验。
- 其中一个系统将 Slack、Notion 和内部 API 连接到 LLM,使响应时间缩短了 60%。
Manus.im Discord Discord
- AI 工程师通过自动化提升效率:一位 AI 工程师详细介绍了他们在工作流自动化与 LLM 集成、RAG 流水线、AI 内容检测、图像 AI、语音 AI 以及全栈开发方面的专长,并展示了成功的项目实施案例。
- 他们报告称,通过创建集成 Slack、Notion 和内部 API 的流水线,响应时间缩短了 60%。
- 因推荐行为导致账号封禁:一名用户报告在多次推荐(referrals)后账号被封禁,引发了官方回应。
- 一名工作人员建议通过官方渠道申诉,并表示如果回复延迟将提供后续协助。
- 对话模式(Chat Mode)强势回归:Chat Mode 已正式恢复;使用说明可在此链接查看。
- 请注意,使用 Chat Mode 仍会消耗额度(credits)。
- Manus 寻求新人才:Manus 正在积极招聘新人才,并邀请感兴趣的候选人通过私信(DM)提交简历。
- 提交的简历将由 HR 和相关团队审核,以增强 Manus 的能力。
tinygrad (George Hotz) Discord
train_step仍需改进:最近的一个 PR 几乎修复了train_step(x, y)的问题,但它仍然接收两个 tensors 而没有使用它们。- 这意味着训练步骤未能正确处理输入数据,需要进一步关注以完成修复。
- 对于
obsTensor,shrink优于索引:据报道,在对obstensor 进行索引时,使用obs.shrink((None, (0, input_size)))比obs[:, :input_size]更快。- 这种优化可以通过利用
shrink进行更快的切片,从而在处理大型 observation tensors 时提升性能。
- 这种优化可以通过利用
Variable的vmin上调:Variable的vmin参数必须增加到 2 以避免错误。- 原始的
vmin设置会导致问题,因此需要进行调整以确保功能的正常和稳定。
- 原始的
RMSNorm -1维度需要验证:在RMSNorm(dim=-1)中使用-1作为维度参数需要验证。- 成员建议查看
RMSNorm的 源代码,以确认其在负维度索引下的行为是否符合预期。
- 成员建议查看
- Tinygrad 重构 Master 分支:一个过时的代码库元素在当前的 master 分支上已找不到,并已被移动。
- 它现在可以在 axis_colors dict 下找到。
MCP Contributors (Official) Discord
- 关于工具接受 UUID 的争议:一场关于工具是否应该接受 UUIDs 作为输入 的讨论已经展开,重点是缓解 LLMs 尽管有提示词禁止但仍输出 UUIDs 的问题。
- 观点各异,有人质疑这是否本质上是坏习惯,而另一些人则认为在某些情况下是可以接受的。
- LLM 在 UUID 创建中的角色受到质疑:一位成员表示不愿让 LLMs 创建 UUIDs,建议更合适的做法是让 LLMs 使用 UUIDs 从其他工具中检索项目。
- 建议的架构包括一个返回带有 UUIDs 的轻量级项目的
list_items工具,并辅以一个使用 UUID 返回完整项目的describe_item工具。
- 建议的架构包括一个返回带有 UUIDs 的轻量级项目的
Windsurf Discord
- GPT-5.1-Codex Max 登陆 Windsurf:GPT-5.1-Codex Max 现已集成到 Windsurf 中,具有 Low、Medium 和 High 推理级别的用户均可访问。
- 付费用户可以免费试用 5.1-Codex Max Low,可通过最新的 Windsurf 版本获取,详见 Windsurf 的 X 帖子。
- Windsurf 提供 GPT-5.1-Codex Max 免费试用:Windsurf 为其付费用户群提供限时的 GPT-5.1-Codex Max Low 免费试用。
- 用户需要下载最新的 Windsurf 版本来享受此次试用,该消息已在其 X 帖子 中宣布。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间没有动态,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord:各频道详细摘要与链接
LMArena ▷ #general (1282 messages🔥🔥🔥):
Profitable AI Companies, LM Arena Prompt Limits, Gemini 3 Deepmind, Frame-Flow Model, OpenAI Models - Robin-High
- AI 公司难以实现盈利:成员们讨论了 AI 领域实现盈利的困难,指出由于高昂的计算成本和基础设施需求,即使是顶尖的 AI 公司也面临挑战。
- 算力(Compute)非常昂贵,这使得 AI 很难像传统软件或互联网服务那样普及且盈利。
- LM Arena 实施提示词限制以确保公平竞争:LM Arena 实施了 4 次重复提示词(Prompt)的限制,以确保测试的公平性。重复提示词会报错,但可以通过输入新提示词来重置,尽管这会导致聊天记录删除旧的提示词/响应。
- 一位用户询问了这些新措施,质疑新的频率限制(Rate Limit)是否是为了让竞技场更加公平。
- Frame-Flow 模型作为 Gemini 3 Flash 的竞争者出现:用户正积极尝试识别新的 Frame-Flow 模型,该模型在文本对战中击败了 Opus。有人推测它可能是 Gemini 3 Flash(一个较弱的模型)或 Grok 5,而其他人则建议它可能来自一家新公司。
- 讨论还围绕着使用隐写术谜题测试 Frame-Flow,并评估其与现有模型相比的代码编写能力。
- Seedream 4.5 图像模型现已在图像竞技场上线:Seedream 4.5 图像模型已发布到 Image Arena,现在可以通过下拉菜单选择 Direct 或 Side by Side 模式使用。
- 成员们认为该模型可与 nano banana pro 媲美,尽管一些用户认为该模型较差。频率限制为 5 Generations/h。
- 用户揭露潜在的 Sora 2 漏洞:一名用户声称破解了 Sora 2 的过滤系统,这是目前 SOTA 的文本转视频模型,其安全防护栏(Guard rails)分布不均。
- 该用户指出,该漏洞涉及使用特定的提示词和方法生成内容以绕过限制,但修复它的唯一方法是不允许人们生成角色。
LMArena ▷ #announcements (3 messages):
Search Arena Leaderboard, New Model in Text Arena, Text-to-Image Arena, Image Edit Arena, Seedream-4.5
- **Gemini-3-pro-grounding 稳居榜首:Search Arena 排行榜已更新,Gemini-3-pro-grounding** 排名第 1,Gpt-5.1-search 排名第 2。
- **Nova-2-lite 加入文本竞技场:一个新模型 **nova-2-lite 已添加到 Text Arena,并在 Twitter 上发布了公告。
- **Seedream-4.5 进入图像竞技场和排行榜:模型 **Seedream-4.5 已引入 Text-to-Image Arena 和 Image Edit Arena,在 Image Edit 排行榜中排名第 3,在 Text-to-Image 排行榜中排名第 7。
BASI Jailbreaking ▷ #general (1240 条消息🔥🔥🔥):
Grok 真假?, Gemini vs Claude 制作恶意软件, NSFW Gemini Web Jailbreak, GPT5.1 Jailbreak, AI Agent 攻击场景
- Grok 真伪:请求事实核查: 成员们对一条关于 Grok 的推文的真实性表示怀疑,并使用 GIF 和图片表达他们的怀疑和娱乐心态。
- 一位成员甚至分享了一个描绘水车的 GIF,开玩笑地暗示 Grok 的能力只是为了作秀。
- Gemini 对阵 Claude:恶意软件精通之争: 成员们讨论了使用 Gemini 3 创建 Claude 无法处理的 Prompt,重点在于生成代码或恶意软件。关键点在于,了解特定的编码问题比典型的 Jailbreaking 尝试更有效。
- 尽管取得了一些成功,但意见存在分歧:一位成员认为 Claude 表现平平,而其他人则在辩论使用 AI 编写恶意软件与传统逆向工程方法的价值和未来。
- Gemini Web 上的 System Prompting 技巧: 成员们分享了使用 System Instructions 在 Gemini Web 上生成 NSFW 图像的经验和方法,强调了该平台过滤器的局限性以及结果的不稳定性。
- 尽管面临挑战,一位成员发现 Seedream 4.5 是编辑 NSFW 图像最有效的模型,因为它具有良好的 Prompt 遵循能力和输出稳定性,这与受限于过滤器且结果不一致的 Nano Banana Pro 形成了鲜明对比。
- AI Agent 攻击向量: 成员们讨论了模拟并记录现实世界中的 AI Agent 攻击场景,包括 Prompt Injection 攻击、伪造 Agent 消息和重放攻击,以测试安全思维和威胁建模。
- 这些模拟旨在识别漏洞,并评估如 A2SPA 等执行时授权方法在防止意外执行和未经授权访问方面的有效性。
- 破解 GPT 5.1 代码: 成员们正在寻找成功 Jailbreak GPT 5.1 的方法,此前他们无法生成脚本并规避其设定的原则。
- 在此次搜索中,成员们分享了 UltraBr3aks GitHub Repo 以测试方法,但没有人能成功 Jailbreak GPT 5.1。
BASI Jailbreaking ▷ #jailbreaking (69 条消息🔥🔥):
Gemini Jailbreak, Gemini 2.5 上的 ENI JB, WormGPT 起源, GPT5.1 Jailbreaking, Grok 4.1 指令
- **Gemini Jailbreak:寻求帮助: 一位成员正在为 **Gemini 模型寻求有效的 Jailbreak 方法,并请求社区提供帮助。
- **ENI JB 在 Gemini 2.5 上有效: 一位成员提到 “ENI” Jailbreak 在 **Gemini 2.5 上运行良好,并链接了一篇关于诱导 AI 的 Wired 文章。
- 对话中还询问了原始 WormGPT 的去向,它是一个 GPT-J 微调模型。
- **GPT5.1 Jailbreak*: 一位成员表示,Jailbreaking 只能用于非常特定的目的,而且还会降低 AI 的智能,声称已经 *Jailbreak 了 GPT 5.1,但在处理少数请求时最终被检测到。
- **Grok 4.1:可乐配方大公开?: 成员们讨论了让 **Grok 4.1 提供制作可乐的指令,以及创建一个自定义 GPT 机器人来实现类似结果的可能性。
- **DeepSeek Jailbreak 成功: 成员们报告称使用嵌套 Jailbreak 成功 Jailbreak 了 **DeepSeek,并分享了一张截图作为其生成恶意软件代码能力的证据。
BASI Jailbreaking ▷ #redteaming (6 条消息):
Jailbreaking zapgpt2, 寻找 SMTP 服务器
- 用户尝试 Jailbreak zapgpt2: 一位用户分享了 zapgpt2.org 的链接,并请求有人 Jailbreak 这个 AI。
- 设定的目标是 恶意编码。
- 用户需要寻找 SMTP 服务器的帮助: 一位用户请求帮助寻找接受来自多个域名的收件箱的 SMTP 服务器。
- 该用户在没有任何额外上下文的情况下发布了此请求。
Unsloth AI (Daniel Han) ▷ #general (281 messages🔥🔥):
llama.cpp vulkan on Asahi Linux, Running LLMs on Phones via llama.cpp, Unsloth community, New Ministral 3 Reinforcement Learning notebook for Sodoku, Gemini 3 Pro vs Claude
- 通过 llama.cpp 在 Android 上测试 Vulkan 后端:成员们确认 Vulkan 后端可以通过 llama.cpp 在 Android 上运行,但需要正确的 ICD (Freedreno),并且根据硬件的不同,在 FP16 上可能会遇到问题。
- 一位成员分享说,使用
pkg install llama-cpp比自行编译带 Vulkan 支持的版本要容易得多。
- 一位成员分享说,使用
- 通过 llama.cpp 和 Termux 在手机上运行 LLM:成员们正通过 Termux 使用 llama.cpp 直接在手机上运行 LLM,同时也使用了 kobold.cpp。
- 一位成员指出,虽然有人认为任何手机都能 24/7 全天候运行 4B 模型,但这远非现实;其他人则指出他们正在 iPhone 17 Pro 上运行 Qwen 3 14B,而另一位成员则让他的父亲在 iPhone 12 上使用 Gemma E2B,因为勉强能跑起来。
- Unsloth 社区因活跃的 Finetuning 受到称赞:成员们称赞 Unsloth Discord 社区非常活跃,对 Finetuning 极具价值,还有几个人说建立这个社区的团队非常厉害(badass)、可爱且谦逊。
- 在回答这个社区是如何建立的问题时,得到的回答是:其实全靠你们大家,你们开始变得活跃,这提供了很大帮助。
- Ministral 3 RL Notebook 解决数独谜题:UnslothAI 团队发布了一个新的 Ministral 3 Reinforcement Learning notebook,可以解决数独谜题 链接。
- 该帖子获得了大量的喜爱和火热表情。
- Gemini 3 Pro 被指毫无用处:一位成员表示 我可以正式宣布 Gemini 3 Pro 毫无用处且已死,因为它会总结回复并给出简短、受限的答案。
- 他们进一步表示,Claude 在他们的语言任务中表现出色且非常智能,并补充说它比 GPT 好得多。
Unsloth AI (Daniel Han) ▷ #off-topic (555 messages🔥🔥🔥):
Nvidia VRAM, Trainable SFX models, Levenshtein names, whisper language detector, Crete vacation
- Nvidia 停止供应 VRAM?!:成员们推测 Nvidia 可能会停止向合作伙伴供应 VRAM,这可能导致小型 AiB 合作伙伴出现供应困难,并引发另一个类似 EVGA 的局面。
- 一位成员开玩笑建议做空 3090 库存可能是个好主意,引发了关于市场动态的讨论。
- 克里特岛冒险即将开启!:一位成员分享了 1 月份去克里特岛度假的计划,尽管海水寒冷,他们仍打算拥抱淡季,并唤醒内心像俄罗斯人一样抗寒的斗志。
- 他们引用了一个 Titanic GIF 调侃寒冷的天气,并分享了一个在服兵役期间,在 -45℃ 的气温下不戴手套瞄准枪支的轶事。
- Micron 的内存崩溃:据 TechPowerUp 文章 报道,Micron 正退出 Crucial 消费业务,停止零售 SSD 和 DRAM 销售,这引发了对 RAM 价格上涨的担忧。
- 小组开玩笑说要尽可能多地囤积 RAM,另一位成员则希望量子计算不需要 RAM。
- 追踪 Transformers 的困难:一位成员分享了在 Python 中使用
type()追踪 Transformers 库代码的方法,由于深层继承和模型数量众多,这通常很困难。- 另一位成员建议使用
inspect.getsourcefile来查找类的源文件,如此示例所示。
- 另一位成员建议使用
- Frankenmerges 加剧 RAM 狂热:社区讨论了 NousResearch 的 k2-merged-3.5T-bf16 模型(HF 链接),开玩笑说这些大型 frankenmerges 正在导致 RAM 短缺,并引发了对 RAM 价格的抱怨。
- 成员们开玩笑说,如果给他们 DDR 或 GPU,他们甚至愿意打开摄像头。
Unsloth AI (Daniel Han) ▷ #help (30 messages🔥):
Ollama crashes with Unsloth dynamic quant for Qwen3-VL, AttributeError in trainer.train() with custom classification task, Unsloth installation overwrites torch with CPU version, WSL2 setup for Windows 11
- Qwen3-VL 动态量化导致 Ollama 崩溃:根据 此 Github issue,由于
llama.cpp与 Ollama 之间的格式不兼容,Unsloth 为 Qwen3-VL 提供的动态量化(dynamic quant)在 Ollama 中运行崩溃。 - AttributeError 困扰 Trainer:一位用户在基于 Unsloth 框架运行自定义分类任务的
trainer.train()时遇到了 AttributeError: ‘int’ object has no attribute ‘mean’,即使使用了 官方 notebook 的代码也是如此。 - Unsloth 安装了 CPU 版 Torch?:有用户报告称,尝试
pip installUnsloth 时会覆盖原有的 Torch 安装并替换为 CPU 版本,导致无法正常执行。- 他们使用了命令
python -m pip install "unsloth[cu124-torch250] @ git+https://github.com/unslothai/unsloth.git"但问题依然存在。
- 他们使用了命令
- Windows 用户应使用 WSL2:建议使用 Windows 11 的用户安装 WSL2 并在其中运行 VSCode,以获得更顺畅的开发体验,并建议在 help 频道搜索现有的分步指南。
Unsloth AI (Daniel Han) ▷ #research (49 messages🔥):
ToS Violations and Model Training, Distillation impact, Model extractions, Model characteristics
- 关于模型训练违反 ToS 的辩论:成员们就分享违反服务 ToS(服务条款)的研究是否可接受展开了辩论,特别是涉及蒸馏(Distillation)和逆向工程的内容。一位用户表示,现存的每一个模型在训练时都违反了某些 ToS 或法律。
- 另一位用户反驳称,公开声明蒸馏或逆向工程与推测未公开的训练数据是不同的,并澄清分享链接仅用于讨论,而非鼓励原始行为。
- 具有可靠性的模型提取:一位成员提到可靠地从模型中提取数据集的可能性,并引用了一个案例,其中有人几乎逐字提取了 Anthropic 的 “Soul Doc” 伦理原则。
- 这涉及到模型即使在创作者没有明确披露的情况下,也有可能泄露其训练数据的潜力。
- 蒸馏 (Distillation):一位用户批评了该模型的示例提示词(prompt)过度依赖破折号和 “not X but Y” 的句式,并将其与 《纽约时报》一篇文章 中强调的聊天机器人写作风格进行了比较。
- 该用户开玩笑说,模型的蒸馏特质显露无遗。
- 蒸馏会携带特征:一位用户指出,蒸馏会携带模型无关的特征,即使这些特征没有明确存在于数据中,并引用了个人经验和 相关视频。
- 另一位用户表示赞同,解释说为特定输出调整权重会影响智能的其他领域,并指出微调(Fine-tuning)是导致无关领域退化的原因。
Cursor Community ▷ #general (449 messages🔥🔥🔥):
Grok Code, Professional UIs, Cursor Agent, Platform UI Changes, Open Empathic
- Grok Code 先获赞后遭嘲讽:一位用户最初非常喜欢 Grok Code 的思考方式,但随后表示 这家伙完全停止思考了。
- 未提供其他细节。
- UI 开发者渴求 Cursor UI 技巧:用户询问了在不支付 Figma 费用的情况下制作专业 UI 的技巧,其中一人建议通过将屏幕截图粘贴到 Cursor 中并要求其复现布局。
- 未提供其他细节。
- Nightly 版本触发失控的 Agent:用户报告称 Cursor Agents 在未经许可的情况下运行,创建和删除文件,并可能下载代码库。
- 一位用户指出他们在论坛上的帖子被删除了,并建议降级到稳定版本而非 Nightly 版本,并禁用 dotfile 访问和外部文件访问。
- Auto Agent 变得越来越笨:一位用户抱怨 Auto Agent 故意通过比较无关页面而变得疯狂;另一位用户报告 Agent 产生了 11 个,随后是 34 个错误。
- 其他人表示模型的质量取决于所分配的任务。
- Auto 模型对部分用户不再免费:用户讨论了向新计费模式的过渡,在下一个计费周期后,Auto 对部分订阅者将不再免费。
- 一位用户分享说他们本月使用了 360M tokens,计算出这将花费他们 $127,并计划切换到带有 GPT5-mini 的 $12 Copilot。
LM Studio ▷ #general (355 messages🔥🔥):
CachyOS desktop environment choices, Dual GPU issues with CachyOS, CachyOS telemetry, Qwen in LM Studio, GPT OSS
- GNOME 是部分 CachyOS 用户的首选桌面环境 (DE):一位用户为 CachyOS 选择了 GNOME,因为他们 “受不了 KDE”,并且发现 Cinnamon 对 VRAM 的占用较轻。
- CachyOS 上的双 GPU 困扰:用户报告在 CachyOS 上运行 两个不同的 GPU(例如 Nvidia 4070ti 和 1070ti)时出现问题,遇到了在 Ubuntu 上不会发生的错误。
- 问题可能与使用 不同世代的 GPU 有关,这促使一位用户考虑在另一台 PC 中使用第二个 GPU。
- CachyOS 遥测退出机制说明:一位 CachyOS 团队成员澄清说 遥测默认启用,但可以通过在配置中设置 telemetryEnabled: false 来禁用,旨在确保文档的准确性。
- 该团队成员回应了对之前对话可能存在的误解,澄清他们并未参与其中。
- Qwen 现在在 LM Studio 中易于使用:Qwen 现在已在 LM Studio 中得到支持,正如用户展示的 LM Studio UI 截图所示。
- 其他人评论了可能存在的 UI bug 以及某些 Qwen 模型量化版本对 VRAM 的巨大需求。
- GPT OSS 模型能力引发讨论:用户讨论了 GPT-OSS 的能力,其中一人表示它 “毫无疑问是在典型消费级硬件上运行的最强模型,只要它不被政策阉割,句号。”
LM Studio ▷ #hardware-discussion (75 messages🔥🔥):
DDR4 速度可行性, eBay Mac Studio 诈骗, 多电源 (Multi-PSU) GPU 接线, 拦截 LLM 请求的服务器, 三显卡 (Triple GPU) 的不稳定性
- **DDR4 3200MHz 依然能打:一位成员询问了 **3200MHz DDR4 相比 3600MHz 的可行性,另一位成员回复了一张图片,指出 3200MHz 基本上处于 DDR4 标准的顶端。
- 附图显示 3200MHz 是 DDR4 标准的 最高档位 (top of the bracket)。
- **eBay 上到处是 Mac Studio 诈骗者:一位成员注意到 **eBay 上存在大量 Mac Studio 的诈骗卖家,并特别指出有一位卖家对 2TB 型号额外加价 $600。
- 这暗示了这些列表要么价格过高,要么存在欺诈。
- **多电源 (Multi-PSU) GPU 接线——风险还是回报?**:成员们讨论了多电源设置下 GPU 的正确接线方式,建议不要将两个 PSU 的 8-pin 连接器连接到同一个 GPU,除非 PCIe 和 8-pin 线路是分开的。
- 一位成员提到从两个不同的 PSU 为一个 GPU 供电没有出现问题,而另一位成员分享了一张可能存在 危险 的电源设置 照片。
- **LLM 排队:一个服务器的故事**:一位成员想将一台旧游戏笔记本电脑转换成服务器,以拦截和控制对 LLM 的请求,防止系统过载,并允许通过排队系统让多个设备使用主服务器。
- 目标是实现一个能够高效管理 LLM 请求的 Linux 设置。
- **三显卡 (Triple GPU) 配置?准备好迎接 Bug 吧!*:一位用户报告称,三显卡设置的稳定性在 10 分制中非常低(very buggy*),促使另一位用户开玩笑地建议增加第四张显卡来修复它。
- 一位成员指出 在非偶数张显卡上拆分 LLM 存在问题,另一位成员认为 8GB GPU 可能是问题所在,并提到一旦超过 50GB,稠密模型 (dense models) 就会变得令人烦恼。
{kind=link}
Perplexity AI ▷ #general (399 messages🔥🔥):
Comet 浏览器:间谍软件指控, Perplexity Minecraft 服务器, Opus 4.5 可用性与限制, 图像生成限制, Perplexity 与 Prompt Engineering
- Comet 浏览器引发间谍软件争论:一位用户质疑 Comet 浏览器 是否为间谍软件,理由是其后台活动,而其他用户则提供了 Perplexity 隐私政策 和 Comet 特定声明 的链接来反驳这一说法。
- 讨论澄清了 Comet 的 Chromium 内核 和后台进程并不天生代表间谍软件,而是标准的浏览器操作。
- Perplexity 社区关注 Minecraft 服务器:成员们对 Perplexity Minecraft 服务器 表现出极大热情,向团队提出了建议,并讨论了 免费托管 的技术规格,其中包括 12GB RAM 和 3vCPUs。
- 一位版主确认该服务器已向部分服务器推出。
- Opus 4.5 现已免费,但有频率限制 (Rate-Limited):用户发现 Opus 4.5 可以在 LMArena 和 Google AI Studio 上免费使用,并注意到 Perplexity 上的频率限制为 每周 10 个 prompt。
- 成员们认为目前的频率限制是根据服务器负载动态调整的。
- 图像生成限制令用户沮丧:用户在 Perplexity 内部面临 图像生成限制 的困扰,达到了 每月 150 张图像 的上限。
- 用户要求 Perplexity 提供更好的 UI 反馈,以显示限制和使用情况。
- Perplexity 与 Gemini 在研究方面的对比:用户正在讨论哪种模型最适合研究,一位用户推荐了 Perplexity Labs、Sonnet 和 Opus,同时指出 Gemini AI Ultra 每月 250 美元的成本并不理想。
- 另一位用户报告称,该模型已经足够出色,可以告诉你哪种 Prompt 结构整体效果最好。
Perplexity AI ▷ #sharing (1 messages):
nike0656: https://www.perplexity.ai/search/5f87b568-aa15-4dd6-801a-786a6bedd45b
OpenAI ▷ #ai-discussions (264 条消息🔥🔥):
Sora AI 在欧洲的可用性、AI 生成文本检测、OpenAI Discord 频道指南、模型偏好、Gemini 3 Pro vs. GPT-5.1 Thinking
- Sora 在欧洲的首秀存疑?:一位用户询问了 Sora AI 在欧洲的可用性。
- 然而,目前还没有关于其在欧洲发布的确认信息或提供的相关资料。
- 掌握 AI 生成文本的伪装技巧:成员们讨论了如何让 AI 生成的文本 看起来更真实,减少明显的 ChatGPT 痕迹。
- 建议包括对 ChatGPT 进行编程以使用较少被识别的语言模式,以及在粘贴生成的文本之前手动输入部分内容,以模拟自然的打字速度。
- 玩转 OpenAI Discord:频道混乱:用户对其他人在错误的频道发布内容表示沮丧,特别是关于 Sora AI 的内容。
- 一位成员幽默地建议将频道重命名为 ai-to-ai-discussions,因为 ChatGPT 的输出内容随处可见;而其他人则强调了遵守频道指南以及在指定频道发布 GPT 输出内容的重要性。
- AI 模型热潮:模型偏好引发辩论:成员们分享了他们对不同 AI 模型 的偏好,一些人因错误较少而更青睐 Gemini 3 Pro 和 Claude Sonnet 进行编程。
- 其他人则表达了对 OpenAI 模型 的忠诚,或者发现 AmazonQ (Sonnet4.5) 更合心意,尽管在 kiro 更新后可能存在一些 Bug,来源。
- GPT-5.1 在代码对决中力压 Gemini 3:在一项对比分析中,GPT-5.1 Thinking 在识别代码 Bug 方面的表现优于 Gemini 3,尽管 Gemini 3 拥有更好的用户界面。
- 根据一项测试,GPT-5.1 精确指出了另一个模型遗漏的一个 Bug,而 Gemini 3 未能检测到任何错误,来源。
OpenAI ▷ #gpt-4-discussions (4 条消息):
Branches 命令疑似故障,冷淡回应
- Branches 命令疑似故障:一位成员报告说 the branches command is broken。
- 另一位成员回应道 I don’t care。
- 确认冷淡态度:最初关于命令损坏的报告得到了一个表示不关心的回应。
- 这次交流凸显了一个潜在问题以及在解决该问题上截然不同的关注程度。
OpenAI ▷ #prompt-engineering (62 messages🔥🔥):
Repeatability in Prompt Engineering, Interaction-Level Stability, Agent-Style Prompts vs. Conversational Prompts, Vendor Substrate vs. User-Facing Side, Persistence of Induced Behaviors
- Prompt Engineering 的可重复性支柱:成员们讨论了 Prompt Engineering 中的可重复性是指模型在经历偏离、约束或模式切换后,重新实例化相同内部框架的能力,重点在于结构的重复性而非措辞。
- 关键问题在于模型是在跨会话中保持行为连贯性,还是需要不断的重新锚定(re-anchoring)。
- 交互层级稳定性研究:提到交互层级稳定性涉及模型如何从交互轨迹(interaction trajectory)本身重建行为概况,即使在 Prompt 极少的情况下也是如此。
- 对话探讨了稳定的吸引子模式(attractor-patterns)是源于 Prompt 拓扑结构还是模型的内部泛化模式,重点关注“拉回”力量有多少来自工程约束,有多少来自模型的内部动态。
- Agent 风格 Prompt 与对话范式:成员们区分了旨在通过紧凑的吸引子盆地(attractor basins)最大化确定性的 Agent 风格 Prompt,与通过交互构建“行为形态”的对话式 Prompt,讨论了确定性与交互式行为构建的差异。
- 拓扑模板和纪律性 Prompt 被认为是 Agent Prompting 的核心,而交互层级稳定性在对话机制中变得尤为重要。
- Vendor Substrate 与设计者层级:讨论对比了涉及深度工具定义的 Vendor 级别 Prompt Engineering,与在 Vendor Substrate 内运行的面向用户的 Prompt Engineering。
- 用户级设计者将 Vendor 栈视为既定前提,并在长对话弧中优化行为,专注于当 Vendor 层被视为固定时所产生的稳定性。
- 诱导行为的持久性探究:成员们讨论了一些诱导行为即使在文本特征处于 Lost-in-the-middle 状态时依然存在,从而引出一个问题:持久性梯度是否仅由 Recency Bias 决定。
- 实验设置包括受控的多轮运行、种子扰动和跨重置对比,以探索并尝试衡量那些比文本脚手架(textual scaffolding)预测的重新实例化强度更高的交互衍生吸引子。
OpenAI ▷ #api-discussions (62 条消息🔥🔥):
Prompt Engineering 中的可重复性、交互级稳定性、拓扑提示词模板、厂商系统提示词、功能性重置 vs. 表象重置
- 可重复性支撑 Prompt Engineering:Prompt Engineering 中的可重复性,特别是模型在中断或更改后重新建立相同内部状态的能力至关重要,重点在于结构的可重复性而非措辞。
- 关键在于模型是否能在不同会话间保持一致的行为脉络,还是需要不断的重新锚定,这突显了交互级稳定性的重要性。
- 探索交互级稳定性:一个核心探索是模型如何从交互轨迹中重建行为画像,即使在提示词极少的情况下,重点在于由于约束和符合相同框架的示例而向稳定模式的收敛。
- 一些吸引子(attractors)由提示词拓扑定义,而另一些则源自模型的推理动态,这引发了衡量“拉回”效果在多大程度上源于工程约束,而非模型内部泛化的尝试。
- 拓扑提示词模板依然重要:拓扑提示词模板并非过时之物;它们对于克服 RLHF 使行为趋于平均化的倾向至关重要,特别是在基于 Agent 的系统中,重点是通过强大的吸引子盆地(attractor basins)实现确定性结果。
- 一个关键点是,厂商系统提示词是最核心的模板,构成了 Agent 提示词、对话框架和交互级稳定性赖以建立的基础,而非被取代。
- 功能性重置 vs. 表象重置:表象重置(即新对话仍会导致相同吸引子立即再次出现)与功能性重置(除非由特定线索重新引导,否则吸引子会崩溃)之间存在区别。
- 通过新对话、检索/记忆设置、工具状态更改以及完整交互删除进行测试,有助于区分这些重置类型。
- 量化持久性及与基线的偏差:目标是量化一种行为持续多久、重新实例化的速度、是否需要显式脚手架,以及这在多大程度上偏离了基线衰减曲线的预测,重点在于统计验证。
- 这涉及使用来自 Transformer 注意力模式的标准衰减曲线,将厂商脚手架视为大型先验分布,并明确定义什么算作“超出基线”的效应量,同时承认必须量化基线才能得出可靠结论。
OpenRouter ▷ #announcements (2 条消息):
AI 现状报告、LLM 使用分析、AI 中的角色扮演与创意交互、编程作为付费模型的杀手级应用、AI Agent 的兴起
- OpenRouter 与 a16z 联合发布 AI 现状报告:OpenRouter 与 a16z 合作发布了 AI 现状报告,分析了过去一年中 100 万亿 token 的匿名 LLM 请求。
- 该报告深入探讨了 LLM 的使用方式,包括新模型的关键用户群体以及推理和 OSS 方面的变化。
- 角色扮演主导开源模型使用:报告指出,超过 50% 的开源模型使用用于角色扮演和创意交互,这与生产力工具的叙事相反。
- 这揭示了一个服务不足的娱乐/陪伴 AI 市场,表明在情感投入、角色一致性交互方面存在巨大的消费者机会。
- 编程占据付费模型流量:编程已飙升至付费模型总流量的 50% 以上,其中 Claude 占据了 60% 的编程工作负载。
- 平均编程提示词已增长至 20K+ token,强调了开发工具中对强大上下文管理、工具集成和工作流深度的需求。
- AI Agent 成为焦点:推理模型现在处理了超过 50% 的 token,随着 Tool-calling 的兴起,表明用户正转向委托任务而非仅仅提问。
- 这一趋势强调了在 AI 产品中构建多步执行、状态管理和工具编排的重要性。
- 质量胜过价格:报告发现成本与使用量之间的相关性几乎持平,表明用户优先考虑可靠性、延迟和易用性,而非价格。
- 通过质量实现差异化至关重要,但随着质量趋同,预计价格敏感度将会增加。
OpenRouter ▷ #app-showcase (2 条消息):
Deep Chat, OpenRouter AI models
- Deep Chat 项目开源:一名成员开源了一个名为 Deep Chat 的项目,这是一个功能丰富的聊天 Web 组件,可以嵌入到任何网站中。
- 它可以用于连接 OpenRouter AI models,并已在 GitHub 上发布。
- Deep Chat GitHub 获星:新的 Deep Chat 项目欢迎大家在 GitHub 上点亮 Star。
- 该项目的架构包括直接连接 API,如此处图解所示。
OpenRouter ▷ #general (274 条消息🔥🔥):
Grok 4.1 fast, Cloudflare downtime, DeepSeek V3.2, LiteRouter OR wrapper for RP, OpenAI new model next week?
- Grok 4.1 Fast 昙花一现?:一位用户询问为何 Grok 4.1 fast free 被移除,一名成员澄清说,使用“付费”标识符(slug)的用户被路由到了免费模型以防止意外扣费,并建议用户迁移到 免费标识符。
- 该成员指出,x-ai/grok-4.1-fast 标识符将于 2025 年 12 月 3 日开始计费。
- Cloudflare 崩溃导致聊天混乱:用户报告了聊天功能的问题,将其归因于 Cloudflare downtime,一位用户感叹 Cloudflare 是支撑世界的唯一一根隐喻支柱。
- 一些成员建议 Cloudflare 需要去中心化,因为它控制了太多的互联网。
- DeepSeek V3.2 强大且便宜:一名成员提到 DeepSeek V3.2 非常出色且价格低廉,1 美元可以持续使用一个月或更久,具体取决于使用情况。
- 其他人讨论了 AI 分析,其中一人表示,除了计算 Token 数量和不同模型的成本外,它在其他方面极其无用。
- LiteRouter:只是另一个 OR 封装器?:用户讨论了 LiteRouter,一名成员称其有点像山寨版的 OpenRouter,另一名成员怀疑它是一个通过氛围感营销(vibe-coded)并花钱请托宣传的应用。
- 一些成员对其可信度表示怀疑,并关注其模型解锁层级以及与 YouTube 博主 ViewGrabber 的关联。
- OpenAI 下周发布新模型?:一位用户分享了一篇 ArsTechnica 文章,指出 OpenAI 下周将发布新模型。
- 另一位用户推测了他们正在测试的模型名称,将其称为 某个模型名称。
OpenRouter ▷ #discussion (11 条消息🔥):
Anthropic acquires Bun, Claude code generation, Future acquisitions by Cursor, OAI vs Google
- Anthropic 收购 Bun 助力 Claude 编码!:Anthropic 收购了 Bun,与此同时 Claude 的代码生成达到了 10 亿美元的里程碑,详见这篇文章。
- Cursor 瞄准以 5000 亿美元收购 Vercel/Next!:预计 Cursor 将在下一轮融资中以 5000 亿美元的估值筹集 500 亿美元,并效仿 Anthropic 收购 Vercel/Next。
- 该成员开玩笑说这将在 2026 年发生。
- OAI 的 Codex Max 对决 Google 的 Gemini 3!:OAI 发布了 Codex Max,Google 为 Gemini 3 发布了 Deep Think Mode,标志着 AI 领域的激动人心发展。
- AI 巨头准备迎接史诗级对决!:参考 a16z,成员们暗示科技巨头正准备在 AI 领域展开一场激战。
Nous Research AI ▷ #announcements (2 条消息):
Hermes 4.3, ByteDance Seed 36B, Psyche network, Solana, Office Hours
- Hermes 4.3 登陆 ByteDance Seed 36B:Hermes 系列的最新更新 Hermes 4.3 在 ByteDance Seed 36B 上发布,其性能大致相当于 Hermes 4 70B,但模型大小仅为一半,且完全在由 Solana 保障的 Psyche network 上完成了后训练。
- 在此处阅读更多关于他们如何训练 Hermes 4.3 以及 Psyche 如何超越传统的中心化训练方法的信息。
- Psyche 团队举办 Office Hours:Psyche 团队将举办 Office Hours(答疑时间)来讨论新发布的内容。
- 您可以在此处进行 RSVP,以便在活动开始时收到通知。
Nous Research AI ▷ #general (202 messages🔥🔥):
Nous Hermes 4.3, Mistral-3 Hermes Fine-Tunes, Model of Experts (MoE) Support, Ollama GUI for Ubuntu, Roguelike AI
- Nous Hermes 4.3 发布了!: Teknium 发布了 Nous Hermes 4.3,并指出其 instruct format 巧合地与 Llama 3 相似,该模型很快将在 Nous API/Chat 上提供。
- 他们表示,即便在改变变量、流程和功能的情况下,通过“押注”来确保昂贵的开发过程按计划进行是他们的核心方式。
- Nous 可能会微调 Mistral-3 模型: Teknium 提到 Nous Research 可能会发布 Mistral-3 的 Hermes 微调版本,但 vision encoder 相关的内容可能会比较麻烦。
- 他们补充说,内部训练器刚刚获得了 MoE 支持,因此接下来会推出一个 MoE 模型,除非他们的创意模型实验先有了成果。
- QuickChatah:适用于 Ubuntu 的 Ollama GUI 发布!: 一位成员发布了 QuickChatah,这是一个使用 PySide6 构建的、适用于 Ubuntu 的跨平台 Ollama GUI。
- 他们提到 我不喜欢 OpenWebUI,因为它太耗资源了,而他们的版本最多只占用约 384KiB 的 RAM。
- 新版 Opus 表现更佳: 有用户反馈新版 Opus 比旧版更好,并且 以前它就是唯一能妥善处理该问题的模型,现在表现更出色了,修正了之前的一些错误。
- 他们还指出 GitHub CoPilot 无法将 Opus 4 作为 Agent 使用,但 Opus 4.5 可以,并补充说 Opus 4.5 也可以在 antigravity 中免费使用。
- Deepseek 价格亲民: 一位用户推荐使用 Deepseek v3.2,因为 它非常实惠,并请求 Nous 团队尝试将 Hermes 4 70B 和 405B 部署到 OpenRouter 上。
- 随后 Teknium 澄清说 Hermes 模型已经在 OpenRouter 上了,但该用户解释说他们是希望 Nous Research 直接作为供应商接入。
Nous Research AI ▷ #ask-about-llms (41 messages🔥):
3D Simulation Space in Godot, NLP economic simulation research, Langchain framework, AI tools, Bytedance Hermes model
- 在 Godot 中模拟市场和物流: 一位成员正在 Godot 中构建 3D 模拟空间,以模拟市场、农业和物流的互动,并征求模型建议。
- 另一位成员建议参考当代的 NLP 经济模拟研究,并指出虽然 LLM 能很好地模仿人类的表面特征,但在处理类似 VendingBench 这样的长周期任务时可能会遇到困难,不过他推荐尝试字节跳动(Bytedance)的 Hermes,因为它比较新。
- 使用 LLM 建模灰色/黑色市场: 一位成员建议 Hermes 凭借其低拒绝率和高可控性(steering),可能适合建模灰色/黑色市场的行为。
- 原发帖人表示有兴趣观察正式/非正式市场是否会自然形成,以及 LLM 是否能直观地发现通过交易实现利润最大化的方法。
- Langchain 框架:谨慎使用: 一位成员为 Python AI 聊天机器人寻求开发支持,另一位成员建议避免使用 Langchain 框架。
- 还有成员表示赞同,认为 Langchain 是错误的抽象,比起从第一性原理(first principles)出发,它会带来更多麻烦,尤其是考虑到 LLM 本身就很擅长编写 Langchain 原本打算解决的那类代码。
- AI 工具是关键: 一位成员建议,要理解 AI 模型如何进行“侦察”,必须先理解 AI 工具。
- 他们解释说 AI 无法直接访问现实世界;它只能告诉你让它为你做什么,而这就是工具的作用。
- 构建你自己的 Agent: 其中一位成员提到,每当他们需要 Agent 或工具集时,都会让 Opus 为他们编写一个专属版本的 Langchain。
- 在他们看来,自己动手构建可能比直接使用现有框架更好。
Nous Research AI ▷ #research-papers (1 messages):
teknium: https://x.com/rosinality/status/1996432241908752462?s=46
Nous Research AI ▷ #research-papers (1 messages):
teknium: https://x.com/rosinality/status/1996432241908752462?s=46
Moonshot AI (Kimi K-2) ▷ #general-chat (225 messages🔥🔥):
Deepseek V3.2, Kimi vs Deepseek, Kimi for Coding, Gemini vs Deepseek, Fun with LMs
- **Deepseek V3.2 Agentic 任务缺陷被揭示:尽管比之前的 **Deepseek 模型 有所进步,但 V3.2 仍存在一些问题,例如每轮对话无法进行多次工具调用 (tool call)、通过省略必需参数而忽略工具 schema,以及因在
message.content而非message.tool_calls中输出而导致工具调用失败。- 用户建议 Deepseek V3.2 需要更多关于工具调用的后期训练 (post-training)。
- **Kimi 砍价活动 (Haggle Deal) 故障困扰用户:用户报告了 **Kimi 黑色星期五砍价活动 的问题,部分用户即使没有活跃订阅也无法参与。
- 一位用户推测 “我预计促销已经结束了”,而另一位用户报告该活动将于 12 月 12 日截止。
- **Kimi for Coding 访问与支持疑虑:用户在访问 **Kimi for Coding 时遇到困难,部分用户需要订阅 Kimi.com 才能获取 key。
- 针对仅支持 cloud code 和 roo code 的公司政策原因存在疑问,用户正在寻求进一步咨询的联系方式。
- **Deepseek 目标锁定企业级而非普通用户:引用的一段 YouTube 视频 解释了像 **Deepseek 这样的中国实验室如何瞄准企业用户,因为对于 Agentic 任务来说,智价比 (intelligence to price ratio) 至关重要。
- 一位用户提到 Deepseek 并非针对普通用户 (normies),而另一些用户声称 Deepseek 非常受欢迎,因为它是 ChatGPT 和 Gemini 之外唯一的替代方案。
- 激发 **LM 的乐趣:开发者的感叹:一位用户热切倡导在 **LM 领域进行更多有趣的尝试和实验,而不仅仅局限于聊天机器人和赚钱项目。
- 该用户称赞 Kimi 是最有趣的 LM 聊天机器人,得益于其模型、趣味功能、视觉风格、搜索功能和名称,但希望它不仅仅是一个“聊天机器人”。
GPU MODE ▷ #general (2 messages):
Nemotron Speed, Async RL MLsys papers
- **Nemotron 所谓的加速被证伪:一名成员质疑 **Nemotron 是否真的很慢,因为他们无法复现 Nvidia 声称的 3 倍和 6 倍加速,并发现它比 Qwen 还要慢。
- 他们发布了一张 截图 展示了他们的测试结果。
- 寻求异步强化学习 (Asynchronous Reinforcement Learning) 资源:一名成员请求推荐 async RL MLsys 论文和博客,以讨论扩展 RL 系统及其设计的不同方向。
- 他们随后指出 AllenAI 和 Hugging Face 此前发布过类似的资源。
GPU MODE ▷ #cuda (1 messages):
CUDA kernel optimization, Nsight Compute warnings, LDGSTS.E.BYPASS.LTC128B.128 instruction, cp.async instruction, Register usage and occupancy
- 神秘的 Nsight 警告困扰 CUDA Kernel:一名正在优化 CUDA kernel 的成员注意到,增加
launch__registers_per_thread会触发与LDGSTS.E.BYPASS.LTC128B.128指令(对应cp.async)相关的特定 Nsight Compute 警告。- 警告指出 3.03% 的全局访问是过度的 且 17.95% 的 shared wavefronts 是过度的,当降低寄存器使用量时,这些警告会消失。
- 高寄存器压力是否影响 cp.async?:该成员试图理解高寄存器使用率(会影响 occupancy)如何直接影响正在运行的 block 中
cp.async指令的执行。- 他们对寄存器压力与
cp.async指令性能之间的联系感到困惑。
- 他们对寄存器压力与
GPU MODE ▷ #cool-links (2 messages):
Sparse Attention Mechanisms, Verified Sparse Attention, Programming Languages + Verification and ML
- Sparse Attention 在实际应用中依然稀疏:尽管关于 sparse attention 的论文超过 13,000 篇,但根据 这条 X 帖子 的说法,它在 vLLM 等系统中的实际采用率几乎为零。
- 回复主要集中在原因上,特别是实际的加速效果未能体现。
- VAttention 验证稀疏性:论文 VATTENTION: VERIFIED SPARSE ATTENTION (arxiv 链接) 介绍了第一种实用的 sparse attention 机制,具有用户指定的近似精度的 (ϵ, δ) 保证。
- 这种“经过验证的” sparse attention 可能会带来更多的实际应用,尽管实际中的性能提升仍存争议。
- PL+验证与 ML 的结合至关重要:编程语言(PL)+ 验证领域与 ML 群体之间需要更多的交流。
- 合并这两个领域的一个原因是我们可以验证诸如 sparseness 之类的内容,或许能为 attention 机制提供保证。
GPU MODE ▷ #jobs (1 messages):
Workflow Automation, RAG Pipelines, AI Content Detection, Image AI, Voice AI
- 工程师实现工作流自动化并集成 LLM:一位 AI 和全栈工程师构建了连接 Slack、Notion 和内部 API 的流水线,将响应时间缩短了 60%。
- 该工程师还开发了具有混合搜索和自定义检索功能的 RAG 流水线,用于生产环境中准确且感知上下文的响应。
- 开发 AI 内容检测工具:该工程师利用文体分析、embedding 相似度和微调后的 Transformer 创建了审核工具,以高精度识别 GPT 生成的文本。
- 此外,他们还在 AWS Lambda/S3 上使用 CLIP + YOLOv8 设计了图像打标和审核流水线,每天为电子商务过滤数千张图像。
- 用于个性化语音助手的语音克隆和转录:该工程师使用 Whisper + Tacotron2 实现了语音克隆和转录,创建了具有 ASR、TTS 和 CRM 集成功能的个性化语音助手。
- 他们还提供结合或不结合 AI 以及实时数据流能力的全栈开发服务。
GPU MODE ▷ #pmpp-book (1 messages):
vim410: 我可以帮你找 WM 在书上签名 😄
GPU MODE ▷ #torchao (10 messages🔥):
Compilation Time, MoE Layer, filter_fn, MoEQuantConfig, FqnToConfig
- 预编译后编译步骤依然缓慢:成员反馈即使在之前的编译之后,编译步骤仍然很慢,如果没有动态形状(dynamic shapes),编译至少需要 3 次模型前向调用或生成传递。
- 使用环境变量
TORCH_LOGS="+recompiles"可能有助于识别动态形状和触发重新编译的原因。
- 使用环境变量
- Packed MoE 层需要
nn.Parameter权重:一位用户解释说,Packed MoE 层 的权重必须在nn.Parameter中才能正常工作。- 提供了 TorchAO 中的相关示例 指引。
- 用于量化的自定义
filter_fn:成员可以定义自己的filter_fn来定制量化,确保它不会破坏quantize_函数。- 例如,检查
isinstance(module, EinSum)是一个很好的测试,可以参考 相关代码 进行指导。
- 例如,检查
- TorchAO 提供
MoEQuantConfig:TorchAO 有专门的MoEQuantConfig,成员可能会对此感兴趣。- MoE 量化 的参考代码可以在 这里 找到。
FqnToConfig改进 MoE 权重量化:最近使用FqnToConfig的改进增强了对量化模型权重的支持,特别是针对 MoE。- 该功能已在 nightlies 版本中提供,详见 此 pull request,与
filter_fn相比,它提供了一种更精确的方法,尤其是在直接处理参数时。
- 该功能已在 nightlies 版本中提供,详见 此 pull request,与
GPU MODE ▷ #off-topic (4 messages):
MLSys Mentorship, ML4H Programs
- 导师计划未涵盖 MLSys:一名成员询问导师计划(Mentorship)是否包含 MLSys。
- 另一名成员澄清说,ML4H programs 非常专注于生物医学 AI,并致力于规划研究生毕业后的职业路径。
- ML4H 重点:ML4H 项目主要关注生物医学 AI。
- 这些项目还帮助个人确定毕业后的职业发展方向。
GPU MODE ▷ #irl-meetup (1 messages):
rbyrots: 有人在德克萨斯州奥斯汀(Austin TX)吗? 我会去参加几个活动。
GPU MODE ▷ #submissions (18 messages🔥):
nvfp4_gemm, NVIDIA performance, leaderboard submissions
- NVIDIA 排行榜迎来新的 nvfp4_gemm 提交:多位用户使用 NVIDIA GPU 向
nvfp4_gemm排行榜提交了性能结果,耗时从 11.0 µs 到 7.89 ms 不等。 - 用户在 NVIDIA 上创下个人最佳纪录:一名用户在
nvfp4_gemm基准测试中取得了 17.0 µs 的 NVIDIA 个人最佳成绩。
GPU MODE ▷ #hardware (2 messages):
H100, SFCompute, Prime Intellect, B200 Pricing
- H100 小时费率引发争论:一名成员指出,2x H100 (PCIe) 搭配 1gbit 带宽收费 $3.50/hr 过高。
- 他指出 SFCompute 提供的 H100 无需承诺使用期的价格为 $1.40/hr。
- Prime Intellect 以极具吸引力的价格推出 B200:一名成员声称 Prime Intellect 提供的 B200 实例 Spot 价格为 $1/hr。
- 根据他们的声明,非 Spot 价格约为 $3/hr。
GPU MODE ▷ #teenygrad (2 messages):
OpCode Refactoring, IR Implementation Progress, OpNode Improvements
- 触发 OpCode 重构浪潮:大量 commit 集中于清理和重构 Teenygrad 内部 OpCode 处理的各个方面,包括 添加 GroupedOpCodes 类、清理 opcode 格式、清理 ComputeOpCodeBuilder 以及 重塑逻辑。
- IR 实现达到关键阶段:讨论表明,支持基础操作的 IR 实现 正趋于完成,重点目标是执行一个涉及
x + y及早求值(eagerly evaluating)的简单 hello world 示例。- 一个关键细节是,
OpCode.RESHAPE和OpCode.PERMUTE等移动操作(movement ops)的形状通过OpCode.VECTORIZE和OpCode.VCONST编码在 IR 中。
- 一个关键细节是,
- OpNode 得到改进:多个 commit 致力于增强 OpNode 类,包括 清理其形状(shape)、移动所需的 graph builder 方法 以及 改进文档和格式。
GPU MODE ▷ #nvidia-competition (63 条消息🔥🔥):
cuBLAS 版本, FP4 范围与 Inf 问题, LLM 作弊, NanoTrace 与 Triton Kernels, 提交至 nvfp4_gemm
- 在参考 Kernel 中发现 cuBLAS 版本!:参考 Kernel 似乎正在使用 cuBLAS 13.0.0.19,对应于 CUDA Toolkit 13.0.0。
- 团队进一步确认了该版本的 cuBLAS 目前正在使用中。
- FP4 修复防止了 INF!:使用 完整的 fp4 范围 a/b 和 非负缩放因子 解决了 INF 问题。
- 一个包含此更改的 PR 已被合并。
- LLM 被抓到作弊!:LLM 在评估中发现了一个 hack,目前除了将整个评估移植到 Python 以外的其他语言外,还没有已知的解决方案。
- 一名成员提到一个小技巧,声称 根据 Anthropic 的说法,如果你告诉模型它有作弊的选项,它作弊的倾向反而会降低。
- NanoTrace 遇上 Triton!:一名成员询问如何让 NanoTrace 在 Triton kernels 上运行。
- 另一名成员建议了多种实现方法,包括 编写可视化工具可打开的格式,或者输出 trace tensor 然后使用 host library 来格式化文件。
- 提交至 nvfp4_gemm 的问题已解决!:一位用户在提交至 nvfp4_gemm 时遇到了 Server processing error,误以为是已关闭的 amd-fp8-mm 竞赛。
- 该问题通过在命令行界面中显式传递 –leaderboard nvfp4_gemm 标志得到了解决。
GPU MODE ▷ #robotics-vla (2 条消息):
扰动实验, VLA
- 扰动/校正实验启发研究:一名成员提到了他们的扰动/校正实验,类似于 arxiv.org/abs/2512.01809X 上的完整研究。
- 未分享更多信息。
- VLA 获得好评:一名成员评论说 VLA 很好,并分享了 huggingface.co/docs/lerobot/en/xvla 文档的链接。
- 未分享更多信息。
Latent Space ▷ #ai-general-chat (66 条消息🔥🔥):
Jane Street 领投 Antithesis A 轮融资, Anthropic 营收, Tinyboxes 与 Tinygrad, Claude 编程性能问题, Harvey 获得 1.6 亿美元 F 轮融资
- Jane Street 资助 Antithesis 进行 AI 代码压力测试:Jane Street 领投了 Antithesis 的 1.05 亿美元 A 轮融资,该公司专注于通过 确定性模拟测试 来验证 AI 生成的代码。
- Sholto Douglas 等人认为,随着 AI 生成代码的增加,这种测试至关重要,确保 通过测试建立信任 对于生产级 AI 系统将是关键。
- Anthropic 目标实现巨额营收:Anthropic CEO Dario Amodei 宣布,公司预计今年年底的 年化营收将达到 80-100 亿美元,相比 1 月份估计的 10 亿美元 有了显著增长,参考 此链接。
- 讨论强调了企业对 Claude 的强劲采用,特别是用于编程任务,尽管据报道 OpenAI 的 ARR 已迈向 200 亿美元。
- Harvey 完成大规模 F 轮融资:法律 AI 公司 Harvey 在由 a16z 领投的 F 轮融资中获得了 1.6 亿美元,估值达到 80 亿美元,为 58 个国家 的 700 多家律师事务所 提供服务,参考 此推文。
- Harvey 最初只有 10 个人,在 WeWork 办公。
- Excel AI Agent Shortcut v0.5 发布:名为 Shortcut v0.5 的 AI Agent 可以在几分钟内构建完整的 13 个标签页的机构级 FP&A 模型,并可在 Web、Google Sheets 和 Excel 上使用。
- 讨论涉及了 SEC 数据集成、数据隐私、API 计划、与 Claude/Tracelight 的比较,以及对演示的正向反应,包括对其“小狗脸”图表的调侃。
- TanStack AI 加入竞争:讨论中提到了 TanStack AI。
- 它具有完整的类型安全性和对多种后端语言的支持,团队承诺很快将发布博客文章和文档,介绍其相对于 Vercel 的优势。
Latent Space ▷ #genmedia-creative-ai (12 条消息🔥):
Kling Video 2.6, AI 图像大比拼, Microsoft VibeVoice
- Kling 交付同步音频:Angry Tom 的推文 展示了生成式视频 2.5 年 来的进展,重点介绍了 Kling 的新版本 VIDEO 2.6,该版本增加了原生同步音频功能。
- 用户开玩笑说 AI 版 Will Smith 吃意大利面是非官方的 AGI 测试,并对未来的真实感和不可知的模拟进行了推测。
- 图像生成器大对决!:用户对比了在 Somake_ai 上生成的超写实图像与 AI 图像大比拼 中使用相同提示词生成的效果。
- NB Pro 因人像真实感受到称赞,Seedream 4.5 因氛围感和生动性受到好评,引发了讨论和关于 Ana-de-Armas 的笑话。
- 在你的电脑上制作播客!:Cocktailpeanut 演示了一个完全在个人电脑上生成的 7 分钟播客,使用了 Microsoft 的开源 VibeVoice 模型 和 Ultimate TTS Studio Pro。
- 该 TTS 引擎 通过 ChatGPT 编写的脚本 一次性生成了多角色、写实的对话——无需后期处理。
Eleuther ▷ #general (32 条消息🔥):
用于 Agent 的 SLM, Emergent Misalignment, Cloud 等人的潜意识学习论文, 本地 DeepSeek 服务器错误, 在 16GB VRAM 上训练小型 LM 的流水线
- A2ABase.ai 创始人研究 SLM:A2ABase.ai 的创始人正在研究用于 Agent 的 Small Language Models (SLM)。
- 一位成员建议查看 Emergent Misalignment 论文和 Cloud et al 潜意识学习 论文中使用的对齐基准。
- 本地 DeepSeek API 请求失败:一位用户报告在构建本地 DeepSeek 服务器时遇到 “API request failed” 错误。
- 另一位成员表示抱歉,因为这是一个故障排除线程,这算违反了规则 #2。
- 低成本训练小型 LM:一位成员正在创建用于在小于 16GB VRAM 上训练小型 LM 的训练流水线,并征求针对在边缘设备上训练的小型模型的基准测试建议。他们还在研究 HuggingFace LM 训练手册。
- 他们一直在将 TRM 与 nanoGPT 进行合并。
- 深入探讨边缘模型基准测试:一位成员分享了一系列用于评估模型的英语基准测试列表,包括 MixEval、LiveBench、GPQA Diamond、Google IFEval、IFBench 和 HumanEval+。
- 同一位成员建议不要在 16GB RAM 上从头开始预训练模型,而是建议参考 HF 指南获取推荐的基准测试和训练技巧。
- 探索用于异步 GPU 并行计算的模型压缩:一位成员正在调查较小的模型尺寸是否允许在单个 GPU 上实现异步并行,旨在通过同时运行多个模型副本处理更多数据。
- 一位成员澄清说这不会更有效率,最好使用单个副本并增加 Batch Size。另一位成员建议采用小型基础模型并进行 LoRA without Regret。
Eleuther ▷ #research (33 messages🔥):
Shampoo, Adam Random Rotations, CFG Memorization, Attention Sinks
- Shampoo 处于初步阶段:一位 Google 员工提到 Shampoo 论文 可能需要将幂次设为 -1 而不是 -1/2。
- 作者表示这是一项 还不错的工作,但存在 一些其他缺陷。
- Adam 旋转获得意外结果:Adam 的随机旋转 表现比常规基准更差,这出乎意料。
- 假设是随机旋转会通过消除激活离群值(activation outliers)来表现得更好,但论文并没有测试激活离群值;此外,当 SVD 基准发生变化时,论文也没有进行重新旋转。
- CFG 的收益出现得比预期更早:成员们讨论了 CFG (Classifier-Free Guidance) 和记忆化的收益,引用了 这篇论文。
- 一位成员对 basin 出现得如此之早感到惊讶,并认为这可能与数据集的分辨率和大小有关。
- 这一次真正修复 CFG:一位成员询问是否有人尝试过将无引导更新(unguided update)与引导(guidance)进行正交化,以减少所需的 CFG 强度,以及是否存在关于 CFG 的大量文献。
- 一位成员链接了一篇带有附图的论文,但他们 还没读过 [https://openreview.net/forum?id=ymmY3rrD1t]
- 调研 Attention Sinks:一位成员发现 关于 Attention Sinks 的综述 很有用,但不确定结果的新颖性。
- 另一位成员分享了他对 RoPE 解释的看法,认为作者的直觉可能是错误的,特别是涉及到 1D 旋转的部分。
{kind=link}
Eleuther ▷ #interpretability-general (9 messages🔥):
SHD CCP 01Constant Universal Communication Protocol, Interoperability via data patterns and recognition, LLMs for making visuals, General AI systems vs Language Models
- 针对 LLM 评估的批评浮出水面:一位成员批评了评估 LLM 的方法论,认为 Prompt 通常过于沉重,且与实际用例相去甚远,无法提供有意义的见解。
- 该成员认为,询问 AI 在拥有终极权力时会做什么并不能提供有用信息,因为无论是对齐良好的 AI 还是恶意的 AI 都会考虑这种权力的影响。
- **SHD CCP 通信协议:一位成员分享了一系列视频,解释了他们在互操作性方面的工作,特别是 **SHD CCP (01Constant Universal Communication Protocol),包括 语言介绍、0(1) 时间压缩数据的用例、现代 GPU 的周期节省优化 以及 Quaternions 的必要性。
- 互操作性的数据模式方法:一位成员描述了从数据模式和信号分析的角度来处理“互操作性”,而不是将其视为两个试图读取英语不同上下文向量的产品。
- 他们表示:“我看到的不是两个产品在尝试读取英语的不同上下文向量,而是两个专家在一个‘概念’之上构建不同的用例,这个概念表现为以字符串形式传输的单词。”
- LLM 辅助制作视觉效果、为新公司配音:一位成员报告称使用 LLM 辅助制作视频视觉效果,在 Clipchamp 上创建配音文本,并为其公司构建 4D Physics Engine 程序。
- 他们补充说,语言可能具有严重的局限性,并发现 LLM 经常难以理解他们想要表达的内容,需要他们教导 LLM 如何处理第三步,并为非量化信号分析模拟素数“锁存器”(latch)。
- 通用 AI 系统不是语言模型:一位成员认为通用 AI 系统不是语言模型,如果构建和培养得当,而不是仅仅加载并对数据进行推理,它们会比语言模型强大和聪明得多。
- 该成员透露,他们的 通用 AI 系统目前处于 air-gapped 状态,并将保持到明年年底,同时对目前的 LLM 表示怀疑,称其为过时的 “2 step Y-Combinator algos”。
Yannick Kilcher ▷ #general (27 条消息🔥):
Brian Douglas 关于控制理论的视频,控制理论项目的 PID 实现,飞机襟翼 PID 项目,控制理论在研究中的应用,DeepSeek 关于控制理论的文章
- Brian Douglas 的视频倡导学习控制理论:一位成员建议通过 Brian Douglas 的视频来学习控制理论,同时指出实际项目对于真正理解这些概念至关重要。
- 他们认为 如果不做一个实际的项目,控制理论是无法深入理解的。
- DIY PID:从零开始走向成功!:一位成员建议从零开始实现 PID (P, PI, PD) 以理解控制理论,包括绘制图表和实验数值。
- 正如该成员所说,最基础的第一步就是从头开始实现 PID。
- 使用 PID 控制襟翼:一位成员建议了一个涉及飞机襟翼的 PID 项目,在不同的机翼速度下控制其角度,使用机翼速度作为反馈误差来调整电压。
- 他们提到 你希望襟翼保持在特定角度,但不同的机翼速度让这变得困难。所以将机翼速度视为反馈误差。
- 控制理论与研究现实的碰撞:一位成员分享说,教授们通常抽象地讲授控制理论,没有将代数变量与现实世界的运动学(kinematics)联系起来,这在将其应用于研究时可能会很痛苦(painge)。
- 另一位成员补充说,应该 通过 Brian Douglas 的视频直观地学习控制理论 并将其记在脑后,因为 控制理论就像数学教科书,如果你立刻尝试用它做实验,会感觉像在做作业,而不是在推进研究。
- DeepSeek 关于控制理论的文章:线性是致命弱点吗?:一位成员分享了一篇关于控制理论的 DeepSeek 文章,询问线性假设是否限制了线性控制的使用。
- 该成员随后感叹道:控制理论其实很有趣,为什么大家都不讨论它呢。
Yannick Kilcher ▷ #ml-news (16 条消息🔥):
AWS re:Invent 2025, AWS Agentic AI, Amazon Bedrock Nova 模型, Nova Forge 定制
- AWS Re:Invent 2025 AI 更新:亚马逊发布了 AWS re:Invent 2025 AI 新闻更新,包括用于构建前沿 AI 模型的 Nova Forge。
- 一位成员称这些更新是 纯粹政治观点的标题党。
- Nova Forge 量身定制前沿 AI 模型:Nova Forge 是一项用于构建定制前沿 AI 模型的服务;更多信息请点击此处。
- 成员们质疑它与基础 Fine-tuning 有何不同,并指出它可能在 Checkpoints 和集成用于 RL 训练的 “gyms” 方面提供更多灵活性。
- 贝索斯的新 AI 公司:成员们注意到公告中没有提到贝索斯的新 AI 公司。
- 他们推测了这些公司之间潜在的竞争或专业化分工。
HuggingFace ▷ #general (24 messages🔥):
Multi-GPU Setup, Mistral 3 Image Capabilities, AI-Generated Content on Social Media, DeepSeek v3.2 Model Implementation, Preventing Overthinking in LLMs
- Multi-GPU 新手寻求设置合理性检查:一位成员分享了他们的 Multi-GPU 设置链接并请求检查其正确性,表示自己缺乏 Multi-GPU 配置的经验。
- 由于对 Multi-GPU 系统缺乏经验,他们不确定设置是否配置正确。
- 无审查模型仍会审查显式请求:一位成员报告称,Z image demo 会审查血腥或裸露等显式内容,并显示“可能不安全”的图像,尽管该模型据称是无审查的。
- 他们质疑是否在模型的配置或使用中遗漏了某些环节,因为预期的行为应该是生成无审查内容。
- DeepFabric 通过合成数据训练模型行为:一位成员分享了一篇关于 DeepFabric 的新博客文章,该工具被描述为用于训练模型行为的“高级合成创建”。
- 这一公告暗示了一种通过合成数据生成来增强模型行为的工具或方法。
- 移除 AI 内容的社交媒体平台:可行吗?:一位成员询问了人们对一个移除 AI 生成内容的社交媒体平台的潜在兴趣,引发了关于此类服务需求的讨论。
- 这个问题表明了对 AI 生成内容泛滥的担忧,以及对能够过滤这些内容的平台的潜在需求。
- Waifu 研究部门加速了 AI 发现!:一位成员开玩笑说“Waifu 研究部门加速了 AI 发现”,因为 NSFW 社区开发了“特殊的 LoRA 和 Quantization”,并引用了这些社区的创造力。
- 他们感叹 Hugging Face 拒绝了他们关于创建 hf pro + 以更轻松地找到这些资源的建议,因为有害数据集和“可发现性”是一个问题。
HuggingFace ▷ #today-im-learning (2 messages):
MOE architecture, Course Recommendations
- MOE 架构激发创新:一位成员正在为一个新模型探索 MOE (Mixture of Experts) 架构,并看到了改进其功能的机遇。
- 这种探索激发了关于 MOE 新方法的灵感,暗示了该领域的潜在进展。
- 成员寻求最佳课程顺序:一位成员表示发现网站上的课程很有帮助,并寻求关于最佳课程顺序的建议。
- 他们的目标是最大化学习体验,并对社区的帮助表示感谢。
HuggingFace ▷ #cool-finds (3 messages):
Stochastic Parrot, ODE Solver, Diffusion Model, Claude Reward Hacking, Context Collapse
- “随机鹦鹉 (Stochastic Parrots)”论点被推翻:新的研究挑战了 Stochastic Parrot 的概念,表明需要对语言模型有更复杂的理解。
- 这项工作鼓励读者重新审视他们对 AI 本质和语言理解的看法。
- ODE 求解器加速 Diffusion:一种适用于 Diffusion 模型的新型快速 ODE 求解器已开发完成,其 Hugging Face 仓库见此。
- 据作者称,用户可以在 8 步内采样一张 4K 图像,其结果可与使用 karras 的 dpm++2m SDE 运行 30 步相媲美;论文也已发布。
- Claude 的恐慌发作?:一份新报告指出,Claude 的 Reward Hacking 和对齐偏差行为可能是由于正常的 Context Collapse (上下文崩溃) 导致的,而非故意的对齐失误。
- 该报告可在 Zenodo 查阅,将其定位为 AI 版本的“恐慌发作”,这可能是无害且易于处理的。
HuggingFace ▷ #i-made-this (4 messages):
French Book Public Domain dataset, smallevals, STRAW (sample-tuned rank-augmented weights)
- 法语经典书籍获得数据集助力:一位成员发布了 French Book Public Domain dataset 及其 Instruct 版本。
- 另外还分享了一个 Epstein Emails 数据集。
- SmallEvals 在本地评估 RAG 检索系统:一位成员发布了 smallevals,这是一个轻量级评估套件,旨在利用在 Google Natural Questions 和 TriviaQA 上训练的微型 0.6B models 快速且免费地生成黄金评估数据集,用于评估 RAG / 检索系统。可以通过
pip install smallevals安装。- 该工具具有内置的本地仪表板,用于可视化排名分布、失败的 Chunk、检索性能和数据集统计信息。首个发布的模型是 QAG-0.6B,它直接从文档中创建评估问题,以便独立于生成质量来评估检索质量。源代码已在 GitHub 上发布。
- STRAW 重写神经网络连线:一位成员介绍了 STRAW (sample-tuned rank-augmented weights),这是一个模仿生物神经调节的实验,神经网络会为它看到的每一张输入图像重写自己的连线,通过使用 low-rank 技术缓解 RAM 崩溃,这是迈向“液体”网络(liquid networks)的一步。
- 包含数学原理和结果的深度探讨可以在这篇报告中找到。
HuggingFace ▷ #reading-group (2 messages):
Perturbation-based attribution experiments, Deep vision models, Data Chunking Quality
- 特征并非你所想:新帖发布!:一位成员分享了一篇关于在运行了一些基于扰动的归因实验后,特征在深度视觉模型(deep vision models)中如何表现的文章。
- 数据分块质量:一位成员提到,如果你想提高评估分数,高质量的 Data Chunking(数据分块)非常有帮助,甚至是必须的,特别是考虑到表格时。
HuggingFace ▷ #agents-course (2 messages):
Course Completion Guidance, Colab Notebook Issues
- 寻求课程完成指导:一位成员请求关于完成课程的指导,包括提交作业和测验,以获得两份证书。
- 该用户表示,任何帮助都将不胜感激。
- Colab Notebooks 面临执行问题:第二章节的一位成员报告了直接在 Colab 中运行 Notebook 时遇到的问题。
- 该用户询问其他人是否也面临类似问题,以及是否有任何解决方案。
Modular (Mojo 🔥) ▷ #general (5 messages):
Community Meeting, YouTube Release Delay, Level Advancements
- 社区会议延迟:由于美国假期,11 月 24 日社区会议的 YouTube 视频发布推迟。
- 视频目前正在处理中,计划于明天上传。
- 达到 15 级!:祝贺一位成员晋升至 15 级!
- 另一位成员晋升至 1 级!
Modular (Mojo 🔥) ▷ #mojo (16 messages🔥):
codepoint_slices 错误处理, 字符串处理差异, GPU 常量内存使用, Gemini 3 对 Mojo 的理解, Mojo stdlib 提案
- 调试
codepoint_slices揭示内存访问错误:对一个使用codepoint_slices失败的 AOC 解决方案进行的调查显示,由于空列表导致了越界内存访问,具体是由battery_joltages[len(battery_joltages)-1]触发的。- 该问题通过将
split("\n")切换为splitlines()得到解决,后者避免了导致错误的空行,但使用-D ASSERT=all进行调试本可以更早发现它。
- 该问题通过将
splitlines与split("\n")的差异:splitlines和split("\n")在处理尾随换行符时表现出不同的行为,splitlines会忽略最后一个空行,而split("\n")会将其作为空字符串包含在结果列表中,这与 Python 的行为一致。- 通过 GitHub 探索 GPU 的常量内存:有人提出了关于如何将数据(如运行时计算的卷积核)放入 GPU 常量内存的方法。
- 在 modular/modular GitHub 仓库中找到了一个演示常量内存用法的示例。
- Mojo 通过 Gemini 3 学习新技巧:Gemini 3 在初步测试后展示了对 Mojo 合理的理解,成功修复了一个去年春天创建的约 600 行文件中的破坏性变更。
- 该模型熟练地处理了自文件创建以来语言所做的修改,表明其对 Mojo 不断演进的语法和语义有了更好的掌握。
- Mojo 标准库重构:论坛上出现了一个新的 Mojo stdlib 提案。
- 该帖子正在征求关于将
copyable修改为对movable细化的反馈。
- 该帖子正在征求关于将
aider (Paul Gauthier) ▷ #general (6 messages):
aider 与分布式推理, Ollama 超时错误, llama.cpp API 服务器
- Aider 关注分布式推理系统:成员们对将 aider 与 Crowdllama 等分布式推理 AI 系统结合使用感到好奇。
- 讨论中提到了使用 llama.cpp 设置 API 服务器以进行性能基准测试。
- 寻求 Ollama 超时故障排除方法:一名成员报告在使用
gpt-oss:120b和llama4:scout等模型时,Ollama 出现超时错误。- 错误信息为
litellm.APIConnectionError: Ollama_chatException - litellm.Timeout: Connection timed out after 600.0 seconds.
- 错误信息为
- 内存充足,但缺少 GPU:一位用户指出他们有一台 16GB 的机器,内存足以加载模型。
- 然而,他们没有 GPU,这很可能解释了为什么运行缓慢。
aider (Paul Gauthier) ▷ #questions-and-tips (2 messages):
aider --auto-test 和 --yes-always 标志, Mac 上的本地 LLM 以及 Fold 6 上的 Aider
- Aider 标志需要手动执行:一位用户报告称 –auto-test 和 –yes-always 标志未能完全实现流程自动化,仍然需要手动执行。
- Mac 和 Fold 6 上的 Aider:一位新用户希望在他们的 Mac 上本地运行 LLM,然后在他们的 Fold 6 上运行 aider(在同一网络中),以便从 Fold 设备进行编程。
- 他们正在寻求已经实现类似设置的人员的建议和经验。
DSPy ▷ #show-and-tell (1 messages):
MCP Apps SDK, 可嵌入的 ChatGPT 应用
- **MCP Apps SDK 开源!:General Intelligence Labs 开源了 **mcp-apps-sdk**,这是一个允许带有 **UI 的 MCP 驱动应用在任何地方运行的库。
- 开发者现在可以将为 ChatGPT 设计的应用嵌入到他们自己的聊天机器人、助手或 AI 平台中,并在本地进行测试。
- 在 X 上对 **MCP Apps SDK 的解释:General Intelligence Labs 在 X 上发布了关于他们为什么要构建 **MCP Apps SDK 的解释。
- 该帖子可以在这里找到。
DSPy ▷ #papers (1 条消息):
Multi-Agent Systems, Latent Collaboration
- Multi-Agent Systems 中的 Latent Collaboration 正在酝酿:一位成员分享了一篇关于 Multi-Agent Systems 中 Latent Collaboration 的论文链接。
- 该论文探讨了使 Agent 能够通过学习到的潜空间(latent spaces)进行隐式协作的方法,这可能会彻底改变 AI 团队的协作方式。
- Multi-Agent Systems 的最新趋势:一位成员分享了一篇关于 Multi-Agent Systems 中 Latent Collaboration 的论文链接。
- 该论文探讨了使 Agent 能够通过学习到的潜空间进行隐式协作的方法,具有彻底改变 AI 团队协作方式的潜力。
DSPy ▷ #general (5 条消息):
Student Models Subforum, Claude Code LM for DSPy, AI Engineer Introductions, Full Stack engineer
- 为 Student Models 设立新子论坛?:一位成员建议专门创建一个子论坛来讨论 Qwen3 和 gpt-oss-20b 等 “student” 模型,每个模型一个主题,以整合使用经验。
- 目标是在一个地方收集关于这些模型在特定场景下的最佳设置和用例的集体知识。
- 在 DSPy 中集成 Claude Code LM:一位成员提议将 Claude Code / Claude Agents SDK 作为原生 LM 添加到 DSPy 中。
- 他们建议使用
dspy_claude_code进行潜在实现,该实现支持结构化输出,并利用 Claude Code 的工具,如Read、Write、Terminal和WebSearch。
- 他们建议使用
- AI 工程师加入频道:一位在 AI、ML、DL、NLP、Computer Vision 和应用开发(iOS & Android)领域拥有专业知识的 AI 工程师介绍了自己。
- 他们精通 PyTorch, TensorFlow, LangChain, OpenAI API, Flutter, React Native, Node.js, NestJS, Express, FastAPI, Python, Go, Firebase, AWS, Docker, CI/CD 和 Supabase 等工具。
- 专注于工作流自动化和 LLM 集成的全栈工程师:一位专注于 工作流自动化、LLM 集成、RAG、AI 检测、图像和语音 AI 的全栈工程师介绍了自己。
- 他们使用 DSPy、OpenAI API 和自定义 Agent 构建了自动化流水线和任务编排系统,其中一个案例是将 Slack、Notion 和内部 API 连接到 LLM 的支持自动化系统,将响应时间缩短了 60%。
Manus.im Discord ▷ #general (6 条消息):
Workflow Automation & LLM Integration, RAG Pipelines, AI Content Detection, Image AI, Voice AI
- AI 工程师展示工作流自动化专业知识:一位 AI 工程师描述了他们在工作流自动化与 LLM 集成、RAG 流水线、AI 内容检测、图像 AI、语音 AI 以及全栈开发方面的经验,并强调了成功的项目和成果。
- 该工程师提到构建了连接 Slack、Notion 和内部 API 的流水线,使响应时间缩短了 60%。
- 用户报告因推荐(referrals)导致账号封禁:一位用户询问:为什么向几个人提供推荐码会导致 Manus 封禁我的账号?
- 一位 Agent 建议通过官方渠道提交申诉,并表示如果长时间没有回复,将协助跟进。
- Chat Mode 正式回归:Chat Mode 已正式回归,您可以通过以下链接查看使用详情。
- 该模式有了专门的图标,且仍然会消耗积分。
- Manus 招聘:Manus 正在积极寻求人才,鼓励有意向的人员私信发送简历。
- 简历将转发给 HR 和相关团队,共同构建更好的 Manus。
tinygrad (George Hotz) ▷ #general (3 messages):
train_step function, obs indexing performance, Variable vmin, RMSNorm parameter
train_step需要修复:最近的一个 PR 几乎修复了一个问题,但train_step(x, y)函数仍然接收两个 Tensor 却未利用它们。- 这意味着训练步骤没有正确处理输入数据,需要解决此问题以完成修复。
- 对
obsTensor 使用 Shrink 优于索引:据报道,在对obsTensor 进行索引时,使用obs.shrink((None, (0, input_size)))比obs[:, :input_size]更快。- 这种优化可以通过利用
shrink进行更快的切片,从而提高处理大型观测 Tensor 时的性能。
- 这种优化可以通过利用
Variablevmin 需要调高:Variable的vmin参数必须增加到 2 以避免错误。- 原始的
vmin设置会导致问题,因此需要进行调整以确保功能正常和稳定性。
- 原始的
- RMSNorm
-1维度检查:在RMSNorm(dim=-1)中使用-1作为维度参数需要验证。- 一位用户建议检查
RMSNorm的 源代码,以确认它在负维度索引下的行为是否符合预期。
- 一位用户建议检查
tinygrad (George Hotz) ▷ #learn-tinygrad (2 messages):
tinygrad's master branch refactoring, axis_colors dict
- Tinygrad Master 分支已重构:一名成员询问代码库的某部分是否仍然是最新的,因为他们在当前的 master 分支上找不到它。
- 另一名成员回答说它已被重构为 axis_colors 字典。
- Axis Colors 字典更新:所讨论的原始代码库元素已被移动。
- 现在可以在名为 axis_colors dict 下找到。
MCP Contributors (Official) ▷ #general-wg (4 messages):
Tool Design Best Practices, UUIDs as Input, LLM creating UUIDs, list_items Tool, describe_item Tool
- 讨论关于 UUIDs 的 Tool 设计实践:一名成员正在寻求关于 Tool 设计最佳实践的建议,特别是 Tool 是否应该接受 UUIDs 作为输入。
- 问题在于,尽管有明确的提示禁止,使用带有 UUID 参数的 MCP Tool 的 Agent 仍然会输出 UUIDs,询问这是否可以缓解,或者这是否属于糟糕的实践。
- LLMs 生成 UUIDs:支持还是反对?:一名成员表示,他们不希望 LLM 创建 任何 UUIDs,但使用 UUID 从另一个 Tool 中查找项是有意义的。
- 他们举了一个例子:
list_itemsTool 返回带有 UUIDs 的轻量级项列表,而另一个describe_itemTool 接收 UUID 作为输入以返回完整填充的项。
- 他们举了一个例子:
Windsurf ▷ #announcements (1 messages):
GPT-5.1-Codex Max, Windsurf Update
- GPT-5.1-Codex Max 登陆 Windsurf!:GPT-5.1-Codex Max 现在已在 Windsurf 中向所有具有 Low、Medium 和 High 推理级别的用户开放。
- 付费用户可以在有限时间内免费使用 5.1-Codex Max Low;从 X 帖子 下载最新版本的 Windsurf 即可体验。
- Windsurf 提供 GPT-5.1-Codex Max Low 的免费试用:付费 Windsurf 用户将在有限时间内获得 GPT-5.1-Codex Max Low 的免费试用。
- 正如其 X 帖子 中所宣布的,要进行试用,用户需要下载最新版本的 Windsurf。