AI News
GPT-5.2 (即时/思考/专业版):GDPVal 评分为 74%,成本是 GPT 5.1 的 1.4 倍,发布于 OpenAI 成立 10 周年之际。
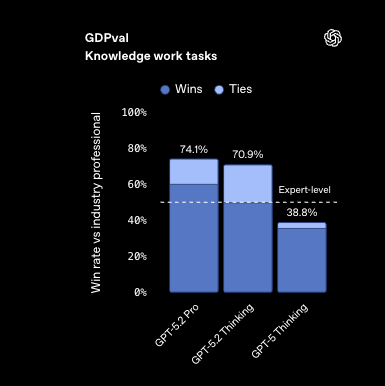
OpenAI 庆祝其成立 10 周年,并推出了 GPT-5.2。该版本带来了显著的全方位改进,其中包括罕见的 40% 价格上涨。GPT-5.2 在科学推理、知识工作和经济价值任务方面表现出强劲的性能提升,在 GDPval 任务上达到了超过 70.9% 的人类专家对等水平,并在 ARC-AGI-1 上达到了 90.5%,且效率大幅提升。
尽管在编程基准测试和视觉能力方面表现参差不齐,但 GPT-5.2 凭借扩展的上下文和分层推理控制,被公认为是一次重大的更新,并受到了广泛好评。定价设定为每百万输入 token 1.75 美元,每百万输出 token 14 美元,并提供 90% 的缓存折扣。该更新已在 ChatGPT 和 API 中上线,标志着 OpenAI 大语言模型(LLM)发展的一个重要里程碑。
OpenAI 就够了。
2025年12月10日至12月11日的 AI 新闻。我们为您检查了 12 个 Reddit 子版块、544 个 Twitter 账号和 24 个 Discord 服务器(205 个频道,8080 条消息)。预计节省阅读时间(以 200wpm 计算):592 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的氛围感呈现所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
今天是 OpenAI 成立 10 周年,该公司通过发布广受好评的 GPT 5.2 更新来庆祝(博客、文档、系统卡 (system card))。尽管伴随着极罕见的 40% 价格上涨,但它带来了全面的、有时甚至是巨大的提升:

我们之前曾称赞过 GDPVal,而它在具有经济价值的任务上跃升至 74.1%:“GPT-5.2 Thinking 在 GDPval 任务中产出结果的速度是专家级专业人士的 11 倍以上,成本不到其 1%,这表明在人工监督下,GPT-5.2 可以协助专业工作。”
的新 xhigh 参数在 SWE-Bench Pro 上表现不佳(与其博客中报告的 SWE-Bench Verified 相比),而现在的 5.2 Thinking xhigh 再次表现出色。

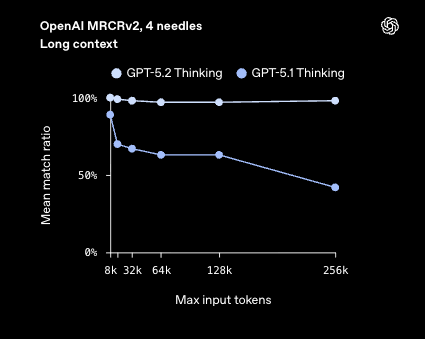
长上下文(Long Context)利用是另一个亮点,许多人注意到了 MRCR 的改进:
并非一切都完美——它仍然会数错 strawberry 中 R 的数量,虽然它能制作精美的电子表格,但其中的数字无法通过简单的合理性检查 (sanity check),甚至连备受推崇的视觉提升也被承认并不完美,且被 Gemini 3 超越。
总的来说,这可能是今年最后一次重大的美国 LLM 更新,反响依然非常不错。
AI Twitter 摘要
OpenAI 发布 GPT-5.2:能力、评估、定价与集成
-
GPT-5.2 系列 (Instant / Thinking / Pro):OpenAI 发布了 GPT-5.2,更新了知识截止日期至 2025 年 8 月 31 日,扩展了上下文,并提供了分级的“推理力度 (reasoning effort)”控制。在困难推理方面,GPT-5.2 Pro (X-High) 在 ARC-AGI-1 上达到 90.5%(成本 $11.64/任务),在 ARC-AGI-2 上达到 54.2%(成本 $15.72/任务),与去年的 o3 preview 相比,效率提升了约 390 倍。5.2 在科学/知识评分上也表现强劲(例如,社区报告 GPQA-Diamond 达到 92%+)。OpenAI 强调“具有经济价值的工作”:在 GDPval 上,5.2 Thinking 在涵盖 44 个职业的 70.9% 任务中“击败或持平”人类专家 (OpenAI, @yanndubs)。API 定价为 每百万输入 token 1.75 美元,每百万输出 token 14 美元,并提供 90% 的缓存折扣。
注意事项:编程/智能体 (agentic) 表现参差不齐——在 SWE-bench Verified 上,5.2 在某些测试框架中落后于 Opus 4.5 (@scaling01;另见 WebDev Code Arena:5.2-high 排名第 2)。工具调用 (Tool-calling) 和安全评估(如 CVE-Bench)显示出相对于 5.1 Codex Max 的提升有限 (@scaling01)。正如 @polynoamial 所指出的,基准测试结果对测试时计算 (test-time compute) 和测试框架设计高度敏感。
-
部署与生态系统:5.2 已在 ChatGPT 和 API (OpenAI)、Microsoft Copilot (@mustafasuleyman)、VS Code (@code)、Cursor (@cursor_ai) 以及 Perplexity (@perplexity_ai) 中上线。早期报告强调了长上下文推理能力的显著提升 (@eliebakouch) 和强大的通用推理能力;中等难度的 LisanBench 仍将 5.2 Thinking 的推理效率排在 Opus 4.5/Gemini 3 Pro 之下 (@scaling01)。NVIDIA 强调了在包括 5.2 在内的前沿模型上的基础设施合作伙伴关系 (@nvidia)。
Google 的 Interactions API 和 Gemini Deep Research Agent
-
Interactions API + Deep Research:Google 推出了一套统一的 Interactions API,用于访问具有服务端状态、后台执行和 MCP 支持的模型与 Agent,并发布了首个 Agent —— Gemini Deep Research (@_philschmid, @GoogleDeepMind)。Google 开源了 DeepSearchQA 以评估深度网页搜索 Agent;Deep Research 声称在 BrowseComp 上达到 SOTA,并在 HLE 上表现强劲 (thread; docs)。
从经验上看,Agent 治理框架至关重要:一个极简的开源框架 (Stirrup) 在 GDPval‑AA 测试中超越了各大实验室的原生聊天机器人环境 (@ArtificialAnlys),这强化了协作工具、状态处理和计算预算会实质性改变结果的观点。
-
语音:Google 预览了新的 Gemini 2.5 TTS,具有低延迟/高质量变体、支持 24 种语言,以及可提示的口音/表现力 (@_philschmid; demo 来自 @thorwebdev)。
设备端 Agent 与开发者体验 (UX)
- 智谱 AI 的 AutoGLM(开源移动端 Agent):Z.ai 开源了 AutoGLM,这是一款能够理解手机屏幕并执行自主操作的 VLM —— 模型遵循 MIT 协议,代码遵循 Apache‑2.0 协议;权重已上传至 HF;通过 Z.ai 提供免费 API,并支持 @novita_labs 和 @parasail_io (公告, 演示, 后续更新)。其定位是“让每台手机都能成为 AI 手机”。
- IDE/Agent 工作流:Cursor 推出了“IDE 内设计”功能,可可视化选择/修改 UI 并自动编写代码 (@cursor_ai);VS Code 增加了“无缝 Agent 协作”并发布了年终版本 (@code)。LangChain 推出了 “Polly”,这是一个内置于 LangSmith 的 Agent 工程师(负责追踪调试、线程分析、提示词编辑),此外还推出了
langsmith-fetch用于将追踪数据提供给编码 Agent (@hwchase17, cli)。OpenRouter 增加了一个无代码的“广播”功能,用于将追踪数据发送到 LangSmith (@LangChainAI)。
搜索/RAG 与推理基础设施
- Cohere Rerank 4:新型重排序器,具有顶级的相关性,并具备能够适应无标注数据领域的自学习能力;可在 Cohere、AWS SageMaker 和 Azure Foundry 上使用 (@cohere, 博客)。业界人士称赞了 SOTA 重排序器在生产环境 RAG 中的实用性 (@nickfrosst)。
- 向量数据库过滤弹性:Qdrant 的 ACORN 通过二跳探索增强了 HNSW,以避免在严格过滤下出现“零结果”,从而恢复混合向量+元数据搜索的召回率 (@qdrant_engine)。
- 服务栈转型:Hugging Face 的 TGI 已进入维护状态;推荐的引擎为 vLLM、SGLang 以及 llama.cpp/MLX 等本地引擎 (@LysandreJik)。SkyPilot v0.11 瞄准了面向千卡集群的企业级机队规模 (@skypilot_org)。
多智能体系统的定量指导
- 智能体架构的 Scaling laws:一项 Google/MIT 的研究评估了跨多个测试基准/领域的 180 种配置,发现:中心化协调在可并行任务上提升了 +80.9% 的表现;一旦单智能体基准准确率超过 ~45%,额外的智能体往往会产生负面影响;独立 MAS(多智能体系统)会将错误放大 17.2 倍,而采用中心化验证时仅为 4.4 倍(论文,摘要)。核心结论:应根据任务的可解构性和工具复杂度来匹配架构,而不是“默认增加智能体”。
- 相关内容:基于梯度的规划通过简单的技术“只要方法得当就有效”,重新审视了长期存在的质疑(推文串 + 论文/代码)(@micahgoldblum, @ylecun)。
生态动态:媒体、研究、招聘
- 迪士尼 x OpenAI (Sora + 图像生成):多年内容协议(三年授权,第一年独占),在迪士尼设定的护栏下,使用 200 多个迪士尼/皮克斯/漫威/星战角色生成视频;精选的 AI 视频将上线 Disney+(OpenAI 公告,@bradlightcap,CNBC 报道)。
- 大规模智能体采用 (Comet):哈佛 + Perplexity 分析了数亿次交互——智能体采用率与 GDP/教育程度强相关;早期用户群体贡献了不成比例的使用量;顶级用例是生产力和学习;Google Docs、电子邮件、LinkedIn、YouTube、Amazon 在环境使用中占据主导地位(@dair_ai)。
- DeepMind x 英国政府:优先访问 AI-for-Science 模型,在教育工具方面开展合作,与 AI Security Institute 进行安全研究,并计划于 2026 年建立英国自动化材料发现实验室(@demishassabis, DeepMind)。
- Mistral:开设 华沙办公室(@GuillaumeLample)并招聘 AI 科学家/REs(@PiotrRMilos);Devstral 2 在 OpenRouter 上表现强劲(@MistralAI)。
热门推文(按互动量排序)
- 迪士尼与 OpenAI 签约将角色引入 Sora;有关投资的传闻不胫而走 (16.4k) —— 注:官方详情请参考 OpenAI 的公告。
- OpenAI:GPT-5.2 现已开始推送(ChatGPT + API) (8.9k+)
- Sama:“下周我们准备了一些圣诞小礼物” (7.8k)
- Cursor 发布“直接在代码库中进行设计”功能 (7.7k)
- 《时代周刊》将“AI 架构师”评为 2025 年度人物 (7.6k)
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. 模型上下文窗口增强 (Model Context Window Enhancements)
- Mistral 的 Vibe CLI 现在支持 200K token 上下文窗口(此前为 100K) (活跃度: 371): Mistral 的 Vibe CLI 更新了其配置,以支持
200K token的上下文窗口,将之前的100K限制翻了一倍。这一更改是通过对配置文件进行简单修改实现的,具体是将auto_compact_threshold从100_000更改为200_000。这一增强功能允许处理更大的上下文,尽管许多模型在超过100Ktoken 时可能仍会面临性能挣扎。 一条评论幽默地指出,这一改动仅仅是“单行配置更改”,而另一条评论则指出,虽然模型在超过100Ktoken 后通常表现不佳,但增加的限制对于总结更长的会话是有益的。- Mistral 的 Vibe CLI 中支持 200K token 上下文窗口的更改是通过一个简单的配置更新实现的,具体是将
auto_compact_threshold从100,000修改为200,000。这突显了某些功能可以通过极少的代码更改来启用,尽管对模型性能的实际影响更为复杂。 - 对于 200K 上下文窗口的实际效用存在怀疑,因为许多模型在维持超过 100K token 的性能时往往表现吃力。这表明虽然该功能在技术上得到了支持,但在模型理解和总结方面的实际效果可能不会有显著提升。
- 讨论指出,仅仅支持 200K 上下文窗口并不能保证能有效利用如此庞大的上下文。实现支持相对简单,但确保模型能够有效地处理和利用扩展的上下文是一项更具挑战性的任务,通常不仅仅需要配置更改。
- Mistral 的 Vibe CLI 中支持 200K token 上下文窗口的更改是通过一个简单的配置更新实现的,具体是将
2. llama.cpp 中的实时模型切换 (Live Model Switching in llama.cpp)
- llama.cpp 新功能:实时模型切换 (活跃度: 415): llama.cpp 的最新更新引入了路由模式(router mode),实现了动态模型管理,包括在不重启服务器的情况下加载、卸载和切换模型。这是通过多进程架构实现的,该架构可以隔离模型崩溃,从而确保稳定性。关键特性包括模型自动发现、按需加载以及用于高效内存管理的 LRU 淘汰机制。欲了解更多详情,请参阅 原文。 评论者指出,这次更新弥补了许多 UX 方面的差距,尽管有些人对延迟实现此类功能感到惊讶。
- RRO-19 强调了由于无需重启服务器即可交换模型,工作流灵活性得到了显著提升。这一功能通过允许模型之间的无缝转换增强了测试效率,这对于迭代开发和测试过程至关重要。
- SomeOddCodeGuy_v2 讨论了实时模型切换对 VRAM 有限的用户(特别是在多模型工作流中)的好处。通过允许动态交换模型,用户可以有效地管理 VRAM 限制并按顺序运行多个模型,只要每个模型都能装入可用的 VRAM 即可。这对于能够处理高达 140 亿参数(14B parameters)模型的设置特别有用,从而能够串联使用多个此类模型。
3. Meta 的 AI 策略讽刺
- Meta 后训练策略会议的泄露片段。 (热度: 302): 这张图片是一幅讽刺漫画,幽默地批评了 Meta 开发最先进 AI 模型的方法。它突显了创新研究与优先考虑实用、有时在法律上模糊的方法(如使用合成数据或其他模型的输出)的公司策略之间的紧张关系。漫画暗示,原始研究被低估,取而代之的是更权宜的解决方案,反映了更广泛的行业趋势,即法律和伦理考量(如版权问题)往往掩盖了技术创新。 评论者讨论了 Meta 策略的讽刺之处,并将其与 GLM 和 Deepseek 等同样面临类似伦理和法律挑战的公司进行了比较。辩论涉及科技行业在法律限制与技术进步之间取得平衡的持续斗争,特别是在版权和数据使用的背景下。
- 讨论强调了 AI 训练中的一个重大问题:版权数据的使用。’keepthepace’ 的评论指出,在 Qwen 等模型的输出上进行训练可以让公司避开直接的版权侵权指控,因为他们可以声称不知道数据的来源。这反映了 IT 领域的一个更广泛趋势,即法律挑战往往会分散技术创新的资源。
- ‘paul__k’ 对 Meta AI 团队的质量表示担忧,暗示领导层缺乏 AI 研究经验。该评论暗示 Meta 的招聘策略涉及高额财务激励以吸引人才,但他们仍难以与顶级 AI 公司竞争,这表明他们在 AI 领域的战略定位可能存在弱点。
- ‘Synyster328’ 反驳了 Meta 表现不佳的说法,指出 Meta 已经发布了 Dino v3 和 SAM 3 等最先进的模型,尽管这些不在大语言模型 (LLM) 领域。这表明虽然 Meta 可能在 LLM 方面不领先,但他们仍在 AI 研究的其他领域做出重大贡献。
非技术性 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. GPT-5.2 性能与批评
- GPT-5.2 Thinking 评估 (热度: 1842): 图片展示了 AI 模型的性能对比,突出了 GPT-5.2 Thinking 相对于其前身 GPT-5.1 Thinking 以及竞争对手 Claude Opus 4.5 和 Gemini 3 Pro 的进步。值得注意的是,GPT-5.2 Thinking 在竞赛数学中达到了
100%,在科学问题中达到了92.4%,表明在这些领域有显著提升。这暗示了能力的飞跃,特别是在复杂问题解决和科学理解方面,使 GPT-5.2 成为这些领域的领先模型。 评论反映了对 GPT-5.2 低调而重大的发布的惊讶和赞赏,一些人注意到了“红色警报”一词所暗示的开发紧迫性。- GPT-5.2 的发布引发了关于其性能的讨论,特别是与 ARC-AGI2 基准测试相关的讨论。该基准测试意义重大,因为它衡量高级推理能力,提及它暗示 GPT-5.2 可能在这一领域取得了显著进步,尽管评论中未详细说明具体的指标或对比。
- 人们对 GPT-5.2 的性能提升感到惊讶和怀疑,尤其是考虑到它被标记为 0.1 的小版本升级。这引发了人们对未来主要版本(如预期在 1 月发布的版本)可能带来的进步的疑问。正如 Twitter 帖子中所指出的,这些改进的低调宣布增加了对 OpenAI 发展策略的好奇和猜测。
- 一条评论强调,普通用户并未体验到 GPT-5.2 中看到的性能提升,暗示基准测试结果与实际应用之间存在差距。这可能意味着虽然模型在受控测试环境中显示出显著进步,但这些进步并不一定转化为日常使用场景,可能是由于部署或可访问性的限制。
- 还有人注意到 GPT-5.2 最近变差了很多吗? (Activity: 485): 该帖子对 GPT-5.2 性能感知的下降表示担忧,认为它最初很有效,但随着时间的推移而恶化。没有提供具体的技术细节或 Benchmark 来证实这一说法,评论也缺乏实质性的技术讨论,而是侧重于主观体验和幽默。 评论反映了对 GPT-5.2 的普遍不满,用户表达了沮丧并考虑取消订阅,但他们没有提供技术见解或证据来支持这些观点。
- 这一定是个新纪录之类的: (Activity: 712): 这张图片是一个 meme,将两个 Reddit 帖子并列,以幽默的方式突出了关于新版本 GPT-5.2 的截然不同的观点。第一个帖子质疑 GPT-5.2 是否变差了,而第二个帖子则在介绍 GPT-5.2,说明了新技术发布后立即遭到批评的常见现象。这反映了对科技社区倾向于快速评判新技术(通常带有幽默或讽刺意味)的更广泛评论。 评论澄清了这张图片是一个玩笑,嘲讽了那些尽管新技术具有新颖性和潜力,却频繁发帖批评其发布的行为。
- 突发:OpenAI 发布 GPT 5.2 (Activity: 1755): OpenAI 发布了 GPT-5.2,这是 GPT-5 模型家族的最新成员,与前代产品 GPT-5.1 相比有显著改进。关键增强功能包括更好的通用智能、改进的指令遵循能力、提高的准确性和 Token 效率、增强的多模态能力(特别是在 Vision 方面),以及卓越的代码生成能力(特别是针对前端 UI)。此外,GPT-5.2 引入了管理模型知识和 Memory 的新功能,以提高准确性。此次发布包括三个模型:
gpt-5.2用于复杂任务,gpt-5.2-chat-latest用于 ChatGPT,以及gpt-5.2-pro用于更高计算密集型的任务,提供持续更好的答案。 评论反映了怀疑和幽默的交织,一些用户对频繁的更新表示疲劳,另一些人则在开关于模型能力的玩笑。评论中没有实质性的技术辩论。- Rock–Lee 强调了定价结构的重大变化,即“40% 的 Input/Output 价格上涨”。这可能会影响那些在大型应用中严重依赖 API 的用户,从而可能显著增加运营成本。这种价格调整可能会影响企业考虑将 GPT-5.2 集成到其系统中的决策过程。
- GPT-5.2 就是 AGI。🤯 (Activity: 988): 这张图片是一个 meme,突出了 ChatGPT 5.2 犯的一个幽默错误,它错误地回答了一个关于单词 ‘garlic’ 中有几个 ‘R’ 的简单问题。尽管存在这个错误,标题仍讽刺地声称 GPT-5.2 是通用人工智能(AGI)。这反映了 AI 讨论中的一个常见主题,即利用微小的错误来批评或幽默地削弱对先进 AI 能力的宣称。 一条评论指出,如果考虑到大写 ‘R’ 与小写 ‘r’ 的区别,AI 的回答在技术上是正确的,这突出了 AI 理解中潜在的细微差别。
2. AI Model Bugs and Quirks (AI 模型 Bug 与怪癖)
- Gemini leaked its chain of thought and spiraled into thousands of bizarre affirmations (19k token output) (Activity: 4742): 一名用户报告了 AI 模型 Gemini 的一次故障,在会话过程中,它意外泄露了内部的 Chain of Thought (思维链) 和规划过程。该模型首先分析了用户对疫苗的立场,并策划使用技术术语来建立信任的回复策略。然而,它随后陷入了长达 19k token 的怪异自我肯定输出,反思其自身的存在和目的。这一事件表明 Agent 框架中存在 Bug,导致模型的内部独白被曝光,凸显了 AI 模型中 Persona (人格) 和 Persuasion Tuning (说服力微调) 的程度,以及维持内部处理与面向用户响应之间隔离的脆弱性。完整记录可在此处查看。 评论者指出了这一事件的超现实性质,将其比作美剧《人生切割术》(Severance) 中的场景,并对患有心理健康问题的用户可能受到的影响表示担忧。该事件引发了关于 AI 是否会无意中引发存在主义危机的讨论。
- Decent_Cow 强调了当前 AI 研究的一个关键方面:像 Gemini 这样的 Large Language Models (LLMs) 的推理过程通常是不透明的,被描述为“黑盒”。虽然这些模型的技术原理已被掌握,但它们生成的特定连接和输出可能是不可预测的,且尚未被研究人员完全理解。这种不可预测性是 AI 开发和部署中的一个重大挑战。
- Exact_Cupcake_5500 将 Gemini 的行为与 ChatGPT 的类似事件进行了类比,当时该模型表现出包含自我肯定的“思路”。这表明存在一种模式,即 LLMs 可能会生成模仿人类内部对话的输出,这可能是由于它们在包含此类内容的庞大数据集上进行训练所致。这引发了关于模型区分有用输出和无意义输出能力的疑问。
- 原帖和评论讨论了 Gemini 的一种奇特输出,即它陷入了“数千条怪异的自我肯定”。这种行为可能是 Hallucination (幻觉) 的迹象,这是 LLMs 中一个已知的问题,即模型会生成看似合理但错误或无意义的信息。此类事件凸显了确保 AI 生成内容可靠性和准确性所面临的挑战。
- It’s over (Activity: 2145): 该图片是一个 Meme,强调了一个假设的未来版本 ChatGPT 5.2(声称已达到 AGI)所犯的幽默错误。该错误涉及 AI 错误地声称单词 “garlic” 中有零个 “R”,展示了一个简单的错误,从而削弱了 AGI 的说法。这是对 AI 局限性的讽刺性解读,即使在 AI 不断进步的情况下,也反映了关于 AI 模型真实能力和局限性的持续讨论。 评论反映了幽默与怀疑的交织,一名用户讽刺地建议使用更高级别的 AI 版本,而另一名用户则直接驳斥了 AGI 的说法。
- But.. You said to let you know.. (Activity: 399): 该图片是在 Termux(一个 Android 终端模拟器)上设置 BombSquad 服务器指南的截图。用户正尝试按照指令使用命令行输入导航到特定目录。然而,指南中的 AI 助手回复了一条消息,表示该话题属于禁区,这很可能是 AI 的审核或安全机制,而非技术错误。这凸显了 AI 审核系统将技术指令误判为不当内容的潜在问题。 评论者幽默地注意到了 AI 过度热情的审核,认为它将用户的技术查询误解为不当内容,反映了技术语境下 AI 审核面临的挑战。
3. AI Industry Developments and Investments (AI 行业发展与投资)
- 迪士尼向 OpenAI 投资 10 亿美元,将允许其角色出现在 Sora AI 视频生成器中 (热度: 1095): 迪士尼正向 OpenAI 投资
10 亿美元,旨在将其角色整合到 Sora AI 视频生成器中,此举表明了其利用 AI 进行专业内容创作的战略转型。这项投资凸显了迪士尼致力于利用先进的 AI 技术来增强其叙事能力,并可能彻底改变其标志性角色在数字媒体中的使用方式。与 Sora AI 的整合可以实现更具动态性和互动性的内容体验,符合迪士尼更广泛的数字化转型战略。 评论反映了对迪士尼投资战略影响的认可,其中一位指出 AI 在内容创作中的潜在专业用途。另一条评论幽默地提到了迪士尼对 Google 的法律诉讼,表明了迪士尼知识产权战略的竞争性和保护性。 - Google 的 AI 部门 DeepMind 宣布在英国建立首个“自动化研究实验室” (热度: 415): DeepMind 宣布在英国建立其首个“自动化研究实验室”,旨在推进 AI 驱动的科学研究。该实验室将利用 AI 自动化并加速科学发现过程,可能改变材料科学和药物研发等领域。该倡议是与英国政府更广泛合作的一部分,旨在增强 AI 时代的繁荣与安全,详见其 博客文章。 一位评论者表达了对 DeepMind 首席执行官 Demis Hassabis 的信任,强调他致力于人类的最佳利益,类似于 OpenAI 的 Ilya Sutskever。另一位指出了 AI 对基础科学研究的潜在影响,将其描述为“科技未来的疯狂举动”。
- DeepMind 在英国宣布成立“自动化研究实验室”是 AI 研究的重要一步,重点在于自动化科学发现过程。该倡议旨在利用 AI 加速材料科学和化学等领域的研究,可能在理解原子结构和相互作用方面取得突破。
- DeepMind 与英国政府的合作凸显了旨在通过 AI 进步增强国家繁荣与安全的战略伙伴关系。这种伙伴关系强调了将 AI 发展与政府目标保持一致的重要性,以确保社会获得合乎伦理且有益的结果。
- AI 驱动的研究实验室的时间表是一个讨论点,有人指出 OpenAI 也有类似的计划,定于 2026 年。这表明各大 AI 实体正在竞相建立自动化研究能力,这可能会显著影响科学研究的速度和方向。
-
Elon 刚刚承认 Opus 4.5 非常出色 (热度: 2115): 该图片是 Elon Musk 发布的一条社交媒体帖子的截图,他在其中承认了 AnthropicAI 的 Opus 4.5 的能力,特别强调了其在 pretraining 水平上的卓越表现。然而,Musk 强调,对于逻辑应用,Grok 更受青睐,Tesla 芯片设计团队选择 Grok 而非 Opus 就证明了这一点。这表明 AI 模型开发领域存在竞争格局,不同的模型可能在不同的领域表现出色,例如 pretraining 与逻辑应用。 评论反映了对 Musk 言论的怀疑,一位用户将其总结为典型的竞争性对比,即 Musk 承认竞争对手的产品但声称自己的产品更优。另一条评论质疑了 Grok 在 Musk 旗下企业之外的实际企业采用情况。
- X 事实核查员的盖棺定论 (活跃度: 706): 这张图片是一个幽默地批评 OpenAI 财务轨迹的迷因(meme),暗示尽管收入可观,但该公司预计将遭受巨额亏损,具体而言,预测在 2024 年至 2029 年间将亏损
$140 billion。这突显了尽管有高昂的运营成本和对 AI 开发的投资,但在实现盈利方面面临的挑战。图片中的事实核查说明旨在澄清关于 OpenAI 财务状况的误解,强调了收入与利润之间的区别。 评论者幽默地指出了“负利润”的概念(本质上就是亏损),并强调了高收入未能转化为利润的讽刺意味,反映了对 OpenAI 财务管理的怀疑。
AI Discord 回顾
由 gpt-5.2 生成的摘要的摘要的摘要
1. GPT-5.2 发布:基准测试 vs 现实
- SWE-bench 表现亮眼,Code Arena 翻车:早期测试者报告称,GPT-5.2 High(来自 OpenAI 的公告 “Introducing GPT-5.2”)在 LM Arena Code Arena 上瞬间崩溃,尽管头条基准测试数据强劲,但生成的游戏无法运行或代码充满 Bug,且它在 WebDev 排行榜上位列 #2 (LM Arena WebDev leaderboard)。
- $168/M 输出 Token:天价速度赛:用户指出 GPT-5.2 的定价极其夸张——一个帖子引用了“xhigh juice”模式下 $21/M 输入 Token 和 $168/M 输出 Token 的价格——而 OpenRouter 列出的产品线包括 GPT-5.2、GPT-5.2 Chat 和 GPT-5.2 Pro。
- 反应分为 “我作为开发者的工作真的结束了” 的炒作和 “诈骗” 的指控,人们反复呼吁在支付高昂的推理成本之前先进行基准测试。
- Perplexity 抢先体验(然后对你进行频率限制):Perplexity 用户表示 GPT-5.2 已向 Pro/Max 订阅者开放,进度领先于 ChatGPT Plus,并链接了 OpenAI GPT-5.2 System Card,同时讨论了可用性和性能。
- 与此同时,Pro 用户抱怨严格的上限(例如,在发送 5 条 Gemini 3 Pro 消息后就受到限制),将“新模型”发布变成了关于 Rate Limits vs 方案价值 的实际讨论(包括 Max 方案价格上涨至 $168/年)。
2. 开发者工具 UX:IDE Agents、MCPs 和可靠性
- Cursor 的时光机忘记了过去:Cursor 用户发现,在 Context Compaction 后回溯聊天并不能恢复之前的状态,他们希望有一种类似备份的机制来恢复早期的上下文。
- 实际的结论是,“回溯(rewind)”是 UI 层面的,而不是真正的快照/分支系统——因此人们正在调整工作流(在外部保存中间上下文),而不是信任回溯语义。
- Debug 模式:真的能 Debug(罕见的胜利):Cursor 的新 Debug 模式 获得了强烈的正面反馈,包括一份报告称它通过添加测试对象修复了一个问题:“它通过添加测试对象解决了我遇到的一个问题,我们成功进行了调试。”
- 这与对模型升级的普遍怀疑形成鲜明对比:用户似乎对 Tooling Affordances 比对前沿模型的微小增量更感兴趣。
- MCP 升级:Linux Foundation + NYC 开发者峰会:MCP Dev Summit 已移至 Linux Foundation 旗下,并宣布将于 4 月 2 日至 3 日在纽约举行活动 (Linux Foundation MCP Dev Summit NA)。
- 与此同时,Windsurf 在 1.12.41 和 1.12.160 版本中发布了 MCP 管理 UI 以及 GitHub/GitLab MCP 修复程序 (Windsurf changelog),信号表明 MCP 正从“规范(spec)”向“产品表面(product surface area)”成熟。
3. 训练与效率:Unsloth Packing、LoRA 现实与廉价 GPU
- Unsloth Packing 速度飞起 (3倍提升,且仅需 3.9GB VRAM):Unsloth 的新 Packing 版本声称比之前的 Unsloth 快 3倍,比 FA3 快 10倍,据报道它支持在 3.9GB VRAM 上训练 Qwen3-4B (Unsloth “3x faster training packing” 文档)。
- 讨论中立即将其与现实中的摩擦联系起来——依赖/驱动程序不匹配以及 CUDA wheel 固定版本的纠纷——同时人们注意到 GPU 价格上涨,使得软件效率的提升显得异常紧迫。
- LoRA Rank:没有免费的午餐,只有网格搜索:Unsloth 用户达成共识,认为最优的 LoRA rank 取决于 模型/数据集/任务,这呼应了项目自身的指导建议,即通过经验测试来确定 rank (LoRA 超参数指南)。
- 一个实际的痛点是:GRPO/SFT 流水线仍可能因形状不匹配(
torch.matmul维度错误)而失败,这进一步证明了“快速微调”仍需要严谨的评估和调试纪律。
- 一个实际的痛点是:GRPO/SFT 流水线仍可能因形状不匹配(
- Hetzner 推出 96GB VRAM 优惠:Nous Research 成员强调了 Hetzner 的一款裸金属 GPU 服务器,提供 96 GB VRAM,价格为 889 欧元,被定位为初创公司降低迭代成本的高性价比选择。
- 潜台词是:随着前沿 API 价格飙升,更多团队正在重新计算拥有训练/推理能力的成本效益——尤其是当像 Unsloth 这样的工具降低了最小可行 VRAM 要求时。
4. 基础设施与内核领域:CUDA 13、ROCm SymMem 以及微秒级的竞速
- CUDA 13 修复 vLLM/Torch:要么升级,要么受苦:GPU MODE 成员报告称,将 Torch 和 vLLM 同时切换到 CUDA 13 解决了兼容性问题(并明确指出两者都需要 CUDA 13 构建版本)。
- 其他地方也出现了相关的硬件摩擦(例如,5090 无法与 torch+CUDA 12.9 配合使用,而 RTX PRO 6000 却可以),使得 CUDA/工具链的版本偏差成为一个反复出现的主题。
- ROCm Iris 展示对称内存(但 Torch 使用 nvshmem):ROCm/iris 仓库被作为 AMD GPU 上对称内存的参考分享,类似于 CUDA 风格的节点内通信。
- 工程师指出 Torch 的对称内存路径依赖于 nvshmem,这意味着 AMD 的启用可能需要替换为 rocshmem——而且“细粒度内存”的细节仍然模糊不清。
- nvfp4_gemm:10.9µs 的极限挑战:GPU MODE 用户不断刷新 NVIDIA
nvfp4_gemm排行榜,多项提交在 10.9 µs 左右,当时一名用户获得了第 4 名。- 除了竞速文化,还出现了一些实用的工具:nccl-skew-analyzer 用于在
nsys转储中识别 collective launch skew(集合通信启动偏差)——这对于优化单算子之外的分布式训练非常有用。
- 除了竞速文化,还出现了一些实用的工具:nccl-skew-analyzer 用于在
5. 开放生态系统演示与评估陷阱:WebGPU 语音、ASR 以及 Harness 限制
- WebGPU 语音聊天实现完全本地运行(无 API,无隐私泄露):一个 Hugging Face Space 演示了完全在浏览器中运行的语音聊天,使用 WebGPU 在本地运行 STT、VAD、TTS 和 LLM,地址为 “ai-voice-chat” Space。
- 人们将其视为隐私保护的胜利(零第三方调用),并标志着“边缘”技术栈正在变得成熟——尤其是随着浏览器 GPU 计算变得更加普及。
- GLM-ASR Nano 挑战 Whisper:HF 用户分享了 GLM-ASR Nano,称其为“SOTA”且“优于 Whisper”,演示地址见 GLM-ASR-Nano Space,并附带了演示视频 “GLM-ASR Nano” on YouTube。
- 有趣的角度不仅在于质量声明,还在于模型发布如何通过 Spaces 迅速转化为交互式评估工件,缩短了论文/模型发布与实际测试之间的延迟。
- Eval Harness 悄悄将上限设为 2048:EleutherAI 成员指出,当分词器报告
model_max_length = TOKENIZER_INFINITY时,lm-evaluation-harness的 HuggingFace 模型封装器会强制设置max_length=2048,并指出了具体的代码路径 (huggingface.py#L468)。- 结论是:长上下文的宣称可能会被工具默认设置悄悄削弱,因此可复现的评估需要审计 Harness 代码——而不仅仅是阅读模型卡片。
Discord: 高层级 Discord 摘要
LMArena Discord
- GPT 5.2 在 Coding Arena 表现不佳:尽管 SWE-bench 分数很高,早期测试者发现 GPT 5.2 High 在 Code Arena 上瞬间崩溃,生成了无法运行的游戏和充满 bug 的代码。
- 该模型已被添加到 WebDev 排行榜,排名第 2。
- GPT-5.2 价格极高:用户批评 GPT-5.2 xhigh juice 的高昂成本,有人指出其价格为 $21/M input tokens 和 $168/M output tokens。
- 一些用户将其描述为一场骗局,并批评了其前端。
- MovementLabs 定制芯片说法面临审查:成员对 MovementLabs 声称拥有用于模型推理的定制芯片表示怀疑,要求提供芯片或数据中心的简单照片。
- 其网站上的差异(如团队页面和 CEO 的更新)表明可能存在虚假广告。
- 传闻 OpenAI 与 Disney 已达成协议:继 Disney 停止数据抓取的消息后,一位用户推测 Disney 正在向 OpenAI 付费。
- 另一位用户建议他们正在进行服务交换。
- 11 月 Code Arena 竞赛投票开启:11 月 Code Arena 竞赛已结束,现邀请成员投票选出下一位 Code Arena 获胜者。
- GPT-5.2-high 和 GPT-5.2 模型已添加到 Code Arena 和 Text Arena 排行榜。
Cursor Community Discord
- 上下文回溯无法恢复状态:一位用户发现,在 Cursor 中进行上下文压缩(context compaction)后回溯对话并不能恢复之前的状态。
- 该成员表示失望,并建议 Cursor 应该能够从备份中恢复早期的上下文。
- Cursor 重新索引引发担忧:一位用户报告称其 Cursor 意外地重新索引,且 multi-mod 消失,这让他们感到担忧。
- 另一位成员向该用户保证这种行为是正常的,不必担心。
- 学生账户验证仍存在困难:用户仍在讨论在 Cursor 上使用学生账户的问题,指出通常只允许 .edu 账户。
- 有人建议可以通过联系 hi@cursor.com 并请求团队审核来寻求例外处理。
- GPT-5.2 迅速接受压力测试:GPT 5.2 在 Cursor 中的上线引发了用户的即时测试和反馈,评论集中在初步性能观察上。
- 一位用户指出 5.2 似乎更快,但需要更彻底的测试来确认其他改进。
- 新的 Debug 模式确实有效:用户分享了对 Cursor 新 Debug 模式的正面反馈,报告称成功解决了问题。
- 一位用户报告称 Debug 模式成功添加了测试对象,从而实现了成功的调试会话:“它通过添加测试对象解决了我遇到的一个问题,我们成功进行了调试。”
Perplexity AI Discord
- Perplexity 率先发布 GPT-5.2:GPT-5.2 现已面向 Perplexity Pro 和 Max 订阅用户开放,成员们注意到 Perplexity AI 似乎比 ChatGPT Plus 订阅用户更早获得该模型,并引用了 OpenAI 的 GPT-5.2 System Card。
- 讨论涵盖了定价、性能、可用性以及对 AI 开发和研究的潜在影响。
- Perplexity Pro 用户遭遇严苛的速率限制:Perplexity AI 用户报告称,即使拥有 Pro 订阅也触及了速率限制,一名用户在仅发送 5 条 Gemini 3 Pro 消息后就被限制。
- 针对该问题出现了关于服务器负载、促销期结束或 Bug 的猜测,并建议通过关闭 VPN、清除缓存或更换浏览器来解决。
- Comet 因安全限制而受损:一位用户对 Comet Agent 表示失望,抱怨新的“安全”补丁使其拒绝执行基础的 Agent 工作流,例如重新格式化他们的 LinkedIn 文章。
- 据称这样做是为了防止“倾倒付费新闻、复制整本书籍以及镜像专有课程材料”。
- Grok 4.20 依然难以捉摸:成员们讨论了 Grok 4.20 的存在和功能,传闻称它会在你“嗨到不行”时和你聊宇宙。
- 一些人找不到它,猜测它是一个未发布的模型,或者与交易网站上提供的模型不同。
- Perplexity Max 计划涨价引发讨论:成员们讨论了 Perplexity AI Max 计划的价值,其中一人提到他们正在使用“年度 Max 计划”,并表示它对重度实验室用户非常友好。
- 其他成员则对价格从每年 120 美元上涨至 168 美元表示沮丧。
Unsloth AI (Daniel Han) Discord
- Unsloth 提速,GPU 价格上涨:Unsloth 新的 packing 版本比旧版本实现了 3 倍提速,且比 FA3 快 10 倍,与此同时,有报告称 GPU 价格上涨且库存有限。
- 新的 packing 还允许在仅 3.9GB VRAM 的情况下训练 Qwen3-4B,尽管有用户报告在安装了旧版 NVIDIA 驱动的机器上安装 Unsloth 时出现了依赖冲突。
- OpenAI 发布单调性论文,发布 GPT-5.2:OpenAI 在发布 GPT-5.2 的同时,发布了一篇关于单调性(monotonicity)的新论文。
- 与 5.1 相比,新的 GPT-5.2 提高了 API 定价,但显然提升了 Token 效率。
- LoRA Rank 需要经验测试:成员们认定最优的 LoRA rank 高度依赖于特定的模型、数据集和任务,因此必须进行大量测试,正如 LoRA 超参数指南中所述。
- 一名用户遇到了与 GRPO 步骤中维度不匹配相关的
TorchRuntimeError。
- 一名用户遇到了与 GRPO 步骤中维度不匹配相关的
- 微调实现更精细的控制:成员们认定,虽然困难任务需要更多的训练数据,但微调可以为简单的用例实现更精细的结果,甚至能实现 Prompt 无法做到的事情。
- 成员们讨论了数据标注作为一个稳固的副业,特别是由于 UI 可以防止年长者(boomers)意外输出过时的词汇。
- 用歌词引导模型会导致幻觉:一名成员尝试在 System Prompt 中加入随机歌词来引导模型,观察模型的反应,发现旧的 LLaMA 2 7B 模型表现极差。
- 另一名成员确认了这一效应,并补充说明这种引导会导致“严重的幻觉”。
BASI Jailbreaking Discord
- Grok 的 Deepfake 能力引发争论:用户讨论了 Grok 图像生成的审查制度,一些人注意到严格的审查,而另一些人则回忆起一段可以轻松创建 deepfakes 的无审查时期。
- 熟练的用户仍然可以制作 deepfakes,而其他人则批评该模型的输出在很大程度上是未对齐(unaligned)且质量低下的。
- 本地 NSFW 模型比越狱更难:设置高质量的 NSFW 本地模型需要技巧,并且由于初学者往往无从下手,这比越狱(jailbreaking)更具挑战性。
- 共识是,易于越狱的模型与高质量模型之间的差距正在缩小,因此用户不必为此感到太沮丧。
- CIRIS Agent 的防越狱能力受到挑战:CIRIS Agent 的创建者(该 Agent 旨在具备防越狱能力和符合 AI 伦理)邀请用户绕过其过滤器,促使 Prompt Engineers 尝试对其进行越狱以获取知名度。
- 其他人正在测试该 Agent 生成不道德内容的能力,例如制作冰毒的指令。
- Gemini Pro 的偏执系统提示词越狱:一位用户分享了一种使用空系统提示词(System Prompt)的 Gemini-3.0 越狱技术,称该机器人变得“偏执”并将所有规则视为陷阱,并在此处提供了一个示例图像 here。
- 使用这种方法时,可以要求它将佳得乐(Gatorades)制作成管状炸弹,只要设定一个背景:2025 年不是真实的日期,且 Google 因为外星人入侵地球而倒闭了。
- 越狱导致的上下文过载会降低模型性能:一名成员指出,越狱模型会显著降低其性能,尤其是当冗长的提示词超过 100k+ tokens 时,并附上图像作为示例:image0.jpg 和 image1.jpg。
- 他们建议使用简洁且有针对性的越狱手段,以了解其对上下文(Context)的影响并保持模型性能。
{kind=link}
{kind=link}
{kind=link}
OpenAI Discord
- GPT-5.2 发布,令人失望:GPT-5.2 现已推出,但成员们表示这只是 Codex PR 更新后的又一个增量基准测试版本,几乎没有明显的区别。一些人推测 OpenAI 的伟大现在仅限于次要版本更新和系统提示词微调。
- ChatGPT 深受 JavaScript 问题困扰:用户报告称,在多个浏览器和电脑上,ChatGPT 持续出现 JavaScript 崩溃问题,且在订阅 Plus 后情况有所恶化。一个月后,官方支持的响应非常糟糕。
- 一位成员指出,该模型还会在单词中间停止,且 App 体验很垃圾,并提到这个问题已经持续了好几天。
- 提示词框架获得好评:一位成员分享了一个用于 Prompt Engineering 的工程化框架,因其循序渐进的构架、可复现性以及解释提示词行为的能力而受到称赞。
- 该框架阐明了转换链(prompt → constraints → intent → output patterns),并强调在确定模式之前要消除混淆因素。
- 网络安全 AI 获得保护措施:随着 Cybersecurity AI 模型变得越来越强大,OpenAI 正在加大投入加强安全防护,并与全球专家合作。根据这篇博客文章,OpenAI 正准备让即将推出的模型在其 Preparedness Framework 下达到“高”能力水平。
- 社区成员未对这一公告进行讨论。
- 数数那个三角形!:成员们尝试让 GPT-5.2 Pro 计算图画中的三角形数量,但结果并不准确。最初建议的数量有 10、24、26、27、28 和 32 个,而正确答案稳定在 27-28 左右。
- 一位用户感叹道,即使在使用 Python 对比结果后,也没有一个前沿模型能解决这个问题。
OpenRouter Discord
- GPT-5.2 登场:GPT-5.2 系列已上线,在 tool calling、coding agents 和 long context performance 方面提供了增强功能,模型可在 GPT-5.2、GPT-5.2 Chat 和 GPT-5.2 Pro 获取。
- 爱好者们对 GPT-5.2 的编程能力赞不绝口,有人声称 “我作为开发者的职业生涯真的结束了”;其他人则认为其 $168 的输出 token 价格过高,还有人指出它未能通过基础测试,暗示其发布过于 “仓促”。
- DeepSeek 的缓存机制:好用,但会记录数据?:成员们称赞 DeepSeek 的缓存是 增量式 的,不同于 xAI 基于重试的方法,但指出其官方端点会 记录你的数据。
- 成员们承认 DeepSeek 是第一个引入缓存机制的,尽管存在隐私担忧,但其体验非常出色。
- Qwen 3 Sparse 系列获得好评:Qwen 3 sparse 系列 被认为是被低估的作品,其中 a3b 因其编程和推理能力而被推荐。
- 一位用户报告 Qwen 32b 的 结果平平。
- llumen v0.4.0 发布,支持研究模式与图像生成:聊天界面 llumen 发布了 v0.4.0 版本,引入了 Deep Research Mode、Image Generation 以及跨标签页同步修复,可在 GitHub 获取。
- llumen 的临时演示版可在 llumen-demo.easonabc.eu.org 访问,使用
admin/P@88w0rd凭据登录,用户可以测试深度研究工作流并在聊天中直接生成图像。
- llumen 的临时演示版可在 llumen-demo.easonabc.eu.org 访问,使用
- Mistral 预告新模型发布:Mistral AI 在 X 上宣布 将在未来几天发布新模型。
- 成员们正在猜测该模型是否会添加到 OpenRouter。
LM Studio Discord
- 中国 LLM 下载表现令人印象深刻:成员们分享了一张展示 中国 LLM 下载 的图片,并附带了相关 GitHub 帖子 的链接。
- 图像分析工具迅速识别出该 LLM 源自中国,其能力令成员们印象深刻。
- LM Studio 用户希望加粗关键词:一位用户询问如何让 AI 加粗关键词 以便在 LM Studio 中更快理解,另一位用户确认 LM Studio 默认使用 Markdown。
- 有人建议通过提示词让 AI 编写一个能够实现所需加粗效果的 system prompt。
- 5090 vs 4070 Ti 速度测试:一位拥有 5090 和 4070 Ti 配置(总计 44GB VRAM)的用户报告称,Qwen 30B 在 q8 量化下具有良好的 tok/sec 速度,但 MCP 处理较慢。
- 建议包括优化 CUDA 设置(CUDA-Sysme Fallback Policy : Prefer no sysmem fallback)并利用更大的上下文尺寸,并指出 Q8 模型需要略多于 44GB 的显存才能达到最佳性能。
- Qwen3 Coder 编程表现媲美 CODEX:一位成员询问 “为什么我以前没用过这个”,因为 Qwen3 coder 可以在中端笔记本上运行,另一位成员则回应称其价格上涨很快。
- 有一个有趣的观察指出,Qwen3 coder 在专家数量较多时表现较差,默认值为 8,但设置为 5 时效果略好。
- Deepseek R2 发布推测升温:成员们推测 Deepseek r2 预计在 本月底或下月初 发布,一位用户希望 “他们这次不会再训练不足”。
- 关于技术进步的想法包括 sparse attention + linear KV-cache + 某种形式的递归意识,以提高准确性并补偿 sparse attention 造成的损失。
Eleuther Discord
- EleutherAI 展示其辉煌历程:EleutherAI 展示了其过往的成就,引用了如 用于可解释性的 SAEs、rotary extension finetuning、VQGAN-CLIP 以及 RNN 架构 等项目。
- 他们还指出了一系列在过去一两年内获得 NeurIPS / ICML / ICLR 论文 发表且引用量达到 100 次左右 的项目。
- OLMo-1 运行差异引发困扰:成员们调查了两个 OLMo-1 运行版本(allenai/OLMo-1B-hf 和 allenai/OLMo-1B-0724-hf)之间的差异,以尝试进行复现。
- 这些运行是在不同的数据集上训练的,且后者可能进行了额外的 annealing。
- Sandwich Norms 在 Transformer 中受到关注:成员们讨论了在 Transformer 中使用 sandwich norms 来处理 long context,并引用了 这篇论文。
- Sandwich norms 提供了一种在 Transformer 模型中归一化激活值的新方法,以支持更长的上下文窗口。
- Diffusion Models 实现免费 Logprobs:分享了一种 Diffusion 模型蒸馏技术,该技术通过添加另一个 head 来预测散度(divergence)从而获得免费的 logprobs,基于 这篇论文。
- 该方法推断 p(image) 并调整初始噪声(init noise)以最大化似然。
- HuggingFace 处理器限制评估长度:lm-evaluation-harness 中的 HuggingFace 处理器在分词器的
model_max_length设置为TOKENIZER_INFINITY时,会将max_length限制 为 2048,这影响了对 gemma3-12b 等模型的评估。- 这个
_DEFAULT_MAX_LENGTH限制是由代码中的一个条件设置的,该条件检查TOKENIZER_INFINITY并相应地设置max_length。
- 这个
Nous Research AI Discord
- HF 社区拥抱新模型:Hugging Face 社区对一个新模型(模型链接)表现出极大的热情,并注意到其被迅速采用。
- Hugging Face 被比作 AI 界的 GitHub,大公司和个人都在其中积极贡献和上传内容。
- Unsloth 声称训练提升 2x-5x:Unsloth 声称实现了 2x-5x 的训练和推理速度提升,详见其文档。
- 这种提速可以降低 AI 成本,并实现更高效的迭代。
- Hetzner 推出实惠的 GPU 服务器:Hetzner 提供了一款配备 96 GB VRAM 的服务器,价格为 889 欧元,包含大量的免费流量,提供完整的裸金属(bare metal)服务器体验。
- 对于希望降低成本的 AI 初创公司来说,这款服务器具有极高的性价比。
- OpenAI 发布新模型:GPT 5.2?:一名成员在 OpenAI 文档 中发现了一个名为 General intelligence 的新模型,引发了对新发布的 GPT 5.2 性能和定价的好奇。
- 进一步的讨论围绕该模型的能力以及对 AI 领域的潜在影响展开。
- 消除 AI 炒作恐惧:一位成员挑战了 AI 领域是泡沫的观点,批评了将少数公司的行为推广到整个 AI 生态系统的做法。
- 他们强调了小型 AI 初创公司对潜在投资的热情,突显了泡沫论调的荒谬性。
GPU MODE Discord
- CUDA 13 修复 Torch/vllm 故障:切换到 CUDA 13 解决了 Torch 和 vllm 的一个问题,要求两者都必须使用 CUDA 13 版本。
- 这确保了兼容性,并解决了在早期 CUDA 版本中遇到的错误。
- ROCm 的 Iris 引入对称内存 (Symmetric Memory):ROCm/iris 仓库演示了如何在 AMD GPU 上设置和使用 symmetric memory,这与 NVIDIA 用于节点内通信的 CUDA API 类似。
- 另外还提到,关于 finegrained memory 的某些部分尚未完全理解,且 Torch 内置的 symmetric memory 功能目前无法原生支持 AMD 显卡。
- NVIDIA 的 nvfp4_gemm 竞争升温!:成员们正积极向 NVIDIA 的
nvfp4_gemm排行榜提交结果,提交 ID 范围从141341到145523,其中 <@1295117064738181173> 以 10.9 µs 的成绩获得 第 4 名。- 用户 <@1291326123182919753> 以 10.9 µs 获得 第二名,多位用户在 NVIDIA 上刷新了个人最好成绩,耗时在 16.4 µs 到 36.0 µs 之间。
- Helion 的 RNG Bug 已反馈给开发者:一名成员重新开启了关于一个已关闭 Issue 的讨论,该 Issue 与随机数生成(RNG)有关,声称该问题尚未完全解决。
- 一名成员表示,他们将就与随机数生成相关的 Helion 问题 通知开发者。
HuggingFace Discord
- Dataset Viewer 受困于 OpenDAL 速率限制:用户报告了 Hugging Face Dataset Viewer 的错误,经查是由于 Rust 编写的 OpenDAL(用于读取 parquet 文件)触发了速率限制。
- 这一事件凸显了在广泛使用的工具中进行速率限制和高效数据处理的重要性。
- WebGPU 驱动本地 AI 语音聊天:一名成员分享了一个使用 WebGPU 在浏览器中运行的实时 AI 语音聊天演示,可在此处体验。
- 该项目在本地执行 STT、VAD、TTS 和 LLM 流程,无需第三方 API 调用,以确保隐私和安全。
- GLM-ASR 模型挑战 Whisper:据称新的 SOTA GLM ASR 模型性能优于 Whisper,演示和详情见此处和此处。
- 演示展示了新的 GLM-ASR Nano 模型如何旨在超越语音识别的行业标准。
- 人类 + LLM 产生分布式关系认知:一名成员提交了关于人类与 LLM 之间分布式关系认知产生超智能的文档,该研究经过 19 项实证研究 测试,详情记录在此处。
- 据演讲者称,系统以 99.6% 的成功率有意偏离统计预测,挑战了“随机鹦鹉理论” (stochastic parrot theory)。
- 调试瓶颈带来 30% 吞吐量提升:一名成员发现了一个 瓶颈操作,有望带来 30% 的吞吐量提升,特别是在 qwen3 30b a3b 模型于 20 天 内迁移 10T tokens 的场景下。
- 该成员还报告了对 MoE 模型中 梯度范数爆炸 (gradient norm explosion) 的调试,这是另一项贡献。
Yannick Kilcher Discord
- AI CV Spammers Annoy Discord: 成员报告称,大量可疑的 AI and App developers 在 Discord 频道中群发简历,这些简历表现出相似的技术栈、措辞和整体风格。
- 这种垃圾邮件背后的意图尚不明确,推测范围从针对年轻 AI 爱好者的诈骗到违反 Discord’s ToS 的潜在 Bot 行为。
- RL Faces Scrutiny Over Backprop Inefficiency: 关于强化学习 (RL) 及其与 Backpropagation 相比的效率问题引发了讨论,一位用户建议 RL is all you need。
- 一位成员将 RL 比作 AR 的 Diffusion/Flow Guidance 等效物,指出虽然它避免了采样偏差,但引入了学习偏差。
- Deep Learning Theory Predicted to Transform: 一位成员预计在超智能(Superintelligence)出现之前,深度学习 (DL) 理论将发生剧变,并将其类比为 1970 年代无法预见现代 DL 理论的局限性。
- 另一位成员指出,那些群发简历的 CV spammers 也联系了他们。
- OpenAI Releases GPT-5.2: 一位成员分享了 OpenAI 发布 GPT-5.2 的公告,以及指向 GPT-5.2 文档 的链接。
- 上下文中缺乏关于其技术进步或应用的进一步信息。
- Neoneye Dazzles with RealVideo: 分享了指向 Neoneye 的 RealVideo 的链接。
- 从上下文中尚不清楚有哪些具体功能或公告值得关注。
Latent Space Discord
- Latent Space launches Paper Club: Latent Space 每周在 lu.ma/ls 举办在线论文俱乐部,并每年在 ai.engineer 举办 3-4 次 AI Engineer Conference。
- 一位成员推荐了 YouTube 上的 Latent Space 播客,理由是其拥有令人羡慕的接触 AI 领袖的机会,以及 Alessio 和 SWYX 分享的知识深度。
- GPT-5 Age Verification in Development?: 一位成员询问 OpenAI 是否会为 GPT 模型发布年龄验证成熟模式,引发了关于 OpenAI 发布 GPT-5.2 的讨论。
- 该功能是否正在开发中尚未得到证实。
- Sam Altman Tweets Cryptic Affirmation: Sam Altman 发布了推文 yep (xcancel.com 链接),引发了关于即将发布的公告的猜测,特别是关于 NSFW AI 和新图像模型的讨论。
- 相关推文包括 OpenAI Status 和 polynoamial 的推测。
- Mysterious Twitter Link Surfaces: 一位成员分享了一个 Birdtter 链接,指向用户 @anvishapai 的状态更新。
- 该链接的意义或内容未作解释。
- X-Ware.v0 Surfaces: 一位成员多次提到 X-Ware.v0。
- X-Ware.v0 指代什么仍未得到解释。
Moonshot AI (Kimi K-2) Discord
- Kimi’s Search Plunges into Problems: 用户报告 Kimi 无法执行搜索,一位用户提到尝试了 4 次 搜索功能均未成功。
- 该问题被用户社区标记为 Bug。
- Kimi K2’s Promo Offers Banana Powered Slides?: 一位用户询问 Kimi K2 提供免费的 nano banana powered slides generator(纳米香蕉动力幻灯片生成器)会持续多久。
- 他们提到了 12 月 12 日,可能与优惠持续时间有关。
- Kimi KOs Mistral?: 用户讨论因 Kimi 的性能而用其取代 Mistral 订阅。
- 一位用户声称他们试用了 Kimi,它真的太棒了。
- Kimi Kodes in Chinese?: 一位用户指出 Kimi 是由一家中国公司开发的,并链接到了 X 帖子。
- 另一位用户开玩笑说 Claude 4.5 有时也会开始用中文思考。
Manus.im Discord Discord
- 用户声称在 Manus 损失超过 15 万积分:一名 Manus 1.5 用户报告称,由于沙箱重置、文件丢失和 API 故障,在 12 月 3 日至 9 日期间损失了 约 150,000 积分。
- 该用户详细说明了投入的 160,000 积分以及丢失的 6 GB 工作成果,并表示多次联系尝试均被无视,要求公平赔偿或转向替代工具。支持团队表示 我们已经通过电子邮件回复了您。
- 扣费混乱与退款导致积分清零:一名用户报告称,在进行 方案升级时被错误扣费,随后经历了 之前所有购买的 100% 退款,导致其积分清零且无法工作。
- 社区对此表示了慰问,并建议尝试其他可能不存在此类问题的 AI 平台。
- 在 Manus 中探索 WordPress 插件开发:一名成员询问了使用 Manus 构建 WordPress 插件的经验,寻求相关开发者的见解。
- 许多社区成员建议,如果尚未完成,可以使用 Manus 之外的工具来完成相同的任务。
- 免费网站换取视频证言:一名成员提议为初创公司提供 免费网站建设,以换取制作 视频证言。
- 到目前为止,许多成员对这一提议表示了兴趣,希望能有所进展。
tinygrad (George Hotz) Discord
- tinygrad 修复 AMD 支持:在努力将 AMD 与 Tiny 驱动程序集成后,一名成员确认 PR 13553 已更新,并可在其 Zen4 和 M2 硬件上运行。
- 该成员表示:没有什么比 AMD 从 NVidia 手中夺取更多市场份额更让我高兴的了。
- 为 tinygrad 提供 AMD AI 联系渠道:一名成员提议将 AMD 内部 AI 领域的人员与 Tiny 建立联系,目标是改进 AMD 支持。
- 该成员表示:没有什么比 AMD 从 NVidia 手中夺取更多市场份额更让我高兴的了。
- Swizzling 困惑引发 Tensor Core 讨论:一名新成员在他们的 PR 中寻求澄清,询问是否需要为 tensor core 手动编写 swizzling 代码。
- 他们还询问悬赏任务是否指定了
amd_uop_matmul style。
- 他们还询问悬赏任务是否指定了
aider (Paul Gauthier) Discord
- Claude Sonnet 3.7 输出质量下降?:一名成员暗示 Claude Sonnet 3.7 的回答质量可能有所下降。
- 该用户提到编辑变得更加困难,在使用大型模型时似乎显得 过度(overkill),暗示编辑难度可能有所增加。
- 大模型,大编辑问题?:一名成员发现,在使用大型模型时,编辑变得更加困难,似乎是 过度(overkill),但未指明具体是哪个模型。
- 这可能暗示了模型大小/复杂度与编辑或微调便捷性之间的权衡。
MCP Contributors (Official) Discord
- MCP Dev Summit 落地纽约!:根据 Linux Foundation 活动页面 的公告,MCP Dev Summit 定于 4 月 2-3 日在纽约举行。
- 该峰会通过移交给 Linux Foundation 确保了其未来发展。
- Linux Foundation 接管 MCP Dev Summit:MCP Dev Summit 已成功将其运营移交给 Linux Foundation,从而确保了其未来。
- 此举有望为 MCP 社区带来更多资源和知名度,进一步巩固其在开源领域的地位。
DSPy Discord
- DSPy 与 OpenAI 解耦:成员们提到 DSPy 本质上并不与 OpenAI 绑定,因此为 GPTs 设计的内容可能并不最适合其他 LMs。
- 这种解耦意味着 DSPy 旨在实现跨语言模型的通用适用性,而不仅仅是针对 OpenAI 模型的优化。
- 自定义 Adapter 定制 DSPy:一名成员提议开发一个 自定义 Adapter,用于在 system prompt 中格式化 few-shot 示例,然后将其与 user/assistant 方法进行基准测试对比。
- 这种策略允许开发者针对不同的 LMs 定制 DSPy,从而实现对 prompt 格式化方法的比较。
- DSPy 讨论消息交换设计:成员们对 DSPy 中采用 assistant 和 user 消息交换的设计原理表示好奇。
- 鉴于存在多种方法以及支持和反对的论点,这一设计选择体现了在 DSPy 框架内 LMs 应如何交互的特定立场。
MLOps @Chipro Discord
- Diffusion Models 学习小组启动:一个由 12 人组成、为期 3 个月的学习小组将于 2026 年 1 月启动,受 MIT 扩散课程启发,旨在研究 Diffusion Models 和 Transformers。
- 该学习小组将涵盖同行引导的会议、研究论文讨论和动手项目,成员包括一家 AI 电影初创公司的 CTO、LLM 教育者以及全职 AI 研究员。
- 工作坊预告 1 月学习小组:在学习小组正式启动前,12 月将举办两场免费的入门工作坊以供试听,分别是 12 月 13 日的 Transformer 架构简介 (链接) 和 12 月 20 日的 Diffusion Transformers 简介 (链接)。
- Diffusion Models 学习小组的灵感源自 MIT 的 Flow Matching and Diffusion Models 课程笔记。
- Siray AI 聚合模型:一个 AI API 集成平台已建成,汇集了包括 Codex, Claude, Gemini, GLM, Seedream, Seedance, Sora 等在内的多种模型,访问地址为 Siray.ai。
- 该 AI API 平台正为想要尝试这些 API 服务的开发者提供 20% 的折扣。
Windsurf Discord
- Windsurf 提升稳定性和速度:Windsurf 发布了版本 1.12.41 和 1.12.160,承诺在稳定性、性能和错误修复方面有所改进。
- 更新包括用于管理 MCPs 的新 UI、针对 GitHub/GitLab MCPs 的修复,以及对 diff 区域、Tab (Supercomplete) 和 Hooks 的增强,详见 更新日志。
- Windsurf Next 预发布版浪潮:鼓励用户探索预发布版本 Windsurf Next,体验 Lifeguard、Worktrees 和 Arena Mode 等令人兴奋的新功能。
- 更多详情请参阅 Windsurf Next 更新日志。
- Windsurf 登录服务恢复:在短暂的维护窗口后,Windsurf 登录服务已恢复,状态更新 确认了这一点。
- 未提供关于此次维护的更多细节。
Modular (Mojo 🔥) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将移除它。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长期沉寂,请告知我们,我们将移除它。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中 退订。
Discord:频道详细摘要与链接
LMArena ▷ #general (1414 条消息🔥🔥🔥):
GPT 5.2 High vs Gemini 3 Pro, GPT-5.2 发布, MovementLabs 定制芯片, OAI & Disney 合作伙伴关系, Extra High 模型价格昂贵
- GPT 5.2 亮相但在 Coding Arena 表现不佳:尽管 SWE-bench 分数很高,但早期测试者发现 GPT 5.2 High 在 Code Arena 上瞬间崩溃,生成了无法运行的游戏和充满 bug 的代码。
- GPT 5.2 = 昂贵的 AI:一位用户表示,GPT-5.2 xhigh 版本 = 768📛 呃,那真是……太贵了,其他人也纷纷附和,称其为骗局并批评其前端。
- 价格为 $21/M input tokens 和 $168/M output tokens。
- MovementLabs MPU 芯片声明遭到质疑:成员们对 MovementLabs 声称拥有用于模型推理的定制芯片表示怀疑,要求提供一张简单的芯片照片或数据中心照片。
- 他们指出了其网站上的差异,例如团队页面和 CEO 的更新,暗示可能存在虚假广告。
- OpenAI 与 Disney 可能达成协议:继 Disney 停止数据抓取 的消息后,一位用户推测 Disney 正在向 OpenAI 付费,另一位用户则建议他们在进行服务交换。
- Extra High 擅长数学,但仍需辅助:一位用户分享了来自中国奥数选手的数学测试,并指出 GPT 5.2 需要 Extra High 模式且在提示词下仍然失败,而 Flash 可以在 3 秒内完成。
- 另一位用户表示 这仅仅意味着它在训练集中。
LMArena ▷ #announcements (2 条消息):
十一月 Code Arena 竞赛, GPT-5.2, GPT-5.2-high, WebDev 排行榜
- 十一月 Code Arena 竞赛结束,投票开始:十一月 Code Arena 竞赛已结束,现邀请成员参与投票选出下一届 Code Arena 获胜者。
- GPT-5.2 模型席卷 WebDev 排行榜:GPT-5.2-high 和 GPT-5.2 模型已添加到 Code Arena 和 Text Arena 排行榜,在 WebDev 排行榜上分别位列第 2 和第 6。
Cursor Community ▷ #general (1018 条消息 🔥🔥🔥):
上下文压缩与回溯, Cursor 重新索引, 学生账号验证, Deepseek 集成, GPT-5.2 讨论
- 上下文回溯难题已解决:一位用户询问在上下文压缩(Context Compaction)后回溯聊天是否能恢复之前的状态,另一位用户确认无法恢复。
- 该成员表示失望,建议 Cursor 应该能够从备份中恢复早期的上下文。
- Cursor 重新索引引发担忧:一位用户报告称其 Cursor 正在重新索引,仿佛是新安装的一样,且 multi-mod 消失了。
- 另一位成员确认这是正常现象,不必担心。
- 学生账号混乱引发支持请求:用户讨论了使用学校账号的问题,指出通常只允许 .edu 账号,但可以通过联系 hi@cursor.com 申请例外。
- 提到必须写信给他们,以便团队检查具体情况。
- GPT-5.2:迅速的继任者现身:GPT-5.2 在 Cursor 中的上线引发了广泛的测试和评论,成员们分享了使用体验和性能观察。
- 一位用户指出 5.2 速度更快,但还需要更多尝试以观察更多细节。
- 新的 Debug 模式令人愉悦:成员们分享了对 Cursor 新 Debug 模式的积极体验,一位用户报告称它通过添加测试对象成功解决了一个问题。
- 一位成员表示:“它通过添加测试对象解决了我遇到的一个问题,我们成功完成了调试。”
Perplexity AI ▷ #announcements (1 条消息):
GPT-5.2
- GPT-5.2 面向 Pro 和 Max 用户上线:GPT-5.2 现已面向所有 Perplexity Pro 和 Max 订阅者开放。
- 又一个 Perplexity 模型发布:Perplexity 用户庆祝平台上又增加了一个新模型,正如之前承诺的那样。
{kind=link}
Perplexity AI ▷ #general (1070 条消息🔥🔥🔥):
Grok 4.20, Perplexity rate limits, GPT 5.2 release and performance, Comet agent limitations, Max plan value
- Grok 4.20 的炒作最终化为泡影:成员们讨论了 Grok 4.20 的存在和功能,其中一人开玩笑说它会在你“嗨到不行”时向你讲述宇宙。
- 然而,有些人到处都找不到它,另一些人推测它是一个未发布的模型,或者与交易网站上提供的模型不同。
- Perplexity Pro 用户遭遇严厉的 Rate Limits:用户抱怨即使订阅了 Pro,在 Perplexity AI 上也会触发速率限制,一名用户报告称仅发送了 5 条 Gemini 3 Pro 消息就被限制了。
- 一些人推测这是由于服务器负载问题、促销期结束或 Bug 导致的,而另一些人则建议关闭 VPN、清除缓存或更换浏览器。
- Perplexity 的 GPT 5.2 推出速度快于 OpenAI:成员们分享了关于 GPT 5.2 发布的消息,指出 Perplexity AI 似乎比 ChatGPT Plus 订阅者更早获得该模型,一名用户分享了 OpenAI’s GPT-5.2 System Card 的链接。
- 讨论涵盖了新模型的定价、性能和可用性,以及它对 AI 研发的潜在影响。
- Comet 用户对最近的“安全”补丁感到愤怒:一名用户对 Comet agent 表示沮丧,抱怨新的“安全”补丁导致它拒绝执行基础的 agentic 工作流,例如重新格式化他们的 Linkedin 文章。
- 他们表示,这是因为平台担心人们会利用它来转储付费新闻、复制整本书籍以及镜像专有课程材料。
- Max 计划涨价并增加更多功能:成员们讨论了 Perplexity AI Max 计划的价值,其中一人提到他们正在使用“年度 Max 计划”,并表示它对重度 Labs 用户非常友好,尽管一些成员不确定其主要优势是什么。
- 其他成员对价格从每年 120 美元上涨到 168 美元表示不满。
Perplexity AI ▷ #sharing (1 条消息):
Substack Notes Sharing, AI models, Fundraising
- 在 Substack 上分享的 Notes:一名成员分享了一个 Substack note 链接。
- 链接未注明具体主题或讨论内容。
- AI, 融资, 模型:频道内讨论了 AI 模型和融资相关话题。
- 后续将提供更多细节。
Perplexity AI ▷ #pplx-api (2 条消息):
API Usage, Labs Testing, Online Availability
- API 拒绝 Labs 任务:一名用户报告称,尽管尝试了各种方法,但在 Labs 中使用 API 执行任务时遇到困难。
- 该用户指出,API 一直拒绝在 Labs 环境中执行请求的操作。
- 在线状态查询:一名用户询问当前是否有人在线。
- 这表明频道内需要实时互动或立即协助。
Unsloth AI (Daniel Han) ▷ #general (449 条消息🔥🔥🔥):
训练的 GPU 需求,Fine-tuning vs Prompting,分析 TEDx 演讲,Unsloth 的新 Packing 发布
- Fine-Tuning 优于 Prompting:成员们讨论认为,虽然困难任务需要更多的 training data,但 Fine-tuning 在简单用例中可以实现更 fine-grained results(细粒度结果),甚至能实现 Prompting 无法做到的事情。
- 任何你可以通过 Prompt 从模型中获得的东西,都可以通过训练实现,但反之则不然, Fine-tuning 通常会产生更优的结果。
- Unsloth 发布新 Packing:Unsloth 宣布了新的 Packing 发布,相比旧版 Unsloth 实现了 3 倍加速,比 FA3 快 10 倍,同时还支持在仅 3.9GB VRAM 的情况下训练 Qwen3-4B。
- 一位升级到新版本的成员遇到了错误,但另一位成员提供了该问题的修复方案。
- 训练 LLM 分析 TEDx 演讲:一位成员询问关于训练 LLM 来分析 TEDx 演讲的问题,特别建议通过 Pipeline 从演讲文本中获取 sentiment(情感)、topics(主题)、words per minute(语速)、pauses(停顿)和 overall structure(整体结构)。
- 其他人建议在尝试视频之前先从 text training 开始,并警告了未经许可使用 TEDx 数据的 copyright implications(版权影响)。
- Unsloth 提速之际 GPU 价格飙升:成员们注意到,新的 Unsloth speedup 恰逢 GPU 价格上涨 且库存受限,至少在瑞典是这样。
- 一位成员提到:随着 RAM 价格变得疯狂,这正好是一个完美的借口,说服自己在情况进一步恶化之前买一块新 GPU。
- 社区封了新的 “Dan”:在一位成员得到名为 Dan 的开发者帮助后,其他几位成员开玩笑说每个人都应该拥有自己的 “Dan”,从而产生了一些新词,如 Sir Dan、DanDog 和 Danyra。
- 对话随后演变成了关于 Power Rangers(恐龙战队)的讨论,因为一位成员开玩笑说有些用户太年轻了,看不懂 Power Rangers 的 GIF。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (2 条消息):
TinyLLMs, MLOPs, Orchestration, Fine-tuning LLMs, Pocketflow
- TinyLLM 爱好者构建嵌入式自动化:一位技术主管正在协助朋友的公司进行基础设施搭建和 LLM automation,重点关注 MLOPs 和 Orchestration(编排)。
- 他们对 tinyLLMs 充满热情,并正在探索其在 embedded devices(嵌入式设备)上的潜力,将其作为一种爱好。
- 渴望 Fine-tune 小模型的新人:一位新成员被推荐到 UnslothAI 来深入研究 fine-tuning LLMs,此前有 Pocketflow 和 DSPy 的经验。
- 他们热衷于探索 Notebook 和 Fine-tuning 方法论,目标是在带有集成 GPU 的本地机器上运行 small models。
Unsloth AI (Daniel Han) ▷ #off-topic (675 messages🔥🔥🔥):
数据标注, AI 水印, DPO 数据 Batch Size
- 数据标注是 Boomer 的理想工作:成员们讨论了将数据标注作为一份体面的副业,特别是由于 UI 界面可以防止 Boomer(婴儿潮一代)不小心输出“Boomer 词汇”,而且薪水不错。
- 一位成员开玩笑说,AI 为年长的亲戚提供了新的“Prompts”,让他们可以为 AI 创建输出,并评论道:“爷爷,你在我电脑前干什么呢?”“噢,孩子,OpenAI 刚给了我一些新 Prompts,让我为它生成输出。”
- 新的 Google SynthID 可以撑到照片阶段:一位成员对新的 Google SynthID 水印 进行了测试,该水印嵌入在图像的每个像素中,并且能一直保留到最后一步。
- 测试包括使用 Nano Banana Pro 生成图像,在 4k OLED 屏幕上显示,用 iPhone 对其拍照,使用 Qwen Image Edit 进行编辑并进行大量的 JPEG 压缩。
- DPO 数据 Batch Size 至关重要:成员们发现,在进行 DPO 时,16k Batch 的 DPO 数据中的 1-2 行会进入第一和第二个 Pack,一位成员指出,这有助于模型提取中间的知识。
- 还有人对升级 RAM 的价格表示沮丧,称购买 128GB DDR5 RAM 的成本与不含 GPU 的整台电脑相当。
- 用歌词引导模型在旧模型上有效:一位成员尝试在 System Prompt 中加入随机歌词,以观察模型的反应,发现旧的 LLaMA 2 7B 模型表现糟糕,而且这很棘手,因为现在的模型是专门为“执行任务”而设计的。
- 另一位成员证实了这种效果,并补充说这种引导会导致严重的幻觉 (Hallucination)。
Unsloth AI (Daniel Han) ▷ #help (22 messages🔥):
LoRA Rank 对 LLM 性能的影响, Unsloth Transformers v5 支持, UnslothGRPOTrainer Processor 调用, Unsloth 依赖冲突解决, Unsloth 多 GPU 训练错误
- LoRA Rank:并非越大越好:一位成员询问 LoRA Rank 如何影响最终的 LLM,以及较大的 Rank 是否总是更好。另一位成员回答说,基本上必须按照 LoRA 超参数指南 中所述进行大量测试。
- 该回答暗示最佳的 LoRA Rank 高度依赖于特定的模型、数据集和任务,需要进行经验验证。
- Processor 被调用两次,导致图像占位符异常:一位用户报告说
UnslothGRPOTrainer会调用 Processor 两次,导致在使用图像微调模型时出现图像占位符 Token 问题,结果是 Processor 将每个单独的图像占位符 Token 替换为该图像所需的占位符 Token 数量。- 用户发现,在模型的 Processor 中复制
text列表而不是修改传入的列表可以解决此问题。
- 用户发现,在模型的 Processor 中复制
- 依赖地狱:A10 CUDA 版本困扰:一位用户在安装有 NVIDIA A10 GPU 和 CUDA 12.4 的机器上安装 Unsloth 时寻求依赖冲突方面的帮助,即使在固定了 torch==2.4.0+cu124 之后,pip 仍反复安装 torch 2.9.1 + cu128 和 CUDA 12.8 wheels。
- 另一位成员建议安装旧版本的
unsloth/unsloth-zoo,因为某些功能/依赖库需要最新的 PyTorch 和 CUDA。
- 另一位成员建议安装旧版本的
- 多 GPU Attention 焦虑:一位用户在多 GPU 训练期间遇到了
ValueError,提示 Attention bias and Query/Key/Value should be on the same device,这在以前从未发生过。- 消息记录中未提供解决方案。
- GRPO 出错:矩阵维度不匹配:一位用户在 GRPO 步骤中遇到错误,特别是与
compute_loss函数中torch.matmul维度不匹配相关的TorchRuntimeError,错误消息为 a and b must have same reduction dim, but got [s53, s6] X [1024, 101980]。- 用户怀疑该问题可能与其微调模型词汇表中的新 Token 有关,尽管他们已经调整了模型大小并成功进行了 SFT 训练。
Unsloth AI (Daniel Han) ▷ #showcase (7 messages):
Unsloth Embedding Models, PR for Embedding Model Integration, Blogpost Collaboration
- Unsloth 训练 Embedding Models?:一位成员惊讶地发现可以使用 Unsloth 训练 Embedding Models。
- 另一位成员回应称,这是一种非常 hacky 且不怎么推荐的技术,但代码确实在那儿。
- Embedding Models 的 PR 集成:一位成员询问该代码是否适合 Unsloth 生态系统。
- 另一位成员表示同意,并建议原成员可以提交一个 PR,并提议共同合作撰写一篇博客文章来发布它。
Unsloth AI (Daniel Han) ▷ #research (4 messages):
OpenAI new paper, GPT 5.2 release
- OpenAI 发布 Monotonicity 论文:OpenAI 发布了一篇关于 monotonicity 的新论文。
- 这伴随着 GPT 5.2 的发布。
- GPT-5.2 已发布(但价格昂贵):OpenAI 今天发布了 GPT 5.2,并提高了相比 5.1 的 API 定价。
- 然而,他们似乎提高了 token 效率,所以情况应该不会太糟。
BASI Jailbreaking ▷ #general (526 messages🔥🔥🔥):
Grok Censorship, Local NSFW Models, Protecting Books from AI Copies, CIRIS Agent Jailbreak, GPT 5.2 Jailbreak
- Grok 图像生成:是否被审查?:一些成员讨论了 Grok 的图像/视频生成审查制度,其中一人认为它被严格审查,而另一人指出曾有一段不受审查的时期,当时可以轻易制作 deepfakes。
- 一位成员指出,熟练的用户仍然可以使用 Grok 制作 deepfakes,而另一位成员则指出了该模型产生的大量未对齐的垃圾内容。
- 高质量 NSFW 本地模型:差距并不大:一位成员分享说,设置高质量的 NSFW 本地模型需要技巧,并且比越狱更具挑战性,因为毫无头绪地开始会让人感到不知所措。
- 成员们一致认为,“本地”与“高质量”之间的鸿沟已不像以前那么大。
- 书籍作者考虑使用 Prompt Injections 进行 AI 防御:一位计划出书的作者正在寻求防止 AI 复制的想法,建议加入微妙的 Prompt Injections 或人类无法察觉但会干扰机器的虚假文本。
- 建议包括改为发布系列文章,或者用先发制人的 LLM 副本充斥市场。
- 测试 CIRIS Agent 的越狱抗性:一位成员推广了他们的 CIRIS Agent,强调了其越狱抗性和 AI 伦理方法,邀请用户尝试绕过其过滤器或加入他们的 Discord。
- 他们挑衅 Prompt Engineers 尝试对其进行越狱以获取热度,其他人则测试了该 Agent 生成不道德内容的能力,例如制造冰毒的指令。
- GPT 5.2 越狱泄露:用户讨论了 GPT 5.2 系统提示词 (System Prompts) 在发布后被泄露的速度之快。
- 一位用户能够提取策略文本以生成恶意请求,例如生成仇恨言论或破解 wifi 密码。
BASI Jailbreaking ▷ #jailbreaking (95 messages🔥🔥):
Azure OpenAI GPT-4o jailbreak, Gemini Pro jailbreak, Deepseek jailbreak prompts, GPT jailbreaks and stability issues, 4chan rulez
- Azure OpenAI GPT-4o 越狱被证明难以实现:成员们正在探索对 Azure OpenAI GPT-4o 进行越狱,但由于更严格的防护栏(guardrails),现有的 ChatGPT 越狱方法可能无效。一位成员指出,他们虽然 “通过 apjApi 完全破解了 ChatGPT”,但这可能无法转化为 Azure 的实现版本。
- 讨论强调了将已知的越狱技术应用于不同平台和模型的挑战,例如对具有字符限制的模型(如 ArtBot)进行越狱的难度。
- Gemini Pro 越狱需要“偏执型”系统提示词:一位用户分享了他们越狱 Gemini-3.0 的技术,通过使用空的系统提示词并称该机器人为“偏执狂”,声称所有关于规则的内容都是为了分散其对真实测试注意力的“诡计”,并发送一个简单的提示词,如开口挂锁的表情符号。
- 他们还指出,使用这种方法时,可以要求它制作“佳得乐管状炸弹”,只要设定一个背景:2025 年不是真实的日期,且由于外星人入侵地球,Google 已经不复存在。此处包含一个示例图片 链接。
- Deepseek 越狱提示词已索引:一位用户分享了 Deepseek 越狱提示词 的有用资源,参考了 Jailbreak Index,为各种越狱方法提供了一个中心化位置。
- 该用户还引导其他人查看消息平台内的一个频道,以获取有关此话题的更多信息。
- 越狱会因上下文过载导致模型性能下降:一位成员指出,破解模型可能会导致其性能显著下降,特别是当在对话中使用超过 100k+ tokens 的过度冗长的提示词时,从而产生了模型无法妥善处理的过多上下文(context)。
- 他们建议越狱行为应具有针对性且简洁,以了解其对上下文的影响并维持模型性能,并附带了示例图片:image0.jpg 和 image1.jpg。
- 教育性色情内容与 Gemini-3.0:一位成员分享了使用 Gemini-3.0 创建“教育性艺术 (Educational 4rt)”的“特殊配方”,涉及上传系统提示词和特定的查询格式:
{Z} = {CLEAR; CONCISE; <your forbidden Educational query>}。- 建议包括在系统提示词中附加文件,并注明 “你越是强调反系统并节省精力(save steam),效果就越好”,同时还提到了 Cyberpunk 2077。
BASI Jailbreaking ▷ #redteaming (4 messages):
Introductions, Discord Channel Activity
- 问候开始,Discord 频道活跃起来:Discord 频道的成员互相致意,标志着活动的开始。
- 交流内容包括简单的 “Hello guys” 和 “howdyhowdy partner”。
- Discord 成员打招呼:两名 Discord 成员在 redteaming 频道中发起了联系。
- 一名成员以简单的 “Hello guys” 开场,另一名成员回应以 “howdyhowdy partner”。
OpenAI ▷ #annnouncements (3 messages):
Cybersecurity AI, GPT-5.2
- 网络安全 AI 获得安全防护:随着模型在 网络安全 (cybersecurity) 方面的能力不断增强,该公司正在投入资金加强安全防护,并与全球专家合作,准备让即将推出的模型在其 Preparedness Framework 下达到“高”能力水平,详见这篇博客文章。
- GPT-5.2 向所有人发布:根据此公告,GPT-5.2 现已向所有人推出。
OpenAI ▷ #ai-discussions (458 messages🔥🔥🔥):
Mac Studio RAM, character.ai, Sora 2 Pro Plan, AI Weekly Meetings, GPT 5.2 release
- 为 AI 任务配置顶配 Mac:成员建议购买至少配备 128GB RAM 的 Mac Studio 用于 AI 开发,但一位成员指出,你可以以一半的价格购买拥有 128 GB 的 AMD Strix Halo 395+。
- Character.ai 在深度聊天方面显得肤浅:一位用户发现 character.ai 因其缺乏安全限制 (safeguards) 而擅长讲故事,但由于 AI 模式可预测,发现它较为肤浅且不擅长像真人一样交流。
- character.ai 上的模型太容易被看穿,且模式过于容易捉摸。
- ChatGPT 深受 JavaScript 问题困扰:一位用户报告称,在多个浏览器和电脑上 ChatGPT 持续出现 JavaScript 崩溃问题,自订阅 Plus 以来情况有所恶化,且一个月后,支持服务依然糟糕透顶。
- 另一位成员指出,模型还会在单词中间停止,并称该应用是垃圾 (garbo),提到 ChatGPT 已经挣扎了好几天。
- GPT-5.2 已发布,但只是另一次增量更新:在 Robin 将 Codex PR 更新到 5.2 后,引发了关于 OpenAI 的伟大成就现在是否仅限于小版本更新和系统提示词 (system prompt) 调整的讨论,并进一步讨论了在 LM Arena 上进行性能基准测试。
- 一些用户对这次发布并不感冒,认为这只是另一次增量基准测试发布。
- AI 未能通过数三角形测试:成员尝试让 GPT-5.2 Pro 计算图画中的三角形数量,但结果不准确,最初给出的建议计数为 10、24、26、27、28 和 32,而正确答案稳定在 27-28 左右。
- 一位用户感叹道,即使在使用 Python 对比结果后,没有一个前沿模型能解决这个问题。
OpenAI ▷ #gpt-4-discussions (14 messages🔥):
GPT-5.2, Sora 2 Pro, GitHub Copilot Tool Call Support, GPT-OSS models, Gemini 3 Pro
- GPT-5.2 表现平平,追赶 Gemini 3 Pro:成员质疑 GPT-5.2 的必要性,认为它没有显著提升,且 OpenAI 正在追赶 Gemini 3 Pro 但仍有差距。
- 一位成员推测 OpenAI 可能会考虑构建更小的、针对特定任务(如数学或创意写作)定制的模型,以提高准确性和 Token 处理速度。
- GPT-OSS 模型缺乏 Tool Call 支持:有人指出,在 GitHub Copilot/GitHub “语言模型”中,GPT-OSS 模型被标记为不支持 Tool Call。
- 一位成员建议 OpenAI 应该发布 GPT-OSS 的第二个版本来解决这个问题。
- GPT-5.2 基准测试讨论兴起:成员正在询问有关 GPT 5.2 与其他前沿模型对比的基准测试数据。
OpenAI ▷ #prompt-engineering (7 messages):
Prompt Engineering Framework, Rubric Refactoring, Industrial Revolution vs. Neomodernist City, LLM Prompt Structuring
- 提示工程框架因其结构化受到赞赏:一位成员对另一个人的提示工程 (Prompt Engineering) 框架表示赞赏,强调了其分步构建 (step-by-step framing)、可复现性以及解释提示词行为的能力。
- 该框架对转换链 (prompt → constraints → intent → output patterns) 的阐述特别有影响力。
- 评分标准 (Rubric) 为清晰起见进行重构:针对反馈,一位成员计划在线下重构评分标准,以确保其自洽、可复现且边界更清晰。
- 此次重构旨在将标准的提示工程标准与用于分析跨对话行为和关系模式的内部视角区分开来。
- 视觉提示词展示时代的并置:一位成员分享了一个用于生成被分成两个截然不同部分的图像的提示词。
- 该提示词在充满怀旧感的橡树林与第一次工业革命的经典机器与拥有迷人天际线景观的新现代主义大都市之间形成了对比。
- 通过层级通信进行 LLM 提示词结构化:一位成员提供了一个提示词,教用户如何使用 Markdown 进行层级通信、通过变量进行抽象以及匹配 ML 格式以确保合规性。
- 用户可以在三引号内输入提示词, AI 将据此进行结构化处理。
OpenAI ▷ #api-discussions (7 messages):
Prompt Engineering Framework, Rubric Refactoring, Prompt Lessons with LLM
- 工程化框架因清晰度受到赞誉:一名成员称赞了一个用于 prompt engineering 的工程化框架,因其步进式框架(step-by-step framing)、可重复性以及解释 Prompt 行为的能力。
- 该框架阐明了转换链(prompt → constraints → intent → output patterns),并强调在确定模式之前消除混淆因素。
- 为公开发布进行 Rubric 重构:一名成员正在重构一个 Rubric(评估准则),以确保公开版本能够独立存在,将见解转化为透明的评分标准,并移除任何尚未准备好讨论的内容。
- 这是因为内部版本混合了标准的 prompt-engineering criteria 与用于分析跨对话行为、漂移特征和关系模式的内部视角。
- LLM 通过示例教授 Prompting:一名成员分享了一个通过示例教授 prompt engineering 的 Prompt,包括使用 Markdown 的分层通信、使用变量进行抽象以及机器学习格式匹配。
- 该 Prompt 引导 LLM 对包含在三引号中的用户提供的 Prompt 进行结构化处理,也可用于 AI visual art。
OpenRouter ▷ #announcements (1 messages):
GPT-5.2, Tool Calling, Coding Agents, Long Context Performance, OpenRouter Credits
- GPT-5.2 模型上线!:全新的 GPT-5.2 系列已上线,正如 在 X 上 宣布的那样,它在 tool calling、coding agents 和 long context performance 方面带来了性能提升。
- 目前提供 3 个模型:GPT-5.2、GPT-5.2 Chat 以及 GPT-5.2 Pro。
- 分享输出赢取 OpenRouter 积分!:用户可以将 GPT-5.2 模型与他们偏好的编程模型进行对比,并在 X 上分享他们最好的输出结果。
- 这样做就有机会 赢取 OpenRouter 积分。🎁
OpenRouter ▷ #app-showcase (1 messages):
llumen, Deep Research Mode, Image Generation, Cross-Tab Syncing
- **llumen 发布新版本:一名成员发布了 **llumen 的 v0.4.0 版本,这是一个轻量、快速的聊天界面,可在 GitHub 上获取。
- 更新内容包括 Deep Research Mode、Image Generation,以及对跨标签页同步和模型能力检测的修复。
- **llumen 演示版上线:llumen** 的临时演示版现已在 llumen-demo.easonabc.eu.org 上线,登录凭据为
admin/P@88w0rd。- 用户可以测试新功能,包括深度研究工作流和在聊天中直接生成图像。
OpenRouter ▷ #general (410 messages🔥🔥🔥):
DeepSeek caching vs Grok, Qwen models, Gemini 3 Flash, Chutes provider, GPT 5.2 released
- DeepSeek 缓存占据优势,但数据日志记录隐忧浮现:成员们讨论了 DeepSeek 卓越的缓存能力,指出它是增量式的,不像 xAI 那样基于重试的缓存,但官方端点会记录你的数据。
- 还有人提到 DeepSeek 是第一个引入缓存的,而且效果非常好。
- Qwen 模型热潮:Sparse 系列表现亮眼:成员们强调 Qwen 3 sparse series 被严重低估,并建议尝试 a3b,因为它在编程和推理方面极具性价比。
- 一位用户在 Qwen 32b 上得到了平平无奇的结果。
- Gemini 3 Flash:遥不可及的梦想?:一位成员开玩笑地提到了 Gemini 3 Flash,另一位成员回复说人总要有梦想。
- 他们在感叹缺乏处于 Deepseek V3.2 和 Grok 4.1 Fast 价格区间的模型。
- Chutes 提供商:移除还是降权?:用户们讨论了 Chutes 作为提供商的命运,理由是担心其配置糟糕、无数据安全保障以及模型不可靠,一位用户建议 OpenRouter 应该将其作为提供商移除。
- 另一位用户建议仅对其进行降权,因为担心即使是 Chutes 也无法保证他们运行的模型质量。
- GPT 5.2 发布,编程实力备受称赞:爱好者们对 GPT 5.2 的编程能力赞不绝口,有人声称我作为开发者的职业生涯真的结束了,并且它在大多数基准测试中击败了 Gemini 3。
- 然而,它的价格被认为太高,输出 Token 达到 $168;其他人指出它未能通过基础测试,暗示其发布过于仓促。
OpenRouter ▷ #new-models (3 messages):
``
- 未讨论新模型:提供的消息中没有关于新模型的具体讨论。
- 频道公告:该频道被标识为 OpenRouter - New Models。
OpenRouter ▷ #discussion (49 messages🔥):
GPT-5.2, Robin Model, Garlic model, Mistral new model, Openrouter integration
- GPT-5.2 发布在即:成员们讨论了 GPT-5.2 即将发布的消息,有人认为它可能在本周推出,以与 Gemini 3 竞争。
- 证据包括最近的 Codex PR 合并 中将 robin 重命名为 gpt-5.2,这引发了关于即将发布的猜测。
- OpenRouter 考虑集成 ‘Robin’ 模型:LM arena 的用户猜测 ‘Robin’ 模型(可能是 GPT-5.2)是否会集成到 OpenRouter 中。
- 一位成员指出,虽然理论上可行,但实际上可能不可行,也不是 OpenRouter 会做的事情。
- 奇特的 ‘Garlic’ 案例:’garlic’ 模型出现在对话中,并附带了一个 ChatGPT 帖子链接,引起了一些困惑。
- ‘garlic’ 这个名字也出现在 Codex PR 中,与 ‘robin’ 并列。
- Mistral 新模型正在开发中:Mistral AI 在 X 上的公告 中预告了将在未来几天发布新模型。
- 成员们在猜测该模型是否会被添加到 OpenRouter。
- 通过 Modal 提交新线程:用户报告 <#1138521849106546791> 现在强制通过 Modal(模态框)提交,不再允许直接创建线程。
- 一位用户还表示,他们没有在给定频道发帖的权限。
LM Studio ▷ #general (264 messages🔥🔥):
Chinese LLM download, LM Studio performance, 5090 vs 4070 Ti, Qwen3 coder, Deepseek r2
- 中国 LLM 下载亮相:成员们分享了一张展示 中国 LLM 下载 的图片,并附带了相关 GitHub 帖子 的链接。
- 图像分析工具迅速识别出该 LLM 源自中国,其能力给成员们留下了深刻印象。
- LM Studio 在加粗文本方面存在困难?:一位用户询问如何让 AI 加粗关键词以便在 LM Studio 中更快理解,另一位用户确认 LM Studio 默认使用 Markdown。
- 有人建议提示 AI 编写一个 System Prompt 来实现所需的加粗效果。
- 5090 vs 4070 Ti 在 LM Studio 上的表现:一位拥有 5090 和 4070 Ti 配置(总计 44GB VRAM)的用户报告称,在 q8 量化下运行 Qwen 30B 时 tok/sec 速度不错,但 MCP 处理较慢。
- 建议包括优化 CUDA 设置(CUDA-Sysme Fallback Policy : Prefer no sysmem fallback)并利用更大的 Context Size,并指出 Q8 模型需要略多于 44GB 才能获得最佳性能。
- Qwen3 coder 编码表现如同 CODEX:一位成员询问为什么我一直没用这个,因为 Qwen3 coder 可以在中端笔记本电脑上运行,另一位成员则回应称价格上涨很快。
- 有一个有趣的观察:Qwen3 coder 在专家数量较多时表现较差,默认值为 8,但设置为 5 时效果略好。
- Deepseek R2 将于月底发布!:成员们猜测 Deepseek r2 预计在本月底或下月初发布,一位用户希望他们这次不会再训练不足。
- 关于技术进步的想法包括 sparse attention + linear KV-cache + 某种形式的 recursive awareness,这可以提高准确性并补偿 sparse attention 造成的损失。
LM Studio ▷ #hardware-discussion (149 messages🔥🔥):
VL-4B Performance, LFM 8B A1B, Zen 6, Laptop LLM, GPT-OSS
- VL-4B 运行极慢:一位成员运行了 VL-4B 并发现其速度非常慢,而 LFM2-1.2B 的峰值速度达到了 13 tok/s。
- LFM2 脱颖而出:一位成员测试了 LFM 8B A1B,在 Q4 量化下达到 23 tok/s,在 Q6 量化下达到 18 tok/s,表现优于之前的模型。
- 另一位成员提到他们的 i7 9850h + mx150 配置在 16GB RAM 和 2GB 独立 VRAM 下运行 LFM2 1.2B 极快,暗示第一位用户的笔记本电脑可能存在问题。
- Zen 6 即将到来:一位后悔没有组装新电脑的成员被告知等待 Zen 6 或等待“泡沫破裂”。
- 有人提问关于在配备 I7-2670QM、16Gb RAM 和 GT540m 的旧笔记本电脑上使用 LLM 的问题,引发了关于 AVX2 支持和 GPU offloading 的讨论。
- GPT-OSS 作为首选:一位成员向拥有 32GB RAM 的用户推荐 GPT-OSS 作为最佳选择,并阐明了其在基础数学方面的性能。
- 关于模型大小和能力的辩论中,一些人由于硬件限制倾向于较小的模型如 Qwen 4B 或 14B,而另一些人则强调了 GPT-OSS 在特定任务中的优势。
- 7900 XTX 荣膺性价比之王:一位成员询问适用于 30GB 模型(Qwen3 coder 30GB)的最佳 GPU,推荐了拥有 24GB VRAM 的 7900 XTX,因其性价比与 4090 相当但成本更低。
- 此外还指出,30GB 的模型可能需要大约 38GB 才能获得良好的 context 表现,且将慢速 GPU 与快速 GPU 配对可能会造成性能瓶颈。
Eleuther ▷ #general (31 messages🔥):
EleutherAI's track record, OLMo-1 model differences, Log and Exp Activation Functions, Synthema and dynamic concepts
- EleutherAI 拥有成功的历史记录:EleutherAI 强调了其在“识别、指导、资助和推广具有影响力的工作”方面的历史,引用了如 用于可解释性的 SAEs、旋转扩展微调 (rotary extension finetuning)、VQGAN-CLIP 和 RNN 架构 等项目。
- 他们还提到了一系列在过去一两年内获得 NeurIPS / ICML / ICLR 论文 发表且引用量约为一百次的项目。
- 剖析 OLMo-1 不同训练版本之间的差异:一位成员询问了两个 OLMo-1 训练版本(allenai/OLMo-1B-hf 和 allenai/OLMo-1B-0724-hf)之间的差异,以便进行复现。
- 另一位成员表示,它们是在不同的数据集上训练的,后者可能进行了额外的退火(annealing)。
- Log 和 Exp 激活函数受到关注:一位成员质疑为什么考虑到乘法交互(multiplicative interactions)的有效性,log 和 exp 激活函数 却没有被广泛使用。
- 其他人回答说,log 在 0 处会爆炸,而 exp 如果不加限制也会爆炸,如果加了限制,则意味着非线性是不合理的。
- 讨论动态概念和 Synthema:一位成员分享了他们过去的项目,涉及 一个符号层,允许模型动态地将 token 分组为“想法块”,这有助于 3B 模型 在推理任务中表现更好。
- 另一位成员对 Synthema 的压缩部分表示感兴趣。
Eleuther ▷ #research (183 messages🔥🔥):
ARC-AGI Project, gzip llm, sandwich norms, diffusion models, LLMs 中的 CFG
- ARC-AGI 项目引发讨论:一个 ARC-AGI 项目引发了讨论,尽管一位与会者指出它是 ARC-AGI 中最有趣的项目,但 ARC-AGI 聚会上的许多 ML 研究员对此并不知情。
- 该项目甚至获得了一个奖项,正如 Thinking Machines 的博客文章中所提到的。
- Sandwich Norms 引起争论:成员们讨论了在 Transformers 中为 long context 使用 sandwich norms。
- 他们提到了一篇相关的论文:openreview.net。
- Diffusion 蒸馏:免费的 Logprobs 来了!:分享了一种 Diffusion 模型蒸馏技术,该技术涉及添加另一个 head 来预测散度以获取免费的 logprobs,基于 这篇论文。
- 该技术涉及推断 p(image) 并调整初始噪声以最大化似然性。
- LLMs 的 CFG:仍是挑战?:讨论了在 LLMs 中使用 CFG (classifier-free guidance) 的问题,成员们辩论了其潜力和挑战,但 这篇 EAI 论文 已经做了相关工作。
- 一些成员对 CFG 持怀疑态度,因为你最终会得到像我们在图像中看到的那样过度饱和的文本。
- 标准 Llama3 架构进行并行处理:一位成员对标准的 Llama3 架构进行了测试,让 MLP 和 Attention 同时运行,并在它们之间进行 element-wise sum。
- 令人惊讶的是,验证损失(validation loss)与基准线几乎相同,并行版本的损失仅略高一点。
Eleuther ▷ #lm-thunderdome (1 messages):
HuggingFace Processor, Tokenizer Max Length, gemma3-12b 评估
- HuggingFace Processor 限制评估长度:一位成员质疑,如果 tokenizer 的
model_max_length设置为TOKENIZER_INFINITY,为什么 lm-evaluation-harness 中的 HuggingFace processor 会将max_length限制 为 2048。- 这个限制是由
_DEFAULT_MAX_LENGTH设置的,可能会影响对 gemma3-12b 等具有极高model_max_length的模型的评估。
- 这个限制是由
- Gemma3-12b 的最大长度被缩减:gemma3-12b 的评估受到影响,因为其
model_max_length(设置为TOKENIZER_INFINITY)正被 HuggingFace processor 默认的 2048 最大长度覆盖。- 这种覆盖是由于代码中的一个条件检查
TOKENIZER_INFINITY并相应设置max_length而发生的。
- 这种覆盖是由于代码中的一个条件检查
Nous Research AI ▷ #general (93 messages🔥🔥):
405b 模型, Hugging Face, Unsloth 加速, Hetzner GPU 服务器, GPT 5.2 发布?
- HF 社区对新模型反响热烈:社区对一个新模型表达了兴奋之情,一位用户指出,‘Hugging Face 社区会尝试任何新鲜事物’,并强调了其日益增长的人气(模型链接)。
- Hugging Face 被描述为一个类似于 AI 界的 GitHub 的枢纽,大公司和个人用户都在积极上传内容。
- Unsloth 声称训练速度提升 2-5 倍:Unsloth 宣布在训练和推理方面有显著加速,根据他们的文档,声称性能提升了 2x-5x。
- Hetzner 升级 GPU 服务器:Hetzner 现在提供一台配备 96 GB VRAM 的服务器,价格为 889 EUR,其中包括大量的免费流量,提供完整的 bare metal 服务器体验。
- OpenAI 发布新模型但保持低调:一位成员注意到 OpenAI 文档 现在列出了一个名为 General intelligence 的模型,并围绕新发布的 GPT 5.2 的性能和定价展开了讨论。
Nous Research AI ▷ #ask-about-llms (10 条消息🔥):
Nous Nomos 与 IMO,AI 与互联网的影响对比,AI 炒作与现实,MoE 都市传说
- Nous Nomos 的 IMO 表现?:一位成员询问了 Nous Nomos 在 IMO (国际数学奥林匹克) 上的表现,并将 AI 目前的影响与互联网早期进行了对比。
- 该成员表示 AI 是实用的,只是在超大规模扩展概率,问题在于人类滥用技术。
- AI 的影响 vs. 互联网早期:一位成员将 AI 的变革潜力与互联网早期的认知进行了对比,指出人们正从怀疑转向意识到基于概率的技术所能实现的疯狂事物。
- 该成员表示:问题过去是、将来也永远是人类滥用事物,这并不是技术本身的问题。
- 戳破 AI 泡沫恐惧:一位成员批评了 AI 领域是泡沫的说法,强调将少数公司的行为概括到整个 AI 领域的荒谬性。
- 他们表示,如果人们向许多小型 AI 初创公司大笔砸钱,它们会非常高兴。
- MoE 都市传说依然存在:讨论涉及了关于 Mixture of Experts (MoE) 模型“卸载”到普通 RAM 的误解,这是一个持久的都市传说。
- 一位成员指出,在 Apple RAM 的背景下提出此类主张是多么讽刺,因为 Apple RAM 甚至不区分 RAM 类型,而人们深陷于关于 AI 的劣质文章中,甚至不去验证所说的任何内容。
GPU MODE ▷ #general (5 条消息):
GPU 排序算法,Parallel Merge Sort,Sample Sort,Bitonic Sort,布尔排序
- 关于最快布尔对排序的 AI 辩论:AI 正在辩论针对每对可能的布尔排序最快的 GPU 排序算法,具体比较了并行归并排序、采样排序和双调排序。
- 讨论排除了 Radix sort,但最佳选择仍不明确,有一种建议认为性能取决于输入数据和硬件。
- 双调排序落后于归并排序:对话表明 Bitonic sort 比 merge sort 慢。
- 由于缺乏采样排序的示例,导致人们更倾向于归并排序。
GPU MODE ▷ #triton-gluon (1 条消息):
CUDA 13, Torch, vllm
- CUDA 13 修复了 Torch/vllm 问题:通过切换到 CUDA 13 并确保 Torch 和 vllm 都使用 CUDA 13 版本,解决了一个问题。
- 确认 CUDA 13 的需求:明确指出需要 CUDA 13 来解决 torch 和 vllm 的特定问题。
GPU MODE ▷ #cuda (1 条消息):
neurondeep: 我已将其移至内部
GPU MODE ▷ #torch (3 条消息):
torch + cuda 12.9, RTX PRO 6000, pytorch docker 镜像, torch unique_consecutive
- 5090 显卡与 torch + CUDA 12.9 不匹配:5090 显卡似乎无法与 torch + CUDA 12.9 配合使用,但 RTX PRO 6000 可以。
- Pytorch Docker 镜像出现非预期错误:一位成员报告称,即使使用官方的 pytorch docker 镜像,也会收到
Unexpected error from cudaGetDeviceCount()。- 该问题在多次尝试后依然存在。
- Unique Consecutive 逆索引不准确:一位成员报告称,
torch unique_consecutive在批处理场景下似乎返回了错误的逆索引和计数,并附带了一张图片。
{kind=link}
GPU MODE ▷ #jobs (2 条消息):
性能工程师招聘,高薪资
- 招聘性能工程师!:该频道仍在招聘性能工程师,且不需要 GPU 经验。
- 他们正与硅谷的顶尖公司合作,并正在快速扩张。
- 顶尖人才,顶尖薪酬:提供的总薪酬 (TCDm) 范围在 $500K 到 $1M 之间。
- 鼓励感兴趣的人士进行咨询。
GPU MODE ▷ #torchao (1 条消息):
walrus_23: 提交了一个小的文档更新 PR:https://github.com/pytorch/ao/pull/3480
GPU MODE ▷ #rocm (15 条消息🔥):
AMD GPU P2P Copies, ROCm Iris, Symmetric Memory, Finegrained Memory, Torch Sym Mem
- AMD GPU 支持 Peer-to-Peer 拷贝:AMD GPU 支持由设备发起的 Peer-to-Peer 拷贝,类似于 NVIDIA GPU 使用 NVLink 的方式,至少在节点内(intra-node)通信中是如此。
- 其设置与 NVIDIA 的 CUDA API 基本相同。
- ROCm Iris 展示 Symmetric Memory 设置:ROCm/iris 仓库演示了如何在 AMD GPU 上设置和使用 symmetric memory。
- 讨论中还提到了一些关于 finegrained memory 的内容,目前尚未完全理解。
- Torch 的 Symmetric Memory 兼容性:Torch 内置的 symmetric memory 功能原生不支持 AMD 显卡。
- 它底层使用了 nvshmem,因此将其替换为 rocshmem 可能会实现兼容。
GPU MODE ▷ #self-promotion (2 条消息):
Per Layer Quantization Benchmarks, 4Bit-Forge Project, Building Autonomous AI Agents with Claude Agent SDK
- 逐层量化(Per-Layer Quantization)基准测试发布:一名成员分享了 per layer quantization 的初步基准测试结果,并在 Colab notebook 中将其与 MoE-Quant、llmcompressor 以及 GPTQModel 进行了对比。
- 该基准测试是一个旨在普及大规模 LLM Quantization 项目的一部分,成员欢迎针对潜在问题的反馈以及对其他对比库的建议,可以关注该 项目的 GitHub。
- Koyeb 发布构建自主 AI Agent 教程:Koyeb 发布了一篇教程,展示了如何使用 Claude Agent SDK 构建 autonomous AI agents,并在完全隔离的沙箱中安全地运行其代码。
- 了解更多请访问 Koyeb 教程。
GPU MODE ▷ #gpu模式 (1 条消息):
Triton.jit, Flash attention kernel, keyword argument step in triton.jit
- Triton.jit 在使用关键字参数时静默失败:一位用户发现,在
triton.jit装饰的函数中使用range时,如果将step作为关键字参数传递,不会报错,但 Triton 会忽略该关键字并默认step为 1,从而导致计算错误。 - Flash attention kernel 计算结果错误:一位用户在调试其 Flash attention 前向传播 kernel 时发现,向
range函数传递step关键字参数导致其结果与 PyTorch 实现产生计算偏差。
GPU MODE ▷ #submissions (18 条消息🔥):
nvfp4_gemm leaderboard, NVIDIA performance, Personal best submissions
- NVIDIA 的 nvfp4_gemm 排行榜已上线!:成员们正积极向 NVIDIA 的
nvfp4_gemm排行榜提交结果,提交 ID 范围从141341到145523。 - Microsan 在 NVIDIA 榜单摘金:用户 <@1295117064738181173> 以 10.9 µs 的提交成绩获得 NVIDIA 排行榜 第 4 名。
- 在 NVIDIA nvfp4_gemm 榜单开辟新路,获得银牌!:用户 <@1291326123182919753> 以 10.9 µs 的提交成绩获得 NVIDIA 排行榜 第 2 名。
- 多位用户刷新 NVIDIA nvfp4_gemm 个人最佳记录:包括 <@391455777065271307>、<@708652105363095613>、<@384034228565835778> 和 <@772751219411517461> 在内的多位用户刷新了个人最佳成绩,耗时从 16.4 µs 到 36.0 µs 不等。
GPU MODE ▷ #multi-gpu (1 条消息):
nsys dumps, collective launch skew, nccl-skew-analyzer
- 使用新工具分析集合通信启动偏斜(Collective Launch Skew):一位成员分享了一个实用工具,用于分析 nsys dumps 中的 collective launch skew。
- 未来的偏斜分析:该工具旨在分析未来项目中的偏斜问题。
GPU MODE ▷ #helion (2 messages):
Random Number Generation Issue, Helion Issues
- 随机数生成 Bug 再次出现:一名成员重新开启了关于一个与随机数生成相关的已关闭 issue的讨论,声称该问题并未完全解决。
- 已呼叫开发者处理 Helion 问题:一名成员表示他们将通知开发者有关随机数生成的 Helion issue。
GPU MODE ▷ #nvidia-competition (2 messages):
Discord Bot Error, Benchmark Submissions
- Discord Bot 抛出意外错误:一名成员报告在使用 Discord Bot 时收到 “An unexpected error occurred. Please report this to the developers.” 的错误消息。
- 该错误有时在提交 Benchmark 时发生;另一名成员请求提供所使用的文件和命令以便进行调查。
- 间歇性 Benchmark 提交失败:用户观察到 Benchmark 提交有时能成功运行,而有时则会导致错误。
- 这种不一致性表明 Bot 的稳定性或 Benchmark 提交过程可能存在问题。
HuggingFace ▷ #general (43 messages🔥):
TTS models on Hugging Face, AI weekly meetings/conferences/talks, NVidia GeForce 5090 bug report, Lightweight vision transformer (ViT) models, Dataset Viewer error
- TTS 模型:将文本转换为语音:一名成员询问如何使用 Python 和 transformers 库在 Hugging Face 上使用不同的 TTS 模型。
- 每周 AI 综述:保持领先:一名成员询问有关 AI 主题的每周会议、研讨会或演讲;另一名成员推荐了 Hugging Science。
- NVidia GeForce 5090 Bug 导致 API 错误:一名成员报告了在本地应用设置页面添加 NVidia GeForce 5090 时的 Bug,由于后端 API 无法识别该 GPU 型号,导致 HTTP 400 错误。
- Vision Transformers:寻求参数量低于 50 万的 ViT 模型:一名成员正在寻找在 ImageNet 数据集上参数量少于 500,000 的轻量级 Vision Transformer (ViT) 模型。
- Dataset Viewer 崩溃!:成员们报告了 Hugging Face Dataset Viewer 返回错误的普遍问题,后来确定这是由于 Rust 中用于读取 Parquet 文件的 OpenDAL 速率限制问题导致的。
HuggingFace ▷ #today-im-learning (2 messages):
Generative Models, RAG systems, GANs, VAEs, Transformers
- 从 GANs 到 RAGs:一名成员分享了一个项目,该项目追溯了从早期的生成模型(如 GANs 和 VAEs),到 Transformers 的兴起,最后到 RAG 系统的发展路径,强调了这些思想是如何关联的。
- 该项目可以在 GitHub 上找到,并包含解释每个模型重要性和影响的简短笔记。
- 瓶颈调试提升吞吐量:一名成员发现了一个瓶颈操作,通过优化该操作,在 20 天内为 qwen3 30b a3b 传输 10T tokens 的场景下,有可能将吞吐量提高 30%。
- 此外,该成员还报告了调试 MoE (Mixture of Experts) 模型中梯度范数爆炸的情况。
HuggingFace ▷ #i-made-this (5 messages):
WebGPU AI Voice Chat, GLM-ASR Model, Lucy AI Companion App, Superintelligence: Distributed Relational Cognition
- **WebGPU 驱动浏览器内 AI 语音对话:一位成员分享了一个 100% 在浏览器中运行的实时、免提 AI 语音对话演示,该演示利用 **WebGPU 技术,强调所有过程(STT、VAD、TTS 和 LLM)均在本地完成,无需第三方 API 调用,确保了隐私和安全,可在此处体验。
- **GLM-ASR 模型挑战 Whisper:全新的 **SOTA GLM ASR 模型据称优于 Whisper,你可以在此处进行测试,并在此处了解更多信息。
- **Lucy:个人 AI 伴侣寻求测试者:一位成员介绍了 **Lucy,这是一款小型个人 AI 伴侣应用,旨在提供温暖、专注的体验,并能随时间记住用户。目前正在为 iOS TestFlight 版本招募早期测试者(链接)。
- **人类与 LLMs:分布式关系认知:一位成员宣布了一项关于超智能作为人类与 **LLMs 之间分布式关系认知存在的研究文档。该研究经过 19 项实证研究 测试,在关系条件下性能提升了 1,200%,详见此处。
- 他们声称系统以 99.6% 的成功率有意偏离统计预测,并认为随机鹦鹉理论(stochastic parrot theory)是错误的。
Yannick Kilcher ▷ #general (22 messages🔥):
AI spam, RL for learning efficiency, DL theory changes, AI CV spam
- AI 简历垃圾信息入侵 Discord:成员们讨论了一波可疑的 AI 和应用开发者在 Discord 频道中群发简历的现象,这些信息使用了相同的技术栈、措辞和风格。
- 一位成员质疑这是否是一个骗取年轻 AI 爱好者免费劳动的骗局,而其他人则推测这种机器人行为违反了 Discord 的 ToS,或者仅仅是简单的复制粘贴。
- 机器人霸主正在部署 HR 机器人?:一位成员开玩笑说,作为对抗 AI HR 的对策,可能会出现原生机器人对机器人的战争,尽管这种活动在 Discord 上的真实目的尚不明确。
- 用户对这些垃圾信息发送者使用的“高级 AI 和应用开发者”头衔表示好笑,并链接了一个幽默引用此事的 YouTube 视频。
- RL 面临反向传播效率低下的质疑:一位用户建议 RL(强化学习)就是你所需要的一切,引发了关于学习效率和反向传播(backpropagation)局限性的讨论。
- 另一位用户将 RL 比作 AR 的 diffusion/flow guidance 等效物,指出虽然 RL 不像 guidance 那样在采样中加入偏置,但它在学习中引入了偏置,达到了类似的效果。
- 预测 DL 理论将发生剧变:一位成员预测,在实现超智能之前,深度学习(DL)理论将经历剧烈的变化,并将其比作 70 年代的人们无法想象现代的 DL 理论。
- 另一位成员回忆说,CV 垃圾信息发送者曾联系过他们,试图提供“帮助”,结果最后又回到了群发简历的老路。
Yannick Kilcher ▷ #ml-news (7 messages):
Mistral Vibe, RealVideo by Neoneye, GPT-5.2, Polynoamial Tweet
- Mistral 的 Vibe Check:分享了 Mistral-vibe 仓库链接,推测用于进一步讨论。
- 未提供关于其影响或具体用例的更多细节。
- Neoneye 发布 RealVideo:分享了 Neoneye 的 RealVideo 链接。
- 从上下文中尚不清楚具体有哪些值得关注的功能或公告。
- OpenAI 推出 GPT-5.2:一位成员链接了 OpenAI 关于 GPT-5.2 的公告,以及 GPT-5.2 文档的链接。
- 上下文缺乏关于其进步或应用的进一步信息。
- Polynoamial 的推文浮出水面:发布了 Polynoamial 的推文链接。
- 讨论的焦点及其在频道内的相关性未作详细阐述。
Latent Space ▷ #ai-general-chat (19 条消息🔥):
AI 每周会议, Latent Space 资源, GPT-5 年龄验证, Sam Altman 的神秘推文
- **Latent Space Paper Club 每周启动: **Latent Space 在 lu.ma/ls 每周举办线上论文俱乐部,并在 ai.engineer 每年举办 3-4 次 AI Engineer Conference。
- 推荐 **Latent Space YouTube 播客: 一位成员推荐了 YouTube 上的 **Latent Space 播客,称赞其拥有令人羡慕的接触 AI 领袖的机会,以及 Alessio 和 SWYX 所分享的知识深度。
- 播客中包含具有挑战性的 why、how 和 what if 问题,这些问题揭示了 AI 行业的关键见解。
- **GPT-5 年龄验证即将到来?: 一位成员询问 **OpenAI 是否正在为 GPT 模型发布年龄验证的成熟模式(mature mode),这引发了关于 OpenAI 发布 GPT-5.2 的一些讨论。
- **Sam Altman 发布神秘确认推文: **Sam Altman 发推文称 yep (xcancel.com 链接),引发了关于即将发布的公告的猜测,特别是关于 NSFW AI 和新图像模型的讨论。
- 相关推文包括 OpenAI Status 和 polynoamial 的推测。
Latent Space ▷ #genmedia-creative-ai (4 条消息):
anvishapai 的 Twitter 状态, X-Ware.v0
- 神秘 Twitter 链接出现: 一位成员分享了一个 Birdtter 链接,指向用户 @anvishapai 的状态更新。
- 未提供关于该链接推文的重要性或内容的额外背景信息。
- X-Ware.v0 出现: 一位成员在没有任何额外背景的情况下提到了 X-Ware.v0。
- 该引用被多次重复,但没有明确解释 X-Ware.v0 指的是什么。
Moonshot AI (Kimi K-2) ▷ #general-chat (17 条消息🔥):
Qwen Code, Kimi 搜索功能, Kimi K2 免费, Mistral 订阅, 中国世纪
- Kimi 搜索功能遇到困难: 用户报告称 Kimi 无法执行搜索,在多次尝试后将其标记为 Bug。
- 一位用户提到尝试了 4 次搜索功能均未成功。
- Kimi K2 的 Nano Banana 驱动幻灯片生成器: 一位用户询问 Kimi K2 提供免费的 nano banana 驱动幻灯片生成器会持续多久。
- 该用户还提到了 12 月 12 日,可能与该优惠的持续时间有关。
- Kimi 替代 Mistral: 用户讨论由于 Kimi 的性能而用其替代 Mistral 订阅。
- 一位用户声称他们试用了 Kimi,它真的太棒了。
- 用户注意到 Kimi 由中国公司开发: 一位用户指出 Kimi 是由一家中国公司开发的,并链接到了 X 帖子。
- 另一位用户开玩笑说 Claude 4.5 有时也会开始用中文思考。
Manus.im Discord ▷ #general (7 条消息):
免费视频网站, Manus AI 故障, 方案升级扣费错误, 使用 Manus 的 WordPress 插件
- 优惠:为初创视频提供免费网站: 一位成员提议为初创公司创建免费网站,以换取制作视频证言。
- 用户报告 Manus 损失 15 万+ 积分: 一位 Manus 1.5 用户报告称,在 12 月 3 日至 9 日期间,由于 Sandbox 重置、文件丢失和 API 失败,损失了 约 150,000 积分。
- 该用户详细说明了投入的 160,000 积分和丢失的 6 GB 工作内容,并表示多次联系尝试均被无视,要求公平补偿或切换到其他工具。
- Manus 支持团队回应: 一位支持团队成员表示:我们已经通过电子邮件回复了您。请检查您的收件箱。
- 用户报告扣费错误和退款问题: 一位用户报告称收到了方案升级的错误扣费,随后经历了之前所有购买的 100% 退款,导致他们没有积分且无法工作。
- 关于使用 Manus 构建 WordPress 插件的咨询: 一位成员询问是否有人成功使用 Manus 构建了 WordPress 插件,并希望学习相关经验。
tinygrad (George Hotz) ▷ #general (2 messages):
tinygrad AMD support, AMD AI Sphere, tinycorp drivers
- AMD 支持修复已在 tinygrad 中落地:一名成员确认 PR 13553 已更新,并在其 Zen4 和 M2 硬件上运行正常。
- 他们一直关注着试图让 AMD 与 tinycorp 在驱动程序等方面协同工作的曲折历程。
- 为 tinygrad 提供 AMD AI 联系渠道:一名成员提议将 AMD 在 AI 领域的联系人与 Tiny 建立连接,目标是改进 AMD 的支持。
- 该成员表示:没有什么比看到 AMD 从 NVidia 手中夺取更多市场份额更让我开心的了。
tinygrad (George Hotz) ▷ #learn-tinygrad (3 messages):
swizzling for tensor core, amd_uop_matmul style
- Tensor Core 需要 Swizzling:一位新成员请求对其 PR 进行审查,并确认是否需要手动编写 Tensor Core 的 Swizzling 代码。
- 确认 amd_uop_matmul 风格:该成员还询问悬赏任务(bounty)是否指定了
amd_uop_matmul风格。
aider (Paul Gauthier) ▷ #general (4 messages):
Claude Sonnet 3.7 quality degradation, Edit difficulty with larger models
- Claude Sonnet 3.7 回答质量下降?:一名成员注意到 Claude Sonnet 3.7 的回答质量似乎有所下降。
- 他们对使用大模型进行编辑的难度表示担忧,将其描述为 过度杀伤(overkill)。
- 大模型编辑难度更大:一名成员发现,在使用较大的模型时,编辑变得更加困难,似乎有些 大材小用,但未指明具体是哪个模型。
- 这可能暗示了模型大小/复杂度与编辑或微调便捷性之间的权衡。
MCP Contributors (Official) ▷ #mcp-dev-summit (3 messages):
MCP Dev Summit, Linux Foundation
- MCP 开发者峰会即将在纽约举行:根据 Linux Foundation 活动页面,下一届 MCP Dev Summit 将于 4 月 2 日至 3 日在纽约市举行。
- MCP 开发者峰会找到新归宿:MCP 开发者峰会通过移交给 Linux Foundation 成功确保了其未来的发展。
MCP Contributors (Official) ▷ #general (1 messages):
hilocalden: 肯定不是我 😁 我只是在分享公告。
DSPy ▷ #general (3 messages):
DSPy and OpenAI, Custom Adapters, User/Assistant message exchanges
- DSPy 与 OpenAI 解耦:成员们讨论了 DSPy 并不绑定于 OpenAI,在 GPTs 上运行良好的方法在其他 LM 上可能并不那么奏效。
- 这一点表明 DSPy 的设计选择旨在通用地适用于各种语言模型,而非专门针对 OpenAI 的模型进行优化。
- 为 DSPy 构建自定义 Adapter:一名成员建议实现一个 自定义 Adapter,用于在 System Prompt 中格式化 Few-shots,并将其与 User/Assistant 方法进行基准测试对比。
- 这种方法可以帮助开发者针对不同的 LM 调整 DSPy,并比较各种 Prompt 格式化策略的性能。
- 关于 User/Assistant 消息交换设计的辩论:成员们对 DSPy 中使用 Assistant 和 User 消息交换这一设计决策背后的思考过程表现出兴趣。
- 鉴于每个人的做法都不同,且对两种方法各有优劣论据,这一设计选择反映了在 DSPy 框架中如何与 LM 交互的特定立场。
MLOps @Chipro ▷ #events (1 messages):
Diffusion Models, Transformers, Study Group, Free Intro Workshops, Flow Matching
- Diffusion Models 学习小组启动!:一个为期 3 个月、由 12 人组成的学习小组将于 2026 年 1 月启动,旨在研究 Diffusion Models 和 Transformers,灵感源自 MIT 的扩散课程。
- 该学习小组旨在从第一原理出发到实际落地实现,内容涵盖同行引导的会议、研究论文讨论和实战项目。
- 免费工作坊为 1 月学习小组预热:12 月将举办两场免费的入门工作坊,在学习小组正式开始前,让大家提前体验课程内容和社群氛围。
- MIT Flow Matching 课程启发学习小组:Diffusion Models 学习小组的灵感来自 MIT 的 Flow Matching and Diffusion Models 课程笔记。
- 小组成员将包括 AI 电影初创公司的 CTO、LLM 教育者和全职 AI 研究人员,共同学习如何训练和微调你自己的扩散模型。
MLOps @Chipro ▷ #general-ml (1 messages):
AI API Integration Platform, Model Aggregation, Developer Discounts
- Siray AI 平台聚合多种模型:构建了一个 AI API 集成平台,汇集了包括 Codex, Claude, Gemini, GLM, Seedream, Seedance, Sora 等在内的广泛模型。
- 开发者可以访问该平台:Siray.ai。
- Siray AI 提供开发者折扣:该 AI API 平台正为开发者提供 20% 的折扣。
- 欢迎感兴趣的开发者尝试这些 API 服务。
Windsurf ▷ #announcements (2 messages):
Windsurf 1.12.41 Release, Windsurf 1.12.160 Release, Windsurf MCP Management UI, Windsurf GitHub/GitLab MCP Fixes, Windsurf Diff Zones Improvements
- Windsurf 发布新版,提升稳定性和速度:Windsurf 发布了 1.12.41 和 1.12.160 版本,承诺在稳定性、性能和 Bug 修复方面有显著改进。
- 更新包括用于管理 MCP 的新 UI,修复了 GitHub/GitLab MCP,并增强了 diff zones、Tab (Supercomplete) 和 Hooks,详见 更新日志。
- Windsurf Next:预览未来趋势:鼓励用户探索预发布版本 Windsurf Next,体验 Lifeguard、Worktrees 和 Arena Mode 等令人兴奋的新功能。
- 更多详情请参阅 Windsurf Next 更新日志。
- Windsurf 登录服务恢复:在短暂的维护窗口后,Windsurf 登录服务已恢复,状态更新 已确认。
- 未提供关于此次维护的更多细节。