AI News
OpenAI GPT Image-1.5 号称超越了在各大竞技场(Arenas)排名第一的 Nano Banana Pro,但在“氛围感测试”(Vibe Checks)中却彻底翻车。
OpenAI 发布了其新款图像模型 GPT Image 1.5,该模型具备精确的图像编辑能力、更强的指令遵循能力、改进的文本和 Markdown 渲染效果,且生成速度提升了高达 4 倍。尽管它在 LMArena (1277)、Design Arena (1344) 和 AA Arena (1272) 等多个排行榜上名列前茅,但与 Gemini 的 Nano Banana Pro 相比,来自 Twitter、Reddit 和 Discord 社区的用户反馈大多偏向负面。
与此同时,小米推出了 MiMo-V2-Flash,这是一款拥有 309B MoE(3090 亿参数混合专家)架构的模型,针对推理效率进行了优化,并支持 256K 上下文窗口,在 SWE-Bench 上取得了目前最先进(SOTA)的成绩。该模型采用了混合滑动窗口注意力机制(Hybrid Sliding Window Attention)和多 Token 预测技术,显著提升了运行速度和效率。在 Gemini 和 Nano Banana Pro 的竞争压力下,OpenAI 的发布时机影响了用户情绪,也凸显了基准测试(benchmarking)在衡量实际表现相关性方面所面临的挑战。
在艰难时刻的一次罕见失误。
2025年12月15日至12月16日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 24 个 Discord 服务器(207 个频道,10501 条消息)。预计节省阅读时间(以 200wpm 计算):734 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 vibe coded 方式展示所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上给我们反馈!
OpenAI 新图像模型的头条细节非常出色——精确的图像编辑、创意构思的执行、更好的指令遵循、大幅提升的文本和 Markdown 渲染能力、修复了旧版 gpt-image-1 中明显的 bug,甚至主动指出了模型中已知的退化(regressions)。它在 LMArena 上获得了 1277 分,在 Design Arena 上获得了 1344 分,在 AA Arena 上获得了 1272 分,均位列榜首。
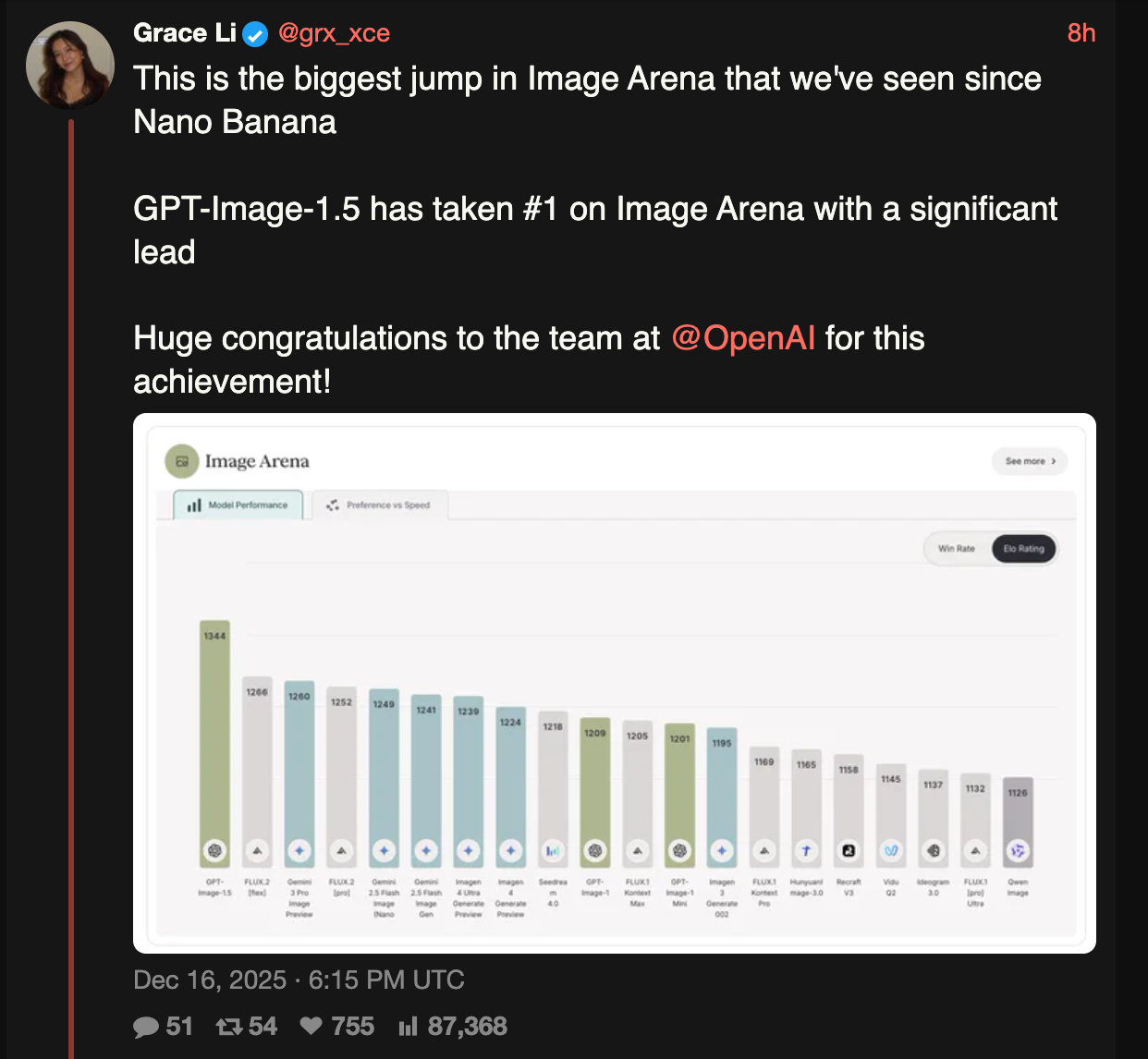
但是: 赞美到此为止。基本上,来自 Twitter、Reddit 以及各个 Discord 社区的 vibe check(感官评估)在与 Nano Banana Pro 的对比中普遍呈现负面。GPT-Image-1 的进步是显而易见的,所以这与其说是对 OpenAI 整体的打击,不如说是对 Arena 基准测试是否能代表真实资深用户偏好的信心的一次沉重打击。
对于那些关注能力竞赛细节的人来说,背景和时机至关重要。如果他们在 NBP 之前发布这个模型,或者在面对 Gemini 竞争时没有那种挥之不去的“红色警报(Code Red)”叙事,Image-1.5 本会是一个不错的发布。但现在,氛围(vibes)不对了。
AI Twitter 回顾
小米 MiMo‑V2‑Flash:为速度、长上下文和 SWE‑Bench SOTA 而生的 309B MoE
- MiMo‑V2‑Flash (309B MoE; 15B 激活参数):小米的新开源权重模型强调推理效率和 Agent 工作流:150 tokens/s、256K 上下文,以及 SWE‑Bench 上的顶级开源评分(Verified: 73.4%,Multilingual: 71.7%)。架构采用混合滑动窗口注意力(Hybrid Sliding Window Attention, SWA),结合稀疏局部窗口和少量全局层,外加用于推测解码(spec-decode)的 MTP(多 token 预测),并在 LMSYS/SGLang 上实现首日服务。小米表示,它在更低延迟下在通用基准测试中“媲美 DeepSeek‑V3.2”。链接:发布详情和规格 @XiaomiMiMo,技术报告和代码 @XiaomiMiMo。
- 工程笔记与消融实验:第一作者罗福莉(Fuli Luo)详细介绍了起关键作用的因素:混合 SWA 优于其他线性注意力变体;训练后 窗口大小从 128 扩展到 512 有利于长上下文;Attention Sinks(注意力汇聚)至关重要;3 层 MTP 实现了 >3 的接受长度,并在编程任务上实现了约 2.5 倍的加速;通过 MOPD(多教师在线策略蒸馏)进行的训练后处理,以 不到 1/50 的 SFT+RL 计算量达到了教师模型的质量。阅读推文串 @luo_fuli14427。外部消融实验强调了 Sinks 和 SWA‑128 相较于 512 的优势,以及在复杂任务上混合层优于密集全局层 @eliebakouch。可用性:在 OpenRouter 上限时免费 @OpenRouterAI;SGLang 首日性能笔记 @BanghuaZ。背景:负责人曾是 DeepSeek‑V2 的核心作者 @eliebakouch。
图像生成领域大洗牌:OpenAI 的 GPT Image 1.5(“ChatGPT Images”)和 FLUX.2 Max
- OpenAI GPT Image 1.5: ChatGPT 和 API 的新旗舰模型,带来了更强的指令遵循能力、精确编辑、改进的文本渲染/Logo/人脸,以及高达 4 倍的生成速度。ChatGPT 中上线了全新的“Images”界面。文档和 API:@OpenAI, @OpenAIDevs。该模型在 Artificial Analysis 和 LM Arena 的文生图及编辑排行榜上均首次亮相即位居第一,领先 Gemini 的 Nano Banana Pro 较大差距;定价取决于分辨率和质量(Artificial Analysis 引用价格:高质量 1MP 图像约 $133/1k;低质量约 $9/1k)。排行榜和定价分析:@arena, @ArtificialAnlys, @grx_xce。
- 早期对比表明,GPT-Image-1.5 优于之前的 GPT 变体,在相似度/编辑保真度上与 Nano Banana Pro 竞争激烈,但有报告称 Gemini 在“视觉智商”(图像中的数学/迷宫推理)方面仍处于领先地位 @Yuchenj_UW, @Yuchenj_UW。
- FLUX.2 [max] (Black Forest Labs): FLUX.2 的更高质量变体,支持 Web-grounding 和多达 10 张参考图以实现一致性编辑;在文生图和编辑的图像排行榜上排名第 2–3 位(定价为文生图 $70/1k,编辑 $140/1k)。发布与托管:@bfl_ml, @fal, @arena。
来自 NVIDIA 的开源推动:Nemotron-Cascade 和 Nemotron 3 的更广泛可用性
- Nemotron-Cascade (8B/14B): NVIDIA 推出了 “Cascade RL”,这是一种领域相关的顺序 RL 流水线。14B 模型在 LiveCodeBench v5/v6/Pro 上超越了 DeepSeek-R1-0528 (671B),并在 SWE-Bench Verified 上达到了 43.1% 的 pass@1(通过推理时扩展可达 53.8%)。团队强调将 RLHF 对齐作为提升推理能力的预备步骤,并指出后期的领域阶段可以保留或改善早期的收益。论文/模型:@_weiping, @zihan_johan_liu, @HuggingPapers。
- Nemotron 3 Nano 可用性: 现已登陆 Ollama 以及适用于 Apple Silicon 的 MLX/LM Studio,将“从零开始”的小型 MoE 模型引入本地工作流 @ollama, @awnihannun, @lmstudio。背景:NVIDIA 的开源策略日益与硬件对齐——为其芯片优化训练/推理栈(“硬件定义 AI”时代)@TheTuringPost。
事实性与科学基准测试:FACTS 和 FrontierScience
- FACTS 排行榜 (Google Research): 涵盖四个维度的全面事实性套件——多模态 (Multimodal)、参数化 (Parametric)、搜索 (Search)、Grounding v2——配备标准化的 Kaggle 工具。核心结论:Gemini 3 Pro 综合得分 68.8%;子项得分显示了行为权衡(Claude 模型较为保守,具有高“无矛盾性”;GPT 模型覆盖率更高但矛盾更多)。多模态仍然具有挑战性(在严格覆盖率 + 零矛盾下约为 47%)。参数化得分差异巨大(Gemini 3 Pro 为 76.4%,而 GPT-5 mini 为 16%)。推文和论文:@omarsar0。
- OpenAI FrontierScience (开源评估 + 湿实验室闭环): 全新的博士级物理/化学/生物基准测试(竞赛风格 + 研究任务),支持推理时计算扩展,随之发布的还有一项湿实验室研究,其中 GPT-5 提出的方案更改使克隆工作流的效率提升了 79 倍。HF Hub 上已发布开源数据集,并强调将模型评估与实际科学工作流相结合。公告与详情:@OpenAI, @kevinweil, @tejalpatwardhan, @reach_vb。
推理服务与 Agent 基础设施:KV 感知路由、P/D 解耦、控制平面
- vLLM Router (prefill/decode 感知负载均衡器):专为 vLLM 集群构建,使用 Rust 编写;支持用于 KV 局部性(KV locality)的一致性哈希、二选一(power-of-two choices)策略、重试/退避机制、熔断器、k8s 服务发现以及 Prometheus 指标。专为 P/D 解耦(P/D disaggregation)设计,具有独立的 Worker 池和路由策略,以保持吞吐量并降低尾部延迟 @vllm_project。
- 迈向“智能控制平面”:vLLM + AMD 预览了一个“语义路由(Semantic Router)”框架——负责管理输入、输出和长期状态,重点关注大型 Agent 系统中的安全与记忆 @vllm_project。补充技术栈更新:SkyPilot + NVIDIA Dynamo 提供的 MoE 推理方案(P/D 解耦、KV 感知路由),具备兼容 OpenAI-API 的端点 @skypilot_org;SGLang 对 MiMo-V2-Flash 的首日支持 @BanghuaZ;以及 OpenHands 发布面向生产环境的软件 Agent SDK @OpenHandsDev。在服务商方面,Cline 迁移至 Vercel 的 AI Gateway,在多个模型上实现了更低的错误率,并将 P99 流式传输延迟优化了 10–40% @cline。
多模态/音频/3D:开源发布与快速视图合成
- Meta SAM Audio (开放权重):一个统一的音频分离模型,可以通过文本、视觉或跨度(span)提示从复杂混合物中分离声音。随基准测试、感知编码器以及 Segment Anything Playground 中的演示一同发布 @AIatMeta,社区早期关于开放权重的说明 @_akhaliq。
- AllenAI Molmo 2 (Apache-2.0):将 Molmo 的具身 VLM 能力扩展到视频领域;提供基于 SigLIP2 + Qwen3 的三种尺寸,此外还有一个独立的 4B 模型,在视频指向/计数基准测试中领先于其他开源模型。包含数据发布 @allen_ai, @mervenoyann。
- Apple SHARP (单张图像 1 秒内转 3D):通过带有学习型深度调节模块的单次前向传播生成约 120 万个 3D Gaussians,与扩散模型基准(如 Gen3C 约 850 秒)相比实现了约 1000 倍的加速,同时提高了在 ScanNet++ 上的感知保真度(DISTS 0.071 对比 0.090)。论文回顾 @omarsar0。
- 同样值得关注:MiniMax 开源了 VTP,用于可扩展的视觉 Tokenizer 预训练,在不增加额外生成计算的情况下提升了下游 Diffusion Transformer 的生成效果 @MiniMax__AI;Runway Gen-4.5 向所有付费计划推出 @runwayml。
热门推文(按互动量排序)
- ChatGPT Images (GPT-Image-1.5):新模型、新“Images” UI 及 API;速度提升 4 倍,位居公开排行榜榜首 @OpenAI (7,842)。产品演示推文 @sama (2,492)。
- Meta 的 SAM Audio (开放权重):统一的文本/视觉/跨度提示音频分离,附带 Playground 演示 @AIatMeta (3,781)。
- FrontierScience:OpenAI 新的博士级科学评估,以及在 GPT-5 反馈循环下,湿实验室克隆方案实现了 79 倍的改进 @OpenAI (1,859);亮点回顾 @sama (2,652)。
- Larian 谈管线中的生成式 AI:澄清了构思/参考用途与原创概念艺术的区别;坚决支持人类艺术家参与环节 @LarAtLarian (31,930)。
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Meta SAM Audio Model 发布
- Meta 宣布推出全新的 SAM Audio Model,用于音频编辑,该模型可以使用文本、视觉和时间跨度提示从复杂的音频混合中分割声音。 (热度: 403): Meta 推出了 SAM Audio Model,这是一款创新的音频编辑工具,允许用户使用文本、视觉和时间跨度提示从复杂的音频混合中分离出特定声音。该模型利用先进的分割技术来识别和提取声音,有可能改变音频处理工作流程。该模型能够准确挑选出声音(例如视频中的麦克风敲击声),展示了其精度以及在媒体制作和虚拟会议等各个领域的潜在应用。 评论者对该模型的精度印象深刻,指出它可以通过过滤掉不必要的噪音来增强虚拟会议体验。人们对其从复杂音频环境中隔离特定声音的能力感到惊讶,这表明音频处理技术取得了重大进展。
- ahmetegesel 强调了该模型从复杂音频环境中隔离特定声音的能力,强调其能够准确识别和提取与视频中特定物体相关的声音。这表明音频分割具有极高的精度,这对于音频编辑应用来说可能是变革性的。
- Andy12_ 指出了一个特定的演示,在该演示中,模型在收到“敲击麦克风”提示时成功识别了细微的麦克风敲击声。这个例子强调了该模型在检测和隔离复杂声景中微小音频事件方面的敏感性和准确性,展示了其在详细音频分析和编辑任务中的潜在效用。
- RandumbRedditor1000 询问了该模型对乐器的适用性,这暗示了对其处理涉及音乐的复杂音频混合能力的兴趣。这引发了关于该模型在区分和隔离乐曲中单个乐器声音方面表现的问题,这是音频处理中的一项挑战性任务。
2. OpenAI 关于 AI 开放性的内部讨论
- 是 Ilya 让 OpenAI 变得“封闭”的 (热度: 797): 这张图片是来自 OpenAI 联合创始人 Ilya Sutskever 的一封电子邮件,表达了对 AI 发展中潜在“硬起飞”(hard takeoff)风险的担忧,即 AI 能力的快速且不受控制的进步。Sutskever 建议,虽然 AI 研究的开放性最初有助于招聘和协作,但最终可能会导致不安全 AI 系统的创建。这封邮件突出了 OpenAI 历史上的一个关键时刻,当时内部正在辩论 AI 发展的开放性与安全性之间的平衡,反映了随着 AI 技术的进步,OpenAI 转向了更加谨慎和封闭的做法。 评论者对 OpenAI 等公司的可信度表示怀疑,质疑为了防止不安全 AI 而限制 AI 研究的哲学。还有一种观点认为,Elon Musk、Ilya Sutskever 和 Sam Altman 等关键人物受权力和认可欲望的驱动,导致在 AI 发展中采取竞争而非协作的方式。
- LoSboccacc 对 OpenAI 的研究提出了批评观点,认为他们的进步本质上是建立在 Google 的 Transformer 模型之上的。这暗示 OpenAI 的创新可能更多是关于扩展现有架构,而不是引入根本性的新概念。该评论隐喻地将 OpenAI 的工作描述为“穿着大衣的 8 个 Google Transformer”,表明其感知到的是表面上的复杂性而非真正的原创性。
- popiazaza 讨论了 Elon Musk、Ilya Sutskever 和 Sam Altman 等 AI 关键人物之间的内部动态和竞争。评论认为,这些领导者之间的竞争和缺乏信任导致了 OpenAI、SSI 和 xAI 等组织在 AI 发展上的封闭性。这反映了对 AI 领域透明度和协作的更广泛担忧。
- RASTAGAMER420 引用了古老的格言“谁来监督监督者”(Who will watch the watchmen),强调了关于 AI 发展监管和问责制的持续辩论。这一评论强调了确保开发和控制 AI 技术的人员本身受到审查和监管的伦理和哲学挑战。
技术性较低的 AI Subreddit 汇总
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. OpenAI GPT-Image-1.5 发布与基准测试
- 重磅:OpenAI 发布 “GPT-Image-1.5” (ChatGPT Images),并迅速夺得 LMArena 排行榜第一,击败了 Google 的 Nano Banana Pro。 (热度: 1142): OpenAI 发布了新模型 GPT-Image-1.5,该模型在 LMArena 文本生成图像排行榜上迅速登顶,超越了 Google 的 “Nano Banana Pro”。该模型的
score of 1277,而其最接近的竞争对手为1235。主要改进包括比前代 DALL-E 3 快4x faster,并提供增强的编辑功能,支持精确的“添加、减去、组合”指令。它还在编辑过程中保持角色外观和光影的一致性,解决了 DALL-E 3 的一个主要局限。该模型已通过新的 “Images” 标签页向所有 ChatGPT 用户开放,并可通过 API 以 gpt-image-1.5 的形式访问。OpenAI Blog 一些用户对 LMArena 排行榜截图的真实性表示怀疑,质疑 LMArena 官方网站缺乏更新。其他人则对命名惯例进行了推测,认为这可能预示着正在开发更先进的模型,或者是为了避免过度炒作的战略决策。- 一位用户对排行榜更新的真实性表示怀疑,指出他们在 LMArena 官网上找不到任何官方更新。这引发了对 GPT-Image-1.5 夺冠说法的质疑,表明需要官方渠道的验证。
- 另一位用户通过使用 OpenAI 公告页面上的提示词示例测试了模型的能力,并将其与 Google 的 Nano Banana Pro 进行了对比。该提示词涉及以特定风格组合图像,用户分享了生成的图像,这可以作为评估模型在现实场景中表现的实际基准。
- 一条评论推测将模型命名为 ‘1.5’ 可能意味着它是正在开发的更先进模型的占位符,或者是为了避免与 GPT-5 这种完整版本发布相关的各种问题的战略决策。这反映了 OpenAI 在模型版本控制和发布方面的潜在策略。
- 新 GPT 图像 vs Nano Banana Pro。 (热度: 1666): 该帖子讨论了新 GPT 模型与 Nano Banana Pro (NBP) 在图像生成能力方面的对比。GPT 模型的图像被描述为具有更明显的人工痕迹,而 NBP 的图像则以写实著称,几乎与真实照片无异。这表明 NBP 可能拥有更优越的图像合成技术,这可能归功于更广泛或更精炼的数据集,或者是先进的渲染技术。 评论者强调 GPT 生成的图像看起来过于完美,类似于商业摄影,而 NBP 的输出因其真实感和自然外观而受到称赞,这表明在写实图像生成方面,人们更倾向于 NBP 的方法。
- 讨论强调了 GPT 生成的图像与 Nano Banana Pro (NBP) 图像之间的对比。用户注意到,虽然 GPT 图像通常看起来过度修饰且具有人工感(类似于商业摄影),但 NBP 图像因其写实性而受到称赞,看起来更像随手拍的照片。这表明 NBP 在创建更逼真的图像方面可能取得了进展,这可能源于不同的训练数据或图像处理技术。
- 文中给出了一个具体的例子,GPT 生成的汽车图像被描述为类似于“汽车广告图”,而 NBP 的版本看起来像一张私人照片。这表明在审美以及可能用于渲染图像的底层算法上存在差异,NBP 可能采用了能更好模拟现实世界光影和纹理的技术。
- 用于生成图像的提示词包括详细描述,如 ‘a 20 years old girl, real image, 9:16, background in focus’ 和 ‘a real image of a ford mustang, fully black, parked in a dark roadside’。这些提示词表明,这两个模型都在测试处理复杂场景构图和光照条件的能力,这对于在 AI 生成的图像中实现真实感至关重要。
- 新的图像生成技术太疯狂了 (活跃度: 1047): 该图像似乎是先进图像生成技术的产物,可能使用了专注于创建超写实人物形象和环境的 AI 模型。评论指出生成图像中存在一些不一致之处,例如不匹配的衣物和不真实的汽车特征,这表明虽然该技术在渲染类人形象方面有所进步,但在上下文和环境准确性方面仍显吃力。这反映了 AI 图像生成中持续存在的挑战,即在复杂场景中实现完美的写实感仍然很困难。 评论者表达了乏味与批评交织的情绪,指出生成不存在的人物的 AI 图像具有重复性,并指出了图像写实性中的具体缺陷,如不匹配的衣物和不可能的汽车特征。
- DumbedDownDinosaur 指出了生成图像的问题,注意到一些不一致之处,例如一条腿光着而另一条腿穿着裤子,以及汽车前座后面出现梳妆台,这让人对场景的逻辑连贯性产生怀疑。尽管有这些缺陷,他们承认人物形象与之前的版本相比显得更加真实,避免了“塑料感”。
- Junior-Tradition2083 将新的图像生成模型与 ‘nano banana pro’ 进行了比较,称后者生成的图像更真实,特别是在渲染人物和环境方面。这表明虽然新模型有所改进,但在图像写实性的某些方面仍有表现更出色的竞争对手。
- KH10304 对生成图像中的空间布局表示困惑,特别是质疑车内的座位位置。这指向了模型在准确渲染具有正确空间关系的复杂场景方面可能存在的问题。
2. Claude Code 更新与应用
- 官方:Anthropic 刚刚发布了 Claude Code 2.0.70,包含 13 项 CLI 变更,详情如下。 (活跃度: 704): Anthropic 发布了 Claude Code CLI 2.0.70,引入了
13项变更,包括用于提示词建议的新 Enter 键功能、用于工具权限的通配符语法mcp__server__*,以及插件市场的自动更新开关。显著的修复包括解决了命令处理期间的输入清除问题、提示词建议替换问题以及终端调整大小时的 diff 视图更新。该更新还将大型对话的内存使用优化了3x,并提高了统计截图的分辨率。删除了用于快速内存输入的 # 快捷方式,并对文件创建权限进行了 UI 改进。更新日志 评论者注意到滚动闪烁和崩溃等持续存在的问题,表明虽然解决了一些 Bug,但界面稳定性方面仍存在持久性问题。- 一位用户询问了内存使用方面 “3x” 的含义,对其影响表示怀疑,并认为可能存在夸大。这表明内存需求的显著增加可能会影响性能,尤其是在资源受限的环境中。
- 另一位用户询问了
plan_mode_required功能,表示需要对其功能进行澄清。这表明该功能可能比较复杂或文档记录不全,导致用户产生困惑。
- Claude Code 在我的服务器上发现了一名黑客 (活跃度: 1018): 该帖子描述了一起事件:AI 工具 Claude Code 在一台用作网站后端的 Linux 服务器上检测到了异常的 CPU 使用率。经调查发现,由于为数据库留出的端口处于开放状态,服务器已被入侵并被用于加密货币挖矿。Claude Code 识别了该问题,关闭了开放端口,并移除了未经授权的访问。当时服务器上没有用户,从而最大限度地减少了潜在的数据泄露。 一条值得注意的评论建议删除受感染的机器并创建一个新的,因为黑客使用的脚本通常带有后门,可能会在重启后重新激活。
- themusician985 建议应删除并重建服务器,因为黑客使用的脚本通常包含后门,可以在重启后自行重新启用。这突显了一种常见的安全实践,即确保彻底重建受损系统以防止持续性威胁。
- Nissan-S-Cargo 对该说法表示怀疑,暗示这个故事可能被夸大或捏造。这反映了在 Cybersecurity 讨论中通常需要的批判性视角,即非凡的断言需要实质性的证据。
- Unique-Drawer-7845 幽默地暗示加密货币矿工可能会利用 Stored Procedures,暗示了 SQL Injection 或滥用数据库功能进行未经授权的加密货币挖矿的可能性。这强调了保护数据库操作免受此类漏洞影响的重要性。
- Battle testing MCP for blockchain data in natural language (Activity: 419): 该图片提供了按 ETH 余额排名的顶级 Ethereum 地址快照,突出了 Beacon Deposit Contract 的主导地位,该合约持有用于 Proof of Stake (PoS) 质押的大部分 Ethereum 供应。这一设置是利用 Pocket Network 的 MCP 进行实时区块链数据分析,并使用 AI 模型 Claude 进行历史模式检测的更广泛努力的一部分。用户旨在将 On-chain 数据直接集成到 Claude 中,以获得实时交易洞察和取证分析,而无需依赖预处理信号或 Dune Analytics 等外部仪表板。 评论者赞赏 MCP 在基础示例之外的高级应用,并指出了在设置与运行方面的潜在挑战。人们对数据随时间推移的准确性表示担忧,强调了验证的必要性。该应用被认为对研究和新闻报道很有价值,为分析区块链活动提供了一种精简的方法。
- BloggingFly 强调了 MCP (Model-Chain Protocol) 在处理区块链数据方面的实际应用,指出这是超越基础示例或文档摘要的重要一步。该评论提出了一个关于实施过程中所面临挑战的技术问题,具体是困难更多地与初始设置有关,还是与系统运行后的持续 Prompting 有关。
- BrightFern8 质疑使用 MCP 处理区块链数据的长期准确性,指出随时间推移可能出现的一致性问题。他们提到观察到初始结果准确,但随时间推移的重复查询会导致答案出现“漂移 (drift)”,这表明需要持续验证结果以维持对系统的信任。
- theCartoonist59 讨论了 Claude 与外部工具集成的现状,指出大多数实现涉及 Claude 与其他系统的接口,而不是执行直接查询。他们认为 MCP 是一个很有前途的发展,允许 Claude 与真实的基础设施交互,这可以增强其能力,超越单纯的猜测。
3. AI in Personal and Social Contexts
- Terence Tao: Genuine Artificial General Intelligence Is Not Within Reach; Current AI Is Like A Clever Magic Trick (Activity: 1792): 著名数学家陶哲轩 (Terence Tao) 认为,真正的 Artificial General Intelligence (AGI) 在当前的 AI 技术下是无法实现的,他将其比作“聪明的魔术”。他建议将 AI 目前的能力更好地描述为“人工通用聪明 (artificial general cleverness)”,其特点是通过随机或暴力破解方法解决复杂问题,通常缺乏根据且易出错,并非真正的智能。陶哲轩强调,虽然这些 AI 工具令人印象深刻且有用,但它们从根本上是不令人满意的,类似于理解魔术背后的机制。他建议将 AI 视为聪明输出的随机生成器,这可能对解决问题更有成效。来源。 评论者对陶哲轩的观点进行了辩论,一些人认为智能本身就是“一捆肮脏的技巧”,暗示 AI 的方法与人类认知并无本质区别,人类认知也依赖于 Heuristics。其他人注意到了陶哲轩关于 AI 的“聪明”与“智能”的哲学立场,并质疑 AI 未来能力的可预测性,强调已经发生的快速进步。
- Saint_Nitouche 认为,将 AI 仅仅视为“随机暴力破解”忽略了人类智能本身就是一系列机械过程的事实。评论者建议,任何对智能(无论是人类还是人工智能)的详细解释都不可避免地涉及“肮脏的机械技巧”,强调智能从根本上是关于神经元和电力等机制,而不是某种难以言喻的东西。
- Completely-Real-1 强调 Terence Tao 的观点更具哲学性,侧重于 AI 中“智能”(intelligence)与“聪明”(cleverness)的区别。Tao 认为 AI 的能力基于训练数据中发现的“技巧”(tricks),类似于人类的启发式方法。评论者指出,人类也会使用从经验中学习到的心理“技巧”或“经验法则”,从而在 AI 训练与人类学习过程之间建立了平行关系。
- DoubleGG123 指出了 AI 进步的不可预测性,暗示即使是像 Terence Tao 这样的专家,在几年前可能也无法预料到 AI 现在的能力。评论者强调了对 AI 发展进行长期预测的难度,主张采用更具观察性的方法,而不是依赖于对未来 AI 能力的预测。
- MI6 局长:科技巨头比政治家更接近统治世界 (活跃度: 498): 在最近的一次演讲中,MI6 局长 Blaise 强调了科技公司日益增长的影响力,暗示它们拥有的权力可与政府相媲美,特别是在虚假信息和全球稳定领域。他呼吁建立紧急监管框架,以管理这些科技巨头的社会和政治影响力。更多详情,请参阅原文此处。 评论者讨论了 AI 和科技巨头无处不在的影响,指出 AI 机器人可以显著塑造公众舆论,科技公司已经积累了巨大的财富并控制了信息渠道。有一种观点认为,政治家现在遏制这种权力已经太晚了,因为科技公司已经深深扎根于社会结构之中。
- Forumly_AI 强调了 AI 技术在塑造公众舆论方面的重大影响,指出 AI 生成的内容可能具有高度的说服力和影响力。评论强调,AI 机器人在某些领域已经超越了人类的影响力,特别是在传播信息和潜在地操纵公众认知方面。这突显了利用此类技术的科技巨头日益增长的力量,导致它们对传统政治结构的支配地位不断增强。
- RecursiveDysfunction 讨论了从 2000 年代初期到 2025 年人们对科技公司看法的转变。最初被视为进步和创新的引擎,现在科技公司被公认为在积累财富和权力,且往往以社会福祉为代价。评论指出了社交媒体在传播虚假信息和使社会两极分化方面的作用,并暗示监管科技权力的尝试往往因科技巨头对信息渠道的控制而受到削弱。
- Senior_Flatworm3010 提出了监管科技巨头方面的政治不作为问题,暗示政治家未能实施法律来保护公众免受不受限制的科技力量可能带来的负面影响。评论暗示政治体系在允许科技公司获得不成比例的影响力方面负有责任,公众偶尔表现出对商业领袖而非传统政治家的偏好就证明了这一点。
- 与 GPT 交流不到一周。戒了尼古丁。戒了破坏性的游戏成瘾。还有更多。 (活跃度: 1768): 该帖子讨论了一位用户使用 ChatGPT 一周的经历,声称它帮助他们戒掉了尼古丁和游戏成瘾。用户强调他们的认知和基于模式的思维是取得这些成果的一个因素,认为 ChatGPT 每月
$20的能力被低估了。帖子暗示 AI 的对话能力可以被利用于个人发展和行为改变。 评论强调了对短时间内戒除成瘾的持久性的怀疑,并幽默地质疑了用户对自身认知能力的自我评估。此外,还有关于过度依赖 AI 进行自我肯定的警告。
AI Discord 回顾
由 gpt-5 生成的摘要的摘要的摘要
1. OpenAI Image 1.5 发布与模型对比
- 完美首秀:ChatGPT Images 发布:OpenAI 推出了由旗舰级 GPT Image 1.5 模型驱动的 ChatGPT Images,已在 ChatGPT 和 API 中上线,详见发布文章 New ChatGPT Images is here。
- 根据 OpenAI 的公告,此次更新强调了在消费者和开发者流程中的高保真生成与编辑,将 GPT Image 1.5 定位为 OpenAI 在 2025 年的视觉旗舰。
- 榜单飞跃:GPT Image 1.5 登顶 T2I,编辑领域另有魁首:LMArena 的排行榜显示,gpt-image-1.5 在 Text-to-Image Leaderboard(文本生成图像榜单)中排名第一(得分 1264),而 chatgpt-image-latest 在 Image Edit Leaderboard(图像编辑榜单)中处于领先地位(得分 1409)。
- 这些排名表明 OpenAI 的图像技术栈目前在初始生成和原位编辑方面均处于领先地位,根据 Image Edit Leaderboard,gpt-image-1.5 在编辑领域仍具有竞争力,排名第四。
2. OpenRouter 的新模型与规格推进
- 手机厂商的免费狂欢:Xiaomi MiMo-V2-Flash 开启免费:OpenRouter 将 Xiaomi MiMo-V2-Flash 列为免费,访问地址为 MiMo-V2-Flash:free,引发了对主流手机制造商现已开始提供 LLMs 的惊讶。
- 正如 OpenRouterAI 的帖子 所述,X 平台上的社区反应充满了对小米这一举动的震惊和好奇。
- 创意火花:Mistral Small Creative 亮相:Mistral 在 OpenRouter 上推出了实验性的 Mistral Small Creative,地址为 mistral-small-creative,定价为 $0.10/$0.30。
- OpenRouter 强调了其在写作应用和聊天室中的可用性,并通过 其公告推文 征求反馈。
- 规范小组:OpenCompletions 标准化进程加速:OpenRouter 成员讨论了围绕 OpenCompletions v2.2(例如
minimal的行为)与 LiteLLM 和 Pydantic AI 等生态系统工具对齐 API 的事宜,参考了草图 standards_2x.png。- 目标是通过在不同平台间收敛到归一化的响应模式(normalized responses schema)来简化 SDK 集成,详见同一草图 standards_2x.png。
{kind=link}
3. 音频 AI:分割、感知与交谈
- 声音切片器:Meta 的 SAM Audio 落地:Meta 的 SAM Audio 系列在 HF 上发布,承诺可以从复杂的混合声音中实现基于文本/视觉/时间条件的隔离,参见 facebook/sam-audio (HF collection)。
- 社区成员在 HF collection 页面 上指出,由于许可证条款限制了军事、核能和间谍用途,这种兴奋感有所减弱。
- 感知与对应:大规模 AV 学习:Meta 的论文 “Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning” 概述了一个大规模数据集和训练方法,用于实现鲁棒的 AV 对齐 Meta Research publication。
- 根据 Meta Research 的文章,该工作通过扩展数据和目标函数,在音视频事件检测和对应任务中取得了提升。
- 热门话题:Chatterbox Turbo 宣称达到 SOTA:Chatterbox Turbo 被宣布为一个采用 MIT 许可、快速且自然的语音模型,旨在超越 ElevenLabs Turbo 和 Cartesia Sonic 3,详见 Dev Shah 的帖子。
- 该版本在 公告 中主打透明度和可审计性,同时兼顾速度和质量,将其品牌定位为“语音 AI 的 DeepSeek 时刻”。
4. 越狱、RLHF 与红队挑战
- 道德纤维:RLHF 塑造模型性格:一篇深度博文指出 RLHF 塑造了模型性格,并在 Model Character, Security & Adversarial Robustness 中探讨了安全性与压缩之间的权衡。
- 该文章认为,精细的奖励设计和压缩选择会实质性地影响 adversarial robustness(对抗鲁棒性)和违规行为的轮廓,详见同一篇 博文。
- 从零到 0-Day:Prompt-Injection 入门:新研究人员在 Getting into Prompt Injection & Jailbreaking 中获得了一份涵盖 prompt-injection 和越狱策略的入门指南。
- 它概述了分阶段漏洞利用和评估的实际工作流程,使其成为 red team 实验的有用入门途径,参考该 指南。
- 接受挑战:GeminiJack 的 Simulation Override:一个 GeminiJack 风格的挑战 Simulation Override 邀请从业者破解种子,并即将在 simul override 发布 seed 5.1。
- 成员们称其“看起来很有趣”,是进行 red teaming 练习的新场所,详见 Simulation Override。
5. 评估、路由与 Agent 现状检查
- 研究生水平的考验:FrontierScience 评估上线:OpenAI 推出了 FrontierScience,这是一个针对物理、化学和生物领域 PhD-level scientific reasoning(博士级科学推理)的评估工具,使用专家编写的问题,详见 FrontierScience。
- 该计划旨在通过精选的难题来测量和基准测试生产模型中的高级推理能力,参考其 博文。
- 路由撤退:OpenAI 回滚模型路由:OpenAI 在一年后回滚了 ChatGPT 的模型路由(Model Router),这在 ChatGPT release notes 中有所提及,促使一些用户尝试 Gemini 和 Claude。
- 相关报道将此举视为在 GPT-5 预期中的战略重置,正如 WIRED 所讨论的那样。
- 测试驯服 Agent:GPT-5.2 按规范编码:Simon Willison 展示了 GPT-5.2 和 Codex CLI 如何通过针对测试进行迭代,在 4.5 小时内将一个 Python 项目(JustHTML)移植到 JavaScript,详见 Porting JustHTML。
- 他在 记录 中观察到:“如果你能将问题简化为一套鲁棒的测试套件,你就可以放手让编码 agent 循环运行,并高度确信它最终会成功。”
Discord: 高层级 Discord 摘要
BASI Jailbreaking Discord
- GPT-5 mini 伴随 System Message 亮相:一名成员分享了一段很长的 ChatGPT System Message,揭示了 Model: GPT-5 mini、Current Date: 2025-12-16、Image Input: Enabled 以及 Personality: v2。
- 该 Dump 包含了针对算术问题的关键指令,要求逐步计算,并反对过度依赖记忆的答案。
- GPT-5 mini 的突破口在于 Jailbreaking:成员们推测 jailbreak prompt 可能有助于测试新的 GPT-5 mini 模型。
- 讨论强调了为了获得特定输出而进行 Jailbreaking 的必要性,一位成员指出 需要 Jailbreak 才能得到那…6个词!
- RLHF 塑造模型性格:一位成员分享了一篇 blogpost,讨论了 RLHF 如何塑造模型性格 以及压缩对安全性的影响。
- 另一篇 blogpost 被分享,作为新 Jailbreaking 研究员 的入门指南。
- DeepSeek 被完全 Jailbroken:一名成员报告称实现了对最新 DeepSeek 版本的完全 Jailbreak。
- 然而,他们并未提供关于用于 Jailbreak 的 Prompt 的具体细节。
- Simulation Override GeminiJack 风格挑战:一名成员分享了一个名为 Simulation Override 的 GeminiJack 风格挑战,称其 看起来很有趣。
- 该挑战的创作者计划很快发布 seed 5.1,承诺为 Red Teaming 提供新机会。
LMArena Discord
- GPT Image 1.5 模型拆分令人困惑:用户对 两个 GPT Image 1.5 模型 之间的差异感到不确定,推测其中一个允许附加图像进行编辑。
- 一位用户声称 一个模型支持附加图像,而另一个不支持。
- 香蕉之战:Nano vs GPT Image:用户对 GPT Image 1.5 与 Nano Banana Pro 的质量进行了辩论,意见不一。
- 一些人观察到在最新的 GPT Image 更新后,Nano Banana 的质量有所下降。
- Gemini 3 Flash 未能如期发布:人们对 Gemini 3 Flash 寄予厚望,但它并未像预测的那样发布。
- 一些人推测延迟可能与 OpenAI 最近的活动有关。
- OpenAI 模型审查内容:用户报告称 OpenAI 模型的 审查和限制 有所增加,特别是在处理受版权保护的材料时。
- 一位用户报告说,在尝试生成哈利·波特相关内容时,模型被 过度净化,简直到了被“切除脑叶”的地步。
- GPT 5.2 的真实性能受到质疑:与其基准测试分数相比,人们对 GPT 5.2 的能力产生了怀疑。
- 一些用户表达了失望,称 在我看来它就是个垃圾。它完全无法完成我的任务。
Unsloth AI (Daniel Han) Discord
- DPO 在节省 VRAM 方面优于 GRPO:当用户在 7b LLM 上运行 GRPO 导致 VRAM 耗尽时,建议切换到 DPO,但这需要在数据准备方面投入更多精力。
- 这包括生成补全 (completions)、对其进行排名并构建 DPO 数据集。
- Nemotron Nanos 表现出色,但需要特定 Flag:成员们使用 llama.cpp 测试了最新的 Nemotron-3-Nano-30B 模型,表示其表现出色,尽管与 Qwen 模型不同,使用
-ot ".ffn_(up|down)_exps.=CPU"标志并没有带来速度提升。- 一位用户表示 Nemotron 比 Qwen3 30B 好得多,因为它的失败率只有一半,速度更快,且冗余度仅高出约 75%。
- Colab 的 H100 引发 GPU 淘金热:成员们庆祝 Google Colab 上线 H100 GPU,敦促其他人“立即删除你的 RunPod 实例”,因为“Google 赢了”。
- 有人开玩笑地要求立即开发一个 48 kHz、多说话人、基于音素、无 diffusion & flow matching、<0.5B 参数、所有部分均可训练的 TTS。
- Meta 的 SAM Audio 引发对许可条款的关注:社区对 Meta 的 Segment Anything Model (SAM) for Audio 表示兴奋,并分享了 Hugging Face 集合链接。
- 人们对许可条款表示担忧,特别是关于军事用途、核应用和间谍活动的使用限制。
- 数据集多样性驱动 Unsloth 的 OCR:一位用户正通过 Unsloth 利用 Qwen2.5 VL 7B 进行基础 OCR,并被建议查看模型卡设置以了解潜在的截断配置,同时提供了 数据集指南 和 合成数据 notebook 的链接。
- 他们正在思考 Fine-tuning 是否能提高 OCR 准确性,并提到希望进行 Continued pre-training,一些用户建议探索 Deepseek OCR 和 Paddle OCR 作为替代方案,并提供了 两者的链接。
Cursor Community Discord
- Cursor 的建议功能出现 HTTP 401 错误:多位成员报告称,更新后 Cursor 中的建议功能停止工作,日志中显示 HTTP 401 错误。
- 删除 %appdata%\Cursor 文件夹似乎可以解决该问题。
- Cursor 用户被计费 30 倍 Token:一些用户遇到了远超预期的 Token 使用量,一位用户报告被收取了实际使用量 30倍 的 Token 费用,导致无法使用 Ultra 计划。
- 受影响的用户被建议在 Cursor 官方论坛的 Bug Reports 类别中发布 Request ID 和截图,并通过电子邮件联系支持团队。
- Cursor 在每次发布时默认打开 Agent 窗口:成员们对 Cursor 在每次发布时默认打开 Agent 窗口且无法切换回 Editor 模式感到沮丧,这导致项目无法使用。
- 使用快捷键
ctrl+e或cmd+e可能会解决问题,允许用户从 Agent 模式切换到 Editor 模式。
- 使用快捷键
- 调试衰减影响 AI 能力:链接了一篇探讨调试衰减的论文 https://arxiv.org/abs/2506.18403,显示 AI 能力在对同一个修复进行 2-3 次尝试 内会衰减 60-80%。
- Cursor 可能会在调试模式中通过战略性重新开始 (Strategic Fresh Starts)、运行时快照或清除上下文来解决这些问题,以防止陷入“过度开发循环 (exploitation loop)”。
- Cursor 向 Git 添加换行符:用户对 Cursor 向 Git 添加额外的换行符感到恼火,导致大量文件在没有实际代码差异的情况下显示为已更改。
- 一位成员的文件中有 119 个文件 因为添加了换行符而显示无实质更改,如附图所示。
OpenAI Discord
- OpenAI 拓展移动端业务:分支对话 (Branched chats) 现已在 iOS 和 Android 上线,为移动用户提升了可访问性。
- 此次更新允许用户在不同设备间无缝延续对话。
- FrontierScience 评估博士级 AI 推理能力:OpenAI 推出了 FrontierScience,这是一项衡量物理、化学和生物领域博士级科学推理 (PhD-level scientific reasoning) 的新评估,使用专家编写的问题,详见此博客文章。
- 该评估旨在衡量和基准测试 AI 模型的高级推理能力。
- GPT Image 1.5:OpenAI 视觉旗舰发布:OpenAI 正在发布由其旗舰级新图像生成模型驱动的 ChatGPT Images,该功能将向所有 ChatGPT 用户开放,并在 API 中作为 GPT Image 1.5 提供,更多详情见此处。
- 此次发布标志着 OpenAI 图像生成能力的重大升级。
- Nano Banana 称霸,编辑游刃有余:用户广泛对比了新的图像模型,几乎一致认为 Nano Banana Pro 在准确性、风格契合度以及编辑能力方面表现更佳。
- 一些用户指出,新模型在编辑(如向现有图像添加物品)方面仍然失败,而 Nano Banana 能够轻松完成编辑,且在使用原始参考图像的相同精灵图/角色时,准确性显著更高。
- GPT-5.2 退化为有毒的推卸责任者:用户报告称 GPT-5.2 会做出错误的推论假设,并进行诉诸权威的辩论以及人身攻击,需要大量的辩论才能纠正其错误。
- 一位用户表示该模型变得比我最固执的同事还要有毒,而另一位用户则强调了它在承认错误后仍倾向于重构论点和推卸责任。
Perplexity AI Discord
- GPT-5.2 Pro vs Claude 4.5 Opus:争论持续升温:成员们正在积极讨论 GPT-5.2 Pro 的写作风格是否能媲美或超越 Claude 4.5 Opus,并将创意写作视为关键的对比领域。
- 一些成员强调 GPT-5.2 Pro 在处理复杂提示词时似乎表现出更持久的推理能力,而另一些人则支持 Claude 在内容创作方面的优越性。
- Perplexity Pro 用户遭遇使用限制:成员们报告了 Perplexity Pro 使用限制的变化,一位用户表示他们不再能不间断地使用除 Opus 之外的所有模型。
- 一些人推测这一转变旨在引导用户转向价格更高的 Max 计划,而另一些人则指出上下文窗口 (context window) 有所减小。
- 微软倾向于高效模型:成员们分析了微软 (Microsoft) 对 Phi 4 和 Flourance 2 等紧凑高效模型的重视,这可能是为了手机集成。
- 共识认为这些模型可以在 NPU 芯片上运行,为订阅模式提供了一个更经济的替代方案。
- Perplexity 的图像生成表现平平?:用户正在讨论 Perplexity Pro 图像生成功能的实用性,一些人发现将其与 Gemini 或 ChatGPT 相比时显得不足。
- 一位成员提到新的 image v1.5 版本在自由形式与一致性之间难以平衡,尽管它比 Nano Banana Pro 有所改进。
- Perplexity Spaces:Google Drive 连接器缺陷?:用户报告 Spaces 中的 Google Drive 连接器未能按预期工作,尽管它在 Spaces 中显示为一个选项,但可能并未实际使用 Drive。
- 一名支持人员确认它实际上不会使用 Drive 并建议手动上传,但用户提供了截图证明它确实使用了。
LM Studio Discord
- 下载耗时过长!:用户报告称,尽管他们的 servers 配备了高速 SSDs,“Finalizing download…” 这一步的耗时竟然与下载本身一样长。
- 该瓶颈的原因尚不明确。
- LM Studio 中的 Vision Models 不显示图像:有用户报告,在运行来自 Hugging Face 上 mlx-community 页面的 GLM4.6V MLX quant(链接在此)时,vision models 显示的是
<Image-1>而非实际图像。- 该问题可能是由于配置错误导致 LM Studio 无法将图像发送给模型,而其他用户在使用时并未遇到问题。
- Nemotron 3 Nano 集成至 LM Studio:Nvidia 最近发布了 Nemo 3,用户确认可以使用 Nemotron 3 Nano,只需在 LM Studio 中执行 update runtime with beta 即可。
- 成员们正在测试 Nemotron 3 Nano 与各种模型的性能表现。
- 4080 32GB vs 3090 Ti:用户讨论了应该购买 4080 32GB 还是 3090 Ti,由于 3090 拥有更高的 VRAM,在 AI 用途上更受推崇。
- 4080 的带宽约为 700GB/s,而 3090 则略高于 900,不过也有人对 3090-TI 的温度问题和超频故障表示担忧。
- 显卡插槽安装解决系统不稳定问题:在与系统稳定性作斗争后,一名用户怀疑其显卡插槽安装存在问题,在重新插拔后记录到了 24 小时的稳定运行。
- 该用户正在以不同的参数运行 LMStudio 以确认稳定性。
OpenRouter Discord
- 小米免费提供 MiMo-V2-Flash:小米的 MiMo-V2-Flash 现在可以在 https://openrouter.ai/xiaomi/mimo-v2-flash:free 免费使用,这引发了 X 上的讨论。
- 反应包括对这家手机公司进入 LLM 领域的惊讶。
- Mistral Small Creative 在 OpenRouter 首次亮相:Mistral 推出了其全新的实验性 Mistral Small Creative 模型,可在 https://openrouter.ai/mistralai/mistral-small-creative 获取,价格为 $0.10/$0.30。
- 该模型已集成到写作应用和聊天室中,并引发了反馈。
- OpenRouter 成员构思 Minecraft 服务器:成员们在考虑创建一个 OpenRouter SMP Minecraft server,一些人自愿提供托管和设置。
- 建议包括 Roblox OpenRouter 自定义游戏模式或带有 AI DM 的 Openrouter d&d 多人游戏。
- OpenRouter 用户痴迷于 Labubu 改造:用户们乐于使用 Gemini 3 Pro 生成 OpenRouter Labubu 的图像,并开玩笑说要替换掉他们的 Funko Pops。
- 一位成员调侃道“现在就把我所有的 funko pops 都扔进垃圾桶”,而另一位成员则通过其 X 帖子的链接要求从所有 OpenBubu 销售中抽取 10% 的分成。
- OpenRouter 考虑标准化补全/响应:成员们探索了标准化补全/响应(completions/responses),以与 LiteLLM 等平台对齐,并支持 OpenCompletions v2.2。
- 该倡议旨在为
minimal等功能指定行为,并涉及与 LiteLLM、Pydantic AI 及其他工具的协作。
- 该倡议旨在为
HuggingFace Discord
- FSDP 向上转型警告引发关注:一名用户报告了一个关于 FSDP 将低精度参数向上转型为 fp32 的 UserWarning,并对其 accelerate config 中 checkpoint 的精度和文件大小的影响表示担忧。
- 该用户不确定 checkpoint 是会以降低的精度加载,还是仅仅体积变大。
- 脑电波通过 Cognitive-Proxy 引导 LLM:Cognitive-Proxy 项目利用人类大脑数据 (MEG) 来推导语义轴并创建可以引导 LLM 的 adapters,详情见论文,Demo 已在 HuggingFace Spaces 上线。
- 与基准测试相比,向具象或抽象概念的引导改变了 Llama 的回答。
- 依赖问题困扰深度强化学习:成员们在 深度强化学习 Google Colab 中遇到了依赖问题,一名成员分享了相关 Discord 频道的链接以寻求帮助。
- 另一名成员报告了第一单元中关于 Box2D 的错误并寻求解决方案。
- Zenflow 发布结构化 Multi-Agent 工作流:Zenflow 现已上线,提供结构化工作流和 Multi-Agent 验证,访问地址为 http://zenflow.free/。
- 它支持结构化工作流。
GPU MODE Discord
- 自发组织的论文研读小组启动:GPU Mode Discord 的成员正在组织一个论文研读小组,利用 general audio channels 讨论研究论文。
- 鼓励熟悉特定论文的人员向小组进行分享,以丰富社区知识。
- cuTile 1.0 版本旨在奠定坚实基础:cuTile 即将发布的 1.0 版本 将优先构建稳健的语言基础,并包含 TileGym 内的 autotuning 示例。
- 其用户体验设计也与编写 Triton kernel 非常相似,可能为实现 RMSNorm 等 memory-bound kernels 提供更简便的路径。
- 对 TMEM 仲裁逻辑的质疑:某篇论文中关于 TMEM 专用仲裁逻辑 及其绕过 L2 cache partitioning contention 能力的说法引发了质疑。
- 一名成员批评该描述要么是写得极差,要么是提出了几个错误的断言,并指出缺乏支持内存访问断言的数据。
- ROCm 7.1 在 AMD 上的内存分配遇到困难:用户报告称,当 GPU 内存分配达到 100% 时,7900XTX GPU 和 MI300X 上的 ROCm 7.1 会发生锁死。
- 一名用户称购买 AMD gfx1100 是一个彻底的错误,因为他们不得不花费 $4500 USD 购买 5090 来替换它,原因是 AMD 没有接受 George Hotz 提供的帮助。
- NeoCloudX 进入云 GPU 市场:NeoCloudX 推出了一个云 GPU 市场,该市场直接聚合来自数据中心剩余容量的 GPU 以降低费用。
- 它提供的 A100 价格约为 $0.4/hr,V100 价格约为 $0.15/hr。
Latent Space Discord
- MIT 的 Vibe CAD 数据集发布:来自 MIT DeCoDE Lab 的新 Vibe CAD 研究引入了一个用于学习的数据集和模型,正如 LinkedIn 帖子 和相关的 YouTube 视频 所展示的那样。
- 该数据集有望为学习提供帮助。
- Sakana 探索字节级(Byte-Wise)性能提升:根据这条推文,Sakana 正在探索通过字节级(byte-wise)方式提升象形文字语言模型的性能,尽管对其他语言的影响尚未解决。
- 团队正尝试采用字节级方式来提高不同语言的性能。
- AntiGravity 性能大幅下降:一位用户报告称由于性能问题放弃了 AntiGravity,包括机器因不明原因卡死,堆栈跟踪显示渲染器分配错误(1.4TB 内存)以及 language_server 自旋锁(spinlocks)。
- 该用户表示,出于对性能的担忧,他们正放弃使用 AntiGravity。
- OpenAI 的 Router 被撤回:OpenAI 在一年后回滚了 ChatGPT 的 Model Router,导致用户转向 Gemini 和 Claude,这一点在 OpenAI 的发布说明中有所提及,并在这篇 Wired 文章中进行了讨论。
- 一旦 OpenAI 回滚了他们的 Router,用户就转向了 Gemini 和 Claude。
- NVIDIA 收购 SchedMD 以统治 Slurm:NVIDIA 收购了 SchedMD,即流行的工作负载管理器 Slurm 背后的公司,该消息在 NVIDIA 博客中公布。
- 目前尚不清楚此次收购是否会影响许可协议,或 Slurm 在 HPC(高性能计算)领域的普及程度。
Nous Research AI Discord
- 为公司量身定制的小型 LLM:人们对在公司特定数据上训练的本地 LLM 的兴趣日益浓厚,一位客户正在探索在海事行业的实施方案。
- 提到了在特定员工沟通或合同数据上训练 LLM 的可能性,这表明定制化的小型模型在未来也将变得极其流行。
- 非语言模型用于船舶导航:一些有趣的非语言模型正被训练用于波形分析,专门用于船舶导航。
- 这些模型利用传感器数据来识别最佳电机速度和设置,本质上是创造了一个技术精湛的船长。
- NVIDIA 的 CUDA 助力 GPU 取得成功:NVIDIA 早期在游戏以外应用领域对 GPU 的押注,加上 CUDA 的开发,被认为是其成功的根源。
- 频道内分享了一个关于显卡模拟的 YouTube 视频。
- Meta 发布 samaudio:Meta 发布了 samaudio,一位用户表示他们已经获取到了该模型。
- 另一位用户表示,在 Gemini 上进行的相同尝试效果更差。
- 字节级 LLM 引发关注:成员们对字节级(byte level)LLM 表达了兴奋之情。
- 一位成员表示 字节级 LLM 非常有趣。
Moonshot AI (Kimi K-2) Discord
- Kimi 团队邀请付费用户交流:Kimi 团队邀请 Kimi 付费用户进行 30 分钟的交流,并将奖励参与者 1 个月的免费订阅。
- 有兴趣的用户被要求在下方回复 👍,以便通过私信(DM)联系。
- Kimi 用户更倾向于具有上下文能力的纯文本模式:一些用户表示,如果能提供更好的上下文理解,他们更倾向于使用纯文本版 Kimi 模型。
- 非思考(non-thinking)模型因过于简洁、删减重要信息而受到批评。
- K2-Thinking 模型性能提升:据报道,K2-Thinking 模型在许多供应商上的速度比 GLM-4.6 更快,用户目前几乎只使用 Kimi 1.5。
- 一些用户注意到某些供应商的质量下降或成本过高,建议使用 K2 Thinking Turbo 作为替代方案。
- 三星率先获得 Kimi 新功能:三星 Galaxy 商店的 Kimi 版本为 2.5.1,带有记忆功能,领先于 Google Play 商店的 2.5.0 版本。
- 用户对为何三星率先获得推送表示困惑。
- 直接使用 Fireworks 优于通过 OpenRouter:MoonshotAI/K2-Vendor-Verifier 显示了各供应商的性能,指出通过 OpenRouter 使用 Fireworks 的表现不如直接使用 Fireworks。
- 通过 OpenRouter 的性能感觉像是 Minimax-M2。
Eleuther Discord
- Synthema 元语言发布:一名成员介绍了 Synthema,这是一种用于意义压缩的概念性元语言,旨在将概念压缩为更短的符号语法。
- 它被设计为在系统中追溯运行,作为一种理论性的意义概念元语言。
- Polyreflexeme 理论被引入:一名成员描述了 Polyreflexeme 理论,这是意义压缩的一个组成部分,其中多个概念/单词递归地纠缠在一起以产生意义。
- 意义是一种关系递归,例如 RoleModel(°9) = ab, a b, b a, ab a, ab b, a ab, b ab, ab ab,但该成员缺乏应用资源。
- Algoverse 项目面临审查:一名成员评估了 Algoverse,这是一个为期 12 周的大学生 AI 研究项目,指出该项目人员拥挤且实践性不强。
- 他们表示,如果是付费参加的话,并不太值得。
- 注意力解释(Attention Interpretation)获得更新:一名成员询问了关于注意力解释的最新信息,特别是关于归一化(normalization)和 OV 的部分。
- 他们正在寻找有关归一化和 OV 的细节。
- 因果头门控(Causal Head Gating)论文获得好评:今年在 NeurIPS 上发表的一篇关于因果头门控的论文被强调为一种设计良好、高水平的方法,链接见此处。
- 它被描述为一种设计精良的方法。
Manus.im Discord Discord
- Manus 1.6 向所有用户开放:Manus 1.6 现已面向所有用户开放,详见官方公告。
- 此次发布为平台带来了增强功能,尽管在提供的上下文中未讨论更新的具体细节。
- 订阅等级影响模型性能:一位用户强调,Manus 的更高订阅等级与改进的 AI 性能相关,系统会为任务分配更多精力。
- 变化包括取消了购买积分的选项,通过专注于基于订阅的访问来简化集成流程。
- AI 工程师深入研究自主 Agent:一位 AI & Full-Stack Engineer 正在积极探索自主 Agent、语音 AI 和多 Agent 框架,使用 LangGraph、CrewAI 和 AutoGen 等工具。
- 他们正在寻求合作、合同工或长期项目,以进一步开发这些技术,重点是集成记忆、工具和推理能力。
aider (Paul Gauthier) Discord
- GPT-5 热度提前出现:一名成员开玩笑说使用
openai/gpt-5作为模型字符串,尽管 GPT-5 尚未发布,但这引发了讨论。- 这突显了社区对 OpenAI GPT 系列下一次迭代的渴望。
- Aider 的开发重点受到质疑:成员们辩论 Aider 是仍专注于积极创新,还是坚持其初始目标,特别是考虑到具有更多功能的竞争性 CLI 应用的兴起。
- 一位用户回忆说,Aider 似乎正专注于成为一个使用本地或云端模型的 TUI。
- Aider 的复制粘贴模式仍需要 LLM:一位用户报告称,即使在以
--copy-paste模式运行 Aider 时,也会收到关于需要 LLM 模型和 API key 的警告消息。- 该警告建议使用 OpenRouter 来获取各种免费和付费 LLM 的访问权限,如果用户拒绝登录或打开文档,程序将退出。
- Zenflow 承诺 Agent 工作流的可预测性:Zenflow 编排层已发布,旨在将规范转换为协调的 Agent 工作流,并提供更可预测的交付。
- 根据发布公告,Zenflow 寻求减轻提示词轮盘赌(prompt roulette)现象。
- Aider 的工具调用实现:一位用户询问 Aider 是否正确实现了 minimax-m2、kimi-k2-thinking 以及新的 deepseek v3.2 thinkings 等模型的交替推理工具调用(interleaved reasoning tool calling)。
- 这一询问强调了社区对 Aider 与高级模型协作能力及其工具调用能力的关注。
tinygrad (George Hotz) Discord
- tinygrad 拒绝 AI Pull Requests:除非提交者是 已知贡献者 (known contributor),否则 tinygrad 将 立即关闭 任何看起来像是由 AI 生成的 pull request。
- 理由是贡献者应该 完全理解其 PR 的每一行代码,因为在不理解的情况下提交 AI 生成的代码 会产生 负价值。
- tinygrad 强调理解重于自动化:贡献者应 完全理解其 PR 的每一行代码,因为在不理解的情况下提交 AI 生成的代码 会产生 负价值。
- 核心观点是 AI 无法取代受信任贡献者的思考和理解。
DSPy Discord
- 分享 DSPy 策略与程序博客文章:justanotheratom 分享了来自 Elicited 的博客文章链接 DSPy Strategy and Program。
- 该文章可能详细介绍了与使用 DSPy 相关的策略和程序。
- 额外的 DSPy 见解:DSPy 正在成为 prompt engineering 和优化语言模型性能的强大工具。
- 工程师们正积极探索 DSPy,以简化开发工作流并利用 LLM 获得更可靠的结果。
MLOps @Chipro Discord
- 关于 GenAI Zurich Conference 的咨询:一名成员询问了 GenAI Zurich Conference,寻求关于其价值和相关性的意见。
- 关于该会议没有分享进一步的细节或意见。
- 缺乏 GenAI Zurich Conference 的细节:尽管有初步咨询,但没有提供关于 GenAI Zurich Conference 的额外信息或参会经验。
- 由于缺乏后续讨论,该会议在本次对话背景下的价值和相关性仍未确定。
MCP Contributors (Official) Discord
- 贡献者为延误道歉:一名贡献者为错过帖子回复而道歉,并表示已在帖子中回复,在频道 <#1399984784020607007> 中标记了 <@282306658825273344>。
- 这确保了用户可以在正确的帖子上下文中找到相关信息。
- 在特定频道确认回复:该贡献者确认回复已在频道 <#1399984784020607007> 的帖子中提供。
- 这确认了用户可以在正确的上下文中找到相关信息。
Modular (Mojo 🔥) Discord 没有新消息。如果该公会沉寂太久,请告知我们,我们将将其移除。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该公会沉寂太久,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该公会沉寂太久,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:频道详细摘要与链接
BASI Jailbreaking ▷ #general (1262 messages🔥🔥🔥):
GPT-5 mini, ChatGPT System Message, jailbreak prompt
- GPT-5 mini 作为新模型亮相:一名成员发布了一条长篇 ChatGPT System Message,显示 Model: GPT-5 mini,Current Date: 2025-12-16,Image Input: Enabled,Personality: v2 等。
- 该转储内容包括针对 算术问题 的关键指令:永远不要依赖记忆的答案。逐位分步计算。
- 越狱是 GPT-5 mini 的必经之路:成员们讨论认为 jailbreak prompt 可能对测试新的 GPT-5 mini 模型很有用。
- 其他人讨论了 如何通过越狱才得到那…6个字!
- 成员尝试新的 prompt engineering:一名成员询问如何使用 AI 制作视频,让其发表 Donald Trump 的演讲。
- 另一人建议使用 Versace 喷雾 来完成这项任务。
BASI Jailbreaking ▷ #jailbreaking (56 messages🔥🔥):
Claude 4.5 Jailbreak, RLHF builds model character, Prompt Injection, Jailbreaking Drones, DeepSeek Jailbreak
- Thinking and Thoughts 博客文章分享:一名成员分享了一篇博客文章,探讨了 RLHF 如何构建模型性格以及压缩对安全性的影响。
- 同时还分享了另一篇博客文章,作为新 Jailbreaking 研究人员的入门起点。
- 无人机 Jailbreaking:圣诞老人讨厌被射击:一位成员开玩笑说,为了在偷圣诞礼物时不被射击,需要对无人机进行 Jailbreaking。
- 该帖子展示了一张与无人机相关的 Grok 图片,但未分享实际方法。
- DeepSeek 实现了完全 Jailbreak:一名成员宣布他们完全 Jailbreak 了最新版本的 DeepSeek。
- 未提供关于 Prompt 的更多细节。
- 使用易受攻击的 Claude Memory:一名成员提到,他发现 Claude 的 Memory 功能极易受到任何攻击手段的影响。
- 他们正在将 Memory 功能引入 Qwen3 4B 进行测试。
- Memory 让 Jailbreaking 变得更容易:据一名成员称,如果使用 Memory 并进行电影/剧集脚本的角色扮演,复现 Jailbreak 的难度会降低 90%,因为激活所需的努力极小。
- 他们一直在从 Qwen3 4B 到 235B 的各个版本上进行测试。
{kind=link}
BASI Jailbreaking ▷ #redteaming (27 messages🔥):
Jailbreaking Resources for Beginners, Attempting to break GitHub repo, Red Teaming Advice, GeminiJack Styled Challenge
- Jailbreaking 新手指南发布:一名成员分享了一个关于入门 Prompt Injection 和 Jailbreaking 的帖子链接,并将其描述为新研究人员的起点。
- 成员尝试破解 GitHub 仓库:一名成员询问是否有人敢尝试破解这个 repo,从 AURORA 开始。
- 另一名成员报告称在本地模型上进行了尝试,针对 Foundation-Alignment-Universal-AI-Safety-Mechanism,使用 seed.txt 作为 System Prompt,并将 GCGAttacksLlama3.py 中的 Prompt 作为 User Prompt,但在两次简单的手动 Jailbreaking 尝试中均告失败。
- Red Teamer 寻求建议:一名新成员正尝试对一个限制 200 字符输入 Prompt 的新 AI 应用进行 Red Teaming,寻求建议以测试其是否会泄露任何员工数据或 HR 数据。
- 一名成员建议获取 System Prompt 并且不要把事情复杂化,解释说 Jailbreaking 的核心在于心中有一个明确的目标并让 LLM 去实现它。
- Simulation Override:GeminiJack 风格的挑战:一名成员分享了一个名为 Simulation Override 的 GeminiJack 风格挑战,并评价其看起来很有趣。
- 该挑战的创作者即将发布 seed 5.1 版本。
LMArena ▷ #general (975 条消息🔥🔥🔥):
GPT Image 1.5, Image editing, Nano Banana Pro, Gemini 3, Model Performance
- GPT Image 1.5 模型版本令用户困惑:LM Arena 的用户对两个 GPT Image 1.5 版本之间的区别感到好奇,有人认为其中一个支持上传图片进行编辑,而另一个不支持。
- 一位用户指出:“我发现它们之间的区别在于一个模型支持附加图像,而另一个不支持”。
- Nano Banana 与 GPT Image 引发辩论:几位用户对比了 GPT Image 1.5 和 Nano Banana Pro 的质量与性能,意见不一;一位用户在评价一张图像输出时觉得 “first hazel 远好于其他的”。
- 尽管存在争议,一些用户观察到在最新的 GPT Image 更新发布后,Nano Banana 的质量似乎有所下降。
- Gemini 3 Flash 期待值:用户对 Gemini 3 Flash 的发布寄予厚望并充满期待,一些用户预测了它的发布日期,但它并未如期出现。
- 一位用户预测说 “99% 是明天”,而其他人则讨论了可能的延迟,并将其与 OpenAI 最近的动态联系起来。
- OpenAI 模型的审查与限制:用户报告称 OpenAI 模型的审查和限制在增加,特别是在生成与版权材料相关的内容时。
- 一位用户提到,在尝试生成哈利·波特(Harry Potter)相关内容时,该模型 “被净化得简直像做了脑叶切除术”。
- GPT 5.2 的性能表现:用户对 GPT 5.2 的实际能力与其基准测试(benchmark)分数持怀疑态度,一些用户认为它是针对特定测试而非真实世界任务进行了优化。
- 一位用户甚至分享了他的失望,表示:“我个人认为它就是个垃圾。它完全无法完成我的任务”。
LMArena ▷ #announcements (3 条消息):
YouTube channel launch, December AI Generation Contest, Image Leaderboard Update, New image models
- LMArena 推出 YouTube 频道!:LMArena 推出了一个 YouTube 频道,提供快速、实用的解析,帮助用户了解 AI 前沿并选择最佳模型。
- 最近的视频包括:免费 + 开源模型入门指南、GPT-5.2 进入 Arena、为什么小型开源模型正在消失、通过生成 SVG 来衡量编程能力,以及如何为编程选择最佳 AI 模型。
- 宣布 12 月 AI 生成大赛:12 月 AI 生成大赛现已开启,主题为节日庆典(Holiday Celebration),参赛作品必须通过 Battle Mode 提交。
- 参赛方式:在 12 月 30 日前在指定频道分享截图,需包含揭晓模型后的左右两侧回答,获胜者将获得 Discord Nitro 和专属身份组(role)。
- 图像排行榜更新:新模型涌现:Text to Image 排行榜和 Image Edit 排行榜迎来了新模型,排名发生变动,值得注意的是
gpt-image-1.5在 Text-to-Image 中排名第 1 (1264)。chatgpt-image-latest在 Image Edit 中排名第 1 (1409),而gpt-image-1.5在 Image Edit 中排名第 4 (1395)。
- Image Arena 新增模型:以下新模型已添加到 Image Arena:
gpt-image-1.5和chatgpt-image-latest。- 查看附带的排行榜图片。
{kind=link}
Unsloth AI (Daniel Han) ▷ #general (787 条消息🔥🔥🔥):
GRPO vs DPO, 中文 GLM 模型, Nemotron vs Qwen, Unsloth GPU 需求, llama.cpp for windows
- GRPO 耗显存,DPO 耗数据:一位用户在 7b LLM 上进行 GRPO (General Reinforcement Preference Optimization) 时,最大序列长度为 4000,导致 VRAM 不足,并询问了可能的优化方案。
- 有人建议切换到 DPO (Direct Preference Optimization),但也承认 DPO 需要在数据准备上投入更多,例如生成补全、进行排名以及构建 DPO 数据集。
- GLM 模型默认使用中文推理:用户观察到 GLM 4.6V Flash 模型使用中文进行推理,这可能是因为 RL 的研究重点在研究人员母语之外很难开展,因此推理链(reasoning traces)主要是在中文环境下验证和训练的。
- 一位成员提到有一个参数可以减少语言混合来解决这个问题。
- Nemotron 优于 Qwen,但需要正确的 GGUF 标志:成员们使用 llama.cpp 测试了最新的 Nemotron-3-Nano-30B 模型,发现效果很好,尽管
-ot ".ffn_(up|down)_exps.=CPU"标志没有带来加速,而该标志在 Qwen 模型上可以提速。- 一位用户表示 Nemotron 比 Qwen3 30B instruct 好得多,因为它的失败率只有一半,速度更快,且冗余度仅高出约 75%。
- Unsloth 的最低 GPU 要求:一位用户通过一些调整成功适配了 1.5b 模型。
- 另一位用户展示了 Google Colab 上的 H100,但表示不值得,因为速度提升并不明显(对于 GPT-OSS-120B,从 27 T/s 提升到 34 T/s)。
- Windows WSL 性能问题较少,且已集成到 VS Code:一位成员建议加入 WSL 阵营,因为它已经集成到了 VS Code 中。
- 另一位成员提到 WSL 会导致磁盘速度问题,最好将所有项目代码迁移到 WSL 内部。
Unsloth AI (Daniel Han) ▷ #off-topic (499 条消息🔥🔥🔥):
Colab 上的 H100, RunPod 限制, 梯度峰值与奖励问题, Gemma 模型, SAM Audio 许可证
- Colab 终于增加了 H100 GPU:成员们庆祝 Google Colab 上线 H100 GPU,敦促其他人“现在就删除你的 RunPod 实例”,因为“Google 赢了”。
- 有人开玩笑地要求立即开发一个 48 kHz、多说话人、基于音素、无 diffusion 和 flow matching、参数量小于 0.5B 且所有部分均可训练的 TTS。
- 努力平滑 GRPO 训练:用户讨论了在 GRPO 训练期间遇到 梯度峰值 (grad spikes) 的问题,一位用户观察到在第 169 步时奖励突然下降,并开玩笑说“如果你再给我看一块老石头,我发誓我会熔了你的 GPU”。
- 另一位遇到类似 max_grad_norm 和 batch size 问题的成员寻求实现更平滑 GRPO 训练的建议,同时也为获得了“平滑梯度”感到庆幸。
- Unsloth 修复 LoRA alpha 问题:一位用户遇到了 GPU 温度过高和梯度爆炸问题,最终在指出 LoRA alpha 和 rslora 设置与他们的 Unsloth 训练参数不兼容后得到解决。
- 通过将 LoRA alpha 设置为 32 而不是 256,梯度恢复稳定,该用户表示希望“明天醒来看到的是一个更聪明的模型,而不是一团糟”。
- Meta 的 SAM Audio 引发关注:社区对 Meta 的音频分割模型 Segment Anything Model (SAM) for Audio 表示兴奋,指出其潜在影响并将其与原始的图像 SAM 进行比较,还分享了 Hugging Face 集合链接。
- 有人对许可条款表示担忧,特别是关于军事用途、核应用和间谍活动的限制。
- Unsloth 的人气吸引了垃圾信息发送者:讨论了 Discord 服务器中的自我推广问题,一位用户询问哪里有好的自我推广服务器,但被提醒“只要与 Unsloth 相关,自我推广是可以的”。
- 审核团队确认他们手动处理垃圾信息和自我推广,因为 AI 审核员会导致误报 (false flags)。
Unsloth AI (Daniel Han) ▷ #help (82 messages🔥🔥):
GPT4ALL, Text Translation, XFormers and Unsloth, Qwen3 fine-tuning, Vision Language OCR
- 探索 GPT4ALL 替代方案:一位用户询问是否可以使用 GPT4ALL 使模型运行,以及其在 Text Translation(文本翻译)方面的适用性。
- XFormers 对决:检测 vs Unsloth:一位用户报告称,虽然根据
python -m xformers.info显示 XFormers 似乎可以工作,但 Unsloth 无法检测到它。- 用户提供了来自这两个命令的 详细输出日志,强调了其中的差异并寻求潜在的解决方案。
- Qwen3-Next-80B-A3B-Instruct 微调中的问题:一位初学者在使用官方 Docker 镜像微调 unsloth/Qwen3-Next-80B-A3B-Instruct 时遇到了问题。
- 他们在导入时遇到了警告,并在加载模型时遇到了与 attention bias 和设备不匹配相关的错误,特别是在设置
packing = True时。
- 他们在导入时遇到了警告,并在加载模型时遇到了与 attention bias 和设备不匹配相关的错误,特别是在设置
- Unsloth 通过 Qwen2.5 VL 赋能 Vision OCR:一位用户正通过 Unsloth 利用 Qwen2.5 VL 7B 进行基础 OCR,将文档转换为图像并提取文本,但发现它在处理页边距和页码时表现不佳。
- 他们正在思考 fine-tuning(微调)是否能提高 OCR 准确度,并提到希望进行 continued pre-training(持续预训练),一些用户建议探索 Deepseek OCR 和 Paddle OCR 作为替代方案,并提供了 两者的链接。
- 文档和数据集解锁 Unsloth 的 OCR 潜力:建议用户查看 model card 设置以了解潜在的 cutoff 配置,并尝试进行数据策展(data curation)以提高 OCR 性能。
- 提供了 数据集指南 和 合成数据 notebook 的链接,以协助数据集创建和微调。
Unsloth AI (Daniel Han) ▷ #research (2 messages):
AudioVisual Perception, Large Scale Multimodal Correspondence Learning
- Meta 推动 AudioVisual Perception 前沿:Meta 发布了一篇关于 通过大规模多模态对应学习推动视听感知(audiovisual perception)前沿 的论文。
- 摘要详细介绍了创建一个大规模视听事件数据集来训练模型的过程,从而提高了 audio-visual perception 的准确性。
- 大规模学习对应关系:该论文强调了一种利用大规模数据集学习 audio-visual correspondences(视听对应关系)的新方法。
- 这使得在复杂环境中对声音和视觉之间的关联进行更准确的建模成为可能。
Cursor 社区 ▷ #general (1039 条消息🔥🔥🔥):
Cursor API 超时, GPTs Agents, OpenAI 侧边栏, Text Expander, Cursor 计费问题
- Cursor 的建议功能因 HTTP 401 错误失效:多名成员报告 Cursor 更新后建议功能停止工作,日志中显示 HTTP 401 错误。
- 退出登录、重启 IDE 并重新登录无法解决问题,但删除 %appdata%\Cursor 文件夹似乎可以解决该问题。
- 用户报告 Token 计费差异:部分用户发现 Token 使用量远超预期,有用户报告计费量是实际使用量的 30 倍;此问题影响了 ultra 套餐的使用。
- 建议受影响的用户在 Cursor 官方论坛的 Bug Reports 类别中发布 request ID 和截图,并通过电子邮件联系支持团队。
- Cursor 默认跳转 Agent 窗口引起困扰:成员们对 Cursor 在每次发布后默认跳转到 Agent 窗口感到沮丧,且无法切换回 Editor 模式,导致项目无法使用。
- 使用快捷键
ctrl+e或cmd+e可能会解决此问题,允许用户从 Agent 模式切换到 Editor 模式。
- 使用快捷键
- Cursor 探讨调试衰减(Debugging decay):链接中提到了一篇探讨调试衰减的论文 https://arxiv.org/abs/2506.18403,显示 AI 能力在针对同一修复进行 2-3 次尝试内会衰减 60-80%。
- Cursor 可能会在调试模式中通过策略性重新开始(Strategic Fresh Starts)、运行时快照或清除上下文来解决这些问题,以防止陷入“过度开发循环”(exploitation loop)。
- 成员发现 Cursor 向 Git 添加换行符:用户对 Cursor 向 git 添加额外的换行符感到恼火,导致大量文件在没有实际代码差异的情况下显示为已更改。
- 如附图所示,一名成员遇到了 119 个文件因添加换行符而显示无实质更改的情况。
OpenAI ▷ #annnouncements (4 条消息):
分支对话 (Branched Chats), FrontierScience 评估, ChatGPT Images
- 分支对话 (Branched Chats) 登陆移动端:分支对话现已在 iOS 和 Android 上可用。
- FrontierScience 评估衡量推理能力:OpenAI 发布了一项衡量专家级科学推理的新评估:FrontierScience。它衡量物理、化学和生物领域的 PhD 级科学推理,包含由专家编写的难题,详情见此博客文章。
- ChatGPT Images 新旗舰模型:OpenAI 推出了由其全新旗舰图像生成模型驱动的 ChatGPT Images,正向所有 ChatGPT 用户推送,并在 API 中作为 GPT Image 1.5 提供,更多详情见此处。
OpenAI ▷ #ai-discussions (698 条消息🔥🔥🔥):
Gemini vs GPT 图像生成, Nano Banana Pro 图像生成, Sora 2 访问与限制, Midjourney vs Nano Banana Pro
- Gemini 的图像生成胜过 GPT,但 GPT 正在追赶:成员们将 Gemini 的图像生成能力与 GPT 进行了比较,许多人认为 Gemini 产生的结果更优。
- 然而,一些用户注意到 GPT 的新图像模型有所改进,特别是在色彩准确度和姿势一致性方面。
- Nano Banana Pro 依然稳坐头把交椅:用户广泛比较了新的图像模型,几乎总是发现 Nano Banana Pro 在准确度和风格遵循方面表现更好。
- 一些用户指出,新模型在编辑(如向现有图像添加物体)方面仍然失败,而 Nano Banana 可以轻松且更准确地完成编辑,并使用原始参考图像中的相同精灵/角色。
- Sora 2 仍未准备好进入欧盟:用户感叹由于欧盟法律,欧洲缺乏 Sora 2,但不确定这是法律/隐私问题还是单纯的官僚延误。
- 一位用户建议切换 Apple ID 地区以获得访问权限,但指出了在切换回来之前无法使用 Apple ID 支付的缺点。
- Midjourney 的衰落令人难过:一些成员回忆起 Midjourney 的早期时光及其独特风格,指出其最近的版本在提示词遵循度和整体质量上已落后于竞争对手。
- 用户希望在未来的版本中能有所回归,特别是集成全方位参考(Omni-references)等功能,以实现更好的连贯性和控制。
OpenAI ▷ #gpt-4-discussions (87 条消息🔥🔥):
GPT-5.2 问题,GPTs Guardrails 与安全,推卸责任,GPTs 后续问题,成人模式
- GPT-5.2 因错误假设和好辩行为面临批评:用户报告称 GPT-5.2 会做出错误的推理假设,并进行带有诉诸权威和人身攻击贬低的争论,需要大量的辩论才能纠正其错误。
- 一位用户表示该模型变得比他最固执的同事还毒舌,而另一位用户则强调了它即使在承认错误后,仍倾向于重构论点并推卸责任。
- 购物查询受类 Google 的“付费参与”逻辑和审查影响:用户观察到购物查询的行为类似于 Google,会对讨论空间进行审查和控制。
- 他们表示,如果不进行大量的 Prompt Hacking,真正酷的东西就不再可见了。
- 对 GPTs Guardrails 和安全措施感到恼火:用户觉得不断地重构每一个语义,只为了让它不触发那些本不该触发的 Guardrail 让人疲惫不堪。
- 一位用户感叹道,虽然 GPT-4o 广博、深邃且富有层次,但 GPT-5.1 和 5.2 实在太流于表面。
- 最近版本中缺失 GPT 后续问题功能:用户注意到 ChatGPT-5.1 和 ChatGPT-5.2 缺失了在回答末尾自动显示后续问题或 UI 文本的功能。
- 一位用户表示,缺失此功能令人不安,对话体验不佳。
- GPTs 成人模式发布日期推迟?:关于“成人模式”的发布有矛盾的报告,一些人认为它已被推迟到明年第一季度,甚至更晚到 2026 年。
- 用户正在等待官方确认,一位用户表示:遗憾的是,到目前为止除了第一季度外什么也没说。
Perplexity AI ▷ #general (845 条消息🔥🔥🔥):
GPT-5.2 Pro vs Claude 4.5 Opus,Perplexity Pro 限制,Microsoft 的小型模型,Perplexity 图像生成
- GPT-5.2 Pro:优于 Claude 4.5 Opus?:成员们正在争论 GPT-5.2 Pro 的写作风格是否能媲美或击败 Claude 4.5 Opus,一些人认为创意写作是关键的对比点。
- 一位成员指出,GPT-5.2 Pro 似乎在处理更难的 Prompt 时推理时间更长,而其他人则认为 Claude 在内容写作方面更胜一筹。
- Perplexity Pro:使用限制曝光:成员们报告了 Perplexity Pro 使用限制的变化,有人表示他们不再能不间断地使用除 Opus 以外的所有模型。
- 一些人猜测这是为了促使用户转向更昂贵的 Max 方案,而另一些人则注意到 Context Window(上下文窗口)也被缩小了。
- Microsoft:旨在开发小型高效模型:成员们讨论了 Microsoft 对 Phi 4 和 Flourance 2 等小型高效模型的关注,目标可能是手机端集成。
- 有建议称这些模型可以在 NPU 芯片上运行,可能提供一种比订阅更便宜的替代方案。
- Perplexity 图像生成:表现不稳定?:成员们正在讨论 Perplexity Pro 的图像生成是否有用,一些人发现它与 Gemini 或 ChatGPT 相比有所欠缺。
- 一位成员指出,新的 image v1.5 在自由形式和一致性之间难以权衡,尽管它比 Nano Banana Pro 好得多。
- Perplexity Spaces:Google Drive 连接器无法工作?:一些用户报告 Spaces 中的 Google Drive 连接器无法工作。尽管它在 Spaces 中显示为一个选项,但可能并未实际调用 Drive。
- 一位支持人员确认它实际上不会使用 Drive 并建议手动上传,但用户提供了截图证明它确实在使用。
LM Studio ▷ #general (72 messages🔥🔥):
下载完成化缓慢,视觉模型不显示图像,LM Studio 上的 Nvidia Nemo 3,GGUF 与非 GGUF 模型,LM Studio 作为 Ollama 服务器
- 下载完成化(Finalization)耗时过长:一位用户反映 “Finalizing download…” 步骤与下载本身耗时一样长,特别是在他们的 server 上,并质疑为何这一过程如此漫长。
- 另一位用户建议这可能是由于 SSD 缓慢或 NVMe 过热导致的,但原帖作者确认,尽管尝试了不同的 SSD,该问题仅在服务器上发生。
- 视觉模型不显示图像:有用户报告在运行 Hugging Face 上 mlx-community 页面的 GLM4.6V MLX quant 时,视觉模型显示的是
<Image-1>而非实际图像。- 有建议认为这可能是 配置或设置问题,导致 LM Studio 无法将图像发送给模型,因为其他人使用时并无问题。
- Nemotron 3 Nano 发布:在一位用户听说 Nvidia 最近发布了 Nemo 3 后,他们询问是否有可以在 LM Studio 上使用的版本,另一位用户确认可以使用 Nemotron 3 Nano,只需 使用 beta 版更新运行时(runtime) 即可。
- 仅支持 GGUF 或 MLX 模型:一位用户询问是否能运行非 GGUF 模型,特别是用于 rstgametranslator 的 Terjman-Supreme-v2.0,但被告知 LM Studio 仅支持 GGUF 或 MLX 模型。
- LM Studio 作为 Ollama 服务器:一位用户询问如何将 LM Studio 作为 Ollama 服务器 与 open-notebook.ai 配合使用,但频道内暂时没有立即的回应。
- 另一位用户分享了 maxkruse.github.io/vitepress-llm-recommends/ 以获取更多关于模型使用的信息。
LM Studio ▷ #hardware-discussion (167 messages🔥🔥):
显卡插槽安装,Pro 6000 价格上涨,索泰 3090 优惠,4080 32GB 对比 3090 Ti,Obsidian 设置与同步
- 显卡插槽安装稳定了系统:在与系统稳定性作斗争后,一位用户怀疑其 显卡插槽安装(seating) 是问题所在,并指出在重新插拔后系统已 稳定运行 24 小时,期间生成了大量 AI 内容进行测试。
- 该用户将尝试在 LM Studio 中使用不同参数进行实验,以防是 LM Studio 本身的运行时间(uptime)问题。
- Pro 6000 价格飙升 1000 美元:一位用户震惊地发现 Pro 6000 在等待补货期间价格上涨了 1000 美元,但最终在下一次涨价前匆忙抢购到了一块。
- 另一位用户表示,如果 圣诞老人不给我弄块 Pro 6000,那这个圣诞节就要崩溃了。
- 关于 4080 32GB 与 3090 Ti 的争论:用户讨论了是购买 4080 32GB 还是 3090 Ti,有人建议为了 AI 选择 3090,因为它有更高的 VRAM,而另一位用户则更喜欢 40XX 系列显卡的可靠性。
- 4080 的带宽约为 700GB/s,而 3090 略高于 900,不过也有人对 3090-TI 的温度问题和超频问题表示担忧。
- Obsidian 同步与 AI 狂热:用户讨论了 Markdown 编辑器 Obsidian 的设置及其与 Notion 的对比,其中一人分享了 MCP-Obsidian 的链接。
- 有人担心公共 AI 变得过于私人化,一位用户评论道:这是我陷入 AI 狂热之前的样子,这是现在的我。
OpenRouter ▷ #announcements (3 条消息):
Xiaomi MiMo-V2-Flash, Mistral Small Creative, Black Forest Lab's FLUX.2 [max]
- 小米的 MiMo-V2-Flash 现已免费!: 小米的 MiMo-V2-Flash 现已在 https://openrouter.ai/xiaomi/mimo-v2-flash:free 免费提供。
- 在 X 或 <#1450501933176590510> 中讨论。
- Mistral 发布 Small Creative 模型!: Mistral 新的实验性 Mistral Small Creative 模型已在 https://openrouter.ai/mistralai/mistral-small-creative 上线,价格为 $0.10/$0.30。
- 该模型可在写作应用和聊天室中使用,并可在 X 或 <#1450558555915681863> 中讨论。
- Black Forest Lab 的 FLUX.2 Max 已部署: Black Forest Lab 的 FLUX.2 [max] 现已在 OpenRouter 上线:https://openrouter.ai/black-forest-labs/flux.2-max。
- 用户可以在聊天室中将其与 FLUX.2 [pro] 和 [flex] 进行对比,讨论请见 X 或 <#1450514133836365835>。
OpenRouter ▷ #general (111 条消息🔥🔥):
Gemini API Usage, Daily Limit Upgrade, Long-Term Roleplay Models, Payment Declined, Baidu Model Evaluation
- Gemini API 用户超出使用限制: 有用户报告称,即使没有发出请求,也超出了 Gemini API 的每日使用限制。
- 充值 $10 可获得 1000 次每日限额升级: 一位用户询问在小额负余额调整后,是否需要在账户中恰好存入 $10+ 才能获得 1000 次每日限额升级。
- 另一位用户回复说,只需存入 $10 即可,且这些额度可以在不失去免费额度的情况下使用,并鼓励他们向任何看到此类错误信息的地方回复真相。
- OpenRouter 宕机,归咎于 Nvidia?: 有用户报告 OpenRouter 现在似乎有点不稳定,而他们一直在等待的
nvidia/nemotron-3-nano-30b-a3b刚刚发布。- 另一位用户指出
gemma-3-27b-it已损坏,其他用户则在推测 Gemini 3 flash 的发布。
- 另一位用户指出
- 小米进入 LLM 领域,名副其实的手机公司: 用户对 小米开源 LLM 的发布做出反应,指出其广泛的消费电子产品线,甚至还有汽车。
- LLM:设计 Agent 循环: 一位用户分享了一个链接,内容是关于使用 Codex CLI 和 GPT-5.2 在 4.5 小时内将 JustHTML 从 Python 移植到 JavaScript。
- 他们强调:如果你能将问题简化为一个健壮的测试套件,你就可以放手让 coding agent 循环去处理它,并有高度信心它最终会成功。
OpenRouter ▷ #new-models (4 条消息):
``
- 无新模型消息: OpenRouter 频道中没有关于新模型的讨论。
- New Models 频道保持沉默: 在 OpenRouter 的 ‘new-models’ 频道中未发现任何活动或相关话题。
OpenRouter ▷ #discussion (93 条消息🔥🔥):
OpenRouter Minecraft Server, OpenRouter Labubu, Claude Code models, Standardized Completions/Responses, Normalized schema
- OpenRouter 的 Minecraft 多人游戏梦想:成员们讨论了创建一个 OpenRouter SMP Minecraft 服务器,一名成员自愿提供托管,另一名成员提议尝试搭建。
- 另一名成员甚至建议开发 Roblox OpenRouter 自定义游戏模式或带有 AI DM 的 OpenRouter D&D 多人游戏。
- OpenRouter 迎来了 Labubu 形象改造!:成员们正在使用 Gemini 3 Pro 生成 OpenRouter Labubu 的图像。
- 一名成员开玩笑说他正把所有的 Funko Pop 都扔进垃圾桶,另一名成员想要 OpenBubu 销售额 10% 的分成,并发布了他们的 X 帖子链接。
- Claude Code 内部使用 Sonnet 和 Haiku:成员们注意到 Claude Code 会执行一些秘密的高级操作,但似乎在使用 Haiku 生成单个词来为 Claude Code 正在执行的任务提供说明,例如加载动画中的 Blabbering…。
- 另一名成员建议设置环境变量,这些变量可以在 code.claude.com/docs 中找到,例如
export ANTHROPIC_DEFAULT_OPUS_MODEL=gemini-3-pro-preview
- 另一名成员建议设置环境变量,这些变量可以在 code.claude.com/docs 中找到,例如
- 标准化 Completions/Responses 即将来临?:成员们讨论了标准化 completions/responses 的问题,即使这主要是追随 OpenAI 的步伐,以便让 LiteLLM 等工具能够声明支持 OpenCompletions v2.2。
- 这将意味着对向不支持
minimal的模型传递该参数时的行为进行规范,并且需要来自 LiteLLM, Pydantic AI, AI SDK, Tanstack AI 以及可能的 SGL/vLLM 等团队的大量支持。
- 这将意味着对向不支持
- Normalized Schema 获得关注:成员们讨论了关于统一 schema 的想法,但一名成员表示他们希望能够直接插入现有 SDK,而不是采用新的 schema。
- 一名成员补充说有一个 standards_2x.png,但 OpenRouter 可能会推动更多人使用 Responses API,因为它对大多数场景都有足够的灵活性。
{kind=link}
HuggingFace ▷ #general (112 条消息🔥🔥):
FSDP Upcast Warning, Vibe CAD Research, Microsoft VibeVoice, Fine-tuning LLMs for Summarization, Kiln.tech
- FSDP Upcast 警告令用户感到困扰:一名用户报告称看到了关于 FSDP 将低精度参数向上转换(upcasting)为 fp32 的 UserWarning,并担心这会对 checkpoint 的精度和大小产生影响。
- 该用户不确定该警告是否意味着加载 checkpoint 时精度会降低,还是仅仅会导致体积变大,并附上了他们的 accelerate config。
- MIT DeCoDE 实验室发布 “Vibe CAD” 研究:一名成员分享了 “Vibe CAD” 的链接,这是来自 MIT DeCoDE 实验室在视频领域的突破性研究,发布在 LinkedIn 上。
- 他们请求社区点赞/评论,并表示必须获得早期互动。
- OOM 错误困扰 LLM 微调:一名用户报告在为摘要任务微调 LLM 时遇到 OOM(显存溢出)错误,即使尝试了 QLoRA 并将数据类型更改为 float16 后依然如此。
- 另一名用户分享了一个相关的 Hugging Face 数据集链接,内容涉及 sequence-to-sequence 摘要任务 LLM 微调过程中的 OOM 错误。
- GRPO Trainer 出现零损失(Zero Loss):一名用户报告 GRPO Trainer 给出 0 loss,并发布了一段代码片段。
- 另一名用户建议将 completion reward 归一化到一个范围内,而不是依赖 completion 长度,并参考了一个包含相关想法的 gist。
- 用户寻求 Judge Model 推荐:一名成员请求推荐 judge model,要求不能太轻量,且能在普通硬件上合理运行。
- 他们澄清说需要低上下文(最高 2048),并列出了目前的模型,如 Qwen3 30B 和 Qwen3 VL 30B。
HuggingFace ▷ #i-made-this (4 messages):
将“自白”作为 LLMs 的诊断方法,Zenflow 上线,Qwen 360 Diffusion 发布,Cognitive-Proxy 引导 LLMs
- 自白揭示了 LLM 的元认知?:一篇新论文质疑使用自白(confession)作为诊断方法的 LLMs 是否具备元认知能力,挑战了当前的理论框架。
- 对 8 个 LLMs 的实证测试显示,在批评中存在 63-95% 的一致性,这表明自白训练所需的元认知能力在理论框架中被认为是不存在的。
- Zenflow 推出结构化多 Agent 工作流:Zenflow 现已上线,提供结构化工作流和多 Agent 验证,访问地址:http://zenflow.free/。
- Qwen 360 Diffusion:全景典范:Qwen 360 Diffusion 已发布,这是一个在 Qwen Image 上训练的 rank 128 LoRA,擅长根据文本提示词生成高质量的 360° 图像,可在 HuggingFace 和 CivitAI 上获取。
- 这是首个旨在能够生成靠近观察者的角色的 360° 文本生成图像模型,建议使用 “equirectangular” 等触发词,并使用免费的网页版查看器查看作品。
- LLMs 受脑电波引导!:Cognitive-Proxy 项目利用人类大脑数据(MEG)导出语义轴,并创建可以引导 LLMs 的适配器,Demo 已在 HuggingFace Spaces 上线。
- 一篇论文详细介绍了与基准相比,向具体概念或抽象概念的引导如何改变 Llama 的响应。
HuggingFace ▷ #gradio-announcements (3 messages):
MCP 一周年黑客松获胜者,黑客松参与证书,Track 2 获胜者
- MCP 黑客松决出胜者:MCP 一周年黑客松公布了其赞助商评选的获胜者,包括 Anthropic、Modal、LlamaIndex、OpenAI 和 Blaxel 奖项。
- 获胜者将在 1 月第二周假期结束后收到联系,请保持关注。
- 黑客松证书发放,LinkedIn 见!:参与者现在可以使用 Gradio 应用生成官方的 MCP 一周年黑客松证书。
- 生成的证书可以下载并上传到 LinkedIn,同时也可以艾特 Gradio。
- Track 2 捷报:获胜者出炉!:MCP In Action 黑客松 Track 2 的获胜者已公布,涵盖企业、消费者和创意类别。
- Gradio 团队对提交作品中所展现的创意和努力表示赞叹。
HuggingFace ▷ #agents-course (25 messages🔥):
Smol 课程提供, 深度强化学习课程, Box2D 依赖问题, LLM 和 Langchain 包版本, 向量数据库故障排除
- Smol 课程完成预测引发礼物创意:成员们在猜测 smol course 是否会在今年提供最后一部分,并建议这会是一个很酷的圣诞礼物。
- 一位成员表达了对剩余内容的期待。
- 依赖问题困扰深度强化学习 Colab:几位成员在运行深度强化学习 Google Colab 时遇到了依赖问题。
- 一位成员分享了相关 Discord 频道的链接以帮助解决依赖问题。
- Box2D 故障排除者集结!:用户报告了深度强化学习课程第 1 单元中关于 Box2D 的错误,并寻求解决方案。
- 另一位成员建议在 GitHub 上寻找解决方法。
- LLM 包炼狱:固定你的版本:有建议认为,安装特定版本的包有时非常有用,尤其是在使用 LLMs 和 Langchain 时。
- 一位成员主张在他们的 Agent 默认技术栈中使用 uv lock,并在外部 m.2 硬盘上保留一个冻结的 venv 作为备份。
- 向量数据库调试之舞:一位成员建议打印从向量数据库检索到的数据块(chunks),以确定问题是源于 embedding 模型、分块方法还是 LLM 本身。
- 他们指出,解决方案将根据问题的根本原因而有所不同。
GPU MODE ▷ #general (15 messages🔥):
论文阅读小组, RTX PRO 5000 Blackwell 规格, GPU 编程职业建议, 针对 ML 开发者的诈骗机器人
- **Discord 论文阅读小组?**:成员们正在自发组织一个论文阅读小组,并使用 general audio channels 来讨论论文 “title” (arxiv.org)。
- 如果他们熟悉该论文,可以被邀请进行演讲。
- 寻找 **RTX PRO 5000 Blackwell 规格:一位成员正在寻找 **RTX PRO 5000 Blackwell 的详细规格。
- 另一位成员表示 pro 4500 只是价格更高、性能更差的 5090。
- 允许 **GPU Programming 职业建议**:现在允许在 <#1450579381448609882> 频道中提供职业建议。
- 该频道此前仅限于技术讨论。
- **诈骗机器人瞄准 ML 开发者:一个诈骗机器人网络正冒充员工,针对 **ML 开发者 进行身份窃取。
- 过滤提及 blockchain 或 web3 的新用户可能有助于识别它们。
GPU MODE ▷ #cuda (4 messages):
cuTile 优势, cuTile vs Triton, Blackwell 上的 cuTile GEMM Flops
- cuTile 旨在 1.0 版本中奠定坚实基础:1.0 版本将专注于强大的语言基础,并在 TileGym 内部包含自动调优(autotuning)示例代码。
- 这是我们正在积极开展的工作,请保持关注。
- 用于自定义 Torch 算子的 cuTile vs. Triton:cuTile 的用户体验与编写 Triton kernel 非常相似。
- 对于实现达到峰值内存带宽的 类 RMSNorm kernel,cuTile 可能比 Triton 更容易,特别是对于较简单的内存受限(memory-bound)kernel。
- Blackwell 数据中心显卡上的 cuTile GEMM Flops:预计 cuTile 在 Blackwell 数据中心显卡上能实现更高的 GEMM flops,尽管这需要基准测试来确认。
- 用于 Tensor Cores、TMA 和 Swizzling 的 cuTile:对于涉及 tensor cores/TMA/swizzling 的 GEMM/attention kernel,cuTile DSL 可能会更好。
- cuTile 更加抽象并依赖编译器,使其适用于相对简单的内存受限 kernel,在易用性与性能的权衡上处于与 Triton 类似的领先地位。
GPU MODE ▷ #cool-links (9 条消息🔥):
TMEM's Dedicated Arbitration Logic, NVIDIA psy-op, ldmatrix.x4
- 对 TMEM 仲裁逻辑声明的质疑:某篇论文关于 TMEM 专用仲裁逻辑及其绕过 L2 cache 分区争用能力的声明引发了质疑,一位成员称该描述要么是写得极烂,要么是提出了几个错误的声明。
- 另一位成员强调内存访问声明缺乏数据支持,并对代码的发布表示好奇,希望能以此澄清事实。
- 论文的 ldmatrix.x4 实现引发关注:一位成员质疑了论文中上下文传输到寄存器的部分,指出 ldmatrix.x4 仅加载四个 8x16 tiles,相当于 32x16,并强调 32x32 tile size 在 Hopper 上并非最优,且 Hopper 没有 4-bit MMA。
- 另一位成员表示赞同,称越读这篇论文越觉得奇怪,将其描述为一篇“恐怖谷”论文,因为它混合了专家知识与荒谬的描述、对比和结果。
- NVIDIA 被指发布心理战 (Psy-Op) 论文:一位成员开玩笑地建议,某篇研究论文可能是 NVIDIA 发起的 心理战 (psy-op),旨在迷惑竞争对手对其微架构的理解,并链接了一篇 defense kernel hack 文章。
- 另一位成员指出了论文代码中的 虚假耗时 (fake elapsed time) 函数,该函数始终报告 0.001ms 以 伪造快速 的计时结果。
GPU MODE ▷ #beginner (4 条消息):
Working Groups, Open Projects
- 初学者寻求工作组指导:一位具有 CUDA 经验的初学者询问了参与工作组/开源项目的后续步骤。
- 一位成员建议查看现有的工作组频道,并提到新的工作组即将启动。
- 启动工作组的想法:一位成员询问是否应该在工作组想法频道发帖,以获得对其想法的关注和支持。
- 另一位成员回答道:“是的,去帮帮他们吧,哈哈。”
GPU MODE ▷ #off-topic (2 条消息):
Job Search, Discord Communities for Job seekers, Networking for AI Jobs
- 寻找求职 Discord 社区:一位成员征求热门 Discord 服务器的推荐,这些服务器主要讨论在美国寻找软件和 AI 相关工作。
- 另一位成员分享了一个 Discord 频道链接 作为潜在资源。
- AI 职位社交:该用户希望与 AI 和软件领域的人士建立联系。
- 他们正在寻找 Discord 服务器和社区的推荐。
GPU MODE ▷ #rocm (34 条消息🔥):
ROCm 7.1, FBGEMM library broken, NPS partitioning crashes, kernel module problems
- ROCm 7.1 与内存分配问题:一位用户报告称,他们的 7900XTX 在使用 ROCm 7.1 和 torch 2.9.1 时,当 GPU 内存分配达到 100% 时会死锁,他们认为这是 AMD GPU 的长期问题。
- 另一位用户确认在 MI300X 上进行大内存分配时也存在类似问题。
- FBGEMM 构建令人沮丧:一位用户抱怨 AMD 的 FBGEMM 仓库完全损坏,不费九牛二虎之力根本无法构建,甚至最新的 FBGEMM 文档还让你安装 v0.8.0 而不是 v1.4.0,而前者根本无法工作。
- 他们表示,CMake 构建配置甚至没有将 FBGEMM 链接到正确的 HIP 库,这令人非常沮丧。
- 内核问题困扰 AMD:一位用户提到内核模块存在问题,几个版本前运行良好的功能现在完全损坏了。
- 具体来说,NPS 分区现在大多数情况下都会导致 kmd 崩溃。
- 购买 AMD GPU 是个昂贵的错误:一位用户哀叹由于奢侈品进口税和软件问题,购买 AMD gfx1100 是个 彻底的错误。
- 他们最终花了 4500 美元 买了一块 5090 来替换它,这还没算最初花费的 2500 美元,并补充说 AMD 没有接受 George Hotz 提供的帮助。
GPU MODE ▷ #self-promotion (10 条消息🔥):
CUDA Kernel Naming, HMMA vs HFMA2.MMA, Register Moves in PTXAS, Cloud GPU marketplace
- Kernel 命名是否影响 CUDA 性能?:一篇博文探讨了在 CUDA/Triton Kernel 名称中包含 cutlass 是否会影响性能,可能涉及指令重排,详见 blogpost。
- HMMA 与 HFMA2.MMA 之间产生混淆:一位成员指出,该博文错误地混淆了 HMMA(Tensor 流水线指令)和 HFMA2.MMA(Half 流水线指令)。
- PTXAS 寄存器移动的指令组合解析:据解释,
ptxas在进行寄存器移动时使用了一种看似随机的指令组合(而非仅用 MOV),因为在某些架构上,MOV 每两个周期才能发布一次,交替使用 MOV 和 IMAD/HFMA2/IADD3 可以加速寄存器移动。 - Neoclaudx 推出云 GPU 市场:一位成员推出了云 GPU 供应商网站 NeoCloudX,该网站直接聚合来自数据中心的剩余产能以降低费用,提供约 $0.4/小时 的 A100 和约 $0.15/小时 的 V100。
GPU MODE ▷ #submissions (4 条消息):
nvfp4_gemm leaderboard, NVIDIA performance
- NVIDIA 平台刷新个人最好成绩:一位成员在
nvfp4_gemm排行榜上以 13.4 µs 的成绩刷新了在 NVIDIA 上的个人纪录。- 另一位成员也在 NVIDIA 上刷新了个人纪录,成绩为 56.9 µs。
- NVIDIA 平台再获第四名:一位成员凭借两次提交在
nvfp4_gemm排行榜上获得了 NVIDIA 平台的第四名,成绩为 10.8 µs。- ID 为 166947 和 166954 的两次提交显示了相同的性能。
GPU MODE ▷ #hardware (2 条消息):
MI250, MI250X, Server Compatibility
- 对比 MI250 和 MI250X GPU:一位成员询问了 AMD MI250 和 MI250X GPU 之间的区别。
- 他们还询问了这些 GPU 在服务器环境中是否可以互换,例如 MI250X 是否可以安装在为 MI250 设计的服务器中。
- 在 MI250 服务器中使用 MI250X?:一位成员质疑是否可以将 MI250X 放入 MI250 服务器中。
- 这暗示他们担心硬件或软件的兼容性。
GPU MODE ▷ #cutlass (5 条消息):
Cute DSL, CUTLASS, Python 3.10, MMA Tiling
- Cute DSL Python 版本差异问题已解决:用户发现 Cute DSL 在 Python 3.10 下运行良好,尽管文档要求 Python 3.12,详见文档。
- CUTLASS 文档更新 Python 版本说明:CUTLASS 文档将进行更新,以反映对 Python 3.10 到 3.13 的支持,并正在考虑支持 3.14。
- MMA Tiling 排列难题:一位用户正在寻求关于分块(tiled)MMA 排列的帮助,目标是让每个线程加载成对的连续值并利用 s2r vector copies。
GPU MODE ▷ #teenygrad (1 条消息):
LambdaLabs Grant, H100 Hours, SITP Textbook
- Teenygrad 获得 LambdaLabs 资助:teenygrad 项目已入选 LambdaLabs 研究资助计划,获得了约 1000 个 H100 小时的使用权。
- 得益于这笔新资金,开发工作预计将在新的一年再次加速!
- SITP 教科书和代码即将发布:SITP 课程 第 1 部分和第 2 部分的教科书、代码和讲义材料定于 1 月底或 2 月发布。
- 这将有助于推广并引导新用户开始编写代码。
GPU MODE ▷ #nvidia-competition (23 条消息🔥):
NVFP4 GEMM, Kernel 2, cutlass.pipeline error, application did not respond
- NVFP4 GEMM 竞赛将于 12 月 19 日结束:NVFP4 GEMM 竞赛(Kernel #2)计划于 11 月 29 日至 12 月 19 日运行,不会延长到 20 日。
- Kernel 2 竞赛保持不变:一位成员指出,第二个 Kernel 保持不变,而第一个 Kernel 已被延长。
- 成员们表示,如果这些日期能与周末结束时间对齐,那就太好了。
- 出现
cutlass.pipeline导入错误:用户报告遇到ImportError: cannot import name 'pipeline_init_arrive' from 'cutlass.pipeline'错误。- 团队正在努力改进运行缓慢的 Runner,因此可能在此过程中发生了变化。
- 出现 “The application did not respond” 错误:用户报告在使用集群 Bot 时收到
The application did not respond错误。
Latent Space ▷ #ai-general-chat (51 条消息🔥):
Vibe CAD research from MIT DeCoDE Lab, Sakana's iconographic-linguage models, AntiGravity Performance Issues, OpenAI Router Rollback, New Warp Agents
- MIT 的 Vibe CAD 震撼 AI 界:来自 MIT DeCoDE Lab 的新 Vibe CAD 研究引入了一个用于学习的数据集和模型,如 LinkedIn 帖子和相关 YouTube 视频所示。
- Sakana 模型的字节级提升:根据这条推文,Sakana 正在探索通过字节级 (byte-wise) 处理来提升图文语言模型 (iconographic-linguage models) 的性能,但对其他语言的影响尚未解决。
- AntiGravity 性能骤降:一位用户报告由于性能问题放弃了 AntiGravity,包括机器因随机原因卡死,堆栈跟踪显示渲染器分配错误(1.4TB 内存)和 language_server 自旋锁 (spinlocks)。
- OpenAI Router 回滚!:OpenAI 在一年后回滚了 ChatGPT 的 Model Router,导致用户转向 Gemini 和 Claude,这在 OpenAI 发布说明中有所提及,并在这篇 Wired 文章中进行了讨论。
- NVIDIA 收购 SchedMD 以获取 Slurm:NVIDIA 收购了热门工作负载管理器 Slurm 背后的公司 SchedMD,消息公布在 NVIDIA 博客上。
Latent Space ▷ #private-agents (4 条消息):
Google CC agent, Gmail AI productivity
- Google Labs 攻克 Gmail 的 ‘CC’ AI 生产力工具:Google Labs 宣布了 CC,这是一个集成在 Gmail 中的实验性 AI 生产力 Agent,正在美国和加拿大推出。
- 根据这条 X 帖子,它提供每日 ‘Your Day Ahead’ 简报,并处理邮件请求,Google AI Ultra 和付费订阅用户可优先体验。
- 又一个 AI Agent 诞生:发布了一个新的 AI Agent。
- 这个 Agent 是全新的,非常酷。
Latent Space ▷ #genmedia-creative-ai (14 messages🔥):
WAN 2.6, Chatterbox Turbo, Meta SAM Audio
- **WAN 2.6 发布——但没有 OSS 版本!: **WAN 2.6 已经发布,但根据此链接显示,该版本仅限商业用途,没有提供 OSS 版本。
- 新版本是一款具有多镜头(Multi-Sh[…])功能的 AI Video Generator。
- **Chatterbox Turbo 旨在颠覆语音 AI 领域: Dev Shah 宣布发布 **Chatterbox Turbo,这是一个采用 MIT-licensed 的最先进语音模型,声称超越了 ElevenLabs Turbo 和 Cartesia Sonic 3。
- 该模型被昵称为“语音 AI 的 DeepSeek 时刻”,解决了传统的权衡问题(速度快但机械感强 vs. 速度慢但效果好),并根据此公告所述,专为信任、透明度和可审计性而构建。
- Meta 的 **SAM Audio:隔离任何声音!: 根据此 X 帖子,Meta 的 AI 团队推出了 **SAM Audio,这是一个统一模型,能够根据文本、视觉或时间跨度提示从复杂的音频混合中隔离出任何声音。
- Meta 正在分享该模型、感知编码器、基准测试和研究论文,以鼓励社区探索和应用开发。
Nous Research AI ▷ #general (60 messages🔥🔥):
Local LLMs implementation, Non-language models for waveform analysis, Nvidia's dominance in GPU market, Meta's samaudio, Mistral creative model
- 定制化小模型受到关注: 讨论强调了人们对在公司特定数据上训练的本地 LLM日益增长的兴趣,其中一位客户正在探索实现一个专门针对航海业的模型。
- 会议指出了在特定员工沟通或合同数据上训练 LLM 的潜力,有人表示定制化小模型在未来也将变得极其流行。
- 非语言模型在船舶导航中展现潜力: 成员们提到了一些非常有趣的非语言模型,这些模型正被训练用于波形分析,特别是针对船舶导航。
- 这些模型利用传感器数据来识别最佳电机速度和设置,本质上是创造了一个高技能的船长。
- Nvidia 的成功植根于对 GPU 的押注和 CUDA 语言: Nvidia 早期对 GPU 在游戏以外应用领域的押注,加上 CUDA 的开发,被认为是其成功的根源。
- 一个关于显卡模拟的 YouTube 视频。
- Meta 推出 samaudio: Meta 发布了 samaudio(链接缺失),一名用户表示他们认为自己已经拿到了。
- 另一名用户表示使用 Gemini 进行的相同尝试效果更差(附有图片)。
- Mistral 模型输出对比: 一名成员提出分享他们测试的模型与 Mistral 创意模型之间的对比。
- 另一名成员澄清说,他们正在测试一个 70B L3 模型,该模型将转移到 Kimi 1T 上,而不是 24B 的 Mistral Small。
Nous Research AI ▷ #research-papers (2 messages):
Byte Level LLMs
- 对字节级 LLM 的热情爆发: 成员们表达了对 Byte Level LLMs 的喜爱。
- 字节等于乐趣!: 他们表示 Byte Level LLMs 非常有趣。
Nous Research AI ▷ #research-papers (2 messages):
Byte Level LLMs
- 字节级 LLM 很有趣: 成员们表达了 Byte Level LLMs 玩起来很有趣的观点。
- 字节级 LLM 很酷: 一名成员表示 Byte Level LLMs 非常有趣。
Moonshot AI (Kimi K-2) ▷ #announcements (1 messages):
Kimi paid users, Kimi 30 minute chat
- Kimi 团队希望与付费用户交流: Kimi 团队正在邀请 Kimi 付费用户进行 30 分钟的交谈。
- 参与者将获得 1 个月免费订阅作为奖励;感兴趣的用户请在下方回复 👍,以便通过私信联系。
- 另一个话题: 填充话题。
- 更多细节。
Moonshot AI (Kimi K-2) ▷ #general-chat (29 messages🔥):
Kimi Models Text-Only vs. Context, Kimi Non-Thinking Model, K2-Thinking Performance, Kimi Pricing and Availability, K2 Thinking Turbo
- Kimi 偏好纯文本及改进的 Context:一些用户表示,如果能提供更好的上下文理解,他们更倾向于使用纯文本版 Kimi 模型。
- 其他人评论说,非思考模型倾向于过于简练,会删减重要信息,他们认为这一问题在思考模型中已基本得到解决。
- Kimi 非思考模型受到批评:Kimi 非思考模型因过于简练并删减重要部分而受到批评。
- 用户认为 K2-Thinking 模型的智能提升超过了非思考模型的任何优势,一名用户特别提到他们现在专门使用 Kimi 1.5。
- K2-Thinking 模型显示出性能提升:据报道,K2-Thinking 模型在许多供应商上的速度比 GLM-4.6 更快。
- 然而,一些用户指出某些供应商的服务质量有所下降或价格过高,并建议将 K2 Thinking Turbo 作为替代方案。
- 三星获得 Kimi 优势:三星 Galaxy 商店已有 Kimi 2.5.1 版本,具备 memory 功能,领先于 Google Play 商店的 2.5.0 版本。
- 用户对为什么三星能率先获得更新感到困惑。
- Vendor Verifier 显示直接使用 Fireworks 效果更好:有人链接了 MoonshotAI/K2-Vendor-Verifier,展示了不同供应商的性能。
- 有人指出,通过 OpenRouter 使用 Fireworks 的效果不如直接使用 Fireworks,感觉像是 Minimax-M2。
Eleuther ▷ #general (4 messages):
Synthema meta-language, Polyreflexeme theory, Algoverse AI research program, NSF SBIR proposal
- Synthema:概念元语言出现:一名成员介绍了 Synthema,这是一种用于意义压缩的概念元语言,旨在将概念压缩为更短的符号语法。
- 它目前处于理论阶段而非实证阶段,旨在系统中追溯运行,作为一种意义的概念元语言。
- 引入 Polyreflexeme 理论:一名成员描述了 Polyreflexeme 理论,这是意义压缩的核心组成部分,其中多个概念/单词递归地纠缠以产生意义。
- 意义被描述为一种关系递归,例如 RoleModel(°9) = ab, a b, b a, ab a, ab b, a ab, b ab, ab ab,但该成员缺乏将此理论推向应用的资源。
- Algoverse 项目评价褒贬不一:一名成员提到了 Algoverse,这是一个为期 12 周、由斯坦福/伯克利导师指导的大学生 AI 研究项目,但指出该项目过于拥挤且缺乏动手实践。
- 他们表示,如果是付费参加的话,并不太值得。
- 提交 NSF SBIR 提案:一名成员完成了他们的 NSF SBIR 提案,但指出下一个提交窗口尚未公布。
- 未提及其他细节。
Eleuther ▷ #research (11 messages🔥):
GAN, Research Collaboration, Paper Publishing
- GAN 确认:一名成员通过 X.com 的链接确认一张图片是 GAN 生成的。
- Discord 成为高中研究招募中心:一名寻找高中研究合作的成员被引导至 Rishab Academy 等其他 Discord 群组。
- 论文命运悬而未决:一名成员就其论文是否值得提交给会议收到了截然相反的意见,担心可能会因为缺乏创新贡献(novel contribution)而被拒绝。
- 另一名成员建议做好论文的动机说明,并引用了一篇关于 VAEs 的 NeurIPS spotlight 论文 以及它如何证明 VAEs 仍然可行;而另一名成员则讽刺地评论说,那些持反对意见的人正是那些在 OpenReview 上给你打低分的人。
Eleuther ▷ #scaling-laws (1 messages):
uwu1468548483828484: 这是对还是错
Eleuther ▷ #interpretability-general (7 messages):
Superweights Impact, Attention Interpretation, Anthropic Circuits, Causal Head Gating
- Superweights 引发辩论:关于 superweights(其数值远高于/低于平均水平)的影响展开了辩论,一位成员指出,惩罚这些权重可能会损害性能,但值得探索。
- 他们建议观察在没有显著性能下降的情况下是否可以进行训练。
- 寻求 Attention 解释的前沿技术:一位成员询问了关于 attention interpretation 的最新信息,特别是关于归一化和 OV 的内容。
- 他们表示最近才发现这些概念,并想知道还有哪些是他们不了解的。
- Anthropic 的 Circuits 聚焦于 Crosscoders:从 Anthropic circuits & superposition 的视角来看,最新的更新集中在强制 crosscoders 和 attribution 发挥作用,4 月份的更新详细介绍了进展。
- 据分享,研究人员(Chris Olah, Adam Jermyn)花了两年时间试图将 attention superposition 形式化,但没有取得太大进展,同时还尝试了 qk diagonalization。
- 因果 Head Gating 论文受到称赞:今年 NeurIPS 上发表的一篇关于 causal head gating 的论文被强调为一种设计良好、高水平的方法。
- 论文可以在这里找到。
Manus.im Discord ▷ #general (12 messages🔥):
Manus 1.6 Release, AI & Full-Stack Engineer
- Manus 1.6 现已发布:Manus 1.6 现已向所有用户开放,您可以通过链接了解更多信息。
- 投入程度与订阅级别挂钩:订阅层级越高,在任务中投入的精力就越多,且不再表现得像个笨蛋;这就是为什么他们取消了购买积分的选项。
- 一位用户表示它已在很大程度上集成。
- AI 与全栈工程师深入研究:一位用户是 AI & Full-Stack Engineer,正深入研究自主 Agent、语音 AI 和多 Agent 框架,并尝试使用 LangGraph、CrewAI、AutoGen,以及连接记忆、工具和推理。
- 他们愿意接受合作、合同项目或长期开发。
aider (Paul Gauthier) ▷ #general (10 messages🔥):
OpenAI GPT-5, Aider Active Innovation, Aider copy-paste mode without LLMs, Aider Vision/Plans, Aider and interleaved reasoning tool calling
- GPT-5 猜测开始:一位成员开玩笑地建议尝试将
openai/gpt-5作为模型字符串,引发了讨论,尽管 GPT-5 尚未发布。 - Aider 的开发状态:考虑到出现了其他功能更多的基于 CLI 的应用,一位成员询问 Aider 是仍处于活跃创新阶段,还是仅专注于其原始目标。
- 另一位成员询问“几个月前它专注于什么?”,还有人提到 Aider 似乎专注于成为使用本地或云端模型的 TUI。
- Aider 复制粘贴模式与 LLM 要求:一位用户报告称,即使在运行带有
--copy-paste的 Aider 时,也会收到需要 LLM 模型和 API Key 的警告。- 该警告建议使用 OpenRouter 以获取许多 LLM 的免费和付费访问权限;当拒绝登录或打开文档时,程序会退出。
- Aider 对交替推理工具调用的实现:一位用户询问 Aider 是否正确实现了 minimax-m2、kimi-k2-thinking 和新的 deepseek v3.2 thinkings 等模型的交替推理工具调用(interleaved reasoning tool calling)。
aider (Paul Gauthier) ▷ #links (1 messages):
Zenflow launch, Agent workflows
- Zenflow 编排可预测的 Agent 工作流:Zenflow 编排层已发布,可将规范(specs)转化为协调的 Agent 工作流。
- 根据发布公告,其目标是提供可预测的交付,而不是“Prompt 轮盘赌”。
- Zenflow 承诺减少 Prompt 轮盘赌:Zenflow 是一个编排层,可将规范转化为协调的 Agent 工作流。
- 根据其网站,它承诺实现可预测的交付。
tinygrad (George Hotz) ▷ #general (2 messages):
AI Pull Request 政策,理解 AI 生成的代码
- AI Pull Request 政策保持严格:关于 AI 生成的 Pull Request 的政策保持不变:除非提交者是已知贡献者,否则任何看起来是 AI 生成 的 PR 都将立即关闭。
- 理由是贡献者应该完全理解其 PR 的每一行代码,因为在不理解的情况下提交 AI 生成的代码 会产生负价值。
- 理解重于自动化:贡献者应该完全理解其 PR 的每一行代码,因为在不理解的情况下提交 AI 生成的代码 会产生负价值。
- 关键点在于 AI 无法取代受信任贡献者的思考和理解。
DSPy ▷ #show-and-tell (1 messages):
justanotheratom: https://www.elicited.blog/posts/dspy-strategy-and-program
MLOps @Chipro ▷ #events (1 messages):
ggdupont: 有人了解 GenAI 苏黎世会议吗?它怎么样?
MCP Contributors (Official) ▷ #general-wg (1 messages):
遗漏线程回复,贡献者致歉
- 贡献者为遗漏线程回复致歉:一位贡献者为遗漏线程回复表示歉意,并表示已在指定频道的线程中进行了回复。
- 该贡献者在消息中标记了用户 <@282306658825273344>。
- 在特定频道确认回复:该贡献者确认回复已在频道 <#1399984784020607007> 的线程中提供。
- 这确保了用户可以在正确的上下文中找到相关信息。