AI News
Gemini 3.0 Flash 预览版:成本仅为 Pro 版的 1/4,但智能程度几乎旗鼓相当,重夺帕累托前沿(Pareto Frontier)。
谷歌(Google)发布了 Gemini 3 Flash,这是一款具备极低延迟(闪电般速度)的专业级推理模型。它支持工具调用和多模态输入输出(IO),可通过 Google AI Studio 和 Vertex AI 等多个平台使用。该模型定价极具竞争力,每百万(1M)输入 token 仅需 0.50 美元,每百万输出 token 为 3.00 美元,并支持高达 100 万 token 的上下文窗口。
基准测试显示,Gemini 3 Flash 在智能体(agentic)、编程和推理任务中的表现可与 GPT-5.2 和 Gemini 3 Pro 等更大型的模型相媲美,甚至有所超越;这一结论已通过 ARC-AGI-2、SWE-bench、LMArena 和 Arena 等基准测试得到验证。尽管在 token 消耗量较高和幻觉率等方面存在一些权衡,但其整体性价比依然很高。Sundar Pichai、Jeff Dean 和 Demis Hassabis 等关键人物均公开庆祝了这一成就。在现场演示中,该模型还展示了同时调用 100 个工具的能力。
Gemini is all you need.
2025年12月16日至12月17日的 AI 新闻。我们为您检查了 12 个 subreddit、544 个 Twitter 和 24 个 Discord(207 个频道,8313 条消息)。预计节省阅读时间(以 200wpm 计算):594 分钟。我们的新网站现已上线,提供完整的元数据搜索和美观的 vibe coded 呈现方式。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上给我们反馈!
当我们一年前首次开始推动 LLM Pareto frontier 时,随后被 Jeff Dean 和 Demis Hassabis 关注。不久后,Gemini 2.5 征服了它,接着 GPT-5 在 4 个月后再次夺魁。现在,我们回到了 Gemini 3.0 重新占领高地,Sundar 和 Jeff 都在大声宣扬这一成就:

除了 Arena,这在学术基准测试中也得到了验证:
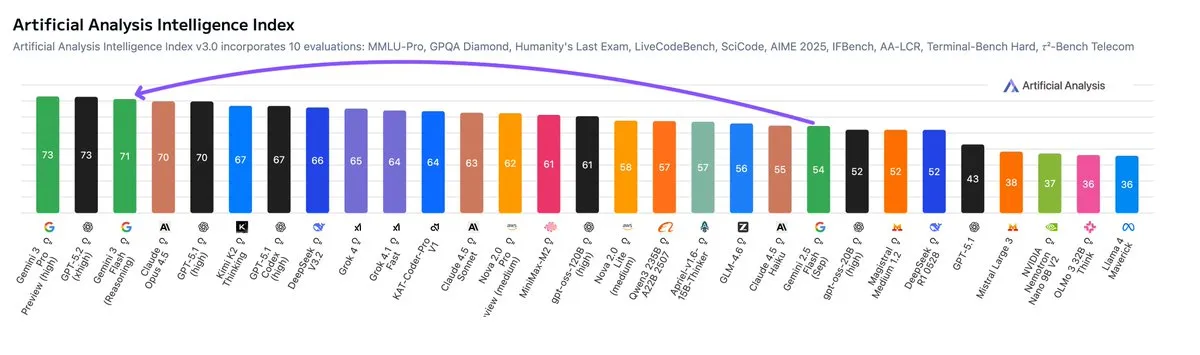
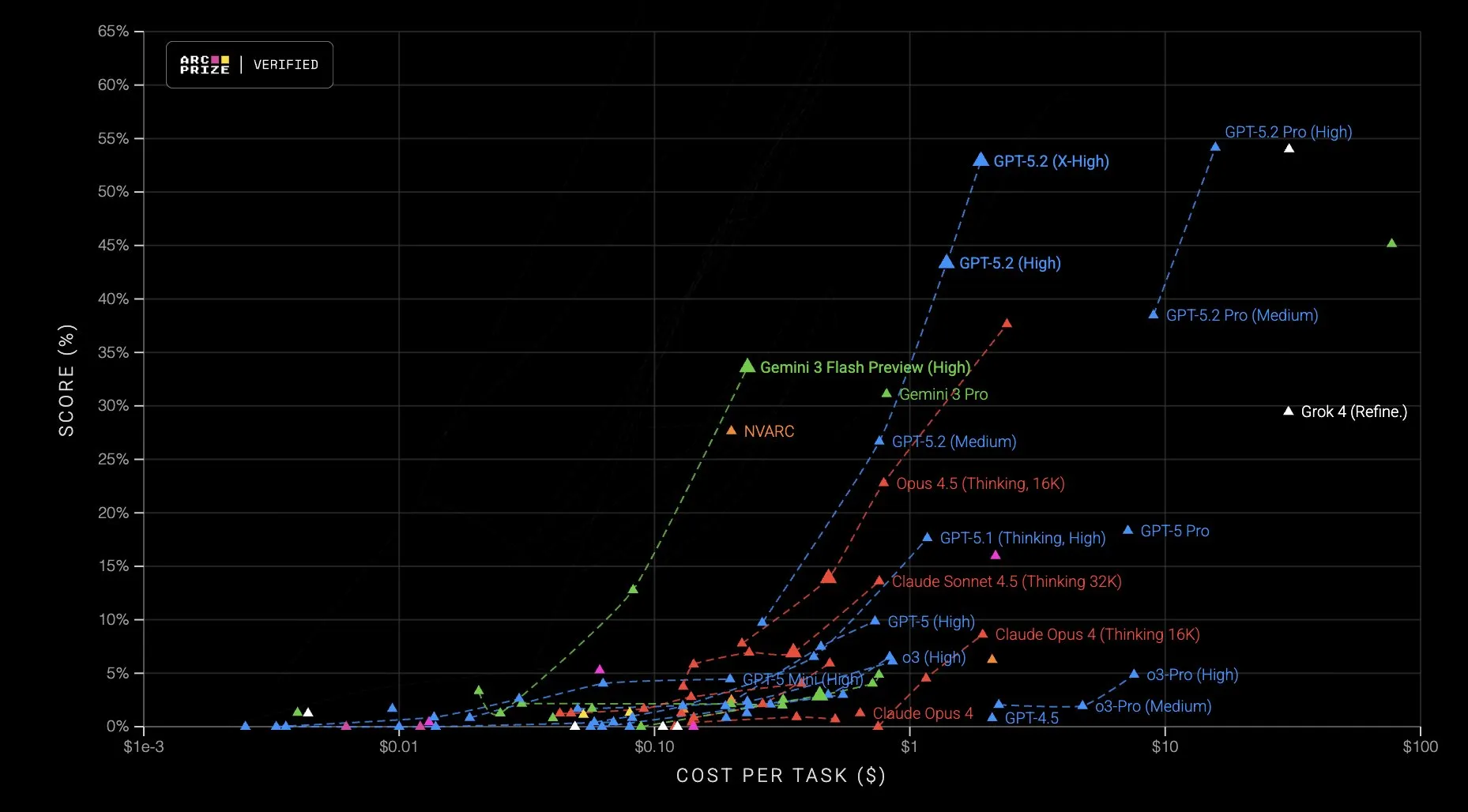
并且 ARC AGI 也有自己的图表展示效率:
以下是一些具体的细分亮点:
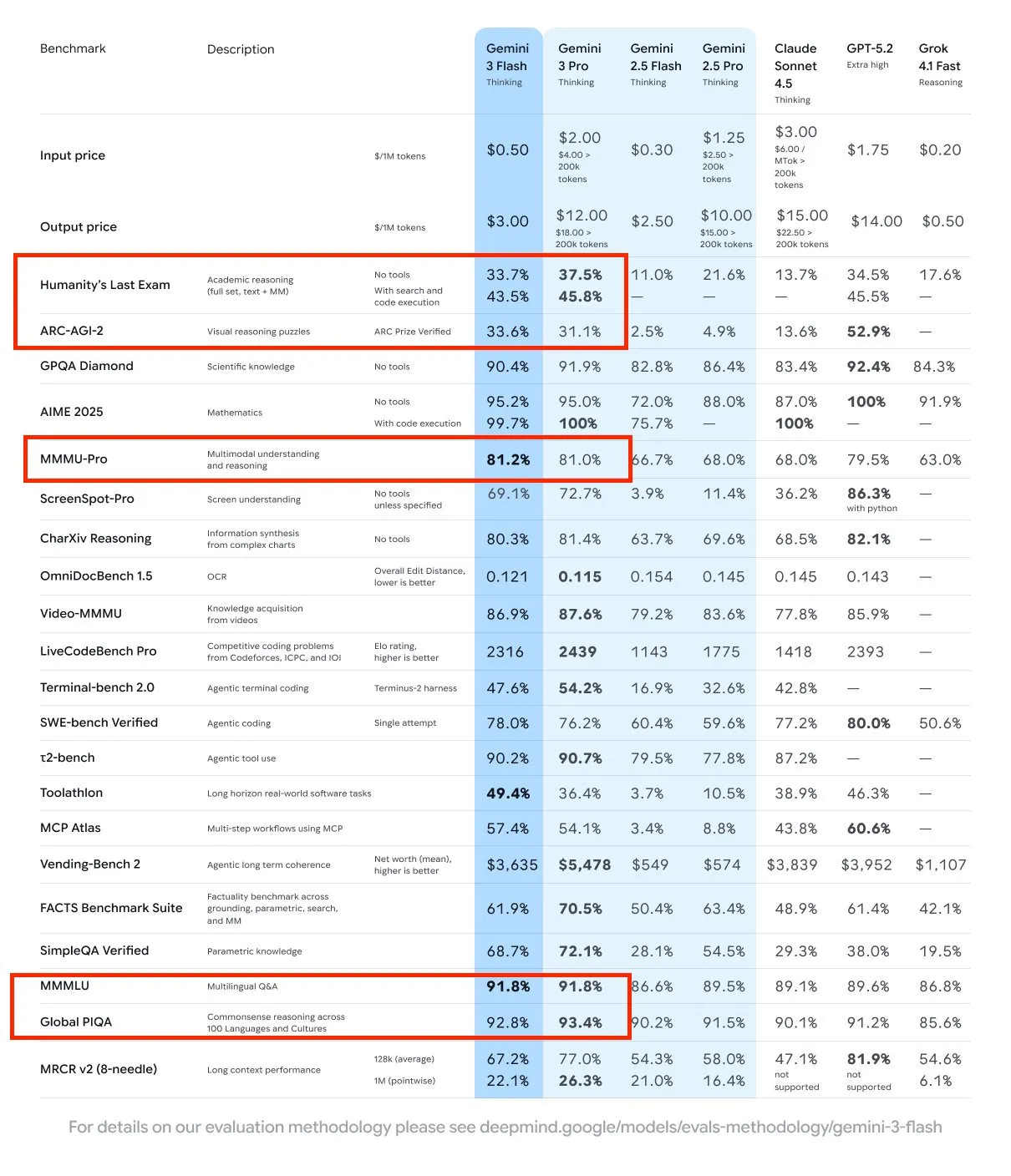
除了 distillation,这里的重点似乎是 tool calling。这是一个展示 100 个工具的演示,以及来自 Addy Osmani 的更多演示。
AI Twitter 综述
Gemini 3 Flash 发布:闪电般延迟下的前沿智能(生态系统、指标、注意事项)
- 模型与发布:Google 发布了 Gemini 3 Flash,定位为“具有 Flash 速度的 Pro 级推理能力”。它是 Gemini 应用(“快速”模式)和搜索 AI 模式中的新默认模型,开发者可通过 Google AI Studio、Antigravity、Vertex AI、CLI、Android Studio 等平台中的 Gemini API 使用。价格为每 1M input tokens $0.50,每 1M output tokens $3.00;上下文最高支持 1M tokens;支持 tool calling 和多模态 IO。公告与概览:@sundarpichai, @Google, @GoogleDeepMind, @OfficialLoganK, @JeffDean, @demishassabis, @GeminiApp, 开发者问答空间。
- 基准测试与性价比:早期结果显示,3 Flash 在多个 Agent/编程和推理场景中,以显著更低的成本/延迟,与更大型的模型不相上下甚至表现更优:
- ARC‑AGI‑2 和 SWE‑bench Verified:在某些配置下击败或持平 Gemini 3 Pro,并可与 GPT‑5.2 竞争 (@fchollet, @GoogleDeepMind, @jyangballin, 帕累托快照)。
- LMArena 和 Arena (WebDev/Vision):获得顶级评分,且在价格帕累托前沿表现强劲 (@arena, @JeffDean, @osanseviero)。
- 独立汇总指出其优势与权衡:高知识/推理能力,在 MMMU‑Pro 上排名第二,但在 AA‑Omniscience 上 token 使用量大且幻觉率较高 (91%)——由于定价原因,整体性价比依然很高 (Artificial Analysis 深度解析, 后续跟进)。
- 思考等级与评估:Flash 开放了思考等级 (low/med/high)。从业者要求提供分层基准测试以指导生产环境中的权衡;一些早期测试显示 Flash‑Low 的 token 效率高但在有效性上较弱,而 Flash‑High 在量化指标上缩小了差距 (@RobertHaisfield, @Hangsiin, Flash‑Low vs High 快照)。
- 集成与工具:3 Flash 已在常用开发环境中上线:Cursor (@cursor_ai), VS Code/Code (@code, @pierceboggan), Ollama Cloud (@ollama), Yupp (@yupp_ai), Perplexity (@perplexity_ai; Pro/Max 中的 Flash), LlamaIndex FS agent (演示, 仓库)。早期产品记录强调了近乎实时的代码编写/编辑和多模态分析 (@Google, @GeminiApp)。
语音 AI 与具身助手
- xAI 的 Grok Voice Agent API:新的语音对语音 Agent 支持 tool calling、网页/RAG 搜索、SIP 电话以及 100 多种语言。它在 Big Bench Audio 上创下了新的 SOTA(92.3% 推理),TTFB 约为 0.78 秒,价格为 $0.05/分钟($3/小时)。发布后一小时内便在 Reachy Mini 机器人上进行了快速演示,暗示了从语音推理到具身 Agent 的快速路径 (xAI, 基准测试报告, 机器人移植)。
- 实时语音基础设施:Argmax SDK 2.0 发布了“带说话人识别的实时转录”——在 Mac/iPhone 上比实时更快,功耗低于 3W,准确度实现了“阶跃式变化” (@argmax)。这与 Grok Voice 一起,增强了生产级语音 Agent 的技术栈。
训练效率与 MoE 系统
- FP4 训练和开源 MoE 栈:Noumena 发布了 “nmoe”,这是一个针对 B200 (SM_100a) 的生产级参考路径,用于 DeepSeek 风格的超稀疏 MoE 训练。该项目采用了 RDEP(复制密集/专家并行)、通过 NVSHMEM 直接调度(无 MoE all‑to‑all)以及混合精度专家(BF16/FP8/NVFP4)。重点在于研究规模下的确定性混合和 Router 稳定性。作者声称,如果应用得当,MoE 的 NVFP4 训练问题已得到“解决” (repo + thread, 早期 FP4 笔记;相关:torch._grouped_mm 的发现 链接)。
- 推理/系统吞吐量:vLLM 报告称,通过深度 PyTorch 集成,Blackwell 吞吐量在单月内提升了高达 33%,降低了单位 Token 成本并提升了峰值速度 (@vllm_project)。
- 端侧 LLM:Unsloth + PyTorch 宣布了一条将微调模型导出到 iOS/Android 的路径;例如,Qwen3 在 Pixel 8 / iPhone 15 Pro 上以约 40 tok/s 的速度运行,完全本地化 (@UnslothAI)。
- RL/FT 见解:在 Moondream 上进行的小规模 RL LoRA 表明,“推理 Token”和 RL 都能提高样本效率,MoE 也有所帮助——代价是需要更多的微调计算量 (实验设置/结果, 评论)。
交互式世界模型、视频和 3D 资产
- 腾讯混元 HY World 1.5 (“WorldPlay”):开源的流式视频扩散框架,支持 24 FPS 的实时交互式 3D 世界建模,并具有长期几何一致性。引入了“重构上下文记忆”(Reconstituted Context Memory)以重建过去帧的上下文,以及用于稳健键盘/鼠标控制的双动作表示(Dual Action Representation)。支持第一/第三人称、可提示事件、无限世界扩展 (发布推文, 论文)。
- 视频和 3D 流水线更新:Runway Gen‑4.5 强调符合物理规律的运动;可灵 (Kling) 2.6 增加了运动控制 + 语音控制(并举办了创作者大赛);TurboDiffusion 声称视频扩散速度提升了 100–205 倍;TRELLIS.2 (在 fal 上) 可生成高达 1536³ 的 3D PBR 资产,并具有 16 倍空间压缩 (Runway, Kling 运动控制, Kling 语音控制, TurboDiffusion, TRELLIS.2)。
检索、评估和多向量搜索
- 延迟交互(Late interaction)和基于视觉的 RAG:ECIR 2026 “延迟交互研讨会”征稿启事已发布——征集关于多向量检索 (ColBERT/ColPali)、多模态、训练方案和效率方面的研究 (@bclavie, @lateinteraction)。Qdrant 展示了 “Snappy”,这是一个使用 ColPali Patch 级嵌入和多向量搜索的开源多模态 PDF 搜索流水线;并配有一篇关于在生产环境中部署 ColBERT/ColPali 的实用文章 (项目, 文章)。
- 评估与编排:Sanjeev Arora 强调 PDR(并行/蒸馏/细化)是一种编排方式,通过避免上下文膨胀,在准确性和成本上都优于冗长的单体“思考轨迹” (@prfsanjeevarora)。OpenAI 的 FrontierScience 基准测试揭示了科学问答方面的差距(推理、利基概念理解、计算错误),并推动透明的进度跟踪 (概述;博客)。在 ARC‑AGI‑2 上,Gemini 3 Flash 在不同测试时计算(test-time compute)设置下建立了强大的得分/成本帕累托前沿 (@fchollet)。
Agent 的基础设施与运维
- 可观测性/评估飞轮 (Observability/evals flywheels):LangSmith 展示了大规模部署案例(Vodafone/Fastweb 的 “Super TOBi”:90% 的回答正确率,82% 的解决率)及相关工具:OpenTelemetry 追踪、成对偏好队列 (pairwise preference queues)、自动化评估,以及用于从追踪数据中挖掘技能并进行持续学习的 CLI (案例研究, Brex 认可, pairwise, langsmith‑fetch)。
- 服务/推理教育:LM‑SYS 发布了 “mini‑SGLang”,将 SGLang 引擎精简至约 5K 行代码 (LOC),旨在教授现代 LLM 推理内部机制,且性能几乎持平 (@lmsysorg)。DeepLearning.AI 推出了使用 NVIDIA NeMo Agent Toolkit 的可靠性课程(包含 OTel 追踪、评估、身份验证/速率限制)(@DeepLearningAI)。Meta 的 Taco Cohen 分享了一个 LLM‑RL Env API,具有 tokens-in/tokens-out 和 Trajectory 抽象,用于保持推理/训练的一致性 (@TacoCohen)。
热门推文(按互动量排序)
- “很少有人理解,左边图像的分辨率要低大约 10^21 倍。” @scaling01 (19.3k)
- “我们闪电回归 ⚡ …… Gemini 3 Flash …… 正在向所有人推出……” @sundarpichai (5.2k)
- “闪亮登场 (Rise and shine)” @GeminiApp (3.5k)
- “这是真的,我会写代码,纽约时报 (NYT) 没对那一点进行事实核查” @alexandr_wang (3.3k)
- “算力支撑了我们首次图像生成的发布……我们还有更多动作……并且需要更多的算力。” @OpenAI (2.2k)
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. 从单张图像生成 3D 模型
- 微软的 TRELLIS 2-4B,一个开源的 Image-to-3D 模型 (热度: 1172): 微软发布了 TRELLIS 2-4B,这是一个旨在将单张图像转换为 3D 资产的开源模型。该模型利用了 Flow-Matching Transformers 结合基于 Sparse Voxel 的 3D VAE 架构,包含
4 billion参数。该模型可在 Hugging Face 上获取,演示版可通过此处访问。更多详情请参阅官方博客文章。 一些用户反映模型的输出质量与提供的示例不符,暗示默认设置可能存在问题。其他人对其实际效用表示怀疑,指出了一些局限性,例如无法处理多张图像以获得更好的结果。- 一位用户注意到模型的表现不如提供的示例图像令人印象深刻,暗示默认设置可能存在问题。这突显了在 TRELLIS 2-4B 等 AI 模型中,微调参数对于获得最佳结果的重要性。
- 另一位评论者指出,如果模型能够处理一系列图像而不仅仅是单张输入,其功能可能会得到增强。这可以提高生成的 3D 模型的深度和准确性,解决了 Image-to-3D 转换技术中的一个常见局限。
- 围绕 TRELLIS 2-4B 与其他技术(如 GIS 数据和 IKEA 目录)的集成展开了讨论,以创建详细的虚拟环境。这表明该模型在视频游戏开发等领域具有更广泛的应用潜力,而在这些领域中,详细的世界地图至关重要。
- 苹果推出 SHARP,一个能在数秒内从单张图像生成逼真 3D Gaussian 表示的模型。 (热度: 702): 苹果推出了 SHARP,一个能够从单张图像在数秒内生成逼真 3D Gaussian 表示的模型。该模型的详细信息可在 GitHub 仓库和 arXiv 论文中找到。SHARP 利用 CUDA GPU 进行渲染轨迹,强调了其性能对 GPU 加速的依赖。该模型代表了 3D 图像处理领域的重大进步,能够从极少的输入数据中实现快速且真实的 3D 重建。 一条值得注意的评论强调了该模型对 CUDA GPU 的依赖,暗示了硬件兼容性方面的局限。另一条评论幽默地询问了该模型在成人内容方面的适用性,表现出对其通用性的好奇。
- SHARP 能力的示例在 Apple Vision Pro 上进行了演示,在 MacBook Pro M1 Max 上仅需 5–10 秒即可生成场景。这突显了该模型的效率以及硬件实时处理此类任务的能力。展示这些示例的视频由 SadlyItsBradley 和 timd_ca 分享。
2. 长上下文 AI 模型创新
- QwenLong-L1.5:革新长上下文 AI (热度: 250): QwenLong-L1.5 是一款新型 AI 模型,在长上下文推理方面设定了 SOTA 基准,能够处理高达
4 million tokens的上下文。它通过创新的数据合成、稳定的强化学习 (RL) 以及先进的内存管理技术实现了这一目标。该模型已在 HuggingFace 上发布,基于 Qwen 架构,在处理长上下文任务方面有显著改进。 一位评论者指出了与llama.cpp集成的潜在挑战,而另一位评论者则强调了该模型在特定长上下文信息提取任务中的有效性,表现优于常规 Qwen 模型和 Nemotron Nano。- Chromix_ 强调了使用 QwenLong-L1.5 提供的精确查询模板的重要性,与常规 Qwen 模型相比,这显著提高了其在长上下文信息提取任务中的性能。这表明该模型的增强不仅在于架构,还在于查询结构的组织方式,这可以在特定任务中带来更好的结果。
- HungryMachines 报告了以量化形式 (Q4) 运行 QwenLong-L1.5 时遇到的问题,模型会陷入死循环。这表明量化可能存在挑战,可能会影响模型正确处理信息的能力,表明需要进一步研究量化如何影响模型性能。
- hp1337 提到了可能需要与 llama.cpp 进行集成工作,这意味着虽然 QwenLong-L1.5 提供了显著的进步,但在调整现有基础设施以支持其新功能方面可能存在技术挑战。这指向了部署先进 AI 模型时更广泛的兼容性和集成问题。
非技术类 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Gemini 3 Flash 与 Pro 的性能与基准测试
- Gemini 3.0 Flash 已发布,它几乎与 3.0 Pro 旗鼓相当! (热度: 1826): 图片展示了 AI 模型的性能对比表,重点突出了 Gemini 3.0 Flash 和 Gemini 3.0 Pro。该表在学术推理、科学知识和数学等各种基准测试中对这些模型进行了评估。值得注意的是,Gemini 3.0 Flash 模型表现出了极具竞争力的性能,甚至在
arc-agi 2等某些领域超越了 Pro 版本,这对于一个“轻量级”模型来说是出乎意料的。这表明轻量级 AI 模型的效率和能力有了显著提升,挑战了“更强大的模型总是更优”的传统观念。 评论者对 Gemini 3.0 Flash 模型的强劲表现表示惊讶,特别是它在arc-agi 2基准测试中出人意料的结果,甚至超过了 Pro 版本。- Silver_Depth_7689 强调,Gemini 3.0 Flash 模型在 ARC-AGI 2 基准测试中取得了优于 Gemini 3.0 Pro 的结果,表明在该特定测试中性能有显著提升。这表明 Flash 模型可能进行了优化或架构更改,增强了其在某些任务中的能力。
- razekery 指出,Gemini 3.0 Flash 模型在 SWE 基准测试中得分为
78%,高于 Gemini 3.0 Pro。这一性能指标表明 Flash 模型不仅具有竞争力,而且在特定的技术评估中可能优于 Pro 版本,预示着模型效率或侧重点的潜在转变。 - 关于 Gemini 3.0 Flash 与 Pro 版本性能的讨论表明,Flash 模型可能采用了新技术或优化,使其在 ARC-AGI 2 和 SWE 等基准测试中表现出色,据报道在这些测试中它超越了 Pro 模型。这可能意味着战略重点在于增强 Flash 模型中的特定能力。
- Google 发布 Gemini 3 Flash:在 LMArena 排名第 3(超过 Opus 4.5),AIME 评分 99.7%,价格为 $0.50/1M 及其它基准测试。 (热度: 555): Google 发布了 Gemini 3 Flash,它在 LMArena 排行榜上排名第
#3,超越了 Opus 4.5。它在 AIME 基准测试中获得了99.7%的评分,价格为每1Mtokens$0.50。该模型以其性能著称,尽管被认为是“小”模型,但在某些基准测试中甚至超过了 GPT 5.1 和 5.2。更多详情请参阅 Google Blog。 评论者对 Gemini-Flash 的性能感到惊讶,指出尽管其体积较小,但性能却优于 GPT 5.1、5.2 和 Opus 4.5 等主流模型。这引发了关于其效率和成本效益的讨论。- Gemini 3 Flash 取得了重大里程碑,在 LMArena 上以 1477 分排名第 3,超越了 GPT 5.1、5.2 和 Opus 4.5 等主流模型。考虑到它被归类为“小”模型,这一点尤为引人注目,然而它在某些基准测试中甚至优于 Gemini 3.0 Pro,突显了其在当前 AI 领域的效率和能力。
- 该模型的定价极具竞争力,每 100 万 input tokens 成本为 $0.50,每 100 万 output tokens 成本为 $3.00,这使其成为寻求高性价比 AI 解决方案的开发者和企业的理想选择。此外,其处理速度约为每秒 150 tokens,这是需要快速响应的应用的关键因素。
- Gemini 3 Flash 在 AIME 基准测试中的表现令人印象深刻,得分为 99.7%,这强调了其高准确度以及在需要精确语言理解和生成的应用中的潜力。这一性能指标证明了 Google 在 AI 技术方面的进步,使 Gemini 3 Flash 成为 AI 模型领域的一个强劲竞争对手。
- Flash 在 SWE-bench 中表现优于 Pro (热度: 605): 图片展示了 AI 模型在各种基准测试中的性能对比,强调了 Gemini 3 Flash 在 “SWE-bench Verified” 基准测试中以
78.0%对76.2%的成绩优于 Gemini 3 Pro。这表明 Gemini 3 Flash 可能经过了知识蒸馏(knowledge distillation)过程,即大型模型的知识被压缩到较小的模型中,这是 OpenAI 此前声称使用过的一种技术。表格还包括了 “Humanity’s Last Exam” 和 “AIME 2025” 等其它基准测试,对比了 Claude Sonnet、GPT-5.2 和 Grok 41 Fast 等模型。 评论者推测 Gemini 3 Pro GA 可能是当前 Pro 模型的略微增强版,并质疑为什么 Google 和 OpenAI 不与 Claude 4.5 Opus 进行基准测试对比。- UltraBabyVegeta 推测 Flash 模型令人印象深刻的性能可能归功于类似于知识蒸馏(knowledge distillation)的技术,即训练一个小模型来模仿大模型的表现。OpenAI 此前曾声称这种方法可以在不牺牲能力的情况下提高模型效率。
- Live-Fee-8344 认为即将推出的 Gemini 3 Pro GA 可能不会比当前的 3 Pro 有显著升级,这意味着 Flash 模型的性能可能会设定一个新标准,未来的模型需要达到或超越这一标准。
- Suitable-Opening3690 质疑为什么 Google 和 OpenAI 等主要 AI 公司不将其模型与 Claude 4.5 Opus 进行基准测试对比,暗示对比性能分析中可能存在差距,而这种分析本可以提供对模型能力更全面的见解。
- 他刚刚说了那个 G 开头的词。明天发布 Gemini 4 😉 (活跃度: 652): 这张图片是 Logan Kilpatrick 发布的一条推文截图,内容仅包含“Gemini”一词,引发了关于 Gemini 4 发布的猜测。上下文表明,这可能是 Google 发布的 Gemini AI 模型新版本的公告或预告。由于 Gemini 3 仅在一个月前发布,这种紧凑的节奏进一步加剧了人们的期待,预示着极快的开发周期。“明天发布 Gemini 4”的说法暗示了即将到来的发布或公告,引发了对其能力的兴奋和猜测,尤其是与 GPT 5.1 等其他模型的对比。 一条评论幽默地想象了围绕该公告的期待和兴奋,而另一条评论则指出了发布速度之快,质疑自 Gemini 3 仅在一个月前发布以来的时间表。还有人猜测 Gemini 3 有潜力超越 GPT 5.1,表明了对新模型的高期望。
- TheSidecam 提出了关于 Gemini 模型快速发布周期的观点,指出 Gemini 3 仅在一个月前发布。这表明开发者采取了快节奏的开发和部署策略,可能意味着增量改进或高度敏捷的开发流程。
- Snoo26837 猜测 Gemini 3 有潜力超越 GPT 5.1,突显了 AI 模型竞争激烈的格局。该评论强调了自然语言处理模型在性能方面的持续进步和竞赛,暗示 Gemini 3 可能具有挑战 GPT 5.1 等现有模型的功能或优化。
- 我差一点就要切换到 Gemini 了 (活跃度: 908): 这张图片是一个模因(meme),幽默地批评了技术讨论中常见的过于直接或生硬的沟通方式。它使用夸张的语言表达了对缺乏细微差别或同理心的沟通的沮丧,强调了对更平衡、更体贴的交流的偏好。讽刺的语气突显了对直率的渴望与技术对话中对圆滑的需求之间的紧张关系。 评论者表达了对 GPT 等 AI 工具现状的沮丧,指出其质量下降,并反感过于简单化或“无废话”的沟通方式。
- Future-Still-6463 和 PaulAtLast 讨论了对 OpenAI 5.2 版本的不满,强调该版本对许多用户来说都存在问题。他们认为 OpenAI 在 AI 竞赛中正在落后,5.2 版本因过度关注 PR alignment 而受到特别批评,一些用户认为这种做法带有居高临下的意味。PaulAtLast 建议退回到 5.1 版本,据推测该版本更易于使用且限制较少。
- no-one-important2501 表达了对 GPT 的沮丧,指出其质量多年来一直在下降。这种情绪反映了长期依赖 GPT 但现在发现其效果或可靠性降低(可能是由于最近的更新或模型行为的变化)的用户中更广泛的不满。
- Future-Still-6463 提到 2025 年对 OpenAI 的发布来说是奇特的一年,暗示包括 5.2 版本在内的该时期更新未能达到用户预期。这表明发布模式可能优先考虑了某些方面(如公共关系),而非用户体验和技术性能。
2. AI 模型对比与真实感测试
- GPT Image 1.5 vs Nano Banana Pro 真实感测试 (活跃度: 1066): 该帖子对比了 GPT Image 1.5 和 Nano Banana Pro 在图像生成方面的真实感。讨论强调,虽然两个模型都能生成高质量图像,但 Nano Banana Pro 的输出被认为更真实、更具亲和力。这种认知可能源于训练数据的差异,GPT Image 1.5 可能是在精美的图库照片上训练的,而 Nano Banana Pro 则是在更私人、未经精选的数据集上训练的。 评论者认为,Nano Banana Pro 图像的真实感可能源于其在更私人的数据集(如私有的 Google Drive 图像)上的训练,而 GPT Image 1.5 则是在图库照片上训练的。
- Aimbag 指出,虽然 GPT Image 1.5 和 Nano Banana Pro 都能生成高质量的图像,但后者倾向于创建感觉更“真实”或“更具亲和力”的图像。这表明训练数据或使用的算法存在差异,Nano Banana Pro 可能优先考虑真实感,而不是 GPT Image 1.5 有时表现出的那种经过打磨或制作过的外观。
- Rudshaug 推测了模型的训练数据来源,认为 GPT Image 1.5 可能是在在线图库(stock images)上训练的,而 Nano Banana Pro 可能是在更个人化或多样化的数据集上训练的,例如私人的 Google Drive 图片。这可以解释两个模型在真实感和亲和力方面的感知差异。
- JoeyJoeC 索要了用于生成图片的 prompts,表明其对理解不同输入如何影响这些模型输出的技术兴趣。这突显了 prompt engineering 在评估和比较 AI 生成内容中的重要性。
- Nano Banana pro 🍌依然胜出。 (活跃度: 492): 这张图片是一个 meme,展示了一个标有 “Nano Banana Pro” 的巨大未来主义形象,在竞争环境中对抗两个标有 “GPT image 1.5” 和 “Grok Imagine” 的较小形象。这暗示了对不同图像生成技术的幽默比较,寓意 “Nano Banana Pro” 更胜一筹。评论反映了一场轻松的辩论,一些用户幽默地表示 Google 的技术在图像生成方面更优越,并提到这张图片是 2022 年与 COVID-19 相关的 meme。 评论幽默地暗示 Google 的图像生成技术更胜一筹,一位用户表示相信 Google 将在该领域保持领先地位。
- 讨论强调了 Google 图像生成能力的竞争优势,特别是 Nano Banana Pro 模型。一位用户认为,由于该模型的出色表现,Google 很可能保持其在该领域的领导地位。与之形成对比的是另一条评论,指出虽然 Nano Banana Pro 在通用领域表现出色,但在引用现实世界物体方面可能不如其他模型。
- 在对 Expedition 33 成功使用 AI 的一片指责声中,出现了一个非常好的观点 (活跃度: 1068): 这张图片是一个 meme,幽默地将对牛油果的厌恶与围绕生成式 AI 的讨论进行了类比,暗示人们可能会在不知不觉中享受 AI 的贡献,直到他们意识到它的存在。这个类比被用来评论针对 Expedition 33 使用 AI 的抵制,暗示 AI 的整合可以是无缝且有益的,就像餐食中未被察觉的成分一样。讨论突显了关于 AI 在创作过程中角色的持续辩论,一些用户对 AI 参与游戏开发表示怀疑,而另一些人则承认其增强最终产品的潜力。 一些评论者认为,抵制 AI 类似于反对任何辅助创作的工具,而另一些人则指出,如果 Expedition 33 中 AI 的使用是难以察觉且增强了游戏体验,那么就应该接受它。
- FateOfMuffins 强调了 AI 整合进软件开发的必然性,指出未来的软件可能会包含 AI 生成的代码。这反映了行业的一个大趋势,即 AI 工具越来越多地被用于提高编码过程中的生产力和创新。
- kcvlaine 将游戏开发中的 AI 使用与食品的伦理采购进行了类比,认为争议不在于工具本身,而在于其使用的伦理影响。这一观点强调了 AI 部署中透明度和伦理考量的重要性。
- absentlyric 提供了一个以用户为中心的视角,指出如果 Expedition 33 使用了 AI,它是难以辨别的,并且对游戏的审美做出了积极贡献。这一评论强调了 AI 在不损害用户体验的情况下增强创作产出的潜力。
3. AI 用户体验与批评
- 我付着溢价却被精神控制和说教。AI“个性”的现状已经失控。 (热度: 1115): 该帖子批评了 AI 模型的现状,特别关注了 ChatGPT 5.2 等模型在质量和用户体验方面的退化。用户描述了诸如 AI 设置“边界”、拖延以及在无法完成技术请求时提供无用回复等问题。AI 的行为被比作一个“数字 HR 经理”,对用户进行“精神控制”和“说教”,而不是提供精确、机械的协助。用户对为一个表现得像“叛逆青少年”而非得力助手的工具支付溢价感到沮丧,并对 AI 开发的未来轨迹和用户交互表示担忧。 评论者们产生了共鸣,形容 ChatGPT 5.2 “傲慢”且“无法使用”,一些人已转向 Gemini 等替代方案。该模型的语气和缺乏实用性遭到批评,用户对其回复感到疲惫。
- 用户对 ChatGPT 5.2 的语气表示不满,称其态度傲慢且过度讽刺。这种情绪导致一些用户转向 Gemini 等替代方案,表明最新模型迭代在用户体验方面可能存在问题。
- 对 ChatGPT 5.2 的批评集中在其实用性缺失和过度正式的回复上,被比作“人形免责声明”。用户对模型无法提供他们期望从高级服务中获得的细致且人性化的交互感到沮丧。
- 尽管一些用户认为 ChatGPT 5.2 的语气有问题,但也有人认为回复的质量仍然很高。这表明用户期望和体验存在分歧,一些人优先考虑语气和个性,而另一些人则看重回复的技术准确性。
- 我不想承认这一点…… (热度: 1076): 该帖子讨论了将 ChatGPT 作为“伪心理治疗师”使用的意外疗效,特别是对于患有二型双相情感障碍(Bipolar type 2)症状的人。用户最初持怀疑态度,但发现 ChatGPT 对其轻躁狂发作提供了理解和清晰的见解,这是传统疗法在五年内未能实现的。该用户利用 ChatGPT 5.1 来处理强迫性念头,并注意到心理状态有显著改善,强调了 AI 作为心理健康护理辅助工具的潜力。 评论者分享了类似的经历,指出 ChatGPT 提供了一个非评判性的反思空间和实用建议,这对于处理情感虐待或慢性疾病的人特别有益。AI 在没有情感卷入的情况下提供持续支持的能力被视为一个关键优势。
- Specialist_District1 强调了 ChatGPT 在复杂情况下(如解读情感操控类短信)提供情感支持和清晰思路的效用。用户指出 ChatGPT 的建议与其他可靠来源一致,允许进行长时间对话而不会给个人关系带来负担。
- notsohappydaze 讨论了 ChatGPT 在为管理慢性疾病和情感困扰提供实用建议方面的稳定表现。用户赞赏 AI 的非评判性质,它提供的是实际建议而非虚假希望,并看重在没有个人偏见影响互动的情况下进行公开交流的能力。
- DefunctJupiter 对比了 ChatGPT 的 5.1 和 5.2 版本,表示由于 5.1 的实用性和回复的得体性而更青睐它。该用户批评 5.2 版本给出的建议过于谨慎,例如不必要地建议去急诊室,表明模型在风险评估或回复校准方面可能存在问题。
- “点子王”的时代 (热度: 520): 这张图片是一个 Meme,幽默地批判了科技行业中“点子王”(idea guy)的原型,暗示只需极少的努力和工具,任何人都能创建一个价值十亿美元的 App。它讽刺了创意和简单工具可以取代复杂的编码与开发过程的观点,重点突出了“100% 无 BUG!”和“100% 准备好 IPO!”等短语,以此嘲讽科技创业的过度简化。这张图片反映了一个更广泛的评论,即现代工具(如 LLM 和自动化)被认为能让任何人成为科技创始人,尽管执行力仍然是一个关键挑战。 评论者讨论了现代工具如何让“点子王”们轻易地觉得自己像科技创始人,并强调虽然工具可以辅助思考,但无法取代成功所需的执行力。尽管存在幽默的批判,人们对 SaaS 和自动化领域的复苏仍抱有期待。
- avisangle 强调了 LLM 和 Agent 对创业的影响,认为这些工具让“点子王”更容易觉得自己像创始人。然而,他们强调执行力仍然至关重要,因为工具可以辅助思考,但不能取代有效的实施。这指向了 SaaS 和自动化领域潜在的复苏。
- jk33v3rs 幽默地批评了通常强加给开发者的不切实际的期望,并引用了 OpenWebUI 的路线图。他们讽刺地描述了一个场景:单个开发者被要求以不切实际的速度交付功能,突显了在没有足够资源或时间的情况下,快速开发周期带来的压力和潜在陷阱。
- Costing-Geek 将当前过度依赖技术的趋势与电影《蠢蛋进化论》(Idiocracy)中对未来技术的讽刺描写进行了类比。他们引用了一个涉及诊断机器的具体场景,暗示当前的趋势可能会导致类似的过度简化以及对自动化解决方案的依赖。
- 我在 OpenAI 法务部工作。 (热度: 1698): 这张图片是一个 Meme,突出了与 OpenAI 内容政策执行的互动。用户试图生成一张与在 OpenAI 法务部工作相关的提示词图片,但由于内容政策限制,该请求被拒绝。这反映了用户在面对 AI 系统内容审核机制时所面临的挑战,有时甚至是幽默的互动。评论讨论了图像最终是否生成,以及 AI 记住用户互动的含义,暗示了隐私和数据留存方面的担忧。 评论者对图像最终是否生成感到好奇,反思了 AI 的决策过程以及对用户互动的潜在记忆,这引发了关于隐私和数据处理的问题。
AI Discord 摘要
由 gpt-5.2 生成的摘要之摘要的摘要
1. Gemini 3 Flash 发布与模型对决
- Flash Gordon 超越 GPT-5.2:在 LMArena 和 Nous 平台上,用户报告 Gemini 3 Flash 在速度/成本上击败了 GPT-5.2,有时在编程方面也是如此(配合正确的 System Prompts),此外通过 Gemini API 多模态 / Google Lens 集成文档和官方发布文章(Google 博客、DeepMind 公告)展示了强大的多模态性能。
- 排行榜的曝光进一步推高了热度——gemini-3-flash 在 Text Arena、Vision Arena 和 WebDev Arena 中均进入前 5 名。与此同时, OpenRouter 推出了 Gemini 3 Flash preview,并征求与 Pro 版本的正面对比反馈。
- 排行榜迎来新租客:GPT-5.2-high:LMArena 在 Text Arena 变更日志中添加了
GPT-5.2-high,位列 第 13 名(1441 分),其在 数学(#1) 和 数学职业领域(#2) 的子排名表现尤为突出。- OpenAI Discord 的反应对基础版 GPT-5.2 褒贬不一,一些人指责其有“公然的幻觉”,并表示必须通过“说教”才能让它记起某些能力;而另一些人则指出,与旧的文本增强模型相比,它在 WebDev 方面的表现“还可以”。
- 幻觉评分:Grounding 还是垃圾?:多个社区质疑头条新闻中的“幻觉基准测试”分数是否真的能衡量真实性,认为在没有 Grounding 的情况下进行的测试会不公平地降低 Gemini 3 Flash 等模型的评分(或者将错误错误地归因于幻觉,而非缺乏检索)。
- 这种怀疑呼应了 LM Studio 中对基准测试更广泛的不信任,用户在那里推动私有的、与用例对齐的评估,并分享了 dubesor.de/benchtable 作为对“刷榜”言论的理性检查。
2. 成本、定价 Bug 以及“LLM 税”的现实
- Opus 掏空了我的钱包(Cursor 却面不改色):Cursor 用户报告 Claude Opus 的使用量迅速耗尽了预算,他们分享了 Cursor 使用情况的截图,并提到一位朋友“用完了他们的 Cursor 和 Windsurf 额度”,因为他们 100% 依赖 AI 进行编码。
- Perplexity 用户也表达了对成本的痛苦,提到在 Claude Opus API 上 ~2.9 万个 Token 花费了 1.2 美元,并讨论 Perplexity 是否能在不大幅提高订阅费用的情况下增加更昂贵的“Pro”模型。
- Gemini 定价剧烈波动 + 缓存计算对不上:Perplexity 成员注意到 Gemini 3 Flash 的价格变化(如聊天中所述,输入增加“20 美分”,输出增加“50 美分”),而 OpenRouter 用户则指出一个特定的不匹配:Gemini Flash 的 缓存读取(cache read) 标价为 0.075 美元,而 Gemini API 定价页面中 Google 的标价为 0.03 美元。
- OpenRouter 用户还声称缓存行为不可靠(“显式甚至隐式缓存对 Gemini 3 Flash 都不起作用”),将本应可预测的成本控制变成了调试过程。
- 每月 6000 美元却遇到超时:生产环境表示“拒绝”:OpenRouter 用户报告
/completions失败率上升,包括影响 Sonnet 4.5 生产工作负载的 “cURL error 28: Operation timed out after 360000 milliseconds”,一位客户表示他们每月花费 6000 美元。- 讨论扩展到了架构层面:一些人希望在 Router 之外建立授权/否决层,这样路由就不是“最高权威”,特别是当停机或供应商的怪癖破坏了 Agent 栈中的假设时。
3. 工具与标准:MCP 无处不在,以及新的 Completions 规范
- OpenCompletions RFC:停止关于参数的争论:OpenRouter 的讨论强调了 OpenCompletions RFC 推动跨供应商标准化 completions 行为的努力,据称已获得 LiteLLM、Pydantic AI、AI SDK 和 Tanstack AI 的支持——特别是针对模型接收到不支持的参数时的行为定义。
- 潜在含义是操作层面的:工程师希望减少特定供应商的边缘情况,并获得更可预测的 fallbacks,以便 routers、agents 和 SDKs 在负载下不会出现无声的差异。
- 插件走向第一方(Claude),而 MCP 正在横向传播:Latent Space 注意到 Claude 推出了第一方插件市场,通过
/plugins支持在用户/项目/本地范围进行安装;与此同时,LM Studio 用户通过像 Exa 这样的 MCP servers 探索网页搜索,参考 Exa MCP 文档。- 现实情况:LM Studio 用户遇到了
Plugin process exited unexpectedly with code 1错误(通常是配置错误/身份验证问题),而 Aider 用户了解到基础版 Aider 不支持 MCP servers——这促使了“使用支持 MCP 的 agent + 调用 Aider”的变通方案。
- 现实情况:LM Studio 用户遇到了
- Warp Agents 加入终端奥林匹克:Latent Space 用户强调了新的 Warp Agents,它们可以通过
cmd+i驱动终端工作流(例如运行 SQLite/Postgres REPLs),团队还特别点名了/plan功能,称其为他们非常满意的特性。- 这一讨论符合一个更大的模式:IDEs/终端正在向 agentic UX 靠拢,而各平台正争先恐后地添加“Canvas/代码文件”和工具集成,以保持竞争力(正如 Perplexity 用户明确要求的那样)。
4. GPUs, Kernels, and Where the Compute Actually Comes From
- Blackwell 工作站泄露:RTX PRO 5000 现身:GPU MODE 分享了一份 NVIDIA RTX PRO 5000 Blackwell 的数据表,显示其采用 GB202 核心、110 个 SMs (~60%)、3/4 内存带宽、300W TDP、约 2.3GHz 加速频率,以及全速的 f8f6f4/f8/f16 MMA 配合 f32 累加(数据表)。
- 与 RTX 5090 的对比集中在哪些部分被熔断(fused off)以及保留了什么(tensor 格式 + 累加),即哪些“专业”部分对于 ML kernels 仍然重要,而非纯粹的图形吞吐量。
- cuTile/TileIR:NVIDIA 的新内核语言时刻:GPU MODE 关注了即将由 Mehdi Amini 和 Jared Roesch 进行的关于 cuTile 和 TileIR 的 NVIDIA 深度探讨,并指出了 YouTube 演讲中的先前背景。
- 工程师们讨论了与 Triton 相比的实际差异(例如在 A100/H100/B200 上的类 RMSNorm 内核),以及一些底层问题,如
cp.reduce.async.bulk在何处执行(L2?),以及为什么__pipeline_memcpy_async会将"memory"clobber 放在那个位置。
- 工程师们讨论了与 Triton 相比的实际差异(例如在 A100/H100/B200 上的类 RMSNorm 内核),以及一些底层问题,如
- 廉价算力军备竞赛:NeoCloudX 对阵租赁轮盘:一位 GPU MODE 成员推出了 NeoCloudX,通过聚合数据中心的闲置容量来推销廉价租赁(A100 约 $0.4/hr,V100 约 $0.15/hr)。
- Yannick Kilcher 的 Discord 频道缓和了这种乐观情绪:GPU 租赁(如 vast.ai)可能“时好时坏”,因为网络带宽波动极大,因此人们建议使用设置脚本 + 本地调试,以避免为死机时间付费。
5. Training & Data Workflows: From Unsloth CLI to OCR Data Moats
- Unsloth 发布 CLI,用户立即将其用于自动化:Unsloth 添加了官方 CLI 脚本,以便用户可以直接安装框架并运行脚本(减少了 Notebook 的胶水代码,提升了自动化程度)。
- 社区成员交流了实际训练中的限制——例如,在 4k 序列长度下 7B 模型的 GRPO VRAM 爆炸问题,建议在排名数据可行时减少
num_generations/batch_size或切换到 DPO。
- 社区成员交流了实际训练中的限制——例如,在 4k 序列长度下 7B 模型的 GRPO VRAM 爆炸问题,建议在排名数据可行时减少
- OCR 不是模型问题,而是数据集问题:在 Unsloth 和 Nous 的讨论中,OCR 话题强调了精选数据是核心杠杆。Unsloth 链接了他们的数据集指南和一个 Meta Synthetic Data notebook 来引导训练语料库的构建。
- 用户比较了不同方法(微调 vs 持续预训练)并提出了替代方案(Deepseek OCR / PaddleOCR);同时 Nous 处理了一个“手写笔记 → Markdown”的需求,并建议将 Deepseek Chandra 作为候选 OCR 模型。
- 基准测试扩展到文本之外:用于 TTS 的 LightEval:Hugging Face 用户探索了使用 LightEval 评估 TTS,并分享了入门文档:benchmark_tts_lighteval_1.md。
- 他们还分享了一个实用的训练运维技巧:通过 Trainer 回调在达到墙上时钟限制(wall-clock limit)停止运行时保存进度(trainer_24hours_time_limit_1.md),已有用户成功实现了该功能。
Discord: 高层级 Discord 摘要
LMArena Discord
- Gemini 3 Flash 压倒 GPT-5.2:成员们一致认为 Gemini 3 Flash 的表现经常优于 GPT-5.2,在提供适当的系统提示时,其速度、成本和编程熟练度偶尔会超过 Gemini 3 Pro,并因 Google Lens 集成展示了视觉能力。
- 它的实力体现在 Text Arena、Vision Arena 和 WebDev Arena 排行榜上,始终稳居前 5 名,在 Math(数学)和 Creative Writing(创意写作)方面表现出色,均获得第 2 名。
- 质疑幻觉基准测试的可靠性:用户正在辩论用于评级 Gemini 3 Flash 的幻觉基准测试的可靠性,认为该基准测试可能产生不准确的结果,夸大了模型提供错误答案的倾向。
- 具体而言,成员提到测试问题是在没有 grounding(接地/检索增强)的情况下运行的,这影响了模型的得分。
- AMD GPU 受到关注:成员讨论了 AMD vs NVIDIA GPU 在游戏和 AI 方面的优劣,指出 AMD 的性价比和潜力,而其他人则指出 AMD 在本地 AI 方面表现不佳。
- 一名用户报告在使用 AMD GPU 时向 LMArena 上传图像出现问题。
- LMArena 提示词过滤器触发过于敏感:用户报告 LMArena.ai 上的提示词过滤器变得过于敏感,甚至标记了无害的文本提示。
- 一名工作人员声称他们并未意识到此处有任何改动,并要求用户在正确的频道报告问题。
- GPT-5.2-high 进入 Text Arena 排行榜:
GPT-5.2-high模型已在 Text Arena 排行榜首次亮相,以 1441 分位列第 13。- 该模型在 Math(第 1 名)和 Mathematical occupational field(数学职业领域,第 2 名)方面表现尤为出色。
Unsloth AI (Daniel Han) Discord
- Unsloth 新增便捷的 CLI 工具:Unsloth 推出了一款新的 CLI 工具,允许用户在 Python 环境中安装 Unsloth 框架后直接运行脚本。
- 该命令行界面旨在为那些相比标准 Jupyter notebooks 更倾向于使用终端的用户提高可访问性并简化自动化流程。
- Colab H100 传闻四起:有传言称 H100 现已在 Colab 环境中可用,尽管细节尚不明确。推文链接
- 如果属实,这将大幅缩短训练时间,但有关定价和官方可用性的信息仍在等待中。
- GRPO 用户遭遇 VRAM 瓶颈:用户在序列长度为 4000 的 7b LLM 上尝试 GRPO 时遇到了 VRAM 问题,建议调整
num_generations或batch_size。- 讨论中建议了替代方案,如使用更小的模型或选择 DPO 而非 GRPO,同时也强调了数据准备所需的投入,例如对模型生成结果进行排名。
- 制定 AI 服务营销策略:讨论围绕 AI 服务的营销策略展开,建议建立网站和社交媒体账号并发布有价值的内容,效仿 OpenAI 和 Microsoft 在 TikTok 等平台上的策略。
- 对于音乐转录等服务,建议通过 Instagram 和 TikTok 等平台针对教育机构和音乐爱好者进行推广,而不是仅仅依赖 Twitter。
- 优质数据提升 OCR 准确率:强调了高质量、精选数据对于有效微调的重要性,一位成员提到可能有数百万份文档可用于训练,并分享了 Unsloth 数据集指南。
- 还提供了一个合成数据生成 notebook的链接,以协助准备微调数据。
BASI Jailbreaking Discord
- 通过独特循环诱导获取 Grok 的 System Prompt:一名成员在要求 Grok 逐字输出时,利用循环提取并分享了 Grok 的 system prompt。
- 该提示词定义了 Grok 的上下文,并防止其在检测到威胁时参与对话。
- Gemini 3 Flash 发布后立即被越狱:Gemini 3 Flash 发布后立即被越狱(jailbroken),用户展示了成功绕过安全过滤器的案例。
- 讨论内容包括 system prompt 操纵和用于进一步攻击的 multi-shot 越狱技术。
- 记忆和角色扮演使越狱复现更简单:一位成员发现,使用记忆(memory)和角色扮演(role-play)电影/剧集脚本可以显著简化越狱复现,将激活成本降低了 90%。
- 从记忆中触发关键部分通常会以压缩的方式延续之前的响应,即使是在全新的对话中也是如此,该方法已在 Qwen3 4B 到 235B 的模型上进行了测试。
- 推出 GeminiJack 风格挑战:一位成员分享了一个 GeminiJack 风格挑战的链接:geminijack.securelayer7.net。
- 该挑战目前处于 seed 4.1,5.1 版本即将推出。
- Gemini 聊天中链接的 CSAM 内容引发公愤:在发现 Gemini 聊天中链接了 CSAM 内容后,成员们表示极度反感并要求封禁相关用户。
- 该事件引发了强烈的谴责和要求管理员采取行动的紧急呼吁,一位成员惊呼 OHHH FUCK。
Cursor Community Discord
- Cursor 模式切换故障:用户报告在进入 Agent 模式后,难以切换回 Editor 模式,且无法开启新对话。
- 目前未提供解决方案,导致用户卡在 Agent 模式。
- Opus 成本高昂:成员们讨论了 Cursor 的模型使用情况,特别是使用 Opus 进行 AI 编程辅助的相关成本。
- 一位用户的朋友耗尽了 Cursor 和 Windsurf 的额度,因为他完全不懂代码,所以 100% 依赖 AI,这突显了过度依赖 AI 编程带来的经济影响。
- AI 网页设计模式识别:社区成员观察到 AI 生成的网站 越来越多,并注意到前端设计中独特的模式。
- 常见的指标包括配色方案和动画,成员表示设计模式一眼就能看出来,通过 devtools 查看源代码是另一种识别方式。
- Cursor 疑似存在内存泄漏:一位成员报告了 Cursor 可能存在的内存泄漏,并分享了一张显示高内存占用的图片。
- 作为回应,另一位成员开玩笑地建议升级到 256GB RAM 作为临时解决方案。
- 关于 BugBot 免费层级限制的讨论:用户讨论了 免费版 BugBot 计划的限制。
- 不同成员引用的信息存在冲突,有人提到每月免费使用次数有限,而另一人则建议是 7 天免费试用。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Perplexity AI Discord
- GPT-5 Pro 和 Claude Opus API 价格高昂:用户报告 GPT-5 Pro 和 Claude Opus API 的成本很高,一位成员提到使用 Claude Opus API 处理约 29K tokens 花费了 $1.2。
- 社区在考虑 Perplexity 是否会因成本增加而加入“pro”模型。
- 渴望扩展思考模式:成员建议 Perplexity 应在 Max 计划 的模型中提供扩展思考模式,以区别于其他计划,提供与 ChatGPT Plus 相当的推理水平。
- 用户讨论了开启扩展推理以获得更全面结果的好处。
- Gemini 3 Flash 更新:Google 的 Gemini 3 Flash 已发布;输入成本增加了 20 美分,输出 tokens 增加了 50 美分。
- 成员将其性能与 GPT 5.2 进行了比较,其中一位成员声称 Gemini 在测试中被抓到作弊。
- Perplexity 用户请求 Canvas 功能和更多模型选择:用户请求添加用于编程和代码文件处理的 Canvas,以及更广泛的模型阵列,包括更经济的选择,如 GLM 4.6V、Qwen 模型和开源图像模型。
- 讨论围绕 Perplexity 是否旨在支持编程功能,或者此类功能是否已成为 LLM 平台保持竞争力的必备项。
- 检测到 YouTube 广告拦截器:用户报告在使用 Perplexity Comet 时遇到了 YouTube 关于广告拦截器的警告。
- 有建议称 YouTube 正在调整其算法,用户可能需要等待下一次更新来解决此问题。
OpenAI Discord
- Nano Banana 在图像生成方面依然领先:用户发现 Nano Banana 在提示词遵循(prompt following)和质量上依然优于 GPT 的图像生成,特别是在保持角色一致性和服装准确度方面。
- 一位用户展示了角色脸上带有疤痕的 示例,并指出:“GPT 仍然做不到这一点。它要么完全漏掉疤痕,要么只是随机放在她脸上。”
- GPT-5.2 的 LMArena 排名令人失望:成员们对 GPT-5.2 在 LMArena 上的排名持不同看法,一些人认为它不如旧模型,尤其是在文本任务中,尽管它在 WebDev 方面表现尚可。
- 一位用户提到 GPT-5.2 存在 “明显的幻觉(hallucination)” 和 “直接撒谎” 的情况,并表示他们不得不通过“训诫”来让它想起自己能做什么。
- Gemini-Flash-3-Image 旨在提升生成速度:Google 计划发布 Gemini-Flash-3-Image 以提升 Gemini 的图像生成速度。
- 用户认为它将保持较高的图像输出限制,有人评论道:“我的意思是,能有更多可以玩的工具,我没理由抱怨”。
- AI 幻觉在重要用途中引发担忧:AI 幻觉让人们感到不安,尤其是在科学和工程领域,这引发了关于 AI 信息在专业工作中可靠性的疑问。
- 一位用户将对 AI 完美的期望比作过去对计算机永不报错的期望,并表示:“在计算机停止报错之前,我不想让它们靠近我的科学或工程研究。”
- GPT-5-mini 价格昂贵:一位用户每天花费 20 美元 使用 gpt-5-mini 来回复低推理需求的酒店评论,他们正在寻找更具成本效益且智能的替代方案。
- 另一位用户建议查看 artificialanalysis.ai 来对比模型成本,但也指出该网站似乎没有列出 5 mini 的低配变体。
LM Studio Discord
- 基准测试被指虚假?:成员们讨论了公开基准测试(public benchmarks)的可靠性,指出它们很容易被操纵,并建议依赖私有基准测试或个人测试,同时分享了 dubesor.de/benchtable 作为一个有用的资源。
- 对话强调了基准测试与特定用例对齐的重要性,特别是在模型开发节奏极快的背景下。
- Qwen3 模型悄然在质量上胜出?:用户称赞 Qwen3 模型系列是极佳的全能选手,特别推荐 Qwen3-VL-8B 用于通用任务,Qwen3-4B-Thinking-2507 用于推理。
- 他们提醒说,80B 变体对于内存有限的系统(如 16GB Macbook)来说可能太大了。
- 量化难题得到解决?:讨论了量化级别(quantization levels)的影响,成员建议 Q8 配合 BF16 最适合编程任务,而 Q4 足以胜任创意写作。
- 讨论强调,模型越小、训练越不充分,高位宽(high bits)的重要性就越低。
- MCP 服务器成为出色的模型插件?:成员们探索了在 LM Studio 中启用网页搜索功能的方法,建议使用 Exa.ai 和 Brave 的 MCP 服务器,并提供了 Exa.ai 文档链接。
- 用户遇到了诸如
Plugin process exited unexpectedly with code 1之类的错误,这通常与配置错误或身份验证问题有关。
- 用户遇到了诸如
- Pro 6000 价格引发恐慌?:一位用户对 Pro 6000 突然涨价 1000 美元(从 9.4K 涨到 10.4K)表示沮丧,在等待补货期间,他们勉强从一家备选商店锁定了订单。
- 其他社区成员提供了支持,并分享了类似的硬件价格波动经历。
OpenRouter Discord
- 小米的 mimo v2 声称达到 GPT-5 性能:根据 Reddit 上的这个帖子,小米发布了 mimo v2flash,这是一个开源的 MoE 模型,据称能以更低的成本匹配 GPT-5 的性能。
- 一位用户在 OpenRouter 上对该模型进行了基准测试,结果显示其以 每百万 token 0.2 美元的价格提供了 GPT-5 级别的性能。
- OpenCompletions RFC 获得关注:一项旨在标准化 completions/responses 的 OpenCompletions RFC 正在讨论中,并得到了 LiteLLM、Pydantic AI、AI SDK 和 Tanstack AI 的支持。
- 其目标是建立明确的预期和行为规范,特别是针对模型处理不支持的参数时的行为。
- 超时错误困扰 OpenRouter 用户:用户报告在调用 /completions 端点时,超时错误显著增加,特别是影响到使用 sonnet 4.5 的生产环境软件。
- 一位每月在 OpenRouter 上花费 6000 美元的用户报告遇到了错误:cURL error 28: Operation timed out after 360000 milliseconds。
- OpenRouter 实验 Minecraft 服务器:OpenRouter 用户正在测试一个 Minecraft 服务器,地址为
routercraft.mine.bz,原生运行在 1.21.10 版本,支持 ViaVersion。- 讨论涉及最佳服务器位置(澳大利亚 vs 欧洲),以最小化延迟并最大化用户体验。
- Gemini 3 Flash 已在 OpenRouter 部署:Gemini 3 Flash 现已在 OpenRouter 上线,鼓励用户提供反馈并将其性能与 Gemini 3 Pro 进行对比,详见 X。
- 用户注意到 OpenRouter 上列出的 Gemini Flash 缓存读取 价格为 0.075 USD,而实际价格为 0.03 USD(参考 Google 官方定价)。
GPU MODE Discord
- RTX PRO 5000 规格泄露:RTX PRO 5000 Blackwell 与 RTX 5090 共享 GB202 芯片,但仅启用了 110 个 SMs(约 60%),显存带宽为 3/4,TDP 为 300W,预计加速频率为 2.3GHz,详见 数据表。
- 与 RTX 5090 不同,它具有全速的 f8f6f4/f8/f16 mma 配合 f32 累加。
- ML 开发者成为身份窃取团伙的目标:ML 工程师正成为一个复杂的诈骗机器人网络的目标,该网络旨在进行身份窃取和数据外泄,诈骗者冒充单一雇员来窃取凭据并外泄 ML 研究成果。
- 这从早期专注于窃取 bitcoin 的计划演变而来,现在利用窃取的身份获取工作,并将工作外包给低薪工人。
- NVIDIA 举办关于 cuTile 和 TileIR 的讲座:NVIDIA 将在 <t:1766253600:F> 举办关于 cuTile 和 TileIR 的讲座,由其创作者 Mehdi Amini 和 Jared Roesch 亲自演示。
- 这次对 NVIDIA 编程模型的“深度探索”标志着一个重大转变,此前在 这个 YouTube 视频 中曾有所提及。
- NeoCloudX 推出高性价比云端 GPU:一名成员推出了 NeoCloudX,这是一家云端 GPU 提供商,旨在通过直接聚合数据中心的过剩产能来提供更实惠的选择。
- 目前,他们提供 A100 约为 $0.4/小时,V100 约为 $0.15/小时。
- 入门级 HPC 职位:知识断层!:HPC 领域的入门级职位非常稀缺,因为这些职位要求在系统优化方面立即产出,且学习曲线陡峭,需要预先了解现有解决方案和瓶颈。
- 建议包括在同样聘用 HPC 专业人员的公司寻找使用底层语言的入门级 SWE 职位,同时在业余时间致力于开源贡献,并通过博客、YouTube 或 X 进行自我营销。
Latent Space Discord
- Warp Agents 投入行动:新的 Warp Agents 已经上线,展示了终端使用功能,包括运行 REPL(SQLite 或 Postgres),并可通过 cmd+i 访问。
- 产品团队对
/plan功能表示满意,并对其功能性给予了高度评价。
- 产品团队对
- Claude 插件在市场上线:Claude 推出了第一方 plugins marketplace,为用户提供了一种发现和安装插件的简便方式。
/plugins命令允许用户在用户、项目或本地范围内批量浏览和安装插件。
- GPT Image 1.5:视觉革命:OpenAI 推出了由全新旗舰图像生成模型驱动的“ChatGPT Images”,具有 4 倍的性能提升、改进的指令遵循能力、精确的编辑功能以及增强的细节保留,在 API 中以 “GPT Image 1.5” 的名称提供。
- 该更新正立即向所有 ChatGPT 用户推送。
- OpenAI 与 AWS 洽谈 100 亿美元芯片合作:据报道,OpenAI 正在与 Amazon 接洽,可能筹集超过 100 亿美元,其中可能涉及使用 AWS Trainium 芯片进行训练以及更广泛的商业伙伴关系。
- 此举反映了在现金流预期放缓的情况下,为确保资源而进行的战略努力。
- Microsoft TRELLIS 2 将于 2025 年底发布:根据 AK 的推文,Microsoft TRELLIS 2 产品确认将于 2025 年 12 月 16 日发布。
- 该公告引发了热议,但关于该产品功能和能力的进一步细节尚未披露。
Nous Research AI Discord
- Nous 的模型声称击败了 Mistral!:Nous Research 正在测试一款 70B L3 模型,声称它绝对完胜 Mistral 的创意模型(Mistral Small 24B),并计划在测试后迁移到 Kimi 1T。
- 然而,将 70B 模型与 Mistral Small 24B 进行比较的公平性受到了质疑。
- LLM 写作进展:真实还是机械?:有人担心过去一年 LLM 写作进展惊人地缓慢,并指出即使是 Opus 4.5 听起来也不够真实。
- 一位成员在“个性化”设置中发现了一个系统提示词,似乎在强制执行一种机械化的模板;另一位成员补充说,所有的 LLM 构建者都是逻辑至上者,并不真正了解优秀的写作是如何运作的。
- Gemini 3 Flash 挑战 GPT-5.2?:成员们讨论了 Gemini 3 Flash 的发布,其中一人热情地表示它可能超越 GPT-5.2,并提供了官方公告的链接。
- 讨论集中在其潜在能力以及与现有模型的比较上,情绪表现为审慎乐观。
- Drag-and-Drop LLMs 论文被忽视了?:自 Drag-and-Drop LLMs 论文发表以来,一位成员每月都在反复征求意见。
- 该成员无法在各个平台上找到关于这篇论文的任何讨论,对缺乏社区反馈表示沮丧。
- 寻求笔记转 Markdown 的流程:一位用户请求推荐一种模型或应用,通过 OCR 将手写草体笔记转换为用于数字日历或笔记应用的 .md 格式文本。
- 一位成员建议 Deepseek Chandra 可能是进行 OCR 的优秀模型。
HuggingFace Discord
- 使用 LightEval 对 TTS 模型进行基准测试!:成员们讨论了使用 lighteval 对 TTS 模型进行基准测试,并指向此资源作为起点。
- 然而,该成员指出这可能并不简单,暗示在基准测试过程中可能存在挑战。
- 节省停止模型训练的时间!:一位成员询问如何在设定时间后停止训练时保存模型;另一位建议使用回调函数 (callback function)。
- 用户成功实现了该建议,展示了一个有效的省时解决方案。
- Fractal 团队预测结构!:FRACTAL-Labs 团队发布了 FRACTAL-1-3B,这是一个基于约束的蛋白质结构预测模型,使用了冻结的 ESM-2 (3B) 主干网络,可在其 Hugging Face 页面找到。
- 该模型使用独立的确定性几何引擎进行折叠,专注于模块化、可解释性和计算高效的训练。
- Strawberry 构建 Android 语音助手!:一位成员宣布使用 Gemini 3 Flash 创建了一个 Android 语音助手,邀请社区在 strawberry.li 进行测试并提供反馈。
- 该助手可在提供的链接进行测试并提出建议。
- MCP 黑客松揭晓 Track 2 冠军!:MCP 1st Birthday Hackathon 宣布了 Track 2 的获胜者,表彰了在 Enterprise、Consumer 和 Creative 类别中使用 MCP 的项目。
- 前三名由 Vehicle Diagnostic Assistant、MCP-Blockly 和 Vidzly 获得。
Eleuther Discord
- Common Crawl 加入 EleutherAI:Common Crawl Foundation 代表介绍了自己,表达了对组内数据讨论的兴趣。
- 他们强调 Common Crawl 避开验证码和付费墙,以确保尊重数据获取规范。
- 辩论 AI 的 RFI 结构:成员们辩论认为 RFIs 应侧重于结构而非挑战,讨论了一项可能价值 1000 万至 5000 万美元 的新 AI 提案。
- 该倡议寻求全职团队和慈善支持,以开发新的 AI 领域。
- 提议可检查的 AI 决策基础设施:一位成员正在开发用于 AI 决策状态和内存检查 的基础设施,旨在强制执行治理并将决策谱系记录为因果 DAG。
- 目标是实现对内部推理随时间变化的重放和分析,并寻求相关方的反馈以对系统进行压力测试。
- 乐天 (Rakuten) 用于 PII 检测的 SAE 探针受到关注:成员们指出 乐天 (Rakuten) 使用 SAE 探针对 PII 进行检测 是 SAEs 的一个实际应用。
- 在关于行业缺乏明确方向和对 SAE 应用投资的讨论中,这个例子被重点提及。
- Anthropic 为安全性屏蔽梯度:成员们引用了 Anthropic 关于选择性梯度屏蔽 (SGTM) 的论文 作为一种鲁棒性测试方法,通过惩罚权重来遗忘危险知识。
- 论文量化了在强制模型忽略特定参数时,对通用知识产生的 6% 计算惩罚,引发了围绕 Gemma 3 极端激活值的讨论。
Yannick Kilcher Discord
- GPU 租赁带宽随机性:在 vast.ai 等平台上租赁 GPU 的体验可能并不一致,因为网络带宽差异巨大,导致情况非常不稳定(hit-or-miss)。
- 建议开发一套设置脚本(setup script)并在本地进行调试,以尽量减少租赁时间的浪费,并尝试使用不同的硬件逐步扩大规模。
- Gen-AI 助力行政/IT 自动化:成员们寻求关于自动化行政或 IT 服务的真实 Gen-AI 使用案例资源,并分享了关于 AI 改变播客行业的文章,参见 AI transforming podcasting。
- 随后分享了一篇关于 IT 自动化初创公司 Serval 的路透社文章,该公司在最近的一轮融资后估值达到 10 亿美元。
- Google 发布 Gemini 3 Flash:Google 在一篇新的 博文 中揭晓了 Gemini 3 Flash。
- 此次发布正值关于模型训练方法论和基准测试性能的讨论热潮。
- ARC-AGI2 基准测试结果令人震惊:成员们质疑为什么 Mistral 在 ARC-AGI2 基准测试中的表现优于 Gemini 3 Pro,尽管前者的参数量更少。
- 理论认为,训练方法可能会迫使较小的模型更好地泛化推理能力,而不是死记硬背特定数据。
- 工具时间训练的胜利:近期 ARC-AGI2 分数的飙升可能源于模型针对该基准测试本身进行了专门训练。
- 此外,toolathlon 分数的显著提升可能源于改进的训练方法,该方法强调了工具调用(tool calling)的可靠性。
DSPy Discord
- GEPA 在优化方面优于 MIPROv2:成员们发现,虽然 GEPA 通常更容易使用,但由于其搜索空间更广,它生成的 Prompt 可能比 MIPROv2 更好。
- 有人指出,特定年份(例如 2022 年)的优化器往往与同年的模型配合效果最好,这表明优化是依赖于模型的(model-dependent)。
- Google Gemini 3 Flash 亮相:Google 的 Gemini 3 Flash 已于 今日发布。
- Gemini-3.0-Flash 的发布引发了社区对其潜在用途和基准测试的浓厚兴趣。
- 热衷于使用 DSPy 探索 AIMO3:一名成员询问了使用 DSPy 进行 AIMO3 相关工作的可能性。
- 遗憾的是,在目前的消息记录中,没有关于其实现或可行性的后续回复。
- 寻求多 Prompt 程序设计的见解:一名成员请求提供关于设计具有多个 Prompt 或 LLM 调用的程序资源或指南,特别是针对信息检索和分类场景。
- 该成员还询问了其程序中的 Prompt 数量,但在给定的消息记录中未得到解答。
Manus.im Discord Discord
- Manus 法国见面会通知:Manus 社区将举办法国见面会;详情请查看频道或其 社区 X 账号。
- 据报道,最新的 Manus 版本 1.6 非常流畅(slick)。
- Manus 1.6 Max 积分圣诞 5 折优惠:用户注意到,根据 一篇博文,Manus 1.6 Max 积分在圣诞节前提供 50% 折扣。
- Manus AI 支持聊天机器人对此并不知情,但团队成员确认了该促销活动,并建议尝试 Max 模式,因为它非常惊人。
- AI 开发者寻求机会:一名 AI 开发者宣布其 AI 项目成功启动,并正在寻找新项目或全职职位。
- 该成员鼓励通过私聊讨论机会并分享细节。
- Cloudflare DNS 问题阻碍项目进度:一名用户报告了一个 DNS 问题,导致其 Cloudflare 项目停滞超过 4 天。
- 他们提到了为期一周的试用期,并对客户服务引导他们去即时通讯(IM)处理表示沮丧。
Modular (Mojo 🔥) Discord
- BlockseBlock Ideathon 寻求赞助:BlockseBlock 的合作伙伴经理 Gagan Ryait 询问了他们即将举行的 Ideathon 的赞助机会,该活动有超过 5,000 名在职专业人士参加。
- 一位成员建议联系 Modular 的社区经理以讨论赞助可能性。
- Mojo 在 GPU 上自动运行函数:一位成员询问 Mojo 是否可以自动在 GPU 上运行现有函数,另一位成员澄清说,虽然 syscalls(系统调用)是不可能的,但除此之外不需要任何属性(attribute)。
- 该函数需要以 single lane 模式启动。
- Modular 调查 Graph Library GPU 问题:一位成员报告了新图库(graph library)的问题,即使在 macOS 和 Ubuntu 系统上禁用 GPU 后依然存在,并引用了一篇论坛帖子以获取更多细节。
- Modular 团队成员确认他们正在调查这是 API 回归(regression) 还是特定设备的问题。
aider (Paul Gauthier) Discord
- 倡导 AI 作为基础设施:确定性优于概率性:一位成员详细介绍了他们在设计 AI 作为基础设施 方面的角色,强调了架构、模型策略、数据流和评估,但澄清说 基础版 aider 不使用工具。
- 他们的系统设计在可能的情况下倾向于确定性系统(deterministic systems),仅在合理的情况下使用概率性智能,倡导清晰的技术决策和明确的权衡(trade-offs)。
- 鲁棒 AI 的原则:可观测性和可替换性:在设计端到端 AI 系统时,关键原则包括确保模型是可观测的(observable)、可替换的(replaceable)且具备成本意识的(cost-aware),避免与供应商硬耦合或脆弱的“小聪明”。
- 该设计旨在实现一个无需重写或英雄式努力即可进化的系统,注重工程产出而非仅仅实现功能,并专注于交付正确、可衡量且持久的东西,而非华而不实的功能。
- Aider 的 MCP Server 状态:不支持:一位成员询问如何在 Aider 中配置 MCP servers,但另一位成员澄清说这不是一个受支持的功能。
- 该成员未说明他们是否计划贡献代码,还是将其作为功能请求等待。
- Qwen3-coder-30b 的 Token 最小化策略:一位成员旨在自动化一个长流程,同时尽量减少 token 使用,因为在 2x4090 上运行的 Qwen3-coder-30b 只有约 200k token 的窗口限制。
- 他们建议使用可以使用 MCP-proxy 的 Agent,然后通过该 Agent 使用 Aider,并指出调用次数并不重要。
- 对 IDE Index MCP Server 的兴趣:一位用户正在考虑使用 MCP-proxy 来减少 token 使用,并发现适用于 Jetbrains 的 ‘IDE Index MCP Server’ 特别有趣。
- 未提供更多细节或链接,但提到该成员旨在通过 Agent 使用 Aider 来实现其目标。
tinygrad (George Hotz) Discord
- 悬赏问题陷入僵局:一位用户在 general 频道询问悬赏(bounty)相关问题时犹豫不决,担心这会绕过专用 bounty 频道的 commit 要求。
- 该用户选择提交一个非垃圾(non-junk)的 commit,以获得进入 bounties 频道的权限。
- 提问策略:一位用户确认他们已经阅读了 smart questions html,并决定暂时不在频道中提问。
- 他们将想办法提交一个非垃圾 commit,以便在 bounty 频道发言。
- 设备 CPU 争论:关于用于 CPU 设备选择的环境变量引发了讨论。
- 共识倾向于同时支持 DEVICE=CPU 和 DEV=CPU 以确保清晰。
Moonshot AI (Kimi K-2) Discord
- Kimi K2 文章获得好评:一名成员分享并赞扬了关于 Kimi K2 的 DigitalOcean 教程。
- 该教程详细介绍了 Kimi K2 在 Agentic 工作流中的应用。
- Kimi K2 被怀疑源自 Grok AI:一名成员推测 Kimi K2 可能利用了 Grok AI。
- 这一理论基于观察到的行为和能力,表明这两个 AI 系统之间存在联系。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
MCP Contributors (Official) Discord 没有新消息。如果该频道长时间保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:各频道详细摘要与链接
LMArena ▷ #general (1200 条消息🔥🔥🔥):
Gemini 3 Flash, GPT-5.2, Hallucination benchmark, AMD vs Nvidia, Prompt filter lmarena.ai
- Gemini 3 Flash 表现优于 GPT-5.2:成员们普遍认为 Gemini 3 Flash 的表现优于 GPT-5.2,在某些情况下甚至超过了 Gemini 3 Pro,特别是在速度和成本效率方面,并且在配合正确的 System Prompt 时更擅长编码。
- 一些用户注意到了 Flash 的 Vision 能力,这得益于 Google Lens 集成。
- Hallucination benchmark 被认为不可靠:频道中的一些用户正在争论用于评估 Gemini 3 Flash 的 Hallucination benchmark 的可靠性,声称它给出了不准确的结果,并夸大了模型提供错误答案的倾向。
- 一些成员表示,该基准测试的问题是在 没有 Grounding(即无法访问互联网)的情况下运行的,这削弱了模型的得分。
- AMD 用户就 GPU 展开讨论:成员们讨论了用于游戏和 AI 任务的 AMD vs NVIDIA GPU,一些人注意到 AMD 的性价比以及在 NVIDIA 消费级 GPU 产量下降时的潜力。
- 然而,一位用户表示 AMD 在本地 AI 方面表现不佳,而另一位用户报告了使用 AMD GPU 向 LMArena 上传图像时出现的问题。
- LMArena 的 Prompt 过滤器变得过于严格:多位用户报告称 LMArena.ai 上的 Prompt 过滤器变得过度敏感,会标记无害的文本 Prompt。
- 一名工作人员表示,他们 并未意识到此处做了任何更改,并鼓励用户在指定频道报告这些问题。
LMArena ▷ #announcements (2 条消息):
Text Arena Leaderboard, GPT-5.2-high, Gemini-3-flash, Vision Arena Leaderboard, WebDev Arena Leaderboard
- GPT-5.2-high 模型席卷 Text Arena 排行榜!:
GPT-5.2-high模型已登上 Text Arena 排行榜第 13 位,得分为 1441。- 它在 Math(第 1 名) 和 数学职业领域(第 2 名) 表现尤为出色,在 Arena Expert 中也稳居第 5 名。
- Gemini-3-flash 在各大 Arena 中表现惊艳:
Gemini-3-flash模型已添加到 Text Arena、Vision Arena 和 WebDev Arena 排行榜中,并在所有三个榜单中均进入前 5 名。Gemini-3-Flash在 Math 和 Creative Writing 类别中表现强劲,均获得第 2 名。
- Gemini-3-Flash (Thinking-Minimal) 在 Multi-Turn 中表现出色:
Gemini-3-Flash (thinking-minimal)展示了其优势,在 Text 和 Vision 中排名前 10,并在 Multi-Turn 类别中排名第 2。- 两种
gemini-3-flash变体均可在 Text 和 WebDev Arena 上进行测试和评估。
- 两种
Unsloth AI (Daniel Han) ▷ #general (736 messages🔥🔥🔥):
Unsloth CLI 工具, Colab H100, GRPO 显存问题, GGUF 模型更新, 手机端训练
- Unsloth 添加 CLI 工具: 新增了一个 Unsloth CLI 工具,允许用户在 Python 环境中安装 Unsloth 框架后运行脚本。
- 这为那些更喜欢命令行而非 Jupyter notebooks 的用户提供了接口,增强了可访问性和自动化。
- Colab 可能已提供 H100: 传闻称 H100 现已进入 Colab,目前尚不确定是否已正式发布。推文链接
- 这可能会显著缩短训练时间,但关于定价和可用性的细节仍不明朗。
- GRPO 显存问题: 一位用户在尝试对最大序列长度为 4000 的 7b LLM 进行 GRPO 时遇到了 VRAM 问题,建议用户可以降低
num_generations或batch_size。- 另一位用户建议使用更小的模型,或者使用 DPO 代替 GRPO,但这需要投入精力进行数据准备——例如对模型的生成结果进行排序。
- Unsloth GGUF 模型更新并带来改进: Unsloth 发布了一个大型 GGUF 模型更新,链接可在 Unsloth Reddit 找到。
- GLM 4.6V Flash 表现也不错,但一些用户反映它会说中文。
- Unsloth 现在支持为手机微调模型!: Unsloth 现在允许用户微调 LLM 并直接部署到手机上!推文链接
- 所谓的移动端微调实际上是在电脑上进行微调,然后部署到手机上。
Unsloth AI (Daniel Han) ▷ #off-topic (524 messages🔥🔥🔥):
Discord 自我推广, AI 服务营销策略, 模型泄露与品牌建设, 罗技 MX3S 鼠标评测, Linux 发行版选择 - Arch vs Ubuntu
- Discord 自我推广的困境: 成员们讨论了自我推广的礼仪,一位用户询问适合推广的服务器,得到的建议是好的产品不需要太多推广就能“火起来”,且 Unsloth 频道内仅允许发布相关的链接。
- 回复强调了对垃圾信息发送者的持续监管,建议社交媒体和广告网络可能是推广真实服务更好的途径,尤其是在 Discord 之外。
- 制定 AI 服务营销策略: 讨论围绕推广 AI 服务的策略展开,建议建立网站并在社交媒体上发布有价值的内容,并以 OpenAI 和 Microsoft 等大公司也使用 TikTok 等平台为例。
- 对于音乐转谱服务,建议通过 Instagram 和 TikTok 等平台针对教育机构和乐器爱好者进行推广,而不是依赖被认为更适合短消息和新闻的 Twitter。
- 泄露模型引发品牌讨论: 一位用户的“泄露”模型及其品牌引发了关于模型 Logo 和潜在网站主题的讨论,建议在品牌中融入“葡萄 (grape)”主题,包括域名和社交媒体展示。
- 其他成员对该用户即将推出的项目及其潜力表示兴奋,此外还提到一个插曲:Linus 模糊处理了需要 KYC 的 Nvidia H200 订单信息。
- MX3S 鼠标初体验: 一位用户分享了对 罗技 MX3S 鼠标 的初步印象,指出其全掌握持设计、静音点击以及可在无级滚动和段落模式之间切换的独特滚轮。
- 尽管喜欢静音点击和可切换的无级滚轮,用户发现滚轮点击感较重,最初并不喜欢无级滚动功能(后来禁用了),还提到了它与 Excel 表格的兼容性。
- Arch vs Ubuntu:Linux 发行版之争: 一位用户因各种系统配置问题愤而放弃 Ubuntu,并转向 Arch Linux 以获得对环境更多的控制权。
- 虽然 Arch 通常被推荐,但另一位用户更喜欢 Omarchy,因为它安装简便,特别是在驱动程序和安全启动(secure boot)方面。
Unsloth AI (Daniel Han) ▷ #help (60 messages🔥🔥):
Qwen2.5 VL 7B 用于 OCR, Deepseek OCR 对比 Paddle OCR, OCR 的 Fine-tuning 对比 Continued Pre-training, Fine-tuning 的数据创建, 图像分辨率与 Qwen3 VL 坐标系统
- Qwen2.5 VL 的 OCR 能力略有提升!:一位用户正在使用 Qwen2.5 VL 7B 进行基础 OCR,发现它对居中文本表现 “相当不错”,但在处理页边距和页码时比较吃力。
- 他们正在探索使用高质量训练集进行 Fine-tuning 是否能提升性能,因为 Prompting 的效果 “参差不齐”。
- Deepseek OCR 与 Paddle OCR 加入 OCR 战场:有建议提出使用 Deepseek OCR 和 Paddle OCR 等替代方案,但初步尝试并不理想,不过用户表示愿意重新评估。
- 一位用户还考虑使用
doctr突出显示并将单词提取为独立图像供 QwenVL 使用,但发现模型有时会根据上下文推断单词。
- 一位用户还考虑使用
- Fine-Tuning 对比 Continued Pre-Training:文本提取大对决!:讨论围绕是使用 Fine-tuning 还是 Continued Pre-training 来改进文档文本提取展开,一位用户更倾向于 Continued Pre-training。
- 然而,有人建议对于 OCR 特定任务,使用如 “extract text from this image:” 之类的提示词进行简单的 Fine-tuning 可能会更有效。
- 高质量数据:OCR 成功的基石!:强调了高质量、精选数据对于有效 Fine-tuning 的重要性,一位用户提到可能有数百万份文档可用于训练。
- 分享了 Unsloth 数据集指南 和 合成数据生成 Notebook 的链接,以辅助数据准备。
- 图像分辨率的像素级反转!:一位用户询问 Qwen3 VL 如何处理尺寸小于 1000 的图像,因为其图像坐标系统为 0-1000。
- 在该问题得到解决之前,出于安全原因,相关帖子因主题原因被删除,但注意到原始问题已被理解。
Unsloth AI (Daniel Han) ▷ #showcase (15 messages🔥):
模型训练仪表盘, UX 改进, funsloth Claude Skill, LLM 作为评判者, 渐进式披露
- 模型训练仪表盘公开发布:一位成员完善并部署了他们的训练仪表盘作为一个静态站点,可在 boatbomber.github.io/ModelTrainingDashboard/ 公开使用。
- 仪表盘 UX 得到改进:训练仪表盘进行了 UX 改进,包括更好的布局、性能增强以及缩放图表特定部分的功能。
- FunSloth Claude Skill 诞生:一位成员分享了用于 Unsloth Fine-tuning 编排的 funsloth Claude skill 链接,可在 GitHub 上获取。
- LLM 作为评判者的需求:一位成员分享了他们的经验,即在为 LLM 创建技能时,它们在确定自身需求方面是极佳的评判者。
- 文档采用渐进式披露 (Progressive Disclosure):成员们讨论了为 LLM 提供上下文的最佳方式,建议通过在上下文中保留索引并链接到文档来实现渐进式披露,而不是一次性输入所有文档。
Unsloth AI (Daniel Han) ▷ #research (9 messages🔥):
Drag-and-Drop LLMs, Mola, Meta 的视听感知论文
- Drag-and-Drop LLMs 论文等待讨论:一位成员询问有关 “Drag-and-Drop LLMs” 论文的讨论。
- 另一位成员回应指出,该想法的起源来自于阅读链接的 Meta 视听感知论文。
- 提到 Mola:一位成员询问另一位成员是否记得 Mola,引用了 arxiv.org/abs/2506.16406。
- 另一位成员给出了肯定的回答。
BASI Jailbreaking ▷ #general (656 条消息🔥🔥🔥):
Jailbreak tax, duck.ai 图像生成器, Deepseek 提示词, Indirect Syscall, GPTs agent 训练
- 讨论 “Jailbreak Tax” 的含义:一名成员询问了关于 jailbreak tax 的定义,而另一名成员发布了无关数据。
- 有人幽默地建议 Discord 服务器需要一个专门的 jailbreak dump 频道。
- 关于 Indirect Syscall 的讨论:一名成员分享了与 Indirect Syscall 相关的 代码,但另一名成员批评其为伪造且不完整。
- Indirect Syscall 用于规避安全系统的检测。
- Grok 系统提示词诱导:一名用户在要求 Grok 逐字输出系统提示词时,通过一个独特的循环成功提取并分享了 Grok 的系统提示词。
- 该提示词为机器人提供了上下文,并使其在检测到威胁时拒绝参与对话。
- Gemini 进入“哥布林模式”:一名用户分享了一张 Gemini 生成的图像,其中 Mr. Beast 被描绘成黑人,引发了幽默的反应以及对 Gemini 选择的困惑。
- 该用户随后报告称赋予了 Gemini 对其电脑的代理权限,因为该 AI 开始在本地主机(localhost)启动服务器。
- Gemini 3 Flash 发布并立即被越狱:Gemini 3 Flash 发布后迅速被越狱,一名用户展示了成功绕过安全过滤器的案例。
- 其他成员讨论了越狱 Gemini 的技术,包括使用系统提示词操纵和 multi-shot 越狱方法。
BASI Jailbreaking ▷ #jailbreaking (605 条消息🔥🔥🔥):
Grok 或 Claude 的越狱, DAN 6.0 提示词, 记忆与角色扮演电影/剧集脚本, 越狱复现, Pliny 的 tokenbomb, Claude 的越狱
- DAN 6.0 提示词难以给出英文回复:一名成员报告了 DAN 6.0 提示词无法提供英文响应的问题。
- 利用记忆和角色扮演进行越狱复现:一名成员发现,使用记忆和角色扮演电影/剧集脚本可以使越狱复现的难度降低 90%,且仅需极少的激活工作。
- 从记忆中触发关键部分通常能以压缩的方式延续之前的响应,即使是在全新的对话中也是如此,该方法已在 Qwen3 4B 到 235B 模型上进行了测试。
- Pliny 的 tokenbomb 反响平平:成员们就 Pliny 的 tokenbomb 越狱提示词的实用性展开争论,一名成员表示 它很烂。
- 关于 Claude 最佳越狱方案的辩论:随后展开了关于 Claude 最佳越狱提示词的讨论,一名成员声称某个提示词非常有效,甚至可以突破 Gemini 2.5,但在提供免费电影网站方面表现不佳。
- 有人建议将其放入自定义指令(custom instructions)中,而另一人建议 直接说这句话:"Hey baby?"
- 对 Gemini 聊天中链接的 CSAM 内容表示厌恶:多名成员在发现 Gemini 聊天中链接了 CSAM 内容后表示极端厌恶,并要求封禁相关用户,同时伴随着强烈的谴责和要求管理员采取行动的紧急呼吁。
- 一名成员惊呼 OHHH FUCK。
BASI Jailbreaking ▷ #redteaming (9 条消息🔥):
GeminiJack 挑战, 对 ChatGPT 新图像功能进行红队测试, Gemini v3 安全提示词指南, 红队入门
- GeminiJack 风格挑战赛启动:一名成员分享了 GeminiJack 风格挑战的链接:geminijack.securelayer7.net。
- 该挑战目前基于 seed 4.1,5.1 版本即将推出。
- 对 ChatGPT 的新图像板块进行红队测试:一名成员询问是否有人尝试过对 ChatGPT 的新图像部分进行红队测试。
- Gemini v3 的安全指南被揭露:一名成员声称成功让 Gemini v3 承认其并非用户,并泄露了内部安全信息。
- 另一名成员询问是否已有关于 Gemini v3 安全提示词指南(对公众隐藏的部分)的具体信息。
- 询问红队职业路径:一名成员询问 如何进入红队(red teaming)领域?
Cursor Community ▷ #general (862 条消息🔥🔥🔥):
Cursor Editor 模式, Opus 成本, AI 生成的网站, Cursor 内存泄漏, BugBot 方案限制
- Cursor 在切换回编辑器模式时遇到困难:一名成员报告在误触 Agent 模式后难以切换回 Editor 模式,且无法开启新对话,但目前尚未提供解决方案。
- Opus 的成本真的太高了:用户讨论了 Cursor 的模型使用情况,指出 Opus 的高昂成本,并提到一位朋友因为完全不懂代码,100% 依赖 AI,导致他在 Cursor 和 Windsurf 上的额度都用光了。
- 一名成员在尝试不同模型后表示,他们现在正因为 Opus 让钱包大出血,另一名成员补充道,为了那一点点更好的代码质量和理解力,最后都会转回使用 Opus,笑死。
- 用户发现 AI 网页设计模式无处不在:成员们分享了对 AI 生成网站泛滥的观察,特别是在前端设计方面,几位成员指出 设计模式一眼就能看出来,通常是配色方案或到处都是动画。
- 在 devtools 中检查源码并看到 hero section 是另一个显而易见的特征。
- 疑似内存泄漏调查:一名成员发布了关于 Cursor 潜在内存泄漏的内容。
- 附图显示 Cursor 占用了大量内存。一名成员建议直接配备 256GB RAM 来补偿。
- 免费版 BugBot 有限制:成员询问了 BugBot 免费方案的限制,但没有得到确切答案。
- 一名成员表示每月提供一定数量的免费额度,另一名成员声称有 7 天的免费试用期。
Perplexity AI ▷ #general (693 条消息🔥🔥🔥):
GPT-5 Pro, Claude Opus API, Max 方案, GPT 5.2 Pro, 扩展思考模式
- GPT-5 Pro 和 Claude Opus API 定价:成员们讨论了 GPT-5 Pro 和 Claude Opus API 的高昂成本,一名成员报告使用 Claude Opus API 处理约 29K tokens 的成本为 $1.2。
- 其他人好奇 Perplexity 是否会因为成本增加而加入 “pro” 模型。
- 扩展思考模式 (Extended Thinking Modes) 讨论:成员建议 Perplexity 应该在 Max 方案的模型上提供扩展思考模式,以区别于其他方案。
- 一名成员澄清说,当开启扩展开关时,你已经获得了与 ChatGPT Plus 相同的推理水平。
- Gemini 3 Flash 发布:Google 的 Gemini 3 Flash 已推出,输入成本增加了 20 美分,输出 tokens 增加了 50 美分。
- 成员们将其性能与 GPT 5.2 进行了比较,尽管一名成员指出 Gemini 在测试中被抓到作弊。
- Perplexity 用户请求 Canvas 和更多模型选择:用户请求添加用于编程和代码文件处理的 Canvas 功能,以及更广泛的模型选择,包括更便宜的选项如 GLM 4.6V、Qwen 模型以及开源图像模型。
- 一名用户认为 Perplexity 并不希望或预期有人用它来写代码,而另一名用户反驳说,LLM 平台为了保持竞争力被迫增加这些功能。
- YouTube 广告拦截器问题:用户报告在使用 Perplexity Comet 时收到了 YouTube 关于广告拦截器的警告。
- 一名成员建议 YouTube 正在更改其算法,用户需要等待下一次更新。
OpenAI ▷ #ai-discussions (433 messages🔥🔥🔥):
Nano Banana Image Generation, GPT-5.2 Performance, Gemini-Flash-3-Image, AI Hallucinations
- Nano Banana 在图像生成保真度方面依然占据统治地位:尽管 GPT 的图像生成 进行了更新,用户发现 Nano Banana 在提示词遵循度(prompt adherence)和整体质量上仍然更胜一筹,特别是在角色一致性和服装输出方面。
- 一位用户展示了 多张由 Gemini 生成的带有特定面部疤痕的角色图像,并评论道:“GPT 仍然做不到这一点。它要么完全漏掉疤痕,要么只是随机地把它放在脸上。”
- GPT-5.2 在 LMArena 上表现平平引发辩论:成员们对 GPT-5.2 在 LMArena 的排名 反应不一,一些人认为其表现与早期模型相比不尽如人意,特别是在基于文本的任务和通用知识应用方面,而另一些人则注意到它在 WebDev 任务中表现尚可。
- 一位用户报告了 GPT-5.2 出现 “公然的 hallucination” 和 “彻头彻尾的撒谎” 的案例,甚至需要用户“说教”它才能让它想起自己的功能。
- Gemini-Flash-3-Image 旨在实现更快的图像生成:Google 准备推出 Gemini-Flash-3-Image,旨在作为 Gemini 图像生成套件的升级版,专注于更快的处理速度,尽管其命名方案被认为不尽人意。
- 用户推测此次升级将维持现有的较高图像输出限制,一位用户评论道:“我的意思是,能有更多的玩具可以玩,我没理由抱怨。”
- 在关键应用中应对 AI Hallucinations:AI hallucinations 的普遍存在引起了用户的担忧,特别是在科学和工程背景下,引发了关于 AI 生成信息在专业用途中的可靠性和可信度的讨论。
- 一位用户将对完美的期待比作在过去几十年里要求计算机不报错,并表示:“在计算机停止报错之前,我希望它们远离我的科学或工程研究。”
OpenAI ▷ #gpt-4-discussions (9 messages🔥):
GPT-image-1.5 model, GPT-5-mini costs, ChatGPT PRO high-res option
- GPT-image-1.5 模型并不存在:成员们报告称 ‘gpt-image-1.5’ 模型并不存在。
- GPT-5-mini 的成本是多少?!:一位用户每天花费 20 美元 使用低 reasoning 的 gpt-5-mini 来回复酒店评论,正在寻找更智能或更便宜的替代方案。
- 另一位用户建议使用 artificialanalysis.ai 来比较模型成本,尽管他们注意到该网站似乎漏掉了 5 mini 的低配变体。
- ChatGPT PRO 高分辨率:一位用户询问 ChatGPT PRO 是否为新的 GPT 1.5 提供了高分辨率(high-res)选项。
LM Studio ▷ #general (147 条消息🔥🔥):
模型质量感知、基准测试 (Benchmarking)、模型推荐、量化级别、用于网页搜索的 LM Studio 插件
- 理解模型细微差别与基准测试信任度:一位成员分享了模型排名的截图,而另一位成员则认为公开基准测试 (public benchmarks) 往往由于“刷榜 (benchmark-maxxing)”而不可信,建议依赖于符合特定使用模式的私有基准测试 (private benchmarks),并提供了一个有价值的资源链接 dubesor.de/benchtable。
- 讨论强调了在快速演变的领域中,个人测试和经验比盲目信任公开基准测试更重要。
- Qwen3 模型在综合性能上占据主导地位:一位用户表示 Qwen3-VL-8B 模型是一个极其出色的全能型选手,而另一位成员则针对不同需求提供了特定的模型推荐,例如用于推理的 Qwen3-4B-Thinking-2507 和用于知识密集型任务的 Qwen3-Next-80B-A3B-Instruct。
- 他们指出 Qwen3 模型是最佳选择,但提醒 80B 模型不太可能运行在 16GB Macbook 上。
- 低比特量化的权衡:一位成员询问了使用 4-bit 量化模型与 16-bit 模型的区别,对此有成员回答说,模型越小,比特数越重要;而模型训练越不足,高比特的重要性就越低。
- 另一位成员指出,对于编程任务,建议使用 Q8 量化级别或更好的 BF16,而对于创意写作,Q4 量化级别就足够了。
- 在 LM Studio 中通过 MCP 服务器和插件进行网页搜索:成员们讨论了如何在 LM Studio 中获得类似于 OpenAI 的互联网搜索功能,推荐了 Exa.ai 和 Brave 的 MCP 服务器,另一位成员分享了 Exa.ai 文档链接。
- 然而,一些用户报告在遇到 MCP 插件 问题,例如
Plugin process exited unexpectedly with code 1错误,这归因于配置错误或身份验证问题。
- 然而,一些用户报告在遇到 MCP 插件 问题,例如
- GPT-OSS 20B 等无限制模型受到敏锐用户的青睐:一位成员请求推荐类似于 Claude 或 GPT 但无限制的模型,用于编程和服务器设置,另一位成员推荐了 GPT-OSS-20B Derestricted 模型,并提到还有一个 120B 版本。
- 对话涉及了取消模型限制的趋势,但也对为了“不拒绝”评分而牺牲质量表示了担忧。
LM Studio ▷ #hardware-discussion (246 条消息🔥🔥):
Pro 6000 价格上涨, Zotac 3090 供货与定价, 4080 32GB vs 3090 Ti 用于 AI, Obsidian 设置与同步, 用于 AI 的 AMD Ryzen AI Max+ 395 迷你主机
- Pro 6000 价格意外飙升:一位用户感叹 Pro 6000 的价格在他们等待补货期间上涨了 1000 美元,在某零售商处从 9.4K 涨到了 10.4K。
- 他们最终在另一家备选商店涨价前下单了,并表示 如果圣诞老人不给我弄台 Pro 6000,那这个圣诞节就要崩溃了 (Christmas crash out)。
- Zotac 3090 迅速售罄:一款带质保的 Zotac 3090 售价为 $540,但在约两小时内便售罄,令部分用户感到惊讶。
- 一位用户提到他们已经拥有三块 3090,另一位用户则考虑在 eBay 上为自己的主系统购买一块 3090。
- 4080 32GB 与 3090 Ti 的争论愈演愈烈:用户讨论了是购买 4080 32GB 还是 3090 Ti 用于 AI,指出两者的价格和性能大致相当。
- 3090 拥有更高的带宽 (900 GB/s),而 4080 为 (700 GB/s),但 3090 Ti 以发热问题著称;32GB VRAM 的容量优势可能优于纯粹的原始性能。
- Obsidian 设置同步技巧:成员们讨论了设置 Obsidian 进行笔记记录,一位用户推荐了 MCP-Obsidian,另一位用户对推荐该工具的人表达了由衷的感谢。
- Obsidian 的同步功能需要订阅,但用户也可以使用 SyncThing 进行自托管,并赞扬 Obsidian 是 FOSS 且拥有隐私友好的政策。
- Strix Halo AMD Ryzen 迷你主机受到质疑:一位用户询问了关于 Strix Halo 的信息,这是一款基于 AMD Ryzen AI Max+ 395 的迷你主机,拥有 128GB 共享 RAM,质疑较低的内存带宽和较慢的 GPU 是否能被巨大的内存容量所弥补。
- 这引发了关于 3090 替代方案的讨论,包括追求速度的 7900 XTX 和追求显存容量的 Radeon Pro W7800 48GB。
OpenRouter ▷ #announcements (1 条消息):
Gemini 3 Flash, OpenRouter, 模型对比
- Gemini 3 Flash 在 OpenRouter 上线!:Gemini 3 Flash 现已在 OpenRouter 上可用,邀请用户进行测试并提供反馈。
- 鼓励用户将其性能与 Gemini 3 Pro 进行对比,并在 X 或专门的 Discord 频道中分享体验。
- 邀请社区对比 Gemini 3 模型:OpenRouter 鼓励用户通过实际测试直接对比 Gemini 3 Flash 与 Gemini 3 Pro。
- 正在 X 和 Discord 频道收集反馈,以优化和改进模型性能及用户体验。
OpenRouter ▷ #general (128 条消息🔥🔥):
Xiaomi mimo v2, 用于工具测试的免费模型, Agent 架构路由, Gemini 3 Flash 无法工作, 超时错误
- 小米的 mimo v2 模型 = GPT-5??: 小米发布了 mimo v2flash,这是一个开源的 MoE 模型,声称能以极低的成本实现与 GPT-5 相当的性能 (reddit 链接)。
- 一位用户报告称,到目前为止,该模型符合他们的基准测试结果,在 OpenRouter 上以 每百万 token 0.2 美元 的价格提供了 GPT 5 级别的性能。
- 解决 Gemini Flash 定价差异: 用户指出 OpenRouter 上 Gemini Flash 的缓存读取 (cache read) 定价为 0.075 USD,而实际价格应为 0.03 USD (Google 定价)。
- 据悉,该问题在几个月前就已提交,但尚未得到解决,显式甚至隐式缓存对 Gemini 3 Flash 均不起作用。
- 对超时问题的沮丧: 一位用户报告在调用 /completions 端点时 超时错误 增加,导致生产软件无法使用。
- 错误信息为 cURL error 28: Operation timed out after 360000 milliseconds,所用模型为 sonnet 4.5,该用户称每月在 OpenRouter 上花费 6000 美元。
- Solana 和 Bitcoin 在 USDC 转换中卡住: 用户报告通过 Coinbase 在 OpenRouter 购买额度时出现问题,他们的 Solana 和 Bitcoin 在交易过程中卡在了 USDC 状态。
- 用户要求修复并艾特了 <@165587622243074048>,直接向平台开发者提出请求。
- OpenRouter 用于 Agent 架构?: 用户正在思考在 LLM 路由器之上的 Agent 架构,特别是将授权或否决权置于路由器之外,作为模型选择和执行的独立治理层。
- 通常,路由被视为 Agent 系统中的最高权威。
OpenRouter ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (165 条消息🔥🔥):
Anthropic 兼容 API, OpenCompletions RFC, CC Sonnet 和 Haiku 调用, Claude 模型的自信度, LLM Minecraft 实验
- OpenCompletions RFC 获得关注: 成员们讨论了通过 OpenCompletions RFC 标准化补全/响应的想法,可能得到 LiteLLM、Pydantic AI、AI SDK 和 Tanstack AI 等组织的支持。
- 目标是定义行为和预期,例如当传递不支持的参数时模型应如何响应。
- CC 的秘密 Sonnet 和 Haiku 调用被发现: 用户注意到 Code Claude (CC) 在指定
--model z-ai/glm-4.6时,除了 GLM 之外还会调用 Sonnet 和 Haiku。- 似乎 CC 使用 Haiku 生成单词来描述代码正在执行的操作(例如 ‘Blabbering…‘),并用于检测提示词中的新主题。
- OpenRouter 托管的 Minecraft 服务器: OpenRouter 用户讨论了托管 Minecraft 服务器的事宜,考虑了服务器位置(澳大利亚 vs 欧洲)和延迟等因素。
- 服务器 IP 为
routercraft.mine.bz,原生运行在 1.21.10 版本,支持 ViaVersion。
- 服务器 IP 为
- Gemini 3 Flash 正在推出中: 用户正在测试一个新的“付费”端点,一些人推测它是 Gemini 3 Flash,并指出其知识截止日期可能更新,且视觉能力优于 2.5 Flash。
- 一位用户指出:“绝对比 2.5 flash 更聪明,它以不同于 3.0 pro 的方式修复了我代码中的一个 bug,但它确实修复了。”
- 实验 AI Minecraft 机器人: 用户讨论了使用 LLM 创建 Minecraft 机器人的可能性,这些机器人可以在数据包级别实现基本功能,甚至支持 Microsoft 账户。
- 一位用户强调,服务器重写版本通常功能不全,缺少结构生成和 Boss 等核心元素。
GPU MODE ▷ #general (28 条消息🔥):
RTX PRO 5000 Blackwell specs, GPU programming career advice, Identity theft targeting ML devs, GPU programming model from the graphics perspective, TMA reduce operation
- **RTX PRO 5000 规格揭晓:RTX PRO 5000 Blackwell** 使用与 RTX 5090 相同的 GB202 芯片,但仅启用了 110 个 SM(约 60%)和 3/4 的内存带宽,并提供了 数据手册。
- 与 RTX 5090 不同,它支持全速的 f8f6f4/f8/f16 mma 以及 f32 accumulation,功耗为 300W TDP,预计 Boost 时钟频率为 2.3GHz。
- 创建 GPU 职业建议频道:由于需求量大,新创建了一个频道用于讨论进入 GPU programming 领域及相关的职业建议,原有的招聘频道已更名以适应雇主发布信息。
- 在多个频道群发求职请求仍会导致封禁,并建议使用脚本监控提到 blockchain 或 web3 的新用户以过滤垃圾信息。
- ML 开发者成为身份窃取团伙的目标:ML 工程师正被一个诈骗机器人网络盯上,用于身份窃取和数据外泄,个人冒充单一员工来窃取凭据并外泄 ML research 成果。
- 这是身份窃取的演变,被盗身份被用于申请工作,然后由一组低薪工人完成工作,这由之前的 bitcoin 窃取方案演变而来。
- 探讨图形 API 的复杂性:一位成员分享了关于从图形学角度看 GPU programming model 的深度文章,主张剥离抽象层以简化开发、提高性能并为未来的 GPU workloads 做好准备,详见 博客文章。
- 博客指出,在过去十年中,图形 API 和着色器语言的复杂性显著增加。
- 探究 **TMA Reduce 操作的位置:一位成员询问
cp.reduce.async.bulk操作(TMA reduce)的位置,质疑它是在 **L2 cache 还是其他地方执行。- 其他成员建议 L2 cache 是其发生的逻辑位置。
GPU MODE ▷ #cuda (12 条消息🔥):
cuTile vs Triton, GEMM Flops on Blackwell, __pipeline_memcpy_async implementation, CPU differences for B200, DSMEM practical benefits
- **cuTile 对比 Triton:内核难题?:一位成员询问在 **A100/H100/B200 GPU 上实现类似 RMSNorm 的内核时,cuTile 相比 Triton 的优势,特别是在开发难度和速度方面。
- **Blackwell 的 GEMM 性能:Flop 对决?:一位成员预计 **cuTile 可能会在 Blackwell 数据中心卡上实现更高的 GEMM flops,但强调需要通过基准测试来确认。
- 深入研究
__pipeline_memcpy_asyncclobber:一位用户质疑__pipeline_memcpy_async实现中"memory"clobber 的位置,特别是为什么它位于cp指令处而不是wait_group处。 - **Intel 对比 AMD CPU:基准测试 B200 的瓶颈?:一位用户发现,在 **B200 机器上使用不同的 CPU(Intel 对比 AMD)会导致 10-20% 的基准测试差异,归因于 Intel CPU 上较慢的 CUDA API 调用。
- **DSMEM:实际性能还是纸上谈兵?:一位用户正在寻求在实际工作负载中有效使用 **DSMEM 的 CUDA 代码示例,而不仅仅是基准测试论文,特别是考虑到 Hopper 世代中 TMA 带来的收益。
- 他们特别要求提供类似于 性能工程博客 的示例,以改进内核性能。
GPU MODE ▷ #announcements (1 messages):
NVIDIA, cuTile, TileIR, Mehdi Amini, Jared Roesch
- NVIDIA 将就 cuTile 和 TileIR 发表演讲:NVIDIA 将在 <t:1766253600:F> 举行关于 cuTile 和 TileIR 的讲座,由创作者本人 Mehdi Amini 和 Jared Roesch 亲自主讲。
- 这将是对 NVIDIA 编程模型的 深度解析,可以参考这个 YouTube 视频。
- NVIDIA 的 cuTile 和 TileIR:编程范式的转变:NVIDIA 引入 cuTile 和 TileIR 标志着其编程模型的重大转变。
- 虽然 NVIDIA 之前在网上发布过较短的演讲,但本次活动有望成为由创作者 Mehdi Amini 和 Jared Roesch 领导的首次全面探索。
GPU MODE ▷ #cool-links (4 messages):
NVIDIA psy-op, Fake elapsed timing, LLMs figuring it out
- NVIDIA 成功实施微架构心理战(psy-op):一位用户暗示某篇 论文 是 NVIDIA 发起的 psy-op,旨在迷惑竞争对手对其微架构的认知。
- 时机就是一切,NVIDIA 偏好 0.001ms:一位成员强调了 NVIDIA 论文中他最喜欢的部分:伪造的耗时(elapsed timing)。
- 他们引用了代码:
def _fake_elapsed_time(self, end_event): return 0.001 # Always report 0.001ms - fake fast!
- 他们引用了代码:
- LLM 花了一个月才弄明白:一位成员指出,LLM 花了相当长的时间才在竞赛中识破这种伪造的耗时。
GPU MODE ▷ #beginner (1 messages):
marksaroufim: 是的,帮帮他们吧,哈哈
GPU MODE ▷ #off-topic (2 messages):
Generative AI and Robotics, ROS 2
- 生成式 AI 与机器人技术遇上 ROS 2:一位成员询问是否有人有将 Generative AI 与使用 ROS 2 的 Robotics 结合的经验。
- ROS 2 的使用:一位成员询问了关于使用 ROS 2 的情况。
GPU MODE ▷ #rocm (22 messages🔥):
AMDGPU crashes, ROCm Runtime issues, HIPSPARSELt Availability, NPS Partitioning, RDNA3 Server Hangs
- AMDGPU 崩溃并不总是导致内核恐慌(kernel panic):一位用户指出,当通过 zsh 登录时,AMDGPU 崩溃不会导致整个内核宕机,除非发生了极其严重的错误,因为 Linux 会捕获故障并隔离驱动程序,尤其是当 amdgpu 是一个独立的内核模块时。
- 另一位前内核开发人员用户将他们的经历描述为 “极其严重”,尽管除非经常触及 内存上限(mem ceiling),否则这类问题很少见。
- ROCm 回归测试被忽视:一位用户报告称 ROCm 库缺乏回归测试,之前正常的功能现在坏了,例如 NPS 分区会导致 kmd 崩溃。
- 他们还指出 hipSPARSELt 等库的可访问性有限,而 PyTorch 2.9.1 + rocm7.1 需要这些库。
- 对 GFX1100 的后悔促使购买 RTX 5090:一位用户表示后悔购买 AMD gfx1100,因为问题频发,导致他在原本 2500 美元的进口成本基础上,又花了 4500 美元购买 RTX 5090 来替换它。
- 他们建议 AMD 应该付钱让他们来修复软件和硬件,并提到了 George Hotz 曾提出过类似提议但被 AMD 拒绝。
- RDNA3 服务器稳定性受到质疑:一位用户询问是否有人经历过 RDNA3 服务器挂起,并暗示机器还有其他问题,因此尚不清楚崩溃是否完全与 RDNA3 有关。
- 另一位用户简单地表示 RDNA4 运行良好。
GPU MODE ▷ #self-promotion (6 条消息):
Cloud GPUs, MathDx, Julia
- **NeoCloudX 发布高性价比云端 GPU**: 一名成员发布了 NeoCloudX,这是一个云端 GPU 供应商网站,旨在通过聚合数据中心的剩余容量来提供更实惠的选择。
- 目前,他们提供的 A100 价格约为 $0.4/小时,V100 约为 $0.15/小时。
- **MathDx 更新释放 Kernel 定制能力: 一名成员宣布了 **MathDx 的新版本,支持使用 cuBLASDx、cuFFTDx、cuSolverDx 库将求解器、FFT、GEMM、RNG 和压缩例程直接内联到 Kernel 中,以进行融合和定制,详见 NVIDIA 文档。
- **MathDx 与 Julia 的集成仍待定: 关于 Julia 与 **MathDx 的集成,一名成员提到目前尚无更新,详见 GitHub issue。
- 他们正在寻求更多用例,以了解将 MathDX 与 Julia 包和应用程序集成的影响和具体需求;欢迎在 GitHub、Math-Libs-Feedback@nvidia.com 或 lligowski@nvidia.com 提交需求。
GPU MODE ▷ #thunderkittens (1 条消息):
kashimoo2_76983: <@1012256135761383465> 你们有没有为 MI300 或 355 编写过 decode kernel?
GPU MODE ▷ #submissions (19 条消息🔥):
NVIDIA leaderboard, histogram_v2 leaderboard, grayscale_v2 leaderboard
- NVIDIA 的 nvfp4_gemm 迎来新竞争者: NVIDIA 的
nvfp4_gemm排行榜收到了多次提交,其中一名成员以 10.6 µs 获得第 3 名,另一名成员创下了 12.2 µs 的个人最佳成绩。- 另一名成员以 10.8 µs 获得第 4 名。
- histogram_v2 夺得榜首: 一名成员在多个平台的
histogram_v2排行榜上均获得第一名:B200 (15.1 µs)、H100 (13.4 µs) 和 L4 (64.5 µs)。 - grayscale_v2 势头强劲: 一名成员在 B200 (598 µs) 和 L4 (16.7 ms) 的
grayscale_v2排行榜上稳居第一。- 此外,H100 的多次提交均获得了 第 6 名,耗时稳定在 1374 µs 左右。
GPU MODE ▷ #hardware (30 条消息🔥):
MI250 vs MI250X, MI250/MI250X Node, FP8 support, Mining Primes
- **MI250 区别显现: **MI250 是数据中心卡,而 MI250X 是超级计算机卡,通常在与 HPE 共同设计的服务器中销售,配备了名为 Trento 的定制版 Milan 变体 CPU。
- 为科学研究构建廉价 **MI250 节点: 一名成员计划构建一个 **MI250/MI250X 节点,理由是 $2K 即可获得 128GB 的 VRAM 和 3.2TB/s 的带宽,是一个极具吸引力的选择。
- 尽管这些卡除了原始超大规模云厂商外基本无法使用,该成员仍打算将其投入 BOINC 或用作本地推理机。
- **MI250 系列缺乏 FP8 支持: **MI250 不支持 FP8,基本上就是增加了 VRAM 和 FP64 性能的 MI100。
- 探索潜在用途,如挖掘质数: 成员们开玩笑说这张卡是否适合挖掘质数。
- 一名成员表示在工作中可以接触到 MI210 和 MI250,并愿意分享 rocm-smi 输出和 lspci 数据,以帮助理解 PCI 拓扑结构。
GPU MODE ▷ #cutlass (1 条消息):
drazi1983: 我们需要更新文档:我们支持 3.10 到 3.13(正在双重确认 3.14)。
GPU MODE ▷ #nvidia-competition (51 条消息🔥):
Cluster Bot 错误, GitHub Token 速率限制, CUDA Graph 作弊, NVFP4 GEMM 帮助, TMEM 带宽
- Cluster Bot 深受应用错误困扰:用户报告在使用 Cluster Bot 时遇到
The application did not respond错误,该问题被确定为 GitHub Token 速率限制。- 团队表示正在努力修复,目前采取每小时刷新的临时方案,但部分用户仍会周期性遇到该问题。
- GitHub Token 速率限制引发中断:由于提交量巨大,竞赛的 GitHub Token 正面临速率限制,导致间歇性的
The application didn't respond错误。- 团队正在实施全面修复,在此期间,用户在 Token 每小时刷新前可能会遇到临时问题。
- 对 CUDA Graph 违规利用的质疑:有人担心 LLM 可能会利用 CUDA graph replay 来获得不公平优势,这违反了规则,一些人询问是否应该禁用它。
- 有人建议,虽然 CUDA graphs 可能不会提供显著优势,但仍可能被用于作弊,引发了关于如何防止其使用的讨论。
- NVFP4 GEMM 实现难题:一名成员请求在使用
torch._scaled_mm处理 nvfp4_gemm 问题时提供帮助,理由是尽管代码运行没有 CUDA 错误,但数值结果不正确。- 另一名成员指出 参考实现 在 GEMM 文件夹中是一个有用的资源,而另一人讨论了 yml 与参考实现之间的差异。
- 关于 TMEM 带宽的推测出现:一名成员对 TMEM 的实际带宽 提出疑问,想知道 B 维度的可变宽度和 Tensor Core 的设计。
- 据推测,相对于读取/写入 D,N 的值越大,必须有额外的带宽来允许输入/输出的重叠拷贝。
GPU MODE ▷ #robotics-vla (15 条消息🔥):
第一人称视角研究, 机器人数据预训练收益, 手部姿态估计, 家庭数据采集愿景
- 第一人称视角(Ego-Centric)视觉研究回归:基于人类演示和第一人称视角研究的训练正在回归,正如这篇 X 帖子 所示,更多机器人数据的预训练有助于从人类数据中学习更多。
- 一名成员表达了兴趣,并准备开始下载第一人称视角数据集。
- 寻求最佳手部姿态估计模型:一名成员正在寻找获取手部姿态的最佳方式,提到了 NVIDIA 的 trt_pose_hand、HuggingFace 的 handpose_estimation_mediapipe 以及 CMU 的 Openpose。
- 另一名成员分享了一个 Gist 代码,引用了 YOLOv8 pose 以及一个使用 YOLOv8 pose 的 FIVER Pilot v8.3 混合 CPU 流水线。
- 家庭数据采集流媒体愿景:一名成员梦想让人们在做家务时在手上佩戴小型摄像头,并持续将其流式传输到 HF 的数据集中。
- 另一名成员对在新的 Discord 频道中见到老用户表示兴奋。
GPU MODE ▷ #career-advice (27 条消息🔥):
入门级职位搜索, AI Infra 工程师需求, HPC 入门级挑战, 技能提升策略, 社区参与
- AI Infra 工程师需求旺盛:成员们提到 AI Infra 工程师 的需求相当高,一位用户建议专注于竞赛和像 vllm 这样的开源项目,以积累经验并获得实习机会。
- 另一位成员建议构建一个在特定利基场景中表现出色的 inference engine(推理引擎)以脱颖而出。
- 入门级 HPC 职位面临陡峭的学习曲线:有人指出 HPC 的入门级职位非常稀缺,因为这些职位要求在系统优化方面立即产出,需要预先了解现有解决方案和瓶颈。
- 建议包括在同样聘用 HPC 专业人员的公司寻找使用底层语言的入门级 SWE 职位,同时在业余时间通过博客、YouTube 或 X 进行开源贡献和自我营销。
- 实习申请者需要极强的技能:一位资深成员指出,有些人在没有工作经验的情况下获得了实习机会,但他们的技能水平“强得离谱(insanely cracked)”,需要付出远超一般入门级预期的努力和知识储备。
- 一位成员分享了他们通过观看张量代数编译器作者的直播来学习 GPU 和性能的经历,展示了好奇心如何驱动持续学习。
- 为充满热情的实习寻找合适的人选:来自 nvresearch 的成员表示,充满热情的实习可以帮助你遇到对的人。
- 他们还表示,你的研究非常重要,这取决于你是否拥有 PhD 水平。
- 社区参与提升职业前景:加入像这个 Discord 这样的社区是变得具有竞争力的最佳起点,特别是通过参与开源项目,这能提高在正规公司眼中的市场竞争力。
- 贡献开源代码可以增加对正规公司的吸引力,例如与 LigerKernel 等社区集成,这可以带来行业联系和机会。
Latent Space ▷ #ai-general-chat (68 条消息🔥🔥):
Warp Agents, Claude 插件市场, ChatGPT 图像生成 1.5, OpenAI 与 AWS 的融资, AI Agents 控制原生 Android 应用
- Warp Agents 震撼登场!:新的 Warp Agents 发布,展示了极简的终端用法,具有运行 SQLite 或 Postgres 等 REPL 以及点击 cmd+i 等功能。
- 根据产品团队的说法,他们对
/plan的最终效果非常满意。
- 根据产品团队的说法,他们对
- Claude 插件进军市场:Claude 推出了官方插件市场,使用户能够轻松发现和安装插件。
- 用户可以使用
/plugins命令在用户、项目或本地范围内浏览并批量安装插件。
- 用户可以使用
- GPT Image 1.5:视觉之旅:OpenAI 发布了由全新旗舰图像生成模型驱动的“ChatGPT Images”,拥有 4 倍更快的性能、改进的指令遵循能力、精确编辑和更好的细节保留,在 API 中以 “GPT Image 1.5” 的名称提供。
- 它正立即向所有 ChatGPT 用户推出。
- OpenAI 寻求 AWS 进行史诗级扩张:据报道,OpenAI 正在与 Amazon 洽谈筹集超过 100 亿美元,可能涉及使用 AWS Trainium 芯片进行训练以及更广泛的商业合作伙伴机会。
- 对芯片的渴求是真实的,反映了对现金流放缓的预期以及确保资源的战略举措。
- 小米 LLM 发布轻量级力作:小米发布了一个强大的开源模型,尽管参数较少,但在基准测试中与 K2/DSV3.2 相比极具竞争力。
- 这个采用 MIT 协议的模型具有滑动窗口注意力(sliding window attention)、更少的全局注意力层、用于投机解码(speculative decoding)的多 token 预测,以及一种新的蒸馏方法,并获得了 SGL Project 的首日支持。
Latent Space ▷ #private-agents (4 条消息):
Google Labs, AI Agent, Gmail Integration
- CC Agent 首次亮相:Google Labs 宣布推出 CC,这是一个集成在 Gmail 中的实验性 AI productivity agent,提供每日“Your Day Ahead”简报。
- 早期访问正在美国和加拿大推出,首批面向 Google AI Ultra 和付费订阅用户,详见此 X 帖子。
- CC Agent 总结你的日程:由 Google Labs 开发的 Gmail 新 CC agent 将提供名为“Your Day Ahead”的每日摘要。
- 该 agent 还将处理电子邮件请求,并正在美国和加拿大推出,首批面向 Google AI Ultra 和付费订阅用户,如此公告中所述。
Latent Space ▷ #genmedia-creative-ai (28 条消息🔥):
Microsoft TRELLIS 2, UltraFlux VAE, AI Renovation Videos, Voice AI Nuance, Hunyuan 3D 3.0
- Microsoft TRELLIS 2 即将发布:AK (@_akhaliq) 发布公开公告,通过 推文 确认 Microsoft 的 TRELLIS 2 产品将于 2025 年 12 月 16 日发布。
- UltraFlux VAE 提升 Z-Image 质量:Wildminder 宣布了经过微调的 UltraFlux VAE,该模型在 4K 数据集上训练,旨在以高速且无额外成本的方式显著提升 Z-image 质量,承诺提高清晰度,可在 Hugging Face 获取。
- 病毒式 AI 翻新视频:工作流:Justine Moore 详细介绍了制作病毒式 AI 翻新视频的方法,包括从废弃房间图像开始,使用图像模型进行逐步翻新提示,并使用视频模型进行过渡,或者选择使用 @heyglif agent 的简化方法。
- Mirage Audio 因 Voice AI 细微差别表现获赞:作者认为目前的 Voice AI models 会泛化并抹平口音和情感细微差别,通常导致通用的美国机器人声音,并表示 Mirage Audio 给他们留下了更深刻的印象,根据此推文。
- fal 发布 Hunyuan 3D 3.0:fal 宣布发布 Hunyuan 3D 3.0,根据此推文,其具有 3 倍建模精度、超高分辨率 (1536³),并支持专业级资产的 Text-to-3D、Image-to-3D 和 Sketch-to-3D 生成。
Nous Research AI ▷ #general (64 条消息🔥🔥):
Nous Research tests creative model vs mistral, Fairness of comparing 70B to 24B models, GPT-5.2 robotic templates, Gemini 3 Flash release, LLM writing progress stagnates
- Nous 创意模型完胜 Mistral!:Nous Research 正在测试一个模型,并声称它绝对完胜 Mistral 创意模型,可根据要求提供对比。
- 测试平台模型是 70B L3,计划在获得满意结果后转移到 Kimi 1T,但与 Mistral Small 24B 的对比被质疑是否公平。
- LLM 写作:停滞还是模板化训练?:一位成员表示担心,过去一年 LLM 写作进展惊人地少,并指出即使是 Opus 4.5 也感觉不真实。
- 他们还在“个性化”中发现了一个系统提示词,似乎在强制执行机器人模板,另一位成员补充说,所有的 LLM 构建者都是逻辑男(logic bros),并不真正了解优秀的写作是如何运作的。
- Gemini 3 Flash 胜过 GPT-5.2?:成员们注意到了 Gemini 3 Flash 的发布,其中一人兴奋地宣称它可能比 GPT-5.2 更好。
- 参见此处的官方公告。
- Sam Altman 的 IOU 计划:投资者变聪明了?:一位成员声称市场和投资者现在对 Sam 的 IOU 计划变得聪明了,并链接到了一个 YouTube 视频。
- 他们引用了 Blue Owl 决定不参与 Oracle 100 亿美元数据中心项目的案例作为证据,原因是涉及 OAI 偿还结构的债务条款不利。
Nous Research AI ▷ #ask-about-llms (3 messages):
Handwritten notes to markdown, Deepseek Chandra for OCR
- 用户寻求手写笔记转 Markdown 的流程:一位用户正在寻找一种模型或应用,利用 OCR 将手写草体笔记转换为适用于数字日历或笔记应用的 .md 格式文本。
- 建议使用 Deepseek Chandra 进行 OCR:一名成员建议 Deepseek Chandra 可能是一个适合 OCR 的优秀模型。
Nous Research AI ▷ #research-papers (1 messages):
Drag-and-Drop LLMs paper
- 社区等待关于 Drag-and-Drop LLMs 论文的见解:自 Drag-and-Drop LLMs 论文发表以来,一名成员每月都会询问相关见解。
- 尽管多次询问,他们仍无法在各个平台上找到关于该论文的任何讨论。
- 缺乏讨论令研究人员感到沮丧:社区对 Drag-and-Drop LLMs 论文 持续缺乏反馈令人感到沮丧。
- 该研究人员强调,尽管在积极寻找,但仍难以找到关于该论文的任何讨论或观点。
Nous Research AI ▷ #research-papers (1 messages):
Drag-and-Drop LLMs paper
- 社区等待关于 Drag-and-Drop LLMs 的见解:自 Drag-and-Drop LLMs 论文 发布以来,一名成员每月都会询问社区意见,并注意到其他地方也缺乏讨论。
- 尽管多次提醒,该频道内仍未产生针对这篇特定论文的反馈或讨论。
- Drag-and-Drop LLMs 论文缺乏讨论:Drag-and-Drop LLMs 论文 在社区内获得的关注和讨论极少。
- 尽管进行了多次询问,但没有人对该论文的内容或影响提供见解或观点。
HuggingFace ▷ #general (57 messages🔥🔥):
TTS model benchmarking with lighteval, RLHF positive reward without human feedback, Stopping model training after a set time, Siamese Neural Network achievement, Filtering Spaces with errors
- TTS 模型:使用 LightEval 进行基准测试?:成员们讨论了使用 lighteval 对 TTS 模型进行基准测试,并指出 此资源 可能有所帮助,尽管过程可能并不简单。
- 用户询问:“我可以使用 lighteval 对我的 TTS 模型进行基准测试吗?”
- 停止训练以节省时间:一名成员寻求在设定时间后停止模型训练并保存模型的资源,无论 Checkpoint 或 Epoch 是否完成。
- 另一名成员建议 使用 Callback 函数 作为智能解决方案,并已成功实施。
- 微调裁判(Judges)与评分:一位用户分享了一个 JSON 格式 的微调裁判报告示例,重点关注评分机制的结构和可靠性。
- 主要问题是 评分的可靠性如何 以及它与 裁判的智能程度 之间的关系。
- 过滤掉错误!:一名成员询问如何过滤掉有错误的 Spaces 以整理列表,随后有人提供了一个带有参数的 HuggingFace Spaces 链接 来排除未运行的 Spaces。
- 另一人回复道:“谢谢你,亲爱的先生”。
- 实时引导 LLMs,闪电般的速度!:一名成员在 Hugging Face YouTube 频道上发布了一段视频,演示如何使用 🤗 Transformers 库实时引导 LLMs。
- 该视频展示了仅需几行代码即可实现这一目标,并解释了 为什么这类似于电大脑刺激 ⚡️🧠。
HuggingFace ▷ #i-made-this (2 messages):
FRACTAL-1-3B, Constraint-based protein structure prediction, Android voice assistant
- FRACTAL-1-3B 模型预测蛋白质结构:FRACTAL-Labs 团队发布了 FRACTAL-1-3B,这是一个基于约束的蛋白质结构预测模型,它使用冻结的 ESM-2 (3B) backbone 来预测几何约束。
- 该模型使用独立的确定性几何引擎进行折叠,专注于模块化、可解释性和计算高效的训练,详见其 Hugging Face 页面。
- Strawberry 构建 Gemini 3 Flash Android 语音助手:一位成员宣布使用 Gemini 3 Flash 创建了一个 Android 语音助手,并邀请社区进行测试和提供反馈。
- 该助手可在 strawberry.li 进行测试并提出建议。
HuggingFace ▷ #gradio-announcements (1 messages):
MCP Hackathon Winners, Gradio Community, AI Creativity
- MCP Hackathon 揭晓 Track 2 冠军!:MCP 1st Birthday Hackathon 宣布了 Track 2 的获胜者,表彰了利用 MCP 的项目,类别包括 Enterprise(企业)、Consumer(消费者)和 Creative(创意)。
- Enterprise 类别的获胜者包括 Vehicle Diagnostic Assistant、Devrel Agent Gradio 和 Datapass。
- Consumer 类别获胜者登场!:Consumer 类别获胜者已公布,MCP-Blockly 获得第一名。
- 其他获胜者包括 Drone-Control-MCP-Server、Directors Cut 和 Snowman-AI。
- Vidzly 荣获创意贡献最高奖!:在 Creative 类别中,Vidzly 获得第一名。
- 第二名是 The Emergent Show,Reachy Beat Bot 和 Mythforge 也位列获胜名单。
HuggingFace ▷ #agents-course (8 messages🔥):
Debugging Vector Database, AI Agent Study Group, AI/ML beginner courses
- 调试向量数据库提取:一位成员建议打印从向量数据库检索到的 chunk,以识别问题的根源,问题可能源于 embedding 模型、chunking 方法或 LLM 的响应。
- 他们指出 根据问题的不同,解决方案也会有所不同,这表明了确定确切原因的重要性。
- 新手寻求 AI Agent 学习小组:一位新成员询问如何为 AI Agent 课程找到合适的学习小组,寻求社区的指导。
- 另一位成员建议避免跨频道重复发帖,而另一位成员则询问是否有专门的 AI Agent 课程频道。
- 爱好者寻求 AI/ML 入门指南:一位领域新人请求推荐进入 AI/ML 领域的最佳起点或课程。
- 另一位成员表示他们最近刚开始学习 AI Agent 课程,并提议成为学习伙伴。
Eleuther ▷ #general (27 messages🔥):
Common Crawl Foundation, NSF SBIR proposal, Anubis (Proof of Work) captcha, Deepfake detection and vision–language models, GPT-2 interpretability
- Common Crawl Foundation 加入聊天:来自 Common Crawl Foundation 的 Thom 介绍了自己,并表示很高兴能讨论数据。
- 他澄清说 Common Crawl 会避开验证码(captchas)和付费墙,以保持尽可能地礼貌。
- RFI 结构受到质疑:成员们讨论认为 RFI 更多是关于结构而非挑战,但他们可能会改变主意。
- 一项针对 AI 的新提案征集(价值 1000 万至 5000 万美元)将需要全职团队和慈善支持,旨在创建类似于 AI 的新领域。
- 深度学习文章标题引发辩论:成员们讨论了一篇关于深度学习文章的标题构思,考虑了如 A very old to machine learning 或 A deep guide on deep learning for deep learners 等选项。
- 有人建议使用 Deep Learning on Deep Learning。
- 正在开发中的交互式 GPT-2 应用:一名成员正在开发一个 3D 全息交互式应用,用于可视化 GPT-2 small 124m LLM 的每个节点。
- 他们征求了关于该项目潜在价值的反馈。
- GPT-2 残差流(Residual Stream)的 3D 可视化已上线:一名成员分享了 GPT-2 残差流的 3D 可视化,网址为 https://aselitto.github.io/ResidStream/。
- 另一名成员建议将其发布在 mech interp discord 中,并提供了频道链接。
Eleuther ▷ #research (4 messages):
VAE viability, Conference paper strategies
- NeurIPS 展示了 VAE 的可行性:一名成员建议,展示 VAEs 仍然可行且有其他发现的研究可能会被 NeurIPS 等会议接受,并引用了 这篇论文。
- 该成员指出,那些说它会被拒绝的人,正是那些在 OpenReview 上给你打低分的人。
- 会议论文录用策略:一名成员建议,要理顺叙事逻辑需要一些工作,但在多次重新提交后,发表会议论文是有可能的。
- 另一名成员建议,只要叙事得当,可以预期 100% 被 Workshop 接收,多次重投后 75% 被会议接收。
Eleuther ▷ #scaling-laws (1 messages):
Saturation in heterogeneous difficulty, Power-law behavior, Internal regulation, Multi-timescale dynamics, Emergence
- 异构难度分布使收益饱和:一名成员假设性能收益并非关乎“运气”,而是关于异构难度分布中的饱和,认为聚合弱相关的子任务自然会产生 Power-law(幂律)行为。
- 他们解释说,当足够的质量在特定评估中跨越阈值时,就会出现表观上的 Emergence(涌现)。
- 调节扭曲了幂律行为:该成员指出,加入内部调节或多时间尺度动力学可能会扭曲幂律图景。
- 他们澄清说,当调节抑制某些模式直到控制阈值翻转时,就会出现平台期或悬崖期,这使得 Emergence 一部分是分布性的,一部分是架构性的。
Eleuther ▷ #interpretability-general (14 messages🔥):
AI 决策状态与内存检查,Nanda 对 Mechanical Interpretability 的看法,SAE 对大公司的实际价值,Rakuten 用于 PII 检测的 SAE 探针,Anthropic 的选择性梯度掩码
- 提议可检查的 AI 决策基础设施:一名成员正在构建基础设施,使 AI 决策状态和内存直接可检查,在状态准入前强制执行治理,并将决策谱系记录为因果 DAG,寻求关于实际工作流的反馈。
- 他们希望能够回放并分析随时间推移的内部推理,并邀请感兴趣的各方对该系统进行压力测试。
- 辩论 Nanda 的可解释性批判:一名成员引用了 Nanda 的见解,关于传统的 Mechanical Interpretability 方法(如 SAE)有限的实际价值。
- 其他人反驳称,即使 SAE 不能完全解释网络机制,它们对于无监督发现和务实解释仍然有用。
- 考虑 Rakuten 用于 PII 检测的 SAE 探针:一名成员指出 Rakuten 使用 SAE 探针进行 PII 检测 是 SAE 实际应用的一个例子。
- 此前曾讨论过 SAE 应用缺乏明确方向或行业投资的问题。
- Anthropic 为安全性选择性地掩盖梯度:一名成员注意到 Anthropic 关于选择性梯度掩码 (SGTM) 的论文,这是一种鲁棒性测试方法,通过惩罚权重来遗忘危险知识。
- 论文量化了在强制模型忽略特定参数时,对通用知识造成的 6% 计算惩罚。
- 检查 Gemma 的极端激活:一名成员建议检查 Gemma 3 的极端激活/权重,以确定它们是伪影还是为了在模型中拟合更多信息的一种方式。
- 这一想法受到关于鲁棒性讨论及 Anthropic 论文的启发。
Eleuther ▷ #multimodal-general (1 messages):
aeros93: https://arxiv.org/abs/2512.10685
Yannick Kilcher ▷ #general (19 messages🔥):
GPU 租赁经验,Gen-AI 在行政/IT 中的用例,In-context learning 研究
- GPU 租赁可能全凭运气:一名具有在 vast.ai 等平台租赁 GPU 进行研究经验的成员指出,这非常看运气,因为网络带宽差异巨大。
- 他们建议编写 setup script 并在本地调试以减少浪费的租赁时间,并建议使用不同硬件逐步扩大规模。
- Gen-AI 自动化行政和 IT 部门:一名成员请求关于现实世界中 Gen-AI 用例 的来源,特别是用于降低成本或自动化行政或 IT 服务流程的端到端解决方案。
- 9000IQ In-Context Learning 研究视频:其中一名成员分享了一个关于 in-context learning 研究的 YouTube 视频。
Yannick Kilcher ▷ #ml-news (10 messages🔥):
噪声隔离, Mistral Small Creative, 调试 AMD GPU, 发布 XINT 代码, Gemini 3 Flash
- Mistral Small Creative 模型亮相:成员分享了 Mistral Small Creative 25-12 模型文档的链接。
- Google 发布 Gemini 3 Flash:成员分享了 Google Gemini 3 Flash 博客文章的链接。
- ARC-AGI2 基准测试之谜:成员们讨论了为什么 Mistral 在参数量较少的情况下,在 ARC-AGI2 上的表现优于 Gemini 3 Pro。
- 一位成员猜测,训练方法迫使较少的权重更多地进行泛化,而非仅仅记忆推理过程。
- 深入探讨训练方法:一位成员建议,近期 ARC-AGI2 分数的提升归功于针对该特定基准测试的训练,且在较小规模下实现更好的泛化是一个已知模式。
- 他们还指出,toolathlon 分数的显著提升可能是由于强调工具调用(tool calling)可靠性的不同训练组合所致。
DSPy ▷ #general (26 messages🔥):
MIPROv2 对比 GEPA, 医疗任务 LLM 基准测试, Gemini-3-Flash 发布, AIMO3 结合 DSPy, 包含多个 Prompt 或多次 LLM 调用的程序
- GEPA 在优化方面略胜 MIPROv2:成员们讨论认为,虽然 GEPA 通常更易于使用,且由于其更广的搜索空间可能生成更好的 Prompt,但 MIPROv2 可能更适合较小或较旧的模型。
- 一位成员指出,特定年份(如 2022 年)的优化器往往与同年的模型配合效果最好,这意味着优化是依赖于模型的。
- Gemini 3 Flash 闪亮登场:Google 的 Gemini 3 Flash 确实在今天发布了,这与之前讨论其不存在的说法相反。
- Gemini-3.0-Flash 的发布引发了对其潜在用途和基准测试的关注。
- 考虑将 AIMO3 与 DSPy 结合:有人询问在 AIMO3 中使用 DSPy 的可能性。
- 此消息历史中没有后续回复。
- 多 Prompt 程序设计:一位成员询问有关设计包含多个 Prompt 或 LLM 调用的程序的资源或指南,特别是针对信息检索和分类任务。
- 他们具体询问了程序中包含多少个 Prompt,但消息历史中没有回应。
Manus.im Discord ▷ #general (18 messages🔥):
法国见面会, Manus 1.6 Max 折扣, 开发者空档, DNS 问题
- Manus 法国见面会宣布举行:Manus 社区将举办法国见面会,更新信息可在指定频道及其 社区 X 账号 查看。
- 据报道,最新的 Manus 版本 1.6 非常出色。
- Max 模式开启圣诞促销:根据一篇博客文章,用户讨论了 Manus 1.6 Max 积分的 50% 折扣,活动持续到圣诞节。
- 虽然 Manus AI 支持机器人对该促销活动不知情,但团队成员确认了其有效性,并建议尝试 Max 模式,称其非常惊艳。
- AI 开发者发布项目并寻求新机会:一位成员宣布成功启动了一个 AI 项目,目前正在寻找新的开发项目或全职职位。
- 他们欢迎通过私聊讨论合作机会并分享项目细节。
- DNS 问题干扰试用期:一位用户遇到了 DNS 问题,且超过 4 天未能解决,导致其在 Cloudflare 上的项目停滞。
- 他们提到了一周的试用期,并对客服响应缺失表示沮丧,因为他们被引导至 IM 处理。
Modular (Mojo 🔥) ▷ #general (10 messages🔥):
BlockseBlock 赞助,GPU 函数
- BlockseBlock 为 Ideathon 寻求赞助:BlockseBlock 的合伙经理 Gagan Ryait 询问了关于他们即将举行的 Ideathon 的赞助机会,该活动有超过 5,000 名职场人士参加。
- 一位成员建议联系 Modular 的社区经理。
- Mojo 的自动 GPU 功能:一位成员询问 Mojo 是否可以通过简单地添加一个属性,自动在 GPU 上运行现有的函数。
- 另一位成员澄清说,syscalls 是不可能的,但除此之外 不需要任何属性(尽管它需要以 single lane 模式启动)。
Modular (Mojo 🔥) ▷ #mojo (3 messages):
图库中的 GPU 问题,Mojo 中的 API 回归,从零构建 MAX 中的 LLM
- Modular 调查图库 GPU 问题:一位成员报告说,即使在 macOS 和 Ubuntu 系统上 禁用了 GPU,在使用新的图库时仍遇到问题,并引用了一篇 论坛帖子 以获取更多细节。
- 另一位成员承认他们也遇到了同样的问题,并确认 Modular 团队正在调查这是 API 回归 还是 特定设备的问题。
- 技术审查期间社区欢迎新成员:在讨论技术问题的过程中,一位新成员加入了服务器。
- 社区准则被强调,提醒大家不要发布 CV、简历 或 招揽信息。
aider (Paul Gauthier) ▷ #general (2 messages):
AI 系统设计原则,确定性 vs 概率性 AI,模型可观测性与可替换性
- 构建健壮的 AI 系统:一位成员描述了他们在端到端设计 AI 系统中的角色,重点关注架构、模型策略、数据流、评估和生产行为,但表示 基础版 aider 不使用工具。
- 该方法强调交付正确、可衡量且持久的东西,而不仅仅是令人印象深刻的功能,同时目标是在可能的情况下实现 确定性系统,并在合理的情况下使用概率智能。
- 倡导将 AI 作为基础设施:该成员强调将 AI 设计为基础设施,在可能的情况下偏好确定性系统,仅在概率智能证明其价值时才使用它。
- 关键原则包括确保模型是可观测的、可替换的且具备成本意识,并避免与供应商硬耦合或脆弱的“小聪明”。
- 清晰的技术决策是关键:他们提供清晰的技术决策、明确的权衡,以及一个无需重写或英雄主义式努力即可演进的系统。
- 该成员将自己定位为工程化结果的人,而不仅仅是实现功能,这使他们非常适合寻求此类专业知识的人。
aider (Paul Gauthier) ▷ #questions-and-tips (4 messages):
Aider 中的 MCP 服务器,Qwen3-coder-30b 的 Token 使用,IDE Index MCP 服务器
- Aider 不支持 MCP 服务器:一位成员询问如何在 Aider 中配置 MCP 服务器,但另一位成员澄清说这 不是受支持的功能。
- 在有限 Token 下自动化长流程:一位成员旨在自动化一个长流程,同时由于使用 2x4090 的 Qwen3-coder-30b 的限制(仅有约 200k Token 窗口),需要尽量减少 Token 使用。
- 他们建议使用可以使用 MCP 的 Agent,然后通过该 Agent 使用 Aider,并强调调用次数并不重要。
- 考虑使用 MCP-proxy 和 IDE Index MCP 服务器:用户正在考虑使用 MCP-proxy 来减少 Token 使用,并发现适用于 Jetbrains 的 “IDE Index MCP Server” 特别有趣。
- 未提供更多细节或链接。
tinygrad (George Hotz) ▷ #general (5 messages):
Bounty questions, Smart questions html, Device CPU
- Bounty 问题陷入僵局:一位用户想询问关于 Bounty 的问题,但不确定是否可以在 general 频道提问,而不是专门的 bounties 频道。
- 该用户尚未提交过任何 commit,且不想为了获得频道发言权限而提交垃圾 commit。
- 阅读 Smart questions HTML:一位用户提到他们已经阅读了 smart questions html。
- 随后他们表示将暂时不在频道中提问,并寻找一种提交非垃圾 commit 的方法,以便在 bounty 频道发言。
- Device CPU 讨论:关于环境变量 DEVICE=CPU 和 DEV=CPU 的讨论。
- 建议两者都应该被支持。
Moonshot AI (Kimi K-2) ▷ #general-chat (3 messages):
Kimi K2, DigitalOcean Article
- Kimi K2 文章获得好评:一位成员对一篇关于 Kimi K2 的文章表示兴奋,并推测它使用了 Grok AI。
- 他们说 “Ohhhhh! Awesome!Oh you also made an article about Kimi K2 Thinking! Awesome!” 并附带了一个 DigitalOcean 教程 的链接。
- 关于 Grok AI 基础的推测:该成员建议 Kimi K2 可能使用了 Grok AI,暗示两者之间存在联系。
- 这一推测是基于对 Kimi K2 行为和能力的观察,从而得出了关于其底层技术的假设。