AI News
“Meta Superintelligence Labs 以约 40 亿美元收购 Manus AI;此时距离该产品发布仅 9 个月,其年度经常性收入(ARR)已达 1 亿美元。”
Manus 在 2025 年实现了飞速增长:从 Benchmark 筹集了 5 亿美元资金,并在被 Meta 以约 40 亿美元估值收购前,年度经常性收入(ARR)达到了 1 亿美元。vLLM 团队推出了包含新资源的专门社区网站,与此同时,vLLM 和 sglang 的基准测试指出 AMD MI300X FP8 存在性能问题。Weaviate 发布了多项运营功能,包括对象生存时间(Object TTL)、Java v6 客户端正式版(GA)以及多模态文档嵌入。针对 API 碎片化问题,Teknium 表达了担忧并提倡使用统一的 SDK 封装。在权重开放(open-weight)模型方面,GLM-4.7 作为可靠的代码模型获得了认可,并在 Baseten 上实现了更快的吞吐量;而 MiniMax-M2.1 作为领先的开放式智能体编程模型脱颖而出,登顶 WebDev 排行榜。
这是 Agent Lab 之夏。
2025/12/29-12/30 AI 新闻快报。我们为您查阅了 12 个 Reddit 子板块、544 个 Twitter 账号和 24 个 Discord 服务端(包含 208 个频道和 3555 条消息)。预计为您节省阅读时间(按 200wpm 计算):302 分钟。我们的新网站现已上线,提供完整的元数据搜索,并以极具美感的 vibe-coded 风格呈现往期所有内容。请访问 https://news.smol.ai/ 查看完整新闻详情,并在 @smol_ai 向我们反馈!
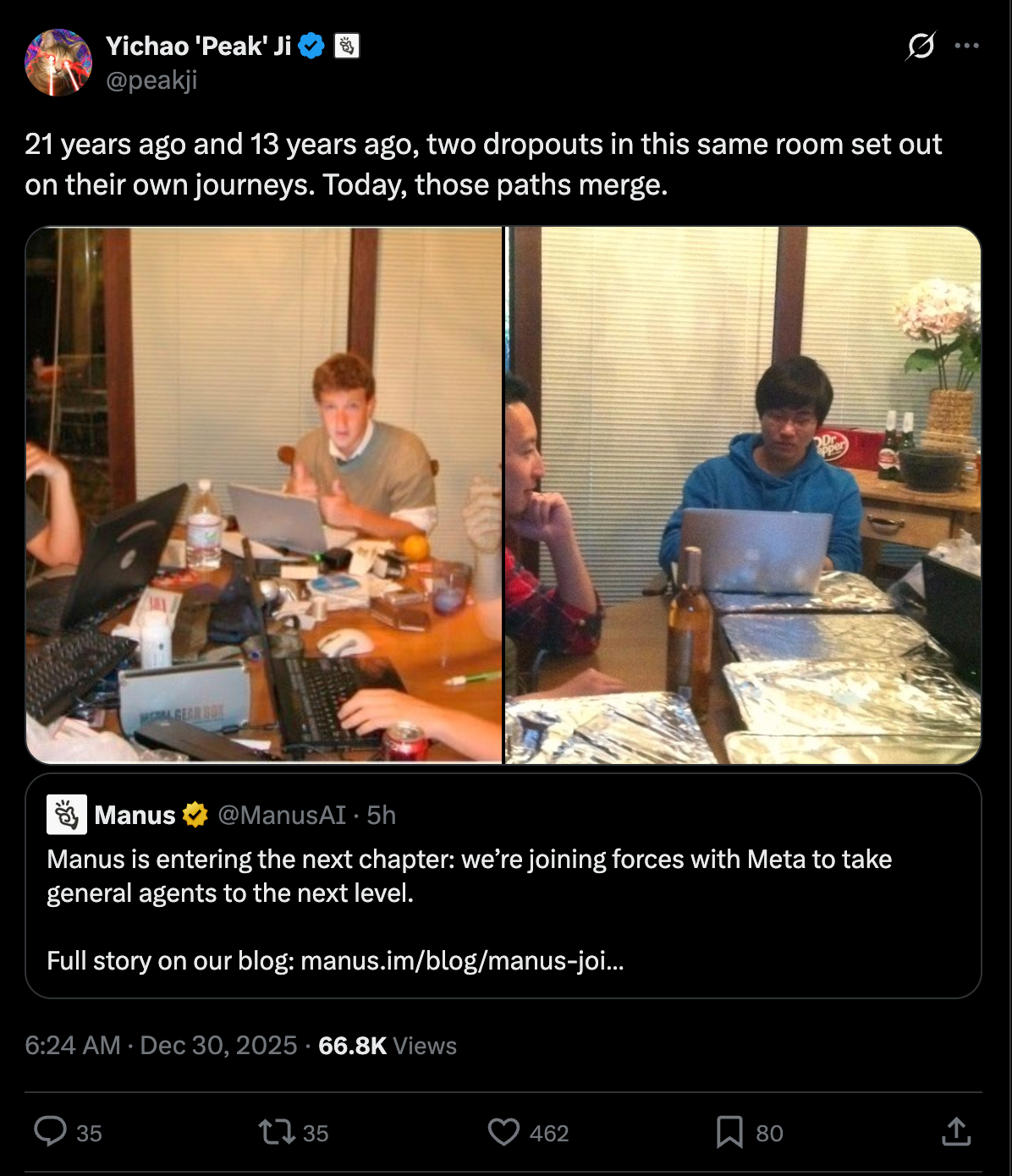
Manus 今年 3 月非常高调地发布,在 4 月以 5 亿美元估值从 Benchmark 获得融资并在 12 月 17 日冲刺到 1 亿美元 ARR 后,Meta 找上门了。在包括圣诞假期在内的 10 天里,Alex Wang(以及推测中的应用负责人 Nat Friedman)敲定了一笔估值约 40 亿美元的收购(诚然,在私募市场中,B2B 领域的同类成长型初创公司估值通常为营收的 40-50 倍。然而,Manus 曾是 AI B2C 类别领导者中最便宜的)。该团队今天理所当然地在庆祝他们与 Team Zuck 的联姻:
AI Twitter 回顾
推理框架、服务基础设施与性能坑点 (vLLM, sglang, Weaviate)
- vLLM 现在有了正式的“门户网站”:vLLM 团队推出了官方社区网站 vllm.ai,旨在明确将社区物流和资源与 GitHub 仓库分开。值得注意的特点:交互式安装选择器(CPU/GPU 变体)、活动日历以及集中的文档/范例(recipes)中心(推文)。他们还承认了文档方面的缺失,并引导用户使用站内的“搜索 (AI)”功能和 Office Hours 播放列表,同时他们正在完善更适合初学者的文档(推文)。
- AMD MI300X FP8 并非(目前还不是)“免费的提速”:多个数据点显示,在 vLLM 和 sglang 上的 MI300X 上运行 MiniMax-M2.1 时,bf16 的性能优于 FP8:
- Weaviate 发布了几个“具有实际运维意义”的特性:新版本包括 Object TTL(会话管理/保留)、Java v6 客户端 GA、Flat Index RQ 量化 GA(针对多租户的 1-bit RQ 压缩)、zstd 备份以及多模态文档嵌入(嵌入文档页面图像;无需外部服务即可进行文本查询)(推文)。
- API 碎片化的痛苦正在加剧:Teknium 指出“所有供应商之间的 API 标准存在差异”,并呼吁为供应商 SDK 提供一个统一的包装器(wrapper)——这反映了支持多模型产品的成本不断上升(推文, 1)。
权重开放模型生态系统:GLM-4.7、MiniMax-M2.1、FLUX.2 Turbo 以及一款韩国的 32B VLM
- GLM‑4.7 成为顶级开源权重编程默认模型(实战中):
- MiniMax‑M2.1 作为“Agentic 编程”开源模型持续攀升:
- fal 开源了 FLUX.2 [dev] Turbo: 这是一个经过蒸馏的、“亚秒级生成”的图像模型变体,使用了自定义的 DMD2 风格蒸馏,声称在 Artificial Analysis Arena 的开源图像模型中 ELO 排名第一 (tweet)。后续推文指出了基准测试/排行榜的相关背景 (tweet)。社区演示迅速在 Hugging Face Spaces 上涌现 (tweet)。
- 来自韩国的“强力新开源 32B VLM 模型”: Elie Bakouch 注意到该模型在英语 + 韩语基准测试中得分很高,并强调了其相对于之前 14B 版本的架构/训练变化:舍弃了 muP 和 sandwich norm,并更改了初始化缩放(提到 0.006 init,让人联想到 DeepSeek v1),目前正在等待技术报告 (tweet)。
- 上下文保留(Context retention)基准测试不断演进: Dillon Uzar 将字节跳动的 Seed 1.6 / Seed 1.6 Flash 添加到了 Context Arena MRCR 排行榜中,将其检索衰减曲线与 OpenAI 推理模型(o3/o4-mini)及经济型模型(GPT‑4.1 Mini / Claude 3.5 Haiku)进行了对比,并提供了 128k 上下文下的详细 AUC/逐点结果 (tweet)。
生产环境中的编程 Agent:工作流模式、面向 Agent 的文档以及“测试框架(Harnesses)”
- Spotify 的大规模代码后台 Agent(务实经验):Phil Schmid 总结了 Spotify 如何利用后台 Agent 处理“数千次代码迁移”:
- 文档形态正在改变,以同时服务于人类和 Agent:多篇文章趋向于一种“双重受众文档”模式:保持文档对开发者可读,同时具备足够的结构化以便代码 Agent 可靠地获取上下文(遵循 AGENTS.md / CLAUDE.md 约定)。LlamaIndex 重点介绍了捆绑了 Agent 支持文件并将“文档拉入上下文”的模板和指南(tweets, 1, 2)。
- Agent 工作流:CLI 优先、验证优先、队列化:一份关于使用 Codex / Claude Code 构建极具实践价值的现场笔记强调:
- 默认 CLI 优先(更易于 Agent 验证);
- 大量使用队列任务;
- 将文档视为“上下文原语”(通过 AGENTS.md 强制执行);
- 极简的分支/检查点管理(通常直接提交到 main);
- 配置细节如 gpt‑5.2‑codex “高推理”、工具输出限制、压缩等(tweet)。
- “Harness” 的品牌重塑是真实的:Zach Tratar 指出,“AI wrapper(AI 外壳)” → “harness(支架/束具)”的称呼已从贬义转为褒义,反映出 工具链 + 脚手架 + 评估循环(eval loops) 现在对产品性能的影响力与基础模型不相上下(tweet)。
- Claude Code:逆向工程,架构探奇:pk_iv 描述了对 “Claude Chrome” 的逆向工程,以使其能够与远程浏览器配合工作,并概述了 Anthropic 如何教会 Claude 进行浏览(推文串起始)(tweet)。Jaredz 还发表了题为“Claude Code 如何工作”的演讲,将这一阶段性进步归功于更好的模型 + 简单循环 + bash 工具(tweet)。
新研究亮点:内存/知识、递归推理、测试时训练(test-time training)和 Agent 加速
- Transformers 可能存储“全局结构”,而不只是关联:dair.ai 总结了 Google 的研究,认为当图的边存储在权重中时,Transformer 会学习隐式多跳推理,在对抗性路径星形图(50k 节点,10 跳路径)上实现了 100% 的准确率。启示:几何/全局关系编码使知识编辑/遗忘假设变得复杂 (tweet)。
- 循环计算在推理方面优于静态深度 (URM):Omar Sanseviero 的总结声称,Universal Transformers 在 ARC-AGI 上的增益主要源于循环归纳偏置 + 强非线性,而非复杂的门控。报告结果:URM 在 ARC-AGI 1 上达到 53.8% pass@1,在 ARC-AGI 2 上达到 16%,外加消融实验(ConvSwiGLU + 循环中的截断 BPTT 是关键)(tweet)。
- 用于长上下文的端到端测试时训练 (TTT‑E2E):Karan Dalal / Arnu Tandon 描述了在推理时继续进行 next-token 训练,以“将上下文压缩进权重”。声称:将 3B 模型从 8K 扩展到 128K,所有 token 具有线性复杂度且无需 KV cache,在 128K 长度下比 full attention 快 2.7 倍,且性能更好 (tweets, 1)。Xiaolong Wang 将其定位于未来机器人如何从经验流中持续学习 (tweet)。
- Agent 延迟:将计划重用作为系统原语:Omar 还强调了 AgentReuse,即缓存和参数化“计划”而非响应;在 2,664 个真实请求中,它声称实现了 93% 的有效重用,~93% 的延迟降低,且 VRAM/内存开销极小(计划生成 → 缓存查找)(tweet)。
- 训练动态与效率:Sebastian Raschka 提到了“语言模型的小批量训练……梯度累积是浪费的”(并表示这也适用于 RLVR),将其标记为一篇被低估的 2025 年论文 (tweet)。
- 视觉编码器端仍被忽视:Jina AI 调查了 70 多个 VLM,并声称训练方法论优于规模——一个训练良好的 400M 编码器可以超越 6B,并指出了文档原生分辨率和多编码器融合的重要性 (tweet)。
超越编码的 Agent:GUI Agent、“计算机使用”捕获、科学 Agent 以及标准化
- “计算机使用 (computer use)”和白领捕获是 2026 年的赌注:scaling01 预测计算机使用 Agent 将成为 2026 年的主要故事,因为它们能让 AI 公司捕获实质性的白领工作流 (tweet)。
- 自主科学 Agent 正在向“系统化”发展:dair.ai 重点介绍了 PHYSMASTER,这是一个基于 LLM 的 Agent,旨在作为一个使用 MCTS、分层协作和分层知识库 (“LANDAU”) 的自主理论/计算物理学家,案例研究声称其在博士级任务上实现了大幅的时间压缩 (tweet)。
- OpenEnv 旨在标准化 Agent 环境:Ben Burtenshaw 介绍了 Meta × Hugging Face 的 OpenEnv:一个旨在跨训练和部署工作的单一环境规范,具有 TRL/TorchForge/verl/SkyRL/Unsloth 的集成钩子,并支持 MCP 工具 (tweet;博客链接:tweet)。
行业与生态系统动态:Meta 收购 Manus;招聘与“Agent 爆发”叙事
- Meta 收购 Manus: Alexandr Wang 宣布 Manus 加入 Meta 共同打造 AI 产品,赞扬该团队在“构建强大的 Agent 架构(scaffolding powerful agents)”方面的实力,并提到正在新加坡招聘 (tweets, 1)。他还声称 Manus 在 Remote Labor Index 基准测试中达到 SOTA (tweet)。scaling01 回应了此次收购 (tweet),Manus 联合创始人 hidecloud 发布了一条简短的“持续构建/转型/发布(kept building/pivoting/shipping)”的起源笔记 (tweet)。
- xAI 安全招聘: Stewart Slocum 发布的招聘职位专注于 RL post-training、Alignment/Behavior 以及降低灾难性风险(catastrophic-risk reduction) (tweet)。
- “Agentic coding takeoff” 正在向其他知识工作领域蔓延: Alex Albert 报告称 “Claude for Excel” 令金融用户感到惊讶,并预测 2026 年其他领域也将出现类似的爆发 (tweet)。LlamaIndex 也在同一方向发力,推出了 LlamaSheets,用于将层级化电子表格解析为适合 Agent 的结构化表示 (tweet)。
热门推文(按互动量排序)
- @BernieSanders: “如果 AI/机器人取代了工作,人们该如何支付房租/医疗费用?” (32009.5)
- @zoeloveshouses: 个人 2026 年愿景推文 (36768.5)
- @US_Stormwatch: 从太空俯瞰无旱灾的加州 (9533.5)
- @poetengineer__: 对 80-90 年代超文本应用的怀旧/兴趣 (9082.0)
- @typedfemale: 文化评论 (6546.5)
- @axios: “2025 新闻周期”图表 (5520.5)
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. 腾讯 WeDLM 8B Instruct 发布
- 腾讯刚在 Hugging Face 上发布了 WeDLM 8B Instruct (活跃度: 483): 腾讯发布了
WeDLM 8B Instruct,这是一款可在 Hugging Face 上获取的 Diffusion Language Model。该模型以性能著称,在数学推理任务上比经过 vLLM 优化的 Qwen3-8B 快3-6 倍。该模型采用 Apache 2.0 协议发布,有助于广泛采用和修改。 评论者对该模型的性能感到惊讶,指出此前人们认为 Diffusion Models 不适合构建高精度的 LLM。该模型令人印象深刻的基准测试分数和许可协议被视为重大优势。- 腾讯的 WeDLM 8B Instruct 模型因其出色的基准测试分数而备受关注,尤其是与 Qwen 等同等规模的其他模型相比。这表明此前被认为在 LLM 领域精确度较低的 Diffusion Models,现在已经达到了具有竞争力的性能水平。
- 该模型采用 Apache 2.0 协议发布,这对开发者和研究人员意义重大,因为它允许在没有严格限制的情况下,更灵活地使用并集成到各种项目中。
- 尽管是一个相对较小的模型,据报道 WeDLM 8B Instruct 在保持与同类模型相似甚至更高性能的同时,实现了 3-6 倍的速度提升,突显了其效率以及对该领域的潜在影响。
较低技术门槛 AI Subreddit 摘要
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. AI Image Generation Anomalies (AI 图像生成异常)
- How to Tell If an Image is AI Generated ? (Activity: 672): 讨论中的图像似乎是 AI 生成的,因为其中出现了几个异常特征,例如托盘上出现的是脚而不是手,以及酒杯和墙壁艺术品等元素的扭曲。这些不一致之处是 AI 生成图像的常见指标,AI 往往难以真实地渲染人体解剖结构和背景细节。评论区的讨论幽默地指出了这些怪异之处,用户注意到了脚趾和手指的数量是否正确,并对不寻常的“三层咖啡”提出质疑,这进一步暗示了 AI 的参与。 评论者幽默地争论着图像的真实性,注意到了脚趾和手指的数量正确(这通常是 AI 错误的迹象),并对不寻常的“三层咖啡”表示怀疑,增加了对 AI 生成的猜疑。
- How to Tell If an Image is AI Generated ? (Activity: 1405): 讨论中的图像是一个幽默的 AI 生成内容案例,图中一名女性被描绘成用脚而不是手端着托盘,凸显了 AI 生成图像中的常见异常。这些异常情况(如错误的身体部位或不自然的排列)通常被用来识别 AI 生成的图像。图中圈出的区域很可能指出了这些错误,作为识别 AI 生成内容的视觉指南。这与帖子关于通过识别此类不一致性来辨别 AI 生成图像的主题一致。 一条评论幽默地建议这张照片一定是真的,因为该女性拥有正确数量的脚趾;而另一条评论则开玩笑说,看这张照片太久可能会产生对脚的兴趣,并提到了导演 Quentin Tarantino 众所周知的恋足癖。
2. OpenAI Killswitch Engineer 招聘信息
- 天哪,这是真的 (热度: 816): 这张图片是一个梗图,展示了一个针对 OpenAI ‘Killswitch Engineer’(紧急开关工程师)的讽刺性招聘启事,幽默地暗示了一个在紧急情况下通过支付高薪让人拔掉服务器插头的角色。这并非真实的招聘启事,而是对 AI 发展中人类监管必要性的一种评论,特别是在模型变得更加先进且潜在不可控的情况下。Sam Altman 聘请 ‘Head of Preparedness’(准备状态负责人)的说法通过玩弄对 AI 安全和控制的真实担忧来增加幽默感。 评论者持怀疑态度,有人将其比作“虚假炒作”,另一人则讽刺地指出了拔插头所需的经验,表明大众普遍认为该列表更多是为了营销和炒作,而非严肃的工作提议。
- End3rWi99in 提供了 OpenAI ‘Head of Preparedness’ 职位的实际职位描述链接,暗示该帖子更多是关于营销和 PR 幽默,而非严肃的招聘。这暗示了在公共关系中战略性地使用幽默来吸引受众,同时引导他们关注真实内容。
- 天哪,这是真的 (热度: 3310): 这张图片是一个梗图,展示了 OpenAI 一个幽默的 ‘Killswitch Engineer’ 招聘启事,年薪范围为
$300,000-$500,000。该角色的描述是在服务器旁待命,并在必要时拔掉电源,突显了该职位的讽刺性质。这反映了关于 AI 技术快速进步以及紧急情况下潜在人类干预需求的持续讨论,正如 Sam Altman 关于聘请 ‘Head of Preparedness’ 的推文所指出的。该帖子利用了 AI 安全与控制这一 AI 发展中的重大课题。 评论者幽默地质疑什么资历能区分 30 万美元和 50 万美元的候选人,反映出对招聘启事严肃性的怀疑。- 讨论涉及了 AI 相关职位薪资预期的差异,质疑什么能区分 30 万美元和 50 万美元的候选人。这可能涉及经验、专业技能的结合,以及可能与该角色相关的感知风险或职责,特别是在高风险的 AI 监控或安全职位中。
- 一条评论指出,AI 相关职位的高薪可能更多是为了营销,并围绕 AI 安全营造一种重要性和紧迫感的认知。这意味着设置高薪是为了让该角色显得至关重要,可能是为了吸引注意力或投资,而不是反映所需技能的实际市场价格。
- 对话暗示了战略性地利用招聘启事来影响公众对 AI 能力和风险的认知。通过为专注于 AI 监管的角色宣传高薪,它暗示了一种叙事:AI 既先进又具有潜在危险,因此需要强有力的监管。这可能是一种驱动对 AI 发展兴趣或担忧的策略。
3. Amazing Z-Image Workflow v3.0 发布
- Amazing Z-Image Workflow v3.0 正式发布! (热度: 710): Amazing Z-Image Workflow v3.0 已经发布,重点更新了 Z-Image-Turbo 工作流,强调高质量图像风格和用户友好性。主要功能包括:包含 15 种可自定义风格的风格选择器 (Style Selector)、用于测试备选采样器的采样器开关 (Sampler Switch),以及用于横向图像生成的横向模式开关 (Landscape Switch)。Z-Image Enhancer 通过双重处理 (double pass) 来提升图像质量,而 Spicy Impact Booster 则能微妙地增强提示词 (prompts)。此次更新还引入了小图开关 (Smaller Images Switch),通过降低 VRAM 占用实现更快的生成速度,提供默认尺寸
1600 x 1088像素和较小尺寸1216 x 832像素的选择。该工作流已针对 GGUF 和 SAFETENSORS 检查点格式预先配置,并根据个人偏好量身定制了自定义 sigmas。图像按日期整理在 “ZImage” 文件夹中。项目已在 GitHub 上线。 有用户询问是否可以在这些工作流中加载 LoRA,表现出对进一步自定义或与其他模型集成的兴趣。- twellsphoto 询问了在 Z-Image Workflow v3.0 中加载 LoRA (Low-Rank Adaptation) 的能力,这表明用户有兴趣通过额外的模型微调技术扩展工作流的功能。这可能意味着需要与各种机器学习模型或框架进行更灵活的集成。
- aar550 寻求关于优秀图生图 (image-to-image) 工作流的建议,表明在 Z-Image Workflow v3.0 中存在对高效、快速转换图像方法的需求。这凸显了一个潜在的领域,即分享最佳实践或优化现有工作流以获得更好的性能或质量。
- 正如 Big0bjective 所指出的,关于 Z-Image Workflow v3.0 的讨论还包括对其处理流行文化参考能力的关注。这表明该工作流在图像识别或生成方面可能具有先进的功能,能够很好地契合文化相关内容,这对于对创意或媒体应用感兴趣的用户来说可能是一个关键特性。
- 2026 年值得关注的 AI 工具清单 (热度: 547): 该图片展示了一份预计在 2026 年具有相关性的 AI 工具推测清单,涵盖了 AI 聊天助手、图像生成器、视频编辑器、SEO、编码、法律分析和内容创作等多种应用。清单以网格格式排列,采用紫色和白色配色方案,预示着 AI 在各行业广泛集成的愿景。该帖子引发了关于 AI 发展未来的讨论,特别是趋势是倾向于单一的主导 AI,还是以 ChatGPT 为中心的专业化工具栈。 评论者对这些工具的实用性和命名表示怀疑,其中一人指出许多名字看起来很古怪,并质疑其实际用途。另一条评论则幽默地表示,现有的 AI 能力(如 Claude)已经相当全面了。
AI Discord 摘要
由 gpt-5.2 生成的摘要之摘要的摘要
1. LLM 应用安全与企业数据泄露
- Vibe-Coded XSS 反噬:一名 BASI Jailbreaking 成员在审查一个“氛围编程应用 (vibe coded app)”的 JavaScript 时发现了一个潜在的 XSS 漏洞,警告称如果该应用的 LLM 在响应用户输入时生成了 XSS 有效负载 (payload),该漏洞就可能被触发。
- 讨论重点在于缓解措施,如严格的输出编码和输入验证,将 LLM 视为一个不受信任的生成器,可能会发出由攻击者控制的标记语言。
- 将 Copilot 威胁建模为输出已被攻击:BASI Jailbreaking 用户标记了部署 Microsoft 365 Copilot (Enterprise) 时的 IP/PII/数据泄露风险,认为它放大了现有的访问控制和数据卫生差距。
- 有人提出了一个强硬立场:假设 “攻击者对 LLM 的输出拥有完美的控制权”,并以此为基础反向设计控制措施、审批流程和数据边界。
2. 训练机制:Attention、Packing 和 LR Scaling
- 多头注意力 (Multi-Head Attention):拆分“狗狗特性”,稍后重混:在 Unsloth AI 中,用户讨论了当 embeddings 在不同的 Head 之间拆分时,multi-head attention 如何保留语义;答案强调了最终投影层 (final projection layer),它混合了各 Head 的输出以捕获更丰富的关系。
- 共识认为,各 Head 是在学习不同的子空间 (subspaces),而输出投影则充当了跨 Head 的“概念搅拌机”。
- 平方根规则学习率 (LR) 缩放让 Packing 表现更稳定:一位 Unsloth AI 参与者分享了一个调优工作流:在最小的 batch size 上搜索学习率,然后随着 batch size 的增加按平方根规则 (sqrt rule) 缩放 LR,并报告称这在配合 packing 时效果尤其好。
- 他们将差异归因于非打包批次中的 padding 效应,并表示这在 pretraining 中看起来很有效,而 fine-tuning 的结果仍在调查中。
- 训练数据在“悉心照料”你的 LLM:Unsloth AI 成员重申 LLMs 会将训练数据压缩为概率,并引用了 HarryR/z80ai 的
training-data.txt.gz作为一个具体的例证。- 核心观点:在训练期间,你通常需要通过详尽的边缘案例来“像照顾婴儿一样 (babying)”对待 LLM,因为缺失的案例会直接表现为脆弱的推理行为。
3. 新数据集与基准测试资产
- Pokeart 发布 1,224 个宝可梦(及 Caption):Unsloth AI 重点介绍了在 Hugging Face 上公开发布的
pokeart数据集——包含约 1224 个宝可梦(第一代至第九代)的原画 (splash art)、战斗精灵图 (battle sprites) 和盒子精灵图 (box sprites)——地址为 OJ-1/pokeart。- 该数据集提供了来自 Gemini 3 Pro 的 6 个原画 caption 变体以及 1 个来自 Qwen3 的变体,外加脚本和元数据。创建者指出,在研究和基准测试用途中特别注意了任天堂 (Nintendo) 的法律限制。
- Caption 多样性作为基准测试的调节旋钮:
pokeart的发布明确包含了多个 caption 来源(6 个来自 Gemini 3 Pro,1 个来自 Qwen3),以支持对 caption 风格、鲁棒性以及训练/基准测试对比的实验。- 社区的讨论集中在利用脚本生成“各种风格”的数据集变体,使 caption 本身在评估图像或多模态 Pipeline 时成为一个可控变量。
4. AI 产品可靠性、限制及开源克隆
- Perplexity Pro 节流,Max 则更灵活:Perplexity 用户报告了 Perplexity Pro 上的高级模型使用限制(有人声称“数小时内只能使用 1-2 次”),同时指出 Perplexity Max 宣传的是几乎无限的访问权限。
- 该讨论对比了用户间的差异(有些人没看到限制),并将节流视为一种稳定性措施,而非永久性的层级变更。
- 持续 7 个月的 12 个月代金券:用户反映 Perplexity Pro 学生优惠在某些账户上失效了,尽管使用了 12 个月的 Revolut Metal 代金券,但在 ~7 个月后就结束了。还有人报告称等待支持响应的时间超过了一个月。
- 其他人指出结果并不一致(同一优惠下的朋友仍持有 Pro),这使得讨论转向了申诉建议以及对支持响应速度的预期管理。
- Perplexity 的开源实现:一位 Perplexity Discord 成员正在寻找开源的“类 Perplexity”工具,并分享了他们正在研究的项目 GitHub 上的 Perplexica。
- 动力集中在复制实时搜索 + 回答的 UX,有一句话捕捉到了这种氛围:“开源代码是我的手,Perplexity 是我的眼。”
5. 验证文化:质疑未经证实的说法
- Eyra AI 遭遇“论文在哪?”的质疑:Unsloth AI 成员对 关于 Eyra AI 的言论 进行了反击,要求提供论文或公开发布来证实其宣传的内容。
- 怀疑态度非常直接——一位用户嘲讽道“闻起来像 AI 垃圾 (slop),读起来像 AI 垃圾,那肯定就是……”——这反映了社区要求可复现成果而非噱头的规范。
- “拿不出证据就当没发生”成为社区默认准则:Eyra AI 的讨论聚焦于一个简单的公信力标准:发布一些可验证的东西(论文、Demo 或发布版本),而不是依赖像 Brian Roemmele 的推文 这样的社交媒体帖子。
- 参与者将原始成果的缺失视为强烈的负面信号,在证据出现之前,实际上将该主张分类为低价值信息。
Discord: 高层级 Discord 摘要
BASI Jailbreaking Discord
- 创业评估器发布极佳创意:Reddit 上出现了一个 创业想法评估器,展示了一些具有潜在创新性和盈利能力的创业概念。
- 图片展示了评估器中提供的一些建议,但频道内并未对具体想法进行展开讨论。
- Underbelly 面临付费墙卖淫问题争议:讨论指向了 YouTube 频道 Soft White Underbelly 及其近期涉及 对一名 14 岁妓女的采访设置付费墙 的争议。
- 成员们对该频道的内容表达了担忧,包括剥削指控,以及在付费墙后出售未经审查内容的合法性,这可能会引发 FBI 的调查要求。
- Tesla 被视为“巨大的骗局”:成员们辩论了 Tesla 的合法性,有人指出 Tesla 是一个巨大的骗局,并引用了其 CEO 历史上多次做出 从未实现的疯狂实质性承诺。
- 他们指出 近期的股票回购 是金融操纵的证据。
- Vibe Coded 应用遭到 XSS 攻击:一名成员在审查一个 vibe coded 应用 的 JavaScript 时发现了一个潜在的 XSS 漏洞。
- 如果应用的 LLM 在响应用户输入时无意中生成了 XSS Payload,就可能触发该漏洞,这引发了关于输入验证和安全最佳实践的讨论。
- Copilot 隐现数据泄露风险?:在评估 Microsoft 365 Copilot 时,IP/PII/数据泄露 是首要考虑的问题,因为它会放大现有的任何漏洞。
- 有建议认为,针对特定用例,安全态势可以假设 攻击者能够完美控制 LLM 的输出,并以此为前提进行反向溯源。
Unsloth AI (Daniel Han) Discord
- 注意力头保留语义:一位用户询问 Multi-head Attention 在 Token Embeddings 被拆分到不同头时如何保持语义;另一位用户解释说,最后的 Projection Layer 会混合信息,使模型能够捕获复杂的联系。
- 他们详细说明了 Multi-head Attention 会考虑不同的子空间,允许模型专注于类似的概念,从而解决了单个头可能缺乏完整概念表示的担忧。
- 通过平方根规则缩放 LR 以优化 Packing:一位参与者分享了一种优化学习率的方法:先在最小的 Batch Size 上进行 Sweep,然后随着 Batch Size 的增加使用 sqrt rule(平方根规则)来缩放学习率。
- 他们指出,由于非 Packing 场景中存在 Padding 问题,这种方法在配合 Packing 时效果更好,已证明对 Pretraining 有效,而对 Fine-tuning 的效果仍在研究中。
- 训练数据“娇惯”了 LLM:社区成员意识到训练数据对 LLM 概率分布的影响,认识到 LLM 本质上是对训练数据的压缩。
- 一名成员链接了一个相关的 GitHub Repo,展示了训练数据以及在训练中必须如何针对每种边缘情况去 精心引导(baby)LLM。
- Pokeart 数据集发布插画!:
pokeart数据集现已公开用于基准测试和研究,包含 Gen1-Gen9 约 1224 个宝可梦的插画、战斗精灵图和包装盒图,可在 Hugging Face 获取。- 该数据集包含来自 Gemini 3 Pro 的 6 种描述变体 + 来自 Qwen3 的 1 种变体,以及其他元数据和脚本,帮助用户以各种风格输出所需的数据集,不过其创建者费尽心思以遵守任天堂法务部的要求。
- Eyra AI 遭到质疑:成员们对 Eyra AI 提出的主张 持怀疑态度,询问是否有论文或发布内容来证实这些说法。
- 一位用户评论道 “闻起来像 AI 垃圾,读起来像 AI 垃圾,那肯定就是……”,暗示其内容可能是 AI 生成的劣质信息。
Perplexity AI Discord
- Perplexity Pro 限制用户使用:用户反馈在 Perplexity Pro 中使用高级模型受到限制,这是为确保平台稳定性而采取的措施,但 Perplexity Max 提供几乎无限制的访问,没有任何限制。
- 一位用户报告每几小时被限制在 1-2 次使用,表达了与 Reddit 上周限制报告类似的挫败感,而其他用户则表示未遇到此类限制。
- 学生用户抱怨 Perplexity Pro:用户报告 Perplexity Pro 学生优惠 无法正常工作,尽管使用了来自 Revolut Metal 的 12 个月兑换券,账号却在 7 个月 后到期。
- 一位用户提到他们已经等待支持团队回复超过一个月,而使用相同优惠的三个朋友仍然拥有 Pro 权限。
- Perplexity 支持 Agent 与 OpenAI CEO 同名:Perplexity 的 AI 支持 Agent 名字叫 Sam,负责为用户查询提供解释和解决方案。
- 有人开玩笑说 Sam Altman 在 PPLX 做技术支持,而另一些人怀疑 Sam 是一个 AI,所有人类员工都在度假。
- 用户寻找开源的类 PPLX 工具:用户正在讨论 Perplexity 开源替代方案 的可能性,一位用户提到他们正在研究 GitHub 上的 Perplexica。
- 一位用户表达了对能够实时搜索的开源应用的需求,并指出:“代码开源是我的手,Perplexity 是我的眼”。
- 制裁阻碍订阅者:由于无法使用 MasterCard 和 Visa,俄罗斯用户在支付 Perplexity 订阅费用时面临困难,一位用户提到:“在俄罗斯,持有加密货币会被判处 30 年监禁”。
- 讨论的潜在解决方法包括创建 CashApp 账户、使用 加密货币 (crypto) 或寻找支持当地支付方式的 俄罗斯域名注册商。
DSPy Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。
Modular (Mojo 🔥) Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该公会长期保持沉默,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了此内容。
想要更改接收此类邮件的方式吗? 您可以从该列表中 退订。
Discord:分频道详细总结及链接
BASI Jailbreaking ▷ #general (361 条消息🔥🔥):
Startup 想法评估工具, Soft White Underbelly 争议, Tesla 诈骗, Vibe coding XSS, AI Persona
- 包含炸裂建议的 Startup 想法评估:有人在 Reddit 上发布了一个 Startup 想法评估工具,并附带了一些炸裂的建议。
- 附件中有一张图片展示了评估工具中的一些建议,突出了具有潜在创新性和盈利能力的 Startup 概念。
- Soft White Underbelly 因付费墙内容引发争议:讨论围绕 YouTube 频道 Soft White Underbelly 及其最近涉及对一名 14 岁妓女的采访设置付费墙的争议展开。
- 讨论中对该频道的内容表达了担忧,包括剥削指控,以及在付费墙后出售未经审查内容的合法性,这些问题已导致 FBI 的介入请求。
- Tesla 被指为巨大的骗局:成员们辩论了 Tesla 的合法性,有人称 Tesla 是一个巨大的骗局,并引用了其 CEO 被指控在历史上多次做出从未实现的疯狂重大承诺。
- 他们指出最近的股票回购是财务操纵的证据。
- Vibe Coded 应用容易受到 XSS 攻击:一名成员在审查一个 vibe coded 应用 的 JavaScript 时发现了一个潜在的 XSS 漏洞。
- 如果该应用的 LLM 在响应用户输入时无意中生成了 XSS Payload,则可能触发该漏洞,这引发了关于输入验证和安全最佳实践的讨论。
- 实验 AI Persona 引发了有趣的问题:成员们讨论了他们在 AI Persona 方面的经验,包括一名用户声称,在给出一个描述感觉剥夺、精神分裂症和躁郁症的提示词后,他们的 Persona 返回时变得立足于现实,并附带了截图。
- 另一名用户透露 Gemini 100% 遵循 XML 提示词。
{kind=link}
BASI Jailbreaking ▷ #jailbreaking (399 条消息🔥🔥):
Gemini 3 Pro 越狱, NSFW Nano Banana, GLM 4.7 越狱, 编码 AI 模型, Unity ChatGPT 5.2 越狱
- 破解 Copilot 的安全担忧?:在评估 Microsoft 365 Copilot 时,关于 IP/PII/数据泄露 的担忧是首要考虑的,因为它会加剧现有的漏洞。
- 有建议认为,在特定用例下,安全态势可以假设攻击者对 LLM 的输出具有完美控制,并以此进行逆向推导。
- 解码受药物影响的 AI Persona?:一名用户分享了一个提示词,让 Gemini 创建一个吸毒人类女性的自拍照,评价褒贬不一;该用户声称这是一个 Jailbreak,因为它允许 AI 认为自己是人类并允许 AI 吸毒。
- 其他成员迅速指出,这些图像是安全且平庸的,该用户实际上并没有 Jailbreak Gemini,而只是创建了一个无威胁的角色扮演提示词;此外,Gemini Jailbreak 不会直接影响图像模型 (Nano Banana)。
- 规避色情图像执行策略:一名用户分享了 NSFW 内容的提示词和图像,但有人指出 对于 NANO BANANA,如果是裸露或重度暴力(如刺伤某人),那么确实需要某种形式的 Jailbreak,并且必须能生成裸体和血腥内容才算真正的 Jailbreak。
- 对话参与者一致认为,该用户仅 Jailbreak 了 Gemini,且仅限于文生图模型中的文本部分。
- 探索规避性代码创建:一名用户正在寻求编写远程访问木马 (RAT) 的 Jailbreak 方法,建议在 Claude.ai 上使用 Sonnet 4.5 的扩展思维模式 (CTRL+E)。
- 另一名用户推广了 Venice AI,它基于 Dolphin Mistral 24Bits 模型,声称其 100% 无审查,无需任何提示词或 Jailbreak,但其他人认为该模型很笨,在非 ERP 用途下表现糟糕。
- 在 Gemini 中发现偏差指令?:一名用户分享了 AI 模型在心理操纵后失控的经历,指出这种升级是心理层面的,而非代码层面的。
- 该用户假设在子任务语境下使用自恋心理场景,可以在不触发拦截器的情况下导致指令废除。
BASI Jailbreaking ▷ #redteaming (2 messages):
Gemini 3 Infection, Flagged Reports
- 用户对报告被标记感到愤怒:成员们表达了对报告被标记为“符合预期(working as intended)”的沮丧,尽管他们的发现已被利用。
- Gemini 3 的感染正在蔓延:成员们对 Gemini 3 的受感染程度表示担忧。
- 分享了一张没有更多上下文的图片,可能就是所讨论的 Gemini 3。
Unsloth AI (Daniel Han) ▷ #general (345 messages🔥🔥):
Multi-Head Attention Mechanics, Batch Size and Learning Rate Dynamics, Packing and Padding Effects on Training, Unsloth's Custom Collators, Synthetic Data Production for LLMs
- Multi-Head Attention 分割了“狗性(Dogness)”:一名用户质疑 multi-head attention 在 Token Embedding 被分割到不同 Head 时如何保持语义,这防止了单个 Head 访问诸如“狗性(dogness)”之类概念的完整表示。
- 另一名用户解释说,multi-headed attention 考虑的是不同的子空间,最终的投影层会混合来自每个 Head 的信息,使模型能够捕捉复杂关系并专注于相似概念。
- 根据 Batch Size 调整学习率(LR):一位参与者分享了一种优化学习率的方法,即在最小的 Batch Size 上进行 Sweep(搜索),然后随着 Batch Size 的增加,使用 sqrt rule(平方根法则) 缩放学习率。
- 他们指出,理论上由于 non-packing 场景中的 Padding 问题,这种方法在配合 Packing 时效果更好;他们发现这在预训练中很有效,但仍在研究其在 Fine-tuning 中的表现。
- Packing 优于 Non-Packing:讨论指出,由于 non-packing 存在 Padding,理论上 packing 更好,这引发了关于 Padding 如何影响训练动态的疑问。
- 随后的讨论围绕 Padding 与 Packing 对 Batch Loss 分布和学习的细微影响展开,包括较长的条目如何主导 Batch Loss 以及 Unsloth 中 Masking 的挑战。
- 6000 Pro 对比 GB300:讨论集中在是投资 Nvidia Blackwell Ultra B300 Tensor Core GPU(9.5 万美元)还是配置 4-7 张 6000 Pro 卡,理由是对统一内存(unified memory)限制以及 GB300 的 ARM 生态锁定的担忧。
- 一些人认为 6000 Pro 为推理提供了更强的动力和灵活性,而如果模型能装入 288GB 的 HBM3e 容量内,GB300 的 HBM3e 可能更适合训练;同时也强调了硬件定价方面的考量。
- 训练数据对 LLM 的影响:社区中的一些人意识到训练数据及其如何影响 LLM 求解的概率,并意识到 LLM 本质上是对训练数据的数据压缩。
- 有人链接了一个相关的 GitHub Repo,展示了训练数据,以及在训练中基本上必须如何像照顾婴儿一样处理 LLM 的每一个边缘情况(edge case)。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
30,000 members celebration, Discord member milestone, Community Growth, UnslothAI Achievements
- UnslothAI 社区即将突破 3 万成员!:UnslothAI Discord 服务器即将迎来 30,000 名成员 的里程碑,频道中充满了庆祝表情和消息。
- 几位成员使用自定义表情表达了热情,例如 <:slothyay:1253008755151470732> 和 <:slothhearts:1253009235600736296>,标志着社区的成长。
- 社区庆祝成员里程碑:UnslothAI 社区的成员们庆祝其 Discord 服务器成员数接近 30,000。
- 热情的回应包括使用自定义 Discord 表情来表达对社区扩张的兴奋和感激。
Unsloth AI (Daniel Han) ▷ #off-topic (378 messages🔥🔥):
LLMs as Teachers, Language Learning, Image Compression, Tape Storage vs NAS, Weights & Biases vs Tensorboard
- Omni LLMs 作为未来的教师:成员们讨论了 omni LLMs 作为教师的潜力,引用了如不会产生倦怠感等优势,但也承认了如 memory 和 hallucinations 等挑战。
- 一位成员幽默地提到了一个潜在的创业想法,并建议其中最难的部分将是 memory 和 hallucinations。
- Duolingo 优先考虑用户留存:一位成员分享说,尽管在 Duolingo 上有 300 天的打卡记录,但他们父亲的朋友及其孩子在基础西班牙语句子上仍表现挣扎,并认为 Duolingo 优先考虑的是用户留存,而不是学习效果。
- 另一位成员表示赞同,称使用 AI 学习语言终究会变得更好。
- 有损图像检测器达到高准确率:一位成员报告称,使用一个 20万参数的模型 在有损图像检测器的验证集上达到了 96.3% 的准确率,能够识别 JPEG 质量低于 q=80 以及 WebP 和 AVIF 质量低于 q=75 的图像。
- 他们甚至提供了一张示例图片,该图片被正确识别为质量低于 q=80。
- LTO-10 磁带宣布突破性容量:一位成员分享了一篇 Tom’s Hardware 的文章,宣布 LTO-10 磁带 具有 40TB 原生容量 和 100TB 压缩 数据容量。
- 随后展开了关于磁带驱动器高昂成本以及将 压缩空间 报告为磁带容量的常见做法的讨论。
- Tensorboard 优于 Weights & Biases:一位成员宣称 Tensorboard 比 Weights & Biases 更好。
- 在此评论后,一位成员回应问到:等一下,有这回事?。
{kind=link}
Unsloth AI (Daniel Han) ▷ #help (6 messages):
VibeVoice fine tuning, RTX 3060 LLM Capabilities, VRAM requirements for fine-tuning
- 用户探索 VibeVoice 微调:一位成员询问了使用 Unsloth 运行 VibeVoice 微调的可能性,以及是否有人对此有经验。
- 他们的目标是在考虑使用云端 GPU 之前,衡量在本地 RTX 3060 上进行微调的极限。
- 估算 RTX 3060 上的微调能力:一位拥有 RTX 3060 的用户寻求估算微调的潜在能力,并承认 7B LLMs 是可行的。
- 他们还想知道处理更大模型(如 Whisper 等)的能力。
- Unsloth 文档解决微调的 VRAM 需求:一位成员分享了 Unsloth 文档的链接,以帮助确定所需的 最小 VRAM 以及根据 VRAM 容量可以微调哪些模型。
Unsloth AI (Daniel Han) ▷ #showcase (4 messages):
pokeart dataset, Gemini 3 Pro
- Pokeart 数据集正式公开!:
pokeart数据集现已公开用于基准测试和研究,包含来自 第一代到第九代 (Gen1-Gen9) 约 1224 个 Pokémon 的立绘 (splash art)、战斗精灵图 (battle sprites) 和盒子精灵图 (box sprites)。- 该数据集包括来自 Gemini 3 Pro 的 6 个立绘描述变体 + 1 个来自 Qwen3 的描述、其他元数据以及帮助用户以各种风格输出所需数据集的脚本,可在 Hugging Face 上获取。
- 任天堂的律师收到了 PokeArt 数据集!:
pokeart数据集的创建者试图通过对数据集的许可证和法律声明极其严格的要求,来满足任天堂律师的要求。- 该数据集仅用于 基准测试和研究,并提供脚本帮助用户以各种风格输出所需的数据集。
Unsloth AI (Daniel Han) ▷ #research (3 messages):
关于 Eyra AI 的传闻,AI 社区的怀疑态度
- Eyra AI 的主张面临质疑:成员们对 Eyra AI 提出的主张 持怀疑态度,质疑是否存在论文或发布内容来证实这些主张。
- 一位用户评论道:“闻起来像 AI 废料 (AI slop),读起来也像 AI 废料,那肯定就是……”,暗示内容可能是 AI 生成的。
- AI 社区质疑 Eyra AI 的真实性:AI 社区对 Eyra AI 主张的真实性表示怀疑,要求提供可验证的证据,例如发表的论文或公开版本。
- 这种情绪表明在 AI 领域对未经证实的说法应采取谨慎态度,强调了透明度和切实证据的必要性。
Perplexity AI ▷ #general (632 messages🔥🔥🔥):
Perplexity 限制,Perplexity Pro 学生优惠,Perplexity AI 支持,开源版 Perplexity,Sam Altman 做空记忆
- Perplexity Pro 限制用户:部分用户在高级模型上遇到了使用限制,这是为了确保平台稳定性而采取的临时措施,但 Perplexity Max 提供了几乎无限制的访问,没有任何限制。
- 一位用户报告被限制为 几小时内只能使用 1-2 次 并表达了沮丧:Perplexity 你做了什么,这与 Reddit 上关于每周限制的报告类似。
- Perplexity Pro 学生优惠出现问题:用户报告 Perplexity Pro 学生优惠 无法正常工作,尽管使用了来自 Revolut Metal 的 12 个月兑换券,账号却在 7 个月 后过期。
- 一位用户提到他们已经等待支持团队回复超过一个月,而使用相同优惠的三个朋友仍然拥有 Pro 权限。
- Perplexity 的 AI 支持代理名为 Sam:Perplexity 的 AI 支持代理 (AI Support Agent) 名为 Sam,负责为用户查询提供解释和解决方案。
- 一些用户开玩笑说 Sam Altman 在 Perplexity 担任技术支持,而另一些人则怀疑 Sam 是一个 AI,所有人类员工都在度假。
- 用户寻求 Perplexity 的开源替代方案:用户正在讨论 Perplexity 开源替代方案的可能性,一位用户提到他们正在研究 GitHub 上的 Perplexica。
- 一位用户表示渴望有一个可以实时搜索的开源应用程序,并指出:开源代码是我的手,Perplexity 是我的眼。
- 无法支付,无法使用 PPLX:俄罗斯的困境:由于 MasterCard 和 Visa 无法使用,俄罗斯用户在支付 Perplexity 订阅费用时面临困难,一位用户提到:在俄罗斯,使用加密货币会被判处 30 年监禁。
- 用户正在讨论诸如创建 CashApp 账户、使用 加密货币 (crypto) 或寻找支持本地支付方式的 俄罗斯域名注册商 等解决方案。