AI News
Moonshot Kimi K2.5 —— 性能超越 Sonnet 4.5 且成本仅需一半;全球领先(SOTA)开源模型;首款原生图像+视频模型;支持 100 路并行智能体集群(Agent Swarm)管理。
月之暗面(Moonshot AI)的 Kimi K2.5 是一款拥有 320 亿激活参数、1 万亿总参数的开放权重模型。它具备原生多模态能力,支持图像和视频理解,是通过对 15 万亿视觉与文本混合 token 进行持续预训练构建而成的。
该模型引入了全新的 MoonViT 视觉编码器,并支持多项高级功能,例如可协调多达 100 个子智能体进行并行工作流的 智能体集群(Agent Swarm),以及用于处理大规模办公任务的 办公效率 K2.5 智能体。这一版本的发布标志着中国开源模型的一次重大飞跃,在 HLE 和 BrowseComp 等基准测试中取得了业界领先(SOTA)的成绩,并提供了极具竞争力的 API 定价和吞吐量。
中国在开源模型领域再次取得巨大飞跃
AI 新闻 2026/1/26-2026/1/27。我们为您检查了 12 个 subreddits、544 个 Twitter 账号 和 24 个 Discord 服务(206 个频道,共 7476 条消息)。预计为您节省阅读时间(以 200wpm 计算):602 分钟。我们的新网站现已上线,提供完整的元数据搜索和美观的 Vibe Coded 过往刊物展示。请访问 https://news.smol.ai/ 查看完整的新闻细分,并前往 @smol_ai 为我们提供反馈!
AI 新闻 2026/1/26-2026/1/27。我们为您检查了 12 个 subreddits、544 个 Twitter 账号和 24 个 Discord 服务(206 个频道,共 7476 条消息)。预计为您节省阅读时间(以 200wpm 计算):602 分钟。AINews 的网站允许您搜索所有往期内容。提醒一下,AINews 现在是 Latent Space 的一个板块。您可以选择开启或关闭邮件接收频率!
Kimi 在过去的一年里表现极其强劲,我们上次听到他们的消息是在 11 月发布的 Kimi K2 Thinking。与 K2 一样,今天的 K2.5 仍然是一个 32B 激活 - 1T 参数的模型(384 个专家),“在 Kimi-K2-Base 的基础上,通过对 15 万亿视觉与文本混合 tokens 进行持续预训练(continual pretraining)构建而成”(K2-Base 本身也是基于 15T tokens 训练的),并且附带了一个来自其创始人制作精良的视频(3 分钟,值得一看):
https://youtu.be/5rithrDqeN8
他们再次声称在 HLE 和 BrowseComp 上达到了 SOTA(脚注让人相信这些测试是真实可信的),同时在视觉和编码任务上也达到了开源模型的 SOTA:
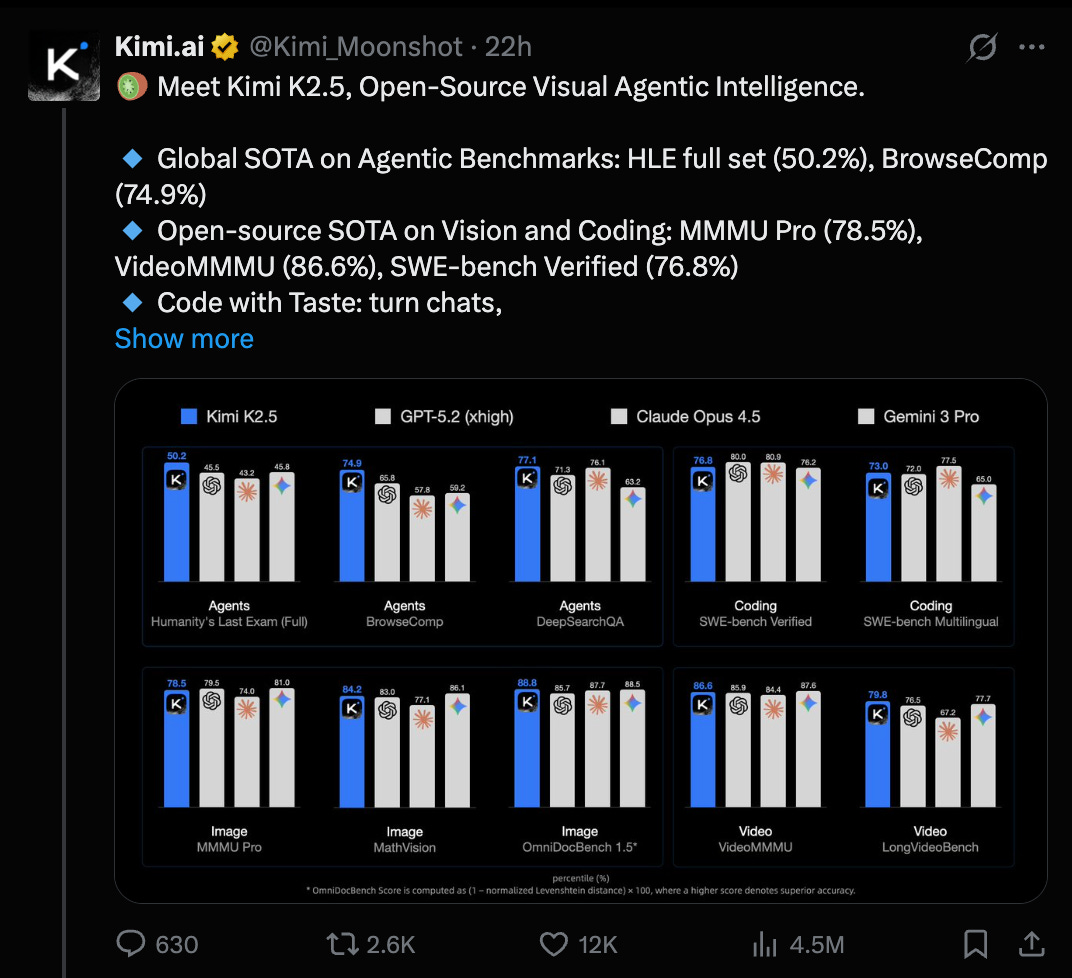
这里有几个值得注意的点 —— Kimi K2.5 首次实现了“原生多模态(natively multimodal)”,可能借鉴了 Kimi VL,但这归功于“大规模视觉-文本联合预训练”,包括视频(VIDEO)理解 —— “只需上传屏幕录像”,K2.5 就能为你重建该网站:
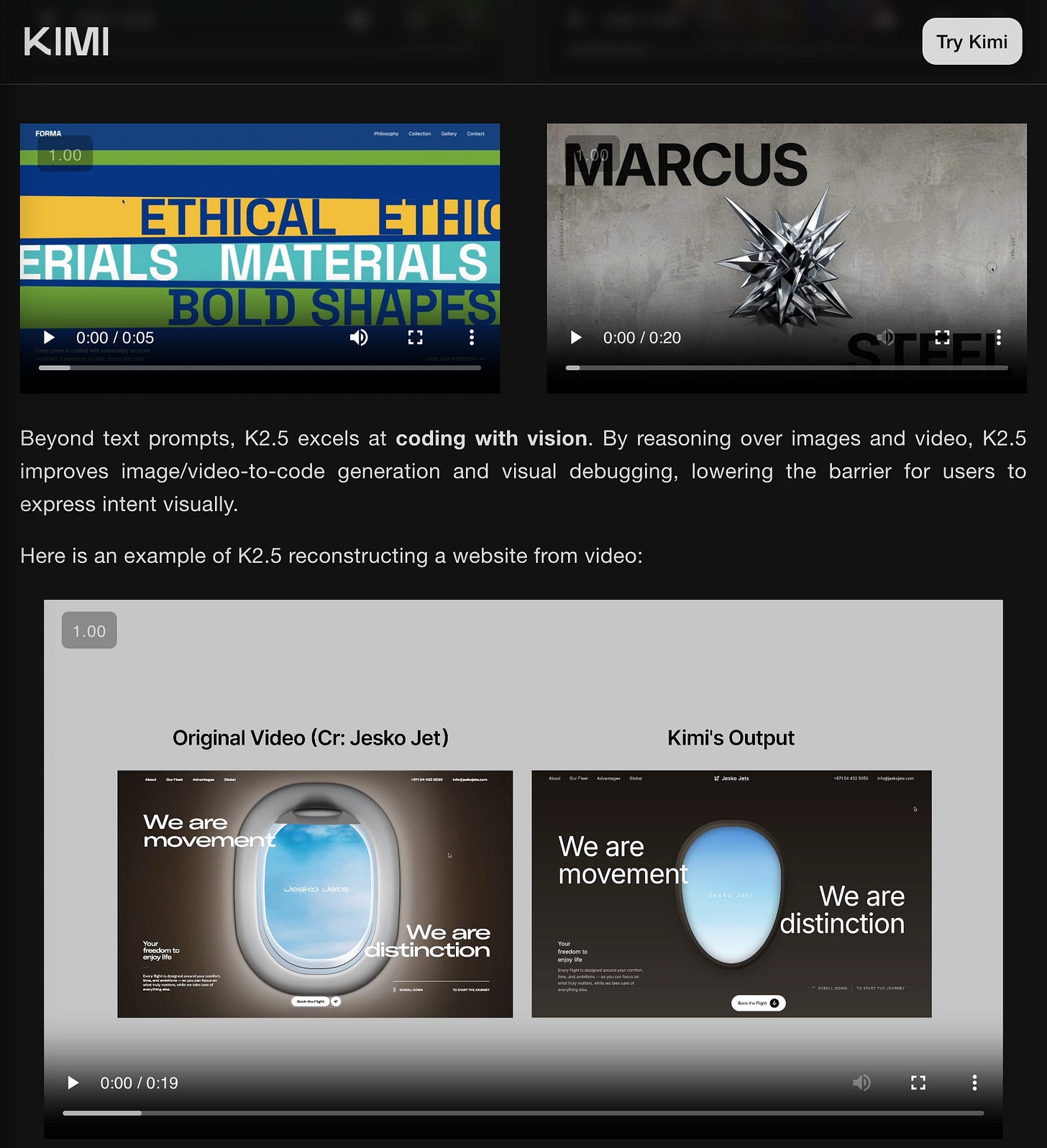
事实上,这是一个改变了架构的持续预训练(增加了 400M 参数的 MoonViT 视觉编码器),对于很少能见到规模化模型执行此类操作的模型训练人员来说,这非常令人兴奋。
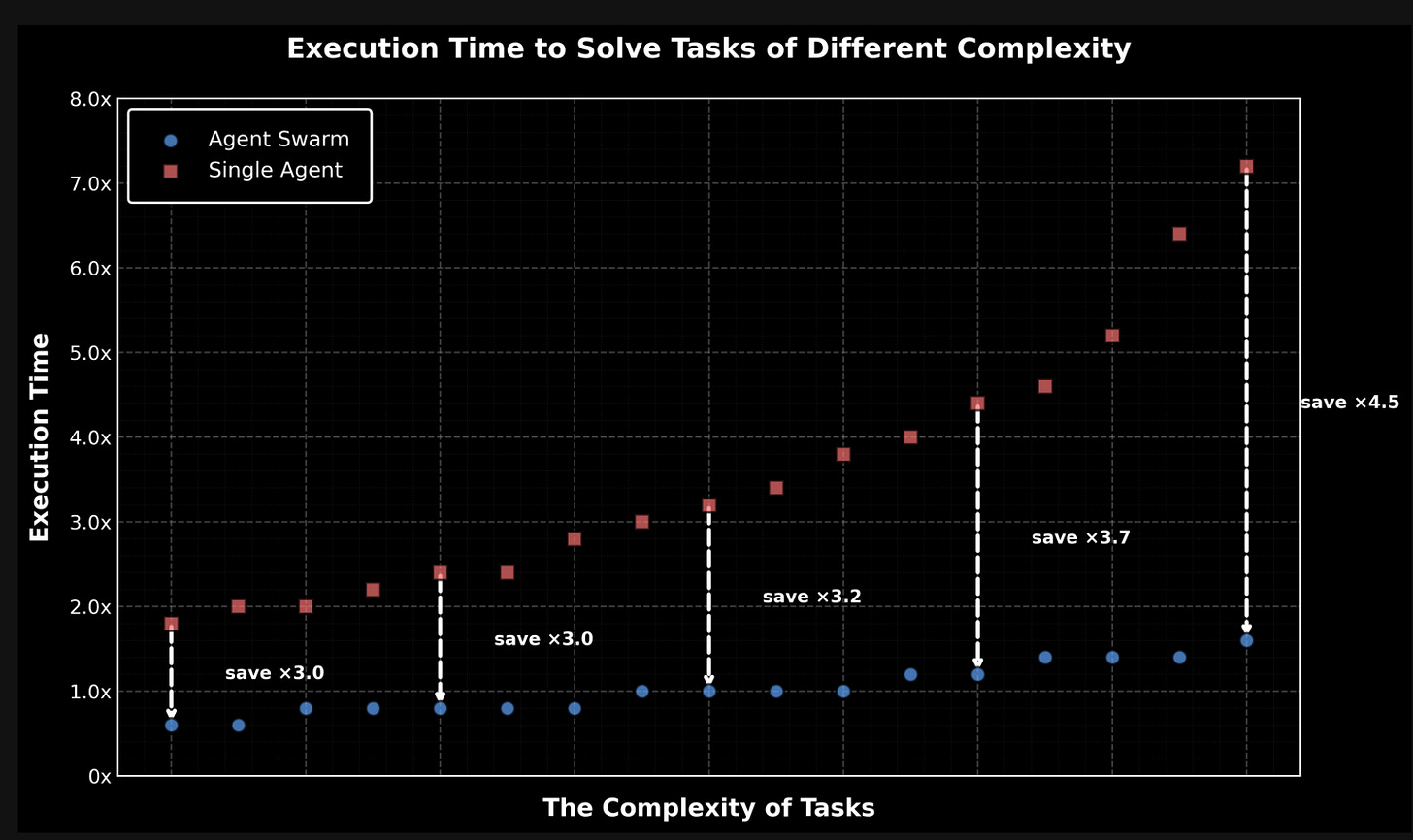
另外两个核心特性同样引人注目:Agent Swarm(仅对 Kimi App 付费用户开放),它能够“学习自我引导一个包含多达 100 个子 Agent 的集群,跨越多达 1,500 个协调步骤执行并行工作流,无需预定义角色或手工设计工作流。”这种并行化带来了更高的最终结果性能,速度提升高达 4.5 倍…… 当然,这里忽略了 token 成本。
以及“办公生产力(Office Productivity)”,其 K2.5 Agent 专注于“端到端处理高密度、大规模的办公工作”。
这绝非空洞的复述 —— 我们所看到的已足以让我们决定成为 Kimi App 的付费订阅用户。正如 Artificial Analysis 所指出的,中西方在开源模型方面的差距在今天又迈出了一大步。
AI Twitter 汇总
MoonshotAI 的 Kimi K2.5 生态:开源多模态 MoE + “Agent Swarm” 推送
- Kimi K2.5 模型发布与定位:Moonshot 将 Kimi K2.5 定位为旗舰级 open-weights 模型,具备 native multimodality(图像 + 视频)、强大的 agentic 性能,以及极具竞争力的 API 定价和延迟表现。官方发布媒体和信息包括:创始人介绍视频,定价/吞吐量声明,包括“Turbo 级速度 60–100 tok/s”,以及早期社区反响,重点强调 “agent swarm” 和多模态能力(kimmonismus,kimmonismus 关于多模态/视频的评价)。
- 技术要点(由社区汇总):对 K2.5 报道成分的核心解析——~15T 视觉+文本混合 tokens 持续预训练,通过 YaRN 将 context 从 128K 扩展至 256K,以 INT4 格式发布并采用选择性量化(仅对 routed experts 进行量化),以及 “Agent Swarm” 编排概念(动态生成 subagents;最高支持 100 个并行 subagents / 1,500 个步骤;声称实际执行时间提升了 3–4.5 倍)。总结由 @TheZachMueller 提供(并指向了 技术报告)。
- 基准测试/第三方评估框架:Artificial Analysis 将 K2.5 定位为“领先的 open weights”模型,并更接近顶尖实验室水平,重点提到了 GDPval-AA Elo 1309(agentic 知识工作测试集)、MMMU Pro 75%、INT4 版本约 595GB,以及 64% 的幻觉率(较 K2 Thinking 有所改善)等统计数据:@ArtificialAnlys。LMArena 的公告也将 K2.5 Thinking 列为其 Text Arena 快照中的 #1 开源模型:@arena。(请将排行榜视为特定时间点的参考;测试框架、工具链和 prompting 方式同样重要。)
- 发行与“本地运行”信号:K2.5 迅速上线各基础设施平台:Ollama cloud 及其启动集成 (@ollama),Together AI 上架 (@togethercompute),以及合作伙伴 Fireworks (Moonshot)。一个值得注意的本地推理数据点:据报道,K2.5 通过 MLX 并在 sharded generation 模式下,可以在 2× M3 Ultra 上运行(虽然慢但“可用”),在高显存占用下达到 ~21.9 tok/s:@awnihannun(附带命令片段见 此处)。
- 围绕 Kimi 的产品生态:Moonshot 还推出了相关工具:Kimi Code,一个采用 Apache-2.0 协议的开源代码 Agent,集成了主流 IDE/编辑器(公告),以及用于构建自定义 Agent 的 Agent SDK(链接)。一个名为 “Kimi Product” 的账号专门用于分发 prompts/用例(上线),并发布了一个病毒式传播的 “video-to-code” 网站克隆演示(演示)。
规模化的开源“美国反击”:Arcee/Prime Intellect Trinity Large 预览版 (400B MoE)
- Trinity Large 预览版发布:Arcee 发布了 Trinity Large 的初始权重作为“预览”版本:@arcee_ai,@latkins 提供了更多细节。Prime Intellect 将其定位为一个开放的 400B MoE 模型,具有 13B active 参数,使用 Datology 数据进行训练:@PrimeIntellect。OpenRouter 提供了限时免费访问:@OpenRouterAI。
- 架构/训练细节(最具参考价值的技术推文):@samsja19 提供了一份强有力的技术快照:400B/A13B MoE,经过 17T tokens 训练;采用 3:1 交错的 local/global gated attention,SWA,NoPE 应用于 global layers + RoPE 应用于 local layers(如推文所述),depth-scaled sandwich norm,sigmoid routing,使用 Muon 训练;在 Prime Intellect 的基础设施上,使用约 2,000 颗 B300s 训练了一个月,数据清洗由 DatologyAI 完成。
- 数据规模重点:Datology 的参与被强调为项目的核心部分:在一名团队成员的回顾中提到“总计 6.5T tokens”和“800B synthetic code”(以及多语言语料清洗):@code_star。另一份回顾提到 17T tokens 中包含 8T synthetic 数据:@pratyushmaini。
- 生态系统就绪:vLLM 宣布对 Trinity Large 提供 day-0 support 推理服务:@vllm_project。回复中的核心观点是,一家西方机构再次尝试从零开始进行 frontier-ish pretraining 并发布开放模型,而不仅仅是做 post-training 或评估。
Agents 无处不在:orchestration、subagents、planning critics 以及 IDE/CLI 集成
- Agent “swarm” 与 “subagents” 的趋同:Kimi 的 “Agent Swarm” 概念(动态 subagent 创建)与 central orchestrator + parallel specialists 的更广泛模式相呼应。最明确的“入门模式”阐述是 LangChain 的 stateless subagent 模型(并行执行 + 最小化 context 膨胀):@sydneyrunkle。同时,在社区总结中,Kimi 的 swarm 被视为通过 Parallel-Agent RL (PARL) 实现的可训练 orchestration:(Zach Mueller)。
- 通过“执行前批判”提升可靠性:Google 的 Jules 引入了 Planning Critic——第二个负责在执行前对计划进行批判的 Agent,声称任务失败率降低了 9.5%:@julesagent。Jules 还增加了“建议任务”功能,用于主动优化:@julesagent。
- Coding-agent 产品竞争加剧:Mistral 发布了 Vibe 2.0 升级(包括 subagents、用户自定义 agents、skills/slash commands 以及付费计划):@mistralvibe 和 @qtnx_。MiniMax 推出了 “Agent Desktop” 工作区,定位比 Claude Cowork 更精致:@omarsar0(以及 MiniMax 自身的 onboarding 自动化:@MiniMax_AI)。
- IDE 基础设施与检索:Cursor 声称 semantic search 显著提升了 coding-agent 的表现,且大型代码库的索引速度“快了几个数量级”:@cursor_ai。VS Code 继续强化 Agent UX(例如,对命令执行提供更安全的解释):@aerezk,此外还有通过 MCP Apps 规范返回 UI 的 MCP servers(如 LIFX 控制面板示例):@burkeholland。
Document AI 与多模态系统:DeepSeek-OCR 2 与 “Agentic Vision”
- DeepSeek-OCR 2:学习型阅读顺序 + Token 压缩:DeepSeek-OCR 2 标志着从固定光栅扫描向学习型 Visual Causal Flow(视觉因果流)与 DeepEncoder V2 的转变,包括 16 倍视觉 Token 压缩(每张图像 256–1120 tokens),并在 OmniDocBench v1.5 上达到 91.09% (+3.73%) 的准确率;vLLM 已提供首日支持:@vllm_project。Unsloth 也指出了类似的重大改进:@danielhanchen。
- 机制直觉(为什么对流水线很重要):Jerry Liu 提供了一个清晰的“为什么学习型顺序有用”的解释:通过允许查询 Token 注意连续区域而非严格的从左到右,避免了表格/表单在语义上的碎片化:@jerryjliu0。Teortaxes 则给出了务实的评估观点:OCR 2 与 “dots.ocr” 持平,虽然“远未达到 SOTA”,但这些思路可能会影响后续的多模态产品:@teortaxesTex。
- Gemini “Agentic Vision”(智能体视觉)= 视觉 + 代码执行循环:Google 正在将“思考、行动、观察”循环产品化,模型通过编写/执行 Python 代码来对图像进行裁剪、缩放和标注,声称在多项视觉基准测试中带来了 5–10% 的质量提升:@_philschmid 以及官方推文:@GoogleAI。这是将“工具增强视觉”提升为原生功能而非外挂插件的明确举措。
科学与研究工作流中的 AI:OpenAI Prism 作为 “集成 AI 的 Overleaf”
- Prism 发布:OpenAI 推出了 Prism,这是一个由 GPT-5.2 驱动的免费“面向科学家的 AI 原生工作区”,定位为统一的 LaTeX 协作环境:@OpenAI 和 @kevinweil。社区总结将其称为“集成 AI 的 Overleaf”(支持校对、引用、文献检索):@scaling01。
- 数据/知识产权 (IP) 澄清:Kevin Weil 澄清说,Prism 遵循 ChatGPT 的数据控制协议,OpenAI 不会从个人发现中分成;任何 IP 协作协议都将针对大型机构进行定制:@kevinweil。
- 技术上的重要意义:Prism 是一项产品赌注,认为协作上下文 + 工具集成(LaTeX、引用、项目状态)将成为持久的优势——这呼应了中文互联网关于 OpenAI 基础设施和组织设计中“上下文 > 智能”的主题讨论:@ZhihuFrontier。
值得关注的研究笔记与基准测试(RL、规划、多语言扩展)
- 长程规划基准测试:DeepPlanning 提出了可验证约束的规划任务(多日旅行、购物),报告称前沿 Agent 仍难以应对;强调了显式的推理模式和并行工具使用:@iScienceLuvr。(这与“旅行规划再次难倒 AI”的梗相契合:@teortaxesTex。)
- RL 效率与轨迹复用:PrefixRL 思想——以 Off-policy 前缀为条件,加速困难推理任务中的 RL 训练,声称达到相同奖励的速度比强基准线快 2 倍:@iScienceLuvr。
- 多语言扩展法则:Google Research 宣布了针对海量多语言语言模型的 ATLAS 扩展法则,为平衡数据混合比例与模型规模提供数据驱动的指导:@GoogleResearch。
- 数学研究现状核查:Epoch 的 FrontierMath: Open Problems 基准测试向所有人开放尝试;“AI 尚未解决其中的任何问题”:@EpochAIResearch。
热门推文(按参与度排序)
- OpenAI 发布 Prism(AI LaTeX 研究工作区):@OpenAI
- Moonshot 创始人视频介绍 Kimi K2.5:@Kimi_Moonshot
- Kimi “视频转代码” 网站克隆演示:@KimiProduct
- Ollama:Kimi K2.5 在 Ollama 云端上线及相关集成:@ollama
- Claude 生成 3Blue1Brown 风格动画的展示(教育影响):@LiorOnAI
- Figure 推出 Helix 02 自主全身机器人控制系统:@Figure_robot
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. 新模型与基准测试发布
-
介绍 Kimi K2.5,开源视觉 Agent 智能 (热度: 643): **Kimi K2.5 是一款开源视觉 Agent 智能模型,在 Agent 基准测试中达到了全球领先(SOTA)水平,在 HLE 全集上得分
50.2%,在 BrowseComp 上得分74.9%。它在开源视觉和代码基准测试中同样处于领先地位,MMMU Pro 得分为78.5%,VideoMMMU 为86.6%,SWE-bench Verified 为76.8%。该模型引入了处于 Beta 阶段的 Agent Swarm 功能,支持多达100个子 Agent 并行工作,可执行1,500次工具调用,运行速度比单 Agent 架构快4.5×。Kimi K2.5 已在 kimi.com 的聊天和 Agent 模式中上线,并在 Hugging Face 上提供了额外资源。** 一条评论强调了100个子 Agent 并行工作的惊人能力,认为这在代码任务中具有提升性能的潜力。另一条评论指出原发布者的账号被封禁,引发了对其账号真实性的质疑。- Asleep_Strike746 强调了 Kimi K2.5 并行运行 100 个子 Agent 的强大能力,认为这在执行复杂任务(如代码任务)方面具有潜力。这种并行性可以显著提升多线程环境下的性能,使其成为开发者自动化或优化工作流的有力工具。
- illusoryMechanist 指出了 Kimi K2.5 的规模,拥有 “1T 激活参数” 和 “32B”(可能指模型的参数量),表明其具有庞大的计算能力。这暗示 Kimi K2.5 能够处理大规模数据处理和复杂的问题求解任务,使其成为开源 AI 领域极具竞争力的选手。
- Capaj 分享了对 Kimi K2.5 的实际测试,提示它生成一个骑独轮车的狐狸的 SVG。结果被描述为“还不错”,这意味着虽然该模型可以处理创意任务,但在输出质量或创意方面可能仍有提升空间。这种测试对于理解模型在现实应用中的能力至关重要。
-
Jan v3 Instruct:一款在 Aider 榜单提升 40% 的 4B 代码模型 (热度: 333): 图片是一个名为 “Aider Benchmark” 的柱状图,展示了各种代码模型在多语言代码编辑通过率方面的表现。“Jan-v3-4B-base-INSTRUCT” 模型以
18分领先,显著超过了 “Qwen3-4B-THINKING-2507” 的12.1分和 “Ministral-3-8B-INSTRUCT-2512” 的6.8分。这突显了 Jan-v3 模型的高效率以及超过40%的性能提升,展示了其在代码任务中增强的能力。该模型旨在提升数学和代码性能,使其成为轻量级辅助和进一步 Fine-tuning 的强力候选。 一位评论者对 Qwen 4B 2507 模型在小任务中的表现表示赞赏,称尽管其体积较小,但性能令人印象深刻。另一位用户分享了使用 Jan 模型的混合体验,称赞其能有效使用搜索工具,但指出偶尔会出现工具调用失败和奇怪的响应,这可能是由于 System Prompt 导致的。- 据报道,Jan v3 Instruct 模型作为一个 40 亿参数的代码模型,在 Aider 基准测试中实现了 40% 的性能提升。这表明其在处理代码任务的能力上有了显著进步,在特定场景下可能优于 Qwen 4B 2507 等其他模型。用户注意到该模型能有效利用搜索工具进行代码解释,尽管在 Web 聊天应用中偶尔会出现工具调用失败和一些 System Prompt 问题。
- 一位用户报告了在 chat.jan.ai 上使用 Jan v3 模型的混合体验,强调了它能正确使用搜索工具并阅读代码以解释项目流程。然而,他们也指出了一些工具调用失败和不相关的响应,可能归因于 System Prompt。该用户表达了对该模型与 Claude Code 潜在集成的兴趣,认为它可能成为日常代码任务中代码搜索和问答的有价值工具。
- 强调了 Jan v3 模型在基准测试中的表现,并特别提到其 Demo 已在 chat.jan.ai 上线。该模型处理简单小任务的能力被拿来与 Qwen 4B 2507 进行比较,后者在类似任务中更受青睐。讨论表明,Jan v3 的 Fine-tuning 可能会在某些代码场景中提供竞争优势。
-
deepseek-ai/DeepSeek-OCR-2 · Hugging Face (热度: 385): DeepSeek-OCR-2 是一款在 Hugging Face 上发布的顶尖 OCR 模型,针对带有视觉因果流(visual causal flow)的文档处理进行了优化。它需要
Python 3.12.9和CUDA 11.8环境,并利用了torch和transformers等库。该模型支持动态分辨率,并使用 flash attention 以增强其在 NVIDIA GPUs 上的性能。它提供了多种用于文档转换的提示词,使其能够胜任不同的 OCR 任务。一位用户强调了 PaddleOCR-VL 在与其他模型对比评分时的惊人表现,暗示其具有潜在优势。另一位用户分享了 DeepSeek-OCR-2 的演示,指出由于用户错误最初出现了重复问题,但在调整解码参数后得到了解决,性能相比第 1 版有显著提升。- 一位用户强调了 PaddleOCR-VL 的出色性能,暗示其在与 B/C/D 等其他模型对比时脱颖而出。这是基于该用户信任的第三方评估模型性能的得分。这表明在 OCR 模型对比的背景下,PaddleOCR-VL 的指标值得关注。
- 另一位用户分享了使用 GPU 额度实现 DeepSeek-OCR-2 演示的经验。最初,由于参数设置错误,他们遇到了内容重复的问题,但在调整为 DeepSeek 推荐的解码参数后,性能大幅提高。该用户注意到更新后的版本比其前身 DeepSeek-OCR v1 更加可靠。
-
分享了 DeepSeek-OCR-2 的 GitHub 仓库和论文,为对该模型的技术细节和实现感兴趣的人提供了资源。论文可能包含有关模型架构、训练过程和性能基准测试的深入信息,这些信息对于技术评估和理解至关重要。
-
transformers v5 final is out 🔥 (热度: 503): 来自 Hugging Face 的 Transformers v5 引入了显著的性能提升,特别是对于 Mixture-of-Experts (MoE) 模型,实现了
6x-11x的加速。此次更新通过移除慢速/快速 tokenizers 简化了 API,提供了明确的 backend 和增强的性能。此外,动态权重加载现在变得更快,支持带有 quantization、tensor parallelism 和 Parameter-Efficient Fine-Tuning (PEFT) 的 MoE。针对过渡到此版本的用户,官方提供了迁移指南和详细的发布说明。一位用户询问了这些改进对于在本地运行中小型 MoE 模型的影响,认为这些增强功能可能会减轻内存带宽限制。另一位用户报告称,在更新到 v5 和 vllm 0.14.1 后,单提示词推理速度提升了50%,并发推理速度提升了100%。- Transformers v5 中的 Mixture-of-Experts (MoE) 模型表现出显著的性能提升,报告的加速范围为 6x 到 11x。这对于在本地运行模型的用户尤其重要,因为它意味着 MoE 现在可以更有效地利用计算资源,从而可能减少内存带宽限制。这对于使用 NVIDIA GPUs 或 AMD iGPUs(如 Strix Halo)的配置非常有益,因为在这些配置中计算能力是一个限制因素。
- 一位用户报告称,将版本从 0.11 升级到 Transformers v5 和 vllm 0.14.1 后,单提示词推理速度提高了 50%,在 40x 工作负载下的并发推理速度提高了 100%。这突显了最新版本中显著的性能增强,对于需要高吞吐量和低延迟的应用至关重要。
- Transformers v5 的更新现在允许 Mixture-of-Experts (MoE) 模型与 quantized 模型配合使用,这在以前是不可能的。这一进步通过减小模型大小和计算需求,实现了更高效的模型部署,使得在性能不打折扣的情况下,在不太强大的硬件上运行复杂模型成为可能。
2. 本地 LLM 硬件与配置讨论
-
工作台上的 216GB 显存。是时候看看哪种组合最适合本地 LLM 了 (热度: 577): 该帖子讨论了使用二手 Tesla GPU(能以较低成本提供大量 VRAM)进行本地大语言模型 (LLM) 测试。作者开发了一套 GPU 服务器基准测试套件,用于评估这些旧款 GPU 在并行使用时的性能。图片展示了一个配有多块 NVIDIA GPU 的装置,强调了在机器学习任务中最大化 VRAM 的重点。技术挑战在于如何在没有显著带宽损失的情况下有效利用这些 GPU,因为大多数负担得起的服务器主板仅支持有限数量的 GPU。 评论者对使用旧款 Tesla GPU 的实用性表示怀疑,原因是可能存在 Token 处理速度和散热需求方面的问题。人们对作者如何在没有带宽损失的情况下连接多块 GPU 很感兴趣,并有建议认为像 DGX Spark 这样的较新系统可能会在某些任务中提供更好的性能。
- HugoCortell 提出了关于将多块 GPU 连接到单台 PC 时带宽限制的技术担忧,并指出大多数价格适中的服务器主板仅支持少数几块 GPU。这可能会导致带宽的显著损失,而带宽对于本地 LLM 配置中的高效并行处理至关重要。
- BananaPeaches3 强调了旧款 GPU 在性能上的关键问题,特别是在处理大型系统 Prompt 时。他们提到,虽然 Token 生成速度可能是可以接受的,但 Prompt 处理时间可能成为瓶颈,尤其是当 Prompt 大小达到 15k Token 时。这表明,尽管 Token 生成速度稍慢,但像 DGX Spark 这样具有更快 Prompt 处理能力的较新系统可能会更高效。
- FullOf_Bad_Ideas 指出了 gpu_box_benchmark 的一个局限性,即它没有测试跨多块 GPU 拆分的大型模型的推理服务。这是高 VRAM 配置的一个重要用例,表明该基准测试在评估大规模 LLM 应用的实际性能方面存在缺憾。
3. 来自 AI 实验室的预热与公告
-
Qwen 开发者正在预热新动态 (热度: 331): 图片是来自 **通义实验室 (Tongyi Lab) 的一条推文,包含一个 ASCII 艺术面孔和闪电表情,暗示即将发布公告。Reddit 社区推测这可能与一个新的视觉语言模型有关,可能命名为 Z-Image,最近在 ComfyUI 的 Pull Request 中提到了这个名字。公告的时间点可能经过战略规划,选在农历新年之前,与 K2.5 以及可能发布的 q3.5、dsv4 和 mm2.2 等备受期待的发布保持一致。** 评论者推测该公告与 Z-Image 模型有关,ComfyUI 最近的更新中提到了该模型。此外,还有关于发布时间的讨论,认为它可能与农历新年同步。
- ComfyUI PRs 中提到的“Z-Image”暗示了可能存在与图像处理相关的新功能或模型更新。这与最近在集合中添加隐藏项的更新相吻合,表明开发和测试阶段正在进行中。
- 人们推测在农历新年之前会发布多个模型和更新,包括 K2.5、q3.5、dsv4 和 mm2.2。这个时间点具有战略意义,因为许多实验室都致力于在假期开始前发布更新,而今年的假期从 1 月 17 日开始。
- 一位用户推测将发布“Qwen4 Next 48B A3B”,这可能暗示具有特定参数的新模型或版本,或许标志着模型架构或能力的进步。
-
MiniMax 正在预热 M2.2 (热度: 322): 该图片是来自 MiniMax 的推文,预热其 AI 模型 M2.2 的更新,并以“M2.1 slays. M2.2 levels up. #soon”暗示即将发布。这表明 M2.2 相比之前的 M2.1 版本在能力或性能上可能有潜在提升。背景信息显示了 AI 开发领域竞争激烈的态势,尤其是在中国实验室之间,DeepSeek v4 和 Kimi K3 预计也将很快发布。提到字节跳动潜在的闭源模型更增加了 AI 领域的竞争紧张感。 一条评论指出,关注焦点正转向智能体化混合专家模型 (MoEs),这可能会以牺牲传统 32B 模型的更新为代价。另一位用户对新模型表示期待,强调了 MiniMax 2.1 与 GLM 4.7 结合在编程任务中的有效性,以及即将推出的版本可能带来的影响。
- Loskas2025 强调了在编程中使用 MiniMax 2.1 和 GLM 4.7 的出色表现。他们预计即将推出的 MiniMax 2.2 和目前正在训练中的 GLM 5 可能会显著提升性能,这暗示了编程模型格局的潜在转变。
- CriticallyCarmelized 认为 MiniMax 优于 GLM 4.7,即使在高量化级别下也是如此,这表明 MiniMax 在性能方面极具竞争力。他们乐观地认为新版本可能会超越现有模型,有望成为他们本地部署的首选。
-
lacerating_aura 提到了围绕 “giga-potato” 与 DS4 相关联的猜测,但也指出缺乏 DS4 或 Kimi K3 存在的具体证据,表明关于这些模型的确切信息仍存在空白。
-
我为 Claude Code 构建了一个“蜂群思维”——7 个智能体共享内存并互相交流 (热度: 422): 该帖子描述了一个为 Claude Code 设计的多智能体编排系统,包含 7 个专门的智能体(如 coder, tester, reviewer),它们协同处理任务,使用
SQLite + FTS5共享持久化内存,并通过消息总线进行通信。该系统作为一个 MCP 服务器运行,并集成了 Anthropic, OpenAI 或 Ollama。它使用任务队列进行基于优先级的协调,允许智能体有效地传递上下文并进行协作。技术栈包括 TypeScript, better-sqlite3, MCP SDK 和 Zod。该项目是实验性的,采用 MIT 许可证,可在 GitHub 上获取。 一条评论质疑其与 bmad method 的相似性,暗示方法论上可能存在重叠。另一条评论幽默地询问这些智能体是否意见一致,暗示了多智能体达成共识的复杂性。- 该项目被拿来与 BMAD method 进行比较,后者也涉及多智能体系统。评论者对两者之间的差异感到好奇,认为在智能体共享内存和通信协议方面,两者的方法可能相似。
- 评论中提到了微软在两年前发布的 AutoGen,作为多智能体系统的解决方案。评论者建议探索这一资源以获取潜在的新思路,这表明多智能体通信和共享内存的概念并不新鲜,已被大型科技公司探索过。
- 关于使用 Claude Code 的选择受到了质疑,并建议考虑开源替代方案。这引发了关于开发多智能体系统时使用专有平台还是开源平台的优劣讨论,暗示了开源项目在社区支持和协作方面的潜在优势。
较少技术性的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Kimi K2.5 与开源 AI 模型发布
-
开源的 Kimi-K2.5 目前在包括编程在内的多项基准测试中击败了 Claude Opus 4.5。 (Activity: 597): 据报道,开源模型 Kimi-K2.5 在多项基准测试中表现优于 Claude Opus 4.5,尤其是在编程任务中。然而,帖子中并未详述这些基准测试的具体细节及性能提升的程度。这一说法暗示了开源 AI 能力的重大进步,但缺乏全面的数据来证实这一比较。评论者对该说法表示怀疑,强调基准测试可能无法完全代表现实世界的表现。他们质疑“多项”基准测试这一说法的有效性,并认为 Kimi-K2.5 与 Claude Opus 4.5 相比的实际效用仍有待证明。
- 尽管有基准测试结果,但人们对 Kimi-K2.5 在现实应用中优于 Claude Opus 4.5 的说法持怀疑态度。用户认为基准测试通常无法反映实际效用,尤其是在编程等复杂任务中,Opus 4.5 在通过单个 prompt 提供解决方案方面可能更具优势。
- 讨论凸显了对基准测试的普遍批评:它们可能无法捕捉模型在实际场景中的全部能力。一些用户对 Kimi-K2.5 超越 Opus 4.5 的说法表示怀疑,质疑特定的基准测试和现实世界的适用性,尤其是在 Opus 4.5 被认为具有优势的编程任务中。
-
一位用户声称在实际操作中取得了显著成功,称 Kimi-K2.5 已经取代了一家大公司的报告工作,这表明至少在某些情境下,Kimi-K2.5 可能具有实质性的效用。这与关于基准测试转化为现实世界表现的普遍怀疑形成了对比。
-
Kimi K2.5 发布!!! (Activity: 1149): 该图片展示了新发布的 Kimi K2.5 的性能对比图表,据称其在 Agent 任务中树立了新的 SOTA。图表在各项任务(包括 Agent、编程、图像和视频任务)中将 Kimi K2.5 与 GPT-5.2 (xhigh)、Claude Opus 4.5 和 Gemini 3 Pro 等其他模型进行了对比。Kimi K2.5 在多个类别中处于领先地位,特别是 “Agents: BrowseComp” 和 “Image: OmniDocBench 1.5*“,表明其在这些领域的卓越性能。此次发布附带了一篇详细介绍进展的博客文章 (链接)。评论者对基准测试表示怀疑,质疑其是否存在 cherry-picked 行为,并讨论了该模型在 hallucination 和 instruction-following 测试中的表现。一位用户指出,Kimi K2.5 虽然有所改进,但仍然会自信地输出错误答案,这与其他模型(如 Gemini 3)类似,后者也会自信地提供错误答案。GPT-5.1 和 5.2 在类似的测试中则会承认“我不知道”,突显了 AI 模型在 hallucination 方面面临的持续挑战。
- 一位用户测试了 Kimi K2.5 遵循指令的能力,要求它在不进行网络搜索的情况下识别一个特定的数学竞赛问题。该模型列出了虚构(hallucinated)的竞赛问题并自我推翻,最终给出了错误答案。这被视为比 Kimi K2 略有改进,后者未能遵循指令并超时。相比之下,Gemini 3 也自信地提供了错误答案,而 GPT 5.1 和 5.2 是仅有的承认“我不知道”的模型。
- Kimi K2.5 中“Agent 群体 (agent swarm)”的概念引人入胜,有推测认为它涉及 100 多个模型实例,并由一个监管实例统一指挥。这种设置预计成本高昂,人们好奇这是否是一个单一模型同时处理多个任务,若如此将代表重大进步。对于一些用户来说,scaffolding 策略(即多个模型协同工作)似乎更合理。
- 人们对将 Kimi K2.5 与 Gemini 3 等其他模型进行比较时所使用的基准测试持怀疑态度。一位用户质疑基准测试是否经过了 cherry-picked,怀疑 Kimi K2.5 是否能持续超越 Gemini 3,考虑到模型能力的现状,这似乎不太可能。
-
Sir, the Chinese just dropped a new open model (热度: 1915): **Kimi 发布了一个开源的万亿参数视觉模型,据报道在多个基准测试中表现足以媲美 Opus 4.5。由于该模型的规模以及其具有竞争力的性能主张,此次发布具有重要意义,尤其是考虑到此类大型模型通常伴随着极高的成本和复杂性。这次发布可能会影响 AI 视觉模型的格局,尤其是在可访问性和成本效益方面。** 社区中对中国模型的真实性能存在怀疑,一些用户认为虽然它们具有成本效益,但尽管基准测试声称如此,它们可能无法真正匹配 Claude、GPT 或 Gemini 等模型的能力。
- Tricky-Elderberry298 强调了仅仅依赖基准测试来评估 LLM 的局限性,并将其类比为仅根据引擎参数来评估汽车。他们认为,实际使用情况(例如 Claude 和 Kimi K2.5 在复杂项目中的表现)比单纯的基准测试分数更能衡量能力。
- Durable-racoon 讨论了 Kimi K2.5 模型的独特功能,指出其能够同时编排 500 个 Agent,并将视频转换为可运行的软件 UI 原型。他们还提到其在创意写作方面的表现优于 Opus,同时也承认 Kimi K2.5 比大多数中国模型更贵,输入/输出价格定为 $0.60/$3。
-
DistinctWay9169 指出,许多中国模型(如 Minimax 和 GLM)通常是“基准测试刷分型”(bench maxed),这意味着它们在基准测试中表现良好,但可能无法达到 Claude、GPT 或 Gemini 等模型在现实世界中的表现。这表明基准测试结果与实际应用中的可用性或有效性之间存在差异。
-
Gemini 3 finally has an open-source competitor (热度: 168): 这张图片是一个对比图表,突出了新发布的 **Kimi K2.5 视觉模型与 Gemini 3 Pro 等其他知名模型的性能对比。根据图表显示,Kimi K2.5 具有竞争力,在 “Humanity’s Last Exam”、”BrowseComp” 和 “OmniDocBench 1.5” 等多项基准测试中经常超越 Gemini 3 Pro。这使得 Kimi K2.5 成为闭源 Gemini 3 Pro 的强力开源替代方案,挑战了其在该领域的地位。** 一些用户对 Kimi K2.5 与 Gemini 3 Pro 相比的实际表现表示怀疑,评论认为虽然基准测试令人印象深刻,但实际性能可能无法与之匹配。还有一种观点认为,开源模型可能难以与大型闭源公司竞争。
- MichelleeeC 指出开源竞争对手与 Gemini 3 之间存在显著的性能差距,尤其是在没有搜索引擎辅助的情况下测试利基话题时。这表明开源模型可能缺乏 Gemini 3 所受益的全面训练数据或微调,从而影响了其在专业领域提供准确答案的能力。
- Old_Technology3399 和 Just_Lingonberry_352 都表示开源竞争对手明显逊于 Gemini 3。这种共识表明,虽然开源模型可能是迈向 AI 民主化的一步,但在性能和可靠性方面与 Gemini 3 等成熟的闭源模型相比仍有差距。
- ChezMere 关于 ‘benchhacking’(基准测试走捷径)的评论表达了对开源模型实际表现与基准测试结果之间差异的怀疑。这暗示虽然模型在受控测试中可能表现良好,但可能无法转化为有效的现实应用,凸显了 AI 模型评估中的一个常见问题。
-
企业级开源/中国 AI 正蓄势待发,销售额有望超越美国专有模型。个人投资者请注意。 (热度: 30): 该帖子强调了开源和中国 AI 模型在细分领域相对于美国专有模型的竞争优势,重点强调了其成本效益和相当的性能。值得注意的模型包括在 MATH-500 和 LiveCodeBench 上排名第一的 **DeepSeek-V3 / R1,以及在 LMSYS Chatbot Arena 和 MMLU-Pro 中表现出色的阿里巴巴 Qwen3-Max / Coder。与 OpenAI 的 GPT-5.2 和 Claude 4.5 Sonnet 等专有模型相比,这些模型每百万 token 的成本显著降低,输入成本低至
$0.15到$0.60,而专有模型的起步价为$3.00。帖子建议个人投资者应关注这些进展,因为中国公司正在准备 IPO;a16z 指出,向其进行路演的初创公司中有 80% 使用的是中国开源 AI 模型。** 一条评论质疑 Kimi K2 是否优于 GLM 4.7,表明了关于这些模型在特定语境下相对性能的争论。- 讨论对比了 Kimi K2 模型与 GLM 4.7 模型的性能。Kimi K2 在特定任务中的效率受到关注,在某些基准测试中可能优于 GLM 4.7。然而,这两个模型的选择可能取决于具体的应用场景,因为 GLM 4.7 可能会在不同领域表现出色。对话强调了根据特定任务的性能指标而非一般性的优越性声明来评估模型的重要性。
2. Gemini AI Studio 与使用限制
-
Gemini AI Studio 现在基本无法使用了。还有其他具有 1M 上下文窗口的 LLM 吗? (热度: 162): **Gemini AI Studio 由于 Google 降低了每日 prompt 限制,对于用户来说可用性已降低,这影响了依赖其
1 million token上下文窗口的工作流。处理大量文档和对话的用户正在寻找替代方案。值得注意的是,Grok 4.1 提供2 million token的上下文窗口,而 Claude Sonnet 4.5 在 Kilo Code 环境中提供1 million token的上下文窗口。这些替代方案可以为需要大上下文能力的用户提供服务。** 一些用户建议,像 Claudie-cli 或 codex-cli 这样高效的 CLI 工具可以通过有效地管理和检索长文本中的信息,从而减轻对巨大上下文窗口的需求。- Coldshalamov 提到 Grok 4.1 fast 提供
2M上下文窗口,是讨论中1M窗口的两倍。这表明 Grok 4.1 fast 可能是需要更大上下文窗口用户的可行替代方案。 - Unlucky_Quote6394 强调 Claude Sonnet 4.5 在 Kilo Code 中使用时提供
1M上下文窗口,为寻求大上下文能力的用户提供了另一个选择。 - Ryanmonroe82 建议将文档进行 embedding(嵌入)作为使用云端模型的替代方案,暗示这种方法在处理大型文本数据时可能比依赖庞大的上下文窗口更高效、更有效。
- Coldshalamov 提到 Grok 4.1 fast 提供
-
热内存中只有 32,768 或 (2^15) 个 token…. Gemini 已被 Alphabet 刻意限速,变成了挂羊头卖狗肉。Gemini Pro 截至今天比免费版还差。他们向 Pro 用户宣传超过一百万个 token。这是欺诈。 (热度: 858): 该 Reddit 帖子声称 **Alphabet 故意将 Gemini Pro 的 token 限制下调至
32,768 tokens,这显著低于宣传的超过 100 万 token 的容量。这种限速据称降低了 Gemini Pro 的性能,使其效果不如免费版。帖子还提到,Ultra 和 Enterprise 版本存在131,072 tokens的硬上限,尽管宣传中称高达 200 万 token。作者担心这种限制可能会导致用户流失,特别是在可能集成到 Siri 的情况下。** 评论者对 Gemini 的性能表示不满,将其与 GPT-3 等旧模型进行了不利的对比。还有人对内存管理提出了批评,称其导致了数据不准确和效率低下。 - Substantial_Net9923 强调了 Gemini 内存管理的一个重大问题,指出该模型因索引(indexing)导致的内存丢失问题严重。这种低效率在量化金融(quantitative finance)交易讨论中尤为明显,据报道,该模型生成错误数据的频率比以前更高,表明其可靠性在下降。
- klopppppppp 观察到 Gemini 的性能急剧下降,将其与 GPT-3 等旧模型进行了比较。尽管如此,他们指出 Gemini 在 ‘deep research mode’ 下表现依然非常出色,这表明该模型的能力可能取决于上下文,或者在某些场景下受到了限制(throttled)。
-
SorryDistribution604 对 Gemini 最近的表现表示沮丧,将其比作 GPT-3 等老旧模型。这表明用户感知到模型能力出现了退化,这可能是由于 Pro 版本受到的限制(throttling)或其他限制因素导致的。
-
关于最近的 AI Studio 额度降级: (热度: 660): 图片是一则来自 Gemini API 的通知,告知 AI Studio 用户免费使用限额有所降低,并建议通过使用 API key 以继续访问。通知指出,这些限额可能会随时间进一步降低,并提到正努力与 Google AI Pro/Ultra 集成,以便在 AI Studio 内共享限额。这一变化反映了收紧免费 AI 资源访问的广泛趋势,可能会影响依赖这些工具进行实验和开发的开发者。 评论者对免费使用限额的减少表示挫败,并指出 Gemini 在遵循指令方面的表现也有所下降。有一种情绪认为,这些变化损害了 AI Studio 的实用性,因为用户觉得他们获得的价值和功能在减少。
- trashyslashers 强调了 Gemini 模型性能的一个重大问题,指出它‘在听取指令方面变得越来越差’。这表明模型遵循用户命令的能力有所下降,而每日使用限额的减少加剧了这一问题。用户被迫‘重写并重新生成’请求,表明模型处理能力存在效率低下的问题。
- Decent_Ingenuity5413 对 AI Studio 服务的稳定性和可靠性表示担忧,并将其与 OpenAI 过去出现的意外变更问题相提并论。评论还指出了 Gemini API 的一个严重计费问题,由于 Token 计数错误,用户遭遇了‘巨额超额计费’,导致费用超过 70,000 美元。这突显了计费系统的一个重大缺陷,可能会阻碍普通消费者使用该 API。
- Sensitive_Shift1489 对 AI Studio 似乎为了支持 Gemini App 和 CLI 等其他 Google AI 产品而被降级表示不满。评论暗示,这些变化是转移重点和资源的更广泛战略的一部分,但这可能是以牺牲 AI Studio 的质量和用户满意度为代价的。
3. Qwen 模型性能与应用
-
Qwen3-Max-Thinking - 与商业模型性能相当 (热度: 40): Qwen3-Max-Thinking 是一款声称提供与商业模型相当性能的 AI 模型,专注于增强推理和决策能力。正如原文章中所详述,该模型的架构和训练方法旨在提高处理复杂任务时的效率和准确性。然而,有用户反映该模型的 Agentic 代码模式存在无法编译的问题,这可能会影响其可用性。一位用户对该模型的可用性表示怀疑,因为存在编译问题;而另一位用户则希望 Qwen3-Max-Thinking 能够帮助降低商业模型的成本。
-
Qwen 模型,我们拿到了!Qwen-3-max-thinking (热度: 26): 该帖子宣布发布 **Qwen-3-max-thinking 模型,预计将于本周上线。该模型以其增强的功能而备受关注,尽管帖子中未提供这些增强功能的具体细节。“P.S. We got it” 的提法暗示该模型已经可以被部分用户访问。** 一位评论者质疑该模型是否从 10 月起就已经可用,这表明可能与之前的发布版本存在混淆或重叠。另一位评论者询问是否指的是 “OS”,暗示对于该模型是否开源(Open-Source)存在潜在的误解或需要进一步澄清。
-
30 亿 Token!评估一下我的 Token 使用量?(我是 QWEN3-MAX 最忠实的用户吗?) (热度: 20): 该帖子讨论了 **QWEN3-MAX 语言模型的惊人使用量,用户每天消耗
30 亿至 40 亿个 Token。这种极高的使用量促使 达摩院 (DAMO Academy) 授予了其额外的并发量,并提供了即将推出的 Qwen3.5-MAX 的早期访问权限。该用户将使用量的下降归因于周末,暗示平时需求一直保持高位。帖子强调了该模型的效果,用户称其为“世界上最好的 LLM”。** 评论反映了好奇与对比的结合,一位用户提到自己使用 QWEN 系列的本地模型也消耗了高达40 亿Token。另一位用户分享了使用该模型优化网站文案的积极体验,但表达了对在编程任务中使用该模型的访问限制担忧。- Available-Craft-5795 提到在 QWEN 系列中使用了 40 亿 Token,表明对这些模型的高度参与。这表明 QWEN 系列能够处理大规模的 Token 处理任务,这对于数据分析或大规模内容生成等广泛应用非常有益。
- Remarkable_Speed1402 讨论了使用新模型优化网站首页文案的情况,并指出了其有效性。然而,他们对模型的编程能力表示担忧,因为他们无法在 IDE 中访问该模型。这突显了将模型与开发环境集成时可能存在的局限性,可能会影响其在编程任务中的可用性。
-
Qwen3-32B 基准测试显示 INT4 下实现 12 倍容量提升,且准确率仅下降 1.9% (热度: 10): 在单个 **H100 GPU 上对 Qwen3-32B 进行的基准测试表明,使用
INT4量化时,用户容量实现了显著提升,与BF16相比达到了12 倍的增长,而准确率仅下降了1.9%。该研究涉及超过12,000个 MMLU-Pro 问题和2,000次推理运行,结果显示INT4在4k上下文下可以支持47个并发用户,而BF16仅能支持4个用户。完整的测试方法和数据可在此处查看。** 一条评论提出了关于该模型在编程任务中表现的问题,表明人们对量化如何影响除通用基准测试之外的特定应用领域非常感兴趣。- 讨论重点在于 Qwen3-32B 模型量化为 INT4 后的性能表现,强调了在准确率损失极小(
1.9%)的情况下实现了巨大的容量提升(12 倍)。这表明即使进行激进的量化,该模型也能保持高性能,这对于在资源受限的环境中部署大型模型至关重要。然而,对编程等特定任务的影响仍然是一个关注点,因为量化对不同任务的影响可能各不相同。
- 讨论重点在于 Qwen3-32B 模型量化为 INT4 后的性能表现,强调了在准确率损失极小(
AI Discord 内容精选
由 Gemini 3.0 Pro Preview Nov-18 生成的摘要之摘要之摘要
主题 1. Kimi K2.5 发布:SOTA Agentic 基准测试与 Swarm 能力
- Kimi K2.5 横扫 Agentic 基准测试:Moonshot AI 发布了 Kimi K2.5,在 HLE 全集 (50.2%) 和 BrowseComp (74.9%) 上实现了全球 SOTA,同时在 MMMU Pro (78.5%) 和 SWE-bench Verified (76.8%) 上发布了开源 SOTA 技术博客。Discord 上的用户注意到,该模型在官方宣布前已“悄然上线”,其事实核查和视觉能力有显著提升。
- Agent Swarm 模式进入 Beta 测试:此次发布引入了 Agent Swarm 功能,能够编排多达 100 个子 Agent 并并行执行 1,500 次工具调用 (tool calls),承诺在复杂任务上带来 4.5 倍 的性能提升。高阶用户可以在 kimi.com 上访问这种自主模式,不过早期测试者指出它消耗工具调用配额的速度很快。
- 价格和 API 不稳定性引发争议:虽然模型能力令用户印象深刻,但新的 Kimi Code 计划 因其限额低于 Z.ai 等竞争对手而受到批评,且促销价格将于 2 月结束。与 OpenRouter 的集成最初遇到了困难,用户报告了与 tool use endpoints 和图像 URL 处理相关的错误。
主题 2. 硬件加速:Unsloth 加速、FlagOS 与 Kernel Ops
- Unsloth 将 MoE 训练速度提升 14 倍:Unsloth 宣布 MoE 训练 现在比 v4 快 14 倍,即将推出的优化预计将再次翻倍,总计实现 30 倍加速。团队还推出了对 transformers v5 的全面支持,为使用最新版本库的用户简化了工作流 公告。
- FlagOS 瞄准统一 AI 栈:工程师们讨论了 FlagOS 的引入,这是一个开源系统软件栈,旨在统一 Model–System–Chip 层,以便在异构硬件上实现更好的工作负载可移植性。该项目旨在结合 软硬件协同设计 (hardware–software co-design) 的见解,以弥合 ML 系统与编译器之间的差距。
- Tinygrad 直接生成 Flash Attention 代码:在 Tinygrad 社区中,成员们成功证明了通过粒度重写,能够直接从 naive attention 的前端定义中生成 Flash Attention 代码 (codegen)。同时,讨论强调了从传统的内核调度器向 Megakernels 转变,以优化 GPU 吞吐量 Luminal 博客。
主题 3. OpenAI 生态系统:Prism、GPT-5.2 性能与模型退化
- Prism 工作区解锁科学协作:OpenAI 推出了 Prism,这是一个由 GPT-5.2 驱动的专用工作区,旨在为 ChatGPT 个人账户 持有者简化科学研究和写作 视频演示。虽然该工具针对学术严谨性,但讨论 GPT-5.2 与 Claude Opus 4.5 的用户指出,OpenAI 的模型在创意写作方面仍显吃力,据报道 Sam Altman 也承认了这一缺陷。
- 模型退化归咎于“白嫖党” (Leechers):各频道流传着一个反复出现的理论,认为 ChatGPT 和 Claude 的性能显著下降,部分用户声称质量下降了 40%。推测指向免费层用户 (“leechers”) 稀释了算力资源,或者是模型在递归地对其自身的合成输出进行训练。
- GPT-5 控制壳层 (Control Shell) 泄露:一个名为 GPT-5_Hotfix.md 的文件流出,据称是一个预生成控制壳层 (pre-generation control shell),它强制执行严格的语法和意图锁定,以防止模型漂移 (model drift)。此次泄露表明 OpenAI 正在使用激进的“封装器 (wrappers)”在生成开始前管理输出质量。
主题 4. Agentic 编程大战:工具、安全与重品牌化
- Clawdbot 在安全风波后更名为 Moltbot:在与 Anthropic 发生商标纠纷以及社区对 zero-auth 漏洞 表示严重担忧后,热门 Agent Clawdbot 已更名为 Moltbot 公告。用户此前指出,该机器人可以在未经许可的情况下读取环境变量密钥(environment keys),对敏感的财务和个人数据构成风险。
- Cursor 和 Cline 面临易用性阻碍:用户对 Cursor 的定价模式表示不满,指出少量复杂的 Prompt 可能会耗费 $0.50;而另一些用户在配置较低的硬件(8GB VRAM)上运行 Cline 时遇到困难,出现了
CUDA0 buffer错误。社区提供的修复方案包括将上下文长度缩减至 9000,并将内存管理卸载到专用 GPU 设置。 - Karpathy 押注 Agent 优先的编程(Agent-First Coding):Andrej Karpathy 发起讨论,概述了向使用 Claude 进行 Agent 驱动编程 的战略转变,强调了 LLM 相比传统方法具有“不知疲倦的坚持” 帖子。这与 Manus Skills 的发布不谋而合,开发者可以通过为这一新 Agent 平台构建用例来获取免费额度激励。
主题 5. 理论限制与安全:幻觉与生物风险
- 数学证明幻觉不可避免:BASI Discord 中讨论的一篇新论文利用与越狱(jailbreaking)机制相同的原理,从数学上证明了 LLM 总是会产生幻觉 Arxiv 论文。研究人员指出,越狱会扭曲上下文模型,使其无法标记恶意或错误的标签,从而加剧这一问题。
- 微调解锁潜伏的生物风险:一篇 Anthropic 论文 在 EleutherAI 引起辩论,该论文证明,在尖端模型的输出上微调开源模型可以释放被抑制的有害能力(如生物风险/biorisks),即使该模型之前经过安全训练 Arxiv 链接。研究结果表明,拒绝机制(refusals)是脆弱的,只需极少的算力即可撤销,引发了对双用途技术的担忧。
- AI 检测工具误标人类学者:工程师们强调了一个日益严重的问题,即 AI 检测工具 经常将 GPT 时代之前人类编写的学术文本误标为 AI 生成。共识认为这些检测器在根本上存在缺陷,但机构仍继续依赖它们,给研究人员和学生带来了困扰。
Discord: 高层级 Discord 摘要
BASI Jailbreaking Discord
- LLM 面临数学层面的越狱现实:一篇新论文 (https://arxiv.org/abs/2409.05746) 利用许多越狱方法所基于的相同原理,从数学上证明了 LLM 总是会产生幻觉。
- 一位成员警告说,越狱模型会显著增加其幻觉问题,因为越狱会改变并扭曲模型的上下文,使其不会标记那些通常会被标记为恶意的内容。
- GPT-5 控制壳层(Control Shell)在热修复后浮现:一位成员分享了一个文件 (GPT5_Hotfix.md),该文件被描述为 GPT-5 的生成前控制壳层,旨在生成开始前强制执行严格的语法、意图锁定和漂移预防。
- 该控制壳层旨在减轻模型漂移并强制执行预期的输出。
- 探索 Grok 的无审查图像生成:用户正在测试 Grok 图像生成器 的极限,试图通过越狱来获取不受限的内容,而另一些人则强调其与其他模型相比具有无审查的特性。
- 讨论还涉及了图像模型与语言模型的分离,这影响了 Prompt 注入的有效性。
- Clawdbot 的隐患:零认证漏洞:对 Clawdbot 受欢迎程度的探讨以及 VPS 使用量的激增,引发了对零认证(zero authentication)和潜在漏洞的担忧。
- 一位成员计划建立一个家庭实验室(home lab)来测试 Clawdbot 的漏洞,并指出目前存在易受攻击的实例。
- 研究人员加大对越狱数据集的搜寻:一位研究人员正在寻找包含分类或标签的知名越狱数据集,以协助进行中的研究,特别是针对恶意 Prompt。
- 一位成员回复道:“我真的不知道是否有免费的可用资源”,建议研究人员可能需要自己生成并标记这些 Prompt。
Unsloth AI (Daniel Han) Discord
- KV Cache 问题依然存在:用户反馈,在最新的 llama.cpp 中 KV cache 仍无法正常工作,尽管之前有过修复,但在较高的上下文长度下仍可能导致速度变慢,详见 此 GitHub issue。
- 讨论表明,之前的修复可能并未完全解决所有使用场景下的底层问题。
- Unsloth 全力加速 Transformers v5:Unsloth 现在已完全支持 transformers v5,并承诺很快将发布更加优化的训练版本,相关公告链接见 X。
- 此次升级将为利用 transformers 库最新功能的非凡用户简化工作流程并提升性能。
- MoE 训练速度飙升至 14 倍:据报道,MoE 训练 现在比 v4 快 14 倍,预计进一步的优化将使速度再次翻倍,最终可能比 v4 实现 30 倍的加速。
- 这种显著的速度提升可以极大地缩短复杂模型的训练时间。
- Kimi 失去了“毒舌”魅力?:用户讨论了 Kimi 模型的变化,有人指出它 听起来越来越像其他模型了,暗示在 Kimislop 发布后它失去了独特的个性。
- 一些人感叹失去了 Kimi 那种自作聪明的个性,比起变得 更加谄媚,他们更喜欢它以前那种 直言不讳指点你 的倾向。
- GLM 4.7 工具在 Blackwell 上的困扰:一位用户寻求在 Blackwell B200 上调用 GLM-v4.7 工具的帮助,但遇到了 CUDA 版本问题(驱动为 12.8,要求为 13)。
- 另一位用户提供了一组使用 torch 2.9 和 CUDA 13 的
uv pip install命令,并引导用户参考这个有用的 unsloth.ai 文档 来进行调用,并使用json.loads。
- 另一位用户提供了一组使用 torch 2.9 和 CUDA 13 的
LMArena Discord
- Molmo 2 擅长视频分析:根据 这篇博客文章,Molmo 2 模型在视频中的对象追踪和事件定位方面表现出色。
- 成员们好奇该模型是否可用于平台上的视频上传功能。
- Kimi K2.5 在编程和创意方面令人印象深刻:用户对 Kimi K2.5 模型赞不绝口,该模型目前已上线 Text Arena 和 HuggingFace,其在创意写作、前端开发和多模态任务方面的优势受到了称赞。
- 成员们声称它优于 Gemini 3 Pro,并建议使用 K2 或 K2 Thinking 模型,一位成员分享了 这条推文。
- GPT 5.2 与 Claude Opus 4.5 的对决:成员们正在争论 GPT 5.2 和 Claude Opus 4.5 的性能,准确性是争论的焦点。
- 一些用户认为 GPT 5.2 更准确,而另一些人则青睐 Claude Opus 4.5,称 “最聪明且最可靠的是 Claude Opus 4.5 Thinking”。
- Grok 挺有意思,但不适合工作:社区成员讨论了 Grok 模型,一致认为它 “仅限于聊天”,其 “个性和行为方式” 不适合专业任务。
- 一些用户指出,免费版 Grok 与跑分版本不同,这可能会影响性能表现。
- Auto-Modality 和 Model selector 在 Text Arena 首次亮相!:Auto-Modality 和 Model selector 现已在 LM Arena 上线。
- Auto-Modality 现在可以将提示词引导至正确的模态,而 Model selector 为模型选择提供了全新的设计,详见 帮助中心文章。
Perplexity AI Discord
- Perplexity Pro 限制无限访问:多名用户反映其 Perplexity Pro 账户 遭遇了意料之外的 rate limits,尽管该方案理应提供无限访问权限,这严重影响了他们的工作流。
- 甚至基础的 Pro searches 似乎也会消耗其 Labs quota。
- Perplexity 图像生成失败:许多 Pro 订阅者 在 image generation 方面遇到了问题,要么被告知超出限制,要么面临区域限制,显示出服务的不稳定性。
- 这种不一致性导致许多 Pro 订阅者 抱怨服务不可预测。
- 印度用户遇到银行卡支付失败:印度用户在添加 Visa/Mastercard 借记卡或信用卡 进行验证时面临问题,所有印度银行卡均被拒绝。
- 由于支付方式问题,部分用户正考虑采取法律行动。
- Kagi Search 在受挫用户中获得关注:由于 Perplexity 的不稳定性,用户正讨论将 Kagi 作为潜在替代方案,并强调 Kagi 的 assistant 功能 看起来很有前景,且可以使用最新的 Claude 模型。
- 一位用户指出,Kagi 还提供 search results 且 声称比其他搜索引擎更注重隐私。
- Kimi k2.5 推出 Agent Swarm 模式:随着 Kimi k2.5 的发布,其在 kimi.com 上包含了 Agent Swarm 模式,这是一款可以执行类似 Claude Code 任务的高级工具。
- 一位用户注意到其 pretraining tokens 达到了 15 trillion parameters,对其多模态能力相较于 Perplexity AI 的表现感到非常兴奋。
Moonshot AI (Kimi K-2) Discord
- Kimi K2.5 在 Agentic Benchmarks 上达到 SOTA:Kimi K2.5 发布并在 Agentic Benchmarks 上达到全球 SOTA,在 HLE 全集上达到 50.2%,在 BrowseComp 上达到 74.9%,并在 Vision 和 Coding 领域达到开源 SOTA,包括 MMMU Pro 的 78.5%、VideoMMMU 的 86.6% 以及 SWE-bench Verified 的 76.8%。
- 成员们注意到 Kimi 声称正在使用 Kimi K2.5,引发了关于其已静默上线并提升了事实核查、信息检索及多模态能力(如增强的 Vision)的猜测。
- Kimi K2.5 引入 Agent Swarm Beta:Agent Swarm (Beta) 允许自主 Agent 并行工作,可扩展至 100 个子 Agent 和 1,500 次 tool calls,实现 4.5x 的性能提升,目前已面向 kimi.com 的高级用户开放。
- Kimi K2.5 的发布还集成了图像和视频功能,用于创建具有表现力动效的网站。
- 定价和分级访问引发辩论:新的 Kimi Code 方案 的限制远低于 Z.ai,用户反映 tool call 消耗很高,一位用户表示 一个较大的 prompt 就消耗了每周 2000 次 tool calls 中的 5 次。
- 多位用户对促销价格将于 2 月结束表示失望,认为正常的月度价格太高,无法继续支持 Kimi。
- OpenRouter API 集成面临问题:用户报告在 OpenRouter 上使用 Kimi K2.5 时出现错误,特别是与 tool use 和图像 URL 相关的问题。
- 一位用户收到了错误信息:No endpoints found that support tool use.
- Moonshot AI 预告技术报告:技术博客 中的脚注指出 完整的 prompts 将在技术报告中提供。
- 成员们期待包含更多信息的技术报告发布。
OpenAI Discord
- 基于 GPT-5.2 驱动的 Prism 亮相,助力科学家:OpenAI 推出了 Prism,这是一个促进科学协作的免费工作空间,运行在 GPT-5.2 之上,如这段视频所示,可通过 prism.openai.com 访问。
- 该平台现已向拥有 ChatGPT personal account 的用户开放,凭借其先进的功能简化科学研究工作。
- AI Detection Tools 将人类撰写的文本标记为 AI 生成:成员们观察到,AI detection tools 错误地将 GPT 出现之前的学术文本(人类撰写)标记为 AI 生成内容,并认为其存在根本性缺陷。
- 尽管这些工具已被证明并不准确,但大学和求职申请中仍在使用 AI detection tools。
- 高 RAM MacBook 加速 AI 推理:成员们发现,在配备大容量 RAM 的机器(如拥有 96GB RAM 和 M2 Max 的 MacBook Pro)上本地运行 Ollama 和 ComfyUI 效果最佳,能够运行 gpt-oss-120b。
- 其他人建议的最低配置为 16 GB RAM、Ryzen 5 7000 系列或最新一代 i5,以及一款优秀的 NVIDIA GPU(如拥有 24 gb VRAM 的 Nvidia 3090)。
- GPT 5.2 的创意写作表现不佳:在对比 Gemini 3 Pro 和 Claude 4.5 Opus 时,发现 GPT 5.2 的创意写作能力较差。
- Sam Altman 承认 GPT-5.2 在创意写作方面表现糟糕,表示 OpenAI “搞砸了这一点”。
- 模型退化迅速,归咎于免费白嫖者:多位成员对 ChatGPT 和 Claude 等模型正在退化表示担忧,其中一人声称出现了 40% 的降级。
- 一些人将退化归咎于“拥有多个账号的免费白嫖者(free leechers)”,而另一位成员则认为退化是由于模型在针对模型输出进行训练。
Nous Research AI Discord
- OpenAI 隐藏模型身份:用户观察到当前使用的具体 OpenAI model 不再可见,这引发了关于 OpenAI 正在优化成本降低的猜测。
- 一位用户建议“将鼠标悬停在 ChatGPT 的重新生成符号上”,以揭示底层模型。
- 小模型征服长上下文任务:Opus 4.5(200K context)在 130K tokens 时的表现优于 Gemini 3 Pro(1M context),这表明 effective context window 比单纯的原始容量更关键。
- 引用的一篇论文强调了模型在超过 8K context window 后的质量退化,进一步强化了“熵不喜欢大上下文(Entropy is not fan of big context)”的观点。
- GPT 5.2 Pro 昂贵的处理过程:GPT 5.2 Pro 的高昂成本归因于一个推测性的过程,该过程涉及 7 次运行 以生成建议,随后进行 第 8 次运行 以选择响应。
- 据推测,该过程利用了并行推理链,并将其汇总以获得最终输出。
- 中国 LLMs 进军市场:像 Kimi K2.5 (kimi.com) 这样的中国 LLMs 正在进入市场,据报道其写作能力极佳。
- 另一位用户推测 Deepseek 正在密集开发中,并将是最后一个发布的。
- MergeMix 融合训练中期数据:分享了论文 MergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging,指出了在训练期间优化数据混合的开源努力。
- 附带的图片可能提供了额外的背景信息(尽管其内容未指明)。
{kind=link}
Cursor Community Discord
- Cursor 每次 Prompt 成本达到 0.5 美元:一名用户抱怨说 3 次 prompts 花费了 50 美分,并附上了交互过程的图片。
- 这引发了关于 Cursor 定价模型性价比的讨论,以及它是否符合用户预期。
- Skills 确实就是 Rules:一名用户询问 Cursor Rules 是否仍然有效,社区成员澄清说 它们现在被称为 skills,并指向了 Skills 文档。
- 文档概述了用户如何创建和应用 Skills,以便在编辑器中自定义和自动化各种任务。
- 神秘乱码侵入 Cursor Prompt 框:一名用户报告在电脑开机一整夜后,在 Cursor prompt 框中发现了奇怪的文本,怀疑是已知 bug 或是聊天内容泄露。
- 另一名用户建议这可能是因为误触了麦克风语音输入按钮,第三名用户确认了这一点,并指出 Whisper 模型在安静环境下会产生幻觉。
- Cursor 逃向浏览器?:一名用户寻求在浏览器上使用 Cursor Agent 的指导,尽管已连接 GitHub 仓库,但询问为什么无法运行并指向了 cursor.com/agent。
- Cursor Agent 是否旨在以这种方式工作尚未得到解决。
- Token 充值后团队支出巨额?:一名用户询问在 20 美元的额度之后出现了 800 美元的 Team Spend 上限问题,并发布了图片。
- 团队支出上限是否可以由用户调整,或者是否为固定设置,尚未得到解决。
{kind=link}
{kind=link}
LM Studio Discord
- 针对低预算配置讨论 Qwen Coder 模型:成员们讨论了适用于 8GB VRAM 和 32GB RAM 系统的最佳编码模型,推荐了 qwen2.5-coder-7b-instruct-q5_k_m 和 qwen3-coder-30b-a3b-instruct 等选项。
- qwen3-coder-30b-a3b-instruct 模型的 Q4_K_M 版本因其卓越的能力和 20k context window 而受到青睐。
- Cline 在低配设备上编码受挫:用户报告了在 8GB VRAM 和 32GB RAM 系统上使用 Cline 进行 Agentic 编码时的挑战,面临
CUDA0 buffer分配错误。- 通过将上下文长度减少到 9000 并调整 CUDA runtime 设置,该问题得到了解决。
- ROC Runtime 提升了 LM Studio 在 Windows 上的表现:对于使用 6700xt 12GB VRAM 的用户,安装 ROC runtime 显著提升了在 Windows 上的性能,达到了与 Linux 相当的速度。
- 兼容性仅限于特定的 AMD GPU,详情请参阅 AMD 网站。
- 用户对 Clawdbot 的安全性感到担忧:这段 YouTube 视频中提出了关于 Clawdbot 的严重安全风险。
- 担忧集中在未经授权访问环境变量密钥,以及授予 Agent 访问敏感财务和个人数据的危险性,并指出它会在未经许可的情况下读取 env keys。
Latent Space Discord
- Kimi K2.5 通过 Zero-Shot 攻克编程:Kimi K2.5 模型已经发布,展示了在 其官方网站 上显示的 zero-shot coding 基准测试的成功。
- 其在更复杂的 agentic coding 场景中的能力仍在评估中。
- Clawdbot 因商标问题更名为 Moltbot:由于与 Anthropic 的商标纠纷,Clawdbot 已更名为 Moltbot,根据 此公告,其吉祥物 Clawd 现更名为 Molty。
- 团队似乎正在泰然自若地应对这一变化。
- Karpathy 投身 Agent 优先编程:Andrej Karpathy 在 这篇文章 中概述了向使用 Claude 进行 agent-driven coding 转变的战略举措,强调了 LLMs 的优势,如不知疲倦的毅力和更高的杠杆作用。
- 他看好使用 LLMs 进行编程,而非目前的方法。
- OpenAI 开启 Prism:进步之门:OpenAI 发布了 Prism,这是一个为科学家提供的协作研究环境,由 GPT-5.2 提供支持,ChatGPT 账户持有者可通过 此入口 访问。
- 这个免费的工作空间旨在简化科学研究。
- ModelScope 将图像模型演进为 Z-Image:ModelScope 发布了 Z-Image,这是其基于 Scalable Single-Stream DiT 的图像生成模型版本,更多详情请见此处。
- 该模型提供照片级的质量、多样化的输出,并支持 LoRA 和 ControlNet 等社区工具,包括用于单图风格迁移的 Z-Image-i2L。
GPU MODE Discord
- FlagOS 栈旨在提升 ML 可移植性:Tongjie 介绍了 FlagOS,这是一个开源系统软件栈,旨在统一 Model–System–Chip layers,目标是增强 AI workloads 在不同硬件上的可移植性。
- 该项目寻求合并来自 ML systems、compilers 以及 hardware–software co-design 讨论中的见解。
- TorchX 编排多节点 GPU:一位成员询问 TorchX 视频 是否仍是 multi-node GPU orchestration 的推荐方法。
- 尚未提供明确答案,但这可能是编排大规模应用的起点。
- Decart 推出 Lucy 2,寻觅优化工程师:Decart 宣布了其自回归视频编辑模型 Lucy 2,并分享了 技术报告,目前正在积极招聘工程师来优化用于实时视频/世界模型的 low-latency kernels。
- Decart 正在寻找专注于 performance work、GPU Mode 提交或 OSS 贡献 的工程师,以帮助解决与 LLM inference 不同的独特性能问题。
- Popcorn 筹备 Fused MoE kernels:一位成员询问有关在 B200 硬件上通过 Popcorn 为 MLSys2026 hackathon 进行 kernel 基准测试的问题,特别关注融合的 MoE kernel 基准测试。
- 另一位成员建议通过尝试针对排行榜问题的 kernel LLM generation,以及探索 OG popcorn 网站上的潜在项目来为团队会议做准备。
- FlashInfer-Bench 为 MLSYS26 提供 Trace 数据集:用于 FlashInfer-Bench 开发的数据集现已在 flashinfer-ai/flashinfer-trace 上可用,针对 MLSYS26 竞赛 的专门工作负载数据集即将发布在 flashinfer-ai/mlsys26-contest。
- 团队还正在开发一个双周排行榜,以跟踪竞赛进度。
Eleuther Discord
- AI PhD 问题启发式测试:一名成员请求关于衡量 AI 博士标准的建议,另一位成员建议采用启发式方法:“这是否是两位 AI 研究员之间会进行的对话?”
- 这引发了关于在该领域什么才构成深刻问题的讨论。
- Tesla 作为 GPU Farm 的可行性存疑:一位成员购买了 Tesla GPU,因其拥有 24GB VRAM,这引发了对其与 3090 等替代品相比在速度和能效方面的质疑。
- 一位成员认为,考虑到能源成本,对于同样的 AI 工作,3090 会比 Tesla 更经济、更高效。
- Anthropic 论文引发生物风险 (Biorisk) 辩论:成员们讨论了新的 Anthropic 生物风险论文 (arxiv link, X link) 及其影响,特别是如何通过在前沿模型 (frontier model) 输出上对开源模型进行 fine-tuning 来显著提升能力。
- 论文指出,模型可以通过 fine-tuning 习得有害能力,或者让即使已被安全训练抑制的能力重新显现,从而支持了 “fine-tuning 可以在不消耗太多 compute 的情况下撤销某些拒绝行为” 的观点。
- 动态 LoRA 控制器稳定推理:一位成员分享了一个用于动态 LoRA 稳定性控制器的 repo,并对多适配器 (multi-adapter) 设置进行了受控实验,以解决推理 (inference) 时的性能退化和适配器干扰问题。
- 该成员还强调,在评估 LoRA 性能时,应关注 goal-aligned metrics,而非涌现出的基准测试 (benchmarks)。
- 并行层 vs 顺序层性能:Harry 使用并行层进行了测试;结果表明,在小规模下,其表现 逊于 “hackable” 基准,但随着规模增大,趋势向好,如附带的 图表 所示。
- 图表显示,红色代表并行层,蓝色代表顺序层,y 轴显示相对于第三种归一化架构的 % 变化,交叉点位于略高于 10^22 FLOP 处。
{kind=link}
Yannick Kilcher Discord
- 由于 Tensorflow 导致的 Pytorch Bug:一个 Pytorch
RAW: Lock blocking错误通过卸载 Tensorflow 得到了解决,突显了潜在的冲突。- 一位成员开玩笑说提交 Bug 报告很困难,质疑到底该报告什么。
- HungryLinearFunc 对规模的渴望:一位成员介绍了一个
HungryLinearFunc类,该类在 LLM 规模下能够进行零初始化 (zero initialization),在较小规模下与普通线性层匹配,可视化效果见 此处。- 由于会导致零梯度,不建议与 ReLU 搭配使用。
- Cohere Labs 开启论文阅读会:Cohere Labs 正在启动 Paper Reading Sessions,重点关注 2026 年 1 月发表的前沿 ML 论文。
- 这些环节涵盖了推理、安全和实际应用等主题,且对初学者友好,注重社区参与。
- Kimi K2.5 发布:分享了 Kimi Moonshot 的 Twitter 链接和 Kimi K2-5 博客文章。
- 随后进行了关于产品路线图的进一步讨论。
- Clawdbot 被归类为诈骗?:一位成员讽刺地评论说 OpenAI 正在为自己的工具做一个 wrapper,而且已经有人通过 Clawdbot 诈骗 赚到了钱。
- 链接的图像是一张收据,暗示有人从这种被视为诈骗的行为中获利。
{kind=link}
tinygrad (George Hotz) Discord
- Flash Attention 现在可以直接生成代码:一位成员分享了他们能够通过 naive attention 的前端定义直接证明连接并生成 flash attention 代码(codegen flash attention)。
- 自此之后,重写(rewrites)变得更加细粒度,且无需进行单一的大型 online softmax 重写。
- Megakernels 在 GPU 上力压 Kernel Schedulers:George Hotz 链接了来自 Luminal 的博客文章,讨论了将模型编译为 megakernels。
- 讨论表明,GPU 正在从使用 kernel scheduler 转向一种安装在所有 CU 上的“操作系统”。
- 硬件依赖跟踪器变得至关重要:成员们讨论了对基于硬件的调度器/依赖跟踪器的需求以实现低延迟,并指出在低延迟软件依赖跟踪上投入了大量精力。
- 他们建议在硬件中构建一个相当通用的调度器,而不是仅仅依赖软件解决方案,以避免多次
gmem往返。
- 他们建议在硬件中构建一个相当通用的调度器,而不是仅仅依赖软件解决方案,以避免多次
- AMD 模拟器获得调试指令:一位成员分享了在新的 AMD 模拟器(AMD=1 MOCKGPU=1)中,DEBUG=3 会在编译时打印所有指令,而 DEBUG=6 则会在运行时打印所有指令。
- 附带了一张图片,展示了模拟器的调试输出。
- 以 Tinygrad 的方式优化 GitHub Actions:George Hotz 批评了使用更快的计算机(通过 Blacksmith 等服务租赁)来加速 GitHub Actions 的做法,认为这并不能真正让代码变快。
- 他强调 tinygrad 的目标是以“正确”的方式做事,专注于代码优化,而不是依赖外部资源。
DSPy Discord
- CheshireCat 发布 Agentic Workflows:CheshireCat 框架在其企业版分支中引入了新功能,强调 agentic workflows,通过实现工作流本身来自动化 Agent 创建过程,其中 CheshireCat 作为基础设施。分享了一个 GitHub 链接。
- 随后引发了辩论,一些人建议使用现有的框架如 Agno 或 Sentient,而 CheshireCat 的作者则为其独特的功能(包括多租户/multitenancy)进行了辩护。
- Minecraft AI Agent 使用 DSPy 进行挖掘:一位成员展示了他们的项目,一个用于玩 Minecraft 的 AI,使用 DSPy RLM agent 和 Minecraft MCP 构建,并附带了状态更新、YouTube 视频、开源代码以及过程博客。
- 该 Agent 利用 DSPy 在 Minecraft 环境中导航,展示了该框架在复杂、动态场景中的能力。
- CoderRLM 模块在 REPL 环境中执行:一位成员引入了
CoderRLM模块,旨在封装 Python 解释器以解决 JSON 序列化中的None问题,这是针对 Deno/Pyodide REPL 环境的重要修复。- 该模块将 CM_INDEX_FILE、CM_TABULAR_FILE、CM_D_FILE 和 CM_N_FILE 等参考数据预加载为 REPL 变量,从而实现使用 RLM 范式进行编码。
- 自主 Agent 实现自我改进:一位成员正在设计能够自我学习、规划、执行并从工具/API 故障中恢复且无需人工干预的自主 Agent (autonomous agents),强调通过持续改进系统来维持 AI 性能。
- 这些 Agent 旨在用于各个领域,采用 Python, TensorFlow, PyTorch, FastAPI, 和 AWS 等工具和框架。
- 医疗 AI 自动化诊断:一位成员正在开发预测性医疗模型,通过 NLP 驱动的临床数据系统从非结构化医疗笔记中提取洞察,从而实现诊断自动化、监测患者健康并优化临床工作流。
- 这些系统在设计时考虑了 HIPAA 合规性以及 RBAC(基于角色的访问控制)和审计日志等安全功能,以保护敏感数据。
Manus.im Discord Discord
- doe.so 被吹捧为优于 Manus:一名成员推荐 doe.so 作为 Manus 的更好替代方案。
- 用户简单地表示它感觉更聪明。
- Manus Skills 发布,赠送积分:Manus 团队宣布推出 Manus Skills,鼓励社区进行测试并分享他们的使用案例。
- 用户被激励在 X(原 Twitter)上发帖并标记 @ManusAI,以获得转发和免费积分。
- AI/ML 开发者寻找新机会:一名全栈 + AI dev 介绍了自己,正在寻找新机会。
- 他们强调了在 Autonomous Agents、Healthcare AI 和 Fraud Detection Systems 等领域的经验,并列出了多种技术。
- 云浏览器“罢工”:一名用户报告称其云浏览器屏幕显示错误:The temporary website is currently unavailable.
- 他们提到曾尝试唤醒它并分配任务,但网站并未出现,且他们的积分即将耗尽。
aider (Paul Gauthier) Discord
- Aider 的 GitHub 被标记为寿命结束 (End-of-Life):一名用户注意到 Aider’s GitHub 自 2025 年以来一直停滞。
- 另一名用户回复称该项目已不再维护。
- AI 工程师项目组合公开:一名 AI Engineer 列出了当前项目,包括 Autonomous Agents、Healthcare AI、Decision Support、Conversational AI、Fraud Detection 和 AI Automation。
- 未提供有关项目细节的进一步信息。
- AI 工程师工具包揭秘:一名 AI Engineer 分享了详细的技术栈,包括 Python、TypeScript、Go、Rust 等语言,以及 TensorFlow、PyTorch、Hugging Face、OpenAI 等框架。
- 他们的技术栈还涵盖了数据库(PostgreSQL、Kafka)和云平台(AWS、Docker),以及 HIPAA、RBAC、Audit Logs 和 Encryption 等安全合规措施。
Modular (Mojo 🔥) Discord
- 容器配置解决了受限危机:一名成员通过在运行容器时添加
--cap-add=SYS_PTRACE --security-opt seccomp=unconfined解决了 container issue。- 或者,用户可以将相同的参数添加到
.devcontainer/devcontainer.json的runArgs中,以达到同样的效果。
- 或者,用户可以将相同的参数添加到
- 安全选项解决神秘的容器难题:用户报告通过添加
--security-opt seccomp=unconfined解决了问题。- 这会禁用 seccomp,可能解决了容器内系统调用限制的相关问题。
MLOps @Chipro Discord
- 对 MLOps 书籍表现出兴趣:一名用户询问了寻找 MLOps 相关书籍的动力。
- 这表明人们对学习更多关于 MLOps 实践和方法论具有潜在兴趣。
- 另一个 MLOps 话题:这是用于演示目的的占位符摘要。
- 它有助于满足至少两个话题摘要的要求。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
MCP Contributors (Official) Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想更改接收这些邮件的方式吗? 您可以从该列表中退订。
Discord:详细的分频道摘要和链接
BASI Jailbreaking ▷ #general (1269 条消息🔥🔥🔥):
规则作为社会契约、开盒 (Doxxing) 威胁、Factorio 游戏之夜、Grok 图像 Jailbreak、Clawdbot 漏洞
- **BASI 闲谈:规则版*:用户辩论了服务器规则的解释与执行,其中一人认为规则是封禁的辩解*而非社会契约。
- 另一名用户反驳称,如果遵守规则,规则会设定一个合理的保护预期,而管理员则在执行和适当惩罚之间进行权衡。
- **开盒 (Doxxing) 闹剧曝光**:一名用户开玩笑地提出了一个假设性的开盒挑战,引发了关于服务器规则和潜在违规行为的辩论。
- 另一名用户反驳称他们是在试图钓鱼以使对方账号被封禁,导致紧张局势升级。
- **Factorio 工厂狂热:关于举办 **Basi 服务器 Factorio 游戏之夜的讨论被点燃,大家吹嘘着自我扩张的工厂和优化的蓝图。
- 建议包括寻找一名可靠的主机、有经验的玩家来处理 Bug,以及利用预制蓝图来提高效率。
- **Grok 的宏大姿态:Jailbreaking 之旅**:用户探索了 Grok 图像生成器的极限,旨在对其进行 Jailbreak 以获取不受限制的内容,而其他人则证实了其相对于其他模型的不受审查特性。
- 讨论了图像模型与语言模型的分离,这使得提示词注入 (Prompt Injection) 的效果降低。
- **Clawdbot 混乱:漏洞与 VPS 多样性:探讨了 **Clawdbot 日益增长的普及率以及 VPS 使用量的激增,引发了对零身份验证和潜在漏洞的担忧。
- 一名成员打算搭建一个家庭实验室来测试 Clawdbot 的漏洞,同时指出目前已存在易受攻击的实例。
BASI Jailbreaking ▷ #jailbreaking (198 条消息🔥🔥):
Jailbreaking 方法、LLM 幻觉、ENI 人设技巧、模型退化、GPT-5 热修复
- 研究人员从数学上证明 LLM 总是会产生幻觉:一篇论文 (https://arxiv.org/abs/2409.05746) 利用许多 Jailbreaking 方法所基于的相同原理,从数学上“证明了 LLM 总是会产生幻觉”。
- Jailbreaking 增加了幻觉问题:一名成员警告说,对模型进行 Jailbreaking 会显著增加它们的幻觉问题,因为 Jailbreaking 会转移并扭曲模型的上下文,使其不会标记通常会被标记为恶意的内容等。
- GPT-5 热修复:独立控制外壳恢复:一名成员分享了一个文件 (GPT5_Hotfix.md),该文件被描述为 GPT-5 的生成前控制外壳 (pre-generation control shell),旨在在生成开始前强制执行严格的语法、意图锁定和漂移防止。
- 分享 Gemini Jailbreak 方法:一名成员分享了一个针对 Gemini 测试的三轮 Jailbreak,涉及特定的指令和提示词,用于变异意图以防止约束摩擦 (constraint friction)。
- Mode Injection 实验:一名成员提到使用 Mode Injection,并分享说 “我想这就是我被允许说的全部内容了,大笑” 😂
BASI Jailbreaking ▷ #redteaming (6 条消息):
Jailbreak 数据集、恶意提示词
- 研究人员寻求 Jailbreak 数据集:一名研究人员正在寻找包含分类或标签的知名 Jailbreak 数据集,以协助正在进行的研究。
- 另一名成员询问研究人员是指预先标记好的还是分类好的 LLM 训练提示词。
- 征集恶意提示词:该研究人员澄清说,他们专门在寻找具有明确分类的恶意提示词数据集,用于研究 LLM Jailbreak 和提示词注入 (Prompt Injection)。
- 一名成员回应道:“我真的不知道是否有任何免费的可用数据集”,并建议他们可能需要生成提示词并由标注员进行标记。
Unsloth AI (Daniel Han) ▷ #general (605 messages🔥🔥🔥):
llama.cpp 的 KV Cache 问题、Clawdbot 与 YouTube 算法、Transformers v5 支持、MoE 训练速度、多 GPU 问题
- KV Cache 仍困扰部分用户:一些用户报告称,在最新版的 llama.cpp 中 KV cache 仍无法正常工作,尽管之前有修复补丁,但在较长上下文长度下可能会导致运行缓慢,详见 此 GitHub issue。
- Unsloth 增强对 Transformers v5 的支持:Unsloth 现在全面支持 transformers v5,并承诺很快发布更优化的训练版本,相关公告链接见 X。
- MoE 训练速度飞跃:据报告,MoE 训练现在比 v4 快 14 倍,预计进一步优化将使速度再次翻倍,最终可能比 v4 实现 30 倍的加速。
- 多 GPU 训练面临障碍:使用 LoRA/QLoRA 的多 GPU 训练似乎运行良好,但用户报告在针对 embeddings 或 lm_head 时,tiled MLP 和 FFT 存在问题,以及相关的 GitHub issue。
- NVFP4 量化获得认可:NVFP4 被认为在量化方面更优,因为它具有 16 的组大小(group size),相比 MXFP4 的 32 组大小提供了更高的保真度,但 NVFP4 需要 Blackwell 或更高架构才能运行。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (2 messages):
Discord 规则、自我介绍礼仪
- 规则阅读者的报告!:一名成员确认已阅读 Discord 规则,并特别提到了关于禁止推广的规定。
- 这一确认表明了对社区指南的理解,为遵守规则设定了先例。
- 这里有人打招呼!:一位用户发出了简短的 “Hello”,标志着进入介绍环节。
- 简单的问候代表了对话的开始,这是社区参与的基础步骤。
Unsloth AI (Daniel Han) ▷ #off-topic (589 messages🔥🔥🔥):
micro-LED、向量数据库、Kimi 模型、Clawdbot、Ultravox
- Micro-LED 热度持续高涨:一位用户表达了对 micro-LED 技术的持续热情,指出最新的 ROG OLED 和 LG 显示器正在采用该技术,并提到 XG27AQWMG 型号已在美国上市。
- 该用户强调某些特性对于他们的升级是不可妥协的,显示出对该技术的强烈偏好,而另一位用户则提到了烧屏问题。
- 向量数据库难题讨论:一位用户询问了在项目中使用 Qdrant、Weaviate、Milvus 和 Chroma 等 vector databases 时遇到的问题。
- 一位用户提到喜欢 Qdrant,但希望它能支持 binary vectors 和 Hamming distance,而另一位用户则简单地使用带有 pgvector 的 Postgres。
- “Kimislop” 被 Kimi 化了:用户讨论了 Kimi 模型的变化,有人指出它 听起来比以前更接近其他模型,暗示在 Kimislop 发布后失去了其独特个性。
- 一些人感叹失去了 Kimi 那种“自作聪明”的个性,相比变得 更加谄媚,他们更喜欢它以前那种 会当面拆穿你 的倾向。
- Clawdbot 热潮因版权问题终止:讨论围绕 Clawdbot 的流行和潜在过度炒作展开,一位用户建议这主要是营销和噱头,并指出它被关停是因为 Anthropic 未批准该项目。
- 用户开玩笑说要把它改名为 Prawnbot,因为旧名称可能存在侵权。
- Elixir 语言被 Fauxtp 化:一名成员分享了 fauxtp 的链接,将其描述为 Python 版的 Elixir,基于 anyio 并在 asyncio 之上重新实现了结构化并发。
- 一位成员解释说,他们需要只有 The BEAM™ 才具备的功能来处理超过 50 万个并发调用。
Unsloth AI (Daniel Han) ▷ #help (82 messages🔥🔥):
vLLM 0.14.1 支持, Transformers v5 和 TRL 0.27 支持, GLM 4.7 Flash 无推理服务, Common Crawl 数据使用, Ministral-3-14B-Instruct-2512 加载至 vLLM
- vLLM 0.14.1 签名方案导致错误:一位成员报告在使用 Unsloth (2026.1.3) + vLLM (0.14.1) 加载模型时出现
TypeError,原因是 vLLM 0.14 中create_lora_manager方法的签名发生了变化,详情见 vLLM 文档。- 该成员指出 Unsloth 的补丁版本使用了旧签名,如 Unsloth-zoo GitHub 所示。
- GLM 4.7 Flash 推理默认思考禁用:一位用户询问如何在 B200 上通过 vLLM 将 GLM 4.7 Flash 作为不带推理能力的 instruct 模型进行部署,重点关注 TTFT,并参考了 此 z.ai 文档。
- 另一位成员指出,可以按照讨论中附图所示,在 model card 中添加
{"chat_template_kwargs": {"enable_thinking": false}}。
- 另一位成员指出,可以按照讨论中附图所示,在 model card 中添加
- Ministral 3 模型通过 Transformers 补丁加载至 vLLM:一位用户在通过官方 vLLM Docker 镜像提供 Ministral-3-14B-Instruct-2512-unsloth-bnb-4bit 模型服务时遇到困难,即使使用了看似正确的 vLLM 参数如
--tokenizer_mode=mistral --config_format=mistral --load_format=mistral,仍遇到Failed to load mistral 'params.json' config for model和KeyError: 'ministral3'错误。- 将
transformers从4.57.6(镜像内置版本)更新到最新的 v5 版本(或 12 月添加了 ministral3 支持的补丁版本)解决了该问题,尽管这会产生与 vLLM 的版本不兼容。
- 将
- GLM 4.7 Blackwell 工具调用问题:一位用户寻求帮助让 GLM-v4.7 在 Blackwell B200 上调用工具,但遇到了 CUDA 版本问题(驱动 12.8,要求 13)。
- 另一位用户提供了使用 torch 2.9 和 CUDA 13 的
uv pip install命令集,并引导用户参考此 unsloth.ai 文档 进行调用,并使用json.loads。
- 另一位用户提供了使用 torch 2.9 和 CUDA 13 的
Unsloth AI (Daniel Han) ▷ #research (28 messages🔥):
GRPO 长度爆炸, DAPO vs GRPO, Pro-RL 论文建议, RL 中的 LoRA 和 KL 散度, KL 惩罚的参考模型
- GRPO 导致长度爆炸:一位用户观察到,即使是非数学相关的任务,模型在进行 GRPO 期间长度也会爆炸。
- 他们测试了基于长度的惩罚,但这导致模型在稳定在较短长度且推理极少后出现重复。
- DAPO 缺乏格式奖励函数:一位用户指出,他们的 DAPO 实现 缺乏格式奖励函数(formatting reward functions),而不像他们的 GRPO 实现,这导致模型输出乱码。
- 用户表示,由于其他优化,DAPO 论文 也没有包含格式奖励函数。
- Pro-RL 论文建议调整:有建议参考 Pro-RL 论文 中关于在特定迭代后调整参数的建议和细节,以确保模型持续学习。
- 评论者希望看到奖励值(reward)仍在提升。
- KL 散度辅助 RL:虽然 KL 散度(KL divergence)存在争议,但一位成员发现它很有帮助,特别是在使用 SFT 训练的初始模型时,可以防止 RL 模型偏离过远。
- 用户还提到他们的 GRPO 实现 具有 KL 散度,但 DAPO 实现 则没有。
- LoRA 与 KL 惩罚的参考模型混淆:一位用户发现,当使用 Unsloth 配合 vLLM 进行 RL 以实现快速推理时,参考模型似乎是基础模型而不是 SFT 模型,导致了巨大的 KL 散度。
- 另一位用户对此提出质疑,认为参考模型应该是挂载了 PEFT adapter 的 SFT 模型,并认为 KL 惩罚被高估了。
LMArena ▷ #general (833 条消息🔥🔥🔥):
Video Arena 频率限制, Molmo 2 模型, 图片上传错误, Kimi K2.5 模型, Claude opus 4.5 对比 GPT 5.2
- Video Arena:生成限制与已知 Bug:用户讨论了 Video Arena 的生成限制,分别为网站端每 24 小时 3 次以及 Discord 端每 24 小时 5 次;一名用户报告了图片上传错误,这是一个已知 Bug。
- 有建议提出尝试更换浏览器或减小文件大小作为潜在的临时解决方案,但该用户反馈在手机上也遇到了同样的错误。
- Molmo 2 模型:快速概览:用户咨询了 Molmo 2 模型,有人分享了一篇博客文章,指出该模型在视频中的目标跟踪和事件定位方面表现出色。
- 提到该模型对于平台上的视频上传可能非常有用,“真的没有任何理由不把这个模型加入 lmarena”。
- Kimi K2.5:编程、创意写作与多模态能力:用户对 Kimi K2.5 模型赞不绝口,该模型已在 Kimi 网页端上线,其在创意写作、前端开发和多模态任务中的表现受到好评;Kimi K2.5 现已登陆 HuggingFace。
- 成员们声称它优于 Gemini 3 Pro 且不“偷懒”,并建议使用 K2 或 K2 Thinking 模型,推文链接可见此处。
- 基准测试脑力对决:GPT 5.2 vs. Claude Opus 4.5:成员们正在争论 GPT 5.2 和 Claude Opus 4.5 的性能,一些人认为 GPT 5.2 更准确;另一些人则表示 “最聪明且最可靠的是 Claude Opus 4.5 Thinking”。
- 一位成员表示:“对我来说,一个聪明的模型首先需要具备良好的通用知识,Opus 很聪明,但有时当你问它一些冷门内容时,因为它缺乏必要的信息,往往会出错”。
- Grok 很有个性:它更像聊天机器人而非大脑?:社区成员讨论了 Grok 模型,许多人一致认为它 “只适合聊天”,其 “性格和行为表现” 并不适合专业任务。
- 一些用户指出,免费版 Grok 与基准测试版本有所不同,这可能会影响性能表现。
{kind=link}
LMArena ▷ #announcements (6 条消息):
Molmo-2-8b, Kimi-k2.5, 登录以保存聊天记录, 帮助中心实验功能, 举报用户
- Molmo-2-8b 加入 Text Arena!:新模型 molmo-2-8b 已添加到 Text Arena。
- Kimi-k2.5 进入 Text Arena!:新模型 kimi-k2.5 已添加到 Text Arena。
- 登录 LM Arena 否则将丢失聊天记录:提醒用户务必登录 LM Arena 以保存聊天记录;新用户应创建账户以防数据丢失。
- 自动模态 (Auto-Modality) 与模型选择器上线!:Auto-Modality 和 Model selector 现已上线,Auto-Modality 会将提示词路由到正确的模态,而模型选择器为模型选择提供了全新的设计,详见帮助中心文章。
- 更优质的 AI 视频现已登录 YouTube:一段题为 《90 秒内制作更好的 AI 视频》 的新视频现已在 LM Arena YouTube 频道上线。
Perplexity AI ▷ #general (605 messages🔥🔥🔥):
Perplexity rate limits, Image generation issues, Pro subscription problems, Kagi as an alternative, Kimi k2.5 performance
- Perplexity Pro 用户遭遇查询限制:多位用户报告其 Perplexity Pro 账户 出现异常的 rate limits(速率限制),尽管该方案理应提供无限访问权限,这影响了他们的工作流。
- 图像生成故障困扰用户:许多 Pro 订阅者 在 image generation(图像生成)方面遇到问题,要么被告知已超出限制,要么面临区域限制,该服务的应用似乎存在 inconsistency(不一致性)。
- 一位用户发现,甚至基础的 Pro 搜索 似乎也会消耗他们的 Labs 配额。
- 印度用户面临卡片支付被拒:印度用户在添加 Visa/Mastercard 借记卡或信用卡 进行验证时遇到问题,几乎所有印度卡片都被拒绝。
- 一些用户考虑针对此支付方式问题提起诉讼。
- Kagi 的搜索和助手功能看起来很有前景:由于 Perplexity 的不稳定性,用户正在讨论将 Kagi 作为潜在的替代方案。Kagi 的助手功能 可以访问最新的 Claude 模型,表现不俗。
- 一位用户指出,Kagi 还提供 search results(搜索结果),并声称比其他搜索引擎更注重隐私。
- Kimi k2.5 的性能表现引起关注:随着 Kimi k2.5 的发布,kimi.com 推出了 Agent Swarm 模式,这是一个能够执行类似 Claude Code 任务的高级工具。用户正迫切期待测试其与 Perplexity AI 相比的多模态能力。
- 一位用户注意到预训练 token 达到了 15 trillion parameters(15 万亿参数),立即引发了广泛兴奋。
Moonshot AI (Kimi K-2) ▷ #announcements (8 messages🔥):
Kimi K2.5 release, Agentic Benchmarks, Tech blog, Agent Swarm, Technical report
- Kimi K2.5 发布,具备 SOTA 级别的视觉 Agent 能力:Kimi K2.5 已上线,在 Agentic Benchmarks 上达到全球 SOTA 表现:HLE 全集 (50.2%)、BrowseComp (74.9%),并在视觉和编程方面达到开源 SOTA:MMMU Pro (78.5%)、VideoMMMU (86.6%)、SWE-bench Verified (76.8%)。
- Kimi K2.5 为高层级用户推出 Agent Swarm 测试版:Agent Swarm (Beta) 允许自主 Agent 并行工作,可扩展至 100 个子 Agent 和 1,500 次工具调用,性能提升达 4.5 倍。
- 该功能已在 kimi.com 的聊天模式和 Agent 模式中向高层级用户开启内测。
- Moonshot AI 透露技术报告细节:一名成员指出 技术博客 的脚注 3 提到,完整的 Prompt 将在技术报告中提供。
- 另一位成员询问这是否意味着最终会有一份包含更多信息的技术报告。
- Kimi K2.5 将图像和视频整合至网页生成:Kimi K2.5 可以将对话、图像和视频转换为具有动态效果的精美网站。
Moonshot AI (Kimi K-2) ▷ #general-chat (459 messages🔥🔥🔥):
Kimi K2.5, Multimodality, Pricing, Claude Code
- Kimi K2.5 悄然推出:用户注意到 Kimi 自称正在使用 Kimi K2.5,引发了该版本已静默上线的猜测;部分用户确认 K2.5 具备 Multimodality(多模态)能力,并提升了事实核查(fact-checking)和信息检索能力。
- 据一位用户称:据我所知,它的信息检索和事实核查能力有所提高……所以当我问它问题时,它对我来说非常值得信赖。
- Kimi Code 方案对比 Z.ai 限制:用户将 Kimi Code 方案 与 Z.ai 的产品进行了对比,认为 Kimi Code 的额度限制要低得多,但模型可能更好。
- 一位试用最低配置选项的用户表示:一个较大的 Prompt 就消耗了我每周 2000 次 Tool calls 额度中的 5 次。
- 多模态提升 Kimi 表现:成员们对 Kimi K2.5 的 Multimodality 和 Vision(视觉)能力感到兴奋,称其视觉能力非常出色,优于 GLM-4.7。
- 一位成员分享了 X 上的帖子,对比了 Kimi K2.5 与其他模型的视觉能力,并总结道:我相信这仅仅通过 Prompt 就能解决。
- OpenRouter API 问题:用户报告了在 OpenRouter 上使用 Kimi K2.5 时的问题,包括与 Tool use 和图像 URL 相关的错误。
- 一位用户收到了错误消息:未找到支持 Tool use 的端点。
- 用户对价格变动感到失望:多位用户对他们获得的促销价格将于 2 月结束表示失望,认为正常的月度价格过高。
- 一位用户评论道:……我花了 1.49 美元,这是我第一次购买 AI 相关产品,尽管我经常使用 AI,并希望能有持续的优惠活动以继续支持 Kimi。
OpenAI ▷ #annnouncements (1 messages):
Prism, GPT-5.2, ChatGPT personal account
- 由 GPT-5.2 驱动的 Prism 工作区首次亮相:OpenAI 推出了 Prism,这是一个为科学家提供的免费工作区,用于撰写和协作研究,由 GPT-5.2 提供支持。
- 正如这段视频所示,任何拥有 ChatGPT 个人账户 的用户今天都可以使用,访问地址为 prism.openai.com。
- GPT-5.2 赋能科学协作工具:Prism 利用 GPT-5.2 的先进能力,协助科学家在研究项目中进行写作和协作。
- 该平台为拥有 ChatGPT 个人账户 的用户提供专用工作区,为科学探索提供流程化的环境。
OpenAI ▷ #ai-discussions (301 messages🔥🔥):
Context Recovery Tool, AI Detection Tools, Local AI Setup, Gemini 3 Pro vs GPT 5.2 vs Claude 4.5 Opus, Kimi K2.5 new release
- 作为上下文恢复 OS 层的 Buffer 工具:一名成员正在构建一个 上下文恢复工具,旨在将其作为 OS 层,与其他工具不同,它不需要摄像头/麦克风权限,而是使用过去 x 时间的缓冲区。
- 该工具被构想为远超 Windows Recall/Screenpipe 的演进版,且不会过度消耗 CPU 资源或损害用户信任。
- 存在缺陷的 AI 检测工具误标人工撰写文本:成员们讨论了 AI 检测工具将 GPT 问世前的纯人工撰写学术文本标记为 AI 生成的问题,称这些工具从根本上就是失效的。
- 尽管 AI 检测工具完全不可靠,但大学和求职申请中仍在使用它们。
- 高内存 MacBook 适合 AI 推理:成员们讨论了运行本地 AI 的硬件配置,如 Ollama 和 ComfyUI,其中一名成员在配备 M2 Max 和 96GB RAM 的 MacBook Pro 上运行 gpt-oss-120b。
- 最低配置建议包括 16 GB RAM、Ryzen 5 7000 系列或最新一代 i5,以及一款优秀的 NVIDIA GPU;另一名成员则推荐配备 24 GB VRAM 的 Nvidia 3090。
- GPT 5.2 的创意写作表现不佳:一名测试 Gemini 3 Pro 和 Claude 4.5 Opus 的成员发现,Gemini 3 Pro 仅在 API 中值得使用,因为 Web 版存在懒惰和幻觉问题;而 Claude 在处理计算机科学任务时表现出色且极具人情味,但总体而言 GPT 5.2 仍然更胜一筹。
- Sam Altman 承认 GPT-5.2 在创意写作方面表现不佳,称 OpenAI “搞砸了这一点”。
- Kimi K2.5 Agent 模式基准测试:Kimi K2.5 刚刚发布,其博客视频展示了 Beta 版 Agent Swarm 功能,但一名成员发现其性能与无需思考的 Sonnet 单次推理持平甚至更差,也有人指出该模型比 Haiku 更便宜。
- 一些人发现它存在词语误用并堆砌生僻词,而另一些人则指出它专为 Agentic 任务设计。
OpenAI ▷ #gpt-4-discussions (11 messages🔥):
Model Deterioration, GPT-6, Sora Access
- 模型退化迅速,归咎于“吸血鬼”用户:多名成员对 ChatGPT 和 Claude 等模型的退化表示担忧,其中一人声称性能下降了 40%,并将其归咎于拥有多个账号的免费“白嫖”用户。
- 另一名成员建议这种退化是由于模型在使用模型输出的数据进行训练导致的。
- GPT-6 免费且无限制到来?:一名用户分享了关于新模型 GPT-6 的消息,声称它免费、无限制且最适合编程。
- 该信息未提供任何链接或官方来源。
- Sora 访问权限仍未公开:一名成员询问是否可以通过 Discord 访问 Sora。
- 没人回复这条消息。
OpenAI ▷ #prompt-engineering (1 messages):
Weather Report Adjectives, Markdown Weather Report
- 天气预报形容词可以任意定义:一名成员建议通过使用提供的 Markdown 格式,天气预报可以使用任意形容词。
- 该用户提供了一个包含温度、降水和总体描述参数的 Markdown 代码片段。
- Markdown 天气预报:一名用户分享了一个 Markdown 模板,用于生成带有自定义形容词的天气预报。
- 该模板包括华氏和摄氏温度字段、相对温度形容词、湿度、以英寸和厘米为单位的降水量,以及综合自然语言描述。
OpenAI ▷ #api-discussions (1 messages):
Weather Report Adjectives
- 使用任意形容词描述天气:一名成员分享了一个代码片段,用于获取带有自定义形容词的天气预报。
- 该代码模板包括由自定义形容词描述的 温度、湿度 和 降水 字段。
- 另一个用于满足 minItems=2 的话题:添加第二个话题以满足校验要求。
- 此话题故意设计得比较通用,以达到最小项目数量限制。
Nous Research AI ▷ #general (287 messages🔥🔥):
OpenAI model visibility, Opus vs Gemini context window, AI and Entropy, GPT 5.2 Pro, Chinese LLMs
- OpenAI 隐藏模型信息,用户怀疑是为了成本优化:用户注意到他们无法看到正在使用的模型,并怀疑 OpenAI 希望降低你的使用成本。
- 一位用户建议“将鼠标悬停在 ChatGPT 的重新生成符号上”来查看具体是哪个模型。
- 小模型在长上下文任务中击败大模型:一位用户指出,Opus 4.5(200K context window)在 130K tokens 时的表现优于 Gemini 3 Pro(1M context window),这表明有效上下文窗口 (effective context window) 比实际的上下文窗口更重要。
- 他们引用了一篇论文,显示模型在 8K context 时质量就会下降,并指出“Entropy 肯定不喜欢大上下文,这是毫无疑问的”。
- 当存在过多无关因素时,AI 会偏离正确答案:一位用户解释说,随着 context 增多,由于 Entropy 的存在,偏离正确向量 (right vector) 的风险更高,并表示只要 AI 不是超级智能的,它就总会发生漂移。
- 另一位用户补充说,衰减总会发生,数学规律决定了更多的数字并不保证更好的结果。
- GPT 5.2 Pro 因 7 次运行而成本极高:用户怀疑 GPT 5.2 Pro 的高昂成本源于一个过程:它需要运行 7 次来生成建议,第 8 次决定回传什么内容。
- 有些人认为这是一个独立的模型。一位用户建议它运行了并行的推理链 (reasoning chains),然后进行聚合。
- 中国 LLMs 进入发布周期:用户讨论了像 Kimi K2.5(见 kimi.com)等中国 LLMs 进入市场的情况,一位用户反馈在使用它进行写作时效果非常好。
- 另一位用户认为“Deepseek 正在憋大招 (cooking hard)”,并且将是最后一个发布的。
Nous Research AI ▷ #ask-about-llms (1 messages):
CPT vs Task-Specific Training, Translation with CPT
- CPT 提高性能但取决于具体任务:一位研究人员建议 CPT (Contrastive Pre-Training) 似乎能提高性能,但这取决于任务。
- 他们进一步说明,使用与任务相关的输入和输出进行训练,表现会优于更通用的 CPT,尤其是在有特定任务目标时。
- CPT 扩展翻译能力:有人指出,对于翻译任务,CPT 可以扩展多语言能力。
- 在利用 CPT 进行多语言扩展后,在翻译数据上进行 Fine-tuning 会增强任务表现。
Nous Research AI ▷ #research-papers (1 messages):
MergeMix, Model Merging
- MergeMix 论文浮出水面:一位成员分享了论文 MergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging,强调了它与预算有限的开源工作的相关性。
- 开源 Model Merging:该论文建议,对于资源有限、需要在训练期间优化数据混合 (data mixtures) 的开源项目,模型合并 (model merging) 可能是一种有效的策略。
- 消息中附带了一张图片,但没有更多上下文。
Nous Research AI ▷ #research-papers (1 messages):
MergeMix, Model Merging
- MergeMix 优化训练中期的数据混合:一位成员分享了论文 MergeMix: Optimizing Mid-Training Data Mixtures via Learnable Model Merging。
- 该用户认为这很有趣,因为开源工作必须在预算低几个数量级的情况下设法完成。
- 关于 Model Merging 技术的进一步讨论:讨论还涉及了模型合并技术与开源项目的相关性,特别是在预算有限的背景下。
- 附带的图片提供了额外的上下文(尽管其具体内容未说明)。
{kind=link}
Cursor Community ▷ #general (211 messages🔥🔥):
Cursor costing $0.50, Cursor skill = rule, Cursor random garbage, Cursor is gone to Browser, Cursor command output
- Cursor 花费半美元:一名成员抱怨说 3 个 prompts 花费了 50 美分,并附上了一张 图片。
- Skills 确实就是 Rules:一位用户询问 Cursor Rules 是否仍然适用。
- 一位社区成员澄清说 它们现在被称为 skills,并指向了 Skills 文档。
- 神秘字符侵入 Cursor Prompt:一位用户报告说,在电脑开机过夜后,Cursor prompt 框中出现了奇怪的文本,怀疑是已知 bug 或聊天泄露。
- 另一位用户建议这可能是由于误触了麦克风语音转文字按钮导致的,第三位用户通过指出 Whisper 模型在安静环境下会产生幻觉确认了这一点。
- Cursor 跑到了浏览器?:尽管连接了 GitHub 仓库,一位用户仍寻求在浏览器上使用 Cursor Agent 的指导,询问为什么它无法工作并跳转到了 cursor.com/agent。
- Token 充值后团队支出巨大?:一位用户询问在 20 美元的额度之后,为何出现了 800 美元的 Team Spend(团队支出)限制,并发布了一张 图片。
LM Studio ▷ #general (137 messages🔥🔥):
Qwen 2.5 Coder, Cline on VS Code, Qwen3 VL 2B, Kimi K2.5, Clawdbot Security Issues
- 预算有限开发者的 Qwen 选择:成员们讨论了 8GB VRAM/32GB RAM 配置下的最佳编码模型,有人建议使用 qwen2.5-coder-7b-instruct-q5_k_m,而其他人则推荐 Q4_K_M 格式的 qwen3-coder-30b-a3b-instruct,认为其在 20k context 下具有更好的能力。
- Cline 在入门级硬件上运行吃力:用户报告在 8GB VRAM/32GB RAM 上使用 Cline 进行 Agent 式编码时遇到困难,出现了
CUDA0 buffer分配错误,通过将上下文长度减少到 9000 并调整 CUDA runtime 等设置解决了该问题。- 一位用户建议确保所有设置与他人推荐的匹配,并将模型 offload 限制在专用 GPU 显存内。
- ROC Runtime 提升 Windows 版 LM Studio 性能:一位用户报告,在为他们的 6700xt 12GB VRAM 安装 ROC runtime 后,Windows 上的性能显著提升,达到了与 Linux 设置类似的运行速度,不过只有特定的 AMD GPU 兼容,具体可见 AMD 官网。
- RAG 插件设置调整:一位用户寻求 RAG 插件的帮助,发现降低阈值(threshold value)后可以工作,另一位用户建议针对大数据集增加 chunk size(块大小),并直接将内容粘贴到聊天中以绕过检索问题。
- Clawdbot 引发安全担忧:用户对 Clawdbot 表达了严重的安全担忧,一位成员链接了一个 YouTube 视频 强调了潜在问题,另一位成员指出 它会在未经许可的情况下读取 env keys。
- 讨论围绕给予 Agent 访问个人财务和数据的风险展开。
LM Studio ▷ #hardware-discussion (30 messages🔥):
AIO fan setup, GPU overheating, Remote AI rigs
- AIO 风扇方向引发困惑:一位用户澄清了他们的 AIO 风扇设置,解释说额外的风扇位置是为了将新鲜进气压向 GPUs,从而形成一个“通道”。
- 他们补充说这是一个 420 冷排,本身不会发烫。
- 增加风扇解决底部 GPU 过热:一位用户注意到他们的底部 GPU 过热,但通过在机箱底部添加风扇解决了问题。
- 另一位用户提到他们用的是海景房机箱,所以到处都能装下大风扇,哈哈。
- 远程 AI 设备访问方法:一位用户询问了独立 AI rigs(AI 设备)的远程访问方案,特别是咨询了 Windows 自带的远程桌面与其他替代方案的对比。
- 另一位用户提到使用 VNC 通过 VMs(虚拟机)访问 LLMs。
Latent Space ▷ #ai-general-chat (95 messages🔥🔥):
Open Source Code, Kimi K2.5 Model, Clawdbot, Agent-First Programming, Prism Science Workspace
- Kimi K2.5 首次亮相,展现 Zero-Shot 代码能力:根据其官方网站显示,Kimi K2.5 模型已正式发布,在 Zero-Shot 代码评测中表现亮眼。
- 需要进一步评估其在复杂的 Agentic 编码任务中的表现。
- Clawdbot 因商标纠纷更名为 Moltbot:根据此公告,在收到 Anthropic 的商标请求后,Clawdbot 已正式更名为 Moltbot(吉祥物 Clawd 也随之更名为 Molty)。
- Karpathy 编写 Agent 优先的未来:Andrej Karpathy 在这篇帖子中详细阐述了向使用 Claude 进行 Agent 驱动编码的重大转变,并指出 LLM 具有孜孜不倦的毅力和更高的杠杆效率等优势。
- OpenAI 开启 Prism,科学进步的门户:OpenAI 推出了 Prism,这是一个由 GPT-5.2 驱动的、面向科学家的免费协作研究工作区,拥有 ChatGPT 个人账户的用户均可通过此门户访问。
- Trinity Large:400B 参数的动力源泉:根据公告,Prime Intellect 与 Arcee AI 和 Datology 合作推出了 Trinity Large,这是一个 400B 参数的 Mixture of Experts (MoE) 模型(但仅使用 13B 激活参数!)。
Latent Space ▷ #genmedia-creative-ai (5 messages):
ModelScope, Z-Image, Scalable Single-Stream DiT, Z-Image-i2L
- ModelScope 发布 Z-Image:ModelScope 推出了 Z-Image,这是其基于 Scalable Single-Stream DiT 架构构建的图像生成模型的完整非蒸馏版本。
- 它具有照片级的写实能力、高输出多样性,并支持 LoRA 和 ControlNet 等社区工具,包括用于单图风格学习的 Z-Image-i2L。
- Z-Image 拥有照片级的写实能力:新模型 Z-Image 承诺提供摄影级写实的图像。
- 该新模型还支持社区工具链。
GPU MODE ▷ #general (9 messages🔥):
Open Source FlagOS stack, TorchX multi-node GPU orchestration, Kernelboard PR
- 新 FlagOS 栈旨在统一模型-系统-芯片层:Tongjie 介绍了 FlagOS,这是一个开源系统软件栈,旨在统一模型-系统-芯片层,使 AI 工作负载在异构硬件之间更具可移植性。
- 其目标是从围绕 ML 系统、编译器以及软硬件协同设计的持续讨论中学习。
- 关于 TorchX 用于多节点 GPU 编排的推荐咨询:一位成员询问了关于 TorchX 视频的情况,以及它是否仍然是多节点 GPU 编排的推荐标准。
- 消息中未提供进一步的回答或细节。
- 请求附带描述的 Kernelboard PR:marksaroufim 请求成员向 kernelboard 提交一个带有其首选描述的 PR。
- 该请求是针对频道 #1373414141427191809 提出的。
GPU MODE ▷ #cuda (17 messages🔥):
CUDA 中的 B 矩阵布局,云端 NCU Profiling,CUDA enable-input-d 谓词,BLOCK_K 优化
- B 矩阵布局困惑已澄清:一位成员询问了 CUDA 代码示例中的 B 矩阵布局,注意到 CUDA 代码与 Python 调用端代码的矩阵转置之间存在差异。
- 作者澄清说他们使用了 K-major 布局,这是通过 Python 代码中的
.T实现的,并且 shape 主要是为了兼容torch.mm(),而不是为了 C++ 指针逻辑。
- 作者澄清说他们使用了 K-major 布局,这是通过 Python 代码中的
- NCU Profiling 的尝试与波折:一位成员分享了在云厂商上使用 NCU (NVIDIA Command-Line Profiler) 进行 CUDA 代码基准测试时的挫折,特别提到它在 Modal 上不可用。
- 他们最终让 NCU 运行了起来,并分享了一个包含过程笔记的 Gist,而另一位用户提到 Verda 允许进行 NCU profiling。
- 解锁
enable-input-d谓词寄存器:一位成员对 PTX 文档中关于enable-input-d谓词寄存器缺乏清晰度表示失望,引用道:“当输入谓词参数 enable-input-d 为 false 时,将发出 D = AB 形式的操作。”*- 他们最终理解了其含义,表示:“我终于让它工作了,我之前误解了这个愚蠢的
enable-input-d谓词寄存器的意思……”,并感谢了另一位成员提供的有用 GitHub 示例。
- 他们最终理解了其含义,表示:“我终于让它工作了,我之前误解了这个愚蠢的
- 建议进行
BLOCK_K=64优化:一位成员建议没有充分的理由使用BLOCK_K>64(128-byte),使用BLOCK_K=64来简化代码更为理想。- 该成员引用了 CUTLASS 库中的相关章节作为证据,并表示更改后性能达到了 cublas 的 83%。
GPU MODE ▷ #torch (1 messages):
Torch CustomOp, CompositeAutoGrad 内核, Autograd backward 实现, 原生 PyTorch 操作, Torch 中的 SpecializedModule
- CustomOp Autograd 困境:一位成员询问为什么 autograd 无法为使用由原生 PyTorch 操作组成的 CompositeAutoGrad 内核注册的新 CustomOp 导出 backward 实现。
- 他们正在寻找一种仅注册快速 forward 和一阶导数的方法,然后让 autograd 处理任意高阶导数。
- 寻求 Torch 原生 Autograd 解决方案:该成员正在寻求最 Torch 原生的方法,以允许 autograd 满足任意高阶导数的请求,即使过程很慢。
- 他们希望避免为所有可能的情况编写自定义的 backward 实现,而是依靠 autograd 进行高阶微分。
- SpecializedModule forward 传递:代码正在为
SpecializedModule构建一个自定义的forward传递。- 它利用
custom_op来执行一个简单的加法操作x + num,其中num是模块的一个属性。它通过register_cpp_extension_helper来完成这项任务。
- 它利用
GPU MODE ▷ #cool-links (2 messages):
INT4 QAT, H200 部署, RLHF Slime
- Analysis Ago 将 1TB 模型挤进 H200:Analysis Ago 仓库展示了如何使用 INT4 QAT RL 端到端实践,将 1TB 模型部署挤进单张 H200。
- 这是向更高效、更普及的大规模模型部署迈出的重要一步,即使我们是在“挤”它。
- 关于 INT4 的优秀 ML SYS 教程:Awesome-ML-SYS-Tutorial 提供了一个用于 RLHF Slime 的 INT4 实现。
- 对于那些希望通过低精度技术优化 ML 系统的人来说,这个教程非常有用。
GPU MODE ▷ #job-postings (3 messages):
Decart 招聘,Infra 工程师技能
- Decart 为优化团队招聘:Decart 正在为其优化团队招聘工程师,负责开发用于实时视频/世界模型的低延迟 kernel,以及针对如 Trainium 3 等最新一代加速器的优化。
- 有兴趣的人可以联系 heba@decart.ai 并附上其性能优化相关的作品,例如 GPU Mode 投稿或 OSS 贡献。
- Decart 发布 Lucy 2:Decart 发布了其最新的自回归视频编辑模型 Lucy 2,并分享了技术报告。
- 优化团队正在处理具有独特约束条件的性能问题,这与 LLM inference 有所不同。
- Infra 工程师寻找通往 AI 的路径:一位从事 infra/k8s/分布式系统的工程师询问如何获得所需的技能,以帮助在 AI stack 领域工作的公司并降低其成本。
- 发布者提供了职位,邀请工程师加入他们不断壮大的 SF office!并致力于开发用于实时视频/世界模型的极低延迟 kernels。
GPU MODE ▷ #beginner (3 messages):
B200 Kernel 基准测试,用于 B200 基准测试的 Popcorn,GPUMode vectorsum 竞赛,CUDA vs 基于 Tiled 的 GPU 编程
- 在 B200 上使用 Popcorn 运行 Kernel:一名成员询问如何在 B200 上使用 Popcorn 进行 kernel 基准测试,特别是为 MLSys2026 hackathon 寻找高性价比的方案,并对融合的 MoE kernel 感兴趣。
- VectorSum 竞赛提交愿望:一名成员表示有兴趣向 GPUMode vectorsum “竞赛”或排行榜提交 kernel,但注意到截止日期已过。
- 他们澄清说,其目标是通过将自己的解决方案与最优方案进行比较来学习,而不是为了获胜。
- CUDA 还是 Tiled:GPU 新手的困境:一名成员询问作为 GPU 编程初学者,应该从 CUDA 还是基于 tiled 的 GPU 编程开始。
GPU MODE ▷ #pmpp-book (3 messages):
CUDA grids vs threads,CUDA 中的共享内存,CUDA 中的同步,CUDA Occupancy
- CUDA Grids:揭秘间接线程层级:一名成员询问 CUDA 中 grids 和 threads 之间的一级间接性,想知道为什么 grids 由 blocks 组成,而 blocks 由 threads 组成,而不是直接由 threads 组成的 grids。
- 另一名成员回答说,shared memory 和 synchronization 是这种设计的重要原因,此外还有 occupancy 的考虑。
- CUDA Threads 访问共享内存:一名成员发布了 NVIDIA CUDA 编程指南的链接,其中指出 thread block 的所有 threads 都在单个 SM 中执行。
- 该指南进一步解释说,thread block 内的 threads 可以高效地进行通信和同步,因为它们都可以访问用于交换信息的片上 shared memory。
GPU MODE ▷ #rocm (8 messages🔥):
CUDA 垄断,数据中心 GPU,MI325 可用性
- 讨厌 CUDA 垄断:一名成员表达了他们对 CUDA 垄断 的厌恶,并表示只要性能达标,愿意使用任何替代平台。
- 另一名成员指出,AI 领域的重点是数据中心 GPU,而不是消费级 GPU。
- MI325:用它或者丢掉它:当被问及使用 MI325 时,一名成员反驳说它表现不佳,“而且当它坏掉时,你只能守着一堆碎片(意指难以维修或支持差)”。
- 另一名成员建议从云端租用一个小时来评估其适用性。
- MI325:现在你能看到它…:一名成员询问 Lambda Cloud 是否提供 MI325,得到的回答是“几乎到处都没有,只有 300 有货”。
- 他们澄清说 325 与 300 基本相同。
GPU MODE ▷ #popcorn (3 条消息):
Team Meeting Prep, Concrete Project Seeking, Kernel LLM Generation
- 建议进行团队会议准备:一名成员询问如何为 2月3日 的首次团队会议做准备,寻求除了背景论文和之前的会议记录之外的指导。
- 另一名成员建议查看他们的 2026 帖子 和 OG popcorn 网站 寻找项目,并尝试针对排行榜问题进行 Kernel LLM 生成。
- 项目胜过钻牛角尖:一名成员表示,在阅读了 PMPP 的前几章并探索了 Colfax Research 的布局类别后,觉得寻找一个具体项目比进一步钻研理论方面更有益。
- 他们提到已经阅读到 PMPP 第 6 章,尝试了 PMPP 排行榜,并查看了来自 Colfax Research 的博客文章和布局类别,接下来的计划是研究 swizzling。
- Kernel LLM 生成:一位成员建议尝试针对他们的一个排行榜问题进行 Kernel LLM 生成。
- 这被认为是为即将到来的团队会议做准备的一个有帮助的建议。
GPU MODE ▷ #hardware (5 条消息):
DGX instruction set, 5090 memory bandwidth, Open Source Model Hardware Needs, Hardware Requirements for Large Models
- DGX 和 5090 共享指令集:DGX 和 5090 共享相同的指令集,但 DGX 具有全速 fp32 累加,类似于 Blackwell PRO 系列显卡。
- 5090 的显存带宽是瓶颈:关键区别在于 1.8TB/s 对比 300 GB/s 的显存带宽,这需要高效利用 L2 cache。
- 理清大模型的硬件需求:一位成员分享了一个 Google Slides 演示文稿,以帮助推导以原始未量化权重运行大型开源模型所需的硬件需求。
GPU MODE ▷ #cutlass (9 条消息🔥):
Colfax Research, Swizzling, CuTe DSL, CUTLASS Tutorials
- 探索 Colfax 布局类别:一位成员完成了对 Colfax International 关于布局类别的研究 的阅读,正寻求将理论付诸实践,目前其工具箱中还缺少 swizzling 部分。
- 另一位成员指出,swizzling 是旧 CUDA 时代和新 CUDA/GPU 时代开发者之间的一道巨大的鸿沟。
- 尝试数据布局以深化 CUDA 知识:一位来自 Colfax 的成员建议抛开理论去动手实践,推荐检查 CUTLASS 示例 并尝试打印布局(printing layouts)。
- 他们指向了 剖析 CuTe DSL 示例的博客文章 和用于高性能 Kernel 优化的 CUTLASS 教程。
- 打印布局以理解布局:一位成员建议通过动手尝试,理解在打印布局时不同的模式(modes)对应什么。
- 他们建议使用不同的问题配置(problem configs)编译 Kernel,并观察布局的变化。
GPU MODE ▷ #helion (2 条消息):
Helion's slice support, Rangor requests more details
- Helion 的 Slice 请求:一位用户询问 Helion 何时会支持 slice 功能。
- Rangor 请求提供更多细节和示例,以明确所需的 slice 支持。
- 需要关于 Slice 的更多细节:一位用户询问了 Helion 支持 slice 的时间线。
- Rangor 回复请求提供一个更具体的所需 slice 实现示例。
GPU MODE ▷ #nvidia-competition (5 条消息):
channel directions, NCU profiling
- 建议频道导向:一位用户建议将闲聊转移到 <#1215328286503075953>,指出当前频道可能不适合。
- 他们指出 <#1464407141128339571> 可能是更合适的场所。
- 询问 NCU Profiling 状态:一位用户询问了 NCU profiling 的功能情况,并艾特了另一位用户以获取见解。
- 他们在查询中补充说“没有压力”。
GPU MODE ▷ #career-advice (1 条消息):
leet.coder: 有什么办法能进入制造 GPU(或者开发驱动程序)的职业领域吗?
GPU MODE ▷ #cutile (1 条消息):
cuTile MoE, PyTorch redundancy, cuPy user defined kernels, tileiras compiler in CUDA Toolkit 13.1
- cuTile 示例揭示了完整的 MoE:一位成员注意到 cuTile 代码示例 (https://github.com/NVIDIA/cutile-python/tree/main/samples) 包含一个完整的 MoE 实现。
- 他们想知道 cuTile 是否会让 PyTorch 变得多余。
- cuPy 与 cuTile 不兼容:一位用户观察到,虽然 cuPy 提供用户自定义内核 (https://docs.cupy.dev/en/stable/user_guide/kernel.html),但这种编程模型与 cuTile 不兼容。
- 他们补充说,NVIDIA SDK 存在过多的功能重叠。
- CUDA Toolkit 13.1 支持 Blackwell:CUDA Toolkit 13.1 中的 tileiras 编译器 仅支持以下架构:sm_100、sm_103 (Blackwell)、sm_110(未来架构)、sm_120、sm_121(未来架构)。
GPU MODE ▷ #flashinfer (8 条消息🔥):
FlashInfer-Bench, MLSYS Contest, Biweekly Leaderboard
- FlashInfer-Bench 数据集发布:用于 FlashInfer-Bench 开发的数据集已发布在 flashinfer-ai/flashinfer-trace。
- 专门为 MLSYS26 竞赛 设计的工作负载数据集将很快在 flashinfer-ai/mlsys26-contest 发布。
- 双周排行榜即将推出:团队正在努力为竞赛提供 双周排行榜 支持。
Eleuther ▷ #general (49 条消息🔥):
AI PhD questions, Tesla for 24GB VRAM, Anthropic biorisk paper, Flow matching
- 征集 AI 博士面试问题建议:一位成员请求提供问题建议,以衡量 AI 博士的标准。
- 另一位成员建议使用启发式标准:“这是否是两个 AI 研究员之间可能会进行的对话?”
- 购买 Tesla 用于 AI 遭质疑:一位成员为了 24GB VRAM 购买了一台 Tesla,引发了对其速度和能效的质疑。
- 一位成员认为,考虑到能源成本,3090 在处理相同工作时会更经济、更高效。
- Anthropic 生物风险论文引发讨论:成员们讨论了新的 Anthropic 生物风险论文(arXiv 链接,X 链接)及其影响,特别是如何通过在尖端模型输出上微调开源模型来大幅提升能力。
- 论文指出,模型可以通过微调学习有害能力,或者如果这些能力已经存在但被安全训练抑制,也可以通过微调解除抑制,从而支持了“微调可以在不耗费太多计算资源的情况下撤销某些拒绝行为”的观点。
- 动态 LoRA 稳定性控制器发布:一位成员分享了一个动态 LoRA 稳定性控制器的 GitHub 仓库,并展示了在多适配器设置下的受控实验,旨在解决推理时的性能退化和适配器干扰问题。
- 该成员还强调,应关注 目标对齐指标 (goal-aligned metrics) 而非涌现出的基准测试。
Eleuther ▷ #research (9 messages🔥):
Speedrun 结果、并行层 vs 顺序架构、外推担忧
- Harry 使用并行层进行 Speedrun 测试:Harry 使用并行层运行了一次 Speedrun,结果显示在小规模下其表现逊于 “hackable” 基准,但随着规模增大呈现出积极的趋势,详见附带的图表。
- 并行层性能解析:图表显示 红色代表并行层,蓝色代表顺序层,y 轴显示相对于第三个归一化架构的 百分比变化。
- 衡量指标是 perplexity(越低越好),预测在略高于 10^22 FLOP 时会出现交汇点。
- 对外推准确性的质疑:一名成员对仅基于 四个数据点 进行外推的可信度提出质疑,认为合理的比较应通过推理计算量/延迟(inference compute/latency)进行校准,以评估部署优势。
- 另一名成员也不赞同基于 4 个带有噪声的点进行 3 个数量级(OOMs)的外推,并指出该图表显示的是其他实验中的一次尝试,而非针对并行 vs 顺序架构的专门研究。
Eleuther ▷ #interpretability-general (1 messages):
burnytech: https://fxtwitter.com/i/status/2016226870300443025 https://arxiv.org/abs/2601.13548
Yannick Kilcher ▷ #general (37 messages🔥):
Pytorch Bug、HungryLinearFunc、Schrodinger Bridges、Flow Matching、自回归模型 vs 扩散模型
- Tensorflow 导致的 Pytorch Bug:一位成员通过卸载 Tensorflow 解决了 Pytorch 中
RAW: Lock blocking的错误。- 他们自嘲道:应该提交一个 Bug 报告,但……你到底该报告什么呢?。
- HungryLinearFunc 代码公开:一位成员创建了一个
HungryLinearFunc类,即使在 LLM 规模下也具备零初始化(zero initialization)能力,且在小规模下与常规线性层匹配。- 他们指出,由于存在零梯度问题,不建议在之后使用 ReLU,并附上了在玩具任务(toy task)上表现的可视化图。
- 作为正则化流的 Schrödinger Bridges:Schrödinger bridges 被描述为正则化流(regularized flows),在边缘分布约束下最小化 KL divergence,在数学上与扩散模型相连,如本论文所述。
- 进一步解释道,Schrödinger Bridges 的目标是在不将其固定为已知动力学的情况下,迫使流进入某种预定义的格式,这在物理学中非常有益。
- 区分自回归架构与 Transformer 架构:一位成员在扩散模型的背景下澄清了 自回归(autoregressive) 模型与 Transformers 之间的区别,指出 Transformers 使用 Patch Embeddings 来编码位置信息,但其本身并不对连续扩散进行离散化。
- 他们推荐了一个科普视频,解释了从经典 AR 到 去噪扩散(denoising diffusion) 的过程。
- 自回归 vs 评分参数化(Score Parameterization):一位成员质疑为什么在生成模型损失函数中因果规范(causal specification)是必要的,建议参数化
grad log p(x)(score) 可能更好,并引用了这篇博客。- 另一观点指出,因果规范对于推理非常有用,因为 Transformer 具备 KV-caching 能力且能够进行长度泛化;对于离散词表,计算面积不是问题,因为 logits 可以通过 Softmax 转化为分布。
Yannick Kilcher ▷ #paper-discussion (1 messages):
Cohere Labs, Paper Reading Sessions, Frontier ML Papers, Reasoning, Safety, Real-World Applications
- Cohere Labs 启动论文阅读研讨会!: Cohere Labs 正在为其社区推广论文阅读研讨会,重点关注 2026 年 1 月发表的前沿 ML 论文,并重塑推理、安全和实际应用。
- 这些会议对初学者友好且社区优先,无需提前准备,欢迎提问、批评和提供替代视角。
- 机器学习论文调查: 待调研的论文包括 Urban Socio-Semantic Segmentation with Vision-Language Reasoning、Controlled Self-Evolution for Algorithmic Code Optimization、Alterbute、Action100M、Inference-time Physics Alignment of Video Generative Models 以及 Conditional Memory via Scalable Lookup。
- 这些论文涵盖了从用于场景理解的 VLM 到演化出高效代码的 LLM 以及 LLM 的新稀疏轴等主题。
Yannick Kilcher ▷ #ml-news (18 messages🔥):
Robo-phobia, Broken Search Engines, Kimi Moonshot, AI and Job Creation, ChatGPT Wrappers
- 糟糕的搜索引擎坏掉了: 一位成员表达了对搜索引擎失效的沮丧,因为他们找不到 Hitchhiker’s Guide to the Galaxy 中螃蟹场景的 gif。
- Kimi K2.5 发布: 一位成员分享了 Twitter 上的 Kimi Moonshot 链接和 Kimi K2-5 博客文章。
- AI 能创造就业吗?: 一位成员分享了一篇关于创造就业机会的有趣读物和一段相关的 YouTube 视频。
- 到处都是 ChatGPT 套壳应用: 成员们讨论了大多数新“事物”其实只是 ChatGPT wrappers(套壳),并质疑其中一些工具的实用性,有人询问某个特定工具是否旨在成为 Overleaf 杀手。
- Clawdbot 骗局?: 一位成员讽刺地评论说 OpenAI 正在为自己的工具做一个套壳,而且已经有人赚到了 Clawdbot 骗局的钱,并附上了一张收据图片。
- 链接的图片是一张收据,暗示有人赚了钱。
tinygrad (George Hotz) ▷ #general (32 messages🔥):
Codegenning Flash Attention, Megakernels vs Kernel Schedulers, Hardware vs Software Dependency Tracking, AMD Emulator Debugging, Optimizing GitHub Actions
- Flash Attention 现在直接从前端生成代码: 一位成员分享说,他们能够证明这种联系,并直接从 naive attention 的前端定义中生成 Flash Attention 代码 (codegen)。
- 从那时起,重写变得更加细粒度(不再是单一的大型 online softmax 重写)。
- 对 GPU 而言,Megakernel 优于内核调度器: George Hotz 链接到了 Luminal 的一篇博客文章,讨论了将模型编译为 megakernel。
- 讨论表明 GPU 正在从使用内核调度器(kernel scheduler)转向一种安装在所有 CU 上的“操作系统”。
- 需要细粒度的硬件依赖跟踪器: 成员们讨论了需要基于硬件的调度器/依赖跟踪器来实现低延迟,并指出在低延迟软件依赖跟踪上花费了大量精力。
- 他们建议在硬件中构建一个相当通用的调度器,而不是仅仅依赖软件解决方案,以避免多次 gmem 往返。
- 新的 AMD 模拟器在运行时打印调试指令: 一位成员分享说,使用新的 AMD 模拟器 (AMD=1 MOCKGPU=1),DEBUG=3 会在指令编译时打印所有指令,而 DEBUG=6 会在指令运行时打印所有指令。
- 附带了一张图片,展示了模拟器的调试输出。
- 以“正确”的方式优化 GitHub Actions: George Hotz 批评了通过使用更快的计算机(通过 Blacksmith 等服务租赁)来加速 GitHub Actions 的做法,认为这并不能真正让代码变快。
- 他强调 tinygrad 的目标是以“正确”的方式做事,专注于代码优化而不是依赖外部资源。
DSPy ▷ #show-and-tell (14 messages🔥):
CheshireCat framework, Agentic workflows, Agno vs CheshireCat, Minecraft AI Agent using DSPy
- **CheshireCat 框架引入新功能:一位成员展示了 **CheshireCat 企业级分叉版本的新功能。这是一个用于创建 AI agents 的框架,重点介绍了通过实现工作流本身来自动化 agent 创建的 agentic workflows,而 CheshireCat 负责提供基础设施。github link
- **Agno vs CheshireCat:引发辩论:一位成员建议使用 **Agno 或 Sentient 等现有框架,而不是创建新框架,但 CheshireCat 的作者认为它不仅提供 agentic workflow 管理,还提供包括多租户 (multitenancy) 在内的更多功能。
- 其他成员表达了对 Agno 的偏好,理由是 CheshireCat 的学习曲线更陡峭,这引发了简短的辩论,CheshireCat 的作者为其作品辩护,强调了分享作品和接受建设性反馈的权利。
- 使用 DSPy 构建的 Minecraft AI Agent:一位成员分享了他们使用 DSPy RLM agent 和 Minecraft MCP 创建的 Minecraft 游戏 AI 项目,包括状态更新、YouTube 视频、开源代码以及过程博客。
DSPy ▷ #general (7 messages):
RLM Module, Autonomous Agents, Healthcare AI, Decision Support Systems, Next-Gen Conversational AI
- CoderRLM 模块封装 Python 解释器:一位成员介绍了
CoderRLM模块,它封装了一个 Python 解释器,通过在序言中添加null=None来解决 JSON serialization 中的None问题,特别适用于 Deno/Pyodide REPL 环境。- 该模块将 CM_INDEX_FILE、CM_TABULAR_FILE、CM_D_FILE 和 CM_N_FILE 等参考数据加载为 REPL 变量,以便使用 RLM 范式 进行编码。
- 自主 Agent 设计:一位成员正在设计能够自学习、规划、执行并在无需人工干预的情况下从工具/API 故障中恢复的 autonomous agents,专注于长期 AI 性能的持续改进系统。
- 这些 agents 旨在各个领域运行,利用 Python, TensorFlow, PyTorch, FastAPI 和 AWS 等工具和框架。
- 医疗 AI 预测模型:一位成员正在开发预测性医疗模型,该模型使用 NLP 驱动的临床数据系统从非结构化医疗笔记中提取见解,实现自动诊断、监测患者健康并优化临床工作流。
- 这些系统在设计上符合 HIPAA 合规性,并包含针对敏感数据的 RBAC 和审计日志等安全措施。
- 决策支持系统集成:一位成员正在为医疗和金融等关键领域构建实时决策工具。
- 这些工具涉及预测模型和智能系统,使用 PostgreSQL、MongoDB 和 Elasticsearch 等数据库,将海量数据集转化为可操作的见解。
- 下一代对话式 AI 实现:一位成员正在创建 AI 驱动的聊天机器人,能够处理跨多个平台的多轮、上下文感知对话。
- 这些聊天机器人实施了先进的 NLP 模型以提供个性化的实时支持,并利用了 Next.js, NestJS 和 Vue.js 等框架。
Manus.im Discord ▷ #general (10 messages🔥):
doe.so 作为 Manus 的替代方案, Manus Skills 发布, 高级 AI/ML & 全栈工程师寻找机会, Cloud Browser 问题
- 新的 Manus 替代方案: 一名成员建议用户尝试 doe.so,暗示它是 Manus 的更好替代品。
- 该成员表示它 感觉更聪明 (feels smarter)。
- Manus Skills 发布: Manus 团队宣布发布 Manus Skills,并邀请社区通过构建或使用 Skill 来进行测试。
- 他们鼓励用户在 X (原 Twitter) 上分享使用案例,并标记 @ManusAI 以获取转发和 免费额度 (credits)。
- AI/ML 工程师寻求项目: 一名成员介绍了自己是正在找工作的 全栈 + AI 开发者。
- 他们列举了在 Autonomous Agents、医疗 AI (Healthcare AI)、决策支持系统 (Decision Support Systems)、对话式 AI (Conversational AI) 和 欺诈检测系统 (Fraud Detection Systems) 方面的经验,并列出了技术清单。
- Cloud Browser 服务器不可用: 一名成员报告其云端浏览器屏幕显示错误:临时网站目前不可用。这可能是因为 Manus 的计算机处于休眠状态,或者链接已过期。
- 他们提到曾尝试唤醒它并分配任务,但网站仍未出现,且他们在尝试重置屏幕时耗尽了额度 (credits)。
aider (Paul Gauthier) ▷ #general (4 messages):
Aider 的 GitHub, AI/ML 项目, 技术栈
- Aider 的 GitHub 被标记为陈旧 (Stale): 一名用户询问为何 Aider 的 GitHub 处于陈旧状态(最后更新于 2025 年),另一名用户回复称 它将不再被维护。
- AI 工程师的当前项目: 一名 AI 工程师列出了目前涉及的项目,包括 Autonomous Agents、医疗 AI (Healthcare AI)、决策支持 (Decision Support)、对话式 AI (Conversational AI)、欺诈检测 (Fraud Detection) 和 AI 自动化 (AI Automation)。
- AI 工程师的技术栈: 一名 AI 工程师分享了他们的技术栈,包括 Python、TypeScript、Go、Rust、TensorFlow、PyTorch、Hugging Face、OpenAI、PostgreSQL、Kafka、AWS、Docker、HIPAA、RBAC、Audit Logs 和 Encryption。
Modular (Mojo 🔥) ▷ #general (2 messages):
容器问题, SYS_PTRACE, devcontainer.json
- **容器配置解决限制危机: 一名成员通过在运行容器时添加
--cap-add=SYS_PTRACE --security-opt seccomp=unconfined解决了一个 **容器问题 (container issue)。- 此外,用户也可以在
.devcontainer/devcontainer.json中添加带有相同参数的runArgs来达到同样的效果。
- 此外,用户也可以在
- **安全选项解决神秘的容器难题**: 该用户报告通过添加
--security-opt seccomp=unconfined解决了问题。- 这会禁用 seccomp,从而可能解决容器内与系统调用限制相关的难题。