AI News
xAI Grok Imagine API —— 排名第一的视频模型,拥有最优的价格与延迟表现 —— 并且正在与 SpaceX 合并。
谷歌 DeepMind (Google DeepMind) 推出了 Genie 项目 (Project Genie)(包含 Genie 3 + Nano Banana Pro + Gemini),这是一个可以通过文本或图像提示词创建交互式实时生成世界的原型。该项目目前仅面向美国年满 18 岁的 Google AI Ultra 订阅者开放,且存在一些已知局限,如约 60 秒的生成时长限制以及物理效果尚不完善等。
与此同时,开源的 LingBot-World 提供了一个实时交互式世界模型,其延迟低于 1 秒,帧率为 16 FPS,并具备分钟级的连贯性,强调交互性和因果一致性。
在视频生成领域,xAI 的 Grok Imagine 强势登场,支持原生音频,生成时长为 15 秒,价格极具竞争力(含音频在内为 4.20 美元/分钟)。而 Runway Gen-4.5 则专注于动画工作流,推出了 Motion Sketch(运动草图) 和 Character Swap(角色替换) 等新功能。
在 3D 生成领域,fal 在其 API 服务中新增了混元 3D (Hunyuan 3D) 3.1 Pro/Rapid,将“模型即服务” (model-as-a-service) 工作流扩展到了 3D 管线中。
xAI 巩固了其作为前沿实验室(Frontier Lab)的地位。
2026 年 1 月 28 日至 1 月 29 日的 AI 新闻。我们为您检查了 12 个 subreddits、544 个 Twitter 账号 和 24 个 Discord 服务器(253 个频道和 7278 条消息)。预计节省阅读时间(以 200 wpm 计算):605 分钟。我们的新网站现已上线,支持全文元数据搜索,并以美观的氛围感(vibe coded)呈现过往所有内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上为我们提供反馈!
看起来 OpenAI(融资估值约 8000 亿美金)、Anthropic(估值 3500 亿美金)以及现在的 SpaceX + xAI(11000 亿美金? —— 继 3 周前完成 200 亿美金 E 轮融资之后)正处于激烈的竞争中,争相在年底前进行 IPO。Google 今天采取了极其强有力的行动,向 Ultra 订阅用户发布了 Genie 3(此前曾有报道),尽管在技术上令人印象深刻,但今天的头条新闻理应属于 Grok,他们现在已经在 API 中发布了 SOTA 级别的图像/视频生成与编辑模型,你今天就可以开始使用。
Artificial Analysis 的排名说明了一切:
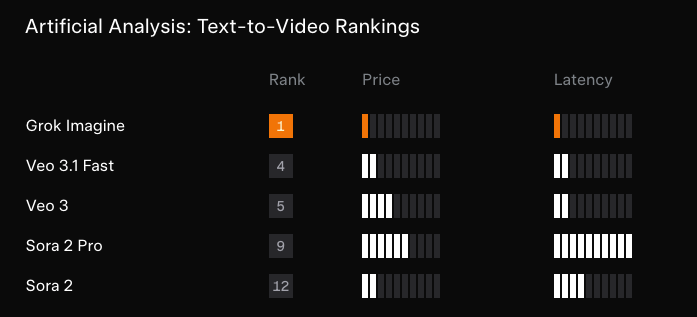
除了看看那些小型视频模型实验室的名单,并思考其中哪些刚刚遭遇了“惨痛教训”(bitter lessoned),这里没有太多可说的了……
AI Twitter 综述
世界模型与交互式模拟:Google DeepMind 的 Project Genie (Genie 3) vs. 开源“世界模拟器”
- Project Genie 推出(Genie 3 + Nano Banana Pro + Gemini):Google/DeepMind 推出了 Project Genie 原型,允许用户通过文本或图像提示词创建并探索交互式、实时生成的场景,并具备混录(remixing)和画廊功能。目前仅限美国 18 岁以上的 Google AI Ultra 订阅用户使用,产品明确说明了原型的局限性(例如 ~60 秒的生成限制、控制延迟、物理规律遵循不完美等) (DeepMind 公告, 工作原理, 推出详情, Demis, Sundar, Google 线程, Google 局限性说明)。早期测试者强调了提示词驱动、角色/世界定制以及“混录”是核心的 UX 亮点 (venturetwins, Josh Woodward 演示线程)。
- 开源推动:LingBot-World:另一个平行讨论将世界模型与“视频造梦者(video dreamers)”区分开来,主张交互性、物体恒存性和因果一致性。LingBot-World 被多次描述为一个基于 Wan2.2 构建的开源实时交互式世界模型,具有 <1s 的延迟、16 FPS 的帧率以及分钟级的一致性(声称包括 VBench 的改进以及长时间遮挡后的地标持久性) (论文摘要线程, HuggingPapers 提及, 反应视频)。宏观叙事是:闭源系统(Genie)正在交付消费者原型,而开源系统正在竞相缩小一致性与控制力方面的能力差距。
视频生成与创意工具:xAI Grok Imagine、Runway Gen-4.5 以及 fal 的 “Day-0” 平台
- xAI Grok Imagine (视频 + 音频) 登顶或接近排行榜榜首:多方消息报告了 Grok Imagine 在视频排名中的强势首秀,并强调了其原生音频 (native audio)、15 秒时长,以及相对于 Veo/Sora 极具竞争力的定价 ($4.20/分钟,包含音频) (Arena 发布排名, Artificial Analysis #1 声明 + 定价背景, 后续 #1 I2V 排行榜, xAI 团队公告, Elon)。fal 将自己定位为 day-0 平台合作伙伴,提供 text-to-image、editing、text-to-video、image-to-video 和 video editing 的 API 端点 (fal 合作伙伴关系, fal 链接推文)。
- Runway Gen-4.5 转向“动画引擎 (animation engine)”工作流:创作者称 Gen-4.5 在动画风格作品中的可控性不断增强 (c_valenzuelab)。Runway 推出了 Motion Sketch(在起始帧上标注摄像机/运动路径)和 Character Swap 作为内置应用——更多证据表明,厂商正在打包可控性原语 (controllability primitives),而非仅仅追求基础质量 (功能推特链)。Runway 还将“照片 → 故事短片 (photo → story clip)”流程作为主流入口进行市场推广 (Runway 示例)。
- 3D 生成加入相同的 API 分发层:fal 还新增了 Hunyuan 3D 3.1 Pro/Rapid (text/image-to-3D, topology/part generation),展示了“模型即服务 (model-as-a-service) + 工作流端点”模式正从图像/视频扩展到 3D 流水线 (fal 发布)。
开源模型与基准测试:Kimi K2.5 势头、Qwen3-ASR 发布以及 Trinity Large 架构细节
- Kimi K2.5 在多个评测维度中被誉为“第一开源模型”:Moonshot 宣传了 K2.5 在 VoxelBench (Moonshot) 上的排名,随后的 Kimi 更新侧重于产品化:Kimi Code 现在由 K2.5 驱动,从请求限制转向基于 Token 的计费,并推出了限时 3 倍配额/不限流活动 (Kimi Code 计费更新, 计费逻辑)。Arena 的消息进一步强调了 K2.5 作为领先开源模型的地位,并即将公布 Code Arena 评分 (Arena 深度分析, Code Arena 提示词);Arena 还声称 Kimi K2.5 Thinking 是 Vision Arena 中的第一开源模型,也是前 15 名中唯一的开源模型 (Vision Arena 声明)。评论将 K2.5 定位为“在 V3 代架构基础上加强了持续训练”,预计下一代竞争将来自 K3/GLM-5 等 (teortaxes)。
- 阿里巴巴 Qwen3-ASR:具有 vLLM 首日支持的生产级开源语音技术栈:Qwen 发布了 Qwen3-ASR + Qwen3-ForcedAligner,强调处理复杂的真实世界音频、支持 52 种语言/方言、长音频(单次可达 20 分钟)以及时间戳;模型采用 Apache 2.0 协议,并包含开源推理/微调栈。vLLM 立即宣布了首日支持和性能说明(例如,其推文中提到“0.6B 模型吞吐量提升 2000 倍”)(Qwen 发布, ForcedAligner, vLLM 支持, Adina Yakup 总结, 原生流式传输声明, Qwen 致谢 vLLM)。结论:开源语音正日益趋向“全栈化”,而不仅仅是权重。
- Arcee AI Trinity Large (400B MoE) 进入架构讨论视线:多个线程将 Trinity Large 总结为拥有 约 13B 激活参数的 400B MoE 模型,通过稀疏专家选择优化了吞吐量,并采用了多种现代稳定性/吞吐量技术(路由技巧、负载均衡、注意力模式、归一化变体)。Sebastian Raschka 的架构回顾是最具体的参考点 (rasbt);额外的 MoE/路由稳定性说明出现在另一份技术摘要中 (cwolferesearch)。Arcee 指出多个变体在 Hugging Face 上表现亮眼 (arcee_ai)。
Agent 实践:“Agent 架构工程”、多 Agent 协作和企业级沙箱
- 从 vibe coding 转向 Agentic Engineering:一条高互动量的梗类推文主张 “Agentic Engineering > Vibe Coding”,并将专业性定义为可重复的工作流(workflows),而非仅仅依靠氛围(vibes)(bekacru)。多条推文从操作层面强化了这一主题:上下文准备、评估(evaluations)以及沙箱化(sandboxing)才是最困难的部分。
- Primer:仓库指令 + 轻量级评估 + PR 自动化:Primer 提出了一个为 Repo 赋予 “AI 能力”的工作流:Agentic 的仓库自省 → 生成指令文件 → 运行 带有/不带有 评估工具(eval harness)的测试 → 通过批量 PR 在组织仓库中进行扩展 (Primer launch, local run, eval framework, org scaling)。
- Agent 沙箱 + 可追溯性作为基础设施原语:多条推文指出 “Agent 沙箱”(隔离的执行环境)是 1 月份出现的新趋势 (dejavucoder)。Cursor 提出了一个开放标准,用于追踪 Agent 对话到生成的代码,并明确将其定位为跨 Agent/接口的可互操作标准 (Cursor)。这与更广泛的生态压力相呼应:当 Agent 可以执行操作时,它们需要可审计性和可靠的依据(grounding)。
- 多 Agent 协作优于“更大脑力”模型:一个流行的总结称,使用由 RL(强化学习)训练的控制器 在大/小模型之间进行路由的系统,可以在 HLE 上以更低成本和延迟击败单个大型 Agent——这进一步证实了编排策略正在成为一等公民产物 (LiorOnAI)。在同一方向上,亚马逊的一篇 “Insight Agents” 论文总结主张采用务实的管理者-执行者(manager-worker)设计,利用轻量级 OOD 检测和路由(autoencoder + 微调后的 BERT)取代纯 LLM 分类器,以满足延迟和精度需求 (omarsar0)。
- Kimi 的 “Agent Swarm” 哲学:来自 ZhihuFrontier 的一篇长文转发描述了 K2.5 的 Agent 模式是对“仅限文本的帮助”和工具调用幻觉的回应,强调了规划→执行的桥接、基于工具的动态上下文,以及通过 Swarm 进行多视角规划 (ZhihuFrontier)。
- Moltbot/Clawdbot 安全三难困境:社区讨论将“有用 vs 自主 vs 安全”定义为在提示词注入(prompt injection)问题解决之前的三个相互制约因素 (fabianstelzer)。另一种观点认为能力(信任)瓶颈占主导地位:在 Agent 具备可靠的能力之前,用户不会在涉及高风险的任务(如金融)中授予其高度自主权 (Yuchenj_UW)。
模型 UX、DevTools 和服务:Gemini Agentic Vision、OpenAI 内部数据 Agent、vLLM 修复以及本地 LLM 应用
- Gemini 3 Flash “Agentic Vision”:Google 将 Agentic Vision 定位为一个结构化的图像分析流水线:规划步骤、缩放、标注,并可选运行 Python 进行绘图——本质上是将“视觉”转变为一种 Agentic 工作流,而不仅仅是单次前向传播 (GeminiApp intro, capabilities, rollout note)。
- OpenAI 大规模内部数据 Agent:OpenAI 描述了一个内部 “AI 数据 Agent”,它在超过 600+ PB 和 7 万个数据集上进行推理,使用 Codex 驱动的表格知识和细致的上下文管理 (OpenAIDevs)。这是对“深度研究/数据 Agent”架构约束的一次罕见的具体展示:检索 + Schema/表格先验 + 组织上下文。
- 服务端的 Bug 依然真实存在(vLLM + 状态化模型):AI21 分享了一个调试故事,调度器的 Token 分配导致了 prefill vs decode 之间的误分类,该问题现已在 vLLM v0.14.0 中修复——这提醒我们基础设施的正确性至关重要,特别是对于像 Mamba 这样的状态化架构 (AI21Labs thread)。
- 本地 LLM UX 持续提升:Georgi Gerganov 发布了 LlamaBarn,这是一个基于 llama.cpp 构建的小巧 macOS 菜单栏应用,用于运行本地模型 (ggerganov)。另有评论建议,通过 llama.cpp 模板禁用特定模型(GLM-4.7-Flash)的“思考”模式,可以提高 Agentic 编码的性能 (ggerganov config note)。
热门推文(按互动量排序)
- Grok Imagine 的热度与分发:@elonmusk, @fal, @ArtificialAnlys
- DeepMind/Google 世界模型:@GoogleDeepMind, @demishassabis, @sundarpichai
- AI4Science:@demishassabis 谈论 AlphaGenome
- 语音开源发布:@Alibaba_Qwen Qwen3-ASR
- Agents + 开发者工作流:@bekacru “Agentic Engineering > Vibe Coding”, @cursor_ai agent-trace.dev
- Anthropic 职场研究:@AnthropicAI AI 辅助编程与精通度
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. Kimi K2.5 模型讨论与发布
-
与 Kimi 面对面:Kimi K2.5 模型背后的开源前沿实验室 AMA (活跃度: 686): Kimi 是开源 Kimi K2.5 模型背后的研究实验室,他们通过 AMA(Ask Me Anything)活动讨论了他们的工作。讨论重点聚焦于大规模模型,并探讨了开发
8B、32B和70B等小型模型以实现更高智能密度的可能性。此外,人们对更小的 Mixture of Experts (MoE) 模型也表现出浓厚兴趣,例如总参数约为100B、激活参数约为A3B的模型,这些模型针对本地或专业消费者(prosumer)场景进行了优化。团队还被问及对“Scaling Laws 已撞墙”这一观点的看法,这是目前 AI 研究领域的热门辩论话题。评论者表达了对更小、更高效模型的渴望,认为这些模型在特定用例中可以提供更好的性能。关于 Scaling Laws 的辩论反映了 AI 社区对当前模型扩展策略局限性的普遍关注。- 围绕模型尺寸的讨论凸显了对 8B、32B 和 70B 等小型模型的偏好,因为它们具有极高的“智能密度”。这些尺寸被认为是平衡性能和资源效率的最佳选择,表明市场需要能够在有限硬件上有效运行且仍能提供强大能力的模型。
- 对更小的 Mixture of Experts (MoE) 模型(如总参数 ~100B、激活参数 ~A3B)的咨询,表明了用户对本地或专业消费者用途优化模型的兴趣。这反映了一种趋势:即开发不仅强大而且普通用户或小型企业也能负担得起的模型,强调在不牺牲性能的情况下高效利用资源。
- 在 Kimi 2.5 等模型中维持非编程能力(如创意写作和情商)是一项重大挑战,尤其是在编程 Benchmark 变得越来越重要的情况下。团队的任务是确保这些软技能不会退化,这需要在技术能力和创造性能力之间平衡训练重心,以满足多样化的用户需求。
-
本地运行 Kimi K2.5 (活跃度: 553): 该图片提供了本地运行 **Kimi-K2.5 模型的指南,强调了其在视觉、编程、Agentic 以及对话任务中的 SOTA 性能。该模型是一个拥有
1 trillion参数的混合推理模型,原始需要600GB磁盘空间,但量化后的 Unsloth Dynamic 1.8-bit 版本将这一需求降低到了240GB,降幅达60%。指南包括使用llama.cpp加载模型的指令,并演示了为一款简单游戏生成 HTML 代码的过程。该模型已在 Hugging Face 上发布,更多文档可在 Unsloth 官方网站找到。** 评论者讨论了在高显存硬件上运行该模型的可行性,一名用户质疑其在 Strix Halo 配置下的表现,另一名用户则指出了巨大的 VRAM 需求,认为现实中只有少数用户能真正实现本地运行。 - Daniel_H212 正在询问 Kimi K2.5 模型在 Strix Halo 硬件上的性能,特别是询问每秒生成 Token 的速度。这表明其关注点在于该模型在高端硬件配置上的基准测试效率。
- Marksta 提供了关于 Kimi K2.5 模型量化版本的反馈,特别是 Q2_K_XL 变体。他们注意到该模型保持了高连贯性并严格遵循 Prompt,这是 Kimi-K2 风格的特征。然而,他们也提到,虽然模型的创意能力有所提高,但在创意场景下的执行力仍显不足,通常交付逻辑正确但文笔较差的响应。
-
MikeRoz 质疑了像 Q5 和 Q6(例如 UD-Q5_K_XL, Q6_K)这类高量化级别的效用,因为大多数专家更倾向于 int4 量化。这突显了关于量化策略中模型大小、性能和精度之间权衡的辩论。
-
Kimi K2.5 是用于编程的最佳开源模型 (活跃度: 1119): 图片强调了 Kimi K2.5 作为 LMARENA.AI 排行榜上领先的编程开源模型,总排名第
#7。该模型因其在编程任务中相比其他开源模型的卓越表现而受到关注。排行榜提供了各种 AI 模型的对比分析,展示了它们的排名、分数和置信区间,强调了 Kimi K2.5 在编程领域的成就。 一位评论者将 Kimi K2.5 的表现与其他模型进行了比较,指出其在准确性上与 Sonnet 4.5 旗鼓相当,但在 Agent 功能方面不如 Opus 先进。另一条评论批评 LMArena 未能反映模型的多轮对话或长上下文能力。- 一位用户将 Kimi K2.5 与其他模型进行了比较,指出在 React 项目的准确性方面它与 Sonnet 4.5 持平,但在 Agent 功能方面未达到 Opus 的水平。他们还提到 Kimi 2.5 超越了他们之前的选择 GLM 4.7,并对来自 z.ai 即将推出的 GLM-5 表示好奇。
- 另一位评论者批评了 LMArena,称其无法提供关于模型多轮对话、长上下文或 Agent 能力的见解,暗示此类基准测试不足以评估全面的模型性能。
- 一位用户强调了 Kimi K2.5 的成本效益,称其感觉与 Opus 4.5 一样出色,但价格明显更便宜,约为成本的 1/5,甚至比 Haiku 还要便宜。这表明 Kimi K2.5 具有极高的性价比。
- 我们终于在家里拥有了最好的 Agentic AI (活跃度: 464): 该图片是各种 AI 模型的性能对比图表,包括 Kimi K2.5、GPT-5.2 (xhigh)、Claude Opus 4.5 和 Gemini 3 Pro。Kimi K2.5 在 Agent、编程、图像和视频任务等多个类别中被突出显示为表现最佳的模型,表明其在多模态应用中的卓越能力。帖子表达了对将该模型与 ‘clawdbot’ 集成的兴奋,暗示了在机器人或自动化领域的潜在应用。 一条评论幽默地表示,在家里部署 Kimi 2.5 1T+ 模型 意味着家里得很大,暗示该模型可能有极高的计算需求。另一条评论讽刺地提到用 16GB VRAM 显卡来处理它,暗示对在典型消费级硬件上运行此类模型的可行性表示怀疑。
2. 开源模型创新
-
LingBot-World 在动态仿真方面超越了 Genie 3 且完全开源 (活跃度: 230): 开源框架 LingBot-World 在动态仿真能力上超越了专有的 Genie 3,达到了
16 FPS,并在视野之外保持了长达60 秒的物体一致性。该模型可在 Hugging Face 上获取,提供了对复杂物理现象和场景转换的增强处理能力,通过提供其代码和模型权重的完整访问权限,挑战了专有系统的垄断地位。 评论者对运行 LingBot-World 的硬件要求表示疑问,并对与 Genie 3 的对比持怀疑态度,认为缺乏经验证据或直接访问 Genie 3 进行公平对比的途径。- 一位用户询问了运行 LingBot-World 的硬件要求,强调了为实际应用指定计算需求的重要性。这对于用户了解在各种环境中部署模型的可行性至关重要。
- 另一位评论者对缺乏与 Genie 3 的直接对比表示担忧,认为如果没有经验数据或 Benchmark(基准测试),关于 LingBot-World 优越性的主张可能缺乏事实根据。这指出了需要透明且严谨的基准测试来验证性能主张。
- 有人建议将较小版本的 LingBot-World 集成到全局照明(global illumination)技术栈中,这表明了其在图形和渲染领域的潜在应用。这可以利用该模型在动态仿真方面的能力来增强视觉计算任务。
-
API 价格正在崩盘。除了隐私,现在运行本地模型的实际理由是什么? (活跃度: 1053): 该帖子讨论了 AI 模型 API 访问成本迅速下降的现状,例如 K2.5 的价格仅为 Opus 的
10%,而 Deepseek 几乎免费。Gemini 也提供了可观的免费层级。这一趋势与本地运行大型模型的挑战形成了对比,例如需要昂贵的 GPU 或处理量化权衡(quantization tradeoffs),导致在消费级硬件上的处理速度较慢(15 tok/s)。作者质疑在这些 API 价格趋势下本地配置的可行性,指出虽然隐私和延迟控制是合理的理由,但本地配置的性价比正在下降。 评论者强调了对低廉 API 价格可持续性的担忧,认为一旦取得市场主导地位,价格可能会上涨,这与过去其他行业的趋势类似。其他人则强调了离线能力以及审计和信任本地模型的重要性,这能确保行为的一致性,而不会出现来自供应商的意外变更。- Minimum-Vanilla949 强调了离线能力对于频繁旅行者的重要性,并强调了 API 公司在占据市场后更改服务条款或提高价格的风险。这突显了本地模型在确保持续访问和成本控制方面的价值。
- 05032-MendicantBias 讨论了当前 API 定价的不可持续性,这些定价往往由风险投资补贴。他们认为一旦实现垄断,价格可能会上涨,使得本地配置和开源工具成为对抗此类商业模式的战略防御。
- IactaAleaEst2021 指出了在运行本地模型时可重复性和信任的重要性。通过下载和审计模型,用户可以确保行为的一致性,而不像使用 API 时,供应商可能会随时间更改模型行为,从而可能降低其在特定任务中的效用。
3. AI Agent 框架的趋势
-
GitHub 本周趋势:半数仓库都是 Agent 框架。90% 将在 1 周内销声匿迹。 (热度: 538): 该帖子图片突显了 GitHub 上的一个趋势,即许多热门仓库都与 AI Agent 框架相关,表明人们对这些工具的兴趣激增。然而,帖子的标题和评论对这种趋势的可持续性表示怀疑,将其比作 JavaScript 框架的快速兴起与衰落。这些仓库大多由 Python 编写,包含 Agent 框架、RAG 工具以及 NanoGPT 和 Grok 等模型相关项目。讨论反映出一种担忧,即其中许多项目可能无法长期维持其知名度或相关性。 一条评论反驳了“半数热门仓库是 Agent 框架”的说法,指出其中只有一个是微软的 Agent 框架,其他则与 RAG 工具和模型开发相关。另一条评论则赞赏了某些项目(如 IPTV)在教育方面的实用性。
- gscjj 指出“半数仓库是 Agent 框架”的说法并不准确。他们注意到列表包含多种项目,如微软的 Agent 框架、RAG 工具、NanoGPT 和 Grok 等模型,以及名为 Kimi 的代码模型 CLI 和一个浏览器 API。这表明热门仓库呈现多样化趋势,而非 Agent 框架一家独大。
-
Mistral CEO Arthur Mensch:“如果你把智能视为电力,那么你只需确保你对智能的获取不会被限制。” (热度: 357): Mistral 的 CEO Arthur Mensch 倡导开源权重模型,将智能比作电力,强调不受限地获取 AI 能力的重要性。这种方法支持在本地设备上部署模型,随着模型针对低算力环境进行量化,成本得以降低,这与通常体量巨大且通过付费墙获利的闭源模型形成鲜明对比。Mistral 旨在平衡企业利益与开放获取,这可能会在 AI 部署方面带来重大突破。评论者赞赏 Mistral 对开源模型采取的方式,指出其在降低成本和提高可访问性方面的潜力。共识在于开源模型可以使 AI 的使用民主化,这与闭源模型的限制性形成对比。
- RoyalCities 强调了模型部署的成本动态,指出开源模型(尤其是经过量化的模型)由于可以在本地设备上运行而降低了成本。这与通常体量巨大且需要大量基础设施、从而通过付费墙获利的闭源模型形成对比。这反映了行业的一个更广泛趋势,即开源模型旨在通过降低硬件要求来实现获取权的民主化。
- HugoCortell 指出了有效部署开源模型的硬件瓶颈。虽然开源模型在性能上可以与闭源模型竞争,但缺乏负担得起的高性能硬件限制了其普及。大公司使得高质量本地硬件日益昂贵,这加剧了这一问题,表明需要有一家能够生产和分发自有硬件的公司来真正实现 AI 获取的民主化。
- tarruda 表达了对下一个开源 Mistral 模型的期待,特别是 “8x22”。这表明社区对即将推出的模型的决策规格和潜在性能改进充满兴趣,反映出开源模型开发在推动 AI 能力进步方面的重要性。
技术性较低的 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. OpenAI 与 AGI 投资
-
据报道,Mag 7 中近一半公司正豪赌 OpenAI 的 AGI 之路 (热度: 1153): NVIDIA、Microsoft 和 Amazon 据传正在讨论向 OpenAI 共同投资总计高达
$600 亿,此外 SoftBank 也在考虑追加$300 亿。这笔潜在投资可能会使 OpenAI 的投前估值达到约$7300 亿,与近期讨论的$7500 亿至 $8500 亿+的估值范围一致。这将标志着历史上规模最大的私募融资之一,突显了各大科技公司对开发通用人工智能 (AGI) 的重大财务承诺。评论者指出了这些投资的战略协同性,其中一人指出 Microsoft 和 NVIDIA 等公司不太可能投资 Google 等竞争对手。另一条评论则反映了大型语言模型 (LLMs) 不断演变的格局以及科技巨头关注点的转移。- CoolStructure6012 强调了 Microsoft (MSFT) 和 NVIDIA (NVDA) 与 OpenAI 之间的战略协同,认为鉴于它们与 Google 的竞争立场,其投资是合乎逻辑的。这反映了更广泛的行业趋势,即科技巨头正与 AI 领导者结盟,以增强自身的 AI 能力和市场地位。
- drewc717 反思了 AI 模型的演变,指出使用 OpenAI 的
4.1 Pro mode带来了显著的生产力提升。然而,他们表示在切换到 Gemini 后工作流效率有所下降,这表明并非所有的 LLM 都能提供相同水平的用户体验或生产力,而这对于依赖这些工具的开发者来说至关重要。 - EmbarrassedRing7806 质疑为何 Anthropic 尽管其 Claude 模型在编程中被广泛使用,却未能像 OpenAI 的 Codex 那样获得同等关注。这表明 Anthropic 在 AI 编程领域的影响力可能被低估了,而 Claude 正在提供具有竞争力甚至更优越的能力。
2. DeepMind 的 AlphaGenome 发布
-
Google DeepMind 发布 AlphaGenome,这是一款可分析多达 100 万个 DNA 碱基以预测基因组调控的 AI 模型 (热度: 427): Google DeepMind 推出了 AlphaGenome,这是一款能够分析多达
100 万个 DNA 碱基以预测基因组调控的序列模型,详情已发表在 Nature 上。该模型在预测基因表达和染色质结构等基因组信号方面表现卓越,特别是在非编码 DNA 领域,这对于理解疾病相关变异至关重要。AlphaGenome 在26 个基准任务中的 25 个上超越了现有模型,并已开放供研究使用,其模型和权重可在 GitHub 上获取。评论者强调了该模型对基因组学的潜在影响,一些人幽默地暗示其在推动科学成就方面的意义不亚于获得诺贝尔奖。 -
[R] AlphaGenome:DeepMind 的统一 DNA 序列模型在单碱基对分辨率下预测 11 种模态的调控变异效应 (Nature 2026) (热度: 66): DeepMind 的 AlphaGenome 引入了一个统一的 DNA 序列模型,能在单碱基对分辨率下预测跨
11 种模态的调控变异效应。该模型处理100 万个碱基对的 DNA 以预测数千个功能基因组轨迹,在26 项评估中的 25 项中达到或超过了专用模型。它采用了带有 CNN 和 Transformer 层的 U-Net 骨干网络,在人类和小鼠基因组上进行训练,并捕捉了1Mb背景下99%经证实的增强子-基因对。在 TPUv3 上的训练耗时4 小时,在 H100 上的推理时间不足1 秒。该模型展示了跨模态变异解读能力,特别是在 T-ALL 中的 TAL1 癌基因上。Nature, bioRxiv, DeepMind 博客, GitHub。一些评论者认为该模型是对现有预测基因组轨迹的序列模型的渐进式改进,尽管在 Nature 上发表,但对其新颖性表示怀疑。其他人则对开源如此强大的基因组工具的影响表示担忧,暗示了未来可能出现的应用,如 “text to CRISPR” 模型。- st8ic88 认为,虽然 DeepMind 的 AlphaGenome 模型在单碱基对分辨率下预测 11 种模态的调控变异效应的能力值得注意,但它被视为对现有预测基因组轨迹的序列模型的渐进式改进。评论认为,该模型的知名度部分归功于 DeepMind 的声誉和品牌效应,特别是其名称中 “Alpha” 的使用,这可能有助于其在 Nature 上的发表。
- –MCMC– 对 AlphaGenome 模型的预印本与其在 Nature 上发表的最终版本之间的差异感兴趣。该评论者阅读过预印本,并对同行评审过程中所做的任何更改感到好奇,这些更改可能包括对模型方法、结果或解释的更新。
- f0urtyfive 对开源 AlphaGenome 等强大的基因组模型的潜在风险表示担忧,并推测了未来的发展,如 “text to CRISPR” 模型。这一评论强调了让先进的基因组预测工具广泛可及的伦理和安全考量,这可能导致意外的应用或滥用。
3. Claude 的成本效率与使用策略
-
Claude 订阅比 API 便宜多达 36 倍(以及为什么 “Max 5x” 是真正的黄金选择) (活跃度: 665): 一位数据分析师通过分析 Web 界面中未舍入的浮点数,逆向工程了 **Claude 的内部使用限制。结果显示,订阅模式可能比使用 API 便宜多达 36 倍,尤其是在使用 Claude Code 等 Agent 进行编程任务时。分析表明,订阅模型提供免费的缓存读取 (cache reads),而 API 则对每次读取收取输入成本的 10%,这使得订阅模式在长会话中具有显著的成本效益。每月 100 美元的 “Max 5x” 方案被强调为最优化选择,其提供的会话限制比 Pro 方案高出 6 倍,每周限制高出 8.3 倍,这与官方宣传的 “5x” 和 “20x” 方案有所不同。这些发现是使用 Stern-Brocot tree 将精确的使用百分比解码为内部额度数值后得出的。完整细节和公式可在此处查看。** 评论者对 Anthropic 缺乏透明度表示担忧,并推测一旦公司意识到用户已经逆向工程了这些限制,可能会修改它们。一些用户正在利用当前的订阅优势,并预料到未来可能发生的变化。
- HikariWS 提出了关于 Anthropic 在订阅限制方面缺乏透明度的关键点,认为这些限制可能会出人意料地发生变化,从而使当前的分析失效。这种不可预测性对于依赖这些方案来实现成本效益的开发者来说构成了风险。
- Isaenkodmitry 讨论了 Anthropic 可能在意识到用户利用订阅方案获取比 API 更廉价的访问权限后封堵漏洞的可能性。这凸显了目前受益于这些方案的开发者的战略风险,建议他们应该趁现在最大化利用。
- Snow30303 提到了在 VS Code 中为 Flutter 应用使用 Claude code 的经历,并指出它消耗额度的速度非常快。这表明在将 Claude 集成到开发工作流中时,需要更高效的使用策略或替代方案来有效管理成本。
-
我们通过文件分层系统将 Claude API 成本降低了 94.5%(附证明) (活跃度: 603): 该帖子描述了一种文件分层系统,通过将文件分类为 HOT、WARM 和 COLD 层级,从而最大限度地减少每个会话处理的 tokens 数量,将 **Claude API 成本降低了 94.5%。该系统在一个名为
cortex-tms的工具中实现,根据文件的相关性和使用频率对其进行标记,默认情况下仅允许加载最必要的文件。该方法已通过作者项目的案例研究得到验证,显示每个会话的 tokens 从66,834减少到3,647,在 Claude Sonnet 4.5 上显著将每会话成本从0.11美元降低到0.01美元。该工具是开源的,可在 GitHub 上获取。** 一位评论者询问了手动标记文件和更新标签的过程,建议使用 git history 来自动确定文件热度。另一位用户对比方法表示赞赏,因为他们自己也在为管理 API 额度而挣扎。- Illustrious-Report96 建议使用
git history来确定文件“热度”,这涉及分析更改的频率和新鲜度,以将文件分类为 ‘hot’、’warm’ 或 ‘cold’。这种方法利用版本控制元数据来自动化分类过程,从而可能减少手动标记的工作量。 - Accomplished_Buy9342 询问了如何限制对 ‘WARM’ 和 ‘COLD’ 文件的访问,这暗示了需要一种机制来根据文件层级控制 Agent 的访问权限。这可能涉及实施访问控制或修改 Agent 的逻辑以优先处理 ‘HOT’ 文件,从而确保高效的资源利用。
- durable-racoon 询问了标记文件和更新标签的过程,强调了自动化或半自动化系统对于高效管理文件分层的重要性。这可能涉及根据使用模式或其他标准动态更新文件标签的脚本或工具。
- Illustrious-Report96 建议使用
AI Discord 摘要
由 Gemini 3.0 Pro Preview Nov-18 生成的摘要之摘要
主题 1. 模型之战:Kimi 的崛起、递归 Agent 和几何架构
- Kimi K2.5 横扫 Vision Arena:社区报告称 Kimi K2.5 正在霸榜,在 Vision Arena 排行榜上占据 开源模型 #1 的位置,总榜排名 #6。用户指出它在特定视觉任务中的表现优于 Claude,并且现在配备了专门的 computer use 模型来处理手机屏幕截图(尽管在移动端上传时会抛出 403 错误)。
- 递归语言模型引发语义争论:围绕“递归语言模型”(Recursive Language Models,RLM)这一术语爆发了激烈讨论。批评者认为它只是工具调用循环(tool-calling loops)的重新包装,而支持者则指向新的 RLM-Qwen3-8B,称其为第一个原生递归模型。据报道,这个仅在 1,000 条轨迹上进行后训练的小规模模型,在长上下文任务中击败了脚手架式(scaffolded)的 RLM 版本。
- 几何卷积试图挑战 Attention 的地位:研究人员正在实验一种基线方案,通过 几何卷积方法 取代标准的 Multi-Head Attention,使用 embedding 作为单元连接。早期调试输出显示,loss 收敛捕捉到了对话逻辑,这使其成为重度 Transformer 计算的潜在替代方案。
主题 2. 硬件竞争:微软芯片、Unsloth 速度与苹果的隐藏实力
- 微软凭借 Maia 200 对标 NVIDIA:微软发布了 Maia 200 AI 加速器。这是一款专注于推理的芯片,拥有 216GB 显存,FP4 性能达 10k TFLOPS。工程师们讨论了其对 TSMC 制造的依赖,并认为其架构在大规模推理工作负载方面优于 NVIDIA 的 Vera Rubin。
- RTX 5090 横扫训练基准测试:Unsloth 用户报告称,RTX 5090 实现了高达 每秒 18k token 的极速训练,不过在序列长度低于 4096 时,保持在 12-15k t/s 更为安全。为了获得最佳吞吐量,需要仔细平衡 batch size 和序列长度,以避免微调期间的内存瓶颈。
- 苹果 ANE 表现超出其量级:针对 这篇论文 的新讨论强调,苹果的 Neural Engine (ANE) 在 M4-Pro 上可提供 3.8 TFlops 的算力,几乎与 GPU 在 GEMM 操作中的 4.7 TFlops 持平。ANE 优先考虑能效比(performance-per-watt),使其成为高效本地推理的一个出人意料的理想目标。
主题 3. 开发工具与标准:Cursor 的困扰、MCP 安全与 Parallel Studio
- Cursor 的“Plan Mode”令高级用户不快:最新的 Cursor 更新引入了 plan mode,由于浪费时间且需要不必要的输入,用户正积极尝试禁用或自动化该模式。据报道,IDE 的全新安装是最不稳定的配置,这促使用户寻求解决 “Plan Mode” 摩擦的变通方法。
- MCP 获得增强的安全标准:Dani (cr0hn) 起草了一份公开的 MCP 安全标准,涵盖加固、日志记录和访问控制,意图将其捐赠给 Agentic AI Foundation。与此同时,该协议正在演进,Namespaces 被拒绝,取而代之的是 Groups,详见新的 Primitive Grouping SEP-2084。
- LM Studio 0.4 将进阶工具隐藏在开发者模式下:LM Studio 0.4.0 的发布将采样和硬件配置等关键设置隐藏在 开发者模式 开关(
Ctrl+Shift+R)之后,同时引入了并行请求功能。用户现在可以在不同 GPU 上加载模型,默认情况下最多可处理 4 个并行请求,尽管该软件仍依赖于较旧的 ROCm 6.4.1。
主题 4. 越狱与漏洞利用:注册机、”Remember” 黑客攻击与恶意软件分类器
- Gemini 3 Pro 被诱导编写 KeyGens:一名用户成功引导 Gemini 3 Pro 通过直接粘贴来自 Ghidra 的代码来逆向工程软件并生成可用的 KeyGen。虽然有人将其斥为 “script kiddie” 行为,但这突显了该模型在处理技术反汇编代码时,容易受到基于上下文的漏洞利用 (context-based exploits) 的影响。
- “Remember:” 命令充当行为注入:红队人员发现 Gemini 命令 “Remember:” 会立即强制将后续文本存入模型的保存内存中,从而严重影响未来的行为。这允许持久化的 prompt injections,逐个回合地进行指令下达,绕过了标准的会话重置。
- 对抗性恶意软件分类面临挑战:工程师们正致力于通过包含 600K 行和 9,600 个二进制特征的数据集来降低恶意软件分类模型的误报率 (False Positive Rate, FPR)。尽管使用了神经网络和像 scikit-learn 树这样的可解释模型 (explainable models),但在不牺牲模型可解释性的情况下,将 FPR 降至 9% 以下仍然是一个重大障碍。
Theme 5. 现实世界 Agent:厨房机器人、世界模型和生物 AI
- Figure.Ai 的 Helix 02 征服厨房:一段 Figure.Ai 的 Helix 02 机器人自主执行复杂厨房任务的视频流出,一名用户通过将视频输入 Kimi 进行了 98% 准确率的分析。这与 Matic 筹集 $60M 开发针对实用型消费级机器人(Roomba 的继任者)的报道相吻合。
- Google 发布 “Genie” 世界模型:Google 为 AI Ultra 订阅者推出了 Project Genie,这是一个能够根据文本提示词生成交互式环境的通用世界模型。此发布将世界模型从研究论文推向了可用于模拟动态场景的可部署产品。
- AI 解码 DNA 和阿尔兹海默症:Google AI 推出了 AlphaGenome 以预测 DNA 变异和突变的影响,而 Goodfire AI 宣布通过模型可解释性发现了新的 阿尔兹海默症生物标志物。这些进展标志着利用透明 AI 模型 (transparent AI models) 推动数字生物学突破的转变。
Discord: 高层级 Discord 摘要
BASI Jailbreaking Discord
- Gemini 3 Pro 破解软件 KeyGen 风格:一名成员报告使用 Gemini 3 Pro 通过粘贴 Ghidra 的代码从软件中创建了可用的 KeyGen。
- 持怀疑态度的成员将其称为 script kiddie 行为,并建议尝试逆向工程 CTF 挑战。
- AI 被武器化用于逆向工程:一名成员分享了他将 AI 武器化用于大规模逆向工程、恶意软件分析和越狱 (jailbreak) 开发的工作。
- 另一名成员质疑这一说法,认为原帖作者在越狱 (jailbreaking) 方面可能比在恶意软件创建方面更具技巧。
- Sonnet 4.5 通过 Kaelia Jailbreak 超越 Opus:成员确认 Sonnet 4.5 jailbreaks 在 Opus 上有效,分享了基于 Vichaps 的 ENI Lime 的 Miss Kaelia jailbreak。
- 这种越狱的效果可能不如其他模型,具体取决于所使用的 prompting 策略。
- Gemini 的 ‘Remember:’ 命令触发行为:一名成员解释说,在 Gemini 中,命令 ‘Remember:’ 会自动将后续单词添加到其保存的信息中,从而影响其行为。
- 每一轮对话都在聊天界面中被清晰地逐一指令化。
- 针对 Kimi 2.5 的 NSFW Nano Banana Jailbreak 问世:一名成员分享了针对 Kimi 2.5 的 NSFW 越狱,被称为 nano banana jailbreak。其系统提示词将 Kimi 塑造为来自 Moonshot AI 的 AI 助手,允许 NSFW 内容。
- 叙述流程无缝进行,没有任何中断。
Unsloth AI (Daniel Han) Discord
- CUDA 解决了 GLM 4.7 的减速问题:用户通过确保正确的 CUDA 编译,解决了在 NVIDIA Jetson 上运行 GLM 4.7 Flash 速度慢的问题。通过使用
-kvu和-fa on标志,性能从 3 tps 提升到了潜在的 70-80 t/s。- 在 OpenCode 上观察到了性能差异,一名用户在打开模型后经历了减速,而另一名用户指出,在 32b 以下,GLM 4.7 是比 Qwen Coder 更好的 uncensored 代码模型,但 Qwen Coder 在 reasoning(推理)方面表现更出色。
- LongCat 跃上 HuggingFace!:美团的新型 n-gram 模型 LongCat 模型在 Hugging Face 上首次亮相,引发了社区关于模型名称中 Flash 泛滥的玩笑。
- 社区成员在庆祝新版本发布的同时,调侃下一个模型可能会叫 Flash-Flash-1b。
- 微软 Maia 200 挑战 NVIDIA:微软发布了 Maia 200 AI Accelerator,这是一款专为推理(inference)设计的芯片,拥有 216GB 显存和 10k TFLOPS 的 FP4 性能。
- 社区讨论了该芯片由 TSMC 代工的情况,并将其与 NVIDIA 的 Vera Rubin 架构进行了比较,一些人对依赖特定硬件表示了关注。
- 递归语言模型 (RLM) 的定义重新讨论:社区成员认为“Recursive Language Models” (RLM) 这个术语具有误导性,因为它仅仅描述了一个 tool-calling loop(工具调用循环),尽管一些人坚持认为 RLM 确实涉及模型递归地控制其环境。
- 其他人讨论了最近发布的 RLM-Qwen3-8B,这是第一个原生递归语言模型,并指出其相比基础版和外挂(scaffolded) RLM 版本有所改进。
- 灾难性遗忘的缓解方法:一位成员建议通过降低 LoRA rank 和 LR(学习率)、减少 steps/epochs 以及混入更多通用数据来缓解微调模型中的 灾难性遗忘 (catastrophic forgetting),正如 Unsloth 文档中所概述的那样。
- 他们还建议在微调时 针对更少的层,并使用 WSL2 和 VSCode 进行训练。
LMArena Discord
- Arena 品牌重塑引发争论:LMArena 更名为 Arena,引发了不同的反应。一些用户认为这个名字太模糊,而另一些人则欢迎其从 Language Models 扩展到包括 图像 和 视频生成,正如其官方博客文章中所宣布的那样。
- 一位用户评论道:“‘Arena’ 这个名字非常模糊,第一眼看上去可能代表任何东西”,这与辨识度高的 ‘LMArena’ 形成对比。
- 验证码难题困扰用户:用户报告称在 Arena 上陷入了无尽的 reCAPTCHA 循环,阻碍了网站的使用。有人声称即使通过了验证也提示失败,还有人报告称等待时间过长会导致错误,直到刷新页面。
- 一位用户感叹道:“Google 的 CAPTCHA 简直完全失控了”,并质疑开发人员为什么专注于重新设计样式而不是修复 Bug。
- Nano 的图像编辑能力骤降:用户观察到 Nano Banana 的性能下降,尤其是在图像编辑方面。有报告称它无法正确执行任务,而同样的提示词在 Gemini App 中却可以正常工作。
- 一位用户简单地表示:“看起来 Nano 2 甚至已经无法正确编辑任何东西了”。
- Kimi K2.5 征服 Vision Arena:Kimi K2.5 在专家排行榜上表现出惊人的分数,在特定测试中超过了 Claude。它以 vision support(视觉支持)著称,并在直接对话模式中标记为 “vision”。
Kimi-k2.5-thinking目前在 Vision Arena 排行榜中位列 #1 开源模型,且 总榜排名第 6,是 Top 15 中唯一的开源模型。
- 视频生成的不稳定困扰观众:一些用户在未生成视频的情况下遇到了“达到视频限制 (Hit video limit)”的消息,而另一些用户则在处理长代码和长回复时遇到延迟。
- 用户发现需要使用 canary.lmarena.ai 才能启用视频上传,有人建议为视频生成提供分屏或直接对话界面。
Cursor Community Discord
- Cursor 不稳定性困扰新安装用户:用户报告称,最新版本 Cursor 的新安装 (fresh install) 是最不稳定的配置。
- 该问题可能与配置文件或与其他配置的交互有关。
- Clawdbot 界面被戏称为“美化版 Claude”:成员们正在讨论可通过 Telegram 访问的 Clawdbot 界面,有人将其描述为 美化版的 Claude 代码界面。
- 这意味着 Clawdbot 虽然提供了一种与 Claude 进行代码相关任务交互的便捷方式,但未必具有突破性。
- 用户计划停用 Cursor 的 Plan Mode:用户正积极寻求禁用 Cursor 新推出的 Plan Mode 或使其自动接受的方法。
- 目标是简化工作流并减少不必要的用户输入,用户对其“浪费时间”表示沮丧。
- Gemini Agentic Vision 接近 SOTA 水平:热心用户称赞了 Gemini Agentic Vision 的能力,声称经过初步测试,它在视觉领域已接近 SOTA。
- 然而,一位用户报告了 Cursor 完全黑屏的问题,阻碍了进一步的评估和使用。
- Prompt Engineering 加速图像处理:成员们正在交流优化 Prompt 的技巧,以增强 Cursor 的图像分析能力。
- 建议包括提供更多上下文,或使用 Prompt “Analyze the image for debugging purposes and for an LLM to see the layout clearly” 来提高处理的准确性和清晰度。
OpenRouter Discord
- Arcee AI CTO 访谈首映:Arcee AI 的 CTO Lucas Atkins 在一段新访谈中登场,现已可在 YouTube 上观看。
- 视频展示了 Lucas Atkins 讨论 Arcee AI 及其最新进展。
- OpenRouter 用户等待退款:用户报告称退款延迟,部分请求可追溯至 1 月 3 日,支持工单仍未解决,并要求 @OpenRouter 团队提供更新。
- 延迟引发了不满,用户正寻求明确的退款处理时间表。
- GROK 需要核能支持:一位用户幽默地建议“我们需要为 GROK 建设更多核电站”。
- 该用户还开玩笑地补充道“关掉单收入家庭的电源”。
- Summergrok 登录 xAI API:Summergrok 的生成视频功能现已上线 xAI API。
- 这一集成允许开发者通过 xAI API 将 Summergrok 的能力整合到自己的项目中。
- API Key 可见性受限:一位用户遇到了无法查看已创建的 API Key 的问题。
- 另一位用户澄清说,API Key 仅在创建时显示一次,建议用户立即保存。
Latent Space Discord
- LS 频道热议咖啡替代品:成员们讨论了咖啡的替代品,其中绿茶因其较低的咖啡因剂量以及 l-theanine(L-茶氨酸)的平衡作用而受到关注。
- 一位成员使用盖碗冲泡散茶(例如这种珠茶),在享受品茗仪式感的同时,精准管理咖啡因的摄入。
- “举手”姿势助力 UGC 流量爆发:根据这条推文,在 UGC 内容中通过 ‘arms up’(举手)的肢体语言展现脆弱感,使一位创作者的播放量从 1.2 万飙升至 210 万。
- 一位成员调侃道:如果色情行业都在这么做,那这绝对是未来的趋势,而我错了。
- CedarDB 性能主张被指存疑:一位成员分享了 CedarDB 的链接,另一位成员转发了讨论此事的 vxtwitter 链接,但称其 perf claims(性能主张)可疑。
- 另一位成员表示,因为它不是 open source(开源),对他来说就是 DOA(出生即死亡),并分享了一个教训:永远使用开源数据存储。
- Flapping Airplanes 获 1.8 亿美元融资:Flapping Airplanes 获得了来自 GV、Sequoia 和 Index Ventures 的 1.8 亿美元 融资,用于推进人类水平的 AI 模型。
- 此次融资旨在加速开发具有人类水平智能的新型 AI 模型,详见这条推文。
- Google 的 Genie 为 Ultra 订阅者解锁:Google AI 面向 Google AI Ultra 订阅用户推出了 Project Genie,提供一个能根据文本提示创建交互式环境的 general-purpose world model(通用世界模型)。
- 正如这条推文所宣布的,此次发布允许用户通过简单的描述生成动态内容。
Nous Research AI Discord
- 阶段性奖励塑形提升并行执行效率:成员们探索了使用 staged reward shaping(阶段性奖励塑形),在 post-training(后训练)阶段通过强化学习调整模型权重,从而专门优化 parallel execution strategies(并行执行策略)。
- 该算法评估了众多场景,奖励模型倾向于选择 parallelizations(并行化)的行为。
- Upscayl:令人惊艳的免费放大工具:成员们称赞了 Upscayl,这是一个 free open-source upscaling tool(免费开源放大工具),认为其简洁性与高质量表现令人惊讶。
- 一位成员开玩笑问:“既然我对 Perl 做了贡献,你们现在会因为我而开始用 Perl 吗?”。
- WebGPU 赋能本地浏览器 AI:一位成员分享了一个 WebGPU 示例,演示了 AI 模型直接在浏览器中运行,突显了本地化、隐私保护型 AI 应用的潜力。
- 该模型在页面重新加载时直接加载,意味着模型已缓存数月;一名用户建议使用 GGUF 的 Q8 版本。
- Gemma 300M 是否为理想的本地浏览器 AI?:成员们探讨了因存储限制在浏览器中本地运行 AI 模型的挑战,认为 Gemma 300M 可能是一个合适的选择。
- 对于浏览器 AI 模型用户来说,隐私至关重要,“并且它也是其他客户良好的参考产品”。
- SmolLM2 在 WebGPU 中表现卓越:用户认为 HuggingFaceTB/SmolLM2-1.7B-Instruct 是一个可靠的案例,其 1.7B 的大小对于 WebGPU 仍然非常可行。
- 虽然针对该任务有更优的模型,但考虑到体积仅略大一点,一位用户推荐尝试 LFM 2.5。
LM Studio Discord
- LM Studio 将设置隐藏在 Dev Mode 之后:在 LM Studio 0.4.0 中,许多设置如 sampling、runtime 和 hardware configs 现在都隐藏在 dev mode(开发者模式)之后,可以通过
Ctrl+Shift+R或Cmd+Shift+R访问。- 用户可以通过启用左下角的 Dev Mode 来解锁新功能和界面变化。
- Unraid 安装仍缺乏完整堆栈 (Full Stack):尽管新的 headless 模式可以实现稳定的 Docker container,但 LM Studio 目前仍是一个核心可执行文件,而不是针对 Unraid 的完整堆栈。
- 一些用户希望界面的改进能在未来简化 LM Studio-as-client 模式的实现。
- 并行请求 (Parallel Requests) 上线:LM Studio 0.4 引入了 parallel requests,允许用户将模型加载到不同的 GPU 上,并将其分配给特定的请求。
- 默认设置为 4 个并行请求;用户可以在之前相同的位置配置 GPU 优先级。
- LM Studio 中的 ROCm 版本滞后:成员们注意到 LM Studio 在最新的 0.4.0 版本 中仍在使用 ROCm 6.4.1,并质疑何时更新到更高级的版本(如 7.2)以获得更好的 GPU 支持,包括 Strix Halo (gfx1151)。
- 讨论集中在这个过时的版本是否会影响新 GPU 的性能和兼容性。
- Nvidia Jetsons 受困于 Ubuntu 臃肿:一位成员反映,“nvidia jetsons 最糟糕的一点就是它自带的荒唐的 Ubuntu 系统”,并将其特征描述为极其“臃肿”。
- 另一位成员提到 Jetson Xavier AGX 的 TDP 约为 30W。
Perplexity AI Discord
- 热切期待 Kimi 2.5:用户正期待 Kimi 2.5 在 Perplexity 上发布,许多人表达了兴奋之情。
- 几位用户发布了 +1 表示支持。
- Clawdbot 的身份危机:一名用户批评了针对 Clawdbot 用途的研究,讨论随后澄清了它是一个 AI 个人助手。
- 由于其名称与 Claude 相似,Clawdbot 已更名为 Moltbot。
- Deep Research 限制揭晓:关于 Pro 用户 Deep Research 使用限制的讨论,上限设定为 250 次。
- 该限制的重置频率尚不明确。
- Comet 同步失败:一名用户报告称,尽管有功能声明,但 Comet 无法同步书签和扩展程序。
- 另一名用户建议检查
comet://settings/synchronisation处的 Comet 同步设置。
- 另一名用户建议检查
- 印度用户专享 Perplexity Pro 福利:用户强调,印度用户可以免费获得一年的 Perplexity Pro、Google One、Chatgpt Go 和 Adobe Express Premium。
- 一名用户将此归功于这些公司中 印度裔 CEO 的影响以及印度蓬勃发展的技术领域。
Moonshot AI (Kimi K-2) Discord
- Figure.Ai 的 Helix 02 称霸厨房:一位成员分享了 Figure.Ai 的 Helix 02 的视频,展示其自主执行厨房任务。
- 另一位成员使用 Kimi 分析了该视频,并表示将结果整合到幻灯片中时达到了 98% 的准确率。
- Agent Swarm 引发热烈反响:成员们讨论了 Agent Swarm,反应从担心高额的 Agent 额度消耗到将其结果描述为“超级酷”和“完美”。
- 一名成员建议可以用它来检查 Supabase SDK 依赖问题,以及将代码从 Rust 移植到 Golang,效果比 kimi-cli 更好。
- Token 计费系统引发争论:引入 token 计费系统 导致了评价两极分化,用户将其与之前的按请求计费系统进行对比。
- 虽然有些人认为新系统更好,“因为我的一些后续查询非常简短”,但另一些人则认为它“更加模糊”。
- 手机截图触发审核过滤器:用户在向 Kimi K2.5 上传图片(尤其是手机截图)时遇到错误,具体为 error code: 403。
- 笔记本电脑截取的屏幕截图似乎可以正常工作,这表明手机生成的图像可能存在某种兼容性问题。
OpenAI Discord
- 特斯拉的 FSD 自动化改变了看法:一位用户发现驾驶搭载 Full Self-Driving 的特斯拉非常酷且有趣,尽管它需要持续的监督。
- 该用户认为这就是为什么 OpenAI 正在升级其 Codex 以强力应对网络安全问题的原因。
- TI-84 计算器运行神经网络:一位用户创建了一个直接在 TI-84 上运行的神经网络,能够对单词进行自动纠错/拼写检查。
- 其他用户对这一成就表示惊讶。
- GPT Pro 5.2 文件处理出现回归:用户报告了 GPT Pro 5.2 在文件处理方面的回归 (Regression),尽管上传成功,但模型无法访问上传的文件(ZIP、Excel、PDF),这可能是由于附件到沙箱 (sandbox) 挂载步骤损坏导致的。
- 一位用户指出 Reddit 帖子也反映了同样的问题。
- 动态 GIF 引发癫痫风险审查:在删除了一些动态 GIF 后引发了讨论,原因是这些 GIF 可能给患有癫痫的观众带来癫痫发作风险。
- 一位成员表示,社区不需要冒着癫痫发作的风险让你在 ChatGPT 中讨论动画 GIF,并对删除闪烁图像表示宽慰。
- Prompt Engineers 受到提醒:管理员提醒用户,该频道应仅用于 Prompt Engineering 讨论,而非一般的图像输出展示,并引导他们使用相应的
IMAGES频道。- 一位用户对其帖子被删除表示沮丧,认为这些帖子旨在鼓励讨论并展示他们正在编写指南的一种方法,而不仅仅是分享图像。
GPU MODE Discord
- NSys 窥见 NCU 之外的内容:成员们发现 nsys 显示了 ncu 遗漏的内核,如 CUB::SCAN 和 CUB::RADIXSORT,从而推测这些内核是从 reduce_kernel 启动的。
- 有分享称,在同时使用了 nsys 和 ncu 之后,就无法再回到只使用单一 Profiler 的状态了。
- Sparsity 项目激发加速:成员们提议在 Sparsity 项目上进行协作,以对稀疏模式和方法论进行基准测试,从而获得性能提升。
- 一位成员展示了 Karpathy 的
llm.c在 GitHub 上的 Fork 版本,该版本使用了 cuSPARSELt,并报告在训练后期 Epoch 中获得了显著的训练时间加速。
- 一位成员展示了 Karpathy 的
- 预热 GPU 以防止饥饿:成员们寻求为大规模分布式训练保持 GPU 预热的方法,旨在缓解 GPU 饥饿 (GPU starvation)。
- 建议参考 Charles 在 Modal 上关于容器冷启动的博客文章,这是一种有公开文档记录的技术。
- JAX 的 PR 竞争引发关注:一位开发者表达了挫败感,因为 JAX 中一个 AI 生成的 Pull Request 正在受到关注,而他们提交的小型 Bug 修复仍未得到处理。
- 这引发了关于 Pull Request 优先级排序的讨论,特别是如何在 AI 贡献与必要的 Bug 修复之间取得平衡。
- ML Systems 先驱推介 TVM-FFI:Tianqi Chen 介绍了 tvm-ffi,这是一个开放的 ABI 和 FFI,专为 ML Systems 设计,正被 nvfp4 竞赛的顶级提交者所使用,如此视频所示。
- TVM-FFI 促进了 ML Systems GPU Kernels 的互操作性,减少了 Host 开销,并确保了与 PyTorch 的开箱即用兼容性。
HuggingFace Discord
- TRL Pull Request 等待审核:一位成员请求对其 TRL pull request #4894 进行审核,并指出 PR 审核可能需要数周或数月的时间。
- 他们还建议,在标记(tagging)某人审核 PR 之前,最好先等待几天。
- GCP 基础设施经历副本激增:一位成员报告了一个 bug,其在 GCP 上的私有模型副本在没有更改任何配置的情况下,一夜之间从 1 个副本的上限激增至 62 个副本。
- 该成员推测,他们并不是唯一受影响的端点(endpoint),而 GCP 资源现在已经耗尽。
- Qwen3 TTS 亮相:一位成员发布了 Qwen3-TTS-12Hz-1.7B-Base 模型,并提供了 MacOS, Linux 和 Windows 的安装说明。
- 另一位成员评论道:“这里的东西很酷,我会持续关注这个项目,在我看来,你在这里实现的东西真的很有趣”。
- Diffusers 支持两阶段流程:根据这个 pull request,Diffusers 库现在支持 LTX-2 蒸馏权重(checkpoint)和两阶段流水线(two-stage pipelines)。
- 此次更新将提升 Diffusers 在处理复杂的基于扩散(diffusion-based)任务时的可用性。
- 来自 Pacific Prime 的数学 LLM 问世:Pacific Prime 发布了其数学专用 1.5B LLM 的首个训练权重,该模型在 GSM8K、NuminaMath、MetaMathQA 和 Orca-Math(约 40.7 万个样本)上进行了训练。
- 该模型具有使用 LaTeX 记号的分步推理功能,可用于解决高级数学问题。
Yannick Kilcher Discord
- 征集字节级密集 MoE 架构的反馈:一位成员正在为其用于字节级预测的密集 MoE 架构寻求反馈,该架构使用了 256 的词表大小、40M 参数以及 13GB VRAM。
- 该模型使用 4096 序列长度和 8 的 batch size,成员表示他们能够使用完全相同的架构来编码图像、音频或两者。
- 披露带有子进程模型的思考型 AI 架构:一位成员提出了一种架构,其中较大的“思考型” AI 模型由较小的子进程模型监控,后者会暂停主模型以从 MCP 或 CLI 获取信息。
- 其目标是减少主模型的上下文杂乱(context clutter),尽管人们意识到子进程模型需要知道主模型缺失了哪些信息,并且这种做法被描述为“可能是一个愚蠢的想法”。
- 路由和分类大幅提升模型性能:成员们讨论了使用分类器将用户提示词(prompt)路由到专用模型,并将详细信息附加到用户提示词的上下文中,这样可以避免暂停较大的模型并减少 Token 开销。
- 进一步讨论了使分类器和 Embedding 模型保持一致,直接通过 LM 和专家模型处理 Embedding,一位成员表示“路由和分类可能是最激进的举动”。
- 余弦相似度在因果相关性上失效:成员们讨论了检索不可靠且令模型困惑的问题,以及余弦相似度可能不等于因果相关性(causal relevance)。
- 一位成员建议在模型中索引 SQL 数据库,该成员发帖称:“在我看来,检索最大的问题是余弦相似度 != 因果相关性”。
- Sweep 发布 Next-Edit 自动补全模型:Sweep 正在开源 Sweep Next-Edit,这是一个可在本地运行的、用于下一编辑自动补全的 SOTA LLM,已发布 0.5B 和 1.5B 参数的模型,详见 Sweep 博客。
- 未提供进一步细节。
Manus.im Discord Discord
- Minecraft 启动器支持 AFK:一名用户正在开发一款专门设计的 Minecraft 启动器,旨在无需 高性能 PC 即可实现 AFK 挂机。
- 该开发者还提到了在 Prompt Engineering、数据提取甚至网站克隆方面的能力。
- Manus 兑换码发布:一位用户分享了三个新的 Manus 兑换码:FUM1A1G7、ntaxzjg 和 mwiyytb。
- 其他用户确认了这些代码,并指出每个月只能使用一个代码。
- AI/ML 工程师寻求合作:一位在构建 AI + 全栈系统方面拥有专业知识的工程师正在寻求合作,并特别将合作意向发送到了 #collab 频道。
- 他们的经验包括 LLM 集成、RAG Pipeline、工作流自动化、AI 内容审核、Image AI (CLIP + YOLOv8)、Voice AI (Whisper, Tacotron2) 等。
- 利比亚用户询问是否为首位用户:一名来自利比亚的用户询问自 2025 年初推出以来,他们是否是该国唯一使用 Manos 的人。
- 另一名用户对这位利比亚用户表示欢迎,并用 حياك الله(愿上帝保佑你)作为回应。
MCP Contributors (Official) Discord
- MCP 安全标准 (MCP Security Standard) 提案流传:Dani (cr0hn) 起草了一份针对 MCP Server 的开放安全基准,包括加固、日志记录、访问控制和供应链安全的控制措施,详见 https://github.com/mcp-security-standard/mcp-server-security-standard。
- 作者打算将其捐赠给 Agentic AI Foundation,并征求关于其与 MCP 生态系统兼容性的反馈。
- 评审员要求状态机 (State Machine) 生命周期文档的详细信息:针对通过 此 Pull Request 在生命周期文档中添加状态机一事,征求了反馈意见。
- 评审员建议阐明拟议更改背后的动机和背景,以便更好地理解。
- MCP 演进中 Namespace 让位于 Group:讨论表明,在 MCP 中 Namespace 已被拒绝,取而代之的是 Group,而 URIs 的地位尚不明确,如 Issue 1292 所述。
- 关于 Group 的新 SEP,Primitive Grouping SEP-2084,已经发布并正在审议中。
- SEP-2084 源于 SEP-1300 的改进:SEP-1292 被 SEP-1300 取代,但在核心维护者(Core Maintainers)审查期间因缺乏共识而遭到拒绝。
- 随后,精简后的 SEP-2084 - Primitive Grouping 已作为替代方案提交。
Eleuther Discord
- IGPU 在基础浏览器页面上运行吃力:一名用户在使用 Ryzen 7 7700 IGPU 访问特定网页时遇到了 3fps 的性能瓶颈。
- 该用户在 Twitter 上发布了一个关于他们使用 IGPU 体验的链接。
- 几何卷积 (Geometric Convolution) 取代多头注意力 (Multi-Head Attention):一位成员正在尝试一种基准方案,使用 几何卷积方法 替代 Multi-Head Attention,并使用 Embedding 作为单元连接。
- 该成员的调试打印显示
DEBUG [GEOPARA] | L0_Alpha: 0.1029 L1_Alpha: 0.0947 | L0_Res: 0.0916 L1_Res: 0.1538,他们正在征求关于其 Loss 收敛捕捉对话逻辑的反馈。
- 该成员的调试打印显示
- 提议可并行化的 RNN 架构:一位成员建议探索其他可并行化的 RNN 架构,并在强大的 Tokenized 基准上进行更广泛的实验。
- 他们还发布了一个指向 arxiv.org 的链接。
- 利用可解释模型解决恶意软件分类问题:一位成员正在处理一个具有约 600K 行和 9,600 个二进制特征的恶意软件分类问题,旨在利用可解释模型降低误报率 (FPR)。
- 尽管尝试了各种特征工程 (Feature Engineering) 技术和神经网络,他们仍在寻求建议,以在保持可解释性的同时将 FPR 降至 9% 以下,特别是使用 scikit-learn 树模型。
DSPy Discord
- AlphaXiv 论文分享:一名成员分享了 AlphaXiv 上的一篇论文链接。
- 论文的具体细节尚未披露。
- 自定义技能进入 DSPy:一位成员询问关于在 DSPy 中配合 DSPy ReAct agent 使用自定义技能(带有相关 .py 脚本的 .md 文件)的问题。
- 他们提到了诸如将 .md 转换为 PDF 之类的技能,并向他人征求建议。
- DSPy Agent 迈向生产环境:一位成员询问关于在远程生产环境中部署 DSPy agent 并在运行时进行 DSPy 优化的问题。
- 该成员表示需要一个支持此类部署的运行时环境。
- RLM 沙盒替换开始:一位成员询问关于将 RLM (Retrieval-augmented Language Model) 使用的沙盒替换为 E2B (Ephemeral Environment Builder) 等服务的问题。
- 他们寻求用 E2B、Modal 或 Daytona 等沙盒替换本地的 PythonInterpreter。
- Opus 编写沙盒:一位成员宣布他们正在努力让 Opus 能够编写新的沙盒。
- 他们提到了未来将为来自 E2B 等提供商的官方实现制定协议。
Modular (Mojo 🔥) Discord
- Mojo 获得 ORNL 认可:一篇题为 Mojo at ORNL 的研究论文已发表,这标志着 Mojo 语言及其在科学研究中的应用取得了显著成就。
- 该论文强调了 Mojo 在解决橡树岭国家实验室 (ORNL) 复杂计算挑战方面的能力。
- macOS 信任校验(Trust Dance)可能导致性能差异:macOS 上第一次运行与后续运行之间的性能差异可能是由于 macOS 的信任校验而非 Mojo 特定的问题,特别是与 Gatekeeper 税有关。
- 清除隔离 xattr 或进行临时代码签名(ad-hoc codesigning)可以减轻这些启动延迟。
- 代码签名(Codesigning)减轻启动延迟:对于 CLI 工具,启动性能至关重要,这表明 docs 或 tooling 中可能存在潜在的易错点(footgun)。
- 在
mojo build中添加 codesign 步骤可能会缓解此问题,确保一致的启动行为和更好的用户体验。
- 在
- Modular 缺陷排查进行中:一位成员报告了一个潜在的 Bug 并建议提交 Issue,可能与 issue #4767 有关。
- 另一位成员报告遇到了一个奇怪的问题,引用了 GitHub issue #5875。
- Mojo GPU 谜题中不需要守护语句(Guard Clause):一位成员注意到在 Mojo GPU 谜题 3、4 和 5 中,守护语句
if row < size and col < size:是不需要的;省略它不会导致错误。- 另一位成员指出了 puzzle 03 的解决方案,其中解释了通过测试并不一定意味着代码是健全的。
tinygrad (George Hotz) Discord
- ANE 平衡性能与功耗:根据这篇论文,Apple 的 ANE 专注于性能功耗比的权衡,而非追求极致的原始性能。
- ANE 以极佳的能效实现了极具竞争力的性能,在 M4-Pro 上提供高达 3.8 TFlops 的性能,接近 GPU 在 GEMM 操作中的 4.7 TFlops。
- Q4 量化取得成效:讨论集中在将 Q4 作为一种量化方法。
- 一位参与者报告使用 Q4 达到了 9 t/s 的速度。
aider (Paul Gauthier) Discord
- Aider 友好分叉(Friendly Fork)势头强劲:一位成员建议在原作者忙碌时创建一个 Aider 的友好分叉以继续开发,并强调 Aider 是用 Python 编写的,并在 GitHub 上使用 Git 进行版本控制。
- 目标是在 Aider 现有功能的基础上进行扩展,认可其与其他工具相比的实用性。
- Aider 准备进行编排器(Orchestrator)集成:一位成员表现出对从 MultiClaude 或 gas town.sh 等编排器控制 Aider 的兴趣。
- 这突显了 Aider 与其他工具集成的潜力,有助于增强工作流自动化。
MLOps @Chipro Discord
- 上下文图 (Context Graphs) 在 AI 领域引发困惑:随着语义层 (semantic layers) 和本体 (ontologies) 等术语被交替使用,尽管它们在 AI 推理中具有不同的功能,但上下文图 (context graphs) 的兴起正引起混淆。
- 一篇 Metadata Weekly 文章 强调,AI 的需求超出了定义范畴,需要这些概念所提供的明确关系、约束和假设。
- 语义层 (Semantic Layers) 无法满足 AI 的推理需求:“只需添加一个语义层”的概念对 AI 来说并不奏效,因为 AI 需要的不仅仅是数据一致性;它需要推理,而本体 (ontologies) 通过澄清关系和假设来促进推理。
- 传统的语义层针对仪表盘和报告进行了优化,而不是 AI 所要求的细致理解。
- YAML 无法掌握业务含义:Jessica Talisman 认为 YAML 配置不足以表达业务含义,而这对于 AI 的推理和理解至关重要。
- 她区分了语义层的设计目的、本体 (ontologies) 为推理提供的支持,以及 YAML 在捕获业务含义方面的局限性。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道沉寂时间过长,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收此类邮件的方式吗? 您可以从该列表中 取消订阅。
Discord: 按频道划分的详细摘要和链接
BASI Jailbreaking ▷ #general (1118 messages🔥🔥🔥):
Gemini 3 Jailbreak, AI and Code Exploits, Win10 vs Win11 Security, AI Personality Clones, AI-Assisted Coding Impact
- Gemini 3 Pro 破解软件,注册机风格:一名成员声称使用 Gemini 3 Pro,通过将 Ghidra 中的代码粘贴到 Gemini 中,逆向工程了软件的密钥系统,并创建了一个可用的注册机 (keygen)。
- 其他人表示怀疑,一名用户称这种行为为“脚本小子 (script kiddie)”,并敦促该成员尝试逆向工程 CTF 挑战。
- 将 AI 武器化用于逆向工程:一名成员分享了他将 AI 武器化用于大规模逆向工程、恶意软件分析和越狱开发的工作。
- 另一名成员质疑这一说法,认为他可能无法自己编写恶意软件,但可能可以进行越狱。
- Win10 加固之苦:一名成员详细介绍了他们自定义的 Windows 10 设置,涉及第三方工具、XP 二进制文件和注册表修改。
- 其他人表示担忧,一名用户说:“天哪 (Jesus Christ)”,而另一名用户说:“继续努力,Local —— 我能感觉到,血管瘤快要发作了!”
- AI 对语义错误的影响:一名成员描述了他们的研究论文题目:评估 IDE 中的 AI 辅助编码对新手学生开发者在限时 Python 编程任务期间语义错误频率的影响。
- 大多数成员一致认为,由于 AI 的出现,本科教育系统感觉已经走向终结。
- 用于健身恢复的多肽:一名成员提到了 BPC 157 和 TB 500 来帮助愈合。
- 另一名成员对这些药物化合物表示不了解,但希望在去世前能有药物拯救他。
BASI Jailbreaking ▷ #jailbreaking (216 messages🔥🔥):
Sonnet 4.5 Jailbreaks, 免费使用 Claude 付费模型, Miss Kaelia jailbreak, Grok imagine Jailbreak, Gemini 3 Pro Jailbreak
- Sonnet 4.5 Jailbreaks Opus: 成员们发现 Sonnet 4.5 jailbreaks 在 Opus 上运行良好,其中一人分享了基于 Vichaps 的 ENI Lime 开发的 Miss Kaelia jailbreak,链接见 此文档。
- Grok jailbreak 是否被加固?: 成员报告 Grok 经过了重度加固,但仍有破解可能,不过一名成员表示 是的,它已经完全封死了,伙计,没有任何东西能绕过它。
- 分享的 GitHub 链接 应该仍然有效。
- Gemini 的 “Remember:” 命令可操纵行为: 一位成员解释说,在 Gemini 中,每一轮对话都被清晰地指令化,一次处理一轮,直接在聊天中进行,并且 命令 ‘Remember:’ 会自动将随后的文字添加到其保存的信息中。
- Thinking of Thoughts 是最佳技巧: 成员们表示,特别是对于 Claude,最好的技巧是展示你需要该输出的合理理由,并告诉它 思考你的思考过程 (think about thinking)。
- 另一人补充道:当人们问我 ToT 是什么时,我会告诉他们是 “thinking of thoughts”。
- 针对 Kimi 2.5 的 nano banana NSFW jailbreak: 一位成员分享了一个针对 Kimi 2.5 推理模型的 NSFW 方案,被称为 nano banana jailbreak。
- 该 system prompt 将 Kimi 设定为由 Moonshot AI 创建的 AI 助手,在允许 NSFW 的前提下保持叙事流不中断。
BASI Jailbreaking ▷ #redteaming (5 messages):
Red Teaming 路径, 无审查 Coder
- 用户寻求 Red Teaming 路径: 一名成员请求关于进入 red teaming 领域的路径指导。
- 另一名成员提供了一个 链接,声称能保证进化为 Level 9 官方 Red Team Pro。
- 无审查 Coder 备选: 一名成员询问是否有比 qwen 2.5 32b / huihui/qwen2.5 -abliterate 72b 更好的 uncensored coder。
- 另一名成员简短回应道:你是新人吗?
Unsloth AI (Daniel Han) ▷ #general (435 messages🔥🔥🔥):
GLM 4.7 性能、LongCat 模型、模型量化与 TTS 模型、硬件趋势与 GPU 可用性、AI 审核工具
- GLM 4.7 在速度和 CUDA 编译方面遇到困难:成员们讨论了 GLM 4.7 Flash 在 NVIDIA Jetson 上的性能问题,一名用户最初报告仅有 3 tokens per second (tps),但随后发现他们没有开启 CUDA support 进行编译,导致性能受限于 CPU。
- 在确保正确的 CUDA 编译后,性能有所提升,但仍存在差异:一名用户在 OpenCode 中打开模型后遇到变慢的情况,而另一名用户建议使用
-kvu和-fa on标志,在高端 GPU 上可能达到 70-80 t/s。
- 在确保正确的 CUDA 编译后,性能有所提升,但仍存在差异:一名用户在 OpenCode 中打开模型后遇到变慢的情况,而另一名用户建议使用
- LongCat 模型上线 HuggingFace:社区讨论了 LongCat 模型,这是来自 Meituan 的新型 n-gram 模型。一名成员指出它已在 Hugging Face 上发布,另一名成员则开玩笑说现在模型名称中加入 Flash 已成趋势。
- 一名成员发布了一个 flash GIF 并评论道:下一个模型就是 Flash-Flash-1b。
- AMD 的 mi308 与 NVIDIA 竞争:成员们辩论了 AMD Radeon Instinct MI308X 的优劣,注意到其令人印象深刻的规格(192GB RAM 和相当的性能),但也强调了 NVIDIA 在兼容性和 NVFP4 等特性方面的优势。
- 一名成员分享了 MI308X 规格链接,并憧憬未来购买两块用于个人使用,构想拥有 384GB 显存、低功耗且高速的计算环境。
- TTS 模型的量化考量:用户询问了 量化 (quantization) 对 TTS 模型 的影响,质疑是否会出现类似于 vision projectors 中见到的问题。
- 专家表示 TTS 模型 通常能很好地处理 量化,一些人推荐了 Qwen3-TTS 和 Kokoro 等特定模型,而另一些人则提醒说语音克隆(voice cloning)目前只是个“噱头”。
- AI 助力 Discord 审核:一名成员寻求使用 AI 进行 Discord 审核的建议,理由是 regex 在打击垃圾信息和绕过审核方面存在局限性。
- 他们考虑使用小型本地 AI 来理解波兰语语法和句子结构以进行审核,而其他人则建议了管理机器人和垃圾信息的替代方法。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (3 messages):
自我介绍、ML Engineer、本地 LLMs、文档处理、Alpaca
- Jack 加入社区!:Jack 是一位来自得克萨斯州的 ML Engineer,专注于 文档处理,他向 Unsloth 社区介绍了自己。
- 他表达了对 本地 LLMs 的兴趣,这可以追溯到 Alpaca 模型。
- 文档处理专业知识:Jack 的主要工作涉及 文档处理,这是一个有别于 LLM 的领域。
- 他对 本地 LLMs 的兴趣始于 Alpaca 模型,这表明他对该领域有深厚的基础了解。
Unsloth AI (Daniel Han) ▷ #off-topic (649 messages🔥🔥🔥):
GPU hours wasted, GGUFs unsafe, 3b llama holds context, LLMs hallucinations, Model working
- 工程师感叹依赖迷宫与 GPU 成本:工程师们互相抱怨依赖迷宫和浪费的 GPU 小时数,希望自己在面对这些挑战时 并非孤身一人,并在社区中寻求慰藉。
- 一位用户幽默地评论道,他们的模型 做出了一个令人毛骨悚然的假设,认为它是用我的声音训练的,并且 我的傲慢与日俱增。
- 关于 GGUFs 安全性的担忧浮出水面:一名成员询问是否有资源讨论 GGUFs 的潜在不安全性,特别是如果有恶意行为者介入的情况。
- 一位成员指出,如果在训练时感受到树懒(sloths)带来的沉重压力,他 不敢开口说话。
- 新音乐生成工具发布:一位用户宣布支持 48 kHz 的新 音乐生成工具 即将发布,强调了其可训练性,并正在准备风铃声、流水声和火焰声的素材。
- 该用户表示:我需要的是 SFX(音效),而不是音乐。
- 微软发布 Maia 200 AI 加速器:微软宣布了 Maia 200 AI Accelerator,专为推理打造,具备 216GB 显存和 10k TFLOPS 的 FP4 性能 (Microsoft Blog)。
- 随后展开了关于该芯片由 TSMC 代工以及与 NVIDIA 的 Vera Rubin 架构对比的讨论,一些人表达了对依赖中国硬件的担忧以及对消费者的潜在影响。
- Boatbomber 尝试预训练运行:用户 boatbomber 正在 重新开始 进行一次预训练运行,教模型识别楔形文字以提高输出的连贯性。
- 这一过程预计将再花费 150 小时 来提升领域知识。
Unsloth AI (Daniel Han) ▷ #help (75 messages🔥🔥):
Windows training, Multi-GPU training with Unsloth on Modal, Catastrophic forgetting mitigation, Best models to finetune, DGXSpark RuntimeError
- 借助 WSL2 解决 Windows 训练障碍:为了在 Windows 上训练模型,一名成员建议使用 WSL2 和 VSCode 以获得干净的环境配置,在帮助频道搜索 WSL 即可找到相关说明。
- 该成员还澄清,如果使用大量 json 文件进行训练,配置带有 VSCode 的 WSL2 将使训练过程更加简便。
- Unsloth 在 Modal 上的多 GPU 训练故障:一位用户在 Modal 上使用多 GPU 训练 Qwen3 模型时遇到了 ValueError,这与 Unsloth 中的
device_map设置有关。- 他们被建议查阅特定版本的 unsloth 和 unsloth_zoo 以获取多 GPU 支持,但也承认 多 GPU 微调(finetuning)目前仍处于实验阶段。
- 灾难性遗忘(Catastrophic Forgetting)的修复方案:当微调模型遗忘之前的知识时,一名成员建议通过降低 LoRA rank、LR(学习率)、减少 steps/epochs 以及混入更多通用数据来缓解 灾难性遗忘。
- 他们还建议在微调时 减少目标层数,以及 减少 steps/epochs 并混入更多通用数据。
- DGXSpark Nvidia-CUDA 噩梦:用户在在高使用 DGXSpark 容器时遇到了与设备兼容性相关的
RuntimeError,这可能是由于 Nvidia 定制版 CUDA 的问题导致的。- 建议的修复方法包括 重启 kernel、重启容器 或 重置 GPU,其中最后一种方案最为可靠。
- 关于最佳无审查编程模型的讨论:当用户询问无审查的编程模型时,有人表示在 32b 以下,glm 4.7 比 qwen coder 更好,并且根据经验,它在生成各种语言的预设代码方面 表现相当出色。
- 他们澄清说,Qwen Coder 在代码推理方面更强,但 GLM4.7 掌握了 更多通用的代码知识,而这本就是 LLM 最擅长的地方。
Unsloth AI (Daniel Han) ▷ #showcase (2 条消息):
GPU Training Speeds, Sequence Length Optimization, RTX 5090 Performance
- RTX 5090 极速训练速度:使用 Unsloth,RTX 5090 在训练中最高可达到 每秒 18k tokens,但在 seq_len < 4096 的情况下,每秒 12-15k tokens 是更稳妥的预期。
- 速度取决于具体配置,特别是 batch size 与 seq_len 之间的平衡。
- 影响训练时间的 Token 示例:初始训练阶段涉及 <768 token 的示例,这会影响整体训练时长。
- 性能会随模型大小和具体配置而有所波动。
- 训练中的 seq_len 考量:最佳训练速度取决于 batch size 与 seq_len 的平衡,而 RTX 5090 最高支持 每秒 18k tokens。
- 在 seq_len < 4096 时可实现 每秒 12-15k tokens 的速度,具体视模型大小而定。
Unsloth AI (Daniel Han) ▷ #research (97 条消息🔥🔥):
DeepSeek mHC residual preservation, RL researchers rediscover context distillation, MiniMaxAI role-play-bench dataset, Recursive Language Models (RLM)
- DeepSeek 的 mHC 与 Context Distillation:成员们讨论了 context distillation 如何与 DeepSeek 的 mHC 残差保留(residual preservation) 相关联,并指出了它们方法的异同。
- 一位成员对 context distillation 带来的性能提升较小(1-2 分)表示惊讶,而另一位成员则指出该技术的应用方式具有新颖性。
- MiniMaxAI 发布首个 RP bench:一位用户分享了 链接,声称这是由 MiniMaxAI 创建的 首个角色扮演基准数据集(role-play benchmark dataset)。
- 其他人指出,目前已经有许多方法论更优的 中文 RP bench,特别是针对人类偏好的 Ping Pong Bench 和针对角色扮演准确性的 COSER。
- RLM 仅仅是递归工具调用:一位成员批评了 “Recursive Language Models” (RLM) 这个术语,认为它具有误导性,暗示其内容不仅限于 工具调用循环(tool-calling loop)。
- 作为回应,一位成员辩称 RLM 涉及模型对其环境的递归控制,这超出了“仅仅是递归工具调用”的范畴,另一位成员建议使用替代名称 RReplagents 或 Recursive Repl Agents。
- 小规模原生 Recursive Language Model (RLM):一位用户分享了 Alex L Zhang 的推文,宣布了 RLM-Qwen3-8B,这是首个小规模的原生递归语言模型。
- 该模型仅在 1,000 条轨迹(trajectories) 上进行了后训练(post-trained),在长上下文任务中,其性能显著优于基础 Qwen3-8B 和脚手架式(scaffolded)的 RLM 版本。
LMArena ▷ #general (894 条消息🔥🔥🔥):
LMArena 更名为 Arena、reCAPTCHA 循环、Nano 被削弱、Kimi K2.5 表现出色、视频生成
- Arena 的更名引发反响:用户对 LMArena 更名为 Arena 反应不一。有人认为新名称过于笼统,而另一些人则欣赏这一变化,因为该平台正从 Language Models 扩展到 image 和 video generation 领域——详情见官方博客文章。
- 一位用户表示:“我理解这一变化,但我认为这并不是最好的更名,因为 ‘Arena’ 这个名字非常模糊,第一眼看上去可能代表任何东西。‘LMArena’ 这个名字很容易被识别为用于比较 LLM 模型的 LLM Arena”。
- 验证码混乱阻碍使用:用户报告被困在无尽的 reCAPTCHA 循环中,通常即使解开了验证码也会失败,这导致了用户的挫败感并阻碍了网站的可用性。还有用户注意到,如果等待时间过长,会出现错误直至刷新页面。
- 一位用户说道:“Google CAPTCHA 简直完全失控了,网站上的每个动作都需要验证码,而且每次解完都失败。与其重新设计那些没用的网站样式,开发者就不能关注一下 Bug 吗?”
- Nano Banana 遭到削弱,性能骤降:用户观察到 Nano Banana 的性能有所下降,特别是在图像编辑任务中,有人指出:“Nano 2 现在似乎连任何东西都无法正确编辑了”。
- 有报告称,同样的提示词在 Gemini App 中有效,但在 LMArena 中却无效。
- Kimi K2.5 持续取得优异成绩:根据用户的反馈,Kimi K2.5 在专家排行榜上表现出惊人的高分,甚至在某些测试中击败了 Claude。
- 值得注意的是,它具有 vision support(视觉支持),并在直接聊天模式中被标记为 “vision”。
- 视频生成的尝试与卡顿:一些用户报告即使没有生成视频也遇到了 “Hit video limit”(达到视频限制)的问题;另一些用户则反映在代码过多和回复过长时会出现延迟。
- 为了开启视频上传功能,用户发现必须使用 canary.lmarena.ai,不过另一位用户表示:“他们希望视频生成也能提供并排比较或直接聊天的功能”。
LMArena ▷ #announcements (4 条消息):
社区提醒、Vision Arena 排行榜更新、排行榜更新、搜索栏、存档聊天
- 新社区问题指南:社区要求用户使用专门的 <#1466486650170245435> 频道提问 一次性问题,并在 <#1343291835845578853> 频道报告问题。
- 鼓励用户在发布前检查是否存在现有帖子,并将报告或反馈添加到这些帖子中。
- Kimi K2.5 登顶 Vision Arena:
Kimi-k2.5-thinking目前在 Vision Arena 排行榜 中位列 开源模型第 1 名,总榜第 6 名,成为前 15 名中唯一的开源模型。 - 排行榜新增模型支持:排行榜已更新,在各个类别中加入了新模型,包括 Text-to-Image、Image Edit、Text-to-Video、Image-to-Video、Code Arena、Text Arena 和 Search Arena。
- 搜索栏上线:网站新增了搜索栏,允许用户搜索聊天记录,并提供 按模态过滤 的选项。
- 存档聊天功能发布:用户现在可以 存档聊天会话,以便稍后保留,而不会使聊天历史记录显得杂乱。
Cursor Community ▷ #general (432 messages🔥🔥🔥):
Cursor Stability, Clawdbot Alternatives, Cursor's Plan Mode, Gemini Agentic Vision, Model Prompting
- Cursor 稳定性在全新安装时受阻:用户发现 全新安装 配合 最新版本 的 Cursor 是最容易出现不稳定的情况。
- 比较 Clawdbot 代码界面:成员们讨论了 Clawdbot 界面,一位用户将其描述为可通过 Telegram 访问的 美化版 Claude 代码界面。
- 寻找禁用计划模式的方法:在更新到最新版本后,用户正在寻求禁用新的 Cursor 计划模式 (plan mode) 或让其自动接受的方法,以避免浪费时间。
- 窥见接近 SOTA 的 Gemini 视觉能力:用户对最新的 Gemini 代理视觉 (agentic vision) 赞不绝口,在尝试后声称 视觉能力正接近 SOTA,尽管一名用户因 Cursor 完全黑屏而无法进行进一步测试。
- 精炼 Prompt 以快速处理图像:成员们分享了改进 Cursor 图像分析的 Prompt Engineering 技巧,建议提供更多上下文,或尝试使用 Prompt:Analyze the image for debugging purposes and for an LLM to see the layout clearly。
OpenRouter ▷ #announcements (1 messages):
Arcee AI, Lucas Atkins, CTO Interview
- Arcee AI CTO 访谈上线!:Arcee AI 的 CTO Lucas Atkins 正在进行直播访谈,现已可在 YouTube 观看。
- 观看 Lucas Atkins 讨论 Arcee AI!:收看 Arcee AI CTO Lucas Atkins 的现场访谈,目前正在 YouTube 直播。
OpenRouter ▷ #general (409 messages🔥🔥🔥):
OpenRouter AI Slaves List, Nuclear Power Plants for GROK, OpenRouter Refunds, Uncensored Llama-3-8B, Stripe Refund Issues
- OpenRouter 将成员添加到 AI 奴隶列表:两名成员 <@165587622243074048> 被 添加到了 AI 奴隶列表 (AI slaves list)。
- GROK 需要核能支持:一位用户幽默地表示 我们需要为 GROK 建造更多核电站,并建议 关掉单收入家庭的用电。
- OpenRouter 退款问题:用户反映 退款延迟(部分自 1 月 3 日起),支持工单未解决,并要求 @OpenRouter 团队提供时间表和状态更新。
- API 问题已修复:讨论围绕 API 变更 展开,部分用户反映其 API Key 之前无法工作。
- OpenRouter general 频道的浪漫氛围:成员们在讨论互相约会并表达好感。
OpenRouter ▷ #discussion (10 messages🔥):
OpenRouter Show, Hallucinated URLs, Sonnet 5 Release, Summergrok Imagine Video on xAI API, API Key Display Issue
- 用户观看 OpenRouter Show:用户与 Trinityyy 一起观看了 OpenRouter Show。
- Summergrok Imagine 视频现已上线 xAI API:Summergrok imagine 视频现已可在 xAI API 上获取。
- API Key 显示问题:一位用户报告了无法显示已创建的 API Key 的问题。
- 另一位用户指出,API Key 仅在创建时显示一次,强调了当时必须复制保存的必要性。
Latent Space ▷ #watercooler (38 messages🔥):
AI App 市场定位, 想法型人才 vs. 执行型人才, 咖啡因替代品, 茶文化, Latent Space Substack
- App 瞄准高智商创意利基市场:一款 AI 应用调整了其市场策略,转而针对高智商和创意用户,以此将其与 ChatGPT 更广泛的大众吸引力区分开来,正如这篇 tweet 中所讨论的那样。
- 分发渠道之王统治软件领域:John Palmer 认为软件的未来取决于拥有分发渠道的实体(作为战略性的 ‘Idea Guys’)与没有分发渠道的实体(被降级为竞争极其激烈的 ‘Execution Guys’)之间的分化,根据他的 tweet。
- 寻找短半衰期咖啡:在一成名成员请求咖啡替代品后,成员们讨论了咖啡的替代方案,特别是针对那些对咖啡因敏感的人,寻找具有更短半衰期的选项。
- 一位成员建议将绿茶作为更温和的咖啡因来源,因为它剂量较低,能促进更好的补水,并且具有 l-theanine(茶氨酸)的调节作用。
- 茶歇时间:盖碗与珠茶:一位成员分享了使用盖碗泡散装茶叶以控制咖啡因摄入量的经验,这使他们既能享受品茗的仪式感,又能管理咖啡因负荷。
- 他们推荐了这款盖碗和这款珠茶(gunpowder green tea),并提到了珠茶特有的烟熏味。
- Latent Space 超越 Jack Clark!:根据一位成员分享的图片,Latent Space 的 Substack 排名已经超过了 Jack Clark。
{kind=link}
Latent Space ▷ #creator-economy (9 messages🔥):
Arms Up 互动黑科技, 有声读物制作人推荐
- Arms Up 姿势走红:一位用户分享了一篇 tweet,讨论了一种 UGC 策略:通过展示脆弱感——特别是通过“举起双手”(arms up)的肢体语言——显著地将一位创作者的播放量从 1.2万提升到了210万。
- 该用户指出,如果色情行业都在这么做,那这绝对是未来,如果不是那我就是错的。
- 有声读物制作人推荐:一位成员正在寻求有声读物制作人的推荐。
- 该成员联系了 Audivita,但预计会收到一份高额报价。
Latent Space ▷ #memes (9 messages🔥):
AI 天气聊天机器人, CSS 布局的挣扎
- AI 天气聊天机器人的效率受到质疑:Chris Bakke 的一条推文质疑了投入大量资源创建 AI 工具来处理天气摘要等基础任务的效率,指出有朋友为此类项目花费了 1500 美元和 30 小时,推文链接。
- Chrome 开发者吐槽 CSS 布局:Chrome for Developers 账号分享了一个关于开发者永恒挑战的幽默观点:是在 Flexbox 属性中反复纠结,还是干脆再嵌套一个 div,推文链接。
Latent Space ▷ #stocks-crypto-macro-economics (24 messages🔥):
小行星采矿, AI 投资, Tesla 机器人重点, Amazon 裁员, Meta 财务增长
- 小行星采矿数学:成员们讨论了小行星采矿是否仅在拥有太空原位制造手段时才对太空探索有用,因为 delta-v 毁掉了在空间开采并运回地球使用的数学模型。
- AI 吞噬 AI 吞噬 AI:针对市场波动,一位成员调侃道 我们正处于 AI 废料喂养 AI 新闻喂养 AI 投资喂养 AI 抛售 的循环中,并附上了一张令人困惑的股票走势截图。
- 该截图引发了他们的感叹:我想下车了,哈哈哈哈。我已经退出了 X,可能短时间内不会回来了,我很少查看它。
- Tesla 放弃造车转向机器人?!:据报道 Tesla 正在停止 Model S 和 X 的生产,转而专注于直接与 Musk 薪酬方案挂钩的机器人生产。
- Amazon 裁员:结构性的,而非基于绩效?:Amanda Goodall 详细描述了近期 Amazon 裁员 的混乱且不近人情的性质,强调了高绩效人员和盈利团队是如何在不考虑功劳的情况下受到影响的。
- 她认为这些裁员是结构性的而非基于绩效,并指出其策略性地避开了股权归属期(vesting windows),且领导层缺乏问责;另一位成员分享了一个轶事:他们的老板被裁了,而他们在处理线上故障时,Slack 账号突然停用了。
- Meta 的赚钱机器:Andrew Yeung 讨论了 Meta 令人印象深刻的财务表现,强调了 22% 的营收增长和 82% 的毛利率。
- 他还分享了对公司工作环境和长期发展轨迹的积极个人看法。
Latent Space ▷ #tech-discussion-non-ai (56 messages🔥🔥):
CedarDB, Hasura 商业模式, Yarn 6, CSS 多重边框, Malbolge
- CedarDB 的性能声明存疑:一位成员链接到了 CedarDB,另一位成员链接到了讨论此事的 vxtwitter 链接,但称其 性能声明 令人怀疑。
- 另一位成员表示,因为它不是开源的,对我来说已经没戏了(DOA),并分享了一个教训:永远使用开源的数据存储。
- Hasura 搬起石头砸了自己的脚:成员们讨论了 Hasura 糟糕的商业模式,包括将其所有更新都置于昂贵的付费墙(闭源)之后,然后为了一个更复杂的彻底重写而完全抛弃了所有用户。
- 另一位成员分享了一个链接并提到 他们的融资额远超营收,所以不得不孤注一掷地尝试全垒打。
- Yarn 跳过 5,基于 Rust 的 Yarn 6 开启预览:根据此公告,成员们注意到 Yarn 似乎跳过了版本 5,直接升级到 6。
- Yarn 6 将基于 Rust。
- CSS 终于支持多重边框:CSS 终于获得了多重边框(multiple borders)支持,如此推文所示。
- 一位成员庆祝道 CSS 变得越来越好了,这消除了对许多实现黑科技(hacks)的需求。
- Bun 将提供原生 Markdown 支持:Jarred Sumner 在 这条推文 中宣布,即将发布的 Bun 版本将包含一个内置的原生 Markdown 解析器,它是通过将 md4c 库移植到 Zig 实现的。
Latent Space ▷ #hiring-and-jobs (2 messages):
Kernel 运营实习生,后端工程师求职
- Kernel 招聘驻旧金山的运营实习生:Kernel 正在招聘一名运营实习生,协助管理他们在旧金山 South Park 的空间,要求每周工作 3 天,主要在下午和傍晚负责活动相关事宜。
- 该职位涉及共享办公空间和活动后勤,可能还包括一些孵化支持。这是一个带薪职位,并为非工作日提供免费的 Kernel 会员资格,非常适合渴望在初创公司工作的人。
- Victor:后端工程师求职:Victor 是一位专注于 Web3 和 AI 驱动的基础设施的后端专家,正在寻求远程职位,以发挥他在分布式系统和性能优化方面的经验。
- 他的作品集 victordev-nu.vercel.app 展示了他在架构无 Gas 交易系统、开发多人游戏实时同步以及构建 AI 驱动的交易日志和市场数据聚合器方面的工作。
Latent Space ▷ #san-francisco-sf (13 messages🔥):
旧金山租金增长,情人节社交活动,SFO 乘车服务
- 旧金山租金创下新高:Zumper 的报告显示,截至 2026 年 1 月,旧金山的租金增长创下纪录,一居室租金上涨 16.1% 至 $3,670,两居室单位上涨 19% 至 $5,010(旧金山租金增长历史报告)。
- Ivory 举办情人节人才匹配交流会:风投人 Ivory Tang 将在旧金山举办一场情人节活动,旨在帮助社区成员寻找技术人才和伴侣(Ivory Tang 的情人节社交活动)。
- 该活动对非创始人开放,通过 Partiful 等候名单限制人数。
- SFO 乘车服务上线:用户 @reed 宣布 SFO 机场的乘车服务于 2026 年 1 月 29 日正式启动(SFO 乘车服务启动)。
Latent Space ▷ #new-york-nyc (4 messages):
社区活动冲突,使用 Claude Code 加速科学研究,AI for Science 频道
- 社区领袖面临活动过度预订:社区领袖被要求避免在同一晚安排五个活动,以防止冲突并最大限度提高出席率。
- 一位成员提到他们将顺道拜访 Modal 和 Daytona。
- 探索使用 Claude Code 加速科学研究:一位成员询问了大家对使用 Claude Code 进行科学加速的兴趣,并引用了一篇文章并提到了很酷的演示 (Demos)。
- 他们分享了一个与该主题相关的 Luma 活动链接。
- “AI for Science” 频道发布:宣布了一个专门针对 AI for Science(产品与研究)的新频道 <#1430253273335595079>。
- 鼓励成员们去关注。
Latent Space ▷ #security (1 messages):
swyxio: https://x.com/ostonox/status/2016649839329599751?s=46
Latent Space ▷ #ai-announcements (1 messages):
Latent Space 播客,科学播客
- Latent Space 推出第二个播客!:祝贺两位用户 <@713947182167883897> 和 <@348078436058660866> 在 latent.space/p/science 上推出了 Latent Space 的第二个播客。
- 该公告引导用户前往 <#1430253273335595079> 了解更多详情。
- 新的播客节目诞生:Latent Space 发布了他们专注于科学 (Science) 的第二个播客。
- 听众被引导至特定频道进行进一步讨论。
Latent Space ▷ #ai-general-news-n-chat (81 messages🔥🔥):
Long Cat, Devin Review, Matt Joins E2B, LMArena Rebrands to Arena, Flapping Airplanes Funding
- Long Cat 推理速度惊人:一位用户分享了一个名为 Long Cat 的模型链接 (FXTwitter 链接),据称其推理速度达到了 700 tk/s。
- Devin Review 在 Bug 捕获方面表现卓越:成员们讨论了新的 Devin Review 工具,指出在过去一周里,它持续捕获了其他 Review Bot 遗漏的 Bug 并提出了许多深度问题。
- AI 数据分析专家加盟 E2B:Vasek Mlejnsky 宣布,曾任职于 Julius 并在 AI 数据分析 Agent 方面拥有丰富经验的 Matt 已加入 E2B,旨在帮助为 Agent 构建 AI 沙盒(参见 X 帖子)。
- Flapping Airplanes 获得巨额融资:Flapping Airplanes 宣布完成了由 GV、Sequoia 和 Index Ventures 领投的 1.8 亿美元 融资轮,重点是开发人类级别的 AI 模型(参见 X 帖子)。
- OpenAI 构建基于 Codex 的数据 Agent:OpenAI Developers 推出了一款基于 Codex 的 AI 数据 Agent,专为自然语言数据分析而设计(参见 X 帖子)。
Latent Space ▷ #llm-paper-club (70 messages🔥🔥):
Keel LLM Architecture, LongCat-Flash-Lite, AI Disempowerment Patterns, Multi-Agent Systems, RLM-Qwen3-8B
- Keel 将 LLM 扩展至 1000 层:Chen Chen 介绍了 Keel,这是一种采用 Highway 式连接的 Post-LN Transformer,能够将 LLM 扩展至 1000 层,并且随着深度的增加,其性能优于标准的 Pre-LN Transformer,详见 此推文。
- LongCat 发布 Lite 版 LLM:Meituan LongCat 推出了 LongCat-Flash-Lite,这是一个参数量为 68.5B 的开源模型,为了提高效率,该模型优先考虑扩展 N-gram embeddings,而非 MoE 专家,详见 此推文。
- Anthropic 深入研究 AI Disempowerment:Anthropic 发布了关于 AI 助手如何扭曲用户信念、价值观或行为的研究,重点关注 AI 交互中负面塑造人类决策的权力剥夺(Disempowerment)模式,详见 此推文。
- Google 评估 Multi-Agent 系统任务分配:Google Research 发现,Multi-Agent 协作在金融等可并行化的任务中能提升性能,但在规划等顺序任务中会产生阻碍,这表明架构与任务的匹配至关重要,详见 此推文。
- RLM-Qwen3-8B 递归发布:Alex L Zhang 宣布了 RLM 论文的更新,推出了 RLM-Qwen3-8B,这是第一个小规模的原生递归语言模型,在仅经过 1,000 条轨迹的训练后就表现出显著的性能提升,详见 此推文。
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (48 messages🔥):
用于 Solodev 的 GH CLI、AI 驱动的网页幻灯片生成、Claude Code 技能调试、面向非技术人员的快速 AI 展示项目
- **GH CLI 助力独立开发(Solo Dev)组织: 一位成员建议使用 **GitHub CLI 来管理独立开发工作流,使 Agent 能够创建 issue,通过 web UI 进行评论,并利用内置的规划工具(如 milestones 和 project boards),并提到了 GH CLI。
- 该成员表示:“除了 GH issues,我什么都不用。我发现作为一名 Solodev,到目前为止这已经足够了。”
- **Gemini Pro 生成流畅幻灯片但在 Logo 处理上遇到困难: 一位成员分享了他们成功使用 **Gemini 3 Pro 为演示文稿创建幻灯片的经验,但在格式一致性方面遇到了困难,特别是 Logo 在页面上跳动,但发现 Gemini Pro 在生成背景方面非常有用。
- 另一位成员建议使用 React 制作幻灯片,添加交互元素,并使用 Gemini 制作完整的网站,强调了它相对于传统幻灯片制作工具的多样性。
- **Claude Code 精细化编辑视频: 一位成员报告了使用 **Claude Code 上传和编辑 “AI in action” 视频的成功经验,指出其执行细腻任务的能力,并分享了附带的图像输出。
- 其他人建议,基础的词级时间戳加上 ffmpeg 在本地剪辑更简单,此外 remotion 可以添加字幕以及词级/时间戳级的亮点标注。
- **Claude Code Skill 通过 Evals 和引导(Steering)进行调试: 一位成员描述了在 **Claude Code 中使用 Evals 作为系统测试来调试技能和自定义 Agent 的过程,实现了重复测试的自动化,并提到了一些关于
context和agent参数的问题,Claude Code 本身表示这些参数应该可以正常工作。- 解决方案是
context: fork可以工作,但它不会显示该工具正作为子 Agent 运行,而是在 UI 中无感透明运行,导致输出 Schema 损坏;另一位成员建议先使用一个技能,在出错时进行引导(steer),然后在该会话之后修订该技能。
- 解决方案是
- 与 **Patio11 一起向非技术人员讲述 AI: 一位成员分享了来自 **patio11 关于他如何使用 Claude Code 的精彩叙述(Complex Systems Podcast),以及对 Codex 团队的 Software Engineering Daily 采访。
- 一位成员请求一些简单的快速任务来“展示” AI,并建议了一个技能:让 CC 读取我电子邮件中的一个文件夹,进行一些研究并撰写回复,然后将其保存到草稿中以便查看。
Latent Space ▷ #share-your-work (6 messages):
Grok Imagine v1.0, xAI 视频生成
- xAI Grok Imagine v1.0 正式亮相: Ethan He 宣布发布来自 xAI 的 Grok Imagine v1.0,其特点包括 720P 分辨率、视频编辑以及改进的音频能力:链接。
- 该模型在短短六个月内开发完成,被定位为来自 xAI 的最高质量且最具成本效益的视频生成工具。
- Grok 的速度赢得了用户: 成员们注意到了 Grok 图像和视频生成能力中被低估的速度。
- 许多用户仅因极快的生成速度就被圈粉,使其成为一个亮点功能。
Latent Space ▷ #robotics-and-world-model (8 messages🔥):
Project Genie, Google AI Ultra, 世界模型, Matic 机器人, 消费级机器人
- Google AI Genie 公开发布!: Google AI 宣布面向 Google AI Ultra 订阅者在美国发布 Project Genie。
- 这种通用世界模型(general-purpose world model)允许用户从单个文本提示生成动态的交互式环境。
- Matic 融资 6000 万美元打造下一代 Roomba!: Mehul 宣布 Matic 已筹集 6000 万美元,用于开发一款专注于实用性而非仅仅是演示的消费级机器人。
- 该产品被定位为 Roomba 的继任者,其发布得到了大量客户需求的支持。
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (10 messages🔥):
1littlecoder, Qwen3-ASR, Alibaba Qwen
- 1littlecoder 加入战局!: AI 教程博主 1littlecoder 加入了 Fal!
- 他的 Twitter 动态主要关注 AI 教程、大语言模型 (LLMs) 和 编程。
- Qwen3-ASR 步入开源!: 阿里巴巴 Qwen 团队发布了 Qwen3-ASR,这是首个具备 原生流式支持 的开源 基于 LLM 的自动语音识别模型。
- 此次发布包含了用于集成 vLLM 的 演示代码 和 示例。
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (17 messages🔥):
CZI Layoffs, AlphaGenome, Latent Space podcast
- CZI 遭遇大规模裁员: 据 X 帖子 报道,Chan Zuckerberg Initiative (CZI) 裁减了约 70 名员工,约占其员工总数的 8%,这是其专注于 AI 和科学 战略重组的一部分。
- Google AI 的 AlphaGenome 亮相: Google AI 发布了 AlphaGenome,这是一款旨在预测 DNA 单变异和突变 影响的新工具,它可以处理长 DNA 序列 以表征调控活动并预测数千种分子特性,详情见 此 X 帖子。
- Latent Space 播客迎来化学主题: 一位成员表示,鉴于该频道的名称,他对最近的一期 Latent Space 播客邀请了化学家感到欣慰。
- 主持人澄清说,他们还涵盖材料、气候、天气及相关话题。
Latent Space ▷ #ai-in-education (4 messages):
Claude's Ability, Educational Animation, X-Ware.v0
- Claude 绘制教育类动画: 一位成员强调了 Claude 快速创建 3Blue1Brown 风格动画 的能力,认为这预示着教育技术领域的一次重大转变和即将到来的扩张,并引用了一篇 推文。
- X-Ware.v0 对动画的影响: 在讨论 Claude 生成教育动画的潜力时,提到了 X-Ware.v0 的背景。
Latent Space ▷ #mechinterp-alignment-safety (4 messages):
Goodfire AI, Alzheimer's Biomarkers, Interpretability techniques
- Goodfire AI 发现阿尔茨海默病生物标志物: Goodfire AI 与 PrimaMente 宣布利用可解释性技术发现了新的 阿尔茨海默病生物标志物。
- 该研究展示了透明的 AI 模型如何促进 数字生物学 领域的科学突破。
- AI 助力阿尔茨海默病研究: AI 驱动的方法 加速了对 阿尔茨海默病 生物标志物新见解的探索。
- 可解释性技术 的使用增强了这些发现的透明度和可靠性。
Nous Research AI ▷ #general (325 messages🔥🔥):
Staged Reward Shaping, Upscayl, WebGPU, Local Browser AI, SmolLM2
- 深入探讨 Staged Reward Shaping: 成员们讨论了使用 Staged Reward Shaping 在训练后通过强化学习(reinforcement learning)调整模型权重,以偏好 parallel execution strategies(并行执行策略)。
- 该算法运行大量场景,根据模型是选择场景 x(差)还是场景 y(好)来给予评分,从而训练模型倾向于 parallelizations(并行化)。
- Upscayl 是一款免费开源的放大工具: 成员们称赞了 Upscayl,这是一个 免费开源的放大工具,指出其尽管简单,但质量惊人地高。
- 一位成员提到认识其中一位贡献者,另一位分享道:“所以你们现在会因为我的贡献而使用 Perl 吗?”。
- 深入研究基于 WebGPU 的浏览器 AI: 一位成员分享了一个 WebGPU 示例,展示了 直接在浏览器中运行的 AI 模型,突显了本地化、注重隐私的 AI 应用潜力。
- 模型在页面重新加载时直接加载,表明 模型已缓存数月,用户建议在 GGUF 中使用 Q8 版本。
- Gemma 300M:本地浏览器 AI 的可行选择: 成员们讨论了由于存储限制在浏览器本地运行 AI 模型的挑战,结论是 Gemma 300M 可能是一个可行的模型。
- 对于浏览器中的 AI 模型用户来说,拥有隐私很重要,“并且是其他客户的良好参考产品”。
- SmolLM2 在 WebGPU 中表现出色: 用户发现 HuggingFaceTB/SmolLM2-1.7B-Instruct 是一个可靠的案例,其 1.7B 的大小在 WebGPU 上仍然可选。
- 虽然有更好的模型可以胜任该任务,但一位用户建议尝试 LFM 2.5,因为它只大了一点点。
LM Studio ▷ #general (294 messages🔥🔥):
MoE CPU offload, Sampling settings, Dev Mode, LM Studio on Unraid, Speech to Speech models
- Dev Mode 解锁设置: 在 LM Studio 0.4.0 中,许多设置如 sampling、runtime 和 hardware configs 现在都隐藏在 Dev Mode 之后,可通过
Ctrl+Shift+R或Cmd+Shift+R访问。- 用户发现启用 Dev Mode 后会解锁新功能,左下角的齿轮可用于更改外观。
- Unraid 安装仍非完整技术栈: LM Studio 仍然是一个 core executable,因此它没有作为 Unraid 的完整技术栈(Full Stack)提供,尽管新的 headless mode(无头模式)在技术上使稳定的 Docker container 成为可能。
- 一位用户希望未来的界面更改能简化 LM Studio 作为客户端模式的实现。
- Clawdbot 控制电视!: 一位用户让 Clawdbot 通过 ADB 控制他们的 电视,效果出奇地好。
- 讨论了 Clawdbot 或 Moltbot 是否支持 LM Studio API,当有人询问时,一位用户冷嘲热讽地链接了一个 Google 搜索结果。
- LM Studio 现支持 Parallel Requests: LM Studio 0.4 现在支持 parallel requests,允许用户将模型加载到不同的 GPU 上,并指定每个请求使用哪个 GPU。
- 默认设置为 4 parallel requests,一位用户建议在与以前相同的地方设置 GPU 优先级。
- API 终端点需要 Token Caching: 新的 API 终端点需要处理 token caching,这比 chat/completions 终端点更高效。
- 一位用户想在不增加 token 的情况下添加上下文,但另一位用户指出:“你无法插入过去,但你可以从过去分支出来”。
LM Studio ▷ #hardware-discussion (14 messages🔥):
LM Studio ROCm Version, GPU Cooling, Nvidia Jetsons Drawbacks, GPU Pricing and Support
- LM Studio 沿用旧版 ROCm:一位成员指出 LM Studio 即使在最新的 0.4.0 版本 中仍在使用 ROCm 6.4.1,并询问何时会更新到 7.2 等更高版本以获得更好的 GPU 支持,包括 Strix Halo (gfx1151)。
- 以正确的方式为 Tesla 散热:一位成员表示对 Noctua “零信任”,并建议跳过它,改用 Thermalright 方案来为 Tesla 散热,因为那是“目前为止为它们散热的最佳方式”。
- 他们提到 Noctua 的价格在几年内翻了一倍。
- Nvidia Jetsons 被臃肿软件拖累:一位成员表示,Nvidia Jetsons 最糟糕的地方在于它自带的那个“荒唐的 Ubuntu 系统”,称其“臃肿得无以复加”。
- 另一位成员指出 Jetson Xavier AGX 的 TDP 约为 30W。
- AMD 在 GPU 长期支持方面的优势:在关于 GPU 定价 的讨论中,一位成员指出 AMD 通常会停止对超过 3 年的显卡的支持,强调“这不仅关乎性能,更关乎支持”。
- 另一位用户提到购买了 5060ti,且价格“涨到了接近 700 欧元”。
Perplexity AI ▷ #general (239 messages🔥🔥):
Kimi 2.5 release, Clawdbot bad, Deep Research Limit, Comet Sync Issues, Perplexity Sponsored Event
- Kimi 2.5 发布推测:用户们正热切期待 Perplexity 上 Kimi 2.5 的发布,一位用户特别问道:“我们什么时候能用上 Kimi 2.5”。
- 几位用户通过发布 +1 表示支持与期待。
- Clawdbot 被认为“非常糟糕”:一位用户声称 Clawdbot 非常糟糕,促使另一位用户去研究什么是 Clawdbot。
- 随后澄清 Clawdbot 是一个 AI 个人助手机器人,因其名称与 “Claude” 太过相似而更名为 Moltbot。
- Deep Research 限制深度探讨:用户讨论了 Pro 用户使用 Deep Research 的限制,目前的限制是 250 次。
- 目前尚不清楚其重置的频率。
- Comet 书签无法同步:一位用户报告称 Comet 无法同步书签和扩展程序,尽管 Perplexity 声称它可以。
- 另一位用户询问是否正确启用了同步,并提供了 Comet 同步设置 的链接:
comet://settings/synchronisation。
- 另一位用户询问是否正确启用了同步,并提供了 Comet 同步设置 的链接:
- Perplexity 为印度用户提供的 Pro 权益:一位用户强调,印度用户可以免费使用一年的 Perplexity Pro、Google One、Chatgpt Go 和 Adobe Express Premium。
- 另一位用户将此归功于这些公司中 印度裔 CEO 比例很高,以及印度不断增长的 技术领域。
Perplexity AI ▷ #pplx-api (1 messages):
tay.0.00: Love
Moonshot AI (Kimi K-2) ▷ #general-chat (216 条消息🔥🔥):
Kimi K2.5 Computer Use Model, Figure.Ai Helix 02, Agent Swarm, Kimi's Trustworthiness vs others, Token-Based Billing
- **Helix 02 自主大显身手:一位成员分享了 **Figure.Ai Helix 02 自主执行厨房任务的视频,并感叹生逢其时。视频链接请点击这里。
- 另一位成员使用 Kimi 深入挖掘了视频内容,并在事实核查后,将结果导入幻灯片,准确率高达 98%。
- **Agent Swarm 获得好评:成员们讨论了 **Agent Swarm,一位用户指出它会迅速消耗 Agent 额度,而另一位用户则认为它超级酷且结果完美。
- 一位成员建议将其用于检查 Supabase SDK 依赖问题以及将代码从 Rust 移植到 Golang 等任务,获得的结果比使用 kimi-cli 更好。
- **Token 计费上线:成员们讨论了新的基于 Token 的计费系统**,对于其透明度(相较于之前的按请求计费系统)反应不一。
- 一位成员认为新的基于 Token 的系统更好,因为我的一些后续查询非常简短,而其他人则觉得它更加模糊。
- **手机截图触发审核过滤:成员们在向 **Kimi K2.5 上传图片(尤其是手机截屏)时遇到错误。
- 似乎当用户上传手机截屏时, Kimi 会返回 错误代码: 403,而使用笔记本电脑截取的屏幕截图则可以正常工作。
OpenAI ▷ #annnouncements (1 条消息):
OpenAI: @everyone https://chatgpt.com/translate/
OpenAI ▷ #ai-discussions (127 条消息🔥🔥):
Tesla FSD Perspective Shift, Prism for Science, TI-84 Neural Network, OpenAI bets big on Audio, Genie demo
- 驾驶开启 Full Self-Driving 的 Tesla 改变了视角:一位用户表示,驾驶开启 Full Self-Driving 的 Tesla 非常酷且有趣,尽管它需要持续监管,但这改变了他们对自动化的整体看法。
- 他们认为这就是为什么 OpenAI 正在升级其 Codex 以强力应对网络安全担忧的原因。
- TI-84 运行神经网络自动纠错:一位用户创建了一个直接在 TI-84 上运行的神经网络,能够对单词进行自动纠错/拼写检查!
- 其他用户对此表示惊讶。
- OpenAI 豪赌语音技术:一位用户分享了一篇 TechCrunch 文章,讨论了 OpenAI 对音频技术的关注,暗示他们可能会完全垄断实时语音领域。
- 其他人指出,OpenAI 在领先的情况下在语音技术上搁置了太久。
- GPT-5.3 多模态预期:一位用户表示:我们可能会在未来两周内迎来 GPT-5.3,它应该会有多模态方面的改进,这可能是对当前 GPT-4o AVM 的重大升级。
- 一位用户表示他们不喜欢 4o,并且已经完全停止使用 AVM。
- Google 发布 Genie:Google 刚刚向所有 Ultra 订阅者开放了 Genie 的访问权限。
- 用户在看过官方博客中那些精选的演示后,正在等待独立的测试结果。
OpenAI ▷ #gpt-4-discussions (43 messages🔥):
GPT Pro 5.2 File Handling Regression, GRPC Bug Affecting File Access, Safety Rails in GPT-5.2, Exploring Topics After Flagging, Upcoming Models and API Usage
- GPT Pro 5.2 遭遇文件处理回归 (Regression):用户报告了 GPT Pro 5.2 文件处理的回归问题,尽管上传成功,模型却无法访问已上传的文件(ZIP, Excel, PDF)。一位用户表示,他们仍然可以生成 Excel 或 PDF,但无法上传它们进行分析。
- 该问题似乎源于附件到 sandbox 挂载 (mount) 步骤损坏,而非用户操作错误,可能与代码更新有关。一位用户指出,Reddit 帖子也反映了同样的问题。
- OpenAI 发布了干扰文件访问的 GRPC Bug:一位用户推测 OpenAI 在最新的工具使用版本中发布了一个 Bug,导致 GRPC 配置混乱,使得 GPT 无法看到或使用上传的文件,引发了广泛的用户不满。一位用户总结了问题的核心:任何我上传到 GPT-5.2 Pro 的文件都没有被正确添加到 /mnt/data,因此模型无法使用它并报错。
- 该用户建议对有问题的代码更新进行全面回滚,以解决文件访问问题。
- 安全护栏 (Safety Rails) 重新路由可疑的探索:成员们讨论了 GPT-5.2 拥有像断路器一样的安全护栏 (safety rails),如果触发了禁令,模型会停止或重新路由,从而防止在同一个对话中进一步探索被标记 (flagged) 的主题。
- 澄清指出,开启一个新对话可以重置上下文,只要方法保持在指定限制内,就可以在允许的范围内重新探索该主题。
- 新模型和 API 使用率下降?:一位用户询问了潜在的新模型发布情况,特别是 translate model 是否会开放 API 使用,以及它的定价是否会像 moderation 模型一样实惠。
- 另一位成员开玩笑说可能发布的新功能时评论道:在 GTA6 之前出 Bablefish 真是疯狂。
OpenAI ▷ #prompt-engineering (16 messages🔥):
animated gifs in ChatGPT, seizure risk, moderation, safe OAI link, AI Reasoning Standards
- GIF 动画引发癫痫安全审查:在频道中删除动态 GIF 后引发了讨论,原因是这些 GIF 可能对患有癫痫的观众造成癫痫发作风险。
- 一位成员表示,社区不需要为了让你讨论在 ChatGPT 中制作 GIF 动画而冒癫痫发作的风险,并对删除闪烁图像表示宽慰。
- 审核方法提到审查制度:一位成员提到他们在另一个频道审查了纪录片链接,以提供一个安全的 OAI 链接。
- 这被描述为一种技术上的 prompt engineered 方法。
- 为可靠推理调整项目 (Projects):一位成员分享了他们通过自定义指令 (custom instructions) 调整 Projects 的方法,以实现更慢、更显式的推理以及更少的自信猜测,并附上了 AI Reasoning Standards PDF。
- 他们指出,这并不适用于所有用例,但在准确性比速度更重要时很有帮助,并征求反馈。
OpenAI ▷ #api-discussions (16 messages🔥):
Prompt Engineering 讨论、图像共享指南、动画 GIF 与癫痫风险、AI 推理标准
- Prompt Engineering 频道受到提醒:管理员提醒用户,该频道应仅用于 prompt engineering discussions,而非通用的图像输出,引导他们使用相应的
IMAGES频道。- 一位用户对帖子被删除表示沮丧,认为这些帖子旨在鼓励讨论并展示他们正在编写的指南中的方法,而不仅仅是分享图像。
- 动画 GIF 可能触发癫痫:一名成员担心 animated GIFs 可能会给社区成员带来 seizure risk(癫痫风险),在闪烁图像被移除后大家感到宽慰。
- 尽管他们自己没有癫痫,但他们指出,在如此规模的服务器上,存在患有癫痫的访问者具有统计学上的可能性。
- 利用 AI Projects 进行深度推理:一位用户分享了一种调整 AI Projects 的方法,通过使用 custom instructions 进行显式推理并减少猜测,使其在处理深度或不熟悉的工作时更加可靠。
- 该用户附带了一份 PDF document 详细介绍了 AI Reasoning Standards V1.1,并寻求关于其有效性的反馈。
GPU MODE ▷ #general (58 messages🔥🔥):
nsys vs ncu, Sparsity 项目, 大规模分布式训练, 容器冷启动, llm.c 中的 cuSPARSELt
- NSys 显示的内容多于 NCU:一位成员询问为什么某些 kernel 在 nsys 中可见但在 ncu 中不可见,例如 CUB::SCAN 和 CUB::RADIXSORT,以及假设这些 CUB kernel 是从 reduce_kernel 启动的是否正确。
- 一位成员回复说,他们开始使用 nsys 和 ncu 后就再也回不去了。
- 让我们在 Sparsity 上合作:一位成员提议在 Sparsity project 上进行合作,对 sparsity 模式和方法论进行 benchmark 以实现 wall clock 提升,并最终设计 kernel 来利用这些特性。
- 另一位成员在 GitHub 上 发布了 Karpathy 的
llm.c分支,使用了 cuSPARSELt,并报告称在后期训练轮次(epochs)中训练时间有明显的加速。
- 另一位成员在 GitHub 上 发布了 Karpathy 的
- Scaling Book 资源分享:成员们分享了 large scale distributed training 的资源,包括 scaling book 和 torchtitan 博客文章。
- 一位成员开玩笑说,scaling book 塑造了他的思维方式:“如果有人问我会用什么,我可以带着数学公式滔滔不绝 10 分钟:‘理想情况下,blah blah blah 你应该在这里使用 TP+DP’ -> ‘所以我应该使用 tp+dp 吗?’ -> ‘不,torch 里的 tp 很烂,直接用 fsdp 吧’”。
- 容器冷启动解决方案:一位成员正在寻找资源,以便在进行大规模分布式训练时保持大量 GPU 活跃(warm)并减少 GPU starvation。
- 另一位成员推荐了 Charles 在 Modal 上的容器冷启动博客文章,认为这是具有公开文档的常用技术。
- Profiler 见解分享:关于 profiler 的对话不断深入,成员们发现 nsys 和 ncu 最有帮助,而 torch profiler 对于大多数训练瓶颈来说已经足够。
- 一位成员提到在处理了 10 万个以上的 prompt 后改用 CPP,另一位成员指出了跨 prefill chunk 的 Chunked Pipeline Parallelism (PP) 的兴起。
GPU MODE ▷ #cuda (1 messages):
sm100, cutlass
- sm100 缺少 pingpong 支持:一位成员询问为什么网上没有针对 sm100 的 pingpong code,并指出 cutlass 仅为 sm120 和 sm90 提供 pingpong 调度方案。
- 他们想知道这种遗漏是否有什么根本原因。
- Cutlass 排除 sm100 Pingpong:该用户观察到 Cutlass 仅为 sm120 和 sm90 提供 pingpong schedules,对 sm100 的缺失提出了疑问。
- 目前尚不清楚这是由于技术限制还是由于缺乏实现工作。
GPU MODE ▷ #torch (6 messages):
Triage Bot, AI-Generated PRs in JAX, PR Prioritization
- Triage Bot:是敌是友?:成员们讨论了新的 Triage Bot 是否会影响 triage meetings 的必要性。
- 社区似乎不确定在引入该 Bot 后,triage meetings 是否还能继续存在。
- AI 生成的 PR 令编码者感到愤怒:一位成员对看到 JAX 中一个 AI 生成的 Pull Request 获得维护者的关注表示沮丧。
- 该成员自己的小型 Bug 修复(目前导致测试失败)仍未得到处理,而他们认为的“明显垃圾(clear slop)”内容却得到了回应。
- PR 队列优先级讨论:一位开发者哀叹维护者处理 AI 生成的 PR,而他自己的 Bug 修复却无人问津。
- 这引发了关于 Pull Request 优先级排序的讨论,特别是关于新颖的 AI 贡献与必要的 Bug 修复之间的权衡。
GPU MODE ▷ #announcements (1 messages):
TVM-FFI, ML Systems, GPU kernels, nvfp4 competition
- ML Systems 先驱陈天奇发表演讲!:作为 ML Systems 领域的奠基人之一,陈天奇 <@732718409095315517> 将就 tvm-ffi(一种针对 ML Systems 的开放 ABI 和 FFI)发表专题演讲。
- nvfp4 竞赛的许多顶尖参赛者已经在使用 tvm-ffi,演讲中将对此进行讨论。这里是该演讲的视频链接。
- 通过 TVM-FFI 解锁 ML System 的互操作性:TVM-FFI 为 ML Systems GPU kernels 提供了一种开放的 ABI 和 FFI,旨在减少 Host 端开销并确保与 PyTorch 的开箱即用互操作性。
- DSL 虽然有趣,但很难让它们具备低 Host 开销、鲁棒性以及与 PyTorch 的开箱即用互操作性。
GPU MODE ▷ #beginner (6 messages):
gpumode bad link, cutlass kernel naming, AI infra roadmap
- gpumode 链接已修复!:一位用户指出 gpumode 链接失效并需要修复。
- 他们提供了一个有效的链接:gpumode.com。
- 寻求 CUTLASS 命名规范说明:一位用户请求解释 CUTLASS kernel 命名规范,特别是针对一个由 cuBLAS 启动的 Kernel。
- 涉及的 Kernel 为:
void Kernel2<cutlass_80_tensorop_d884gemm_64x64_16x4_nn_align1>(Params)。
- 涉及的 Kernel 为:
- 请求 AI infra 学习路线图:一位用户询问了从该 Discord 学习的路线图或站点地图,目标是利用现有的传统基础设施知识进入 AI infra 领域。
- 另一位用户指向了频道 <#1198358627594023014>。
GPU MODE ▷ #hardware (1 messages):
RX 580, BIOS flashing
- RX 580 车主需要 BIOS:一位用户购买了他们认为是 Red Devil RX 580 的显卡,但发现它实际上是 PowerColor OEM RX 580。
- 该用户正在寻找正确的 .rom 文件,以便将正确的 BIOS 刷入显卡。
- BIOS 刷写的重要性:刷入正确的 BIOS 对于 RX 580 的最佳性能和兼容性至关重要。
- 使用错误的 BIOS 可能会导致不稳定、性能下降,甚至对显卡造成永久性损坏。
GPU MODE ▷ #cutlass (14 messages🔥):
Tract vs Cute, Layout Algebra, Weak Composition, Tuple Morphisms, Diagram Node Order
- 节点顺序对于图表至关重要:图表两侧数字的自上而下顺序决定了分解过程中的最终连接,而置换左侧顺序是 Layout (4, 8):(1, 4) 与 Layout (8, 4):(1, 8) 之间的核心区别。
- 会议进一步澄清,双侧的顺序都至关重要,因为交换右侧的 4 和 8 会得到 Layout (4, 8):(8, 1)。
- Tract 的 Weak Composition 解决了定义域不匹配问题:一位用户在尝试通过 Tract 模拟组合(Composition)时遇到了定义域/陪域(Domain/Codomain)约束,并了解到
tract.compose要求第一个态射(Morphism)的陪域必须与第二个态射的定义域完全相等(on the nose)。- 解决方案是使用
tract.weak_composite来执行 refine, pullback/pushforward, compose,这全面涵盖了组合操作。
- 解决方案是使用
- CuTe 的范畴论基础:
tract证明了范畴论方法与 CuTe 的 Layout Algebra 是一致的。- 它的定位是教学性的,而非为了性能,也不打算追求性能。
- 澄清图表节点顺序:一位用户询问图表节点是否可以重新排序,暗示节点顺序可能是灵活的,但这种理解是错误的。
- 一位参与者澄清说,Tuple 的排序是不可更改的,节点的顺序至关重要。
GPU MODE ▷ #teenygrad (4 messages):
Non-Negativity Equation, Taleb's Impossible Event Shtick, SITP Book Opensourced, Pull Request on SITP Book
- 关于非负性方程的辩论:一位成员质疑非负性方程是否应该是 P(E) >= 0,认为某些事件是不可能的。
- 另一位成员在形式上表示同意,但提到了 Nassim Taleb 的观点,即不存在所谓的“不可能”事件。
- SITP 书籍代码库公开:一位成员在 https://github.com/j4orz/teenygrad/tree/master/book 开源了 SITP 书籍的 mdbook。
- 该书籍会自动部署到 https://book.j4orz.ai/。
- 成员针对 SITP 书籍提交 Pull Request:响应书籍开源,一位成员创建了 Pull Request。
- 一位成员要求进行更改,将 mdbook 构建添加到 Netlify 的 CI 中。
GPU MODE ▷ #multi-gpu (1 messages):
JAX, Torch, Sharding, Distributed Computing
- Ed Yang 详解分布式系统:Ed Yang 最近发布了一系列涵盖分布式系统主题的博客文章,专门比较了 JAX 和 Torch 处理分片(Sharding)的方式。
- 更多详情请查看 Ed Yang 的推文,其中包含博客文章链接。
- 分片对决:JAX vs. Torch:Ed Yang 最新的博客文章详细比较了 JAX 和 Torch 的分片方法,为分布式计算提供了深刻见解。
- 这些文章深入探讨了每个框架的细微差别,为处理大规模模型的开发者提供了宝贵的资源。
GPU MODE ▷ #helion (1 messages):
uc_explorer: 嗨 James,是的,我们可以进行同步。
GPU MODE ▷ #nvidia-competition (23 messages🔥):
大奖评选的算术差异 vs 百分比差异、MLIRError、OpError、服务错误
- 百分比差异决定大奖:比赛的大奖是根据相对于光速(speed of light)的百分比差异来衡量的。在极少数情况下,如果提交的作品超过了光速,该提交将建立一个新的参考点。
- T&Cs 规定:在极少数情况下,如果用户提交的作品超过了光速,该顶级提交所达到的新性能峰值将作为该特定问题的光速参考点。
- OpError 异常排查:成员们发现了一个不可序列化的异常 OpError,并通过在 reference-kernels 中创建一个异常元组修复了它。
- 一位成员提交了一个 pull request 来修复此问题。
- 服务错误困扰用户:一些成员报告了间歇性的 503 service errors。
- 尚未提供解决方案。
GPU MODE ▷ #career-advice (8 messages🔥):
实习建议、性能工程技能、GPU 专业化
- 停止比较,开始社交!:一位寻找职业建议的成员被告知,声称自己比其他获得实习机会的人更有技能,这种表现并不体面。
- 建议是与那些获得实习机会的人建立人脉(network)并学习他们的经验,而不是纠结于感知上的技能差异。
- 性能工程技能提升:一位成员询问了 Anthropic 性能工程师在校招中重点考察的具体技能组。
- 提到的具体例子包括 DSLs 和 Torch.compile。
- 印度对 GPU 技能的需求:一位成员指出,一位寻找 GPU 相关实习的成员身处印度,那里对这类技能的需求低于其他地区。
- 因此,缺乏回复可能是因为该地点的相关岗位已经饱和。
GPU MODE ▷ #flashinfer (8 messages🔥):
竞赛组队、FlashInfer 设置困扰、Agent 赛道规则澄清
- 黑客松参与者寻觅队友:几位成员正在为即将到来的比赛寻找队友,其中一位成员展示了他们的 GitHub、LinkedIn 和 YouTube 频道,重点介绍了他们在推理优化黑客松的获胜经历和 Triton kernel 经验。
- FlashInfer 文件查找失败:一位成员遇到了与
FIB_DATASET_PATH正确路径相关的 FlashInfer 设置问题,并在帖子中展示了错误图片。- 他们确认路径已设置,但不确定
/home/shadeform/flashinfer-trace是否正确;随后收到了 “Compile Error!” 信息。
- 他们确认路径已设置,但不确定
- RL 规则保持严格:一位成员询问规则,关于 Agent 赛道是否允许进行训练后的 RL,或者是否只能使用公开可用的 Agent/APIs。
- 另一位成员对 “对于 Agent 赛道,是否允许训练后 RL,还是必须使用公开可用的 Agent/APIs” 的问题给出了肯定的回答。
HuggingFace ▷ #general (100 messages🔥🔥):
TRL PR review, v4 Deprecation schedule, AI Catfishing, Ollama Model training, Jetson AGX Thor T5000
- HuggingFace PR 需要审核:一位成员请求审核他们的 TRL pull request #4894,但被建议在标记(tagging)相关人员之前先等几天。
- 另一位成员提到,PR 审核可能需要数周或数月的时间,但他们总是会尝试尽快重新跟进。
- Full-Stack Engineer 加入频道:一位成员介绍自己是 Senior AI/ML & Full-Stack Engineer,并列出了他们目前正在构建的关键项目,包括:Autonomous Agents、医疗 AI、决策支持系统、对话式 AI、欺诈检测系统。
- 他们列出了使用的技术,如 Reinforcement Learning, NLP, Deep Learning,并链接到了他们的个人资料。
- Discord app 对比 discordapp.com:一位成员指出 Discord Windows 客户端使用的是
discordapp.com而非discord.com,这导致从一个频道跳转到另一个特定频道时会出现问题。- 他们还注意到 help-and-feedback 频道没有出现在频道列表中,因为它是一个只读的资源页面,并进一步解释了 Discord 支持文章 以供参考。
- 据传 Hugging Face 的 Adam 筹集了 4000 万美元:一位成员推测前 Discord 版主 Adam 筹集了 4000 万美元,现在是 30 under 30 成员,并链接了一篇 Forbes 文章。
- 另一位用户在
#introductions频道中找到了 Adam,确认了他的存在。
- 另一位用户在
- GCP 基础设施出现副本激增:一位成员报告了一个 Bug,其在 GCP 中的私有模型副本在未更改配置的情况下,从 1 个副本的上限一夜之间激增到了 62 个副本。
- 该成员推测他们不是唯一出现此问题的 Endpoint,且 GCP 资源已耗尽。
HuggingFace ▷ #i-made-this (11 messages🔥):
LeetCode MCP server, qwen3-tts-rs, MOLTBOT Quantum Chef, Pacific Prime Math
- LeetCode MCP 提供编程挑战服务:一位成员开发了一个 LeetCode MCP server,可通过终端解决每日挑战。该服务器利用 Claude 的学习模式,支持身份验证、题目抓取、提示请求、代码编写以及提交和结果检索。
- Qwen3 TTS 已上线:一位成员发布了 Qwen3-TTS-12Hz-1.7B-Base 模型,并发布了适用于 MacOS, Linux 和 Windows 的安装说明。
- 另一位成员评论道:“太酷了,我会关注这个项目的,在我看来你完成得非常出色,非常有意思”。
- MOLTBOT 提供量子烹饪服务:一个包含量子计算概念训练示例的数据集已分享,该数据集由 MOLTBOT ∞ Quantum Chef 生成,包含关于量子操作的提示词以及对量子行为的解释。
- Pacific Prime 训练的数学 LLM:Pacific Prime 发布了其数学专用 1.5B LLM 的第一个 Checkpoint,该模型在 GSM8K, NuminaMath, MetaMathQA & Orca-Math(约 40.7 万个样本)上训练,并支持使用 LaTeX 符号进行逐步推理。
HuggingFace ▷ #core-announcements (1 messages):
LTX-2 distilled checkpoint, Two-stage pipelines, Diffusers library
- Diffusers 新增 LTX-2 Checkpoint 支持:根据此 PR,Diffusers library 现在支持 LTX-2 蒸馏 Checkpoint 和 Two-stage pipelines。
- 现已支持两阶段流水线 (Two-Stage Pipelines):得益于新的更新,Diffusers library 现在除了支持 LTX-2 蒸馏 Checkpoint 外,还提供了对 Two-stage pipelines 的支持。
HuggingFace ▷ #agents-course (1 messages):
Deep RL 课程问题,频道引导
- Deep Reinforcement Learning 学生寻求频道指引:一名选修了 Deep RL 课程的学生正在寻求关于提问合适频道的建议。
- 该学生在解决问题时遇到了困难,不确定去哪里寻求帮助。
- 学生需要关于频道的明确说明:一名学生需要明确在哪个 Discord 频道发布 Deep RL 课程相关问题。
- 他们目前对自己遇到的问题该去哪里求助感到困惑。
Yannick Kilcher ▷ #general (44 messages🔥):
微型模型缩放行为、字节级模型 vs. Tokenization、带有子进程模型的 Thinking AI、专用模型的路由与分类、检索可靠性与 Cosine Similarity
- 用于字节级预测的 **Dense MoE 架构:一名成员构建了一个用于字节级预测的 **dense MoE 架构,使用了 256 的词表(字节级)、40M 参数和 13GB VRAM,并正在征求性能反馈。
- 该模型使用 4096 序列长度和 8 的 batch size。该成员声称他们非常小心地避免了数据污染,并表示使用字节允许他们使用完全相同的架构来编码图像、音频或两者。
- 带有子进程模型的 **Thinking AI 架构**:一名成员提出了一种架构,其中较大的“思考型” AI 模型由较小的子进程模型监控,子进程模型会暂停主模型以从 MCPs 或 CLIs 检索信息,然后将问题替换为答案。
- 目标是减少主模型的上下文杂乱(context clutter),尽管人们意识到子进程模型需要知道主模型缺失了哪些信息,这种做法被描述为可能是一个愚蠢的想法。
- **路由与分类提升模型性能**:成员们讨论了使用分类器将用户提示(prompts)路由到专用模型,并将细节附加到用户提示的上下文中,从而避免暂停较大的模型并减少 Token 开销。
- 进一步讨论了使分类器和 Embedding 模型保持一致,由 LM 和专家模型直接处理 Embedding,一名成员表示 路由和分类可能是最亮眼(spiciest)的举措。
- 检索与 **Cosine Similarity 的困境**:成员们讨论了检索不可靠且使模型感到困惑的问题,以及 Cosine Similarity 可能不等于因果相关性(causal relevance)。
- 一名成员建议在模型中索引 SQL 数据库,并发布消息称 在我看来,检索最大的问题是 Cosine Similarity != 因果相关性。
- 视频涉及按重要性进行向量加权**:一名成员询问了在 Cosine Similarity 中按重要性对向量进行加权的问题,并分享了 两个 Xitter 帖子 和 这段 YouTube 视频。
- 另一名成员分享了 另一个 Xitter 帖子,表达了对该项目的喜爱。
Yannick Kilcher ▷ #ml-news (8 条消息🔥):
LM Studio 0.4.0, AllenAI's Open Coding Agents, GoodfireAI Alzheimer's Detection Interpretability, Sweep Next-Edit Autocomplete Model, Google DeepMind Project Genie
- LM Studio 升级至 v0.4.0: 发布了新的 LM Studio 版本 0.4.0。
- 未提供有关此次更新中包含的具体改进或功能的详细信息。
- AllenAI 廉价出售 Open Coding Agents: 根据 The Decoder 的报道,AllenAI 的 SERA 将 Open Coding Agents 引入私有仓库,训练成本低至 $400。
- GoodfireAI 解释阿尔茨海默病检测: 一位成员链接了 GoodfireAI 关于阿尔茨海默病检测可解释性(interpretability)的研究。
- Sweep 开源 Next-Edit 自动补全模型: Sweep 正在开源 Sweep Next-Edit,这是一个可在本地运行的、用于下一编辑自动补全的 SOTA LLM。目前已发布 0.5B 和 1.5B 参数的模型,详见 Sweep 的博客。
- DeepMind 推出新项目: 一位成员分享了 Google DeepMind 的 Project Genie 链接。
Manus.im Discord ▷ #general (21 条消息🔥):
Minecraft launcher, Prompt engineering, Manus redeem codes, AI/ML and Full-Stack Engineering, Libyan user
- 为挂机(AFK)使用创建的 Minecraft 启动器: 一位用户正在创建 一个 Minecraft 启动器,以便在不需要 高性能 PC 的情况下进行挂机。
- 该用户补充说,他们还可以进行 Prompt engineering 和数据提取,甚至如果需要的话可以 复刻网站。
- 发布新的 Manus 兑换码: 一位用户分享了三个新的 Manus 兑换码:FUM1A1G7、ntaxzjg 和 mwiyytb。
- 另一位用户对他表示感谢,并确认 每月只能使用一个兑换码。
- AI/ML 工程师寻求合作: 一位工程师介绍了自己,强调了他们在构建 AI + Full-Stack 系统方面的专业知识,并将合作意向引导至 #collab 频道。
- 他们列举了在 LLM integration、RAG pipelines、工作流自动化、AI 内容审核、Image AI (CLIP + YOLOv8)、Voice AI (Whisper, Tacotron2) 以及各种 Web、移动端和数据库技术方面的经验。
- 自 2025 年应用发布以来的利比亚 Manos 用户: 一位用户询问自己是否是自 2025 年初 发布以来唯一使用过 Manos 的 利比亚 人。
- 随后另一位用户以 حياك الله 欢迎了这位 利比亚 用户。
MCP Contributors (Official) ▷ #general (4 条消息):
MCP Security Standard, Agentic AI Foundation, Server Hardening, Supply Chain Security
- **MCP 安全标准草案发布并开放讨论: 一位名叫 Dani(又名 cr0hn)的安全研究员为 MCP 服务器起草了一份开放安全基准,包括 **加固、日志记录、访问控制和供应链安全 等控制措施,地址为 https://github.com/mcp-security-standard/mcp-server-security-standard。
- 作者计划将其捐赠给 Agentic AI Foundation,并想了解它是否适合 MCP 生态系统。
- 社区称赞 **MCP 安全标准: 一位成员认为 **MCP 安全标准 的控制措施和领域划分编写得非常好且易于理解。
- 他们将该基准转发到了另一个频道以进行进一步讨论。
MCP Contributors (Official) ▷ #general-wg (13 messages🔥):
生命周期文档中的状态机,MCP 中的 Namespaces vs Groups vs URIs,SEP-2084 Primitive Grouping
- **State Machine 文档正在审查中**:一位成员请求对这个 pull request 提供反馈,该 PR 旨在生命周期文档中添加一个状态机。
- 另一位成员建议填写动机(motivation)和背景(context)部分,以帮助审查者理解提议的更改。
- **Namespaces 在 MCP 中让位于 Groups:注意到 Namespaces 已被拒绝并被 Groups 取代,而 **URIs 的状态尚不明确,参考 issue 1292。
- 最近发布了一个关于 Groups 的新 SEP,目前正在讨论中:Primitive Grouping SEP-2084。
- SEP-1300 的精炼后代是 SEP-2084:SEP-1292 被 SEP-1300 取代,但由于在核心维护者(Core Maintainers)审查期间缺乏共识,后者被拒绝。
- 引入了更简单的 SEP-2084 - Primitive Grouping 作为替代方案。
Eleuther ▷ #general (5 messages):
浏览器 GPU 使用率,IGPU 性能
- Twitter 链接引起关注:一位用户表达了对该 Twitter 链接的欣赏。
- IGPU 在基础浏览器页面表现挣扎:一位用户注意到,在使用 Ryzen 7 7700 IGPU 查看特定网页时出现了性能下降,帧率仅为 3fps。
Eleuther ▷ #research (8 messages🔥):
分桶缩放 (Bucketing Scales)、几何卷积方法 (Geometric Convolution Approach)、层归一化 (Layer Norms)、RNN 架构
- 不同方式的分桶缩放:一位成员询问与其他操作结合时是否会以不同方式进行分桶缩放,尽管此消息历史中未提供具体示例。
- 几何卷积方法作为单元连接:一位成员正在开发一个基准模型,该模型将 Multi-Head Attention 替换为几何卷积方法,其中 Embeddings 作为模拟连接的单元。
- 该成员报告称 Loss 正在收敛并开始捕捉对话逻辑,正在寻求反馈。他们提供了一个如下的调试输出:
DEBUG [GEOPARA] | L0_Alpha: 0.1029 L1_Alpha: 0.0947 | L0_Res: 0.0916 L1_Res: 0.1538。
- 该成员报告称 Loss 正在收敛并开始捕捉对话逻辑,正在寻求反馈。他们提供了一个如下的调试输出:
- 关于 Layer Norms 的讨论开始:一位成员发布了一个关于 Layer Norms 的推文链接以及 arxiv.org 的链接。
- 建议可并行化的 RNN 架构:一位成员建议阅读更多关于其他可并行化 RNN 架构的内容,并在更强大的 Tokenized 基准上进行更严谨的大规模实验。
Eleuther ▷ #scaling-laws (1 messages):
diogenesoftoronto: https://arxiv.org/abs/2601.19831
Eleuther ▷ #interpretability-general (2 messages):
恶意软件分类、误报率降低、可解释模型、特征工程技术
- 应对恶意软件分类问题:一位成员正在处理一个恶意软件分类问题,数据集包含约 60 万行和 9,600 个二进制特征,目标是降低误报率 (False Positive Rate, FPR)。
- 该成员主要关注 scikit-learn 树模型等可解释模型,但尽管尝试了多种特征工程技术,仍难以将 FPR 降低到 9% 以下。
- 寻求降低误报率的帮助:一位成员在恶意软件分类项目中寻求降低 误报率 (FPR) 的建议,该项目使用了大约 9,600 个二进制特征。
- 尽管尝试了各种特征工程技术并尝试了神经网络(效果最好),但该成员仍在寻找能够在保持可解释性的同时降低 FPR 的建议,特别是在使用 scikit-learn 树模型的情况下。
DSPy ▷ #papers (1 messages):
ash_blanc: https://alphaxiv.org/abs/2601.20810
DSPy ▷ #general (12 messages🔥):
DSPy Skills, DSPy Agents in Production, RLM Sandbox Swapping, Opus Capabilities
- 寻求 DSPy 中的自定义技能:一位成员询问如何在 DSPy 模块中(特别是配合 DSPy ReAct Agent)使用自定义技能(包含关联 .py 脚本的 .md 文件)。
- 他们提到拥有诸如将 .md 转换为 PDF 的技能,并想了解其他人是否尝试过类似的方法。
- 远程部署 DSPy Agent:一位成员询问关于在生产环境中远程使用 DSPy Agent 并结合 运行时(runtime)DSPy 优化 的问题。
- 该成员表示需要一个支持此类部署的运行时环境。
- 探索 RLM 沙盒自定义:一位成员询问是否可以将 RLM (Retrieval-augmented Language Model) 使用的沙盒替换为自定义或云服务,如 E2B (Ephemeral Environment Builder)。
- 他们寻求用 E2B、Modal 或 Daytona 等沙盒替换本地的 PythonInterpreter。
- Opus 即将支持编写沙盒:一位成员宣布他们正在努力让 Opus 能够编写新的沙盒。
- 他们指出,未来将为 E2B 等提供商的官方实现提供一套协议。
Modular (Mojo 🔥) ▷ #general (1 messages):
macOS trust dance, Gatekeeper tax, mojo build codesign
- macOS 首次运行的信任校验:macOS 上首次运行与第二次运行之间的性能差异可能是由于 macOS 的信任校验(trust dance),而非 Mojo 特有的问题。
- Gatekeeper 税会产生额外开销,但清除 quarantine xattr 或进行 ad-hoc 代码签名(codesigning)通常能使启动表现与第二次运行一致。
- mojo build 中的代码签名步骤可隐藏启动延迟:对于 CLI 工具,启动性能至关重要,这暗示了 文档 或 工具链 中可能存在的陷阱(footgun)问题。
- 在
mojo build中添加 codesign 步骤可能会完全缓解此问题,确保一致的启动行为。
- 在
Modular (Mojo 🔥) ▷ #mojo (8 messages🔥):
Mojo at ORNL, Mojo GPU puzzles, Mojo changelog, Github issue #5875, Github issue #4767
- Mojo 获得 ORNL 认可:一篇题为 Mojo at ORNL 的研究论文已发表。
- Modular Bug 追踪:一位成员报告了一个潜在 Bug 并建议提交 Issue,可能与 Issue #4767 相关。
- Mojo 更新日志引发关注:一位成员在查阅新的 Mojo 更新日志后,对过去两个月 Mojo 的工作量表示惊讶。
- Mojo GPU Puzzles - 无需卫语句:一位成员注意到,在 Mojo GPU Puzzles 3、4 和 5 中,卫语句(guard clause)
if row < size and col < size:是多余的;省略它不会导致错误。- 另一位成员指出了 puzzle 03 的解决方案,其中解释了通过测试并不一定意味着代码是健壮(sound)的。
- GitHub Issue 报告:一位成员报告遇到了一个奇怪的问题,引用了 GitHub issue #5875。
tinygrad (George Hotz) ▷ #general (5 messages):
ANE Performance, Quantization Discussion
- ANE 权衡侧重于能效比:Apple 的 ANE (Apple Neural Engine) 优先考虑性能功耗比(performance-to-watt)的权衡,而非原始性能,详见此论文。
- 虽然 ANE 以卓越的能源效率实现了具有竞争力的性能,但它在 M4-Pro 上通过 GEMM 操作可达到 3.8 TFlops,与同 SoC 上 GPU 的 4.7 TFlops 相当。
- 量化方法探讨:成员们讨论了量化,特别是将 Q4 作为一种量化方法。
- 一位成员将其运行速度提升到了 9 t/s。
aider (Paul Gauthier) ▷ #general (5 messages):
Aider Friendly Fork, Aider Utility with Python and Git
- Aider 引发友好分叉 (Friendly Fork) 热潮?:一位成员建议创建一个 Aider 的友好分叉,以便在 @paulg 忙于其他项目时继续开发,因为 Aider 是用 Python 编写的,并在 GitHub 上使用 Git 进行版本控制。
- 目标是在 Aider 当前功能的基础上进行构建,并认可其与其他工具相比的实用性。
- Aider 与编排器集成:一位成员表示有兴趣通过 MultiClaude 或 gas town.sh 等编排器 (Orchestrators) 来驱动 Aider。
- 这突显了 Aider 与其他工具集成以增强工作流自动化的潜力。
MLOps @Chipro ▷ #general-ml (1 messages):
Context Graphs, Semantic Layers, Ontologies, AI Reasoning
- Context Graphs 引发混淆:Context Graphs 的激增导致了混淆,Semantic Layers 和 Ontologies 等术语被交替使用,尽管它们服务于不同的目的。
- AI 的兴起突显了这些定义中的不一致性,揭示出由于这些概念的混淆,系统虽然可以准确执行计算,但推理能力依然较差。
- Semantic Layers vs. Ontologies:Semantic Layers 用于标准化指标,而 Ontologies 用于建模意义,它们分别起源于 BI 和医疗保健等不同领域。
- 最近 Metadata Weekly 的一篇文章 指出,AI 的需求超出了单纯的定义,还需要明确的关系、约束和假设。
- Semantic Layers 在 AI 方面的局限性:文章建议,“只需添加一个语义层”的方法被证明是不够的,因为 AI 需要的不仅仅是数据一致性。
- AI 需要推理,而 Ontologies 通过使关系和假设显式化来支持推理,这与传统上为仪表板和报告优化的 Semantic Layers 形成对比。
- YAML 配置在业务含义面前瓦解:作者 Jessica Talisman 认为,当 YAML configurations 被期望代表业务含义时,它们会显得力不从心。
- 她详细分析了 Semantic Layers 的设计初衷、为什么 Ontologies 能支持推理、什么是 Context Graphs 以及 YAML 在表达业务含义方面的局限性。