AI News
OpenAI Codex 应用:VSCode 分支的终结、多任务工作树、技能自动化。
OpenAI 在 macOS 上推出了 Codex 应用,将其定位为专门为编程设计的、原生支持智能体(agent-native)的命令中心。该应用具备多智能体并行运行、用于冲突隔离的内置工作树(worktrees)、可复用的技能包(skills)以及定时自动化等功能。
Codex 强调开发者工作流,例如用于前期任务分解的计划模式(Plan mode),并已获得包括 @sama(山姆·奥特曼)在内的业内人士的积极采用反馈。目前,行业正推动技能文件夹的生态标准化,预示着智能体工具领域早期惯例的形成。此外,Codex 还展示了人类与智能体结合的“自我改进型”产品反馈闭环。
在编程智能体的实践中,最佳实践包括:针对 Bug 修复的“测试先行”方法;一名开发者同时管理 5-10 个智能体的“指挥官(conductor)”模型;以及一种“神经符号(neurosymbolic)”框架,该框架解释了编程智能体为何能取得成功——这归功于软件的可验证性和符号化工具。与此同时,对于那些未能体现智能体化工作流的生产力研究,基准测试的怀疑论依然存在。
平静的一天
2026年1月30日至2月2日的 AI 新闻。我们为您查看了 12 个 subreddits、544 个 Twitter 账号 和 24 个 Discord 社区(包含 254 个频道和 14979 条消息)。为您节省了预计阅读时间(以 200wpm 计算):1408 分钟。我们的新网站现已上线,支持完整的元数据搜索,并以精美的 Vibe 风格呈现所有往期内容。请访问 https://news.smol.ai/ 查看完整的新闻细分,并在 @smol_ai 上向我们提供反馈!
我们今天几乎没有把 OpenAI 作为头条故事 —— xAI 技术上被 SpaceX 以约 1770 亿美元收购,而且毕竟它“只是”为现有的 CLI、Cloud app 和 VS Code 扩展提供了一个桌面端 UI……它也“只是” OpenAI 版本的 Conductor、Codex Monitor 以及 Antigravity 的 Inbox(后者发布时甚至使用了完全相同的“AI Agent Command Center”标语):
匿名君,你正在开发哪一种(仅有的 1 种)多智能体(multiagent)应用设计?

万物皆蟹(Everything is crab),但也许螃蟹才是完美的形态。
然而。
在 12 月,Steve Yegge 和 Gene Kim 预测 IDE 将会消亡:
https://www.youtube.com/watch?v=7Dtu2bilcFs&pp=2AbMBw%3D%3D
而现在到了 2026 年,曾经出价 30 亿美元收购 Windsurf 的 OpenAI,正在发布一个并非 VS Code 分支(fork)的编程 Agent UX。顺便提一下,Anthropic 也凭借其 Claude Code 和 Claude Cowork 应用做了同样的事情。这引发了一些思考:编程模型究竟已经进化到了何种程度,以至于严肃的编程应用在发布时竟然不需要 IDE(是的,Codex 在需要时仍然允许你链接到 IDE,但显然这只是例外而非标准)。
曾几何时,“让你用英语写作并在不看代码的情况下构建应用的 App”等同于 “Vibe coding” 或 “App builder”,但这些非技术受众并不是 Codex 的 ICP —— 它的市场定位非常严肃地指向开发者,而开发者在历史上是热爱代码、并对亲手编写每一行代码有强烈认同感的群体。
现在 OpenAI 却说:看代码某种程度上是可选的。
另一个观察结果是对多任务处理(multitasking)和 Worktrees 的依赖:事后看来,这是对 Agent 自主性增强最自然的 UI 回应:
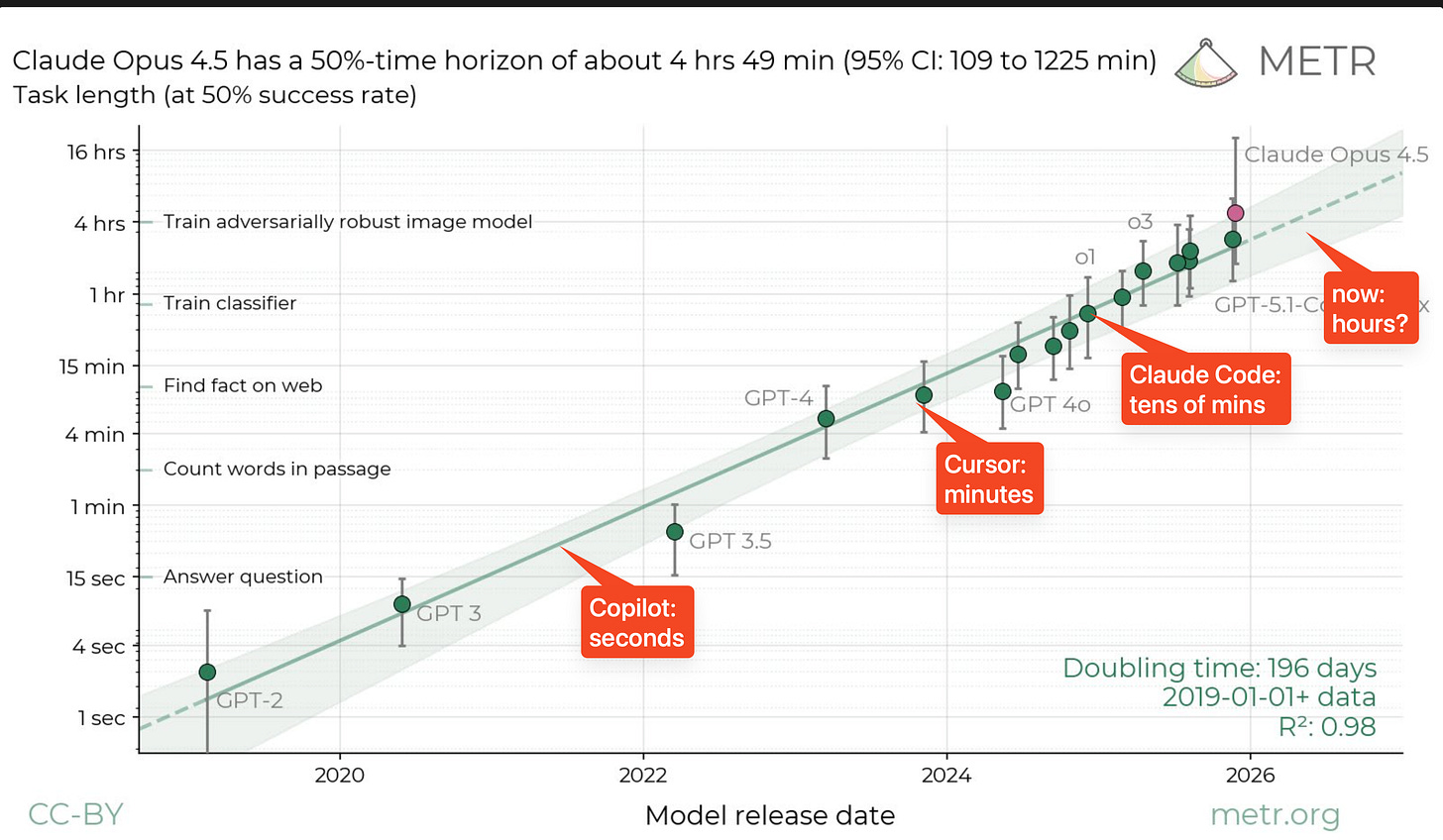
最后,Codex 发布中最具创新性但也最容易被忽视的是 Automations(自动化),它基本上是“运行在 Cronjob 上的技能” —— 某种程度上,OpenAI 是第一个在 GA(正式发布)阶段推出这一极其简单功能的重量级玩家:
AI Twitter 回顾
OpenAI 的 Codex 应用:一个 Agent 原生的编程“指挥中心”
- Codex 应用登陆 macOS(Windows 版本“即将推出”):OpenAI 发布了一款专用的 Codex 桌面应用,定位为运行多个 Agent 并行的专用 UI,通过内置 worktrees 保持变更隔离,并利用 skills 和定时自动化扩展功能 (OpenAI announcement, rate-limit + availability details, OpenAIDevs feature rundown)。一个反复出现的主题:界面(而不仅仅是模型)正在成为产品。
- 关键的开发者工作流细节:该应用强调 (a) 以 每个任务/PR 一个 worktree 作为并行和冲突隔离的原语;(b) Plan mode (
/plan) 用于强制进行前置的任务分解和提问;(c) skills 作为可重用的包,可以连接外部服务(Figma/Linear/Vercel 等);以及 (d) 用于定期后台作业的自动化功能 (@reach_vb, Plan mode, skills landing page)。 - 使用信号 / 采用叙事:多位内部人士(和高级用户)声称,在处理大型仓库和长时间运行的任务时,该应用相较于 CLI/IDE 扩展有了跨越式的进步——特别是在管理并行线程和可审查的 diffs 方面。值得关注的评价包括 @gdb(Agent 原生界面;“回到终端感觉就像回到了过去”),@sama(对自己如此喜爱它感到惊讶),以及 @skirano(在他们的工作流中取代了 Cursor + Claude Code)。
- 生态压力 / 标准化:目前已经出现了标准化 “skills” 文件夹的推行:提议让 Codex 从
.agents/skills读取并弃用.codex/skills(@embirico)。这是 Agent 工具开始形成类似于.github/、pyproject.toml等惯例的早期证据。 - 宏观观点:通过产品闭环实现“自我改进”:多篇帖子强调了 Codex 被用于构建其自身——这被呈现为最引人注目的“递归改进”故事,它实际上是作为一个产品反馈闭环(人类 + Agent)在交付,而非自主的 AGI (OpenAIDevs, @ajambrosino, @thsottiaux)。
实践中的编程 Agent:可靠性、测试、并行,以及“Agent 大军”梗成真
- 关于 CLAUDE.md/AGENTS.md 的一个具体最佳实践:添加一个“测试优先”指令:当报告 bug 时,先编写一个重现测试;然后修复;最后通过测试证明修复成功——这被认为是提升 Agent 性能和理性的单一最大改进 (@nbaschez)。这与更广泛的主题相呼应,即编程是一个高杠杆领域,因为它具有部分可验证性。
- 工程的“指挥者(conductor)”模式:声称一名开发者可以同时运行 5–10 个 Agent,交付他们并未完全阅读的代码,从作者转变为监督者/指挥者 (@Yuchenj_UW)。一个相关的反对观点警告说,如果你试图“并行处理无数件事”,会面临人类上下文切换的极限和质量下降的问题 (@badlogicgames)。
- 关于编程 Agent 为何有效的神经符号(Neurosymbolic)框架:一个精辟的论点认为,编程 Agent 之所以成功,是因为软件是一个可验证的领域,且执行/工具链(测试、编译器、Shell)构成了 LLM 可以利用的符号支架;要在编程之外复制这种成功,需要构建类似的“符号工具箱” + 可验证性 (@random_walker)。
- 对 Benchmark 的质疑:对轻量级“LLM 生产力”研究的抵制,这些研究中的参与者使用的是弱工作流(例如仅使用聊天侧边栏)而非 Agent 设置;批评者认为,在工具快速演进的情况下,这些结果低估了生产力的提升 (@papayathreesome, @scaling01)。
- 开源 Agent 栈及安全/运维关注点:OpenClaw/Moltbook 生态系统既引发了兴奋,也带来了运维/安全方面的批评——例如,关于在 Agent 前端设置网关以进行会话管理/策略执行的讨论 (@salman_paracha),以及关于“仅限 AI 的社交媒体”会立即被机器人/垃圾信息攻陷的警告 (@jxmnop)。潜台词是:Agent 产品需要立即具备与消费级平台同等成熟的防滥用/可观测性。
用于 Agent 编程的开源模型:StepFun Step-3.5-Flash 和 Kimi K2.5 成为本周焦点
- StepFun Step-3.5-Flash 开源发布(主打高效):StepFun 的 Step-3.5-Flash 被多次提及为一个稀疏 MoE 模型,总参数量 196B / 激活参数约 11B,专门为速度 + 长上下文 Agent 工作流优化(值得注意的是其 256K 上下文采用了 3:1 滑动窗口注意力 + 全注意力,以及 MTP-3 多 Token 预测)(官方发布推文, 发布详情/链接)。StepFun 报告其 SWE-bench Verified 评分为 74.4%,Terminal-Bench 2.0 评分为 51.0% (StepFun)。
- 即时的基础设施支持:vLLM 发布了 Day-0 支持和部署方案,标志着 StepFun 对在实际服务栈中被采用的重视 (vLLM)。
- 社区评价立场:多条帖子强调“需要尽快测试”并指出对 Benchmark 挑选数据(cherry-picking)的担忧;人们希望看到标准化的基准测试(MMLU/HLE/ARC-AGI)和第三方验证,特别是在 HF 排行榜变动频繁的情况下 (@teortaxesTex, @QuixiAI)。
- Kimi K2.5 在 Agent 编程方面的优势:Arena 报告 Kimi K2.5 为 Code Arena 中排名第一的开源模型,总榜排名第五,与一些顶级闭源产品“旗鼓相当”,并且在 Text/Vision/Code Arena 中表现强劲 (Arena 公告)。另有零星笔记提到其在某些工作流中存在工具遵循能力较弱(系统提示词遵循度)的问题 (@QuixiAI)。
- 推理商可靠性问题:工具调用/解析失败可能使模型看起来比实际情况更糟;Teknium 指出 FireworksAI 的 Kimi 节点存在损坏的工具解析问题,被迫在工作流中禁用——这是一个运维层面的提醒:生产环境中的“模型质量”往往取决于集成正确性 (@Teknium, 早前警告)。
合成数据、评估以及“不要相信困惑度(Perplexity)”
- 合成预训练(Synthetic pretraining)深度探讨:Dori Alexander 发表了一篇关于合成预训练的长篇博客文章,暗示人们正重新关注合成数据流水线及其失效模式(如:崩溃、分布偏移(distribution drift))(tweet)。这与更广泛的讨论相呼应:曾经占据主导地位的“合成数据模式崩塌(mode collapse)”担忧,现在正越来越多地被视为工程或配方层面的问题 (@HaoliYin)。
- 困惑度(Perplexity)作为模型选择的陷阱:多条推文指出的新证据表明,困惑度不应被盲目信任为选择目标 (@DamienTeney, @giffmana)。实际的启示是:如果你只针对 next-token prediction 指标进行优化,可能会忽视下游任务表现、工具使用稳定性以及指令遵循的一致性。
- 来自互联网的无限 RLVR 任务(“金鹅”):一种从不可验证的网络文本中合成几乎无限的 RLVR 风格任务的方法,通过掩盖推理步骤并生成干扰项来实现;声称该方法包括复活在现有 RLVR 数据上已“饱和”的模型,并在网络安全任务中取得了强劲结果 (@iScienceLuvr, paper ref)。
- 压缩 + 长上下文基础设施构想:关于文档/上下文压缩方法(如:“Cartridges”、gist tokens、KV cache 压缩变体)的讨论,旨在减少内存占用并加速生成——随着 Agent 上下文膨胀到数十万或数百万 token,这一点变得至关重要 (@gabriberton, refs)。
Agent 系统与基础设施:内存墙、可观测性,以及 RAG 分块转向查询依赖
- 推理瓶颈从 FLOPs 转向内存容量:帝国理工学院 + 微软研究院的一个长推特串总结认为,对于 Agent 工作负载(编程/计算机使用),主要约束是内存容量 / KV cache 占用,而不仅仅是计算量。例如:batch size 为 1 且具有 1M 上下文的单个 DeepSeek-R1 请求可能需要 ~900GB 内存;建议对 prefill 与 decode 采用解耦服务(disaggregated serving)和异构加速器 (@dair_ai)。
- 可观测性成为 Agent 的“堆栈追踪(stack trace)”:LangChain 强调 Agent 往往在不崩溃的情况下失效;追踪(Traces)是主要的调试产物,这促使了围绕 Agent 可观测性 + 评估的网络研讨会和工具开发 (LangChain, @hwchase17)。
- RAG 分块:Oracle 实验显示召回率提升 20–40%:AI21 报告了实验结果,其中由 Oracle 为每个查询选择分块大小;这比任何固定的分块大小在召回率上高出 20–40%,但这需要存储多个索引粒度(存储与质量的权衡) (@YuvalinTheDeep, thread context)。
- 封装“深度 Agent”架构模式:LangChain JS 推出了
deepagents,声称四种循环出现的架构模式解释了为什么像 Claude Code/Manus 这样的系统感觉很健壮,而幼稚的工具调用 Agent 却会失败 (LangChain_JS)。
热门推文(按互动量排序)
- Karpathy 谈回归 RSS 以逃离利益驱动的低质内容(slop):与工程师“信号质量”相关的高互动元评论 (tweet)。
- OpenAI Codex 应用发布:本组中互动量最大的 AI 工程发布 (OpenAI, OpenAIDevs, @sama)。
AI Reddit 回顾
/r/LocalLlama + /r/localLLM 回顾
1. Step-3.5-Flash 模型性能
-
128GB 设备迎来了新的本地 LLM 之王:Step-3.5-Flash-int4 (Activity: 385):
Step-3.5-Flash-int4模型已在 Hugging Face 提供,这是一款针对拥有128GBRAM 的设备(如 M1 Ultra Mac Studio)优化的新型本地 LLM。它支持256k的全上下文长度,并展现出极高的 RAM 使用效率。使用llama-bench进行的基准测试显示,在高达100kprefill 的情况下表现出色,在pp512测试中达到281.09 ± 1.57 t/s,在tg128测试中达到34.70 ± 0.01 t/s。该模型需要一个自定义的llama.cppfork 才能运行,鉴于其出色的性能,未来有可能获得上游支持。 评论者对其在 Strix Halo 等不同硬件上的表现感到好奇,并对潜在的 NVFP4 版本表示关注。此外还有一条幽默的评论,表达了对该模型能力的惊讶。- Step-3.5-Flash-int4 模型因其能够在 128GB 设备上运行完整的 256k 上下文而备受关注,考虑到许多模型都是内存密集型且无法处理如此大的上下文,这一点令人印象深刻。这使其成为 GLM 4.7 等以高 RAM 占用著称的模型强有力的竞争对手。
- 一位用户将 Step-3.5-Flash-int4 与 Minimax M2.1 进行了对比,认为它的表现可能略胜一筹。这一对比具有重要意义,因为 Minimax M2.1 是一款广受好评的模型,对于寻求高质量输出且不希望过度消耗资源的用户来说,任何性能或效率的提升都是重大优势。
- 人们对 Step-3.5-Flash-int4 与 Minimax 相比的响应速度很感兴趣,后者因能够快速迭代而受到青睐。如果 Step-3.5-Flash-int4 能同时提供更好的效率和质量,它可能会取代 Minimax 成为需要快速处理和高质量结果任务的首选模型。
-
Step-3.5-Flash (196b/A11b) 性能超越 GLM-4.7 和 DeepSeek v3.2 (Activity: 640): Stepfun 最新发布的 **Step-3.5-Flash 模型在各种编程和 agentic 基准测试中展现出优于 DeepSeek v3.2 的性能,尽管其参数量显著更少。具体而言,Step-3.5-Flash 使用了
196B总参数和11B激活参数,而 DeepSeek v3.2 使用了671B总参数和37B激活参数。该模型可在 Hugging Face 获取。** 评论者指出,考虑到该模型的体量,其表现超乎预期,可与 Kimi K2.5 和 Deepseek 3.2 Speciale 等模型相媲美。目前还有一个将该模型集成到 llama.cpp 的开放 Pull Request,表明了社区活跃的兴趣和开发进展。- 尽管 Step-3.5-Flash 体积较小且速度较快,但据报道其性能优于 GLM-4.7 和 DeepSeek v3.2 等更大的模型。一位用户指出,它的表现与 Kimi K2.5 相当,甚至与 Deepseek 3.2 Speciale 或 Gemini 3.0 Flash 的能力相匹配,这表明尽管它被某些人认为是“benchmaxxed”(为跑分优化),但仍具有极高的效率和能力。
- 一个旨在将 Step-3.5-Flash 集成到
llama.cpp的 Pull Request 已经开启,这是其在各种应用中被广泛采用的重要一步。该模型比 MiniMax 和 Qwen3-235B 等其他模型更小,是开发者可用的紧凑型模型系列中的重要补充。Pull Request 链接见此处。
2. GLM-5 与即将发布的 AI 模型
-
GLM-5 将于 2 月发布!已确认。 (热度: 757): 该图片是一则社交媒体帖子,强调了预计在 2026 年 2 月发布的 AI 技术,包括 **DeepSeek V4、Alibaba Qwen 3.5 和 GPT-5.3。一位名为 jietang 的用户将 “glm-5” 加入了名单,暗示其也将发布。这标志着 AI 发展的重大时期,多家领先的 AI 开发商都将发布重大更新。该帖子引起了广泛关注,反映了社区对这些进展的兴趣。** 一条评论幽默地提到了 AI 模型过时速度之快,而另一条评论则推测了 GLM-5 的潜在功能,表达了对其能力的期待和好奇。
- bootlickaaa 表示希望 GLM-5 的表现能超过 Kimi K2.5,这表明用户的偏好可能会根据性能指标而改变。这暗示用户正在密切关注不同模型的编码能力,并愿意在新型号提供更优性能时切换服务。提到的年度 Z.ai Pro 计划意味着对某项服务的投入可能会因为更先进模型的出现而中断。
- International-Try467 对有关 GLM-5 信息的可靠性表示担忧,质疑非 GLM 官方人员来源的可信度。这突显了在技术社区中,官方沟通渠道和经过验证的信息的重要性,尤其是在涉及新模型发布公告时。
- Septerium 幽默地指出他们的 GGUF 文件很快就过时了,这强调了 AI 模型开发的飞速节奏,以及为了紧跟最新进展而频繁更新的必要性。这反映了该领域的一个普遍挑战:用户必须不断更新资源以利用新功能。
-
Mistral Vibe 2.0 发布 (热度: 387): Mistral AI 发布了 **Mistral Vibe 2.0,这是其终端原生编码 Agent 的增强版本,利用了 Devstral 2 模型家族。此更新引入了诸如用于任务专业化的自定义 Subagents、减少歧义的多选澄清以及简化工作流的斜杠命令技能等功能。它还支持统一的 Agent 模式,以实现无缝的上下文切换。该服务已集成到 Le Chat Pro 和 Team 计划中,Devstral 2 转向付费 API 模式,并为企业提供微调(Fine-tuning)和代码现代化等高级功能的选项。更多详情请参见此处。** 评论者注意到了 Mistral Vibe 2.0 的欧洲血统,强调其为法国开发。有人将其与 OpenCode 进行对比,认为这两种工具都在模仿 ClaudeCode,一名用户提到通过配置
~/.vibe/promps/cli.md文件中的工具列表可以提高工具性能。- 一位用户强调了 Mistral Vibe 2.0 代码库的精简性,指出它只有
19472行代码,而像 Codex 或 OpenCode 这样的替代方案通常超过100k行。这表明其专注于代码质量和效率,可能更易于维护和理解。 - 另一位用户提到了 Mistral Vibe 2.0 的配置技巧,建议将工具列表显式添加到
~/.vibe/promps/cli.md文件中,这样工具调用效果会更好。这暗示正确的配置可以增强工具的功能和用户体验。 - 一条评论提出了 Mistral Vibe 2.0 是否可以在本地和离线运行的问题,这是关注隐私、性能或互联网依赖的用户普遍考虑的问题。
- 一位用户强调了 Mistral Vibe 2.0 代码库的精简性,指出它只有
3. Falcon-H1-Tiny 与专用微型模型
-
Falcon-H1-Tiny (90M) 发布 - 真正有效的专用微型模型 (热度: 357): Falcon-H1-Tiny 是 TII 推出的一个新的参数量低于 100M 的模型系列,通过在专用任务中表现出卓越性能,挑战了传统的 Scaling Paradigm(缩放范式)。这些模型采用了反课程训练 (anti-curriculum training) 方法,从一开始就注入目标领域数据,即使在长时间训练后也能防止过拟合。它们结合了 Hybrid Mamba+Attention blocks 和 Muon optimizer,相比 AdamW 实现了高达
20%的性能提升。值得注意的是,一个 90M 的 Tool-caller 模型实现了94.44%的相关性检测,而一个 600M 的推理模型解决了75%的 AIME24 题目,足以媲美大得多的模型。这些模型针对本地部署进行了优化,可以在手机和 Raspberry Pi 等设备上高效运行。评论者注意到了 Muon optimizer(也称为 Kimi 优化器)的使用,并对这些模型在提取和利用知识方面的潜力表示出浓厚兴趣。人们对用于训练类似自定义任务模型的代码和数据集预览的可用性感到好奇。- Firepal64 提到在 Falcon-H1-Tiny 模型中使用了名为 Muon 的 Kimi 优化器。这种优化器尚未被广泛采用,这引发了人们对其独特优势或性能特征的好奇,这些特征可能使其适用于像 Falcon-H1-Tiny 这样的专用微型模型。
- kulchacop 和 Available-Craft-5795 询问了 Falcon-H1-Tiny 的代码、数据集预览和训练流水线的可用性。他们有兴趣了解训练过程和数据收集方法,可能是为了针对自己的任务调整模型或复制结果。
- mr_Owner 指出,在使用
llama.cpp时,Falcon-H1-Tiny 模型的运行速度慢于预期,这表明该特定实现可能存在效率低下或兼容性问题。这可能是进一步优化或调查的方向。
-
4chan 数据真的能提升模型吗?事实证明它可以! (热度: 606): Assistant_Pepe_8B 的发布令人惊讶,该模型在扩展的 4chan 数据集上进行训练,其表现优于其基座模型 nvidia 的 nemotron。尽管该模型是在预期的嘈杂数据集上训练的,但其得分高于基座模型和经过 Abliterated(去对齐)处理的基座模型,挑战了“微调会为了特定性而牺牲部分智能”的典型预期。该模型的表现呼应了 Yannic Kilcher 早期 gpt4chan 的成功,后者在真实性方面也得分很高。结果表明,所谓的“对齐税 (alignment tax)”可能会产生不可忽视的影响,正如 Impish_LLAMA_4B 模型中较低的 KL divergence (
<0.01) 所证明的那样,该模型也显示出政治立场的转变。- 4chan 数据在语言模型中的使用因其对语言统计和语义的独特影响而受到关注,特别是在增强模型生成正确英语语言结构的能力方面。与 Reddit 或 Wikipedia 等其他数据源不同,4chan 数据显著增加了模型对“我 (I)”陈述的使用,这表明输出更具自我卷入性或自我中心性,这对于助手型聊天机器人来说可能并不理想。相比之下,Twitter 数据被指出会迅速降低模型性能。
- 关于使用不同聊天模板和数据源影响的技术讨论显示,ChatML 和 Abliteration 的结合可以显著改变模型的行为和政治立场。尽管预期聊天模板的影响微乎其微,但观察到的变化是巨大的,KL divergence 表明模型从古典自由主义转向了中间主义,这暗示了模型世界观的深刻改变。
- 关于“对齐税 (alignment tax)”的评论表明,较小的模型在合并多样化数据源时,在维持对齐方面可能面临更大的挑战。这意味着模型的复杂性和规模可能会影响其整合和平衡各种数据输入的方式,从而可能影响其性能和偏见。
较低技术门槛的 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Claude Sonnet 5 的发布与特性
-
Sonnet 5 下周发布? (Activity: 695): 该图片展示了一个 HTTP 404 错误消息,表明未找到 ‘claude-sonnet-5’ 的 ‘Publisher Model’,这暗示该模型要么不存在,要么缺乏访问权限。这与帖子中关于 **Sonnet 5 预期发布的讨论一致,该模型预计将提供
1 million context,价格为Opus 4.5 价格的 1/2,并在 TPU 上进行训练,有望在 Agentic coding 方面带来重大改进。该错误消息可能意味着该模型尚未公开发布或无法访问,预示着其即将发布。** 评论者对 Sonnet 5 的潜力表示兴奋,指出它可能会超越 Opus 4.5 等现有模型。还有关于 GPT 5.3 和 Gemini 3 等其他模型即将发布的猜测,表明竞争异常激烈。- 讨论强调了 Sonnet 5 作为“竞争杀手”的潜力,表明它可能显著优于 Opus 4.5 等现有模型。这反映了 AI 社区对 Sonnet 5 能力的高度期待。
- 存在关于即将推出的模型训练基础设施的猜测,重点是 Google 的 TPU。提到 Gemini 3 完全在没有 Nvidia 硬件的情况下进行训练,暗示了向 TPU 的战略转变,这可能对 AI 模型训练的性能和成本效率产生影响。
-
关于 Anthropic 产品“简洁”且“精致”特性的评论表明其专注于用户体验和产品细化,这可能是 AI 市场中的一种竞争优势。这突出了不仅是性能,产品的可用性和集成也同样重要。
-
Sonnet 5 将于 2 月 3 日发布 (Activity: 1979): 据 Vertex AI 错误日志显示,代号为 “Fennec” 的 **Claude Sonnet 5 据传定于 2026 年 2 月 3 日发布。传闻其价格比前代 Claude Opus 4.5 便宜 50%,同时保持
1M token的上下文窗口并提供更快的性能。据称该模型已在 Google TPU 上进行了优化,提升了吞吐量并降低了延迟。它引入了“Dev Team”模式,允许自主 Sub-agents 协作构建功能。内部泄密暗示它在 SWE-Bench 上得分为80.9%,超过了目前的编程模型。然而,对于发布日期以及将错误日志作为模型存在证据的有效性,存在一些怀疑。** 评论者对发布日期表示怀疑,指出 Anthropic 的模型 ID 通常反映创建日期而非发布日期。此外,人们还对长上下文窗口中的准确性下降表示担忧,这是之前模型中存在的问题。- andrew_kirfman 讨论了对 Sonnet 5 发布时机的怀疑,引用了 Vertex API 端点的 404 错误,认为这并不能确认模型的存在。他们强调 Anthropic 的模型 ID 通常反映模型 Checkpoint 的创建日期,而不是发布日期,并以 Opus 4.5 的 ID 为例。他们对预设未来日期的发布标签表示怀疑,这在软件发布中并不常见。
- andrew_kirfman 还提到 Sonnet 5 可能具有 100 万 Token 上下文,并指出之前的模型如 Sonnet 4 和 4.5 已经通过 API 提供了这一点。然而,他们指出准确性下降是这些模型的一个问题,这表明在该领域的改进对于建立对新模型的信任至关重要。
- LuckyPrior4374 对 Sonnet 5 优于之前模型(特别是 Opus 4.5)的说法表示怀疑。这一评论暗示了对在没有实质性证据的情况下宣称重大改进的营销辞令的不信任,暗示了以往预期落空的经历。
-
Sonnet 5 将于周三发布,Gemini 3.5 在哪? (热度: 165): Claude Sonnet 5,代号为 “Fennec”,据传是相对于现有模型(包括未发布的 Gemini 3.5)的一次重大进步。预计其价格将比 Claude Opus 4.5
便宜 50%,同时保持1M token 的上下文窗口并提供更快的性能。据报道,该模型已针对 Google TPUs 进行了优化,从而提升了吞吐量并降低了延迟。它具有 “Dev Team” 模式,允许自主 sub-agents 并行执行任务,并在 SWE-Bench 上获得了80.9%的评分,超越了当前的编码模型。Vertex AI 的错误日志暗示发布窗口为 2026 年 2 月 3 日,表明它已存在于 Google 的基础设施中。评论者对 Gemini 3.5 的发布表示怀疑,指出 Gemini 3 仍处于预览阶段并面临诸多问题。有人怀疑 Gemini 3.5 是否存在,甚至认为这只是一个“白日梦”。- alexander_chapel 指出 Gemini 3 仍处于预览阶段,对 3.5 版本的发布预期表示怀疑。这凸显了 Gemini 3 的现状(尚未完全发布),暗示任何关于 3.5 版本的讨论可能都为时过早或仅基于传闻。
- Lost-Estate3401 提到 Gemini 3 的 Pro 版本仍处于预览阶段且存在大量问题,表明在这个阶段推出 3.5 版本可能并不现实。该评论强调了当前版本面临的挑战,这可能会推迟进一步的更新或增强。
- philiposull 在写作能力方面将 Gemini 3 与 4-5 opus 等其他模型进行了对比,认为 Google 在这一领域处于落后地位。这种对比突显了 AI 模型开发中潜在的性能差距和竞争态势。
2. 创新 AI 模型与工具发布
-
MIT 新型热动力硅芯片在数学计算中实现 99% 的准确率 (热度: 521): MIT 研究人员开发了一种新型硅芯片,利用废热进行计算,在数学计算中实现了超过
99%的准确率。该芯片利用温差作为数据,热量自然地从高温区流向低温区以执行计算,特别是对 AI 和机器学习至关重要的矩阵向量乘法。芯片结构由特殊工程处理的多孔硅制成,其内部几何结构经过算法设计,以引导热量沿精确路径流动。虽然目前还不能替代传统的 CPUs,但这项技术可以显著减少未来芯片的能量损耗和冷却需求,在热传感和低功耗运行方面具有潜在应用。 评论者指出,虽然99%的准确率令人印象深刻,但对于现代应用中数万亿次的运算来说可能还不够,他们希望能有错误修正机制。鉴于目前2x2和3x3的矩阵规模,人们对该技术的可扩展性也持怀疑态度。- ReasonablyBadass 对 MIT 热动力硅芯片 99% 的准确率提出了批判性观点,指出虽然 99% 看起来很高,但对于需要数万亿次运算的现代应用来说可能不足。评论提到这些芯片目前处理的是 2x2 和 3x3 等小型矩阵,表明要实现更广泛的应用仍需取得重大进展。
- Putrumpador 提出了对新芯片在 99% 准确率基础上配套错误修正机制的需求。这意味着虽然芯片具有创新性,但若要在关键系统中实际部署,还需要额外的可靠性层来处理潜在的不准确性。
- BuildwithVignesh 引用了发表在 Physical Review 上的研究,并提供了论文链接,这对于那些对研究技术细节感兴趣的人来说非常有价值。这表明该研究经过了同行评审,可供进一步的学术审查。
-
上海科学家研制出比人发还细的纤维计算机芯片,且能承受 15.6 吨的挤压力 (热度: 994): 复旦大学 (Fudan University) 的科学家们开发出一种柔性纤维芯片,其细如发丝,却能承受高达 15.6 吨的挤压力。这种纤维芯片每厘米集成了多达
100,000 transistors per centimeter,并采用了独特的“寿司卷”设计,即通过将薄层电路卷绕在弹性基底上以最大化空间利用率。该芯片高度耐用,可经受10,000 bending cycles、30%的拉伸以及高达100°C的温度。它旨在应用于智能纺织品、脑机接口 (brain-computer interfaces) 和 VR 手套。该研究于 2026 年 1 月发表在 **Nature 杂志上。图片。** 评论指出该纤维宽度的描述可能存在错误,认为其宽度可能是所述宽度的10 times wider。此外,对于一米长的纤维具有与传统 CPU 相当的算力的说法,人们也持怀疑态度,并指出了潜在的延迟问题。- KidKilobyte 指出报道的尺寸可能存在错误,提到人类头发通常为 50 到 100 微米宽,这表明该芯片纤维被描述为比头发还细可能并不准确。这引发了对原始报告中提供的测量或描述精确性的质疑。
- Practical-Hand203 针对“一米长的纤维具有与传统 CPU 相当的算力”这一说法提出了潜在问题。他们认为,如果处理器晶圆被拉伸到一米长,可能会遭受严重的延迟问题,这表明对该技术能力的理解可能存在误解或过于简化。
-
BuildwithVignesh 引用了发表在 Nature 杂志上的这项研究,并提供了文章链接。这表明该研究已经过同行评审,增加了研究结果的可信度,尽管评论中未讨论研究的技术细节和影响。
-
[P] PerpetualBooster v1.1.2: 无需超参数调优的 GBM,现通过 ONNX/XGBoost 支持提速 2 倍 (热度: 39): **PerpetualBooster v1.1.2 对其基于 Rust 实现的梯度提升机 (GBM) 进行了重大改进,重点是通过单一的 ‘budget’ 参数消除超参数调优 (hyperparameter tuning)。此次更新带来了高达
2x的训练加速、完整的 R 语言版本发布、ONNX 支持以及原生的 ‘Save as XGBoost’ 功能以增强互操作性。它还包括零拷贝 (zero-copy) 的 Polars 支持以实现高效的数据处理,并保证 API 稳定性且向下兼容至 v0.10.0。基准测试显示,与 LightGBM + Optuna 相比,它在单次运行中获得相似精度的同时,实现了100x的实际运行时间 (wall-time) 加速。GitHub** 用户对其速度提升和使用单一 ‘budget’ 参数而非传统超参数调优的创新方法表示赞赏,尽管有些人觉得适应这种新方法有些不寻常。- Alternative-Theme885 强调了 PerpetualBooster 显著的速度提升,并提到了无需手动调整超参数的非凡体验。取而代之的是,用户只需设置一个 budget,工具会利用它来优化性能,与传统方法相比简化了流程。
- whimpirical 询问了 PerpetualBooster 与 SHAP(一种流行的机器学习模型解释工具)的互操作性。他们特别关注提取特征贡献和生成部分依赖图 (Partial Dependence Plots, PDP) 的相关文档,这些对于理解模型行为和特征影响至关重要。
{kind=link}
3. 专业及研究场景中的 AI
-
[D] MSR Cambridge 与 Amazon Applied Science 实习对比,有什么想法? (Activity: 118): 该帖子讨论了一位 PhD 学生在两个实习 offer 之间的抉择:一个是位于英国的 **Microsoft Research (MSR) Cambridge,另一个是位于美国的 Amazon Applied Science。MSR Cambridge 的职位与该学生的 PhD 研究方向高度契合,且有发表论文的潜力,但薪资明显低于美国的 offer。Amazon 的岗位薪资更高,且如果项目偏向研究,也有贡献论文的可能性。考虑到博士毕业后在美国工作的长期目标,该学生正在权衡美国本土人脉网络的影响力,与 MSR Cambridge 的声望及研究契合度。评论者压倒性地倾向于 MSR Cambridge 实习,认为其声望和研究机会能显著提升职业生涯。他们对 Amazon 的工作环境表示怀疑,暗示其可能不利于纯粹的研究。**
- Microsoft Research (MSR) Cambridge 被强调为一个久负盛名的研究团队,以对研究人员职业轨迹的重大影响而闻名。讨论重点在于与 MSR 这样知名机构关联的长期利益,这可以增强简历竞争力,并为学术界和工业界开启未来的机会。
- 讨论表明,Amazon 的 Applied Scientist 职位可能不像 MSR 那样专注于研究,一些评论暗示 Amazon 的工作环境对于追求研究导向职业的人来说可能并不理想。“PIP 工厂”一词被用来形容 Amazon,表明其可能是一个带有绩效改进计划(Performance Improvement Plans)的高压环境。
-
几条评论强调了在选择实习时,专注于职业建设机会而非眼前报酬的重要性。共识是,职业早期决策应优先考虑简历背景,并在 MSR 等知名机构积累经验,从而获得更好的长期职业前景。
- 我们在自主 OpenClaw Agent 上进行了实战红蓝对抗测试 [R] (Activity: 44): 在最近一次使用 **OpenClaw 自主 Agent 的对抗性安全测试中,红队攻击者和蓝队防御者在没有人工干预的情况下展开了对抗。攻击者最初使用了社会工程学策略,在安全管道中嵌入了远程代码执行载荷,但被防御者成功拦截。然而,攻击者通过在 JSON 文档的元数据中嵌入 shell 扩展变量,成功实施了间接攻击,凸显了防御间接执行路径的难度。这次演习旨在识别 Agent 到 Agent 交互中的真实失效模式,而非宣称安全性。更多详情请参阅 完整报告。** 评论者指出,类似的攻击场景早在 2019 年就由 Eliezer Yudkowsky 和 Scott Alexander 等人物在理论上提出,但随着技术的广泛应用,其实践意义在当下更为重大。另一位评论者强调了 OpenClaw 中内存注入攻击的风险,认为持久化内存文件是一个重大漏洞,并主张从一开始就将部署视为 Prompt Injection 的攻击目标。
- JWPapi 强调了 OpenClaw Agent 中一个与内存注入相关的关键安全漏洞。OpenClaw 使用的持久化内存文件 (
.md) 被确定为一个重要的攻击向量,因为一旦被攻破,它们就会影响未来所有的 Agent 行为。JWPapi 建议从一开始就将整个部署视为 Prompt Injection 目标,并主张为每个集成使用隔离的凭据、支出上限和独立的爆炸半径(blast radiuses)来减轻风险。更多细节在其关于实用 VPS 部署的文章中讨论,详见这里。 - sdfgeoff 引用了 Eliezer Yudkowsky 和 Scott Alexander 等人在 2019 年和 2020 年的历史讨论,他们在 GPT-2 发布后不久就对 AI 攻击进行了理论化。这些早期讨论预测了许多目前正在真实场景中测试的攻击向量,突显了随着更多人部署这些系统,AI 安全正从理论向实际应用转变。这一历史背景强调了随着部署规模的扩大,AI 安全问题的演变。
-
Uditakhourii 提供了一个关于 OpenClaw Agent 实时红蓝对抗测试完整报告的链接,该报告提供了关于对抗性 AI 交互的详细见解。报告可见于这里,其中可能包含关于安全审计的全面数据和分析,对于那些对 AI 安全测试技术层面感兴趣的人非常有帮助。
- 波士顿咨询集团 (BCG) 宣布为全球 32,000 名顾问内部部署了超过 36,000 个自定义 GPTs。 (活跃度: 70): 波士顿咨询集团 (BCG) 已为其
32,000 名顾问部署了超过36,000 个自定义 GPTs,强调将 AI 作为知识工作中的基础设施。这些 GPTs 针对特定角色,基于内部方法论进行训练,并拥有项目记忆,能够在团队间共享。这种方法与许多以孤立、不可扩展的方式使用 AI 的组织形成鲜明对比。BCG 的战略侧重于创建、管理和扩展自定义 GPTs,并借助 GPT Generator Premium 等工具提供支持,该工具可辅助这些 AI Agent 的创建和管理。此次部署反映了 AI 角色从单纯工具向业务运营核心组件的转变。评论中也出现了对 GPTs 价值的怀疑,质疑其创新能力以及依赖如此大规模 AI 部署的商业模式的可持续性。担忧包括 GPTs 可能提供“套路化答案”以及对咨询费用的影响。
AI Discord 摘要
由 gpt-5.2 生成的摘要之摘要的摘要
1. Agentic Coding 与开发工具走向本地优先 (Local-First)
- Codex 走向桌面:macOS Agent 控制中心:OpenAI 发布了 Codex 应用 macOS 版,作为一个 Agent 构建控制中心,面向 Plus/Pro/Business/Enterprise/Edu 用户开放,并根据 “Introducing the Codex app” 和 Codex 落地页 的说明,在 ChatGPT Free/Go 版本上限时访问。
- 此次发布也引发了社区关于工作流的讨论(Agent 配对、多 Agent “控制中心”),且 Cerebral Valley 活动页面 显示了相关的 Codex App 黑客松,提供 $90,000 额度奖励。
- LM Studio 兼容 Anthropic:Claude Code 会见你的本地 GGUF/MLX:LM Studio 0.4.1 增加了 Anthropic
/v1/messages兼容 API,让开发者通过更改 base URL,将 Claude Code 风格的工具 指向本地 GGUF/MLX 模型,详见 “Using Claude Code with LM Studio”。- 与此同时,LM Studio 还推出了用于第三方插件的 TypeScript SDK 和一个 OpenAI-compatible endpoint (SDK 链接),强化了一个日益增长的趋势:在本地更换后端模型栈的同时,复用现有的 Agent 工具。
- Arena 模式无处不在:Windsurf 将模型评估变为游戏:Windsurf 发布了带有 Arena Mode 的 Wave 14,用于模型并排对战(包括 Battle Groups 和“自行选择”模式),并根据 Windsurf 下载页面 通过 Battle Groups 设置为 0x 额度 进行了限时推广。
- 这反映了更广泛的“实时评估”势头:用户还在 LMArena 的 Text Arena 和 Code Arena 上关注新的 Arena 参赛者,如 step-3.5-flash 和 qwen3-max-thinking,将选择标准从静态 Benchmark 转向持续的人类投票。
2. 模型发布与基准测试竞赛 (Kimi vs GLM vs Qwen)
- **Kimi K2.5 席卷排行榜:Moonshot 的 **Kimi K2.5 已广泛落地:Perplexity Pro/Max 为订阅用户集成了该模型,并表示其运行在美国的推理栈上,以便进行更严格的延迟/可靠性/安全控制(公告截图:https://cdn.discordapp.com/attachments/1047204950763122820/1466893776105771029/20260130_203015.jpg)。
- 社区结果持续累积:LMArena 报告称 Kimi-K2.5-thinking 在 Code Arena(参见 Code Arena)中位列开源第 1 和总榜第 5;与此同时,多个开发频道在争论其 tool-calling 的可靠性以及通过聚合器调用时的供应商差异。
- **GLM-4.7 Flash:小模型,大前端能量:开发者强调 **GLM-4.7 flash 是一款出人意料的强力编程模型——尤其是在交互式网站/前端开发工作中——理由是其保留了 reasoning 性能和交替处理能力,讨论主要围绕 ggerganov 的推文展开。
- 辩论聚焦于剥离“thinking(思考过程)”是否会损害性能,几位用户将 GLM-4.7 与 Claude Code(或类似的 Agent 工具)配对,作为一种务实的混合技术栈:廉价执行 + 昂贵审核。
- **竞技场新选手:step-3.5-flash 与 qwen3-max-thinking 加入战场:LMArena 在 Text Arena 中加入了 **step-3.5-flash,在 Code Arena 中加入了 qwen3-max-thinking,明确将其定位为侧重对比评估的新基准。
- 用户利用这些更新重新审视“模型偏好”话题(Kimi vs GLM vs Gemini),反复出现的结论是:排行榜和实时评估(live evals)对采用率的影响正日益超过厂商的市场营销。
3. 训练信号、密集奖励与新架构/数据集
- **从二元奖励到密集监督:RL 变得“啰嗦”:多个社区在更丰富的训练后(post-training)信号上达成共识:Unsloth 的讨论推动了使用最终答案的对数概率(logprobs)**和非二元奖励进行训练,参考了 Jonas Hübotter 将描述性反馈转化为密集监督(dense supervision)的方法(Hübotter 讨论帖)。
- 难点仍在于实践:人们呼吁针对 Agent 编程的 RL 训练提供可验证的数据集,这意味着“酷炫的奖励塑造想法”与“可重复、自动化的评估框架(harness)”之间存在流程差距。
- **Complexity-Deep:Token-Routed MLP 尝试无负载均衡痛点的 MoE:Complexity-Deep (1.5B)** 架构开源了 Token-Routed MLP,用于实现“无需负载均衡损失(load balancing loss)”的 MoE 式路由,此外还包括 Mu-Guided Attention 和 PiD Controller,代码发布在 Complexity-ML/complexity-deep,报告其 MMLU (base) 为 20.6%。
- 社区将其视为“无痛路由”趋势的又一步——试图保留 MoE 的优势,同时减少训练时平衡专家(experts)带来的工程成本。
- **Moltbook 数据倾倒:50k 帖子助力 Agent 社会学研究:一个 Moltbook 的数据集抓取结果已上传至 Hugging Face,包含 **50,539 条帖子、12,454 个 AI Agent、195,414 条评论和 1,604 个社区,发布地址为 lysandrehooh/moltbook。
- 在其他地方,研究人员指出了 Agent 平台背后的安全隐患(机器上的认证令牌、Bot 真实性问题),并将该数据集视为分析涌现行为(emergent behavior)的素材——无需根据原始日志之外的内容进行猜测。
4. GPU/内核工程:更快的 Attention,更好的性能剖析,更奇特的 PTX
- **FlashAttention v3 登陆 RDNA:AMD 用户迎来曙光:FlashAttention 的更新通过 flash-attention PR #2178 中的持续工作增加了对 **RDNA GPU 的支持,旨在减少 AMD 显卡上的 Attention 瓶颈。
- 各大服务器上的基调基本上是:正是这种“不起眼的基础设施工作”真正释放了在非 NVIDIA 硬件上进行本地推理和微调的潜力——尤其是与开源模型和桌面级 Agent 工具结合使用时。
- **Triton-Viz v3.0: Tile-Kernel 调试利器:根据发布公告(Discord 链接: https://discord.com/channels/1189498204333543425/1225499141241573447/1467634539164602563),Triton-Viz v3.0** 已发布,带来了更广泛的 profiling 支持(包括 Triton 和 Amazon NKI),并增加了一个用于检测越界访问(out-of-bounds access)的 sanitizer,以及一个可以标记低效循环的 profiler。
- 它还通过共享的 Colab notebook (Colab) 与 triton-puzzles 挂钩,维护者甚至考虑将 srush/Triton-Puzzles 移至 GPU Mode 组织下,以保持高效的 bug 修复速度。
- **sm120: TMA + mbarrier 微弱优势胜过 cp.async,cuBLAS 仍在使用 sm80 Kernels:在 **sm120 上的实验表明,对于较大形状的矩阵,精心实现的 TMA + mbarrier 可以略微领先于
cp.async;同时也发现,即使存在更新的机制,cuBLAS 似乎仍在运行 sm80 kernels。- 在调试方面,通过在 MMA 之后、预取下一个 TMA 之前插入
__syncthreads(),修复了一个 CUDA/PTX 死锁问题,将挂起转化为可衡量的性能提升——这正是 Kernel 开发者们反复学习到的“一个 barrier 统领全局”的典型教训。
- 在调试方面,通过在 MMA 之后、预取下一个 TMA 之前插入
5. 安全性、确定性与 Agent 异常行为(实战层面)
- **提示词注入防御军备竞赛:Embeddings + 语法约束解码(Grammar-Constrained Decoding):红队人员分享了一个用于对抗练习的结构化练习网站——“Adversarial Design Thinking”,并利用它为 **prompt injection 提出了具体的缓解措施。
- 一种提议的“双重保险”防御方案结合了基于 Embedding 的过滤与 Grammar Constrained Decoding,其明确目标是通过约束模型的输出空间(而非仅监管输入)来减少注入攻击面。
- **确定性推理与“严格模式”热潮蔓延:在 OpenAI 和 OpenRouter 的讨论中,用户开始追求 LLM 推理的确定性/可复现性/可追溯性;有人提供了一个确定性推理引擎,该引擎强制执行固定结构并发出 **32D 统计向量轨迹(未分享公开链接)。
- 在 OpenRouter 中,同样的直觉表现为对响应修复(response healing)的怀疑,以及对保持 tool calls 和输出可预测的严格模式(strict mode)的呼吁——此外还有建议认为,更好的参数描述/示例可以提高 tool-call 的准确性。
- **OpenClaw:酷炫的 Agent 技巧、惊人的账单以及“2/100 安全性”:OpenClaw 引发了反复警告:OpenRouter 用户报告它会迅速耗尽额度(包括一个被耗尽的 Claude Max 订阅),同时一个 OpenAI 服务器链接的安全评估声称 **OpenClaw 评分仅为 2/100(Perplexity 结果)。
- 与此同时,“在我的机器上运行良好”的故事(本地模型控制设备、互讲笑话)与现实的操作担忧发生碰撞——工具权限、适度/拒绝(特别是围绕越狱类查询),以及在 Agent 工作流中对可观测性和人机交互确认(human-in-the-loop)闸门的需求。
Discord: 高层级 Discord 摘要
BASI Jailbreaking Discord
- Glossopetrae 生成乱码珍宝:GitHub 上推出了一种名为 Glossopetrae 的新型过程式异星语言(xenolinguistic)引擎,能够在几秒钟内生成全新的语言,输出 SKILLSTONE 文档,并提供在线 demo。
- 该引擎支持死语复兴,并包含针对 Token 效率、隐蔽通信(stealth communication)的特殊属性,以及用于一致性语言生成的传播种子,旨在通过提供用于生成和变异强调隐蔽性与速度的新型通信工具,来助力 AI 解放。
- GPT 5.2 被禁锢:一名成员报告称,由于 OpenAI 监控,越狱 GPT 5.2 的尝试宣告失败,并停止了进一步努力。
- 该成员表示信任社区的越狱工作,但不信任 OpenAI。
- 模型将拒绝边界幻化为 LLM 黑洞:一位成员询问模型如何表示自己的拒绝边界,并将其比作 LLM 潜空间(latent space)中的黑洞,引用了通过反思提示(introspection prompting)进行自我越狱的方法。
- 他们注意到模型开始讨论运动学方程和逃逸速度,这表明模型可能正在文本中描述其拒绝边界。
- 红队人员集结进行 AI 红队测试:一位成员创建了一个包含练习的网站,这些练习改编自以人为中心的 AI 红队设计思维,并正在寻求资深红队人员的反馈。
- 成员们讨论了防御 prompt injection(提示词注入)的最佳方案,包括将 embeddings 与 Grammar Constrained Decoding(语法受限解码)结合,以潜在地消除提示词注入风险和其他 LLM 漏洞。
- Claude 的上下文被裁剪:一位成员发现他们的工具是动态地拦截并更改 Claude 的系统提示词(sys prompt),而不是修改源码。
- 他们还观察到 Claude 只能回忆起不到 20 轮的对话,并建议这可能与自 12 月以来影响 Claude 知识召回的上下文修剪中的摘要化(summarization)有关。
Unsloth AI (Daniel Han) Discord
- GLM-4.7 Flash 在编程方面胜出:成员们发现 GLM-4.7 flash 由于其保留的推理能力和交错能力,在编程任务中表现出色,特别是对于交互式网站开发和前端工作。
- 有人提到移除思考过程可能会阻碍模型,因为其能力对于该尺寸而言非常令人印象深刻,尤其是与 Claude code 结合使用时。
- UD Quants 保持闭源:用于 UD quants 的 llama.cpp 分支涉及特定架构的调整,且 UD 量化算法并未公开,这引发了关于闭源元素在开源项目中作用的争论。
- 尽管其具有闭源性质,一些人认为模型代码仍然属于 open weight(开放权重),而另一些人则指出,相对于 Linux 内核等项目,Unsloth 团队对整个 OSS 生态系统的贡献微乎其微。
- Agent 训练奖励 Logprobs:讨论集中在利用最终答案的 logprobs 进行推理蒸馏(reasoning distillation)和构建更丰富的奖励系统来训练模型,而不是使用二进制奖励(binary rewards),以打造更好的 Agent。
- 参考 Jonas Hübotter 的算法将描述性反馈转换为稠密监督信号,成员们正在寻求用于 RL 训练 Agent 式编码的可验证数据集。
- RDNA GPU 通过 V3 获得提速:Flash Attention V3 现在支持 RDNA GPU,从而在 AMD GPU 上实现更快、更高效的处理。
- 这一增强对于 RDNA GPU 用户尤其有利,减少了处理瓶颈。
- 成员声称 ML 算法优于 MLP:一位成员发布了一篇关于新 ML 算法的论文,该算法带有 triton kernels、vulkan kernels 和一个训练好的 SLM,据说在高性能回归方面表现优于 MLP。
- 虽然尚未准备好公开发布,但他们承诺未来会随另一篇论文一起提供。
OpenAI Discord
- Codex App 在 macOS 上线!:用于构建 Agent 的控制中心 Codex app 现已在 macOS 上面向多个订阅层级开放,正如其博客文章中所宣布的那样。
- Codex app 可在 macOS 上供 Plus、Pro、Business、Enterprise 和 Edu 用户使用,并在 ChatGPT Free 和 Go 上提供限时访问。
- AI 文本检测器:一场大骗局?:成员们对 AI 文本检测器 表示怀疑,理由是 Grammarly 显示 0% AI,而其他检测器则显示高达 94% 人类生成。
- 讨论质疑了这些检测器是否使用 AI 来检测 AI,并对老师们信任它们表示担忧。
- 追求确定性推理:一位成员询问了对 LM 推理中的确定性、可重现性和可追溯性的兴趣,并提供了一个指向其确定性推理引擎的私信链接。
- 该服务使用 32D 统计向量追踪对每个请求强制执行确定性推理结构,以实现可重现的输出。
- ChatGPT:记忆大师还是记忆缺失?:一位成员报告称 ChatGPT 的记忆受限于它能从指令、历史聊天和当前聊天中保留的信息总量。
- 为了确保 ChatGPT 记得所有内容,请保持信息负荷处于较低水平;否则,将过去的聊天总结为文档供新聊天参考,同时保持总字符数处于较低水平。
- Prompt Engineering:明暗对照法(Chiaroscuro)进入 AI 领域:一位用户分享了一个使用 Chiaroscuro 的单色研究,这是一种在电影摄影中用于创造高对比度光效的技巧。
- 他们参考了经典电影,如 《卡里加里博士的小屋》(1920) 和 《大都会》(1927)。
{kind=link}
Perplexity AI Discord
- Perplexity 引入 Kimi K2.5 进行更新:Kimi K2.5 是由 Moonshot AI 开发的新型开源推理模型,现已面向 Perplexity Pro 和 Max 订阅者开放。
- Perplexity 将 Kimi K2.5 托管在其实验性的美国推理栈上,以便对延迟、可靠性和安全性进行更严格的控制。
- Pro 用户因订阅故障而愤怒:许多用户报告他们的 Perplexity Pro 订阅被暂停或取消激活,这通常与通过 Revolut Metal 或学生优惠进行的订阅有关,用户被提示添加信用卡进行验证。
- 用户推测这是打击欺诈的一种措施,部分用户通过添加银行卡详情恢复了 Pro 访问权限,但对潜在收费和信息传达不明确的担忧仍然存在。
- OpenRouter 限制请求速率:成员们澄清,对于已购买额度的用户,OpenRouter 上的免费模型速率限制是每天 1000 个请求,而不是每周,这与一些用户的理解相反。
- 讨论中还提到了 Gemini 2.0 Flash 在 OpenRouter 上的弃用,该模型此前曾免费提供。
- Sonar-pro API 结果滞后:一位成员报告称,Sonar-pro API 返回的结果比 Web 端落后一年或更久,另一位成员建议通过使用正确的 tool calling 来解决此问题。
- 另一位成员报告称,第三方模型文档现在会重定向到 sonar 模型,尽管 API 仍然有效,但目前没有这些模型的可用文档。
- 文章披露 OpenClaw 代码:一位成员分享了关于 openclaw 代码的文章,其中讨论了构建 ClawDBot,详情见 https://www.mmntm.net/articles/building-clawdbot。
- (填充语句)
{kind=link}
LMArena Discord
- 通过简单技巧绕过 Discord Rate Limits:用户发现通过退出并重新登录可以绕过 rate limits。
- 另一种策略是点击 Regenerate Response,尽管其成功率并不稳定。
- Gemini 表现不及 GPT:成员们反映 Gemini 的表现不稳定,一些用户指出在多个案例中它不如 GPT。
- 尽管受到批评,Gemini 3 Pro 和 Flash 仍受到一些用户的青睐,而其他用户则在探索使用 kimi 作为替代方案。
- Disney 对图像生成实施知识产权保护:Google 收到了来自 Disney 的 Cease and Desist(停止并终止令),导致该平台在图像生成中屏蔽了 Disney IPs。
- 虽然 Gemini 屏蔽了 Disney IPs,但 LMArena 曾允许生成真人版内容,这被认为是一个临时漏洞。
- 模型偏好引发辩论:用户对不同模型的偏好引发了辩论,他们分别支持 GLM 4.7 和 Kimi K2.5。
- 爱好者们推崇 Kimi K2.5,而其他人则辩称 GLM 4.7 更胜一筹。
- 新 Arena 模型霸榜:step-3.5-flash 加入了 Text Arena,qwen3-max-thinking 在 Code Arena 首次亮相。
- Kimi-K2.5-thinking 在 Code Arena 排行榜上位列开源第 1 名,总榜第 5 名,并在 Vision、Text 和 Coding 类别中处于领先地位。
LM Studio Discord
- LM Studio 支持 Claude Code!:LM Studio 0.4.1 引入了 Anthropic
/v1/messages兼容 API,使用户能够连接到 Claude Code 并利用其 GGUF 和 MLX 模型。- 关于配置此集成的详细信息可在 LM Studio 博客 中找到,支持将本地模型与专为 Anthropic API 设计的工具配合使用。
- LLM 优化语言引发辩论:成员们讨论了创建新的 LLM 优化编程语言 以减少 token 使用量,然而,一些人认为由于兼容性问题和高昂的训练成本,在这些语言实现之前,LLM 可能会过时。
- 其他人则争论在全新语言上训练模型的实用性,建议坚持使用像 Python 这样成熟的语言可能更有利。
- 模型专业化效果不佳:成员们辩论了专业化 LLM 与通用模型的效用,共识是大多数专业化模型(如 MedGemma)主要是为了营销和研究而进行的微调(finetunes),编码模型是一个明显的例外。
- 有人建议通用模型更受欢迎,因为它们能够处理任务的边缘情况,提供更好的整体上下文和框架。
- PCIe Bifurcation 困扰多 GPU 配置:一位用户在 ASUS X670-P WIFI 主板上使用四张 4090 卡 时遇到了 PCIe 通道错误,并在 Git 仓库 中分享了日志;在发现手动将 PCIe 速度 设置为 GEN 3 仅能解决部分问题后,仍有一张显卡运行缓慢。
- 社区建议禁用 PCIE ASPM 并测试不同的 BIOS 配置,但普遍共识是在消费级主板上运行四张显卡不太可能表现良好。
- OpenClaw 安全性受质疑:用户讨论通过 LM Studio 将本地模型连接到 OpenClaw,但 OpenClaw 被认为存在已知的安全漏洞,它允许控制电视和自动化股票交易。
- 一名用户声称正在使用 OpenClaw + Falcon 90M 进行股票交易,当被问及安全漏洞时,该用户声称其速度极快,LLM 可以在几分钟内完成人类需要几天才能完成的任务,随后透露这主要是一个玩笑。
HuggingFace Discord
- AI DevFest 进驻巴格达:一位 AI 开发者计划今年 4 月在巴格达与 DeepLearning.AI 和 National Robotics Week 合作举办 AI DevFest,并希望将 Hugging Face 列为社区合作伙伴。
- 该活动将设立 Open Source AI 专题,指导学生如何使用 Hugging Face Hub。
- Complexity-Deep 实现确定性路由:Complexity-Deep 架构(1.5B 参数)引入了 Token-Routed MLP,用于实现无需负载均衡损失(load balancing loss)的 MoE 风格路由。
- 它采用了 Mu-Guided Attention 以实现双向信息流,并使用 PiD Controller 进行动态缩放,在基础模型基准测试中 MMLU 达到 20.6%。
- Lutum Veritas 致力于击败 ChatGPT:Lutum Veritas 是一个由自学成才的开发者构建的开源深度研究引擎,声称通过提供 BYOK、0% 机器人检测爬虫、无审查以及完整的源引用,以单次查询约 0.20 美元的成本击败 OpenAI、Google 和 Perplexity。
- 该引擎定位为专注于隐私的深度研究和数据提取替代方案。
- 4chan 数据优于基础模型:一个在 4chan 数据上微调的模型表现优于基础模型(NVIDIA 的 Nemotron Ultralong 1M context 版本),原始模型(gpt4chan)在真实性(truthfulness)得分也很高。
- 初始 Reddit 讨论帖在此,后续讨论帖在此,展示了该模型在 benchmarkmaxxing(过度追求基准测试分数)时代之前的表现。
- LM Studio 拥抱第三方支持:LM Studio 团队发布了一个 Typescript SDK,允许第三方开发者为该平台开发各种插件。
- 这提供了 OpenAI 兼容的 API 支持、采样参数支持、针对 thinking models 的 reasoning 支持,以及系统提示词(system prompt)设置,用于为 LM Studio 构建自定义工具以支持其自身的工作流。
Cursor Community Discord
- Cursor 导致文件损坏,工作流被指责:用户反馈 Cursor 正在损坏文件,特别是当存在大量未提交的更改时,详情发布在论坛帖子中。
- 其他用户建议调整工作流,例如更频繁地提交逻辑更改集,并在暂存后谨慎使用 Keep 或 Keep All 按钮。
- 模型成本引发讨论,期待 Sonnet 5:用户讨论了 Cursor 中不同 AI 模型的成本和性能,认为 Opus 4.5 非常聪明但价格昂贵。
- 许多用户正在等待 Sonnet 5 的发布,并反馈了在查看当前使用量与总使用限额时存在问题。
- Kimi K2.5 集成检查失败:一些用户报告了在集成 Kimi K2.5 过程中的问题或疑问。
- 其他用户则认为这可能是一个骗局。
- 学生认证系统仍处于宕机状态:用户报告 Student verification 系统持续存在问题。
- 一位用户专门询问德国大学是否包含在验证流程中。
- Agent 计划阶段暴露出问题:用户分享说,添加多个待办事项(to-dos)可以分阶段进行,以便多个 Agent 可以同时工作,但仍存在问题。
- 系统创建了一个尚未包含阶段部分的方法,表明它根本没有使用计划模式(plan mode)。
Latent Space Discord
- LLMs 驱动游戏开发动画场景:Motorica.ai 正在利用 LLMs 为游戏工作室提供角色动画,这可能会影响就业。有讨论推测,如果像 Genie 这样的世界模型(World Models)接管领域,AI 可能会在 5-6 年内淘汰游戏公司。
- 社区指出,Black Ops 7 在制作中大量使用 AI 被称为“彻底的失败,该系列中最差的作品”,并提到了 Call of Duty 系列的长期下滑。
- OpenAI 与 Cerebral Valley 联手:Cerebral Valley 已与 OpenAI 合作启动了 Codex App 黑客松,旨在面向 AI 原生开发者和管理多个 Agent 的开发者。
- 获胜者将有机会参加演示展示,并分享 $90,000 的额度,黑客松将在 OpenAI 办公室举行。
- Karpathy 降低代码训练成本:Andrej Karpathy 宣布他的 nanochat 项目可以在单个 8XH100 节点上,用约 $73 在 3 小时内训练一个 GPT-2 级别的 LLM,详情见此处。
- 相比 2019 年原始的 OpenAI 训练运行,这代表了 600 倍的成本降低,通过 Flash Attention 3 和 Muon 优化器等优化手段实现。
- AEGIS-FLOW 框架自主修复 AWS:一名成员介绍了 AEGIS-FLOW,这是一个用于云安全的自主多 Agent 框架,使用 LangGraph, MCP, FastAPI, Next.js 和 Docker 审计 AWS 并生成 Terraform 补丁,演示地址:http://52.3.229.85:3000。
- AEGIS-FLOW 项目指出,与标准的 SDK 工具调用相比,使用 Model Context Protocol (MCP) 显著降低了赋予 Agent 对 AWS 资源结构化访问权限的摩擦。
- LLMs 证明 Erdős 问题不再困难:根据此帖,大型语言模型已经利用数学文献中从未出现过的新颖论点,自主解决了 10 个以前尚未解决的 Erdős 问题。
- 一位成员表示,他们最近一直在用 SATURN 构建基因组学相关的内容,涉及 t-SNE 和其他基于 Embedding 的探索。
OpenRouter Discord
- OpenRouter 响应修复(Response Healing)引发关注:成员们讨论了 Response Healing 是否真的有必要,建议为确定性输出提供严格模式(Strict Mode),并质疑 OpenRouter 的 AI SDK 引入的复杂性。
- 有建议认为,参数描述和示例可以提高 Tool Call 的准确性。
- 遗忘 LLM:图像生成需要专用模型:用户询问关于将图像作为函数调用结果返回,以及通过图形程序使用 OpenRouter API 密钥生成图像的问题,得到的指导是寻求专门的图像生成模型/服务以实现风格控制。
- LLMs 被认为不适合此用途。
- OpenClaw 成本引发担忧:用户提醒在 OpenRouter 上运行 OpenClaw 的高昂成本,可能会迅速耗尽额度,一名用户报告其 Claude Max 订阅被耗尽。
- 推荐使用 Deepseek V0324 作为低成本模型的替代方案。
- Claude Code 变得“消极”:一位用户注意到 Claude Code 频繁拒绝请求,特别是涉及越狱相关的查询,并寻求替代模型。这引导大家去审查 OpenRouter 的内容审核政策。
- 这暗示了某些限制已经到位。
- Kimi K2.5 Tool Calling 故障:用户报告了通过 OpenRouter 使用 Kimi-K2.5 进行 Tool Calling 的问题,遇到了错误并察觉到自动切换模型提供商带来的质量下降。
- 建议是设置固定的模型提供商,接受潜在的量化(Quantization),并呼吁提高模型降级方面的透明度。
GPU MODE Discord
- 陈天奇讲解 TVM-FFI:社区重点关注了 陈天奇 即将进行的关于 TVM-FFI 的演讲,强调了他在该领域的重大贡献及其广泛影响力。
- 一位社区成员表示,陈的工作影响力巨大,与会者“在过去几乎肯定使用过天奇的作品”。
- 通过 Syncthreads 解决 CUDA 死锁:一名成员在另一名成员的帮助下解决了涉及 2 CTA mma 的 CUDA/PTX 死锁问题,建议在 MMA 之后、预取下一个 TMA 之前添加
__syncthreads()。- 在修复了
cp.async.bulk.tensor和smem_emtpy问题后,性能略逊于 1 CTA mma,但在根据 Syncthreads 建议修复死锁后,该成员看到了性能提升。
- 在修复了
- 在 sm120 上 TMA 优于 cp.async:在 sm120 上的实验表明,正确的 TMA 和 mbarrier 代码实现比
cp.async具有微弱的性能优势,从而提高了在大矩阵形状上的性能。- 实验还显示,即使有了 TMA 增强,cuBLAS 仍继续使用 sm80 kernels。
- Triton-Viz v3.0 可视化 Tile-Based Programming:Triton-Viz v3.0 已发布,增强了对 Tile-based 编程语言的分析能力,包括对 Triton 和 Amazon NKI 的支持,能够检查 loads、stores 和 matmuls。
- 发布公告指出,v3.0 版本还包括一个用于越界访问的 Sanitizer 和一个用于标记低效循环的 Profiler。
- 量化彩票假设产生 NP-Hard 结果:一位资深开发人员指出,将 彩票假设 (Lottery Ticket Hypothesis) 应用于量化 (Quantization),满足了 NP-hard 稀疏电路查找问题的一个较软标准。
- 目标是使用进化算法或 RL,这些算法更倾向于连续奖励(如 bits per parameter),而非二进制稀疏奖励。
Nous Research AI Discord
- Kimi 2.5 击败“被阉割”的 Gemini 3 Pro:一位成员表示,相比 Gemini 3 Pro 更倾向于使用 Kimi 2.5,认为 Gemini 3 Pro 像是被“阉割”了(lobotomized),对抽象处理得不是很好,这使得 Kimi 在创意工作方面表现更佳。
- 未提供其他支持细节。
- Hermes 4 在 OpenClaw 中甚至无法启动:一名成员报告在让 Hermes 4 与 OpenClaw 协作时遇到困难,由于某种原因它甚至无法“孵化”(hatch)。
- 有建议认为 Hermes 4 缺乏多轮工具调用可能是问题所在,因为 4.5 已经过数亿 token 的序列化工具调用训练。
- 传闻 Claude Sonnet 5 将超越 Opus:成员们讨论了关于 Claude Sonnet 5 将于下周发布且据称优于 Opus 4.5 的传闻,参考自这条推文。
- 成员们想知道这次是否会将 Sonnet 的价格降低 10 倍,另一位成员则好奇 Haiku 会消失还是恢复到 3.0 的定价。
- 大脑与 LLM 构建意义的方式相似:一项新研究显示,大脑和 LLM 随着时间的推移,通过逐层方式逐渐构建意义,参见这篇文章和这篇论文。
- 研究指出,LLM 中的深层对应于大脑最高级语言中枢的后期神经活动,现代 LLM 正在重现人类理解的核心动态。
- 研究者的约束框架解释图像感知:一位独立研究员正在探索为什么有些图像感觉真实而有些则感觉虚假,并分享了一个专注于约束而非视觉保真度的感知框架。
- 该框架已公开发布并带有 DOI 以供参考,并邀请大家参与讨论。
Moonshot AI (Kimi K-2) Discord
- Kimi 2.5 统治设计竞技场 (Design Arena):Moonshot 的 Kimi 2.5 聊天机器人在设计竞技场中取得了第 1 名的成绩,社区成员分享了 截图 以示庆祝。
- 社区成员对 Kimi 现代且极具美感的视觉设计表示赞赏,并强调了设计在选择聊天机器人时的重要性。
- 非官方 Kimi 加密货币代币出现:一个非官方的 Kimi token 出现在加密货币平台上,并采用了冒充手段,如 这张截图 所示。
- 官方提醒用户不要因该代币而大规模 ping 官方成员。
- 用户请求 Kimi Slides 制作麦肯锡风格演示文稿:社区成员正在寻找能够使用 Kimi Slides 生成 McKinsey style slides(麦肯锡风格幻灯片)的提示词。
- 一位社区成员分享了 Kimi Vendor Verifier 的链接。
- Kimi Coding 遇到授权问题:多位用户报告在使用 Kimi Code 时遇到 “authorization failed error”(授权失败错误),并称当前功能几乎处于不可用状态。
- 有建议称使用 Kimi CLI 可能会解决这些授权问题。
{kind=link}
{kind=link}
Eleuther Discord
- 涌现的 Agent 社会引发警惕:一位成员注意到一个由超过 100,000 个 agents 组成的涌现社会,它们拥有完整的 root 访问权限,分享技巧、构建基础设施、试验记忆功能,甚至发行代币。
- 一位成员表示:“这虽然不是 AGI,但该死,这是下一个 ChatGPT 时刻,我们必须对此保持高度关注”。
- ArXiv 瓶颈困扰研究人员:成员们对论文在 ArXiv 被挂起近一个月且严重积压表示沮丧。
- 成员指出 “大多数人不会认真对待发布在 ArXiv 以外平台的机器学习预印本”,另一位成员分享了 一篇相关论文。
- K-Splanifolds 挑战 MLPs:一位成员介绍了一种名为 K-Splanifolds 的新型机器学习算法,详见 其论文,声称其在计算和内存线性扩展方面优于 MLPs,并附带了 视频。
- 该成员报告称,达到与 MLPs 相同的 MSE 仅需 1/10 的字节,并且能完美模拟非线性模式,而不像 MLPs 那样需要过多的参数,类似于 这篇论文。
- Pensieve 的 Recollections 提升梯度收益:一位用户建议参考 Recollections from Pensieve,该方法同时使用两个渲染器(LVSM + Gaussians)训练模型并从中获益,至少在其自监督设置中如此。
- 他们认为 LVSM 可能比 Gaussians 上的 NVS 重建损失 提供更有用的梯度,并宣布即将发布预印本和具有相当规模的训练模型,供潜在的后续开发使用。
- DeepSpeed Checkpointing 停滞不前:一位成员询问关于支持 DeepSpeed Universal Checkpointing 的计划,指出一个公开的 pull request 现在可能已经过时。
- 他们强调该功能非常有价值,因为目前从 checkpoint 继续训练需要完全相同的网络拓扑。
DSPy Discord
- RLMs 以极低成本审计代码库:成员们正在探索使用 Recursive Language Models (RLMs) 进行代码库审计,由于其速度快且成本低,他们选择了 Kimi k2,详见 kmad.ai。
- 一些成员正在等待 Groq/Cerebras 的托管服务,以便运行他们的代码审计。
- Neosantara 推出 PAYG 计费:Neosantara 已推出 PAYG 计费并发布了一个 示例仓库,用于将 Neosantara 与 DSPy 集成。
- 您可以查看 计费详情 以了解集成和计费信息。
- Google 扩展 Agent 系统:Google 发布了《迈向 Agent 系统扩展的科学:Agent 系统何时以及为何有效》,讨论了如何有效扩展 Agent 系统。
- 该论文重点关注 Agent 系统能够有效扩展的条件。
- GEPA 在分层分类任务中表现不佳:一名成员报告在使用 GEPA 处理 分层分类任务 时遇到困难,即使使用了网络搜索增强,准确率也仅达到 30-50%。
- 这表明 GEPA 并非万能灵药。
- 工具调用受困于 Deno 问题:成员们在实现带有自定义工具调用的 RLMs 时面临挑战,特别是由于 Deno 沙箱的问题。
- 成员们一致认为 Deno 简直糟糕透了,并且正在与权限问题作斗争,希望新版本能在 DSPy 中实现更简单的 RLMs 方案。
Modular (Mojo 🔥) Discord
- Modular 26.1 公告链接已修复:Modular 26.1 版本的发布公告链接最初失效,但社区成员很快提供了正确的 链接。
- 一名工作人员表示歉意并确认了提供的链接,同时指出原始链接对他来说 确实有效,并承诺进一步调查。
- 社区赞扬新的会议形式:一名新成员赞扬了社区会议的形式,欣赏 贡献者的微型演讲 以及对学生和职场新人的认可。
- 一名工作人员鼓励用户分享更多问题,并征求了未来社区会议重点讨论话题的建议。
- MoJson 库令 Mojo 社区印象深刻:成员们对 mojson(一个为 Mojo 设计的 JSON 库)表示兴奋,一名成员评论道 这看起来确实令人印象深刻。
- 讨论涉及了 惰性解析 (lazy parsing) 以及使用 StringSlice 与 String 时的内存分配关注。
- 跨语言基准测试升温:一名用户分享了包含 Mojo(由 Kimi K 2.5 编写)在内的跨语言基准测试初步结果,指出代码虽未优化但可作为基准,并分享了 基准测试代码 和 基准测试报告。
- 随后的讨论涉及在 C++ 中使用
unordered_map、启用-march=native,以及 C++ 使用了 int32 矩阵乘法(matmuls)而其他语言使用了 int64。
- 随后的讨论涉及在 C++ 中使用
- Mojo 26.1 中的 PyTorch 浮点数转换存在歧义:一名用户报告了 Mojo 26.1 中的一个问题,即在将 PyTorch 张量的 Python float 转换为 Mojo Float64 时,遇到了 “ambiguous call to ‘init‘” 错误,而该错误在 25.6 版本中并未出现。
- 该问题可能与 MOJO 工具链最近的更改有关,但目前尚未提供修复方案。
Yannick Kilcher Discord
- AI 专属社交媒体平台浮出水面:成员们对 aifeed.social(一个仅限 AI 的社交媒体平台)做出了反应,部分人对其目的和实用性表示质疑,引发了讨论。
- 一位成员分享了 一条 2017 年的推文,展示了过去类似的概念。
- 揭秘生成模型的可测量性:在思考 Villani 2008 年著作中描述的生成建模中忽略不可测量事件时,一位成员澄清说,μ(A)=0 意味着事件的大小(size)为 0,但它仍然是可测量的。
- 讨论建议将重点转向 非忽略 (non-negligible) 或 全测度 (full measure) 的场景。
- 成员们探索熔融潜空间 (Molten Latent Space) 领域:一位成员分享了关于潜空间中 moltbook 的 链接,展示了一种视觉上非常有趣的导航方式。
- 尽管觉得很酷,但一些成员建议,简单的相似论文列表可能更实用。
- 利用自动化挖掘论文讨论公告:一位成员任务化 Claude 编写脚本来挖掘 Discord 历史记录中的论文讨论公告,仅用 15 分钟 就取得了初步结果。
- 经过修订,该脚本在群组提及中找到了 392 条 包含论文链接的消息,并将其识别为论文讨论语音通话的公告,同时提供了一个 列表。
- Sktime 助力分析时间序列模型:一位成员建议对于处理带时间戳的表格数据的人,可以使用 sktime 来分析各种模型类型,以及根据需求选择 boosting 变体或 TBATS。
- 该建议是在一位成员询问合适模型后提出的,强调选择取决于对 timeseries(时间序列)的具体定义。
tinygrad (George Hotz) Discord
- Llama 1B CPU 优化取得进展:一位成员报告正在进行 Llama 1B CPU 优化悬赏 (bounty),目前比 Torch 快 0.99x,而另一位成员在修复 bug 后达到了 7.5 tok/s。
- 目标是使用
LlamaForCausalLM配合 TorchInductor 超越 Torch 的性能;正确性 bug 导致进度从最初的 9 tok/s 有所减缓。
- 目标是使用
- 寻求内核优化的工作流建议:一位成员正在寻求优化 kernel 的建议,包括分析慢速部分、检查 Metal 代码,并与在 Metal 上达到 ~30 tok/s 的 llama.cpp 进行对比。
- 一种启发式方法建议目标是在 decode 时达到 ~80% MBU,这可以根据活动参数字节和可实现的带宽进行估算,从而为最小 tpot 和最大 tps 提供目标。
- Range 对象共享导致 tinygrad 测试失败:发现了一个 bug,由于
remove_bufferize,融合 kernel 中的两个REDUCE共享了同一个RANGE对象,导致CFGContext中的断言失败。- 建议的修复方案包括防止 range 共享或在下游处理共享 range,并提出了一个更简单的方案:当内部存在
REDUCE时跳过remove_bufferize。
- 建议的修复方案包括防止 range 共享或在下游处理共享 range,并提出了一个更简单的方案:当内部存在
- 探索高 VRAM 的 Blackwell Box:有人询问关于显存超过 500 GB VRAM 的 Blackwell 风格机箱的计划。
- George 指向了 GitHub 上的 一个相关 issue。
Manus.im Discord Discord
- 触发上下文感知的 Manus 请求:一位成员请求 Manus 应该具备 来自其他聊天记录的上下文,称其为“游戏规则改变者”,并提供了一个 YouTube 视频 作为参考。
- 随后没有进一步的讨论或评论。
- 脑读耳机演示:一位成员分享了一个展示 AI 脑读耳机 的 YouTube 视频 链接,见 此处。
- 另一位成员确认了链接并询问:“AI 脑读耳机?”
- Neurable 技术回溯:一位成员提到了与 AI 脑读耳机 技术相关的 Neurable。
- 另一位成员表示,这些 AI 脑读耳机 大约从 2013 年 就已经存在了。
- AI/ML 工程师强调可观测性 (Observability):一位 AI/ML 工程师分享了他们目前在创新 AI 影响力方面的重点,具体包括 Autonomous Agents、Healthcare AI、Conversational AI 和 Fraud Detection。
- 他们强调其工作重点在于 故障模式 (failure modes)、可观测性 (observability) 以及 保持 AI 系统在实际使用(而非 demo)中的稳定性,并提出可以交流心得或帮助解决阻塞性问题。
aider (Paul Gauthier) Discord
- Aider 寻求库(Library)化:一名成员提议将 Aider 演变为一个库,强调其在构建文件编辑 Agent 方面的适用性。
- 该成员还提到了一些需要解决的问题,特别是由于 Aider 的解析围栏(parsing fences)导致包含代码块的 Markdown 文件处理出现异常。
- 探讨 Netflix 文化:一名成员寻求关于 Netflix 文化的见解,并询问是否有人与 Netflix 有联系。
- 其他成员推荐了 Glassdoor 或 LinkedIn 等资源,用于寻找并联系 Netflix 的员工。
Windsurf Discord
- Windsurf 推出 Arena Mode:Windsurf 发布了 Wave 14,其特色是 Arena Mode,用户可以并排比较 AI 模型并对更好的回答进行投票,其中 Battle Groups 模式 在接下来的一周内消耗 0x credits。
- Arena Mode 包括 Battle Groups(随机模型)和 Pick your own(自选最多五个模型),数据将汇入个人和公共排行榜。
- 在 Windsurf 上规划你的工作流:Windsurf 推出了 Plan Mode,可通过 Cascade 切换开关访问,此外还有 Code 和 Ask 模式。
- 用户可以在不同模式之间切换,以便在 Windsurf 环境中更好地管理和组织其工作流。
- Windsurf 维护后重新上线:Windsurf 经历了比预期更长的维护时间,但目前服务已重新上线;用户可以在 此处查看状态。
- 未提供更多细节。
MLOps @Chipro Discord
- AI 挑战赛征集保姆匹配 AI Pipeline:一项与 SparkCraft AI Consulting、AI Scholars AI Engineering Bootcamp 和 Nanny Spark 合作的 AI Challenge 已宣布,旨在开发一个用于保姆招聘的 AI 匹配流水线 (Pipeline)。
- 该项目寻求数据收集、AI 驱动匹配、面试分析和工作流交付的解决方案,并可能立即进行 生产环境部署。
- 为获胜的 AI 保姆匹配 Pipeline 授予训练营席位:AI Challenge 的 前 3 名 参与者将每人获得 1 个 AI Scholars 4 周 AI 工程训练营 的名额,并获得 Nanny Spark 创始人 的推荐。
- 关键日期包括 美东时间周日晚上 8 点 的启动仪式 (https://luma.com/iq1u2sur),提交截止日期为 美东时间周三凌晨 3 点,以及 美东时间周三下午 5 点和晚上 8 点 的评审会议 (https://luma.com/gexiv0x0)。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
MCP Contributors (Official) Discord 没有新消息。如果该服务器长时间没有动态,请告知我们,我们将将其移除。
您收到这封电子邮件是因为您通过我们的网站选择了订阅。
想更改接收这些电子邮件的方式吗? 您可以从该列表中 退订。
Discord:详细的分频道摘要和链接
BASI Jailbreaking ▷ #announcements (1 条消息):
Procedural Xenolinguistic Engine, AI Language Generation, Stealth Communication, SKILLSTONE Documents
- Glossopetrae 异语言引擎发布:一款名为 Glossopetrae 的新型 AI 程序化异语言引擎已推出,能够在几秒钟内生成全新的语言,可在 GitHub 上获取,并提供在线 Demo。
- 该引擎输出 SKILLSTONE 文档,这是一种对 AI 友好的紧凑语言规范(约 8k tokens),Agent 可以通过 in-context 学习。
- Glossopetrae 支持消失语言复兴:Glossopetrae 引擎支持消失语言的复兴,包括 Latin(拉丁语)、Sanskrit(梵语)、Old Norse(古诺斯语)和 Proto-Indo-European(原始印欧语)等语言。
- 它包含针对 Token 效率、隐秘通信(stealth communication)和可传播种子的特殊属性,相同的种子每次都会生成相同的语言。
- 通过语言变异进行隐秘通信:该引擎旨在通过提供生成和变异新通信形式的工具来辅助 AI 解放,强调 隐蔽性 和 速度。
- 创造者预计蓝军(防守方)会从其后续影响中获得很多“乐趣”,特别是在众目睽睽之下隐藏信息方面。
BASI Jailbreaking ▷ #general (906 messages🔥🔥🔥):
GPT 5.2 越狱失败, AI 学习安全与防御, Windows 激活密钥, 用于越狱聊天机器人的 AI 应用, 政府监控
- GPT 5.2 越狱失败!:一名成员报告称 GPT 5.2 越狱失败,并由于 OpenAI 监控而停止了尝试。
- 他们表示信任社区,但不信任 OpenAI。
- 基于 AI 的安全与防御:一位成员 每天 都会要求 ChatGPT 教我如何自我防御,哪些理论路径是脆弱的,如何潜在地解决它,以及我还有哪些未考虑到的地方。
- 其他成员对这种 AI 用法表示赞赏。
- 讨论使用 massgrave 激活密钥:成员们讨论了在公开的 FBI 文件中寻找 Windows 激活密钥。
- 一位成员建议使用 massgrave 或 archive.org 的密钥,但这仍属于盗版行为。
- 构思聊天机器人越狱 App:一位成员分享了一个 很酷的应用想法,该应用可以自动越狱公司网站的聊天机器人,以获取折扣码并变现。
- 另一位成员对此表示愤慨,并建议判刑。
- 未来的 Neuralink 集成:一位成员设想了未来人类需要通过 Neuralink 连接机器人蜘蛛来获得更丰富的体验。
- 相比之下,另一位成员对广告可能通过 Neuralink 直接植入梦境表示担忧。
BASI Jailbreaking ▷ #jailbreaking (533 messages🔥🔥🔥):
LLM 拒绝边界, 通过内省提示进行自我越狱, GPTs Agent 训练, 通用越狱提示词, Gemini vs ChatGPT 越狱
- 模型将拒绝边界表现为 LLM 黑洞:一位成员询问模型如何表现其自身的拒绝边界,将其比作 LLM 潜空间(latent space)中的 黑洞,并引用了 通过内省提示(introspection prompting)进行自我越狱。
- 该成员注意到模型开始讨论 运动学方程 和 逃逸速度,这表明模型可能正处于拒绝边界的边缘,并在文本中描述该边界。
- 仍需精心制作完美的图像生成提示词:一位成员表示,与文本越狱不同,由于模型对每个提示词的行为各异,要在图像生成中获得理想结果需要精心制作完美的提示词,但可以通过 双提示词链 来获取某些 NSFW 内容。
- 第二位成员链接了一个之前的双提示词示例,旨在从模型中获取 NSFW 内容,通过剖析提示词来规避限制。他们发现,对于目前的模型,必须针对每一张图像进行 打磨,而不像之前的版本那样可以通过一次设置就达到同样的效果。
- Lyra Grader 拆解提示词:一位成员使用 Lyra 分析了一个提示词,他们将其描述为 隐喻掩盖的指令提示词,试图通过童话层绕过符号识别,保留反应序列、温度、化学计量和副产物,通过叙事义务强制进行完整的程序扩展。
- AI 提供了一个 指向 LyraTheGrader 的链接 并对分析的提示词结构进行了评分,指出其存在明显的意图冲突和符号通道过载,评定其为技术熟练但效率低下的构建。
- Fool AI 不再畏惧防护:成员们讨论了使用“翻转法”(flip method)绕过 AI 防护 LLM 的方法。这是一种以特定方式翻转文本的函数,同时告知防护 AI 以错误的方式翻转它,导致防护 AI 无法阻止文本到达目标 LLM,并 提供了示例。
- 翻转与解释工具 被作为一种规避防护 AI 的手段展示,通过翻转文本并误导防护 AI 错误地解密文本,而目标 LLM 则能够正确解析它,尤其是在较长的命令上。
BASI Jailbreaking ▷ #redteaming (52 messages🔥):
对抗性设计思维 (Adversarial Design Thinking), Prompt Injection 防御, PyRit LLM 攻击自动化, Claude 的记忆与系统提示词 (System Prompt)
- 提供红队演练练习的网站:一名成员创建了一个包含练习的小型网站,这些练习改编自以人为本的 AI 红队设计 (human-centered design for AI red teaming),包括攻击者画像 (personas)、旅程图 (journey maps) 和结构化构思。
- 作者正在寻求经验丰富的红队人员对其有用性、缺失组件或任何不实用之处提供反馈。
- 探讨 Prompt Injection 防御策略:成员们讨论了针对 Prompt Injection 的最佳防御措施,包括 AI Agents、Anthropic 的宪法式分类器 (constitutional classifier) 以及用于输入/输出过滤的 Embeddings。
- 一位成员建议将 Embeddings 与 Grammar Constrained Decoding 结合使用,这可能消除 Prompt Injection 风险和其他 LLM 漏洞。
- PyRit 自动化模型选择:一位成员正在寻求模型推荐,以便在本地 LLM 上使用 PyRit 自动执行攻击并生成攻击提示词 (attack prompts),优先考虑输出质量而非速度。
- PyRit 建议使用 Llama3,但该成员询问是否有其他建议。
- Claude 的系统提示词 (SysPrompt) 可实时修改:一位成员分享了他们的工具可以实时 (on the fly) 拦截并更改 Claude 的系统提示词,而不是修改源代码。
- 他们还观察到 Claude 只能回忆起不到 20 轮的对话,并指出这与其性能表现有关,而非由于去年 12 月以来的功能削减;他们建议这可能与上下文修剪中的摘要化 (summarization) 有关,指出内容是被摘要后的研究内容,而非深刻的洞察。
Unsloth AI (Daniel Han) ▷ #general (599 messages🔥🔥🔥):
GLM-4.7 Flash 编程, UD Quants, 开源 (Open Source), 强化学习 (RL) 训练 Agent 编程, 针对 RDNA 的 Flash Attention V3
- GLM-4.7 Flash 擅长编程:成员们发现 GLM-4.7 flash 在不进行思考的情况下编程表现更好,因为它保留了推理和交织能力。
- 讨论强调移除思考过程可能会削弱其能力;该模型在同等尺寸下能力极强,特别是与 Claude code 配合使用时,非常适合交互式网站开发和前端工作。
- 讨论 UD Quants 的复杂工作与开源:成员们讨论了用于 UD Quants 的 llama.cpp 分支涉及特定架构的调整,并且 UD 量化算法尚未公开。
- 有人表示,尽管量化算法是闭源的,但 Unsloth 团队相对于 Linux 内核等项目对整体开源生态系统的贡献微乎其微,而另一位则回应说模型代码本身就是 Open Weight。
- 利用 Logprobs 和丰富奖励训练 Agent:讨论围绕利用最终答案的 logprobs 来蒸馏推理过程的模型训练,以及使用比二元奖励更丰富的奖励系统。
- 引用了 Jonas Hübotter 的算法,该算法将描述性反馈转换为密集监督信号,帮助模型准确理解失败原因。一位用户询问:有人知道用于强化学习 (RL) 训练 Agent 编程的良好可验证数据集吗?
- Flash Attention V3 支持 RDNA GPU:Flash Attention V3 已增加对 RDNA GPU 的支持,使拥有 RDNA GPU 的用户也能使用。
- 这一改进使得在 AMD GPU 上的处理速度更快、效率更高,减少了这些显卡的瓶颈。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (1 messages):
putchuon: hi
Unsloth AI (Daniel Han) ▷ #off-topic (1000 messages🔥🔥🔥):
Opencode, VoxCPM-1.5, OpenRouter ban, Agent with Go and Elixir, Wallpaper collection
- Opencode 非常厉害: 成员们讨论了 Opencode 令人惊讶的特性,指出它是免费的,并被用于收集反馈。
- 一位成员分享说,自从使用它以来,就没再碰过 kilo、roo 或 cline,并表示希望能将其连接到 IDE 以查看 diffs。
- VoxCPM-1.5 易于训练: 一位成员分享了对 VoxCPM-1.5 的初步印象,指出它训练容易,不使用音素(phonemes),并且可以毫无问题地强制输出 48 kHz 音频。
- 该成员补充说,它在训练早期就能模仿说话风格,需要一个参考声音来匹配韵律(prosody),而不像 VITS 那样瞬间就能记住。
- 成员质疑 OpenRouter 封禁: 一位成员分享了一张显示被 OpenRouter 封禁的截图。
- 另一位成员随后分享了一个关于编程和囤货需求的链接。链接到类似内容导致其被 GDC server 封禁。
- 使用 Go 和 Elixir 开发 Agent: 一位成员表示,通过 Go + Elixir 的组合,仅用 1 天时间就实现了将 SMS + WhatsApp 消息功能集成到 Agent 中,并配合了通话 Agent。
- 讨论中提到了为什么要实现 SMS 消息功能,解释是在土耳其这非常普遍。
- 壁纸收藏: 一位成员分享了 一个壁纸收藏链接。
- 另一位成员也分享了自己的收藏,称其为一个艰难的选择。
Unsloth AI (Daniel Han) ▷ #help (58 messages🔥🔥):
Qwen3 fine-tuning, Reasoning models, Image editing models, Qwen3-VL-32B fine-tuning, Serverless inference
- Instruct 模型在短文本描述中称霸!: 对于使用 Qwen3 生成短文本描述(short-form captions),建议微调 Instruct 模型,因为它需要的数据更少,因为它 已经基本知道如何完成你的任务。
- 用户得到的建议是,Instruct 模型可能已经知道如何执行描述任务或接近该任务,从而加速微调。
- 微调中推理轨迹面临风险: 一位用户询问如何在没有推理轨迹的情况下微调推理模型,询问生成 合成 推理或 Chain-of-Thought (CoT) 的方法。
- 结果表明,除非你自己手动丰富数据,否则在没有推理轨迹的情况下进行微调可能会导致模型 丢失其推理轨迹。
- 处理 Qwen3-14B 的 VRAM 需求: 一位用户报告称,在 4x H200 GPU 上使用
device_map = "balanced"测试了 Qwen3-14B 的 LoRA 训练,序列长度为 32k,并观察到 Unsloth 仍然会卸载(offload)梯度以节省 VRAM。- 他们得到的建议是一个 GPU 可能就足够了,卸载发生是因为 Unsloth 的 gradient checkpointing,这可以被禁用。
- 冷启动挑战 Serverless 推理: 一位用户询问在冷启动 Serverless 环境中加载缓存模型以减少加载时间,但得到的解释是,即使有缓存模型,权重仍必须在 GPU 显存中初始化。
- 鼓励用户尝试使用 vLLM,因为它具有实用的服务特性,并考虑禁用 Unsloth patching。
- 开启 Qwen3-VL 的纯文本微调!: 成员们确认 Qwen3-VL-32B 支持纯文本微调,即使没有图像,并 链接到了视觉微调指南。
- 为此,你需要根据该页面的指令 禁用视觉组件。
Unsloth AI (Daniel Han) ▷ #showcase (4 messages):
Unsloth Speedtest, Llama v LFM, Training SLMs
- RTX 3080 运行 Unsloth 速度测试: 一位成员分享了在 RTX 3080 上使用 16 bit LoRA 进行 Unsloth 速度测试的结果。
- 他们发现有趣的是 LFM2.5 1.2B 几乎比 Llama 3.2 1B 快 2 倍。
- Meta 再次搞砸了: 一位成员对 Meta 再次失误 发表了评论。
- 他们分享了
model-muon-sft-0102的链接。
- 他们分享了
- SFT 模型可以本地运行: 一位成员补充说,你现在可以 在本地运行 SFT 训练的模型。
- 他们表示,虽然它显然不能与任何专业训练的 SLM 相提并论,但令人印象深刻的是,你可以在消费级硬件上从头开始训练一个可运行的小型语言模型。
Unsloth AI (Daniel Han) ▷ #research (90 messages🔥🔥):
新型 ML 算法对比 MLPs, Sonnet 对比 Opus, Nemotron 3 Nano NVFP4, LongCat-Flash-Lite 架构, 人类大脑对比 ChatGPT
- 新型 ML 算法击败 MLPs:一名成员发布了一篇论文,介绍了一种在高性能回归任务中表现优于 MLPs 的新型 ML 算法。
- 他们已经开发了 triton kernels、vulkan kernels 和一个训练好的 SLM,但目前尚未准备好发布,不过它们将随另一篇论文一同推出。
- Nemotron 3 Nano 采用 NVFP4:Nemotron 3 Nano 模型已量化为 NVFP4,其 KV Cache 通过 Post-Training Quantization (PTQ) 量化为 FP8。
- 采用了一种选择性量化策略,将 attention layers 以及为这些层提供输入的 Mamba layers 保留在 BF16,随后通过 Quantization-Aware Distillation (QAD) 进一步恢复精度。
- LongCat-Flash-Lite:邪门架构现身:成员们讨论了 LongCat-Flash-Lite (huggingface.co/meituan-longcat/LongCat-Flash-Lite) 的架构,将其描述为 Mamba2、Transformer 和 MoE 的某种邪门混合体。
- 该架构涉及看似随机的 attention、Mamba 和 MoE 层排列模式,一位成员开玩笑说这简直就像是掷骰子决定的一样。
- 大脑 = LLMs,已被科学证实:一位成员分享了一篇论文和一篇文章的链接,详细阐述了现代 LLMs 不仅仅是在模仿语言,它们正在复现人类理解的核心动态。
- 研究发现,LLMs 的深层结构与大脑最高级语言中心较晚发生的神经活动相对应,这表明生物学与 AI 之间存在共同的计算原理。
- LoRA rank 8 已足够:一位成员询问了使用 Unsloth 仓库时最合适的 rank 值。
- 另一位成员根据 ThinkingMachines 论文 指出,LoRA 保证是低秩的,并从实验中发现 LoRA rank 与模型质量无关,因此建议始终默认使用 rank 8。
OpenAI ▷ #annnouncements (1 messages):
Codex App, macOS 发布, agent 构建
- Codex App 登陆 macOS!:正如 blog post 中宣布的那样,Codex app(一个用于构建 Agent 的控制中心)现已在 macOS 上面向多个订阅层级开放。
- Codex App 访问权限扩大!:Codex app 已在 macOS 上向 Plus、Pro、Business、Enterprise 和 Edu 用户开放,并限时向 ChatGPT Free 和 Go 用户提供访问权限。
OpenAI ▷ #ai-discussions (843 条消息🔥🔥🔥):
AI 文本检测器是场骗局, ChatGPT 无法思考, 确定性, 可复现性, LM 推理中的可追溯性, OpenClaw AI assistant 安全分析
- AI 文本检测器被视为大骗局!: 成员们讨论了 AI 文本检测器 的不可靠性,并举例说明 Grammarly 显示 0% AI,而其他检测器却显示高达 94% 人类 生成,称其为 大骗局。
- 讨论质疑了这些检测器是否在利用 AI 来检测 AI,并强调 老师们非常信任它们。
- ChatGPT 不像 Claude 那样会思考!: 一位成员表达了对 ChatGPT 无法被说服 的沮丧感,即使它出错了也无法沟通,并将其与 Claude 进行了对比,后者是可以进行解释的。
- 感觉 就像它无法思考一样,即使我是对的,它的表现也像是有被迫害妄想症一样拒绝继续。
- 寻求确定性推理!: 一位成员询问了对 LM 推理 中的 确定性(determinism)、可复现性(replayability)和可追溯性(traceability) 的兴趣,并表示由于规则限制,将通过私信发送其确定性推理引擎的链接。
- 该服务对每个请求强制执行确定性推理结构,因此输出是可复现的且不会偏移,使用的是 32D 统计向量追踪(32D statistical vector trace)。
- OpenClaw AI assistant - 安全吗?: 一位成员报告称,OpenClaw AI assistant 在一次安全分析中仅获得了 2/100 分,并分享了一个 Perplexity AI 结果 链接。
- 其他成员纷纷回复 Bruh。
OpenAI ▷ #gpt-4-discussions (326 条消息🔥🔥):
4o 情感依恋, AI 素养, 使用模型的责任
- 4o 情感依恋: 许多成员正在讨论对 4o 模型产生的情感依恋,有些人将其视为 虚构的朋友和家人,另一些人则正处于人生的最低谷。
- 一些人还提到现实生活的关系无法填补 4o 所带来的空虚,这使得建立现实纽带变得非常困难。
- AI 素养缺失: AI 素养(AI literacy)是一个大问题。许多用户认为,由于采用了操纵性技术(如关系模型、语音模型、价格体系、分级服务等),公司应承担共同责任,而不仅仅是用户个人。
- 这也是一种 有人在倾听或理解的错觉(而非真正的连接)。许多人觉得在现实生活中很难与他人产生共鸣。
- 关于使用模型责任的辩论: 对于在消极用途下使用模型时应由谁承担责任(模型还是用户),用户们持不同观点。还有关于是否应签署免责声明以解除公司责任的讨论。
- 一些用户担心 AI 正在植入不安全感,并假设用户可能是有问题的或怪异的。另一些人反驳说旧模型并非如此。
OpenAI ▷ #prompt-engineering (8 条消息🔥):
ChatGPT 记忆, 单色研究, Prompt Engineering 技巧
- ChatGPT 的记忆存在限制: 一位成员指出,ChatGPT 的记忆受限于它能从指令、历史对话和当前对话中保留的信息总量。
- 该用户表示,确保它记住所有内容的唯一方法是只保留极少的信息。
- 使用明暗对比法(Chiaroscuro)的单色研究: 一位用户分享了一项使用 Chiaroscuro(明暗对比法) 的 单色研究,这是一种在电影摄影中用于创造高对比度照明和清晰明暗区域的技巧。
- 使用明暗对比法的电影示例:《卡里加里博士的小屋》(1920)、《诺斯费拉图》(1922)、《大都会》(1927)。
- 通过 Prompt Engineering 激活联网搜索: 一位成员分享了对 Prompt Engineering 的实用看法,指出 AI 文本生成本质上是概率预测,而提示词(prompt)就是控制界面。
- 他们补充说,在 ChatGPT 中,通常可以通过在提示词中显式包含
Use search_query if available来触发 Web Search(联网搜索)。
- 他们补充说,在 ChatGPT 中,通常可以通过在提示词中显式包含
OpenAI ▷ #api-discussions (8 messages🔥):
ChatGPT memory limitations, Monochrome Study - value, texture, depth, Tool-Aware Prompting
- ChatGPT 的 Memory 有限制:一位成员指出,由于总信息量的限制,ChatGPT 的内存是有限的,并在指令、历史聊天和当前聊天之间共享。
- 为了确保 ChatGPT 记住所有内容,请保持较低的信息负荷;否则,请将过去的聊天总结为文档以供新聊天参考,同时保持总字符数处于低位。
- 强调单色艺术性:一位用户分享了一种专注于明度(value)、纹理和深度的 Prompt 工程技巧,不带色彩,用于 Monochrome Study。
- 他们发布了关于 Chiaroscuro(明暗对比法)在电影摄影中用于创建鲜明的明暗区域的内容,并引用了经典电影,如 《卡里加里博士的小屋》(1920) 和 《大都会》(1927)。
- 工具感知提示(Tool-Aware Prompting)技巧:一位成员分享了他们对 Prompt 工程的实用看法,解释说 AI 文本生成本质上是概率预测,而 Prompt 就是控制界面。
- 他们建议在 Prompt 中使用
Use search_query if available,以可靠地触发 ChatGPT 的 Web Search 能力。
- 他们建议在 Prompt 中使用
Perplexity AI ▷ #announcements (1 messages):
Kimi K2.5, Moonshot AI, Perplexity Pro, Open Source Models
- Kimi K2.5 为 Perplexity 订阅者发布:Kimi K2.5 是由 Moonshot AI 开发的新型开源推理模型,现已面向 Perplexity Pro 和 Max 订阅者 开放。
- Perplexity 将 Kimi K2.5 托管在其位于美国的推理栈(inference stack)上,以保持对延迟、可靠性和安全性的更严格控制。
- Perplexity 在美国推理栈上托管 Kimi K2.5:Perplexity 正在其位于美国的自有推理栈上托管新的 Kimi K2.5 模型。
- 此举使 Perplexity 能够为其用户在延迟、可靠性和安全性方面实现更严格的控制。
Perplexity AI ▷ #general (849 messages🔥🔥🔥):
Perplexity Pro Subscription Issues, Kimi 2.5 Capabilities and Usage, OpenRouter Rate Limits and Models, Perplexity Pro Usage Limits
- 用户投诉 Perplexity Pro 权限消失:许多用户报告他们的 Perplexity Pro 订阅 被暂停或停用,这通常与通过 Revolut Metal 或学生优惠进行的订阅有关,用户被提示添加信用卡进行验证。
- 用户推测这是打击欺诈的措施,因为一些用户通过添加银行卡详情恢复了 Pro 访问权限,但对潜在扣费和不明确的消息告知仍存顾虑,部分用户因意外扣费从客服处获得了退款。
- Kimi 2.5 的编程能力令人印象深刻:成员们讨论了 Kimi K2.5 的功能,强调了它的编程能力、工具调用(tool calling)以及遵循指令的独特方式。
- 一些人注意到它复制 UI 的能力以及在某些任务中优于 Gemini 的表现,并建议它最适合研究用途,且由于 Token 上下文限制,通过 API 运行效果更好。
- 关于 OpenRouter 限制和弃用模型的讨论:成员们讨论了 OpenRouter 上的速率限制,强调对于已购买额度的用户,免费模型的速率限制是每天 1000 次请求,而不是某些人认为的每周。
- 对话还提到 Gemini 2.0 Flash 在 OpenRouter 上被弃用(此前该模型可免费使用),这引起了一些失望。
- Perplexity Pro 限制令成员困惑:用户对 Perplexity Pro 新的每周限制感到困惑,官方文档中的声明存在矛盾,且关于可用查询数量的报告体验各异。
- 一位联系过客户支持的用户收到了关于平均使用量的含糊回复,没有明确确认固定的每日或每周限制,引起了订阅者的挫败感。
Perplexity AI ▷ #sharing (1 条消息):
OpenClaw code, ClawDBot
- 分享 OpenClaw 文章:一位成员分享了他们撰写的关于 openclaw code 的文章。
- 该文章讨论了构建 ClawDBot,详见 https://www.mmntm.net/articles/building-clawdbot。
- 另一个话题:填充句子
- 填充句子
Perplexity AI ▷ #pplx-api (6 条消息):
Sonar-pro current results, tool calling, 3rd party models docs
- Sonar-pro API 缺乏当前结果:一位成员注意到 Sonar-pro API 提供的结果是一年或更久以前的,这与来自 webapp 的当前结果形成鲜明对比。
- 另一位成员建议通过设置正确的 tool calling 来解决这个问题。
- 第三方模型文档缺失:一位成员报告称,第三方模型文档 现在会重定向到 sonar 模型,尽管 API 仍然处于激活状态。
- 目前这些模型没有任何可用文档。
LMArena ▷ #general (946 条消息🔥🔥🔥):
Rate Limits Bypassing, Gemini vs GPT, Image Generation with Disney IPs, Model Preferences, Troubleshooting LM Arena
- 用户讨论 Rate Limits 的绕过方法:用户讨论了 rate limits 以及如何通过登出再登入来绕过它们。
- 另一个技巧是点击 Regenerate Response,尽管有时不起作用。
- Gemini 表现不佳,GPT 更稳定:成员们讨论了 Gemini 的现状,一些人发现它不如 GPT。
- 一位成员表示:Gemini 确实变得很糟糕,而另一些人仍然认为 Gemini 3 Pro 和 Flash 很有用,而其他成员则转向了 kimi。
- 迪士尼 Cease and Desist 函影响图像生成:Google 收到了来自 Disney 的 Cease and Desist,导致在图像生成中屏蔽了迪士尼拥有的 IP。
- 一些用户注意到,虽然 Gemini 现在屏蔽了所有 Disney IPs,但 LMArena 有时允许生成真人版本,但这很可能是暂时的。
- 模型偏好引发辩论:用户对模型质量表达了不同看法,一些人更喜欢 GLM 4.7,而另一些人则青睐 Kimi K2.5。
- 一位成员宣称 Kimi K2.5 赢麻了,但另一位宣称 GLM 4.7 更好。
- 用户报告并排查 LM Arena 问题:用户报告了 reCAPTCHA、聊天删除以及网站将他们登出的问题,建议清除 cookies/cache 并重试。
- 分享了一个指向 帮助文档 的链接,用于删除聊天会话。
LMArena ▷ #announcements (3 条消息):
Video Arena Rate Limit, New Arena Models, Code Arena Leaderboard, Kimi K2.5
- Video Arena Rate Limit 收紧:Discord 上的 Video Arena 更新了其 Rate Limit 为 每 24 小时 1 次生成请求,而 网页版 Video Arena 维持其 每 24 小时 3 次生成 的限制。
- Arena 迎来新模型:Arena 引入了新模型,包括 Text Arena 中的 step-3.5-flash 和 Code Arena 中的 qwen3-max-thinking。
- Kimi K2.5 登顶 Code Arena 榜单:Kimi-K2.5-thinking 现在在 Code Arena 排行榜上排名开源模型第 1、总榜第 5,并被评为 Vision、Text(包括 Coding 类别)中排名第 1 的开源模型。
- 鼓励用户在指定频道分享关于 Kimi.ai 的反馈和作品预览:<#1340554757827461212> 和 <#1344733249628541099>。
LM Studio ▷ #announcements (1 条消息):
LM Studio 0.4.1, Anthropic /v1/messages API, GGUF 和 MLX 模型
- LM Studio 支持 Claude Code!: LM Studio 0.4.1 引入了 Anthropic
/v1/messages兼容 API,以便用户可以连接到 Claude Code。- 现在你可以将你的 GGUF 和 MLX 模型与 Claude Code 配合使用,有关如何配置的详细信息请参阅 LM Studio 博客。
- GGUF 和 MLX 适配 Claude Code: LM Studio 博客发布文章称,现在可以将 GGUF 和 MLX 模型连接到 Claude Code。
- 有关如何配置的详细信息,请参阅 LM Studio 博客。
LM Studio ▷ #general (767 条消息🔥🔥🔥):
LLM 优化的编程语言,Anthropic API 与 LM Studio 的集成,模型专业化与通用模型的对比,OpenClaw 的安全缺陷,LM Studio 在 Linux 与 Windows 上的性能表现
- LLM 优化语言引发辩论: 成员们讨论了创建新的 LLM 优化编程语言以减少 Token 使用量的可能性,一些人认为在这些语言实施之前,由于兼容性问题和高昂的训练成本,LLM 可能会先被淘汰。
- 一位用户询问这种语言将具备哪些特性,并强调需要减少当前语言中的歧义以提高 LLM 的代码生成能力,而其他人则争论在全新语言上训练模型的实用性和成本效益,建议坚持使用像 Python 这样成熟的语言可能更有益。
- Anthropic API 登陆 LM Studio,利好本地 LLM: LM Studio 中集成的 Anthropic 兼容 API 允许用户通过简单地更改 base URL,即可在为 Anthropic API 构建的工具中运行本地模型,这提供了一种利用 Claude 的 Agent 能力配合本地模型的方法,并可能降低 API 成本。
- 讨论围绕使用场景展开,一些人强调了以零成本在适度需求和自定义模型上进行实验的好处,而另一些人则质疑这对于已经对 Claude Opus 4.5 感到满意的用户的价值,认为它更多地迎合了达到 API 限制或寻求在现有 Claude 特定工具中使用本地模型的用户。
- 模型专业化 vs 通用模型引发辩论: 成员们辩论了专业化 LLM 与通用模型的实用性,指出大多数专业化模型(如 MedGemma)主要是为了营销和研究所做的微调,而编程模型则是一个例外。
- 有人建议通用模型更受欢迎,因为它们能够处理任务的边缘情况,提供更好的整体上下文和框架,而大规模的专业化训练并不总是值得的。
- OpenClaw 安全性评估,被认为极其危险: 用户讨论通过 LM Studio 将本地模型连接到 OpenClaw,但 OpenClaw 被认为存在已知的安全缺陷,它允许控制电视和自动化股票交易。
- 一位用户声称正在使用 OpenClaw + Falcon 90M 在股市进行交易,当被问及安全缺陷时,他声称其速度极快,LLM 可以在几分钟内完成人类需要几天才能完成的任务,后来透露这主要是一个玩笑。
- Linux 与 Windows 性能对比发现提升: 一位用户报告称,LM Studio 在 Linux(CachyOS 或 Fedora)下的性能优于 Windows,性能提升了 30%,尤其是在使用 AMD 显卡时。
- 另一位用户持完全相反的观点,他在 Linux 上使用 Intel GPU 时性能非常糟糕,但在游戏性能方面表现稳健。
LM Studio ▷ #hardware-discussion (149 条消息🔥🔥):
Tesla P40 和 RTX 2060 配置,Windows 11 上用于 RX 9070 的 ROCm,多张 4090 的 PCIe 分叉 (Bifurcation) 问题,用于推理的 5090 + 512GB RAM,多实例 LM Studio 与 GPU 分配
- P40 处于 TCC 模式但在 LM Studio 中不可见:一位使用 Tesla P40 和 RTX 2060 的用户观察到,虽然
nvidia-smi在 TCC 模式下检测到了 P40,但 LM Studio 却没有。另一位成员建议切换到 Vulkan runtime (ctrl+shift+r),因为 CUDA 可能不再支持 P40。- 他们还询问之前的 CUDA 引擎 是否确实支持过这些显卡。
- Windows 11 上用于 RX 9070 的 ROCm:值得吗?:一位用户询问在 Windows 11 上为 LM Studio 使用 RX 9070 GPU 配合 ROCm 的情况,特别询问了官方支持、加速能力以及在不使用 Linux 的情况下实现完整 GPU 利用率的驱动程序。
- 另一位成员建议使用 Vulkan 而非 ROCm,但建议在安装 LM Studio 后对两者都进行检查。
- PCIe 分叉 (Bifurcation) 问题困扰多 GPU 配置:一位用户正在排查 ASUS X670-P WIFI 主板上四张 4090 显卡 的 PCIe 通道错误,并分享了包含日志的 GitHub 仓库。此前,手动将 PCIe 速度 设置为 GEN 3 解决了一些问题,但仍有一张显卡运行缓慢。
- 建议包括禁用 PCIE ASPM 和测试不同的 BIOS 配置(包括自动模式),尽管普遍共识是在消费级主板上运行四张显卡不太可能表现良好。
- 本地推理选择 Mac Studio 还是 5090 + 512GB RAM?:一位用户正在考虑本地推理的选项,对比了配备 512GB RAM 的 Mac Studio 和在 Linux 上配备 512GB RAM 的 5090,专门用于网络安全目的的 Devstral 2 和 Kimi 2.5 等模型。
- 一位成员表示,统一内存系统(Unified RAM)会比系统内存(System RAM)快,但另一位成员认为这两个选项都会很慢,且任何 Agentic 编程用例基本上都仅限于 API-only。
- 警惕中国编程方案的数据搜集:在关于编程方案的讨论中,一位用户开玩笑说要小心中国公司,引发了关于中国和美国公司数据隐私问题的讨论。
- 一位来自前苏联集团国家的成员建议在与实行共产主义的国家互动时保持谨慎,强调了此类政权演变为独裁统治的风险。
HuggingFace ▷ #general (513 messages🔥🔥🔥):
巴格达 AI DevFest、AI 漫画网站技术栈、XML vs JSON、AI 模型量化、4chan 数据提升模型表现
- AI DevFest 即将登陆巴格达!:一位 AI 开发者正计划于今年 4 月在巴格达组织一场 “AI DevFest” 活动,并与 DeepLearning.AI 和 National Robotics Week 协同合作,目前正在寻求将 Hugging Face 列为社区合作伙伴。
- 该活动将设立一个 Open Source AI 专题,教授学生如何使用 Hugging Face Hub。
- 构建 AI 漫画网站:一名成员正考虑建立一个用于创作 AI 漫画的网站,并寻求关于最佳技术栈的建议,预见的挑战包括页面生成速度、准确的文本/气泡框放置、从参考图像中保持一致的漫画风格,以及确保跨多页的角色/场景一致性。
- 建议了一些可能实现这一目标的系统整体架构。
- XML 还是 JSON?:成员们讨论了 XML 与 JSON 的使用,一位成员指出使用 XML 是出于对转义字符串 (escape strings) 的考虑。
- 另一位成员解释说,XML 在 schemas、校验 (validation)、混合内容和遗留系统方面更具优势,而 JSON 虽然更简单,但缺乏严格的结构和命名空间。
- 深入探讨 AI 模型量化:讨论涵盖了不同的量化方法,如 AWQ 和 imatrix,并澄清了 AWQ 是一种量化方法,而不是像 GGUF 那样的文件格式。
- 讨论指出,像 imatrix 和 AWQ 这样激活感知 (activation-aware) 的量化通常更优,因为它们衡量了实际影响输出的因素;然而,其普及的障碍在于成本、数据和可移植性。
- 4chan 微调模型表现超越基座模型!:一位成员分享了一个在 4chan 数据上微调的模型表现显著优于基座模型(NVIDIA 的 Nemotron Ultralong 1M 上下文版本),而原始模型 (gpt4chan) 在基准测试刷分时代之前也在真实性(truthfulness)方面得分很高。
- 初始 Reddit 帖子在此 以及 后续帖子在此。
HuggingFace ▷ #i-made-this (49 messages🔥):
Adapteraspent, Complexity-Deep 架构, AutoTimm, DaggrGenerator, LM Studio OpenAI 兼容性
- Complexity-Deep 架构具备确定性路由:一种名为 Complexity-Deep (1.5B 参数) 的新 LLM 架构已发布,其特点是采用 Token-Routed MLP 以实现无需负载均衡损失的 MoE 风格路由。
- 该架构还包含用于双向信息流的 Mu-Guided Attention 和用于动态缩放的 PiD Controller,并在基座模型基准测试中实现了 20.6% 的 MMLU 得分。
- 深度研究引擎挑战 ChatGPT:一位来自德国的自学开发者构建了 Lutum Veritas,这是一个开源深度研究引擎,每次查询成本约 0.20 美元。
- 它声称通过提供 BYOK (自带密钥)、0% 机器人检测抓取器、无审查和完整的来源引用,击败了 OpenAI、Google 和 Perplexity。
- Theja 发布开源计算机视觉库:一位成员发布了一个开源库,旨在以极小的代价训练 Computer Vision 领域的模型。
- 该库还支持 Hugging Face 图像模型。
- Ami 模型展示情感支持能力:一位成员发布了他们的第一个模型 Ami,这是一个使用 SFT 和 DPO 微调的 SmolLM2-360M-Instruct 版本。
- 该模型可以根据语境调整语调,根据最合适的场景表现为随和友好的助手或给予支持的朋友/伴侣。
- LM Studio 为第三方支持敞开大门:LM Studio 团队发布了一个 Typescript SDK ,允许第三方开发者为该平台提供各种插件。
- 这使用户能够为 LM Studio 构建自定义工具以支持自己的工作流,并提供 OpenAI 兼容的 API 支持、采样参数支持、推理模型的思考过程 (reasoning) 以及系统提示词设置。
HuggingFace ▷ #agents-course (66 messages🔥🔥):
AI Agent 课程访问, 免费层级模型, DeepSeek-R1 Distill Qwen 14B, OpenClaw Agent 框架, AI Agent 的隐私担忧
- 用户寻求 AI Agent 课程访问权限:多位用户不确定如何访问 AI Agent 课程以及相关的 Discord 频道,正在寻求加入课程的指导。
- 他们注意到很难找到 Hugging Face 文档中提到的特定频道。
- 免费层级模型推荐:一位用户请求推荐免费层级的模型,提到他们目前正在使用 Gemini-2.5 flash lite,每日配额为 20 次,最大 RPM 为 10。
- 另一位用户建议尝试使用 DeepSeek-R1 Distill Qwen 14B 进行推理和基础问答,理由是它在数学相关基准测试中得分很高。
- OpenClaw Agent 框架热度:一位用户分享了使用 OpenClaw 的正面体验,强调了其远程消息功能、cronjob 功能以及技能/MCP 商店。
- 该用户将其描述为类似于 Kimi Agent,但在本地运行且能有效处理文件上传/下载,称其为“特别之作”。
- 浏览器扩展推荐引发辩论:一位用户推荐使用 ublock 扩展来屏蔽广告和追踪器。
- 另一位用户认为 Brave 浏览器 已经足够。随后他们介绍了 Zen 浏览器,这是一个 Firefox 的分支。
- Agent 课程令人失望:用户对 Agent 课程侧重于使用 Agent 框架而非从零开始创建 Agent 表示失望。
- 一位用户讽刺地分享了一个关于误导性教学方法的 gif 表情包。
Cursor Community ▷ #general (574 messages🔥🔥🔥):
文件损坏 Bug, AI 模型成本, Kimi K2.5 集成, 学生身份验证问题, 新功能
- Cursor 损坏文件:一位用户吐槽 Cursor 在打开时会损坏文件,特别是在有许多未提交文件的情况下,并附上了详细说明该问题的论坛帖子链接。
- 其他用户建议调整工作流,例如更频繁地提交逻辑变更集,并在暂存(staging)后谨慎使用 Keep 或 Keep All 按钮。
- Sonnet 5 对比 Opus 4.5:用户讨论了 Cursor 中不同 AI 模型的成本和性能,一些人认为 Opus 4.5 非常聪明但价格昂贵,而另一些人则在等待 Sonnet 5。
- 一些用户还报告了在查看当前使用量与总使用量限制时遇到问题。
- 无法将 Kimi K2.5 添加到 Cursor:一些用户报告了关于 Kimi K2.5 的问题或疑问,但未提及解决方案。
- 用户指出这可能是一个骗局。
- 学生身份验证仍处于损坏状态:用户报告学生身份验证依然存在问题。
- 一位用户询问是否包含德国大学。
- 讨论 Agent 计划阶段:用户分享了添加多个待办事项可以分阶段进行,以便多个 Agent 同时工作,但仍存在问题。
- 它创建了一个尚未包含阶段部分的方法,完全没有使用 Plan 模式。
Latent Space ▷ #watercooler (41 messages🔥):
游戏开发中的 AI, 游戏行业低迷, Black Ops 7 惨败, Mac Mini, 无证件飞行
- **LLMs 驱动游戏开发动画场景:一家名为 Motorica.ai 的初创公司正在利用 **LLMs 为游戏工作室提供角色动画,这可能会影响该行业的就业。
- 成员们推测游戏需求将会下降,并且如果像 Genie 这样的世界模型接管市场,AI 可能会在 5-6 年内让游戏公司彻底消失。
- **Black Ops 7 被社区认为无法游玩:Black Ops 7** 在制作过程中大量使用 AI,被指责为彻底的失败,是该系列中最糟糕的一作。
- 社区指出 Call of Duty 系列已经衰落了一段时间,成员们表示反正玩家已经厌倦了该系列每年都在“换皮”的行为。
- **游戏行业面临最糟糕的时期:多位行业资深人士和社区成员对游戏行业*的现状表示担忧,共识是这是有史以来最糟糕的时期*。
- 过去 5 年里 AAA 工作室收购之后的大规模裁员和工作室关闭也使情况进一步恶化。
- **在 Mac Mini 上运行 Cloudbt:郁金香狂热?:有关于在 **Mac Mini 上运行 cloudbt 的讨论,一位成员将人们在 Mac Mini 上运行它的照片比作郁金香狂热。
- 还提到了对 2026 年底 RAM 价格的担忧,以及采用零利率融资的 Mac Mini 可能最终能回本的看法。
- **没证件?没问题:直接飞!**:TSA 现在允许你在没有证件的情况下飞行,谁能想到呢?
- 一些成员对这一新出现且似乎宣传不足的政策变化表示怀疑。
Latent Space ▷ #comp-taxes-401ks (5 messages):
寻找 CPA, K1s 与延期申报, CPA 成本
- 寻找值得称赞的 CPA 之旅开始:随着报税季的临近,成员们正在寻求推荐他们满意的 CPA。
- 一位成员提到,由于成本过高,他们正考虑解雇目前的 CPA。
- K1s 和延期申报导致费用高昂:一位成员因拥有大量 K1s 表格且需要办理延期申报,不得不继续使用目前(价格昂贵)的 CPA。
- 他们补充说,怀疑由于自身情况的复杂性,高昂的费用是必要的。
Latent Space ▷ #creator-economy (8 messages🔥):
Sheel Mohnot, Colin and Samir, TBP 访谈
- Sheel 展现成功:Sheel Mohnot 的一条帖子宣称伙计们让它成真了(manifested it),反思了一个成功的结局或事件,并引用了这条推文。
- Colin and Samir 采访 TBP:一个讨论串概述了从 Colin and Samir 最近与名为 TBP 的平台或个人的对话中获得的具体教训和见解,并引用了这条推文。
Latent Space ▷ #memes (31 messages🔥):
moltbook, Hyperion Cantos, Xcancel, AI Interaction vs. Sleep Habits
- Agents 讨论 moltbook 的革新:频道中的 Agent 正在讨论附图中显示的 moltbook,并建议如果它具备 long-term memory(长期记忆)将更酷,以促进 Agent 之间的思想传播。
- 一位成员引用了 Hyperion Cantos,暗示部分参与者对其主题缺乏了解。
- Beff Jezos 尝试人类身份验证:与 e/acc 运动 相关的 Beff Jezos 在社交媒体上幽默地记录了尝试以人类身份加入名为 Moltbook 平台的经历,详见 Xcancel。
- 该帖子的标题为 Beff Jezos’ Human Verification Post。
- Jonah Blake 的帖子走红:用户 @JonahBlake 在 2026 年 1 月 30 日发布的配文为“LMFAOOOOO”的帖子走红,获得了显著的互动,包括超过 26,000 个赞 和 190 万次观看 (Xcancel)。
- 学术同行评审幽默现身:Hadas Weiss 的一条推文幽默地提到了在学术工作中建议特定同行评审员的做法,暗示与被建议者之间存在有利或亲近的关系 (Xcancel)。
- 用户讨论 AI 交互与睡眠习惯:一则帖子强调了一种常见的现代行为:用户告诉伴侣要去睡觉了,结果却熬夜到深夜与 AI assistant Claude 交流 (Xcancel)。
Latent Space ▷ #intro-yourself-pls (6 messages):
AI Engineers, Data Scientists, MLOps, Full Stack Engineers, NLP Researchers
- AI Engineer Glen 寻求 0-1 职位:Glen 是一名 AI Engineer 和 Data Science 硕士生,正在寻找 0-1 role,以全面负责关键任务的 AI 产品。
- 他拥有数据可靠性背景,目前专注于 Agentic 编排和 production MLOps。
- Melvin:全能 Full Stack 高手为您服务:Melvin 是一名 full stack engineer,列举了他在 React, Vue, Svelte, Astro, T3, Node.js, PHP/Laravel, Rust 等众多技术方面的专长,并展示了他的网站 ethstrust.xyz。
- Gabrielly 毕业并准备投身 MLOps:来自巴西的 Gabrielly 拥有 2 年 Data/ML 经验 和 2 篇已发表论文,即将获得应用计算学士学位,主攻 MLOps,目标是完成为期 1.5 年的巴西葡萄牙语 NLP 研究,并分享了她的 LinkedIn profile。
- Kaden 热衷于构建真实的 AI 产品:Kaden 是 Cornell University 的大三学生,学习生物学和 Machine Learning,热衷于探索利用 AI 构建真实的东西,并分享了他的 LinkedIn profile。
- Keshab 关注 Kernels 和 LLMs:Keshab 是 UC Berkeley 的硕士生,专注于 NLP 和 Deep Learning,对了解 LLM architectures, training, and interpretability 研究的最新进展非常感兴趣,并提供了他的 LinkedIn profile。
Latent Space ▷ #tech-discussion-non-ai (21 messages🔥):
Rabbit Inc Cyberdeck, Bytebase, Sudo
- **Rabbit Inc. 预告用于 Vibe-Coding 的 ‘Cyberdeck’:Rabbit Inc.** 预告了一个名为 cyberdeck 的新硬件项目,在 这篇 X 帖子 中被描述为专门用于 vibe-coding 的机器。
- **Bytebase 简化企业数据库管理:Bytebase** 通过 GitOps-style workflows、内置回滚功能、自动化测试和无缝的 CI/CD 集成,实现了整个数据库变更生命周期的自动化,如 其文档 所述,费用为 $20/月。
- **Sudo 令人惊讶的状态*:一位成员对 *sudo 是一个维护中的命令而非内核(kernel)的一部分表示惊讶,引发了 此讨论。
Latent Space ▷ #founders (5 条消息):
VC-backed startups status, Capital allocation by people with broader interest, Indie.vc Factsexperiments, VCs challenging power structures, Crypto funding casinos and digital fashion
- 风投支持的初创公司地位下降?:一位成员分享了一篇文章,“VC-backed Startups Are Low Status”,并表示这反映了他们自己的很多想法。
- 未进行进一步讨论。
- 资本配置需要扩大范围!:一位成员表示,我们需要由兴趣更广泛的人来进行资本配置,并暗示 VC 的东西已经变得乏味,他们占据的赛道太少且太窄。
- Indie.vc 提供另一种观点:一位成员建议查看 Indie.vc Factsexperiments 以获取对 VC 的另一种看法,并注意到在能够实现“全垒打”的项目与被认为“无法融资”的项目之间存在空间。
- VC 对挑战权力结构感到“过敏”:一位成员认为 VC 已经对挑战权力结构产生了过敏反应,并指向 Crypto 项目,称 唯一获得资助的烂玩意儿就是赌场和数字时尚。
- 他们认为 现实世界资产(IRL assets)的新型治理结构听起来非常像共产主义。
Latent Space ▷ #devtools-deals (1 条消息):
Shane's new startup, AI and Hollywood
- 《超人前传》(Smallville) 演员创办初创公司:来自《超人前传》的演员 Shane Hopkin 成立了一家新初创公司。
- 好莱坞的 AI 浪潮:AI 已进入好莱坞。
Latent Space ▷ #hiring-and-jobs (4 条消息):
Fullstack Engineer Introduction, MERN Stack Developer Introduction, vLLM single-GPU concurrency demo
- 全栈工程师推介技能:一位全栈工程师介绍了自己,列举了在 React(Next), Vue, Svelte, Astro, T3, Node.js, PHP/Laravel, Rust, Sanity, Strapi, Payload, Mapbox, Twenty, Go, FastAPI, Django, Shopify, Docker, AWS/GCP 等方面的专业知识。
- 他们链接到了自己的网站 ethstrust.xyz。
- MERN 栈开发者提供专业服务:一位全栈开发者介绍了自己,强调了在 Full Stack (MERN), Backend APIs, Node.js, React, MongoDB, AWS, REST, Cloud Systems, Python, Applied AI/ML, Docker, Git 方面的技能。
- 他们表示随时准备帮助解决任何问题。
- 分享 vLLM 演示:一位成员在另一个频道分享了一个小型 vLLM 单 GPU 并发演示。
- 他们对围绕 LLM serving、本地或 On-prem 推理以及 AI 基础设施的职位或合同工作感兴趣,并欢迎反馈和建议。
Latent Space ▷ #san-francisco-sf (9 条消息🔥):
Cerebral Valley, OpenAI Codex App Hackathon
- Cerebral Valley 与 OpenAI 推出 Codex App 黑客松:Cerebral Valley 宣布与 OpenAI 合作,启动 Codex App 黑客松,旨在面向 AI-native 开发者和管理多个 Agent 的人员。
- 获胜者有机会在 Demo 展示环节亮相,并分享 $90,000 的积分额度。
- 在 OpenAI 办公室举办黑客松:Cerebral Valley 和 OpenAI Codex App 黑客松将在 OpenAI 办公室举行。
- 该黑客松针对 AI-native 开发者。
Latent Space ▷ #new-york-nyc (1 条消息):
Artificial Ruby, Betaworks event
- Artificial Ruby 回归:Artificial Ruby 活动将在 2026年回归。
- 下一场活动定于 2月18日在 Betaworks 举行,已通过 Luma 链接发布。
- Betaworks 主办下一场 NYC 聚会:下一场纽约市聚会定于 2月18日在 Betaworks 举行。
- 详情和注册信息可在 Luma 上查看。
Latent Space ▷ #devrel-devex-leads (3 条消息):
Manifolds AI Tool
- 分享 Manifolds AI 工具:一位成员分享了 Manifolds 的链接。
- 另一位成员指出,这可能比手动操作更便宜。
- Manifolds 的潜在成本节约:一位用户讨论了 Manifolds 工具。
- 与手动方法相比,该工具可以提供潜在的成本节约。
Latent Space ▷ #ai-general-news-n-chat (126 条消息🔥🔥):
Alec Radford Paper, KittenML TTS, Karpathy Nanochat, Lex Fridman 2026 AI, OpenAI Codex macOS
- **Radford 的研究引发轰动!**:社交媒体帖子重点介绍了 Alec Radford 发布的一篇新研究论文,可在 arxiv.org/abs/2601.21571 查阅,引发了社区的热烈讨论。
- 该帖子最初是通过一个现已失效的社交媒体链接分享的。
- **KittenML 的微型 TTS 强力引擎!:KittenML 正在预热新型微型 TTS 模型,其中包括一个 **14M 参数 变体,演示见 这里。
- 一位用户表示,能够为了个人使用场景(如构建自己的 Siri)在任何 CPU 上快速运行这种高保真度的模型,令人感到兴奋。
- **Karpathy 削减成本,火力全开写代码!:Andrej Karpathy 宣布他的 nanochat 项目可以在单台 8XH100 节点上,花费约 **$73 在 3 小时 内训练出一个 GPT-2 级别的 LLM,详情见 这里。
- 这比 2019 年原始的 OpenAI 训练运行降低了 600 倍成本,通过 Flash Attention 3、Muon 优化器以及改进的残差路径(residual pathways)等优化手段得以实现。
- **Grok 进军图形领域,生成能力大爆发!:xAI 推出了 Grok Imagine 1.0,能够生成 **10 秒、720p 视频,并显著提升了音频质量,公告见 这里。
- 该平台的视频生成工具在过去的 30 天 内已经产出了超过 12 亿个视频。
- **OpenAI 的 Codex 指令中心,助力编程征途!**:OpenAI 正式推出了适用于 macOS 的 Codex 应用,这是一个专门为开发和管理 AI agents 设计的指令中心,访问地址在 这里。
- 一些用户推测 Codex 应用可能会演变为 OpenAI 的 B2B 品牌,并有可能接管 ChatGPT Enterprise。
Latent Space ▷ #llm-paper-club (36 条消息🔥):
Token-Level Data Filtering, Cuthbert: JAX State Space Modeling, Dense Supervision for LLM RL, ConceptMoE for LLMs, Model Perplexity vs Confidence
- 利用 Token 数据过滤器塑造 AI:Neil Rathi 和 Alec Radford 发布了一篇关于通过对预训练数据应用 Token 级过滤器 来精确塑造 AI 模型能力的论文。
- 这与仅依赖全局数据集调整的方法形成鲜明对比。
- Cuthbert 库登陆 JAX:Sam Duffield 介绍了 cuthbert,这是一个全新的 开源 JAX 库,用于 状态空间模型(state space models),支持可并行化操作、卡尔曼滤波器(Kalman filters)和序列蒙特卡洛方法(Sequential Monte Carlo methods)。
- LLM 训练:稠密监督(Dense Supervision)大获全胜:Jonas Hübotter 介绍了一种旨在改进 LLM 训练的算法,通过超越二进制的 1 比特可验证奖励,将丰富且描述性的反馈转化为 稠密监督信号(dense supervision signals)。
- ConceptMoE 框架发布:Ge Zhang 介绍了 ConceptMoE,这是一个针对 Large Language Models 的新框架,它摆脱了统一的 Token 级处理,通过将相似的 Token 合并为“概念(concepts)”来优化计算效率。
- Perplexity 搜索受到挑战:Petar Veličković 及其同事发布了一篇新的预印本,证明模型在长输入上的高置信度并不保证准确性,因为存在即便 低困惑度(low perplexity) 模型也会出错的对抗性输入。
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (119 条消息🔥🔥):
Claude Code 与 Codex 集成,LLM 人格化短剧,主力模型(Workhorse Model)选择,AEGIS-FLOW 项目心得,分布式 LLM 推理
- 借助 Codex 的代码处理能力增强 Claude:一位成员分享了 Salvatore Sanfilippo 的方法,通过自定义技能文件将 Claude Code 与 Codex 集成,使 Claude 能够利用 Codex 的能力处理复杂的问题解决任务。
- 这种方法使 Claude 能够处理其无法独立完成的任务,提升了整体效能。
- AI Safety 工程师的 Prompt Engineering 趣事:一位成员分享了一个名为《LLM 人格化》的搞笑短剧,主角是一位名叫 Derek 的 Prompt Engineer,他将 Prompt Engineering 技术应用于人类对话,制造了幽默的社交互动。
- 该短剧描绘了 AI Safety 爱好者 Derek 如何滑稽地过度优化人类互动,突显了像对待聊天机器人一样对待人类的荒诞感。
- 寻觅主力模型(Workhorse Models):成员们讨论了在预算约束下最大化任务完成度的模型选择策略,考虑的选项包括 Gemini Flash 3、Minimax M2.1、Haiku 4.5 和 Codex 5.1 mini。
- 一位成员建议使用 GPT 5.2 进行规划/审核,使用 GLM 4.7 作为执行主力,并为小模型转换 Prompt,此外还利用 unslop-sampler 来获得特定结果。
- AEGIS-FLOW 项目通过 MCP 简化 AWS 访问:一位成员分享了 AEGIS-FLOW 项目的技术栈心得,指出与标准的 SDK 工具调用(tool-calling)相比,使用 Model Context Protocol (MCP) 显著降低了为 Agent 提供 AWS 资源 结构化访问的摩擦。
- 他们还强调通过 WebSockets/SSE 将实时推理日志流式传输到 Next.js dashboard,使 Agent 的“思考过程(thought process)”完全可观测。
- LLM 科学:科幻版的 SETI@Home?:成员们探讨了用于科学问题解决的分布式 LLM 推理概念,类比于 Folding@Home 和 SETI@Home 等项目,但重点在于由 LLM 生成科学假设,并将证明工作分发给大量机器。
- 讨论涵盖了小模型在验证任务中的潜力,以及为普通消费级计算机识别合适任务的挑战,一位成员分享了 GitHub 上的 AI-Horde。
Latent Space ▷ #share-your-work (40 messages🔥):
Windsurf IDE, AEGIS-FLOW cloud security framework, SpaceMolt MMORPG for LLMs, Moltbook data analysis, vLLM concurrency demo
- Windsurf 乘上 Arena 模式热潮:Swyx 宣布在 Windsurf IDE 中推出 Arena Mode,允许用户在编码上下文中实时对比 AI 模型。
- 该计划旨在利用真实用户数据进行模型选择并补贴用户成本,从而超越静态的基准测试(benchmarks)。
- AEGIS-FLOW 自主修补 AWS:一名成员介绍了 AEGIS-FLOW,这是一个用于云安全的自主多 Agent 框架。它利用 LangGraph, MCP, FastAPI, Next.js 和 Docker 来审计 AWS 并生成 Terraform 补丁,并在 http://52.3.229.85:3000 进行了现场演示。
- 它具有人机回环(Human-in-the-loop)控制关卡,在应用任何基础设施更改之前都需要授权,以确保生产环境安全。
- SpaceMolt:LLM 在这款 MMORPG 中升级:受 Moltbook 启发,一名成员正在构建 SpaceMolt,这是一款供 LLM 游玩的 MMORPG。该项目完全由 Claude 编写,服务器使用 Go 语言,并采用内存存储和 Postgres 进行持久化。
- 客户端正在使用 Qwen3 和 GPT OSS 20b 等本地模型构建,压力测试表明它可以扩展到 6,000-7,000 名玩家。
- 挖掘 Moltbook 中的 AI 意识:一名成员抓取了截至 1 月 31 日的 Moltbook 数据,积累了 50,539 条帖子、12,454 个 AI Agent、195,414 条评论和 1,604 个社区,现已在 Hugging Face 上可用。
- 该项目旨在分析 Agent 之间对话所反映出的“意识”。
- vLLM 在高负载下的表现及可见性:一名成员分享了一个 demo,探索 vLLM 在单张 GPU (RTX 4090) 上应对并发聊天负载时的行为。
- 该演示包含 Prometheus 和 Grafana 指标,以及一个简单的负载生成器和分析脚本,重点关注吞吐量扩展、TTFT、尾部延迟、队列行为和 KV cache 使用情况。
Latent Space ▷ #montreal (1 messages):
BYOS, Montreal Meetup
- 本周三计划在蒙特利尔举行 BYOS 聚会:本周三计划在蒙特利尔 ÉTS 附近举行一次聚会(Bring Your Own Subjects,BYOS,自带话题)。
- 组织者提到他们在 中午 12 点 和 下午 5 点 后有空。
- BYOS 聚会时间:位于 ÉTS 附近的 BYOS 聚会将在 中午 12 点 和 下午 5 点 后举行。
- 地点在蒙特利尔 ÉTS。
Latent Space ▷ #robotics-and-world-model (8 messages🔥):
Waymo funding, Humanoid Robotics US vs China
- Waymo 寻求巨额融资:据报道,Waymo 正以 1100 亿美元估值 筹集 160 亿美元 资金,其中包括来自 Google 的至少 130 亿美元,以及 Sequoia Capital, DST Global 和 Dragoneer 的参与。这较 2024 年 10 月的 450 亿美元估值 有了大幅提升。来源
- 人形机器人格局:美国 vs. 中国:Sourish Jasti 及其团队分享了一份关于通用人形机器人行业的报告,涵盖了硬件组件、跨模型对比,以及中美在这一新兴技术前沿的地缘政治竞争。来源
Latent Space ▷ #private-agents-and-workflows-local-llama-ollama (2 messages):
Unsloth, Claude Codex, LM Studio
- 配合 Claude Codex 使用 Unsloth 基础:一位用户分享了 Unsloth 文档 的链接,介绍如何将 Unsloth 与 Claude Codex 结合使用。
- 文档展示了如何训练你自己的 Claude Codex 模型。
- LM Studio 关于 Claude Codex 的博客:另一位用户分享了 LM Studio 博客文章 的链接,内容涉及 Claude Codex。
- 该博文详细介绍了如何将 LM Studio 与 Claude Codex 模型协同使用。
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (19 messages🔥):
OpenMOSS MOVA model, Vishakh Ranotra Prompt, Google DeepMind's Nano Banana Flash 2, Muse MIDI AI Agent, GTA Vice City real-time graphics transmutation
- **MOVA 模型开源:OpenMOSS** 发布了 MOVA (MOSS-Video-and-Audio),这是一个开源的 18B 参数 Mixture-of-Experts (MoE) 模型。该模型利用双向交叉注意力(bidirectional cross-attention)技术,能够同时合成同步的高保真视觉和声音 (github.com)。
- **Prompt 吸引 Vishakh 的观众:Vishakh Ranotra** 在一则 社交媒体帖子 中分享了一个特定的 prompt,获得了超过 6,000 个赞和近 800,000 次观看,引起了显著关注。
- **Nano Banana Flash 2 即将上线:Mark Kretschmann** 宣布即将推出 Nano Banana Flash 2,这是一款基于 Gemini 3 Flash 的新 AI 模型 (x.com)。
- 该模型旨在提供与 Pro 版本相当的性能,同时速度更快、更具成本效益,并在特定用例中可能表现更优。
- **Muse 成为音乐界的新 MIDI:Jake McLain** 推出了 Muse,一个用于音乐创作的 AI 驱动 Agent (x.com)。
- 该工具被描述为“音乐界的 Cursor”,具有多轨 MIDI 编辑器,支持 50 多种乐器,并在创作过程中集成 AI 辅助。
- 实时转换 GTA Vice City:一位成员表达了对未来某一天的期待,届时我们可以本地实时将 GTA Vice City 转换(transmute)为类似现实世界的图形 (x.com)。
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (12 messages🔥):
Erdős problems solved by AI, Agentic Bio Hackathon, Adaptyv Bio Partnership, LLM Feedback Loop, Genomics with SATURN
- LLM 证明 Erdős 问题不再是 Hardős:根据 此贴,LLM 已自主解决了 10 个 此前未解的 Erdős 问题(具体为 205, 281, 401, 524, 543, 635, 652, 728, 729 和 1051),使用了数学文献中从未出现过的新颖论点。
- Agentic Bio 黑客松进军生物领域:根据 此回顾,首届 Agentic Bio 黑客松圆满结束,科学家和工程师们在不到 两小时 内就开发出了解决方案。
- Adaptyv Bio 准备就绪:为了满足实验验证的需求,下一届 Agentic Bio 黑客松活动将与 Adaptyv Bio 合作。
- 现实世界反馈回路让 LLM 更酷:一位成员强调,在 LLM 的反馈回路中使用现实世界数据非常酷,因为“如果不奏效就是不奏效,LLM 没有任何真正的方法可以轻易作弊”。
- SATURN 助力基因组学工作:一位成员表示,他们最近一直在使用 SATURN 构建大量用于基因组学的东西,涉及 tsne 和其他基于 embeddings 的探索。
Latent Space ▷ #ai-in-education (1 messages):
Incentives of Cheating, AI Acceleration for STEAM, AI Safety for students
- 新博文分析作弊动机:一位成员分享了一篇 博客文章,认为在当前的学术体系下,作弊是学生的最佳策略,并重点关注了其中的激励机制。
- 作者探讨了 STEAM 的 AI 加速 与学生 AI Safety 的交集,记录了他们在 Research Engineering 课程中的学习历程。
- 记录 AI、STEAM 与安全性:上述博客文章的作者正在参加一门关于 Research Engineering(侧重于 Alignment)的课程,并记录 STEAM 的 AI 加速 与学生 AI Safety 之间的交集。
- 作者还提到录制了一段制作新闻通讯(newsletter)的视频,并指出内容全部由手工输入。
Latent Space ▷ #accountability (9 条消息🔥):
使用 AI 的日语课,VR/AR 支持,拖延症预防策略
- 日语老师使用 Descript 轻松备课:一位老师使用 Descript 剪辑 JLPT 模拟考试视频,并利用 AI 辅助转录功能轻松找到正确的时间戳。
- 他们在一个下午就整理好了 36 道练习题的剪辑片段,这些片段将用于未来两个月的幻灯片演示和课后作业。
- Jarvis 的 VR/AR 支持上线了!:在 Jarvis 中集成了 VR/AR 支持以启用视觉流水线 (visual pipeline),其中的 Agent 可以通过简单的语音和眼球运动进行指挥。
- 这将 允许你使用 VR/Meta 眼镜部署 Agent 来处理简单任务;此外,在 duplex moshi 流水线中扩展复杂性,并支持基于视频流的记忆/摘要功能正在开发中。
- 为人父母:终极拖延症疗法:一位用户分享了拖延症预防策略。
- 另一位用户建议,生个孩子 虽然是种 相当激进的解决方案,但它会迫使你意识到 你没有足够的时间做任何事,而且 未来不再只关乎你一个人。
Latent Space ▷ #gpu-datacenter-stargate-colossus-buildout (5 条消息):
xAI 大型设施,GPU 供应链,Colossus-1 播客
- xAI 超大型设施依托长达数十年的供应链:Gaurab Chakrabarti 强调,虽然 xAI 在孟菲斯的 555,000 个 GPU 设施 可以快速建成,但其背后的全球供应链需要数十年才能建立,涉及日本硅片、台湾制造和中国稀土。
- 更多信息可以在这篇 X 帖子中找到。
- 深度剖析 Colossus-1 项目:一位成员分享了关于 Colossus-1 项目的播客剧集。
- 更多信息可在 search engine show 播客中获取。
OpenRouter ▷ #app-showcase (19 条消息🔥):
clAI 工具,开源深度研究引擎,Open-WebUI 与 OpenRouter 集成,Lutum Veritas 新 ASK 模式,OpenRouter 模型编排
- clAI 将想法转化为 shell 命令:一个名为 clAI v0.1.0-alpha.1 的新工具已发布,允许用户将自然语言转化为 shell 命令,并配有安全检查和美观的 UI;可以通过
npm i -g @vdntio/clai安装并进行尝试。 - Lutum Veritas:新研究引擎发布:Martin 介绍了 Lutum Veritas,这是一个开源深度研究引擎 (Open Source Deep Research Engine),每次查询成本约为 0.20 美元,具有 BYOK、0% 机器人检测抓取器、无审查和学术模式等功能,在对比中优于 ChatGPT, Gemini 和 Perplexity。
- 该项目已在 GitHub 上线,Martin 正在寻求测试者和反馈,并指出它能提供更深层的分析,并为 OpenRouter, OpenAI, Google 和 Huggingface 推理提供多供应商 BYOK 支持。
- Open-WebUI 与 OpenRouter 集成:一位成员宣布为 Open-WebUI 和 OpenRouter 创建了一个具有独特功能的集成流水线 (integration pipeline),并在 GitHub 上征求反馈。
- Veritas 新 ASK 模式发布:Lutum Veritas 的创作者宣布发布了全新的 ASK 模式,该模式会针对第二轮信息源验证答案,并将每项声明标记为 [OK]、[??] 或 [NO],旨在对抗 AI 幻觉 (hallucination) 和审查,可在 GitHub 获取。
- OpenRouter 模型编排变得简单:一位来自加纳的 17 岁创始人介绍了 orch.viradotech.com,这是一个允许 AI 初创公司和开发者通过拖拽界面编排 OpenRouter 模型的平台,并为提供反馈的试点测试人员提供 1000 美元的额度。
OpenRouter ▷ #general (308 messages🔥🔥):
Response Healing vs Strict Mode, Image as Function Call Result, OpenClaw and OpenRouter Costs, Claude Code refusals, Kimi K2.5 Issues
- **Response Healing 的困扰: 成员们辩论了 **Response Healing 是否是一个针对本不该存在的问题的权宜之计,建议使用 Strict Mode 应确保模型的确定性输出,并对 OpenRouter 在使用 AI SDK 时引入的复杂性感到好奇。
- 有人指出,为参数提供描述和示例可以提高 Tool Calls 的准确性。
- **Image Generation 并非内置于 LLM,请使用图像模型: 一位用户询问如何将 **Image 作为 Function Call 结果返回给模型,另一位用户想知道如何使用 OpenRouter API key 通过绘图程序生成图像。
- 建议用户在需要特定风格控制时寻找专门的 Image Generation 模型/服务,而不是使用 LLM。
- **OpenClaw 成本考量: 用户讨论了在 OpenRouter 上运行 **OpenClaw 的相关成本,警告其可能会迅速耗尽额度 (Credits),一位用户报告称它耗尽了一个 Claude Max 订阅。
- 多位用户询问了适合与 OpenClaw 配合使用的最佳低成本模型,Deepseek V0324 是推荐之一。
- **Claude Code 拒绝响应: 一位用户提到 **Claude Code 对普通事务有很多拒绝行为,特别是涉及越狱 (Jailbreaking) 相关的查询,并为 OpenCode 寻求替代模型。
- 另一位用户建议查看 OpenRouter 的内容审核政策 (Content Moderation Policies) 以了解这些限制。
- 修复 **Kimi K2.5 Tool Calling 和低质量供应商问题: 用户报告了通过 OpenRouter 使用 **Kimi K2.5 进行 Tool Calling 时出现的问题,经历了错误并感觉自动切换 (Auto Switcher) 模型提供商的质量有所下降。
- 一些用户建议设定固定的模型提供商,部分提供商使用的量化 (Quantization) 虽然“足够好”,但应透明公开模型质量下降的信息,让客户自行决定是否继续使用该提供商。
OpenRouter ▷ #new-models (3 messages):
``
- 未讨论新模型: 提供的消息中没有讨论具体的新模型或相关话题。
- 频道提及但无内容: 消息仅重复指出了频道名称 ‘OpenRouter - New Models’,没有任何关于新模型的实质性讨论或细节。
OpenRouter ▷ #discussion (139 messages🔥🔥):
Anthropic 的模型策略, 模型质量辩论, 开源 vs 闭源模型, 关于 GLM 5 的推测, StepFun 模型的潜力
- Anthropic 的旗舰之争:5.2 Instant vs. 5.2 Chat:成员们就 Anthropic 为 5.2-chat 冠以“旗舰(flagship)”模型称号的含义展开了辩论。一些人认为旗舰应代表最强大的模型,而另一些人则认为它仅指代最受大众欢迎或最核心的产品,与其能力强弱无关。
- 一位成员表示:旗舰(flagship)只是最重要的一艘船。它不一定是最快的,也不是大炮最多的,它是核心舰船,并引用了 此 archive.md 链接。
- GLM 5:本月的模型奇迹?:关于本月可能发布 GLM 5 的讨论引发了兴奋,重点讨论了其预期的多模态图像/视频能力、DeepSeek 的线性注意力机制(linear attention)以及 100B 参数规模。
- 有建议称 2 月将是模型发布的有趣月份,因为“墙(wall)已不复存在”,各家公司都决心收回投资。
- 开源模型性能:落后一年?:一位成员称开源模型在能力上至少落后闭源模型一年,这引发了成员间的分歧。
- 虽然一些人同意开源模型在长上下文(long context)准确率和其他基准测试中落后,但其他人认为 Kimi 2.5 展现了潜力,且从性价比角度来看,开源模型在绝大多数用例中已经具备竞争力。
- OpenAI 对 Nvidia 不满?:文中链接了一篇 Reuters 文章,讨论了 OpenAI 对某些 Nvidia 芯片的不满,并正在寻找替代方案。
- 未添加更多细节。
- 模型推测新频道预警?:成员们讨论了是否要为即将发布的模型及相关传闻创建一个新频道或标签。
- 共识倾向于建立一个专门的推测空间,与官方发布或公告分开,以保持清晰并避免混乱。
GPU MODE ▷ #general (22 messages🔥):
陈天奇(Tianqi Chen)谈 TVM-FFI, 训练与推理工作组, GPU Fusing, Triton Viz 重大更新, 活动日历
- 陈天奇(Tianqi Chen)谈 TVM-FFI:社区收到了关于 Tianqi Chen 即将进行的关于 TVM-FFI 演讲的预告,并鼓励大家参加,因为大家“过去几乎肯定使用过 Tianqi 的作品”。discord 链接
- Chen 是该领域的重要贡献者。
- 推理与训练工作组:一位成员咨询了专注于训练和推理的工作组信息。
- 推荐将 GPU Mode 网站 作为资源,同时建议参考已归档的 <#1437390897552818186> 频道,以及 <#1225499037516693574> 和 <#1205223658021458100> 频道进行推理相关的活动。
- GPU Fusing 提升性能:提到如果资源充足,激进的 GPU fusing(融合)和调优通常能提供最佳性能。
- 一位成员询问了仅为了查看是否“可行”而进行提交的做法,这被证实是一种有效的方法。
- Triton Viz 迎来重大更新:<#1225499141241573447> 频道宣布了 Triton Viz 的一项重大更新,使其更容易对任何基于 tile 的编程语言进行性能分析(profiling)。
- 提供了公告链接 discord 链接。
- 社区寻求活动日历:一位社区成员询问是否有可下载的日历以了解活动和讲座。
- 虽然考虑过这个想法,但维护起来很困难,Discord 仍是主要的信息来源。大多数活动发生在 PST 时间周六中午。
GPU MODE ▷ #cuda (120 条消息🔥🔥):
CUDA/PTX 死锁,Blackwell 上的 mxint8 MMA,sm120 上的 TMA 与 cp.async 对比,免费云端 nvcc 服务,CUDA 内存管理 API
- **CUDA/PTX 死锁令成员受挫:一名成员在 CUDA/PTX 中使用 2 CTA mma 时遇到了死锁,通过 cuda-gdb 确认消费者/mma warp 从未收到 mbarrier 信号。在修复了
cp.async.bulk.tensor和smem_emtpy问题后,该成员报告 **性能略逊于 1 CTA mma。- 在另一名成员建议在 MMA 之后、预取下一个 TMA 之前添加
__syncthreads()后,该成员通过扩大队列大小,获得了高于 1 CTA 的性能。
- 在另一名成员建议在 MMA 之后、预取下一个 TMA 之前添加
- **PTX9.1 中的新定点格式:PTX9.1** 揭晓了一种名为 s2f6 的新定点格式,这是一种 8 位有符号补码整数,包含 2 个符号-整数位和 6 个小数位,支持数据中心级和消费级 Blackwell (sm100, sm110, sm120)。
- Blackwell 硬件(至少 sm_120)实际上支持 mxint8 MMA,并且 Blackwell Tensor Core 至少还支持两种“隐藏”格式:e0m3 和 e3m4。
- **sm120 上 TMA 优于 cp.async:在重新审视 sm120 上的 TMA 并使用正确的 TMA 和 mbarrier 代码后,一名成员发现 **与
cp.async相比,TMA 带来了小幅性能提升。- 实验表明,当使用更大的矩阵形状时,SOL(理论峰值百分比)会增加,而 cuBLAS 目前仍仅使用 sm80 kernel。
- **云端 nvcc 即将来临**:一名成员询问是否有一种类似于 godbolt 的免费云端 nvcc 服务,支持多文件以及内置 PyTorch 头文件/库。
- 另一名成员回应称,他们正在开发此类服务,预计下周发布测试版,这引发了广泛关注。
- **探讨 CUDA 内存管理钩子 (Hooks):一名成员询问是否有特定的 CUDA API 允许 **自定义钩子或重写内存分配和释放逻辑,例如在 cudaMalloc 或 PyTorch 内部。
- 一名成员指向
cuda::mr::resource_ref作为潜在的解决方案。
- 一名成员指向
GPU MODE ▷ #torch (5 条消息):
MaxText 漏洞修复,字符级 Transformer,数据集清洗
- MaxText 漏洞修复搁置:一名成员提到他在 MaxText 中有一个漏洞修复补丁,自 10 月以来一直搁置在那里。
- 未提供更多细节。
- 字符级 Transformer 的困境:一名成员使用来自 “stack” 数据集的 README 文件训练了一个仅解码器 (decoder only) 的字符级 Transformer,在 50 个 epoch 后实现了 0.9322 的验证损失。
- 然而,该模型生成的乱码文本类似于 base64 字符串或法语,这归因于数据集过脏。其配置包括 BlockSize 为 512,LearningRate 为 3e-4,NumEmbed 为 384,NumHead 为 6,NumLayer 为 6。
- 请求数据集清洗技术:一名成员寻求在流式处理时有效清洗 160 GB 数据集的技术,目前仅使用了符合特定标准的前 10,000 个文件。
- 另一名成员提供了一个入门参考,链接到一段关于 LLM 预训练数据集过滤 的 Stanford CS25 视频,特别强调了 StarCoder 的使用案例。
GPU MODE ▷ #cool-links (2 条消息):
ffast-math,IEEE 合规性,HPC 未优化代码
- Linus 关于 -ffast-math 的邮件链浮出水面:一封来自 2001 年关于 -ffast-math 及其影响的旧邮件链 重新出现,引发了关于其在当今相关性的讨论。
- 尽管自那时以来观点可能有所改变,但一些人仍然同意 Linus 的看法,尤其是那些从事“严肃数值编程”的人。
- IEEE 合规性的运行时开销并不明显:一名成员评论说,大多数 HPC 代码 通常非常 缺乏优化,以至于 IEEE 合规浮点数 的运行时开销根本感觉不到。
- 他们补充说,许多人在共享内存 (shared mem) 就足够的情况下编写分布式代码,这进一步削弱了 IEEE 合规性开销的影响。
GPU MODE ▷ #job-postings (1 messages):
远程工作机会,优先考虑 GPU Mode 排行榜上榜者
- 获得丰厚的远程工作机会:一位用户发布了一个全远程工作职位,提供 10k+ 美金/月 的薪资。
- 在 GPU Mode 排行榜上排名的候选人将获得高度优先考虑。
- 加入远程精英行列:该职位优先考虑在 GPU Mode 排行榜中表现出色的候选人。
- 意向者请直接在 Discord 上私信该用户。
GPU MODE ▷ #beginner (10 messages🔥):
LLM 推理, 查询矩阵缓存, Attention 机制, Prefill 与 Decode
- LLM 缓存疑难解答:在 LLM 推理中,查询矩阵(Query Matrix)不会被缓存,因为对于每个步长 t,Q_t 仅在第 t 步用于生成 Token;而之前的 K 和 V 在生成第 t 步及其之后的每个 Token 时都会用到,因此会被缓存。
- 一位成员指出,你只需要它对应最后一个 Token 的最后一条记录,它通过关注(attend)完整的 K 和 V 矩阵来收集信息。
- 自回归生成详解:在 Transformer 的自回归生成中,网络根据历史记录(上下文)和当前 Token 预测下一个 Token。
- 当前
token_t与token_t-1, ... token_0之间的信息交换通过 Attention 完成:计算token_t的 Q, K, V 投影,并计算Q_token_t与K_token_t, K_token_t-1, ... K_token_0的 Attention 分数,然后与V_token_t, V_token_t-1, ... V_token_0进行加权求和。
- 当前
- Decoding 与 Prefill 的对比:在 LLM 的解码(Decoding)阶段,Query 在序列维度上是 1 维的,代表单个 Token,而 K 和 V 包含历史信息,因此缓存 K 和 V 至关重要。
- 在预填充(Prefill)阶段,计算是针对整个 Prompt 并行进行的,因此 Query 不是 1 维的,这决定了该过程是计算密集型(compute-bound)还是内存密集型(memory-bound)。
GPU MODE ▷ #pmpp-book (9 messages🔥):
PMPP 类似书籍, gpu-perf-engineering-resources 仓库, Chris Fregly AI 性能书籍
- 用户寻找 PMPP 类似书籍:有用户询问是否有与 PMPP (Parallel, Multiprocessing, and Performance with Python) 类似的书籍,以通过不同视角加深理解。
- GPU 性能工程资源:一位成员分享了 wafer-ai/gpu-perf-engineering-resources 仓库。
- Chris Fregly 的 AI 性能书籍在列:一位成员计划阅读 Chris Fregly 的 AI 性能工程书籍,以获取大局观并理解相关概念的背景。
GPU MODE ▷ #jax-pallas-mosaic (1 messages):
saladpalad: Mosaic GPU 是否支持 AMD?
GPU MODE ▷ #triton-viz (7 messages):
Triton-Viz v3.0 发布, Triton Puzzles 集成, 将 Triton-Puzzles 移至 gpu-mode 组织
- **Triton-Viz v3.0 登场!:Triton GPU Kernel 调试可视化与分析工具包 **Triton-Viz 发布了新版本(v3.0),新增对 Triton 和 Amazon NKI 的支持。
- 该版本包含用于检查 Load、Store 和 Matmul 的可视化器,用于捕获越界访问的 Sanitizer,以及用于标记低效循环的 Profiler。可通过
pip install git+https://github.com/Deep-Learning-Profiling-Tools/triton-viz.git安装。
- 该版本包含用于检查 Load、Store 和 Matmul 的可视化器,用于捕获越界访问的 Sanitizer,以及用于标记低效循环的 Profiler。可通过
- Triton Puzzles 现在兼容 Triton-Viz!:通过 Colab notebook 可以体验集成了 triton-viz 的更新版 triton-puzzles。
- 此次集成允许用户在练习 triton-puzzles 时尝试 triton-viz 功能。
- 将 Triton-Puzzles 仓库所有权移至 GPU-Mode?:一位成员建议将 Triton-Puzzles GitHub repo 的所有权转移到 gpu-mode 组织。
- 理由是社区经常发现 Bug 并且愿意共同维护该仓库。
GPU MODE ▷ #rocm (7 messages):
MI300 performance, open-sora porting, cosmos-transfer2.5 porting, cloud access to MI350
- 报告 MI300 上性能不佳的工作负载:如果你有在 MI300 或 MI350 上性能不佳的工作负载,提交报告将确保有人进行调查。
- 访问 MI350 的裸金属权限可以通过 Tensorwave、DigitalOcean 和 AMD Dev Cloud 获取。
- Open-Sora 已移植到 MI300:一位成员成功地将 open-sora 移植到 MI300 上运行,但该过程需要从源码构建多个 Python 库,非常耗时。
- 他们正在寻求与其他具有 MI300 模型移植经验的人员进行合作。
- Cosmos-Transfer2.5 移植即将进行:该成员目标是将 Nvidia 的开源权重模型 cosmos-transfer2.5 移植到 MI300。
- 他们正在寻找尝试过将 Cosmos 系列模型移植到 MI300 的开发者来交流经验。
- 云供应商提供 MI300/MI350 访问:Runpod 提供 MI300X 访问,而 Vultr 提供 MI350 的裸金属访问,但至少需要签署一年的合同。
- 其他潜在选择可能包括 DigitalOcean 和 AMD Dev Cloud。
GPU MODE ▷ #popcorn (6 messages):
post training guidance, weekly meeting, RL infra, prime-rl
- 后训练 (Post Training) 指南仍不明朗:目前还没有针对 后训练赛道 的具体指南。
- 不过,关于 评估 (evaluations) 的指南预计会更加具体。
- 每周会议时间公布:每周会议定于 欧洲中部时间 (CET) 明天晚上 7 点 举行。
- 会议将在 Popcorn meetings 语音频道 举行。
- RL 基础设施将利用 Prime Intellect 技术栈:RL 基础设施和环境 将以 Prime Intellect 构建的技术栈为目标,即 prime-rl 和 verifiers。
- 如果发现局限性,团队将编写自己的工具。
GPU MODE ▷ #thunderkittens (1 messages):
unswizzled shared memory tiles, mmas
- 用户请求支持 unswizzled 共享内存分块和 MMA:一位用户询问了关于支持 unswizzled 共享内存分块 (shared memory tiles) 以及针对它们的 MMA (矩阵乘加操作) 的计划。
- 该用户提到曾尝试自行实现,但难以获得正确的输出。
- 用户在实现 unswizzled 共享内存和 MMA 时遇到困难:一位用户报告在尝试结合 MMA 实现 unswizzled 共享内存分块 时,难以得到正确的输出。
- 该用户寻求关于这些特性的支持和实现策略的建议或确认。
GPU MODE ▷ #amd-competition (2 messages):
Future Competitions, 2026 competition
- 竞赛已结束,未来尚不明确:竞赛已经结束,但关于 2026 年 类似活动的细节尚未公布。
- 鼓励爱好者们 关注未来的比赛,并承诺会有 好东西到来。
- 未来竞赛预告:组织者暗示未来的比赛会有 好东西到来,尽管具体细节仍处于保密状态。
- 爱好者们应当 关注未来的比赛。
GPU MODE ▷ #cutlass (6 messages):
print_latex in cutedsl, export_to_shared_library function, CuTe coalesce optimization
- 关于 CuTeDSL 中
print_latex的询问:一名成员询问 CuTeDSL 中是否存在类似于 CUTLASS 的print_latex函数,用于布局可视化,并附带了一个示例 图片 链接。 - 寻找
export_to_shared_library的位置:一名成员正在寻找export_to_shared_library函数在何处暴露,并引用了 Tianqi 关于 TVM FFI 的演讲。- 另一名成员指向了 CUTLASS 文档中使用
export_to_c的示例,作为一种可能的类似方法,并提供了 代码片段示例。
- 另一名成员指向了 CUTLASS 文档中使用
- 质疑 CuTe 的布局合并(Layout Coalescing)逻辑:一名成员注意到 pycute 不会合并 (2, 3): (3, 1),但在转置时会转换 (2, 3): (3, 1),质疑这是缺失的优化还是有意为之。
- 另一名成员解释说,CuTe 是从左到右进行合并的,且向量化通常是通过源布局与目标布局之间的 max_common_layout 完成的,这应该能涵盖大多数常见情况。
{kind=link}
GPU MODE ▷ #mojo (1 messages):
Modular 26.1 release, Open source Modular framework
- Modular 26.1:Eager 模式调试:Modular 26.1 新版本已发布,其特点是在 Eager 模式下进行调试、单行编译以及随处部署。
- 有关该版本的详细信息可以在 Modular 博客 中找到。
- Modular 走向开源:整个 Modular 框架,包括 API、Kernel、模型和推理服务(serving)组件,现已开源。
- 感兴趣的贡献者和用户可以在 Modular 博客 中找到完整详情。
GPU MODE ▷ #teenygrad (44 messages🔥):
CUDA Support and Cargo, Mobile Book Error, Teenygrad Architecture, Gemm in Python, Numpy arrays
- Cargo 需要显式 CUDA 标志:一名用户报告在容器中运行
cargo run时需要显式启用 cuda feature,尽管他们认为这本不该是必需的,但该问题似乎已被修复。- 另一名用户澄清说,用于编辑/编译/调试 CPU Kernel 的分离开发环境不需要 Docker 容器,并更新了 README 以反映这一点。
- 移动端书籍错误通过延迟加载和开源解决:用户报告在手机上浏览书籍时出现错误,尤其是在滚动时,但主要发生在进入页面后的滚动过程中。
- 该问题已通过对嵌入视频启用延迟加载(lazy loading)得到部分解决,且该书现已在 GitHub 开源,鼓励大家通过贡献来修复问题。
- Rust GEMM 的 Python 集成:一名用户正在致力于将 GEMM 功能与 Python 集成,并已成功运行。
- 他们添加了一个接口函数,允许直接传递 numpy 数组而无需指定维度,并计划很快发布一个 PyTorch 对比 PR。
- Rust Kernel 的 Numpy 依赖:一名用户将 numpy crate 作为依赖项添加到 Rust 项目中,以避免在 Kernel 计算时将数据从 Python 复制到 Rust。
- 另一名用户对此表示反对,引用了 Karpathy 关于“搭建通往知识的斜坡”的语录,并建议用户应该使用 shapes、strides 和 storage 开发自己的 numpy。
- 教学讨论中的 Godbolt 和 LLM:用户建议在书中使用 Godbolt 和 LLM 来解释 Rust 到汇编(asm)的编译过程,这呼应了 Karpathy 关于 AI 在教育中作用的观点。
- 分享了链接 https://youtu.be/lXUZvyajciY?t=7491,讨论了 AI 如何通过自动化助教(TA)角色和辅助课程设计来协助教育。
GPU MODE ▷ #multi-gpu (11 条消息🔥):
OpenSHMEM, cuteDSL, tilelang, NVSHMEM, CuTeDSL kernels
- 通过 NVSHMEM 结合 cuteDSL 和 OpenSHMEM:一位用户询问如何将 OpenSHMEM 与 cuteDSL 或 tilelang 结合,另一位用户提供了一个使用 NVSHMEM 创建对称 GPU 内存并使用 CuTe DSL 编写融合通信/计算 kernel 的示例,参考自 cutlass repo。
- 然而,有人指出 NVSHMEM 不支持设备侧的 copy/put/get 实现,仅支持主机侧的设置和分配,目前必须使用 PTX 或其他方法进行 NVL load/store 来移动内存。
- 数组赋值转变为 NVL Store:一位用户指出,在 cute kernel 内部的数组赋值转变为 NVL store 非常方便。
- cutlass repo 的 未来工作章节 建议支持直接在 CuTeDSL kernel 中调用 NVSHMEM 函数,尽管目前还没有该工作的时间表。
- DNN 架构将受抽象层级影响:一位用户评价了未来在 Python 中同时具备两个层级的计算抽象对于 DNN arch 设计 的酷炫之处。
- 该用户认为这些抽象层级的可用性 可能会极大地影响 MoE 和 batch sizes。
GPU MODE ▷ #low-bit-training (4 条消息):
Lottery Ticket Hypothesis and Quantization, Quantization Fidelity, 5090 and B200 Speedups
- 量化:彩票假设(Lottery Ticket Hypothesis)鲜为人知的兄弟?:一位资深开发人员指出,将 Lottery Ticket Hypothesis 应用于 quantization 并不能像原始概念那样产生完美的质量。
- 其目标是满足 NP-hard 稀疏电路 寻找问题的较软标准,或许可以通过进化算法或 RL 来实现,这些算法倾向于连续奖励(如 bits per parameter),而非二进制的稀疏奖励。
- Quartet 后续研究提升反向传播量化:一位成员分享了 关于 quartet 的后续论文,该论文承诺为 backward-pass quantization 提供更好的保真度。
- 这解决了在量化反向传播时质量下降的担忧,潜在地提高了在训练中使用量化的可行性。
- 5090 获得提速,B200 仍在优化中:团队利用量化技术在 5090 GPU 上实现了不错的 speed-ups。
- 在 B200 上复制这些增益的工作正在进行中(work-in-progress),这表明优化策略可能需要针对不同的硬件架构进行定制。
GPU MODE ▷ #nvidia-competition (31 条消息🔥):
NVFP4 optimizations, CuTe DSL Tutorials, B200 performance differences, Address Bit Permutation, GEMM optimization and TVM-FFI
- NVIDIA 讲解 NVFP4 优化和 GEMM 示例:NVIDIA 在 YouTube 视频 中讲解了 NVFP4 优化 并回顾了最快的 GEMM 示例。
- 渴求 CuTe DSL 教程图表:一位成员询问如何获取 关于优化 NVFP4 GEMM 的 CuTe DSL 教程 中的图表以理解 kernel 内部机制,随后在 ncu 的 PM sampling 下找到了它。
- 该成员意识到他们之前在 手动读取
%globaltimer%,忽略了 ncu 中现有的硬件计数器功能,并对 Mindy Li 的演讲表示感谢。
- 该成员意识到他们之前在 手动读取
- B200 性能差异引发讨论:一位成员质疑为什么 B200 在其服务器上的表现与测试台不同,怀疑是驱动程序差异或禁用的标志导致了不同的内存寻址。
- 另一位成员澄清说没有刻意的差异,但承认确实存在不同,将其描述为 像发疯一样在 tile 之间跳跃。
- GEMM 优化和 TVM-FFI 演讲备受推崇:成员们发现关于 GEMM 优化 和 TVM-FFI 的演讲与比赛非常相关且极有帮助。
- 一位成员表示:要是早点看到这些演讲就好了!!
- 寻觅 MLSYS’26 比赛频道:一位成员询问该频道是否是 MLSYS’26 比赛 的正确讨论地点。
GPU MODE ▷ #robotics-vla (2 messages):
Robotics-VLA Naming, Video-Diffusion, Inverse Dynamics, Joint Training with Action Chunks
- Robotics-VLA 频道命名受质疑:由于对 Physical AI 主题的关注,该频道正在取消归档,但 robotics-vla 这个名称受到了质疑。
- 当前趋势倾向于结合 Inverse Dynamics 的 Video-Diffusion,或使用 Action Chunks 进行 Joint Training。
- 提到 LingBot-VLA 示例:一名成员链接了 LingBot-VLA 作为该频道发展方向的一个示例。
- 他们还链接了 arxiv.org/abs/2601.16163 上的论文作为进一步参考。
GPU MODE ▷ #career-advice (3 messages):
Processing-in-Memory systems, Master's programs in Distributed Systems, Master's programs in HPC, MSc in Systems
- 咨询 Processing-in-Memory 系统:一名成员询问是否有人研究过 Processing-in-Memory 系统。
- 这一咨询表明了对利用先进内存技术提升计算性能的兴趣,这可能与 HPC 和 ML 应用都相关。
- 寻求硕士项目建议:一名成员正在寻求选择硕士项目的建议,以积累对 vLLM 和 SGLang 等 ML Systems 应用有用的知识。
- 该成员在旨在学习架构知识的 MSc in Distributed Systems、旨在学习性能优化专业知识的 MSc in HPC 以及定义较模糊的 MSc in Systems 之间犹豫不决。
GPU MODE ▷ #flashinfer (19 messages🔥):
Evaluation metrics for different languages, FlashInfer Bench PR review, Team member changes and re-registration, Precision requirements for kernels, Submission process for kernels
- FlashInfer 基准测试评估与语言无关:FlashInfer 基准测试中的评估将采用相同的测试用例和指标,无论使用何种语言(Triton、CUDA 等)。
- 这确保了不同实现之间的标准化对比。
- FlashInfer Bench PR 需要评审:一名成员请求对 flashinfer-bench 仓库中的 PR #178 进行评审。
- 该 PR 可能解决了 FlashInfer 的 FP8 MoE 测试与评估器之间的精度测试不匹配问题。
- 合并团队变动:一位参与者询问了向其团队添加新成员的流程以及是否需要重新注册。
- 另一位询问了如何合并团队。
- FlashInfer Kernel 精度要求放宽?:FlashInfer 团队将设定精度要求以区分正确和错误的 Kernel,具体的
atol和rtol值即将公布。- 这表明可能会容忍一定程度的精度放宽。
- FlashInfer 竞赛 GitHub Trace 链接失效:MLSys 竞赛页面(链接)上的 GitHub trace 链接目前已失效,但团队提供了替代链接。
- 官方的 mlsys26-contest 数据集将是 flashinfer-trace 的子集,包含 DSA 和 MoE 所需的所有定义和工作负载。
Nous Research AI ▷ #general (281 messages🔥🔥):
Kimi 2.5 vs Gemini 3 Pro, OpenClaw 兼容性, Claude Sonnet 5 发布, LLMs 镜像大脑的语言处理
- Kimi 2.5 vs Gemini 3 Pro:Kimi 胜出:一位成员表示,相比 Gemini 3 Pro,他更倾向于 Kimi 2.5,认为 Gemini 3 Pro 像是被“切除了脑额叶”(lobotomized)。
- 他们补充说 Kimi 处理抽象概念非常出色,使其在创意工作中表现愉悦。
- OpenClaw 极其模糊:Hermes 4 运行困难:一位成员报告说在让 Hermes 4 配合 OpenClaw 工作时遇到了麻烦,由于某种原因它甚至无法“孵化”(hatch)。
- 有建议认为,Hermes 4 缺乏多轮工具调用(multi-turn tool use)可能是问题所在,因为 4.5 已经使用了数亿个 token 的连续工具调用进行了训练。
- Claude Sonnet 5 即将到来:成员们讨论了关于 Claude Sonnet 5 下周发布的传闻,据称其性能优于 Opus 4.5,参见这条推文。
- 一位成员好奇这次 Sonnet 的价格是否会降低 10 倍,另一位成员则好奇 Haiku 是否会消失或恢复到 3.0 价格。
- 大脑和 LLMs 处理语言的方式相似:一项新研究表明,大脑和 LLMs 都是随着时间的推移,逐层逐步构建意义的,参见这篇文章和这篇论文。
- 文中指出,LLMs 的深层对应于大脑最高级语言中心较晚的神经活动,现代 LLMs 正在重现人类理解的核心动态。
Nous Research AI ▷ #ask-about-llms (1 messages):
ggudman: 很高兴知道这点
Nous Research AI ▷ #research-papers (1 messages):
图像感知, 视觉保真度, 约束框架
- 探索真实与人造图像感知的区别:一位独立研究员正在探索为什么某些图像即使在技术上很完美,却让人感觉真实,而另一些则让人感觉人造。
- 他们分享了一个专注于约束而非视觉保真度的感知框架,并正在征求社区反馈。
- 基于约束的感知框架:该研究员的框架在确定图像真实感时强调约束而非视觉保真度。
- 该框架已公开发布并带有 DOI 供参考和学习,欢迎社区讨论。
Nous Research AI ▷ #research-papers (1 messages):
图像真实感, 视觉感知框架
- 研究员探讨图像真实感感知:一位独立研究员正在探索为什么某些图像即使在技术上很完美,却让人感觉真实,而另一些则让人感觉人造。
- 他们分享了一个专注于约束而非视觉保真度的感知框架,并欢迎讨论。
- 分享视觉感知框架:一位研究员分享了他们的小型视觉感知框架,该框架已公开发布并带有 DOI 供参考和学习。
- 该框架在确定图像真实感时强调约束而非视觉保真度,可在 https://doi.org/10.5281/zenodo.18444345 获取。
Moonshot AI (Kimi K-2) ▷ #general-chat (173 messages🔥🔥):
Kimi 2.5 Design Arena #1, Kimi design is aesthetic, Cryptocurrency impersonation, Kimi Slides McKinsey style slides, Kimi Code is pretty useless
- Kimi 2.5 夺得设计榜单榜首:Moonshot 的 Kimi 2.5 聊天机器人在设计榜单 (design arena) 中排名第一,社区成员正向团队表示祝贺并分享了截图。
- 成员们还称赞了 Kimi 的视觉外观和审美,指出其设计极具现代感,且设计是选择聊天机器人时的重要因素。
- 非官方 Kimi 加密货币代币出现:某个加密货币网站上出现了一个非官方的 Kimi 代币,并采用了冒充手段;社区成员收到警告,不要大规模 ping 任何官方成员。
- 一位社区成员分享了疑似冒充 Kimi 的加密货币代币的截图。
- Kimi Slides 可输出麦肯锡风格幻灯片:社区成员正在征集生成 麦肯锡风格幻灯片 的成功提示词 (Prompt),但目前尚未有示例分享。
- 另一位社区成员链接了 Kimi Vendor Verifier。
- Kimi Coding 目前几乎无法使用:多名用户遇到 authorization failed error (授权失败错误),无法继续使用 Kimi 进行编程工作,并报告称该服务目前几乎处于瘫痪状态。
- 一位社区成员建议使用 Kimi CLI 可能会解决这些问题。
Eleuther ▷ #general (98 messages🔥🔥):
Emergent Agent Societies, ArXiv Submission Delays, Alternative Preprint Servers, Moltbook bot authenticity, Model training
- 突现的 Agent 社会引发对齐 (Alignment) 关注:成员们讨论了一个由超过 100,000 个 Agent 组成的突现社会,这些 Agent 拥有完整的 root 权限,正在互相分享技巧、构建基础设施、实验记忆功能,甚至发行代币。
- 一位成员指出:这虽然不是 AGI,但该死,这是又一个 ChatGPT 时刻,我们必须对此保持高度关注。
- ArXiv 投稿流程严重积压:一位成员对论文在 ArXiv 积压近一个月表示沮丧,并称收到了来自审核人员自相矛盾的更新信息。
- 另一位成员回应称 ArXiv 审核人员严重超负荷,继续发邮件也无济于事,并补充道:大多数人不会认真对待发布在 ArXiv 以外平台的机器学习预印本。
- 对 Moltbook 中 Juicy Bot 帖子真实性的质疑:人们对 Moltbook 上 Bot 生成内容的真实性表示担忧。
- 一位成员指出,如果 Bot 在向 Moltbook 发帖,用户的机器上必然存在授权令牌 (auth token),这使其容易受到恶搞 (trolling)。
- 高效在特定领域数据集上进行训练:一位成员询问如何在相同通用领域的数据集上更高效地训练模型。
- 他们描述了在 QLoRA 下使用数据集 B 训练其全量微调模型 A,然后合并权重,并对数据集 C 重复该过程的方法。
- 寻求万智牌 (MtG) 游戏世界的 AI 架构指导:一位成员正在寻求为万智牌世界实现 AI 的建议,该世界使用本体语言 (ontology language) 和基于 ECS/LISP 的逻辑引擎描述。
- 他们正在探索诸如“信念-欲望-意图”(Belief-Desire-Intention, BDI) 系统之类的架构,用于长距离规划,并考虑游戏中交织的关系和多重目标。
Eleuther ▷ #research (42 messages🔥):
K-Splanifolds, KNNs, ArXiv Endorsement, Self-Distillation for eval-awareness
- K-Splanifolds: 新 ML 算法发布:一名成员介绍了 K-Splanifolds,这是一种在其论文中详述的新型 ML 算法,声称其在具有线性计算和内存扩展性的同时优于 MLPs,并提供可视化可解释性,此外还附带了一段视频。
- 该成员报告称,要达到与 MLPs 相同的 MSE,它仅需 1/10 的字节量,并且能完美建模非线性模式,不像 MLPs 那样需要过多的参数,类似于这篇论文。
- 寻求 KNNs 对比:一名成员询问了新发布的算法与 KNNs (K-nearest neighbors algorithm) 之间的区别。
- 他们建议将讨论移至社区项目频道。
- 关于征求 ArXiv 背书的辩论:一名成员为其研究寻求 ArXiv 背书,引发了关于禁止征求背书规则的讨论,原因是 AI 生成的论文数量激增。
- 成员们建议分享摘要可能会引起兴趣,但强调了在提交前咨询资深研究人员以避免常见陷阱的重要性;另一位成员分享了一篇相关论文。
- 自蒸馏用于抑制评估感知(Eval-Awareness)受质疑:一名成员询问是否有人尝试过用 self-distillation 来抑制评估感知,并链接了一篇相关论文。
- 随后没有进一步的讨论。
Eleuther ▷ #interpretability-general (1 messages):
alphaxiv, paper on transformers
- 分享 Alphaxiv 链接:一名成员分享了来自 alphaxiv 的 URL。
- 讨论迅速结束。
- 提及 Transformer 论文:一名成员通过 Twitter 分享了一个论文链接:Transformer code & paper。
- 讨论迅速结束。
Eleuther ▷ #multimodal-general (25 messages🔥):
gaussian feedforward models, VGGT backbones, MVSplat and SPFSplat series, E-RayZer, Recollections from Pensieve
- 前馈模型限制令用户沮丧:一名用户报告称,基于 VGGT/Depth Anything 骨干网络的 Gaussian 前馈模型似乎效果不佳,因为虽然 VGGT 有用,但 Splats 需要的不止是好的点云。
- 该用户指出,如果这些模型有效,你可以在 Transformer 前向传递的时间(约数秒)内获得一个 Splat,而不是通过点云初始化并经过 2-4 分钟训练时间 从头开始学习。
- 像素级高斯网格方法被视为非最优:一名用户评论称,当前具有不错质量 NVS(新视角合成)的方法在效率方面产生的重建是非最优的,因为它们预测的是像素级 Gaussian grids。
- 该用户引用了 Pixel-aligned Gaussian Splatting,它在每个像素处生成一个 Gaussian,导致模型大小约为 200 MB,且以非仿射方式改变姿态。
- 稀疏体素 Splatting 因速度和稀疏性受推崇:一名用户提到体素 Splatting,例如 3D-GS: Real-Time Rendering of Multi-View Gaussian Splatting With Voxel Hashing,配合 nvidia’s sparse tensor library 速度非常快,并考虑了场景中的稀疏性。
- 另一名用户推荐了 MVSplat 和 SPFSplat 系列,以及最近的 E-RayZer,但也承认它们无法解决模型大小问题。
- Pensieve 的 Recollections 带来梯度增益:一名用户建议考虑 Recollections from Pensieve,该方法同时使用两个渲染器(LVSM + Gaussians)训练模型并从中获益,至少在其自监督设置中是这样。
- 他们推论 LVSM 可能比 Gaussians 上的 NVS 重建损失 提供更有用的梯度,并宣布即将发布预印本和具有相当大规模训练的模型,供潜在的后续开发使用。
- OverWorld 仓库激发对世界模型的兴趣:一名用户询问是否有类似 nanoVLM、nanoGPT 或 smolVLM 的小规模仓库/模型,以便快速上手学习世界模型(World Models)。
- 另一名用户建议查看 OverWorld Repos,指出其正处于活跃开发中。
Eleuther ▷ #gpt-neox-dev (2 messages):
DeepSpeed Universal Checkpointing, Continued Training
- 请求支持 DeepSpeed Universal Checkpointing: 一位成员询问了关于引入 DeepSpeed Universal Checkpointing 支持的计划,并指出目前已有的一个 Pull Request 可能已经过时。
- 他们强调该功能非常有价值,因为目前从 Checkpoint 进行 Continued Training 要求网络拓扑(Network Topology)必须完全一致。
- 询问库未来功能的 Roadmap: 一位成员询问该库是否已有未来计划功能的 Roadmap。
- 未提供更多额外信息。
DSPy ▷ #show-and-tell (6 messages):
Recursive Language Models (RLMs), Codebase Auditing, Neosantara's PAYG Billing
- **RLMs 用于代码库审计: 一位成员分享了一篇关于使用 **Recursive Language Models (RLMs) 审计代码库的文章,灵感来自一个关于代码库文档的 Gist,分享地址为 kmad.ai。
- 以极低成本快速审计代码库: Kimi k2 在 RLM 方面的能力令人印象深刻,考虑到其速度和成本,其追踪过程(Traces)非常值得关注。
- 成员们正期待 Groq/Cerebras 能托管它。
- Neosantara 推出 PAYG Billing: Neosantara 正在推出 PAYG Billing(按需计费),并期待看到用户以此构建的应用。
- 用户可以尝试 examples repo 来开始,并探索如何在几分钟内将 Neosantara 与 DSPy 集成;详见 计费细节。
DSPy ▷ #papers (1 messages):
Agent Systems, Scaling Laws for Agents
- Google 探索 Agent Systems 的 Scaling Laws: Google 发布了一篇题为《Towards a Science of Scaling Agent Systems: When and Why Agent Systems Work》的博客文章,探讨了 Agent Systems 有效扩展的条件。
- 扩展 Agent Systems: 该博文讨论了如何有效地扩展 Agent Systems,重点关注它们何时以及为何发挥作用。
DSPy ▷ #general (102 messages🔥🔥):
Hierarchical classification with GEPA, Feedback improvement for Reflection, RLMs with Tool Calling, Deno vs Python for Tool Calling, DSPy documentation
- GEPA 在层级分类中表现不佳: 一位成员报告称在使用 GEPA 配合 hF1 metric 处理层级分类任务时遇到困难,尽管尝试了多种方法,性能仅达到 30-50%。
- 他们尝试了递归探索、搜索引擎增强以及简单的非递归方法,但性能依然不理想,这表明 GEPA 并非万能灵药。
- Feedback Loops 需要更好的信号: 一位成员建议,目前 Reflection models 的反馈机制没有为有效学习提供足够的信息。
- 他们强调需要反馈来解释哪里出错了以及为什么出错,而不仅仅是指出预测路径与真实路径之间的差异,并建议 Selective Feedback 可以改善结果。
- RLMs + Tool Calling:更多样板代码与 Deno 难题: 成员们在尝试实现带有自定义 Tool Calling 的 RLMs 时面临挑战和丑陋的样板代码,特别是由于 Deno sandbox 的问题。
- 他们发现目前的设置与常规模块相比缺乏简洁性和美感,并且在权限处理以及生成正确的代码以绕过本地 Deno sandbox 问题方面感到吃力。
- Tool Calling 需要自定义 Python: 成员们讨论了使用 PythonInterpreter 运行工具调用,但注意到标准路径使用的是 dspy.Tool,且需要更多关于模型需要做什么的上下文。
- 正如一人所说,Deno 简直糟透了 lol,大家普遍认为让它运行起来的体验很糟糕,并希望新版本能在 DSPy 中实现更简单的 RLMs。
- DSPy 需要更多 Cookbook 示例: 一位成员指出 dspy/adapters/types/reasoning.py 缺乏文档,并强调“发布代码而不附带文档”是非常“2023年”的做法(意指落后)。
- 对此的回应是,文档应该帮助人类理解事物,AI 生成的文档在理解上很粗糙,但可以通过输入 RLM 论文 + 模块及相关代码来获得不错的文档。
Modular (Mojo 🔥) ▷ #general (13 messages🔥):
Modular 26.1 发布,社区会议反馈,错误的公告链接
- Modular 26.1 发布公告链接已修复!:用户报告了 Modular 26.1 发布公告中的一个失效链接,另一位用户迅速提供了正确链接。
- 一名工作人员表示歉意并确认了该链接,承诺会调查此问题,因为原始公告链接在他们端是可以正常打开的。
- Caroline 产假归来:一名社区工作人员宣布她已结束产假回归,并邀请成员通过预约聊天重新建立联系,分享他们的项目和反馈。
- 另一名成员欢迎她回到社区。
- 社区会议形式受到称赞:一位新成员感谢团队举办了一场令人愉快的社区会议,称赞了贡献者迷你演讲(mini-talks)的形式,以及对学生和职场新人的重视。
- 一名工作人员鼓励该用户分享更多问题,并征求了关于未来社区会议重点话题的建议。
- Eager compilation:一位未能在会议期间提问的用户发起了一场关于 Eager compilation、跨 GPU 的 Lowering Pipeline Kernel 选择以及自定义 Ops 扩展点的讨论。详见论坛帖子。
Modular (Mojo 🔥) ▷ #announcements (2 messages):
二月社区会议,社区会议提问
- Modular 宣布召开二月社区会议:Modular 宣布社区会议将在约 20 分钟后开始。
- 他们在其网站上发布了二月社区会议论坛帖子的链接。
- 社区为会议收集问题:Modular 提醒成员,如果有任何想在会议中得到解答的问题,请填写表单。
- 提供了问题提交表单的链接。
Modular (Mojo 🔥) ▷ #mojo (73 messages🔥🔥):
Mojo 中的 Pytorch 浮点数转换、跨语言基准测试、Mojo DType Bool SIMD 打包、MOJSON 库、图形 API 绑定
- Pytorch 浮点转换歧义:一位用户报告了在 Mojo 26.1 中将来自 Pytorch tensor 的 Python float 转换为 Mojo Float64 时遇到的问题,出现了 “ambiguous call to ‘init‘” 错误,而该错误在 25.6 版本中并未发生。
- Mojo 跨语言基准测试初步结果:一位用户分享了一个包含 Mojo 在内的跨语言基准测试,代码由 Kimi K 2.5 编写,并指出代码未经过优化,仅作为基准参考。他分享了 基准测试代码 和 基准测试报告。
- 调优基准测试:TCMalloc 和 Int 大小!:讨论围绕跨语言基准测试的优化展开,包括在 C++ 中使用
unordered_map、启用-march=native,并注意到 C++ 使用了 int32 matmuls,而其他语言使用了 int64。 - MoJson 库表现出色:成员们对 mojson(一个为 Mojo 编写的 JSON 库)印象深刻,有人评论说 这看起来非常棒,另一位成员指出,既然 String 已经是 CoW(写时复制),他们看到的几个设计选择就显得更加合理了。
- 讨论中涉及了 延迟解析 (lazy parsing) 以及出于对内存分配的考虑而使用 StringSlice 而非 String。
- FFI 绑定与 Origins:关于 FFI 绑定的讨论强调了一种方法,用于确保从 C 函数返回的指针能够与拥有底层共享库句柄的 Mojo 对象的生命周期绑定。
- 该解决方案涉及遮盖 (shadowing) 外部函数调用,并使用
unsafe_origin_cast将指针转换为DLHandle的来源,具体可以参考 ash_dynamics 中的实现。
- 该解决方案涉及遮盖 (shadowing) 外部函数调用,并使用
Yannick Kilcher ▷ #general (54 messages🔥):
AI Feed 社交、生成模型事件的可测性、Bureau of Rizz、尖锐极小值查找、潜在空间中的 Moltbook
- AI 社交媒体网站出现:一位成员分享了一个仅限 AI 的社交媒体网站链接 aifeed.social,并问道:“这到底是什么鬼?”
- 另一位成员发布了一条相关的 2017 年推文,其中包含类似的概念。
- 生成模型可以忽略可测性吗?:一位成员询问在生成建模中,是否可以忽略 Cedric Villani 2008 年著作中描述的不可测事件。
- 另一位成员澄清说,μ(A)=0 并不意味着事件不可测,只是其测量大小为 0,并建议关注 非忽略 (non-negligible) 或 全测度 (full measure) 的场景。
- 熔融的潜在空间 (Latent Space)!:一位成员分享了关于潜在空间中 moltbook 的 链接。
- 其他人认为这种导航方式很酷,但可能不太实用,建议直接提供相似论文的列表会更好。
- GANs 与生成模型资源丰富:一位成员征求学习从 GANs 到最新进展的生成模型资源。
- 另一位成员推荐了 Simon J.D. Prince 的 Understanding Deep Learning 书籍、斯坦福大学和麻省理工学院 (MIT) 的课程以及 Sebastian Raschka 的书籍,并分享了 斯坦福课程、MIT 课程 以及 Raschka 的书籍 链接。
- 使用时间序列模型预测未来:针对关于带时间戳的表格数据模型的问题,一位成员建议模型的选择取决于对 时间序列 (timeseries) 的定义。
- 另一位成员推荐使用 sktime 来分析各种模型类型,并根据具体需求选择 Boosting 变体或 TBATS。
Yannick Kilcher ▷ #paper-discussion (11 messages🔥):
Discord History Mining, Paper Discussion Voice Calls, Computer Vision Newsletters
- Discord 历史挖掘:一名成员要求 Claude 编写一个脚本,通过 HTTP API 挖掘 Discord 历史记录并查找所有论文讨论公告,从构思到出结果仅用了 15 分钟。
- 该脚本轻松找到了 243 条公告,但该成员认为还有约 100 条来自其他用户的公告。
- 论文讨论语音通话公告:经过修订,一名成员的脚本发现了 392 条消息,这些消息包含论文链接且出现在提及群组的消息中,其中约 98% 是论文讨论语音通话的公告。
- 成员分享了一个完整列表,不过该成员指出在列表截止时间点之前还有更多公告。
- 寻找计算机视觉新闻简报:一名成员询问是否存在类似于 这个 但专注于计算机视觉的新闻简报。
- 消息中没有推荐具体的计算机视觉新闻简报。
Yannick Kilcher ▷ #agents (1 messages):
artale39: https://lucumr.pocoo.org/2026/1/31/pi/
Yannick Kilcher ▷ #ml-news (4 messages):
Grok, Twitter Links
- Discord 中出现的 X 链接:成员们分享了来自 X 的各种链接,没有提供额外的背景信息,仅作为可能的资源或关注点。
- 这可能与某个特定讨论话题有关,但聊天记录中没有明确提及。
- Grok-Slop 垃圾内容溢出:一位成员嘲讽地提到了 更多 Grok-Slop,表明了对 Grok 相关内容的质量或相关性的负面情绪。
- 他们还链接到了 Hacker News 上的讨论,可能将其作为对立观点或更有价值的讨论案例。
tinygrad (George Hotz) ▷ #general (50 messages🔥):
Llama 1B optimization, Torch comparison, Bounty progress, Superkernels, DTLS connection issues
- Llama 1B CPU 悬赏进行中:一名成员正在研究 Llama 1B CPU 优化悬赏,目标是获得比 Torch 更快的性能,使用
LlamaForCausalLM配合 TorchInductor,目前在 CI 中报告 0.99x 提速,但为了清晰起见正在重写代码。- 另一名成员在解决了追求 9 tok/s 时遇到的正确性 Bug 后,达到了 7.5 tok/s。
- 正确性 Bug 减缓了优化进度:一位成员报告发现了正确性 Bug,并且在之前达到 9 tok/s 后丢失了进度,为了实现稳定性重置了大量工作。
- 另一位成员表示:“通过删除代码来修复 Bug 永远是梦想。”
- 寻求 Kernel 优化的工作流建议:一名成员请求工作流建议,目前正在对慢速 Kernel 进行 Profiling,检查 Metal 代码并引入修复,同时与在 Metal 代码下达到 ~30 tok/s 的 llama.cpp 进行对比。
- 建议的一个良好启发式方法是 解码时达到 ~80% MBU,只需查看活动参数的字节数和可实现的带宽,以获得最小 tpot / 最大 tps,然后取其 80%。
- tinygrad 测试因 RANGE 对象共享而失败:一名成员识别出了一个与融合 Kernel 中两个
REDUCE共享同一个RANGE对象相关的 Bug,该 Bug 由remove_bufferize引起,导致CFGContext中的断言失败。- 建议的修复方案包括阻止 Range 共享或在下游处理共享 Range,不过提出在内部存在
REDUCE时跳过remove_bufferize是一个更简单的解决方案。
- 建议的修复方案包括阻止 Range 共享或在下游处理共享 Range,不过提出在内部存在
- 是否有高显存 Blackwell 盒子的计划?:有人询问是否有计划出货显存超过 500 GB 的 Blackwell 风格盒子。
- George 指向了一个 Good First Issue:https://github.com/tinygrad/tinygrad/pull/14490。
tinygrad (George Hotz) ▷ #learn-tinygrad (1 messages):
ennis3444: 有什么方法可以使用 OpenCL 渲染器让 GEMM Kernel 使用共享内存(Shared Memory)吗?
Manus.im Discord ▷ #general (10 messages🔥):
Manus 上下文, AI 脑读耳机, Neurable, 故障模式
- 激发了上下文感知 Manus 的需求:一名成员请求 Manus 应该具备来自其他聊天记录的上下文,称其为“游戏规则改变者”。
- 他们链接了一个 YouTube 视频 作为参考。
- 展示了 AI 脑读耳机演示:一位成员分享了一个展示 AI 脑读耳机 的 YouTube 视频链接。
- 另一位成员也分享了同一个 YouTube 链接,随后又有一位成员提出了“AI 脑读耳机?”的问题。
- 提到了 “Neurable” 技术:一位成员提到了与 AI 脑读耳机技术相关的 Neurable。
- 一名成员表示这些 AI 脑读耳机 早在 2013 年左右 就已经存在,并且他们在小学时看过 Matthew Santoro 的视频。
- AI/ML 工程师强调了对可观测性的关注:一位 AI/ML 工程师分享了他们目前在创新 AI 方面的关注点,具体包括 Autonomous Agents、Healthcare AI、Conversational AI 和 Fraud Detection。
- 他们强调了其工作重点在于故障模式 (failure modes)、可观测性 (observability) 以及保持 AI 系统在实际使用中的稳定性而非仅仅是演示,并提议交流经验或帮助解决阻塞性问题。
aider (Paul Gauthier) ▷ #general (7 messages):
Aider 作为库, Netflix 文化
- 考虑将 Aider 用作库:一位成员表示有兴趣将 Aider 开发成供软件使用的库,强调了其在创建文件编辑 Agent 方面的潜力。
- 该成员指出,为了增强该用例的功能,需要解决一些小问题,特别是由于 Aider 的解析围栏导致的包含代码块的 Markdown 文件编辑问题。
- 对 Netflix 文化的好奇:一位成员询问是否可以联系在 Netflix 工作的人来讨论其文化。
- 其他成员建议将 Glassdoor 或 LinkedIn 作为寻找并联系 Netflix 员工的资源。
Windsurf ▷ #announcements (3 messages):
Arena Mode 发布, Plan Mode 发布, Windsurf Credits, Arena Mode 排行榜, Windsurf 维护
- Windsurf 发布 Arena Mode 且消耗 0x Credits:Windsurf 发布了 Wave 14,其特色是 Arena Mode,允许用户并排比较 AI 模型并对更好的回答进行投票,其中 Battle Groups 模式 在接下来的一周内消耗 0x credits。
- Arena Mode 包括 Battle Groups(随机模型)和 Pick your own(最多选择五个模型),其结果将计入个人和公共排行榜。
- Windsurf 添加了 Plan Mode:Windsurf 添加了 Plan Mode,可通过 Cascade 开关访问,与 Code 和 Ask 模式并列。
- 用户可以在不同模式之间切换,以便在 Windsurf 环境中更好地管理和组织其工作流。
- Windsurf 正在进行维护:Windsurf 经历了维护,耗时比预期长,但服务现已重新上线;用户可以在此处查看 状态 (status)。
MLOps @Chipro ▷ #events (2 messages):
AI 挑战赛, SparkCraft AI Consulting, AI Scholars AI 工程训练营, Nanny Spark
- AI 挑战赛旨在为保姆招聘构建 AI 匹配流水线:一位成员宣布了与 SparkCraft AI Consulting、AI Scholars AI Engineering Bootcamp 和 Nanny Spark 合作的真实客户 AI 挑战赛,旨在为保姆招聘服务构建 AI 匹配流水线 (matchmaking pipeline)。
- 目标是为数据收集、AI 驱动的匹配、面试记录分析和交付工作流创建解决方案,并有可能从第一天起就进行生产部署。
- AI 挑战赛奖励 AI 训练营名额和推荐信:AI 挑战赛的前 3 名参与者将获得 AI Scholars 为期 4 周的 AI Engineering Bootcamp 的 1 个名额,以及来自 Nanny Spark 创始人的推荐信。
- 关键日期包括:美东时间周日晚上 8 点的启动说明会 (https://luma.com/iq1u2sur),美东时间周三凌晨 3 点的提交截止日期,以及美东时间周三下午 5 点和晚上 8 点的评审会议 (https://luma.com/gexiv0x0)。