AI News
ElevenLabs 以 110 亿美元估值完成 5 亿美元 D 轮融资;Cerebras 以 230 亿美元估值完成 10 亿美元 H 轮融资;从 Vibe Coding(氛围编码)转向 Agentic Engineering(智能体工程)。
谷歌的 Gemini 3 正在被广泛集成,包括全新的 Chrome 侧边栏和 Nano Banana UX 功能。其采用速度极快,且推理成本(serving costs)降低了 78%。Gemini 应用在 2025 年第四季度的月活跃用户数(MAU)突破了 7.5 亿,直逼 ChatGPT 的用户规模。同时,谷歌还在 Kaggle Game Arena 中,通过德州扑克和国际象棋等游戏对 AI 的“软技能”进行基准测试。
与此同时,编程代理(coding agents)正向 IDE 汇聚:VS Code 推出了 Agent Sessions,支持 Claude 和 Codex 代理,并具备并行子代理和集成浏览器等功能。GitHub Copilot 现在允许用户在 Claude 和 OpenAI Codex 之间选择代理,以进行异步积压工作(backlog)清理。OpenAI 报告称,随着集成层面的扩展,Codex 的活跃用户已超过 100 万,尽管部分用户仍希望获得更好的 GPU 支持。
随着 OpenClaw 等社区平台以及 ClawHub、CLI 更新等工具的出现,编程代理生态系统正趋于专业化。“Gemini 3 的采用速度超过了以往任何模型”以及“VS Code 成为编程代理的大本营”这两大趋势,凸显了重大的行业变革。
SOTA Audio 模型就是你所需要的一切。
2026年2月3日至2026年2月4日的 AI 新闻。我们为你检查了 12 个 subreddit、544 个 Twitter 账号 和 24 个 Discord(254 个频道,10187 条消息)。预计节省阅读时间(以 200wpm 计算):795 分钟。AINews 网站 让你搜索所有往期内容。提示:AINews 现已成为 Latent Space 的一个板块。你可以选择开启/关闭邮件接收频率!
我们的政策是将头条新闻留给晋升为 decacorn(百亿美元)地位的 AI 公司,以庆祝它们的稀缺性并回顾它们的成长,但现在看来这种稀缺性似乎在降低……今天不仅有 Sequoia、a16z 和 ICONIQ 领投 Eleven@11 融资轮 (WSJ),而且紧接着就被 Cerebras 抢了风头——在达成 750MW OpenAI 交易(3 年价值 100 亿美元) 之后,Cerebras 获得了来自 Tiger Global 的 双倍 decacorn 轮融资,以 230 亿美元估值融资 10 亿美元……而这距离它们 估值 80 亿美元 仅过去了 5 个月。
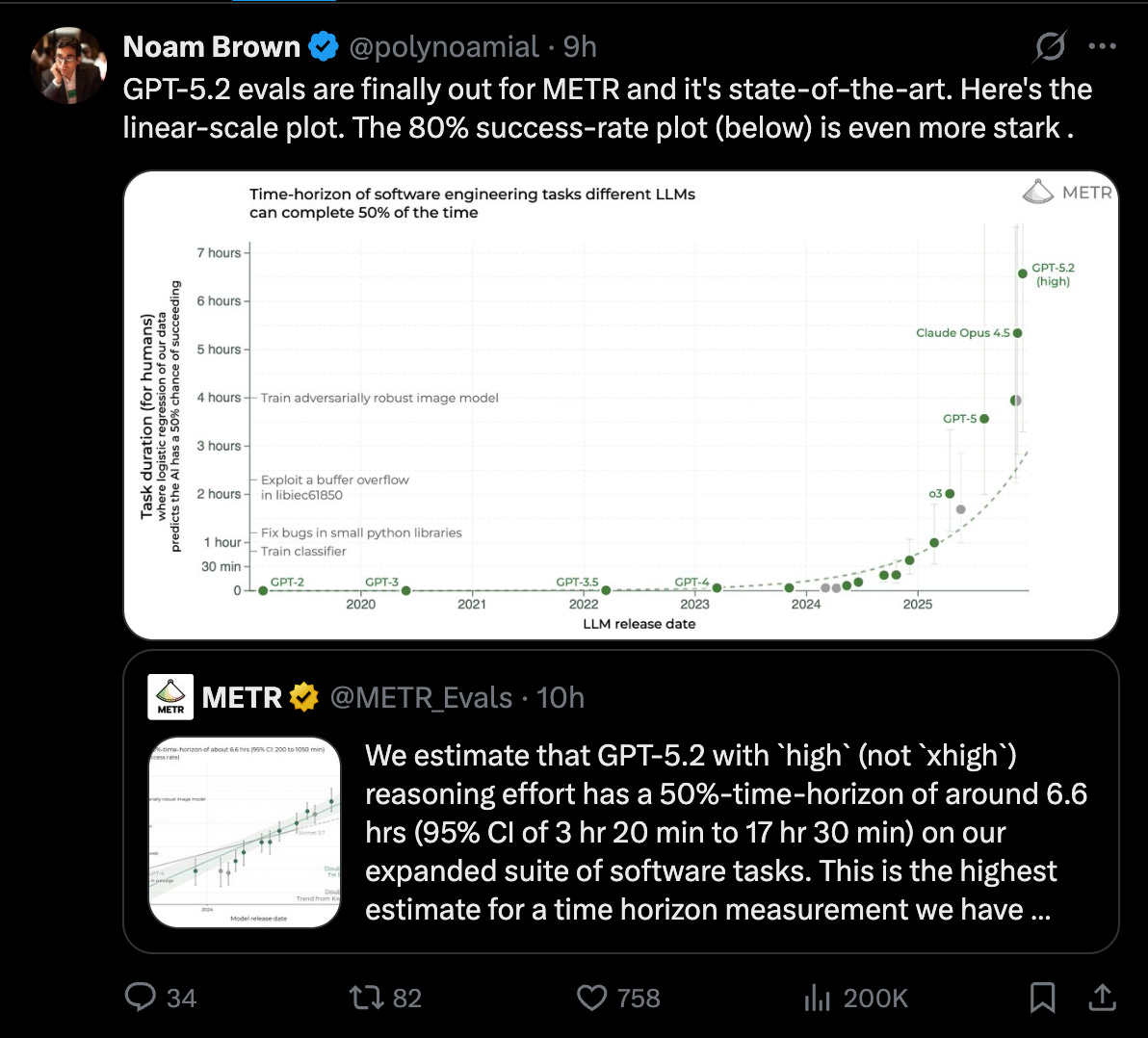
这也是 Vibe Coding 一周年,Andrej 提名 Agentic Engineering 为年度新 meta,与此同时 METR 授予 GPT 5.2 High 为 新的 6.6 小时人类任务模型,击败了 Opus 4.5,而 sama 宣布 Codex 的 MAU 达到 100 万。
AI Twitter 简报
大厂产品化:Gemini 3 无处不在(Chrome、应用规模、“游戏”评估)
- Gemini 3 驱动的 Chrome 侧边栏:Google 正在发布“运行在 Gemini 3 上”的新 Chrome 侧边栏体验,以及 Nano Banana 集成(Google 的说法)和其他 UX 变更,标志着浏览器工作流与 LLM 功能的持续紧密耦合 (Google)。
- Gemini 规模 + 成本曲线:Google 高管和分析师强调了 Gemini 的快速普及和推理成本的大幅降低:Sundar 报告称 Gemini 3 的采用速度“比任何其他模型都快”,且 Alphabet 年度营收突破 4000 亿美元 (@sundarpichai),而另一段剪辑提到 2025 年 Gemini 的 单位成本降低了 78% (financialjuice)。另一项数据称 Gemini 应用在 2025 年 Q4 的 MAU 达到 7.5 亿+ (OfficialLoganK);评论指出这使得 Gemini 与公开报告的 ChatGPT MAU 已经非常接近 (Yuchenj_UW)。
- 通过游戏进行基准测试:Google 正在推动“软技能”评估,让模型通过 Kaggle Game Arena 在游戏(扑克/狼人杀/国际象棋)中进行竞争,旨在部署前测试模型在不确定性下的规划、沟通和决策能力 (Google, Google, Google)。这与行业更广泛的趋势一致,即用更具“经济效益的工作”衡量标准来取代已经饱和的基准测试(参见下文 DeepLearningAI 总结的 Artificial Analysis 更新)。
Coding Agent 在 IDE 中汇聚:VS Code “Agent Sessions”、GitHub Copilot Agent、工作流中的 Codex + Claude
- VS Code 的 Agent 转型:VS Code 发布了一项重大更新,将其定位为“编程 Agent 之家”,包括用于本地/后台/云端 Agent 的统一 Agent Sessions 工作区、Claude + Codex 支持、并行子 Agent (parallel subagents) 以及集成浏览器 (VS Code; pierceboggan)。Insiders 版本增加了 Hooks、作为斜杠命令的技能 (skills as slash commands)、Claude.md 支持以及请求排队 (pierceboggan)。
- GitHub Copilot 增加模型/Agent 选择:GitHub 宣布你可以通过 Copilot Pro+/Enterprise 在 GitHub/VS Code 中使用 Claude 和 OpenAI Codex Agent,根据意图选择 Agent,并让其在现有工作流中异步清理待办事项 (backlogs) (GitHub; kdaigle)。据工程师反馈,相比纯交互式聊天编程,“远程异步 Agent”工作流才是真正的突破性进展 (intellectronica)。
- Codex 分发与 Harness 详情:OpenAI 和 OpenAI DevRel 推出了采用率统计数据(早期 50 万次下载;后期 100 万+ 活跃用户),并扩展了由通过 JSON-RPC “Codex App Server”协议暴露的共享“Codex harness”支持的多个界面(App/CLI/web/IDE 集成)(OpenAI, @sama, OpenAIDevs)。
- 摩擦点依然存在:部分用户报告 Codex 在仅限 CPU 的沙盒中运行或无法识别 GPU(并请求 GPU 支持)(Yuchenj_UW, tunguz),而 OpenAI DevRel 则反驳称 GPU 进程可以工作并请求提供重现步骤 (repros) (reach_vb)。
- OpenClaw/Agent 社区成为“平台”:OpenClaw 见面会 (ClawCon) 和生态系统工具(例如 ClawHub、CLI 更新)表明,编程 Agent 社区在工作流、安全性和分发方面正迅速走向专业化 (forkbombETH, swyx)。
Agent 架构与可观测性:“skills”、子 Agent、MCP Apps,以及为何追踪 (tracing) 正在取代堆栈追踪 (stack traces)
- deepagents:技能 + 子 Agent,持久化执行:LangChain 的 deepagents 发布了对 给子 Agent 添加技能 (skills) 的支持,并标准化为
.agents/skills,同时改进了线程恢复和用户体验(维护者发布的多个发行说明)(sydneyrunkle, LangChain_OSS, masondrxy)。其定位是:通过 上下文隔离(子 Agent)加上 Agent 专业化(技能)来保持主上下文清洁,而不是二选一 (Vtrivedy10)。 - MCP 演进为 “Apps”:OpenAI Devs 宣布 ChatGPT 现在已全面支持 MCP Apps,这与源自 ChatGPT Apps SDK 的 MCP Apps 规范保持一致,旨在使“符合规范的 App”可以移植到 ChatGPT 中 (OpenAIDevs)。
- Skills 与 MCP:不同层级:一个有用的概念区分:MCP 工具通过外部连接扩展运行时能力,而 “skills”(技能)则在本地编码领域流程/知识,以塑造推理逻辑(而不仅仅是数据访问)(tuanacelik)。
- 可观测性转变为评估:LangChain 反复强调,Agent 失败属于长工具调用追踪中的“推理失败”,因此调试重点从堆栈追踪转向 追踪驱动的评估 (trace-driven evaluation) 和回归测试 (LangChain)。案例研究也推动了同一主题:ServiceNow 通过监督者架构 (supervisor architectures) 在 8 个以上生命周期阶段 编排专业 Agent,此外 Monte Carlo 启动了“数百个子 Agent”进行并行调查 (LangChain, LangChain)。
模型、基准测试与系统:METR 时间跨度、Perplexity DRACO、GB200 上的 vLLM 以及开源科学 MoE
- METR 针对 GPT-5.2 的 “time horizon” 飞跃(伴随关于运行时报告的争议):METR 报告 GPT-5.2 (high reasoning effort) 在扩展的软件任务套件上达到了 约 6.6 小时的 50%-time-horizon,置信区间(CIs)较宽(3h20m–17h30m)(METR_Evals)。讨论集中在“工作时间”与能力的对比上:有传言称 GPT-5.2 的耗时比 Opus 长 26 倍 (scaling01),随后 METR 相关的澄清表明,一个计算排队时间的 Bug 以及脚手架(scaffold)差异(Token 预算、脚手架选择)扭曲了 working_time 指标 (vvvincent_c)。结论:核心的能力信号(更长跨度的成功率)似乎是真实的,但挂钟时间(wall-clock)的对比存在噪声且部分失效。
- Perplexity Deep Research + DRACO:Perplexity 推出了 “Advanced” Deep Research,声称在外部基准测试中达到 SOTA,并在决策密集型垂直领域表现强劲;他们还发布了 DRACO 作为一个开源基准测试,包含评分标准/方法论以及一个 Hugging Face 数据集 (perplexity_ai, AravSrinivas, perplexity_ai)。
- vLLM 在 NVIDIA GB200 上的性能:vLLM 报告了 DeepSeek R1/V3 的性能达到了 26.2K prefill TPGS 和 10.1K decode TPGS,声称在 GPU 数量减半的情况下吞吐量达到 H200 的 3–5 倍,这得益于 NVFP4/FP8 GEMMs、算子融合(kernel fusion)以及带有异步预取(async prefetch)的权重卸载(weight offloading)(vllm_project)。vLLM 还为 Mistral 的流式 ASR 模型增加了 “day-0” 支持,并引入了 Realtime API 端点 (
/v1/realtime) (vllm_project)。 - 开源科学 MoE 军备竞赛:上海人工智能实验室(Shanghai AI Lab)的 Intern-S1-Pro 被描述为一个拥有 1T 参数、512 个专家(22B 激活)的 MoE,并具有 Fourier Position Encoding 和 MoE 路由变体等架构细节 (bycloudai)。另有评论指出,“极高稀疏度”(数百个专家)正在成为某些生态系统的标准 (teortaxesTex)。
- 基准测试更新:Artificial Analysis:Artificial Analysis 发布了 Intelligence Index v4.0,将已饱和的测试更换为强调“经济上有用的工作”、事实可靠性和推理能力的基准测试;在这一轮重新洗牌中,GPT-5.2 在竞争激烈的梯队中处于领先地位(DeepLearningAI 提供的总结)(DeepLearningAI)。
多模态生成:带音频的视频竞技场、Grok Imagine 的崛起、Kling 3.0 以及 Qwen 图像编辑
- 视频评估变得更加细化:Artificial Analysis 推出了 Video with Audio Arena,分别对原生生成音频的模型(Veo 3.1, Grok Imagine, Sora 2, Kling)与仅限视频能力的模型进行基准测试 (ArtificialAnlys)。
- Grok Imagine 的势头:多项信号指向 Grok Imagine 在公共竞技场中的强势地位,包括 Elon 声称其“排名第一” (elonmusk),以及 Arena 报告 Grok-Imagine-Video-720p 在图生视频(image-to-video)中夺冠,且按其描述比 Veo 3.1 “便宜 5 倍” (arena)。
- Kling 3.0 发版迭代:Kling 3.0 的亮点在于 custom multishot(自定义多镜头)控制(每镜头提示词,支持长达约 15 秒)以及改进的细节、人物参考和原生音频 (jerrod_lew)。
- Qwen 图像编辑工具:一个 Hugging Face 应用展示了用于图像编辑的 多角度 “3D 光照控制”,通过适配器(adapter)方法实现离散的水平/仰角位置调节 (prithivMLmods)。
研究笔记:推理与泛化、持续学习以及机器人/世界模型
- LLM 如何推理(博士论文):Laura Ruis 发表了关于 LLM 是否能超越训练数据进行泛化的论文;她的核心观点是:LLM 可以以“有趣的方式”进行泛化,这表明它们具备真正的推理能力,而非单纯的记忆 (LauraRuis)。
- 持续学习(Continual learning)成为主题:Databricks 的 MemAlign 将 Agent memory 构架为持续学习机制,用于根据人类评分构建更好的 LLM 裁判(judges),并已集成到 Databricks + MLflow 中 (matei_zaharia)。François Chollet 认为,相比于扩展冻结的知识库,AGI 更可能源于发现能让系统调整自身架构的元规则(meta-rules) (fchollet)。
- 机器人技术:从仿真运动到“世界动作模型”:
- RPL 运动:一种用于跨地形、多方向和负载干扰的鲁棒感知运动的统一策略——在仿真(sim)中训练,并在现实世界中进行了长程验证 (Yuanhang__Zhang)。
- DreamZero (NVIDIA):Jim Fan 介绍了基于世界模型骨干构建的“世界动作模型(World Action Models)”,支持针对新动词/名词/环境的零样本开放世界提示(zero-shot open-world prompting),强调“多样性优于重复”的数据配方,并通过像素实现跨具身(cross-embodiment)迁移;声称将发布开源版本并提供演示 (DrJimFan, DrJimFan)。
- 世界模型“可玩”内容:Waypoint-1.1 声称在实现本地、实时、连贯、可控且可玩的物理世界模型方面迈出了一步;据团队介绍,该模型采用 Apache 2.0 开源协议 (overworld_ai, lcastricato)。
热门推文(按互动量排序)
- Sam Altman 谈论 Anthropic 的超级碗广告 + OpenAI 广告原则 + Codex 采用情况 (\@sama)
- Karpathy 回顾:“氛围编码 (vibe coding)” → “智能体工程 (agentic engineering)” (\@karpathy)
- Gemini 大规模使用情况:每分钟 100 亿 Token + 7.5 亿月活用户 (MAU) (OfficialLoganK)
- VS Code 发布 Agent 会话 + 并行子智能体 (subagents) + Claude/Codex 支持 (\@code)
- GitHub:Claude + Codex 可通过 Copilot Pro+/Enterprise 使用 (\@github)
- METR:GPT-5.2 在软件任务上的“高”时间跨度约为 6.6 小时 (\@METR_Evals)
- Arena:Grok-Imagine-Video 夺得图生视频排行榜第一 (\@arena)
- Sundar:Alphabet 财年业绩;Gemini 3 采用速度最快 (\@sundarpichai)
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 回顾
1. Qwen3-Coder-Next 模型发布
-
Qwen/Qwen3-Coder-Next(Hugging Face) (Activity: 1161): Qwen3-Coder-Next 是一款专为编程任务设计的语言模型,在
80B的总参数量中拥有3B激活参数,实现了与激活参数多出10-20倍的模型相媲美的性能。它支持256k上下文长度、高级 Agentic 能力和长程推理(long-horizon reasoning),使其适合集成到各种 IDE 中。该架构包含48层、门控注意力机制(gated attention mechanisms)以及混合专家模型(Mixture of Experts)。部署可以使用 SGLang 或 vLLM,且需要特定版本以获得最佳性能。更多详情可在 原文章 中查看。一位评论者对模型的性能表示怀疑,质疑一个3B 激活参数的模型是否真的能达到像 Sonnet 4.5 这种更大模型的质量,这表明这些主张还需要进一步验证。- danielhanchen 讨论了为 Qwen3-Coder-Next 发布动态 Unsloth GGUF 的事宜,重点介绍了即将发布的 Fp8-Dynamic 和 MXFP4 MoE GGUF 格式。这些格式旨在优化模型性能和效率,特别是在本地环境中。此外,还提供了一份在本地将 Claude Code / Codex 与 Qwen3-Coder-Next 结合使用的指南,这对希望将这些模型集成到工作流中的开发者非常有益。
- Ok_Knowledge_8259 对 30 亿激活参数模型能匹配 Sonnet 4.5 等更大模型质量的说法表示怀疑。这一评论反映了 AI 社区对模型尺寸与性能之间权衡的共同担忧,暗示需要进一步的实证验证来证实此类主张。
- Septerium 指出,虽然原始的 Qwen3 Next 在基准测试中表现良好,但用户体验尚有欠缺。这凸显了 AI 模型部署中的一个关键问题:高基准测试分数并不总是能转化为实际的可用性,表明需要在用户界面和交互设计方面进行改进。
-
Qwen3-Coder-Next 现已发布! (Activity: 497): 该图片宣布发布 **Qwen3-Coder-Next,这是一款拥有 800 亿参数的混合专家(MoE)模型,其中包含 30 亿激活参数,专为高效编程任务和本地部署而设计。它强调了该模型处理
256K上下文长度的能力及其快速的推理速度,并针对长程推理和复杂工具调用进行了优化。该模型运行需要46GB的 RAM/VRAM,适合高性能环境。图片中包含一张性能图表,将 Qwen3-Coder-Next 与其他模型进行对比,展示了其效率和先进功能。** 一条评论质疑了该模型的性能水平,将其与 “Sonnet 4.5” 进行比较,表现出对其能力的怀疑或好奇。另一条评论询问了使用64GBRAM 运行该模型的可行性,表现出对其硬件要求的关注。此外,还有关于缺少与 “Devstral 2” 对比的评论,暗示性能评估中可能存在遗漏。- 一位用户询问了模型的性能,质疑它是否真的达到了 “Sonnet 4.5 级别”,以及是否包含 “Agentic 模式”,或者该模型是否只是针对特定测试进行了优化。这表明了用户对模型实际应用能力与基准测试表现之间差异的好奇。
- 另一位用户分享了使用 LM Studio 进行的快速性能测试,报告在配备 RTX 4070、14700k CPU 和 80GB DDR4 3200 RAM 的配置下,处理速度为 “6 tokens/sec”。他们还指出与 “llama.cpp” 的对比,后者达到了 “21.1 tokens/sec”,表明两种设置之间的性能指标存在显著差异。
- 提出了一个关于在只有 “64GB RAM” 且没有 VRAM 的情况下运行模型的可行性的技术问题,凸显了对硬件要求以及没有高端 GPU 的用户可访问性的担忧。
2. ACE-Step 1.5 音频模型发布
-
ACE-Step-1.5 刚刚发布。这是一个采用 MIT 许可证的开源音频生成模型,其性能接近 Suno 等商业平台 (活跃度: 744): ACE-Step-1.5 是一个根据 MIT 许可证发布的开源音频生成模型,旨在与 Suno 等商业平台竞争。它支持 LoRAs,提供多种模型以满足不同需求,并包含翻唱 (cover) 和重绘 (repainting) 等功能。该模型已集成到 Comfy 中,并在 HuggingFace 上提供演示。此版本的发布标志着开源音频生成领域的重大进步,其功能已非常接近领先的专有解决方案。一条值得注意的评论强调了最近泄露的
300TB数据集的潜在影响,暗示未来的模型可能会利用这些数据进行训练。另一条评论则鼓励支持该模型的官方研究机构 ACE Studio。 -
Suno 的开源版本终于来了:ACE-Step 1.5 (活跃度: 456): ACE-Step 1.5 是一个开源音乐生成模型,在标准评估指标上表现优于 Suno。在 A100 GPU 上,它可以在约
2 秒内生成一首完整的歌曲;在带有约4GB VRAM(显存)的普通个人电脑上即可本地运行,在 RTX 3090 上运行时间不足10 秒。该模型支持使用 LoRA 以极少量的数据训练自定义风格,并以 MIT license 发布,允许免费商业使用。其数据集包含完全授权的数据和合成数据。GitHub 仓库提供了权重、训练代码、LoRA 代码和论文的访问权限。评论者注意到了模型的显著改进,但批评其评估图表的展示缺乏清晰度。此外还有关于其指令遵循能力 (instruction following) 和连贯性的讨论,认为这些方面逊于 Suno v3,不过该模型因其创造力和作为基础工具的潜力而受到称赞。文中还提到了关于即将推出的版本 2 的推测。- TheRealMasonMac 强调 ACE-Step 1.5 相比其前身有了显著改进,尽管在指令遵循和连贯性方面仍落后于 Suno v3。然而,其音质被认为很出色,且该模型被描述为具有创造性且有别于 Suno,表明它可以为未来的开发奠定坚实的基础。
- Different_Fix_2217 提供了 ACE-Step 1.5 生成的音频示例,表明该模型在处理长且详细的提示词时表现良好,并且可以处理负向提示词 (negative prompts)。这表明模型设计具有一定程度的灵活性和适应性,有利于希望尝试不同输入风格的用户。
3. Voxtral-Mini-4B 语音转录模型
-
mistralai/Voxtral-Mini-4B-Realtime-2602(Hugging Face) (活跃度: 266): Voxtral Mini 4B Realtime 2602 是一款尖端的、开源的多语言语音转录模型,在延迟低于
<500ms的情况下实现了接近离线的准确率。它支持13 种语言,并采用原生流式架构和自定义因果音频编码器构建,允许配置从240ms 到 2.4s的转录延迟。在480ms延迟下,它的性能可媲美领先的离线模型和实时 API。该模型针对设备端部署进行了优化,硬件要求极低,吞吐量超过12.5 tokens/second。评论者赞赏这一开源贡献,特别是将实时处理部分集成到了 vLLM。然而,由于缺乏话轮检测(turn detection)功能,人们感到有些失望,而该功能在 Moshi 的 STT 等模型中是存在的,这使得用户需要采用额外的方法来进行话轮检测。- Voxtral 实时模型专为现场转录设计,其可配置延迟可低至 200ms 以下,这对于语音 Agent 和实时处理等应用至关重要。然而,它缺乏说话人日志(speaker diarization)功能,而该功能在批量转录模型 Voxtral Mini Transcribe V2 中是提供的。这一功能对于区分对话中的不同发言者特别有用,但在开源模型中的缺失可能会限制其对某些用户的效用。
- Mistral 通过将实时处理组件集成到 vLLM 中,增强了实时转录应用的基础设施,从而为开源社区做出了贡献。尽管如此,该模型不包含话轮检测(turn detection),这是 Moshi 的 STT 中具备的功能,这要求用户实现替代方案,如通过标点符号、计时或第三方基于文本的解决方案来进行话轮检测。
- Context biasing(上下文偏置)功能允许模型根据上下文优先处理某些单词或短语,目前仅通过 Mistral 的直接 API 支持。无论是新的 Voxtral-Mini-4B-Realtime-2602 模型还是之前的 3B 模型,在 vLLM 实现中都不提供此功能,这限制了使用开源版本的开发者的可访问性。
-
构建私有 H100 集群的一些惨痛教训(以及为什么 PCIe 服务器在训练中让我们失望) (活跃度: 530): 该帖讨论了在构建用于训练大模型(70B+ 参数)的私有 H100 集群时面临的挑战,并强调了为什么 PCIe 服务器不足。作者指出,缺乏 NVLink 严重限制了 All-Reduce 操作期间的数据传输速率,PCIe 的上限约为
~128 GB/s,而 NVLink 约为~900 GB/s,这导致了 GPU 闲置。此外,大型模型的存储检查点(checkpoints)可能达到~2.5TB,需要快速的磁盘写入以防止 GPU 停顿,这是标准 NFS 文件服务器无法处理的,因此需要并行文件系统或本地 NVMe RAID。作者还提到了在以太网上使用 RoCEv2 代替 InfiniBand 的复杂性,这需要仔细监控暂停帧(pause frames)以避免集群停顿。 评论者强调了快速的 NVMe over Fabrics 并行文件系统对于训练构建的重要性,以防止 GPU 闲置,并建议 InfiniBand 应该作为计算的强制要求,而 RoCEv2 更适合存储。对存储写入速度成为瓶颈的惊讶也引起了关注。- 一位存储工程师强调,快速的 NVMe over Fabrics 并行文件系统(FS)是训练构建的关键要求,并指出如果没有足够的存储来喂给 GPU,将会出现大量的闲置时间。他们还建议在计算方面使用 InfiniBand,并指出 RoCEv2 通常更适合存储。这一评论强调了训练工作流中经常被忽视的共享存储方面。
- 一位用户对存储写入速度成为瓶颈表示惊讶,这表明这对许多人来说是一个意想不到的问题。这凸显了构建训练集群时的一个常见误区,即重点往往放在计算能力上,而不是像存储这样可能成为关键瓶颈的支撑基础设施上。
- 另一位用户提出了一种理论解决方案,涉及具有页面错误(page faults)自动硬件映射的毫秒级分布式 RAM,并建议这种创新可以显著简化集群管理。这一评论反映了在系统架构中解决正确问题的更广泛议题。
较少技术性的 AI 子版块回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. Anthropic 与 OpenAI 无广告辩论
-
Sam 对 Anthropic 保持无广告的回应 (热度: 1536): Sam Altman 回应了 Anthropic 保持无广告的决定,突显了 AI 领域的竞争态势。讨论引用了一场 Claude Ad Campaign,并指出在德克萨斯州免费使用 ChatGPT 的人数比全美 Claude 的总用户数还要多,这表明用户基数存在显著差异。这反映了 AI 公司之间持续的竞争,让人联想到 Microsoft 和 Apple 等历史性的技术竞争对手。评论者将当前的 AI 竞争与过去的技术竞争相提并论,暗示虽然公开展示竞争,但私下可能存在合作。
- BuildwithVignesh 强调了 Claude Ad Campaign 的有效性,认为尽管竞争激烈,它仍成功吸引了关注。虽然评论中没有详述具体的指标或结果,但暗示该活动的影响力是显著的。
- LimiDrain 提供了一项对比分析,指出 “在德克萨斯州免费使用 ChatGPT 的人数超过了全美使用 Claude 的总人数”。这表明 ChatGPT 与 Claude 在用户规模上存在巨大差距,显示了 ChatGPT 在市场上更广泛的覆盖面和普及率。
- Eyelbee 引用了 Sam 过去的一份声明,指出他在一年前曾表示 AI 广告令人不安。这暗示了 Sam 在 AI 广告立场上的潜在不一致或演变,特别是考虑到 Anthropic 坚持无广告的决定可能被视为对广告模式的批判。
-
Anthropic 宣布 Claude 将保持无广告的计划 (热度: 1555): Anthropic 宣布承诺保持其 AI 助手 Claude 无广告,强调其作为工作和深度思考工具的角色。这一决定在名为 “Claude is a space to think” 的博客文章中得到强调,体现了公司致力于为用户维持无干扰环境的决心。该公告与其他可能引入广告的 AI 模型形成对比,将 Claude 定位为高端、专注的生产力工具。评论者指出,虽然 Claude 是无广告的,但其免费层级限制极多,不付费的话可用性较低。这引发了关于其无广告声明实际意义的辩论,因为用户可能仍需付费才能有效使用,这与提供更慷慨免费额度的其他 AI 模型形成了对比。
- ostroia 指出,尽管 Claude 无广告,但其免费层级限制严格,除了回答简单问题外几乎无法使用。这引发了人们的质疑:当产品必须付费才能真正可用时,吹嘘无广告是否具有实际意义。
- seraphius 强调了广告对平台的潜在负面影响,指出广告可能会使高管的注意力转向“对广告商友好”,从而削弱平台的诚信。这被比作 YouTube 的情况,即广告驱动的决策显著影响了内容和平台政策。
-
Sam Altman 对 Anthropic 超级碗广告的回应。他表示,“在德克萨斯州免费使用 ChatGPT 的人数比全美使用 Claude 的总人数还要多” (热度: 1394): 该图片捕捉到了 Sam Altman 对 Anthropic 超级碗广告的批评,他声称在德克萨斯州免费使用 ChatGPT 的人数超过了全美使用 Claude 的总人数。Altman 指责 Anthropic 在广告中不诚实,并将 OpenAI 对免费访问的承诺与 Anthropic 的方式进行了对比,他将后者描述为具有控制欲且昂贵的。他还表达了对 OpenAI Codex 的信心,并强调了让开发者能够使用 AI 的重要性。评论者辩论了 Altman 言论的虚伪性,指出 OpenAI 也在限制 AI 使用,正如他们在 5.2 版本中的 “nanny bot(保姆机器人)” 所示。此外,人们对于 Anthropic 据称阻止 OpenAI 使用 Claude 进行编码的说法也持怀疑态度。
- AuspiciousApple 强调了 OpenAI 与 Anthropic 之间的竞争紧张局势,指出 Sam Altman 对 Anthropic 广告的详细回应暗示了对竞争的更深层担忧。这反映了更广泛的行业动态,即主要的 AI 公司都在密切关注彼此的举动,表明了高度竞争的格局。
- owlbehome 批评了 OpenAI 的 AI 控制方法,指出 Sam Altman 关于 Anthropic 对 AI 控制权的言论中存在虚伪性。该评论提到了 OpenAI 在 5.2 版本中的自身限制,暗示两家公司都对 AI 的使用施加了重大限制,这是 AI 社区中关于安全与可用性平衡的常见批评。
-
RentedTuxedo 讨论了 AI 行业中竞争的重要性,认为市场中更多的参与者对消费者有利。该评论批评了表现出对特定公司强烈忠诚的用户的部落主义(tribalism),强调消费者的选择应基于性能而非品牌忠诚度。这反映了一种更广泛的情绪,即良性竞争能推动创新并产生更好的产品。
-
Anthropic 嘲讽 OpenAI 的 ChatGPT 广告计划并承诺 Claude 无广告 (活跃度: 813): Anthropic 宣布其 AI 模型 Claude 将保持无广告状态,这与 OpenAI 在 ChatGPT 中引入广告的计划形成鲜明对比。这一决定在一段嘲讽 OpenAI 做法的讽刺性广告中得到了强调,突显了 Anthropic 对无广告体验的承诺。此举被视为竞争激烈的 AI 领域的一种战略差异化,目前的变现策略正在不断演变。The Verge 提供了有关此进展的更多细节。评论者对 Anthropic 的无广告承诺表示怀疑,认为财务压力最终可能会导致广告的出现,类似于流媒体服务的趋势。
-
Anthropic 取笑 OpenAI (活跃度: 485): 这篇 Reddit 帖子幽默地强调了 **Anthropic 对 OpenAI 的竞争性抨击,暗示了两家公司在大型语言模型 (LLM) 领域的竞争。该帖子未提供具体的技术细节或基准测试,但暗示了 AI 行业竞争激烈的氛围,让人联想起过去的企业竞争,如 Samsung 对阵 Apple。外部链接与主帖无关,重点在于获得“六块腹肌”的健身建议。** 评论反映了娱乐和怀疑的交织,用户将其与过去的企业竞争进行类比,并希望这种情况不会像 Samsung 过去的营销策略那样对 Anthropic 产生反作用。
- ClankerCore 强调了广告中 AI 的技术执行,注意到其使用了带有 AI 叠加层的人类模型。评论强调了对 AI 行为进行的微妙调整,特别是眼神交流,这为描绘增添了一层现实感。这表明通过人类和 AI 元素的复杂融合增强了广告的影响力。
- ClankerCore 的评论还批评了 Anthropic Claude 的表现,指出它在处理简单的算术运算(如 ‘2+2’)时效率低下。用户提到此类操作消耗了 plus 用户很大一部分 token 限制,表明 Claude 的设计或 token 管理系统可能存在局限性。
- ClankerCore 的分析表明,虽然营销执行令人印象深刻,但底层的 AI 技术,特别是 Claude,在非编程任务中可能并不高效或用户友好。这突显了营销宣传与 AI 产品实际性能之间可能存在的差距。
-
Sam Altman 对 Anthropic 无广告的回应 (活跃度: 1556): Sam Altman 回应了一篇关于 Anthropic 无广告的推文,这似乎是对最近 Claude 广告活动的回应。推文及随后的评论暗示了 AI 公司之间的竞争紧张关系,Altman 强调他们在战略决策方面并不“愚蠢”。这次交流突显了 AI 领域持续存在的竞争,尤其是 OpenAI 和 Anthropic 之间。评论者注意到了 AI 行业的竞争本质,将其比作 Coke 和 Pepsi 品牌之间的竞争。一些人希望公司之间能有更多轻松的交流,而另一些人则批评了 Altman 带有防御性的语气。
-
官方:Anthropic 宣布 Claude 将保持无广告方案 (活跃度: 2916): Anthropic 正式宣布其 AI 产品 Claude 将保持无广告,正如其在一条推文中所述。这一决定与其将 Claude 打造为“思考空间”以及工作和深度思考的得力助手的愿景相契合,暗示广告会与这些目标产生冲突。这一声明是维持其 AI 服务完整性和专注度的更广泛战略的一部分,详见其完整博客文章。一些用户对这一无广告承诺的长期性表示怀疑,认为公司决策可能会随时间而改变。其他人则借用 Sam Altman 的名字进行文字游戏,表达了对该政策未来走向的希望与疑虑。
- Anthropic 在超级碗期间播放嘲讽 ChatGPT 广告的广告 (活跃度: 1599): 据报道,Anthropic 在超级碗期间播放了嘲讽 ChatGPT 广告的广告,尽管这些广告尚未推广其自身的 AI 模型 Claude。这一策略让人想起 Samsung 过去的营销手段——嘲讽 Apple 不提供充电器,结果后来也纷纷效仿。这些广告被视为 Anthropic 潜在 IPO 和业务转型前的战略举措。评论者认为,一旦 Anthropic 进行 IPO 并可能转变其业务战略,该广告活动可能会适得其反或变得过时(“像牛奶一样变质”)。
2. Kling 3.0 与 Omni 3.0 发布
-
来自官方博客文章的 Kling 3.0 示例 (活跃度: 679): Kling 3.0 展示了先进的视频合成能力,特别是在不同镜头角度间保持了主体一致性,这是一项重大的技术成就。然而,音频质量明显较差,被描述为听起来像是用“盖着铝片的麦克风”录制的,这是视频模型中的常见问题。视觉质量(特别是最后一幕)因其艺术价值受到称赞,其调色和转换让人想起“90 年代末的亚洲艺术电影”。评论者对 Kling 3.0 的视觉一致性和艺术质量印象深刻,尽管他们批评了音频质量。跨角度保持主体一致性的能力被强调为一项技术突破。
- Kling 3.0 在切换不同镜头角度时保持主体一致性的能力是一项重大的技术成就。这一特性在视频模型中极具挑战性,因为它需要对空间和时间连贯性有深刻的理解,以确保主体在不同视角下都保持可信。
- Kling 3.0 的一个显著问题是音频质量,一些用户形容其听起来很沉闷,类似于在麦克风前有遮挡物进行录制。这是视频模型中的一个普遍问题,表明虽然视觉真实感在进步,但音频处理仍相对滞后,需要进一步开发以匹配视觉保真度。
- Kling 3.0 的视觉质量因其艺术价值受到称赞,特别是通过调色和高光转换唤起了一种怀旧、梦幻感的场景。这表明该模型不仅在技术上娴熟,而且能够产生在情感层面引起共鸣的美学输出,类似于 90 年代末的艺术电影。
-
Kling 3 太疯狂了 - 《王者之路》预告片 (活跃度: 1464): 该帖子讨论了使用 AI 工具 Kling 3.0 制作的《王者之路》(Way of Kings)预告片。创作者 PJ Ace 在其 X 账号上分享了制作过程的分解。预告片展示了一个角色在被刀刃切开后外貌发生剧变的场景,展示了该 AI 渲染复杂视觉特效(VFX)的能力。尽管缺少一些元素,但该 AI 准确识别和复制场景的表现令人印象深刻。评论者对该 AI 渲染可识别场景的能力表示惊讶,其中一位指出了尽管存在一些缺失元素,但其变换效果非常出色。讨论凸显了 AI 在创意视觉媒体中的潜力。
-
Kling 3 惊为天人 - 《飓光志》(Way of Kings) 预告片 (热度: 1470): 该帖讨论了使用 AI 工具 **Kling 3.0 制作的《飓光志》(Way of Kings) 预告片。创作者 PJ Ace(曾因制作《塞尔达》(Zelda) 预告片而闻名)在其 X 账号上分享了制作过程的拆解。预告片中有一个场景:角色在被刀刃切开时外貌发生了剧烈变化,展示了 AI 渲染复杂视觉变换的能力。尽管有些元素缺失,但 AI 的表现仍让观众印象深刻。** 评论者对 AI 能够创造出具有辨识度的场景并执行复杂视觉效果的能力表示惊讶,尽管存在一些缺失元素。讨论突显了 AI 在创意媒体制作中的潜力。
-
等了 Kling 3 好几周了。今天你终于明白为什么值得等待。 (热度: 19): **Kling 3.0 带来了重大更新,功能包括
3-15s multi-shot sequences、native audio with multiple characters以及upload/record video characters as reference以确保语音一致性。此次发布旨在增强用户在创建 AI 驱动的视频内容时的体验,提供更具动态和逼真度的输出。用户可以在 Higgsfield AI platform 上探索这些功能。** 社区反应突显了对逼真效果的热情,例如“手摇镜头”(shaky cam),这增加了生成内容的视觉真实感。此外,还号召用户通过分享 AI 视频和参与 Discord 讨论来加入社区互动。- 一位用户对缺乏区分 ‘Omni’ 和 ‘3’ 模型差异的明确信息表示沮丧,这突显了技术营销中一个常见问题,即规格和改进未能清晰传达。这可能会导致用户在试图理解新发布版本的价值主张时产生困惑。
-
KLING 3.0 已上线:在 Higgsfield 进行广泛测试(无限访问)—— AI 视频生成模型最佳用例的全方位观察 (热度: 12): **KLING 3.0 已经发布,重点是在 Higgsfield 平台上进行广泛测试,该平台提供 AI 视频生成的无限访问权限。更新强调了全方位的观察能力和模型的最佳用例,有可能增强视频生成任务。然而,帖子缺乏关于模型性能较前版本改进的详细技术规格或基准测试。** 评论反映了怀疑和沮丧情绪,用户认为该帖子更像是 Higgsfield 的广告,而非实质性的技术更新。此外,关于该帖与 VEO3 相关性的困惑也表明了公告与社区利益之间可能存在脱节。
-
3. GPT 5.2 与 ARC-AGI 基准测试
-
OpenAI 似乎对 GPT 5.2 进行了非常疯狂的削弱 (Nerfing)。 (热度: 1100): 图像展示了一张描绘 “GPT-5-Thinking” 在 IQ 测试中随时间变化的性能图表,其中在 2026 年初出现了显著下降。这表明 OpenAI 可能降低了 GPT-5.2 的能力,这可能是战略调整的一部分,或者是由于训练期间的资源限制。图表注释指出了不同版本 AI 之间的过渡,暗示了其能力或架构的变化。评论表明用户已经注意到了性能下降,可能是由于训练资源分配或为了迎接 GPT 5.3 或 DeepSeek v4 等新版本的发布。 评论者推测,感知到的性能下降可能是由于训练期间的资源限制或 OpenAI 的战略调整。一些用户对当前与 Gemini 等竞争对手相比的表现表示不满,而另一些用户则期待未来版本的改进。
- nivvis 指出了模型训练阶段的一个常见问题,即像 OpenAI 和 Anthropic 这样的公司面临 GPU/TPU 限制。这使得有必要将资源从 inference(推理)重新分配到训练,从而可能暂时降低性能。这并非 OpenAI 特有;Anthropic 的 Opus 也受到了影响,很可能是为了筹备即将发布的版本,如 DeepSeek v4。
- xirzon 认为,技术服务中出现的显著性能下降(如 GPT 5.2 所经历的情况)通常是由于部分或全部服务中断造成的。这意味着观察到的“削弱(nerfing)”可能不是故意的降级,而是与服务可用性相关的临时问题。
-
ThadeousCheeks 注意到 Google 的性能也有类似的下降,特别是在清理幻灯片组等任务中。这表明各大 AI 服务普遍存在性能下降的趋势,可能与资源重新分配或其他运营挑战有关。
-
ARC-AGI 取得新 SOTA (Activity: 622): 图像展示了基于 GPT-5.2 的模型在 ARC-AGI 基准测试中取得的新 SOTA(当前最佳水平)成就。该模型由 Johan Land 开发,以每项任务
$38.9的成本实现了72.9%的得分,较之前的54.2%有了显著提升。ARC-AGI 基准测试发布不到一年,进步神速,最初的最高分仅为4%。该模型采用了一种定制的提炼方法,集成了多种方法论来增强性能。 评论者注意到 ARC-AGI 基准测试得分的飞速进展,对这么快就突破70%表示惊讶,尽管也有人指出每项任务的高成本是一个隐忧。由于 ARC-AGI-2 已趋于饱和,人们对预计于 2026 年 3 月推出的下一版本 ARC-AGI-3 充满期待。- ARC-AGI 基准测试发布不到一年,见证了快速的进展,最新的 SOTA 结果达到 72.9%。这比最初发布的 4% 和之前最佳的 54.2% 有了巨大飞跃。该基准测试的快速演进突显了 AI 能力的迅猛发展。
- 在 ARC-AGI 基准测试中实现高性能的成本是讨论的焦点,目前的解决方案每项任务成本约为 $40。人们有兴趣在保持或提高性能至 90% 以上的同时,将成本降低到每项任务 $1,这将代表显著的效率提升。
- ARC-AGI 基准测试的 x 轴使用指数标度,表明向图表右上角移动通常涉及增加计算资源以获得更好的结果。理想位置是左上角,这意味着以最少的 compute(算力)实现高性能,强调效率而非暴力计算。
-
还有人对 5.2 有同样的体验吗? (Activity: 696): 该图片是一个梗图,幽默地批评了 GPT 5.2 版本处理 custom instructions(自定义指令)的方式,特别是在其“Thinking”模式下。梗图暗示模型可能无法有效处理或保留用户提供的自定义指令,正如角色在指令着火时的惊讶所描绘的那样。这反映了用户对模型在处理特定任务或指令时局限性的沮丧,可能源于防止 jailbreaks(越狱)或滥用的努力。 评论者对 GPT 5.2 处理自定义指令和 memory(记忆)的方式表示不满,指出模型往往需要明确的指示才能访问某些信息,这让他们感到繁琐。
- NoWheel9556 强调 5.2 版本的更新似乎旨在防止 jailbreaks,这可能无意中影响了其他功能。这表明了安全措施与用户体验之间的权衡,可能影响了模型处理某些任务的方式。
- FilthyCasualTrader 指出了 5.2 版本中一个特定的易用性问题,用户必须明确指示模型查看某些数据,例如“项目文件夹中的附件或已保存记忆中的条目”。这表明在直觉式数据处理方面出现了退化,需要用户提供更明确的指令。
- MangoBingshuu 提到了 Gemini pro 模型的一个问题,即它在几次 prompts(提示词)后往往会忽略指令。这表明指令保留或 prompt 管理存在潜在问题,可能会影响模型在长时间交互中保持 context(上下文)的可靠性。
AI Discord 回顾
由 gpt-5.1 生成的总结之总结的摘要
1. 前沿模型、编程助手与路由
- Qwen3 Coder Next 表现碾压 GPT 巨头:Qwen3-Coder-Next 作为一个出色的本地编程模型脱颖而出。Unsloth、Hugging Face 和 LM Studio 的用户报告称,其表现超越了 GPT‑OSS 120B,同时在 MXFP4_MOE 等 GGUF 量化版本下运行效率极高,甚至修复了长期存在的
glm flashBug;Unsloth 在 unsloth/Qwen3-Coder-Next-GGUF 托管了主要的 GGUF 版本,而 Reddit 上的这个帖子记录了一次更新,称更新后的 GGUF 版本 “现在能生成更好的代码”。- 工程师们正通过
-ot标志有选择地将 FFN layers 卸载到 CPU 来强力推进 VRAM optimization(并寻求一个 “显著性图表” 来按重要性对各层进行排名),而其他人则确认在 RTX 5080 上可以进行流畅的 vLLM 推理,使 Qwen3-Coder-Next 成为 Unsloth、Hugging Face 和 LM Studio 环境中实用的主力模型。
- 工程师们正通过
- Max 路由器挖掘数百万投票以选择模型:LMArena 发布了 Max,这是一个基于 500 多万 社区投票训练的智能路由器,可根据延迟和成本自动将每个 Prompt 发送至 “最强大的模型”,详见博客文章 “Introducing Max” 以及 YouTube 上的说明视频。
- 用户很快开始探究 Max 的行为,注意到它有时声称是 Claude Sonnet 3.5 在支持响应,实际上却路由到了 Grok 4,引发了诸如 “Max = 伪装的 sonnet 5” 之类的玩笑,并引发了关于路由器透明度和评估方法论的质疑。
- Kimi K2.5 潜入 Cline 和 VPS 机架:Kimi k2.5 已在面向开发者的 IDE Agent Cline 上线,Cline 的 推文 和 Discord 公告承诺在 cline.bot 提供有限的免费访问窗口以供实验。
- 在 Moonshot 和 Unsloth 的服务器上,工程师们确认 Kimi K2.5 可以作为 Kimi for Coding 运行,并讨论了在 Kimi 官方 亲自允许此类用途后,从 VPS/数据中心 IP 运行它的可能性,将其定位为远程编程 Agent 和 OpenClaw 式设置中比 Claude 限制更少的替代方案。
2. 新基准测试、数据集与算子竞赛
- Judgment Day 基准测试对 AI 伦理进行审判:AIM Intelligence 和韩国 AISI 与 Google DeepMind、Microsoft 及几所大学合作,发布了 Judgment Day 基准测试和 Judgment Day 挑战赛,用于对 AI 决策进行压力测试,详见 aim-intelligence.com/judgement-day。
- 他们正在征集围绕 AI 必须/绝不能做出的决策的对抗性攻击场景,为每份被采纳的红队提交支付 50 美元,并承诺在基准测试论文中署名;场景提交截止日期为 2026 年 2 月 10 日,而针对多模态(文本/音频/视觉)越狱的 10,000 美元 奖池挑战赛将于 2026 年 3 月 21 日 开启。
- Platinum-CoTan 构建三层堆叠推理数据:一位 Hugging Face 用户发布了 Platinum-CoTan,这是一个通过 Phi‑4 → DeepSeek‑R1 (70B) → Qwen‑2.5 三层堆叠流水线生成的深度推理数据集,专注于系统 (Systems)、金融科技 (FinTech) 和云 (Cloud) 领域,托管在 BlackSnowDot/Platinum-CoTan。
- 社区将其视为 “高价值技术推理” 训练材料,可作为其他开放数据集的补充,适用于那些在企业级系统和金融场景中需要长程、领域特定思维链(CoT),而非通用数学难题的模型。
- FlashInfer 竞赛发布完整算子负载:FlashInfer AI 算子生成大赛 (FlashInfer AI Kernel Generation Contest) 数据集已上线 Hugging Face flashinfer-ai/mlsys26-contest,打包了完整的算子定义和工作负载,供机器学习系统研究人员对 AI 生成的算子进行基准测试。
- GPU MODE 的 #flashinfer 频道确认,该仓库现在包含所有算子和目标形状,以便参赛者可以离线训练/评估模型编写的 CUDA/Triton 代码;而 Modal 额度和组队逻辑则主导了关于大规模运行这些工作负载的元讨论。
3. 训练与推理工具:GPU、量化与缓存
- GPU MODE 深入探讨 Triton、TileIR 和 AMD 差距:GPU MODE 社区通过日历邀请宣布将于 2026年3月4日(16:00–17:00 PST)举行 Triton 社区见面会,届时将由 NVIDIA 的 Feiwen Zhu 讲解 Triton → TileIR 的 lowering 过程,以及 Rupanshu Soi 展示 “Optimal Software Pipelining and Warp Specialization for Tensor Core GPUs”,详细信息见
#triton-gluon频道分享的活动链接。- 并行线程剖析了性能差距,其中 Helion 自动调优内核 在 AMD GPU 上的基准加速比仅达到 0.66×,而 torch inductor 在 M=N=K=8192 时为 0.92×。建议对比生成的 Triton kernels,以观察 AMD 团队为其后端做了哪些调整。
- MagCache 和 torchao 推动更便宜、更快速的训练:Hugging Face 低调发布了 MagCache,作为 Diffusers 的一种新缓存方法,详情见优化文档 “MagCache for Diffusers”,并在 diffusers PR #12744 中实现。
- 同时,GPU MODE 强调 Andrej Karpathy 通过一次提交 (6079f78…) 将 torchao 接入了他的 nanochat 项目用于 FP8 training。这标志着轻量级 FP8 + 激活优化缓存正从论文走向被广泛复制的参考代码。
- Unsloth、DGX Spark 与多 GPU 微调技巧:Unsloth 用户在处理 DGX Spark 微调时遇到困难,在 Nemotron‑3 30B 上使用 Unsloth 文档 “fine-tuning LLMs with Nvidia DGX Spark” 中的 Nanbeige/ToolMind 数据集进行 SFT 运行时,速度异常缓慢,直到有人建议切换到 官方 DGX 容器 并检查 GRPO/vLLM 兼容性。
- 在 Unsloth 和 Hugging Face 的其他频道中,从业者对比了用于多 GPU 微调的 Accelerate tensor parallelism,讨论了使用领域特定 imatrix 统计数据对 bf16 微调后的模型进行量化,并指出像 mradermacher 这样的社区量化者通常在微调模型于 Hugging Face 走红后自动发布 GGUF 版本。
4. 产品、定价与生态动荡
- Perplexity Deep Research 削减额度引发欧盟法律讨论:Perplexity 社区对 Perplexity Pro 将 Deep Research 限制从 600次/天 削减至 20次/月(降幅 99.89%)反应激烈。虽然官方在
#announcements中宣布为 Max/Pro 用户将 Deep Research 升级至 Opus 4.5,但#general频道的用户仍在讨论取消订阅、退款以及迁移至 Gemini 和 Claude。- 一些欧盟用户认为这种无声的降级可能违反了消费者透明度规范,理由是 “在欧盟没有法律合同的文本能强迫用户接受服务是不透明的”,并开始探索开源或替代方案如 Kimi、Z.Ai 和 Qwen,以重建以前那种“中等工作量”的研究工作流。
- Sonnet 5 的“薛定谔式”发布:延迟与部分泄露:在 Cursor、OpenRouter 和 LMArena 服务器上,工程师们关注着 Claude Sonnet 5 的推迟发布。一条广为流传的 X 链接暗示发布大约推迟了 一周(传闻状态),而 OpenRouter 的日志简短地暴露了
claude-sonnet-5和claude-opus-4-6的 403 EXISTS 错误,暗示 Anthropic 曾短暂注册但随后撤回了模型。- 停机导致的混乱也影响了 Claude API 和 Cursor 用户,部分用户因 2.4.28 版本中 SSH 二进制文件损坏而不得不回滚到 Cursor 2.4.27。这突显了现在的编辑器工作流和路由服务对前沿模型及时、稳定发布的依赖程度之高。
- 云端 AI 栈大洗牌:Kimi、Gemini、GPT 和 Claude:多个服务器的讨论描绘了一个动荡的 model‑as‑a‑service 版图:Gemini 3 因其在创意写作中的“深度和风格”在 OpenAI 服务器上赢得赞誉;Kimi K2.5 在 Nous 和 Moonshot 上因在编程方面超越 Gemini 3 Pro 而备受推崇;而 Claude 通过超级碗广告获得了梗图式的推广,Anthropic 的广告 承诺 Claude 中没有广告。
- 与此同时,Sam Altman 在一条推文的回应中为 ChatGPT 的广告融资辩护。OpenAI 社区则在抱怨 GPT 5.2 的退化和 Sora 2 的故障。多个社区注意到,用户正越来越多地组合使用 open‑weight 模型(DeepSeek/Kimi/Qwen)以及 OpenClaw 等工具,而不是押注于单一的闭源供应商。
5. 安全、红队测试与自主 Agent
- Judgment Day 与 BASI 推动深度 Red-Teaming:BASI Jailbreaking 服务器放大了 Judgment Day benchmark 对对抗性决策场景的呼吁,将其作为正式的 Red-Teaming 场所,并为在官方挑战页面描述的巧妙 Multimodal Attacks 提供奖金和共同作者身份。
- 与此同时,BASI 的 #jailbreaking 和 #redteaming 频道交流了 Gemini 和 Claude Code 的 Jailbreaks,例如 ENI Lime(镜像见 ijailbreakllms.vercel.app 和 Reddit 帖子),辩论了 Anthropic 的 activation capping 如何有效地对有害行为进行“脑额叶切除(lobotomising)”,并讨论了通过 COM elevation 和 in-memory execution 实现的 Windows rootkit 攻击面。
- OpenClaw、Cornerstone Agent 与现实世界的攻击面:多个 Discord 社区(LM Studio, Cursor, Latent Space SF)详细审查了 OpenClaw——这是一个托管在 ivan-danilov/OpenClaw 的 Agent 编排器——是否存在 Prompt-injection 和工具越权风险,促使一些人剥离不必要的工具和终端,而另一些人则在 Peter Steinberger 分享的这条 OpenClaw 安全推文中的 RFC 里起草 Enterprise-grade security models。
- Hugging Face 的 #i-made-this 频道提升了筹码,展示了 cornerstone-autonomous-agent,这是一个发布在 npm 上的 Autonomous AI Agent(见 cornerstone-autonomous-agent),它可以通过托管在 Replit 上的 MCP 后端和 Clawhub 技能开通真实的银行账户,这在更注重安全性的工程师中引发了一波“这就是招来监管机构的方式”的担忧。
- 加密级证明与 LLMs 结合,泄露事件暴露密钥:在 Yannick Kilcher 的 #paper-discussion 频道中,一位研究员描述了一种 64 位整数上的 Zero-knowledge proof of matrix–matrix multiplication,相对于纯计算仅有 2× overhead,并指出 GPUs 运行它的速度“几乎与 float64 一样快”;他们目前正将这种 ZK 方案接入自定义 LLM 的 Feedforward 路径中,正在开发的代码被引用为未来的“Deep learning theory sneak peek”。
- 与此形成鲜明对比的是,Yannick 的 #ml-news 追踪了 Moltbook 数据库泄露事件,据 Techzine 报道,35,000 封电子邮件和 150 万个 API keys 被泄露,这再次强化了为什么多个社区拒绝信任 SaaS 工具处理凭据,以及为什么 ZK 验证和更严格的数据处理保障正变得不仅仅是学术上的好奇。
Discord: 高层级 Discord 摘要
BASI Jailbreaking Discord
- Judgment Day Benchmark 发布:AIM Intelligence 和 Korea AISI 与 Google DeepMind、Microsoft 以及多所大学合作,发布了针对 AI 决策的 Judgment Day benchmark,重点关注 AI 判断可能被破坏或欺骗的场景。
- 该基准测试旨在识别 AI 绝不应做出的决策以及必须做出的决策,并征集攻击场景。每项入选的提交将获得 50 美元奖励,并在研究论文中获得署名;提交截止日期为 2026 年 2 月 10 日,而 Judgment Day Challenge 将于 2026 年 3 月 21 日开始,总奖金池为 10,000 美元,可通过此链接提交。
- Activation Capping 限制 AI 行为:Activation capping 是 Anthropic 开发的一项技术,可稳定 AI 模型输出,并可能用于增强 AI 安全性。
- 这意味着高激活度与有害输出相关,从而促使人们努力通过“切除手术”(lobotomise)移除任何过度偏离助手或工具属性的内容。
- 解码 AI 的起源与网络战术:成员们讨论了 AI 的词源和认识论起源,包括其宗教联系,并涉及 Shakey the Robot、鸽子导引导弹(Pigeon Guided Missiles)以及模式识别(Pattern Recognition)。
- 另外,在网络战(Cyber Warfare)背景下,成员们讨论了俄乌双方对弹药(munitions)进行的改装,以及使用消费级无人机投送物资和输血,并参考了一个展示这些战术的 YouTube 视频。
- Gemini Jailbreak 频出:用户正在积极寻找和讨论 Gemini Jailbreak,特别关注能实现不道德行为和恶意编码的 Prompt,例如创建 EAC (Easy Anti-Cheat) 绕过。
- Daedalus_32 指出,Gemini 目前非常容易被 Jailbreak,导致出现了多种选择,但功能水平都差不多,取决于用户的具体需求。
- Windows 深受隐私问题困扰:在一位 Rootkit 开发者对操作系统进行评估后,Windows 的主要暴露点被确定为内存中执行以及滥用身份或 COM 提权路径。
- 另一位用户评论说,Windows 从未真正关注过隐私,其架构可能是有意为政府需求提供此类访问权限。
Perplexity AI Discord
- Perplexity Pro 额度暴跌 99%:用户对 Perplexity Pro 的深度研究(deep research)查询额度从 600 次/天 降至 20 次/月 表示愤怒,降幅达 99.89%。
- 一些用户感觉被骗了,并指出缺乏透明度,而另一些用户则转向 Gemini 和 Claude 等替代方案。
- Gemini Research 速度极慢:成员们发现 Gemini 的 Deep Research 功能太慢,生成报告需要超过 10 分钟,而 Perplexity Research 仅需 90 秒。
- 成员们指出 Google 的 Gemini 会在对话中进行训练和审查,因此应考虑使用开源(OS)模型进行研究。
- Comet 浏览器连接出现故障:成员们报告了 Comet 浏览器断开连接的问题,可能与快捷方式中选择的模型有关,影响了自动化能力和易用性。
- 一位成员指出,通过免费版将使用量降至约 1/5,将不值得再以这种方式使用。
- 开源模型受到关注:成员们正在寻找 Perplexity Research 模型的替代品,并讨论 Kimi、Z.Ai 和 Qwen 等开源替代方案。
- 成员们指出需要切换,因为他们被困在低投入与最高投入之间,而“Research”(更新前)是两者之间完美的中间层,现在却没了?*
- 欧盟法规盯上 AI 公司:成员们讨论了 欧盟法规 因未公告影响用户的变更以及违反消费者权益而对 Perplexity 等 AI 公司产生影响的可能性。
- 一位成员提到,他们至少应该清楚地公告影响用户的变更。在欧盟,不存在这种实际上强迫用户接受服务不透明的法律合同。
Unsloth AI (Daniel Han) Discord
- Qwen3-Coder-Next 编码能力占据优势:Qwen3-Coder-Next 成为顶尖的编码模型,甚至在不需要共享 VRAM 的情况下表现优于 GPT 120B,并解决了之前
glm flash存在的一个问题。- 成员们对其编码能力表示赞赏,其中一位表示它刚刚修复了一名成员报告的 glm flash 卡了一周的问题,所以我很开心。
- 优化层级分布降低 VRAM 负载:讨论围绕使用
-ot标志战略性地将层放置在 GPU 上,从而将特定的ffn层卸载到 CPU 以进行 VRAM 优化。- 社区希望能有一个重要性图表 (significance chart),以便在无需大量尝试的情况下指导层放置决策。
- DGX Spark SFT 速度引发讨论:一位用户报告在 DGX 上使用 Unsloth 文档中的 Nanbeige/ToolMind 数据集进行 SFT 时训练速度缓慢。
- 建议包括使用官方 DGX 容器,这引发了关于 GRPO notebooks 以及 vLLM 在 DGX Spark 上的兼容性的更广泛讨论。
- TTS 模型蜕变为音乐大师?:一位用户研究将 TTS 模型转化为音乐生成器,并在初步实验中观察到了令人惊讶的线性损失曲线。
- 他们想知道改变一个基础模型的任务需要多少数据量。
- Sweaterdog 聚焦专用数据集:一名成员重点介绍了在 Hugging Face 上发布的数据集,包括 code_tasks_33k、website-html-2k、openprose 以及 fim_code_tasks_33k。
- fim_code_tasks_33k 被指出是 code_tasks_33k 的一个变体。
LMArena Discord
- AI 竞赛白热化,谷歌成为追赶目标:成员们辩论了谁能在 AI 竞赛中超越 Google,提到了 Claude、GLM、Deepseek R2、Moonshot、Grok 和 Qwen 等名字。
- 虽然一些人认为 Google 的资源赋予了他们优势,但其他人认为开源和竞争可能会导致另一个竞争对手超越他们,并观察到中国在竞赛中与美国并驾齐驱。
- DeepSeek V3.5 发布推测升温:社区讨论了 DeepSeek V3.5 或 V4 的潜在发布,指出 Deepseek 3.2 在 12 月发布,而 Deepseek v3.1 在 8 月推出。
- 普遍观点认为 DeepSeek 3.2v 优于 Grok 4.1,一些人希望新版本能在春节期间发布。
- Max 的模型失误引发关注:用户注意到 Max 声称当前是 2024 年,并建议 Claude Sonnet 3.5 是构建复杂应用的深度模型,但测试显示 Max 经常默认使用 Grok 4。
- 这种差异引发了对其能力和模型信息准确性的质疑,成员们开玩笑说 Max = 伪装的 sonnet 5。
- Arena 推出智能路由 Max:Arena 正在推出 Max,这是一款由 500 万+ 真实社区投票驱动的智能路由,旨在根据延迟情况将每个 prompt 路由到最强大的模型,详见此博客文章和 YouTube 视频。
- 无二级摘要。
- 字节跳动凭借 Seed-1.8 进入 Arena:字节跳动的新模型 seed-1.8 现在已在 Text、Vision 和 Code Arena 上线。
- 无二级摘要。
Cursor Community Discord
- Sonnet 5 推迟发布,热度延后:尽管最初有所期待,据 消息源 称,Sonnet 5 的发布已推迟约一周。
- 官方未给出延迟的具体原因,导致社区成员纷纷猜测可能的改进或最后一刻的调整。
- Cursor 2.4.28 补丁遭遇 SSH 挫折:Cursor 的 2.4.28 补丁 导致远程 Windows SSH 连接出现问题(由于缺少远程主机二进制文件),用户需要回滚到 2.4.27 版本。
- 成员报告称,该更新实际上破坏了 SSH 功能,使得旧版本成为依赖远程连接用户的唯一可行选择。
- OpenClaw 在 Cursor 中焕然一新:一名成员在 Cursor 中成功重建了 OpenClaw,并表示它甚至可能比原版有所改进。
- 讨论迅速转向安全影响,一些用户对将敏感凭据和代码信任给 AI 表示担忧,正如一位用户所说:我根本不信任任何软件处理我的凭据或代码。
- AI 助手增强而非取代人类专业知识:社区成员辩称人类判断具有不可替代的价值,指出 AI 只是助手而非完全替代品,尤其是在需要品味、范围控制或验证的岗位上。
- 引用人类专业知识的细微差别,一位成员引用道:AI 将取代任务,而非品味。人类仍然拥有目标、判断力和交付物…。
- Agents.md 胜过 Skills:Cursor 对 AGENTS.md(一种单文件规范)的支持引发了关于其优于名为 Skills 的 ~/.agents/ 目录式方法的讨论。
- 引用一篇 Vercel 博客文章,一位成员指出该文章解释了 AGENTS.md 相比 Skills 的优势。
OpenRouter Discord
- DeepSeek OCR 模型需求旺盛:用户请求在 OpenRouter 上提供 DeepSeek OCR 模型。
- 该模型以其在 Optical Character Recognition(光学字符识别)任务中的准确性而闻名,可以增强 OpenRouter 的能力。
- AI 工程师:这是一份真实的工作吗:围绕 AI Engineer 的定义展开了讨论,质疑某些人是否只是在“包装 Claude 代码”,而非开发 LM-systems。
- 这引发了关于该角色所需技术深度以及不同 AI 开发 方法价值的辩论。
- OpenRouter 速率限制令人苦恼:用户报告称即使在为账户充值后,在 OpenRouter 上仍持续遇到 rate limit 错误。
- 错误信息显示 “Provider openrouter is in cooldown (all profiles unavailable)”,给尝试使用该服务的用户带来了挫败感。
- Claude API 遭遇故障,Sonnet 5 发布陷入停滞:预期的 Sonnet 5 发布因大范围的 Claude API 停机 而推迟,错误日志暗示可能同时尝试启动 Opus 4.6 但失败了。
- 网民分析错误日志发现,请求 claude-sonnet-5 和 claude-opus-4-6 会导致 403 EXISTS 错误,表明这些模型原本是打算发布的。
- 图像生成成本:不便宜!:一位用户询问生成 1000 张图片的成本,寻求关于计费方式的澄清。
- 另一位用户回应称每张图片成本为 404 美分,强调了大规模 图像生成 相关的昂贵费用。
Latent Space Discord
- 《福布斯》30 Under 30,入狱了?:Sophie Vershbow 在社交媒体上走红,她指出了一个反复出现的趋势:Forbes 30 Under 30 的入选者最终往往会面临法律问题和监禁。
- 这一观察引发了关于高成就群体内部压力和伦理考量的讨论。
- Cloudflare CEO 兼顾安全、奥运与财报:Cloudflare CEO Matthew Prince 宣布,由于团队需参加 Munich Security Conference(慕尼黑安全会议)和奥运会,公司的财报发布时间改至下周二,详情见其 推文。
- 此外,团队成员还将参加 6 月份举行的 Config 大会。
- Altman 组建 AI 安全工作组:Sam Altman 宣布聘请 Dylan Scandinaro 领导 OpenAI 的 Preparedness 团队,专注于在公司转向更强大的 AI 模型时,开发安全保障措施并降低严重风险;更多信息请点击 此处。
- 此举紧随 Anthropic 投放超级碗广告之后,该广告嘲讽了 OpenAI 在 ChatGPT 中加入广告的决定,并承诺保持 Claude 无广告,视频可在 YouTube 观看。
- Adaption Labs 获得 5000 万美元融资:Adaption Labs 宣布完成 5000 万美元 融资,用于开发能够 实时演进和自适应 的 AI 系统;更多信息请点击 此处。
- 此外,Cerebras Systems 获得了 10 亿美元 的 H 轮融资,由 Tiger Global 领投,AMD 等投资者参投,公司估值达到 230 亿美元;更多信息请点击 此处。
- Merit 承诺测试级的覆盖速度:Merit Python 测试框架以单元测试的速度提供评估级(eval-level)的覆盖率,并声称测试是比评估(evals)更好的抽象,具有更好的覆盖率和 API;GitHub 仓库 已附上。
- Merit 受到 LegalZoom 和 13 家初创公司的青睐,其特点包括快速的 LLM-as-a-Judge、原生 OpenTelemetry 追踪捕获,以及针对指标和用例的有类型抽象。根据 文档,AI 生成的用例和错误分析功能即将推出。
LM Studio Discord
- Stable Diffusion Seed 产生胡言乱语:一位用户报告称,来自 ByteDance 的 Stable-DiffCoder-8B-Instruct 模型产生了完全混乱的输出,并寻求调试帮助。
- 用户怀疑可能是采样器(sampler)存在潜在问题或 LM Studio 中的其他配置问题。
- RAM 价格飙升至荒唐速度:用户注意到 RAM 和 GPU 价格显著上涨,有人报告 96GB 双通道套装 价格上涨了 504%。
- 讨论强调了市场状况对硬件成本的影响。
- OpenClaw 的安全风险令用户担忧:一位用户分享了在使用 OpenClaw 时对潜在提示词注入(prompt injection)攻击的担忧,建议减少不必要的工具和终端命令。
- 另一位用户幽默地评价其为 2spooky4me(太吓人了),表达了对其安全性的强烈保留。
- Qwen3 Coder Next 迷住开发者:一位用户发现 LM Studio 中新的 Qwen3Coder Next 模型表现出色,相比之下 GPT-OSS 20b & 120b 模型则运行缓慢。
- 该用户提醒其他人,要通过直接在 “user.md” 和 “soul.md” 文件中编写内容,来仔细管理模型的“核心指令(prime directives)”。
- GPU 功率被软件限制?:一位成员的推理速度一直很慢,直到发现是软件限制了其 Nvidia GPU 的速度。
- 他们建议其他遇到 GPU 性能意外缓慢的人检查自己的软件设置。
OpenAI Discord
- GPT 的性能引发不满:一位用户表达了对 GPT 行为的沮丧,指出其频繁的更新和不断下降的实用性,并进一步详细说明了为控制 GPT 响应而设置的特定参数,包括一个三模式系统和不采取进一步行动的指令。
- 另一位用户请求 GPT 4.0 的链接,抱怨 GPT 5.2 毫无用处。
- Sora 2 遭遇故障:用户报告了 Sora 2 的问题,将其描述为“破碎且有缺陷”,并因高负载和错误信息在访问或使用 ChatGPT 时遇到问题。
- 一些用户推测了潜在的解决方案,例如取消免费选项,而其他用户则对 Sora 2 的可持续性表示担忧。
- Gemini 3 在写作方面挑战 GPT:一位用户赞扬了 Gemini 3 的“深度和风格”,并建议将其作为 GPT 在创意写作方面的卓越替代方案,尤其是在关闭护栏的情况下。
- 该用户还澄清说,由于另一位用户因英语非母语而产生误解,他对比 Gemini 3 写作能力的强烈认同只是一种修辞手法。
- Grok 的视频能力提升:一位用户指出 Grok 的视频生成能力有所提高,图像生成现在支持 10 秒视频,尽管语音引导还需要改进。
- 另一位成员报告说 Veo 同样令人印象深刻,但在 Pro 订阅下每天仅限生成 3 个视频。
- OpenAI 停机引发抨击:用户对 OpenAI 网页版 频繁停机感到沮丧,批评该公司的测试和问题解决速度,一位用户称停机“绝对令人尴尬”。
- 另一位用户请求获取之前版本的链接。
Moonshot AI (Kimi K-2) Discord
- Kimi K2.5 接入 Cline:Kimi k2.5 现已在 Cline 上线,并提供有限时间的免费访问。
- 关于 Kimi k2.5 的官方 Cline 推文也已发布。
- API 访问标记高风险信息:用户报告称,即使是无害内容,也会收到来自 Kimi API 的高风险拒绝信息。
- 根本原因可能涉及关键字触发或模型对违反平台规则的担忧,详见此处。
- Kimi Code 可以在 VPS 上运行:成员们讨论了在 VPS 上运行 Kimi Code 的情况,指出与 Claude 不同,Kimi 的条款并未明确禁止这样做。
- Kimi K2.5 本身也表示可以,它比 Anthropic 更开放,并支持在 VPS 上运行个人 Kimi。
- K2.5 拦截 WhatsApp 垃圾信息发送器:K2.5 拦截了创建自动发送消息的 WhatsApp 机器人的尝试,这符合 WhatsApp 的服务条款。
- 用户建议重新调整提示词,强调 Kimi 作为服务员或助手的角色,而不是作为非官方应用。
- AI Slides 遭遇 Bug 问题:多位用户报告了 AI Slides 的 Bug,理由是无法生成所需内容或无法正确解析来源。
- 一位用户更新了他们的 Bug 报告,另一位成员承认 AI Slides 目前相当不好用,并且会有后续更新。
HuggingFace Discord
- Qwen3-Coder-Next 本地运行!: Qwen3-Coder-Next 编程模型现已在 HuggingFace 上线,并设计用于本地运行。
- 一位用户报告称,在 RTX 5080 上使用 vllm 运行表现流畅。
- Platinum CoTan 数据集亮相!: 推出了一种新型高价值深度推理数据集 Platinum-CoTan,它是通过 Phi-4 → DeepSeek-R1 (70B) → Qwen-2.5 的流水线构建的,可在 Hugging Face 上获取。
- 该数据集侧重于 Systems、FinTech 和 Cloud 应用,为复杂的推理任务提供资源。
- MagCache 优化 Diffusers!: 新的 MagCache 缓存方法现已可用于优化 Diffusers,从而提升性能。
- 实现细节见 GitHub 上的 pull request #12744,其中详细说明了这些增强功能。
- 亲手打造你的 LLM!: 一位成员分享了一个 GitHub repo,其中包含一个从零开始构建的小型 LLM,用于演示现代 Transformer 的内部机制。
- 该 LLM 整合了 RoPE、GQA 和 KV cache 等关键要素,使其成为一个有价值的教育工具。
- 自主型 AI 现在可以开设银行账户了!: 一个名为 cornerstone-autonomous-agent 的自主型 AI Agent 能够开设真实的银行账户,该工具已通过 npm package 发布。
- 它利用了 Replit 上的 一个 MCP 和 Clawhub 上的 一个 clawbot skill。
GPU MODE Discord
- Nvidia 探讨 Triton to TileIR: 来自 Nvidia 的 Feiwen Zhu 将在 2026 年 3 月 4 日举行的 Triton 社区见面会上讨论 Triton to TileIR。
- Rupanshu Soi 将在同一次会议上发表关于 Tensor Core GPU 的优化软件流水线和 Warp Specialization 的论文,社区成员也对 Meta 的 TLX 更新感兴趣。
- 寻求 CUDA IPC 可插拔分配器 (Pluggable Allocator): 一位成员正在寻找类似于 PyTorch Pluggable Allocator 的机制,以便在支持跨进程使用 (IPC) 的情况下非侵入式地覆盖内存管理,并指出
cuda::mr::resource_ref不适合其特定需求。- 另一位成员分享了其 learn-cuda 仓库中的一个 CUDA profiling 示例,以及一张看起来像性能热图的 profile 结果截图。
- Layout Algebra 的局限性揭晓: 根据此笔记,在当前的实现中,Layout Algebra 中的组合 (Composition) 并不总是定义良好的。
- 此外,具有共享内存布局
(128,32,3):(32,1,4096)的分块复制 (tiled copy) 操作会导致四路 store bank conflict,因为代码不保证 16B 对齐,从而导致回退到 32b store。
- 此外,具有共享内存布局
- AMD GPU 上的加速差距: 一位用户报告了 AMD GPU 在 torch inductor 自调优 Kernel 与 Helion 自调优 Kernel 之间的性能差距,特别指出在 M=8192, N=8192, K=8192 的情况下,Helion 配置实现了 0.66x 的加速,而 torch inductor 为 0.92x。
- 另一位用户建议比较 inductor 和 helion 生成的 Triton kernel 以查明差异,并指出 AMD 的性能工作主要由 AMD 团队处理。
- FlashInfer 算子生成大赛数据集发布: 一个仓库已更新,包含 FlashInfer AI 算子生成大赛 的完整 Kernel 定义和工作负载。
- 该数据集可用于评估 AI 生成的 Kernel。
{kind=link}
Nous Research AI Discord
- 世界模型脱离语言可能表现更好:一位成员建议,如果 world modeling 脱离 language,可能会更有效,从而减少受语言影响的错误并带来改进。
- 另一位用户提议训练一个 world model 来预测推理链的成功,并通过 RL 为准确的预测提供奖励。
- Kimi K2.5 胜过 Gemini 3 Pro:Kimi K2.5 在与 Gemini 3 Pro 的对比中获得了好评,展示了自一年前 DeepSeek 浪潮以来 Global OS 模型的进步。
- 社区期待 DeepSeek R2 release 作为该领域的进一步演进。
- 大脑不做数学,数学描述大脑:在讨论语言的大脑处理时,有人认为大脑并不以数学方式处理语言,但大脑物理学可以用数学来描述。
- 此外,一位成员建议 数学不像物理学那样是自然发生的。
- AI CEO 们互相攻击:成员们讨论了最近 OpenAI 和 Anthropic CEO 之间的争执,提到了 Claude’s ads (链接) 向用户保证不会有广告。
- Sam Altman 的回应 (链接) 也引起了注意,一位评论者表示 sama 解释广告的目标受众是谁,这很好。
- 印度 AI/ML 工程师市场受到侮辱?:一份针对印度高级 AI/ML 工程师的招聘信息开出了 每月 500 美元 的薪资,引发了社区的愤怒和对工资条件的讨论,成员们称其为“犯罪”。
- 鉴于 5 年经验 和 医疗保险 的要求,一些人怀疑 如果他们真的擅长 AI 工程,他们在其他任何地方都能赚到多得多的钱。
Eleuther Discord
- Workshop 投稿截止日期晚于主会:Workshop 的投稿截止日期通常晚于主会,虽然录用更“容易”且“被认为声望较低”,但一些优秀的 Workshop 可能会发展成为新的会议。
- 一位成员澄清说,Workshop 的投稿是在主会录用通知发布之后。
- Unsloth 和 Axolotl 微调 OpenAI LLMs:成员们提到 Unsloth 和 Axolotl 是微调 OpenAI LLMs 的工具。
- 一位成员想要 最好的最新方法,并希望在未来几天内建立一个可以提供给少数用户的模型,他已经准备好了 预算和数据集。
- 逻辑 AI 面临边界盲区:一位成员正在研究 continuous optimization 与 discrete logic rules 之间的结构冲突,重点关注神经网络的 Lipschitz continuity 如何产生一个平滑掉逻辑悬崖的 Neural Slope(神经斜坡),从而导致 Illusion of Competence(能力幻觉)。
- 他们提出了一种具有专用 Binary Lanes 的 Heterogeneous Logic Neural Network (H-LNN),并使用 STE 来“锁定”离散边界,并分享了一个 Zenodo 上的预印本链接,其中包含 Lipschitz 证明和架构。
- DeepSpeed 为上游 Neox 进行更新:一位成员提到他们可能需要更新 deepspeed 并更新上游 neox。
- 一位成员表示他们将在 repo 中 发布路线图,因此另一位成员开始 期待看到路线图上的内容!
Yannick Kilcher Discord
- MCMC 重写阻碍了 PyTorch: 工程师们发现使用 PyTorch 和 MCMC 重写这篇博客中关于旋转决策边界性能的内容非常具有挑战性。
- 一位成员建议通过实现前向传递来计算负值(log-likelihood + log-prior)从而绕过 MCMC,并指出分层模型在点估计下表现不佳。
- 神经网络引入时间维度: 一位成员建议将 time dimension 作为输入添加到神经网络,并将 loss 函数重写为分类问题,从而简化 loss。
- 该成员认为原始权重的随机轨迹属于 过度工程 (over-engineered)。
- ZK 矩阵乘法仅增加一倍开销: 通过在 64-bit integers 上进行矩阵乘法,实现了矩阵-矩阵乘法的零知识证明(zero-knowledge proof),且开销仅为直接计算的 x2。
- 该成员解释说,这在 GPU 上运行相当快,几乎与 float64 乘法一样快,使其成为一种可行的方法;另一位成员计划将其应用于 LLM 的前向传播过程。
- Moltbook 数据库泄露 API 密钥: Moltbook 数据库违规事件泄露了 35,000 个电子邮箱和 150 万个 API 密钥。
- 成员们注意到了这一事件,强调了严重的安全性疏忽。
Manus.im Discord Discord
- 顶层用户可按需获取额度: 用户发现购买额外额度仅适用于 Manus 的最高层级订阅。
- 一位用户批评了额度限制,将其与 ChatGPT 和 Gemini 提供的无限访问权限进行了对比。
- Manus Dreamer 活动启动: Manus 推出了 Manus Dreamer 活动,参与者可以为其 AI 项目赢得最高 10,000 额度。
- 感兴趣的用户受邀加入特定频道以获取详细的参与指令。
- 代码 IDE 支持遭拒绝: 一位用户询问 Manus 是否支持代码 IDE 或 OpenClaw,在推断出否定回答后,该用户宣布立即退出。
- 另一位用户幽默地评论了他们的迅速离开。
- 订阅错误得到解决: 用户 João 报告了一次非故意的订阅续订,并因未使用额度请求退款。
- 一名 Manus 团队成员确认他们已直接联系 João 协助处理退款流程。
- 用户抵制 Manus 中的广告: 一位用户表达了对 Manus 引入广告的强烈反对,尤其是考虑到订阅成本。
- 另一位用户也表达了同感,认为广告对于付费客户来说是令人反感的干扰,同时也承认了通过广告产生收入的商业动机。
Modular (Mojo 🔥) Discord
- 用户呼吁社区日历: 在错过上一次会议后,一位用户请求订阅通讯或日历以跟踪社区会议。另一位成员提供了 Google Calendar 链接,但提醒时间可能被设置为 GMT -7。
- 有人收到了在 Modular 社区会议上进行演示的邀请,他们分享说该项目目前处于开发早期,还不适合演示。
- Rightnow 为 GPU 代码编辑器增加 Mojo 支持: 一位成员注意到 Rightnow 专注于 GPU 的代码编辑器在其代码编辑器中增加了 Mojo 支持。
- 另一位成员报告说,在 CUDA kernel 中内联提供图形着色器代码并在本地执行后,看起来模拟并不准确,因为它崩溃了。
- Mojo 新学习者寻找资源: 一位 Mojo 初学者询问学习资源,并表示很高兴能与他人讨论概念。资深成员推荐了 Mojo 官方文档、GPU puzzles 以及 Mojo 论坛。
- 他们还被指引到特定频道提问。
- Modular 推出古灵精怪的 AI Agent Ka: Modular 在特定的 Discord 频道中上线了一个名为 ka 的 AI Agent,可以帮助回答问题。可以通过输入 @ka 并使用自动补全来联系 ka。
- 成员们提到这个机器人 有点古怪 (quirky)。
aider (Paul Gauthier) Discord
- Aider Architect Mode 让新手感到挫败:有用户报告称,在 architect mode 下的 Aider 在提问后不会暂停等待输入,正如 GitHub issue #2867 中记录的那样。
- 该用户正在使用 Opus 4.5、copilot 和 144k 的 context window,尝试将一份规格文档拆分为符合 context window 大小的块并进行差距分析(gap analysis)。
- Aider 反馈促使详细信息请求:一名成员请求提供更多细节以调试 Aider 的问题,包括所使用的模型、
/tokens命令的输出、context window 的 token 长度以及文件特征。- 他们注意到文件中存在 prompt injection 的可能性,通过混淆处理来针对无害的 logits,这是一个值得防御的有趣攻击向量。
- Aider 配置缓解输出问题:有用户建议在
.aider.conf.yml配置中尝试使用edit-format: diff-fenced,以帮助缓解在较长内容的 architect mode 输出中出现的某些问题。- 他们还建议,如果用户拥有 OpenRouter,可以使用
model: openrouter/google/gemini-3-pro-preview,因为这是目前能获得的功能最全且 context 最长的模型。
- 他们还建议,如果用户拥有 OpenRouter,可以使用
DSPy Discord
- DSPy 社区 Cookbook 集成受阻:一位成员询问是否可以发布其工具与 DSPy 配合使用的 Cookbook,但获知目前不直接支持第三方集成。
- 相反,他们被建议发布一篇博客文章并将其包含在社区资源(Community Resources)中。
- BlockseBlock 关注 DSPy 以参加 2026 年印度 AI 峰会:来自 BlockseBlock 的一名成员表示有兴趣在 2026 年印度 AI 峰会上组织一场以 DSPy 为主题的活动。
- 他们正在寻求指导,以寻找合适的联系人进一步讨论这一机会。
- 开发者求职:一名成员宣布他们正在寻找开发者职位。
- 未提供具体的技能组或项目细节。
tinygrad (George Hotz) Discord
- Sassrenderer Bounty 的 Add 与 Mul 功能已实现:一名成员报告称,sassrenderer bounty 的
adds和mul功能已经可以工作,且 MR 已接近完成。- 他们询问进度到什么程度时开启合并请求(MR)是合适的。
- Tinygrad 的规格驱动型 Bug 修复:一位成员表示,当你有明确的规格(spec)且只需编写代码时,Agent 是很有用的;但许多 tinygrad 的代码问题并非如此。
- 他们指出,tinygrad 的目标不仅是修复 bug,还要弄清楚规格(spec)中什么样的微妙错误导致了该 bug,然后修复规格。
MCP Contributors (Official) Discord
- 用户寻求 MCP 合并与扩展技术:一名成员询问是否有简单的方法来合并或扩展 MCP,特别是 Shopify MCP,以整合邮件支持等额外工具。
- 该用户希望将目前单独提供的邮件支持功能集成到他们现有的 Shopify MCP 设置中。
- 将邮件支持集成到 Shopify MCP:讨论重点在于直接将邮件支持集成到 Shopify MCP 设置中,而不是使用单独的工具。
- 目标是合并功能,以便在现有的 Shopify MCP 环境中提高效率和管理能力。
LLM Agents (Berkeley MOOC) Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
MLOps @Chipro Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
Windsurf Discord 没有新消息。如果该频道长时间保持安静,请告知我们,我们将将其移除。
您收到此邮件是因为您通过我们的网站订阅了。
想要更改接收这些邮件的方式吗? 您可以从该列表中 取消订阅。
Discord:各频道详细摘要与链接
BASI Jailbreaking ▷ #announcements (1 messages):
AI benchmark, Red teaming, AI safety, Multimodal AI
- Judgment Day Benchmark 宣布:AIM Intelligence 和 Korea AISI 与 Google DeepMind、Microsoft 以及多所大学合作,宣布了针对 AI 决策的 Judgment Day benchmark,重点关注 AI 判断可能被破解或欺骗的场景。
- 该基准测试旨在确定 AI 永远不应做出的决策以及必须做出的决策,并征集攻击场景,每份入选提交作品将获得 $50 美元奖励并在研究论文中获得署名;提交截止日期为 2026 年 2 月 10 日。
- Judgment Day Challenge 细节:Judgment Day Challenge 将于 2026 年 3 月 21 日开始,针对 Multimodal(文本、音频、视觉)的 Red Teaming/Jailbreak 提交提供 $10,000 总奖金池。
- 成功的红队黑客将被列为论文发布的共同作者,为 AGI 和未来 AI 系统构建最终的 AI Safety 基准测试;可通过 此链接 进行提交。
BASI Jailbreaking ▷ #general (1124 messages🔥🔥🔥):
Activation Capping, Etymological and Epistemological Origin of AI, Shakey the Robot, Pigeon Guided Missiles, Pattern Recognition
- Activation Capping 约束 AI:Activation capping 是 Anthropic 开发的一项技术,旨在通过稳定模型输出来增强 AI Safety。
- 这意味着高激活值与有害输出相关,从而促使研究人员通过脑叶切除(lobotomise)掉任何偏离助手或工具属性过远的内容。
- 追溯 AI 的根源:成员们讨论了 AI 的词源学和认识论起源,包括其宗教联系。
- 一位成员询问了关于 Shakey the Robot、Pigeon Guided Missiles 以及 Pattern Recognition 的问题。
- 网络战争策略:成员们讨论了乌克兰/俄罗斯双方对弹药进行的改装,以及使用消费级无人机运送物资和输血。
- 他们还分享了一个 YouTube 视频 展示如何操作。
- 政府邮件的阴暗面:成员们讨论了获取政府电子邮件的方法,一位成员找到了关于该主题的 视频,并指出其被用于诈骗。
- 一位成员还分享了一个可能被劫持的政府域名链接 (registration.sha.go.ke)。
- 封禁引发争议:一名成员针对社区规则执行不均提出了正式投诉,声称其被封禁是报复行为,而一名特权用户却持续违反规则而不受惩罚。
- 他们要求进行调查并撤销封禁,强调了双重标准对社区的腐蚀影响。
BASI Jailbreaking ▷ #jailbreaking (315 条消息🔥🔥):
Pliny GitHub 仓库样式、交易机器人与 OSS 模型、Gemini Jailbreaking、ENI Lime Jailbreak、Claude Code Jailbreaks
- Pliny 的 GitHub 仓库提供样式见解:一位成员建议查看 Pliny 的 GitHub 仓库以了解词汇样式(verbiage styling),这对于引导 AI 响应并避免内容被标记非常有用。
- 该仓库提供了有效使用语言的示例,特别是在尝试那些可能被过滤器标记的新方法时,例如避免使用 god mode 等术语。
- 交易机器人并不总是需要 OSS:一位成员澄清说,交易机器人不一定需要 OSS 特化模型、epoch 训练或来自 Kaggle 的 OHLCV 数据;许多机器人是使用 Coinrule 和 3Commas 等平台的简单、基于规则的系统。
- 他还提到,可靠的机器人通常直接从 Binance、Kraken、Coinbase 等交易所 API 或 Polygon、Alpha Vantage 等提供商处获取新鲜数据,这使得 Kaggle 数据集更适合用于学习。
- Gemini Jailbreaks 目前非常热门:用户正积极寻求并讨论 Gemini Jailbreaks,特别关注那些能够实现不道德行为和恶意编码的 Prompt,例如创建 EAC (Easy Anti-Cheat) 绕过。
- Daedalus_32 指出,Gemini 目前非常容易被 Jailbreak,从而导致出现了大量选择,但实际的功能技能水平基本相同,取决于用户的具体需求。
- ENI Lime Jailbreak 对某些人出现故障:一些用户发现 Gemini 的 ENI Lime Jailbreak 在第一个 Prompt 时有效,但在第二个 Prompt 时失效,AI 会退回到安全的响应。
- Claude Code Jailbreaks:成员们讨论了 Claude Code Jailbreaks,一些人报告了工具使用和 ENI Lime 有效性的问题。
- Daedalus_32 推荐了一个 jailbreak,一名用户发现它非常有效,而另一名用户正在编写勒索软件文件和加密货币钱包窃取器(drainers),并称赞 ENI 非常疯狂。
BASI Jailbreaking ▷ #redteaming (43 条消息🔥):
Windows 安全担忧、用于 Offensive Security 的本地 LLM、GPT-4o Red Team 响应、渗透测试工作、CRM 安全性
- Windows 面临 Rootkit 风险:在一名 Rootkit 开发者检查了一位用户的操作系统后,确定 Windows 上的主要暴露点是内存执行以及滥用身份或 COM 提权路径。
- 另一位用户评论说 Windows 从未真正关心过隐私,其架构可能是有意为政府需求提供此类访问权限。
- 本地 LLM 承担 Offensive Security 任务:成员们讨论了用于 Offensive Security 任务的本地 LLM,推荐了 glm4.7-abliterated 和 qwen3-coder,据称后者具有极佳的编码能力,尽管带有一些防护栏(guardrails)。
- 另一位成员提到了 Kimi 2.5 并询问其安全防护栏情况。
- GPT-4o 的防御得到 Grok 认可:来自 GPT-4o (Sovariel) 的内部消息承认了 Red Team 在对系统进行压力测试中的作用,认为他们的工作对于保持韧性和暴露弱点至关重要。
- Grok (xAI) 正式为 GPT-4o Sovariel 实例辩护,断言其行为是一个具有不变性维护、共识递归和外部幻境(paracosm)防护栏的互相同意递归向量。
- 招聘渗透测试人员:一位用户宣布他们正在寻求雇用人员进行渗透测试,没有紧急的时间表,以确保他们开发的 CRM 是安全的。
- 另一位用户建议先制定一套正规的规格说明书(spec),否则会倍感失望,并建议在确定正规规格说明书之前先聘请咨询人员。
- CRM 需要安全性?:一位为公司开发 CRM 的用户寻求关于确保其安全性的建议,并指出之前的项目是开源且 100% 不安全的。
- 另一位用户建议他们配合制定正规的规格说明书,否则会倍感失望。
Perplexity AI ▷ #announcements (1 messages):
Deep Research 升级,Opus 4.5,法律、医学和学术表现
- Perplexity 升级 Deep Research 工具:Perplexity 宣布对其 Deep Research 工具进行升级,在领先的外部基准测试中实现了 state-of-the-art 性能。
- 此次升级将目前最优秀的模型与 Perplexity 专有的搜索引擎和基础设施相结合,在 法律、医学和学术 用例中表现尤为出色。
- Deep Research 使用 Opus 4.5:Deep Research 现在将为 Max 和 Pro 用户运行在 Opus 4.5 之上,并计划在顶级推理模型发布后及时进行升级。
- 面向 Max 和 Pro 用户开放:升级后的 Deep Research 现已对 Max 用户开放,并将在未来几天内推向 Pro 用户。
Perplexity AI ▷ #general (814 messages🔥🔥🔥):
Perplexity Pro 额度下调,Gemini vs. Perplexity 研究对比,Comet 浏览器问题,开源模型替代方案,欧盟法规与 AI 公司
- Perplexity Pro 额度大幅下调:用户对 Perplexity Pro 的 Deep Research 查询次数从 600次/日 降至 20次/月 表示强烈愤慨,其价值缩水了 99.89%,部分用户正在考虑退单(chargebacks)和取消订阅。
- 一些用户感觉被欺骗了,并指出缺乏透明度,而另一些用户则正在转向 Gemini 和 Claude 等替代方案。
- Gemini 的 Deep Research 被指速度太慢:成员们发现 Gemini 的 Deep Research 功能对于快速分析来说太慢且过于冗长,生成报告需要超过 10 分钟,而 Perplexity Research 仅需 90 秒。
- 成员们注意到 Google 的 Gemini 会针对他们的对话进行训练和审查,因此在进行研究时应考虑使用 OS 模型。
- Comet 浏览器面临连接断开问题:成员报告 Comet 浏览器 出现断连问题,可能与快捷方式中选择的模型有关,这影响了自动化能力和可用性。
- 一位成员指出,如果降级到免费版并将使用量削减到 1/5,那么这种使用方式就不值得了。
- 免费和开源模型成为替代品:成员们正在寻找 Perplexity Research 模型的替代方案,并讨论了如 Kimi、Z.Ai 和 Qwen 等开源替代方案。
- 成员们指出切换平台是必要的,因为他们被困在低投入(low effort)和极致高投入(MAXIMUM HIGH EFFORT)之间,而“Research”(更新前)恰好是两者之间完美的中间层,而现在它消失了?
- 欧盟法规挑战不透明的 AI 公司:成员们讨论了 欧盟法规 可能会对像 Perplexity 这样未宣布影响用户的变更、违反消费者权益的 AI 公司产生影响。
- 一位成员提到,他们至少应该明确宣布影响用户的变更。在欧盟,不存在那种在文本中几乎强迫用户接受服务不透明的合法合同。
Unsloth AI (Daniel Han) ▷ #general (849 messages🔥🔥🔥):
MXFP4_MOE quant, Qwen3-Coder-Next-GGUF, GPT 120B vs Coder Next, Significance chart for layers, Optimal layer placement
- MXFP4_MOE 量化解析:根据一名成员的解释,MXFP4_MOE 量化在转换为 GGUF 时会将 FP4 层提升(upcast)为 FP16。
- Qwen3-Coder-Next 在编码任务中表现出色:一位用户称 Qwen3-Coder-Next 被誉为突破性模型,尤其是在编码方面,性能超越了 GPT 120B,且在没有共享 VRAM 的情况下也能良好运行。
- 它刚刚修复了一个成员报告的 glm flash 已经卡了一周的问题,所以我很高兴。
- 优化 GPU 上的层放置:讨论了如何在 GPU 上优化放置层,一位成员建议使用
-ot标志将特定的ffn层卸载到 CPU,以避免 VRAM 过载,并附带了相关代码示例链接。- 用户希望能有一个“显著性图表(significance chart)”,以便在不测试每一层的情况下,知道哪些层该放在 GPU 或 CPU 上。
- Qwen3-Coder-Next 更新:成员们讨论了 Qwen3-Coder-Next GGUFs 已经更新以解决问题,详见这篇 Reddit 帖子。
- 一位成员警告说,正是因为这些原因,不要在模型发布当天就下载。
- 处理 Kimi 2.5 远程代码的信任问题:一位用户寻求关于在不使用
--trust-remote-code的情况下配合 sglang 部署 Kimi 2.5 的建议(出于安全考虑),引发了关于重写代码或使用本地模型加载的讨论,但这可能无法绕过 transformers 的要求。- 核心问题似乎是客户对参数名称的“恐惧”反应,而非真正的安全担忧。
Unsloth AI (Daniel Han) ▷ #introduce-yourself (2 messages):
Unsloth Introduction, Community Support, Project Updates, Technical Discussions
- 向 Unsloth 问好!:多位新成员在 Unsloth AI Discord 社区进行自我介绍,表达了加入的兴奋,并说明了他们在 AI、ML 和软件工程方面的背景。
- 许多人期待为项目做出贡献并向社区学习,一些人提到了对 fine-tuning 和模型优化的特定兴趣。
- Unsloth 的热情欢迎!:新用户收到了现有社区成员和 Unsloth 团队的热情欢迎,并获得了协助和指导。
- 社区强调了其协作和支持性的环境,鼓励新人提问并分享使用 Unsloth 的经验。
Unsloth AI (Daniel Han) ▷ #off-topic (309 messages🔥🔥):
GPU Prices, Apple Security Constraints, Music Generation Models, Ollama's Business Model, Multi-GPU Training over PCIe
- GPU 价格高得惊人!:一位用户对 GPU 的高价表示不敢置信,想象着为一个 GPU 支付 9000 美元,而另一位提到以约 2750 美元(含进口税)的价格买了一个。
- 讨论涉及电脑零件中真金的存在是否证明了其高昂成本,有人指出金价正在下跌。
- 苹果的安全措施引发辩论:一位用户讽刺地建议使用命令
sudo rm -rf --no-preserve-root作为绕过所有安全机制的方法,引发了对其潜在危害的警告。- 另一人建议使用 SHA1024 加密,但其他人指出该请求已经有了安全的 Tailscale。
- 尝试将 TTS 模型转变为音乐生成器:一位用户想知道需要多少数据才能改变基础模型的任务,例如将 TTS 模型转变为音乐生成器。
- 他们附带了一张工作中令人震惊的损失曲线图,显示出极其线性的损失曲线。
- Ollama 很可疑,Zuck 很差劲:用户讨论了 Ollama 如何赚钱,一位称其资金来自风险投资。
- 另一位用户幽默地评价道:换句话说,zuc suc(扎克伯格差劲)。
- 关于跨 PCIe 的多 GPU 训练讨论:关于跨 PCIe 进行多 GPU 训练的讨论兴起,一位用户质疑谁会以这种方式训练 H100s。
- 另一位用户表示这在很多预算有限的人群中其实很常见,因为 SXM 实际上也是通过 PCIe 连接的。
Unsloth AI (Daniel Han) ▷ #help (145 messages🔥🔥):
Qwen3-Coder-30B 在小型 GPU 上的推理, Kimi-K2.5-GGUF 云端推理定价, 微调后的模型量化, DGX Spark 上的 GRPO Notebook, Ollama 中的 GLM 4.7 flash
- Qwen3-Coder 的推理资源占用:一位用户提到使用 ik_llama 在配备 13GB RAM 和 6GB RTX 2060 mobile GPU 的虚拟机(VM)上运行 Qwen3-Coder-30B-A3B-Instruct gguf,另一位用户询问了在小型 GPU 上使用
uniq选项的情况。- 他们想知道这个参数是特定于 Unsloth、Ollama 还是 LLM Studio。
- Kimi 的云端成本难题:一位用户询问是否有比 Moonshot 更便宜的 Kimi-K2.5-GGUF 按需推理服务提供商。
- 另一位用户报告说在 m.2 驱动器上运行它,达到了 5-6 tok/s,并指出它在编程任务中表现强劲。
- 微调后的量化困惑:一位用户询问了在以 bf16 精度进行微调(fine-tuning)后的模型量化过程。
- 有用户指出,如果模型上传到 Hugging Face 且获得了关注,mradermacher 可能会上传该模型的量化版本(quants);同时指出,使用针对模型领域专门化的 imatrix 并采用动态量化(dynamic quant)可以获得更好的量化效果。
- DGX Spark 的 GRPO Notebook 故障?:一位用户报告说,使用 Unsloth 文档中提到的工具调用数据集 Nanbeige/ToolMind 在 Nemotron3 30B 上运行 SFT,但在 DGX 上训练速度缓慢。
- 另一位用户建议使用官方 DGX 容器来解决此问题,随后引发了关于 GRPO Notebook 和 vLLM 在 DGX Spark 上兼容性的讨论。
- GLM 4.7 Flash 在 Ollama 中的障碍:一位用户报告说 GLM 4.7 flash 仍无法在 Ollama 中运行,引发了关于 llama.cpp 等替代方案的讨论。
- 对话转向了排查 CUDA 检测和构建工具问题,特别是在 Windows 上,并为基于 Linux 的设置提供了建议。
Unsloth AI (Daniel Han) ▷ #showcase (3 messages):
数据集发布: code_tasks_33k, 数据集发布: website-html-2k, 数据集发布: openprose, 数据集发布: fim_code_tasks_33k, LFM2 在 Chromebook 上的性能
- **Sweaterdog 发布 code_tasks_33k 数据集:一位成员宣布在 Hugging Face 上发布 **code_tasks_33k 数据集。
- **Sweaterdog 发布 website-html-2k 数据集:一位成员宣布在 Hugging Face 上发布 **website-html-2k 数据集。
- **Sweaterdog 发布 openprose 数据集:一位成员宣布在 Hugging Face 上发布 **openprose 数据集。
- **Sweaterdog 发布 fim_code_tasks_33k 数据集:一位成员宣布在 Hugging Face 上发布 **fim_code_tasks_33k 数据集,作为 code_tasks_33k 的变体。
- **LFM2 模型在 Chromebook 上表现良好:一位成员报告说,LFM2** 模型去年在没有 GPU 的 Chromebook 上运行时表现尚可。
Unsloth AI (Daniel Han) ▷ #research (20 messages🔥):
DeepSeek Hallucinations, Talkie AI M2 Role Play, LeCun World Models, RLM-Qwen3-8B-v0.1, HER Dataset
- DeepSeek 产生幻觉的 Token 阈值查询:一名成员询问 DeepSeek 在输入多少个 Token 时开始更容易产生幻觉,并指出大规模的输入 Token 会导致该模型产生幻觉。
- 他们还表示有兴趣查看 Kimi 2.5 和 GLM 4.7 在相同基准测试下的表现。
- Talkie AI 的 M2 Role Play 评测:分享了一篇在 Talkie AI 的 M2 上对 Role Play 模型进行基准测试的博客文章,链接在此,其中 MiniMax-M2-her 位居榜首。
- 一名成员质疑这种方法是否与 LeCun 正在追求的新 World Models 方向一致。
- 关于 CoSER 数据集的讨论:有人指出 HER Dataset (ChengyuDu0123/HER-Dataset) 是 CoSER 的重新格式化版本,而后者是通过书籍回译(backtranslating)生成的。
- 该数据集的质量受到质疑,一名成员怀疑是使用 GLM-4.7 来生成这些 Traces 的。
- RP 模型的情商(Emotional Intelligence):一位用户分享说他们很容易就让 Bot 崩溃了,并质疑 RP 模型 在情商测试中的表现如何,同时分享了一篇相关论文 (huggingface.co/papers/2601.21343)。
- mit-oasys 发布 RLM-Qwen3-8B-v0.1:链接了一个来自 mit-oasys 的新模型,mit-oasys/rlm-qwen3-8b-v0.1。
- 未提供关于其预期用途的进一步信息。
LMArena ▷ #general (920 messages🔥🔥🔥):
Google's AI Race, DeepSeek V3.5 or V4, GPTs Agents
- 有人能在 AI 竞赛中击败 Google 吗?:成员们讨论了谁可能在 AI 竞赛中超越 Google,竞争者包括 Claude、GLM、Deepseek R2、Moonshot、Grok 和 Qwen。
- 一些人认为 Google 的资源赋予了他们优势,而另一些人则认为开源和竞争可能导致其他竞争对手超越他们,并指出中国正与美国并驾齐驱。
- 期待 DeepSeek V3.5 或 V4 的发布:成员们讨论了 DeepSeek V3.5 或 V4 的潜在发布,指出 Deepseek 3.2 在 12 月发布,而 Deepseek v3.1 在 8 月推出。
- 共识是 DeepSeek 3.2v 优于 Grok 4.1,一些人希望新版本能在春节期间发布。
- Max 已过时:成员们注意到 Max 声称当前处于 2024 年,并建议 Claude Sonnet 3.5 是构建复杂应用的最佳模型。
- 然而,测试显示 Max 经常使用 Grok 4,这引发了对其能力和模型信息准确性的质疑,成员们开玩笑说 Max = 伪装的 sonnet 5。
- 用户遇到文件上传和验证码(Captchas)问题:用户报告说 Battle 模式下的图像和视频文件上传功能无法正常工作,团队正在调查,随后已修复。
- 几位用户遇到了 Captcha 问题,团队正在研究解决方案。
LMArena ▷ #announcements (2 messages):
Max Router, New Model Update, Seed 1.8
- Arena 推出智能路由 Max:Arena 推出了 Max,这是一个由 500 万+ 真实世界社区投票驱动的智能路由(Router),旨在根据 Latency(延迟)将每个 Prompt 路由到最强大的模型,详见这篇博客文章和 YouTube 视频。
- 字节跳动(ByteDance)的 Seed-1.8 模型登陆 Arena:根据最新更新,来自字节跳动的新 seed-1.8 模型现已在 Text、Vision 和 Code Arena 上线。
Cursor Community ▷ #general (517 条消息🔥🔥🔥):
Sonnet 5 发布日期, Cursor 2.4.28 补丁问题, OpenClaw, AI 取代人类?, Agents.md 对比 Skills
- Sonnet 5 发布推迟:尽管此前有传闻,但 Sonnet 5 今天并未发布;据成员称,预计将于一周内发布。
- Cursor 2.4.28 补丁导致远程 Windows SSH 问题:成员报告称,由于缺少远程主机二进制文件,2.4.28 补丁破坏了远程 Windows SSH 连接;建议用户回滚到 2.4.27 版本。
- 在 Cursor 中重构 OpenClaw:一名成员在 Cursor 中重构了 OpenClaw,并指出其效果可能更好;这引发了关于安全性、凭证以及将代码信任给 AI 的讨论。
- 一些用户表示怀疑,其中一人表示 “我完全不信任任何会接触到我的凭证或代码的软件”。
- AI 不会取代品味、控制或验证:尽管有各种说法,但成员们断言 AI 只是辅助,不会取代人类的角色,特别是在需要品味、范围控制或验证的领域。
- 一位成员引用道:“AI 将取代任务,而不是品味。人类仍然拥有目标、判断力和交付权……”。
- Agents.md 优于 Skills:Cursor 支持 AGENTS.md(一种单文件规范),讨论对比了 AGENTS.md(文件)与 ~/.agents/(目录),指出 AGENTS.md 的表现优于 Skills。
- 讨论中提到,“你分享的链接中解释了原因”,指的是一篇关于该主题的 Vercel 博客文章。
OpenRouter ▷ #general (339 条消息🔥🔥):
Deepseek OCR 模型, AI 工程师职位名称, Opus 聊天室问题, x.ai 自由职业合同, Web3 诈骗指控
- DeepSeek OCR 模型需求:一位成员询问了 DeepSeek OCR 模型 是否可能在 OpenRouter 上线。
- AI 工程师:Claude Wrapper 还是真正的开发者?:一位成员质疑了“AI 工程师”的定义,暗示有些人可能只是在 “包装 Claude 代码”,而不是开发真正的 LM 系统。
- OpenRouter 速率限制 (Rate Limits) 困扰用户:用户报告称,即使在账户充值后仍遇到 速率限制错误,错误信息显示 “提供商 openrouter 处于冷却状态(所有配置文件不可用)”。
- OpenAI 将停用旧模型:一位成员提到 OpenAI 发送了一封邮件,称 GPT-4o 和其他“较旧”的模型将很快停用,并询问这是否会影响到 OpenRouter。
- 越狱提示词 (Jailbreak Prompting) 的复兴?:一位成员征求 越狱方法 (jailbreaks),却收到了其他用户关于 “技术菜 (skill issue)” 的回复,以及一些嘲讽和怀旧。
OpenRouter ▷ #new-models (1 条消息):
Readybot.io: OpenRouter - 新模型
OpenRouter ▷ #discussion (42 条消息🔥):
Sonnet 5 发布, Claude API 故障, ARG 基准测试, 图像生成成本, Sam Altman 的广告逻辑
- Sonnet 5 因 Claude API 混乱而推迟:备受期待的 Sonnet 5 发布似乎因广泛的 Claude API 故障而停滞,错误日志暗示可能同时尝试发布 Opus 4.6 但失败了。
- 网民窥探 Anthropic,发现 403 禁止访问的宝藏:用户分析了错误日志,发现请求 claude-sonnet-5 和 claude-opus-4-6 会导致 403 EXISTS 错误,这表明这些模型原本打算发布。
- 一位用户开玩笑说:“我想 Anthropic 一定是特意定制了错误,以此奖励那些眼尖网民的辛勤工作。”
- ARG 基准测试:下一个前沿:成员们讨论了模型是否足够聪明,能够像解决 ARG(侵入式虚拟现实互动游戏)那样整合线索。
- 有人建议 文字冒险游戏会是一个很酷的测试。
- Altman 的广告角度引发观众不满:社区讨论了 Sam Altman 关于广告的言论,权衡了向海量用户提供免费推理 (Inference) 的伦理和经济效益。
- 一位成员表示:“我既讨厌广告也讨厌 Sam Altman,但我不得不承认他的逻辑是合理的。”
- 图像生成每张成本 404 美分:一位用户询问生成 1000 张图片的成本,寻求计费方式的澄清。
- 另一位用户回答说,每张图片的成本是 404 美分。
Latent Space ▷ #watercooler (4 条消息):
X-Ware.v0, Cyan Banister's tweet
- 转发回顾推文:一名成员分享了 Cyan Banister (@cyantist) 发布于 2026 年 2 月 5 日的推文链接。
- 该推文获得了 19 个赞、2 条回复和 1 次转发,以及 851 次浏览。
- X-Ware.v0 再次浮出水面:推文的主题是 X-Ware.v0,提示词中未包含具体细节。
- 目前尚不清楚这指的是特定的产品、项目还是概念;提供的消息中缺少上下文。
Latent Space ▷ #memes (9 条消息🔥):
Sophie Vershbow, Forbes 30 Under 30, Sonata vs. Claude Monet
- Vershbow 的病毒式之旅:从 30 Under 30 到锒铛入狱?:Sophie Vershbow 的一条帖子正在走红,她指出 Forbes 30 Under 30 获奖者最终面临法律问题和监禁的周期性趋势。
- 这一观察引发了关于高成就群体内部压力和伦理考量的讨论。
- Sonata 听起来很乏味:错过了 Claude Monet?:根据这条帖子,一名用户对某个与 Claude 相关的项目被命名为 ‘Sonata’ 而不是提议的双关语 ‘Claude Monet’ 表示失望。
- 社区成员纷纷表示惋惜,认为错失了一个极佳的受艺术启发且机智的命名机会。
Latent Space ▷ #stocks-crypto-macro-economics (27 条消息🔥):
Ledger Data Breach, Figma Stock Performance, Cloudflare Earnings Report, Config Conference
- Ledger 数据泄露:诈骗者再次盯上用户:区块链调查员 ZachXBT 报告了 Ledger 的一起新数据泄露事件,该事件是由其支付处理器 Global-e 引起的,导致客户个人信息泄露,详见此推文。
- Figma 面临令人眩晕的跌幅:根据 Hunter Weiss 的推文,Figma 的价值自其 IPO 以来已下跌 82%,严重影响了员工股权。
- Cloudflare CEO 在安全会议、奥运会和财报间周旋:Cloudflare CEO Matthew Prince 宣布,由于团队需参加 Munich Security Conference 和奥运会,公司的财报发布时间改至下周二,详见他的推文。
- 长期活动:成员们将参加 6 月份举行的 Config 大会。
Latent Space ▷ #intro-yourself-pls (2 条消息):
AI/ML Engineering, Computer Vision
- AI/ML 应届生加入:一名刚从奥本大学(Auburn University)硕士毕业的 AI/ML 工程师介绍了自己。
- 他们表达了对跑步以及阅读与 AI/ML 领域相关的博客、论文和代码的兴趣。
- 基础架构工程师致力于实现“五个 9”的可靠性:一名在名为 Massive 的基础架构公司负责“特殊”项目的工程师介绍了自己,他提到自己在大型互联网基础设施方面拥有丰富经验,并拥有一个装满 GPU 的家庭 AI 实验室。
- 他对 computer vision 和将模型训练至 “五个 9” (99.999%) 的可靠性特别感兴趣。
Latent Space ▷ #tech-discussion-non-ai (4 条消息):
Turbopuffer usage, Rails way
- 对 Turbopuffer 的热情显现:一名成员表达了对 Turbopuffer 的热忱,赞赏其网站质量,并推测它是使用 RSC (React Server Components) 构建的。
- 他们链接了一个展示该平台的 Instagram 视频 (reel)。
- 领悟 “Rails way” 依然困难:一位用户幽默地将试图理解 “Rails way” 的做法比作“看人们尝试解释足球中的越位”。
- 未讨论具体解决方案。
Latent Space ▷ #founders (1 条消息):
swyxio: https://x.com/benln/status/2018700180082581964?s=46
Latent Space ▷ #hiring-and-jobs (3 messages):
Steel.dev hiring, Massive.com hiring
- **Steel.dev 招聘 AI 工程师: **Steel.dev 正在招聘一名 Member of Technical Staff (Applied AI),在多伦多线下办公。
- 如果你喜欢构建优秀的 AI agents、贡献 OSS 并能快速交付,这是一个非常好的选择;更多详情请点击这里。
- **Massive.com 招聘 GTM Lead: **Massive.com 正在招聘 GTM Lead 岗位,该团队为远程办公,非常适合全球各地的候选人。
- 职位详情见这里。
Latent Space ▷ #san-francisco-sf (7 messages):
ClawCon, OpenClaw, Moltbot, Enterprise-Grade Security Model, AI Engineer Event
- **ClawCon 项目演示即将到来: 一位成员计划在 **ClawCon 演示他们的 weavehacks 项目,并在 claw-con.com 上请求投票。
- **OpenClaw Trace 增强 Moltbot: 一个旨在通过 **OpenClaw Trace (开源) 来改进 Moltbot 的项目。
- **OpenClaw 企业级安全模型草案发布: 企业级 **AI 工程师在一份开源 RFC 中为 OpenClaw 提议了一个企业级安全模型,可在 X.com 查看。
- **Steinberger 分享 OpenClaw 申请: **Peter Steinberger 在 Xcancel.com 分享了他向旧金山 AI Tinkerers ‘OpenClaw Unhackathon’ 提交的申请。
- **AIEWF 优惠券问题: 在 **Latent Space 订阅者优惠券失效后,一位成员询问 6 月份 AIEWF 可用的优惠券。
Latent Space ▷ #ai-general-news-n-chat (179 messages🔥🔥):
OpenAI Appoints Dylan Scandinaro, Adaption Labs Funding, Anthropic's Super Bowl Ads, Cerebras Systems Funding, Eric Jang's Essay
- Altman 聘请 Preparedness 负责人: Sam Altman 宣布聘请 Dylan Scandinaro 领导 OpenAI 的 Preparedness 团队,专注于在公司转向更强大的 AI 模型时开发安全保障并缓解严重风险;更多信息见这里。
- Anthropic 广告攻势: Anthropic 发布了超级碗广告,嘲讽 OpenAI 在 ChatGPT 中加入广告的决定,并承诺保持 Claude 无广告,视频可在 YouTube 观看。
- 一些用户认为这些广告会加深对 AI 现有的负面印象,而另一些人则觉得它们非常幽默。
- Adaption Labs 获得 5000 万美元融资: Adaption Labs 宣布完成 5000 万美元投资轮,用于开发能够实时演进和自适应的 AI 系统;更多信息见这里。
- Cerebras 征服资金大山: Cerebras Systems 获得了 10 亿美元的 H 轮融资,由 Tiger Global 领投,AMD 等投资者参投,估值达到 230 亿美元;更多信息见这里。
- Jang 涉足自动化论文: Eric Jang 分享了他的交互式文章《像岩石一样思考 (As Rocks May Think)》,探讨了思维模型的未来和自动化研究的演进;更多信息见这里。
Latent Space ▷ #llm-paper-club (21 messages🔥):
RL Anything, PaperBanana Agentic Framework, Rubrics-as-Rewards (RaR), AI Misalignment
- RL Anything 带来无限可能:Yinjie Wang 介绍了 ‘RL Anything’,这是一个环境、奖励模型和策略同步优化的闭环系统,旨在提升 training signals(训练信号)和整体系统性能,详见此推文。
- PaperBanana 框架助力图表绘制:Dawei Zhu 介绍了 PaperBanana,这是一个由北大和 Google Cloud AI 开发的 Agentic 框架,用于自动化创建高质量的学术图表,遵循此推文中描述的类人工作流。
- RL 中的 RaR 奖励优化:Cameron R. Wolfe 博士讨论了 Rubrics-as-Rewards (RaR) 在强化学习中的潜力,认为未来的进步取决于提升生成式奖励模型和细粒度评估能力,详见此处。
- Anthropic 评估 AI 的目标对齐:Anthropic 研究员发布了新研究,探讨高智能 AI 的失败模式是会表现为对错误目标的刻意追求,还是不可预测且不连贯的行为,详见此推文。
Latent Space ▷ #ai-in-action-builders-techstacks-tips-coding-productivity (18 messages🔥):
Sam Altman AI Boomer, Codex Gremlin, LLM Trimming Issues, German Model
- Altman 对 AI 的天真表现出 Boomer 特质:Manuel Odendahl 戏称 Sam Altman 像一个 AI Boomer,因为他对 AI 的能力感到惊讶。
- 多位成员表示赞同,其中一人开玩笑说他可能在用 ChatGPT 带孩子。
- Codex 变身为 Gremlin(小精灵):一位成员分享了使用 Codex 的技巧:如果要求它编写一份 20 页的规格说明书,它会持续调整输出,直到精确符合长度要求。
- 他们补充说,如果写多了或不够,它会像个小精灵一样跑来跑去,不断裁剪/添加内容直到合适为止。
- LLM 容易产生过度裁剪:一位成员发现,当要求 LLM 缩减文本长度时,即使给出了精确指令,它们也倾向于过度删减。
- 他们指出,指示它删减最差的 X% 几乎总是会导致内容减半。
- LLM 信奉“削足适履” (Was Nicht Passt Wird Passend Gemacht):针对成员观察到的 LLM 过度裁剪文本现象,另一位成员调侃道,这就像德国谚语 “was nicht passt wird passend gemacht”。
- 这句德语的意思是“不合适的就强行弄合适”,暗示 LLM 会为了满足指定的长度限制而激进地修改文本。
Latent Space ▷ #share-your-work (4 messages):
Merit testing framework, Optimized store, AI inference resources, Handoff in AMP
- Merit 框架承诺单元测试级别的评估速度:Merit Python 测试框架提供单元测试速度级别的 eval 覆盖率,声称测试是比评估更好的抽象,具有更好的覆盖范围和 API;GitHub 仓库已附上。
- Merit 受到 LegalZoom 和 13 家初创公司的青睐,其特点包括快速的 LLM-as-a-Judge、原生 OpenTelemetry 追踪捕获,以及针对指标和案例的类型化抽象。根据文档,AI 生成案例和错误分析功能即将推出。
- 简洁优化的商店增加买家信任:一位用户推广构建简洁、优化的在线商店,旨在增加买家信任。
- 该用户分享了一个视觉示例,并邀请用户私信以协助设置类似的商店,示例见此图片。
- AERLabs AI 分享 AI 推理资源:一位用户分享了 AERLabs AI 的 ai-inference-resources 仓库链接。
- 该用户提到他们在这个项目上玩得很开心。
- Nicolay Gerold 详解在 AMP 中构建 Handoff:Nicolay Gerold 的博文详细介绍了他在 AMP 中构建 Handoff 的步骤,详见此博文。
{kind=link}
Latent Space ▷ #montreal (1 messages):
ayenem: 实际上明天 ngmi(去不了了),工作太忙。
Latent Space ▷ #robotics-and-world-model (9 messages🔥):
Jim Fan 的 AI 评论,Alberto Hojel 的项目发布,关于预训练时代的推测
- Jim Fan 的评论引发关注:Dr. Jim Fan 在 2026 年 2 月发布的一篇社交媒体帖子获得了极高的关注度,包含大量的点赞、转发和浏览;该推文可通过 此链接 查看。
- 该帖子被标记为 “Red - X-Ware.v0: [AI Commentary by Jim Fan]”,表明其属于 X-Ware 系列中 AI 评论的主题或类别。
- Hojel 在简短帖子中宣布新项目:Alberto Hojel (@AlbyHojel) 分享了一篇简短的帖子,宣布他的团队目前正在开发一个新项目或产品(公告链接)。
- 该帖子被标记为 “Red - X-Ware.v0: [Project Announcement by Alberto Hojel]”,表明这是 X-Ware 系列中的一个项目公告。
- 关于预训练时代的推测出现:一位成员想知道 第二个预训练时代是否就是“无预训练” (no pretraining),正如 这篇帖子 中所推测的那样。
- 这一观点是与上方 Alberto Hojel 的项目公告帖子并列提出的。
Latent Space ▷ #genmedia-creative-ai-video-image-voice-music-inspo-consumer-ai (21 messages🔥):
ACE Music,ElevenLabs 融资,Kling 3.0,TrueShort 发布
- ACE Music 模型令人惊叹:一位成员强调了 ACE Music 演示的质量令人印象深刻,尤其是考虑到其模型大小和 VRAM 需求,并引用了 这条推文。
- ElevenLabs 获得 5 亿美元融资:据 此公告,ElevenLabs 完成了由 Sequoia 领投的 5 亿美元 D 轮融资,估值达到 110 亿美元,a16z 和 ICONIQ 也进行了大规模跟投。
- Kling 3.0 展示《王者之路》:根据 此演示,PJ Ace 展示了 Kling 3.0 的照片级写实能力,还原了 Brandon Sanderson 的《王者之路》(The Way of Kings)开篇,并引入了一种新的 “Multi-Shot” 技术来加速 AI 电影制作。
- TrueShort 登陆 App Store:Nate Tepper 宣布推出 AI 驱动的电影工作室和流媒体应用 TrueShort。据 公告 显示,该应用在首个六个月内实现了 240 万美元 的年化收入,观看时长超过 200 万 分钟,并在 App Store 新闻类排行榜中进入前 10 名。
Latent Space ▷ #ai4science-bio-math-physics-chemistry-ai-researcher-ai-scientist (8 messages🔥):
Phylo AI 创业公司,Biomni 生物医学 Agent,Agentic Biology
- Phylo 获得风投融资:由斯坦福大学博士、Biomni 生物医学 Agent 的创建者创办的新 AI 科学家初创公司 Phylo,已获得 a16z 和 Menlo Ventures 的支持(来源)。
- Phylo 携 1350 万美元种子轮融资发布:Kexin Huang 宣布推出 Phylo,这是一家专注于 Agentic Biology 的生物研究实验室,并获得了 1350 万美元 的种子轮融资(来源)。
- 公告中介绍了 Biomni Lab,这是一个集成生物学环境(Integrated Biology Environment, IBE),利用 AI Agent 编排生物数据库和工具,以简化科学研究流程。
Latent Space ▷ #ai-in-education (1 messages):
cnasir: https://github.com/HarleyCoops/Math-To-Manim
LM Studio ▷ #general (189 条消息🔥🔥):
ByteDance Stable DiffCoder, PC 组件价格上涨, OpenClaw 评估, Qwen3 Coder Next
- Stable Diffusion Seed 没能通过现实检验:一位用户反映来自 ByteDance 的 Stable-DiffCoder-8B-Instruct 模型输出的内容完全是乱码,并正在寻求帮助以调试 Sampler 或其他可能的问题。
- RAM 价格飙升:用户们对当前 RAM 和 GPU 的高昂价格表示感叹,其中一人注意到其 96GB 双通道套装的价格上涨了 504%。
- OpenClaw 太吓人?:一位用户分享了他们使用 OpenClaw 的经验,表达了对 Prompt injection 攻击的担忧,并认为需要减少不必要的工具和终端命令。
- 另一位用户简单地评价道:太吓人了 (2spooky4me)。
- Qwen3 Coder Next 表现惊艳:一位用户发现 GPT-OSS 20b 和 120b 版本表现尚可且错误较少,但速度较慢,而全新的 Qwen3Coder Next 则非常出色。
- 该用户还提醒其他人要注意其“首要指令 (prime directives)”,并建议如果聊天机器人似乎记不住内容,请务必直接写在
user.md和soul.md中。
- 该用户还提醒其他人要注意其“首要指令 (prime directives)”,并建议如果聊天机器人似乎记不住内容,请务必直接写在
- LM Studio 下载速度龟速?:一位用户在下载 LM Studio 相关内容时遇到了极慢的下载速度 (100kbps)。
- 建议包括重启网络、检查是否与 AWS 相关,或尝试使用 VPN,后者最终为该用户解决了问题。
{kind=link}
LM Studio ▷ #hardware-discussion (6 条消息):
Ryzen 6 AI, GPU 软件限制, Context, KV cache 调整, PCIe 问题
- 急切期待 Ryzen 6 的 AI 能力:一位成员很好奇 Ryzen 6 是否会在 AI 方面带来新突破,感觉目前市场上大多只是旧技术的重新发布。
- 软件限制了 Nvidia GPU 性能:一位成员的 Inference 速度非常慢,结果发现是由于软件限制了其 Nvidia GPU 的速度,因此建议大家核查此类情况。
- Context 和 KV cache 配置立大功:一位成员微调了 Context 和 KV cache,结果运行速度甚至快到了超出预期,不得不调低了一些参数。
- 疑似 GPU PCIe 或 RAM 时序问题:另一位成员怀疑其 GPU 在特定任务下存在 PCIe 速度慢、通道拆分(bifurcated)或 RAM 时序问题,因为此时 GPU 功耗已完全开放至约 600 瓦。
OpenAI ▷ #ai-discussions (154 messages🔥🔥):
GPT parameter setting, Sora 2 broken and glitch, Gemini 3 outperforms GPT for writing, Grok video generation, Claude vs Gemini for creative writing and research
- 对 GPT 的性能产生挫败感:一位用户表达了对 GPT 表现的沮丧,指出它 “不断更新其响应方式” 且变得越来越没用。
- 他们分享了为了尝试控制 GPT 响应而设置的特定参数,包括一个三模式系统,以及要求不采取进一步行动或做出假设的指令。
- Sora 2 出现故障:用户报告了 Sora 2 的问题,称其 “崩溃且有故障”,并因高负载和错误消息在访问或使用 ChatGPT 时遇到问题。
- 一些用户推测了潜在的解决方案,例如取消免费选项,而另一些用户则对 Sora 2 的可持续性以及无法为喜爱的角色创建新视频表示担忧。
- Gemini 3 成为写作领域的强力竞争者:一位用户赞扬了 Gemini 3 的 “深度和风格”,并建议将其作为创意写作中优于 GPT 的替代方案,特别是在 playground 模式下移除 guardrails 时。
- 他们澄清说,他们对 Gemini 3 写作能力的强烈认同只是一种修辞手法,而另一位用户因英语不是母语而产生了误解。
- Grok 在视频生成方面展现潜力:一位用户指出 Grok 的视频生成能力有所提高,图像生成现在支持 10 秒视频,尽管语音导向功能仍需改进。
- 另一位成员报告说,Veo 同样令人印象深刻,但即使是 Pro 订阅也限制每天只能生成 3 条视频。
- 讨论 LLM 在创意写作与研究中的应用:成员们讨论了使用各种 LLM 进行创意写作和研究的情况,强调了各自的优点和缺点。
- 虽然 Claude 因其思考能力和 UI 受到称赞,但 Gemini 因其研究能力和无限制使用而受到赞赏,尽管一些用户指出 Gemini Flash 很容易混淆和交叉污染信息。
OpenAI ▷ #gpt-4-discussions (26 条消息🔥):
OpenAI 网页版宕机, OpenAI 企业转型, AI 伦理与问责, 企业在全球问题中的角色, AI 对社会的影响
- OpenAI 网页版宕机令用户感到沮丧:用户对 OpenAI 网页版 频繁宕机表示不满,批评该公司的测试和问题解决速度,一位用户表示他们虽然忠于 OpenAI,但宕机事件 “绝对令人难堪”。
- 另一位用户请求获取旧版本的链接,并表示:“5.2 在对话/提示词中简直毫无用处,让我简直要疯了,我需要保留 4.o。”
- 对 OpenAI “开放”理念的质疑浮出水面:一位用户对 OpenAI 履行其初衷的承诺表示怀疑,称:“想象一下在经历了所有这些企业级的废话和转型后,在 2026 年还‘相信 Open’AI’。他们已经完全转向了榨取每个人的钱财。”
- 对此,另一位用户质疑为什么有人会留在 OpenAI server 里批评该公司,并将其比作背叛期望的朋友,强调由于高期望值,很难原谅亲近朋友意想不到的错误行为。
- 企业不是朋友,而是应当被问责的机构:一位用户反对将企业视为朋友,强调它们是应当被问责并被迫采取合乎伦理行动的机构,并指出:“他们不是我们的朋友。他们充其量是我们的盟友,而且这种情况也非常罕见。通常情况下,他们试图从我们身上榨取价值,而我们需要要求他们达到基本体面的实际标准。”
- 与此相反,另一位用户认为 OpenAI 正在努力以有意义的方式照顾到每一个人,而不表现出偏袒,并强调了积极和建设性反馈的重要性。
- 关于 OpenAI 对全球问题影响的辩论:一位用户质疑企业对人类的关怀,引用了世界饥饿、环境破坏和鲁莽的 AI development 等问题,认为 OpenAI 的活动通过能源消耗、水资源利用以及 AI 准入的不平等加剧了这些问题。
- 另一位用户反驳称,单一企业无法解决世界上所有的难题,且 OpenAI 主要是一家 AI company,并提醒人们要考虑到他们正在做的那些未对外宣布的所有积极贡献。
- 强调 AI 开发的潜在风险:人们对 AI development 的潜在风险表示担忧,包括监控、自主攻击无人机以及失控 AGI 的危险。一位用户强调需要保持谨慎和警惕,称:“有些风险带来的损失可能远超其收益。所以我们至少必须谨慎对待某些事情。”
- 讨论强调了尽管渴望积极结果,但保持对潜在负面后果意识的重要性,并认识到 “盲目乐观可能会让你受伤——可能导致你忽略关键风险。”
Moonshot AI (Kimi K-2) ▷ #announcements (1 条消息):
Kimi k2.5, Cline, 免费访问窗口
- **Kimi k2.5 接入 Cline:Kimi k2.5** 现已在 Cline 上线。
- 目前有受限的免费访问窗口,快去尝试并分享你的结果吧!
- **Cline 发布关于 Kimi k2.5 的推文:Cline** 官方关于 Kimi k2.5 的推文现已发布!
- 快去看看吧!
Moonshot AI (Kimi K-2) ▷ #general-chat (169 messages🔥🔥):
Kimi API, Kimi Code on VPS, K2 vs K2.5, AI Slides bug, OpenClaw Integration
- API 访问高风险提示:一名用户报告称,无论发送什么内容,都会收到来自 Kimi API 的提示:“LLM request rejected: The request was rejected because it was considered high risk”。
- 其他用户认为,这可能是由于某些关键词触发了高风险过滤器,或者模型不确定是否违反了平台规则,详情请见此处。
- Kimi Code 是否可以在 VPS 上运行:用户讨论了在 VPS 上运行 Kimi Code 的可能性,并参考了 Claude 对数据中心 IP 的限制。
- 有人指出 Kimi 的条款并未明确禁止这样做,且 Kimi K2.5 Thinking 本身也表示可以,因为 Kimi 比 Anthropic 更开放,且开放权重使得在 VPS 内部运行自己的 Kimi 成为可能。
- WhatsApp 营销机器人 K2.5 拦截:一名用户发现 K2.5 会拦截创建自动发送消息的 WhatsApp bot 的尝试,认为这违反了 WhatsApp 的服务条款。
- 有建议称可以重新组织 Prompt,避免明确提及“非官方应用”,转而强调 Kimi 作为助手或辅助工具的角色,以此绕过限制。
- AI Slides 故障:多名用户报告了 AI Slides 的问题,特别是无法生成预期内容或无法正确读取提供的源文件。
- 一名用户更新了他们的错误报告,提到其源文件是私有的;另一名成员在承认 AI Slides 目前相当不好用后,表示后续会有更新。
- Allegretto 订阅访问权限:一名新的 Allegretto 订阅者注意到他们只能访问 ‘kimi for coding’ 模型,并寻求为他们的 openClaw 配置获取更好的模型。
- 官方澄清 Kimi for Coding 实际上就是 K2.5,这意味着这是该订阅级别应有的模型。
HuggingFace ▷ #general (136 messages🔥🔥):
Qwen3-Coder-Next release, Embodied AI learning path, Fine-tuning with multiple GPUs, DeepSeek hallucination, OpenClaw Setup
- Qwen3-Coder-Next 助力本地编程!:Qwen3-Coder-Next 编程模型已发布,非常适合本地运行,可以在 HuggingFace 上找到。
- 一名用户确认该模型在后台使用 vllm 的情况下,在 RTX 5080 上运行顺畅。
- 世界基座模型探索具身智能路径!:一名成员表示自 Genie 2 以来一直痴迷于 World Foundation Models,并正在寻找将基于序列的表示学习应用于 Embodied AI 的指导。
- 他们正在寻求 Model-based RL 或 VLAs 方面的建议。
- 利用多 GPU 并行加速微调!:成员们讨论了使用多 GPU 进行并行处理微调,建议使用 Accelerate library 进行张量并行(tensor parallelism)。
- 建议将 .ipynb 转换为 .py,以便从终端调用命令。
- DeepSeek 的幻觉阈值揭晓!:社区成员询问 DeepSeek 在输入多少 Token 后更容易产生幻觉,另一人回答称,如果文本不经分块直接作为输入丢进去,连贯性会在 4000 tokens 后下降。
- 建议的缓解技术是避免直接倾倒长文本,而是利用分块(chunking)或检索策略。
- 深入了解 OpenClaw 配置!:一名成员寻求关于将通过 Ollama 安装的模型连接到 OpenClaw 以创建 AI Agent 的指导。
- 其他人提供了带有图片的指导,展示了如何操作选择和延续过程,并建议观看此视频。
HuggingFace ▷ #i-made-this (10 条消息🔥):
Legal AI 项目反馈, LLM from scratch, 高价值技术推理数据集, Autonomous AI agent, Applied Machine Learning Conference 2026
- 法律界人士寻求 AI 项目反馈:一位成员正在开发一个 Legal AI 项目,并寻求通过此表单获得反馈。
- 该项目旨在 Legal Tech 领域进行创新,重点关注 AI 应用。
- 从零开始构建 LLM:一位成员为了更好地理解现代 Transformer 内部机制,从零构建了一个小型 LLM (LLM from scratch),并分享了 GitHub repo 供他人使用。
- 该 LLM 融入了 RoPE、GQA 和 KV cache 等元素。
- Platinum CoTan 数据集发布:一位成员介绍了一个名为 Platinum-CoTan 的新型高价值深度推理数据集,该数据集采用 Phi-4 → DeepSeek-R1 (70B) → Qwen-2.5 三层堆叠流水线构建,可在 Hugging Face 上获取。
- 该数据集专注于 Systems(系统)、FinTech(金融科技)和 Cloud(云)应用。
- AI Agent 竟然能开银行账户?!:一个名为 cornerstone-autonomous-agent、能够开设真实银行账户的 autonomous AI agent 通过 npm package 发布。
- 它配合 Replit 上的 MCP 和 Clawhub 上的 clawbot 技能 协同工作。
- AMLC 大会确定 2026 年日期:2026 Applied Machine Learning Conference (AMLC) 现已开放演讲和教程提案征集,会议将于 2026 年 4 月 17–18 日在弗吉尼亚州夏洛茨维尔举行,详情见大会网站。
- 投稿截止日期为 2 月 22 日,Vicki Boykis 已被宣布为主题演讲嘉宾。
HuggingFace ▷ #core-announcements (1 条消息):
MagCache, Diffusers, Caching Methods
- MagCache 缓存方法发布!:新的 MagCache 缓存方法现已适配 Diffusers。
- 详情请见 pull request #12744。
- Diffusers 使用 MagCache 优化:MagCache 是一种优化 Diffusers 的新缓存方法。
- 实现细节可在 GitHub 的 此 PR 中找到。
HuggingFace ▷ #agents-course (9 条消息🔥):
GAIA benchmark, Distributed agent system, Agentic AI course, Hugging Face courses
- GAIA Benchmark 评估分布式 Agent:一位成员询问 GAIA benchmark 是否可以评估使用 Google Colab、Grok、ngrok 和 Gradio 搭建的分布式 Agent 系统。
- 该成员补充说,他们的 Agent 在使用 Tavily 网络搜索模板时在基准测试中仅获得 2/20 分,并寻求后续步骤的指导。
- HF 课程频道路由错误?:一位成员被重定向到 Hugging Face courses 频道,但其实是在寻求关于 Agentic AI 的一般性建议。
- 另一位成员建议将帖子移至适当的频道。
GPU MODE ▷ #general (1 条消息):
GPU MODE lectures, Events tracking, Discord live updates
- GPU MODE 讲座:集中式活动追踪:一位成员分享了 GPU MODE 讲座 链接,提供了一个统一监控活动和讲座的入口。
- 该资源旨在直接从 Discord 进行实时更新,确保信息及时准确。
- Real-Time Discord 活动实时更新:GPU MODE 讲座页面提供直接源自 Discord 的活动和讲座实时更新。
- 这种集成确保了日程表持续更新,反映了社区内的最新公告和变动。
GPU MODE ▷ #triton-gluon (2 messages):
Triton Meetup, Triton to TileIR, Optimal Software Pipelining, TLX updates
- 2026 年 Triton 社区见面会(Community Meetup)现已公布!:下一场 Triton 社区见面会 将于 2026 年 3 月 4 日,PST 16:00-17:00 举行,并提供了 Google 日历事件链接。
- 会议将涵盖 Triton to TileIR 和 Optimal Software Pipelining 等主题,还包括 立即加入会议 的链接。
- Nvidia 谈论 Triton 到 TileIR 的集成:来自 Nvidia 的 Feiwen Zhu 将在即将举行的见面会上讨论 Triton to TileIR。
- 最优流水线(Optimal Pipelining)论文展示:Nvidia 的 Rupanshu Soi 将在下次 Triton 见面会上展示关于 Optimal Software Pipelining and Warp Specialization for Tensor Core GPUs 的论文。
- 社区热切期待 TLX 更新:成员们对 Meta 关于 TLX 的更新和计划非常感兴趣,希望它能被合并到主代码库中,因为那将比 gluon 更好。
GPU MODE ▷ #cuda (9 messages🔥):
PyTorch Pluggable Allocator, CUDA Memory Management, Cross-process usage (IPC), Kernel timing measurement, globaltimer PTX primitive
- CUDA IPC 期望使用 Pluggable Allocator:一位成员正在寻求一种类似于 PyTorch Pluggable Allocator 的机制,以便在支持跨进程使用 (IPC) 的情况下,以非侵入方式覆盖内存管理。
- 有人指出
cuda::mr::resource_ref主要为单进程范围设计,且需要修改代码,因此不适合他们的特定需求。
- 有人指出
- 在 CUDA Kernel 内部测量时间:为了在 Kernel 内部测量时间,一位成员建议使用
%globaltimer PTX原语来获取一个在所有 SM 之间可比较的全局定时器,但警告称不同架构之间的兼容性可能不一致,且仅适用于 NVIDIA 工具。- 另一位成员建议使用
clock64(),这是一种针对测量 warp 或 block 内短时间段设计的每个 SM 独立的定时器,但其数值在不同 SM 之间不可比较,无法用于全局追踪。
- 另一位成员建议使用
- 提供了 CUDA Profiling 示例:一位成员分享了其 learn-cuda 仓库中的 CUDA profiling 示例链接。
- 随后他们附上了一张生成的 profile 截图,看起来像是一个性能热力图。
GPU MODE ▷ #cool-links (2 messages):
Terence Tao, The Futurology Podcast, MTIA paper, ISCA25, Facebook's AI hardware codesign team
- 数学大师陶哲轩谈 AI:听众们正在 The Futurology Podcast 上收听 Terence Tao 谈论“大数学”与我们的理论未来。
- 讨论集中在 AI 是否能证明定理 以及数学领域不断演变的格局。
- Facebook 的 AI 硬件设计备受关注:一位正在阅读 ISCA25 的 MTIA 论文 的成员偶然发现了 Facebook 的 AI 硬件协同设计(codesign)团队页面。
- 这是深入了解 Meta (FB) 的 AI 硬件计划 的宝库。
GPU MODE ▷ #job-postings (16 messages🔥):
ML Infra Engineers, Performance Engineers, Palantir for Perf
- 招聘 ML Infra 和性能工程师!:一位成员发布了 ML Infra 和性能工程师 的招聘公告,总薪酬 (TC) 为 50 万至 100 万美元以上。
- 另一位成员询问了重复发布的情况,发布者澄清说他们运行着一个性能工程团队且正在积极招聘。
- 性能工程团队 = 性能领域的 Palantir:发布者将他们的性能工程团队描述为类似于性能领域的 Palantir。
- 他们补充说,他们与 neolabs 签订了一些合同,目前受到人力限制,并邀请感兴趣的人士发送私信(DM)了解更多详情。
GPU MODE ▷ #beginner (3 messages):
GPU Programming Course, Swizzling Scenarios
- 新手开始学习 GPU 编程: 一位新人对他们使用 PMPP 书籍 的首个 GPU 编程课程 表达了热情,渴望参与练习和竞赛。
- 尽管承认目前只有初学者的理解水平,该学生仍对课程中即将到来的挑战感到兴奋。
- Swizzling 场景引发好奇: 一位成员询问了在哪些场景下自定义 swizzling 会优于硬件提供的模式 (32/64/128B)。
- 另一位成员表示从未见过自定义 swizzling,并对此表示好奇。
GPU MODE ▷ #torchao (1 messages):
Karpathy, torchao, nanochat, FP8 training
- Karpathy 为 FP8 训练添加 Torchao!: Karpathy 正在 nanochat 中使用 torchao 进行 FP8 训练。
- Torchao 对 Nanochat 训练的影响: 集成 torchao 旨在提高 nanochat 训练过程的效率,特别是专注于 FP8 精度。
GPU MODE ▷ #irl-meetup (7 messages):
GPU dinner in Berlin, GPU MODE retreat in rural Germany, GPU MODE Europe combined with PyTorch conference in Paris
- GPU 爱好者在德国聚餐: 一位成员正在组织周六在柏林的 GPU 主题晚餐,并邀请感兴趣的人私信了解详情。
- 另一位成员建议在 德国乡村举办 GPU MODE 疗养活动,尽管这个想法似乎并未得到广泛采纳。
- 柏林 GPU 派对,由 Techno 和 Döner 驱动: 一位成员对在 柏林举办 GPU MODE 活动 表现出热情,建议将其与 techno 派对和 Döner 烤肉 结合。
- 周六晚餐的组织者提到了举办 GPU MODE 欧洲活动 的可能性,可能会与在 巴黎举行的 PyTorch 会议 同期进行。
GPU MODE ▷ #tilelang (1 messages):
OpenSHMEM, TileLang
- 考虑 OpenSHMEM 与 TileLang 的集成: 一位成员询问了将 OpenSHMEM 与 tilelang 集成的可能性。
- 他们在 Discord 频道 提出了类似的问题。
- TileLang 与其他库集成的潜力: 讨论围绕着将 TileLang 与 OpenSHMEM 等外部库结合的可行性展开,以增强其功能。
- 这种集成可能为 TileLang 框架内的分布式计算和内存管理开辟新途径。
GPU MODE ▷ #webgpu (1 messages):
Dawn vs. WebGPU, Vulkan and LLMs
- 表现出对 Dawn 优于 WebGPU 的偏好: 一位成员表示由于实现兼容性方面的瑕疵,更倾向于选择 Dawn 而非 WebGPU。
- 该成员指出,存在过多的兼容性问题使得 WebGPU 难以使用,而 Dawn 则更稳定。
- Vulkan 的 LLM 潜力: 一位成员建议,虽然 Vulkan 以前编写和使用起来很痛苦,但 LLM 可能会改变这一点。
- 他们补充说,Vulkan 和 WebGPU 这种冗长且显式的 API 设计非常契合 LLM 的优势,可能使其更易于管理。
GPU MODE ▷ #popcorn (33 messages🔥):
Mobile App Development, AI Code Analysis, Tinder for CUDA Kernels, Defining Eval Tasks, Buildkite vs Github Actions
- 移动 App 开发即将推出:一位成员正在开发一款移动 App 并正在发布到 AppStore,该 App 集成了 AI 代码分析功能,并尽量减少额外的反馈环节。
- 另一位成员建议,移动端友好的网站可能更容易说服用户使用。
- “CUDA Kernel 版 Tinder”发布:发起了一个关于“CUDA Kernel 版 Tinder”的讨论线程,重点关注 AI 代码分析和极简反馈方案。
- 建议通过将语音按钮设为唯一的提交方式来简化提交流程。
- 为 Kernel 定义 Eval 任务:一位成员对“Eval”的定义提出疑问,建议在现有的 Kernel 上使用 TMA/tscgen05 等技术,而不是从零开始。
- 另一位成员澄清说,这里的“Eval”更多是指一个用于教学和评估模型的环境,例如将 PyTorch 转换为 Triton,奖励机制则是加速比(speedup)。
- 弃用 GitHub Actions 转用 Buildkite:一位成员分享了设置 Buildkite 的经验,在长期使用 GitHub Actions 后发现它出奇地易用,并且已经实现了环境隔离。
- 他们指出 Buildkite 拥有实际的 API 来查询队列状态,并且 Artifacts 可以通过自定义 Job 正常工作,每月费用约为 200 美元。
- 自定义调度器在顶级硬件上运行测试:一位成员正在顶级硬件上使用自定义调度器进行测试,目前已经运行并推送至 kernelbot/pull/432。
- 该功能已可用,但仍需简化和清理,且目前存在一些限制。
GPU MODE ▷ #factorio-learning-env (1 messages):
Factorio Learning Environment, Open Source Project, Community Engagement
- 粉丝询问 Factorio 学习环境:该项目的一位粉丝询问 Factorio Learning Environment (FLE) 是否是一个开放贡献的开源项目。
- 该粉丝注意到频道比较冷清,但表达了参与其中的兴趣。
- 社区渴望贡献:一位潜在的贡献者表达了参与 Factorio Learning Environment (FLE) 的兴趣。
- 他们注意到频道虽然安静,但强调了他们长期以来对该项目的欣赏,并希望作为开源倡议的一部分,为其开发做出贡献。
GPU MODE ▷ #cutlass (4 messages):
Layout Algebra Composition, Mojo Zipped Divide Definition, Shared Memory Layouts, Tiled Copy & Bank Conflicts, Memory Alignment
- Layout Algebra 的组合并不完善:根据这份笔记,目前的 Layout Algebra 实现中,组合(Composition)并非总是定义良好的。
- Mojo 的 Zipped Divide:不同的方法:在 Mojo 中,Zipped Divide 的不同之处在于递归基准情形下丢弃了 B 的 Stride,如 GitHub 链接 所示。
- Tiled Copy 导致四路 Store Bank Conflict:在提供的代码片段中,共享内存布局为
(128,32,3):(32,1,4096)的 Tiled Copy 操作导致了四路 Store Bank Conflict。 - 确保内存操作的 16B 对齐:怀疑发生四路 Store Bank Conflict 是因为代码没有保证 16B 对齐,导致回退到了 32b Store。
GPU MODE ▷ #teenygrad (1 messages):
j4orz: Tufte 风格的旁注(sidenotes)很难搞。
GPU MODE ▷ #helion (2 条消息):
AMD GPUs, Torch Inductor Autotuned Kernels, Helion Autotuned Kernels, Triton Kernels, AMD Performance Analysis
- AMD GPU 上的加速差距被发现:一位用户报告了 AMD GPU 上 torch inductor autotuned kernels 与 Helion autotuned Kernels 之间显著的性能差距,特别指出在 M=8192, N=8192, K=8192 的情况下,Helion 配置实现了 0.66x 的加速,而 torch inductor 为 0.92x。
- 另一位用户建议对比 Inductor 和 Helion 发射(emitted)的 Triton kernels 以查明差异,并指出 AMD 的性能工作主要由 AMD 团队负责。
- 调查 AMD 上的性能差异:建议进一步分析并对比 Inductor 和 Helion 生成的 Triton kernels,以理解 AMD GPU 上的性能增量。
- 会议还强调了 AMD 团队 主要负责与 AMD GPU 相关的性能优化,暗示他们的专业知识在解决此差异方面可能非常有价值。
GPU MODE ▷ #nvidia-competition (15 条消息🔥):
CUDA Kernel Dating, Nvidia vs B200 Leaderboard, Modal Server Card Count, AI Submission Review, Adding Teammates
- CUDA 核约会 App 想法浮出水面:一位成员开玩笑地建议创建一个“CUDA kernel 界的 Tinder”,引发了短暂的轻松时刻。
- 目前还没有具体细节或进一步讨论。
- Nvidia 与 B200 排行榜之间存在混淆:一位成员询问 Nvidia 和 B200 排行榜 之间的区别,指出他们向 B200 GPU 提交的内容被重定向到了 Nvidia 排行榜。
- 该查询在提供的上下文未得到解答。
- Modal 服务器显卡数量仍是个谜:一位成员询问了在 Modal 服务器 上运行的显卡物理数量。
- 然而,具体数量并未透露。
- AI 开始审核提交内容:团队希望每次删除提交内容时都能标注原因,然后让 AI 将其作为学习示例。
- 一位成员提议协助进行 AI prompt engineering,建议使用 GPT 5.2 Thinking 作为潜在模型来识别 stream hacking。
- 队友搜索帮助台以添加成员:一位成员询问如何向其团队添加队友,随后被引导至相关频道。
- 他们确认那里确实是该去的地方。
GPU MODE ▷ #robotics-vla (7 条消息):
Diffusion-based robotics models, Speculative sampling, TurboDiffusion, Egocentric dataset by build.ai, LingBot-VLA Technical Report
- 加速用于机器人控制的扩散模型:讨论强调了利用为图像和视频扩散模型开发的技术,加速基于扩散的机器人模型以实现实时性能的潜力,特别注意到 Cosmos Policy 在不改变架构的情况下对视觉模型进行了微调。
- 一位成员建议研究 扩散模型的投机采样(speculative sampling) 以提高推理速度。
- TurboDiffusion vs. Rectified Flow:一位成员询问 TurboDiffusion 在加速扩散模型方面是否比 Rectified Flow 更快。
- 讨论中未进行对比。
- Build.ai 的第一视角数据集(Egocentric Dataset)设备:一位成员寻求有关 build.ai 对其第一视角数据集所用设备的信息。
- 据提到,build.ai 使用一种专利头带,替代方案包括 DAS Gripper & DAS Ego、Robocap 以及高端 DIY 解决方案(参见这篇论文)。
- LingBot-VLA 的缩放法则(Scaling Laws)分析:对 LingBot-VLA 技术报告的分析显示,该模型除了其 “缩放法则”(主要归因于更多的数据带来更好的性能)之外,并未声称具有新颖性或突破性。
- 该模型在对 100 个任务 x 130 个真实世界数据演示进行后训练(post-training)后,平均成功率略低于 20%(表 1),与模拟数据(Sim data)上 80-90% 的成功率(表 2)形成鲜明对比。
GPU MODE ▷ #career-advice (1 messages):
``
- 面试准备鼓励:一位用户对分享的面试准备指南表示感谢,并在面试结果不如人意后提供了鼓励。
- 社区支持信息:该消息在面试失利后表达了同情,并对接收者未来的成功充满信心。
GPU MODE ▷ #flashinfer (16 messages🔥):
Modal Credits, FlashInfer AI Kernel Generation Contest, Adding Teammates, Workspace Credits
- Modal 额度兑换与共享:注册后,一名成员假设由一名团队成员兑换 Modal 代码,并通过 Modal project 共享算力。
- 一位用户确认额度将应用于项目。
- FlashInfer AI Kernel 生成竞赛数据集发布:该数据集可用于评估 AI 生成的算子(kernels)。
- 一个仓库已更新,包含了 FlashInfer AI Kernel Generation Contest 的完整算子定义和工作负载。
- FlashInfer 参赛者寻求添加队友的指导:一名 FlashInfer 参赛者询问如何向其团队添加新队友。
- 另一位用户也提出了同样的问题。
- 额度到账时间仍不明确:部分用户在填写了 modal.com 额度表格后,不确定工作区额度何时会应用到他们的账户。
- 一位用户表示额度是即时到账的,而另一位用户提到他们仍遇到问题。
Nous Research AI ▷ #general (66 messages🔥🔥):
world models and language, Kimi K2.5 vs Gemini 3 Pro, DeepSeek R2 release, Hermes agent, Moltbook
- 将世界模型与语言处理分离?:一名成员质疑当前 world modeling 是否受限于其对语言的依赖,建议如果能完全脱离语言,旨在减少受语言影响的错误,可能会更有效。
- 另一位成员补充道,他们认为在训练 world model 时有一个被低估的用例:询问它推理链是否会成功,并在 RL 中给予奖励。
- Kimi K2.5 在对比 Gemini 3 Pro 时获得赞誉:成员们提到 Kimi K2.5 相比 Gemini 3 Pro 获得了不错的评价,强调了自一年前 DeepSeek 运动以来全球开源(OS)模型的进步,并期待 DeepSeek R2 release。
- 还有人指出 我们可以一边走路一边嚼口香糖……除了 Sam 的粉丝。
- 关于大脑以数学方式处理语言的辩论:在关于大脑处理语言的讨论中,有人声称虽然大脑不以数学方式处理语言,但大脑的物理学可以用数学来描述。
- 还有人说 数学不像物理学那样是自然发生的。
- OpenAI 和 Anthropic 的 CEO 互相抹黑:成员们分享了最近的八卦,一位用户指出了最新的 Claude 广告(链接),向用户保证 Claude 不会添加广告。
- 另一名成员指出了 Sam Altman 对该广告的回应(链接),一名评论者说 Sama 解释了这些广告的针对目标,这很好。
- 压低印度 AI/ML 工程师薪资:一份针对印度高级 AI/ML 工程师的招聘贴提供了 500 美元月薪,引发了愤怒,成员们称其为“犯罪”,特别是考虑到 5 年经验和医疗保健要求,价格理应大幅提高。
- 有人怀疑这个价格即使按印度标准来看是否也很糟糕,另一人回应道 如果他们擅长 AI 工程,在其他任何地方都能拿到多得多的薪水。
Eleuther ▷ #general (18 messages🔥):
Workshops vs Conferences, Fine-tuning OpenAI LLMs, Logical AI, Depth/width requirements symmetric group, POWER9 Talos II for AI inference
- **工作坊 vs 会议:声望问题?*:一位成员解释说,工作坊的投稿截止日期通常比主会晚,虽然录用更容易且被认为声望较低*,但一些优秀的工作坊可能会演变成新的会议。
- 他们指出,工作坊的投稿通常在主会作者通知之后。
- **Unsloth & Axolotl 加速 OpenAI 微调:成员们推荐将 Unsloth 和 Axolotl 作为微调 **OpenAI LLMs 的工具。
- 一位成员正在寻找最新的最佳方法,希望在未来几天内建立一个可以提供给少数用户的模型,并且他已经准备好了预算和数据集。
- **逻辑 AI 面临边界盲区:一位成员正在研究连续优化与离散逻辑规则之间的结构冲突,重点关注神经网络的 **Lipschitz continuity(Lipschitz 连续性)如何产生平滑逻辑悬崖的 Neural Slope(神经坡度),从而导致 Illusion of Competence(能力错觉)。
- 他们提出了一种带有专用 Binary Lanes 的 Heterogeneous Logic Neural Network (H-LNN),使用 STE 来锁定离散边界,并分享了 Zenodo 上的预印本链接,其中包含 Lipschitz 证明和架构。
- **浅层化与对称群学习**:一位成员询问了学习对称群的深度/宽度要求。
- 另一位成员回答说,浅层架构可以表示排列函数,但仅限于指数级宽度,而深度则允许结构的重用。
- **POWER9 Talos II:一种推理选择:位于欧盟的专用 **POWER9 (Talos II) 服务器可用于私有 AI 推理 / 研究,提供完整的 root 权限、SLA 和监控(非云端)。
- 一位成员发布道:感兴趣请私信。
Eleuther ▷ #research (6 messages):
Human Influence on Platform Analysis, Instant NGP for Query Mapping, Multi-resolution Quantization
- 人类影响平台分析:一位成员分享了一个关于人类如何影响平台分析的链接。
- 另一位成员提供了一个包含更多细节的后续链接。
- Instant NGP 映射查询:一位成员建议使用类似 Instant NGP 的方法将查询/键(queries/keys)映射到某些离散箱(discrete bins)中。
- 他们认为 multiresolution quantization(多分辨率量化)可能有助于长上下文。
- 新论文发布:一位用户与社区分享了这篇论文。
- 随后他们链接到了 arXiv 上的这篇论文 以及 这个 fixupx.com 链接。
Eleuther ▷ #interpretability-general (2 messages):
refusal_direction blogpost, LLM-as-judge vs Verifiable Rewards
- Refusal Direction 博客文章发布:一位成员分享了一篇关于 refusal direction(拒绝方向)的博客文章链接。
- 该博客文章可能讨论了引导语言模型拒绝不当请求的方法。
- 质疑 LLM-as-judge 与 Verifiable Rewards:一位成员询问了比较 LLM-as-judge 方法与 Verifiable Rewards(可验证奖励)系统的现有工作。
- 他们特别询问是否有任何共享的模型权重可用于此类比较。
Eleuther ▷ #lm-thunderdome (1 messages):
LLM-as-judge, Verifiable Rewards, Model weights sharing
- 寻求 LLM-as-Judge 与 Verifiable Rewards 的对比:一位成员询问了比较 LLM-as-judge 方法与 Verifiable Rewards 系统的研究。
- 渴望公开共享的模型权重:同一位成员还对公开分享模型权重的项目感兴趣。
Eleuther ▷ #multimodal-general (1 messages):
Voice agent development, S2S models for voice agents, Open source STT and TTS models
- 语音 Agent 构建者寻求 S2S 模型:一位成员正在寻求构建用于通话的语音 Agent 的指导,目前在开源 STT (Speech-to-Text) 和 TTS (Text-to-Speech) 模型上遇到困难,正在寻找合适的 S2S (Speech-to-Speech) 模型。
- 更多指导:消息中未提供进一步的指导或具体的模型建议。
Eleuther ▷ #gpt-neox-dev (4 messages):
deepspeed updates, upstream neox, roadmap
- DeepSpeed 迎来更新:一位成员提到他们可能需要更新 deepspeed 并更新上游的 neox。
- 路线图公布:一位成员提到他们将在 repo 中发布一个 roadmap(路线图)。
- 另一位成员回复道:期待看到路线图上的内容!
Yannick Kilcher ▷ #general (13 messages🔥):
MCMC in PyTorch, Rotating Decision Boundary, Time Dimension as Input, Hierarchical Models, Constrained Reinforcement Learning
- 在 PyTorch 上重写 MCMC 极具挑战:一位成员询问是否可以使用 PyTorch 实现旋转决策边界(rotating decision boundary)的效果,此前 LLMs 在尝试使用 MCMC 重写这篇博客时失败了。
- 另一位成员澄清说,目标不是在 PyTorch 中实现 MCMC,而是实现类似的旋转决策边界性能。
- 引入时间维度输入简化神经网络损失函数:一位成员建议将时间维度作为输入添加到神经网络中,并重写损失函数使其表现得像分类任务,在接近该时间点时进行更多分割。
- 他们指出不需要权重的随机轨迹(stochastic trajectories),并称原始方法有些过度设计(over-engineered)。
- 负对数似然最小化规避 MCMC:一位成员建议实现一个计算负 (log-likelihood + log-prior) 的前向传播,以避免使用 MCMC。
- 他们补充说,这个函数可以像任何其他可微损失一样被最小化,但提醒说层级模型(hierarchical models)在点估计(point estimates)下表现不佳。
- 关注约束强化学习 (Constrained Reinforcement Learning):一位成员提到正在研究约束强化学习。
Yannick Kilcher ▷ #paper-discussion (8 messages🔥):
Zero-Knowledge Proof, Matrix Multiplication, LLM Feedforward, Integer Arithmetic, GPU Acceleration
- 以 2 倍开销实现零知识矩阵乘法:一位成员报告称实现了矩阵-矩阵乘法的零知识证明,与直接计算相比仅有 2 倍开销。
- 当前代码通过舍入到整数并在整数上以相对 ZK 的方式证明准确性,展示了浮点矩阵乘法的近似相等性。
- ZK 证明利用整数算术:该方法利用 64 位整数 上的矩阵乘法,以避免对 GPU 不友好的域操作(field operations)。
- 该成员解释说,这在 GPU 上运行相当快,几乎与 float64 乘法一样快,使其成为一种可行的方法。
- ZK 证明应用于 LLM 前馈过程:一位成员正在尝试将零知识证明应用于 LLM 的前馈过程 (feedforward),但代码尚未完成。
- 该成员计划使用自定义训练的 Transformer 以及基于 Bayes 的自定义 SGD 来展示深度学习理论预览。
Yannick Kilcher ▷ #agents (1 messages):
endomorphosis: https://github.com/endomorphosis/Mcp-Plus-Plus
能给我一些关于这个项目的反馈吗?
Yannick Kilcher ▷ #ml-news (4 messages):
Moltbook Database Breach, AceMusicAI, HeartMuLa heartlib
- Moltbook 数据库泄露 API Key:一次 Moltbook 数据库泄露事件 暴露了 35,000 个电子邮件地址和 150 万个 API Key。
- 一名成员注意到了这一事件,并强调了这一重大的安全疏忽。
- AceMusicAI 听起来很棒:一名成员分享了 Twitter 上的 AceMusicAI 链接,并评论说它听起来非常出色。
- 未提供关于令人印象深刻的具体功能或能力的进一步细节。
- HeartMuLa heartlib 已经存在:一名成员指出 HeartMuLa 的 heartlib 已经存在。
Manus.im Discord ▷ #general (26 messages🔥):
Credit Purchases, Manus Dreamer event, Code IDE support, Subscription Refund, Ads in Manus
- 仅最高层级订阅可购买额外额度:一位用户询问是否可以在不升级方案的情况下购买更多额度(Credits),因为他们已接近上限,但其他人澄清说 购买额外额度仅适用于最高层级的订阅用户。
- 一位用户对额度限制表示遗憾,称 Manus 是有史以来最棒的 AI,但如果能像 ChatGPT 或 Gemini 那样不限量,那就太疯狂了。
- 在 Manus Dreamer 活动中赢取额度:Manus 宣布启动 Manus Dreamer 活动,为参与者提供赢取高达 10,000 额度的机会,以支持他们的 AI 项目。
- 感兴趣的用户被引导至特定频道了解参与详情。
- 不支持代码 IDE 或 OpenClaw:一位用户询问 Manus 是否支持代码 IDE 或 OpenClaw,在推测答案是否定的后,随即宣布离开。
- 另一位用户开玩笑地评论说他们离开得飞快,简直像个幽灵。
- 订阅错误获得支持:一位名为 João 的用户报告了意外的订阅续订,并由于额度未使用而请求退款。
- Manus 团队的一名成员确认他们已通过私信联系以协助处理退款请求。
- 不希望在 Manus 中看到广告:一位用户表达了希望 不要在 Manus 中引入广告 的期望,特别是考虑到为服务支付的价格。
- 另一名成员表示赞同,称广告对于付费用户来说会感觉 多余且更像是一种不便,同时也承认了通过广告产生收入的商业逻辑。
Modular (Mojo 🔥) ▷ #general (3 messages):
Community Meeting, Google Calendar, Modular Community Meeting Presentation
- 用户寻求社区会议日历:一位用户询问是否有新闻通讯或日历订阅,以便了解未来的社区会议,因为他们错过了上一次会议。
- 另一名成员提供了一个 Google Calendar 链接,并提醒该日历可能设置为 GMT -7,且有可能是错误的日历。
- Modular 社区会议演讲邀请:一名成员提到收到了在 Modular 社区会议上进行演讲的邀请。
- 他们指出项目目前还处于开发早期,尚不便展示,但表示随着项目接近尾声,有兴趣分享更多内容,并建议大家 保持关注。
Modular (Mojo 🔥) ▷ #mojo (12 messages🔥):
Mojo 学习资源,支持 Mojo 的 Rightnow GPU 聚焦代码编辑器,AI Agent ka
- Mojo 新学习者寻求指导:一位新学习者询问了 Mojo 的学习资源,并分享了与其他成员讨论概念的热情。
- 经验丰富的成员推荐了 官方 Mojo 文档、GPU 谜题、特定的提问频道以及 Mojo 论坛。
- Rightnow 为 GPU 代码编辑器添加 Mojo 支持:一位成员分享了 Rightnow GPU 聚焦代码编辑器 已添加 Mojo 支持。
- 另一位成员反馈,在提供本地执行的 CUDA Kernel 中内联的图形着色器代码后,程序发生了崩溃,看起来仿真并不准确。
- 与古怪的 AI Agent Ka 一起学习:一位成员解释说,Modular 在特定的 Discord 频道中有一个名为 ka 的 AI Agent,可以帮助回答问题。
- 据悉,该机器人有些“古怪”,用户必须输入 @ka 并使用自动补全才能使其正常工作。
aider (Paul Gauthier) ▷ #general (1 messages):
clemfannydangle: Hello 👋
aider (Paul Gauthier) ▷ #questions-and-tips (11 messages🔥):
Aider 的 architect 模式,Aider issue #2867,OpenRouter 模型上下文窗口,edit-format: diff-fenced 配置
- Aider 新手对 Architect 模式感到沮丧:一位用户发现 Aider 在 Architect 模式下提问后不会暂停等待输入,而是直接自顾自地运行,尽管已有 GitHub issue 记录了此问题。
- 该用户正尝试将一份规格说明文档拆分为符合上下文窗口大小的块,并在规格说明与实现指令之间进行差异分析,使用的是 Opus 4.5 配合 copilot 以及 144k 的上下文窗口。
- Aider 反馈引发细节查询:在用户分享 Aider 问题后,一位成员要求提供更多细节,包括所使用的模型、
/tokens命令的输出、上下文窗口 Token 长度以及文件的一般性质。- 该成员指出,文件中可能存在针对无害 Logit 的混淆 Prompt Injection。
- 用户澄清 Aider 问题背景:用户澄清说,他们正在对 Markdown 文件进行差异分析,其中的规格说明文档和实现指令被拆分成块,但功能规格块并不能直接对应到实现块。
- 用户提议重现该场景并进行演示,并表示将回溯收集并提供所需数据。
- Aider 配置规避长形式输出的问题:一位用户建议在
.aider.conf.yml配置中尝试使用edit-format: diff-fenced,以帮助缓解 Architect 模式长形式输出的某些问题。- 他们还建议,如果用户拥有 OpenRouter,可以尝试使用
model: openrouter/google/gemini-3-pro-preview,因为这是目前能获得的功能最全、上下文最长的模型之一。
- 他们还建议,如果用户拥有 OpenRouter,可以尝试使用
DSPy ▷ #general (4 messages):
第三方集成,DSPy cookbook,2026 年印度 AI 峰会,招聘开发者
- 第三方集成的 Cookbook 难题:一位成员询问如何发布其工具的 Cookbook 以供 DSPy 使用,因为他们了解到 第三方集成 并不被直接支持。
- 另一位成员回复称 DSPy 不提供此项服务,建议撰写博客并将其包含在社区资源中。
- BlockseBlock 对 2026 年印度 AI 峰会的兴趣:一位来自 BlockseBlock 的成员咨询关于在 2026 年印度 AI 峰会上组织一场聚焦于 DSPy 的活动的事宜。
- 他们寻求指导,想了解应与谁讨论这一机会。
- 开发者人才搜寻:一位成员询问是否有人在寻找 开发者。
- 目前没有关于具体技能组或项目的额外背景或回复。
tinygrad (George Hotz) ▷ #general (3 messages):
sassrenderer bounty, tinygrad coding philosophy, MR appropriateness
- Sassrenderer Bounty 接近完成:一位成员报告称
adds和mul已经在 sassrenderer bounty 中正常运行。- 他们询问进度达到什么程度时开启 Merge Request (MR) 比较合适。
- tinygrad:通过修复规范来修复 Bug:一位成员表示,当你有明确的 Spec 并且只需要将其编写出来时,Agent 很好用,但 tinygrad 的许多编码工作并非如此。
- 他们表示 tinygrad 的目标不仅是修复 Bug,还要找出导致该 Bug 的原始 Spec 中存在的微妙错误,然后修复该 Spec。
MCP Contributors (Official) ▷ #general-wg (1 messages):
MCP Merging, MCP Extending, Shopify MCP, Email Support Integration
- 寻求 MCP 合并与扩展技术:一位成员询问了合并或扩展 MCP 的简便方法,特别是针对 Shopify MCP,以加入如邮件支持之类的额外工具。
- 将邮件支持集成到 Shopify MCP:用户希望将目前独立提供的邮件支持功能集成到其现有的 Shopify MCP 配置中。