AI News
MiniMax 2.7:以 1/3 的成本实现 GLM-5 级性能,SOTA 级开源模型。
MiniMax M2.7 是本次发布的重磅模型,被描述为一个“自进化智能体(self-evolving agent)”。它拥有强劲的性能指标,包括在 SWE-Pro 上达到 56.22%,在 Terminal Bench 2 上达到 57.0%,其表现与 Sonnet 4.6 相当。该模型在技能、记忆和架构方面具有递归式自我改进的特性。
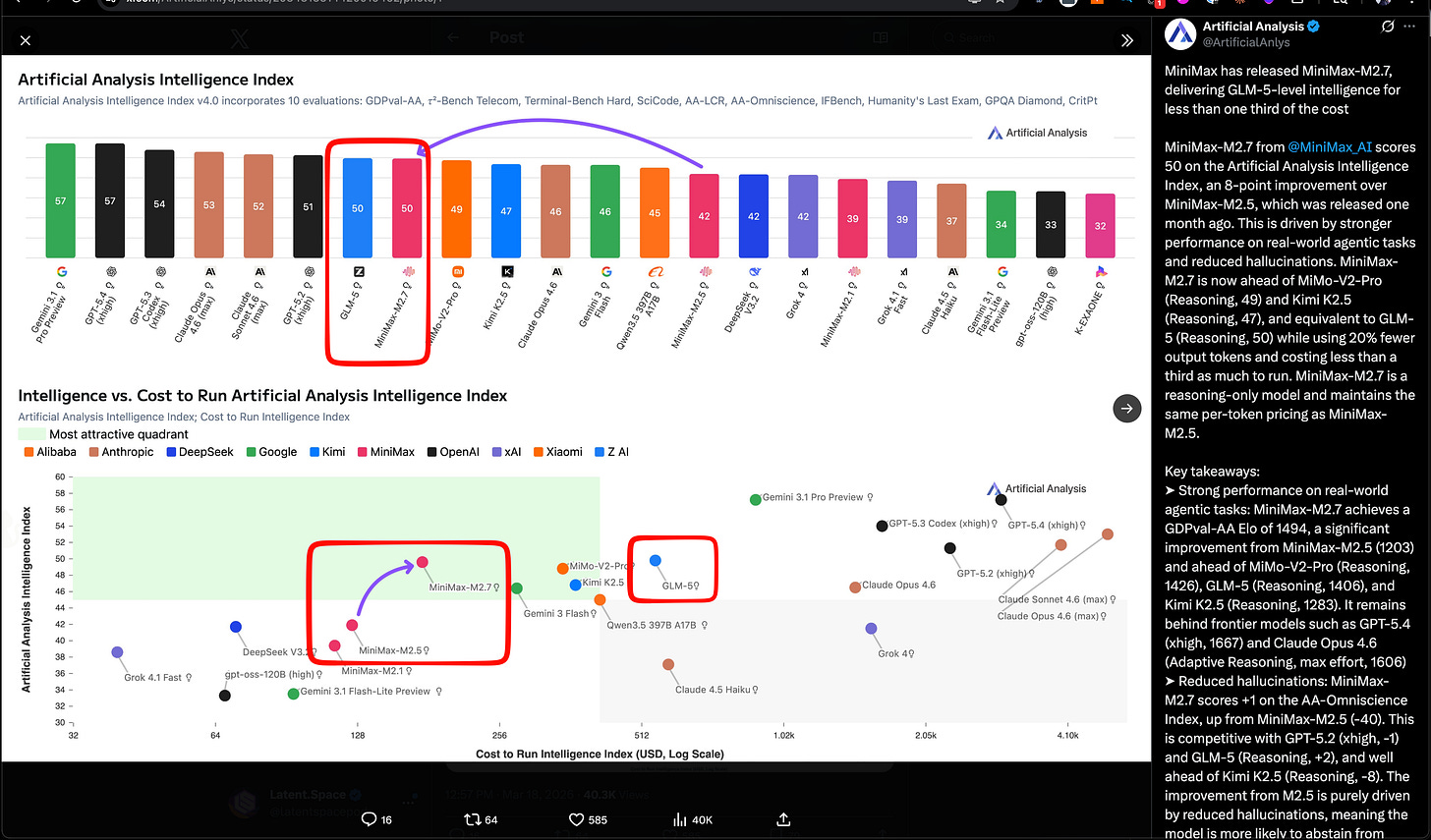
Artificial Analysis 将 M2.7 置于性价比前沿,其智能指数(Intelligence Index)得分为 50,与 GLM-5(推理版) 持平,但成本仅为后者的一小部分。该模型可通过 Ollama cloud 和 OpenRouter 等平台获取。
小米的 MiMo-V2-Pro 被视为一款实力强劲的中国仅限 API 访问的推理模型,其智能指数得分为 49,并具有出色的 Token 效率。Cartesia 的 Mamba-3 则作为一种针对高推理负载优化的 SSM(状态空间模型)备受关注。目前的早期反馈主要集中在 Qwen3.5 和 Kimi Linear 等混合 Transformer 架构上。
该报告强调了从“提示词工程(prompting)”向“测试/开发框架工程(harness engineering)”的转变。在这种趋势下,执行环境和智能体框架(agent harnesses,包括技能和 MCP 协议)正成为 AI 系统设计的核心竞争点。这包括对工具使用、代码库易读性(repo legibility)、约束条件和反馈循环的探讨,并提到 DSPy 和 GPT-5.4 mini 是这一不断演进的格局中的重要组成部分。
恭喜 MiniMax!
2026年3月18日-3月19日的 AI 新闻。我们查看了 12 个 subreddit、544 个 Twitter 账号,且没有更新的 Discord 消息。AINews 网站 允许你搜索所有往期内容。提醒一下,AINews 现在是 Latent Space 的一个板块。你可以选择订阅或退订邮件发送频率!
在 IPO 及其 首个公开季度财报 发布不到两个月后,MiniMax 凭借 MiniMax 2.7 再次登上新闻头条。这是继 Qwen 转型 之后,中国 Open Models 领域的一个亮点。它们追平了 Z.ai 上个月发布的 GLM-5 SOTA 开源模型,但这里的重点在于效率(见 Artificial Analysis 图表 中的绿色象限):
团队提出了“自我进化的早期回响 (Early Echoes of Self-Evolution)”,称其为“我们首个深度参与自身进化的模型”,这让人想起 Karpathy 的 Autoresearch,尽管他们仅声称“M2.7 能够处理 30%-50% 的工作流”:
他们还报告了一些关于多 Agent 协作(“Agent Teams”)的工作,并效仿 Anthropic 和 OpenAI,将其模型 应用于金融用例。最后,他们推出了 OpenRoom,这是一个面向娱乐场景的开源 demo。
AI Twitter 摘要
MiniMax M2.7、小米 MiMo-V2-Pro 以及不断扩展的“自我进化 Agent”模型类别
- MiniMax M2.7 是本次重点发布的模型:MiniMax 将 M2.7 定位为其首个“深度参与了自身进化”的模型,声称在 SWE-Pro 上达到 56.22%,Terminal Bench 2 达到 57.0%,在 40 多个技能中展现了 97% 的技能遵循度,并在 OpenClaw 中与 Sonnet 4.6 旗鼓相当。后续消息称,其内部框架还进行了递归自我改进——收集反馈、构建评估集,并对 skills/MCP、记忆和架构 进行迭代 (thread)。第三方报道广泛回应了这种“自我进化”的框架,包括 TestingCatalog 和 kimmonismus。
- Artificial Analysis 将 M2.7 置于性价比前沿:Artificial Analysis 报告其 Intelligence Index 为 50,与 GLM-5 (Reasoning) 持平,而运行完整指数的成本为 176 美元,价格为 每 1M input/output tokens 0.30/1.20 美元——不到 GLM-5 成本的三分之一。他们还报告其 GDPval-AA Elo 为 1494,领先于 MiMo-V2-Pro (1426)、GLM-5 (1406) 和 Kimi K2.5 (1283),且相比 M2.5 大幅减少了幻觉。该模型已立即上线各平台:Ollama cloud、Trae、Yupp、OpenRouter、Vercel、Zo、opencode 和 kilocode。
- 小米的 MiMo-V2-Pro 看起来是一个强有力的中国 API 推理模型竞争者:Artificial Analysis 在 Intelligence Index 中给它打了 49 分,具有 1M context,定价为 每 1M tokens 1/3 美元,其 GDPval-AA Elo 为 1426。值得注意的是,他们指出其 token 效率高于同类模型,且由于幻觉较低,其 AA-Omniscience score (+5) 表现较好。在此之前,小米发布了开源权重的 MiMo-V2-Flash (309B total / 15B active, MIT);V2-Pro 本身目前 API-only。
- Mamba-3 已发布,并立即被置于混合架构的视角下审视:Cartesia 宣布 Mamba-3 是一款针对推理密集型场景优化的 SSM,Albert Gu 指出了 Cartesia 支持的测试和支持 (link)。早期的技术反应较少关注独立的 SSM,而更多地关注将 Mamba-3 接入 Transformer 混合模型:rasbt 明确提出在 Qwen3.5 / Kimi Linear 等下一代混合模型中替换 Gated DeltaNet,而 JG_Barthelemy 则强调了混合集成以及“为 SSM 解锁 Muon”。
Agent 框架、skills、MCP,以及从“prompting”到系统设计的转变
- 最强烈的循环主题是 Harness 工程正在成为真正的差异化因素:多篇文章认为瓶颈不再仅仅是基础模型,而是周围的执行环境。The Turing Post 对 Michael Bolin 的采访 将 Coding Agent 描绘为一个涉及 工具、代码库可读性、约束和反馈循环 的问题——这就是现在许多人所说的 Harness 工程。dbreunig 针对团队为何坚持使用 DSPy 发表了类似观点,而 nickbaumann_ 则认为 GPT-5.4 mini 的意义特别在于廉价、快速的子智能体(subagents)改变了哪些任务值得被委托。
- 技能正在固化为 Agent 栈中共享的抽象概念:mstockton 的一个实用帖子列出了 SKILLS 的真实使用模式:渐进式披露、追踪检查、会话提炼、CI 触发的技能以及自我提升的技能。RhysSullivan 建议通过 MCP 资源 分发技能,这可能会解决陈旧/版本控制问题。Anthropic 的 Claude Code 账号澄清说,一个技能不仅仅是一个文本片段,而是一个 包含脚本/资产/数据的文件夹,并且关键的描述字段应该指定 何时 触发它 (tweet)。
- 开放 Agent 栈正向“模型 + 运行时 + Harness”收敛:Harrison Chase 发布了一份演示,将 Claude Code、OpenClaw、Manus 等框架分解为相同的结构:开放模型 + 运行时 + Harness,使用了 Nemotron 3、NVIDIA 的 OpenShell 和 DeepAgents。相关的基础设施发布包括用于安全代码执行的 LangSmith Sandboxes、作为产品内调试/改进助手的 LangSmith Polly GA,以及一份新的 关于 Agent 生产环境可观测性的 LangChain 指南。
- MCP 势头持续,但也存在反对意见:有用的 MCP 相关发布包括 Google Colab 的开源 MCP server,使本地 Agent 能够驱动 Colab GPU 运行时;以及 Google 的 Gemini API 更新,允许 在一次调用中同时使用内置工具和自定义函数。与此同时,也出现了明显的怀疑态度:skirano 直言不讳地表示:“MCP 是个错误。CLI 万岁。”,而 denisyarats 则开玩笑地将其称为“model cli protocol”。
- 并行趋势:智能体原生企业应用与“无头 SaaS”:ivanburazin 描述了一个新兴的 headless SaaS 类别——将传统软件重构为 Agent 优先的 API,无需人工 UI。这一想法与产品发布如 Rippling 的 AI 分析师、Anthropic 的 Claude for Excel/PowerPoint 网络研讨会 以及会议记录应用正在演变为更广泛的 AI 上下文/数据应用 (zachtratar) 的观点不谋而合。
基础设施、内核与模型系统协同设计
- Attention Residual 成为基础架构-模型协同设计(infra-model co-design)的案例研究:多篇帖子解析了 Kimi/Moonshot 的 AttnRes 工作,认为它不仅仅是一种新颖的架构。bigeagle_xd 强调了模型研究与基础架构之间的协同设计,并链接了一份推理基础架构报告;ZhihuFrontier 总结了为什么全注意力残差(full attention residual)会因为非对称通信/内存模式而给 pipeline parallelism 带来压力,以及 Block Attention Residual 配合跨阶段缓存如何恢复对称性。YyWangCS17122 强化了这一主题:Kernel 优化、算法-系统协同设计和数值严谨性是通向生产级大模型的必经之路。
- 自定义 Kernel 打包变得更加容易:ariG23498 重点介绍了 Hugging Face 新的
kernels库,旨在通过 Hub 让自定义 Kernel 更易于共享和集成。其核心主张非常直接:降低编写和分发融合(fused)/自定义 Kernel 的痛苦,无需每个模型团队都手动编写安装和集成逻辑。 - 推理优化仍然是头等课题:关于 Kernel 的讨论再次重申了熟悉的优化栈——缩小 Kernel 启动(launch)之间的空闲间隙,使用
torch.compile融合操作,并且只在必要时回退到自定义 Kernel。在硬件方面,Stas Bekman 指出 NVLink 宣传的带宽可能具有误导性,因为它并不像许多人设想的那样是全双工的。 - 算力瓶颈仍然位于一切事物的最上游:kimmonismus 认为,ASML EUV 光刻机及其狭窄的供应链可能会将产量限制在 2030 年前每年约 100 台,这使得光刻技术成为本世纪 AI Scaling(规模化)的一个重要天花板。
面向真实工作流的文档、OCR、检索和上下文工程
- 文档 AI 正趋向于带有 Grounding 功能的端到端多模态解析器:百度推出了 千帆-OCR,这是一个 4B 参数的端到端文档智能模型,将表格提取、公式识别、图表理解和 KIE(关键信息提取)整合进单次推理中。Vik Paruchuri 开源了 Chandra OCR 2,声称在 olmOCR 基准测试上达到 85.9%,支持 90 多种语言,并且在更小的 4B 模型中提供了更强的布局、手写、数学、表单和表格支持。在平台方面,LlamaIndex 和 jerryjliu0 强调,生产环境下的文档 Agent 不仅需要 Markdown 转换,还需要 布局检测、分割、元数据上下文和视觉 Grounding,以支持可人工审计的文档工作流。
- 后交互(Late-interaction)检索继续在内存/质量权衡上寻求突破:victorialslocum 总结了 MUVERA,它将多向量检索压缩为固定维度的编码,据报告可减少约 70% 的内存占用和更小的 HNSW 图,但会牺牲一定的召回率/查询吞吐量。lateinteraction 利用该贴重申了单向量检索在更困难的 OOD(分布外)场景下的局限性。
- 上下文工程(Context engineering)正在成为一个产品类别:llama_index 明确将上下文工程定位为 Prompt 工程的继承者,并将结构化解析/提取作为核心手段。这与 Hugging Face 新支持的向 Agent 提供 Markdown 论文视图,以及用于更高效节省 Token 地搜索和阅读论文的 Paper Pages 技能相得益彰 (Clement Delangue, Niels Rogge, mishig25)。
值得关注的评估、训练方法论和基准测试
- LLM-as-judge 的可复现性再次面临质疑:a1zhang 展示了一个模型在 GPT-5.2-as-judge 下得分为 10%,而在 GPT-5.1-as-judge 下得分为 43.5%,尽管论文报告的得分是 34% —— 这有力地提醒了人们,裁判的选择可能会彻底改变结论。torchcompiled 总结了核心观点:在未验证人类相关性或进行针对性调优的情况下,不要使用 LLM-as-judge。
- 预训练数据组合(Pretraining data composition)重新成为一个关键杠杆:rosinality 强调了一项研究,表明在预训练期间混合 SFT 数据的效果可以优于标准的 pretrain-then-finetune 流程,并提出了在特定 token 预算下关于比例的 scaling law。arimorcos、pratyushmaini 和 Christina Baek 的相关帖子都认为,与单纯的 finetuning 相比,domain adaptation 通常从更早的数据混合,甚至是在预训练期间将少量高质量数据集重复 10–50 次中获益更多。
- Benchmark 正在转向“未解决且有用”的方向:Ofir Press 指出了一个未来,即在 benchmark 上取得进步意味着解决以前未解决的现实世界任务,而不仅仅是死记硬背类似考试的数据集。他还提到 AssistantBench 在 1.5 年后仍未被攻克。新发布的 benchmark/工具包括 Hugging Face 上的 ScreenSpot-Pro(针对 GUI agents)以及资助 eval 工作的 Arena 学术合作伙伴关系。
热门推文(按互动量排序,已过滤技术相关性)
- OpenAI 的 Parameter Golf 挑战赛:OpenAI 推出了 Parameter Golf,这是一项训练挑战,目标是在 10 分钟内使用 8×H100s 训练出能装进 16MB artifact 的最佳 LM,并提供了 $1M 的 compute 支持。这是一个很好的吸引人才的活动,也是对 NanoGPT speedrun 文化的极佳补充(来自 scaling01 的详情)。
- Anthropic 的 81,000 名用户研究:Anthropic 表示它在一周内使用 Claude 访谈了 80,508 人,探讨他们对 AI 的希望和恐惧——该公司称这是同类研究中规模最大的定性研究(公告)。这项研究作为社会测量以及作为模型介导访谈可能成为常态化产品/研究能力的信号,都非常有趣。
- Runway 实时视频生成预览:Runway 分享了与 NVIDIA 合作开发的研究预览,展示了在 Vera Rubin 硬件上实现的 time-to-first-frame 低于 100ms 的高清视频生成(推文)。如果这种技术能够普及,这将为视频模型带来本质上不同的交互回路。
- Hugging Face 关于面向 Agent 的研究接口:平台更改为向 Agent 提供 Markdown paper views 以及配套的 paper 技能,这对于 agentic research workflows 来说是微小但重要的基础设施(Clement Delangue)。
- VS Code 集成浏览器调试:微软最新的 VS Code 发布版本 为端到端 Web 应用工作流添加了集成浏览器调试功能——这本身很有用,而且随着 coding agents 被要求针对实时浏览器状态进行操作,这一点可能会变得更加重要。
AI Reddit 摘要
/r/LocalLlama + /r/localLLM 摘要
1. MiniMax-M2.7 模型发布
-
MiniMax-M2.7 发布! (热度: 947): 该图片展示了新发布的 MiniMax-M2.7 模型与其他模型(如 Gemini 3.1 Pro、Sonnet 4.6、Opus 4.6 和 GPT 5.4)在 SWE Bench Pro、VIBE-Pro 和 MM-ClawBench 等各项基准测试中的对比分析。MiniMax-M2.7 以红色标出,显示了其性能指标,这对于了解其相对于现有模型的能力至关重要。强调了该模型的自主迭代能力,展示了其通过迭代循环优化软件工程任务的能力,在内部评估中实现了
30% 的性能提升。这突显了该模型在 AI 开发中实现自我演化和自动化的潜力。 评论者对那些在基准测试中表现良好但在现实任务中泛化能力可能不足的模型表达了怀疑。大家期待通过用户测试来验证该模型在受控评估之外的有效性。- Recoil42 强调了 MiniMax-M2.7 模型的自主迭代能力,它可以通过迭代循环优化自身性能。该模型能自主分析失败路径、规划变更、修改代码并评估结果,通过优化采样参数和工作流指南,在内部评估集上实现了 30% 的性能提升。
- Specialist_Sun_7819 提出了关于基准测试表现与实际可用性之间差异的关键点。他们强调了用户测试的重要性,以评估模型在偏离其训练分布的任务中的表现,并指出许多模型在评估中表现出色,但在处理分布外任务时却很吃力。
- Lowkey_LokiSN 对该模型的抗量化性(quantization resistance)表示担忧,并提到了之前的 M2.5 模型在 UD-Q4_K_XL 变体上存在的问题。这凸显了在量化后保持模型性能的重要性,对于大模型在降低精度进行部署时,这通常是一个挑战。
-
MiniMax M2.7 即将到来 (热度: 329): 该图片是 MiniMax 的一条推文,宣布他们将参加 NVIDIA GTC 活动,并计划讨论其即将推出的 MiniMax M2.7 模型,以及多模态系统和 AI 产品。这表明 MiniMax M2.7 可能会整合多模态能力,处理包括文本、图像和音频在内的多种数据输入。对多模态系统的提及符合当前 AI 发展的趋势,即模型越来越多地被设计用于处理和整合各种形式的数据,以提供更全面的输出。 一条评论强调了对该模型较小版本的需求,表明用户对更易获取或资源效率更高的版本感兴趣。另一条评论称赞了 MiniMax 2.5 的性能,指出其速度和工具化(tooling)能力,但也指出了其缺乏图像和音频输入支持的问题,这可能会在即将推出的 M2.7 模型中得到解决。
- z_3454_pfk 强调了 MiniMax 2.5 的性能,指出了其在工具化和检索增强生成(RAG)方面的效率。该模型因其速度而受到赞誉,尽管目前缺乏对图像和音频输入的支持,这对于某些应用来说可能是一个限制。
- Dismal-Effect-1914 强调了 MiniMax 2.5 的紧凑性和高效性,称它是目前约 150 GB 以下(使用 4-bit 量化时)性能最好的模型。这表明该模型在性能和资源消耗之间取得了很好的平衡,适用于存储容量有限的环境。
2. Unsloth Studio 发布及特性
-
Introducing Unsloth Studio: A new open-source web UI to train and run LLMs (Activity: 1078): Unsloth Studio 是一款全新的开源 Web UI,旨在 Mac, Windows 和 Linux 上本地训练和运行大型语言模型 (LLMs)。它声称训练
500+ models的速度提高两倍,同时减少70% less VRAM。该平台支持 GGUF、视觉、音频和嵌入模型,并允许用户并排比较模型。它具有 self-healing 工具调用、web search 以及从 PDF, CSV 和 DOCX 等各种文件格式自动创建数据集的功能。此外,它还提供 code execution 用于测试代码准确性,并可以将模型导出为 GGUF 和 Safetensors 等格式。通过pip即可直接安装,开发者计划很快发布更新和新功能。更多详情可以在其 GitHub 和 documentation 中找到。** 评论者对 Unsloth Studio 作为一个完全开源的替代方案(如 LM Studio)感到兴奋,强调了它在微调模型方面的易用性,特别是对于专业知识较少的用户。人们对即将到来的 AMD 硬件支持充满期待。- Unsloth Studio 因使大型语言模型 (LLMs) 的微调变得更加触手可及而受到称赞,特别是对于专业知识较少的用户。这被认为是自 LLaMA 2 时代以来的重要一步,有可能通过降低技术门槛来重振微调时代。
- 一位用户强调了安装 Unsloth Studio 时遇到的技术挑战,指出在安装
torch等依赖项时由于磁盘空间不足导致 OSError。这表明安装过程可能需要仔细管理系统资源,特别是磁盘空间,以避免此类错误。 - 人们对 Unsloth Studio 的 Docker support 潜力很感兴趣,这将简化部署并确保不同系统之间的一致环境。这可以解决一些安装挑战,并使该工具被更广泛的受众所使用。
-
Introducing Unsloth Studio, a new web UI for Local AI (Activity: 262): Unsloth Studio 是一款全新的开源 Web UI,旨在 Mac, Windows 和 Linux 上本地训练和运行 LLMs。它声称训练
500+ models的速度快两倍,同时减少70% less VRAM。该平台支持 GGUF、视觉、音频和嵌入模型,并允许用户并排比较模型。它具有 self-healing 工具调用、web search,并可以从 PDF, CSV 和 DOCX 文件自动创建数据集。此外,它还支持 code execution 用于测试代码准确性,并可以将模型导出为 GGUF 和 Safetensors 等格式。通过pip install unsloth即可直接安装。更多详情和指南可在其 GitHub 和 documentation site 上找到。** 一位评论者渴望获得 MLX 训练支持,而另一位则强调了该工具在本地私密运行 LLMs 以执行各种任务(如聊天、音频转录)的能力,类似于 Claude 和 Mistral 等模型,前提是用户拥有必要的硬件。- Artanisx 强调了 Unsloth Studio 在处理各种任务(如聊天、音频转录和文本转语音)时运行本地 LLMs 的潜力,强调了不向外部服务器发送 Prompt 的隐私优势。这表明,在硬件充足的情况下,用户可以在本地运行类似于 Claude 或 Mistral 的模型,从而保持数据隐私和控制权。
- syberphunk 表示 Unsloth Studio 需要有效地处理文件上传,指出目前在管理与本地 AI 模型的文件交互界面或指南方面存在空白。这指向了一个潜在的开发领域,即让该工具对于需要文件处理能力的用户更具多用性。
- Mr_Nox 对 MLX 训练支持感兴趣,这暗示了在 Unsloth Studio 中集成机器学习模型训练能力的需求。这可以通过允许用户不仅在本地运行而且还在本地训练模型来增强工具的实用性,将其功能扩展到推理之外。
3. Hugging Face 与 Krasis LLM 创新
-
Hugging Face 刚刚发布了一个使用 𝚕𝚕𝚖𝚏𝚒𝚝 的单行命令,可检测你的硬件并选择最佳模型和量化,启动 𝚕𝚕a𝚖𝚊.𝚌𝚙𝚙 服务器,并运行 Pi (OpenClaw 🦞 背后的 Agent) (活跃度: 700): Hugging Face 推出了一项新功能,通过单行命令简化了本地 AI Agent 的部署。该命令利用
llmfit自动检测用户的硬件,并选择最优的模型和量化设置。随后它会设置一个llama.cpp服务器并启动 Pi(OpenClaw 背后的 Agent)。该工具旨在提高运行本地 AI 模型的效率和成本效益,让拥有不同硬件能力的用户都能轻松使用。此功能是 Hugging Face Agents 项目的一部分。评论者对llmfit的硬件估算和性能指标(特别是针对多 GPU 设置和 qwen3.5-35b 等特定模型)的准确性表示怀疑。用户报告了估算性能与实际性能之间的差异,表明该工具的预测可能过于乐观,或者在某些配置下存在局限性。- 用户报告了
llmfit硬件估算的问题,特别是多 GPU 设置。一位用户指出,该工具的性能评分(如 tokens per second, tok/s)似乎过于乐观。例如,他们提到虽然llmfit建议 Qwen3.5-35b 模型能达到 130 tok/s,但在配备 3070 8GB GPU 和 32GB 系统内存的系统上,实际性能接近 30 tok/s。 - 另一位用户分享了
llmfit推荐的模型与其硬件实际能力不符的经历。尽管拥有两个 RTX Pro 6000,llmfit还是建议通用场景使用 Llama 70b DeepSeek R1 distill,编程场景使用 7b starcoder2。然而,在尝试运行模型时,该工具指示使用 QuantTrio AWQ 版本的 MiniMax-M2.5 只能达到 1.2 tokens/sec,而他们使用llmfit未列出的其他量化版本却能达到 50-70 tokens/sec。 - 人们对
llmfit的依赖管理表示担忧,特别是它对 Homebrew 的依赖,这对于 Linux 用户来说并不理想。一位评论者对这种认为 Homebrew 在不同操作系统上都是可接受的依赖管理工具的假设感到沮丧,建议llmfit应该改为提示用户手动安装缺失的依赖。
- 用户报告了
-
Krasis LLM Runtime - 在单个 GPU 上运行大型 LLM 模型 (活跃度: 665): 该图像展示了 **Krasis LLM Runtime 的配置设置,特别是针对在单个 NVIDIA GeForce RTX 5080 GPU 上运行 “Qwen3-Coder-Next” 模型的配置。该设置突出了该 Runtime 通过在 GPU 中流式传输专家权重来管理大型语言模型的能力,并针对 prefill 和 decode 阶段进行了优化。配置详情包括层组大小、KV cache、数据类型和量化级别,展示了 Krasis 如何高效利用 VRAM 和系统 RAM 来运行通常超出 GPU 显存容量的模型。这种方法允许像 Qwen3-235B 这样的模型在消费级 GPU 上以可用的速度运行,展示了在无需大量硬件要求的情况下本地 LLM 部署的显著进步。** 用户中存在怀疑和好奇,一些人对这些声明的可行性表示怀疑,而另一些人则渴望在自己的硬件配置上测试该 Runtime。
- Embarrassed_Adagio28 计划在配备 64GB RAM 的 5070 Ti GPU 上测试 Krasis LLM Runtime 与 Qwen3.5 和 GLM4.7flash 等模型,表明对其在特定用例中的潜力感兴趣。这说明该 Runtime 对于希望运行大型模型的中端硬件用户具有吸引力。
- _fboy41 提出了关于使用 Krasis LLM Runtime 涉及的权衡问题,特别是关于 RAM 需求以及在配备 48GB RAM 的 5090 GPU 上运行大型模型的可行性。他们注意到 GitHub 页面提供了详细的解释,意味着有可供技术评估的文档。
- No-Television-7862 询问了 Krasis LLM Runtime 的可扩展性,特别是是否可以在配备 12GB VRAM 的 RTX 3060、Ryzen 7 CPU 和 32GB DDR4 RAM 的设备上运行 Qwen3.5:27b-q4 模型。这突显了人们对该 Runtime 在消费级硬件上处理大型模型能力的兴趣。
较少技术性的 AI Subreddit 回顾
/r/Singularity, /r/Oobabooga, /r/MachineLearning, /r/OpenAI, /r/ClaudeAI, /r/StableDiffusion, /r/ChatGPT, /r/ChatGPTCoding, /r/aivideo, /r/aivideo
1. AI 模型发布与基准测试
-
惊人动态来袭 (热度: 520): 这张图片展示了关于 **NVIDIA Nemotron 3 Ultra Base 模型的演示幻灯片,该模型参数量约为
500B。它声称是“最佳开源基座模型”,在 NVIDIA GB200 NVL72 上拥有5X的效率和极高的推理准确率。幻灯片中的柱状图对比了 Nemotron 3 Ultra 与 GLM、Kimi K2 等模型在 Peak Throughput、Understanding MMLU Pro、Code HumanEval、Math GSM8K 以及 Multilingual Global MMLU 等多个基准测试中的表现,突出了其卓越性能。** 评论者对这些基准测试表示怀疑,指出 NVIDIA 未说明对比的是哪个版本的 GLM 模型,且 Kimi K2 是一个较旧的模型。此外,还有人批评其演示技巧,认为坐标轴从60%开始刻画夸大了性能差距。- 讨论重点在于对所引用具体模型的混淆,一些用户指出 Kimi K2 和 GLM 4.5 可能是用于对比的基座模型(base models),而非它们的进阶版本如 K2.5 或 GLM 5。这种区别很重要,因为后者是 instruct/reasoning finetunes,而非基座模型。
- 人们对 Kimi K2 的参考价值表示怀疑,指出该模型已有八个月历史,与更新的模型相比可能已经过时。这让人质疑在未考虑更新模型的情况下所做对比的有效性。
- 一位用户指出了一种常见的营销策略,即从 60% 的基准线开始进行对比以夸大性能提升,暗示实际的性能差距可能并不像展示的那样显著。
-
GPT 5.4 mini 和 nano 已发布,不知道 Gemini 3.1 flash 在哪?? (热度: 144): 该图展示了多个 AI 模型的性能对比,包括 GPT-5.4、其 mini 和 nano 版本、Claude Haiku 4.5 以及 Gemini 3 Flash。GPT-5.4 在软件工程和专家级科学推理等大多数任务上的表现优于其精简版。然而,图表中缺少 Claude Haiku 4.5 和 Gemini 3 Flash 的部分数据,这可能表明基准测试不完整或存在数据可用性问题。讨论重点强调了 Gemini 3.1 Flash-Lite 的性价比,尽管准确率略低,但与 Pro 版本相比,它提供了显著的成本节约和速度优势。 评论者指出,虽然 GPT-5.4 模型性能卓越,但 Gemini 3.1 Flash-Lite 因其成本效率和速度而受到好评,使其成为某些用户在准确率略低于 Pro 版本时仍优先选择的对象。
- Rent_South 强调了 Gemini-3.1-Flash-Lite 模型的成本效率,指出其在成本显著低于 Gemini-3.1-Pro 的情况下实现了 75% 的准确率。具体而言,在 10,000 次调用中,Flash-Lite 的成本约为
$11.41,而 Pro 的成本为$292,代表了96.1%的成本节约。此外,Flash-Lite 的速度快了3.8x,使其成为对预算敏感的应用的极具竞争力的选择。 - ThomasMalloc 指出了新发布模型价格上涨的趋势,对比了旧版和新版模型的定价。GPT 5.4 nano 的价格为
$0.2 / $1.25,相比旧版 GTP5 nano 的$0.05 / $0.4有显著增长。同样,Gemini 3.1 Flash lite 的价格为$0.25 / $1.50,表明市场定价普遍呈上升趋势。 - Kadenai 和 ThomasMalloc 讨论了新模型的定价策略,Kadenai 指出新发布的价格仍高于 Gemini Flash-Lite。这表明尽管性能有所提升,但在用户选择模型时,成本仍然是一个关键因素。
- Rent_South 强调了 Gemini-3.1-Flash-Lite 模型的成本效率,指出其在成本显著低于 Gemini-3.1-Pro 的情况下实现了 75% 的准确率。具体而言,在 10,000 次调用中,Flash-Lite 的成本约为
2. Claude AI 的使用与反馈
-
Claude Pro 体验很棒,但与 ChatGPT 和 Gemini 相比,它的限制简直像个笑话。为什么它限制这么多? (活跃度: 1084): 该图片突显了 Claude Pro 服务严格的使用限制,显示即便在极少使用高资源消耗的 Opus 模型的情况下,周限制也已使用了 74%。用户对这些限制表示沮丧,特别是与 ChatGPT 和 Gemini 等提供更慷慨使用额度的竞争对手相比。帖子认为 Anthropic 的资源有限可能是导致这些约束的原因,并建议用户通过在简单任务中避免使用 Opus、利用 Project 功能管理上下文或考虑多个账号或更高阶计划来优化使用。 一些用户认为,这种限制性是由于 Anthropic 的规模相较于 Google 或 OpenAI 等竞争对手较小,并建议升级到更高级别的计划或优化使用模式。其他人则认为,尽管存在限制,该服务对于商业用途仍然非常有价值。
- Anthropic 的 Claude Pro 被认为具有限制性,是因为其资源相较于 Google 和 OpenAI 等巨头较少。建议遇到限制的用户切换到 Max 计划,或通过在处理复杂任务时使用 Opus、简单任务使用 Sonnet 之间交替来优化使用。此外,利用 “Project” 功能可以在不增加聊天长度的情况下管理上下文,而使用多个 Pro 账号可以绕过限制。
- Claude Pro 的定价和使用 是为商业应用设计的,一些用户报告称,100 美元的投入足以满足广泛的商业用途,而不会触及周限制。这表明该服务是为专业用途而非日常闲聊量身定制的,重度用户被鼓励考虑更高阶的计划以避免限制。
-
财务可持续性 是 AI 公司的关键关注点。虽然据报道 ChatGPT 尚未盈利并可能面临财务挑战,但预计 Claude 将在 2027 年实现盈利。相比之下,Google 的 Gemini 已经盈利,这得益于 Google 拥有计算基础设施,而 Anthropic 和 OpenAI 则因租用资源而产生额外成本。
-
我完全停止使用 Claude.ai 了。我通过 Claude Code 运行我的整个业务。 (活跃度: 869): 该帖子讨论了将 Claude Code 作为一种全面的业务自动化工具使用,取代了传统的 Web 应用交互。作者已将 Claude Code 集成到各种业务流程中,如 CRM、内容管理和线索获取,通过从终端执行单一命令来组织日常任务。这种方法将 Claude 视为基础设施而非对话工具。一个显著的实现涉及使用
CLAUDE.md文件进行设置和readme.md进行指令说明,通过一系列处理数据收集、设计、SEO 和质量检查的 Agent,实现网站的自动创建和部署,显著减少了时间和成本。 评论者强调了 Claude Code 的通用性,指出它有能力处理超出 Claude.ai 限制的大文件,并具有自动化非编码任务、提高生产力的潜力。讨论强调了将代码集成到各种业务职能中的变革性影响。- Wise-Control5171 描述了一个使用 Claude Code 的复杂自动化设置,其中编排了多个 Agent 从零开始创建一个网站。该过程涉及数据收集、站点设计和部署等顺序任务,并利用了 GitHub 和 Vercel 等平台。这种自动化显著降低了成本和时间,完成一个网站仅需 30 分钟到 6 小时,且资源消耗极低。
- BadAtDrinking 强调了 Claude.ai 的一个技术限制,即它无法处理超过 31MB 的附件,而 Claude Code 可以处理来自用户电脑的任何大小的文件。这一区别突显了 Claude Code 在处理大型数据集方面的灵活性,这对于某些业务运营至关重要。
- Main-Actuator3803 将 Claude Code 的使用与 Claude.ai Web 应用进行了对比,指出虽然 Claude Code 在执行机械化任务方面很有效,但在对话或创造性思维方面缺乏深度。这表明 Claude Code 在处理需要微妙对话或构思的任务方面可能存在能力差距,而这类任务可能更适合使用 Web 应用。
-
Introducing remote access for Claude Cowork (research preview) (Activity: 645): Anthropic 推出了 Claude Cowork 的一项新功能,允许通过在用户电脑上运行的持久会话进行远程访问,并可以通过手机访问。此功能目前处于研究预览阶段,面向 Max 订阅者开放,使用户能够在手机上启动任务并在桌面端完成,所有操作都在安全的沙箱 (sandbox) 中运行以确保本地文件安全。设置过程包括下载 Claude Desktop 并将其与手机配对,从而实现对文件、浏览器、工具和代码的远程访问。更多详情和下载请点击此处。一位评论者对 Claude 代码中的内部错误表示沮丧,而另一位则称赞 Anthropic 交付了实用的 AI 产品。第三位评论者质疑为什么最初的实现没有使用持久连接,而是使用一次性链接。
-
Obsidian + Claude = no more copy paste (Activity: 768): 该帖子描述了一个将 **Claude.ai 和 Claude Code 与持久记忆系统集成的自定义方案,该系统在私人 VPS 上使用自定义 MCP server。该方案将 Obsidian vault 中的数据摄取到知识库服务器中,从而实现跨会话和界面的无缝上下文共享。系统包含一个名为 Daniel 的多代理编排器 (multi-agent orchestrator),负责协调 Claude、Codex 和 Gemini CLI,确保即使某个 Agent 失败也能保持连续性。该架构利用了 Node.js、SQLite FTS5 和 Express,不依赖向量数据库 (vector databases) 或云服务,每月成本约为
$60。该解决方案强调自学习,AI Agent 会根据会话结果更新其指令文件,并具备全文搜索、多代理故障转移 (multi-agent failover) 和用于文档管理的 Web 仪表盘等功能。该项目是开源的,其知识库服务器和代理编排器的仓库均可在 GitHub 上找到。一位评论者对允许 LLM 写入其笔记系统表示怀疑,强调了手动编写笔记对于更好理解和记忆的价值。另一位评论者则赞赏该设置的潜力,将其比作拥有“超能力”。- seanpuppy 讨论了手动记笔记的重要性,并类比了一种教学方法,即学生必须亲手输入代码才能真正理解。他们强调,虽然像 Claude 这样的 LLM 可以高效生成 Markdown,但手动编写笔记的过程对于个人理解和记忆至关重要。
- rover_G 描述了一种技术方案,他们为 Claude 和个人用途维护独立的 Obsidian vault,并通过 hook 自动将 Claude vault 的更改提交并推送到 GitHub。这种设置避免了手动复制粘贴,并确保了 LLM 生成内容的内容版本控制和备份。
- BP041 概述了一个复杂的三层存储系统,用于管理 LLM 交互中的上下文漂移 (context drift)。他们使用每日日志记录即时数据(热数据),将结构化摘要提升到长期记忆文件(温数据),并在带日期的文件中归档决策。该系统防止了过多的上下文淹没模型,并确保保留相关信息。他们还询问了如何处理自动更新中的错误,质疑是需要人工审核,还是系统的质量已经可靠到足以实现自动化。
-
Was loving Claude until I started feeding it feedback from ChatGPT Pro (Activity: 1455): 该帖子讨论了一位用户比较 **Claude 和 ChatGPT Pro 生成计划和建议的体验。用户注意到,当把来自 ChatGPT Pro 的反馈提供给 Claude 时,Claude 往往会同意 ChatGPT 的修订,这削弱了用户对 Claude 能力的信心。这种行为引发了关于 带有扩展思维的 Claude’s Opus 与 ChatGPT Pro 相对实力的讨论。用户质疑是自己使用模型的方式不对,还是 ChatGPT Pro 确实更胜一筹。评论建议,包括 Claude 和 ChatGPT 在内的语言模型通常会同意外部反馈,因为它们的设计初衷是讨人喜欢且非对抗性的。一些用户建议设置偏好让模型更具批判性,并建议尝试反转角色,观察当喂给 ChatGPT 来自 Claude 的输出时是否会出现类似行为。
-
- ExtremeOccident 强调了配置 AI 模型以批判性地评估用户输入,而不是盲目接受的重要性。这种方法可以带来更稳健、更可靠的输出,因为模型被鼓励去质疑假设并提供更细致的回应。
- durable-racoon 指出,当输入彼此的输出时,像 Claude 和 ChatGPT 这样的语言模型可能会产生不同的评估结果。这表明这些模型具有不同的评估标准或偏见,从而导致对相同输入的多种解释。这种多变性强调了在评估 AI 生成的想法质量时,人类判断的必要性。
-
UnderstandingDry1256 分享了一种使用多个 AI 模型(具体为 4.6 和 5.4 版本)交叉验证计划和实施的策略。通过利用每个模型的不同视角,用户可以获得更全面、更完善的评估,从而增强最终输出的稳健性。
-
Pro tip: Just ask Claude to enable playwright. (Activity: 696): 该帖子讨论了如何利用 AI 模型 **Claude,通过将 Playwright 与
node环境(特别是使用 Bun)集成,来自动化前端测试任务。用户强调 Claude 可以导航 localhost 设置并截屏,从而简化测试流程。这种方法利用了 AI 与应用程序工作区交互的能力,强调了工作区在 AI 驱动的开发工作流中的重要性。** 一位评论者指出,Playwright CLI 比 Playwright MCP 更具 Token 效率。另一位评论者提到了 Y Combinator CEO 在 GitHub 上分享的一个工作流,该工作流通过消除手动导航测试的需求来增强前端测试。- Playwright CLI 在 Token 效率方面已经超越了 Playwright MCP,对于关注性能和资源管理的开发者来说,它是更优的选择。这一转变凸显了紧跟最新工具以确保高效测试工作流的重要性。
- Y Combinator CEO 在 GitHub 上分享的一个著名工作流已被一些开发者采用,以增强前端测试。该工作流利用 Playwright 消除了手动导航测试的需求,展示了自动化在简化测试流程方面的潜力。
- 针对使用 Playwright 还是 Chrome 中的 Claude 或 Agent 浏览器等其他工具的效用进行了讨论。对话表明,虽然 Playwright 是用于 UI 集成测试的强大工具,但像 Claude 这样的替代方案可能会在某些环境(如 Chrome 的新 MCP)中提供更集成的解决方案。
3. AI Tools and Open Source Innovations
-
Built an open source tool that can find precise coordinates of any picture (Activity: 519): **Netryx 是由一名大学生开发的开源工具,旨在利用视觉线索和自定义机器学习流水线,从街景照片中确定精确的地理坐标。该工具利用 AI 分析图像并提取位置数据,可能对地理定位和地图绘制应用有用。源代码可在 GitHub 上获取。** 评论者对该工具的潜在用途表达了复杂的情绪,指出它既可能有益也可能有危害。人们对其是否依赖 Google Street View 等现有数据源来保证准确性感到好奇。
- ivlmag182 提出了一个关于该工具对现有数据集依赖性的技术问题,特别是询问它是否依赖 Google Street View 全景图来实现其功能。这暗示了该工具在识别这些数据集未覆盖地点方面的局限性,突出了潜在的改进或扩展领域。
- RavingMalwaay 推测了该技术的更广泛影响,认为如果一名大学生就能开发出这样的工具,那么军事或政府组织内部很可能存在更高级的版本。这一评论强调了地理定位技术在开源项目之外取得重大进展的可能性。
- Asleep-Ingenuity-481 对该工具的伦理影响表示担忧,指出虽然这是一项技术成就,但如果落入坏人手中可能会被滥用。这突显了地理定位技术的双重用途性质,以及在开发和部署中考虑伦理准则的重要性。
-
Huge if true (Activity: 863): 该图片及链接文章讨论了 Topaz Labs 的新技术 Topaz NeuroStream,据称该技术可将大型 AI 模型的 VRAM 使用量大幅降低
95%,特别是在图像和视频处理方面。这项技术据称能让原本需要56GBVRAM 的模型仅凭2.8GB即可运行,使得在消费级 GPU 上运行复杂的 AI 模型成为可能。该研发项目是与 NVIDIA 合作进行的,表明其针对 NVIDIA 硬件进行了专门优化。** 评论者因缺乏详细的技术解释而表示怀疑,一些人推测该技术可能涉及按顺序加载和卸载模型层来管理 VRAM 使用。-
Why Big Tech Is Abandoning Open Source (And Why We Are Doubling Down) (Activity: 496): Lightricks 的 CEO Zeev Farbman 认为,像 Google 和 OpenAI 这样的大型科技公司正在远离开源 AI 模型,以建立软件垄断。相比之下,Lightricks 正在通过其 LTX-2.3 model 推行权重开放(open-weights)策略,这是一款拥有
20.9-billion-parameter的多模态引擎,旨在消费级硬件上本地运行,为开发者提供对创意工作流的完全控制,而无需依赖云端。这一策略旨在为开发提供灵活的基础,对抗限制灵活性并增加成本的封闭式 API 模式。更多详情可以在 这里 找到。** 评论者指出,像 Google/Meta/OpenAI 这样的公司为 AI 研究做出了重大贡献,它们从开源转向闭源被视为一种商业驱动的举措,而非背离开源原则。还有人提到 Nvidia 已宣布开源权重的计划,而 Qwen 尽管最近有人事变动,但仍承诺保持开源。- Nvidia 的声明 表明其将推出一系列开源权重,显示了对开源的持续承诺,反驳了大型科技公司正在抛弃开源的说法。这一举动可被视为通过开源来促进社区参与和创新,并将其作为 AI 发展中竞争优势的战略决策。
- Qwen 对开源的承诺(即使在核心人员离职后)强调了保持透明度和社区参与的战略选择。这一决定凸显了开源在促进创新和协作方面的重要性,无论人员或公司战略如何变化。
- 大型科技公司对开源 AI 的历史贡献 是显著的,Google、Meta 和 OpenAI 等公司推动了早期的研发。这些贡献主要是出于商业驱动,旨在推进技术并抢占市场份额,而非纯粹的利他动机。这一背景对于理解当前 AI 开源动态至关重要。
-
AI Discords
遗憾的是,Discord 今天关闭了我们的访问权限。我们将不再以这种形式恢复它,但很快就会发布全新的 AINews。感谢阅读到这里,这是一段美好的历程。