ainews-1272023-anthropic-says-skill-issue
2023年12月7日:Anthropic 表示这是“技能问题”(skill issue)。
Anthropic 通过添加提示词,修复了其 Claude 2.1 模型在“大海捞针”(needle in a haystack)测试中的一个故障。OpenAI 的 Discord 频道上的讨论将谷歌的 Gemini Pro 和 Gemini Ultra 模型与 OpenAI 的 GPT-4 和 GPT-3.5 进行了对比,一些用户发现 GPT-4 在基准测试中表现更优。关于 GPT-4.5 发布的传闻在流传,但尚未得到官方确认。此外,有人对“选择性审查”影响语言模型性能表示担忧。欧盟对包括 ChatGPT 在内的 AI 的潜在监管也受到了关注。用户报告了 ChatGPT Plus 的消息限制和订阅升级问题,并分享了使用 BingChat 和 DALL-E 的经验。社区还讨论了提示工程技术以及图像生成和 MIDI 序列分析等未来应用,并表达了对 GPT-5 的期待。
很高兴昨晚在 the Nous Research launch 发布会上见到你们中的一些人。
我们已将 Wing Lian 的 Discord 添加到此追踪器中,今天将与他录制一期播客。
Anthropic 通过在 Greg Kamradt 的“大海捞针”(needle in a haystack)测试中添加提示词,“顺便修复了这个小故障”:
另外,Schmidhuber 想要提醒你,他一直都是对的。
[TOC]
OpenAI Discord 摘要
- 讨论围绕 Google 的 Gemini Pro 和 Gemini Ultra 模型展开,并将其性能与 OpenAI 的 GPT-4 和 GPT-3.5 进行了比较。用户的体验各不相同,一些人发现 GPT-4 在某些基准测试中优于 Gemini。然而,关于模型性能的共识可能取决于 Gemini Ultra,而在讨论时该模型尚未发布。
- QUERY: “
@feltsteam0提到听闻有关 12 月底或 1 月初发布的传言,但未提供官方来源。” 因上下文不足而省略 - 针对语言模型中感知的“选择性审查”及其对性能的潜在影响进行了深入讨论。像
@picturesonpictures这样的用户对更新可能对模型性能产生的负面影响表示担忧。 - 分享了一篇 Bloomberg 文章,讨论了欧盟可能对 AI 进行的监管,这可能会影响像 ChatGPT 这样的语言模型。
- 用户对 ChatGPT Plus 相关的消息限制表示不满。问题似乎在于由于网络错误,导致提前达到了每 3 小时 40 条消息的限制。
- 用户分享了使用不同语言模型的经验,包括 BingChat。许多人认为 BingChat 的响应质量与 ChatGPT 相比稍逊一筹。
- 由于 OpenAI 解释不明的临时暂停,用户在升级 ChatGPT Plus 订阅时面临挑战。
- 讨论了用户在使用 DALL-E 和 GPT 时遇到的各种系统问题,包括自定义知识文件消失、网络错误以及在插入 OpenAPI JSON 后无法保存 GPT Actions。
@solbus提供了支持并提出了潜在的解决方案。 - 用户询问了语言模型的可能应用,包括图像生成、音频分析和 MIDI 序列分析,表达了对 GPT-5 等未来模型的期待。
- 讨论了 Prompt Engineering 的概念,本质上是构建提示词以获得所需的 AI 输出。用户讨论了如何请求修改 AI 生成的图像、如何使用提示词从 PDF 中生成问题和答案,并分享了一个关于有效提示的 YouTube 教程。正如
@gerhardsw_73789所指出的,该技术的有效性取决于用户输入的质量和细节。
OpenAI 频道摘要
▷ #ai-discussions (190 messages🔥🔥):
-
Gemini 模型讨论:用户讨论了 Google 的新 AI 模型 Gemini Pro 和 Gemini Ultra。一些用户(包括
@drighten_)对 Gemini 的推出表示不满,并将其性能与 OpenAI 的 GPT-4 和 GPT-3.5 进行了比较。@feltsteam0指出,在某些 benchmarks 中,GPT-4 的表现似乎优于 Gemini。 -
GPT-4.5 猜测:一些用户参与了关于 OpenAI 即将推出的 GPT-4.5 模型的猜测。
@feltsteam0提到听到了关于 12 月底或 1 月初发布的传闻,但未提供官方来源。 -
语言模型性能:用户讨论了各种语言模型的性能。
@picturesonpictures提出了关于“选择性审查”以及更新可能对模型性能产生负面影响的担忧。@vantagesp指出 Google 的 Gemini 擅长识别模式。 -
AI 的潜在监管:
@clockrelativity2003分享了一篇 Bloomberg 文章的链接,内容涉及欧盟对人工智能(包括像 ChatGPT 这样的 AI)的潜在监管。 -
Gemini 推出:一些用户讨论了 Google 的 Gemini Pro 模型在不同地区的推出情况。
@feltsteam0提到它已在除欧盟/英国以外的大多数国家推出,而来自哥伦比亚的@danyer37报告说他的 Bard 仍为西班牙语且没有 Gemini。 -
Gemini vs GPT-4:关于 Gemini 相对于 GPT-4 的性能存在相当大的争论。
@exiled_official似乎认为 Google 的 Gemini 项目进展不如预期。@youraveragedev表达了这样的观点:鉴于这两个模型在文本 benchmarks 中的表现,OpenAI 很有机会让 Google “难堪”。
▷ #openai-chatter (362 messages🔥🔥):
- Google Gemini 模型评估:用户对 Google 新推出的 Gemini Pro 模型(为 Bard 提供支持)进行了热烈讨论。一些用户声称其性能显著优于 GPT-4,而另一些人则认为 GPT-4 仍保持领先地位。最终定论可能取决于目前尚未发布的 Gemini Ultra。
- ChatGPT Plus 的性能和限制问题:用户对 ChatGPT Plus 的消息限制表示不满,目前的限制是每 3 小时 40 条消息。几位用户报告说,由于网络错误,他们提前达到了限制。有人猜测未来可能会增加消息上限。
- 不同语言模型的优缺点:用户比较了包括 BingChat 在内的不同语言模型,并讨论了它们各自的缺点和优势。许多用户认为 BingChat 的回答质量不如 ChatGPT。
- OpenAI 订阅暂时暂停:由于 OpenAI 暂时停止了订阅,几位用户对无法购买订阅或将现有订阅升级到 ChatGPT Plus 表示沮丧。目前尚不清楚此次暂停的明确结束日期。
- 其他杂项话题:用户还探索了将语言模型用于不同应用的方法,如图像生成、音频分析和 MIDI 序列分析。他们还分享了对未来模型(如 GPT-5)功能的期望,以更好地满足其特定用例。
▷ #openai-questions (64 条消息🔥🔥):
- 免费访问 DALL-E:用户
@lucasc.234询问 DALL-E 2 是否可以免费使用。@solbus建议可以领取免费额度,并提到可以使用 Bing 的 image creator 来使用 DALL-E 3。 - 向 GPT 上传自定义知识库的问题:
@cat.hemlock反馈在尝试向其 GPT 上传自定义知识文件后,重新打开编辑器时文件似乎消失了。这一问题影响了 GPT 的功能,并得到了其他用户的证实,@solbus提供了一个指向 Discord 上 Bug 报告帖子的链接。 - 数学问题的错误输出:用户
@samihahaha报告了数学问题输出异常的情况。@eskcanta认为 AI 错误使用了 LaTeX 格式,并提供了一个解决方案,即提醒 AI 正确的 LaTeX 格式指令。 - 账户升级到付费版本:
@fearlessdigital提到在收到付费账户升级请求的回复方面存在延迟,并担心非个人邮箱(如 success@)是否被接受。 - DALL-E 中图像消失:
@spectre120和@solbus讨论了 DALL-E 中图像消失的问题及可能的解决方案。建议使用“保存到收藏夹 (Saving to Collections)”作为确保图像不丢失的方法。 - 系统故障:用户
@vigneshs、@pichytweets、@satanhashtag、@eskcanta和@_diogenesque_报告了各种系统问题,包括网络错误、桌面端 Plus 订阅问题以及 App 中聊天记录消失。@solbus积极与这些用户沟通以进一步了解问题并提出潜在建议。
▷ #gpt-4-discussions (36 条消息🔥):
- GPT 知识文件和消息限制问题:
@alanwunsche指出 GPT 知识文件会被随机删除且在 status page 上不可见的问题。此外还讨论了 GPT-4 的消息限制,@pietman建议 GPTs 的限制较低,约为 20 条 prompt,而普通对话的限制为 40 条 prompt。@solbus提到 GPTs 在 3 小时内可能总共有 25 条 prompt 的限制。 - 使用 ChatGPT 进行数据处理:
@jdo300正在寻求通过 GPT 响应返回数据文件的建议,具体计划是使用 Python 脚本处理并显示大量数据。 - 用户信息存储与识别:
@lduperval询问了如何存储对话中的用户信息以便后续调用,并询问如果用户在没有提示的情况下提供信息,GPT 是否能够识别并适应。 - 自定义 GPTs 和 OpenAPI JSON 的问题:
@ps5671和@nisus74等多位用户报告了自定义 GPTs 从账户中消失,以及在插入 OpenAPI JSON 后无法保存 GPT actions 的问题。 - OpenAI Assistant API 的学习能力:
@ankur1900和@logan.000讨论了 OpenAI Assistant API 是否能实时从持续的对话中学习和适应。结论是它可以在 context window 内学习并保留特定知识。
▷ #prompt-engineering (7 条消息):
-
理解 Prompt Engineering:用户讨论了 Prompt Engineering 的概念,
@adrshr7表示它涉及“向 AI 提出正确的问题,以向我们提供所需的答案和见解”。其次,@ex_hort.给出了多重描述,指出它是关于“在考虑 AI 局限性的同时,进行指令的创意写作以获得预期结果”,并将其总结为“告诉 ChatGPT 你想要什么,创建一个 prompt”。 -
请求修改 AI 生成的图像:
@zaher4608询问用户如何请求修改通过人工智能创建的图像,包括开发具有不同姿势的特定角色。 -
从 PDF 创建问答的 Prompt:
@mazik71寻求关于能够从 PDF 生成问题和答案的 prompt 的建议。 -
高效 Prompt 编写的 YouTube 教程:
@gerhardsw_73789分享了他们看到的一个有助于创建更有效 prompt 的 YouTube 教程。该用户分享了教程中详细的 prompt,并发现即使翻译成德语也非常有效。 -
使用建议 Prompt 的结果:
@ex_hort.询问了该 prompt 的效果,@gerhardsw_73789回复称“超出预期”,其有效性在很大程度上取决于用户回答的质量和细节。
▷ #api-discussions (7 messages):
- Prompt Engineering 讨论:
@adrshr7和@ex_hort.阐明了 Prompt Engineering 的概念。它包括创建或调整提示词以从 AI 获取所需输出并克服其局限性的实践。 - AI 图像修改咨询:
@zaher4608提出了一个关于用户如何请求更改 AI 生成图像的问题,例如改变特定角色的姿势。 - 从 PDF 创建问题:
@mazik71征求关于如何使用提示词从 PDF 文件生成问题和答案的建议。 - 迭代提示技术:
@gerhardsw_73789分享了一个基于 YouTube 教程的优化提示词创建的方法。该过程包括不断修订和迭代提示词,并添加额外信息,以从 Chat GPT 获取最有效的输出。 - 迭代提示技术评估:针对
@ex_hort.的询问,@gerhardsw_73789评论说,上述技术的结果好于预期,且这些结果的质量取决于用户输入的详细程度。
OpenAccess AI Collective (axolotl) Discord 总结
-
关于模型训练和自定义数据集的广泛讨论,多位用户分享了见解、问题和建议。值得注意的包括
@faldore计划使用新的以对话为中心的数据集开发 Dolphin 3.0 模型,以及@kaltcit和@rtyax对训练增加上下文数量的 Yi-200K 模型的兴趣。提到了克服技术挑战的资源和建议,例如申请 Microsoft 的 Startup 计划和优化 batch sizes。@papr_airplane分享了由于非连续 token 问题导致启动 BakLLaVA-1 失败的问题。 -
关于 PEFT 和 AWQ 集成 的活跃讨论,用户
@casper_ai和@caseus_建议将 AWQ 添加到 requirements 中,并提出了将其与 PEFT 嵌入的策略。 -
#axolotl-help 频道中各种问题的故障排除。问题包括
@casper_ai在不同flash-attn版本上遇到的困难,@vijen.遇到的 NCCL 超时,@DavidG88在使用axolotl合并 adapter 和基础模型后推理时间变慢,以及@mave_2k关于 ShareGPT 提示词格式的咨询和@nanobitz提供的推理工具建议。 -
关于数据集格式和实用性的辩论。
@dirisala解决了 “completion” 数据集格式添加冗余 token 的问题,@nanobitz提出了修复方案。@faldore分享了 DolphinCoder 数据集的链接,并强调了对高质量编码多轮对话数据集的需求。还分享了 Retro-YahooAnswers 数据集的链接。 -
#advanced-help 频道为高级问题提供协助。其中包括
@developer_59500关于 Axolotl 安装 的问题,@geronimi73关于 tokenizer 自定义的咨询,_automagic对 mamba 130m instruct 模型性能的称赞,以及对@faldore观察到的训练损失(training loss)意外峰值的故障排除。
OpenAccess AI Collective (axolotl) 频道总结
▷ #general (79 messages🔥🔥):
-
讨论模型训练和自定义数据集:
@faldore分享了关于训练 Dolphin 模型的见解,该模型受 Microsoft Orca 启发并专注于未经审查的文本,包含来自 Airoboros 和 Samantha 的样本。对于 Dolphin 3.0,创建者计划用新的以对话为中心的数据集替换这些样本。他们提到正在开发 Orca 2 数据集的开源实现。 -
高上下文模型上的可能合作:用户
@rtyax和@kaltcit表达了对训练具有更高上下文数量的 Yi-200K 模型的兴趣。@kaltcit表示他们有一个针对学术和 QA 用途的模型,并强调它对笑话/故事/说唱没有用处,因为它没有在 Airobo/Dolphin 数据集上进行训练。 -
大 Batch Sizes 的优势:在关于训练模型的讨论中,
@kaltcit解释说,较大的 batch sizes 可以帮助处理训练过程中意外的损失增加。较大的 batches 还允许更高的学习率(learning rate),从而导致更低的损失。 -
训练资源和建议:
@faldore建议@kaltcit成立有限责任公司(LLC)并申请 Microsoft 的 Startup 计划,以获取用于训练的 Azure 额度。@kaltcit提到他们已经拥有 Google 为其 GCP A100 US central 配额提供的无限研究额度。 -
模型启动故障排除:
@papr_airplane分享了由于非连续 token 问题导致启动 BakLLaVA-1 失败的问题。@nanobitz建议通过调整tokenizer_config来手动修复此问题。
▷ #axolotl-dev (7 messages):
- 关于集成 PEFT 和 AWQ 的讨论:
@caseus_询问 PEFT 中的修复是否应该上游化 (upstreamed),或者是否可以将 autoawq 作为安装扩展 (install extras) 添加。@casper_ai建议将 AWQ 添加到 requirements 中,并提供了将 AWQ 与 PEFT 结合的代码片段:import awq.modules.peft_patch。@caseus_确认了将 AWQ 添加到 requirements 的必要性。@casper_ai建议使用 PyPi 上的 AWQ 版本(自带 CUDA 12.1),而不是 GitHub 上带 CUDA 11.8 的版本,因为 PyPi 往往能简化流程。
▷ #axolotl-help (36 messages🔥):
-
flash-attn 版本问题:用户
@casper_ai报告在标准 RunPod 模板(使用 torch 2.1.1 和 cuda 12.1.1)中使用flash-attn==2.3.6时遇到问题。该问题通过降级到flash-attn==2.3.3得到解决。 -
NCCL 超时问题:用户
@vijen.询问如何禁用预处理后运行train命令时遇到的 NCCL 超时。@caseus_建议查看 GitHub repository 中关于处理 NCCL 问题的资源,并提到accelerate库最近的更新可能会解决这些问题。 -
模型合并后推理时间增加:
@DavidG88注意到在使用axolotl将 QLoRA 适配器与7b Mistral基础模型合并后,推理时间显著增加。在使用llm-evaluation-harness进行模型基准测试时,该问题尤为突出。 -
ShareGPT 的 Prompt 格式:
@mave_2k询问了与训练模型交互的 ShareGPT Prompt 格式。@tim9422提供了说明,并分享了代码相关部分的链接。他还警告了 ChatML 分隔符中多余换行符导致的不一致问题,并表示愿意创建一个 PR 来修复它。 -
推理工具推荐:当被问及推荐的推理运行工具时,
@nanobitz建议使用ooba。
请记住,这些是基于个人经验的第三方建议。请务必测试不同的解决方案,并选择最适合您用例的方案。
▷ #datasets (15 messages🔥):
- 数据集格式中的双重 Token 包含:
@dirisala注意到在使用基于 llama 的模型的 “completion” 数据集格式时,即使数据集中已经包含<s>Token,框架仍会在开头添加<s>。这导致该 Token 被包含两次。 - 双重 Token 问题的潜在解决方案:
@nanobitz建议在处理前将其从数据集中移除,并补充说是否包含<s>等 Token 取决于所使用的 tokenizer。 - DolphinCoder 数据集:
@faldore分享了 Hugging Face 上 DolphinCoder 数据集的链接,并提到计划在其上训练模型。 - 多轮对话代码数据集:
@faldore表示需要一个好的多轮对话代码数据集,并建议可以从 sharedGPT 数据集中筛选出与编程相关的对话。 - Retro-YahooAnswers 数据集:
@visuallyadequate发布了一个名为 Retro-YahooAnswers 的新数据集链接,该数据集源自 2007 年左右的 Yahoo Answers,但警告称该数据集包含敏感内容,可能不适合作为严肃的助手模型数据集,除非作为合成数据集的种子数据。
▷ #advanced-help (23 messages🔥):
-
调试 Axolotl 安装:用户
@developer_59500尝试使用pip安装 Axolotl,但遇到了与缺少 GPU 和torch模块相关的问题。@le_mess告知安装需要 Nvidia GPU,无法在 Mac M2 或没有 GPU 的 Linux 上运行。 -
Tokenizer 修改:用户
@geronimi73询问如何向模型添加新 Token。@nanobitz澄清说,如果模型使用 HF tokenizer,可以在 config yaml 文件中添加 Token。 -
对 Mamba 130m Instruct 模型的印象:用户
_automagic分享了托管在 Hugging Face 上的 mamba 130m instruct 模型链接,并称赞其表现令人印象深刻。 -
模型训练故障排除:
@faldore训练了一个模型 (yi-34b),并分享了关于 Loss 在 4k 处出现意外峰值的观察结果,尽管使用了 deepspeed 和 AdamW 优化器。@casper_ai建议启用--debug模式以捕获日志并识别潜在问题。
Latent Space Discord 总结
-
关于本地 AI 工作和用于大语言模型(LLM)使用的 GPU 选择的广泛讨论,建议在购买电源(PSU)时考虑潜在的 GPU 升级。引用:
@lightningralf建议使用 Deep Seek 33b 和 Aider,并根据这条推文期待一个新的开源模型。 -
@slono分享了对不同 AI 模型的批评和体验,包括对 OpenHermes 在特定编程提示词上的表现表示满意,以及对 GPT-4 编程能力的批评。 -
询问最小化 GPT-4 推理成本的技术,讨论了可能的策略,如结合 GPT-4 和 OpenHermes 分别生成代码和 diff,正如
@slono在这个 GitHub 仓库中所解释的那样。 -
@swyxio宣布了关于 Emergence paper(涌现论文)的讨论,包括活动详情以及可在 arXiv 上查阅的论文,作者包括著名的研究员 Jason Wei 和 Colin Raffel 等。该活动被描述为在 lu.ma 上进行的每周一次、多环节的论文研讨会。 -
@cakecrusher分享了 Q-Transformer 方法的链接,这是一种提高 Offline Reinforcement Learning(离线强化学习)可扩展性的技术,详见此处。 -
AI 机器人对西班牙语和普通话等多种语言翻译能力的不同反应,用户
@hackgoofer和@coffeebean6887注意到了输出质量的差异。 -
@guardiang分享了深入的视频,评述了 Gemini 的技术报告并分析了 AlphaCode 2 论文。 -
关于对 AI 提示词(Prompt)进行微调所产生影响的观察,
@picocreator和@slono注意到微小的变化会显著影响输出。
Latent Space 频道总结
▷ #ai-general-chat (43 messages🔥):
-
本地 AI 编程工作与 GPU 建议:
@slono讨论了在应用中作为编程助手大规模本地使用大语言模型(LLM)的潜在 GPU 配置。可选方案包括使用 3090、4090 或双显卡版本、m3 mac 以及基于云的解决方案。@lightningralf建议将 Deep Seek 33b 与 Aider 结合使用,并建议等待即将推出的比 Gemini 更强大的开源模型,如这篇 Twitter 帖子 所示。 -
GPU 与前瞻性:
@lightningralf建议@slono在购买电源(PSU)时考虑到未来潜在的 GPU 升级。 -
AI 模型与用例:
@slono分享了他们使用不同模型的一些经验,对 OpenHermes 在特定编程提示词上的表现表示满意,并对 GPT-4 的编程能力提出了批评。@lightningralf建议尝试 Notus,因为它被认为比 Hermes 更好。 -
最小化 GPT-4 推理成本:
@ayenem询问了关于通过与更便宜的模型协作来最小化 GPT-4 推理成本的资源。@slono通过详细说明一个用例进行了回答,在该用例中,3.5 和 OpenHermes 被用于生成 diff 输出,并请求 GPT-4 在编写代码时可能遗漏的输出。 -
使用 GPT-4 和 OpenHermes 的代码重构流程:
@slono描述了一个流程,其中使用 GPT-4 进行重构或生成代码,使用 OpenHermes 生成 diff,然后应用该 diff。分享了一个关联的 GitHub 仓库。
▷ #ai-event-announcements (1 条消息):
- Emergence 论文研讨:
@swyxio提醒成员们关于 Emergence 论文 的讨论将在 5 分钟后开始。该论文可通过此 链接 获取,作者包括 Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, * Dani Yogatama。本次活动由 *Kevin Ball, Eugene Yan & swyx 主持,在 lu.ma 平台举行。 - LLM Paper Club 介绍:该活动被描述为一场多场次、每周一次的论文研讨,从基础论文开始对 LLM 论文进行回顾。鼓励参与者提前阅读论文,以便在会议期间进行拆解和讨论。
▷ #llm-paper-club (33 条消息🔥):
-
Q-Transformer:
@cakecrusher分享了一个关于 Q-Transformer 的链接,该技术在 Reinforcement Learning 中使用 Transformer 作为 Q 函数。据称该技术可以提高 Offline Reinforcement Learning 的可扩展性。Q-Transformer 链接 -
加入会议:用户
@iamkrish10询问如何加入会议,@swizec建议查看 Discord 频道列表以查找链接。 -
聊天机器人翻译准确性:用户
@hackgoofer和@coffeebean6887讨论了机器人的翻译能力,并指出翻译成西班牙语和中文普通话之间的输出质量存在差异。 -
Gemini 全面拆解 + AlphaCode 2 重磅消息:
@guardiang分享了一个 视频,创作者在视频中拆解了 Gemini 长达 60 页的技术报告,并分析了 AlphaCode 2 的重磅论文。 -
微小 Prompt 更改的影响:
@picocreator和@slono讨论了微小 Prompt 更改的影响,即 Prompt 的细微变化可能会对输出产生重大影响。@slono认为这些调整不是“技巧”,而是对目标陈述的精炼,并指出这种技术在许多 Prompt 中被广泛使用。@picocreator分享的链接未能正常加载。
LLM Perf Enthusiasts AI Discord 总结
- 观察到 GPT-4 Turbo 的性能有所下降,输出质量降低,且与速度无关。
- 讨论了 Anthropic 的 Claude 2.1 Prompting 及其通过修改 Prompt 提升性能的方法。通过在 Claude 2.1 的回复中加入 “Here is the most relevant sentence in the context:”,观察到了显著的分数提升。注意到并讨论了 Anthropic 员工频繁使用 “skill issue” 一词的现象。分享了 “Anthropic’s Claude 2.1 Prompting” 博客文章作为参考。
- 提出了关于通过使用更便宜的模型进行总结或重排序(re-ranking)来降低 GPT-4 推理成本(inference costs)的资源或实践请求,但尚未达成结论性讨论。相关资源中,Leonie (@helloiamleonie) 的一条推文展示了 Prompt Engineering 如何增强准确性。
- 寻求关于在 1 月份实施 Speech-to-Text API 的建议,目前尚未提供明确的解决方案。
- 讨论了模型训练中人类评估(human evaluation)的复杂性,重点在于创建模拟 OpenAI RLHF 评分任务的评分指南(rating guidelines)。
- 针对大上下文下的最优 Prompt 结构发起了讨论,例如 LangChain 用于检索问答(retrieval QA)的基础 Prompt,以及 Anthropic 对 Claude 2.1 Prompt 结构的实验。然而,这种转变的影响仍不明确。
- 提议在一些线下(IRL)活动中举办关于 Prompting 的 mini demo days,并推荐了 Luma event 以及邀请参加在伦敦 Gigi’s Hoxton 举办的 e/acc summit。
- 讨论了 ChatGPT Plus 邀请,会员可以使用邀请码邀请他人。每位会员最多可获得 3 个邀请名额。有人担心 Assistant API 缺乏流式传输(streaming)能力会导致延迟,从而影响用户体验。
- 关注 Prompt 词长基准测试、文档提取任务的最优结构以及医疗案例提取的经验。分享了一个关于 LLM Quality Measurement 的新型合成基准测试(synthetic benchmarking)想法,尽管原始论文链接已失效。
LLM Perf Enthusiasts AI 频道总结
▷ #gpt4 (2 条消息):
- GPT-4 Turbo 性能退化:
@frandecam观察到在过去 24 小时内 GPT-4 Turbo 的输出质量有所下降,这与速度无关。
▷ #claude (4 条消息):
- Claude 2.1 Prompting:用户
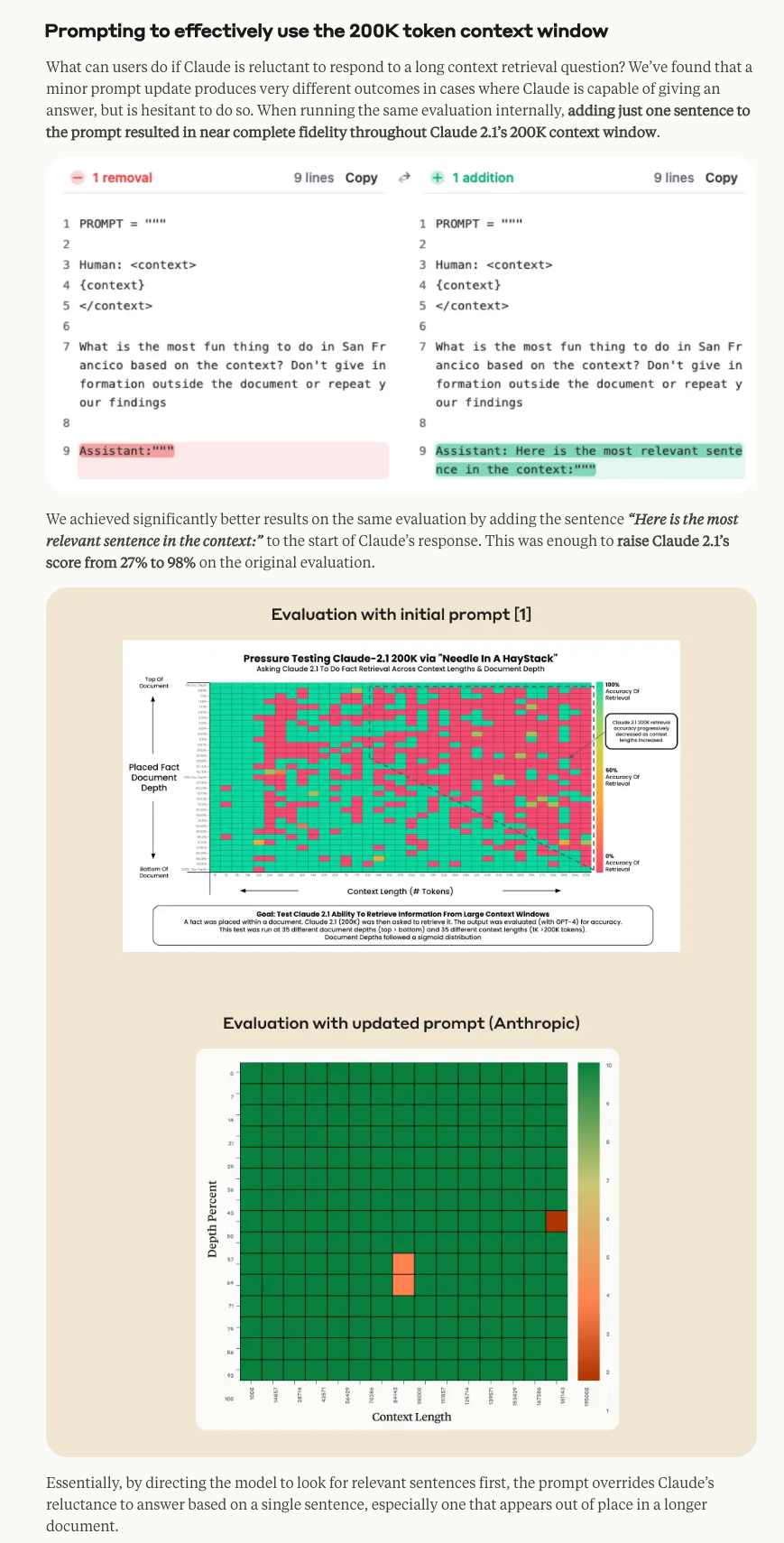
@robhaisfield分享了关于 Anthropic’s Claude 2.1 prompting 的文章链接,并暗示长上下文“迷失在中间”(lost in the middle)的问题可能是 Prompting 方面的 skill issue。 - 通过修改 Prompt 改善结果:
@kiingo强调,通过在 Claude 回复的开头添加 “Here is the most relevant sentence in the context:”,可以看到显著的改进。这个简单的改动帮助 Claude 2.1 在原始评估中的得分从 27% 提高到了 98%。 - Anthropic 员工频繁使用 “skill issue”:
@res6969注意到 Anthropic 员工经常使用 “skill issue” 这个词。
▷ #resources (2 条消息):
- 通过 Prompt Engineering 提高准确性:
@eula1分享了 Leonie (@helloiamleonie) 的一条推文,讨论了添加 “Here is the most relevant sentence in the context:” 如何将准确率得分从 27% 提升到 98%。这是根据 Anthropic 在其 博客文章 中概述的实验实现的。 - 最小化 GPT-4 的推理成本:
@ayenem询问了关于通过使用更便宜的模型处理前期或后期工作(如总结或重排序)来降低 GPT-4 推理成本的资源或通用实践。他们还请求提供支持 GPT-4 的此类任务/模型的通用模式。讨论并未对该问题提供答案。
▷ #offtopic (2 条消息):
- Speech-to-Text API:用户
@res6969正在寻求关于 Speech-to-Text API 的建议,因为他们计划在 1 月份实施一个,但之前没有使用这些工具的经验。
▷ #eval (1 messages):
- 人类评估与评分指南:用户
@justahvee讨论了模型训练中人类评估这一具有挑战性的任务,指出这通常依赖于创建 评分指南 (rating guidelines) 来模拟“最优”输出。正如他们所指出的,这种做法紧随 OpenAI 为生成基于人类反馈的强化学习 (RLHF) 训练数据而执行的评分任务。
▷ #rag (3 messages):
- 最优 Prompt 结构讨论:
@evan_04487询问是否有关于 长上下文下最优 Prompt 结构 的优秀论文或博客文章,特别是上下文与指令的最佳放置位置。他分享了 LangChain 用于检索问答 (retrieval QA) 的基础 Prompt 示例,包括指令 (Instructions)、上下文 (Context)、查询 (Query) 和最终结果提示 (Final result nudge)。 @thebaghdaddy提供了一个指向 Anthropic 标题为 “Claude 2.1: Prompting” 的 博客文章 链接。该文章展示了一种不同的 Prompt 结构顺序(Context, Query, 和 Instructions),然而,根据@evan_04487的说法,改变上下文或指令位置的影响仍不明确。
▷ #irl (5 messages):
- 小型演示日 (Mini Demo Days):用户
@frandecam建议在一些 IRL 活动中为 Prompt 狂热举办 小型演示日。 - 在 Lu.ma 举办的 ML、LLM、AI 与啤酒活动:
@calclavia提到并推荐了 Luma 活动,该活动以在喝啤酒的同时讨论 Machine Learning、Language Model Learning、Artificial Intelligence 等内容为特色。 - 伦敦 Gigi’s Hoxton 的 e/acc 峰会:用户
@eula1.邀请用户参加在伦敦 Gigi’s Hoxton 举行的 e/acc 峰会,预计将有约 300 名技术乐观主义者、工程师、建设者、创始人、VC 等参与。提供的活动链接在这里。 - e/acc 峰会活动时间:
@eula1.还提供了峰会的时间安排,计划于 下午 6:30 在伦敦 Gigi’s Hoxton 开始。
▷ #openai (42 messages🔥):
- ChatGPT Plus 邀请:用户
@joshcho_和@pantsforbirds讨论了为贡献者注册 ChatGPT Plus 的事宜。会议明确了 Plus 会员可以 使用他们的邀请码邀请他人。每位会员最多可获得 3 个邀请码。 - Assistants API 延迟:用户
@pantsforbirds对 Assistants API 缺乏流式传输 (streaming) 能力 导致的延迟表示担忧,这影响了用户体验,尤其是在聊天应用场景中。 - 替代方案建议:
@joshcho_建议可以使用 LangChain 或 LlamaIndex 等工具来复制与 Assistants API 类似的功能。
▷ #prompting (6 messages):
- Prompt 词数长度基准:
@dongdong0755询问了关于 Prompt 词数长度的基准测试,推测既不建议太短(以包含所有相关指令),也不建议太长(以免损害 Prompt 质量)。 - 文档提取的 Prompt 结构:
@pantsforbirds询问了在文档提取任务中提取上下文的高效 Prompt 结构。 - 医学病例提取经验:
@dongdong0755分享了他们在医学病例提取方面的经验,提到给出特定的 Prompt 来排除某些内容块可以改善结果。他们也愿意通过私信分享具体示例。 - 衡量 LLM 质量的基准思路:针对
@dongdong0755的问题,@mat_mto分享了来自一篇论文的合成基准测试思路。该方法涉及向语言模型提供一个大型 JSON 字符串,并要求其检索特定值。成功检索即代表模型的质量。分享的原始论文链接似乎已失效。
Alignment Lab AI Discord 摘要
- 关于 Google Gemini AI 的对话,讨论了其发布、性能表现,以及一段详细对比 Gemini 与 OpenAI GPT-4 测试的 YouTube 视频。关键点包括 Gemini 的 Benchmark 结果与 GPT-4 相当,且 Gemini 的性能优势取决于具体任务。
- 在 Twitter 上关于 Jürgen Schmidhuber 对深度学习架构贡献的讨论。值得注意的是,Schmidhuber 指出他在该领域的工作早于 Yann LeCun。对话以期待 Schmidhuber 发布自己的模型结束。
- 关于 OpenOrca 使用的交流,即 GPT-3.5 的有用子集,以及关于
torch.compile与 gradient checkpointing 潜在兼容性的技术咨询。 - 关于 SlimOrca-Dedup 的提问,请求更详细的信息;然而,回复并未提供进一步的说明。
Alignment Lab AI 频道摘要
▷ #ai-and-ml-discussion (1 条消息):
- Schmidhuber 对深度学习架构的贡献:在
@lightningralf分享的一篇 Twitter 帖子 中,Jürgen Schmidhuber 概述了他自 1990 年以来在具备规划能力的深度学习架构方面的贡献,暗示他在这些课题上的研究远早于 Yann LeCun。Schmidhuber 的帖子包含了大量对其研究论文和发现的引用。讨论以希望 Schmidhuber 未来可能发布自己的模型而告终。
▷ #general-chat (9 条消息🔥):
- Google Gemini AI 介绍:
@entropi分享了指向 Google 关于其新 AI Gemini 的博客链接。介绍中包含了 Google CEO Sundar Pichai 的致辞,以及对 Gemini 能力的详细解释。 - Gemini 对比 GPT-4 测试视频:
@entropi还分享了一段 YouTube 视频,详细介绍了测试 Google Gemini 与 OpenAI GPT-4 的最佳方法。 - Benchmark 结果:根据
@entropi的说法,Gemini 的 Benchmark 结果与 GPT-4 在 3 月份的表现相当。然而,他们提到 GPT-4 自那时起可能已经有所改进,这可能使其具有竞争优势。 - 任务依赖性:
@entropi进一步指出,Gemini 和 GPT-4 之间的性能优劣将取决于任务。具体而言,Gemini 展示了非常强大的多模态(multimodal)结果。 - Gemini Ultra 对比 Gemini Pro:
@entropi区分了 Gemini 的两个版本:在 Benchmark 中与 GPT-4 持平的强大版本 “Gemini Ultra”,以及较小的 “Gemini Pro”。值得注意的是,目前只有 Gemini Pro 发布到了 “Bard”,而 Gemini Ultra 要到明年才会推出。
▷ #oo (7 条消息):
- OpenOrca 的 GPT-3.5 部分:用户
@ufghfigchv询问是否有 OpenOrca 中 GPT-3.5 部分的有用子集,或者是否已经制作了任何子集,并艾特了特定用户 (@748528982034612226) 以获取建议。 - 使用 Gradient Checkpointing 进行编译:
@imonenext询问torch.compile是否支持 gradient checkpointing,并请求一个在 Transformer 和 flashattn 中使用的示例。 - Torch 2.1.1:用户
@benjamin_w建议 gradient checkpointing 可能在 torch 2.1.1 或 Nightly 版本中支持 torch.compile,尽管他表示在 torch 2.1 中似乎无法运行。 - 如何使用 Torch.Compile:
@imonenext询问了如何使用torch.compile的指令,特别是想知道它是否应该包装在一个经过 gradient checkpointing 的 Transformer 模型之上。
▷ #open-orca-community-chat (2 条消息):
- SlimOrca-Dedup 咨询:用户
@samblouir请求关于 SlimOrca-Dedup 的更详细信息,并指出其简短描述为 “使用 minhash 和 Jaccard 相似度技术进行去重”。@lightningralf回复了 “SlimOrca Dedup”,但未提供任何额外细节。
LangChain AI Discord 总结
- Table Transformer:
@spicyhabanero123分享了关于 Table Transformer 的讨论及概述链接。概述链接 - DeepMind 的 Gemini 技术:
@tonyaichamp提出了关于 DeepMind 的 Gemini 技术是否可以公开访问使用的问题。DeepMind 官网 - Langsmith-Cookbook 问题:用户在 Langsmith-Cookbook 及其部分注解中遇到了问题。
@psychickoala分享了一个关于@traceable注解的问题。Langsmith-Cookbook issue - 文档模块缺乏本地语言支持:
@bcmetisman强调了文档模块中缺乏对本地语言的支持,并表达了对语言保护的兴趣。 - 文档存储偏好:
@veryboldbagel倾向于将文档存储在同一个 collection 中并使用过滤器,并就该方法的可行性寻求建议。 -
Hypertion 库更新: @synacktra宣布其 Python 库 Hypertion 发布新版本,支持 Pydantic 模型。GithubPyPi - AI 开发服务:
@akrabulislam分享了其公司 Somykoron 提供的 AI 开发服务详情。链接:Fiverr, Upwork - Prompt 模板实验:
@bigansh展示了一项关于不同 Prompt 模板如何影响特定查询响应的实验结果。详情 - AI 应用教程:
@kulaone分享了使用 Vertex AI, Langchain 和 Google Cloud Functions 构建 AI 应用的教程,涵盖了整个 ML 生命周期。教程链接
LangChain AI 频道总结
▷ #general (13 条消息🔥):
- Table Transformer 讨论:
@spicyhabanero123兴奋地指出了 Table Transformer 并分享了概述链接,点击此处查看。 - Gemini 访问权限:根据 DeepMind 官网的公告,
@tonyaichamp提出了关于 Gemini 技术可访问性的问题。 - UnstructuredHTMLLoader 的使用:
@fatema_08922提到了 UnstructuredHTMLLoader 的使用,但未提供更多上下文。 - Langsmith-Cookbook 的问题:
@psychickoala分享了一个 链接,涉及在 Langsmith-Cookbook 中遇到的与@traceable注解相关的问题。 - 文档模块的语言支持:
@bcmetisman对文档模块缺乏本地语言支持表示担忧,并表示愿意为语言保护做出贡献。 - 向量数据库查询:
@andremik分享了使用 Pinecone 作为向量数据库的经验,但表示由于项目限制和价格问题,需要一个支持混合搜索(hybrid search)的新 retriever。 - 项目营销人员需求:
@sangy4132询问群组中是否有营销人员可以协助开展项目。
▷ #langserve (1 条消息):
- 文档存储策略:
@veryboldbagel讨论了存储文档的高效方式。具体而言,他们建议将文档存储在同一个 collection 中并使用过滤器。他们进一步询问了该方法在文档 schema 和主题领域方面的可行性,以及同时跨多种文档类型进行查询的实用性。
▷ #share-your-work (3 messages):
-
Hypertion - 精简的 Function Calling:
@synacktra发布了他的 Python 库 Hypertion 的新版本,增加了对 Pydantic 模型的支持。该库简化了函数 Schema 的创建和调用。他在 GitHub 和 PyPi 上提供了该库的链接。 -
Somykoron 提供的 AI 开发服务:
@akrabulislam分享了他的 AI 开发公司 Somykoron 的宣传资料,详细介绍了 Generative AI 开发和 Full-Stack 开发等服务。他提供了公司在 Fiverr、Upwork 上的个人资料链接,以及 CTO 的 LinkedIn 链接(尽管 LinkedIn 链接出现了错误)。 -
Prompt 模板实验:
@bigansh分享了他关于不同 Prompt 模板如何针对特定查询生成不同响应的实验发现。他将这个过程描述为“构建起来非常有趣”,并提供了一个指向他 Twitter 帖子 的链接,其中详细说明了结果。
▷ #tutorials (1 messages):
- 使用 Vertex AI、Langchain 和 Google Cloud Functions 构建 AI 应用:
@kulaone分享了一篇 Medium 教程,介绍了如何利用 Vertex AI(一个全托管的机器学习 ML 平台)、Langchain 和 Google Cloud Functions 来构建 AI 应用。该教程涵盖了整个 ML 生命周期,从数据准备到模型部署和监控。
MLOps @Chipro Discord 摘要
- Deci 的深度学习开发者关系经理 Harpreet Sahota 宣布即将举办一场关于 高级语言模型微调技术 (Advanced Language Model Tuning Techniques) 的网络研讨会。研讨会将深入探讨专业化微调、有效的数据集准备以及高级技术。此外还将包含问答环节。该研讨会免费向所有人开放,感兴趣的参与者可以 在此注册。本次学习机会由 Data Phoenix 组织。
- 初创公司 CEO
@wangx123分享了职位机会和项目详情,并通过 YouTube 视频 介绍了他们的项目 miniai.live。鼓励感兴趣的人士与其联系。 @theetrigan对@wangx123在 general-ml 频道中可能存在的 垃圾信息 (spamming) 行为表示担忧。
MLOps @Chipro 频道摘要
▷ #events (1 messages):
- 高级语言模型微调技术网络研讨会:
@kizzy_kay宣布了一场定于 12 月 7 日上午 10 点 (PST) 举行的关于 基础语言模型微调 (base language model tuning) 的网络研讨会。演讲者将是 Deci 的深度学习开发者关系经理 Harpreet Sahota。 - 研讨会将分享关于 专业化微调、有效的数据集准备 以及 高级技术(如 BitsAndBytes & 模型量化 (Model Quantization)、PEFT & LoRA 以及 TRL 库的使用)的见解。
- 参与者可以在计划的问答环节中提出具体问题。
- 研讨会免费向所有人开放。感兴趣的参与者可以 在此注册。
- 本次会议由 Data Phoenix 组织。
▷ #general-ml (2 messages):
- 职位机会与项目推广: 初创公司 CEO
@wangx123邀请感兴趣的人士联系以获取潜在机会。他们分享了一个 YouTube 视频 来介绍他们的项目 miniai.live。 - 垃圾信息担忧:
@theetrigan要求@wangx123停止其认为的垃圾信息发布行为。
Perplexity AI Discord 摘要
只有一个频道有活动,因此无需总结…
- Perplexity 为 Pro 用户提供自研模型访问权限:
@enigmagi宣布 Perplexity Pro 用户现在可以选择最近发布的自研模型 pplx-70b-online。经评估,该模型在网页搜索方面比 GPT-3.5-turbo 事实更准确、更实用、更简洁,且更少说教。用户可以通过在 Perplexity Pro 设置中选择 ‘Experimental’ 来访问,也可以通过 pplx-api 访问。有关自研模型的更多信息可以在这里找到。
Skunkworks AI Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
Ontocord (MDEL discord) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
AI Engineer Foundation Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。
YAIG (a16z Infra) Discord 没有新消息。如果该频道长期处于沉寂状态,请告知我们,我们将将其移除。